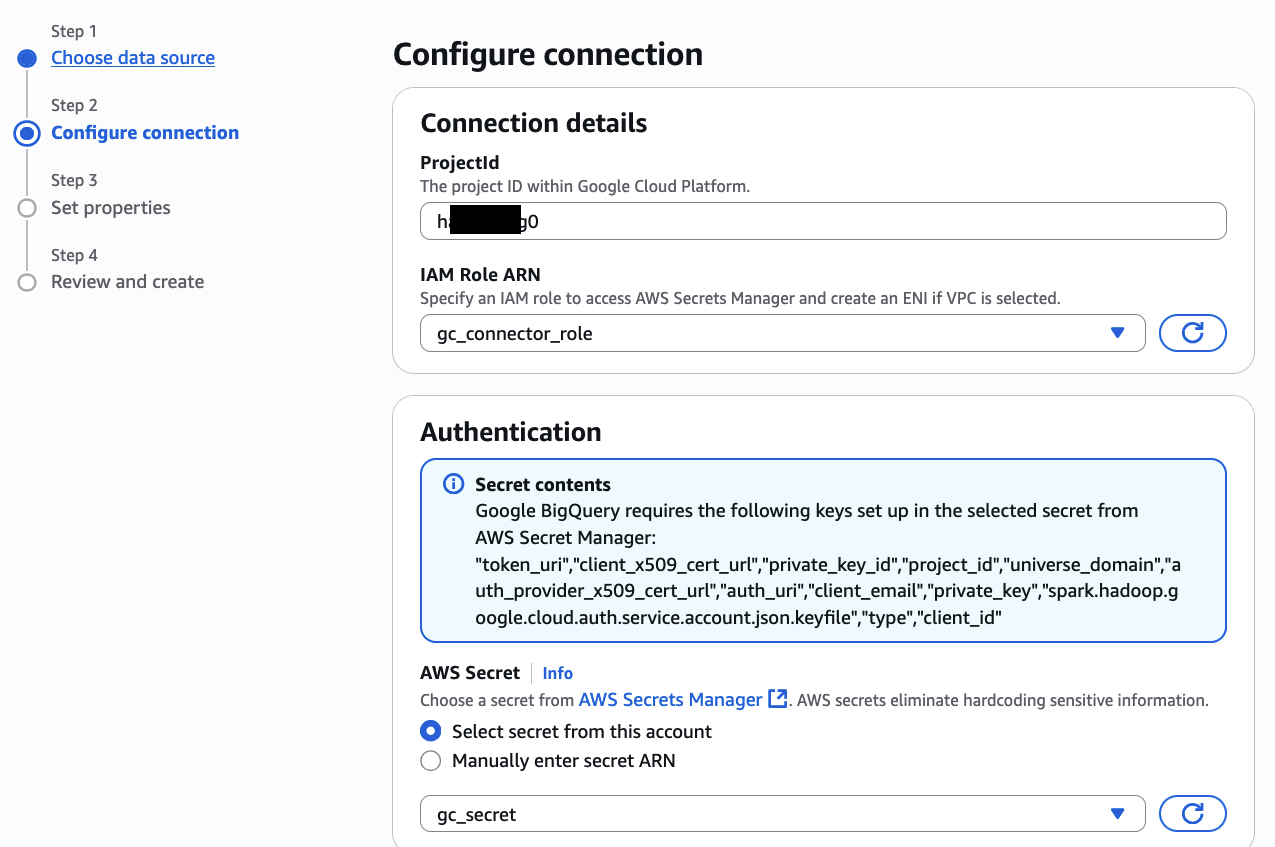
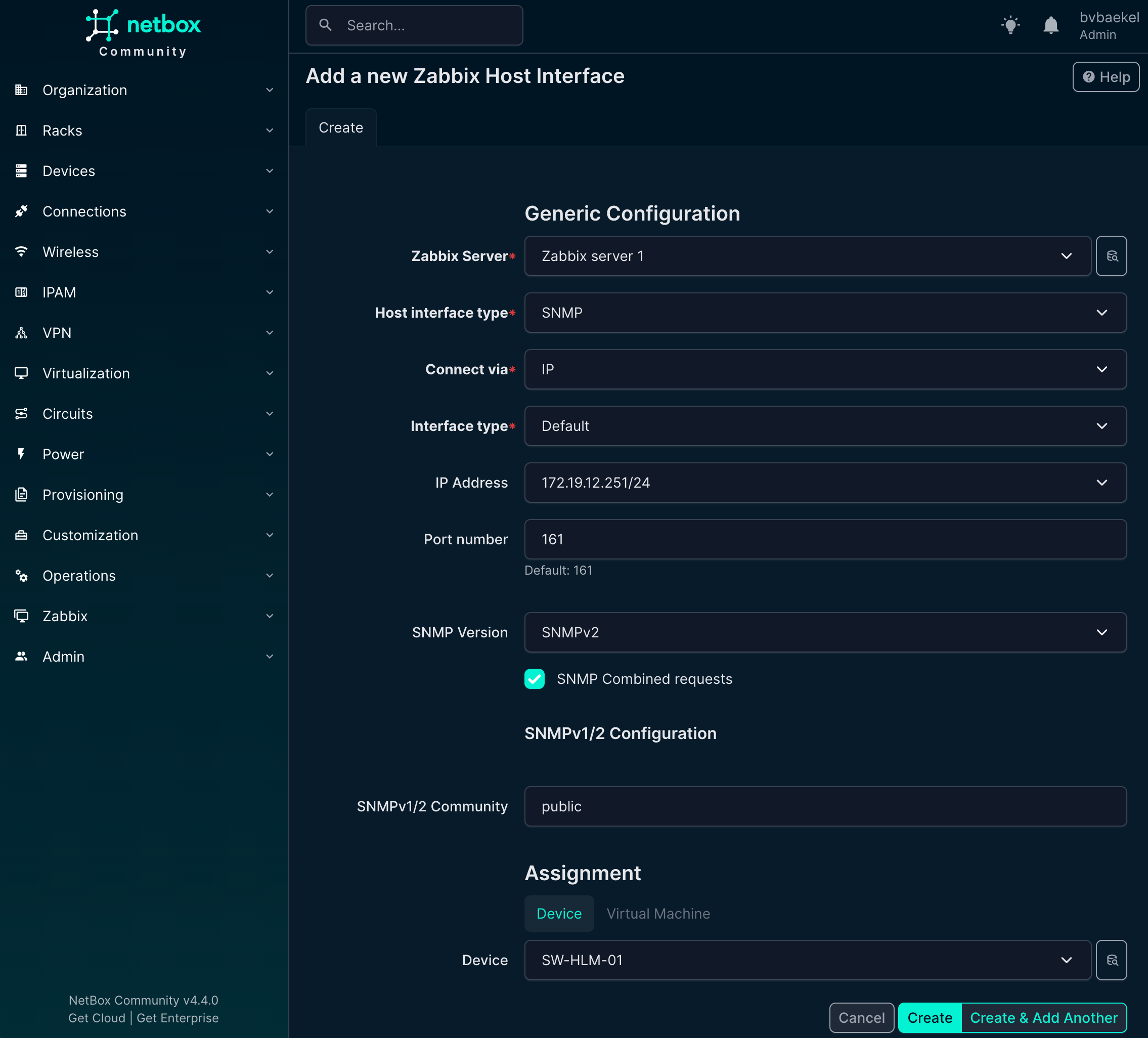
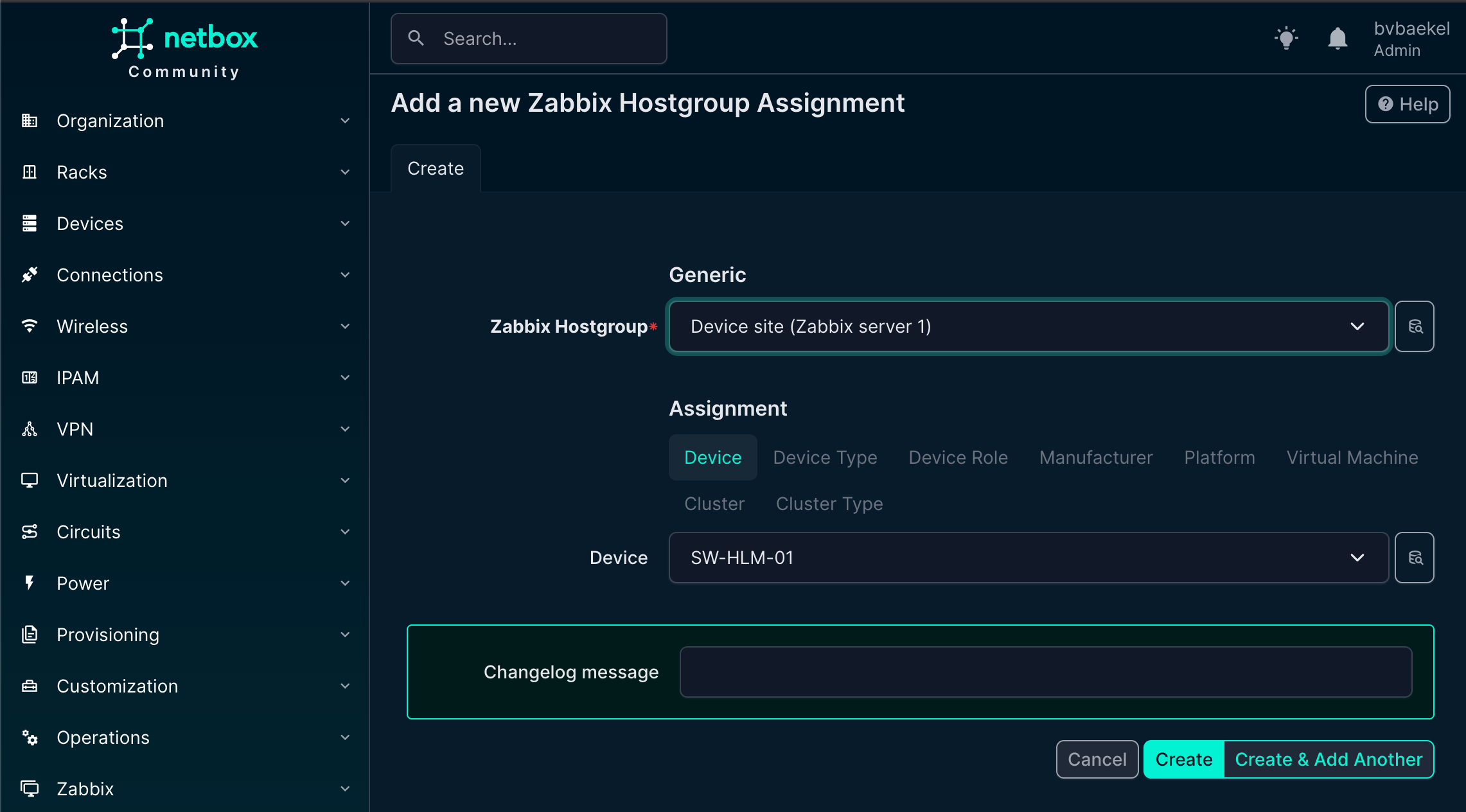
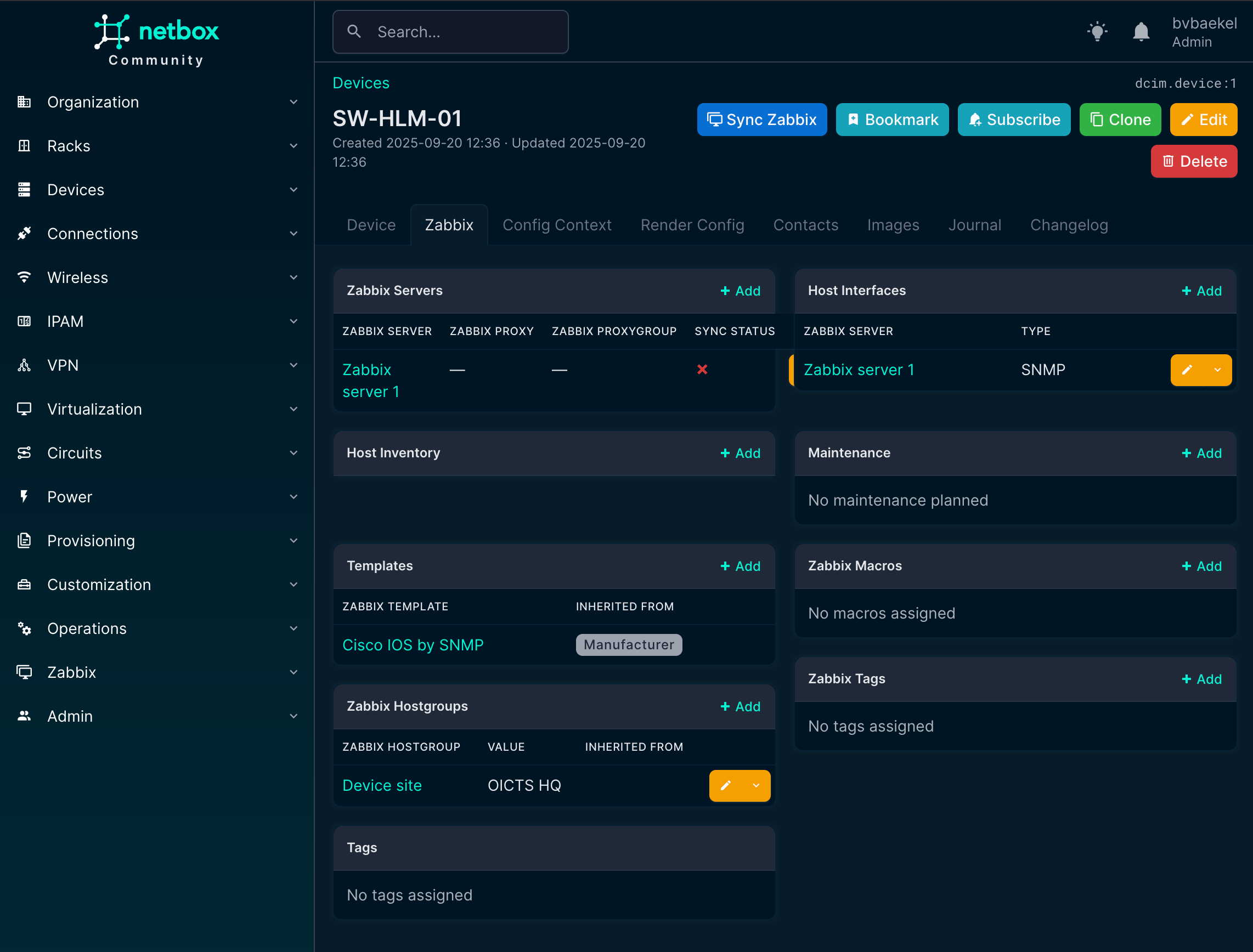
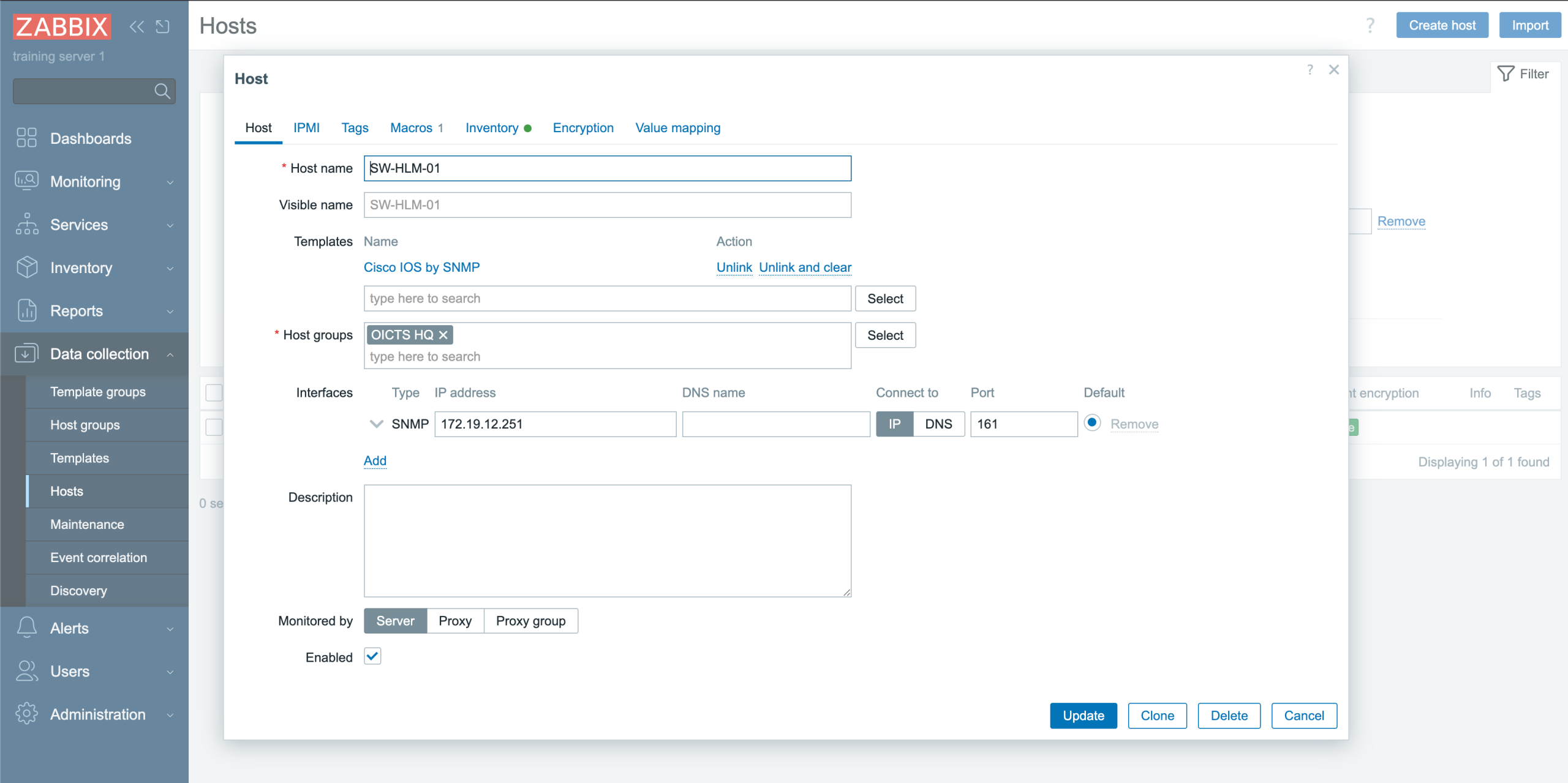
Post Syndicated from Ина Иванова original https://www.toest.bg/violeta-martinova-tam-kudeto-nyamashe-puteki-nie-napravihme-putishta/

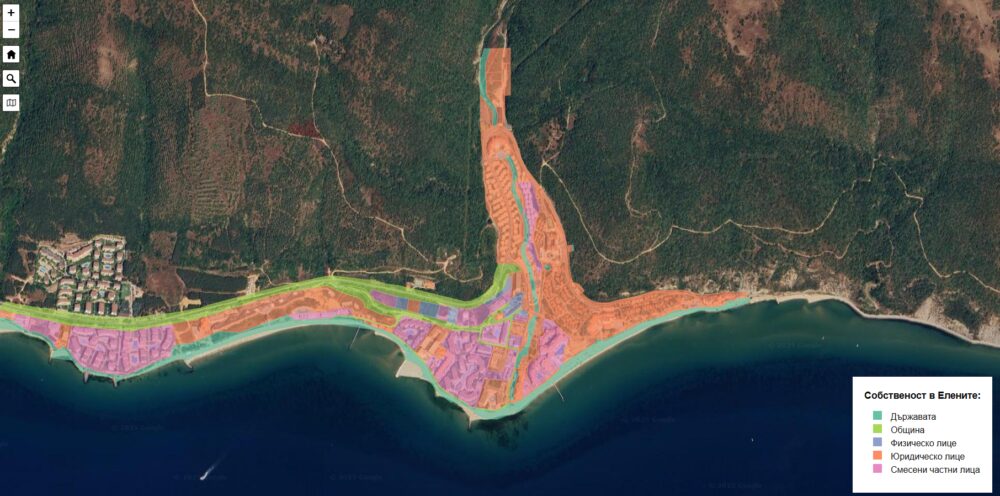
Повечето хора свързват розовия цвят с надежда и деликатност. В областта на социалните услуги обаче са тема, по която положението никак не е розово. В България има един-единствен нископрагов център за работа с хора, зависими от наркотици и алкохол – и това е Розовата къща.
Тя предоставя защитена среда (в рамките на работното време), подслон, храна, топла напитка, пералня, баня, дреха, подкрепяща комуникация или консултация с психолог, както и базови медицински грижи за зависими хора, които живеят в лоши битови условия, а често са и бездомни.
Философията на този подход е, че специалистът отива при човека със зависимост, предлагайки базови услуги – предотвратяване на инфекции, обучение за рискове, вместо да чака зависимият сам да потърси лечение.
Целта е да се съхрани здравето на хората, докато достигнат етап, в който са готови за лечение.
От началото на 2025 г. филиал на Розовата къща има и в Пловдив. Психолог и основен двигател е Виолета Мартинова – и макар да не обича да застава в светлината на прожекторите, именно тя сформира екипа. Филиалът заработва почти мигновено, в момента го посещават около 50 души, тъй като е на познато място. Община Пловдив предоставя на екипа малка сграда, в която е имало център за работа със социално уязвими хора още през 2003 г. Организацията тогава е една от първите в България, които започват да предлагат услуги за намаляване на вредите (Harm Reduction) сред употребяващи наркотици. „Големият бум“ на хероинозависими избухва в средата на 90-те, а държавата се оказва напълно неподготвена да реагира. Обществените нагласи към зависимите хора са крайно негативни и отхвърлящи, стигмата се прехвърля дори върху социалните работници. Едва напоследък ангажираните с проблема забелязват промяна, може би защото все повече хора лично се сблъскват с факта, че никой не е застрахован, че всеки би могъл да бъде здраво хванат в капана на наркотици, алкохол или хазартна зависимост.
„Нашите хора“ нарича Виолета Мартинова всички, които посещават Розовата къща.
И когато ретроспективно поглежда към над двайсетгодишния си стаж, признава, че нашето общество все още не е готово да приеме зависимостите като хронично заболяване (каквито са диабетът, хипертонията, исхемичната болест на сърцето и др.).
Като специалисти от помагащи професии полагаме доживотни грижи и подкрепа за хората с т.нар. социалнозначими и хронични заболявания, но очакваме тези, страдащи от зависимости, да се справят без същата грижа и подкрепа – „защото сами са си го причинили“. Имаме държавни метадонови програми, но не и достъпни програми за психосоциална рехабилитация. Разчитаме, че хората ще се справят сами. Укоряваме ги. Да, те са избрали да опитат наркотици. Но нека не забравяме, че част от тях са започнали във време, в което информацията беше силно изкривена и не особено достъпна. Да, те са експериментирали. След това обаче наркотикът започва да говори вместо тях.
Виолета Мартинова не е работила в център за зависими единствено в интервала между 2019 и 2024 г., когато е част от корпоративния свят. После ѝ се обажда Юлия Георгиева от Розовата къща в София, споделя, че „нашите хора в Пловдив“ имат нужда от дом, и ѝ предлага да се върне – на същото място, където е започнала като млад социален работник, отново на ул. „Пламък“.
„Където е трудно, ние сме там“, обосновава своя етичен избор Виолета.
Ако нямаш безусловното приемане на тези хора, които са в труден етап от живота си, не можеш да отделиш тяхната личност от измененията, които са част от зависимостта им. Между нас има много ценни, много човешки разговори.
Виолета Мартинова и екипът на Розовата къща с изненада установяват, че получават подкрепа от различни хора. Вярват, че промяната в отношението към зависимите се дължи на информираността:
Хората направиха важни допускания. Осъзнаха, че към зависимостите можем да прибавим хазартната, зависимостта от устройства, пазаруване или храна. В началото зависимостта започва като нещо, което ти носи удоволствие. При наркотиците много бързо тя те лишава от собствената ти воля.
Какво обаче прави държавата? Виолета е категорична:
Държавата разчита основно на субституираща терапия – метадон или друг вид заместване, което е изключително недостатъчно, защото това е само част от лечението. Да, този тип лечение е необходимо, но хората са оставени без възможност да научат или актуализират базови социални и трудови умения. А те тепърва трябва да изградят навици, за да бъдат в състояние да продължат живота си. Разбира се, нашите хора ще продължат да бъдат хронично болни, но им трябва система от умения, за да се адаптират. За един тесен сегмент заместващата програма ще остане единствената възможност, но за повечето има смисъл от подкрепа за интеграция в обществото, за да водят пълноценен живот.
Това, което пропускаме всъщност, е, че физиологично е допустимо човек дълго време да бъде на медикаментозна терапия, но не е необходимо. Необходимо е да му бъде предложена алтернатива, за да се научи да организира ежедневието си и да изгради базови социални умения.
Понякога обаче става въпрос и за конкретна битова грижа.
Розовата къща е нашият малък оазис. Ние успяваме с много малко средства да предложим тесен сегмент от услуги. Но на фона на това, че няма нищо друго, нашите хора са благодарни. Част от зависимите живеят без дом. Когато видиш бездомен човек, който е гладен, зависим и в момент на криза, той изглежда много различно от човека, който е изкъпан и преоблечен. Тук, при нас, някой ще му помогне да се подстриже и избръсне, ще му предложи набор от чисти дрехи и обувки.
Съществуващата социална подкрепа в България обаче е обвързана с адресна регистрация, тоест за бездомните такава помощ априори е недостъпна.
Това, което ние можем да им предложим, е да бъдат прегледани при нас, защото те често са с тежки, страховити рани, гангренозни рани и абсцеси. Имаме медицинска сестра, която прави превръзки, и през лятото наистина спасихме няколко живота. Имаме и джипи, което следи състоянието на нашите хора.
Повечето посещаващи Розовата къща зависими са над 40-годишни, но има и млади хора, особено от ромската общност, които са потенциални жертви. Често децата на наркозависими са живели в изключително трудни условия и без равен старт в живота са обречени да последват съдбата на родителите си.
Виолета Мартинова и колегите ѝ се сблъскват с наистина тежки човешки съдби.
Розовата къща е място, на което нашите хора няма да бъдат съдени и те добре го знаят. Ние си даваме сметка, че не вървят по пътя, който на нас ни се иска, но трябва да се съобразим с факта, че всеки един от тях има собствен ход, собствено темпо. Да бъдем назидателни и да им обясняваме как трябва да спрат и колко увреждат здравето си… това не работи.
Дали Виолета Мартинова успява да се абстрахира от случаите, с които се сблъсква ежедневно? Дали успява да излезе от Къщата, да заключи вратата и да не мисли по казусите до следващия ден? Тя казва, че се е научила.
Когато съм в Розовата къща, горя на сто процента, но след края на работното си време имам и други ангажименти. Открих, че това работи при мен. Истината е, че иначе е доста изчерпващо. И психологически погледнато, трябва да получавам някаква емоционална награда.
Затова Виолета има също индивидуална практика с клиенти. А времето, в което е работила корпоративна работа, ѝ дава възможността сега да консултира хора от висшия мениджмънт и да води групи по справяне с работа в екип, комуникативни трудности, мотивиране на персонал, описание и картографиране на бизнес процеси и др. Смяната на различни амплоа вероятно е спасителна, самата тя я назовава „за момента работещ механизъм, в който виждаш различни светове“.
Каузата ѝ (която тя деликатно и дисциплинирано нарича „работа“) я среща с трудни съдби, със счупени човешки същества, понякога с невъзвратимото. „Приех, че не мога винаги да помогна. Когато съм подала ръка и отсреща не я приемат, трябва да уважа избора.“ Това ѝ върши работа и в личния живот.
Обществото ни зрее за това да приема различните. Бавно, но ние сме доста консервативни, така че очевидно това е нашето темпо, Но днес, благодарение на дарители, ние успяваме да изхранваме 45–50 човека, които бяха отчаяни. Притеснителното е, че трябва да успеем да подсигурим това и занапред, защото броят на хората, които се нуждаят от нашите услуги, е доста стабилен, а разчитаме основно на дарения за всички режийни разходи. Надяваме се през 2026 г. да получим финансиране през програма на Министерството по труда и социалните грижи, за да можем да осигурим устойчивост на предлаганите в Розовата къща грижи и услуги.
Работата в Розовата къща е крайно специфична, насочена към тесен социален сегмент и хората в екипа не се стараят да шумят около нея. Напоследък обаче осъзнават, че не е лошо за обществото да бъдат озвучени подобни услуги. Ако споделят, че имат нужда от конкретна помощ, това всъщност дава възможност на хората да допринесат. Да откликнат. Лично. Затова и Виолета Мартинова е благодарна на Юлия Георгиева, която от години стои зад каузата на Фондация „Център за хуманни политики“ и която публично оповестява ежемесечно дейността на Розовата къща.
В гласа на Виолета Мартинова има звънливост и вяра. Точно тя и хората от екипа ѝ, които работят със социално най-уязвимите – парадоксално, – намират основания да вярват в човешката способност за съчувствие и съпричастност. В хуманността на дело.
Бяхме писали, че имаме нужда от огледало, и получихме 4 огледала,
споделя тя и – сигурна съм! – двете чуваме знаковата стойност на казаното.
Виолета завършва „Социални дейности“ преди малко повече от двайсет години и с ентусиазъм се хвърля в първата си работа отново тук, на същото място на ул. „Пламък“ №2. След това надгражда образованието си с психология. В момента завършва специализация по когнитивно-поведенческа психотерапия, а втора година учи фамилна психотерапия. Като дете е искала да стане лекарка, по-късно родителите ѝ я съветват да избере правото. По някакъв начин сегашните ѝ дейности съчетават и двете.
Изборът да посветя голяма част от времето си на Розовата къща е емоционален. Харесвам предизвикателствата – те ме държат в кондиция, карат ме да се променям, да търся решения. Разликата от преди, когато бях заета само с корпоративна работа, е, че сега мога да избирам в кои проекти да участвам, както и методите и подходите, с които да работя.
Хората, които тихо и кротко променят средата, формират общности и задават посоки, в които има смисъл да тръгнем заедно. Тук ви срещаме с тях. Това са „Тези хора“.