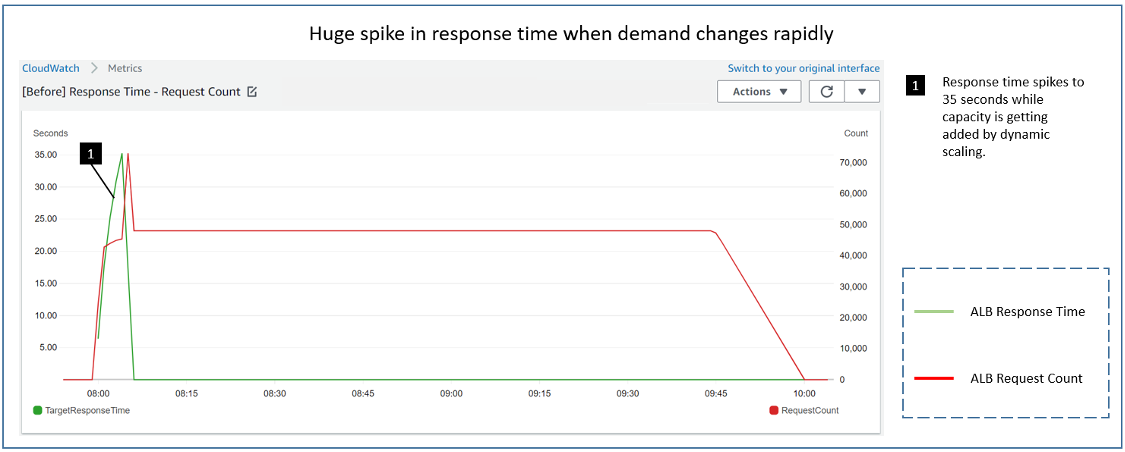
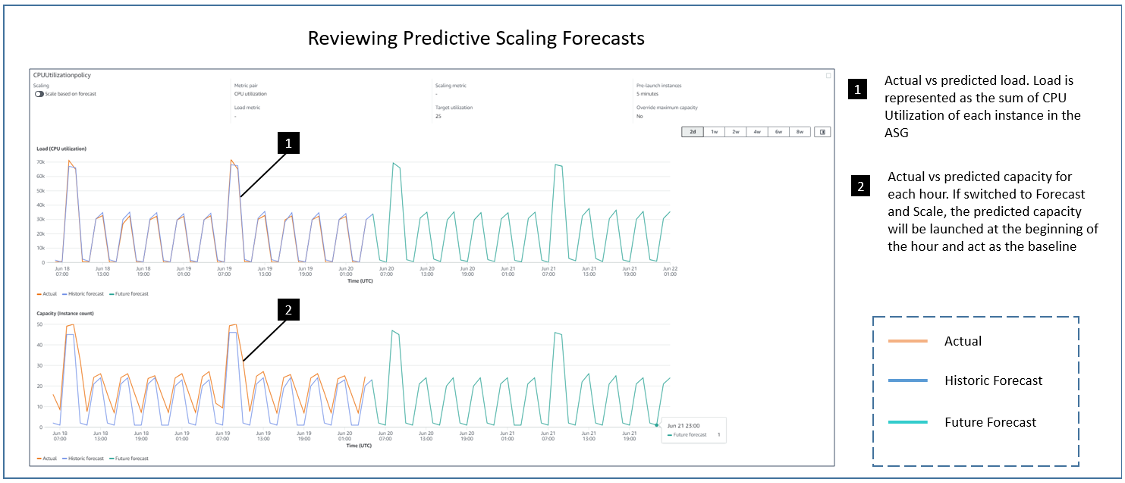
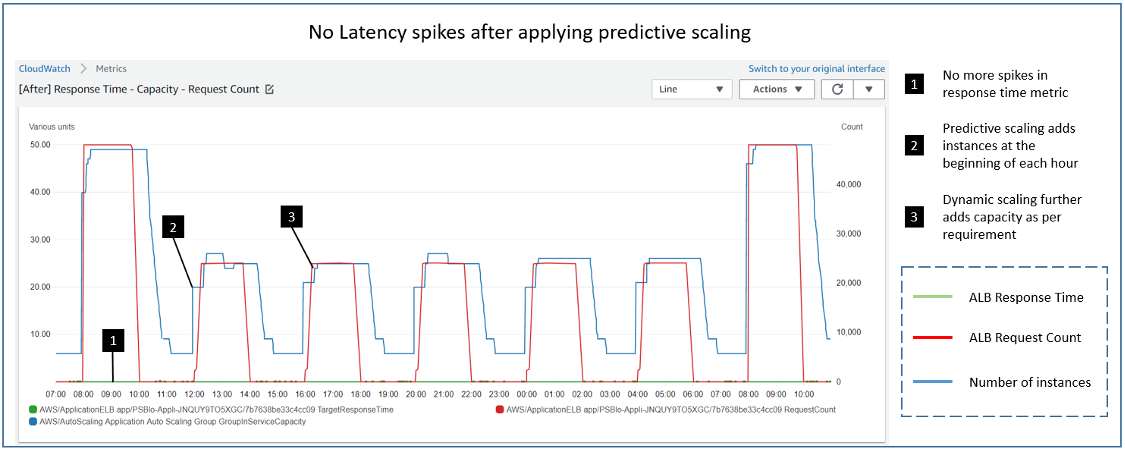
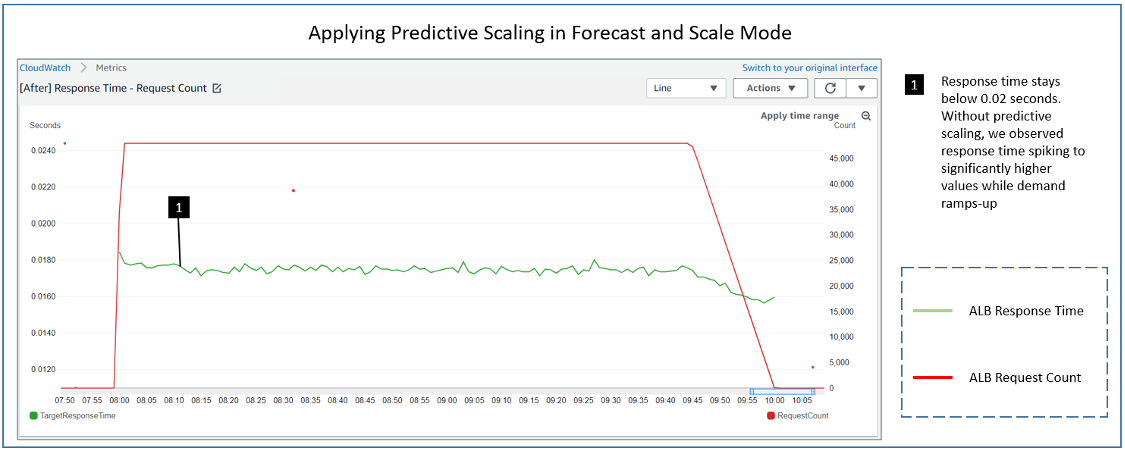
Post Syndicated from Rick Armstrong original https://aws.amazon.com/blogs/compute/implementing-autoscaling-for-ec2-mac-instances/
This post is written by: Josh Bonello, Senior DevOps Architect, AWS Professional Services; Wes Fabella, Senior DevOps Architect, AWS Professional Services
Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides secure, resizable compute capacity in the cloud. The introduction of Amazon EC2 Mac now enables macOS based workloads to run in the AWS Cloud. These EC2 instances require Dedicated Hosts usage. EC2 integrates natively with Amazon CloudWatch to provide monitoring and observability capabilities.
In order to best leverage EC2 for dynamic workloads, it is a best practice to use Auto Scaling whenever possible. This will allow your workload to scale to demand, while keeping a minimal footprint during low activity periods. With Auto Scaling, you don’t have to worry about provisioning more servers to handle peak traffic or paying for more than you need.
This post will discuss how to create an Auto Scaling Group for the mac1.metal instance type. We will produce an Auto Scaling Group, a Launch Template, a Host Resource Group, and a License Configuration. These resources will work together to produce the now expected behavior of standard instance types with Auto Scaling. At AWS Professional Services, we have implemented this architecture to allow the dynamic sizing of a compute fleet utilizing the mac1.metal instance type for a large customer. Depending on what should invoke the scaling mechanisms, this architecture can be easily adapted to integrate with other AWS services, such as Elastic Load Balancers (ELB). We will provide Terraform templates as part of the walkthrough. Please take special note of the costs associated with running three mac1.metal Dedicated Hosts for 24 hours.
How it works
First, we will begin in AWS License Manager and create a License Configuration. This License Configuration will be associated with an Amazon Machine Image (AMI), and can be associated with multiple AMIs. We will utilize this License Configuration as a parameter when we create a Host Resource Group. As part of defining the Launch Template, we will be referencing our Host Resource Group. Then, we will create an Auto Scaling Group based on the Launch Template.
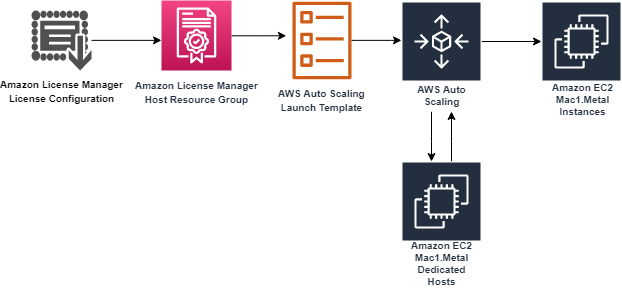
The License Configuration will control the software licensing parameters. Normally, License Configurations are used for software licensing controls. In our case, it is only a required element for a Host Resource Group, and it handles nothing significant in our solution.
The Host Resource Group will be responsible for allocating and deallocating the Dedicated Hosts for the Mac1 instance family. An available Dedicated Host is required to launch a mac1.metal EC2 instance.
The Launch Template will govern many aspects to our EC2 Instances, including AWS Identity and Access Management (IAM) Instance Profile, Security Groups, and Subnets. These will be similar to typical Auto Scaling Group expectations. Note that, in our solution, we will use Tenancy Host Resource Group as our compute source.
Finally, we will create an Auto Scaling Group based on our Launch Template. The Auto Scaling Group will be the controller to signal when to create new EC2 Instances, create new Dedicated Hosts, and similarly terminate EC2 Instances. Unutilized Dedicated Hosts will be tracked and terminated by the Host Resource Group.
Limits
Some limits exist for this solution. To deploy this solution, a Service Quota Increase must be submitted for mac1.metal Dedicated Hosts, as the default quota is 0. Deploying the solution without this increase will result in failures when provisioning the Dedicated Hosts for the mac1.metal instances.
While testing scale-in operations of the auto scaling group, you might find that Dedicated Hosts are in “Pending” state. Mac1 documentation says “When you stop or terminate a Mac instance, Amazon EC2 performs a scrubbing workflow on the underlying Dedicated Host to erase the internal SSD, to clear the persistent NVRAM variables. If the bridgeOS software does not need to be updated, the scrubbing workflow takes up to 50 minutes to complete. If the bridgeOS software needs to be updated, the scrubbing workflow can take up to 3 hours to complete.” The Dedicated Host cannot be reused for a new scale-out operation until this scrubbing is complete. If you attempt a scale-in and a scale-out operation during testing, you might find more Dedicated Hosts than EC2 instances for your ASG as a result.
Auto Scaling Group features like dynamic scaling, health checking, and instance refresh can also cause similar side effects as a result of terminating the EC2 instances. These side effects will subside after 24 hours when a mac1 dedicate host can be released.
Building the solution
This walkthrough will utilize a Terraform template to automate the infrastructure deployment required for this solution. The following prerequisites should be met prior to proceeding with this walkthrough:
- An AWS account
- Terraform CLI installed
- A Service Quota Increase for mac1.metal Dedicated Hosts
Before proceeding, note that the AWS resources created as part of the walkthrough have costs associated with them. Delete any AWS resources created by the walkthrough that you do not intend to use. Take special note that at the time of writing, mac1.metal Dedicated Hosts require a 24 minimum allocation time to align with Apple macOS EULA, and that mac1.metal EC2 instances are not charged separately, only the underlying Dedicated Hosts are.
Step 1: Deploy Dedicated Hosts infrastructure
First, we will do one-time setup for AWS License Manager to have the required IAM Permissions through the AWS Management Console. If you have already used License Manager, this has already been done for you. Click on “create customer managed license”, check the box, and then click on “Grant Permissions.”

To deploy the infrastructure, we will utilize a Terraform template to automate every component setup. The code is available at https://github.com/aws-samples/amazon-autoscaling-mac1metal-ec2-with-terraform. First, initialize your Terraform host. For this solution, utilize a local machine. For this walkthrough, we will assume the use of the us-west-2 (Oregon) AWS Region and the following links to help check resources will account for this.
terraform -chdir=terraform-aws-dedicated-hosts init

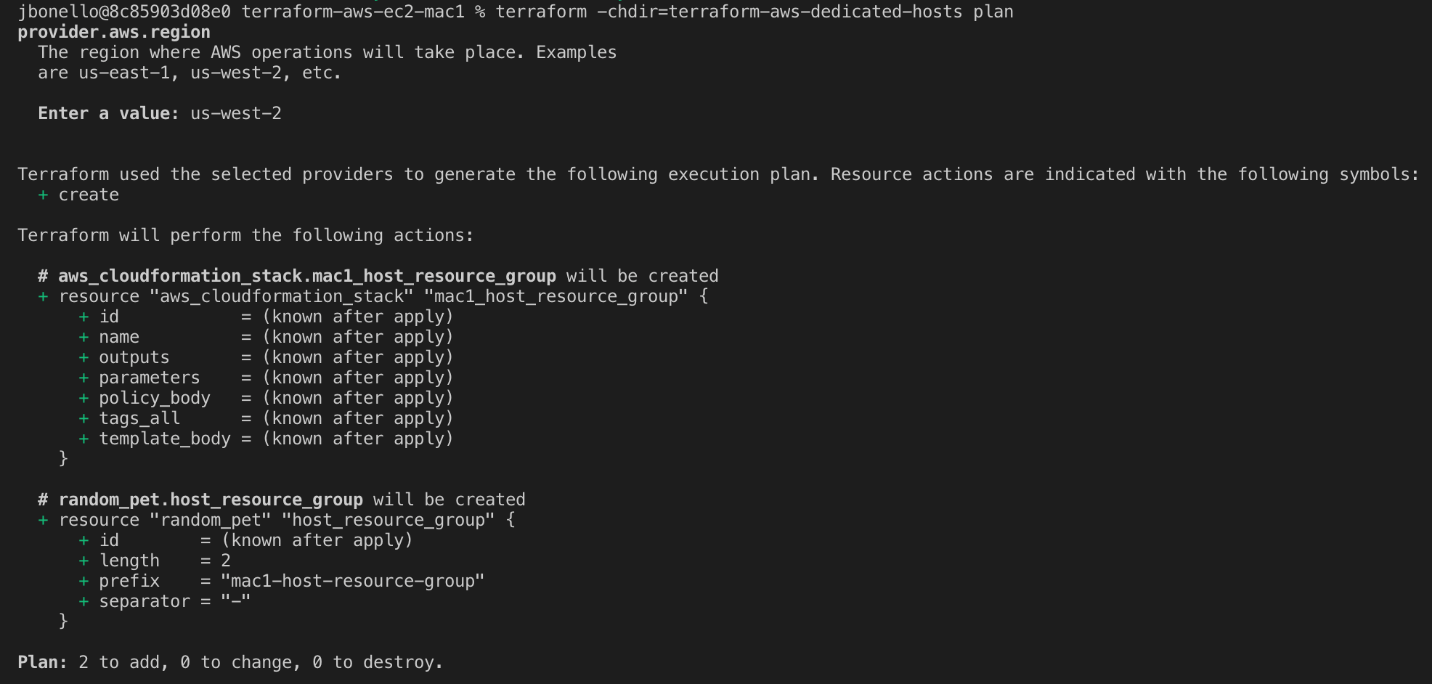
Then, we will plan our Terraform deployment and verify what we will be building before deployment.
terraform -chdir=terraform-aws-dedicated-hosts plan
In our case, we will expect a CloudFormation Stack and a Host Resource Group.
Then, apply our Terraform deployment and verify via the AWS Management Console.
terraform -chdir=terraform-aws-dedicated-hosts apply -auto-approve

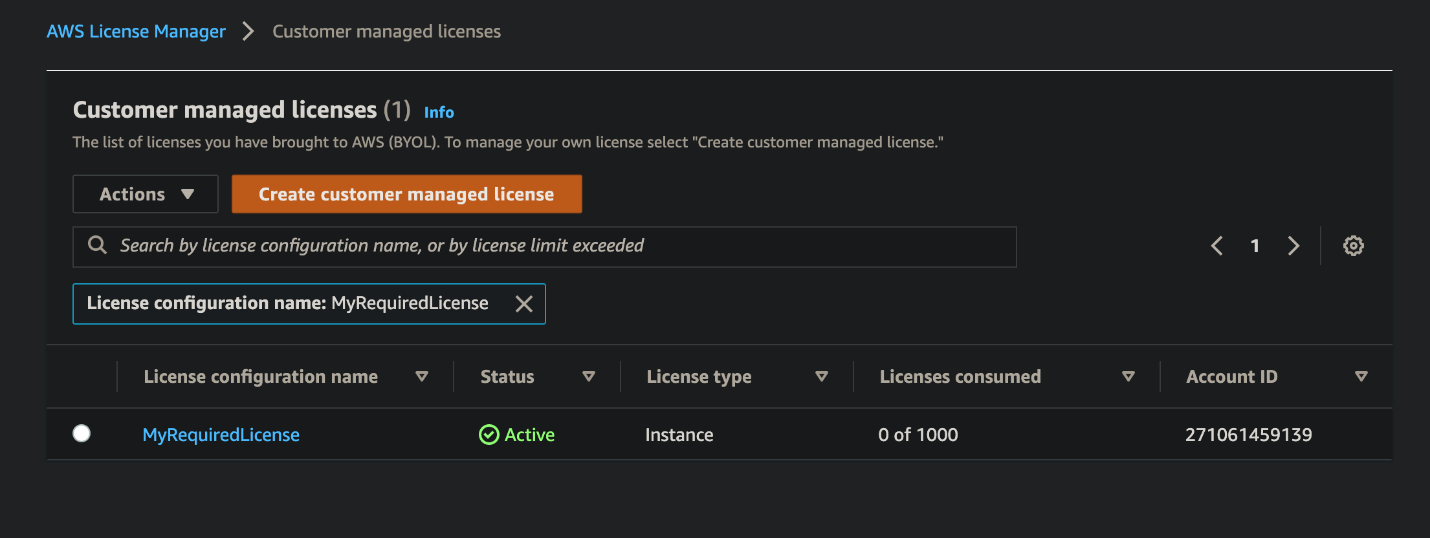
Check that the License Configuration has been made in License Manager with a name similar to MyRequiredLicense.
Check that the Host Resource Group has been made in the AWS Management Console. Ensure that the name is similar to mac1-host-resource-group-famous-anchovy.
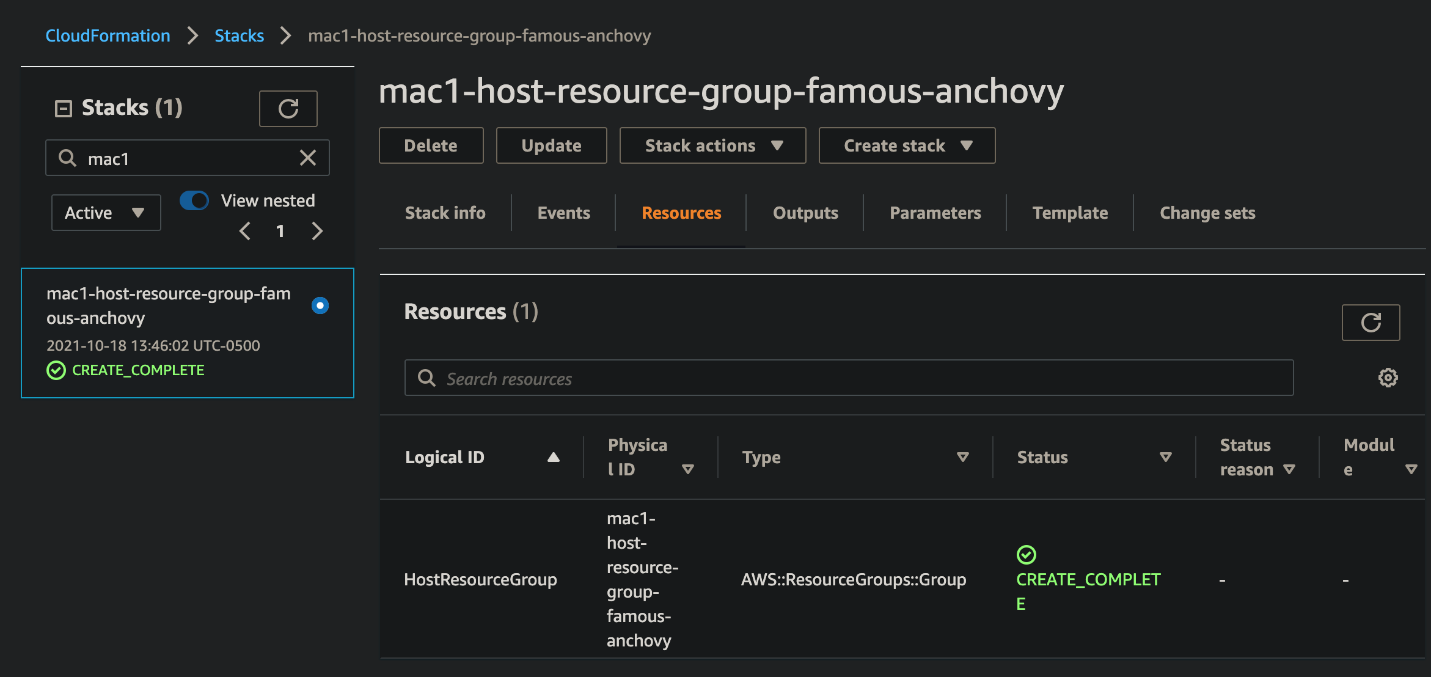
Note the host resource group name in the HostResourceGroup “Physical ID” value for the next step.
Step 2: Deploy mac1.metal Auto Scaling Group
We will be taking similar steps as in Step 1 with a new component set.
Initialize your Terraform State:
terraform -chdir=terraform-aws-ec2-mac init
Then, update the following values in terraform-aws-ec2-mac/my.tfvars:
vpc_id : Check the ID of a VPC in the account where you are deploying. You will always have a “default” VPC.
subnet_ids : Check the ID of one or many subnets in your VPC.
hint: use https://us-west-2.console.aws.amazon.com/vpc/home?region=us-west-2#subnets
security_group_ids : Check the ID of a Security Group in the account where you are deploying. You will always have a “default” SG.
host_resource_group_cfn_stack_name : Use the Host Resource Group Name value from the previous step.
Then, plan your deployment using the following:
terraform -chdir=terraform-aws-ec2-mac plan -var-file="my.tfvars"
Once we’re ready to deploy, utilize Terraform to apply the following:
terraform -chdir=terraform-aws-ec2-mac apply -var-file="my.tfvars" -auto-approve
Note, this will take three to five minutes to complete.
Step 3: Verify Deployment
Check our Auto Scaling Group in the AWS Management Console for a group named something like “ec2-native-xxxx”. Verify all attributes that we care about, including the underlying EC2.

Check our Elastic Load Balancer in the AWS Management Console with a Tag key “Name” and the value of your Auto Scaling Group.
Check for the existence of our Dedicated Hosts in the AWS Management Console.
Step 4: Test Scaling Features
Now we have the entire infrastructure in place for an Auto Scaling Group to conduct normal activity. We will test with a scale-out behavior, then a scale-in behavior. We will force operations by updating the desired count of the Auto Scaling Group.
For scaling out, update the my.tfvars variable number_of_instances to three from two, and then apply our terraform template. We will expect to see one more EC2 instance for a total of three instances, with three Dedicated Hosts.
terraform -chdir=terraform-aws-ec2-mac apply -var-file="my.tfvars" -auto-approve
Then, take the steps in Step 3: Verify Deployment in order to check for expected behavior.
For scaling in, update the my.tfvars variable number_of_instances to one from three, and then apply our terraform template. We will expect your Auto Scaling Group to reduce to one active EC2 instance and have three Dedicated Hosts remaining until they are capable of being released 24 hours later.
terraform -chdir=terraform-aws-ec2-mac apply -var-file="my.tfvars" -auto-approve
Then, take the steps in Step 3: Verify Deployment in order to check for expected behavior.
Cleaning up
Complete the following steps in order to cleanup resources created by this exercise:
terraform -chdir=terraform-aws-ec2-mac destroy -var-file="my.tfvars" -auto-approve
This will take 10 to 12 minutes. Then, wait 24 hours for the Dedicated Hosts to be capable of being released, and then destroy the next template. We recommend putting a reminder on your calendar to make sure that you don’t forget this step.
terraform -chdir=terraform-aws-dedicated-hosts destroy -auto-approve
Conclusion
In this post, we created an Auto Scaling Group using mac1.metal instance types. Scaling mechanisms will work as expected with standard EC2 instance types, and the management of Dedicated Hosts is automated. This enables the management of macOS based application workloads to be automated based on the Well Architected patterns. Furthermore, this automation allows for rapid reactions to surges of demand and reclamation of unused compute once the demand is cleared. Now you can augment this system to integrate with other AWS services, such as Elastic Load Balancing, Amazon Simple Cloud Storage (Amazon S3), Amazon Relational Database Service (Amazon RDS), and more.
Review the information available regarding CloudWatch custom metrics to discover possibilities for adding new ways for scaling your system. Now we would be eager to know what AWS solution you’re going to build with the content described by this blog post! To get started with EC2 Mac instances, please visit the product page.