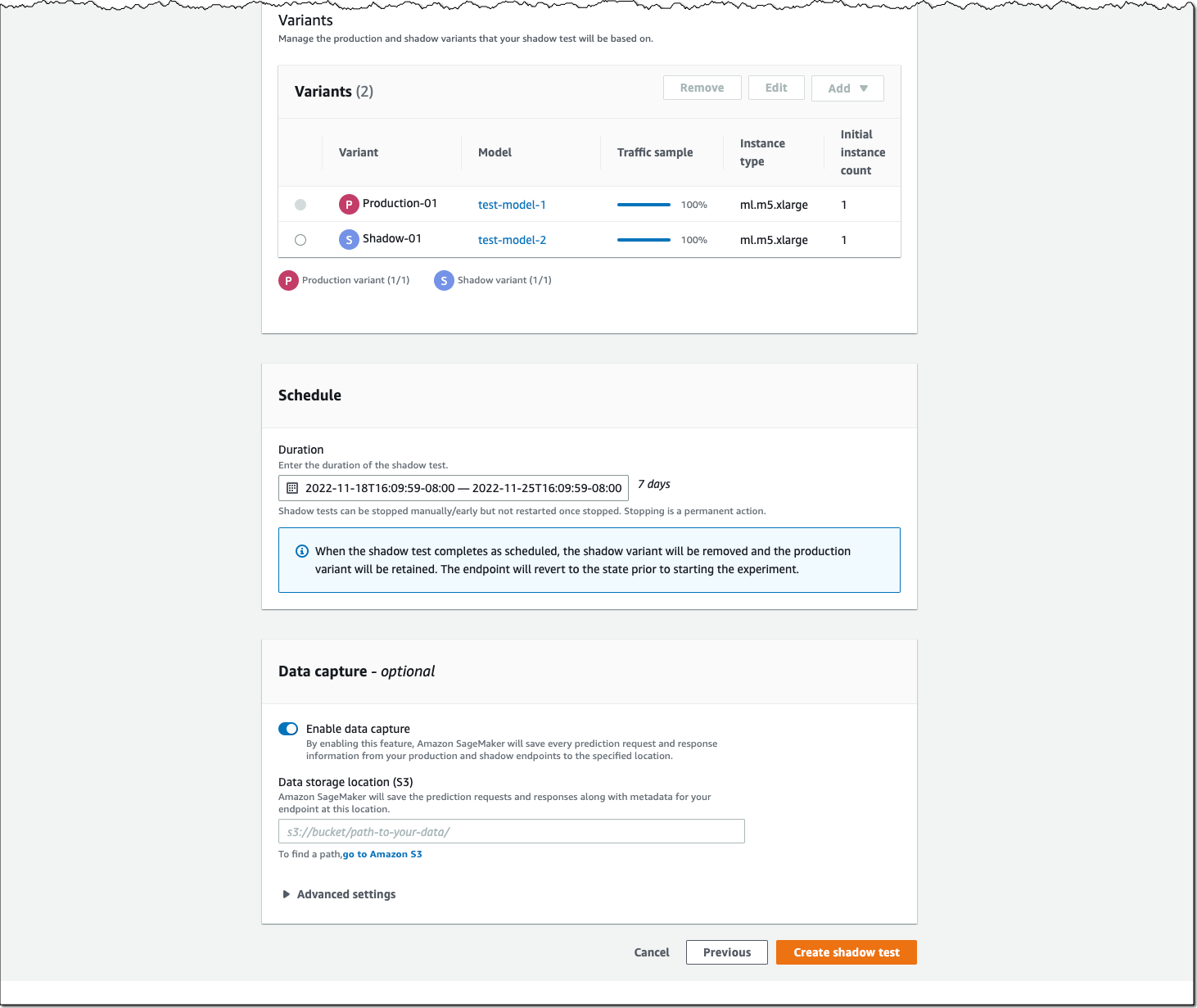
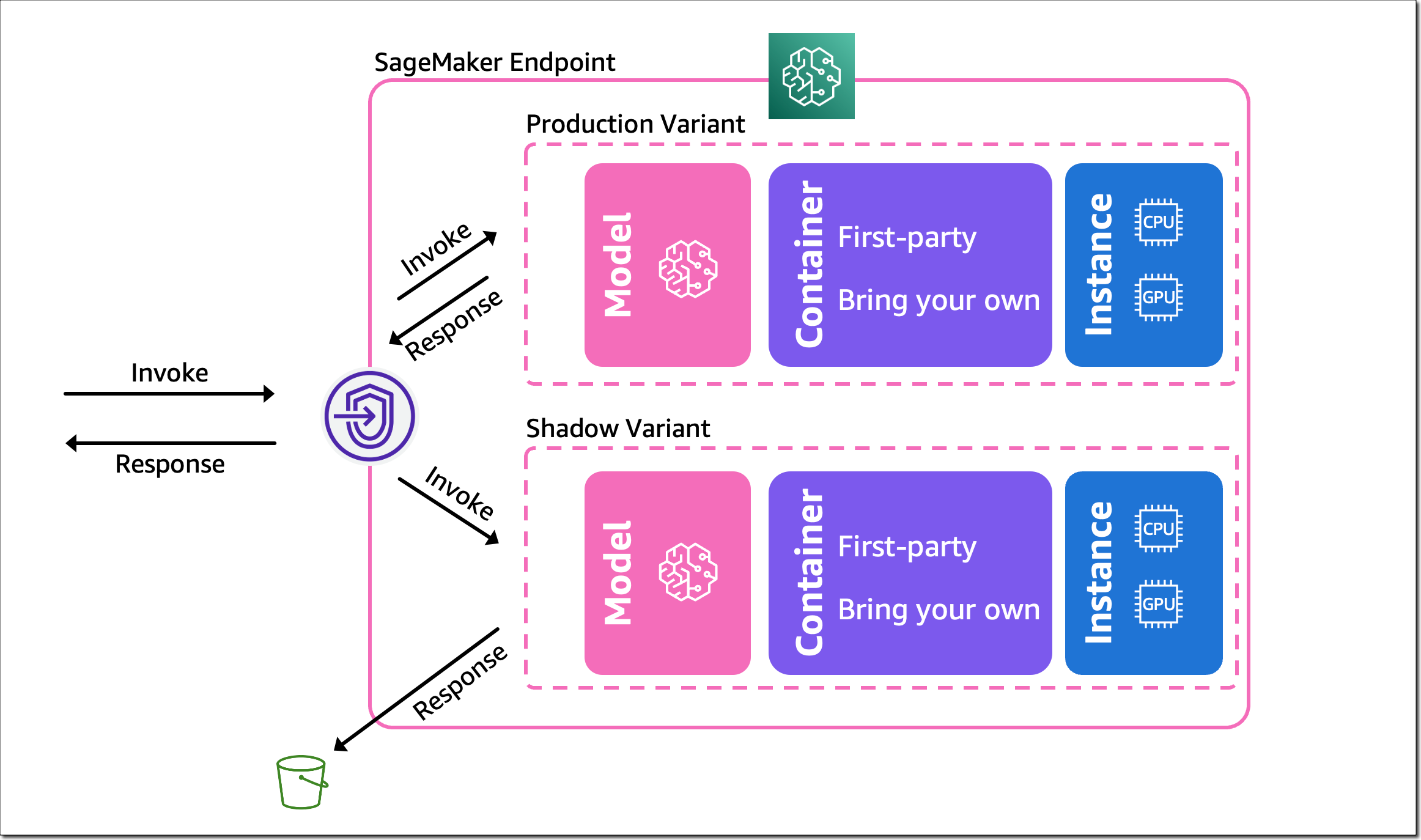
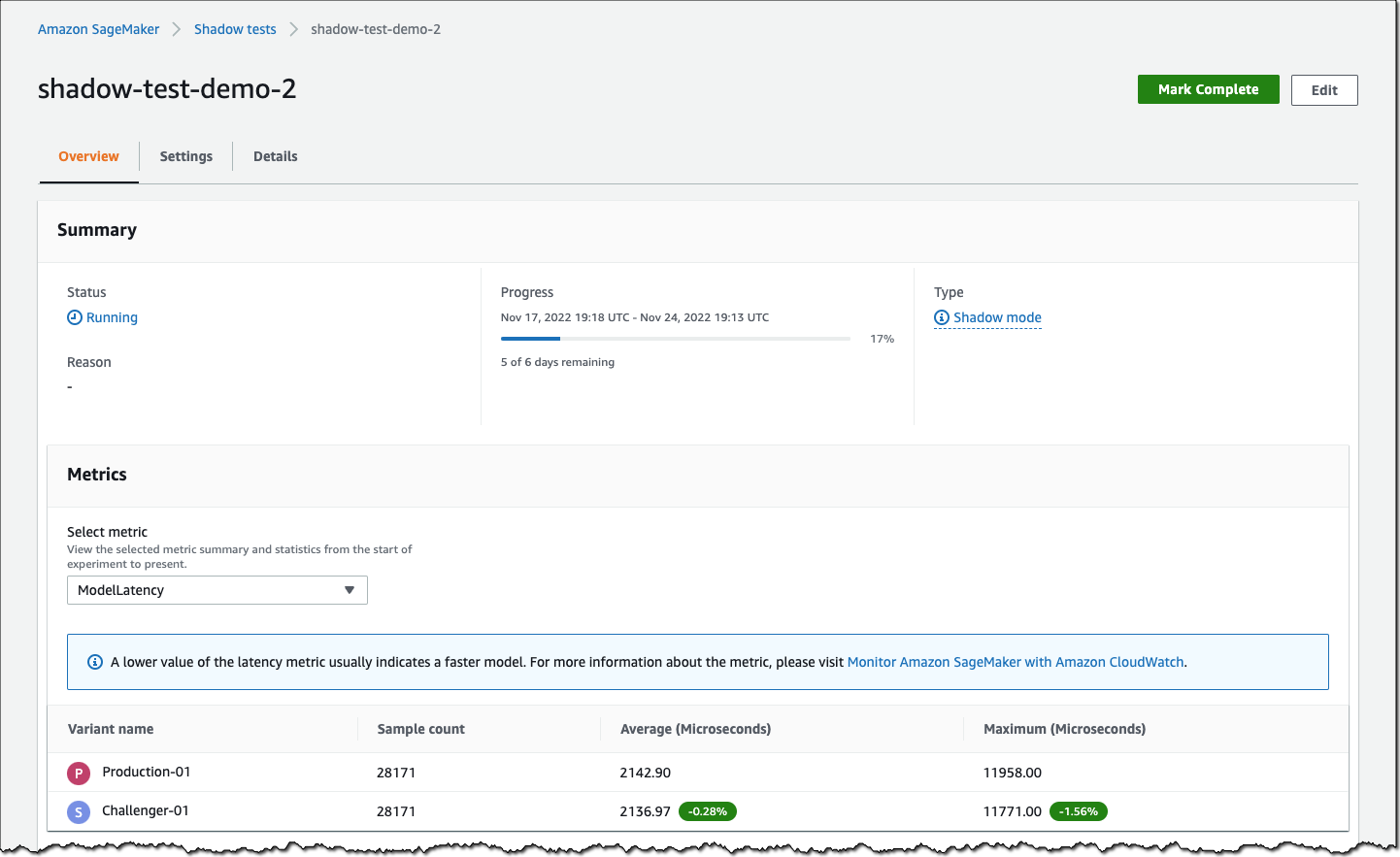
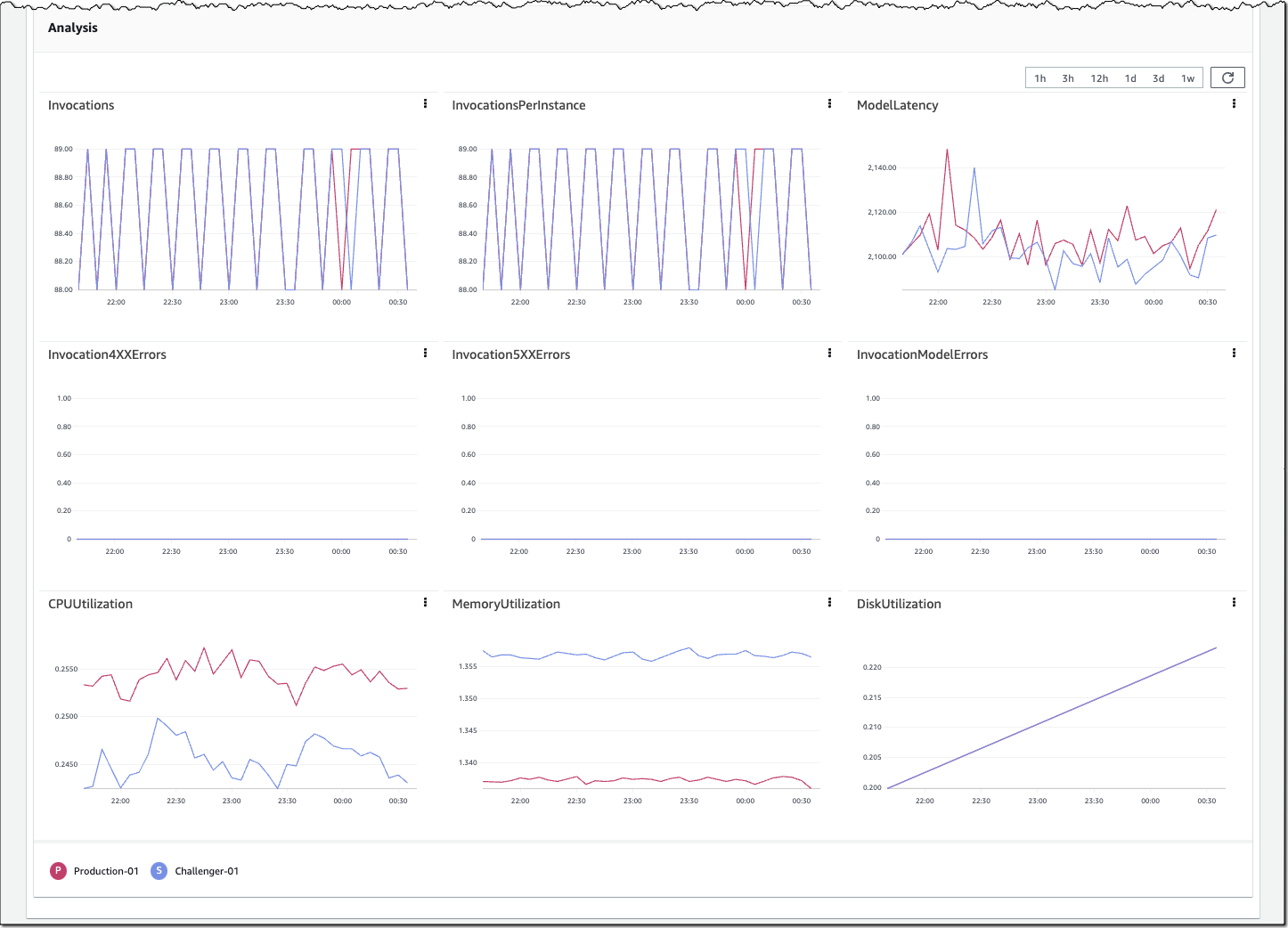
Post Syndicated from Katie Collins original https://aws.amazon.com/blogs/security/the-security-attendees-guide-to-aws-reinvent-2023/

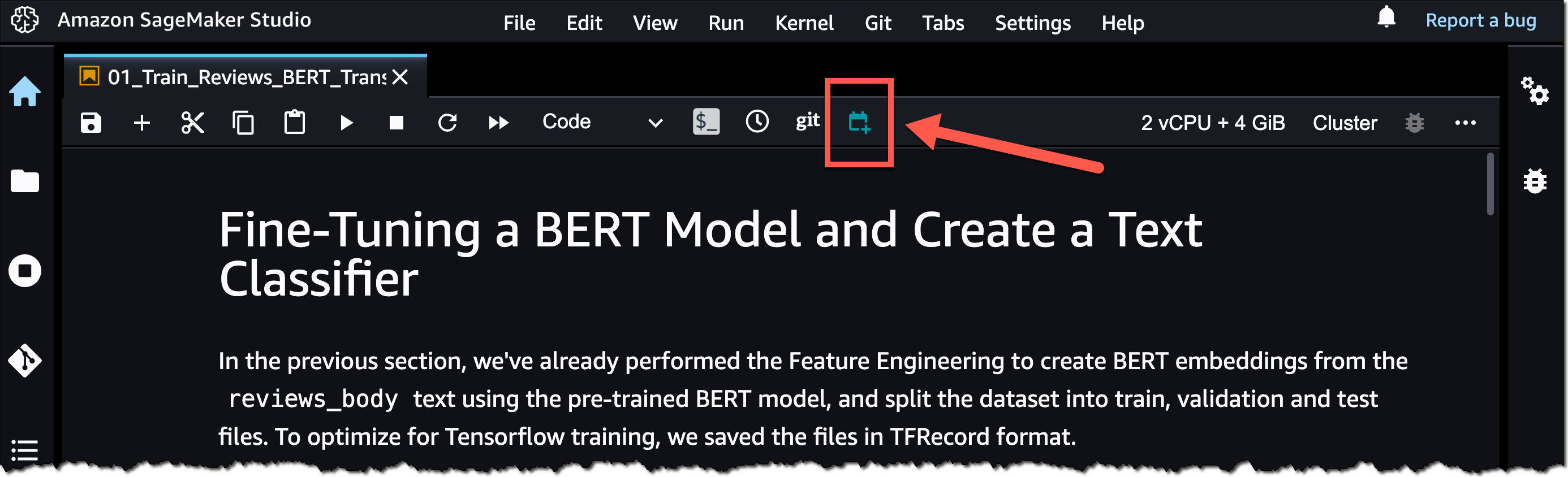
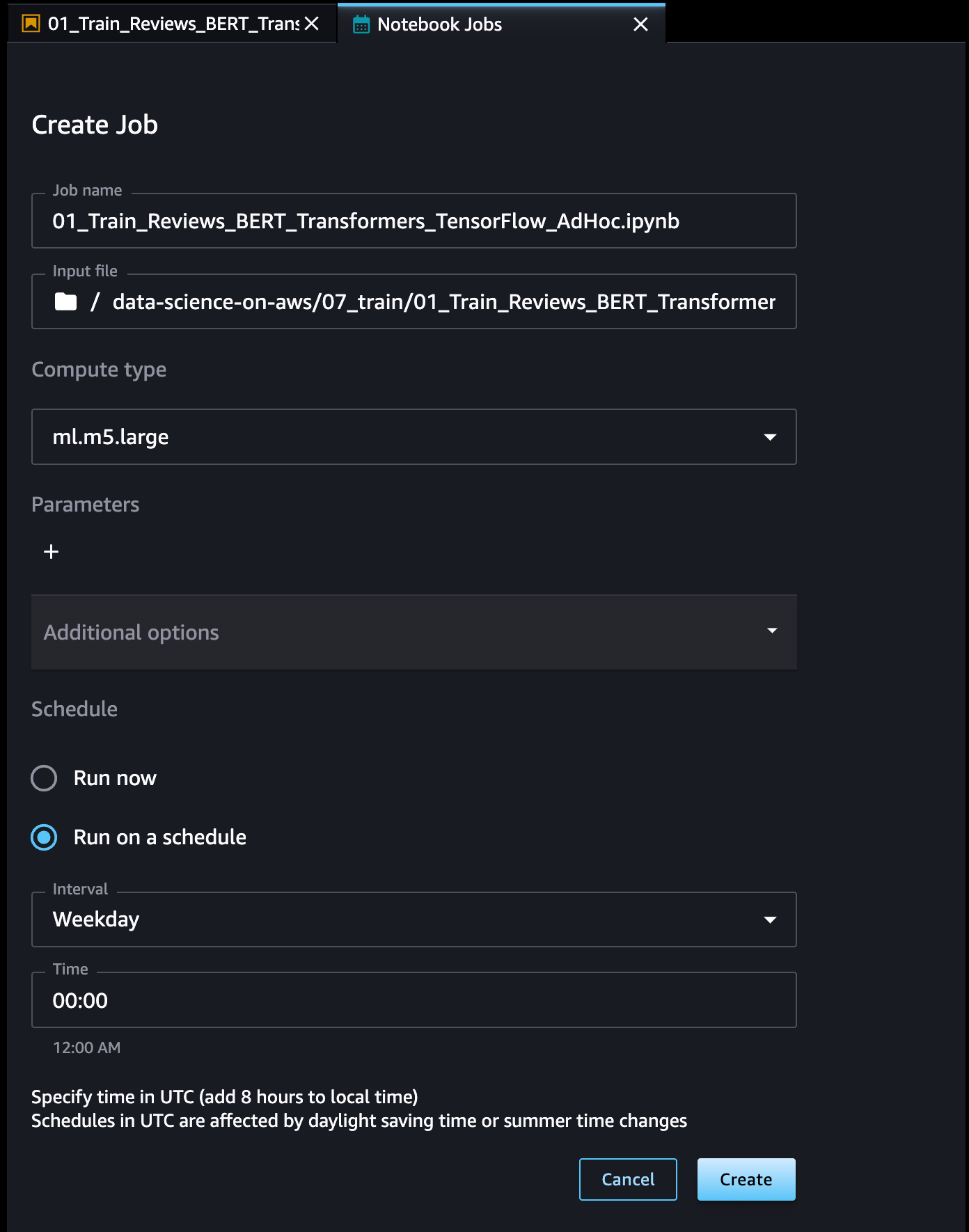
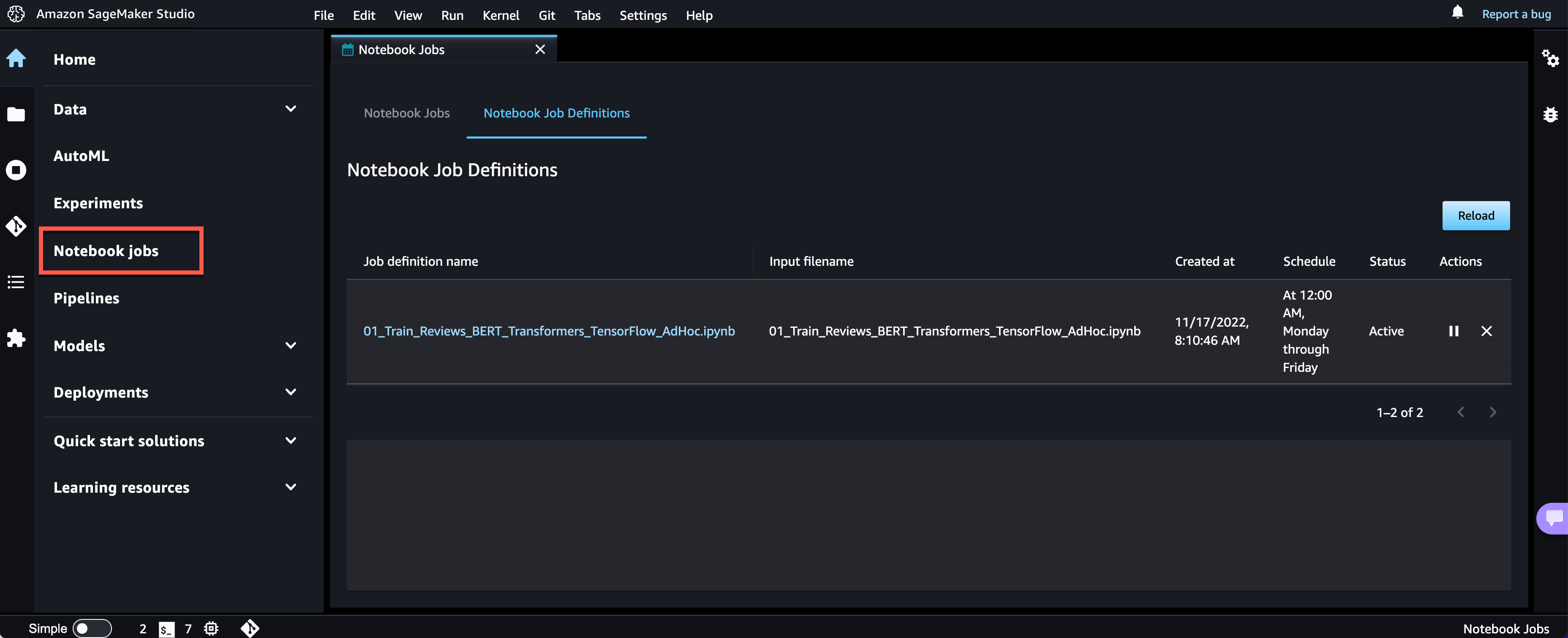
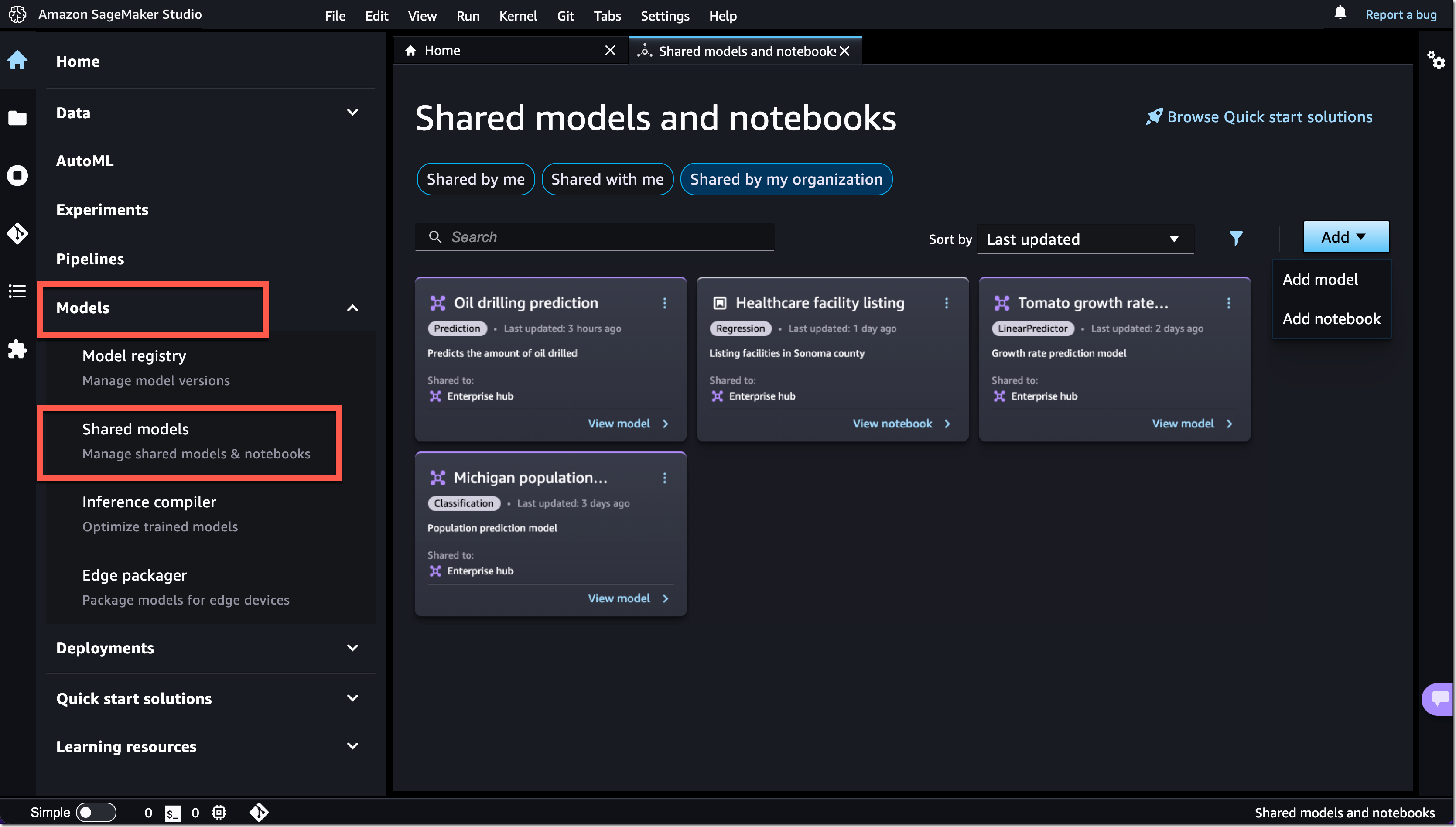
AWS re:Invent 2023 is fast approaching, and we can’t wait to see you in Las Vegas in November. re:Invent offers you the chance to come together with cloud enthusiasts from around the world to hear the latest cloud industry innovations, meet with Amazon Web Services (AWS) experts, and build connections. This post will highlight key security sessions organized by various themes, so you don’t miss any of the newest and most exciting tech innovations and the sessions where you can learn how to put those innovations into practice.
re:Invent offers a diverse range of content tailored to all personas. Seminar-style content includes breakout sessions and innovation talks, delivered by AWS thought leaders. These are curated to focus on topics most critical to our customers’ businesses and spotlight advancements AWS has enabled for them. For more interactive or hands-on content, check out chalk talks, dev chats, builder sessions, workshops, and code talks.
If you plan to attend re:Invent 2023, and you’re interested in connecting with a security, identity, or compliance product team, reach out to your AWS account team.
Sessions for security leaders
Security leaders are always reinventing, tasked with aligning security goals to business objectives and reducing overall risk to the organization. Attend sessions at re:Invent where you can learn from security leadership and thought leaders on how to empower your teams, build sustainable security culture, and move fast and stay secure in an ever-evolving threat landscape.
INNOVATION TALK
- SEC237-INT | Move fast, stay secure: Strategies for the future of security
BREAKOUT SESSIONS
- SEC211 | Sustainable security culture: Empower builders for success
- SEC216 | The AWS Digital Sovereignty Pledge: Control without compromise
- SEC219 | Build secure applications on AWS the well-architected way
- SEC236 | The AWS data-driven perspective on threat landscape trends
- NET201 | Safeguarding infrastructure from DDoS attacks with AWS edge services
The role of generative AI in security
The swift rise of generative artificial intelligence (generative AI) illustrates the need for security practices to quickly adapt to meet evolving business requirements and drive innovation. In addition to the security Innovation Talk (Move fast, stay secure: Strategies for the future of security), attend sessions where you can learn about how large language models can impact security practices, how security teams can support safer use of this technology in the business, and how generative AI can help organizations move security forward.
BREAKOUT SESSIONS
- SEC210 | How security teams can strengthen security using generative AI
- SEC214 | Threat modeling your generative AI workload to evaluate security risk
CHALK TALKS
- SEC317 | Building secure generative AI applications on AWS
- OPN201 | Evolving OSPOs for supply chain security and generative AI
- AIM352 | Securely build generative AI apps and control data with Amazon Bedrock
DEV CHAT
- COM309 | Shaping the future of security on AWS with generative AI
Architecting and operating container workloads securely
The unique perspectives that drive how system builders and security teams perceive and address system security can present both benefits and obstacles to collaboration within a business. Find out more about how you can bolster your container security through sessions focused on best practices, detecting and patching threats and vulnerabilities in containerized environments, and managing risk across your AWS container workloads.
BREAKOUT SESSIONS
- CON325 | Securing containerized workloads on Amazon ECS and AWS Fargate
- CON335 | Securing Kubernetes workloads
- CON320 | Building for the future with AWS serverless services
CHALK TALKS
- SEC332 | Comprehensive vulnerability management across your AWS environments
- FSI307 | Best practices for securing containers and being compliant
- CON334 | Strategies and best practices for securing containerized environments
WORKSHOP
- SEC303 | Container threat detection with AWS security services
BUILDER SESSION
- SEC330 | Patch it up: Building a vulnerability management solution
Zero Trust
At AWS, we consider Zero Trust a security model—not a product. Zero Trust requires users and systems to strongly prove their identities and trustworthiness, and enforces fine-grained identity-based authorization rules before allowing access to applications, data, and other systems. It expands authorization decisions to consider factors like the entity’s current state and the environment. Learn more about our approach to Zero Trust in these sessions.
INNOVATION TALK
- SEC237-INT | Move fast, stay secure: Strategies for the future of security
CHALK TALKS
- WPS304 | Using Zero Trust to reduce security risk for the public sector
- OPN308 | Build and operate a Zero Trust Apache Kafka cluster
- NET312 | Connecting and securing services with Amazon VPC Lattice
- NET315 | Building Zero Trust architectures using AWS Verified Access
WORKSHOPS
- SEC302 | Zero Trust architecture for service-to-service workloads
Managing identities and encrypting data
At AWS, security is our top priority. AWS provides you with features and controls to encrypt data at rest, in transit, and in memory. We build features into our services that make it easier to encrypt your data and control user and application access to data. Explore these topics in depth during these sessions.
BREAKOUT SESSIONS
- SEC209 | Modernize authorization: Lessons from cryptography and authentication
- SEC336 | Spur productivity with options for identity and access
- SEC333 | Better together: Using encryption & authorization for data protection
CHALK TALKS
- SEC221 | Centrally manage application secrets with AWS Secrets Manager
- SEC322 | Integrate apps with Amazon Cognito and Amazon Verified Permissions
- SEC223 | Optimize your workforce identity strategy from top to bottom
WORKSHOPS
- SEC247 | Practical data protection and risk assessment for sensitive workloads
- SEC203 | Refining IAM permissions like an expert
For a full view of security content, including hands-on learning and interactive sessions, explore the AWS re:Invent catalog and under Topic, filter on Security, Compliance, & Identity. Not able to attend in-person? Livestream keynotes and leadership sessions for free by registering for the virtual-only pass!
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.