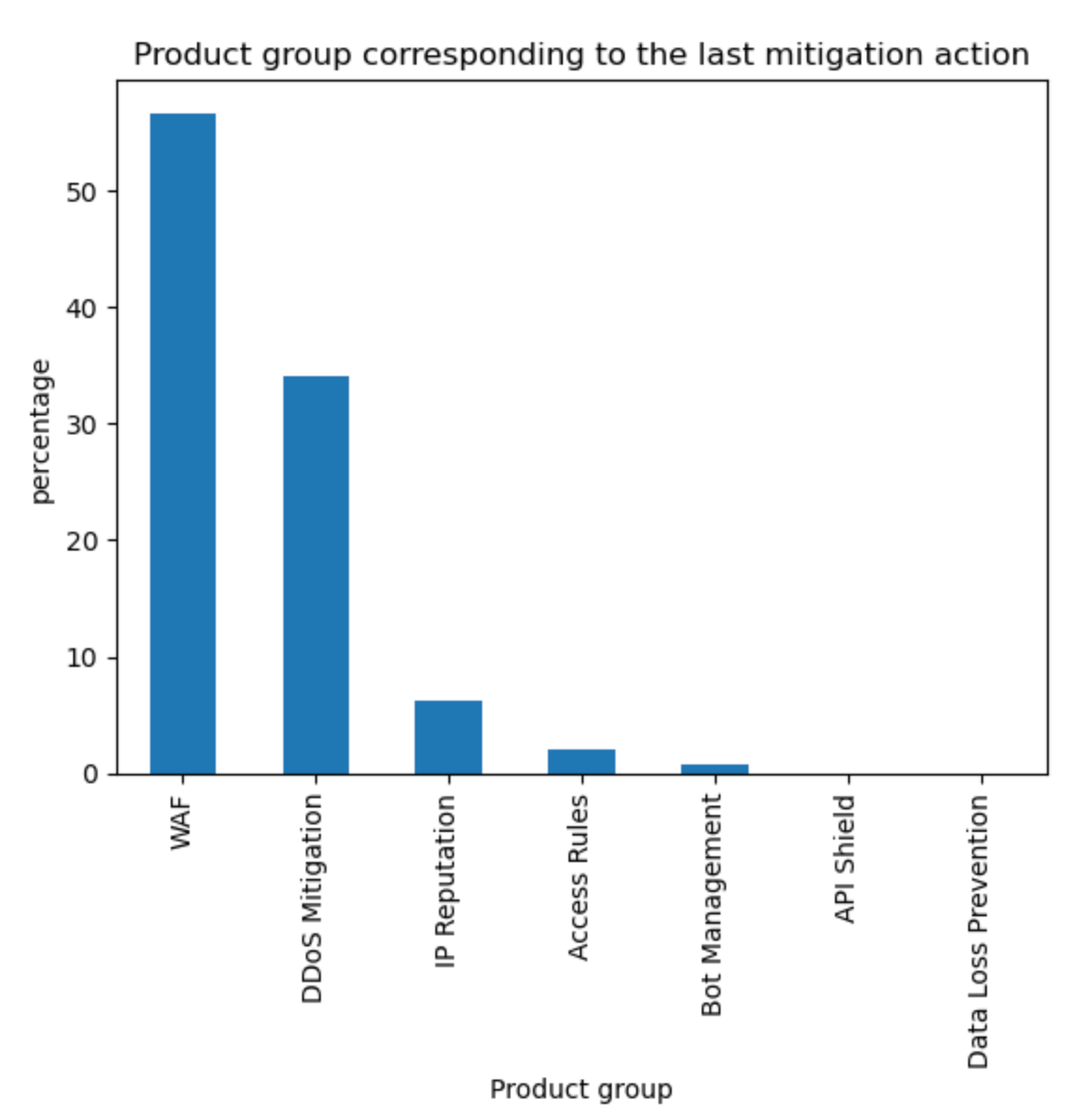
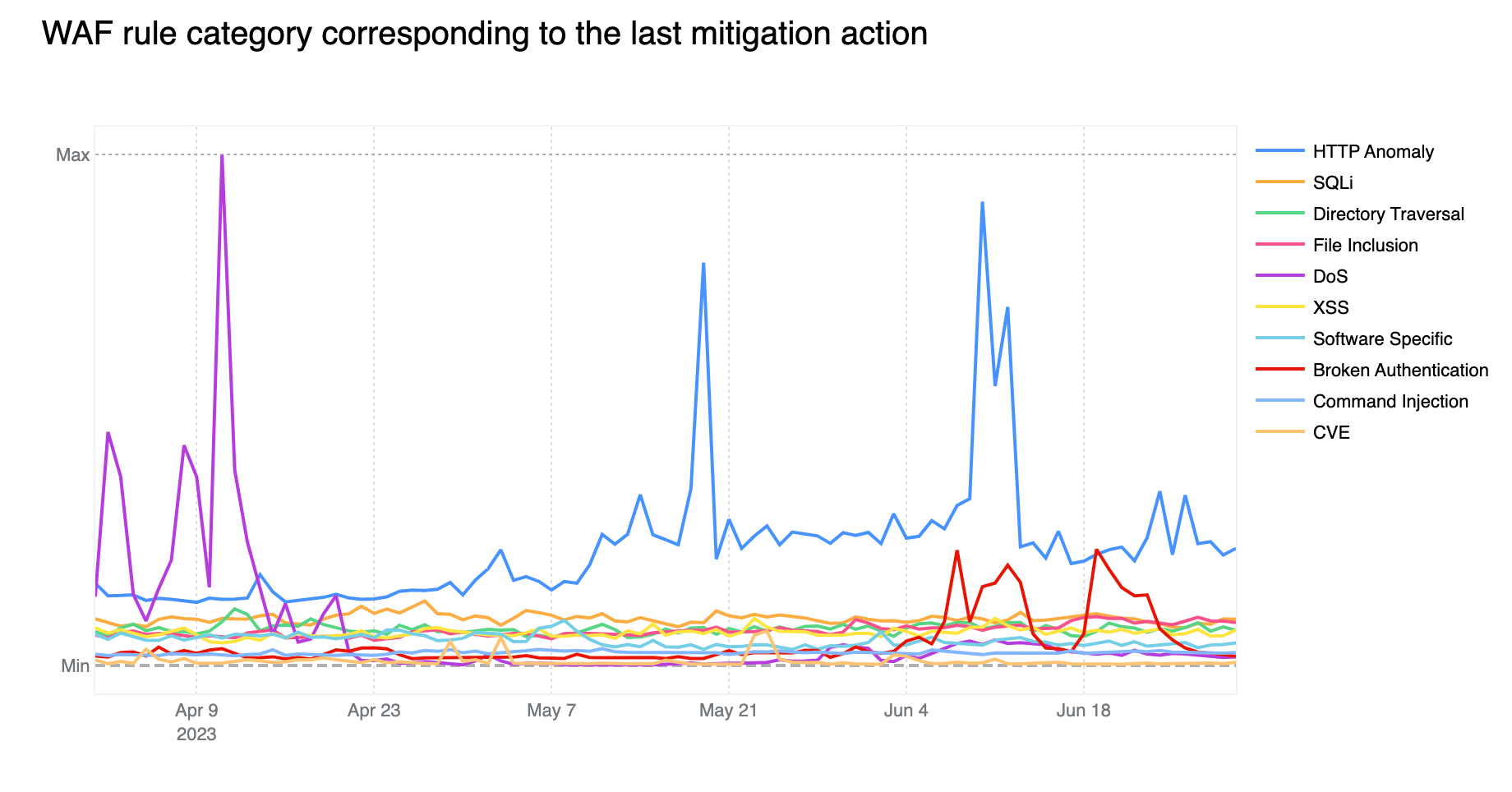
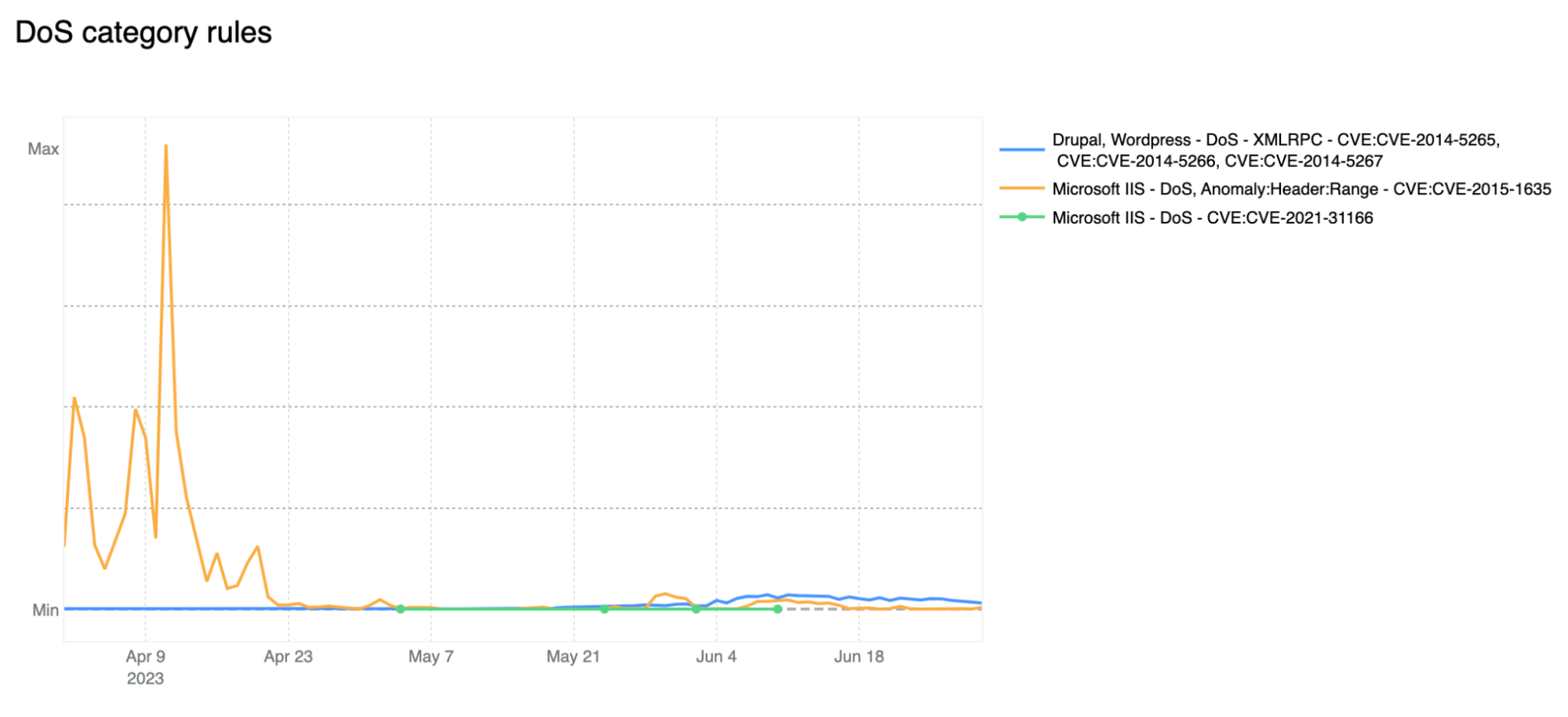
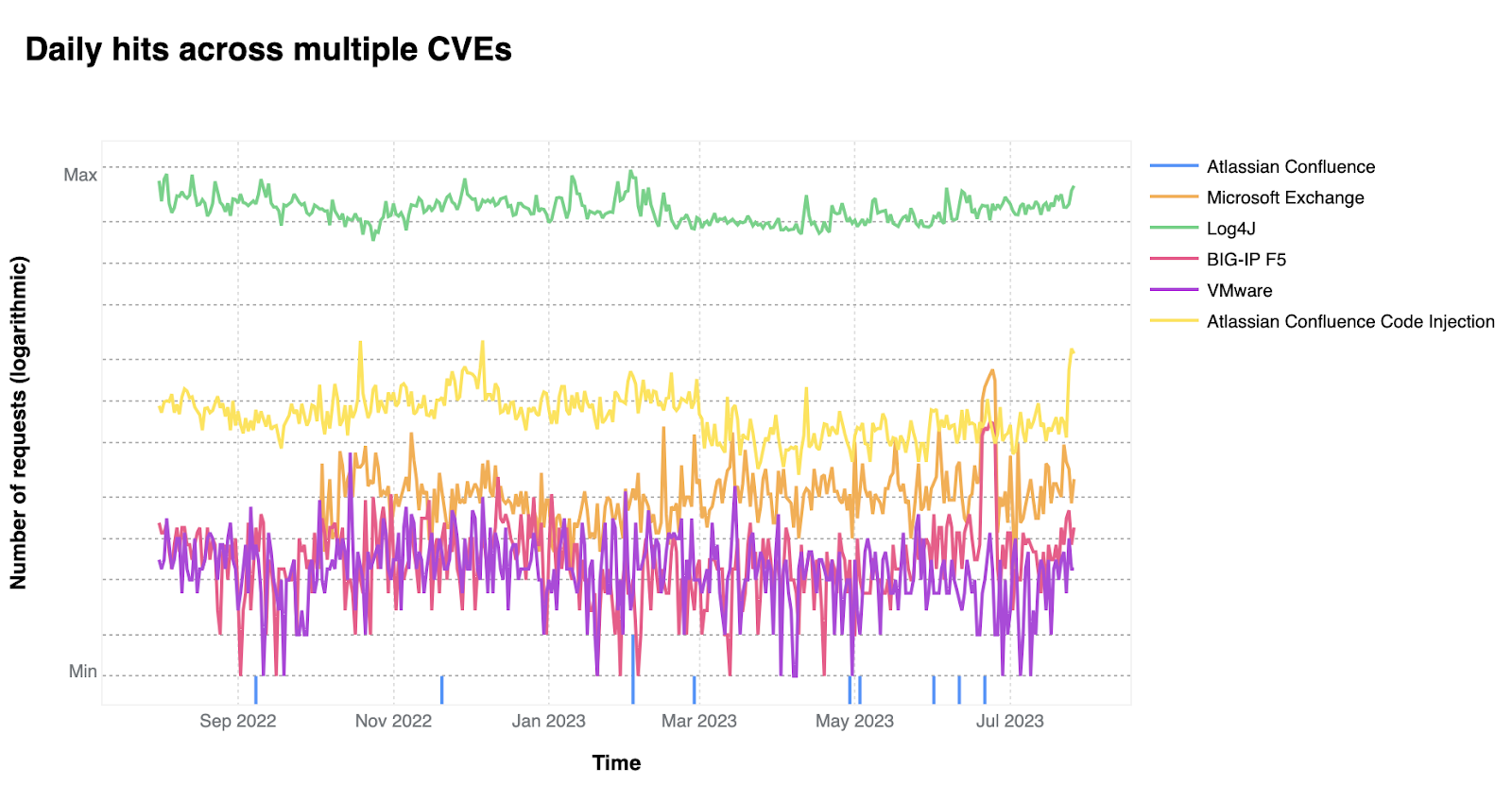
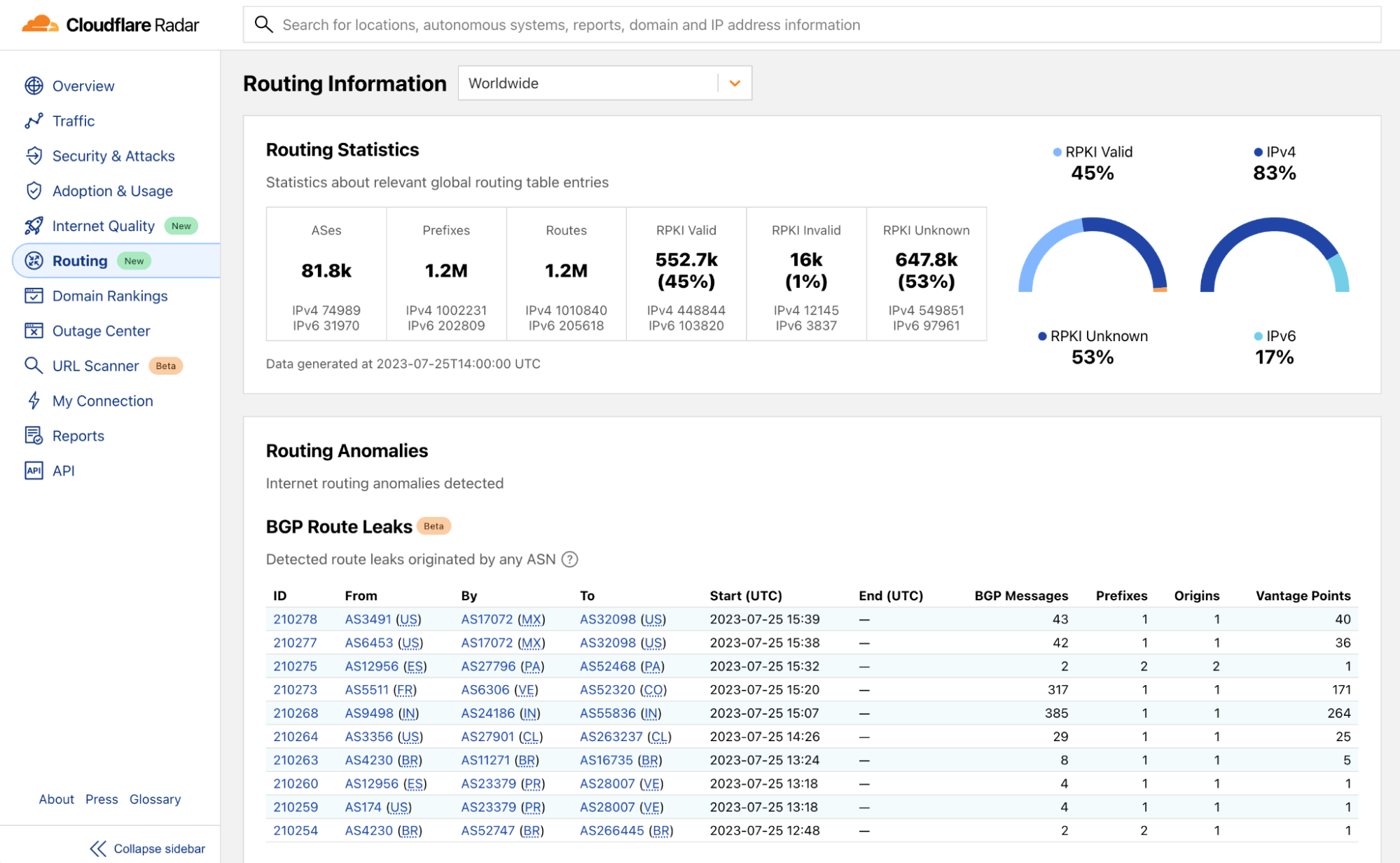
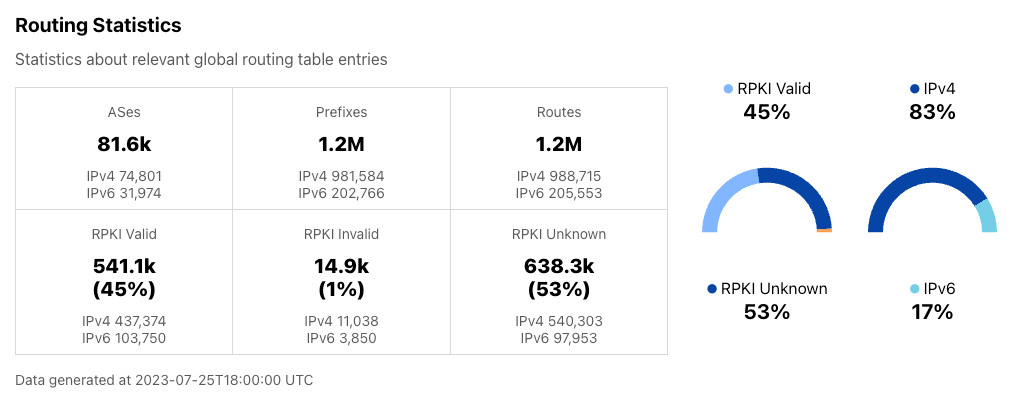
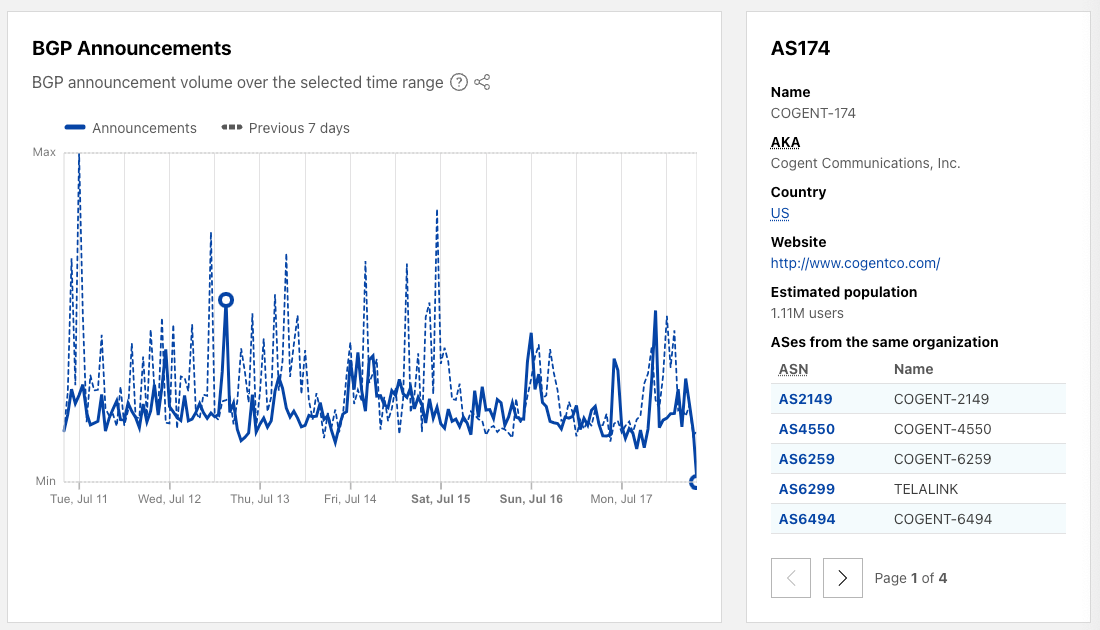
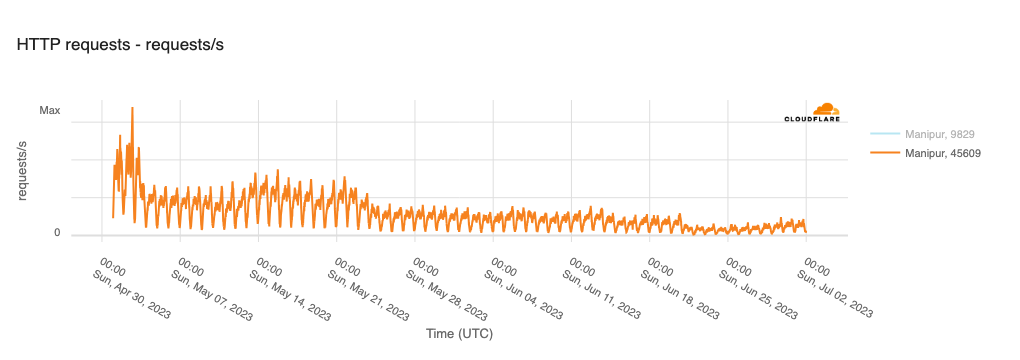
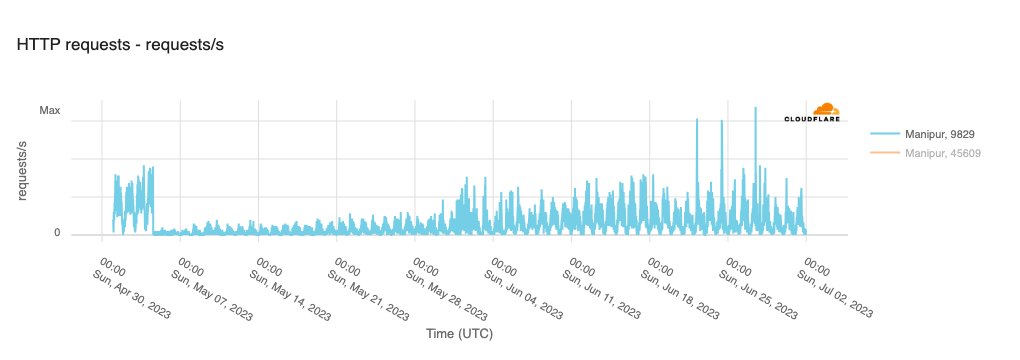
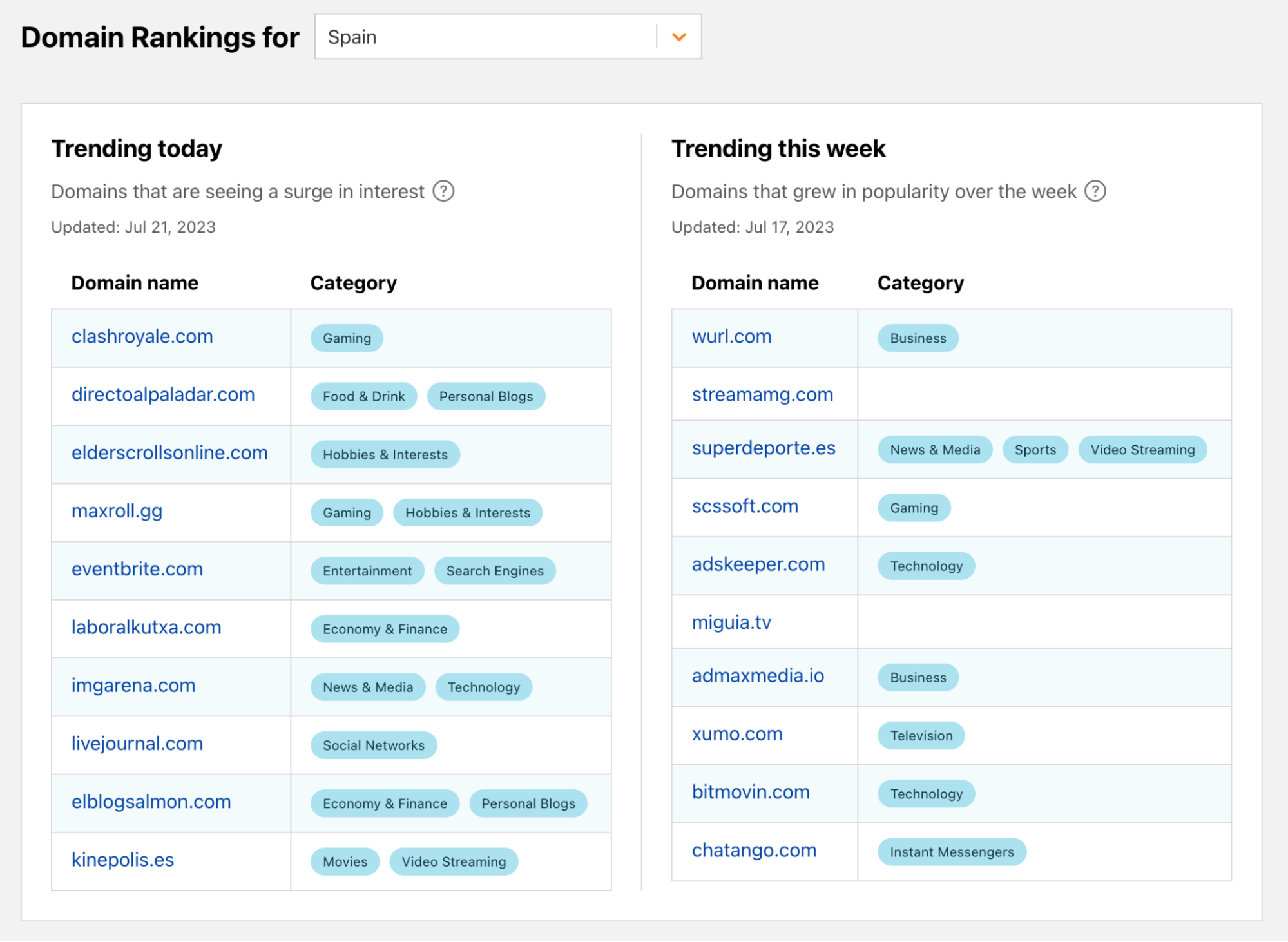
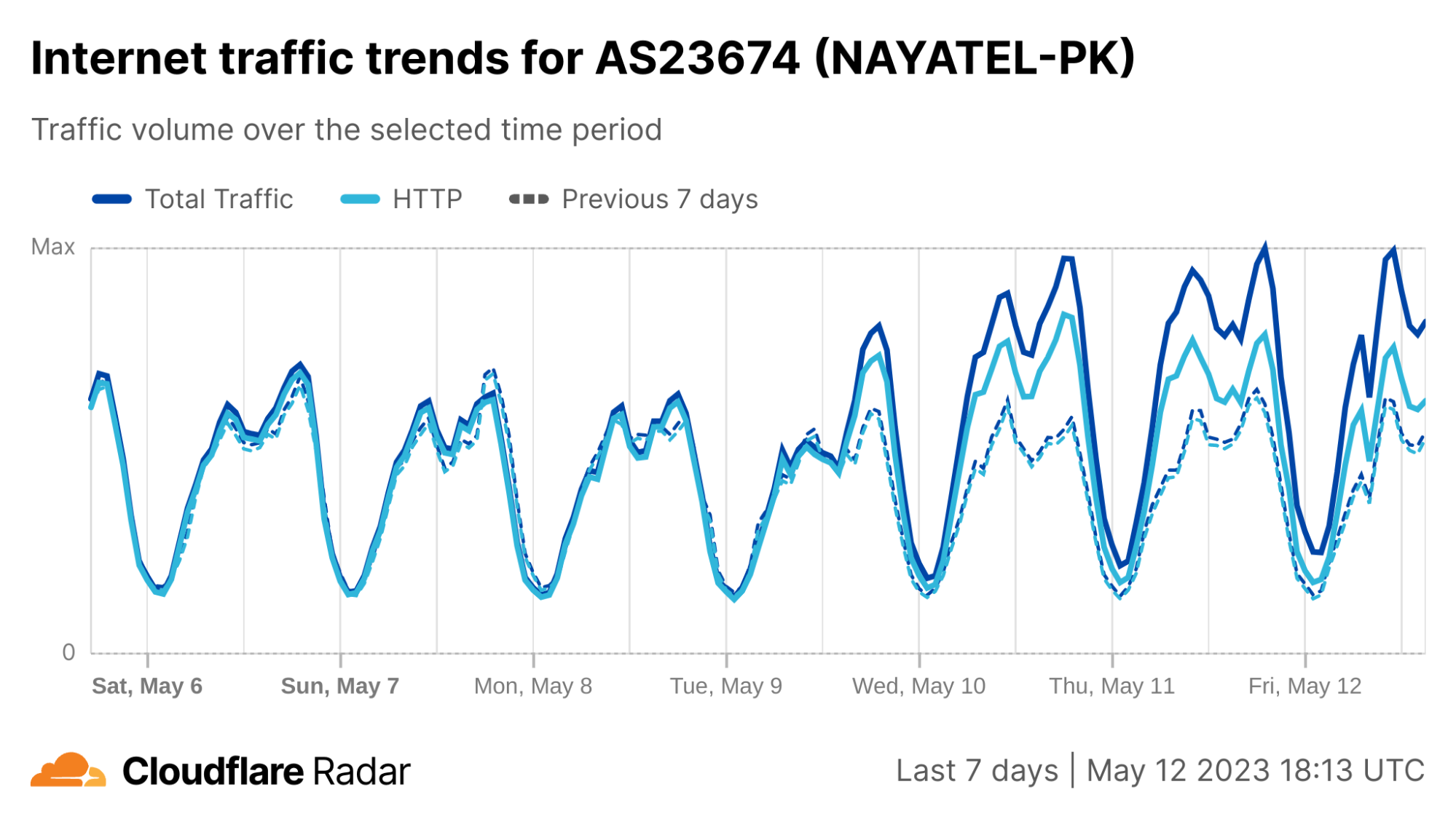
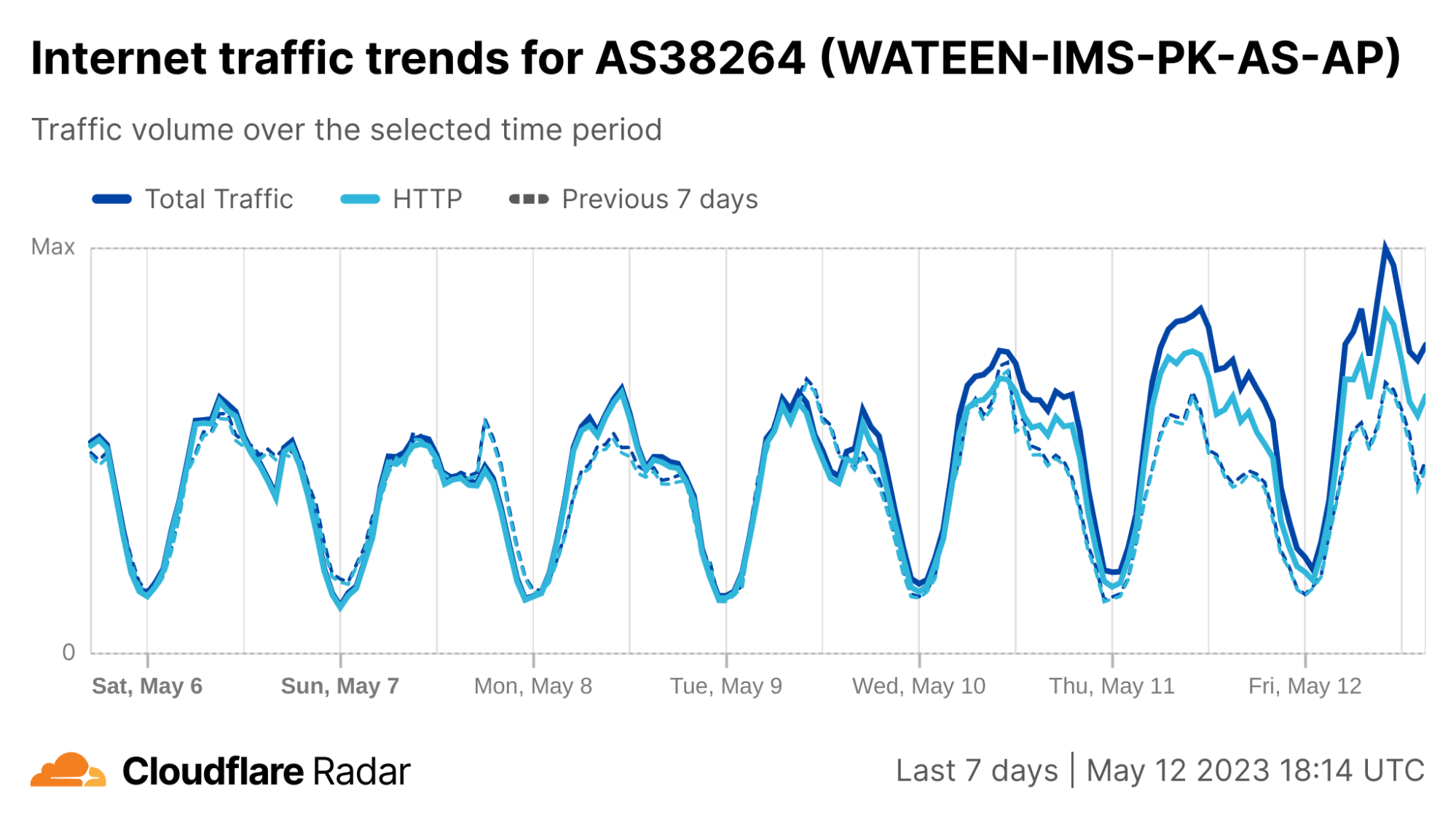
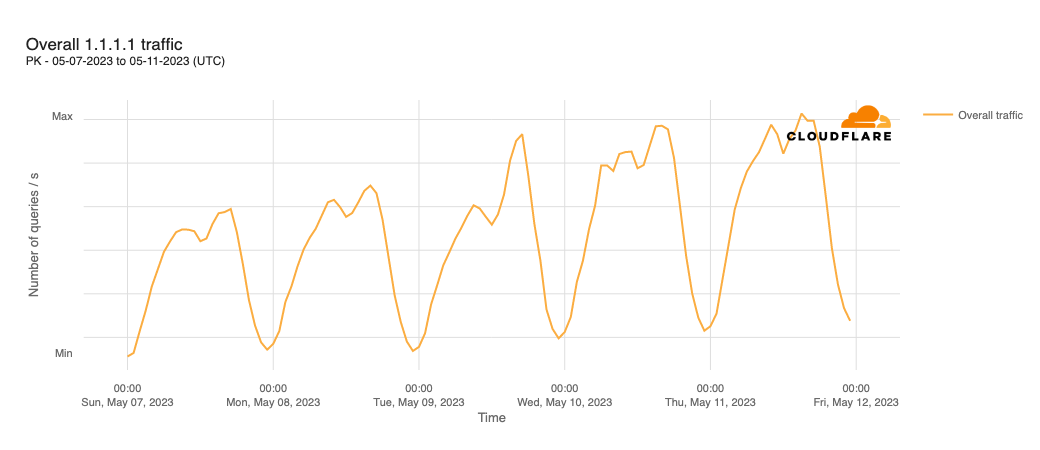
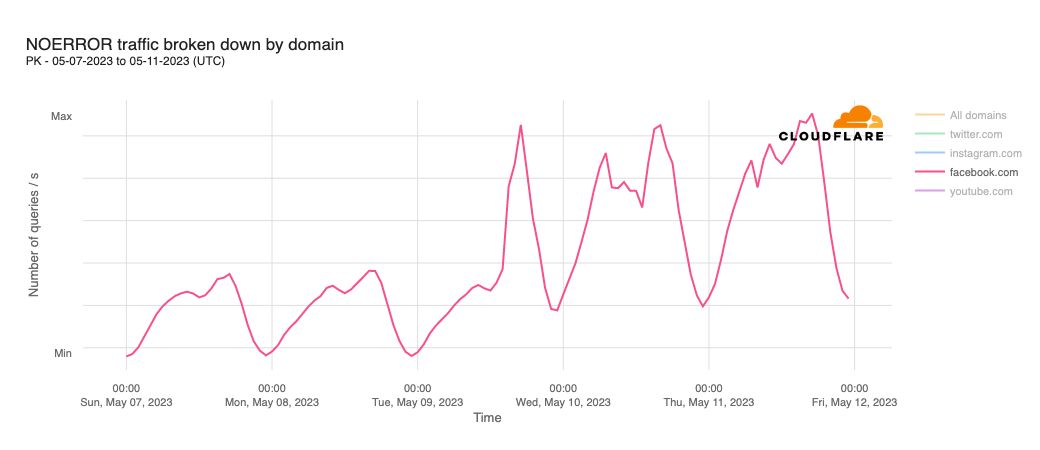
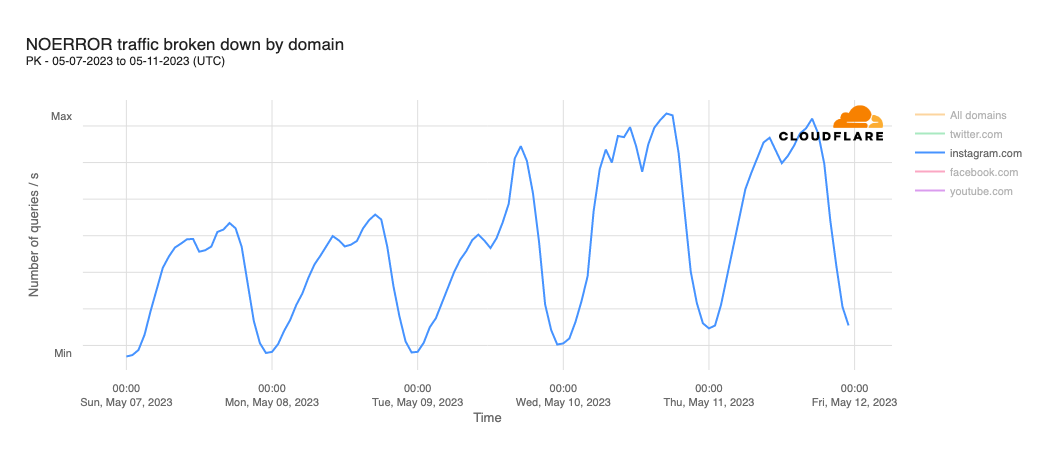
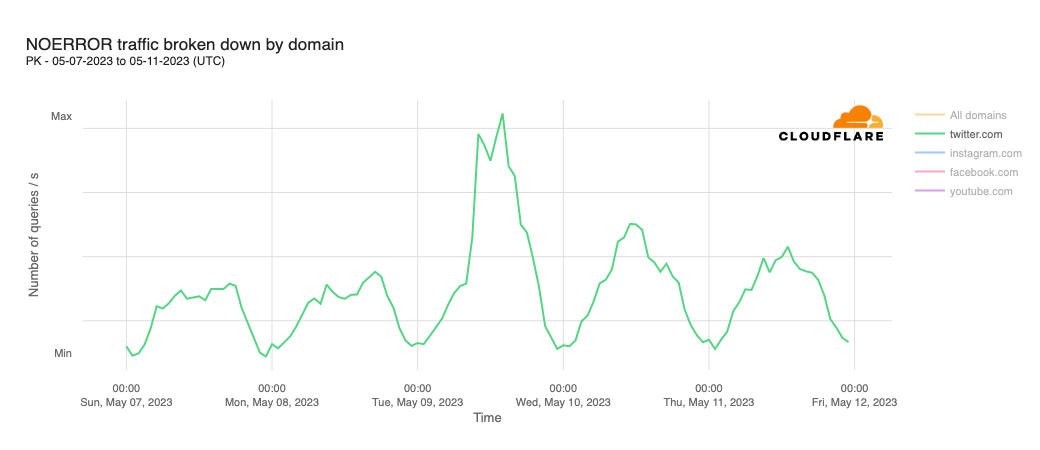
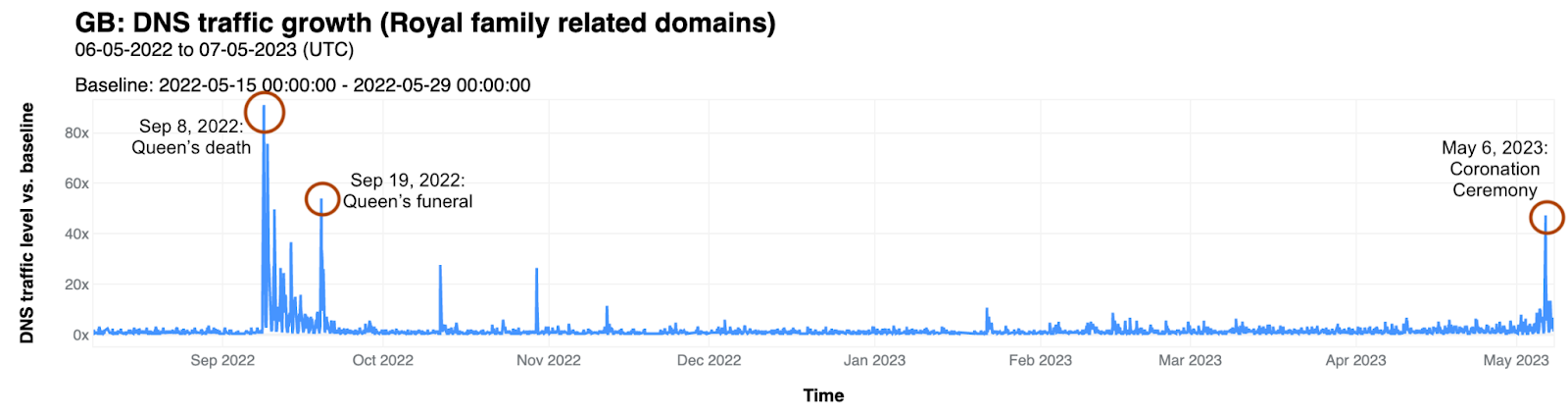
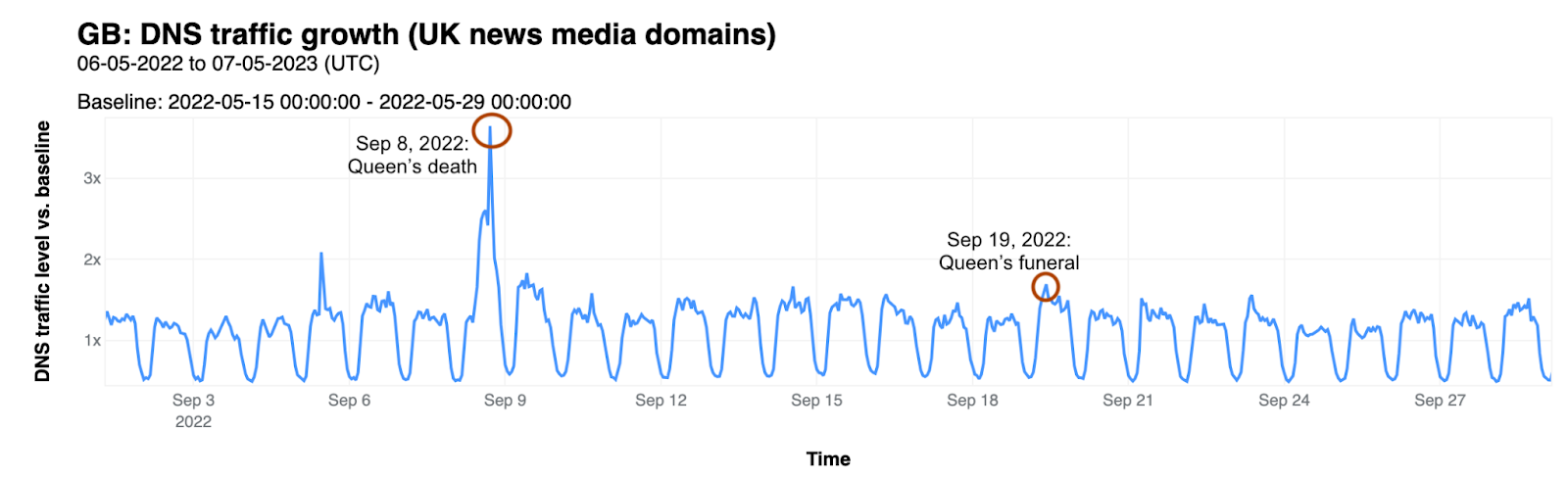
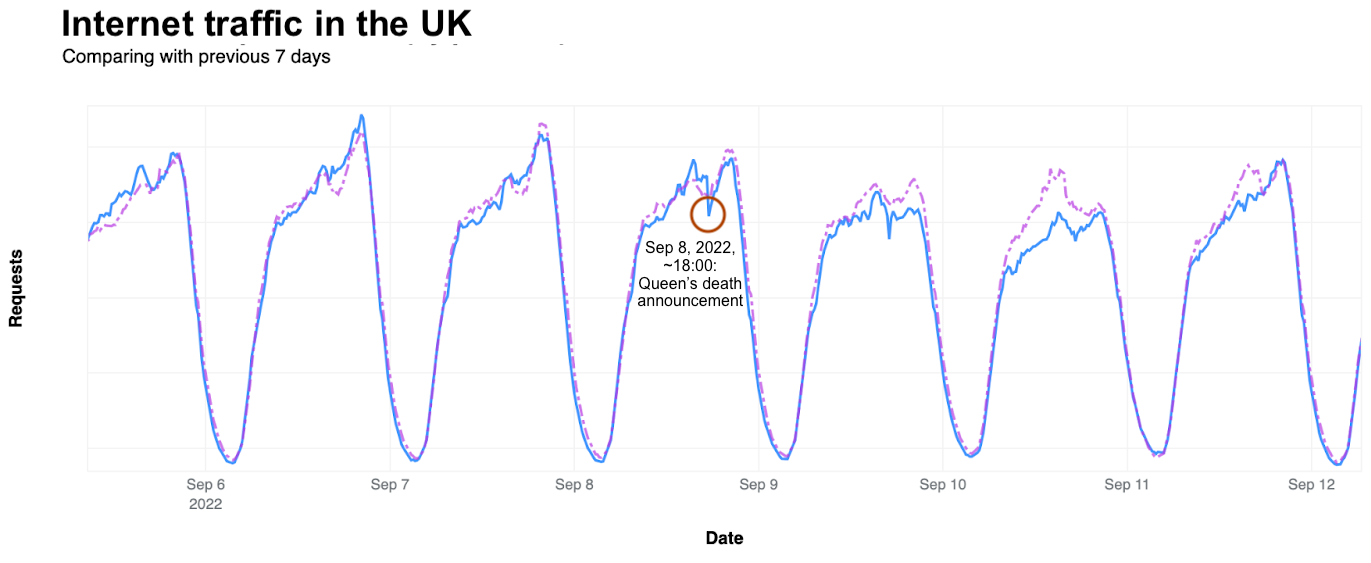
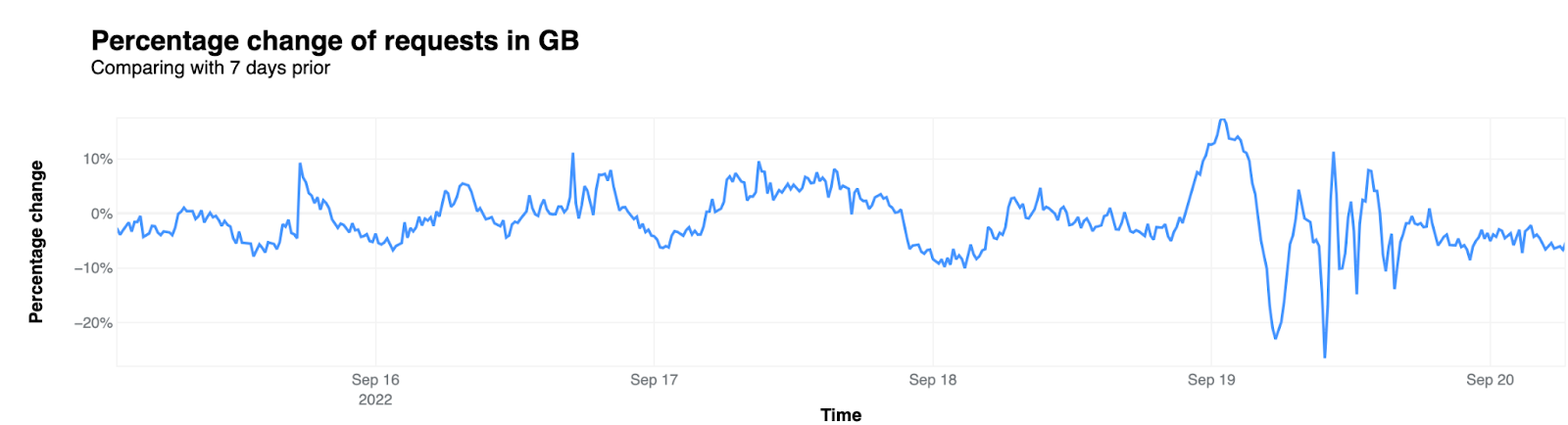
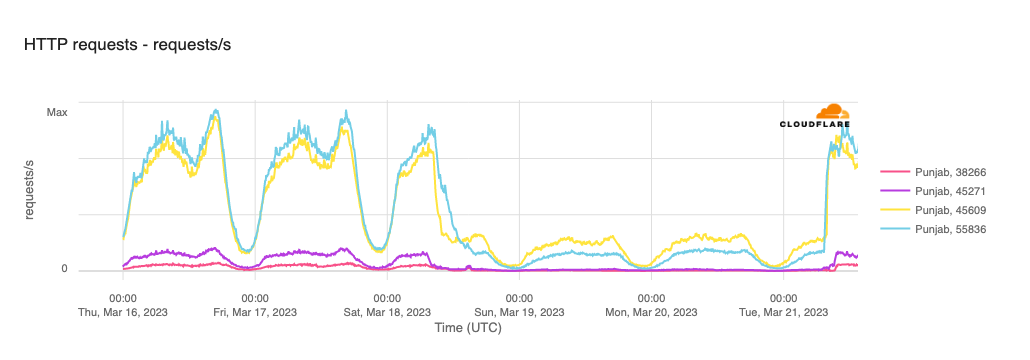
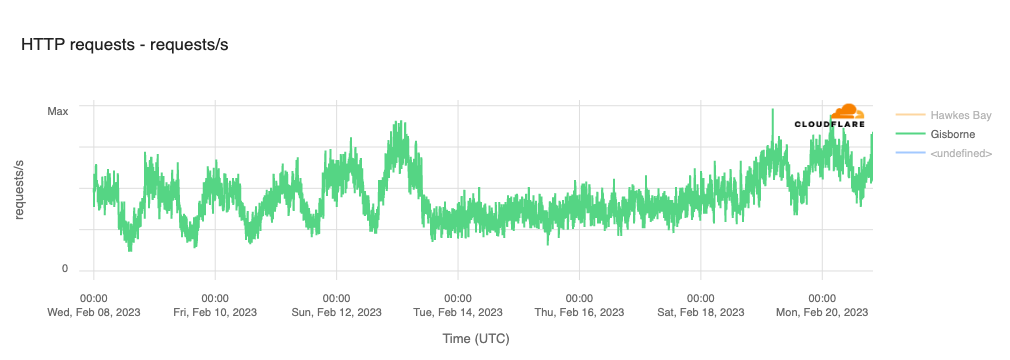
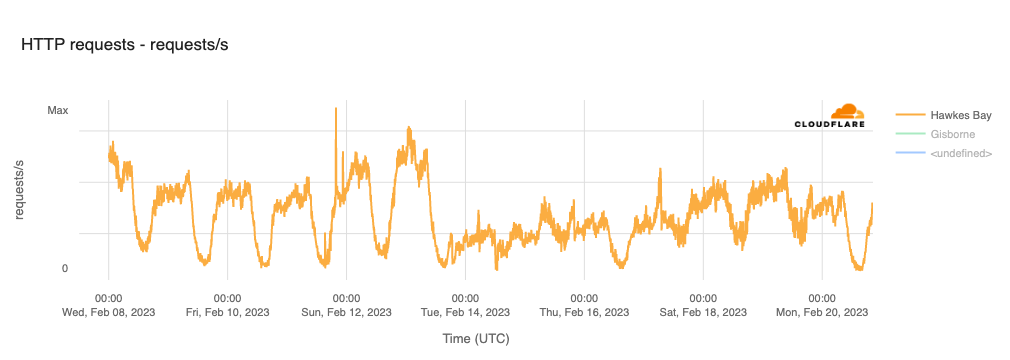
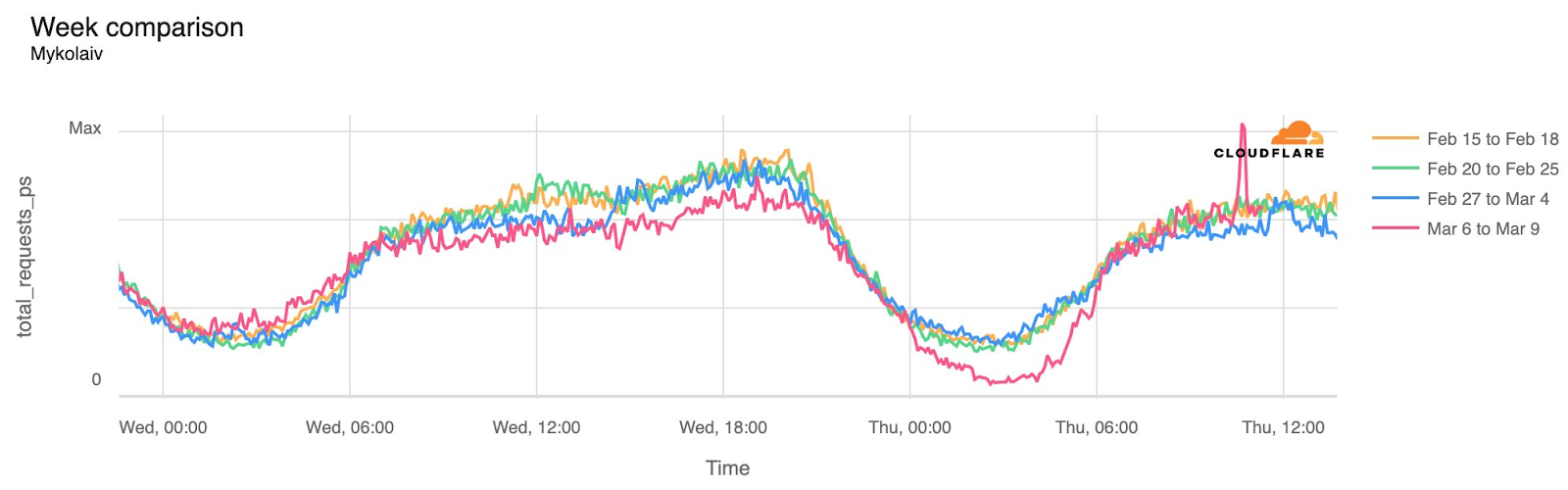
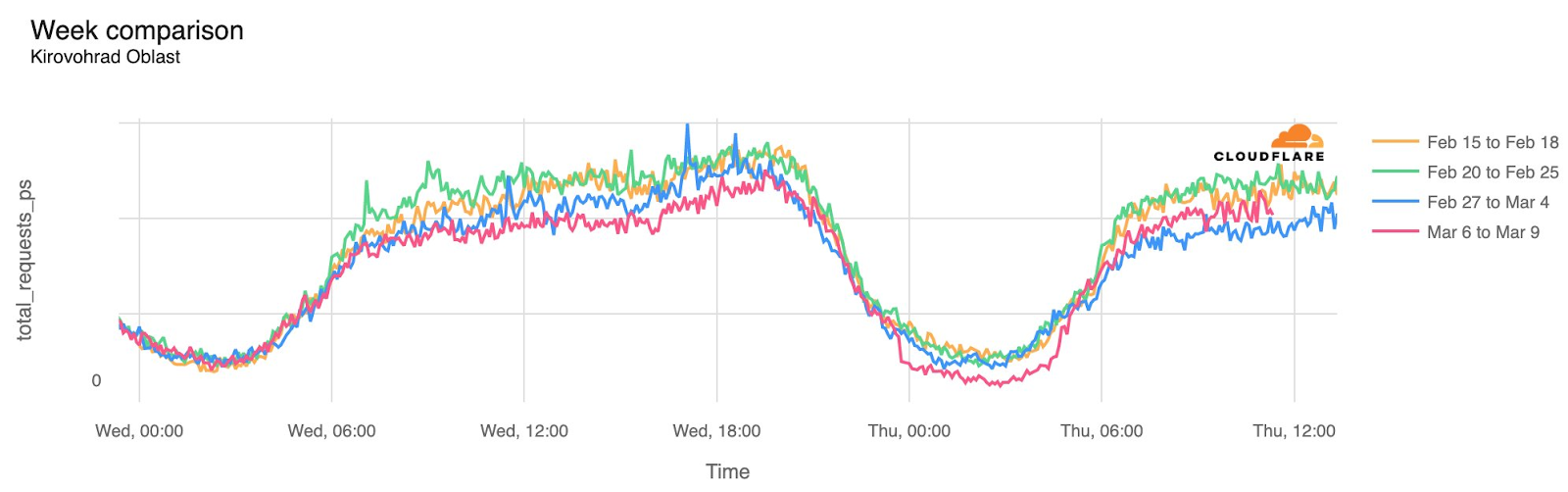
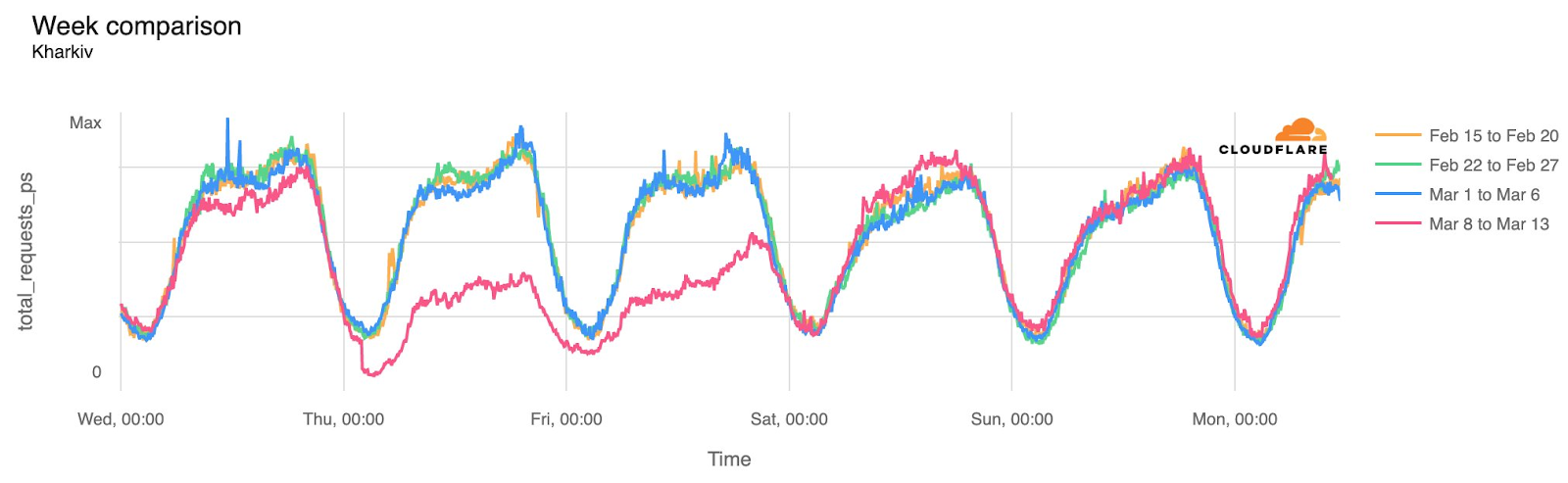
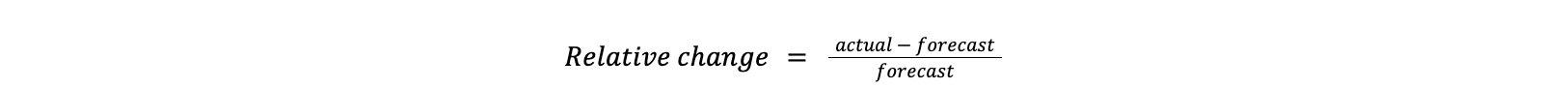In order for one device to talk to other devices on the Internet using the aptly named Internet Protocol (IP), it must first be assigned a unique numerical address. What this address looks like depends on the version of IP being used: IPv4 or IPv6.
IPv4 was first deployed in 1983. It’s the IP version that gave birth to the modern Internet and still remains dominant today. IPv6 can be traced back to as early as 1998, but only in the last decade did it start to gain significant traction — rising from less than 1% to somewhere between 30 and 40%, depending on who’s reporting and what and how they’re measuring.
With the growth in connected devices far exceeding the number of IPv4 addresses available, and its costs rising, the much larger address space provided by IPv6 should have made it the dominant protocol by now. However, as we’ll see, this is not the case.
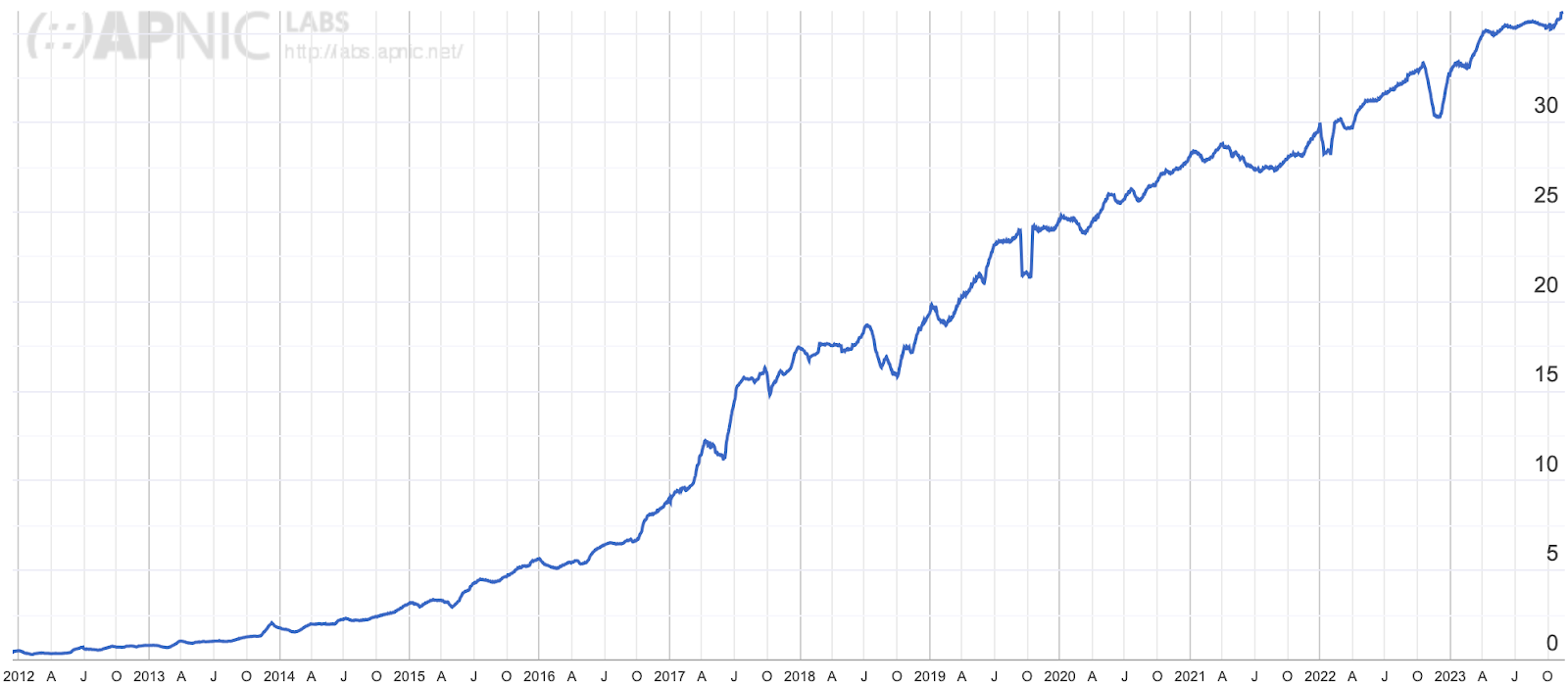
Cloudflare has been a strong advocate of IPv6 for many years and, through Cloudflare Radar, we’ve been closely following IPv6 adoption across the Internet. At three years old, Radar is still a relatively recent platform. To go further back in time, we can briefly turn to our friends at APNIC1 — one of the five Regional Internet Registries (RIRs). Through their data, going back to 2012, we can see that IPv6 experienced a period of seemingly exponential growth until mid-2017, after which it entered a period of linear growth that’s still ongoing:
IPv6 adoption is slowed down by the lack of compatibility between both protocols — devices must be assigned both an IPv4 and an IPv6 address — along with the fact that virtually all devices on the Internet still support IPv4. Nevertheless, IPv6 is critical for the future of the Internet, and continued effort is required to increase its deployment.
Cloudflare Radar, like APNIC and most other sources today, publishes numbers that primarily reflect the extent to which Internet Service Providers (ISPs) have deployed IPv6: the client side. It’s a very important angle, and one that directly impacts end users, but there’s also the other end of the equation: the server side.
With this in mind, we invite you to follow us on a quick experiment where we aim for a glimpse of server side IPv6 adoption, and how often clients are actually (or likely) able to talk to servers over IPv6. We’ll rely on DNS for this exploration and, as they say, the results may surprise you.
IPv6 Adoption on the Client Side (from HTTP)
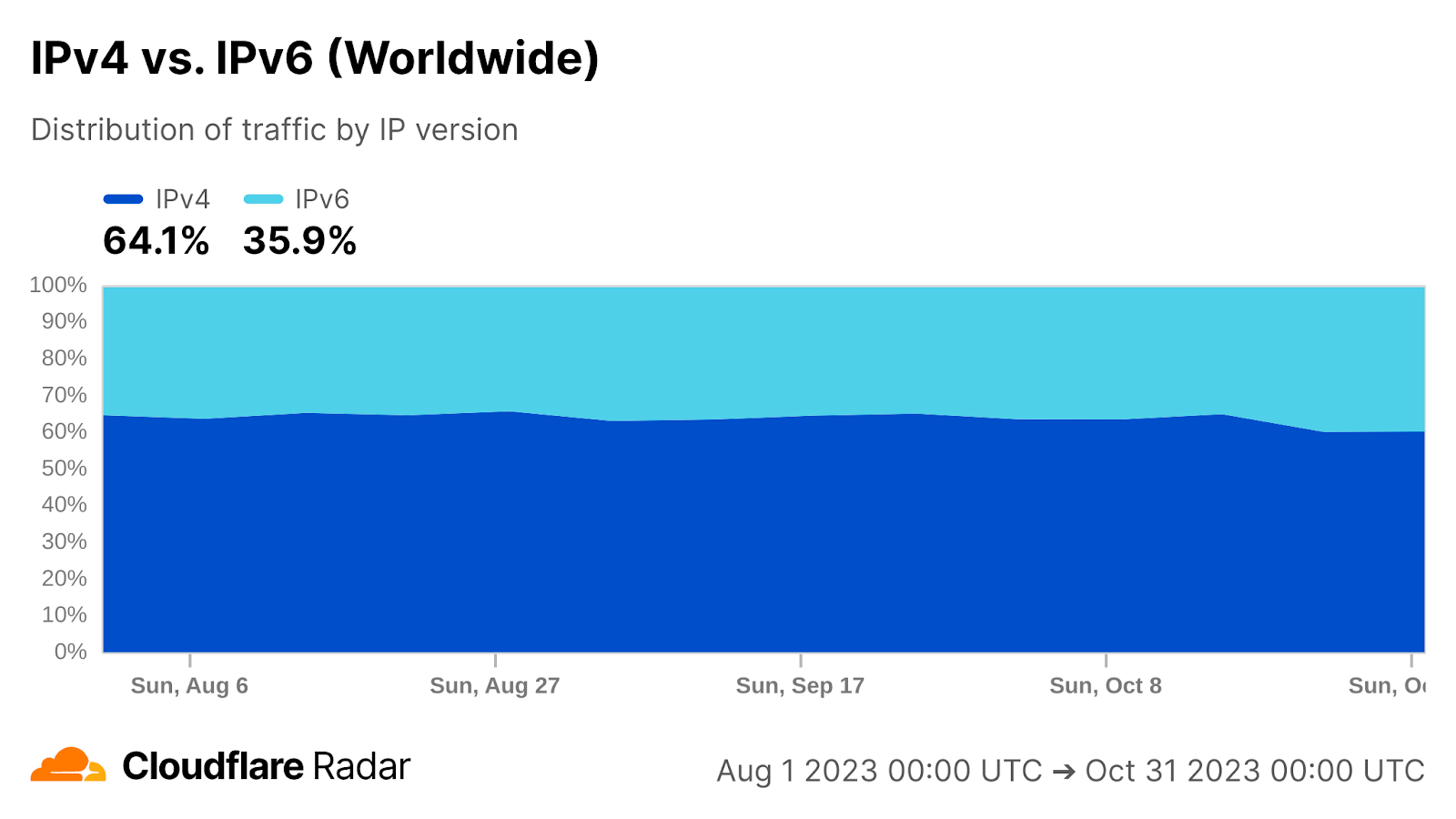
By the end of October 2023, from Cloudflare’s perspective, IPv6 adoption across the Internet was at roughly 36% of all traffic, with slight variations depending on the time of day and day of week. When excluding bots the estimate goes up to just over 46%, while excluding humans pushes it down close to 24%. These numbers refer to the share of HTTP requests served over IPv6 across all IPv6-enabled content (the default setting).
For this exercise, what matters most is the number for both humans and bots. There are many reasons for the adoption gap between both kinds of traffic — from varying levels of IPv6 support in the plethora of client software used, to varying levels of IPv6 deployment inside the many networks where traffic comes from, to the varying size of such networks, etc. — but that’s a rabbit hole for another day. If you’re curious about the numbers for a particular country or network, you can find them on Cloudflare Radar and in our Year in Review report for 2023.
It Takes Two to Dance
You, the reader, might point out that measuring the client side of the client-server equation only tells half the story: for an IPv6-capable client to establish a connection with a server via IPv6, the server must also be IPv6-capable.
This raises two questions:
What’s the extent of IPv6 adoption on the server side?
How well does IPv6 adoption on the client side align with adoption on the server side?
There are several possible answers, depending on whether we’re talking about users, devices, bytes transferred, and so on. We’ll focus on connections (it will become clear why in a moment), and the combined question we’re asking is:
How often can an IPv6-capable client use IPv6 when connecting to servers on the Internet, under typical usage patterns?
Typical usage patterns include people going about their day visiting some websites more often than others or automated clients calling APIs. We’ll turn to DNS to get this perspective.
Enter DNS
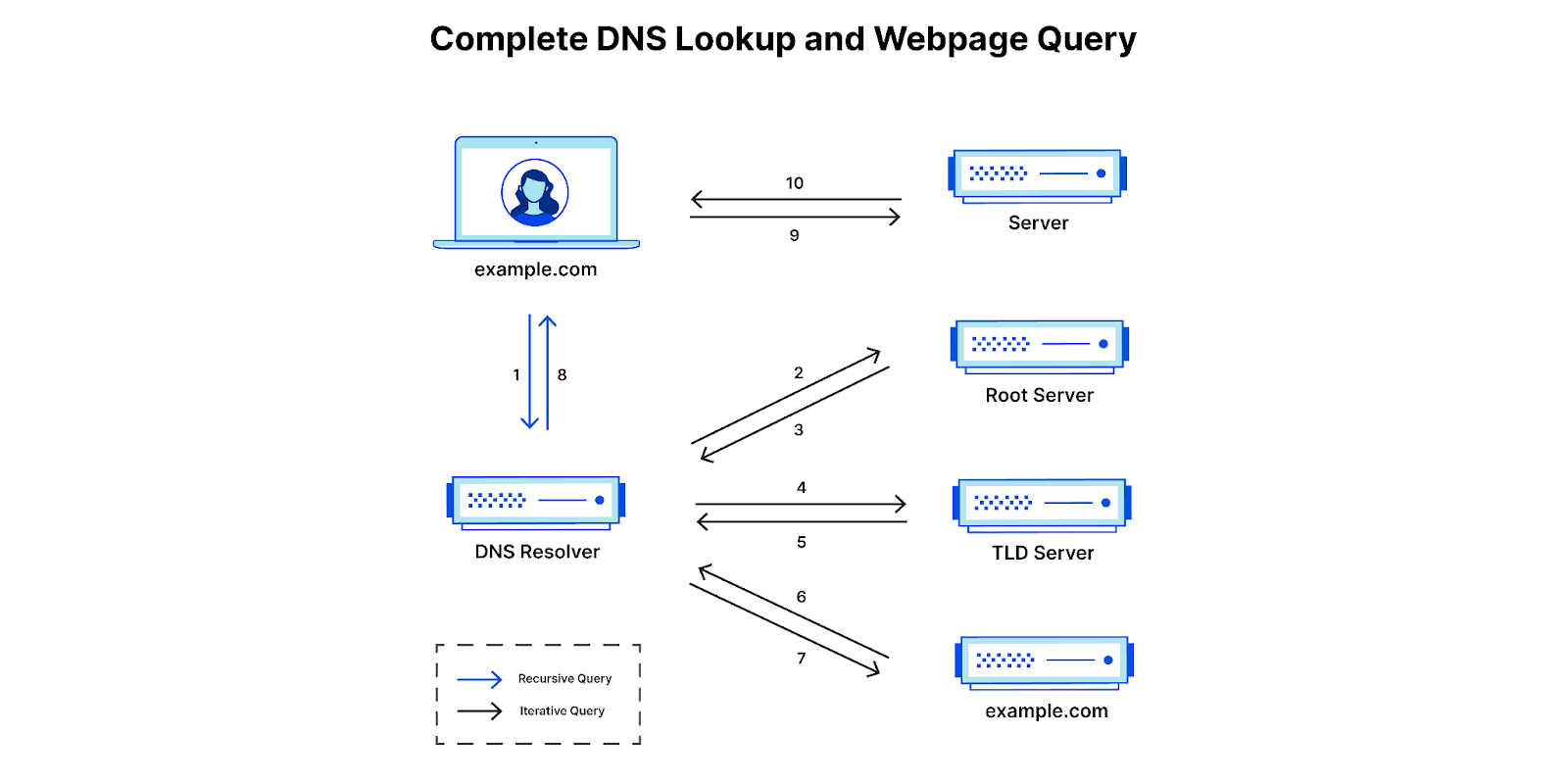
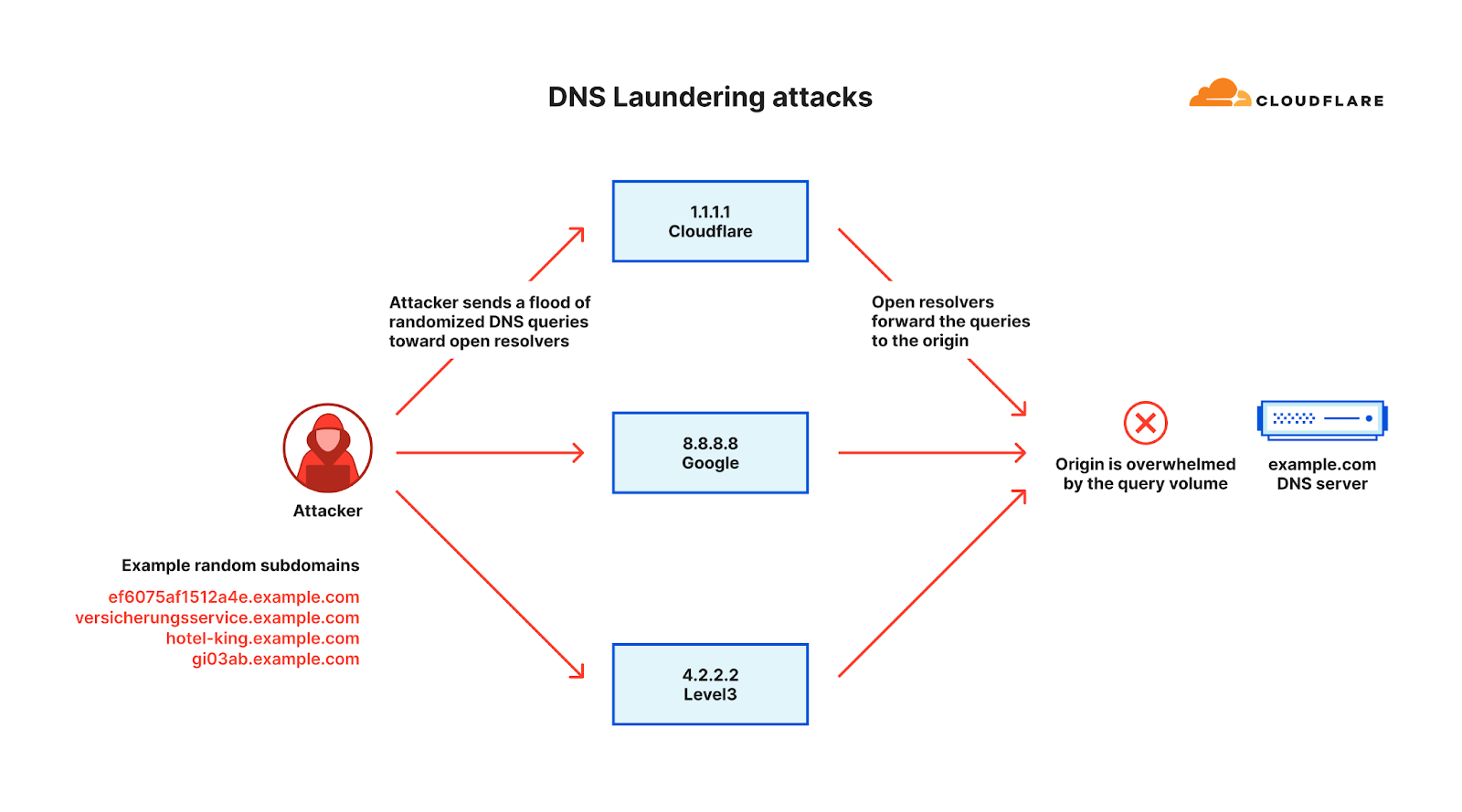
Before a client can attempt to establish a connection with a server by name, using either the classic IPv4 protocol or the more modern IPv6, it must look up the server’s IP address in the phonebook of the Internet, the Domain Name System (DNS).
Looking up a hostname in DNS is a recursive process. To find the IP address of a server, the domain hierarchy (the dot-separated components of a server’s name) must be followed across several DNS authoritative servers until one of them returns the desired response2. Most clients, however, don’t do this directly and instead ask an intermediary server called a recursive resolver to do it for them. Cloudflare operates one such recursive resolver that anyone can use: 1.1.1.1.
As a simplified example, when a client asks 1.1.1.1 for the IP address where “www.example.com” lives, 1.1.1.1 will go out and ask the DNS root servers3 about “.com”, then ask the .com DNS servers about “example.com”, and finally ask the example.com DNS servers about “www.example.com”, which has direct knowledge of it and answers with an IP address. To make things faster for the next client asking a similar question, 1.1.1.1 caches (remembers for a while) both the final answer and the steps in between.
This means 1.1.1.1 is in a very good position to count how often clients try to look up IPv4 addresses (A-type queries) vs. how often they try to look up IPv6 addresses (AAAA-type queries), covering most of the observable Internet.
But how does a client know when to ask for a server’s IPv4 address or its IPv6 address?
The short answer is that clients with IPv6 available to them just ask for both — doing separate A and AAAA lookups for every server they wish to connect to. These IPv6-capable clients will prioritize connecting over IPv6 when they get a non-empty AAAA answer, whether they also get a non-empty A answer (which they almost always get, as we’ll see). The algorithm driving this preference for modernity is called Happy Eyeballs, if you’re interested in the details.
We’re now ready to start looking at some actual data…
IPv6 Adoption on the Client Side (from DNS)
The first step is establishing a baseline by measuring client IPv6 deployment from 1.1.1.1’s perspective and comparing it with the numbers from HTTP requests that we started with.
It’s tempting to count how often clients connect to 1.1.1.1 using IPv6, but the results are misleading for a couple of reasons, the strongest one being hidden in plain sight: 1.1.1.1 is the most memorable address of the set of IPv4 and IPv6 addresses that clients can use to perform DNS lookups through the 1.1.1.1 service. Ideally, IPv6-capable clients using 1.1.1.1 as their recursive resolver should have all four of the following IP addresses configured, not just the first two:
1.1.1.1 (IPv4)
1.0.0.1 (IPv4)
2606:4700:4700::1111 (IPv6)
2606:4700:4700::1001 (IPv6)
But, when manual configuration is involved4, humans find IPv6 addresses less memorable than IPv4 addresses and are less likely to configure them, viewing the IPv4 addresses as enough.
A related, but less obvious, confounding factor is that many IPv6-capable clients will still perform DNS lookups over IPv4 even when they have 1.1.1.1’s IPv6 addresses configured, as spreading lookups over the available addresses is a popular default option.
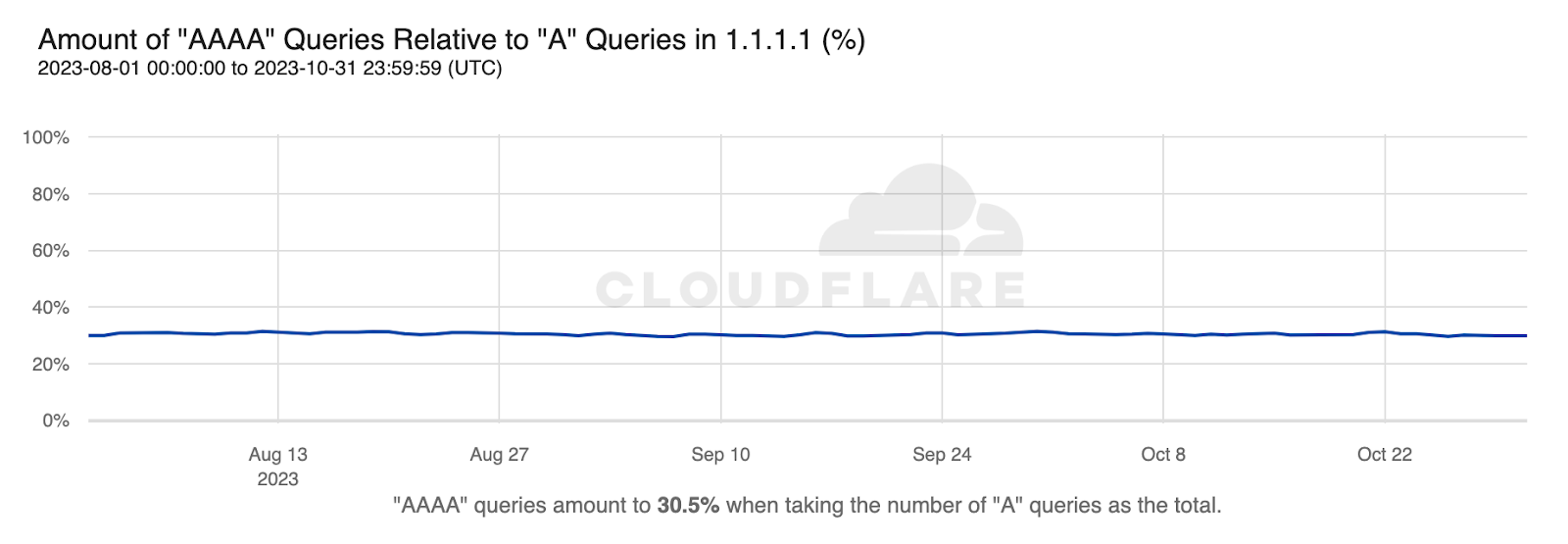
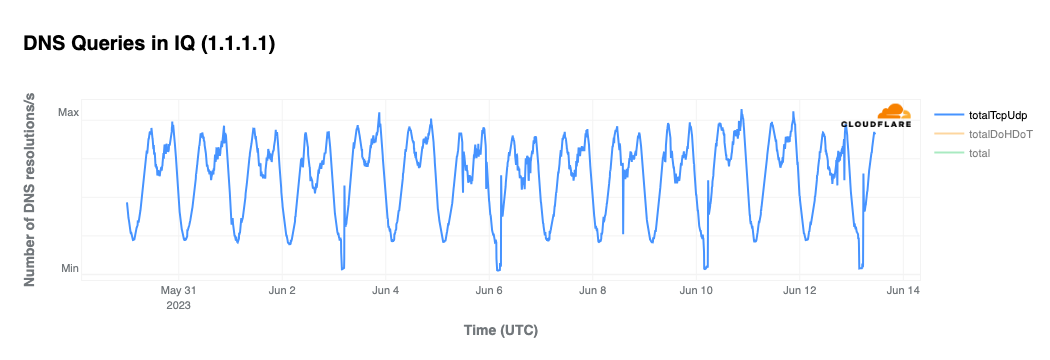
A more sensible approach to assess IPv6 adoption from DNS client activity is calculating the percentage of AAAA-type queries over the total amount of A-type queries, assuming IPv6-clients always perform both5, as mentioned earlier.
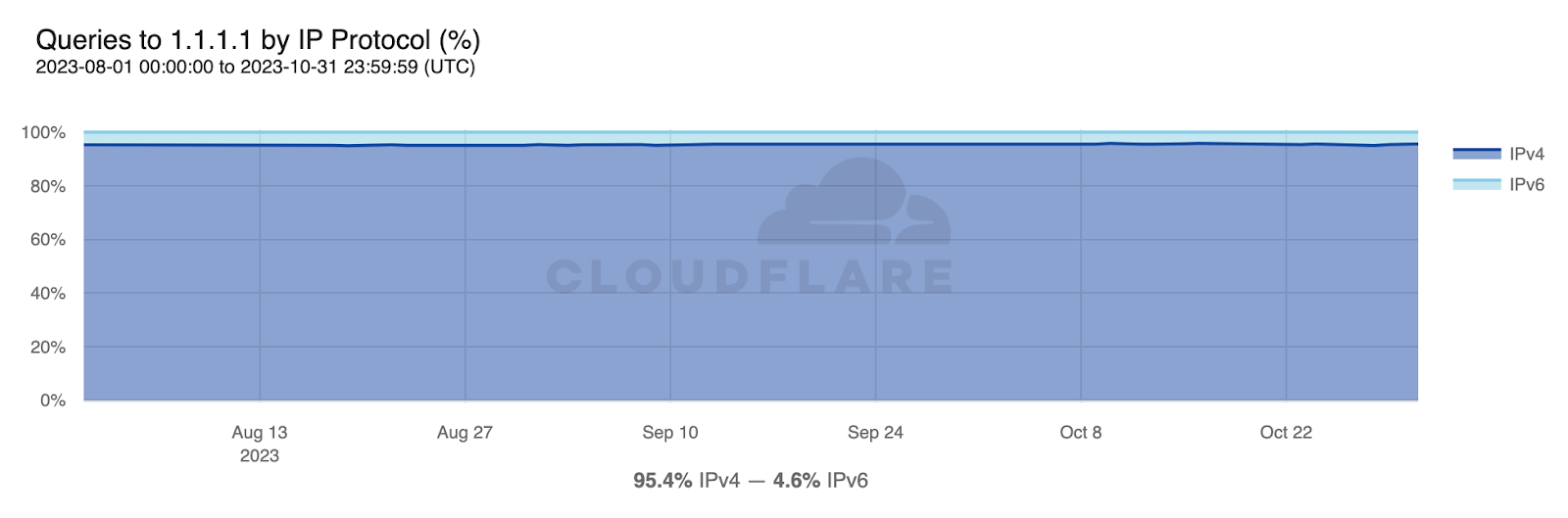
Then, from 1.1.1.1’s perspective, IPv6 adoption on the client side is estimated at 30.5% by query volume. This is a bit under what we observed from HTTP traffic over the same time period (35.9%) but such a difference between two different perspectives is not unexpected.
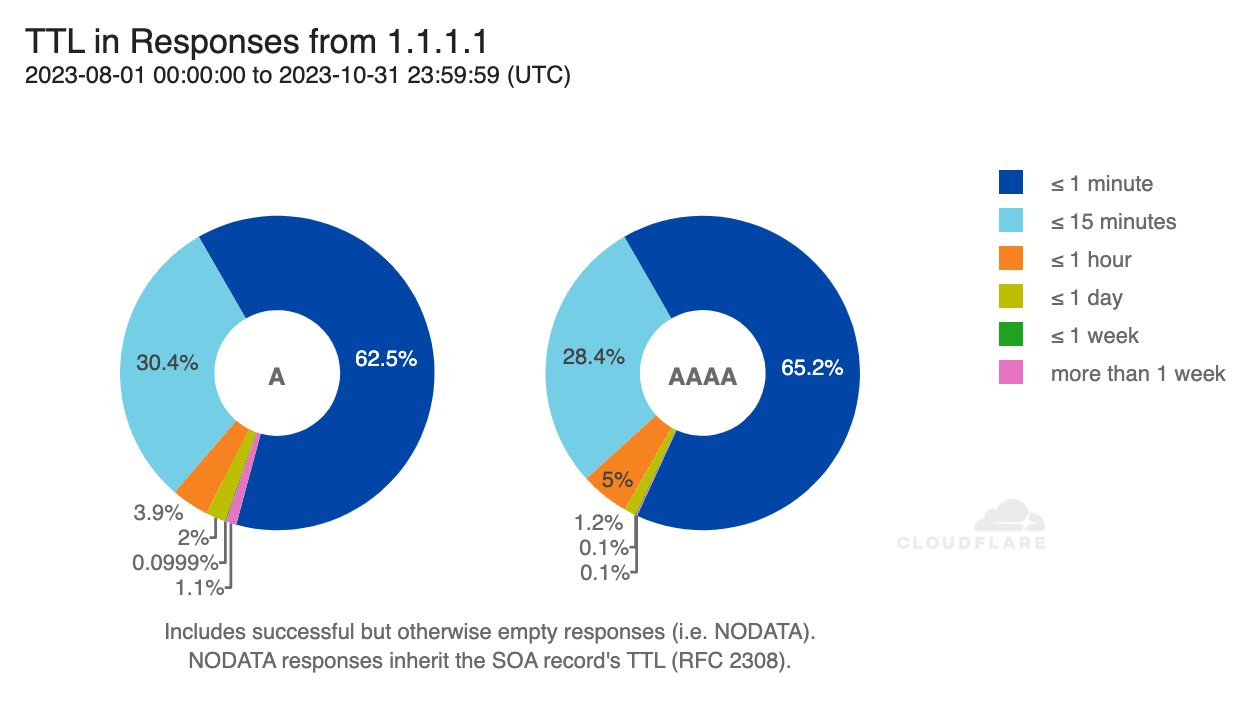
A Note on TTLs
It’s not only recursive resolvers that cache DNS responses, most DNS clients have their own local caches as well. Your web browser, operating system, and even your home router, keep answers around hoping to speed up subsequent queries.
How long each answer remains in cache depends on the time-to-live (TTL) field sent back with DNS records. If you’re familiar with DNS, you might be wondering if A and AAAA records have similar TTLs. If they don’t, we may be getting fewer queries for just one of these two types (because it gets cached for longer at the client level), biasing the resulting adoption figures.
The pie charts here break down the minimum TTLs sent back by 1.1.1.1 in response to A and AAAA queries6. There is some difference between both types, but the difference is very small.
IPv6 Adoption on the Server Side
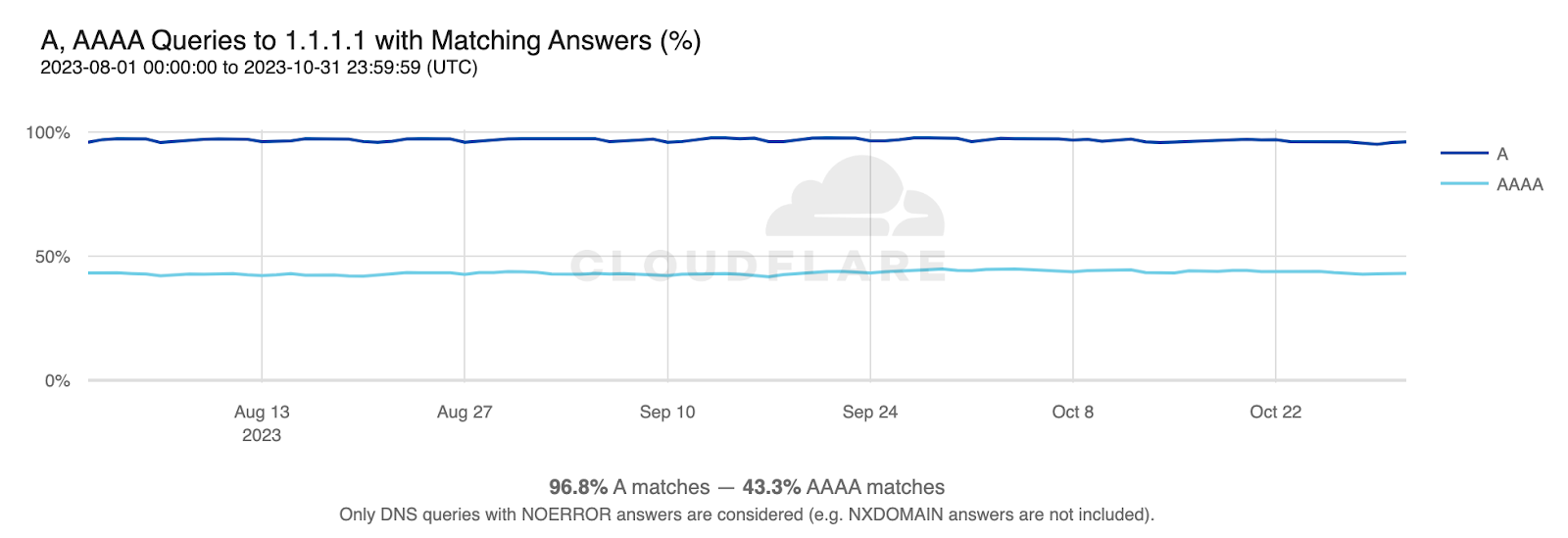
The following graph shows how often A and AAAA-type queries get non-empty responses, shedding light on server side IPv6 adoption and getting us closer to the answer we’re after:
IPv6 adoption by servers is estimated at 43.3% by query volume, noticeably higher than what was observed for clients.
How Often Both Sides Swipe Right
If 30.5% of IP address lookups handled by 1.1.1.1 could make use of an IPv6 address to connect to their intended destinations, but only 43.3% of those lookups get a non-empty response, that can give us a pretty good basis for how often IPv6 connections are made between client and server — roughly 13.2% of the time.
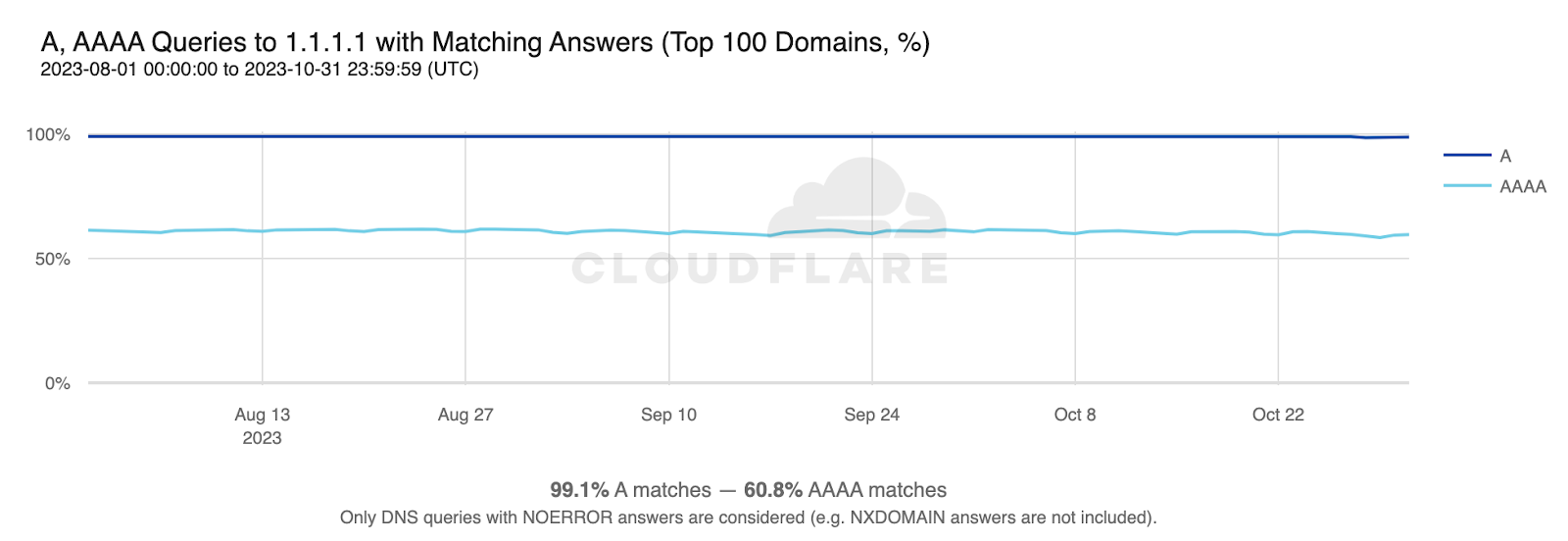
The Potential Impact of Popular Domains
IPv6 server side adoption measured by query volume for the domains in Radar’s Top 100 list is 60.8%. If we exclude these domains from our overall calculations, the previous 13.2% figure drops to 8%. This is a significant difference, but not unexpected, as the Top 100 domains make up over 55% of all A and AAAA queries to 1.1.1.1.
If just a few more of these highly popular domains were to deploy IPv6 today, observed adoption would noticeably increase and, with it, the chance of IPv6-capable clients establishing connections using IPv6.
Closing Thoughts
Observing the extent of IPv6 adoption across the Internet can mean different things:
Counting users with IPv6-capable Internet access;
Counting IPv6-capable devices or software on those devices (clients and/or servers);
Calculating the amount of traffic flowing through IPv6 connections, measured in bytes;
Counting the fraction of connections (or individual requests) over IPv6.
In this exercise we chose to look at connections and requests. Keeping in mind that the underlying reality can only be truly understood by considering several different perspectives, we saw three different IPv6 adoption figures:
35.9% (client side) when counting HTTP requests served from Cloudflare’s CDN;
30.5% (client side) when counting A and AAAA-type DNS queries handled by 1.1.1.1;
43.3% (server side) of positive responses to AAAA-type DNS queries, also from 1.1.1.1.
We combined the client side and server side figures from the DNS perspective to estimate how often connections to third-party servers are likely to be established over IPv6 rather than IPv4: just 13.2% of the time.
To improve on these numbers, ISPs, cloud and hosting providers, and corporations alike must increase the rate at which they make IPv6 available for devices in their networks. But large websites and content sources also have a critical role to play in enabling IPv6-capable clients to use IPv6 more often, as 39.2% of queries for domains in the Radar Top 100 (representing over half of all A and AAAA queries to 1.1.1.1) are still limited to IPv4-only responses.
On the road to full IPv6 adoption, the Internet isn’t quite there yet. But continued effort from all those involved can help it to continue to move forward, and perhaps even accelerate progress.
On the server side, Cloudflare has been helping with this worldwide effort for many years by providing free IPv6 support for all domains. On the client side, the 1.1.1.1 app automatically enables your device for IPv6 even if your ISP doesn’t provide any IPv6 support. And, if you happen to manage an IPv6-only network, 1.1.1.1’s DNS64 support also has you covered.
*** 1Cloudflare’s public DNS resolver (1.1.1.1) is operated in partnership with APNIC. You can read more about it in the original announcement blog post and in 1.1.1.1’s privacy policy. 2There’s more information on how DNS works in the “What is DNS?” section of our website. If you’re a hands-on learner, we suggest you take a look at Julia Evans’ “mess with dns”. 3Any recursive resolver will already know the IP addresses of the 13 root servers beforehand. Cloudflare also participates at the topmost level of DNS by providing anycast service to the E and F-Root instances, which means 1.1.1.1 doesn’t need to go far for that first lookup step. 4When using the 1.1.1.1 app, all four IP addresses are configured automatically. 5For simplification, we assume the amount of IPv6-only clients is still negligibly small. It’s a reasonable assumption in general, and other datasets available to us confirm it. 61.1.1.1, like other recursive resolvers, returns adjusted TTLs: the record’s original TTL minus the number of seconds since the record was last cached. Empty A and AAAA answers get cached for the amount of time defined in the domain’s Start of Authority (SOA) record, as specified by RFC 2308.
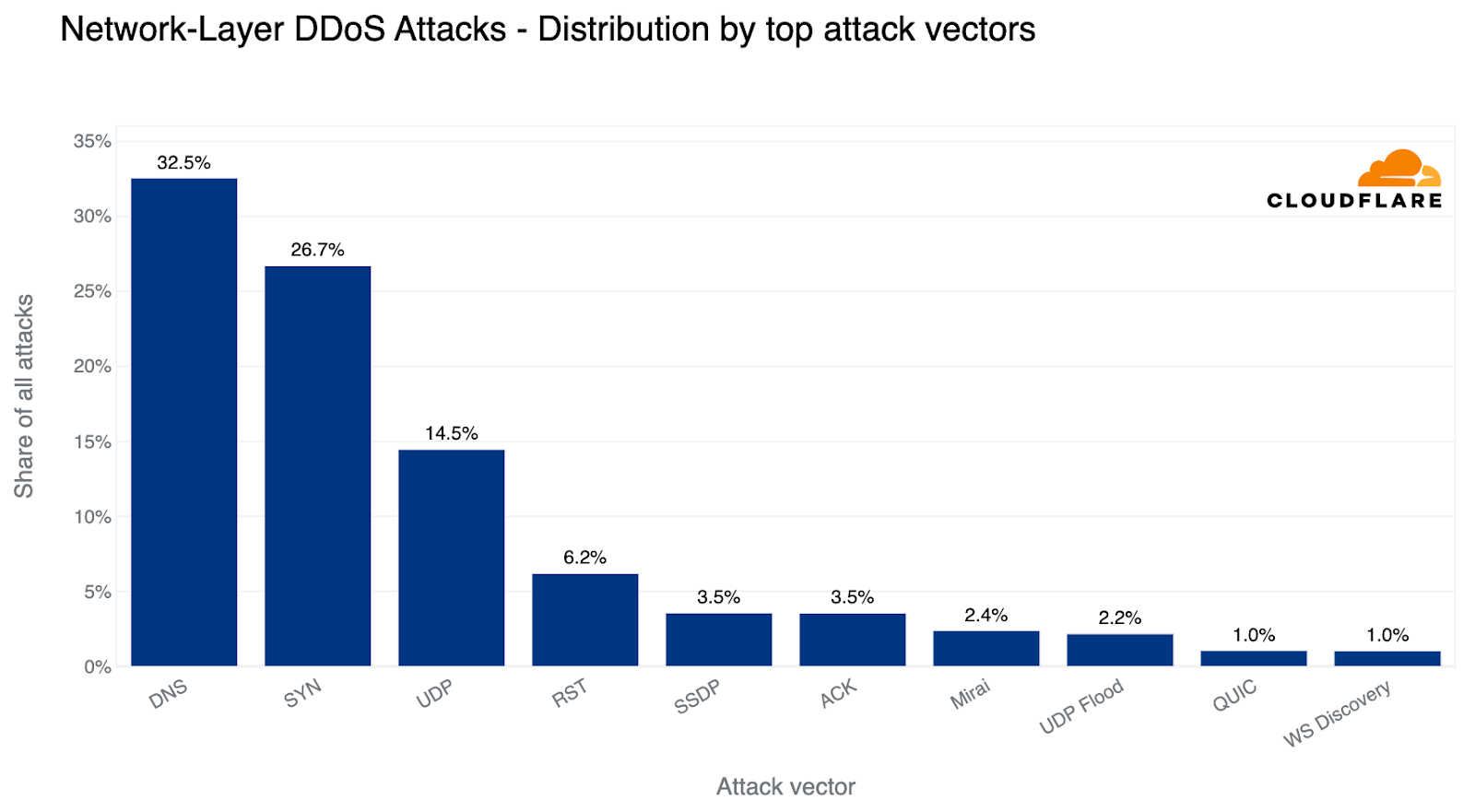
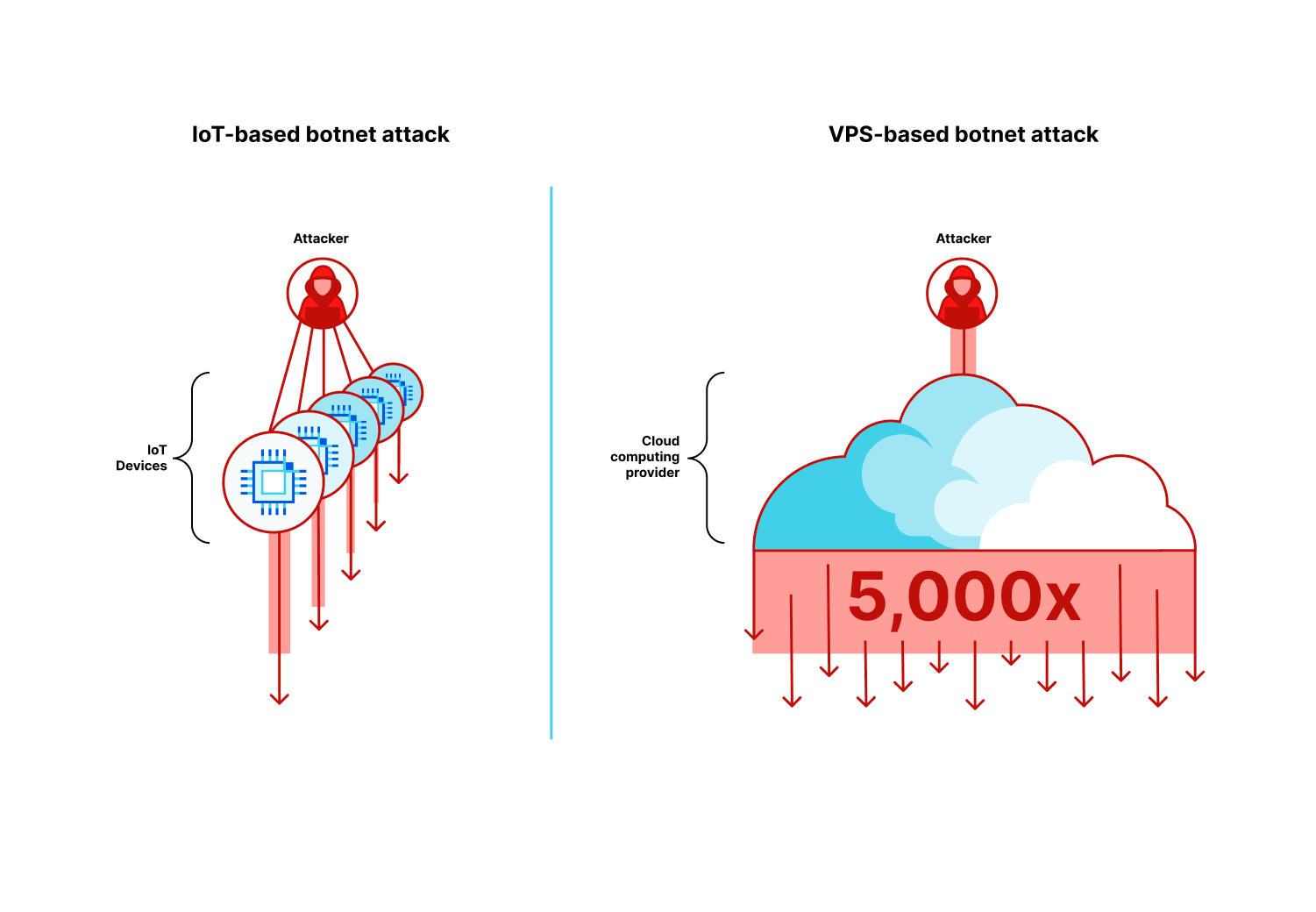
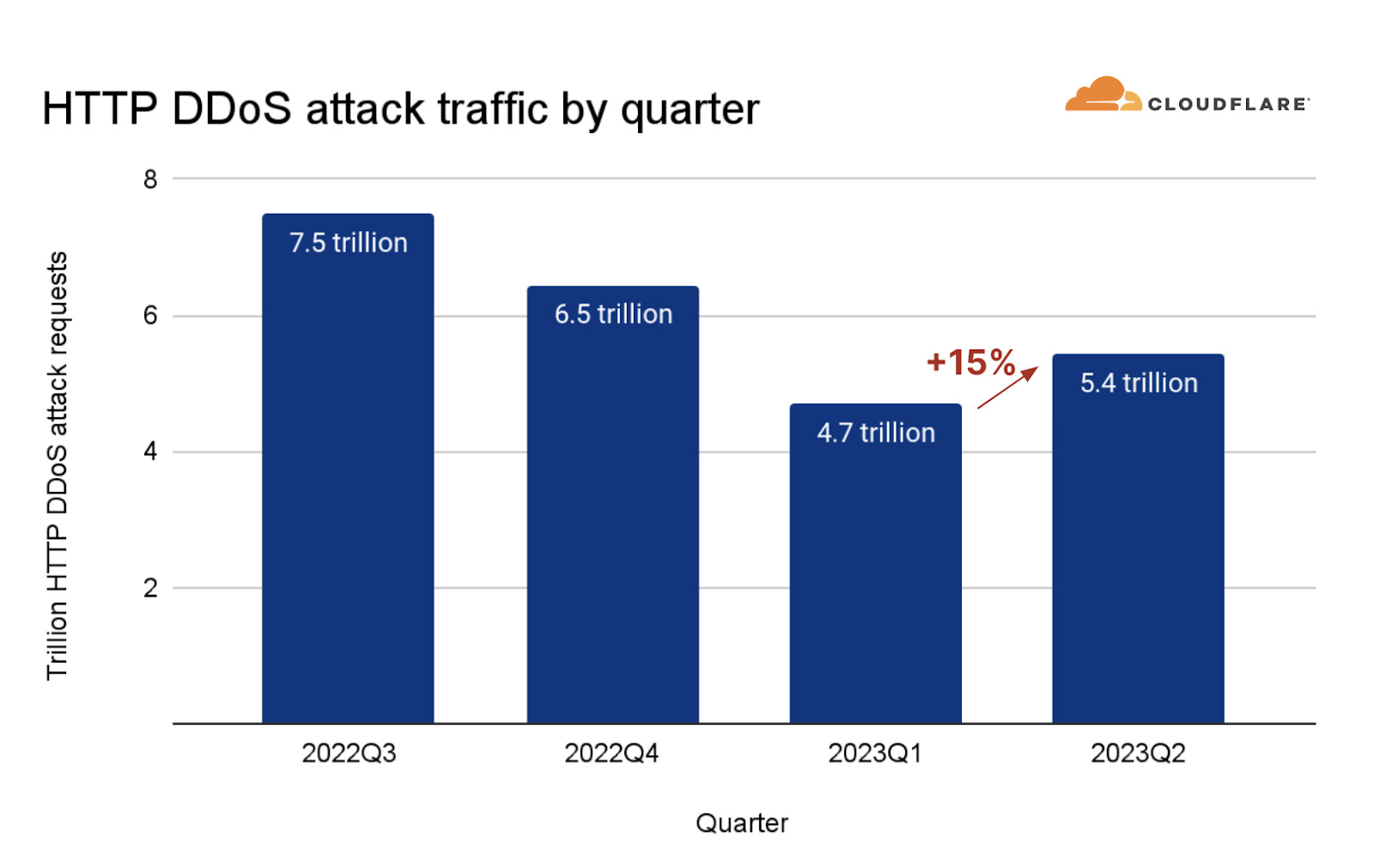
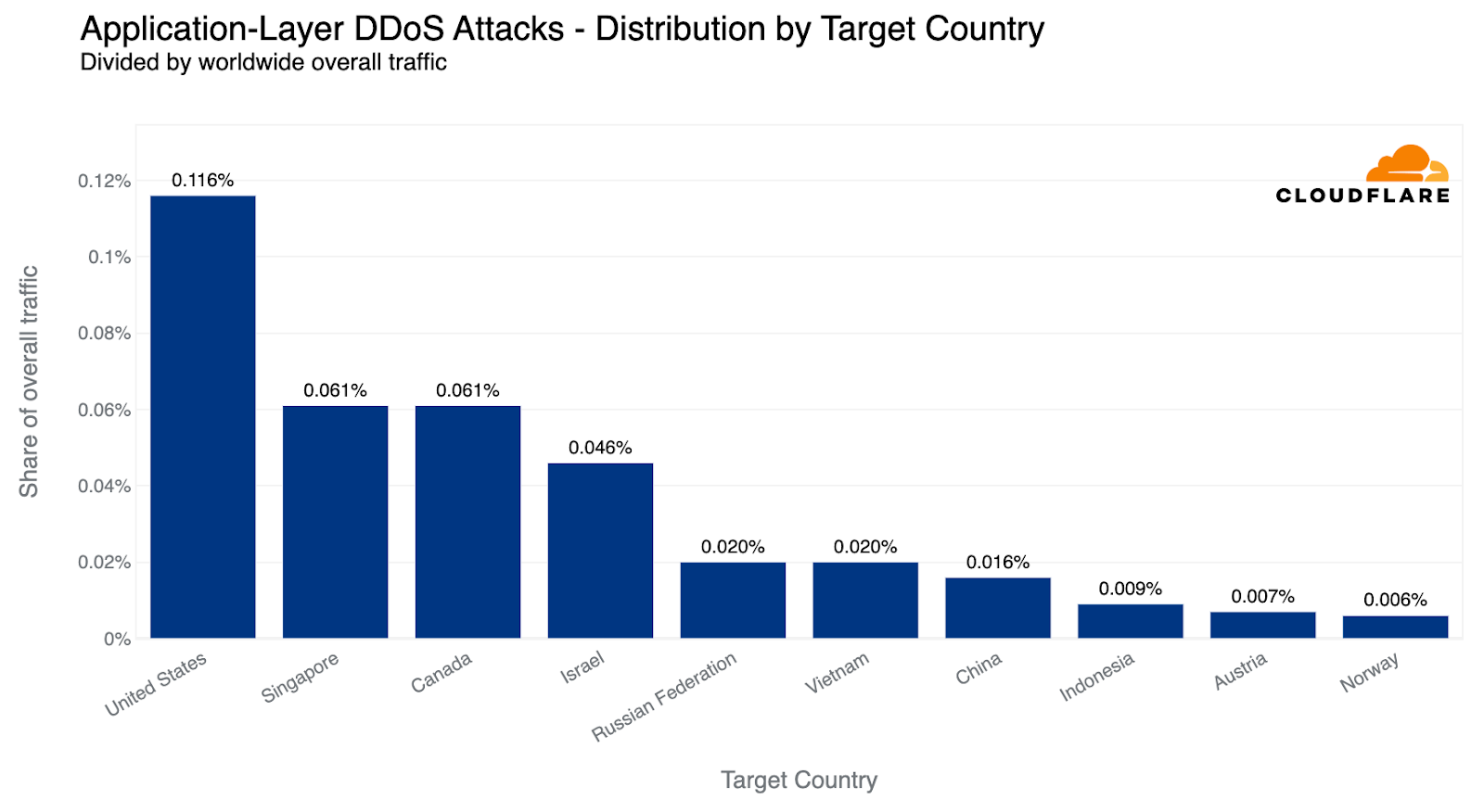
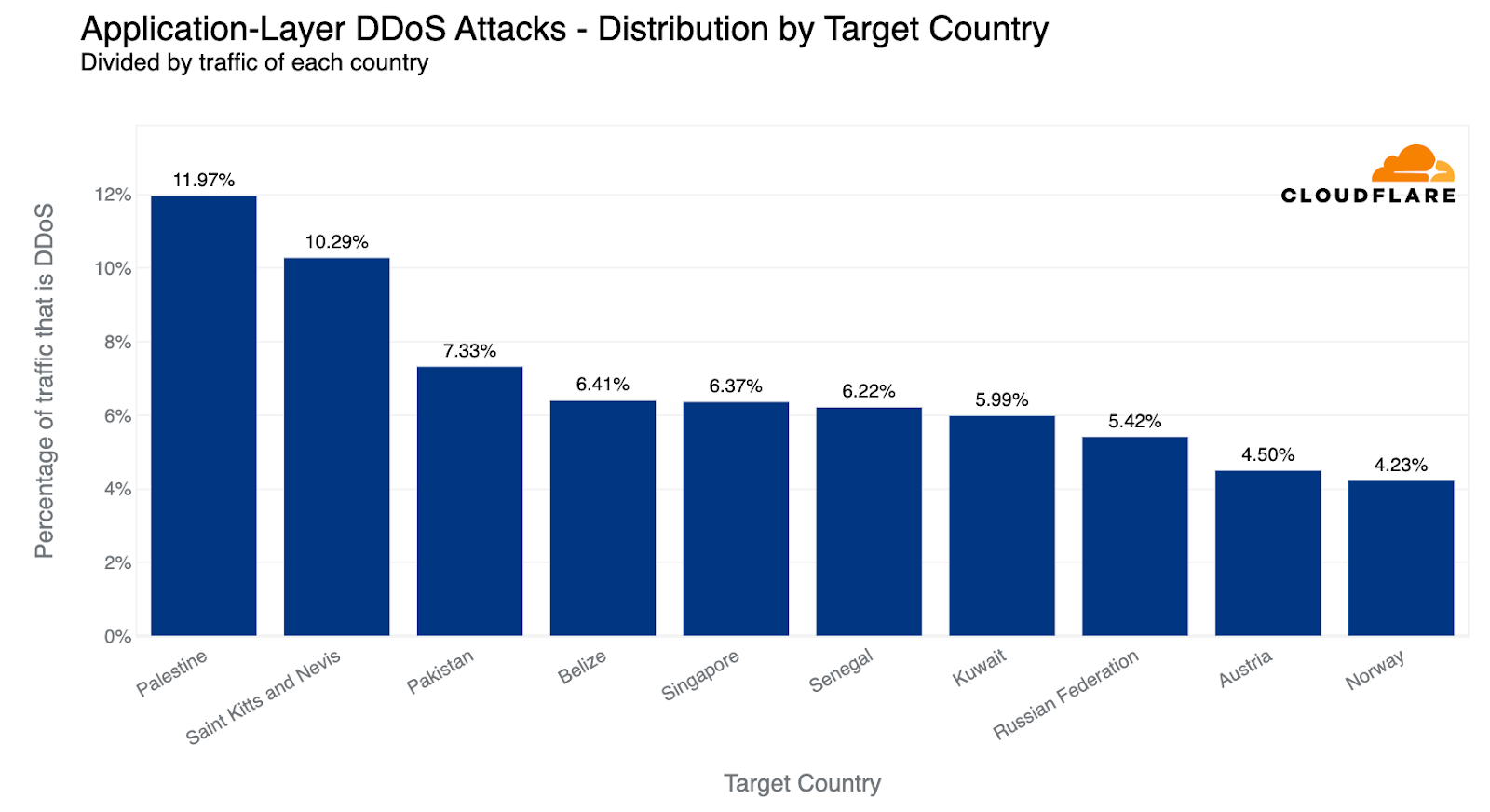
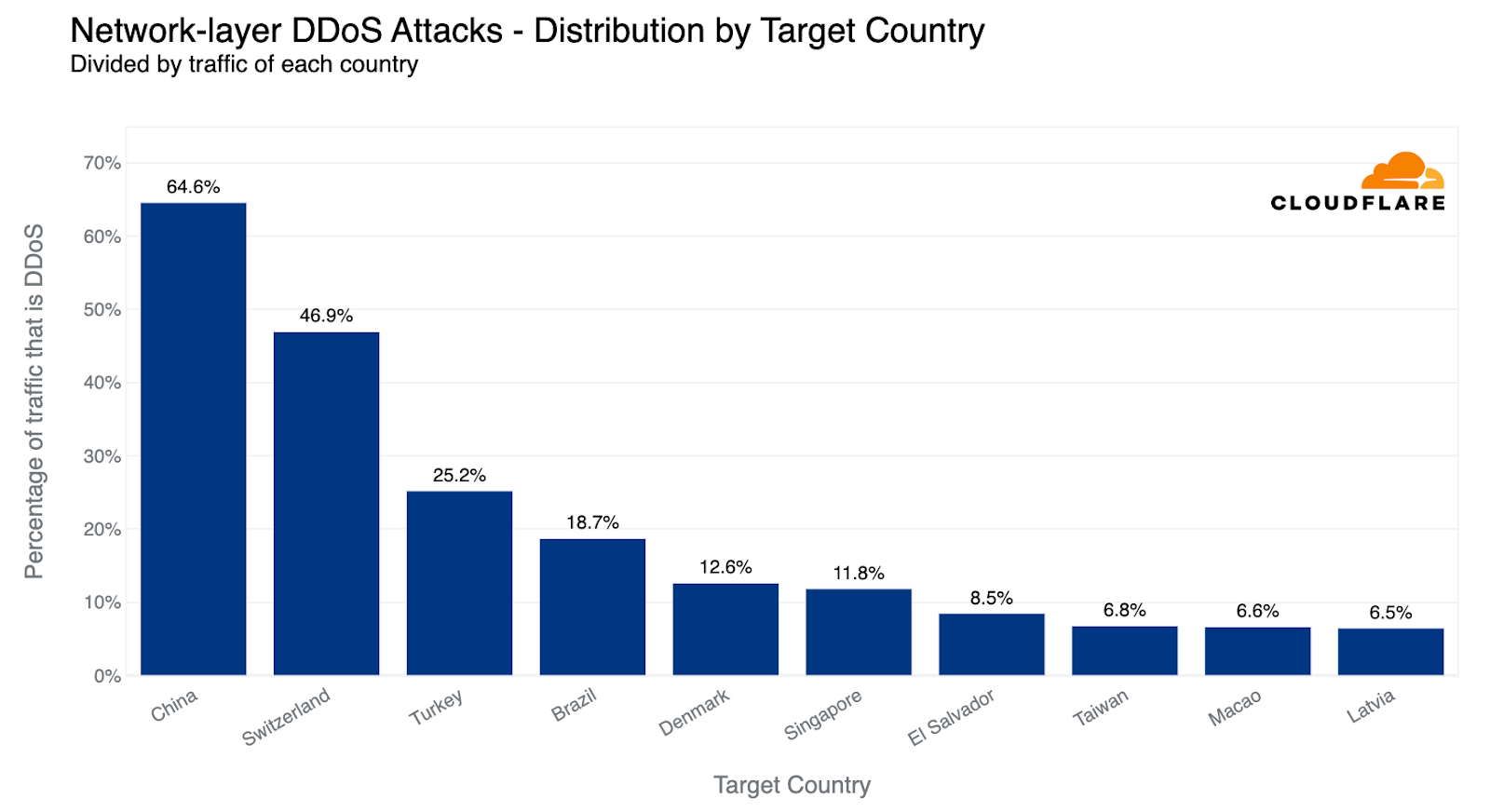
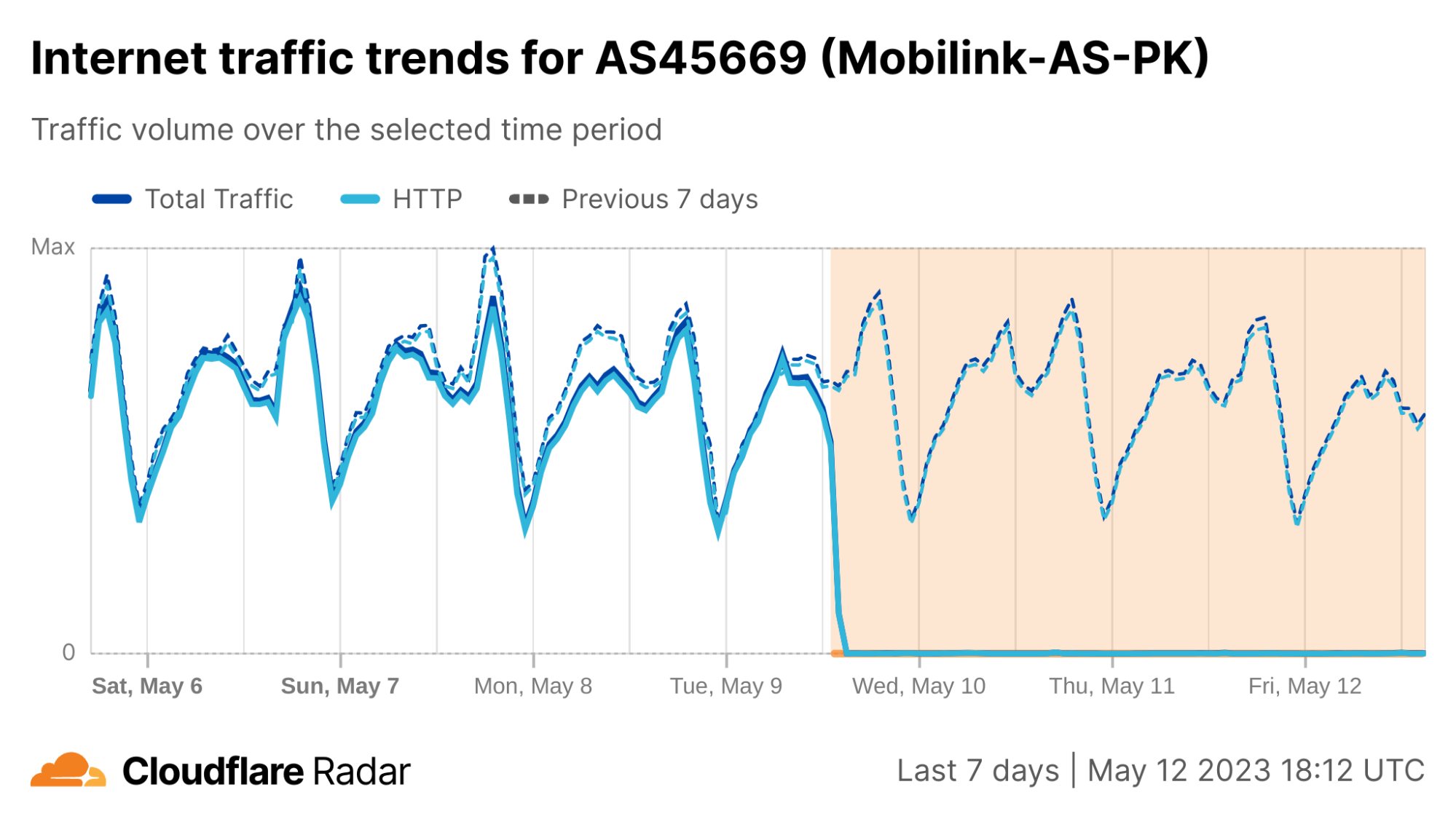
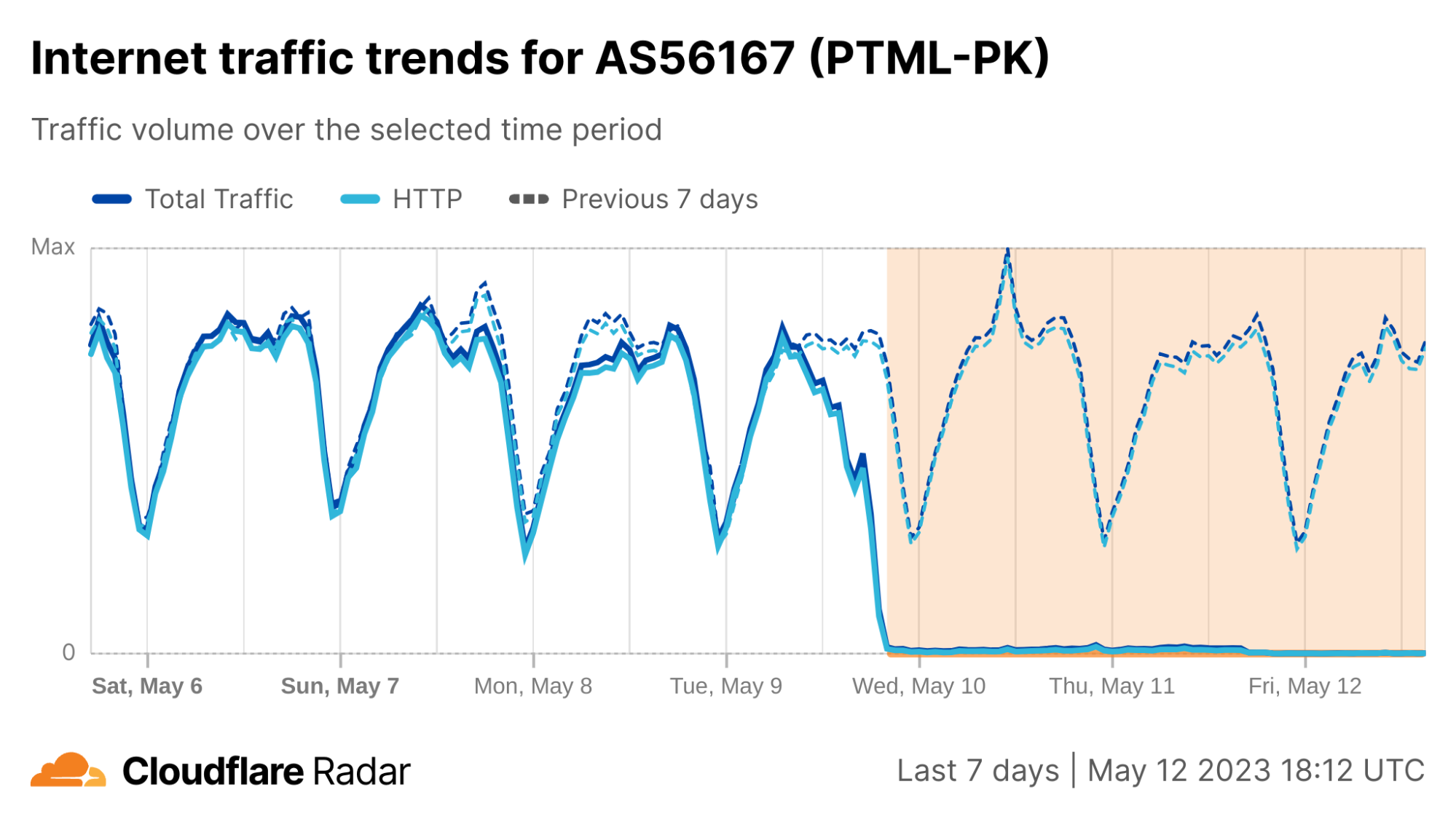
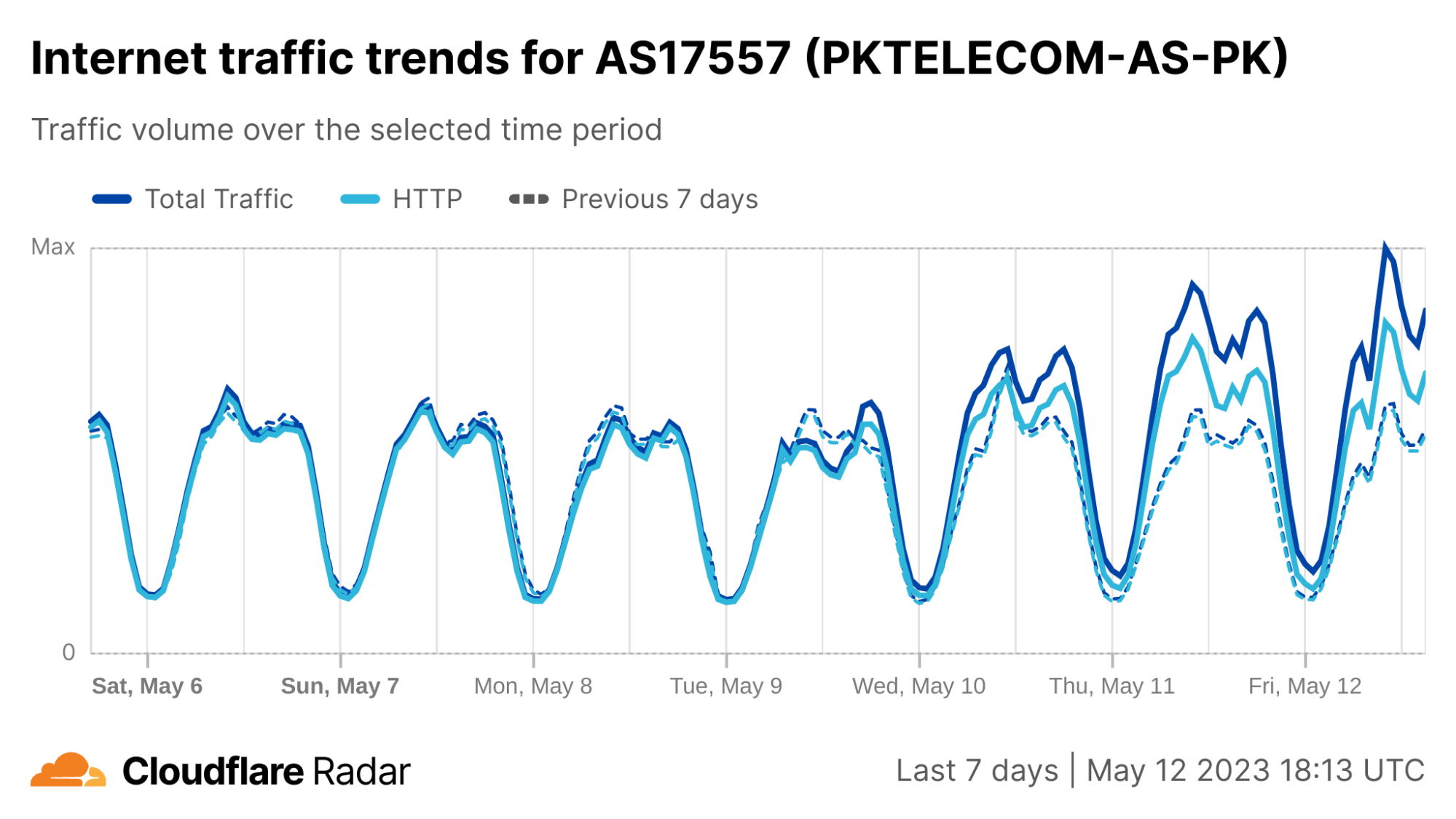
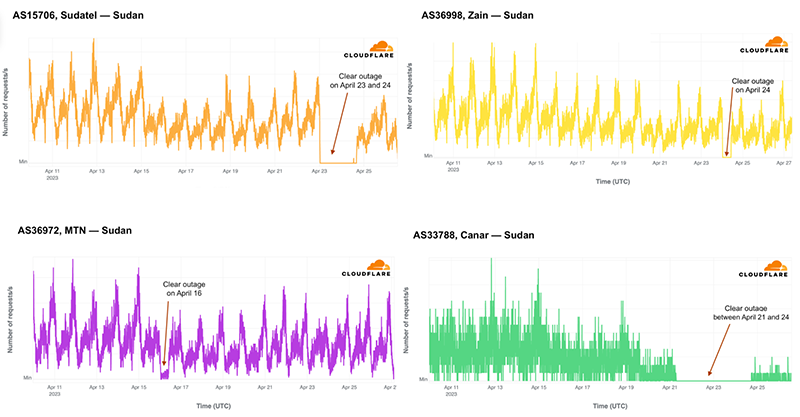
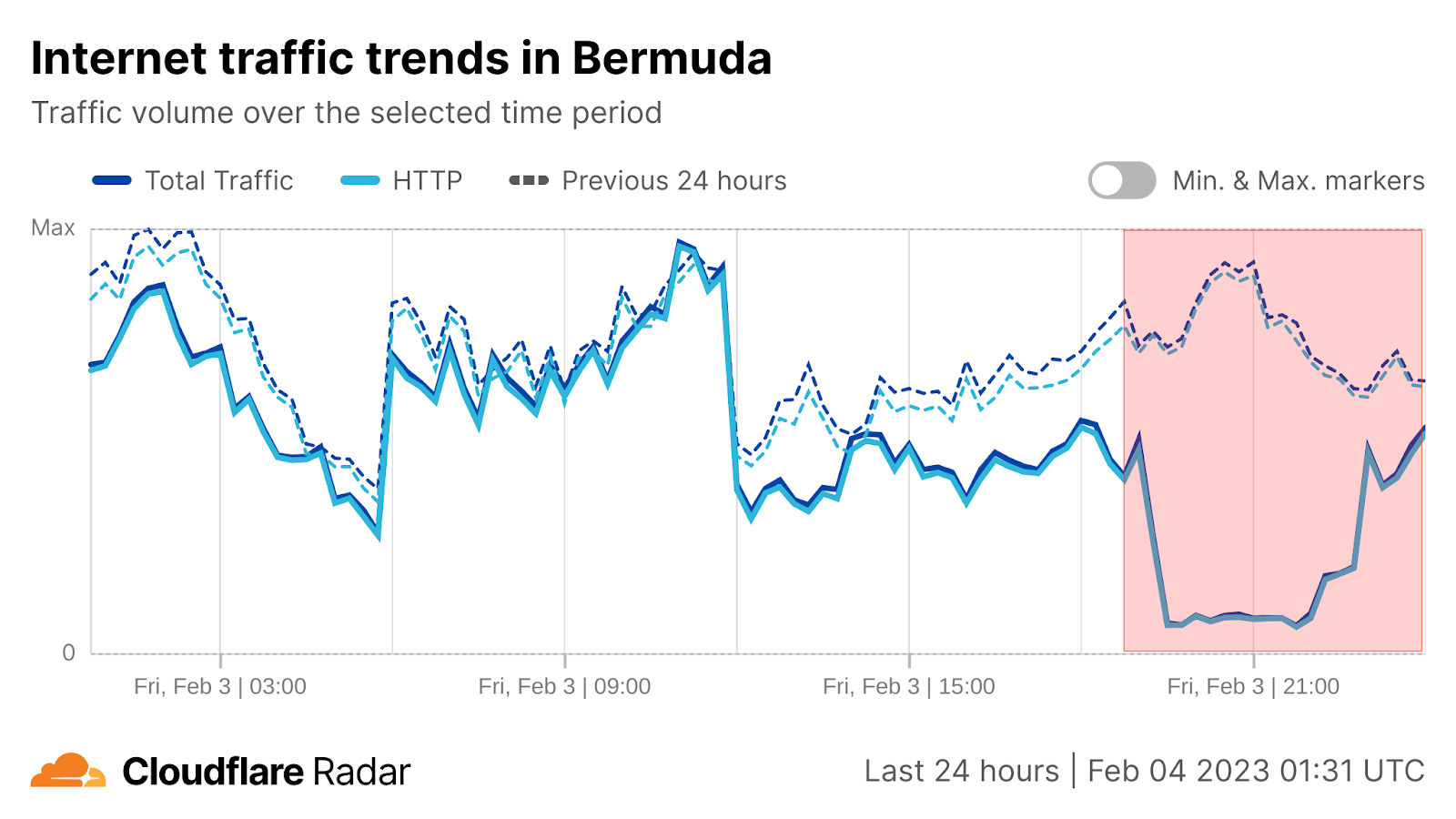
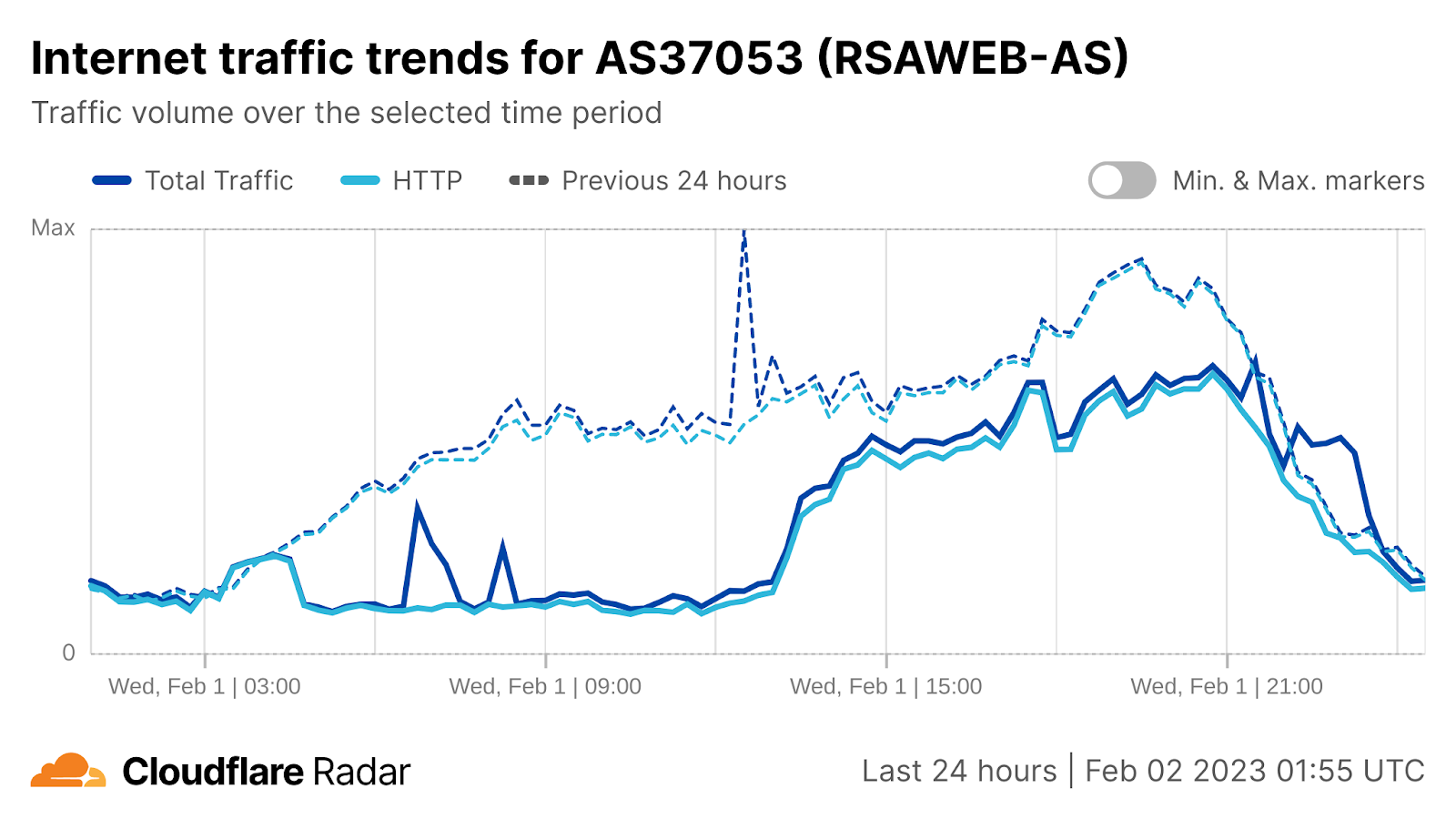
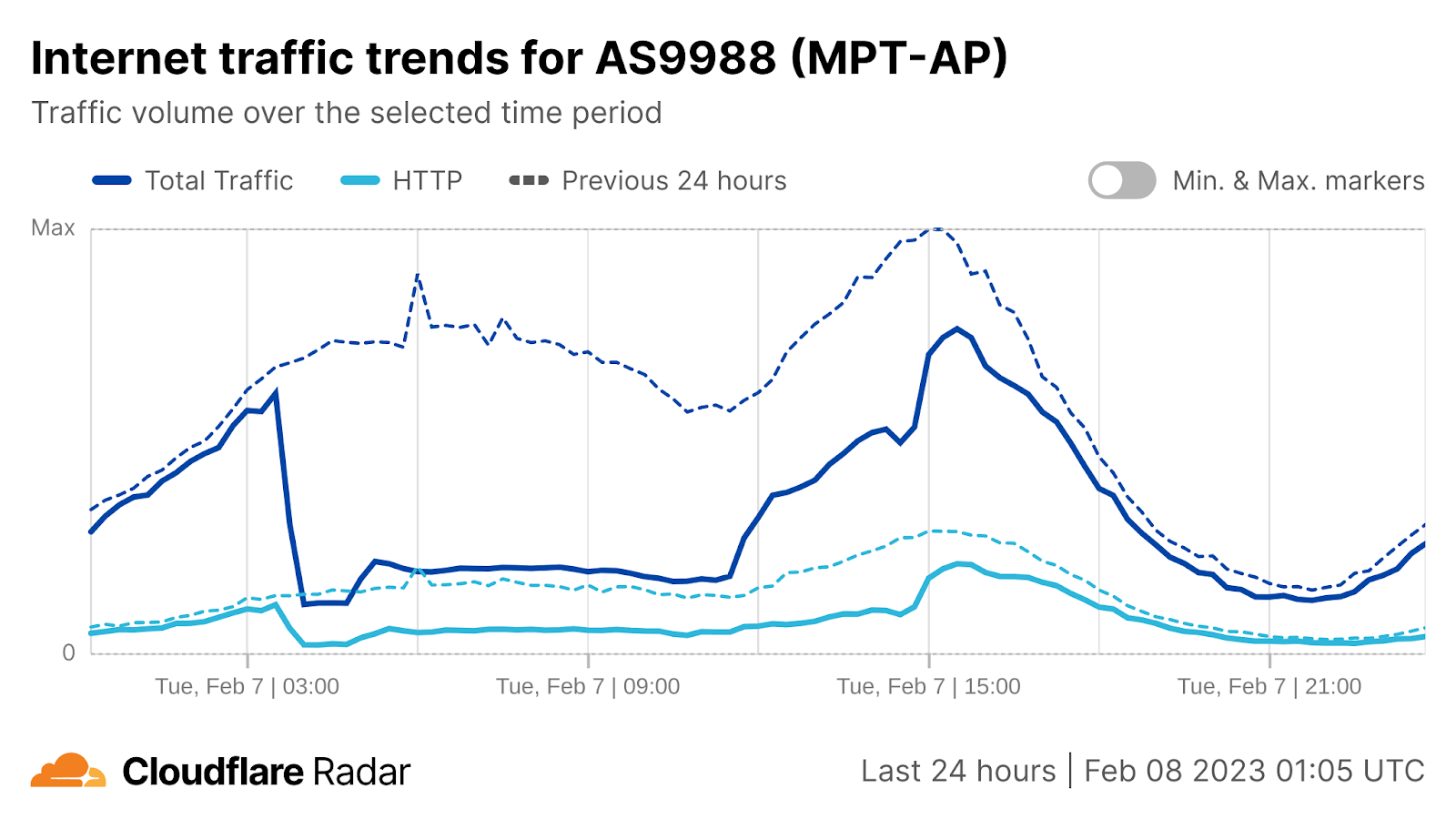
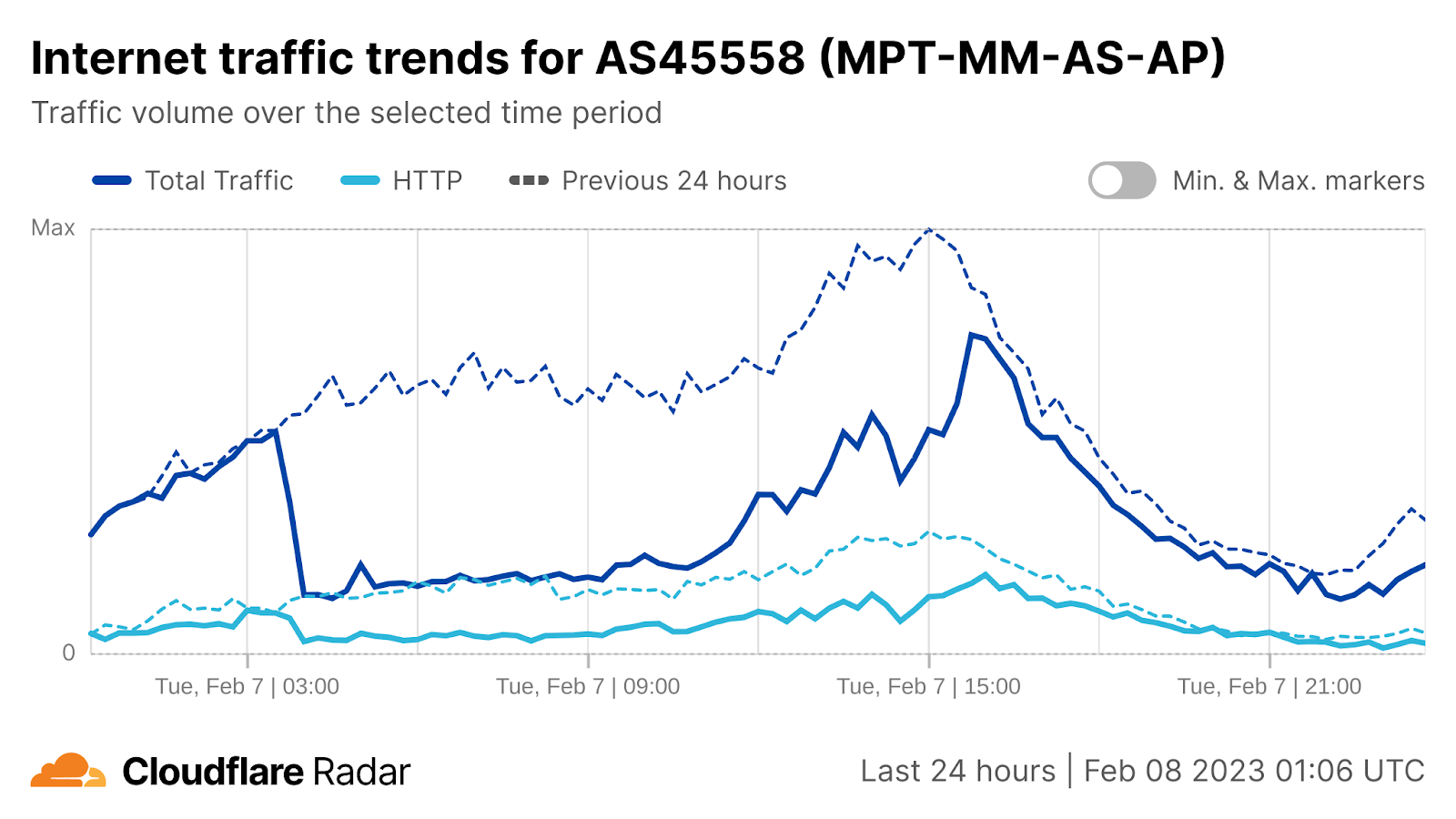
On Saturday, October 7, 2023, attacks from the Palestinian group Hamas launched from the Gaza Strip against the south of Israel started a new conflict in the region. Israel officially declared that it is at war the next day. Cloudflare's data shows that Internet traffic was impacted in different ways, both in Israel and Palestine, with two networks (autonomous systems) in the Gaza Strip going offline a few hours after the attacks. Subsequently, on October 9, two additional networks also experienced outages. We also saw an uptick in cyberattacks targeting Israel, including a 1.26 billion HTTP requests DDoS attack, and Palestine.
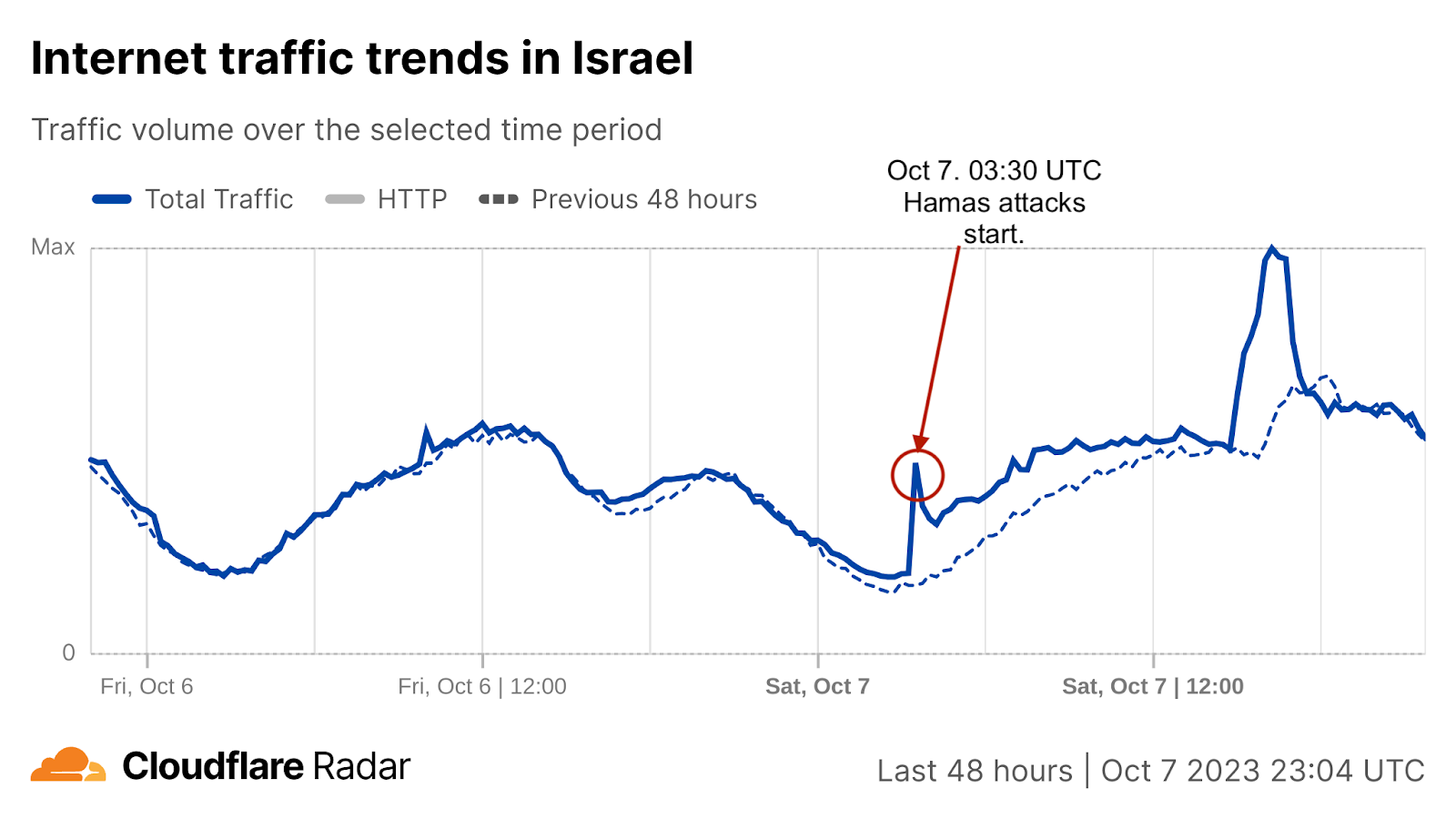
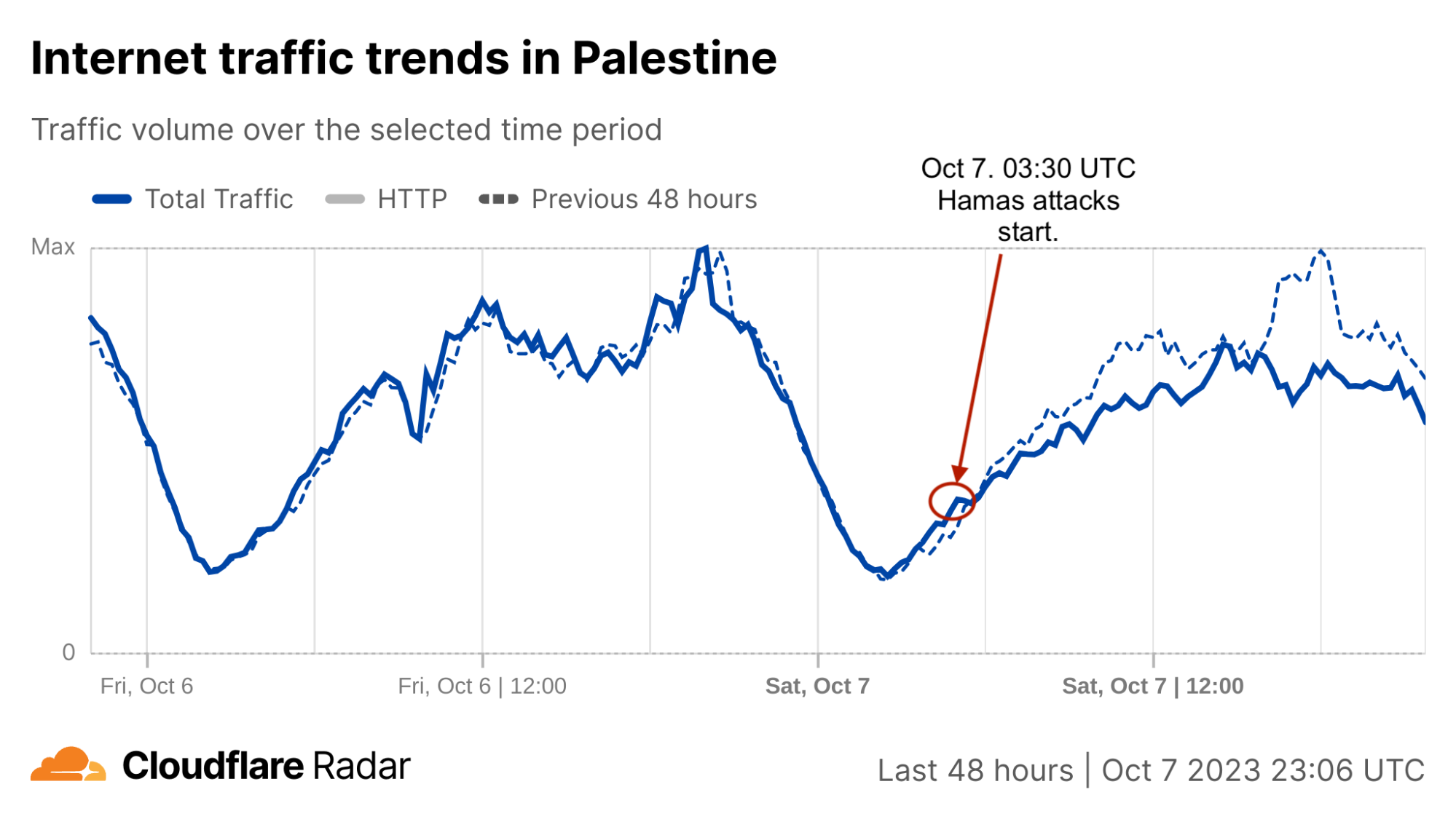
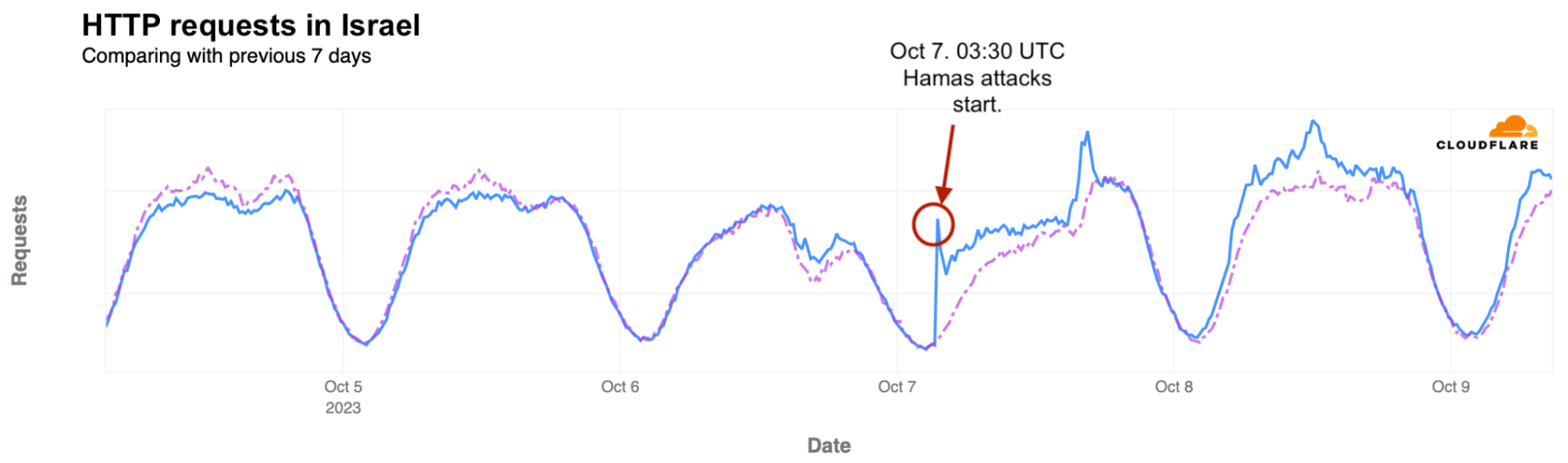
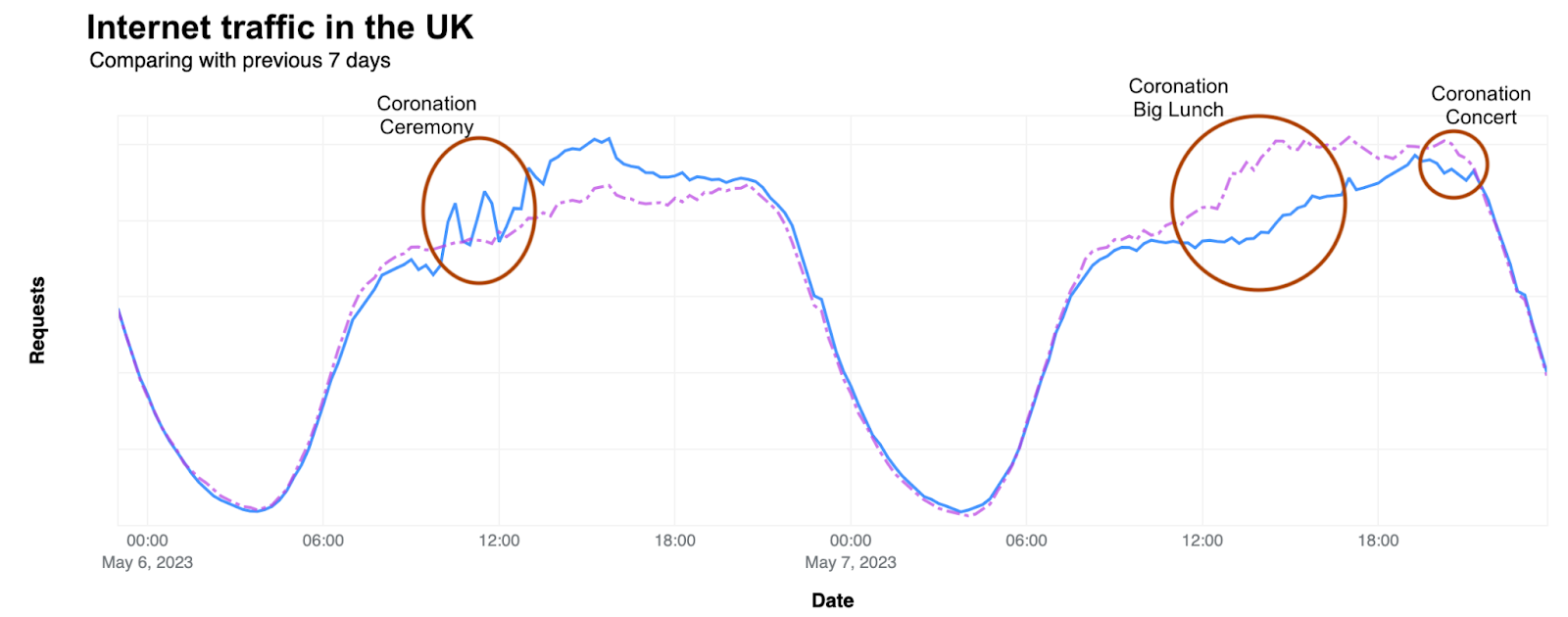
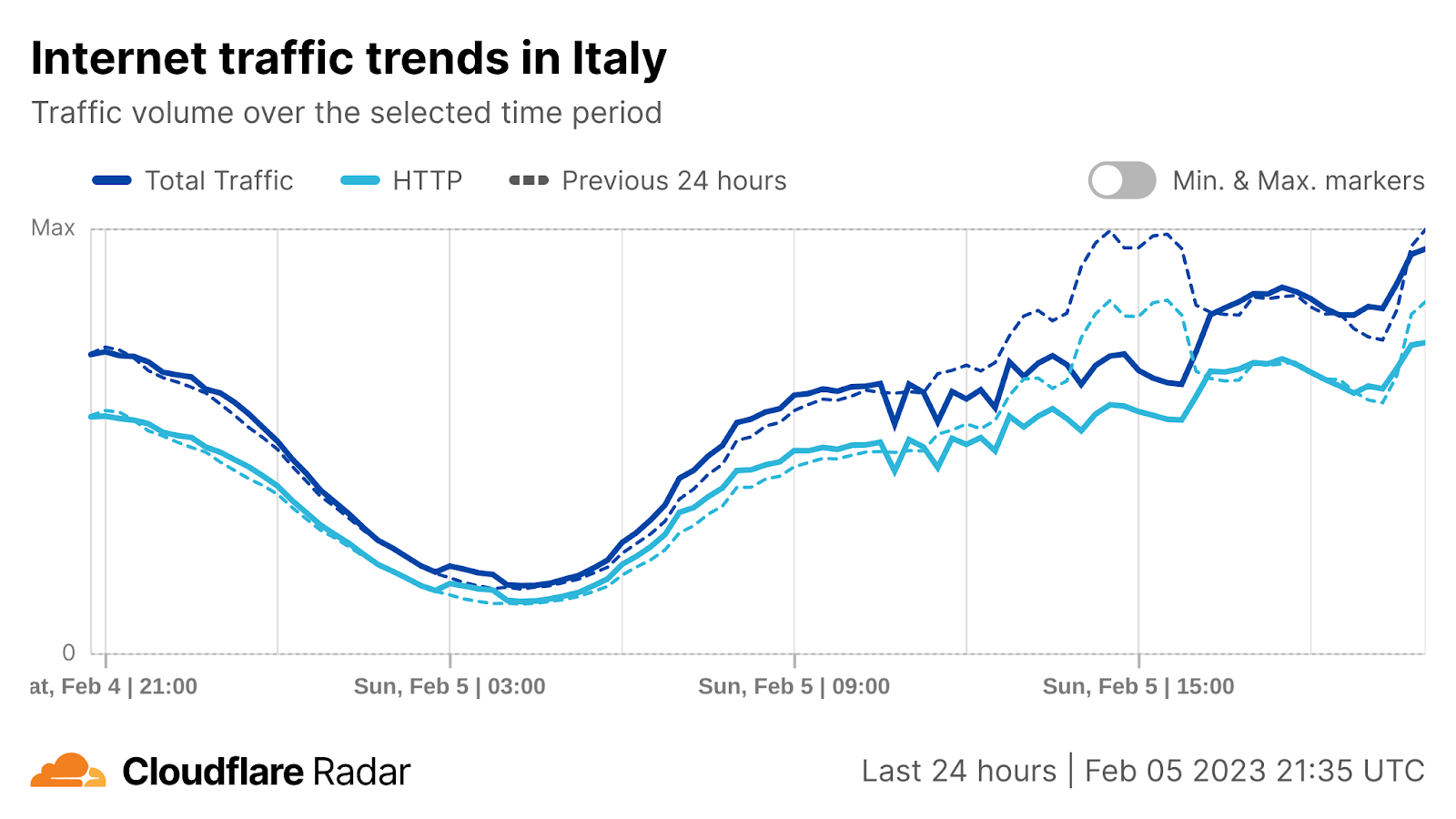
Starting with general Internet traffic trends, there was a clear increase in Internet traffic right after the attacks reportedly began (03:30 UTC, 06:30 local time). Traffic spiked at around 03:35 UTC (06:35 local time) in both Israel (~170% growth compared with the previous week) and Palestine (100% growth).
That growth is consistent with other situations, where we’ve seen surges in Internet traffic when countrywide events occur and people are going online to check for news, updates, and more information on what is happening, with social media and messaging also playing a role. However, in Palestine, that traffic growth was followed by a clear drop in traffic around 08:00 UTC (11:00 local time).
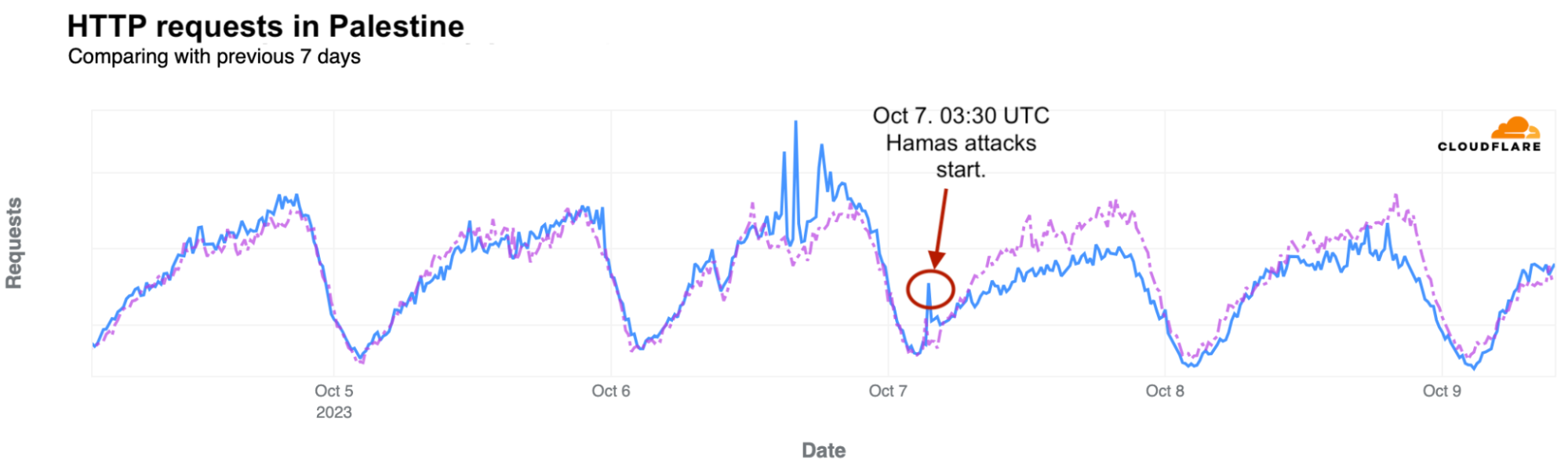
The Palestine uptick in traffic after the Hamas attacks started is more visible when only looking at HTTP requests. Requests in Palestine dropped on Saturday and Sunday, October 7 and 8, as much as 20% and 25%, respectively.
Palestine's outages and Internet impact
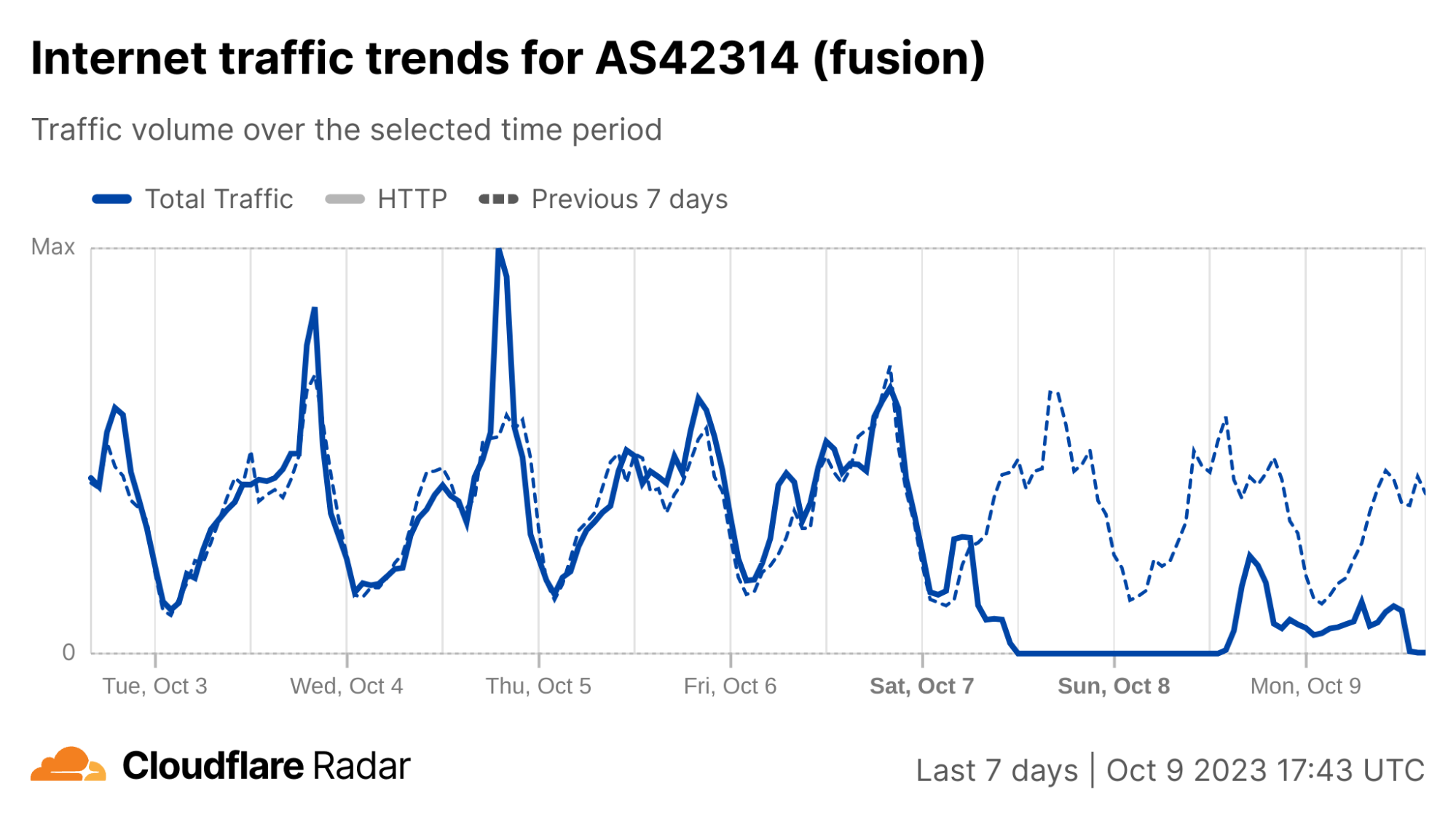
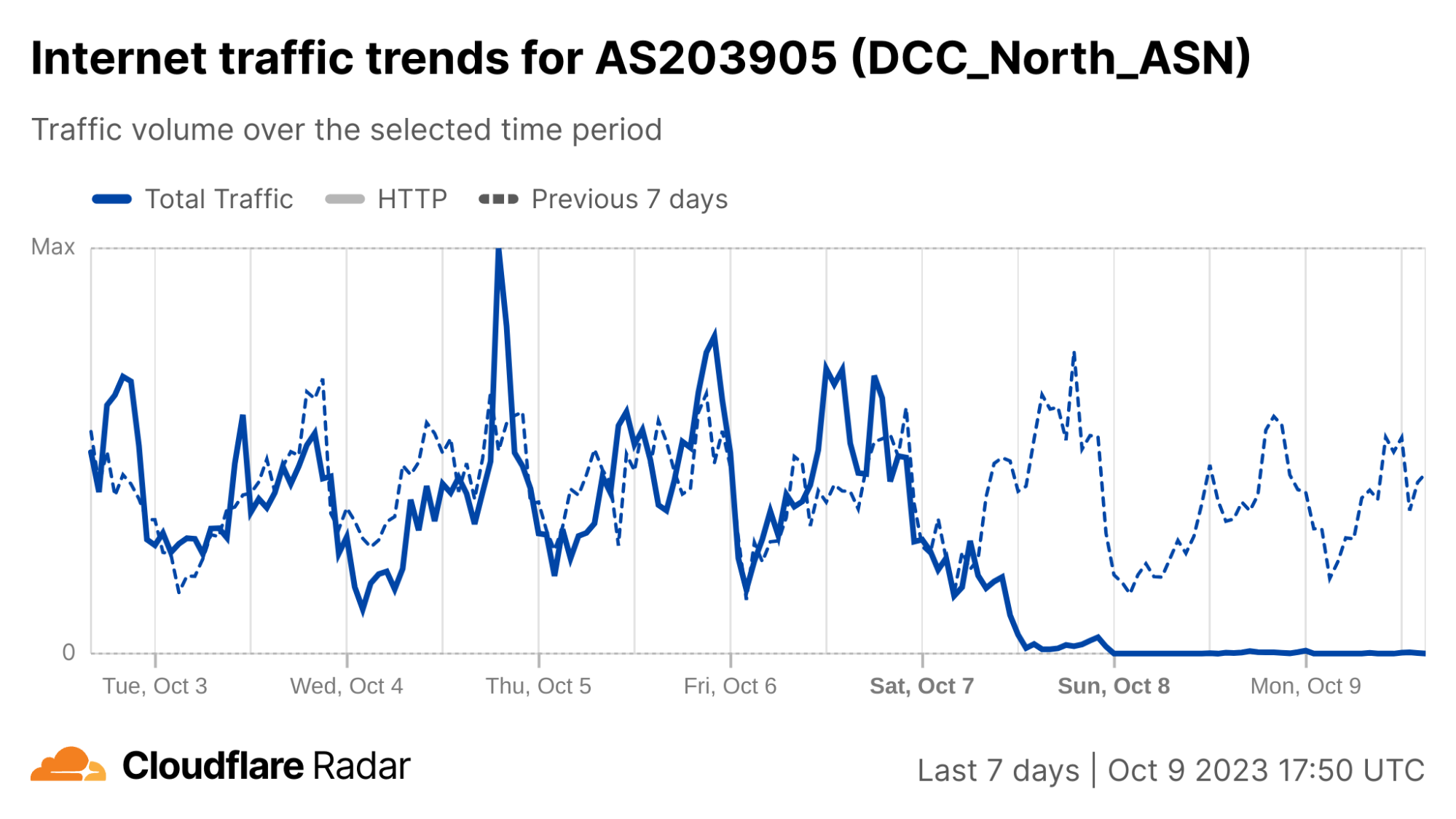
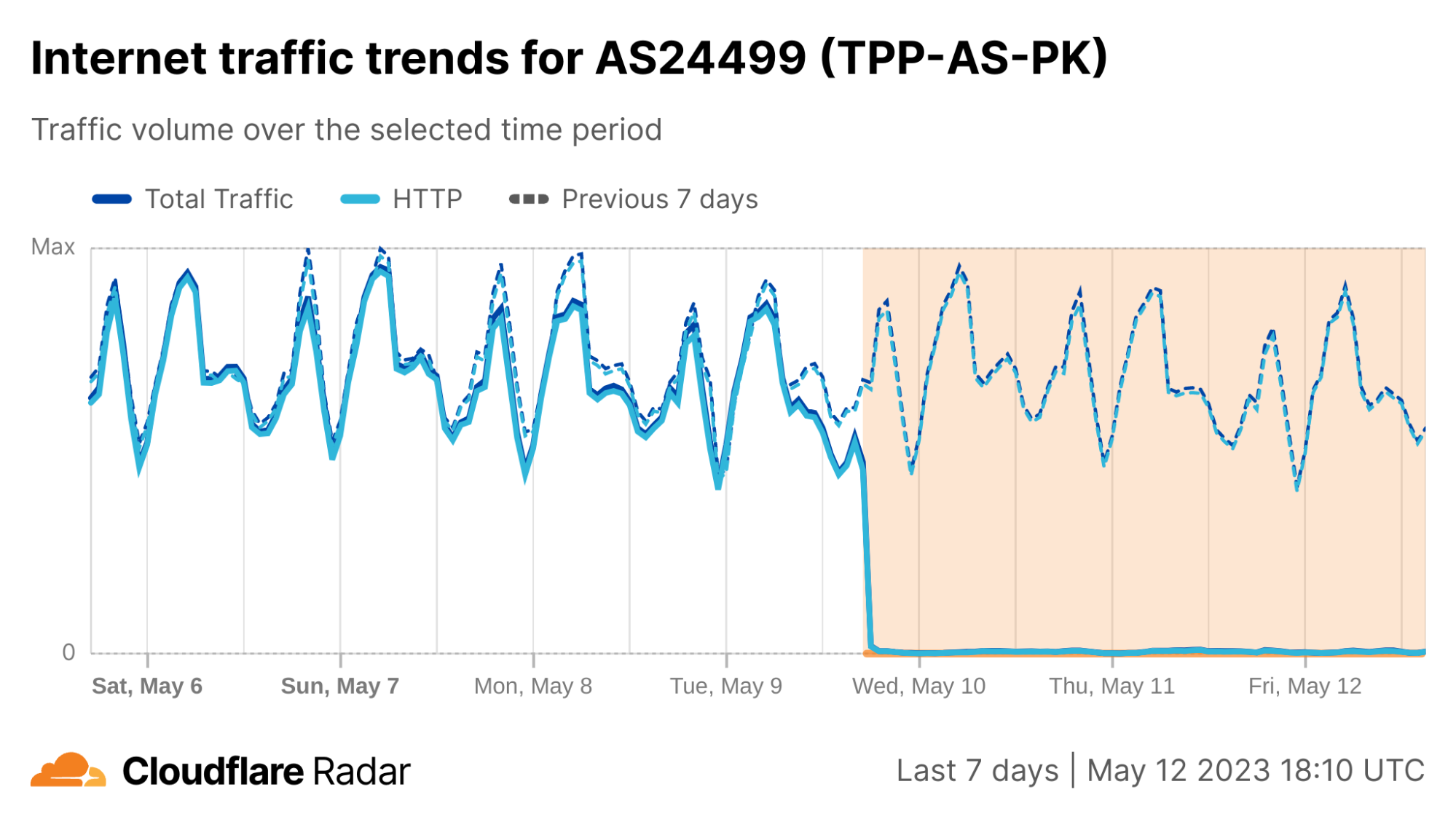
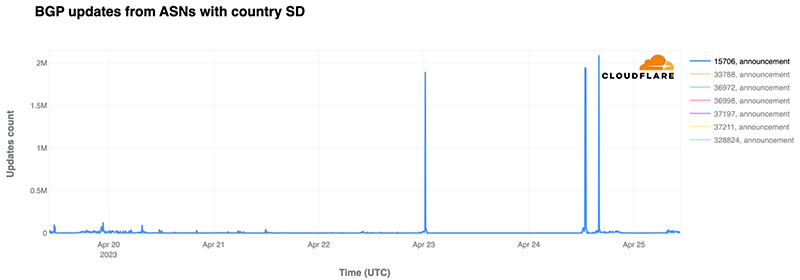
What drove the drop in Internet traffic in Palestine? Our data shows that two Gaza Strip related networks (autonomous systems or ASNs) were offline on that October 7 morning. Fusion (AS42314) was offline from 08:00 UTC, but saw some recovery after 17:00 UTC the next day; this only lasted for a few hours, given that it went back offline after 12:00 UTC this Monday, October 9.
It was the same scenario for DCC North (AS203905), but it went offline after 10:00 UTC and with no recovery of traffic observed as of Monday, October 9. These Internet disruptions may be related to power outages in the Gaza Strip.
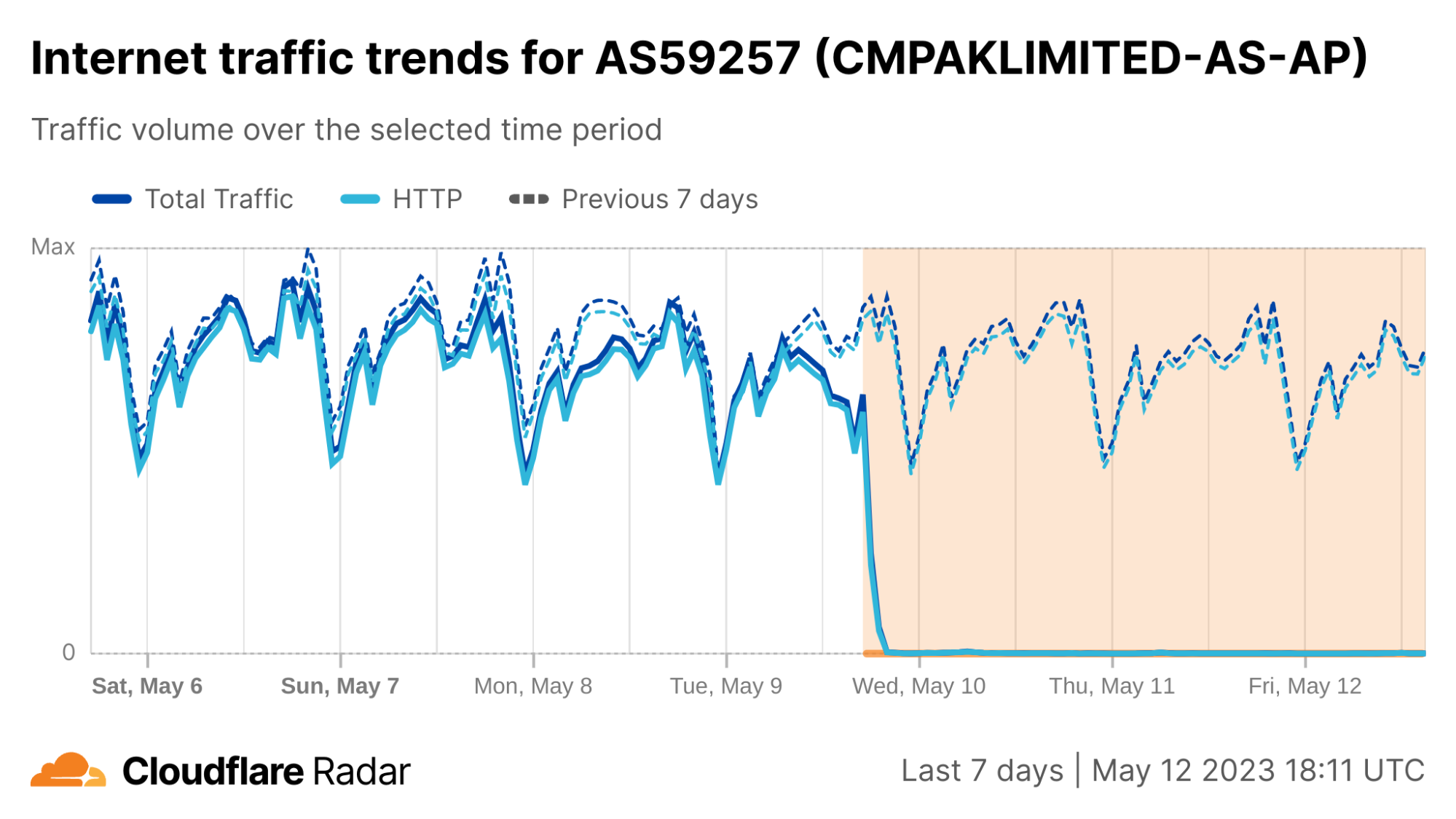
During the day on October 7, other Palestinian networks saw less traffic than usual. JETNET (AS199046) had around half of the usual traffic after 08:00 UTC, similar to SpeedClick (AS57704), which had around 60% less traffic. After 14:15 on October 9, traffic to those networks dropped sharply (a 95% decrease compared with the previous week), showing only residual traffic.
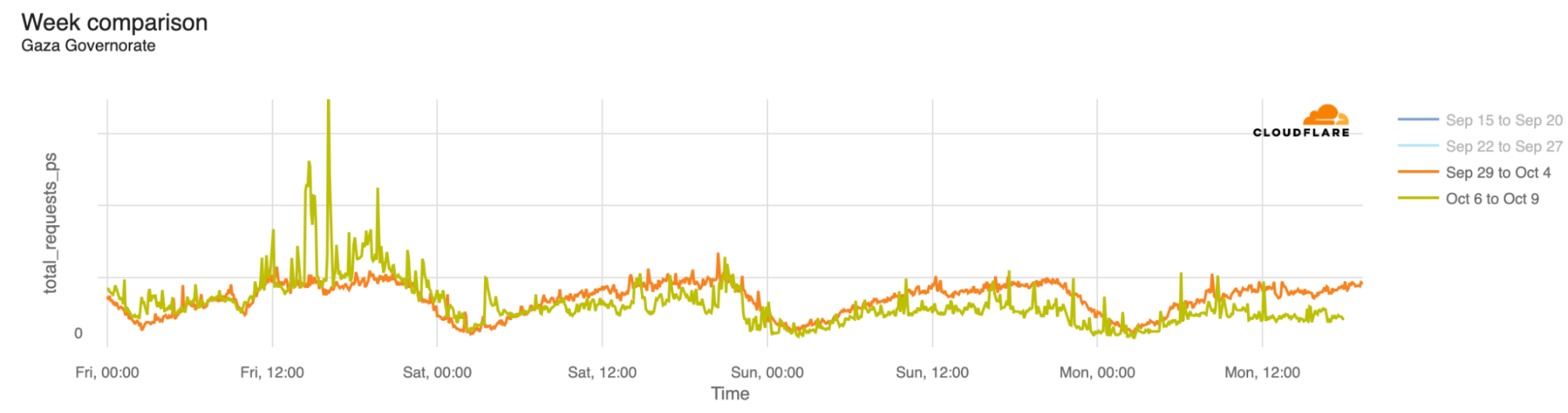
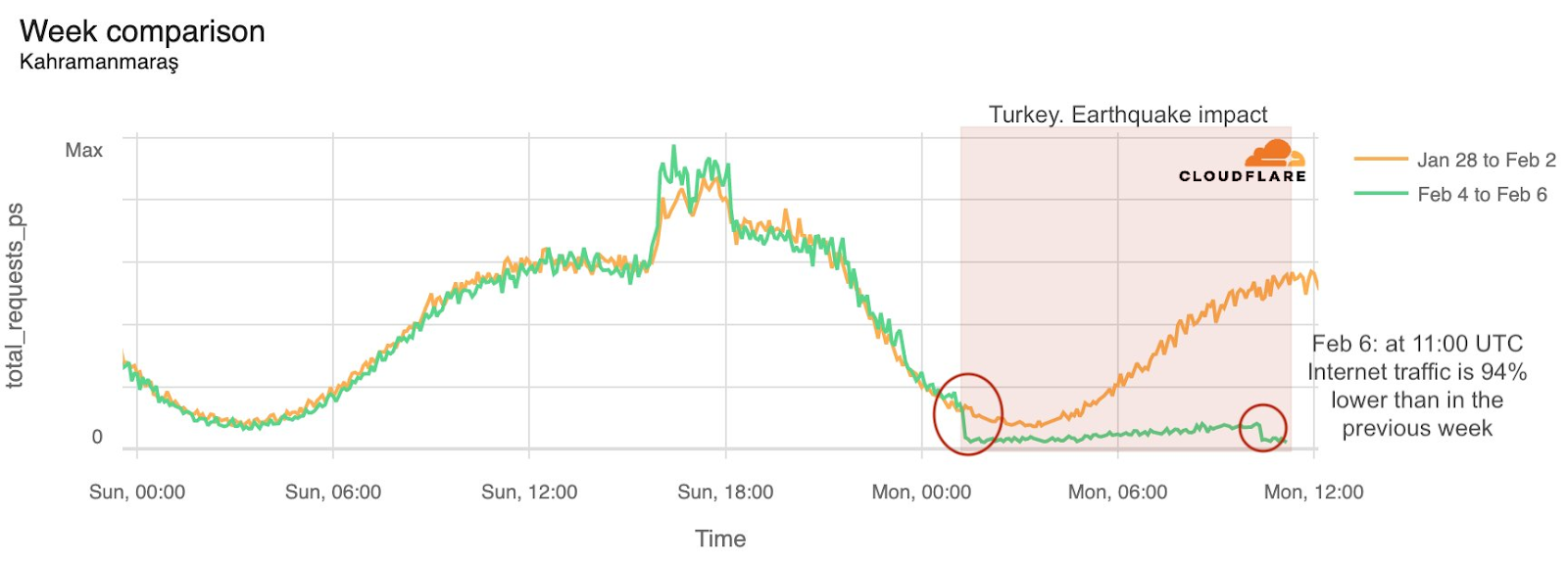
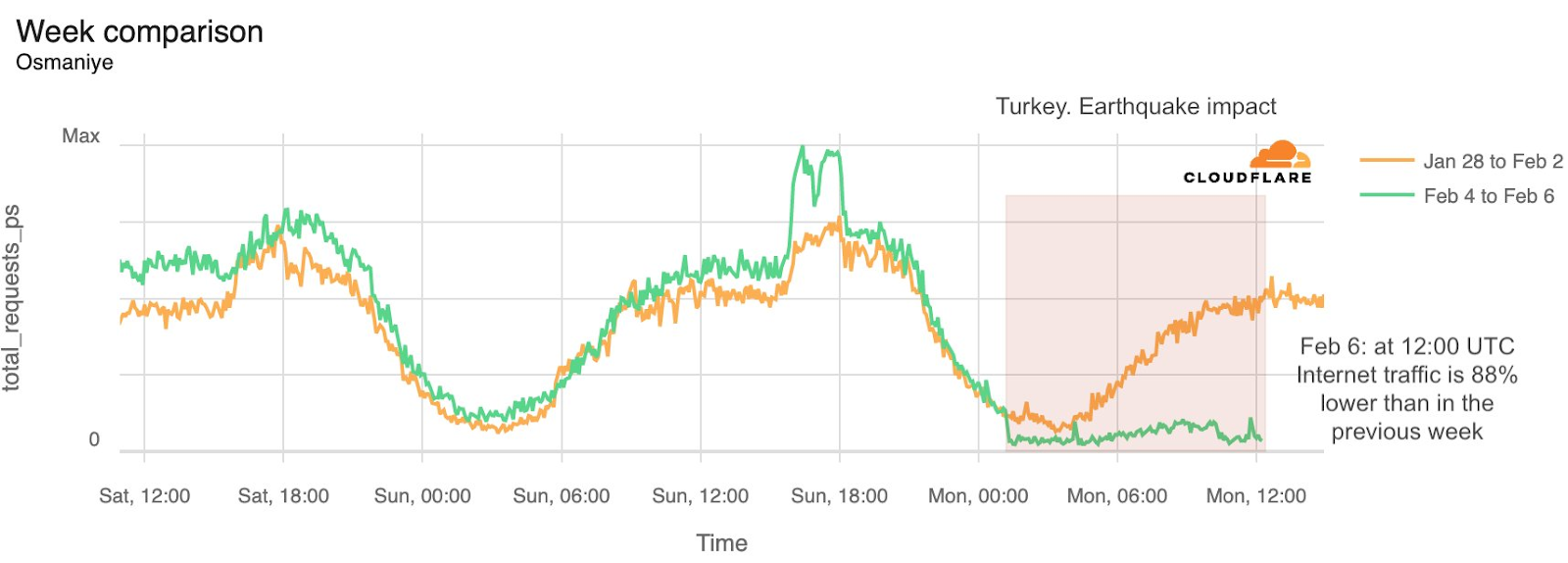
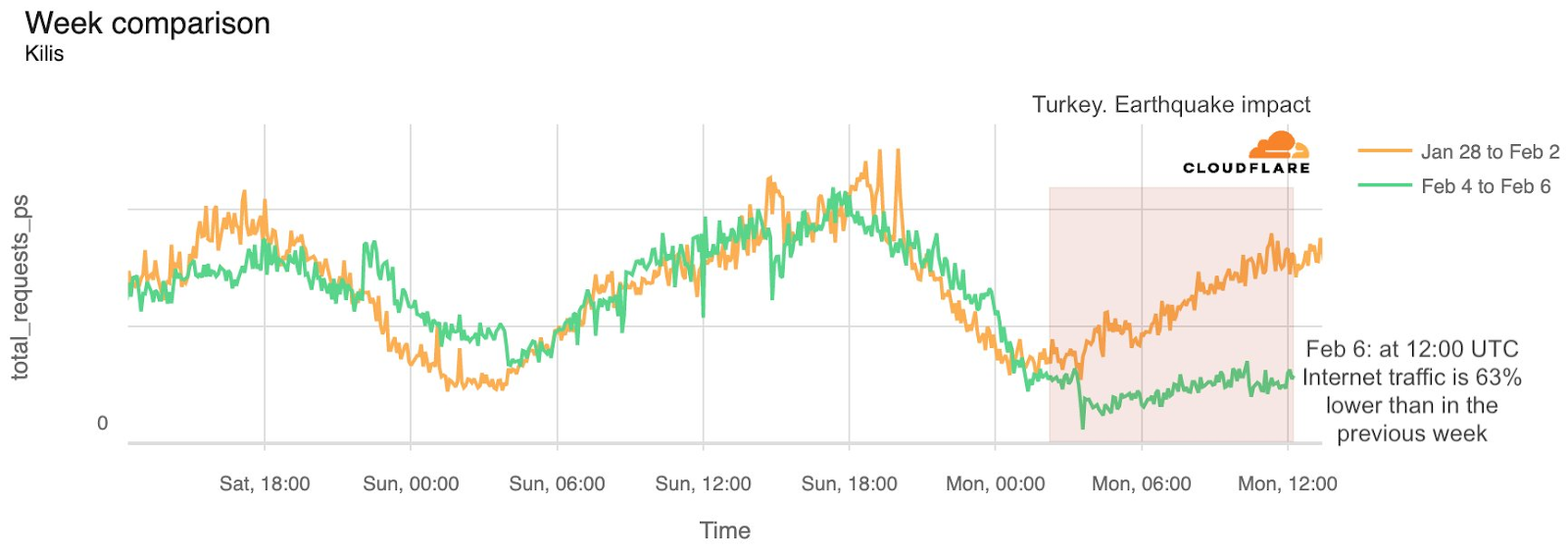
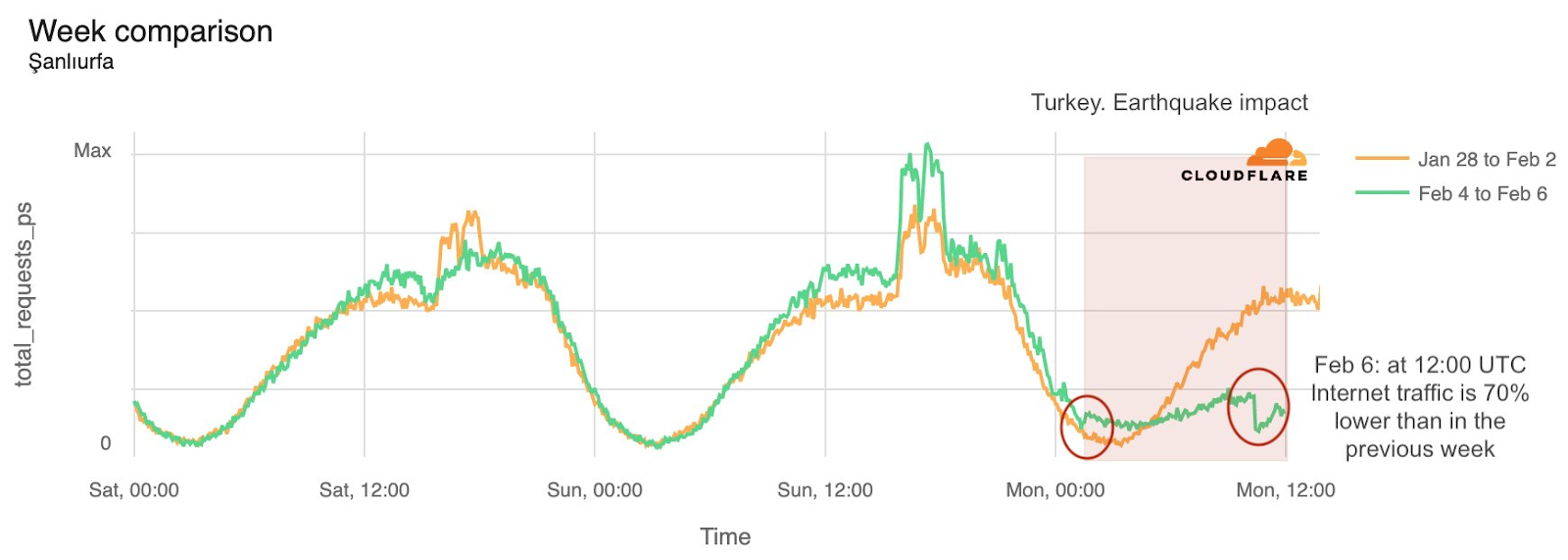
When looking more closely at the Gaza Strip specifically, we can see that some districts or governorates had a drop in HTTP requests a few hours after the first Hamas attacks. The Gaza Governorate was impacted, with traffic dropping on October 7, 2023, after 09:15 UTC. On October 9, at 18:00 UTC, traffic was 46% lower than in the previous week. (Note: there were spikes in traffic during Friday, October 6, several hours before the attacks, but it is unclear what caused those spikes.)
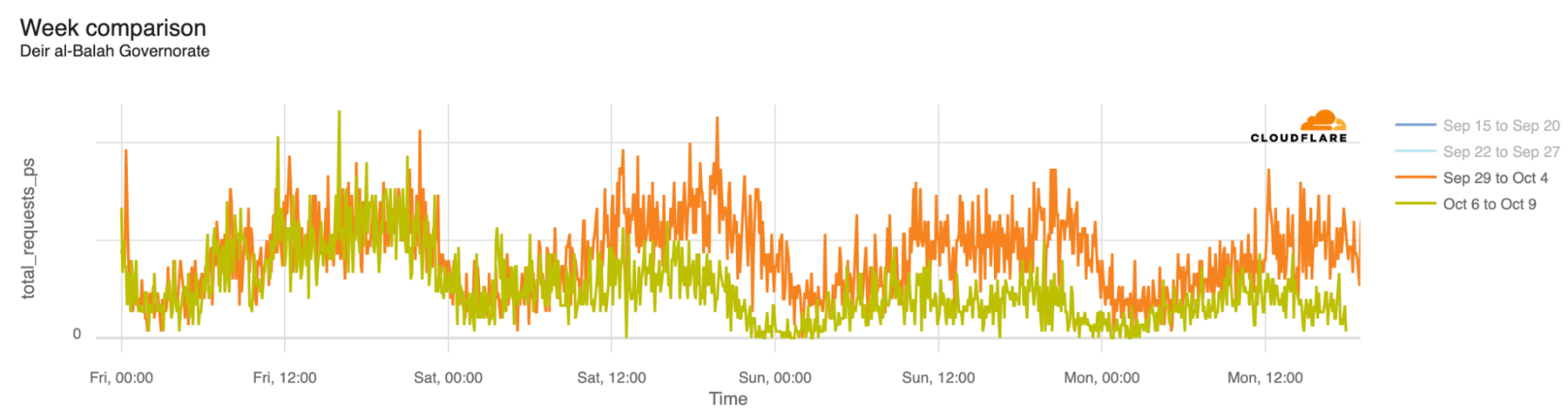
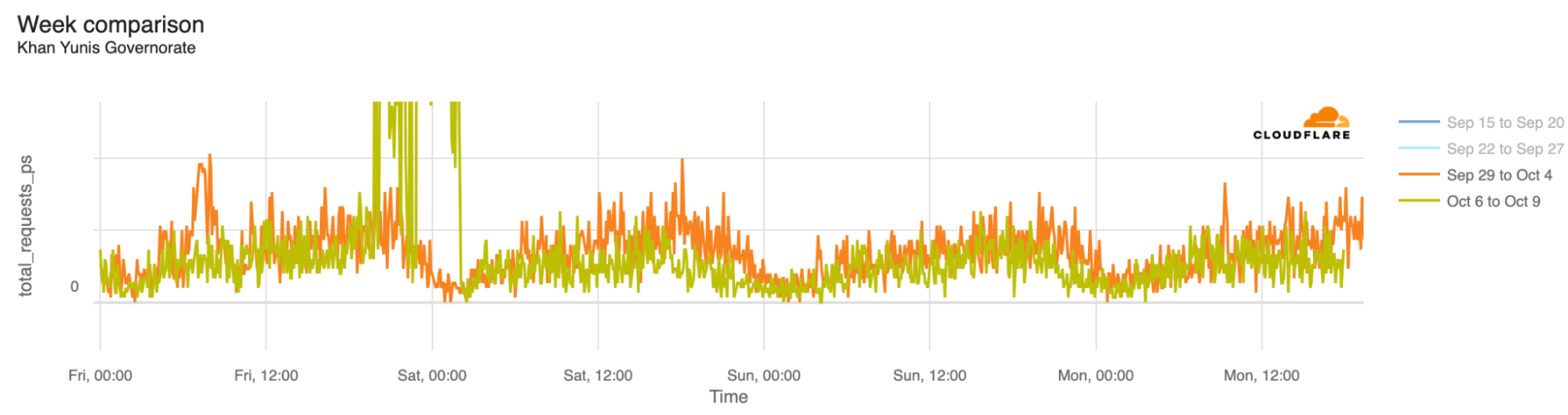
The Deir al-Balah Governorate (on October 9, at 18:00 UTC, traffic was 46% lower than in the previous week) and the Khan Yunis Governorate (50% lower) also both experienced similar drops in traffic:
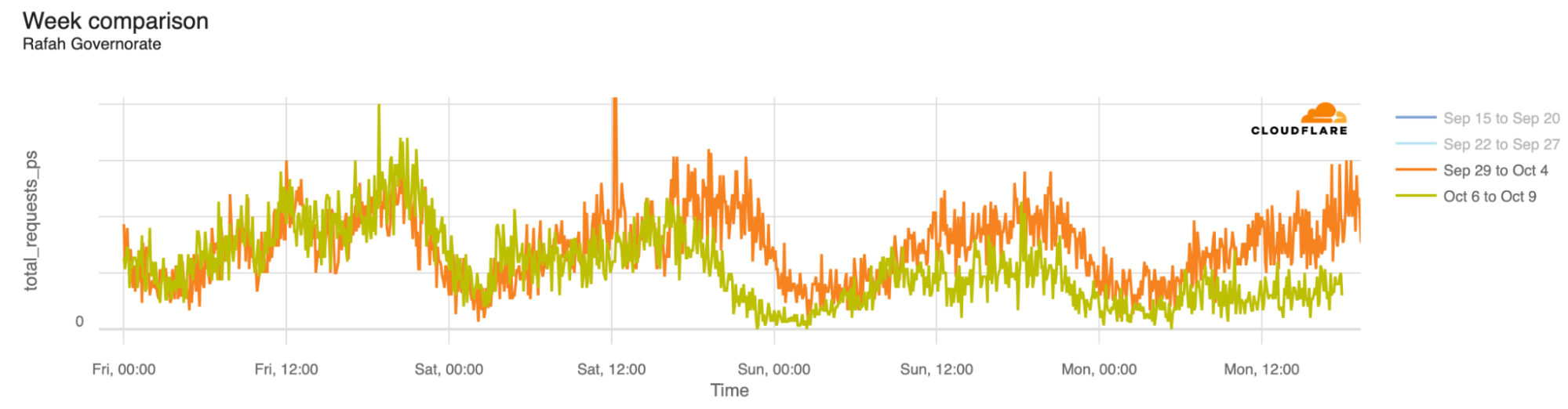
In the Rafah Governorate traffic dropped after 19:00 UTC on October 8 (and on October 9, at 18:00 UTC, traffic was 65% lower than in the previous week).
Other Palestinian governorates in the West Bank did not experience the same impact to Internet traffic.
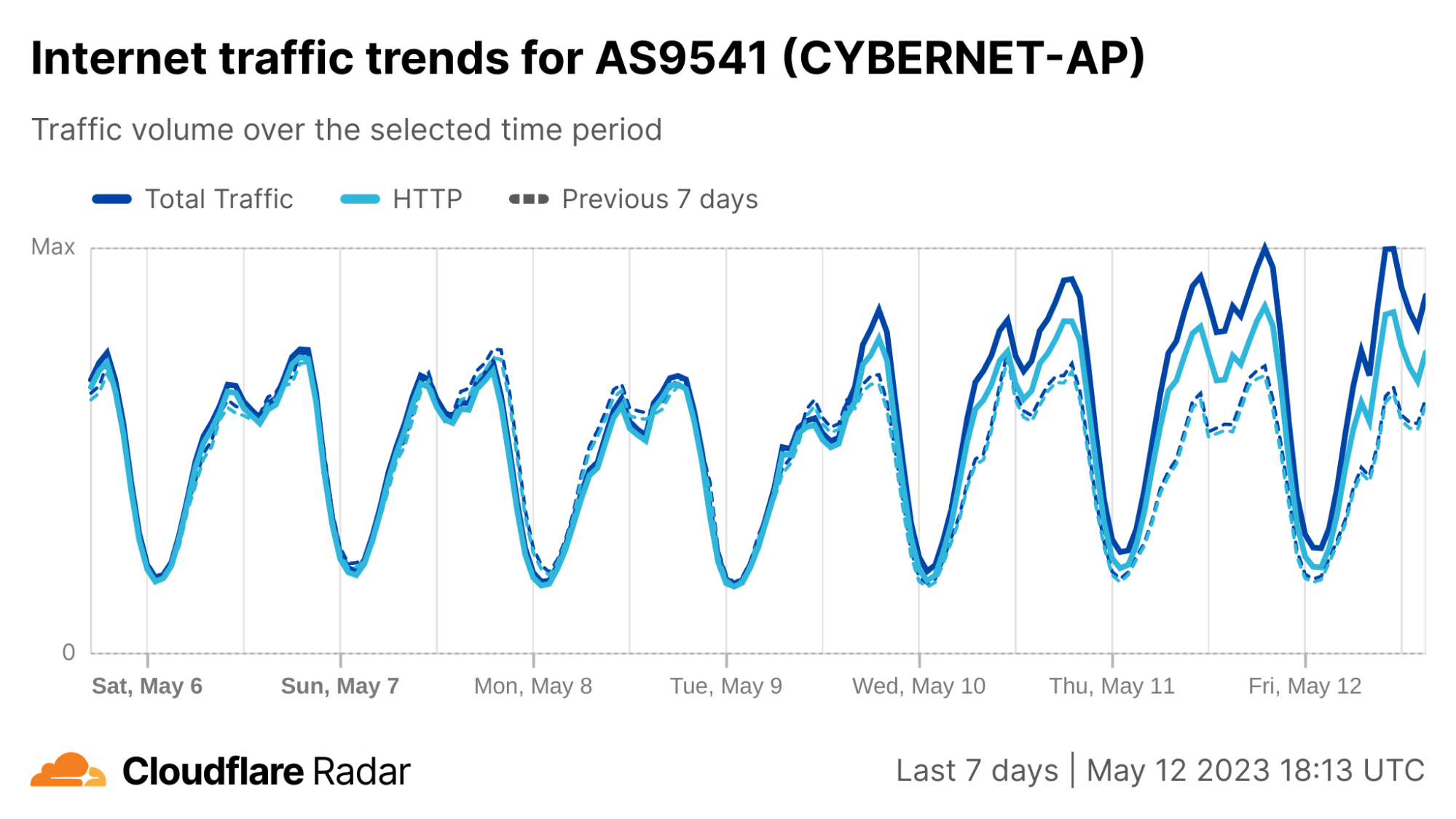
Spikes in Internet traffic in Israel
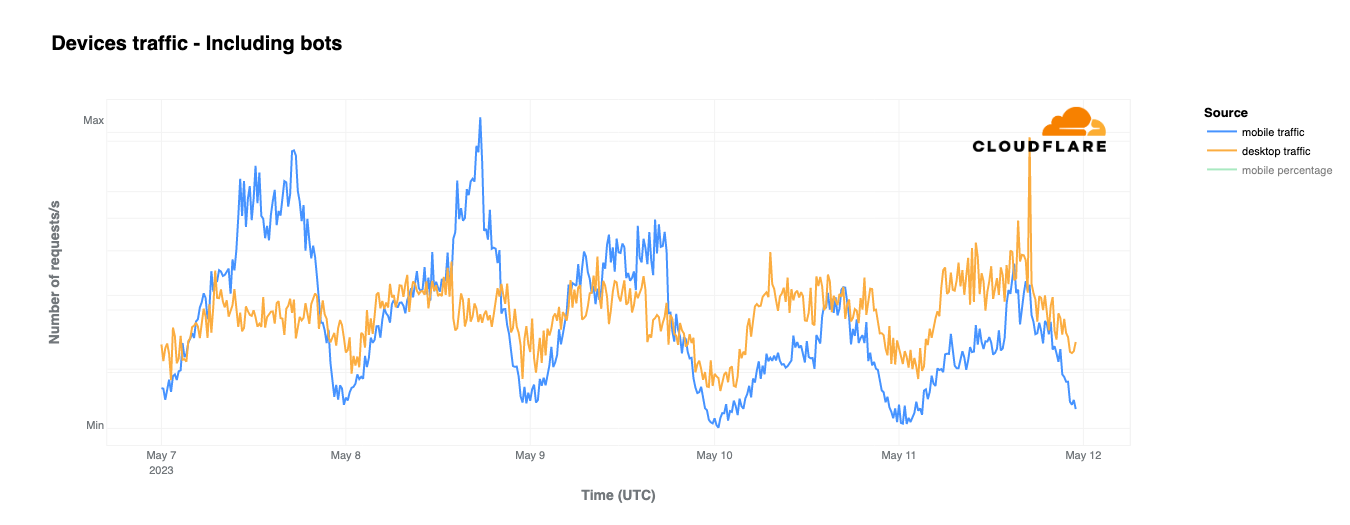
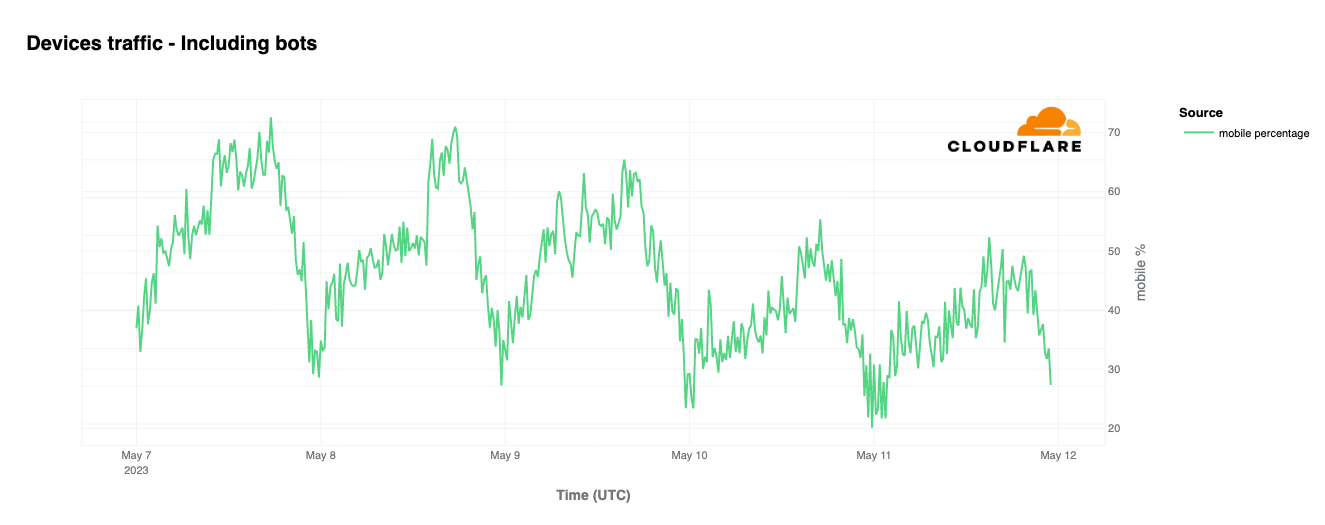
In Israel, Internet traffic surged to ~170% as compared to the previous week right after the Hamas attacks on October 7 at around 03:35 UTC (06:35 local time), and again at around 16:00 UTC (19:00 local time), with ~80% growth compared to the previous week. In both cases, the increase was driven by mobile device traffic.
There was also increased traffic, as compared with usual levels, on Sunday, October 8, with notable spikes at around 06:00 (09:00 local time) and 12:00 UTC (15:00 local time), seen in the HTTP requests traffic graph below.
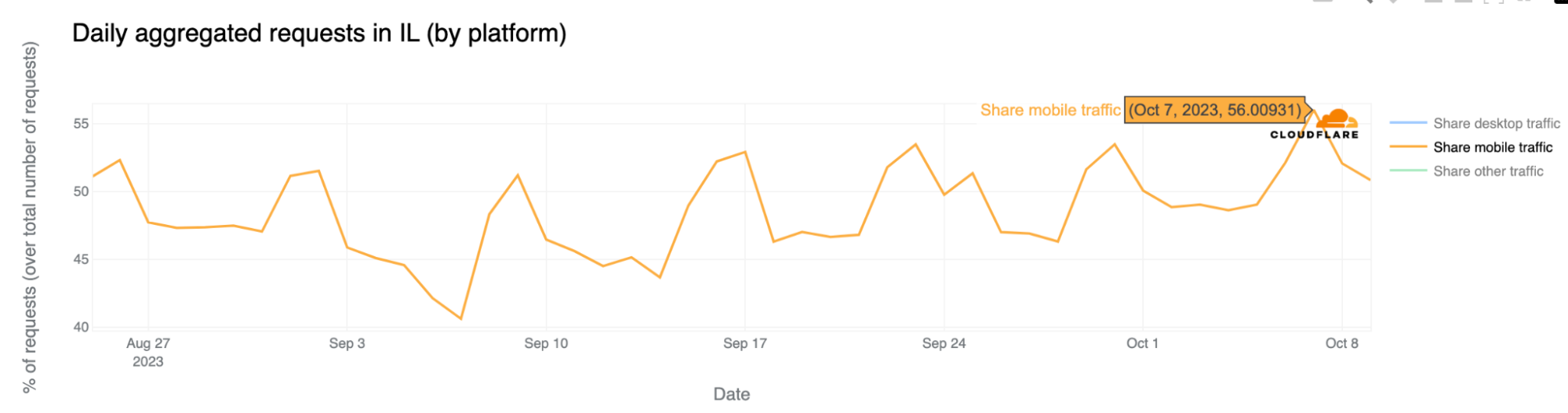
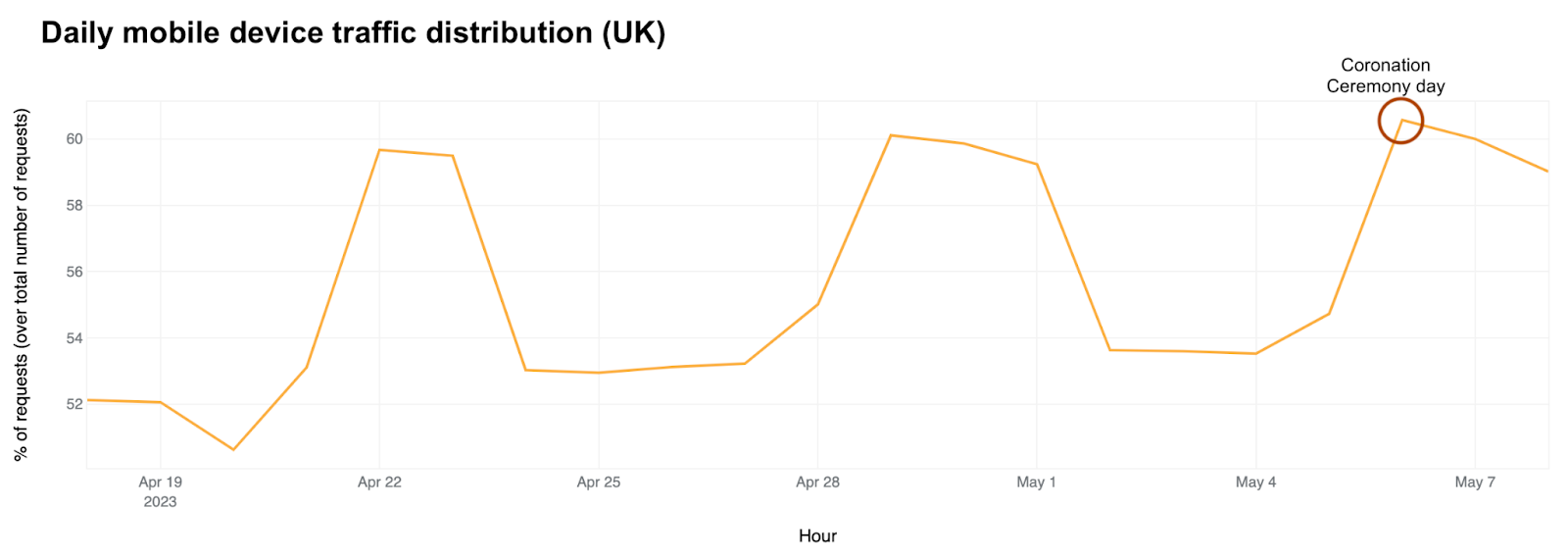
Mobile device traffic drove the Saturday, October 7 spikes in traffic, with the daily mobile device usage percentage reaching its highest in the past two months, reaching 56%.
Looking at specific Israel districts, traffic looks similar to the nationwide perspective.
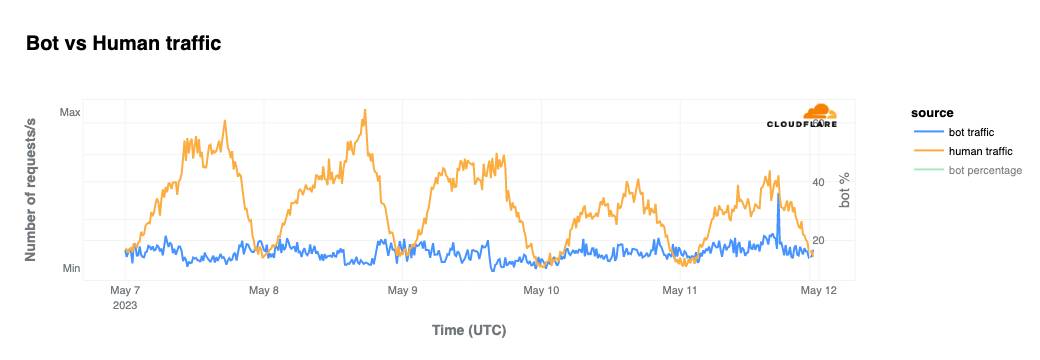
Cyber attacks targeting Israel
Cyber attacks are frequent, recurrent, and are not necessarily dependent on actual wars on the ground, as our 2023 attacks landscape clearly showed. However, it is not unusual to see cyberattacks launched in tandem with ground assaults. We saw that in Ukraine, an uptick in cyber attacks started just before war began there on February 24, 2022, and were even more constant, and spread to other countries after that day.
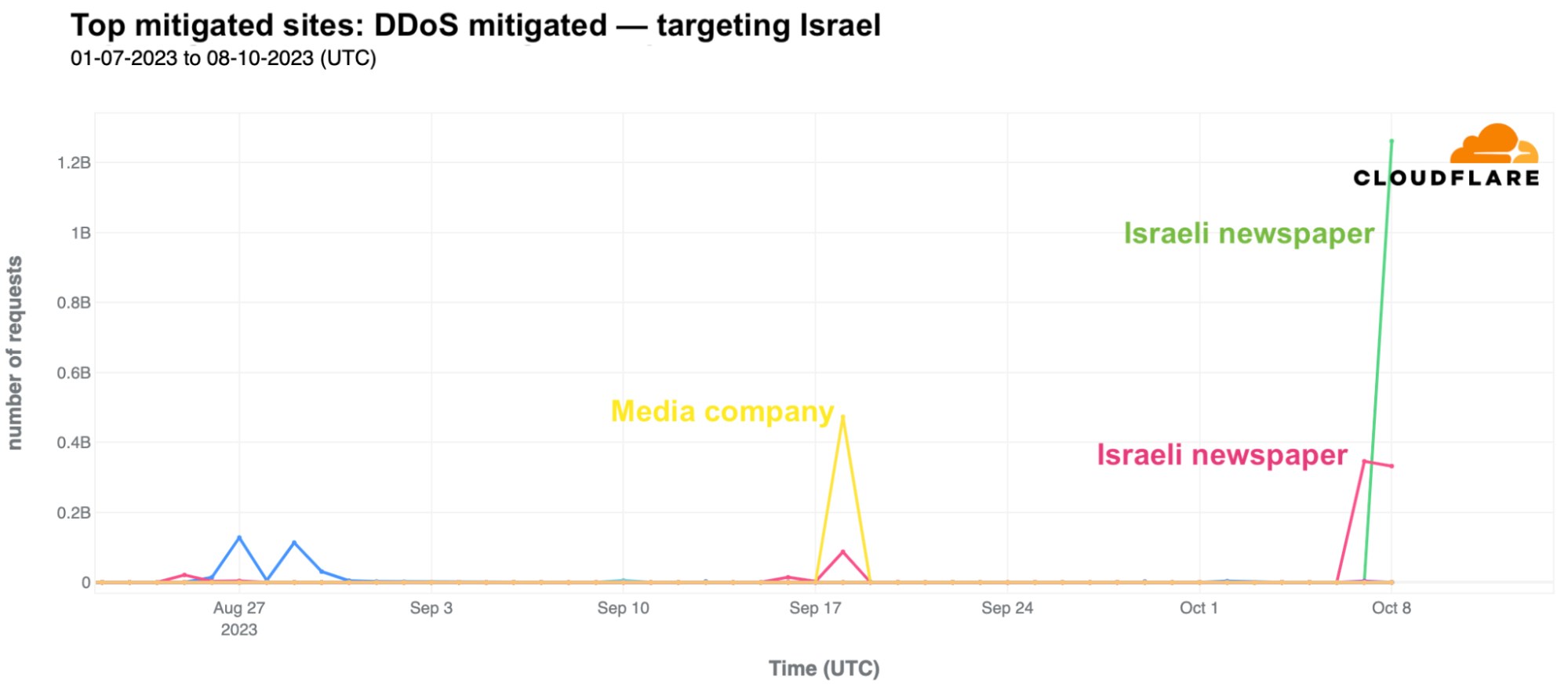
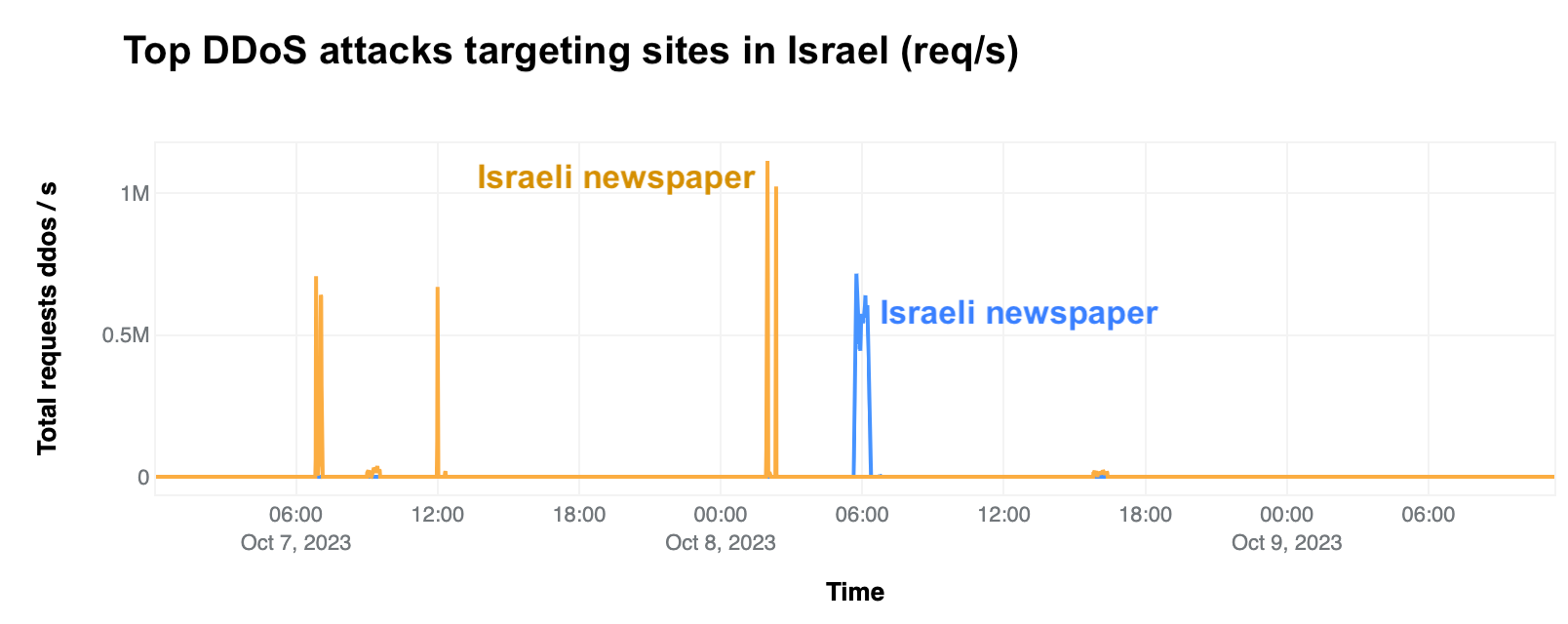
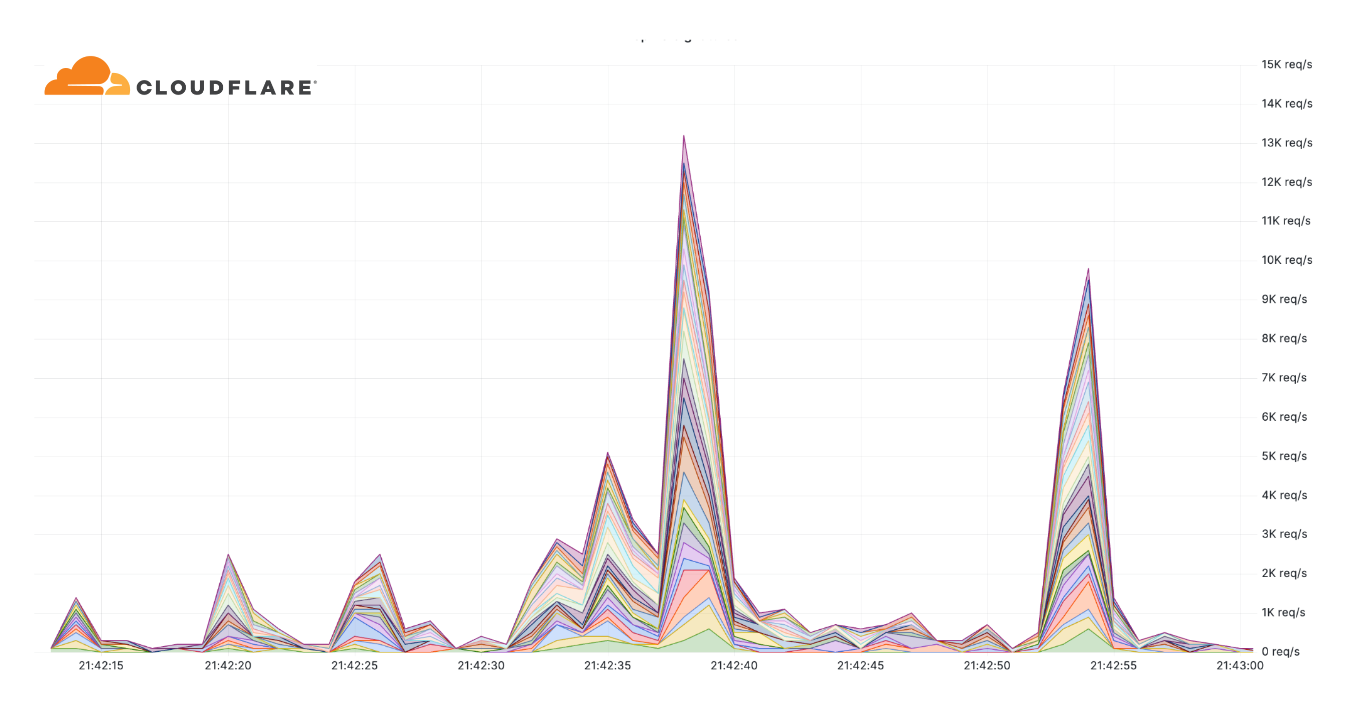
In Israel, we saw a clear uptick in cyber attacks earlier this year, with another wave of notable attacks on October 7 and October 8, 2023, after the Hamas attacks. The largest ones were DDoS attacks targeting Israeli newspapers. One attack on October 8, reached 1.26 billion daily requests blocked by Cloudflare as DDoS attacks, and the other reached 346 million daily requests on October 7, and 332 million daily requests the following day.
Looking at these DDoS attacks in terms of requests per second, one of the impacted sites experienced a peak of 1.1 million requests per second on October 8 at 02:00 UTC, and the other Israeli newspaper saw a peak of 745k requests per second at around 06:00 the same day.
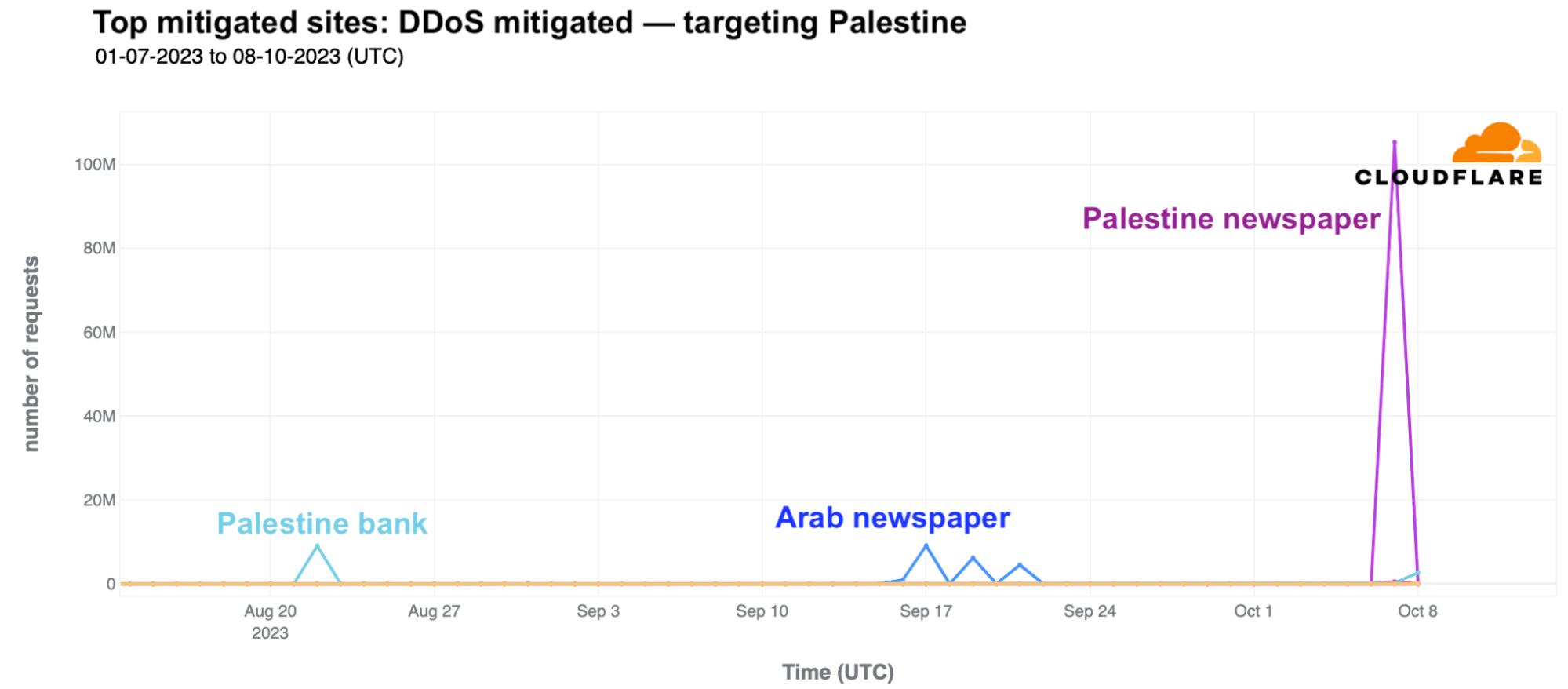
In Palestine, we also saw application layer DDoS attacks, but not as big. The main one in the past three months was on October 7, 2023, targeting a Palestine online newspaper, reaching 105 million daily requests.
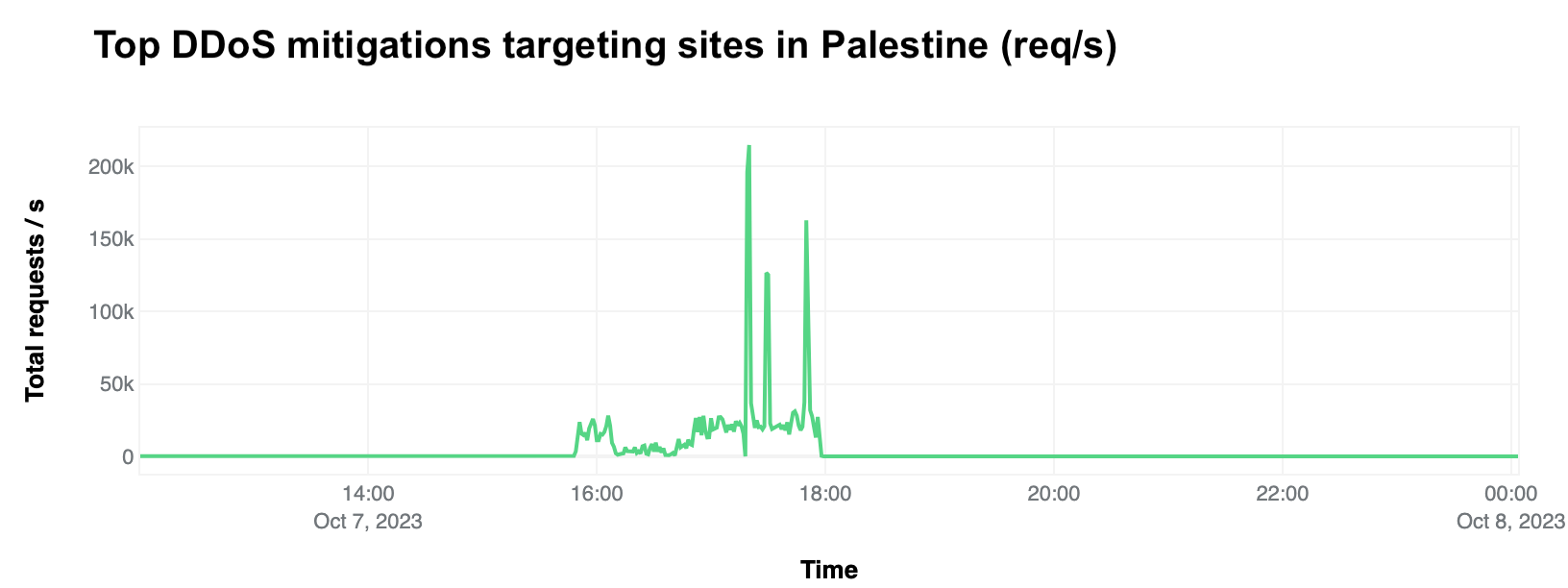
Looking at these most notable DDoS attacks targeting Palestine in terms of requests per second (rps), the most impacted site (a Palestinian newspaper) experienced a peak of 214k requests per second at around 17:20 UTC on October 7.
Follow Cloudflare Radar for up to date information
We constantly measure our own network’s performance against other networks, look for ways to improve our performance compared to them, and share the results of our efforts. Since June 2021, we’ve been sharing benchmarking results we’ve run against other networks to see how we compare.
In this post we are going to share the most recent updates since our last post in June, and tell you about our tools and processes that we use to monitor and improve our network performance.
How we stack up
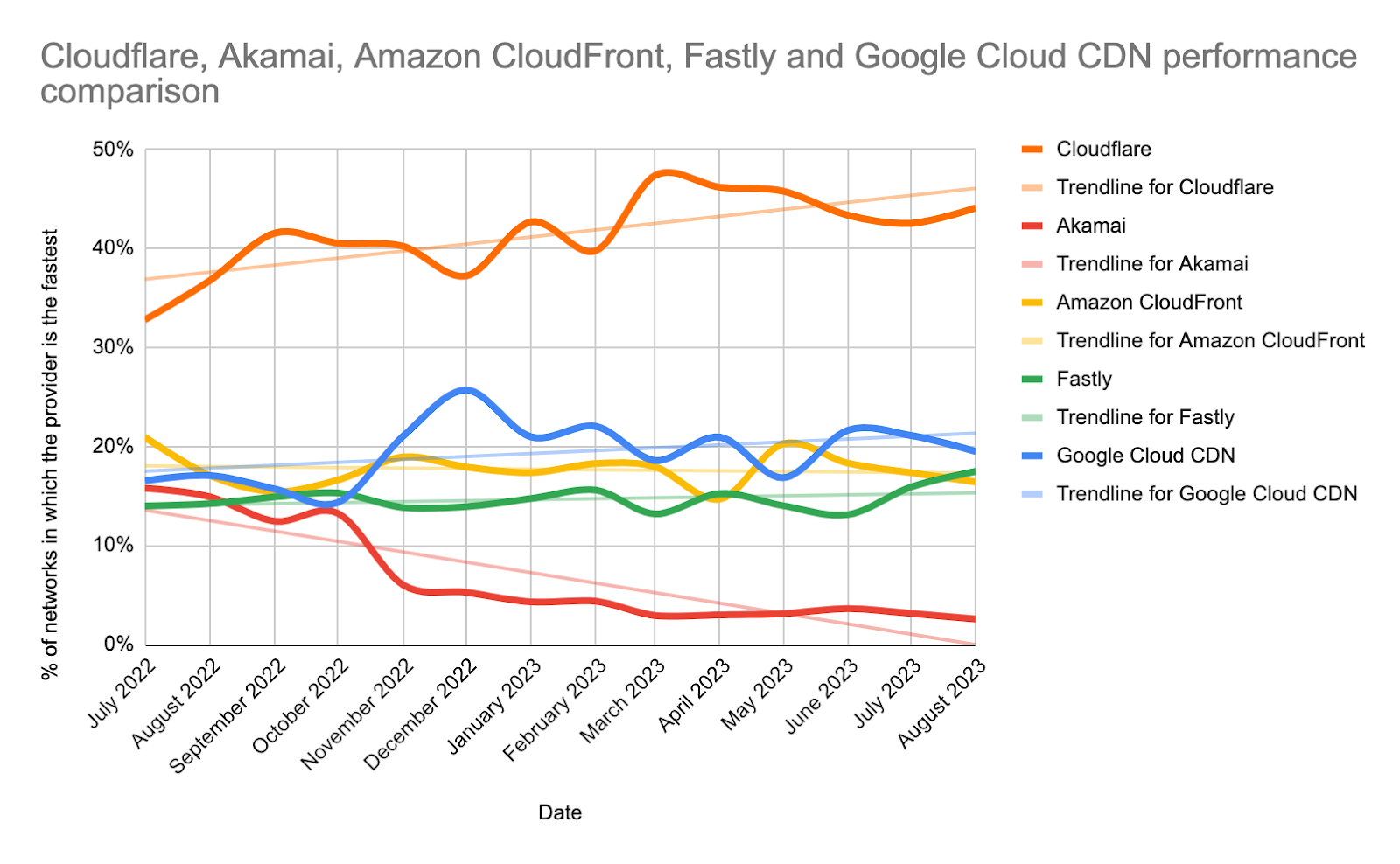
Since June 2021, we’ve been taking a close look at every single network and taking actions for the specific networks where we have some room for improvement. Cloudflare was already the fastest provider for most of the networks around the world (we define a network as country and AS number pair). Taking a closer look at the numbers; in July 2022, Cloudflare was ranked #1 in 33% of the networks and was within 2 ms (95th percentile TCP Connection Time) or 5% of the #1 provider for 8% of the networks that we measured. For reference, our closest competitor on that front was the fastest for 20% of networks.
As of August 30, 2023, Cloudflare is the fastest provider for 44% of networks—and was within 2 ms (95th percentile TCP Connection Time) or 5% of the fastest provider for 10% of the networks that we measured—whereas our closest competitor is now the fastest for 19% of networks.
Below is the change in percentage of networks in which each provider is the fastest plotted over time.
Cloudflare is maintaining our steady growth in the percentage of networks where we’re the fastest. Despite the slight tick down the past couple of months, the trendline is still positive and with a higher rate of increase than other networks.
Now that we’ve reviewed how we stack up compared to other networks, let’s dig a little more into the other metrics we use to make us the fastest.
Our tooling
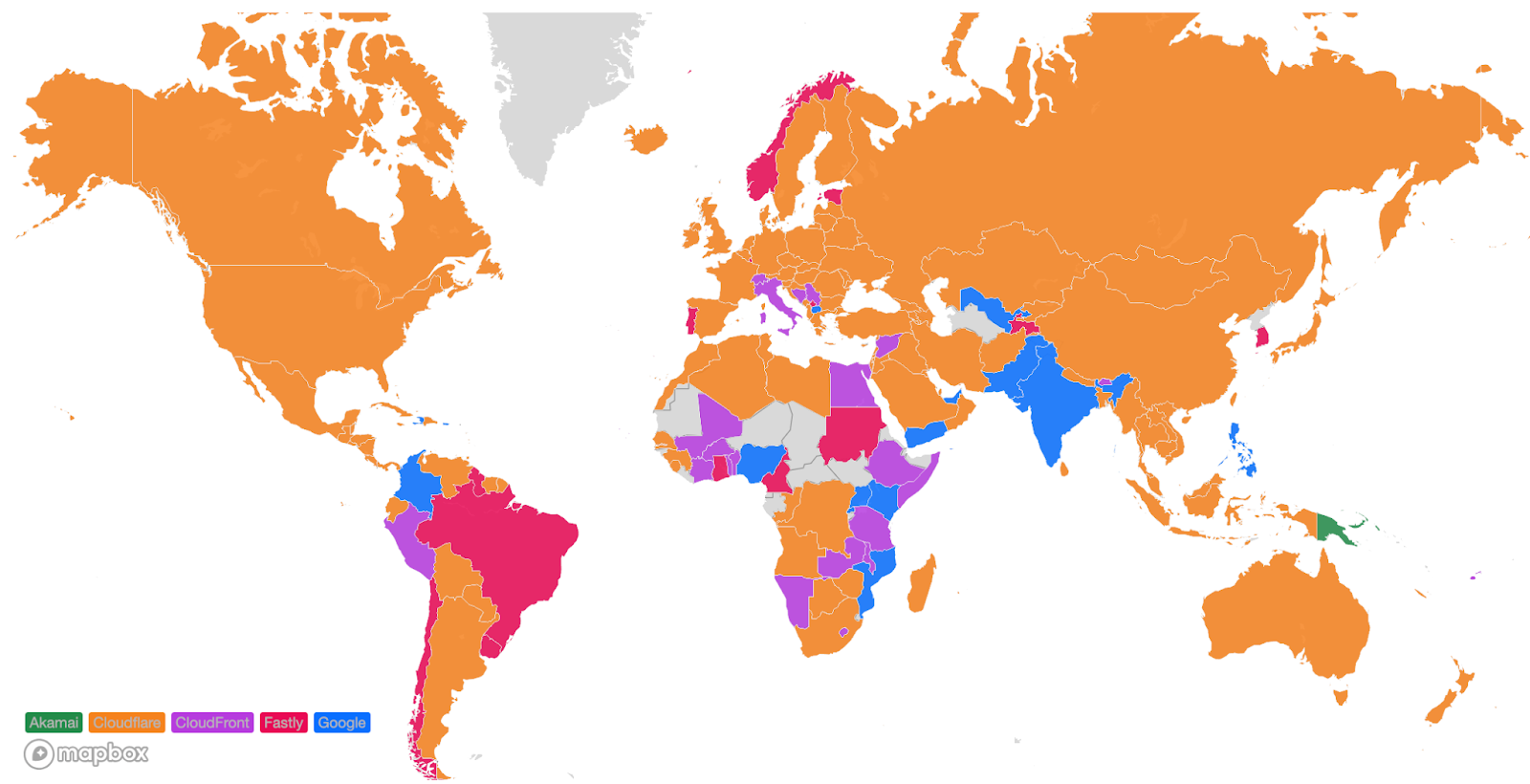
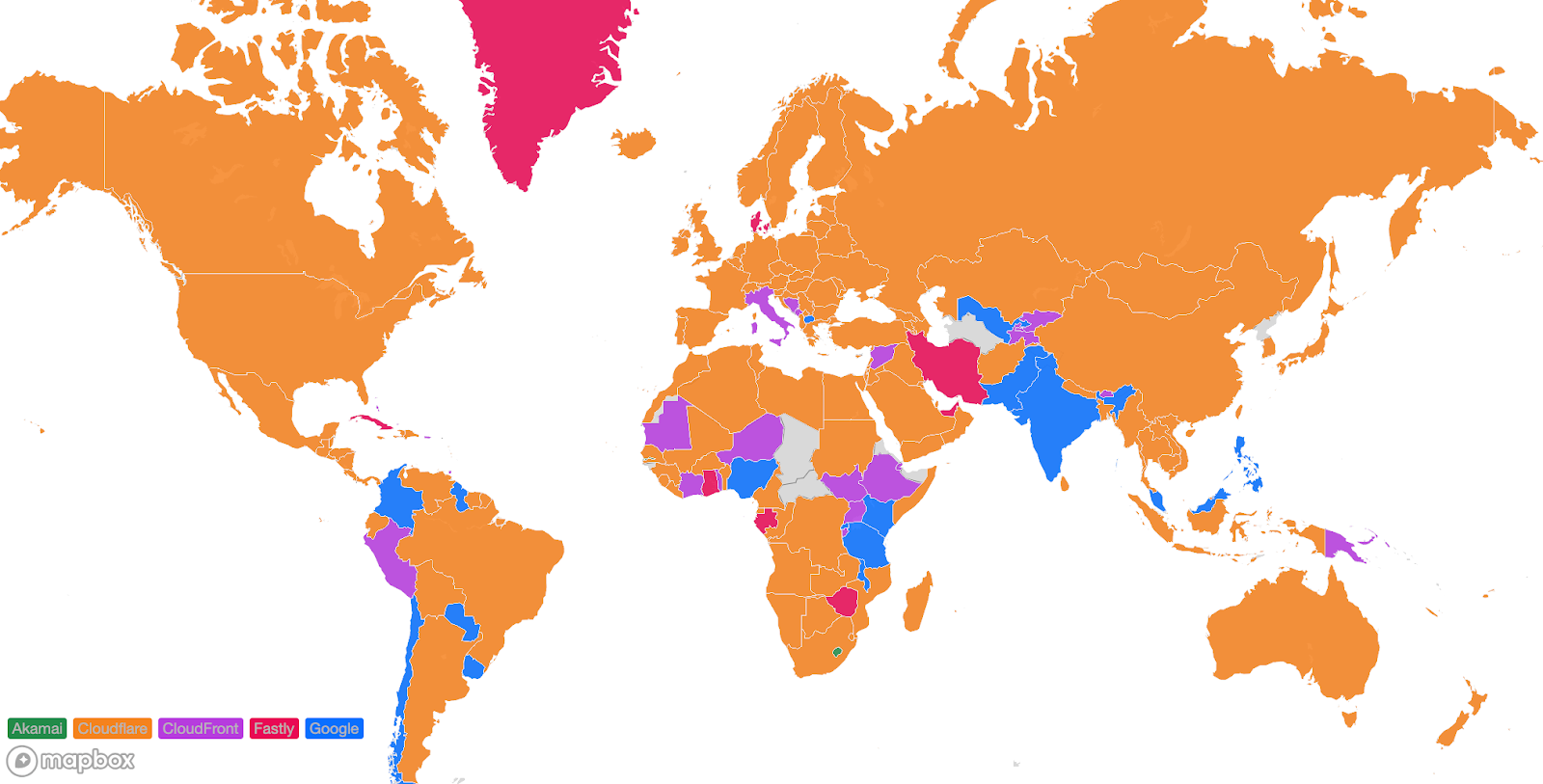
To provide insight into network performance, we use Real User Measurements (RUM) and fetch a small file from Cloudflare, Akamai, Amazon CloudFront, Fastly and Google Cloud CDN. Browsers around the world report the performance of those providers from the perspective of the end-user network they are on. The goal is to provide an accurate picture of where different providers are faster, and more importantly, where Cloudflare can improve. You can read more about the methodology in the original Speed Week blog post here.
Using the RUM data, we are able to measure various performance metrics, such as TCP Connection Time, Time to First Byte (TTFB), Time to Last Byte (TTLB), for ourselves and other networks.
Let’s take a look at some of the metrics we monitor and what’s changed since our last blog in June.
The first metric we closely monitor is the percent of networks that we are ranked #1 in terms of TCP Connection Time. That's a key performance indicator that we evaluate ourselves against. This first line of the table shows that Cloudflare was ranked #1 in 45% of networks in June 2023 and 44% in August 2023. Here’s the full picture of how we looked in June versus how we look today.
Cloudflare’s rank by TCP connection time
% of networks in June 2023
% of networks in August 2023
1
45
44
2
26
24
3
16
16
4
9
10
5
4
6
Overall, these metrics align with what we saw above: Cloudflare is still the fastest provider in the most last mile networks, and while there has been slight changes in the month-to-month fluctuations, the overall trend shows us as being the fastest.
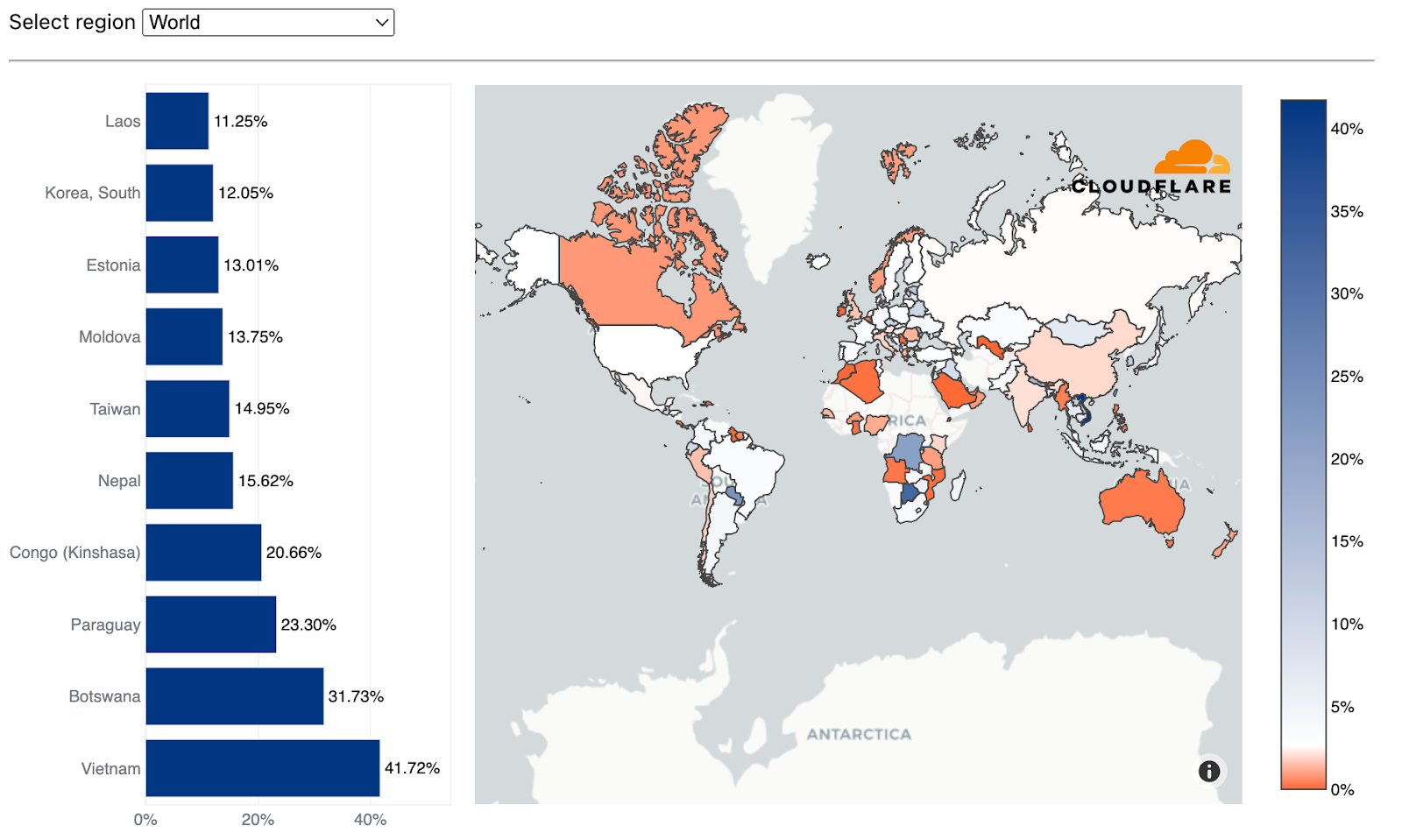
The second metric we monitor is our overall performance in each country. This gives us visibility into the countries or regions that we need to pay closer attention to and take action towards improving our performance. Those actions will be listed later. Orange indicates the countries that Cloudflare is the fastest provider based on the TCP Connection Time. Here’s how we look as of September 2023:
For comparison, this is what that map looks like from June 2023:
We’ve become faster in Iran and Paraguay, and in the few cases where we are no longer number 1, we are within 2ms of the fastest provider. In Brazil and Norway for example, we trail Fastly by only 1ms. In various countries in Africa, Amazon CloudFront pulled ahead but only by 2ms. We aim to fix that in the coming weeks and months and return to the #1 spot there also.
The third set of metrics we use are TCP Connection Time and TTLB. The number of networks where we are #1 in terms of 95th percentile TCP Connection Time is one of our key performance indicators. We actively monitor and work on improving that metric so that we are #1 in the most metrics for 95th percentile TCP Connection Time. For September 2023, we are still #1 in the most networks for TCP Connection Time, more than double the next best provider.
Provider
# of networks where the provider is fastest for 95th percentile TCP connection time
Cloudflare
826
Google
392
Fastly
348
Cloudfront
337
Akamai
52
The way we achieve these great results is by having our engineering teams constantly investigate the underlying reasons for degraded performance if there are any, and we track open work items until they are resolved.
What’s next
We’re sharing our updates on our journey to become #1 everywhere so that you can see what goes into running the fastest network in the world. From here, our plan is the same as always: identify where we’re slower, fix it, and then tell you how we’ve gotten faster.
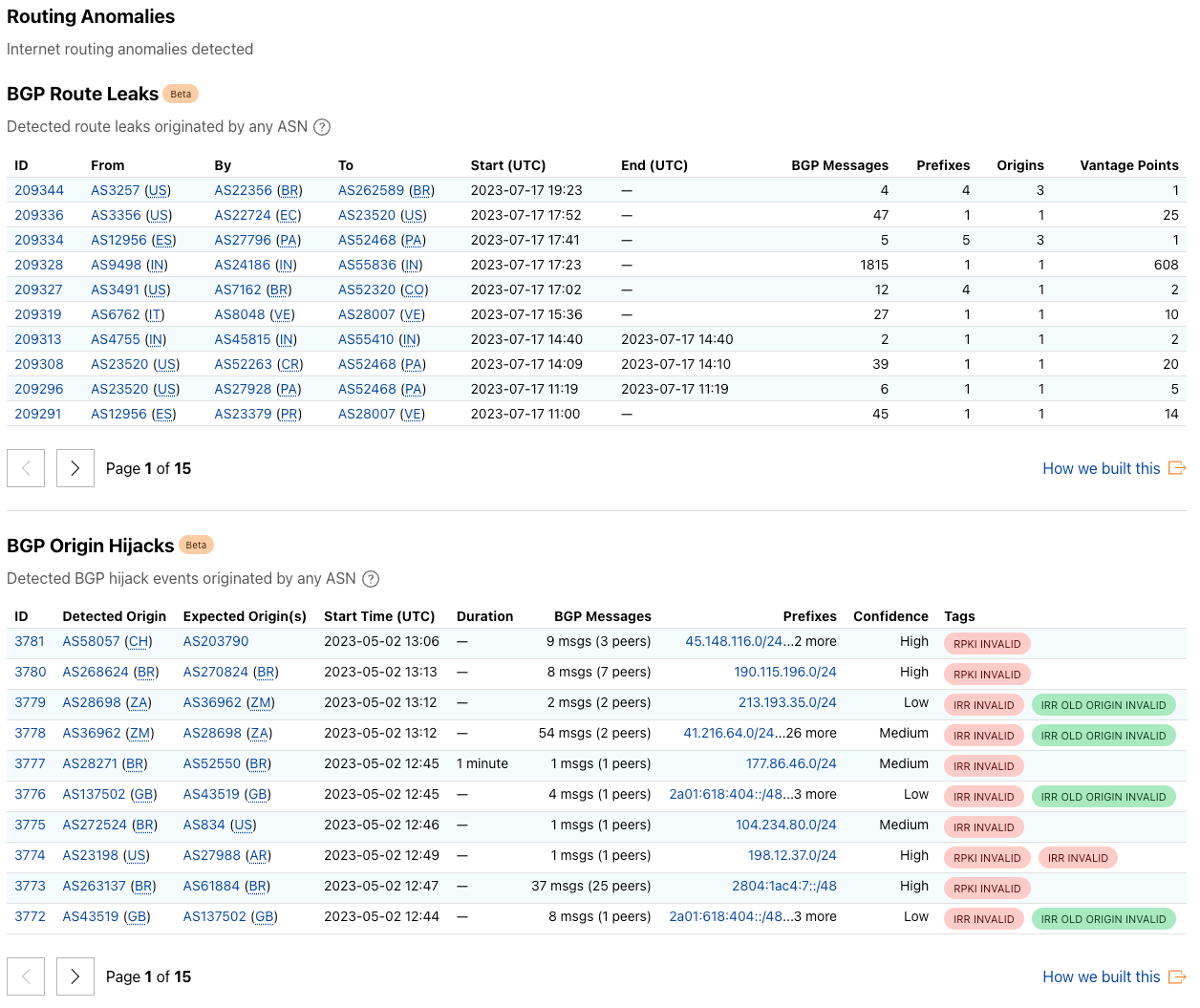
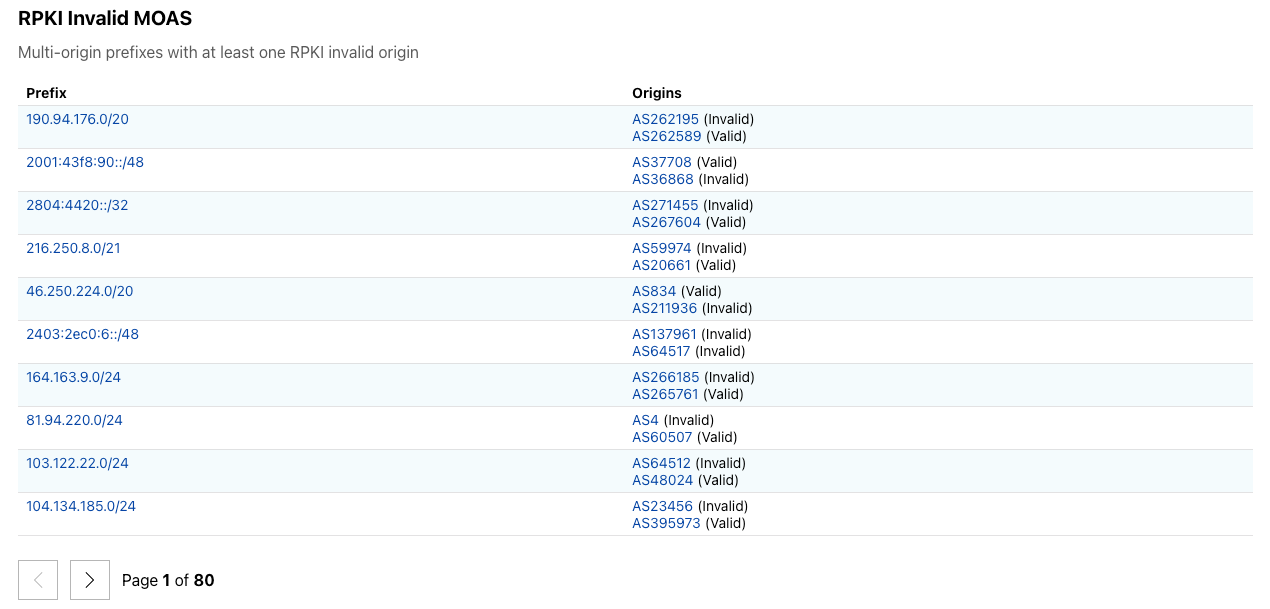
We launched the Cloudflare Radar Outage Center (CROC) during Birthday Week 2022 as a way of keeping the community up to date on Internet disruptions, including outages and shutdowns, visible in Cloudflare’s traffic data. While some of the entries have their genesis in information from social media posts made by local telecommunications providers or civil society organizations, others are based on an internal traffic anomaly detection and alerting tool. Today, we’re adding this alerting feed to Cloudflare Radar, showing country and network-level traffic anomalies on the CROC as they are detected, as well as making the feed available via API.
Building on this new functionality, as well as the route leaks and route hijacks insights that we recently launched on Cloudflare Radar, we are also launching new Radar notification functionality, enabling you to subscribe to notifications about traffic anomalies, confirmed Internet outages, route leaks, or route hijacks. Using the Cloudflare dashboard’s existing notification functionality, users can set up notifications for one or more countries or autonomous systems, and receive notifications when a relevant event occurs. Notifications may be sent via e-mail or webhooks — the available delivery methods vary according to plan level.
Traffic anomalies
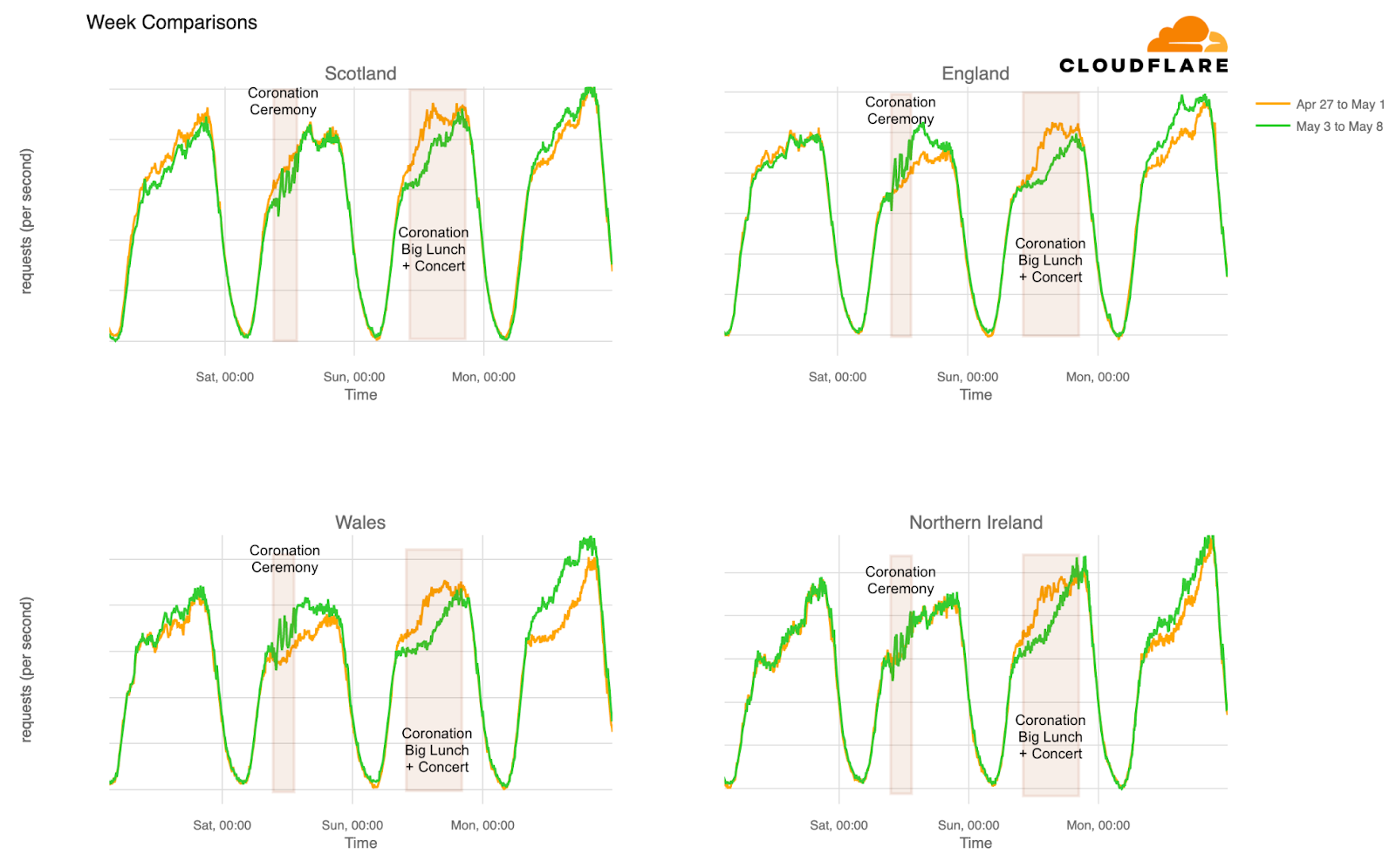
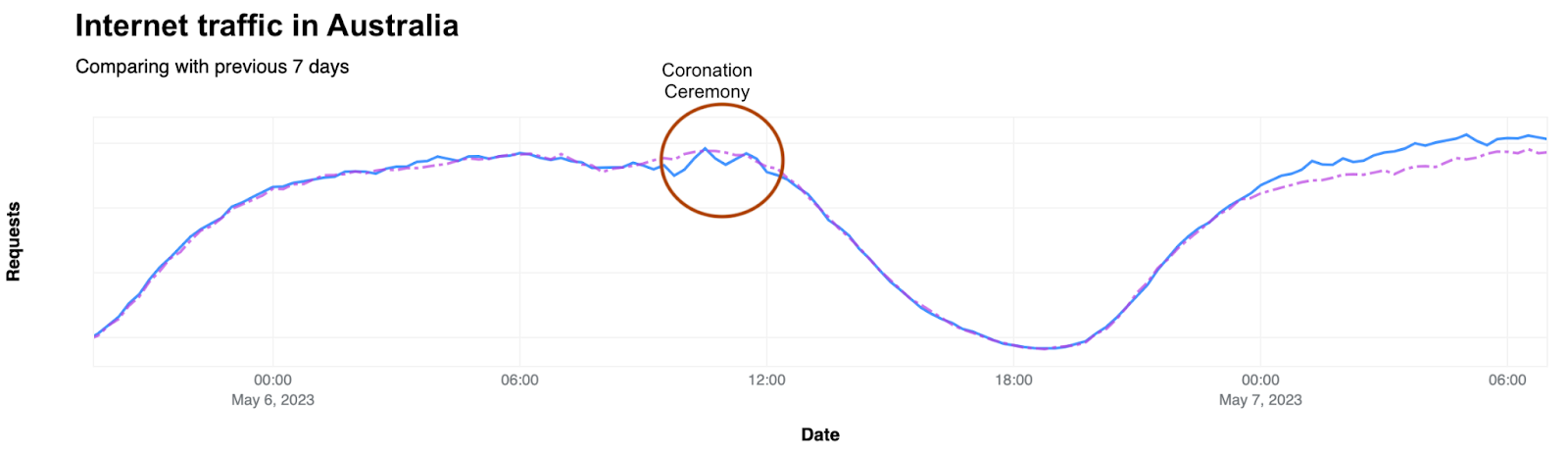
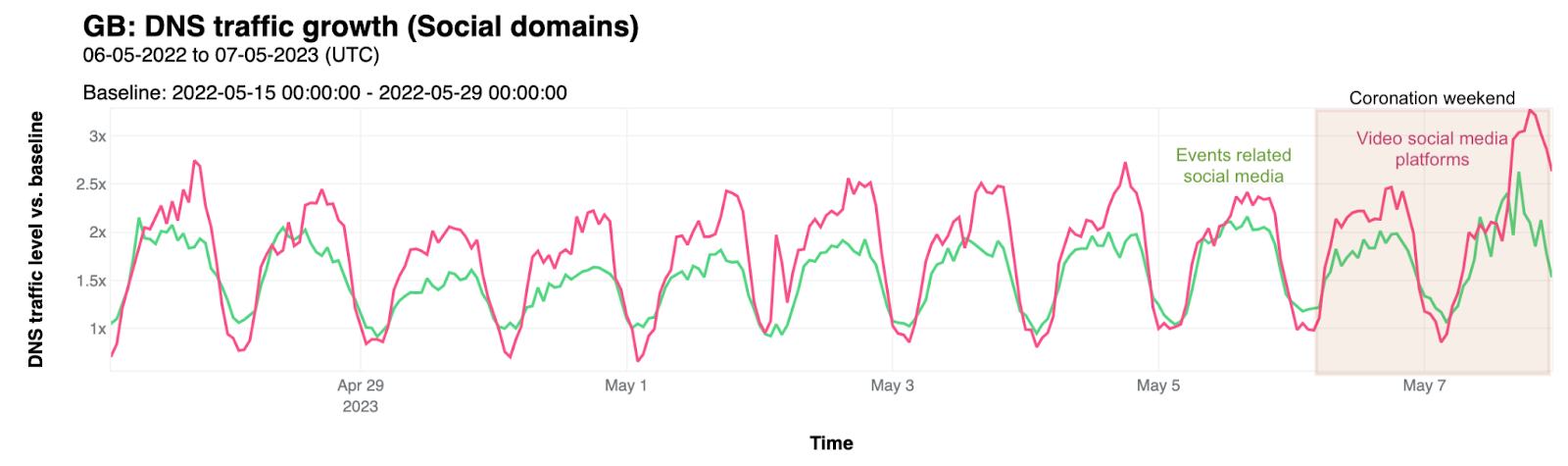
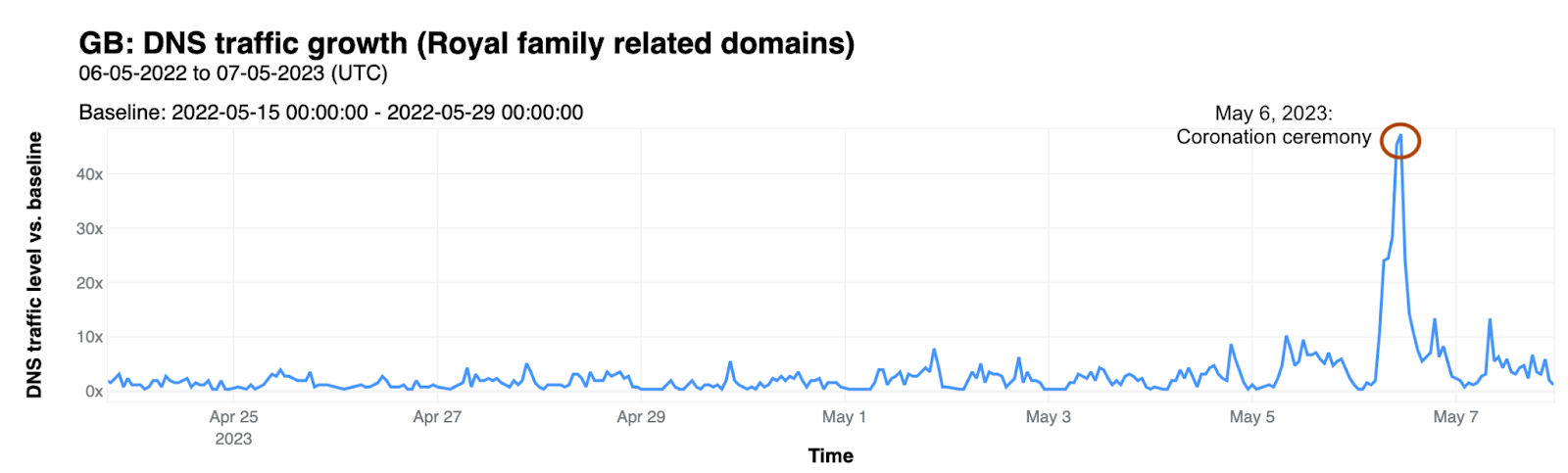
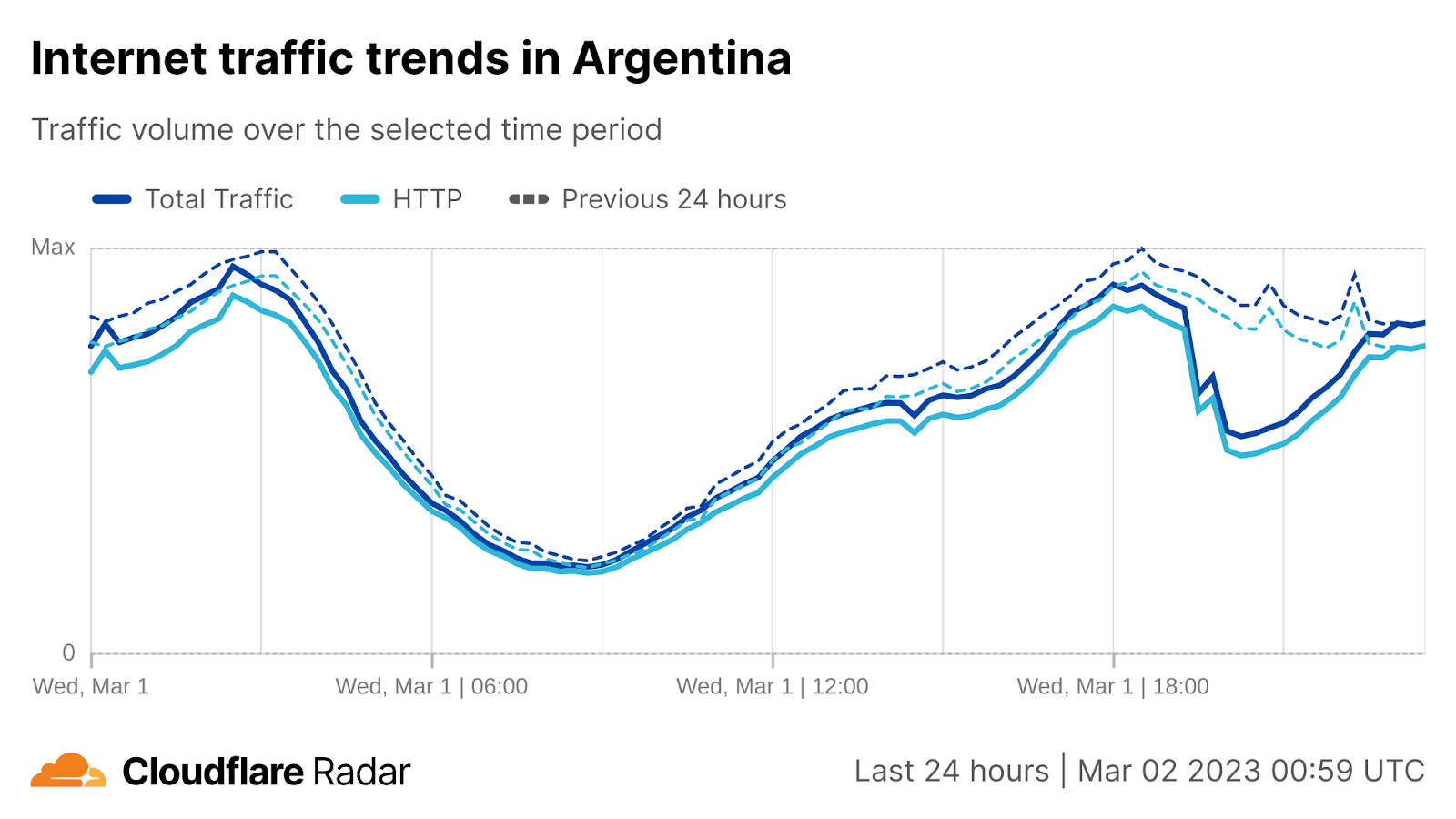
Internet traffic generally follows a fairly regular pattern, with daily peaks and troughs at roughly the same volumes of traffic. However, while weekend traffic patterns may look similar to weekday ones, their traffic volumes are generally different. Similarly, holidays or national events can also cause traffic patterns and volumes to differ significantly from “normal”, as people shift their activities and spend more time offline, or as people turn to online sources for information about, or coverage of, the event. These traffic shifts can be newsworthy, and we have covered some of them in past Cloudflare blog posts (King Charles III coronation, Easter/Passover/Ramadan, Brazilian presidential elections).
However, as you also know from reading our blog posts and following Cloudflare Radar on social media, it is the more drastic drops in traffic that are a cause for concern. Some are the result of infrastructure damage from severe weather or a natural disaster like an earthquake and are effectively unavoidable, but getting timely insights into the impact of these events on Internet connectivity is valuable from a communications perspective. Other traffic drops have occurred when an authoritarian government orders mobile Internet connectivity to be shut down, or shuts down all Internet connectivity nationwide. Timely insights into these types of anomalous traffic drops are often critical from a human rights perspective, as Internet shutdowns are often used as a means of controlling communication with the outside world.
Over the last several months, the Cloudflare Radar team has been using an internal tool to identify traffic anomalies and post alerts for followup to a dedicated chat space. The companion blog post Gone Offline: Detecting Internet Outages goes into deeper technical detail about our traffic analysis and anomaly detection methodologies that power this internal tool.
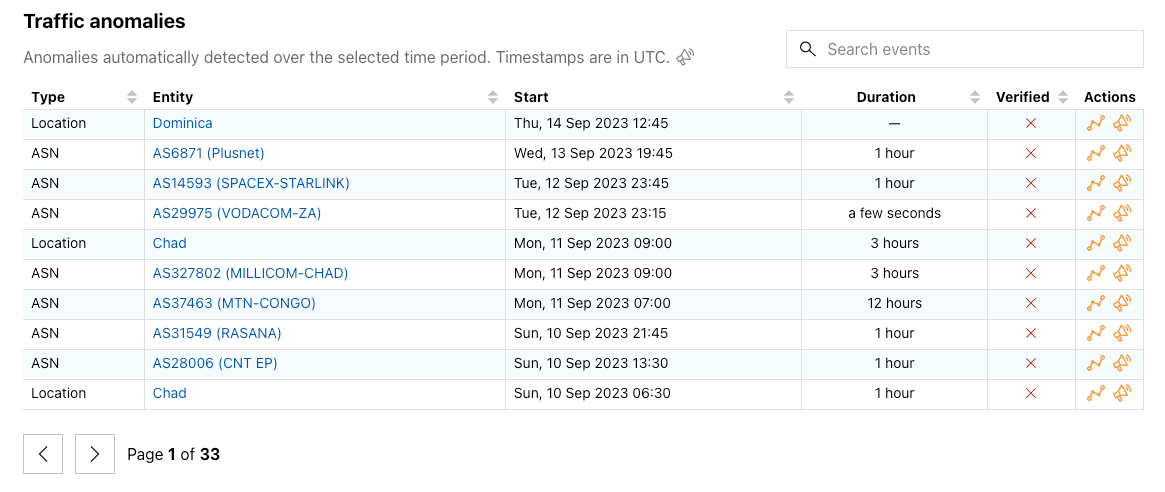
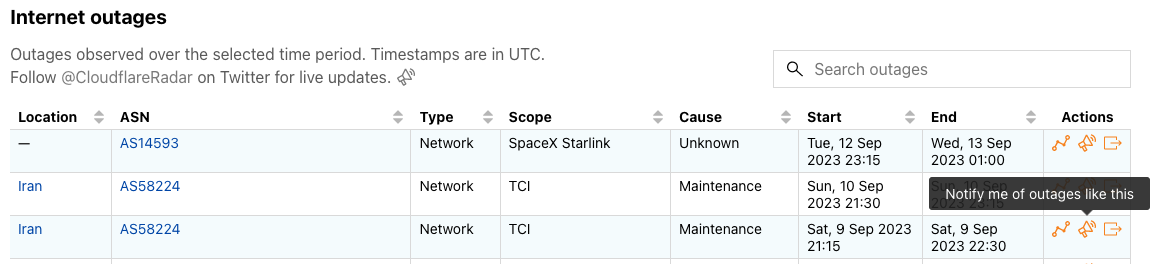
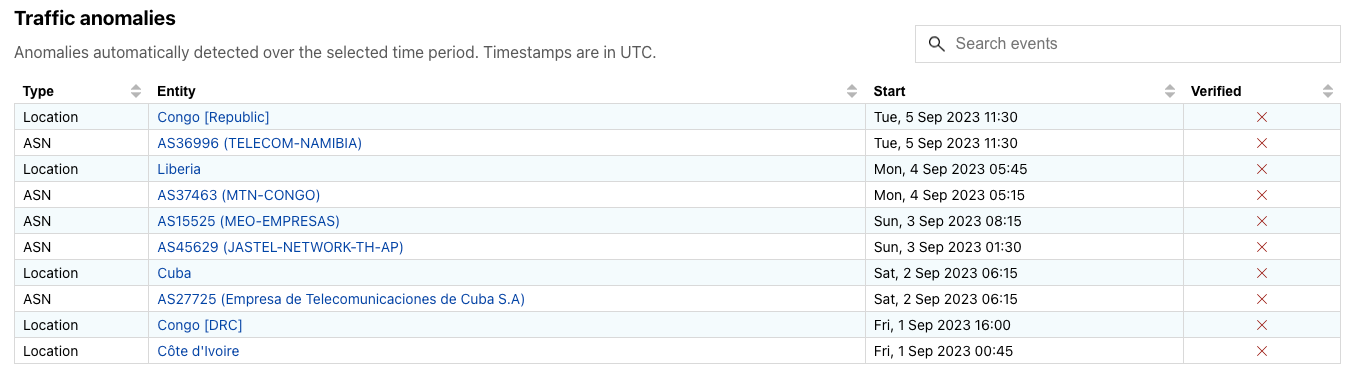
Many of these internal traffic anomaly alerts ultimately result in Outage Center entries and Cloudflare Radar social media posts. Today, we’re extending the Cloudflare Radar Outage Center and publishing information about these anomalies as we identify them. As shown in the figure below, the new Traffic anomalies table includes the type of anomaly (location or ASN), the entity where the anomaly was detected (country/region name or autonomous system), the start time, duration, verification status, and an “Actions” link, where the user can view the anomaly on the relevant entity traffic page or subscribe to a notification. (If manual review of a detected anomaly finds that it is present in multiple Cloudflare traffic datasets and/or is visible in third-party datasets, such as Georgia Tech’s IODA platform, we will mark it as verified. Unverified anomalies may be false positives, or related to Netflows collection issues, though we endeavor to minimize both.)
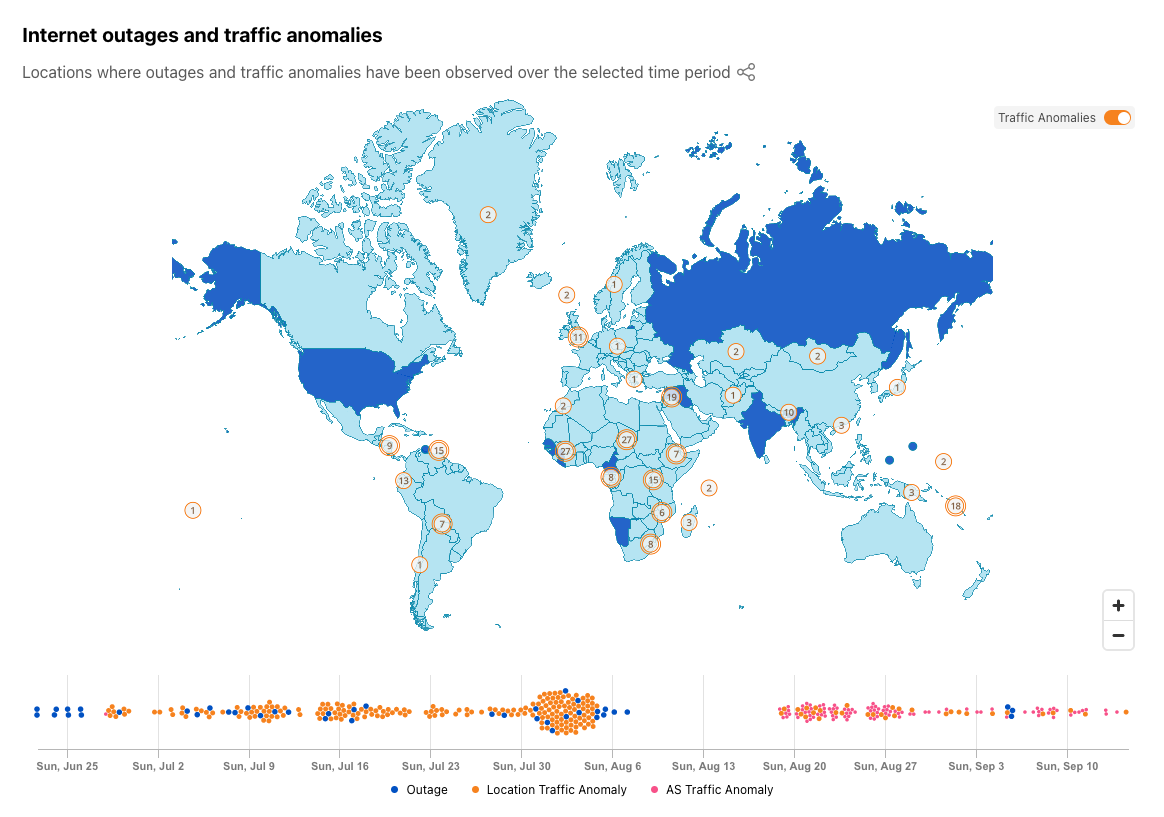
In addition to this new table, we have updated the Cloudflare Radar Outage Center map to highlight where we have detected anomalies, as well as placing them into a broader temporal context in a new timeline immediately below the map. Anomalies are represented as orange circles on the map, and can be hidden with the toggle in the upper right corner. Double-bordered circles represent an aggregation across multiple countries, and zooming in to that area will ultimately show the number of anomalies associated with each country that was included in the aggregation. Hovering over a specific dot in the timeline displays information about the outage or anomaly with which it is associated.
Internet outage information has been available via the Radar API since we launched the Outage Center and API in September 2022, and traffic anomalies are now available through a Radar API endpoint as well. An example traffic anomaly API request and response are shown below.
Timely knowledge about Internet “events”, such as drops in traffic or routing issues, are potentially of interest to multiple audiences. Customer service or help desk agents can use the information to help diagnose customer/user complaints about application performance or availability. Similarly, network administrators can use the information to better understand the state of the Internet outside their network. And civil society organizations can use the information to inform action plans aimed at maintaining communications and protecting human rights in areas of conflict or instability. With the new notifications functionality also being launched today, you can subscribe to be notified about observed traffic anomalies, confirmed Internet outages, route leaks, or route hijacks, at a country or autonomous system level. In the following sections, we discuss how to subscribe to and configure notifications, as well as the information contained within the various types of notifications.
Subscribing to notifications
Note that you need to log in to the Cloudflare dashboard to subscribe to and configure notifications. No purchase of Cloudflare services is necessary — just a verified email address is required to set up an account. While we would have preferred to not require a login, it enables us to take advantage of Cloudflare’s existing notifications engine, allowing us to avoid having to dedicate time and resources to building a separate one just for Radar. If you don’t already have a Cloudflare account, visit https://dash.cloudflare.com/sign-up to create one. Enter your username and a unique strong password, click “Sign Up”, and follow the instructions in the verification email to activate your account. (Once you’ve activated your account, we also suggest activating two-factor authentication (2FA) as an additional security measure.)
Once you have set up and activated your account, you are ready to start creating and configuring notifications. The first step is to look for the Notifications (bullhorn) icon – the presence of this icon means that notifications are available for that metric — in the Traffic, Routing, and Outage Center sections on Cloudflare Radar. If you are on a country or ASN-scoped traffic or routing page, the notification subscription will be scoped to that entity.
Look for this icon in the Traffic, Routing, and Outage Center sections of Cloudflare Radar to start setting up notifications.In the Outage Center, click the icon in the “Actions” column of an Internet outages table entry to subscribe to notifications for the related location and/or ASN(s). Click the icon alongside the table description to subscribe to notifications for all confirmed Internet outages.In the Outage Center, click the icon in the “Actions” column of a Traffic anomalies table entry to subscribe to notifications for the related entity. Click the icon alongside the table description to subscribe to notifications for all traffic anomalies.On country or ASN traffic pages, click the icon alongside the description of the traffic trends graph to subscribe to notifications for traffic anomalies or Internet outages impacting the selected country or ASN.On country or ASN routing pages, click the icon alongside the description to subscribe to notifications for route leaks or origin hijacks related to the selected country or ASN.Within the Route Leaks or Origin Hijacks tables on the routing pages, click the icon in a table entry to subscribe to notifications for route leaks or origin hijacks for referenced countries and/or ASNs.
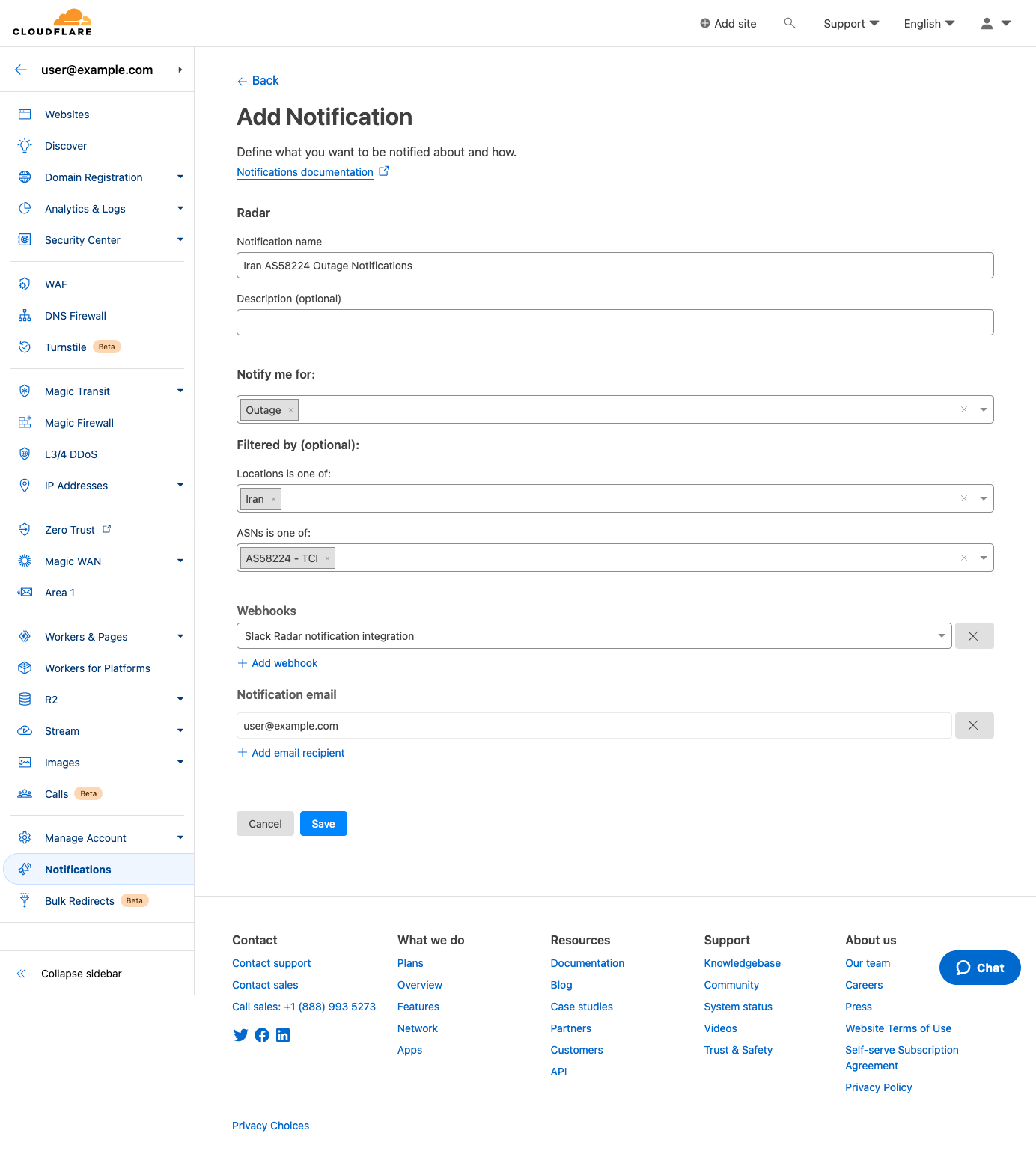
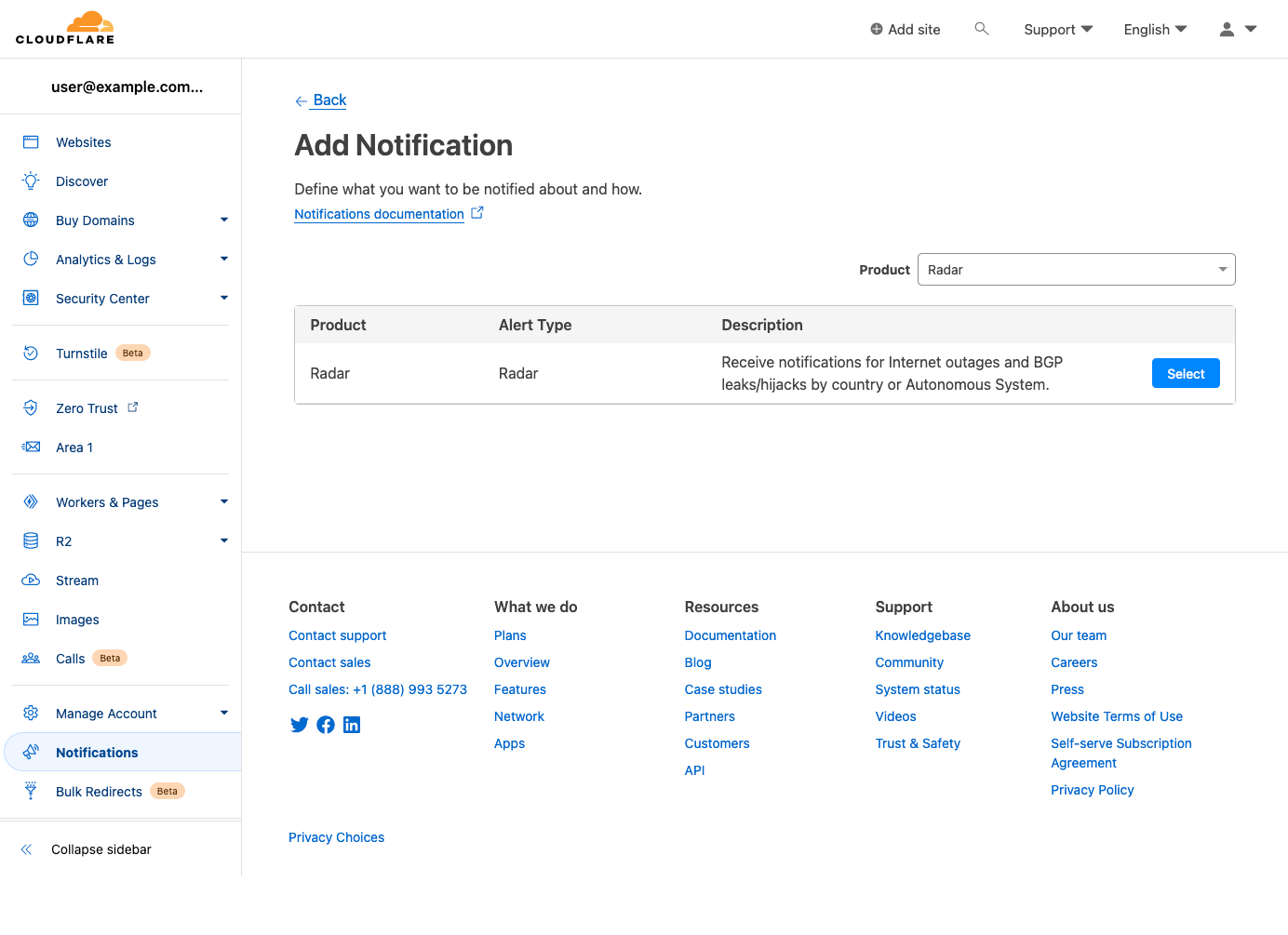
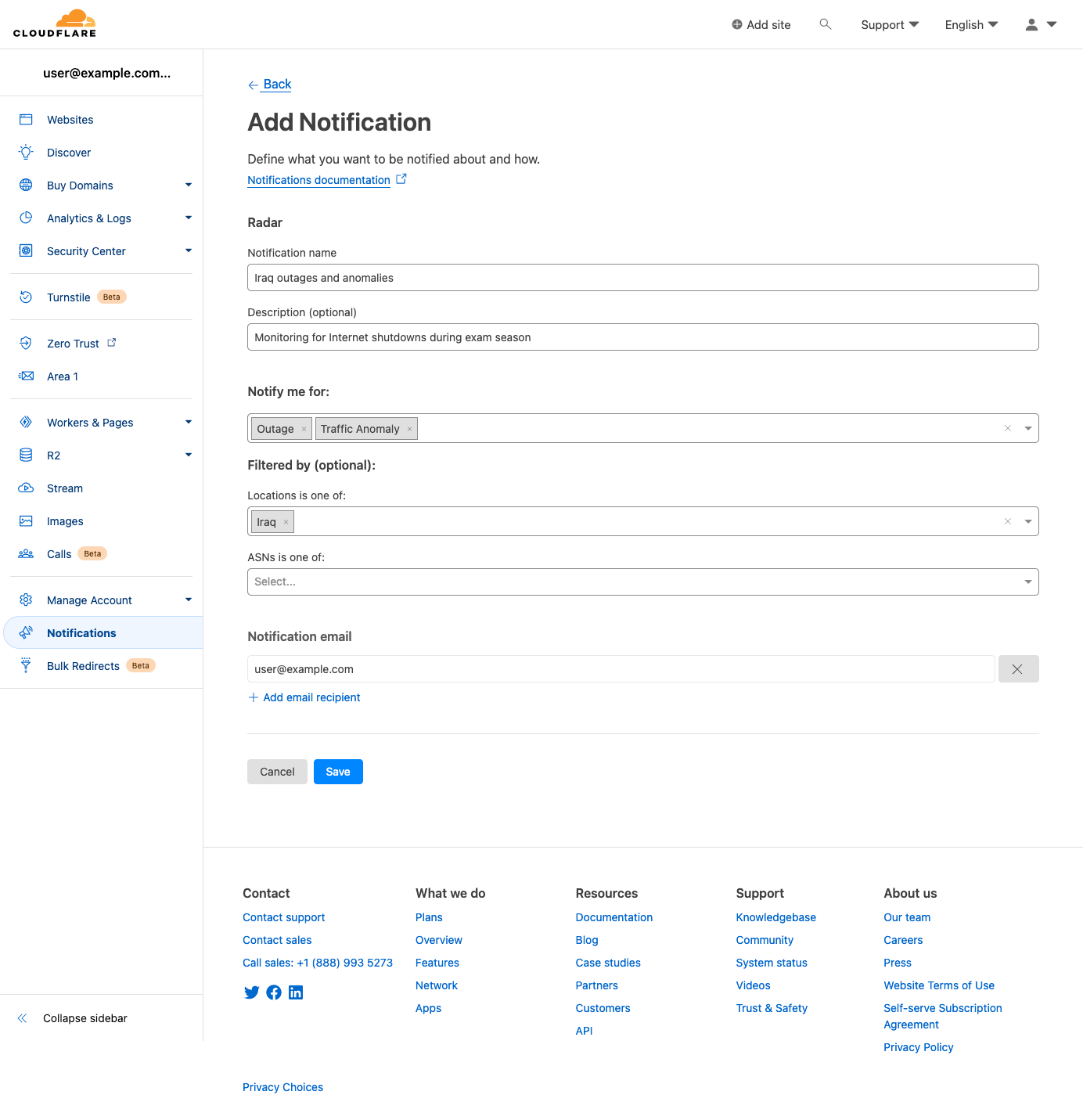
After clicking a notification icon, you’ll be taken to the Cloudflare login screen. Enter your username and password (and 2FA code if required), and once logged in, you’ll see the Add Notification page, pre-filled with the key information passed through from the referring page on Radar, including relevant locations and/or ASNs. (If you are already logged in to Cloudflare, then you’ll be taken directly to the Add Notification page after clicking a notification icon on Radar.) On this page, you can name the notification, add an optional description, and adjust the location and ASN filters as necessary. Enter an email address for notifications to be sent to, or select an established webhook destination (if you have webhooks enabled on your account).
Click “Save”, and the notification is added to the Notifications Overview page for the account.
You can also create and configure notifications directly within Cloudflare, without starting from a link on Radar a Radar page. To do so, log in to Cloudflare, and choose “Notifications” from the left side navigation bar. That will take you to the Notifications page shown below. Click the “Add” button to add a new notification.
On the next page, search for and select “Radar” from the list of Cloudflare products for which notifications are available.
On the subsequent “Add Notification” page, you can create and configure a notification from scratch. Event types can be selected in the “Notify me for:” field, and both locations and ASNs can be searched for and selected within the respective “Filtered by (optional)” fields. Note that if no filters are selected, then notifications will be sent for all events of the selected type(s). Add one or more emails to send notifications to, or select a webhook target if available, and click “Save” to add it to the list of notifications configured for your account.
It is worth mentioning that advanced users can also create and configure notifications through the Cloudflare API Notification policies endpoint, but we will not review that process within this blog post.
Notification messages
Example notification email messages are shown below for the various types of events. Each contains key information like the type of event, affected entities, and start time — additional relevant information is included depending on the event type. Each email includes both plaintext and HTML versions to accommodate multiple types of email clients. (Final production emails may vary slightly from those shown below.)
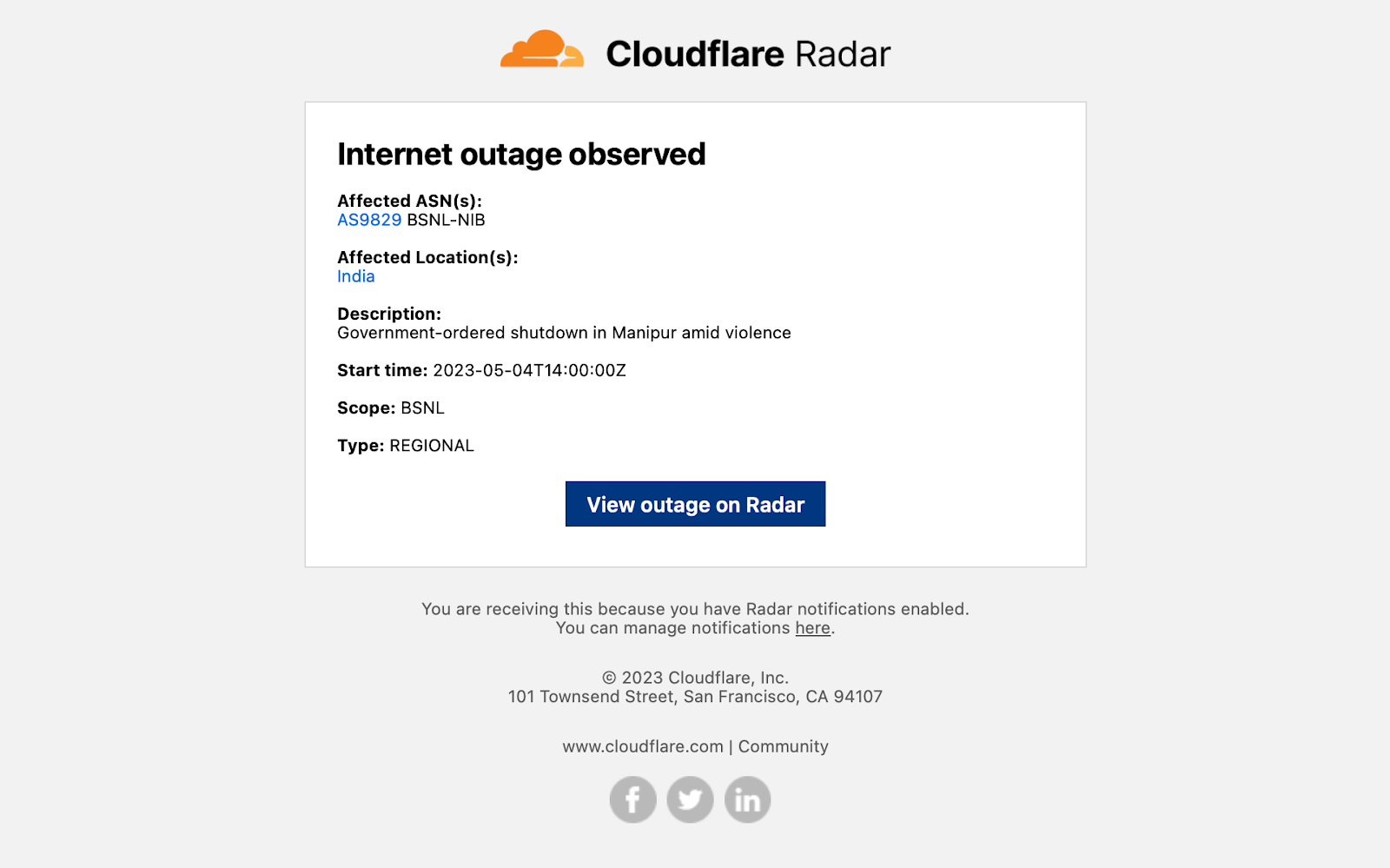
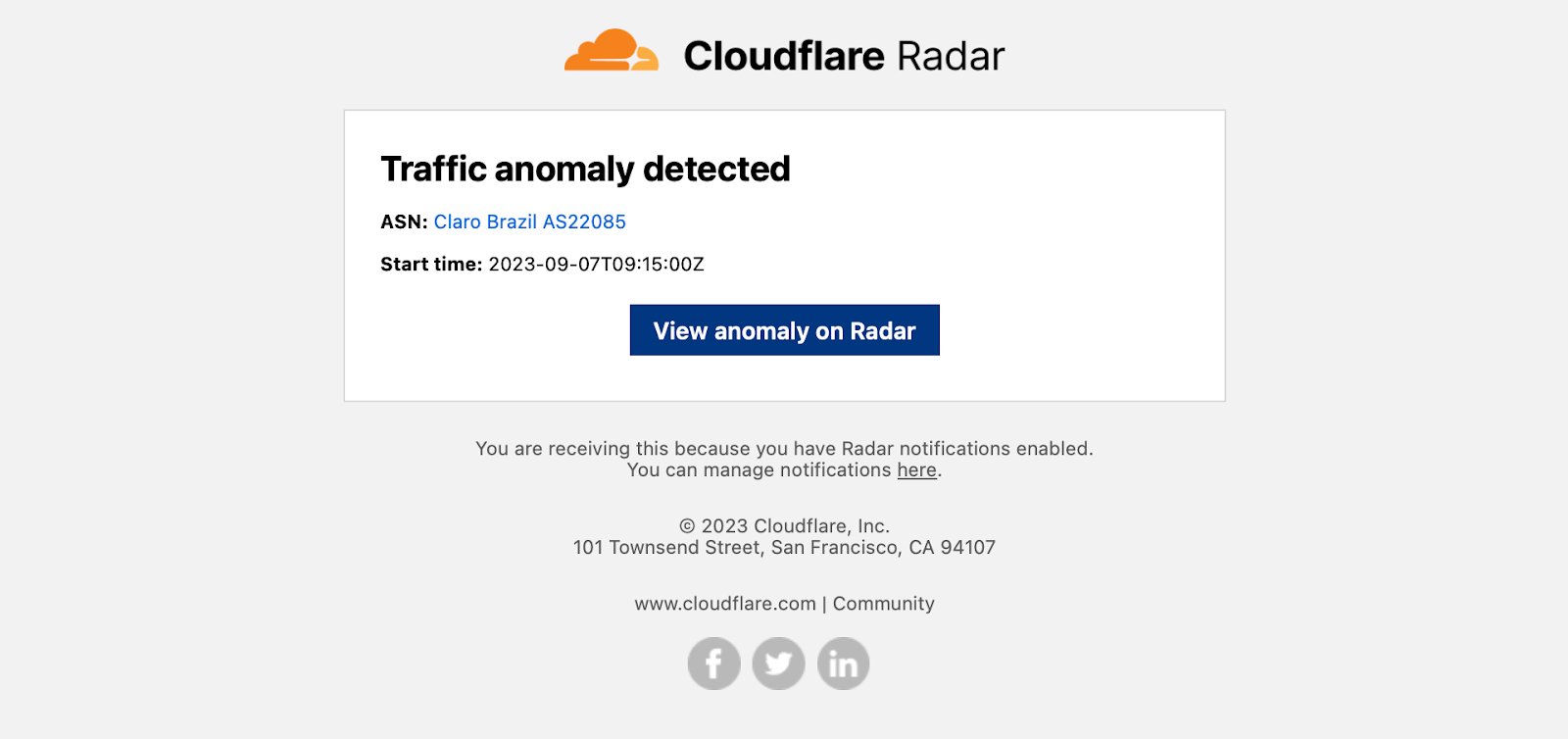
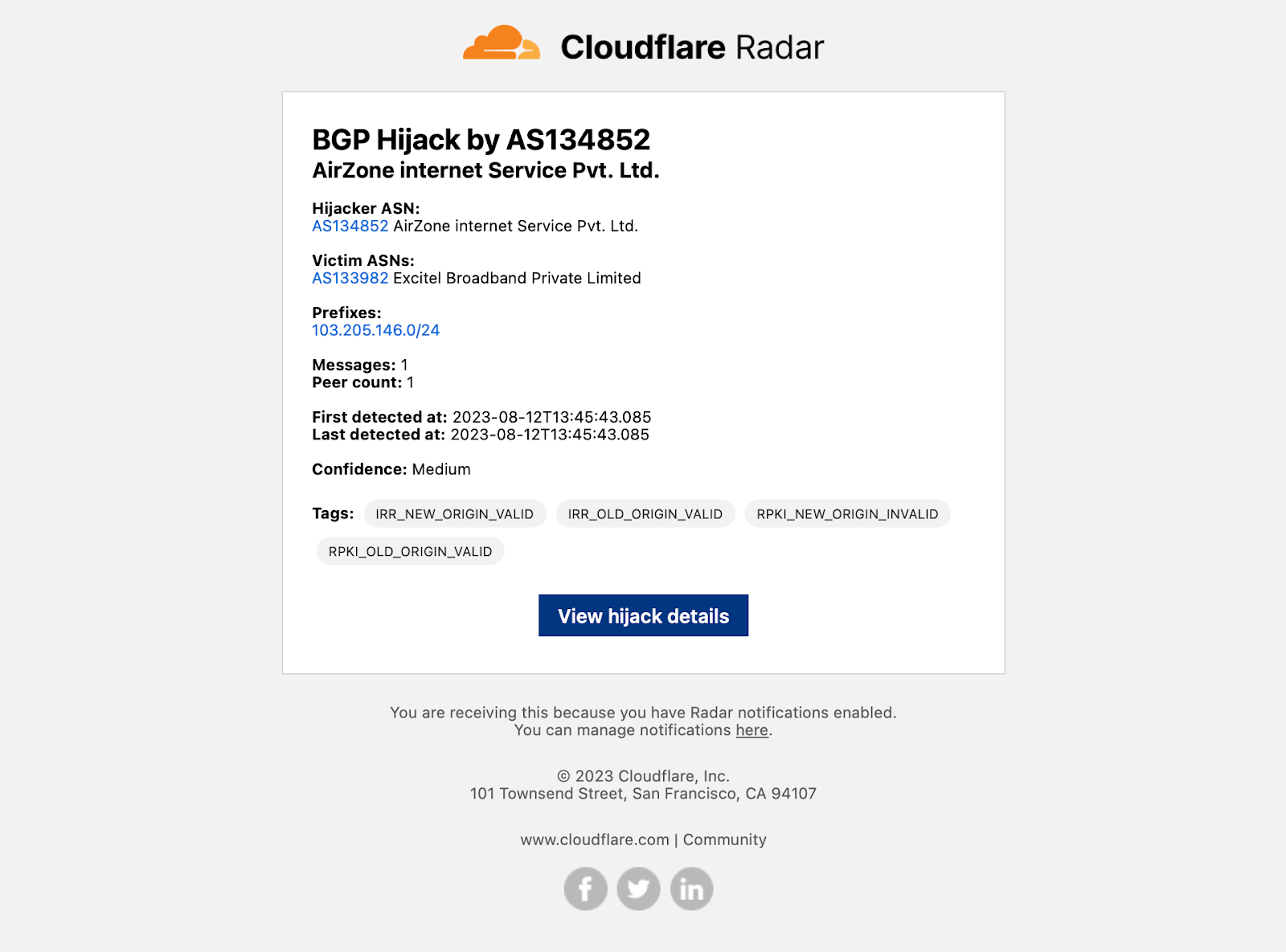
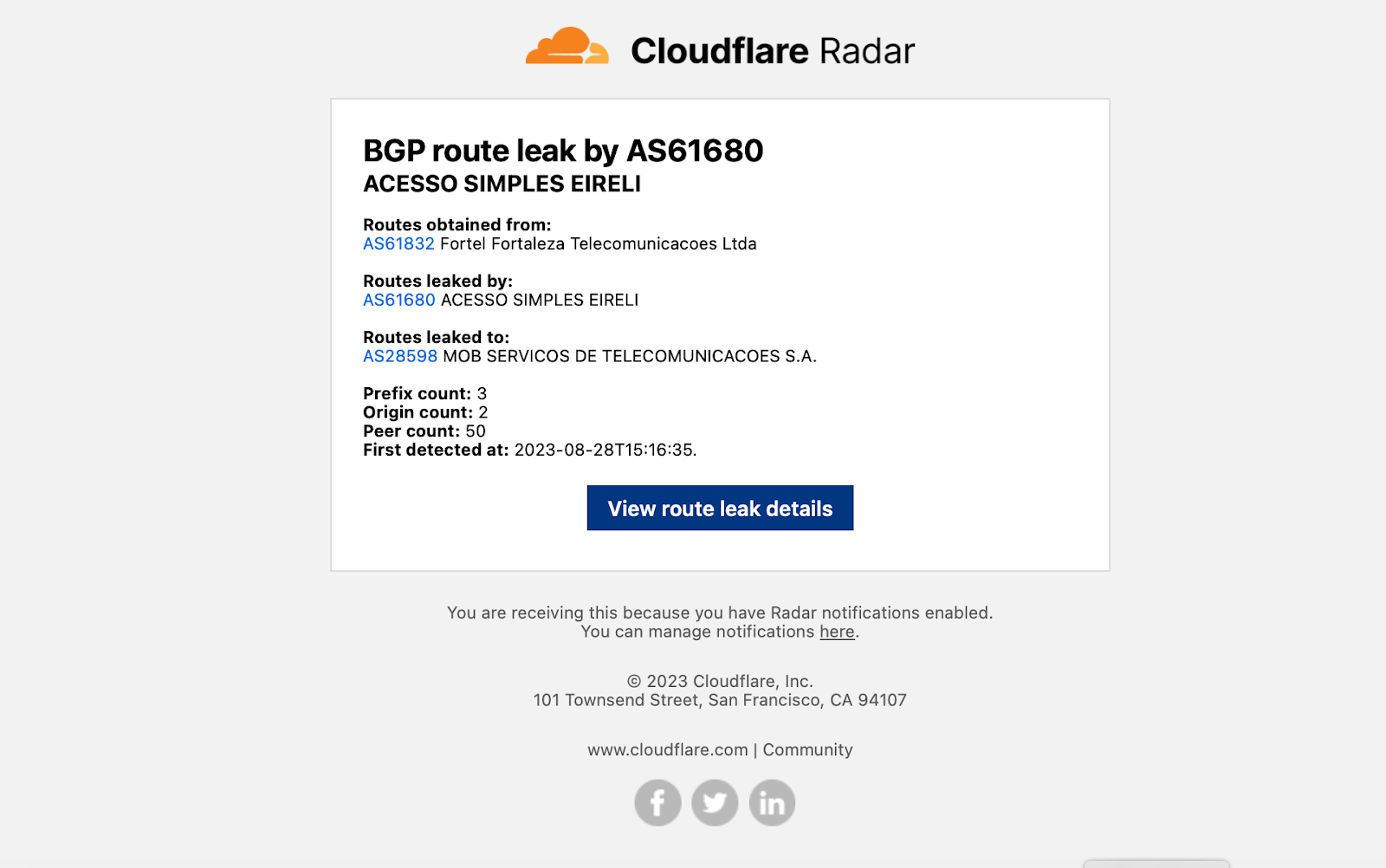
Internet outage notification emails include information about the affected entities, a description of the cause of the outage, start time, scope (if available), and the type of outage (Nationwide, Network, Regional, or Platform), as well as a link to view the outage in a Radar traffic graph.Traffic anomaly notification emails simply include information about the affected entity and a start time, as well as a link to view the anomaly in a Radar traffic graph.BGP hijack notification emails include information about the hijacking and victim ASNs, affected IP address prefixes, the number of BGP messages (announcements) containing leaked routes, the number of peers announcing the hijack, detection timing, a confidence level on the event being a true hijack, and relevant tags, as well as a link to view details of the hijack event on Radar.BGP route leak notification emails include information about the AS that the leaked routes were learned from, the AS that leaked the routes, the AS that received and propagated the leaked routes, the number of affected prefixes, the number of affected origin ASes, the number of BGP route collector peers that saw the route leak, and detection timing, as well as a link to view details of the route leak event on Radar.
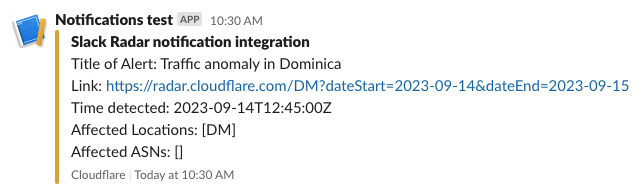
If you are sending notifications to webhooks, you can integrate those notifications into tools like Slack. For example, by following the directions in Slack’s API documentation, creating a simple integration took just a few minutes and results in messages like the one shown below.
Conclusion
Cloudflare’s unique perspective on the Internet provides us with near-real-time insight into unexpected drops in traffic, as well as potentially problematic routing events. While we’ve been sharing these insights with you over the past year, you had to visit Cloudflare Radar to figure out if there were any new “events”. With the launch of notifications, we’ll now automatically send you information about the latest events that you are interested in.
We encourage you to visit Cloudflare Radar to familiarize yourself with the information we publish about traffic anomalies, confirmed Internet outages, BGP route leaks, and BGP origin hijacks. Look for the notification icon on the relevant graphs and tables on Radar, and go through the workflow to set up and subscribe to notifications. (And don’t forget to sign up for a Cloudflare account if you don’t have one already.) Please send us feedback about the notifications, as we are constantly working to improve them, and let us know how and where you’ve integrated Radar notifications into your own tools/workflows/organization.
Currently, Cloudflare Radar curates a list of observed Internet disruptions (which may include partial or complete outages) in the Outage Center. These disruptions are recorded whenever we have sufficient context to correlate with an observed drop in traffic, found by checking status updates and related communications from ISPs, or finding news reports related to cable cuts, government orders, power outages, or natural disasters.
However, we observe more disruptions than we currently report in the outage center because there are cases where we can’t find any source of information that provides a likely cause for what we are observing, although we are still able to validate with external data sources such as Georgia Tech’s IODA. This curation process involves manual work, and is supported by internal tooling that allows us to analyze traffic volumes and detect anomalies automatically, triggering the workflow to find an associated root cause. While the Cloudflare Radar Outage Center is a valuable resource, one of key shortcomings include that we are not reporting all disruptions, and that the current curation process is not as timely as we’d like, because we still need to find the context.
As we announced today in a related blog post, Cloudflare Radar will be publishing anomalous traffic events for countries and Autonomous Systems (ASes). These events are the same ones referenced above that have been triggering our internal workflow to validate and confirm disruptions. (Note that at this time “anomalous traffic events” are associated with drops in traffic, not unexpected traffic spikes.) In addition to adding traffic anomaly information to the Outage Center, we are also launching the ability for users to subscribe to notifications at a location (country) or network (autonomous system) level whenever a new anomaly event is detected, or a new entry is added to the outage table. Please refer to the related blog post for more details on how to subscribe.
The current status of each detected anomaly will be shown in the new “Traffic anomalies” table on the Outage Center page:
When the anomaly is automatically detected its status will initially be Unverified
After attempting to validate ‘Unverified’ entries:
We will change the status to ‘Verified’ if we can confirm that the anomaly appears across multiple internal data sources, and possibly external ones as well. If we find associated context for it, we will also create an outage entry.
We will change status to ‘False Positive’ if we cannot confirm it across multiple data sources. This will remove it from the “Traffic anomalies” table. (If a notification has been sent, but the anomaly isn’t shown in Radar anymore, it means we flagged it as ‘False Positive’.)
We might also manually add an entry with a “Verified” status. This might occur if we observe, and validate, a drop in traffic that is noticeable, but was not large enough for the algorithm to catch it.
A glimpse at what Internet traffic volume looks like
At Cloudflare, we have several internal data sources that can give us insights into what the traffic for a specific entity looks like. We identify the entity based on IP address geolocation in the case of locations, and IP address allocation in the case of ASes, and can analyze traffic from different sources, such as DNS, HTTP, NetFlows, and Network Error Logs (NEL). All the signals used in the figures below come from one of these data sources and in this blog post we will treat this as a univariate time-series problem — in the current algorithm, we use more than one signal just to add redundancy and identify anomalies with a higher level of confidence. In the discussion below, we intentionally select various examples to encompass a broad spectrum of potential Internet traffic volume scenarios.
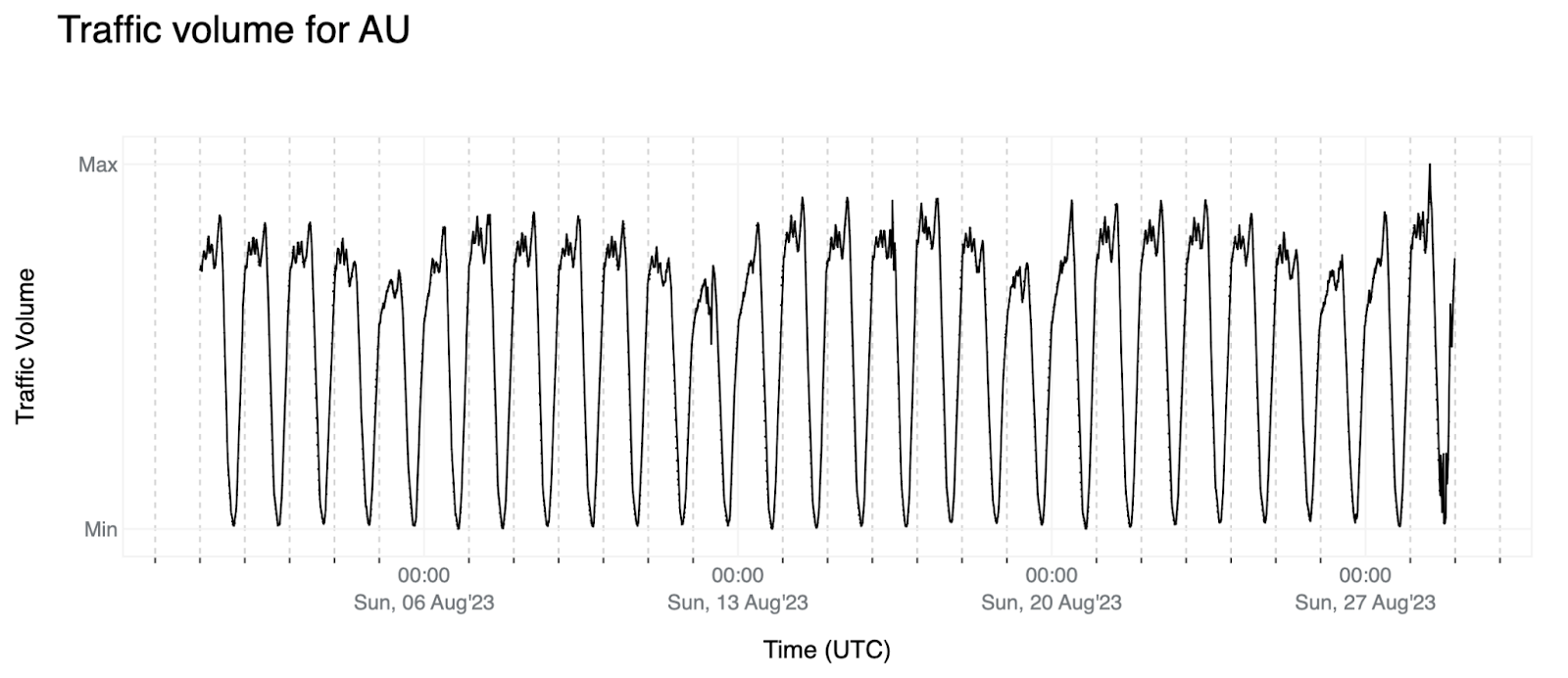
1. Ideally, the signals would resemble the pattern depicted below for Australia (AU): a stable weekly pattern with a slightly positive trend meaning that the trend average is moving up over time (we see more traffic over time from users in Australia).
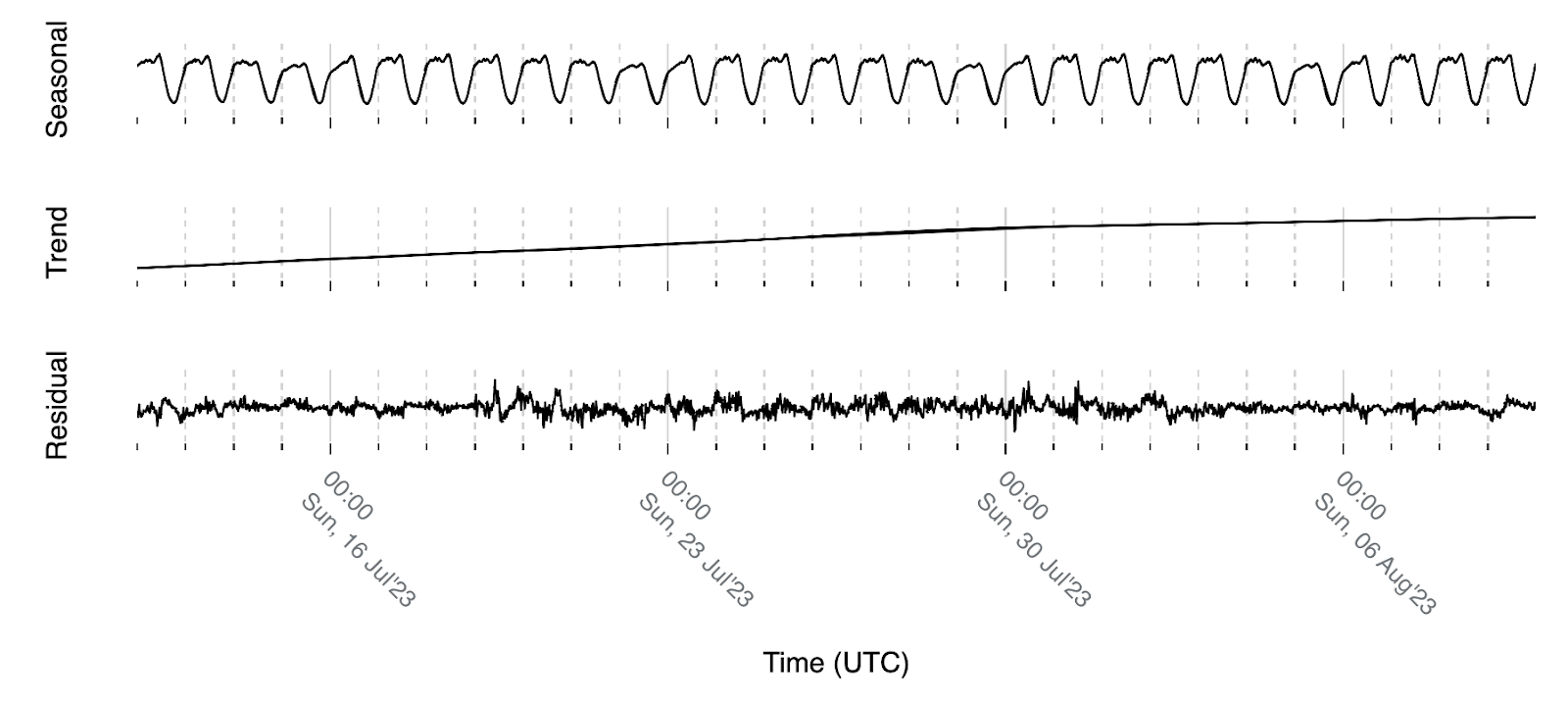
These statements can be clearly seen when we perform time-series decomposition which allows us to break down a time-series into its constituent parts to better understand and analyze its underlying patterns. Decomposing the traffic volume for Australia above assuming a weekly pattern with Seasonal-Trend decomposition using LOESS (STL) we get the following:
The weekly pattern we are referring to is represented by the seasonal part of the signal that is expected to be observed due to the fact that we are interested in eyeball / human internet traffic. As observed in the image above, the trend component is expected to move slowly when compared with the signal level and the residual part ideally would resemble white noise meaning that all existing patterns in the signal are represented by the seasonal and trend components.
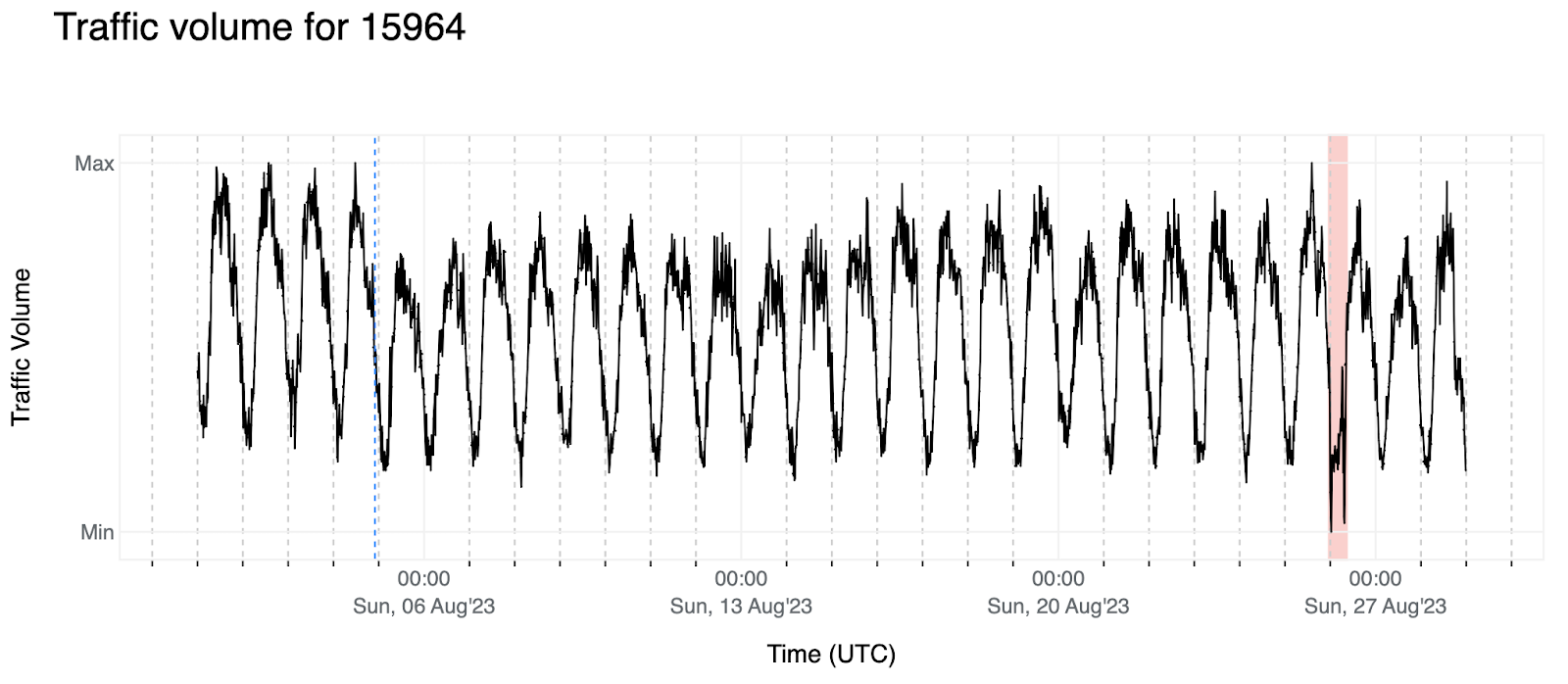
2. Below we have the traffic volume for AS15964 (CAMNET-AS) that appears to have more of a daily pattern, as opposed to weekly.
We also observe that there’s a value offset of the signal right after the first four days (blue dashed-line) and the red background shows us an outage for which we didn’t find any reporting besides seeing it in our data and other Internet data providers — our intention here is to develop an algorithm that will trigger an event when it comes across this or similar patterns.
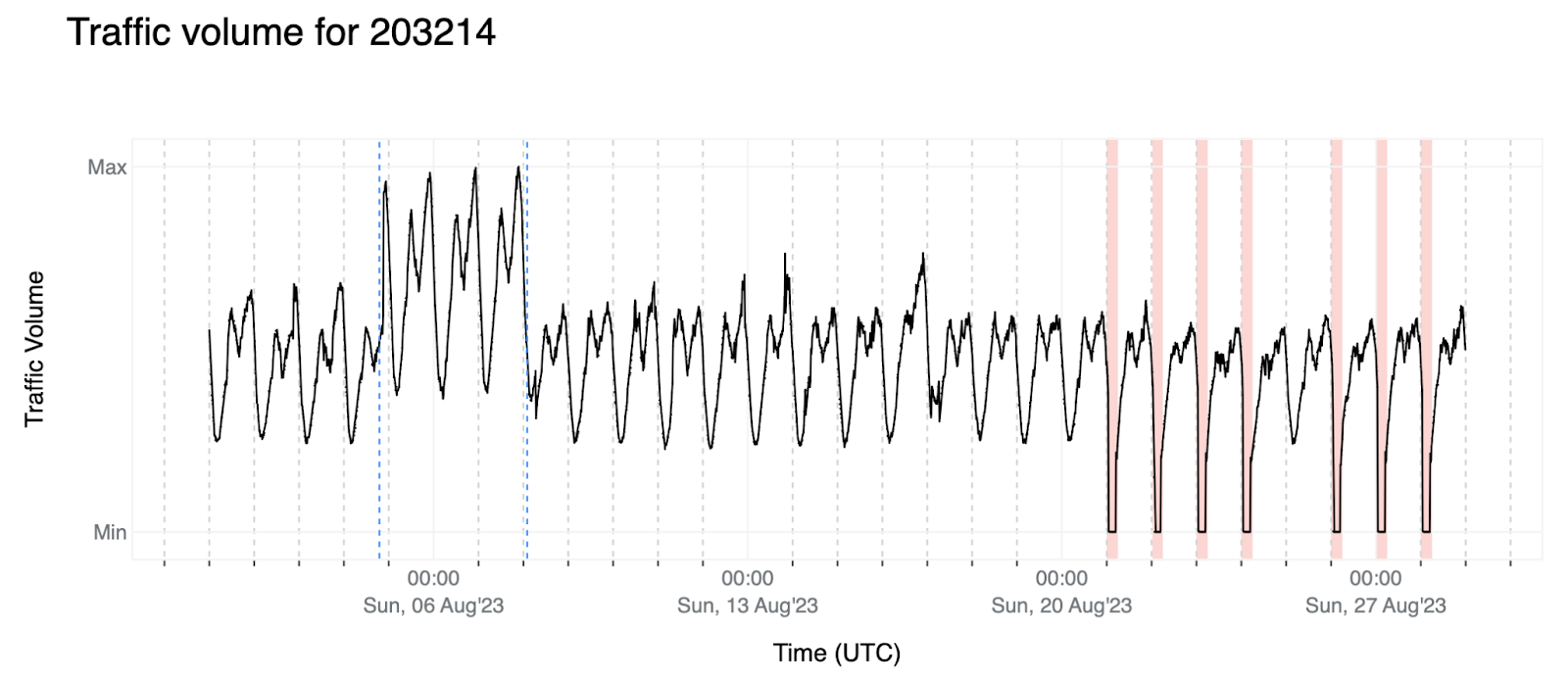
4. Another scenario is several scheduled outages for AS203214 (HulumTele), for which we also have context. These anomalies are the easiest to detect since the traffic goes to values that are unique to outages (cannot be mistaken as regular traffic), but it poses another challenge: if our plan was to just check the weekly patterns, since these government-directed outages happen with the same frequency, at some point the algorithm would see this as expected traffic.
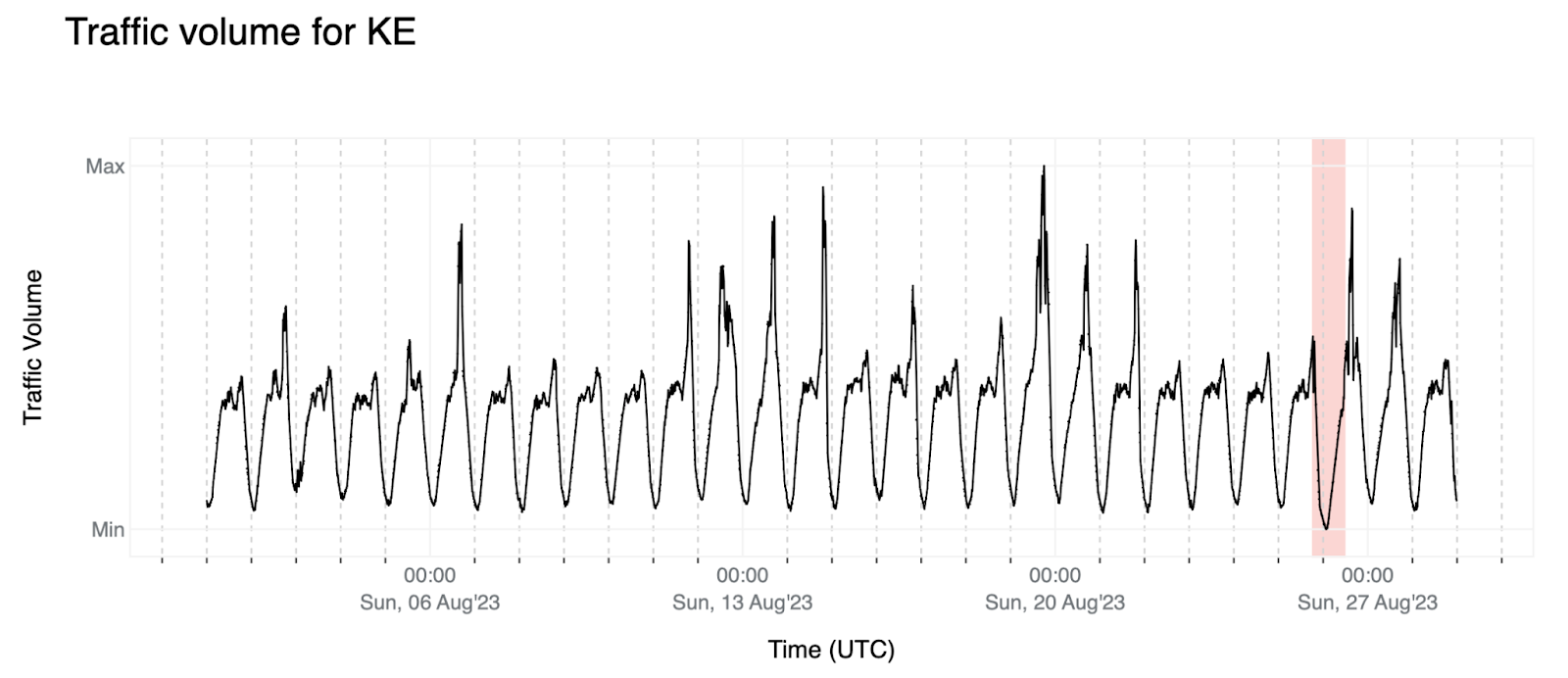
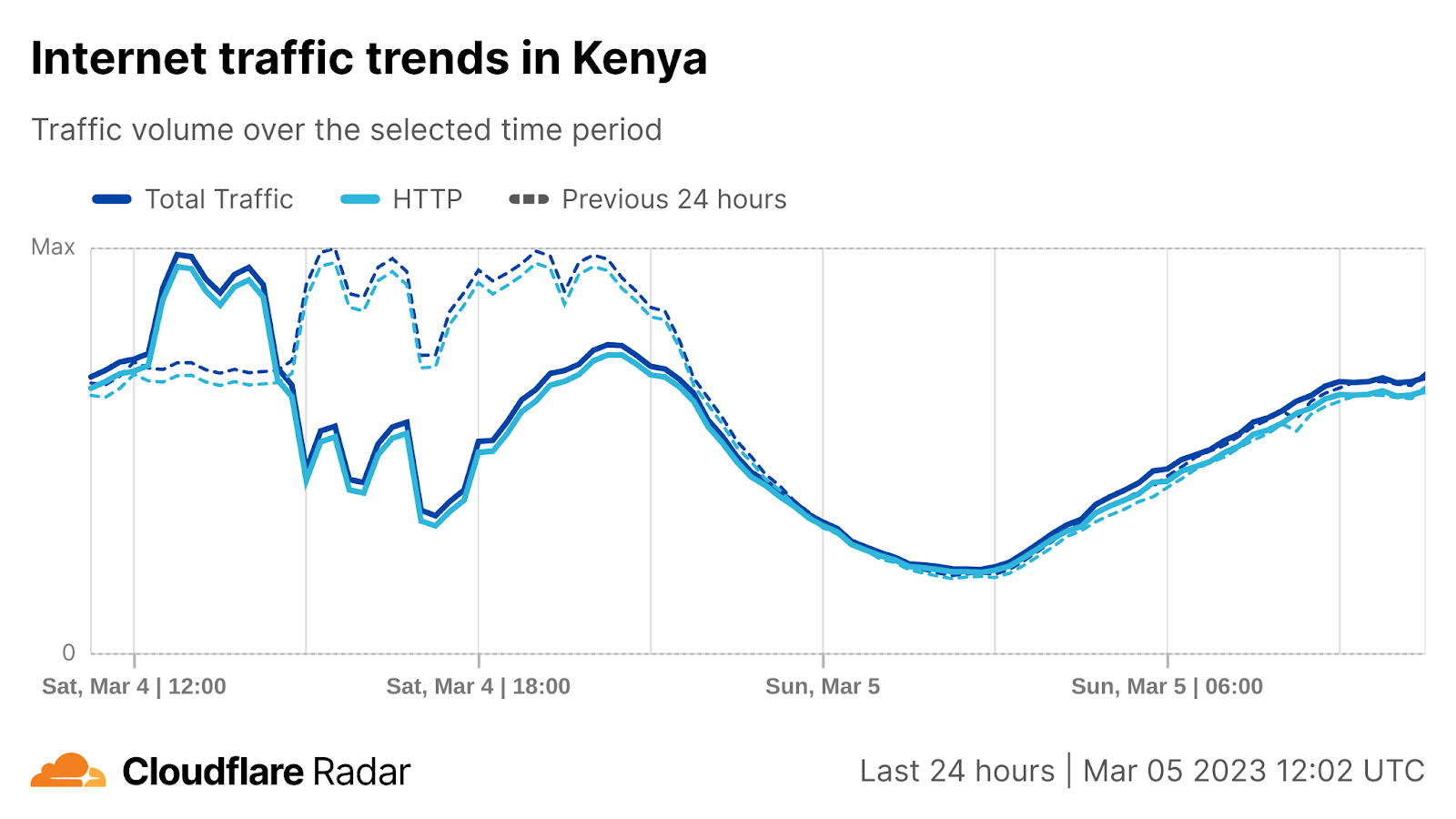
5. This outage in Kenya could be seen as similar to the above: the traffic volume went down to unseen values although not as significantly. We also observe some upward spikes in the data that are not following any specific pattern — possibly outliers — that we should clean depending on the approach we use to model the time-series.
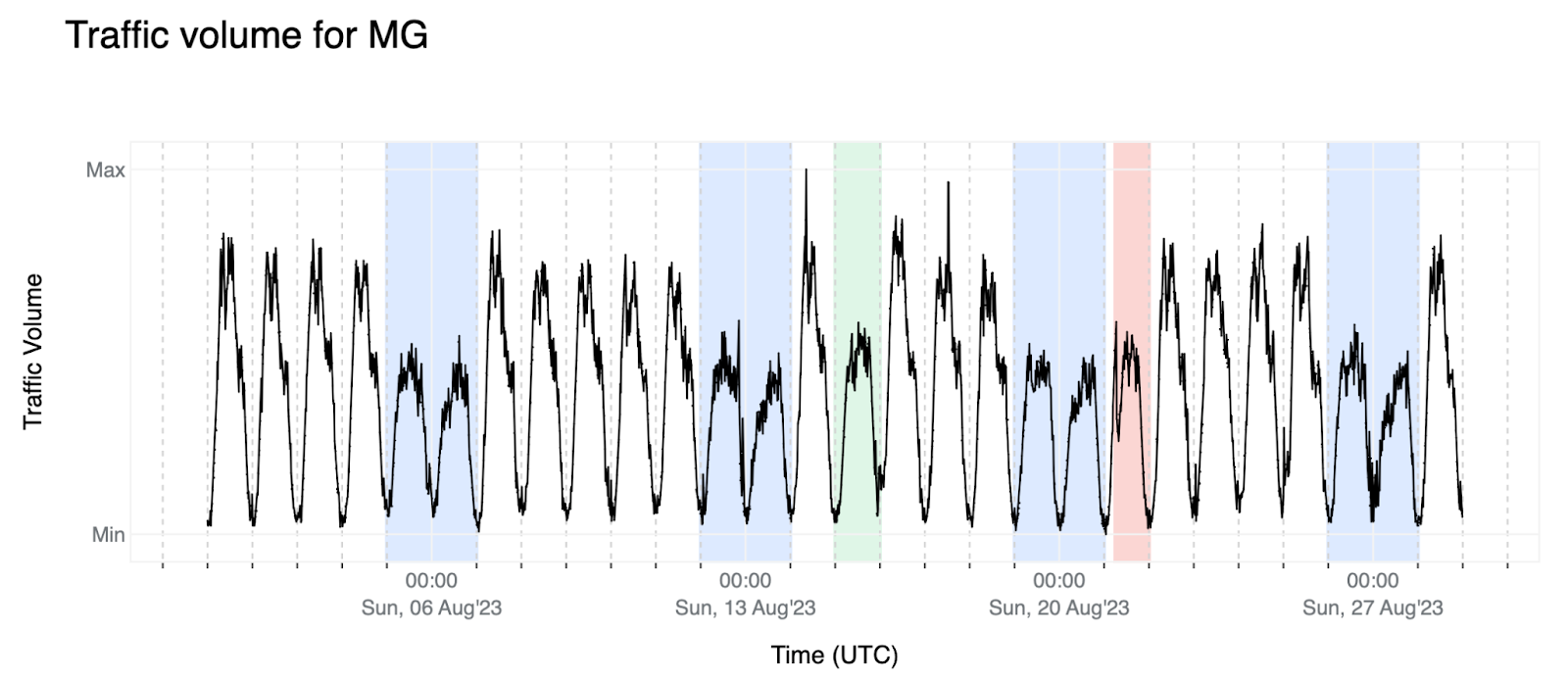
6. Lastly, here's the data that will be used throughout this post as an example of how we are approaching this problem. For Madagascar (MG), we observe a clear pattern with pronounced weekends (blue background). There’s also a holiday (Assumption of Mary), highlighted with a green background, and an outage, with a red background. In this example, weekends, holidays, and outages all seem to have roughly the same traffic volume. Fortunately, the outage gives itself away by showing that it intended to go up as in a normal working day, but then there was a sudden drop — we will see it more closely later in this post.
In summary, here we looked over six examples out of ~700 (the number of entities we are automatically detecting anomalies for currently) and we see a wide range of variability. This means that in order to effectively model the time-series we would have to run a lot of preprocessing steps before the modeling itself. These steps include removing outliers, detecting short and long-term data offsets and readjusting, and detecting changes in variance, mean, or magnitude. Time is also a factor in preprocessing, as we would also need to know in advance when to expect events / holidays that will push the traffic down, apply daylight saving time adjustments that will cause a time shift in the data, and be able to apply local time zones for each entity, including dealing with locations that have multiple time zones and AS traffic that is shared across different time zones.
To add to the challenge, some of these steps cannot even be performed in a close-to-real-time fashion (example: we can only say there’s a change in seasonality after some time of observing the new pattern). Considering the challenges mentioned earlier, we have chosen an algorithm that combines basic preprocessing and statistics. This approach aligns with our expectations for the data's characteristics, offers ease of interpretation, allows us to control the false positive rate, and ensures fast execution while reducing the need for many of the preprocessing steps discussed previously.
Above, we noted that we are detecting anomalies for around 700 entities (locations and autonomous systems) at launch. This obviously does not represent the entire universe of countries and networks, and for good reason. As we discuss in this post, we need to see enough traffic from a given entity (have a strong enough signal) to be able to build relevant models and subsequently detect anomalies. For some smaller or sparsely populated countries, the traffic signal simply isn’t strong enough, and for many autonomous systems, we see little-to-no traffic from them, again resulting in a signal too weak to be useful. We are initially focusing on locations where we have a sufficiently strong traffic signal and/or are likely to experience traffic anomalies, as well as major or notable autonomous systems — those that represent a meaningful percentage of a location’s population and/or those that are known to have been impacted by traffic anomalies in the past.
Detecting anomalies
The approach we took to solve this problem involves creating a forecast that is a set of data points that correspond to our expectation according to what we’ve seen in historical data. This will be explained in the section Creating a forecast. We take this forecast and compare it to what we are actually observing — if what we are observing is significantly different from what we expect, then we call it an anomaly. Here, since we are interested in traffic drops, an anomaly will always correspond to lower traffic than the forecast / expected traffic. This comparison is elaborated in the section Comparing forecast with actual traffic.
In order to compute the forecast we need to fulfill the following business requirements:
We are mainly interested in traffic related to human activity.
The more timely we detect the anomaly, the more useful it is. This needs to take into account constraints such as data ingestion and data processing times, but once the data is available, we should be able to use the latest data point and detect if it is an anomaly.
A low False Positive (FP) rate is more important than a high True Positive (TP) rate. As an internal tool, this is not necessarily true, but as a publicly visible notification service, we want to limit spurious entries at the cost of not reporting some anomalies.
Selecting which entities to observe
Aside from the examples given above, the quality of the data highly depends on the volume of the data, and this means that we have different levels of data quality depending on which entity (location / AS) we are considering. As an extreme example, we don’t have enough data from Antarctica to reliably detect outages. Follows the process we used to select which entities are eligible to be observed.
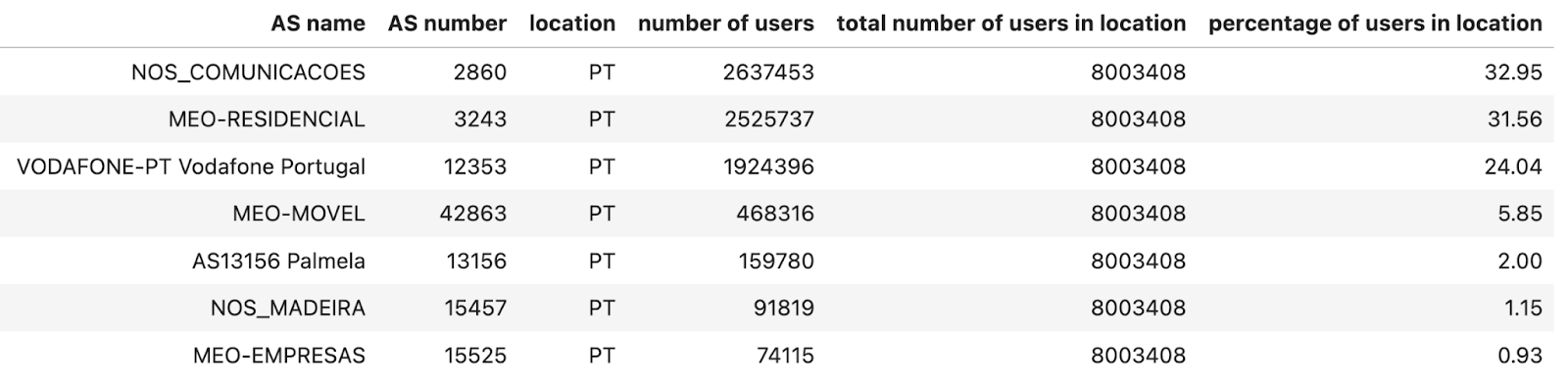
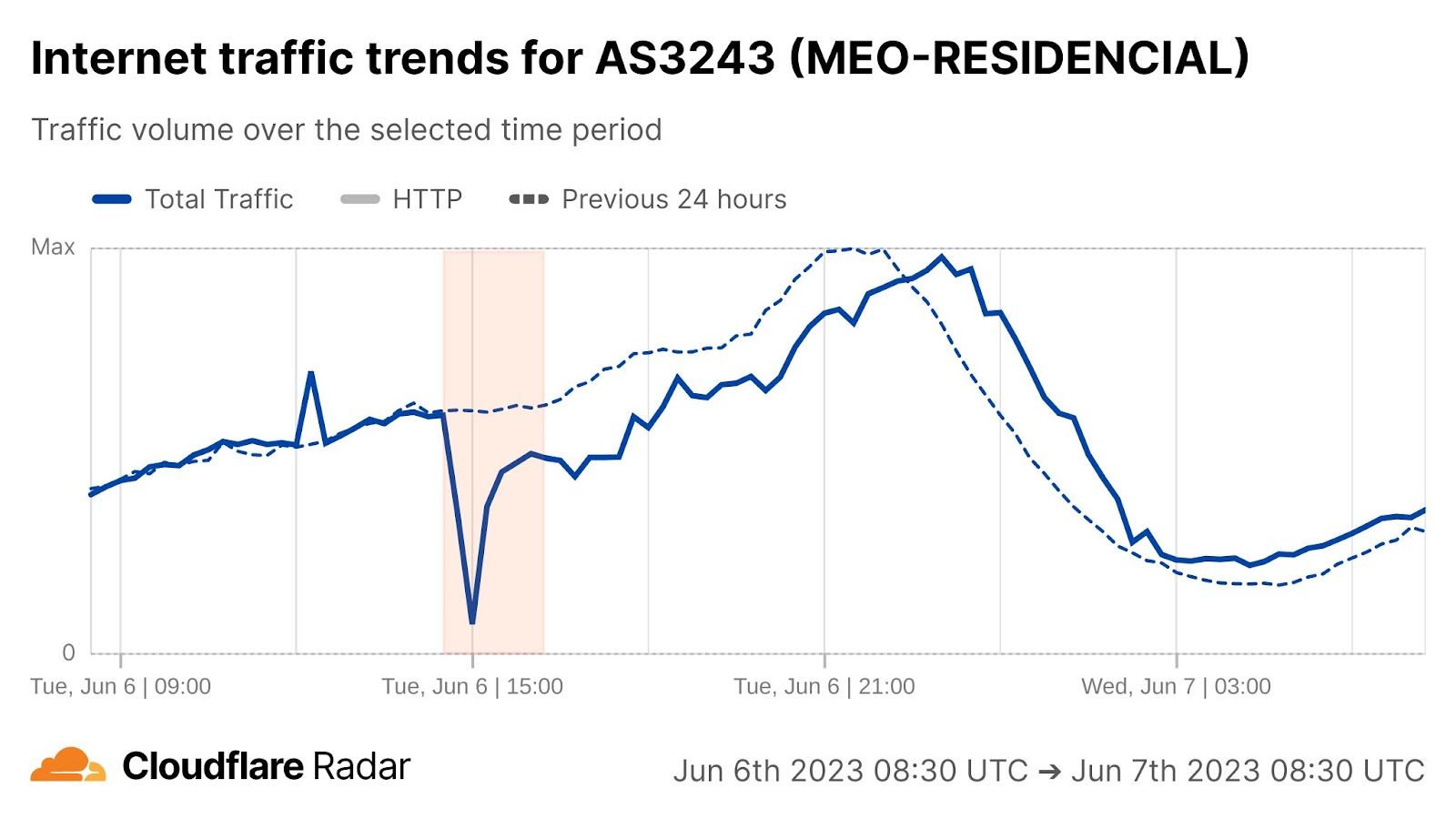
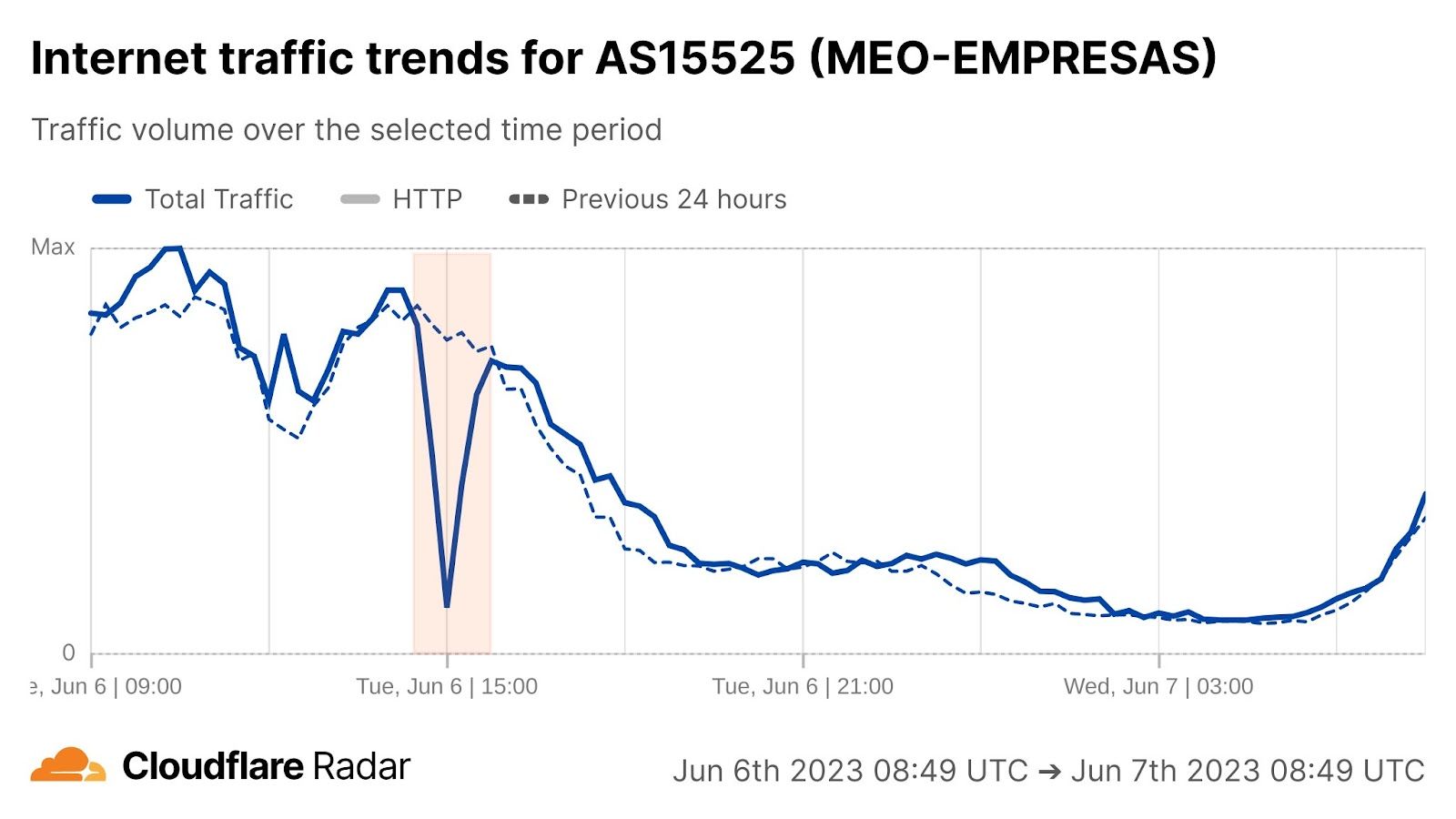
For ASes, since we are mainly interested in Internet traffic that represents human activity, we use the number of users estimation provided by APNIC. We then compute the total number of users per location by summing up the number of users of each AS in that location, and then we calculate what percentage of users an AS has for that location (this number is also provided by the APNIC table in column ‘% of country’). We filter out ASes that have less than 1% of the users in that location. Here’s what the list looks like for Portugal — AS15525 (MEO-EMPRESAS) is excluded because it has less than 1% of users of the total number of Internet users in Portugal (estimated).
At this point we have a subset of ASes and a set of locations (we don’t exclude any location a priori because we want to cover as much as possible) but we will have to narrow it down based on the quality of the data to be able to reliably detect anomalies automatically. After testing several metrics and visually analyzing the results, we came to the conclusion that the best predictor of a stable signal is related to the volume of data, so we removed the entities that don’t satisfy the criteria of a minimum number of unique IPs daily in a two weeks period — the threshold is based on visual inspection.
Creating a forecast
In order to detect the anomalies in a timely manner, we decided to go with traffic aggregated every fifteen minutes, and we are forecasting one hour of data (four data points / blocks of fifteen minutes) that are compared with the actual data.
After selecting the entities for which we will detect anomalies, the approach is quite simple:
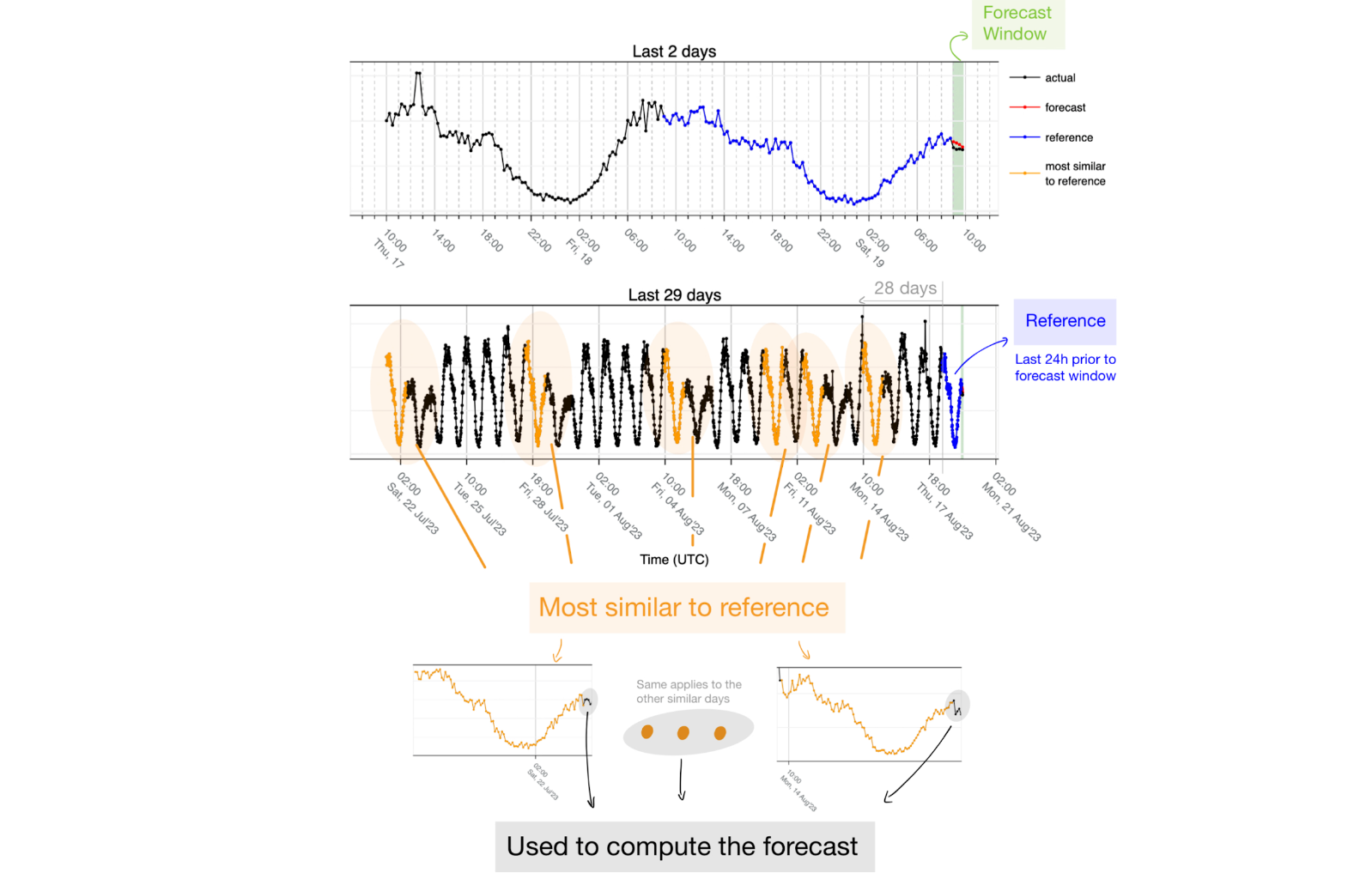
1. We look at the last 24 hours immediately before the forecast window and use that interval as the reference. The assumption is that the last 24 hours will contain information about the shape of what follows. In the figure below, the last 24 hours (in blue) corresponds to data transitioning from Friday to Saturday. By using the Euclidean distance, we get the six most similar matches to that reference (orange) — four of those six matches correspond to other transitions from Friday to Saturday. It also captures the holiday on Monday (August 14, 2023) to Tuesday, and we also see a match that is the most dissimilar to the reference, a regular working day from Wednesday to Thursday. Capturing one that doesn't represent the reference properly should not be a problem because the forecast is the median of the most similar 24 hours to the reference, and thus the data of that day ends up being discarded.
There are two important parameters that we are using for this approach to work:
We take into consideration the last 28 days (plus the reference day equals 29). This way we ensure that the weekly seasonality can be seen at least 4 times, we control the risk associated with the trend changing over time, and we set an upper bound to the amount of data we need to process. Looking at the example above, the first day was one with the highest similarity to the reference because it corresponds to the transition from Friday to Saturday.
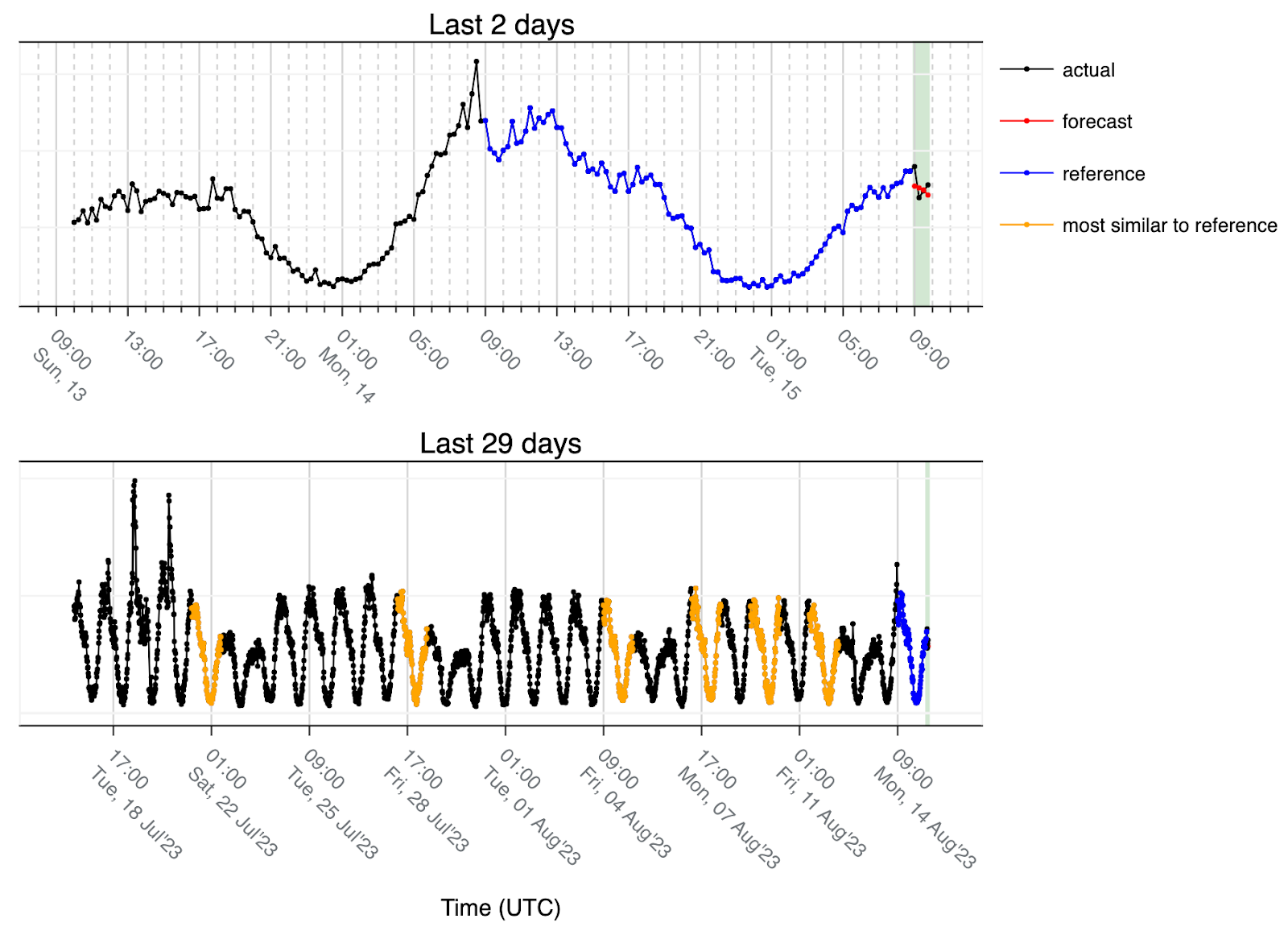
The other parameter is the number of most similar days. We are using six days as a result of empirical knowledge: given the weekly seasonality, when using six days, we expect at most to match four days for the same weekday and then two more that might be completely different. Since we use the median to create the forecast, the majority is still four and thus those extra days end up not being used as reference. Another scenario is in the case of holidays such as the example below:
A holiday in the middle of the week in this case looks like a transition from Friday to Saturday. Since we are using the last 28 days and the holiday starts on a Tuesday we only see three such transitions that are matching (orange) and then another three regular working days because that pattern is not found anywhere else in the time-series and those are the closest matches. This is why we use the lower quartile when computing the median for an even number of values (meaning we round the data down to the lower values) and use the result as the forecast. This also allows us to be more conservative and plays a role in the true positive/false positive tradeoff.
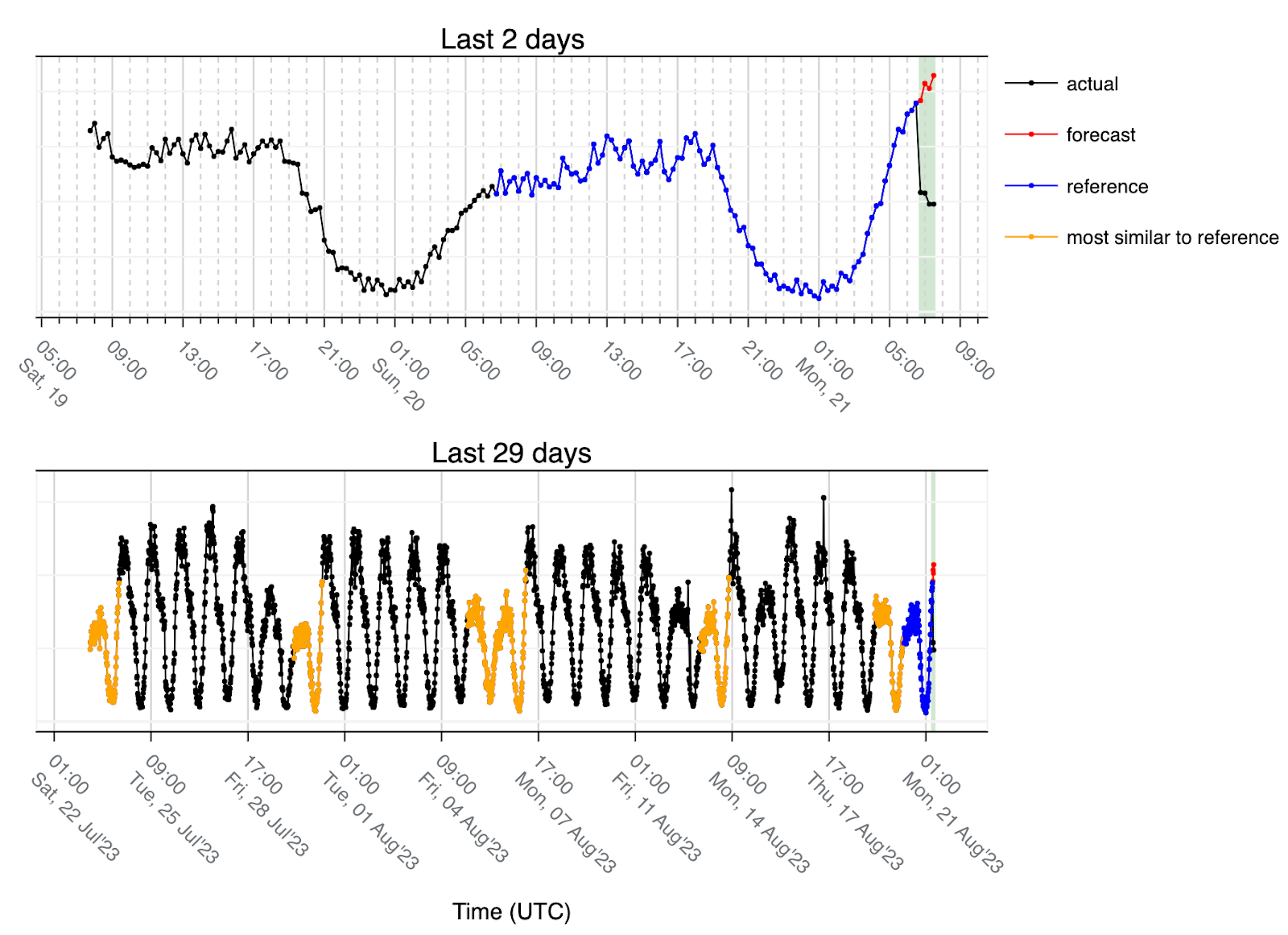
Lastly let's look at the outage example:
In this case, the matches are always connected to low traffic because the last 24h (reference) corresponds to a transition from Sunday to Monday and due to the low traffic the lowest Euclidean distance (most similar 24h) are either Saturdays (two times) or Sundays (four times). So the forecast is what we would expect to see on a regular Monday and that’s why the forecast (red) has an upward trend but since we had an outage, the actual volume of traffic (black) is considerably lower than the forecast.
This approach works for regular seasonal patterns, as would several other modeling approaches, and it has also been shown to work in case of holidays and other moving events (such as festivities that don’t happen at the same day every year) without having to actively add that information in. Nevertheless, there are still use cases where it will fail specifically when there’s an offset in the data. This is one of the reasons why we use multiple data sources to reduce the chances of the algorithm being affected by data artifacts.
Below we have an example of how the algorithm behaves over time.
Comparing forecast with actual traffic
Once we have the forecast and the actual traffic volume, we do the following steps.
We calculate relative change, which measures how much one value has changed relative to another. Since we are detecting anomalies based on traffic drops, the actual traffic will always be lower than the forecast.
After calculating this metric, we apply the following rules:
The difference between the actual and the forecast must be at least 10% of the magnitude of the signal. This magnitude is computed using the difference between 95th and 5th percentiles of the selected data. The idea is to avoid scenarios where the traffic is low, particularly during the off-peaks of the day and scenarios where small changes in actual traffic correspond to big changes in relative change because the forecast is also low. As an example:
a forecast of 100 Gbps compared with an actual value of 80 Gbps gives us a relative change of -0.20 (-20%).
a forecast of 20 Mbps compared with an actual value of 10 Mbps gives us a much smaller decrease in total volume than the previous example but a relative change of -0.50 (50%).
Then we have two rules for detecting considerably low traffic:
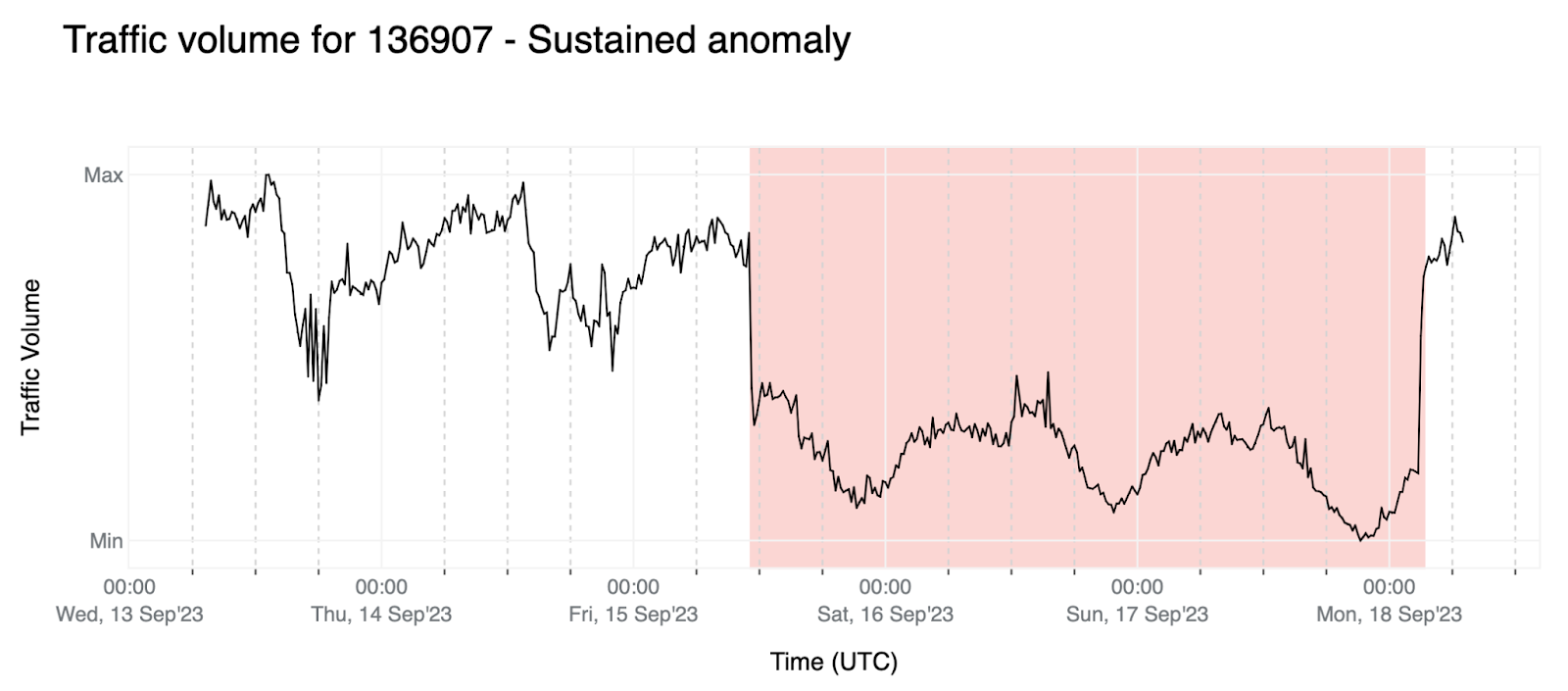
Sustained anomaly: The relative change is below a given threshold α throughout the forecast window (for all four data points). This allows us to detect weaker anomalies (with smaller relative changes) that are extended over time.
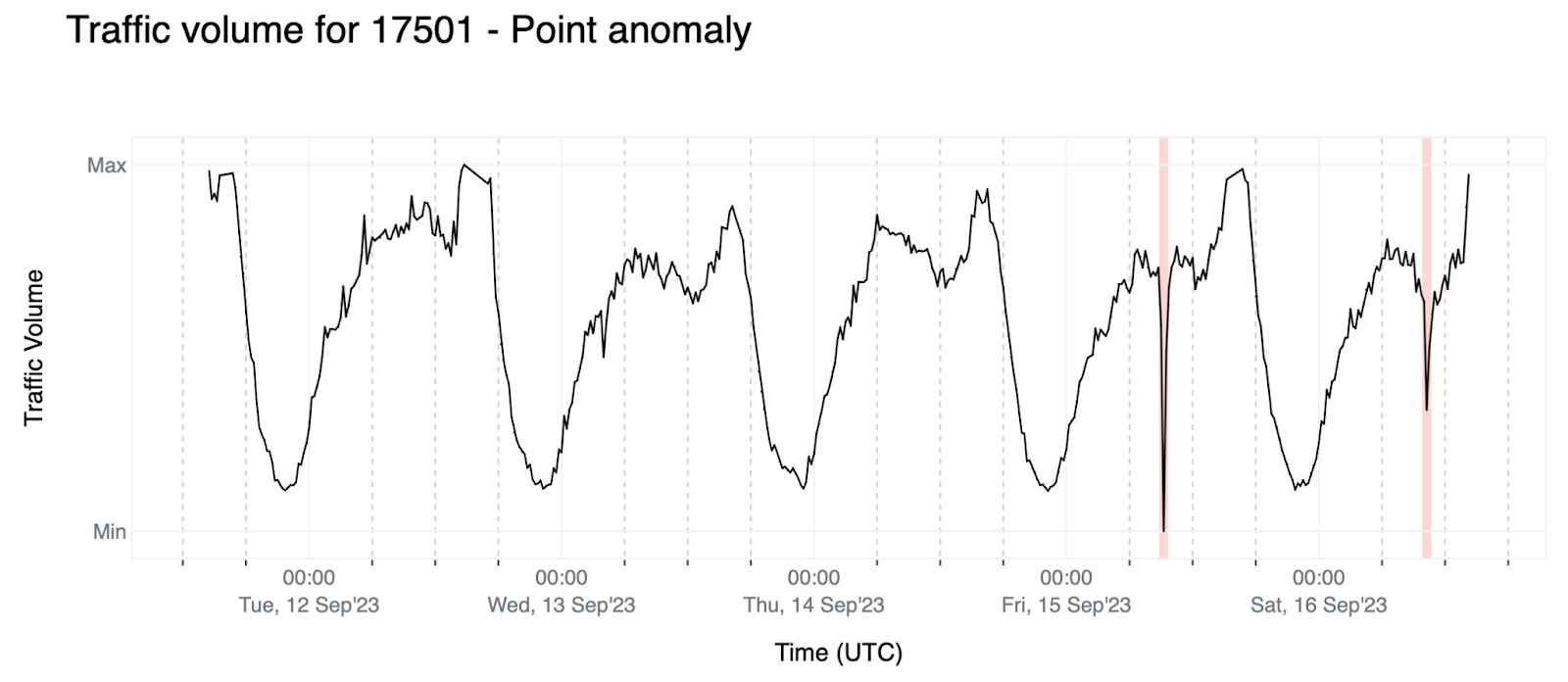
Point anomaly: The relative change of the last data point of the forecast window is below a given threshold β (where β < α — these thresholds are negative; as an example, β and α might be -0.6 and -0.4, respectively). In this case we need β < α to avoid triggering anomalies due to the stochastic nature of the data but still be able to detect sudden and short-lived traffic drops.
The values of α and β were chosen empirically to maximize detection rate, while keeping the false positive rate at an acceptable level.
Closing an anomaly event
Although the most important message that we want to convey is when an anomaly starts, it is also crucial to detect when the Internet traffic volume goes back to normal for two main reasons:
We need to have the notion of active anomaly, which means that we detected an anomaly and that same anomaly is still ongoing. This allows us to stop considering new data for the reference while the anomaly is still active. Considering that data would impact the reference and the selection of most similar sets of 24 hours.
Once the traffic goes back to normal, knowing the duration of the anomaly allows us to flag those data points as outliers and replace them, so we don’t end up using it as reference or as best matches to the reference. Although we are using the median to compute the forecast, and in most cases that would be enough to overcome the presence of anomalous data, there are scenarios such as the one for AS203214 (HulumTele), used as example four, where the outages are frequently occurring at the same time of the day that would make the anomalous data become the expectation after few days.
Whenever we detect an anomaly we keep the same reference until the data comes back to normal, otherwise our reference would start including anomalous data. To determine when the traffic is back to normal, we use lower thresholds than α and we give it a time period (currently four hours) where there should be no anomalies in order for it to close. This is to avoid situations where we observe drops in traffic that bounce back to normal and drop again. In such cases we want to detect a single anomaly and aggregate it to avoid sending multiple notifications, and in terms of semantics there’s a high chance that it’s related to the same anomaly.
Conclusion
Internet traffic data is generally predictable, which in theory would allow us to build a very straightforward anomaly detection algorithm to detect Internet disruptions. However, due to the heterogeneity of the time series depending on the entity we are observing (Location or AS) and the presence of artifacts in the data, it also needs a lot of context that poses some challenges if we want to track it in real-time. Here we’ve shown particular examples of what makes this problem challenging, and we have explained how we approached this problem in order to overcome most of the hurdles. This approach has been shown to be very effective at detecting traffic anomalies while keeping a low false positive rate, which is one of our priorities. Since it is a static threshold approach, one of the downsides is that we are not detecting anomalies that are not as steep as the ones we’ve shown.
We will keep working on adding more entities and refining the algorithm to be able to cover a broader range of anomalies.
A typo is one of those common mistakes with unpredictable results when it comes to the Internet’s domain names (DNS). In this blog post we’re going to analyze traffic for exmaple.com, and see how a very simple human error ends up creating unintentional traffic on the Internet.
Cloudflare has owned exmaple.com for a few years now, but don’t confuse it with example.com! example.com is a reserved domain name set by the Internet Assigned Numbers Authority (IANA), under the direction of the Internet Engineering Task Force (IETF). It has been used since 1999 as a placeholder, or example, in documentation, tutorials, sample network configurations, or to prevent accidental references to real websites. We use it extensively on this blog.
As I’m writing it, the autocorrect system transforms exmaple.com into example.com, every time, assuming I must have misspelled it. But in situations where there’s no automatic spelling correction (for example, while editing a configuration file) it’s easy for example to become exmaple.
And so, lots of traffic goes to exmaple.com by mistake — whether it was a typoed attempt to reach example.com or due to other random reasons. Fake email accounts in marketing forms are among these reasons (more details below). This phenomenon of "typosquatting" is used by attackers hoping someone misspells the name of a known brand, as we saw in March in our blog “Top 50 most impersonated brands in phishing attacks and new tools you can use to protect your employees from them”. Random typos that cause networks (big or small) problems have also been around for a while.
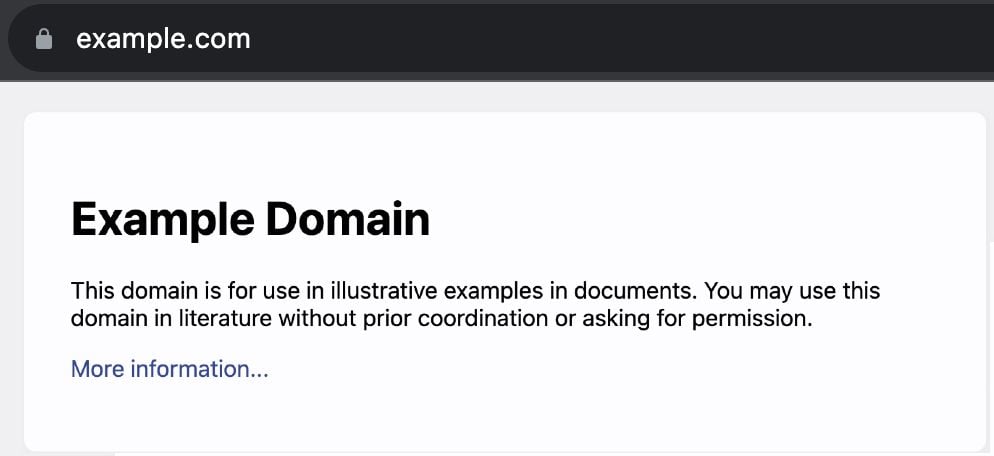
Here is what the example.com web page shows to a user who goes directly to that domain name:
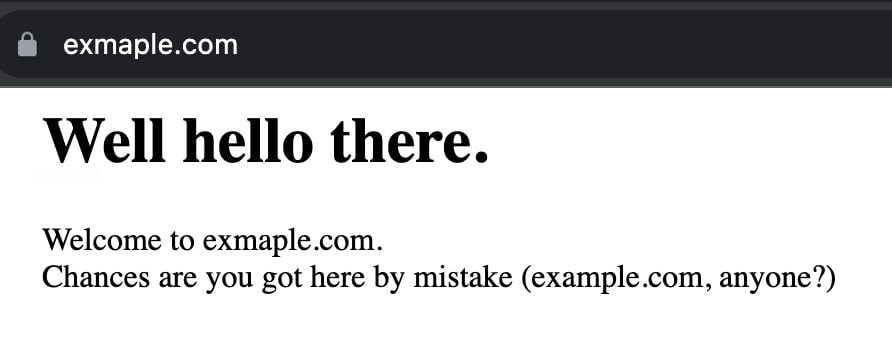
And this is what exmaple.com looks like:
A bit of exmaple.com history
exmaple.com came to us a few years ago from a customer. He registered the domain to prevent malicious exploitation, but got tired of dealing with more traffic than expected — it’s not the first time that this has happened (icanhazip.com was another similar example). Too much traffic does come at a financial cost. So, why would a domain name like exmaple.com, that is not promoted anywhere, have traffic? It shows how unintentional traffic is a real thing with the right domain name. It could also be a result of a typo in network configurations or a misconfigured router, as we’re going to see next.
Let’s explore, then, what traffic goes to exmaple.com by answering some questions.
How much traffic does it get?
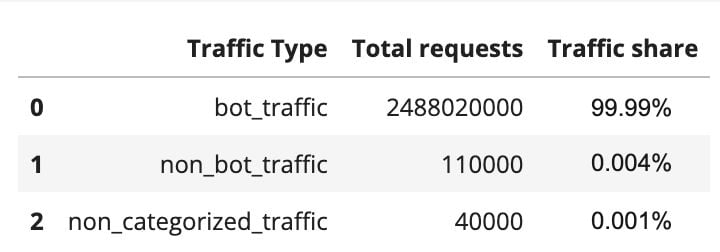
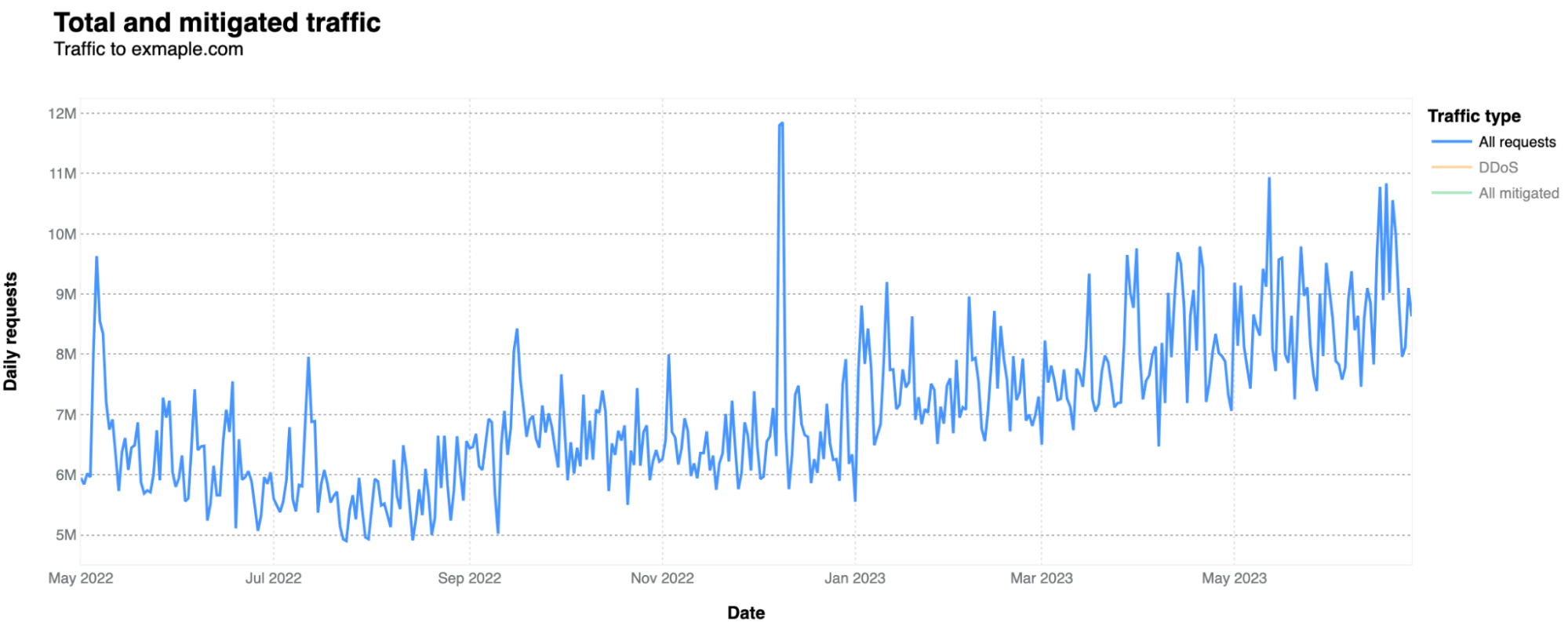
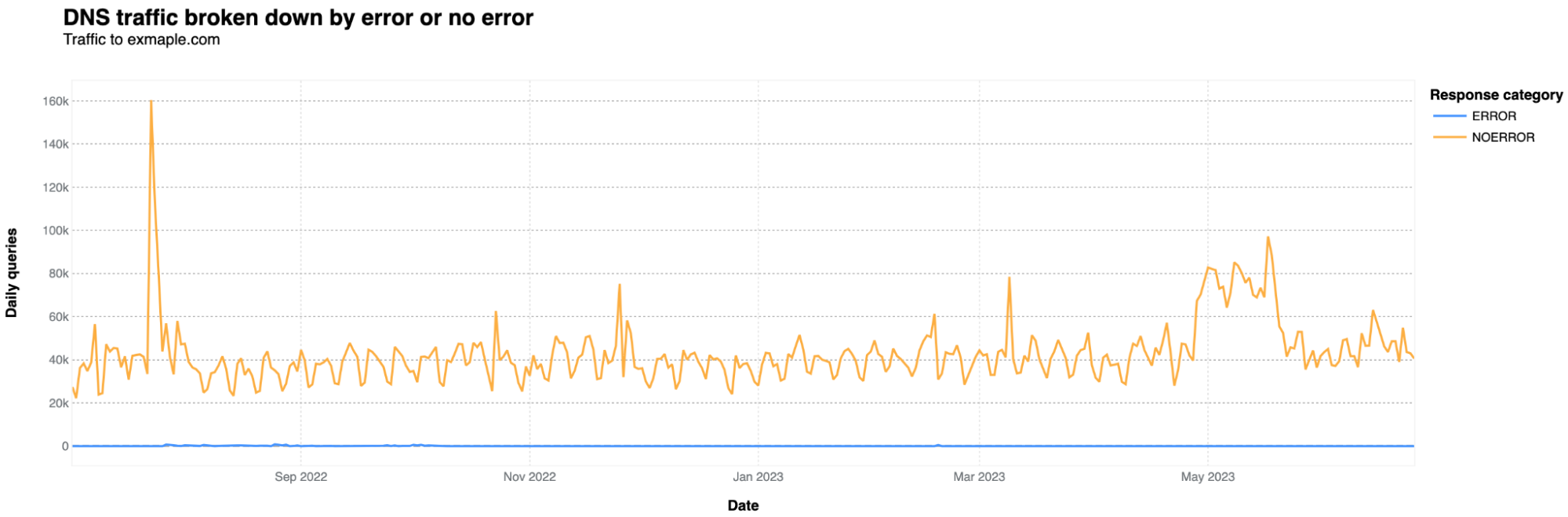
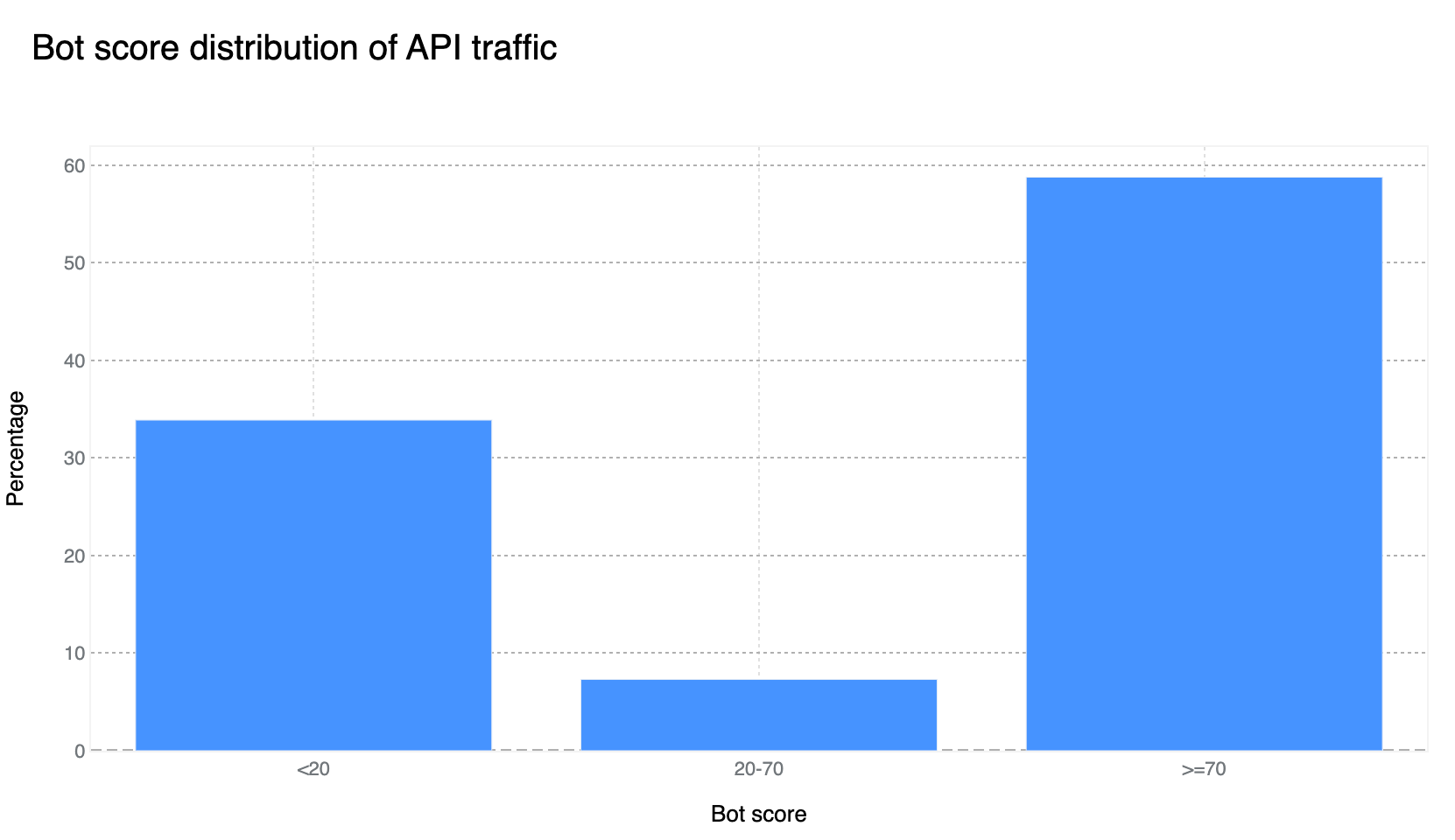
It gets much more traffic than one would expect in terms of HTTP requests, given that it is mostly used because someone or a system/router set by someone, misspelled example.com. In terms of bytes, the numbers are minimal, as this is a very simple site with only a short text sentence, as shown above. Usually, on a daily basis, it doesn’t go over 1 Mbps. In a 12-month period (May 2022-June 2023), it had 2.48 billion HTTP requests, but it has been increasing over recent months. In April 2023, it was 243 million requests, an 8.13 million daily average, against a 6.07 million daily average in June 2022.
What type of traffic is it? Almost all HTTP traffic that goes to exmaple.com is categorized as bot-related. That’s around 99.99%: 2.48 billion requests were from bots, 110,000 were not from bots, and 40,000 we weren’t able to categorize. This already gives us some information, showing that the majority of traffic is not a typical user simply adding exmaple.com by mistake to some documentation or tutorial. This is mostly automated traffic (more on that below).
There are also a few peaks worth mentioning. There’s a clear spike in bot traffic on December 8 and 9, 2022 (11.8 and 11.85 million requests, respectively), the week after Cyber Monday week.
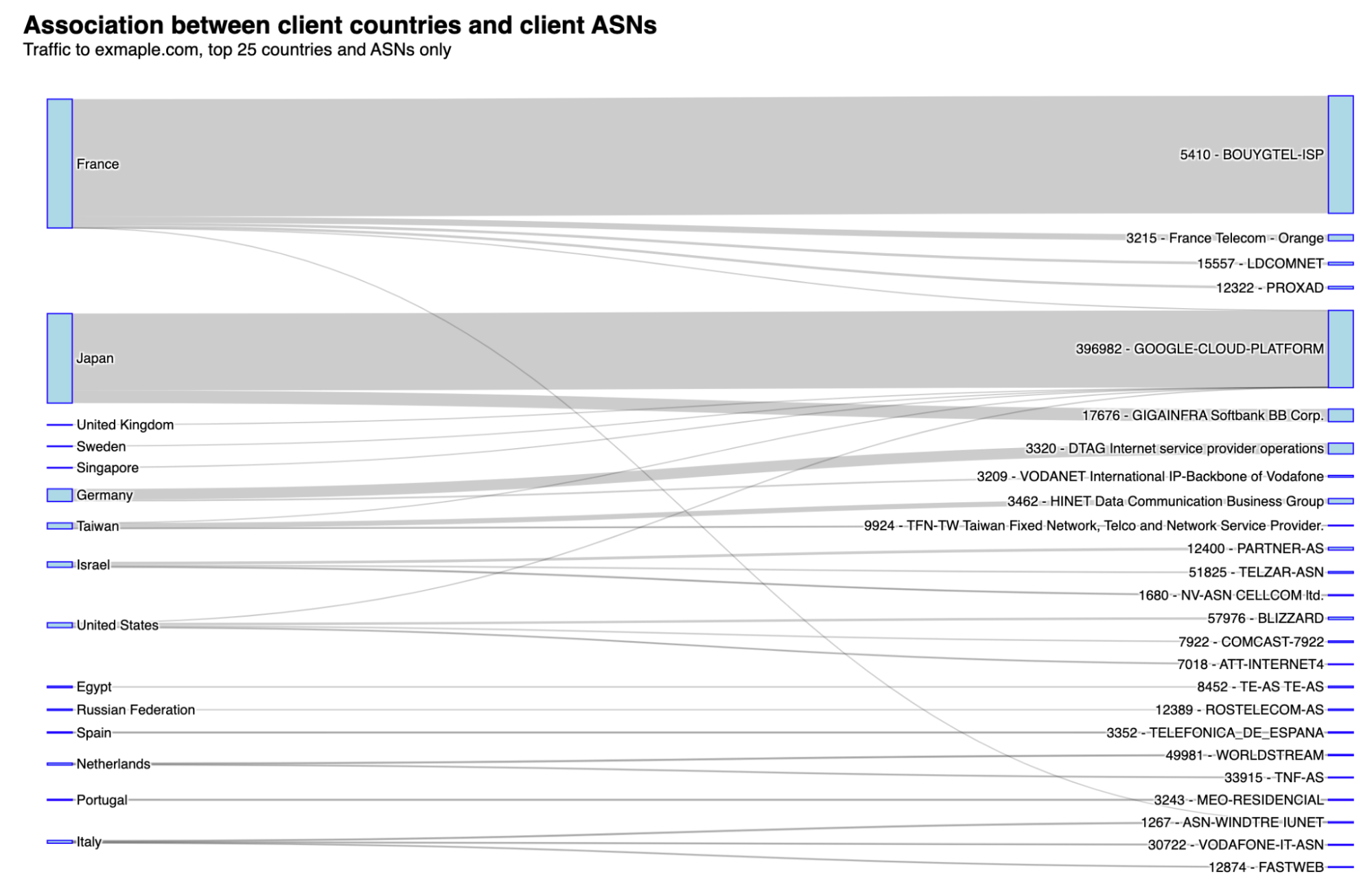
From which countries are requests coming from? The top countries include France, Japan, Germany, and the US. Below, we’re going to check why this happens by looking at the autonomous system (ASNs) perspective. Never forgetting that connected networks or AS’s make up the Internet.
How about HTTP protocols?
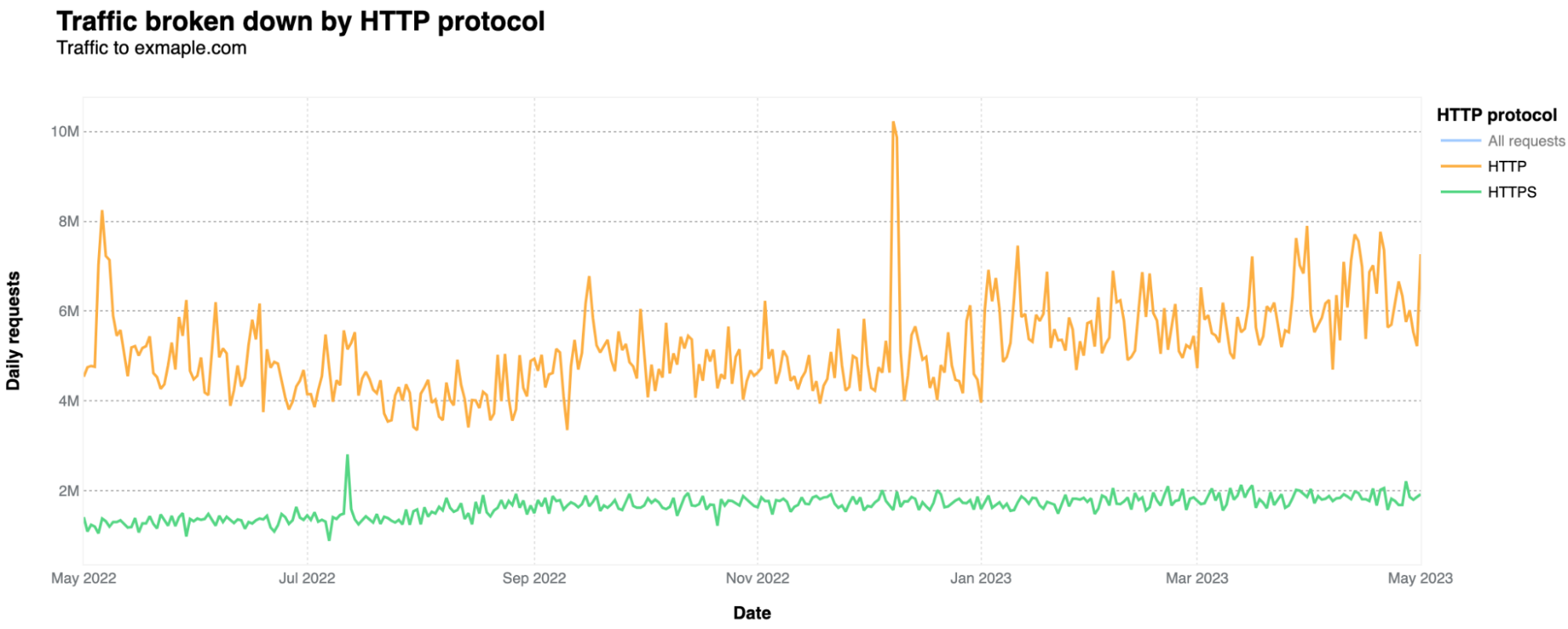
In terms of the HTTP protocols, the majority uses unencrypted HTTP only, accounting for 76% of all requests, while HTTPS represents 24%. That is actually unusual in the modern day Internet. As Cloudflare Radar data shows, excluding bots, HTTPS represents 99.3% of all requests in a general Cloudflare perspective, and its 80.8% of HTTPS for bots-only traffic. HTTPS adds a layer of security (SSL/TLS encryption), ensuring data remains confidential.
HTTP is definitely more used by automated traffic, given that HTTPS is more used for human consumption, as browsers tend to prioritize HTTPS. Only 6% of human-related requests use HTTP (the rest is HTTPS). That HTTP percentage jumps to 76%, when considering automated requests-only.
Is exmaple.com the target of cyber attacks?
The short answer is yes. But it’s a very low percentage of requests that are mitigated. The biggest spike in application layer attacks was on December 9, 2022, with 560k HTTP daily requests categorized as DDoS attacks. Nothing of large scale, but that said, small attacks can also take down under-protected sites. WAF mitigations had a 10k spike on November 2, 2022.
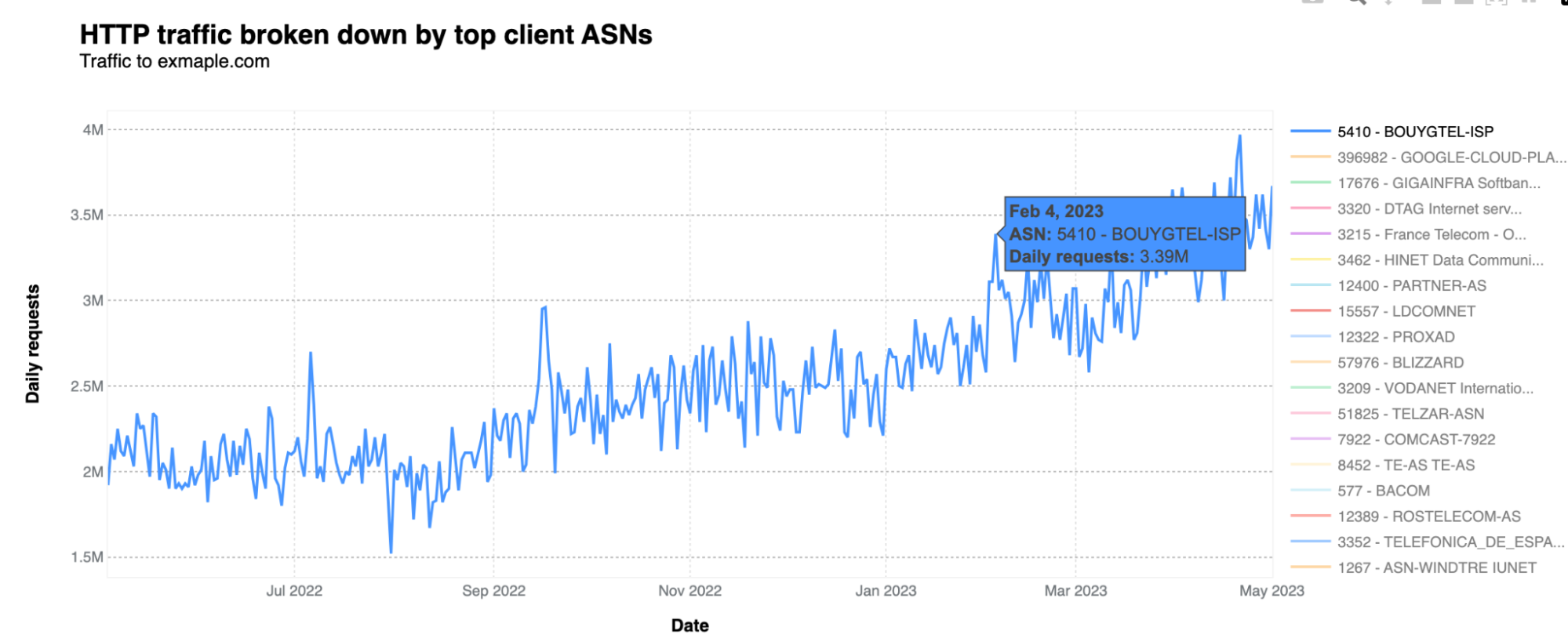
Generating the most traffic: a French ISP
What drives most of the traffic are very specific ASNs. In this case, the dominant one is one of France's main Internet operators, Bouygues Telecom. Its AS5410 is generating the most traffic to exmaple.com, followed by Google Cloud, in Japan. Bouygues Telecom traffic to exmaple.com means more than three million daily requests at least since February 2023. Here’s the AS5410 over time traffic:
We contacted Bouygues Telecom to let them know a couple of weeks ago, and shared information about where we were seeing traffic from. So far, they haven’t found the needle in the haystack sending traffic to exmaple.com, potentially related to some erroneous configuration.
And since, exmaple.com is not a malicious site, so there’s no harm, no foul. However, one could wonder what might happen if this were a malicious domain. Identifying and resolving misconfigurations is important for network administrators to ensure efficient and secure network operations.
There are a few other ASN-related oddities. A major spike in traffic on December 8, 2022, with 5.84 million HTTP requests on a single day, came from the Netherlands-based AS49981, Worldstream (an Infrastructure-as-a-Service provider). And on March 28-29, 2023, it was Russian Rostelecom AS12389, with a double spike of around 1.8 million requests per day. On June 18, 2022, it was German Deutsche Telekom AS3320, and on May 6, 2022, there was a 2.31 million HTTP requests daily spike from Bell Canada’s ISP, AS577, just to mention those with clearer spikes.
Here is the list that associates countries with the ASNs that are generating more traffic to exmaple.com:
Why does this happen in specific ASNs in different regions of the world, you may ask? Even without a definitive answer, the amount of daily traffic from those ASNs, and the prevalence of bot traffic, seems to indicate that most traffic is related to a possible misconfiguration in a router, software or network setting, intended to go to example.com.
As we observed previously, example.com is used for testing, educational, or illustrative purposes, including in routers from specific networks. It could be for network troubleshooting and testing, training, simulations, or it also could be in the documentation or guides for configuring routers, as examples to illustrate how to set up DNS configurations, route advertisement, or other networking settings.
What are the main IP versions and browsers?
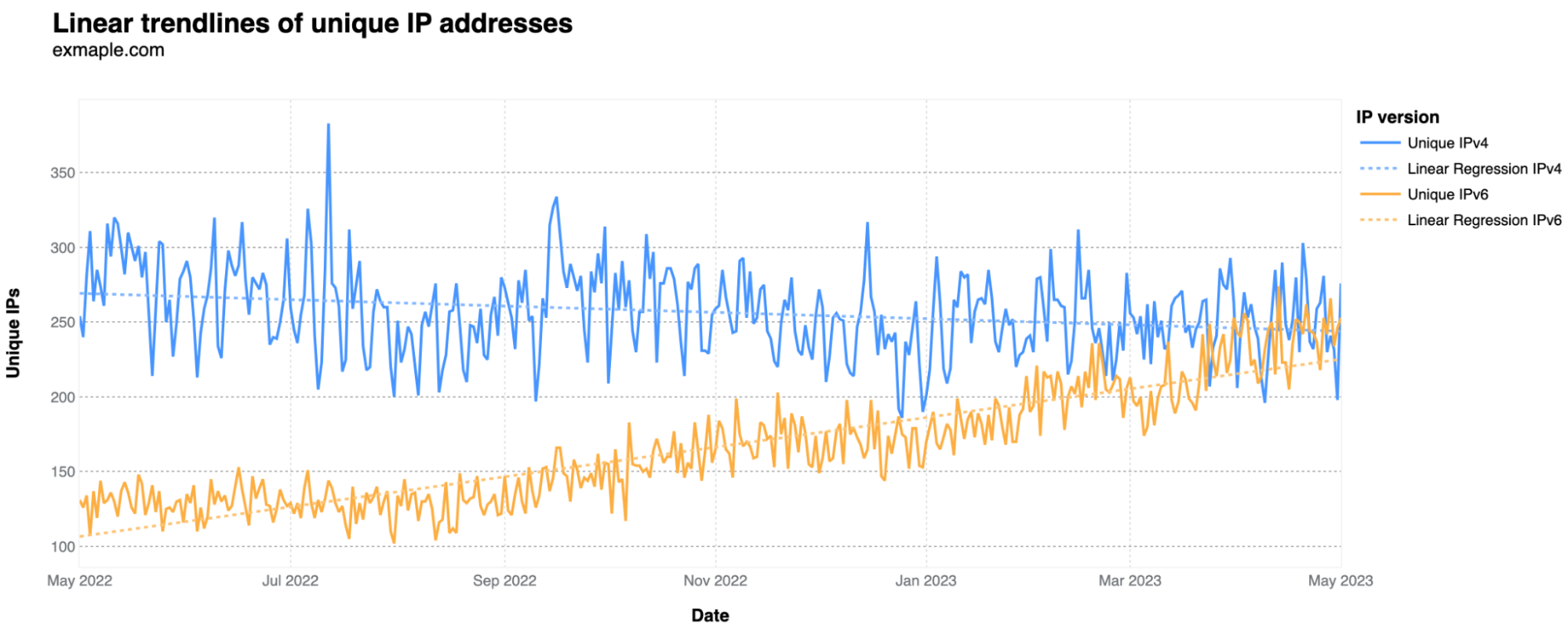
Regarding IP versions, they can be IPv4 or IPv6 — v6 emerged as a solution when the initial v4 wasn't prepared for the Internet's growth. For exmaple.com unique visitors, looking at the daily number of unique IPs where requests originate, IPv6 has been rising in comparison to IPv4. This suggests that IPv6 is now more frequently used by the services and bots generating most of this traffic. It started in May at 30% IPv6 usage and is now around 50%.
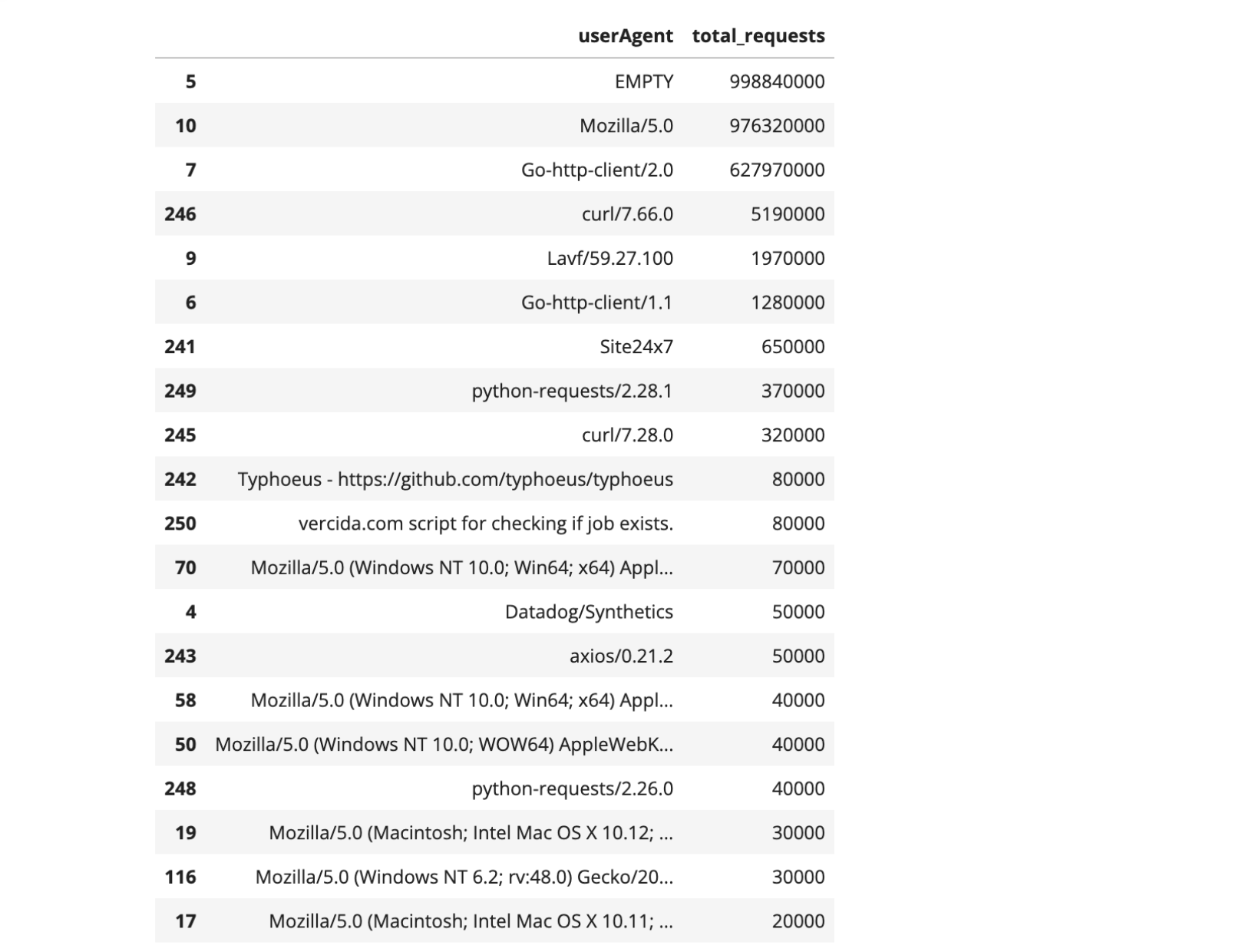
The user-agent header sent by the visitor's web browser in the HTTP request typically contains information about the used browser, operating system, and sometimes even the device. But in this case, the user-agent information doesn’t give us much detail, even of there’s some odd ones. “Empty” (when user agents are absent) comes first, followed by “Mozilla/5.0” and “Go-http-client/2.0”. What do those user-agents mean?
The user agent string "Mozilla/5.0" is widely used by a variety of web browsers, both mainstream and niche, including Mozilla Firefox, Google Chrome, Safari, and Opera. Therefore, it is challenging to attribute the usage of "Mozilla/5.0" specifically to a single browser or user category. While "Mozilla/5.0" is associated with legitimate browsers, it's worth noting that user agent strings can be easily manipulated or forged by bots and malicious actors.
“Go-http-client/2.0” indicates that the request is coming from a program or application written in the Go programming language (often referred to as Golang).
There are also a few others represented with known meanings, such as “curl/7.66.0” (the numbers correspond to the specific version being used). This user agent string indicates that the HTTP request was made using the cURL command-line tool, a popular tool used for tasks like downloading files, automated testing, debugging, or server monitoring. There’s also “Lavf/59.27.100”, a less common user agent tied to FFmpeg's Lavf library for multimedia tasks, and “python-requests/2.28.1”, that indicates the use of the Python Requests library, popular for sending HTTP requests and interacting with web services.
In the camp of more unusual user agents, with a few thousand requests, are instances like a specific GitHub page (a software library called Typhoeus) or a possible “script for checking if job exists” for the job searching site vercida.com.
From where did the users access the website? Let's examine the distribution of HTTP referrers. Note that the term "referer" is based on a misspelling in the original specification that has persisted (it should be "referrer header" instead) in HTTP — in the original HTTP proposal Tim Berners-Lee spells it “referrer” as well. The referer or referrer header is an optional field that provides information about the URL of the web page from which a particular request originated.
The predominant “referer” used is “empty”, which occurs when a user agent isn’t provided, also possibly meaning direct access or by bookmark. Next is exmaple.com itself (an unusual pattern, given there are no links on exmaple.com), with a peak of 160,000 requests on February 6, 2023. Following that is a curious spike of 10,000 requests from "reddit.com" on January 30, 2023, possibly due to a misspelling of example.com in a Reddit post that got popular.
We didn’t find a specific Reddit post from January 30 mentioning exmaple.com, but there were a few there over the years, clearly aiming to show example.com. Some of those are as recent as one year or even 10 months, like this Reddit post on the AWS subreddit, or this one from January 31, 2023, related to SEO.
On that note, regarding human misuse of misconfigurations impacting the Internet, in 2018, a member of the Cloudflare team gave a presentation about “Internet Noise” during a RIPE event that can be consulted here. It’s about unwanted traffic due to misconfigurations and misuse of proxies and internal use situations.
How about exmaple.com email trends?
Although no email address online intentionally targets exmaple.com, that address still gets some email attention. We configured a Gmail account to monitor these random emails in early 2022. Within 16 months, the 15 GB email capacity was fully used, containing 216,000 emails — an average of 432 daily emails. These emails reflect various scenarios: some are marketing-related, others appear to be network tests, and some are from individuals who, by error or to avoid spam, ended up at “@exmaple.com”. Among these use cases, we noticed accounts linked to PlayStation, Apple devices, Pandora music, Facebook, and more.
What the exmaple.com Inbox typically looks like.
Examining a 30-day span of emails (late July to late August), we noticed that certain types of emails are more common than others. This is notably seen in tests conducted by computer software applications that monitor systems, networks, and infrastructure. The main example of this is Nagios.
Since late July, nearly 83% of almost 4,000 emails were from Nagios. The sender used a “local domain” from Nagios, and the email address was “[email protected]”—where example.com was likely the intended recipient. The subjects alternated between “PROBLEM Service Alert: [Name of company] ATM/PING is WARNING” and “RECOVERY Service Alert: [Name of company]_Backup/PING is OK”, indicating service tests.
Analyzing the regions where most emails originate (based on our data centers), it's evident that North America and Southeast Asia are the primary sources, along with Europe. Regarding languages, English dominates, but some emails are in German, Spanish, Chinese, Japanese, Thai, and Russian.
Microsoft (56 emails), Apple (30), and Google (20 emails) are in the mix. Surprisingly, emails from various golf courses (31 emails from eight different golf courses) were also present, along with emails from cruise ship companies. Additionally, there are emails from well-known brands such as Call of Duty, PlayStation, HP, Uber (related to Uber Eats), McAfee, and even the U.S. Patent and Trademark Office (in newsletter subscription emails) that were observed (in this case, from the actual brands and not spam look alike). While Facebook-related emails were present in previous months, they haven't been seen recently.
Some emails clearly reveal their "fake" email intent, like “[email protected]”, sent by a virtual learning platform, likely when someone provided a randomly false email address. There are also repeated instances of people’s names like Mike or others, including surnames, before “@exmaple.com”. This suggests that people use the same fictitious email address when asked for their email by companies.
Here are some of the most creatively formed or interesting email addresses provided between July and August 2023, organized by us based on types of chosen email addresses (we included the number of emails in the most frequently used ones):
In the realm of email, DMARC (that stands for "Domain-based Message Authentication, Reporting, and Conformance") is a security protocol that helps prevent email spoofing and phishing attacks by providing a framework. It is used by email senders to authenticate their messages and receivers to verify their authenticity. DMARC is based on both SPF (verifies if an email was sent by an authorized sender) and DKIM (the receiving server will check the DKIM-Signature header), and the domains used by those two protocols. So, DMARC requires that SPF or DKIM “pass”.
The implementation of DMARC signals that an email sender is taking measures to improve email security and protect their domain's reputation. With this context, let’s delve into DMARC validation. How did these random email senders to “@exmaple.com”? Only 11% (433) of all emails (3890) from the past 30 days passed the DMARC authentication successfully, most of those were from recognized senders like Apple, Uber, or Microsoft.
This is also because a significant 83% (3252) of emails originated from what appear to be tests conducted by computer software applications that monitor systems, networks, and infrastructure — specifically, Nagios. All of these emails are categorized as "none" in terms of DMARC policies, indicating that the sender is not using a DMARC policy. This approach is frequently adopted as an initial phase to gauge the impact of DMARC policies before adopting more robust measures. Just 1% of all emails "failed" DMARC authentication, implying that these emails didn't align with the sender's designated policies.
In such instances, domain owners can instruct email providers to take actions such as quarantining the email or outright rejection, thus shielding recipients from potentially malicious messages. This was evident in domains like amazon.co.jp or sanmateo.flester.com (where "Undelivered Mail Returned to Sender" messages originated from the Mail Delivery System).
Our email perspective could have been even more comprehensive if this “@exmaple.com” email account had Cloudflare Area 1 — our cloud-native email security service that detects and thwarts attacks before they reach user inboxes. Perhaps in a future geeky venture, we will also incorporate that viewpoint, complete with percentages for spam, malicious content, and threat categories.
Where is example.com on our domain popularity ranking? What about exmaple.com?
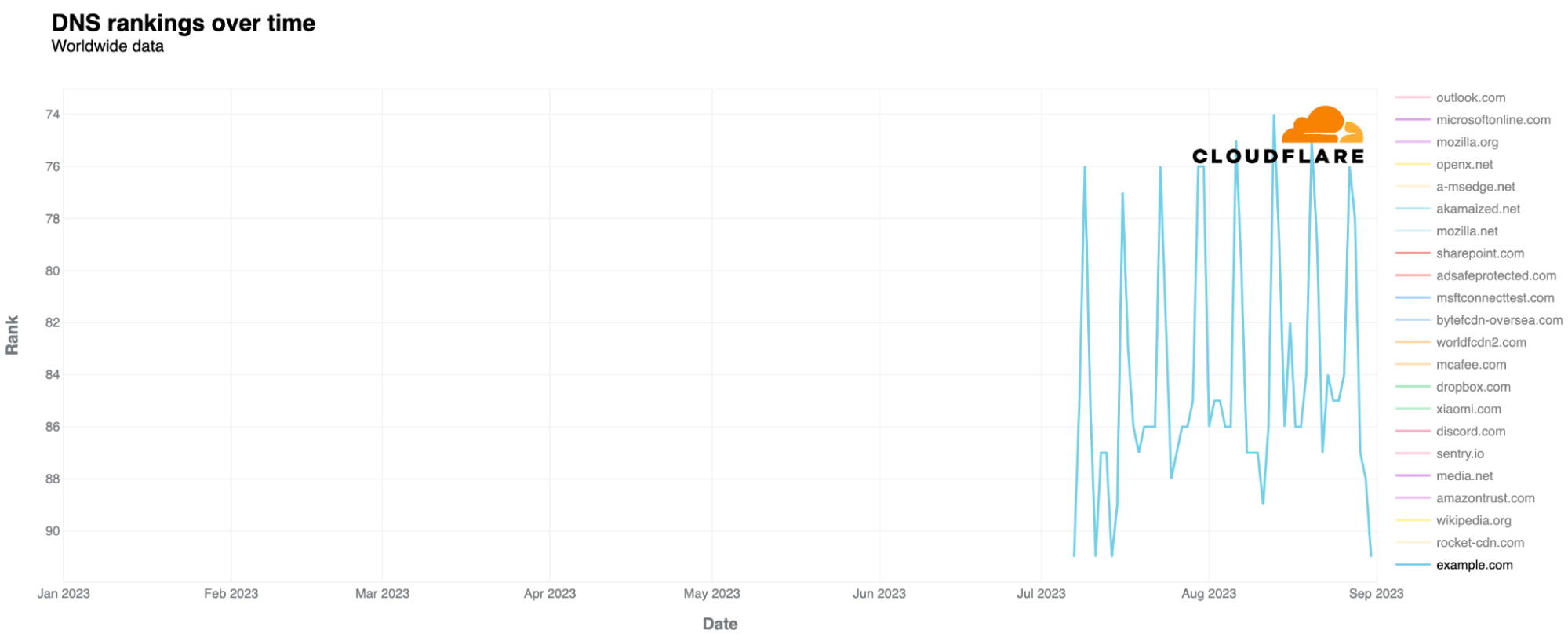
Last but not least, we also have insight into example.com itself. Looking at our most popular domains list (using data from our 1.1.1.1 resolver), example.com or “example.org” are no strangers to our popular domains ranking. Those two are usual “guests” of our top 500 domains ranking, both worldwide and in specific countries, which also is an expression of its popularity and usage for all the use cases we already discussed. example.com usually sits higher, in the top 300. Since July, it has even appeared in our top 100 for the first time in 2023.
exmaple.com, on the other hand, is not in our top 100 list, and only appears in our top 100k top domains list. You can find our domains lists, including a top 100, and unordered CSV lists up to Top 1 million domains, on Cloudflare Radar and through our API.
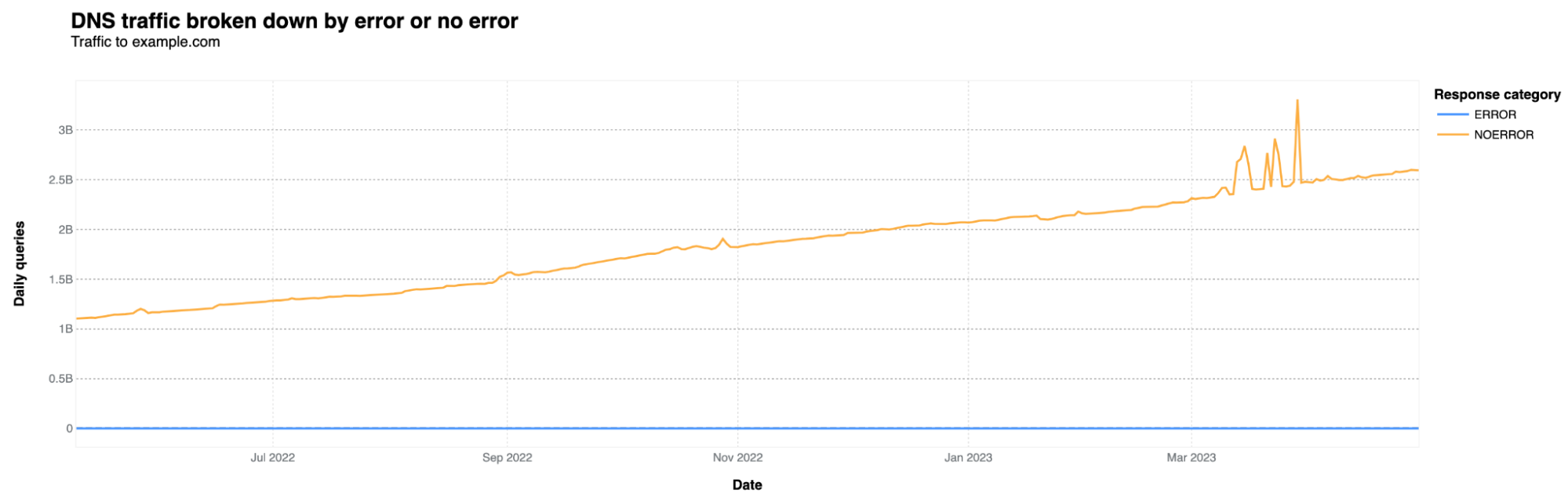
Just by checking DNS data from those who use our resolver, the original example.com gets around 2.6 billion DNS queries every day. This number has been consistently increasing since 2022, more than doubling. Here's the chart to show it:
What about exmaple.com? DNS queries are significantly lower by an order of magnitude. On average, it receives around 40,000 DNS queries per day, with occasional spikes reaching 80,000 to 90,000 — there’s one 160k July 23, 2022, spike. It's also noteworthy that there are more DNS queries on weekdays and fewer on weekends, which is not the case for example.com.
Conclusion: Errare humanum est
“Some of the worst problems that happen on the Internet are not because somebody deliberately caused the problem. It’s because somebody made a mistake. We’ve lost half the networks ability to transport traffic or route it to the right destinations because somebody made a configuration mistake”. — Vint Cerf, American Internet pioneer, in a 2016’s article: Vinton G. Cerf: Human error, not hackers threaten Net.
Even if traffic to exmaple.com arrives without consequences, a typo from a technician in a device for the wrong and malicious domain, could definitely have a negative impact if protections are not put in place. The typical Internet user is also susceptible to sending emails to the wrong address due to typos or could be tricked by domains resembling popular brands, but with errors.
Stoic philosopher of Ancient Rome Lucius Seneca stated two thousand years ago, Errare humanum est or in plain English: to err is human. This held true for humans in the year AD 30 and remains so for humans in 2023. And the Internet, the complex network of networks that has grown larger than even its human inventors anticipated, is no stranger of these human errors, and its consequences. Quoting once again from Vint Cerf, “we need to have much better tools for writing software to avoid some of those stupid mistakes that cause problems in the Internet”.
After all this geeky analysis, my autocorrect finally recognizes "exmaple.com" and doesn't change it to "example.com". Success.
(Thanks to Jorge Pacheco, Sofia Cardita, Jérôme Fleury, and Marek Majkowski for their contributions to this blog post.)
Cloudflare Radar was launched in September 2020, almost three years ago, when the pandemic was affecting Internet traffic usage. It is a free tool to show Internet usage patterns from both human and automated systems, as well as attack trends, top domains, and adoption and usage of browsers and protocols. As Cloudflare has been publishing data-driven insights related to the general Internet for more than 10 years now, Cloudflare Radar is a natural evolution.
This year, we have introduced several new features to Radar, also available through our public API, that enables deeper data exploration. We’ve also launched an Internet Quality section, a Trending Domains section, a URL Scanner tool, and a Routing section to track network interconnection, routing security, and observed routing anomalies.
In this reading list, we want to highlight some of those new additions, as well as some of the Internet disruptions and trends we’ve observed and published posts about during this year, including the war in Ukraine, the impact of Easter, and exam-related shutdowns in Iraq and Algeria.
We also encourage everyone to explore Cloudflare Radar and its new features, and to give you a partial review of the year, in terms of Internet insights — our 2023 Year in Review is coming later this year.
New additions to Cloudflare Radar
In 2022, Cloudflare Radar 2.0 was released last September, refreshing the look & feel and building on a new platform that allows us to easily add new features in the future. At that time, we added two new sections:
Cloudflare Radar’s 2022 Year in Review and the related blog were published at the end of the year.
Without further ado, here are some of the new features launched in 2023.
Analyze any URL safely using the Cloudflare Radar URL Scanner (✍️)
If you're invited to click on a link and if you're unsure about its safety, or if you simply want to verify technical details about a particular site, URL Scanner is here to assist. Provide us with a URL, and our scanner will compile a report containing a myriad of technical details: risk assessment, SSL certificate data, HTTP request and response data, page performance data, DNS records, associated cookies, what technologies and libraries the page uses, and more.
Introducing the Cloudflare Radar Internet Quality Page (✍️)
In June 2023, the new Internet Quality page was introduced to Cloudflare Radar, offering both country and network (autonomous system) level insight. This provides information on Internet connection performance (bandwidth) and quality (latency, jitter) over time based on benchmark test data as well as speed.cloudflare.com test results.
You can also see in a world map how the different countries compare with each other in different metrics from bandwidth to latency and jitter. Autonomous systems (AS) or networks are presented on individual pages, including Starlink’s AS14593. Latency is the metric that gives a better perspective on quality and improved Internet experience. Here’s the most recent global view on latency-based connection quality (lower is better):
Measuring the Internet's pulse: trending domains now on Cloudflare Radar (✍️)
Starting July 2023, our Domain Rankings page received enhancements through the inclusion of specific Trending Domains lists. While the top 100 list is typically dominated by the big names such as Google, Facebook, and Apple, there are trending domains that also tell interesting and even more local stories.
The Trending Domains lists highlight surges in interest from the previous day and previous week. For instance, we captured how nba.com was trending in 28 locations during the NBA Draft 2023, and how rt.com (a Russian-based news site) gained attention in multiple countries during the Wagner group mutiny in Russia. More recently, on the same subject, after the death of Wagner’s leader, Yevgeny Prigozhin, in a plane crash, flightradar24.com was trending in our daily list both in Russia and Ukraine.
The Internet is a vast, sprawling collection of networks (autonomous systems) that connect to each other, and routing is one of the most critical operations of the Internet. Launched in late July 2023, the new Cloudflare Radar Routing page examines the routing status of the Internet, including secure routing protocol deployment for a country and routing changes and anomalies. Included are routing security statistics, and also announced prefixes and connectivity insights. Why is that important? Routing decides how and where the Internet traffic should flow from the source to the destination, and deviations or anomalies can indicate potential issues that lead to connectivity disruptions.
Border Gateway Protocol (BGP), is considered the postal service of the Internet, but as a routing protocol suffers from a number of security weaknesses. Within the Routing page, we also present BGP route leaks and BGP hijack detection results, highlighting relevant events detected for any given network or globally. Notably, BGP origin hijacks allow attackers to intercept, monitor, redirect, or drop traffic destined for the victim's networks. In this related blog post, we also explain how Cloudflare built its BGP hijack detection system (including notifications), from its design and implementation to its integration: Cloudflare Radar's new BGP origin hijack detection system.
General Internet insights from 2023
One year of war in Ukraine: Internet trends, attacks, and resilience (✍️)
This blog post details Internet insights during the war in Europe and discusses how Ukraine's Internet remained resilient in spite of dozens of attacks and disruptions in three different stages of the conflict.
Cloudflare observed multiple Internet disruptions in the first weeks of the war (Internet infrastructure was damaged, and Internet access was limited in besieged areas, like Mariupol), as well as airstrikes on Ukrainian energy infrastructure. We also emphasize how application-layer cyber attacks in Ukraine rose 1,300% in early March 2022 as compared to pre-war levels, the country’s Internet resilience during the war, and major growth in Starlink traffic from the country.
Cloudflare’s view of the Virgin Media outage in the UK (✍️)
At times, major Internet operators experience significant outages due to technical issues. In 2022, it was Canada’s Rogers that experienced a 17-hour disruption impacting millions of users, and in early April 2023, a similar incident occurred with the United Kingdom’s Virgin Media. In this case, there were two clear outages for a few hours during April 4, 2023.
The post examines the impact on Internet traffic, the availability of Virgin Media web properties, and how BGP activity offered insights into the root cause.
How Easter, Passover and Ramadan show up in Internet trends (✍️)
National holidays celebrated in various countries can influence local Internet traffic trends. That was the case during Easter, celebrated between April 7-10, 2023. In countries including Italy, Poland, Germany, France, Spain, Portugal, the United States, Mexico, and Australia, the Easter long weekend led to the lowest traffic levels of 2023 up to that point—over 100 days into the year. Traffic dipped most significantly on Easter Sunday, compared to the previous Sunday, in Poland (22% lower), Italy (18% lower), France (16% lower).
The post also illustrates Orthodox Easter trends, with Greece being most impacted. It examines Ramadan-related changes, where eating rituals impacted Internet patterns in several countries with significant Muslim populations, and Passover trends, showing how Israel’s Internet traffic dropped as much as 24%.
Effects of the conflict in Sudan on Internet patterns (✍️)
We’ve been monitoring changes and disruptions in Internet patterns linked to military interventions. In this Sudan-related blog post, we analyze the impact of the armed conflict between rival factions of the military government that began on April 15, 2023. Cloudflare observed varying disruptions in Internet traffic after that day, with a mix of clear outages and general decrease in traffic.
The most recent Internet pattern change linked to military intervention is the ongoing coup in Niger. This particular event caused a distinct traffic drop, likely tied to shifts in human Internet usage, given the absence of signs of consistent connectivity disruption.
How the coronation of King Charles III affected Internet traffic (✍️)
As the coronation ceremony of King Charles III unfolded in London on May 6, 2023, distinct spikes and dips in Internet traffic were observed, each coinciding with key moments of the event. Also, on Sunday during the Coronation Big Lunch event, and Prince William’s speech at night, both instances led to a clear traffic drop of up to 18% compared with the previous Sunday. The accompanying chart displays this trend.
During the coronation weekend, Canada and Australia also exhibited shifts in Internet traffic patterns. And within this coronation post, there’s also analysis on Internet traffic pattern changes when Queen Elizabeth II passed away on September 8, 2022.
Cloudflare’s view of Internet disruptions in Pakistan (✍️)
Following the arrest of ex-PM Imran Khan, violent protests led the Pakistani government to order the shutdown of mobile Internet services and blocking of social media platforms. Mobile network shutdowns in the country lasted for several days.
We examined the impact of these shutdowns on Internet traffic in Pakistan and traffic to Cloudflare’s 1.1.1.1 DNS resolver and how Pakistanis appeared to be using it in an attempt to maintain access to the open Internet.
Nine years of Project Galileo and how the last year has changed it (✍️)
For the ninth anniversary of our Project Galileo in June 2023, the focus turned towards providing access to affordable cybersecurity tools and sharing our learnings from protecting the most vulnerable communities. We also published a ninth anniversary Project Galileo report.
One of the highlights of the report was a clear DDoS attack targeting an organization related to international law. This incident occurred on the same day an international arrest warrant was issued for Russian President Vladimir Putin and Russian official Maria Lvova-Belova, on March 17, 2023. Another standout observation involved the spikes in traffic experienced by Ukrainian emergency and humanitarian services, coinciding with bombings within the country.
Exam-related Internet shutdowns in Iraq and Algeria put connectivity to the test (✍️)
Since early June 2023, we’ve seen Iraq implementing a series of multi-hour shutdowns that continued through July and into August, as documented in our Outage Center. Algeria took similar actions, but using a content blocking-based approach, instead of the wide-scale Internet shutdowns, to prevent cheating on baccalaureate exams. This summer, these exam-related shutdowns were also implemented in Syria.
Cloudflare has previously observed and reported on similar occurrences in 2022 and also in 2021, in Syria and Sudan.
2023 has been a busy year for different types of Internet disruptions and outages, from government-directed shutdowns to natural incidents.
Reports: DDoS, Internet disruptions, and application security
Within Cloudflare Radar’s reports section, you will find a diverse array of perspectives on the Internet. From the Project Galileo 9th Anniversary — focused on aiding significant yet vulnerable online voices — to the more recent Q2 2023 Browsers and Search Engines reports. Some reports, such as the DDoS attack trends one, are also blog posts. Others are only available as blog posts, like the Internet disruptions summary, expanding on entries in the Outage Center, and the Application Security report.
This post delves into Internet disruptions observed by Cloudflare during the second quarter of 2023. Since 2022, we have been consistently offering these quarterly overviews of disruptions, and Q2 proved to be a busy quarter, with different types of disruptions:
There were several government directed shutdowns, including the ones related to “exam season” in several Middle Eastern and African countries, that continue through August.
Severe weather also played a role with a “Super Typhoon”-related disruption on the US territory of Guam.
Cable damage was behind disruptions in Bolivia, the Gambia and the Philippines.
Power outage-related Internet disruptions were observed in Curaçao, Portugal, and Botswana.
More generic technical problems impacted SpaceX Starlink’s satellite service, and Virgin Media in the United Kingdom.
Cyberattacks played a role in disruptions in both Russia and Ukraine.
Military action-related outages were observed in Chad and Sudan.
There were also maintenance related outages that affected Togo, Republic of Congo (Brazzaville), and Burkina Faso.
The Internet disruptions overview for Q1 2023 included another cause, a massive earthquake. The early February 7.8 magnitude earthquake in Turkey, which also affected Syria, caused widespread damage and tens of thousands of fatalities, and resulted in significant disruptions to Internet connectivity in multiple regions for several weeks.
Since 2020, our DDoS reports/blog posts have been focused on uncovering new attack trends, identifying the most affected countries, and showing targeted industries. Our Q2 2023 DDoS threats blog post highlights an unprecedented escalation in DDoS attack sophistication. Pro-Russian hacktivists REvil, Killnet, and Anonymous Sudan joined forces to attack Western sites. Exploits related to the zero-day vulnerability known as TP240PhoneHome surged by a whopping 532%, and attacks on crypto rocketed up by 600%.
An associated interactive version of this report is available on Cloudflare Radar. Furthermore, we’ve also added a new interactive component to Radar’s security section that allows you to dive deeper into attack activity in each country or region.
Our Application Security report has been around since 2022. The latest one highlights new attack trends and insights visible through Cloudflare’s global network. Some highlights include:
Daily mitigated HTTP requests decreased by 2 percentage points to 6% on average from 2021 to 2022, but days with larger than usual malicious activity were clearly seen across the network.
Application owners are increasingly relying on geo location blocks.
On average, more than 10% of non-verified bot traffic is mitigated. Compared to the last report, non-verified bot HTTP traffic mitigation is currently on a downward trend (down 6 percentage points).
65% of global API traffic is generated by browsers.
HTTP Anomalies are the most common attack vector on API endpoints, with 64%, followed by SQLi injection attacks (11%) and XSS attacks (9%).
The network of networks, also known as the Internet, is both complex and already seen as a human basic right—enabling work, leisure, communication, knowledge acquisition, and the pursuit of opportunities.
In 2023, Cloudflare Radar introduced new capabilities that facilitate the exploration of a broader array of insights and trends showing the Internet's various facets. These include Internet quality, insights into trending domains, and pertinent routing changes. There’s also no lack of general Internet insights and reports that try to offer different perspectives on 2023 events and occurrences and their impact. And already in August 2023, we’ve launched the “date picker” functionality, allowing any user to go back in time by selecting arbitrary date ranges. It looks like this:
Cloudflare has a unique vantage point on the Internet. From this position, we are able to see, explore, and identify trends that would otherwise go unnoticed. In this report we are doing just that and sharing our insights into Internet-wide application security trends.
Since the last report, our network is bigger and faster: we are now processing an average of 46 million HTTP requests/second and 63 million at peak. We consistently handle approximately 25 million DNS queries per second. That's around 2.1 trillion DNS queries per day, and 65 trillion queries a month. This is the sum of authoritative and resolver requests served by our infrastructure. Summing up both HTTP and DNS requests, we get to see a lot of malicious traffic. Focusing on HTTP requests only, in Q2 2023 Cloudflare blocked an average of 112 billion cyber threats each day, and this is the data that powers this report.
But as usual, before we dive in, we need to define our terms.
Definitions
Throughout this report, we will refer to the following terms:
Mitigated traffic: any eyeball HTTP* request that had a “terminating” action applied to it by the Cloudflare platform. These include the following actions: BLOCK, CHALLENGE, JS_CHALLENGE and MANAGED_CHALLENGE. This does not include requests that had the following actions applied: LOG, SKIP, ALLOW. In contrast to last year, we now exclude requests that had CONNECTION_CLOSE and FORCE_CONNECTION_CLOSE actions applied by our DDoS mitigation system, as these technically only slow down connection initiation. They also accounted for a relatively small percentage of requests. Additionally, we improved our calculation regarding the CHALLENGE type actions to ensure that only unsolved challenges are counted as mitigated. A detailed description of actions can be found in our developer documentation.
Bot traffic/automated traffic: any HTTP* request identified by Cloudflare’s Bot Management system as being generated by a bot. This includes requests with a bot score between 1 and 29 inclusive. This has not changed from last year’s report.
API traffic: any HTTP* request with a response content type of XML or JSON. Where the response content type is not available, such as for mitigated requests, the equivalent Accept content type (specified by the user agent) is used instead. In this latter case, API traffic won’t be fully accounted for, but it still provides a good representation for the purposes of gaining insights.
Unless otherwise stated, the time frame evaluated in this post is the 3 month period from April 2023 through June 2023 inclusive.
Finally, please note that the data is calculated based only on traffic observed across the Cloudflare network and does not necessarily represent overall HTTP traffic patterns across the Internet.
* When referring to HTTP traffic we mean both HTTP and HTTPS.
Global traffic insights
Mitigated daily traffic stable at 6%, spikes reach 8%
Although daily mitigated HTTP requests decreased by 2 percentage points to 6% on average from 2021 to 2022, days with larger than usual malicious activity can be clearly seen across the network. One clear example is shown in the graph below: towards the end of May 2023, a spike reaching nearly 8% can be seen. This is attributable to large DDoS events and other activity that does not follow standard daily or weekly cycles and is a constant reminder that large malicious events can still have a visible impact at a global level, even at Cloudflare scale.
75% of mitigated HTTP requests were outright BLOCKed. This is a 6 percentage point decrease compared to the previous report. The majority of other requests are mitigated with the various CHALLENGE type actions, with managed challenges leading with ~20% of this subset.
Shields up: customer configured rules now biggest contributor to mitigated traffic
In our previous report, our automated DDoS mitigation system accounted for, on average, more than 50% of mitigated traffic. Over the past two quarters, due to both increased WAF adoption, but most likely organizations better configuring and locking down their applications from unwanted traffic, we’ve seen a new trend emerge, with WAF mitigated traffic surpassing DDoS mitigation. Most of the increase has been driven by WAF Custom Rule BLOCKs rather than our WAF Managed Rules, indicating that these mitigations are generated by customer configured rules for business logic or related purposes. This can be clearly seen in the chart below.
Note that our WAF Managed Rules mitigations (yellow line) are negligible compared to overall WAF mitigated traffic also indicating that customers are adopting positive security models by allowing known good traffic as opposed to blocking only known bad traffic. Having said that, WAF Managed Rules mitigations reached as much as 1.5 billion/day during the quarter.
Our DDoS mitigation is, of course, volumetric and the amount of traffic matching our DDoS layer 7 rules should not be underestimated, especially given that we are observing a number of novel attacks and botnets being spun up across the web. You can read a deep dive on DDoS attack trends in our Q2 DDoS threat report.
Aggregating the source of mitigated traffic, the WAF now accounts for approximately 57% of all mitigations. Tabular format below with other sources for reference.
Source
Percentage %
WAF
57%
DDoS Mitigation
34%
IP Reputation
6%
Access Rules
2%
Other
1%
Application owners are increasingly relying on geo location blocks
Given the increase in mitigated traffic from customer defined WAF rules, we thought it would be interesting to dive one level deeper and better understand what customers are blocking and how they are doing it. We can do this by reviewing rule field usage across our WAF Custom Rules to identify common themes. Of course, the data needs to be interpreted correctly, as not all customers have access to all fields as that varies by contract and plan level, but we can still make some inferences based on field “categories”. By reviewing all ~7M WAF Custom Rules deployed across the network and focusing on main groupings only, we get the following field usage distribution:
Field
Used in percentage % of rules
Geolocation fields
40%
HTTP URI
31%
IP address
21%
Other HTTP fields (excluding URI)
34%
Bot Management fields
11%
IP reputation score
4%
Notably, 40% of all deployed WAF Custom Rules use geolocation-related fields to make decisions on how to treat traffic. This is a common technique used to implement business logic or to exclude geographies from which no traffic is expected and helps reduce attack surface areas. While these are coarse controls which are unlikely to stop a sophisticated attacker, they are still efficient at reducing the attack surface.
Another notable observation is the usage of Bot Management related fields in 11% of WAF Custom Rules. This number has been steadily increasing over time as more customers adopt machine learning-based classification strategies to protect their applications.
Old CVEs are still exploited en masse
Contributing ~32% of WAF Managed Rules mitigated traffic overall, HTTP Anomaly is still the most common attack category blocked by the WAF Managed Rules. SQLi moved up to second position, surpassing Directory Traversal with 12.7% and 9.9% respectively.
If we look at the start of April 2023, we notice the DoS category far exceeding the HTTP Anomaly category. Rules in the DoS category are WAF layer 7 HTTP signatures that are sufficiently specific to match (and block) single requests without looking at cross request behavior and that can be attributed to either specific botnets or payloads that cause denial of service (DoS). Normally, as is the case here, these requests are not part of “distributed” attacks, hence the lack of the first “D” for “distributed” in the category name.
Tabular format for reference (top 10 categories):
Source
Percentage %
HTTP Anomaly
32%
SQLi
13%
Directory Traversal
10%
File Inclusion
9%
DoS
9%
XSS
9%
Software Specific
7%
Broken Authentication
6%
Common Injection
3%
CVE
1%
Zooming in, and filtering on the DoS category only, we find that most of the mitigated traffic is attributable to one rule: 100031 / ce02fd… (old WAF and new WAF rule ID respectively). This rule, with a description of “Microsoft IIS – DoS, Anomaly:Header:Range – CVE:CVE-2015-1635” pertains to a CVE dating back to 2015 that affected a number of Microsoft Windows components resulting in remote code execution*. This is a good reminder that old CVEs, even those dating back more than 8 years, are still actively exploited to compromise machines that may be unpatched and still running vulnerable software.
* Due to rule categorisation, some CVE specific rules are still assigned to a broader category such as DoS in this example. Rules are assigned to a CVE category only when the attack payload does not clearly overlap with another more generic category.
Another interesting observation is the increase in Broken Authentication rule matches starting in June. This increase is also attributable to a single rule deployed across all our customers, including our FREE users: “WordPress – Broken Access Control, File Inclusion”. This rule is blocking attempts to access wp-config.php – the WordPress default configuration file which is normally found in the web server document root directory, but of course should never be accessed directly via HTTP.
On a similar note, CISA/CSA recently published a report highlighting the 2022 Top Routinely Exploited Vulnerabilities. We took this opportunity to explore how each CVE mentioned in CISA’s report was reflected in Cloudflare’s own data. The CISA/CSA discuss 12 vulnerabilities that malicious cyber actors routinely exploited in 2022. However, based on our analysis, two CVEs mentioned in the CISA report are responsible for the vast majority of attack traffic we have seen in the wild: Log4J and Atlassian Confluence Code Injection. Our data clearly suggests a major difference in exploit volume between the top two and the rest of the list. The following chart compares the attack volume (in logarithmic scale) of the top 6 vulnerabilities of the CISA list according to our logs.
Bot traffic insights
Cloudflare’s Bot Management continues to see significant investment as the addition of JavaScript Verified URLs for greater protection against browser-based bots, Detection IDs are now available in Custom Rules for additional configurability, and an improved UI for easier onboarding. For self-serve customers, we’ve added the ability to “Skip” Super Bot Fight Mode rules and support for WordPress Loopback requests, to better integrate with our customers’ applications and give them the protection they need.
Our confidence in the Bot Management classification output remains very high. If we plot the bot scores across the analyzed time frame, we find a very clear distribution, with most requests either being classified as definitely bot (score below 30) or definitely human (score greater than 80), with most requests actually scoring less than 2 or greater than 95. This equates, over the same time period, to 33% of traffic being classified as automated (generated by a bot). Over longer time periods we do see the overall bot traffic percentage stable at 29%, and this reflects the data shown on Cloudflare Radar.
On average, more than 10% of non-verified bot traffic is mitigated
Compared to the last report, non-verified bot HTTP traffic mitigation is currently on a downward trend (down 6 percentage points). However, the Bot Management field usage within WAF Custom Rules is non negligible, standing at 11%. This means that there are more than 700k WAF Custom Rules deployed on Cloudflare that are relying on bot signals to perform some action. The most common field used is cf.client.bot, an alias to cf.bot_management.verified_bot which is powered by our list of verified bots and allows customers to make a distinction between “good” bots and potentially “malicious” non-verified ones.
Enterprise customers have access to the more powerful cf.bot_management.score which provides direct access to the score computed on each request, the same score used to generate the bot score distribution graph in the prior section.
The above data is also validated by looking at what Cloudflare service is mitigating unverified bot traffic. Although our DDoS mitigation system is automatically blocking HTTP traffic across all customers, this only accounts for 13% of non-verified bot mitigations. On the other hand, WAF, and mostly customer defined rules, account for 77% of such mitigations, much higher than mitigations across all traffic (57%) discussed at the start of the report. Note that Bot Management is specifically called out but refers to our “default” one-click rules, which are counted separately from the bot fields used in WAF Custom Rules.
Tabular format for reference:
Source
Percentage %
WAF
77%
DDoS Mitigation
13%
IP reputation
5%
Access Rules
3%
Other
1%
API traffic insights
58% of dynamic (non cacheable) traffic is API related
The growth of overall API traffic observed by Cloudflare is not slowing down. Compared to last quarter, we are now seeing 58% of total dynamic traffic be classified as API related. This is a 3 percentage point increase as compared to Q1.
Our investment in API Gateway is also following a similar growth trend. Over the last quarter we have released several new API security features.
First, we’ve made API Discovery easier to use with a new inbox view. API Discovery inventories your APIs to prevent shadow IT and zombie APIs, and now customers can easily filter to show only new endpoints found by API Discovery. Saving endpoints from API Discovery places them into our Endpoint Management system.
Next, we’ve added a brand new API security feature offered only at Cloudflare: the ability to control API access by client behavior. We call it Sequence Mitigation. Customers can now create positive or negative security models based on the order of API paths accessed by clients. You can now ensure that your application’s users are the only ones accessing your API instead of brute-force attempts that ignore normal application functionality. For example, in a banking application you can now enforce that access to the funds transfer endpoint can only be accessed after a user has also accessed the account balance check endpoint.
We’re excited to continue releasing API security and API management features for the remainder of 2023 and beyond.
65% of global API traffic is generated by browsers
The percentage of API traffic generated by browsers has remained very stable over the past quarter. With this statistic, we are referring to HTTP requests that are not serving HTML based content that will be directly rendered by the browser without some preprocessing, such as those more commonly known as AJAX calls which would normally serve JSON based responses.
HTTP Anomalies are the most common attack vector on API endpoints
Just like last quarter, HTTP Anomalies remain the most common mitigated attack vector on API traffic. SQLi injection attacks, however, are non negligible, contributing approximately 11% towards the total mitigated traffic, closely followed by XSS attacks, at around 9%.
Tabular format for reference (top 5):
Source
Percentage %
HTTP Anomaly
64%
SQLi
11%
XSS
9%
Software Specific
5%
Command Injection
4%
Looking forward
As we move our application security report to a quarterly cadence, we plan to deepen some of the insights and to provide additional data from some of our newer products such as Page Shield, allowing us to look beyond HTTP traffic, and explore the state of third party dependencies online.
Stay tuned and keep an eye on Cloudflare Radar for more frequent application security reports and insights.
Border Gateway Protocol (BGP) is the de facto inter-domain routing protocol used on the Internet. It enables networks and organizations to exchange reachability information for blocks of IP addresses (IP prefixes) among each other, thus allowing routers across the Internet to forward traffic to its destination. BGP was designed with the assumption that networks do not intentionally propagate falsified information, but unfortunately that’s not a valid assumption on today’s Internet.
Malicious actors on the Internet who control BGP routers can perform BGP hijacks by falsely announcing ownership of groups of IP addresses that they do not own, control, or route to. By doing so, an attacker is able to redirect traffic destined for the victim network to itself, and monitor and intercept its traffic. A BGP hijack is much like if someone were to change out all the signs on a stretch of freeway and reroute automobile traffic onto incorrect exits.
You can learn more about BGP and BGP hijacking and its consequences in our learning center.
At Cloudflare, we have long been monitoring suspicious BGP anomalies internally. With our recent efforts, we are bringing BGP origin hijack detection to the Cloudflare Radar platform, sharing our detection results with the public. In this blog post, we will explain how we built our detection system and how people can use Radar and its APIs to integrate our data into their own workflows.
What is BGP origin hijacking?
Services and devices on the Internet locate each other using IP addresses. Blocks of IP addresses are called an IP prefix (or just prefix for short), and multiple prefixes from the same organization are aggregated into an autonomous system (AS).
Using the BGP protocol, ASes announce which routes can be imported or exported to other ASes and routers from their routing tables. This is called the AS routing policy. Without this routing information, operating the Internet on a large scale would quickly become impractical: data packets would get lost or take too long to reach their destinations.
During a BGP origin hijack, an attacker creates fake announcements for a targeted prefix, falsely identifying an autonomous systems (AS) under their control as the origin of the prefix.
In the following graph, we show an example where AS 4 announces the prefix P that was previously originated by AS 1. The receiving parties, i.e. AS 2 and AS 3, accept the hijacked routes and forward traffic toward prefix P to AS 4 instead.
As you can see, the normal and hijacked traffic flows back in the opposite direction of the BGP announcements we receive.
If successful, this type of attack will result in the dissemination of the falsified prefix origin announcement throughout the Internet, causing network traffic previously intended for the victim network to be redirected to the AS controlled by the attacker. As an example of a famous BGP hijack attack, in 2018 someone was able to convince parts of the Internet to reroute traffic for AWS to malicious servers where they used DNS to redirect MyEtherWallet.com, a popular crypto wallet, to a hacked page.
Prevention mechanisms and why they’re not perfect (yet)
The key difficulty in preventing BGP origin hijacks is that the BGP protocol itself does not provide a mechanism to validate the announcement content. In other words, the original BGP protocol does not provide any authentication or ownership safeguards; any route can be originated and announced by any random network, independent of its rights to announce that route.
To address this problem, operators and researchers have proposed the Resource Public Key Infrastructure (RPKI) to store and validate prefix-to-origin mapping information. With RPKI, operators can prove the ownership of their network resources and create ROAs, short for Route Origin Authorisations, cryptographically signed objects that define which Autonomous System (AS) is authorized to originate a specific prefix.
Cloudflare committed to support RPKI since the early days of the RFC. With RPKI, IP prefix owners can store and share the ownership information securely, and other operators can validate BGP announcements by checking the prefix origin to the information stored on RPKI. Any hijacking attempt to announce an IP prefix with an incorrect origin AS will result in invalid validation results, and such invalid BGP messages will be discarded. This validation process is referred to as route origin validation (ROV).
In order to further advocate for RPKI deployment and filtering of RPKI invalid announcements, Cloudflare has been providing a RPKI test service, Is BGP Safe Yet?, allowing users to test whether their ISP filters RPKI invalid announcements. We also provide rich information with regard to the RPKI status of individual prefixes and ASes at https://rpki.cloudflare.com/.
However, the effectiveness of RPKI on preventing BGP origin hijacks depends on two factors:
The ratio of prefix owners register their prefixes on RPKI;
The ratio of networks performing route origin validation.
Unfortunately, neither ratio is at a satisfactory level yet. As of today, July 27, 2023, only about 45% of the IP prefixes routable on the Internet are covered by some ROA on RPKI. The remaining prefixes are highly vulnerable to BGP origin hijacks. Even for the 45% prefix that are covered by some ROA, origin hijack attempts can still affect them due to the low ratio of networks that perform route origin validation (ROV). Based on our recent study, only 6.5% of the Internet users are protected by ROV from BGP origin hijacks.
Despite the benefits of RPKI and RPKI ROAs, their effectiveness in preventing BGP origin hijacks is limited by the slow adoption and deployment of these technologies. Until we achieve a high rate of RPKI ROA registration and RPKI invalid filtering, BGP origin hijacks will continue to pose a significant threat to the daily operations of the Internet and the security of everyone connected to it. Therefore, it’s also essential to prioritize developing and deploying BGP monitoring and detection tools to enhance the security and stability of the Internet's routing infrastructure.
Design of Cloudflare’s BGP hijack detection system
Our system comprises multiple data sources and three distinct modules that work together to detect and analyze potential BGP hijack events: prefix origin change detection, hijack detection and the storage and notification module.
The Prefix Origin Change Detection module provides the data, the Hijack Detection module analyzes the data, and the Alerts Storage and Delivery module stores and provides access to the results. Together, these modules work in tandem to provide a comprehensive system for detecting and analyzing potential BGP hijack events.
Deciding where to forward traffic based on the reachability information received.
The reachability change information is encoded in BGP update messages while the routing decision results are encoded as a route information base (RIB) on the routers, also known as the routing table.
In our origin hijack detection system, we focus on investigating BGP update messages that contain changes to the origin ASes of any IP prefixes. There are two types of BGP update messages that could indicate prefix origin changes: announcements and withdrawals.
Announcements include an AS-level path toward one or more prefixes. The path tells the receiving parties through which sequence of networks (ASes) one can reach the corresponding prefixes. The last hop of an AS path is the origin AS. In the following diagram, AS 1 is the origin AS of the announced path.
Withdrawals, on the other hand, simply inform the receiving parties that the prefixes are no longer reachable.
Both types of messages are stateless. They inform us of the current route changes, but provide no information about the previous states. As a result, detecting origin changes is not as straightforward as one may think. Our system needs to keep track of historical BGP updates and build some sort of state over time so that we can verify if a BGP update contains origin changes.
We didn't want to deal with a complex system like a database to manage the state of all the prefixes we see resulting from all the BGP updates we get from them. Fortunately, there's this thing called prefix trie in computer science that you can use to store and look up string-indexed data structures, which is ideal for our use case. We ended up developing a fast Rust-based custom IP prefix trie that we use to hold the relevant information such as the origin ASN and the AS path for each IP prefix and allows information to be updated based on BGP announcements and withdrawals.
The example figure below shows an example of the AS path information for prefix 192.0.2.0/24 stored on a prefix trie. When updating the information on the prefix trie, if we see a change of origin ASN for any given prefix, we record the BGP message as well as the change and create an Origin Change Signal.
The prefix origin changes detection module collects and processes live-stream and historical BGP data from various sources. For live streams, our system applies a thin layer of data processing to translate BGP messages into our internal data structure. At the same time, for historical archives, we use a dedicated deployment of the BGPKIT broker and parser to convert MRT files from RouteViews and RIPE RIS into BGP message streams as they become available.
After the data is collected, consolidated and normalized it then creates, maintains and destroys the prefix tries so that we can know what changed from previous BGP announcements from the same peers. Based on these calculations we then send enriched messages downstream to be analyzed.
Hijack detection module
Determining whether BGP messages suggest a hijack is a complex task, and no common scoring mechanism can be used to provide a definitive answer. Fortunately, there are several types of data sources that can collectively provide a relatively good idea of whether a BGP announcement is legitimate or not. These data sources can be categorized into two types: inter-AS relationships and prefix-origin binding.
The inter-AS relationship datasets include AS2org and AS2rel datasets from CAIDA/UCSD, AS2rel datasets from BGPKIT, AS organization datasets from PeeringDB, and per-prefix AS relationship data built at Cloudflare. These datasets provide information about the relationship between autonomous systems, such as whether they are upstream or downstream from one another, or if the origins of any change signal belong to the same organization.
Prefix-to-origin binding datasets include live RPKI validated ROA payload (VRP) from the Cloudflare RPKI portal, daily Internet Routing Registry (IRR) dumps curated and cleaned up by MANRS, and prefix and AS bogon lists (private and reserved addresses defined by RFC 1918, RFC 5735, and RFC 6598). These datasets provide information about the ownership of prefixes and the ASes that are authorized to originate them.
By combining all these data sources, it is possible to collect information about each BGP announcement and answer questions programmatically. For this, we have a scoring function that takes all the evidence gathered for a specific BGP event as the input and runs that data through a sequence of checks. Each condition returns a neutral, positive, or negative weight that keeps adding to the final score. The higher the score, the more likely it is that the event is a hijack attempt.
The following diagram illustrates this sequence of checks:
As you can see, for each event, several checks are involved that help calculate the final score: RPKI, Internet Routing Registry (IRR), bogon prefixes and ASNs lists, AS relationships, and AS path.
Our guiding principles are: if the newly announced origins are RPKI or IRR invalid, it’s more likely that it’s a hijack, but if the old origins are also invalid, then it’s less likely. We discard events about private and reserved ASes and prefixes. If the new and old origins have a direct business relationship, then it’s less likely that it’s a hijack. If the new AS path indicates that the traffic still goes through the old origin, then it’s probably not a hijack.
Signals that are deemed legitimate are discarded, while signals with a high enough confidence score are flagged as potential hijacks and sent downstream for further analysis.
It's important to reiterate that the decision is not binary but a score. There will be situations where we find false negatives or false positives. The advantage of this framework is that we can easily monitor the results, learn from additional datasets and conduct the occasional manual inspection, which allows us to adjust the weights, add new conditions and continue improving the score precision over time.
Aggregating BGP hijack events
Our BGP hijack detection system provides fast response time and requires minimal resources by operating on a per-message basis.
However, when a hijack is happening, the number of hijack signals can be overwhelming for operators to manage. To address this issue, we designed a method to aggregate individual hijack messages into BGP hijack events, thereby reducing the number of alerts triggered.
An event aggregates BGP messages that are coming from the same hijacker related to prefixes from the same victim. The start date is the same as the date of the first suspicious signal. To calculate the end of an event we look for one of the following conditions:
A BGP withdrawn message for the hijacked prefix: regardless of who sends the withdrawal, the route towards the prefix is no longer via the hijacker, and thus this hijack message is considered finished.
A new BGP announcement message with the previous (legitimate) network as the origin: this indicates that the route towards the prefix is reverted to the state before the hijack, and the hijack is therefore considered finished.
If all BGP messages for an event have been withdrawn or reverted, and there are no more new suspicious origin changes from the hijacker ASN for six hours, we mark the event as finished and set the end date.
Hijack events can capture both small-scale and large-scale attacks. Alerts are then based on these aggregated events, not individual messages, making it easier for operators to manage and respond appropriately.
Alerts, Storage and Notifications module
This module provides access to detected BGP hijack events and sends out notifications to relevant parties. It handles storage of all detected events and provides a user interface for easy access and search of historical events. It also generates notifications and delivers them to the relevant parties, such as network administrators or security analysts, when a potential BGP hijack event is detected. Additionally, this module can build dashboards to display high-level information and visualizations of detected events to facilitate further analysis.
Lightweight and portable implementation
Our BGP hijack detection system is implemented as a Rust-based command line application that is lightweight and portable. The whole detection pipeline runs off a single binary application that connects to a PostgreSQL database and essentially runs a complete self-contained BGP data pipeline. And if you are wondering, yes, the full system, including the database, can run well on a laptop.
The runtime cost mainly comes from maintaining the in-memory prefix tries for each full-feed router, each costing roughly 200 MB RAM. For the beta deployment, we use about 170 full-feed peers and the whole system runs well on a single 32 GB node with 12 threads.
Under the “Security & Attacks” section of the Cloudflare Radar for both global and ASN view, we now display the BGP origin hijacks table. In this table, we show a list of detected potential BGP hijack events with the following information:
The detected and expected origin ASes;
The start time and event duration;
The number of BGP messages and route collectors peers that saw the event;
The announced prefixes;
Evidence tags and confidence level (on the likelihood of the event being a hijack).
For each BGP event, our system generates relevant evidence tags to indicate why the event is considered suspicious or not. These tags are used to inform the confidence score assigned to each event. Red tags indicate evidence that increases the likelihood of a hijack event, while green tags indicate the opposite.
For example, the red tag "RPKI INVALID" indicates an event is likely a hijack, as it suggests that the RPKI validation failed for the announcement. Conversely, the tag "SIBLING ORIGINS" is a green tag that indicates the detected and expected origins belong to the same organization, making it less likely for the event to be a hijack.
Users can now access the BGP hijacks table in the following ways:
Global view under Security & Attacks page without location filters. This view lists the most recent 150 detected BGP hijack events globally.
When filtered by a specific ASN, the table will appear on Overview, Traffic, and Traffic & Attacks tabs.
Cloudflare Radar API
We also provide programmable access to the BGP hijack detection results via the Cloudflare Radar API, which is freely available under CC BY-NC 4.0 license. The API documentation is available at the Cloudflare API portal.
The following curl command fetches the most recent 10 BGP hijack events relevant to AS64512.
curl -X GET "https://api.cloudflare.com/client/v4/radar/bgp/hijacks/events?invlovedAsn=64512&format=json&per_page=10" \
-H "Authorization: Bearer <API_TOKEN>"
Users can further filter events with high confidence by specifying the minConfidence parameter with a 0-10 value, where a higher value indicates higher confidence of the events being a hijack. The following example expands on the previous example by adding the minimum confidence score of 8 to the query:
curl -X GET "https://api.cloudflare.com/client/v4/radar/bgp/hijacks/events?invlovedAsn=64512&format=json&per_page=10&minConfidence=8" \
-H "Authorization: Bearer <API_TOKEN>"
As we continue improving Cloudflare Radar, we are planning to introduce additional Internet routing and security data. For example, Radar will soon get a dedicated routing section to provide digestible BGP information for given networks or regions, such as distinct routable prefixes, RPKI valid/invalid/unknown routes, distribution of IPv4/IPv6 prefixes, etc. Our goal is to provide the best data and tools for routing security to the community, so that we can build a better and more secure Internet together.
Routing is one of the most critical operations of the Internet. Routing decides how and where the Internet traffic should flow from the source to the destination, and can be categorized into two major types: intra-domain routing and inter-domain routing. Intra-domain routing handles making decisions on how individual packets should be routed among the servers and routers within an organization/network. When traffic reaches the edge of a network, the inter-domain routing kicks in to decide what the next hop is and forward the traffic along to the corresponding networks. Border Gateway Protocol (BGP) is the de facto inter-domain routing protocol used on the Internet.
Today, we are introducing another section on Cloudflare Radar: the Routing page, which focuses on monitoring the BGP messages exchanged to extract and present insights on the IP prefixes, individual networks, countries, and the Internet overall. The new routing data allows users to quickly examine routing status of the Internet, examine secure routing protocol deployment for a country, identify routing anomalies, validate IP block reachability and much more from globally distributed vantage points.
It’s a detailed view of how the Internet itself holds together.
Collecting routing statistics
The Internet consists of tens of thousands of interconnected organizations. Each organization manages its own internal networking infrastructure autonomously, and is referred to as an autonomous system (AS). ASes establish connectivity among each other and exchange routing information via BGP messages to form the current Internet.
When we open the Radar Routing page the “Routing Statistics” block provides a quick glance on the sizes and status of an autonomous system (AS), a country, or the Internet overall. The routing statistics component contains the following count information:
The number of ASes on the Internet or registered from a given country;
The number of distinct prefixes and the routes toward them observed on the global routing table, worldwide, by country, or by AS;
The number of routes categorized by Resource Public Key Infrastructure (RPKI) validation results (valid, invalid, or unknown).
We also show the breakdown of these numbers for IPv4 and IPv6 separately, so users may have a better understanding of such information with respect to different IP protocols.
For a given network, we also show the BGP announcements volume chart for the past week as well as other basic information like network name, registration country, estimated user count, and sibling networks.
Identifying routing anomalies
BGP as a routing protocol suffers from a number of security weaknesses. In the new Routing page we consolidate the BGP route leaks and BGP hijacks detection results in one single place, showing the relevant detected events for any given network or globally.
The BGP Route Leaks table shows the detected BGP route leak events. Each entry in the table contains the information about the related ASes of the leak event, start and end time, as well as other numeric statistics that reflect the scale and impact of the event. The BGP Origin Hijacks table shows the detected potential BGP origin hijacks. Apart from the relevant ASes, time, and impact information, we also show the key evidence that we collected for each event to provide additional context on why and how likely one event being a BGP hijack.
With this release, we introduce another anomaly detection: RPKI Invalid Multiple Origin AS (MOAS) is one type of routing conflict where multiple networks (ASes) originate the same IP prefixes at the same time, which goes against the best practice recommendation. Our system examines the most recent global routing tables and identifies MOASes on the routing tables. With the help of Resource Public Key Infrastructure (RPKI), we can further identify MOAS events that have origins that were proven RPKI invalid, which are less likely to be legitimate cases. Users and operators can quickly identify such anomalies relevant to the networks of interest and take actions accordingly.
The Routing page will be the permanent home for all things BGP and routing data in the future; we will gradually introduce more anomaly detections and improve our pipeline to provide more security insights.
Examining routing assets and connectivity
Apart from examining the overall routing statistics and anomalies, we also gather information on the routing assets (IP prefixes for a network and networks for a country) and networks’ connectivity.
Tens of thousands autonomous systems (ASes) connect to each other to form the current Internet. The ASes differ in size and operate in different geolocations. Generally, larger networks are more well-connected and considered “upstream” and smaller networks are less connected and considered “downstream” on the Internet. Below is an example connectivity diagram showing how two smaller networks may connect to each other. AS1 announces its IP prefixes to its upstream providers and propagates upwards until it reaches the large networks AS3 and AS4, and then the route propagates downstream to smaller networks until it reaches AS6.
In the routing page, we examine what IP prefixes any given AS originates, as well as the interconnections among ASes. We show the full list of IP prefixes originated for any given AS, including the breakdown lists by RPKI validation status. We also show the detected connectivity among other ASes categorized into upstream, downstream and peering connections. Users can easily search for any ASes upstream, downstream, or peers.
For a given country, we show the full list of networks registered in the country, sorted by the number of IP prefixes originated from the corresponding networks. This allows users to quickly glance and find networks from any given country. The table is also searchable by network name or AS number.
Routing data API access
Like all the other data, the Cloudflare Radar Routing data is powered by our developer API. The data API is freely available under Creative Commons Attribution-NonCommercial 4.0 (CC BY-NC 4.0) license. In the following table, we list all of our data APIs available at launch. As we improve the routing section, we will introduce more APIs in the future.
Example 1: lookup origin AS for a given prefix with cURL
The Cloudflare Radar prefix-to-origin mapping API returns the matching prefix-origin pairs observed on the global routing tables, allowing users to quickly examine the networks that originate a given prefix or listing all the prefixes a network originates.
In this example, we ask of “which network(s) originated the prefix 1.1.1.0/24?” using the following cURL command:
The returned JSON result shows that Cloudflare (AS13335) originates the prefix 1.1.1.0/24 and it is a RPKI valid origin. It also returns the meta information such as the UTC timestamp of the query as well as when the dataset is last updated (data_time field).
Example 2: integrate Radar API into command-line tool
BGPKIT monocle is an open-source command-line application that provides multiple utility functions like searching BGP messages on public archives, network lookup by name, RPKI validation status for a given IP prefix, etc.
By integrating Cloudflare Radar APIs into monocle, users can now quickly lookup routing statistics or prefix-to-origin mapping by running monocle radar stats [QUERY] and monocle radar pfx2as commands.
Cloudflare operates in more than 300 cities in over 100 countries, where we interconnect with over 12,000 network providers in order to provide a broad range of services to millions of customers. The breadth of both our network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the impact of Internet disruptions.
As we have noted in the past, this post is intended as a summary overview of observed disruptions, and is not an exhaustive or complete list of issues that have occurred during the quarter.
Government directed
Late spring often marks the start of a so-called “exam season” in several Middle Eastern and African countries, where students sit for a series of secondary school exams. In an attempt to prevent cheating on these exams, governments in the countries have taken to implementing wide-scale Internet shutdowns covering time periods just before and during the exams. We have covered these shutdowns in the past, including Sudan and Syria in 2021 and Syria, Sudan, and Algeria in 2022. This year, we saw governments in Iraq, Algeria, and Syria taking such actions.
Iraq
In the weeks prior to the start of this year’s shutdowns, it was reported that the Iraqi Ministry of Communications had announced it had refused a request from the Ministry of Education to impose an Internet shutdown during the exams as part of efforts to prevent cheating. Unfortunately, this refusal was short-lived, with shutdowns ultimately starting two weeks later.
In Iraq, two sets of shutdowns were observed: one impacted networks nationwide, except for the Kurdistan Region, while the other impacted networks within the Kurdistan Region. The former set of shutdowns were related to 9th and 12th grade exams, and were scheduled to occur from June 1 through July 15, between 04:00 and 08:00 local time (01:00 – 05:00 UTC). The graphs below show that during June, shutdowns took place on June 1, 4, 6, 8, 11, 13, 15, 17, 21, 22, 24, 25, and 26, resulting in significant disruptions to Internet connectivity. The shutdowns were implemented across a number of network providers, including AS203214 (HulumTele), AS59588 (Zain), AS199739 (Earthlink), AS203735 (Net Tech), AS51684 (Asiacell), and AS58322 (Halasat). The orange-highlighted areas in the graphs below show traffic on each network provider dropping to zero during the shutdowns.
As noted above, exam-related Internet shutdowns were also implemented in the Kurdistan region of Iraq. One report quoted the Minister of Education of the Kurdistan Regional Government as stating "The Internet will be turned off as needed during exams, but just like in previous years, the period of the Internet shutdown will not be lengthy, but rather short.” To that end, the observed shutdowns generally lasted about two hours, occurring between 06:30 and 08:30 local time (03:30 – 05:30 UTC) on June 3, 6, 10, 13, 17, and 24. The graphs below show the impact across three network providers in the region: AS21277 (Newroz Telecom), AS48492 (IQ Online), and AS59625 (KorekTel).
2023 marks the sixth year that Algeria has disrupted Internet connectivity to prevent cheating during nationwide exams. In 2022, we noted that “it appears that the Algerian government has shifted to a content blocking-based approach, instead of a wide-scale Internet shutdown.” It appears that the same approach was taken this year, as we again observed two nominal drops in traffic during each of the exam days, rather than a complete loss of traffic. These traffic shifts were observed on mobile network providers AS33779 (Ooredoo/Wataniya), AS327931 (Djezzy/Optimum), and AS327712 (Mobilis/Telecom Algeria). The first disruption takes place between 08:00 – 12:00 local time (07:00 – 11:00 UTC), with the second occurring between 14:00 – 17:00 local time (13:00 – 16:00 UTC).
Syria
After implementing four exam-related Internet shutdowns in 2022, this year saw just two. On June 25 and 26, Internet shutdowns took place between 05:00 – 08:30 local time (02:00 – 05:30 UTC). Syrian Telecom (AS29256), the government-affiliated telecommunications company, informed subscribers in a Facebook post that the Internet would be cut off at the request of the Ministry of Education.
Senegal
In Senegal, violent protests over the sentencing of opposition leader Ousmane Sonko to jail led the government to restrict access to platforms including WhatsApp, Facebook, Twitter, Instagram, TikTok, Telegram, Signal, and YouTube. On June 4, the Senegal Ministry of Communication issued a statement temporarily suspending mobile Internet access, with a followup statement on June 6 ending the suspension. These disruptions to mobile Internet access were visible on two network providers within the country: AS37196 (Sudatel Senegal) and AS37649 (Tigo/Free).
As shown in the graphs below, the shutdowns on Sudatel Senegal occurred from 15:00 local time on June 3 through 01:00 local time on June 5, and then again from 13:00 local time on June 5 until 01:00 local time on June 6. The three shutdowns seen on Tigo/Free took place between 15:30 – 19:00 local time on June 3, from 13:45 local time on June 4 until 02:05 local time on June 5, and from 13:05 local time on June 5 through 01:00 local time on June 6. (Senegal is UTC+0, so the local times are the same as UTC.)
Mauritania
In Mauritania, authorities cut off mobile Internet services after protests over the death of a young man in police custody. The shutdown began at 23:00 local time on May 30, and lasted six days, with connectivity returning at 23:00 local time on June 6. (Mauritania is UTC+0, so the local times are the same as UTC.) The graphs below show a near complete loss of Internet traffic during that period from AS37541 (Chinguitel) and AS37508 (Mattel), two mobile network providers within the country.
Pakistan
On May 9, Imran Khan, former Prime Minister of Pakistan was arrested on corruption charges. Following the arrest, violent protests erupted in several cities, leading the government of Pakistan to order the shutdown of mobile Internet services, as well as the blocking of several social media platforms. The figures below show the impact of the ordered shutdown to traffic on four mobile network providers within the country: AS24499 (Telenor Pakistan), AS59257 (China Mobile Pak), AS45669 (Mobilink/Jazz), and AS56167 (Ufone/PTML). The ordered shutdown caused a complete loss of Internet traffic from these networks that started at 22:00 local time (17:00 UTC) on May 9 at Telenor and China Mobile Pakistan, 18:00 local time (13:00 UTC) on Mobilink/Jazz, and 01:00 local time on May 10 (20:00 UTC on May 9) at Ufone/PTML. Traffic was restored at 22:00 local time (17:00 UTC) on May 12.
Looking at Cloudflare Radar’s recently launchedInternet Quality page for Pakistan during the duration of the shutdown, we observed that median latency within Pakistan dropped slightly after mobile networks were shut down, shown in the graph below. Prior to the shutdown, median latency (as observed to Cloudflare and a set of other providers) was in the 90-100ms range, while afterward, it averaged closer to 75ms. This may be a result of users shifting to lower latency fixed broadband connections – several fixed broadband providers in the country experienced increased traffic volumes while the mobile networks were unavailable.
Additional details about the mobile network shutdowns, content blocking, and the impact at an administrative unit and city level can be found in our May 12 blog post Cloudflare’s view of Internet disruptions in Pakistan.
India
Internet shutdowns are unfortunately frequent in India, with digital rights organization Access Now reporting at least 84 shutdowns within the country in 2022. The shutdowns are generally implemented at a more local level, and often last for a significant amount of time. One such shutdown took place in the northeastern Indian state of Manipur starting on May 3 after the escalation of ethnic conflict, and was reportedly intended to “thwart the design and activities of anti-national and anti-social elements… by stopping the spread of disinformation and false rumours'' and the likelihood of “serious disturbances to the entire peaceful coexistence of the communities and maintenance of public order”. Mobile data services were initially suspended for a five-day period, with the suspension continually extended through additional templated orders issued every five days.
The graphs below show the impact of the ordered shutdown to traffic from two major network providers in Manipur. Traffic from both AS45609 (Airtel) and AS9829 (BSNL) fell significantly around 18:00 local time (12:30 UTC) on May 4. Traffic on Airtel has remained low, and continued to drop further through the end of June. Traffic on BSNL showed slight signs of recovery starting in early June, but remains extremely low.
The shutdown order remains in place as of the time of this writing (late July).
Severe weather
Guam
On May 24, “Super Typhoon” Mawar wreaked havoc on the US territory of Guam, causing widespread physical damage after it made landfall, taking down trees, buildings, power lines, and communications infrastructure across the island. One result of this damage was a significant disruption to Internet connectivity, as shown in the country-level graph below. Restoration efforts started almost immediately, with Guam Power Authority, Docomo Pacific, and GTA Teleguam all posting regular status updates on their websites and/or social media accounts.
Among the two Internet providers, GTA Teleguam (AS9246) was largely able to complete service restoration in June, with traffic returning to pre-storm levels around June 17, as seen in the graph below. In fact, in a June 20 Facebook post they noted that “As of today, a majority of our wireless network cell sites are operational.” However, recovery at Docomo Pacific (AS3605) is taking significantly longer. The graph below shows that as of the end of June, traffic remained significantly below pre-storm levels.
Cable damage
Bolivia
On June 19, COTAS, a Bolivian telecommunications company, posted an update on their Facebook page that alerted users that a fiber optic cable had been cut in the town of Pongo. As seen in the graphs below, this cut significantly disrupted Internet connectivity across COTAS and two other network providers in the country: AS25620 (COTAS), AS27839 (Comteco), and AS52495 (Cotel) between 13:00 – 18:00 local time (17:00 – 22:00 UTC).
The Gambia
Gamtel, the state telecommunications company in The Gambia, notified subscribers via a Twitter post on June 7 of a localized fiber cut, and then of additional cable cuts on June 8. These fiber cuts disrupted Internet connectivity on AS25250 (Gamtel) between 14:00 local time on June 7 and 00:00 local time on June 9, with traffic volumes down as much as 80% as compared to the previous period. (The Gambia is UTC+0, so the local times are the same as UTC.)
Philippines
An advisory posted on Twitter by Philippines telecommunications provider PLDT at 18:43 local time (10:43 UTC) on June 5 stated “One of our submarine cable partners confirms a loss in some of its internet bandwidth capacity, and thus causing slower Internet browsing. We are working with our partners to provide alternate capacity that would restore the browsing experience in the next few hours.” The traffic graph below shows a minor disruption to Internet traffic for AS9299 (PLDT) starting around 14:00 local time (06:00 UTC), and the “slower Internet browsing” noted by PLDT is evident in the Internet quality graphs below, with increased latency and decreased bandwidth evident around that same time. PLDT stated in a subsequent tweet that as of 06:22 local time on June 6 (22:22 UTC on June 5), “Our submarine cable partner confirms supplementing additional capacity, restoring browser experience.”
Power outages
Curaçao
Aqualectra is the primary utility company in Curaçao, providing water and power services. On June 8, they posted a series of alerts to their Facebook page (1, 2, 3, 4) regarding a power outage impacting “all neighborhoods”, caused by a malfunction in one of the main power cables connected to the substation at Parera. This loss of power impacted Internet connectivity on the island, with a significant loss of traffic observed at a country level, as seen in the graph below, as well as across several Internet service providers, including AS11081 (UTS), AS52233 (Columbus Communications), and AS27660 (Curaçao Telecom). A followup Facebook post dated 01:25 local time on June 9 (05:25 UTC) confirmed the restoration of power to all neighborhoods.
Portugal
A power outage at an Equinix data center in Prior Velho (near Lisbon) on the afternoon of June 6 affected local utilities, banking services, and court networks, according to published reports (1, 2). Portuguese Internet service provider MEO was also impacted by the power outage, which caused a drop in traffic for AS3243 (MEO-RESIDENCIAL) and AS15525 (MEO-EMPRESAS), seen in the graphs below. The disruptions caused by the power outage also impacted connectivity quality within Portugal, as the Radar Internet quality graphs below highlight – a concurrent drop in bandwidth and increase in latency is visible, indicating that end users likely experienced poorer performance during that period of time.
Botswana
A countrywide power outage in Botswana on May 19 caused an Internet disruption that lasted about 90 minutes, from 10:45 until 12:15 local time (08:45 – 10:15 UTC), visible in the graph below. A tweet from Botswana Power Corporation provided public notice of the incident, but did not include a root cause.
Barbados
On April 4, The Barbados Light & Power Company tweeted an “Outage Notice”, stating “We are aware that our customers across the island are currently without electricity.” Posted at 11:46 local time (15:46 UTC), the notice comes shortly after a significant drop in traffic was observed country-wide, indicating that the power outage also impacted Internet connectivity across the country. After posting several additional updates throughout the day, a final update posted at 18:00 local time (22:00 UTC) indicated that power had been restored to 100% of impacted customers. The graph below shows that traffic took several additional hours to return to normal levels. (Note that the orange highlighting in the graph represents the duration of the disruption, and the red shading is related to an internal data collection issue.)
Technical problems
Namibia
A seven-hour Internet disruption observed in Namibia on June 15 and 16 was caused by unspecified “technical challenges” faced by Telecom Namibia. According to a tweet from the provider, “Telecom Namibia experienced technical challenges on its fixed and mobile data services on Thursday leading to intermittent Internet connectivity.” The impact of these challenges is visible in both the country- and network-level traffic graphs below.
Solomon Islands
Unspecified “technical reasons” also disrupted mobile Internet connectivity for Our Telekom customers in the Solomon Islands on April 26 and 27. An April 26 Facebook post from Our Telekom simply stated “Our mobile data network is currently down due to technical reasons.” The graphs below show a significant drop in traffic for AS45891 (Our Telekom/SBT) between 06:30 local time on April 27 (19:30 UTC on April 26) and 17:00 local time on April 27 (06:00 UTC). The loss of mobile traffic from Our Telekom also impacted traffic at a country level, as the graph shows a similar disruption for the Solomon Islands.
SpaceX Starlink
With an increasingly global service footprint, disruptions observed on SpaceX Starlink potentially impact users across multiple countries around the world. Just before midnight UTC on April 7, Internet traffic seen from AS14593 (SpaceX-Starlink) began to decline significantly. The disruption was short-lived, with traffic returning to expected levels within two hours. According to a Twitter post from Elon Musk, CEO of SpaceX, the problem was “Caused by expired ground station cert” (an expired digital certificate associated with one or more Starlink ground stations, likely preventing communication between the satellite constellation and the ground station(s)).
Madagascar
In Madagascar, a “problem with the backbone”, reported by Telma Madagascar, caused a loss of as much as two-thirds of Internet traffic between 09:15 – 14:00 local time (06:15 – 11:00 UTC) on April 7. The graphs below show that the backbone issue disrupted traffic at a national level, as well as for AS37054 (Telma Madagascar).
United Kingdom
On April 4, UK Internet provider Virgin Media suffered multiple service disruptions that impacted Internet connectivity for broadband customers. The first outage started just before 01:00 local time (midnight UTC)l, lasting until approximately 09:00 local time (08:00 UTC). The second outage started around 16:00 local time (15:00 UTC), with traffic volumes going up and down over the next several hours before appearing to stabilize around 21:30 local time (20:30 UTC).
Virgin Media’s Twitter account acknowledged the early morning disruption several hours after it began, posting “We’re aware of an issue that is affecting broadband services for Virgin Media customers as well as our contact centres. Our teams are currently working to identify and fix the problem as quickly as possible and we apologise to those customers affected.” A subsequent post after service restoration noted “We’ve restored broadband services for customers but are closely monitoring the situation as our engineers continue to investigate. We apologise for any inconvenience caused.”
However, the second disruption was acknowledged on Virgin Media’s Twitter account much more rapidly, with a post at 16:25 UTC stating “Unfortunately we have seen a repeat of an earlier issue which is causing intermittent broadband connectivity problems for some Virgin Media customers. We apologise again to those impacted, our teams are continuing to work flat out to find the root cause of the problem and fix it.”
Although no additional details have been shared via social media by Virgin Media about the outages or their resolution, some additional information was shared via Twitter by an apparent customer, who posted “Virgin Media engineers re-seated fibre cards and reset hub equipment to restore service. TTL was extended as a workaround to maintain stability whilst a permanent fix is implemented.”
A little more than a year later, on May 26, we observed an Internet outage at Miranda Media. Traffic started to fall around 16:30 local time (13:30 UTC), dropping to zero around 18:15 local time (15:15 UTC). The outage disrupted connectivity on the Crimean Peninsula and parts of occupied Ukraine and lasted until approximately 06:00 local time on May 27 (03:00 UTC). Published reports (1,2) suggest that the outage was due to a cyberattack targeting Miranda Media, reportedly carried out by Ukrainian hacktivists.
Russia
Russian satellite provider Dozor Teleport, whose customers include Russia’s Ministry of Defense, ships of the Northern Fleet, Russian energy firm Gazprom, remote oil fields, the Bilibino nuclear power plant, the Federal Security Service (FSB), Rosatom, and other organizations, experienced a multi-hour outage on June 29. The outage, which occurred between 01:30 – 17:30 UTC, was reportedly the result of a cyberattack that at least two groups claimed responsibility for.
Military action
Chad
Multiple Internet disruptions occurred in Chad on April 23 and 24, impacting several Internet providers, and were ultimately visible at a country level as well. As seen in the graphs below, the outages occurred from 04:30 – 06:00 local time (03:30 – 05:00 UTC) and 15:00 – 20:00 local time (14:00 – 19:00 UTC) on April 23, and 04:00 – 08:30 local time (03:00 – 07:30 UTC) on April 24. The impacted network providers in Chad included AS327802 (Millicom Chad), AS327756 (Airtel Chad), AS328594 (Sudat Chad), and AS327975 (ILNET-TELECOM). The outages were reportedly caused by damage to fiber infrastructure that links Chad with neighboring Cameroon and Sudan, with the latter experiencing Internet service disruptions amid clashes between the Sudanese Armed Forces (SAF) and Rapid Support Forces (RSF).
Sudan
As noted above, military action in Sudan disrupted Internet connectivity in Chad in April. Starting in mid-April, multiple Internet outages were observed at major Sudanese Internet providers, three of which are shown in the graphs below. The fighting in the country has led to fuel shortages and power cuts, ultimately disrupting Internet connectivity.
AS15706 (Sudatel) experienced complete Internet outages from 03:00 on April 23 to 17:00 on April 24 local time (01:00 on April 23 to 15:00 on April 24 UTC) and again from 03:00 on April 25 until 01:00 on April 28 local time (01:00 on April 25 to 23:00 on April 27 UTC). Internet connectivity on AS36972 (MTN) was disrupted between 03:00 and 12:00 local time on April 16 (01:00 – 10:00 UTC) and again between 20:00 on April 27 until 02:00 on April 29 (18:00 on April 27 to 00:00 on April 29). After a nominal multi-day recovery, a long-term near complete outage started on May 5, lasting for multiple weeks. Similar to MTN, multiple extended outages were also observed on AS33788 (Kanar Telecommunication). After seeing a significant drop in traffic midday on April 19, a near complete outage is visible between 12:00 on April 21 and 01:00 on April 29 (10:00 on April 21 to 23:00 on April 28 UTC), with a very brief minor recovery late in the day on April 24. A longer duration outage began around 00:00 local time on May 11 (22:00 on May 10 UTC), also lasting for multiple weeks.
Togo, Republic of Congo (Brazzaville), Burkina Faso
Repair work on the West Africa Cable System (WACS) submarine cable disrupted Internet connectivity across multiple countries, including Togo, Republic of Congo (Brazzaville), and Burkina Faso on April 6. According to the Google translation of a Facebook post from Canalbox Congo, the repair work was likely to cause “very strong disruptions on Internet connections with the risk of a total outage”. (Canalbox (GVA) is an African telecommunications operator that provides services across multiple countries in Africa.)
The graph below for AS36924 (GVA-Canalbox) shows three overlapping outage annotations, with each related to a disruption observed on that autonomous system (network) in one of the impacted countries. In the Republic of Congo (Brazzaville), a significant traffic disruption is visible between 16:15 – 23:15 local time (15:15 – 22:15 UTC). In Burkina Faso, the disruption happened earlier and was less severe, taking place between 09:15 – 18:00 local time (09:15 – 18:00 UTC), with a similar impact in Togo, where traffic was disrupted between 11:00 – 23:15 local time (11:00 – 23:15 UTC).
Conclusion
Because of how tightly interwoven the Internet has become with commerce, financial services, and everyday life around the world, any disruption to Internet connectivity ultimately carries an economic impact. The providers impacted by disruptions caused by unexpected or unavoidable events such as cable cuts or severe weather generally try to minimize the scope and duration of such disruptions, ultimately limiting the economic impact. However, in the case of government-directed Internet shutdowns, the damage to the economy is ultimately self-inflicted. The Internet Society’s new Net Loss Calculator now provides a way to quantify this damage, enabling the public, advocacy groups, and governments themselves to understand the potential cost of an Internet shutdown from gross domestic product (GDP), foreign direct investment (FDI), and unemployment perspectives.
In 2022, we launched the Radar Domain Rankings, with top lists of the most popular domains based on how people use the Internet globally. The lists are calculated using a machine learning model that uses aggregated 1.1.1.1 resolver data that is anonymized in accordance with our privacy commitments. While the top 100 list is updated daily for each location, typically the first results of that list are stable over time, with the big names such as Google, Facebook, Apple, Microsoft and TikTok leading. Additionally, these global big names appear for the majority of locations.
Today, we are improving our Domain Rankings page and adding Trending Domains lists. The new data shows which domains are currently experiencing an increase in popularity. Hence, while with the top popular domains we aim to show domains of broad appeal and of interest to many Internet users, with the trending domains we want to show domains that are generating a surge in interest.
How we generate the Trending Domains
When we started looking at the best way to generate a list of trending domains, we needed to answer the following questions:
What type of popularity changes do we want to capture?
What should we use as a baseline to calculate the change?
And how do we quantify it?
We soon realized that we needed two lists. One reflecting sudden increased interest related to a particular event or a topic, showing spikes in popularity in domains that jump in the ranking from one day to the next, and another one reflecting steady growth in popularity, showing domains that are increasing their user base over a longer period.
For this reason, we are launching both the Trending Today and Trending This Week top 10 lists to capture the two different types of popularity increase.
To select the baseline for calculating the increase in popularity, we analyzed the volatility of the Radar Domain Ranking list for different top list sizes. The advantage of starting with the Radar Ranking lists is that they already incorporate a good popularity metric that quantifies the estimated relative size of the user population that accesses a domain over some period of time. You can read more about how we define popularity in our “Goodbye, Alexa. Hello, Cloudflare Radar Domain Rankings” blog.
As expected, smaller list sizes were more stable, meaning the percentage of domains in the top 100 that changed the ranking from one day to the next was much lower than the percentage of domains that changed in the top 10,000. Hence, to have a dynamic daily list of trending domains, we had to look beyond the top 100 most popular domains.
However, we did not want to go all the way to the long tail of the list, as we already know that the ranks there are based on “significantly smaller and hence less reliable numbers” (see the paper "A Long Way to the Top: Significance, Structure, and Stability of Internet Top Lists"). Hence, we selected an appropriate list size for each location, based on the distribution of the number of DNS queries per domain. For example, for the Worldwide trending list we analyzed the top 20,000 most popular domains, for Brazil we looked at the top 10,000, Angola 5,000 and for the Faroe Islands top 500.
Trending Today
We then evaluated how much the domains change rank from one day to the next.
We saw that on average, the biggest changes in the top lists, from one day to the next, happen from Fridays to Saturdays and from Sundays to Mondays, and hence on Saturdays and Mondays the lists have the least overlap with the lists of the previous day. We also compared the rank changes from one day to the next corresponding weekday, say from one Monday to the next and saw that on average, rankings on Mondays typically have more overlap with the rankings of the previous Mondays, than with the rankings of Sunday. From this we decided that in order to capture which domains are trending due to the weekend effect, we needed to compare the domain's daily rank to the rank of the previous day(s), and not of the corresponding weekday.
However, we also did not want to show as trending those domains that highly oscillate in the rankings, jumping up and down from one day to the next, showing up as trending every few days. Hence, we could not simply compare the daily rank with the rank from the day before. Instead, as a compromise between capturing the most recent trends, including the weekend trends, but still filtering out the domains whose ranking oscillates over a short period of time, we decided to compare the domain's daily rank with its best rank of the previous four days.
Then, to calculate the increase in popularity, we simply calculate the percentage change in the current rank compared to the best rank of the previous four days.
Trending This Week
For calculating the domains steadily growing over the week, we used a slightly different approach.
We want to highlight domains that keep improving their rank day by day and especially those that have been really trending in the most recent days. Therefore, we decided not to directly compare the current rank with the best rank during the previous week. Instead, we looked at the weighted average per day rank improvement and compared it with the best rank of the previous six days, with more recent days being given more weight.
Example trending domains
What do these lists look like at the end? We compiled the lists for the eventful days of June 21 to 24.
On June 22, nba.com was trending in 28 locations, shown in the table below, the United States, as expected, but also Austria, Australia and Japan, to name a few, reflecting the interest in the events of NBA Draft 2023.
Trending Today data from Friday, June 23, 2023:
Location
Trending rank
Domain
Albania
5
nba.com
Argentina
9
nba.com
Australia
1
nba.com
Austria
9
nba.com
Belgium
5
nba.com
Canada
5
nba.com
Chile
6
nba.com
Colombia
3
nba.com
Dominican Republic
5
nba.com
Greece
2
nba.com
Honduras
6
nba.com
Hong Kong
1
nba.com
India
7
nba.com
Indonesia
4
nba.com
Ireland
3
nba.com
Japan
9
nba.com
Mexico
2
nba.com
New Zealand
1
nba.com
Norway
1
nba.com
Philippines
1
nba.com
Poland
9
nba.com
Serbia
2
nba.com
South Korea
3
nba.com
Taiwan
1
nba.com
Thailand
1
nba.com
Ukraine
1
nba.com
United States
6
nba.com
Venezuela
4
nba.com
Two domains trending in multiple locations on Saturday, June 24, were: rt.com, a Russian news site in English, and liveuamap.com, a site with interactive map of Ukraine. These are probably the effects of the events related to the Wagner group on June 23 and 24. Related to the same events, domain jetphotos.com was trending on the same day in Russia, Norway and Albania.
Trending Today data from Saturday, June 24, 2023:
Location
Trending rank
Domain
Armenia
4
rt.com
Australia
5
rt.com
Belgium
2
rt.com
Bulgaria
9
rt.com
Canada
6
rt.com
Denmark
6
rt.com
Greece
6
rt.com
Italy
2
rt.com
Kazakhstan
8
rt.com
Lebanon
4
rt.com
Netherlands
8
rt.com
Papua New Guinea
9
rt.com
Singapore
2
rt.com
Spain
6
rt.com
Turkey
4
rt.com
United Kingdom
5
rt.com
United States
3
rt.com
Uzbekistan
2
rt.com
Other domains trending in various locations on Friday and Saturday were different Gaming and Video Streaming domains such as roblox.com, twitch.tv and callofduty.com, showing an increased interest in gaming activities as the weekend approaches.
Yet another interesting effect of the weekend was the presence of five weather forecast sites on the top 10 trending sites on Friday, in Croatia, showing preoccupation with the summer weekend plans.
Trending Today in Croatia (data from Friday, June 23, 2023)
Trending rank
Domain
Category
1
lightningmaps.org
Weather; Education
2
freemeteo.com.hr
Weather
3
Vrijeme.hr (Croatian Meteorological and Hydrological Service)
Politics, Advocacy, and Government-Related
4
arso.gov.si
5
rain-alarm.com
Weather; News & Media
6
sorbs.net
Information Security
7
neverin.hr
Information Technology
8
meteo.hr (Croatian Meteorological and Hydrological Service)
Business
9
gamespot.com
Gaming; Video Streaming
10
grad.hr
Business
These were all examples of daily trending domains, but what domains have steadily grown in popularity that week?
In multiple countries we had travel sites trending that week, sites such as booking.com, rentcars.com and amadeus.com, as many people were making their summer vacation plans. Weather forecast, specifically windy.com domain, was also trending the whole week in locations such as the Dominican Republic, Saint Lucia and Reunion, which was not surprising as the hurricane season began.
Trending This Week (Week June 17 -23, 2023)
Dominican Republic
Reunion
Saint Lucia
cecomsa.com
atera.com
adition.com
blur.io
sharethis.com
windy.com
pxfuel.com
windy.com
bbc.co.uk
windy.com
baidu.com
ampproject.org
mihoyo.com
inmobi.com
aniview.com
Final words
Both Trending Today and Trending This Week top 10 lists are now available on Radar starting today and on Radar API. Feel free to explore them and see what is trending on the Internet.
Visit Cloudflare Radar for additional insights around (Internet disruptions, routing issues, Internet traffic trends, attacks, Internet quality, etc.). Follow us on social media at @CloudflareRadar (Twitter), cloudflare.social/@radar (Mastodon), and radar.cloudflare.com (Bluesky), or contact us via e-mail.
Popular domains are domains of broad appeal based on how people use the Internet. Trending domains are domains that are generating a surge in interest.
Welcome to the second DDoS threat report of 2023. DDoS attacks, or distributed denial-of-service attacks, are a type of cyber attack that aims to disrupt websites (and other types of Internet properties) to make them unavailable for legitimate users by overwhelming them with more traffic than they can handle — similar to a driver stuck in a traffic jam on the way to the grocery store.
We see a lot of DDoS attacks of all types and sizes and our network is one of the largest in the world spanning more than 300 cities in over 100 countries. Through this network we serve over 63 million HTTP requests per second at peak and over 2 billion DNS queries every day. This colossal amount of data gives us a unique vantage point to provide the community access to insightful DDoS trends.
For our regular readers, you might notice a change in the layout of this report. We used to follow a set pattern to share our insights and trends about DDoS attacks. But with the landscape of DDoS threats changing as DDoS attacks have become more powerful and sophisticated, we felt it's time for a change in how we present our findings. So, we'll kick things off with a quick global overview, and then dig into the major shifts we're seeing in the world of DDoS attacks.
Reminder: an interactive version of this report is also available on Cloudflare Radar. Furthermore, we’ve also added a new interactive component that will allow you to dive deeper into attack activity in each country or region.
New interactive Radar graph to shed light on local DDoS activity
The DDoS landscape: a look at global patterns
The second quarter of 2023 was characterized by thought-out, tailored and persistent waves of DDoS attack campaigns on various fronts, including:
Multiple DDoS offensives orchestrated by pro-Russian hacktivist groups REvil, Killnet and Anonymous Sudan against Western interest websites.
An increase in deliberately engineered and targeted DNS attacks alongside a 532% surge in DDoS attacks exploiting the Mitel vulnerability (CVE-2022-26143). Cloudflare contributed to disclosing this zero-day vulnerability last year.
Attacks targeting Cryptocurrency companies increased by 600%, as a broader 15% increase in HTTP DDoS attacks was observed. Of these, we’ve noticed an alarming escalation in attack sophistication which we will cover more in depth.
Additionally, one of the largest attacks we’ve seen this quarter was an ACK flood DDoS attack which originated from a Mirai-variant botnet comprising approximately 11K IP addresses. The attack targeted an American Internet Service Provider. It peaked at 1.4 terabit per seconds (Tbps) and was automatically detected and mitigated by Cloudflare’s systems.
Despite general figures indicating an increase in overall attack durations, most of the attacks are short-lived and so was this one. This attack lasted only two minutes. However, more broadly, we’ve seen that attacks exceeding 3 hours have increased by 103% QoQ.
Now having set the stage, let’s dive deeper into these shifts we’re seeing in the DDoS landscape.
Mirai botnet attacks an American Service Provider, peaks at 1.4 Tbps
Hacktivist alliance dubbed “Darknet Parliament” aims at Western banks and SWIFT network
On June 14, Pro-Russian hacktivist groups Killnet, a resurgence of REvil and Anonymous Sudan announced that they have joined forces to execute “massive” cyber attacks on the Western financial system including European and US banks, and the US Federal Reserve System. The collective, dubbed “Darknet Parliament”, declared its first objective was to paralyze SWIFT (Society for Worldwide Interbank Financial Telecommunication). A successful DDoS attack on SWIFT could have dire consequences because it's the main service used by financial institutions to conduct global financial transactions.
Beyond a handful of publicized events such as the Microsoft outage which was reported by the media, we haven’t observed any novel DDoS attacks or disruptions targeting our customers. Our systems have been automatically detecting and mitigating attacks associated with this campaign. Over the past weeks, as many as 10,000 of these DDoS attacks were launched by the Darknet Parliament against Cloudflare-protected websites (see graph below).
REvil, Killnet and Anonymous Sudan attacks
Despite the hacktivists’ statements, Banking and Financial Services websites were only the ninth most attacked industry — based on attacks we’ve seen against our customers as part of this campaign.
Top industries attacked by the REvil, Killnet and Anonymous Sudan attack campaign
The most attacked industries were Computer Software, Gambling & Casinos and Gaming. Telecommunications and Media outlets came in fourth and fifth, respectively. Overall, the largest attack we witnessed in this campaign peaked at 1.7 million requests per second (rps) and the average was 65,000 rps.
For perspective, earlier this year we mitigated the largest attack in recorded history peaking at 71 million rps. So these attacks were very small compared to Cloudflare scale, but not necessarily for an average website. Therefore, we shouldn’t underestimate the damage potential on unprotected or suboptimally configured websites.
Sophisticated HTTP DDoS attacks
An HTTP DDoS attack is a DDoS attack over the Hypertext Transfer Protocol (HTTP). It targets HTTP Internet properties such as websites and API gateways. Over the past quarter, HTTP DDoS attacks increased by 15% quarter-over-quarter (QoQ) despite a 35% decrease year-over-year (YoY).
Illustration of an HTTP DDoS attack
Additionally, we've observed an alarming uptick in highly-randomized and sophisticated HTTP DDoS attacks over the past few months. It appears as though the threat actors behind these attacks have deliberately engineered the attacks to try and overcome mitigation systems by adeptly imitating browser behavior very accurately, in some cases, by introducing a high degree of randomization on various properties such as user agents and JA3 fingerprints to name a few. An example of such an attack is provided below. Each different color represents a different randomization feature.
Example of a highly randomized HTTP DDoS attack
Furthermore, in many of these attacks, it seems that the threat actors try to keep their attack rates-per-second relatively low to try and avoid detection and hide amongst the legitimate traffic.
This level of sophistication has previously been associated with state-level and state-sponsored threat actors, and it seems these capabilities are now at the disposal of cyber criminals. Their operations have already targeted prominent businesses such as a large VoIP provider, a leading semiconductor company, and a major payment & credit card provider to name a few.
Protecting websites against sophisticated HTTP DDoS attacks requires intelligent protection that is automated and fast, that leverages threat intelligence, traffic profiling and Machine Learning/statistical analysis to differentiate between attack traffic and user traffic. Moreover, even increasing caching where applicable can help reduce the risk of attack traffic impacting your origin. Read more about DDoS protection best practices here.
DNS Laundering DDoS attacks
The Domain Name System, or DNS, serves as the phone book of the Internet. DNS helps translate the human-friendly website address (e.g. www.cloudflare.com) to a machine-friendly IP address (e.g. 104.16.124.96). By disrupting DNS servers, attackers impact the machines’ ability to connect to a website, and by doing so making websites unavailable to users.
Over the past quarter, the most common attack vector was DNS-based DDoS attacks — 32% of all DDoS attacks were over the DNS protocol. Amongst these, one of the more concerning attack types we’ve seen increasing is the DNS Laundering attack which can pose severe challenges to organizations that operate their own authoritative DNS servers.
Top DDoS attack vectors in 2023 Q2
The term “Laundering” in the DNS Laundering attack name refers to the analogy of money laundering, the devious process of making illegally-gained proceeds, often referred to as "dirty money," appear legal. Similarly, in the DDoS world, a DNS Laundering attack is the process of making bad, malicious traffic appear as good, legitimate traffic by laundering it via reputable recursive DNS resolvers.
In a DNS Laundering attack, the threat actor will query subdomains of a domain that is managed by the victim’s DNS server. The prefix that defines the subdomain is randomized and is never used more than once or twice in such an attack. Due to the randomization element, recursive DNS servers will never have a cached response and will need to forward the query to the victim’s authoritative DNS server. The authoritative DNS server is then bombarded by so many queries until it cannot serve legitimate queries or even crashes all together.
Illustration of a DNS Laundering DDoS attack
From the protection point of view, the DNS administrators can’t block the attack source because the source includes reputable recursive DNS servers like Google’s 8.8.8.8 and Cloudflare’s 1.1.1.1. The administrators also cannot block all queries to the attacked domain because it is a valid domain that they want to preserve access to legitimate queries.
The above factors make it very challenging to distinguish legitimate queries from malicious ones. A large Asian financial institution and a North American DNS provider are amongst recent victims of such attacks. An example of such an attack is provided below.
Example of a DNS Laundering DDoS attack
Similar to the protection strategies outlined for HTTP applications, protecting DNS servers also requires a precise, fast, and automated approach. Leveraging a managed DNS service or a DNS reverse proxy such as Cloudflare’s can help absorb and mitigate the attack traffic. For those more sophisticated DNS attacks, a more intelligent solution is required that leverages statistical analysis of historical data to be able to differentiate between legitimate queries and attack queries.
The rise of the Virtual Machine Botnets
As we’ve previously disclosed, we are witnessing an evolution in botnet DNA. The era of VM-based DDoS botnets has arrived and with it hyper-volumetric DDoS attacks. These botnets are comprised of Virtual Machines (VMs, or Virtual Private Servers, VPS) rather than Internet of Things (IoT) devices which makes them so much more powerful, up to 5,000 times stronger.
Illustration of an IoT botnet compared with a VM Botnet
Because of the computational and bandwidth resources that are at the disposal of these VM-based botnets, they’re able to generate hyper-volumetric attacks with a much smaller fleet size compared to IoT-based botnets.
These botnets have executed one largest recorded DDoS attacks including the 71 million request per second DDoS attack. Multiple organizations including an industry-leading gaming platform provider have already been targeted by this new generation of botnets.
Cloudflare has proactively collaborated with prominent cloud computing providers to combat these new botnets. Through the quick and dedicated actions of these providers, significant components of these botnets have been neutralized. Since this intervention, we have not observed any further hyper-volumetric attacks yet, a testament to the efficacy of our collaboration.
While we already enjoy a fruitful alliance with the cybersecurity community in countering botnets when we identify large-scale attacks, our goal is to streamline and automate this process further. We extend an invitation to cloud computing providers, hosting providers, and other general service providers to join Cloudflare’s free Botnet Threat Feed. This would provide visibility into attacks originating within their networks, contributing to our collective efforts to dismantle botnets.
“Startblast”: Exploiting Mitel vulnerabilities for DDoS attacks
This exploit operates by reflecting traffic off vulnerable servers, amplifying it in the process, with a factor as high as 220 billion percent. The vulnerability stems from an unauthenticated UDP port exposed to the public Internet, which could allow malicious actors to issue a 'startblast' debugging command, simulating a flurry of calls to test the system.
As a result, for each test call, two UDP packets are sent to the issuer, enabling an attacker to direct this traffic to any IP and port number to amplify a DDoS attack. Despite the vulnerability, only a few thousand of these devices are exposed, limiting the potential scale of attack, and attacks must run serially, meaning each device can only launch one attack at a time.
Top industries targeted by Startblast DDoS attacks
Overall, in the past quarter, we’ve seen additional emerging threats such as DDoS attacks abusing the TeamSpeak3 protocol. This attack vector increased by a staggering 403% this quarter.
TeamSpeak, a proprietary voice-over-Internet Protocol (VoIP) that runs over UDP to help gamers talk with other gamers in real time. Talking instead of just chatting can significantly improve a gaming team’s efficiency and help them win. DDoS attacks that target TeamSpeak servers may be launched by rival groups in an attempt to disrupt their communication path during real-time multiplayer games and thus impact their team’s performance.
DDoS hotspots: The origins of attacks
Overall, HTTP DDoS attacks increased by 15% QoQ despite a 35% decrease YoY. Additionally, network-layer DDoS attacks decreased this quarter by approximately 14%.
HTTP DDoS attack requests by quarter
In terms of total volume of attack traffic, the US was the largest source of HTTP DDoS attacks. Three out of every thousand requests we saw were part of HTTP DDoS attacks originating from the US. China came in second place and Germany in third place.
Top source countries of HTTP DDoS attacks (percentage of attack traffic out of the total traffic worldwide)
Some countries naturally receive more traffic due to various factors such as market size, and therefore more attacks. So while it’s interesting to understand the total amount of attack traffic originating from a given country, it is also helpful to remove that bias by normalizing the attack traffic by all traffic to a given country.
When doing so, we see a different pattern. The US doesn’t even make it into the top ten. Instead, Mozambique, Egypt and Finland take the lead as the source countries of the most HTTP DDoS attack traffic relative to all of their traffic. Almost a fifth of all HTTP traffic originating from Mozambique IP addresses were part of DDoS attacks.
Top source countries of HTTP DDoS attacks (percentage of attack traffic out of the total traffic per country)
Using the same calculation methodology but for bytes, Vietnam remains the largest source of network-layer DDoS attacks (aka L3/4 DDoS attacks) for the second consecutive quarter — and the amount even increased by 58% QoQ. Over 41% of all bytes that were ingested in Cloudflare’s Vietnam data centers were part of L3/4 DDoS attacks.
Top source countries of L3/4 DDoS attacks (percentage of attack traffic out of the total traffic per country)
Industries under attack: examining DDoS attack targets
When examining HTTP DDoS attack activity in Q2, Cryptocurrency websites were targeted with the largest amount of HTTP DDoS attack traffic. Six out of every ten thousand HTTP requests towards Cryptocurrency websites behind Cloudflare were part of these attacks. This represents a 600% increase compared to the previous quarter.
After Crypto, Gaming and Gambling websites came in second place as their attack share increased by 19% QoQ. Marketing and Advertising websites not far behind in third place with little change in their share of attacks.
Top industries targeted by HTTP DDoS attacks (percentage of attack traffic out of the total traffic for all industries)
However, when we look at the amount of attack traffic relative to all traffic for any given industry, the numbers paint a different picture. Last quarter, Non-profit organizations were attacked the most — 12% of traffic to Non-profits were HTTP DDoS attacks. Cloudflare protects more than 2,271 Non-profit organizations in 111 countries as part of Project Galileo which celebrated its ninth anniversary this year. Over the past months, an average of 67.7 million cyber attacks targeted Non-profits on a daily basis.
Overall, the amount of DDoS attacks on Non-profits increased by 46% bringing the percentage of attack traffic to 17.6%. However, despite this growth, the Management Consulting industry jumped to the first place with 18.4% of its traffic being DDoS attacks.
Top industries targeted by HTTP DDoS attacks (percentage of attack traffic out of the total traffic per industry)
When descending the layers of the OSI model, the Internet networks that were most targeted belonged to the Information Technology and Services industry. Almost every third byte routed to them were part of L3/4 DDoS attacks.
Surprisingly enough, companies operating in the Music industry were the second most targeted industry, followed by Broadcast Media and Aviation & Aerospace.
Top industries targeted by L3/4 DDoS attacks (percentage of attack traffic out of the total traffic per industry)
Top attacked industries: a regional perspective
Cryptocurrency websites experienced the highest number of attacks worldwide, while Management Consulting and Non-profit sectors were the most targeted considering their total traffic. However, when we look at individual regions, the situation is a bit different.
Top industries targeted by HTTP DDoS attacks by region
Africa
The Telecommunications industry remains the most attacked industry in Africa for the second consecutive quarter. The Banking, Financial Services and Insurance (BFSI) industry follows as the second most attacked. The majority of the attack traffic originated from Asia (35%) and Europe (25%).
Asia
For the past two quarters, the Gaming and Gambling industry was the most targeted industry in Asia. In Q2, however, the Gaming and Gambling industry dropped to second place and Cryptocurrency took the lead as the most attacked industry (~50%). Substantial portions of the attack traffic originated from Asia itself (30%) and North America (30%).
Europe
For the third consecutive quarter, the Gaming & Gambling industry remains the most attacked industry in Europe. The Hospitality and Broadcast Media industries follow not too far behind as the second and third most attacked. Most of the attack traffic came from within Europe itself (40%) and from Asia (20%).
Latin America
Surprisingly, half of all attack traffic targeting Latin America was aimed at the Sporting Goods industry. In the previous quarter, the BFSI was the most attacked industry. Approximately 35% of the attack traffic originated from Asia, and another 25% originated from Europe.
Middle East
The Media & Newspaper industries were the most attacked in the Middle East. The vast majority of attack traffic originated from Europe (74%).
North America
For the second consecutive quarter, Marketing & Advertising companies were the most attacked in North America (approximately 35%). Manufacturing and Computer Software companies came in second and third places, respectively. The main sources of the attack traffic were Europe (42%) and the US itself (35%).
Oceania
This quarter, the Biotechnology industry was the most attacked. Previously, it was the Health & Wellness industry. Most of the attack traffic originated from Asia (38%) and Europe (25%).
Countries and regions under attack: examining DDoS attack targets
When examining the total volume of attack traffic, last quarter, Israel leaped to the front as the most attacked country. This quarter, attacks targeting Israeli websites decreased by 33% bringing it to the fourth place. The US takes the lead again as the most attacked country, followed by Canada and Singapore.
Top countries and regions targeted by HTTP DDoS attacks (percentage of attack traffic out of the total traffic for all countries and regions)
If we normalize the data per country and region and divide the attack traffic by the total traffic, we get a different picture. Palestine jumps to the first place as the most attacked country. Almost 12% of all traffic to Palestinian websites were HTTP DDoS attacks.
Top countries and regions targeted by HTTP DDoS attacks (percentage of attack traffic out of the total traffic per country and region)
Last quarter, we observed a striking deviation at the network layer, with Finnish networks under Cloudflare's shield emerging as the primary target. This surge was likely correlated with the diplomatic talks that precipitated Finland's formal integration into NATO. Roughly 83% of all incoming traffic to Finland comprised cyberattacks, with China a close second at 68% attack traffic.
This quarter, however, paints a very different picture. Finland has receded from the top ten, and Chinese Internet networks behind Cloudflare have ascended to the first place. Almost two-thirds of the byte streams towards Chinese networks protected by Cloudflare were malicious. Following China, Switzerland saw half of its inbound traffic constituting attacks, and Turkey came third, with a quarter of its incoming traffic identified as hostile.
Top countries and regions targeted by L3/4 DDoS attacks (percentage of attack traffic out of the total traffic per country and region)
Ransom DDoS attacks
Occasionally, DDoS attacks are carried out to extort ransom payments. We’ve been surveying Cloudflare customers over three years now, and have been tracking the occurrence of Ransom DDoS attack events.
High level comparison of Ransomware and Ransom DDoS attacks
Unlike Ransomware attacks, where victims typically fall prey to downloading a malicious file or clicking on a compromised email link which locks, deletes or leaks their files until a ransom is paid, Ransom DDoS attacks can be much simpler for threat actors to execute. Ransom DDoS attacks bypass the need for deceptive tactics such as luring victims into opening dubious emails or clicking on fraudulent links, and they don't necessitate a breach into the network or access to corporate resources.
Over the past quarter, reports of Ransom DDoS attacks decreased. One out of ten respondents reported being threatened or subject to Ransom DDoS attacks.
Wrapping up: the ever-evolving DDoS threat landscape
In recent months, there's been an alarming escalation in the sophistication of DDoS attacks. And even the largest and most sophisticated attacks that we’ve seen may only last a few minutes or even seconds — which doesn’t give a human sufficient time to respond. Before the PagerDuty alert is even sent, the attack may be over and the damage is done. Recovering from a DDoS attack can last much longer than the attack itself — just as a boxer might need a while to recover from a punch to the face that only lasts a fraction of a second.
Security is not one single product or a click of a button, but rather a process involving multiple layers of defense to reduce the risk of impact. Cloudflare's automated DDoS defense systems consistently safeguard our clients from DDoS attacks, freeing them up to focus on their core business operations. These systems are complemented by the vast breadth of Cloudflare capabilities such as firewall, bot detection, API protection and even caching which can all contribute to reducing the risk of impact.
The DDoS threat landscape is evolving and increasingly complex, demanding more than just quick fixes. Thankfully, with Cloudflare's multi-layered defenses and automatic DDoS protections, our clients are equipped to navigate these challenges confidently. Our mission is to help build a better Internet, and so we continue to stand guard, ensuring a safer and more reliable digital realm for all.
Methodologies
How we calculate Ransom DDoS attack insights
Cloudflare’s systems constantly analyze traffic and automatically apply mitigation when DDoS attacks are detected. Each attacked customer is prompted with an automated survey to help us better understand the nature of the attack and the success of the mitigation. For over two years, Cloudflare has been surveying attacked customers. One of the questions in the survey asks the respondents if they received a threat or a ransom note. Over the past two years, on average, we collected 164 responses per quarter. The responses of this survey are used to calculate the percentage of Ransom DDoS attacks.
How we calculate geographical and industry insights
Source country At the application-layer, we use the attacking IP addresses to understand the origin country of the attacks. That is because at that layer, IP addresses cannot be spoofed (i.e., altered). However, at the network layer, source IP addresses can be spoofed. So, instead of relying on IP addresses to understand the source, we instead use the location of our data centers where the attack packets were ingested. We’re able to get geographical accuracy due to our large global coverage in over 285 locations around the world.
Target country For both application-layer and network-layer DDoS attacks, we group attacks and traffic by our customers’ billing country. This lets us understand which countries are subject to more attacks.
Target industry For both application-layer and network-layer DDoS attacks, we group attacks and traffic by our customers’ industry according to our customer relations management system. This lets us understand which industries are subject to more attacks.
Total volume vs. percentage For both source and target insights, we look at the total volume of attack traffic compared to all traffic as one data point. Additionally, we also look at the percentage of attack traffic towards or from a specific country, to a specific country or to a specific industry. This gives us an “attack activity rate” for a given country/industry which is normalized by their total traffic levels. This helps us remove biases of a country or industry that normally receives a lot of traffic and therefore a lot of attack traffic as well.
How we calculate attack characteristics To calculate the attack size, duration, attack vectors and emerging threats, we bucket attacks and then provide the share of each bucket out of the total amount for each dimension. On the new Radar component, these trends are calculated by number of bytes instead. Since attacks may vary greatly in number of bytes from one another, this could lead to trends differing between the reports and the Radar component.
General disclaimer and clarification
When we describe ‘top countries’ as the source or target of attacks, it does not necessarily mean that that country was attacked as a country, but rather that organizations that use that country as their billing country were targeted by attacks. Similarly, attacks originating from a country does not mean that that country launched the attacks, but rather that the attack was launched from IP addresses that have been mapped to that country. Threat actors operate global botnets with nodes all over the world, and in many cases also use Virtual Private Networks and proxies to obfuscate their true location. So if anything, the source country could indicate the presence of exit nodes or botnet nodes within that country.
Internet connections are most often marketed and sold on the basis of "speed", with providers touting the number of megabits or gigabits per second that their various service tiers are supposed to provide. This marketing has largely been successful, as most subscribers believe that "more is better”. Furthermore, many national broadband plans in countries around the world include specific target connection speeds. However, even with a high speed connection, gamers may encounter sluggish performance, while video conference participants may experience frozen video or audio dropouts. Speeds alone don't tell the whole story when it comes to Internet connection quality.
Additional factors like latency, jitter, and packet loss can significantly impact end user experience, potentially leading to situations where higher speed connections actually deliver a worse user experience than lower speed connections. Connection performance and quality can also vary based on usage – measured average speed will differ from peak available capacity, and latency varies under loaded and idle conditions.
The new Cloudflare Radar Internet Quality page
A little more than three years ago, as residential Internet connections were strained because of the shift towards working and learning from home due to the COVID-19 pandemic, Cloudflare announced the speed.cloudflare.com speed test tool, which enabled users to test the performance and quality of their Internet connection. Within the tool, users can download the results of their individual test as a CSV, or share the results on social media. However, there was no aggregated insight into Cloudflare speed test results at a network or country level to provide a perspective on connectivity characteristics across a larger population.
Today, we are launching these long-missing aggregated connection performance and quality insights on Cloudflare Radar. The new Internet Quality page provides both country and network (autonomous system) level insight into Internet connection performance (bandwidth) and quality (latency, jitter) over time. (Your Internet service provider is likely an autonomous system with its own autonomous system number (ASN), and many large companies, online platforms, and educational institutions also have their own autonomous systems and associated ASNs.) The insights we are providing are presented across two sections: the Internet Quality Index (IQI), which estimates average Internet quality based on aggregated measurements against a set of Cloudflare & third-party targets, and Connection Quality, which presents peak/best case connection characteristics based on speed.cloudflare.com test results aggregated over the previous 90 days. (Details on our approach to the analysis of this data are presented below.)
Users may note that individual speed test results, as well as the aggregate speed test results presented on the Internet Quality page will likely differ from those presented by other speed test tools. This can be due to a number of factors including differences in test endpoint locations (considering both geographic and network distance), test content selection, the impact of “rate boosting” by some ISPs, and testing over a single connection vs. multiple parallel connections. Infrequent testing (on any speed test tool) by users seeking to confirm perceived poor performance or validate purchased speeds will also contribute to the differences seen in the results published by the various speed test platforms.
And as we announced in April, Cloudflare has partnered with Measurement Lab (M-Lab) to create a publicly-available, queryable repository for speed test results. M-Lab is a non-profit third-party organization dedicated to providing a representative picture of Internet quality around the world. M-Lab produces and hosts the Network Diagnostic Tool, which is a very popular network quality test that records millions of samples a day. Given their mission to provide a publicly viewable, representative picture of Internet quality, we chose to partner with them to provide an accurate view of your Internet experience and the experience of others around the world using openly available data.
Connection speed & quality data is important
While most advertisements for fixed broadband and mobile connectivity tend to focus on download speeds (and peak speeds at that), there’s more to an Internet connection, and the user’s experience with that Internet connection, than that single metric. In addition to download speeds, users should also understand the upload speeds that their connection is capable of, as well as the quality of the connection, as expressed through metrics known as latency and jitter. Getting insight into all of these metrics provides a more well-rounded view of a given Internet connection, or in aggregate, the state of Internet connectivity across a geography or network.
The concept of download speeds are fairly well understood as a measure of performance. However, it is important to note that the average download speeds experienced by a user during common Web browsing activities, which often involves the parallel retrieval of multiple smaller files from multiple hosts, can differ significantly from peak download speeds, where the user is downloading a single large file (such as a video or software update), which allows the connection to reach maximum performance. The bandwidth (speed) available for upload is sometimes mentioned in ISP advertisements, but doesn’t receive much attention. (And depending on the type of Internet connection, there’s often a significant difference between the available upload and download speeds.) However, the importance of upload came to the forefront in 2020 as video conferencing tools saw a surge in usage as both work meetings and school classes shifted to the Internet during the COVID-19 pandemic. To share your audio and video with other participants, you need sufficient upload bandwidth, and this issue was often compounded by multiple people sharing a single residential Internet connection.
Latency is the time it takes data to move through the Internet, and is measured in the number of milliseconds that it takes a packet of data to go from a client (such as your computer or mobile device) to a server, and then back to the client. In contrast to speed metrics, lower latency is preferable. This is especially true for use cases like online gaming where latency can make a difference between a character’s life and death in the game, as well as video conferencing, where higher latency can cause choppy audio and video experiences, but it also impacts web page performance. The latency metric can be further broken down into loaded and idle latency. The former measures latency on a loaded connection, where bandwidth is actively being consumed, while the latter measures latency on an “idle” connection, when there is no other network traffic present. (These specific loaded and idle definitions are from the device’s perspective, and more specifically, from the speed test application’s perspective. Unless the speed test is being performed directly from a router, the device/application doesn't have insight into traffic on the rest of the network.) Jitter is the average variation found in consecutive latency measurements, and can be measured on both idle and loaded connections. A lower number means that the latency measurements are more consistent. As with latency, Internet connections should have minimal jitter, which helps provide more consistent performance.
Our approach to data analysis
The Internet Quality Index (IQI) and Connection Quality sections get their data from two different sources, providing two different (albeit related) perspectives. Under the hood they share some common principles, though.
IQI builds upon the mechanism we already use to regularly benchmark ourselves against other industry players. It is based on end user measurements against a set of Cloudflare and third-party targets, meant to represent a pattern that has become very common in the modern Internet, where most content is served from distribution networks with points of presence spread throughout the world. For this reason, and by design, IQI will show worse results for regions and Internet providers that rely on international (rather than peering) links for most content.
IQI is also designed to reflect the traffic load most commonly associated with web browsing, rather than more intensive use. This, and the chosen set of measurement targets, effectively biases the numbers towards what end users experience in practice (where latency plays an important role in how fast things can go).
For each metric covered by IQI, and for each ASN, we calculate the 25th percentile, median, and 75th percentile at 15 minute intervals. At the country level and above, the three calculated numbers for each ASN visible from that region are independently aggregated. This aggregation takes the estimated user population of each ASN into account, biasing the numbers away from networks that source a lot of automated traffic but have few end users.
The Connection Quality section gets its data from the Cloudflare Speed Test tool, which exercises a user's connection in order to see how well it is able to perform. It measures against the closest Cloudflare location, providing a good balance of realistic results and network proximity to the end user. We have a presence in 285 cities around the world, allowing us to be pretty close to most users.
Similar to the IQI, we calculate the 25th percentile, median, and 75th percentile for each ASN. But here these three numbers are immediately combined using an operation called the trimean — a single number meant to balance the best connection quality that most users have, with the best quality available from that ASN (users may not subscribe to the best available plan for a number of reasons).
Because users may choose to run a speed test for different motives at different times, and also because we take privacy very seriously and don’t record any personally identifiable information along with test results, we aggregate at 90-day intervals to capture as much variability as we can.
At the country level and above, the calculated trimean for each ASN in that region is aggregated. This, again, takes the estimated user population of each ASN into account, biasing the numbers away from networks that have few end users but which may still have technicians using the Cloudflare Speed Test to assess the performance of their network.
Navigating the Internet Quality page
The new Internet Quality page includes three views: Global, country-level, and autonomous system (AS). In line with the other pages on Cloudflare Radar, the country-level and AS pages show the same data sets, differing only in their level of aggregation. Below, we highlight the various components of the Internet Quality page.
Global
The top section of the global (worldwide) view includes time series graphs of the Internet Quality Index metrics aggregated at a continent level. The time frame shown in the graphs is governed by the selection made in the time frame drop down at the upper right of the page, and at launch, data for only the last three months is available. For users interested in examining a specific continent, clicking on the other continent names in the legend removes them from the graph. Although continent-level aggregation is still rather coarse, it still provides some insight into regional Internet quality around the world.
Further down the page, the Connection Quality section presents a choropleth map, with countries shaded according to the values of the speed, latency, or jitter metric selected from the drop-down menu. Hovering over a country displays a label with the country’s name and metric value, and clicking on the country takes you to the country’s Internet Quality page. Note that in contrast to the IQI section, the Connection Quality section always displays data aggregated over the previous 90 days.
Country-level
Within the country-level page (using Canada as an example in the figures below), the country’s IQI metrics over the selected time frame are displayed. These time series graphs show the median bandwidth, latency, and DNS response time within a shaded band bounded at the 25th and 75th percentile and represent the average expected user experience across the country, as discussed in the Our approach to data analysis section above.
Below that is the Connection Quality section, which provides a summary view of the country’s measured upload and download speeds, as well as latency and jitter, over the previous 90 days. The colored wedges in the Performance Summary graph are intended to illustrate aggregate connection quality at a glance, with an “ideal” connection having larger upload and download wedges and smaller latency and jitter wedges. Hovering over the wedges displays the metric’s value, which is also shown in the table to the right of the graph.
Below that, the Bandwidth and Latency/Jitter histograms illustrate the bucketed distribution of upload and download speeds, and latency and jitter measurements. In some cases, the speed histograms may show a noticeable bar at 1 Gbps, or 1000 ms (1 second) on the latency/jitter histograms. The presence of such a bar indicates that there is a set of measurements with values greater than the 1 Gbps/1000 ms maximum histogram values.
Autonomous system level
Within the upper-right section of the country-level page, a list of the top five autonomous systems within the country is shown. Clicking on an ASN takes you to the Performance page for that autonomous system. For others not displayed in the top five list, you can use the search bar at the top of the page to search by autonomous system name or number. The graphs shown within the AS level view are identical to those shown at a country level, but obviously at a different level of aggregation. You can find the ASN that you are connected to from the My Connection page on Cloudflare Radar.
Exploring connection performance & quality data
Digging into the IQI and Connection Quality visualizations can surface some interesting observations, including characterizing Internet connections, and the impact of Internet disruptions, including shutdowns and network issues. We explore some examples below.
Characterizing Internet connections
Verizon FiOS is a residential fiber-based Internet service available to customers in the United States. Fiber-based Internet services (as opposed to cable-based, DSL, dial-up, or satellite) will generally offer symmetric upload and download speeds, and the FiOS plans page shows this to be the case, offering 300 Mbps (upload & download), 500 Mbps (upload & download), and “1 Gig” (Verizon claims average wired speeds between 750-940 Mbps download / 750-880 Mbps upload) plans. Verizon carries FiOS traffic on AS701 (labeled UUNET due to a historical acquisition), and in looking at the bandwidth histogram for AS701, several things stand out. The first is a rough symmetry in upload and download speeds. (A cable-based Internet service provider, in contrast, would generally show a wide spread of download speeds, but have upload speeds clustered at the lower end of the range.) Another is the peaks around 300 Mbps and 750 Mbps, suggesting that the 300 Mbps and “1 Gig” plans may be more popular than the 500 Mbps plan. It is also clear that there are a significant number of test results with speeds below 300 Mbps. This is due to several factors: one is that Verizon also carries lower speed non-FiOS traffic on AS701, while another is that erratic nature of in-home WiFi often means that the speeds achieved on a test will be lower than the purchased service level.
Traffic shifts drive latency shifts
On May 9, 2023, the government of Pakistan ordered the shutdown of mobile network services in the wake of protests following the arrest of former Prime Minister Imran Khan. Our blog post covering this shutdown looked at the impact from a traffic perspective. Within the post, we noted that autonomous systems associated with fixed broadband networks saw significant increases in traffic when the mobile networks were shut down – that is, some users shifted to using fixed networks (home broadband) when mobile networks were unavailable.
Examining IQI data after the blog post was published, we found that the impact of this traffic shift was also visible in our latency data. As can be seen in the shaded area of the graph below, the shutdown of the mobile networks resulted in the median latency dropping about 25% as usage shifted from higher latency mobile networks to lower latency fixed broadband networks. An increase in latency is visible in the graph when mobile connectivity was restored on May 12.
Bandwidth shifts as a potential early warning sign
On April 4, UK mobile operator Virgin Media suffered several brief outages. In examining the IQI bandwidth graph for AS5089, the ASN used by Virgin Media (formerly branded as NTL), indications of a potential problem are visible several days before the outages occurred, as median bandwidth dropped by about a third, from around 35 Mbps to around 23 Mbps. The outages are visible in the circled area in the graph below. Published reports indicate that the problems lasted into April 5, in line with the lower median bandwidth measured through mid-day.
Submarine cable issues cause slower browsing
On June 5, Philippine Internet provider PLDTTweeted an advisory that noted “One of our submarine cable partners confirms a loss in some of its internet bandwidth capacity, and thus causing slower Internet browsing.” IQI latency and bandwidth graphs for AS9299, a primary ASN used by PLDT, shows clear shifts starting around 06:45 UTC (14:45 local time). Median bandwidth dropped by half, from 17 Mbps to 8 Mbps, while median latency increased by 75% from 37 ms to around 65 ms. 75th percentile latency also saw a significant increase, nearly tripling from 63 ms to 180 ms coincident with the reported submarine cable issue.
Conclusion
Making network performance and quality insights available on Cloudflare Radar supports Cloudflare’s mission to help build a better Internet. However, we’re not done yet – we have more enhancements planned. These include making data available at a more granular geographical level (such as state and possibly city), incorporating AIM scores to help assess Internet quality for specific types of use cases, and embedding the Cloudflare speed test directly on Radar using the open source JavaScript module.
In the meantime, we invite you to use speed.cloudflare.com to test the performance and quality of your Internet connection, share any country or AS-level insights you discover on social media (tag @CloudflareRadar on Twitter or @[email protected] on Mastodon), and explore the underlying data through the M-Lab repository or the Radar API.
Over the last several years, governments in a number of countries in the Middle East/Northern Africa (MENA) region have taken to implementing widespread nationwide shutdowns in an effort to prevent cheating on nationwide academic exams. Although it is unclear whether such shutdowns are actually successful in curbing cheating, it is clear that they take a financial toll on the impacted countries, with estimated losses in the millions of US dollars.
During the first two weeks of June 2023, we’ve seen Iraq implementing a series of multi-hour shutdowns that will reportedly occur through mid-July, as well as Algeria taking similar actions to prevent cheating on baccalaureate exams. Shutdowns in Syria were reported to begin on June 7, but there’s been no indication of them in traffic data as of this writing (June 13). These actions echo those taken in Iraq, Syria, Sudan, and Algeria in 2022 and in Syria and Sudan in 2021.
(Note: The interactive graphs below have been embedded directly into the blog post using a new Cloudflare Radar feature. This post is best viewed in landscape mode when on a mobile device.)
Iraq
Iraq had reportedly committed on May 15 to not implementing Internet shutdowns during the 2023 exam season, with a now unavailable page on the Iraqi Ministry of Communications web site (although captured in the Internet Archive’s Wayback Machine) noting (via Google Translate) “Her Excellency the Minister of Communications, Dr. Hayam Al-Yasiri: We rejected a request to cut off the internet service during the ministerial exams.” However, that commitment was apparently short-lived, as the first shutdown was implemented just a couple of weeks later, on June 1. The shutdowns observed across Iraq thus far have impacted networks and localities nationwide, with the exception of the autonomous Kurdistan region. However, networks in that region have experienced their own set of connectivity restrictions due to local exams.
In Iraq, the impact of the shutdowns between 04:00 – 08:00 local time (01:00 – 05:00 UTC) is clearly visible at a country level, as seen in the figure below.
The impact is, of course, also visible in the network-level graphs shown below, with traffic dropping to or near zero during each of the four-hour shutdown windows.
The shutdowns are also visible in the BGP announcement activity from the impacted networks, with spikes in announcement volume clearly visible around the shutdown windows each day that they have occurred. The announcement activity represents withdrawals ahead of the shutdown, removing routes to prefixes within the network, effectively cutting them off from the Internet, and updates after the shutdown period has ended, restoring the previously withdrawn routes, effectively reconnecting the prefixes to the Internet. (Additional announcement activity may also be visible for periods outside of the scheduled shutdowns, and is likely unrelated.)
While the shutdowns discussed above didn’t impact the Kurdistan region of Iraq, that region has also chosen to implement their own shutdowns. In the Kurdistan region, exams started June 3, we saw shorter traffic disruptions across three local network providers on June 3, 6, 10, and 13. The disruptions lasted from 06:30 – 07:30 local time (03:30 to 04:30 UTC) on the 3rd, and 06:40 – 08:30 local time (03:30 to 05:30 UTC) on the 6th, 10th, and 13th). Impacted regions include Erbil, Sulaymaniyah, and Duhok.
BGP announcement activity for the impacted networks in the Kurdistan region did not show the same patterns as those observed on the other Iraqi network providers discussed above.
Both sets of shutdowns in Iraq are also visible in traffic to Cloudflare’s 1.1.1.1 DNS resolver, although they highlight a difference in usage between the autonomous Kurdistan region and the rest of the country. The “totalTcpUdp” graph (blue line) below shows requests made to the resolver over UDP or TCP on port 53, the standard port used for DNS requests. The “totalDoHDoT” graph (orange line) below shows requests made to the resolver using DNS-over-HTTPS or DNS-over-TLS using port 443 or 853 respectively.
In the “totalTcpUdp” graph, we can see noticeable drops in traffic that align with the dates and times where we observed the traffic disruptions across Kurdistani networks. This drop in DNS traffic, combined with the lack of BGP announcement activity, suggests that the Internet disruptions in the Kurdistan region may be implemented as widespread blocking of Internet traffic, rather than routing-based shutdowns.
In the “totalDoHDoT” graph below, we can see noticeable drops in traffic that align with the dates and times where we observed the traffic disruptions in the rest of Iraq.
It isn’t immediately clear why there is a difference in the use of 1.1.1.1 between the two parts of the country.
Algeria
In Algeria, it appears that the country is following a similar pattern as that seen in 2021 and 2022, with two multi-hour Internet disruptions each day. Also similar to last year, it appears that they are pursuing a content blocking-based approach, instead of the wide-scale Internet shutdowns implemented in 2021, as impacted networks are not experiencing complete outages, nor do they show patterns of BGP announcement activity.
A published report indicates that two Internet disruptions will be implemented each day between June 11 and June 15. The first takes place between 08:00 – 12:00 local time (07:00 – 11:00 UTC), with the second occurring between 14:00 – 17:00 local time (13:00 – 16:00 UTC). These disruptions are visible in the shaded areas of the network-level graphs below as two distinct drops in traffic each day.
Conclusion
In cooperation with the Internet Society and Lebanese digital rights organization SMEX, digital rights organization Access Now is coordinating a #NoExamShutdown campaign across social media platforms. The campaign calls on MENA governments to end the practice of Internet shutdowns during exams, and aims to highlight how these shutdowns undermine human rights and disrupt essential social, political, economic, and cultural activities. Cloudflare Radar will continue to bring visibility to these, and other similar Internet disruptions, as they occur. You can follow them through the Cloudflare Radar Outage Center, or by following Cloudflare Radar on Twitter or Mastodon.
On Tuesday, May 9, Imran Khan, former Prime Minister of Pakistan was arrested on corruption charges. Following the arrest, violent protests erupted in several cities, leading the government of Pakistan to order the shutdown of mobile Internet services, as well as the blocking of several social media platforms. Below, we examine the impact of these shutdowns at a national and local level, as seen through Cloudflare traffic data. In addition, we illustrate how Pakistanis appear to be turning to Cloudflare’s 1.1.1.1 resolver in an attempt to maintain access to the open Internet.
General traffic trends
Since Tuesday, May 9, peak traffic levels aggregated at a country level (as measured by HTTP request volume) have been declining, down nearly 30% during the first several days of the mobile Internet shutdowns. The lowest traffic levels (nadirs of the graph) have also declined, dropping by as much as one-third as well. In the sections below, we drill down into this traffic loss, looking at outages at a network level, and the impact of those outages at an administrative unit and city level.
The mobile network shutdowns have also impacted the profile of traffic that Cloudflare sees from Pakistan. In analyzing traffic from desktop devices vs. mobile devices, we observed a 60% drop in request volume from mobile devices, while desktop traffic request volume remained fairly consistent. Peak mobile device traffic share dropped from 70% to 43%.
Cloudflare uses a bot score assigned to each request to indicate how likely it is that the request came from a bot or a human user. Since these shutdowns began, peak human request volume has dropped by 40%, while bot traffic has remained relatively consistent.
Mobile network shutdowns
On Wednesday, May 10, the Pakistan Telecommunication Authority (PTA) announced that Internet services would remain suspended across the country for an “indefinite” period, responding to a directive from the Ministry of the Interior to block mobile broadband services. As a result of the shutdowns associated with this directive, Cloudflare observed outages on the four major mobile providers within the country:
Although Pakistan has high mobile Internet usage, it appears that fixed broadband Internet connections are readily used as a backup when mobile connectivity becomes unavailable. Autonomous systems associated with fixed broadband networks saw significant increases in traffic when the mobile networks were shut down.
Interestingly, median latency within Pakistan also dropped slightly after mobile networks were shut down. Prior to the shutdown, median latency (as observed to Cloudflare and a set of other providers) was in the 90-100ms range, while afterwards, it has averaged closer to 75ms. This may be a result of users shifting to lower latency fixed broadband connections, as discussed above.
Administrative unit-level disruptions
Because the mobile network providers that were affected by the shutdown directive provide services nationwide, we also observed an impact to traffic across multiple administrative units within the country. None of these locations has experienced a complete outage, but peak traffic levels have clearly been declining in comparison to previous days.
Gilgit-Baltistan experienced the largest loss, where peak traffic has fallen nearly 60%. In Sindh, peak traffic is down around 35%, followed by Khyber Pakhtunkhwa, where it is down 30%. Islamabad and Azad Jammu and Kashmir have seen peak traffic declines of ~20%.
City-level disruptions
The impact of the mobile network shutdowns is also visible at a more local level, with lower peak traffic levels clearly visible in four cities. The significant traffic loss has been in Peshawar (Khyber Pakhtunkhwa), which has dropped nearly 55% from prior days. Faisalabad (Punjab), Karachi (Sindh), and Multan (Punjab) have all seen peak traffic drop approximately 40%.
Content blocking
In addition to the government-directed mobile network shutdowns, Pakistan’s authorities have also ordered Internet service providers to block access to social media platforms including Facebook, Instagram, YouTube, and Twitter. Testing by the Open Observatory for Network Interference (OONI), an Internet censorship measurement organization, suggests that this blocking is using a combination of TLS-level interference and DNS-based blocking. When the latter occurs in a country, Cloudflare’s 1.1.1.1 DNS resolver often sees an increase in request volume from the country as users seek ways to continue to access the open Internet.
Over the last several days, as expected, 1.1.1.1 request volume from Pakistan has increased, up approximately 40%. Peak request volume for the blocked social media platforms has also increased. Traffic for facebook.com saw a significant increase starting around 14:00 UTC (19:00 local time) on May 9, with peak request volume more than doubling. Request volume for instagram.com, also owned by Facebook parent Meta, also began to increase around the same time, and has grown nearly 50%. Requests for twitter.com began to spike around 08:00 UTC (13:00 local time) on May 9, growing as much as 150% that afternoon. Request volume for youtube.com also spiked on May 9, increasing by approximately 40%. And like twitter.com, request volume on May 10 was higher than earlier in the week, but lower than the spike seen the previous day.
Conclusion
Because of the ubiquity of Internet connectivity and social media tools in everyday life, Internet shutdowns and website blocking ultimately come with a significant human and financial cost. The mobile network shutdowns in Pakistan have impacted tens of thousands of “gig workers” and freelancers that depend on mobile connectivity. Many point-of-sale terminals in the country also depend on mobile connectivity, with transactions through Pakistan’s main digital payment systems fell by around 50% after the shutdowns were put into place. Telecommunications operators within Pakistan have estimated the extent of the financial damage thus far to be Rs. 820 million (approximately $2.8 million USD).
Use Cloudflare Radar to monitor the impact of such government-directed Internet disruptions, and follow @CloudflareRadar on Twitter for updates on Internet disruptions as they occur.
When major events in a country happen Internet traffic patterns are often impacted, depending on the type of event. But what about the coronation of a king or queen? There’s no similar precedent, with a worldwide impact, in the Internet age, except maybe the coronation of the king of Thailand, in 2019. The last time it happened in the United Kingdom was 70 years ago (June 2, 1953), with Queen Elizabeth II; it was the first British coronation to be fully televised. Neither the Internet nor ARPANET were around at the time.
Imagine a grand royal event (if you saw the broadcast or the news, there’s no need), filled with pomp and pageantry, that's so captivating it impacts Internet traffic. That's what happened during the coronation of Charles III and Camilla, the newly crowned king and queen of the United Kingdom and other Commonwealth realms. As the coronation ceremony unfolded, on Saturday morning, May 6, 2023, there were clear spikes and dips in traffic, each coinciding with key moments of the ceremony.
Then came Sunday, and with it, the Coronation Big Lunch event. As the nation sat down to enjoy a communal meal throughout the country, Internet traffic took a significant nosedive, dropping by as much as 18%. The Sunday trends didn't stop there. As night fell and Prince William took to the stage to deliver a speech during the Coronation Concert, there was a clear drop in Internet traffic. Monday, May 8, was a bank holiday in the UK in honor of the coronation, and after a weekend of outdoor coronation events, Internet traffic was buzzing, noticeably higher than usual.
In the past, we’ve seen Internet traffic drop when a national televised event is happening — last year, we saw it, including in the UK, during the Eurovision, although traffic does increase when results are in. Different types of events and broadcasts yield different Internet patterns.
Coronation day: a rollercoaster of Internet traffic
Let's take a closer look at coronation day, May 6, 2023, when Internet traffic in the UK had its own peaks and valleys. There were moments when the digital realm seemed to hold its breath, with traffic dipping to its lowest points. The arrival of the royals and their guests marked one such moment. As the anticipation built and all eyes turned to the grand entrances, Internet traffic dipped to a notable 7% lower than the previous week.
Here's a play-by-play of the day's traffic trends, compared to the previous week. We’re using a 15-minute granularity, and aligning with key events as reported live by the BBC:
When the royals and guests were arriving at Westminster Abbey. The King and Queen arrived at 11:00.
#2 — 12:00 (-2%)
When King Charles III (12:02) was crowned.
#3 — 13:00 (-3%)
When King Charles and Queen Camilla left Westminster Abbey. The Coronation Procession started.
On Saturday, May 6, 2023, a downward trend in traffic began after 06:15, with traffic 5% lower than the previous week. This trend shifted to a traffic increase after 11:15 (+6%), coinciding with the ongoing ceremony. The exceptions were the previously mentioned traffic dips. The following table illustrates clear traffic spikes after significant moments, some of which are represented in the previous table. Here's a list of periods with higher growth:
This happened after the military flypast (14:35), when the royals were on the balcony of Buckingham Palace.
#2 — 12:30 (+13.7%)
After King Charles III was crowned at 12:02 (at which time traffic dropped 2%) and after Queen Camilla (12:16) was crowned, when a choir was singing Agnus Dei (12:30).
#3 — 15:30-16:15 (+13%)
During the highlights of the event and reactions from royal fans.
#4 — 14:00 (+13%).
When the UK’s national anthem was played in the gardens of Buckingham Palace.
#5 — 11:30 (+11%).
Just after the coronation oath and during the choir’s singing.
As guests and royals arrived and during moments like the king's crowning, Internet traffic noticeably dropped. However, during parts of the ceremony such as the choir singing, Internet traffic seemed to increase. That was also clear after the military flypast, over the Buckingham Palace balcony.
The following chart illustrates UK Internet traffic during the weekend, with the purple dotted line representing the previous weekend.
On a daily basis, daily traffic was 4% higher on Saturday, May 6, compared to the previous Saturday.
The Big Lunch and Prince William’s speech
Another trend from the coronation weekend relates to the events that took place on Sunday, May 7. Internet trends here align with what we observed almost a year ago during Queen Elizabeth II's Platinum Jubilee. Sunday was a day of celebration with both the Coronation Big Lunch (where neighbors and communities were invited to share food and fun together across the country) and the Coronation Concert taking place.
Next, we present the percentages of increase/decrease in requests during this past weekend, compared with the previous week (a slightly different perspective from the previous chart):
On Sunday, May 7, it's clear that UK traffic was lower than usual right after 07:00 local time (-2% in traffic), but it dropped the most after 12:00 (-5%), compared to the previous week. The moment with the biggest drop in traffic, compared to the previous week, was between 14:15 and 15:30, when traffic was around 18% lower. That was still Big Lunch time, given that it’s a multiple hour event full of “food and fun” — there were more than 65,000 Coronation Big Lunch events around the UK. During last year's Queen Elizabeth II's Platinum Jubilee, traffic dropped as much as 25% on Sunday, June 5, 2022, at 15:00.
At night, the Coronation Concert took center stage, broadcast live from Windsor Castle on the BBC after 20:00. The lineup included musical guests such as Take That, Lionel Richie, Katy Perry, and Andrea Bocelli. However, the star of the event, at least in terms of when Internet traffic was at its lowest that evening, was William, Prince of Wales. Cloudflare observed another significant drop in traffic, compared to the previous week, around 21:15-21:30, when traffic was 7% lower than the previous week. At that time, Lionel Richie had just performed, and Prince William was on stage for a special address to the king.
In terms of daily traffic, if on Coronation Saturday we saw an increase (4%), on Coronation Sunday there was a 6% drop compared to the previous week. On Monday, the coronation bank holiday, there weren't any major coronation events, and traffic was 4% higher than the previous week (May 1, also a bank holiday in the UK).
Coronation, a mobile devices day
Zooming in on the distribution of traffic from mobile devices, we find that Saturday, May 6, stands out in 2023. On this day, mobile traffic accounted for 61% of total traffic, a figure only matched by April 15 and January 1, 2023. Similarly, Sunday, May 7, was one of the Sundays with the highest percentage of mobile traffic, at 60%. This percentage was only surpassed by Easter Sunday, April 9 (60.4%), and, unsurprisingly, January 1, 2023 (61%).
Wales sees the largest Sunday drop in Internet traffic
Which UK countries were more impacted? Looking at both coronation weekend days, we saw a similar pattern (growth in traffic at around the time of the coronation ceremony on Saturday, and decrease on Sunday) in all of them. Looking at the Sunday drop, England had as much as 16% in traffic at 15:30; Scotland had as much as a 17% drop at around 13:30; Wales had as much as a 19% drop at around 15:00; and Northern Ireland had as much as an 18% drop in traffic, compared to the previous week, at the same time. Wales had the biggest drop.
From Canada to Australia
Last year, in early June, we observed the impact of Queen Elizabeth II’s Platinum Jubilee on the Internet in the UK. This event, which celebrated the first British monarch to reach a 70th anniversary on the throne, caused a significant drop in traffic, as much as 25% (on Sunday, June 5, 2022). This trend was also noticeable in other Commonwealth countries.
Several Commonwealth countries also held notable events to celebrate both the Queen’s Platinum Jubilee and the recent coronation. In Canada, events and activities related to the coronation mirrored those for the Queen’s Platinum Jubilee. Whether related or not, we observed on Saturday, May 6, as much as an ~8% drop in Internet traffic compared to the previous week, between 09:30 and 16:30 Toronto time. On Sunday, the drop was even larger, with about 10% less traffic between 10:30 and 12:00.
In Australia, the difference in traffic wasn't as pronounced as in Canada. However, traffic was 7% lower than the previous week at 20:00 Sydney time (10:00 UTC), when the coronation ceremony began on May 6. This was the only period over the past weekend when traffic was lower than the previous one.
Social media and royals trends
And what about the impact on DNS traffic to our 1.1.1.1 resolver from UK users? Social media apps certainly felt the ripple. Domains linked to social media platforms, which typically surge in popularity during major events, such as Twitter, experienced a notable uptick. We saw a 33% increase in DNS traffic in those around 14:00 local time on Saturday, May 6, compared to the previous week. By 18:00 on May 7, traffic had soared to 64% higher, and it remained elevated during the Coronation Concert: at 22:00, it was 36% higher.
Meanwhile, video-centric social media platforms, like TikTok, hit their peak at around 20:00 on May 7, when the Coronation Concert was starting, with a whopping 57% surge in DNS traffic.
During the coronation weekend, the peak period for DNS traffic to domains related to the royal family fell between 11:00 and 12:00 local time. In this hour, traffic was an impressive forty times higher than the same time the previous weekend (that growth is higher, more than 40x, when using a May 2022 baseline, as is seen in the next chart).
If we broaden our view to the past 12 months, we see that the domains associated with the royal family hit their highest point on the day Queen Elizabeth II passed away, September 8. Around 18:00 local time, DNS traffic was 12x higher than the previous week. This was followed by the day of Her Majesty's funeral, September 19, when around 11:00, DNS traffic was 6x higher than usual.
A similar impact was seen, related to the Queen's death, on British news organizations, in the past 12 months. September 8, around 18:00, was the peak of the whole year in terms of DNS traffic to news organizations, according to our data. At that time, DNS traffic was 263% higher than at the same time in the previous week. During the September 19 funeral, at 11:00, DNS traffic was 24% higher than before.
During the recent coronation weekend, DNS traffic to UK news organizations on Saturday, May 6, was higher than usual during the morning by as much as 47%, at 11:00, and continued higher than before mostly during that day.
September 8, 2022: The end of a 70-year reign
We already mentioned domain trends related to when Queen Elizabeth II passed away on September 8, 2022. But what about the impact on Internet traffic? We saw a 7% decrease in Internet traffic in the UK on that day at around 18:30 local time compared to the previous week, coinciding with the announcement of her death.
The following weekend, on Saturday, September 10, 2022, traffic was as much as 17% lower at 15:00. This was the day Charles was proclaimed the new king and people flocked to the royal palaces to pay their respects — Prince William and Kate, and Prince Harry and Meghan, paused outside Windsor Castle to read messages left by mourners.
Internet traffic dropped even further compared to the previous week during Queen Elizabeth II’s funeral: on September 19, 2022, traffic was 27% lower at 10:45. According to Wikipedia, this was when the Queen's coffin was transported from Westminster Hall to Westminster Abbey on the State Gun Carriage of the Royal Navy.
Old traditions in a recent medium
In this blog post, we've seen how a very old tradition, like the British coronation, can impact a very recent innovation, the Internet. Almost 70 years ago, Queen Elizabeth II's coronation was the first ever to be televised, at a time when television in the UK was less than 20 years old. The event, which took place at Westminster Abbey in London (the site of coronations since 1066), was watched by 27 million people in the UK alone and millions more around the world.
This time around, King Charles III's coronation could be viewed through that now old medium called television, or online, via streaming services. The Internet is much younger than Britain’s former monarch's reign or even Sir Tim Berners-Lee (born in 1955), and it was only 30 years ago that the World Wide Web protocol and code were made available royalty-free, enabling the web's widespread use.
Streaming media events online, on the other hand, at least on a large scale, are a more recent development — YouTube was launched in 2005. Looking at video platforms trends in the UK, we could see how DNS traffic was 13% higher at around 12:00, during the coronation ceremony, on May 6 — it was broadcast on YouTube.
British broadcasters, such as the BBC, also included a streaming version of the event. There, the increase in DNS traffic was even higher. Between 11:00 and 12:00, on May 6, DNS traffic was 197% higher than in the previous week.
The difference in DNS traffic to UK's streaming services was even more pronounced when Queen Elizabeth II passed away on September 8, with a 470% increase in DNS traffic around 18:00 compared to the previous week. During the Queen's funeral on September 19, DNS traffic was 150% higher around 11:00 compared to the previous week.
On Saturday, April 15, 2023, an armed conflict between rival factions of the military government of Sudan began. Cloudflare observed a disruption in Internet traffic on that Saturday, starting at 08:00 UTC, which deepened on Sunday. Since then, the conflict has continued, and different ISPs have been affected, in some cases with a 90% drop in traffic. On May 2, Internet traffic is still ~30% lower than pre-conflict levels. This blog post will show what we’ve been seeing in terms of Internet disruption there.
On the day that clashes broke out, our data shows that traffic in the country dropped as much as 60% on Saturday, after 08:00 UTC, with a partial recovery on Sunday around 14:00, but it has consistently been lower than before. Although we saw outages and disruptions on major local Internet providers, the general drop in traffic could also be related to different human usage patterns because of the conflict, with people trying to leave the country. In Ukraine, we saw a clear drop in traffic, not always related to ISP outages, after the war started, when people were leaving the country.
Here’s the hourly perspective of Sudan’s Internet traffic over the past weeks as seen on Cloudflare Radar, with the orange shading highlighting the disruption since April 15.
The next chart of daily traffic in Sudan (that is dominated by mobile device traffic — more on that below) clearly shows a daily drop in traffic after April 15. On that Saturday, traffic was 27% lower than on the previous Saturday, and it was a 43% decrease on Sunday, April 16, compared to the previous week.
Frequent outages on different ISPs
On April 23 and 24, there was a more significant outage affecting multiple ISPs (and their ASNs or autonomous systems) that brought Internet traffic in the country, as the previous chart clearly shows, even lower. There was no official reason given for those major disruptions that had a nationwide impact. That said, the disruptions were also felt in neighbor country Chad in several ISPs, given that Sudan’s Sudatel (AS15706) seems to be an upstream provider.
Cloudflare saw a 74% decrease in traffic on Sunday, April 23, compared to Sunday, April 9, before the conflict, and a 70% drop on Monday, April 24, compared with Monday, April 10. In some ISPs, the impact was bigger.
In the news, ISP MTN (AS36972) reportedly blocked Internet services on April 16, and, according to Reuters, was told by the authorities to restore it a few hours after. We saw a clear outage in that ASN, an almost 90% drop in traffic compared with previous weeks for about 10 hours, after 00:00 UTC on April 16, and it mostly recovered after 10:00 UTC.
The most impacted ISPs were Sudatel (AS15706), Zain (AS36998), and Canar (AS33788) with almost complete outages. Canar was the outage that lasted the longest, with 83 hours, from April 21 to 25. Next, it was the main ISP in the country, Sudatel, with 40 hours of almost complete Internet blackout, followed by Zain, with 10 hours on April 24.
The return of traffic coincided with the time a nationwide ceasefire of 72 hours was agreed upon on April 24.
BGP or Border Gateway Protocol is a mechanism to exchange routing information between networks on the Internet, and a crucial part that enables the existence of the network of networks (the Internet). BGP announcements or updates can signal disruption in connectivity or outages, as we saw in Canada in 2022 with Rogers ISP or in the UK in 2023 with Virgin Media, for example. In this case, highlighted in the next chart, BGP updates biggest spikes from Sudatel (AS15706) are consistent with both the start of the outage, and the return to traffic.
Mobile device traffic percentage grew after April 15
Sudan is typically one of the countries with the highest percentage of mobile device traffic in the world. We’ve written about this in the past (see the 2021 mobile device traffic blog post), and at the time the average was 83%. Observing data from the past week, as seen on our Cloudflare Radar traffic worldwide page, Sudan leads our ranking with 88% of traffic coming from mobile devices.
Looking at the past few weeks, we can see mobile device traffic growing as a percentage of all Internet traffic in Sudan. The April 3 week showed a lower percentage than it is now, with 77% (23% was desktop traffic percentage). In the April 10 week, which includes April 15 and 16, mobile device traffic rose to 80%. In the week of April 17, it was 85%, and the week of April 24, it’s 88%.
How is Internet traffic holding up more recently in Sudan? Looking at a week-over-week hourly comparison, traffic last Friday was still around 55% lower than before April 15, and on May 2, traffic is still around 30% lower than pre-conflict levels (April 11).
In the previous chart, there’s a regular drop in traffic observed at around 16:00 UTC, ~18:00 local time. It’s more evident before April 15, but it generally continues after that. That drop in traffic is consistent with Ramadan trends we discussed recently in a blog post. It is related to the Iftar, the first meal after sunset that breaks the fast and often serves as a family or community event — sunset in Khartoum, Sudan, is at 18:07.
As of this Tuesday, Internet traffic data (from a linear perspective) shows that traffic continues to be much lower than before, and this morning at 08:00 UTC it is ~30% lower than it was three weeks ago (pre-conflict), at the same time, showing some recovery in the past couple of days.
According to the BBC, reporting from Sudan, the Internet continues to be impacted, an observation that is consistent with our data.
Looking more closely at Sudan’s capital, Khartoum, where most people live and the conflict began, traffic was impacted after April 15 (the blue line in the next chart). On April 27, Internet traffic was around 76% lower than it was on the same pre-conflict weekday (April 13). The next chart also shows the typical drop around 18:00, for Ramadan’s Iftar, the first meal after sunset.
Changes in messaging and social media trends
Looking at DNS queries (from Cloudflare’s resolver) to websites or domains in Sudan, we saw a clear shift from the use of WhatsApp-related domains for messaging to Signal ones after April 15 — the drop in DNS traffic to WhatsApp was similar to the increase in DNS traffic to Signal domains.
Social media platforms such as LinkedIn, but also TikTok or YouTube, had a clear decrease since April 15. On the other hand, Facebook and Twitter saw an increase, especially on April 15 and 16, with some disruptions (possibly related to Internet access), but with bigger spikes than before, usually at night, since then. Here’s the aggregated view to social media platforms:
Conclusion: ongoing impact
The conflict in Sudan continues, and so does its Internet traffic impact. We will continue to monitor the Internet situation on Cloudflare Radar, where you can check Sudan’s country page and the Outage Center.
Cloudflare operates in more than 285 cities in over 100 countries, where we interconnect with over 11,500 network providers in order to provide a broad range of services to millions of customers. The breadth of both our network and our customer base provides us with a unique perspective on Internet resilience, enabling us to observe the impact of Internet disruptions.
We entered 2023 with Internet disruptions due to causes that ran the gamut, including several government-directed Internet shutdowns, cyclones, a massive earthquake, power outages, cable cuts, cyberattacks, technical problems, and military action. As we have noted in the past, this post is intended as a summary overview of observed disruptions, and is not an exhaustive or complete list of issues that have occurred during the quarter.
Government directed
Iran
Over the last six-plus months, government-directed Internet shutdowns in Iran have largely been in response to protests over the death of Mahsa Amini while in police custody. While these shutdowns are still occurring in a limited fashion, a notable shutdown observed in January was intended to prevent cheating on academic exams. Internet shutdowns with a similar purpose have been observed across a number of other countries, and have also occurred in Iran in the past. Access was restricted across AS44244 (Irancell) and AS197207 (MCCI), with lower traffic levels observed in Alborz Province, Fars, Khuzestan, and Razavi Khorasan between 08:00 to 11:30 local time (04:30 to 08:00 UTC) on January 19.
A shutdown of mobile Internet connectivity in Punjab, India began on March 19, ordered by the local government amid concerns of protest-related violence. Although the initial shutdown was ordered to take place between March 18, 12:00 local time and March 19, 12:00 local time, it was extended several times, ultimately lasting for three days. Traffic for AS38266 (Vodafone India), AS45271 (Idea Cellular Limited), AS45609 (Bharti Mobility), and AS55836 (Reliance Jio Infocomm) began to fall around 12:30 local time (07:00 UTC) on March 18, recovering around 12:30 local time (07:00 UTC) on March 21. However, it was subsequently reported that connectivity remained shut down in some districts until March 23 or 24.
Cable cuts
Bolivia
Bolivian ISP Cometco (AS27839)reported on January 12 that problems with international fiber links were causing degradation of Internet service. Traffic from the network dropped by approximately 80% starting around 16:00 local time (20:00 UTC) before returning to normal approximately eight hours later. It isn’t clear whether the referenced international fiber links were terrestrial connections to neighboring countries, or issues with submarine cables several network hops upstream. As a landlocked country, Bolivia is not directly connected to any submarine cables.
A brief connectivity disruption was observed on Bangladeshi provider Grameenphone on February 23, between 11:45-14:00 local time (05:45-08:00 UTC). According to a Facebook post from Grameenphone, the outage was caused by fiber cuts due to road maintenance.
Venezuela
Venezuela, and more specifically, AS8048 (CANTV), are no stranger to Internet disruptions, seeing several (Q1, Q2) during 2022, as well as others in previous years. During the last couple of days in February, a few small outages were observed on CANTV’s network in several Venezuelan states. However, a more significant near-complete outage occurred on February 28, starting around midnight local time (04:00 UTC), and lasting for the better part of the day, with traffic recovering at 17:30 local time (21:30 UTC). A Tweet posted the morning of February 28 by CANTV referenced an outage in their fiber optic network, which was presumably the cause.
Power outages
Pakistan
A country-wide power outage in Pakistan on January 23 impacted more than 220 million people, and resulted in a significant drop in Internet traffic being observed in the country. The power outage began at 07:34 local time (02:34 UTC), with Internet traffic starting to drop almost immediately. The figure below shows that traffic volumes dropped as much as 50% from normal levels before recovering around 04:15 local time on January 24 (23:15 UTC on January 23). This power outage was reportedly due to a “sudden drop in the frequency of the power transmission system”, which led to a “widespread breakdown”. Nationwide power outages have also occurred in Pakistan in January 2021, May 2018, and January 2015.
Bermuda
BELCO, the power company servicing the island of Bermuda, tweeted about a mass power outage affecting the island on February 3, and linked to their outage map so that customers could track restoration efforts. BELCO’s tweet was posted at 16:10 local time (20:10 UTC), approximately one hour after a significant drop was observed in Bermuda’s Internet traffic. The power outage, and subsequent Internet disruption, lasted over five hours, as BELCO later tweeted that “As of 9.45 pm [00:45 UTC, February 4], all circuits have been restored.”
Argentina
Soaring temperatures in Argentina triggered a large-scale power outage across the country that resulted in multi-hour Internet disruption on March 1. Internet traffic dropped by approximately one-third during the disruption, which lasted from 16:30 to 19:30 local time (19:30 to 22:30 UTC). Cities that experienced visible impacts to Internet traffic during the power outage included Buenos Aires, Cordoba, Mendoza, and Tucuman.
Kenya
Just a few days later on March 4, Kenya Power issued a Customer Alert at 18:25 local time (15:25 UTC) regarding a nationwide power outage, noting that it had “lost bulk power supply to various parts of the country due to a system disturbance.” The alert came approximately an hour after the country’s Internet traffic dropped significantly. A subsequent tweet dated midnight local time (21:00 UTC) claimed that “electricity supply has been restored to all areas countrywide” and the figure below shows that traffic levels returned to normal levels shortly thereafter.
Earthquake
Turkey
On February 5, a magnitude 7.8 earthquake occurred 23 km east of Nurdağı, Turkey, leaving many thousands dead and injured. The quake, which occurred at 04:17 local time (01:17 UTC), was believed to be the strongest to hit Turkey since 1939. The widespread damage and destruction resulted in significant disruptions to Internet connectivity in multiple areas of the country, as shown in the figures below. Although Internet traffic volumes were relatively low because it was so early in the morning, the graphs show it dropping even further at or around the time of the earthquake. Nearly half a day later, traffic volumes in selected locations were between 63-94% lower than at the same time the previous week. A month later, after several aftershocks, traffic volumes had mostly recovered, although some regions were still struggling to recover.
Weather
New Zealand
Called the “country’s biggest weather event in a century”, Cyclone Gabrielle wreaked havoc on northern New Zealand, including infrastructure damage and power outages impacting tens of thousands of homes. As a result, regions including Gisborne and Hawkes Bay experienced Internet disruptions that lasted several days, starting at 00:00 local time on February 14 (11:00 UTC on February 13). The figures below show that in both regions, peak traffic volume returned to pre-cyclone levels around February 19.
Vanuatu
Later in February, Cyclone Judy hit the South Pacific Ocean nation of Vanuatu, the South Pacific Ocean nation made up of roughly 80 islands that stretch 1,300 kilometers. The Category 4 cyclone damaged homes and caused power outages, resulting in a significant drop in the country’s Internet traffic. On February 28, Vanuatu’s traffic dropped by nearly 80% as the cyclone struck, and as seen in the figure below, it took nearly two weeks for traffic to recover to the levels seen earlier in February.
Malawi
Cyclone Freddy, said to be the longest-lasting, most powerful cyclone on record, hit Malawi during the weekend of March 11-12, and into Monday, March 13. The resulting damage disrupted Internet connectivity in the east African country, with traffic dropping around 11:00 local time (09:00 UTC) on March 13. The disruption lasted for over two days, with traffic levels recovering around 21:00 local time (19:00 UTC) on March 15.
Technical problems
South Africa
Just before 07:00 local time (05:00 UTC) on February 1, South African service provider RSAWEB initially tweeted about a problem that they said was impacting their cloud and VOIP platforms. However, in several subsequent tweets, they noted that the problem was also impacting internal systems, as well as fiber and mobile connectivity. The figure below shows traffic for RSAWEB dropping at 06:30 local time (04:30 UTC), a point at which it would normally be starting to increase for the day. Just before 16:00 local time (14:00 UTC), RSAWEB tweeted“…engineers are actively working on restoring services post the major incident. Customers who experienced no connectivity may see some services restoring.” The figure below shows a sharp increase in traffic around that time with gradual growth through the evening. However, full restoration of services across all of RSAWEB’s impacted platforms took a full week, according to a February 8 tweet.
Italy
An unspecified “international interconnectivity problem” impacting Telecom Italia caused a multi-hour Internet disruption in Italy on February 5. At a country level, a nominal drop in traffic is visible in the figure below starting around 11:45 local time (10:45 UTC) with some volatility visible in the lower traffic through 17:15 local time (16:15 UTC). However, the impact of the problem is more obvious in the traffic graphs for AS3269 and AS16232, both owned by Telecom Italia. Both graphs show a more significant loss of traffic, as well as greater volatility through the five-plus hour disruption.
Myanmar
A fire at an exchange office of MPT (Myanma Posts and Telecommunications) on February 7 disrupted Internet connectivity for customers of the Myanmar service provider. A Facebook post from MPT informed customers that “We are currently experiencing disruptions to our MPT’s services including MPT’s call centre, fiber internet, mobile internet and mobile and telephone communications.” The figure below shows the impact of this disruption on MPT-owned AS9988 and AS45558, with traffic dropping significantly at 10:00 local time (03:30 UTC). Significant recovery was seen by 22:00 local time (15:30 local time).
Republic of the Congo (Brazzaville)
Congo Telecomtweeted a “COMMUNIQUÉ” on March 15, alerting users to a service disruption due to a “network incident”. The impact of this disruption is clearly visible at a country level, with traffic dropping sharply at 00:45 local time (23:45 on March 14 UTC), driven by complete outages at MTN Congo and Congo Telecom, as seen in the graphs below. While traffic at MTN Congo began to recover around 08:00 local time (07:00 UTC), Congo Telecom’s recovery took longer, with traffic beginning to increase around 17:00 local time (16:00 UTC). Congo Telecom tweeted on March 16 that the nationwide Internet outage had been resolved. MTN Congo did not acknowledge the disruption on social media, and neither company provided more specific information about the reported “network incident”.
Lebanon
Closing out March, disruptions observed at AS39010 (Terranet) and AS42334 (Mobi) in Lebanon may have been related to a strike at upstream provider Ogero Telecom, common to both networks. A published report quoted the Chairman of Ogero commenting on the strike, “We are heading to a catastrophe if a deal is not found with the government: the network will completely stop working as our generators will gradually run out of fuel. Lebanon completely relies on Ogero for its bandwidth, leaving no one exempt from a blackout.” Traffic at both Terranet and Mobi dropped around 05:00 local time (03:00 UTC) on March 29, with the disruption lasting approximately 4.5 hours, as traffic recovered at 09:30 local time (07:30 UTC).
Cyberattacks
South Korea
On January 29, South Korean Internet provider LG Uplus suffered two brief Internet disruptions which were reportedly caused by possible DDoS attacks. The first disruption occurred at 03:00 local time (18:00 UTC on January 28), and the second occurred at 18:15 local time (09:15 UTC). The disruptions impacted traffic on AS17858 and AS3786, both owned by LG. The company was reportedly hit by a second pair of DDoS attacks on February 4.
Guam
In a March 17 tweet posted at 11:30 local time (01:30 UTC), Docomo Pacific reported an outage affecting multiple services, with a subsequent tweet noting that “Early this morning, a cyber security incident occurred and some of our servers were attacked”. This outage is visible at a country level in Guam, seen as a significant drop in traffic starting around 10:00 local time (00:00 UTC) in the figure below. However, in the graph below for AS3605 (ERX-KUENTOS/Guam Cablevision/Docomo Pacific), the cited outage results in a near-complete loss of traffic starting around 05:00 local time (19:00 on March 16 UTC). Traffic returned to normal levels by 18:00 local time on March 18 (08:00 UTC).
Ukraine/Military Action
In February, the conflict in Ukraine entered its second year, and over this past year, we have tracked its impact on the Internet, highlighting traffic shifts, attacks, routing changes, and connectivity disruptions. In the fourth quarter of 2022, a number of disruptions were related to attacks on electrical infrastructure, and this pattern continued into the first quarter of 2023.
One such disruption occurred in Odessa on January 27, amid news of Russian airstrikes on local energy infrastructure. As seen in the figure below, Internet traffic in Odessa usually begins to climb just before 08:00 local time (06:00 UTC), but failed to do so that morning after several energy infrastructure facilities near Odessa were hit and damaged. Traffic remained lower than levels seen the previous week for approximately 18 hours.
Power outages resulting from Russian attacks on energy generation and distribution facilities on March 9 resulted in disruptions to Internet connectivity in multiple locations around Ukraine. As seen in the figures below, traffic dropped below normal levels after 02:00 local time (00:00 UTC) on March 9. Traffic in Kharkiv fell over 50% as compared to previous week, while in Odessa, traffic fell as much as 60%. In Odessa, Mykolaiv, and Kirovohrad Oblast, traffic recovered by around 08:00 local time (06:00 UTC), while in Kharkiv, the disruption lasted nearly two days, returning to normal levels around 23:45 local time (21:45 UTC) on Friday, March 10.
Conclusion
The first quarter of 2023 seemed to be particularly active from an Internet disruption perspective, but hopefully it is not a harbinger of things to come through the rest of the year. This is especially true of government-directed shutdowns, which occurred fairly regularly through 2022. To that end, civil society organization Access Now recently published their Internet shutdowns in 2022 report, finding that In 2022, governments and other actors disrupted the internet at least 187 times across 35 countries. Cloudflare Radar is proud to support Access Now’s #KeepItOn initiative, using our data to help illustrate the impact of Internet shutdowns and other disruptions.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.