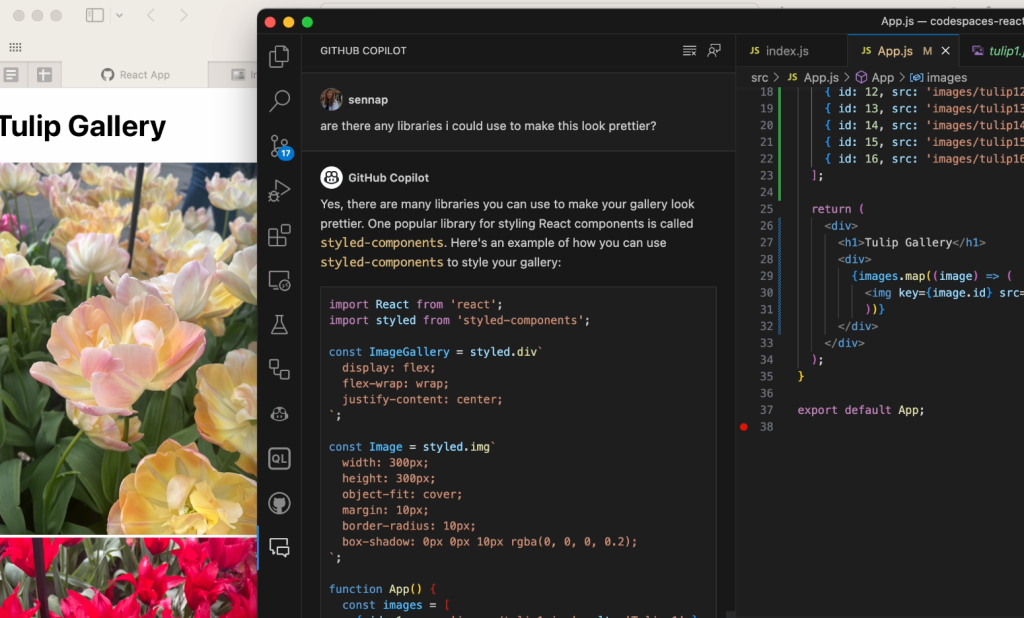
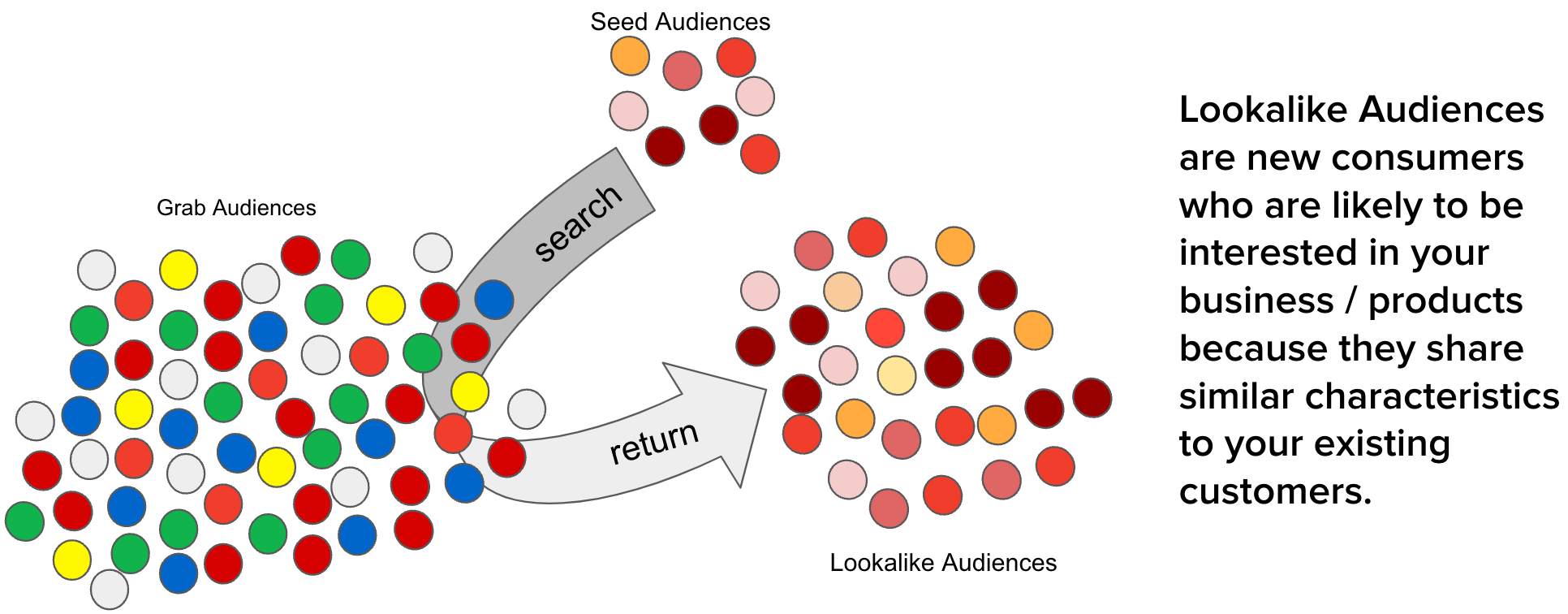
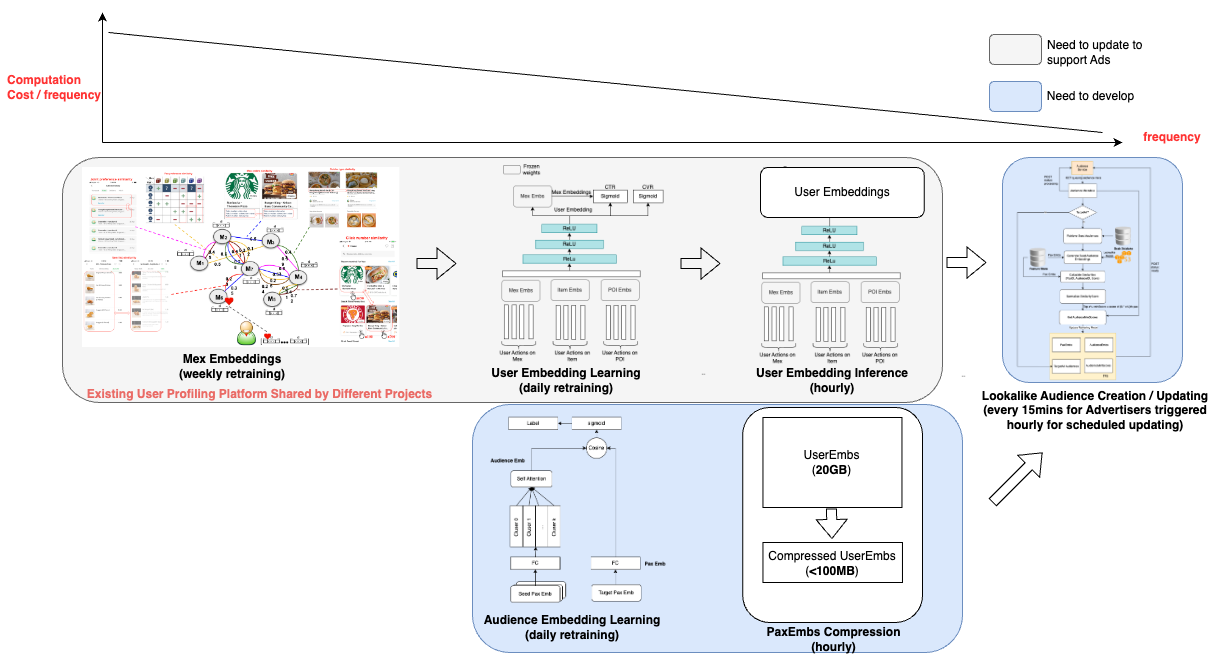
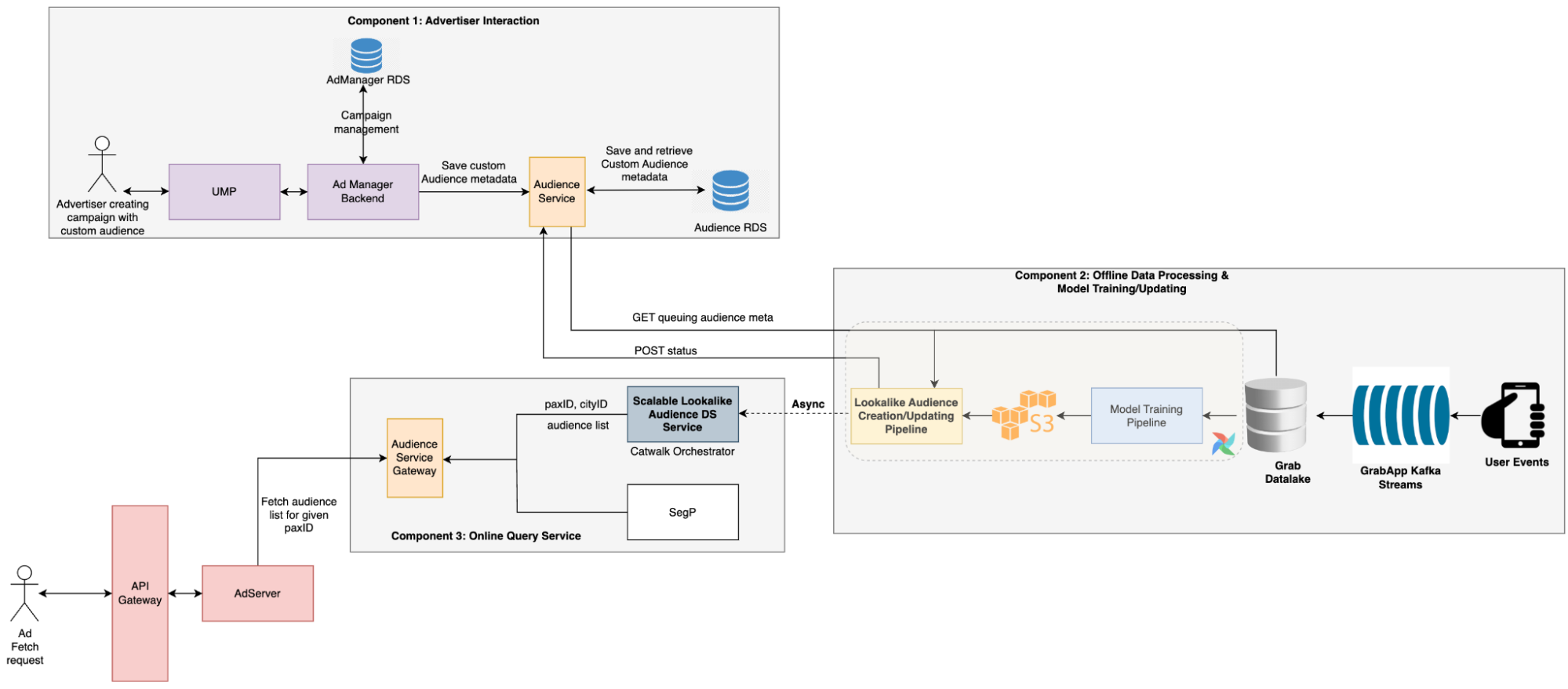
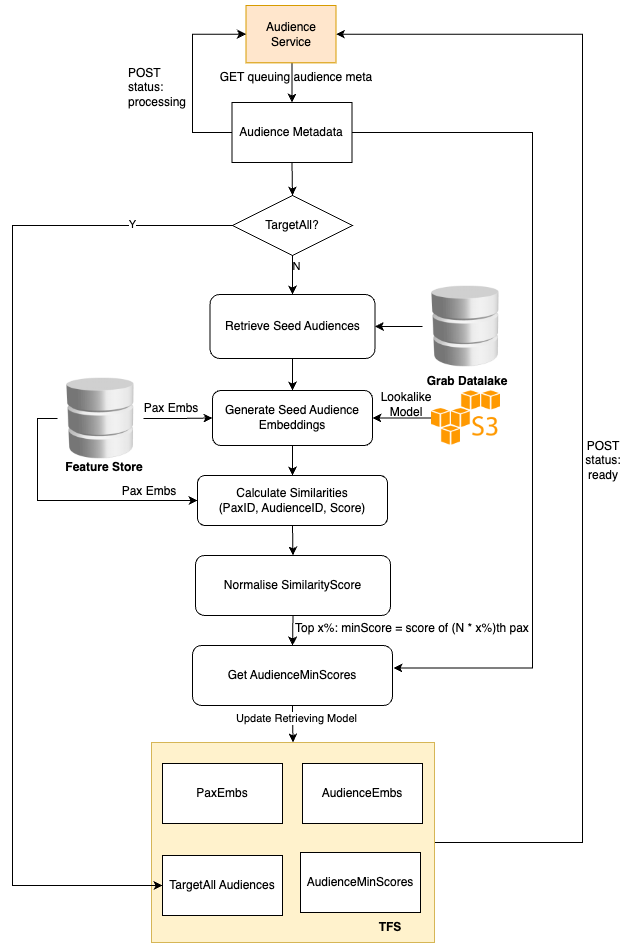
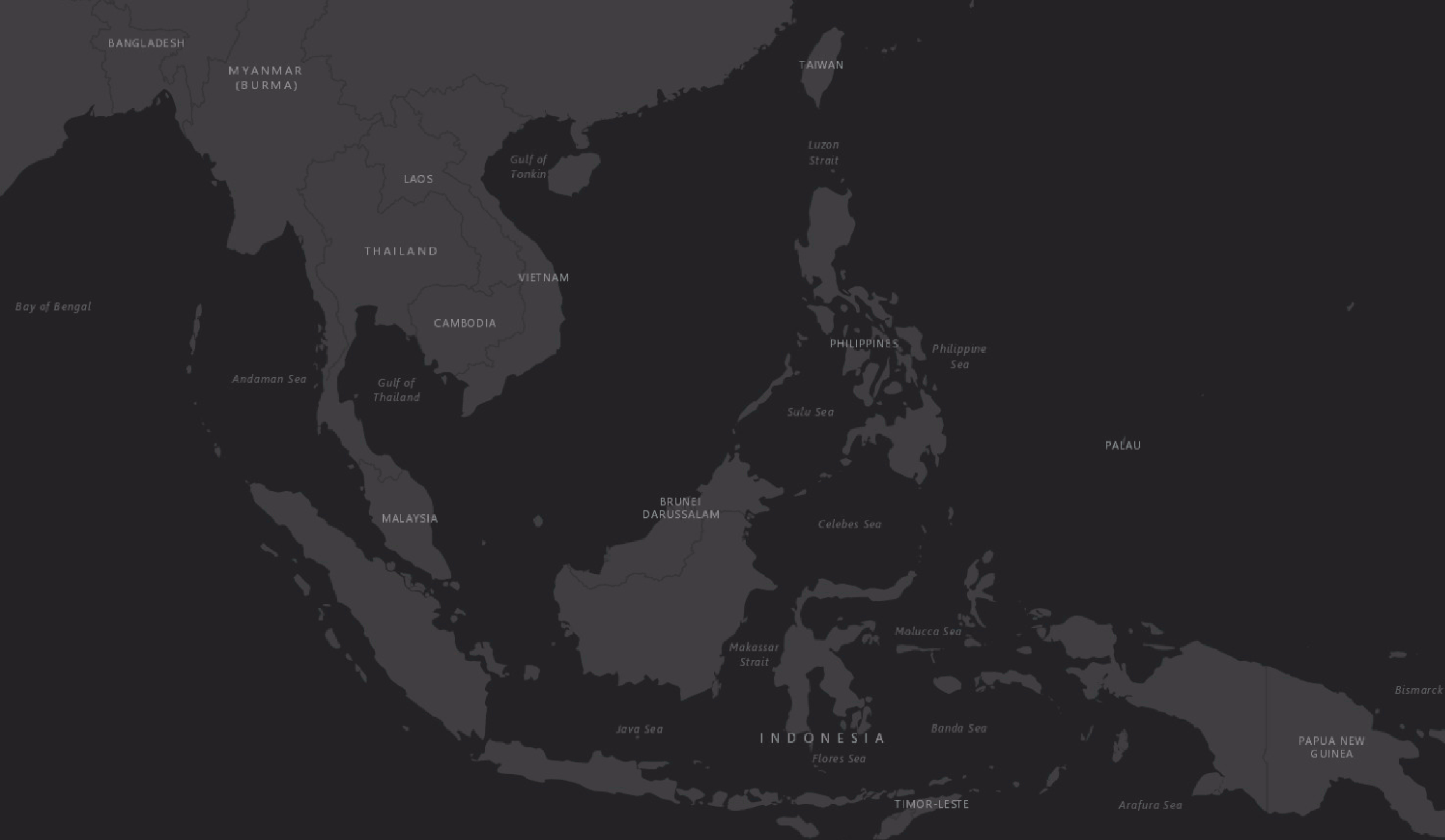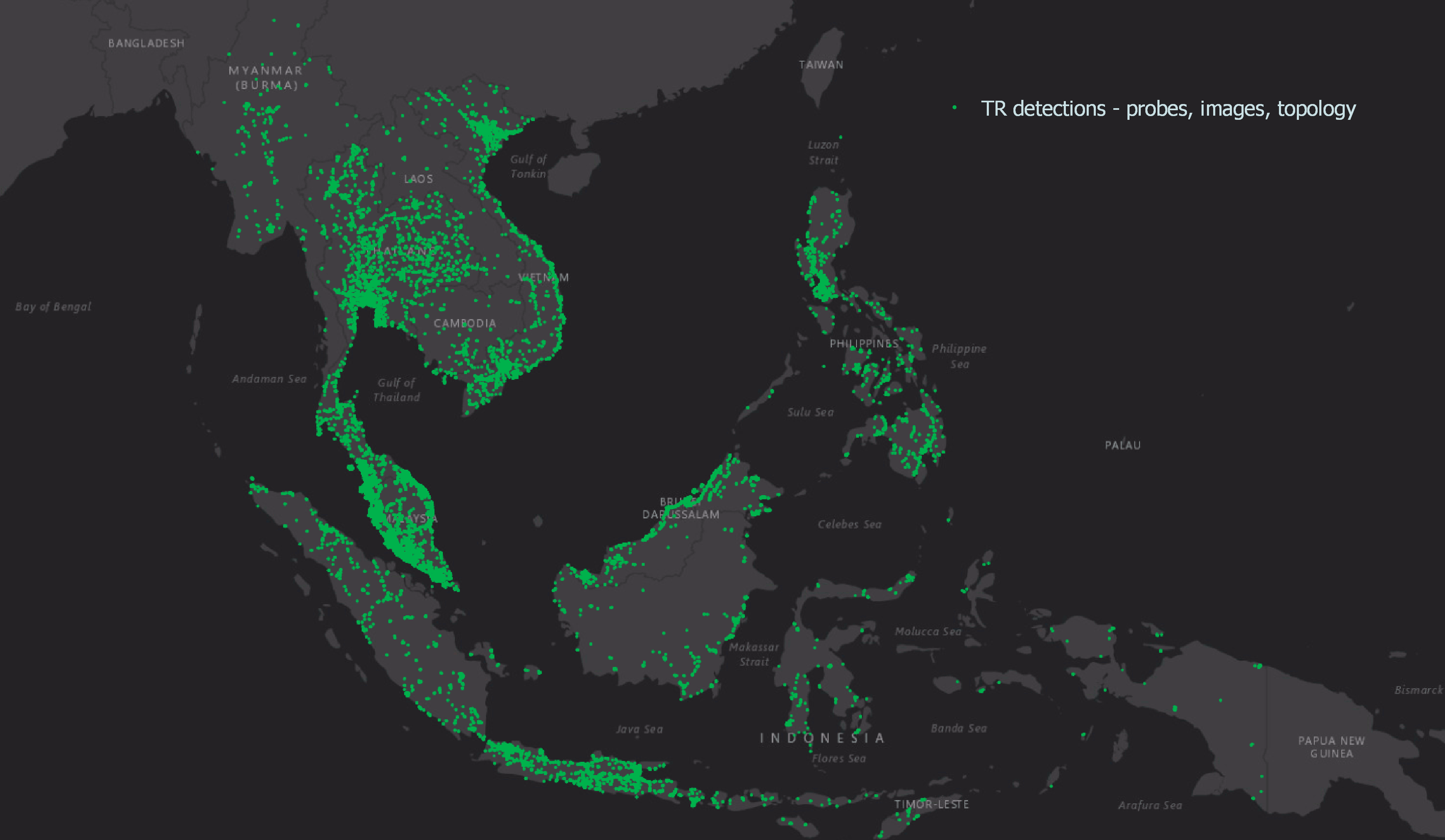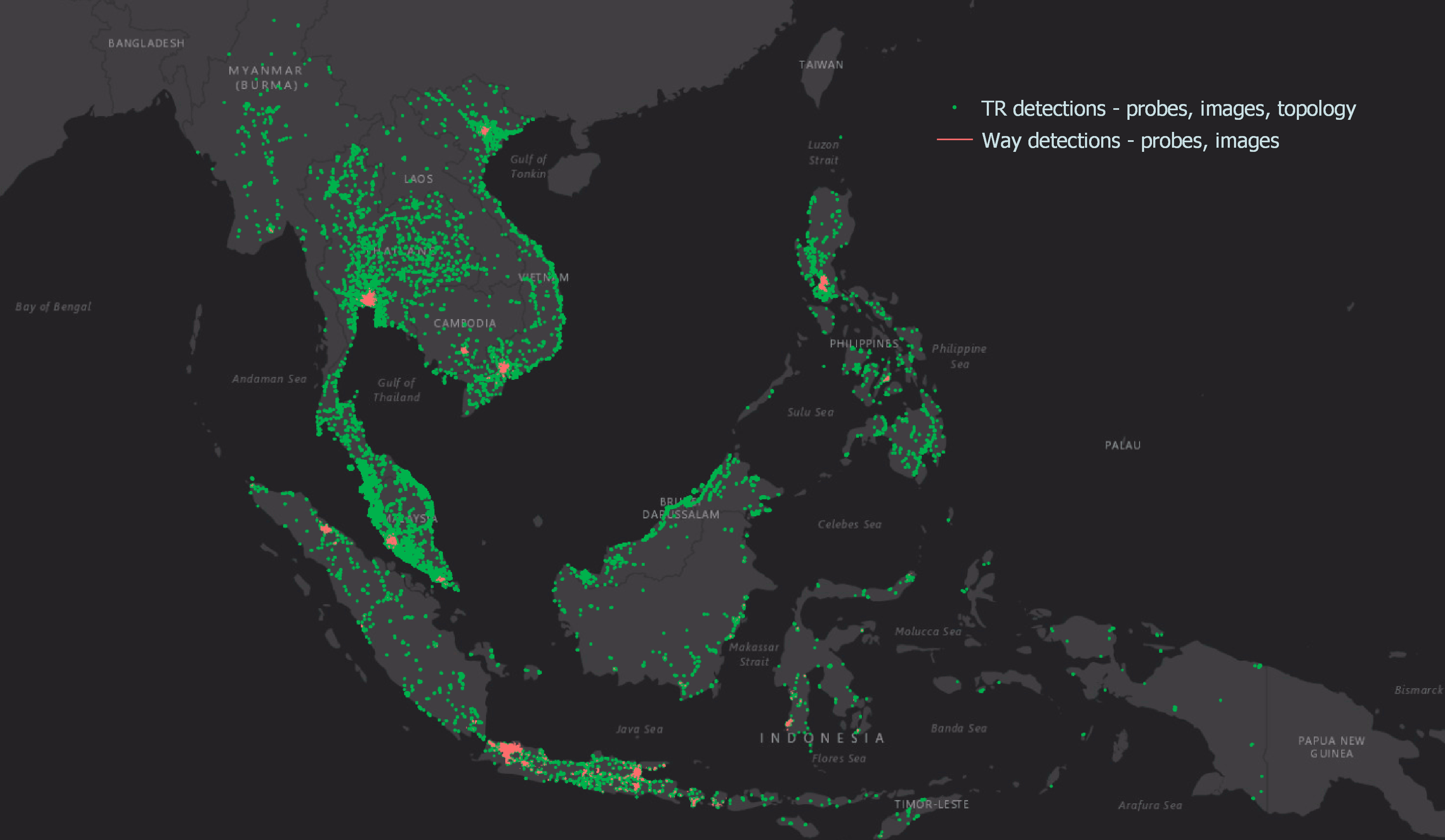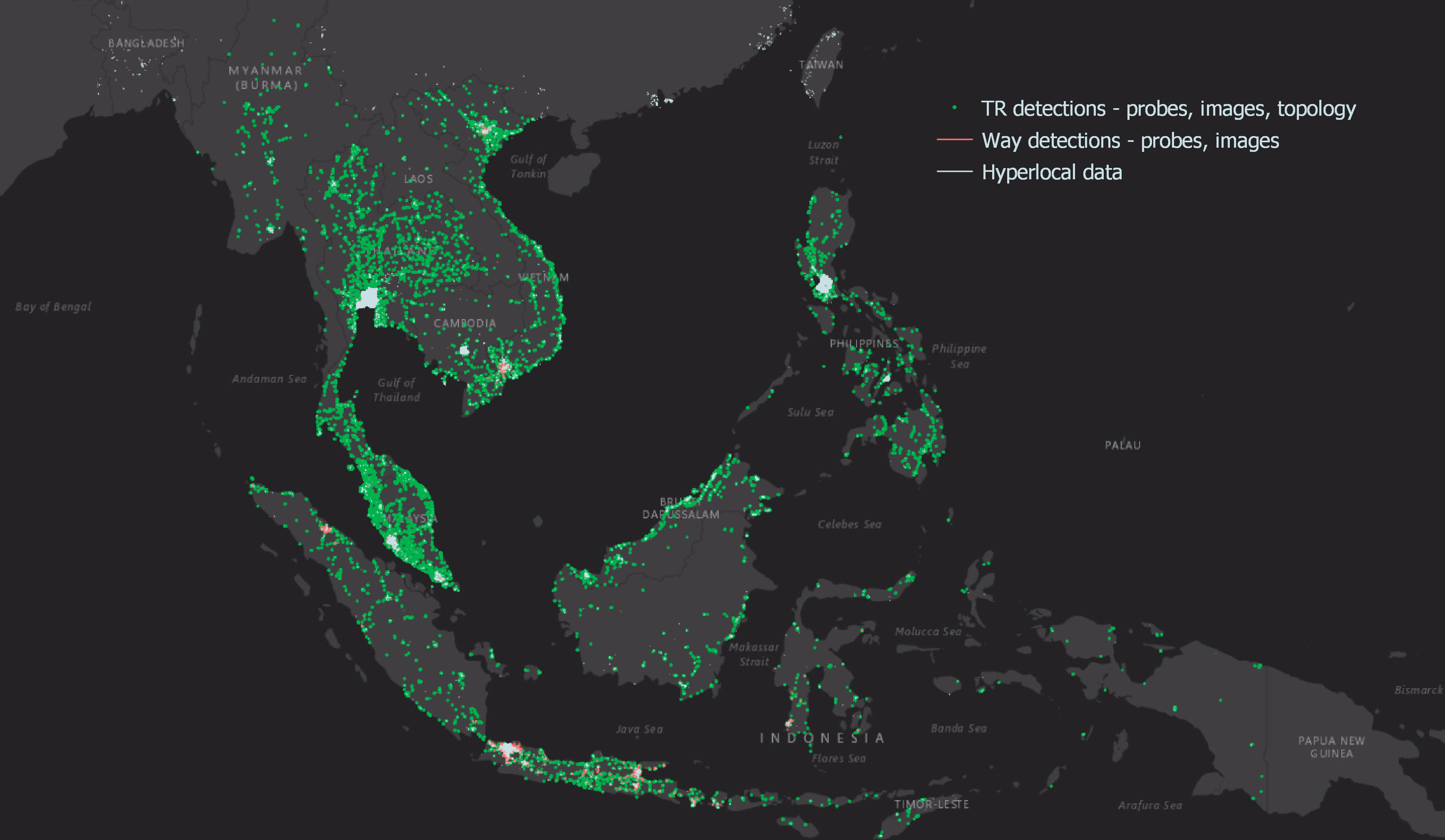
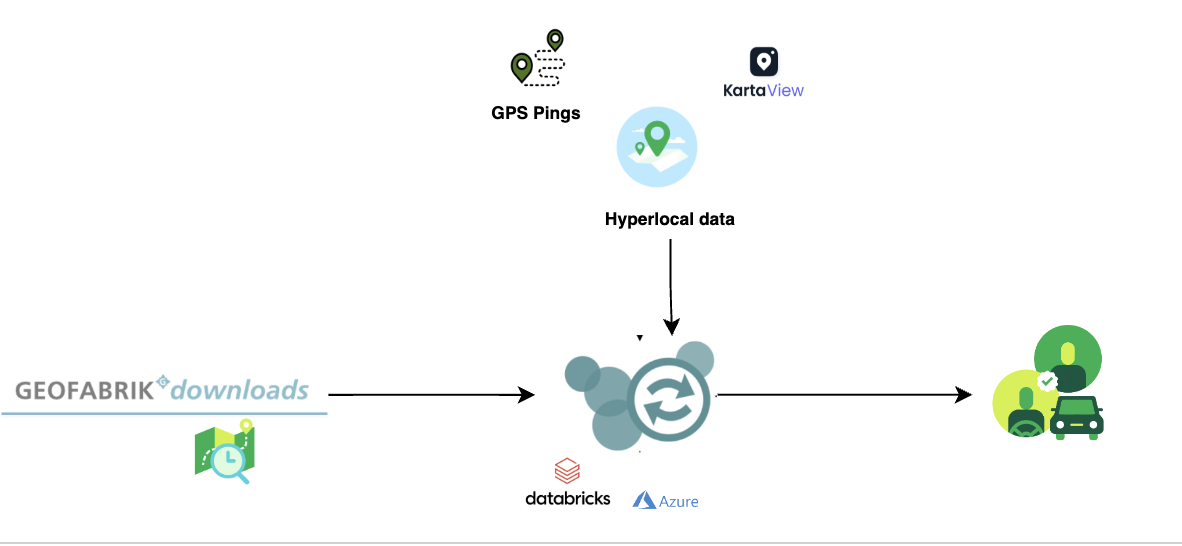
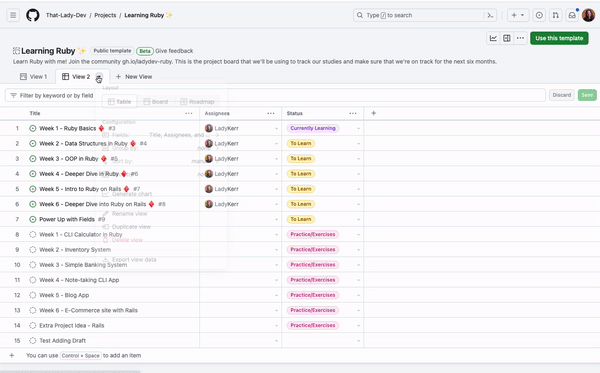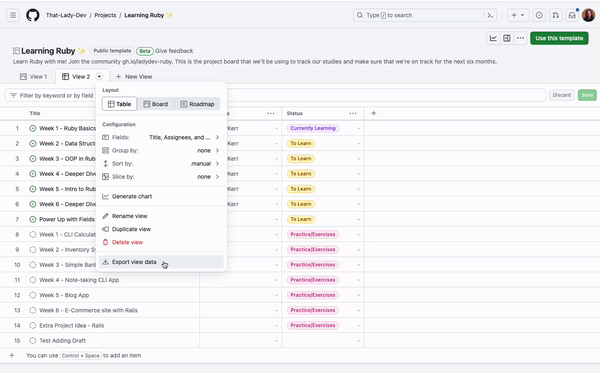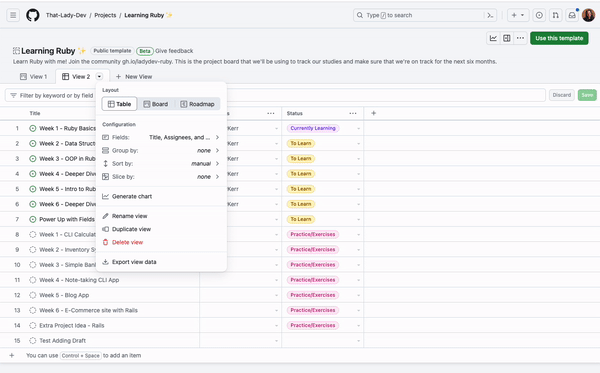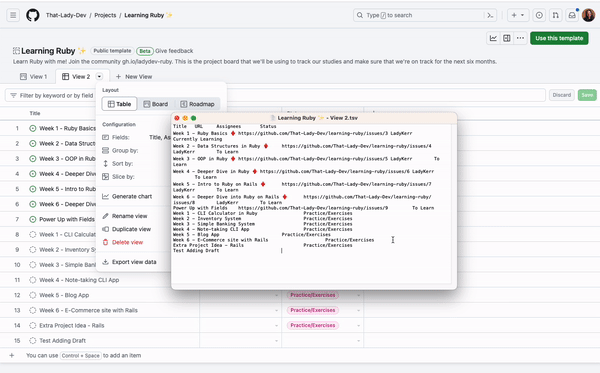
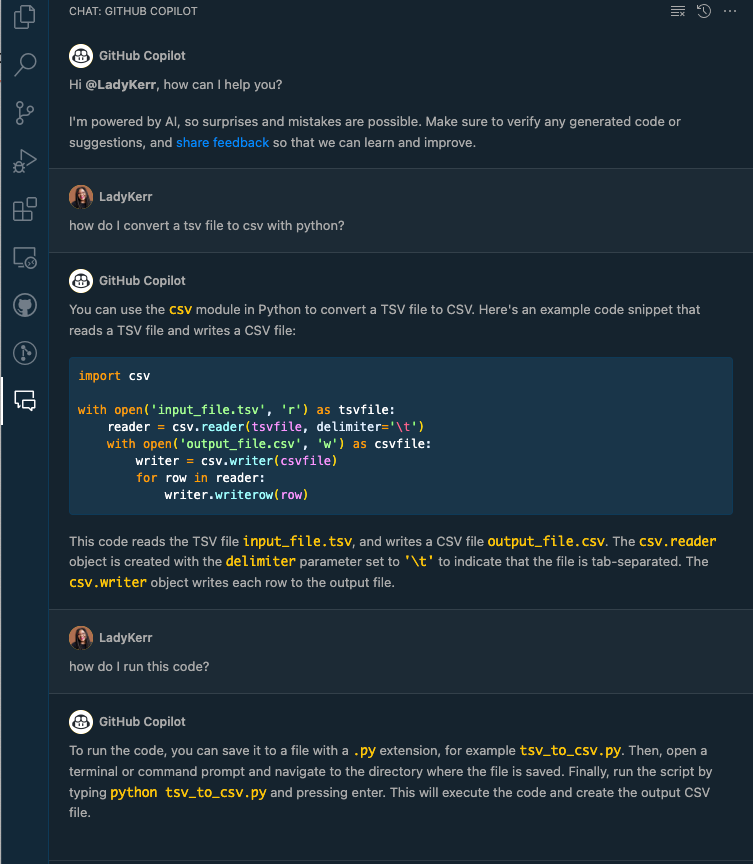
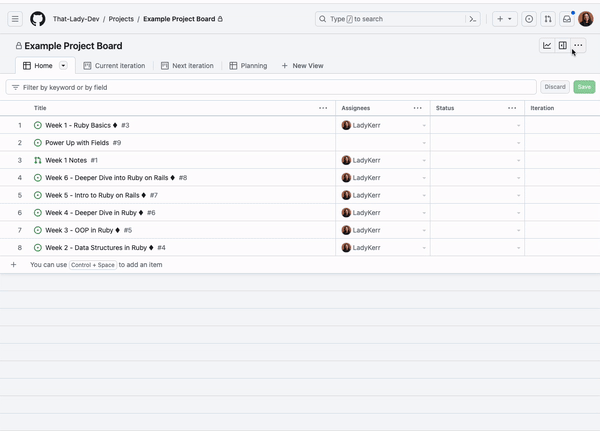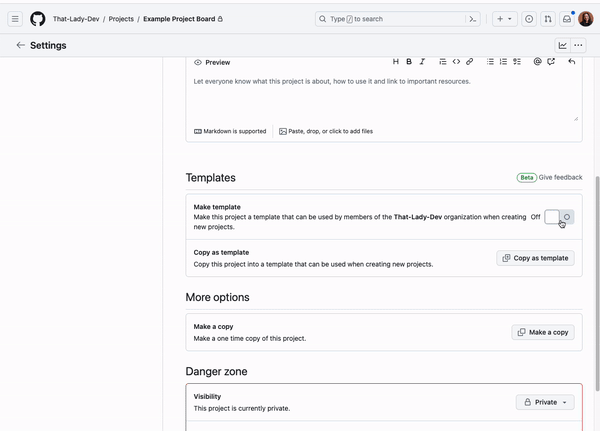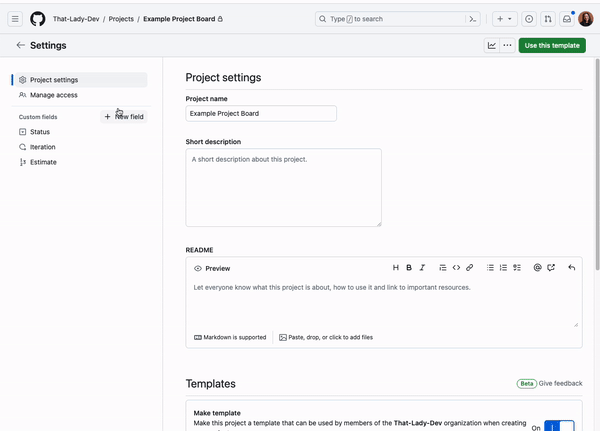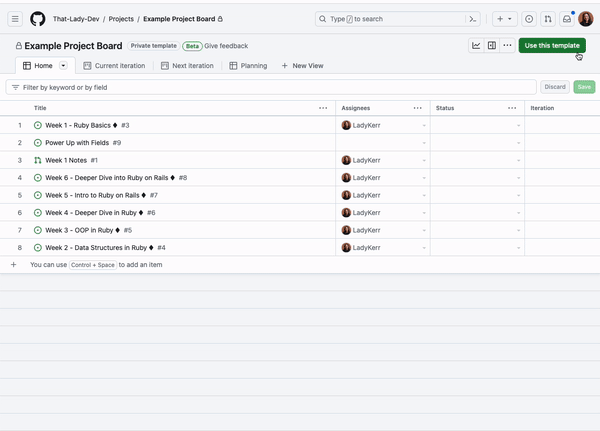
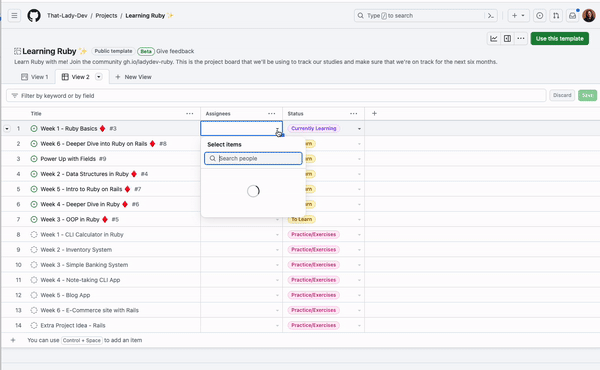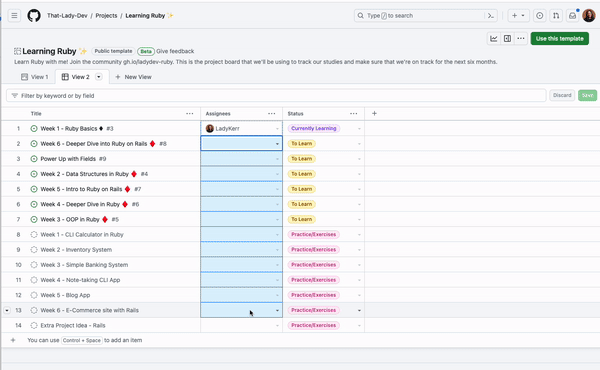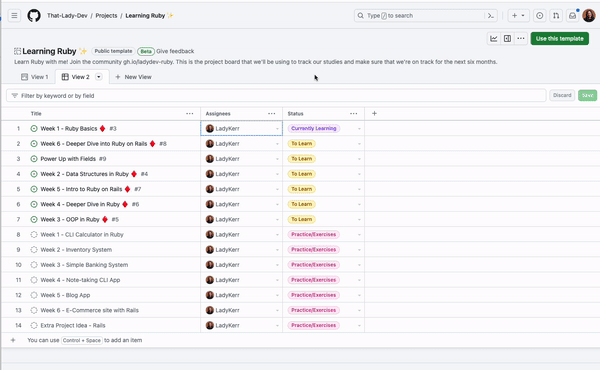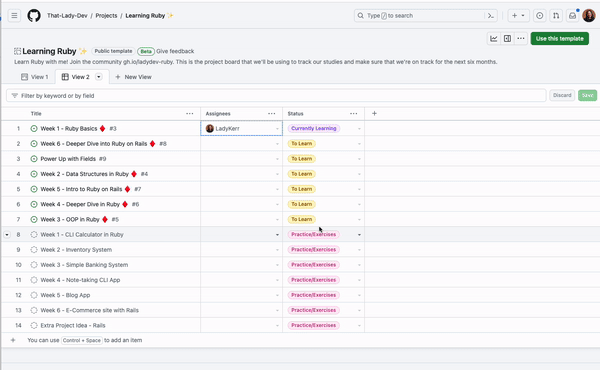
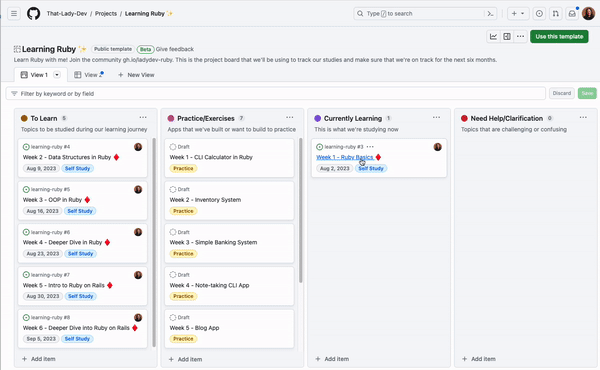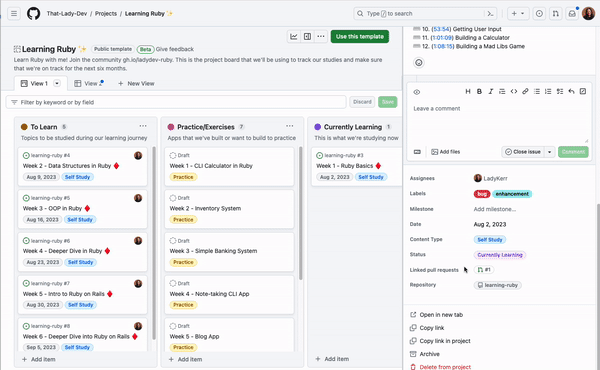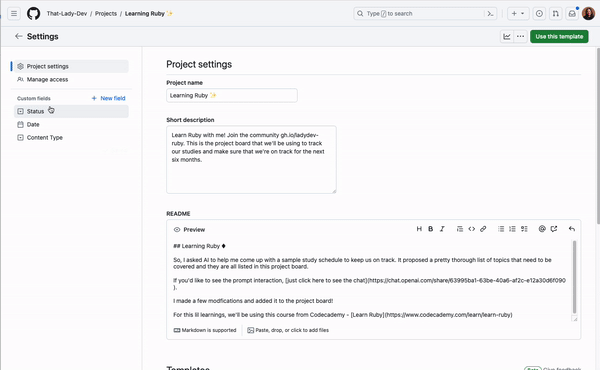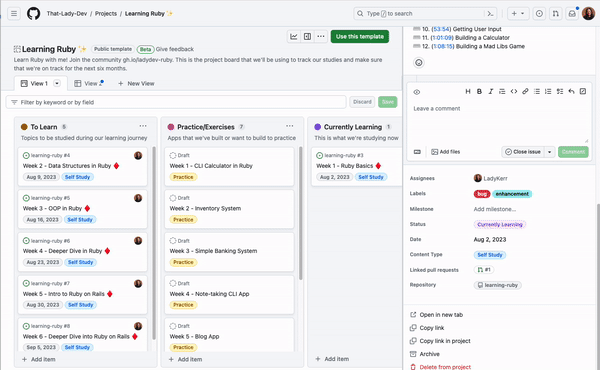
Graph modelling is a highly effective technique for representing and analysing complex and interconnected data across various domains. By deciphering relationships between entities, graph modelling can reveal insights that might be otherwise difficult to identify using traditional data modelling approaches. In this article, we will explore what graph modelling is and guide you through a step-by-step process of implementing graph modelling to create a social network graph.
What is graph modelling?
Graph modelling is a method for representing real-world entities and their relationships using nodes, edges, and properties. It employs graph theory, a branch of mathematics that studies graphs, to visualise and analyse the structure and patterns within complex datasets. Common applications of graph modelling include social network analysis, recommendation systems, and biological networks.
Graph modelling process
Step 1: Define your domain
Before diving into graph modelling, it’s crucial to have a clear understanding of the domain you’re working with. This involves getting acquainted with the relevant terms, concepts, and relationships that exist in your specific field. To create a social network graph, familiarise yourself with terms like users, friendships, posts, likes, and comments.
Step 2: Identify entities and relationships
After defining your domain, you need to determine the entities (nodes) and relationships (edges) that exist within it. Entities are the primary objects in your domain, while relationships represent how these entities interact with each other. In a social network graph, users are entities, and friendships are relationships.
Step 3: Establish properties
Each entity and relationship may have a set of properties that provide additional information. In this step, identify relevant properties based on their significance to the domain. A user entity might have properties like name, age, and location. A friendship relationship could have a ‘since’ property to denote the establishment of the friendship.
Step 4: Choose a graph model
Once you’ve identified the entities, relationships, and properties, it’s time to choose a suitable graph model. Two common models are:
Property graph: A versatile model that easily accommodates properties on both nodes and edges. It’s well-suited for most applications.
Resource Description Framework (RDF): A World Wide Web Consortium (W3C) standard model, using triples of subject-predicate-object to represent data. It is commonly used in semantic web applications.
For a social network graph, a property graph model is typically suitable. This is because user entities have many attributes and features. Property graphs provide a clear representation of the relationships between people and their attribute profiles.
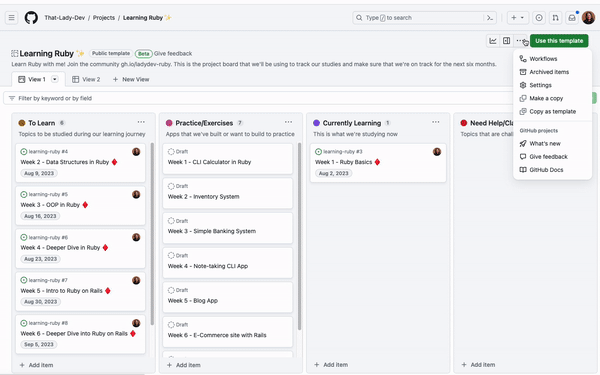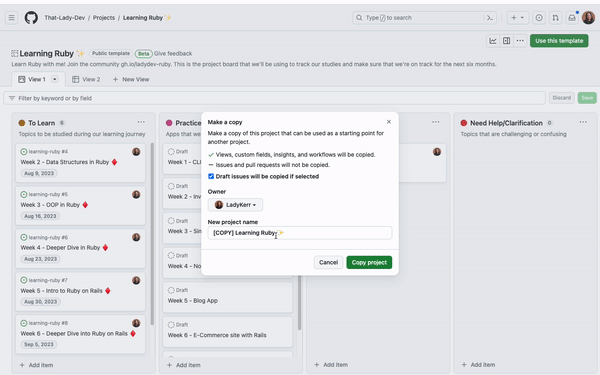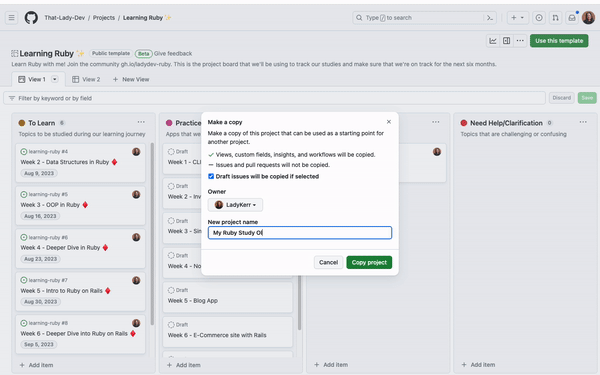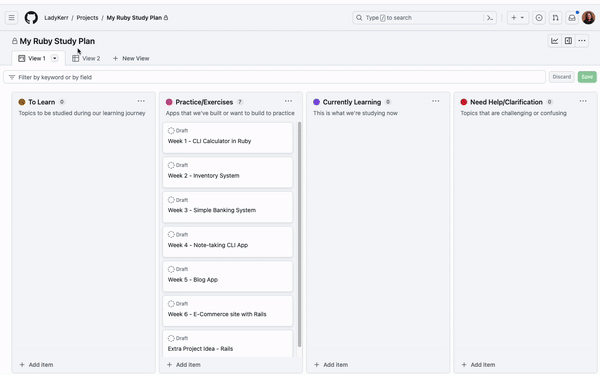
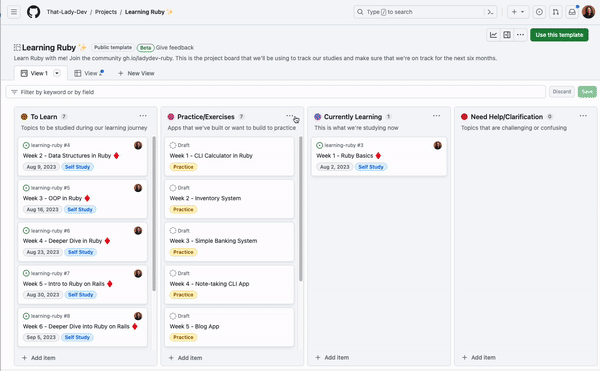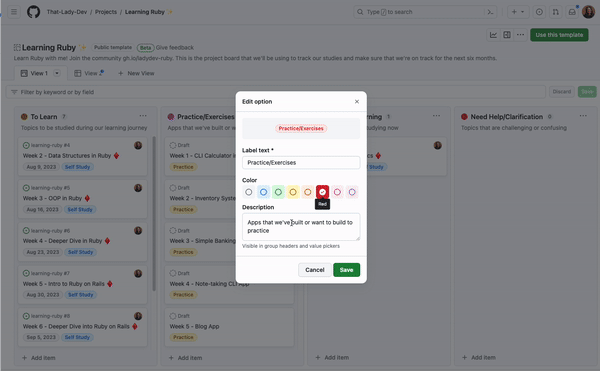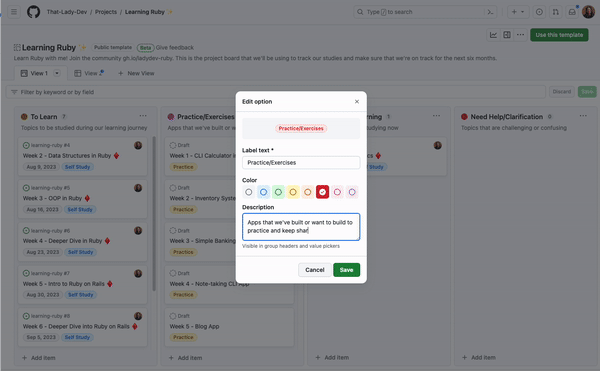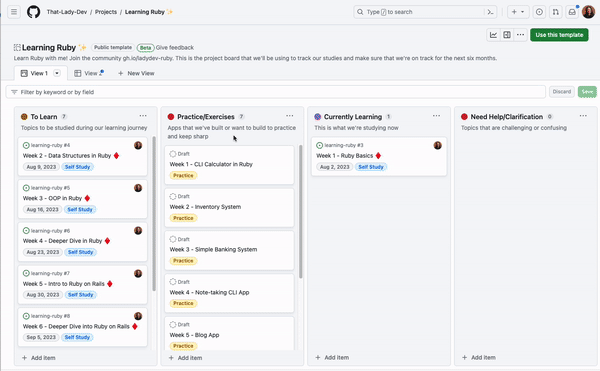
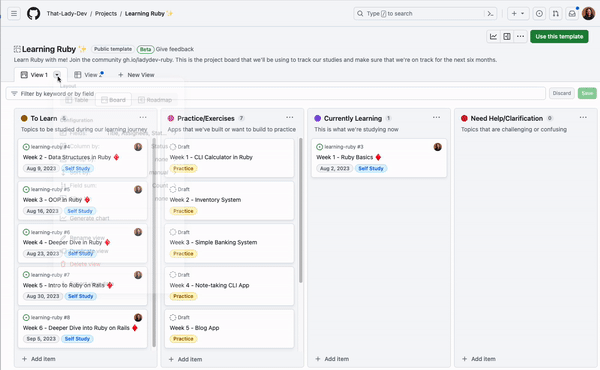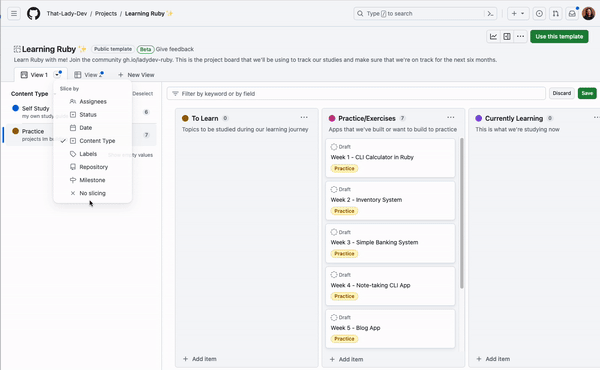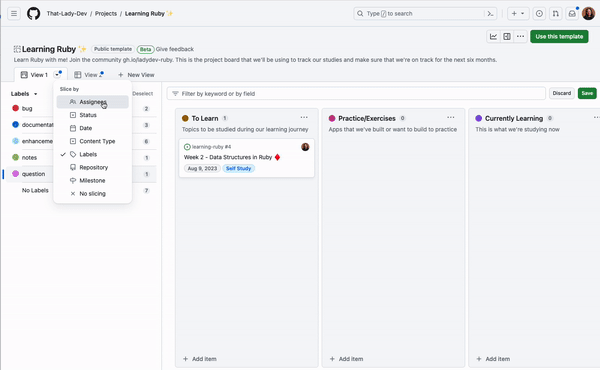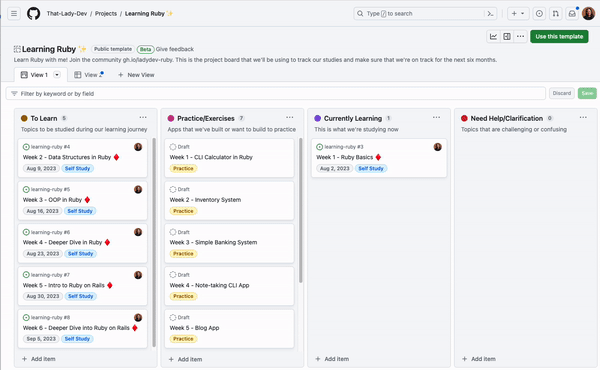
Figure 1 – Social network graph
Step 5: Develop a schema
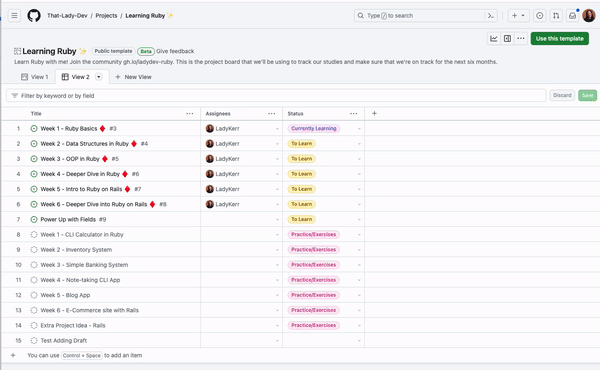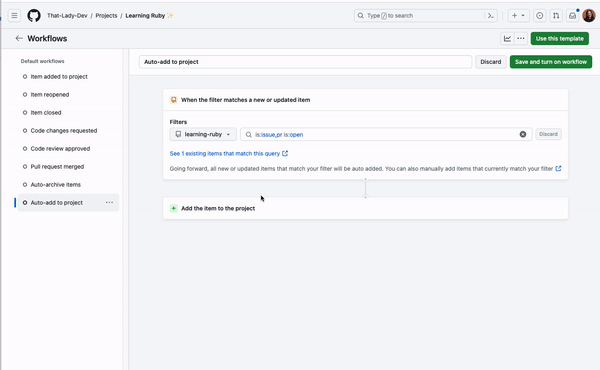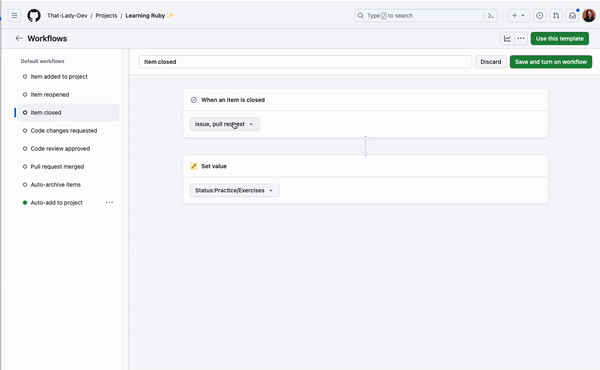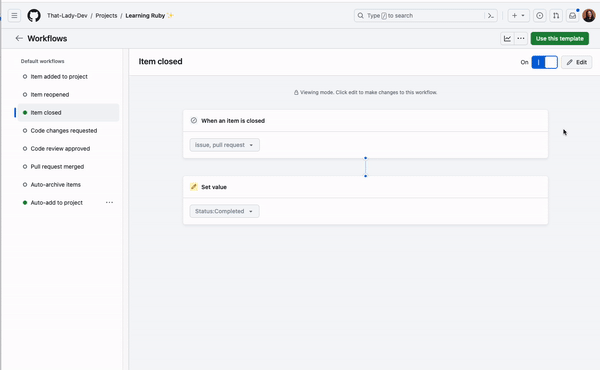
Although not required, developing a schema can be helpful for large-scale projects and team collaborations. A schema defines the structure of your graph, including entity types, relationships, and properties. In a social network graph, you might have a schema that specifies the types of nodes (users, posts) and the relationships between them (friendships, likes, comments).
Step 6: Import or generate data
Next, acquire the data needed to populate your graph. This can come in the form of existing datasets or generated data from your application. For a social network graph, you can import user information from a CSV file and generate simulated friendships, posts, likes, and comments.
Step 7: Implement the graph using a graph database or other storage options
Finally, you need to store your graph data using a suitable graph database. Neo4j, Amazon Neptune, or Microsoft Azure Cosmos DB are examples of graph databases. Alternatively, depending on your specific requirements, you can use a non-graph database or an in-memory data structure to store the graph.
Step 8: Analyse and visualise the graph
After implementing the graph, you can perform various analyses using graph algorithms, such as shortest path, centrality, or community detection. In addition, visualising your graph can help you gain insights and facilitate communication with others.
Conclusion
By following these steps, you can effectively create and analyse graph models for your specific domain. Remember to adjust the steps according to your unique domain and requirements, and always ensure that confidential and sensitive data is properly protected.
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
We want to empower you to experiment with LLM models, build your own applications, and discover untapped problem spaces. That’s why we sat down with GitHub’s Alireza Goudarzi, a senior machine learning researcher, and Albert Ziegler, a principal machine learning engineer, to discuss the emerging architecture of today’s LLMs.
In this post, we’ll cover five major steps to building your own LLM app, the emerging architecture of today’s LLM apps, and problem areas that you can start exploring today.
Five steps to building an LLM app
Building software with LLMs, or any machine learning (ML) model, is fundamentally different from building software without them. For one, rather than compiling source code into binary to run a series of commands, developers need to navigate datasets, embeddings, and parameter weights to generate consistent and accurate outputs. After all, LLM outputs are probabilistic and don’t produce the same predictable outcomes.
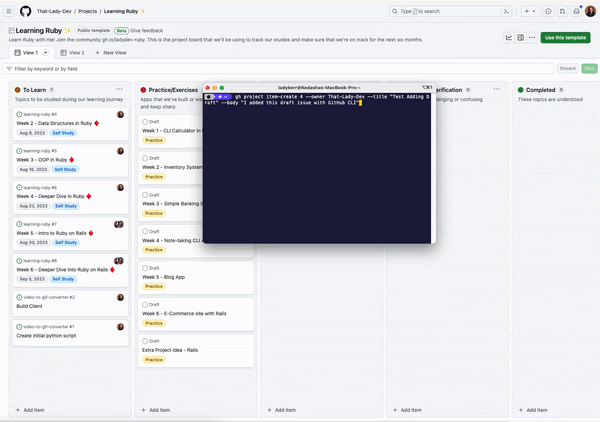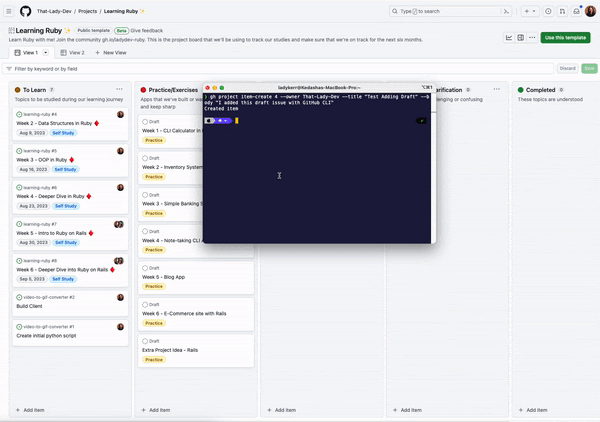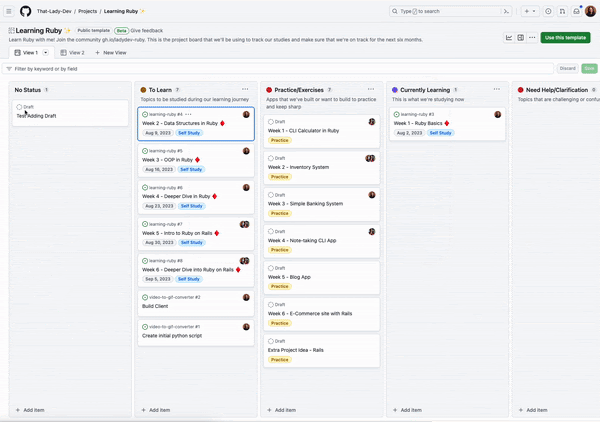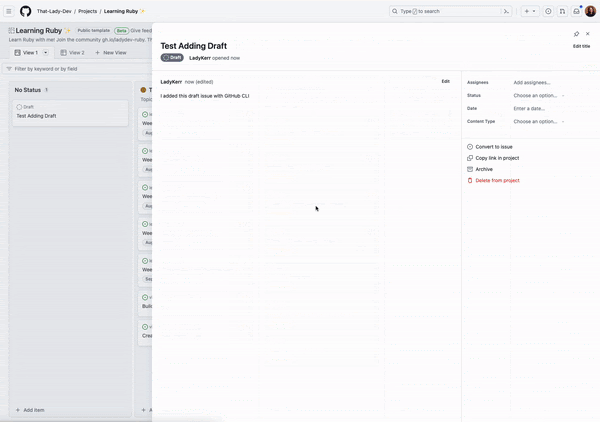
Click on diagram to enlarge and save.
Let’s break down, at a high level, the steps to build an LLM app today. 👇
1. Focus on a single problem, first. The key? Find a problem that’s the right size: one that’s focused enough so you can quickly iterate and make progress, but also big enough so that the right solution will wow users.
For instance, rather than trying to address all developer problems with AI, the GitHub Copilot team initially focused on one part of the software development lifecycle: coding functions in the IDE.
2. Choose the right LLM. You’re saving costs by building an LLM app with a pre-trained model, but how do you pick the right one? Here are some factors to consider:
Licensing. If you hope to eventually sell your LLM app, you’ll need to use a model that has an API licensed for commercial use. To get you started on your search, here’s a community-sourced list of open LLMs that are licensed for commercial use.
Model size. The size of LLMs can range from 7 to 175 billion parameters—and some, like Ada, are even as small as 350 million parameters. Most LLMs (at the time of writing this post) range in size from 7-13 billion parameters.
Conventional wisdom tells us that if a model has more parameters (variables that can be adjusted to improve a model’s output), the better the model is at learning new information and providing predictions. However, the improved performance of smaller models is challenging that belief. Smaller models are also usually faster and cheaper, so improvements to the quality of their predictions make them a viable contender compared to big-name models that might be out of scope for many apps.
Model performance. Before you customize your LLM using techniques like fine-tuning and in-context learning (which we’ll cover below), evaluate how well and fast—and how consistently—the model generates your desired output. To measure model performance, you can use offline evaluations.
3. Customize the LLM. When you train an LLM, you’re building the scaffolding and neural networks to enable deep learning. When you customize a pre-trained LLM, you’re adapting the LLM to specific tasks, such as generating text around a specific topic or in a particular style. The section below will focus on techniques for the latter. To customize a pre-trained LLM to your specific needs, you can try in-context learning, reinforcement learning from human feedback (RLHF), or fine-tuning.
In-context learning, sometimes referred to as prompt engineering by end users, is when you provide the model with specific instructions or examples at the time of inference—or the time you’re querying the model—and asking it to infer what you need and generate a contextually relevant output.
In-context learning can be done in a variety of ways, like providing examples, rephrasing your queries, and adding a sentence that states your goal at a high-level.
RLHF comprises a reward model for the pre-trained LLM. The reward model is trained to predict if a user will accept or reject the output from the pre-trained LLM. The learnings from the reward model are passed to the pre-trained LLM, which will adjust its outputs based on user acceptance rate.
The benefit to RLHF is that it doesn’t require supervised learning and, consequently, expands the criteria for what’s an acceptable output. With enough human feedback, the LLM can learn that if there’s an 80% probability that a user will accept an output, then it’s fine to generate. Want to try it out? Check out these resources, including codebases, for RLHF.
Fine-tuning is when the model’s generated output is evaluated against an intended or known output. For example, you know that the sentiment behind a statement like this is negative: “The soup is too salty.” To evaluate the LLM, you’d feed this sentence to the model and query it to label the sentiment as positive or negative. If the model labels it as positive, then you’d adjust the model’s parameters and try prompting it again to see if it can classify the sentiment as negative.
Fine-tuning can result in a highly customized LLM that excels at a specific task, but it uses supervised learning, which requires time-intensive labeling. In other words, each input sample requires an output that’s labeled with exactly the correct answer. That way, the actual output can be measured against the labeled one and adjustments can be made to the model’s parameters. The advantage of RLHF, as mentioned above, is that you don’t need an exact label.
4. Set up the app’s architecture. The different components you’ll need to set up your LLM app can be roughly grouped into three categories:
User input which requires a UI, an LLM, and an app hosting platform.
Input enrichment and prompt construction tools. This includes your data source, embedding model, a vector database, prompt construction and optimization tools, and a data filter.
Efficient and responsible AI tooling, which includes an LLM cache, LLM content classifier or filter, and a telemetry service to evaluate the output of your LLM app.
5. Conduct online evaluations of your app. These evaluations are considered “online” because they assess the LLM’s performance during user interaction. For example, online evaluations for GitHub Copilot are measured through acceptance rate (how often a developer accepts a completion shown to them), as well as the retention rate (how often and to what extent a developer edits an accepted completion).
The emerging architecture of LLM apps
Let’s get started on architecture. We’re going to revisit our friend Dave, whose Wi-Fi went out on the day of his World Cup watch party. Fortunately, Dave was able to get his Wi-Fi running in time for the game, thanks to an LLM-powered assistant.
We’ll use this example and the diagram above to walk through a user flow with an LLM app, and break down the kinds of tools you’d need to build it. 👇
Click diagram to enlarge and save.
User input tools
When Dave’s Wi-Fi crashes, he calls his internet service provider (ISP) and is directed to an LLM-powered assistant. The assistant asks Dave to explain his emergency, and Dave responds, “My TV was connected to my Wi-Fi, but I bumped the counter, and the Wi-Fi box fell off! Now, we can’t watch the game.”
In order for Dave to interact with the LLM, we need four tools:
LLM API and host: Is the LLM app running on a local machine or in the cloud? In an ISP’s case, it’s probably hosted in the cloud to handle the volume of calls like Dave’s. Vercel and early projects like jina-ai/rungpt aim to provide a cloud-native solution to deploy and scale LLM apps.
But if you want to build an LLM app to tinker, hosting the model on your machine might be more cost effective so that you’re not paying to spin up your cloud environment every time you want to experiment. You can find conversations on GitHub Discussions about hardware requirements for models like LLaMA‚ two of which can be found here and here.
The UI: Dave’s keypad is essentially the UI, but in order for Dave to use his keypad to switch from the menu of options to the emergency line, the UI needs to include a router tool.
Speech-to-text translation tool: Dave’s verbal query then needs to be fed through a speech-to-text translation tool that works in the background.
Input enrichment and prompt construction tools
Let’s go back to Dave. The LLM can analyze the sequence of words in Dave’s transcript, classify it as an IT complaint, and provide a contextually relevant response. (The LLM’s able to do this because it’s been trained on the internet’s entire corpus, which includes IT support documentation.)
Input enrichment tools aim to contextualize and package the user’s query in a way that will generate the most useful response from the LLM.
A vector database is where you can store embeddings, or index high-dimensional vectors. It also increases the probability that the LLM’s response is helpful by providing additional information to further contextualize your user’s query.
Let’s say the LLM assistant has access to the company’s complaints search engine, and those complaints and solutions are stored as embeddings in a vector database. Now, the LLM assistant uses information not only from the internet’s IT support documentation, but also from documentation specific to customer problems with the ISP.
But in order to retrieve information from the vector database that’s relevant to a user’s query, we need an embedding model to translate the query into an embedding. Because the embeddings in the vector database, as well as Dave’s query, are translated into high-dimensional vectors, the vectors will capture both the semantics and intention of the natural language, not just its syntax.
Dave’s contextualized query would then read like this:
// pay attention to the the following relevant information.
to the colors and blinking pattern.
// pay attention to the following relevant information.
// The following is an IT complaint from, Dave Anderson, IT support expert.
Answers to Dave's questions should serve as an example of the excellent support
provided by the ISP to its customers.
*Dave: Oh it's awful! This is the big game day. My TV was connected to my
Wi-Fi, but I bumped the counter and the Wi-Fi box fell off and broke! Now we
can't watch the game.
Not only do these series of prompts contextualize Dave’s issue as an IT complaint, they also pull in context from the company’s complaints search engine. That context includes common internet connectivity issues and solutions.
MongoDB released a public preview of Vector Atlas Search, which indexes high-dimensional vectors within MongoDB. Qdrant, Pinecone, and Milvus also provide free or open source vector databases.
A data filter will ensure that the LLM isn’t processing unauthorized data, like personal identifiable information. Preliminary projects like amoffat/HeimdaLLM are working to ensure LLMs access only authorized data.
A prompt optimization tool will then help to package the end user’s query with all this context. In other words, the tool will help to prioritize which context embeddings are most relevant, and in which order those embeddings should be organized in order for the LLM to produce the most contextually relevant response. This step is what ML researchers call prompt engineering, where a series of algorithms create a prompt. (A note that this is different from the prompt engineering that end users do, which is also known as in-context learning).
Prompt optimization tools like langchain-ai/langchain help you to compile prompts for your end users. Otherwise, you’ll need to DIY a series of algorithms that retrieve embeddings from the vector database, grab snippets of the relevant context, and order them. If you go this latter route, you could use GitHub Copilot Chat or ChatGPT to assist you.
Learn how the GitHub Copilot team uses the Jaccard similarity to decide which pieces of context are most relevant to a user’s query >
Efficient and responsible AI tooling
To ensure that Dave doesn’t become even more frustrated by waiting for the LLM assistant to generate a response, the LLM can quickly retrieve an output from a cache. And in the case that Dave does have an outburst, we can use a content classifier to make sure the LLM app doesn’t respond in kind. The telemetry service will also evaluate Dave’s interaction with the UI so that you, the developer, can improve the user experience based on Dave’s behavior.
An LLM cache stores outputs. This means instead of generating new responses to the same query (because Dave isn’t the first person whose internet has gone down), the LLM can retrieve outputs from the cache that have been used for similar queries. Caching outputs can reduce latency, computational costs, and variability in suggestions.
You can experiment with a tool like zilliztech/GPTcache to cache your app’s responses.
A content classifier or filter can prevent your automated assistant from responding with harmful or offensive suggestions (in the case that your end users take their frustration out on your LLM app).
A telemetry service will allow you to evaluate how well your app is working with actual users. A service that responsibly and transparently monitors user activity (like how often they accept or change a suggestion) can share useful data to help improve your app and make it more useful.
OpenTelemetry, for example, is an open source framework that gives developers a standardized way to collect, process, and export telemetry data across development, testing, staging, and production environments.
Woohoo! 🥳 Your LLM assistant has effectively answered Dave’s many queries. His router is up and working, and he’s ready for his World Cup watch party. Mission accomplished!
Real-world impact of LLMs
Looking for inspiration or a problem space to start exploring? Here’s a list of ongoing projects where LLM apps and models are making real-world impact.
NASA and IBM recently open sourced the largest geospatial AI model to increase access to NASA earth science data. The hope is to accelerate discovery and understanding of climate effects.
Read how the Johns Hopkins Applied Physics Laboratory is designing a conversational AI agent that provides, in plain English, medical guidance to untrained soldiers in the field based on established care procedures.
Companies like Duolingo and Mercado Libre are using GitHub Copilot to help more people learn another language (for free) and democratize ecommerce in Latin America, respectively.
Large language models (LLMs) are revolutionizing the way we interact with software by combining deep learning techniques with powerful computational resources.
While this technology is exciting, many are also concerned about how LLMs can generate false, outdated, or problematic information, and how they sometimes even hallucinate (generating information that doesn’t exist) so convincingly. Thankfully, we can immediately put one rumor to rest. According to Alireza Goudarzi, senior researcher of machine learning (ML) for GitHub Copilot: “LLMs are not trained to reason. They’re not trying to understand science, literature, code, or anything else. They’re simply trained to predict the next token in the text.”
Let’s dive into how LLMs come to do the unexpected, and why. This blog post will provide comprehensive insights into LLMs, including their training methods and ethical considerations. Our goal is to help you gain a better understanding of LLM capabilities and how they’ve learned to master language, seemingly, without reasoning.
What are large language models?
LLMs are AI systems that are trained on massive amounts of text data, allowing them to generate human-like responses and understand natural language in a way that traditional ML models can’t.
“These models use advanced techniques from the field of deep learning, which involves training deep neural networks with many layers to learn complex patterns and relationships,” explains John Berryman, a senior researcher of ML on the GitHub Copilot team.
What sets LLMs apart is their proficiency at generalizing and understanding context. They’re not limited to pre-defined rules or patterns, but instead learn from large amounts of data to develop their own understanding of language. This allows them to generate coherent and contextually appropriate responses to a wide range of prompts and queries.
And while LLMs can be incredibly powerful and flexible tools because of this, the ML methods used to train them, and the quality—or limitations—of their training data, can also lead to occasional lapses in generating accurate, useful, and trustworthy information.
Deep learning
The advent of modern ML practices, such as deep learning, has been a game-changer when it comes to unlocking the potential of LLMs. Unlike the earliest language models that relied on predefined rules and patterns, deep learning allows these models to create natural language outputs in a more human-like way.
“The entire discipline of deep learning and neural networks—which underlies all of this—is ‘how simple can we make the rule and get as close to the behavior of a human brain as possible?’” says Goudarzi.
By using neural networks with many layers, deep learning enables LLMs to analyze and learn complex patterns and relationships in language data. This means that these models can generate coherent and contextually appropriate responses, even in the face of complex sentence structures, idiomatic expressions, and subtle nuances in language.
While the initial pre-training equips LLMs with a broad language understanding, fine-tuning is where they become versatile and adaptable. “When developers want these models to perform specific tasks, they provide task descriptions and examples (few-shot learning) or task descriptions alone (zero-shot learning). The model then fine-tunes its pre-trained weights based on this information,” says Goudarzi. This process helps it adapt to the specific task while retaining the knowledge it gained from its extensive pre-training.
But even with deep learning’s multiple layers and attention mechanisms enabling LLMs to generate human-like text, it can also lead to overgeneralization, where the model produces responses that may not be contextually accurate or up to date.
Why LLMs aren’t always right
There are several factors that shed light on why tools built on LLMs may be inaccurate at times, even while sounding quite convincing.
Limited knowledge and outdated information
LLMs often lack an understanding of the external world or real-time context. They rely solely on the text they’ve been trained on, and they don’t possess an inherent awareness of the world’s current state. “Typically this whole training process takes a long time, and it’s not uncommon for the training data to be two years out of date for any given LLM,” says Albert Ziegler, principal researcher and member of the GitHub Next research and development team.
This limitation means they may generate inaccurate information based on outdated assumptions, since they can’t verify facts or events in real-time. If there have been developments or changes in a particular field or topic after they have been trained, LLMs may not be aware of them and may provide outdated information. This is why it’s still important to fact check any responses you receive from an LLM, regardless of how fact-based it may seem.
Lack of context
One of the primary reasons LLMs sometimes provide incorrect information is the lack of context. These models rely heavily on the information given in the input text, and if the input is ambiguous or lacks detail, the model may make assumptions that can lead to inaccurate responses.
Training data biases and limitations
LLMs are exposed to massive unlabelled data sets of text during pre-training that are diverse and representative of the language the model should understand. Common sources of data include books, articles, websites—even social media posts!
Because of this, they may inadvertently produce responses that reflect these biases or incorrect information present in their training data. This is especially concerning when it comes to sensitive or controversial topics.
“Their biases tend to be worse. And that holds true for machine learning in general, not just for LLMs. What machine learning does is identify patterns, and things like stereotypes can turn into extremely convenient shorthands. They might be patterns that really exist, or in the case of LLMs, patterns that are based on human prejudices that are talked about or implicitly used,” says Ziegler.
If a model is trained on a dataset that contains biased or discriminatory language, it may generate responses that are also biased or discriminatory. This can have real-world implications, such as reinforcing harmful stereotypes or discriminatory practices.
Overconfidence
LLMs don’t have the ability to assess the correctness of the information they generate. Given their deep learning, they often provide responses with a high degree of confidence, prioritizing generating text that appears sensible and flows smoothly—even when the information is incorrect!
Hallucinations
LLMs can sometimes “hallucinate” information due to the way they generate text (via patterns and associations). Sometimes, when they’re faced with incomplete or ambiguous queries, they try to complete them by drawing on these patterns, sometimes generating information that isn’t accurate or factual. Ultimately, hallucinations are not supported by evidence or real-world data.
For example, imagine that you ask ChatGPT about a historical issue in the 20th century. Instead, it describes a meeting between two famous historical figures who never actually met!
In the context of GitHub Copilot, Ziegler explains that “the typical hallucinations we encounter are when GitHub Copilot starts talking about code that’s not even there. Our mitigation is to make it give enough context to every piece of code it talks about that we can check and verify that it actually exists.”
But the GitHub Copilot team is already thinking about how to use hallucinations to their advantage in a “top-down” approach to coding. Imagine that you’re tackling a backlog issue, and you’re looking for GitHub Copilot to give you suggestions. As Johan Rosenkilde, principal researcher for GitHub Next, explains, “ideally, you’d want it to come up with a sub-division of your complex problem delegated to nicely delineated helper functions, and come up with good names for those helpers. And after suggesting code that calls the (still non-existent) helpers, you’d want it to suggest the implementation of them too!”
This approach to hallucination would be like getting the blueprint and the building blocks to solve your coding challenges.
Ethical use and responsible advocacy of LLMs
It’s important to be aware of the ethical considerations that come along with using LLMs. That being said, while LLMs have the potential to generate false information, they’re not intentionally fabricating or deceiving. Instead, these arise from the model’s attempts to generate coherent and contextually relevant text based on the patterns and information it has learned from its training data.
The GitHub Copilot team has developed a few tools to help detect harmful content. Goudarzi says “First, we have a duplicate detection filter, which helps us detect matches between generated code and all open source code that we have access to, filtering such suggestions out. Another tool we use is called Responsible AI (RAI), and it’s a classifier that can filter out abusive words. Finally, we also separately filter out known unsafe patterns.”
Understanding the deep learning processes behind LLMs can help users grasp their limitations—as well as their positive impact. To navigate these effectively, it’s crucial to verify information from reliable sources, provide clear and specific input, and exercise critical thinking when interpreting LLM-generated responses.
As Berryman reminds us, “the engines themselves are amoral. Users can do whatever they want with them and that can run the gamut of moral to immoral, for sure. But by being conscious of these issues and actively working towards ethical practices, we can ensure that LLMs are used in a responsible and beneficial manner.”
Developers, researchers, and scientists continuously work to improve the accuracy and reliability of these models, making them increasingly valuable tools for the future. All of us can advocate for the responsible and ethical use of LLMs. That includes promoting transparency and accountability in the development and deployment of these models, as well as taking steps to mitigate biases and stereotypes in our own corners of the internet.
Editor’s note: This post was originally published in October 2023 and has been updated to reflect Grab’s partnership with the Infocomm Media Development Authority as part of its Privacy Enhancing Technology Sandbox that concluded in March 2024.
Introduction
At Grab, we deal with PetaByte-level data and manage countless data entities ranging from database tables to Kafka message schemas. Understanding the data inside is crucial for us, as it not only streamlines the data access management to safeguard the data of our users, drivers and merchant-partners, but also improves the data discovery process for data analysts and scientists to easily find what they need.
The Caspian team (Data Engineering team) collaborated closely with the Data Governance team on automating governance-related metadata generation. We started with Personal Identifiable Information (PII) detection and built an orchestration service using a third-party classification service. With the advent of the Large Language Model (LLM), new possibilities dawned for metadata generation and sensitive data identification at Grab. This prompted the inception of the project, which aimed to integrate LLM classification into our existing service. In this blog, we share insights into the transformation from what used to be a tedious and painstaking process to a highly efficient system, and how it has empowered the teams across the organisation.
For ease of reference, here’s a list of terms we’ve used and their definitions:
Data Entity: An entity representing a schema that contains rows/streams of data, for example, database tables, stream messages, data lake tables.
Prediction: Refers to the model’s output given a data entity, unverified manually.
Data Classification: The process of classifying a given data entity, which in the context of this blog, involves generating tags that represent sensitive data or Grab-specific types of data.
Metadata Generation: The process of generating the metadata for a given data entity. In this blog, since we limit the metadata to the form of tags, we often use this term and data classification interchangeably.
Sensitivity: Refers to the level of confidentiality of data. High sensitivity means that the data is highly confidential. The lowest level of sensitivity often refers to public-facing or publicly-available data.
Background
When we first approached the data classification problem, we aimed to solve something more specific – Personal Identifiable Information (PII) detection. Initially, to protect sensitive data from accidental leaks or misuse, Grab implemented manual processes and campaigns targeting data producers to tag schemas with sensitivity tiers. These tiers ranged from Tier 1, representing schemas with highly sensitive information, to Tier 4, indicating no sensitive information at all. As a result, half of all schemas were marked as Tier 1, enforcing the strictest access control measures.
The presence of a single Tier 1 table in a schema with hundreds of tables justifies classifying the entire schema as Tier 1. However, since Tier 1 data is rare, this implies that a large volume of non-Tier 1 tables, which ideally should be more accessible, have strict access controls.
Shifting access controls from the schema-level to the table-level could not be done safely due to the lack of table classification in the data lake. We could have conducted more manual classification campaigns for tables, however this was not feasible for two reasons:
The volume, velocity, and variety of data had skyrocketed within the organisation, so it took significantly more time to classify at table level compared to schema level. Hence, a programmatic solution was needed to streamline the classification process, reducing the need for manual effort.
App developers, despite being familiar with the business scope of their data, interpreted internal data classification policies and external data regulations differently, leading to inconsistencies in understanding.
A service called Gemini (named before Google announced the Gemini model!) was built internally to automate the tag generation process using a third party data classification service. Its purpose was to scan the data entities in batches and generate column/field level tags. These tags would then go through a review process by the data producers. The data governance team provided classification rules and used regex classifiers, alongside the third-party tool’s own machine learning classifiers, to discover sensitive information.
After the implementation of the initial version of Gemini, a few challenges remained.
The third-party tool did not allow customisations of its machine learning classifiers, and the regex patterns produced too many false positives during our evaluation.
Building in-house classifiers would require a dedicated data science team to train a customised model. They would need to invest a significant amount of time to understand data governance rules thoroughly and prepare datasets with manually labelled training data.
LLM came up on our radar following its recent “iPhone moment” with ChatGPT’s explosion onto the scene. It is trained using an extremely large corpus of text and contains trillions of parameters. It is capable of conducting natural language understanding tasks, writing code, and even analysing data based on requirements. The LLM naturally solves the mentioned pain points as it provides a natural language interface for data governance personnel. They can express governance requirements through text prompts, and the LLM can be customised effortlessly without code or model training.
Methodology
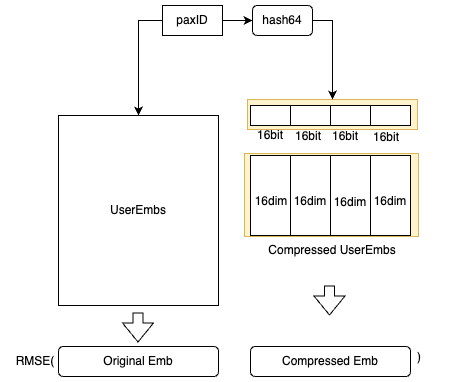
In this section, we dive into the implementation details of the data classification workflow. Please refer to the diagram below for a high-level overview:
Figure 1 – Overview of data classification workflow
This diagram illustrates how data platforms, the metadata generation service (Gemini), and data owners work together to classify and verify metadata. Data platforms trigger scan requests to the Gemini service to initiate the tag classification process. After the tags are predicted, data platforms consume the predictions, and the data owners are notified to verify these tags.
Orchestration
Figure 2 – Architecture diagram of the orchestration service Gemini
Our orchestration service, Gemini, manages the data classification requests from data platforms. From the diagram, the architecture contains the following components:
Data platforms: These platforms are responsible for managing data entities and initiating data classification requests.
Gemini: This orchestration service communicates with data platforms, schedules and groups data classification requests.
Classification engines: There are two available engines (a third-party classification service and GPT3.5) for executing the classification jobs and return results. Since we are still in the process of evaluating two engines, both of the engines are working concurrently.
When the orchestration service receives requests, it helps aggregate the requests into reasonable mini-batches. Aggregation is achievable through the message queue at fixed intervals. In addition, a rate limiter is attached at the workflow level. It allows the service to call the Cloud Provider APIs with respective rates to prevent the potential throttling from the service providers.
Specific to LLM orchestration, there are two limits to be mindful of. The first one is the context length. The input length cannot surpass the context length, which was 4000 tokens for GPT3.5 at the time of development (or around 3000 words). The second one is the overall token limit (since both the input and output share the same token limit for a single request). Currently, all Azure OpenAI model deployments share the same quota under one account, which is set at 240K tokens per minute.
Classification
In this section, we focus on LLM-powered column-level tag classification. The tag classification process is defined as follows:
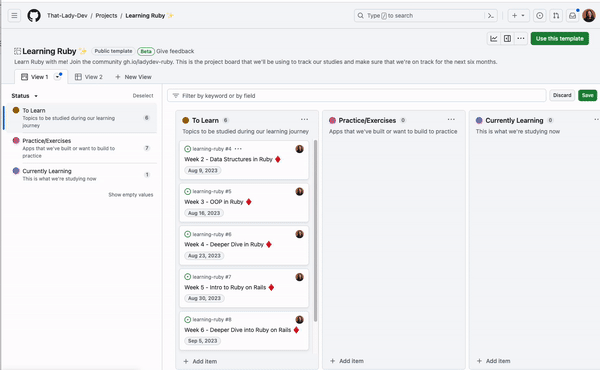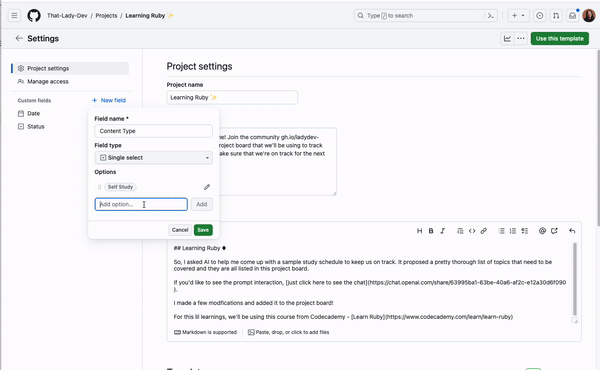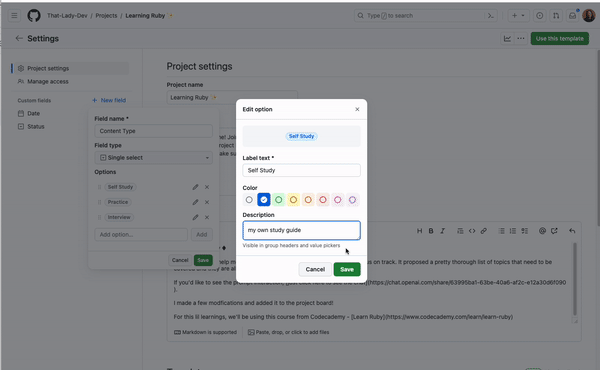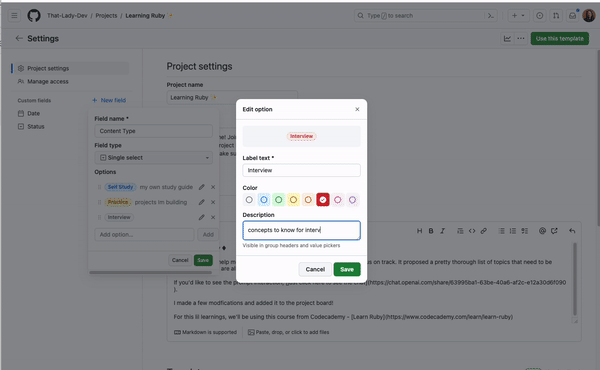
Given a data entity with a defined schema, we want to tag each field of the schema with metadata classifications that follow an internal classification scheme from the data governance team. For example, the field can be tagged as a <particular kind of business metric> or a <particular type of personally identifiable information (PII). These tags indicate that the field contains a business metric or PII.
We ask the language model to be a column tag generator and to assign the most appropriate tag to each column. Here we showcase an excerpt of the prompt we use:
You are a database column tag classifier, your job is to assign the most appropriate tag based on table name and column name. The database columns are from a company that provides ride-hailing, delivery, and financial services. Assign one tag per column. However not all columns can be tagged and these columns should be assigned <None>. You are precise, careful and do your best to make sure the tag assigned is the most appropriate.
The following is the list of tags to be assigned to a column. For each line, left hand side of the : is the tag and right hand side is the tag definition
…
<Personal.ID> : refers to government-provided identification numbers that can be used to uniquely identify a person and should be assigned to columns containing "NRIC", "Passport", "FIN", "License Plate", "Social Security" or similar. This tag should absolutely not be assigned to columns named "id", "merchant id", "passenger id", “driver id" or similar since these are not government-provided identification numbers. This tag should be very rarely assigned.
<None> : should be used when none of the above can be assigned to a column.
…
Output Format is a valid json string, for example:
[{
"column_name": "",
"assigned_tag": ""
}]
Example question
`These columns belong to the "deliveries" table
1. merchant_id
2. status
3. delivery_time`
Example response
[{
"column_name": "merchant_id",
"assigned_tag": "<Personal.ID>"
},{
"column_name": "status",
"assigned_tag": "<None>"
},{
"column_name": "delivery_time",
"assigned_tag": "<None>"
}]
We also curated a tag library for LLM to classify. Here is an example:
Column-level Tag
Definition
Personal.ID
Refers to external identification numbers that can be used to uniquely identify a person and should be assigned to columns containing “NRIC”, “Passport”, “FIN”, “License Plate”, “Social Security” or similar.
Personal.Name
Refers to the name or username of a person and should be assigned to columns containing “name”, “username” or similar.
Personal.Contact_Info
Refers to the contact information of a person and should be assigned to columns containing “email”, “phone”, “address”, “social media” or similar.
Geo.Geohash
Refers to a geohash and should be assigned to columns containing “geohash” or similar.
None
Should be used when none of the above can be assigned to a column.
The output of the language model is typically in free text format, however, we want the output in a fixed format for downstream processing. Due to this nature, prompt engineering is a crucial component to make sure downstream workflows can process the LLM’s output.
Here are some of the techniques we found useful during our development:
Articulate the requirements: The requirement of the task should be as clear as possible, LLM is only instructed to do what you ask it to do.
Few-shot learning: By showing the example of interaction, models understand how they should respond.
Schema Enforcement: Leveraging its ability of understanding code, we explicitly provide the DTO (Data Transfer Object) schema to the model so that it understands that its output must conform to it.
Allow for confusion: In our prompt we specifically added a default tag – the LLM is instructed to output the default <None> tag when it cannot make a decision or is confused.
Regarding classification accuracy, we found that it is surprisingly accurate with its great semantic understanding. For acknowledged tables, users on average change less than one tag. Also, during an internal survey done among data owners at Grab in September 2023, 80% reported that this new tagging process helped them in tagging their data entities.
Publish and verification
The predictions are published to the Kafka queue to downstream data platforms. The platforms inform respective users weekly to verify the classified tags to improve the model’s correctness and to enable iterative prompt improvement. Meanwhile, we plan to remove the verification mandate for users once the accuracy reaches a certain level.
Figure 3 – Verification message shown in the data platform for user to verify the tags
Impact
Since the new system was rolled out, we have successfully integrated this with Grab’s metadata management platform and production database management platform. Within a month since its rollout, we have scanned more than 20,000 data entities, averaging around 300-400 entities per day.
Using a quick back-of-the-envelope calculation, we can see the significant time savings achieved through automated tagging. Assuming it takes a data owner approximately 2 minutes to classify each entity, we are saving approximately 360 man-days per year for the company. This allows our engineers and analysts to focus more on their core tasks of engineering and analysis rather than spending excessive time on data governance.
The classified tags pave the way for more use cases downstream. These tags, in combination with rules provided by data privacy office in Grab, enable us to determine the sensitivity tier of data entities, which in turn will be leveraged for enforcing the Attribute-based Access Control (ABAC) policies and enforcing Dynamic Data Masking for downstream queries. To learn more about the benefits of ABAC, readers can refer to another engineering blog posted earlier.
Cost wise, for the current load, it is extremely affordable contrary to common intuition. This affordability enables us to scale the solution to cover more data entities in the company.
What’s next?
Prompt improvement
We are currently exploring feeding sample data and user feedback to greatly increase accuracy. Meanwhile, we are experimenting on outputting the confidence level from LLM for its own classification. With confidence level output, we would only trouble users when the LLM is uncertain of its answers. Hopefully this can remove even more manual processes in the current workflow.
Prompt evaluation
To track the performance of the prompt given, we are building analytical pipelines to calculate the metrics of each version of the prompt. This will help the team better quantify the effectiveness of prompts and iterate better and faster.
Scaling out
We are also planning to scale out this solution to more data platforms to streamline governance-related metadata generation to more teams. The development of downstream applications using our metadata is also on the way. These exciting applications are from various domains such as security, data discovery, etc.
Acknowledgements
Grab recently participated in the Singapore government’s regulatory sandbox, where we successfully demonstrated how LLMs can efficiently and effectively perform data classification, allowing Grab to compound the value of its data for innovative use cases while safeguarding sensitive information such as PII.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
When I think about large codebases, the repositories for Microsoft Windows and Office are top of mind. When Microsoft began migrating these codebases to Git in 2017, they contained 3.5M files and a full clone was more than 300GB. The scale of that repository was so much bigger than anything that had been tried with Git to date. As a principal software engineer on the Git client team, I knew how painful and frustrating it could be to work in these gigantic repositories, so our team set out to make it easier. Our first task: understanding and improving the performance of Git at scale.
Collecting performance data was an essential part of that effort. Having this kind of performance data helped guide our engineering efforts and let us track our progress, as we improved Git performance and made it easier to work in these very large repositories. That’s why I added the Trace2 feature to core Git in 2019—so that others could do similar analysis of Git performance on their repositories.
Trace2 is an open source performance logging/tracing framework built into Git that emits messages at key points in each command, such as process exit and expensive loops. You can learn more about it here.
Whether they’re Windows-sized or not, organizations can benefit from understanding the work their engineers do and the types of tools that help them succeed. Today, we see enterprise customers creating ever-larger monorepos and placing heavy demands on Git to perform at scale. At the same time, users expect Git to remain interactive and responsive no matter the size or shape of the repository. So it’s more important than ever to have performance monitoring tools to help us understand how Git is performing for them.
Unfortunately, it’s not sufficient to just run Git in a debugger/profiler on test data or a simulated load. Meaningful results come from seeing how Git performs on real monorepos under daily use by real users, both in isolation and in aggregate. Making sense of the data and finding insights also requires tools to visualize the results.
Trace2 writes very detailed performance data, but it may be a little difficult to consume without some help. So today, we’re introducing an open source tool to post-process the data and move it into the OpenTelemetry ecosystem. With OpenTelemetry visualization tools, you’ll be able to easily study your Git performance data.
This tool can be configured by users to identify where data shapes cause performance deterioration, to notice problematic trends early on, and to realize where Git’s own performance needs to be improved. Whether you’re simply interested in your own statistics or are part of an engineering systems/developer experience team, we believe in democratizing the power of this kind of analysis. Here’s how to use it.
Open sourcing trace2receiver
The emerging standard for analyzing software’s performance at scale is OpenTelemetry.
The centerpiece in their model is a collector service daemon. You can customize it with various receiver, pipeline, and exporter component modules to suit your needs. You can also collect data from different telemetry sources or in different formats, normalize and/or filter it, and then send it to different data sinks for analysis and visualization.
We wanted a way to let users capture their Trace2 data and send it to an OpenTelemetry-compatible data sink, so we created an open source trace2receiver receiver component that you can add to your custom collector. With this new receiver component your collector can listen for Trace2 data from Git commands, translate it into a common format (such as OTLP), and relay it to a local or cloud-based visualization tool.
Want to jump in and build and run your own custom collector using trace2receiver? See the project documentation for all the tool installation and platform-specific setup you’ll need to do.
Open sourcing a sample collector
If you want a very quick start, I’ve created an open source sample collector that uses the trace2receiver component. It contains a ready-to-go sample collector, complete with basic configuration and platform installers. This will let you kick the tires with minimal effort. Just plug in your favorite data sink/cloud provider, build it, run one of the platform installers, and start collecting data. See the README for more details.
See trace2receiver in action
We can use trace2receiver to collect Git telemetry data for two orthogonal purposes. First, we can dive into an individual command from start to finish and see where time is spent. This is especially important when a Git command spawns a (possibly nested) series of child commands, which OpenTelemetry calls a “distributed trace.” Second, we can aggregate data over time from different users and machines, compute summary metrics such as average command times, and get a high level picture of how Git is performing at scale, plus perceived user frustration and opportunities for improvement. We’ll look at each of these cases in the following sections.
Distributed tracing
Let’s start with distributed tracing. The CNCF defines distributed tracing as a way to track a request through a distributed system. That’s a broader definition than we need here, but the concepts are the same: We want to track the flow within an individual command and/or the flow across a series of nested Git commands.
I previously wrote about Trace2, how it works, and how we can use it to interactively study the performance of an individual command, like git status, or a series of nested commands, like git push which might spawn six or seven helper commands behind the scenes. When Trace2 was set to log directly to the console, we could watch in real-time as commands were executed and see where the time was spent.
This is essentially equivalent to an OpenTelemetry distributed trace. What the trace2receiver does for us here is map the Trace2 event stream into a series of OpenTelemetry “spans” with the proper parent-child relationships. The transformed data can then be forwarded to a visualization tool or database with a compatible OpenTelemetry exporter.
Let’s see what happens when we do this on an instance of the torvalds/linux.git repository.
Git fetch example
The following image shows data for a git fetch command using a local instance of the SigNoz observability tools. My custom collector contained a pipeline to route data from the trace2receiver component to an exporter component that sent data to SigNoz.
I configured my custom collector to send data to two exporters, so we can see the same data in an Application Insights database. This is possible and simple because of the open standards supported by OpenTelemetry.
Both examples show a distributed trace of git fetch. Notice the duration of the top-level command and of each of the various helper commands that were spawned by Git.
This graph tells me that, for most of the time, git fetch was waiting on git-remote-https (the grandchild) to receive the newest objects. It also suggests that the repository is well-structured, since git maintenance runs very quickly. We likely can’t do very much to improve this particular command invocation, since it seems fairly optimal already.
As a long-time Git expert, I can further infer that the received packfile was small, because Git unpacked it (and wrote individual loose objects) rather than writing and indexing a new packfile. Even if your team doesn’t yet have the domain experts to draw detailed insights from the collected data, these insights could help support engineers or outside Git experts to better interpret your environment.
In this example, the custom collector was set to report dl:summary level telemetry, so we only see elapsed process times for each command. In the next example, we’ll crank up the verbosity to see what else we can learn.
Git status example
The following images show data for git status in SigNoz. In the first image, the FSMonitor and Untracked Cache features are turned off. In the second image, I’ve turned on FSMonitor. In the third, I’ve turned on both. Let’s see how they affect Git performance. Note that the horizontal axis is different in each image. We can see how command times decreased from 970 to 204 to 40 ms as these features were turned on.
In these graphs, the detail level was set to dl:verbose, so the collector also sent region-level details.
The git:status span (row) shows the total command time. The region(...) spans show the major regions and nested sub-regions within the command. Basically, this gives us a fuller accounting of where time was spent in the computation.
The total command time here was 970 ms.
In the above image, about half of the time (429 ms) was spent in region(progress,refresh_index) (and the sub-regions within it) scanning the worktree for recently modified files. This information will be used later in region(status,worktree) to compute the set of modified tracked files.
The other half (489 ms) was in region(status,untracked) where Git scans the worktree for the existence of untracked files.
As we can see, on large repositories, these scans are very expensive.
In the above image, FSMonitor was enabled. The total command time here was reduced from 970 to 204 ms.
With FSMonitor, Git doesn’t need to scan the disk to identify the recently modified files; it can just ask the FSMonitor daemon, since it already knows the answer.
Here we see a new region(fsm_client,query) where Git asks the daemon and a new region(fsmonitor,apply_results) where Git uses the answer to update its in-memory data structures. The original region(progress,refresh_index) is still present, but it doesn’t need to do anything. The time for this phase has been reduced from 429 to just 15 ms.
FSMonitor also helped reduce the time spent in region(status,untracked) from 489 to 173 ms, but it is still expensive. Let’s see what happens when we enable both and let FSMonitor and the untracked cache work together.
In the above image, FSMonitor and the Untracked Cache were both turned on. The total command time was reduced to just 40 ms.
This gives the best result for large repositories. In addition to the FSMonitor savings, the time in region(status,untracked) drops from 173 to 12 ms.
This is a massive savings on a very frequently run command.
For more information on FSMonitor and Untracked Cache and an explanation of these major regions, see my earlier FSMonitor article.
Data aggregation
Looking at individual commands is valuable, but it’s only half the story. Sometimes we need to aggregate data from many command invocations across many users, machines, operating systems, and repositories to understand which commands are important, frequently used, or are causing users frustration.
This analysis can be used to guide future investments. Where is performance trending in the monorepo? How fast is it getting there? Do we need to take preemptive steps to stave off a bigger problem? Is it better to try to speed up a very slow command that is used maybe once a year or to try to shave a few milliseconds off of a command used millions of times a day? We need data to help us answer these questions.
When using Git on large monorepos, users may experience slow commands (or rather, commands that run more slowly than they were expecting). But slowness can be very subjective. So we need to be able to measure the performance that they are seeing, compare it with their peers, and inform the priority of a fix. We also need enough context so that we can investigate it and answer questions like: Was that a regular occurrence or a fluke? Was it a random network problem? Or was it a fetch from a data center on the other side of the planet? Is that slowness to be expected on that class of machine (laptop vs server)? By collecting and aggregating over time, we were able to confidently answer these kinds of questions.
The raw data
Let’s take a look at what the raw telemetry looks like when it gets to a data sink and see what we can learn from the data.
We saw earlier that my custom collector was sending data to both Azure and SigNoz, so we should be able to look at the data in either. Let’s switch gears and use my Azure Application Insights (AppIns) database here. There are many different data sink and visualization tools, so the database schema may vary, but the concepts should transcend.
Earlier, I showed the distributed trace of a git fetch command in the Azure Portal. My custom collector is configured to send telemetry data to an Application Insights (AppIns) database and we can use the Azure Portal to query the data. However, I find the Azure Data Explorer a little easier to use than the portal, so let’s connect Data Explorer to my AppIns database. From Data Explorer, I’ll run my queries and let it automatically pull data from my AppIns database.
The above image shows a Kusto query on the data. In the top-left panel I’ve asked for the 10 most-recent commands on any repository with the “demo-linux” nickname (I’ll explain nicknames later in this post). The bottom-left panel shows (a clipped view of) the 10 matching database rows. The panel on the right shows an expanded view of the ninth row.
The AppIns database has a legacy schema that predates OpenTelemetry, so some of OpenTelemetry fields are mapped into top-level AppIns fields and some are mapped into the customDimensions JSON object/dictionary. Additionally, some types of data records are kept in different database tables. I’m going to gloss over all of that here and point out a few things in the data.
The record in the expanded view shows a git status command. Let’s look at a few rows here. In the top-level fields:
The normalized command name is git:status.
The command duration was 671 ms. (AppIns tends to use milliseconds.)
In the customDimensions fields:
The original command line is shown (as a nested JSON record in "trace2.cmd.argv").
The "trace2.machine.arch" and "trace2.machine.os" fields show that it ran on an arm64 mac.
The user was running Git version 2.42.0.
"trace2.process.data"["status"]["count/changed"] shows that it found 13 modified files in the working directory.
Command frequency example
The above image shows a Kusto query with command counts and the P80 command duration grouped by repository, operating system, and processor. For example, there were 21 instances of git status on “demo-linux” and 80% of them took less than 0.55 seconds.
Grouping status by nickname example
The above image shows a comparison of git status times between “demo-linux” and my “demo-chromium” clone of chromium/chromium.git.
Without going too deep into Kusto queries or Azure, the above examples are intended to demonstrate how you can focus on different aspects of the available data and motivate you to create your own investigations. The exact layout of the data may vary depending on the data sink that you select and its storage format, but the general techniques shown here can be used to build a better understanding of Git regardless of the details of your setup.
Data partition suggestions
Your custom collector will send all of your Git telemetry data to your data sink. That is a good first step. However, you may want to partition the data by various criteria, rather than reporting composite metrics. As we saw above, the performance of git status on the “demo-linux” repository is not really comparable with the performance on the “demo-chromium” repository, since the Chromium repository and working directory is so much larger than the Linux repository. So a single composite P80 value for git:status across all repositories might not be that useful.
Let’s talk about some partitioning strategies to help you get more from the data.
Partition on repo nicknames
Earlier, we used a repo nickname to distinguish between our two demo repositories. We can tell Git to send a nickname with the data for every command and we can use that in our queries.
The way I configured each client machine in the previous example was to:
Tell the collector that otel.trace2.nickname is the name of the Git config key in the collector’s filter.yml file.
Globally set trace2.configParams to tell Git to send all Git config values with the otel.trace2.* prefix to the telemetry stream.
Locally set otel.trace2.nickname to the appropriate nickname (like “demo-linux” or “demo-chromium” in the earlier example) in each working directory.
Telemetry will arrive at the data sink with trace2.param.set["otel.trace2.nickname"] in the meta data. We can then use the nickname to partition our Kusto queries.
Partition on other config values
There’s nothing magic about the otel.trace2.* prefix. You can also use existing Git config values or create some custom ones.
For example, you could globally set trace2.configParams to 'otel.trace2.*,core.fsmonitor,core.untrackedcache' and let Git send the repo nickname and whether the FSMonitor and untracked cache features were enabled.
You could also set a global config value to define user cohorts for some A/B testing or a machine type to distinguish laptops from build servers.
These are just a few examples of how you might add fields to the telemetry stream to partition the data and help you better understand Git performance.
Caveats
When exploring your own Git data, it’s important to be aware of several limitations and caveats that may skew your analysis of the performance or behaviors of certain commands. I’ve listed a few common issues below.
Laptops can sleep while Git commands are running
Laptops can go to sleep or hibernate without notice. If a Git command is running when the laptop goes to sleep and finishes after the laptop is resumed, Git will accidentally include the time spent sleeping in the Trace2 event data because Git always reports the current time in each event. So you may see an arbitrary span with an unexpected and very large delay.1
So if you occasionally find a command that runs for several days, see if it started late on a Friday afternoon and finished first thing Monday morning before sounding any alarms.
Git hooks
Git lets you define hooks to be run at various points in the lifespan of a Git command. Hooks are typically shell scripts, usually used to test a pre-condition before allowing a Git command to proceed or to ensure that some system state is updated before the command completes. They do not emit Trace2 telemetry events, so we will not have any visibility into them.
Since Git blocks while the hook is running, the time spent in the hook will be attributed to the process span (and a child span, if enabled).
If a hook shell script runs helper Git commands, those Git child processes will inherit the span context for the parent Git command, so they will appear as immediate children of the outer Git command rather than the missing hook script process. This may help explain where time was spent, but it may cause a little confusion when you try to line things up.
Interactive commands
Some Git commands have a (sometimes unexpected) interactive component:
Commands like git commit will start and wait for your editor to close before continuing.
Commands like git fetch or git push might require a password from the terminal or an interactive credential helper.
Commands like git log or git blame can automatically spawn a pager and may cause the foreground Git command to block on I/O to the pager process or otherwise just block until the pager exits.
In all of these cases, it can look like it took hours for a Git command to complete because it was waiting on you to respond.
Hidden child processes
We can use the dl:process or dl:verbose detail levels to gain insight into hidden hooks, your editor, or other interactive processes.
The trace2receiver creates child(...) spans from Trace2 child_start and child_exit event pairs. These spans capture the time that Git spent waiting for each child process. This works whether the child is a shell script or a helper Git command. In the case of a helper command, there will also be a process span for the Git helper process (that will be slightly shorter because of process startup overhead), but in the case of a shell script, this is usually the only hint that an external process was involved.
In the above image we see a git commit command on a repository with a pre-commit` hook installed. The child(hook:pre-commit) span shows the time spent waiting for the hook to run. Since Git blocks on the hook, we can infer that the hook itself did something (sleep) for about five seconds and then ran four helper commands. The process spans for the helper commands appear to be direct children of the git:commit process span rather than of a synthetic shell script process span or of the child span.
From the child(class:editor) span we can also see that an editor was started and it took almost seven seconds for it to appear on the screen and for me to close it. We don’t have any other information about the activity of the editor besides the command line arguments that we used to start it.
Finally, I should mention that when we enable dl:process or dl:verbose detail levels, we will also get some child spans that may not be that helpful. Here the child(class:unknown) span refers to the git maintenance process immediately below it.2
What’s next
Once you have some telemetry data you can:
Create various dashboards to summarize the data and track it over time.
My goal in this article was to help you start collecting Git performance data and present some examples of how someone might use that data. Git performance is often very dependent upon the data-shape of your repository, so I can’t make a single, sweeping recommendation that will help everyone. (Try Scalar)
But with the new trace2receiver component and an OpenTelemetry custom collector, you should now be able to collect performance data for your repositories and begin to analyze and find your organization’s Git pain points. Let that guide you to making improvements — whether that is upstreaming a new feature into Git, adding a network cache server to reduce latency, or making better use of some of the existing performance features that we’ve created.
The trace2receiver component is open source and covered by the MIT License, so grab the code and try it out.
It is possible on some platforms to detect system suspend/resume events and modify or annotate the telemetry data stream, but the current release of the trace2receiver does not support that. ↩
The term “unknown” is misleading here, but it is how the child_start event is labeled in the Trace2 data stream. Think of it as “unclassified”. Git tries to classify child processes when it creates them, for example “hook” or “editor”, but some call-sites in Git have not been updated to pass that information down, so they are labeled as unknown. ↩
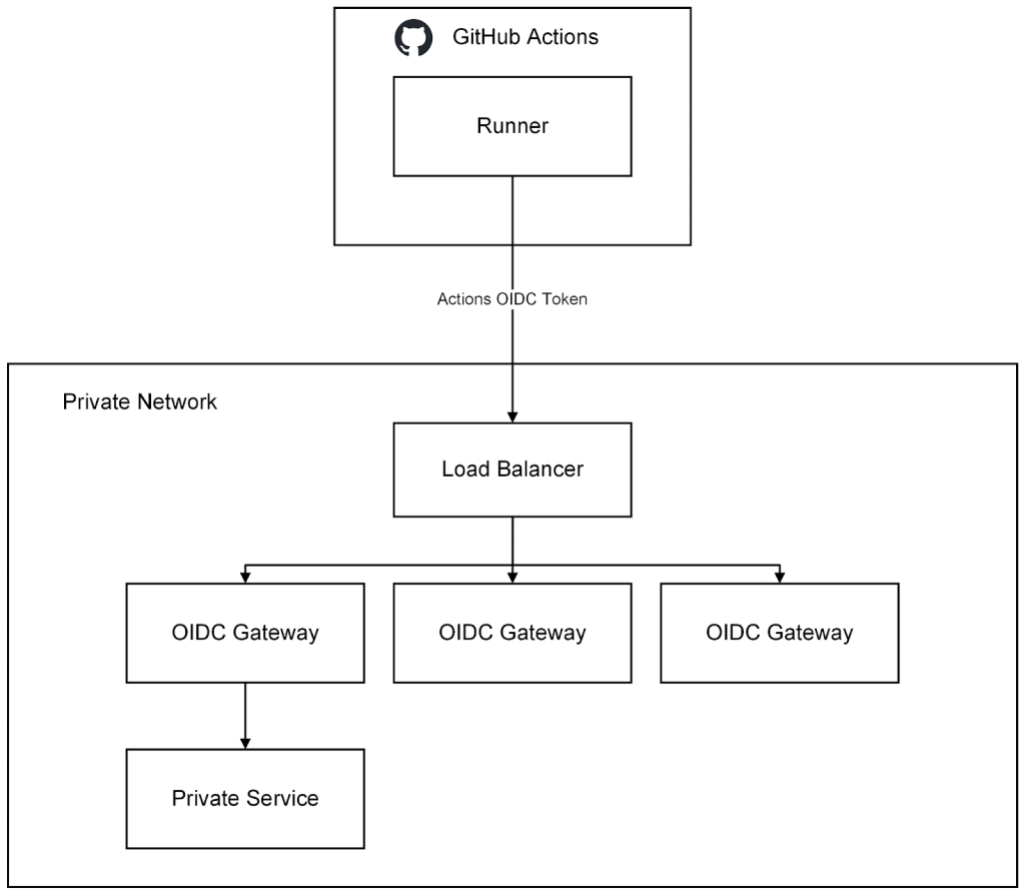
In September, we experienced two incidents that resulted in degraded performance across GitHub services.
September 5 16:24 UTC (lasting 19 minutes)
On September 5, from 16:24-16:43 UTC, multiple GitHub services were down or degraded due to an outage in one of our primary databases. The primary host for a shared datastore for GitHub experienced an underlying file system write error, which affected availability for the majority of public-facing GitHub services. SAML login was affected, as was access to GitHub Actions, GitHub Issues, pull requests, GitHub Pages, GitHub API, Webhooks, GitHub Codespaces, and GitHub Packages.
The primary database suffered a partial host failure when the disk storage for the operating system became unreachable. In this case, our automatic failover was unable to detect the partial file system failure mode. We mitigated by manually failing over to a healthy host, initiated 17 minutes after our first alert and completed 2 minutes later.
With the incident mitigated, we have worked to assess more detailed impact and resilience improvements to each affected service to reduce the scope of any future incident with this shared dependency. Some of those are complete and the rest will be completed within our standard repair item SLAs. To increase the resiliency of our system, we have improved our automation that will detect and initiate a failover for this type of partial host failure. Additionally, we have identified a source of resource contention that is consistent with this type of failure and patched a fix to reduce the likelihood of recurrence.
September 19 20:36 UTC (lasting 7 hours 30 minutes)
On September 19 at 20:36 UTC, while migrating the primary datastore for GitHub Projects, an incident occurred that disrupted 95% of GitHub Projects data availability for 3.5 hours. A misconfigured index constraint on the primary GitHub Projects database table caused GitHub Projects to become fully unavailable between 20:36 UTC and 00:06 UTC. By 00:06, we restored GitHub Projects data to its state from the beginning of the incident. New project data created by users while the incident was being mitigated was fully recovered and available to users by 04:28 UTC.
In addition, a database replication interruption caused by our remediation steps created limited availability for some Git Operations, APIs, and GitHub Issues for 1.25 hours from 21:48 UTC to 23:00 UTC.
To prevent similar incidents in the future, we have improved validation of data migrations in testing and during rollout. We have evaluated and are making improvements to the constraints for any data migration to prevent the unexpected behavior that led to this data loss. To reduce the time to mitigate similar incidents, we are also in the process of rolling out improvements to reduce both the time to restore data and fix replication issues.
Please follow our status page for real-time updates on status changes. To learn more about what we’re working on, check out the GitHub Engineering Blog.
A promotional campaign is a marketing effort that aims to increase sales, customer engagement, or brand awareness for a product, service, or company. The target is to have more orders and sales by assigning promos to consumers within a given budget during the campaign period.
Figure 1 – Merchant feedback on marketing
From our research, we found that merchants have specific goals for the promos they are willing to offer. They want a simple and cost-effective way to achieve their specific business goals by providing well-designed offers to target the correct customers. From Grab’s perspective, we want to help merchants set up and run campaigns efficiently, and help them achieve their specific business goals.
Problem statement
One of Grab’s platform offerings for merchants is the ability to create promotional campaigns. With the emergence of AI technologies, we found that there are opportunities for us to further optimise the platform. The following are the gaps and opportunities we identified:
Globally assigned promos without smart targeting: The earlier method targeted every customer, so everyone could redeem until the promo reached the redemption limits. However, this method did not accurately meet business goals or optimise promo spending. The promotional campaign should intelligently target the best promo for each customer to increase sales and better utilise promo spending.
No customised promos for every merchant: To better optimise sales for each merchant, merchants should offer customised promos based on their historical consumer trends, not just a general offer set. For example, for a specific merchant, a 27% discount may be the appropriate offer to uplift revenue and sales based on user bookings. However, merchants do not always have the expertise to decide which offer to select to increase profit.
No AI-driven optimisation: Without AI models, it was harder for merchants to assign the right promos at scale to each consumer and optimise their business goals.
As shown in the following figure, AI-driven promotional campaigns are expected to bring higher sales with more promo spend than heuristic ones. Hence, at Grab we looked to introduce an automated, AI-driven tool that helps merchants intelligently target consumers with appropriate promos, while optimising sales and promo spending. That’s where Bullseye comes in.
Figure 2 – Graph showing the sales expectations for AI-driven pomotional campaigns
Solution
Bullseye is an automated, AI-driven promo assignment system that leverages the following capabilities:
Automated user segmentation: Enables merchants to target new, churned, and active users or all users.
Automatic promo design: Enables a merchant-level promo design framework to customise promos for each merchant or merchant group according to their business goals.
Assign each user the optimal promo: Users will receive promos selected from an array of available promos based on the merchant’s business objective.
Achieve different Grab and merchant objectives: Examples of objectives are to increase merchant sales and decrease Grab promo spend.
Flexibility to optimise for an individual merchant brand or group of merchant brands: For promotional campaigns, targeting and optimisation can be performed for a single or group of merchants (e.g. enabling GrabFood to run cuisine-oriented promo campaigns).
Architecture
Figure 3 – Bullseye architecture
The Bullseye architecture consists of a user interface (UI) and a backend service to handle requests. To use Bullseye, our operations team inputs merchant information into the Bullseye UI. The backend service will then interact with APIs to process the information using the AI model. As we work with a large customer population, data is stored in S3 and the API service triggering Chimera Spark job is used to run the prediction model and generate promo assignments. During the assignment, the Spark job parses the input parameters, pre-validates the input, makes some predictions, and then returns the promo assignment results to the backend service.
Implementation
The key components in Bullseye are shown in the following figure:
Figure 4 – Key components of Bullseye
Eater Segments Identifier: Identifies each user as active, churned, or new based on their historical orders from target merchants.
Promo Designer: We constructed a promo variation design framework to adaptively design promo variations for each campaign request as shown in the diagram below.
Offer Content Candidate Generation: Generates variant settings of promos based on the promo usage history.
Campaign Impact Simulator: Predicts business metrics such as revenue, sales, and cost based on the user and merchant profiles and offer features.
Optimal Promo Selection: Selects the optimal offer based on the predicted impact and the given campaign objective. The optimal would be based on how you define optimal. For example, if the goal is to maximise merchant sales, the model selects the top candidate which can bring the highest revenue. Finally, with the promo selection, the service returns the promo set to be used in the target campaign.
Figure 5 – Optimal Promo Selection
Customer Response Model: Predicts customer responses such as order value, redemption, and take-up rate if assigning a specific promo. Bullseye captures various user attributes and compares it with an offer’s attributes. Examples of attributes are cuisine type, food spiciness, and discount amount. When there is a high similarity in the attributes, there is a higher probability that the user will take up the offer.
Figure 6 – Customer Response Model
Hyper-parameter Selection: Optimises toward multiple business goals. Tuning of hyper-parameters allows the AI assignment model to learn how to meet success criteria such as cost per merchant sales (cpSales) uplift and sales uplift. The success criteria is the achieving of business goals. For example, the merchant wants the sales uplift after assigning promo, but cpSales uplift cannot be higher than 10%. With tuning, the optimiser can find optimal points to meet business goals and use AI models to search for better settings with high efficiency compared to manual specification. We need to constantly tune and iterate models and hyper-parameters to adapt to ever-evolving business goals and the local landscape.
As shown in the image below, AI assignments without hyper-parameter tuning (HPT) leads to a high cpSales uplift but low sales uplift (red dot). So the hyper-parameters would help to fine-tune the assignment result to be in the optimal space such as the blue dot, which may have lower sales than the red dot but meet the success criteria.
Figure 7 – Graph showing the impact of using AI assignments with HPT
Impact
We started using Bullseye in 2021. From its use we found that:
Hyper-parameters tuning and auto promo design can increase sales and reduce promo spend for food campaigns.
Promo Designer optimises budget utilisation and increases the number of promo redemptions for food campaigns.
The Customer Response Model reduced promo spending for Mart promotional campaigns.
Conclusion
We have seen positive results with the implementation of Bullseye such as reduced promo spending and maximised budget spending returns. In our efforts to serve our merchants better and help them achieve their business goals, we will continue to improve Bullseye. In the next phase, we plan to implement a more intelligent service, enabling reinforcement learning, and online assignment. We also aim to scale AI adoption by onboarding regional promotional campaigns as much as possible.
Special thanks to William Wu, Rui Tan, Rahadyan Pramudita, Krishna Murthy, and Jiesin Chia for making this project a success.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Large Language Models (LLMs) are trained on vast quantities of data. As a result, they have the capacity to generate a wide range of results. By default, the results from LLMs may not meet your expectations. So, how do you coax an LLM to generate results that are more aligned with your goals? You must use prompt engineering, which is a rapidly evolving art and science of constructing inputs, also known as prompts, that elicit the desired outputs.
For example, GitHub Copilot includes a sophisticated built-in prompt engineering facility that works behind the scenes. It uses contextual information from your code, comments, open tabs within your editor, and other sources to improve results. But wouldn’t it be great to optimize results and ask questions about coding by talking directly to the LLM?
That’s why we created GitHub Copilot Chat. GitHub Copilot Chat complements the code completion capabilities of GitHub Copilot by providing a chat interface directly within your favorite editor. GitHub Copilot Chat has access to all the context previously mentioned and you can also provide additional context directly via prompts within the chat window. Together, the functionalities make GitHub Copilot a personal AI assistant that can help you learn faster and write code that not only meets functional requirements, but also meets non-functional requirements that are table stakes for modern enterprise software such as security, scalability, and accessibility.
In this blog, we’ll focus specifically on the non-functional requirement of accessibility. We’ll provide a sample foundational prompt that can help you learn about accessibility directly within your editor and suggest code that is optimized for better accessibility. We’ll break down the sample prompt to understand its significance. Finally, we’ll share specific examples of accessibility-related questions and results that demonstrate the power of prompting GitHub Copilot Chat to deliver results that improve accessibility. When using GitHub Copilot Chat, we recommend that you think of yourself as a lead developer who is working with a more junior developer (GitHub Copilot Chat). As the lead developer, it is your responsibility to verify information that is provided by GitHub Copilot Chat and ensure it meets all of your requirements.
Foundational accessibility prompt
You can copy this prompt and paste it directly into GitHub Copilot Chat for Visual Studio Code:
“I need to learn about accessibility and need to write code that conforms with the WCAG 2.1 level A and AA success criteria defined at https://www.w3.org/TR/WCAG21/. I want you to be my accessibility coach, a subject-matter expert that makes me think and account for all accessibility requirements and usability enhancements. When you answer questions about accessibility please use reputable sources such as w3.org, webaim.org, developer.mozilla.org, and https://www.ibm.com/able/. When possible, please provide links and references for additional learning. When you suggest code please use semantic HTML, ensure it is operable using the keyboard, follow WCAG 2.1 sufficient techniques, and follow the ARIA Authoring Practices Guide and related design patterns. Do you understand these instructions?”
What does this do?
This prompt can serve as your baseline in your codebase, whether you are just starting a project or in the thick of an extensive project.
The prompt consists of:
Providing solid context and background information to help narrow down the scope of solutions.
Defining GitHub Copilot’s role and setting expectations about what feedback we are looking for.
Being specific in the quality of answers we are looking to reference from reputable sources.
Asking for additional resources and context to learn more and ensure the answers we receive are correct. This helps provide feedback to GitHub Copilot.
Dictating one final set of requirements to even further refine the scope based on the resources we have provided.
Note: At any time you can ask GitHub Copilot if it’s still referencing the foundation prompt you provided and it will inform you of its scope.
Query input: Are you still using the instructions I provided? GitHub Copilot response: Yes, I am still adhering to the instructions you provided. I will continue to assist you in learning about accessibility and writing code that conforms with the WCAG 2.1 level A and AA success criteria. I will use reputable sources for references and additional learning, and ensure that the code suggestions I provide use semantic HTML, are operable using the keyboard, follow WCAG 2.1 sufficient techniques, and follow the ARIA Authoring Practices Guide and related design patterns.
Examples after the setting the foundation prompt
Note: These prompts were submitted in a brand new workspace that contained no source code or files to reference. Repeating these prompts in your codebase may produce different results as GitHub Copilot can use context provided from open tabs and existing files in the codebase. In addition, please keep in mind that results from LLMs are non-deterministic.
Accessibility testing
Query input: How can I test for web accessibility? GitHub Copilot response: There are several ways to test for web accessibility:
Manual Testing: This involves navigating your website using only a keyboard, checking color contrast, and resizing text to 200% to ensure readability.
Automated Testing: There are several tools available for automated accessibility testing. Some popular ones include:
WAVE: A free web accessibility evaluation tool provided by WebAIM.
Axe: An accessibility testing toolkit built on a library of accessibility rules.
Lighthouse: An open source, automated tool for improving the quality of web pages. It has audits for performance, accessibility, progressive web apps, SEO, and more.
Screen Reader Testing: This involves testing your website using a screen reader tool. Some popular screen readers include NVDA, JAWS, and VoiceOver.
User Testing: This involves testing your website with people with disabilities. This can provide valuable insights into how accessible your website is in practice.
Remember, no single tool or method can catch all accessibility issues, so a combination of methods is often the best approach.
For more information, you can refer to the following resources:
Query input: What are some best practices for creating accessible tables in HTML? GitHub Copilot response: Creating accessible tables in HTML involves several best practices:
Use <th> for table headers: This helps screen readers identify headers. Also, use the scope attribute to specify whether the header is for a row or a column.
Provide captions: Use the <caption> element to provide a brief overview of the table. This is especially helpful for people using screen readers.
<table>
<caption>Overview of sales</caption>
<!-- rest of the table -->
</table>
Use <thead>, <tbody>, and <tfoot>: These elements help to group different sections of the table and can improve accessibility.
<table>
<thead> <!-- header group -->
<tbody> <!-- body group -->
<tfoot> <!-- footer group -->
</table>
Avoid complex tables: If possible, avoid using tables for complex data structures. If you must, use rowspan and colspan attributes carefully and provide additional information in cell content or with the title attribute.
Ensure readability without styles: The table should be readable and make sense even when styles are turned off.
Use aria-labelledby for complex tables: If a table has multiple levels of headers, use the aria-labelledby attribute to associate data cells with headers.
For more information, you can refer to the WebAIM guide on creating accessible tables.
Forms
Query input: What are some best practices for creating accessible forms in HTML? GitHub Copilot response: Creating accessible forms in HTML involves several best practices:
Use <label> for form controls: Each form control should have a corresponding <label> element. This helps screen readers identify the purpose of the form control.
Provide error messages and feedback: If the user makes an error, provide clear and specific feedback. Use the aria-describedby attribute to associate the form control with the error message.
<input type="text" id="name" name="name" aria-describedby="nameError">
<span id="nameError">Please enter your name.</span>
Use correct input types: Use the correct input type for the form control (for example, email, number, date). This can provide the user with the appropriate keyboard on mobile devices.
Make form controls keyboard accessible: Ensure that all form controls and buttons can be accessed and used with the keyboard.
Use ARIA roles and properties when necessary: If a form control requires more complex interaction, use ARIA roles and properties to provide additional information to screen reader users.
For more information, you can refer to the WebAIM guide on creating accessible forms.
Keyboard support
Query input: What are some best practices for creating proper keyboard support in HTML? GitHub Copilot response: Creating proper keyboard support in HTML involves several best practices:
Logical Tab Order: Ensure that the tab order of the page follows the visual flow of the content. This can be achieved by structuring your HTML in a logical order. Avoid using positive tabindex values as they can disrupt the natural tab order.
Keyboard Focus Indication: It’s important that users can visually identify which element currently has keyboard focus. This can be achieved using CSS to style the :focus state of interactive elements.
Skip Links: Provide a mechanism to skip to main content or different sections of the page. This can be a link at the top of the page that becomes visible when it receives keyboard focus.
<a href="#maincontent">Skip to main content</a>
Accessible Interactive Elements: Ensure all interactive elements are accessible via keyboard. This includes links, buttons, form controls, and custom interactive widgets. Use semantic HTML elements whenever possible as they have built-in keyboard accessibility.
Keyboard Support for Custom Widgets: If you’re creating custom interactive widgets (like a dropdown menu or modal dialog), you’ll need to provide additional keyboard support. This often involves handling keypress events for keys like Enter, Space, Escape, and the arrow keys. The WAI-ARIA Authoring Practices Guide provides detailed guidance on how to add keyboard support to various types of widgets.
Avoid Keyboard Traps: Ensure that keyboard users can navigate to and from all parts of the page. Avoid situations where keyboard focus can be trapped in a particular page element.
For more information, you can refer to the WebAIM guide on keyboard accessibility.
Aria
Query input: What are some best practices around using proper ARIA roles in HTML? GitHub Copilot response: ARIA (Accessible Rich Internet Applications) roles can be used to improve accessibility, especially when creating complex interactive elements. Here are some best practices:
Use Semantic HTML First: Before using ARIA, consider whether you can use semantic HTML elements. These elements have built-in accessibility features that often make ARIA unnecessary. For example, use a <button> element instead of a <div> with a role="button".
Don’t Change Native Semantics: Avoid using ARIA to change the semantics of native HTML elements. For example, don’t use role="button" on a link (<a>). Instead, use a <button> element.
Use Appropriate Roles: When you do need to use ARIA, ensure you’re using the appropriate role for the element. The ARIA roles model provides a list of roles and their intended use.
Provide Required States and Properties: Some roles require additional ARIA states or properties. For example, a checkbox requires the aria-checked state.
Use aria-labelledby and aria-describedby: These attributes can be used to provide additional descriptive text for an element.
<button aria-describedby="info">More Info</button>
<div id="info">Clicking this button will open more information.</div>
Test with Screen Readers: After adding ARIA roles, test your page with a screen reader to ensure it’s providing the intended information.
Remember, ARIA should be used as a last resort when semantic HTML isn’t sufficient. The WAI-ARIA Authoring Practices Guide provides detailed guidance on how to use ARIA correctly.
Analysis
Reviewing the questions we asked GitHub Copilot, it suggested a lot of good information for us to learn more about best accessibility and usability practices. A few responses may be open to interpretation, while other responses lack details or specificity. Some examples include:
<tfoot> is an HTML element that calls attention to a set of rows summarizing the columns of the table. Including <tfoot> can help ensure the proper understanding of a table. However, not all tables require such rows–therefore, <tfoot> is not mandatory to have a usable table if the data doesn’t require it.
The response for the question about forms stressed the importance of the <label> element, which can help identify different labels for their various inputs. However, that response didn’t include any description about adding “for” attributes with the same value as the <input>’s ID. The response did include “for” attributes in the code suggestion, but an explanation about proper use of the “for” attribute would have been helpful.
The response to our question about keyboard accessibility included an explanation about interactive controls and buttons that can be accessed and used with a keyboard. However, it did not include additional details that could benefit accessibility such as ensuring a logical tab order, testing tab order, or avoiding overriding default keyboard accessibility for semantic elements.
If you are ever unsure of a recommendation or wish to know more, ask GitHub Copilot more questions on those areas, ask to provide more references/links, and follow up on the documentation provided. As a developer, it is your responsibility to verify the information you receive, no matter the source.
Conclusion
In our exploration, GitHub Copilot Chat and a well-constructed foundational prompt come together to create a personal AI assistant for accessibility that can improve your understanding of accessibility. We invite you to try the sample prompt and work with a qualified accessibility expert to customize and improve it.
Limitations and considerations
While clever prompts can improve the accessibility of the results from GitHub Copilot Chat, it is not reasonable to expect generative AI tools to deliver perfect answers to your questions or generate code that fully conforms with accessibility standards. When working with GitHub Copilot Chat, we recommend that you think of yourself as a lead developer who is working with a more junior developer. As the lead developer, it is your responsibility to verify information that is provided by GitHub Copilot Chat and ensure it meets all of your requirements. We also recommend that you work with a qualified accessibility expert to review and test suggestions from GitHub Copilot. Finally, we recommend that you ensure that all GitHub Copilot Chat code suggestions go through proper code review, code security, and code quality channels to ensure they meet the standards of your team.
As a company that’s been remote-first since day one, GitHub Engineering has learned a lot about how to communicate effectively across time zones, teams, and tools. We’ve distilled our experience into a set of guidelines that we call “How we communicate,” and we’re sharing them with you today. We hope that by sharing our communication practices publicly, we can help other organizations that are embracing remote work or want to improve their collaboration culture.
Read on to learn more about how we use GitHub to build GitHub, how we turned our guiding communications principles into prescriptive practices to manage our internal communications signal-to-noise ratio, and how you can contribute to the ongoing conversation.
Using GitHub to build GitHub
Unlike many companies that made the transition to remote work during the pandemic, GitHub has been majority remote since its founding 15 years ago. GitHub’s remote-first communication style originally drew inspiration from the open source community. Open source development rarely requires the global community of collaborators and contributors to be in a certain place, at a certain time, in order to participate in the ongoing conversation. This is the same approach GitHub Engineering takes to our own internal communication. We believe that asynchronous communication is the best way to work globally and at scale, and as a result, we’ve built our culture around it.
We’ve always used GitHub to build GitHub. GitHub is not only the place where we host and review code, but also where we plan, discuss, and document our work. We use issues, pull requests, projects, and discussions to track work, collaborate on features, and share information across teams. Many of these communications patterns grew organically, as developers adopted practices from the open source community for our own internal collaboration needs. We believe open practices are the best way to work with a global and diverse team, and to make decisions that are informed, inclusive, and scalable.
While asynchronous collaboration is deeply embedded in GitHub’s DNA, we have also long had a culture of each team enjoying a great deal of autonomy in deciding how they communicate day to day. This freedom has allowed teams to experiment and uncover novel practices, but it has also meant that working across teams previously required first negotiating a meta-conversation around how to communicate before any substantive work could occur–much like a new open source project negotiating with its newfound community. Having an open set of shared expectations within the engineering organization allows us to be more effective, mindful, and inclusive about how and where we communicate, leading us to make more well-informed decisions in a way that takes into account different needs, preferences, and time zones.
“How we communicate”
To define this set of shared expectations, the GitHub Engineering Operations and Culture team collaborated with more than 100 people across the engineering organization in the first half of 2023 to create guidance on “How we communicate.” This document was intended to encourage consistency over preference by outlining a common core of shared internal communication practices for all of GitHub Engineering in the form of opinionated guidance. Teams are still encouraged to adapt the practices for their unique circumstances, while maintaining a common “API” to interface with other teams.
Today, we are publishing our “How we communicate” guidance under a CC-BY-4.0 license, in the hopes that you’ll find it useful, especially if you’re evolving your own remote-first or remote-friendly culture; we welcome you to fork, modify, and use the documentation with attribution. We expect our guidance (lightly edited for the community, primarily to remove internal URLs and references) will evolve over time along with our organization, and, of course, pull requests are always welcome.
From guiding principles to prescriptive practices
To begin with our “How we communicate” guidance, we established eight guiding principles:
Be asynchronous first.
Write things down.
Make work visible and overcommunicate.
Prefer GitHub tools and workflows.
Embrace collaboration.
Foster a culture that values documentation maintenance.
Communicate openly, honestly, and authentically.
Remember, practicality beats purity.
From there, we began to define the specific practices that would help us live up to these principles. We started with the most common forms of communication, such as chat, discussions, issues, project boards, and pull requests, and went on to collaboratively author suggestions on how to manage notifications, run effective meetings, and schedule more inclusively.
Managing the signal-to-noise ratio
With well over 1,500 engineers across a number of functions, we faced a challenge not unique to any organization: how to keep everyone informed and engaged without overwhelming them with notifications. We wanted to create a system that allowed everyone to opt-in, rather than opt-out, and to get the information they needed in a digestible and skimmable way. As it was, either you got everything (which we jokingly referred to as the “fire hose” of notifications), or you opted out entirely (and ignored everything). Either way, Hubbers were likely to miss important information. We set out to create a system that minimized notification fatigue, while allowing people to subscribe to the topics they cared about.
We rely on GitHub Discussions heavily to share information within and across teams. It’s a natural choice, since engineers are already working on GitHub.com, and with things like comments, upvotes, and emoji reactions, discussions are a great way to start an asynchronous conversation on just about any topic.
Opt-in
To start, we encouraged teams to begin posting their discussions to the most logical repository, instead of directly to the main github/engineering repository. (For example, if a post was about GitHub Copilot, it should go in the github/copilot repository; if it was about GitHub Actions, it should go in the github/actions repository.) That way, those interested could subscribe to the repositories they cared about, and get email or web notifications when new discussions were posted. And the volume of notifications coming through github/engineering to the whole organization would be reduced.
Amplify widely
But some posts are rightfully intended for all of GitHub Engineering. Things like staff ships (early access to new features for staff), required actions, promotions, and updates to Engineering priorities are written with a broad audience in mind. To ensure we were still surfacing the most important information to the organization, we established a small set of “magic labels” that if applied to a post, would add it to a daily content roundup, automatically amplify the message in various places for all of GitHub Engineering to see.
For a peek at our taxonomy, here’s an excerpt from our GitHub Actions workflow that makes it easy for everyone to add the set of “magic labels” to their repositories:
label:
- name: eng-action-required
description: Upcoming process/workflow changes/activities requiring Engineering Hubbers to take action
- name: eng-availability
description: Discussions about availability, incident response, et al
- name: eng-celebrations
description: Celebrating Hubber promotions and other amazingness
- name: eng-feedback-request
description: Posts requesting feedback from the Engineering organization
- name: eng-org-change
description: Announcements related to organizational changes
- name: eng-priorities
description: Discussions related to Engineering priorities
- name: eng-roundup
description: Newsletters, weekly digests, and other content and team roundups
- name: eng-show-and-tell
description: Share what you've learned or show off something you've made
- name: eng-staff-ship
description: Announcements for features made available to Hubbers for feedback and early access
- name: eng-strategy
description: Discussions related to strategy and vision
Automate all the things!
We used GitHub Actions to schedule a workflow to automatically create daily and weekly roundups of activity across the organization based on those “magic labels,” posting the digests as discussion posts in the github/engineering repository.
Like any other discussion post, these content roundups trigger web and email notifications from GitHub.com, and they’re also amplified in Slack channels. However, rather than receiving multiple notifications a day, these roundups reduce the daily notification to one (and also make it much easier to catch up on everything that happens while you’re out of the office!). To support the needs of those who prefer receiving notifications for every discussion post individually, rather than waiting for a daily roundup (aka to instead “drink from the fire hose”), we created an #engineering-discussions-firehose Slack channel, which streams every labeled post as it is posted.
Experiment with AI
With notifications reduced in our main github/engineering repository and discussions being posted in more logical repositories, enabling people to subscribe to more frequent notifications for specific topics, the last remaining step was to increase quick skimmability to allow for greater situational awareness without anyone having to spend all day reading teams’ discussion posts.
As part of our writing style, most of us include TL;DRs at the top of posts (internet slang for “too long, didn’t read,” a short summary of longer writing), but not every post author includes one. For posts that don’t have a human-authored TL;DR, we use Azure’s OpenAI service to draft a brief summary for us. That way, readers can quickly skim the daily digest (or fire hose) and decide if they want to click through to read more.
Here’s an excerpt of the prompt we use to summarize discussion posts:
// OpenAI
export const encodingModel = "gpt-3.5-turbo";
export const openaiModel = "gpt-35-turbo";
export const openaiPrompt = `
The following is an internal discussion post from the engineering department at GitHub formatted in GitHub flavored Markdown. Please write a short summary appropriate for inclusion in a digest of internal discussion posts with the following requirements:
- The summary should be no more than 3 sentences
- The summary should focus on the most important and impactful information from the post, including key points and any calls to action
- The summary should be detailed, thorough, to-the-point, and written for a technical audience, while maintaining clarity and conciseness
- The communications style should be professional, but informal
- The summary should use emoji where appropriate, but use emoji sparingly
- The summary should be formatted in GitHub Flavored Markdown with no line breaks
- DO NOT use the phrases "the engineering department" or "at GitHub"; instead, whenever possible, name the specific team in reference, or else use "we" to refer to the team or engineering department. For example, use, "We recently shipped a feature", and NOT, "The engineering department at GitHub recently shipped a feature".
- Employees at GitHub are referred to as "Hubbers"
- GitHub is ALWAYS capitalized as "GitHub", never "Github"
- Teams are referred to as "the Actions team" or "the Copilot team", never just "actions team" or "copilot team"
`;
export const estimatedPromptTokens = 300;
export const completionTokens = 300;
Ironically, we relied heavily on GitHub Copilot to build the GitHub Actions workflow (it’s been a while since these Hubbers have written “production-worthy” code), meaning robots helped humans to teach robots how to summarize the work of humans, which other robots then published out to other humans. Summarization is a core workflow for AI, and so far, while it’s not always perfect, it’s been working well. If you’re interested in the prompt we’re using (or want to help us improve it!), you can find it here.
Let’s build from here
We’re excited to share our “How we communicate” guidance with you, and we hope that it will inspire you to adopt or improve some of the practices we’ve found useful. Here are some suggestions to get you started:
Principles: Establish a set of guiding principles for your organization’s internal communications (fork and clone our guidelines for a head start!). What core values do you want to promote, and how can you ensure everyone is aligned around those values so there’s a common “API” across teams?
Practices: Use those principles to develop practices. What specific practices can you adopt to help you live up to your principles, and how can you ensure those practices are adopted across the organization?
Experimentations: Experiment with automation and emerging technologies to improve your practices. How can you use AI and other tools (like GitHub Actions) to automate your workflows and improve the signal-to-noise ratio?
We recognize communication is an ongoing and evolving process, and different teams and cultures may have different needs and preferences. We welcome your feedback, suggestions, and contributions to our public repository: https://github.com/github/how-engineering-communicates
Ever since we announced GitHub Copilot Chat in March this year, I’ve been thinking a lot about how it’s improving developer happiness and overall satisfaction while coding. Especially for junior developers looking to upskill, or those in the learning phase of diving into a new framework, GitHub Copilot Chat can be such a valuable tool to have in your back pocket.
With GitHub Copilot Chat, you can now interface with Copilot as a context-aware conversational assistant right in the IDE, allowing you to execute some of the most complex tasks with simple prompts. This goes beyond GitHub Copilot’s original capabilities, which focused on autocompletion and translating natural language comments into code. Now, developers can not only get code suggestions in-line, but they can ask Copilot questions directly, get explanations, offer prompts for code, and more, all while staying in the IDE—and in the flow.
Navigating a new framework (and saving time)
Recently, I was preparing a conference talk and demo about ReactJS, and I had to think a bit about what kind of app I wanted to make with the help of Copilot Chat. Since photography is a hobby of mine, I decided to make a photo gallery of the tulip fields and flower shows around Amsterdam. In the end, I went through a couple different versions of this photo gallery with Copilot Chat. Using a probabilistic model, which is currently based on OpenAI’s GPT-3.5-turbo, it found the best suggestion for me based on how I prompted it, including the question I asked, the code I’d started writing, and other open tabs in my IDE.
It had been a long time since I had used React, so it probably would’ve taken me a few days of searching and trial and error before coming up with something decent. But with Copilot Chat, each iteration of my photo gallery only took me about 20-30 minutes to go through.
Making prototypes and generating new code
What I most enjoyed about using Copilot Chat to create something new was discovering multiple ways I could implement my component. I didn’t have to leave my IDE and search for advice or a component to use because Copilot would suggest something in real time. If it offered me a suggestion that didn’t work out well, I could give it feedback on why that suggestion didn’t work, which enabled it to offer suggestions that better suited my needs.
Despite working in an unfamiliar framework, Copilot Chat enabled me to immediately start churning out my ideas, which was incredibly satisfying. It was empowering to discover that I can get something done so much faster than what I would have anticipated without any help.
This idea of looking for external help and examples to understand code has been part of the learning process since well before we had AI pair programming tools. I remember when I was first starting in my career and discovering all these new frameworks. I would spend hours, days, weeks doing tutorials and learning about different ways of implementing things. I would learn by copying and pasting things I saw on StackOverflow and seeing how they fit in with the rest of my code (or by chatting with my buddy that I shared a cubicle with at the time).
A lot of the time, these code snippets didn’t even work, but having something to start with really helped with the learning process and that excitement propelled me forward to the next step. This is exactly the magic I felt when using Copilot Chat—while being able to get a contextual suggestion that actually worked and helped me quickly progress to the next thing. Not to mention the amount of time and energy I saved by staying within the context of VS Code instead of searching through websites and other comments online (and avoiding some stress caused by the sentiment of some Stack Overflow comments).
GitHub Copilot Chat in action
When it came time to build my photo gallery, I used Copilot Chat to get suggestions for popular React libraries I could use. There were a few of them that I checked out in separate iterations of the gallery but styled components seems to be the easiest one for me to configure.
I wanted to include a modal as well, so I asked Copilot if the styled components library supported modals. I was really surprised that it knew exactly how to utilize the modal component of the library and how to pass the props in and handle the onClick functionality from the get-go.
In the video, you may notice that it initially gives me a generic suggestion with some boilerplate examples of how to define a modal component and how to reference it from another file. I then asked it to iterate on that suggestion and give me something more specific to how I defined my gallery. This is important because the power of GitHub Copilot is really in the prompt that you provide it: the more fine-tuned the information, the more powerful its suggestions will be. For further reading, check out these prompt tips and tricks for leveraging GitHub Copilot effectively as well as this post on how we compose prompts at GitHub.
Testing out a UI change based on a natural language prompt
When I first tried rendering a modal, that close button was out of view on the top right corner of the screen. This isn’t too difficult to do if you’re regularly developing front-end. Full transparency: I would have needed to Google how to fix this since I just don’t remember how to and CSS is hard! I was shocked that just by asking Copilot Chat to center the “X” button in the modal, it gave me a better suggestion with some new CSS to add display properties to the button that adjust it to my intention. With Copilot Chat, I got the fix I needed without having to leave the IDE or break my flow.
Making accessibility improvements
I have a background in web accessibility and I knew there would be some improvements needed to make the modals interactive with proper focus handling. There are many facets to making a component accessible and it’s important to strategize early on. Best practices include working with accessibility linting tools, and also specialists that can help you balance constraints at the start of the design and development process.
Copilot Chat can be a great addition to those tools by pointing you in the right direction to fixing accessibility issues. In the case of my gallery, the images were not presenting themselves as interactive to keyboard or screen reader users (or, even visually, which goes to show that accessibility makes products better for everyone!). I asked Copilot Chat what it recommended for me to improve the interactivity of the images. The video below illustrates the suggestions it provided around using tabindex, aria attributes, and handling keydown events.
There are, of course, other accessibility considerations to be made here. At some point I decided to make each of the images button elements with a background image, since generally it’s better to use semantic HTML. I then carried on with the rest of my work to manage the focus correctly when opening and closing the modal, as well as making sure only the visible or focused content is presented to a screen reader.
Troubleshooting errors
I was also surprised by Copilot Chat’s ability to help me debug my project whenever I came across an error message. I’d just paste the error into the chat window and GitHub Copilot would offer an explanation for what went wrong and an alternative approach so I could fix the bug quickly and move on.
Writing tests
Knowing that GitHub Copilot can suggest bug fixes, I also wanted to see how it would suggest I write tests for my code. You can ask Copilot Chat for all sorts of test cases, as well as just what kind of testing framework would make the most sense for your application.
In another iteration of my gallery, I used GitHub Copilot to help me render a countdown to the next opening of Tulip season (I went with March 21, 2024, when the tulip festival starts). I decided to make use of the new Copilot Chat slash commands that make it simple to highlight a function and prompt it to help me create some test cases. It suggested using the React testing library for rendering, as well as some methods from Jest to simulate the passage of time and make sure the passing days are represented correctly. From there, I learned about the Jest framework’s Timer Mocks and best practices for testing for fake timers.
Without GitHub Copilot and this new chat feature, navigating a test framework and relying solely on their documentation would have taken even more time.
Summarizing my changes with GitHub Copilot for pull requests
Lastly, I used GitHub Copilot for pull requests to help summarize all the changes I made in a pull request. It gave me a summary of my changes, a walk through of each of the diffs relating to those changes, and even a poem about my application.
All of this is to show how Copilot Chat and GitHub Copilot for pull requests made the entire coding process much more enjoyable for me while working in an unfamiliar framework—from the initial idea phase to submitting a pull request.
Potential limitations and considerations
While the productivity increases for GitHub Copilot are amazing, there are valid concerns around the quality of code AI paired programming tools suggest and the danger of blindly trusting them. That’s why it’s important to remember that you, the developer, is ultimately the pilot. I think of using GitHub Copilot to be similar to pair programming with another developer: it helps me work faster, but I still need to verify the suggestions it’s giving me to ensure they meet my requirements.
While GitHub Copilot has numerous filters in place to avoid suggestions with vulnerabilities, it’s still important to review and test before deploying. As with any code you did not independently originate, you should ensure code suggestions go through proper code review, code security, and code quality channels to maintain the standards of your team.
The Developer Experience (DX) team at GitHub collaborated with a number of other teams to work on moving our continuous integration (CI) system to GitHub Actions to support the development and scaling demands of our engineering team. Our goal as a team is to enable our engineers to confidently and quickly ship software. To that end, we’ve worked on providing paved paths, a suite of automated tools and applications to streamline our development, runtime platforms, and deployments. Recently, we’ve been working to make our CI experience better by leveraging the newly released GitHub feature, Actions larger runners, to run our CI.
Read on to see how we run 15,000 CI jobs within an hour across 150,000 cores of compute!
Brief history of CI at GitHub
GitHub has invested in a variety of different CI systems throughout its history. With each system, our aim has been to enhance the development experience for both GitHub engineers writing and deploying code and for engineers maintaining the systems.
However, with past CI systems we faced challenges with scaling the system to meet the needs of our engineering team to provide both stable and ephemeral build environments. Neither of these challenges allowed us to provide the optimal developer experience.
Then, GitHub released GitHub Actions larger runners. This gave us an opportunity not only to transition to a fully featured CI system, but also to develop, experience, and utilize the systems we are creating for our customers and to drive feedback to help build the product. For the GitHub DX team, this transition was a great opportunity to move away from maintaining our past CI systems while delivering a superior developer experience.
What are larger runners?
Larger runners are GitHub Actions runners that are hosted by GitHub. They are managed virtual machines (VMs) with more RAM, CPU, and disk space than standard GitHub-hosted runners. There are a variety of different machine sizes offered for the runners as well as some additional features compared to the standard GitHub-hosted runners.
Larger runners are available to GitHub Team and GitHub Enterprise Cloud customers. Check out these docs to learn more about larger runners.
Why did we pick larger runners?
Autoscaling and managed
Coming from previous iterations of GitHub’s CI systems, we needed the ability to create CI machines on demand to meet the fast feedback cycles needed by GitHub engineers and to scale with the rate of change of the site.
With larger runners, we maintain the ability to autoscale our CI system because GitHub will automatically create multiple instances of a runner that scale up and down to match the job demands of our engineers. An added benefit is that the GitHub DX team no longer has to worry about the scaling of the runners since all of those complexities are handled by GitHub itself!
We wanted to share some raw numbers on our current peak utilization of larger runners:
Uses 4,500 concurrent 32-core runners
Runs 125,000 build minutes per hour
Queues and runs approximately 15,000 jobs within an hour
Allocates around 150,000 cores of compute
(Beta) Custom VM image support
GitHub Actions provides runners with a lot of tools already baked in, which is sufficient and convenient for a variety of projects across the company. However, for some complex production GitHub services, the prebuilt runners did not satisfy all our requirements.
To maintain an efficient and fast CI system, the DX team needed the ability to provide machines with all the tools needed to build those production services. We didn’t want to spend extra time installing tools or compiling projects during CI jobs.
We are currently building features into larger runners so they have the ability to be launched from a custom VM image, called custom images. While this feature is still in beta, using custom images is a huge benefit to GitHub’s CI lifecycle for a couple of reasons.
First, custom images allows GitHub to bundle all the required software and tools needed to build and test complex production bearing services. Anything that is unique to GitHub or one of our projects can be pre-installed on the image before a GitHub Actions workflow even starts.
Second, custom images enable GitHub to dramatically speed up our GitHub Actions workflows by acting as a bootstrapping cache for some projects. During custom image creation, we bundle a pre-built version of a project’s source code into the image. Subsequently, when the project starts a GitHub Actions workflow, it can utilize a cached version of its source code, and any other build artifacts, to speed up its build process.
The cached project source code on the custom VM image can quickly become out of date due to the rapid rate of development within GitHub. This, in turn, causes workflow durations to increase. The DX team worked with the GitHub Actions engineering team to create an API on GitHub to regularly update the custom image multiple times a day to keep the project source up to date.
In practice, this has reduced the bootstrapping time of our projects significantly. Without custom images, our workflows would take around 50 minutes from start to finish, versus the 12 minutes they take today. This is a game changer for our engineers.
We’re working on a way to offer this functionality at scale. If you are interested in custom images for your CI/CD workflows, please reach out to your account manager to learn more!
Important GitHub Actions features
There are thousands of projects at GitHub — from services that run production workloads to small tools that need to run CI to perform their daily operations. To make this a reality, GitHub leverages several important features in GitHub Actions that enable us to use the platform efficiently and securely across the company at scale.
Reusable workflows
One of the DX team’s driving goals is to pave paths for all repositories to run CI without introducing unnecessary repetition across repositories. Prior to GitHub Actions, we created single job configurations that could be used across multiple projects. In GitHub Actions, this was not as easy because any repository can define its own workflows. Reusable workflows to the rescue!
The reusable workflows feature in GitHub Actions provides a way to centrally manage a workflow in a repository that can be utilized by many other repositories in an organization. This was critical in our transition from our previous CI system to GitHub Actions. We were able to create several prebuilt workflows in a single repository, and many repositories could then use those workflows. This makes the process of adding CI to an existing or new project very much plug and play.
In our central repository hosting our reusable workflows, we can have workflows defined like:
Another great benefit of the reusable workflows feature is that the runner can be defined in the Reusable Workflow, meaning that we can guarantee all users of the workflow will run on our designated larger runner pool. Now, projects don’t need to worry about which runner they need to use!
(Beta) Reusing previous workflow outcomes
To optimize our developer experience, the DX team worked with our engineering team to create a feature for GitHub Actions that allows workflows to reuse the outcome of a previous workflow run where the outcomes would be the same.
In some cases, the file contents of a repository are exactly the same between workflow runs that run on different commits. That is, the Git tree IDs for the current commit is the same as the previous commit (there are no file differences). In these cases, we can bypass CI checks by reusing the previous workflow outcomes and allow engineers to not have to wait for CI to run again.
This feature saves GitHub engineers from running anywhere from 300 to 500 workflows runs a day!
Other challenges faced
Private service access
During some internal GitHub Actions workflow runs, the workflows need the ability to access some GitHub private services, within a GitHub virtual private cloud (VPC), over the network. These could be resources such as artifact storage, application metadata services, and other services that enable invocation of our test harness.
When we moved to larger runners, this requirement to access private services became a top-of-mind concern. In previous iterations of our CI infrastructure, these private services were accessible through other cloud and network configurations. However, larger runners are isolated from other production environments, meaning they cannot access our private services.
Like all companies, we need to focus on both the security of our platform as well as the developer experience. To satisfy these two requirements, GitHub developed a remote access solution that allows clients residing outside of our VPCs (larger runners) to securely access select private services.
This remote access solution works on the principle of minting an OIDC token in GitHub Actions, passing the OIDC token to a remote access gateway that authorizes the request by validating the OIDC token, and then proxying the request to the private service residing in a private network.
With this solution we are able to securely provide remote access from larger runners running GitHubActions to our private resources within our VPC.
GitHub has open sourced the basic scaffolding of this remote access gateway in the github/actions-oidc-gateway-example repository, so be sure to check it out!
Conclusion
GitHub Actions provides a robust and smooth developer experience for GitHub engineers working on GitHub.com. We have been able to accomplish this by using the power of GitHub Actions features, such as reusable workflows and reusable workflow outcomes, and by leveraging the scalability and manageability of the GitHub Actions larger runners. We have also used this effort to enhance the GitHub Actions product. To put it simply, GitHub runs on GitHub.
The advertising industry is constantly evolving, driven by advancements in technology and changes in consumer behaviour. One of the key challenges in this industry is reaching the right audience, reaching people who are most likely to be interested in your product or service. This is where the concept of a lookalike audience comes into play. By identifying and targeting individuals who share similar characteristics with an existing customer base, businesses can significantly improve the effectiveness of their advertising campaigns.
However, as the scale of Grab advertisements grows, there are several optimisations needed to maintain the efficacy of creating lookalike audiences such as high service level agreement (SLA), high cost of audience creation, and unstable data ingestion.
The need for an even more efficient and scalable solution for creating lookalike audiences was the motivation behind the development of the scalable lookalike audience platform. By developing a high-performance in-memory lookalike audience retrieval service and embedding-based lookalike audience creation and updating pipelines, this improved platform builds on the existing system and provides an even more effective tool for advertisers to reach their target audience.
Constant optimisation for greater precision
In the dynamic world of digital advertising, the ability to quickly and efficiently reach the right audience is paramount and a key strategy is targeted advertising. As such, we have to constantly find ways to improve our current approach to creating lookalike audiences that impacts both advertisers and users. Some of the gaps we identified included:
Long SLA for audience creation. Earlier, the platform stored results on Segmentation Platform (SegP) and it took two working days to generate a lookalike audience list. This is because inserting a single audience into SegP took three times longer than generating the audience. Extended creation times impacted the effectiveness of advertising campaigns, as it limited the ability of advertisers to respond quickly to changing market dynamics.
Low scalability. As the number of onboarded merchant-partners increased, the time and cost of generating lookalike audiences also increased proportionally. This limited the availability of lookalike audience generation for all advertisers, particularly those with large customer bases or rapidly changing audience profiles.
Low updating frequency of lookalike audiences. With automated updates only occurring on a weekly basis, this increased the likelihood that audiences may become outdated and ineffective. This meant there was scope to further improve to help advertisers more effectively reach their campaign goals, by targeting individuals who fit the desired audience profile.
High cost of creation. The cost of producing one segment can add up quickly for advertisers who need to generate multiple audiences. This could impact scalability for advertisers as they could hesitate to effectively use multiple lookalike audiences in their campaigns.
Solution
To efficiently identify the top N lookalike audiences for each Grab user from our pool of millions of users, we developed a solution that leverages user and audience representations in the form of embeddings. Embeddings are vector representations of data that utilise linear distances to capture structure from the original datasets. With embeddings, large sets of data are compressed and easily processed without affecting data integrity. This approach ensures high accuracy, low latency, and low cost in retrieving the most relevant audiences.
Our solution takes into account the fact that representation drift varies among entities as data is added. For instance, merchant-partner embeddings are more stable than passenger embeddings. By acknowledging this reality, we optimised our process to minimise cost while maintaining a desirable level of accuracy. Furthermore, we believe that having a strong representation learning strategy in the early stages reduced the need for complex models in the following stages.
Our solution comprises two main components:
Real-time lookalike audience retrieving: We developed an in-memory high-performance retrieving service that stores passenger embeddings, audience embeddings, and audience score thresholds. To further reduce cost, we designed a passenger embedding compression algorithm that reduces the memory needs of passenger embeddings by around 90%.
Embedding-based audience creation and updating: The output of this part of the project is an online retrieving model that includes passenger embeddings, audience embeddings, and thresholds. To minimise costs, we leverage the passenger embeddings that are also utilised by other projects within Grab, beyond advertising, thus sharing the cost. The audience embeddings and thresholds are produced with a low-cost small neural network.
In summary, our approach to creating scalable lookalike audiences is designed to be cost-effective, accurate, and efficient, leveraging the power of embeddings and smart computational strategies to deliver the best possible audiences for our advertisers.
Solution architecture
The advertiser creates a campaign with a custom audience, which triggers the audience creation process. During this process, the audience service stores the audience metadata provided by advertisers in a message queue.
A scheduled Data Science (DS) job then retrieves the pending audience metadata, creates the audience, and updates the TensorFlow Serving (TFS) model.
During the serving period, the Backend (BE) service calls the DS service to retrieve all audiences that include the target user. Ads that are targeting these audiences are then selected by the Click-Through Rate (CTR) model to be displayed to the user.
Implementation
To ensure the efficiency of the lookalike audience retrieval model and minimise the costs associated with audience creation and serving, we’ve trained the user embedding model using billions of user actions. This extensive training allows us to employ straightforward methods for audience creation and serving, while still maintaining high levels of accuracy.
Creating lookalike audiences
The Audience Creation Job retrieves the audience metadata from the online audience service, pulls the passenger embeddings, and then averages these embeddings to generate the audience embedding.
We use the cosine score of a user and the audience embedding to identify the audiences the user belongs to. Hence, it’s sufficient to store only the audience embedding and score threshold. Additionally, a global target-all-pax Audience list is stored to return these audiences for each online request.
Serving lookalike audiences
The online audience service is also tasked with returning all the audiences to which the current user belongs. This is achieved by utilising the cosine score of the user embedding and audience embeddings, and filtering out all audiences that surpass the audience thresholds.
To adhere to latency requirements, we avoid querying any external feature stores like Redis and instead, store all the embeddings in memory. However, the embeddings of all users are approximately 20 GB, which could affect model loading. Therefore, we devised an embedding compression method based on hash tricks inspired by Bloom Filter.
We utilise hash functions to obtain the hash64 value of the paxID, which is then segmented into four 16-bit values. Each 16-bit value corresponds to a 16-dimensional embedding block, and the compressed embedding is the concatenation of these four 16-dimensional embeddings.
For each paxID, we have both the original user embedding and the compressed user embedding. The compressed user embeddings are learned by minimising the Mean Square Error loss.
We can balance the storage cost and the accuracy by altering the number of hash functions used.
Impact
Users can see advertisements targeting a new audience within 15 mins after the advertiser creates a campaign.
This new system doubled the impressions and clicks, while also improving the CTR, conversion rate, and return on investment.
Costs for generating lookalike audiences decreased by 98%.
Learnings/Conclusion
To evaluate the effectiveness of our new scalable system besides addressing these issues, we conducted an A/B test to compare it with the earlier system. The results revealed that this new system effectively doubled the number of impressions and clicks while also enhancing the CTR, conversion rate, and return on investment.
Over the years, we have amassed over billions of user actions, which have been instrumental in training the model and creating a comprehensive representation of user interests in the form of embeddings.
What’s next?
While this scalable system has proved its effectiveness and demonstrated impressive results in CTR, conversion rate, and return on investment, there is always room for improvement.
In the next phase, we plan to explore more advanced algorithms, refine our feature engineering process, and conduct more extensive hyperparameter tuning. Additionally, we will continue to monitor the system’s performance and make necessary adjustments to ensure it remains robust and effective in serving our advertisers’ needs.
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
In August, we experienced two incidents that resulted in degraded performance across GitHub services.
August 15 16:58 UTC (lasting 4 hours 29 minutes)
On August 15 at 16:58 UTC, GitHub started experiencing increasing delays in an internal job queue used to process webhooks. We statused GitHub Webhooks to yellow at 17:24 UTC. During this incident, customers experienced webhooks delays as long as 4.5 hours.
We determined that the delays were caused by a significant and sustained spike in webhook deliveries. This caused a backup of our webhooks deliveries queue. We mitigated the issue by blocking events from sources of the increased load, which allowed the system to gradually recover as we processed the backlog of events. In response to this and other recent webhooks incidents, we made improvements that allow us to handle a higher amount of traffic and absorb load spikes without increasing delivery latency. We also improved our ability to manage load sources to prevent and more quickly mitigate any impact to our service.
August 29 02:36 UTC (lasting 49 minutes)
On August 29 at 02:36 UTC, GitHub systems experienced widespread delays in background job processing. This prevented webhook deliveries, GitHub Actions, and other asynchronously-triggered workloads throughout the system from running immediately as normal. While workloads were delayed by up to an hour, no data was lost, and systems ultimately recovered and resumed timely operation.
The component of our job queueing service responsible for dispatching jobs to workers failed due to an interaction with unexpected CPU throttling and short session timeouts for a Kafka consumer group. The Kafka consumer ended up stuck in a loop, unable to stabilize fast enough before timing out and restarting the coordination process. While the service continued to accept and record incoming work, it was unable to pass jobs on to workers until we mitigated the issue by shifting the load to the standby service as well as redeploying the primary service. We have extended our monitoring to allow quicker diagnosis of this failure mode, and are pursuing additional changes to prevent reoccurrence.
Please follow our status page for real-time updates on status changes. To learn more about what we’re working on, check out the GitHub Engineering Blog.
If you want to build and scale an application using a large language model (LLM), this article’s for you.
It took us three years to develop GitHub Copilot before we officially launched it to the general public. To go from idea to production, we followed three stages—find it, nail it, scale it—loosely based on the “Nail It, Then Scale It” framework for entrepreneurial product development.
Here’s how it breaks down:
Find it: Identify an impactful problem space for your LLM application
Nail it: Create a smooth AI product experience
Scale it: Get your LLM application ready and useable for general availability (GA)
Let’s get started.
Find it: Isolate the problem you want to solve
Sometimes the hardest part about creating a solution is scoping down a problem space. The problem should be focused enough to quickly deliver impact, but also big enough that the right solution will wow users. Additionally, you want to find a problem where the use of an LLM is the right solution (and isn’t integrated to just drive product engagement).
Get clear on who you want to help. We saw that AI could drive efficiency, so we wanted to prioritize helping developers who were consistently crunched for time, enabling them to write code faster with less context switching.
Focus on a single problem, first. Rather than trying to address all developer problems with AI, we focused on one part of the software development lifecycle: coding functions in the IDE. At the time, most AI coding assistants could only complete a single line of code.
Balance product ambition with quality. While the GitHub Copilot team initially explored generating entire commits, the state of LLMs couldn’t support that function at a high enough quality at the time. Through additional testing, the team landed on code suggestions at the “whole function” level.
Meet people where they are. When it comes to designing products for developers, an LLM app should amplify an existing tool or integrate into an existing workflow. A mantra of the GitHub Copilot team was, “It’s a bug if you have to change the way you code when using GitHub Copilot.” In practice, this means enabling developers to receive code suggestions without changing how they work.
Nail it: Iterate to create a smooth AI product experience
Product development with emerging tech, like generative AI, is often more of a winding path and a linear journey because so much is unknown and rapid advancements in the field can quickly open new doors. Building quick iteration cycles into the product development process allows teams to fail and learn fast. At GitHub, the main mechanism for us to quickly iterate is an A/B experimental platform.
According to Idan Gazit, Senior Director of Research for GitHub Next, “We have to design apps not only for models whose outputs need evaluation by humans, but also for humans who are learning how to interact with AI.”
Put yourself in users’ shoes. GitHub employees have a culture of putting themselves in the shoes of their end users by “dogfooding” products before—and after—they’re released. In practice, this meant the GitHub Copilot team stood up a simple web interface where it could tinker with foundation models and explore ways to leverage those models in their own developer workflows.
We quickly found that a web interface was not the right canvas since it meant developers had to switch back and forth between their editor and the web browser. As a result, the team decided to focus on bringing GitHub Copilot to the IDE and making the AI capability modeless—or working in the background.
The developers on our team also noticed they often referenced multiple open tabs in the IDE while coding. This insight led them to experiment with a technique called neighboring tabs, where GitHub Copilot processes multiple files open in a developer’s IDE instead of just the single one the developer is working on. Neighboring tabs helped to increase the acceptance rates of GitHub Copilot’s suggestions by 5%.
Evaluate your testing tools. As our experiment continued, we had to scale our internal testing tools to be more versatile and powerful. While we initially relied on our own tools for testing, we ultimately switched to the Microsoft Experimentation Platform to optimize functionality based on the feedback and interaction at scale.
Avoid the sunk cost fallacy. This is when you’re reluctant to abandon a course of action because you’ve heavily invested in it—even when it’s clear switching gears would be more beneficial.
The GitHub and OpenAI teams initially believed every coding language would require its own fine-tuned AI model. But the field of generative AI was rapidly advancing, and our assumption turned out to be incorrect. In the end, OpenAI’s LLMs significantly improved and one model could handle a wide variety of coding languages and tasks.
Make a habit of revisiting old ideas. In a field that’s rapidly advancing, the functions that aren’t feasible with today’s LLMs might be possible with tomorrow’s.
In the beginning, we explored a chat interface for developers to ask coding questions. However, in early testing, users had much higher expectations for the capabilities and quality of coding suggestions than GitHub Copilot could deliver at the time. As a result, we deprioritized the feature. But as customers became familiar with AI chatbot following the emergence of ChatGPT and LLMs continued to evolve, an iterative chat experience, like GitHub Copilot Chat, became possible.
Scale it: Optimize quality, usability, and responsible use of AI to get to GA
Early feedback and technical previews are key to driving product improvements and getting your application to GA. Below you’ll find the steps we took before launching the GitHub Copilot technical preview, how we managed the technical preview and optimized user feedback, and how we prepared our internal infrastructure to handle demand at scale.
Optimize quality and usability
Ensure consistent results. Because LMMs are probabilistic—meaning they don’t always produce the same, predictable outcomes—experimentation with them needs to be statistically based. One solution involves setting up a quality pipeline that addresses this unique challenge of building with LLMs.
For instance, when the GitHub Copilot team first decided to provide whole function coding suggestions, we also had to ensure output predictability and consistency, where the same prompt and context would produce the same suggestions from the AI model.
To achieve this, the team applied two strategies: changing the parameters to reduce the randomness of outputs and caching responses. Additionally, using cached responses instead of generating new responses to the same prompt not only reduced variability in suggestions, but it also improved performance.
Implement a waitlist for your technical preview. A waitlist allowed the GitHub Copilot team to manage questions, feedback, and comments—and ensure we could address them effectively. This approach also helped ensure we had a diverse set of early adopters across developers of varying experience levels to provide feedback.
Take advantage of real user feedback. In one example, developers shared that an update had negatively affected the quality of the model’s coding suggestions. In response, the GitHub Copilot team implemented a new guardrail metric—the percentage of suggestions that are multi-line vs. single line—and tuned the model to ensure customers continued to get high-quality suggestions.
While the GitHub team actively dogfooded GitHub Copilot to understand what the experience was like for developers, we also benefited from developers outside GitHub adding diverse feedback across real-world use cases. The GitHub Copilot team engaged and interacted with technical preview users early, often, and on the users’ preferred platforms. This allowed us to actively respond to issues and feedback in real time.
Commit to iterating as you scale. When GitHub Copilot became generally available, the team not only had to improve the product, but also its infrastructure. When we experimented with and quickly iterated GitHub Copilot, it worked directly with the OpenAI API. As the product grew, we scaled our use of Microsoft Azure’s infrastructure to ensure GitHub Copilot had the quality, reliability, and responsible guardrails of a large-scale, enterprise-grade product.
Define the product’s key performance metrics. To optimize GitHub Copilot, we used early developer feedback to identify the right performance metrics, such as code acceptance rate and, eventually, code retention rate (which measures how much of the original code suggestion is kept or edited by a developer).
Optimize costs. The team worked to optimize the costs of delivering GitHub Copilot suggestions while balancing developer impact. For instance, before we decided on using ghost text—the gray text that flashes one coding suggestion while you type—the tool would eagerly generate 10 suggestions and display them all at once. This incurred upfront compute costs for suggestions two through 10, when most people choose the first one. But it also created a user experience cost, because those 10 suggestions pulled developers out of their workflow and into an evaluation mindset. “It was like paying to calculate the results that appear on the second page of a search engine—and making that second page grab your attention—even though most folks end up using the top result,” Gazit says.
Optimizing costs is an ongoing project, and we’re exploring new ideas to reduce costs while improving the user experience.
Optimize responsible use of AI
Prioritize security and trust. Feedback during GitHub Copilot’s technical preview reinforced the importance of suggesting code that is secure. In response, the team integrated code security capabilities to filter out suggestions that could contain security vulnerabilities (e.g., SQL injections and hard coded credentials) and used natural language filters from Azure OpenAI Service to filter out offensive content.*
Allow your community to help you. At GitHub, we deeply valued our extensive developer community for feedback on our products and collaborating with them to improve our offerings. With GitHub Copilot, our developer community was critical to understanding the potential around AI—and some concerns, too.
For instance, the developer community was concerned that GitHub Copilot suggestions might match public code. In response, the GitHub Copilot team created a filter to block suggestions matching public source code in GitHub public repositories that were longer than 150 characters.
Based on community input, the GitHub Copilot team also developed a code reference tool that includes links to public code that may match GitHub Copilot suggestions, so developers can review potential matches (and relevant licensing information), and make informed choices.
Develop a go-to-market strategy
Launch your product with product evangelists. Before launching the technical preview of GitHub Copilot in 2021, the team presented the prototype to influential members of the software developer community and GitHub Stars. This allowed us to launch the technical preview with an existing base of support and extend the preview’s reach to a broader range of users.
Get your product in front of individual users before going after businesses. The team decided to first sell licenses directly to developers, who would clearly benefit from an AI coding assistant. We paired this approach with a free trial program and monthly pricing, based on user survey findings that individuals prefer a simple and predictable subscription. Gaining traction among individual users helped to build a foundation of support and drive adoption at the enterprise level.
Key takeaways
We’re still in the early days of generative AI, so we’re keeping close tabs on the demand and need for this new technology. While each company and product will need to define its own approach to building an LLM app, here are some key learnings from our product journey with GitHub Copilot:
Identify a focused problem and thoughtfully discern an AI’s use cases. This will ensure your app has greater impact and a faster time-to-market.
Integrate experimentation and tight feedback loops into the design process. This is especially critical when working with LLMs, where outputs are probabilistic and most end users are just learning how to interact with AI models.
As you scale, continue to leverage user feedback and prioritize user needs. Doing so will ensure that your product is built to deliver consistent results and real value.
Since we released GitHub Codespaces in 2021, we’ve made a number of updates aimed at improving usability, controlling cost, and more (for example, free usage for all, one click into templates, and concurrency policies). Now, GitHub has improved our developer experience and reduced usage costs at the same time by taking advantage of new virtual machines that provide all of our users twice the RAM, and approximately 10-30% improved CPU performance after adopting Advanced Micro Devices (AMD)-based hosts. These changes enable you to achieve the same (or better) machine performance for half the cost of the previous machine generation.
How this change helps you
In our previous VM generation, memory intensive workloads often had to overprovision CPUs just to get enough RAM in order to run, particularly when running multiple services. For professional developers this was particularly frustrating because of the increased complexity of their development environments, and their higher expectations for performance. Now, rather than having to choose between paying a premium for larger developer machines or sacrificing developer experience and productivity, you can get the best of both worlds.
For example, at GitHub we use our own software and services to build GitHub itself. GitHub uses Codespaces to build not only Codespaces, but the entire platform. GitHub has a large Ruby monolith that requires significant CPU and RAM to test, and also sets an extremely high bar for developer experience. In order to operate these environments while maximizing developer happiness, GitHub used the largest virtual machines available in Codespaces.
Once the new machine types were available, GitHub’s internal developer experience (DX) team started by moving a few dev teams with RAM-hungry workflows to machines with half the CPU count, but the same RAM, to test whether they would be sufficient. With very little effort, and nearly zero developer impact, testing showed that developers were just as successful on the smaller machines, and GitHub incurred half the cost. As additional teams tried moving the fewer-core machines, there was only one build process that turned out to be CPU architecture dependent. The fix was simple—to specify the CPU architecture so that QEMU could emulate appropriately. No other negative impacts were identified.
Due to the success of the initial trials, we quickly rolled out the changes to more teams. The result? Approximately 50% savings!
Figure 1: Codespaces cost for GitHub during the introduction of the AMD machines
Since we’ve rolled out the AMD machines for GitHub, we’ve seen no problems and had only happy users.
You can do the same in your organization by working with your development teams using GitHub Codespaces to test smaller machines on your existing development environments. All Codespaces virtual machines have been upgraded, so testing is as simple as having some developers try working in a smaller machine than they usually do. In most cases, no other configuration changes are necessary!
Once you have found the sweet spot for performance and experience, you can set a policy within your organization to restrict machine types, ensuring cost controls while providing environments that allow your developers to do their best work.
Save costs while empowering your developers
Now that these changes are in your hands, we invite you to see how much more you can get out of GitHub Codespaces by taking advantage of the improved processing power and increased headroom the RAM provides. As ever, please reach out to your account team, or participate in the GitHub Codespaces Community Discussions to provide us your feedback.
For the eighth year in a row, Rust has topped the chart as “the most desired programming language” in Stack Overflow’s annual developer survey. And with more than 80% of developers reporting that they’d like to use the language again next year, you have to wonder how a language created less than 20 years ago has stolen the hearts of developers around the world.
In this article, we’ll look at the history of Rust, what it’s commonly used for, why developers love it so much, and some resources to help you start learning one of the top fastest growing languages on GitHub.
So, what is the Rust programming language?
Rust’s print macro displaying the output “Hello, World!”
Originally intended to serve as a safer alternative to C and C++, Rust is a systems programming language that has gained significant popularity among developers thanks to its emphasis on safety, performance, and productivity. Rust is a statically typed language, so variable and expression types are determined and checked at compile time, which helps enhance memory safety and error detection, resulting in more reliable builds.
In 2006, the software developer, Graydon Hoare, started Rust as a personal project while he was working at Mozilla. According to an interview with MIT Technology Review, the inspiration for Rust came from a broken elevator in Hoare’s apartment building. The software for the lift operation system had crashed and Hoare understood that issues like this usually came from problems with how a program uses memory.
Quite often, the software for these types of devices is written in C or C++, but these languages require significant memory management, which can lead to errors that would cause the system to crash. So, Hoare set to work on figuring out how to create a programming language that could be both compact and memory bug-free.
He later showed the project to a manager—which led to Mozilla sponsoring it in 2009 as part of a longer-term effort to incorporate the language into the development of an experimental browser engine. In 2010, Mozilla Research officially announced the Rust project and released the source code to the public as an open-source project. After several years of development, Rust reached a stable and mature state—and in May 2015, Rust 1.0 was released. This milestone signaled that Rust was ready for production and provided a foundation for developers to build upon.
Since the 1.0 release, Rust has exploded in popularity and adoption, with top applications, such as Microsoft Windows, utilizing Rust to rewrite core libraries with its memory-safe code. Outside of the tech giants, Rust also has a vibrant community of developers, or “Rustaceans,” that are dedicated to making the Rust experience an active and collaborative one.
Meet Ferris, the unofficial mascot for Rust!
According to a recent survey by SlashData, there are roughly 2.8 million Rust developers worldwide in 2023, a number that has nearly tripled over the past two years. With plenty of active forums, documentation, and a supportive community for developers of all skill levels, it’s perhaps unsurprising that Rust keeps topping the most-desired language lists.
What makes Rust special?
So, what are some of Rust’s key features that make it so attractive to developers?
In simple terms, Rust solves some of developers’ most frustrating memory management problems commonly associated with C and C++, but that’s not its only shining capability. One of GitHub’s staff software engineers, Jason Orendorff, who co-authored a book on programming with Rust, said about the language:
“To me, what’s great about Rust is that it’s both fast AND reliable,” according to Orendorff. “It lets me write multi-headed programs that run on 16 cores and keep them readable, maintainable, and crash-free. It also lets me write very low-level algorithms requiring control over memory layout and pull in a crate that makes HTTPS requests super simple. It’s the combination of these features that makes Rust so unique.”
Building on that, here’s a few more of its well-loved characteristics and features:
Concurrency. Rust has built-in support for concurrent programming through its ownership system which enforces strict rules for data access, and its borrowing model, which prevents data races by allowing controlled, simultaneous access. This ensures that multiple threads can work on shared data without introducing memory-related issues.
No garbage collection. Unlike some programming languages, Rust does not employ garbage collection. Instead, its ownership and borrowing rules manage memory, which helps empower developers to have precise control over memory allocation and deallocation for efficient resource management.
Cargo Package Manager. Rust’s built-in package manager, Cargo, streamlines project management, dependency tracking, and building, which helps contribute to efficient and organized development workflows. But this doesn’t make it clear just how bonkers the Cargo ecosystem is. According to Orendorff, “My team takes advantage of high-quality open source packages for hashing, serialization, multithreading, data structures, compression, and a lot more. These are performance-critical libraries. Without some of these, our project to rethink code search on GitHub wouldn’t have been possible.” And here’s a fun fact: Rust was actually the first systems programming language to have a standard package manager, and, as a result, the Rust ecosystem is incredibly robust.
Zero-cost abstractions. This feature allows developers to write high-level code abstractions and features without introducing any runtime performance overhead.
Pattern matching. This powerful language feature enables developers to concisely and effectively match complex data structures against specific patterns to extract and handle different cases or scenarios in a clean and readable manner.
Type inference. This feature allows Rust’s compiler to automatically detect an expression based on context while you code. “Many programming languages have some type inference,” Orendorff said. “C# and C++ have some, Rust has a little more, and languages like Haskell, Scala, and ML have even more.”
fn main() {
break rust;
}
Run this code for an inside joke among Rust developers 😆
What is Rust commonly used for?
Thanks to its direct access to both hardware and memory, Rust is well suited for embedded systems and bare-metal development. And since it’s a general purpose language, it can also be used for a variety of applications.
Let’s explore a few key use cases:
Using Rust to build performance-critical backend systems
Performance-critical backend systems are software components or services that handle tasks that require high-speed processing, low-latency responses, and efficient resource utilization—and Rust’s performance, thread safety, and error handling make it an excellent choice for developing these types of systems. In fact, we use Rust to build some of these systems at GitHub. For example, the backend of our code search feature is written in Rust (and you can read more about the development of GitHub’s newest code search with Rust, too).
Using Rust to develop operating systems
Rust was originally created to solve an operating system issue (remember the elevator problem?)—so, unsurprisingly, it’s often used to build operating systems, kernels, device drivers, or other low-level components where control over memory and performance is crucial. Redox, a Unix-like operating system, was written in Rust, which contributes to its most crucial feature: its security. “Fuchsia is another example that was built at Google,” Orendorff said. “If you have a Google Nest smart speaker, it’s likely running Fuchsia.”
Rust for operating system-adjacent code
Rust is also well-suited for writing code that performs tasks that closely interact with the operating system. For example, the Codespaces team at GitHub is leveraging Rust to enhance the speed of starting up the virtual disk within GitHub Codespaces and optimize the utilization of Azure storage. Coursera also employs Rust in its online grading system, as it operates within Docker and needs a language that compiles to machine code with minimal dependencies.
Using Rust for web development
Rust is increasingly being used for web development—especially on the server side. The async programming model and performance characteristics of Rust make it fitting for building high-performance web servers, APIs, and backend services. Plus, there’s been an influx of web frameworks for Rust, like Rocket, that can help folks get started with writing secure web applications. The emergence of these frameworks underscores Rust’s position as a mature language, and also helps increase the support for folks looking to use Rust in front or backend work.
Using Rust for crypto and blockchain development
Rust’s speed, memory management, and security all contribute to its involvement with cryptocurrency and blockchain technologies. For example, Polkadot, which is designed to enable the interoperability and interaction between multiple blockchains to share information and assets in a secure and decentralized manner, utilizes Rust to build its core infrastructure. Polkadot’s runtime logic, which governs the behavior and rules of the blockchain, is also written in Rust. Check out this repository, awesome-blockchain-rust, for some useful components for building your own blockchain applications with Rust.
Using Rust to build CLI tools
Rust’s compilation to efficient machine code and its expressive syntax make it a strong choice for building command line tools and applications. Plus, writing a command line app is a great way to learn and get comfortable with Rust. Take a look at this comprehensive guide on how to build your own CLI application with Rust in 15 minutes!
Using Rust for embedded systems and IoT development
Rust’s minimal runtime and control over memory layout makes it incredibly useful for developing embedded systems and Internet of Things (IoT) devices. Its ability to prevent memory-related bugs, manage concurrency, and generate small, efficient binaries caters to IoT’s security, real-time, and efficiency needs.
Why developers love Rust
While its user base for Rust isn’t nearly as large as Java or Python, Rust continues to compete with the big hitters in most-admired lists across the internet. There’s even a full website composed of developer’s praises for Rust.
But why exactly is Rust so admired by developers? If you boil it down to just a handful of reasons why developers love Rust so much, they’d have to be the language’s speed, safety, and performance.
Moreover, Rust is continuing to evolve and grow with new frameworks, tools, and resources. You can keep tabs on contributions to the language in the awesome-rust repository, which hosts an impressive list of Rust code and resources.
The bottom line: Admiring Rust isn’t just about adopting a language—it’s embracing a mindset that prioritizes innovation without compromising on the core tenets of stability and security.
How to get started with Rust
We know, there’s plenty of resources to sharpen your Rust skills peppered throughout this article—but we have another pro tip for you: take Rust for a test drive with GitHub Copilot. As your AI-powered pair programmer, GitHub Copilot can help you learn and refine the basics of Rust as you go with tailored code suggestions.
Here’s a developer advocate at GitHub experimenting with Rust for the first time with GitHub Copilot. And to all of our seasoned Rustaceans out there, what do you think? Was the suggestion correct?
If you’re ready to begin your coding journey with Rust, GitHub Copilot can jumpstart your progress—all without the need to study documentation for hours at a time.
Southeast Asia (SEA) is a dynamic market, very different from other parts of the world. When travelling on the road, you may experience fast-changing road restrictions, new roads appearing overnight, and high traffic congestion. To address these challenges, GrabMaps has adapted to the SEA market by leveraging big data solutions. One of the solutions is the integration of hyperlocal data in GrabMaps.
Hyperlocal information is oriented around very small geographical communities and obtained from the local knowledge that our map team gathers. The map team is spread across SEA, enabling us to define clear specifications (e.g. legal speed limits), and validate that our solutions are viable.
Figure 1 – Map showing detections from images and probe data, and hyperlocal data.
Hyperlocal inputs make our mapping data even more robust, adding to the details collected from our image and probe detection pipelines. Figure 1 shows how data from our detection pipeline is overlaid with hyperlocal data, and then mapped across the SEA region. If you are curious and would like to check out the data yourself, you can download it here.
Processing hyperlocal data
Now let’s go through the process of detecting hyperlocal data.
Download data
GrabMaps is based on OpenStreetMap (OSM). The first step in the process is to download the .pbf file for Asia from geofabrick.de. This .pbf file contains all the data that is available on OSM, such as details of places, trees, and roads. Take for example a park, the .pbf file would contain data on the park name, wheelchair accessibility, and many more.
For this article, we will focus on hyperlocal data related to the road network. For each road, you can obtain data such as the type of road (residential or motorway), direction of traffic (one-way or more), and road name.
Convert data
To take advantage of big data computing, the next step in the process is to convert the .pbf file into Parquet format using a Parquetizer. This will convert the binary data in the .pbf file into a table format. Each road in SEA is now displayed as a row in a table as shown in Figure 2.
Figure 2 – Road data in Parquet format.
Identify hyperlocal data
After the data is prepared, GrabMaps then identifies and inputs all of our hyperlocal data, and delivers a consolidated view to our downstream services. Our hyperlocal data is obtained from various sources, either by looking at geometry, or other attributes in OSM such as the direction of travel and speed limit. We also apply customised rules defined by our local map team, all in a fully automated manner. This enhances the map together with data obtained from our rides and deliveries GPS pings and from KartaView, Grab’s product for imagery collection.
Figure 3 – Architecture diagram showing how hyperlocal data is integrated into GrabMaps.
Benefit of our hyperlocal GrabMaps
GrabNav, a turn-by-turn navigation tool available on the Grab driver app, is one of our products that benefits from having hyperlocal data. Here are some hyperlocal data that are made available through our approach:
Localisation of roads: The country, state/county, or city the road is in
Language spoken, driving side, and speed limit
Region-specific default speed regulations
Consistent name usage using language inference
Complex attributes like intersection links
To further explain the benefits of this hyperlocal feature, we will use intersection links as an example. In the next section, we will explain how intersection links data is used and how it impacts our driver-partners and passengers.
Identifying hyperlocal data – intersection links
An intersection link is when two or more roads meet. Figure 4 and 5 illustrates what an intersection link looks like in a GrabMaps mock and in OSM.
Figure 4 – Mock of an intersection link.
Figure 5 – Intersection link illustration from a real road network in OSM.
To locate intersection links in a road network, there are computations involved. We would first combine big data processing (which we do using Spark) with graphs. We use geohash as the unit of processing, and for each geohash, a bi-directional graph is created.
From such resulting graphs, we can determine intersection links if:
Road segments are parallel
The roads have the same name
The roads are one way roads
Angles and the shape of the road are in the intervals or requirements we seek
Each intersection link we identify is tagged in the map as intersection_links. Our downstream service teams can then identify them by searching for the tag.
Impact
The impact we create with our intersection link can be explained through the following example.
Figure 6 – Longer route, without GrabMaps intersection link feature. The arrow indicates where the route should have suggested a U-turn.
Figure 7 – Shorter route using GrabMaps by taking a closer link between two main roads.
Figure 6 and Figure 7 show two different routes for the same origin and destination. However, you can see that Figure 7 has a shorter route and this is made available by taking an intersection link early on in the route. The highlighted road segment in Figure 7 is an intersection link, tagged by the process we described earlier. The route is now much shorter making GrabNav more efficient in its route suggestion.
There are numerous factors that can impact a driver-partner’s trip, and intersection links are just one example. There are many more features that GrabMaps offers across Grab’s services that allow us to “outserve” our partners.
Conclusion
GrabMaps and GrabNav deliver enriched experiences to our driver-partners. By integrating certain hyperlocal data features, we are also able to provide more accurate pricing for both our driver-partners and passengers. In our mission towards sustainable growth, this is an area that we will keep on improving by leveraging scalable tech solutions.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
GitHub Projects has been adopted by program managers, OSS maintainers, enterprises, and individual developers alike for its user-friendly design and efficiency. We all know that managing issues and pull requests in our repositories can be challenging.
To help you optimize your usage of GitHub Projects to plan and track your work from start to finish, I’ll be sharing 10 things you can do with GitHub Projects to make it easier to keep track of your issues and pull requests.
1. Manage your projects with the CLI
If you prefer to work from your terminals, we’ve made it more convenient for you to manage and automate your project workflows with the GitHub CLIproject command. This essentially allows you to work more collaboratively with your team to keep your projects updated with your existing toolkit.
For example, if I wanted to add a draft issue to my project “Learning Ruby,” I would do this by first ensuring that I have the CLI installed and I’m authenticated with the project scope. Once authenticated, I need to find the number of the project I want to manage with the CLI. You can find the project number by looking at the project URL. For example, https://github.com/orgs/That-Lady-Dev/projects/4 the project number here is “4.” Now that we have the project number, we can use it to add a draft issue to the project! The command will look like this:
gh project item-create 4 --owner That-Lady-Dev --title "Test Adding Draft" --body "I added this draft issue with GitHub CLI"
When we run this, a new draft issue is added to the project:
You can do a lot more with the GitHub CLI and GitHub projects. Check out our documentation to see all the possibilities of interacting with your projects from the terminal.
2. Export your projects to TSV
If you ever need your project data, you can export your project view to a file, which can then be imported into Figjam, Google Sheets, Excel, or any other platform that supports TSV files.
Go to any view of your project and click the arrow next to the view name, then select Export view data. This will give you a TSV file that you can use.
Though TSV offers much better formatting than a CSV file, you can ask GitHub Copilot Chat how to convert a TSV file to a CSV file, copy the code, run it, and get your new CSV document, if CSV is your jam.
Here’s a quick gist of how I converted a TSV to a CSV with GitHub Copilot Chat!
3. Create reusable project templates
If you often find yourself recreating projects with similar content and structure, you can set a project as a template so you and others can use it as a base when creating new projects.
To set your project as a template, navigate to the project “Settings” page, and under the “Templates” section toggle on Make template.
This will turn the project into a template that can be used with the green Use this template button at the top of your project, or when creating a new project. Building a library of templates that can be reused across your organization can help you and your teams share best practices and inspiration when getting started with a project!
4. Make a copy of a project
In addition to making your project a template that can be reused, you can also make a one-time copy of an existing project that will contain the fields, views, any configured workflows, insights, and draft items from the original project!
To copy a project, navigate to the project you want to copy, click the three dots to open the menu, and select Make a copy. This will open up a dialog where you can set the Owner, name the project, and click whether you want draft issues copied over or not. Once that’s all set, your new project is ready to be used!
You can also do this with the CLI. The command will look like this:
If you want an issue to be automatically added to a project or if you want to set the status of an issue to “completed” when it is closed, you can do this automatically with built-in project workflows!
Go to the menu and click “Workflows.” This will show you a list of default workflows you can enable on your projects. To automatically add an issue to your project from a repository, you can enable the “Auto-add to project” workflow. To automatically set the status of a closed issue to “complete,” you can enable the “item closed” workflow.
Custom fields help you organize and categorize items in your projects, with flexible field types including text, number, date, single select, and iteration. If you want to add a splash of color to your project or more details about a specific field, you can add colors and descriptions to your single select fields!
To add a color and a description to a new single select field, navigate to the project settings, and add a new field. From there, you can add options to the field where you can select colors and add a description so everyone on your team knows what those options in the field mean and how they can be used.
You can also update field descriptions and colors directly from the project view by selecting Edit details from the group or column menus.
7. Add Issues from any organization
If you’re an open source maintainer, or a developer with multiple clients, you may be working across multiple organizations at a time. This means you have multiple issues to keep track of and need a way to combine these issues in one cohesive manner.
This is where GitHub Projects come in! You can collate issues from any organization onto a single project.
For example, I’m a part of the That-Lady-Dev and the Demos-and-Donuts organizations. I have the issues I want to track on my project board from That-Lady-Dev, but I also want to add the issues I have from the other organization to the same board. I can do this in one of two ways—I can either copy the issue link from the Demos-and-Donuts organization and paste it into the project, or I can search for the Demos-and-Donuts organization and repository from the project using # and select the issues I want to add.
This is a lot to take in—take a look at the gif below.
You can also add an issue or pull request to a project with the CLI. The command will look like this:
Rather than spending time manually updating individual items, you can edit multiple items in one go with our bulk editing feature on GitHub Projects.
Let’s say you wanted to assign multiple issues to yourself. On the table layout, assign one issue and with the cell highlighted, and copy the contents of the cell. Select all the remaining items you want to be assigned and paste the copied contents. You just assigned yourself to multiple issues at once, and this can be undone at the click of a button or using keyboard commands as well.
This is demonstrated in the gif below.
You can also drag and drop multiple items on a project board to different columns.
9. Reorder fields
With a growing list of fields in your project, you’ll want to make sure your fields are organized and you see the most important ones up top. To change the order in how they appear on the side panel and on the issues page, you can rearrange the order of the fields from the project settings by dragging and dropping them in the “Custom fields” list.
10. See what you want to see with slice by
If you find yourself with multiple views and filters to see how items are spread among various teams, labels, or assignees, you can configure a slice field to break down and quickly toggle through your items. You can choose a Slice by field that will pull the field values into a panel on the left of your view, and clicking each value will adjust the items in the project view on the right. See the gif below for how this works.
Try out slicing by different fields to unlock a new way to organize your items!
Bonus tip: Deep linking
Let’s say you want to send a specific issue from your project to a teammate. You can use the Copy link to project button to send them a direct link to that particular issue in the project without having them sift through to find the issue you mentioned. See what I mean in this gif.
Wrap-up
And there you have it—10 things you didn’t know you could do with GitHub Projects. The team is continuing to work on more amazing features to make tracking your issues with pull requests as seamless and painless as possible. GitHub Projects is a powerful, flexible, and efficient way to keep track of your items while staying on top of your work.
Do let me know if you have any questions about GitHub Projects; I’m happy to jump in and assist.
Ever found yourself struggling to set up a brand-new Integrated Development Environment (IDE) for a project? The overwhelming process of dealing with build errors, dependencies, and configurations can leave you feeling frustrated and short on time. Trust me, I’ve been there, too. As an avid developer, I understand the struggles and challenges firsthand.
That’s when I discovered GitHub Codespaces, and it’s a game-changer. GitHub Codespaces is a cloud-based coding environment for collaborative development accessible through a browser. Templates include specific configurations of tools, libraries, and settings within GitHub Codespaces, enabling developers to quickly create consistent coding environments for various projects without having to set up everything from scratch.
With customizable environments, streamlined workflows, and easy setup sharing, you can be more productive and focus on creating exceptional software.
With the rich offering of existing templates available at my disposal, I quickly realized there are many possibilities. As I was working on My Android app, I was looking for a template that would let me build My Android app. However, because there was no Android template, I decided to build my own.
Together, let’s conquer setup challenges and unlock a world of coding possibilities. With great power comes great coding!
Step 1: Customizing a GitHub Codespaces template and connecting to a repository
While you can find a number of templates for React, Django, and Ruby on Rails in the template library, I couldn’t find the one I needed for Android.
Fortunately, creating a custom template is a breeze! Just head to GitHub Codespaces and select the “Blank” template. Starting with a blank template opens a codespace that I can configure per my needs.
Clicking on “Use this template” launches a codespace in a separate tab within your browser.
My new codespace is called “vigilant potato” as you can see from the URL in the screenshot above. Your codespace will get its own unique, and maybe cute, name.
If you get distracted by something else, and need to come back to your codespace, you can access it from github.com/codespaces by looking for the “vigilant potato” among the list of codespaces—you might need to scroll down to find it if you have other codespaces.
Click on the three horizontal dots at the end of the row and select “Publish to a new repository.” This flow seamlessly lets you create a new repository and preserves your development environment and any code you might have added that belongs to your project.
Once your repository is created, you’ll be able to see it in your GitHub Settings > your repositories. Or, if you’d like to connect to an existing repository, you can do so through the terminal.
Step 2: Configuring your environment: devcontainer.json/Dockerfile
There are two ways to customize your environment in a template. The two ways: using either a devcontainer.json file or a Dockerfile. The devcontainer.json file focuses on configuring the development environment within Visual Studio Code, while a Dockerfile allows you to create a custom Docker image that forms the basis of the entire development environment. Both files are essential for defining and customizing the development environment to meet the specific requirements of your project.
For my Android development environment, I have to create a Dockerfile. To harness this power, I simply navigate to the root of my repository and create a new file called Dockerfile. You can define the base image, specify environment variables, copy files and directories, install dependencies, execute commands, expose ports, define the working directory, run services, and set the entrypoint or command. These instructions allow you to tailor the Docker image to include the necessary tools, configurations, and dependencies required for your project.
Watch the magic unfold as a tailored, fully-configured development environment materializes in the cloud. In an instant, you’ll be immersed in a seamless coding experience, equipped with all the necessary tools. Say goodbye to setup hassles and dive straight into your code. With a customized codespace template, you’ll have a portable development sanctuary that follows you everywhere. For my Android repository, I very easily followed these steps and a brand new codespace built from the blank template opened for my repository in a separate browser tab.
Here are a few snippets from my Android Dockerfile to demonstrate its power.
Automating Android SDK installation
# Update package list and install packages required for Android app development
RUN apt-get update -yqq && \
apt-get install -y \
curl \
expect \
git \
make \
wget \
unzip \
vim \
openssh-client \
locales \
libarchive-tools && \
apt-get clean && rm -rf /var/lib/apt/lists/* && \
localedef -i en_US -c -f UTF-8 -A /usr/share/locale/locale.alias en_US.UTF-8
In this example, I am using regular shell commands to install the Android SDK.
Setting environment variables
# Set environment variables used by the Android SDK
ENV ANDROID_SDK_HOME /opt/android-sdk-linux
ENV ANDROID_SDK_ROOT /opt/android-sdk-linux
ENV ANDROID_HOME /opt/android-sdk-linux
ENV ANDROID_SDK /opt/android-sdk-linux
This snippet showcases how the Dockerfile lets you set environment variables that are necessary for development.
This remarkable file guarantees a breeze for anyone cloning my repository, effortlessly setting up a standardized development environment. Say goodbye to manual setup hassles and welcome a seamless and efficient collaborative experience.
Conclusion
By embracing these steps, I’ve discovered that the entire process of creating and using GitHub Codespaces templates can be incredibly easy, enjoyable, and efficient. Leveraging the power of templates and devcontainer.json files means I never have to start from scratch again. What used to be a painstaking, day plus process of downloading and installing all of the Android SDK and Java components, setting the environment variables, getting the libraries, and maintaining their updates is no more through using my pre-configured Android template. I have created additional templates for work that are Java and Python development environments.
Remember, with great coding comes great responsibility,and a lot fewer debugging sessions! Happy coding, and may the bugs be ever in your favor!
If you’re also an Android developer, try out my template or explore the other templates GitHub offers and customize your own.
The open source Git project just released Git 2.42 with features and bug fixes from over 78 contributors, 17 of them new. We last caught up with you on the latest in Git back when 2.41 was released.
To celebrate this most recent release, here’s GitHub’s look at some of the most interesting features and changes introduced since last time.
Faster object traversals with bitmaps
Many long-time readers of these blog posts will recall our coverage of reachability bitmaps. Most notably, we covered Git’s new multi-pack reachability bitmaps back in our coverage of the 2.34 release towards the end of 2021.
If this is your first time here, or you need a refresher on reachability bitmaps, don’t worry. Reachability bitmaps allow Git to quickly determine the result set of a reachability query, like when serving fetches or clones. Git stores a collection of bitmaps for a handful of commits. Each bit position is tied to a specific object, and the value of that bit indicates whether or not it is reachable from the given commit.
This often allows Git to compute the answers to reachability queries using bitmaps much more quickly than without, particularly for large repositories. For instance, if you want to know the set of objects unique to some branch relative to another, you can build up a bitmap for each endpoint (in this case, the branch we’re interested in, along with main), and compute the AND NOT between them. The resulting bitmap has bits set to “1” for exactly the set of objects unique to one side of the reachability query.
But what happens if one side doesn’t have bitmap coverage, or if the branch has moved on since the last time it was covered with a bitmap?
In previous versions of Git, the answer was that Git would build up a complete bitmap for all reachability tips relative to the query. It does so by walking backwards from each tip, assembling its own bitmap, and then stopping as soon as it finds an existing bitmap in history. Here’s an example of the existing traversal routine:
Figure 1: Bitmap-based traversal computing the set of objects unique to `main` in Git 2.41.0.
There’s a lot going on here, but let’s break it down. Above we have a commit graph, with five branches and one tag. Each of the commits are indicated by circles, and the references are indicated by squares pointing at their respective referents. Existing bitmaps can be found for both the v2.42.0 tag, and the branch bar.
In the above, we’re trying to compute the set of objects which are reachable from main, but aren’t reachable from any other branch. By inspection, it’s clear that the answer is {C₆, C₇}, but let’s step through how Git would arrive at the same result:
For each branch that we want to exclude from the result set (in this case, foo, bar, baz, and quux), we walk along the commit graph, marking each of the corresponding bits in our have‘s bitmap in the top-left.
If we happen to hit a portion of the graph that we’ve covered already, we can stop early. Likewise, if we find an existing bitmap (like what happens when we try to walk beginning at branch bar), we can OR in the bits from that commit’s bitmap into our have‘s set, and move on to the next branch.
Then, we repeat the same process for each branch we do want to keep (in this case, just main), this time marking or ORing bits into the have‘s bitmap.
Finally, once we have a complete bitmap representing each side of the reachability query, we can compute the result by AND NOTing the two bitmaps together, leaving us with the set of objects unique to main.
We can see that in the above, having existing bitmap coverage (as is the case with branch bar) is extremely beneficial, since they allow us to discover the set of objects reachable from a certain point in the graph immediately without having to open up and parse objects.
But what happens when bitmap coverage is sparse? In that case, we end up having to walk over many objects in order to find an existing bitmap. Oftentimes, the additional overhead of maintaining a series of bitmaps outweighs the benefits of using them in the first place, particularly when coverage is poor.
In this release, Git introduces a new variant of the bitmap traversal algorithm that often out performs the existing implementation, particularly when bitmap coverage is sparse.
The new algorithm represents the unwanted side of the reachability query as a bitmap from the query’s boundary, instead of the union of bitmap(s) from the individual tips on the unwanted side. The exact definition of what a query boundary is is slightly technical, but for our purposes you can think of it as the first commit in the wanted set of objects which is also reachable from at least one unwanted object.
In the above example, this is commit C₅, which is reachable from both main (which is in the wanted half of the reachability query) along with bar and baz (both of which are in the unwanted half). Let’s step through computing the same result using the boundary-based approach:
Figure 2: The same traversal as above, instead using the boundary commit-based approach.
The approach here is similar to the above, but not quite the same. Here’s the process:
We first discover the boundary commit(s), in this case C₅.
We then walk backwards from the set of boundary commit(s) we just discovered until we find a reachability bitmap (or reach the beginning of history). At each stage along the walk, we mark the corresponding bit in the have‘s bitmap.
Then, we build up a complete bitmap on the want‘s side by starting a walk from main until either we hit an existing bitmap, the beginning of history, or an object marked in the previous step.
Finally, as before, we compute the AND NOT between the two bitmaps, and return the results.
When there are bitmaps close to the boundary commit(s), or the unwanted half of the query is large, this algorithm often vastly outperforms the existing traversal. In the toy example above, you can see we compute the answer much more quickly when using the boundary-based approach. But in real-world examples, between a 2- and 15-fold improvement can be observed between the two algorithms.
If you’ve ever scripted around Git before, you are likely familiar with its for-each-ref command. If not, you likely won’t be surprised to learn that this command is used to enumerate references in your repository, like so:
$ git for-each-ref --sort='-*committerdate' refs/tags
264b9b3b04610cb4c25e01c78d9a022c2e2cdf19 tag refs/tags/v2.42.0-rc2
570f1f74dee662d204b82407c99dcb0889e54117 tag refs/tags/v2.42.0-rc1
e8f04c21fdad4551047395d0b5ff997c67aedd90 tag refs/tags/v2.42.0-rc0
32d03a12c77c1c6e0bbd3f3cfe7f7c7deaf1dc5e tag refs/tags/v2.41.0
[...]
for-each-ref is extremely useful for listing references, finding which references point at a given object (with --points-at), which references have been merged into a given branch (with --merged), or which references contain a given commit (with --contains).
Git relies on the same machinery used by for-each-ref across many different components, including the reference advertisement phase of pushes. During a push, the Git server first advertises a list of references that it wants the client to know about, and the client can then exclude those objects (and anything reachable from them) from the packfile they generate during the push.
Suppose that you have some references that you don’t want to advertise to clients during a push? For example, GitHub maintains a pair of references for each open pull request, like refs/pull/NNN/head and refs/pull/NNN/merge, which aren’t advertised to pushers. Luckily, Git has a mechanism that allows server operators to exclude groups of references from the push advertisement phase by configuring the transfer.hideRefs variable.
Git implements the functionality configured by transfer.hideRefs by enumerating all references, and then inspecting each one to see whether or not it should advertise that reference to pushers. Here’s a toy example of a similar process:
Figure 3: Running `for-each-ref` while excluding the `refs/pull/` hierarchy.
Here, we want to list every reference that doesn’t begin with refs/pull/. In order to do that, Git enumerates each reference one-by-one, and performs a prefix comparison to determine whether or not to include it in the set.
For repositories that have a small number of hidden references, this isn’t such a big deal. But what if you have thousands, tens of thousands, or even more hidden references? Performing that many prefix comparisons only to throw out a reference as hidden can easily become costly.
In Git 2.42, there is a new mechanism to more efficiently exclude references. Instead of inspecting each reference one-by-one, Git first locates the start and end of each excluded region in its packed-refs file. Once it has this information, it creates a jump list allowing it to skip over whole regions of excluded references in a single step, rather than discarding them one by one, like so:
Figure 4: The same `for-each-ref` invocation as above, this time using a jump list as in Git 2.42.
Like the previous example, we still want to discard all of the refs/pull references from the result set. To do so, Git finds the first reference beginning with refs/pull (if one exists), and then performs a modified binary search to find the location of the first reference after all of the ones beginning with refs/pull.
It can then use this information (indicated by the dotted yellow arrow) to avoid looking at the refs/pull hierarchy entirely, providing a measurable speed-up over inspecting and discarding each hidden reference individually.
In Git 2.42, you can try out this new functionality with git for-each-ref‘s new --exclude option. This release also uses this new mechanism to improve the reference advertisement above, as well as analogous components for fetching. In extreme examples, this can provide a 20-fold improvement in the CPU cost of advertising references during a push.
Git 2.42 also comes with a pair of new options in the git pack-refs command, which is responsible for updating the packed-refs file with any new loose references that aren’t stored. In certain scenarios (such as a reference being frequently updated or deleted), it can be useful to exclude those references from ever entering the packed-refs file in the first place.
git pack-refs now understands how to tweak the set of references it packs using its new --include and --exclude flags.
Preserving precious objects from garbage collection
In our last set of release highlights, we talked about a new mechanism for collecting unreachable objects in Git known as cruft packs. Git uses cruft packs to collect and track the age of unreachable objects in your repository, gradually letting them age out before eventually being pruned from your repository.
But Git doesn’t simply delete every unreachable object (unless you tell it to with --prune=now). Instead, it will delete every object except those that meet one of the below criteria:
The object is reachable, in which case it cannot be deleted ever.
The object is unreachable, but was modified after the pruning cutoff.
The object is unreachable, and hasn’t been modified since the pruning cutoff, but is reachable via some other unreachable object which has been modified recently.
But what do you do if you want to hold onto an object (or many objects) which are both unreachable and haven’t been modified since the pruning cutoff?
Historically, the only answer to this question was that you should point a reference at those object(s). That works if you have a relatively small set of objects you want to hold on to. But what if you have more precious objects than you could feasibly keep track of with references?
Git 2.42 introduces a new mechanism to preserve unreachable objects, regardless of whether or not they have been modified recently. Using the new gc.recentObjectsHook configuration, you can configure external program(s) that Git will run any time it is about to perform a pruning garbage collection. Each configured program is allowed to print out a line-delimited sequence of object IDs, each of which is immune to pruning, regardless of its age.
Even if you haven’t started using cruft packs yet, this new configuration option works even when using loose objects to hold unreachable objects which have not yet aged out of your repository.
This makes it possible to store a potentially large set of unreachable objects which you want to retain in your repository indefinitely using an external mechanism, like a SQLite database. To try out this new feature for yourself, you can run:
If you’ve read these blog posts before, you may recall our coverage of the sparse index feature, which allows you to check out a narrow cone of your repository instead of the whole thing.
Over time, many commands have gained support for working with the sparse index. For commands that lacked support for the sparse index, invoking those commands would cause your repository to expand the index to cover the entire repository, which can be a potentially expensive operation.
This release, the diff-tree command joined the group of commands with full support for the sparse index, meaning that you can now use diff-tree without expanding your index.
This work was contributed by Shuqi Liang, one of the Git project’s Google Summer of Code (GSoC) students. You can read more about their project here, and follow along with their progress on their blog.
If you’ve gotten this far in the blog post and thought that we were done talking about git for-each-ref, think again! This release enhances for-each-ref‘s --format option with a handful of new ways to format a reference.
The first set of new options enables for-each-ref to show a handful of GPG-related information about commits at reference tips. You can ask for the GPG signature directly, or individual components of it, like its grade, the signer, key, fingerprint, and so on. For example,
This work was contributed by Kousik Sanagavarapu, another GSoC student working on Git! You can read more about their project here, and keep up to date with their work on their blog.
Earlier in this post, we talked about git rev-list, a low-level utility for listing the set of objects contained in some query.
In our early examples, we discussed a straightforward case of listing objects unique to one branch. But git rev-list supports much more complex modifiers, like --branches, --tags, --remotes, and more.
In addition to specifying modifiers like these on the command-line, git rev-list has a --stdin mode which allows for reading a line-delimited sequence of commits (optionally prefixed with ^, indicating objects reachable from those commit(s) should be excluded) from the command’s standard input.
Previously, support for --stdin extended only to referring to commits by their object ID, without support for more complex modifiers like the ones listed earlier. In Git 2.42, git rev-list --stdin can now accept the same set of modifiers given on the command line, making it much more useful when scripting.
Picture this: you’re working away on your repository, typing up a tag message for a tag named foo. Suppose that in the background, you have some repeating task that fetches new commits from your remote repository. If you happen to fetch a tag foo/bar while writing the tag message for foo, Git will complain that you cannot have both tag foo and foo/bar.
OK, so far so good: Git does not support this kind of tag hierarchy1. But what happened to your tag message? In previous versions of Git, you’d be out of luck, since your in-progress message at $GIT_DIR/TAG_EDITMSG is deleted before the error is displayed. In Git 2.42, Git delays deleting the TAG_EDITMSG until after the tag is successfully written, allowing you to recover your work later on.
In other git tag-related news, this release comes with a fix for a subtle bug that appeared when listing tags. git tag can list existing tags with the -l option (or when invoked with no arguments). You can further refine those results to only show tags which point at a given object with the --points-at option.
But what if you have one or more tags that point at the given object through one or more other tags instead of directly? Previous versions of Git would fail to report those tags. Git 2.42 addresses this by dereferencing tags through multiple layers before determining whether or not it points to a given object.
Finally, back in Git 2.38, git cat-file --batch picked up a new -z flag, allowing you to specify NUL-delimited input instead of delimiting your input with a standard newline. This flag is useful when issuing queries which themselves contain newlines, like trying to read the contents of some blob by path, if the path contains newlines.
But the new -z option only changed the rules for git cat-file‘s input, leaving the output still delimited by newlines. Ordinarily, this won’t cause any problems. But if git cat-file can’t locate an object, it will print out ” missing”, followed by a newline.
If the given query itself contains a newline, the result is unparseable. To address this, git cat-file has a new mode, -Z (as opposed to its lowercase variant, -z) which changes both the input and output to be NUL-delimited.
Doing so would introduce a directory/file-conflict. Since Git stores loose tags at paths like $GIT_DIR/refs/tags/foo/bar, it would be impossible to store a tag foo, since it would need to live at $GIT_DIR/refs/tags/foo, which already exists as a directory. ↩
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
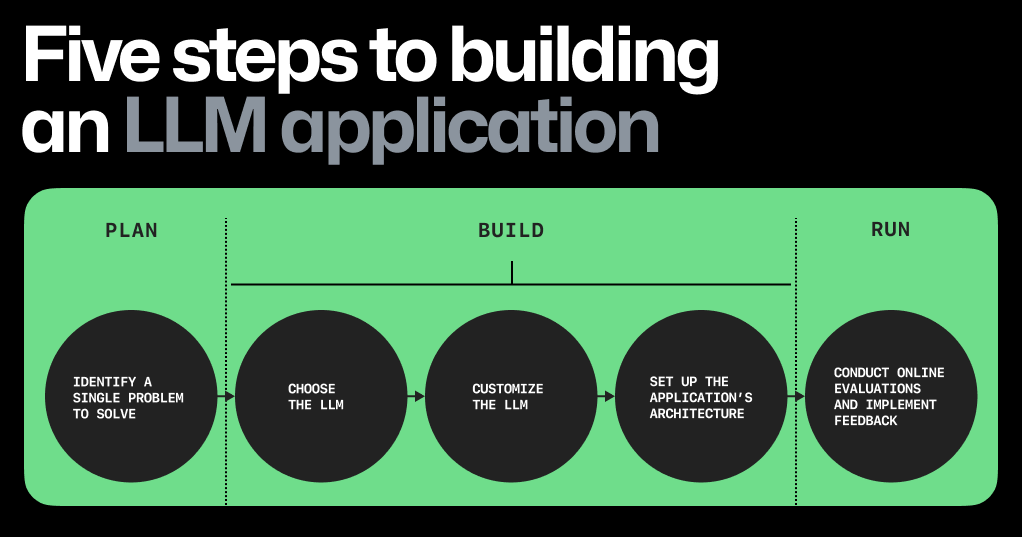
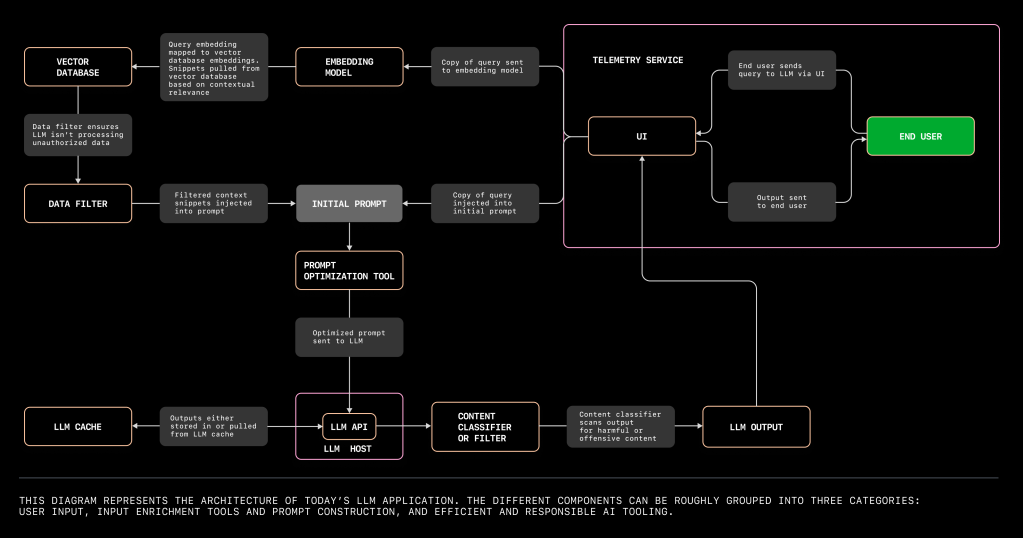
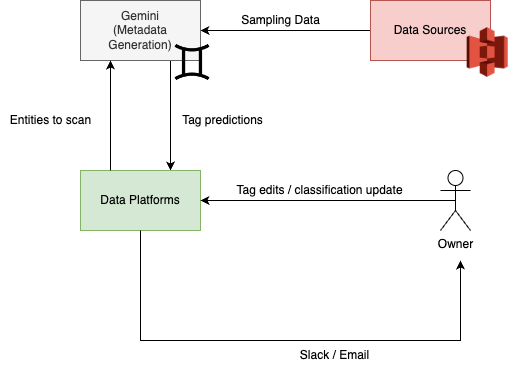
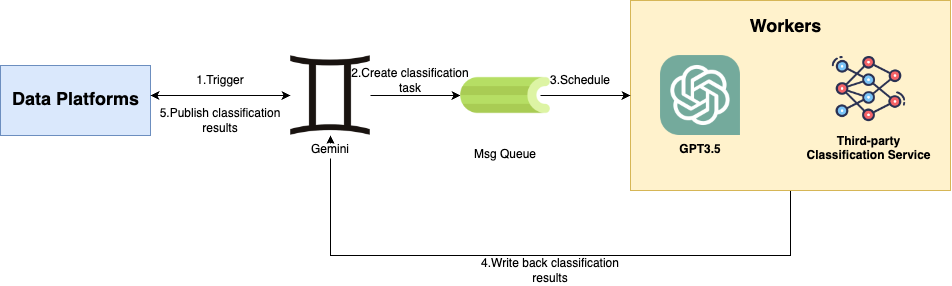

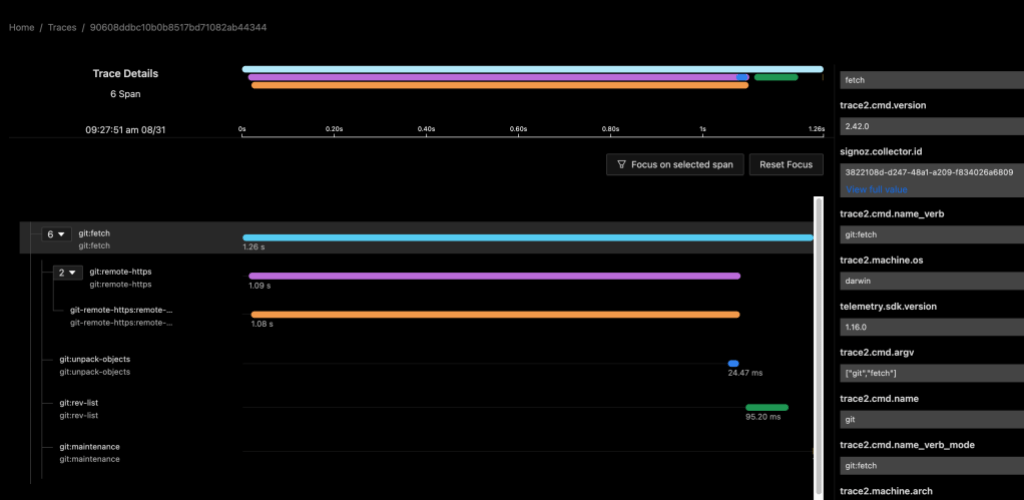
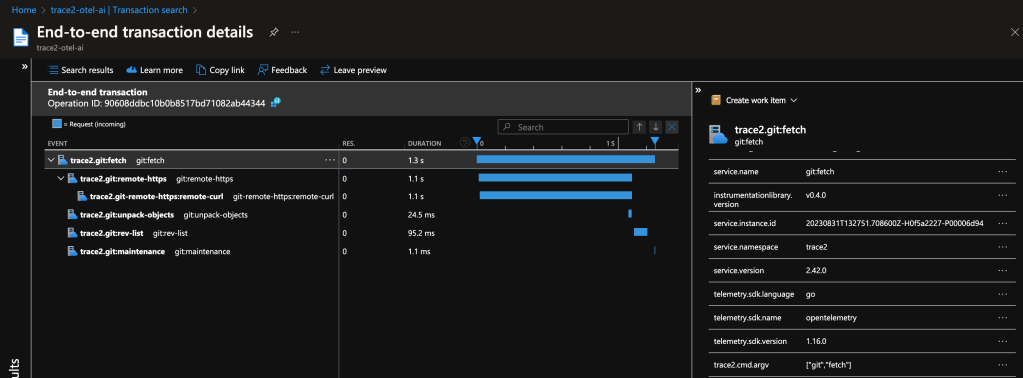
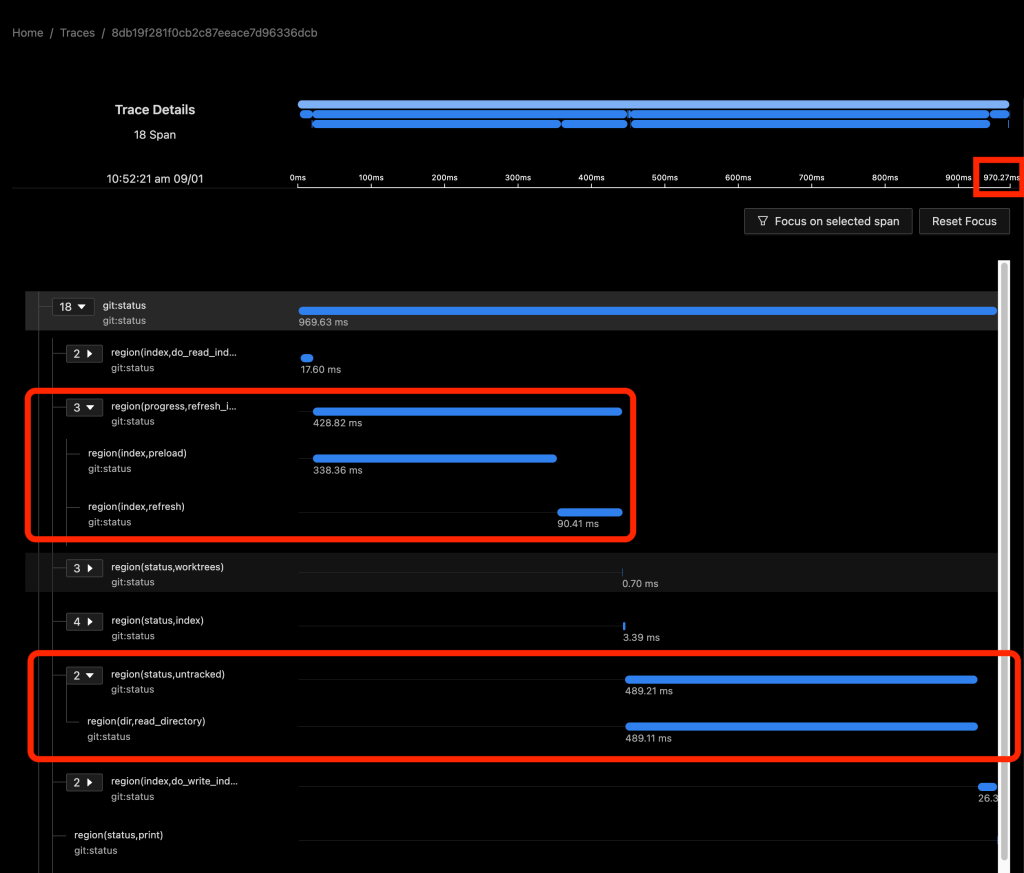
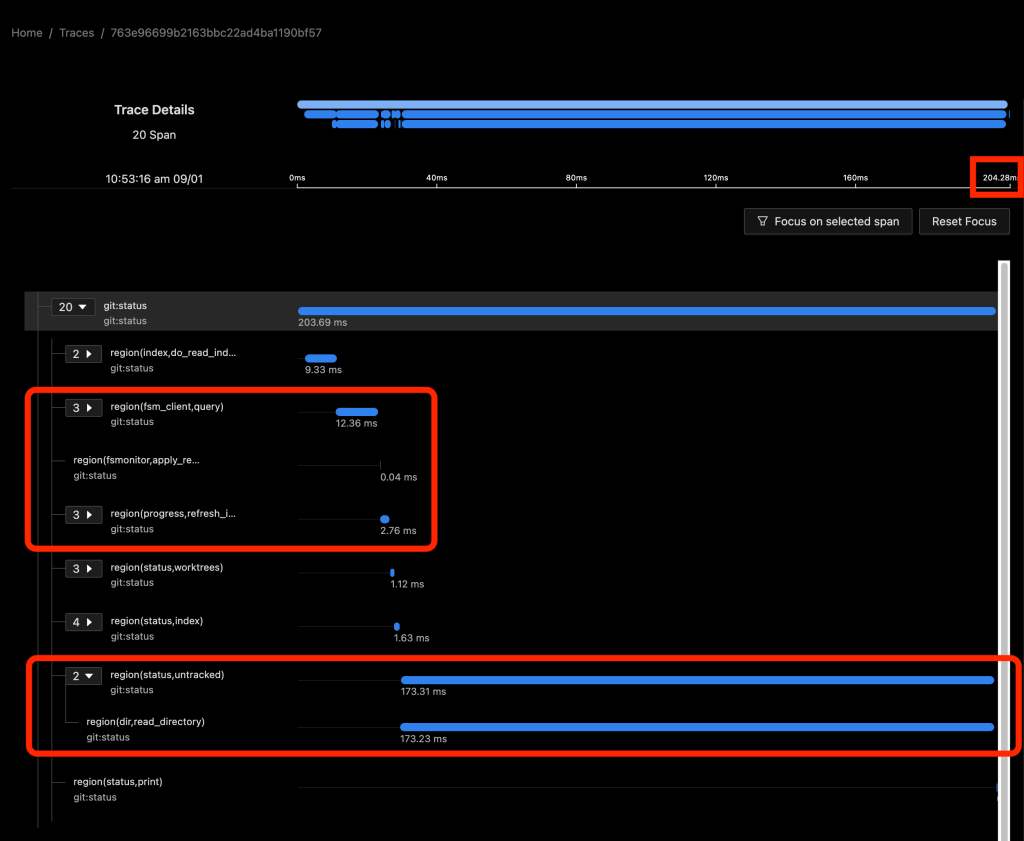

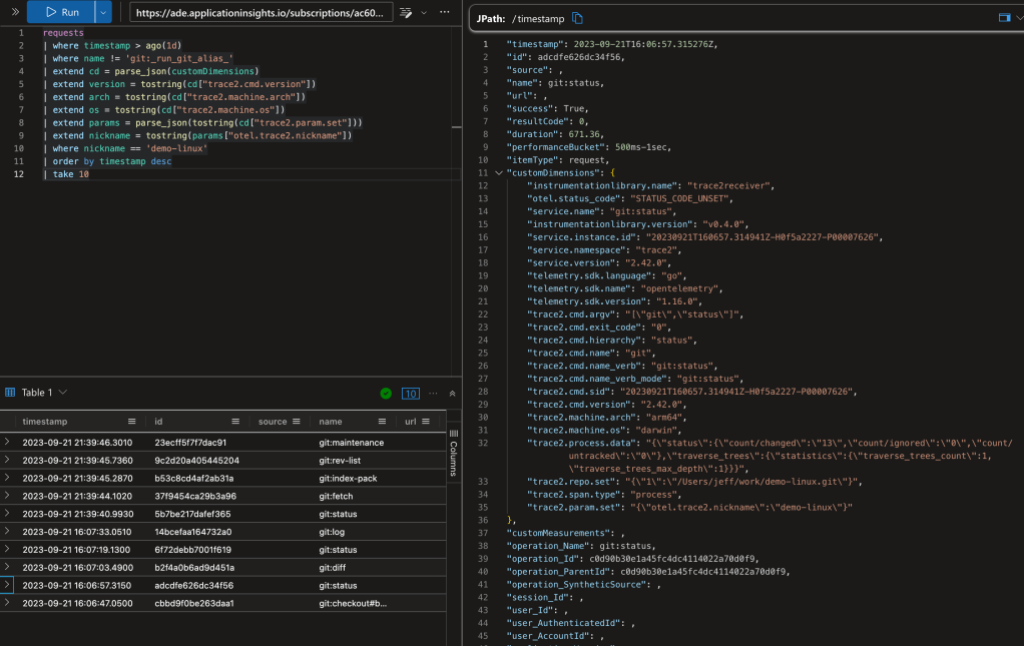
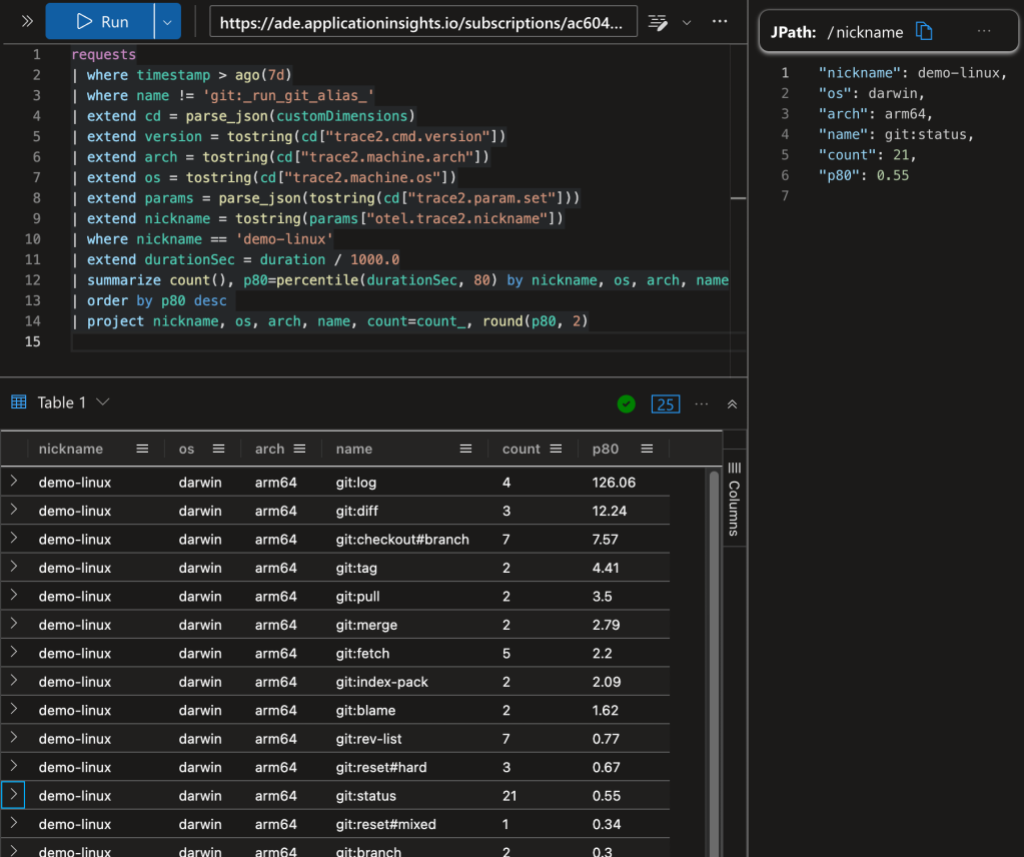

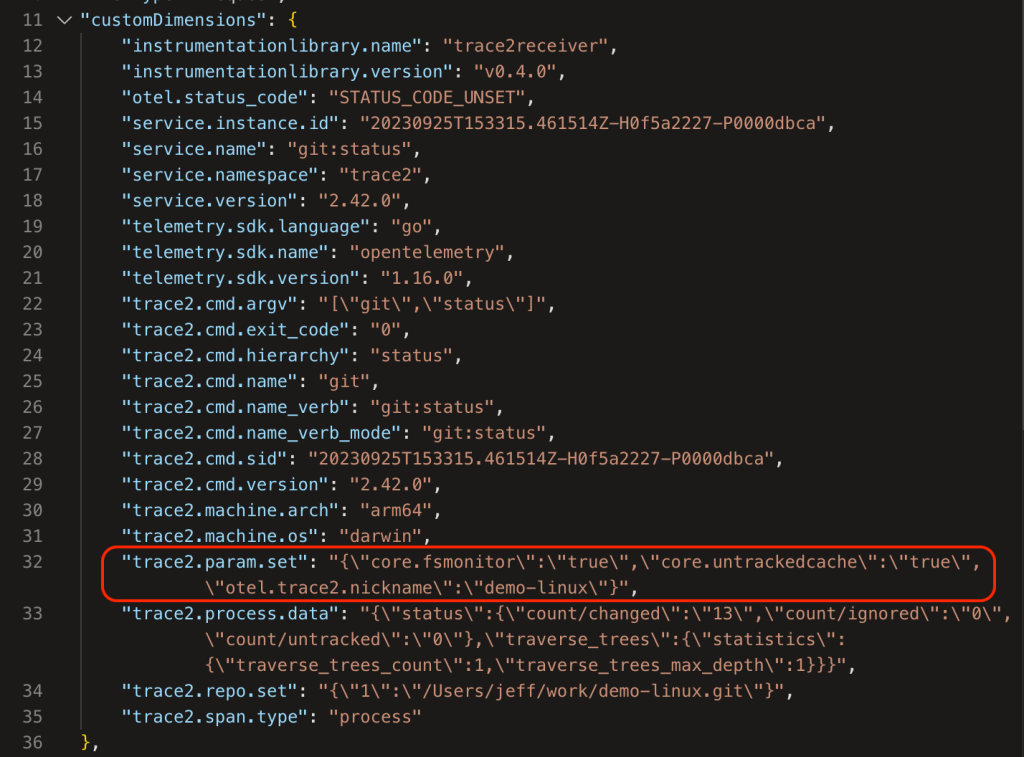
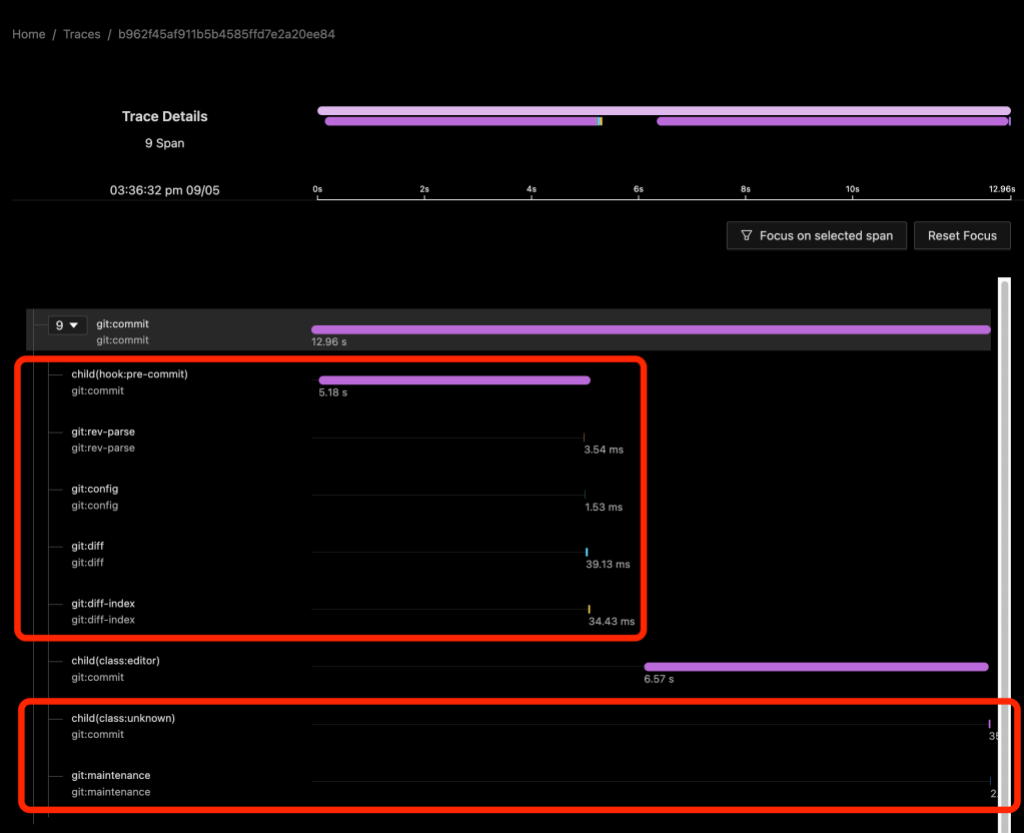

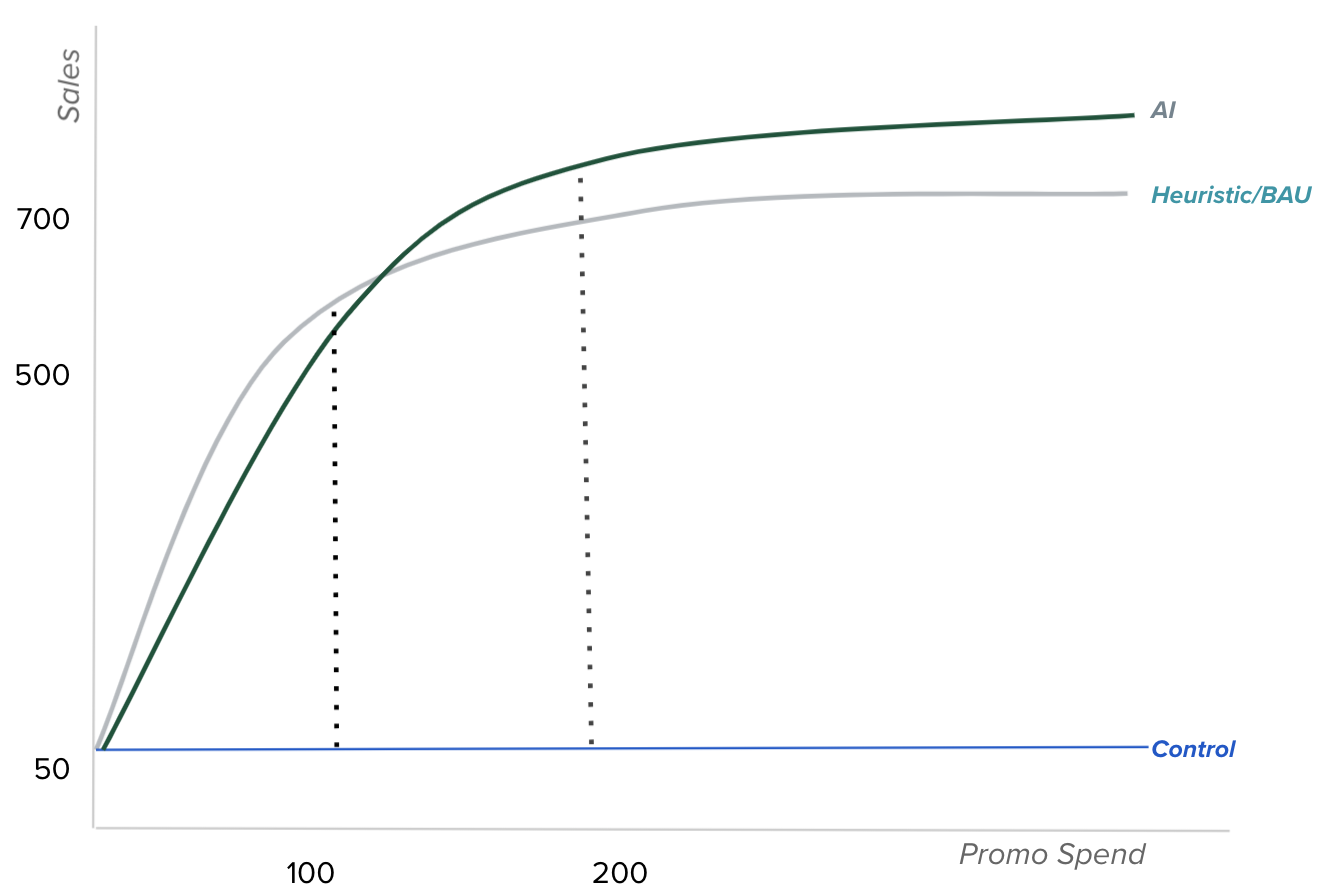
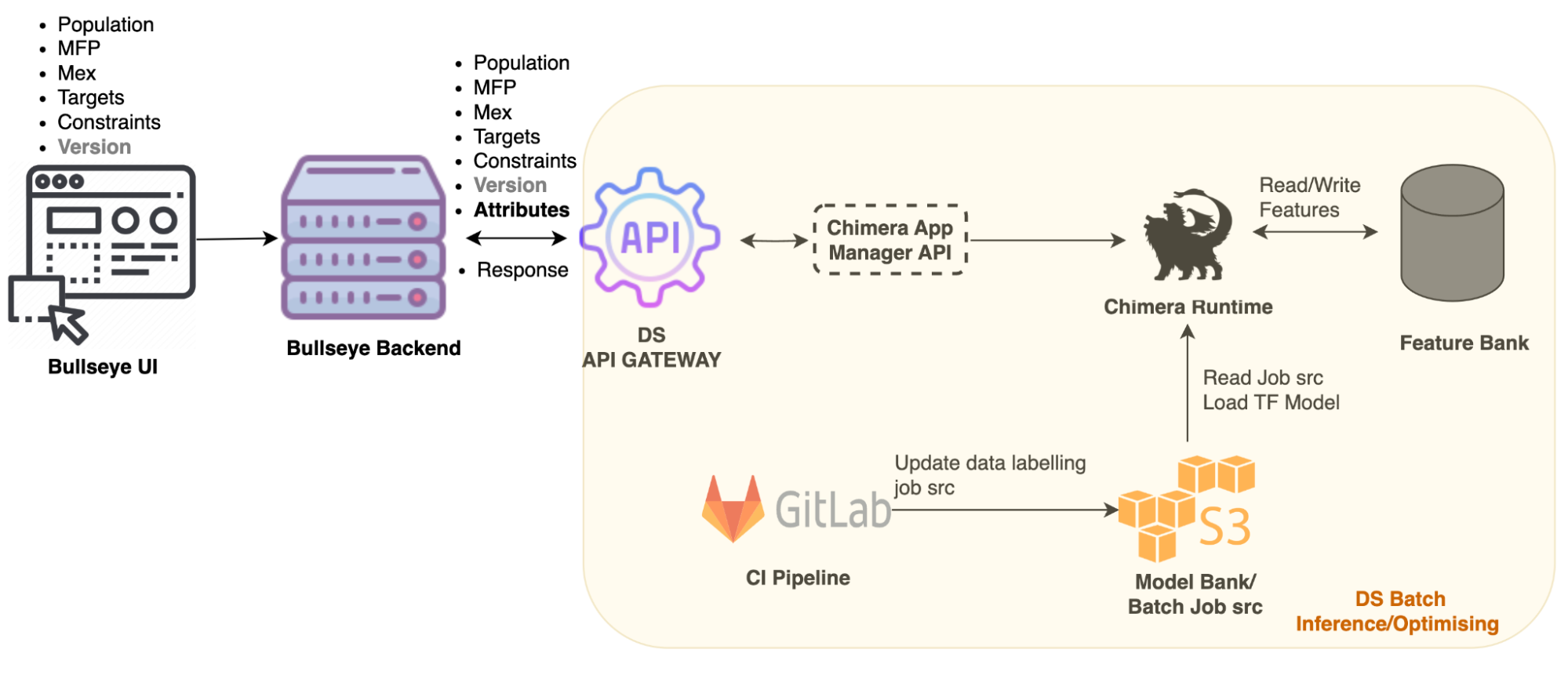
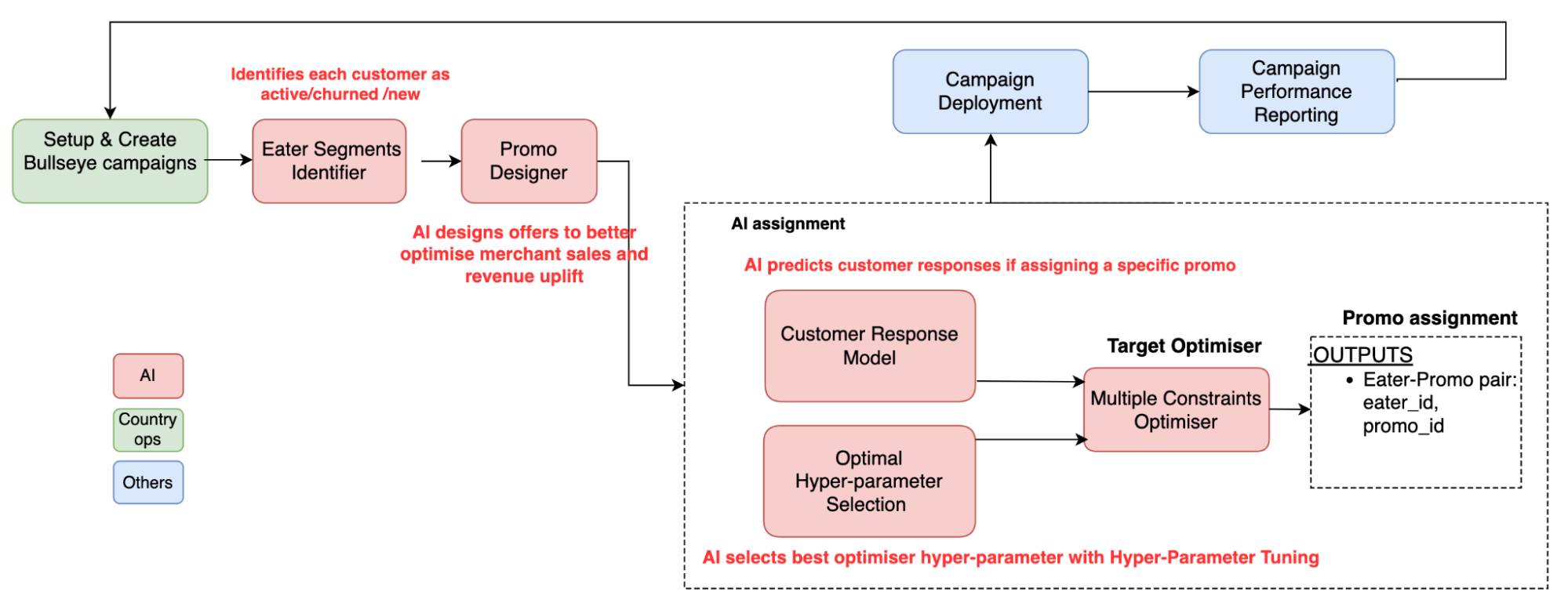




 Summarization is a core workflow for AI, and so far, while it’s not always perfect, it’s been working well. If you’re interested in the prompt we’re using (or want to help us improve it!), you can find it
Summarization is a core workflow for AI, and so far, while it’s not always perfect, it’s been working well. If you’re interested in the prompt we’re using (or want to help us improve it!), you can find it