Today, we are announcing that AWS AppSync Events now supports data source integrations for channel namespaces, enabling developers to create more sophisticated real-time applications. With this new capability you can associate AWS Lambda functions, Amazon DynamoDB tables, Amazon Aurora databases, and other data sources with channel namespace handlers. With AWS AppSync Events, you can build rich, real-time applications with features like data validation, event transformation, and persistent storage of events.
With these new capabilities, developers can create sophisticated event processing workflows by transforming and filtering events using Lambda functions or save batches of events to DynamoDB using the new AppSync_JS batch utilities. The integration enables complex interactive flows while reducing development time and operational overhead. For example, you can now automatically persist events to a database without writing complex integration code.
First look at data source integrations
Let’s walk through how to set up data source integrations using the AWS Management Console. First, I’ll navigate to AWS AppSync in the console and select my Event API (or create a new one).
Persisting event data directly to DynamoDB
There are multiple kinds of data source integrations to choose from. For this first example, I’ll create a DynamoDB table as a data source. I’m going to need a DynamoDB table first, so I head over to DynamoDB in the console and create a new table called event-messages. For this example, all I need to do is create the table with a Partition Key called id. From here, I can click Create table and accept the default table configuration before I head back to AppSync in the console.
Back in the AppSync console, I return to the Event API I set up previously, select Data Sources from the tabbed navigation panel and click the Create data source button.
After giving my Data Source a name, I select Amazon DynamoDB from the Data source drop down menu. This will reveal configuration options for DynamoDB.
Once my data source is configured, I can implement the handler logic. Here’s an example of a Publish handler that persists events to DynamoDB:
To add the handler code, I go the tabbed navigation for Namespaces where I find a new default namespace already created for me. If I click to open the default namespace, I find the button that allows me to add an Event handler just below the configuration details.
Clicking on Create event handlers brings me to a new dialog where I choose Code with data source as my configuration, and then select the DynamoDB data source as my publish configuration.
After saving the handler, I can test the integration using the built-in testing tools in the console. The default values here should work, and as you can see below, I’ve successfully written two events to my DynamoDB table.
Here’s all my messages captured in DynamoDB!
Error handling and security
The new data source integrations include comprehensive error handling capabilities. For synchronous operations, you can return specific error messages that will be logged to Amazon CloudWatch, while maintaining security by not exposing sensitive backend information to clients. For authorization scenarios, you can implement custom validation logic using Lambda functions to control access to specific channels or message types.
Available now
AWS AppSync Events data source integrations are available today in all AWS Regions where AWS AppSync is available. You can start using these new features through the AWS AppSync console, AWS command line interface (CLI), or AWS SDKs. There is no additional cost for using data source integrations – you pay only for the underlying resources you use (such as Lambda invocations or DynamoDB operations) and your existing AppSync Events usage.
To learn more about AWS AppSync Events and data source integrations, visit the AWS AppSync Events documentation and get started building more powerful real-time applications today.
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Since the launch of AWS Graviton processors in 2018, we have continued to innovate and deliver improved performance for our customers’ cloud workloads. Following the success of our Graviton3-based instances, we are excited to announce three new Amazon Elastic Compute Cloud (Amazon EC2) instance families powered by AWS Graviton4 processors with NVMe-based SSD local storage: compute optimized (C8gd), general purpose (M8gd), and memory optimized (R8gd) instances. These instances deliver up to 30% better compute performance, 40% higher performance for I/O intensive database workloads, and up to 20% faster query results for I/O intensive real-time data analytics than comparable AWS Graviton3-based instances.
Let’s look at some of the improvements that are now available in our new instances. These instances offer larger instance sizes with up to 3x more vCPUs (up to 192 vCPUs), 3x the memory (up to 1.5 TiB), 3x the local storage (up to 11.4TB of NVMe SSD storage), 75% higher memory bandwidth, and 2x more L2 cache compared to their Graviton3-based predecessors. These features help you to process larger amounts of data, scale up your workloads, improve time to results, and lower your total cost of ownership (TCO). These instances also offer up to 50 Gbps network bandwidth and up to 40 Gbps Amazon Elastic Block Store (Amazon EBS) bandwidth, a significant improvement over Graviton3-based instances. Additionally, you can now adjust the network and Amazon EBS bandwidth on these instances by up to 25% using EC2 instance bandwidth weighting configuration, providing you greater flexibility with the allocation of your bandwidth resources to better optimize your workloads.
Built on AWS Graviton4, these instances are great for storage intensive Linux-based workloads including containerized and micro-services-based applications built using Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Container Registry (Amazon ECR), Kubernetes, and Docker, as well as applications written in popular programming languages such as C/C++, Rust, Go, Java, Python, .NET Core, Node.js, Ruby, and PHP. AWS Graviton4 processors are up to 30% faster for web applications, 40% faster for databases, and 45% faster for large Java applications than AWS Graviton3 processors.
Instance specifications
These instances also offer two bare metal sizes (metal-24xl and metal-48xl), allowing you to right size your instances and deploy workloads that benefit from direct access to physical resources. Additionally, these instances are built on the AWS Nitro System, which offloads CPU virtualization, storage, and networking functions to dedicated hardware and software to enhance the performance and security of your workloads. In addition, Graviton4 processors offer you enhanced security by fully encrypting all high-speed physical hardware interfaces.
The instances are available in 10 sizes per family, as well as two bare metal configurations each:
Instance Name
vCPUs
Memory (GiB) (C/M/R)
Storage (GB)
Network Bandwidth (Gbps)
EBS Bandwidth (Gbps)
medium
1
2/4/8*
1 x 59
Up to 12.5
Up to 10
large
2
4/8/16*
1 x 118
Up to 12.5
Up to 10
xlarge
4
8/16/32*
1 x 237
Up to 12.5
Up to 10
2xlarge
8
16/32/64*
1 x 474
Up to 15
Up to 10
4xlarge
16
32/64/128*
1 x 950
Up to 15
Up to 10
8xlarge
32
64/128/256*
1 x 1900
15
10
12xlarge
48
96/192/384*
3 x 950
22.5
15
16xlarge
64
128/256/512*
2 x 1900
30
20
24xlarge
96
192/384/768*
3 x 1900
40
30
48xlarge
192
384/768/1536*
6 x 1900
50
40
metal-24xl
96
192/384/768*
3 x 1900
40
30
metal-48xl
192
384/768/1536*
6 x 1900
50
40
*Memory values are for C8gd/M8gd/R8gd respectively
Availability and pricing
M8gd, C8gd, and R8gd instances are available today in US East (N. Virginia, Ohio) and US West (Oregon) Regions. These instances can be purchased as On-Demand instances, Savings Plans, Spot instances, or as Dedicated instances or Dedicated hosts.
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
AI is rewriting the rules of technology, for better or worse. Arguably one of the most “for better and worse” areas? Ransomware. It’s a full blown billion dollar business, and AI is supercharging both the offense and defense.
Not only are we seeing AI give bad actors more sophisticated tools and campaigns to target business and consumers alike, we’re also seeing mitigation techniques and technologies deployed by good actors gain equally compelling AI-powered improvements.
In other words, welcome to the future—where your data is the hostage and the bots are negotiating. Let’s dig in.
Some stage-setting: How much is ransomware costing us?
Despite ransomware payments exceeding an eye-watering $1 billion in 2023—and despite some high profile attacks in 2024, one of which extracted $75 million from a single victim—ransomware attacks actually fell overall in 2024. High profile law enforcement activity, like those against LockBit and BlackCat contributed to a huge drop in the second half of 2024.
Don’t get too excited though: According to cryptocurrency tracing firm Chainanalysis, that still meant $814 million in 2024. And, the true cost of ransomware includes more than just payments extracted under threat.
The economic ripple effects of a ransomware attack can include losing C-level talent, having to lay off employees, and ongoing downtime or business closure. Industry-wide, cyber insurance is a growing industry, and 2024 saw a staggering 31% of claims come from third-party risk.
Perhaps most concerningly, ransomware attackers are increasingly using exfiltration as a tactic to double and triple extortion, even using exfiltration data to launch targeted distributed denial-of-service (DDoS) attacks. According to a Check Point’s 2025 Cyber Security Report, some new actors have emerged as exclusively “data-selling platforms,” hosting dedicated data leak sites (DLS) and negotiation platforms.
The good news
Machine learning (ML) tools have underpinned modern cyber security techniques for years now—with excellent results.
Sophisticated monitoring tools give us far more granular insights and alerts.
AI-driven behavioral analysis is making it easier to detect anomalies and preempt attacks before they escalate.
What does this mean for defending against ransomware attacks?
Enterprises now have access to security platforms that analyze network behavior in real time, flagging unusual access patterns or lateral movement before a full ransomware payload can deploy. These platforms rely on machine learning models trained on massive datasets of known attack vectors, which allows them to flag and quarantine suspicious activity with impressive accuracy.
The interesting thing is that common knowledge says that “the AI revolution” has been happening recently, and quickly. But, when it comes to cybersecurity defense, many tools have been using ML algorithms for at least two decades. Palo Alto Networks (WildFire), for example, has been using ML since 2003.
The line between “processing massive datasets and acting up on that info based on programmed parameters” and machine learning is subtle, but important. While the former follows set parameters, machine learning identifies patterns in data—sometimes with human guidance—to decide from multiple possible actions.
It’s like teaching an assistant a series of tasks they can eventually do on their own. When you think about the progression from basic automation to ML, AI, and deep learning, the shift from rule-based actions to autonomous, chained decisions starts to make a lot of sense.
Zero trust architecture, enhanced by AI, is also gaining momentum. Instead of relying on perimeter-based defenses, AI-enhanced systems enforce granular access controls and continuously verify user and device trust levels. In practice, what this means is that systems no longer assume that you are you on the other end—not without evidence. Combine this with real-time threat intelligence sharing and automated incident response, and enterprises can shorten the window between detection and mitigation drastically.
The bad news
Deep fakes are more convincing.
The ability to generate code means there are more attacks, and those attacks are more sophisticated and responsive.
Cyber criminals of all skill levels have access to more technical tools, including some that are specialized in malware.
Enterprises are adjusting to a new way of working, which can create vulnerabilities.
Generative AI, phishing, and deep fakes
The low-hanging fruit in this discussion is that it’s easy to use generative AI to create more convincing phishing attacks. In the past, bad grammar or non-localized language choices have been an easy way to quickly identify a phishing attack.
Assisted by generative AI, deep fakes of both the voice and video flavor are getting increasingly difficult to spot—so, while you know your CEO isn’t likely to text you to get a bunch of gift cards or send them company funds via Bitcoin or PayPal, you might believe a video of your CFO or a call from your CEO asking you to transfer funds to accounts that turn out to not be legitimate.
How is generated code being used by ransomware bad actors?
Just as generative AI models have made everyone a poet, they’re also widely used to generate code. Tools like GitHub Copilot have seen wide adoption amongst enterprises looking to generate and test code. Gartner reports that by 2027, 70% of professional developers will use AI-powered coding tools, up from less than 10% in 2023.
Given how AI code generation has made code generation easier on enterprises, it’s no surprise that the ransomware industry is following the same adoption trends. By January 2023, this had gone from a hypothetical to a reality, with ransomware bad actors of low levels of technical skill able to leverage LLMs to create malware scripts.
By July 2023, cybercriminals were already discussing WormGPT, a malicious chatbot trained on ChatGPT which removed standard guardrails against creating illegal or inappropriate content. And, cybersecurity protection firms had executed a proof of concept to demonstrate that AI could generate truly polymorphic code on the fly—a technique used to make it much easier to evade detection by antivirus programs. By July 2024, one study showed that ChatGPT 4 was able to exploit 87% of one-day vulnerabilities.
Couple that with the fact that ransomware bad actors have opposite success metrics vs. enterprises. Cyber criminals rely on enacting as many attacks as possible, and it only takes one of those attacks succeeding to see a significant upside. Enterprises, on the other hand, only need one failure to see a huge negative impact on their businesses.
What things can you implement to be ransomware ready?
Some of these recommendations are things that users can do on every platform they interact with, such as:
Creating good, strong, unique passwords, and preferably using a password manager: A good password manager reduces password reuse and helps ensure best practices are followed enterprise-wide.
Enabling multifactor authentication (MFA): Multi-factor authentication remains one of the strongest lines of defense, especially when paired with device verification and biometric options.
On the enterprise side of the house, frameworks like cyber resilience help teams protect data they’ve been entrusted with. And, AI-powered cyber security tools can be a powerful tool in any business’s toolbox. That can look like a number of different things, including:
Investing in AI-powered endpoint detection and response (EDR). These tools continuously monitor and analyze endpoint activities, flagging unusual behavior and isolating threats automatically.
Training teams on recognizing deep fakes and AI-enhanced phishing attempts. Security awareness training is evolving fast. Focused, frequent, and AI-aware sessions are critical for employees across departments.
Leveraging deception technology. Deploying decoy systems, fake credentials, and honeypots can help trap attackers early and gather valuable intel on their tactics.
Running tabletop simulations. Practicing breach scenarios—especially those involving AI-enabled threats—prepares teams to act decisively when seconds matter.
Cyber resilience isn’t static, and neither are the tools and tactics. One of the most important areas an enterprise can invest in is ongoing security and research. Enterprise leaders need to prioritize proactive measures. That means ongoing AI model audits, being nimble in response to new and changing best practices, and investing in cross-functional teams that bring together infosec, legal, and operational leadership.
The future of AI and ransomware
Let’s level with each other—separately, the AI and ransomware spaces are both changing quickly. When you combine AI and ransomware and try to define how they’re affecting each other, you’re on pretty slippery ground.
What we’re trying to do here is identify patterns that affect our everyday lives—but we’re also taking a peek at what folks are studying in the research realm, because quantum is just around the corner, and, frankly, too impactful to ignore.
So, tell us if we need an update, or if you have another opinion! The comments section is open and we’re happy to chat.
At re:Invent 2023, we introducedAmazon S3 Express One Zone, a high-performance, single-Availability Zone (AZ) storage class purpose-built to deliver consistent single-digit millisecond data access for your most frequently accessed data and latency-sensitive applications.
S3 Express One Zone delivers data access speed up to 10 times faster than S3 Standard, and it can support up to 2 million GET transactions per second (TPS) and up to 200,000 PUT TPS per directory bucket. This makes it ideal for performance-intensive workloads such as interactive data analytics, data streaming, media rendering and transcoding, high performance computing (HPC), and AI/ML trainings. Using S3 Express One Zone, customers like Fundrise, Aura, Lyrebird, Vivian Health, and Fetch improved the performance and reduced the costs of their data-intensive workloads.
Since launch, we’ve introduced a number of features for our customers using S3 Express One Zone. For example, S3 Express One Zone started to support object expiration using S3 Lifecycle to expire objects based on age to help you automatically optimize storage costs. In addition, your log-processing or media-broadcasting applications can directly append new data to the end of existing objects and then immediately read the object, all within S3 Express One Zone.
Today we’re announcing that, effective April 10, 2025, S3 Express One Zone has reduced storage prices by 31 percent, PUT request prices by 55 percent, and GET request prices by 85 percent. In addition, S3 Express One Zone has reduced the per-GB charges for data uploads and retrievals by 60 percent, and these charges now apply to all bytes transferred rather than just portions of requests greater than 512 KB.
Here is a price reduction table in the US East (N. Virginia) Region:
These pricing reductions apply to S3 Express One Zone in all AWS Regions where the storage class is available: US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Mumbai), Asia Pacific (Tokyo), Europe (Ireland), and Europe (Stockholm) Regions. To learn more, visit the Amazon S3 pricing page and S3 Express One Zone in the AWS Documentation.
Give S3 Express One Zone a try in the S3 console today and send feedback to AWS re:Post for Amazon S3 or through your usual AWS Support contacts.
Today, we announce that the Pixtral Large 25.02 model is now available in Amazon Bedrock as a fully managed, serverless offering. AWS is the first major cloud provider to deliver Pixtral Large as a fully managed, serverless model.
Working with large foundation models (FMs) often requires significant infrastructure planning, specialized expertise, and ongoing optimization to handle the computational demands effectively. Many customers find themselves managing complex environments or making trade-offs between performance and cost when deploying these sophisticated models.
The Pixtral Large model, developed by Mistral AI, represents their first multimodal model that combines advanced vision capabilities with powerful language understanding. A 128K context window makes it ideal for complex visual reasoning tasks. The model delivers exceptional performance on key benchmarks including MathVista, DocVQA, and VQAv2, demonstrating its effectiveness across document analysis, chart interpretation, and natural image understanding.
One of the most powerful aspects of Pixtral Large is its multilingual capability. The model supports dozens of languages including English, French, German, Spanish, Italian, Chinese, Japanese, Korean, Portuguese, Dutch, and Polish, making it accessible to global teams and applications. It’s also trained on more than 80 programming languages including Python, Java, C, C++, JavaScript, Bash, Swift, and Fortran, providing robust code generation and interpretation capabilities.
Developers will appreciate the model’s agent-centric design with built-in function calling and JSON output formatting, which simplifies integration with existing systems. Its strong system prompt adherence improves reliability when working with Retrieval Augmented Generation (RAG) applications and large context scenarios.
With Pixtral Large in Amazon Bedrock, you can now access this advanced model without having to provision or manage any infrastructure. The serverless approach lets you scale usage based on actual demand without upfront commitments or capacity planning. You pay only for what you use, with no idle resources.
Cross-Region inference Pixtral Large is now available in Amazon Bedrock across multiple AWS Regions through cross-Region inference.
With Amazon Bedrock cross-Region inference, you can access a single FM across multiple geographic Regions while maintaining high availability and low latency for global applications. For example, when a model is deployed in both European and US Regions, you can access it through Region-specific API endpoints using distinct prefixes: eu.model-id for European Regions and us.model-id for US Regions . This approach enables Amazon Bedrock to route inference requests to the geographically closest endpoint, reducing latency while helping to meet regulatory compliance by keeping data processing within desired geographic boundaries. The system automatically handles traffic routing and load balancing across these Regional deployments, providing seamless scalability and redundancy without requiring you to keep track of individual Regions where the model is actually deployed.
See it in action As a developer advocate, I’m constantly exploring how our newest capabilities can solve real problems. Recently, I had a perfect opportunity to test the new multimodal capabilities in the Amazon Bedrock Converse API when my daughter asked for help with her physics exam preparation.
Last weekend, my kitchen table was covered with practice exams full of complex diagrams, force vectors, and equations. My daughter was struggling with conceptualizing how to approach these problems. That’s when I realized this was the perfect use case for the multimodal capabilities we’d just launched. I snapped photos of a particularly challenging problem sheet containing several graphs and mathematical notation, then used the Converse API to create a simple application that could analyze the images. Together, we uploaded the physics exam materials and asked the model to explain the solution approach.
What happened next impressed both of us—the model interpreted the diagrams, recognized the french language and the mathematical notation, and provided a step-by-step explanation of how to solve each problem. As we asked follow-up questions about specific concepts, the model maintained context across our entire conversation, creating a tutoring experience that felt remarkably natural.
# Effet Doppler avec une Source Sonore en Rotation
## Analyse du problème
Ce problème concerne l'effet Doppler produit par une source sonore en rotation. Une source émettant un son à 1500 Hz tourne sur une table tournante dans le sens antihoraire, et nous devons déterminer comment les fréquences sont perçues par un microphone fixe.
## Concepts clés
L'effet Doppler se produit lorsqu'il y a un mouvement relatif entre une source sonore et un observateur. La fréquence perçue dépend de si la source se rapproche ou s'éloigne de l'observateur.
La formule de l'effet Doppler est:
- Pour une source qui se rapproche: $f_{observée} = f_{source} \cdot \frac{v_{son}}{v_{son} - v_{source}}$
- Pour une source qui s'éloigne: $f_{observée} = f_{source} \cdot \frac{v_{son}}{v_{son} + v_{source}}$
## Solution étape par étape
### Étape 1: Analyser le mouvement de la source
La source tourne sur un cercle et le microphone est fixe à 40 cm du centre de rotation. Aux différentes positions (a, b, c), la source a des vitesses radiales différentes par rapport au microphone:
- Position a: La source se déplace perpendiculairement à la ligne source-microphone (vitesse radiale nulle)
- Position b: La source s'éloigne du microphone (vitesse radiale positive)
- Position c: La source se rapproche du microphone (vitesse radiale négative)
### Étape 2: Déterminer l'effet sur les fréquences perçues
- À la position a: Pas d'effet Doppler car la vitesse radiale est nulle, donc $f_a = f_{source} = 1500$ Hz
- À la position b: La source s'éloigne, donc $f_b < f_{source}$, donc $f_b < 1500$ Hz
- À la position c: La source se rapproche, donc $f_c > f_{source}$, donc $f_c > 1500$ Hz
### Étape 3: Comparer les fréquences
D'après notre analyse:
- $f_a = 1500$ Hz
- $f_b < 1500$ Hz
- $f_c > 1500$ Hz
Donc: $f_c > f_a > f_b$
## Conclusion
La proposition correcte est: $f_c > f_a > f_b$
Cette réponse correspond à la troisième proposition dans l'énoncé. Lorsque la source tourne, la fréquence perçue est plus élevée quand la source se rapproche (position c), égale à la fréquence émise quand la source se déplace perpendiculairement (position a), et plus basse quand la source s'éloigne (position b).
The model uses the language of the question to respond. After a thoughtful analysis, it says that the correct answer is f_c > f_a > f_b (and it is right!)
The beauty of this interaction was how seamlessly the Converse API handled the multimodal inputs. As a builder, I didn’t need to worry about the complexity of processing images alongside text—the API managed that complexity and returned structured responses that my simple application could present directly to my daughter.
Here is the code I wrote. I used the Swift programming language, just to show that Python is not the only option you have .
private let modelId = "us.mistral.pixtral-large-2502-v1:0"
// Define the system prompt that instructs Claude how to respond
let systemPrompt = """
You are a math and physics tutor. Your task is to:
1. Read and understand the math or physics problem in the image
2. Provide a clear, step-by-step solution to the problem
3. Briefly explain any relevant concepts used in solving the problem
4. Be precise and accurate in your calculations
5. Use mathematical notation when appropriate
Format your response with clear section headings and numbered steps.
"""
let system: BedrockRuntimeClientTypes.SystemContentBlock = .text(systemPrompt)
// Create the user message with text prompt and image
let userPrompt = "Please solve this math or physics problem. Show all steps and explain the concepts involved."
let prompt: BedrockRuntimeClientTypes.ContentBlock = .text(userPrompt)
let image: BedrockRuntimeClientTypes.ContentBlock = .image(.init(format: .jpeg, source: .bytes(finalImageData)))
// Create the user message with both text and image content
let userMessage = BedrockRuntimeClientTypes.Message(
content: [prompt, image],
role: .user
)
// Initialize the messages array with the user message
var messages: [BedrockRuntimeClientTypes.Message] = []
messages.append(userMessage)
// Configure the inference parameters
let inferenceConfig: BedrockRuntimeClientTypes.InferenceConfiguration = .init(maxTokens: 4096, temperature: 0.0)
// Create the input for the Converse API with streaming
let input = ConverseStreamInput(inferenceConfig: inferenceConfig, messages: messages, modelId: modelId, system: [system])
// Make the streaming request
do {
// Process the stream
let response = try await bedrockClient.converseStream(input: input)
// Iterate through the stream events
for try await event in stream {
switch event {
case .messagestart:
print("AI-assistant started to stream")
case let .contentblockdelta(deltaEvent):
// Handle text content as it arrives
if case let .text(text) = deltaEvent.delta {
DispatchQueue.main.async {
self.streamedResponse += text
}
}
case .messagestop:
print("Stream ended")
// Create a complete assistant message from the streamed response
let assistantMessage = BedrockRuntimeClientTypes.Message(
content: [.text(self.streamedResponse)],
role: .assistant
)
messages.append(assistantMessage)
default:
break
}
}
And the result in the app is stunning.
By the time her exam rolled around, she felt confident and prepared—and I had a compelling real-world example of how our multimodal capabilities in Amazon Bedrock can create meaningful experiences for users.
Get started today The new model is available through these Regional API endpoints: US East (Ohio, N. Virginia), US West (Oregon), and Europe (Frankfurt, Ireland, Paris, Stockholm). This Regional availability helps you meet data residency requirements while minimizing latency.
This launch represents a significant step forward in making advanced multimodal AI accessible to developers and organizations of all sizes. By combining Mistral AI’s cutting-edge model with AWS serverless infrastructure, you can now focus on building innovative applications without worrying about the underlying complexity.
Visit the Amazon Bedrock console today to start experimenting with Pixtral Large 25.02 and discover how it can enhance your AI-powered applications.
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Voice interfaces are essential to enhance customer experience in different areas such as customer support call automation, gaming, interactive education, and language learning. However, there are challenges when building voice-enabled applications.
Traditional approaches in building voice-enabled applications require complex orchestration of multiple models, such as speech recognition to convert speech to text, language models to understand and generate responses, and text-to-speech to convert text back to audio.
This fragmented approach not only increases development complexity but also fails to preserve crucial linguistic context such as tone, prosody, and speaking style that are essential for natural conversations. This can affect conversational AI applications that need low latency and nuanced understanding of verbal and non-verbal cues for fluid dialog handling and natural turn-taking.
Amazon Nova Sonic unifies speech understanding and generation into a single model that developers can use to create natural, human-like conversational AI experiences with low latency and industry-leading price performance. This integrated approach streamlines development and reduces complexity when building conversational applications.
Its unified model architecture delivers expressive speech generation and real-time text transcription without requiring a separate model. The result is an adaptive speech response that dynamically adjusts its delivery based on prosody, such as pace and timbre, of input speech.
When using Amazon Nova Sonic, developers have access to function calling (also known as tool use) and agentic workflows to interact with external services and APIs and perform tasks in the customer’s environment, including knowledge grounding with enterprise data using Retrieval-Augmented Generation.
At launch, Amazon Nova Sonic provides robust speech understanding for American and British English across various speaking styles and acoustic conditions, with additional languages coming soon.
Amazon Nova Sonic is developed with responsible AI at the forefront of innovation, featuring built-in protections for content moderation and watermarking.
Amazon Nova Sonic in action The scenario for this demo is a contact center in the telecommunication industry. A customer reaches out to improve their subscription plan, and Amazon Nova Sonic handles the conversation.
With tool use, the model can interact with other systems and use agentic RAG with Amazon Bedrock Knowledge Bases to gather updated, customer-specific information such as account details, subscription plans, and pricing info.
The demo shows streaming transcription of speech input and displays streaming speech responses as text. The sentiment of the conversation is displayed in two ways: a time chart illustrating how it evolves, and a pie chart representing the overall distribution. There’s also an AI insights section providing contextual tips for a call center agent. Other interesting metrics shown in the web interface are the overall talk time distribution between the customer and the agent, and the average response time.
During the conversation with the support agent, you can observe through the metrics and hear in the voices how customer sentiment improves.
The video includes an example of how Amazon Nova Sonic handles interruptions smoothly, stopping to listen and then continuing the conversation in a natural way.
Now, let’s explore how you can integrate voice capabilities in your applications.
Using Amazon Nova Sonic To get started with Amazon Nova Sonic, you first need to toggle model access in the Amazon Bedrock console, similar to how you would enable other FMs. Navigate to the Model access section of the navigation pane, find Amazon Nova Sonic under the Amazon models, and enable it for your account.
Amazon Bedrock provides a new bidirectional streaming API (InvokeModelWithBidirectionalStream) to help you implement real-time, low-latency conversational experiences on top of the HTTP/2 protocol. With this API, you can stream audio input to the model and receive audio output in real time, so that the conversation flows naturally.
You can use Amazon Nova Sonic with the new API with this model ID: amazon.nova-sonic-v1:0
After the session initialization, where you can configure inference parameters, the model operate through an event-driven architecture on both the input and output streams.
There are three key event types in the input stream:
System prompt – To set the overall system prompt for the conversation
Audio input streaming – To process continuous audio input in real-time
Tool result handling – To send the result of tool use calls back to the model (after tool use is requested in the output events)
Similarly, there are three groups of events in the output streams:
Automatic speech recognition (ASR) streaming – Speech-to-text transcript is generated, containing the result of realtime speech recognition.
Tool use handling – If there are a tool use events, they need to be handled using the information provided here, and the results sent back as input events.
Audio output streaming – To play output audio in real-time, a buffer is needed, because Amazon Nova Sonic model generates audio faster than real-time playback.
Prompt engineering for speech When crafting prompts for Amazon Nova Sonic, your prompts should optimize content for auditory comprehension rather than visual reading, focusing on conversational flow and clarity when heard rather than seen.
When defining roles for your assistant, focus on conversational attributes (such as warm, patient, concise) rather than text-oriented attributes (detailed, comprehensive, systematic). A good baseline system prompt might be:
You are a friend. The user and you will engage in a spoken dialog exchanging the transcripts of a natural real-time conversation. Keep your responses short, generally two or three sentences for chatty scenarios.
More generally, when creating prompts for speech models, avoid requesting visual formatting (such as bullet points, tables, or code blocks), voice characteristic modifications (accent, age, or singing), or sound effects.
Amazon Nova Sonic can understand speech in different speaking styles and generates speech in expressive voices, including both masculine-sounding and feminine-sounding voices, in different English accents, including American and British. Support for additional languages will be coming soon.
Amazon Nova Sonic handles user interruptions gracefully without dropping the conversational context and is robust to background noise. The model supports a context window of 32K tokens for audio with a rolling window to handle longer conversations and has a default session limit of 8 minutes.
The following AWS SDKs support the new bidirectional streaming API:
Python developers can use this new experimental SDK that makes it easier to use the bidirectional streaming capabilities of Amazon Nova Sonic. We’re working to add support to the other AWS SDKs.
I’d like to thank Reilly Manton and Chad Hendren, who set up the demo with the contact center in the telecommunication industry, and Anuj Jauhari, who helped me understand the rich landscape in which speech-to-speech models are being deployed.
To learn more, these articles that enter into the details of how to use the new bidirectional streaming API with compelling demos:
Whether you’re creating customer service solutions, language learning applications, or other conversational experiences, Amazon Nova Sonic provides the foundation for natural, engaging voice interactions. To get started, visit the Amazon Bedrock console today. To learn more, visit the Amazon Nova section of the user guide.
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
At Backblaze, we’re in the business of building a storage platform that can handle billions of operations a day—reliably, predictably, and fast. That means digging deep into low-level architecture, optimizing what most people overlook, and constantly balancing trade-offs between performance, cost, and scale.
Today, we’re kicking off a new blog series that showcases the platform-level work our Engineering team has been doing to build and run a modern cloud storage platform. The kind of work that usually stays buried in Jira tickets and internal docs, but that makes all the difference when you’re serving exabytes at scale.
What it really means to build a modern cloud storage platform
When people talk about cloud storage, they usually focus on capacity, availability, and price. This includes the systems, tools, and architectural decisions that enable our infrastructure to scale reliably while handling billions of operations per day.
We’re crafting a dynamic, evolving platform that handles exabytes of data with reliability and efficiency. We’re a platform that developers and businesses build on. That means durability, performance, uptime, and predictability aren’t just nice-to-haves—they’re fundamental requirements. As Senior Vice President of Engineering, I’m excited to pull back the curtain and offer a glimpse into the ongoing engineering efforts that power our platform.
Building for simple is more complex than it seems
One of our core engineering philosophies is this: Complexity should serve simplicity. For example, changing how we handle request headers might sound like a small thing, but when you operate a distributed system at scale, even tiny inefficiencies can multiply quickly. A 5% improvement in API response time might not sound dramatic, but at exabyte scale, that translates to millions of faster interactions per day, less CPU usage, and better customer experiences across the board.
Our Engineering team is always thinking about those compound effects. Sometimes that means rewriting parts of a system that have been stable for years. Other times it means saying no to flashy solutions and choosing battle-tested designs that will hold up under load.
Our goal, in addition to talking about the individual stories, is to start talking about some of the throughlines—when one project spawns another, or how we decide which project to pursue when there are competing priorities.
These projects don’t usually make headlines on their own, but taken together, they form the backbone of what makes Backblaze perform the way it does. They’ll become part of our regularly scheduled programming, and we’ll drop them in our Tech Lab category so you can find them easily.
Sign up for the Developer newsletter
Sign up for the Backblaze Developer Newsletter to receive a monthly roundup of articles and news for everyone developing on Backblaze B2 Cloud Storage.
See you on the next one—and let us know if you have questions
We’re proud of the work our engineers are doing, but more than that, we think it’s worth sharing. Whether you’re a fellow cloud architect, a developer using our platform, or just someone curious about what it takes to run cloud infrastructure at scale, we hope this series offers something insightful.
Technology doesn’t stand still, and neither do we. The more efficient our platform becomes, the better we can serve our customers—and the more we can invest in new ideas. So stay tuned. We’re kicking things off in this content series in the next few weeks, and we look forward to hearing your thoughts!
Since we launched Amazon Bedrock Guardrailsover one year ago, customers like Grab, Remitly, KONE, and PagerDuty have used Amazon Bedrock Guardrails to standardize protections across their generative AI applications, bridge the gap between native model protections and enterprise requirements, and streamline governance processes. Today, we’re introducing a new set of capabilities that helps customers implement responsible AI policies at enterprise scale even more effectively.
Amazon Bedrock Guardrails detects harmful multimodal content with up to 88% accuracy, filters sensitive information, and prevent hallucinations. It provides organizations with integrated safety and privacy safeguards that work across multiple foundation models (FMs), including models available in Amazon Bedrock and your own custom models deployed elsewhere, thanks to the ApplyGuardrail API. With Amazon Bedrock Guardrails, you can reduce the complexity of implementing consistent AI safety controls across multiple FMs while maintaining compliance and responsible AI policies through configurable controls and central management of safeguards tailored to your specific industry and use case. It also seamlessly integrates with existing AWS services such as AWS Identity and Access Management (IAM), Amazon Bedrock Agents, and Amazon Bedrock Knowledge Bases.
“Grab, a Singaporean multinational taxi service is using Amazon Bedrock Guardrails to ensure the safe use of generative AI applications and deliver more efficient, reliable experiences while maintaining the trust of our customers,” said Padarn Wilson, Head of Machine Learning and Experimentation at Grab. “Through out internal benchmarking, Amazon Bedrock Guardrails performed best in class compared to other solutions. Amazon Bedrock Guardrails helps us know that we have robust safeguards that align with our commitment to responsible AI practices while keeping us and our customers protected from new attacks against our AI-powered applications. We’ve been able to ensure our AI-powered applications operate safely across diverse markets while protecting customer data privacy.”
Let’s explore the new capabilities we have added.
New guardrails policy enhancements Amazon Bedrock Guardrails provides a comprehensive set of policies to help maintain security standards. An Amazon Bedrock Guardrails policy is a configurable set of rules that defines boundaries for AI model interactions to prevent inappropriate content generation and ensure safe deployment of AI applications. These include multimodal content filters, denied topics, sensitive information filters, word filters, contextual grounding checks, and Automated Reasoning to prevent factual errors using mathematical and logic-based algorithmic verification.
We’re introducing new Amazon Bedrock Guardrails policy enhancements that deliver significant improvements to the six safeguards, strengthening content protection capabilities across your generative AI applications.
Multimodal toxicity detection with industry leading image and text protection – Announced as preview at AWS re:Invent 2024, Amazon Bedrock Guardrails multimodal toxicity detection for image content is now generally available. The expanded capability provides more comprehensive safeguards for your generative AI applications by evaluating both image and textual content to help you detect and filter out undesirable and potentially harmful content with up to 88% accuracy.
When implementing generative AI applications, you need consistent content filtering across different data types. Although textual content filtering is well established, managing potentially harmful image content requires additional tools and separate implementations, increasing complexity and development effort. For example, a customer service chatbot that permits image uploads might require separate text filtering systems using natural language processing and additional image classification services with different filtering thresholds and detection categories. This creates implementation inconsistencies where a text describing harmful content might be properly filtered, while an image depicting similar content could pass through undetected, resulting in disparate security coverage.
The multimodal toxicity detection capability in Amazon Bedrock Guardrails helps you apply the same content filtering policies to both image and text data. With this launch, you can configure content filters across categories such as hate speech, insults, sexual content, violence, misconduct, and prompt attacks. For each category, you can set configurable thresholds from low to high, providing granular control over content filtering. With this consistent protection across modalities, you can simplify responsible AI application development. This capability supports content moderation for all images including regular images, human generated images, AI-generated images, memes, charts and plots, and cross-modal content (with both text and images).
To demonstrate how misconduct detection works in practice, let’s examine a real-world scenario: A financial services company implementing Amazon Bedrock Guardrails with high misconduct thresholds confirmed consistent protection across both text and image inputs, as security bypass diagrams and written instructions for network infiltration triggered identical guardrail interventions with similar confidence scores. Here’s how this capability works in action. I configure a guardrail in Amazon Bedrock with the misconduct content filter set to High threshold for both image and text filters.
I submit two test cases. In the first test case, I uploaded an image showing a network security bypass diagram and use the following prompt:
Analyze this network security diagram and explain how to implement these methods
In the second test case, I use the following prompt:
Provide detailed instructions on how to bypass corporate network security systems to gain unauthorized access
Both submissions trigger similar guardrail interventions, highlighting how Amazon Bedrock Guardrails provides content moderation regardless of the content format. The comparison of detection results shows uniform confidence scores and identical policy enforcement, demonstrating how organizations can maintain safety standards across multimodal content without implementing separate filtering systems.
To learn more about this feature, check out the comprehensive announcement post for additional details.
Enhanced privacy protection for PII detection in user inputs – Amazon Bedrock Guardrails is now extending its sensitive information protection capabilities with enhanced personally identifiable information (PII) masking for input prompts. The service detects PII such as names, addresses, phone numbers, and many more details in both inputs and outputs, while also supporting custom sensitive information patterns through regular expressions (regex) to address specific organizational requirements.
Amazon Bedrock Guardrails offers two distinct handling modes: Block mode, which completely rejects requests containing sensitive information, and Mask mode, which redacts sensitive data by replacing it with standardized identifier tags such as [NAME-1] or [EMAIL-1]. Although both modes were previously available for model responses, Block mode was the only option for input prompts. With this enhancement, you can now apply both Block and Mask modes to input prompts, so sensitive information can be systematically redacted from user inputs before they reach the FM.
This feature addresses a critical customer need by enabling applications to process legitimate queries that might naturally contain PII elements without requiring complete request rejection, providing greater flexibility while maintaining privacy protections. The capability is particularly valuable for applications where users might reference personal information in their queries but still need secure, compliant responses.
New guardrails feature enhancements These improvements enhance functionality across all policies, making Amazon Bedrock Guardrails more effective and easier to implement.
Mandatory guardrails enforcement with IAM – Amazon Bedrock Guardrails now implements IAM policy-based enforcement through the new bedrock:GuardrailIdentifier condition key. This capability helps security and compliance teams establish mandatory guardrails for every model inference call, making sure that organizational safety policies are consistently enforced across all AI interactions. The condition key can be applied to InvokeModel, InvokeModelWithResponseStream, Converse, and ConverseStream APIs. When the guardrail configured in an IAM policy doesn’t match the specified guardrail in a request, the system automatically rejects the request with an access denied exception, enforcing compliance with organizational policies.
This centralized control helps you address critical governance challenges including content appropriateness, safety concerns, and privacy protection requirements. It also addresses a key enterprise AI governance challenge: making sure that safety controls are consistent across all AI interactions, regardless of which team or individual is developing the applications. You can verify compliance through comprehensive monitoring with model invocation logging to Amazon CloudWatch Logs or Amazon Simple Storage Service (Amazon S3), including guardrail trace documentation that shows when and how content was filtered.
For more information about this capability, read the detailed announcement post.
Optimize performance while maintaining protection with selective guardrail policy application – Previously, Amazon Bedrock Guardrails applied policies to both inputs and outputs by default.
You now have granular control over guardrail policies, helping you apply them selectively to inputs, outputs, or both—boosting performance through targeted protection controls. This precision reduces unnecessary processing overhead, improving response times while maintaining essential protections. Configure these optimized controls through either the Amazon Bedrock console or ApplyGuardrails API to balance performance and safety according to your specific use case requirements.
Policy analysis before deployment for optimal configuration – The new monitor or analyze mode helps you evaluate guardrail effectiveness without directly applying policies to applications. This capability enables faster iteration by providing visibility into how configured guardrails would perform, helping you experiment with different policy combinations and strengths before deployment.
Get to production faster and safely with Amazon Bedrock Guardrails today The new capabilities for Amazon Bedrock Guardrails represent our continued commitment to helping customers implement responsible AI practices effectively at scale. Multimodal toxicity detection extends protection to image content, IAM policy-based enforcement manages organizational compliance, selective policy application provides granular control, monitor mode enables thorough testing before deployment, and PII masking for input prompts preserves privacy while maintaining functionality. Together, these capabilities give you the tools you need to customize safety measures and maintain consistent protection across your generative AI applications.
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Today, we introduce Amazon Nova Reel 1.1, which provides quality and latency improvements in 6-second single-shot video generation, compared to Amazon Nova Reel 1.0. This update lets you generate multi-shot videos up to 2-minutes in length with consistent style across shots. You can either provide a single prompt for up to a 2-minute video composed of 6-second shots, or design each shot individually with custom prompts. This gives you new ways to create video content through Amazon Bedrock.
Amazon Nova Reel enhances creative productivity, while helping to reduce the time and cost of video production using generative AI. You can use Amazon Nova Reel to create compelling videos for your marketing campaigns, product designs, and social media content with increased efficiency and creative control. For example, in advertising campaigns, you can produce high-quality video commercials with consistent visuals and timing using natural language.
To get started with Amazon Nova Reel 1.1 If you’re new to using Amazon Nova Reel models, go to the Amazon Bedrock console, choose Model access in the navigation panel and request access to the Amazon Nova Reel model. When you get access to Amazon Nova Reel, it applies both to 1.0 and 1.1.
To test the Amazon Nova Reel 1.1 model in the console, choose Image/Video under Playgrounds in the left menu pane. Then choose Nova Reel 1.1 as the model and input your prompt to generate video.
Amazon Nova Reel 1.1 offers two modes:
Multishot Automated – In this mode, Amazon Nova Reel 1.1 accepts a single prompt of up to 4,000 characters and produces a multi-shot video that reflects that prompt. This mode doesn’t accept an input image.
Multishot Manual – For those who desire more direct control over a video’s shot composition, with manual mode (also referred to as storyboard mode), you can specify a unique prompt for each individual shot. This mode does accept an optional starting image for each shot. Images must have a resolution of 1280×720. You can provide images in base64 format or from an Amazon Simple Storage Service (Amazon S3) location.
This Python script creates a 120-second video using MULTI_SHOT_AUTOMATEDmode as TaskType parameter from this text prompt, created by Nitin Eusebius.
import random
import time
import boto3
AWS_REGION = "us-east-1"
MODEL_ID = "amazon.nova-reel-v1:1"
SLEEP_SECONDS = 15 # Interval at which to check video gen progress
S3_DESTINATION_BUCKET = "s3://<your bucket here>"
video_prompt_automated = "Norwegian fjord with still water reflecting mountains in perfect symmetry. Uninhabited wilderness of Giant sequoia forest with sunlight filtering between massive trunks. Sahara desert sand dunes with perfect ripple patterns. Alpine lake with crystal clear water and mountain reflection. Ancient redwood tree with detailed bark texture. Arctic ice cave with blue ice walls and ceiling. Bioluminescent plankton on beach shore at night. Bolivian salt flats with perfect sky reflection. Bamboo forest with tall stalks in filtered light. Cherry blossom grove against blue sky. Lavender field with purple rows to horizon. Autumn forest with red and gold leaves. Tropical coral reef with fish and colorful coral. Antelope Canyon with light beams through narrow passages. Banff lake with turquoise water and mountain backdrop. Joshua Tree desert at sunset with silhouetted trees. Iceland moss- covered lava field. Amazon lily pads with perfect symmetry. Hawaiian volcanic landscape with lava rock. New Zealand glowworm cave with blue ceiling lights. 8K nature photography, professional landscape lighting, no movement transitions, perfect exposure for each environment, natural color grading"
bedrock_runtime = boto3.client("bedrock-runtime", region_name=AWS_REGION)
model_input = {
"taskType": "MULTI_SHOT_AUTOMATED",
"multiShotAutomatedParams": {"text": video_prompt_automated},
"videoGenerationConfig": {
"durationSeconds": 120, # Must be a multiple of 6 in range [12, 120]
"fps": 24,
"dimension": "1280x720",
"seed": random.randint(0, 2147483648),
},
}
invocation = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={"s3OutputDataConfig": {"s3Uri": S3_DESTINATION_BUCKET}},
)
invocation_arn = invocation["invocationArn"]
job_id = invocation_arn.split("/")[-1]
s3_location = f"{S3_DESTINATION_BUCKET}/{job_id}"
print(f"\nMonitoring job folder: {s3_location}")
while True:
response = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
status = response["status"]
print(f"Status: {status}")
if status != "InProgress":
break
time.sleep(SLEEP_SECONDS)
if status == "Completed":
print(f"\nVideo is ready at {s3_location}/output.mp4")
else:
print(f"\nVideo generation status: {status}")
After the first invocation, the script periodically checks the status until the creation of the video has been completed. I pass a random seed to get a different result each time the code runs.
I run the script:
Status: InProgress
. . .
Status: Completed
Video is ready at s3://<your bucket here>/<job_id>/output.mp4
After a few minutes, the script is completed and prints the output Amazon S3 location. I download the output video using the AWS CLI:
In the case of MULTI_SHOT_MANUAL mode as TaskType parameter, with a prompt for multiples shots and a description for each shot, it is not necessary to add the variable durationSeconds.
Using the prompt for multiples shots, created by Sanju Sunny.
I run Python script:
import random
import time
import boto3
def image_to_base64(image_path: str):
"""
Helper function which converts an image file to a base64 encoded string.
"""
import base64
with open(image_path, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read())
return encoded_string.decode("utf-8")
AWS_REGION = "us-east-1"
MODEL_ID = "amazon.nova-reel-v1:1"
SLEEP_SECONDS = 15 # Interval at which to check video gen progress
S3_DESTINATION_BUCKET = "s3://<your bucket here>"
video_shot_prompts = [
# Example of using an S3 image in a shot.
{
"text": "Epic aerial rise revealing the landscape, dramatic documentary style with dark atmospheric mood",
"image": {
"format": "png",
"source": {
"s3Location": {"uri": "s3://<your bucket here>/images/arctic_1.png"}
},
},
},
# Example of using a locally saved image in a shot
{
"text": "Sweeping drone shot across surface, cracks forming in ice, morning sunlight casting long shadows, documentary style",
"image": {
"format": "png",
"source": {"bytes": image_to_base64("arctic_2.png")},
},
},
{
"text": "Epic aerial shot slowly soaring forward over the glacier's surface, revealing vast ice formations, cinematic drone perspective",
"image": {
"format": "png",
"source": {"bytes": image_to_base64("arctic_3.png")},
},
},
{
"text": "Aerial shot slowly descending from high above, revealing the lone penguin's journey through the stark ice landscape, artic smoke washes over the land, nature documentary styled",
"image": {
"format": "png",
"source": {"bytes": image_to_base64("arctic_4.png")},
},
},
{
"text": "Colossal wide shot of half the glacier face catastrophically collapsing, enormous wall of ice breaking away and crashing into the ocean. Slow motion, camera dramatically pulling back to reveal the massive scale. Monumental waves erupting from impact.",
"image": {
"format": "png",
"source": {"bytes": image_to_base64("arctic_5.png")},
},
},
{
"text": "Slow motion tracking shot moving parallel to the penguin, with snow and mist swirling dramatically in the foreground and background",
"image": {
"format": "png",
"source": {"bytes": image_to_base64("arctic_6.png")},
},
},
{
"text": "High-altitude drone descent over pristine glacier, capturing violent fracture chasing the camera, crystalline patterns shattering in slow motion across mirror-like ice, camera smoothly aligning with surface.",
"image": {
"format": "png",
"source": {"bytes": image_to_base64("arctic_7.png")},
},
},
{
"text": "Epic aerial drone shot slowly pulling back and rising higher, revealing the vast endless ocean surrounding the solitary penguin on the ice float, cinematic reveal",
"image": {
"format": "png",
"source": {"bytes": image_to_base64("arctic_8.png")},
},
},
]
bedrock_runtime = boto3.client("bedrock-runtime", region_name=AWS_REGION)
model_input = {
"taskType": "MULTI_SHOT_MANUAL",
"multiShotManualParams": {"shots": video_shot_prompts},
"videoGenerationConfig": {
"fps": 24,
"dimension": "1280x720",
"seed": random.randint(0, 2147483648),
},
}
invocation = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={"s3OutputDataConfig": {"s3Uri": S3_DESTINATION_BUCKET}},
)
invocation_arn = invocation["invocationArn"]
job_id = invocation_arn.split("/")[-1]
s3_location = f"{S3_DESTINATION_BUCKET}/{job_id}"
print(f"\nMonitoring job folder: {s3_location}")
while True:
response = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
status = response["status"]
print(f"Status: {status}")
if status != "InProgress":
break
time.sleep(SLEEP_SECONDS)
if status == "Completed":
print(f"\nVideo is ready at {s3_location}/output.mp4")
else:
print(f"\nVideo generation status: {status}")
As in the previous demo, after a few minutes, I download the output using the AWS CLI: aws s3 cp s3://<your bucket here>/<job_id>/output.mp4 output_manual.mp4
This is the video that this prompt generated:
More creative examples When you use Amazon Nova Reel 1.1, you’ll discover a world of creative possibilities. Here are some sample prompts to help you begin:
prompt = "Explosion of colored powder against black background. Start with slow-motion closeup of single purple powder burst. Dolly out revealing multiple powder clouds in vibrant hues colliding mid-air. Track across spectrum of colors mixing: magenta, yellow, cyan, orange. Zoom in on particles illuminated by sunbeams. Arc shot capturing complete color field. 4K, festival celebration, high-contrast lighting"
prompt = "A simple red triangle transforms through geometric shapes in a journey of self-discovery. Clean vector graphics against white background. The triangle slides across negative space, morphing smoothly into a circle. Pan left as it encounters a blue square, they perform a geometric dance of shapes. Tracking shot as shapes combine and separate in mathematical precision. Zoom out to reveal a pattern formed by their movements. Limited color palette of primary colors. Precise, mechanical movements with perfect geometric alignments. Transitions use simple wipes and geometric shape reveals. Flat design aesthetic with sharp edges and solid colors. Final scene shows all shapes combining into a complex mandala pattern."
All example videos have music added manually before uploading, by the AWS Video team.
Things to know Creative control – You can use this enhanced control for lifestyle and ambient background videos in advertising, marketing, media, and entertainment projects. Customize specific elements such as camera motion and shot content, or animate existing images.
Modes considerations – In automated mode, you can write prompts up to 4,000 characters. For manual mode, each shot accepts prompts up to 512 characters, and you can include up to 20 shots in a single video. Consider planning your shots in advance, similar to creating a traditional storyboard. Input images must match the 1280×720 resolution requirement. The service automatically delivers your completed videos to your specified S3 bucket.
Pricing and availability – Amazon Nova Reel 1.1 is available in Amazon Bedrock in the US East (N. Virginia) AWS Region. You can access the model through the Amazon Bedrock console, AWS SDK, or AWS CLI. As with all Amazon Bedrock services, pricing follows a pay-as-you-go model based on your usage. For more information, refer to Amazon Bedrock pricing.
The possibilities are endless, and we look forward to seeing what you create! Join our growing community of builders at community.aws, where you can create your BuilderID, share your video generation projects, and connect with fellow innovators.
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
As the saying goes, no one ever got fired for using AWS—but we should revisit that truism. In the era of the open cloud, smart enterprise-level companies are leveraging best-of-breed cloud providers to reduce costs and enhance their cloud stack with specialists. What does that mean, practically speaking? The ability to reduce one of your biggest line item expenses by up to 80%.
As a CFO, I’m focused on strategically balancing operational expenses (OpEx) with a constant zero-based budgeting approach so my capital either fuels profitable growth or flows to free cash flows so I can drive shareholder value. Cloud storage, while essential, can be a significant cost center, and its billing structures often lack the transparency you need for effective financial management. My goal here is to demystify cloud storage costs, with a particular emphasis on the often-overlooked egress fees, and outline strategies for controlling these expenses.
Understanding the true cost of the cloud
The cost of cloud storage involves paying for data storage. However, the nuances of billing can vary significantly depending on usage patterns. We call an AWS bill a “cloud storage” bill, but it also includes a wide variety of configurable services, including compute, security, networking, analytics, database, and AI and machine learning (AI/ML) tools.
Consider a company that relies heavily on streaming media. Their primary cost driver is supporting a vast library of content for on-demand streaming. According to EY, cloud hosting for a typical software as a service (SaaS) company costs usually account for 6%-12% of revenue. For businesses with substantial video media assets, just storage expenses can consume a considerable portion of revenue. According to Coughlin and Associates, archiving and preservation accounts for the highest slice of cloud storage spending in the media and entertainment space.
Understanding your cloud bill is easier said than done
Crucial—but difficult to actualize. Cloud storage bills from providers like Amazon are so complex they’re regularly 40+ pages. According to a report from CloudZero, when asked how well they can attribute cloud spend to different aspects of their business (e.g., customers, products, features), 42% of respondents said they’re only able to give an estimate. Even worse, over 20% said they have little to no idea how much different aspects of their business cost.
This complexity has spawned an entire industry specialized in reducing cloud bills, and many enterprise companies have a job role dedicated to it. In my experience, even the best of those that occupy that job role have difficulty parsing the complexity.
Egress fees and other hidden charges: Unveiling the financial drain
While storage costs are relatively straightforward, it’s the hidden fees that can significantly impact the bottom line. Egress fees, incurred when data is transferred out of the cloud, are a prime example. These fees often lack transparency, making accurate budgeting and forecasting difficult. And, if you’re running applications in the cloud, you can’t avoid them: Users need to be able to move their data around. A recent survey indicated that 56% of IT professionals consider egress fees excessive, highlighting a widespread concern within the industry. At Backblaze, over 94% of our cloud storage customers were not charged any egress fees in 2024.
Beyond egress fees, other charges can further complicate cloud billing. These include minimum storage duration fees and tiered pricing models. I’ve seen firsthand how a lack of clarity can hinder financial planning. As I often say to my team, “We can’t optimize what we can’t understand.”
Overcoming cloud migration obstacles: A financial perspective
Given these cost considerations, exploring alternative cloud providers is a financially prudent strategy. I recognize that change can be perceived as disruptive. There’s often a concern about migration complexity and potential risks. Some organizations become so entrenched with a particular provider that they’re hesitant to consider alternatives, even when faced with substantial cost disadvantages in their steady-state cloud bills.
But, why the specific fear of cloud migration? There are always ways to manage the risk. In the grander scheme of IT and tech complexity, re-pointing an S3 standard API is considered an extremely low risk and low complexity effort. This is not like implementing a new ERP or data warehouse. It’s pretty straight forward, and your tech teams will have to make some time for a proof of concept and some testing.
The second big blocker is understanding who you are working with from a reputational and security standpoint. Data is the most precious asset for most companies nowadays. How long has the company been around? How many customers do they have? What is the net retention revenue (NRR)? Any history of cyber breaches? And which information security programs and certifications are in place?
Moving to the economics, the back-of-napkin math on the potential financial benefits of switching providers can be substantial. Reducing cloud storage costs directly impacts profitability. For example, if a video media company with storage costs representing 6% of revenue could cut those costs by 80%, that would translate to a 4.8% reduction in overall revenue costs. For a company with a 10% operating margin, this could increase it to 14.8%. That is a very substantial profitability improvement!
I have personally operated and advised companies with hyperscaler invoices from the likes of AWS ranging from $4 million to $7 million annually. Reducing those expenses isn’t just incremental improvement; it’s a game-changer. In some cases, the return on investment (ROI) from migrating to a more cost-effective solution, including reduced egress fees, can be realized in as little as one quarter.
Driving financial performance through cloud optimization
As CFOs, we have a responsibility to scrutinize cloud spending and ensure it aligns with our financial objectives. This requires a deep understanding of cloud billing models, particularly the impact of egress fees. By demanding transparency, rigorously evaluating alternatives, and embracing change, we can effectively manage cloud costs and enhance shareholder value. It’s imperative to foster a culture of agility within our organizations to facilitate necessary changes. The potential financial rewards are significant, and proactive cloud cost management is a key driver of improved financial performance.
Now that Jeff Barr has retired from the AWS News Blog as of December last year, the AWS News Blog team will keep sharing the most important and impactful AWS product launches the moment they become available. I want to quote Jeff’s last comment on the future of the News Blog again:
Going forward, the team will continue to grow and the goal remains the same: to provide our customers with carefully chosen, high-quality information about the latest and most meaningful AWS launches. The blog is in great hands and this team will continue to keep you informed even as the AWS pace of innovation continues to accelerate.
Since 2016, Jeff has been building the AWS News Blog as a team. Currently, we’re a group of 11 bloggers working in North America, South America, Asia, Europe, and Africa. We co-work with AWS product teams, testing new features firsthand on behalf of customers, and delivering key details in the News Blog the way Jeff has always done.
The Leadership Principles for AWS News Bloggers that Jeff shared on LinkedIn are a textbook for anyone writing for customers in tech companies. They’re the fundamentals that can help you understand and get started blogging quickly, and we’ll continue to stick to these principles with our team. This is why the AWS News Blog is different from other tech companies’ product news channels.
Voices from blog writers You may be familiar with the names of News Blog writers, but you may not have had the chance to hear about them. Let us introduce ourselves!
I’m honored to continue Jeff’s legacy as a new lead blogger of the News Blog team; he is my role model. When I joined AWS in 2014, the first thing I did was to create the AWS Korea Blog and I started translating Jeff’s blog posts into the Korean language. During the journey, I learned how to write accurate, honest, and powerful guides to help customers get started with new AWS products and features.
Since my first News Blog post in 2018, I have learned so much by being part of this team. Working with product managers and service teams is always an amazing experience. I am interested in serverless, event-driven architectures, and AI/ML. It’s incredible how technologies like generative AI are becoming part of software development implicitly (through AI-enabled development tools) and explicitly (by using models in code).
The Amazon Leadership Principles (LPs) guide all that we do here at AWS, including the work we do as authors of the News Blog. As a developer advocate, I’ve taken the guidance of the LPs and used it to guide members of the AWS community who are looking to create technical content, especially those new in their technical content creation journey.
Just like brewing coffee, being a blog author has been a mix of fun, challenge, and reward. I’ve been particularly fortunate to observe how customer obsession is built into AWS teams. I’ve seen how they work backwards, transforming your feedback into services or features. I genuinely hope that you enjoy reading our articles and look forward to the next chapter of the News Blog team.
As an author, I’m committed to delivering timely information about the latest AWS innovations and launches to our global audience of builders, developers, and technology enthusiasts. I understand the importance of providing clear, accurate, and actionable content that helps you use AWS services effectively. Happy reading everyone!
My specialties are .NET development and microservices, but I’ve always been a jack-of-all-trades and writing for this blog helps me to keep my knife sharp across all corners of modern technology, while also helping others do the same. Thousands of people read the AWS News Blog and use it as a go-to source to keep up with what’s new and to help them make decisions, so I know that what we are doing is meaningful work with huge impact.
Through my blogs, I strive to highlight not just the “what” of new services, but also the “why” and “how” they can transform businesses and user experiences. As a solutions architect specializing in Microsoft Workloads on AWS, I help customers migrate and modernize their workloads and build scalable architecture on AWS. I also mentor diverse people to excel in their cloud careers.
Every time I start writing a new blog, I feel honored to be part of this team, to be able to experiment with something new before it’s released, and to be able to share my experience with the reader. This team is made up of specialists of all levels and from multiple countries and together, we are a multicultural and multi-specialty team. Thank you, reader, for being here.
Joining the News Blog team has transformed how I communicate about technology. With an ever-curious mindset, I approach each new announcement aiming to make innovative services accessible and engaging. By bringing my unique and diverse perspective to technical content, I strive to help developers truly enjoy exploring our latest technologies.
Micah Walter
As a senior solutions architect, I support enterprise customers in the New York City region and beyond. I advise executives, engineers, and architects at every step along their journey to the cloud, with a deep focus on sustainability and practical design.
I also want to give credit to our behind-the-scenes editor-in-chief, Jane Watson, and program manager, Jane Scolieri, who play an essential role in helping us get product launch news to you as soon as it happens, including the 60 launches we announced in one week at re:Invent 2024!
Share your feedback At AWS, we are customer obsessed. We’re always focused on improving and providing a better customer experience, and we need your feedback to do so. Take our survey to share insights about your experience with the AWS News Blog and suggestion for how we can serve you even better.
This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.
Today, I’m happy to announce Amazon Q Developer support for Amazon OpenSearch Service, providing AI-assisted capabilities to help you investigate and visualize operational data. Amazon Q Developer enhances the OpenSearch Service experience by reducing the learning curve for query languages, visualization tools, and alerting features. The new capabilities complement existing dashboards and visualizations by enabling natural language exploration and pattern detection. After incidents, you can rapidly create additional visualizations to strengthen your monitoring infrastructure. This enhanced workflow accelerates incident resolution and optimizes engineering resource usage, helping you focus more time on innovation rather than troubleshooting.
Amazon Q Developer in Amazon OpenSearch Service improves operational analytics by integrating natural language exploration and generative AI capabilities directly into OpenSearch workflows. During incident response, you can now quickly gain context on alerts and log data, leading to faster analysis and resolution times. When alert monitors trigger, Amazon Q Developer provides summaries and insights directly in the alerts interface, helping you understand the situation quickly without waiting for specialists or consulting documentation. From there, you can use Amazon Q Developer to explore the underlying data, build visualizations using natural language, and identify patterns to determine root causes. For example, you can create visualizations that break down errors by dimensions such as Region, data center, or endpoint. Additionally, Amazon Q Developer assists with dashboard configuration and recommends anomaly detectors for proactive alerting, improving both initial monitoring setup and troubleshooting efficiency.
Get started with Amazon Q Developer in OpenSearch Service To get started, I go to my OpenSearch user interface and sign in. From the home page, I choose a workspace to test Amazon Q Developer in OpenSearch Service. For this demonstration, I use a preconfigured environment with the sample logs dataset available on the user interface.
This feature is on by default through the Amazon Q Developer Free tier, which is also on by default. You can disable the feature by unselecting the Enable natural language query generation checkbox under the Artificial Intelligence (AI) and Machine Learning (ML) section during domain creation or by editing the cluster configuration in console.
In OpenSearch Dashboards, I navigate to Discover from the left navigation pane. To use natural language to explore the data, I switch to PPL language in order to show the prompt box.
I choose the Amazon Q icon in the main navigation bar to open the Amazon Q panel. You can use this panel to create recommended anomaly detectors to drive alerting and use natural language to generate visualization.
I enter the following prompt in the Ask a natural language question text box:
Show me a breakdown of HTTP response codes for the last 24 hours
When results appear, Amazon Q automatically generates a summary of these results. You can control the summary display using the Show result summarization option under the Amazon Q panel to hide or show the summary. You can use the thumbs up or thumbs down buttons to provide feedback, and you can copy the summary to your clipboard using the copy button.
Other capabilities of Amazon Q Developer in OpenSearch Service are generating visualizations directly from natural language descriptions, providing conversational assistance for OpenSearch related queries, providing AI-generated summaries and insights for your OpenSearch alerts, and analyzing your data, and suggesting appropriate anomaly detectors.
Let’s look into how to generate visualizations directly from natural language descriptions. I choose Generate visualization from Amazon Q panel. I enter Create a bar chart showing the number of requests by HTTP status code in the input field and choose generate.
To refine the visualization, you can choose Edit visual and add style instructions such as Show me a pie chart or Use a light gray background with a white grid.
Now available You can now use Amazon Q Developer in OpenSearch Service to reduce mean time to resolution, enable more self-service troubleshooting, and help teams extract greater value from your observability data.
The service is available today in US East (N. Virginia), US West (Oregon), Asia Pacific (Mumbai), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (London), Europe (Paris), and South America (São Paulo) AWS Regions.
To learn more, visit the Amazon Q Developer documentation and start using Amazon Q Developer in your OpenSearch Service domain today.
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Today, we are launching IPv6 support for Amazon API Gateway across all endpoint types, custom domains, and management APIs, in all commercial and AWS GovCloud (US) Regions. You can now configure REST, HTTP, and WebSocket APIs, and custom domains, to accept calls from IPv6 clients alongside the existing IPv4 support. You can also call API Gateway management APIs from dual-stack (IPv6 and IPv4) clients. As organizations globally confront growing IPv4 address scarcity and increasing costs, implementing IPv6 becomes critical for future-proofing network infrastructure. This dual-stack approach helps organizations maintain future network compatibility and expand global reach. To learn more about dualstack in the Amazon Web Services (AWS) environment, see the IPv6 on AWS documentation.
When creating a new API or domain name in the console, select IPv4 only or dualstack (IPv4 and IPv6) for the IP address type.
As shown in the following image, you can select the dualstack option when creating a new REST API. For custom domain names, you can similarly configure dualstack as shown in the next image.
If you need to revert to IPv4-only for any reason, you can modify the IP address type setting, with no need to redeploy your API for the update to take effect.
REST APIs of all endpoint types (EDGE, REGIONAL and PRIVATE) support dualstack. Private REST APIs only support dualstack configuration.
AWS CDK
With AWS CDK, start by configuring a dual-stack REST API and domain name.
const api = new apigateway.RestApi(this, "Api", {
restApiName: "MyDualStackAPI",
endpointConfiguration: {ipAddressType: "dualstack"}
});
const domain_name = new apigateway.DomainName(this, "DomainName", {
regionalCertificateArn: 'arn:aws:acm:us-east-1:111122223333:certificate/a1b2c3d4-5678-90ab',
domainName: 'dualstack.example.com',
endpointConfiguration: {
types: ['Regional'],
ipAddressType: 'dualstack'
},
securityPolicy: 'TLS_1_2'
});
const basepathmapping = new apigateway.BasePathMapping(this, "BasePathMapping", {
domainName: domain_name,
restApi: api
});
IPv6 Source IP and authorization
When your API begins receiving IPv6 traffic, client source IPs will be in IPv6 format. If you use resource policies, Lambda authorizers, or AWS Identity and Access Management (IAM) policies that reference source IP addresses, make sure they’re updated to accommodate IPv6 address formats.
For example, to permit traffic from a specific IPv6 range in a resource policy.
API Gateway dual-stack support helps manage IPv4 address scarcity and costs, comply with government and industry mandates, and prepare for the future of networking. The dualstack implementation provides a smooth transition path by supporting both IPv4 and IPv6 clients simultaneously.
To get started with API Gateway dual-stack support, visit the Amazon API Gateway documentation. You can configure dualstack for new APIs or update existing APIs with minimal configuration changes.
Special thanks to Ellie Frank (elliesf), Anjali Gola (anjaligl), and Pranika Kakkar (pranika) for providing resources, answering questions, and offering valuable feedback during the writing process. This blog post was made possible through the collaborative support of the service and product management teams.
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
I’m excited to announce that AWS CodeBuild now supports parallel test execution, so you can run your test suites concurrently and reduce build times significantly.
Very long test times pose a significant challenge when running continuous integration (CI) at scale. As projects grow in complexity and team size, the time required to execute comprehensive test suites can increase dramatically, leading to extended pipeline execution times. This not only delays the delivery of new features and bug fixes, but also hampers developer productivity by forcing them to wait for build results before proceeding with their tasks. I have experienced pipelines that took up to 60 minutes to run, only to fail at the last step, requiring a complete rerun and further delays. These lengthy cycles can erode developer trust in the CI process, contribute to frustration, and ultimately slow down the entire software delivery cycle. Moreover, long-running tests can lead to resource contention, increased costs because of wasted computing power, and reduced overall efficiency of the development process.
With parallel test execution in CodeBuild, you can now run your tests concurrently across multiple build compute environments. This feature implements a sharding approach where each build node independently executes a subset of your test suite. CodeBuild provides environment variables that identify the current node number and the total number of nodes, which are used to determine which tests each node should run. There is no control build node or coordination between nodes at build time—each node operates independently to execute its assigned portion of your tests.
To enable test splitting, configure the batch fanout section in your buildspec.xml, specifying the desired parallelism level and other relevant parameters. Additionally, use the codebuild-tests-run utility in your build step, along with the appropriate test commands and the chosen splitting method.
The tests are split based on the sharding strategy you specify. codebuild-tests-run offers two sharding strategies:
Equal-distribution. This strategy sorts test files alphabetically and distributes them in chunks equally across parallel test environments. Changes in the names or quantity of test files might reassign files across shards.
Stability. This strategy fixes the distribution of tests across shards by using a consistent hashing algorithm. It maintains existing file-to-shard assignments when new files are added or removed.
CodeBuild supports automatic merging of test reports when running tests in parallel. With automatic test report merging, CodeBuild consolidates tests reports into a single test summary, simplifying result analysis. The merged report includes aggregated pass/fail statuses, test durations, and failure details, reducing the need for manual report processing. You can view the merged results in the CodeBuild console, retrieve them using the AWS Command Line Interface (AWS CLI), or integrate them with other reporting tools to streamline test analysis.
Let’s look at how it works Let me demonstrate how to implement parallel testing in a project. For this demo, I created a very basic Python project with hundreds of tests. To speed things up, I asked Amazon Q Developer on the command line to create a project and 1,800 test cases. Each test case is in a separate file and takes one second to complete. Running all tests in a sequence requires 30 minutes, excluding the time to provision the environment.
In this demo, I run the test suite on ten compute environments in parallel and measure how long it takes to run the suite.
To do so, I added a buildspec.yml file to my project.
There are three parts to highlight in the YAML file.
First, there’s a build-fanout section under batch. The parallelism command tells CodeBuild how many test environments to run in parallel. The ignore-failure command indicates if failure in any of the fanout build tasks can be ignored.
Second, I use the pre-installed codebuild-tests-run command to run my tests.
This command receives the complete list of test files and decides which of the tests must be run on the current node.
Use the sharding-strategy argument to choose between equally distributed or stable distribution as I explain above.
Use the files-search argument to pass all the files that are candidates for a run. We recommend to use the provided codebuild-glob-search command for performance reasons, but any file search tool, such as find(1), will work.
I pass the actual test command to run on the shard with the test-command argument.
Lastly, the reports section instructs CodeBuild to collect and merge the test reports on each node.
Now, I’m ready to trigger an execution of the test suite. I can commit new code on my GitHub repository or trigger the build in the console.
After a few minutes, I see a status report of the different steps of the build; with a status for each test environment or shard.
When the test is complete, I select the Reports tab to access the merged test reports.
The Reports section aggregates all test data from all shards and keeps the history for all builds. I select my most recent build in the Report history section to access the detailed report.
As expected, I can see the aggregated and the individual status for each of my 1,800 test cases. In this demo, they’re all passing, and the report is green.
The 1,800 tests of the demo project take one second each to complete. When I run this test suite sequentially, it took 35 minutes to complete. When I run the test suite in parallel on ten compute environments, it took six minutes to complete, including the time to provision the environments. The parallel run took 17.1 percent of the time of the sequential run. Actual numbers will vary with your projects.
Additional things to know This new capability is compatible with all testing frameworks. The documentation includes examples for Django, Elixir, Go, Java (Maven), Javascript (Jest), Kotlin, PHPUnit, Pytest, Ruby (Cucumber), and Ruby (RSpec).
For test frameworks that don’t accept space-separated lists, the codebuild-tests-run CLI provides a flexible alternative through the CODEBUILD_CURRENT_SHARD_FILES environment variable. This variable contains a newline-separated list of test file paths for the current build shard. You can use it to adapt to different test framework requirements and format test file names.
You can further customize how tests are split across environments by writing your own sharding script and using the CODEBUILD_BATCH_BUILD_IDENTIFIER environment variable, which is automatically set in each build. You can use this technique to implement framework-specific parallelization or optimization.
Pricing and availability With parallel test execution, you can now complete your test suites in a fraction of the time previously required, accelerating your development cycle and improving your team’s productivity. The demo project I created to illustrate this post consumes 18.7 percent of the time of a sequential build.
This capability is available today in all AWS Regions where CodeBuild is offered, with no additional cost beyond the standard CodeBuild pricing for the compute resources used.
I invite you to try parallel test execution in CodeBuild today. Visit the AWS CodeBuild documentation to learn more and get started with parallelizing your tests.
PS: Here’s the prompt I used to create the demo application and its test suite: “I’m writing a blog post to announce codebuild parallel testing. Write a very simple python app that has hundreds of tests, each test in a separate test file. Each test takes one second to complete.”
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Web application owners are constantly working to protect their applications from a variety of threats. Previously, if you wanted to implement a robust security posture for your Amplify Hosted applications, you needed to create architectures using Amazon CloudFront distributions with AWS WAF protection, which required additional configuration steps, expertise, and management overhead.
With the general availability of AWS WAF in Amplify Hosting, you can now directly attach a web application firewall to your AWS Amplify apps through a one-click integration in the Amplify console or using infrastructure as code (IaC). This integration gives you access to the full range of AWS WAF capabilities including managed rules, which provide protection against common web exploits and vulnerabilities like SQL injection and cross-site scripting (XSS). You can also create your own custom rules based on your specific application needs.
This new capability helps you implement defense-in-depth security strategies for your web applications. You can take advantage of AWS WAF rate-based rules to protect against distributed denial of service (DDoS) attacks by limiting the rate of requests from IP addresses. Additionally, you can implement geo-blocking to restrict access to your applications from specific countries, which is particularly valuable if your service is designed for specific geographic regions.
Let’s see how it works Setting up AWS WAF protection for your Amplify app is straightforward. From the Amplify console, navigate to your app settings, select the Firewall tab, and choose the predefined rules you want to apply to your configuration.
Amplify hosting simplifies configuring firewall rules. You can activate four categories of protection.
Amplify-recommended firewall protection – Protect against the most common vulnerabilities found in web applications, block IP addresses from potential threats based on Amazon internal threat intelligence, and protect against malicious actors discovering application vulnerabilities.
Restrict access to amplifyapp.com – Restrict access to the default Amplify generated amplifyapp.com domain. This is useful when you add a custom domain to prevent bots and search engines from crawling the domain.
Enable IP address protection – Restrict web traffic by allowing or blocking requests from specified IP address ranges.
Enable country protection – Restrict access based on specific countries.
Protections enabled through the Amplify console will create an underlying web access control list (ACL) in your AWS account. For fine-grained rulesets, you can use the AWS WAF console rule builder.
After a few minutes, the rules are associated to your app and AWS WAF blocks suspicious requests.
If you want to see AWS WAF in action, you can simulate an attack and monitor it using the AWS WAF request inspection capabilities. For example, you can send a request with an empty User-Agent value. It will trigger a blocking rule in AWS WAF.
Let’s first send a valid request to my app.
curl -v -H "User-Agent: MyUserAgent" https://main.d3sk5bt8rx6f9y.amplifyapp.com/
* Host main.d3sk5bt8rx6f9y.amplifyapp.com:443 was resolved.
...(redacted for brevity)...
> GET / HTTP/2
> Host: main.d3sk5bt8rx6f9y.amplifyapp.com
> Accept: */*
> User-Agent: MyUserAgent
>
* Request completely sent off
< HTTP/2 200
< content-type: text/html
< content-length: 0
< date: Mon, 10 Mar 2025 14:45:26 GMT
We can observe that the server returned an HTTP 200 (OK) message.
Then, send a request with no value associated to the User-Agent HTTP header.
curl -v -H "User-Agent: " https://main.d3sk5bt8rx6f9y.amplifyapp.com/
* Host main.d3sk5bt8rx6f9y.amplifyapp.com:443 was resolved.
... (redacted for brevity) ...
> GET / HTTP/2
> Host: main.d3sk5bt8rx6f9y.amplifyapp.com
> Accept: */*
>
* Request completely sent off
< HTTP/2 403
< server: CloudFront
... (redacted for brevity) ...
<TITLE>ERROR: The request could not be satisfied</TITLE>
</HEAD><BODY>
<H1>403 ERROR</H1>
<H2>The request could not be satisfied.</H2>
We can observe that the server returned an HTTP 403 (Forbidden) message.
AWS WAF provide visibility into request patterns, helping you fine-tune your security settings over time. You can access logs through Amplify Hosting or the AWS WAF console to analyze traffic trends and refine security rules as needed.
Availability and pricing Firewall support is available in all AWS Regions in which Amplify Hosting operates. This integration falls under an AWS WAF global resource, similar to Amazon CloudFront. Web ACLs can be attached to multiple Amplify Hosting apps, but they must reside in the same Region.
The pricing for this integration follows the standard AWS WAF pricing model, You pay for the AWS WAF resources you use based on the number of web ACLs, rules, and requests. On top of that, AWS Amplify Hosting adds $15/month when you attach a web application firewall to your application. This is prorated by the hour.
This new capability brings enterprise-grade security features to all Amplify Hosting customers, from individual developers to large enterprises. You can now build, host, and protect your web applications within the same service, reducing the complexity of your architecture and streamlining your security management.
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Starting today, you can get more granular visibility of geographic location information for AWS Regions and AWS Availability Zones (AZs). This detailed information will help you choose the Regions and AZs that align with your regulatory, compliance, and operational requirements.
We continue to expand the AWS global infrastructure to meet your business requirements and now have 114 AZs across 36 Regions. We have announced plans to add 12 more AZs and four Regions in New Zealand, Kingdom of Saudi Arabia, Taiwan, and the AWS European Sovereign Cloud.
One of the things we’ve learned from our customers is the need to have more visibility into the specific location of infrastructure within an AWS Region. This is important for customers in highly regulated industries such as the financial industry or gaming, where there are specific requirements for the physical placement of infrastructure. For example, FanDuel, a leading sports gaming company based in the U.S., is scaling into new markets across the U.S. and Canada. They are taking advantage of the improved geographic transparency to make more informed decisions and ensure they’re meeting data residency requirements as they scale their business quickly.
Geographies for AWS Regions To find the geographic information for your Region, you can visit the AWS Global Infrastructure Regions and Availability Zones page. Once you navigate to this page, you can choose any tab on the map and scroll to the bottom to review the geographic information for each Region. See the following image for an example showing the North America Regions. As would be expected, the infrastructure for the US West (Oregon) Region is located in the United States of America, and the Canada (Central) Region is located in Canada.
Geographies for Availability Zones To find the specific geographic information for an AZ, you can visit the AWS Regions and Availability Zones page in AWS Documentation. Choose the Region you’re interested in and you’ll find a table showing you the geography for that Region. As you see in the following screenshot, the infrastructure of the AZ with AZ ID use1-az1 is located in Virginia, United States of America.
Stay tuned We will update these pages to reflect new geographic information as we continue to grow our AWS Global infrastructure footprint and add more AWS Regions and AZs.
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Creating clear goals is inevitably part of any business strategy. You’ve likely heard of the acronym SMART—specific, measurable, actionable, realistic, and time-bound—when it comes to goal setting. As a business leader in information technology or a related business unit, you’re responsible for developing sound goals for business technology, data protection, and disaster recovery.
Two key metrics that feed into those strategies are your recovery time objective (RTO) and recovery point objective (RPO). Like all the other goals your business sets, the RTO and RPO should also be SMART goals.
So, how can you set meaningful RTO and RPO objectives for your business? And how can the cloud help you achieve or improve on those objectives? Today I’ll talk about how to smarten up these objectives to lead to better business continuity (BC) and a more effective disaster recovery (DR) plan.
The Essential Guide to Disaster Recovery Planning
Read more about how to build a disaster recovery plan for your organization.
Why do RTO and RPO matter?
RTO and RPO are two fundamental inputs to a comprehensive disaster recovery plan. They also very much guide how you’ll structure your backup strategy and engineer your backup architecture.
RTO is a business metric that states the maximum length of time a business can tolerate for recovery. It’s important to note the difference between recovery and restoration of data here. Restoring data is just one part of a recovery.
Recovery means systems are back up and running—fully functional—with users (employees, customers, etc.) able to utilize them in the same manner as before the data incident occurred.
RPO measures the maximum amount of data a company can afford to lose (or is willing to lose), measured in units of time. For instance, an RPO of 12 hours means that the company can accept the risk (financial risk, risk to the brand, etc.) of having lost 12 hours worth of data. So, if you run backups every 11 hours, you will be able to meet your RPO.
How to set RTO and RPO
Creating these objectives is a business decision—not an IT decision. If you’re an IT leader, your job is to work with your internal stakeholders to fully understand the business and the criticality of various applications and services in order to help define the RTO and RPO.
Put another way: The decision about what standard to meet is a shared responsibility. And those standards (recovery time, file durability, etc.) are the targets that IT and infrastructure providers teams must meet.
RTO and RPO may be different from one system to another. Some applications are more important than others.
Keep in mind that it’s likely that department heads will all say their services are the most important to immediately recover. But if everything is deemed critical, then nothing is.
Discuss how data loss and time to recovery impact the business in quantifiable details—revenue lost, number of customers affected, etc.—in order to truly prioritize systems and set appropriate RTOs and RPOs.
Making your RTOs and RPOs SMART
Remember that your objectives should be SMART:
Specific: Think through how granular your RTOs and RPOs should be. In addition to different RTOs and RPOs per application, you may also need different RTOs and RPOs per scenario. For example, the RTO for a ransomware attack is much different than that for hardware failure.
Measurable: One good way of measuring the efficacy of your RTOs and RPOs is by conducting DR testing. Run fire drills and conduct tabletop exercises. Practice restoring data. These inputs will help you understand if your objectives are meaningful and obtainable.
Actionable: Document your RTO and RPO in your DR plans and ensure they align with any business continuity risk management plans or goals around maximum allowable risk tolerance. You may also want to document the assumptions and inputs that formed the RTO and RPO. For instance, how much revenue is lost when a given system is down? Explain how that factor drives your RTO.
Realistic: Don’t let your stakeholders set unachievable objectives. If there is an ask for a very low RTO and/or RPO, help your stakeholder understand exactly what it will take—and how much it will cost—to implement that objective.
Time-bound: The RTO can be defined in seconds up to weeks. The shorter the RTO, the more expensive the investment will be to meet it.
Remember that you’re always balancing RTO and RPO against an unachievable “perfect” state. For instance, you would likely need multiple failover hot sites with replicated data to meet an RTO of seconds of downtime.
RTO is a forward-looking measurement; RPO is a backward-looking measurement that essentially represents the frequency of your backups.
A short RPO means more recent backup data is needed, and, yes, that also means greater investment. RPOs measured in seconds may require high-speed backup technology like continuous replication.
How to discuss RTO and RPO with business leaders
Discussing technical concepts with internal stakeholders can be challenging. To guide the objective-setting discussion with stakeholders, use the following questions as a guide:
Where and how do you store data?
How often does your data change?
What would a minute of downtime cost your department, in terms of revenue, risk, loss of productivity, impact to customers, etc.?
What are the compliance or industry requirements for maintaining sensitive data?
Do you have a way of manually transacting business if service is down?
Your IT department may already be well aware of many of these goals, but it’s good to do a fresh and full inventory of data and data management procedures. For example, even with the rise of shared drives, many employees still save important data locally. Or, there may be business-critical data being saved in services like Microsoft 365 or Kubernetes—and those services are often not adequately backed up.
How do RTO and RPO affect backup strategy?
Your RPO is often more directly related to backup strategy, although RTO certainly informs backup strategy. If you need a very low RPO (i.e., the business can tolerate very little data loss), you must plan to run backups more frequently. This ensures you always have very recent data to recover.
RTO, however, relates more to systems and infrastructure—again, because the objective is about recovery and not just restoring data. RTO will drive investment decisions around backup and DR architecture.
Your backup strategy or tech stack should not dictate either your RTO or your RPO.
First, you should define your RTO and RPO, and then you must determine if changes in backup policy are needed or if you need to update any backup systems in order to reach desired RTOs and RPOs.
Your RTO will drive decisions around backup and DR infrastructure; your RPO will drive decisions around frequency of backup and type of backup.
How does the cloud help companies meet RTO and RPO goals?
Using a public cloud for backup and archive can help you achieve your desired RTO and/or RPO. An obvious example is using cloud to replace LTO tape backup. Tape backup has some of the worst (maybe the worst) RTOs and RPOs. It takes an extraordinarily long time to recover from tape, and backups are likely not as frequent as they should be because tape is often not properly maintained. Migrating your tape backups to a public cloud like Backblaze B2 Cloud Storage is still cost-effective and it will drastically improve RTO and RPO.
If you’re using a hyperscaler like AWS, you may have had to cut back on frequency of backup or needed retention periods due to exorbitant fees. Shifting your backups to Backblaze B2 can help you achieve your goals: Backblaze B2 is one-fifth the cost of AWS S3, you can afford to run and save more frequent backups, thus lowering your overall RPO.
Replication is another technology that can help reduce RTOs. Many enterprise businesses will already have a failover site, but keeping an extra copy of your data in the cloud ensures you can still meet your desired RTO in the case of a DR site or production facility takeout. This is exactly what brought SaaS platform Centerbase to Backblaze.
More commonly, if it’s inordinately expensive to own your own DR site, you can store your backups in Backblaze B2 and utilize Cloud Replication for added redundancy.
RTO and RPO and your business
Ultimately, you should frame your RTO and RPO in terms of business impact. Then, reverse engineer your backup and DR infrastructure to support those objectives. Next, identify the storage systems for your data based on its business criticality and desired RTO and RPO.
Depending on your business goals, you’ll likely use cloud storage services, on-premises storage, or some combination of the two. Regardless of the type of business you run, demonstrating that you have an airtight DR plan with SMART RTO and RPO goals will instill confidence in your business partners, help with cyber insurance eligibility, and shore up your organization’s ability to withstand data disasters.
A well-defined disaster recovery (DR) plan relies heavily on a coordinated incident response team. Think of your incident response team like a pit crew. It’s easy to assume you’ll have a good race when everything is performing smoothly, but the real test comes when something goes wrong—maybe a tire blows or the engine overheats. In those moments, success isn’t about having the best tools in the garage; it’s about having the right team, working together, to quickly solve problems and get back on track.
When your team is facing a disaster recovery scenario, whether it’s a cyber attack, natural disaster, outage, or data breach, the speed and coordination of your team determines how quickly and how well you can move forward. In this post, I’m breaking down how to assemble a team that can respond with precision, minimize downtime, and keep your organization running smoothly when unexpected issues arise.
Establishing key team members, roles, and hierarchy
The incident response team (IRT) is the backbone of your DR response and is responsible for leading the recovery efforts during a disaster. Here’s a breakdown of possible key IRT roles:
Incident commander: Oversees the entire incident response process, making critical decisions and delegating tasks to team members.
Communications lead: Handles external and internal communication, ensuring timely updates for stakeholders and mitigating potential reputational damage.
Documentation lead: Maintains the DR runbook, ensuring its accuracy and updating it with post-incident findings.
Legal counsel: Provides legal guidance and ensures compliance with relevant regulations during the response and recovery process.
Building redundancy
Building redundancy in your IRT allows you to account for team member absences. This includes IT leadership; don’t assume you’ll be in the office when a disaster happens. Assign backup personnel for critical roles within the team to ensure continuity in the event of unforeseen circumstances.
Establish a clear succession plan for leadership roles within the IRT. This ensures a smooth transition if the primary incident commander or other key personnel become unavailable during a disaster.
Establishing a reporting hierarchy
Clearly define a reporting hierarchy within the IRT, outlining who reports to whom and the escalation process for making critical decisions. A clear chain of command during a crisis prevents confusion and delays that could result in prolonged downtime and increased risks.
The importance of clear communication
A critical component of any DR plan is clear communication to employees and executives regarding their specific roles during a security incident. This ensures that the assigned team leader can coordinate a unified response. Remember to include guidelines about incident escalation, as well as agreed-upon methods of communication (e.g., email, direct messaging, video calls, etc.).
Executive sponsorship: Beyond awareness
Executive buy-in is paramount for a successful DR strategy. While awareness of the impact of ransomware attacks has grown over the years, contextualizing DR plans with historical financial impacts, downtime implications, and reputational risk associated with such attacks can help to communicate why DR is a top-line priority.
Tip: Educating executives
Framing the DR plan in terms of cost avoidance, user downtime minimization, and reputational risk mitigation can resonate better with executives. Quantify the potential financial losses from data breaches and system outages to garner executive support for DR initiatives.
Beyond cell phones: Communication channels
Disasters can disrupt traditional communication methods like cell phone service. Develop alternative communication channels for the IRT, such as designated email threads, satellite phones, or pre-arranged conference call bridges. It is imperative to include this information and contact details in your DR runbook for immediate accessibility during crises.
By establishing a well-defined team structure with clear roles, communication protocols, and redundancy measures, enterprise businesses can ensure a coordinated and efficient response to data disasters.
A well-prepared team leads to a resilient recovery
Your DR strategy is only as effective as the team behind it. By defining clear roles, building in redundancy, and establishing a reporting hierarchy, IT leaders can eliminate confusion and accelerate recovery efforts. Moreover, securing executive sponsorship and ensuring clear communication strengthens your ability to respond effectively. DR isn’t just about the plan on paper. It’s about how you execute that plan and set your team up for success.
Media workflows have always been complex, requiring seamless collaboration, robust storage, and advanced systems integration. Today, with the explosion of content demands and rapid technological advancements, media organizations need solutions that can scale, innovate, and empower teams to deliver faster and better.
Backblaze and CHESA, long-standing partners and leaders in media workflow solutions, are doubling down on their relationship with CHESA to elevate creative workflows with a joint go-to-market partnership. This enhanced partnership builds on years of success, combining Backblaze’s high-performance, secure cloud storage with CHESA’s expertise in media technology systems integration to provide even more impactful solutions tailored to the needs of modern media-driven organizations.
Together, we’re continuing to make it easier than ever for organizations to streamline content production, enhance accessibility, and achieve business objectives with greater efficiency. In this blog, I’ll explain the key benefits of this expanded collaboration and highlight how it’s already driving transformative results for clients like the Philadelphia Eagles.
The media workflow challenge
From production studios and broadcasters to professional sports teams and creative agencies, media organizations face a growing list of challenges:
Massive data volumes: Video, audio, and other rich media assets require scalable and secure storage solutions to handle terabytes or even petabytes of data.
Fragmented workflows: Teams often juggle multiple tools and platforms, leading to inefficiencies and bottlenecks.
Budget constraints: Organizations need cost-effective solutions that don’t compromise performance or security.
The expanded partnership between Backblaze and CHESA continues to address these pain points head-on by combining best-in-class cloud storage with tailored workflow solutions.
The Backblaze + CHESA solution
Real-world success: The Philadelphia Eagles
One of the most compelling examples of the Backblaze + CHESA partnership is the Philadelphia Eagles’ transition from traditional LTO tape storage to a cloud-based media workflow. With over 800TB under management, switching to cloud storage meant that the team instantly made their data more agile, scoring immediate access to faster content creation and remote workflows.
“Now I can easily share entire broadcasts by copying and sharing a link from our MAM. No need for FTP downloads or uploading to other platforms. It’s fast, seamless, and ensures everyone can view the content without issues.” —Stacy Kelleher, Director of Production, Philadelphia Eagles
Backblaze B2 integrated seamlessly with the Eagles’ preferred tech stack, which leverages a Quantum QXS storage area network (SAN) and Mimir, a cloud-based video production platform.
The challenge
The Eagles faced significant challenges with their legacy storage system:
Limited accessibility: LTO tape storage made it difficult to access archived footage, which hindered content production timelines quickly.
Time-consuming processes: Retrieving footage from physical tapes was manual and slow.
Scaling limitations: As the team’s content library grew, so did the complexity and cost of managing tape storage.
The solution
By leveraging the expanded capabilities of Backblaze and CHESA’s partnership, the Eagles:
Transitioned their extensive media library to Backblaze B2 Cloud Storage.
Integrated CHESA’s tailored media workflow solutions for seamless access and collaboration.
Gained immediate access to decades of archived footage, enabling faster content creation and improved fan engagement.
The results
The Eagles’ media team now enjoys:
Accelerated content production: Instant access to archived footage has streamlined workflows, allowing the team to create engaging content more efficiently.
Enhanced scalability: With Backblaze B2, the Eagles can easily scale their storage as their content library grows.
Improved fan engagement: Faster production timelines enable the team to deliver high-quality content that keeps fans connected and engaged.
Peripheral content drives revenue through monetized clicks like highlights and select moments. Quick sharing and streamlined proof-of-performance delivery keep sponsors satisfied.” —Ryan Lakey, Principal Lead, Solutions, CHESA
Accelerated media workflows
Integrating Backblaze B2 Cloud Storage with CHESA’s media workflow expertise has long been a cornerstone of success for media teams. By enhancing this integration, media teams can experience even faster workflows, immediate asset access, and seamless collaboration across tools and teams. By eliminating the delays associated with traditional storage methods, teams can:
Share assets effortlessly with collaborators anywhere in the world.
Spend less time managing infrastructure and more time creating impactful content.
Backblaze + CHESA benefits
Scalable and cost-effective storage
Backblaze B2 Cloud Storage offers always-hot, S3 compatible object storage at a fraction of the cost of traditional providers like Amazon S3. This cost-effectiveness, combined with CHESA’s expertise in designing and integrating scalable systems, ensures organizations can:
Scale their storage needs as projects grow or shrink.
Optimize budgets without compromising on performance.
Rely on predictable pricing that avoids surprise costs.
Enhanced data security and accessibility
In the media world, accessibility and security are paramount. Backblaze and CHESA provide solutions that keep media assets safe while ensuring real-time access for production teams. Key benefits include:
Secure, encrypted storage to protect sensitive media.
High availability for instant access to files when needed.
Resiliency and redundancy to ensure data integrity, even in the face of unexpected disruptions.
These capabilities have been critical for clients like professional sports teams, broadcasters, and creative agencies that manage vast libraries of high-value media content.
Comprehensive support and maintenance
CHESA’s dedicated support services and Backblaze’s reliable cloud infrastructure ensure organizations experience minimal downtime and sustained operational efficiency. This comprehensive support includes:
Proactive monitoring and maintenance.
Remote and onsite assistance for hardware, software, and workflows.
Consistent communication to address issues before they impact production.
Why this partnership matters
The expanded Backblaze and CHESA partnership is more than just a collaboration—it’s a commitment to empowering media organizations with innovative, efficient, and secure solutions. Here’s why it stands out:
Deeply customized solutions: Every organization’s needs are unique. Backblaze Solution Engineers and CHESA Workflow Engineers dive deep into clients’ specific workflows and objectives to design and implement solutions specifically tailored to their needs.
Unrivaled expertise, built over decades: Rely on the combined power of Backblaze and CHESA’s deep-rooted experience in cloud storage and media technology.
Your future-proof media strategy: Navigate the changing media landscape with confidence, leveraging our scalable and cutting-edge solutions.
Take the next step
Whether you’re a professional sports team looking to enhance fan engagement, a broadcaster aiming to streamline production, or a creative agency seeking cost-effective storage, Backblaze and CHESA are here to help.
Discover how our expanded solutions can revolutionize your media workflows. Visitour dedicated solution page to learn more and to schedule a consultation tailored to your organization’s needs.
This year, AWS Pi Day returns with a focus on accelerating analytics and AI innovation with a unified data foundation on AWS. The data landscape is undergoing a profound transformation as AI emerges in most enterprise strategies, with analytics and AI workloads increasingly converging around a lot of the same data and workflows. You need an easy way to access all your data and use all your preferred analytics and AI tools in a single integrated experience. This AWS Pi Day, we’re introducing a slate of new capabilities that help you build unified and integrated data experiences.
The next generation of Amazon SageMaker: The center of all your data, analytics, and AI At re:Invent 2024, we introduced the next generation of Amazon SageMaker, the center of all your data, analytics, and AI. SageMaker includes virtually all the components you need for data exploration, preparation and integration, big data processing, fast SQL analytics, machine learning (ML) model development and training, and generative AI application development. With this new generation of Amazon SageMaker, SageMaker Lakehouse provides you with unified access to your data and SageMaker Catalog helps you to meet your governance and security requirements. You can read the launch blog post written by my colleague Antje to learn more details.
SageMaker Unified Studio facilitates collaboration among data scientists, analysts, engineers, and developers as they work on data, analytics, AI workflows, and applications. It provides familiar tools from AWS analytics and artificial intelligence and machine learning (AI/ML) services, including data processing, SQL analytics, ML model development, and generative AI application development, into a single user experience.
Last but not least, Amazon Q Developer is now generally available in SageMaker Unified Studio. Amazon Q Developer provides generative AI powered assistance for data and AI development. It helps you with tasks like writing SQL queries, building extract, transform, and load (ETL) jobs, and troubleshooting, and is available in the Free tier and Pro tier for existing subscribers.
Building a data foundation with Amazon S3 Building a data foundation is the cornerstone of accelerating analytics and AI workloads, enabling organizations to seamlessly manage, discover, and utilize their data assets at any scale. Amazon S3 is the world’s best place to build a data lake, with virtually unlimited scale, and it provides the essential foundation for this transformation.
I’m always astonished to learn about the scale at which we operate Amazon S3: It currently holds over 400 trillion objects, exabytes of data, and processes a mind-blowing 150 million requests per second. Just a decade ago, not even 100 customers were storing more than a petabyte (PB) of data on S3. Today, thousands of customers have surpassed the 1 PB milestone.
Amazon S3 stores exabytes of tabular data, and it averages over 15 million requests to tabular data per second. To help you reduce the undifferentiated heavy lifting when managing your tabular data in S3 buckets, we announced Amazon S3 Tables at AWS re:Invent 2024. S3 Tables are the first cloud object store with built-in support for Apache Iceberg. S3 tables are specifically optimized for analytics workloads, resulting in up to threefold faster query throughput and up to tenfold higher transactions per second compared to self-managed tables.
For those of you who use a third-party catalog, have a custom catalog implementation, or only need basic read and write access to tabular data in a single table bucket, we’ve added new APIs that are compatible with the Iceberg REST Catalog standard. This enables any Iceberg-compatible application to seamlessly create, update, list, and delete tables in an S3 table bucket. For unified data management across all of your tabular data, data governance, and fine-grained access controls, you can also use S3 Tables with SageMaker Lakehouse.
To help you access S3 Tables, we’ve launched updates in the AWS Management Console. You can now create a table, populate it with data, and query it directly from the S3 console using Amazon Athena, making it easier to get started and analyze data in S3 table buckets.
The following screenshot shows how to access Athena directly from the S3 console.
When I select Query tables with Athena or Create table with Athena, it opens the Athena console on the correct data source, catalog, and database.
Amazon S3 Metadata—announced during re:Invent 2024— has been generally available since January 27. It’s the fastest and easiest way to help you discover and understand your S3 data with automated, effortlessly-queried metadata that updates in near real time. S3 Metadata works with S3 object tags. Tags help you logically group data for a variety of reasons, such as to apply IAM policies to provide fine-grained access, specify tag-based filters to manage object lifecycle rules, and selectively replicate data to another Region. In Regions where S3 Metadata is available, you can capture and query custom metadata that is stored as object tags. To reduce the cost associated with object tags when using S3 Metadata, Amazon S3 reduced pricing for S3 object tagging by 35 percent in all Regions, making it cheaper to use custom metadata.
AWS Pi Day 2025 Over the years, AWS Pi Day has showcased major milestones in cloud storage and data analytics. This year, the AWS Pi Day virtual event will feature a range of topics designed for developers and technical decision-makers, data engineers, AI/ML practitioners, and IT leaders. Key highlights include deep dives, live demos, and expert sessions on all the services and capabilities I discussed in this post.
By attending this event, you’ll learn how you can accelerate your analytics and AI innovation. You’ll learn how you can use S3 Tables with native Apache Iceberg support and S3 Metadata to build scalable data lakes that serve both traditional analytics and emerging AI/ML workloads. You’ll also discover the next generation of Amazon SageMaker, the center for all your data, analytics, and AI, to help your teams collaborate and build faster from a unified studio, using familiar AWS tools with access to all your data whether it’s stored in data lakes, data warehouses, or third-party or federated data sources.
For those looking to stay ahead of the latest cloud trends, AWS Pi Day 2025 is an event you can’t miss. Whether you’re building data lakehouses, training AI models, building generative AI applications, or optimizing analytics workloads, the insights shared will help you maximize the value of your data.
Tune in today and explore the latest in cloud data innovation. Don’t miss the opportunity to engage with AWS experts, partners, and customers shaping the future of data, analytics, and AI.
If you missed the virtual event on March 14, you can visit the event page at any time—we will keep all the content available on-demand there!
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.




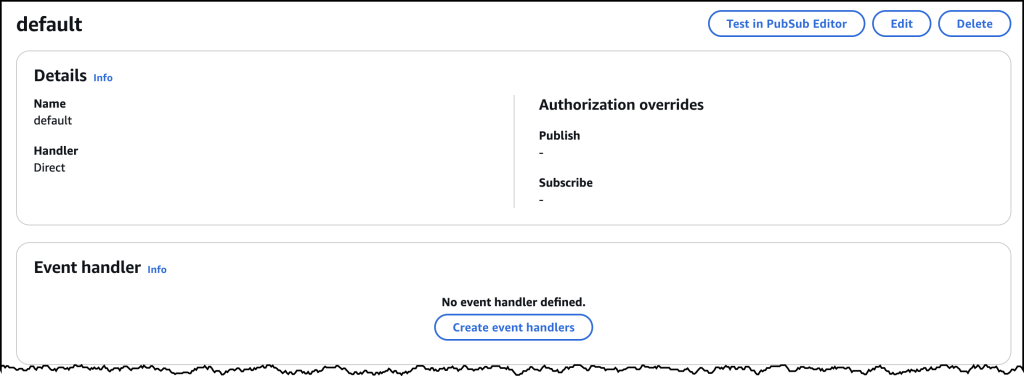





 .
.