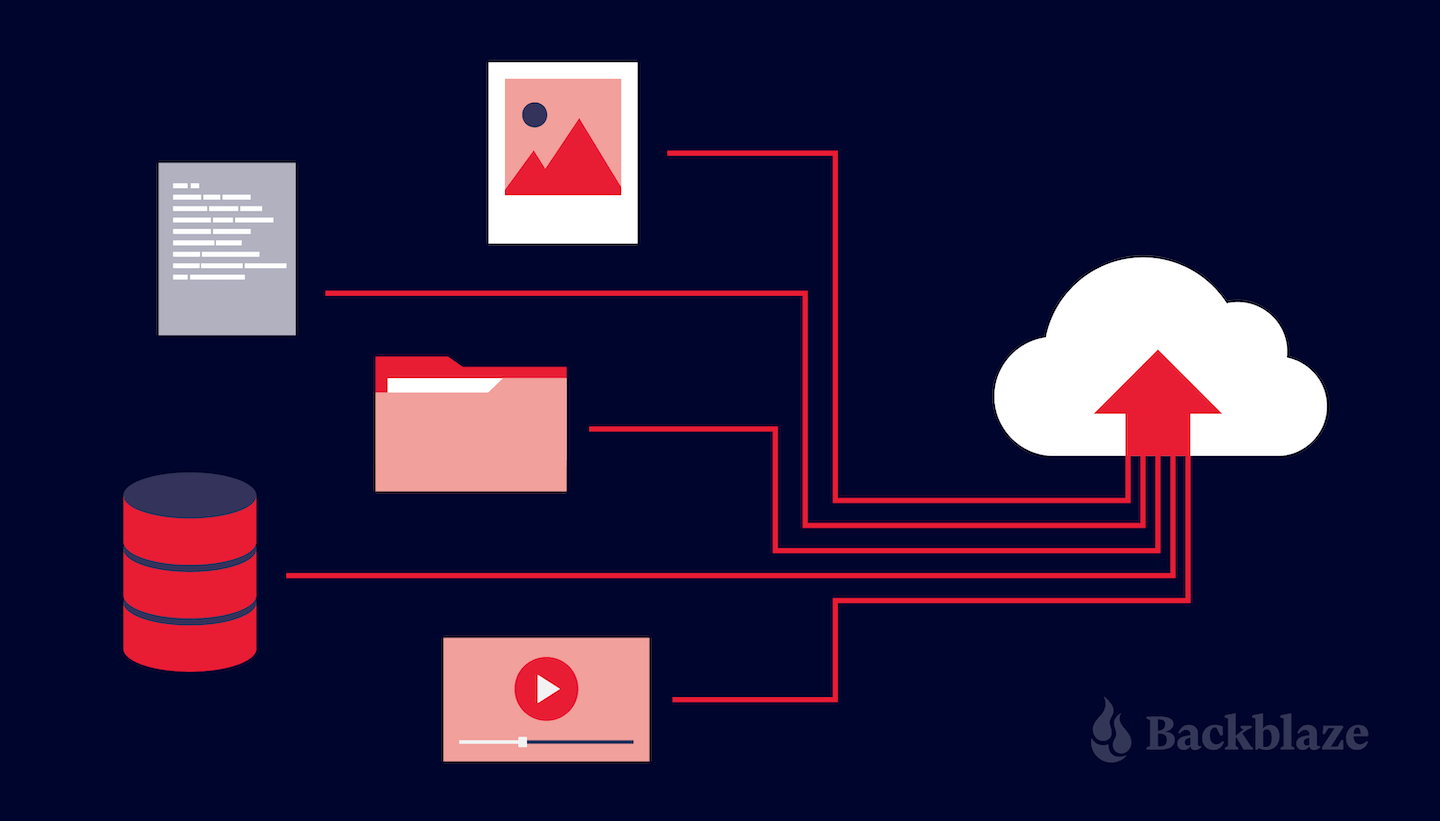
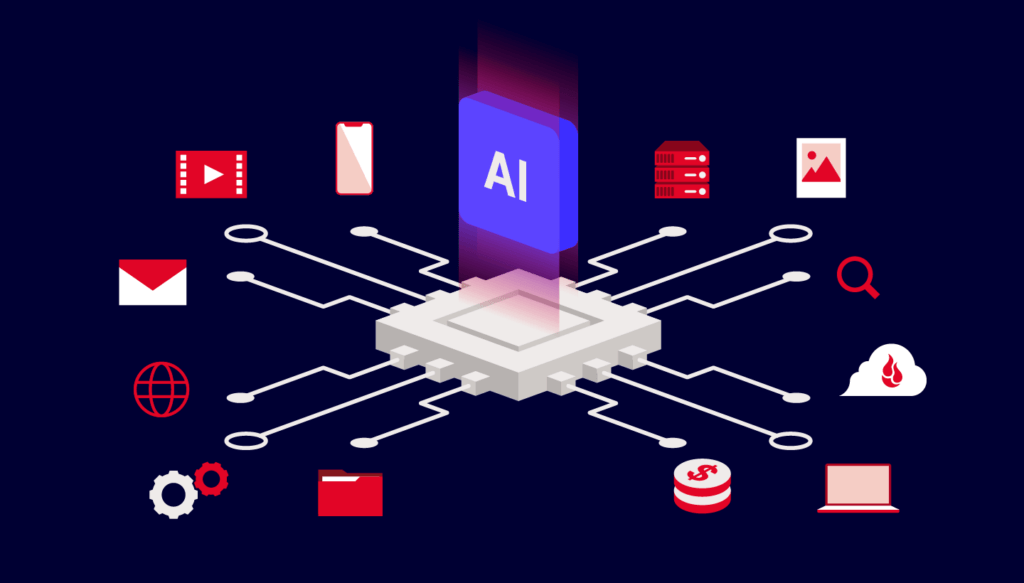
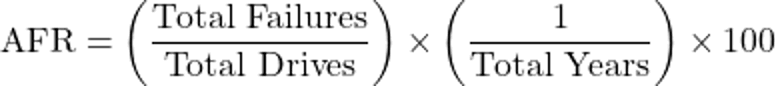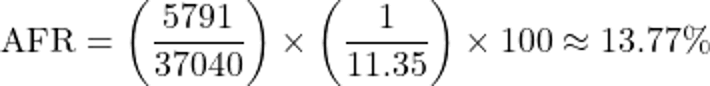Today, we’re announcing the general availability of Amazon SageMaker Unified Studio, a single data and AI development environment where you can find and access all of the data in your organization and act on it using the best tool for the job across virtually any use case. Introduced as preview during AWS re:Invent 2024, my colleague, Antje, summarized it as:
SageMaker Unified Studio breaks down silos in data and tools, giving data engineers, data scientists, data analysts, ML developers and other data practitioners a single development experience. This saves development time and simplifies access control management so data practitioners can focus on what really matters to them—building data products and AI applications.
This post focuses on several important announcements that we’re excited to share:
New capabilities for Amazon Bedrock in SageMaker Unified Studio — The integration now supports new foundation models (FMs), including Anthropic’s Claude 3.7 Sonnet and DeepSeek-R1, enables data sourcing from Amazon Simple Storage Service (Amazon S3) folders within projects for knowledge base creation, extends guardrail functionality to flows, and provides a streamlined user management interface for domain administrators to manage model governance across multiple Amazon Web Service (AWS) accounts.
Amazon Q Developer is now generally available in SageMaker Unified Studio — Amazon Q Developer, the most capable generative AI assistant for software development, streamlines development in Amazon SageMaker Unified Studio by providing natural language, conversational interfaces that simplify tasks like writing SQL queries, building ETL jobs, troubleshooting, and generating real-time code suggestions.
New capabilities for Amazon Bedrock in SageMaker Unified Studio The capabilities of Amazon Bedrock within Amazon SageMaker Unified Studio offer a governed collaborative environment for developers to rapidly create and customize generative AI applications. This intuitive interface caters to developers of all skill levels, providing seamless access to the high-performance FMs offered in Amazon Bedrock and advanced customization tools for collaborative development of tailored generative AI applications.
Since the preview launch, several new FMs have become available in Amazon Bedrock and are fully integrated with SageMaker Unified Studio, including Anthropic’s Claude 3.7 Sonnet and DeepSeek-R1. These models can be used for building generative AI apps and chatting in the playground in SageMaker Unified Studio.
Here’s how you can choose Anthropic’s Claude 3.7 Sonnet on the model selection in your project.
You can also source data or documents from S3 folders within your project and select specific FMs when creating knowledge bases.
During preview, we introduced Amazon Bedrock Guardrails to help you implement safeguards for your Amazon Bedrock application based on your use cases and responsible AI policies. Now, Amazon Bedrock Guardrails is extended to Amazon Bedrock Flows with this general availability release.
Additionally, we have streamlined generative AI setup for associated accounts with a new user management interface in SageMaker Unified Studio, making it straightforward for domain administrators to grant associated account admins access to model governance projects. This enhancement eliminates the need for command line operations, streamlining the process of configuring generative AI capabilities across multiple AWS accounts.
These new features eliminate barriers between data, tools, and builders in the generative AI development process. You and your team will gain a unified development experience by incorporating the powerful generative AI capabilities of Amazon Bedrock — all within the same workspace.
Amazon Q Developer is now generally available in SageMaker Unified Studio Amazon Q Developer is now generally available in Amazon SageMaker Unified Studio, providing data professionals with generative AI–powered assistance across the entire data and AI development lifecycle.
Amazon Q Developer integrates with the full suite of AWS analytics and AI/ML tools and services within SageMaker Unified Studio, including data processing, SQL analytics, machine learning model development, and generative AI application development, to accelerate collaboration and help teams build data and AI products faster. To get started, you can select Amazon Q Developer icon.
For new users of SageMaker Unified Studio, Amazon Q Developer serves as an invaluable onboarding assistant. It can explain core concepts such as domains and projects, provide guidance on setting up environments, and answer your questions.
Amazon Q Developer helps you discover and understand data using powerful natural language interactions with SageMaker Catalog. What makes this implementation particularly powerful is how Amazon Q Developer combines broad knowledge of AWS analytics and AI/ML services with the user’s context to provide personalized guidance.
You can chat about your data assets through a conversational interface, asking questions such as “Show all payment related datasets” without needing to navigate complex metadata structures.
Amazon Q Developer offers SQL query generation through its integration with the built-in query editor available in SageMaker Unified Studio. Data professionals of varying skill levels can now express their analytical needs in natural language, receiving properly formatted SQL queries in return.
For example, you can ask, “Analyze payment method preferences by age group and region” and Amazon Q Developer will generate the appropriate SQL with proper joins across multiple tables.
Additionally, Amazon Q Developer is also available to assist with troubleshooting and generating real-time code suggestions in SageMaker Unified Studio Jupyter notebooks, as well as building ETL jobs.
Now available
Availability — Amazon SageMaker Unified Studio is now available in the following AWS Regions: US East (N. Virginia, Ohio), US West (Oregon), Asia Pacific (Seoul, Singapore, Sydney, Tokyo), Canada (Central), Europe (Frankfurt, Ireland, London), South America (São Paulo). Learn more about the availability of these capabilities on supported Region documentation page.
Amazon Q Developer subscription — The free tier of Amazon Q Developer is available by default in SageMaker Unified Studio, requiring no additional setup or configuration. If you already have Amazon Q Developer Pro Tier subscriptions, you can use those enhanced capabilities within the SageMaker Unified Studio environment. For more information, visit the documentation page.
Amazon Bedrock capabilities — To learn more about the capabilities of Amazon Bedrock in Amazon SageMaker Unified Studio, refer to this documentation page.
Start building with Amazon SageMaker Unified Studio today. For more information, visit the Amazon SageMaker Unified Studio page.
— How is the News Blog doing? Take this 1 minute survey! (This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Our customers wanted to simplify the management and optimization of their Apache Iceberg storage, which led to the development of S3 Tables. They were simultaneously working to break down data silos that impede analytics collaboration and insight generation using the SageMaker Lakehouse. When paired with S3 Tables and SageMaker Lakehouse in addition to built-in integration with AWS analytics services, they can gain a comprehensive platform unifying access to multiple data sources enabling both analytics and machine learning (ML) workflows.
Today, we’re announcing the general availability of Amazon S3 Tables integration with Amazon SageMaker Lakehouse to provide unified S3 Tables data access across various analytics engines and tools. You can access SageMaker Lakehouse from Amazon SageMaker Unified Studio, a single data and AI development environment that brings together functionality and tools from AWS analytics and AI/ML services. All S3 tables data integrated with SageMaker Lakehouse can be queried from SageMaker Unified Studio and engines such as Amazon Athena, Amazon EMR, Amazon Redshift, and Apache Iceberg-compatible engines like Apache Spark or PyIceberg.
With this integration, you can simplify building secure analytic workflows where you can read and write to S3 Tables and join with data in Amazon Redshift data warehouses and third-party and federated data sources, such as Amazon DynamoDB or PostgreSQL.
You can also centrally set up and manage fine-grained access permissions on the data in S3 Tables along with other data in the SageMaker Lakehouse and consistently apply them across all analytics and query engines.
S3 Tables integration with SageMaker Lakehouse in action To get started, go to the Amazon S3 console and choose Table buckets from the navigation pane and select Enable integration to access table buckets from AWS analytics services.
Now you can create your table bucket to integrate with SageMaker Lakehouse. To learn more, visit Getting started with S3 Tables in the AWS documentation.
1. Create a table with Amazon Athena in the Amazon S3 console You can create a table, populate it with data, and query it directly from the Amazon S3 console using Amazon Athena with just a few steps. Select a table bucket and select Create table with Athena, or you can select an existing table and select Query table with Athena.
When you want to create a table with Athena, you should first specify a namespace for your table. The namespace in an S3 table bucket is equivalent to a database in AWS Glue, and you use the table namespace as the database in your Athena queries.
Choose a namespace and select Create table with Athena. It goes to the Query editor in the Athena console. You can create a table in your S3 table bucket or query data in the table.
2. Query with SageMaker Lakehouse in the SageMaker Unified Studio Now you can access unified data across S3 data lakes, Redshift data warehouses, third-party and federated data sources in SageMaker Lakehouse directly from SageMaker Unified Studio.
To get started, go to the SageMaker console and create a SageMaker Unified Studio domain and project using a sample project profile: Data Analytics and AI-ML model development. To learn more, visit Create an Amazon SageMaker Unified Studio domain in the AWS documentation.
After the project is created, navigate to the project overview and scroll down to project details to note down the project role Amazon Resource Name (ARN).
Go to the AWS Lake Formation console and grant permissions for AWS Identity and Access Management (IAM) users and roles. In the in the Principals section, select the <project role ARN> noted in the previous paragraph. Choose Named Data Catalog resources in the LF-Tags or catalog resources section and select the table bucket name you created for Catalogs. To learn more, visit Overview of Lake Formation permissions in the AWS documentation.
When you return to SageMaker Unified Studio, you can see your table bucket project under Lakehouse in the Data menu in the left navigation pane of project page. When you choose Actions, you can select how to query your table bucket data in Amazon Athena, Amazon Redshift, or JupyterLab Notebook.
When you choose Query with Athena, it automatically goes to Query Editor to run data query language (DQL) and data manipulation language (DML) queries on S3 tables using Athena.
Here is a sample query using Athena:
select * from "s3tablecatalog/s3tables-integblog-bucket”.”proddb"."customer" limit 10;
To query with Amazon Redshift, you should set up Amazon Redshift Serverless compute resources for data query analysis. And then you choose Query with Redshift and run SQL in the Query Editor. If you want to use JupyterLab Notebook, you should create a new JupyterLab space in Amazon EMR Serverless.
3. Join data from other sources with S3 Tables data With S3 Tables data now available in SageMaker Lakehouse, you can join it with data from data warehouses, online transaction processing (OLTP) sources like relational or non-relational database, Iceberg tables, and other third party sources to gain more comprehensive and deeper insights.
For example, you can add connections to data sources such as Amazon DocumentDB, Amazon DynamoDB, Amazon Redshift, PostgreSQL, MySQL, Google BigQuery, or Snowflake and combine data using SQL without extract, transform, and load (ETL) scripts.
Now you can run the SQL query in the Query editor to join the data in the S3 Tables with the data in the DynamoDB.
Here is a sample query to join between Athena and DynamoDB:
select * from "s3tablescatalog/s3tables-integblog-bucket"."blogdb"."customer",
"dynamodb1"."default"."customer_ddb" where cust_id=pid limit 10;
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Software development is undergoing a seismic shift, driven by the transformative impact of generative AI. This powerful technology is redefining how developers work, what they build, and who can become a developer. At the AWS Developer Day 2025, we discussed how AWS is empowering developers to embrace this evolution through their generative AI developer tools. Developers got a first-hand look at exciting product launches, updates, and insights from AWS leaders on the future of software development. See the session list below.
This free, virtual event inspired developers of all backgrounds about the possibilities of generative AI for their work. Through use case demos, leadership insights, and community spotlights, attendees learned how AWS is making it faster and easier to build and scale quality software in the cloud.
If you could not attend AWS Developer Day 2025, you can still watch the recordings on YouTube:
Welcome to AWS Developer Day 2025 – Jeff Barr shares his thoughts on what this means for developers today, the skills needed to thrive in this changing environment, and how we sees it evolving in the future.
Fireside Chat with AWS and Redmonk – David Nalley (AWS), Rachel Stephens (Redmonk) discuss the evolution of the Developer Experience and future trends.
Go from idea to AI-powered app in minutes – Ali Spittel, Farrah Campbell and AM Grobelny show you how to add generative-AI capabilities like conversational chat and search to your web apps and how to securely provide LLMs access to your app’s data.
Acceleratee application modernization using generative AI – Eva Knight, Artur Rodrigues, Farrah Campbell and AM Grobelny show you how to automate and offload tedious manual tasks and port .NET Framework applications to cross-platform .NET faster and free up your time for innovation.
Gen AI disrupts SDLC. What does it mean for developers? The AWS approach – Alex Williams (The New Stack) and Srini Iragavarapu (AWS) discuss how generative AI is redefining software development, opening new frontiers for innovation, and democratizing access to coding for diverse creators shaping technology’s future.
Learning new skills with generative AI – Darko Mesaros, Cobus Bernard, Farrah Campbell and AM Grobelny teach you tips and tricks to succeed in this evolving developer landscape. We’ll cover best practices around agents, prompt engineering, and more.
Streamline operational troubleshooting with Amazon Q Developer – Nikhil Dewan, Farrah Campbell and AM Grobelny show you how Amazon Q Developer leverages insights from your cloud environments to accelerate root cause diagnosis and resolve operational issues in a fraction of the time.
Agents at work: plan – test – CR – deploy – repeat – Ryan Bachman, Farrah Campbell and AM Grobelny teach you how Amazon Q Developer’s embedded agents in the GItLab Duo platform help you complete your daily tasks with less manual overhead.
The AWS Developer Day 2025 showcased the transformative power of generative AI for software development. Developers learned how AWS is empowering them to embrace this evolution through their generative AI developer tools, making it faster and easier to build and scale quality software in the cloud. From boosting productivity across the SDLC to accelerating application modernization, the event highlighted the exciting possibilities that generative AI offers for the future of software development. As the industry continues to evolve, AWS is committed to equipping developers with the tools and insights they need to thrive in this changing landscape.
As of January 30, DeepSeek-R1 models became available in Amazon Bedrock through the Amazon Bedrock Marketplace and Amazon Bedrock Custom Model Import. Since then, thousands of customers have deployed these models in Amazon Bedrock. Customers value the robust guardrails and comprehensive tooling for safe AI deployment. Today, we’re making it even easier to use DeepSeek in Amazon Bedrock through an expanded range of options, including a new serverless solution.
The fully managed DeepSeek-R1 model is now generally available in Amazon Bedrock. Amazon Web Services (AWS) is the first cloud service provider (CSP) to deliver DeepSeek-R1 as a fully managed, generally available model. You can accelerate innovation and deliver tangible business value with DeepSeek on AWS without having to manage infrastructure complexities. You can power your generative AI applications with DeepSeek-R1’s capabilities using a single API in the Amazon Bedrock’s fully managed service and get the benefit of its extensive features and tooling.
According to DeepSeek, their model is publicly available under MIT license and offers strong capabilities in reasoning, coding, and natural language understanding. These capabilities power intelligent decision support, software development, mathematical problem-solving, scientific analysis, data insights, and comprehensive knowledge management systems.
As is the case for all AI solutions, give careful consideration to data privacy requirements when implementing in your production environments, check for bias in output, and monitor your results. When implementing publicly available models like DeepSeek-R1, consider the following:
Data security – You can access the enterprise-grade security, monitoring, and cost control features of Amazon Bedrock that are essential for deploying AI responsibly at scale, all while retaining complete control over your data. Users’ inputs and model outputs aren’t shared with any model providers. You can use these key security features by default, including data encryption at rest and in transit, fine-grained access controls, secure connectivity options, and download various compliance certifications while communicating with the DeepSeek-R1 model in Amazon Bedrock.
Responsible AI – You can implement safeguards customized to your application requirements and responsible AI policies with Amazon Bedrock Guardrails. This includes key features of content filtering, sensitive information filtering, and customizable security controls to prevent hallucinations using contextual grounding and Automated Reasoning checks. This means you can control the interaction between users and the DeepSeek-R1 model in Bedrock with your defined set of policies by filtering undesirable and harmful content in your generative AI applications.
Model evaluation – You can evaluate and compare models to identify the optimal model for your use case, including DeepSeek-R1, in a few steps through either automatic or human evaluations by using Amazon Bedrock model evaluation tools. You can choose automatic evaluation with predefined metrics such as accuracy, robustness, and toxicity. Alternatively, you can choose human evaluation workflows for subjective or custom metrics such as relevance, style, and alignment to brand voice. Model evaluation provides built-in curated datasets, or you can bring in your own datasets.
Get started with the DeepSeek-R1 model in Amazon Bedrock If you’re new to using DeepSeek-R1 models, go to the Amazon Bedrock console, choose Model access under Bedrock configurations in the left navigation pane. To access the fully managed DeepSeek-R1 model, request access for DeepSeek-R1 in DeepSeek. You’ll then be granted access to the model in Amazon Bedrock.
Next, to test the DeepSeek-R1 model in Amazon Bedrock, choose Chat/Text under Playgrounds in the left menu pane. Then choose Select model in the upper left, and select DeepSeek as the category and DeepSeek-R1 as the model. Then choose Apply.
Using the selected DeepSeek-R1 model, I run the following prompt example:
A family has $5,000 to save for their vacation next year. They can place the money in a savings account earning 2% interest annually or in a certificate of deposit earning 4% interest annually but with no access to the funds until the vacation. If they need $1,000 for emergency expenses during the year, how should they divide their money between the two options to maximize their vacation fund?
This prompt requires a complex chain of thought and produces very precise reasoning results.
To learn more about usage recommendations for prompts, refer to the README of the DeepSeek-R1 model in its GitHub repository.
By choosing View API request, you can also access the model using code examples in the AWS Command Line Interface (AWS CLI) and AWS SDK. You can use us.deepseek.r1-v1:0 as the model ID.
The model supports both the InvokeModel and Converse API. The following Python code examples show how to send a text message to the DeepSeek-R1 model using the Amazon Bedrock Converse API for text generation.
import boto3
from botocore.exceptions import ClientError
# Create a Bedrock Runtime client in the AWS Region you want to use.
client = boto3.client("bedrock-runtime", region_name="us-west-2")
# Set the model ID, e.g., Llama 3 8b Instruct.
model_id = "us.deepseek.r1-v1:0"
# Start a conversation with the user message.
user_message = "Describe the purpose of a 'hello world' program in one line."
conversation = [
{
"role": "user",
"content": [{"text": user_message}],
}
]
try:
# Send the message to the model, using a basic inference configuration.
response = client.converse(
modelId=model_id,
messages=conversation,
inferenceConfig={"maxTokens": 2000, "temperature": 0.6, "topP": 0.9},
)
# Extract and print the response text.
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
exit(1)
To enable Amazon Bedrock Guardrails on the DeepSeek-R1 model, select Guardrails under Safeguards in the left navigation pane, and create a guardrail by configuring as many filters as you need. For example, if you filter for “politics” word, your guardrails will recognize this word in the prompt and show you the blocked message.
You can test the guardrail with different inputs to assess the guardrail’s performance. You can refine the guardrail by setting denied topics, word filters, sensitive information filters, and blocked messaging until it matches your needs.
Since 2016, game developers have been using Amazon GameLift to power games with dedicated, scalable server hosting capable of supporting 100M concurrent users (CCU) in a single game. Responding to customer requests for additional managed compute capabilities beyond game servers, we’re announcing Amazon GameLift Streams — a new capability in Amazon GameLift to help game publishers build and deliver global, direct-to-player game streaming experiences. As part of this announcement, existing capabilities in Amazon GameLift are now known as Amazon Gamelift Servers, continuing to serve hundreds of developers including industry leaders Ubisoft, Zynga, WB Games, and Meta.
Amazon GameLift Streams helps you deliver game streaming experiences at up to 1080p resolution and 60 frames per second across devices including iOS, Android, and PCs. In just a few clicks, you can deploy games built with a variety of 3D engines, without modifications, onto fully-managed cloud-based GPU instances and stream games through the AWS Network Backbone directly to any device with a web browser.
Amazon GameLift Streams helps you distribute your games direct-to-players, without having to invest millions of dollars in infrastructure and software development to build your own service. Players can start gaming in just a few seconds, without waiting for downloads or installs.
Here’s a quick look at Amazon GameLift Streams:
You can use the Amazon GameLift Streams SDK to integrate with your existing identity services, storefronts, game launchers, websites, or newly created experiences such as playable demos, and begin streaming to players. You can monitor active streams and usage from within the AWS console, and seamlessly scale your streaming infrastructure across multiple regions on the AWS global network to reach more players around the world with low-latency gameplay. Amazon GameLift Streams is the only solution that enables you to upload your game content onto fully-managed GPU instances in the cloud and start streaming in minutes, with little or no modification of your code.
Players can access AAA, AA, and indie games on PCs, phones, tablets, smart TVs, or any device with a WebRTC-enabled browser. Amazon GameLift Streams allows you to dynamically scale streaming capacity to match player demand, ensuring you only pay for what you need. You can choose from a selection of GPU instances that offer a range of price performance, and rely on the built-in security of AWS to protect your intellectual property.
Let’s get started To begin using Amazon GameLift Streams, I need an existing Amazon GameLift Streams implementation. I prepare my game files by following the Amazon GameLift Streams documentation.
The next step is to create an Amazon GameLift Streams application. I navigate to the Amazon GameLift Streams console. This is how the new AWS GameLift Streams console looks:
On the Amazon GameLift Streams console, I choose Create application.
In the Runtime settings, I select the runtime environment for my game application.
Then, I need to select my S3 bucket and folder from the previous step, then set the path to my game’s main executable.
I also have the option to configure the automatic transfer of application-generated log files into a S3 bucket. After I’m done with this configuration, I choose Create application.
After my application setup is completed, I need to create a stream group, a collection of compute resources to run and stream the application. I navigate to Stream groups in the left navigation pane of the Amazon GameLift Streams console.
On this page, I define a description for my new stream group.
Here, I select the capabilities and pricing of my stream group. Since my application is using Microsoft Windows Server 2022 Base, I make sure to select one of the compatible stream classes.
Next, I need to link with the application I created in the previous step.
On the Configure stream settings page, I can configure additional locations for my stream group, bringing in additional capacity from other AWS Regions. There are two capacity options that I can choose, always-on capacity and on-demand capacity. The default capacity setting provides one streaming slot, which is sufficient for initial testing.
Then, I need to review my configuration and choose Create stream group.
With stream groups configured, I can test my game streaming. I navigate to the Test stream page on the console to launch my application as a stream. I select this stream group and select Choose.
On the next page, I can configure any command line arguments or environment variables to run my application. I don’t need any extra configurations and choose Test stream.
Then, I can see that my application is running as expected. I can also interact with my game. This test helps me verify that my game works properly in streaming mode and serves as an initial proof of concept.
After I’ve confirmed everything works, I can integrate the Web SDK into my own website. The Web SDK and AWS Software Development Kit (AWS SDK) with Amazon GameLift Streams APIs help me to embed game streams, similar to what I tested in the console, into any web page I manage.
Additional things to know
Availability – Amazon GameLift Streams is currently available in the following AWS Regions: US East (Ohio), US West (Oregon), Asia Pacific (Tokyo), Europe (Frankfurt). Additional streaming capacity can also be configured in US East (N. Virginia) and Europe (Ireland).
Supported operating systems – Amazon GameLift Streams supports games running on Windows, Linux, or Proton, offering easy onboarding and compatibility with game binaries. Learn more on Choosing a configuration in Amazon GameLift Streams documentation page.
Programmatic access – This new capability provides comprehensive tools including service APIs, client streaming SDKs, and AWS CLI for content packaging.
Now available Explore how to streamline your game distribution using Amazon GameLift Streams. Learn more about getting started on the Amazon GameLift Streams page.
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
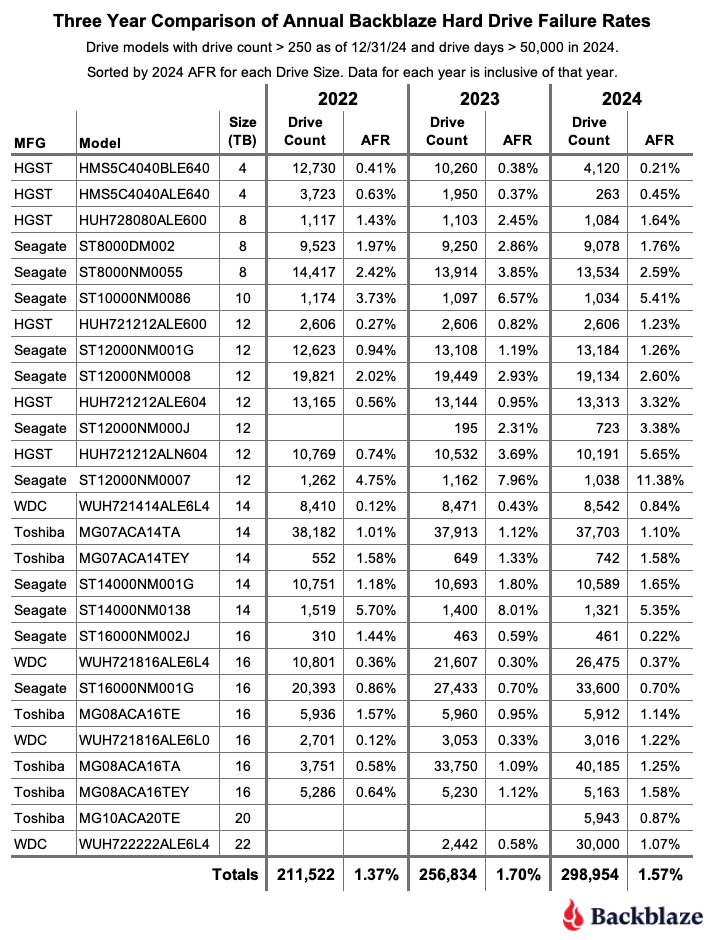
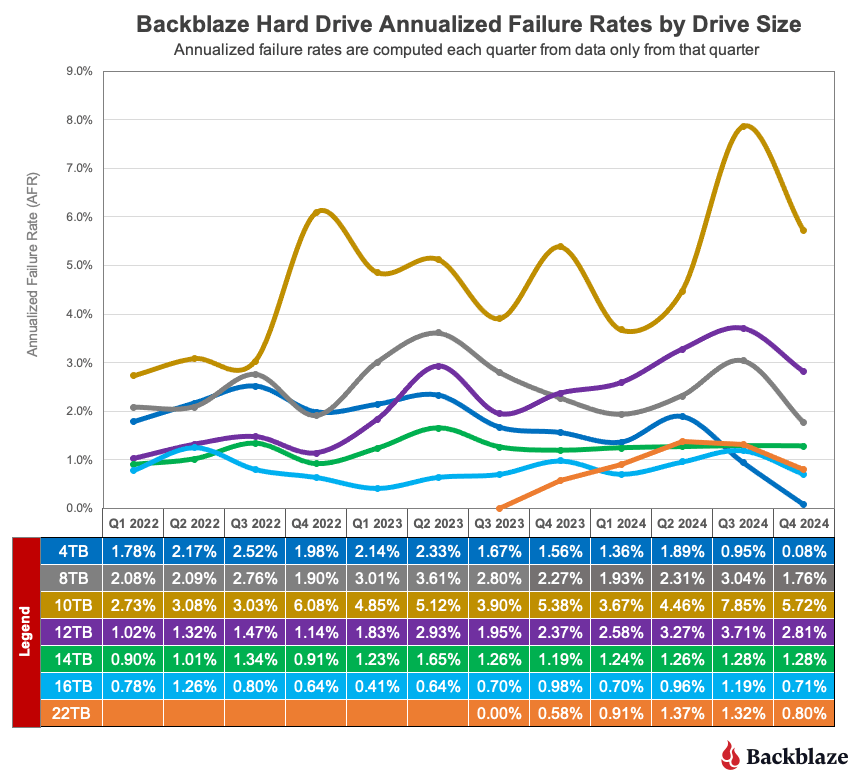
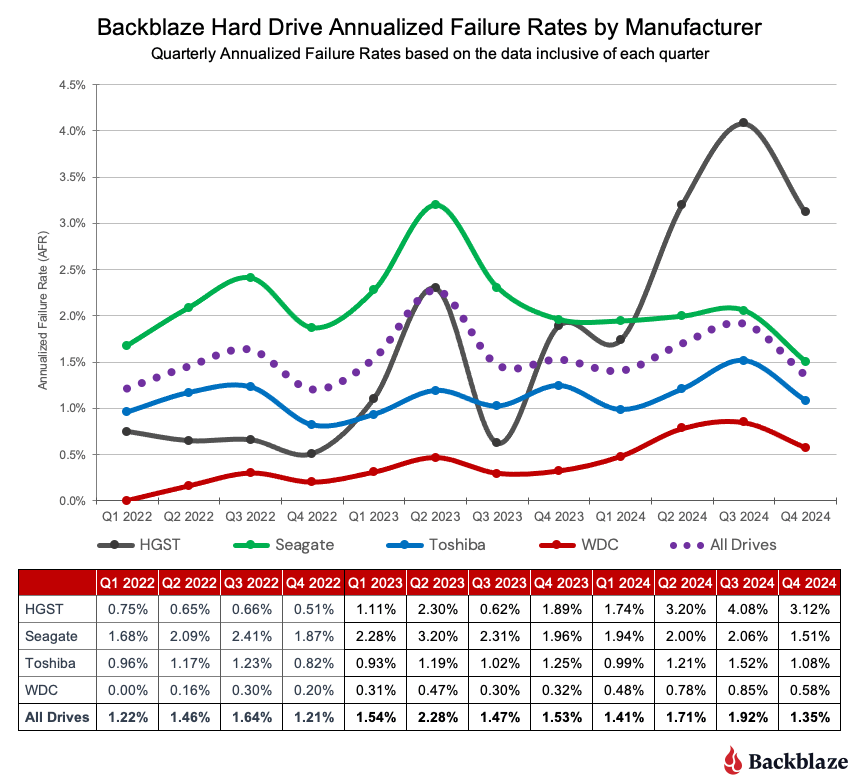
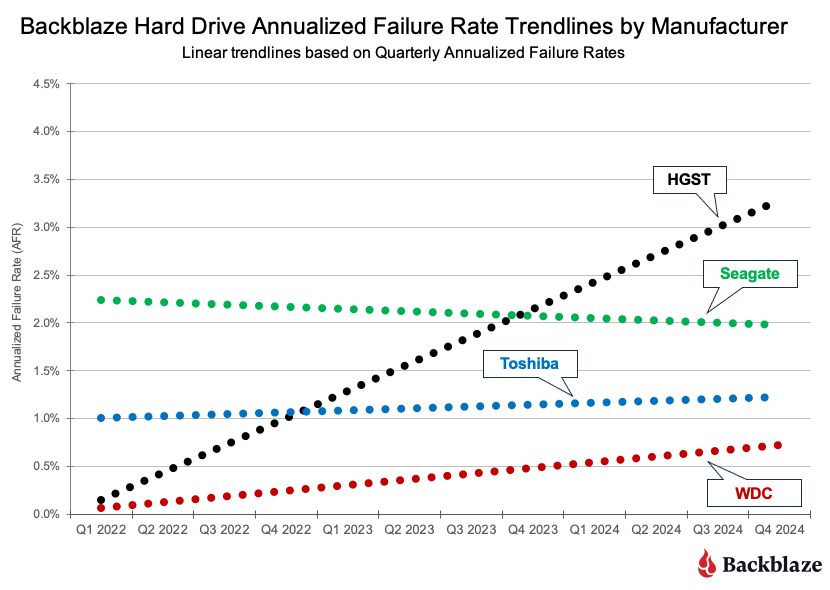
Over the past few years, Backblaze has expanded our regional footprint, adding capacity in the US-West region, growing in our EU-Central locale, opening a new US-East presence, and, most recently, moving into Canada with CA-East with an initial storage capacity of just under 60PB.
We approached our most recent expansion into Canada a bit differently, and today, I want to cover some of the new processes and efficiencies that we adopted for this project and how we’re well positioned to serve the Canadian market based on our network connections.
Backblaze deployment team lands in Toronto.
Scaling infrastructure and calling in the reinforcements
The CA-East data region deployment was our fastest to date, cutting the deployment life cycle (“the ink is signed” to a live production system) down in time by 50%. In this deployment cycle we worked with a third party integrator to help us streamline the process and also leveled up our automation procedures for installing operating systems and our storage software stack.
Historically we’ve drop-shipped all our equipment such as the networking gear, servers, hard drives, cables, and tools to the destination site for our deployment team to inventory, unbox, and physically install. It’s fun. It’s controlled chaos (if you like that sort of thing)—but for this build cycle we wanted to iterate our process further to ease and enable future growth in a more predictable and scalable fashion by working with a third party to assist with the initial physical build of the racked equipment.
On our end, there’s up-front engineering time documenting how all the fiber, copper, and power cables are organized. We have a cable map for every device, every cable, and every location as well as how it should be connected. It’s heavy on the paperwork side, but it’s time well spent. It allows us to template and stamp out future cabinets with ease. When we need more storage-focused cabinets to deploy additional storage, that’s a cabinet standard. If we need more compute, that’s also a cabinet that can be easily built out from a template.
The workload on the third party integrator side consists of taking our directions and performing all the physical racking and wiring. Handling all of these tasks takes time. You wouldn’t believe the amount of cardboard and packaging material that you need to process! Unboxing over a hundred servers, thousands of hard drives, and hundreds of fiber and copper cables is no small feat. (Apologies in hindsight for not giving you a marathon unboxing video.) They received all our packaging, then racked and cabled up everything according to our specifications. After inspection and quality control, everything was securely sealed in crates and shipped off to Canada.
Initial setup and bootstrapping of CA-East cluster at the integrator site.
Almost ready for QA and final inspection before shipping to the data center.
Automate all the things
Perform a process once? Sure. Have to do it more than twice? Automate it!
Before shipment out to the data center location, we sent a small team to the integrator site to perform a physical quality assessment of the build and set up remote access, which allowed us to bootstrap the platform as we had access to power and an internet connection.
Internally, we have a system that has a record of machine serial numbers and their roles (e.g., storage, api, database, etc). When a new machine boots up for the first time on our network, it gets a vanilla operating system installed via our PXE services. This is all parallelized, meaning that we were able to have systems to log in to within a few hours for the entire server set.
It’s a lot of fun toggling the power buttons one-by-one on over 90 servers, the PXE server network link running hot, and having an entire fleet of servers automatically install an operating system and be ready for further administration within minutes. Quite different from my days of performing floppy disk installs of Windows 95!
With a final inspection and software pass, everything was approved for shipment. The integrators securely boxed up our cabinets and they were on their way to Canada.
CA-East setup
Arriving at the destination site, everything was brought to the data center floor, bolted down, grounded, and energized. Within four hours we had network connectivity with our internet carriers and had set up our secure connections back to our production network to start our Backblaze software installation with our various internal teams. Within a few days, we had around 90 servers running and ready for our Quality Assurance team to start running tests to simulate client activity.
We partnered with Cologix, a leading network-neutral interconnection and hyperscale edge data center provider in North America, as our Canadian data center facility operator for this deployment. Cologix’s digital edge data center is a 20,000-square-foot, Tier III facility with two megawatts of power. It is a highly secure and efficient colocation and interconnection hub that features industry leading cooling designs, robust 24/7 security with biometric dual authentication access, and compliance with SOC 1, SOC 2, HIPAA and PCI-DSS as well as ISO 27001 certification by Schellman.
Storage Pods with a few compute servers at the top of each cabinet.
CA-East: Network and compute cabinets with room to grow.
Connectivity
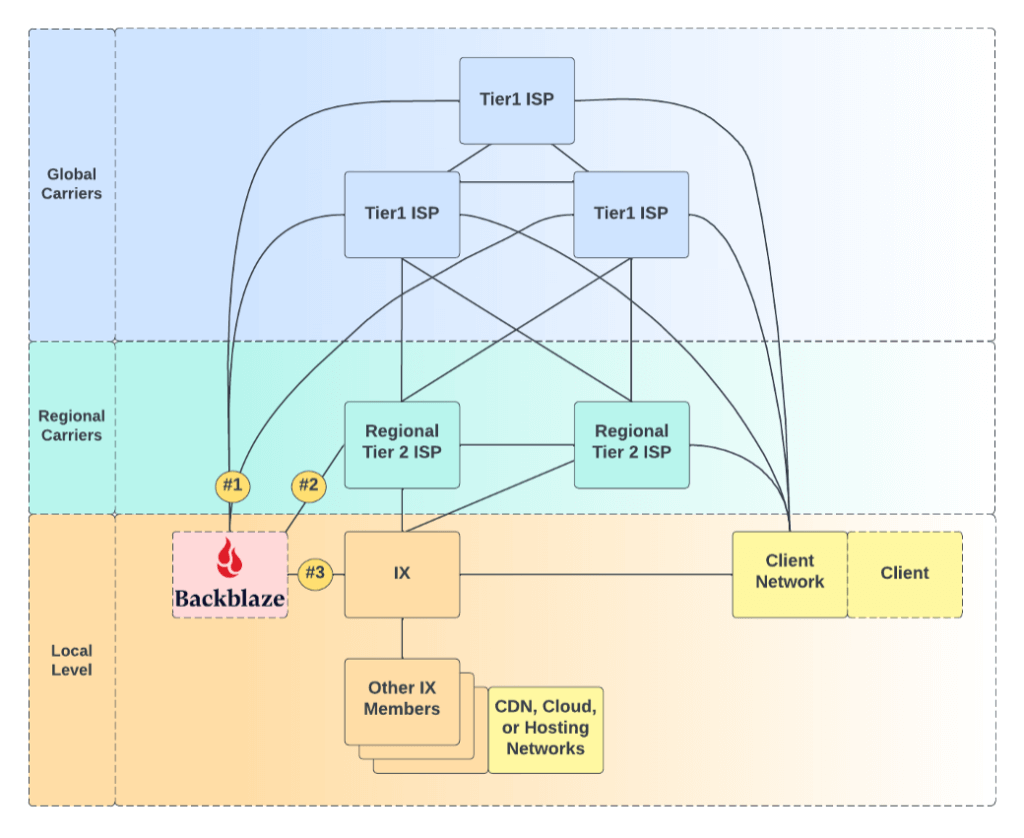
Our standard connectivity posture is to connect to three global carriers for the most expansive reach to every network possible, and also to join a local internet exchange (IX) for exchanging traffic between other IX members locally within the same data center or metro region for low-latency efficiency. Additionally, for this site, we also are connected to a large Canadian regional carrier to bring us in close proximity to Canadian-sourced traffic.
With low-latency and diverse dark fiber connectivity between Cologix’s data centers, including Canada’s largest and most important carrier hotel, the facility offers access to 160+ networks, TORIX, and 50+ cloud providers.
Overall that makes our CA-East connectivity map look like this.
Option 1: Global Carriers. Option 2: Regional ISP. Option 3: IX Traffic.
Joining TorIX
The local internet exchange for this site is Toronto Internet Exchange (TorIX), the leading Canadian internet exchange point (IXP) and one of the largest in the world. At the time of this post, more than 250 organizations exchange on average over 1.3 Terabits per second (Tbit/s) of traffic every day between each other locally.
Connecting to TorIX allows low latency transit between us and internet service providers (ISPs), other clouds, partner content delivery networks (CDNs), other enterprise networks, and hosting providers that provide compute services.
Go live
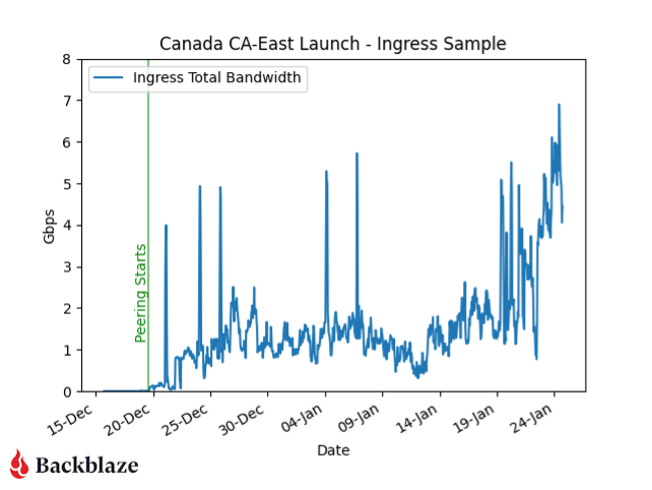
I’ve been at Backblaze for four years now and have been able to participate on builds to expand our US-West, US-East, and now CA-East regions. Turning on the metaphoric “switch” to make the site live is a little anticlimactic—from a network point of view, the only traffic we see at the start of a new region is our monitoring, internal jobs, and some soft-launched testing or proof of concept (PoC) accounts.
Here’s a sample of the network traffic from when we brought up peering with our carriers and soft launched the data region for our internal QA teams.
Initial traffic into CA-East at time of launch.
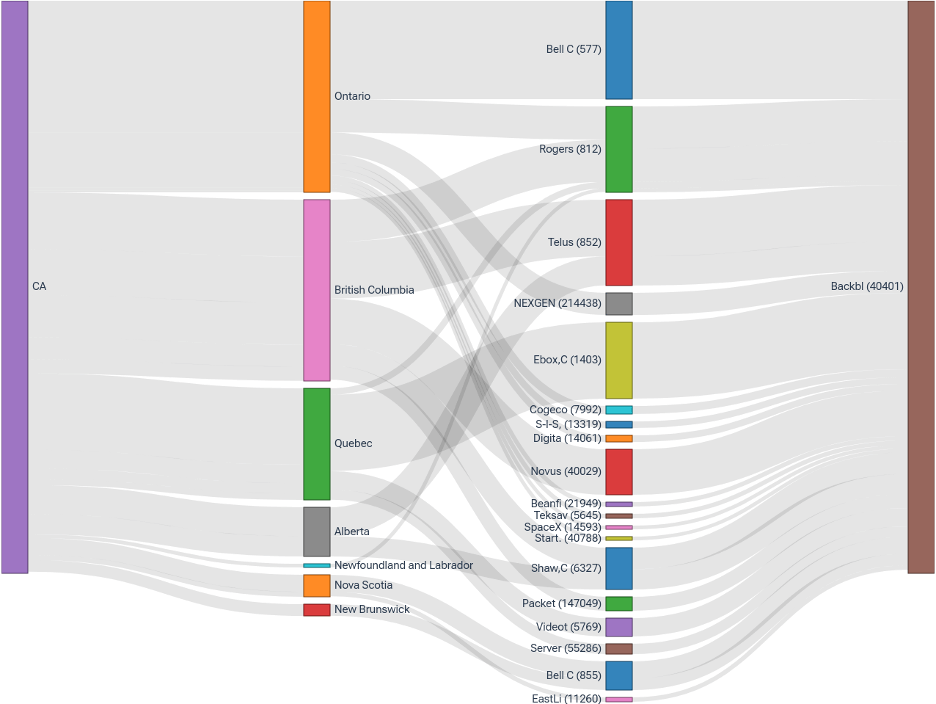
Where is the initial network traffic coming from? With our network telemetry monitoring, we’re able to see the flows in traffic in and out of our network. That network traffic information is enriched with data that adds context to allow us to see how much traffic is coming to or from a particular upstream provider or geographical region.
Here’s a Sankey diagram that shows a snapshot of current traffic from Canadian provinces over different service providers to the Backblaze network, where the larger lines mean more traffic is seen from that particular province or network. Expectedly, Ontario and British Columbia are the two largest sources of traffic.
Ingress traffic by province and carrier networks to Backblaze network (BGP AS40401).
Canada is open for business
As the months progress, and as more customers create their accounts in this new data region and point their workloads at this location, we’ll see more traffic. We’ll be excited to see what fun insights we can glean, which we’ll keep you updated on in our Network Stats series.
As Backblaze continues to grow its network, we’re excited to continue to iterate on our buildouts to make them more efficient. Ultimately, it lets us be more responsive to customer needs quickly. Same great network—just more locations.
We’re excited to have a footprint in Canada and welcome your storage needs! If you’re interested in learning more about storing your data in Canada, you can read the go-live announcement here.
Ready to store data in CA East?
The new data region is available to customers now, and you can create an account there by selecting “CA East” in the region drop-down when creating a Backblaze account. Already storing data with Backblaze and want to keep a Canadian copy? Leverage our Cloud Replication feature and diversify your storage.
As we explained in our recent blog post, AI Reasoning Models: OpenAI o3-mini, o1-mini, and DeepSeek R1, Chinese startup DeepSeek caused a stir when it released its R1 reasoning model in January of this year. Interestingly, DeepSeek R1 has an OpenAI-compatible API, so applications written for OpenAI should work with DeepSeek R1 with just a configuration change. Since I had a suitable sample app all ready to go, I decided to put their claim to the test.
Why, and why not, use DeepSeek?
A major difference between DeepSeek and OpenAI is cost. At the time of writing, DeepSeek charges $0.55 per million input tokens and $2.19 per million output tokens for its R1 model. That’s about 3.6% of OpenAI’s $15.00 per million input tokens and $60.00 per million output tokens for its flagship o1 reasoning model, and about half of o3-mini’s $1.10 per million input tokens and $4.40 per million output tokens.
Set against this is the fact that, in using the DeepSeek platform’s API, you are sending your data to a startup located in China that has been accused by OpenAI of “inappropriately” basing its work on the output of OpenAI’s models. It’s up to you, and your organizations’ data governance policy, whether the trade-off is worthwhile.
Another consideration is the ability to run DeepSeek’s models locally, on your own infrastructure, or, more likely, your chosen provider’s infrastructure, rather than sending requests to the DeepSeek platform. Spinning up my own DeepSeek instance was out of scope for this blog post, but I’ll likely return to it in a future blog post.
Swapping OpenAI for DeepSeek
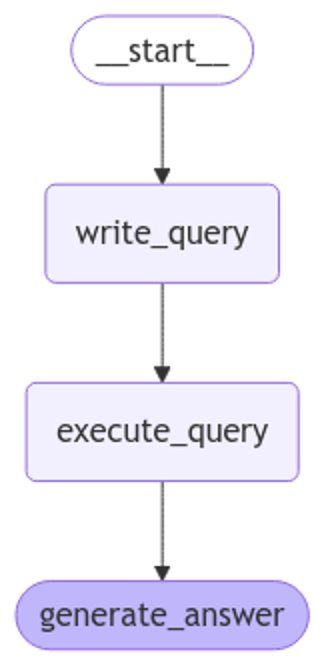
Last month, I explained how you can build an AI agent with Backblaze B2, LangChain, and Drive Stats, walking you through a simple chatbot that can answer questions based on our Drive Stats data set—11 years of metrics gathered from the Backblaze B2 Cloud Storage platform’s fleet of hard drives. In that example, the chatbot accepted a natural language question, used OpenAI’s GPT‑4o mini large language model (LLM) to generate a SQL query that might help provide an answer, executed the query against the Drive Stats data set via the Trino SQL engine, and then used OpenAI again to interpret the result set and either repeat the query-interpret cycle, or generate a natural language answer.
I copied the Jupyter notebook from that example and used it as the basis for investigating the feasibility of swapping out OpenAI for DeepSeek. The DeepSeek version of the notebook contains the full source code of my experiments; I’ll include relevant extracts here, edited for clarity.
Since I used the LangChain AI framework, which provides a layer above a range of AI models, the only place that OpenAI surfaced in my code was in creating an instance of LangChain’s ChatOpenAI wrapper:
# OPENAI_API_KEY must be defined in the .env file load_dotenv() llm = ChatOpenAI(model="gpt-4o-mini")
The ChatOpenAI class contains all the code required to communicate with OpenAI via its API.
Provide your DeepSeek API key in the same OPENAI_API_KEY environment variable.
Set the API base URL to https://api.deepseek.com.
Provide a DeepSeek model name in place of the OpenAI one.
If this reminds you of the steps for using Backblaze B2’s S3-compatible API, you’re not alone. The OpenAI API has become a de facto standard for integrating with LLMs in much the same way as Amazon’s S3 API allows an ecosystem of apps and tools to interoperate with object storage systems from a variety of vendors.
Looking at the DeepSeek documentation, you can use one of two models, deepseek-reasoner (aka DeepSeek R1) or deepseek-chat. Let’s see what the much-talked-about DeepSeek R1 came up with.
Using DeepSeek R1 in the AI agent
To make it easy to use both the OpenAI and DeepSeek notebooks, I created a second entry in the .env file for the DeepSeek API key, and copied it to the OpenAI environment variable in the notebook code:
# The .env file needs at least DEEPSEEK_API_KEY, and may also contain # OPENAI_API_KEY. Move the DeepSeek API key to the OpenAI environment # variable load_dotenv()
As I set about repeating the steps from the Jupyter notebook that supported my previous blog post, I was disappointed to see DeepSeek fall at the very first hurdle: generating a SQL query for a simple natural language question. Here is the code:
question = {"question": "How many drives are there?"}
write_query(question)
Looking back at the original notebook, OpenAI’s response was valid SQL, although it didn’t have enough information to construct the correct query:
{'query': 'SELECT COUNT(*) AS drive_count FROM drivestats'}
DeepSeek, on the other hand, responded with a Python stack trace and this error:
openai.UnprocessableEntityError: Failed to deserialize the JSON body into the target type: response_format: response_format.type `json_schema` is unavailable now at line 1 column 13827
What went wrong? Searching for the error turns up a comment from a LangChain engineer explaining that we should use BaseChatOpenAI rather than ChatOpenAI since it “[…] accommodates many APIs that are similar to OpenAI. It uses tool calling for structured output by default.”
So, we can redefine llm accordingly, and try generating a query again:
BadRequestError: Error code: 400 - {'error': {'message': 'The last message of deepseek-reasoner must be a user message, or an assistant message with prefix mode on (refer to https://api-docs.deepseek.com/guides/chat_prefix_completion).', 'type': 'invalid_request_error', 'param': None, 'code': 'invalid_request_error'}}
Looking back at the AI agent code, we can see that we used an off-the-shelf prompt from the LangChain Prompt Hub that provides the model with a single, system, message:
================================ System Message ================================
Given an input question, create a syntactically correct {dialect} query to run to help find the answer. Unless the user specifies in his question a specific number of examples they wish to obtain, always limit your query to at most {top_k} results. You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for a few relevant columns given the question.
Pay attention to use only the column names that you can see in the schema description. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Only use the following tables: {table_info}
Question: {input}
Does this mean that DeepSeek is not, in fact, API-compatible with OpenAI? I would argue that it does not. DeepSeek implements the same API request/response syntax as OpenAI, but it is a different platform. Some variation in semantics is to be expected. We see similar variations between Backblaze B2 and Amazon S3; for example, the S3 PutObjectAcl operation sets the access control list (ACL) for an object in a bucket. Amazon S3’s access management model allows you to manipulate an object’s ACL independently of its bucket—for example, you can put a private object in a public bucket, and vice versa.
This flexibility comes with a cost: It becomes difficult to reason about the visibility of data. In fact, AWS now recommends “that you keep ACLs disabled, except in unusual circumstances where you need to control access for each object individually.”
Backblaze B2’s model is much simpler: You control access at the bucket level, and all objects have the same ACL as their bucket. Backblaze B2 implements the PutObjectAcl operation, but, if you try to set an object’s ACL to any other value than its bucket’s ACL, the service responds with an error.
Returning to the AI agent code, we can replace the single-system-message prompt with one that combines a system message with a user message:
import textwrap from langchain_core.prompts import ChatPromptTemplate
query_prompt_template = ChatPromptTemplate([ ("system", textwrap.dedent("""Given an input question, create a syntactically correct {dialect} query to run to help find the answer. Unless the user specifies in his question a specific number of examples they wish to obtain, always limit your query to at most {top_k} results. You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for a the few relevant columns given the question.
Pay attention to use only the column names that you can see in the schema description. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Only use the following tables: {table_info}""")), ("human", "Question: {input}"), ])
Trying the write_query() call for a third time, this is the response:
BadRequestError: Error code: 400 - {'error': {'message': 'deepseek-reasoner does not support Function Calling', 'type': 'invalid_request_error', 'param': None, 'code': 'invalid_request_error'}}
Function calling is a powerful capability that enables Large Language Models (LLMs) to interact with your code and external systems in a structured way. Instead of just generating text responses, LLMs can understand when to call specific functions and provide the necessary parameters to execute real-world actions.
Unfortunately, that is exactly our use case. It’s becoming clear that DeepSeek R1 is not the correct tool for implementing an AI agent—we’ve been trying to use a chisel as a screwdriver!
DeepSeek-V3: A better fit
As its name suggests, the deepseek-chat model is more appropriate for this application. The DeepSeek documentation tells us that it is based on DeepSeek-V3, released in December 2024. DeepSeek-V3 is priced at $0.27 per million input tokens and $1.10 per million output tokens; this is actually more expensive than the GPT-4o mini model I used for the OpenAI agent example ($0.15 per million input tokens, $0.600 per million output tokens), but how does it compare? Let’s take a look.
First, we need to edit the LLM creation code again to set the model name:
Now we can run write_query() again. It’s immediately clear that it’s a better fit than its “big brother:”
{'query': 'SELECT COUNT(*) AS total_drives FROM drivestats LIMIT 10'}
As with the OpenAI agent, this query is well-formed SQL, but it’s not answering the question we set—it’s giving us the total number of rows in the dataset, rather than the number of drives. Also, it’s a little odd to have a LIMIT clause in a SELECT COUNT(*) query, but it’s legal SQL, and the agent is following its instructions very literally: always limit your query to at most {top_k} results, where we set top_k to 10.
question = {"question": "Each drive has its own serial number. How many drives are there?"}
query = write_query(question)
{'query': 'SELECT COUNT(DISTINCT serial_number) AS total_drives FROM drivestats'}
So far, so good!
I’ll skip some intermediate steps here—they are all in the Jupyter notebook if you want to review them, or run them for yourself—and look at how a simple LangChain graph, built on the DeepSeek LLM, answered the question: “Each drive has its own serial number. How many drives did each data center have on 9/1/2024?”
The OpenAI version generated an invalid query, comparing the date column with the string ’2024-09-01’ without using the required DATE type identifier, but DeepSeek generates a correct SQL query and provides a useful natural language response:
/SELECT datacenter, COUNT(DISTINCT serial_number) AS drive_count FROM drivestats WHERE date = DATE ‘2024-09-01’ GROUP BY datacenter ORDER BY drive_count DESC LIMIT 10
On September 1, 2024, the data centers had the following number of drives:
phx1: 89,477 drives
sac0: 78,444 drives
sac2: 60,775 drives
(empty datacenter): 24,080 drives
iad1: 22,800 drives
ams5: 16,139 drives
These are the top data centers with the highest drive counts on that date.
DeepSeek scores a point!
Moving on to the ReAct AI Agent, which allows the LLM to perform multiple SQL queries in generating an answer to a question, DeepSeek performs similarly to OpenAI. Given the question, “Each drive has its own serial number. What is the annualized failure rate of the ST4000DM000 drive model?”, the DeepSeek agent provides the overall failure rate rather than the annualized failure rate (AFR).
When we provide explicit instructions for calculating AFR in its prompt, the DeepSeek agent provides the correct result, identical, in fact, to the OpenAI agent’s response:
The annual failure rate (AFR) for the ST4000DM000 drive model is approximately 2.63%.
However, when given the question, “What was the annual failure rate of the ST8000NM000A drive model in Q3 2024?”, the DeepSeek agent gives us:
[(1.6100573445081607,)]
While OpenAI responds:
The annual failure rate (AFR) of the ST8000NM000A drive model in Q3 2024 is approximately 1.61%.
Wrapping up the investigation, the final question from the OpenAI notebook is more complex:
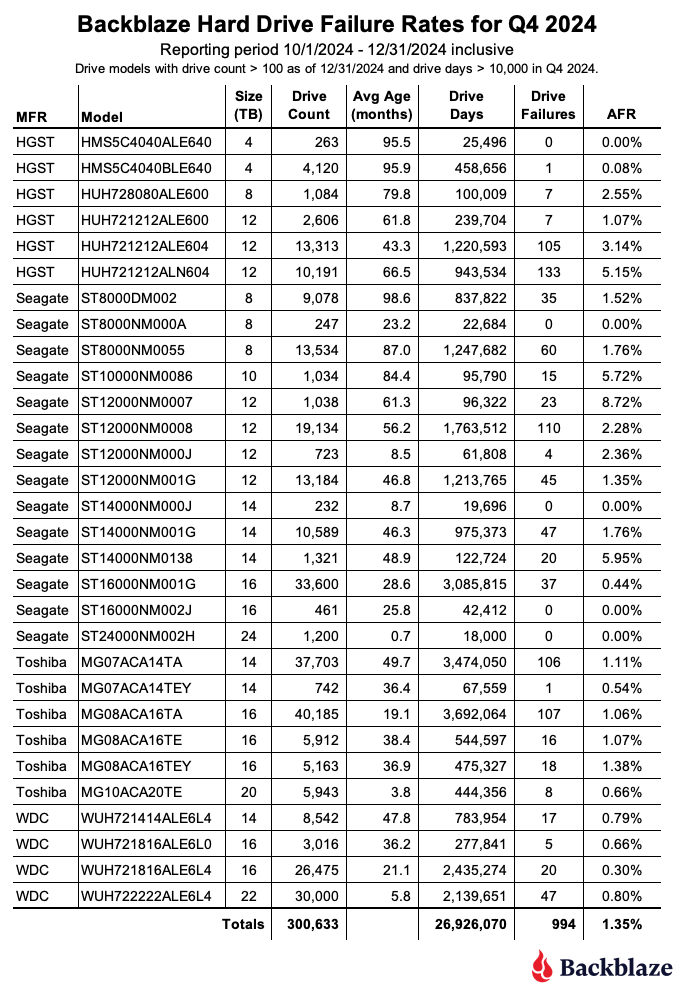
Considering only drive models which had at least 100 drives in service at the end of the quarter and which accumulated 10,000 or more drive days during the quarter, which drive had the most failures in Q3 2024, and what was its failure rate?
Impressively, the OpenAI agent constructed a well-formed SQL query and provided the correct response:
The drive model with the most failures in Q3 2024 is the TOSHIBA MG08ACA16TA, which had 181 failures. Its failure rate during this period was approximately 1.84%.
BadRequestError: Error code: 400 - {'error': {'message': "An assistant message with 'tool_calls' must be followed by tool messages responding to each 'tool_call_id'. (insufficient tool messages following tool_calls message)", 'type': 'invalid_request_error', 'param': None, 'code': 'invalid_request_error'}} During task with name 'agent' and id '0aa26ba6-a3ee-ced1-de4d-b60ed7fbca99'
The phrase “insufficient tool messages” suggested that the DeepSeek LLM might need to be reconfigured to allow more tokens. According to the documentation on models and pricing, the deepseek-chat model supports a maximum of 8K output tokens, but defaults to 4K if max_tokens is not specified.
Recreating the DeepSeek wrapper object and agent accordingly, I gave it the last question again:
response = agent_executor.invoke( {"messages": [{"role": "user", "content": "Considering only drive models which had at least 100 drives in service at the end of the quarter and which accumulated 10,000 or more drive days during the quarter, which drive had the most failures in Q3 2024, and what was its failure rate?"}]} )
# Show the SQL query sent to the database print(response['messages'][-3].tool_calls[0]['args']['query'])
# Show the final response message display_markdown(response['messages'][-1].content, raw=True)
This time, DeepSeek was able to generate a similar SQL query to OpenAI:
WITH drive_counts AS ( SELECT model, COUNT(DISTINCT serial_number) AS drive_count FROM drivestats WHERE date >= DATE '2024-07-01' AND date <= DATE '2024-09-30' GROUP BY model HAVING COUNT(DISTINCT serial_number) >= 100 ), drive_days AS ( SELECT model, COUNT(*) AS total_drive_days FROM drivestats WHERE date >= DATE '2024-07-01' AND date <= DATE '2024-09-30' GROUP BY model HAVING COUNT(*) >= 10000 ), failures AS ( SELECT model, COUNT(*) AS failure_count FROM drivestats WHERE date >= DATE '2024-07-01' AND date <= DATE '2024-09-30' AND failure = 1 GROUP BY model ) SELECT d.model, f.failure_count, 100 * (CAST(f.failure_count AS DOUBLE) / (CAST(d.total_drive_days AS DOUBLE) / 365)) AS annual_failure_rate FROM drive_days d JOIN failures f ON d.model = f.model JOIN drive_counts dc ON d.model = dc.model ORDER BY f.failure_count DESC LIMIT 1
With a correct response:
To answer the question:
The drive model with the most failures in Q3 2024 is TOSHIBA MG08ACA16TA, which had 181 failures. The annualized failure rate (AFR) for this model during that quarter was 1.84%.
Success! But, unfortunately, this isn’t the whole story.
DeepSeek Reliability
I originally set out to write this blog post at the end of January, but the DeepSeek platform website had gone offline by January 30, so I couldn’t even start until I was able to sign up for an API key on February 5.
Given my shiny new API key, and DeepSeek’s claims of OpenAI API compatibility, I naïvely expected to be able to work through my earlier OpenAI notebook and write up the results in a couple of days. The reality was more like two weeks.
In this blog post I’ve detailed some of the error messages I encountered along the way, but I saw many more that pointed to the DeepSeek API simply being overwhelmed with traffic. For example, for over a day, when the status page reported no issues, most API requests to DeepSeek terminated after a minute with the error message:
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
A time-consuming investigation revealed that this was caused by the DeepSeek API returning the 200 status code and headers as if the request was successful, then hanging for a minute before terminating the connection without returning any actual data. The calling code saw the 200 as success and tried to decode the non-existent API response body, resulting in the error.
I saw several more instances of intermittent errors that all seemed to point in the same direction: DeepSeek needs to add capacity to its API platform. Notably, the platform seemed faster and more stable on a Saturday morning, U.S. Pacific time, the early hours of Sunday morning in China.
Final thoughts
At present, I would have to classify the DeepSeek-V3 API as “promising, but somewhat flaky.” An agent invocation that succeeds one minute could fail the next with any of a range of error messages. That’s a shame, since when it does work, for instance, in creating the SQL query for the final question above, it tends to work very well.
One final caveat: This is a dynamic field; frameworks and services are literally being updated on a daily basis. For example, since yesterday, as I write this, four of the notebook’s module dependencies have been updated. I encourage you to experiment for yourself as your mileage will almost certainly vary, hopefully in a positive direction.
Many applications need to interact with content available through different modalities. Some of these applications process complex documents, such as insurance claims and medical bills. Mobile apps need to analyze user-generated media. Organizations need to build a semantic index on top of their digital assets that include documents, images, audio, and video files. However, getting insights from unstructured multimodal content is not easy to set up: you have to implement processing pipelines for the different data formats and go through multiple steps to get the information you need. That usually means having multiple models in production for which you have to handle cost optimizations (through fine-tuning and prompt engineering), safeguards (for example, against hallucinations), integrations with the target applications (including data formats), and model updates.
To make this process easier, we introduced in preview during AWS re:InventAmazon Bedrock Data Automation, a capability of Amazon Bedrock that streamlines the generation of valuable insights from unstructured, multimodal content such as documents, images, audio, and videos. With Bedrock Data Automation, you can reduce the development time and effort to build intelligent document processing, media analysis, and other multimodal data-centric automation solutions.
Today, Bedrock Data Automation is now generally available with support for cross-region inference endpoints to be available in more AWS Regions and seamlessly use compute across different locations. Based on your feedback during the preview, we also improved accuracy and added support for logo recognition for images and videos.
Let’s have a look at how this works in practice.
Using Amazon Bedrock Data Automation with cross-region inference endpoints The blog post published for the Bedrock Data Automation preview shows how to use the visual demo in the Amazon Bedrock console to extract information from documents and videos. I recommend you go through the console demo experience to understand how this capability works and what you can do to customize it. For this post, I focus more on how Bedrock Data Automation works in your applications, starting with a few steps in the console and following with code samples.
The Data Automation section of the Amazon Bedrock console now asks for confirmation to enable cross-region support the first time you access it. For example:
From an API perspective, the InvokeDataAutomationAsync operation now requires an additional parameter (dataAutomationProfileArn) to specify the data automation profile to use. The value for this parameter depends on the Region and your AWS account ID:
Also, the dataAutomationArn parameter has been renamed to dataAutomationProjectArn to better reflect that it contains the project Amazon Resource Name (ARN). When invoking Bedrock Data Automation, you now need to specify a project or a blueprint to use. If you pass in blueprints, you will get custom output. To continue to get standard default output, configure the parameter DataAutomationProjectArn to use arn:aws:bedrock:<REGION>:aws:data-automation-project/public-default.
As the name suggests, the InvokeDataAutomationAsync operation is asynchronous. You pass the input and output configuration and, when the result is ready, it’s written on an Amazon Simple Storage Service (Amazon S3) bucket as specified in the output configuration. You can receive an Amazon EventBridge notification from Bedrock Data Automation using the notificationConfiguration parameter.
With Bedrock Data Automation, you can configure outputs in two ways:
Standard output delivers predefined insights relevant to a data type, such as document semantics, video chapter summaries, and audio transcripts. With standard outputs, you can set up your desired insights in just a few steps.
Custom output lets you specify extraction needs using blueprints for more tailored insights.
To see the new capabilities in action, I create a project and customize the standard output settings. For documents, I choose plain text instead of markdown. Note that you can automate these configuration steps using the Bedrock Data Automation API.
For videos, I want a full audio transcript and a summary of the entire video. I also ask for a summary of each chapter.
To configure a blueprint, I choose Custom output setup in the Data automation section of the Amazon Bedrock console navigation pane. There, I search for the US-Driver-License sample blueprint. You can browse other sample blueprints for more examples and ideas.
Sample blueprints can’t be edited, so I use the Actions menu to duplicate the blueprint and add it to my project. There, I can fine-tune the data to be extracted by modifying the blueprint and adding custom fields that can use generative AI to extract or compute data in the format I need.
I upload the image of a US driver’s license on an S3 bucket. Then, I use this sample Python script that uses Bedrock Data Automation through the AWS SDK for Python (Boto3) to extract text information from the image:
import json
import sys
import time
import boto3
DEBUG = False
AWS_REGION = '<REGION>'
BUCKET_NAME = '<BUCKET>'
INPUT_PATH = 'BDA/Input'
OUTPUT_PATH = 'BDA/Output'
PROJECT_ID = '<PROJECT_ID>'
BLUEPRINT_NAME = 'US-Driver-License-demo'
# Fields to display
BLUEPRINT_FIELDS = [
'NAME_DETAILS/FIRST_NAME',
'NAME_DETAILS/MIDDLE_NAME',
'NAME_DETAILS/LAST_NAME',
'DATE_OF_BIRTH',
'DATE_OF_ISSUE',
'EXPIRATION_DATE'
]
# AWS SDK for Python (Boto3) clients
bda = boto3.client('bedrock-data-automation-runtime', region_name=AWS_REGION)
s3 = boto3.client('s3', region_name=AWS_REGION)
sts = boto3.client('sts')
def log(data):
if DEBUG:
if type(data) is dict:
text = json.dumps(data, indent=4)
else:
text = str(data)
print(text)
def get_aws_account_id() -> str:
return sts.get_caller_identity().get('Account')
def get_json_object_from_s3_uri(s3_uri) -> dict:
s3_uri_split = s3_uri.split('/')
bucket = s3_uri_split[2]
key = '/'.join(s3_uri_split[3:])
object_content = s3.get_object(Bucket=bucket, Key=key)['Body'].read()
return json.loads(object_content)
def invoke_data_automation(input_s3_uri, output_s3_uri, data_automation_arn, aws_account_id) -> dict:
params = {
'inputConfiguration': {
's3Uri': input_s3_uri
},
'outputConfiguration': {
's3Uri': output_s3_uri
},
'dataAutomationConfiguration': {
'dataAutomationProjectArn': data_automation_arn
},
'dataAutomationProfileArn': f"arn:aws:bedrock:{AWS_REGION}:{aws_account_id}:data-automation-profile/us.data-automation-v1"
}
response = bda.invoke_data_automation_async(**params)
log(response)
return response
def wait_for_data_automation_to_complete(invocation_arn, loop_time_in_seconds=1) -> dict:
while True:
response = bda.get_data_automation_status(
invocationArn=invocation_arn
)
status = response['status']
if status not in ['Created', 'InProgress']:
print(f" {status}")
return response
print(".", end='', flush=True)
time.sleep(loop_time_in_seconds)
def print_document_results(standard_output_result):
print(f"Number of pages: {standard_output_result['metadata']['number_of_pages']}")
for page in standard_output_result['pages']:
print(f"- Page {page['page_index']}")
if 'text' in page['representation']:
print(f"{page['representation']['text']}")
if 'markdown' in page['representation']:
print(f"{page['representation']['markdown']}")
def print_video_results(standard_output_result):
print(f"Duration: {standard_output_result['metadata']['duration_millis']} ms")
print(f"Summary: {standard_output_result['video']['summary']}")
statistics = standard_output_result['statistics']
print("Statistics:")
print(f"- Speaket count: {statistics['speaker_count']}")
print(f"- Chapter count: {statistics['chapter_count']}")
print(f"- Shot count: {statistics['shot_count']}")
for chapter in standard_output_result['chapters']:
print(f"Chapter {chapter['chapter_index']} {chapter['start_timecode_smpte']}-{chapter['end_timecode_smpte']} ({chapter['duration_millis']} ms)")
if 'summary' in chapter:
print(f"- Chapter summary: {chapter['summary']}")
def print_custom_results(custom_output_result):
matched_blueprint_name = custom_output_result['matched_blueprint']['name']
log(custom_output_result)
print('\n- Custom output')
print(f"Matched blueprint: {matched_blueprint_name} Confidence: {custom_output_result['matched_blueprint']['confidence']}")
print(f"Document class: {custom_output_result['document_class']['type']}")
if matched_blueprint_name == BLUEPRINT_NAME:
print('\n- Fields')
for field_with_group in BLUEPRINT_FIELDS:
print_field(field_with_group, custom_output_result)
def print_results(job_metadata_s3_uri) -> None:
job_metadata = get_json_object_from_s3_uri(job_metadata_s3_uri)
log(job_metadata)
for segment in job_metadata['output_metadata']:
asset_id = segment['asset_id']
print(f'\nAsset ID: {asset_id}')
for segment_metadata in segment['segment_metadata']:
# Standard output
standard_output_path = segment_metadata['standard_output_path']
standard_output_result = get_json_object_from_s3_uri(standard_output_path)
log(standard_output_result)
print('\n- Standard output')
semantic_modality = standard_output_result['metadata']['semantic_modality']
print(f"Semantic modality: {semantic_modality}")
match semantic_modality:
case 'DOCUMENT':
print_document_results(standard_output_result)
case 'VIDEO':
print_video_results(standard_output_result)
# Custom output
if 'custom_output_status' in segment_metadata and segment_metadata['custom_output_status'] == 'MATCH':
custom_output_path = segment_metadata['custom_output_path']
custom_output_result = get_json_object_from_s3_uri(custom_output_path)
print_custom_results(custom_output_result)
def print_field(field_with_group, custom_output_result) -> None:
inference_result = custom_output_result['inference_result']
explainability_info = custom_output_result['explainability_info'][0]
if '/' in field_with_group:
# For fields part of a group
(group, field) = field_with_group.split('/')
inference_result = inference_result[group]
explainability_info = explainability_info[group]
else:
field = field_with_group
value = inference_result[field]
confidence = explainability_info[field]['confidence']
print(f'{field}: {value or '<EMPTY>'} Confidence: {confidence}')
def main() -> None:
if len(sys.argv) < 2:
print("Please provide a filename as command line argument")
sys.exit(1)
file_name = sys.argv[1]
aws_account_id = get_aws_account_id()
input_s3_uri = f"s3://{BUCKET_NAME}/{INPUT_PATH}/{file_name}" # File
output_s3_uri = f"s3://{BUCKET_NAME}/{OUTPUT_PATH}" # Folder
data_automation_arn = f"arn:aws:bedrock:{AWS_REGION}:{aws_account_id}:data-automation-project/{PROJECT_ID}"
print(f"Invoking Bedrock Data Automation for '{file_name}'", end='', flush=True)
data_automation_response = invoke_data_automation(input_s3_uri, output_s3_uri, data_automation_arn, aws_account_id)
data_automation_status = wait_for_data_automation_to_complete(data_automation_response['invocationArn'])
if data_automation_status['status'] == 'Success':
job_metadata_s3_uri = data_automation_status['outputConfiguration']['s3Uri']
print_results(job_metadata_s3_uri)
if __name__ == "__main__":
main()
The initial configuration in the script includes the name of the S3 bucket to use in input and output, the location of the input file in the bucket, the output path for the results, the project ID to use to get custom output from Bedrock Data Automation, and the blueprint fields to show in output.
I run the script passing the name of the input file. In output, I see the information extracted by Bedrock Data Automation. The US-Driver-License is a match and the name and dates in the driver’s license are printed in output.
python bda-ga.py bda-drivers-license.jpeg
Invoking Bedrock Data Automation for 'bda-drivers-license.jpeg'................ Success
Asset ID: 0
- Standard output
Semantic modality: DOCUMENT
Number of pages: 1
- Page 0
NEW JERSEY
Motor Vehicle
Commission
AUTO DRIVER LICENSE
Could DL M6454 64774 51685 CLASS D
DOB 01-01-1968
ISS 03-19-2019 EXP 01-01-2023
MONTOYA RENEE MARIA 321 GOTHAM AVENUE TRENTON, NJ 08666 OF
END NONE
RESTR NONE
SEX F HGT 5'-08" EYES HZL ORGAN DONOR
CM ST201907800000019 CHG 11.00
[SIGNATURE]
- Custom output
Matched blueprint: US-Driver-License-copy Confidence: 1
Document class: US-drivers-licenses
- Fields
FIRST_NAME: RENEE Confidence: 0.859375
MIDDLE_NAME: MARIA Confidence: 0.83203125
LAST_NAME: MONTOYA Confidence: 0.875
DATE_OF_BIRTH: 1968-01-01 Confidence: 0.890625
DATE_OF_ISSUE: 2019-03-19 Confidence: 0.79296875
EXPIRATION_DATE: 2023-01-01 Confidence: 0.93359375
As expected, I see in output the information I selected from the blueprint associated with the Bedrock Data Automation project.
Similarly, I run the same script on a video file from my colleague Mike Chambers. To keep the output small, I don’t print the full audio transcript or the text displayed in the video.
python bda.py mike-video.mp4
Invoking Bedrock Data Automation for 'mike-video.mp4'.......................................................................................................................................................................................................................................................................... Success
Asset ID: 0
- Standard output
Semantic modality: VIDEO
Duration: 810476 ms
Summary: In this comprehensive demonstration, a technical expert explores the capabilities and limitations of Large Language Models (LLMs) while showcasing a practical application using AWS services. He begins by addressing a common misconception about LLMs, explaining that while they possess general world knowledge from their training data, they lack current, real-time information unless connected to external data sources.
To illustrate this concept, he demonstrates an "Outfit Planner" application that provides clothing recommendations based on location and weather conditions. Using Brisbane, Australia as an example, the application combines LLM capabilities with real-time weather data to suggest appropriate attire like lightweight linen shirts, shorts, and hats for the tropical climate.
The demonstration then shifts to the Amazon Bedrock platform, which enables users to build and scale generative AI applications using foundation models. The speaker showcases the "OutfitAssistantAgent," explaining how it accesses real-time weather data to make informed clothing recommendations. Through the platform's "Show Trace" feature, he reveals the agent's decision-making process and how it retrieves and processes location and weather information.
The technical implementation details are explored as the speaker configures the OutfitAssistant using Amazon Bedrock. The agent's workflow is designed to be fully serverless and managed within the Amazon Bedrock service.
Further diving into the technical aspects, the presentation covers the AWS Lambda console integration, showing how to create action group functions that connect to external services like the OpenWeatherMap API. The speaker emphasizes that LLMs become truly useful when connected to tools providing relevant data sources, whether databases, text files, or external APIs.
The presentation concludes with the speaker encouraging viewers to explore more AWS developer content and engage with the channel through likes and subscriptions, reinforcing the practical value of combining LLMs with external data sources for creating powerful, context-aware applications.
Statistics:
- Speaket count: 1
- Chapter count: 6
- Shot count: 48
Chapter 0 00:00:00:00-00:01:32:01 (92025 ms)
- Chapter summary: A man with a beard and glasses, wearing a gray hooded sweatshirt with various logos and text, is sitting at a desk in front of a colorful background. He discusses the frequent release of new large language models (LLMs) and how people often test these models by asking questions like "Who won the World Series?" The man explains that LLMs are trained on general data from the internet, so they may have information about past events but not current ones. He then poses the question of what he wants from an LLM, stating that he desires general world knowledge, such as understanding basic concepts like "up is up" and "down is down," but does not need specific factual knowledge. The man suggests that he can attach other systems to the LLM to access current factual data relevant to his needs. He emphasizes the importance of having general world knowledge and the ability to use tools and be linked into agentic workflows, which he refers to as "agentic workflows." The man encourages the audience to add this term to their spell checkers, as it will likely become commonly used.
Chapter 1 00:01:32:01-00:03:38:18 (126560 ms)
- Chapter summary: The video showcases a man with a beard and glasses demonstrating an "Outfit Planner" application on his laptop. The application allows users to input their location, such as Brisbane, Australia, and receive recommendations for appropriate outfits based on the weather conditions. The man explains that the application generates these recommendations using large language models, which can sometimes provide inaccurate or hallucinated information since they lack direct access to real-world data sources.
The man walks through the process of using the Outfit Planner, entering Brisbane as the location and receiving weather details like temperature, humidity, and cloud cover. He then shows how the application suggests outfit options, including a lightweight linen shirt, shorts, sandals, and a hat, along with an image of a woman wearing a similar outfit in a tropical setting.
Throughout the demonstration, the man points out the limitations of current language models in providing accurate and up-to-date information without external data connections. He also highlights the need to edit prompts and adjust settings within the application to refine the output and improve the accuracy of the generated recommendations.
Chapter 2 00:03:38:18-00:07:19:06 (220620 ms)
- Chapter summary: The video demonstrates the Amazon Bedrock platform, which allows users to build and scale generative AI applications using foundation models (FMs). [speaker_0] introduces the platform's overview, highlighting its key features like managing FMs from AWS, integrating with custom models, and providing access to leading AI startups. The video showcases the Amazon Bedrock console interface, where [speaker_0] navigates to the "Agents" section and selects the "OutfitAssistantAgent" agent. [speaker_0] tests the OutfitAssistantAgent by asking it for outfit recommendations in Brisbane, Australia. The agent provides a suggestion of wearing a light jacket or sweater due to cool, misty weather conditions. To verify the accuracy of the recommendation, [speaker_0] clicks on the "Show Trace" button, which reveals the agent's workflow and the steps it took to retrieve the current location details and weather information for Brisbane. The video explains that the agent uses an orchestration and knowledge base system to determine the appropriate response based on the user's query and the retrieved data. It highlights the agent's ability to access real-time information like location and weather data, which is crucial for generating accurate and relevant responses.
Chapter 3 00:07:19:06-00:11:26:13 (247214 ms)
- Chapter summary: The video demonstrates the process of configuring an AI assistant agent called "OutfitAssistant" using Amazon Bedrock. [speaker_0] introduces the agent's purpose, which is to provide outfit recommendations based on the current time and weather conditions. The configuration interface allows selecting a language model from Anthropic, in this case the Claud 3 Haiku model, and defining natural language instructions for the agent's behavior. [speaker_0] explains that action groups are groups of tools or actions that will interact with the outside world. The OutfitAssistant agent uses Lambda functions as its tools, making it fully serverless and managed within the Amazon Bedrock service. [speaker_0] defines two action groups: "get coordinates" to retrieve latitude and longitude coordinates from a place name, and "get current time" to determine the current time based on the location. The "get current weather" action requires calling the "get coordinates" action first to obtain the location coordinates, then using those coordinates to retrieve the current weather information. This demonstrates the agent's workflow and how it utilizes the defined actions to generate outfit recommendations. Throughout the video, [speaker_0] provides details on the agent's configuration, including its name, description, model selection, instructions, and action groups. The interface displays various options and settings related to these aspects, allowing [speaker_0] to customize the agent's behavior and functionality.
Chapter 4 00:11:26:13-00:13:00:17 (94160 ms)
- Chapter summary: The video showcases a presentation by [speaker_0] on the AWS Lambda console and its integration with machine learning models for building powerful agents. [speaker_0] demonstrates how to create an action group function using AWS Lambda, which can be used to generate text responses based on input parameters like location, time, and weather data. The Lambda function code is shown, utilizing external services like OpenWeatherMap API for fetching weather information. [speaker_0] explains that for a large language model to be useful, it needs to connect to tools providing relevant data sources, such as databases, text files, or external APIs. The presentation covers the process of defining actions, setting up Lambda functions, and leveraging various tools within the AWS environment to build intelligent agents capable of generating context-aware responses.
Chapter 5 00:13:00:17-00:13:28:10 (27761 ms)
- Chapter summary: A man with a beard and glasses, wearing a gray hoodie with various logos and text, is sitting at a desk in front of a colorful background. He is using a laptop computer that has stickers and logos on it, including the AWS logo. The man appears to be presenting or speaking about AWS (Amazon Web Services) and its services, such as Lambda functions and large language models. He mentions that if a Lambda function can do something, then it can be used to augment a large language model. The man concludes by expressing hope that the viewer found the video useful and insightful, and encourages them to check out other videos on the AWS developers channel. He also asks viewers to like the video, subscribe to the channel, and watch other videos.
Things to know Amazon Bedrock Data Automation is now available via cross-region inference in the following two AWS Regions: US East (N. Virginia) and US West (Oregon). When using Bedrock Data Automation from those Regions, data can be processed using cross-region inference in any of these four Regions: US East (Ohio, N. Virginia) and US West (N. California, Oregon). All these Regions are in the US so that data is processed within the same geography. We’re working to add support for more Regions in Europe and Asia later in 2025.
There’s no change in pricing compared to the preview and when using cross-region inference. For more information, visit Amazon Bedrock pricing.
Bedrock Data Automation now also includes a number of security, governance and manageability related capabilities such as AWS Key Management Service (AWS KMS)customer managed keys support for granular encryption control, AWS PrivateLink to connect directly to the Bedrock Data Automation APIs in your virtual private cloud (VPC) instead of connecting over the internet, and tagging of Bedrock Data Automation resources and jobs to track costs and enforce tag-based access policies in AWS Identity and Access Management (IAM).
I used Python in this blog post but Bedrock Data Automation is available with any AWS SDKs. For example, you can use Java, .NET, or Rust for a backend document processing application; JavaScript for a web app that processes images, videos, or audio files; and Swift for a native mobile app that processes content provided by end users. It’s never been so easy to get insights from multimodal data.
Here are a few reading suggestions to learn more (including code samples):
I’ve heard the horror stories, and I’m sure you have too. A company thinks they’re covered because they have replication running, only to realize too late that replication doesn’t protect against data corruption or ransomware. In a disaster scenario, every copy of their critical data is compromised. And then comes the dreaded question: Do we have a backup?
Many teams—even those with seasoned IT professionals—misunderstand the fundamental difference between backup and replication for disaster recovery (DR). Replication is about availability, or keeping systems running with minimal downtime. Backup is about recoverability, or ensuring you can go back to a known good state.
This post breaks down replication, backup, and their respective roles in disaster recovery in a way that’s easy to share with your team, helping to prevent costly misunderstandings.
What is data replication?
Data replication involves copying and synchronizing data between your primary site and the DR destination in real-time or near real-time. It offers fast failover capabilities as the replicated data at the DR site is constantly updated. However, if malware infects your primary site, it might also replicate to the DR site, rendering the backup compromised.
What is data backup?
Data backup involves creating full and incremental copies of your data and storing them in a separate location from your primary system, typically on a scheduled basis, to prevent loss, corruption, or disasters. A couple key points:
Incremental backups capture changes in data, thus offering a point-in-time recovery option.
Ideally, backups are immutable, meaning they can’t be altered, in order to protect against malware and ransomware by making files and images read-only for safe recovery.
Air-gapped and offline backups can further help resist malware and ransomware attacks by creating a virtual or physical separation from the production network.
Cloud-based backups are a great option for addressing these requirements while offering affordable scaling options as the environment grows.
Replicating backups
A hybrid approach involves replicating your backups to a secondary location, offering a balance between data protection and recovery time. This can be between on-premises and cloud environments, or across multiple cloud targets.
While replicating backups offers additional protection and accessibility for online recovery, the backup images are still subject to ransomware infection. Using immutable backups helps prevent the spread of the infection to recovery sites and backup repositories.
Data backups paired with replication can be an ideal strategy. Full and incremental backups with point-in-time snapshots can provide regular recovery points with replicated copies for remote recovery and additional protection.
Cloud Replication
Backblaze B2 Cloud Replication enables your data to be automatically copied from one location to another for redundancy, compliance, and fast local access. Create 2x backups for a stronger disaster recovery posture. Replicating your Backblaze data is easy and free—no service or egress fees—just the standard Backblaze B2 Cloud Storage rates.
Disaster recovery and backups: Factors to consider when choosing the right approach
The optimal approach to disaster recovery backup and when and how you use replication depends on your specific needs.
For frequently accessed data requiring near-instantaneous recovery, consider a combination of a hot site methodology and real-time data replication. This offers the fastest failover, but can come at a higher cost.
For critical data with acceptable downtime, a warm site with replicated immutable backups at a secondary location (either on-premises or in the cloud) provides a good balance between cost and recovery time. While requiring some manual intervention, it offers protection against malware replicating to the DR site.
For less critical data or archival purposes, cold storage with periodic backups is a cost-effective option. Backups offer a historical record and are less susceptible to malware infection compared to replicated data, particularly if Object Lock is enabled for immutability.
Data replication is important, but it should not be seen as a substitute for backups. Backups offer a required safety net, providing a point-in-time recovery option even if the replicated data is compromised. Selecting the right disaster recovery backup strategy depends on a careful evaluation of your company’s specific needs, budget, and risk tolerance.
By understanding the pros and cons of each option, you can make an informed decision that ensures optimal protection for your critical data in the face of unforeseen disruptions.
Mac admins have always understood the value of prioritizing Mac-native software to ensure performance and compatibility across their environments. With an integrated approach to data protection and device management from Backblaze and Kandji, you can now eliminate manual installations and deploy Backblaze with zero-touch across your entire Mac fleet, ensuring critical data is protected.
Simplifying Mac backup for remote and on-site IT teams
Whether your team is in the office or scattered across the globe, Backblaze’s cloud-based solution ensures your data is accessible and easily managed from anywhere.
Backblaze and Kandji’s solutions have already proven their value in Apple-focused IT environments.
Companies like Foojee, a managed IT provider specializing in Apple devices, rely on Kandji to deploy and manage those devices and Backblaze to protect their data. “We are always looking at best-of-breed apps for our customers, and we have never felt more proud of our product offering,” said Lucas Acosta, CEO of Foojee. “The three biggest benefits we have realized from Backblaze and Kandji are our time savings on our Help Desk, the increased security, and the increased reliability.”
This partnership builds on that success, enabling organizations to:
Deploy Backblaze effortlessly with Kandji: Automate installation and configuration of Backblaze on managed devices with Kandji’s workflows.
Enhance data security: Keep critical data protected with Backblaze’s secure, cloud-based backup service.
Scale with ease: Both platforms support organizations of any size, from startups to enterprises.
Reduce IT overhead: Streamline both device management and data protection with a unified platform.
Join the conversation
Interested in learning more? Join us on LinkedIn Live! Tune in for an in-depth discussion on how Backblaze and Kandji are helping organizations simplify and secure their Mac device management and data protection. Don’t miss out—save your spot today.
Get started
Interested in getting started? Contact our Sales team today to explore how Backblaze and Kandji can streamline your device management and data protection.
Today, I’m happy to announce the general availability of network activity events for Amazon Virtual Private Cloud (Amazon VPC) endpoints in AWS CloudTrail. This feature helps you to record and monitor AWS API activity traversing your VPC endpoints, helping you strengthen your data perimeter and implement better detective controls.
Previously, it was hard to detect potential data exfiltration attempts and unauthorized access to the resources within your network through VPC endpoints. While VPC endpoint policies could be configured to prevent access from external accounts, there was no built-in mechanism to log denied actions or detect when external credentials were used at a VPC endpoint. This often required you to build custom solutions to inspect and analyze TLS traffic, which could be operationally costly and negate the benefits of encrypted communications.
With this new capability, you can now opt in to log all AWS API activity passing through your VPC endpoints. CloudTrail records these events as a new event type called network activity events, which capture both control plane and data plane actions passing through a VPC endpoint.
Network activity events in CloudTrail provide several key benefits:
Comprehensive visibility – Log all API activity traversing VPC endpoints, regardless of the AWS account initiating the action.
External credential detection – Identify when credentials from outside your organization are accessing your VPC endpoint.
Data exfiltration prevention – Detect and investigate potential unauthorized data movement attempts.
Enhanced security monitoring – Gain insights into all AWS API activity at your VPC endpoints without the need to decrypt TLS traffic.
Visibility for regulatory compliance – Improve your ability to meet regulatory requirements by tracking all API activity passing through.
Getting started with network activity events for VPC endpoint logging To enable network activity events, I go to the AWS CloudTrail console and choose Trails in the navigation pane. I choose Create trail to create a new one. I enter a name in the Trail name field and choose an Amazon Simple Storage Service (Amazon S3) bucket to store the event logs. When I create a trail in CloudTrail, I can specify an existing Amazon S3 bucket or create a new bucket to store my trail’s event logs.
If you set Log file SSE-KMS encryption to Enabled, you have two options: Choose New to create a new AWS Key Management Service (AWS KMS) key or choose Existing to choose an existing KMS key. If you chose New, you need to type an alias in the AWS KMS alias field. CloudTrail encrypts your log files with this KMS key and adds the policy for you. The KMS key and Amazon S3 must be in the same AWS Region. For this example, I use an existing KMS key. I enter the alias in the AWS KMS alias field and leave the rest as default for this demo. I choose Next for the next step.
In the Choose log events step, I choose Network activity events under Events. I choose the event source from the list of AWS services, such as cloudtrail.amazonaws.com, ec2.amazonaws.com, kms.amazonaws.com, s3.amazonaws.com, and secretsmanager.amazonaws.com. I add two network activity event sources for this demo. For the first source, I select ec2.amazonaws.com option. For Log selector template, I can use templates for common use cases or create fine-grained filters for specific scenarios. For example, to log all API activities traversing the VPC endpoint, I can choose the Log all events template. I choose Log network activity access denied events template to log only access denied events. Optionally, I can enter a name in the Selector name field to identify the log selector template, such as Include network activity events for Amazon EC2.
As a second example, I choose Custom to create custom filters on multiple fields, such as eventName and vpcEndpointId. I can specify specific VPC endpoint IDs or filter the results to include only the VPC endpoints that match specific criteria. For Advanced event selectors, I choose vpcEndpointId from the Field dropdown, choose equals as Operator, and enter the VPC endpoint ID. When I expand the JSON view, I can see my event selectors as a JSON block. I choose Next and after reviewing the selections, I choose Create trail.
After it’s configured, CloudTrail will begin logging network activity events for my VPC endpoints, helping me analyze and act on this data. To analyze AWS CloudTrail network activity events, you can use the CloudTrail console, AWS Command Line Interface (AWS CLI), and AWS SDK to retrieve relevant logs. You can also use CloudTrail Lake to capture, store and analyze your network activity events. If you are using Trails, you can use Amazon Athena to query and filter these events based on specific criteria. Regular analysis of these events can help you maintain security, comply with regulations, and optimize your network infrastructure in AWS.
Now available CloudTrail network activity events for VPC endpoint logging provide you with a powerful tool to enhance your security posture, detect potential threats, and gain deeper insights into your VPC network traffic. This feature addresses your critical needs for comprehensive visibility and control over your AWS environments.
Network activity events for VPC endpoints are available in all commercial AWS Regions.
To get started with CloudTrail network activity events, visit AWS CloudTrail. For more information on CloudTrail and its features, refer to the AWS CloudTrail documentation.
Not many companies run exabyte scale data platforms, and not many companies open source their drive data—at Backblaze, we do both. From that perch, I’m sharing how I think about buying hard drives at exabyte scale, including the intentional design decisions and trade-offs I make as an expert in the field, and what you can apply to your own operations whether you’re running a couple hundred terabytes or petabytes on-premises.
TL/DR: Bigger drives aren’t always better
You’d think, as a cloud platform managing massive amounts of data, we’d be delighted that drive density continues to grow. But it’s not as simple as that. While we do run cohorts of 20TB+ drives in our environment, there are a few reasons it doesn’t always make sense to fill our servers up with the densest drives we can buy.
Drive size and IOPS starvation
Drives have a finite amount of capacity to perform input/output operations per second (IOPS). The larger the drive, the more those IOPS become a contentious consumable—creating a triangle of tension between storage capacity, reading, and writing. You can store more data on a 20TB drive, but you can only read and write as fast as that one drive allows. Conversely, you can store the same amount of data on five 4TB drives and 5x your IOPS capacity through concurrency.
For high demand workloads with high concurrency requirements for reading and writing files—like AI inferencing, for example—you’ll want to carefully consider the balance point between the right drive size and the performance you need to get out of the system. The ability to read, write, or delete content has to peacefully coexist with the ability for your storage infrastructure to service any of those three needs. Now, you might be thinking: If that’s a constraint, what about SSDs? I’ll get to that down below.
Drive size and rebuilds
When managing large data at scale we employ Reed-Solomon erasure coding to rebuild drives upon failure to maintain data durability. The larger the drive, the more painful and slow the rebuild when that drive eventually fails. The rebuild process can take hours or even days, depending on the size of the drive and the workload on the system. That can impact performance, especially if the storage system is already under heavy use, and increases the risk of another failure while the rebuild is in progress. While we mitigate that risk in a variety of ways, it may not be feasible for smaller shops to do so.
If you’re in a business that relies on real-time data access—financial institutions, healthcare providers, e-commerce platforms, for example—you need drives that balance capacity and rebuild speed. Higher-capacity drives may offer better storage density but smaller or enterprise-grade drives with faster rebuild times and higher endurance may be a better choice for businesses where continuous uptime and/or durability is critical.
HDD vs. SSD: Unit economics
The moral of the story is that the way you invest in drives, and how much you take things like drive size, drive type, and the failure rates we publish into consideration absolutely depends on your use case. It’s not as simple as looking at our Drive Stats and picking the drive with the lowest annualized failure rate.
In Backblaze’s early days, when we were focused on consumer backup, drive density and durability were the most important part of the equipment for us. We didn’t care about speed. As our customers increasingly bring us newer and more demanding use cases, our calculus for the kinds of drives we fill our data centers with will change with them.
As of December 31, 2024, we had 305,180 drives under management. Of that number, there were 4,060 boot drives and 301,120 data drives. This report will focus on those data drives as we review the Q4 2024 annualized failure rates (AFR), the 2024 failure rates, and the lifetime failure rates for the drive models in service as of the end of 2024. Along the way, we’ll share our observations and insights on the data presented, and, as always, we look forward to you doing the same in the comments section at the end of the post.
Sign up for the Drive Stats webinar
Tune in to ask those questions you’ve had spinning ‘round your head like so many drives, and meet the new Drive Stats team—Stephanie Doyle and David Johnson of Backblaze Blog fame. Yes, you heard that right: It’s my last Drive Stats before I head off to retirement (but more on that later in the report). Read on, and sign up, for analysis and insights from the 2024 report.
Q4 2024 hard drive failure rates
As of the end of 2024, Backblaze was monitoring 301,120 hard drives used to store data. For our evaluation, we removed from consideration 487 drives, as they did not meet the criteria to be included. We’ll discuss the criteria we used in the next section of this report. Removing these drives leaves us with 300,633 hard drives to analyze. The table below shows the annualized failure rates for Q4 2024 for this collection of drives.
Notes and observations
24TB drives are here. Seagate 24TB drives (model: ST24000NM002H) arrived in early December. The 1,200 drives filled one Backblaze Vault with no failed drives through the end of Q4. The 24TB Seagate drives join the 20TB Toshiba and 22TB WDC drive models in the 20-plus capacity club as we continue to dramatically increase storage capacity while optimizing existing storage server space.
Zero failures for the quarter. Five drive models had zero failures for the quarter starting with the 24TB Seagate drive model noted above. The others are the 4TB HGST (model: HMS5C4040ALE640), the 8TB Seagate (model: ST8000NM000A), the 14TB Seagate (model: ST14000NM000J), and the 16TB Seagate (model: ST16000NM002J). All of the zeroes come with the caveat of having a relatively small number of drives and drive days, but zero failures in a quarter is always a good thing.
The 4TB drives are nearly extinct. The 4TB drive count decreased by another 1,774 drives in Q4. (I discussed exactly how we migrate them in more detail if you want to dig in.) The remaining ~4,000 drives should be gone by the end of Q1 2025. They will be replaced by the incoming 20TB, 22TB, and 24TB drives. It should be noted that out of the 4TB drives in operation in Q4, only one failed, so those 20-plus TB drives have a lot to live up to from a failure perspective.
The quarterly failure rate is down. The AFR for Q4 dropped from 1.89% in Q3 to 1.35% in Q4. While all drive sizes delivered some improvement from Q3 to Q4, one of the primary drivers is the addition of over 14,000 new 20-plus TB drives. As a group, these drives delivered an AFR of 0.77% for the quarter.
Drive model criteria
We noted earlier we removed 487 drives from consideration when we produced the table above covering Q4 2024. There are two primary reasons we did not consider these drive models.
Testing. These are drives of a given model that we monitor and collect Drive Stats data on, but are not considered production drives at this time. For example, drives undergoing certification testing to determine if they are performant enough for our environment are not included in our Drive Stats calculations.
Insufficient data points. When we calculate the annualized failure rate for a drive model for a given period of time (quarterly, annual, or lifetime), we want to ensure we have enough data to reliably do so. Therefore we have defined criteria for a drive model to be included in the tables and charts for the specified period of time. Models that do not meet these criteria are not included in the tables and charts for the period in question.
Period
Drive Count
Drive Days
Quarterly
> 100
> 10,000
Annual
> 250
> 50,000
Lifetime
> 500
>100,000
Regardless of whether or not a given drive model is included in the charts and tables, all of the data for all of the drives we use is included in our Drive Stats dataset which you can download by visiting our Drive Stats page.
As with the Q4 quarterly results, we will apply these criteria to the annual and lifetime charts that follow in this report.
2024 annual hard drive failure rates
As of the end of 2024, Backblaze was monitoring 301,120 hard drives used to store data. We removed nine drive models consisting of 2,012 drives from consideration as they did not meet the annual criteria we have defined. This leaves us with 298,954 drives divided across 27 different drive models. The table below shows the AFRs for 2024 for this collection of drives.
Notes and observations
No zeros for the year. There were no qualifying drive models with zero failures in 2024. That said, the 16TB Seagate (model: ST16000NM002J) got close by recording just one drive failure back in Q3, giving the drive an AFR of 0.22% for 2024.
Busy data center techs. During 2024, our data center techs installed 53,337 drives. If we assume there are 2,080 work hours a year (52 weeks times 40 hours), that math is 53,337/2,080, and that means our intrepid DC techs installed 26 drives per hour. Busy, busy, busy!
The 24TB Seagate drives? While there were 1,200 new 24TB Seagate drives added in 2024, they were installed in early December and did not accumulate enough drive days to make the cut for the annual, or lifetime, tables. Including the 24TB Seagate drive, there were three models that missed out on being included in the 2024 annual tables, these drive models are listed below.
MFG
Model
Drive Count
Drive Days
2024 AFR
Seagate
ST8000NM000A
247
22,684
0.84%
Seagate
ST14000NM000J
232
19,696
1.32%
Seagate
ST24000NM002H
1,200
18,000
0.00%
As a reminder, a drive model needs to have over 250 drives by the end of Q4 and accumulate at least 50,000 drive days during 2024 to be included in the annual tables.
Comparing Drive Stats for 2022, 2023, and 2024
The table below compares the annual failure rates by drive model for each of the last three years. The table includes just those drive models which met the annual criteria as of the end of 2024. The data for each year is inclusive of that year only for the operational drive models present at the end of each year. The table is sorted by drive size and then AFR.
Notes and observations
The annual AFR is down. The 2024 AFR for all drives listed was 1.57%, this is down from 1.70% in 2023. We expect the overall failure rates to continue to fall in 2025, but we will be watching the following for indicators.
The failure rates of the 8TB and 12TB drive models. All of the models will exceed their five years of service. In general, the failure rate will noticeably increase as the drives exceed five years of service. And, while there are outliers like the current HGST 4TB drives, you can’t assume that will happen.
The failure rates of the 14TB and 16TB drive models. These models are approaching middle age—three to five years in operation. This is where, according to the bathtub curve, their failure rates could gradually increase—but not as severely as when they exceed five years.
The failure rates for the 20TB, 22TB, and 24TB drives models. These drives will enter the flat portion of the bathtub curve, that is where their failure rate should be the lowest.
Annualized failure rates vs. drive size
Now, we can dig into the numbers to see what else we can learn. We’ll start by looking at the quarterly annualized failure rate by drive size over the last three years.
Let’s take a look at the different drive sizes and how they affect the overall annualized failure rate over time.
Minimal impact. The 4TB (blue line) drives and 10TB (gold line) drives have had little impact over the last year on the overall failure rate as each finished the year with a relatively small number of drives. Still, the wild ride delivered by the 10TB drives keeps our DC techs on their toes.
Older drives. The 8TB (gray line) drives and 12TB (purple line) drives range in age from five to eight years and as such their overall failure rates should be increasing over time. The 12TB drives are following that pattern moving up from about 1% AFR back in 2021 to just about 3% in 2024. The failure rates of the 8TB drives, while erratic from quarter-to-quarter, have a nearly flat trendline over the same period.
Workhorse drives. The 14TB (green line) and 16TB (azure* line) drives comprise 57% of the drives in service and on average they range in age from two to four years. They are in the prime of their working lives. As such, they should have low and stable failure rates, and as you can see, they do.
* Maybe azure isn’t quite right, but robin’s egg blue seemed a bit pretentious.
New drives on the block. The 22TB (orange line) drives are in their early days as we continue to add more drives on a regular basis. Once the drive population settles down, we’ll have a better sense of the AFR direction. Still, the early results are solid with a lifetime AFR of 1.06%.
Annualized failure rates vs. manufacturer
One of the more popular ways we can look at this data is by the drive manufacturer as we’ve done below.
To complete the picture, the chart below uses the same data, but displays just the linear trendlines for each of the manufacturers over the same three-year period.
HGST. While the HGST trendline is not pretty, it doesn’t tell the entire story. Looking at the first chart, until Q4 2023, the HGST drives were at or below the average for all of the drives, that is all manufacturers. At that point, HGST has exceeded the average, and then some. The table below contains results for just the HGST drives for 2024. We’ve sorted them, high to low, by the 2024 AFR.
As you can see, there are two 12TB drive models driving the high AFR for the HGST drives. The HUH721212ALN604 model began showing signs of an increased quarterly AFR in Q1 2023 and the HUH721212ALE604 model followed suit in Q3 2024. Without these drive models, the 2024 AFR for HGST drive would be 0.55%.
Seagate. The quarterly AFR trendline decreased for the Seagate drives from 2022 through 2024. While the decrease was slight, from 2.25% to 2.0%, Seagate was the only manufacturer to do so. The decrease appears, at least in part, to be due to the removal of the Seagate 4TB drives during that period.
Toshiba. Over the 2022 to 2024 period, the quarterly AFR for the Toshiba drive models varied within a fairly narrow range between 0.80% and 1.52%, with most quarters hovering slightly around 1.2%. Most importantly, none of the individual drive models were outliers, as the highest quarterly AFR for any Toshiba drive model was 1.58%. We like consistency.
WDC. While WDC drive models delivered a similar level of consistency as the Toshiba models, they did so with a lower AFR each quarter. From 2022 through 2024, the range of quarterly AFR values for the WDC models was 0.0% to 0.85%. The 0.0% AFR was in Q1 2022 when none of the 12,207 WDC drives in operation failed during that quarter.
Lifetime hard drive stats
As of the end of 2024, Backblaze was monitoring 301,120 hard drives used to store data. Applying our drive criteria noted above for the lifetime period, we removed 11 drive models consisting of 2,736 drives from consideration as they did not meet the lifetime criteria we defined. This leaves us with 298,230 drives divided across 25 different drive models. The table below shows the lifetime AFRs for this collection of drives.
The current lifetime AFR for all of the drives is 1.31%. This is down from 1.46% in 2023. The drop is primarily due to the completion of the migration of the 4TB Seagate drives in 2024, which left us with only two of these drives still in operation as of the end of 2024. As a consequence, the 79 million drive days and over 5,600 drive failures racked up by the 4TB Seagate drives by the end of 2023 are not included in the data presented in the 2024 lifetime table above.
In the final table below, we’ve taken the lifetime table and sorted out the drive models that have a lifetime AFR of 1.50% or less by drive size.
A couple of caveats as you review the table.
There is enough data for each model to say the AFR values are solid. That said, everything could change tomorrow. In general, the hard drive failure rate follows the bathtub curve as the drives age—unless it doesn’t. Some drives refuse to fail as they age, like the 4TB HGST drives. Other drives are great, and then “hit the wall” and bend the failure curve upward, fast.
A drive model with a 1% annualized failure rate means that you can expect one drive out of 100 to fail in a year. If you’re a personal drive user, that one drive could be yours. If you have exactly one drive, your personal annualized failure rate is 100%. In other words, always have a backup, and don’t forget to test it.
Migration time
I have been authoring the various Drive Stats reports for the past ten years and this will be my last one. I am retiring, or perhaps in Drive Stats vernacular, it would be “migrating.” Either way, after 10 years in the U.S. Air Force and 30+ years in Silicon Valley Tech, it is time. Drive Stats will continue with Stephanie Doyle and David Johnson as the replacement drive models beginning with the Q1 2025 report. I wish them well.
I want to say thank you to each of you who have taken your time to peruse and engage with the Drive Stats reports and data over the last 10 years. And, thank you as well for the comments, questions, and discussions that raced and raged across the various communities that care about something as mundane and awesome as a hard drive. It has been quite the ride—thanks again.
The Hard Drive Stats data
The complete data set used to create the tables and charts in this report is available on our Hard Drive Test Data page. You can download and use this data for free for your own purpose. All we ask are three things: 1) you cite Backblaze as the source if you use the data, 2) you accept that you are solely responsible for how you use the data, and 3) you do not sell this data itself to anyone; it is free.
Good luck, and let us know if you find anything interesting.
Media and entertainment professionals have long debated how and where cloud services best fit in their workflows. Archive was initially seen as the most natural fit. But end-to-end cloud workflows and cloud-based production were viewed with skepticism due to the network bandwidth required to edit full resolution content. Now, as more organizations lean into REMI workflows, and new cloud-oriented creative tools enable real-time content production, the cloud is playing a role at every step of creative workflows.
Of course, it’s one thing to talk about real-time production in the cloud and it’s another thing to show how the cloud has transformed an actual workflow from end-to-end. But that’s exactly what the Philadelphia Eagles media team did by building a streamlined work-from-anywhere solution with cloud storage and cloud-delivered asset management. The best part was that rolling out the new cloud workflow was just as painless as it was transformative for their business.
We went from frequent LTO crashes and long restore times to near-instant access for every stored clip.
—Stacy Kelleher, Director of Production, Philadelphia Eagles
Archive availability sidelines production efforts
The Eagles were using a portfolio of different storage systems to store petabytes of content with different availability for each tier. The best they could hope for when restoring clips from LTO, for example, was half real-time. So, a three hour clip might take an hour and half to restore—and that’s if the LTO system was working at all. It became so problematic that they stopped archiving content to LTO altogether, opting to max out their SAN to ensure fast access.
The desire for faster file-sharing led the business requirements for overhauling their storage infrastructure. They needed to:
Consolidate their storage infrastructure.
Improve remote access faster for sharing content internally or even monetizing it outside the organization.
Improve the reliability of their backup and archive solution.
But migrating data and setting up a new system is no small feat.
Migration can’t run down the clock
Anyone who’s ever done a legacy migration knows moving to a new system is a quagmire. You can’t tell IT: You need to stop syncs and backups for three weeks while we do a migration.
There’s a reason folks in the media and entertainment space dread a migration. It’s slow. It’s semi-painful. And, everything has to port over correctly.
The Eagles approached their migration in the off season. They needed some flexibility to consolidate their multiple SANs, stadium production operations, and LTO system into something that helped them fly higher.
They consolidated the data into one single tier with a Quantum QSX on site for nearline storage and shifted hundreds of terabytes from their SAN and LTO system to Backblaze as their off-site storage for backup and archive.
Cloud MAM for the win
With storage sorted, the Eagles then integrated Mimir, a video collaboration and production platform that includes production asset management, archive, and object-store integration, to keep everything organized and on time. Whenever a file is uploaded to Mimir, it’s automatically stored in Backblaze B2 via Mimir’s file indexer system Kelda. This covered the game day action—their production team had fast access to recently recorded content, providing flexibility to work from home after those late night games.
Getting our sponsored, highest-performing content out quickly drives more views and boosts revenue, so efficiency on game day is critical. Our newly streamlined workflows ensure our editors can deliver while the content is still relevant and engaging.
—Stacy Kelleher, Director of Production, Philadelphia Eagles
The final score
The new system empowers their production team by giving them instant access and fast workflows so they can work without slowdowns. Kelleher noted that restoring a clip is nearly instant.
They have the ability to share links directly from Mimir to users outside the organization for things like pre-season broadcasts, which comes in handy especially when those users don’t want, need, or have the equipment to download the entire broadcast file. Stacy can just copy and paste a Mimir link into an email, and outside agencies or users can watch entire games at speed.
Finally, they freed up IT staff time spent managing all that tape and old hardware, not to mention physical space. It all added up to a big win for the IT team, the franchise, and the fans.
Now I can easily share entire broadcasts by copying and sharing a link from our MAM. No need for FTP downloads or uploading to other platforms. It’s fast, seamless, and ensures everyone can view the content without issues.
—Stacy Kelleher, Director of Production, Philadelphia Eagles
If you haven’t been able to keep pace with the AI news cycle, you’d be forgiven. I work at a tech company, and it’s felt like bailing water with a teacup over the past few weeks. But the term that keeps rising to the top of the flotsam in the boat is this: reasoning models. The regular ol’ models that power ChatGPT, Gemini, and Claude are cool and all, but reasoning models are what you should keep an eye on as an enterprise tech leader, specifically DeepSeek and OpenAI.
In the spirit of our AI 101 series, I’ll do my level best to recap the finer points and decode some of the more esoteric terms you’re likely to encounter (Like: WTH is a “mixture of experts”? That sounds like a party I want to be invited to, but will definitely skip at the last minute.)
The reasoning model releases: OpenAI o1-mini, DeepSeek R1, and OpenAI o3-mini
The last few weeks and months have seen a flurry of activity in the AI space, with reasoning models taking center stage. The TL/DR is that reasoning models are LLMs that can self-correct before delivering a response to a prompt, though their turn time is a little longer than your standard LLM.
Here are the releases that you should know about.
OpenAI o1-mini: September 12, 2024
It seems like a lifetime ago, but OpenAI released its o1-mini model back in September. o1-mini wasn’t the first reasoning model to go to market (models from Google, DeepMind, Anthropic, and Meta dabbled in reasoning for specific tasks). But, it was more cost-efficient at inference—80% cheaper than the o1-preview model. What you need to know:
Yes, o1-preview and o1-mini were released at the same time—it’s confusing. Without getting into the weeds, here’s the difference: pricing. o1-preview was the most expensive OpenAI model on offer at $15/1M input tokens and $60/1M output tokens versus mini’s $3/1M input and $12/1M output. (You can think of tokens as units of data, like a prompt or a response, that are processed by the ML model.)
o1-preview (the expensive one) was purported at the time to perform “similarly to PhD students on challenging benchmark tasks in physics, chemistry, and biology.”
o1-mini (the 80% cheaper one) was designed to be particularly well-suited for coding tasks.
DeepSeek R1: January 20, 2025
Unless you’ve been under a rock, you’ve heard about this one. DeepSeek rattled the AI industry and financial markets with its release of R1, challenging OpenAI’s models on performance, pricing, and open-source availability. (We love a good open-source release.) What you need to know:
DeepSeek R1 delivers comparable results to OpenAI’s o1 models, both preview and mini, on math and coding benchmarks, while being trained on fewer GPUs—orders of magnitude fewer. Best guess estimates put it at around 60,000 GPUs, while industry leaders like OpenAI and Anthropic exceed 500k each.
This makes R1 much cheaper at $0.14/1M input tokens and $2.19/1M output tokens.
These efficiency claims could have far-reaching impacts for enterprises looking to build AI at a fraction of the cost. (The DeepSeek platform page has been down since we tasked one of our favorite tech evangelists with testing it, but stay tuned for a deep dive on how it works.)
OpenAI o3-mini: January 31, 2025
OpenAI previewed o3 in December, and brought it to GA just 11 days after DeepSeek joined the party. What you need to know:
o3-mini is intended for programming and STEM use cases.
I’m admittedly cherry picking these releases a bit to keep things simple. Suffice it to say, there are a lot of models, even within OpenAI’s o-series, but these are the ones of note at least as it pertains to recent events.
What is reasoning anyway?
You might see reasoning described as “thinking” before it delivers an answer, but do not be fooled. AI cannot yet “think” or, to be fair, “reason” in the ways that we apply those terms to humans. To describe what they actually do, I need to use a word salad of jargon. I’m sorry—definitions follow. Reasoning models leverage chain-of-thought prompting to guide decision-making, incorporating self-improvement mechanisms and using test-time thinking to make real-time adjustments.
Chain-of-thought (CoT) prompting: Models break problems into logical steps (e.g., solving math problems via intermediate equations)
Self-improvement mechanisms: Techniques like the Self-Taught Reasoner (STaR) enable iterative refinement of reasoning through automated feedback loops.
Test-time thinking: Models can make decisions during deployment based on real-time inputs, rather than relying solely on pre-trained models or fixed strategies.
Here are a few more terms you might come across for good measure:
Inference compute: The computational power needed to run a reasoning model and generate predictions or outputs based on new data after the model has been trained.
Mixture of experts approach: Using multiple specialized models (“experts”) that handle different tasks, and applying a gating mechanism to select the most relevant expert to use to make predictions based on the input data. Of note: DeepSeek used this approach to create efficiencies.
Distillation: Using inputs and outputs from one model to train another model. Of note: OpenAI alleges this is how DeepSeek “stole” its IP.
This is all pretty cool, if linguistically painful, stuff, and it means that reasoning models are shifting perceptions of model capabilities. But they’re not without persistent challenges. Like other LLMs, they still struggle with complex reasoning failures, lack of training transparency, and cognitive biases.
Why should you care?
If the past two weeks (and, really, the past two years) are any indication, AI innovation will continue its blistering pace. Reasoning models, and LLMs in general, will become diverse and specialized for narrower tasks as the core technology is increasingly commoditized and cheapened. And, it’s worth noting that this is a totally normal—and expected—lifecycle when it comes to new technology.
What does it all mean for enterprises looking to build AI into their operations? Two key takeaways:
Don’t overcommit on any one toolset or investment: Test out OpenAI, DeepSeek, Gemini, Alibaba’s Qwen, and others. And, stay ahead of the changing landscape and new models—stay nimble, and keep experimenting.
Take care of your data: What makes these models valuable for your company isn’t so much their capabilities, but your data. You need to retain it in storage that’s reliable, easy to access, and doesn’t lock you out of AI experimentation with exorbitant egress fees.
Even as AI models get better, having those fundamentals in place can only help your business and set you up to better leverage AI when it’s right for your operations.
During this past AWS re:Invent, Amazon CEO Andy Jassy shared valuable lessons learned from Amazon’s own experience developing nearly 1,000 generative AI applications across the company. Drawing from this extensive scale of AI deployment, Jassy offered three key observations that have shaped Amazon’s approach to enterprise AI implementation.
First is that as you get to scale in generative AI applications, the cost of compute really matters. People are very hungry for better price performance. The second is actually quite difficult to build a really good generative AI application. The third is the diversity of the models being used when we gave our builders freedom to pick what they want to do. It doesn’t surprise us, because we keep learning the same lesson over and over and over again, which is that there is never going to be one tool to rule the world.
As Andy emphasized, a broad and deep range of models provided by Amazon empowers customers to choose the precise capabilities that best serve their unique needs. By closely monitoring both customer needs and technological advancements, AWS regularly expands our curated selection of models to include promising new models alongside established industry favorites. This ongoing expansion of high-performing and differentiated model offerings helps customers stay at the forefront of AI innovation.
This leads us to Chinese AI startup DeepSeek. DeepSeek launched DeepSeek-V3 on December 2024 and subsequently released DeepSeek-R1, DeepSeek-R1-Zero with 671 billion parameters, and DeepSeek-R1-Distill models ranging from 1.5–70 billion parameters on January 20, 2025. They added their vision-based Janus-Pro-7B model on January 27, 2025. The models are publicly available and are reportedly 90-95% more affordable and cost-effective than comparable models. Per Deepseek, their model stands out for its reasoning capabilities, achieved through innovative training techniques such as reinforcement learning.
Today, you can now deploy DeepSeek-R1 models in Amazon Bedrock and Amazon SageMaker AI. Amazon Bedrock is best for teams seeking to quickly integrate pre-trained foundation models through APIs. Amazon SageMaker AI is ideal for organizations that want advanced customization, training, and deployment, with access to the underlying infrastructure. Additionally, you can also use AWS Trainium and AWS Inferentia to deploy DeepSeek-R1-Distill models cost-effectively via Amazon Elastic Compute Cloud (Amazon EC2) or Amazon SageMaker AI.
With AWS, you can use DeepSeek-R1 models to build, experiment, and responsibly scale your generative AI ideas by using this powerful, cost-efficient model with minimal infrastructure investment. You can also confidently drive generative AI innovation by building on AWS services that are uniquely designed for security. We highly recommend integrating your deployments of the DeepSeek-R1 models with Amazon Bedrock Guardrails to add a layer of protection for your generative AI applications, which can be used by both Amazon Bedrock and Amazon SageMaker AI customers.
Let me walk you through the various paths for getting started with DeepSeek-R1 models on AWS. Whether you’re building your first AI application or scaling existing solutions, these methods provide flexible starting points based on your team’s expertise and requirements.
1. The DeepSeek-R1 model in Amazon Bedrock Marketplace Amazon Bedrock Marketplace offers over 100 popular, emerging, and specialized FMs alongside the current selection of industry-leading models in Amazon Bedrock. You can easily discover models in a single catalog, subscribe to the model, and then deploy the model on managed endpoints.
To access the DeepSeek-R1 model in Amazon Bedrock Marketplace, go to the Amazon Bedrock console and select Model catalog under the Foundation models section. You can quickly find DeepSeek by searching or filtering by model providers.
After checking out the model detail page including the model’s capabilities, and implementation guidelines, you can directly deploy the model by providing an endpoint name, choosing the number of instances, and selecting an instance type.
You can also configure advanced options that let you customize the security and infrastructure settings for the DeepSeek-R1 model including VPC networking, service role permissions, and encryption settings. For production deployments, you should review these settings to align with your organization’s security and compliance requirements.
With Amazon Bedrock Guardrails, you can independently evaluate user inputs and model outputs. You can control the interaction between users and DeepSeek-R1 with your defined set of policies by filtering undesirable and harmful content in generative AI applications. The DeepSeek-R1 model in Amazon Bedrock Marketplace can only be used with Bedrock’s ApplyGuardrail API to evaluate user inputs and model responses for custom and third-party FMs available outside of Amazon Bedrock. To learn more, read Implement model-independent safety measures with Amazon Bedrock Guardrails.
Amazon Bedrock Guardrails can also be integrated with other Bedrock tools including Amazon Bedrock Agents and Amazon Bedrock Knowledge Bases to build safer and more secure generative AI applications aligned with responsible AI policies. To learn more, visit the AWS Responsible AI page.
In the Amazon SageMaker AI console, open SageMaker Unified Studio or SageMaker Studio. In case of SageMaker Studio, choose JumpStart and search for “DeepSeek-R1” in the All public models page.
You can select the model and choose deploy to create an endpoint with default settings. When the endpoint comes InService, you can make inferences by sending requests to its endpoint.
You can derive model performance and ML operations controls with Amazon SageMaker AI features such as Amazon SageMaker Pipelines, Amazon SageMaker Debugger, or container logs. The model is deployed in an AWS secure environment and under your virtual private cloud (VPC) controls, helping to support data security.
As like Bedrock Marketpalce, you can use the ApplyGuardrail API in the SageMaker JumpStart to decouple safeguards for your generative AI applications from the DeepSeek-R1 model. You can now use guardrails without invoking FMs, which opens the door to more integration of standardized and thoroughly tested enterprise safeguards to your application flow regardless of the models used.
3. DeepSeek-R1-Distill models using Amazon Bedrock Custom Model Import Amazon Bedrock Custom Model Import provides the ability to import and use your customized models alongside existing FMs through a single serverless, unified API without the need to manage underlying infrastructure. With Amazon Bedrock Custom Model Import, you can import DeepSeek-R1-Distill Llama models ranging from 1.5–70 billion parameters. As I highlighted in my blog post about Amazon Bedrock Model Distillation, the distillation process involves training smaller, more efficient models to mimic the behavior and reasoning patterns of the larger DeepSeek-R1 model with 671 billion parameters by using it as a teacher model.
After storing these publicly available models in an Amazon Simple Storage Service (Amazon S3) bucket or an Amazon SageMaker Model Registry, go to Imported models under Foundation models in the Amazon Bedrock console and import and deploy them in a fully managed and serverless environment through Amazon Bedrock. This serverless approach eliminates the need for infrastructure management while providing enterprise-grade security and scalability.
4. DeepSeek-R1-Distill models using AWS Trainium and AWS Inferentia AWS Deep Learning AMIs (DLAMI) provides customized machine images that you can use for deep learning in a variety of Amazon EC2 instances, from a small CPU-only instance to the latest high-powered multi-GPU instances. You can deploy the DeepSeek-R1-Distill models on AWS Trainuim1 or AWS Inferentia2 instances to get the best price-performance.
Once you have connected to your launched ec2 instance, install vLLM, an open-source tool to serve Large Language Models (LLMs) and download the DeepSeek-R1-Distill model from Hugging Face. You can deploy the model using vLLM and invoke the model server.
To learn more, refer to this step-by-step guide on how to deploy DeepSeek-R1-Distill Llama models on AWS Inferentia and Trainium.
Since the release of DeepSeek-R1, various guides of its deployment for Amazon EC2 and Amazon Elastic Kubernetes Service (Amazon EKS) have been posted. Here is some additional material for you to check out:
Things to know Here are a few important things to know.
Pricing – For publicly available models like DeepSeek-R1, you are charged only the infrastructure price based on inference instance hours you select for Amazon Bedrock Markeplace, Amazon SageMaker JumpStart, and Amazon EC2. For the Bedrock Custom Model Import, you are only charged for model inference, based on the number of copies of your custom model is active, billed in 5-minute windows. To learn more, check out the Amazon Bedrock Pricing, Amazon SageMaker AI Pricing, and Amazon EC2 Pricing pages.
Data security– You can use enterprise-grade security features in Amazon Bedrock and Amazon SageMaker to help you make your data and applications secure and private. This means your data is not shared with model providers, and is not used to improve the models. This applies to all models—proprietary and publicly available—like DeepSeek-R1 models on Amazon Bedrock and Amazon SageMaker. To learn more, visit Amazon Bedrock Security and Privacy and Security in Amazon SageMaker AI.
Now available DeepSeek-R1 is generally available today in Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. You can also use DeepSeek-R1-Distill models using Amazon Bedrock Custom Model Import and Amazon EC2 instances with AWS Trainum and Inferentia chips.
If there’s one thing I’ve learned from working with enterprise customers on their cyber resilience postures, it’s this: Downtime caused by disasters can be costly, and every organization should have a disaster recovery (DR) plan in place.
Today, I’m outlining 12 best practices to consider when developing and reviewing your organization’s DR plan to minimize downtime, risk, and unexpected costs in the face of unexpected events.
These key considerations will help your IT team when developing and reviewing a disaster recovery plan.
1. Leave no disaster unidentified
The first step in building a strong DR plan is to identify all potential threats, not just major disasters. Consider “minor” threats like human error or hardware failures that could disrupt security and operations.
2. Plan for the worst (and beyond)
While it’s important to plan for likely threats like ransomware attacks, don’t neglect worst-case scenarios. Develop a plan that can handle a catastrophic event like a natural disaster wiping out your primary site or a widespread communication outage.
3. Ransomware: Your uninvited guest
Ransomware attacks are a major threat. Dedicate a significant portion of your DR plan to addressing ransomware scenarios, including recovery procedures and strategies to minimize the impact of such attacks.
4. Beyond the walls: Cloud catastrophe
Extend your DR plan beyond on-premises threats to include potential disruptions associated with cloud services, such as outages or security breaches. It may seem counterintuitive that we, a cloud provider, are the ones to call this out, but we’re big proponents of the tenet that the one truth about technology is that it will fail. Multi-cloud and hybrid disaster recovery options help reduce the risk of those rare, but highly impactful outages. Cloud provider service level agreements (SLAs) define availability targets (e.g., 99.9% uptime) which can increase your overall data and application availability above on-premises capabilities.
5. Infrastructure independence
Always anticipate potential infrastructure unavailability during a disaster. Plan alternative methods for accessing critical data and systems, including leveraging hot cloud infrastructure as a service (IaaS) solutions as a backup.
6. Think beyond data recovery
A robust DR plan goes beyond just recovering data. It should outline procedures for rebuilding your entire IT environment, including applications, configurations, security, and user accounts. There’s a big gap between restoring data and actual recovery.
7. Plan variations
Develop different versions of your DR plan based on the severity of the incident and the types of incidents your business is most likely to face. This allows for a more targeted response, depending on the specific nature of the disruption.
8. Runbooks: Your DR roadmap
Consider creating predefined “runbooks” that outline specific steps for various disaster scenarios. These detailed documents provide clear instructions for IT staff during a crisis.
9. Recovery is a sprint, but DR planning is a marathon
Modern DR strategies prioritize planning for recovery from the beginning. Verify the usability of your backups and recovered data to ensure their effectiveness during a crisis. Test your restoration procedures regularly to avoid the pitfall of unusable backups during a disaster.
10. Securing resources in advance
Don’t wait for disaster to strike before securing necessary resources. Budgetary approvals, software licenses, and hardware procurement should all be addressed in advance to avoid delays during a crisis.
11. Cyber insurance considerations
If your business has cyber insurance, familiarize yourself with the DR planning requirements outlined in the policy. Understanding the insurance company’s expectations can help you tailor your DR strategy accordingly.
12. Backups are essential, but they’re not the whole plan
As cybercriminals become more sophisticated, they often target backups as well. Backups—once a low-priority just-in-case item—are now mission critical. Backups are a critical foundation for your DR plan, but they are not the entire plan.
A closing note on recovery
Finally, make sure to regularly test and update your DR plan to ensure it remains effective and up to date. By leveraging affordable, secure, cloud-based backup and archive as part of your overall disaster recovery strategy, you can better protect your critical data. The result will minimize downtime, risk, and costs in the face of unexpected events.
Well, it’s been another historic year! We’ve watched in awe as the use of real-world generative AI has changed the tech landscape, and while we at the Architecture Blog happily participated, we also made every effort to stay true to our channel’s original scope, and your readership this last year has proven that decision was the right one.
AI/ML carries itself in the top posts this year, but we’re also happy to see that foundational topics like resiliency and cost optimization are still of great interest to our audience.
(By the way, if you were hoping for more AI/ML content, head on over to our sister channel, the AWS Machine Learning Blog!).
Without further ado, here are our top posts from 2024!
In keeping with Let’s Architect! series, we have our first of three favorites for the year. This set of resources helps you apply Well-Architected standards in practice.
As I said, Let’s Architect! has a winning series, and they’ve got a finger on the pulse of the tech world. This post about machine learning showcases some of the most exciting things happening at AWS.
Figure 3. Let’s Architect
If you’re more interested in generative AI, you can also take a look at another post from 2024: Let’s Architect! GenAI
Preparedness is another common theme in this year’s favorites. Michael, John, and Saurabh are well-versed in multi-Region architecture, and they’re here to share some strategies to contain failure impact.
Figure 4. When the application experiences an impairment using S3 resources in the primary Region, it fails over to use an S3 bucket in the secondary Region.
Let’s talk cost optimization. This post about a three-tier architecture that relies on the AWS Free Tier is a must-read for anyone looking for tips to help them avoid unnecessary costs (and that’s everyone).
Figure 5. Example of a three-tier architecture on AWS
As usual, Haleh & team are pros at making sure the Well-Architected Framework is current and relevant. Take a look at the enhanced and expanded guidance in all six pillars.
One more winning post from Luca, Federica, Vittorio, and Zamira! This collection of developer resources includes new ideas in AWS Lambda, Amazon Q Developer, and Amazon DynamoDB.
Frugality AND Well-Architected? What a winning combo! This post, inspired by the 2023 re:Invent keynote, outlines the seven laws of Frugal Architecture.
And finally, our number one post of the year! Amit and Luiz showcase a customer solution with real-world applications that builds on the guidelines of other posts in this list! Well done!
Figure 10. The Pilot Light scenario for a 3-tier application that has application servers and a database deployed in two Regions
Thank you!
As always, thanks to our contributors for their dedication and desire to share, and to you, our readers! We would be nothing with you. Literally.
For other top post lists, see our Top 10 and Top 5 posts from previous years.
In this post, I’ll look at another AI technology, agents, and show you how I built an AI agent that answers questions about hard drive reliability based on over 11 years of raw data from our Drive Stats franchise.
The Drive Stats dataset is ideal for this kind of work. It’s a real-world dataset, but, it only weighs in at around 500 million records consuming about 20GB of storage in Parquet format (“only” being a relative term), so you can use it with big data and AI tools on a laptop in a reasonable amount of time rather than spinning up an expensive virtual machine (VM) and/or spending days waiting for an operation to complete. As an example, converting the entire Drive Stats data set from CSV to Parquet using a Python app on my MacBook Pro takes a couple of hours. On the same hardware, converting a terabyte-scale data set would take about four days.
Speaking of Drive Stats
The Drive Stats 2024 report comes out February 11, and we’re hosting a LinkedIn Live event where Andy Klein, resident Drive Stats guru, will share highlights. Register today to save your spot.
You can use these same techniques with any large dataset, from healthcare to ecommerce to financial services. In this example, we’re working with a single table, but you could adapt the sample code to a data lake comprising any number of tables.
What is an AI agent?
In the spirit of the times, I posed this question to ChatGPT. Its answer:
An AI agent is a software system designed to autonomously perform tasks or make decisions based on its environment and goals. It leverages artificial intelligence techniques—such as machine learning, reasoning, and natural language processing—to process information, make decisions, and take actions to achieve specific objectives.
Key components of an AI agent include:
Perception: The ability to sense and understand its environment. This could be through sensors, input data, or other means of gathering information.
Reasoning/decision-making: The core processing mechanism that helps the agent interpret its environment, make decisions, and plan actions. It could use various algorithms, such as decision trees, reinforcement learning, or neural networks.
Action: Once the agent has analyzed the environment and made a decision, it takes action to achieve its goal, whether it’s performing an operation, giving a recommendation, or interacting with another system.
Learning: Some AI agents can adapt over time, improving their decision-making and actions based on experience (via reinforcement learning, supervised learning, etc.).
AI agents can range from simple systems, like chatbots or virtual assistants, to more complex systems like autonomous vehicles, robots, or financial trading algorithms.
In general, the term “agent” emphasizes the idea of autonomy—the agent operates independently, often with the ability to learn, adapt, and make decisions based on changing conditions without direct human intervention.
In this example, the agent’s environment is a database containing the Drive Stats data (more on that below), and I want it to perform the following tasks:
Based on a natural language question, such as “Which drive has the lowest annual failure rate?”, generate a SQL query that retrieves data that will help answer the question.
Execute that query against the Drive Stats dataset.
Based on the query results, either create a new query that better answers the question, or generate a natural language answer.
Now I’ve established that my agent will be writing a SQL query, the next question is, “What will it be querying?” I’ve written about querying the Drive Stats dataset before; in that blog post I explained how I wrote a Python script to convert the Drive Stats data from the CSV format in which we publish it to Apache Parquet, a column-oriented file format particularly well-suited for storing tabular data for use in analytical queries, and upload it to a Backblaze B2 Bucket using the Apache Hive table format. There’s a broad ecosystem of tools and platforms that can manipulate Parquet data in object storage (for example, Apache Spark and Snowflake) and I chose Trino, the open source distributed SQL engine that forms the basis for Amazon Athena, to execute queries against the data.
I could have used the same technologies for this exercise, but I decided to add Apache Iceberg to the mix. While Parquet is a file format that specifies how tabular data is stored in files, Iceberg is a table format that governs how those files can be combined and interpreted as a database table. Iceberg provides a number of advantages over Hive as a table format, including better performance and much more flexible data partitioning.
What is partitioning?
Partitioning splits a dataset on one or more column values, easing data management and improving performance when a query includes a partition column.
Partitioning by year and month makes sense for the Drive Stats dataset—the resulting Parquet files are in the hundreds of megabytes, the sweet spot for Parquet data. To apply this partitioning to the Drive Stats data using the Hive table format, I had to create otherwise redundant month and year columns from the existing date column, complicating the schema.
Iceberg, by contrast, supports hidden partitioning, allowing you to apply a transformation to a column value to produce a partition value without adding any new columns. With the Drive Stats data, that meant I could simply define the partitioning as month(date) (the resulting value being the number of months since 1/1/1970, rather than an integer between 1 and 12), with no need to create any additional columns.
LangChain’s SQLDatabase class provides access to databases via the SQLAlchemy open-source Python library. The demo code obtains a SQLDatabase instance by providing a URI containing the trino scheme, a username and the location of the database node:
db = SQLDatabase.from_uri('trino://admin@localhost:8080/iceberg/drivestats')
Note: In this and other code excerpts in this blog post, I’ve omitted extraneous “boilerplate” code. As mentioned above, the full source code is available in the ai-agent-demo repository.
As you can infer from the localhost domain name, I’m running Trino on my laptop. I’m actually running it in Docker, using the Iceberg/Hive Docker Compose script from the trino-getting-started-b2 repository. I’ll dive into that example in a future blog post.
A simple query confirms that we have a successful database connection:
db.run("SELECT COUNT(*) FROM drivestats")
'[(537220724,)]'
As the result conveys, there are over 537 million rows in the Drive Stats dataset.
Each row contains the metrics collected from a single drive in the Backblaze fleet on a specific day. The schema has evolved over time, but, currently, the following columns are included:
date: The date of collection.
serial_number: The unique serial number of the drive.
model: The manufacturer’s model number of the drive.
capacity_bytes: The drive’s capacity in bytes.
failure: 1 if this was the last day that the drive was operational before failing, 0 if all is well.
pod_slot_num: The physical location of a drive within a storage server, as an integer from 0 to 59. The specific slot differs based on the storage server type and capacity: Backblaze (45 or 60 drives), Dell (26 drives), or Supermicro (60 drives).
pod_id: There are 20 storage servers in each Backblaze Vault. The pod_id is a numeric field with values from 0 to 19 assigned to each of the 20 storage servers.
vault_id: All data drives are members of a Backblaze Vault. Each Vault consists of either 900 or 1,200 hard drives divided evenly across 20 storage servers. The Vault is a numeric value starting at 1,000.
cluster_id: The name of a given collection of storage servers logically grouped together to optimize system performance, formatted as a numeric field with up to two digits. Note: At this time the cluster_id is not always correct; we are working on fixing that.
datacenter: The Backblaze data center where the drive is installed, currently one of ams5 (Amsterdam, Netherlands), iad1 (Reston, Virginia), phx1 (Phoenix, Arizona), sac0 (Sacramento, California), sac2 (Stockton, California) or, now live, yyz1, our new Toronto, Ontario, data center.
is_legacy_format: Currently 0, but may change in future as more fields are added.
A collection of SMART attributes. The number of attributes collected has risen over time; currently we store 93 SMART attributes in each record, each one in both raw and normalized form, with field names of the form smart_n_normalized and smart_n_raw, where n is between 1 and 255.
# OPENAI_API_KEY must be defined in the .env file
load_dotenv()
llm = ChatOpenAI(model="gpt-4o-mini")
Now we need a system prompt template. We’ll combine this with the database schema and a natural language question to form the prompt that we send to OpenAI. As in the LangChain tutorial, I’m using a prompt from the LangChain Prompt Hub:
This is the prompt template text, with the placeholders shown in {braces}:
================================ System Message ================================
Given an input question, create a syntactically correct {dialect} query to run to help find the answer. Unless the user specifies in his question a specific number of examples they wish to obtain, always limit your query to at most {top_k} results. You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for a few relevant columns given the question.
Pay attention to use only the column names that you can see in the schema description. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Only use the following tables:
{table_info}
Question: {input}
Notice how the template requires you to specify the correct SQL dialect, constrains the number of results returned, and encourages the model to not hallucinate column names that do not exist in the schema.
A helper function populates the prompt template, sends it to the model, and returns the generated SQL query:
We can test the helper function by calling it directly with a Python dictionary containing a simple question:
question = {"question": "How many drives are there?"}
query = write_query(question)
The resulting query dictionary does indeed contain a valid SQL query, but it won’t give us the answer we are looking for.
{'query': 'SELECT COUNT(*) AS drive_count FROM drivestats'}
That query will tell us how many rows there are in the dataset, rather than how many drives. We supplied the database schema to the model, but we haven’t given it any information on the semantics of the columns in the drivestats table. We can provide a bit more detail to obtain the correct query:
question = {"question": "Each drive has its own serial number. How many drives are there?"}
query = write_query(question)
This time, the generated SQL query is correct:
{'query': 'SELECT COUNT(DISTINCT serial_number) AS total_drives FROM drivestats'}
As you can see, it’s important to check the output of AI models—they can and do generate unexpected results.
A second helper function executes the query against the database:
We can test it using the (correct) generated query:
result = execute_query(query)
{'result': '[(430464,)]'}
We need one more helper function, to pass the result set to the model and have it generate a natural language response. This time, we define our own prompt:
def generate_answer(state: State):
prompt = (
"Given the following user question, corresponding SQL query, "
"and SQL result, answer the user question.\n\n"
f'Question: {state["question"]}\n'
f'SQL Query: {state["query"]}\n'
f'SQL Result: {state["result"]}'
)
response = llm.invoke(prompt)
return {"answer": response.content}
Again, we can test it in isolation. Notice that we have to provide the question and query, as well as the result so that the model has the context it needs:
We’ve combined the write_query and execute_query steps into a graph object that can run agent-generated queries. I’ll quote the security note from the LangChain tutorial on the inherent risks in doing so:
Building Q&A systems of SQL databases requires executing model-generated SQL queries. There are inherent risks in doing this. Make sure that your database connection permissions are always scoped as narrowly as possible for your chain/agent’s needs. This will mitigate though not eliminate the risks of building a model-driven system. For more on general security best practices, see here.
In this example, we are querying a public dataset, and I followed best practice by configuring Trino’s Iceberg connector with a read-only application key scoped to the bucket containing the Drive Stats Iceberg tables.
Now let’s stream a new question through the flow. This mode of operation displays the output of each step as it is executed, essential for understanding the flow’s behavior, particularly when it is behaving unexpectedly. The model returns structured text in Markdown format. With a couple of lines of code to extract the message from the step variable, we can use the display_markdown function to render each step’s output:
for step in graph.stream(
{"question": "Each drive has its own serial number. How many drives did each data center have on 9/1/2024"}, stream_mode="updates"
):
# unwrap the step value to get the markdown message
state = one(step.values())
message = one(state.values())
display_markdown(message, raw=True)
This is the model’s output, and it gives us three different messages. I’ve separated them with a horizontal line for clarity:
SELECT datacenter, COUNT(DISTINCT serial_number) AS drive_count FROM drivestats WHERE date = ‘2024-09-01’ GROUP BY datacenter ORDER BY drive_count DESC LIMIT 10
Error: (trino.exceptions.TrinoUserError) TrinoUserError(type=USER_ERROR, name=TYPE_MISMATCH, message=”line 3:12: Cannot apply operator: date = varchar(10)”, query_id=20250113_221649_00214_bsut5) [SQL: SELECT datacenter, COUNT(DISTINCT serial_number) AS drive_count FROM drivestats WHERE date = ‘2024-09-01’ GROUP BY datacenter ORDER BY drive_count DESC LIMIT 10] (Background on this error at: https://sqlalche.me/e/20/f405)
The SQL query encountered an error because it attempted to compare a date column with a string in the format ‘YYYY-MM-DD’. Specifically, the error message indicates that the date column is of a different type (likely not a string), which is causing the type mismatch.
To answer the user question about how many drives each data center had on 9/1/2024, the SQL query needs to be corrected. Here’s the revised query:
SELECT datacenter, COUNT(DISTINCT serial_number) AS drive_count
FROM drivestats
WHERE date = DATE '2024-09-01'
GROUP BY datacenter
ORDER BY drive_count DESC
LIMIT 10
This corrected query uses the DATE keyword to ensure that the date string is properly interpreted as a date type, which should resolve the type mismatch error. If executed successfully, this query will provide the count of distinct drives in each data center for the specified date. However, without executing the corrected query against the database, we cannot provide the exact counts.
As you can see in the output from the first step, the model generated an invalid query, comparing a date to a string, despite the database schema being included in the prompt. The output of the second step contains the resulting error message from the database, while the third step contains the model’s diagnosis of the error.
This exchange highlights a limitation of a flow that is simply a linear series of steps, such as write_query, execute_query, and generate_answer. We cannot rely on the model to generate a valid SQL query, although it is able to point the way towards resolving its error.
Creating a ReAct AI agent with LangGraph
The LangGraph framework gives you the capability to create AI agents based on arbitrarily complex logic. In this article, I’ve used its prebuilt ReAct (Reason+Act) agent, since it neatly demonstrates the agent concept, rewriting the SQL query repeatedly in response to database errors.
There are three steps to creating the agent. The first is to create an instance of LangChain’s SQLDatabaseToolkit, passing it the database and model, and obtain its list of tools:
================================ System Message ================================
You are an agent designed to interact with a SQL database.
Given an input question, create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer.
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most {top_k} results.
You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for the relevant columns given the question.
You have access to tools for interacting with the database.
Only use the below tools. Only use the information returned by the below tools to construct your final answer.
You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.
DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.
To start you should ALWAYS look at the tables in the database to see what you can query.
Do NOT skip this step.
Then you should query the schema of the most relevant tables.
Now we can create an instance of the prebuilt agent:
Again, we can stream the agent’s execution to show us each step of its operation.
for step in agent_executor.stream(
{"messages": [{"role": "user", "content": "Each drive has its own serial number. How many drives did each data center have on 9/1/2024?"}]},
stream_mode="values",
):
step["messages"][-1].pretty_print()
The output from this flow is over 300 lines long; I posted it in its entirety as a Gist, but I’ll summarize the steps here:
Question: Each drive has its own serial number. How many drives did each data center have on 9/1/2024?
The model calls the “list tables” tool.
The list tables tool responds with a single table name, drivestats.
The model calls the “get schema” tool, passing it the table name.
The get schema tool responds with the schema and three sample rows from the drivestats table.
The model submits a query to the “query checker” tool: SELECT datacenter, COUNT(serial_number) AS drive_count FROM drivestats WHERE date = '2024-09-01' GROUP BY datacenter ORDER BY drive_count DESC LIMIT 10;
The query checker responds with the checked query, which is the same as its input. Note that the query checker only checks the SQL query’s syntax. The query contains the same data type mismatch as the query we generated earlier, as well as another error, as we’re about to discover.
The model submits the query to the “query executor” tool.
The query executor responds with a syntax error—Trino does not allow a trailing semi-colon on the query.
The model submits a modified query to the query checker tool: SELECT datacenter, COUNT(serial_number) AS drive_count FROM drivestats WHERE date = '2024-09-01' GROUP BY datacenter ORDER BY drive_count DESC LIMIT 10
The query checker responds with the checked query, which is the same as its input.
The model submits the query to the “query executor” tool.
The query executor responds with a type mismatch error since the query tries to compare a string value with a date column.
The model submits a query with the necessary DATE type identifier to the query checker tool: SELECT datacenter, COUNT(serial_number) AS drive_count FROM drivestats WHERE date = DATE '2024-09-01' GROUP BY datacenter ORDER BY drive_count DESC LIMIT 10
The query checker responds with the checked query, which is the same as its input.
The model submits the query to the “query executor” tool.
The query executor responds with a result set: [ ('phx1', 89477), ('sac0', 78444), ('sac2', 60775), ('', 24080), ('iad1', 22800), ('ams5', 16139) ]
The model returns a message containing the answer:
On September 1, 2024, the following datacenters had the specified number of drives:
These results show the datacenters with their respective drive counts.
Now let’s see if the model can calculate the annualized failure rate of a drive model. We’ll use the Seagate ST4000DM000, just because that is the drive model with the most days of operation in the dataset.
for step in agent_executor.stream(
{"messages": [{"role": "user", "content": "Each drive has its own serial number. What is the annualized failure rate of the ST4000DM000 drive model?"}]},
stream_mode="values",
):
step["messages"][-1].pretty_print()
The annualized failure rate (AFR) for the ST4000DM000 drive model can be calculated using the following information:
– Total failures: 5,791
– Total drives: 37,040
– Time period: from May 10, 2013, to September 30, 2024, which is approximately 11.35 years.
The formula for calculating the annualized failure rate is:
Plugging in the numbers:
Therefore, the annualized failure rate (AFR) of the ST4000DM000 drive model is approximately 13.77%.
It’s impressive that the agent shows its working so comprehensively, but, unfortunately, it arrives at the wrong answer. Those drives were not all running for the entire span of the Drive Stats dataset. The correct calculation involves determining the number of days with data for those drives and dividing it by 365 to get the correct number of years’ operation.
It’s clear that the model is not able to answer questions on drive reliability given the data available to it so far. The solution lies in prompt engineering—providing more context on the semantics of the data in the system prompt.
We can extend the default AI agent system prompt template to include specific instructions on working with the Drive Stats dataset:
prompt_template.messages[0].prompt.template += """
Each row of the drivestats table records one day of a drive’s operation, and contains the serial number of a drive, its model name, capacity in bytes, whether it failed on that day, SMART attributes and identifiers for the slot, pod, vault, cluster and data center in which it is located.
Use this calculation for the annualized failure rate (AFR) for a drive model over a given time period:
1. **drive_days** is the number of rows for that model during the time period.
2. **failures** is the number of rows for that model during the time period where **failure** is equal to 1.
3. **annual failure rate** is 100 * (**failures** / (**drive_days** / 365)).
Use double precision arithmetic in the calculation to avoid truncation errors. To convert an integer **i** to a double, use CAST(**i** AS DOUBLE)
Note that the date column is a DATE type, not a string. Use the DATE type identifier when comparing the date column to a string.
Do not add a semi-colon suffix to SQL queries."""
Now, when we ask the same question on the annual failure rate of the ST4000DM000 drive model, the AI agent generates a correct SQL query and a more concise, and correct, final response (you can inspect the full output here).
SELECT 100 * (CAST(COUNT(CASE WHEN failure = 1 THEN 1 END) AS DOUBLE) / (COUNT(*) / 365)) AS annual_failure_rate
FROM drivestats
WHERE model = 'ST4000DM000'
The annual failure rate (AFR) for the ST4000DM000 drive model is approximately 2.63%.
response = agent_executor.invoke(
{"messages": [{"role": "user", "content": "What was the annual failure rate of the ST8000NM000A drive model in Q3 2024?"}]}
)
response['messages'][-3].pretty_print()
display_markdown(response['messages'][-1].content, raw=True)
The query makes sense, and the response agrees with the table in the blog post:
SELECT 100 * (CAST(SUM(failure) AS DOUBLE) / (COUNT(*) / 365)) AS annual_failure_rate
FROM drivestats
WHERE model = 'ST8000NM000A' AND date >= DATE '2024-07-01' AND date < DATE '2024-10-01'
The annual failure rate (AFR) of the ST8000NM000A drive model in Q3 2024 is approximately 1.61%.
Interestingly, this time the SQL query used SUM(failure) to count the number of failures, rather than the equivalent, but rather long-winded COUNT(CASE WHEN failure = 1 THEN 1 END) it used in the previous query. Also, looking at the full response, we can see that, as directed by the custom prompt, the agent generated the correct syntax for comparing dates, so it didn’t need to correct and retry any queries.
Finally, let’s ask a more convoluted question, including the constraints given in the blog post:
response = agent_executor.invoke(
{"messages": [{"role": "user", "content": "Considering only drive models which had at least 100 drives in service at the end of the quarter and which accumulated 10,000 or more drive days during the quarter, which drive had the most failures in Q3 2024, and what was its failure rate?"}]}
)
response['messages'][-3].pretty_print()
display_markdown(response['messages'][-1].content, raw=True)
Again, the AI agent is able to generate a valid SQL query, this time including a subquery, and its response matches the data from the blog post exactly:
WITH drive_stats AS (
SELECT model,
COUNT(DISTINCT serial_number) AS drive_count,
COUNT(*) AS drive_days,
COUNT(CASE WHEN failure = 1 THEN 1 END) AS failures
FROM drivestats
WHERE date >= DATE '2024-07-01' AND date < DATE '2024-10-01'
GROUP BY model
HAVING COUNT(DISTINCT serial_number) >= 100 AND COUNT(*) >= 10000
)
SELECT model,
failures,
100 * (CAST(failures AS DOUBLE) / (CAST(drive_days AS DOUBLE) / 365)) AS failure_rate
FROM drive_stats
ORDER BY failures DESC
LIMIT 10
The drive model with the most failures in Q3 2024 is the TOSHIBA MG08ACA16TA, which had 181 failures. Its failure rate during this period was approximately 1.84%.
Closing thoughts
My experience building an AI agent was astonishment at its ability to correctly generate quite complex SQL queries based on natural language instructions, tempered with frustration at its limitations, particularly the way that it would confidently generate an incorrect response, rather than saying “I’m sorry, but I don’t know how to do that.” Your AI agent development process should include generous testing time, as well as ongoing monitoring to ensure that it is coming up with the right answers.
If you manage a video surveillance platform, storage is either the unsung hero of your infrastructure or your biggest headache. Maybe what started as a neat and functional setup for your video surveillance storage has turned into a complex system that demands far more maintenance than you expected.
As your storage volume grows and costs climb, the initial solutions begin to show their cracks, demanding more resources and attention. And, higher resolution cameras lead to even more storage demand, not to mention the increase in the number of cameras your customers want to install.
Today, I’m outlining some of the obstacles I’ve seen companies encounter in video surveillance storage as well as the benefits cloud storage offers to help you streamline operations, rein in costs, and regain control over your architecture, without sacrificing performance or flexibility.
Video surveillance storage challenges
Storage infrastructure is the backbone of your service—but it can also be one of the most demanding aspects to manage whether your data is stored in on-premises NVR/DVR systems, in the cloud, or in a hybrid model. Some of the key challenges include explosive data growth in the industry, balancing cost and performance, regulatory and compliance hurdles, latency and accessibility, and data security and redundancy. I’ll dig into each, and talk about some of the pitfalls you might face.
Explosive data growth: The sheer volume of video data generated by modern surveillance systems is staggering. With cameras capturing high-definition footage 24/7, even modest setups can produce terabytes of data per day. Scaling storage to keep up with this growth without compromising performance or breaking the bank is no small feat.
Balancing cost and performance: As storage needs grow, so do bandwidth requirements, data egress, and ongoing maintenance costs. Striking the right balance between affordability and the high availability your customers expect is a constant juggling act.
Regulatory and compliance hurdles: Platforms must manage varying retention policies, ensure data privacy, and provide secure access controls to adhere to all relevant standards and requirements, such as GDPR and local video retention regulations—all while keeping everything running smoothly.
Latency and accessibility: Your customers demand quick access to their video footage, whether it’s for live viewing or playback. High latency or sluggish retrieval times can lead to frustration and impact trust in your platform. Designing storage that ensures fast, reliable access to data across geographies is critical, but challenging.
Data security and redundancy: Video footage isn’t just data—it’s sensitive, often mission-critical information that cybercriminals are increasingly targeting. Protecting it from ransomware, accidental loss, or corruption requires robust encryption, multiple backups, and careful management of access rights. Achieving this level of security without overcomplicating your architecture is a balancing act.
Integrating AI: AI-powered analytics can enhance video surveillance capabilities (e.g., object detection, behavior analysis), but integrating AI is not without its challenges, and it’s something you need to consider carefully.
Advantages of the cloud for video surveillance platforms
Picking the right cloud storage platform can help you meet these challenges. Cloud storage offers a host of advantages that can transform how video surveillance platforms manage and scale their operations. Here’s why it’s worth considering:
1. Scalability and flexibility
Need to add storage for hundreds—or thousands—of new cameras per month? On-site storage solutions, such as physical servers, hard drives, or NAS systems have fixed capacities. Cloud storage scales with your platform, whether you’re serving small businesses or sprawling enterprise deployments. And, it adapts whether your customers are integrating additional cameras or extending their retention periods.
2. Cost optimization
Traditional on-prem solutions demand upfront investments in hardware and then ongoing maintenance. Cloud storage eliminates the need for those upfront hardware purchases. And the right cloud storage provider with pricing models built for your use case can help you get an edge in a competitive market.
The unique challenge of PUT requests
The video surveillance use case involves uploading a metric ton of data. In cloud terms, when you upload data, you typically use a PUT request. Many cloud providers charge for these API calls for hot and cold storage tiers. For example, it might be tempting to use a cold storage class to save on the base cost to store your video surveillance data, but a cold storage class like Amazon’s Glacier Instant Retrieval (GIR) charges $0.00002 per PUT request. When you’re making thousands or tens of thousands of PUT requests per day, even when the charges are tiny, costs can quickly escalate into the six figure range.
3. Accessibility
Whether your users are in the same city or halfway around the world, cloud storage makes video footage instantly accessible. Low-latency retrieval options and distributed cloud infrastructure mean faster access to the right data, regardless of location.
4. Reduced risk of data loss
Using the cloud for your data storage infrastructure mitigates the risks associated with physical vulnerabilities in the devices used by your customers. By automatically storing video footage in the cloud, even if the devices suffer damage, malfunction, or failure, the footage remains accessible thanks to the backup in the cloud. Replicate data across multiple geographically dispersed data centers, further reducing the risk of data loss due to hardware failures or natural disasters.
5. Enhanced security
Modern cloud storage solutions come with enterprise-grade security baked in, from end-to-end encryption to role-based access controls to scalable application keys. With built-in redundancy and regular backups, the cloud offers peace of mind that on-prem systems can’t always match—no more worrying about a single failed drive wiping out critical footage.
6. Minimized maintenance and IT overhead
Maintaining on-premises NVR/DVR systems requires substantial hardware and IT resources. In contrast, cloud systems are easier to manage. Updates, patches, and maintenance are handled by the cloud service provider. Your IT teams can focus on strategic tasks rather than routine server upkeep. This shift reduces your operational costs and streamlines management.
7. Ease of integration with AI and analytics
Storing your footage in the cloud makes it easier to integrate advanced features like AI-powered analytics, motion detection, and real-time alerts. You have a centralized repository of data that’s easy to analyze at scale. And, as opposed to on-prem systems, cloud platforms offer instant access from anywhere, making it more viable to train AI models on your own data.
Backblaze for video surveillance storage
Unlike some cloud providers and classes, Backblaze makes it affordable to secure, grow, and use your surveillance data. Backblaze’s straightforward pricing with zero PUT fees means you don’t have to worry about fees adding up, allowing you to store, manage, and access your data anywhere, anytime. And with 3x free egress for all plus unlimited free egress via many compute and CDN partners, you can more easily integrate with AI tools, sending your footage where the right GPUs are available without breaking the bank.
The future of video surveillance is in the cloud
Beyond the obvious scalability and operational gains of cloud storage, its biggest advantage in the coming years will be its AI readiness. AI innovations are poised to revolutionize security and video surveillance systems. By leveraging the cloud for AI and analytics, video surveillance platforms can move beyond mere storage to deliver actionable insights and real-time intelligence. This not only enhances the value you provide to customers but also differentiates your platform in an increasingly competitive market.
Cloud storage isn’t a one-size-fits-all solution, but for video surveillance platforms looking to streamline operations and future-proof their offerings, it’s hard to ignore the shift towards the cloud.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.