Amazon OpenSearch Ingestion is a powerful data ingestion pipeline that AWS customers use for many different purposes, such as observability, analytics, and zero-ETL search. Many customers today push logs, traces, and metrics from their applications to OpenSearch Ingestion to store and analyze this data.
Today, we are happy to announce that OpenSearch Ingestion pipelines now support cross-account ingestion for push-based sources such as HTTP and OpenTelemetry (OTel). Organizations can now use this feature to effortlessly share data across teams. For example, many organizations have central observability teams—now these teams can create OpenSearch Ingestion pipelines and share them with other teams in their organization. You can also use this feature to ingest data into Amazon OpenSearch Service domains or Amazon OpenSearch Serverless collections in other accounts.
Previously, sharing OpenSearch Ingestion pipelines across accounts required teams to use virtual private cloud (VPC) features to share access. For example, teams could use VPC peering, which is not always feasible, or AWS Transit Gateway. The new cross-account ingestion features in OpenSearch Ingestion can simplify your deployment and reduce cost for sharing pipelines.
Solution overview
Let’s look at how to share a pipeline from a central logging account with two other development accounts (A and B). The central logging account can create an OpenSearch Ingestion pipeline using a push-based source, for example, HTTP. After creating the pipeline, a member of the central logging team can grant access to the other teams. They can use a resource policy that gives permissions to the two other team accounts to create pipeline endpoints. After making this change, the OpenSearch Ingestion pipeline is available for use by the other teams.
The following diagram illustrates this configuration.
In the following sections, we demonstrate how to implement this solution.
Prerequisites
First, the central logging account must have a VPC with two options enabled.
The development accounts that are going to connect to the pipeline also must have VPCs in the same region with the same DNS options enabled.
enableDnsSupport must be set to true
enableDnsHostnames must be set to true
Create resource policy
As the owner of the pipeline, you can create a resource policy that allows the two development accounts to create pipeline endpoints against your pipeline.
The following is an example resource policy for this scenario:
The OpenSearch Ingestion console makes it straightforward to create these policies, as shown in the following screenshot.
Create pipeline endpoint
Now that the central logging account has shared permissions on their pipeline, the development accounts can create pipeline endpoints. A pipeline endpoint is a connection from one VPC to an OpenSearch Ingestion pipeline.
The development accounts are responsible for creating the pipeline endpoints in the VPCs they want to connect from. They create this in the subnets they need and provide a security group. The security group should have an inbound rule allowing access port HTTPS over port 443 from any source that the development accounts need to ingest logs.
Development team A can create a pipeline endpoint using a command similar to the following:
Development team A can also use the OpenSearch Ingestion console to create the pipeline endpoint.
After performing this change, the VPC for development team A will have a pipeline endpoint. This pipeline endpoint now allows for ingesting data into the central logging pipeline. Now, Amazon Elastic Compute Cloud (Amazon EC2) instances, Amazon Elastic Container Service (Amazon ECS) tasks, Kubernetes pods, and other compute running in the VPC can ingest their log data into the pipeline using tools such as FluentBit.
At the same time or at a later time, development team B can create a pipeline endpoint as well. This team will create it for their own VPC.
After this, the pipeline will now have two pipeline endpoints, so both teams can ingest their log data into the central logging VPC.
Clean up
After a pipeline endpoint is created, either account can remove it. The development teams in our scenario can use the DeletePipelineEndpoint API to delete it from their accounts. Additionally, if the central logging account needs to remove a pipeline endpoint from a pipeline, it can use the RevokePipelineEndpointConnections API. Both options are available on the OpenSearch Ingestion console as well.
After the pipeline endpoints are removed, the central logging team can also remove the pipeline if they no longer need it.
Conclusion
The new pipeline endpoint feature for OpenSearch Ingestion simplifies how you can share pipelines for cross-account ingestion. This can help teams use the powerful features of OpenSearch Ingestion and open up new possibilities for teams or organizations using multiple accounts and VPCs. The new pipeline endpoint feature is available today in AWS Regions where OpenSearch Ingestion is available.
To get started with cross-account ingestion in OpenSearch Ingestion, refer to OpenSearch Ingestion documentation or try creating your first cross-account pipeline on the OpenSearch Ingestion console.
Amazon SageMaker Unified Studio is a single data and AI development environment that brings together data preparation, analytics, machine learning (ML), and generative AI development in one place. By unifying these workflows, it saves teams from managing multiple tools and makes it straightforward for data scientists, analysts, and developers to build, train, and deploy ML models and AI applications while collaborating seamlessly.
In SageMaker Unified Studio, a project is a boundary where you can collaborate with other users to work on a business use case. A blueprint defines what AWS tools and services members of a project can use as they work with their data. Blueprints are defined by an administrator and are powered by AWS CloudFormation. Instead of manually piecing together project structures or workflow configurations, teams can rapidly spin up secure, compliant, and consistent analytics and AI environments. This streamlined approach significantly reduces setup time and provides standardized workspaces across the organization. Out of the box, SageMaker Unified Studio comes with several default blueprints.
We recently launched the custom blueprints feature in SageMaker Unified Studio. Organizations can now incorporate their specific dependencies, security controls using their own managed AWS Identity and Access Management (IAM) policies, and best practices, making it straightforward for them to align with internal standards. Because they’re defined through infrastructure as code (IaC), blueprints are straightforward to version control, share across teams, and evolve over time. This speeds up onboarding and keeps projects consistent and governed, no matter how big or distributed your data organization becomes.
For enterprises, this means more time focusing on insights, models, and innovation. The custom blueprints feature is designed to help teams move faster and stay consistent while maintaining their organization’s security controls and best practices. In this post, we show how to get started with custom blueprints in SageMaker Unified Studio.
Solution overview
We provide a CloudFormation template to implement a custom blueprint in SageMaker Unified Studio. The template deploys the following resources in the project environment:
The CloudFormation template uses parameters that are reserved to your SageMaker environment, such as datazoneEnvironmentEnvironmentId, datazoneEnvironmentProjectId, s3BucketArn, and privateSubnets. These parameters are automatically populated by SageMaker when creating the project. The parameters also help in retrieving other environment variables, such as SecurityGroupIds, as shown in the following snippets.
The following code illustrates defining reserved environment parameters:
"Parameters": {
"datazoneEnvironmentEnvironmentId": {
"Type": "String",
"Description": "EnvironmentId for which the resource will be created for."
},
"datazoneEnvironmentProjectId": {
"Type": "String",
"Description": "DZ projectId for which project the resource will be created for."
},
"s3BucketArn": {
"Type": "String",
"Description": "Project S3 Bucket ARN"
},
"privateSubnets": {
"Type": "String",
"Description": "Project Private Subnets"
}
}
The following code illustrates using reserved environment parameters to import other necessary values:
By default, SageMaker Unified Studio creates a project role and attaches several managed policies to the role. These managed policies are defined in the tooling blueprint. With custom blueprints, you can configure and attach your own IAM policies, in addition to the default policies, to the project role. To do this, include the IAM policies in your CloudFormation template and use the Export feature in the Outputs section, as shown in the following code. SageMaker Unified Studio gathers the policy information and adds it to the project role.
"GlueAccessManagedPolicy": {
"Description": "ARN of the created managed policy",
"Value": {
"Ref": "GlueAccessManagedPolicy"
},
"Export": {
"Name": {
"Fn::Sub": "datazone-managed-policy-glue-${glueDbName}-${datazoneEnvironmentEnvironmentId}"
}
}
},
"RedshiftAccessManagedPolicy": {
"Description": "ARN of the created Redshift managed policy",
"Value": {
"Ref": "RedshiftAccessManagedPolicy"
},
"Export": {
"Name": {
"Fn::Sub": "datazone-managed-policy-redshift-${redshiftWorkgroupName}-${datazoneEnvironmentEnvironmentId}"
}
}
}
Create custom blueprint
Complete the following steps to create a custom blueprint using the CloudFormation template:
On the Amazon SageMaker console, open the domain where you want to create a custom blueprint.
On the Blueprints tab, choose Create.
Under Name and description, enter a name and optional description.
Under Upload CloudFormation template, select Upload a template file and upload the provided template.
Choose Next. SageMaker will automatically detect the reserved parameters defined in the template, as shown in the following screenshot.
For Editable parameters, edit the Value column if necessary, and specify whether the values can be editable at the time of project creation.
Choose Next. As shown in the following screenshot, the reserved parameters described earlier are not shown on this page.
Select Enable blueprint.
Choose the provisioning role to be used by SageMaker to provision the environment resources.
Choose the domain units authorized to use the blueprint.
Choose Next.
Review the blueprint information and choose Create blueprint.
Create project profile
Complete the following steps to create a custom project profile that includes the custom blueprint created in the previous section:
On the SageMaker console, open your domain.
On the Project profiles tab, choose Create.
Enter the project profile name and optional description.
Select Custom create.
Choose the blueprints to be included in the project profile, including the custom blueprint you created in the previous section.
Choose the account and AWS Region to be used.
Choose the authorized users.
Select Enable project profile on creation.
Choose Create project profile.
Create project
Complete the following steps to create a new project that is based on the custom project profile and custom blueprint created in the previous sections:
In the SageMaker Unified Studio environment, choose Create project.
Enter a project name and optional description.
For Project profile, choose the profile created in the previous section.
Choose Continue.
On the Customize blueprint parameters page, review the parameters, modify as necessary, and choose Continue.
Review your selections and choose Create project.
SageMaker Unified Studio will create the project environments with the resources defined in your custom blueprint.
It will also attach the custom IAM policies defined and add them to the project role, as shown in the following screenshot.
Clean up
To avoid incurring additional costs, complete the following steps:
In this post, we discussed custom blueprints, a new option during administrator setup in SageMaker Unified Studio. We showed how to create new custom blueprints and create custom project profiles that include the newly created custom blueprints. We also demonstrated how to create projects that implement custom blueprints.
Custom blueprints in SageMaker Unified Studio are intended to streamline and standardize data, analytics and AI workflows. By helping organizations create templated environments with preconfigured resources, security controls, and best practices, custom blueprints can reduce setup time while providing consistency and compliance across projects.
Organizations can now enforce their specific security standards and access controls at the project level using the ability to incorporate custom IAM policies directly into these blueprints. This granular control over permissions helps organizations create projects that adhere to corporate security policies right from inception. Custom blueprints can help you scale analytics and AI/ML operations securely, by including tooling designed to version control these templates, share them across teams, and automatically apply custom IAM policies.
To learn more about custom blueprints in SageMaker Unified Studio, refer to Custom blueprints.
Serverless applications often comprise multiple AWS services, such as AWS Lambda, Amazon Simple Queue Service (Amazon SQS), Amazon EventBridge, and Amazon DynamoDB. Although serverless architectures make it easy to build applications that are generally simple to operate and scale, testing them requires extra steps for developers. Recently, AWS brought you the capability to help developers remotely debug Lambda functions to accelerate the development process. Today, we’re excited to announce new capabilities that further simplify the local testing experience for Lambda functions and serverless applications through integration with LocalStack, an AWS Partner, in the AWS Toolkit for Visual Studio Code.
In this post, we will show you how you can enhance your local testing experience for serverless applications with LocalStack using AWS Toolkit.
Challenges with local serverless development
When building serverless applications with infrastructure as code (IaC) tools like the AWS Serverless Application Model (AWS SAM), developers often face challenges during local integration testing of applications that depend on interactions across multiple AWS services. These friction points slow down the critical code-test-debug cycle. Developers might encounter the following common roadblocks:
Cloud-based validation slows iteration – Developers previously needed to deploy AWS SAM templates to the cloud to test changes, introducing delays in feedback loops. AWS research shows that developers spend considerable time on deployment and testing, rather than writing code.
Tool context switching adds friction – Developers routinely shift between integrated development environments (IDEs), command line interfaces (CLIs), and resource emulators like LocalStack, leading to fragmented workflows.
Manual setup increases configuration complexity – Port mapping and code edits for local service integration tests can introduce inconsistencies between local and cloud environments.
Service integration debugging is limited – Troubleshooting Lambda functions in the context of AWS service integrations, such as DynamoDB, Amazon Simple Storage Service (Amazon S3), or Amazon SQS, requires manual configuration, extending the duration of troubleshooting efforts.
These challenges directly impact developer productivity and make local testing of integrated serverless applications complex.
Solution overview
Starting today, AWS helps simplify local serverless development by integrating LocalStack directly into the AWS Toolkit for VS Code. This integration helps developers test and debug serverless applications—defined using IaC tools like AWS SAM—entirely within their IDE. The enhanced local testing experience delivers four major improvements:
Integrated LocalStack experience – Connect to LocalStack directly within VS Code and manage local resources alongside cloud resources through a unified interface.
Emulated service interactions – Test Lambda functions with their interactions with other AWS services like Amazon SQS, DynamoDB, and EventBridge locally.
Simplified debugging – Start debugging sessions with LocalStack emulated environment, with a single click – no manual port configurations or code changes required, streamlining the debugging workflow.
Streamlined workflow – Deploy, test, and debug serverless applications without leaving the IDE, avoiding context switching between tools.
To set up LocalStack in VS Code (either the free version supporting over 30 core services like Lambda, Amazon S3, DynamoDB, Amazon SQS, and Amazon API Gateway, or the Ultimate version with over 110 services and advanced debugging features) you need essential development tools, including Docker, the AWS Command Line Interface (AWS CLI), AWS SAM CLI, and your preferred IDE such as VS Code. This combination enables full local integration testing of AWS services, including Lambda functions, messaging queues, databases, event-driven architectures, and serverless workflows, so you can develop and test your entire AWS application stack locally before deploying to the cloud.
Automated setup process
LocalStack is a cloud service emulator that you can use to run AWS applications locally for testing and development. To enhance your local testing capabilities, you can install the LocalStack VSCode Extension directly from AWS Walkthrough in AWS Toolkit, which offers a streamlined setup process through an intelligent wizard. After installation, the extension automatically detects whether LocalStack is configured on your system and prompts you to run the setup wizard through a notification. The entire process is quick and requires no manual configuration.
LocalStack extension has an integrated authentication wizard, that simplifies the process of connecting your development environment to LocalStack. During setup, the wizard opens a browser-based authentication flow and maintains an active connection until authentication completes. After it’s verified, it securely stores the authentication token in the ~/.localstack/auth.json file, enabling communication between your local environment and LocalStack services.
The wizard also checks if LocalStack AWS CLI profiles exist, and if not found, automatically creates them by updating the ~/.aws/config and ~/.aws/credentials files with LocalStack-specific endpoints and credentials. This seamless integration of AWS profiles enhances the development workflow by allowing developers to easily switch between different AWS environments, including the local LocalStack setup. By leveraging these profiles, developers can effortlessly point their AWS CLI or SDK to the appropriate endpoint, whether it’s a real AWS account or the LocalStack instance running on their machine. This configuration not only ensures a clear separation between local and cloud environments but also minimizes the risk of cross-environment interference. The automatic creation of these profiles streamlines the setup process, reducing manual configuration errors and saving valuable development time. Visual Studio Code (VS Code) provides real-time feedback throughout the setup. The status bar initially displays an error or warning indicator when LocalStack is not configured and then transitions to a normal or connected state once a successful connection is established. After setup completes, you’re ready to deploy, test, and debug serverless applications locally—without additional configuration. These settings persist across VS Code sessions, so the setup process is a one-time task.The following figure illustrates the process to start and verify LocalStack from VS Code.
To learn more, including installation steps, configuration examples, and troubleshooting guidance, visit the LocalStack Docs.
Test a serverless application
To demonstrate the enhanced local testing capabilities, let’s explore a practical serverless pattern: building and testing an event-driven order processing system that integrates Lambda with Amazon SQS, API Gateway, and Amazon Simple Notification Service (Amazon SNS). The application processes orders through an event-driven workflow: orders are submitted through API Gateway to an SQS queue and processed by a Lambda function, and the status is published to Amazon SNS to trigger customer email notifications.
After you set up LocalStack in VS Code, you can test your entire serverless workflow without deploying to the cloud:
Deploy locally – Use the LocalStack AWS profile to deploy your AWS SAM application. The process mirrors cloud deployment but targets local endpoints. You can use the Application builder pane to initiate the deployment to LocalStack environment. The following figure illustrates the process of deploying a sample serverless application.
Debug Lambda function deployed in LocalStack – Set breakpoints in your Lambda function and step through execution using VS Code’s integrated debugger. With the AWS Toolkit extension, you can invoke your Lambda with one click and inspect live interactions across services, all while running against a LocalStack container on your machine. This setup makes it possible to debug your AWS applications in a controlled, local environment that mimics the cloud infrastructure, without the need for deploying actual AWS services.
Validate end-to-end Flows – Test complete workflows from message ingestion through processing and notification, confirming all service integrations work correctly before cloud deployment.
For an in-depth technical demonstration of this LocalStack integration, refer to this youtube video.
Best practices for local Lambda function testing
In this section, we discuss various strategies and best practices for local Lambda function testing.
Optimizing your development workflow
Consider the following strategies to optimize your development workflow:
Start with a strong testing foundation – Use the AWS SAM CLI to perform unit tests that validate the core programmatic and business logic of your Lambda functions. Isolating function behavior early helps identify logic errors before introducing external dependencies.
Establish environment parity early in the development process – Many production issues stem from discrepancies between local and cloud environments. Use consistent service versions, configurations, and data structures across environments to confirm that what works locally behaves the same in production.
Adopt IaC from day one – Whether you choose AWS SAM, AWS CloudFormation, or another IaC framework, defining your application infrastructure as code reduces configuration drift and makes your deployments reproducible across teams and environments.
Apply a progressive testing strategy – Follow a structured testing pyramid that starts with fast, isolated unit tests and builds up to broader integration and system-level validation. This layered approach helps you catch issues earlier—when they’re easier and less expensive to fix—while still providing full application coverage.
A strategic approach to testing
Testing should be an integrated part of your serverless development workflow—not an afterthought. Successful teams implement layered testing strategies that use both local and cloud environments to strike a balance between speed and accuracy:
Begin with unit tests that focus on isolated function logic. Use tools like the AWS SAM CLI, AWS Toolkit for VS Code and LocalStack extensions to run and debug functions locally.
After validation, proceed to local integration testing using LocalStack to confirm how your Lambda functions interact with services such as Amazon SQS, DynamoDB, and Amazon SNS. These tests typically complete within minutes and catch most service integration issues before they reach production.
After local testing, validate your application in the actual AWS environment. Cloud testing helps surface issues not present in local emulation, such as AWS Identity and Access Management (IAM) permission mismatches, Amazon Virtual Private Cloud (Amazon VPC) networking challenges, or service-specific nuances such as Lambda concurrency. For troubleshooting issues in the cloud environment, you can also remotely debug your Lambda functions using AWS Toolkit for VS Code.
Lastly, conduct performance testing in AWS to assess how your application handles real-world traffic. These longer-running tests help validate scaling behavior and system resilience under load.
The result is higher-quality applications delivered faster, with fewer production surprises and more confident deployments.
Security considerations
When using LocalStack for local development, follow these security best practices:
Isolate the local environment – Use Docker networking to restrict LocalStack access and bind services to localhost to prevent external connections.
Use placeholder credentials – Use test credentials (for example, test/test) instead of real AWS credentials.
Protect your data – Use synthetic or anonymized datasets instead of production data and regularly purge local data stores to reduce risk.
When to use local versus cloud testing
Although local testing offers significant advantages, it’s important to understand when to use it versus testing in the cloud. The following table lists the potential use cases for each strategy.
Testing Scenario
Local Testing
Cloud Testing
Reason
Function logic validation
✓
Fast feedback for core business logic
Service integration testing
✓
Quick validation of AWS service interactions
Rapid iteration during development
✓
Immediate feedback without deployment overhead
Cost-sensitive development environments
✓
Minimizes cloud resource costs during development
Offline development scenarios
✓
No internet connectivity required
Performance and scalability testing
✓
Requires actual AWS infrastructure for accurate results
IAM permission validation
✓
LocalStack doesn’t fully replicate IAM behavior
VPC networking scenarios
✓
Network configurations can’t be accurately emulated
Production-like load testing
✓
Real performance metrics only available in AWS
Final validation before deployment
✓
Supports compatibility with actual AWS environment
Conclusion
In this post, we discussed how to streamline local testing for AWS Serverless applications using LocalStack and the AWS Toolkit for VS Code. By running and debugging serverless applications directly in your IDE, you can reduce context switching, test complex integrations locally, and catch issues earlier—without deploying to the cloud.
We also showed how to apply progressive testing strategies that combine local emulation with cloud validation, optimize development costs, and build event-driven workflows with confidence.These enhancements lead to faster test cycles, lower development costs, and higher-quality deployments—all while staying fully in control of your development environment.
Have questions or feedback about this post? Connect with us on the AWS Compute Blog or join the AWS Developer community.
When you’re spinning up your Amazon OpenSearch Service domain, you need to figure out the storage, instance types, and instance count; decide the sharding strategies and whether to use a cluster manager; and enable zone awareness. Generally, we consider storage as a guideline for determining instance count, but not other parameters. In this post, we offer some recommendations based on T-shirt sizing for log analytics workloads.
Log analytics and streaming workload characteristics
When you use OpenSearch Service for your streaming workloads, you send data from one or more sources into OpenSearch Service. OpenSearch Service indexes your data in an index that you define.
Log data naturally follows a time series pattern, and therefore a time-based indexing strategy (daily or weekly indexes) is recommended. For efficient management of log data, you must implement time-based index patterns and set retention periods. You further define time slicing and a retention period for the data to manage its lifecycle in your domain.
For illustration, consider that you have a data source producing a continuous stream of log data, and you’ve configured a daily rolling index and set a retention period of 3 days. As the logs arrive, OpenSearch Service creates an index per day with names like stream1_2025.05.21, stream1_2025.05.22, and so on. The prefix stream1_* is what we call an index pattern, a naming convention that helps group-related indexes.
The following diagram shows three primary shards for each daily index. These shards are deployed across three OpenSearch Service data instances, with one replica for each primary shard. (For simplicity, the diagram doesn’t show that primary and replica shards are always placed on different instances for fault tolerance.)
When OpenSearch Service processes new log entries, they are sent to all relevant primary shards and their replicas in the active index, which in this example is only today’s index due to the daily index configuration.
There are several important characteristics of how OpenSearch Service processes your new entries:
Total shard count – Each index pattern will have a D * P * (1 + R) total shards, where D represents retention in days, P represents primary shards, and R is the number of replicas. These shards are distributed across your data nodes.
Active index – Time slicing means that new log entries are only written to today’s index.
Resource utilization – When sending a _bulk request with log entries, these are distributed across all shards in the active index. In our example with three primary shards and one replica per shard, that’s a total of six shards processing new data simultaneously, requiring 6 vCPUs to efficiently handle a single _bulk request.
Similarly, OpenSearch Service distributes queries across the shards for the indexes involved. If you query this index pattern across all 3 days, you will engage 9 shards, and need 9 vCPUs to process the request.
This will get even more complicated when you add in more data streams and index patterns. For each additional data stream or index pattern, you deploy shards for each of the daily indexes and use vCPUs to process requests in proportion to the shards deployed, as shown in the preceding diagram. When you make concurrent requests to more than one index, each shard for all the indexes involved must process those requests.
Cluster capacity
As the number of index patterns and concurrent requests increases, you can quickly overwhelm the cluster’s resources. OpenSearch Service includes internal queues that buffer requests and mitigate this concurrency demand. You can monitor these queues using the _cat/thread_pool API, which shows queue depths and helps you understand when your cluster is approaching capacity limits.
Another complicating dimension is that the time to process your updates and queries depends on the contents of the updates and queries. As requests come in, the queues are filling at the rate you are sending them. They are draining at a rate that is governed by the available vCPUs, the time they take on each request, and the processing time for that request. You can interleave more requests if those requests clear in a millisecond than if they clear in a second. You can use the _nodes/stats OpenSearch API to monitor average load on your CPUs. For more information about the query phases, refer to A query, or There and Back Again on the OpenSearch blog.
If you see the queue depths increasing, you are moving into a “warning” area, where the cluster is handling load. But if you continue, you can start to exceed the available queues and must scale to add more CPUs. If you start to see load increasing, which is correlated with queue depth increasing, you are also in a “warning” area and should consider scaling.
Recommendations
For sizing a domain, consider the following steps:
Determine the storage required – Total storage = (daily source data in bytes × 1.45) × (number_of_replicas + 1) × number of days retained. This accounts for the additional 45% overhead on daily source data, broken down as follows:
10% for larger index size than source data.
5% for operating system overhead (reserved by Linux for system recovery and disk defragmentation protection).
20% for OpenSearch reserved space per instance (segment merges, logs, and internal operations).
10% for additional storage buffer (minimizes impact of node failure and Availability Zone outages).
Define the shard count – Approximate number of primary shards = storage size required per index / desired shard size. Round up to the nearest multiple of your data node count to maintain even distribution. For more detailed guidance on shard sizing and distribution strategies, refer to “Amazon OpenSearch Service 101: How many shards do I need” For log analytics workloads, consider the following:
Recommended shard size: 30–50 GB
Optimal target: 50 GB per shard
Calculate CPU requirements – Recommended ratio is 1.25 vCPU:1 Shard for lower data volumes. Higher ratios are recommended for larger volumes. Target utilization is 60% average, 80% maximum.
Choose the right instance type – Consider the following based on your nodes:
Data nodes (small to large workloads): M or R family AWS Graviton instances with Amazon Elastic Block Store (Amazon EBS)
Data nodes (very large workloads): I family instances with NVMe SSDs
Let’s look at an example for domain sizing. The initial requirements are as follows:
Daily log volume: 3 TB
Retention period: 3 months (90 days)
Replica count: 1
We make the following instance calculation.
The following table recommends instances, amount of source data, storage needed for 7 days of retention, and active shards based on the preceding guidelines.
T-Shirt Size
Data (Per Day)
Storage Needed (with 7 days Retention)
Active Shards
Data Nodes
Primary Nodes
XSmall
10 GB
175 GB
2 @ 50 GB
3 * r7g.large. search
3 * m7g.large. search
Small
100 GB
1.75 TB
6 @ 50 GB
3 * r7g.xlarge. search
3 * m7g.large. search
Medium
500 GB
8.75 TB
30 @ 50 GB
6 * r7g.2xlarge.search
3 * m7g.large. search
Large
1 TB
17.5 TB
60 @ 50 GB
6 * r7g.4xlarge.search
3 * m7g.large. search
XLarge
10 TB
175 TB
600 @ 50 GB
30 * i4g.8xlarge
3 * m7g.2xlarge.search
XXL
80 TB
1.4 PB
2400 @ 50 GB
87 * I4g.16xlarge
3 * m7g.4xlarge.search
As with all sizing recommendations, these guidelines represent a starting point and are based on assumptions. Your workload will differ, and so your actual needs will differ from these recommendations. Make sure to deploy, monitor, and adjust your configuration as needed.
For T-shirt sizing the workloads, an extra-small use case encompasses 10 GB or less of data per day from a single data stream to a single index pattern. A small use case falls between 10–100 GB per day of data, a medium use case between 100–500 GB of data, and so on. Default instance count per domain is 80 for most of the instance family. Refer to the “Amazon OpenSearch Service quotas “ for details.
Additionally, consider the following best practices:
Isolate the ingestion using an OpenSearch Ingestion pipeline for smaller to large workloads and reduce the operational overhead of managing the ingestion pipelines.
Use reserved instances for long-term cost savings.
Consider using Availability Zone awareness for high availability.
Conclusion
This post provided comprehensive guidelines for sizing your OpenSearch Service domain for log analytic workloads, covering several critical aspects. These recommendations serve as a solid starting point, but each workload has unique characteristics. For optimal performance, consider implementing additional optimizations like data tiering and storage tiers. Evaluate cost-saving options such as reserved instances, and scale your deployment based on actual performance metrics and queue depths.By following these guidelines and actively monitoring your deployment, you can build a well-performing OpenSearch Service domain that meets your log analytics needs while maintaining efficiency and cost-effectiveness.
AWS recently announced that Amazon SageMaker now offers Amazon Simple Storage Service (Amazon S3) based shared storage as the default project file storage option for new Amazon SageMaker Unified Studio projects. This feature addresses the deprecation of AWS CodeCommit while providing teams with a straightforward and consistent way to collaborate on project files across the integrated development tools in SageMaker.
This new Amazon S3 storage option provides the following benefits:
Simplified collaboration – File sharing between project members directly without Git operations
Clear workspace separation – Built-in personal storage separation with Amazon Elastic Block Store (Amazon EBS) volumes
Global availability – Available in AWS Regions where SageMaker is supported
Although Amazon S3 is the default option for file storage, you can also use Git version control for more robust source control capabilities.
In this post, we discuss this new feature and how to get started using Amazon S3 shared storage in SageMaker Unified Studio.
Solution overview
When you create a new SageMaker Unified Studio domain, the service automatically configures Amazon S3 storage as your default project storage option. Each project receives a dedicated shared location in Amazon S3, accessible to project members, following the structure [bucket]/[domain-id]/[project-id]/shared/.
SageMaker tools JupyterLab and Code Editor provide the following to users:
A personal EBS volume for individual work in JupyterLab and Code Editor tools
A mounted shared folder containing the project’s Amazon S3 shared storage
Clear separation between personal and shared spaces
The shared storage is accessible across SageMaker integrated development tools:
JupyterLab and Code Editor show shared files along with personal files
Query Editor filters for relevant SQL notebooks
Visual ETL provides direct access to shared extract, transform, and load (ETL) workflows
Files saved to the shared location are immediately visible and available to project members. Users can continue working with personal files in their EBS volumes in tools like JupyterLab and Code Editor and explicitly move files to shared storage when ready to collaborate.If you want to use Git for collaboration, you can continue to do so by integrating projects with your GitHub version control, GitLab version control, or managed Bitbucket repositories.
Migration and version control options
For teams currently using Amazon CodeCommit, existing projects will remain fully functional. New projects will default to Amazon S3 storage. If you want to have version control for Amazon S3 based projects, you can enable versioning in Amazon S3 directly.
Prerequisites
You will need to complete the following prerequisites before you can follow the instructions in the next section:
To begin using Amazon S3 shared storage, complete the following steps:
Create a new SageMaker Unified Studio domain.
Create a new project (Amazon S3 storage is the default file storage option).
Open the new project and choose JupyterLab from the Build menu.
Save the new notebook you just created.
Rename the file.
After the project is saved, project users can view the saved notebook in the Project files section under the S3 path [bucket]/[domain-id]/[project-id]/shared/.
Enable version control using Git
To enable version control using Git, complete the following steps:
On the SageMaker console, create a new project profile.
Provide the necessary details for your project profile.
In the Project files storage section, the Amazon S3 option is selected by default. To enable version control for the project, you can use existing Git repository connections by selecting Git repository.
Use shared storage in Query Editor
To use the shared storage feature in Query Editor, complete the following steps:
Choose Query Editor from the Build menu.
Compose your query, and on the Actions menu, choose Save to save the query to shared storage.
Navigate back to the Project files section, where you can view the query notebook files under the S3 path [bucket]/[domain-id]/[project-id]/shared/.
Use shared storage in Visual ETL flows
To use the shared storage feature in Visual ETL flows, complete the following steps:
Choose Visual ETL flows from the Build menu.
Develop your ETL workflow and save the code to the project.
Navigate back to the Project files section, where you can view the files under the S3 path [bucket]/[domain-id]/[project-id]/shared/jobs/uploads/<ETL name>.
Clean up
Make sure you remove the SageMaker Unified Studio resources to mitigate any unexpected costs. This involves a few steps:
Delete the projects.
Delete the domain.
Delete the S3 bucket named amazon-datazone-AWSACCOUNTID-AWSREGION-DOMAINID
Conclusion
The launch of Amazon S3 shared storage in SageMaker represents another step in simplifying the analytics and machine learning (ML) development experience for our customers. By reducing the complexity of Git operations while maintaining robust collaboration capabilities, teams can now focus on building and deploying analytics and ML solutions faster. The feature is now available in Regions where SageMaker is available.
For detailed information about this feature, including setup instructions and best practices, refer to Unified storage in Amazon SageMaker Unified Studio. Share your feedback on this feature in the comments section.
In our previous blog post (Part 1 of our key replication series), Automatically replicate your card payment keys across AWS Regions, we explored an event-driven, serverless architecture using AWS PrivateLink to securely replicate card payment keys across AWS Regions. That solution demonstrated how to build a custom replication framework for payment cryptography keys.
Based on customer feedback requesting a more automated, no-code approach, we’re excited to announce an additional option to this capability with Multi-Region keys for AWS Payment Cryptography in Part 2 of our series.
By using this new feature, you can automatically synchronize payment cryptography keys from a primary Region to other Regions that you select, improving resilience and availability of payment applications. You can also choose between account-level replication or key-level replication, giving more flexibility in how to manage payment keys across Regions.
Multi-Region keys: Overview and benefits
The new Multi-Region key replication feature for AWS Payment Cryptography offers you flexible control over your key replication strategy through the following primary capabilities:
Control whether keys are replicated
Select specific Regions for key replication
Manage replication configuration changes
Configure either account-level or key-level replication to meet business needs
Multi-Region keys help deliver several benefits for global payment operations, including:
Improved availability: Access your payment keys even if a Region becomes unavailable
Disaster recovery: Maintain business continuity with replicated keys across Regions
Global operations: Support payment processing across multiple geographic regions
Simplified management: Centralized control with distributed availability
Consistent key IDs: The same key ID across Regions simplifies application development
Configuration options
Payment Cryptography provides two distinct methods for configuring Multi-Region key replication, giving flexibility to implement a strategy that best fits your organization’s needs. You can choose between a broad, account-level approach or a more granular, key-level method.
Account-level
With account-level configuration, AWS automatically replicates exportable symmetric keys created in your Payment Cryptography account from your designated primary Region to other Regions you specify. This simplifies key management in multi-Region deployments, provides consistent key availability in the Regions that you specify, and reduces the operational overhead of key management.
To configure account-level replication using the AWS Command Line Interface (AWS CLI), use the new enable-default-key-replication-regions API to set the Regions where AWS will replicate your keys. To remove Regions from your default replication list, use the disable-default-key-replication-regions API.
Note: Only symmetric keys created after the account-level replication is enabled will be replicated.
Key-level replication
By using key-level replication, you can achieve more granular control by:
Designating specific keys as multi-Region keys
Defining custom replication targets for each multi-Region key
Maintaining Region-specific keys when needed
Note: Within each Region, Payment Cryptography maintains redundancy of your keys across multiple Availability Zones for high availability. Multi-Region key replication extends across geographic boundaries, giving you additional resilience against Regional outages while maintaining control over where your keys are stored.
You can specify replication Regions during key creation using the --replication-regions parameter, using the AWS CLI, with the create-key or import-key APIs. For existing keys, you can use the new add-key-replication-regions and remove-key-replication-regions APIs to manage which regions receive your replicated keys.
Important: When you specify replication Regions during key creation, these settings take precedence over default replication Regions configured at the account level.
How it works
Figure 1 shows the process when you replicate a key in Payment Cryptography.
The key is created in your designated primary Region
Payment Cryptography automatically replicates the key material asynchronously to the specified replica Regions
The replicated keys maintain the same key ID across Regions; only the Region portion of the Amazon Resource Name (ARN) changes
The key in the primary Region is marked with MultiRegionKeyType: PRIMARY
Keys in replica Regions are marked with MultiRegionKeyType: REPLICA and include a reference to the primary Region
When deleting a key, its deletion cascades from the primary to replica Regions
Figure 1: Representation of key replication from us-east-1 to us-west-2
Example: Creating a multi-Region key at key level
The following is an example of creating a card verification key (CVK) in the primary Region (us-east-1) with replication to us-west-2:
When using multi-Region keys, several important aspects should be considered. Multi-Region key replication supports only symmetric keys with the exportable attribute enabled, and asymmetric keys are not supported. For billing purposes, AWS bills per key per Region, which means replicating to three Regions incurs costs for the primary key plus costs for each key in the replica Regions.
Key aliases and tags require separate management in each Region because they are not part of the replication process. While primary keys support modifications and updates, replica keys are read-only copies that support only cryptographic operations. Modifications must be made to the key in the primary Region, and Payment Cryptography automatically propagates these changes to the replica Regions. Monitor the replication status to confirm successful synchronization of these changes.
The deletion process for multi-Region keys follows specific behavior patterns that are important to understand. When a primary key is scheduled for deletion, associated replica keys are deleted immediately. The primary key enters a pending deletion state with a minimum 3-day waiting period, during which the deletion can be canceled. However, if you restore the primary key by canceling its deletion, you will need to re-enable replication to recreate the replica keys in your desired Regions. After the 3-day waiting period expires, the primary key is permanently deleted and becomes unrecoverable. Note that deleting a replica key affects only that specific Region and does not impact the primary key or other replica keys.
Multi-Region key replication operates with eventual consistency. When creating new keys or making changes to existing keys, these updates might not appear immediately across all Regions. Applications should be designed to handle this eventual consistency model and not assume immediate availability of keys or key changes in replica Regions. If your application requires strong consistency, implement polling mechanisms using the GetKey API to verify that changes have been synchronized before proceeding with key operations.
Logging and monitoring
Payment Cryptography logs API activity through AWS CloudTrail, which now includes new events and attributes specific to Multi-Region key replication.
New CloudTrail event
The service logs a new event type called SynchronizeMultiRegionKey, which appears in primary and replica Regions.
Primary Region events:
Two SynchronizeMultiRegionKey events are logged in the primary Region for each replication Region defined:
To start using Multi-Region key replication in Payment Cryptography:
Determine your primary Region.
Determine your replica Regions and if you will use account-level or key-level configuration.
Create new exportable symmetric keys or update existing keys to use the Multi-Region key replication feature.
Update your applications to use the consistent key IDs across Regions.
Conclusion
The new Multi-Region key replication feature in Payment Cryptography enhances our automatic key replication capabilities, providing improved resilience and simplified management for global payment applications. This feature helps make sure your payment cryptography keys are available when and where you need them, with the flexibility to choose between account-level or key-level replication strategies.
Organizations are innovating and growing their cloud presence to deliver better customer experiences and drive business value. To support and protect this growth, organizations can use Amazon GuardDuty, a threat detection service that continuously monitors for malicious activity and unauthorized behavior across your AWS environment. GuardDuty uses artificial intelligence (AI), machine learning (ML), and anomaly detection using both AWS and industry-leading threat intelligence to help protect your AWS accounts, workloads, and data. Building on these foundational capabilities, GuardDuty offers a comprehensive suite of protection plans and the Extended Threat Detection feature.
In this post, we explore how to use these features to provide robust security coverage for your AWS workloads, helping you detect sophisticated threats across your AWS environment.
Understanding GuardDuty protection plans
GuardDuty starts with foundational security monitoring, which analyzes AWS CloudTrail management events, Amazon Virtual Private Cloud (Amazon VPC) Flow Logs, and DNS logs. Building on this foundation, GuardDuty offers several protection plans that extend its threat detection capabilities to additional AWS services and data sources. These protection plans are optional features that analyze data from specific AWS services in your environment to provide enhanced security coverage. GuardDuty offers the flexibility to customize how new accounts inherit protection plans, so you can add coverage for your accounts or select specific accounts based on your security needs. You can enable or disable these protection plans at any time to align with your evolving workload requirements.
Here are the available GuardDuty protection plans and their capabilities:
Detects the potential presence of malware by scanning the Amazon Elastic Block Store (Amazon EBS) volumes associated with your EC2 instances. There is an option to use this feature on-demand.
Monitors AWS Lambda network activity logs, starting with VPC Flow Logs, to detect threats to your Lambda functions. Examples of these potential threats include crypto mining and communicating with malicious servers.
Let’s explore how these protection plans help secure different aspects of your AWS environment.
S3 Protection
S3 Protection extends threat detection capabilities of GuardDuty to your S3 buckets by monitoring object-level API operations. Beyond basic monitoring, it analyzes patterns of behavior to detect sophisticated threats. When a threat actor attempts to exfiltrate data, GuardDuty can detect unusual sequences of API calls, such as ListBucket operations followed by suspicious GetObject requests from unusual locations. It also identifies potential security risks like attempts to disable S3 server access logging or unauthorized changes to bucket policies that could indicate an attempt to make buckets public. For instance, GuardDuty would generate an UnauthorizedAccess finding if it detects these suspicious API calls originating from known malicious IP addresses.
EKS Protection
For containerized workloads, EKS Protection monitors your Amazon EKS clusters’ control plane audit logs for security threats. It’s specifically designed to detect container-based exploits by analyzing Kubernetes audit logs from your EKS clusters. GuardDuty detects scenarios such as containers deployed with suspicious characteristics (like known malicious images), attempted privilege escalation through role binding modifications, and suspicious service account activities that could indicate compromise of your Kubernetes environment. When detecting such activities, GuardDuty would generate a PrivilegeEscalation finding, alerting you to potential unauthorized access attempts within your clusters. For a comprehensive understanding of the tactics, techniques, and procedures (TTPs), see the AWS Threat Technique Catalog.
Runtime Monitoring
Runtime Monitoring provides deeper visibility into potential threats by analyzing runtime behavior in EC2 instances, EKS clusters, and container workloads. This capability detects threats that manifest at the operating system level by monitoring process executions, file system changes, and network connections. GuardDuty can identify defense evasion tactics, execution of suspicious processes, and file access patterns indicating potential malware activity. For example, if a compromised instance attempts to disable security monitoring or creates unusual processes, GuardDuty would generate a Runtime finding indicating potential malicious activity at the OS level.
Malware Protection
Malware Protection offers two distinct capabilities: scanning EBS volumes attached to EC2 instances and scanning objects uploaded to S3 buckets. For EC2 instances, GuardDuty can perform both agentless scan-on-demand and continuous scanning of EBS volumes, detecting both known malware and potentially malicious files using advanced heuristics. For S3, it automatically scans newly uploaded objects, helping protect against malware distribution through your S3 buckets. When malware is detected, GuardDuty generates a Malware finding, specifying whether the threat was found in an EC2 instance or S3 bucket, helping you quickly identify and respond to the threat.
RDS Protection
RDS Protection focuses on database security by analyzing login activity for supported Amazon Aurora databases. It creates behavioral baselines of normal database access patterns and can detect anomalous sign-in attempts that might indicate unauthorized access attempts. This includes detecting unusual sign-in patterns, access from unexpected locations, and potential database compromise attempts. When suspicious database access is detected, GuardDuty generates an RDS finding, alerting you to potential unauthorized access or credential compromise.
Lambda Protection
Lambda Protection monitors your serverless applications by analyzing Lambda function activity through VPC Flow Logs. It can detect threats specific to serverless environments, such as when Lambda functions exhibit signs of compromise through unexpected network connections or potential cryptocurrency mining activity. If a Lambda function attempts to communicate with known malicious IP addresses or shows signs of cryptojacking, GuardDuty will generate a Lambda finding, so you can quickly identify and remediate compromised functions.
Each protection plan adds specialized detection capabilities designed for specific workload types, working together to provide comprehensive threat detection across your AWS environment. By enabling the protection plans relevant to your workloads, you can help make sure that GuardDuty provides targeted security monitoring for your specific use cases
Tailoring GuardDuty protection plans to your workload types
To maximize threat detection coverage, consider enabling all applicable GuardDuty protection plans across your AWS environment. This approach helps provide comprehensive coverage while maintaining cost efficiency, because you’re only charged for active protections on resources that exist in your account. For example, if you don’t use Amazon EKS, you won’t incur charges for EKS Protection even if it’s enabled. This strategy also helps facilitate automatic security coverage if teams deploy new services, without requiring immediate security team intervention. You retain the flexibility to adjust your protection plans at any time as your workload requirements evolve.
Based on AWS security best practices, we offer recommendations for different protection plan combinations aligned with common workload profiles. These recommendations help you understand how different protection plans work together to secure your specific architectures. For Amazon EC2 and Amazon S3 workloads, GuardDuty recommends Foundational, Amazon S3 Protection, and Amazon GuardDuty Malware Protection for Amazon EC2 to detect threats to compute instances, data storage, and AWS Identity and Access Management (IAM) misuse.
Container-heavy environments using Amazon EKS and Amazon ECS benefit from Foundational, Amazon EKS Protection, Amazon GuardDuty Runtime Monitoring, and Amazon GuardDuty Malware Protection for Amazon EC2. These plans work together to monitor container control-plane and runtime for threats and malware.
For serverless-first architectures built on Lambda, GuardDuty suggests Foundational, AWS Lambda Protection, and Amazon S3 Protection (if using Amazon S3 triggers) to identify anomalous function behavior and suspicious traffic patterns.
Data systems using Amazon Aurora or Amazon RDS should consider Foundational, Amazon RDS Protection, Amazon S3 Protection, and Amazon GuardDuty Malware Protection for Amazon S3. This combination helps detect anomalous database sign-ins and potential S3 bucket misuse.
For regulated environments or those implementing zero-trust architectures, enabling all GuardDuty protection plans helps provide comprehensive threat detection coverage that can support your broader security monitoring and compliance program requirements.
For quick reference, here’s what protection plans you should use to actively monitor your different workload types:
Workload profile
Expected security outcomes
Recommended GuardDuty plans
Amazon EC2 and Amazon S3
Detect threats to compute instances, data storage, and IAM misuse
Foundational, Amazon S3 Protection, and Amazon GuardDuty Malware Protection for Amazon EC2
Container-heavy (Amazon EKS, Amazon ECS)
Monitor container control-plane and runtime for threats and malware
Foundational, Amazon EKS Protection, Amazon GuardDuty Runtime Monitoring, and Amazon GuardDuty Malware Protection for Amazon EC2
Serverless-first (AWS Lambda)
Identify anomalous function behavior and suspicious traffic patterns
Foundational, GuardDuty Lambda Protection, GuardDuty S3 Protection (if using Amazon S3 triggers), and GuardDuty Runtime Monitoring for ECS on Fargate
Data system (Amazon Aurora or Amazon RDS)
Detect anomalous database logins and potential S3 bucket misuse
Foundational, Amazon RDS Protection, GuardDuty S3 Protection, and Amazon GuardDuty Malware Protection for Amazon S3
Regulated and Zero-Trust
Comprehensive threat detection to support compliance requirements
All Amazon GuardDuty protection plans
The power of GuardDuty Extended Threat Detection
Building upon these protection plans, GuardDuty offers Extended Threat Detection by default at no additional cost, using AI/ML capabilities to provide improved threat detection for your applications, workloads, and data. This capability correlates security signals to identify active threat sequences, offering a more comprehensive approach to cloud security.
Extended Threat Detection includes a Critical severity level for the most urgent and high-confidence threats based on correlating multiple steps taken by adversaries, such as privilege discovery, API manipulation, persistence activities, and data exfiltration. Integration with the MITRE ATT&CK® framework allows GuardDuty to map observed activities to tactics and techniques, providing context for security teams. To help teams respond quickly, GuardDuty provides specific remediation recommendations based on AWS best practices for each identified threat.
Real-world protection: Extended Threat Detection in action
To understand how GuardDuty protection plans and Extended Threat Detection work together in practice, let’s examine two sophisticated threat scenarios that security teams commonly face: data compromise and container cluster compromise.
Data compromise detection
GuardDuty Extended Threat Detection continuously analyzes and correlates events across multiple protection plans, providing comprehensive visibility when data compromise attempts occur in Amazon S3. For example, in a recent incident, GuardDuty identified a critical severity attack sequence spanning 24 hours. The sequence began with discovery actions through unusual S3 API calls, progressed to defense evasion through CloudTrail modifications, and culminated in potential data exfiltration attempts.
During the discovery phase, S3 Protection detected an IAM role making unusual ListBuckets and GetObject API calls across multiple buckets—a significant deviation from their normal pattern of accessing only specific assigned buckets. Extended Threat Detection then correlated this suspicious activity with subsequent actions from the same IAM role: attempts to disable CloudTrail logging and modify bucket policies (classic signs of defense evasion), followed by the creation of new access keys. This connected sequence of events, all from the same identity, indicated a progressing exploit moving from initial discovery to establishing persistence through credential creation.
Container environment compromise
Protecting containerized environments requires visibility across multiple layers of your Amazon EKS infrastructure. GuardDuty combines signals from EKS control plane (through EKS Protection), container runtime behavior (through Runtime Monitoring), and foundational infrastructure logs to provide comprehensive threat detection for your Kubernetes clusters. For example, EKS Protection detects suspicious activities at the Kubernetes control plane level, such as unusual kubernetes API server authentication attempts or the creation of service accounts with elevated permissions. Runtime Monitoring provides visibility into container behavior, identifying unexpected privileged commands or suspicious file system access. Together with foundational logs, these components provide multi-layer threat detection for your container workloads.
Here’s how these components worked together in detecting an attack sequence: The exploit began when EKS Protection detected unusual Kubernetes API server authentication attempts from a container within the cluster. Runtime Monitoring simultaneously observed commands that deviated from the container’s baseline behavior, such as privilege escalation attempts and unauthorized system calls. As the exploit progressed, GuardDuty detected the creation of a Kubernetes service account with elevated permissions, followed by attempts to mount sensitive host paths to containers.
The scenario then escalated when the compromised Kubernetes Pod established connections to other Pods across namespaces, suggesting lateral movement. GuardDuty Extended Threat Detection correlated these events with the Pod accessing sensitive Kubernetes secrets and AWS credentials stored in Kubernetes ConfigMaps. The final stage revealed the compromised Pod making AWS API calls using stolen credentials, targeting resources outside the cluster’s normal operational scope.
The detection of this multi-stage attack, spanning container exploitation, privilege escalation, and credential theft, demonstrates the power of the correlation capabilities of Extended Threat Detection. Security teams received a single critical finding that mapped the entire exploit sequence to MITRE ATT&CK® tactics, providing clear visibility into the exploit progression and specific remediation steps.
These real-world scenarios illustrate how GuardDuty protection plans work in concert with Extended Threat Detection to provide deep security insights. The combination of targeted protection plans and AI-powered correlation helps security teams identify and respond to sophisticated threats that might otherwise go unnoticed or be difficult to piece together manually.
Conclusion
GuardDuty protection plans, coupled with its built-in Extended Threat Detection feature, offer a powerful suite of managed detections to secure your AWS environment. By tailoring your security strategy to your specific workload types and using AI-powered insights, you can significantly enhance your ability to detect and respond to sophisticated threats. To get started with GuardDuty protection plans and Extended Threat Detection, visit the GuardDuty console. Each protection plan includes a 30-day trial at no additional cost per AWS account and AWS Region, allowing you to evaluate the security coverage for your specific needs. Remember, you can adjust your enabled plans at any time to align with your evolving security requirements and workload changes. By using these capabilities, you can strengthen your organization’s threat detection and response in the face of evolving security risks.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Developers and machine learning (ML) engineers can now connect directly to Amazon SageMaker Unified Studio from their local Visual Studio Code (VS Code) editor. With this capability, you can maintain your existing development workflows and personalized integrated development environment (IDE) configurations while accessing Amazon Web Services (AWS) analytics and artificial intelligence and machine learning (AI/ML) services in a unified data and AI development environment. This integration provides seamless access from your local development environment to scalable infrastructure for running data processing, SQL analytics, and ML workflows. By connecting your local IDE to SageMaker Unified Studio, you can optimize your data and AI development workflows without disrupting your established development practices.
In this post, we demonstrate how to connect your local VS Code to SageMaker Unified Studio so you can build complete end-to-end data and AI workflows while working in your preferred development environment.
Solution overview
The solution architecture consists of three main components:
Local computer – Your development machine running VS Code with AWS Toolkit for Visual Studio Code and Microsoft Remote SSH installed. You can connect through the Toolkit for Visual Studio Code extension in VS Code by browsing available SageMaker Unified Studio spaces and selecting their target environment.
SageMaker Unified Studio – Part of the next generation of Amazon SageMaker, SageMaker Unified Studio is a single data and AI development where you can find and access your data and act on it using familiar AWS tools for SQL analytics, data processing, model development, and generative AI application development.
AWS Systems Manager – A secure, scalable remote access and management service that enables seamless connectivity between your local VS Code and SageMaker Unified Studio spaces to streamline data and AI development workflows.
The following diagram shows the interaction between your local IDE and SageMaker Unified Studio spaces.
Prerequisites
To try the remote IDE connection, you must have the following prerequisites:
Access to a SageMaker Unified Studio domain with connectivity to the internet. For domains set up in virtual private cloud (VPC)-only mode, your domain should have a route out to the internet through a proxy or a NAT gateway. If your domain is completely isolated from the internet, refer to the documentation for setting up the remote connection. If you don’t have a SageMaker Unified Studio domain, you can create one using the quick setup or manual setup option.
Access to or can create a SageMaker Unified Studio project.
A JupyterLab or Code Editor compute space with a minimum instance type requirement of 8 GB of memory. In this post, we use an ml.t3.large instance. SageMaker Distribution image version 2.8 or later is supported.
You have the latest stable VS Code with Microsoft Remote SSH (version 0.74.0 or later), and AWS Toolkit (version 3.74.0) extension installed on your local machine.
Solution implementation
To enable remote connectivity and connect to the space from VS Code, complete the following steps. To connect to a SageMaker Unified Studio space remotely, the space must have remote access enabled.
Navigate to your JupyterLab or Code Editor space. If it’s running, stop the space and choose Configure space to enable remote access, as shown in the following screenshot.
Turn on Remote access to enable the feature and choose Save and restart, as shown in the following screenshot.
Navigate to AWS Toolkit in your local VS Code installation.
On the SageMaker Unified Studio tab, choose Sign in to get started and provide your SageMaker Unified Studio domain URL, that is, https://<domain-id>.sagemaker.<region>.on.aws.
You will be prompted to be redirected to your web browser to allow access to AWS IDE extensions. Choose Open to open a new web browser tab.
Choose Allow access to connect to the project through VS Code.
You’ll receive a Request approved notification, indicating that you now have permissions to access the domain remotely.
You can now navigate back to your local VS Code to access your project to continue building ETL jobs and data pipelines, training and deploying ML models, or building generative AI applications. To connect to the project for data processing and ML development, follow these steps:
Choose Select a project to view your data and compute resources. All projects in the domain are listed, but you’re only allowed access to projects where you’re a project member.
You can only view one domain and one project at a time. To switch projects or sign out of a domain, choose the ellipsis icon.
You can also view compute and data resources that you created previously.
Connect your JupyterLab or Code Editor space by selecting the connectivity icon, as shown in the following image. Note: If this option does not show as available, then you may have remote access disabled in the space. If the space is in “Stopped” state, hover over the space and choose the connect button. This should enable remote access, start the space and connect to it. If the space is in “Running” state, the space must be restarted with remote access enabled. You can do this by stopping the space and connecting to it as shown below from the toolkit.
Another VS Code window will open that is connected to your SageMaker Unified Studio space using remote SSH.
Navigate to the Explorer to view your space’s notebooks, files, and scripts. From the AWS Toolkit, you can also view your data sources.
Use your custom VS Code setup with SageMaker Unified Studio resources
When you connect VS Code to SageMaker Unified Studio, you keep all your personal shortcuts and customizations. For example, if you use code snippets to quickly insert common analytics and ML code patterns, these continue to work with SageMaker Unified Studio managed infrastructure.
In the following graphic, we demonstrate using analytics workflow shortcuts. The “show-databases” code snippet queries Athena to show available databases, “show-glue-tables” lists tables in AWS Glue Data Catalog, and “query-ecommerce” retrieves data using Spark SQL for analysis.
You can also use shortcuts to automate building and training an ML model on SageMaker AI. In the below graphic, the code snippets show data processing, configuring, and launching a SageMaker AI training job. This approach demonstrates how data practitioners can maintain their familiar development setup while using managed data and AI resources in SageMaker Unified Studio.
Disabling remote access in SageMaker Unified Studio
As an administrator, if you want to disable this feature for your users, you can enforce it by adding the following policy to your project’s IAM role:
SageMaker Unified Studio by default shuts down idle resources such as JupyterLab and Code Editor spaces after 1 hour. If you’ve created a SageMaker Unified Studio domain for the purposes of this post, remember to delete the domain.
Conclusion
Connecting directly to Amazon SageMaker Unified Studio from your local IDE reduces the friction of moving between local development and scalable data and AI infrastructure. By maintaining your personalized IDE configurations, this reduces the need to adapt between different development environments. Whether you’re processing large datasets, training foundation models (FMs), or building generative AI applications, you can now work from your local setup while accessing the capabilities of SageMaker Unified Studio. Get started today by connecting your local IDE to SageMaker Unified Studio to streamline your data processing workflows and accelerate your ML model development.
With the release of Grafana 9.4, Amazon Managed Grafana added support for service accounts, which have become the recommended authentication method for applications interacting with Amazon Managed Grafana, replacing the previous API key system.
While API keys are created with a specific role that determines their level of access, service accounts offer a more flexible and maintainable approach. They support multiple tokens, can be enabled or disabled independently, and aren’t tied to individual users, allowing applications to remain authenticated even if a user is deleted. Permissions can be assigned directly to service accounts using role-based access control, simplifying management of long-lived access for non-human entities like applications or scripts.
In this blog post, we walk through how to migrate from API keys to service account tokens when automating Amazon Managed Grafana resource management. We will also show how to securely store tokens using AWS Secrets Manager and automate token rotation with AWS Lambda. All infrastructure is deployed using Terraform, though the pattern can be adapted to your infrastructure-as-code framework of choice.
What are service accounts and tokens?
A service account is designed to authenticate automated tools and systems with Amazon Managed Grafana and is intended for programmatic access. A service account token is a secure credential issued to a service account and can be used to authenticate requests to the Amazon Managed Grafana HTTP API. Multiple tokens can be associated with a single service account, and tokens can be individually revoked or rotated without affecting other services or requiring changes to user accounts.
In this solution, we show you how to create a service account, reference it in your Terraform stack, and then implement rotation of the token associated with it using Lambda and Secrets Manager as shown in the following diagram:
Architecture diagram illustrating the integration between Terraform, AWS Secrets Manager secret store, and an Amazon Managed Grafana workspace, with secret rotation functionality.
The following are the basic steps to set up the solution.
Set up Amazon Managed Grafana with service accounts.
Update the secret in Secrets Manager with the token value.
Automate resource creation in Amazon Managed Grafana using service account tokens in Terraform.
Create a service account and token in your Amazon Managed Grafana workspace.
An AWS account with permissions to create resources such as Lambda functions, AWS Identity and Access Management (IAM) roles, Secrets Manager secrets, and Amazon Managed Grafana workspaces.
Solution walkthrough
Use the following steps to set up and configure the solution.
This step creates the Amazon Managed Grafana workspace and the Secrets Manager secret. In the next step, you bind the workspace with AWS IAM Identity Center and generate the service account token.
Retrieve service account token from the Amazon Managed Grafana workspace
You must have administrative privileges in your Amazon Managed Grafana workspace to perform this step. This applies whether you’re using IAM Identity Center or an external identity provider for authentication.
To change a user’s role in AWS IAM Identity Center (console)
Open the Amazon Managed Grafana console.
In the navigation pane, choose Workspaces.
Select the workspace you want to manage.
On the AWS IAM Identity Center, choose the Assigned users tab.
Select the row of the user that you want to modify.
For Action, choose the following:
Make admin
Confirm the role change.
Select the workspace URL and sign in using your credentials, you should be able to create a service account under the name grafana-sa (or the name of the variable defined in /variables.tf).
Assign the Editor role to the service account to allow it to create dashboards and folders. Learn more about service account roles in the Assign roles to a service account in Grafana.
After the service account is created, add a service account token to it, again the name should be similar to the one defined in /variables.tf.
Add the token to Secrets Manager and create the rest of the resources
After you complete this step, the access token will be stored in Secrets Manager and will automatically be used in the provider definition during future runs of terraform apply.
Copy the service account token.
Paste it into the plaintext section of the Secrets Manager secret created in the previous section
With the access token stored in Secrets Manager, there is no longer a need to restrict the apply operation to the rotation module using the --target flag. Use the following code to remove the restriction.
To avoid incurring future charges, use the following command to delete unused Amazon Managed Grafana service accounts and Terraform-managed resources run the cli command terraform destroy.
Security notes
To protect the security of your organization, we recommend the following best practices:
Always follow least privilege principles. Grant the minimum permissions needed to the service account (for example, Editor instead of Admin).
In this post, we demonstrated how to migrate from API keys to Amazon Managed Grafana service account tokens using Terraform, with secure storage in AWS Secrets Manager and optional automated token rotation via AWS Lambda.This modern approach improves security, scalability, and auditing in your automation pipelines.
Amazon DataZone and Amazon SageMaker announced a new feature that allows an Amazon DataZone domain to be upgraded to the next generation of SageMaker, making the investment customers put into developing Amazon DataZone transferable to SageMaker. All content created and curated through Amazon DataZone such as assets, metadata forms, glossaries, subscriptions, and so on are available to users through Amazon SageMaker Unified Studio after the upgrade.
As an Amazon DataZone administrator, you can choose which of your domains to upgrade to SageMaker through a user interface driven experience. You can use the upgraded domain to use your existing Amazon DataZone implementation in the new SageMaker environment and expand to new SQL analytics, data processing and AI uses cases. Additionally, after the upgrade, both Amazon DataZone and SageMaker portals remain accessible. This provides administrators flexibility with user rollout of SageMaker while providing business continuity for users operating within Amazon DataZone. By upgrading to SageMaker, users can build on their investment from Amazon DataZone by using the SageMaker unified platform, which serves as a central hub for all data, analytics, and AI needs.
SageMaker delivers an integrated experience for analytics and AI with unified access to all your data. Collaborate and build faster from a unified studio using familiar Amazon Web Services (AWS) tools for model development, generative AI, data processing, and SQL analytics, accelerated by Amazon Q Developer, the most capable generative AI assistant for software development. Access all your data whether it’s stored in data lakes, data warehouses, or third-party or federated data sources, with governance built in to meet enterprise security needs.
What we hear from customers
Customers have successfully used Amazon DataZone, enabling data analysts, data engineers, and machine learning teams to collaborate around a shared data catalog. With generative AI moving to center stage, these organizations now aim to address a wider range of use cases, from interactive notebook exploration to prompt engineering for generative-AI projects. Upgrading their Amazon DataZone domains to SageMaker Unified Studio brings everyone together in one place. Data analysts, data engineers, machine learning (ML) specialists, and AI innovators can create integrated solutions on the same governed data while using the tools that best match their work. For example, one of our customers, HEMA, uses Amazon DataZone as a single solution for cataloging, discovery, sharing, and governance of their enterprise data across business domains. They are moving to SageMaker to enable more machine learning and generative AI use cases.
“The launch of the domain upgrade feature allows us to take the investment from our production Amazon DataZone deployment and utilize it in Amazon SageMaker. Organizationally, we are doing more in the generative AI space and with Amazon SageMaker we can accomplish new use cases that leverage the assets curated through Amazon DataZone. With this feature we also love that both portals remain open at the same time so that we can thoughtfully transition user populations to Amazon SageMaker.”
– Tommaso Paracciani, Head of Data & Cloud Platforms at HEMA.
“We’ve invested a lot in building our data management platform for production and logistics, using Amazon DataZone, to accelerate our digital transformation. Evolving our data management solution to use Amazon SageMaker Unified Studio means Data Analysis, Data Engineering, Machine Learning & Generative AI features can now be done from the same place. With the domain upgrade feature, it allows us to onboard to Amazon SageMaker faster by utilizing the work done from Amazon DataZone“
– Volkswagen AG
Upgrade your Amazon DataZone domain to SageMaker Unified Studio
On your Amazon DataZone domain home page, a banner appears at the top announcing the new domain upgrade feature. Choose Get started on this banner to open the upgrade wizard.
A summary page explains the actions the upgrade wizard will perform and what to expect while it runs. Read the information carefully, then choose Start to begin the upgrade.
Domain execution role – The runtime role the domain assumes for SageMaker operations.
Domain service role – Authorizes the service to create and manage domain resources.
Root domain owner (optional) – Designates the administrators of the upgraded root domain. IAM roles cannot sign in to the SageMaker Unified Studio UI. It is helpful to have a root domain owner who can sign in to the UI to modify authorization policies for the root domain.
After selecting the appropriate roles—and, if applicable, a root owner—choose Upgrade domain to launch the upgrade.
When the upgrade finishes, a confirmation banner appears at the top of the domain detail page with two items:
The Amazon DataZone portal URL
The Manage Amazon DataZone upgrade button. Here you can see the Amazon DataZone URL, information about the upgrade, and an option to roll back the upgrade to Amazon DataZone.
Scroll to the Users section of the SageMaker Unified Studio console. All identities that belonged to your original Amazon DataZone domain—along with the root domain owner you assigned in Step 3—now appear in the new domain automatically. No additional setup is required.
Use the URL provided in Step 4 to open SageMaker Unified Studio, then sign in with your existing credentials. You’ll land on the SageMaker Unified Studio home page, confirming that you’re now working in your upgraded domain.
In the Projects list, choose a project that existed in your original Amazon DataZone domain and that the current user can access. Select its name to open it and confirm that every asset and permission transferred correctly to SageMaker Unified Studio.
Inside the project, you can view two key areas:
Project Environments – Verify that every environment linked to the project has been migrated.
Overview – Confirm the project’s general information, including owner, description, and status.
Checking both sections helps ensure that the project moved to SageMaker Unified Studio as expected.
Conclusion
In this post, we discussed the new capability in Amazon DataZone that allows a domain to be upgraded to the next generation of Amazon SageMaker. The investment customers put into developing Amazon DataZone is now transferable to SageMaker. All content created and curated through Amazon DataZone such as assets, metadata forms, glossaries, subscriptions, and so on are available to users through SageMaker Unified Studio after the upgrade. By upgrading to SageMaker, customers build on their investment from Amazon DataZone by using the SageMaker unified platform.
David Victoria is a Senior Technical Product Manager with Amazon SageMaker at AWS. He focuses on improving administration and governance capabilities needed for customers to support their analytics systems. He is passionate about helping customers realize the most value from their data in a secure, governed manner.
Leonardo David Gomez Virahonda is a Principal Analytics Specialist Solutions Architect at AWS, with a strong focus on data governance. He helps organizations across industries implement effective governance strategies using AWS services like Amazon DataZone, AWS Glue, Lake Formation, and SageMaker Catalog. Leonardo’s work spans metadata management, data lineage, access control, and compliance—empowering customers to make their data secure, discoverable, and ready for analytics and AI. He regularly shares best practices through technical blogs, enablement content, and sessions at AWS events like re:Invent and regional Summits.
Today, we announce the availability of a Security Technical Implementation Guide (STIG) for Amazon Linux 2023 (AL2023), developed through collaboration between Amazon Web Services (AWS) and the Defense Information Systems Agency (DISA). The STIG guidelines are important for U.S Department of Defense (DOD) and Federal customers needing strict security compliance derived from the National Institute of Standards and Technology (NIST) 800-53 and related documents. This new technical implementation guide provides detailed Operating System (OS) security hardening configurations for organizations deploying AL2023 in DOD environments and other agencies requiring DISA STIG alignment. The AL2023 STIG provides customers with access to an OS guide that complies with stringent government security standards. This guide for implementing STIG configurations will streamline security processes for organizations seeking robust cybersecurity controls, whether they are needed to maintain DOD compliance or voluntarily adopting these best security practices to enhance their security posture.
Implementing the AL2023 DISA STIG with AWS
AWS Systems Manager (SSM) and EC2 Image builder offer native solutions for implementing the AL2023 DISA STIG configurations in your environment. For customers with existing AL2023 EC2 workload, they can utilize AWS Systems Manger (SSM) to streamline the STIG implementation. For customers who would like to build STIG compliant AL2023 EC2 instances to use for deployment, they can utilize EC2 Image Builder and automate the application of the AL2023 DISA STIG.
Customers can utilize EC2 Image builder to enhance and streamline their implementation of the AL2023 DISA STIG. This integrated approach significantly reduces the operational overhead traditionally associated with maintaining STIG compliance. Therefore, our customers can focus on their core missions while maintaining the highest security standards. Our customers can use AWS EC2 Image Builder’s existing Linux hardening components, which now support AL2023 Category I, II, and III findings to automatically create STIG-compliant AL2023 EC2 images with minimal manual intervention. This automation significantly reduces the time and effort typically needed for security hardening implementations. The EC2 Image Builder Linux hardening component extends its proven capabilities to AL2023, providing the same streamlined security configuration process available for other Linux distributions. For more information, refer to the Image Builder documentation.
Automating the STIG for Existing Fleets via Systems Manager
For existing AL2023 EC2 instances, you can use AWS-managed SSM command documents to automate the implementation of the STIG configurations. . These command documents can be executed through the SSM console, API, or AWS Command Line Interface (AWS CLI). The key mechanism here is the AWS managed Systems Manager command document, which contains the pre-defined STIG configurations. By leveraging these command documents through Systems Manager execution capabilities, customers can systematically deploy and maintain AL2023 STIG configurations across their fleet of EC2 instances. This generates consistent security baselines that meet government and enterprise requirements. This solution is particularly effective for environments with existing AL2023 EC2 instances as it allows customers to implement STIG controls without rebuilding or redeploying instances. For more information about the command document, refer to Apply STIG settings with Systems Manager in the EC2 User Guide.
The AL2023 STIG represents the continued commitment of Amazon Linux to providing customers with the security tools and guidance they need to succeed in highly regulated environments. Amazon Linux, in collaboration with DISA is providing their customers with access to authoritative, government-validated security configurations that meet the most demanding compliance requirements.
Ready to implement AL2023 STIG in your environment? Explore our comprehensive documentation and begin streamlining your security compliance journey today. To learn more about STIG hardening for your EC2 instances, refer to STIG compliance for your EC2 instance and for STIG settings that are applied to EC2 Linux instances, refer to the STIG settings for EC2 Linux instances. To apply STIG settings to your AL 2023 EC2 instance, download the AL2023 DISA STIG.
When modernizing applications, customers in regulated industries like government, financial, and research face a critical challenge: how to transform their systems while meeting strict digital sovereignty and security compliance requirements. A common misconception tied to this is that data must be moved to an AWS Region to fully use Amazon Web Services (AWS) security services.
In this blog post, we dispel that misconception by addressing how to use the following Region-based AWS security services while keeping your data within AWS Dedicated Local Zones.
AWS CloudTrail maintains governance through monitoring and auditing
Dedicated Local Zones are AWS-managed on-premises infrastructure configured for your exclusive use. They help meet specific regulatory requirements while providing cloud benefits such as elasticity, scalability, and pay-as-you-grow pricing. You can place data in your chosen location and use it with enhanced security and governance features provided by AWS to monitor and control application access while maintaining data isolation, in-country data residency, digital sovereignty, and meeting compliance requirements.
AWS Nitro System
Many organizations with strict compliance and data sovereignty requirements are understandably hesitant about moving confidential workloads to the cloud. Their concerns are legitimate and specific: they need a solution that provides independently verifiable protection and isolation from data access by privileged parties, including cloud provider personnel. These organizations also require assurance that unauthorized data access through the cloud control plane is technically impossible, not just contractually prohibited.
Perhaps most critically, they need side-channel protection to help make sure that sensitive data cannot leak through memory or other means to other hypervisor tenants sharing the same physical infrastructure. Traditional cloud security approaches often rely on operational controls and promises rather than technical impossibility, which doesn’t meet the stringent requirements these organizations face.
The AWS Nitro System, which is the foundation of AWS next generation Amazon Elastic Compute Cloud (Amazon EC2) instances that run in a Dedicated Local Zone and its parent Region, addresses each of these concerns through its architecture. This purpose-built combination of specialized hardware and software creates a secure enclave that shields your data from unauthorized access during processing on EC2 instances.
The EC2 instances that run in your Dedicated Local Zones are based on AWS Nitro System, which is designed to provide robust security for compute workloads. It uses specialized hardware and software components to help protect your data from unauthorized access during processing on Amazon EC2.
The three key components of Nitro System include a purpose-built Nitro cards, the Nitro Security Chip, and a Nitro Hypervisor. Together, these three components are designed to enforce restrictions and provide physical and logical security boundaries so that no one, including AWS employees, can access customer workloads or data running on Amazon EC2 without your explicit authorization.
The Nitro System whitepaper details how the Nitro System, by design, removes the possibility of administrator access to an EC2 instance, the overall passive communications design of the Nitro System, and the Nitro System change management process. The security design of the Nitro System has also been independently validated by the NCC Group in a public report.
AWS Key Management Service
Working with customers, we’ve noticed that one of the most persistent sources of confusion and concern isn’t just about whether their data is encrypted, but about who controls the keys that protect that encryption. Many organizations struggle with a fundamental tension: they want the operational benefits of cloud computing, but they also need to maintain strict control over their encryption keys to meet compliance requirements.
This concern is particularly acute for organizations in regulated industries, which often ask pointed questions like “Where exactly are my encryption keys stored?” and “Who can access my keys?” AWS KMS addresses this by offering multiple approaches to key management, each designed for different security and operational requirements. The service provides centralized control over the lifecycle and permissions of encryption keys, so you can create new keys whenever needed and control key management access separate from key policies
By default, Dedicated Local Zones customers can use the integration with AWS KMS in the parent Region to store and control encryption keys. You can then use these encryption keys to encrypt your data stored locally in Amazon EBS, and Amazon S3 in the Dedicated Local Zones.
If your use cases require an external encryption key store to maintain strict data sovereignty requirements, then the combination of Dedicated Local Zones and an AWS KMS external key store can provide a robust solution.
Using an external key store in Dedicated Local Zones, you can host the external hardware security module (HSM) that stores your encryption keys on-premises or colocated with your other infrastructure. By doing this, you maintain full control over the physical security and management of the HSM, while benefiting from the low-latency access and data processing capabilities of Dedicated Local Zones.
The main components of AWS KMS external key store architecture are:
XKS proxy server: You provision an external key store proxy (XKS proxy) server within your on-premises data center (as shown in Figure 1) or within the Dedicated Local Zones. The role of the XKS proxy is to act as the intermediary between AWS KMS and your on-premises HSM. The XKS proxy must be registered as target of a Network Load Balancer (NLB) in Region, this means that if it’s hosted on your on-premises data center, then NLB Amazon Virtual Private Cloud (Amazon VPC) must have private connectivity to the on-premises network through a site-to-site VPN or AWS Direct Connect connection.
On-premises HSM: You configure your on-premises HSM to securely store the root encryption keys that will be used to protect your data encryption keys.
External key store: You create an external key store resource in AWS KMS, which maps to your on-premises HSM through the XKS proxy.
Figure 1: AWS KMS external key store in a Dedicated Local Zone
AWS KMS sends a request to the XKS proxy, which communicates with your on-premises HSM to generate the root key material.
AWS KMS uses this root key to encrypt the data encryption key before returning it to the requesting service and stores the encrypted data encryption key alongside the encrypted data in Amazon S3 or Amazon EBS.
For future encrypt/decrypt operations, the AWS service uses the previously generated and AWS KMS-encrypted data encryption key, without needing to interact with the on-premises HSM.
Note: The on-premises HSM only participates in the initial root key generation to protect the data encryption key, not in the high-volume encrypt/decrypt operations on the data itself.
This architecture delivers two key benefits:
You maintain complete control of your encryption keys by storing them in your data center, helping you meet security compliance requirements.
Dedicated Local Zones keep your data isolated in your chosen location, providing low latency for your users.
It’s important to note that using an AWS KMS external key store requires you to manage additional operational tasks beyond standard AWS KMS. To maintain continuous access to your encrypted data, you must provide 24/7 availability of your on-premises HSM, monitor XKS proxy infrastructure performance, implement robust security controls, and create backup and recovery procedures.
Because system outages can prevent access to your encrypted data, we recommend that you develop detailed operational runbooks, set up comprehensive monitoring, test your recovery procedures regularly, and maintain redundant systems where possible.
Another common concern we hear from organizations evaluating Dedicated Local Zones is whether they’ll need to compromise on security capabilities to maintain data residency. The reality is that AWS security services running in a Region, such as Amazon Inspector, are specifically designed to provide comprehensive protection while respecting your data location requirements.
Organizations running regulated applications in Dedicated Local Zones require robust protection from zero-day vulnerabilities, prioritized patch remediation, and automated vulnerability management to meet compliance requirements. Amazon Inspector addresses these needs by continuously scanning your workloads to detect software vulnerabilities and unintended network exposure without requiring data movement from your chosen location.
Amazon Inspector helps protect your workloads through two distinct scanning modes: hybrid scanning and agent-based scanning. However, for the context of this blog, let’s consider only agent-based scanning mode.
To securely meet data residency requirements in Dedicated Local Zones, enable agent-based scanning mode on AWS Systems Manager (AWS SSM)-managed instances in your account. It’s the default mode for new accounts offering enhanced security through continuous scanning, immediately responding to new common vulnerabilities and exposures (CVEs) and instance changes. It also enables deep inspection capabilities for eligible instances, providing comprehensive vulnerability assessment.
The reference architecture in Figure 2 shows:
Amazon Inspector agent running on AWS SSM managed instances, keeping your application data within Dedicated Local Zones.
Amazon Inspector evaluates and generates findings for detected vulnerabilities.
Figure 2: Amazon Inspector in Dedicated Local Zones
Amazon GuardDuty
Maintaining data sovereignty with Dedicated Local Zones doesn’t mean sacrificing advanced security capabilities. GuardDuty demonstrates how sophisticated threat detection can operate effectively while honoring strict data residency requirements.
Protecting your AI workloads from ransomware and advanced security threats requires an AI and machine learning (AL/ML)-integrated threat intelligence solution that can detect suspicious activity and respond proactively. GuardDuty uses AI/ML-based threat detection and integrated threat intelligence from AWS and leading third parties to protect your AWS accounts, workloads, and data. It continuously monitors malicious activity, delivers detailed security findings, and you can use the information it provides to respond quickly to threats.
GuardDuty Runtime Monitoring observes and analyzes operating system, networking, and file events to detect potential threats in your AWS workloads. The parent Region receives only threat reports while Dedicated Local Zones retain your data.
The reference architecture in Figure 3 shows how GuardDuty helps protect your data in a Dedicated Local Zones:
GuardDuty monitors EC2 instances while your data stays in Dedicated Local Zones.
GuardDuty analyzes data sources from AWS CloudTrail event logs, management events, and Amazon VPC flow logs that your AWS account captures in the Region.
Figure 3: Amazon GuardDuty in Dedicated Local Zones
AWS Certificate Manager
Organizations frequently express concern about certificate management complexity when deploying applications in Dedicated Local Zones. AWS Certificate Manager (ACM), which operates in the parent Region, addresses these challenges by serving as the primary service that customers use to provision, manage, and deploy certificates for use in both public-facing and private Dedicated Local Zones workloads.
ACM integrates seamlessly with ALBs in Dedicated Local Zones to manage your complete certificate lifecycle, as shown in Figure 4.
Figure 4: ACM in Dedicated Local Zones
Follow these steps to implement TLS certificates in Dedicated Local Zones:
Provision or import certificates through ACM in the parent Region.
Associate your certificates with ALB HTTPS listeners in Dedicated Local Zones to enable secure, low-latency SSL/TLS termination near your users.
ACM renews certificates automatically, avoids manual management tasks, and maintains continuous HTTPS service availability. This integration delivers enterprise-grade security with your data residing locally in Dedicated Local Zones. It also provides enhanced performance and reduced latency through proximity to users.
AWS Shield
Business-critical applications in Dedicated Local Zones need maximum availability and responsiveness. AWS Shield Standard, a managed distributed denial of service (DDoS) protection service that runs at the AWS edge, automatically helps protect your applications by detecting and mitigating network (Layer 3) and transport (Layer 4) DDoS attacks even before they reach your workloads.
AWS CloudTrail
A common concern when deploying workloads in Dedicated Local Zones is whether organizations can maintain the same level of governance and compliance oversight they expect from traditional AWS deployments. CloudTrail demonstrates how comprehensive auditing capabilities can extend seamlessly across distributed infrastructure while respecting data residency requirements.
CloudTrail, running in the parent Region, enables governance, compliance, operational auditing, and risk auditing of your AWS account providing you aggregated and consolidated record of multisource events in a single place. This includes a detailed history of AWS API calls for your account, including API calls made using the AWS Management Console, the AWS SDKs, the command line tools, and higher-level AWS services used by the applications running in your Dedicated Local Zones. Only the logs are stored in the parent Region, while your data remains within the Dedicate Local Zones. AWS CloudTrail helps you to enable operational and risk auditing, governance, and compliance of your AWS accounts.
Conclusion
Dedicated Local Zones provide a robust solution for running regulated workloads for all industries, to meet strict data residency and digital sovereignty. Through integrated security services like AWS Nitro System, AWS KMS External Key Store, ACM, AWS Shield, Amazon GuardDuty, Amazon Inspector, and AWS CloudTrail, your organization can achieve stronger security compliance for their mission-critical applications running in AWS Dedicated Local Zones.
To learn more about implementing these security solutions in your Dedicated Local Zones deployment, contact your AWS account team.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Organizations face an ever-increasing need to process and analyze data in real time. Traditional batch processing methods no longer suffice in a world where instant insights and immediate responses to market changes are crucial for maintaining competitive advantage. Streaming data has emerged as the cornerstone of modern data architectures, helping businesses capture, process, and act upon data as it’s generated.
As customers move from batch to real-time processing for streaming data, organizations are facing another challenge: scaling data management across the enterprise, because the centralized data platform can become the bottleneck. Data mesh for streaming data has emerged as a solution to address this challenge, building on the following principles:
Distributed domain-driven architecture – Moving away from centralized data teams to domain-specific ownership
Data as a product – Treating data as a first-class product with clear ownership and quality standards
Self-serve data infrastructure – Enabling domains to manage their data independently
Federated data governance – Following global standards and policies while allowing domain autonomy
A streaming mesh applies these principles to real-time data movement and processing. This mesh is a modern architectural approach that enables real-time data movement across decentralized domains. It provides a flexible, scalable framework for continuous data flow while maintaining the data mesh principles of domain ownership and self-service capabilities. A streaming mesh represents a modern approach to data integration and distribution, breaking down traditional silos and helping organizations create more dynamic, responsive data ecosystems.
AWS provides two primary solutions for streaming ingestion and storage: Amazon Managed Streaming for Apache Kafka (Amazon MSK) or Amazon Kinesis Data Streams. These services are key to building a streaming mesh on AWS. In this post, we explore how to build a streaming mesh using Kinesis Data Streams.
Kinesis Data Streams is a serverless streaming data service that makes it straightforward to capture, process, and store data streams at scale. The service can continuously capture gigabytes of data per second from hundreds of thousands of sources, making it ideal for building streaming mesh architectures. Key features include automatic scaling, on-demand provisioning, built-in security controls, and the ability to retain data for up to 365 days for replay purposes.
Benefits of a streaming mesh
A streaming mesh can deliver the following benefits:
Scalability – Organizations can scale from processing thousands to millions of events per second using managed scaling capabilities such as Kinesis Data Streams on-demand, while maintaining transparent operations for both producers and consumers.
Speed and architectural simplification – Streaming mesh enables real-time data flows, alleviating the need for complex orchestration and extract, transform, and load (ETL) processes. Data is streamed directly from source to consumers as it’s produced, simplifying the overall architecture. This approach replaces intricate point-to-point integrations and scheduled batch jobs with a streamlined, real-time data backbone. For example, instead of running nightly batch jobs to synchronize inventory data of physical goods across regions, a streaming mesh allows for instant inventory updates across all systems as sales occur, significantly reducing architectural complexity and latency.
Data synchronization – A streaming mesh captures source system changes one time and enables multiple downstream systems to independently process the same data stream. For instance, a single order processing stream can simultaneously update inventory systems, shipping services, and analytics platforms while maintaining replay capability, minimizing redundant integrations and providing data consistency.
The following personas have distinct responsibilities in the context of a streaming mesh:
Producers – Producers are responsible for generating and emitting data products into the streaming mesh. They have full ownership over the data products they generate and must make sure these data products adhere to predefined data quality and format standards. Additionally, producers are tasked with managing the schema evolution of the streaming data, while also meeting service level agreements for data delivery.
Consumers – Consumers are responsible for consuming and processing data products from the streaming mesh. They rely on the data products provided by producers to support their applications or analytics needs.
Governance – Governance is responsible for maintaining both the operational health and security of the streaming mesh platform. This includes managing scalability to handle changing workloads, enforcing data retention policies, and optimizing resource usage for efficiency. They also oversee security and compliance, enforcing proper access control, data encryption, and adherence to regulatory standards.
The streaming mesh establishes a common platform that enables seamless collaboration between producers, consumers, and governance teams. By clearly defining responsibilities and providing self-service capabilities, it removes traditional integration barriers while maintaining security and compliance. This approach helps organizations break down data silos and achieve more efficient, flexible data utilization across the enterprise.A streaming mesh architecture consists of two key constructs: stream storage and the stream processor. Stream storage serves all three key personas—governance, producers, and consumers—by providing a reliable, scalable, on-demand platform for data retention and distribution.
This combination of storage and flexible processing capabilities supports the diverse needs of multiple personas while maintaining operational simplicity.
Common access patterns for building a streaming mesh
When building a streaming mesh, you should consider data ingestion, governance, access control, storage, schema control, and processing. When implementing the components that make up the streaming mesh, you must properly address the needs of the personas defined in the previous section: producer, consumer, and governance. A key consideration in streaming mesh architectures is the fact that producers and consumers can also exist outside of AWS entirely. In this post, we examine the key scenarios illustrated in the following diagram. Although the diagram has been simplified for clarity, it highlights the most important scenarios in a streaming mesh architecture:
External sharing – This involves producers or consumers outside of AWS
Internal sharing – This involves producers and consumers within AWS, potentially across different AWS accounts or AWS Regions
Building a streaming mesh on a self-managed streaming solution that facilitates internal and external sharing can be challenging because producers and consumers require the appropriate service discovery, network connectivity, security, and access control to be able to interact with the mesh. This can involve implementing complex networking solutions such as VPN connections with authentication and authorization mechanisms to support secure connectivity. In addition, you must consider the access pattern of the consumers when building the streaming mesh.The following are common access patterns:
Shared data access with replay – This pattern allows multiple (standard or enhanced fan-out) consumers to access the same data stream as well as the ability to replay data as needed. For example, a centralized log stream might serve various teams: security operations for threat detection, IT operations for system troubleshooting, or development teams for debugging. Each team can access and replay the same log data for their specific needs.
Messaging filtering based on rules – In this pattern, you must filter the data stream, and consumers are only reading a subset of the data stream. The filtering is based on predefined rules at the column or row level.
Fan-out to subscribers without replay – This pattern is designed for real-time distribution of messages to multiple subscribers with each subscriber or consumer. The messages are delivered under at-most-once semantics and can be dropped or deleted after consumption. The subscribers can’t replay the events. The data is consumed by services such as AWS AppSync or other GraphQL-based APIs using WebSockets.
The following diagram illustrates these access patterns.
Build a streaming mesh using Kinesis Data Streams
When building a streaming mesh that involves internal and external sharing, you can use Kinesis Data Streams. This service offers a built-in API layer that deliver secure and highly available HTTP/S endpoints accessible through the Kinesis API. Producers and consumers can securely write and read from the Kinesis Data Streams endpoints using the AWS SDK, the Amazon Kinesis Producer Library (KPL), or Kinesis Client Library (KCL), alleviating the need for custom REST proxies or additional API infrastructure.
Security is inherently integrated through AWS Identity and Access Management (IAM), supporting fine-grained access control that can be centrally managed. You can also use attribute-based access control (ABAC) with stream tags assigned to Kinesis Data Streams resources for managing access control to the streaming mesh, because ABAC is particularly helpful in complex and scaling environments. Because ABAC is attribute-based, it enables dynamic authorization for data producers and consumers in real time, automatically adapting access permissions as organizational and data requirements evolve. In addition, Kinesis Data Streams provides built-in rate limiting, request throttling, and burst handling capabilities.
In the following sections, we revisit the previously mentioned common access patterns for consumers in the context of a streaming mesh and discuss how to build the patterns using Kinesis Data Streams.
Shared data access with replay
Kinesis Data Stream has built-in support for the shared data access with replay pattern. The following diagram illustrates this access pattern, focusing on same-account, cross-account, and external consumers.
Governance
When you create your data mesh with Kinesis Data Streams, you should create a data stream with the appropriate number of provisioned shards or on-demand mode based on your throughput needs. On-demand mode should be considered for more dynamic workloads. Note that message ordering can only be guaranteed at the shard level.
Configure the data retention period of up to 365 days. The default retention period is 24 hours and can be modified using the Kinesis Data Streams API. This way, the data is retained for the specified retention period and can be replayed by the consumers. Note that there is an additional fee for long-term data retention fee beyond the default 24 hours.
To enhance network security, you can use interface VPC endpoints. They make sure the traffic between your producers and consumers residing in your virtual private cloud (VPC) and your Kinesis data streams remain private and don’t traverse the internet. To provide cross-account access to your Kinesis data stream, you can use resource policies or cross-account IAM roles. Resource-based policies are directly attached to the resource that you want to share access to, such as the Kinesis data stream, and a cross-account IAM role in one AWS account delegates specific permissions, such as read access to the Kinesis data stream, to another AWS account. At the time of writing, Kinesis Data Streams doesn’t support cross-Region access.
You can build producer applications using the AWS SDK or the KPL. Using the KPL can facilitate the writing because it provides built-in functions such as aggregation, retry mechanisms, pre-shard rate limiting, and increased throughput. The KPL can incur an additional processing delay. You should consider integrating Kinesis Data Streams with the AWS Glue Schema Registry to centrally control discover, control, and evolve schemas and make sure produced data is continuously validated by a registered schema.
You must make sure your producers can securely connect to the Kinesis API whether from inside or outside the AWS Cloud. Your producer can potentially live in the same AWS account, across accounts, or outside of AWS entirely. Typically, you want your producers to be as close as possible to the Region where your Kinesis data stream is running to minimize latency. You can enable cross-account access by attaching a resource-based policy to your Kinesis data stream that grants producers in other AWS accounts permission to write data. At the time of writing, the KPL doesn’t support specifying a stream Amazon Resource Name (ARN) when writing to a data stream. You must use the AWS SDK to write to a cross-account data stream (for more details, see Share your data stream with another account). There are also limitations for cross-Region support if you want to produce data to Kinesis Data Streams from Data Firehose in a different Region using the direct integration.
To securely access the Kinesis data stream, producers need valid credentials. Credentials should not be stored directly in the client application. Instead, you should use IAM roles to provide temporary credentials using the AssumeRole API through AWS Security Token Service (AWS STS). For producers outside of AWS, you can also consider AWS IAM Roles Anywhere to obtain temporary credentials in IAM. Importantly, only the minimum permissions that are required to write the stream should be granted. With ABAC support for Kinesis Data Streams, specific API actions can be allowed or denied when the tag on the data stream matches the tag defined in the IAM role principle.
Consumer
You can build consumers using the KCL or AWS SDK. The KCL can simplify reading from Kinesis data streams because it automatically handles complex tasks such as checkpointing and load balancing across multiple consumers. This shared access pattern can be implemented using standard as well as enhanced fan-out consumers. In the standard consumption mode, the read throughput is shared by all consumers reading from the same shard. The maximum throughput for each shard is 2 MBps. Records are delivered to the consumers in a pull model over HTTP using the GetRecords API. Alternatively, with enhanced fan-out, consumers can use the SubscribeToShard API with data pushed over HTTP/2 for lower-latency delivery. For more details, see Develop enhanced fan-out consumers with dedicated throughput.
Both consumption methods allow consumers to specify the shard and sequence number from which to start reading, enabling data replay from different points within the retention period. Kinesis Data Streams recommends to be aware of the shard limit that is shared and use fan-out when possible. KCL 2.0 or later uses enhanced fan-out by default, and you must specifically set the retrieval mode to POLLING to use the standard consumption model. Regarding connectivity and access control, you should closely follow what is already suggested for the producer side.
Messaging filtering based on rules
Although Kinesis Data Streams doesn’t provide built-in filtering capabilities, you can implement this pattern by combining it with Lambda or Managed Service for Apache Flink. For this post, we focus on using Lambda to filter messages.
Governance and producer
Governance and producer personas should follow the best practices already defined for the shared data access with replay pattern, as described in the previous section.
Consumer
You should create a Lambda function that consumes (shared throughput or dedicated throughput) from the stream and create a Lambda event source mapping with your filter criteria. At the time of writing, Lambda supports event source mappings for Amazon DynamoDB, Kinesis Data Streams, Amazon MQ, Managed Streaming for Apache Kafka or self-managed Kafka, and Amazon Simple Queue Service (Amazon SQS). Both the ingested data records and your filter criteria for the data field must be in a valid JSON format for Lambda to properly filter the incoming messages from Kinesis sources.
When using enhanced fan-out, you configure a Kinesis dedicated-throughput consumer to act as the trigger for your Lambda function. Lambda then filters the (aggregated) records and passes only those records that meet your filter criteria.
Fan-out to subscribers without replay
When distributing streaming data to multiple subscribers without the ability to replay, Kinesis Data Streams supports an intermediary pattern that’s particularly effective for web and mobile clients needing real-time updates. This pattern introduces an intermediary service to bridge between Kinesis Data Streams and the subscribers, processing records from the data stream (using a standard or enhanced fan-out consumer model) and delivering the data records to the subscribers in real time. Subscribers don’t directly interact with the Kinesis API.
A common approach uses GraphQL gateways such as AWS AppSync, WebSockets API services like the Amazon API Gateway WebSockets API, or other suitable services that make the data available to the subscribers. The data is distributed to the subscribers through networking connections such as WebSockets.
The following diagram illustrates the access pattern of fan-out to subscribers without replay. The diagram displays the managed AWS services AppSync and API Gateway as intermediary consumer options for illustration purposes.
Governance and producer
Governance and producer personas should follow the best practices already defined for the shared data access with replay pattern.
Consumer
This consumption model operates differently from traditional Kinesis consumption patterns. Subscribers connect through networking connections such as WebSockets to the intermediary service and receive the data records in real time without the ability to set offsets, replay historical data, or control data positioning. The delivery follows at-most-once semantics, where messages might be lost if subscribers disconnect, because consumption is ephemeral without persistence for individual subscribers. The intermediary consumer service must be designed for high performance, low latency, and resilient message distribution. Potential intermediary service implementations range from managed services such as AppSync or API Gateway to custom-built solutions like WebSocket servers or GraphQL subscription services. In addition, this pattern requires an intermediary consumer service such as Lambda that reads the data from the Kinesis data stream and immediately writes it to the intermediary service.
Conclusion
This post highlighted the benefits of a streaming mesh. We demonstrated why Kinesis Data Streams is particularly suited to facilitate a secure and scalable streaming mesh architecture for internal as well as external sharing. The reasons include the service’s built-in API layer, comprehensive security through IAM, flexible networking connection options, and versatile consumption models. The streaming mesh patterns demonstrated—shared data access with replay, message filtering, and fan-out to subscribers—showcase how Kinesis Data Streams effectively supports producers, consumers, and governance teams across internal and external boundaries.
Delightful developer experience is an important part of building serverless applications efficiently, whether you’re creating an automation script or developing a complex enterprise application. While AWS Lambda has transformed modern application development in the cloud with its serverless computing model, developers spend significant time working in their local environments. They rely on familiar IDEs, debugging tools, testing frameworks, and build within established organizational workflows to deliver production-ready applications.
This post covers some recent enhancements to local developer experience. Two new Lambda features, namely console to IDE and remote debugging, further bridge the gap between cloud and local development, enabling you to leverage the full power of your local tools while working with Lambda functions in the cloud.
Overview
Serverless development with Lambda spans both cloud and local environments, each with its unique strengths. While the Lambda console offers rapid deployment and prototyping, local development provides the depth and flexibility needed for a complex application development workflow that includes integration testing, deployment to shared environments, continuous integration/continuous deployment (CI/CD) pipelines, and collaboration with other team members. The local developer experience encompasses the tools, workflows, and practices that developers use on their local devices to build and maintain their applications. An intuitive local development experience helps application development teams achieve high productivity, ensure code quality, and confidently ship changes to production.
Recent local serverless development experience enhancements
Local development workflows can be seen as two distinct but interconnected loops: the inner loop of writing, testing, and debugging code locally, and the outer loop that extends to cloud deployment, integration testing, release pipeline, and monitoring, as shown in the following figure. For serverless applications, developers want immediate feedback within the inner loop, as they iterate on function code and test integrations with AWS services. AWS has been steadily enhancing the local development experience for developers building on Lambda, with a focus on accelerating the inner loop, where developers spend most of their time.
Figure 1: Inner and outer loop
Visual Studio Code (VS Code) is the most popular IDE among developers according to the 2024 Stack Overflow Developer Survey. Enhanced local IDE experience enables developers to code, test, debug, and deploy Lambda-based serverless applications more efficiently in their local IDE when using VS Code. It introduced the Application Builder interface, which streamlines the entire development workflow from setup to deployment with features such as guided walkthrough for environment setup, pre-configured sample applications, build setting management, and improved local debugging capabilities. This eliminates the need to switch between multiple interfaces. This experience also integrates with AWS Infrastructure Composer, which enables visual application building directly from VS Code, and provides quick-action buttons for common tasks like building, deploying, and invoking functions both locally and in the cloud.
Figure 2 Guided walkthrough in VS Code IDE
With Serverless Land’s extensive ready-to-use pattern library available directly in VS Code, you can now browse, search, and implement a collection of curated, pre-built serverless patterns without leaving the IDE. This integration makes it easier to use proven architectures and AWS best practices while building serverless applications. Amazon CloudWatch Logs Live Tail support for Lambda functions in VS Code brings real-time log streaming and analytics capabilities directly into the IDE, enabling you to monitor and troubleshoot your Lambda functions without context switching. Whether testing a new feature or debugging an issue, you can now see the immediate impact of your code changes without leaving the IDE.
Console to IDE
Over the past decade, the Lambda console has enabled developers to quickly get started with writing Lambda functions, allowing them to rapidly iterate through changing code, testing, and deploying their functions. The console IDE experience saw a major usability refresh in 2024, including the introduction of Amazon Q Developer in the Lambda console.
As applications grow in complexity, developers often need to refactor code, add complex logic, include utility libraries as dependencies, or handle edge cases in their Lambda functions. Examples include using external libraries for complex time calculations or adding modules that perform caller-specific validations. This can make functions too bulky to manage in the console.
Developers may also want to move their functions into a software development lifecycle (SDLC) process that includes test frameworks, security scanning tools, infrastructure as code (IaC) templates, or CI/CD pipelines. This may necessitate that they use version control to collaborate across the team or develop with an AI agent steered by custom rules.
Previously, setting this up required manually configuring a local development environment, including IDE, language runtime, and build/package toolchains. Then, you had to download your function code, configuration, and integration settings and copy them into the IDE. You also had to create the required IaC template with AWS Serverless Application Model (AWS SAM). Only then could you deploy to the cloud to validate the accuracy of your code and configuration and continue with your development workflow.
The new Lambda console to IDE feature enables seamless transition from a cloud-hosted code/test cycle to a local environment, allowing you to download your function code and configuration to local VS Code IDE with just one click. From there, you can easily add dependencies and commit code into source control. Furthermore, you can sync back to the cloud for deployment or export a full AWS SAM template with the “Convert to SAM” capability and continue managing your function as if you had started locally. Console to IDE guides you through setting up the IDE on your local device, if you don’t already have one, along with any necessary configuration. The following figures show a function open in the Lambda console and thereafter in the local VS Code IDE.
Figure 3: A Lambda function as seen in the console IDE
Figure 4: The same Lambda function as seen in a local IDE after Console to IDE export
By making it easy to transition inner loop development between cloud and local development environments, the console to IDE feature makes it easy to quickly scale an idea from proof-of-concept to a full-fledge serverless application. Visit the Lambda documentation to learn more.
Remote debugging
Developers building serverless applications with Lambda often need to test and debug cross-service integrations. While local debugging tools offer valuable capabilities, they do not fully replicate the Lambda runtime environment and its interactions with other AWS services, especially when dealing with Amazon Virtual Private Cloud (VPC) resources and AWS Identity and Access Management (IAM) permissions. Therefore, developers had to rely on print statements and verbose logging, and for complex scenarios they had to deploy their functions multiple times to diagnose and resolve issues. This process extended development cycles, particularly when troubleshooting issues specific to the production environment. Developers wished they could use advanced local development tools like debuggers to investigate issues with code running in Lambda functions deployed in the cloud.
Lambda’s new remote debugging feature now enables you to debug your functions running in the cloud directly from your local VS Code IDE using the AWS Toolkit extension. You can now debug the execution environment of the function running in the cloud in its IAM execution role’s security context with access to configured VPC resources, and trace execution through entire service flows in the cloud.
To start debugging, enable Remote debugging when invoking your function through the AWS Toolkit. Configure your local code path and payload and choose Remote Invoke. AWS Toolkit automatically adds an AWS-managed debugging Lambda layer to your function, extends the timeout, publishes a temporary version, and reverts the config change. AWS Toolkit then invokes the published debug version. You can then start debugging. This feature establishes a secure connection between your local debugger and the function running in the cloud using AWS IoT Secure Tunneling. When your debug session is finished, Lambda automatically removes the temporary function version. You can end your debug session explicitly. Otherwise, it will end automatically after 60 seconds of inactivity or when the Lambda function timeout is reached.
The following figure shows how setting a breakpoint in VS Code IDE during a remote debugging session pauses execution so that you can inspect the data with which the function running in the cloud is called, along with your function’s variables. You can continue to step forward from this point line-by-line to follow the function’s execution.
Figure 5: VS Code IDE debugger attached to execution environment of a Lambda function running in the cloud
All of this means that you don’t have to set up local emulators to approximate cloud behavior, manage complex test frameworks, or continuously capture expensive logs with TRACE-level detail to understand how your code executes. Your debugger can show you exactly what invocation parameters look like, such as event and context, when they reach your function handler. You can step through how your function behaves for different inputs and inspect variable values along the way. Since your code is running in the cloud, you can even see how your function’s IAM execution role affects its behavior. As you step through, you can immediately see when an AWS SDK service call fails due to lack of permissions.
Moreover, you can combine this with the console to IDE feature described previously in this post. When you’ve downloaded your function and scaffolded your local environment with console to IDE, you can debug the function as it runs in the cloud with remote debugging. This gives you much more visibility into the Lambda developer experience, which helps you find issues more easily, fix bugs quickly, and deliver new features rapidly. Follow the steps in the documentation to get started.
Best practices
Although the improved developer experience enables you to move faster when building serverless applications using Lambda, you should incorporate AWS-recommended best practices into your application development workflow.
For large or complex functions, refactor the code following the programming language norms so that developers and AI agents can better understand it. For example, move complex business logic, such as inventory calculations, out of the function handler into a separate module. Console to IDE allows you to use your local refactoring tools to refactor function code.
For isolated cost allocation and security boundaries between development and production, use separate AWS environments for different stages of your development process. You can use console to IDE to generate an AWS SAM template for your application with properties of your function and related AWS resources, which streamlines consistent cross-environment deployments. Then, you can then automate deployments of your template and function code with a CI/CD pipeline.
During development, you should test your functions in the cloud when you can. Remote debugging makes it easier to test functions running in the cloud from your local environment, allowing you to step through your code to validate logic and least-privilege function execution permissions. To optimize cost, focus on logging just enough to recreate problem scenarios, including necessary context about function execution, rather than logging everything you need to diagnose behavior. This also means that you have smaller log volumes to sift through.
You should recreate problem scenarios in an environment where you control the flow of input and can use remote debugging. When possible, you should use a development environment where there are no other sources of invokes. There’s a small window while remote debugging applies the temporary config change where other traffic to $LATEST might cause unexpected results, such as a slower cold start. By default, the debugger does not initialize when running on $LATEST. You should also use Aliases and Versions to explicitly pin environments to the appropriate version of a function, which avoids this problem and gives you more deterministic behavior along with the ability to do canary deployments.
Conclusion
The local development experience enhancements, including debugging workflows and IDE integrations, minimize the configuration and setup needed for developers to locally build serverless applications using Lambda. This enables developers to focus on building business logic. These enhancements also provide the rapid feedback loop developers need while making sure that their local environment accurately reflects cloud behavior.
AWS continues to streamline the local developer experience for serverless applications in areas such as local testing of service integrations, IaC workflows, troubleshooting capabilities, and using AI assistance more deeply in local development workflows. All of this helps developers build more efficient and secure serverless applications.
To get started with these new capabilities, visit the Lambda developer guide for detailed walkthroughs and best practices. Share your experiences and suggestions through the Lambda GitHub issues page to help shape the future of serverless developer experience.
Security and compliance concerns are key considerations when customers across industries rely on Amazon SageMaker Catalog. Customers use SageMaker Catalog to organize, discover, and govern data and machine learning (ML) assets. A common request from domain administrators is the ability to enforce governance controls on certain metadata terms that carry compliance or policy significance. Examples include terms used to classify assets with sensitive data (such as PHI in healthcare or PCI in financial services) or terms used to trigger automatic access grants based on regulatory or organizational policies.
AWS announced restricted classification terms in SageMaker Catalog. This new capability allows domain administrators to define governance-controlled terms and enforce which teams and users are authorized to apply them. Restricted classification terms are designed to allow organizations to set standards for consistent classification of sensitive data, help prevent misuse of regulatory tags, and enable downstream workflows such as automatic access grants across the enterprise.
Restricted classification (glossary) terms
Customers have told us that the flexibility of applying glossary terms in SageMaker Catalog has been valuable for collaboration and scale. At the same time, many enterprises—especially in regulated industries—wanted an additional layer of control for certain classifications. For example, terms like PHI (Protected Health Information) in healthcare or PCI (payment card industry) in financial services should only be applied by authorized personnel, because they carry compliance and policy significance. Customers also asked for a way to enforce these governance policies without adding operational overhead. As catalogs grow to thousands of assets, forms, and columns, validating tens of thousands of terms can create performance and compliance challenges. A solution was needed to combine the openness of cataloging with governance precision for sensitive use cases.With this launch, SageMaker Catalog introduces a restricted classification terms section on each asset:
Business glossary terms (existing): Open tagging, no restrictions.
Restricted glossary terms (new): Only authorized users or groups can apply terms. Unauthorized users can view and filter assets based on these terms but not assign them.
Customer spotlight
As a large-scale organization with diverse data needs, the Business Data Technologies (BDT) team at Amazon manages thousands of assets across business units. Making sure these assets are consistently classified and governed is critical to maintaining compliance and enabling secure data sharing at scale. With restricted classification terms in SageMaker Catalog, the BDT team can now enforce which groups are authorized to apply terms, such as policy-driven classifications for merchants or payment data, while keeping discovery seamless for users.
“Restricted classification terms are instrumental in helping us scale data onboarding and governance across Amazon. By enforcing who can apply policy-related terms in the Amazon SageMaker Catalog, we’re able to accelerate consolidation of data assets across business units without compromising compliance. This facilitates consistent classification, prevents misuse, and allows us to automate downstream access grants—enabling our builders to innovate quickly while maintaining the highest standards of governance.”
– Gerry Moses, Senior Principal Technologist, Business Data Technologies, Amazon
Key benefits
With the introduction of restricted classification terms, customers gain stronger governance controls without losing the flexibility of open cataloging. This capability is designed to provide customers with the following key benefits:
Governance enforcement – Sensitive terms such as PHI or PCI can only be applied by approved users or groups, supporting compliance with organizational and regulatory policies.
Consistency at scale – Helps prevent misclassification across thousands of assets, maintaining a single source of truth for governed terms across domains and projects.
Automatic access workflows – Restricted terms can trigger downstream policies, such as auto-granting access to regulated projects or routing assets to compliance-approved environments.
Sample use case
A pharmaceutical company uses SageMaker Catalog to manage clinical trial data. They define a glossary called Regulated Data Categories with restricted terms like PHI and Genomic Data. Only compliance-approved data stewards are authorized to apply these terms to assets. When applied, the term PHI can automatically trigger policies that restrict access only to approved research groups or environments with HIPAA compliance enabled. This makes sure clinical datasets containing PHI to be consistently tagged and subject to the right access policies, while still discoverable for approved researchers.
A retail bank manages transaction and credit data in its domain catalog. They create a glossary called Data Sensitivity Levels with restricted terms like PCI and Credit Bureau Data. When an authorized risk officer classifies an asset with PCI, SageMaker Catalog can automatically grant access only to members of the bank’s Payments Compliance project. Other users, such as analysts in marketing, can see the classification exists but cannot apply or override it. This approach helps prevent accidental misuse of sensitive financial terms while automating secure access grants aligned with regulatory requirements.
Solution overview
In this section, we will walk through how to create and apply restricted classification terms.
Prerequisites
To follow this post, you should have an Amazon SageMaker Unified Studio domain set up with a domain owner or domain unit owner privileges. You should also have existing projects or permissions to create new projects and business glossaries. For instructions to create them, see the Getting started guide. In this post, we created a project named Clinical Study Trials.
Create a restricted business glossary
In this step, a compliance officer creates a new glossary called Regulated Data Categories and marks it as restricted. Usage grants are given to the Clinical Data Stewardship project.
Log in to your Amazon SageMaker Unified Studio (off-console) portal. Select the project, navigate to Business Glossaries tab and choose Create Glossary.
Enter a name and description for the glossary. Select Restrict this glossary for governed term use and choose Add projects.
Select the projects that should have permissions to tag governed terms to assets. Choose Add policy grant.
Choose Create to create the restricted business glossary.
The Regulated Data Categories business glossary is created and ready to populate.
Add restricted business glossary terms
In this step you will add two terms: PHI and Genomic Data to the glossary.
Choose Create term.
Enter a Name and Description. Turn on Enabled and choose Create term.
Follow the same steps to add the second term and both terms should be available in the glossary.
Apply restricted glossary terms to classify assets
In this step, a data steward will publish a new asset and apply the restricted terms.
Go to the Data Steward project and navigate to the asset where Restricted Terms should be tagged and choose Add terms.
From Regulated Data Categories select PHI and Genomic Data and choose Add terms.
Restricted terms are attached to the asset.
If a project that doesn’t have grants to use restricted term tries to attach restricted terms, you would receive the error Unable to apply restricted terms.
Search and discovery
Data consumers can search for assets and filter by restricted terms filters on the left filters tab (for example, PHI or PCI) to discover governed assets.
As customers expand their use of SageMaker Catalog, the need for governance becomes clear. From our work with customers in healthcare, life sciences, and financial services, we learned that organizations value the flexibility of open cataloging but need precise controls for terms that carry compliance or policy weight.
Restricted classification terms are designed to bring the best of both worlds: Flexibility for builders to continue tagging and discovering assets, and governance precision to help ensure that sensitive classifications are applied consistently. This capability lays the foundation for future enhancements such as column-level governance and deeper integration with enterprise data governance services. By balancing openness with control, SageMaker Catalog continues to help customers organize, govern, and scale their data and ML assets with confidence.
In March 2025, AWS announced the general availability of the next generation of Amazon SageMaker, including Amazon SageMaker Unified Studio, a single data and AI development environment that brings together the functionality and tools from existing AWS Analytics and AI/ML services, including Amazon EMR, AWS Glue, Amazon Athena, Amazon Redshift, Amazon Bedrock, and Amazon SageMaker AI. You can discover data and AI assets from across your organization, then work together in projects to securely build and share analytics and AI artifacts, including data, models, and generative AI applications in a trusted and secure environment. Governance features including fine-grained access control are built into Amazon SageMaker Unified Studio using Amazon SageMaker Catalog to help you meet enterprise security requirements across your entire data estate. Unified access to your data is provided by a unified, open, and secure data lakehouse architecture built on Apache Iceberg open standards. Whether your data is stored in Amazon Simple Storage Service (Amazon S3) data lakes, Amazon Redshift data warehouses, or third-party and federated data sources, you can access it from one place and use it with Iceberg-compatible engines and tools.
AWS for Financial Services is a pioneer at the intersection of financial services and technology, enabling our customers to optimize operations and push the boundaries of innovation with the broadest set of services and partner solutions—all while maintaining security, compliance, and resilience at scale. Financial institutions are using AI and machine learning (ML), and generative AI services on AWS to transform their organizations faster and in ways never before possible. With Amazon SageMaker Unified Studio, financial services industry (FSI) customers can seamlessly work across different compute resources and clusters using unified notebooks, including generative AI–powered troubleshooting capabilities, and use the built-in SQL editor to query data stored in data lakes, data warehouses, databases, and applications.
Workshops
In this post, we’re excited to announce the release of four Amazon SageMaker Unified Studio publicly available workshops that are specific to each FSI segment: insurance, banking, capital markets, and payments. These workshops can help you learn how to deploy Amazon SageMaker Unified Studio effectively for business use cases. Follow the links for each FSI use case listed in the following table to get started for these self-paced workshops.
In this workshop, you’ll use Amazon SageMaker Unified Studio and analytics services to transform your insurance business challenges into opportunities. It provides hands-on experience in developing data-driven, generative AI–powered solutions for insurance that deliver measurable business value.
In this workshop, you’ll explore how leading retail banks can unlock business value by using Amazon SageMaker Unified Studio to build, scale, and govern end-to-end data analytics and ML workflows. The workshop walks you through a reference architecture and curated banking-specific datasets covering common retail banking use cases, such as customer segmentation, fraud detection, churn prediction, and generative AI applications like personalized communication.
In this workshop, you’ll use Amazon SageMaker Unified Studio to analyze trade and quote data for the S&P 500 stocks to generate insights. The data is stored in various formats across different sources. This solution will unify the data from disparate sources using a lakehouse architecture and offer team members flexibility to access the data using familiar SQL constructs.
In this workshop, you’ll use Amazon SageMaker Unified Studio and analytics services to enable organizations to ingest, store, process, and analyze payment data, supporting needs from data ingestion and storage to big data analytics, streaming analytics, business intelligence, and machine learning.
Conclusion
We appreciate your comments and feedback to help us accelerate adoption of Amazon SageMaker Unified Studio for financial services workloads. Contact your AWS account team to engage a FSI specialist solutions architect if you require additional expert guidance.
Learn more about AWS for financial services, customer case studies, and additional resources on our Financial Services website.
The Amazon SageMakerlakehouse architecture has expanded its tag-based access control (TBAC) capabilities to include federated catalogs. This enhancement extends beyond the default AWS Glue Data Catalog resources to encompass Amazon S3 Tables, Amazon Redshift data warehouses. TBAC is also supported on federated catalogs from data sources Amazon DynamoDB, MySQL, PostgreSQL, SQL Server, Oracle, Amazon DocumentDB, Google BigQuery, and Snowflake. TBAC provides you a sophisticated permission management that uses tags to create logical groupings of catalog resources, enabling administrators to implement fine-grained access controls across their entire data landscape without managing individual resource-level permissions.
Traditional data access management often requires manual assignment of permissions at the resource level, creating significant administrative overhead. TBAC solves this by introducing an automated, inheritance-based permission model. When administrators apply tags to data resources, access permissions are automatically inherited, eliminating the need for manual policy modifications when new tables are added. This streamlined approach not only reduces administrative burden but also enhances security consistency across the data ecosystem.
TBAC can be set up through the AWS Lake Formation console, and accessible using Amazon Redshift, Amazon Athena, Amazon EMR, AWS Glue, and Amazon SageMaker Unified Studio. This makes it valuable for organizations managing complex data landscapes with multiple data sources and large datasets. TBAC is especially beneficial for enterprises implementing data mesh architectures, maintaining regulatory compliance, or scaling their data operations across multiple departments. Furthermore, TBAC enables efficient data sharing across different accounts, making it easier to maintain secure collaboration.
In this post, we illustrate how to get started with fine-grained access control of S3 Tables and Redshift tables in the lakehouse using TBAC. We also show how to access these lakehouse tables using your choice of analytics services, such as Athena, Redshift, and Apache Spark in Amazon EMR Serverless in Amazon SageMaker Unified Studio.
Solution overview
For illustration, we consider a fictional company called Example Retail Corp, as covered in the blog post Accelerate your analytics with Amazon S3 Tables and Amazon SageMaker Lakehouse. Example Retail’s leadership has decided to use the SageMaker lakehouse architecture to unify data across S3 Tables and their Redshift data warehouse. With this lakehouse architecture, they can now conduct analyses across their data to identify at-risk customers, understand the impact of personalized marketing campaigns on customer churn, and develop targeted retention and sales strategies.
Alice is a data administrator with the AWS Identity and Access Management (IAM) role LHAdmin in Example Retail Corp, and she wants to implement tag-based access control to scale permissions across their data lake and data warehouse resources. She is using S3 Tables with Iceberg transactional capability to achieve scalability as updates are streamed across billions of customer interactions, while providing the same durability, availability, and performance characteristics that S3 is known for. She already has a Redshift namespace, which contains historical and current data about sales, customers prospects, and churn information. Alice supports an extended team of developers, engineers, and data scientists who require access to the data environment to develop business insights, dashboards, ML models, and knowledge bases. This team includes:
Bob, a data steward with IAM role DataSteward, is the domain owner and manages access to the S3 Tables and warehouse data. He enables other teams who build reports to be shared with leadership.
Charlie, a data analyst with IAM role DataAnalyst, builds ML forecasting models for sales growth using the pipeline or customer conversion across multiple touchpoints, and makes those available to finance and planning teams.
Doug, a BI engineer with IAM role BIEngineer, builds interactive dashboards to funnel customer prospects and their conversions across multiple touchpoints, and makes those available to thousands of sales team members.
Alice decides to use the SageMaker lakehouse architecture to unify data across S3 Tables and Redshift data warehouse. Bob can now bring his domain data into one place and manage access to multiple teams requesting access to his data. Charlie can quickly build Amazon QuickSight dashboards and use his Redshift and Athena expertise to provide quick query results. Doug can build Spark-based processing with AWS Glue or Amazon EMR to build ML forecasting models.
Alice’s goal is to use TBAC to make fine-grained access much more scalable, because they can grant permissions on many resources at once and permissions are updated accordingly when tags for resources are added, changed, or removed.The following diagram illustrates the solution architecture.
Alice as Lakehouse admin and Bob as Data Steward determines that following high-level steps are needed to deploy the solution:
Create an S3 Tables bucket and enable integration with the Data Catalog. This will make the resources available under the federated catalog s3tablescatalog in the lakehouse architecture with Lake Formation for access control. Create a namespace and a table under the table bucket where the data will be stored.
Create a Redshift cluster with tables, publish your data warehouse to the Data Catalog, and create a catalog registering the namespace. This will make the resources available under a federated catalog in the lakehouse architecture with Lake Formation for access control.
Delegate permissions to create tags and grant permissions on Data Catalog resources to DataSteward.
As DataSteward, define tag ontology based on the use case and create Tags. Assign these LF-Tags to the resources (database or table) to logically group lakehouse resources for sharing based on access patterns.
Share the S3 Tables catalog table and Redshift table using tag-based access control to DataAnalyst, who uses Athena for analysis and Redshift Spectrum for generating the report.
Share the S3 Tables catalog table and Redshift table using tag-based access control to BIEngineer, who uses Spark in EMR Serverless to further process the datasets.
Data steward defines the tags and assignment to resources as shown:
Create an IAM role named DataSteward and attach permissions for AWS Glue and Lake Formation access. For instructions, refer to Data lake administrator permissions.
Create an IAM role named DataAnalyst and attach permissions for Amazon Redshift and Athena access. For instructions, refer to Data analyst permissions.
Create an IAM role named BIEngineer and attach permissions for Amazon EMR access. This is also the EMR runtime role that the Spark job will use to access the tables. For instructions on the role permissions, refer to Job runtime roles for EMR serverless.
In the navigation pane, under Data Catalog, choose Catalogs. Under Pending catalog invitations, you will see the invitation initiated from the Redshift Serverless namespace salescluster.
Select the pending invitation and choose Approve and create catalog.
Provide a name for the catalog. For example, redshift_salescatalog.
Under Access from engines, select Access this catalog from Iceberg-compatible engines and choose RedshiftS3DataTransferRole for IAM role.
Choose Next.
Choose Add permissions.
Under Principals, choose the LHAdmin role for IAM users and roles, choose Super user for Catalog permissions, and choose Add.
Choose Create catalog.After you create the catalog redshift_salescatalog, you can inspect the sub-catalog dev, namespace and database sales, and table store_sales underneath it.
Alice has now completed creating an S3table catalog table and Redshift federated catalog table in the Data Catalog.
Delegate LF-Tags creation and resource permission to the DataSteward role
Alice completes the following steps to delegate LF-Tags creation and resource permission to Bob as DataSteward:
In the navigation pane, choose LF Tags and permissions, then choose the LF-Tag creators tab.
Choose Add LF-Tag creators.
Choose DataSteward for IAM users and roles.
Under Permission, select Create LF-Tag and choose Add.
In the navigation pane, choose Data permissions, then choose Grant.
In the Principals section, for IAM users and roles, choose the DataSteward role.
In the LF-Tags or catalog resources section, select Named Data Catalog resources.
Choose <account_id>:s3tablescatalog/tbacblog-customer-bucket and <account_id>:redshift_salescatalog/dev for Catalogs.
In the Catalog permissions section, select Super user for permissions.
Choose Grant.
You can verify permissions for DataSteward on the Data permissions page.
Alice has now completed delegating LF-tags creation and assignment permissions to Bob, the DataSteward. She had also granted catalog level permissions to Bob.
Create LF-Tags
Bob as DataSteward completes the following steps to create LF-Tags:
In the navigation pane, choose LF Tags and permissions, then choose the LF-tags tab.
Choose Add-LF-Tag.
Create LF tags as follows:
Key: Domain and Values: sales, marketing
Key: Sensitivity and Values: true, false
Assign LF-Tags to the S3 Tables database and table
Bob as DataSteward completes the following steps to assign LF-Tags to the S3 Tables database and table:
In the navigation pane, choose Catalogs and choose s3tablescatalog.
Choose tbacblog-customer-bucket and choose tbacblog_namespace.
Choose Edit LF-Tags.
Assign the following tags:
Key: Domain and Value: sales
Key: Sensitivity and Value: false
Choose Save.
On the View dropdown menu, choose Tables.
Choose the customer table and choose the Schema tab.
Choose Edit schema and select the columns c_first_name, c_last_name, c_email_address, and c_birth_year.
Choose Edit LF-Tags and modify the tag value:
Key: Sensitivity and Value: true
Choose Save.
Assign LF-Tags to the Redshift database and table
Bob as DataSteward completes the following steps to assign LF-Tags to the Redshift database and table:
In the navigation pane, choose Catalogs and choose salescatalog.
Choose dev and select sales.
Choose Edit LF-Tags and assign the following tags:
Key: Domain and Value: sales
Key: Sensitivity and Value: false
Choose Save.
Grant catalog permission to the DataAnalyst and BIEngineer roles
Bob as DataSteward completes the following steps to grant catalog permission to the DataAnalyst and BIEngineer roles (Charlie and Doug, respectively):
In the navigation pane, choose Datalake permissions, then choose Grant.
In the Principals section, for IAM users and roles, choose the DataAnalyst and BIEngineer roles.
In the LF-Tags or catalog resources section, select Named Data Catalog resources.
For Catalogs, choose <account_id>:s3tablescatalog/tbacblog-customer-bucket and <account_id>:salescatalog/dev.
In the Catalog permissions section, choose Describe for permissions.
Choose Grant.
Grant permission to the DataAnalyst role for the sales domain and non-sensitive data
Bob as DataSteward completes the following steps to grant permission to the DataAnalyst role (Charlie) for the sales domain for non-sensitive data:
In the navigation pane, choose Datalake permissions, then choose Grant.
In the Principals section, for IAM users and roles, choose the DataAnalyst role.
In the LF-Tags or catalog resources section, select Resources matched by LF-Tags and provide the following values:
Key: Domain and Value: sales
Key: Sensitivity and Value: false
In the Database permissions section, choose Describe for permissions.
In the Table permissions section, select Select and Describe for permissions.
Choose Grant.
Grant permission to the BIEngineer role for sales domain data
Bob as DataSteward completes the following steps to grant permission to the BIEngineer role (Doug) for all sales domain data:
In the navigation pane, choose Datalake permissions, then choose Grant.
In the Principals section, for IAM users and roles, choose the BIEngineer role.
In the LF-Tags or catalog resources section, select Resources matched by LF-Tags and provide the following values:
Key: Domain and Value: sales
In the Database permissions section, choose Describe for permissions.
In the Table permissions section, select Select and Describe for permissions.
Choose Grant.
This completes the steps to grant S3 Tables and Redshift federated tables permissions to various data personas using LF-TBAC.
Verify data access
In this step, we log in as individual data personas and query the lakehouse tables that are available to each persona.
Use Athena to analyze customer information as the DataAnalyst role
Charlie signs in to the Athena console as the DataAnalyst role. He runs the following sample SQL query:
SELECT * FROM
"redshift_salescatalog/dev"."sales"."store_sales" s
JOIN
"s3tablescatalog/tbacblog-customer-bucket"."tbacblog_namespace"."customer" c
ON c.c_customer_sk = s.customer_sk
LIMIT 5;
Run a sample query to access the 4 columns in the S3table customer that DataAnalyst does not have access to. You should receive an error as shown in the screenshot. This verifies column level fine grained access using LF-tags on the lakehouse tables.
Use the Redshift query editor to analyze customer data as the DataAnalyst role
Charlie signs in to the Redshift query editor v2 as the DataAnalyst role and runs the following sample SQL query:
SELECT * FROM
"dev@redshift_salescatalog"."sales"."store_sales" s
JOIN
"tbacblog-customer-bucket@s3tablescatalog"."tbacblog_namespace"."customer" c
ON c.c_customer_sk = s.customer_sk
LIMIT 5;
This verifies the DataAnalyst access to the lakehouse tables with LF-tags based permissions, using Redshift Spectrum
Use Amazon EMR to process customer data as the BIEngineer role
Doug uses Amazon EMR to process customer data with the BIEngineer role:
Sign-in to the EMR Studio as Doug, with BIEngineer role. Ensure EMR Serverless application is attached to the workspace with BIEngineer as the EMR runtime role. Download the PySpark notebook tbacblog_emrs.ipynb. Upload to your studio environment.
Change the account id, AWS Region and resource names as per your setup. Restart kernel and clear output.
Once your pySpark kernel is ready, run the cells and verify access.This verifies access using LF-tags to the lakehouse tables as the EMR runtime role. For demonstration, we are also providing the pySpark script tbacblog_sparkscript.py that you can run as EMR batch job and Glue 5.0 ETL.
Doug has also set up Amazon SageMaker Unified Studio as covered in the blog post Accelerate your analytics with Amazon S3 Tables and Amazon SageMaker Lakehouse. Doug logs in to SageMaker Unified Studio and select previously created project to perform his analysis. He navigates to the Build options and choose JupyterLab under IDE & Applications. He uses the downloaded pyspark notebook and updates it as per his Spark query requirements. He then runs the cells by selecting compute as project.spark.fineGrained.
Doug can now start using Spark SQL and start processing data as per fine grained access controlled by the Tags.
Clean up
Complete the following steps to delete the resources you created to avoid unexpected costs:
Delete the Redshift Serverless associated namespace.
Delete the EMR Studio and EMR Serverless instance.
Delete the AWS Glue catalogs, databases, and tables and Lake Formation permissions.
Delete the S3 Tables bucket.
Empty and delete the S3 bucket.
Delete the IAM roles created for this post.
Conclusion
In this post, we demonstrated how you can use Lake Formation tag-based access control with the SageMaker lakehouse architecture to achieve unified and scalable permissions to your data warehouse and data lake. Now administrators can add access permissions to federated catalogs using attributes and tags, creating automated policy enforcement that scales naturally as new assets are added to the system. This eliminates the operational overhead of manual policy updates. You can use this model for sharing resources across accounts and Regions to facilitate data sharing within and across enterprises.
We encourage AWS data lake customers to try this feature and share your feedback in the comments. To learn more about tag-based access control, visit the Lake Formation documentation.
Acknowledgment: A special thanks to everyone who contributed to the development and launch of TBAC: Joey Ghirardelli, Xinchi Li, Keshav Murthy Ramachandra, Noella Jiang, Purvaja Narayanaswamy, Sandya Krishnanand.
About the Authors
Sandeep Adwankar is a Senior Product Manager with Amazon SageMaker Lakehouse . Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that help customers improve how they manage, secure, and access data.
Srividya Parthasarathy is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with the product team and customers to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community.
Aarthi Srinivasan is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with AWS customers and partners to architect lakehouse solutions, enhance product features, and establish best practices for data governance.
Amazon’s threat intelligence team has identified and disrupted a watering hole campaign conducted by APT29 (also known as Midnight Blizzard), a threat actor associated with Russia’s Foreign Intelligence Service (SVR). Our investigation uncovered an opportunistic watering hole campaign using compromised websites to redirect visitors to malicious infrastructure designed to trick users into authorizing attacker-controlled devices through Microsoft’s device code authentication flow. This opportunistic approach illustrates APT29’s continued evolution in scaling their operations to cast a wider net in their intelligence collection efforts.
The evolving tactics of APT29
This campaign follows a pattern of activity we’ve previously observed from APT29. In October 2024, Amazon disrupted APT29’s attempt to use domains impersonating AWS to phish users with Remote Desktop Protocol files pointed to actor-controlled resources. Also, in June 2025, Google’s Threat Intelligence Group reported on APT29’s phishing campaigns targeting academics and critics of Russia using application-specific passwords (ASPs). The current campaign shows their continued focus on credential harvesting and intelligence collection, with refinements to their technical approach, and demonstrates an evolution in APT29’s tradecraft through their ability to:
Compromise legitimate websites and initially inject obfuscated JavaScript
Rapidly adapt infrastructure when faced with disruption
On new infrastructure, adjust from use of JavaScript redirects to server-side redirects
Technical details
Amazon identified the activity through an analytic it created for APT29 infrastructure, which led to the discovery of the actor-controlled domain names. Through further investigation, Amazon identified the actor compromised various legitimate websites and injected JavaScript that redirected approximately 10% of visitors to these actor-controlled domains. These domains, including findcloudflare[.]com, mimicked Cloudflare verification pages to appear legitimate. The campaign’s ultimate target was Microsoft’s device code authentication flow. There was no compromise of AWS systems, nor was there a direct impact observed on AWS services or infrastructure.
Analysis of the code revealed evasion techniques, including:
Using randomization to only redirect a small percentage of visitors
Employing base64 encoding to hide malicious code
Setting cookies to prevent repeated redirects of the same visitor
Pivoting to new infrastructure when blocked
Image of compromised page, with domain name removed.
Amazon’s disruption efforts
Amazon remains committed to protecting the security of the internet by actively hunting for and disrupting sophisticated threat actors. We will continue working with industry partners and the security community to share intelligence and mitigate threats. Upon discovering this campaign, Amazon worked quickly to isolate affected EC2 instances, partner with Cloudflare and other providers to disrupt the actor’s domains, and share relevant information with Microsoft.
Despite the actor’s attempts to migrate to new infrastructure, including a move off AWS to another cloud provider, our team continued tracking and disrupting their operations. After our intervention, we observed the actor register additional domains such as cloudflare[.]redirectpartners[.]com, which again attempted to lure victims into Microsoft device code authentication workflows.
Protecting users and organizations
We recommend organizations implement the following protective measures:
For end users:
Be vigilant for suspicious redirect chains, particularly those masquerading as security verification pages.
Always verify the authenticity of device authorization requests before approving them.
Enable multi-factor authentication (MFA) on all accounts, similar to how AWS now requires MFA for root accounts.
Be wary of web pages asking you to copy and paste commands or perform actions in Windows Run dialog (Win+R).
This matches the recently documented “ClickFix” technique where attackers trick users into running malicious commands.
For IT administrators:
Follow Microsoft’s security guidance on device authentication flows and consider disabling this feature if not required.
Enforce conditional access policies that restrict authentication based on device compliance, location, and risk factors.
Implement robust logging and monitoring for authentication events, particularly those involving new device authorizations.
Indicators of compromise (IOCs)
findcloudflare[.]com
cloudflare[.]redirectpartners[.]com
Sample JavaScript code
Decoded JavaScript code, with compromised site removed: “[removed_domain]”
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
As your organization grows, the amount of data you own and the number of data sources to store and process your data across multiple Amazon Web Services (AWS) accounts increases. Enforcing consistent access controls that restrict access to known networks might become a key part in protecting your organization’s sensitive data.
Previously, AWS customers could rely on AWS Identity and Access Management (IAM) global condition keys such as aws:SourceVpc and aws:SourceVpce to restrict access to specific virtual private clouds (VPCs) or VPC endpoints. These condition keys work well for organizations with few accounts and for use cases limited to specific workloads. However, as the number of your VPCs grow, using these keys could introduce challenges in scaling the control across a large set of resources.
To address this challenge, AWS has introduced three new global condition keys for scalable access controls based on request origin: aws:VpceAccount, aws:VpceOrgPaths, and aws:VpceOrgID.
In this blog post, we demonstrate how these keys can help make sure that your AWS resources are accessible only from expected VPCs, so that you can scale your data perimeter implementation across your organization within AWS Organizations.
Background
Organizations often store data in AWS resources such as Amazon Simple Storage Service (Amazon S3) buckets. For example, you might use Amazon S3 as your data lake foundation with data scientists and analysts running their data processing and analytics workflows against data stored in a centralized S3 bucket.
To limit access to data stored in your S3 buckets to expected networks, you can use IAM policies associated with your identities and resources. You can define expected networks in a policy using specific IAM global condition keys based on your organization’s intended data access patterns and unique requirements. For example, use aws:SourceIp to specify your corporate IP CIDR ranges, and aws:SourceVpc or aws:SourceVpce to list VPC and VPC endpoint IDs you expect requests to come from. These condition keys help make sure that only workloads operating within your expected network boundaries can access sensitive data.
However, there are scenarios where you might want to allow access from multiple networks within your organization, as illustrated in Figure 1.
Figure 1: Applications and users accessing an S3 bucket from VPCs and public networks
In such cases, using the aws:SourceVpc and aws:SourceVpce condition keys requires enumerating all expected VPC and VPC endpoint IDs and updating policies whenever new VPCs or VPC endpoints are added or deleted. This approach creates operational overhead and increases the risk of misconfigurations. The operational complexity grows as organizations scale their data processing capacity across multiple AWS Regions and accounts. While many organizations have developed automated mechanisms to detect changes in VPC configurations and update policies accordingly, auditing lengthy policies that enumerate VPCs within their organization remains challenging.
The new global condition keys provide a more scalable way to restrict access to expected networks:
aws:VpceAccount – Restricts the use of your identities and resources to networks that belong to a specific AWS account.
aws:VpceOrgID – Restricts the use of your identities and resources to networks that belong to your organization.
The value of these keys in the request context is the ID of the account (for example, 111122223333), organization unit (OU) (for example, o-abcdef0123/r-acroot/ou-development/*), or organization (for example, o-abcdef0123) that owns the VPC endpoint the request is made through.
Note that at the time of writing, not all services support these keys. See AWS global condition context keys for a list of supported services.
Implementation examples
Let’s look at how to restrict access to expected networks using the three new condition keys for common use cases. Each of the use cases demonstrates how the new condition keys help simplify controlling access to your resources in the sample scenario from Figure 1.
Use case 1: Allow access to your S3 buckets only from networks of data processing accounts
Data owners might want to strictly manage what data workflows can access their data sources and restrict cross-account access to specific data processing accounts and networks. They can use the aws:VpceAccount condition key to allow access based on the account that owns the VPC endpoint the request is made through. The following is an example S3 bucket policy.
This policy allows specific principals listed in the Principal element to list and download objects from the data lake bucket but only if they make requests from networks in one of the specified AWS accounts (StringEquals and aws:VpceAccount). Using the aws:VpceAccount condition key in this policy alleviates the need to maintain a list of VPC IDs or VPC endpoint IDs for the data processing accounts, reduces the size of the policy document, and simplifies auditing.
Use case 2: Restricting access to company networks for resources across multiple accounts
Central security teams often look for ways to enforce a set of standard access controls on resources across their entire organization. This is to meet compliance and security requirements, fulfill legal and contractual obligations, and to protect corporate data from unintended access. One such control could be used to limit access to only expected networks within the organization. In our sample scenario, this control helps prevent your data analysts and scientists from using their credentials to access data outside of your corporate environment. The following RCP demonstrates how to enforce the network perimeter controls on S3 buckets:
This policy denies access to S3 buckets and objects unless it is from expected networks defined as: your corporate IP CIDR range (NotIpAddressIfExists and aws:SourceIp), VPC endpoints in your organization (StringNotEqualsIfExists and aws:VpceOrgID), networks of AWS services that use their service principals or forward access sessions (FAS) to act on your behalf (BoolIfExists with aws:PrincipalIsAWSService and aws:ViaAWSService). It also allows access to networks of AWS services using specific service roles to access your resources (StringNotEqualsIfExists and aws:PrincipalTag/network-perimeter-exception set to true). Some organizations might need to edit this policy to allow third-party partner access. See Establishing a data perimeter on AWS: Allow access to company data only from expected networks for additional information on access patterns that need to be accounted for to meet the needs of your organization.
We used an RCP because it can be used to apply access controls centrally on resources across multiple accounts. Central security teams use RCPs to enforce security invariants on resources across their entire organization. For best practices in designing and deploying RCPs, see Effectively implementing resource control policies in a multi-account environment.
Remember to reference the list of services that support aws:VpceOrgID before using it in a policy such as an RCP. Enforcing it on an unsupported service might prevent your developers from using the service. If you need to restrict access to expected networks on a wider range of services, consider using the aws:SourceVpc and aws:SourceVpce condition keys. See the data perimeter policy examples repository that illustrate how to implement network perimeter controls for a wider range of services.
Use case 3: Restricting access based on intra-organization boundaries
Organizations often need to segment environments within their organization with varying data access requirements. For example, they might need to separate production from non-production environments or create boundaries between different business units, such as Finance, Marketing, and Sales; each operating in separate accounts. This might include making sure that resources within a specific OU can only be accessed from networks in the same OU. Central security teams can use aws:VpceOrgPaths to achieve this objective at scale.
The following is an example RCP that restricts access to your Amazon S3 and AWS Key Management Service (AWS KMS) resources so that they can only be accessed through VPC endpoints in a specific OU.
This policy is similar to the one we built for the previous use case but uses aws:VpceOrgPaths instead of aws:VpceOrgID to enforce a more granular boundary based on the requests’ network origin.
Best practices and considerations
When implementing the new condition keys, consider the following best practices.
Identify opportunities to adopt the new global condition keys by reviewing your security objectives and controls
If you currently restrict access to a wide range of resources using the aws:SourceVpc and aws:SourceVpce condition keys and want to avoid the need to enumerate VPC or VPC endpoint IDs in your policies, evaluate if you can migrate to aws:VpceAccount, aws:VpceOrgPaths, or aws:VpceOrgID. This migration decision depends on whether services you restrict access to are supported by the new condition keys. Similarly, if you plan to add network perimeter restrictions to your security baseline, first evaluate whether the new condition keys offer a more scalable solution for your target services. Only enforce the new keys on services that are currently supported. If you need to enforce the restriction on a service not yet supported, you should use aws:SourceVpc and aws:SourceVpce. Also, continue using aws:SourceVpc and aws:SourceVpce to achieve your least privilege objectives, for example if the network boundary you need to maintain for a subset of resources is scoped to specific VPCs or VPC endpoints.
Plan the implementation of the new condition keys
We recommend that you test access controls updates in a non-production environment and only promote them to production after validating their expected behavior. If you currently maintain an automation to enumerate VPC or VPC endpoint IDs in your policies and plan to migrate to the new keys, deactivate your automation only after you have completed policy updates across all environments. This approach helps make sure that your existing security posture remains intact while you progressively deploy the changes.
Monitor and validate the implementation
Use AWS CloudTrail to audit access patterns and regularly review and update your access controls as your organization structure evolves and security objectives change. For example, you might need to adjust access controls when accounts requiring access to your data lakes change, or when organizational boundaries need modification to accommodate new integrations between business units. You must establish processes to continuously evaluate the effectiveness of your controls in meeting both security and business objectives.
Conclusion
In this post, you learned how to use the new global condition keys—aws:VpceAccount, aws:VpceOrgPaths, and aws:VpceOrgID—to restrict access to expected networks at scale. By using these keys, you can:
Implement network perimeter controls that scale with your AWS organization.
Reduce the operational overhead of managing access to your data.
Simplify your IAM policies and reduce the risk of misconfigurations.
Scale your data lake implementation while maintaining security.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on AWS IAM re:Post or contact AWS Support.
In July 2025, Amazon SageMakerannounced support for Amazon Simple Storage Service (Amazon S3) general purpose buckets and prefixes in Amazon SageMaker Catalog that delivers fine-grained access control and permissions through S3 Access Grants. This integration addresses the challenge data teams face when manually managing data discovery and Amazon S3 permissions as separate workflows. Data consumers, such as data scientists, engineers, and business analysts, can now discover and access S3 buckets or prefixes data assets through SageMaker Catalog, while administrators can maintain granular access controls using S3 Access Grants permissions.
Building upon existing SageMaker support for structured data in Amazon S3 Tables buckets, the added support for S3 general purpose buckets makes it straightforward for teams to find, access, and collaborate on different types of data, including unstructured data such as documents, images, audio, and video, while providing access management. Data administrators and data stewards can now implement fine-grained access permissions for a bucket or a prefix using S3 Access Grants, supporting secure and appropriate data usage across their organization.
In this post, we explore how this integration addresses key challenges our customers have shared with us, and how data producers, such as administrators and data engineers, can seamlessly share and govern S3 buckets and prefixes using S3 Access Grants, while making it readily discoverable for data consumers. We walk you through a practical example of bringing Amazon S3 data into your projects and implementing effective governance for both analytics and generative AI workflows.
Challenges in working with unstructured data
Organizations face challenges in maximizing the value of their unstructured data assets. Although customers want to incorporate insights derived from unstructured data for comprehensive analysis, they often resort to building bespoke integrations to extract structured information from unstructured sources, leading to inefficient and fragmented solutions. Three critical roadblocks have historically hindered enterprises:
Organizations struggle to maintain a catalog that offers equal discoverability for both structured and unstructured data, often resulting in separate systems for different data types.
Data consumers throughout organizations want to analyze unstructured data using familiar tools like notebooks, just as they do with structured data, but are forced to use separate interfaces and workflows instead.
Working with unstructured data lacks streamlined access management—users who discover relevant data can’t readily request access from owners, load information into analytics tools, or collaborate with colleagues directly from the workspaces or projects.
Amazon S3 unstructured data as a managed asset in Amazon SageMaker
SageMaker Catalog now supports S3 general purpose buckets. Data producers can publish S3 buckets and prefixes as S3 Object Collection assets, making those assets searchable and discoverable. As managed S3 Object Collection assets in SageMaker Catalog, access permissions are automatically handled using S3 Access Grants when data consumer teams subscribe to cataloged datasets, replacing bespoke data discovery and permission management workflows. Data producers can add business context to technical metadata, including glossary terms and descriptions. Data consumers can search, review, and request access to data assets through a unified workflow. Teams can then collaborate in SageMaker projects, incorporating datasets and conducting analysis while maintaining security and governance standards.The key benefits in the simplified discoverability and access to S3 data in SageMaker Catalog include:
Seamless S3 data integration – You can use existing Amazon S3 data in SageMaker without migration or restructuring
Enhanced cataloging and governance – SageMaker Catalog facilitates data publishing, discovery, and subscription with business metadata and security controls
Improved data sharing – Cataloged Amazon S3 data becomes discoverable organization-wide, accelerating insights and collaboration
Self-service data access – SageMaker provides tools for data preparation, ETL (extract, transform, and load), and connectivity from various sources, supporting faster analytics and AI solution development
With these benefits, you can accelerate time-to-insight and unlock the full potential of organizational data assets across teams.
Customer spotlight
Across industries, the true power of data emerges when organizations can seamlessly connect and analyze different types of information across their operations. Bayer, a leading pharmaceutical and biotechnology company, has vast sets of unstructured data organized across multiple S3 buckets and prefixes.
“Bringing a new drug to market is widely known across the industry to be a lengthy and expensive process, often taking 10–15 years and costing $1–2 billion on average, with a low overall success rate ranging from around 8% to 12%. SageMaker now allows us to easily discover and securely access data, structured and unstructured, while maintaining governance controls using S3 Access Grants. With SageMaker Catalog, we now have a streamlined approach to data management that enables us to combine datasets, both structured and unstructured, reducing research time and increasing productivity throughout the drug development lifecycle,” said Avinash Erupaka, Principal Engineer Lead, Bayer Pharma Drug Innovation Platform.
Solution overview
In life sciences organizations, unstructured and semi-structured data files are prevalent in research, development, bio-manufacturing, and diagnostics divisions. These might include digital pathology images, genetic sequence data, microwell plate readouts, analytical spectra, and chromatograms. Along with unstructured and semi-structured data, data engineers collect various business metadata, including study, project, laboratory protocol, and assay information, and operational metadata, including algorithmic steps, compute tasks, and process outputs.Scientists and business users can use SageMaker Catalog search for data assets using keywords that are found in the associated business metadata and operational metadata that are captured as metadata forms. For example, there might be searches for sample ID, experiment ID, group, platform, file names, dates, or keywords within the experimental description. These searches return a list of data assets that have association with those keywords, which are collections of S3 objects. Scientists and business users are given access to those collections of S3 objects.In the following sections, we walk through the setup step-by-step. We use the example of digital pathology images use case from the life sciences industry to demonstrate how researchers discover and get access to S3 objects using SageMaker.
To follow along with this post, refer to Setting up Amazon SageMaker to set up a domain and create projects. This domain setup and project creation is a prerequisite for the other tasks in SageMaker.
Get data ready in Amazon S3
To store digital pathology images, create an S3 bucket (for example, researchdatafordigitalpathology), create a folder (for example, dpimages) under it, and upload digital pathology images. Ideally, you will have a collection of images under a given prefix, but for this example, we have chosen just one image file (dp_cancer.jpg). For instructions to create a bucket, refer to Creating a general purpose bucket.
Set up a data producer project
For data engineers, create a producer project in Amazon SageMaker Unified Studio to create digital pathology images as data assets. For more details on how to create projects, refer to Create a project. Add data engineers as members of the projects. For instructions to add members, refer to Add project members.
Add an Amazon S3 location
To add the collection of digital pathology images (to bring your own S3 buckets), complete the following steps:
In SageMaker Unified Studio, go to the project where you want to add Amazon S3.
Choose Data in the navigation pane, then choose the plus sign.
On the Add data page, choose Add S3 location, then choose Next.
To obtain the details to create a connection, you can choose from two options:
Using the project role:
You, the project user, retrieves the project role and shares it with the AWS Management Console admin.
Publish data to SageMaker Catalog to make it discoverable
After you add the Amazon S3 location, complete the following steps to publish the data:
In SageMaker Unified Studio, go to your project.
Choose Data in the navigation pane and choose the Amazon S3 location.
On the Actions dropdown menu, choose Publish to Catalog.
After you publish the assets, you can find the assets on the Published tab in the Assets page under Project catalog in the navigation pane.
Create a consumer project
Create a consumer project for researchers to collaborate and bring necessary assets for their analysis and add researchers as members to the project. Consumers can search for available (published) data assets on digital pathology images for cancer research and then subscribe to work with it using JupyterLab notebooks in SageMaker. For more details on how to create projects, refer to Create a project. For instructions to add members, refer to Add project members.
Find relevant assets and request access
Researchers can search the SageMaker Catalog for available (published) data assets using the string digitalpathology. Complete the following steps:
In SageMaker Unified Studio, on the Discover dropdown menu, choose Data Catalog.
Find the asset you want to subscribe to by browsing or entering the name of the asset into the search bar.
Choose Subscribe.
Provide the following information:
The project to which you want to subscribe the asset.
A short justification for your subscription request. This information is used by the data producer to validate the request to grant access.
Choose Request.
After you’re approved, the project will be subscribed to the asset and access is granted automatically. To provide access, SageMaker Catalog uses S3 Access Grants to grant read permission to the subscribing project for the specific S3 bucket or prefix.
To view the status of the subscription request, go to the project with which you subscribed to the asset. Choose Subscription requests in the navigation pane, then choose the Outgoing requests tab. This page lists the assets to which the project has requested access. You can filter the list by the status of the request.
Review and approve the subscription request
The data producer or engineer of the publishing project must receive the request from the researcher and approve the request. After the request is approved, the researcher will have access to the objects for the S3 bucket (or prefix).
Before approving, the data producer can view the details of the subscription request to make sure they know who will get access to the data they own.
After they approve the request, the data producers can audit the different requests they have for the assets they own.
Access the subscribed data in notebooks
After the access request is approved, the researcher can open a JupyterLab notebook from SageMaker Unified Studio and access S3 objects to work on their research.To navigate to the JupyterLab notebook, complete the following steps:
In SageMaker Unified Studio, open your project.
On the Build dropdown menu, choose JupyterLab.
The following is sample Python code to access subscribed data. This sample code retrieves the S3 object that the researcher has been given access to and uses Matplotlib (a comprehensive 2D plotting library for Python language) to display the image in the notebook. In a real-world use case, a researcher typically uses these images for displaying or training machine learning models or performing multimodal analysis.
# Install necessary libraries
pip install aws-s3-access-grants-boto3-plugin
pip install matplotlib pillow
import botocore.session
from aws_s3_access_grants_boto3_plugin.s3_access_grants_plugin import S3AccessGrantsPlugin
session = botocore.session.get_session()
s3 = session.create_client('s3')
plugin = S3AccessGrantsPlugin(s3, fallback_enabled=False, customer_session=session)
plugin.register()
from PIL import Image
import io
import matplotlib.pyplot as plt
# S3 bucket and object details for digital pathology image
bucket_name = '[bucket name]'
object_key = '[prefix]/[object]'
# Get the image object from S3
response = s3.get_object(Bucket=bucket_name, Key=object_key)
# Read the image data
image_data = response['Body'].read()
# Create an image object
image = Image.open(io.BytesIO(image_data))
# Display the image
plt.imshow(image)
plt.axis('off') # Hide axis
plt.show()
SageMaker and S3 Access Grants integrations
The SageMaker Catalog integration with S3 Access Grants facilitates secure data access across Amazon EMR Serverless, AWS Glue, Amazon EMR on Amazon EC2, and JupyterLab notebooks through simple configuration settings. By enabling S3 Access Grants with two properties ('fs.s3.s3AccessGrants.enabled': 'true' and 'fs.s3.s3AccessGrants.fallbackToIAM': 'true'), users gain streamlined access control while maintaining IAM as a fallback option. These configurations are automated in SageMaker Unified Studio. To learn more about S3 Access Grants integrations, see S3 Access Grants integrations, and for Boto3 S3 Access Grants support, refer to the following GitHub repo.
Conclusion
In this post, we discussed the added support for S3 general purpose buckets in SageMaker, and how they can be cataloged in SageMaker Catalog to help users quickly discover and securely manage access when sharing with other teams.
Priya Tiruthani is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about building innovative products to simplify customers’ end-to-end data journey, especially around data governance and analytics. Outside of work, she enjoys being outdoors to hike, capture nature’s beauty, and recently play pickleball.
Subrat Das is a Principal Solutions Architect and part of the Global Healthcare and Life Sciences industry division at AWS. He is passionate about modernizing and architecting complex customer workloads. When he’s not working on technology solutions, he enjoys long hikes and traveling around the world.
Santhosh Padmanabhan is a Software Development Manager at AWS, leading the Amazon SageMaker Catalog engineering team. His team designs, builds, and operates services specializing in data, machine learning, and AI governance. With deep expertise in building distributed data systems at scale, Santhosh plays a key role in advancing AWS’s data governance capabilities.
Yuhang Huang is a Software Development Manager on the Amazon SageMaker Unified Studio team. He leads the engineering team to design, build, and operate scheduling and orchestration capabilities in SageMaker Unified Studio. In his free time, he enjoys playing tennis.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
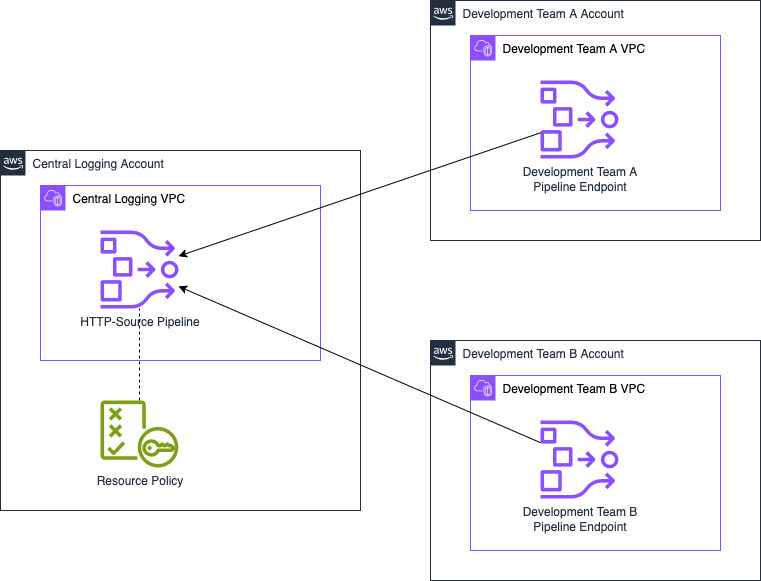
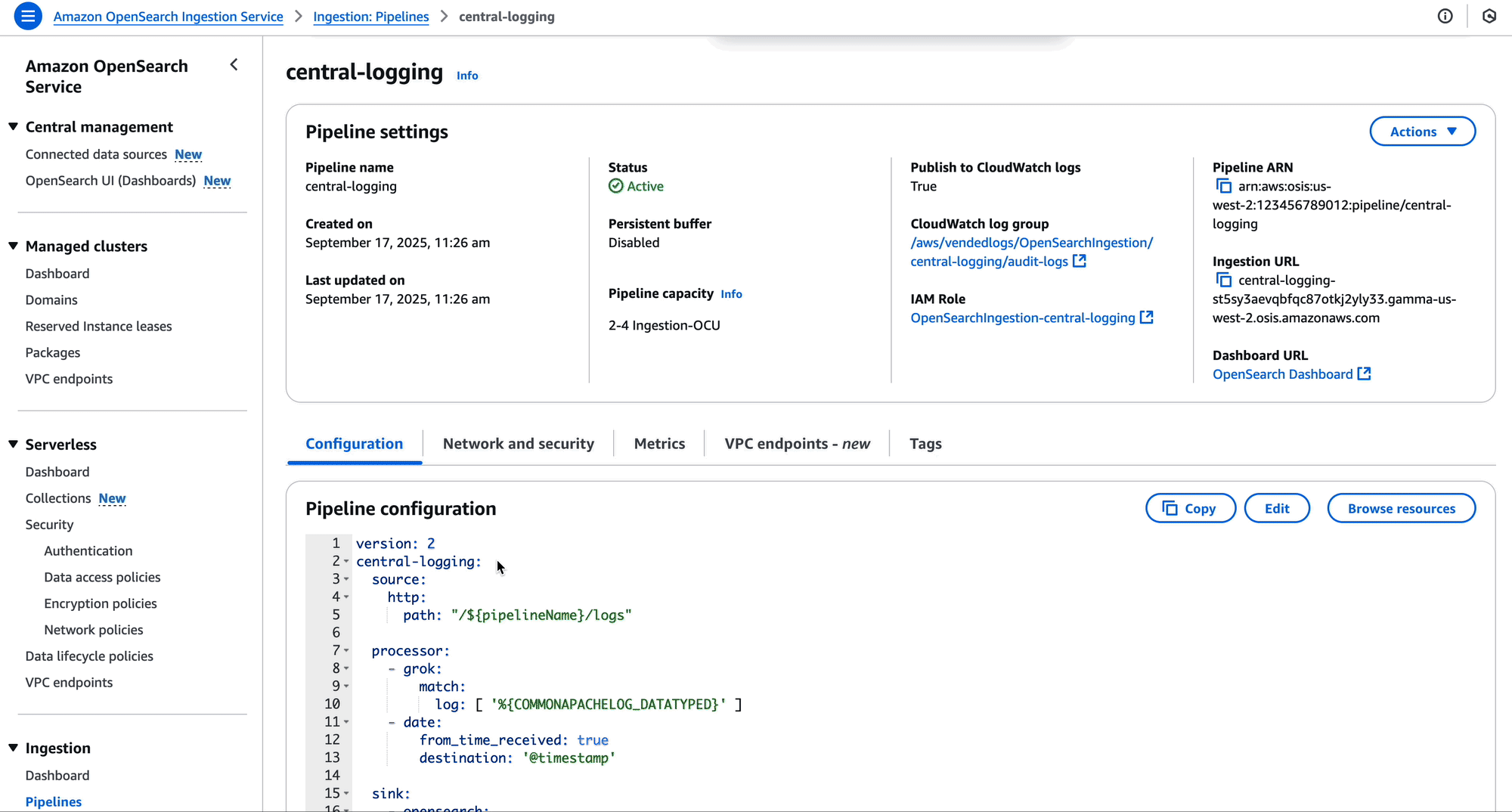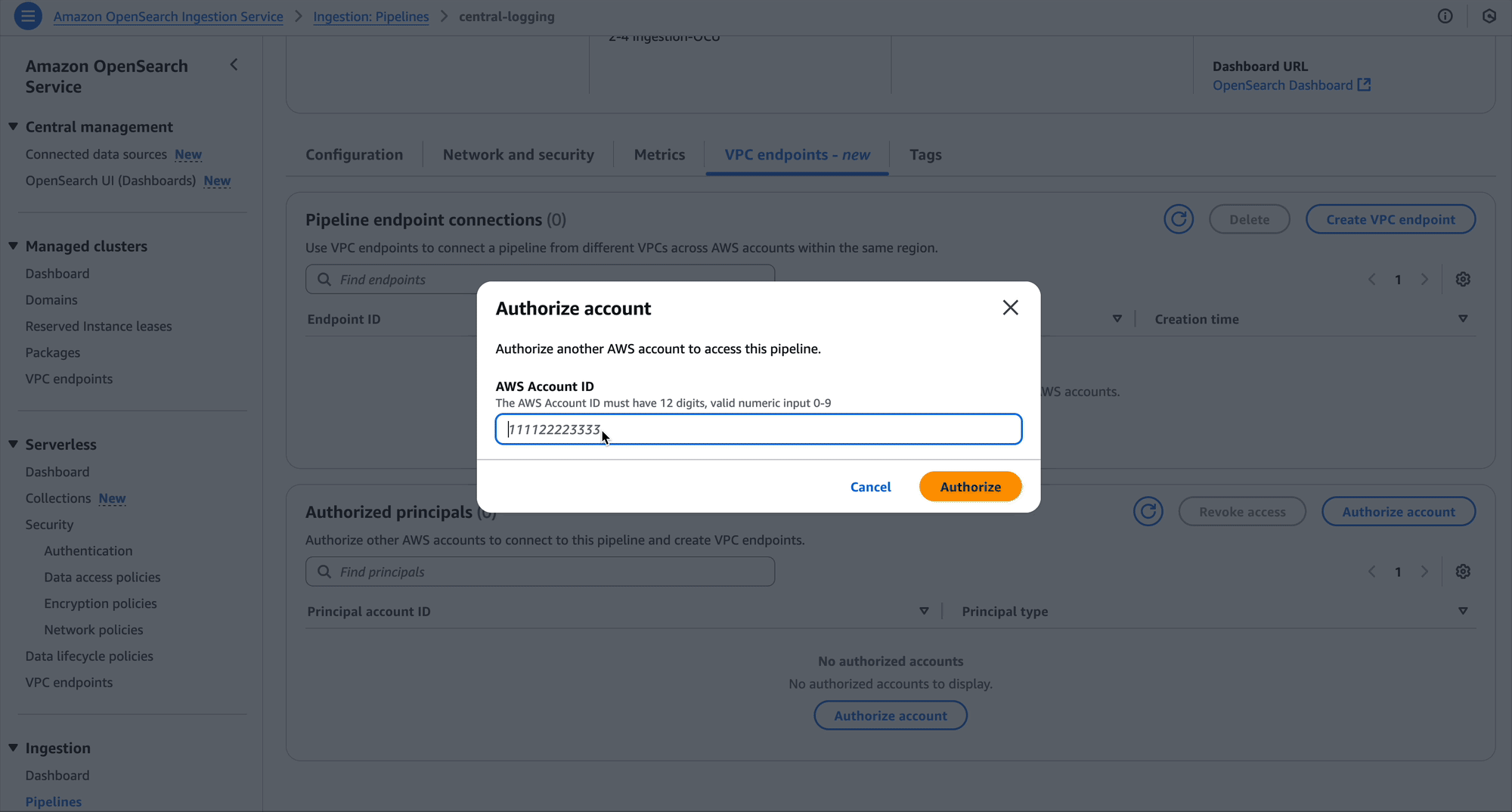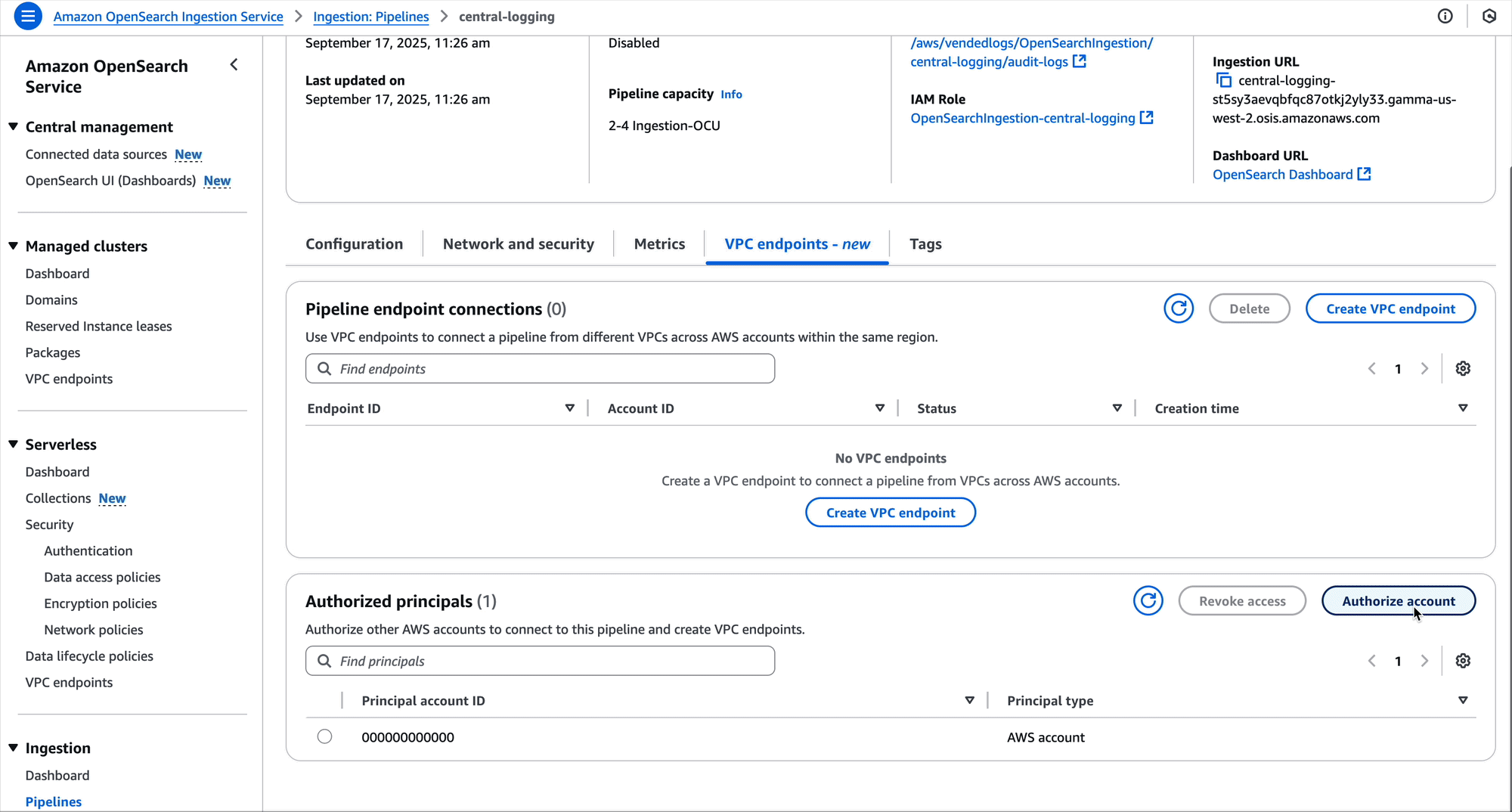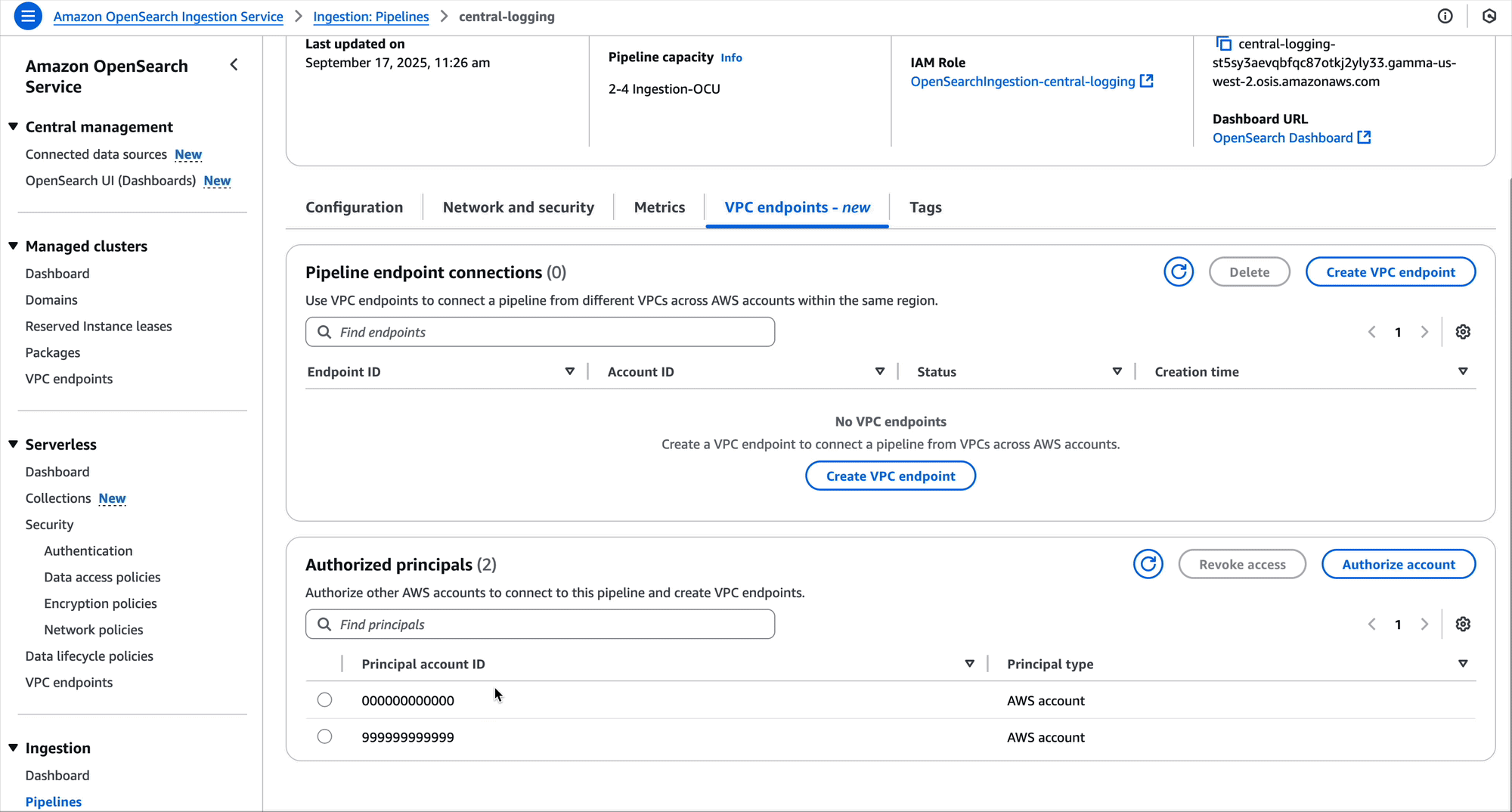
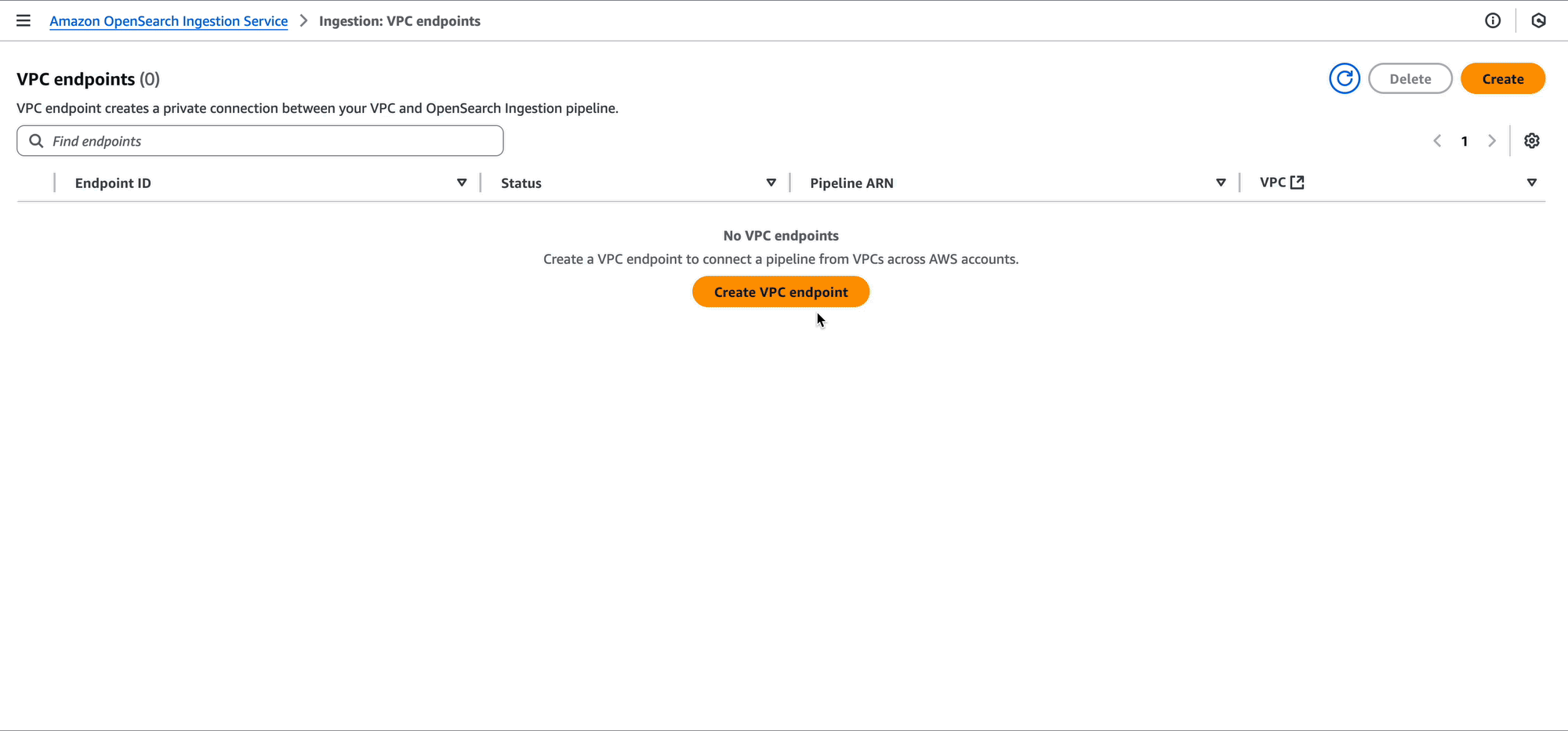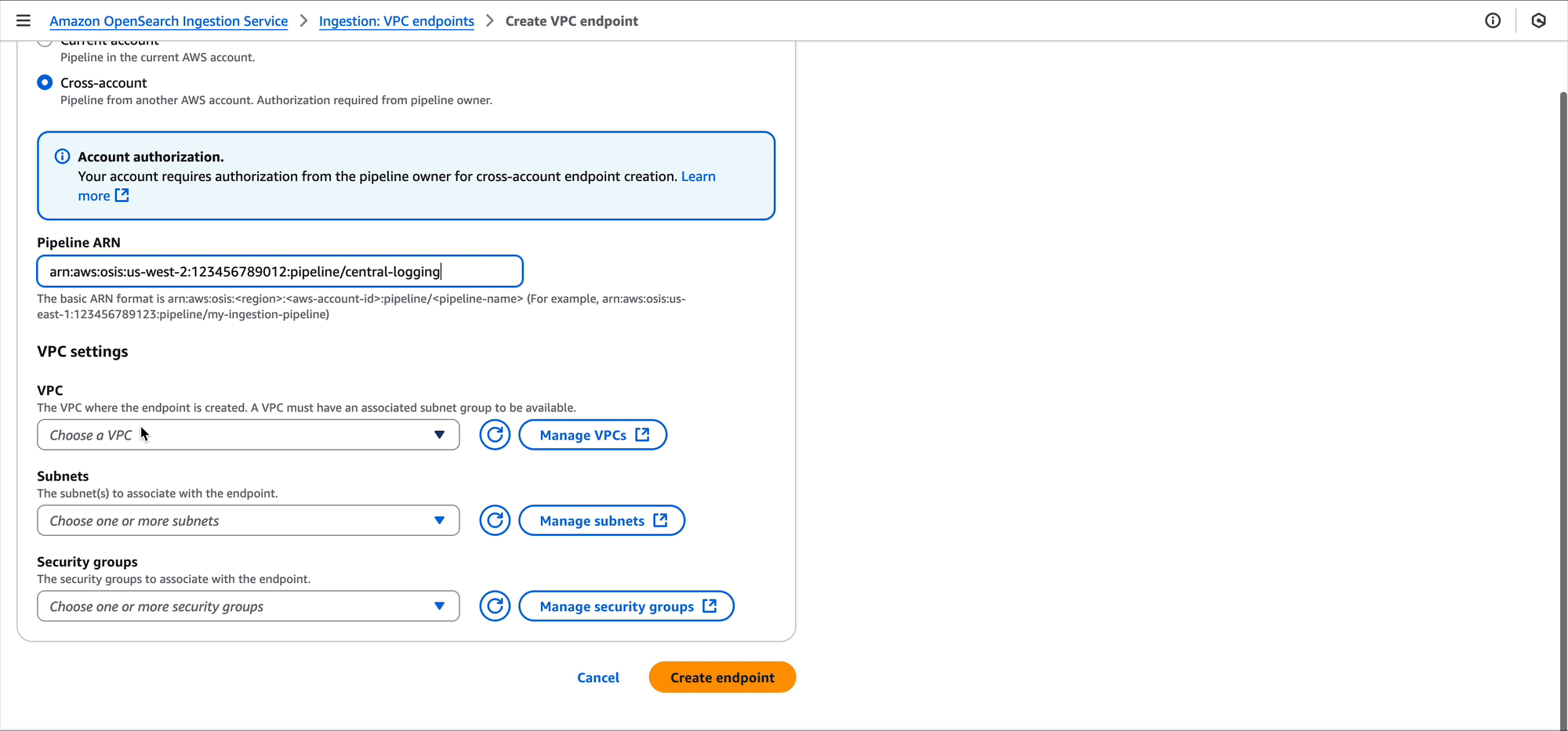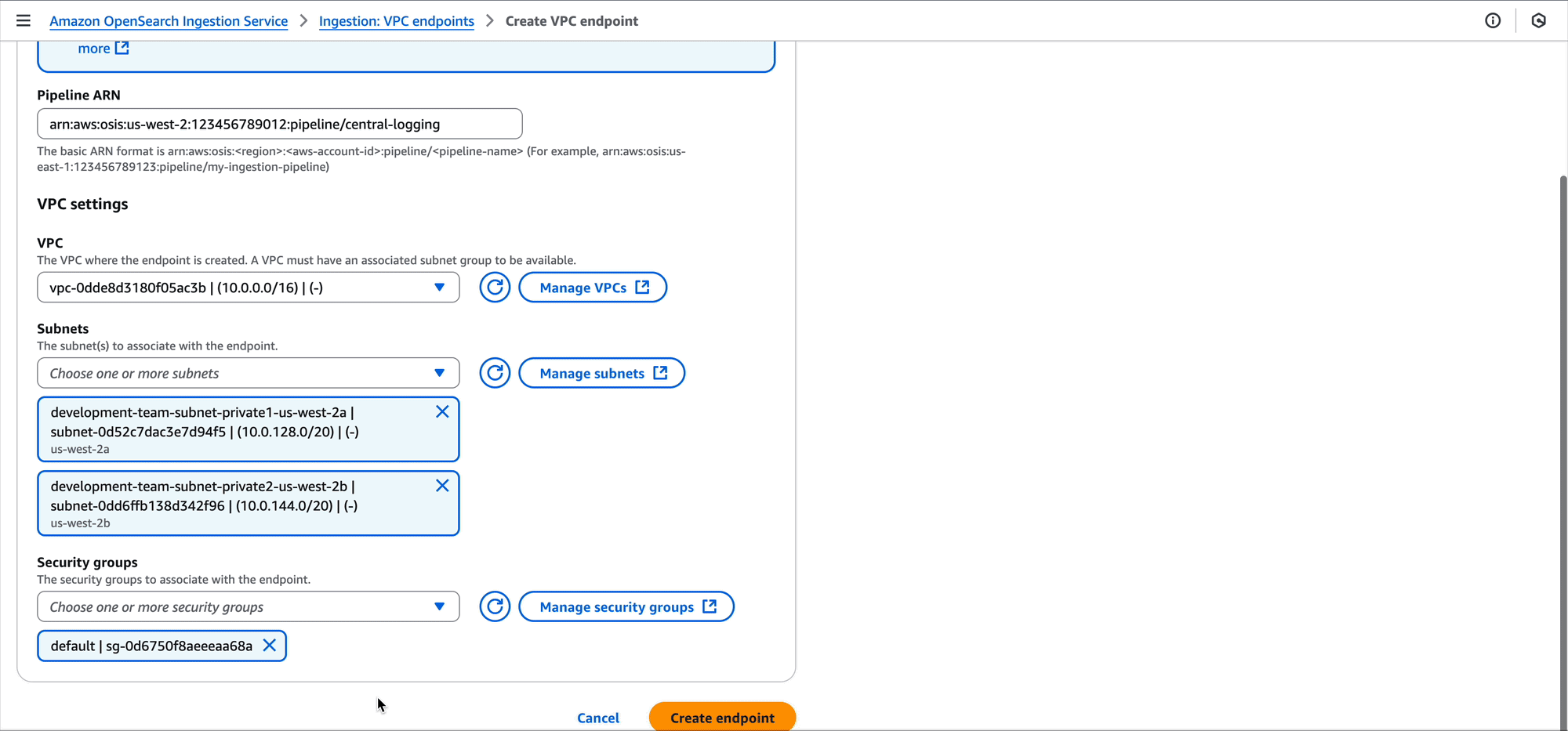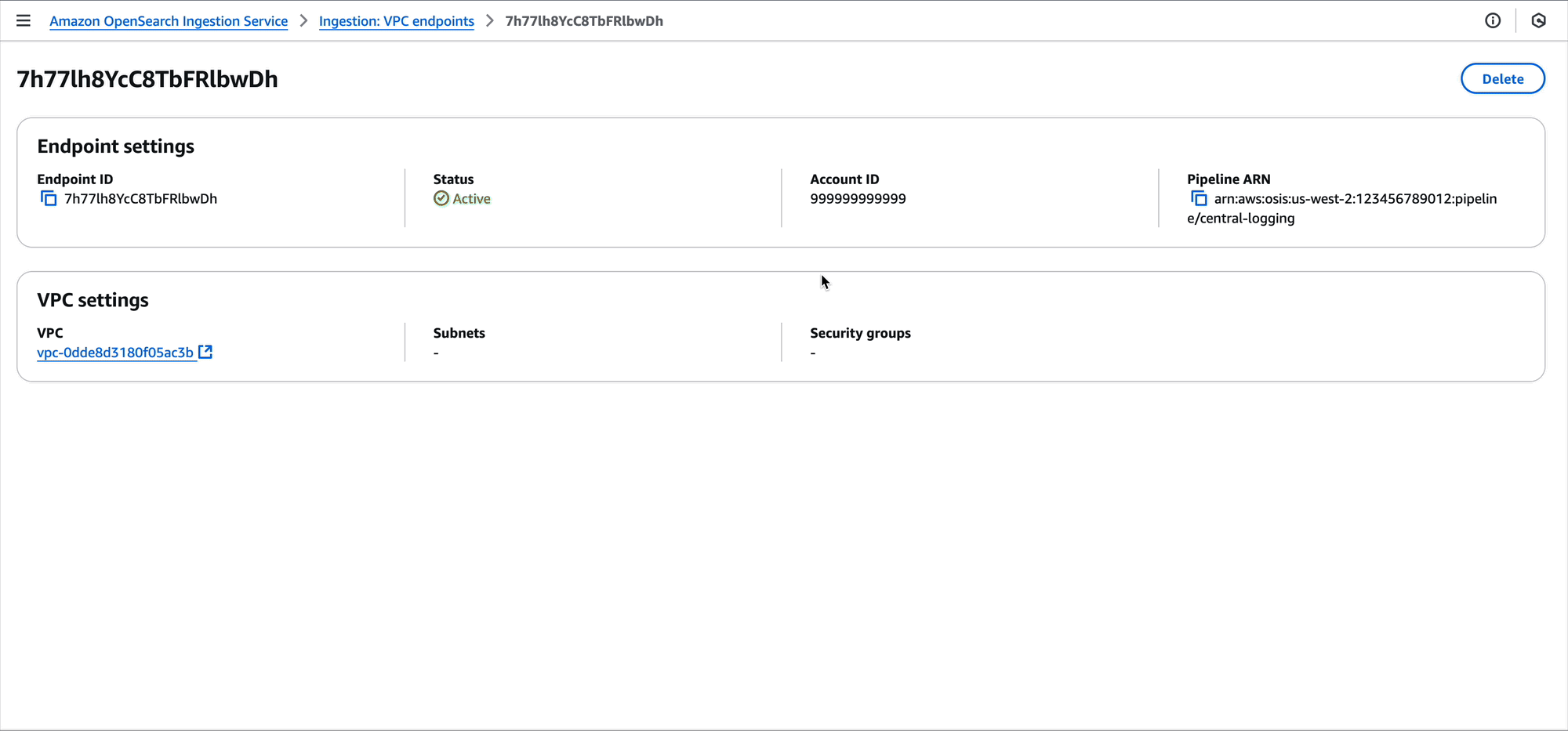
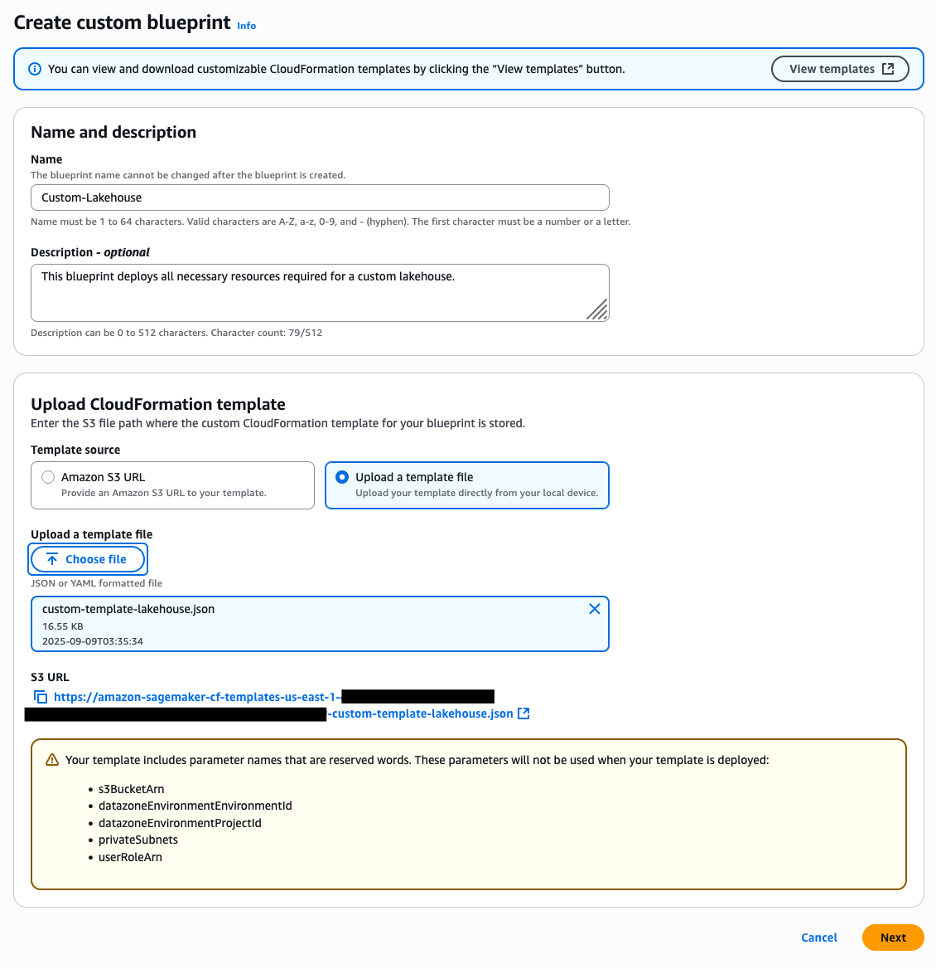
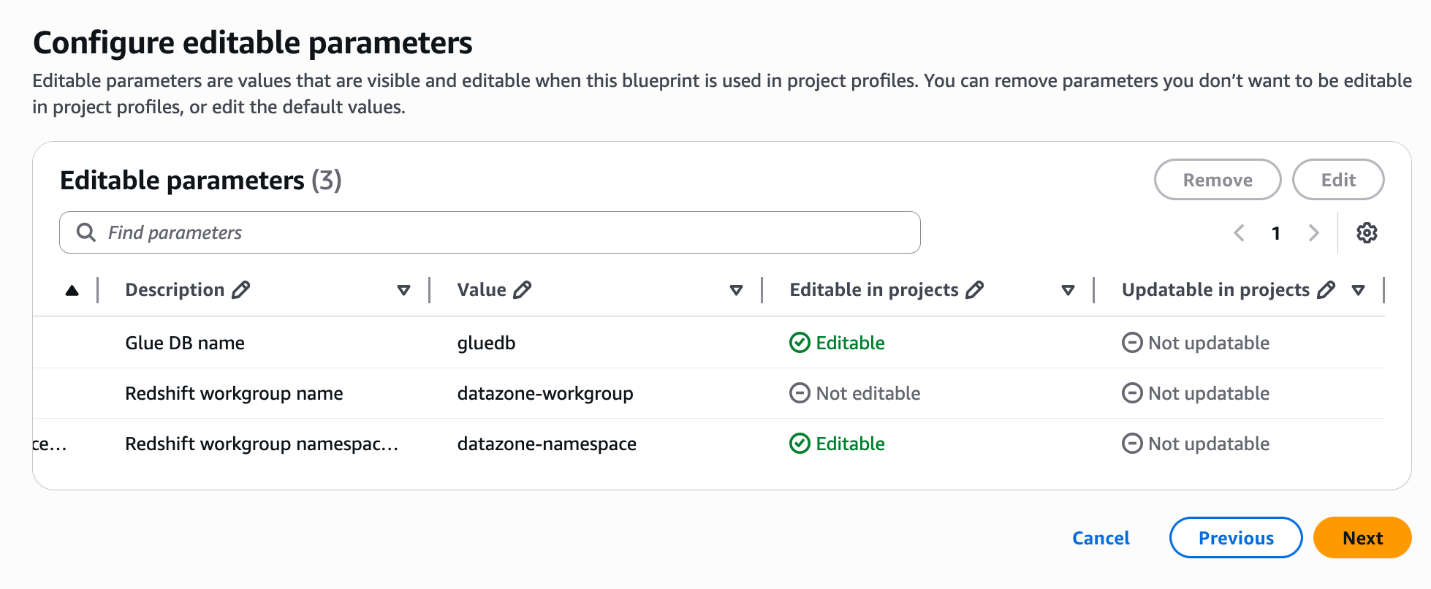
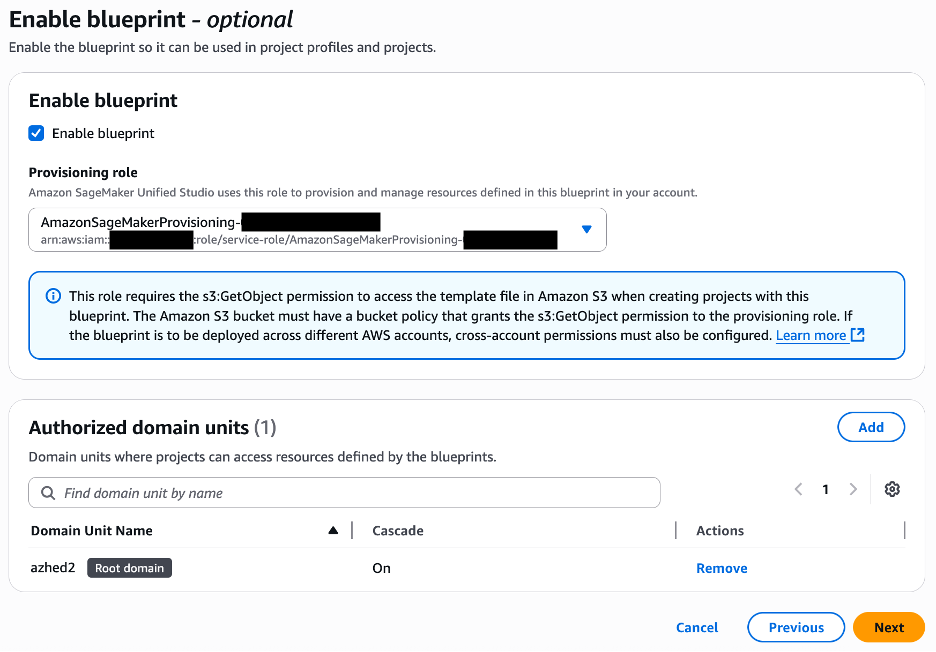
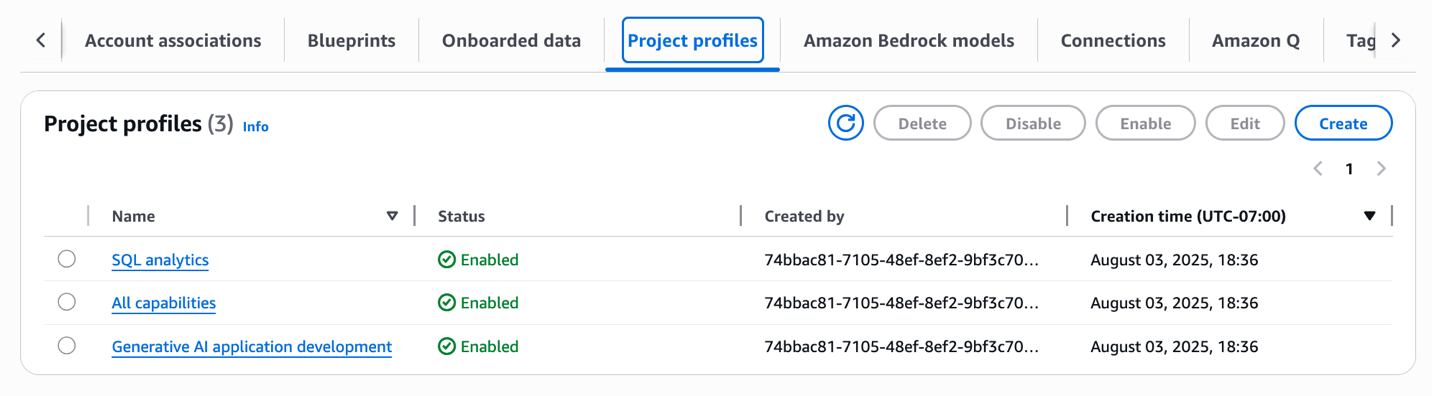
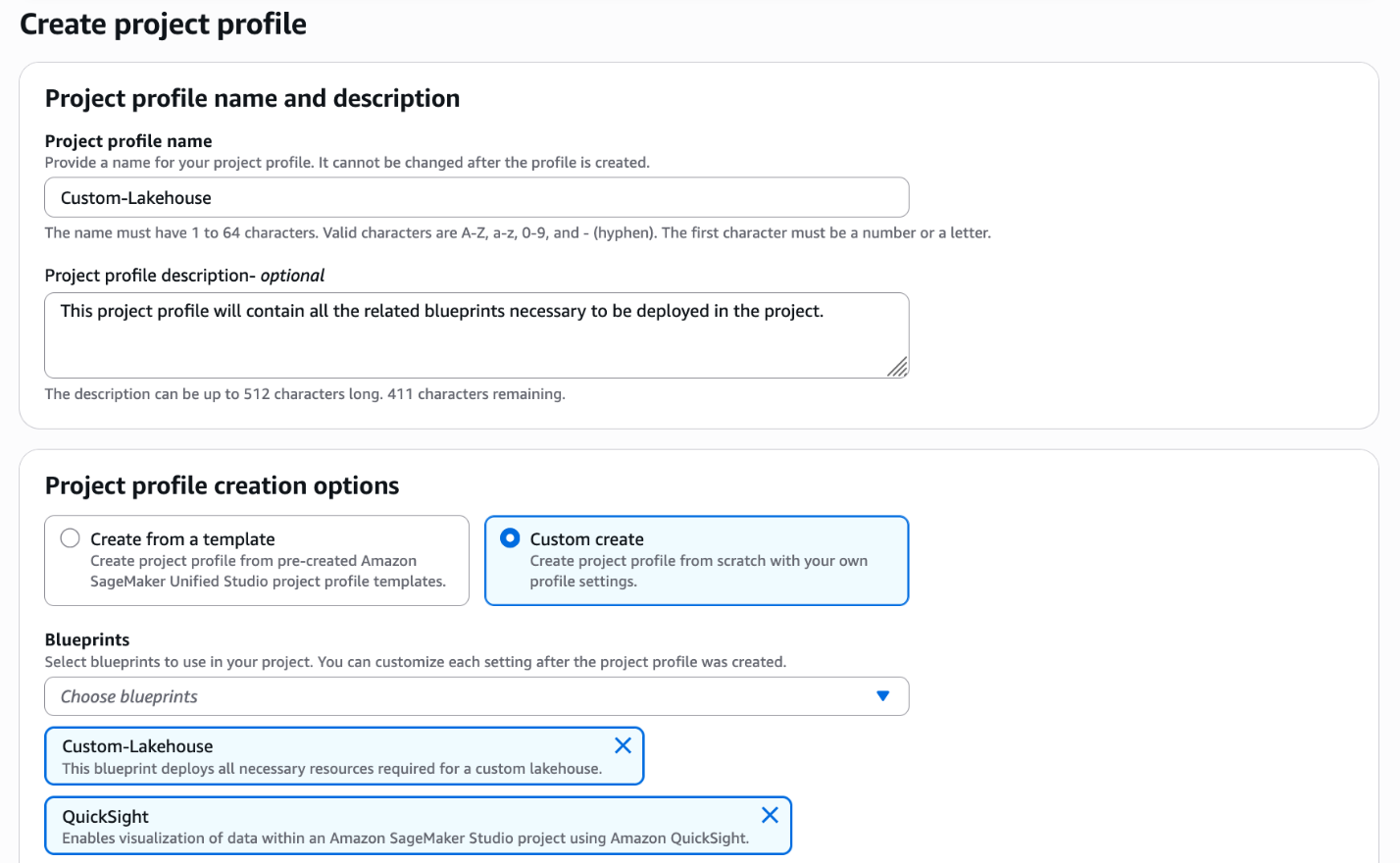
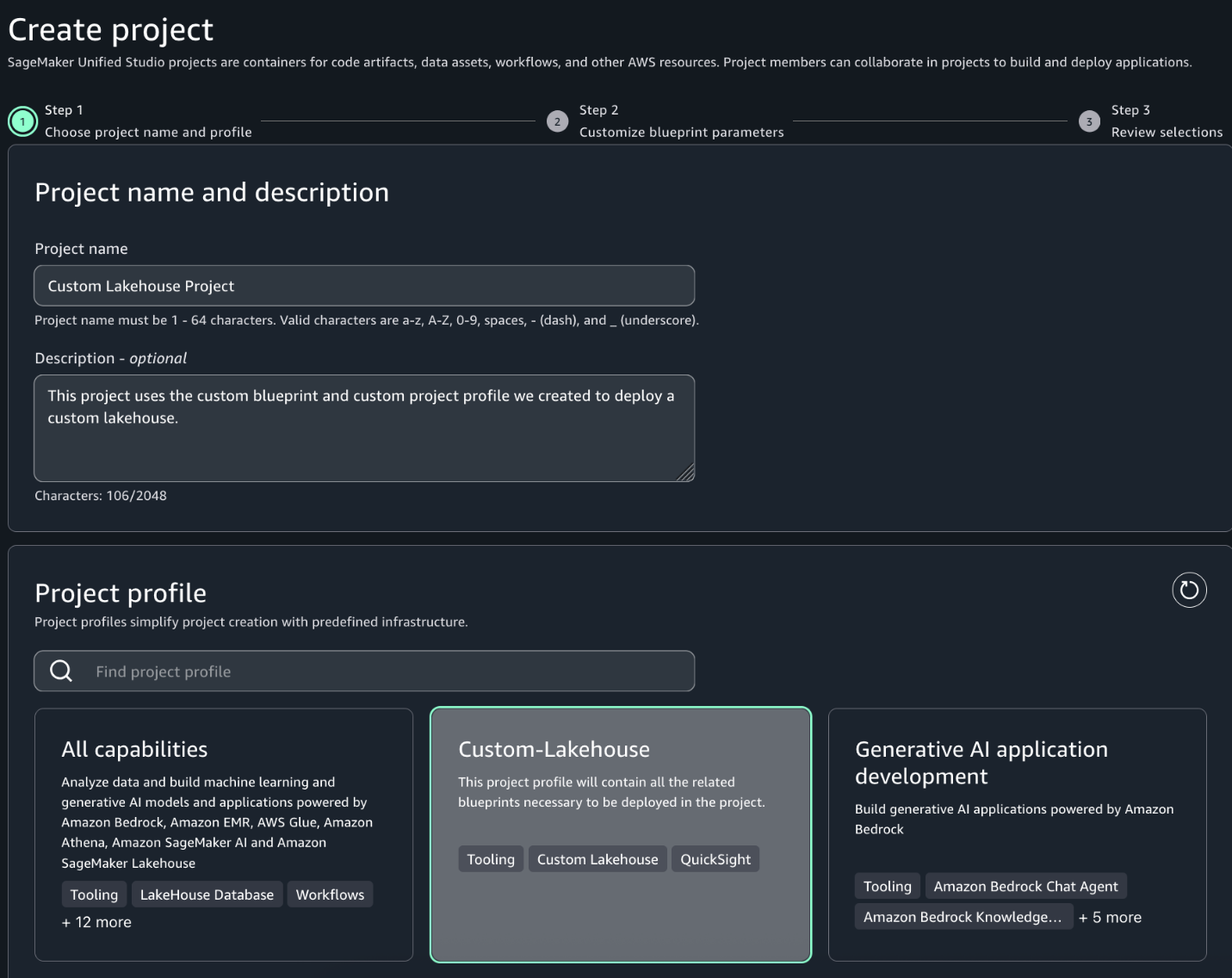
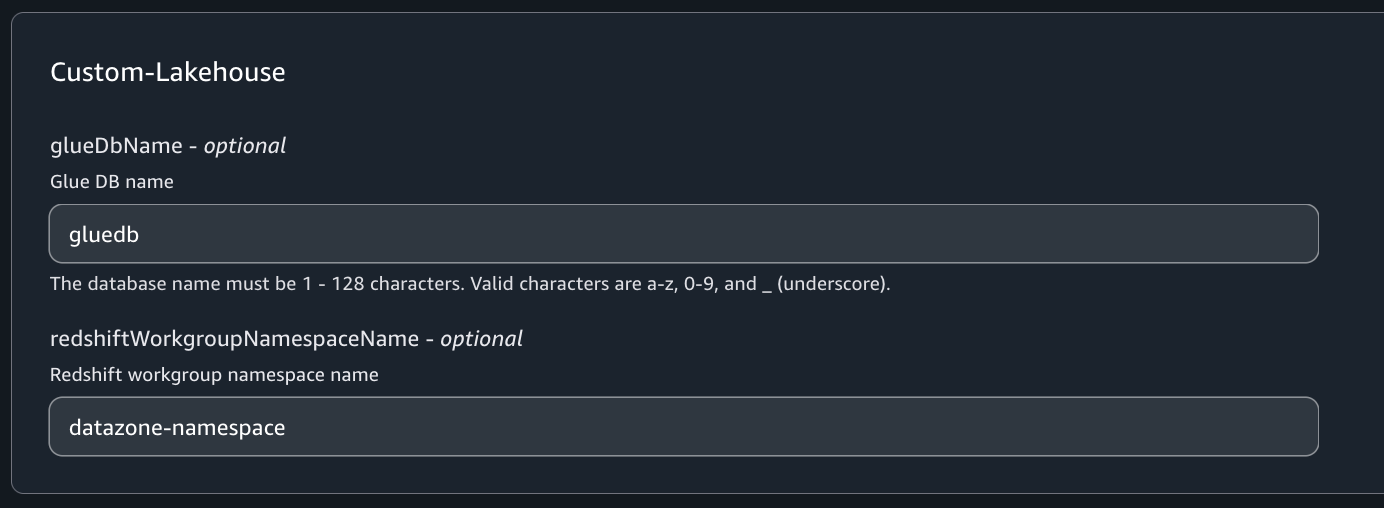
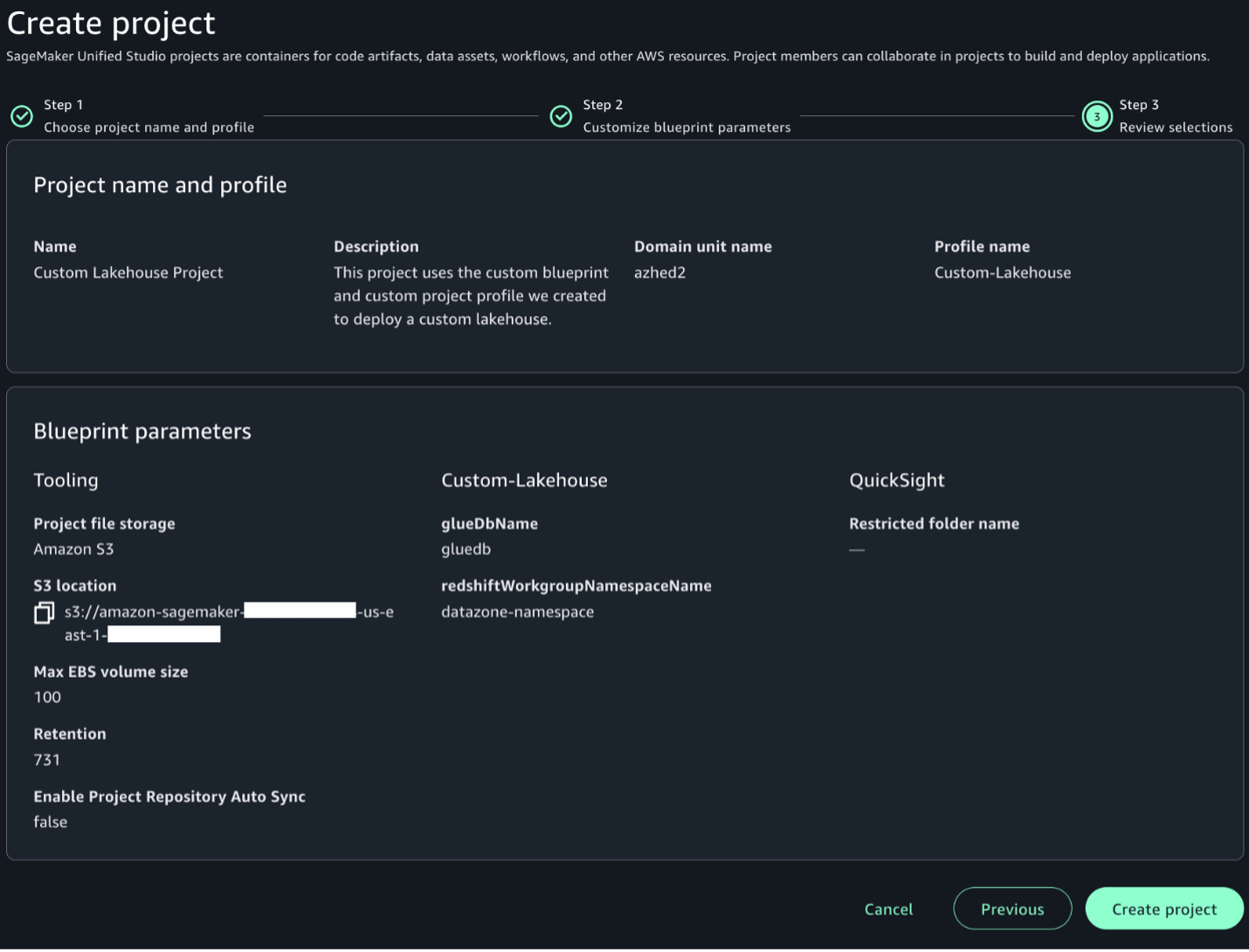
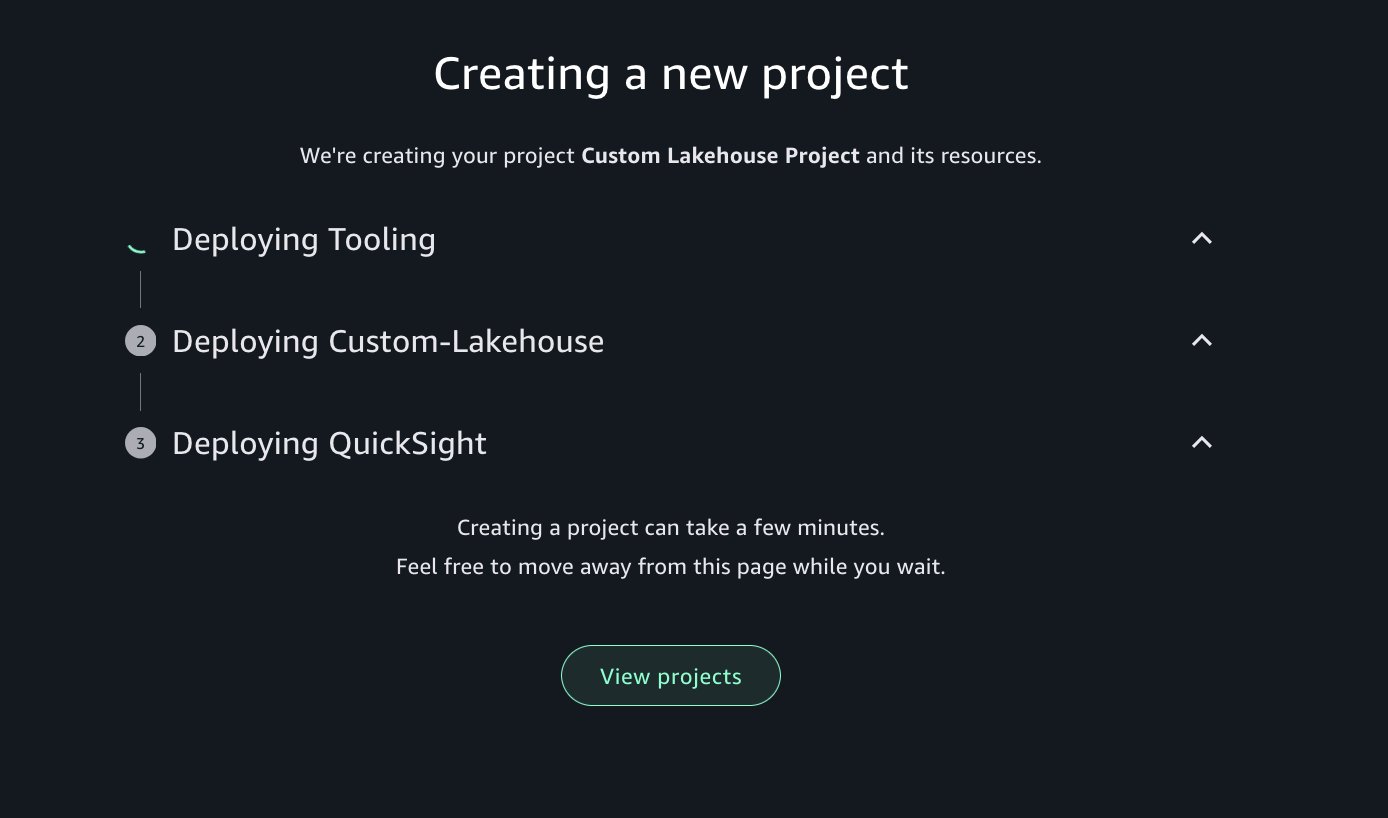
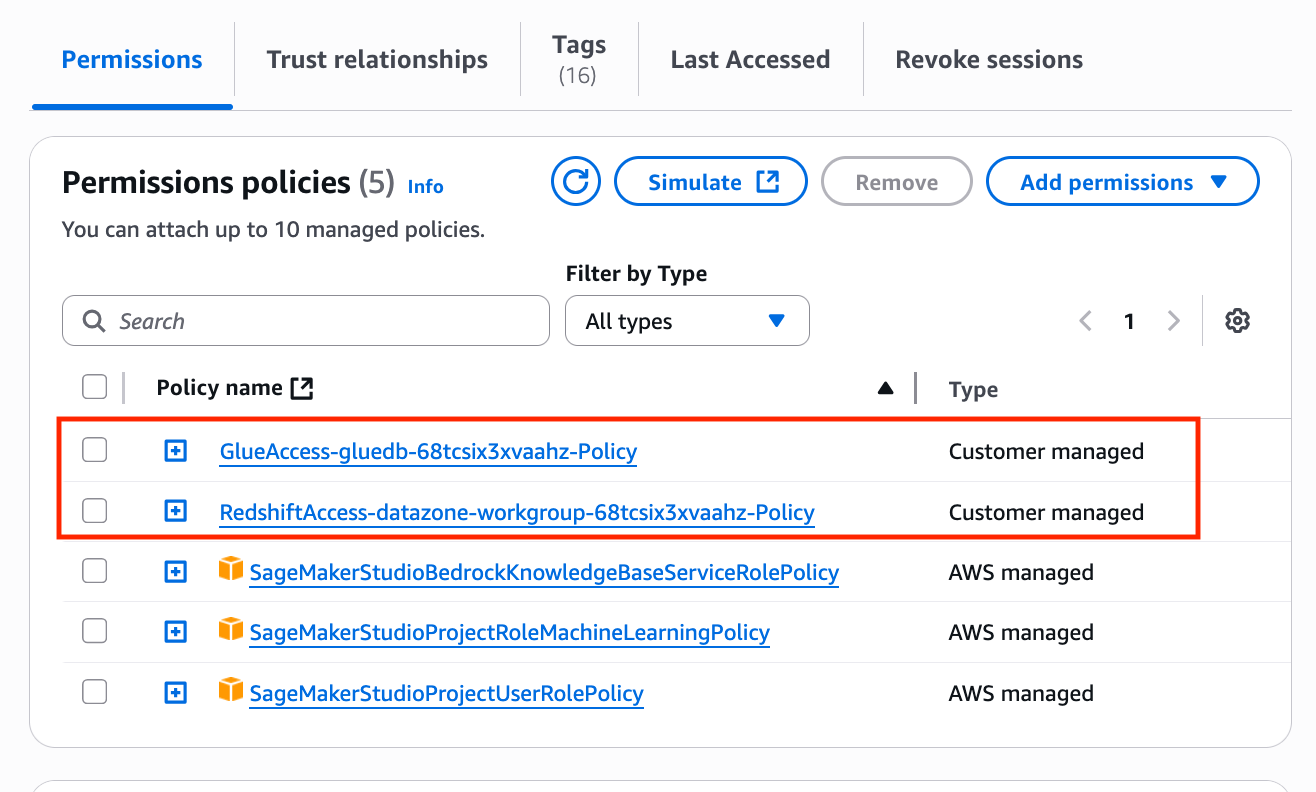
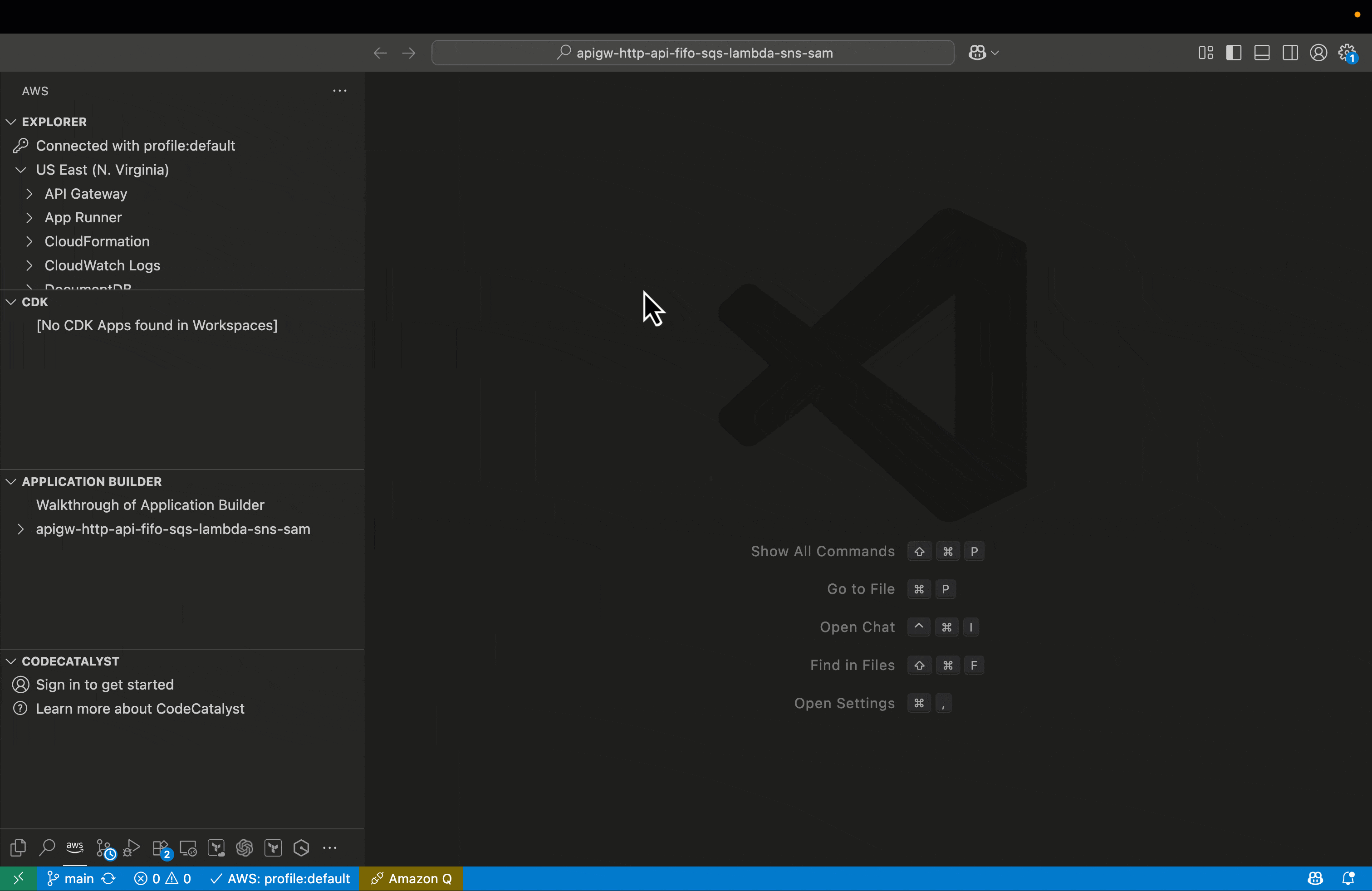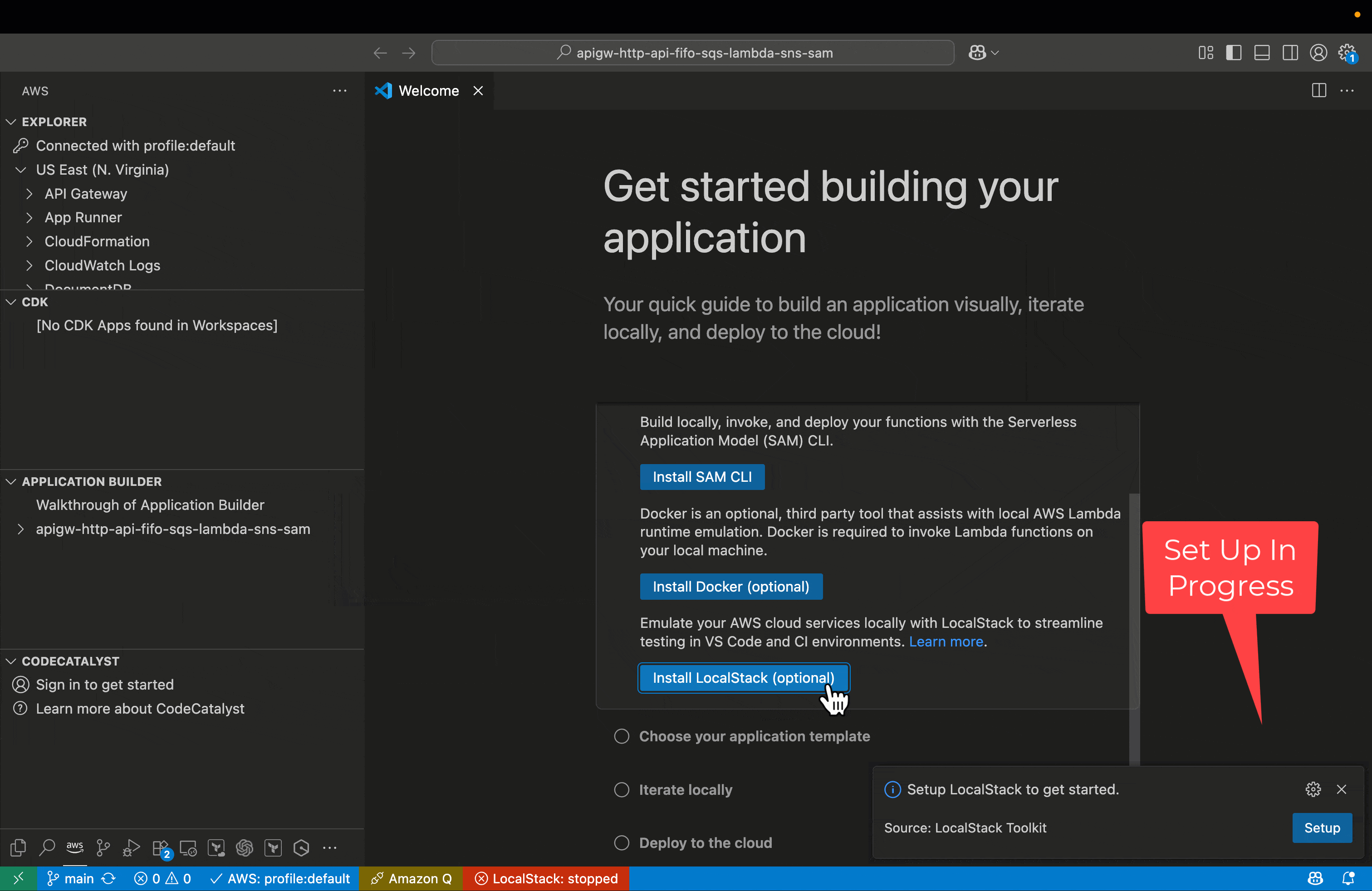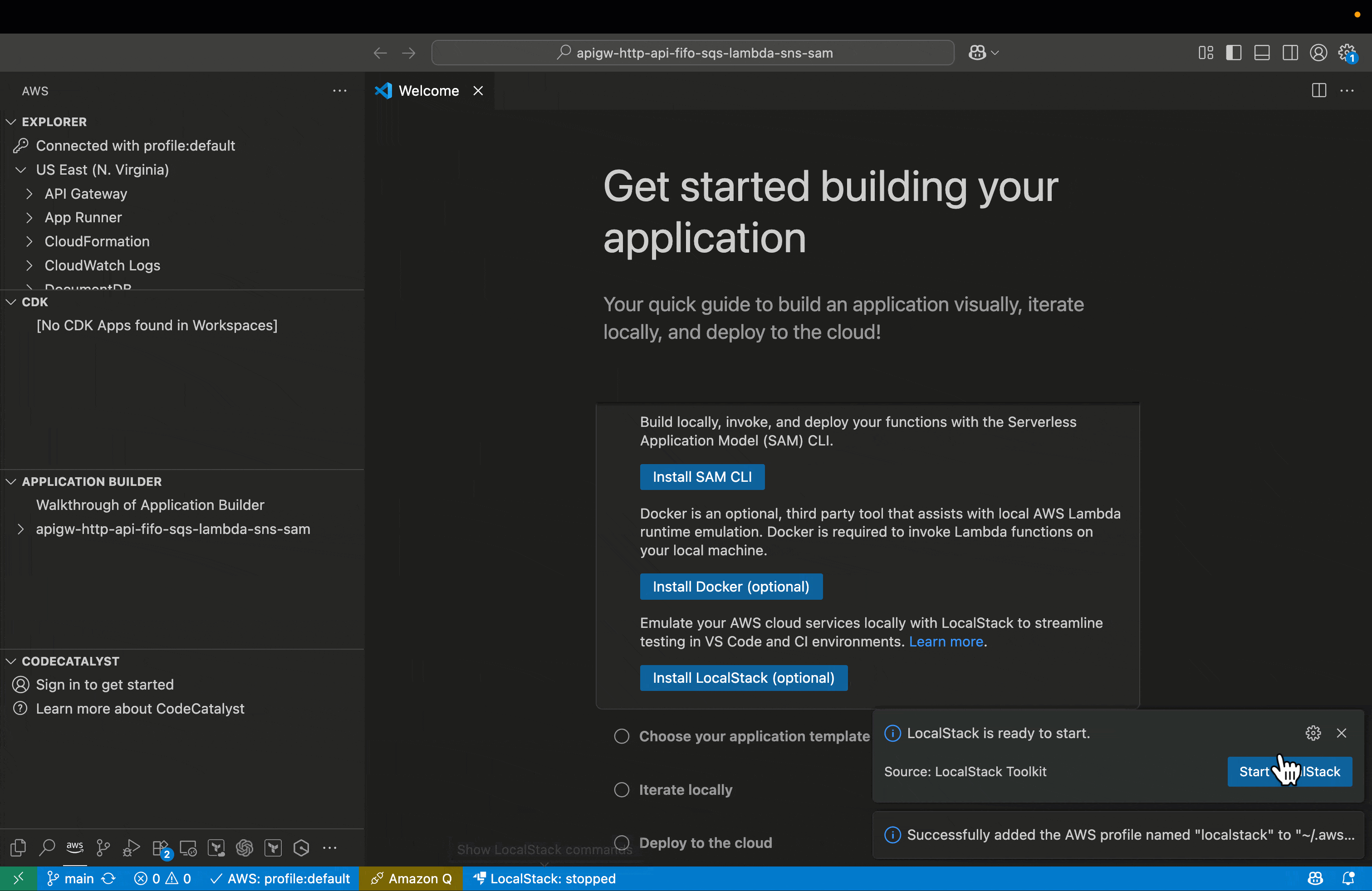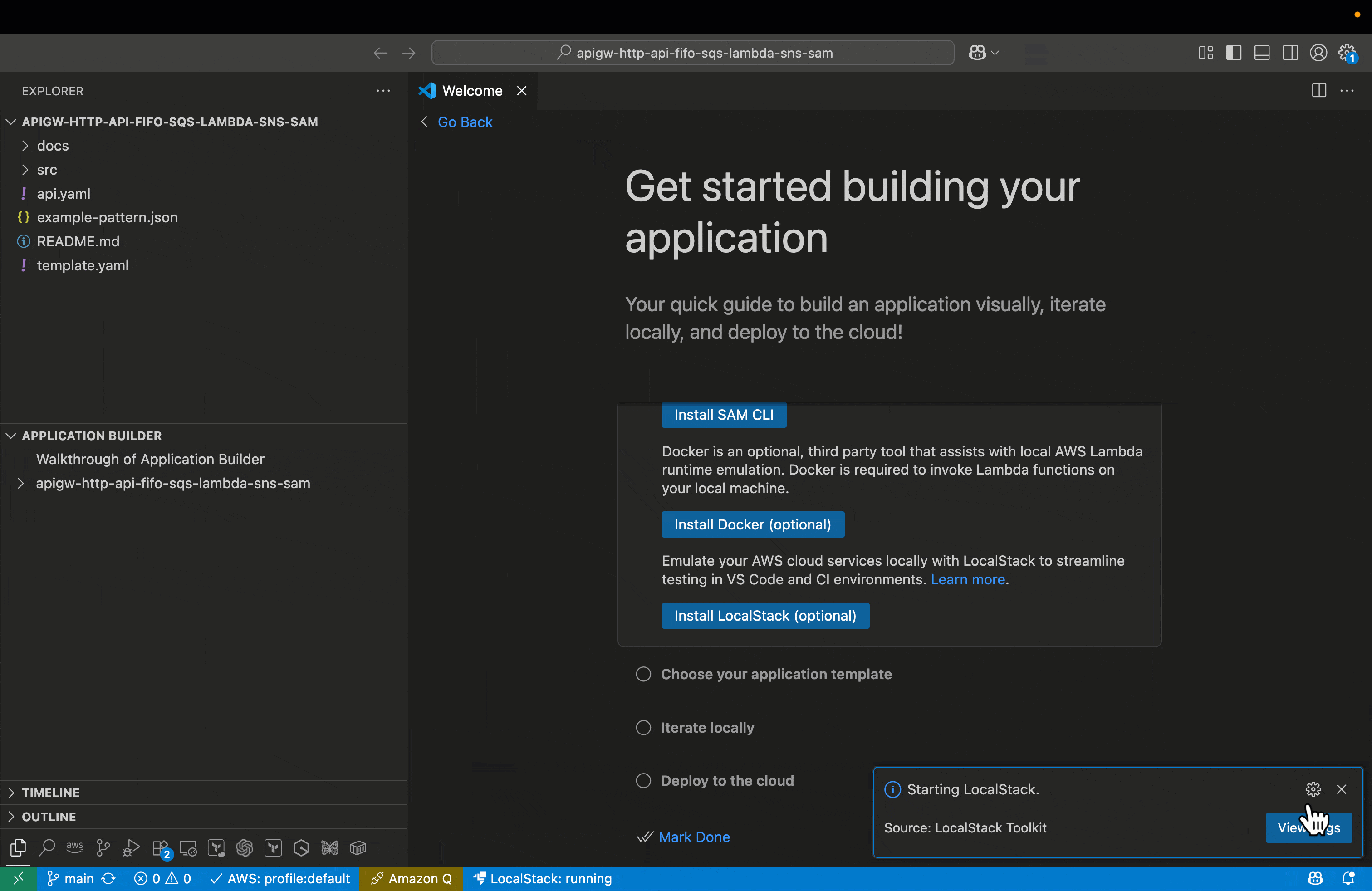
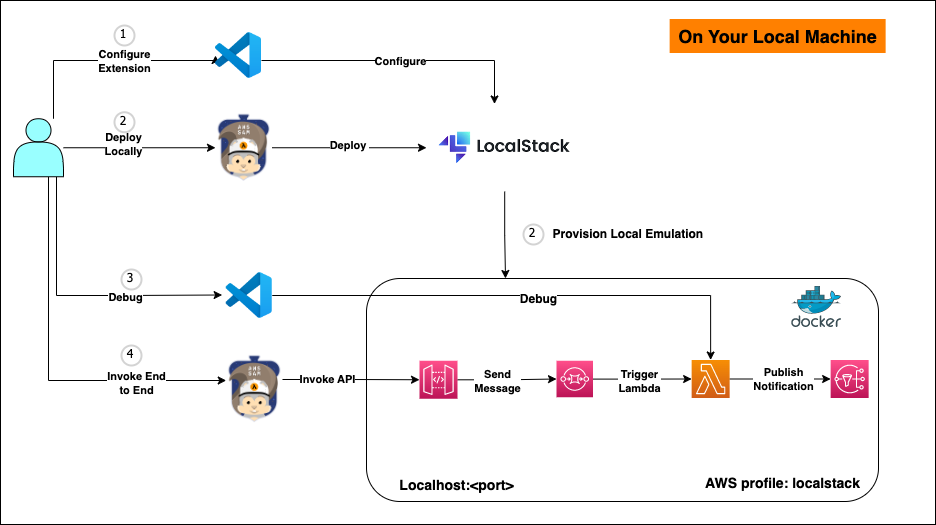

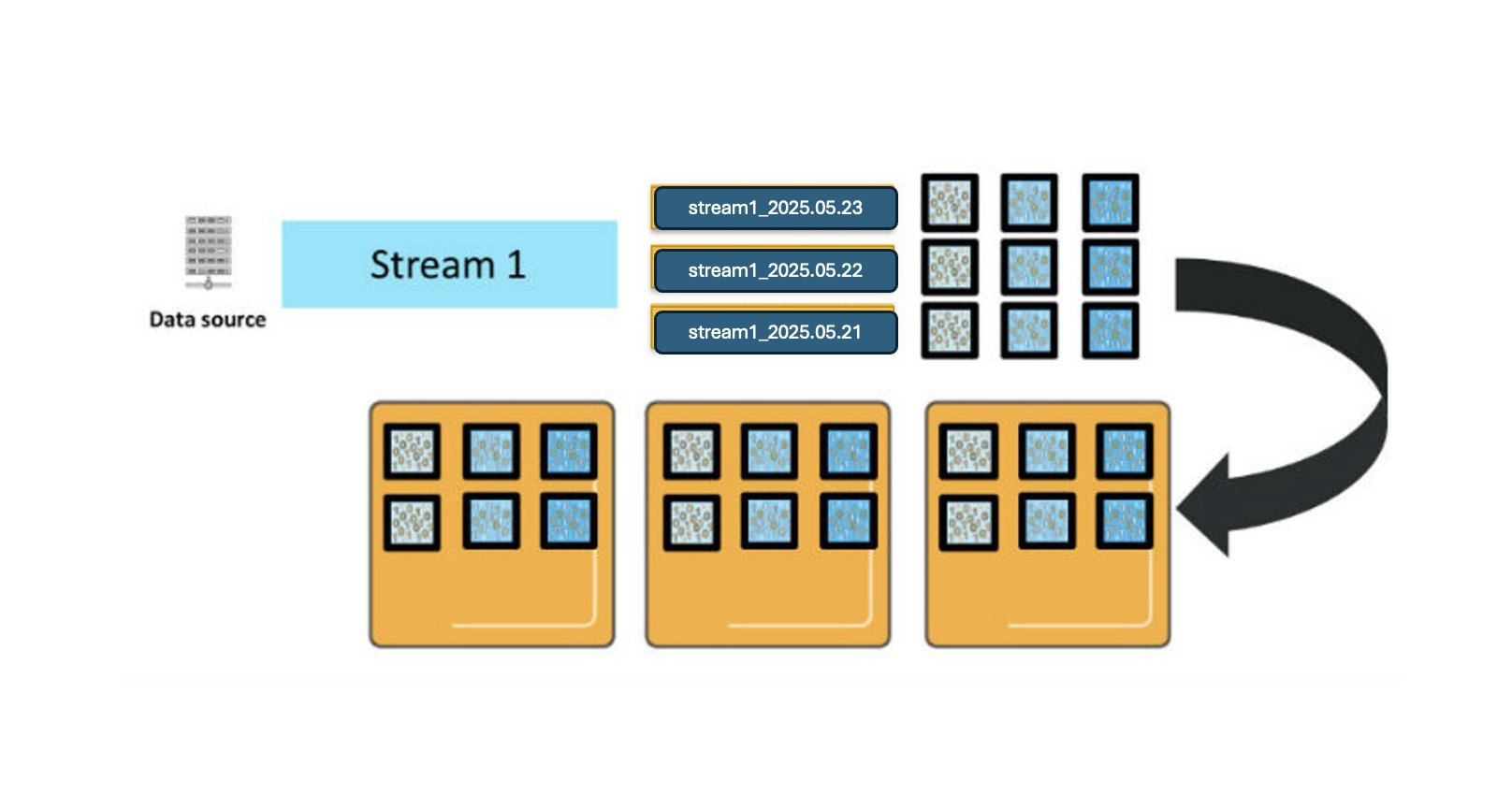
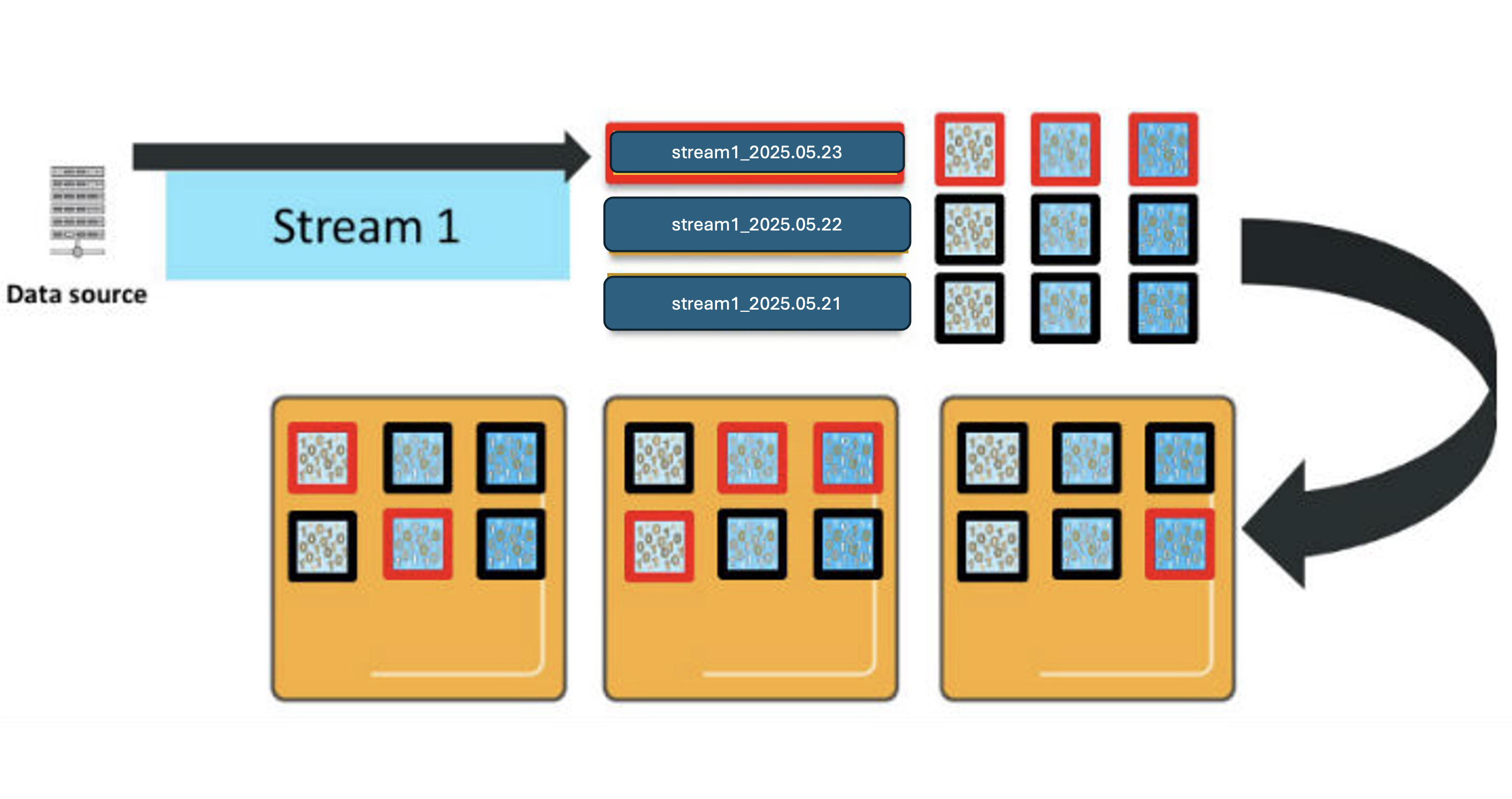
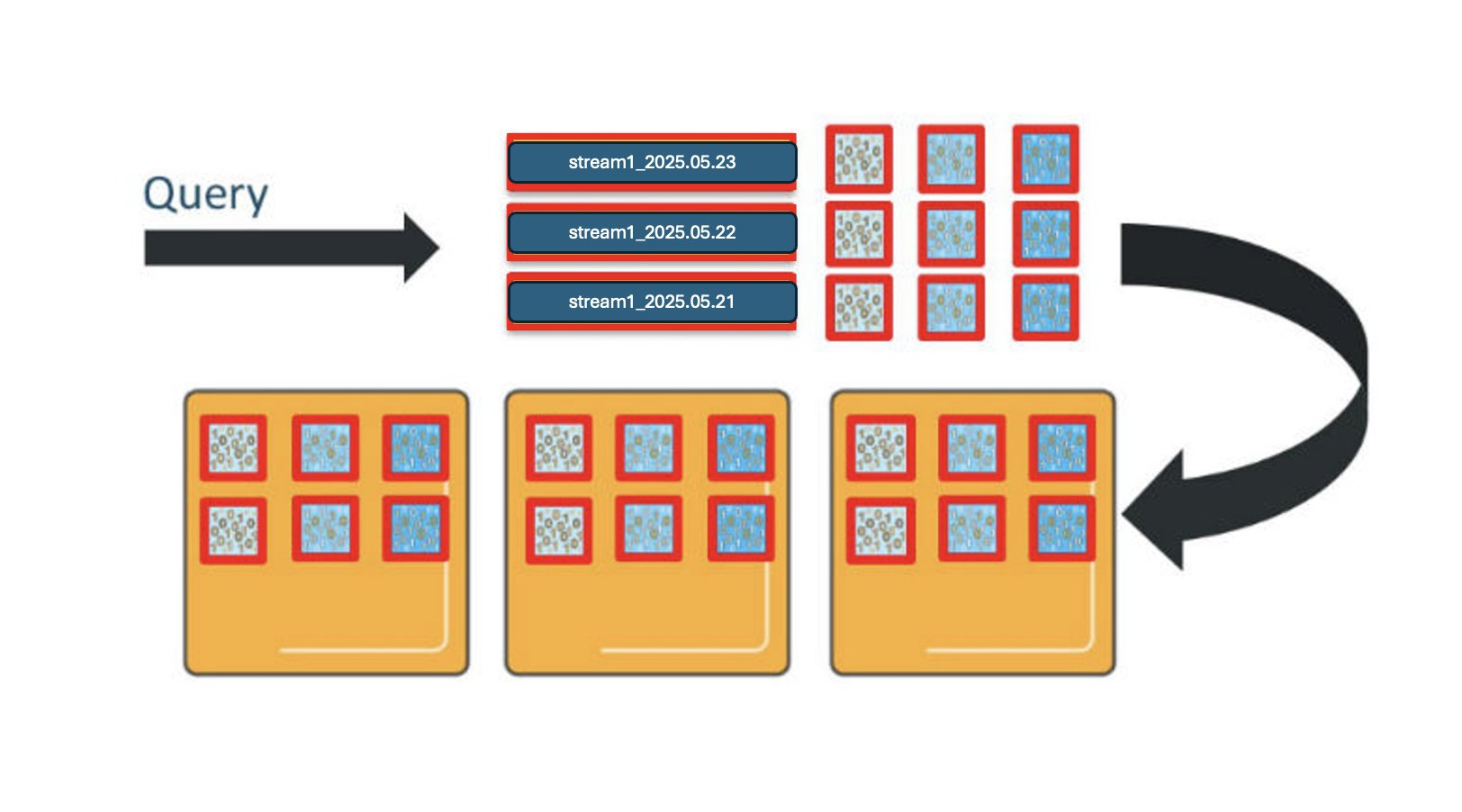
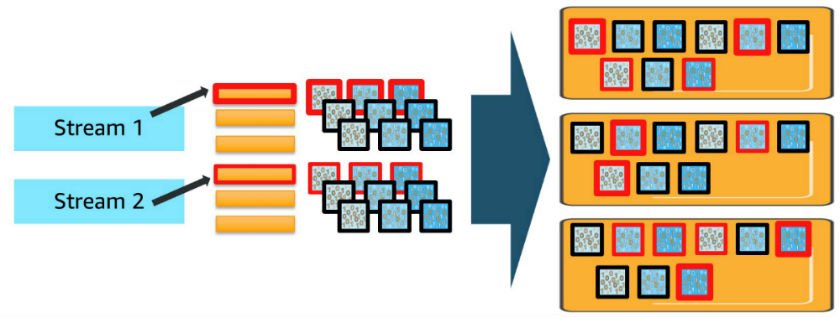

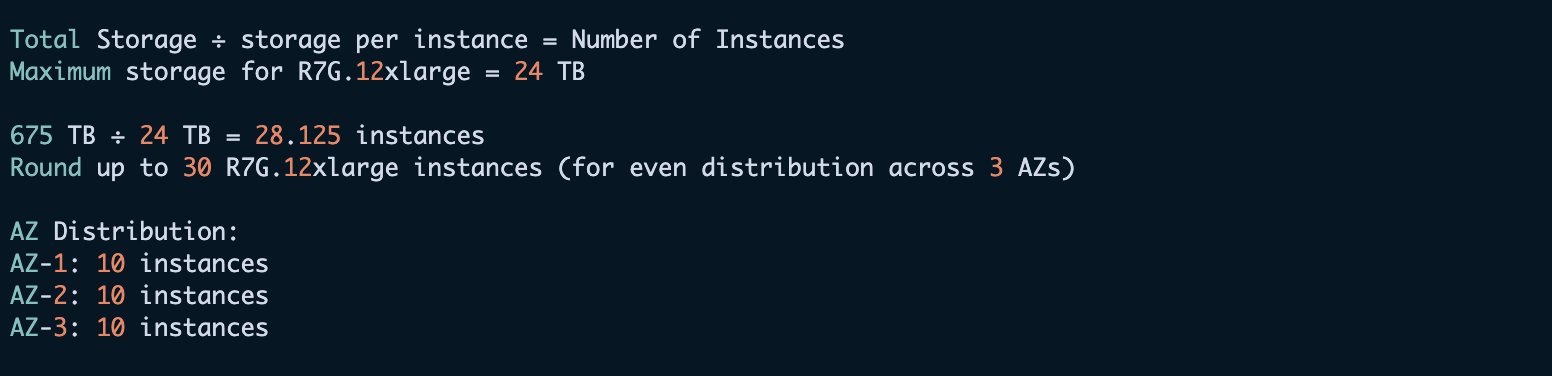

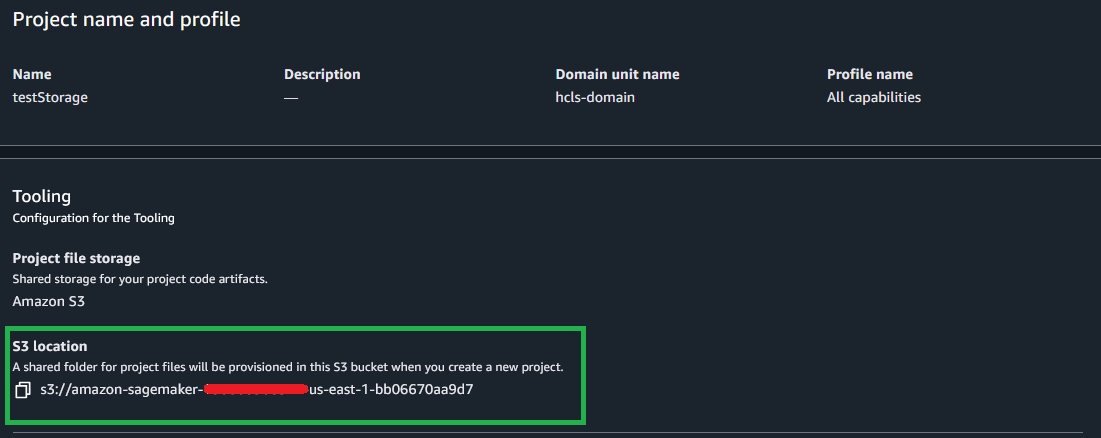

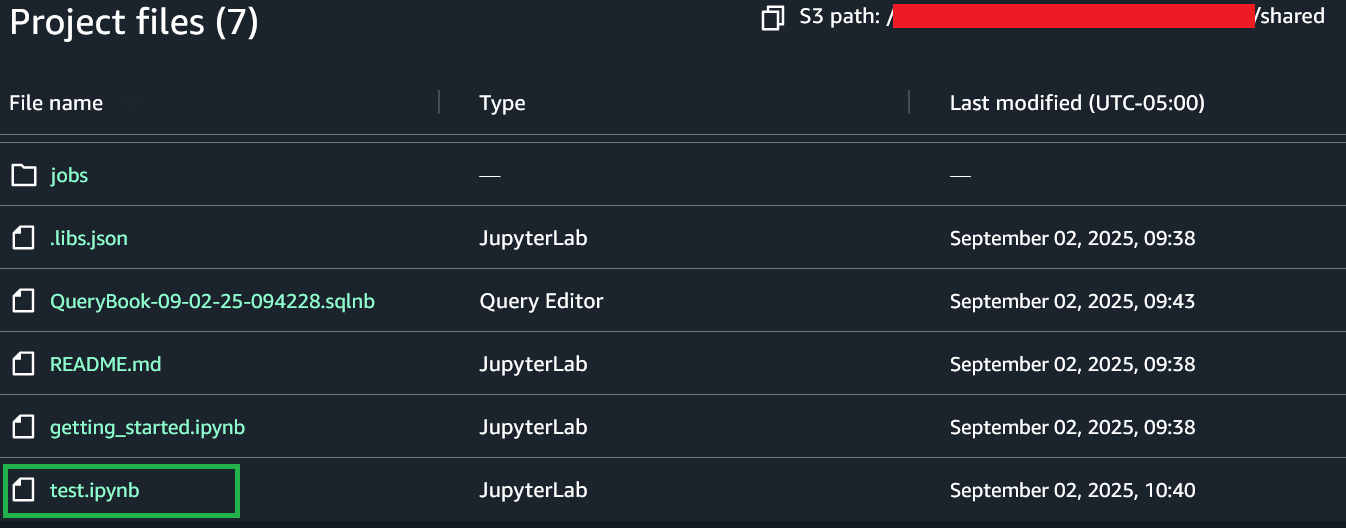
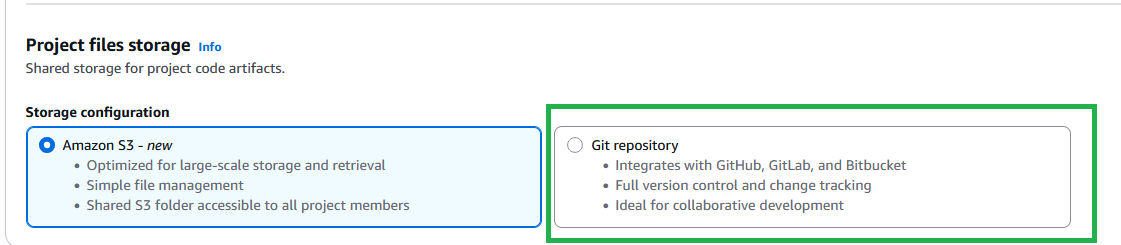
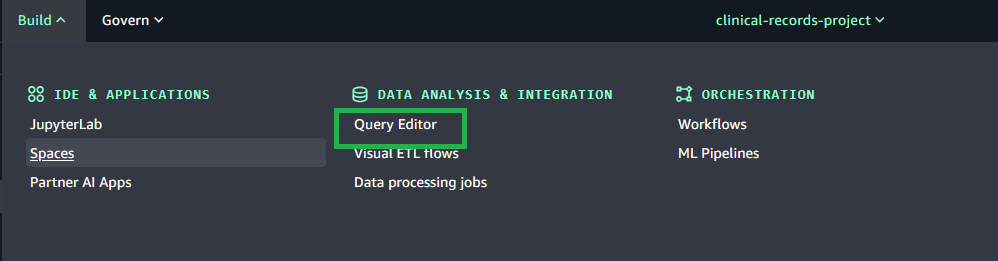
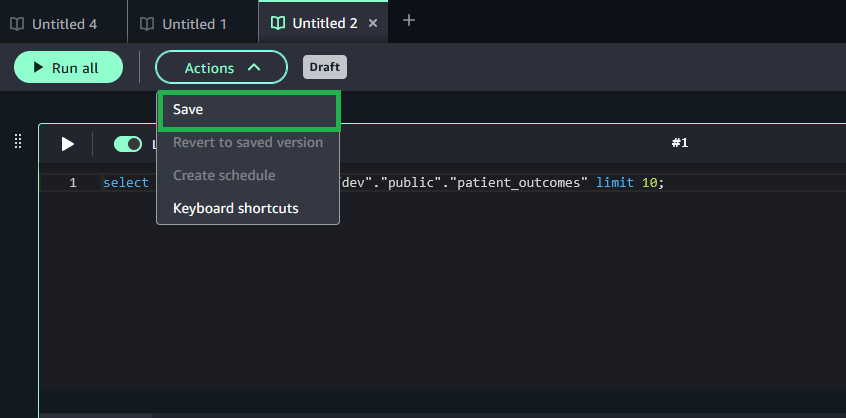
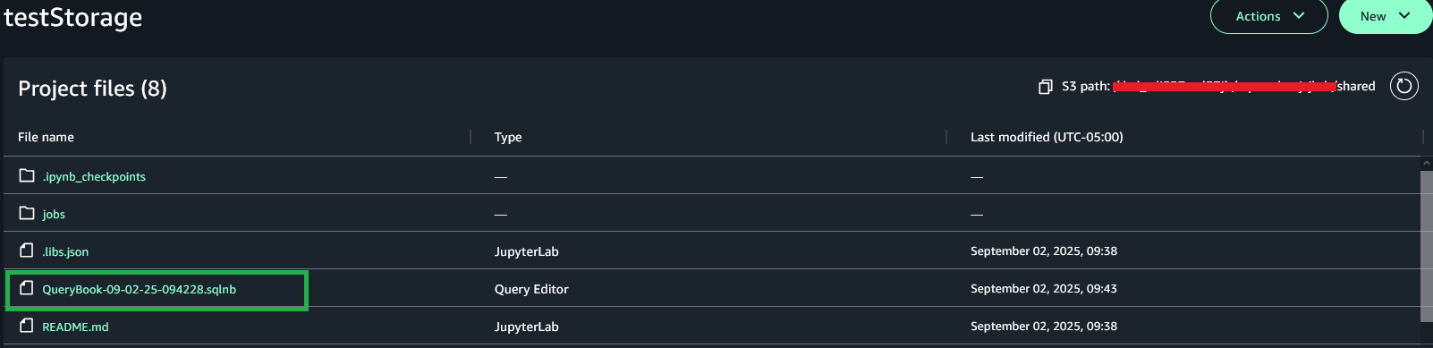




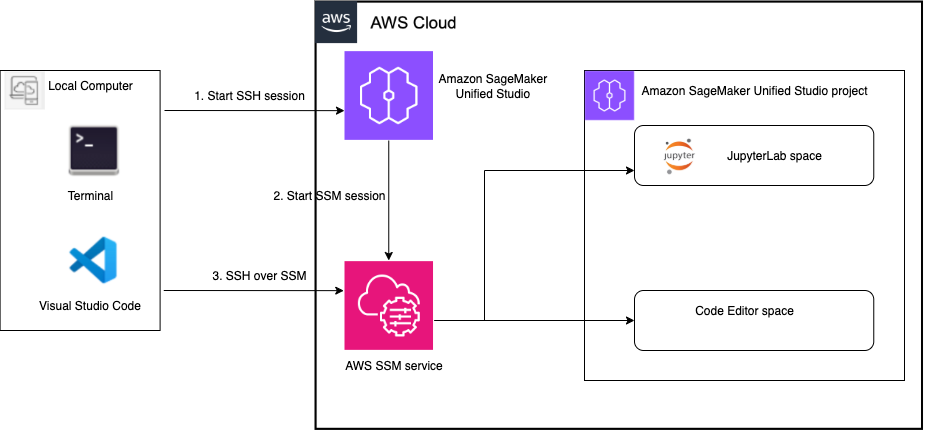

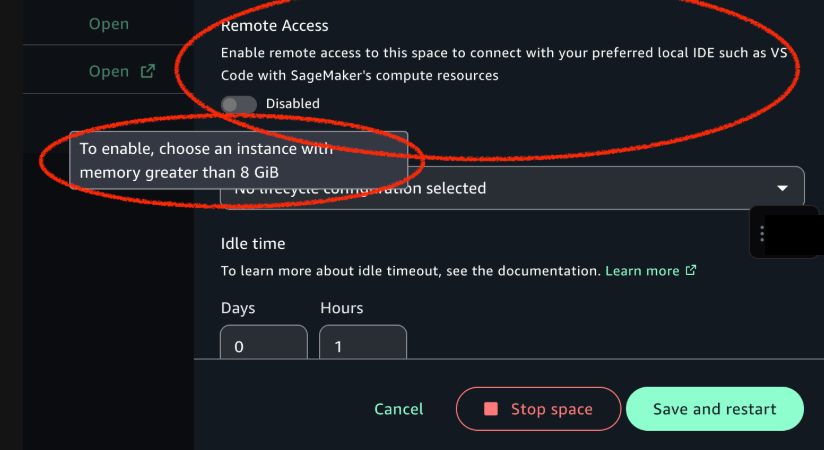
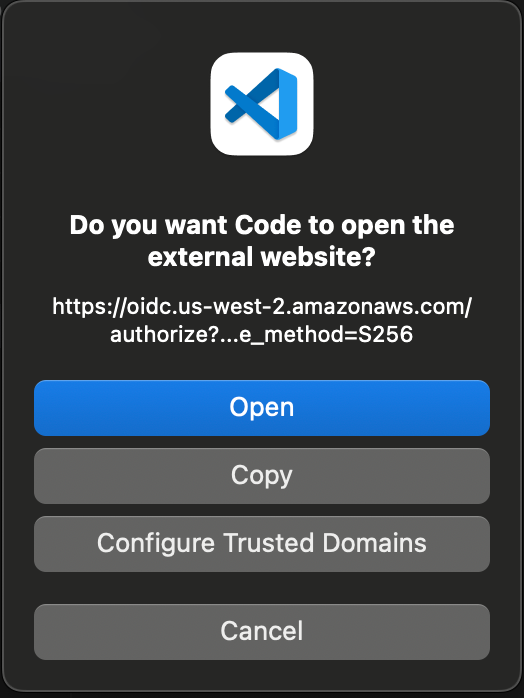
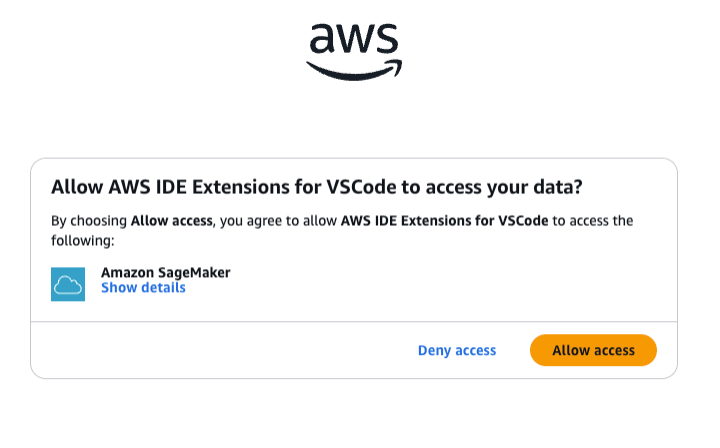
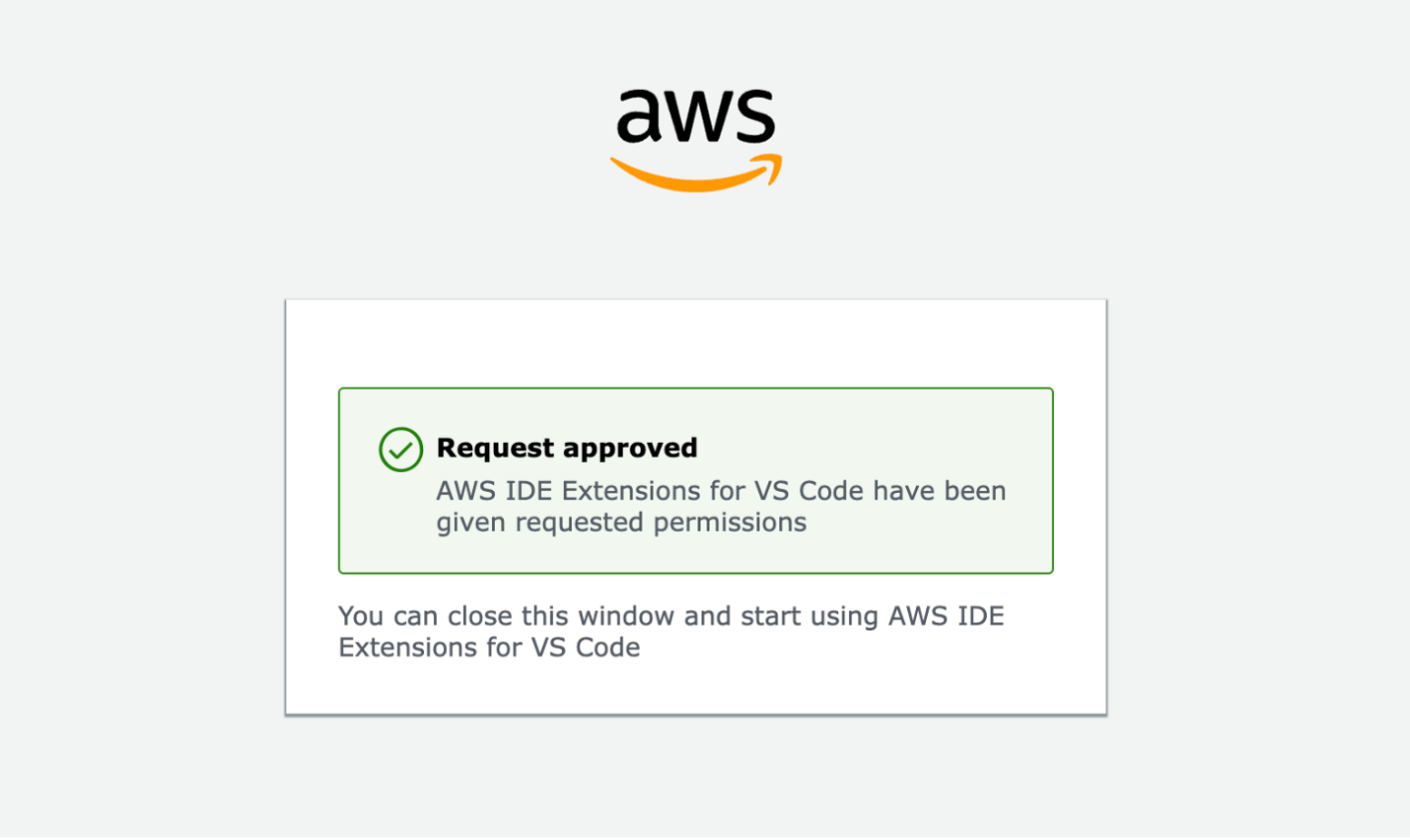
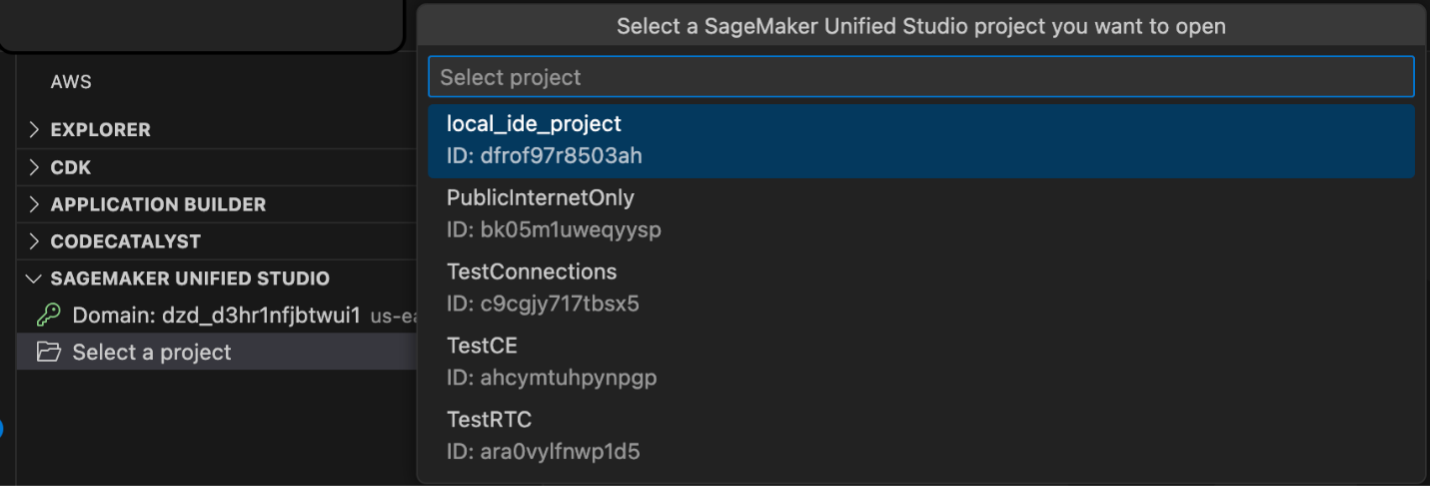
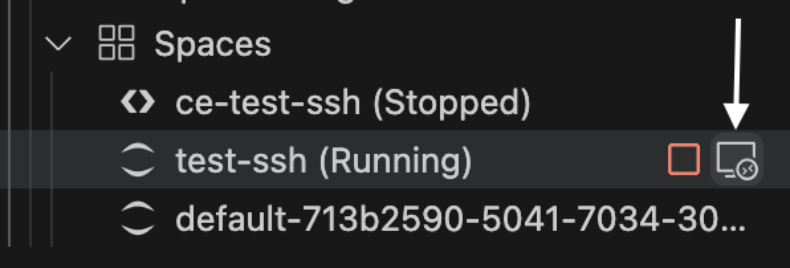
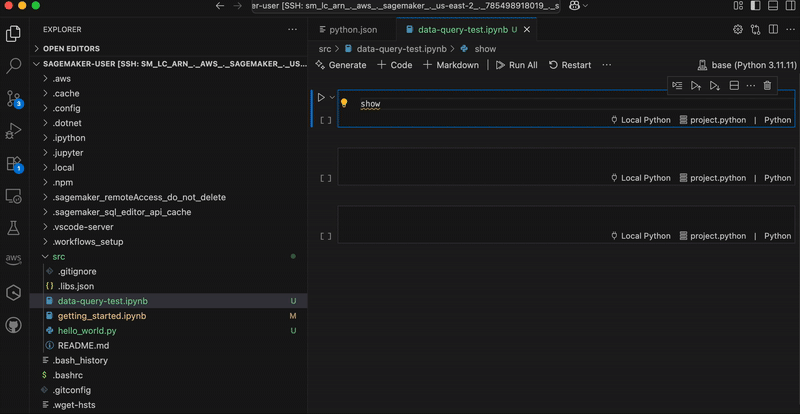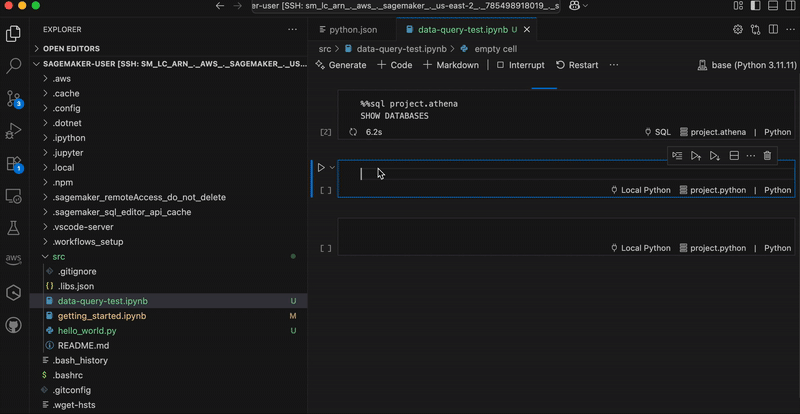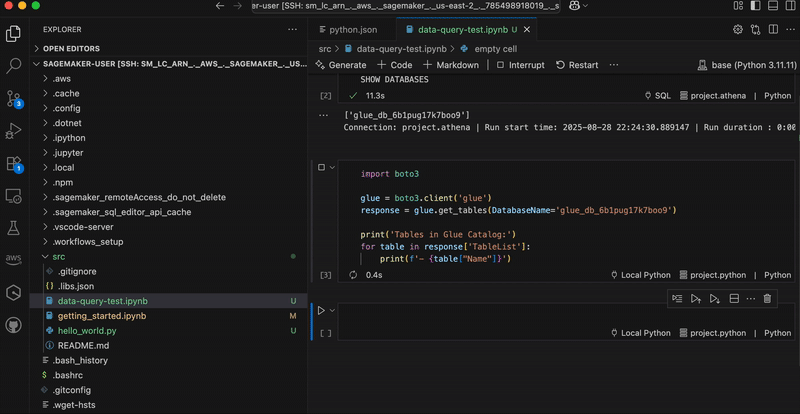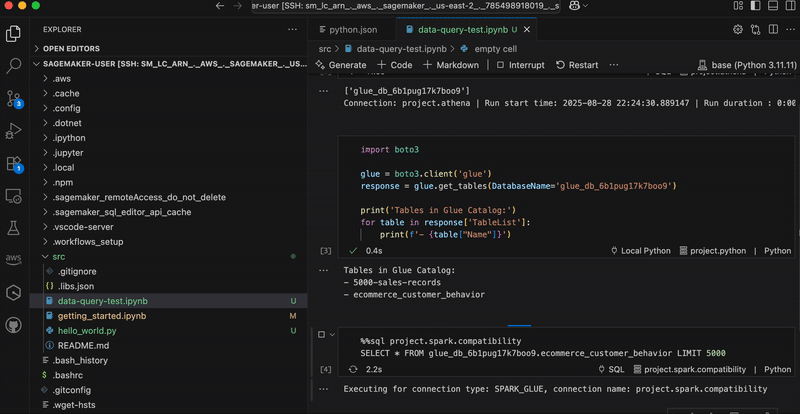
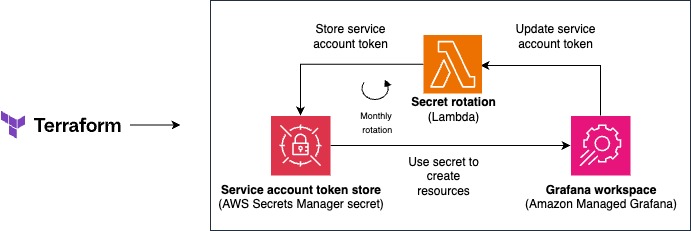
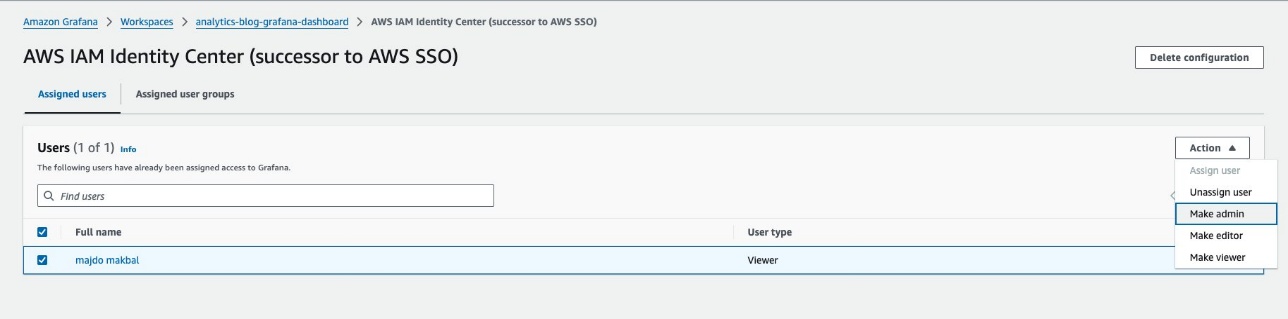
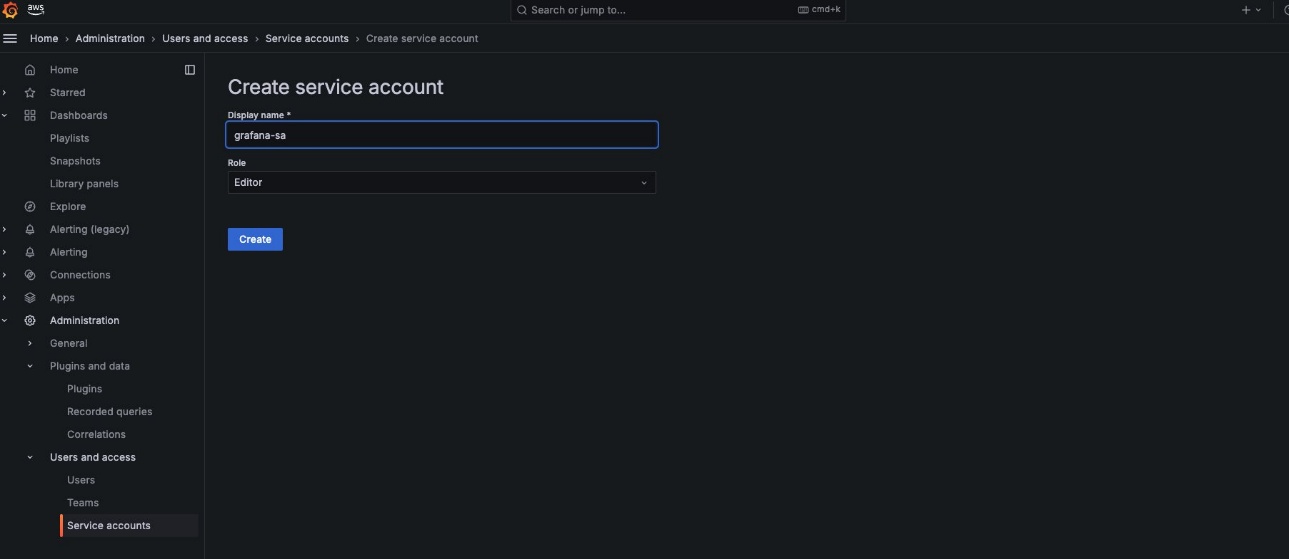
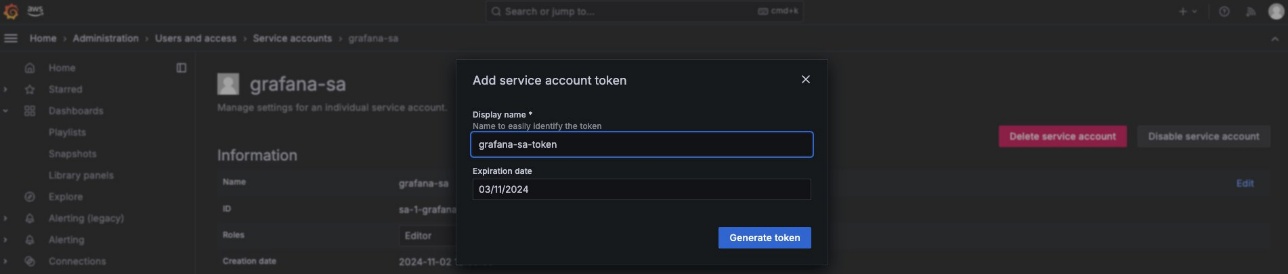
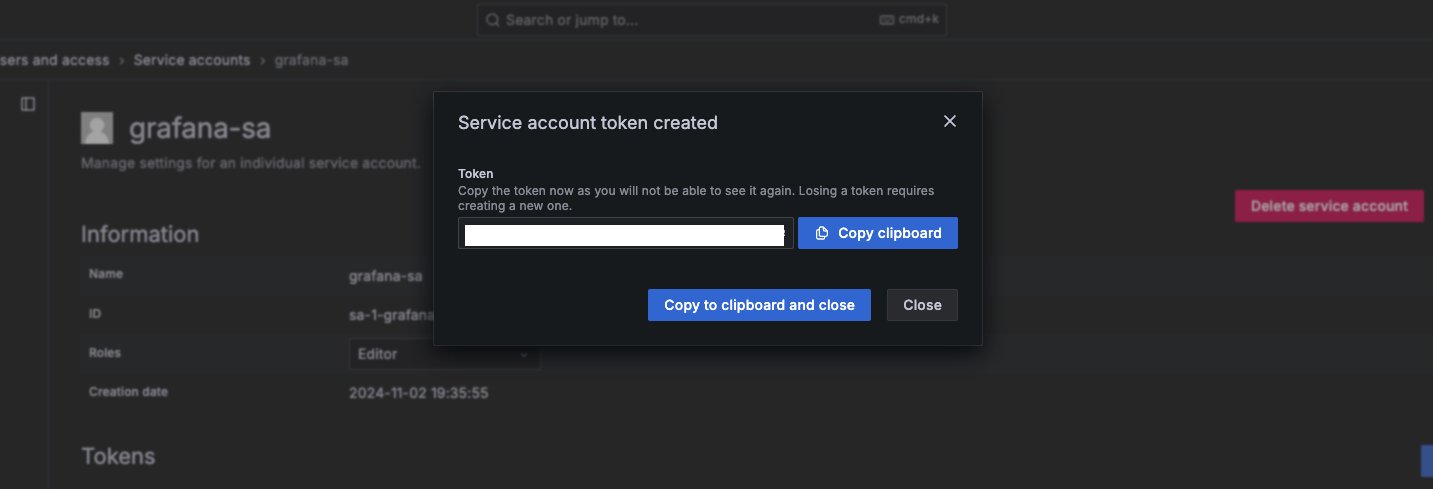
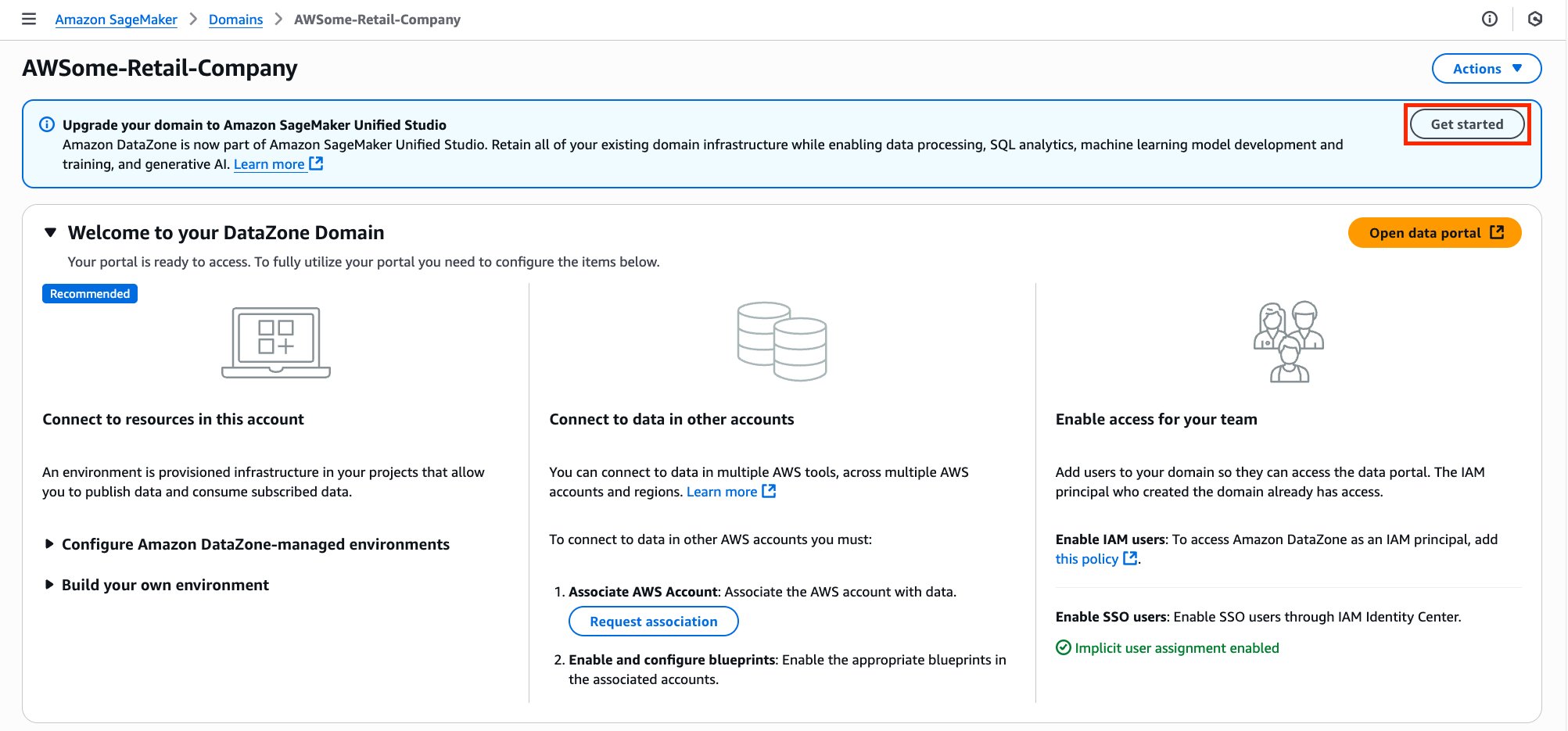
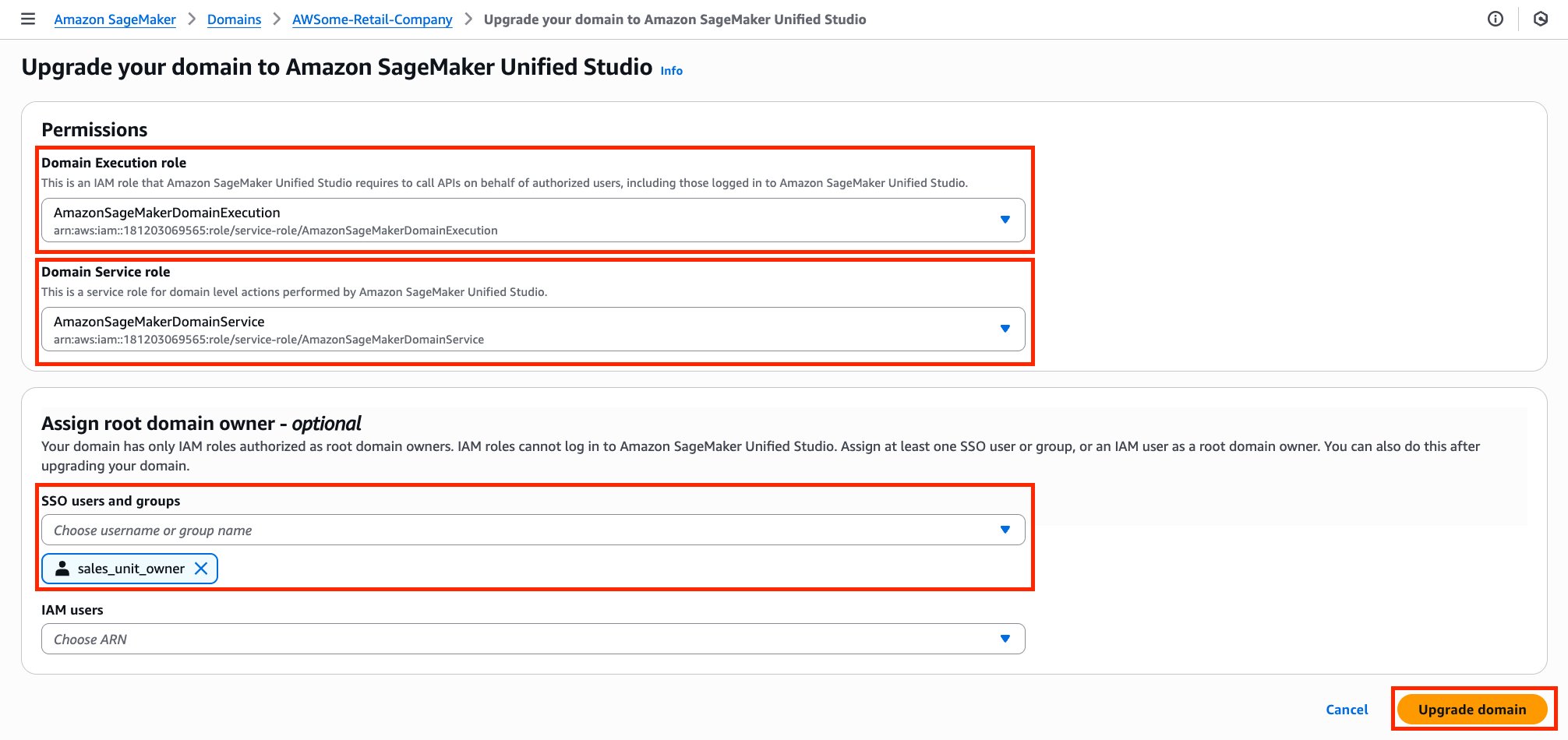
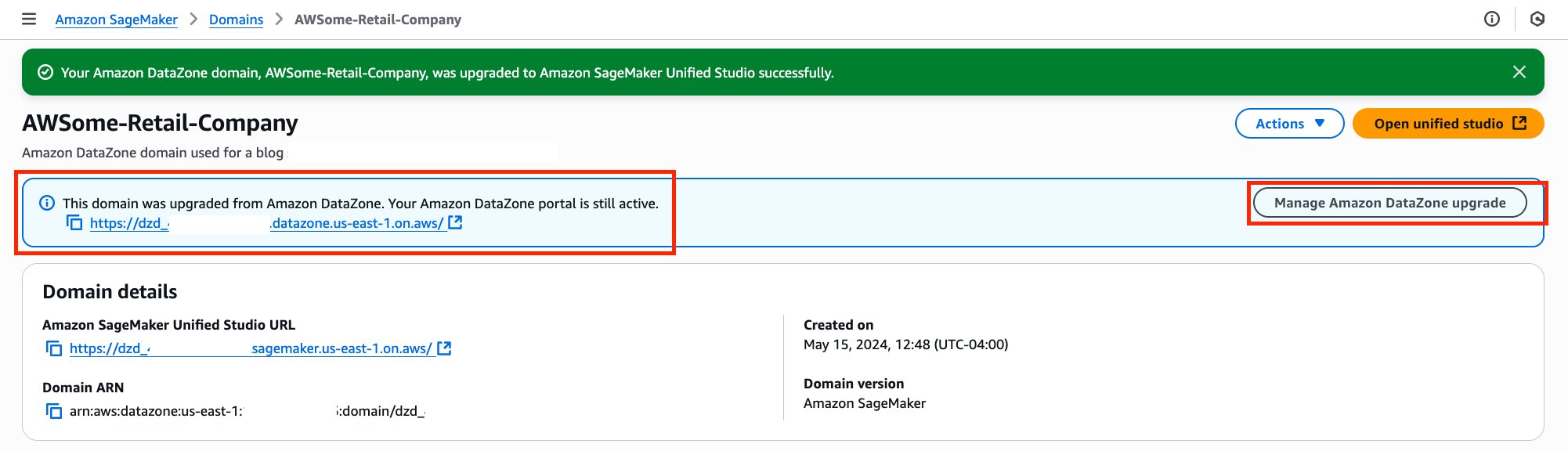
 David Victoria is a Senior Technical Product Manager with Amazon SageMaker at AWS. He focuses on improving administration and governance capabilities needed for customers to support their analytics systems. He is passionate about helping customers realize the most value from their data in a secure, governed manner.
David Victoria is a Senior Technical Product Manager with Amazon SageMaker at AWS. He focuses on improving administration and governance capabilities needed for customers to support their analytics systems. He is passionate about helping customers realize the most value from their data in a secure, governed manner. Leonardo David Gomez Virahonda is a Principal Analytics Specialist Solutions Architect at AWS, with a strong focus on data governance. He helps organizations across industries implement effective governance strategies using AWS services like Amazon DataZone, AWS Glue, Lake Formation, and SageMaker Catalog. Leonardo’s work spans metadata management, data lineage, access control, and compliance—empowering customers to make their data secure, discoverable, and ready for analytics and AI. He regularly shares best practices through technical blogs, enablement content, and sessions at AWS events like re:Invent and regional Summits.
Leonardo David Gomez Virahonda is a Principal Analytics Specialist Solutions Architect at AWS, with a strong focus on data governance. He helps organizations across industries implement effective governance strategies using AWS services like Amazon DataZone, AWS Glue, Lake Formation, and SageMaker Catalog. Leonardo’s work spans metadata management, data lineage, access control, and compliance—empowering customers to make their data secure, discoverable, and ready for analytics and AI. He regularly shares best practices through technical blogs, enablement content, and sessions at AWS events like re:Invent and regional Summits.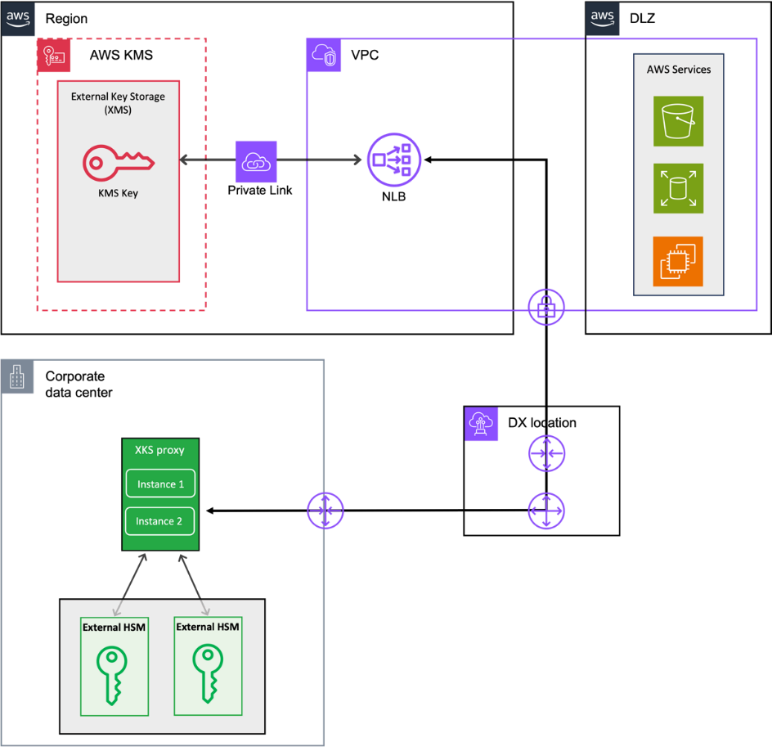
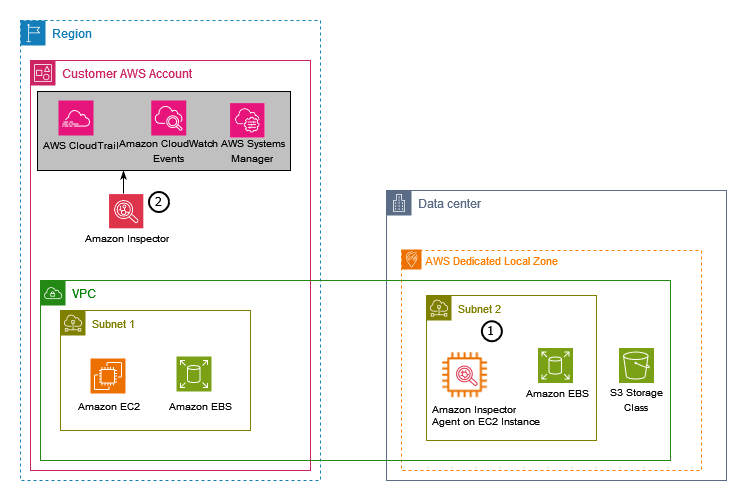
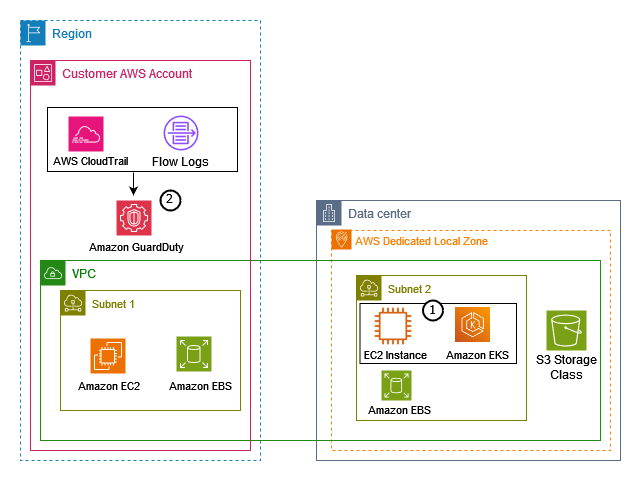
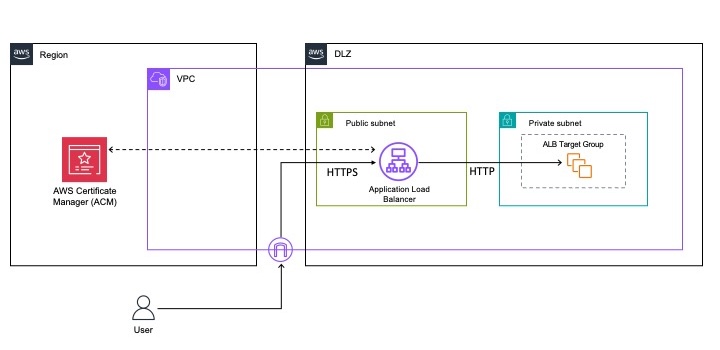
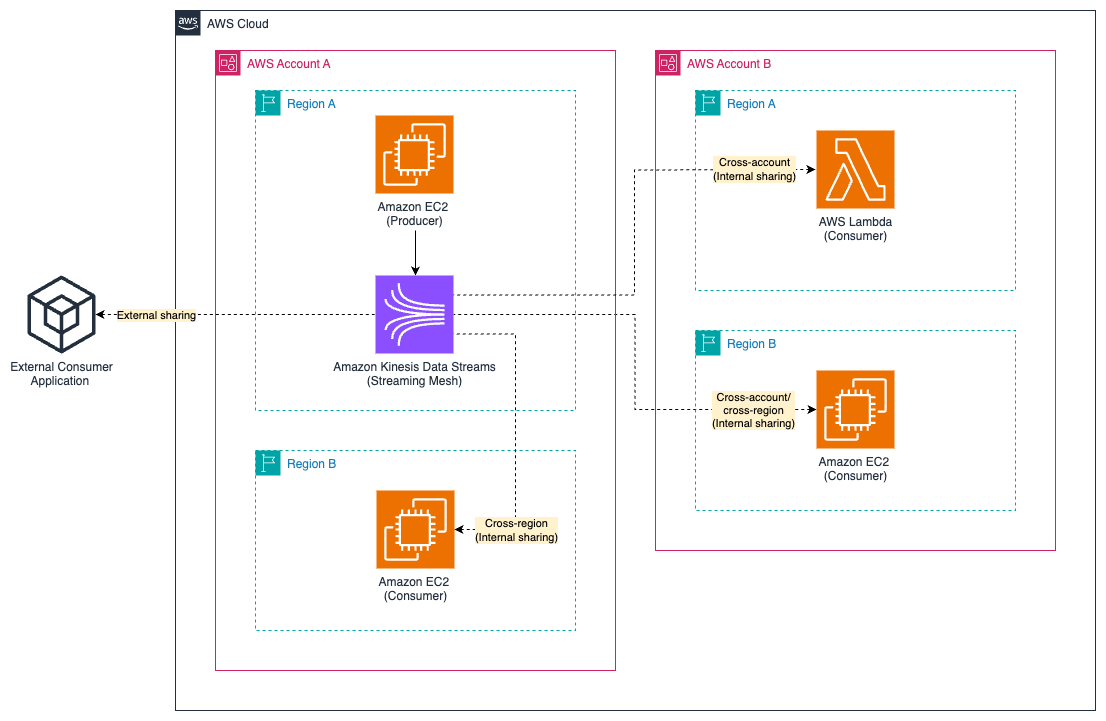
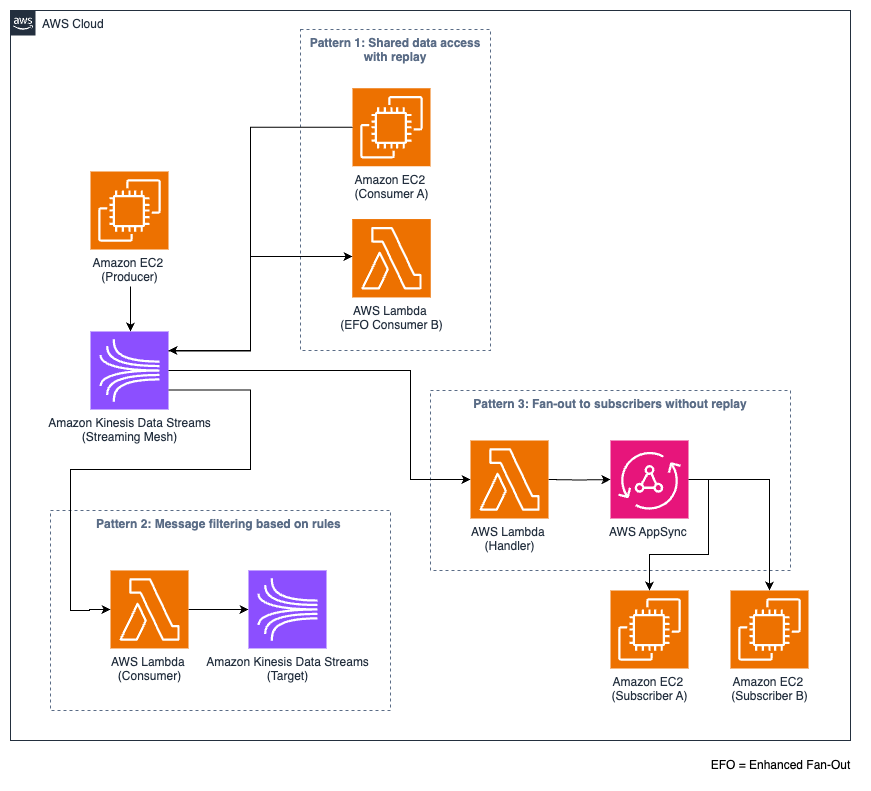
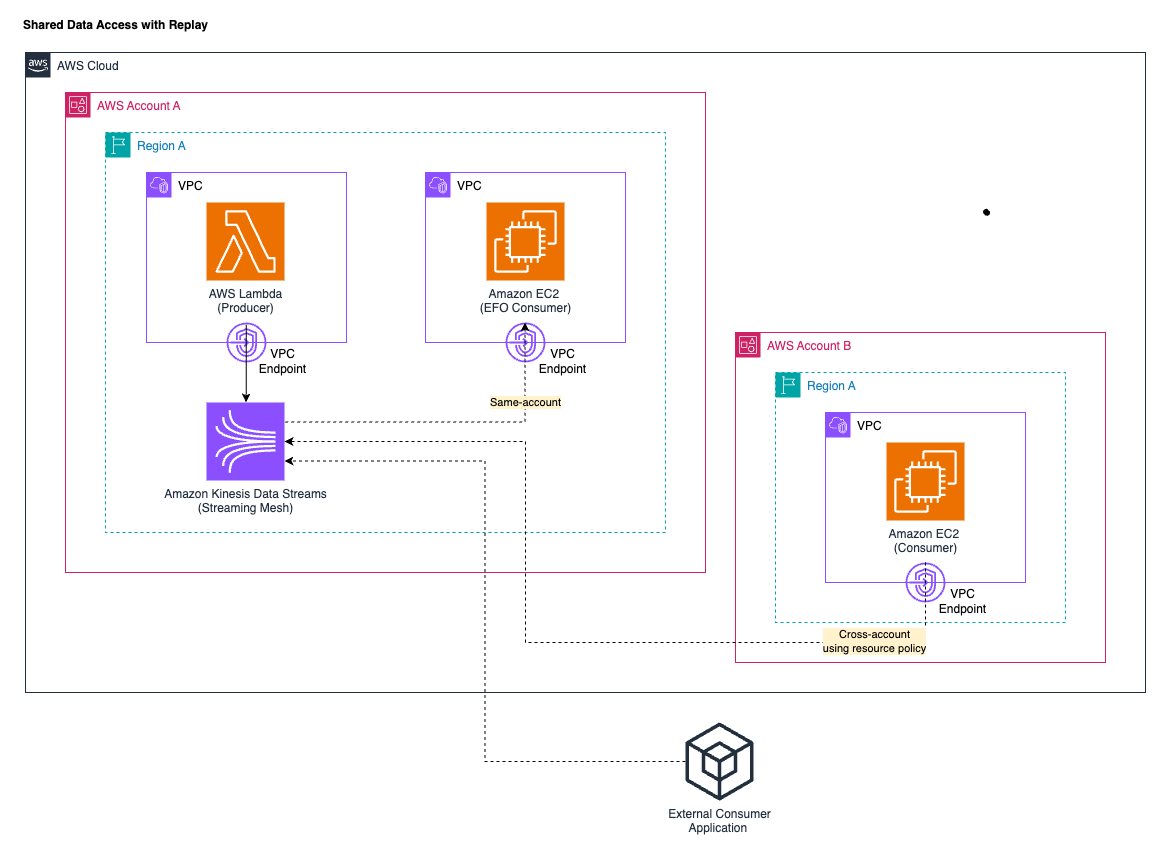
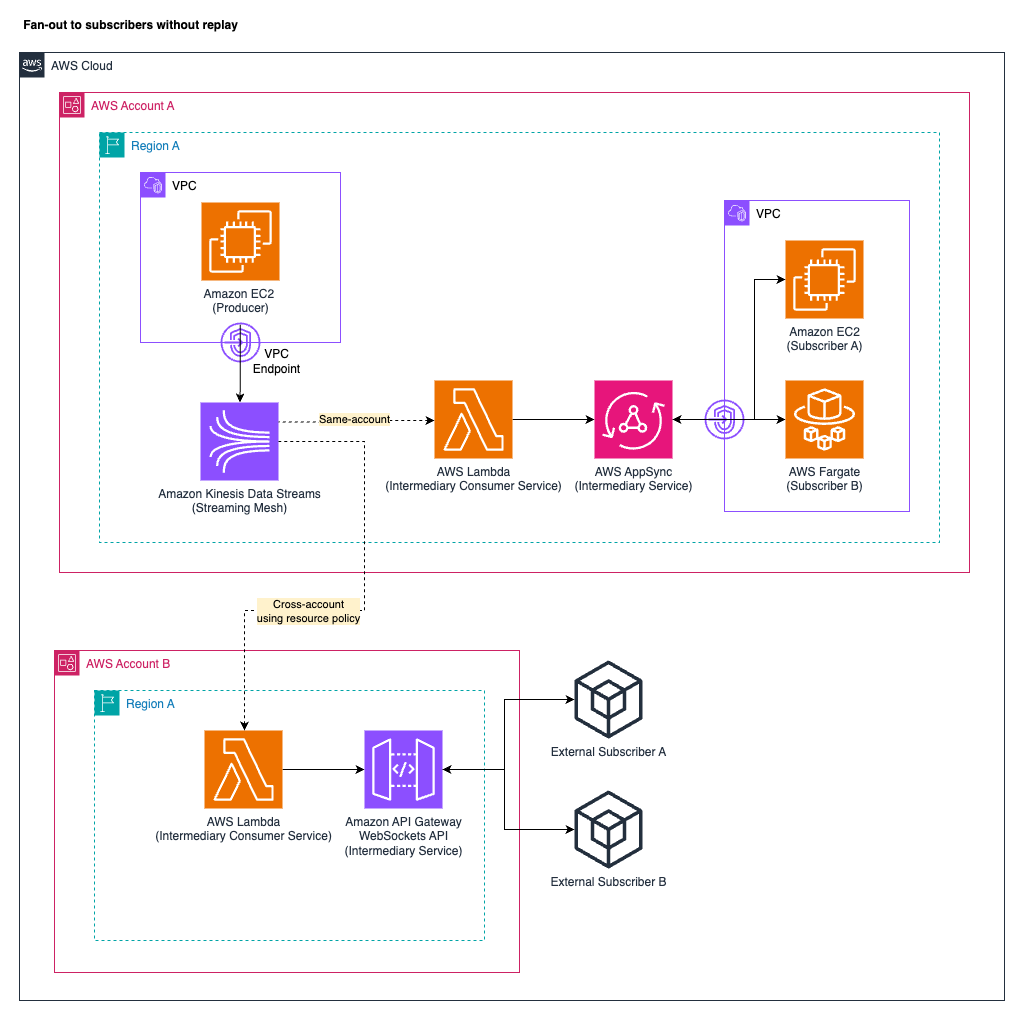
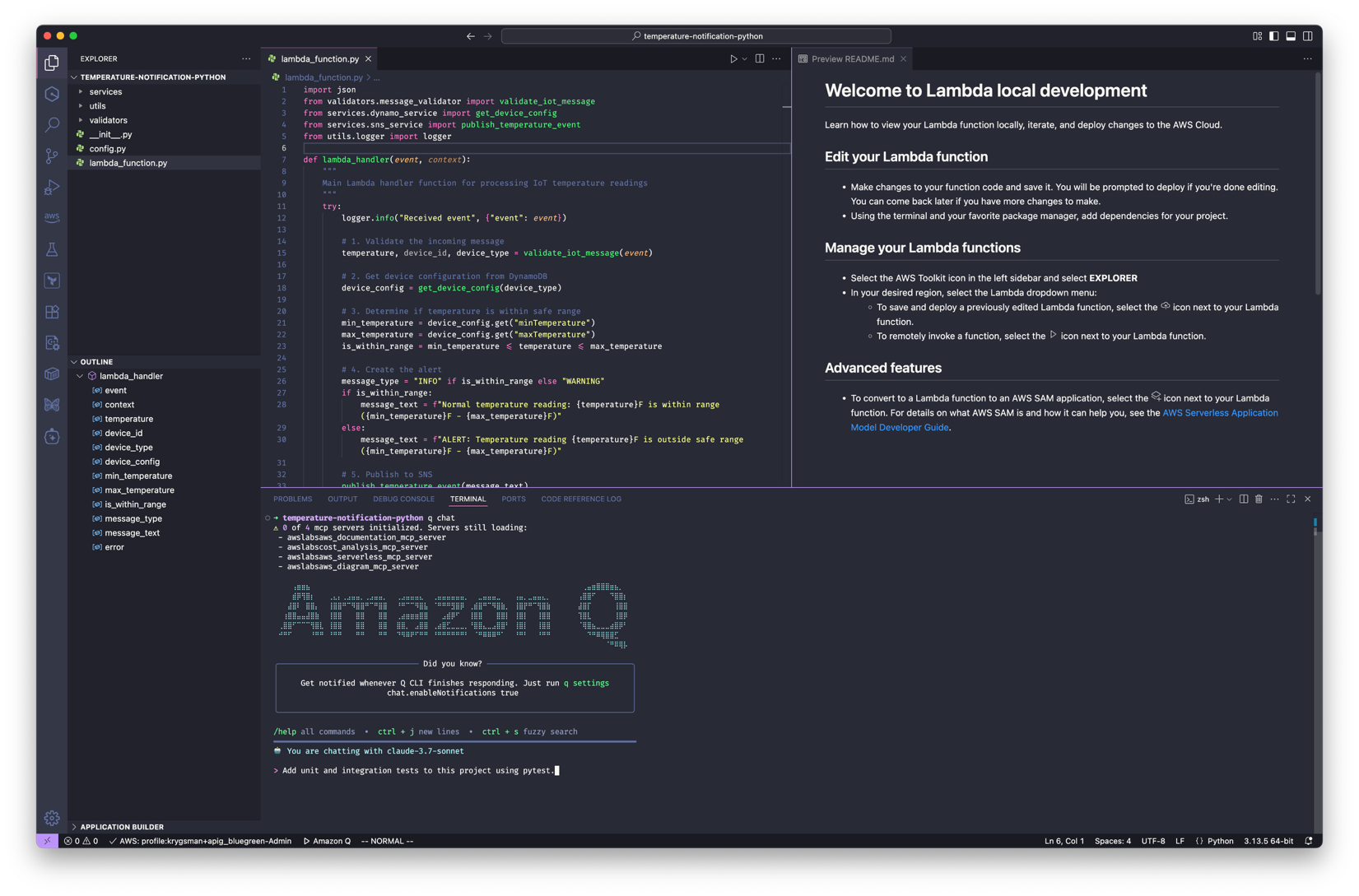
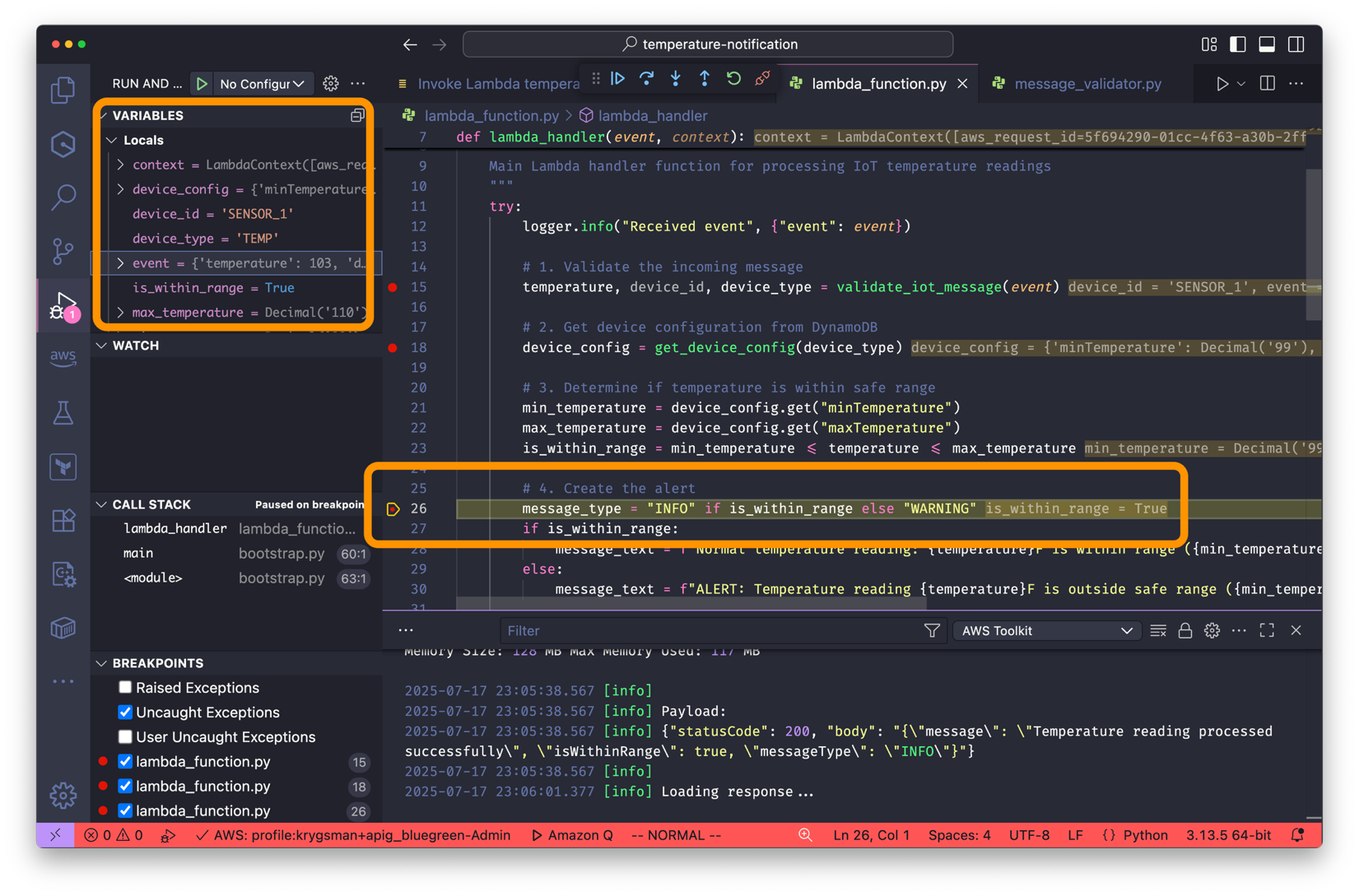
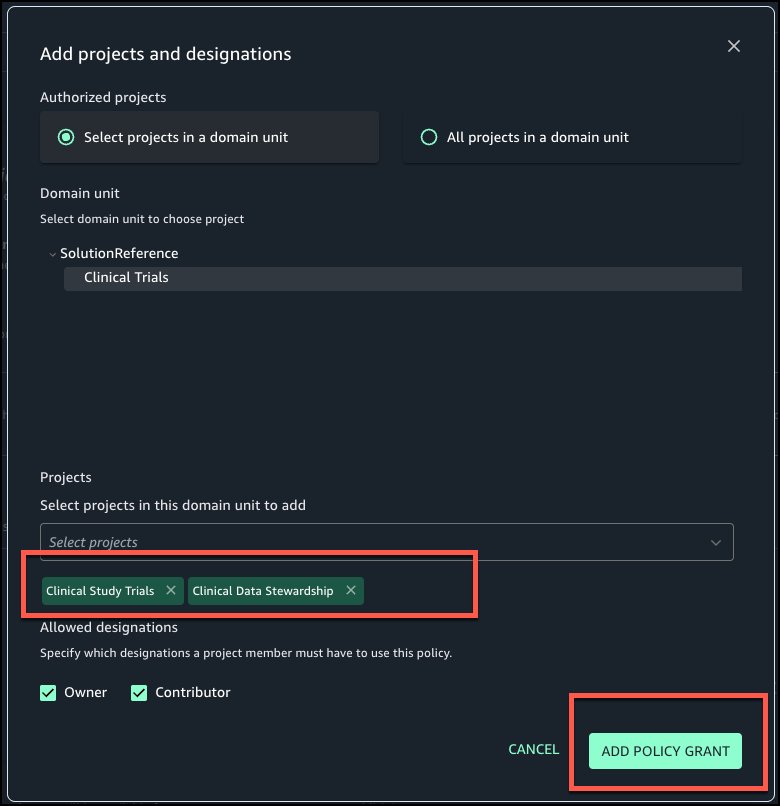
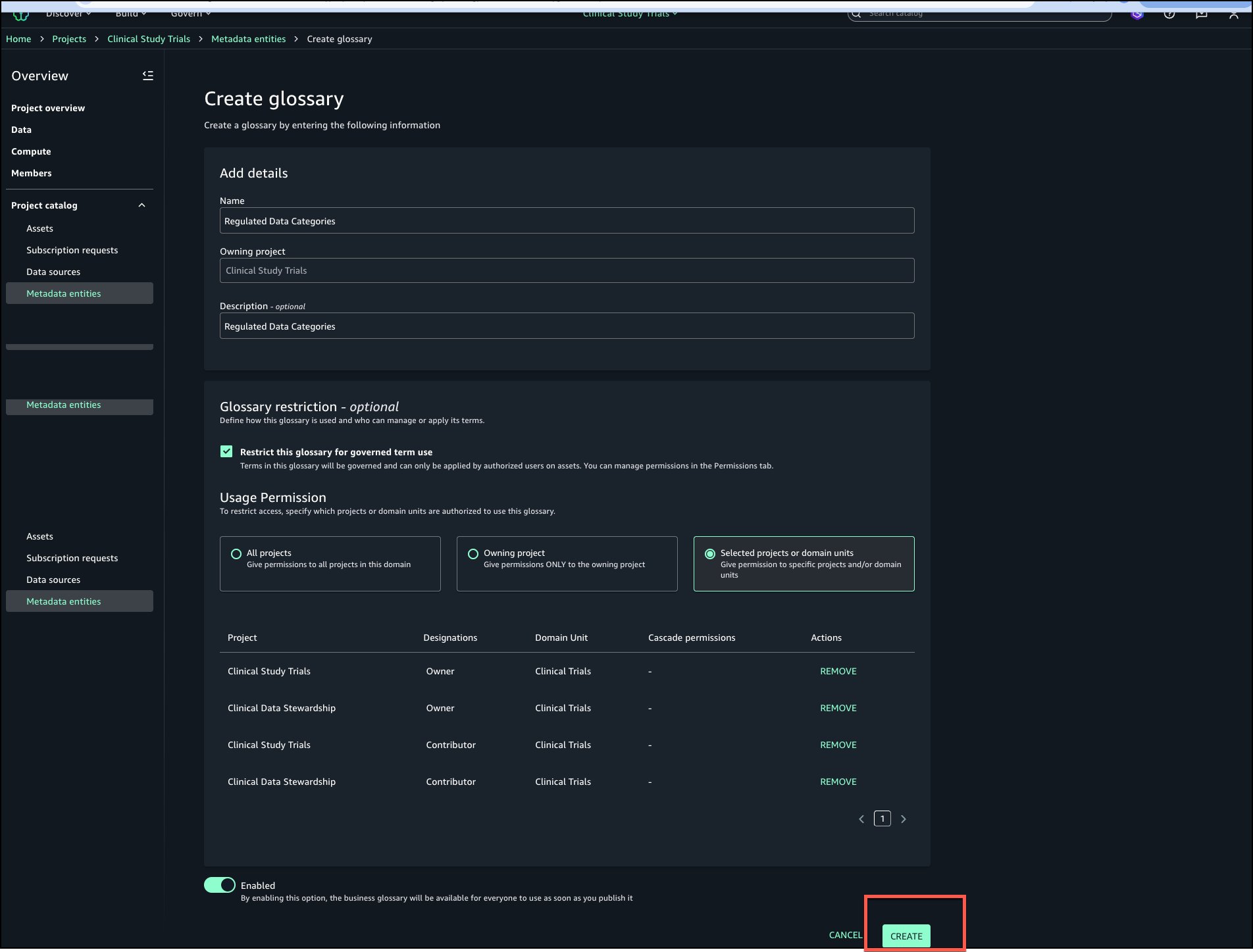
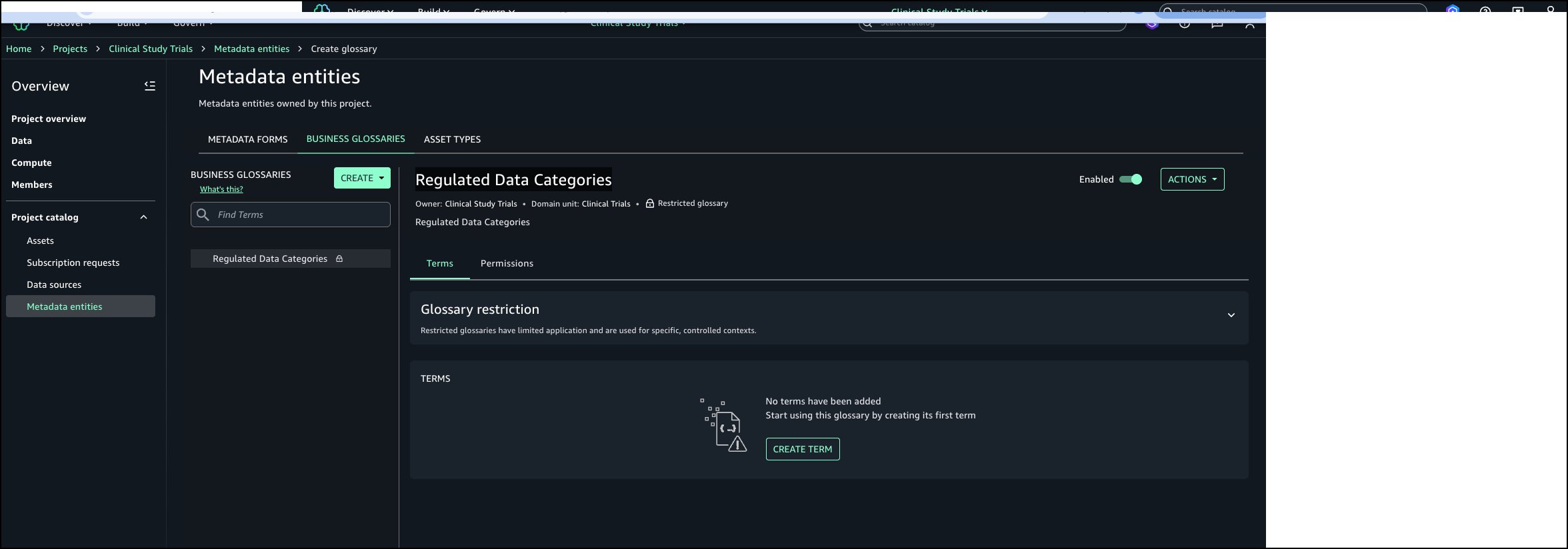
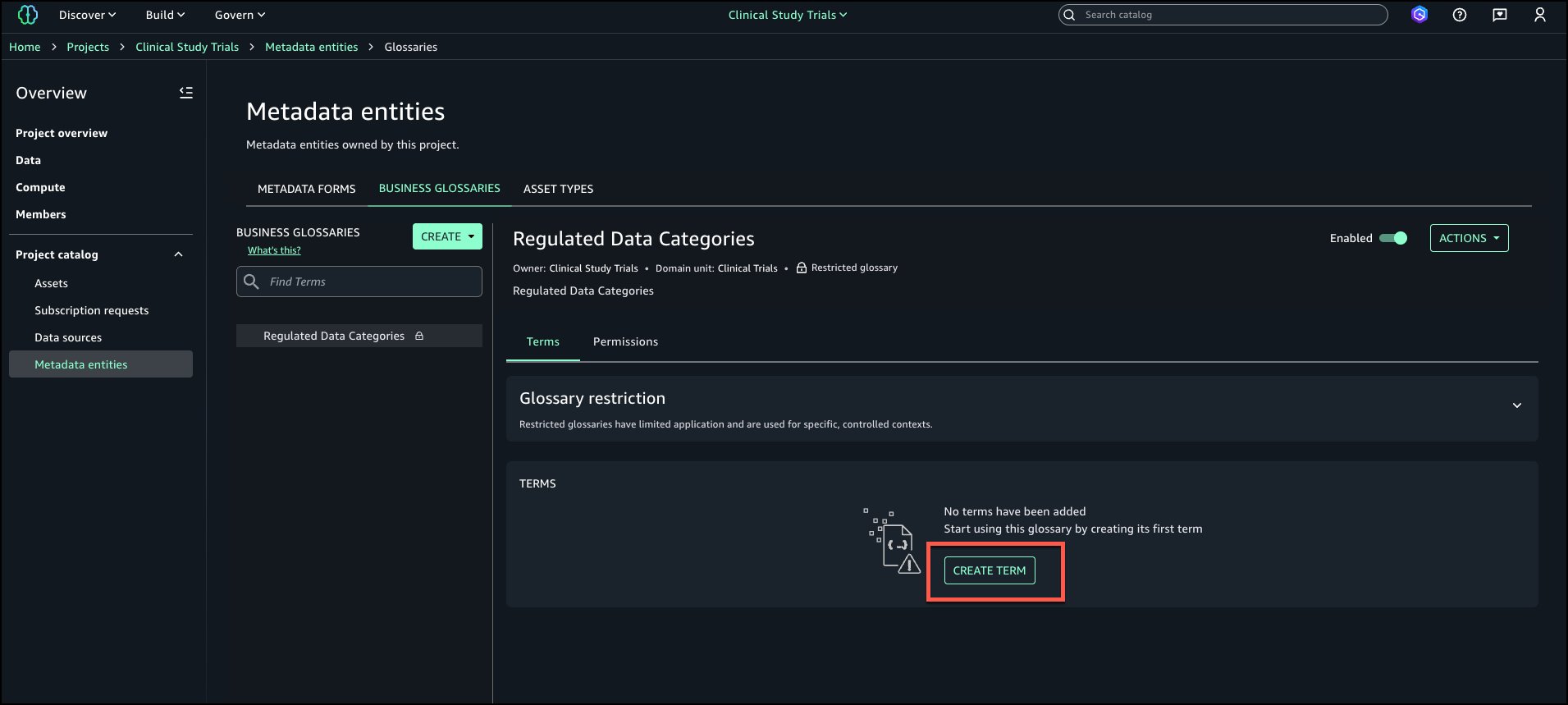
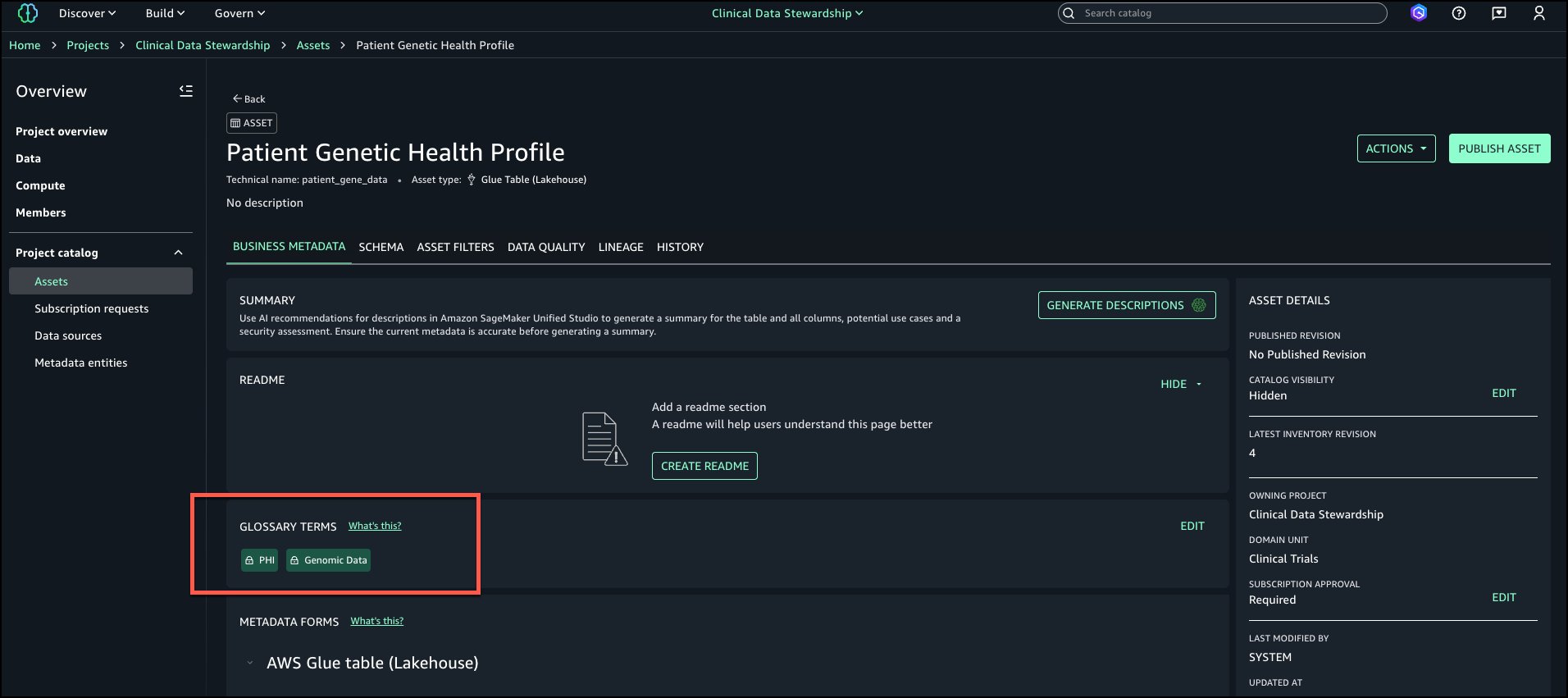

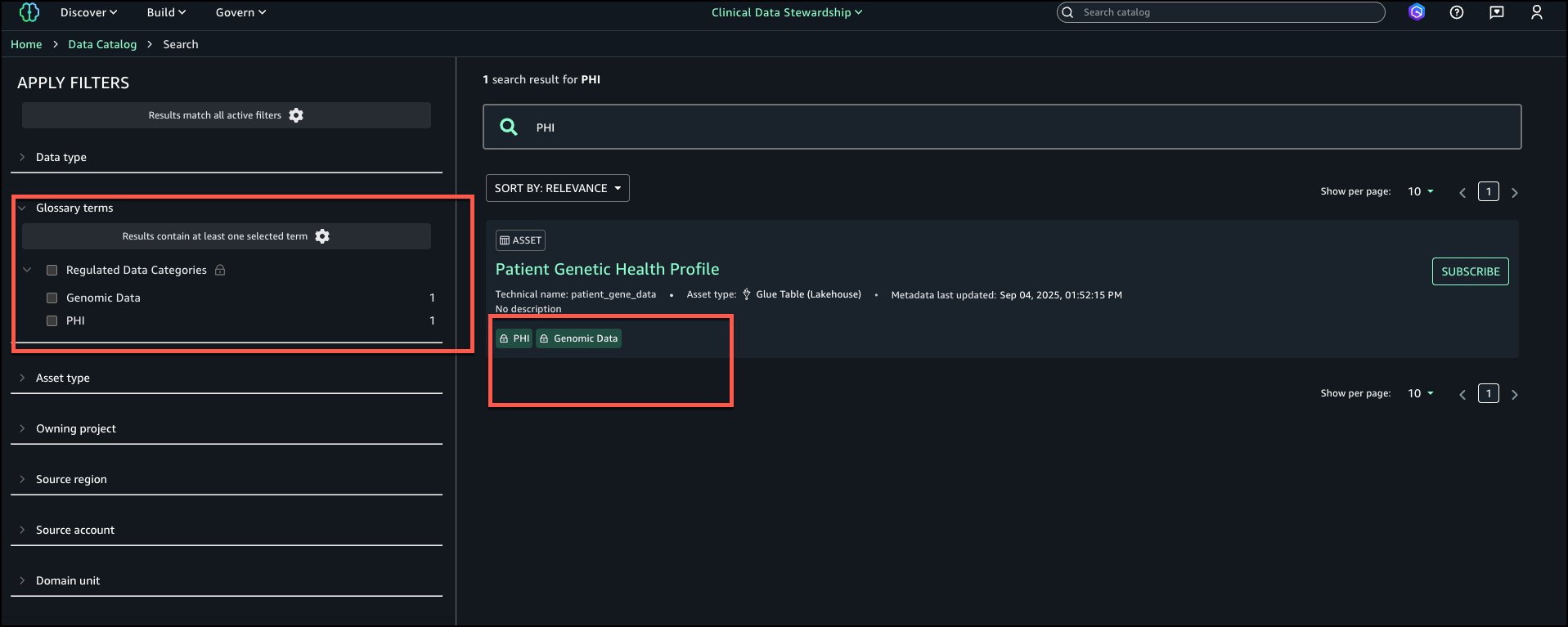
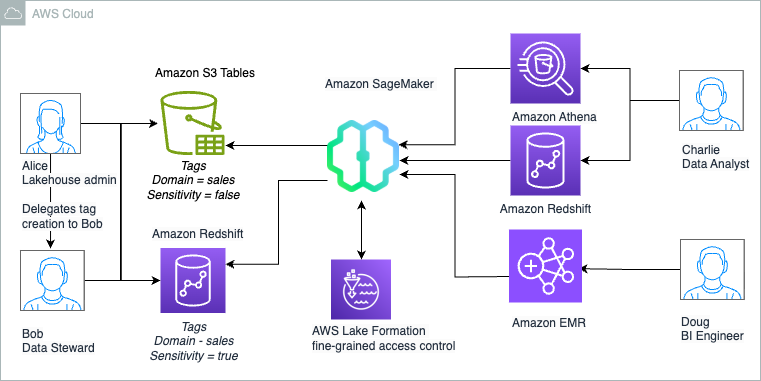
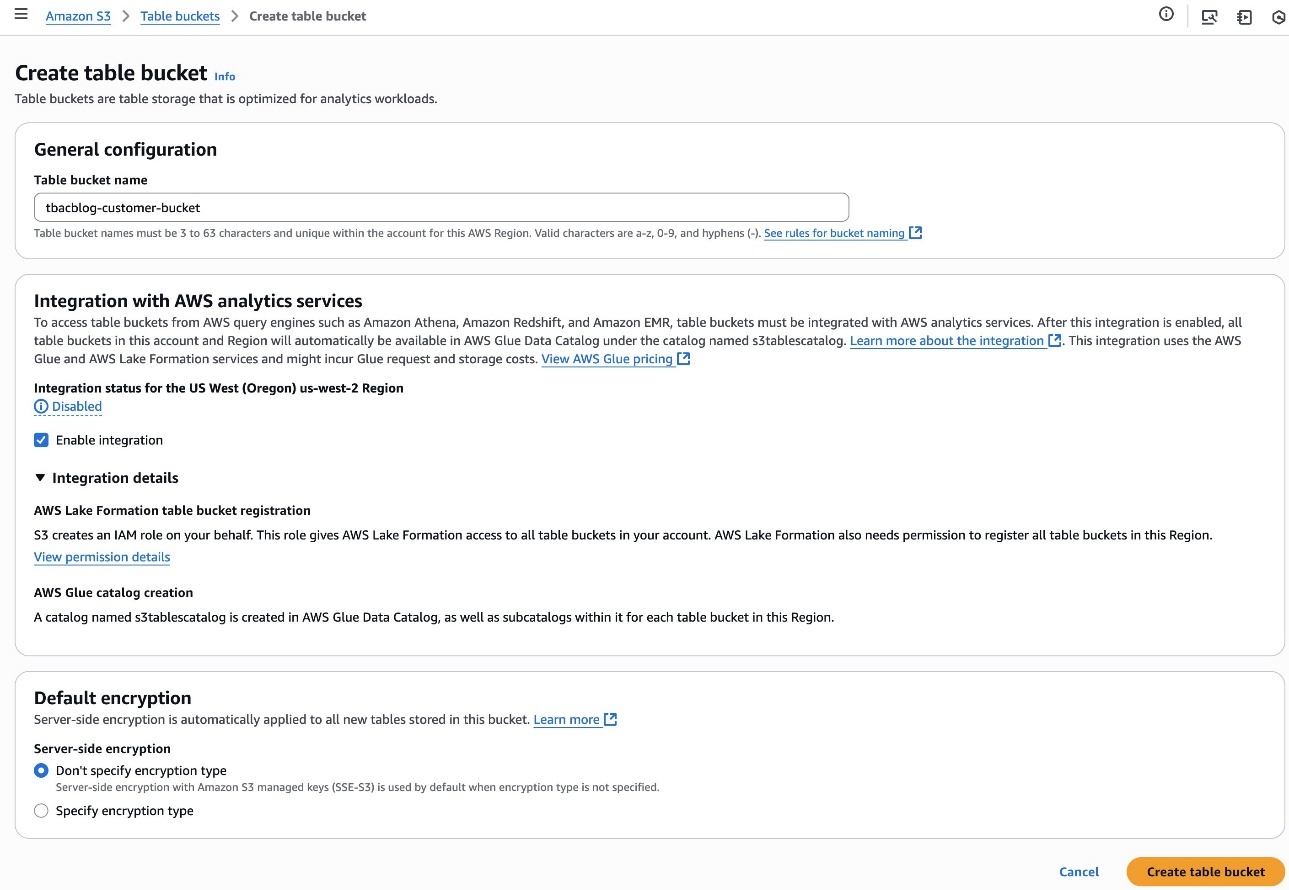
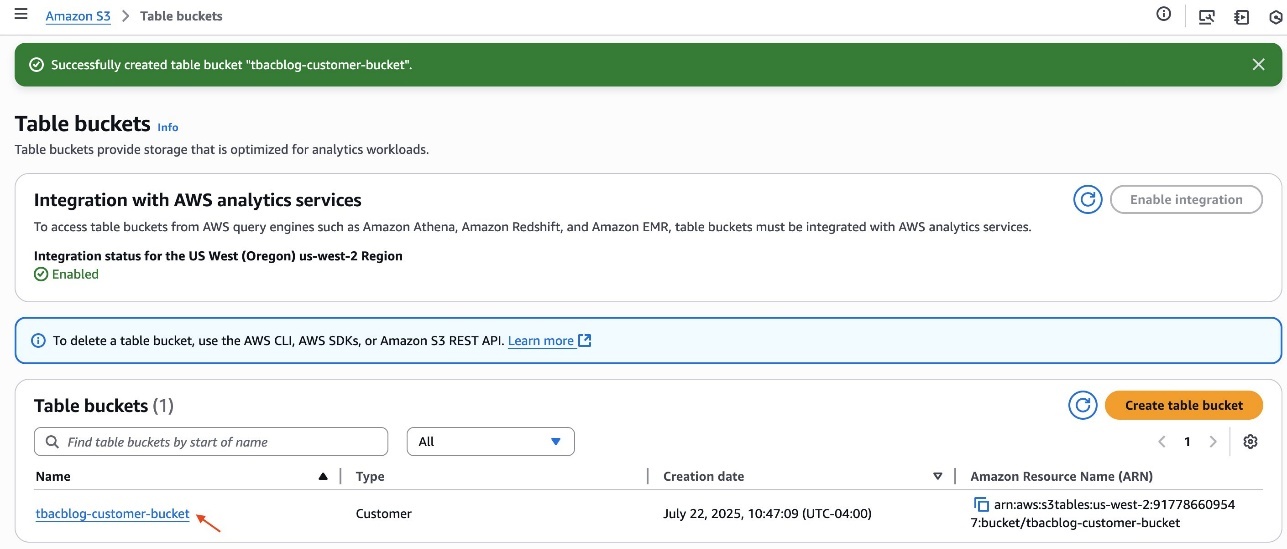
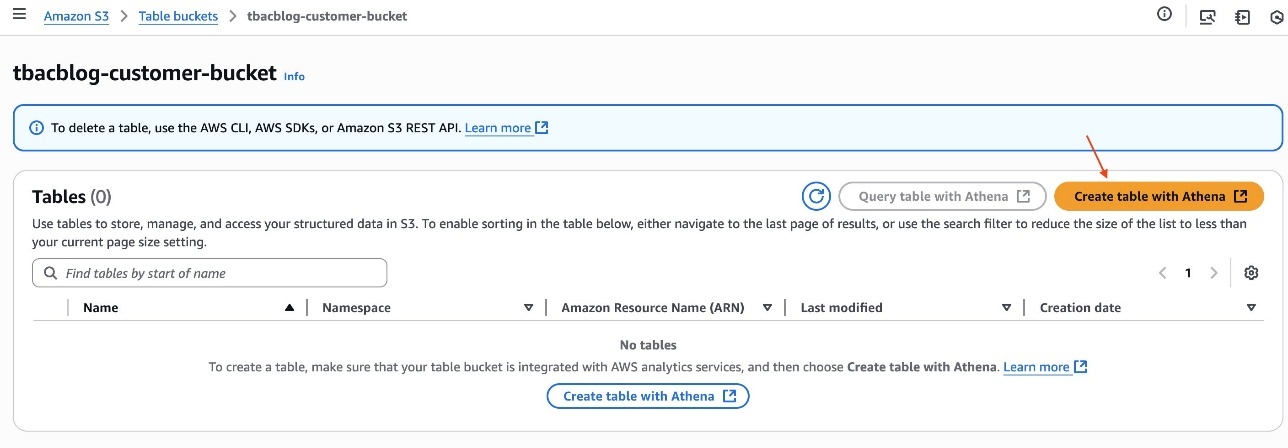
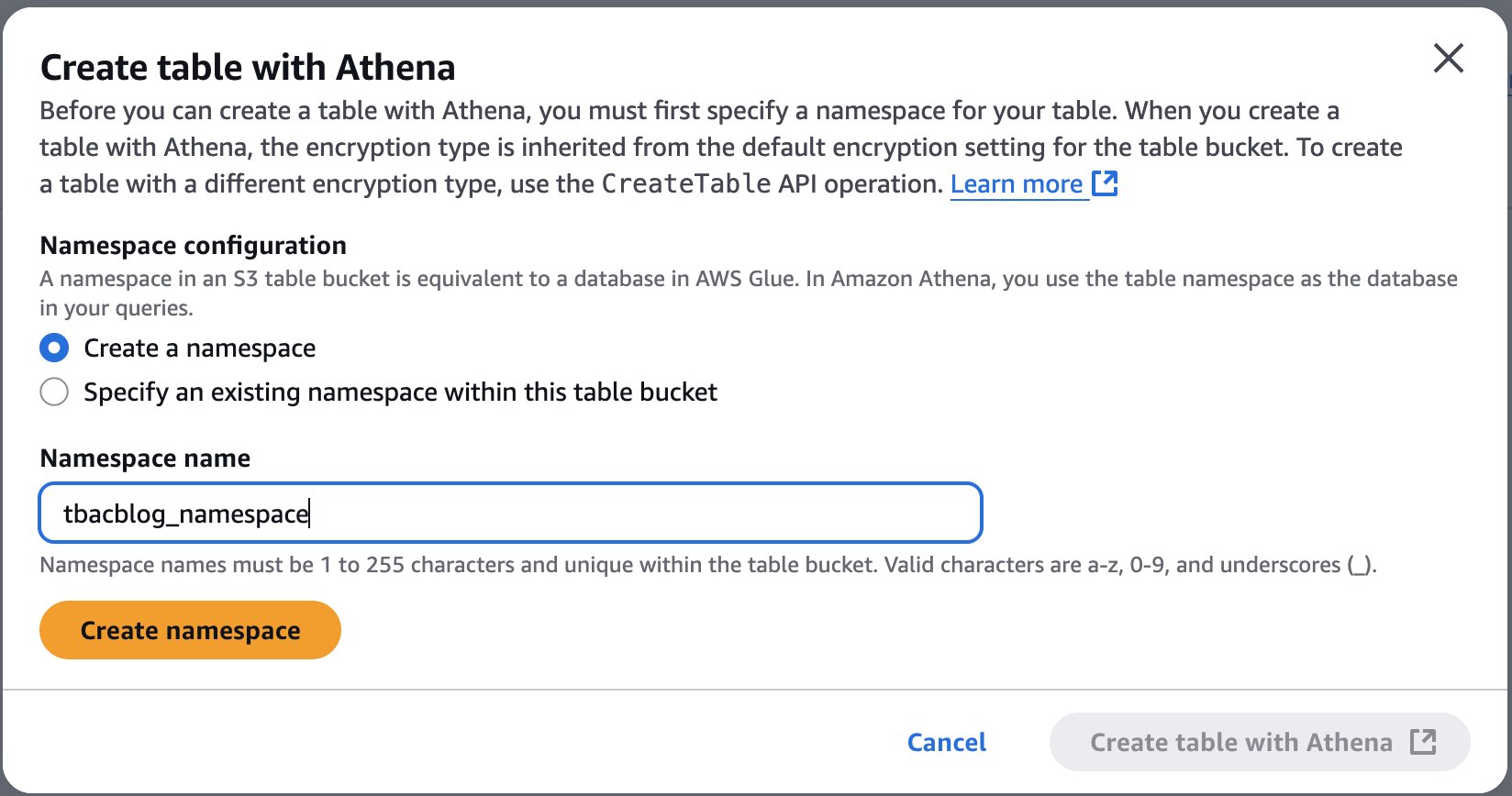
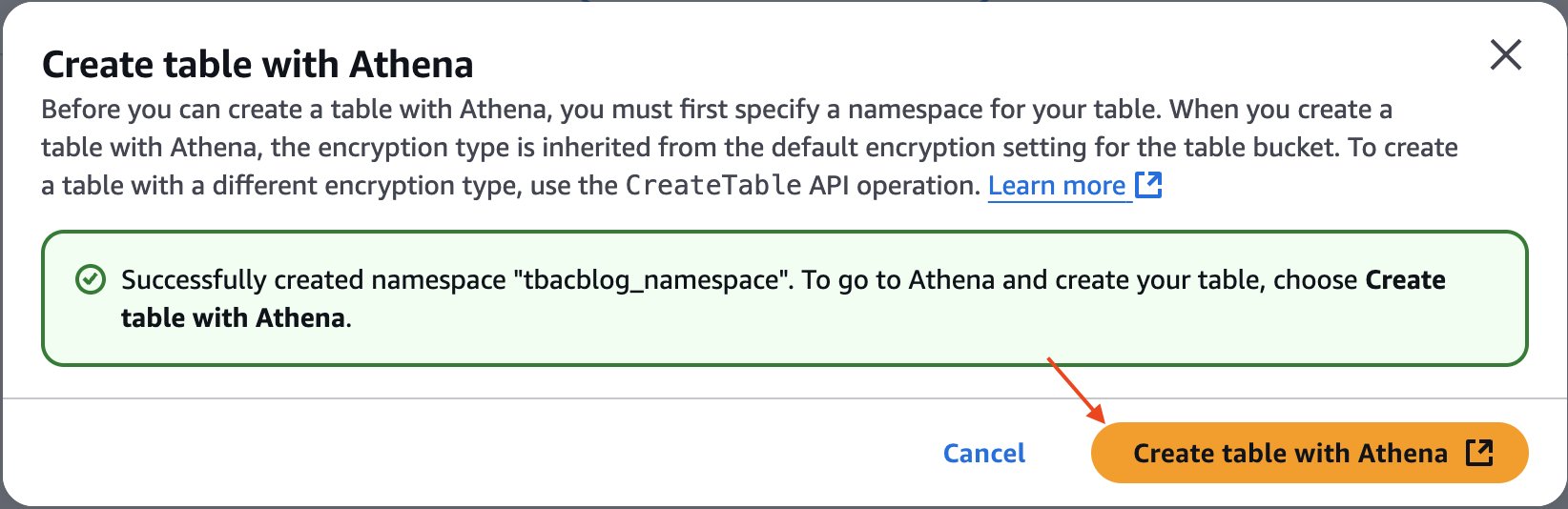
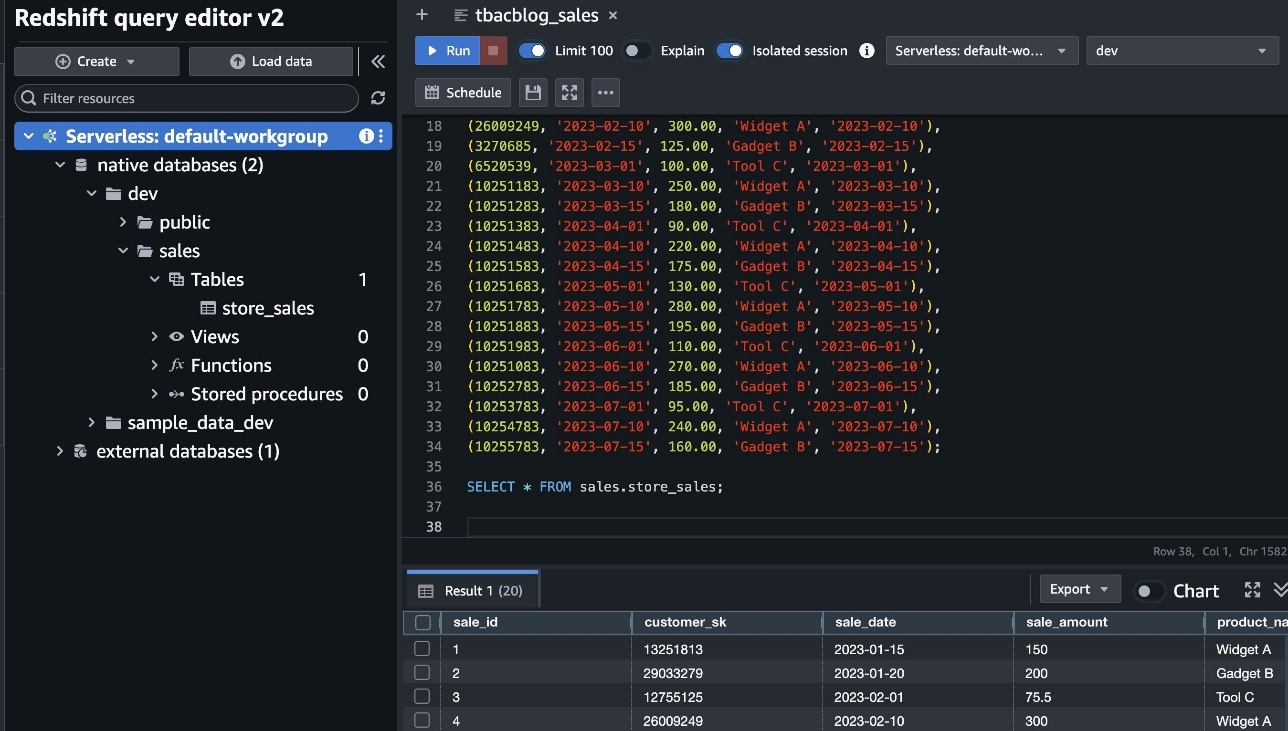
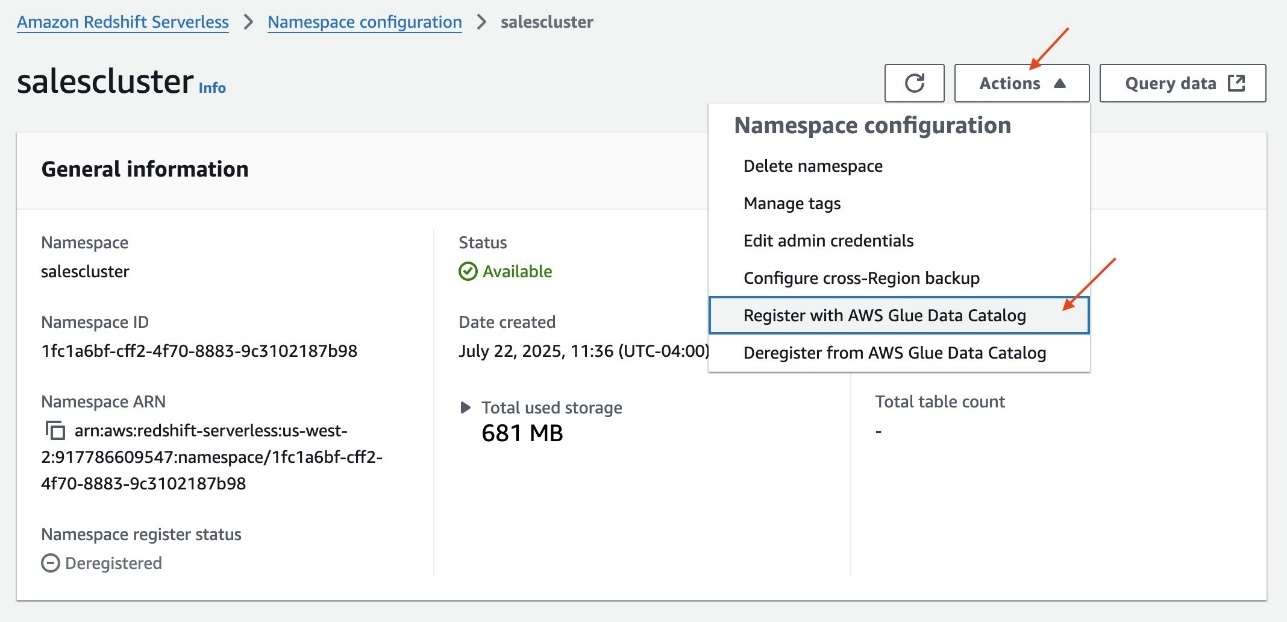
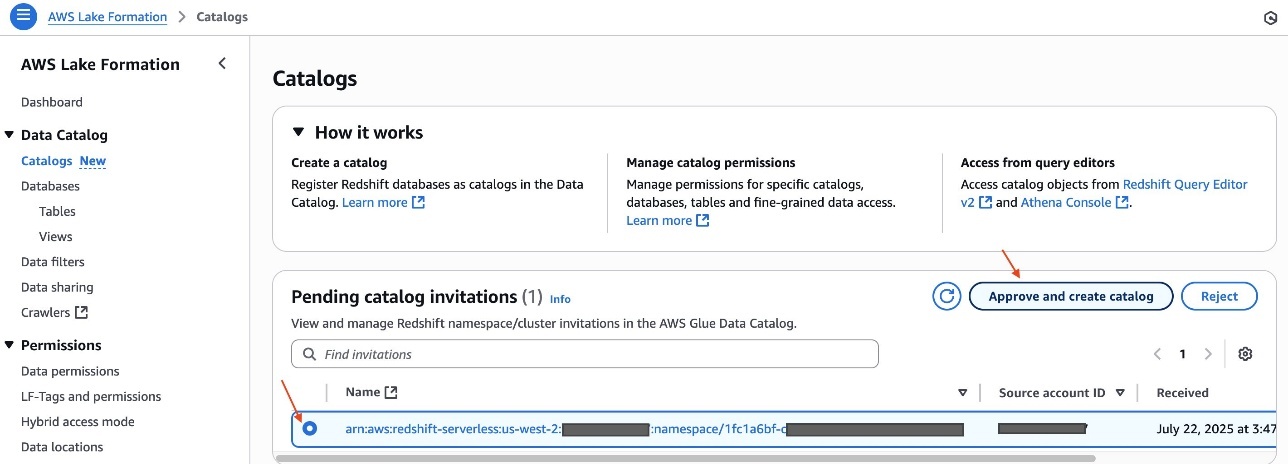
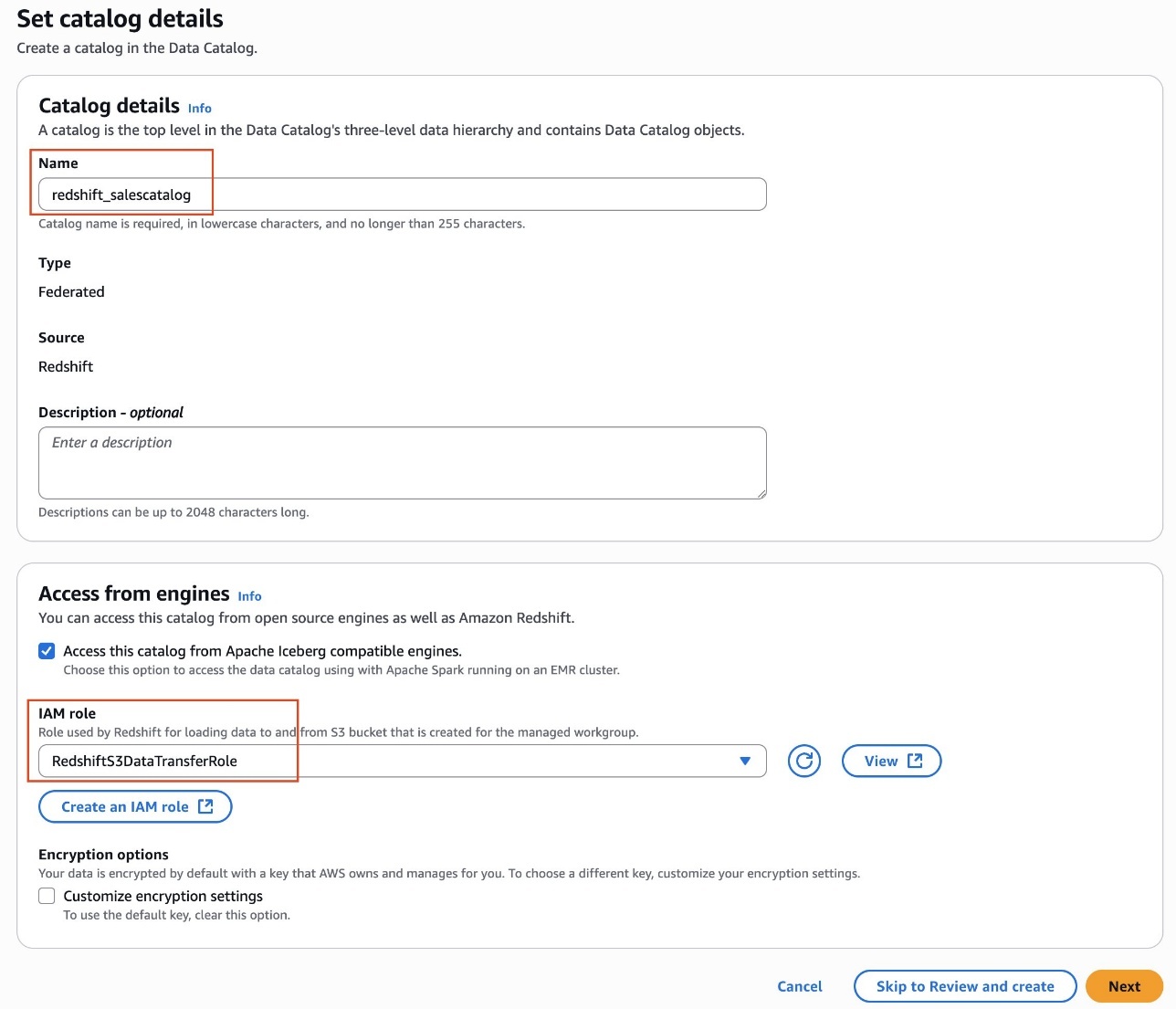
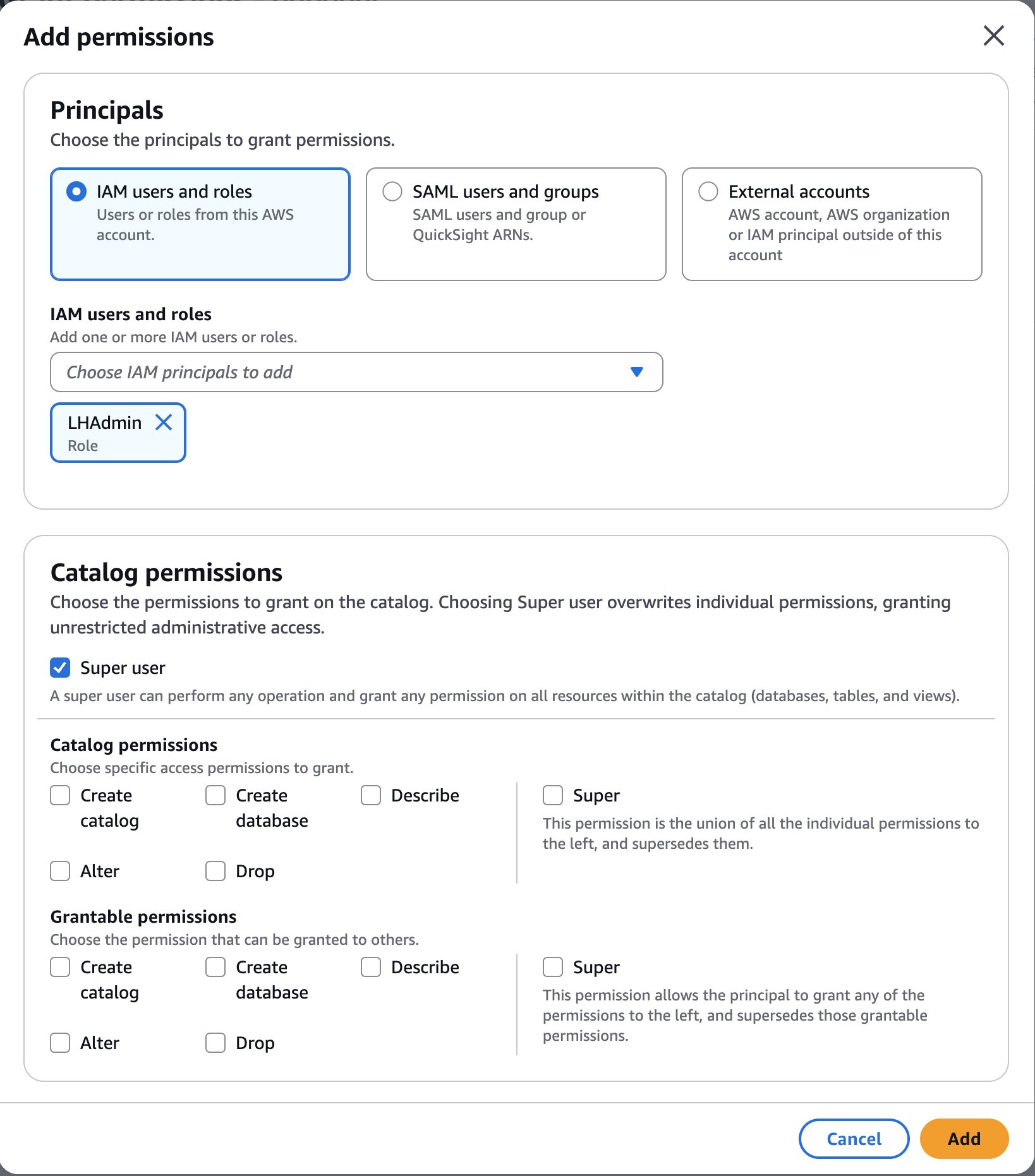
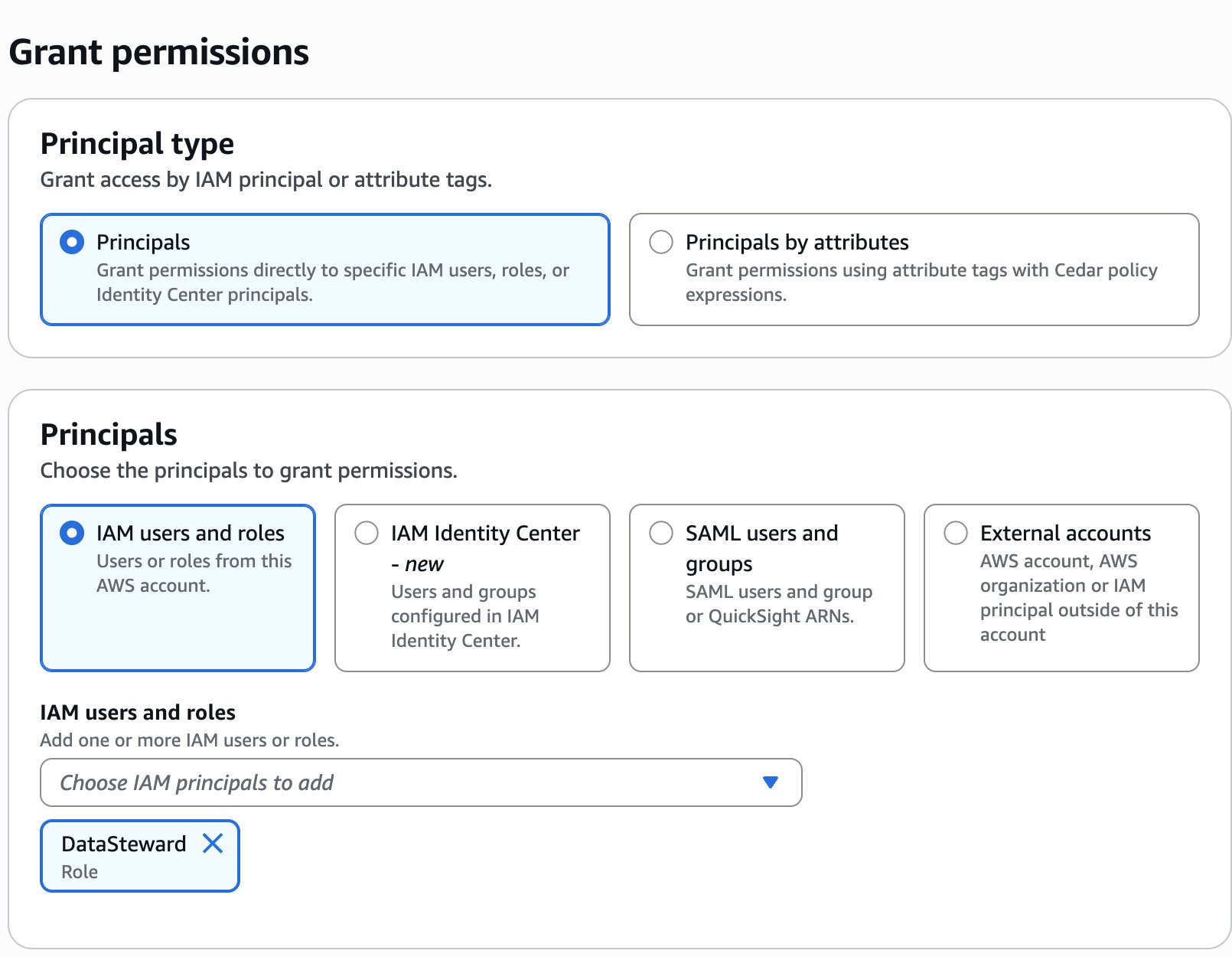
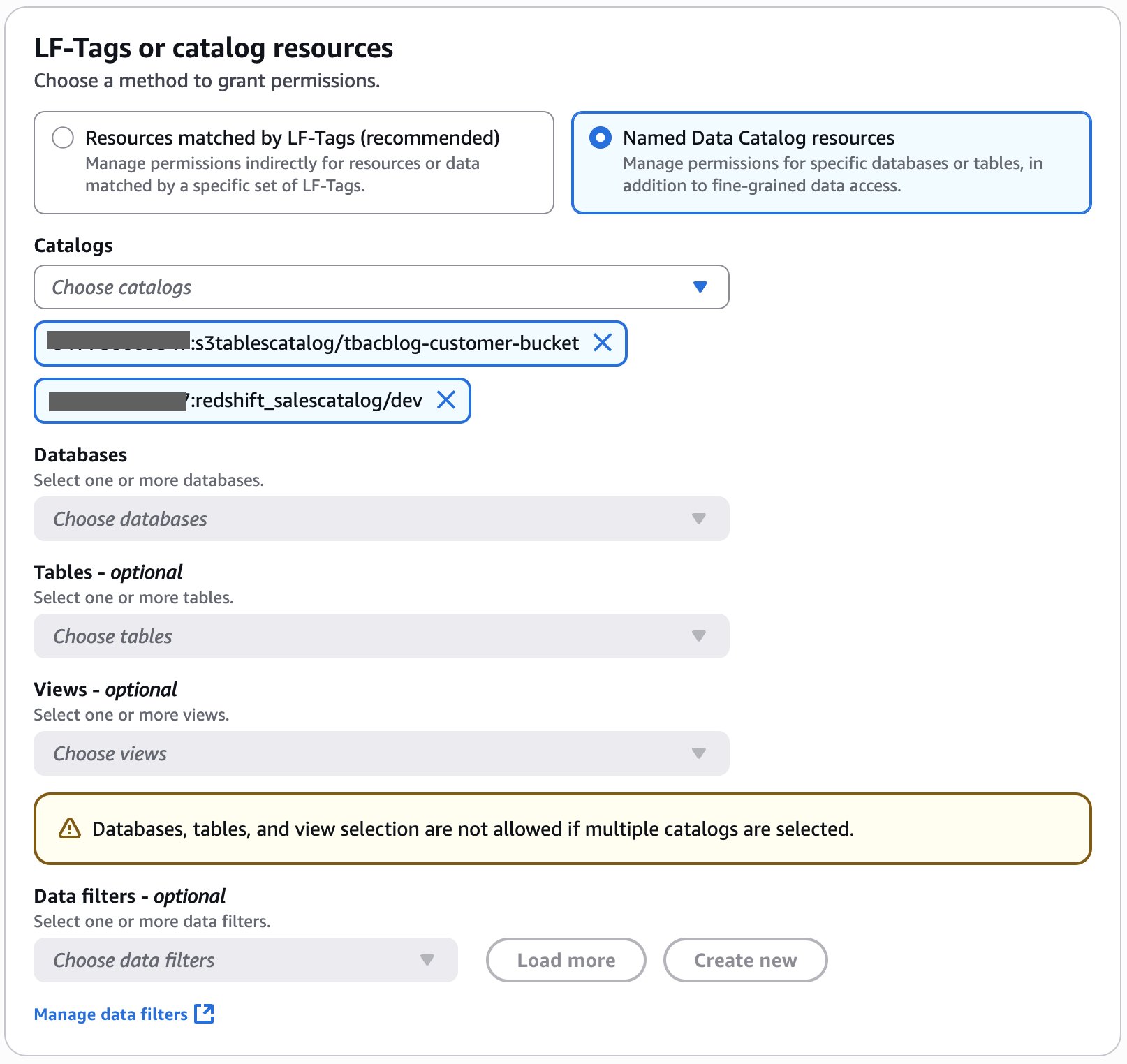
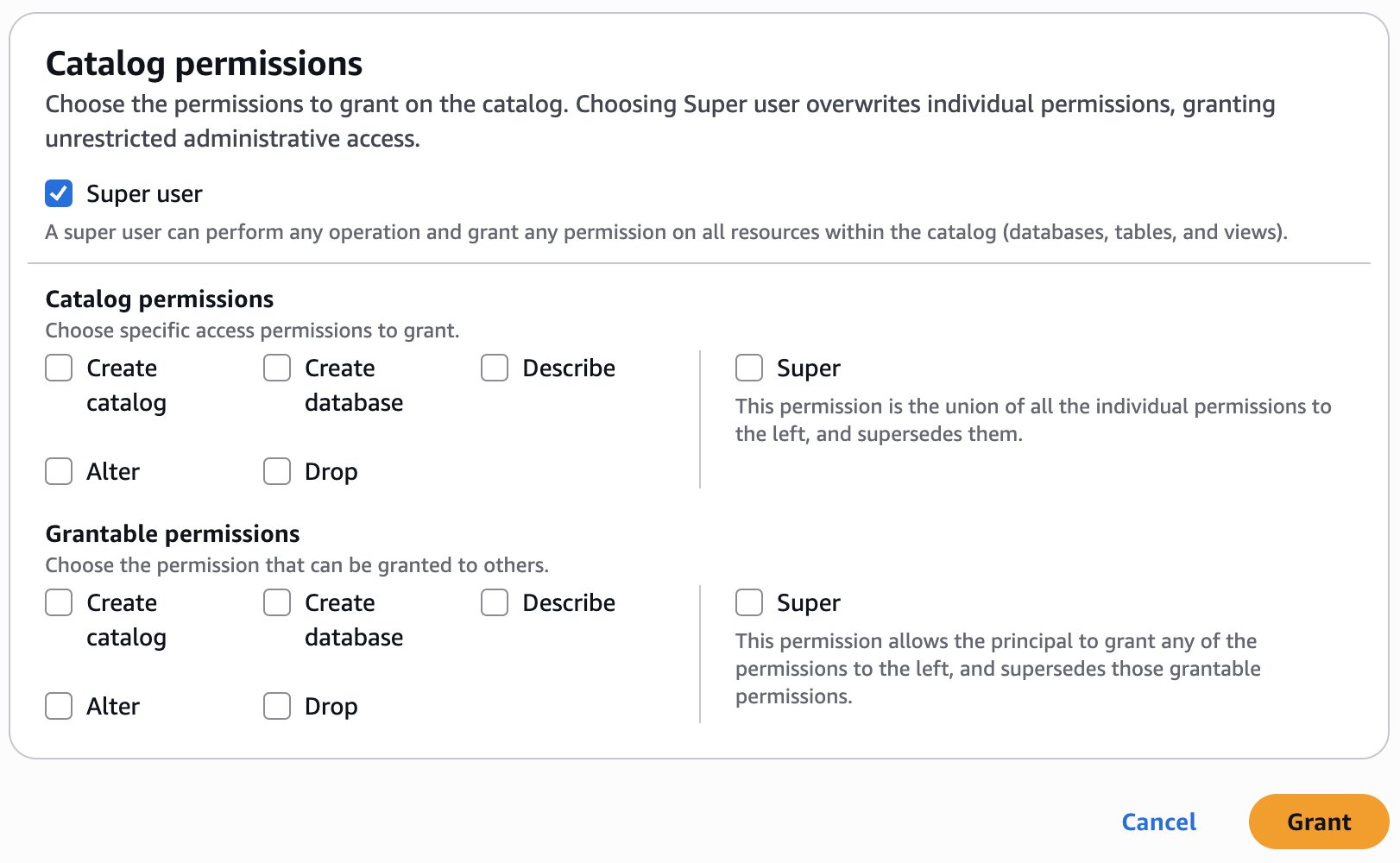
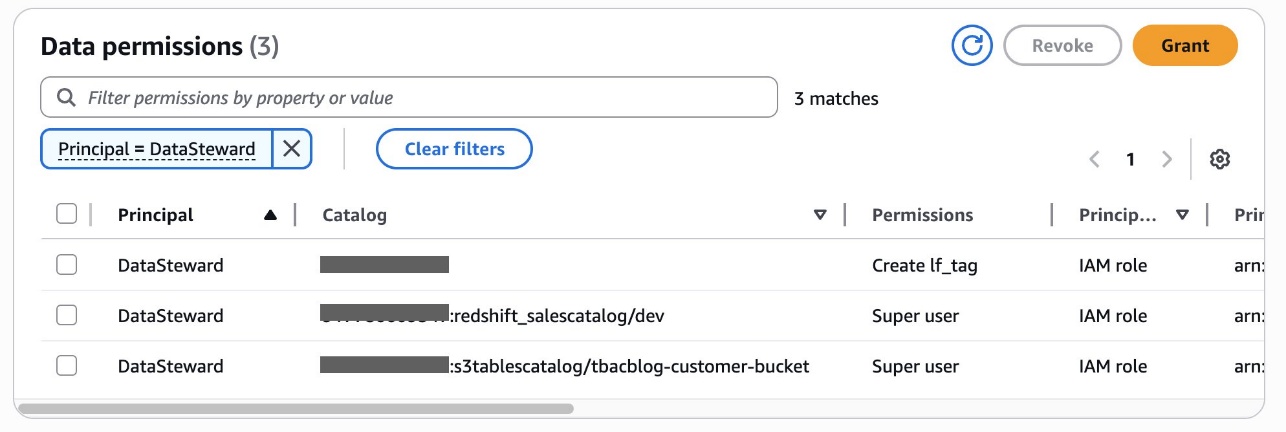
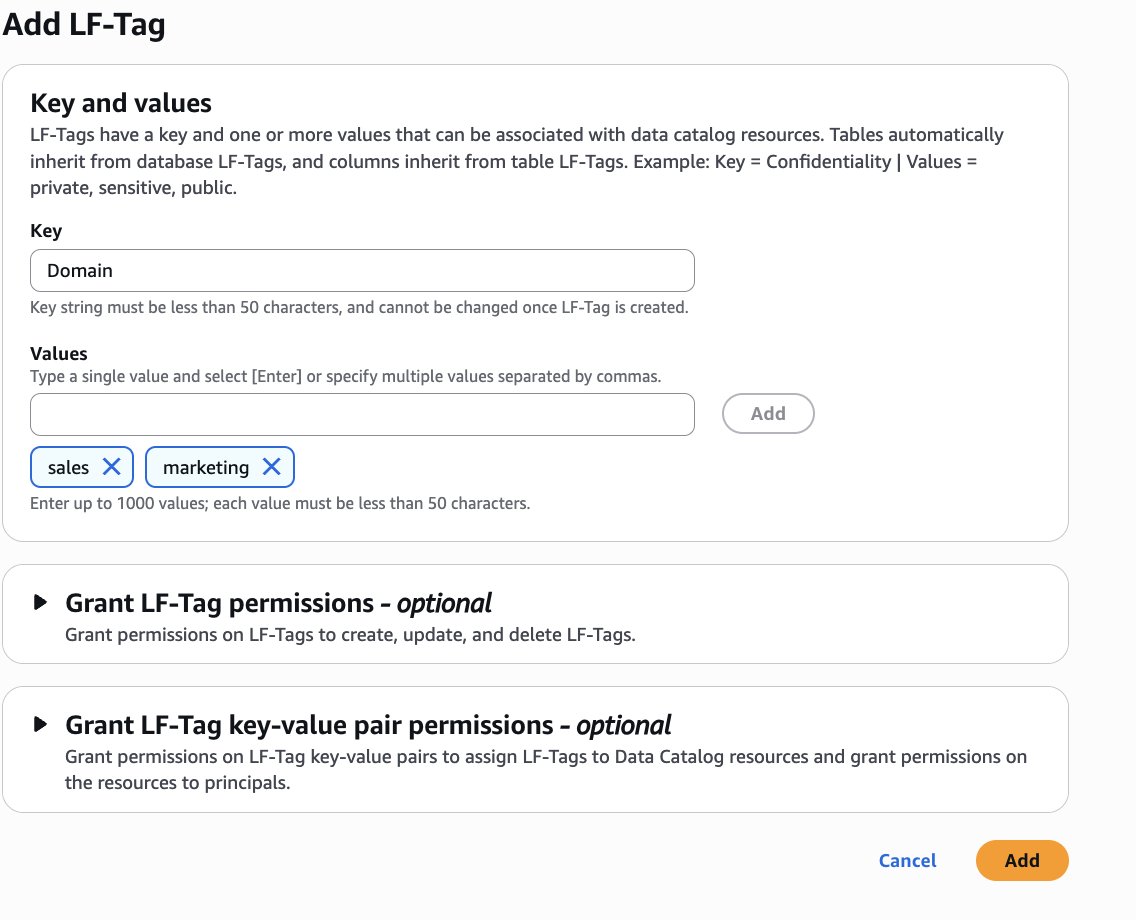
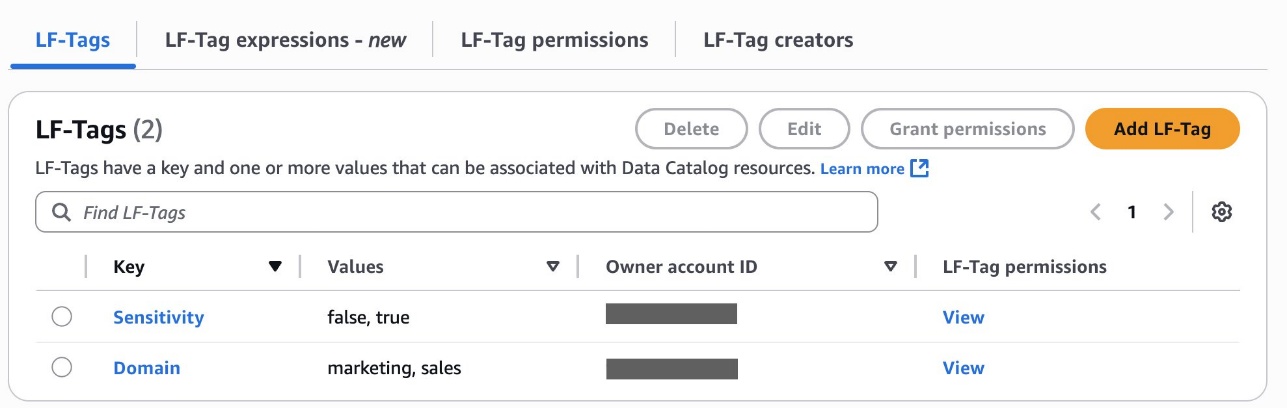
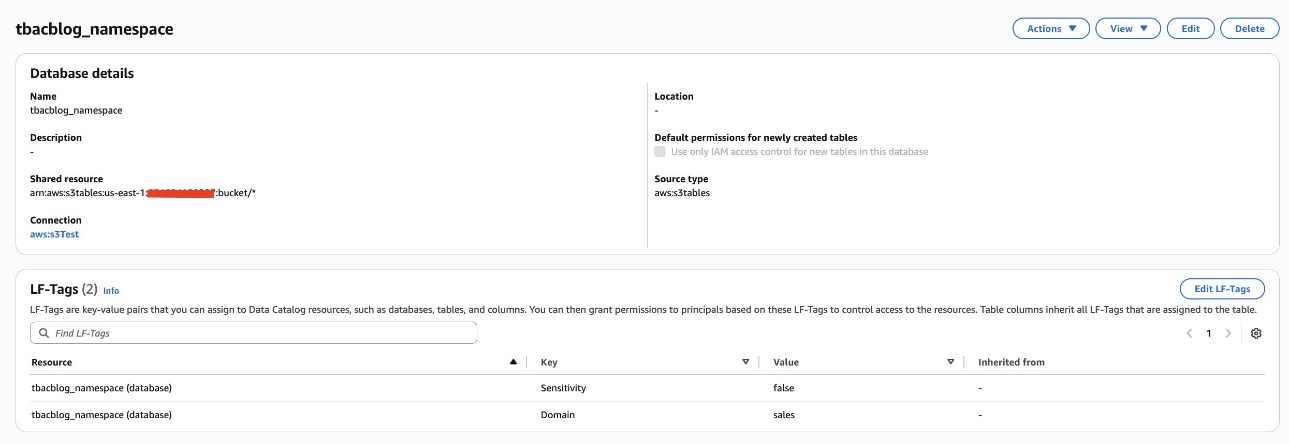
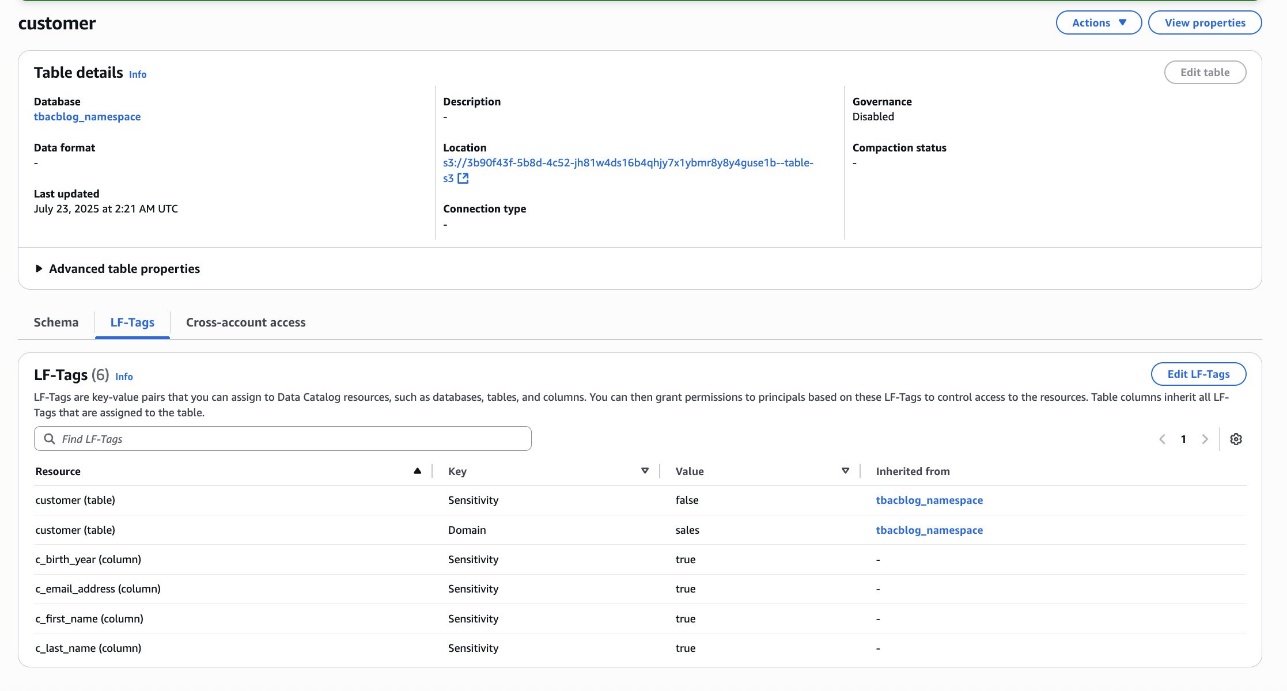
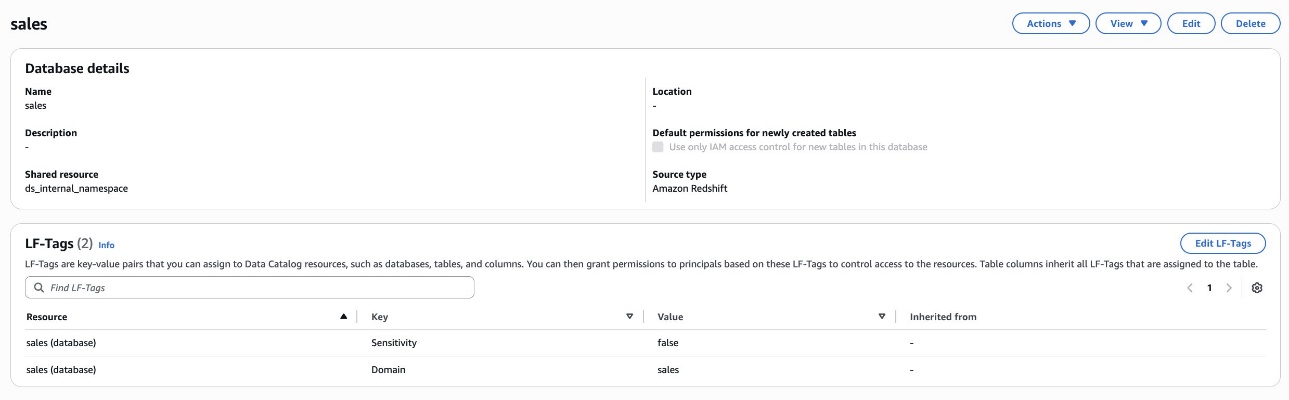
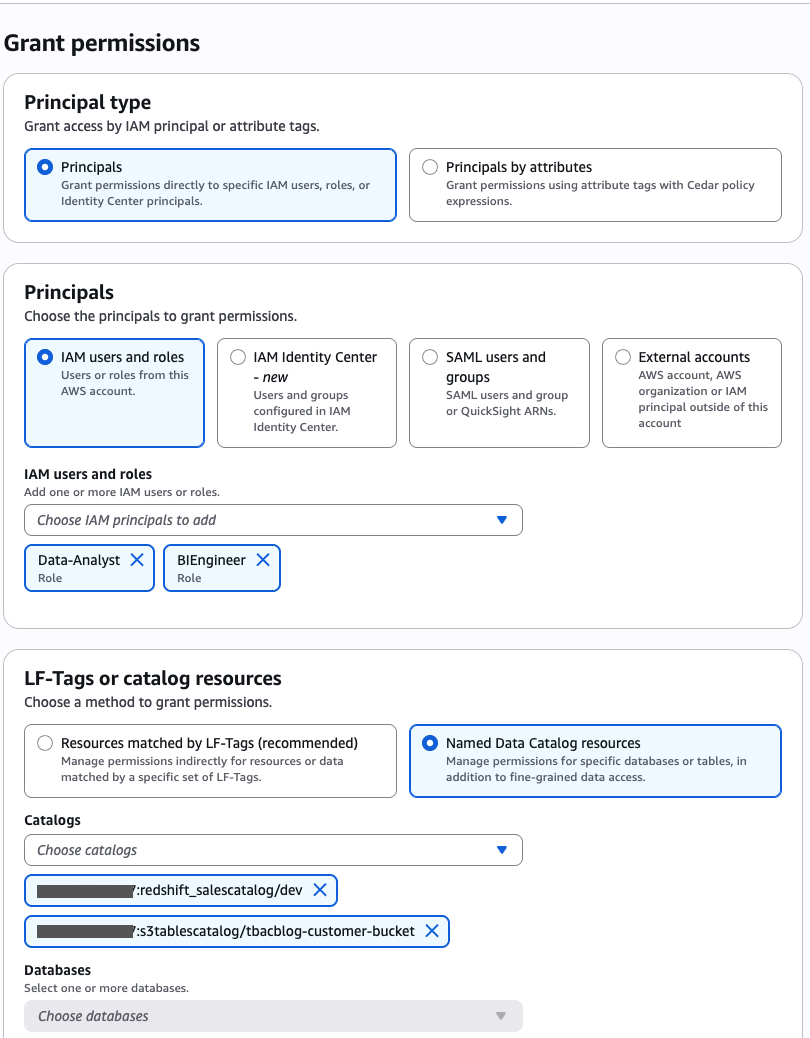
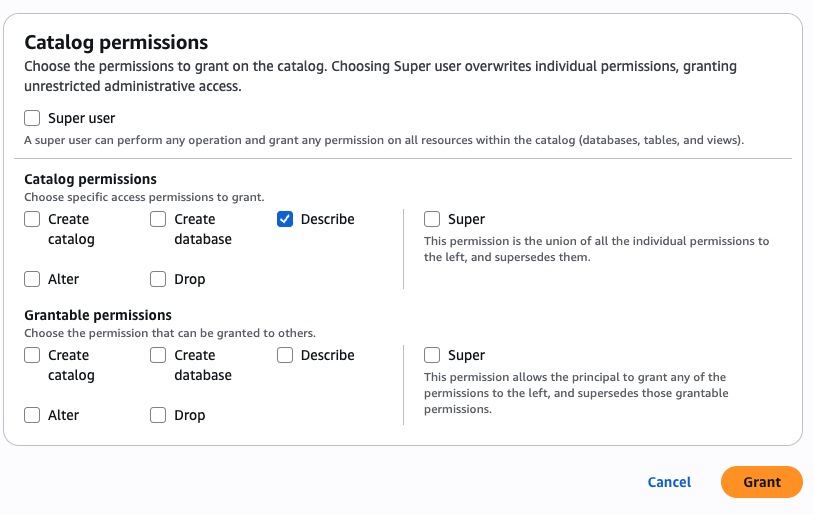
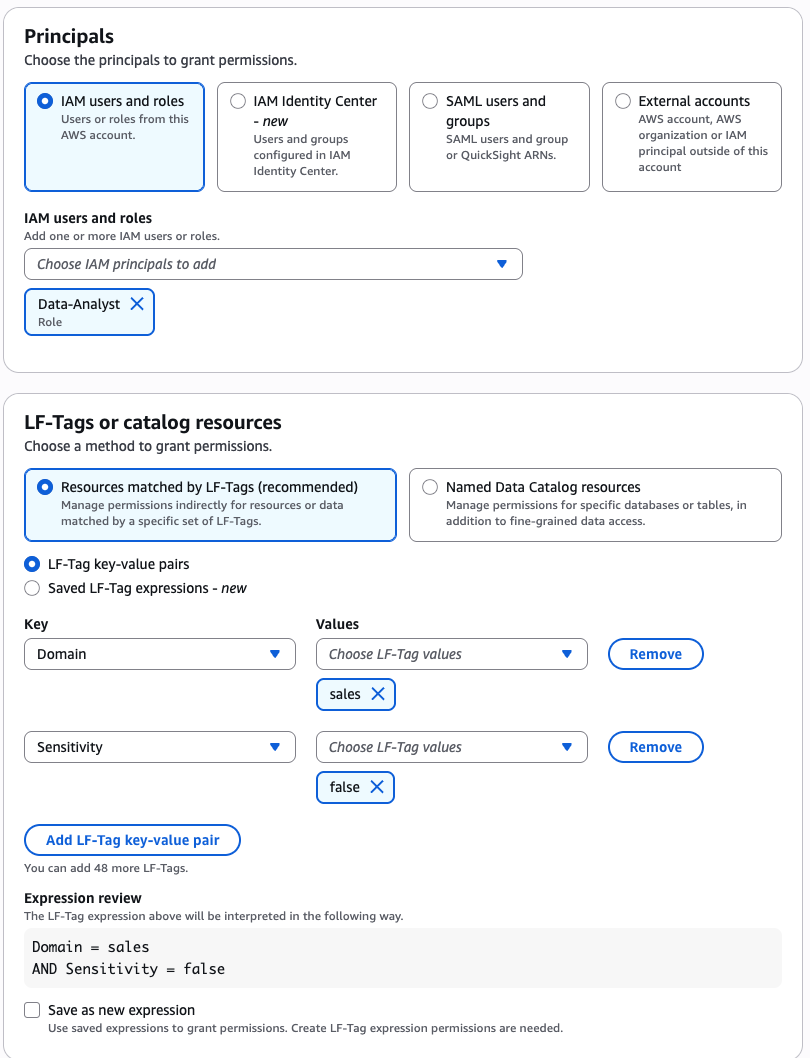
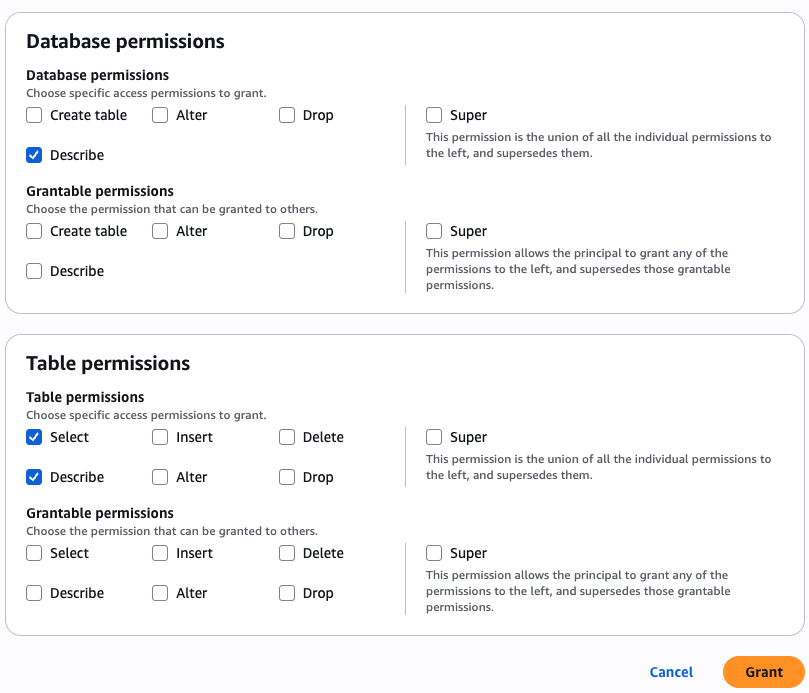
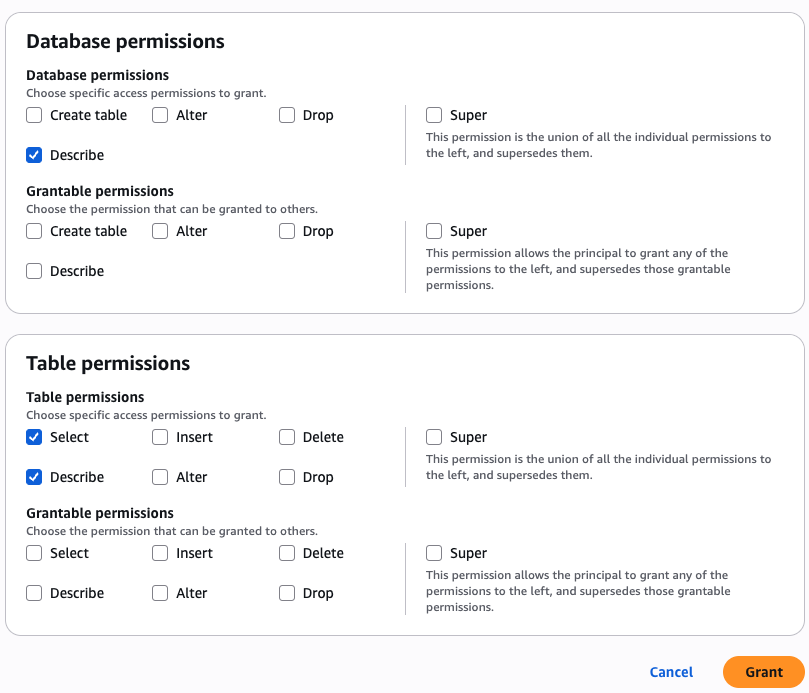
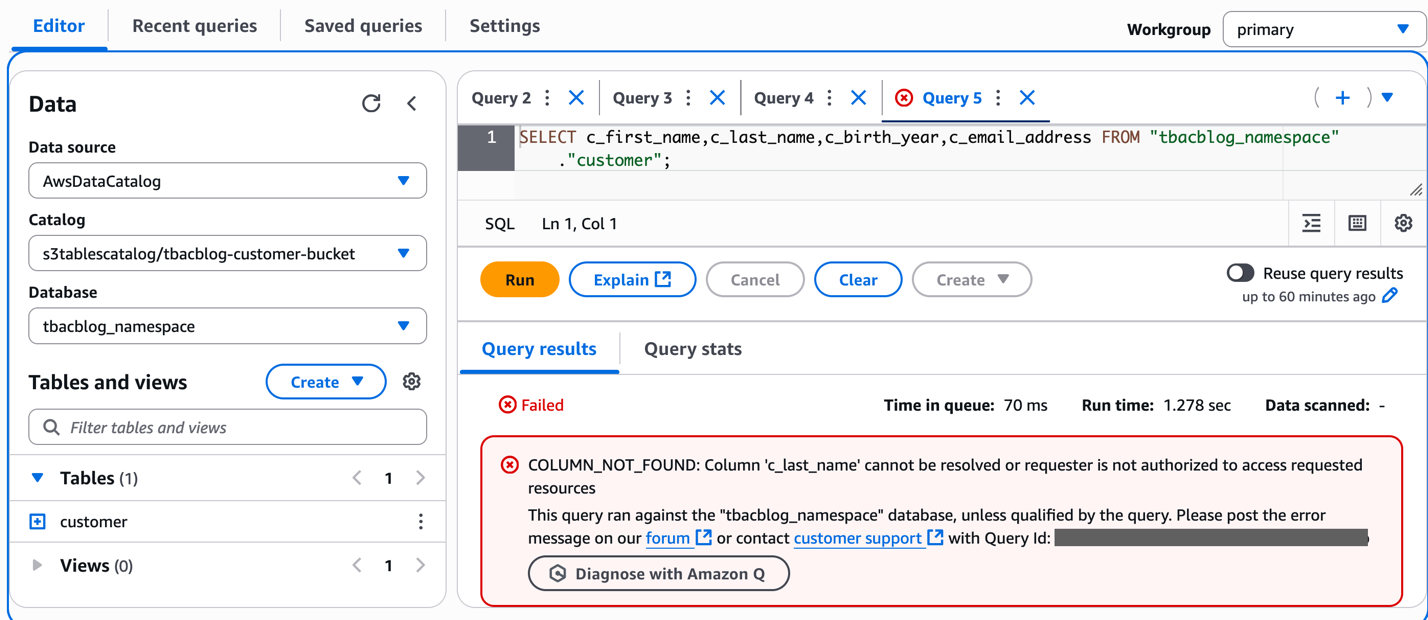
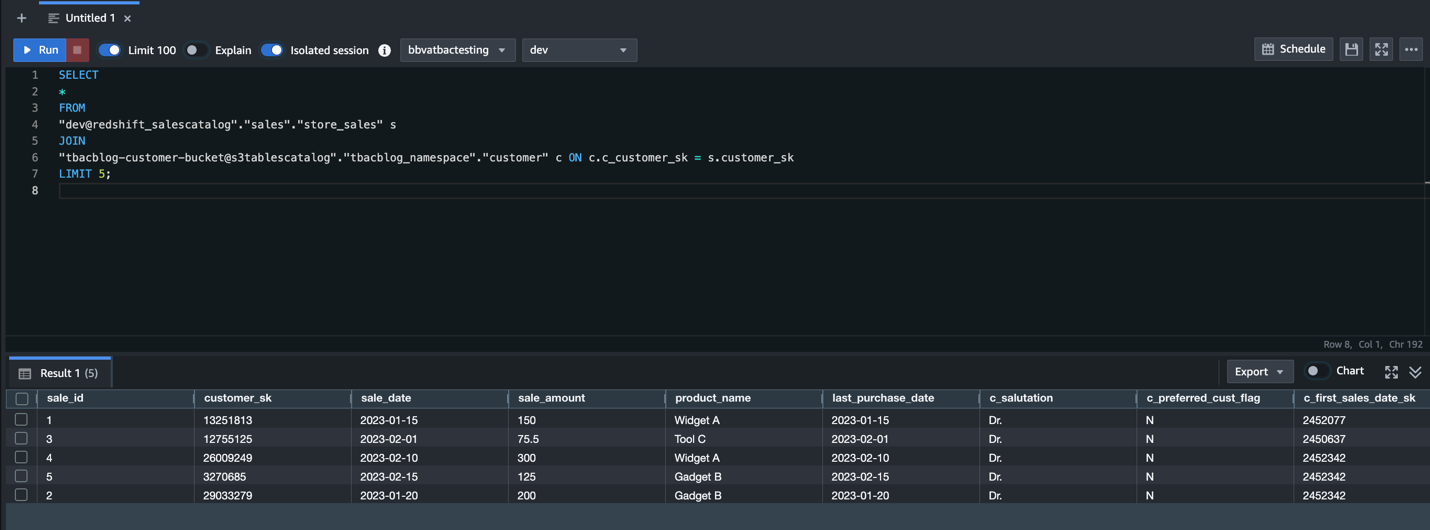
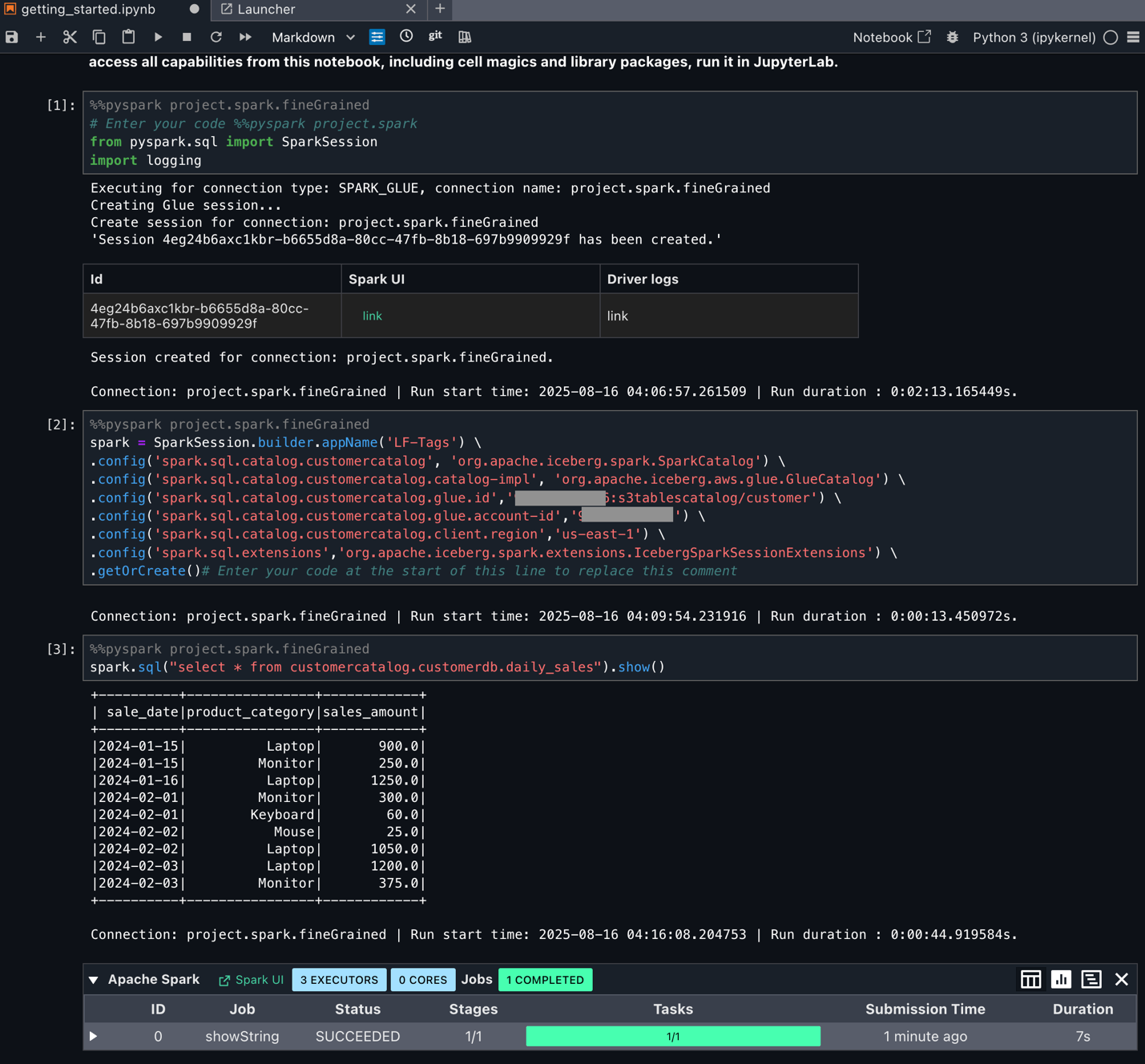
 Sandeep Adwankar is a Senior Product Manager with Amazon SageMaker Lakehouse . Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that help customers improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager with Amazon SageMaker Lakehouse . Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that help customers improve how they manage, secure, and access data. Srividya Parthasarathy is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with the product team and customers to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with the product team and customers to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community. Aarthi Srinivasan is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with AWS customers and partners to architect lakehouse solutions, enhance product features, and establish best practices for data governance.
Aarthi Srinivasan is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with AWS customers and partners to architect lakehouse solutions, enhance product features, and establish best practices for data governance.
![Decoded JavaScript code, with compromised site removed: "[removed_domain]"](https://d2908q01vomqb2.cloudfront.net/22d200f8670dbdb3e253a90eee5098477c95c23d/2025/08/29/img2-1.png)
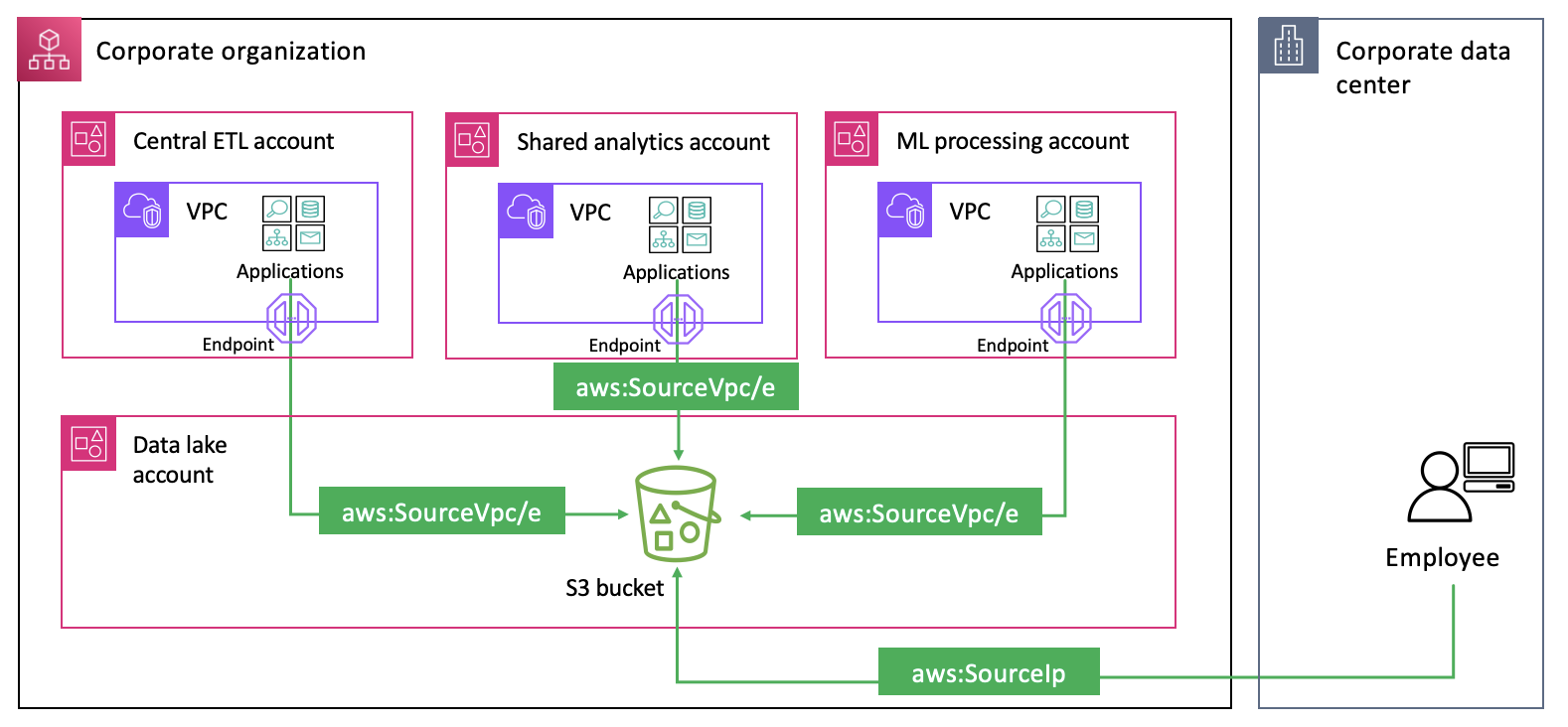

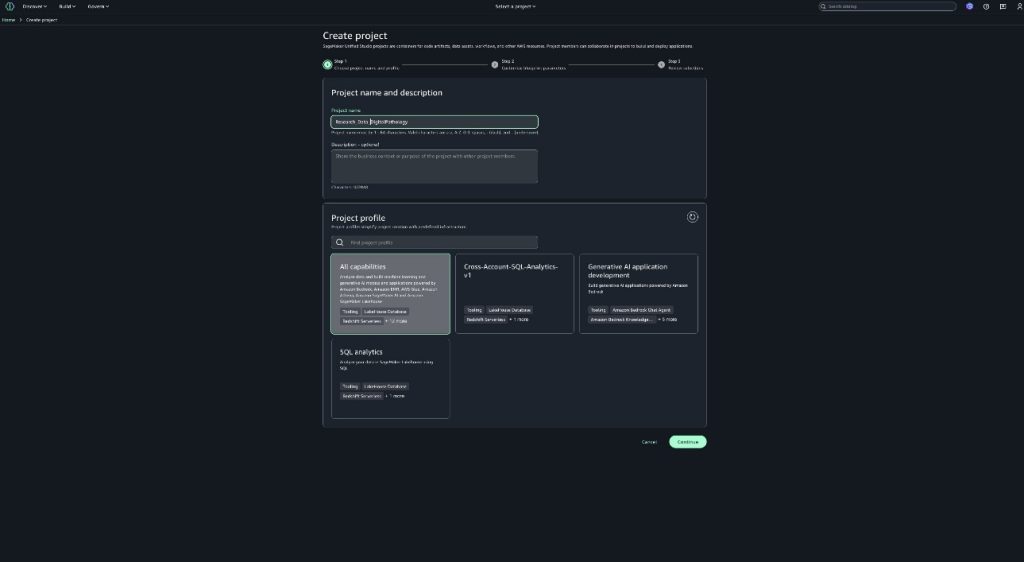
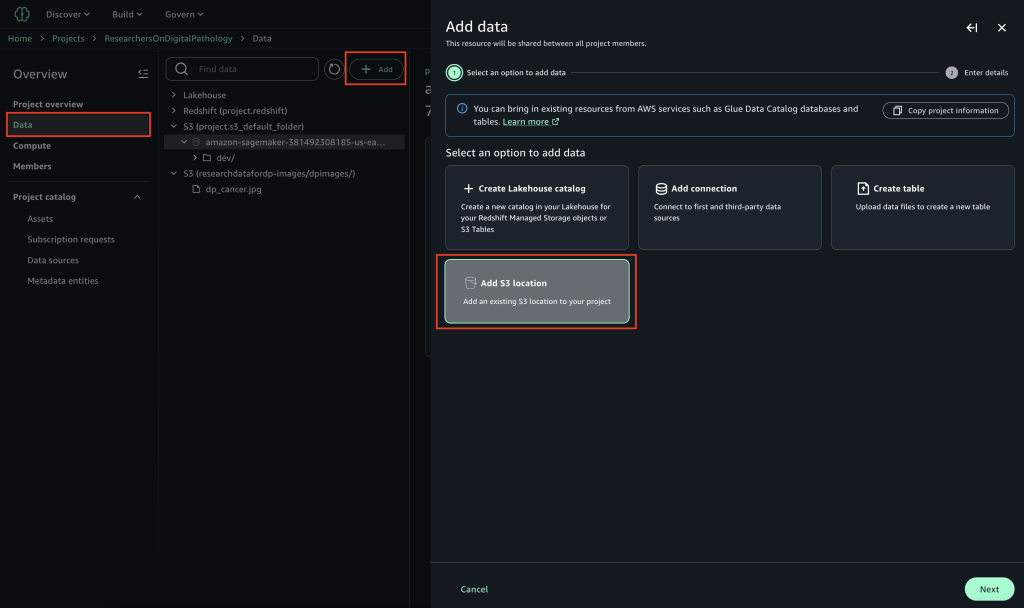
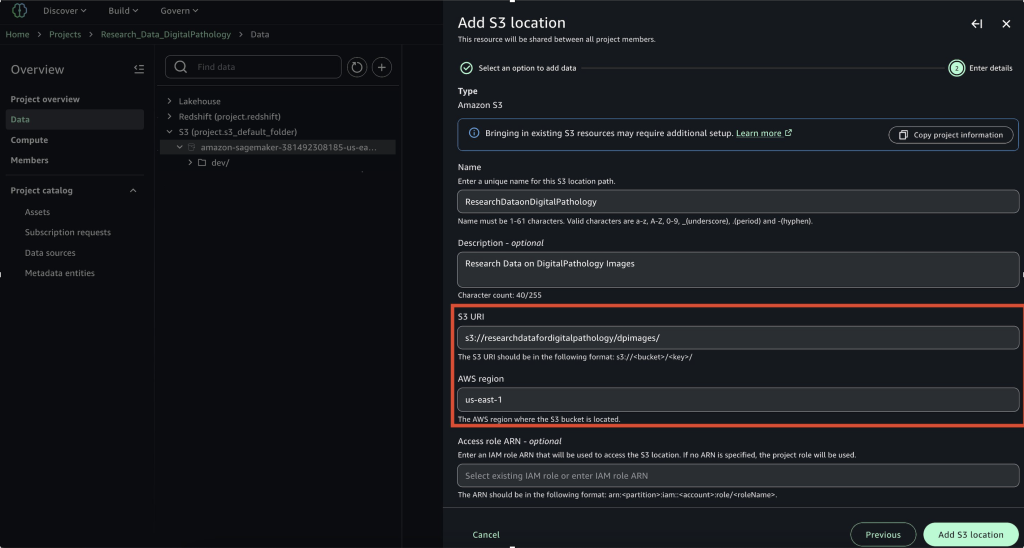
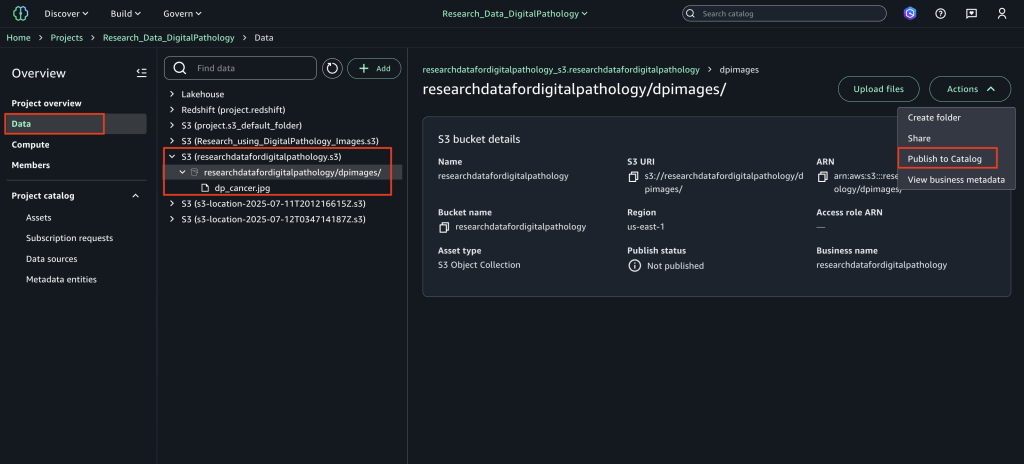
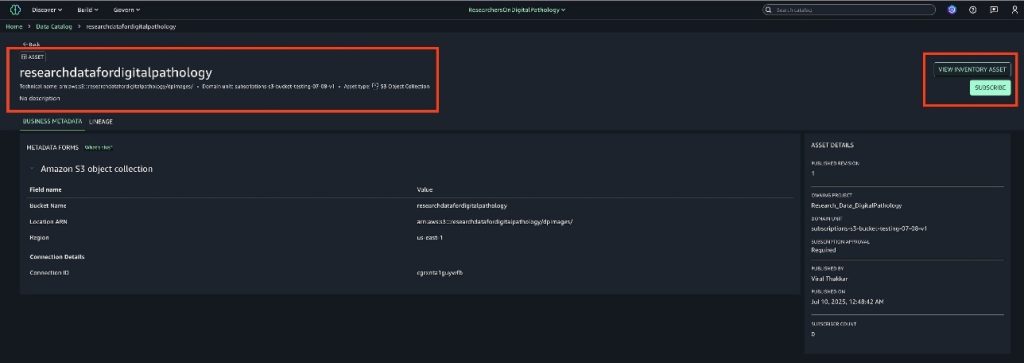
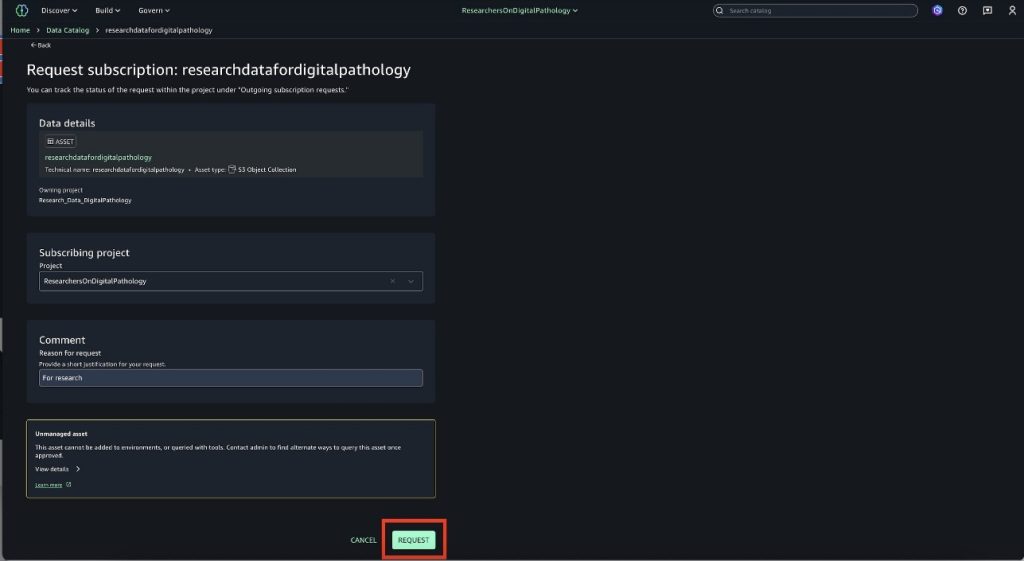
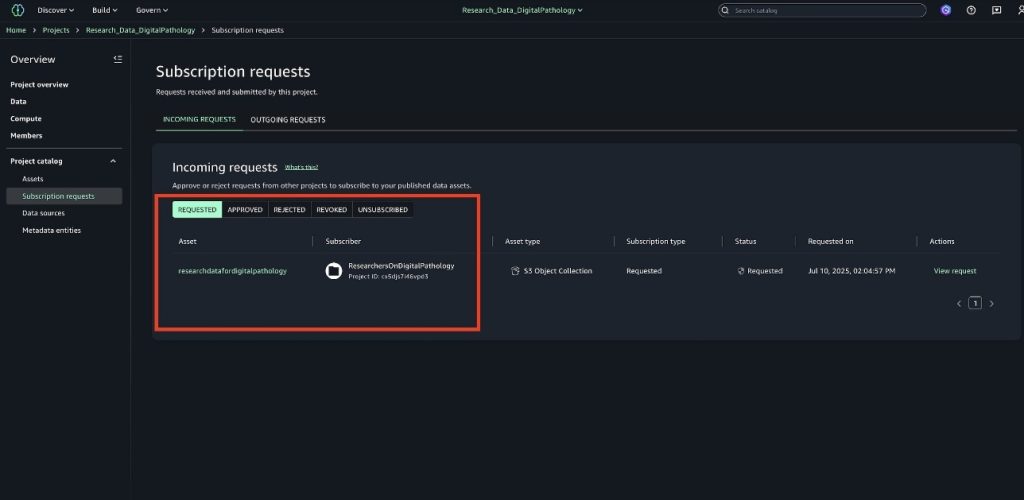
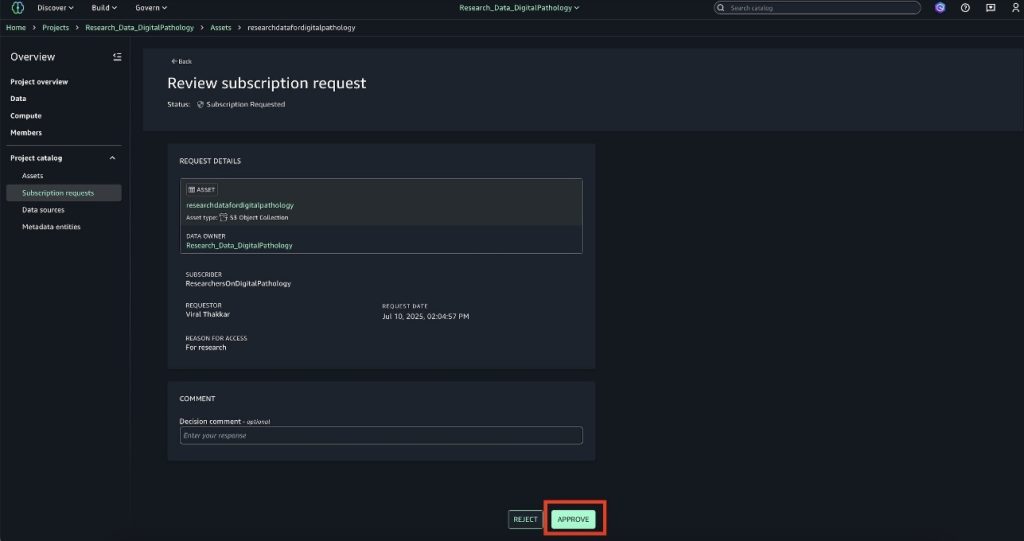
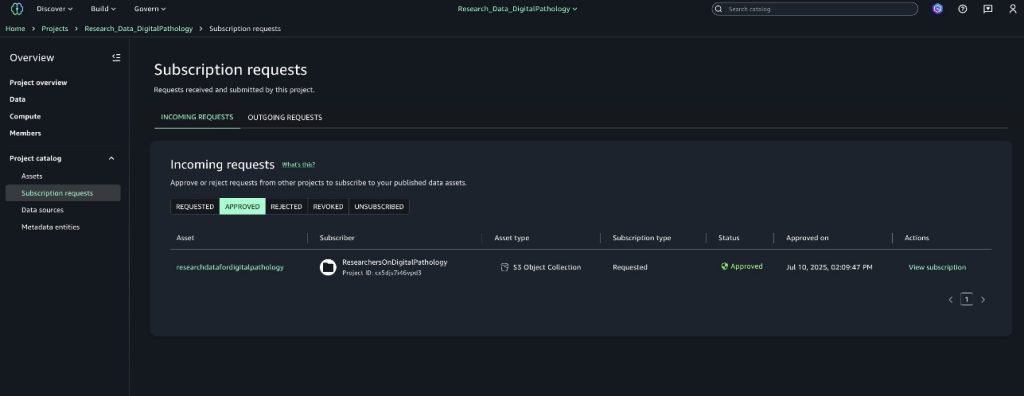
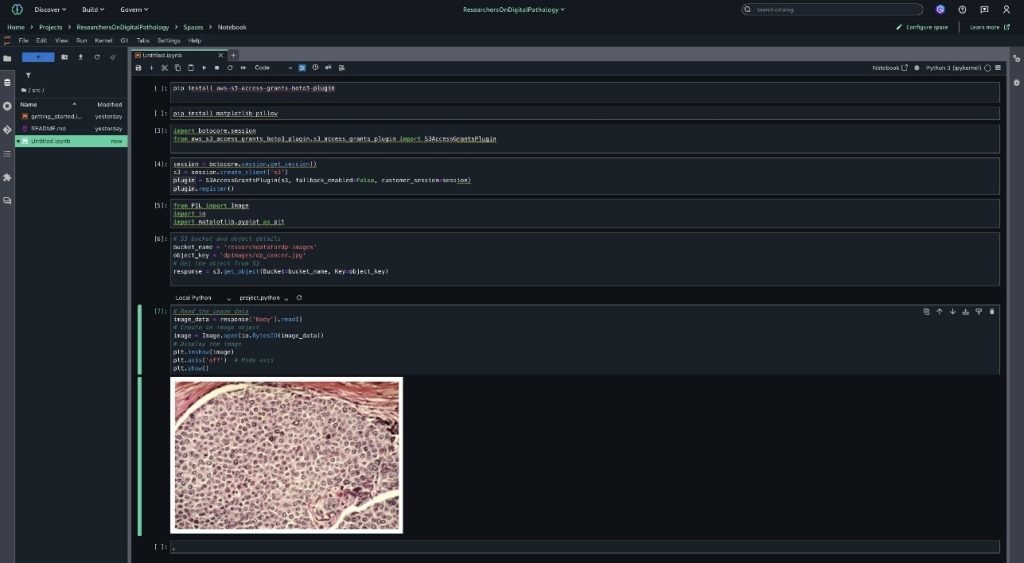
 Priya Tiruthani is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about building innovative products to simplify customers’ end-to-end data journey, especially around data governance and analytics. Outside of work, she enjoys being outdoors to hike, capture nature’s beauty, and recently play pickleball.
Priya Tiruthani is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about building innovative products to simplify customers’ end-to-end data journey, especially around data governance and analytics. Outside of work, she enjoys being outdoors to hike, capture nature’s beauty, and recently play pickleball. Subrat Das is a Principal Solutions Architect and part of the Global Healthcare and Life Sciences industry division at AWS. He is passionate about modernizing and architecting complex customer workloads. When he’s not working on technology solutions, he enjoys long hikes and traveling around the world.
Subrat Das is a Principal Solutions Architect and part of the Global Healthcare and Life Sciences industry division at AWS. He is passionate about modernizing and architecting complex customer workloads. When he’s not working on technology solutions, he enjoys long hikes and traveling around the world. Santhosh Padmanabhan is a Software Development Manager at AWS, leading the Amazon SageMaker Catalog engineering team. His team designs, builds, and operates services specializing in data, machine learning, and AI governance. With deep expertise in building distributed data systems at scale, Santhosh plays a key role in advancing AWS’s data governance capabilities.
Santhosh Padmanabhan is a Software Development Manager at AWS, leading the Amazon SageMaker Catalog engineering team. His team designs, builds, and operates services specializing in data, machine learning, and AI governance. With deep expertise in building distributed data systems at scale, Santhosh plays a key role in advancing AWS’s data governance capabilities. Yuhang Huang is a Software Development Manager on the Amazon SageMaker Unified Studio team. He leads the engineering team to design, build, and operate scheduling and orchestration capabilities in SageMaker Unified Studio. In his free time, he enjoys playing tennis.
Yuhang Huang is a Software Development Manager on the Amazon SageMaker Unified Studio team. He leads the engineering team to design, build, and operate scheduling and orchestration capabilities in SageMaker Unified Studio. In his free time, he enjoys playing tennis.