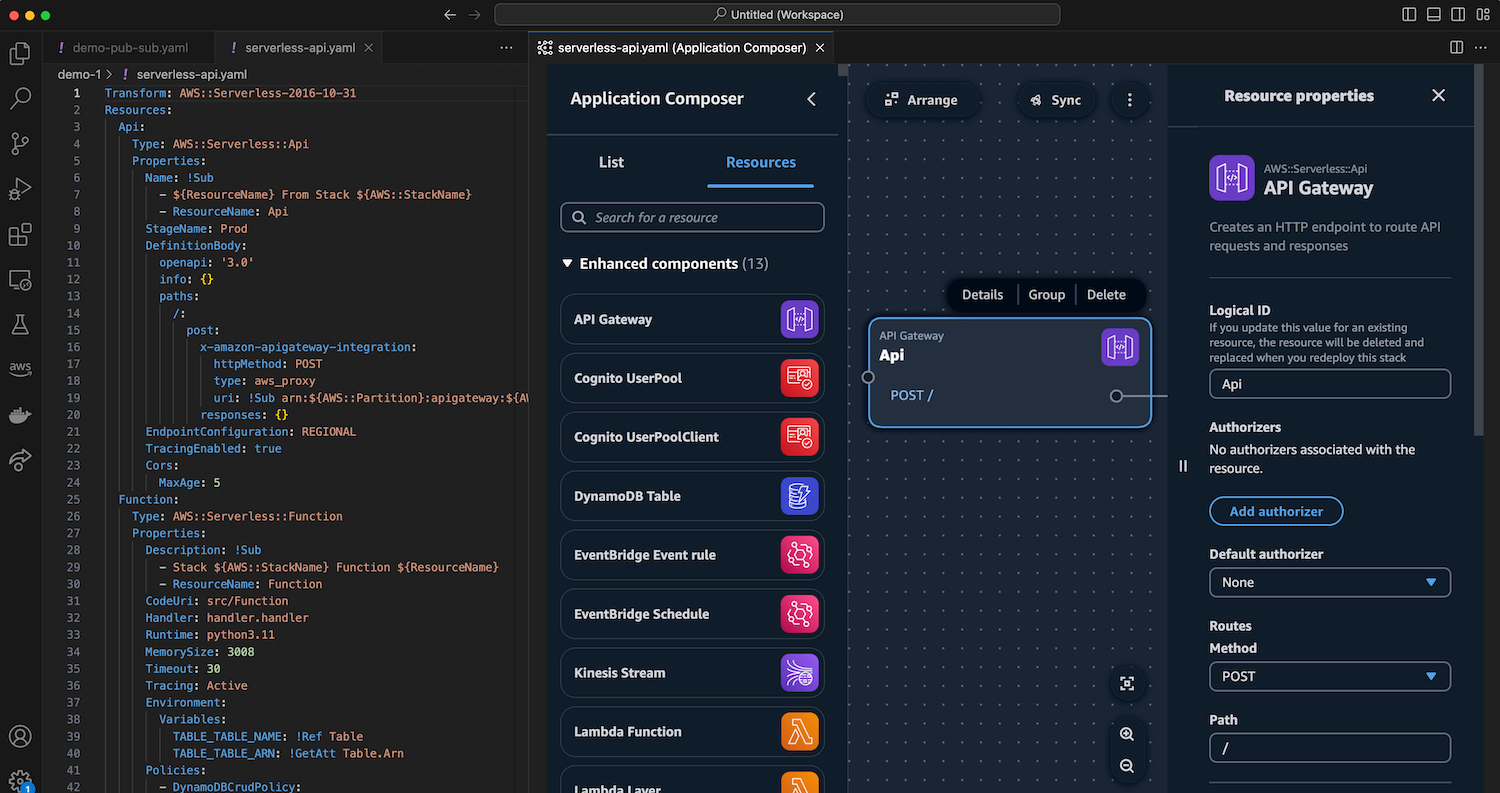
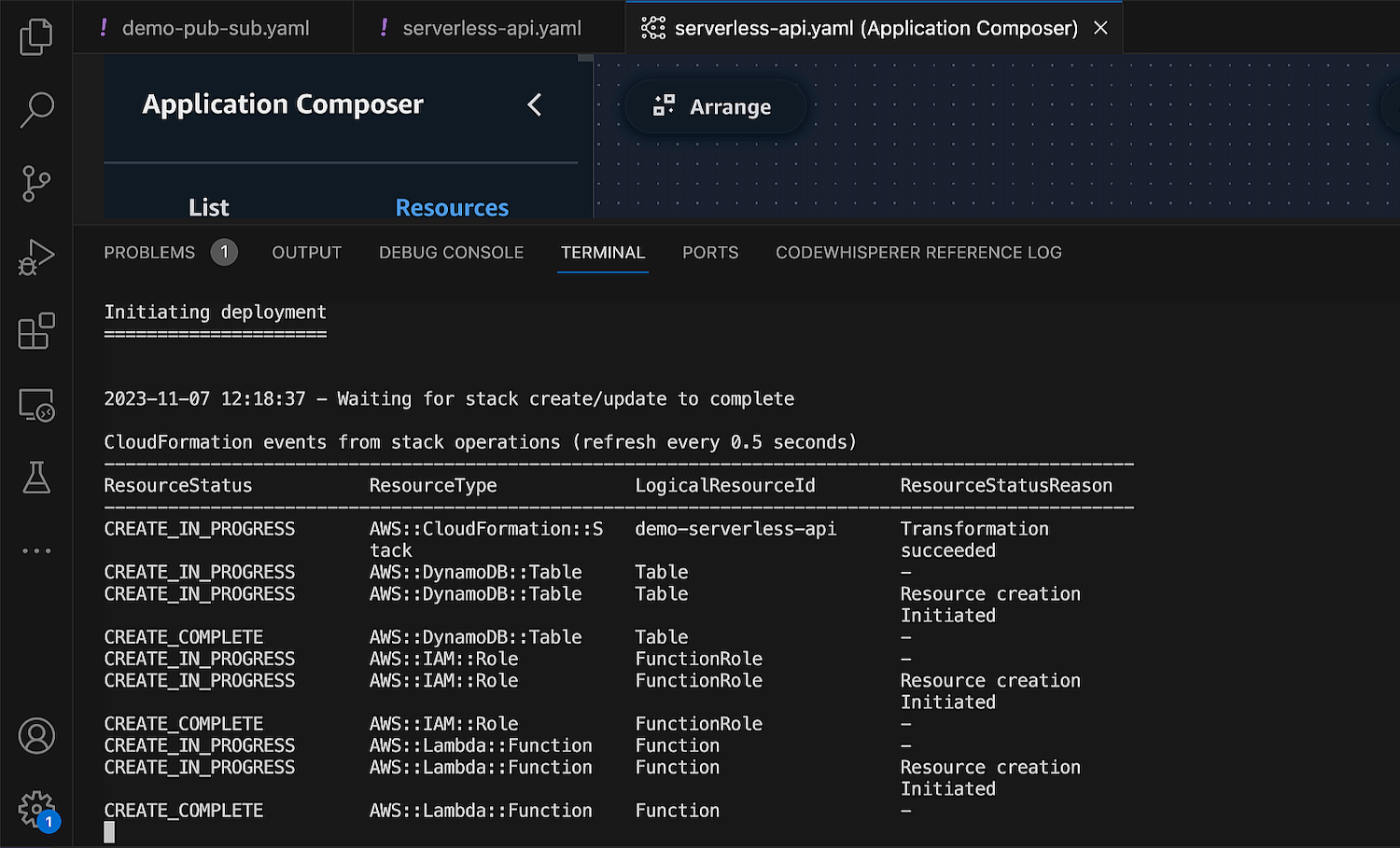
Post Syndicated from Sébastien Stormacq original https://aws.amazon.com/blogs/aws/the-aws-canada-west-calgary-region-is-now-available/
Today, we are opening a new Region in Canada. AWS Canada West (Calgary), also known as ca-west-1, is the thirty-third AWS Region. It consists of three Availability Zones, for a new total of 105 Availability Zones globally.
This second Canadian Region allows you to architect multi-Region infrastructures that meet five nines of availability while keeping your data in the country.
A global footprint
Our approach to building infrastructure is fundamentally different from other providers. At the core of our global infrastructure is a Region. An AWS Region is a physical location in the world where we have multiple Availability Zones. Availability Zones consist of one or more discrete data centers, each with redundant power, networking, and connectivity, housed in separate facilities. Unlike with other cloud providers, who often define a region as a single data center, having multiple Availability Zones allows you to operate production applications and databases that are more highly available, fault tolerant, and scalable than would be possible from a single data center.
AWS has more than 17 years of experience building its global infrastructure. And there’s no compression algorithm for experience, especially when it comes to scale, security, and performance.
Canadian customers of every size, including global brands like BlackBerry, CI Financial, Keyera, KOHO, Maple Leaf Sports & Entertainment (MLSE), Nutrien, Sun Life, TELUS, and startups like Good Chemistry and Cohere, and public sector organizations like the University of Calgary and Natural Resources Canada (NRCan), are already running workloads on AWS. They choose AWS for its security, performance, flexibility, and global presence.
AWS Global Infrastructure, including AWS Local Zones and AWS Outposts, gives our customers the flexibility to deploy workloads close to their customers to minimize network latency. For example, one customer that has benefited from AWS flexibility is Canadian decarbonization technology scale-up, BrainBox AI. BrainBox AI uses cloud-based artificial intelligence (AI) and machine learning (ML) on AWS to help building owners around the world reduce HVAC emissions by up to 40 percent and energy consumption by up to 25 percent. The AWS Global Infrastructure allows their solution to manage with low latency hundreds of buildings in over 20 countries, 24-7.
Services available
You can deploy your workloads on any of the C5, M5, M5d, R5, C6g, C6gn, C6i, C6id, M6g, M6gd, M6i, M6id, R6d, R6i, R6id, I4i, I3en, T3, and T4g instance families. The new AWS Canada West (Calgary) has 65 AWS services available at launch. Here is the list, sorted by alphabetical order: Amazon API Gateway, AWS AppConfig, AWS Application Auto Scaling, Amazon Aurora, Aurora PostgreSQL, AWS Batch, AWS Certificate Manager, AWS CloudFormation, Amazon CloudFront, AWS Cloud Map, AWS CloudTrail, Amazon CloudWatch, Amazon CloudWatch Events, Amazon CloudWatch Logs, AWS CodeDeploy, AWS Config, AWS Database Migration Service (AWS DMS), AWS DataSync, AWS Direct Connect, Amazon DynamoDB, Amazon ElastiCache, Amazon Elastic Block Store (Amazon EBS), Amazon Elastic Compute Cloud (Amazon EC2), Amazon EC2 Auto Scaling, Amazon Elastic Container Registry (Amazon ECR), Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS), Elastic Load Balancing, Elastic Load Balancing – Gateway (GWLB), Elastic Load Balancing – Network (NLB), Amazon EMR, Amazon EventBridge, AWS Fargate, AWS Health Dashboard, AWS Identity and Access Management (IAM), Amazon Kinesis Data Firehose, Amazon Kinesis Data Streams, AWS Key Management Service (AWS KMS), AWS Lambda, AWS Management Console, AWS Marketplace, Amazon OpenSearch Service, AWS Organizations, Amazon Redshift, Amazon Relational Database Service (Amazon RDS), AWS Resource Access Manager, Resource Groups, Amazon Route 53, AWS Secrets Manager, AWS Security Hub, AWS Security Token Service, Service Quotas, AWS Shield Standard, Amazon Simple Notification Service (Amazon SNS), Amazon Simple Queue Service (Amazon SQS), Amazon Simple Storage Service (Amazon S3), Amazon Simple Workflow Service (Amazon SWF), AWS Site-to-Site VPN, AWS Step Functions, AWS Support API, AWS Systems Manager, AWS Trusted Advisor, Amazon Virtual Private Cloud (Amazon VPC), VM Import/Export, and AWS X-Ray.
AWS in Canada
We have been supporting our customers and partners with infrastructure in Canada since December 2016, when the first Canadian AWS Region, AWS Canada (Central), was launched. In the same year, we launched Amazon CloudFront locations in Toronto and Montreal to better serve your customers in the region. To date, there are ten CloudFront points of presence (PoPs) in Canada: five in Toronto, four in Montreal, and one in Vancouver. We also have engineering teams located in multiple cities in the country.
From 2016–2021, AWS has invested over 2.57 billion CAD (1.9 billion USD) in Canada and plans to invest up to 24.8 billion CAD (18.3 billion USD) by 2037 in the two Regions. Using the input-output methodology and statistical tables provided by Statistics Canada, we estimate that the planned investment will add 43.02 billion CAD (31 billion USD) to the gross domestic product (GDP) of Canada and support more than 9,300 full-time equivalent (FTE) jobs in the Canadian economy.
In addition to providing our customers with world-class infrastructure benefits, Amazon is committed to reaching net zero carbon across its business by 2040 and is on a path to powering its operations with 100 percent renewable energy by 2025. In 2022, 90 percent of the electricity consumed by Amazon was attributable to renewable energy sources. Additionally, AWS has a goal to be water positive by 2030, returning more water to communities than it uses in its direct operations. Amazon has a total of four renewable energy projects in Canada: three south of Calgary and one close to Edmonton. According to BloombergNEF, Amazon is the largest corporate purchaser of renewable energy in the country (and the world). These projects generate more than 2.3 million megawatt hours (MWH) of clean energy–enough to power 1.69 million Canadian homes.
Education is one of our top priorities as well. Since 2017, we have trained more than 200,000 Canadians on cloud computing skills through free and paid AWS Training and Certification programs. Learners of various skill levels, roles, and backgrounds can build knowledge and practical skills with more than 600 free online courses in up to 14 languages on AWS Skills Builder. Amazon is committed to providing 29 million people around the world with free cloud computing skills training by 2025.
Security
Customers around the world trust AWS to keep their data safe, and keeping their workloads secure and confidential is foundational to how we operate. Since the inception of AWS, we have relentlessly innovated on security, privacy tools, and practices to meet, and even exceed, our customers’ expectations.
For example, you decide where to store your data and who can access it. Services such as AWS CloudTrail allow you to verify how and when data are accessed. Our virtualization technology, AWS Nitro System, has been designed to restrict any operator access to customer data. This means no person, or even service, from AWS can access data when it is being used in an EC2 instance. NCC Group, a leading cybersecurity consulting firm based in the United Kingdom, audited the Nitro architecture and affirmed our claims.
Our core infrastructure is built to satisfy the security requirements of the military, global banks, and other high-sensitivity organizations.
In Canada, Neo Financial is a financial tech startup that uses the elasticity of the AWS Cloud to scale its business. They chose AWS in 2019 because we helped them to meet their regulatory requirements. They use EC2 for their core infrastructure, S3 for highly durable storage, Amazon GuardDuty to improve their security posture, and CloudFront to improve performance for their customers.
Performance
The AWS Global Infrastructure is built for performance, offering the lowest latency, lowest packet loss, and highest overall network quality. This is achieved with a fully redundant 400 GbE fiber network backbone, often providing many terabits of capacity between Regions.
To help provide Canadian customers with even lower latency, we have announced two AWS Local Zones in Toronto and Vancouver.
Performance is specially important when you are streaming your favorite TV show. Calgary-based Kidoodle.TV offers a streaming service for children. They have more than 100 million app downloads worldwide and more than 1 billion ad seconds for sale every 2 days. Using AWS, Kidoodle.TV was able to build the same service architecture that multibillion-dollar companies can deploy, which allowed them to seamlessly scale up from 400,000 monthly active users to 12 million in a year.
Additional things to know
We preannounced 12 additional Availability Zones in four future Regions in Malaysia, New Zealand, Thailand, and the AWS European Sovereign Cloud. We will be happy to share more information on these Regions so, stay tuned.
I can’t wait to discover how you will innovate and what amazing services you will deploy on this new AWS Region. Go build and deploy your infrastructure on ca-west-1 today.
— seb
Aujourd’hui, nous inaugurons une nouvelle Région Amazon Web Services (AWS) au Canada. La Région AWS Canada Ouest (Calgary), également connue sous le nom ca‑west‑1, est la 33e Région AWS. Elle compte trois Zones de disponibilité, emmenant ainsi le total des Zones de disponibilité à travers le monde à 105.
Cette deuxième Région au Canada vous permet d’élaborer des infrastructures multi-Régions qui demeurent disponibles 99,999 % du temps, tout en conservant vos données à l’intérieur des frontières canadiennes.
Une empreinte mondiale
Notre approche en matière de développement de notre infrastructure est fondamentalement différente de celle adoptée par d’autres fournisseurs. Au cœur de notre infrastructure mondiale, vous trouvez des Régions. Une Région AWS est un lieu physique dans le monde, dans lequel nous avons plusieurs Zones de disponibilité. Les Zones de disponibilité sont formées d’un ou plusieurs centres de données distincts, chacun doté de systèmes d’alimentation, de réseau et de connectivité redondants, et hébergés dans des installations séparées. Contrairement aux autres fournisseurs infonuagiques, qui définissent souvent une région comme étant un centre de données unique, le fait de pouvoir compter sur plusieurs Zones de disponibilité vous permet d’exploiter des applications et des bases de données de production ayant une plus grande disponibilité, une meilleure tolérance aux pannes et une plus importante évolutivité, allant ainsi au-delà des possibilités offertes par un centre de données unique.
AWS compte plus de 17 années d’expérience dans la mise en œuvre de son infrastructure mondiale. Il n’existe pas d’algorithme de compression pour remplacer une telle expérience, surtout lorsqu’il est question d’évolutivité, de sécurité et de performances.
Des clients canadiens de toute taille, dont des marques mondiales telles que BlackBerry, CI Financial, Keyera, KOHO, Maple Leaf Sports & Entertainment (MLSE), Nutrien, Sun Life et TELUS, ainsi que de jeunes pousses comme Good Chemistry and Cohere, en plus d’organismes du secteur public telles que l’Université de Calgary et Ressources naturelles Canada (RNCan), exécutent déjà des charges de travail sur AWS. Ces entreprises et organismes ont choisi AWS pour la sécurité, les performances, la flexibilité et la présence mondiale que nous offrons.
L’infrastructure mondiale AWS, dont font partie les Zones locales AWS et les AWS Outposts, offre à nos clients la flexibilité de déployer leurs charges de travail à proximité de leur clientèle, minimisant ainsi la latence du réseau. Par exemple, un de nos clients qui bénéfice de la flexibilité d’AWS est BrainBox AI, une jeune entreprise en croissance qui élabore des technologies de décarbonation. BrainBox AI utilise l’intelligence artificielle (IA) et l’apprentissage automatique (AA) basés dans le Nuage AWS pour aider des propriétaires d’édifice, partout au monde, à réduire les émissions liées aux systèmes de chauffage, de ventilation et de climatisation jusqu’à 40 %, et la consommation énergétique jusqu’à 25 %. L’infrastructure mondiale AWS permet à leur solution de gérer, avec une latence faible, des centaines d’immeubles dans plus de 20 pays, et ce 24 heures sur 24, sept jours sur sept.
Services disponibles
Vous pouvez déployer vos charges de travail sur n’importe laquelle des familles d’instance C5, M5, M5d, R5, C6g, C6gn, C6i, C6id, M6g, M6gd, M6i, M6id, R6d, R6i, R6id, I4i, I3en, T3 et T4g. La nouvelle Région Canada Ouest (Calgary) compte 65 services AWS, tous disponibles dès le lancement. En voici la liste, en ordre alphabétique : Amazon API Gateway, AWS AppConfig, AWS Application Auto Scaling, Amazon Aurora, Aurora PostgreSQL, AWS Batch, AWS Certificate Manager, AWS CloudFormation, Amazon CloudFront, AWS Cloud Map, AWS CloudTrail, Amazon CloudWatch, Amazon CloudWatch Events, Amazon CloudWatch Logs, AWS CodeDeploy, AWS Config, AWS Database Migration Service (AWS DMS), AWS DataSync, AWS Direct Connect, Amazon DynamoDB, Amazon Elastic Block Store (Amazon EBS), Amazon Elastic Compute Cloud (Amazon EC2), Amazon EC2 Auto Scaling, Amazon Elastic Container Registry (Amazon ECR), Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS ), , Elastic Load Balancing, , Elastic Load Balancing – Gateway (GWLB), Amazon EMR, Amazon EventBridge, AWS Fargate, AWS Health Dashboard, AWS Identity and Access Management (IAM), Amazon Kinesis Data Streams, AWS Key Management Service (AWS KMS), AWS Lambda, AWS Management Console, AWS Marketplace, Amazon OpenSearch Service, AWS Organizations, Amazon Redshift, AWS Resource Access Manager, Resource Groups, Amazon Route 53, AWS Secrets Manager, AWS Security Hub, AWS Security Token Service, Service Quotas, AWS Shield Standard, Amazon Simple Notification Service (Amazon SNS), Amazon Simple Queue Service (Amazon SQS), Amazon Simple Storage Service (Amazon S3), Amazon Simple Workflow Service (Amazon SWF), AWS Site-to-Site VPN, AWS Step Functions, AWS Support API, AWS Systems Manager, AWS Trusted Advisor, VM Import/Export et AWS X-Ray.
AWS au Canada
Nous soutenons nos clients et partenaires grâce à notre infrastructure canadienne depuis décembre 2016, lorsque la première Région AWS au Canada, soit la Région AWS Canada (Centre), a été inaugurée. Au cours de cette même année, nous avons lancé des emplacements Amazon CloudFront à Toronto et Montréal afin de mieux servir vos clients dans ces régions. Actuellement, nous comptons 10 points de présence (PdP) au Canada : cinq à Toronto, quatre à Montréal et un à Vancouver. Nous avons également des équipes d’ingénieurs basées dans plusieurs villes à travers le pays.
Entre 2016 et 2021, AWS a investi plus de 2,57 milliards $ CAD (1,9 milliards $ USD) au Canada et prévoit investir jusqu’à 24,8 milliards $ CAD (18,3 milliards $ USD) dans nos deux Régions d’ici 2037. En se basant sur la méthodologie entrée-sortie et les tableaux statistiques fournies par Statistique Canada, nous estimons que les investissements prévus ajouteront 43,02 milliards $ CAD (31 milliards USD) au produit intérieur brut (PIB) du Canada et soutiendront plus de 9 300 emplois équivalents temps plein (ETP) au sein de l’économie canadienne.
En plus d’offrir les avantages d’une infrastructure de classe mondiale à nos clients, Amazon s’est engagé à atteindre une empreinte carbone nette zéro pour l’ensemble de ses activités d’ici 2040, et est en voie d’alimenter l’ensemble de ses opérations avec des énergies 100 % renouvelables d’ici 2025. En 2022, 90 % de l’électricité consommée par Amazon provenait de sources d’énergie renouvelables. En outre, AWS s’est donné comme objectif d’avoir un bilan positif en matière d’eau d’ici 2030, restituant ainsi plus d’eau aux communautés que la quantité utilisée pour ses activités directes. Amazon compte quatre projets d’énergie renouvelable au Canada, soit trois situés au sud de Calgary et un autre près d’Edmonton. Selon BloombergNEF, Amazon est la plus grande entreprise acheteuse d’énergie renouvelable au pays (et au monde). Ces projets génèrent plus de 2,3 millions de mégawattheures (MWh) d’énergie propre, soit suffisamment pour alimenter 1,69 million de foyers canadiens.
La formation est également l’une de nos principales priorités. Depuis 2017, nous avons formé plus de 200 000 Canadiens et Canadiennes en compétences infonuagiques par le biais de programmes de formation et certification AWS gratuits et payants. Des apprenants ayant différents niveaux de compétences, de responsabilités et d’expérience peuvent acquérir des connaissances et des compétences pratiques grâce à AWS Skills Builder, qui offre plus de 600 cours en ligne gratuits en jusqu’à 14 langues. Amazon s’est engagé à offrir des formations gratuites en compétences infonuagiques à 29 millions de personnes à travers le monde d’ici 2025.
Sécurité
Des clients du monde entier font confiance à AWS pour assurer la sécurité de leurs données, alors que la sécurisation et la confidentialité de leurs charges de travail sont des éléments fondamentaux de notre mode de fonctionnement. Depuis les tous débuts d’AWS, nous innovons sans relâche en matière de sécurité, d’outils de protection de la vie privée et de pratiques afin de répondre aux attentes de nos clients, et même dépasser ces attentes.
Par exemple, les décisions concernant l’emplacement de stockage de vos données, et qui peut y accéder, vous appartiennent. Des services tels qu’AWS CloudTrail vous permettent de vérifier comment et quand les données sont consultées. Notre technologie de virtualisation, AWS Nitro System, a été conçue pour restreindre l’accès de tout opérateur aux données de la clientèle. Cela signifie qu’aucun membre du personnel d’AWS, ou même un service AWS, peut accéder aux données lorsqu’elles sont utilisées au sein d’une instance Amazon Elastic Compute Cloud (Amazon EC2). En effet, NCC Group, une des principales firmes de conseil en cybersécurité au Royaume‑Uni, a procédé à une vérification de notre architecture Nitro et a confirmé nos affirmations.
Notre infrastructure de base est conçue pour répondre aux exigences de sécurité des armées, des banques mondiales, ainsi que d’autres organisations traitant des informations hautement sensibles.
Basée au Canada, Neo est une jeune pousse spécialisée en technologie financière qui profite de l’élasticité du Nuage AWS pour développer ses activités. En 2019, l’entreprise a choisi AWS car nous l’avions aidée à répondre aux exigences réglementaires du secteur. Elle utilise Amazon Elastic Compute Cloud (Amazon EC2) pour son infrastructure de base, Amazon Simple Storage Service (Amazon S3) pour un stockage très durable, Amazon GuardDuty pour améliorer sa posture de sécurité, ainsi qu’Amazon CloudFront afin d’optimiser les performances de ses systèmes pour sa clientèle.
Performances
L’infrastructure mondiale AWS est conçue pour offrir les meilleures performances et la plus faible latence atteignable, minimiser la perte de paquets et fournir la meilleure qualité générale pour l’ensemble du réseau. Cela est rendu possible grâce à un réseau dorsal de fibre optique de 400 GbE entièrement redondant, permettant souvent plusieurs térabits de capacité entre les Régions.
Afin d’offrir une latence encore plus faible à nos clients canadiens, nous avons annoncé la mise en place de deux Zone locales AWS à Toronto et Vancouver.
Les performances sont davantage importantes lorsque vous visionnez la diffusion en continu de votre émission préférée. L’entreprise Kidoodle.TV, basée à Calgary, offre un service de diffusion en continu destiné aux enfants. Elle compte plus de 100 millions de téléchargements de son application à travers le monde et plus d’un milliard de secondes publicitaires à vendre par période de 48 heures. En utilisant AWS, Kidoodle.TV a pu mettre en place le même type d’architecture de service que les entreprises multimilliardaires sont en mesure de déployer. Cela a permis à l’entreprise de passer, en une année, de 400 000 à 1,2 million d’utilisateurs actifs mensuels.
Informations complémentaires
Nous avons annoncé 12 futures Zones de disponibilité dans quatre Régions additionnelles en Malaisie, en Nouvelle‑Zélande, en Thaïlande et la Région souveraine en Europe; nous aurons le plaisir de partager des informations supplémentaires le moment venu.
Je suis impatient de découvrir vos innovations ainsi que les extraordinaires services que vous allez mettre en œuvre au sein de la Région AWS Canada Ouest (Calgary). N’hésitez pas à développer et à déployer votre infrastructure sur ca‑west‑1 dès aujourd’hui.
— Seb
 We are launching three new modules for
We are launching three new modules for 


















 Dagney Braun is a Senior Manager of Product at Amazon Web Services OpenSearch Team. She is passionate about improving the ease of use of OpenSearch, and expanding the tools available to better support all customer use-cases.
Dagney Braun is a Senior Manager of Product at Amazon Web Services OpenSearch Team. She is passionate about improving the ease of use of OpenSearch, and expanding the tools available to better support all customer use-cases. Stavros Macrakis is a Senior Technical Product Manager on the OpenSearch project of Amazon Web Services. He is passionate about giving customers the tools to improve the quality of their search results.
Stavros Macrakis is a Senior Technical Product Manager on the OpenSearch project of Amazon Web Services. He is passionate about giving customers the tools to improve the quality of their search results. Dylan Tong is a Senior Product Manager at Amazon Web Services. He leads the product initiatives for AI and machine learning (ML) on OpenSearch including OpenSearch’s vector database capabilities. Dylan has decades of experience working directly with customers and creating products and solutions in the database, analytics and AI/ML domain. Dylan holds a BSc and MEng degree in Computer Science from Cornell University.
Dylan Tong is a Senior Product Manager at Amazon Web Services. He leads the product initiatives for AI and machine learning (ML) on OpenSearch including OpenSearch’s vector database capabilities. Dylan has decades of experience working directly with customers and creating products and solutions in the database, analytics and AI/ML domain. Dylan holds a BSc and MEng degree in Computer Science from Cornell University. Happy New Year! Cloud technologies, machine learning, and generative AI have become more accessible, impacting nearly every aspect of our lives. Amazon CTO Dr. Werner Vogels offers four tech predictions for 2024 and beyond:
Happy New Year! Cloud technologies, machine learning, and generative AI have become more accessible, impacting nearly every aspect of our lives. Amazon CTO Dr. Werner Vogels offers four tech predictions for 2024 and beyond: