Post Syndicated from James Beswick original https://aws.amazon.com/blogs/compute/aws-integrated-application-test-kit/
This post is written by Dan Fox, Principal Specialist Solutions Architect, and Brian Krygsman, Senior Solutions Architect.
Today, AWS announced the public preview launch of the AWS Integrated Application Test Kit (IATK). AWS IATK is a software library that helps you write automated tests for cloud-based applications. This blog post presents several initial features of AWS IATK, and then shows working examples using an example video processing application. If you are getting started with serverless testing, learn more at serverlessland.com/testing.
Overview
When you create applications composed of serverless services like AWS Lambda, Amazon EventBridge, or AWS Step Functions, many of your architecture components cannot be deployed to your desktop, but instead only exist in the AWS Cloud. In contrast to working with applications deployed locally, these types of applications benefit from cloud-based strategies for performing automated tests. For its public preview launch, AWS IATK helps you implement some of these strategies for Python applications. AWS IATK will support other languages in future launches.
Locating resources for tests
When you write automated tests for cloud resources, you need the physical IDs of your resources. The physical ID is the name AWS assigns to a resource after creation. For example, to send requests to Amazon API Gateway you need the physical ID, which forms the API endpoint.
If you deploy cloud resources in separate infrastructure as code stacks, you might have difficulty locating physical IDs. In CloudFormation, you create the logical IDs of the resources in your template, as well as the stack name. With IATK, you can get the physical ID of a resource if you provide the logical ID and stack name. You can also get stack outputs by providing the stack name. These convenient methods simplify locating resources for the tests that you write.
Creating test harnesses for event driven architectures
To write integration tests for event driven architectures, establish logical boundaries by breaking your application into subsystems. Your subsystems should be simple enough to reason about, and contain understandable inputs and outputs. One useful technique for testing subsystems is to create test harnesses. Test harnesses are resources that you create specifically for testing subsystems.
For example, an integration test can begin a subsystem process by passing an input test event to it. IATK can create a test harness for you that listens to Amazon EventBridge for output events. (Under the hood, the harness is composed of an EventBridge Rule that forwards the output event to Amazon Simple Queue Service.) Your integration test then queries the test harness to examine the output and determine if the test passes or fails. These harnesses help you create integration tests in the cloud for event driven architectures.
Establishing service level agreements to test asynchronous features
If you write a synchronous service, your automated tests make requests and expect immediate responses. When your architecture is asynchronous, your service accepts a request and then performs a set of actions at a later time. How can you test for the success of an activity if it does not have a specified duration?
Consider creating reasonable timeouts for your asynchronous systems. Document timeouts as service level agreements (SLAs). You may decide to publish your SLAs externally or to document them as internal standards. IATK contains a polling feature that allows you to establish timeouts. This feature helps you to test that your asynchronous systems complete tasks in a timely manner.
Using AWS X-Ray for detailed testing
If you want to gain more visibility into the interior details of your application, instrument with AWS X-Ray. With AWS X-Ray, you trace the path of an event through multiple services. IATK provides conveniences that help you set the AWS X-Ray sampling rate, get trace trees, and assert for trace durations. These features help you observe and test your distributed systems in greater detail.
Learn more about testing asynchronous architectures at aws-samples/serverless-test-samples.
Overview of the example application
To demonstrate the features of IATK, this post uses a portion of a serverless video application designed with a plugin architecture. A core development team creates the primary application. Distributed development teams throughout the organization create the plugins. One AWS CloudFormation stack deploys the primary application. Separate stacks deploy each plugin.
Communications between the primary application and the plugins are managed by an EventBridge bus. Plugins pull application lifecycle events off the bus and must put completion notification events back on the bus within 20 seconds. For testing, the core team has created an AWS Step Functions workflow that mimics the production process by emitting properly formatted example lifecycle events. Developers run this test workflow in development and test environments to verify that their plugins are communicating properly with the event bus.
The following demonstration shows an integration test for the example application that validates plugin behavior. In the integration test, IATK locates the Step Functions workflow. It creates a test harness to listen for the event completion notification to be sent by the plugin. The test then runs the workflow to begin the lifecycle process and start plugin actions. Then IATK uses a polling mechanism with a timeout to verify that the plugin complies with the 20 second service level agreement. This is the sequence of processing:

- The integration test starts an execution of the test workflow.
- The workflow puts a lifecycle event onto the bus.
- The plugin pulls the lifecycle event from the bus.
- When the plugin is complete, it puts a completion event onto the bus.
- The integration test polls for the completion event to determine if the test passes within the SLA.
Deploying and testing the example application
Follow these steps to review this application, build it locally, deploy it in your AWS account, and test it.
Downloading the example application
- Open your terminal and clone the example application from GitHub with the following command or download the code. This repository also includes other example patterns for testing serverless applications.
git clone https://github.com/aws-samples/serverless-test-samples - The root of the IATK example application is in
python-test-samples/integrated-application-test-kit. Change to this directory:cd serverless-test-samples/python-test-samples/integrated-application-test-kit
Reviewing the integration test
Before deploying the application, review how the integration test uses the IATK by opening plugins/2-postvalidate-plugins/python-minimal-plugin/tests/integration/test_by_polling.py in your text editor. The test class instantiates the IATK at the top of the file.
iatk_client = aws_iatk.AwsIatk(region=aws_region)In the setUp() method, the test class uses IATK to fetch CloudFormation stack outputs. These outputs are references to deployed cloud components like the plugin tester AWS Step Functions workflow:
stack_outputs = self.iatk_client.get_stack_outputs(
stack_name=self.plugin_tester_stack_name,
output_names=[
"PluginLifecycleWorkflow",
"PluginSuccessEventRuleName"
],
)
The test class attaches a listener to the default event bus using an Event Rule provided in the stack outputs. The test uses this listener later to poll for events.
add_listener_output = self.iatk_client.add_listener(
event_bus_name="default",
rule_name=self.existing_rule_name
)
The test class cleans up the listener in the tearDown() method.
self.iatk_client.remove_listeners(
ids=[self.listener_id]
)
Once the configurations are complete, the method test_minimal_plugin_event_published_polling() implements the actual test.
The test first initializes the trigger event.
trigger_event = {
"eventHook": "postValidate",
"pluginTitle": "PythonMinimalPlugin"
}
Next, the test starts an execution of the plugin tester Step Functions workflow. It uses the plugin_tester_arn that was fetched during setUp.
self.step_functions_client.start_execution(
stateMachineArn=self.plugin_tester_arn,
input=json.dumps(trigger_event)
)
The test polls the listener, waiting for the plugin to emit events. It stops polling once it hits the SLA timeout or receives the maximum number of messages.
poll_output = self.iatk_client.poll_events(
listener_id=self.listener_id,
wait_time_seconds=self.SLA_TIMEOUT_SECONDS,
max_number_of_messages=1,
)
Finally, the test asserts that it receives the right number of events, and that they are well-formed.
self.assertEqual(len(poll_output.events), 1)
self.assertEqual(received_event["source"], "video.plugin.PythonMinimalPlugin")
self.assertEqual(received_event["detail-type"], "plugin-complete")
Installing prerequisites
You need the following prerequisites to build this example:
- An AWS account
- The AWS Serverless Application Model (AWS SAM) CLI with credentials that can manage AWS resources
- Python 3.11
- Node.js 18.x
- Docker (optional, but recommended for building Python applications with AWS SAM)
Build and deploy the example application components
- Use AWS SAM to build and deploy the plugin tester to your AWS account. The plugin tester is the Step Functions workflow shown in the preceding diagram. During the build process, you can add the
--use-containerflag to the build command to instruct AWS SAM to create the application in a provided container. You can accept or override the default values during the deploy process. You will use “Stack Name” and “AWS Region” later to run the integration test.cd plugins/plugin_tester # Move to the plugin tester directory sam build --use-container # Build the plugin tester
- Deploy the tester:
sam deploy --guided # Deploy the plugin tester
- Once the plugin tester is deployed, use AWS SAM to deploy the plugin.
cd ../2-postvalidate-plugins/python-minimal-plugin # Move to the plugin directory sam build --use-container # Build the plugin
- Deploy the plugin:
sam deploy --guided # Deploy the plugin



Running the test
You can run tests written with IATK using standard Python test runners like unittest and pytest. The example application test uses unittest.
-
- Use a virtual environment to organize your dependencies. From the root of the example application, run:
python3 -m venv .venv # Create the virtual environment source .venv/bin/activate # Activate the virtual environment - Install the dependencies, including the IATK:
cd tests pip3 install -r requirements.txt - Run the test, providing the required environment variables from the earlier deployments. You can find correct values in the
samconfig.tomlfile of theplugin_testerdirectory.

cd integration PLUGIN_TESTER_STACK_NAME=video-plugin-tester \ AWS_REGION=us-west-2 \ python3 -m unittest ./test_by_polling.py
- Use a virtual environment to organize your dependencies. From the root of the example application, run:

You should see output as unittest runs the test.
Open the Step Functions console in your AWS account, then choose the PluginLifecycleWorkflow-<random value> workflow to validate that the plugin tester successfully ran. A recent execution shows a Succeeded status:

Review other IATK features
The example application includes examples of other IATK features like generating mock events and retrieving AWS X-Ray traces.
Cleaning up
Use AWS SAM to clean up both the plugin and the plugin tester resources from your AWS account.
- Delete the plugin resources:
cd ../.. # Move to the plugin directory sam delete # Delete the plugin
- Delete the plugin tester resources:
cd ../../plugin_tester # Move to the plugin tester directory sam delete # Delete the plugin tester


The temporary test harness resources that IATK created during the test are cleaned up when the tearDown method runs. If there are problems during teardown, some resources may not be deleted. IATK adds tags to all resources that it creates. You can use these tags to locate the resources then manually remove them. You can also add your own tags.
Conclusion
The AWS Integrated Application Test Kit is a software library that provides conveniences to help you write automated tests for your cloud applications. This blog post shows some of the features of the initial Python version of the IATK.
To learn more about automated testing for serverless applications, visit serverlessland.com/testing. You can also view code examples at serverlessland.com/testing/patterns or at the AWS serverless-test-samples repository on GitHub.
For more serverless learning resources, visit Serverless Land.
















































 Ismail Makhlouf is a Senior Specialist Solutions Architect for Data Analytics at AWS. Ismail focuses on architecting solutions for organizations across their end-to-end data analytics estate, including batch and real-time streaming, big data, data warehousing, and data lake workloads. He primarily works with direct-to-consumer platform companies in the ecommerce, FinTech, PropTech, and HealthTech space to achieve their business objectives with well-architected data platforms.
Ismail Makhlouf is a Senior Specialist Solutions Architect for Data Analytics at AWS. Ismail focuses on architecting solutions for organizations across their end-to-end data analytics estate, including batch and real-time streaming, big data, data warehousing, and data lake workloads. He primarily works with direct-to-consumer platform companies in the ecommerce, FinTech, PropTech, and HealthTech space to achieve their business objectives with well-architected data platforms.
















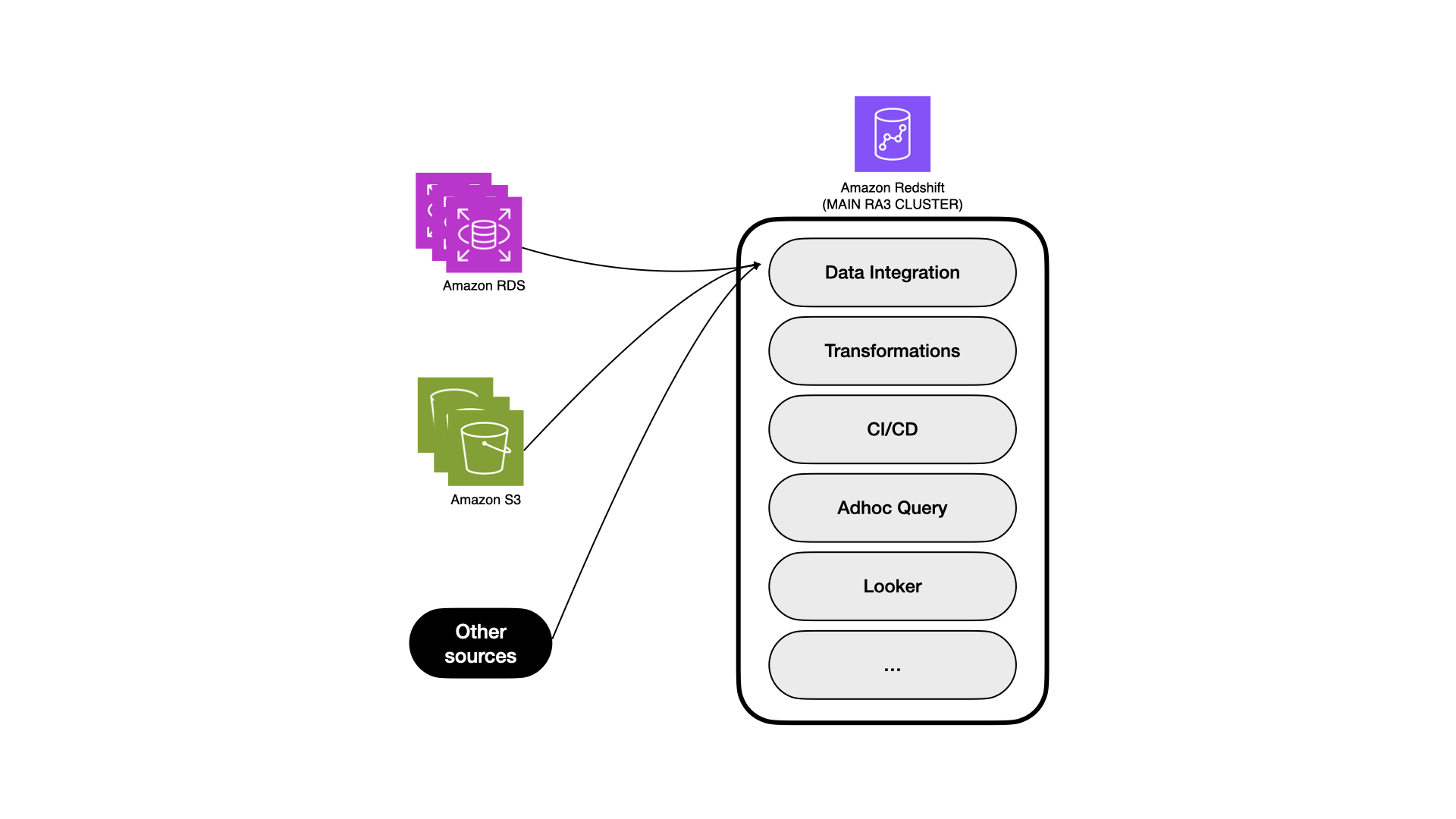

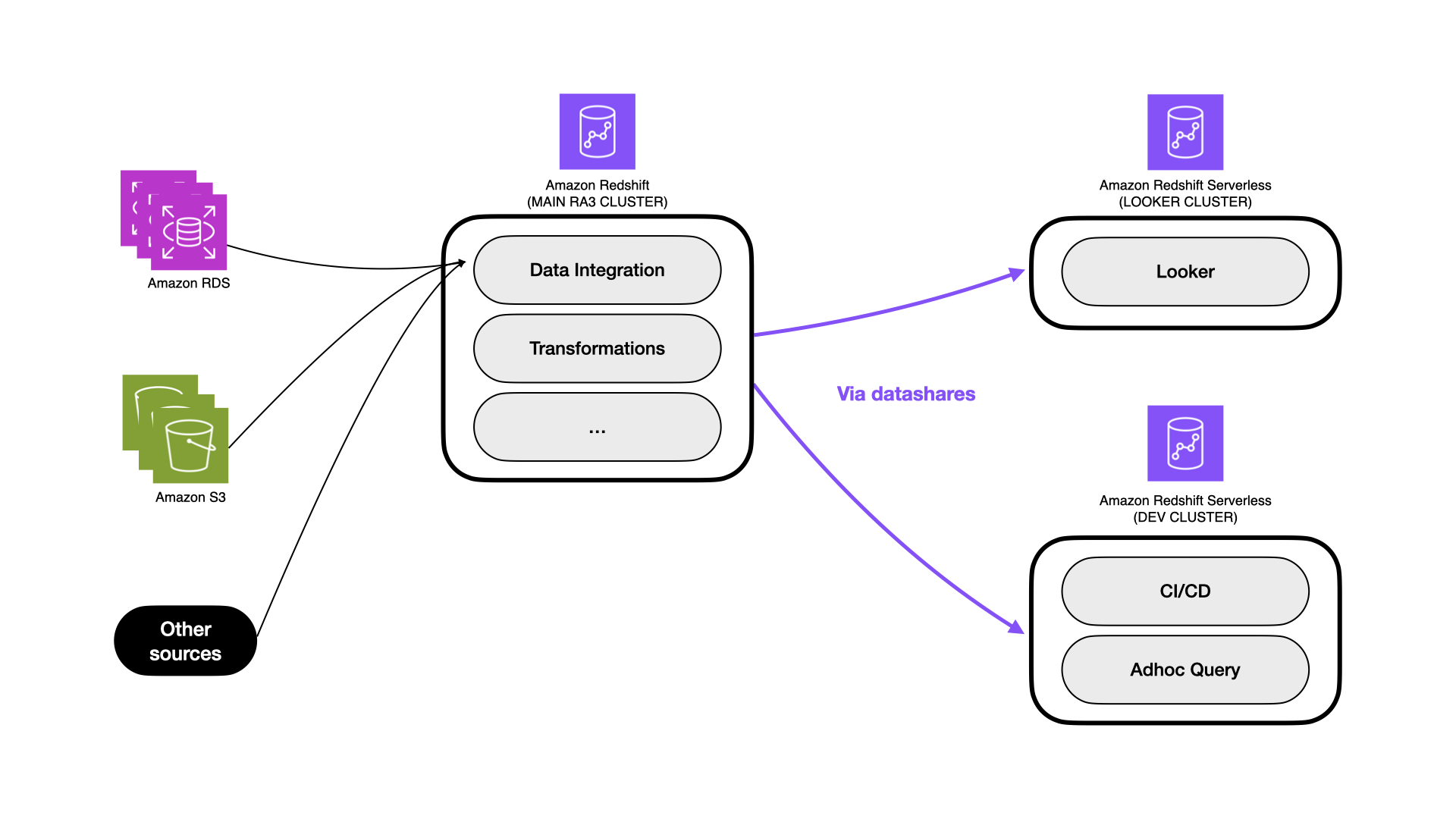

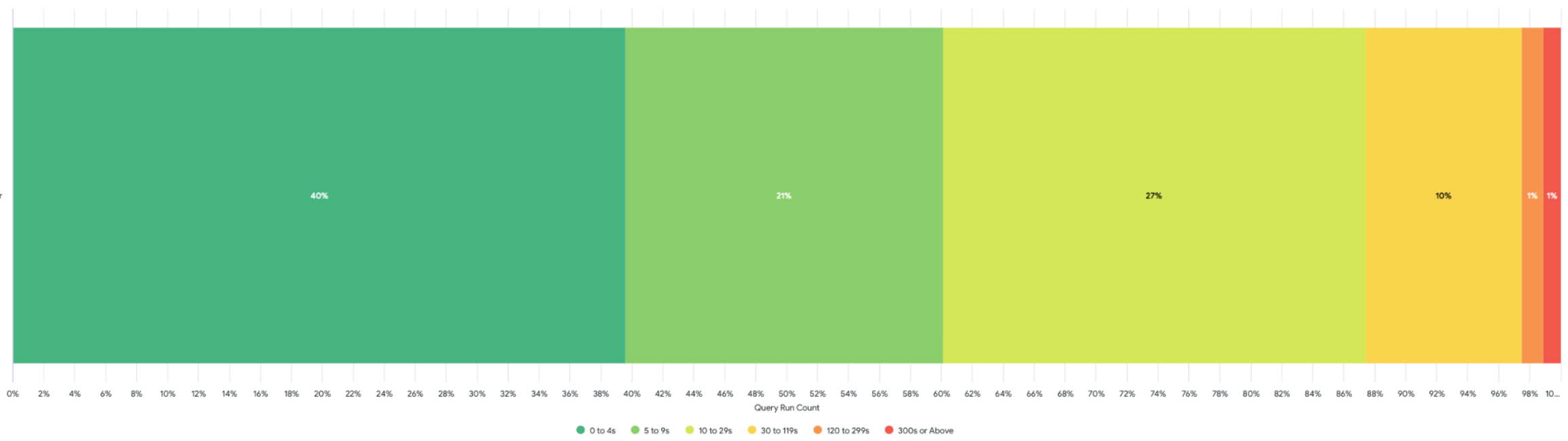
 Eduard Lopez is the Data Engineer Manager at Wallapop. He is a software engineer with over 6 years of experience in data engineering, machine learning, and data science.
Eduard Lopez is the Data Engineer Manager at Wallapop. He is a software engineer with over 6 years of experience in data engineering, machine learning, and data science. Daniel Martinez is a Solutions Architect in Iberia Digital Native Businesses (DNB), part of the worldwide commercial sales organization (WWCS) at AWS.
Daniel Martinez is a Solutions Architect in Iberia Digital Native Businesses (DNB), part of the worldwide commercial sales organization (WWCS) at AWS. Jordi Montoliu is a Sr. Redshift Specialist in EMEA, part of the worldwide specialist organization (WWSO) at AWS.
Jordi Montoliu is a Sr. Redshift Specialist in EMEA, part of the worldwide specialist organization (WWSO) at AWS. Ziad Wali is an Acceleration Lab Solutions Architect at Amazon Web Services. He has over 10 years of experience in databases and data warehousing, where he enjoys building reliable, scalable, and efficient solutions. Outside of work, he enjoys sports and spending time in nature.
Ziad Wali is an Acceleration Lab Solutions Architect at Amazon Web Services. He has over 10 years of experience in databases and data warehousing, where he enjoys building reliable, scalable, and efficient solutions. Outside of work, he enjoys sports and spending time in nature. Semir Naffati is a Sr. Redshift Specialist Solutions Architect in EMEA, part of the worldwide specialist organization (WWSO) at AWS.
Semir Naffati is a Sr. Redshift Specialist Solutions Architect in EMEA, part of the worldwide specialist organization (WWSO) at AWS.





















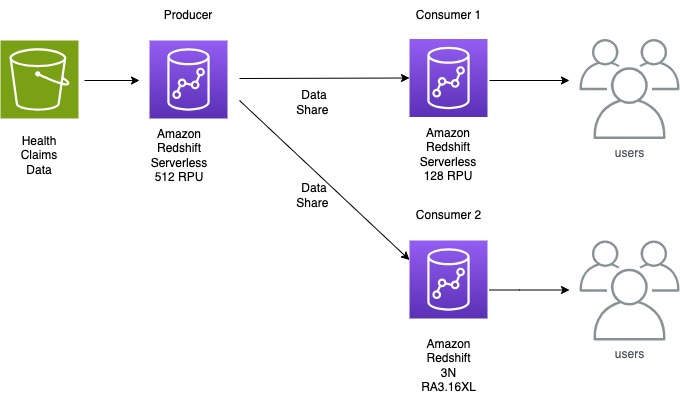
 Rajiv Arora is a Director of Clinical Data Science at Gilead Sciences with over 20 years of experience in the industry. He is responsible for the multi-modal data platform for the development organization and supports all statistical and predictive analytical infrastructure for RWE and Advanced Analytical functions.
Rajiv Arora is a Director of Clinical Data Science at Gilead Sciences with over 20 years of experience in the industry. He is responsible for the multi-modal data platform for the development organization and supports all statistical and predictive analytical infrastructure for RWE and Advanced Analytical functions. Ritesh Kumar Sinha is an Analytics Specialist Solutions Architect based out of San Francisco. He has helped customers build scalable data warehousing and big data solutions for over 16 years. He loves to design and build efficient end-to-end solutions on AWS. In his spare time, he loves reading, walking, and doing yoga.
Ritesh Kumar Sinha is an Analytics Specialist Solutions Architect based out of San Francisco. He has helped customers build scalable data warehousing and big data solutions for over 16 years. He loves to design and build efficient end-to-end solutions on AWS. In his spare time, he loves reading, walking, and doing yoga. Raks Khare is an Analytics Specialist Solutions Architect at AWS based out of Pennsylvania. He helps customers architect data analytics solutions at scale on the AWS platform.
Raks Khare is an Analytics Specialist Solutions Architect at AWS based out of Pennsylvania. He helps customers architect data analytics solutions at scale on the AWS platform. Brent Strong is a Senior Solutions Architect in the Healthcare and Life Sciences team at AWS. He has more than 15 years of experience in the industry, focusing on data and analytics and DevOps. At AWS, he works closely with large Life Sciences customers to help them deliver new and innovative treatments.
Brent Strong is a Senior Solutions Architect in the Healthcare and Life Sciences team at AWS. He has more than 15 years of experience in the industry, focusing on data and analytics and DevOps. At AWS, he works closely with large Life Sciences customers to help them deliver new and innovative treatments. Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS with over 25 years of data warehouse experience.
Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS with over 25 years of data warehouse experience.












 Mukul Sharma is a Software Development Engineer on Data & Analytics (DnA) organization at GoDaddy. He is a polyglot programmer with experience in a wide array of technologies to rapidly deliver scalable solutions. He enjoys singing karaoke, playing various board games, and working on personal programming projects in his spare time.
Mukul Sharma is a Software Development Engineer on Data & Analytics (DnA) organization at GoDaddy. He is a polyglot programmer with experience in a wide array of technologies to rapidly deliver scalable solutions. He enjoys singing karaoke, playing various board games, and working on personal programming projects in his spare time. Ozcan Ilikhan is a Director of Engineering on Data & Analytics (DnA) organization at GoDaddy. He is passionate about solving customer problems and increasing efficiency using data and ML/AI. In his spare time, he loves reading, hiking, gardening, and working on DIY projects.
Ozcan Ilikhan is a Director of Engineering on Data & Analytics (DnA) organization at GoDaddy. He is passionate about solving customer problems and increasing efficiency using data and ML/AI. In his spare time, he loves reading, hiking, gardening, and working on DIY projects. Harsh Vardhan Singh Gaur is an AWS Solutions Architect, specializing in analytics. He has over 6 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.
Harsh Vardhan Singh Gaur is an AWS Solutions Architect, specializing in analytics. He has over 6 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data. Ramesh Kumar Venkatraman is a Senior Solutions Architect at AWS who is passionate about containers and databases. He works with AWS customers to design, deploy, and manage their AWS workloads and architectures. In his spare time, he loves to play with his two kids and follows cricket.
Ramesh Kumar Venkatraman is a Senior Solutions Architect at AWS who is passionate about containers and databases. He works with AWS customers to design, deploy, and manage their AWS workloads and architectures. In his spare time, he loves to play with his two kids and follows cricket.



















 Kartikay Khator is a Solutions Architect in Global Life Sciences at Amazon Web Services (AWS). He is passionate about building innovative and scalable solutions to meet the needs of customers, focusing on AWS Analytics services. Beyond the tech world, he is an avid runner and enjoys hiking.
Kartikay Khator is a Solutions Architect in Global Life Sciences at Amazon Web Services (AWS). He is passionate about building innovative and scalable solutions to meet the needs of customers, focusing on AWS Analytics services. Beyond the tech world, he is an avid runner and enjoys hiking. Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect and Amazon AppFlow expert. He’s on a mission to make life easier for customers who are facing complex data integration challenges. His secret weapon? Fully managed, low-code AWS services that can get the job done with minimal effort and no coding.
Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect and Amazon AppFlow expert. He’s on a mission to make life easier for customers who are facing complex data integration challenges. His secret weapon? Fully managed, low-code AWS services that can get the job done with minimal effort and no coding. Anshul Sharma is a Software Development Engineer in AWS Glue Team. He is driving the connectivity charter which provide Glue customer native way of connecting any Data source (Data-warehouse, Data-lakes, NoSQL etc) to Glue ETL Jobs. Beyond the tech world, he is a cricket and soccer lover.
Anshul Sharma is a Software Development Engineer in AWS Glue Team. He is driving the connectivity charter which provide Glue customer native way of connecting any Data source (Data-warehouse, Data-lakes, NoSQL etc) to Glue ETL Jobs. Beyond the tech world, he is a cricket and soccer lover.