Post Syndicated from Omer Yoachimik http://blog.cloudflare.com/author/omer/ original https://blog.cloudflare.com/ddos-threat-report-2023-q4-ko-kr

Cloudflare DDoS 위협 보고서 제16호에 오신 것을 환영합니다. 이번 호에서는 2023년 4분기이자 마지막 분기의 DDoS 동향과 주요 결과를 다루며, 연중 주요 동향을 검토합니다.
DDoS 공격이란 무엇일까요?
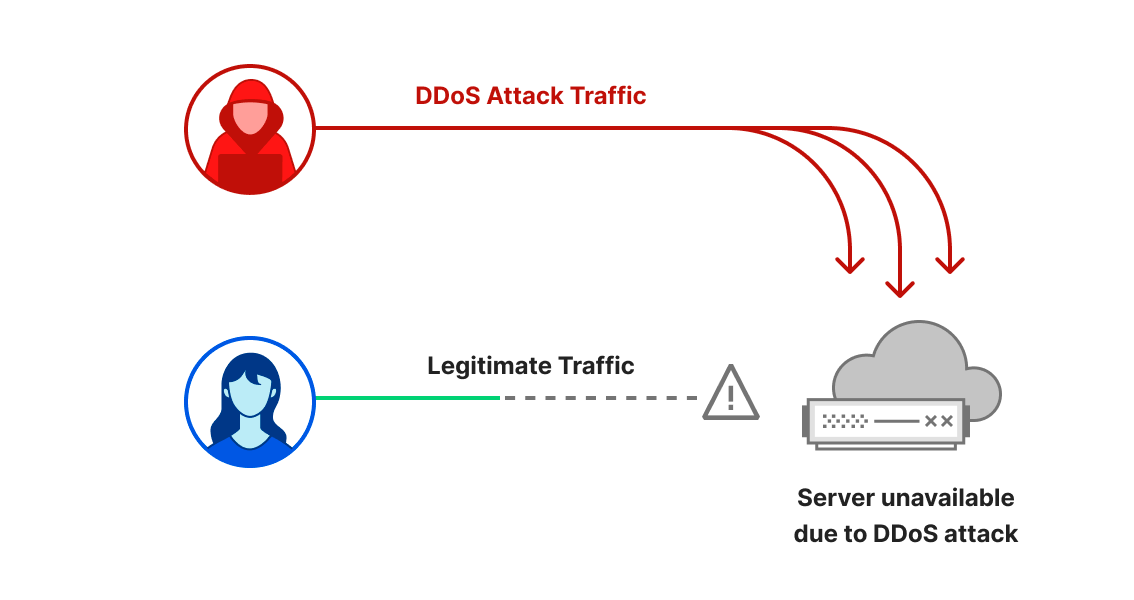
DDoS 공격 또는 분산 서비스 거부 공격은 웹 사이트와 온라인 서비스가 처리할 수 있는 트래픽을 초과하여 사용자를 방해하고 서비스를 사용할 수 없게 만드는 것을 목표로 하는 사이버 공격의 한 유형입니다. 이는 교통 체증으로 길이 막혀 운전자가 목적지에 도착하지 못하는 것과 유사합니다.
이 보고서에서 다룰 DDoS 공격에는 크게 세 가지 유형이 있습니다. 첫 번째는 HTTP 서버가 처리할 수 있는 것보다 더 많은 요청으로 서버를 압도하여 서비스 거부 이벤트를 발생시키는 것을 목표로 하는 HTTP 요청집중형 DDoS 공격입니다. 두 번째는 라우터, 방화벽, 서버 등의 인라인 장비에서 처리할 수 있는 패킷보다 많은 패킷을 전송하여 서버를 압도하는 것을 목표로 하는IP 패킷집중형 DDoS 공격입니다. 세 번째는 비트 집중형 공격으로, 인터넷 링크를 포화 상태로 만들어 막히게 함으로써 앞서 설명한 ‘정체’를 유발하는 것을 목표로 합니다. 이 보고서에서는 세 가지 유형의 공격에 대해 다양한 기법과 인사이트를 중점적으로 다룹니다.
보고서의 이전 버전은 여기에서 확인할 수 있으며, 대화형 허브인Cloudflare Radar에서도 확인할 수 있습니다. Cloudflare Radar는 전 세계 인터넷 트래픽, 공격, 기술 동향, 인사이트를 보여주며, 드릴 다운 및 필터링 기능을 통해 특정 국가, 산업, 서비스 공급자에 대한 인사이트를 확대할 수 있습니다. Cloudflare Radar는 학자, 데이터 전문가, 기타 웹 애호가가 전 세계 인터넷 사용량을 조사할 수 있는 무료 API도 제공합니다.
Cloudflare에서 이 보고서를 작성한 방법을 알아보려면 방법론을 참조하세요.
핵심 결과
- Cloudflare에서 관찰한 바에 따르면, 4분기에는 네트워크 계층 DDoS 공격이 전년 동기 대비 117% 증가했으며, 블랙 프라이데이와 연말연시를 전후해 소매, 배송, 홍보 웹 사이트를 겨냥한 DDoS 활동이 전반적으로 증가했습니다.
- 4분기에 대만을 겨냥한 DDoS 공격 트래픽은 총선이 다가오고 중국과의 긴장이 고조된 가운데 전년 대비 3,370% 증가했습니다. 이스라엘과 하마스 간의 군사적 갈등이 지속됨에 따라 이스라엘 웹 사이트를 겨냥한 DDoS 공격 트래픽의 비율은 전 분기 대비 27% 증가했으며, 팔레스타인 웹 사이트를 의 군사적 갈등이 지속됨에 따라 이스라엘 웹 사이트를 겨냥한 DDoS 공격 트래픽의 비율은 전 분기 대비 1,126% 증가했습니다.
- 4분기에는 제28차 유엔 기후변화회의(COP 28)가 열린 시기와 맞물려 환경 서비스 웹 사이트를 겨냥한 DDoS 공격 트래픽이 전년 대비 무려 61,839% 급증했습니다.
이러한 주요 조사 결과에 대한 심층 분석과 현재의 사이버 보안 과제에 대한 이해를 새롭게 정의할 수 있는 추가 인사이트를 확인하려면 계속 읽어보세요!
대규모 볼류메트릭 HTTP DDoS 공격
2023년은 미지의 영역이 펼쳐지는 해였습니다. DDoS 공격은 규모와 정교함에 있어서 새로운 차원에 도달했습니다. Cloudflare를 포함한 광범위한 인터넷 커뮤니티에서는 전례 없는 속도로 수천 건에 이르며 지속적이고 의도적으로 설계된 대규모 볼류메트릭 DDoS 공격 캠페인에 직면했습니다.
이러한 공격은 매우 복잡하고 HTTP/2 취약점을 악용했습니다. Cloudflare에서는 취약점의 영향을 완화하기 위해 특수하게 마련한 기술을 개발했으며, 업계의 다른 기업들과 협력하여 취약점을 공개하는 일을 담당했습니다.
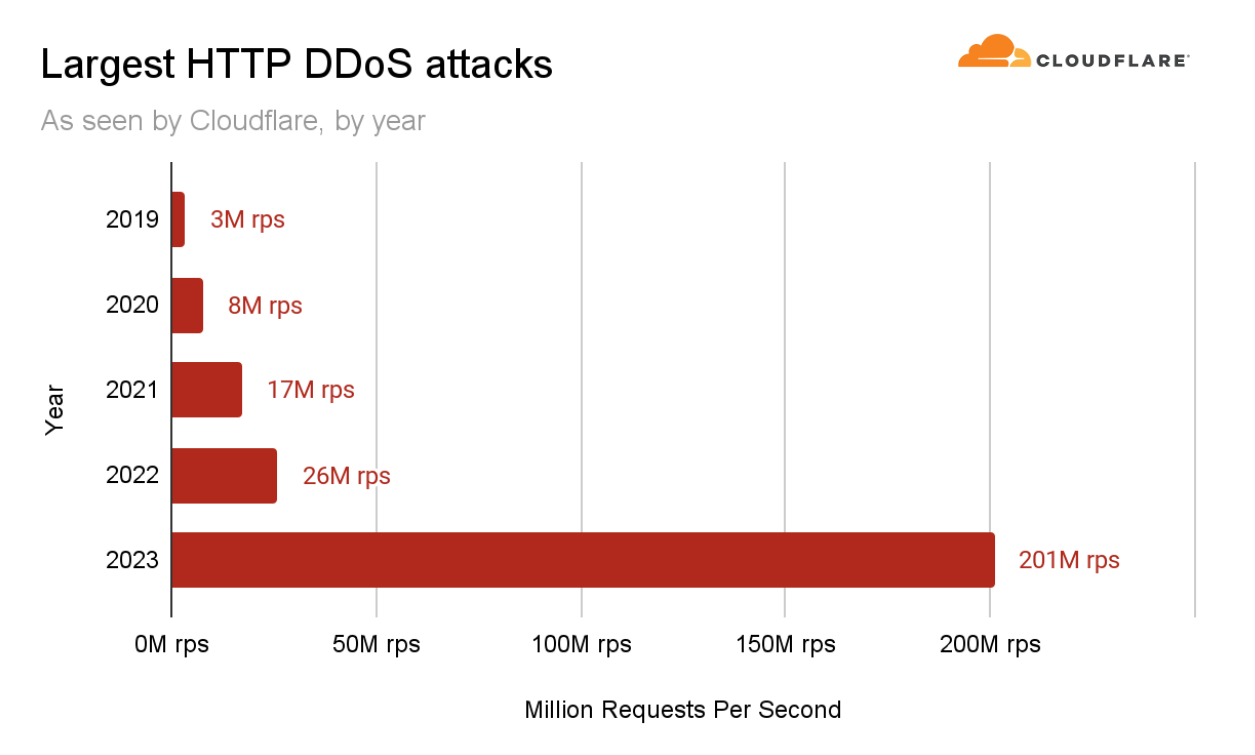
이러한 DDoS 캠페인의 일환으로 3분기에 Cloudflare의 시스템에서는 초당 2억 100만 건에 달하는 사상 최대 규모의 요청으로 이루어진 공격을 방어했습니다. 이는 지난 2022년의 기록인 초당 2,600만 요청보다 거의 8배나 많은 수치입니다.
네트워크 계층 DDoS 공격의 증가
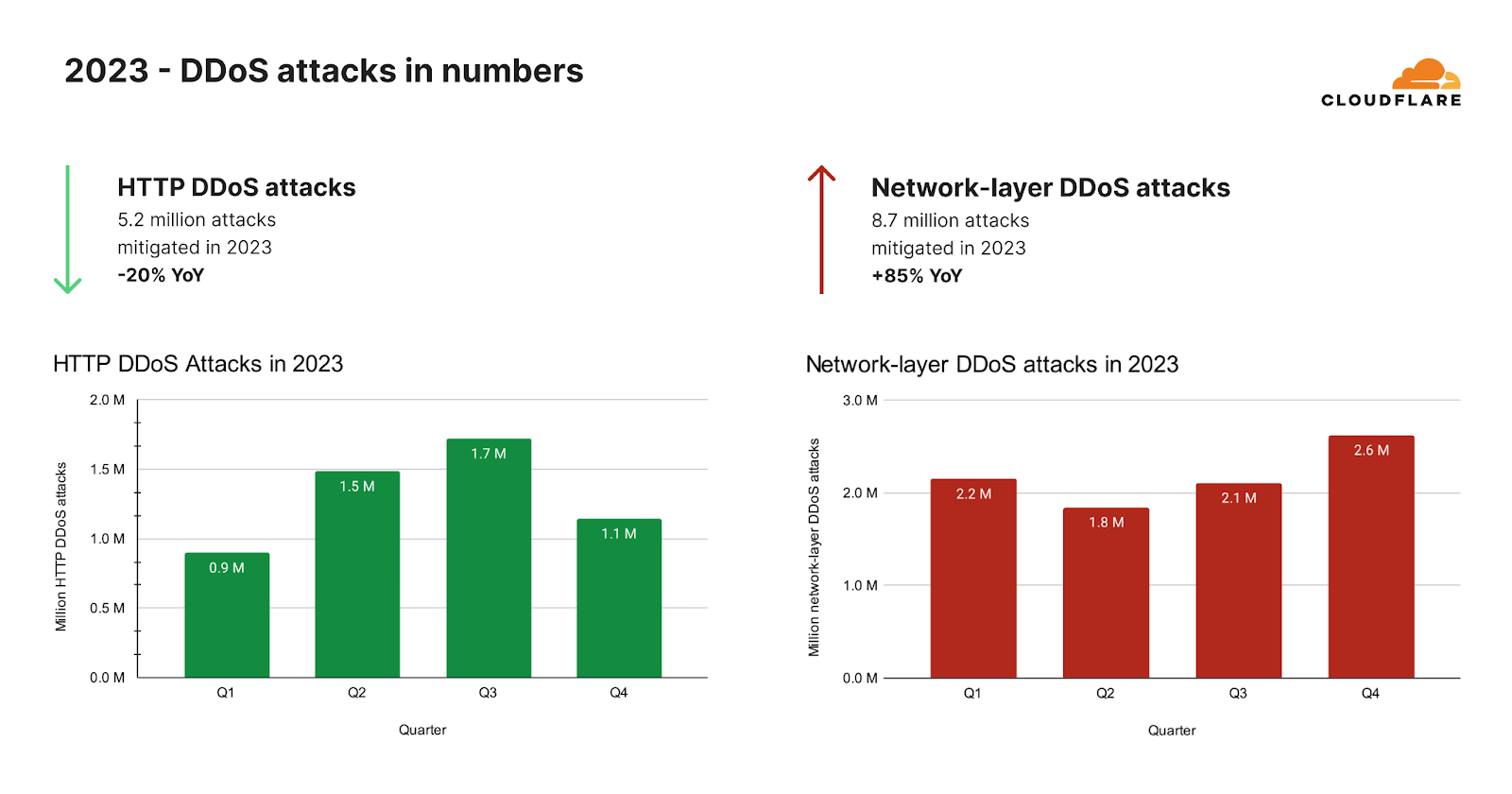
대규모 캠페인이 진정된 후 우리는 HTTP DDoS 공격이 예상치 않게 감소하는 것을 확인했습니다. 2023년 전체적으로는 26조 건이 넘는 요청으로 이루어진 520만 건 이상의 HTTP DDoS 공격을 자동화된 방어 기능으로 막아냈습니다. 이는 시간당 평균 594건의 HTTP DDoS 공격과 30억 건의 요청을 완화한 수치입니다.
이러한 천문학적 수치에도 불구하고 HTTP DDoS 공격 요청량은 실제로 2022년에 비해 20% 감소했습니다. 이러한 감소세는 연간뿐만 아니라 2023년 4분기에도 관찰되었는데, HTTP DDoS 공격 요청 건수는 전년 동기 대비 7%, 전 분기 대비 18% 감소했습니다.
네트워크 계층에서는 완전히 다른 추세를 확인했습니다. Cloudflare에서는 자동화된 방어 기능으로2023년에 870만 건의 네트워크 계층 DDoS 공격을 방어했습니다. 이는 2022년에 비해 85% 증가한 수치입니다.
2023년 4분기에 Cloudflare에서는 자동화된 방어 기능으로 80페타바이트가 넘는 네트워크 계층 공격을 완화했습니다. 평균적으로 우리 시스템에서는 매시간 996건의 네트워크 계층 DDoS 공격과 27테라바이트를 자동으로 방어했습니다. 2023년 4분기의 네트워크 계층 DDoS 공격 건수는 전년 동기 대비 175%, 전 분기 대비25% 증가했습니다.
COP 28 기간과 그 전후의DDoS 공격 증가
2023년 마지막 분기에는 사이버 위협의 환경이 크게 변화했습니다. 초기에는 암호화폐 분야가 HTTP DDoS 공격 요청량 측면에서 선두를 달리고 있었지만, 새로운 공격 대상이 주요 피해자로 등장했습니다. 환경 서비스 업계를 겨냥한 HTTP DDoS 공격이 전례 없이 급증했으며, 이 공격이 전체 HTTP 트래픽의 절반을 차지했습니다. 이는 전년 대비 무려 618배 증가한 수치로, 사이버 위협 환경의 불안한 추세를 보여줍니다.
이처럼 사이버 공격이 급증한 시기는 2023년 11월 30일부터 12월12일까지 열린 유엔기후변화협약 당사국총회(COP 28)와 맞물렸습니다. 이 회의는 중추적인 이벤트로, 많은 사람이 화석 연료 시대의 ‘종말의 시작’이라고 생각했던 것을 알리는 신호탄이었습니다. COP 28을 앞둔 기간 동안 환경 서비스 웹 사이트를 겨냥한 HTTP 공격이 눈에 띄게 급증한 것으로 관찰되었습니다. 이러한 패턴은 이 이벤트에만 국한된 것이 아니었습니다.
특히 COP 26과 COP 27, 그리고 다른 유엔 환경 관련 결의안이나 발표의 과거 데이터를 살펴보면 비슷한 패턴이 나타납니다. 이러한 이벤트가 있을 때마다 환경 서비스 웹 사이트를 겨냥한 사이버 공격도 함께 증가했습니다.
2023년 2월과 3월, 유엔의 기후 정의 결의안과 유엔환경계획의 담수 챌린지시작과 같은 중요한 환경 이벤트 때문에 환경 웹 사이트의 인지도가 높아졌고, 이는 이러한 사이트에 대한 공격의 증가와 관련이 있을 수 있습니다.
이러한 반복적인 패턴을 보면 환경 문제와 사이버 보안이 점점 더 밀접하게 연관되어 있으며, 사이버 보안은 디지털 시대에 점점 더 공격자의 초점이 되고 있음을 실감할 수 있습니다.
DDoS 공격과 철검
DDoS 공격을 촉발하는 것은 유엔 결의안만이 아닙니다. 사이버 공격, 특히 DDoS 공격은 오랫동안 전쟁과 혼란의 도구로 사용되어 왔습니다. 우크라이나와 러시아 사이의 전쟁에서 DDoS 공격 활동이 증가되는 것이 관찰되었고, 이제는 이스라엘과 하마스 사이의 전쟁에서도 DDoS 공격이 증가하고 있습니다. Cloudflare에서는 이스라엘-하마스 전쟁에서의 사이버 공격 보고서에서 사이버 활동을 처음 보고했으며, 4분기 내내 지속해서 사이버 활동을 모니터링했습니다.
“철검” 작전은 하마스가 주도한 10월 7일 공격 이후 이스라엘이 하마스를 상대로 시작한 군사 공격입니다. 이 무력 충돌이 계속되는 Cloudflare에서는 동안 양측을 겨냥한DDoS 공격을 계속 목격하고 있습니다.
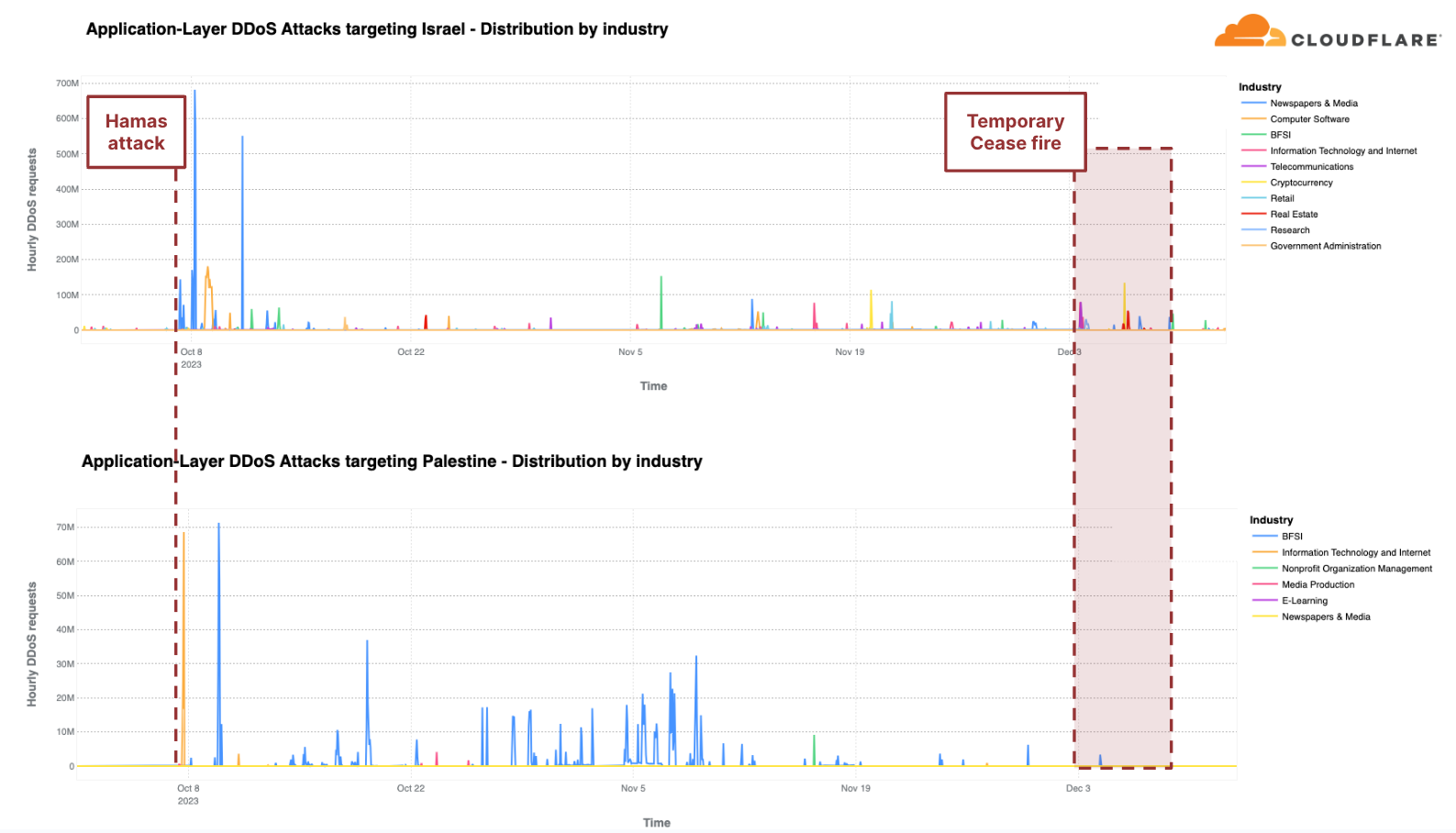
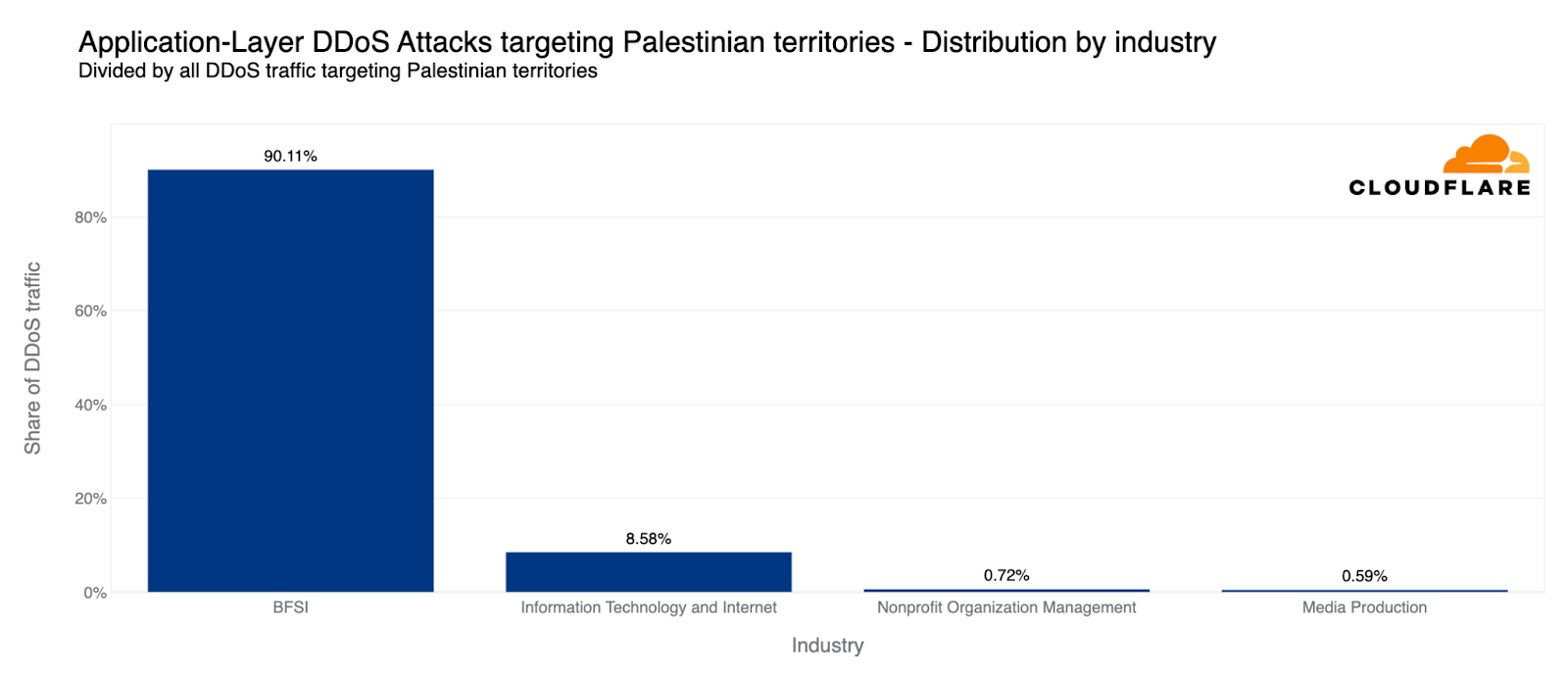
지역별 트래픽을 기준으로 볼 때, 팔레스타인 지역은 4분기에 HTTP DDoS 공격이 두 번째로 많이 발생한 지역이었습니다. 팔레스타인 웹 사이트를 향한 전체 HTTP 요청의 10% 이상이 DDoS 공격이었으며, 총 13억 건의DDoS 요청이 발생하여 전 분기 대비 1,126% 증가했습니다. 이러한 DDoS 공격의 90%는 팔레스타인 은행 웹 사이트를 겨냥했습니다. 또 다른 8%는 정보 기술 및 인터넷 플랫폼을 겨냥했습니다.
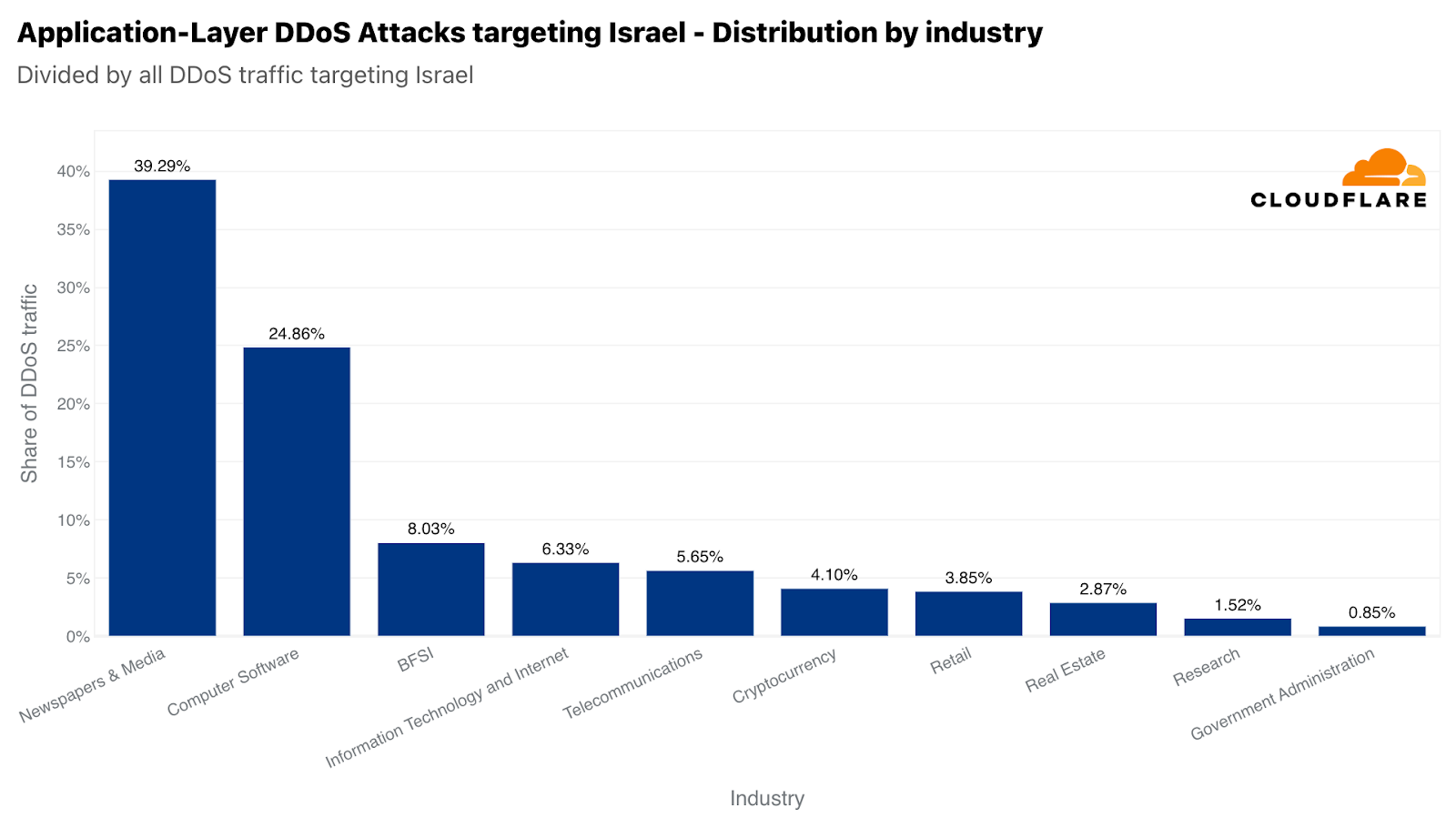
유사하게, Cloudflare의 시스템에서는 이스라엘 웹 사이트를 겨냥한 22억 건 이상의 HTTP DDoS 요청을 자동으로 방어했습니다. 22억 건은 전 분기 및 전년 동기 대비 감소한 수치이지만, 이스라엘로 향하는 전체 트래픽 중에서 차지하는 비중은 여전히 높았습니다. 이 정규화 수치는 전 분기 대비 27% 증가했지만, 전년 동기 대비로는 92% 감소한 수치입니다. 공격 트래픽의 양이 많음에도 불구하고 이스라엘은 자국 트래픽 대비 77번째로 공격을 많이 받은 지역이었습니다. 또한 총 공격 건수 기준으로는 33번째로 공격을 많이 받은 반면 팔레스타인 영토는 42번째로 공격을 많이 받았습니다.
공격받은 이스라엘 웹 사이트 중 신문 및 미디어가 주요 표적이었으며, 이스라엘을 향하는 HTTP DDoS 공격의 약 40%를 신문 및 미디어 부문에서 받았습니다. 두 번째로 공격을 많이 받은 산업은 컴퓨터 소프트웨어 산업이었습니다. 은행, 금융 기관 및 보험(BFSI) 산업이 3위를 차지했습니다.
네트워크 계층에서도 동일한 추세를 확인할 수 있습니다. 팔레스타인 네트워크는 470테라바이트에 이르는 공격 트래픽의 표적이 되었으며, 이는 팔레스타인 네트워크에 대한 전체 트래픽의 68% 이상을 차지했습니다. 이는 중국에만 뒤지는 수치로, 팔레스타인 지역으로 향하는 모든 트래픽을 기준으로, 팔레스타인이 네트워크 계층 DDoS 공격이 세계에서 두 번째로 많이 발생한 지역이 되었습니다. 절대적인 트래픽 규모로는 3위를 차지했습니다. 이 470테라바이트는 Cloudflare에서 완화한 전체 DDoS 트래픽의 약 1%를 차지합니다.
하지만 이스라엘 네트워크에서 받은 공격 트래픽은 2.4테라바이트 밖에 되지 않아, 네트워크 계층 DDoS 공격을 가장 많이 받은 국가(정상화 기준) 순위에서 8위에 올랐습니다. 이 2.4테라바이트는 이스라엘 네트워크로 향하는 전체 트래픽의 거의 10%를 차지했습니다.
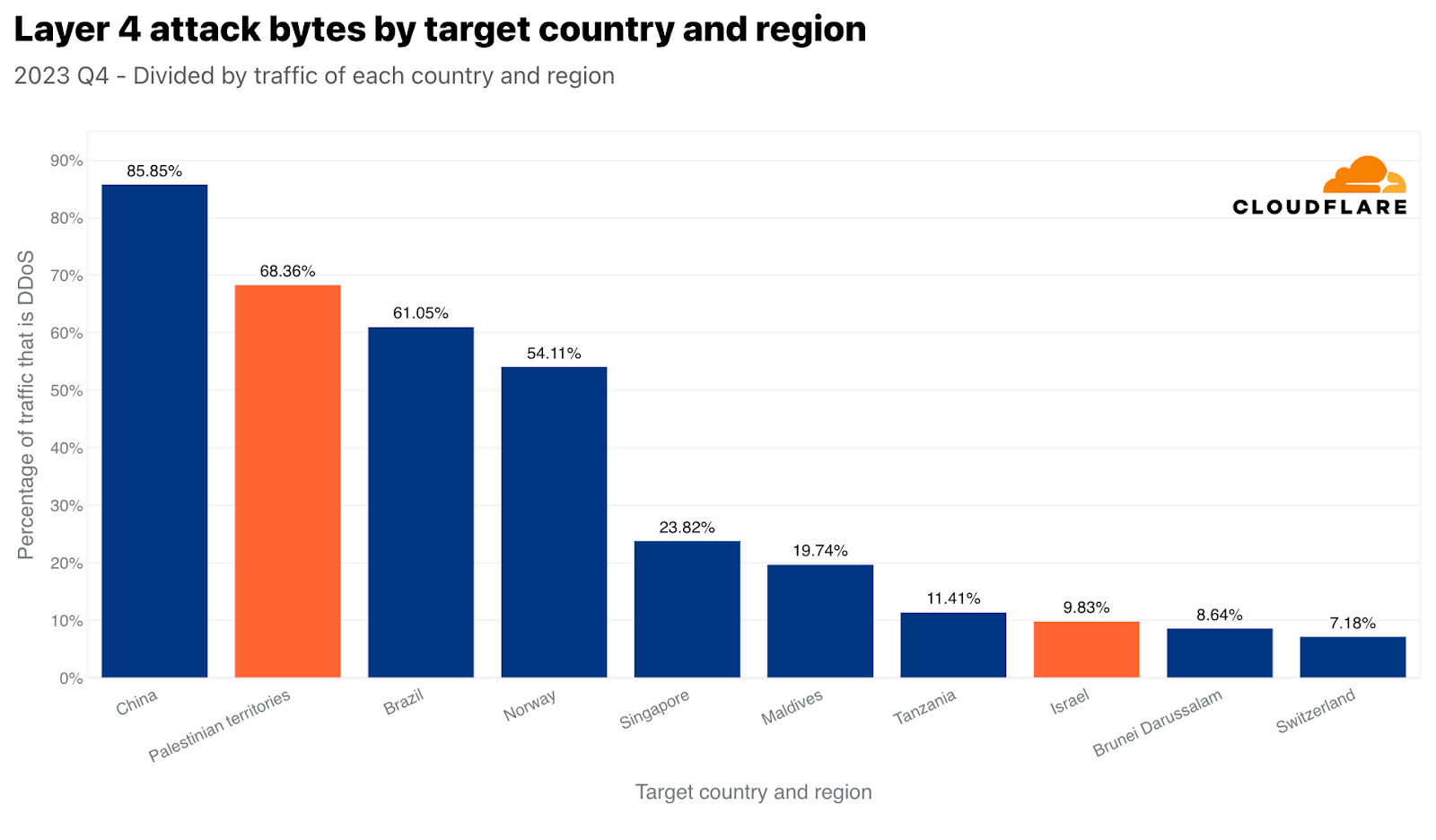
우리는 이스라엘에 위치한 우리 데이터 센터에서 수집된 전체 바이트의 3%가 네트워크 계층 DDoS 공격이라는 사실을 확인했습니다. 팔레스타인에 위치한 우리 데이터 센터에서는 이 수치가 전체 바이트의 약 17%로 훨씬 더 높았습니다.
애플리케이션 계층에서는 팔레스타인 IP 주소에서 시작된 HTTP 요청의 4%가 DDoS 공격이며, 이스라엘 IP 주소에서 시작된 HTTP 요청의 약 2%도 DDoS 공격인 것으로 나타났습니다.
DDoS 공격의 주요 출처
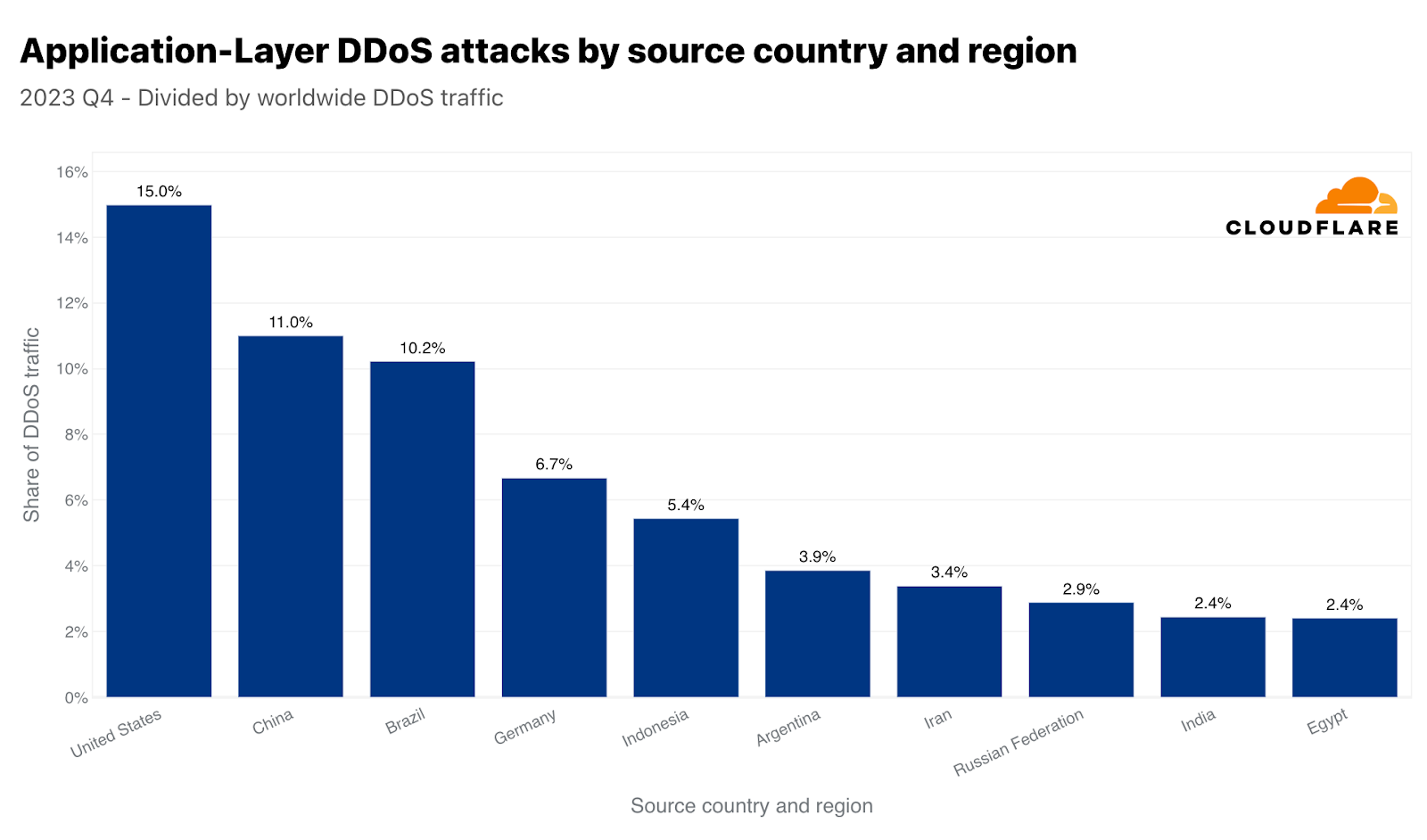
2022년 3분기에는 중국이 HTTP DDoS 공격 트래픽의 최대 출처였습니다. 그러나 2022년 4분기부터는 미국이 HTTP DDoS 공격의 최대 출처가 되었으며, 이후 5분기 연속으로 이 바람직하지 않은 위치를 유지하고 있습니다. 마찬가지로 미국의 데이터 센터는 전체 공격 바이트의 38%가 넘는 네트워크 레이어 DDoS 공격 트래픽을 가장 많이 수집하는 곳입니다.
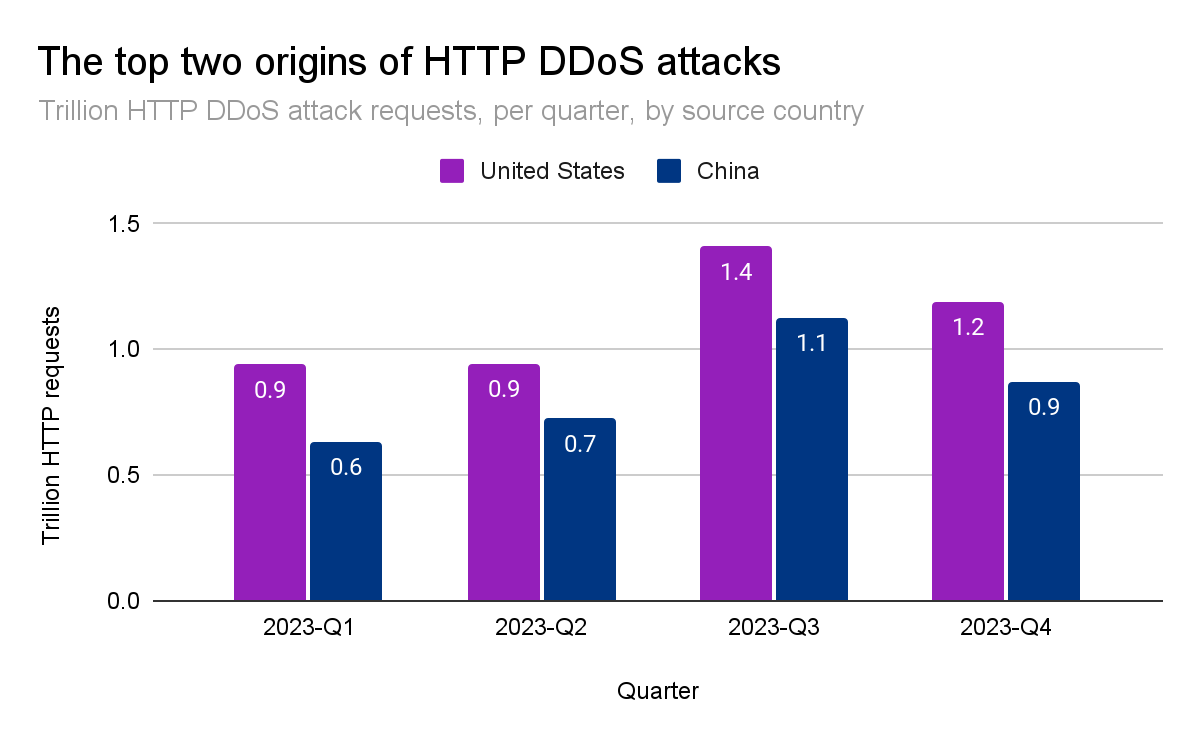
중국과 미국은 함께 전 세계 HTTP DDoS 공격 트래픽의 4분의 1 이상을 차지합니다. 브라질, 독일, 인도네시아, 아르헨티나가 그 다음 25%를 차지합니다.
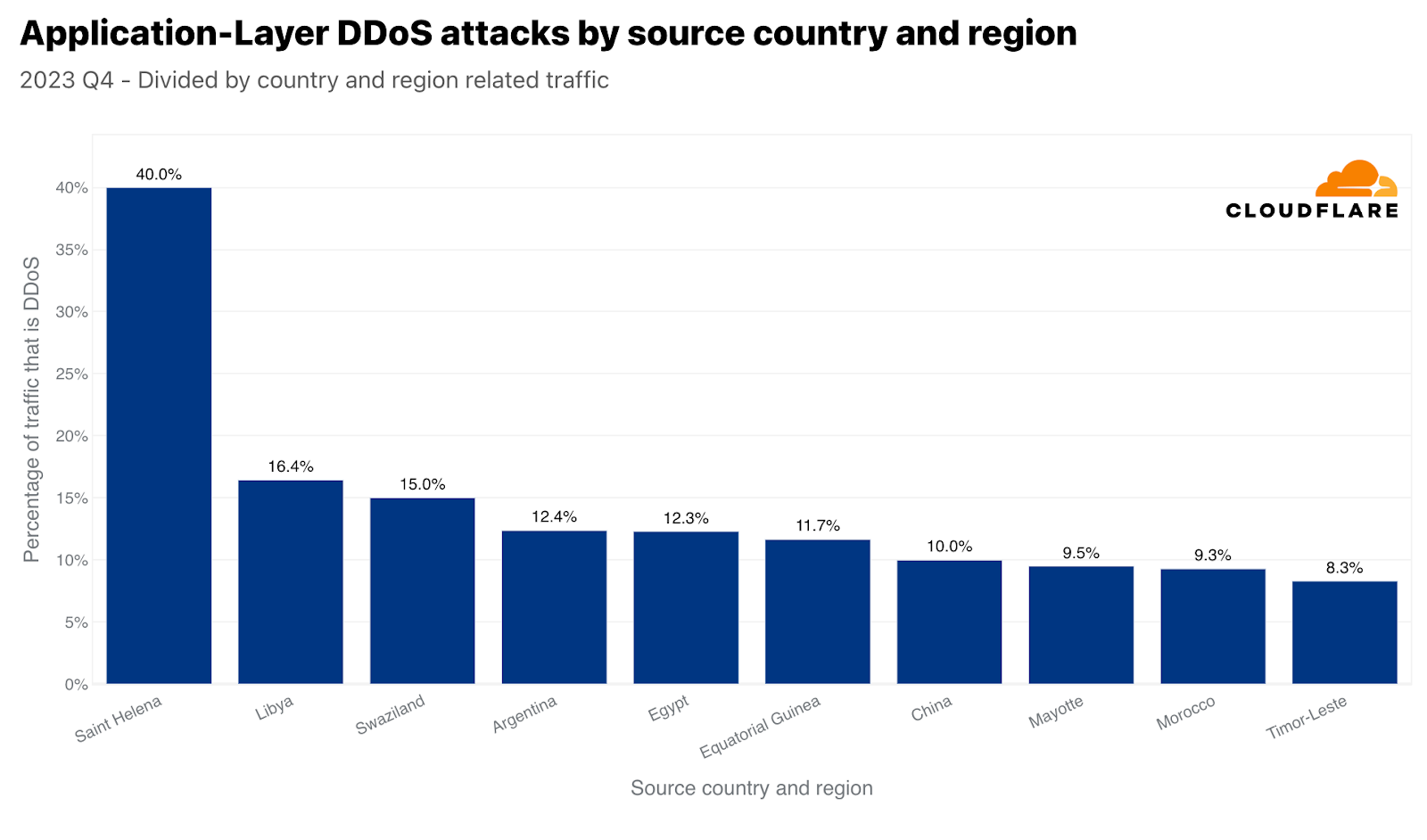
이러한 큰 수치는 일반적으로 큰 시장에 들어맞습니다. 그러한 이유로 각 국가의 아웃바운드 트래픽을 비교하여 각 국가에서 기원하는 공격 트래픽을 정규화하기도 합니다. 이 작업을 수행하면 작은 섬나라나 시장 규모가 작은 국가에서 불균형적인 공격 트래픽이 기원하는 경우가 종종 있습니다. 4분기에는, 세인트 헬레나의 아웃바운드 트래픽 중 40%가 HTTP DDoS 공격으로 1위를 차지했습니다. 이 ‘외딴 열대 화산 섬‘에 이어 리비아가 2위, 스와질란드(에스와티니라고도 함)가 3위를 차지했습니다. 아르헨티나와 이집트가 그 뒤를 이어 각각 4위와 5위를 차지했습니다.
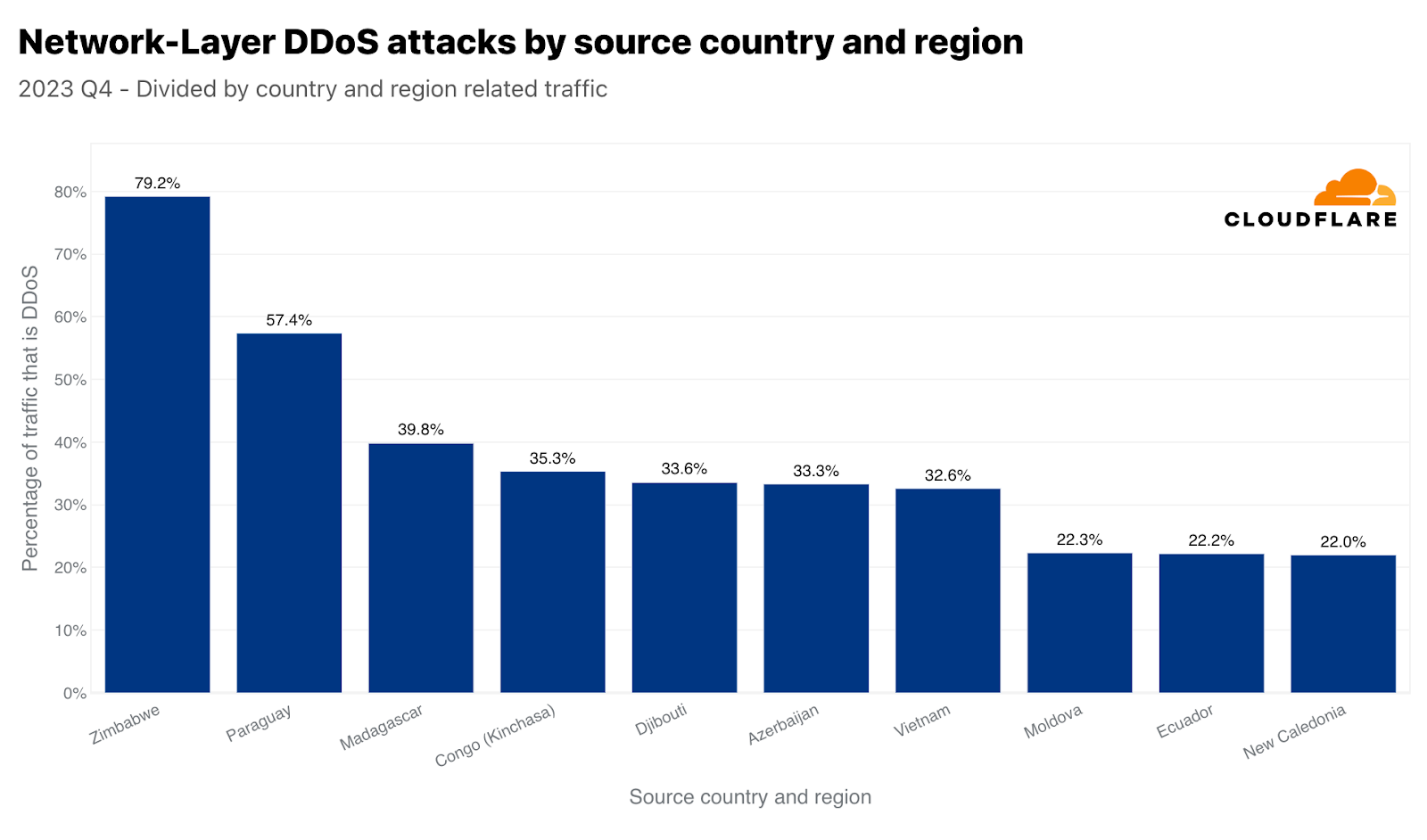
네트워크 계층에서는 짐바브웨가 1위에 올랐습니다. 짐바브웨에 위치한 Cloudflare 데이터 센터에서 수집한 전체 트래픽의 거의 80%가 악의적 트래픽이었습니다. 2위는 파라과이, 3위는 마다가스카르가 차지했습니다.
가장 많이 공격받는 산업
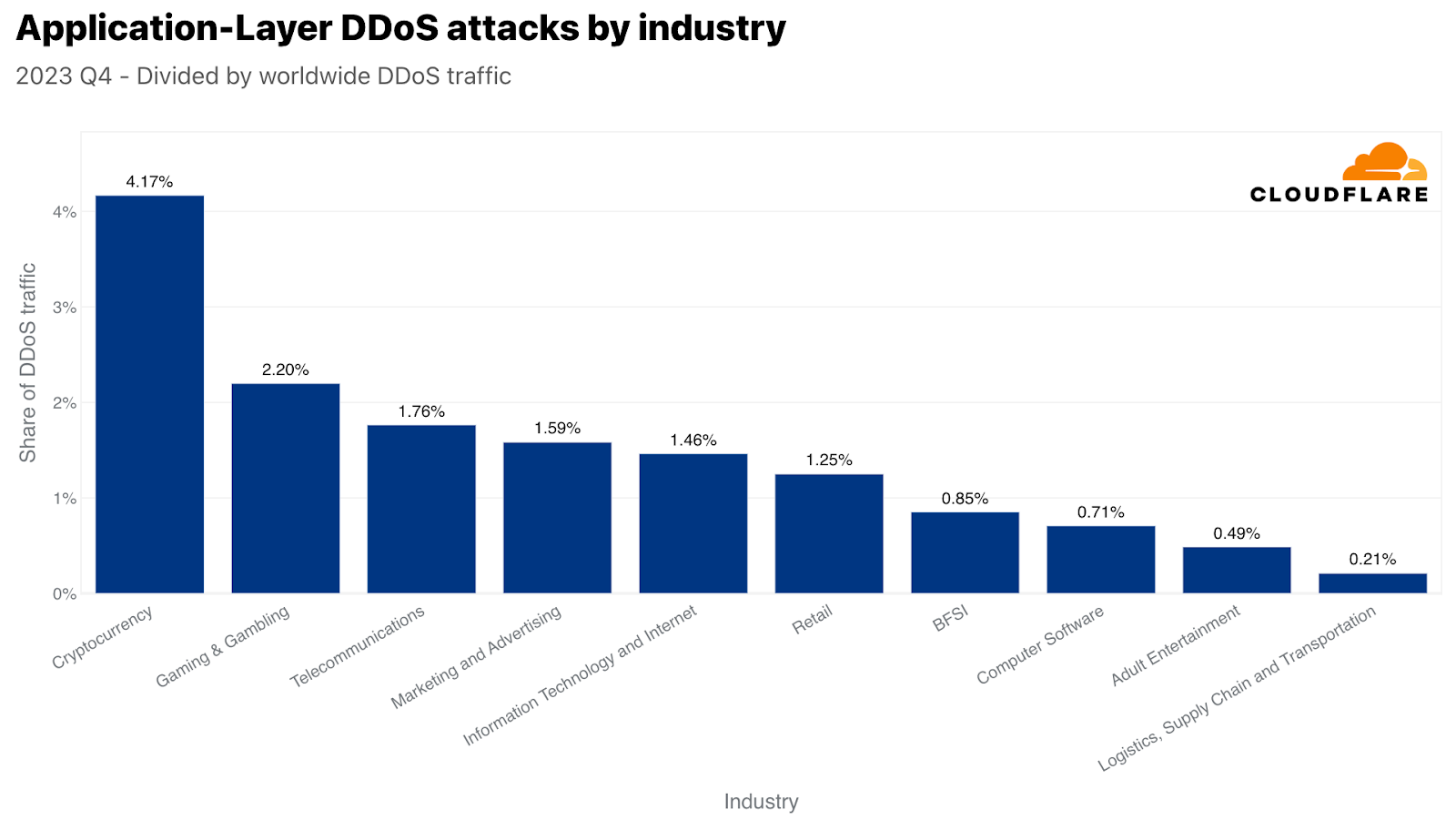
공격 트래픽 규모 기준으로 4분기에 가장 많이 공격을 받은 산업은 암호화폐 산업이었습니다. 3,300억 건 이상의 HTTP 요청이 이 산업을 겨냥했습니다. 이 수치는 해당 분기 전체 HTTP DDoS 트래픽의 4% 이상을 차지합니다. 두 번째로 공격을 많이 받은 산업은 게임 및 도박이었습니다. 이들 산업은 탐나는 표적으로 알려져 있으며 많은 트래픽과 공격을 유발합니다.
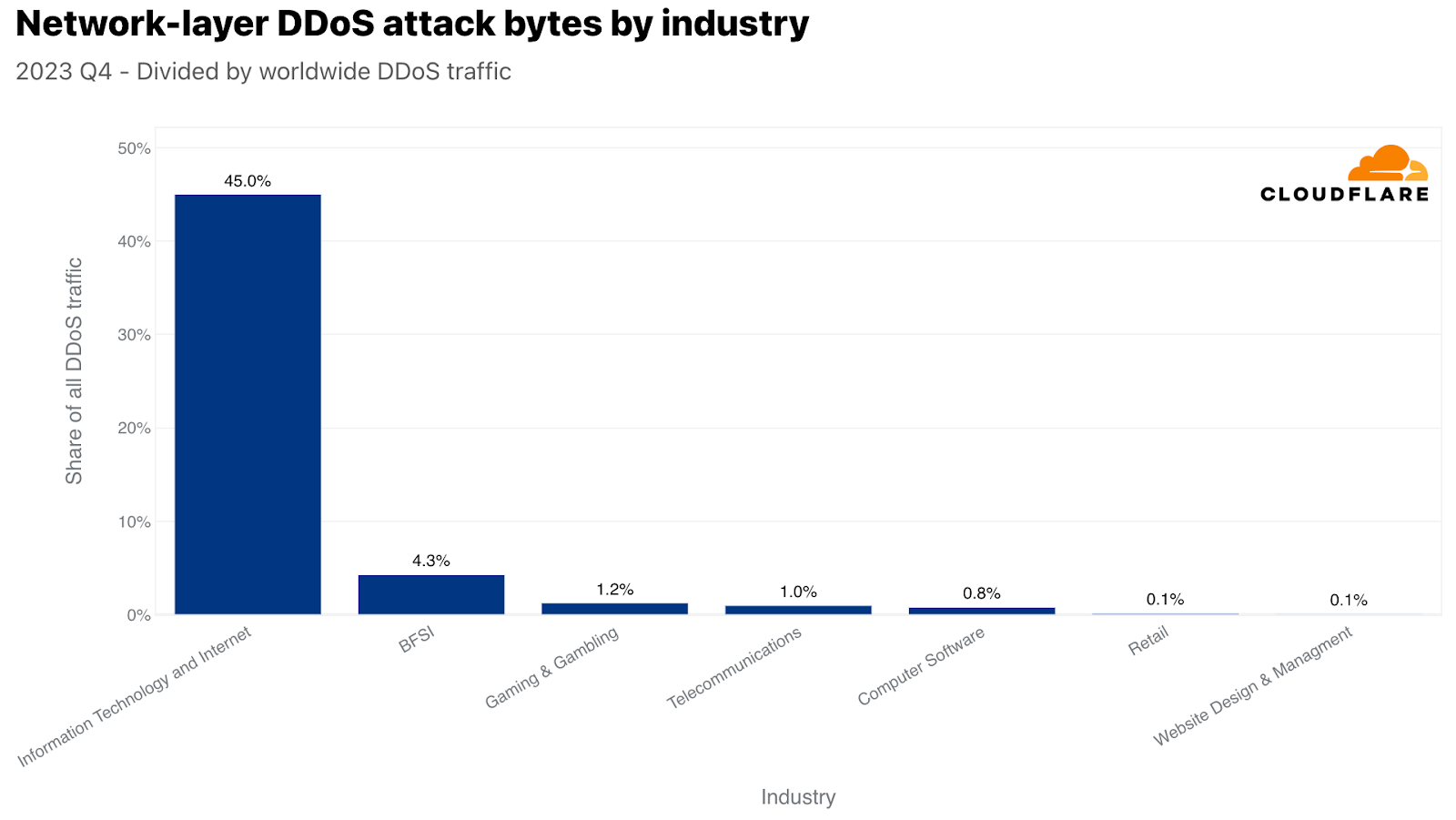
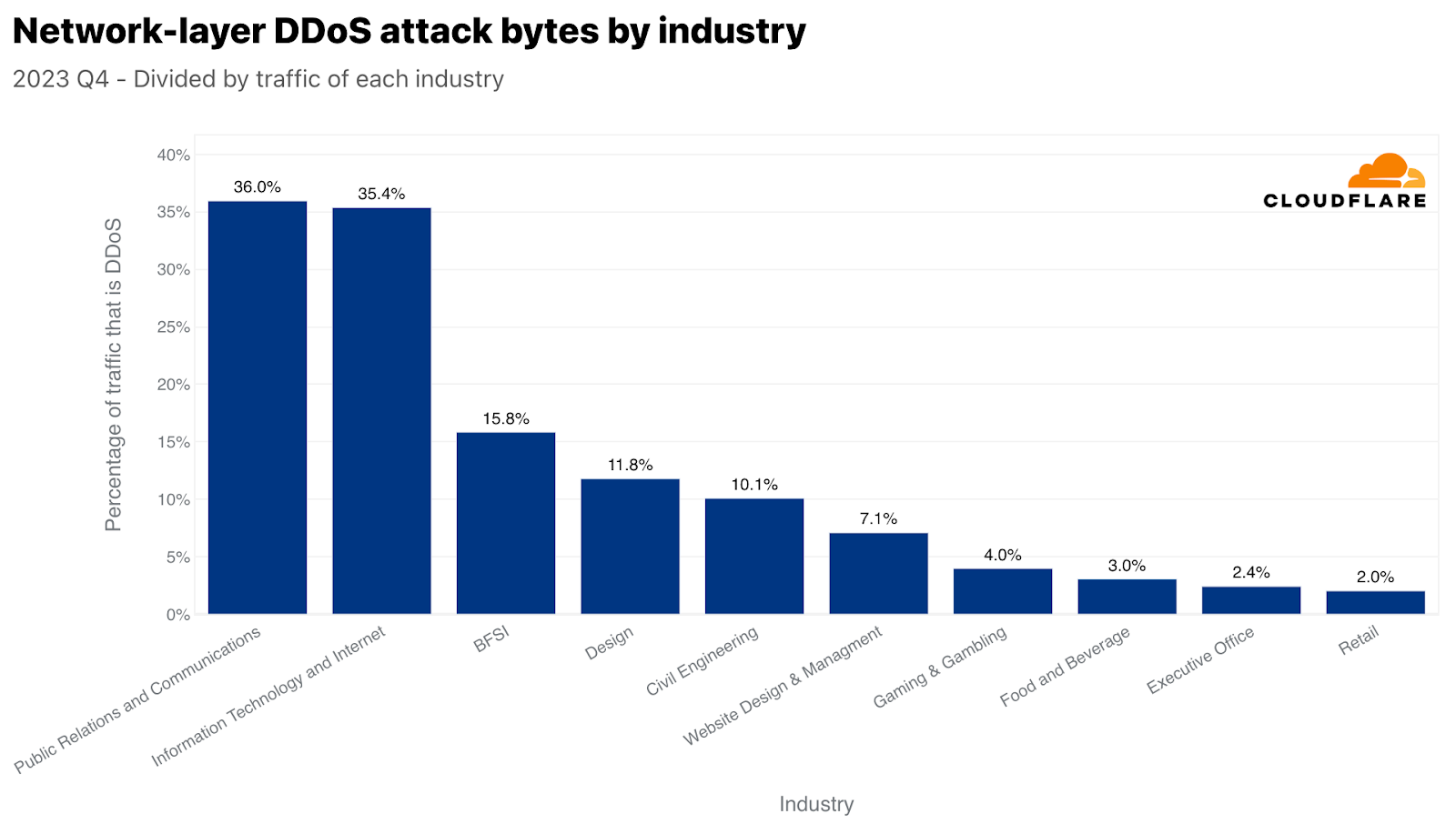
네트워크 계층에서는 정보 기술 및 인터넷 산업이 가장 많은 공격을 받았으며, 전체 네트워크 계층 DDoS 공격 트래픽의 45% 이상이 이 산업을 겨냥했습니다. 은행, 금융 서비스, 보험(BFSI), 게임 및 도박, 통신 산업이 그 뒤를 이었습니다.
관점을 바꾸기 위해 여기에서도 공격 트래픽을 특정 산업의 전체 트래픽으로 정규화했습니다. 그럴 경우 그림이 달라집니다.
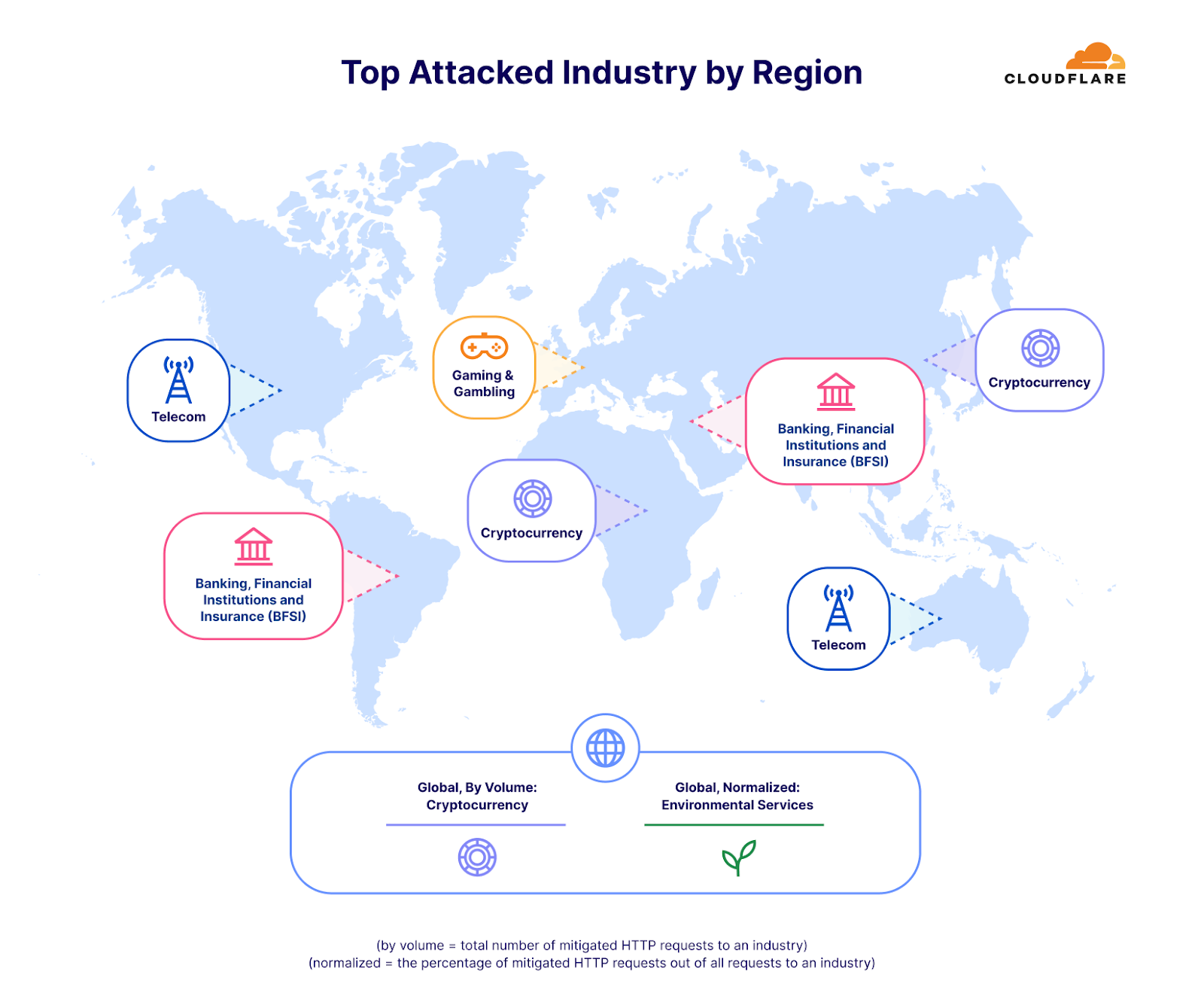
이 보고서의 서두에서 이미 환경 서비스 산업이 자체 트래픽 대비 가장 많은 공격을 받았다고 언급한 바 있습니다. 2위는 포장 및 화물 배송 산업으로, 블랙 프라이데이 및 겨울 휴가철 온라인 쇼핑과 시기상으로 상관관계가 있다는 점에서 흥미로웠습니다. 판매된 선물과 상품을 어떻게든 목적지에 보내야 하는데, 공격자가 이를 방해하려고 시도한 것으로 보입니다. 마찬가지로 소매업체에 대한 DDoS 공격도 전년 대비 23% 증가했습니다.
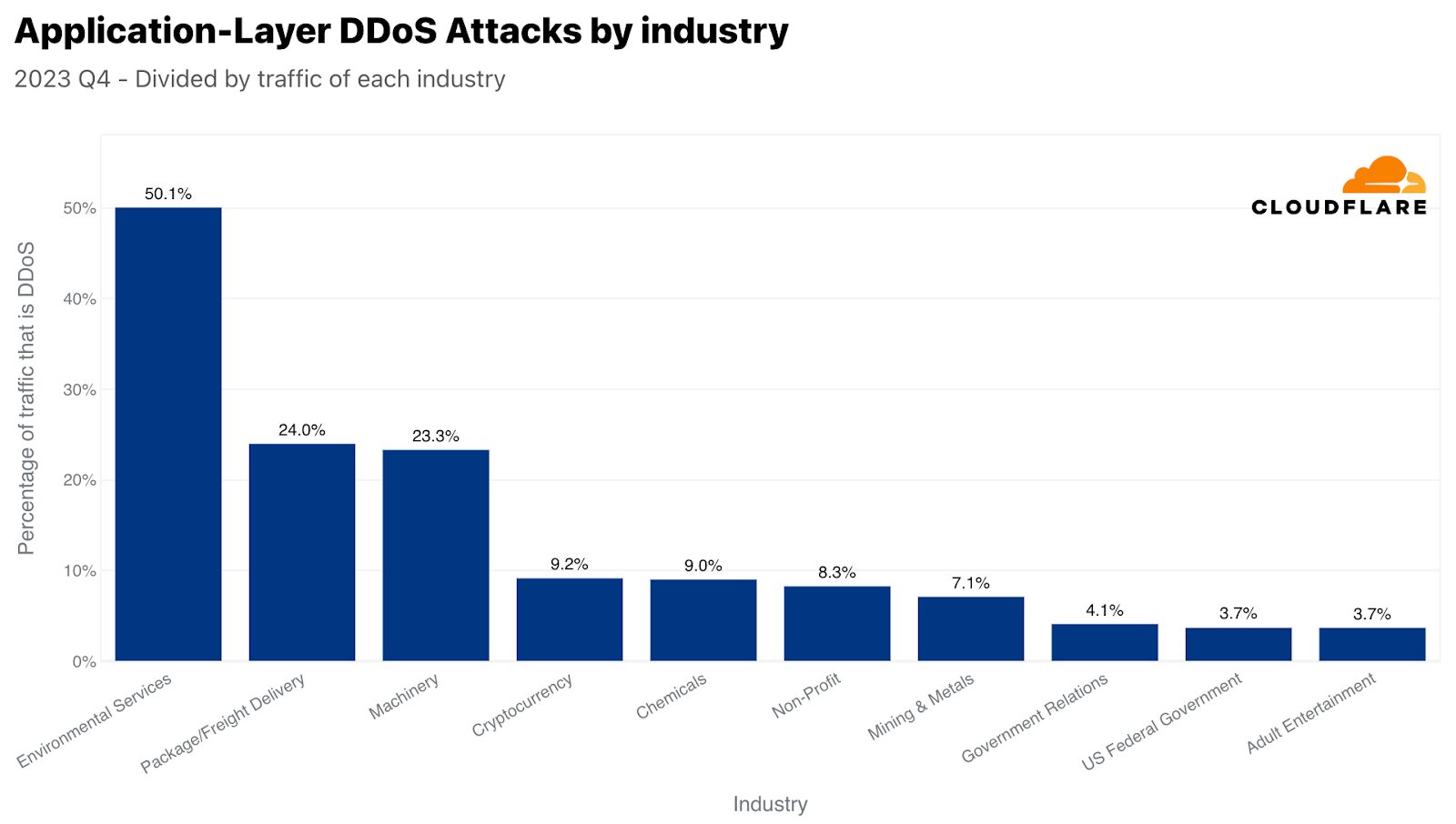
네트워크 계층에서 가장 많이 표적이 된 산업은 홍보 및 커뮤니케이션으로, 전체 트래픽의 36%가 악의적 트래픽이었습니다. 이 역시 시기를 고려할 때 매우 흥미롭습니다. 홍보 및 커뮤니케이션 기업은 일반적으로 대중의 인식 및 커뮤니케이션 관리와 관련이 있습니다. 이러한 기업의 운영이 중단되면 평판에 즉각적이고 광범위한 영향이 미칠 수 있으며, 이는 4분기 연말연시 시즌에 더욱 중요해집니다. 이 분기에는 휴일, 연말 결산, 새해 준비 등으로 인해 홍보 및 커뮤니케이션 활동이 증가하는 경우가 많습니다. 따라서 일부에서는 이 시기를 누군가가 업무를 방해하기를 원할 수 있는 중요한 운영 기간으로 여기기도 합니다.
가장 많이 공격받은 국가 및 지역
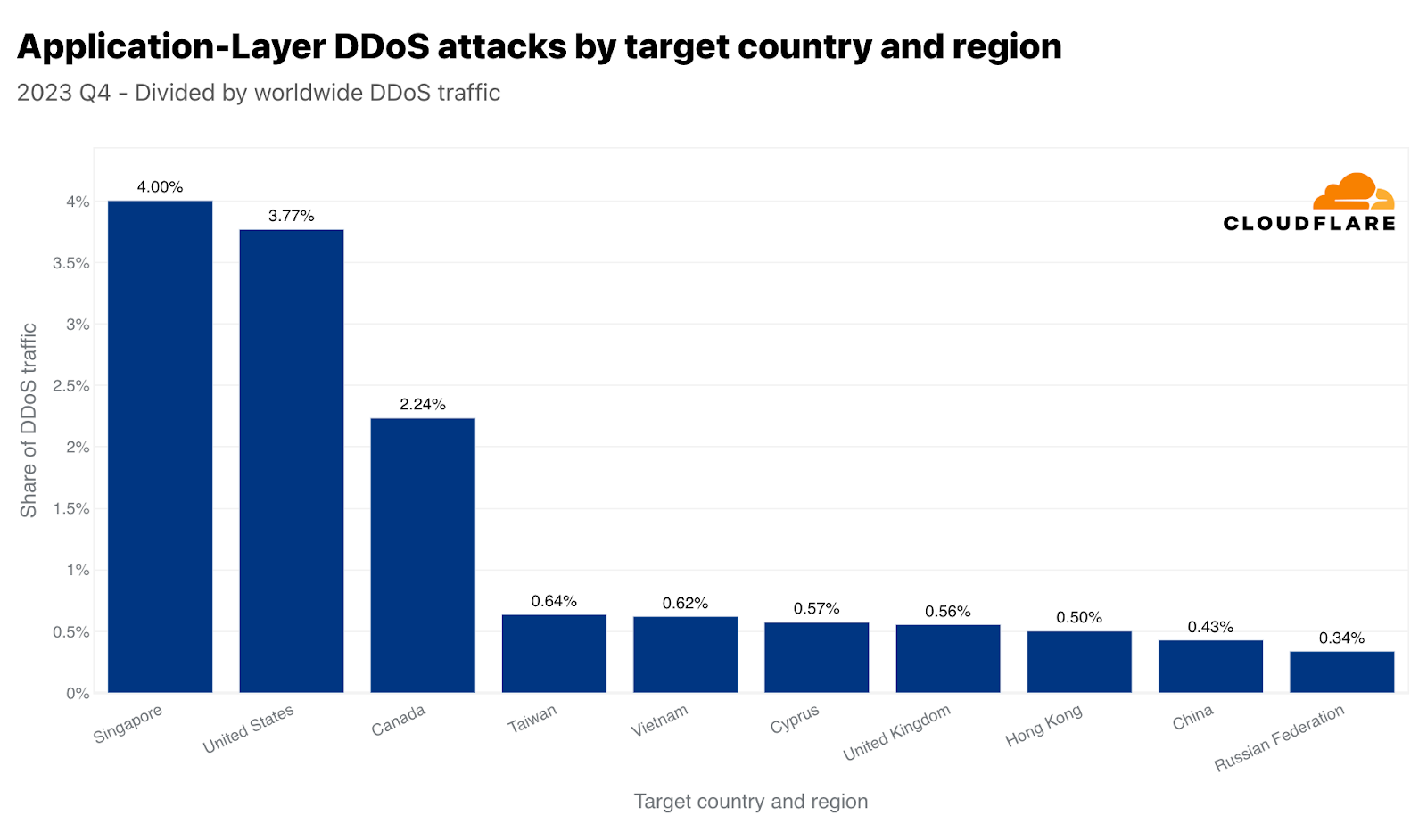
싱가포르는 4분기에 HTTP DDoS 공격의 주요 표적이었습니다. 전 세계 DDoS 트래픽의 4%인3,170억 건이 넘는 HTTP 요청이 싱가포르 웹 사이트를 겨냥했습니다. 뒤이어 미국이 2위, 캐나다가 3위를 차지했습니다. 대만은 다가오는 총선과 중국과의 긴장 관계로 인해 네 번째로 공격을 많이 받은 지역으로 기록되었습니다. 4분기에 대만을 향한 공격 트래픽은 전년 대비 847%, 전 분기 대비2,858% 증가했습니다. 이러한 증가는 절대값에만 국한되지 않습니다. 정규화했을 때, 대만을 향한 전체 트래픽 대비 대만을 겨냥한HTTP DDoS 공격 트래픽의 비율도 전 분기 대비 624%, 전년 동기 대비 3,370%로 크게 증가했습니다.
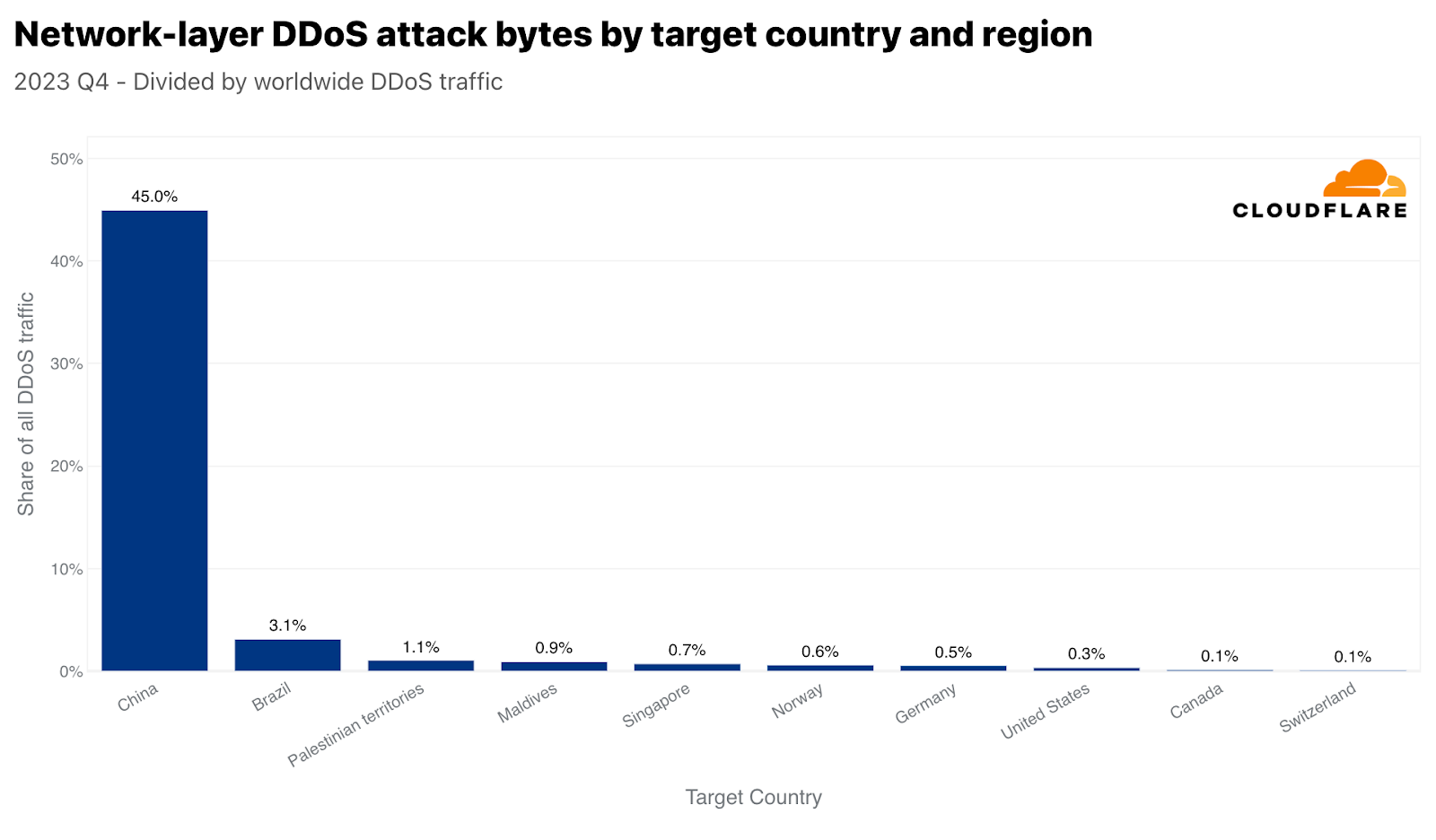
중국은 HTTP DDoS 공격을 가장 많이 받은 국가 중 9번째이지만, 네트워크 계층 공격을 가장 많이 받은 국가로는 1위에 올랐습니다. Cloudflare에서 전 세계에 걸쳐 완화한 모든 네트워크 계층 DDoS 트래픽의 45%가 중국을 향한 트래픽이었습니다. 나머지 국가들은 거의 무시할 수 있을 정도로 뒤져 있었습니다.
데이터를 정규화하면 이라크, 팔레스타인 지역, 모로코가 총 인바운드 트래픽 대비 가장 많은 공격을 받은 지역으로 나타났습니다. 흥미롭게도 싱가포르가 4위에 올랐습니다. 따라서 싱가포르는 가장 많은 양의 HTTP DDoS 공격 트래픽에 직면해 있을 뿐만 아니라 해당 트래픽은 싱가포르를 향한 전체 트래픽의 상당 부분을 차지합니다. 이와는 대조적으로, 미국은(위의 애플리케이션 계층 그래프에 따르면) 양적으로는 두 번째로 많은 공격을 받았지만, 미국으로 향하는 전체 트래픽을 기준으로 보면 50위에 그쳤습니다.
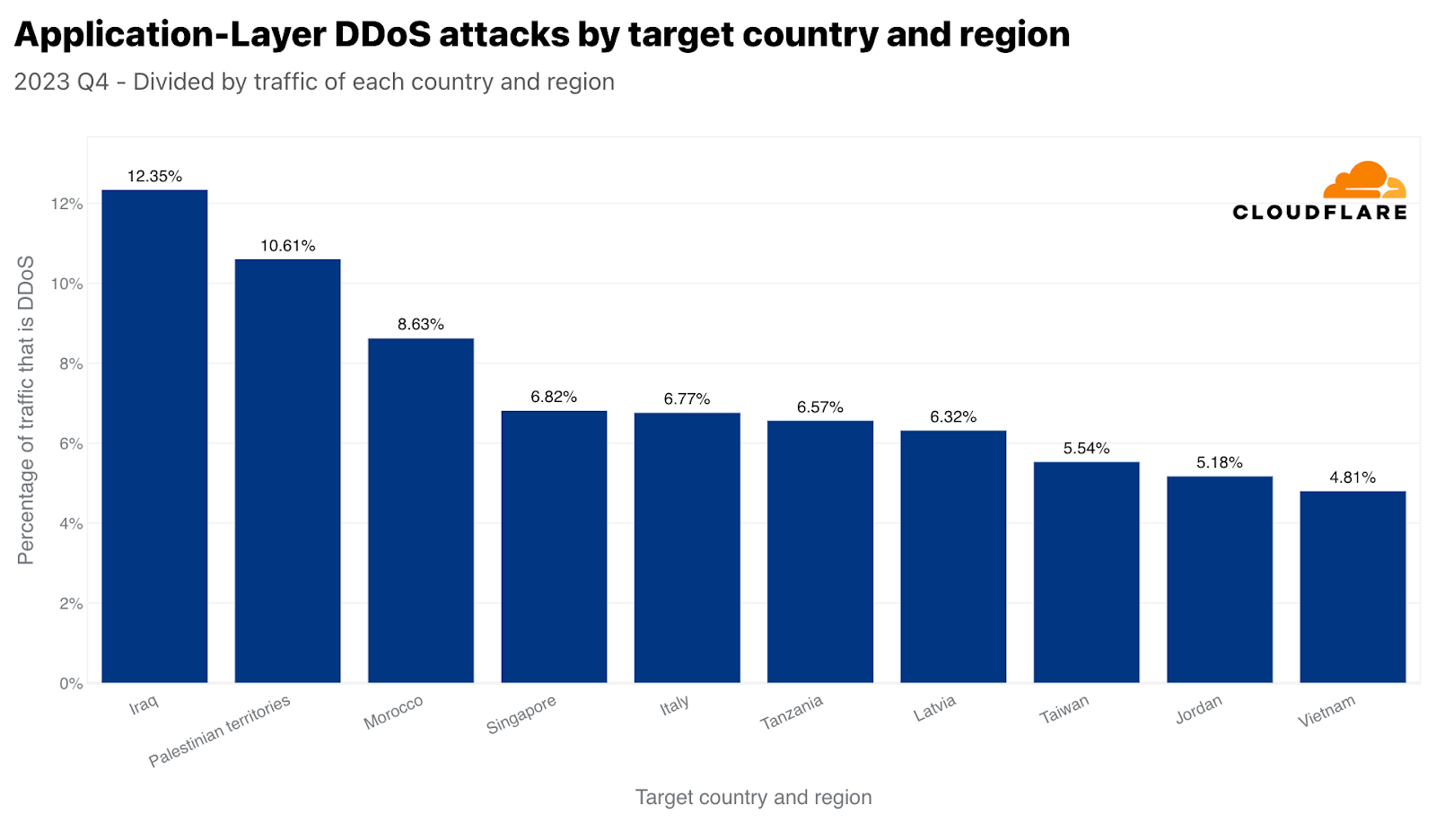
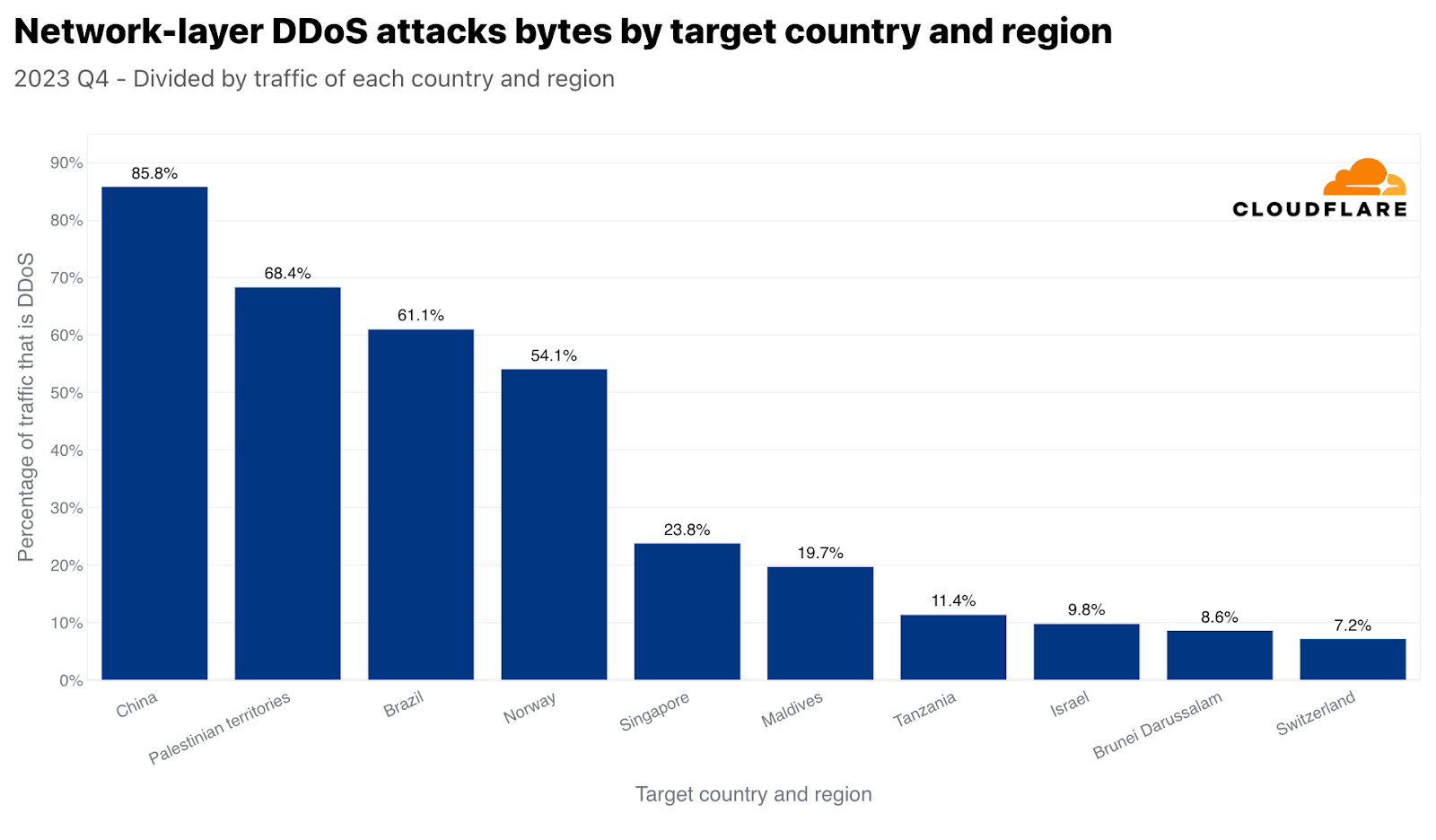
싱가포르와 유사하지만, 훨씬 더 극적일 수 있는 중국은 네트워크 계층 DDoS 공격 트래픽 및 중국으로 향하는 모든 트래픽에 있어서 가장 많이 공격받는 국가입니다. 중국으로 향하는 전체 트래픽의 거의 86%가 네트워크 계층 DDoS 공격으로, Cloudflare에 의해 완화되었습니다. 팔레스타인 지역, 브라질, 노르웨이, 그리고 다시 싱가포르가 공격 트래픽 비율이 높은 국가로 그 뒤를 이었습니다.
공격 벡터 및 속성
대부분의 DDoS 공격은 Cloudflare의 기준으로 볼 때 짧고 규모가 작습니다. 그러나 보호되지 않은 웹 사이트와 네트워크는 적절한 인라인 자동 보호 기능이 없으면 짧은 소규모의 공격으로도 중단될 수 있으며, 따라서 조직에서 강력한 보안 태세를 선제적으로 도입해야 할 필요성이 강조됩니다.
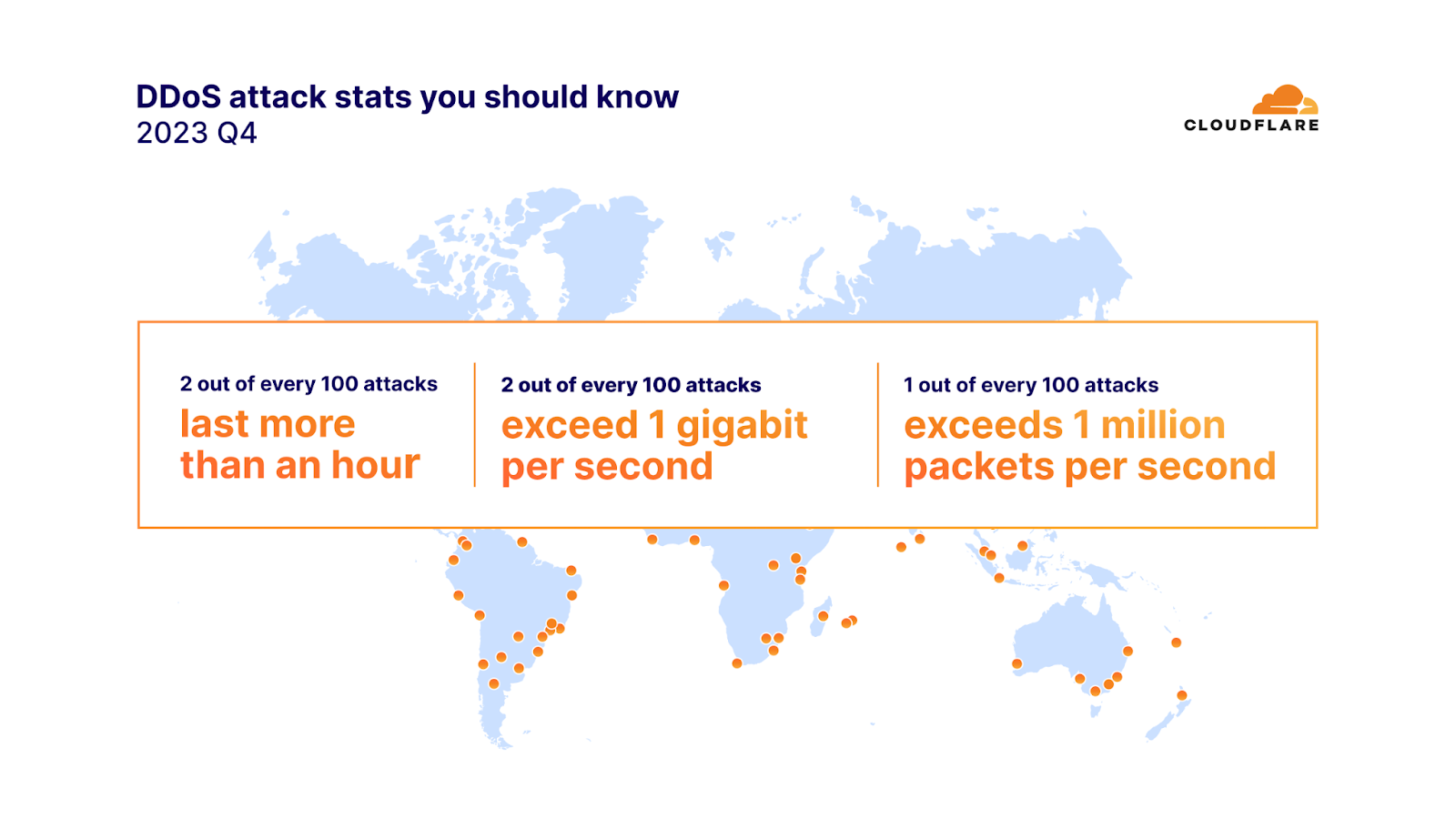
2023년 4분기에는 공격의 91%가 10분 이내에 종료되었고, 97%는 정점에서도 초당 500메가비트(mbps) 미만이었으며, 88%는 초당 5만 패킷(pps)을 넘은 적이 없었습니다.
네트워크 계층 DDoS 공격 100건 중 2건은 1시간 이상 지속되었고, 초당 1기가비트(gbps)를 초과했습니다. 100건 중 1건의 공격이 초당 100만 패킷을 초과했습니다. 또한 초당 1억 패킷을 초과하는 네트워크 계층 DDoS 공격의 양은 전 분기 대비 15% 증가했습니다.
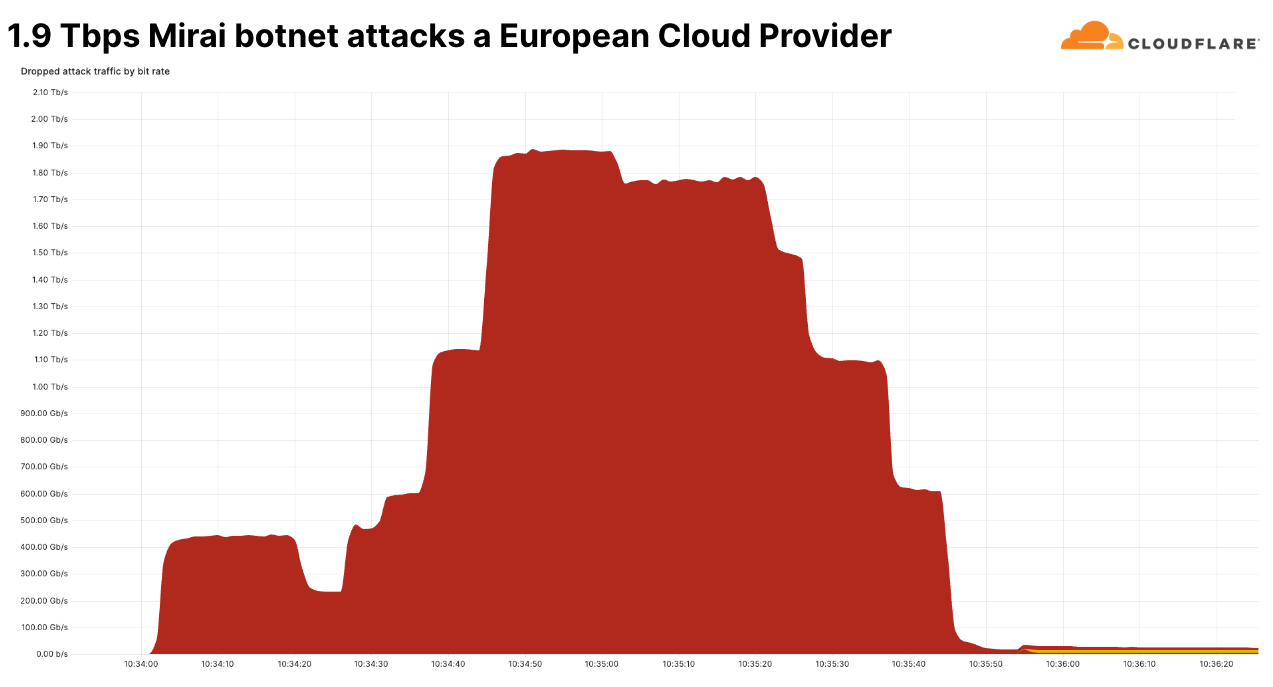
이러한 대규모 공격 중 하나는 초당 1억 6천만 개의 패킷을 전송한 Mirai 봇넷 공격이었습니다. 초당 패킷 전송량은 역대 최대가 아니었습니다. 역대 최대 규모는 초당 7억 5,400만 패킷이었습니다. 이 공격은 2020년에 발생했으며, 이보다 더 큰 규모의 공격은 아직 관찰된 적이 없습니다.
하지만 최근에 발생한 이 공격은 초당 비트 전송률이 특이했습니다. 이 공격은 4분기에 발생한 네트워크 계층 공격 중 가장 큰 규모의 DDoS 공격이었습니다. 이 공격은 초당 1.9 테라비트로 최고치를 기록했으며 Mirai 봇넷으로부터 시작되었습니다. 이 공격은 여러 가지 공격 방법이 결합된 멀티 벡터 공격이었습니다. 이러한 방법 중 일부에는 UDP 조각 폭주, UDP/Echo 폭주, SYN 폭주, ACK 폭주, TCP 기형 폭주가 포함되었습니다.
이 공격은 알려진 유럽 클라우드 공급자를 겨냥했으며, 스푸핑된 것으로 추정되는 18,000여 개의 고유 IP 주소에서 시작되었습니다. 이 공격은 Cloudflare의 방어 기능에서 자동으로 감지되어 완화되었습니다.
이는 최대 규모의 공격도 매우 빠르게 종료된다는 것을 보여줍니다. Cloudflare에서 확인한 이전의 대규모 공격들은 몇 초 만에 종료되었으므로 인라인 자동 방어 시스템의 필요성이 강조되었습니다. 아직은 드물지만, 테라비트 규모 범위의 공격이 점점 더 두드러지고 있습니다.
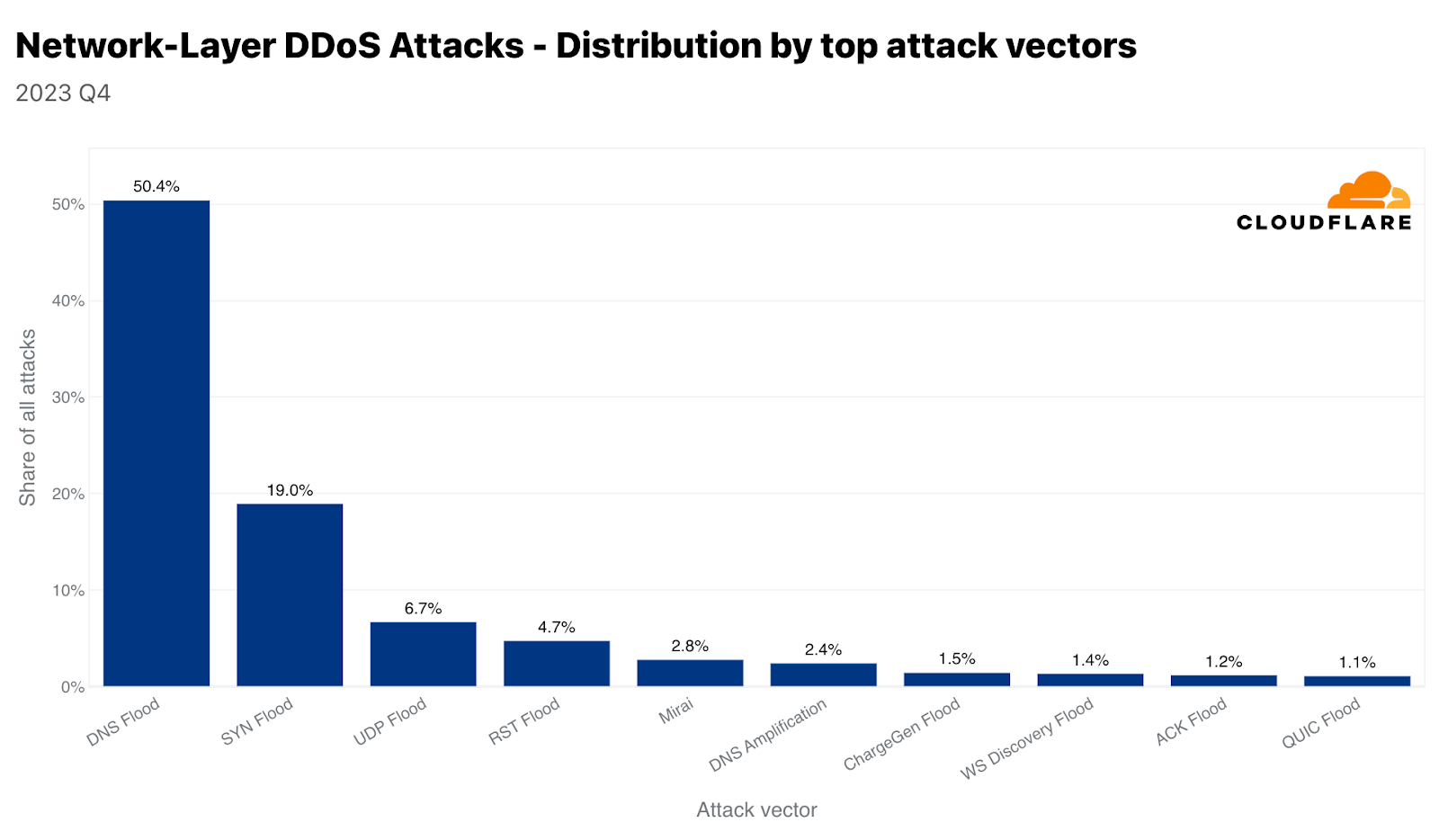
Mirai 변종 봇넷의 사용은 여전히 아주 흔합니다. 4분기에는 전체 공격의 약 3%가 Mirai에서 비롯되었습니다. 하지만 모든 공격 방법 중에서 DNS 기반 공격은 여전히 공격자들이 가장 선호하는 방법입니다. DNS 폭주와 DNS 증폭 공격을 합할 경우 4분기 전체 공격의 약 53%를 차지합니다. SYN 폭주가 뒤를 이어 2위, UDP 폭주가 3위를 차지했습니다. 여기에서는 두 가지 DNS 공격 유형에 대해 다루며, 학습 센터에서 하이퍼링크로 이동하여 UDP 폭주와 SYN 폭주에 대해 자세히 알아볼 수 있습니다.
DNS 폭주 및 증폭 공격
DNS 폭주와 DNS 증폭 공격은 모두 도메인 네임 시스템(DNS)을 악용하지만, 작동 방식은 다릅니다. DNS는 인터넷의 전화번호부와 같습니다. “www.cloudfare.com”과 같이 사람에게 친숙한 도메인 이름을 숫자로 된 IP 주소로 변환하며, 이를 컴퓨터가 네트워크에서 상호 식별하는 데 사용하는 합니다.
간단히 말해, DNS 기반 DDoS 공격은 실제로 서버를 ‘다운’시키지 않고도 컴퓨터와 서버가 서로를 식별하여 서비스 중단 또는 장애를 유발하는 방법입니다. 예를 들어 서버는 가동 중이지만, DNS 서버가 다운되었을 수 있습니다. 따라서 클라이언트는 DNS 서버에 연결할 수 없으며 중단을 경험하게 됩니다.
DNS 폭주 공격은 압도적인 수의 DNS 쿼리로 DNS 서버를 폭주시키는 공격입니다. 이는 일반적으로 DDoS 봇넷을 사용하여 수행됩니다. 엄청난 양의 쿼리로 DNS 서버가 압도되어 정상적인 쿼리에 응답하기 어렵거나 불가능하게 될 수 있습니다. 이로 인해 앞서 언급한 서비스 중단, 지연, 심지어는 웹 사이트나 공격 대상 DNS 서버에 의존하는 서비스에 액세스하려는 사용자의 서비스 중단이 발생할 수 있습니다.
반면, DNS 증폭 공격은 스푸핑된 IP 주소(피해자의 주소)가 포함된 작은 쿼리를 DNS 서버로 전송하는 것입니다. 여기서 비결은 DNS 응답이 요청보다 훨씬 크다는 것입니다. 그러면 서버는 이 큰 응답을 피해자의 IP 주소로 보냅니다. 공격자는 개방형 DNS 확인자를 악용하여 피해자에게 전송되는 트래픽의 양을 증폭시켜 훨씬 더 큰 영향을 미칠 수 있습니다. 이러한 유형의 공격은 피해자를 방해할 뿐만 아니라 전체 네트워크를 정체시킬 수 있습니다.
두 경우 모두 공격자는 네트워크 운영에서DNS의 중요한 역할을 악용합니다. 완화 전략에는 일반적으로 DNS 서버 오용 방지, 트래픽 관리를 위한 레이트 리미팅 구현, 악의적 요청 식별 및 차단을 위한 DNS 트래픽 필터링이 포함됩니다.
Cloudflare에서 추적하는, 새롭게 떠오르는 위협 중 지난 분기에 비해ACK-RST 폭주가 1,161%, CLDAP 폭주가 515%, SPSS 폭주가 243% 각각 증가했습니다. 이들 공격의 종류와 이들 공격이 어떻게 업무 중단을 유발하는지를 살펴보겠습니다.
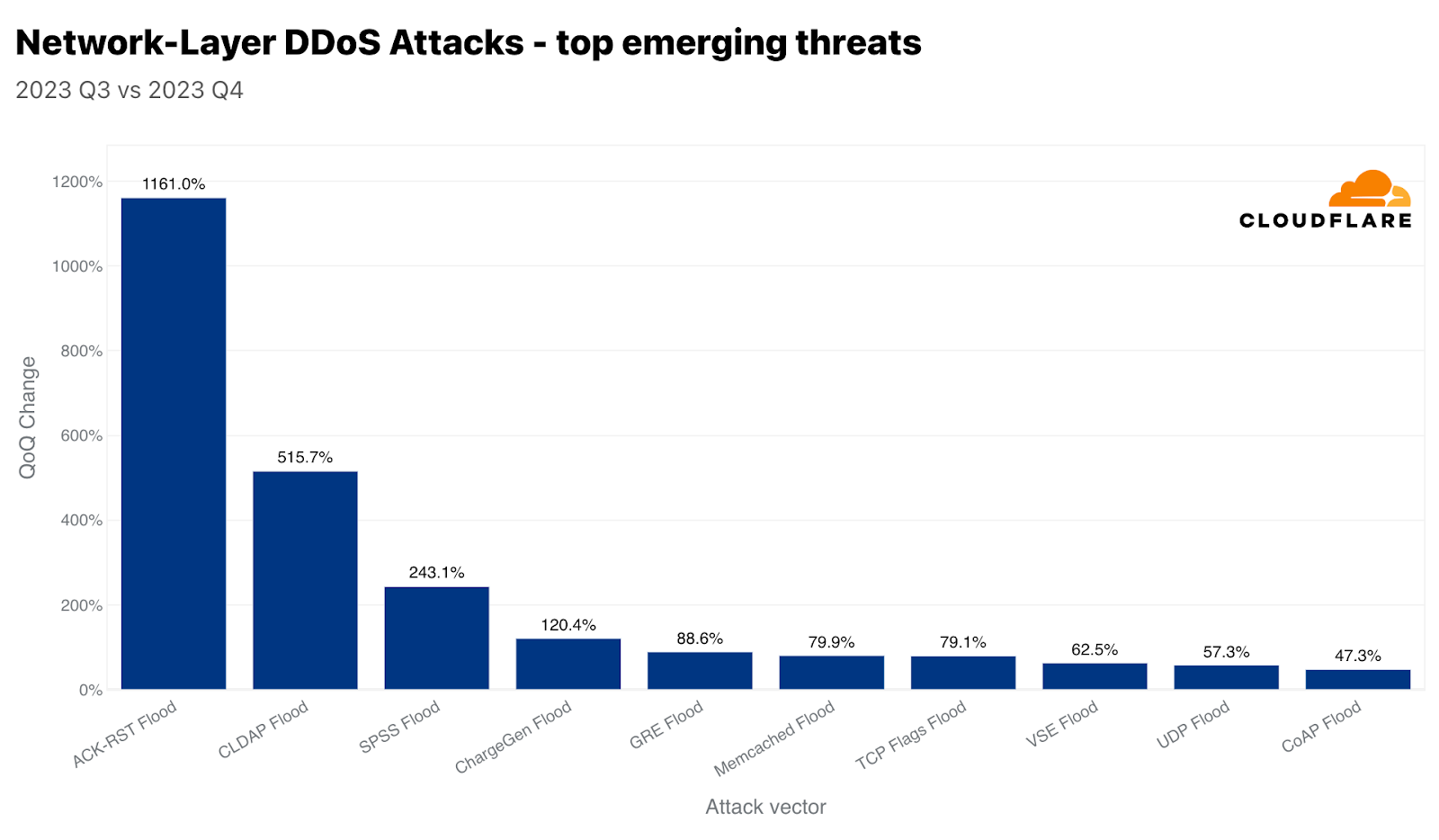
ACK-RST 폭주
ACK-RST 폭주는 피해자에게 많은 ACK 및 RST 패킷을 전송하여 전송 제어 프로토콜(TCP)을 악용합니다. 이로 인해 피해자가 이 패킷을 처리하고 응답하는 능력이 과부하되어 서비스 중단으로 이어집니다. 이 공격은 각 ACK 또는 RST 패킷이 피해자의 시스템에서 응답을 유도하여 리소스를 소모하기 때문에 효과적입니다. ACK-RST 폭주는 합법적인 트래픽을 모방하므로 필터링이 어려운 경우가 많아 감지 및 방어가 어렵습니다.
CLDAP 폭주
연결 없는 경량 디렉터리 액세스 프로토콜(CLDAP)는 경량 디렉터리 액세스 프로토콜(LDAP)의 변형입니다. CLDAP는 IP 네트워크에서 실행되는 디렉터리 서비스를 쿼리하고 수정하는 데 사용됩니다. CLDAP는 연결이 필요 없고 TCP 대신 UDP를 사용하므로 더 빠르지만, 안정성이 떨어집니다. UDP를 사용하므로 공격자가 IP 주소를 스푸핑할 수 있는 핸드셰이크가 필요하지 않으므로 공격자가 이를 반사 벡터로 악용할 수 있습니다. 이러한 공격에서는 스푸핑된 소스 IP 주소(피해자의 IP)로 작은 쿼리를 전송하여 서버가 피해자에게 대량의 응답을 전송하여 서버를 과부하시키도록 합니다. 완화 조치에는 비정상적인 CLDAP 트래픽을 필터링하고 모니터링하는 것이 포함됩니다.
SPSS 폭주
Source Port Service Sweep(SPSS) 프로토콜을 악용하는 폭주는 무작위 또는 스푸핑된 많은 원본 포트에서 표적 시스템 또는 네트워크의 다양한 대상 포트로 패킷을 전송하는 네트워크 공격 방법입니다. 이 공격의 목적은 두 가지입니다. 첫째, 피해자의 처리 능력을 압도하여 서비스 중단 또는 네트워크 중단을 유발하고, 둘째, 열린 포트를 검색하고 취약한 서비스를 식별하는 데 사용하는 것입니다. 폭주는 대량의 패킷을 전송하여 피해자의 네트워크 리소스를 포화시키고 방화벽과 침입 감지 시스템의 용량을 소진시켜 이루어질 수 있습니다. 이 공격을 완화하려면 인라인 자동 감지 기능을 활용하는 것이 필수적입니다.
공격 유형, 규모, 기간과 관계없이 Cloudflare에서 지원합니다
Cloudflare의 사명은 더 나은 인터넷을 구축하는 것이며, 더 나은 인터넷이란 안전하고 성능이 뛰어나며 누구나 이용할 수 있는 인터넷이라고 믿습니다. 공격 유형, 공격 규모, 공격 지속 시간, 공격의 동기와 상관없이 Cloudflare의 방어는 강력합니다. Cloudflare에서는 2017년 무제한 DDoS 방어를 선도적으로 출시한 이래, 모든 조직에서 성능 저하 없이 엔터프라이즈급 DDoS 방어를 무료로 이용할 수 있도록 하겠다는 약속을 지키기 위해 노력해 왔습니다. 이러한 약속을 지킬 수 있었던 것은 Cloudflare의 독보적인 기술과 강력한 네트워크 아키텍처 덕분입니다.
보안은 하나의 제품이나 스위치 하나로 해결되는 것이 아니라 하나의 프로세스라는 점을 기억해야 합니다. 자동화된DDoS 방어 시스템 외에도 우리는 방화벽, 봇 감지, API 보호, 캐싱 등의 포괄적인 기능을 번들로 제공하여 방어 체계를 강화합니다. Cloudflare에서는 다계층 접근 방식을 통해 보안 태세를 최적화하고 잠재적 영향을 최소화합니다. 또한 DDoS 공격에 대한 방어를 최적화하는 데 도움이 되는 권장 사항 목록을 마련했으며, 고객은 단계별 마법사를 따라 애플리케이션을 보호하고 DDoS 공격을 방지할 수 있습니다. DDoS 및 기타 인터넷 공격에 대한 업계 최고의 보호 기능을 간편하게 이용하고 싶으시면 Cloudflare.com에서 무료로 가입하실 수 있습니다! 공격을 받고 있다면 여기에 표시된 사이버 긴급 핫라인 번호로 등록하거나 전화하여 신속하게 대응하세요.








 Happy New Year! Cloud technologies, machine learning, and generative AI have become more accessible, impacting nearly every aspect of our lives. Amazon CTO Dr. Werner Vogels offers four tech predictions for 2024 and beyond:
Happy New Year! Cloud technologies, machine learning, and generative AI have become more accessible, impacting nearly every aspect of our lives. Amazon CTO Dr. Werner Vogels offers four tech predictions for 2024 and beyond:













 Raghavarao Sodabathina is a Principal Solutions Architect at AWS, focusing on Data Analytics, AI/ML, and cloud security. He engages with customers to create innovative solutions that address customer business problems and to accelerate the adoption of AWS services. In his spare time, Raghavarao enjoys spending time with his family, reading books, and watching movies.
Raghavarao Sodabathina is a Principal Solutions Architect at AWS, focusing on Data Analytics, AI/ML, and cloud security. He engages with customers to create innovative solutions that address customer business problems and to accelerate the adoption of AWS services. In his spare time, Raghavarao enjoys spending time with his family, reading books, and watching movies. Hang Zuo is a Senior Product Manager on the Amazon Kinesis Data Streams team at Amazon Web Services. He is passionate about developing intuitive product experiences that solve complex customer problems and enable customers to achieve their business goals.
Hang Zuo is a Senior Product Manager on the Amazon Kinesis Data Streams team at Amazon Web Services. He is passionate about developing intuitive product experiences that solve complex customer problems and enable customers to achieve their business goals. Shwetha Radhakrishnan is a Solutions Architect for AWS with a focus in Data Analytics. She has been building solutions that drive cloud adoption and help organizations make data-driven decisions within the public sector. Outside of work, she loves dancing, spending time with friends and family, and traveling.
Shwetha Radhakrishnan is a Solutions Architect for AWS with a focus in Data Analytics. She has been building solutions that drive cloud adoption and help organizations make data-driven decisions within the public sector. Outside of work, she loves dancing, spending time with friends and family, and traveling. Brittany Ly is a Solutions Architect at AWS. She is focused on helping enterprise customers with their cloud adoption and modernization journey and has an interest in the security and analytics field. Outside of work, she loves to spend time with her dog and play pickleball.
Brittany Ly is a Solutions Architect at AWS. She is focused on helping enterprise customers with their cloud adoption and modernization journey and has an interest in the security and analytics field. Outside of work, she loves to spend time with her dog and play pickleball.