Post Syndicated from Matt Howard original https://aws.amazon.com/blogs/compute/implementing-advanced-aws-graviton-adoption-strategies-across-aws-regions/
AWS Graviton Processors can offer cost savings, improved performance, and reduce your carbon footprint when using Amazon Elastic Compute Cloud (Amazon EC2) instances. When expanding your Graviton deployment across multiple AWS Regions, careful planning helps you navigate considerations around regional instance type availability and capacity optimization. This post shows how to implement advanced configuration strategies for Graviton-enabled EC2 Auto Scaling groups across multiple Regions, helping you maximize instance availability, reduce costs, and maintain consistent application performance even in AWS Regions with limited Graviton instance type availability.
Instance type flexibility strategies
One of the most effective strategies for maximizing Graviton availability is to be flexible across multiple instance types and families. Instance families (such as m7g, c7g, and r7g) group similar instances with different sizes, where each size offers proportionally more vCPUs and memory. When configuring EC2 Auto Scaling groups, aim for at least 10 instance types rather than limiting to just one or two specific types. EC2 Auto Scaling supports this flexibility through the mixed instances group, which allows you to specify multiple instance types in a single group. Consider this example AWS CloudFormation template snippet for an EC2 Auto Scaling group MixedInstancesPolicy that only specifies two Graviton instance types across two different families:
This limited selection significantly reduces your ability to access available capacity pools. Assuming this workload needs a minimum of 2 vCPU and 8 GiB of memory, you can add these additional eight Graviton instance types: m6g.large, m8g.large, m6gd.large, m7gd.large, m8gd.large, c6g.xlarge, c6gd.xlarge, and c8g.xlarge. These allow you to meet the recommendation of being flexible across 10 instance types. While some of these instance types may have different price points, you can manage these cost implications through allocation strategies discussed later in this post.
To efficiently identify all compatible Graviton instance types available for your workload, you can use the GetInstanceTypesFromInstanceRequirements Amazon EC2 API. This approach removes the manual effort of researching and choosing individual instance types.
This example command returns dozens of compatible Graviton instance types across multiple families (c7g, c7gd, c7gn, m7g, m7gd, etc.), thus expanding your capacity options. An EC2 Auto Scaling group’s mixed instance policy can allow up to 40 instance types, thus you have more room for even greater flexibility.
After expanding your instance type selection, you need to configure how EC2 Auto Scaling chooses between the available instance types. The OnDemandAllocationStrategy CloudFormation property controls this behavior, offering two approaches: “lowest-price” and “prioritized”. With the “lowest-price” strategy, EC2 Auto Scaling launches instances from the lowest-priced capacity pool available:
This strategy helps manage costs when you’ve included a variety of instance types. Even with expanded instance type flexibility, your workloads will automatically select the most cost-effective option from available capacity pools. Alternatively, you can use the “prioritized” strategy when you want more control over which instance types are chosen first:
Regional adaptation techniques
Not all AWS Regions have the same Graviton instance types available. Regional variation in instance type availability creates a challenge when deploying applications consistently across multiple AWS Regions. To handle these differences, expand your instance type flexibility beyond the minimum 10 types to make sure of sufficient options in each AWS Region where you operate.
To implement this flexibility across AWS Regions, you must determine which Graviton instance types are available in each target AWS Region. AWS provides several methods to access this information: check the Amazon EC2 Instance Types by Region documentation for a comprehensive list, use the DescribeInstanceTypeOfferings Amazon EC2 API to programmatically identify available types, or visit the EC2 Instance Types page in the AWS Management Console.
You can also run the GetInstanceTypesFromInstanceRequirements API across different AWS Regions to understand Regional differences. For example, running identical queries in the US East (N. Virginia) and Asia Pacific (Taipei) Regions reveals significant variations: over 70 compatible instance types in the US East (N. Virginia) and 27 in Asia Pacific (Taipei) Regions.
When operating across multiple AWS Regions, design a single mixed instance policy that works everywhere by including instance types available in all AWS Regions where you operate. Based on the previous query results, you might include these 10 instance types that are available in both AWS Regions: m6g.large, m7g.large, m6gd.large, m7gd.large, c6g.xlarge, c7g.xlarge, m6g.xlarge, m7g.xlarge, c6gn.xlarge, and m6gd.xlarge.
You should also span your EC2 Auto Scaling group across multiple Availability Zones (AZs) for greater resiliency and access to deeper capacity pools. To determine available AZs in your AWS Region, refer to the Availability Zones documentation or check your Amazon Virtual Private Cloud (Amazon VPC) to identify which AZs its subnets use through the DescribeSubnets Amazon EC2 API. Configure your EC2 Auto Scaling group to use all available AZs using the CloudFormation AWS::AutoScaling::AutoScalingGroup AvailabilityZones parameter:
Best practices for EC2 Spot Instances usage with Graviton-based instances
Although optimizing for regional availability and AZ distribution provides a strong foundation, further enhancing your Graviton deployment strategy with proper Amazon EC2 Spot Instances configuration can significantly improve cost efficiency without sacrificing reliability. When using Spot Instances with Graviton, you should implement strategies that maximize your chances of obtaining and maintaining capacity.
First, the Spot Instance Advisor provides valuable information about the interruption frequency of different instance types across AWS Regions. Use this tool to identify Graviton instance types with lower interruption rates in your target AWS Regions. Then, expand your mixed instance group to include these other instance types. Especially for Spot Instance workloads, maximize your instance type flexibility by specifying up to the full limit of 40 instance types for EC2 Auto Scaling groups mixed instance policies. This broad selection increases your chances of finding available Spot Instances capacity.
Beyond instance type selection, the allocation strategy you choose significantly impacts your ability to maintain Spot Instances capacity. Configure your Spot allocation strategy using the AWS::AutoScaling::AutoScalingGroup InstancesDistribution property with the SpotAllocationStrategy parameter set to price-capacity-optimized to choose Spot pools with the lowest interruption risk while still considering price:
For workloads that can benefit from more time beyond the standard two-minute Spot interruption notice, enable Capacity Rebalancing. This feature, configured using the AWS::AutoScaling::AutoScalingGroup CapacityRebalanceproperty, enables EC2 Auto Scaling to proactively respond to rebalance recommendations by launching a new Spot Instance before a running instance receives the two-minute Spot Instance interruption notice, which provides more time for graceful transitions:
For maximum flexibility and capacity access, consider mixing x86 and ARM architectures in your launch templates. Although the Graviton capacity pools are newer and sometimes smaller than their x86 counterparts, a mixed architecture approach makes sure that you can still launch instances even when one architecture has limited availability. For detailed instructions, refer to the AWS post: Supporting AWS Graviton2 and x86 instance types in the same Auto Scaling group.
Attribute-based instance type selection
Although mixed instance policies with explicit instance type lists provide excellent flexibility, AWS offers an even more powerful approach for dynamic instance selection: attribute-based instance type selection. This streamlines management by allowing you to specify the attributes your application needs rather than specific instance types, automatically adapting to new instance types and handling Regional differences in availability.
Implement attribute-based instance type selection in your EC2 Launch Template through the AWS::EC2::LaunchTemplate InstanceRequirements property:
The BaselinePerformanceFactors parameter of the AWS::EC2::LaunchTemplate InstanceRequirements property enables performance protection. This feature makes sure that your EC2 Auto Scaling group uses instance types that meet or exceed a specified performance baseline. When you specify an instance family such as “c7g” as the baseline reference, Amazon EC2 automatically excludes instance types that fall below this performance level, even if they match your other specified attributes. For Graviton deployments, specifying “c7g” makes sure that only instance types with performance like or better than Graviton3 processors are chosen.
Attribute-based instance type selection also allows you to specify instance types in your template that may not yet be available in an AWS Region by using the AllowedInstanceTypes parameter:
This approach allows your EC2 Auto Scaling group to use newer instance types where available and automatically deploy them in other AWS Regions as soon as they become available. This single template approach simplifies the deployment and management of your EC2 instance selection in EC2 Auto Scaling groups across many regions.
Special considerations
The following special considerations should be taken into account.
Performance testing with multiple instance types
When implementing instance type flexibility, a common concern is the need to test all instance types with your application. Testing 40 different instance types isn’t practical for most organizations. Instead, consider these streamlined approaches to reduce testing overhead while maintaining performance confidence. First, Graviton instance families within the same generation (for example, c7g, m7g, and r7g) use the same processor, providing similar performance profiles across families. Therefore, you can include multiple instance types from the same generation after testing a representative instance. Second, you should also consider including variants within families (such as c7gd with NVMe storage), because these provide specialized capabilities without changing the fundamental CPU architecture. Third, for maximum flexibility, include multiple instance generations. If your application runs well on Graviton3, then it likely performs even better on Graviton4, allowing you to specify both in your EC2 Auto Scaling group.
Reserving specific Graviton instance types
If your workload needs a specific Graviton instance type, then we recommend that you use EC2 Capacity Reservations, which allow you to reserve compute capacity for EC2 instances in a specific AZ for any duration. On-Demand Capacity Reservations (ODCR) are for immediate use and come with no term commitment. Alternatively, Future-dated Capacity Reservations allow you to specify when you need the capacity to become available along with a commitment duration.
Amazon EMR workloads
Although Amazon EMR clusters must exist in only one AZ, you can use Amazon EMR instance fleets to choose multiple subnets across different AZs. Then, when launching a cluster, Amazon EMR searches across these subnets to find specified instances and purchasing options, thus providing access to a deeper capacity pool. For Instance Fleets you can specify up to 30 EC2 instance types for each primary, core, and task node group, which significantly improves instance flexibility and availability. For more information go to the Responding to Amazon EMR cluster insufficient instance capacity events documentation.
Conclusion
In this post, we covered advanced strategies for maximizing AWS Graviton adoption across multiple AWS Regions. You can use the AWS CloudFormation examples provided in this post as templates for your own implementations. Following these approaches allows you to maintain consistent application performance and maximize Graviton instance availability across all AWS Regions where you operate, even as Graviton availability continues to expand across the AWS global infrastructure. For comprehensive guidance on maximizing your Graviton deployment, explore the AWS Graviton Technical Guide.

 Gagan Brahmi is a Specialist Senior Solutions Architect at Amazon Web Services (AWS), specializing in Data Analytics and AI/ML solutions. With over 20 years in information technology, he helps customers architect scalable, high-performance analytics platforms using distributed data processing, real-time streaming technologies, and machine learning services on AWS. When not designing cloud solutions, Gagan enjoys exploring new places with his family.
Gagan Brahmi is a Specialist Senior Solutions Architect at Amazon Web Services (AWS), specializing in Data Analytics and AI/ML solutions. With over 20 years in information technology, he helps customers architect scalable, high-performance analytics platforms using distributed data processing, real-time streaming technologies, and machine learning services on AWS. When not designing cloud solutions, Gagan enjoys exploring new places with his family. Arun Shanmugam is a Senior Analytics Solutions Architect at AWS, with a focus on building modern data architecture. He has been successfully delivering scalable data analytics solutions for customers across diverse industries. Outside of work, Arun is an avid outdoor enthusiast who actively engages in CrossFit, road biking, and cricket.
Arun Shanmugam is a Senior Analytics Solutions Architect at AWS, with a focus on building modern data architecture. He has been successfully delivering scalable data analytics solutions for customers across diverse industries. Outside of work, Arun is an avid outdoor enthusiast who actively engages in CrossFit, road biking, and cricket. George Oakes is a Senior Hybrid Solutions Architect at AWS, with a focus on edge, on-premise, and low latency architectures. He has been successfully delivering scalable hybrid AWS solutions for customers across diverse industries. Outside of work, George is an avid outdoor enthusiast who enjoys hiking and visiting parks and UNESCO sites around.
George Oakes is a Senior Hybrid Solutions Architect at AWS, with a focus on edge, on-premise, and low latency architectures. He has been successfully delivering scalable hybrid AWS solutions for customers across diverse industries. Outside of work, George is an avid outdoor enthusiast who enjoys hiking and visiting parks and UNESCO sites around.
 Before continuing with this AWS Weekly Roundup, I’d like to share that last month I moved with my family to San Francisco, California, to start a new role as Developer Advocate/SDE, GenAI.
Before continuing with this AWS Weekly Roundup, I’d like to share that last month I moved with my family to San Francisco, California, to start a new role as Developer Advocate/SDE, GenAI.









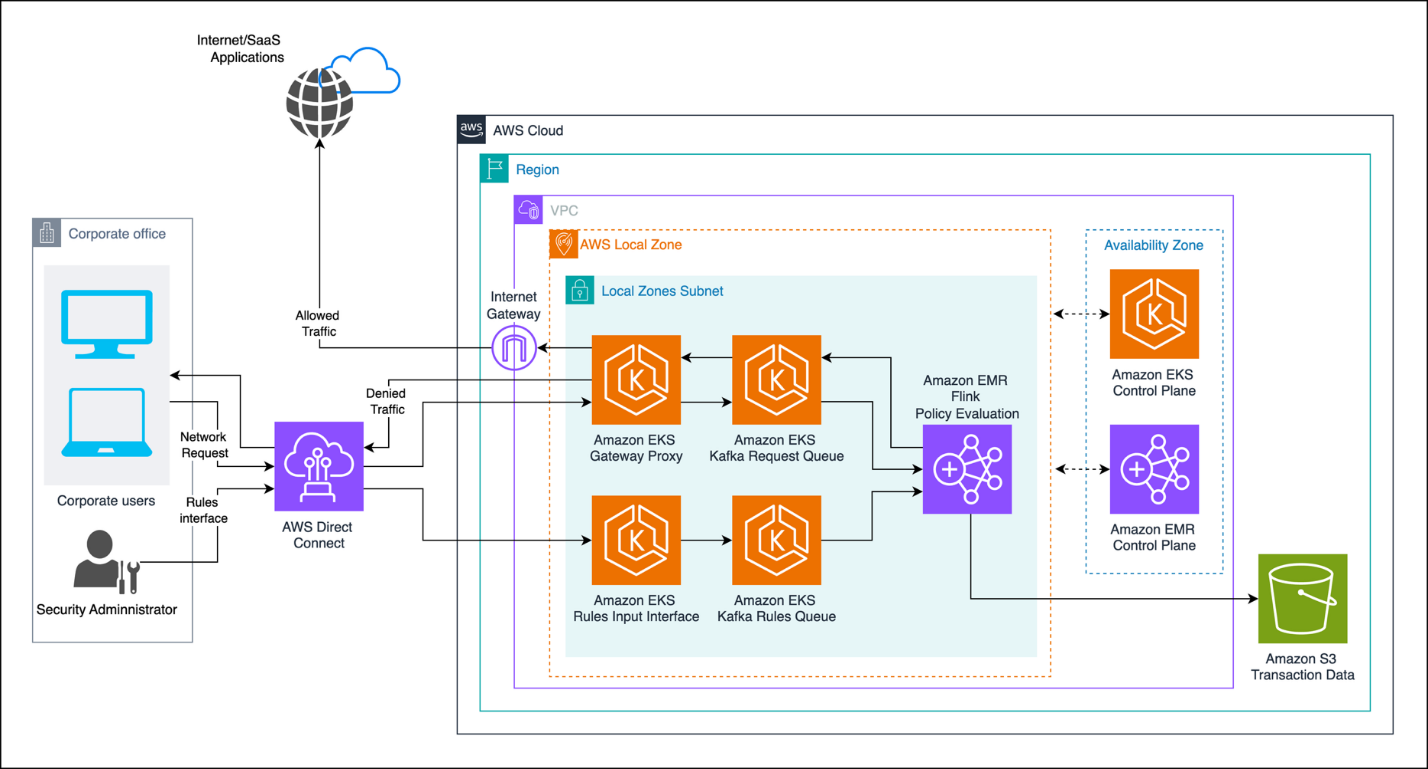
 Sairam Vangapally is a Data Engineer at Amazon with extensive experience architecting real-time, large-scale data platforms that power critical logistics operations across North America. He has led the design and deployment of end-to-end data pipelines, enabling high-throughput ingestion, transformation, and analytics at scale. He is passionate about building resilient data infrastructure and driving cross-functional collaboration to deliver solutions that accelerate operational insights and business impact.
Sairam Vangapally is a Data Engineer at Amazon with extensive experience architecting real-time, large-scale data platforms that power critical logistics operations across North America. He has led the design and deployment of end-to-end data pipelines, enabling high-throughput ingestion, transformation, and analytics at scale. He is passionate about building resilient data infrastructure and driving cross-functional collaboration to deliver solutions that accelerate operational insights and business impact. Nitin Goyal serves as a Data Engineering Manager in Amazon’s Sort Center organization, where he leads initiatives to optimize operational efficiency across North American facilities. With over nine years of tenure at Amazon spanning multiple teams, he specializes in architecting high-performance data systems, with particular emphasis on real-time streaming pipelines, artificial intelligence, and low-latency solutions. His expertise drives the development of sophisticated operational workflows that enhance sort center productivity and effectiveness.
Nitin Goyal serves as a Data Engineering Manager in Amazon’s Sort Center organization, where he leads initiatives to optimize operational efficiency across North American facilities. With over nine years of tenure at Amazon spanning multiple teams, he specializes in architecting high-performance data systems, with particular emphasis on real-time streaming pipelines, artificial intelligence, and low-latency solutions. His expertise drives the development of sophisticated operational workflows that enhance sort center productivity and effectiveness.












