Post Syndicated from Satish Sarapuri original https://aws.amazon.com/blogs/big-data/design-patterns-for-an-enterprise-data-lake-using-aws-lake-formation-cross-account-access/
In this post, we briefly walk through the most common design patterns adapted by enterprises to build lake house solutions to support their business agility in a multi-tenant model using the AWS Lake Formation cross-account feature to enable a multi-account strategy for line of business (LOB) accounts to produce and consume data from your data lake.
A modern data platform enables a community-driven approach for customers across various industries, such as manufacturing, retail, insurance, healthcare, and many more, through a flexible, scalable solution to ingest, store, and analyze customer domain-specific data to generate the valuable insights they need to differentiate themselves. Building a data lake on Amazon Simple Storage Service (Amazon S3), together with AWS analytic services, sets you on a path to become a data-driven organization.
Overview of Lake House Architecture on AWS
You can deploy data lakes on AWS to ingest, process, transform, catalog, and consume analytic insights using the AWS suite of analytics services, including Amazon EMR, AWS Glue, Lake Formation, Amazon Athena, Amazon QuickSight, Amazon Redshift, Amazon Elasticsearch Service (Amazon ES), Amazon Relational Database Service (Amazon RDS), Amazon SageMaker, and Amazon S3. These services provide the foundational capabilities to realize your data vision, in support of your business outcomes. You can deploy a common data access and governance framework across your platform stack, which aligns perfectly with our own Lake House Architecture.
Large enterprise customers require a scalable data lake with a unified access enforcement mechanism to support their analytics workload. For this, you want to use a single set of single sign-on (SSO) and AWS Identity and Access Management (IAM) mappings to attest individual users, and define a single set of fine-grained access controls across various services. The AWS Lake House Architecture encompasses a single management framework; however, the current platform stack requires that you implement workarounds to meet your security policies without compromising on the ability to drive automation, data proliferation, or scale.
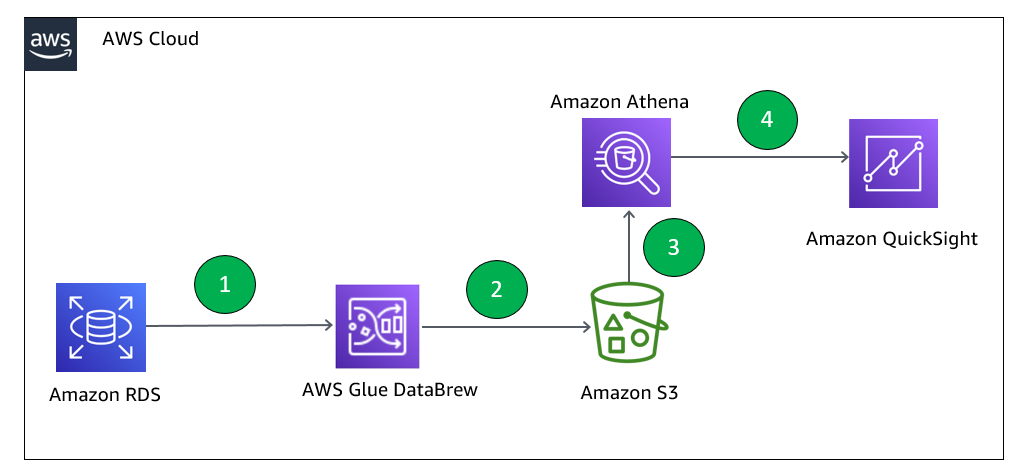
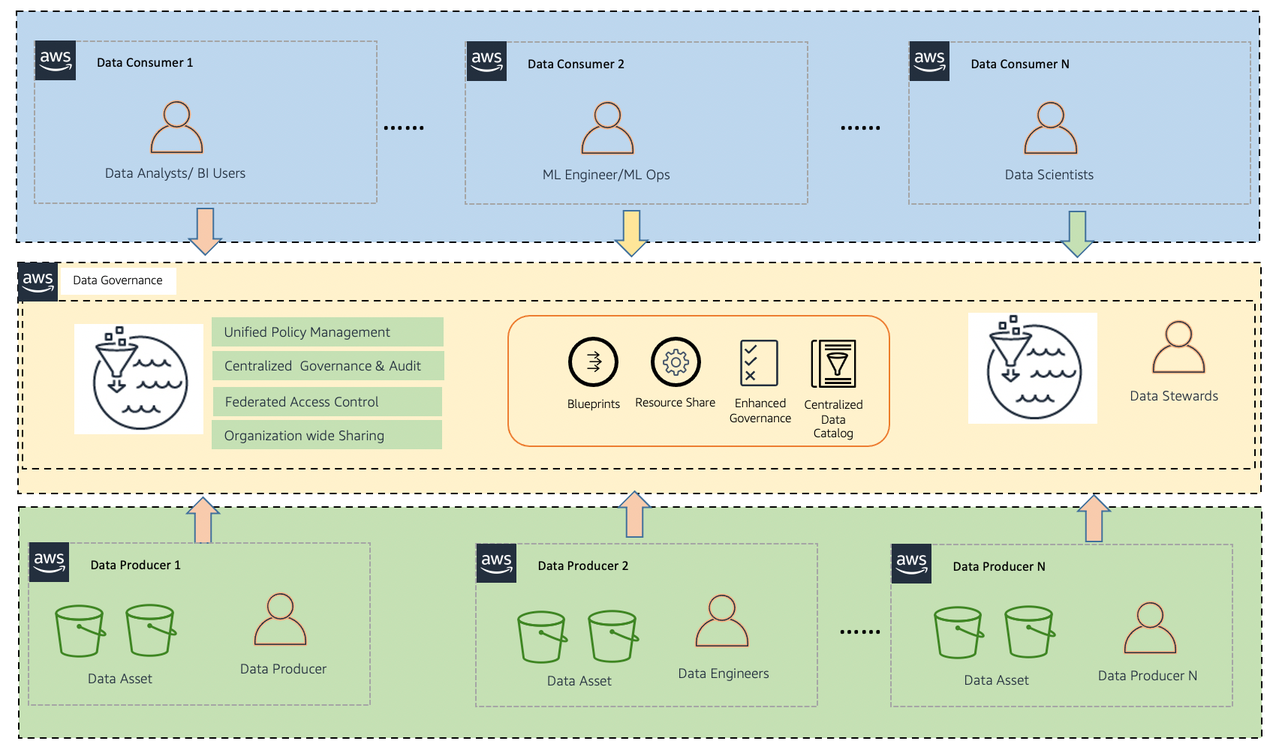
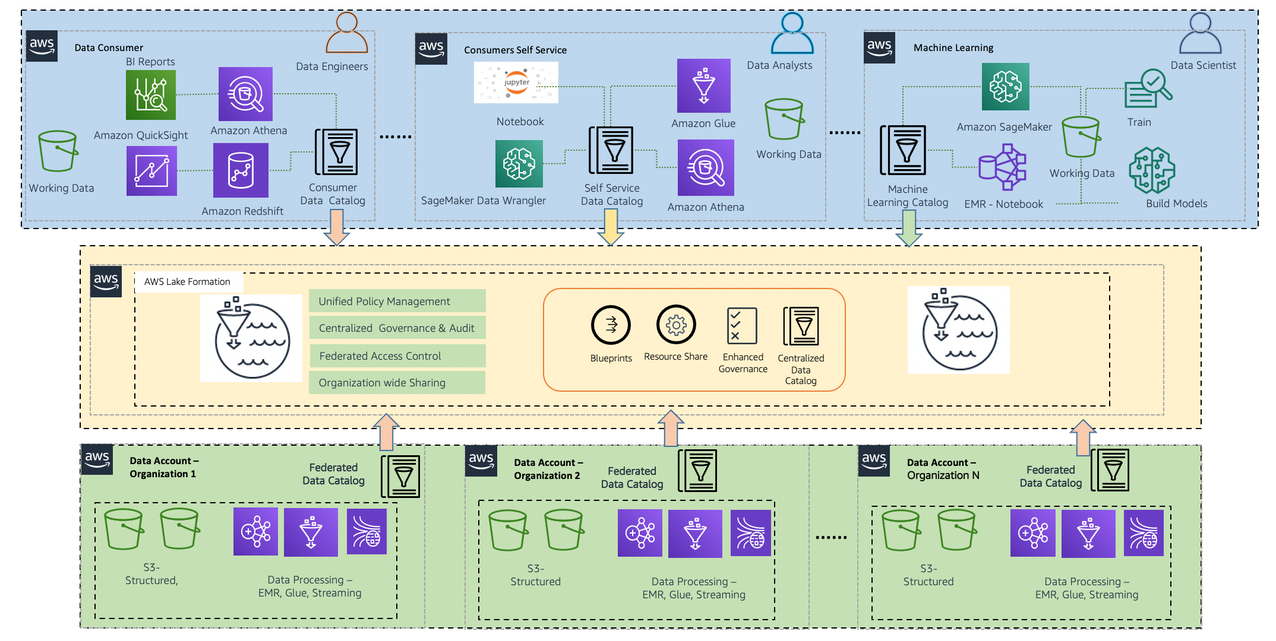
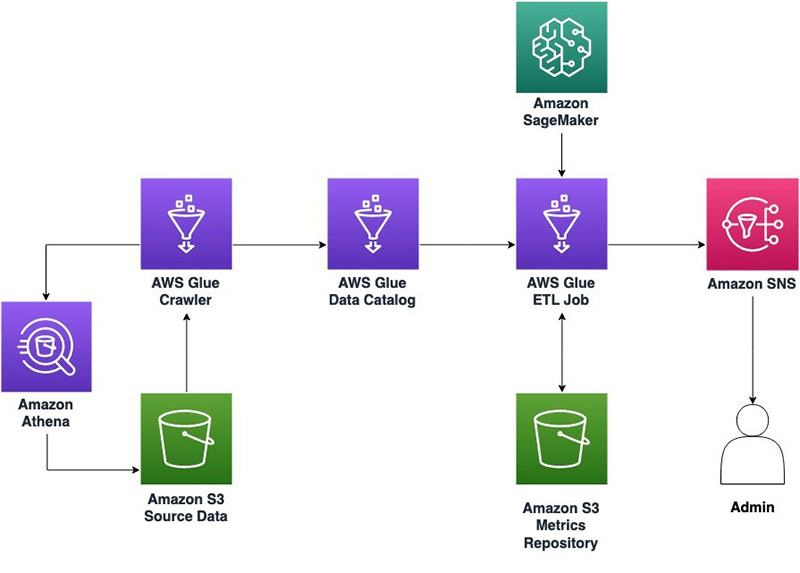
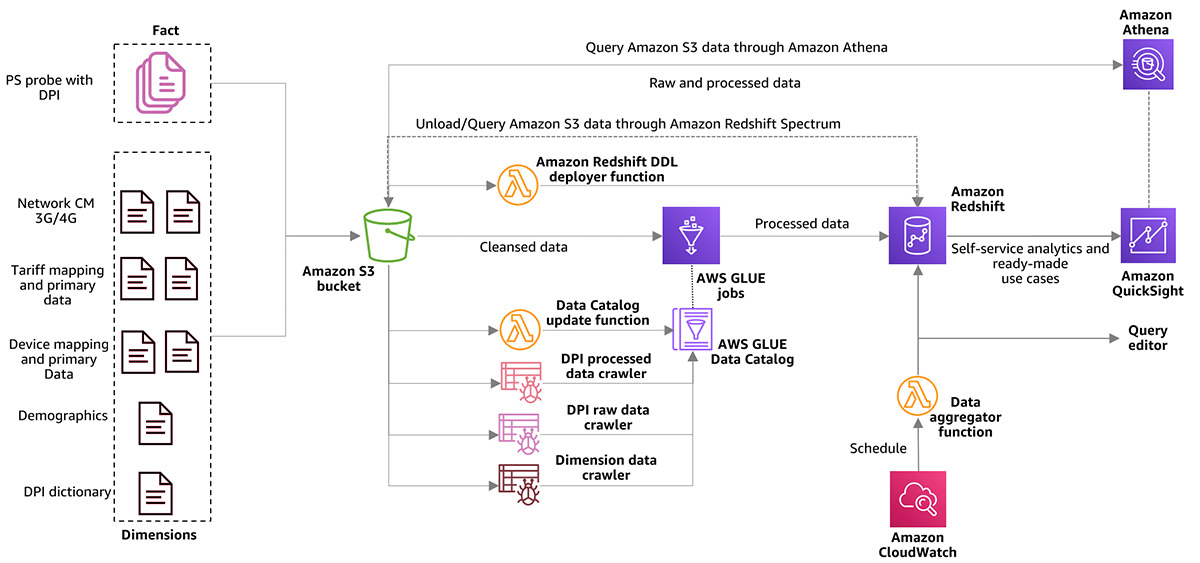
The following diagram illustrates the Lake House architecture.

Lake Formation serves as the central point of enforcement for entitlements, consumption, and governing user access. Furthermore, you may want to minimize data movements (copy) across LOBs and evolve on data mesh methodologies, which is becoming more and more prominent.
Most typical architectures consist of Amazon S3 for primary storage; AWS Glue and Amazon EMR for data validation, transformation, cataloging, and curation; and Athena, Amazon Redshift, QuickSight, and SageMaker for end users to get insight.
Introduction to Lake Formation
Lake Formation is a fully managed service that makes it easy to build, secure, and manage data lakes. Lake Formation simplifies and automates many of the complex manual steps that are usually required to create data lakes. These steps include collecting, cleansing, moving, and cataloging data, and securely making that data available for analytics and ML.
Lake Formation provides its own permissions model that augments the IAM permissions model. This centrally defined permissions model enables fine-grained access to data stored in data lakes through a simple grant or revoke mechanism, much like a relational database management system (RDBMS). Lake Formation permissions are enforced at the table and column level (row level in preview) across the full portfolio of AWS analytics and ML services, including Athena and Amazon Redshift.
With the new cross-account feature of Lake Formation, you can grant access to other AWS accounts to write and share data to or from the data lake to other LOB producers and consumers with fine-grained access. Data lake data (S3 buckets) and the AWS Glue Data Catalog are encrypted with AWS Key Management Service (AWS KMS) customer master keys (CMKs) for security purposes.
Common lake house design patterns using Lake Formation
A typical lake house infrastructure has three major components:
- Data producer – Publishes the data into the data lake
- Data consumer – Consumes that data out from the data lake and runs predictive and business intelligence (BI) insights
- Data platform – Provides infrastructure and an environment to store data assets in the form of a layer cake such as landing, raw, and curated (conformance) data, and establishes security controls between producers and consumers
Although you can construct a data platform in multiple ways, the most common pattern is a single-account strategy, in which the data producer, data consumer, and data lake infrastructure are all in the same AWS account. There is no consensus if using a single account or multiple accounts most of the time is better, but because of the regulatory, security, performance trade-off, we have seen customers adapting to a multi-account strategy in which data producers and data consumers are in different accounts and the data lake is operated from a central, shared account.
This raised the concern of how to manage the data access controls across multiple accounts that are part of the data analytics platform to enable seamless ingestion for producers as well as improved business autonomy and agility for the needs of consumers.
With the general availability of the Lake Formation cross-account feature, the ability to manage data-driven access controls is simplified and offers an RDBMS style of managing data lake assets for producers and consumers.
You can drive your enterprise data platform management using Lake Formation as the central location of control for data access management by following various design patterns that balance your company’s regulatory needs and align with your LOB expectation. The following table summarizes different design patterns.
| Design Type |
Lake Formation |
Glue Data Catalog |
Storage (Amazon S3) |
Compute |
| Centralized |
Centralized |
Centralized |
Centralized |
De-Centralized |
| De-Centralized |
De-Centralized |
Centralized |
De- Centralized |
De-Centralized |
We explain each design pattern in more detail, with examples, in the following sections.\
Terminology
We use the following terms throughout this post when discussing data lake design patterns:
- LOB – The line of business, such as inventory, marketing, or manufacturing
- Enterprise data lake account (EDLA) – A centralized AWS account for data lake storage with a centralized AWS Glue Data Catalog and Lake Formation
- Producer – The process or application producing data for its LOB
- Consumer – The consumer of the LOB data via AWS services (such as Athena, AWS Glue, Amazon EMR, Amazon Redshift Spectrum, AWS Lambda, and QuickSight)
Centralized data lake design
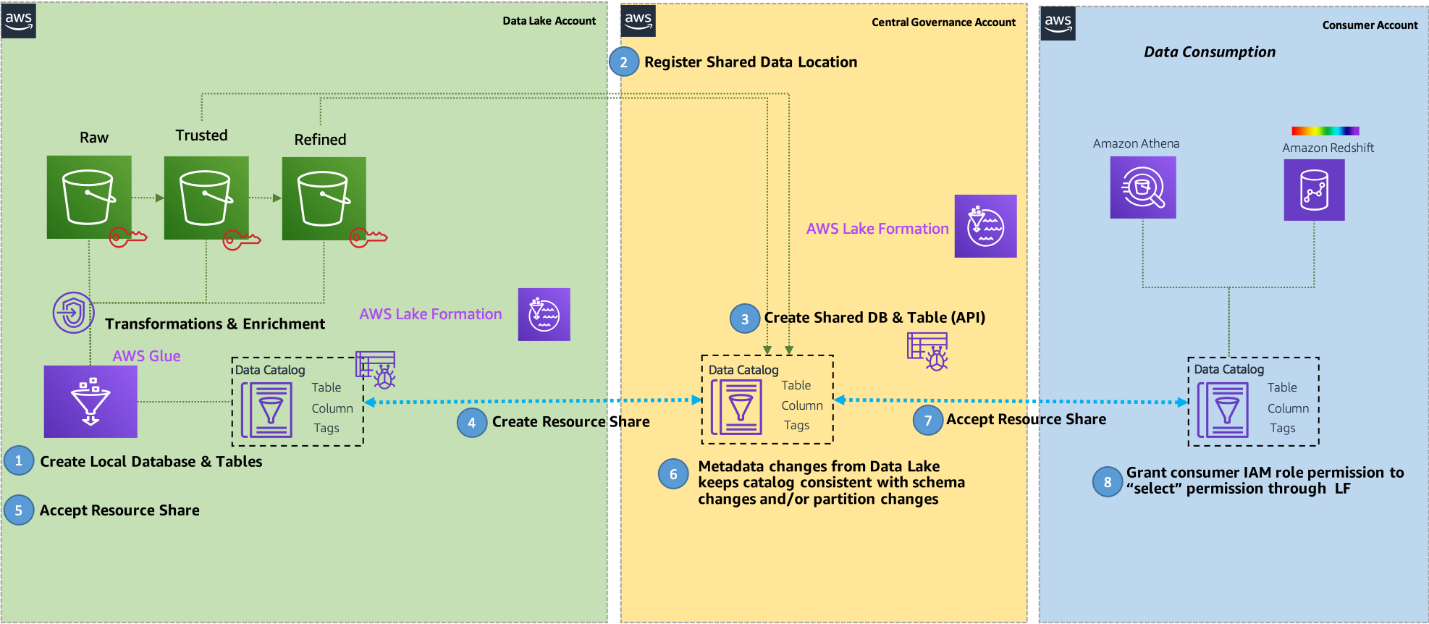
In a centralized data lake design pattern, the EDLA is a central place to store all the data in S3 buckets along with a central (enterprise) Data Catalog and Lake Formation. The respective LOB producer and consumer accounts have all the required compute to write and read data in and from the central EDLA data, and required fine-grained access is performed using the Lake Formation cross-account feature. That’s why this architecture pattern (see the following diagram) is called a centralized data lake design pattern.

For this post, we use one LOB as an example, which has an AWS account as a producer account that generates data, which can be from on-premises applications or within an AWS environment. This account uses its compute (in this case, AWS Glue) to write data into its respective AWS Glue database. The database is created in the central EDLA where all S3 data is stored using the database link created with the Lake Formation cross-account feature. The same LOB consumer account consumes data from the central EDLA via Lake Formation to perform advanced analytics using services like AWS Glue, Amazon EMR, Redshift Spectrum, Athena, and QuickSight, using the consumer AWS account compute. The following section provides an example.
Create your database, tables and register S3 locations
In the EDLA, complete the following steps:
- Register the EDLA S3 bucket path in Lake Formation.
- Create a database called
edla_lob_a, which points to the EDLA S3 bucket for LOB-A.


- Create a
customer table in this edla_lob_a database , which points to the EDLA S3 bucket.
The LOB-A producer account can directly write or update data into tables, and create, update, or delete partitions using the LOB-A producer account compute via the Lake Formation cross-account feature.
You can trigger the table creation process from the LOB-A producer AWS account via Lambda cross-account access.

Grant Lake Formation cross-account access
Grant full access to the LOB-A producer account to write, update, and delete data into the EDLA S3 bucket via AWS Glue tables.

If your EDLA and producer accounts are part of same AWS organization, you should see the accounts on the list. If not, you need to enter the AWS account number manually as an external AWS account.

The following screenshot shows the granted permissions in the EDLA for the LOB-A producer account.


When you grant permissions to another account, Lake Formation creates resource shares in AWS Resource Access Manager (AWS RAM) to authorize all the required IAM layers between the accounts. To validate a share, sign in to the AWS RAM console as the EDLA and verify the resources are shared.
The first time you create a share, you see three resources:
- The AWS Glue Data Catalog in the EDLA
- The database containing the tables you shared
- The table resource itself
You only need one share per resource, so multiple database shares only require a single Data Catalog share, and multiple table shares within the same database only require a single database share.
For the share to appear in the catalog of the receiving account (in our case the LOB-A account), the AWS RAM admin must accept the share by opening the share on the Shared With Me page and accepting it.
If both accounts are part of the same AWS organization and the organization admin has enabled automatic acceptance on the Settings page of the AWS Organizations console, then this step is unnecessary.
If your EDLA Data Catalog is encrypted with a KMS CMK, make sure to add your LOB-A producer account root user as the user for this key, so the LOB-A producer account can easily access the EDLA Data Catalog for read and write permissions with its local IAM KMS policy. Data encryption keys don’t need any additional permissions, because the LOB accounts use the Lake Formation role associated with the registration to access objects in Amazon S3.
When you sign in with the LOB-A producer account to the AWS RAM console, you should see the EDLA shared database details, as in the following screenshot.

Create a database resource link in the LOB-A producer account
Resource links are pointers to the original resource that allow the consuming account to reference the shared resource as if it were local to the account. As a pointer, resource links mean that any changes are instantly reflected in all accounts because they all point to the same resource. No sync is necessary for any of this and no latency occurs between an update and its reflection in any other accounts.
- Create a resource link to the shared Data Catalog database from the EDLA called
shared_edla_lob_a.

- Grant full access to the AWS Glue role in the LOB-A producer account for this newly created shared database link from the EDLA so a producer AWS Glue job can create, update, and delete tables and partitions.
You need to perform two grants: one on the database shared link and one on the target to the AWS Glue job role. Granting on the link allows it to be visible to end-users. Data-level permissions are granted on the target itself.
- Create an AWS Glue job using this role to create and write data into the EDLA database and S3 bucket location.
The AWS Glue table and S3 data are in a centralized location for this architecture, using the Lake Formation cross-account feature.

This completes the configuration of the LOB-A producer account remotely writing data into the EDLA Data Catalog and S3 bucket. You can create and share the rest of the required tables for this LOB using the Lake Formation cross-account feature.
Because your LOB-A producer created an AWS Glue table and wrote data into the Amazon S3 location of your EDLA, the EDLA admin can access this data and share the LOB-A database and tables to the LOB-A consumer account for further analysis, aggregation, ML, dashboards, and end-user access.

Share the database to the LOB-A consumer account
In the EDLA, you can share the LOB-A AWS Glue database and tables (edla_lob_a, which contains tables created from the LOB-A producer account) to the LOB-A consumer account (in this case, the entire database is shared).

Next, go to the LOB-A consumer account to accept the resource share in AWS RAM.
Accepting the shared database in AWS RAM of the LOB-A consumer account
Sign in with the LOB-A consumer account to the AWS RAM console. You should see the EDLA shared database details.

Accept this resource share request so you can create a resource link in the LOB-A consumer account.

Create a database resource link in the LOB-A consumer account
Create a resource link to a shared Data Catalog database from the EDLA as consumer_edla_lob_a.

Now, grant full access to the AWS Glue role in the LOB-A consumer account for this newly created shared database link from the EDLA so the consumer account AWS Glue job can perform SELECT data queries from those tables. You need to perform two grants: one on the database shared link and one on the target to the AWS Glue job role.
A grant on the resource link allows a user to describe (or see) the resource link, which allows them to point engines such as Athena at it for queries. A grant on the target grants permissions to local users on the original resource, which allows them to interact with the metadata of the table and the data behind it. Permissions of DESCRIBE on the resource link and SELECT on the target are the minimum permissions necessary to query and interact with a table in most engines.
Create an AWS Glue job using this role to read tables from the consumer database that is shared from the EDLA and for which S3 data is also stored in the EDLA as a central data lake store. This data is accessed via AWS Glue tables with fine-grained access using the Lake Formation cross-account feature.

This completes the process of granting the LOB-A consumer account remote access to data for further analysis.
This data can be accessed via Athena in the LOB-A consumer account. LOB-A consumers can also access this data using QuickSight, Amazon EMR, and Redshift Spectrum for other use cases.

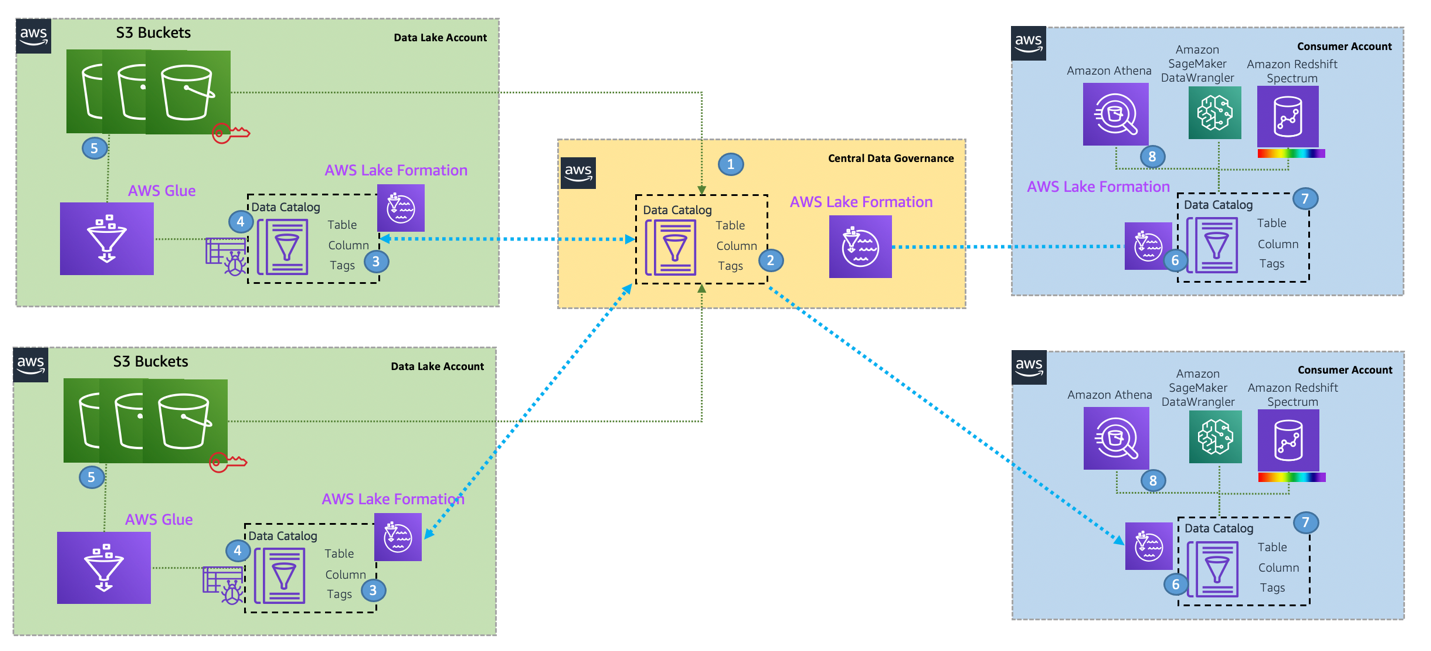
De-centralized data lake design
In the de-centralized design pattern, each LOB AWS account has local compute, an AWS Glue Data Catalog, and a Lake Formation along with its local S3 buckets for its LOB dataset and a central Data Catalog for all LOB-related databases and tables, which also has a central Lake Formation where all LOB-related S3 buckets are registered in EDLA.
EDLA manages all data access (read and write) permissions for AWS Glue databases or tables that are managed in EDLA. It grants the LOB producer account write, update, and delete permissions on the LOB database via the Lake Formation cross-account share. It also grants read permissions to the LOB consumer account. The respective LOB’s local data lake admins grant required access to their local IAM principals.
Refer to the earlier details on how to share database, tables, and table columns from EDLA to the producer and consumer accounts via Lake Formation cross-account sharing via AWS RAM and resource links.
Each LOB account (producer or consumer) also has its own local storage, which is registered in the local Lake Formation along with its local Data Catalog, which has a set of databases and tables, which are managed locally in that LOB account by its Lake Formation admins.

Clean up
To avoid incurring future charges, delete the resources that were created as part of this exercise.
Delete the S3 buckets in the following accounts:
- Producer account
- EDLA account
- Consumer account (if any)
Delete the AWS Glue jobs in the following accounts:
- Producer account
- Consumer account (if any)
Lake Formation limitations
This solution has the following limitations:
- The
spark-submit action on Amazon EMR is not currently supported
- AWS Glue Context does not yet support column-level fine-grained permissions granted via the Lake Formation
Conclusion
This post describes how you can design enterprise-level data lakes with a multi-account strategy and control fine-grained access to its data using the Lake Formation cross-account feature. This can help your organization build highly scalable, high-performance, and secure data lakes with easy maintenance of its related LOBs’ data in a single AWS account with all access logs and grant details.
About the Authors
 Satish Sarapuri is a Data Architect, Data Lake at AWS. He helps enterprise-level customers build high-performance, highly available, cost-effective, resilient, and secure data lakes and analytics platform solutions, which includes streaming and batch ingestions into the data lake. In his spare time, he enjoys spending time with his family and playing tennis.
Satish Sarapuri is a Data Architect, Data Lake at AWS. He helps enterprise-level customers build high-performance, highly available, cost-effective, resilient, and secure data lakes and analytics platform solutions, which includes streaming and batch ingestions into the data lake. In his spare time, he enjoys spending time with his family and playing tennis.
 UmaMaheswari Elangovan is a Principal Data Lake Architect at AWS. She helps enterprise and startup customers adopt AWS data lake and analytic services, and increases awareness on building a data-driven community through scalable, distributed, and reliable data lake infrastructure to serve a wide range of data users, including but not limited to data scientists, data analysts, and business analysts. She also enjoys mentoring young girls and youth in technology by volunteering through nonprofit organizations such as High Tech Kids, Girls Who Code, and many more.
UmaMaheswari Elangovan is a Principal Data Lake Architect at AWS. She helps enterprise and startup customers adopt AWS data lake and analytic services, and increases awareness on building a data-driven community through scalable, distributed, and reliable data lake infrastructure to serve a wide range of data users, including but not limited to data scientists, data analysts, and business analysts. She also enjoys mentoring young girls and youth in technology by volunteering through nonprofit organizations such as High Tech Kids, Girls Who Code, and many more.
 Zach Mitchell is a Sr. Big Data Architect. He works within the product team to enhance understanding between product engineers and their customers while guiding customers through their journey to develop data lakes and other data solutions on AWS analytics services.
Zach Mitchell is a Sr. Big Data Architect. He works within the product team to enhance understanding between product engineers and their customers while guiding customers through their journey to develop data lakes and other data solutions on AWS analytics services.


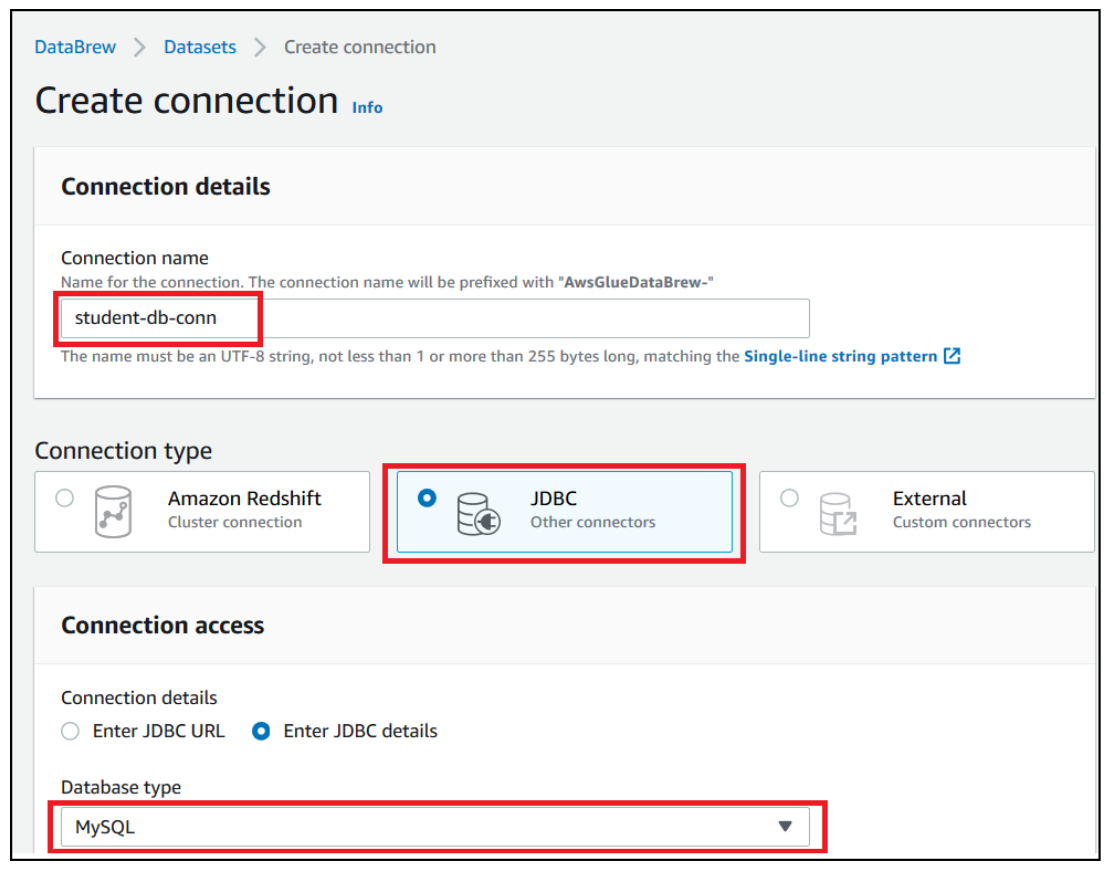
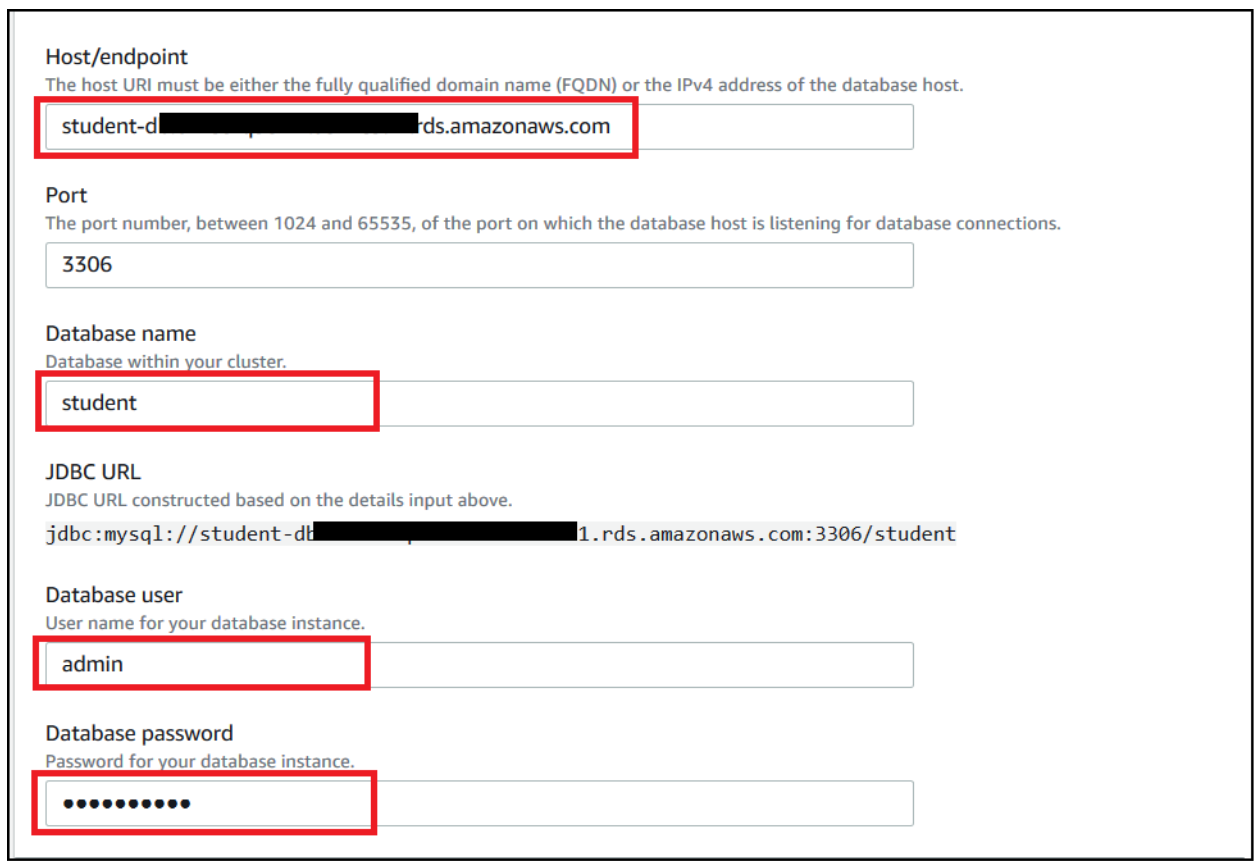

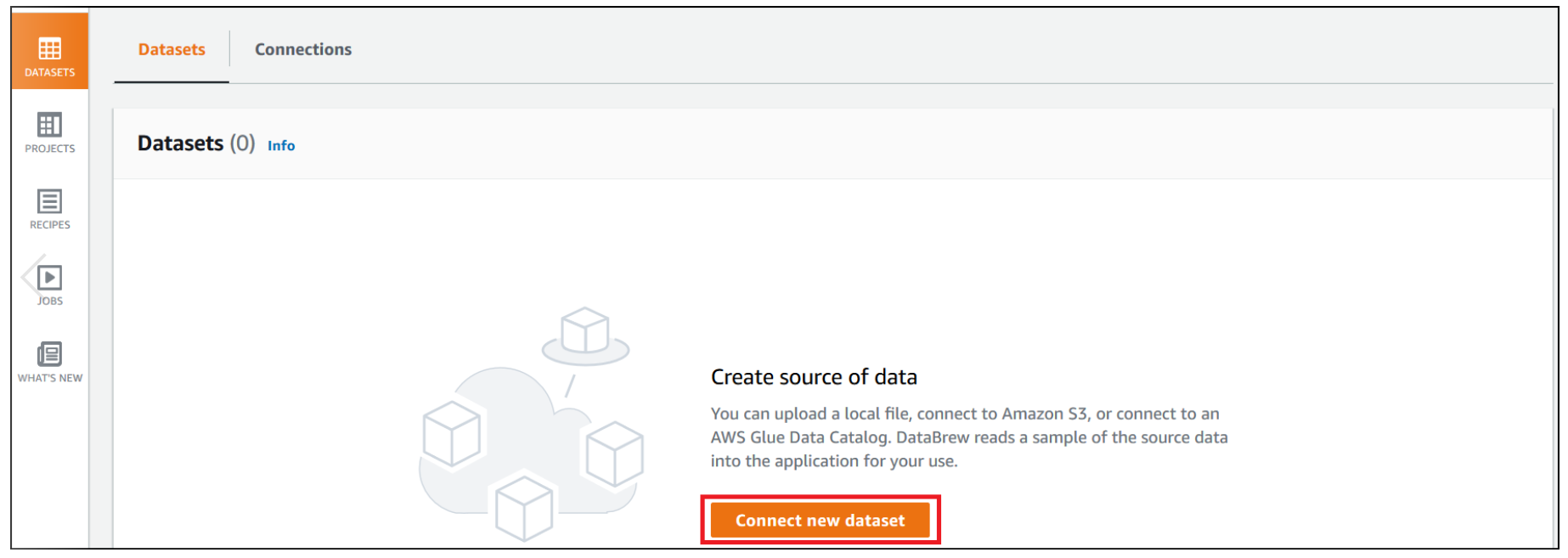




 Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration, and strategy. He is passionate about technology and enjoys building and experimenting in the analytics and AI/ML space.
Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration, and strategy. He is passionate about technology and enjoys building and experimenting in the analytics and AI/ML space.





 Shehzad Qureshi is a Senior Software Engineer at Amazon Web Services.
Shehzad Qureshi is a Senior Software Engineer at Amazon Web Services. Bin Pang is a software development engineer at Amazon Web Services.
Bin Pang is a software development engineer at Amazon Web Services. Deenbandhu Prasad is a Senior Analytics Specialist at AWS, specializing in big data services. He is passionate about helping customers build modern data platforms on the AWS Cloud. He has helped customers of all sizes implement data management, data warehouse, and data lake solutions.
Deenbandhu Prasad is a Senior Analytics Specialist at AWS, specializing in big data services. He is passionate about helping customers build modern data platforms on the AWS Cloud. He has helped customers of all sizes implement data management, data warehouse, and data lake solutions.




















 Nivas Shankar is a Principal Data Architect at Amazon Web Services. He helps and works closely with enterprise customers building data lakes and analytical applications on the AWS platform. He holds a master’s degree in physics and is highly passionate about theoretical physics concepts.
Nivas Shankar is a Principal Data Architect at Amazon Web Services. He helps and works closely with enterprise customers building data lakes and analytical applications on the AWS platform. He holds a master’s degree in physics and is highly passionate about theoretical physics concepts. Roy Hasson is the Global Business Development Lead of Analytics and Data Lakes at AWS. He works with customers around the globe to design solutions to meet their data processing, analytics, and business intelligence needs. Roy is big Manchester United fan, cheering his team on and hanging out with his family.
Roy Hasson is the Global Business Development Lead of Analytics and Data Lakes at AWS. He works with customers around the globe to design solutions to meet their data processing, analytics, and business intelligence needs. Roy is big Manchester United fan, cheering his team on and hanging out with his family. Zach Mitchell is a Sr. Big Data Architect. He works within the product team to enhance understanding between product engineers and their customers while guiding customers through their journey to develop data lakes and other data solutions on AWS analytics services.
Zach Mitchell is a Sr. Big Data Architect. He works within the product team to enhance understanding between product engineers and their customers while guiding customers through their journey to develop data lakes and other data solutions on AWS analytics services. Ian Meyers is a Sr. Principal Product Manager for AWS Database Services. He works with many of AWS largest customers on emerging technology needs, and leads several data and analytics initiatives within AWS including support for Data Mesh.
Ian Meyers is a Sr. Principal Product Manager for AWS Database Services. He works with many of AWS largest customers on emerging technology needs, and leads several data and analytics initiatives within AWS including support for Data Mesh.
























 Satish Sarapuri is a Data Architect, Data Lake at AWS. He helps enterprise-level customers build high-performance, highly available, cost-effective, resilient, and secure data lakes and analytics platform solutions, which includes streaming and batch ingestions into the data lake. In his spare time, he enjoys spending time with his family and playing tennis.
Satish Sarapuri is a Data Architect, Data Lake at AWS. He helps enterprise-level customers build high-performance, highly available, cost-effective, resilient, and secure data lakes and analytics platform solutions, which includes streaming and batch ingestions into the data lake. In his spare time, he enjoys spending time with his family and playing tennis. UmaMaheswari Elangovan is a Principal Data Lake Architect at AWS. She helps enterprise and startup customers adopt AWS data lake and analytic services, and increases awareness on building a data-driven community through scalable, distributed, and reliable data lake infrastructure to serve a wide range of data users, including but not limited to data scientists, data analysts, and business analysts. She also enjoys mentoring young girls and youth in technology by volunteering through nonprofit organizations such as High Tech Kids, Girls Who Code, and many more.
UmaMaheswari Elangovan is a Principal Data Lake Architect at AWS. She helps enterprise and startup customers adopt AWS data lake and analytic services, and increases awareness on building a data-driven community through scalable, distributed, and reliable data lake infrastructure to serve a wide range of data users, including but not limited to data scientists, data analysts, and business analysts. She also enjoys mentoring young girls and youth in technology by volunteering through nonprofit organizations such as High Tech Kids, Girls Who Code, and many more.






















 Ninad Phatak is a Principal Data Architect at Amazon Development Center India. He specializes in data engineering and datawarehousing technologies and helps customers architect their analytics use cases and platforms on AWS.
Ninad Phatak is a Principal Data Architect at Amazon Development Center India. He specializes in data engineering and datawarehousing technologies and helps customers architect their analytics use cases and platforms on AWS. Vinay Kondapi is Head of product for Amazon AppFlow. He specializes in Application and data integration with SaaS products at AWS.
Vinay Kondapi is Head of product for Amazon AppFlow. He specializes in Application and data integration with SaaS products at AWS.






 Noritaka Sekiyama is a Senior Big Data Architect at AWS Glue and AWS Lake Formation. He is passionate about big data technology and open source software, and enjoys building and experimenting in the analytics area.
Noritaka Sekiyama is a Senior Big Data Architect at AWS Glue and AWS Lake Formation. He is passionate about big data technology and open source software, and enjoys building and experimenting in the analytics area. Sachet Saurabh is a Senior Software Development Engineer at AWS Glue and AWS Lake Formation. He is passionate about building fault tolerant and reliable distributed systems at scale.
Sachet Saurabh is a Senior Software Development Engineer at AWS Glue and AWS Lake Formation. He is passionate about building fault tolerant and reliable distributed systems at scale. Vikas Malik is a Software Development Manager at AWS Glue. He enjoys building solutions that solve business problems at scale. In his free time, he likes playing and gardening with his kids and exploring local areas with family.
Vikas Malik is a Software Development Manager at AWS Glue. He enjoys building solutions that solve business problems at scale. In his free time, he likes playing and gardening with his kids and exploring local areas with family.
























 Nitin Aggarwal is a Senior Solutions Architect at AWS, where helps digital native customers with architecting data analytics solutions and providing technical guidance on various AWS services. He brings more than 16 years of experience in software engineering and architecture roles for various large-scale enterprises.
Nitin Aggarwal is a Senior Solutions Architect at AWS, where helps digital native customers with architecting data analytics solutions and providing technical guidance on various AWS services. He brings more than 16 years of experience in software engineering and architecture roles for various large-scale enterprises. Gaurav Sharma is a Solutions Architect at AWS. He works with digital native business customers providing architectural guidance on AWS services.
Gaurav Sharma is a Solutions Architect at AWS. He works with digital native business customers providing architectural guidance on AWS services. Vivek Kumar is a Solutions Architect at AWS. He works with digital native business customers providing architectural guidance on AWS services.
Vivek Kumar is a Solutions Architect at AWS. He works with digital native business customers providing architectural guidance on AWS services.













 Joan Aoanan is a ProServe Consultant at AWS. With her B.S. Mathematics-Computer Science degree from Gonzaga University, she is interested in integrating her interests in math and science with technology.
Joan Aoanan is a ProServe Consultant at AWS. With her B.S. Mathematics-Computer Science degree from Gonzaga University, she is interested in integrating her interests in math and science with technology. Veronika Megler, PhD, is Principal Data Scientist for Amazon.com Consumer Packaging. Until recently she was the Principal Data Scientist for AWS Professional Services. She enjoys adapting innovative big data, AI, and ML technologies to help companies solve new problems, and to solve old problems more efficiently and effectively. Her work has lately been focused more heavily on economic impacts of ML models and exploring causality.
Veronika Megler, PhD, is Principal Data Scientist for Amazon.com Consumer Packaging. Until recently she was the Principal Data Scientist for AWS Professional Services. She enjoys adapting innovative big data, AI, and ML technologies to help companies solve new problems, and to solve old problems more efficiently and effectively. Her work has lately been focused more heavily on economic impacts of ML models and exploring causality. Calvin Wang is a Data Scientist at AWS AI/ML. He holds a B.S. in Computer Science from UC Santa Barbara and loves using machine learning to build cool stuff.
Calvin Wang is a Data Scientist at AWS AI/ML. He holds a B.S. in Computer Science from UC Santa Barbara and loves using machine learning to build cool stuff.






 Gopalakrishnan Ramaswamy is a Solutions Architect at AWS based out of India with extensive background in database, analytics, and machine learning. He helps customers of all sizes solve complex challenges by providing solutions using AWS products and services. Outside of work, he likes the outdoors, physical activities and spending time with friends and family.
Gopalakrishnan Ramaswamy is a Solutions Architect at AWS based out of India with extensive background in database, analytics, and machine learning. He helps customers of all sizes solve complex challenges by providing solutions using AWS products and services. Outside of work, he likes the outdoors, physical activities and spending time with friends and family.





























 Vikas Omer is an analytics specialist solutions architect at Amazon Web Services. Vikas has a strong background in analytics, customer experience management (CEM), and data monetization, with over 11 years of experience in the telecommunications industry globally. With six AWS Certifications, including Analytics Specialty, he is a trusted analytics advocate to AWS customers and partners. He loves traveling, meeting customers, and helping them become successful in what they do.
Vikas Omer is an analytics specialist solutions architect at Amazon Web Services. Vikas has a strong background in analytics, customer experience management (CEM), and data monetization, with over 11 years of experience in the telecommunications industry globally. With six AWS Certifications, including Analytics Specialty, he is a trusted analytics advocate to AWS customers and partners. He loves traveling, meeting customers, and helping them become successful in what they do.





 Bo Li is a software engineer in AWS Glue and devoted to designing and building end-to-end solutions to address customer’s data analytic and processing needs with cloud-based data-intensive technologies.
Bo Li is a software engineer in AWS Glue and devoted to designing and building end-to-end solutions to address customer’s data analytic and processing needs with cloud-based data-intensive technologies. Yubo Xu is a Sofware Development Engineer on the AWS Glue team. His main focus is to improve the stability and efficiency of Spark runtime for AWS Glue and the easiness to connect to various data sources. Outside of work, he enjoys reading books and hiking the trails in the Bay area with his dog, Luffy, a one-year old Shiba Inu.
Yubo Xu is a Sofware Development Engineer on the AWS Glue team. His main focus is to improve the stability and efficiency of Spark runtime for AWS Glue and the easiness to connect to various data sources. Outside of work, he enjoys reading books and hiking the trails in the Bay area with his dog, Luffy, a one-year old Shiba Inu. Xiaoxi Liu is a software engineer at AWS Glue team. Her passion is building scalable distributed systems for efficiently managing big data on cloud and her concentrations are distributed system, big data and cloud computing
Xiaoxi Liu is a software engineer at AWS Glue team. Her passion is building scalable distributed systems for efficiently managing big data on cloud and her concentrations are distributed system, big data and cloud computing Mohit Saxena is a Software Development Manager at AWS Glue. His team works on Glue’s Spark runtime to enable new customer use cases for efficiently managing data lakes on AWS and optimize Apache Spark for performance and reliability.
Mohit Saxena is a Software Development Manager at AWS Glue. His team works on Glue’s Spark runtime to enable new customer use cases for efficiently managing data lakes on AWS and optimize Apache Spark for performance and reliability.













 Srinivas Kesanapally is a principal partner solution architect at AWS and has over 25 years of experience in working with database and analytics products from traditional to modern database vendors and has helped many large technology companies in designing data analytics solutions as well as led engineering teams involved in modernizing data analytic platforms.
Srinivas Kesanapally is a principal partner solution architect at AWS and has over 25 years of experience in working with database and analytics products from traditional to modern database vendors and has helped many large technology companies in designing data analytics solutions as well as led engineering teams involved in modernizing data analytic platforms.