Post Syndicated from davelem original https://aws.amazon.com/blogs/messaging-and-targeting/advanced-amazon-pinpoint-templates-using-message-template-helpers/
Personalization of customer messages is a proven way to increase engagement of promotional and transactional communications. In order to make these communications repeatable and scalable, building personalization through templates is often required.
Using the Advanced Template Capabilities feature of Amazon Pinpoint, it’s now possible to create highly customized templates used for email, SMS, and Push Notifications.

Pinpoint templates are personalized using Handlebars.js. The new message template helpers are an expansion on the default Handlebars.js features. Please refer to handlebarsjs.com for more information on the default functionality of Handlebars.js
In this blog we will build an Order Confirmation template that will demonstrate a few helpers from each of the following categories:
Prerequisites
Before creating a template, you need to have an existing Amazon Pinpoint Project with the email channel enabled. The following will walk you through creating a project if you don’t already have one: Create and configure a Pinpoint Project
Architecture Overview

Step 1: Create a CSV file with sample Endpoint and Imported Segment
In Amazon Pinpoint, an endpoint represents a specific method of contacting a customer. This could be their email address (for email messages) or their phone number (for SMS messages) or a custom endpoint type. Endpoints can also contain custom attributes, and you can associate multiple endpoints with a single user. In this step, we create a simple CSV file which we will use to create a Segment in Pinpoint.
The data below contains the sample Order and Product data we will use in our Order Confirmation Email.
- Create a .CSV file named AdvancedTemplatesSegment.csv with the following data:
NOTE: The file above has a few attributes that are the key to personalizing our email and including multiple items in our Order Confirmation table:
- Attributes.FirstName – This will allow us to personalize with a salutation if available.
- Attributes.CLVTier – This is an attribute that could be specified from a Machine Learning model to determine the customers CLV Tier. We will be using it to provide coupons specific to a given CLV Tier. See Predictive Segmentation Using Amazon Pinpoint and Amazon SageMaker for an example solution that demonstrates using Machine Learning to analyze information in Pinpoint.
- Attributes.ProductNumber – Note that we have multiple columns that repeat for the product information in the order. Pinpoint attributes are actually stored as a list, so if you pass multiple columns with the same name it will add items to the attribute list.This is the key to how we are able to display a table of information, but note that it does require making sure the attributes are aligned in the proper columns. For example,
Attributes.ProductNumber[0]needs to align withAttributes.ProductName[0]See Using variables with message template helpers for more details.
- Search for [email protected] above and replace with two valid email addresses. Note that if your account is still in the sandbox these will need to be verified email addresses. If you only have access to a single email address you can use labels by adding a plus sign (+) followed by a string of text after the local part of the address and before the at (@) sign. For example: [email protected] and [email protected]
- Create a Pinpoint Segment
- Open the Amazon Pinpoint console at http://console.aws.amazon.com/pinpoint, and then choose the project that you created as part of the Prerequisites.
- In the navigation pane, choose Segments, and then choose Create a segment.
- Select Import a Segment.
- Browse to or Drag and Drop the .CSV file you created in the previous step.
- Use the default Segment Name and select Create Segment.
Step 2: Build The Message Template
- Open the Amazon Pinpoint console at http://console.aws.amazon.com/pinpoint.
- In the navigation pane, choose Message templates, and then choose Create template.
- Select Email as the Channel.
- For Template name use: AdvancedTemplateExample.
- For Subject use: AdvancedTemplateExample.
- Paste the following code into the HTML Editor. We will take some time later on to dig into the specific Handlebars helpers:
- Click Create to finish creating your template
Step 3: Create an Amazon Pinpoint Campaign
By sending a campaign, we can verify that our Amazon Pinpoint project is configured correctly, and that we created the segment and template correctly.
To create the segment and campaign:
- Open the Amazon Pinpoint console at http://console.aws.amazon.com/pinpoint, and then choose the project that you created in step 1.
- In the navigation pane, choose Campaigns, and then choose Create a campaign.
- Name the campaign “AdvancedTemplateTest.” Under Choose a channel for this campaign, choose Email, and then choose Next.
- On the Choose a segment page, choose the “AdvancedTemplateExample” segment that you just created, and then choose Next.
- In Create your message, choose the template we just created, ‘AdvancedTemplateExample. Note: You will see an Alert with: “This template contains a reference to an attribute from another project…” This is expected as Pinpoint is scanning the template for attributes allowing you to specify default values in case the endpoint doesn’t contain a value for the attribute. In this blog post we are using the
{{#if}}conditional helper to handle any missing data, i.e.{{#if Attributes.FirstName.[0]}} - On the Choose when to send the campaign page, keep all of the default values, and then choose Next.
- On the Review and launch page, choose Launch campaign.
Within a few seconds, you should receive an email:

So what just happened?
Let’s take a deeper dive at each of helpers we included in the template:
First you will notice that we are making use of Inline Partials. Using Inline Partials allows you to build a library of frequently used snippets of content. In this case we frequently use a salutation in our communications. You can build and maintain your own frequently used snippets and include them at the beginning of the template.
Later in the message we can simply include: {{> salutation}} to include a salutation in our email.
In this example we also see the {{#if}} helper which is used to evaluate if a first name is available on the endpoint. If the name is found, a greeting is returned that passes the user’s first name in the response. Otherwise, the else statement returns an alternative greeting.
Again, we are using Inline Partials to organize our code. Additionally we are using {{#if}} to see if the user has a CLVTier attribute and if so, we use the {{#eq}} conditional helper to see if their CLVTier is “High” as we only want this coupon to display for customers that fall into that tier.
Note that CLVTier is an attribute that is populated along with the Endpoint when we created the Segment above. You could also use a solution such as Predictive Segmentation using Amazon Pinpoint and Amazon SageMaker to incorporate Machine Learning to classify your existing users.
In the example above we are using the {{sha256}} and {{join}} helpers to create a secure link to the Preference Center deployed as part of the Amazon Pinpoint Preference Center solution.
This is where all of our hard work implementing Inline Partials really starts to pay off. To include our salutation and coupon we simply need to specify: {{> salutation}} and {{> clvcoupon}}
The {{now}} string helper allows us to display the current date and time in the format of our choosing. Please reference the following for more details on the date pattern and available timezones:
This particular section has a lot going on. We will break each part down for further explanation:
{{#each}}– Allows us to loop through each of the values in our attribute. In this case our ProductNumber attribute will contain:[“order#1”, “order#2”,”order#3, etc.]
Note that if you only have one item in the attribute array. Pinpoint will simplify that into a single string attribute. That is why we have the{{each}}part of the{{#else}}statement. This allows us to reference the attribute as a single string in case we don’t have a collection of values in the attribute.{{#eq (modulo @index 2) “1.0”}}– In order to alternate our background color for even/odd rows, we are making use of the{{modulo}}operator from the Math and encoding helpers which will return the remainder of two given numbers allowing us to determine if this is an odd or even row.
@index is a native Handlebars.js property that contains the current index we are on in the loop.{{this}}– When iterating through a collection using{{#each}},{{this}}allows you to reference the current item in the collection{{#with (lookup ../Attributes.ProductName @index)}}{{this}}{{/with}}– Lookup is a built-in handlebars helper that allows us to find values in another collection. We are using the index combined with lookup to find the Product Name that goes along with the Product Number we are currently on. The same pattern is used for the remaining columns of the table.The ability to lookup values in another attribute collection is the key to how we are able to display a table of information, but note that it does require making sure the attributes are aligned in the proper columns. For example,Attributes.ProductNumber[0]needs to align withAttributes.ProductName[0]See Using variables with message template helpers for more details.
And just to wrap things up, let’s pull in the footer we defined with Inline Partials.
Next Steps
Using the techniques above, you can create sophisticated and personalized communications using Amazon Pinpoint.
Think about your existing communications to see if you can use personalization to increase customer engagement for your promotional and transactional messages.
Amazon Pinpoint is a flexible and scalable outbound and inbound marketing communications service. Learn more here: https://aws.amazon.com/pinpoint/























































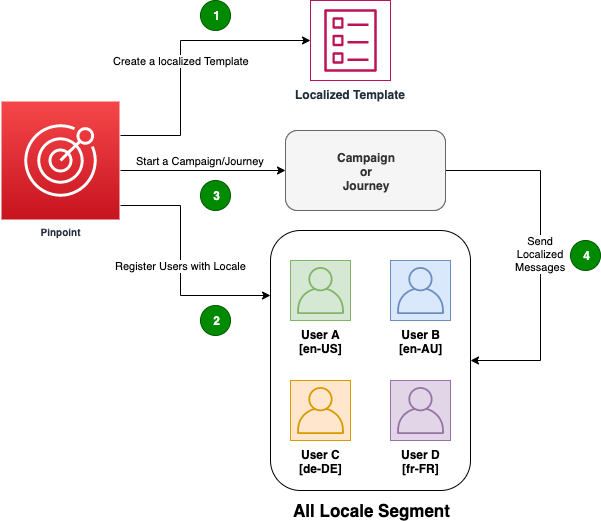
 3. Register your users with locale property
3. Register your users with locale property