Post Syndicated from Netflix Technology Blog original https://netflixtechblog.com/snaring-the-bad-folks-66726a1f4c80
Project by Netflix’s Cloud Infrastructure Security team (Alex Bainbridge, Mike Grima, Nick Siow)
Cloud security is a hard problem, but an even harder one is cloud security at scale. In recent years we’ve seen several cloud focused data breaches and evidence shows that threat actors are becoming more advanced with their techniques, goals, and tooling. With 2021 set to be a new high for the number of data breaches, it was plainly evident that we needed to evolve how we approach our cloud infrastructure security strategy.
In 2020, we decided to reinvent how we handle cloud security findings by redefining how we write and respond to cloud detections. We knew that given our scale, we needed to rely heavily on automations and that we needed to build our solutions using battle tested scalable infrastructure.
Introducing Snare

Snare is our Detection, Enrichment, and Response platform for handling cloud security related findings at Netflix. Snare is responsible for receiving millions of records a minute, analyzing, alerting, and responding to them. Snare also provides a space for our security engineers to track what’s going on, drill down into various findings, follow their investigation flow, and ensure that findings are reaching their proper resolution. Snare can be broken down into the following parts: Detection, Enrichment, Reporting & Management, and Remediation.
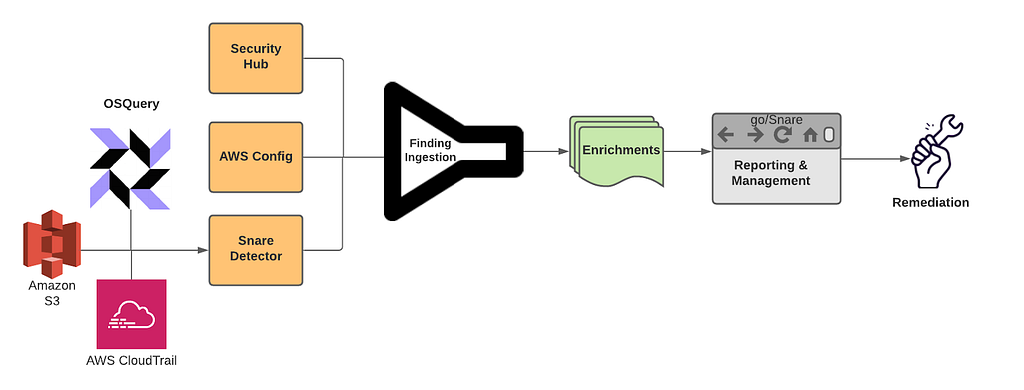
Overview
Snare was built from the ground up to be scalable to manage Netflix’s massive scale. We currently process tens of millions of log records every minute and analyze these events to perform in-house custom detections. We collect findings from a number of sources, which includes AWS Security Hub, AWS Config Rules, and our own in-house custom detections. Once ingested, findings are then enriched and processed with additional metadata collected from Netflix’s internal data sources. Finally, findings are checked against suppression rules and routed to our control plane for triaging and remediation.
Where We Are Today
We’ve developed, deployed, and operated Snare for almost a year, and since then, we’ve seen tremendous improvements while handling our cloud security findings. A number of findings are auto remediated, others utilize slack alerts to loop in the oncall to triage via the Snare UI. One major improvement was a direct time savings for our detection squad. Utilizing Snare, we were able to perform more granular tuning and aggregation of findings leading to an average of 73.5% reduction in our false positive finding volume across our ingestion streams. With this additional time, we were able to focus on new detections and new features for Snare.
Speaking of new detections, we’ve more than doubled the number of our in-house detections, and onboarded several detection solutions from security vendors. The Snare framework enables us to write detections quickly and efficiently with all of the plumbing and configurations abstracted away from us. Detection authors only need to be concerned with their actual detection logic, and everything else is handled for them.
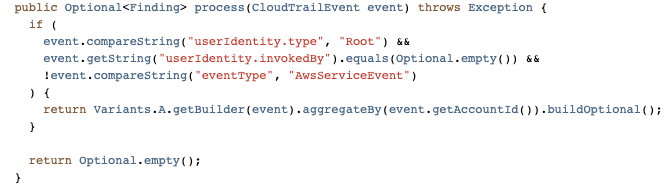
As for security vendors, we’ve most notably worked with AWS to ensure that services like GuardDuty and Security Hub are first class citizens when it comes to detection sources. Integration with Security Hub was a critical design decision from the start due to the high amount of leverage we get from receiving all of the AWS Security findings in a normalized format and in a centralized location. Security Hub has played an integral role in our platform, and made evaluations of AWS security services and new features easy to try out and adopt. Our plumbing between Security Hub and Snare is managed through AWS Organizations as well as EventBridge rules deployed in every region and account to aid in aggregating all findings into our centralized Snare platform.
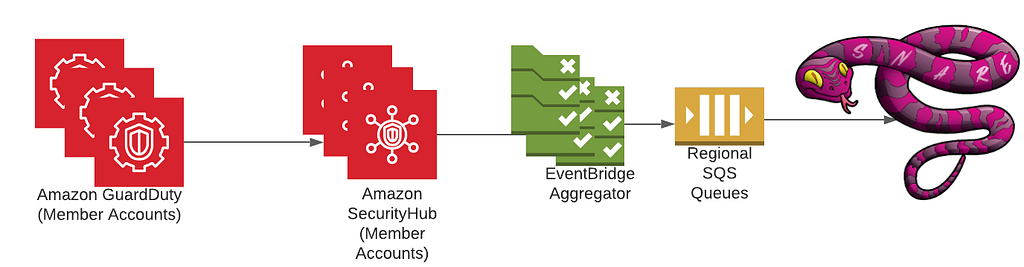
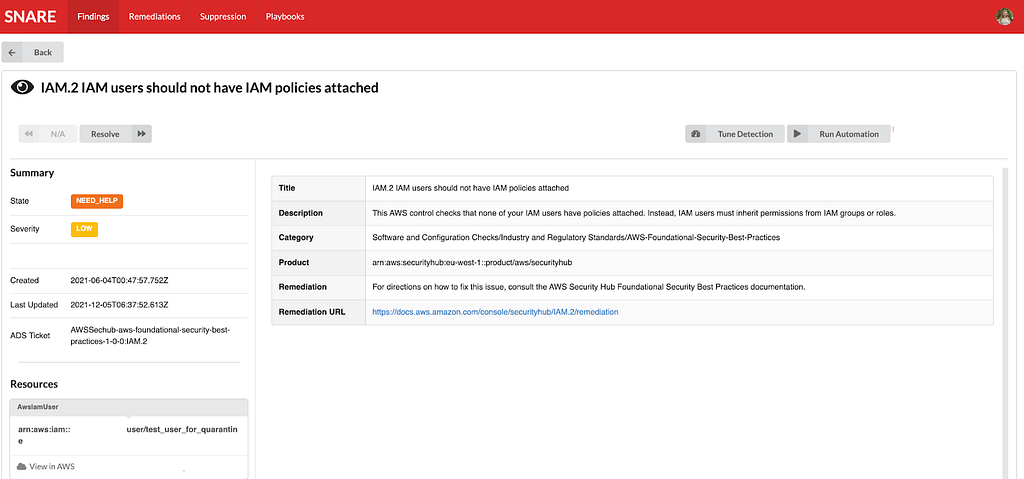
One area that we are investing heavily is our automated remediation potential. We’ve explored a few different options ranging from fully automated remediations, manually triggered remediations, as well as automated playbooks for additional data gathering during incident triage. We decided to employ AWS Step Functions to be our execution environment due to the unique DAGs we could build and the simplistic “wait”/”task token” functionality, which allows us to involve humans when necessary for approval/input.
Building on top of step functions, we created a 4 step remediation process: pre-processing, decision, remediation, and post-processing. Pre/post processing can be used for managing out-of-band resource checks, or any work that needs to be done in order to ensure a successful remediation. The decision step is used to perform a final pre-flight check before remediation. This can involve a human reachout, verifying the resource is still around, etc. The remediation step is where we perform our actual remediation. We’ve been able to use this to a great deal of success with infrastructure-wide misconfigured resources being automatically fixed near real time, and enabling the creation of new fully automated incident response playbooks. We’re still exploring new ways we might be able to use this, and are excited for how we might evolve our approach in the near future.
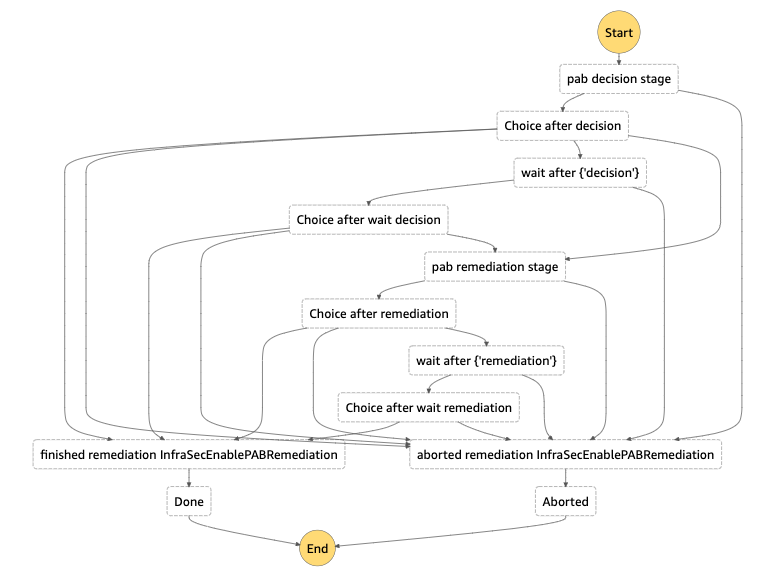
Diagram from a remediation to enable S3’s public access block on a non-compliant bucket. Each choice stage allows for dynamic routing to a variety of different stages based on the output of the previous function. Wait stages are used when human intervention/approval is needed.
Extensible Learnings
We’ve come a long way in our journey, and we’ve had numerous learning opportunities that we wanted to collect and share. Hopefully, we’ve made the mistakes and learned from those experiences.
Information is Key
Home grown context and metadata streams are invaluable for a detection and response program. By uniting detections and context, you’re able to unlock a new world of possibilities for reducing false positives, creating new detections that rely on business specific context, and help better tailor your severities and automated remediation decisions based on your desired risk appetite. A common theme we’ve often encountered is the need to bring additional context throughout various stages of our pipeline, so make sure to plan for that from the get-go.
Step Functions for Remediations
Step functions provide a highly extensible and unique platform to create remediations. Utilizing the AWS CDK, we were able to build a platform to enable us to easily roll out new remediations. While creating our remediation platform, we explored SSM Automation Runbooks. While SSM Automation Runbooks have great potential for remediating simple issues, we found they weren’t flexible enough to cover a wide spread of our needs, nor did they offer some of the more advanced features we were looking for such as reaching out to humans. Step functions gave us the right amount of flexibility, control, and ease of use in order to be a great asset for the Snare platform.
Closing Thoughts
We’ve come a long way in a year, and we still have a number of interesting things on the horizon. We’re looking at continuing to create new, more advanced features and detections for Snare to reduce cloud security risks in order to keep up with all of the exciting things happening here at Netflix. Make sure to check out some of our other recent blog posts!
Special Thanks
Special thanks to everyone who helped to contribute and provide feedback during the design and implementation of Snare. Notably Shannon Morrison, Sapna Solanki, Jason Schroth from our partner team Detection Engineering, as well as some of the folks from AWS — Prateek Sharma & Ely Kahn. Additional thanks to the rest of our Cloud Infrastructure Security team (Hee Won Kim, Joseph Kjar, Steven Reiling, Patrick Sanders, Srinath Kuruvadi) for their support and help with Snare features, processes, and design decisions!
![]()
Snaring the Bad Folks was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.






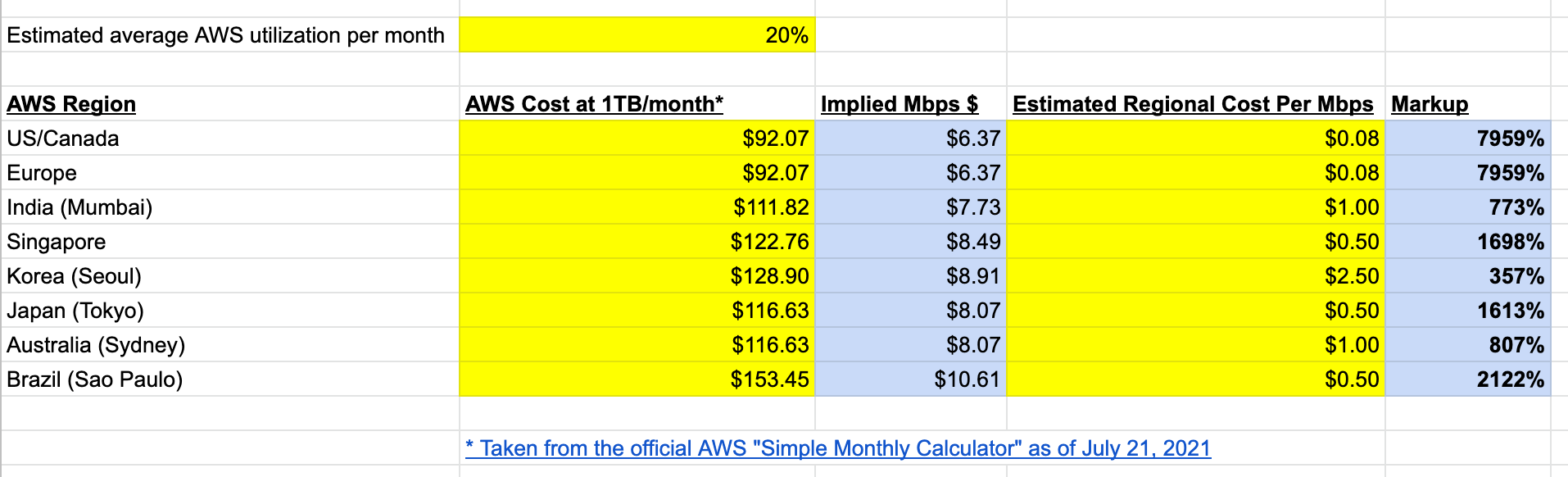
 Once you create the data source Quicksight lists all the views and tables available under the specified database (in our case it is:- due_eventdb). Select the email_all_events view as data source.
Once you create the data source Quicksight lists all the views and tables available under the specified database (in our case it is:- due_eventdb). Select the email_all_events view as data source. Select the event data location for analysis. There are mainly two options available which are a/ Import to Spice quicker analysis b/ Directly query your data. Please select the preferred options and then click on “visualize the data”.
Select the event data location for analysis. There are mainly two options available which are a/ Import to Spice quicker analysis b/ Directly query your data. Please select the preferred options and then click on “visualize the data”. Now that you have selected a data source, you will be taken to a blank quick sight canvas (Blank analysis page) as shown in the following Image, please drag and drop what
Now that you have selected a data source, you will be taken to a blank quick sight canvas (Blank analysis page) as shown in the following Image, please drag and drop what  As part of this blog, we have displayed how to create some simple analysis graphs to visualize the engagement events.
As part of this blog, we have displayed how to create some simple analysis graphs to visualize the engagement events. Select all the event dimensions that you want to put it as part of the Table in X axis. Amazon Quicksight table can be extended to show as many as tables columns, this completely depends upon the business requirement how much data marketers want to visualize.
Select all the event dimensions that you want to put it as part of the Table in X axis. Amazon Quicksight table can be extended to show as many as tables columns, this completely depends upon the business requirement how much data marketers want to visualize.
 To create a Quicksight dashboards from the Quicksight analysis click Share menu option at the top right corner then select publish dashboard”. Provide required dashboard name while publishing the dashboard”. Same dashboard can be shared with multiple audiences in the Organization.
To create a Quicksight dashboards from the Quicksight analysis click Share menu option at the top right corner then select publish dashboard”. Provide required dashboard name while publishing the dashboard”. Same dashboard can be shared with multiple audiences in the Organization. Following is the final version of the dashboard. As mentioned above Quicksight dashboards can be shared with other stakeholders and also complete dashboard can be exported as excel sheet.
Following is the final version of the dashboard. As mentioned above Quicksight dashboards can be shared with other stakeholders and also complete dashboard can be exported as excel sheet.
























 Rafael Rodrigues is an Enterprise Solution Architect for AWS based in Sao Paulo, Brazil. He helps customers innovate with modern IT architecture on cloud computing.
Rafael Rodrigues is an Enterprise Solution Architect for AWS based in Sao Paulo, Brazil. He helps customers innovate with modern IT architecture on cloud computing.






 Syed Ali Abbas Gardezi is a Sr. Solution Architect for AWS based in London, United Kingdom. He works with AWS GSI Partners architecting, designing and implementing various large-scale IT solution. Before joining AWS he worked in several Architecture roles in a tier 1 financial organisation in London.
Syed Ali Abbas Gardezi is a Sr. Solution Architect for AWS based in London, United Kingdom. He works with AWS GSI Partners architecting, designing and implementing various large-scale IT solution. Before joining AWS he worked in several Architecture roles in a tier 1 financial organisation in London.













































 Rajat Kashyap is a Solutions Architect at AWS. He is Containers, DevOps, BigData, Analytics and AI/ML enthusiast and loves helping customers design secure, reliable, scalable and cost-effective solutions on AWS. As a trusted customer advisor, he help organizations understand best practices for advanced AWS cloud-based solutions and help them in migration and modernization of their workload using Well Architected design principles and best practices.
Rajat Kashyap is a Solutions Architect at AWS. He is Containers, DevOps, BigData, Analytics and AI/ML enthusiast and loves helping customers design secure, reliable, scalable and cost-effective solutions on AWS. As a trusted customer advisor, he help organizations understand best practices for advanced AWS cloud-based solutions and help them in migration and modernization of their workload using Well Architected design principles and best practices. Ashish Mehra is a Solutions Architecture Manager at AWS. He is a Middleware, Serverless, IoT and Containers enthusiast and loves helping customers design secure, reliable and cost-effective solutions on AWS.
Ashish Mehra is a Solutions Architecture Manager at AWS. He is a Middleware, Serverless, IoT and Containers enthusiast and loves helping customers design secure, reliable and cost-effective solutions on AWS.



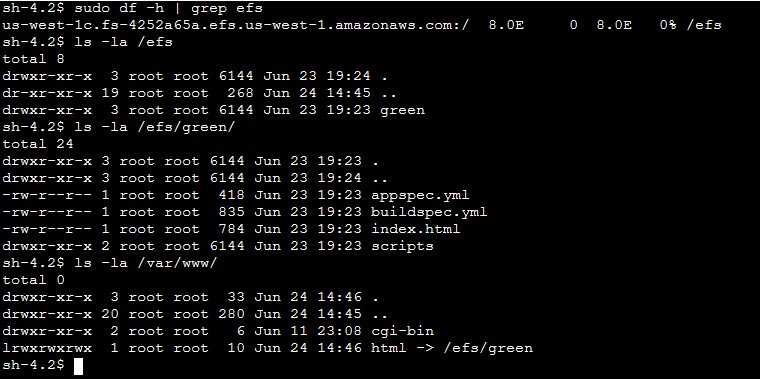

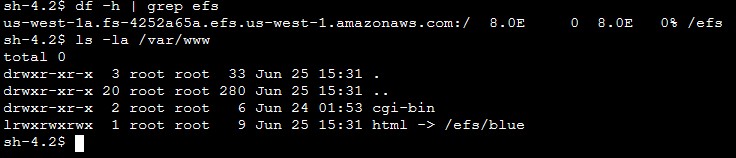
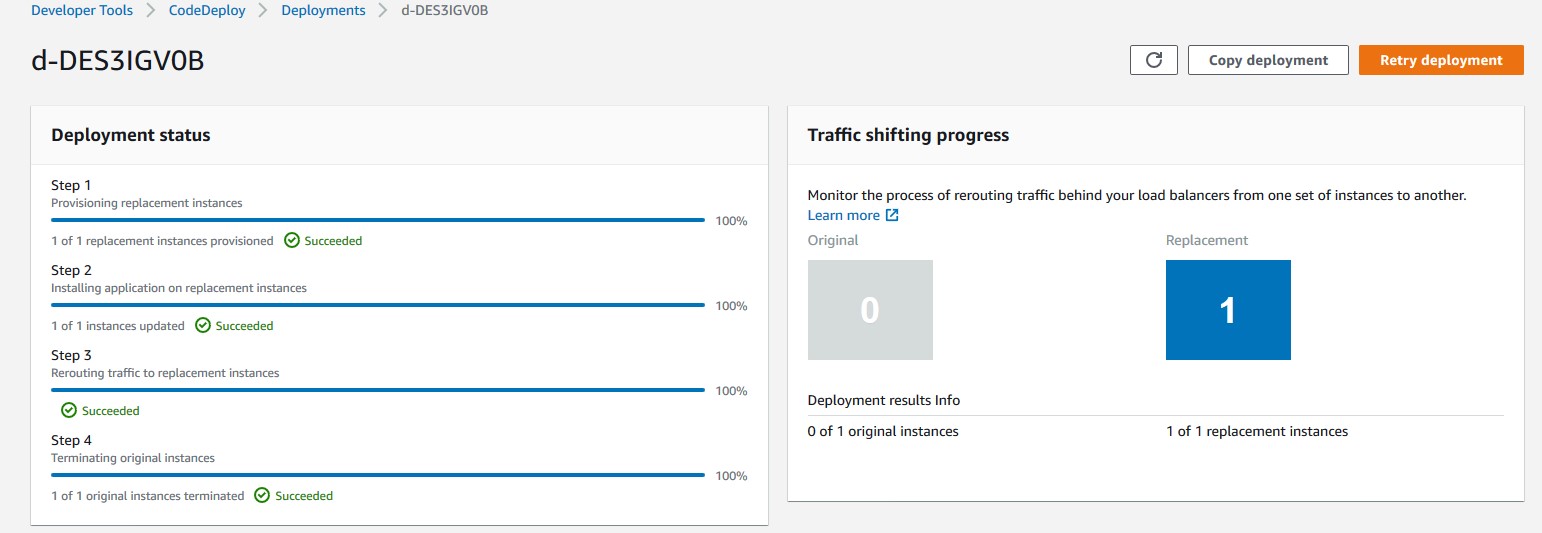
 Rakesh Singh
Rakesh Singh



 Mikhail is a Solutions Architect for RUS-CIS. Mikhail supports customers on their cloud journeys with Well-architected best practices and adoption of DevOps techniques on AWS. Mikhail is a fan of ChatOps, Open Source on AWS and Operational Excellence design principles.
Mikhail is a Solutions Architect for RUS-CIS. Mikhail supports customers on their cloud journeys with Well-architected best practices and adoption of DevOps techniques on AWS. Mikhail is a fan of ChatOps, Open Source on AWS and Operational Excellence design principles.