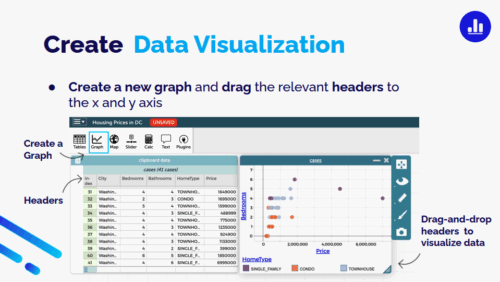
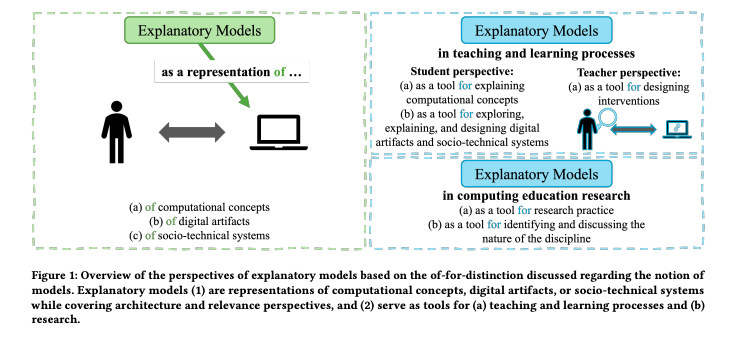
The Cloudflare Research team spends our time investigating how we can apply new technologies to continue to help build a better Internet. We don’t just write papers – we put ideas into practice, and test our hypotheses in real time.
Our work is deeply collaborative by nature, working closely with academia, standards bodies like the IETF, the open-source community, and our own product and engineering teams. We believe in doing this research in the open so that others can learn from it, give us feedback, and work with us to make the next version of the Internet even better. That’s why this week we’re publishing a series of posts to make more of our research public – research that we think will help push forward a more measurable, resilient, and transparent Internet.
Internet Measurement will be one of the week’s major themes because our posts here coincide with the Association for Computing Machinery (ACM)’s annual Internet Measurement Conference, a venue for new work that measures and analyzes the behavior, performance, and evolution of the Internet and networked systems. Internet measurement is hard to get right, so we’re taking the opportunity to dive deeper into some of the foundational concepts and products that define how we do measurement at Cloudflare scale.
Each day this week we share new stories from our Research team and friends in our engineering groups elsewhere at Cloudflare. We will dive deep into Internet measurement data, establish new frameworks for Internet resilience, discuss cryptographic protocols for an increasingly automated web, and explore new advances in networking technologies.
We’re excited to showcase this work, so stay tuned this week for the posts to follow. Want a preview of what to expect? Read on for an outline of what we will cover this week.
An ode to Internet measurement
We’ll start the week with a foundational look at what Internet measurement actually consists of, explaining the jargon behind the science and some of the fundamental tradeoffs one has to make when trying to do measurement well. A former Cloudflare intern will share how working with Cloudflare-scale data completely changed his perspective on detecting connection tampering. We’ll also dig into how Cloudflare Radar has evolved in the past few years, and take a deeper look at how our Internet speed test works!
A better Internet is a more resilient Internet
Something that we take for granted, but notice when it fails: a network’s ability not just to stay online, but to withstand, adapt to, and rapidly recover from breakdowns – otherwise known as Internet Resilience. There are many factors that can cause Internet disruption, from cyberattack to natural disaster to government-directed shutdowns. We’ll go deeper into these disruptions in our quarterly Internet Disruption Summary, which details the length and impact of each outage as observed from Cloudflare’s network.
It’s easy to say Internet Resilience is the goal, but it can be harder to define what that actually means. In our blog “A Framework for Internet Resilience,” we do exactly that – establish a framework for how governments, infrastructure providers, and researchers can assess how resilient their infrastructure is, from first principles.
A resilient Internet is also immune to quantum compromise. Much has happened since we published our highly cited State of the Post-Quantum Internet, so we’ll share an updated view of progress of post-quantum deployment over the past year, as well as a deep dive into Merkle Tree Certificates, an experimental design with Chrome to make post-quantum certificates deployable at scale.
A transparent look into Cloudflare’s network
Cloudflare sees millions of connections and IP addresses per second – and characterizing them at scale isn’t easy. We’ll take a deeper look at what a connection actually means at Cloudflare: what server-side characteristics we observe and measure across our network, and what they tell us about the size and flow of data through the Internet.
Many products at Cloudflare aren’t possible without pushing the limits of network hardware and software to deliver improved performance, increased efficiency, or novel capabilities. That’s why we’re sharing a deep dive into how we bend the limits of our Linux networking stack to be economical with addressing space while maintaining performance.
All of this theory has real-world applications we’ll dive into: from detecting shared IP space (CGNAT), to defending against DDoS attacks, to improving the efficiency of our cache.
Cryptographic protocols for an agentic web
The rise of AI agents and AI crawlers is a turning point for infrastructure providers. For instance, traffic from many users is condensed into a few beefy datacenters, and request patterns appear to be more automated as LLMs orchestrate web browsers. Measuring the impact of this shift has become an interesting and complex problem.
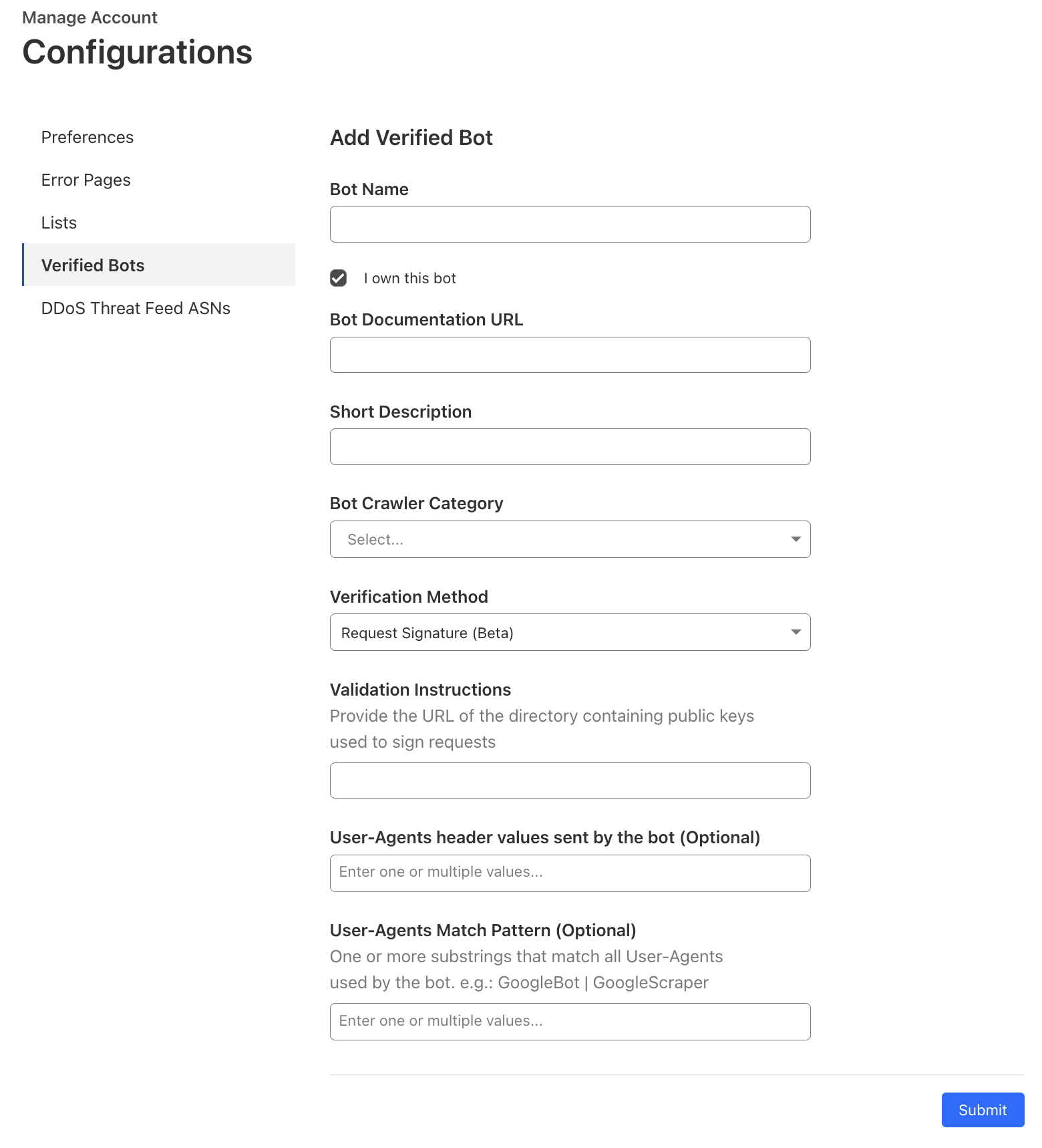
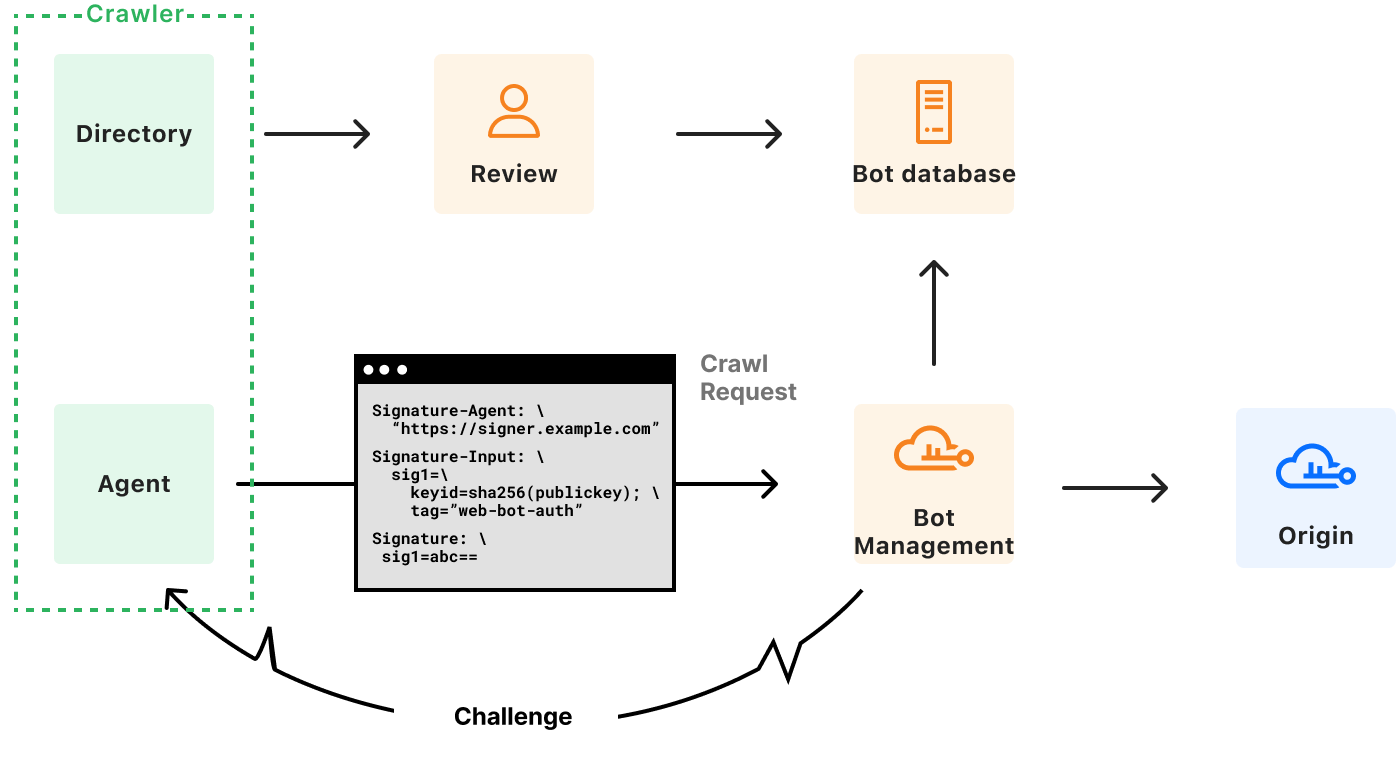
This week, we’ll dive into how honest agents and website operators can work together to stay safe, private, and resilient. We’ll discuss new work being done in the IETF that builds upon Web Bot Auth – a protocol that allows automated HTTP clients like bots and agents to identify themselves to the rest of the Internet. In addition, in order to empower honest users, we’ll propose new cryptographic protocols that allow them through while protecting websites from DDoS, fraud, or scraping attacks. We will present real-world deployment considerations, as well as mechanisms to future-proof them in the face of the imminent post-quantum transition.
Get your reading glasses on
Expect blog posts this week that push the boundaries of emerging research in their respective fields, establish new frameworks and ideas, and bridge the gap between academic theory and real-world applications. We couldn’t be more excited to share them with you!
The Internet is constantly changing in ways that are difficult to see. How do we measure its health, spot new threats, and track the adoption of new technologies? When we launched Cloudflare Radar in 2020, our goal was to illuminate the Internet’s patterns, helping anyone understand what was happening from a security, performance, and usage perspective, based on aggregated data from Cloudflare services. From the start, Internet measurement, transparency, and resilience has been at the core of our mission.
The launch blog post noted, “There are three key components that we’re launching today: Radar Internet Insights, Radar Domain Insights and Radar IP Insights.” These components have remained at the core of Radar, and they have been continuously expanded and complemented by other data sets and capabilities to support that mission. By shining a brighter light on Internet security, routing, traffic disruptions, protocol adoption, DNS, and now AI, Cloudflare Radar has become an increasingly comprehensive source of information and insights. And despite our expanding scope, we’ve focused on maintaining Radar’s “easy access” by evolving our information architecture, making our search capabilities more powerful, and building everything on top of a powerful, publicly-accessible API.
Now more than ever, Internet observability matters. New protocols and use cases compete with new security threats. Connectivity is threatened not only by errant construction equipment, but also by governments practicing targeted content blocking. Cloudflare Radar is uniquely positioned to provide actionable visibility into these trends, threats, and events with local, network, and global level insights, spanning multiple data sets. Below, we explore some highlights of Radar’s evolution over the five years since its launch, looking at how Cloudflare Radar is building one of the industry’s most comprehensive views of what is happening on the Internet.
Making Internet security more transparent
The Cloudflare Research team takes a practical approach to research, tackling projects that have the potential to make a big impact. A number of these projects have been in the security space, and for three of them, we’ve collaborated to bring associated data sets to Radar, highlighting the impact of these projects.
The 2025 launch of the Certificate Transparency (CT) section on Radar was the culmination of several months of collaborative work to expand visibility into key metrics for the Certificate Transparency ecosystem, enabling us to deprecate the original Merkle Town CT dashboard, which was launched in 2018. Digital certificates are the foundation of trust on the modern Internet, and Certificate Authorities (CAs) serve as trusted gatekeepers, issuing those certificates, with CT logs providing a public, auditable record of every certificate issued, making it possible to detect fraudulent or mis-issued certificates. The information available in the new CT section allows users to explore information about these certificates and CAs, as well as about the CT logs that capture information about every issued certificate.
In 2024, members of Cloudflare’s Research team collaborated with outside researchers to publish a paper titled “Global, Passive Detection of Connection Tampering”. Among the findings presented in the paper, it noted that globally, about 20% of all connections to Cloudflare close unexpectedly before any useful data exchange occurs. This unexpected closure is consistent with connection tampering by a third party, which may occur, for instance, when repressive governments seek to block access to websites or applications. Working with the Research team, we added visibility into TCP resets and timeouts to the Network Layer Security page on Radar. This graph, such as the example below for Turkmenistan, provides a perspective on potential connection tampering activity globally, and at a country level. Changes and trends visible in this graph can be used to corroborate reports of content blocking and other local restrictions on Internet connectivity.
The research team has been working on post-quantum encryption since 2017, racing improvements in quantum computing to help ensure that today’s encrypted data and communications are resistant to being decrypted in the future. They have led the drive to incorporate post-quantum encryption across Cloudflare’s infrastructure and services, and in 2023 we announced that it would be included in our delivery services, available to everyone and free of charge, forever. However, to take full advantage, support is needed on the client side as well, so to track that, we worked together to add a graph to Radar’s Adoption & Usage page that tracks the post-quantum encrypted share of HTTPS request traffic. Starting 2024 at under 3%, it has grown to just over 47%, thanks to major browsers and code libraries activating post-quantum support by default.
Measuring AI bot & crawler activity
The rapid proliferation and growth of AI platforms since the launch of OpenAI’s ChatGPT in November 2022 has upended multiple industries. This is especially true for content creators. Over the last several decades, they generally allowed their sites to be crawled in exchange for the traffic that the search engines would send back to them — traffic that could be monetized in various ways. However, two developments have changed this dynamic. First, AI platforms began aggressively crawling these sites to vacuum up content to use for training their models (with no compensation to content creators). Second, search engines have evolved into answer engines, drastically reducing the amount of traffic they send back to sites. This has led content owners to demand solutions.
Among these solutions is providing customers with increased visibility into how frequently AI crawlers are scraping their content, and Radar has built on that to provide aggregated perspectives on this activity. Radar’s AI Insights page provides graphs based on crawling traffic, including traffic trends by bot and traffic trends by crawl purpose, both of which can be broken out by industry set as well. Customers can compare the traffic trends we show on the dashboard with trends across their industry.
One key insight is the crawl-to-refer ratio: a measure of how many HTML pages a crawler consumes in comparison to the number of page visits that they refer back to the crawled site. A view into these ratios by platform, and how they change over time, gives content creators insight into just how significant the reciprocal traffic imbalances are, and the impact of the ongoing transition of search engines into answer engines.
Over the three decades, the humble robots.txt file has served as something of a gatekeeper for websites, letting crawlers know if they are allowed to access content on the site, and if so, which content. Well-behaved crawlers read and parse the file, and adjust their crawling activity accordingly. Based on the robots.txt files found across Radar’s top 10,000 domains, Radar’s AI Insights page shows how many of these sites explicitly allow or disallow these AI crawlers to access content, and how complete that access/restriction is. With the ability to filter the data by domain category, this graph can provide site owners with visibility into how their peers may be dealing with these AI crawlers.
Improving Internet resilience with routing visibility
Routing is the process of selecting a path across one or more networks, and in the context of the Internet, routing selects the paths for Internet Protocol (IP) packets to travel from their origin to their destination. It is absolutely critical to the functioning of the Internet, but lots of things can go wrong, and when they do, they can take a whole network offline. (And depending on the network, a larger blast radius of sites, applications, and other service providers may be impacted.
Routing visibility provides insights into the health of a network, and its relationship to other networks. These insights can help identify or troubleshoot problems when they occur. Among the more significant things that can go wrong are route leaks and origin hijacks. Route leaks occur when a routing announcement propagates beyond its intended scope — that is, when the announcement reaches networks that it shouldn’t. An origin hijack occurs when an attacker creates fake announcements for a targeted prefix, falsely identifying an autonomous systems (AS) under their control as the origin of the prefix — in other words, the attacker claims that their network is responsible for a given set of IP addresses, which would cause traffic to those addresses to be routed to them.
In 2022 and 2023 respectively, we added route leak and origin hijack detection to Radar, providing network operators and other interested groups (such as researchers) with information to help identify which networks may be party to such events, whether as a leaker/hijacker, or a victim. And perhaps more importantly, in 2023 we also launched notifications for route leaks and origin hijacks, automatically notifying subscribers via email or webhook when such an event is detected, enabling them to take immediate action.
In 2025, we further improved this visibility by adding two additional capabilities. The first was real-time BGP route visibility, which illustrates how a given network prefix is connected to other networks — what is the route that packets take to get from that set of IP addresses to the large “tier 1” network providers? Network administrators can use this information when facing network outages, implementing new deployments, or investigating route leaks.
An AS-SET is a grouping of related networks, historically used for multiple purposes such as grouping together a list of downstream customers of a particular network provider. Our recently announced AS-SET monitoring enables network operators to monitor valid and invalid AS-SET memberships for their networks, which can help prevent misuse and issues like route leaks.
Not just pretty pictures
While Radar has been historically focused on providing clear, informative visualizations, we have also launched capabilities that enable users to get at the underlying data more directly, enabling them to use it in a more programmatic fashion. The most important one is the Radar API, launched in 2022. Requiring just an access token, users can get access to all the data shown on Radar, as well as some more advanced filters that provide more specific data, enabling them to incorporate Radar data into their own tools, websites, and applications. The example below shows a simple API call that returns the global distribution of human and bot traffic observed over the last seven days.
The Model Context Protocol is a standard way to make information available to large language models (LLMs). Somewhat similar to the way an application programming interface (API) works, MCP offers a documented, standardized way for a computer program to integrate services from an external source. It essentially allows AI programs to exceed their training, enabling them to incorporate new sources of information into their decision-making and content generation, and helps them connect to external tools. The Radar MCP server allows MCP clients to gain access to Radar data and tools, enabling exploration using natural language queries.
Radar’s URL Scanner has proven to be one of its most popular tools, scanning millions of sites since launching in 2023. It allows users to safely determine whether a site may contain malicious content, as well as providing information on technologies used and insights into the site’s headers, cookies, and links. In addition to being available on Radar, it is also accessible through the API and MCP server.
Finally, Radar’s user interface has seen a number of improvements over the last several years, in service of improved usability and a better user experience. As new data sets and capabilities are launched, they are added to the search bar, allowing users to search not only for countries and ASNs, but also IP address prefixes, certificate authorities, bot names, IP addresses, and more. Initially launching with just a few default date ranges (such as last 24 hours, last 7 days, etc.), we’ve expanded the number of default options, as well as enabling the user to select custom date ranges of up to one year in length. And because the Internet is global, Radar should be too. In 2024, we launched internationalized versions of Radar, marking availability of the site in 14 languages/dialects, including downloaded and embedded content.
This is a sampling of the updates and enhancements that we have made to Radar over the last five years in support of Internet measurement, transparency, and resilience. These individual data sets and tools combine to provide one of the most comprehensive views of the Internet available. And we’re not close to being done. We’ll continue to bring additional visibility to the unseen ways that the Internet is changing by adding more tools, data sets, and visualizations, to help users answer more questions in areas including AI, performance, adoption and usage, and security.
Visit radar.cloudflare.com to explore all the great data sets, capabilities, and tools for yourself, and to use the Radar API or MCP server to incorporate Radar data into your own tools, sites, and applications. Keep an eye on the Radar changelog feed, Radar release notes, and the Cloudflare blog for news about the latest changes and launches, and don’t hesitate to reach out to us with feedback, suggestions, and feature requests.
Cloudflare recently announced our goal to hire 1,111 interns in 2026 — that’s equivalent to about 25% of our full-time workforce. This means countless opportunities to develop and ship working code into production. It also creates novel opportunities to measure aspects of the Internet that are otherwise hard to observe — and more difficult still to understand.
Measurement is hard, even at Cloudflare, despite the vast amount of data generated by our traffic (much of it published via Cloudflare Radar). A common misconception we often hear is, “Cloudflare has so much data that it must have all the answers.” Having a huge amount of data is great — but it also means much more noise to filter out, and lots of additional work to rule out alternative explanations.
Ram Sundara Raman was an intern at Cloudflare in 2022 as he pursued his PhD. He’s now an assistant professor at University of California, Santa Cruz, and we’ve invited him back to share his insights about working with data at Cloudflare.
Ram’s project is a great example of how insights that researchers shared and brought from their university research lab can lay the groundwork for a valuable project at Cloudflare — in this case, detecting and explaining connection failures to customers. One tip for prospective interns: If you’re applying and thinking about data and measurement ideas to work on at Cloudflare, a good question to ponder is if, how, or why, your idea might matter to Cloudflare. We love hearing your ideas!
Without further ado, here’s Ram. We hope his insights are as informative and refreshing to future interns — and practitioners — as they are to us here at Cloudflare.
Insights from data at large scale might just be a small miracle
by Ram Sundara Raman, Assistant Professor of Computer Science and Engineering, UC Santa Cruz
Before joining Cloudflare as a research intern in the summer of 2022, I’d worked on multiple network security and privacy research problems as a PhD student at the University of Michigan. My previous experience involved active measurements, in which probes were carefully crafted and transmitted to detect and quantify security issues such as HTTPS interception and connection tampering. These attacks, performed by powerful network middleboxes between users and Internet servers, can block Internet content and services for numerous users in various regions, and can also reduce their security. For example, the HTTPS Interception Man-in-the-Middle Attack in Kazakhstan in 2019 was detected in 7-24% of all measurements we performed in the country.
Detecting such attacks is challenging. The underlying mechanisms are diverse, with both geographic and temporal variations — and they’re entirely opaque. Moreover, the Internet has no technical mechanisms to report to users when their traffic is being manipulated, and third party actors rarely, if ever, are transparent with affected users.
My active measurement work before Cloudflare helped resolve these challenges. Along with my PI and team at the University of Michigan, I helped develop Censored Planet, one of the largest active Internet censorship observatories, detecting connection tampering in more than 200 countries. However, active measurements face barriers on scale, resources, and real-world view. For instance, Censored Planet is only able to measure blocking and connection tampering for the 2,000 most popular websites, simply because of limits on time and resources.
While working on projects like Censored Planet, I’d often look at large network operators or cloud providers and think: “If only I had my hands on the data they collect, I could solve this problem so easily. They have a global view of real-world traffic from nearly every network, and probably enough resources and telemetry to scale analysis to that level of data. How hard could it be to use this data, for example, to detect when middleboxes interfere?”
My perspectives on censorship evolved as a direct result of my experience at Cloudflare, which taught me that detection at scale is hard, even with large-scale data. The research I did during my internship helped reveal that network middleboxes block or otherwise interfere with certain connections not only in limited places, but also at various scales around the world.
An internship project built on real insights, using production data
In this research, we built upon insights gathered by the wider active measurement community, namely that middleboxes interfere with Internet TCP connections by dropping packets, or injecting RST packets to cause connections to abort. The same insights revealed that the patterns of packet drops and RSTs are deterministic — and, as a result, potentially detectable. Such is the flexibility of active measurement: craft a custom request, or ‘probe,’ that elicits a response from the environment. However, such a targeted approach would be difficult to scale and maintain, even for Cloudflare: What probes should be crafted? Where should they be sent? What motivation would Cloudflare have to even try, if the risk of missing so much is so high?
The goal of my internship was to see if we could instead flip the approach: to be passive instead of active. Everything Cloudflare does must be both scalable and sustainable. However, it was entirely uncertain whether a system restricted to passive observation could be constructed, even if the tampering events could be detected. The requirement was clear: Only observe and use data that comes to Cloudflare naturally. No mixing in other datasets, no running our own active measurements. Either would have made life easier: we could have controlled the variables, maybe even obtained ground truth that would help us confirm our observations. But where’s the fun in that? Besides, Cloudflare has all the data anyway… right?
Yes, maybe — if it is sampled appropriately, can be teased out reliably, and correctly interpreted.
Here’s a useful insight: I’ve often heard people say that finding middleboxes that tamper with Internet connections using active measurements is like finding a needle in a haystack — rare, finicky, and hard to pin down. When we started looking at this problem from the lens of Cloudflare’s passive dataset, we quickly realized we were still looking for the same needle — and in some ways, it was now even harder to find.
That’s because as a passive observer we lose the ability to choose where to look. Also, the haystack now stretches across continents, millions of users, and — I’m not exaggerating here — thousands of ways connections can be made and broken. Not only did we have to identify tampering from millions of real-world data points, we had to do it with data that was full of obstacles and pitfalls. It felt a lot like working with unseen traps and their tripwires.
The traps and tripwires of large-scale passive data
There were multiple challenges that I only truly understood once faced with them. Let’s start with the obvious one: scale.
First, there was a glut of large-scale datasets, primarily associated with incoming connections to Cloudflare. For example, at the time of my internship, Cloudflare was serving more than 45 million HTTP requests per second globally, across more than 285 data centers. Cloudflare also gets TCP connections to its 1.1.1.1 DNS server. We also explored Network Error Logging(NEL) data, primarily from Firefox users. Usually, in measurement research, we’re dealing with the issue of too little scale. Here, we had the opposite problem: too much of a good thing. In practice, each of these datasets had their own independent sampling methods, making it all but impossible to utilize them all together. Moreover, datasets like NEL are biased since only some clients support it, and because only some websites enable it. After evaluating these biases, NEL did not make the final cut.
To manage the scale, we constructed special IPTABLES rules to log and store incoming TCP connections across all of Cloudflare’s points of presence — every server in each of 285 datacenters. However, due to the extremely large scale of the data, we had to limit ourselves to work with a uniformly random sample of one in every 10,000 connections. For each sample, we only logged the first 10 inbound packets of each connection. That meant we could not detect certain infrequent types of tampering, or any tampering that occurs later in a flow, after the first 10 packets.
Still, within those constraints, we managed to develop tampering signatures — distinctive packet patterns that reveal when middleboxes interfere. However, developing these signatures was anything but straightforward, due to the second tripwire: noisy data.
It’s difficult to imagine that we could have anticipated all the different sources of noise. For example, the resolution of time-keeping in event records was milliseconds, but many packets could arrive in a single millisecond, which meant we could not trust the ordering of logged packets. We eventually learned that some denial-of-service attack traffic, as well as port scans, can look eerily like tampering events, and certain “best practices” designed to help improve the Internet, such as Happy Eyeballs, became quirks that messed with our detection. We spent a lot of time analyzing these sources of noise and iterating on our signatures to understand them. We accepted events as tampering only if supported by other sources of evidence that we identified, including but not limited to inconsistent changes in the Time-To-Live (TTL) field in the IP header.
That brings me to our last tripwire: a lack of ground truth.
Without active, controlled experiments, it would have been extremely difficult for us to confirm when something we detected was indeed tampering, and not one of the thousand other phenomena on the Internet. Fortunately, thanks to the amazing work of many researchers in the censorship measurement space, we were able to recognize at least some known signals and patterns in the data, and these helped us confirm many cases of tampering.
There were plenty more tripwires. But the key realization for me was this: While providers have lots of data that can tell you things, it’s incredibly hard to know which thing, how much of it, and about what. Large infrastructure operators see a filtered, sampled, and often partial view of the Internet. For example,
Services like Cloudflare can see only which connections were affected and where the connections were initiated, but not who did the tampering;
It was sometimes possible to understand which domains were blocked, but not always, because the necessary packets can be dropped before they get to Cloudflare;
As a passive observer, it’s possible only to see users’ activity that is affected, not what could be affected.
For a company that handles a double-digit percentage of Internet websites and services, these were surprising — but understandable – limitations.
It may seem like the exercise is impossible, but it’s not. It’s just more challenging than I expected it to be. Despite all that, we found ways to extract meaning from chaos. For example, we carefully and painstakingly enumerated all common packet sequences Cloudflare observed, and extracted from them those that might indicate tampering, based on prior work. Moreover, we used signals like the TTL field mentioned above as supporting evidence that these packet signatures did indeed show tampering.
All of this adds up to a simple but important conclusion: large infrastructure providers are not omniscient.Having a global view can be powerful, but doesn’t automatically translate into easy observations. You can have all the data in the world and still struggle to tell the difference between a middlebox, a security filter, a confused IoT device, and even regular users closing tabs and browsers.
But that dichotomy is also the beauty of the problem space. Working with imperfect data forces us to be creative, to find patterns in the noise, and to design methods that work despite what’s missing. And no, before you ask, you can’t just throw machine learning at the problem, nor do you need to — even with all the noise, the protocols are tightly specified, meaning patterns can be enumerated easily but must still be debated manually.
An internship project built on real insights, using production data
Using our packet-level samples and 19 tampering signatures, we saw distinctive tampering behaviors across hundreds of networks, including being able to track large increases in tampering rates (Figure 1). And it worked because, despite the data’s limits, Cloudflare’s networks let us see the real-world effects of tampering. Also, thanks to the tireless efforts of Luke Valenta and the Cloudflare Radar team, the data from our project is continuously being published on Cloudflare Radar (Figure 2).
Figure 1: Increase in mach rates of our 19 tampering signatures during a period of nationwide protests in Iran in late-2022.
Figure 2: Data from our connection tampering research is available live on Radar.
In the future, though, I think solving challenges like these will require a combination of passive and active probing, using the scale of providers like Cloudflare together with targeted, controlled measurements to paint the full picture of Internet tampering. My team at UCSC’s RANDLab and the research group at Censored Planet continue to work on this problem, especially asking how we can automatically identify tampering when attacks happen or networks change.
While collaborations between academia and industry aren’t always straightforward, they hold strong potential to help build a better Internet. If you’re interested in an internship adventure like the one I described, apply today!
Readers of a certain age may remember the so-called “dot com boom” that took place in the early 2000’s. The boom’s “dot com” is what is known as a Top-Level Domain (TLD). Originally intended to organize domain names into a small set of categorical groupings, over the past 40+ years, the set of TLDs has expanded to include country code top-level domains (ccTLDs, like .us, .pt, and .cn), as well as additional generic top-level domains (gTLDs) beyond the initial seven, such as .biz, .shop, and .nyc. Internationalized TLDs, such as .сайт, .онлайн,.شبكة, .游戏, and brand TLDs, like .google and .nike have also been added. As of October 2025, over 1,400 entries can be found in ICANN’s list of all valid top-level domains, and a further expansion is expected to begin in April 2026.
Building on this, today we are launching a new TLD page on Radar that, based on aggregated data from multiple Cloudflare services, provides insights into TLD popularity, activity, and security, along with links directly into Cloudflare Registrar to enable users to register domain names in supported TLDs.
Initial security-related insights
Before today, Radar already offered insights into TLDs, though these were distributed across a couple of different pages and datasets.
In March 2024, when we launched the Email Security page, we introduced the “Most abused TLDs” metric. This chart highlights TLDs associated with the largest shares of malicious and spam email. The analysis is based on the sending domain’s TLD, extracted from the From: header in email messages, with data sourced from Cloudflare’s cloud email security service.
More recently, during 2025’s Birthday Week, we introducedCertificate Transparency (CT) insights on Radar, leveraging data from CT logs monitored by Cloudflare. One highlight is the Certificate Coverage section, which visualizes the distribution of pre-certificates across the top 10 TLDs. These insights give a different perspective on TLD activity, complementing email-based metrics by showing which domains are actively securing web traffic.
A new aggregate overview based on DNS Magnitude
Today, we’re excited to announce the new TLD page on Radar. The landing page and the dedicated per-TLD pages provide TLD managers and site owners with a perspective on the relative popularity of TLDs they manage or may be considering domains in, as well as insights into TLD traffic volume and distribution.
Located under the DNS menu, the landing page introduces a ranking of top-level domains based on DNS Magnitude — a metric originally developed by nic.at to estimate a domain’s overall visibility on the Internet.
Instead of simply counting the total number of DNS queries, DNS Magnitude incorporates a sense of how many unique clients send queries to domains within the TLD. This approach gives a more accurate picture of a TLD’s reach, since a small number of sources can generate a large number of queries. Our ranking is based on queries observed at Cloudflare’s 1.1.1.1 resolver. We aggregate individual client IP addresses into subnets, referred to here as “networks”.
The magnitude value ranges from 0 to 10, with higher values (closer to 10) indicating that the TLD is queried by a broader range of networks. This reflects greater global visibility and, in some cases, a higher likelihood of name collision across different systems. According to ICANN, a name collision occurs when an attempt to resolve a name used in a private name space (such as under a non-delegated Top-Level Domain) results in a query to the public Domain Name System (DNS). When the administrative boundaries of private and public namespaces overlap, name resolution may yield unintended or harmful results. For example, if ICANN were to delegate .home, that could cause significant issues for hobbyists that use the (currently non-delegated) TLD within their local networks.
The table displays a paginated ranking of the top 2,500 TLDs, along with several key attributes. Each entry includes the TLD itself — which links to a dedicated page for delegated TLDs — as well as its type:
gTLD (generic TLD): used for general purposes, such as .com or.info.
grTLD (generic restricted TLD): limited to specific communities or uses, such as.name.
ccTLD (country code TLD): assigned to individual countries or territories, such as.uk or .jp.
iTLD (infrastructure TLD): reserved for technical infrastructure, such as .arpa.
sTLD (sponsored TLD): operated by a sponsoring organization representing a defined community, such as .edu or .gov.
The status column indicates whether the TLD is delegated, meaning it is officially assigned and active in the root zone of the DNS, or non-delegated, meaning it is not currently part of the public DNS. The table also shows the manager of each TLD — typically the organization or registry responsible for its operation — and the corresponding DNS magnitude value.
While the top 10 TLDs include stalwarts such as .com/.net/.org and ccTLDs that have been commercially repurposed, such as .io/.co/.tv, the TLD at the top of the list may be a bit surprising: .su.
This TLD was delegated for the Soviet Union back in 1990, but its use waned after the dissolution of the USSR, with constituent republics becoming independent and using their own dedicated ccTLDs. (ICANN reportedly plans to retire.su in 2030.) Looking at a single day’s worth of data, the .su TLD does not rank #1 by unique networks. However, over a longer period of time, such as seven days, it sees queries from more unique networks than other TLDs, placing it atop the magnitude list. Further analysis of the top hostnames observed within this TLD suggests that they are mostly associated with a popular online world-building game. Interestingly, over half of the queries for .su domains come from the United States, Germany, and Brazil.
More detailed TLD insights
The new TLD section also offers dedicated pages for individual TLDs. By clicking on a TLD in the DNS Magnitude table or searching for a TLD in the top search bar, users can access a page with detailed insights and information about that TLD. It’s important to note that while non-delegated TLDs are included in the DNS Magnitude ranking, TLD-specific pages are only available for delegated TLDs. The list of delegated TLDs, along with their type and manager, is sourced from the IANA’s Root Zone Database.
When a user enters an individual TLD page, they see two main cards. The first card provides general information about the TLD, including its type, manager, DNS magnitude value, DNSSEC support, and RDAP support. DNSSEC support is determined by checking whether the TLD has a Delegation Signer (DS) record in the root zone. We also parse the record to get the associated DNSSEC algorithm. RDAP support is indicated if the TLD is listed in the IANA RDAP bootstrap file. RDAP (Registration Data Access Protocol) is a new standard for querying domain contact and nameserver information for all registered domains.
The second card contains WHOIS data for the TLD, including its creation date, the date of the last update, and the list of nameservers. If the TLD is supported by Cloudflare Registrar, an additional card appears, giving users direct access to registration options. As of today, Cloudflare Registrar supports over 400 TLDs.
Below these cards, the page features the DNS query volume section, which presents insights based on queries to Cloudflare’s 1.1.1.1 resolver for domains under the TLD. This section includes a chart showing DNS queries over the selected time period, along with a donut chart breaking down queries by type, response code, and DNSSEC support. A choropleth map further illustrates the percentage of DNS queries by country, highlighting which regions generate the most queries for domains under the TLD.
Each individual TLD page also includes a Certificate Transparency section, offering visibility into TLS/SSL certificate issuance for the TLD. This section displays a line chart showing the total number of certificates issued over the selected period, as well as a donut chart depicting the distribution of certificate issuance among the top Certificate Authorities.
When we launched the DNS page earlier in 2025, we provided query volumes by TLDs, but this was limited to ccTLDs. Today, we’re extending that dataset to include all delegated TLDs. With these new insights, we’ve added the “Top-level domain distribution” section to the DNS page, featuring a line chart that shows the distribution of queries to 1.1.1.1 across the top 10 TLDs, alongside a table extending this ranking to the top 100. Not surprisingly, .com tops the ranking with more than 60% of queries, followed by .net, .arpa (an infrastructure TLD), and .org.
Because TLDs are a foundational component of the Domain Name System, it is critical that the associated name servers are highly performant. Based on billions of daily queries to these name servers, we plan to add insights into their performance to Radar’s TLD pages in 2026. These insights will provide TLD managers with an external perspective on query responsiveness, and will give developers and site owners a perspective on the potential impact of the performance of the associated TLD name servers as they look to register new domain names.
The underlying data for these new TLD pages is available via the API and can be interactively explored in more detail using Radar’s Data Explorer and AI Assistant. And as always, Radar and Data Assistant charts and graphs are downloadable for sharing, and embeddable for use in your own blog posts, websites, or dashboards.
If you share our TLD charts and graphs on social media, be sure to tag us: @CloudflareRadar (X), noc.social/@cloudflareradar (Mastodon), and radar.cloudflare.com (Bluesky). If you have questions or comments, or suggestions for data that you’d like to see us add to Radar, you can reach out to us on social media, or contact us via email.
The web is the most powerful application platform in existence. As long as you have the right API, you can safely run anything you want in a browser.
Well… anything but cryptography.
It is as true today as it was in 2011 that Javascript cryptography is Considered Harmful. The main problem is code distribution. Consider an end-to-end-encrypted messaging web application. The application generates cryptographic keys in the client’s browser that lets users view and send end-to-end encrypted messages to each other. If the application is compromised, what would stop the malicious actor from simply modifying their Javascript to exfiltrate messages?
It is interesting to note that smartphone apps don’t have this issue. This is because app stores do a lot of heavy lifting to provide security for the app ecosystem. Specifically, they provide integrity, ensuring that apps being delivered are not tampered with, consistency, ensuring all users get the same app, and transparency, ensuring that the record of versions of an app is truthful and publicly visible.
It would be nice if we could get these properties for our end-to-end encrypted web application, and the web as a whole, without requiring a single central authority like an app store. Further, such a system would benefit all in-browser uses of cryptography, not just end-to-end-encrypted apps. For example, many web-based confidential LLMs, cryptocurrency wallets, and voting systems use in-browser Javascript cryptography for the last step of their verification chains.
In this post, we will provide an early look at such a system, called Web Application Integrity, Consistency, and Transparency (WAICT) that we have helped author. WAICT is a W3C-backed effort among browser vendors, cloud providers, and encrypted communication developers to bring stronger security guarantees to the entire web. We will discuss the problem we need to solve, and build up to a solution resembling the current transparency specification draft. We hope to build even wider consensus on the solution design in the near future.
Defining the Web Application
In order to talk about security guarantees of a web application, it is first necessary to define precisely what the application is. A smartphone application is essentially just a zip file. But a website is made up of interlinked assets, including HTML, Javascript, WASM, and CSS, that can each be locally or externally hosted. Further, if any asset changes, it could drastically change the functioning of the application. A coherent definition of an application thus requires the application to commit to precisely the assets it loads. This is done using integrity features, which we describe now.
Subresource Integrity
An important building block for defining a single coherent application is subresource integrity (SRI). SRI is a feature built into most browsers that permits a website to specify the cryptographic hash of external resources, e.g.,
This causes the browser to fetch underscore.js from cdnjs.cloudflare.com and verify that its SHA-512 hash matches the given hash in the tag. If they match, the script is loaded. If not, an error is thrown and nothing is executed.
If every external script, stylesheet, etc. on a page comes with an SRI integrity attribute, then the whole page is defined by just its HTML. This is close to what we want, but a web application can consist of many pages, and there is no way for a page to enforce the hash of the pages it links to.
Integrity Manifest
We would like to have a way of enforcing integrity on an entire site, i.e., every asset under a domain. For this, WAICT defines an integrity manifest, a configuration file that websites can provide to clients. One important item in the manifest is the asset hashes dictionary, mapping a hash belonging to an asset that the browser might load from that domain, to the path of that asset. Assets that may occur at any path, e.g., an error page, map to the empty string:
The other main component of the manifest is the integrity policy, which tells the browser which data types are being enforced and how strictly. For example, the policy in the manifest below will:
Reject any script before running it, if it’s missing an SRI tag and doesn’t appear in the hashes
Reject any WASM possibly after running it, if it’s missing an SRI tag and doesn’t appear in hashes
Thus, when both SRI and integrity manifests are used, the entire site and its interpretation by the browser is uniquely determined by the hash of the integrity manifest. This is exactly what we wanted. We have distilled the problem of endowing authenticity, consistent distribution, etc. to a web application to one of endowing the same properties to a single hash.
Achieving Transparency
Recall, a transparent web application is one whose code is stored in a publicly accessible, append-only log. This is helpful in two ways: 1) if a user is served malicious code and they learn about it, there is a public record of the code they ran, and so they can prove it to external parties, and 2) if a user is served malicious code and they don’t learn about it, there is still a chance that an external auditor may comb through the historical web application code and find the malicious code anyway. Of course, transparency does not help detect malicious code or even prevent its distribution, but it at least makes it publicly auditable.
Now that we have a single hash that commits to an entire website’s contents, we can talk about ensuring that that hash ends up in a public log. We have several important requirements here:
Do not break existing sites. This one is a given. Whatever system gets deployed, it should not interfere with the correct functioning of existing websites. Participation in transparency should be strictly opt-in.
No added round trips. Transparency should not cause extra network round trips between the client and the server. Otherwise there will be a network latency penalty for users who want transparency.
User privacy. A user should not have to identify themselves to any party more than they already do. That means no connections to new third parties, and no sending identifying information to the website.
User statelessness. A user should not have to store site-specific data. We do not want solutions that rely on storing or gossipping per-site cryptographic information.
Non-centralization. There should not be a single point of failure in the system—if any single party experiences downtime, the system should still be able to make progress. Similarly, there should be no single point of trust—if a user distrusts any single party, the user should still receive all the security benefits of the system.
Ease of opt-in. The barrier of entry for transparency should be as low as possible. A site operator should be able to start logging their site cheaply and without being an expert.
Ease of opt-out. It should be easy for a website to stop participating in transparency. Further, to avoid accidental lock-in like the defunct HPKP spec, it should be possible for this to happen even if all cryptographic material is lost, e.g., in the seizure or selling of a domain.
Opt-out is transparent. As described before, because transparency is optional, it is possible for an attacker to disable the site’s transparency, serve malicious content, then enable transparency again. We must make sure this kind of attack is detectable, i.e., the act of disabling transparency must itself be logged somewhere.
Monitorability. A website operator should be able to efficiently monitor the transparency information being published about their website. In particular, they should not have to run a high-network-load, always-on program just to notify them if their site has been hijacked.
With these requirements in place, we can move on to construction. We introduce a data structure that will be essential to the design.
Hash Chain
Almost everything in transparency is an append-only log, i.e., a data structure that acts like a list and has the ability to produce an inclusion proof, i.e., a proof that an element occurs at a particular index in the list; and a consistency proof, i.e., a proof that a list is an extension of a previous version of the list. A consistency proof between two lists demonstrates that no elements were modified or deleted, only added.
The simplest possible append-only log is a hash chain, a list-like data structure wherein each subsequent element is hashed into the running chain hash. The final chain hash is a succinct representation of the entire list.
A hash chain. The green nodes represent the chain hash, i.e., the hash of the element below it, concatenated with the previous chain hash.
The proof structures are quite simple. To prove inclusion of the element at index i, the prover provides the chain hash before i, and all the elements after i:
Proof of inclusion for the second element in the hash chain. The verifier knows only the final chain hash. It checks equality of the final computed chain hash with the known final chain hash. The light green nodes represent hashes that the verifier computes.
Similarly, to prove consistency between the chains of size i and j, the prover provides the elements between i and j:
Proof of consistency of the chain of size one and chain of size three. The verifier has the chain hashes from the starting and ending chains. It checks equality of the final computed chain hash with the known ending chain hash. The light green nodes represent hashes that the verifier computes.
Building Transparency
We can use hash chains to build a transparency scheme for websites.
Per-Site Logs
As a first step, let’s give every site its own log, instantiated as a hash chain (we will discuss how these all come together into one big log later). The items of the log are just the manifest of the site at a particular point in time:
A site’s hash chain-based log, containing three historical manifests.
In reality, the log does not store the manifest itself, but the manifest hash. Sites designate an asset host that knows how to map hashes to the data they reference. This is a content-addressable storage backend, and can be implemented using strongly cached static hosting solutions.
A log on its own is not very trustworthy. Whoever runs the log can add and remove elements at will and then recompute the hash chain. To maintain the append-only-ness of the chain, we designate a trusted third party, called a witness. Given a hash chain consistency proof and a new chain hash, a witness:
Verifies the consistency proof with respect to its old stored chain hash, and the new provided chain hash.
If successful, signs the new chain hash along with a signature timestamp.
Now, when a user navigates to a website with transparency enabled, the sequence of events is:
The site serves its manifest, an inclusion proof showing that the manifest appears in the log, and all the signatures from all the witnesses who have validated the log chain hash.
The browser verifies the signatures from whichever witnesses it trusts.
The browser verifies the inclusion proof. The manifest must be the newest entry in the chain (we discuss how to serve old manifests later).
The browser proceeds with the usual manifest and SRI integrity checks.
At this point, the user knows that the given manifest has been recorded in a log whose chain hash has been saved by a trustworthy witness, so they can be reasonably sure that the manifest won’t be removed from history. Further, assuming the asset host functions correctly, the user knows that a copy of all the received code is readily available.
The need to signal transparency. The above algorithm works, but we have a problem: if an attacker takes control of a site, they can simply stop serving transparency information and thus implicitly disable transparency without detection. So we need an explicit mechanism that keeps track of every website that has enrolled into transparency.
The Transparency Service
To store all the sites enrolled into transparency, we want a global data structure that maps a site domain to the site log’s chain hash. One efficient way of representing this is a prefix tree (a.k.a., a trie). Every leaf in the tree corresponds to a site’s domain, and its value is the chain hash of that site’s log, the current log size, and the site’s asset host URL. For a site to prove validity of its transparency data, it will have to present an inclusion proof for its leaf. Fortunately, these proofs are efficient for prefix trees.
A prefix tree with four elements. Each leaf’s path corresponds to a domain. Each leaf’s value is the chain hash of its site’s log.
To add itself to the tree, a site proves possession of its domain to the transparency service, i.e., the party that operates the prefix tree, and provides an asset host URL. To update the entry, the site sends the new entry to the transparency service, which will compute the new chain hash. And to unenroll from transparency, the site just requests to have its entry removed from the tree (an adversary can do this too; we discuss how to detect this below).
Proving to Witnesses and Browsers
Now witnesses only need to look at the prefix tree instead of individual site logs, and thus they must verify whole-tree updates. The most important thing to ensure is that every site’s log is append-only. So whenever the tree is updated, it must produce a “proof” containing every new/deleted/modified entry, as well as a consistency proof for each entry showing that the site log corresponding to that entry has been properly appended to. Once the witness has verified this prefix tree update proof, it signs the root.
The sequence of updating a site’s assets and serving the site with transparency enabled.
The client-side verification procedure is as in the previous section, with two modifications:
The client now verifies two inclusion proofs: one for the integrity policy’s membership in the site log, and one for the site log’s membership in a prefix tree.
The client verifies the signature over the prefix tree root, since the witness no longer signs individual chain hashes. As before, the acceptable public keys are whichever witnesses the client trusts.
Signaling transparency. Now that there is a single source of truth, namely the prefix tree, a client can know a site is enrolled in transparency by simply fetching the site’s entry in the tree. This alone would work, but it violates our requirement of “no added round trips,” so we instead require that client browsers will ship with the list of sites included in the prefix tree. We call this the transparency preload list.
If a site appears in the preload list, the browser will expect it to provide an inclusion proof in the prefix tree, or else a proof of non-inclusion in a newer version of the prefix tree, thereby showing they’ve unenrolled. The site must provide one of these proofs until the last preload list it appears in has expired. Finally, even though the preload list is derived from the prefix tree, there is nothing enforcing this relationship. Thus, the preload list should also be published transparently.
Filling in Missing Properties
Remember we still have the requirements of monitorability, opt-out being transparent, and no single point of failure/trust. We fill in those details now.
Adding monitorability. So far, in order for a site operator to ensure their site was not hijacked, they would have to constantly query every transparency service for its domain and verify that it hasn’t been tampered with. This is certainly better than the 500k events per hour that CT monitors have to ingest, but it still requires the monitor to be constantly polling the prefix tree, and it imposes a constant load for the transparency service.
We add a field to the prefix tree leaf structure: the leaf now stores a “created” timestamp, containing the time the leaf was created. Witnesses ensure that the “created” field remains the same over all leaf updates (and it is deleted when the leaf is deleted). To monitor, a site operator need only keep the last observed “created” and “log size” fields of its leaf. If it fetches the latest leaf and sees both unchanged, it knows that no changes occurred since the last check.
Adding transparency of opt-out. We must also do the same thing as above for leaf deletions. When a leaf is deleted, a monitor should be able to learn when the deletion occurred within some reasonable time frame. Thus, rather than outright removing a leaf, the transparency service responds to unenrollment requests by replacing the leaf with a tombstone value, containing just a “created” timestamp. As before, witnesses ensure that this field remains unchanged until the leaf is permanently deleted (after some visibility period) or re-enrolled.
Permitting multiple transparency services. Since we require that there be no single point of failure or trust, we imagine an ecosystem where there are a handful of non-colluding, reasonably trustworthy transparency service providers, each with their own prefix tree. Like Certificate Transparency (CT), this set should not be too large. It must be small enough that reasonable levels of trust can be established, and so that independent auditors can reasonably handle the load of verifying all of them.
Ok that’s the end of the most technical part of this post. We’re now going to talk about how to tweak this system to provide all kinds of additional nice properties.
(Not) Achieving Consistency
Transparency would be useless if, every time a site updates, it serves 100,000 new versions of itself. Any auditor would have to go through every single version of the code in order to ensure no user was targeted with malware. This is bad even if the velocity of versions is lower. If a site publishes just one new version per week, but every version from the past ten years is still servable, then users can still be served extremely old, potentially vulnerable versions of the site, without anyone knowing. Thus, in order to make transparency valuable, we need consistency, the property that every browser sees the same version of the site at a given time.
We will not achieve the strongest version of consistency, but it turns out that weaker notions are sufficient for us. If, unlike the above scenario, a site had 8 valid versions of itself at a given time, then that would be pretty manageable for an auditor. So even though it’s true that users don’t all see the same version of the site, they will all still benefit from transparency, as desired.
We describe two types of inconsistency and how we mitigate them.
Tree Inconsistency
Tree inconsistency occurs when transparency services’ prefix trees disagree on the chain hash of a site, thus disagreeing on the history of the site. One way to fully eliminate this is to establish a consensus mechanism for prefix trees. A simple one is majority voting: if there are five transparency services, a site must present three tree inclusion proofs to a user, showing the chain hash is present in three trees. This, of course, triples the tree inclusion proof size, and lowers the fault tolerance of the entire system (if three log operators go down, then no transparent site can publish any updates).
Instead of consensus, we opt to simply limit the amount of inconsistency by limiting the number of transparency services. In 2025, Chrome trusts eight Certificate Transparency logs. A similar number of transparency services would be fine for our system. Plus, it is still possible to detect and prove the existence of inconsistencies between trees, since roots are signed by witnesses. So if it becomes the norm to use the same version on all trees, then social pressure can be applied when sites violate this.
Temporal Inconsistency
Temporal inconsistency occurs when a user gets a newer or older version of the site (both still unexpired), depending on some external factors such as geographic location or cookie values. In the extreme, as stated above, if a signed prefix root is valid for ten years, then a site can serve a user any version of the site from the last ten years.
As with tree inconsistency, this can be resolved using consensus mechanisms. If, for example, the latest manifest were published on a blockchain, then a user could fetch the latest blockchain head and ensure they got the latest version of the site. However, this incurs an extra network round trip for the client, and requires sites to wait for their hash to get published on-chain before they can update. More importantly, building this kind of consensus mechanism into our specification would drastically increase its complexity. We’re aiming for v1.0 here.
We mitigate temporal inconsistency by requiring reasonably short validity periods for witness signatures. Making prefix root signatures valid for, e.g., one week would drastically limit the number of simultaneously servable versions. The cost is that site operators must now query the transparency service at least once a week for the new signed root and inclusion proof, even if nothing in the site changed. The sites cannot skip this, and the transparency service must be able to handle this load. This parameter must be tuned carefully.
Beyond Integrity, Consistency, and Transparency
Providing integrity, consistency, and transparency is already a huge endeavor, but there are some additional app store-like security features that can be integrated into this system without too much work.
Code Signing
One problem that WAICT doesn’t solve is that of provenance: where did the code the user is running come from, precisely? In settings where audits of code happen frequently, this is not so important, because some third party will be reading the code regardless. But for smaller self-hosted deployments of open-source software, this may not be viable. For example, if Alice hosts her own version of Cryptpad for her friend Bob, how can Bob be sure the code matches the real code in Cryptpad’s Github repo?
WEBCAT. The folks at the Freedom of Press Foundation (FPF) have built a solution to this, called WEBCAT. This protocol allows site owners to announce the identities of the developers that have signed the site’s integrity manifest, i.e., have signed all the code and other assets that the site is serving to the user. Users with the WEBCAT plugin can then see the developer’s Sigstore signatures, and trust the code based on that.
We’ve made WAICT extensible enough to fit WEBCAT inside and benefit from the transparency components. Concretely, we permit manifests to hold additional metadata, which we call extensions. In this case, the extension holds a list of developers’ Sigstore identities. To be useful, browsers must expose an API for browser plugins to access these extension values. With this API, independent parties can build plugins for whatever feature they wish to layer on top of WAICT.
Cooldown
So far we have not built anything that can prevent attacks in the moment. An attacker who breaks into a website can still delete any code-signing extensions, or just unenroll the site from transparency entirely, and continue with their attack as normal. The unenrollment will be logged, but the malicious code will not be, and by the time anyone sees the unenrollment, it may be too late.
To prevent spontaneous unenrollment, we can enforce unenrollment cooldown client-side. Suppose the cooldown period is 24 hours. Then the rule is: if a site appears on the preload list, then the client will require that either 1) the site have transparency enabled, or 2) the site have a tombstone entry that is at least 24 hours old. Thus, an attacker will be forced to either serve a transparency-enabled version of the site, or serve a broken site for 24 hours.
Similarly, to prevent spontaneous extension modifications, we can enforce extension cooldown on the client. We will take code signing as an example, saying that any change in developer identities requires a 24 hour waiting period to be accepted. First, we require that extension dev-ids has a preload list of its own, letting the client know which sites have opted into code signing (if a preload list doesn’t exist then any site can delete the extension at any time). The client rule is as follows: if the site appears in the preload list, then both 1) dev-ids must exist as an extension in the manifest, and 2) dev-ids-inclusion must contain an inclusion proof showing that the current value of dev-ids was in a prefix tree that is at least 24 hours old. With this rule, a client will reject values of dev-ids that are newer than a day. If a site wants to delete dev-ids, they must 1) request that it be removed from the preload list, and 2) in the meantime, replace the dev-ids value with the empty string and update dev-ids-inclusion to reflect the new value.
Deployment Considerations
There are a lot of distinct roles in this ecosystem. Let’s sketch out the trust and resource requirements for each role.
Transparency service. These parties store metadata for every transparency-enabled site on the web. If there are 100 million domains, and each entry is 256B each (a few hashes, plus a URL), this comes out to 26GB for a single tree, not including the intermediate hashes. To prevent size blowup, there would probably have to be a pruning rule that unenrolls sites after a long inactivity period. Transparency services should have largely uncorrelated downtime, since, if all services go down, no transparency-enabled site can make any updates. Thus, transparency services must have a moderate amount of storage, be relatively highly available, and have downtime periods uncorrelated with each other.
Transparency services require some trust, but their behavior is narrowly constrained by witnesses. Theoretically, a service can replace any leaf’s chain hash with its own, and the witness will validate it (as long as the consistency proof is valid). But such changes are detectable by anyone that monitors that leaf.
Witness. These parties verify prefix tree updates and sign the resulting roots. Their storage costs are similar to that of a transparency service, since they must keep a full copy of a prefix tree for every transparency service they witness. Also like the transparency services, they must have high uptime. Witnesses must also be trusted to keep their signing key secret for a long period of time, at least long enough to permit browser trust stores to be updated when a new key is created.
Asset host. These parties carry little trust. They cannot serve bad data, since any query response is hashed and compared to a known hash. The only malicious behavior an asset host can do is refuse to respond to queries. Asset hosts can also do this by accident due to downtime.
Client. This is the most trust-sensitive part. The client is the software that performs all the transparency and integrity checks. This is, of course, the web browser itself. We must trust this.
We at Cloudflare would like to contribute what we can to this ecosystem. It should be possible to run both a transparency service and a witness. Of course, our witness should not monitor our own transparency service. Rather, we can witness other organizations’ transparency services, and our transparency service can be witnessed by other organizations.
Supporting Alternate Ecosystems
WAICT should be compatible with non-standard ecosystems, ones where the large players do not really exist, or at least not in the way they usually do. We are working with the FPF on defining transparency for alternate ecosystems with different network and trust environments. The primary example we have is that of the Tor ecosystem.
A paranoid Tor user may not trust existing transparency services or witnesses, and there might not be any other trusted party with the resources to self-host these functionalities. For this use case, it may be reasonable to put the prefix tree on a blockchain somewhere. This makes the usual domain validation impossible (there’s no validator server to speak of), but this is fine for onion services. Since an onion address is just a public key, a signature is sufficient to prove ownership of the domain.
One consequence of a consensus-backed prefix tree is that witnesses are now unnecessary, and there is only need for the single, canonical, transparency service. This mostly solves the problems of tree inconsistency at the expense of latency of updates.
Next Steps
We are still very early in the standardization process. One of the more immediate next steps is to get subresource integrity working for more data types, particularly WASM and images. After that, we can begin standardizing the integrity manifest format. And then after that we can start standardizing all the other features. We intend to work on this specification hand-in-hand with browsers and the IETF, and we hope to have some exciting betas soon.
In the meantime, you can follow along with our transparency specification draft, check out the open problems, and share your ideas. Pull requests and issues are always welcome!
Acknowledgements
Many thanks to Dennis Jackson from Mozilla for the lengthy back-and-forth meetings on design, to Giulio B and Cory Myers from FPF for their immensely helpful influence and feedback, and to Richard Hansen for great feedback.
The Internet is in constant motion. Sites scale, traffic shifts, and attackers adapt. Security that worked yesterday may not be enough tomorrow. That’s why the technologies that protect the web — such as Transport Layer Security (TLS) and emerging post-quantum cryptography (PQC) — must also continue to evolve. We want to make sure that everyone benefits from this evolution automatically, so we enabled the strongest protections by default.
During Birthday Week 2024, we announced Automatic SSL/TLS: a service that scans origin server configurations of domains behind Cloudflare, and automatically upgrades them to the most secure encryption mode they support. In the past year, this system has quietly strengthened security for more than 6 million domains — ensuring Cloudflare can always connect to origin servers over the safest possible channel, without customers lifting a finger.
Now, a year after we started enabling Automatic SSL/TLS, we want to talk about these results, why they matter, and how we’re preparing for the next leap in Internet security.
The Basics: TLS protocol
Before diving in, let’s review the basics of Transport Layer Security (TLS). The protocol allows two strangers (like a client and server) to communicate securely.
Every secure web session begins with a TLS handshake. Before a single byte of your data moves across the Internet, servers and clients need to agree on a shared secret key that will protect the confidentiality and integrity of your data. The key agreement handshake kicks off with a TLS ClientHello message. This message is the browser/client announcing, “Here’s who I want to talk to (via SNI), and here are the key agreement methods I understand.” The server then proves who it is with its own credentials in the form of a certificate, and together they establish a shared secret key that will protect everything that follows.
TLS 1.3 added a clever shortcut: instead of waiting to be told which method to use for the shared key agreement, the browser can guess what key agreement the server supports, and include one or more keyshares right away. If the guess is correct, the handshake skips an extra round trip and the secure connection is established more quickly. If the guess is wrong, the server responds with a HelloRetryRequest (HRR), telling the browser which key agreement method to retry with. This speculative guessing is a major reason TLS 1.3 is so much faster than TLS 1.2.
Once both sides agree, the chosen keyshare is used to create a shared secret that encrypts the messages they exchange and allows only the right parties to decrypt them.
The nitty-gritty details of key agreement
Up until recently, most of these handshakes have relied on elliptic curve cryptography (ECC) using a curve known as X25519. But looming on the horizon are quantum computers, which could one day break ECC algorithms like X25519 and others. To prepare, the industry is shifting toward post-quantum key agreement with MLKEM, deployed in a hybrid mode (X25519 + MLKEM). This ensures that even if quantum machines arrive, harvested traffic today can’t be decrypted tomorrow. X25519 + MLKEM is steadily rising to become the most popular key agreement for connections to Cloudflare.
The TLS handshake model is the foundation for how we encrypt web communications today. The history of TLS is really the story of iteration under pressure. It’s a protocol that had to keep evolving, so trust on the web could keep pace with how Internet traffic has changed. It’s also what makes technologies like Cloudflare’s Automatic SSL/TLS possible, by abstracting decades of protocol battles and crypto engineering into a single click, so customer websites can be secured by default without requiring every operator to be a cryptography expert.
History Lesson: Stumbles and Standards
Early versions of TLS (then called SSL) in the 1990s suffered from weak keys, limited protection against attacks like man-in-the-middle, and low adoption on the Internet. To stabilize things, the IETF stepped in and released TLS 1.0, followed by TLS 1.1 and 1.2 through the 2000s. These versions added stronger ciphers and patched new attack vectors, but years of fixes and extensions left the protocol bloated and hard to evolve.
The early 2010s marked a turning point. After the Snowden disclosures, the Internet doubled down on encryption by default. Initiatives like Let’s Encrypt, the mass adoption of HTTPS, and Cloudflare’s own commitment to offer SSL/TLS for free turned encryption from optional, expensive, and complex into an easy baseline requirement for a safer Internet.
All of this momentum led to TLS 1.3 (2018), which cut away legacy baggage, locked in modern cipher suites, and made encrypted connections nearly as fast as the underlying transport protocols like TCP—and sometimes even faster with QUIC.
The CDN Twist
As Content Delivery Networks (CDNs) rose to prominence, they reshaped how TLS was deployed. Instead of a browser talking directly to a distant server hosting content (what Cloudflare calls an origin), it now spoke to the nearest edge data center, which may in-turn speak to an origin server on the client’s behalf.
This created two distinct TLS layers:
Edge ↔ Browser TLS: The front door, built to quickly take on new improvements in security and performance. Edges and browsers adopt modern protocols (TLS 1.3, QUIC, session resumption) to cut down on latency.
Edge ↔ Origin TLS: The backhaul, which must be more flexible. Origins might be older, more poorly maintained, run legacy TLS stacks, or require custom certificate handling.
In practice, CDNs became translators: modernizing encryption at the edge while still bridging to legacy origins. It’s why you can have a blazing-fast TLS 1.3 session from your phone, even if the origin server behind the CDN hasn’t been upgraded in years.
This is where Automatic SSL/TLS sits in the story of how we secure Internet communications.
Automatic SSL/TLS
Automatic SSL/TLS grew out of Cloudflare’s mission to ensure the web was as encrypted as possible. While we had initially spent an incredibly long time developing secure connections for the “front door” (from browsers to Cloudflare’s edge) with Universal SSL, we knew that the “back door” (from Cloudflare’s edge to origin servers) would be slower and harder to upgrade.
One option we offered was Cloudflare Tunnel, where a lightweight agent runs near the origin server and tunnels traffic securely back to Cloudflare. This approach ensures the connection always uses modern encryption, without requiring changes on the origin itself.
But not every customer uses Tunnel. Many connect origins directly to Cloudflare’s edge, where encryption depends on the origin server’s configuration. Traditionally this meant customers had to either manually select an encryption mode that worked for their origin server or rely on the default chosen by Cloudflare.
To improve the experience of choosing an encryption mode, we introduced our SSL/TLS Recommender in 2021.
The Recommender scanned customer origin servers and then provided recommendations for their most secure encryption mode. For example, if the Recommender detected that an origin server was using a certificate signed by a trusted Certificate Authority (CA) such as Let’s Encrypt, rather than a self-signed certificate, it would recommend upgrading from Full encryption mode to Full (Strict) encryption mode.
Based on how the origin responded, Recommender would tell customers if they could improve their SSL/TLS encryption mode to be more secure. The following encryption modes represent what the SSL/TLS Recommender could recommend to customers based on their origin responses:
However, in the three years after launching our Recommender we discovered something troubling: of the over two million domains using Recommender, only 30% of the recommendations that the system provided were followed. A significant number of users would not complete the next step of pushing the button to inform Cloudflare that we could communicate with their origin over a more secure setting.
We were seeing sub-optimal settings that our customers could upgrade from without risk of breaking their site, but for various reasons, our users did not follow through with the recommendations. So we pushed forward by building a system that worked with Recommender and actioned the recommendations by default.
How does Automatic SSL/TLS work?
Automatic SSL/TLSworks by crawling websites, looking for content over both HTTP and HTTPS, then comparing the results for compatibility. It also performs checks against the TLS certificate presented by the origin and looks at the type of content that is served to ensure it matches. If the downloaded content matches, Automatic SSL/TLS elevates the encryption level for the domain to the compatible and stronger mode, without risk of breaking the site.
More specifically, these are the steps that Automatic SSL/TLS takes to upgrade domain’s security:
Each domain is scheduled for a scan once per month (or until it reaches the maximum supported encryption mode).
The scan evaluates the current encryption mode for the domain. If it’s lower than what the Recommender thinks the domain can support based on the results of its probes and content scans, the system begins a gradual upgrade.
Automatic SSL/TLS begins to upgrade the domain by connecting with origins over the more secure mode starting with just 1% of its traffic.
If connections to the origin succeed, the result is logged as successful.
If they fail, the system records the failure to Cloudflare’s control plane and aborts the upgrade. Traffic is immediately downgraded back to the previous SSL/TLS setting to ensure seamless operation.
If no issues are found, the new SSL/TLS encryption mode is applied to traffic in 10% increments until 100% of traffic uses the recommended mode.
Once 100% of traffic has been successfully upgraded with no TLS-related errors, the domain’s SSL/TLS setting is permanently updated.
Special handling for Flexible → Full/Strict: These upgrades are more cautious because customers’ cache keys are changed (from http to https origin scheme).
In this situation, traffic ramps up from 1% to 10% in 1% increments, allowing customers’ cache to warm-up.
After 10%, the system resumes the standard 10% increments until 100%.
We know that transparency and visibility are critical, especially when automated systems make changes. To keep customers informed, Automatic SSL/TLS sends a weekly digest to account Super Administrators whenever updates are made to domain encryption modes. This way, you always have visibility into what changed and when.
In short, Automatic SSL/TLS automates what used to be trial and error: finding the strongest SSL/TLS mode your site can support while keeping everything working smoothly.
How are we doing so far?
So far we have onboarded all Free, Pro, and Business domains to use Automatic SSL/TLS. We also have enabled this for all new domains that will onboard onto Cloudflare regardless of plantype. Soon, we will start onboarding Enterprise customers as well. If you already have an Enterprise domain and want to try out Automatic SSL/TLS we encourage you to enable it in the SSL/TLS section of the dashboard or via the API.
As of the publishing of this blog, we’ve upgraded over 6 million domains to be more secure without the website operators needing to manually configure anything on Cloudflare.
Previous Encryption Mode
Upgraded Encryption Mode
Number of domains
Flexible
Full
~ 2,200,000
Flexible
Full (strict)
~ 2,000,000
Full
Full (strict)
~ 1,800,000
Off
Full
~ 7,000
Off
Full (strict)
~ 5,000
We’re most excited about the over 4 million domains that moved from Flexible or Off, which uses HTTP to origin servers, to Full or Strict, which uses HTTPS.
If you have a reason to use a particular encryption mode (e.g., on a test domain that isn’t production ready) you can always disable Automatic SSL/TLS and manually set the encryption mode that works best for your use case.
Today, SSL/TLS mode works on a domain-wide level, which can feel blunt. This means that one suboptimal subdomain can keep the entire domain in a less secure TLS setting, to ensure availability. Our long-term goal is to make these controls more precise, so that Automatic SSL/TLS and encryption modes can optimize security per origin or subdomain, rather than treating every hostname the same.
Impact on origin-facing connections
Since we began onboarding domains to Automatic SSL/TLS in late 2024 and early 2025, we’ve been able to measure how origin connections across our network are shifting toward stronger security. Looking at the ratios across all origin requests, the trends are clear:
Encryption is rising. Plaintext connections are steadily declining, a reflection of Automatic SSL/TLS helping millions of domains move to HTTPS by default. We’ve seen a correlated 7-8% reduction in plaintext origin-bound connections. Still, some origins remain on outdated configurations, and these should be upgraded to keep pace with modern security expectations.
TLS 1.3 is surging. Since late 2024, TLS 1.3 adoption has climbed sharply, now making up the majority of encrypted origin traffic (almost 60%). While Automatic SSL/TLS doesn’t control which TLS version an origin supports, this shift is an encouraging sign for both performance and security.
Older versions are fading. Month after month, TLS 1.2 continues to shrink, while TLS 1.0 and 1.1 are now so rare they barely register.
The decline in plaintext connections is encouraging, but it also highlights a long tail of servers still relying on outdated packages or configurations. Sites like SSL Labs can be used, for instance, to check a server’s TLS configuration. However, simply copy-pasting settings to achieve a high rating can be risky, so we encourage customers to review their origin TLS configurations carefully. In addition, Cloudflare origin CA or Cloudflare Tunnel can help provide guidance for upgrading origin security.
Upgraded domain results
Instead of focusing on the entire network of origin-facing connections from Cloudflare, we’re now going to drill into specific changes that we’ve seen from domains that have been upgraded by Automatic SSL/TLS.
By January 2025, most domains had been enrolled in Automatic SSL/TLS, and the results were dramatic: a near 180-degree shift from plaintext to encrypted communication with origins. After that milestone, traffic patterns leveled off into a steady plateau, reflecting a more stable baseline of secure connections across the network. There is some drop in encrypted traffic which may represent some of the originally upgraded domains manually turning off Automatic SSL/TLS.
But the story doesn’t end there. In the past two months (July and August 2025), we’ve observed another noticeable uptick in encrypted origin traffic. This likely reflects customers upgrading outdated origin packages and enabling stronger TLS support—evidence that Automatic SSL/TLS not only raised the floor on encryption but continues nudging the long tail of domains toward better security.
To further explore the “encrypted” line above, we wanted to see what the delta was between TLS 1.2 and 1.3. Originally we wanted to include all TLS versions we support but the levels of 1.0 and 1.1 were so small that they skewed the graph and were taken out. We see a noticeable rise in the support for both TLS 1.2 and 1.3 between Cloudflare and origin servers. What is also interesting to note here is the network-wide decrease in TLS 1.2 but for the domains that have been automatically upgraded a generalized increase, potentially also signifying origin TLS stacks that could be updated further.
Finally, for Full (Strict) mode,we wanted to investigate the number of successful certificate validations we performed. This line shows a dramatic, approximately 40%, increase in successful certificate validations performed for customers upgraded by Automatic SSL/TLS.
We’ve seen a largely successful rollout of Automatic SSL/TLS so far, with millions of domains upgraded to stronger encryption by default. We’ve seen help Automatic SSL/TLS improve origin-facing security, safely pushing connections to stronger modes whenever possible, without risking site breakage. Looking ahead, we’ll continue to expand this capability to more customer use cases as we help to build a more encrypted Internet.
What will we build next for Automatic SSL/TLS?
We’re expanding Automatic SSL/TLS with new features that give customers more visibility and control, while keeping the system safe by default. First, we’re building an ad-hoc scan option that lets you rescan your origin earlier than the standard monthly cadence. This means if you’ve just rotated certificates, upgraded your origin’s TLS configuration, or otherwise changed how your server handles encryption, you won’t need to wait for the next scheduled pass—Cloudflare will be able to re-evaluate and move you to a stronger mode right away.
In addition, we’re working on error surfacing that will highlight origin connection problems directly in the dashboard and provide actionable guidance for remediation. Instead of discovering after the fact that an upgrade failed, or a change on the origin resulted in a less secure setting than what was set previously, customers will be able to see where the issue lies and how to fix it.
Finally, for newly onboarded domains, we plan to add clearer guidance on when to finish configuring the origin before Cloudflare runs its first scan and sets an encryption mode. Together, these improvements are designed to reduce surprises, give customers more agency, and ensure smoother upgrades. We expect all three features to roll out by June 2026.
Post Quantum Era
Looking ahead, quantum computers introduce a serious risk: data encrypted today can be harvested and decrypted years later once quantum attacks become practical. To counter this harvest-now, decrypt-later threat, the industry is moving towards post-quantum cryptography (PQC)—algorithms designed to withstand quantum attacks. We have extensively written on this subject in our previous blogs.
In August 2024, NIST finalized its PQC standards: ML-KEM for key agreement, and ML-DSA and SLH-DSA for digital signatures. In collaboration with industry partners, Cloudflare has helped drive the development and deployment of PQC. We have deployed the hybrid key agreement, combining ML-KEM (post-quantum secure) and X25519 (classical), to secure TLS 1.3 traffic to our servers and internal systems. As of mid-September 2025, around 43% of human-generated connections to Cloudflare are already protected with the hybrid post-quantum secure key agreement – a huge milestone in preparing the Internet for the quantum era.
But things look different on the other side of the network. When Cloudflare connects to origins, we act as the client, navigating a fragmented landscape of hosting providers, software stacks, and middleboxes. Each origin may support a different set of cryptographic features, and not all are ready for hybrid post-quantum handshakes.
To manage this diversity without the risk of breaking connections, we relied on HelloRetryRequest. Instead of sending post-quantum keyshare immediately in the ClientHello, we only advertise support for it. If the origin server supports the post-quantum key agreement, it uses HelloRetryRequest to request it from Cloudflare, and creates the post-quantum connection. The downside is this extra round trip (from the retry) cancels out the performance gains of TLS 1.3 and makes the connection feel closer to TLS 1.2 for uncached requests.
Back in 2023, we launched an API endpoint, so customers could manually opt their origins into preferring post-quantum connections. If set, we avoid the extra roundtrip and try to create a post-quantum connection at the start of the TLS session. Similarly, we extended post-quantum protection to Cloudflare tunnel, making it one of the easiest ways to get origin-facing PQ today.
Starting Q4 2025, we’re taking the next step – making it automatic. Just as we’ve done with SSL/TLS upgrades, Automatic SSL/TLS will begin testing, ramping, and enabling post-quantum handshakes with origins—without requiring customers to change a thing, as long as their origins support post-quantum key agreement.
Behind the scenes, we’re already scanning active origins about every 24 hours to test support and preferences for both classical and post-quantum key agreements. We’ve worked directly with vendors and customers to identify compatibility issues, and this new scanning system will be fully integrated into Automatic SSL/TLS.
And the benefits won’t stop at post-quantum. Even for classical handshakes, optimization matters. Today, the X25519 algorithm is used by default, but our scanning data shows that more than 6% of origins currently prefer a different key agreement algorithm, which leads to unnecessary HelloRetryRequests and wasted round trips. By folding this scanning data into Automatic SSL/TLS, we’ll improve connection establishment for classical TLS as well—squeezing out extra speed and reliability across the board.
As enterprises and hosting providers adopt PQC, our preliminary scanning pipeline has already found that around 4% of origins could benefit from a post-quantum-preferred key agreement even today, as shown below. This is an 8x increase since we started our scans in 2023. We expect this number to grow at a steady pace as the industry continues to migrate to post-quantum protocols.
As part of this change, we will also phase out support for the pre-standard version X25519Kyber768 to support the final ML-KEM standard, again using a hybrid, from edge to origin connections.
With Automatic SSL/TLS, we will soon by default scan your origins proactively to directly send the most preferred keyshare to your origin removing the need for any extra roundtrip, improving both security and performance of your origin connections collectively.
At Cloudflare, we’ve always believed security is a right, not a privilege. From Universal SSL to post-quantum cryptography, our mission has been to make the strongest protections free and available to everyone. Automatic SSL/TLS is the next step—upgrading every domain to the best protocols automatically. Check the SSL/TLS section of your dashboard to ensure it’s enabled and join the millions of sites already secured for today and ready for tomorrow.
Organizations have finite resources available to combat threats, both by the adversaries of today and those in the not-so-distant future that are armed with quantum computers. In this post, we provide guidance on what to prioritize to best prepare for the future, when quantum computers become powerful enough to break the conventional cryptography that underpins the security of modern computing systems. We describe how post-quantum cryptography (PQC) can be deployed on your existing hardware to protect from threats posed by quantum computing, and explain why quantum key distribution (QKD) and quantum random number generation (QRNG) are neither necessary nor sufficient for security in the quantum age.
Are you quantum ready?
“Quantum” is becoming one of the most heavily used buzzwords in the tech industry. What does it actually mean, and why should you care?
At its core, “quantum” refers to technologies that harness principles of quantum mechanics to perform tasks that are not feasible with classical computers. Quantum computers have exciting potential to unlock advancements in materials science and medicine, but also pose a threat to computer security systems. The term Q-day refers to the day that adversaries possess quantum computers that are large and stable enough to break the conventional public-key cryptography that secures much of today’s data and communications. Recent advances in quantum computing have made it clear that it is no longer a question of if Q-day will arrive, but when.
What does it mean, then, for your organization to be quantum ready? At Cloudflare, our definition is simple: your systems and communications should be secure even after Q-day.
However, this definition often gets muddied by vendors insisting that products built using quantum technology are required in order to secure an organization against quantum adversaries. In this blog post we explain why quantum technologies are neither necessary nor sufficient to protect against attacks by a quantum adversary.
The good news is that there is already a solution: post-quantum cryptography (PQC). PQC protects against attacks by quantum adversaries, but PQC is not a quantum technology — it runs on conventional computers without specialized hardware. You can use PQC today on the computers you already have, without buying expensive new hardware.
Post-quantum cryptography
We’ve written quite a few blog posts on post-quantum cryptography already, so we will keep this section brief.
The public-key cryptography that we’ve used for decades to secure our data and communications is based on math problems (like factoring large numbers) that are believed to be computationally hard to solve on conventional computers. If you can efficiently solve the underlying math problem, you can efficiently break the cryptography and the systems that depend on it. As it turns out, the math problems underlying much of today’s public-key cryptography can be efficiently solved by specialized algorithms, like Shor’s algorithm, on large-scale quantum computers.
Post-quantum cryptography (PQC) runs on your existing phones, laptops, and servers. PQC runs at Internet scale and can even be more performant than classical cryptography. Except in rare cases, like when you need additional hardware acceleration in cheap smartcards or to replace legacy systems that lack cryptographic agility, there is no need to purchase new hardware to migrate to PQC.
If you want to know how to protect your organization from security threats posed by quantum computers, you can stop reading now. Post-quantum cryptography is the solution.
Alternatively, you can read below for our perspective on hardware-based quantum security technologies that are sometimes marketed as security solutions.
This is exciting technology and fundamental scientific research. But this technology is not required to secure data and communications against quantum attackers.
In this section, we’ll explain why quantum security technologies do not need to be part of your quantum readiness strategy, and any decision to invest in quantum technology should not be based on a desire to defend data and communications systems against the threat of quantum adversaries. Instead, investments should be based on a desire to improve quantum technologies in their own right, for example to help with applications like chemistry, machine learning, and financial modeling.
Quantum key distribution (QKD) is a hardware-based solution to secure communications across point-to-point links. Rather than relying on hard mathematical problems, QKD relies on principles of quantum physics to establish a shared symmetric secret between two parties, while ensuring that eavesdropping can be detected. QKD provides security guarantees that are based on physical properties of the communication channel. Once a shared secret is established, parties can switch to traditional symmetric-key cryptography for secure communication. QKD is the first step towards a futuristic “quantum Internet.” However, there are some fundamental reasons why QKD cannot be a general replacement for classical cryptography running on conventional hardware.
Most importantly, QKD does not operate at Internet scale. QKD is used to establish an unauthenticated secret between pairs of parties with a direct physical link between them. The parties can then use an authentication mechanism based on conventional cryptography to bootstrap a secure communication channel over that link. While building dedicated physical links may be feasible for cross-datacenter communication or across major Internet backbones, it is not possible for most pairs of parties on the Internet. In particular, deploying QKD for the “last-mile” connection to end-user devices would require that each device has a direct physical connection to every server or device it needs to securely communicate with.
Connectivity aside, there’s a good reason why the Internet doesn’t rely on secure point-to-point links: they do not scale (or rather, they scale exponentially). Bringing a new device online would require a change to every other device it needs to communicate with, a massive operational burden on everyone. Fortunately, there’s a better way. The OSI model for networking provides an abstraction such that two parties can communicate even if they don’t share a direct physical link, so long as some chain of physical links exists between them. Public-key cryptography, invented in the seminal “New Directions in Cryptography” paper in 1976, allows two parties participating in the same public-key infrastructure to establish a secure end-to-end encrypted communication channel, without requiring any prior setup between them. The massive scaling enabled by these technologies is why the secure Internet exists as we know it. Secure point-to-point links are not part of the solution.
Lack of scalability is enough for us to disqualify QKD outright: if a technology can’t bring security to the whole Internet, we’re not going to spend much time on it.
The challenges with QKD don’t stop there though.
QKD touts theoretical security guarantees, but achieving security in practice is not so simple. QKD systems have been plagued by implementation attacks, both classical sidechannel attacks and new ones specific to the technology. Further, QKD works best over a special medium: either fiber or a vacuum. QKD has been demonstrated over the air, but performance and the implementation security mentioned before suffers. We still have not seen QKD work on a mobile phone or over Wi-Fi networks.
Further, neither QKD nor any other quantum technologies provide authentication to prove that the party on the other end of the key exchange is who you think they are. This opens the door for a classic monster in the middle (MITM) attack, where an adversary intercepts your connection, establishes a separate secure QKD link to you and your intended destination, and then sits in the middle reading and relaying all traffic. To prevent this, you must authenticate the identity of the party you are connecting to, using either pre-shared keys or conventional public-key cryptography. The bottom line is, whether or not you invest in QKD, you still need a solution for authentication to protect against active attackers armed with quantum computers. Practically speaking, that means you need PQC, but PQC is already a standalone solution that provides both authentication and key agreement, which leads to questions of why use QKD in the first place.
Some proponentsargue that QKD should be integrated into existing systems as an extra security layer. The value proposition of QKD relates to the “harvest now, decrypt later” threat. In public-key cryptography, the key exchange messages used to set up encryption keys to secure a communication channel are exchanged in full view of a potential adversary. If an adversary records the key exchange messages, they might hope to use improved techniques in the future to solve the hard math problems upon which the security of the key exchange relies, allowing them to recover the encryption keys and decrypt the communication. If encryption keys are exchanged directly via QKD instead, the eavesdropper protections provided by QKD stop an adversary from recording messages that could later allow them to recover the encryption key (e.g. by using a quantum computer or other advances in cryptanalysis). The problem is, however, that this “extra security layer” is brittle, and limited to a single physical link. As soon as the data is transmitted elsewhere — for instance at an Internet exchange point or to travel to an end-user — the QKD security ends. For the rest of its journey, the data is protected by standard protocols like TLS, making the value of the initial QKD link questionable.
While we hope the technology progresses, QKD is neither necessary nor sufficient for security against a quantum adversary. PQC is sufficient for security against a quantum adversary, already runs on your existing hardware, and works everywhere.
In cryptography and computer security, the essential property required from a random number generator is that the outputs are unpredictable and unbiased. This can be achieved by taking a small seed (say, 256 bits) of true randomness and feeding it to a cryptographically-secure pseudorandom number generator (CSPRNG) to produce an essentially limitless stream of pseudorandom output indistinguishable from true randomness. The randomness used to seed the CSPRNG can be based on either classical or quantum physical processes, as long as it is not known to the adversary. Whether or not you use a QRNG to generate the seed, a CSPRNG is essential for cryptographic applications.
We are the first to get excited about funnewsources of randomness. However, we’d like to emphasize that randomness derived from quantum effects is not necessary to combat threats from quantum computers. Quantum computers do not enable any practical new attacks against classical TRNGs in widespread use today. Your decision to invest in QRNGs should be based on a perceived improvement in the quality of randomness they produce and not on a perceived threat to classical TRNGs from quantum computing.
Post-quantum cryptography at Cloudflare
Cloudflare has been at the forefront of developing and deploying PQC, and we are committed to making PQC available for free and by default for all of our products. And we run it at scale — already over 40% of the human-generated traffic to our network uses PQC.
So what’s in that 40%? PQC is supported for all website and API traffic served through Cloudflare, most of Cloudflare’s internal network traffic, and traffic running over our Zero-Trust platform. All these connections use post-quantum key agreement to protect against the “harvest now, decrypt later” threat, where an adversary intercepts and stores encrypted data today with the hope of decrypting with a quantum computer or other cryptanalytic advances in the future. Key agreement is an important first step, but there’s still more work to be done. We’re actively working with stakeholders in the industry to prepare for the upcoming migration to post-quantum signatures to prevent active impersonation attacks from quantum adversaries (after Q-day).
Quantum readiness strategy
If purchasing quantum hardware is not necessary, how should organizations prepare for a quantum future? The most effective strategy will depend on your organization’s individual needs, but some general strategies will pay off for most organizations:
Investing in basic security practices is a good start. Hire the right expertise if you don’t already have it. Find vendors that support post-quantum encryption in their offerings today, and whose products are cryptographically agile so you can enjoy a seamless transition to post-quantum signatures and certificates when the industry migrates before Q-day. Follow a tunneling strategy: routing application traffic over the Internet via secure quantum safe tunnels allows you to reduce your attack surface area with minimal changes to existing systems. If you’re already a Cloudflare customer (or want to be), our Content Distribution Network and Zero Trust platform makes this easy. Learn more about how we can help at our Post-Quantum Cryptography webpage.
Part of teaching young people AI literacy skills is teaching them to critically think about AI, and to design AI applications that address problems they care about. How to do this was the focus of our June research seminar.
Working together to design AI
Our June research seminar was delivered by Netta Iivari, Professor in Information Systems at the University of Oulu’s INTERACT Research Unit.
The INTERACT research group focuses on understanding and supporting participatory design, user-centered design, user-driven innovation, and human interaction with technology in everyday life contexts. From this perspective, “users” aren’t considered as passive consumers, but as valuable co-creators and content producers. This calls for different approaches that place emphasis on empowerment and inclusion in designing, shaping, and co-creating information technology in everyday life.
As part of this work, Netta introduced the idea of ‘transformative agency’ — empowering children to believe they can solve problems they care about — and its application in secondary computing education. She showed examples of how to foster young people’s transformative agency within computing, specifically focusing on transdisciplinary approaches to learning about AI and inviting young people to critically analyse and design their futures with AI tools in it.
The Make a difference (MAD) project (2019–2023) explored critical design with young people, focusing on their emerging designer and maker identities in the context of tackling a significant societal problem — in this case, bullying.
Children’s transformative agency and emerging technologies for social good (TAKEOVER) (2024–2028), a current project, explores the potential of emerging technologies (artificial intelligence, virtual reality (VR), social robots, etc.) to address societal problems, such as climate change, gender equality, bullying, and discrimination. It focuses on children’s emerging transformative agency and activist identities when engaging with these tools and topics.
Netta explained that these projects give young people an opportunity to begin to address the problems they care about, even though they may be very complex problems. From this problem-solving perspective, children are introduced (or ‘sensitised’) to emerging technologies as tools for social good.
She then went on to outline the key pedagogical approaches that underpin these projects:
Critical, ethical, empowering design This pedagogy draws on critical and speculative design traditions in design research and encourages young people to take a critical perspective towards society, its norms, and the status quo, as part of design thinking. Children consider the ethical values and consequences of their designs. They begin to experience the ways in which engaging in the design process can be empowering and transformative for them, collectively as well as individually.
Transformative agency of children This approach encourages young people to consider their capacity to have agency in the world, by enabling them to envision change and commit to taking action to solve problems that they care about.
Fostering transformative agency of children in the age of AI Transformative agency is achieved when young people engage in ‘expansive learning’ — when they learn something novel, together, and are encouraged to look beyond the confines of school work, the topic, themselves, and the tools available for solving the problem. This approach fosters an active, critical, reflective mindset that encourages children to believe that they can make change and have impact in the world.
The project design process
The projects follow 3 design phases and include a range of plugged and unplugged activities, as shown in Figure 1.
Netta then described in more detail some of the activities that have been used to address these different project phases and the design process involved. For example, to explore what are the problems that children really care about, they are asked to imagine ‘carrying a stone in your pocket for one week, as if it was a magic tool. Where could it be used in your everyday life? What problems could it solve? What problems would you like it to solve and how?’
Young people are then introduced to a range of novel technologies, for example, VR headsets, robots, and emulators of AI-driven social media platforms, such as “Somekone”, developed as part of the Generative AI project at the University of Eastern Finland. They deconstruct and reconstruct generative AI tools by prompting large language model chatbots such as ChatGPT, Gemini, Claude, etc. and exploring bias in their outputs. They perform small-scale algorithmic auditing and create mini language models (with Google Colab), using the text in Alice in Wonderland to train their models, and then open datasets (books as text files from Project Gutenberg). In exploring the responses generated, they experience the potential and the limitations of such tools and gain an important understanding of the human activity involved in the development of AI technologies.
Once they have had this ‘sensitising‘ exposure to a range of tools, they then work in groups on a project that makes use of AI to solve the societal problem they have chosen. These problems could encompass a range of topics, such as racism, animal rights, the impact of AI, war, mental health, bullying. The young people are prompted to think about how large language models can be used to solve the problem, or parts of the problem. But importantly, they are also asked to consider the different motives and perspectives of the multiple stakeholders involved in the problem and its solution and whether their model ideas will create new problems when deployed.
They follow the 3 project phases shown in Figure 1 to design and make a range of digital (robots, apps, videos) and non-digital artefacts to solve their problem. Netta emphasised that although it could take 10 weeks or more to implement all the suggested activities, it is also possible to pick and choose individual tasks from the 3 phases to suit available curriculum timescales.
Envisioning and critiquing AI futures
Other project tasks involve:
Envisioning AI futures by imagining that a miracle has happened overnight and the problem has disappeared — what is the result?
Critiquing AI futures by creating best and worst case scenarios of the consequences of the AI systems they design, creating video adverts promoting their AI solutions and anti-adverts, focusing on the possible negative consequences of their prototypes
Fostering action-taking by presenting theatrical performances to showcase how their designs tackle a problem and illustrating the AI-related issues surrounding the topic or by creating activism campaign material to mobilise the school community on the same themes
These projects situate learning about data-driven technologies in real-world contexts and promote a transdisciplinary approach, teaching and learning about AI from a problem-solving perspective.
This perspective conveys important messages to young people — that they do have agency and can take action in the face of many of the world’s problems, that they can and should be active, critical users of the new technologies that surround them, and that these technologies can be used to change the world for good.
Netta ended the seminar by asking viewers to consider how they could foster transformative agency in the young people they teach and whether or not they consider it to be important in computing education.
Resources relating to the projects can be found at interact.oulu.fi.
Join our next seminar
In our current seminar series, we’re exploring teaching about AI and data science. Join us at our next seminar on Tuesday 14 October from 17:00 to 18:30 GMT to hear Viktoriya Olari talk about data-related concepts and practices for AI education in K–12.
To sign up and take part, click the button below. We’ll then send you information about joining. We hope to see you there.
New research by the Alan Turing Institute, published in June, shows that in the UK nearly one in four children aged 8 to 12 is using artificial intelligence (AI) tools like ChatGPT. With learners exploring these tools at such young ages, it’s more urgent than ever to develop teaching resources that help them understand how AI works.
One of the biggest challenges with AI is that it’s hard to tell how these tools function. With a chatbot, you enter a prompt and the tool returns a response, but what happens in between is invisible. For educators, that’s a problem: how can we help young people become thoughtful, creative users of AI tools if the technology feels like a closed box?
In our May research seminar, we welcomed Matti Tedre and Henriikka Vartiainen from the University of Eastern Finland. They’ve been working on how to teach about AI for years and were frustrated with existing educational platforms: many of these are either too complex, raise privacy concerns, or rely on coding skills that not all students (or teachers) have. In response, they created an award-winning, classroom-friendly tool designed to make AI technology more transparent and more hands-on.
A practical way to teach AI in schools
Matti and Henriikka began by discussing the unique challenges of teaching young learners about AI technology. Many students start with “folk theories”, for example, thinking that computers understand language like humans do. These misconceptions can be surprisingly hard to shake.
They also pointed out broader issues:
The abstract nature of AI means there are very few research-based approaches to teaching it effectively
Mastery of AI concepts requires sustained practice and curricular change, not just a few one-off interventions
In countries like Finland, where programming isn’t part of the curriculum, any teaching tool must be no-code to be accessible
To address these challenges, Matti and Henriikka have spent three years co-designing tools and approaches with local schools, teachers, and over 200 students. Their approach is grounded in educational theory and a set of core AI learning principles:
No-code for inclusivity: Removing the need for programming lowers the barrier to entry for both teachers and students
Learner-centred co-design: Every part of the experience is developed in collaboration with schools to make sure it’s engaging and relevant
Working with personal data: Learners create and work with their own data sets, which makes the experience more engaging and personally relevant
Integration with school subjects: Integrating AI concepts into other subjects helps to make the uses of AI tools more concrete for learners
Focus on specific applications: Rather than teaching about generic ‘AI’, the focus is on specific and understandable applications, such as facial recognition
Hands-on experimentation: Practical projects help students understand tricky ideas like bias, fairness, and social impact
Collaborative learning: Working together helps students reflect, question, and learn from each other
GenAI Teachable Machine: Opening the box
Frustrated by existing platforms that require programming skills, raise privacy concerns, or don’t allow collaboration, Matti and Henriikka’s team developed GenAI Teachable Machine: a no-code, browser-based tool designed to make key AI concepts tangible. In the central research study, the team used the tool with Finnish students in grade 4–7 (10 to 14 years of age). It’s a great introductory tool that could also be used with younger and older students.
GenAI Teachable Machine is freely available online and maintains a “line of sight”: All important steps are visible to the learner
Matti demonstrated how the tool addresses their core AI learning principles with a simple, creative project. Using hand puppets, he trained a model to recognise four distinct classes: a background, a bunny, a calm wolf, and an angry wolf. For each class, he assigned a specific action: a sound, an image, or both. This hands-on process gives students a direct line of sight from the data they might create (visuals of hand puppets) to the final behaviour of the model (outputted sounds and images). They learn about classifiers, training, and confidence levels not as abstract definitions, but as creative tools they can control.
Matti Tedre demonstrating a bunny and wolf recognition model
But the learning really starts when things don’t work as expected. Students can easily open their models on their phones with an automatically created QR code and then move around the classroom to test their models. At this point, they quickly notice how fragile AI technology can be. For example, in the case of a simple recognition model trained on specific colours or features, with a change of lighting or a different shirt, the model might fail. These “failures” turn into powerful lessons. For instance, a face-recognition app trained mostly on students with blonde hair might not work well for someone with brown hair — sparking immediate conversations about bias. As Matti put it, students very quickly start asking deep questions.
GenAI Teachable Machine also allows students to apply their AI models to the physical world. By connecting to a simple, low-cost robotics kit, students can use their models to control motors, lights, and other actuators. This step into the physical world teaches fundamental concepts that are difficult to grasp in a purely virtual environment. Students learn about causality, as their model’s classifications trigger real, physical actions. They also learn about the need for a world model — an understanding of how the physical world works — and see that they must take responsibility for what happens when their abstract models have real-world consequences.
Examples of students’ robot creations
By combining a no-code platform with practical, well-designed learning experiences, Matti, Henriikka, and their team are showing what AI education can look like: hands-on, accessible, and grounded in real understanding. Their work is helping students see inside the box, and giving them the tools to think critically about the AI technologies that are becoming part of their everyday lives.
You may also be interested in our own Experience AI resources, which are designed to help you and your learners navigate the fast-moving world of AI and machine learning technologies.
Join us at our next seminar
In September, Matti and his team are returning to discuss other ways to teach young people about AI technologies.
To sign up and take part in the Matti’s seminar on Tues 9 Sept at 17:00–18:30 BST, click the button below. We’ll then send you information about joining. We hope to see you there.
As a site owner, how do you know which bots to allow on your site, and which you’d like to block? Existing identification methods rely on a combination of IP address range (which may be shared by other services, or change over time) and user-agent header (easily spoofable). These have limitations and deficiencies. In our last blog post, we proposed using HTTP Message Signatures: a way for developers of bots, agents, and crawlers to clearly identify themselves by cryptographically signing requests originating from their service.
Since we published the blog post on Message Signatures and the IETF draft for Web Bot Auth in May 2025, we’ve seen significant interest around implementing and deploying Message Signatures at scale. It’s clear that well-intentioned bot owners want a clear way to identify their bots to site owners, and site owners want a clear way to identify and manage bot traffic. Both parties seem to agree that deploying cryptography for the purposes of authentication is the right solution.
Today, we’re announcing that we’re integrating HTTP Message Signatures directly into our Verified Bots Program. This announcement has two main parts: (1) for bots, crawlers, and agents, we’re simplifying enrollment into the Verified Bots program for those who sign requests using Message Signatures, and (2) we’re encouraging all bot operators moving forward to use Message Signatures over existing verification mechanisms. Because Verified Bots are considered authenticated, they do not face challenges from our Bot Management to identify as bots, given they’re already identified as such.
For site owners, no additional action is required – Cloudflare will automatically validate signatures on our edge, and if that validation is a success, that traffic will be marked as verified so that site owners can use the verified bot fields to create Bot Management and WAF rules based on it.
This isn’t just about simplifying things for bot operators — it’s about giving website owners unparalleled accuracy in identifying trusted bot traffic, cutting down on the overhead for cryptographic verification, and fundamentally transforming how we manage authentication across the Cloudflare network.
Become a Verified Bot with Message Signatures
Cloudflare’s existing Verified Bots program is for bots that are transparent about who they are and what they do, like indexing sites for search or scanning for security vulnerabilities. You can see a list of these verified bots in Cloudflare Radar:
A preview of the Verified Bots page on Cloudflare Radar.
In the past, in order to apply to be a verified bot, we used to ask for IP address ranges or reverse DNS names so that we could verify your identity. This required some manual steps like checking that the IP address range is valid and is associated with the appropriate ASN.
With the integration of Message Signatures, we’re aiming to streamline applications into our Verified Bot program. Bots applying with well-formed Message Signatures will be prioritized, and approved more quickly!
At a high level, signing your requests with web bot auth consists of the following steps:
Generate a valid signing key. See Signing Key section for step-by-step instructions.
Host a JSON web key set containing your public key under /.well-known/http-message-signature-directory of your website.
Sign responses for that URL using a Web Bot Auth library, one signature for each key contained in it, to prove you own it. See the Hosting section for step-by-step instructions.
Register that URL with us, using our Verified Bots form. This can be done directly in your Cloudflare account. See our documentation.
Sign requests using a Web Bot Auth library.
As an example, Cloudflare Radar’s URL Scanner lets you scan any URL and get a publicly shareable report with security, performance, technology, and network information. Here’s an example of what a well-formed signature looks like for requests coming from URL Scanner:
GET /path/to/resource HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
Signature-Agent: "https://web-bot-auth-directory.radar-cfdata-org.workers.dev"
Signature-Input: sig=("@authority" "signature-agent");\
created=1700000000;\
expires=1700011111;\
keyid="poqkLGiymh_W0uP6PZFw-dvez3QJT5SolqXBCW38r0U";\
tag="web-bot-auth"
Signature:sig=jdq0SqOwHdyHr9+r5jw3iYZH6aNGKijYp/EstF4RQTQdi5N5YYKrD+mCT1HA1nZDsi6nJKuHxUi/5Syp3rLWBA==:
Since we’ve already registered URLScanner as a Verified Bot, Cloudflare will now automatically verify that the signature in the Signature header matches the request — more on that later.
Register your bot
Access the Verified Bots submission form on your account. If that link does not immediately take you there, go to your Cloudflare account → Account Home → the three dots next to your account name → Configurations → Verified Bots.
For the verification method, select “Request Signature”, then enter the URL of your key directory in Validation Instructions. Specifying the User-Agent values is optional if you’re submitting a Request Signature bot.
Once your application has gone through our (now shortened) review process, you don’t need to take any further action.
Message Signature verification for origins
Starting today, Cloudflare is ramping up verification of cryptographic signatures provided by automated crawlers and bots. This is currently available for all Free and Pro plans, and as we continue to test and validate at scale, will be released to all Business and Enterprise plans. This means that as time passes, the number of unauthenticated web crawlers should diminish, ensuring most bot traffic is authenticated before it reaches your website’s servers, helping to prevent spoofing attacks.
At a high level, signature verification works like this:
A bot or agent sends a request to a website behind Cloudflare.
Cloudflare’s Message Signature verification service checks for the Signature, Signature-Input, and Signature-Agent headers.
It checks that the incoming request presents a keyid parameter in your Signature-Input that points to a key we already know.
It looks at the expires parameter in the incoming bot request. If the current time is after expiration, verification fails. This guards against replay attacks, preventing malicious agents from trying to pass as a bot by retrying messages they captured in the past.
It checks that you’ve specified a tag parameter indicating web-bot-auth, to indicate your intent that the message be handled using web bot authentication specifically
It looks at all the components chosen in your Signature-Input header, and constructs a signature base from it.
If all pre-flight checks pass, Cloudflare attempts to verify the signature base against the value in Signature field using an ed25519 verification algorithm and the key supplied in keyid.
Verified Bots and other systems at Cloudflare use a successful verification as proof of your identity, and apply rules corresponding to that identity.
If any of the above steps fail, Cloudflare falls back to existing bot identification and mitigation mechanisms. As the system matures, we would strengthen these requirements, and limit the possibilities of a soft downgrade.
As a site owner, you can segment your Verified Bot traffic by its type and purpose by adding the Verified Bot Categories field cf.verified_bot_category as a filter criterion in WAF Custom rules, Advanced Rate Limiting, and Late Transform rules. For instance, to allow the Bibliothèque nationale de France and the Library of Congress, and institutions dedicated to academic research, you can add a rule that allows bots in the Academic Research category.
Where we’re going next
HTTP Message Signatures is a primitive that is useful beyond Cloudflare – the IETF standardized it as part of RFC 9421.
As discussed in our previous blog post, Cloudflare believes that making Message Signatures a core component of bot authentication on the web should follow the same path. The specifications for the protocol are being built in the open, and they have already evolved following feedback.
Moreover, due to widespread interest, the IETF is considering forming a working group around Web Bot Auth. Should you be a crawler, an origin, or even a CDN, we invite you to provide feedback to ensure the solution gets stronger, and suits your needs.
A better, more trusted Internet
For bot, agent, and crawler operators that act transparently and provide vital services for the Internet, we’re providing a faster and more automated path to being recognized as a Verified Bot, reducing manual processes. We trust that this approach improves bot authentication from what were formerly brittle and unreliable authentication methods, to a secure and reliable alternative. It should reduce the overall volume of friction and hurdles genuinely useful bots face.
For site owners, Message Signatures provides better assurance that the bot traffic is legitimate — automatically recognized and allowed, minimizing disruption to essential services (e.g., search engine indexing, monitoring). In line with our commitments to making TLS/SSL and Post-Quantum certificates available for everyone, we’ll always offer the cryptographic verification of Message Signatures for all sites because we believe in a safer and more efficient Internet by fostering a trusted environment for both human and automated traffic.
If you have a feature request, feedback, or are interested in partnering with us, please reach out.
Developing a new video conferencing application often begins with a peer-to-peer setup using WebRTC, facilitating direct data exchange between clients. While effective for small demonstrations, this method encounters scalability hurdles with increased participants. The data transmission load for each client escalates significantly in proportion to the number of users, as each client is required to send data to every other client except themselves (n-1).
In the scaling of video conferencing applications, Selective Forwarding Units (SFUs) are essential. Essentially a media stream routing hub, an SFU receives media and data flows from participants and intelligently determines which streams to forward. By strategically distributing media based on network conditions and participant needs, this mechanism minimizes bandwidth usage and greatly enhances scalability. Nearly every video conferencing application today uses SFUs.
In 2024, we announced Cloudflare Realtime (then called Cloudflare Calls), our suite of WebRTC products, and we also released Orange Meets, an open source video chat application built on top of our SFU.
We also realized that use of an SFU often comes with a privacy cost, as there is now a centralized hub that could see and listen to all the media contents, even though its sole job is to forward media bytes between clients as a data plane.
We believe end-to-end encryption should be the industry standard for secure communication and that’s why today we’re excited to share that we’ve implemented and open sourced end-to-end encryption in Orange Meets. Our generic implementation is client-only, so it can be used with any WebRTC infrastructure. Finally, our new designated committer distributed algorithm is verified in a bounded model checker to verify this algorithm handles edge cases gracefully.
End-to-end encryption for video conferencing is different than for text messaging
End-to-end encryption describes a secure communication channel whereby only the intended participants can read, see, or listen to the contents of the conversation, not anybody else. WhatsApp and iMessage, for example, are end-to-end-encrypted, which means that the companies that operate those apps or any other infrastructure can’t see the contents of your messages.
Whereas encrypted group chats are usually long-lived, highly asynchronous, and low bandwidth sessions, video and audio calls are short-lived, highly synchronous, and require high bandwidth. This difference comes with plenty of interesting tradeoffs, which influenced the design of our system.
We had to consider how factors like the ephemeral nature of calls, compared to the persistent nature of group text messages, also influenced the way we designed E2EE for Orange Meets. In chat messages, users must be able to decrypt messages sent to them while they were offline (e.g. while taking a flight). This is not a problem for real-time communication.
The bandwidth limitations around audio/video communication and the use of an SFU prevented us from using some of the E2EE technologies already available for text messages. Apple’s iMessage, for example, encrypts a message N-1 times for an N-user group chat. We can’t encrypt the video for each recipient, as that could saturate the upload capacity of Internet connections as well as slow down the client. Media has to be encrypted once and decrypted by each client while preserving secrecy around only the current participants of the call.
Messaging Layer Security (MLS)
Around the same time we were working on Orange Meets, we saw a lot of excitement around new apps being built with Messaging Layer Security (MLS), an IETF-standardized protocol that describes how you can do a group key exchange in order to establish end-to-end-encryption for group communication.
Previously, the only way to achieve these properties was to essentially run your own fork of the Signal protocol, which itself is more of a living protocol than a solidified standard. Since MLS is standardized, we’ve now seen multiple high-quality implementations appear, and we’re able to use them to achieve Signal-level security with far less effort.
Implementing MLS here wasn’t easy: it required a moderate amount of client modification, and the development and verification of an encrypted room-joining protocol. Nonetheless, we’re excited to be pioneering a standards-based approach that any customer can run on our network, and to share more details about how our implementation works.
We did not have to make any changes to the SFU to get end-to-end encryption working. Cloudflare’s SFU doesn’t care about the contents of the data forwarded on our data plane and whether it’s encrypted or not.
Orange Meets: the basics
Orange Meets is a video calling application built on Cloudflare Workers that uses the Cloudflare Realtime SFU service as the data plane. The roles played by the three main entities in the application are as follows:
The user is a participant in the video call. They connect to the Orange Meets server and SFU, described below.
The Orange Meets Server is a simple service run on a Cloudflare Worker that runs the small-scale coordination logic of Orange Meets, which is concerned with which user is in which video call — called a room — and what the state of the room is. Whenever something in the room changes, like a participant joining or leaving, or someone muting themselves, the app server broadcasts the change to all room participants. You can use any backend server for this component, we just chose Cloudflare Workers for its convenience.
Cloudflare Realtime Selective Forwarding Unit (SFU) is a service that Cloudflare runs, which takes everyone’s audio and video and broadcasts it to everyone else. These connections are potentially lossy, using UDP for transmission. This is done because a dropped video frame from five seconds ago is not very important in the context of a video call, and so should not be re-sent, as it would be in a TCP connection.
The network topology of Orange Meets
Next, we have to define what we mean by end-to-end encryption in the context of video chat.
End-to-end encrypting Orange Meets
The most immediate way to end-to-end encrypt Orange Meets is to simply have the initial users agree on a symmetric encryption/decryption key at the beginning of a call, and just encrypt every video frame using that key. This is sufficient to hide calls from Cloudflare’s SFU. Some source-encrypted video conferencing implementations, such as Jitsi Meet, work this way.
The issue, however, is that kicking a malicious user from a call does not invalidate their key, since the keys are negotiated just once. A joining user learns the key that was used to encrypt video from before they joined. These failures are more formally referred to as failures of post-compromise security and perfect forward secrecy. When a protocol successfully implements these in a group setting, we call the protocol a continuous group key agreement protocol.
Fortunately for us, MLS is a continuous group key agreement protocol that works out of the box, and the nice folks at Phoenix R&D and Cryspen have a well-documented open-source Rust implementation of most of the MLS protocol.
All we needed to do was write an MLS client and compile it to WASM, so we could decrypt video streams in-browser. We’re using WASM since that’s one way of running Rust code in the browser. If you’re running a video conferencing application on a desktop or mobile native environment, there are other MLS implementations in your preferred programming language.
Our setup for encryption is as follows:
Make a web worker for encryption. We wrote a web worker in Rust that accepts a WebRTC video stream, broken into individual frames, and encrypts each frame. This code is quite simple, as it’s just an MLS encryption:
Postprocess outgoing audio/video. We take our normal stream and, using some newer features of the WebRTC API, add a transform step to it. This transform step simply sends the stream to the worker:
Once we do this for both audio and video streams, we’re done.
Handling different codec behaviors
The streams are now encrypted before sending and decrypted before rendering, but the browser doesn’t know this. To the browser, the stream is still an ordinary video or audio stream. This can cause errors to occur in the browser’s depacketizing logic, which expects to see certain bytes in certain places, depending on the codec. This results in some extremely cypherpunk artifacts every dozen seconds or so:
Fortunately, this exact issue was discovered by engineers at Discord, who handily documented it in their DAVE E2EE videocalling protocol. For the VP8 codec, which we use by default, the solution is simple: split off the first 1–10 bytes of each packet, and send them unencrypted:
fn split_vp8_header(frame: &[u8]) -> Option<(&[u8], &[u8])> {
// If this is a keyframe, keep 10 bytes unencrypted. Otherwise, 1 is enough
let is_keyframe = frame[0] >> 7 == 0;
let unencrypted_prefix_size = if is_keyframe { 10 } else { 1 };
frame.split_at_checked(unencrypted_prefix_size)
}
These bytes are not particularly important to encrypt, since they only contain versioning info, whether or not this frame is a keyframe, some constants, and the width and height of the video.
And that’s truly it for the stream encryption part! The only thing remaining is to figure out how we will let new users join a room.
“Join my Orange Meet”
Usually, the only way to join the call is to click a link. And since the protocol is encrypted, a joining user needs to have some cryptographic information in order to decrypt any messages. How do they receive this information, though? There are a few options.
DAVE does it by using an MLS feature called external proposals. In short, the Discord server registers itself as an external sender, i.e., a party that can send administrative messages to the group, but cannot receive any. When a user wants to join a room, they provide their own cryptographic material, called a key package, and the server constructs and sends an MLS External Add message to the group to let them know about the new user joining. Eventually, a group member will commit this External Add, sending the joiner a Welcome message containing all information necessary to send and receive video.
A user joining a group via MLS external proposals. Recall the Orange Meets app server functions as a broadcast channel for the whole group. We consider a group of 3 members. We write member #2 as the one committing to the proposal, but this can be done by any member. Member #2 also sends a Commit message to the other members, but we omit this for space.
This is a perfectly viable way to implement room joining, but implementing it would require us to extend the Orange Meets server logic to have some concept of MLS. Since part of our goal is to keep things as simple as possible, we would like to do all our cryptography client-side.
So instead we do what we call the designated committer algorithm. When a user joins a group, they send their cryptographic material to one group member, the designated committer, who then constructs and sends the Add message to the rest of the group. Similarly, when notified of a user’s exit, the designated committer constructs and sends a Remove message to the rest of the group. With this setup, the server’s job remains nothing more than broadcasting messages! It’s quite simple too—the full implementation of the designated committer state machine comes out to 300 lines of Rust, including the MLS boilerplate, and it’s about as efficient.
A user joining a group via the designated committer algorithm.
One cool property of the designated committer algorithm is that something like this isn’t possible in a text group chat setting, since any given user (in particular, the designated committer) may be offline for an arbitrary period of time. Our method works because it leverages the fact that video calls are an inherently synchronous medium.
Verifying the Designated Committer Algorithm with TLA+
The designated committer algorithm is a pretty neat simplification, but it comes with some non-trivial edge cases that we need to make sure we handle, such as:
How do we make sure there is only one designated committer at a time? The designated committer is the alive user with the smallest index in the MLS group state, which all users share.
What happens if the designated committer exits? Then the next user will take its place. Every user keeps track of pending Adds and Removes, so it can continue where the previous designated committer left off.
If a user has not caught up to all messages, could they think they’re the designated committer? No, they have to believe first that all prior eligible designated committers are disconnected.
To make extra sure that this algorithm was correct, we formally modeled it and put it through the TLA+ model checker. To our surprise, it caught some low-level bugs! In particular, it found that, if the designated committer dies while adding a user, the protocol does not recover. We fixed these by breaking up MLS operations and enforcing a strict ordering on messages locally (e.g., a Welcome is always sent before its corresponding Add).
You can find an explainer, lessons learned, and the full PlusCal program (a high-level language that compiles to TLA+) here. The caveat, as with any use of a bounded model checker, is that the checking is, well, bounded. We verified that no invalid protocol states are possible in a group of up to five users. We think this is good evidence that the protocol is correct for an arbitrary number of users. Because there are only two distinct roles in the protocol (designated committer and other group member), any weird behavior ought to be reproducible with two or three users, max.
Preventing Man-in-the-Middle attacks
One important concern to address in any end-to-end encryption setup is how to prevent the service provider from replacing users’ key packages with their own. If the Orange Meets app server did this, and colluded with a malicious SFU to decrypt and re-encrypt video frames on the fly, then the SFU could see all the video sent through the network, and nobody would know.
To resolve this, like DAVE, we include a safety number in the corner of the screen for all calls. This number uniquely represents the cryptographic state of the group. If you check out-of-band (e.g., in a Signal group chat) that everyone agrees on the safety number, then you can be sure nobody’s key material has been secretly replaced.
In fact, you could also read the safety number aloud in the video call itself, but doing this is not provably secure. Reading a safety number aloud is an in-band verification mechanism, i.e., one where a party authenticates a channel within that channel. If a malicious app server colluding with a malicious SFU were able to construct believable video and audio of the user reading the safety number aloud, it could bypass this safety mechanism. So if your threat model includes adversaries that are able to break into a Worker and Cloudflare’s SFU, and simultaneously generate real-time deep-fakes, you should use out-of-band verification 😄.
Future work
There are some areas we could improve on:
There is another attack vector for a malicious app server: it is possible to simply serve users malicious Javascript. This problem, more generally called the Javascript Cryptography Problem, affects any in-browser application where the client wants to hide data from the server. Fortunately, we are working on a standard to address this, called Web Application Manifest Consistency, Integrity, and Transparency. In short, like our Code Verify solution for WhatsApp, this would allow every website to commit to the Javascript it serves, and have a third party create an auditable log of the code. With transparency, malicious Javascript can still be distributed, but at least now there is a log that records the code.
We can make out-of-band authentication easier by placing trust in an identity provider. Using OpenPubkey, it would be possible for a user to get the identity provider to sign their cryptographic material, and then present that. Then all the users would check the signature before using the material. Transparency would also help here to ensure no signatures were made in secret.
Conclusion
We built end-to-end encryption into the Orange Meets video chat app without a lot of engineering time, and by modifying just the client code. To do so, we built a WASM (compiled from Rust) service worker that sets up an MLS group and does stream encryption and decryption, and designed a new joining protocol for groups, called the designated committer algorithm, and formally modeled it in TLA+. We made comments for all kinds of optimizations that are left to do, so please send us a PR if you’re so inclined!
As data and data-driven technologies become a bigger part of everyday life, it’s more important than ever to make sure that young people are given the chance to learn data science concepts and skills.
David WeintropRotem Israel-FishelsonPeter F Moon
In our April research seminar, David Weintrop, Rotem Israel-Fishelson, and Peter Moon from the University of Maryland introduced API Can Code, a data science curriculum designed with high school students for high school students. Their talk explored how their innovative work uses real-world data and students’ own experiences and interests to create meaningful, authentic learning experiences in data science.
Quick note for educators: Are you interested in joining our free, exploratory data science education workshop for teachers on 10 July 2025 in Cambridge, UK? Then find out the details here.
David started by explaining the motivation behind the API Can Code project. The team’s goal was not to turn students into future data scientists, but to offer students the data literacy they need to explore and critically engage with a data-driven world.
The work was also guided by a shared view among leading teachers’ organisations that data science should be taught across all subjects in the K–12 curriculum. It also draws on strong research showing that when educational experiences connect with students’ own lives and interests, it leads to deeper engagement and better learning outcomes.
Reviewing the landscape
To prepare for the design of the curriculum, David, Rotem, and Peter wanted to understand what data science education options already exist for K–12 students. Rotem described how they compared four major K–12 data science curricula and examined different aspects, such as the topics they covered and the datasets they used. Their findings showed that many datasets were quite small in size, and that the datasets used were not always about topics that students were interested in.
The team also looked at 30 data science tools used across different K–12 platforms and analysed what each could do. They found that tools varied in how effective they were and that many lacked accessibility features to support students with diverse learning needs.
This analysis helped to refine the team’s objective: to create a data science curriculum that students find interesting and that is informed by their values and voices.
Participatory design
To work towards this goal, the team used a methodology called participatory design. This is an approach that actively involves the end users — in this case, high school students — in the design process. During several in-person sessions with 28 students aged 15 to 18 years old, the researchers facilitated low-tech, hands-on activities exploring the students’ identities and interests and how they think about data.
One activity, Empathy Map, involved students working together to create a persona representing a student in their school. They were asked to describe the persona’s daily life, interests, and concerns about technology and data:
The students’ involvement in the design process gave the team a better understanding of young people’s views and interests, which helped create the design of the API Can Code curriculum.
API Can Code: three units, three key tools
Peter provided an overview of the API Can Code curriculum. It follows a three-unit flow covering different concepts and tools in each unit:
Unit 1 introduces students to different types of data and data science terminology. The unit explores the role of data in the students’ daily lives, how use and misuse of data can affect them, different ways of collecting and presenting data, and how to evaluate databases for aspects such as size, recency, and trustworthiness. It also introduces them to RapidAPI, a hub that connects to a wide range of APIs from different providers, allowing students to access real-world data such as Zillow housing prices or Spotify music data.
Unit 2 covers the computing skills used in data science, including the use of programming tools to run efficient data science techniques. Students learn to use EduBlocks, a block-based programming environment where students can draw in JSON files from RapidAPI datasets, and process and filter data without needing a lot of text-based programming skills. The students also compare this approach with manual data processing, which they discover is very slow.
Unit 3 focuses on data analysis, visualisation, and interpretation. Students use CODAP, a web-based interactive data science tool, to calculate summary statistics, create graphs, and perform analyses. CODAP is a user-friendly but powerful platform, making it perfect for students to analyse and visualise their data sets. Students also practise interpreting pre-made graphs and the graphs and statistics that they are creating.
Peter described an example activity carried out by the students, showing how these three units flow together and build both technical skills and an understanding of the real-world uses of data science. Students were tasked with analysing a dataset from Zillow, a property website, to explore the question “How much does a house in my neighbourhood cost?” The images below show the process the students followed, which uses the data science skills and tools from all three units of the curriculum.
Click on an image to enlarge it.
Interest-driven learning in action
A central tenet of API Can Code is that students should explore data that matters to them. A diverse range of student interests was identified during the design work, and the curriculum uses these areas of interest, such as music, movies, sports, and animals, throughout the lessons.
The curriculum also features an open-ended final project, where students can choose a research question that is important to them and their lives, and answer it using data science skills.
The team shared two examples of memorable final projects. In one, a student set out to answer the question “Is Jhené Aiko a star?” The student found a publicly available dataset through an API provided by Deezer, a music streaming platform. She wrote a program that retrieved data on the artist’s longevity and collaborations, analysed the data, and concluded that Aiko is indeed a star. What stood out about this project wasn’t just the fact that the student independently defined stardom and answered their research question using real data, but that this was a truly personal, interest-driven project. David noted that the researchers could never have come up with this activity, since they had never previously heard of Jhené Aiko!
Jhené Aiko, an R&B singer-songwriter (Photo by Charito Yap, licensed under CC BY-ND 2.0)
Another student’s project analysed data about housing in Washington DC to answer the question “Which ward in DC has the most affordable houses?” Rotem explained that this student was motivated by her family thinking about moving away from the city. She wanted to use her project to persuade her parents to stay by identifying the most affordable ward in DC that they could move to. She was excited by the outcome of her project, and she presented her findings to other students and her parents.
These projects underscore the power of personally important data science projects driven by students’ interests. When students care about the questions they are exploring, they’re more invested in the process and more likely to keep using the skills and concepts they learn.
Resources
API Can Code is available online and completely free to use. Teachers can access lesson plans, tutorial videos, assessment rubrics, and more from the curriculum’s website https://apicancode.umd.edu/. The site also provides resources to support students, including example programs and glossaries.
Join our next seminar
In our current seminar series, we’re exploring teaching about AI and data science. Join us at our next seminar on Tuesday, 17 June from 17:00 to 18:30 BST to hear Netta Iivari (University of Oulu) introduce transformative agency and its importance for children’s computing education in the age of AI.
To sign up and take part in our research seminars, click below:
Are you a teacher who is interested in data science education for key stage 5 (age 16 to 18)? Then we invite you to join our free, in-person workshop exploring the topic, taking place in Cambridge, UK on 10 July 2025.
You will be among the very first educators to see some of our first test activities for teacher training to build data science concepts, and your contributions will feed into our future work. Sign up by 20 June to take part.
Data science: What do we need to teach school-age learners?
Current artificial intelligence (AI) methods, especially machine learning (ML), rely heavily on data. While young people learn mathematics, and some statistics, at school, data science concepts are not commonly taught.
To complement our work on AI literacy, we have been investigating what data science teaching resources and education research are currently available.
Our goals for this work are:
To work out what data science concepts may need to be taught in schools, initially with a focus on key stage 5
To develop related teacher professional development and classroom resources
Join us to discuss data science education
If you are interested in data science education for young people, and maybe even have experience of teaching it to learners aged 16 to 18 in your school (in any subject, including computer science, social sciences, mathematics, statistics, and ethics), please join our free workshop on Thursday 10 July in our office in Cambridge. We are able to reimburse some travel expenses.
At the workshop:
We would love to hear about your experience of teaching any elements of data science
We will share some exploratory concept building activities with you and discuss them together
You’ll be the first group of working teachers we will share these activities with — your feedback will be invaluable, and you’ll have the chance to shape our work going forward.
You will then receive more information from us by 27 June. Spaces in the workshop are limited, so please do not book any travel until we confirm your space.
We’re looking forward to shaping the future of data science education with you.
Rapid7’s Q1 2025 incident response data highlights several key initial access vector (IAV) trends, shares salient examples of incidents investigated by the Rapid7 Incident Response (IR) team, and digs into threat data by industry as well as some of the more commonly seen pieces of malware appearing in incident logs.
Is having no MFA solution in place still one of the most appealing vulnerabilities for threat actors? Will you see the same assortment of malware regardless of whether you work in business services or media and communications? And how big a problem could one search engine query possibly be, anyway?
The answer to that last question is “very,” as it turns out. As for the rest…
Initial access vectors
Below, we highlight the key movers and shakers for IAVs across cases investigated by Rapid7’s IR team. While you’ll notice a fairly even split among several vectors such as exposed remote desktop protocol (RDP) services and SEO poisoning, one in particular is clearly the leader of the pack where compromising organizations is concerned: stolen credentials to valid/active accounts with no multi-factor authentication (MFA) enabled.
Valid account credentials — with no MFA in place to protect the organization should they be misused — are still far and away the biggest stumbling block for organizations investigated by the Rapid7 IR team, occurring in 56% of all incidents this first quarter.
Exposed RDP services accounted for 6% of incidents as the IAV, yet they were abused by attackers more generally in 44% of incidents. This tells us that third parties remain an important consideration in an organization’s security hygiene.
Valid accounts / no MFA: Top of the class
Rapid7 regularly bangs the drum for tighter controls where valid accounts and MFA are concerned. As per the key findings, 56% of all incidents in Q1 2025 involved valid accounts / no MFA as the initial access vector. In fact, there’s been very little change since Q3 2024, and as good as no difference between the last two quarters:
Vulnerability exploitation: Cracks in the armor
Rapid7’s IR services team observed several vulnerabilities used, or likely to have been used, as an IAV in Q1 2025. CVE-2024-55591 for example, the IAV for an incident in manufacturing, is a websocket-based race condition authentication bypass affecting Fortinet’s FortiOS and FortiProxy flagship appliances. Successful exploitation results in the ability to execute arbitrary CLI console commands as the super_admin user. The CVE-2024-55591 advisory was published at the beginning of 2025, and it saw widespread exploitation in the wild.
One investigation revealed attackers using the above flaw to exploit vulnerable firewall devices and create local and administrator accounts with legitimate-looking names (e.g., references to “Admin”, “I.T.”, “Support”). This allowed access to firewall dashboards, which may have contained useful information about the devices’ users, configurations, and network traffic. Policies were created which allowed for leveraging of remote VPN services, and the almost month-long dwell time observed in similar incidents may suggest initial access broker (IAB) activity, or a possible intended progression to data exfiltration and ransomware.
Exposed RMM tooling: A path to ransomware
As noted above, 6% of IAV incidents were a result of exposed remote monitoring and management (RMM) tooling. RMMs, used to remotely manage and access devices, are often used to gain initial access, or form part of the attack chain leading to ransomware.
One investigation revealed a version of SimpleHelp vulnerable to several critical privilege escalation and remote code execution vulnerabilities, which included CVE-2024-57726, CVE-2024-57727, and CVE-2024-57728.
These CVEs target the SimpleHelp remote access solution. Exploiting CVE-2024-57727 permits an unauthenticated attacker to leak SimpleHelp “technician” password hashes. If one is cracked, the attacker can log-in as a remote-access technician. Lastly, the attacker can exploit CVE-2024-57726 and CVE-2024-57728 to elevate to SimpleHelp administrator and trigger remote code execution, respectively. CVE-2024-57727 was added to CISA KEV in February 2025.
The vulnerable RMM solution was used to gain initial access and threat actors used PowerShell to create Windows Defender exclusions, with the ultimate goal of deploying INC Ransomware on target systems.
SEO poisoning: When a quick search leads to disaster
SEO poisoning, once the scourge of search engines everywhere, may not be high on your list of priorities. However, it still has the potential to wreak havoc on a network. Here, the issue isn’t so much rogue entries in regular search results, but instead the paid sponsored ads directly above typical searches. Note how many sponsored results sit above the genuine site related to this incident:
Multiple sponsored searches above the official (and desired) search result
This investigation revealed a tale of two search results, where one led to a genuine download of a tool designed to monitor virtual environments, and the other led to malware. When faced with both options, a split-second decision went with the latter and what followed was an escalating series of intrusion, data exfiltration and—eventually—ransomware.
An imitation website offering malware disguised as genuine software
On the same day of initial compromise, the attacker moved laterally using compromised credentials via RDP, installing several RMM tools such as AnyDesk and SplashTop. It is likely that the threat actor searched for insecurely stored password files and targeted password managers. They also attempted to modify and/or disable various security tools in order to evade detection, and create a local account to enable persistence and avoid domain-wide password resets.
An unauthorized version of WinSCP was used to exfiltrate a few hundred GB of sensitive company data from several systems, and with this mission accomplished only a few tasks remained. The first: attempting to inhibit system recovery by tampering with the Volume Shadow Copy Service (VSS), clearing event logs, deleting files, and also attempting to target primary backups for data destruction. The second: deployment of Qilin ransomware and a blackmail note instructing the victim to communicate via a TOR link lest the data be published to their leak site.
Qilin ranked 7 in our top ransomware groups of Q1 2025 for leak post frequency, racking up 111 posts from January through March. Known for double-extortion attacks across healthcare, manufacturing, and financial sectors, Qilin (who, despite their name, are known not to be Chinese speakers, but rather Russian-speaking) has also recently been seen deployed by North Korean threat actors Moonstone Sleet.
Attacker behavior observations
Bunnies everywhere: Tracking a top malware threat
BunnyLoader, the Malware as a Service (MaaS) loader possessing a wealth of capabilities including clipboard and credential theft, keylogging, and the ability to deploy additional malware, is one of the most prolific presences Rapid7 has seen this first quarter of 2025. In many cases, it’s also daisy-chained to many of the other payloads and tactics which make repeated appearances.
To really drive this message home: BunnyLoader is the most observed payload across almost every industry we focused on. Whether we’re talking manufacturing, healthcare, business services or finance, it’s typically well ahead of the rest of the pack. Here are our findings across the 5 most targeted industries of Q1:
BunnyLoader is in pole position not only for the 5 industries shown above, but across 12 of 13 industries overall, with 40% of all incidents observed involving this oft-updated malware.
Just over half of that 40% total involved a fake CAPTCHA (commonly used for the purpose of victims executing malicious code), with malicious / compromised sites appearing in a quarter of BunnyLoader cases. Rogue documents, which may be booby-trapped with malware or pave the way for potential phishing attacks, bring up the rear at just 9% of all BunnyLoader appearances recorded. First offered for sale in 2023 for a lifetime-use cost of $250, its continued development and large range of features make it an attractive proposition for rogues operating on a budget.
Targeted organizations: The manufacturing magnet
Manufacturing organizations were targeted in more than 24% of incidents the Rapid7 IR team observed, by far the most targeted industry in Q1 based on both Rapid7’s ransomware analytics and IR team observations. The chart below compares Rapid7’s industry-wide data (comprising a wide range of payloads and tactics) with ransomware leak post specific data. In both cases, manufacturing is a fair way ahead of other industries; this reflects its status as one of the most popular targets for ransomware groups over the last couple of years.
The manufacturing industry is an attack vector for nation states because it is an important component of global trade. It is also an area that has many legacy and older, operational technologies (OT). Combine unpatched legacy systems with complicated supply chains, and you have a risk that nation state actors will find an attractive target. This is especially the case when considering that many manufacturing organizations have critical contracts with governments, and attacks can cause severe disruption if they’re not speedily resolved.
Conclusion
Q1 2025 resembles a refinement of successful tactics, as opposed to brand new innovations brought to the table. Our Q1 ransomware analytics showed threat actors making streamlined tweaks to a well-oiled machine, and we find many of the same “evolution, not revolution” patterns occurring here.
This progression is particularly applicable in the case of initial access via valid accounts with no MFA protection. We expect to see no drop in popularity while businesses continue to leave easy inroads open and available to skilled (and unskilled) attackers.
In addition, the risk of severe compromise stemming from seemingly harmless online searches underscores the necessity for organizations to reexamine basic security best practices, alongside deploying robust detection and response capabilities. Businesses addressing these key areas for concern will be better equipped to defend against what should not be an inevitable slide into data exfiltration and malware deployment.
In the course of a penetration testing engagement, Rapid7 discovered three vulnerabilities in MICI Network Co., Ltd’s NetFax server versions < 3.0.1.0. These issues allowed for an authenticated attack chain resulting in Remote Code Execution (RCE) against the device as the root user. While authentication is necessary for exploitation, default credentials for the application are automatically configured to be provided in cleartext through responses sent to the client, allowing for automated exploitation against vulnerable hosts.
Rapid7 enlisted the help of TWCERT to contact the vendor as an intermediary. On Friday, May 2, 2025, Rapid7 received a notification from TWCERT stating the following: “…they (MICI) have responded that they will not address the vulnerability in this product.”
The first vulnerability, a default credential disclosure, started with HTTP GET requests made during initial access to the server which displayed the default System Administrator credentials in cleartext. The display of these credentials appeared to be present due to implemented functionality for support of the ‘OneIn’ client.
Using the credentials, Rapid7 conducted a review of system configuration settings. A lack of sufficient sanitization was found within multiple parameters in regard to the ‘`’ character. This lack of sanitization could be used to store a system command such as ‘whoami’ within the configuration file.
Rapid7 discovered a function that conducted various system tests to confirm valid configuration such as ‘ping’ commands. This function ingested the data from the stored configuration which led to confirmed Remote Code Execution. By using the ‘mkfifo’ and ‘nc’ binaries present within the system, a reverse shell was obtained as the root user.
In addition, within the system it was noted that while the SMTP password displayed within the user interface had been properly redacted, the request which provided the system configuration contained the password in cleartext.
Product Description
MICI’s Network Fax (NetFax) server is a product suite to facilitate receipt of fax messages to user mailboxes through email traffic. The vendor, MICI, operates from Taiwan. During analysis of internet connected devices, Rapid7 noted 34 systems exposed to the internet. Rapid7 notes that the number of devices on internal networks would likely be much higher.
During review, Rapid7 noted systems running on the same ‘wfaxd’ server architecture used in the application with the name ‘CoFax Server’. A majority of those systems were found to be present within Iran. These devices did not necessarily appear to possess the same vulnerabilities from a passive review.
CWE-201: Insertion of Sensitive Information Into Sent Data
Upon accessing the web application on port 80 and intermittently afterwards, a GET request is made to ‘/client.php’ which disclosed default administrative user credentials to clients by providing information contained within an automatically configured setup file:
Remediation:Do not expose user credentials to the client, instead process any occurrences of configuration calls server-side. Present only the necessary information to the client such as the application name and version. Require users to reset the default administrator password upon initial access.
CVE-2025-48046 – Disclosure of Stored Passwords – Moderate (5.3)
Using the credentials, the application was reviewed for security. During this process, the SMTP password configured within the application was found to be properly redacted:
The configuration file, accessed through a GET request to ‘/config.php’ however, provided the cleartext password to the user:
Remediation: Do not expose user credentials to the client. Redact sensitive information before displaying it to the client.
CWE-78: Improper Neutralization of Special Elements used in an OS Command (‘OS Command Injection’)
A server test function which executed commands such as ‘ping’ was located at the /test.php endpoint. This function appeared to ingest data sent to the configuration file such as ‘ETHNAMESERVER’:
The configuration file was changed to include various commands such as a reverse shell using the ‘nc’ binary and ‘whoami’:
The system test was then run, confirming the ‘`’ characters had not been sanitized. This led to remote code execution via command injection. A reverse shell was also obtained through these methods after the existence of the ‘mkfifo’ and ‘nc’ binaries were confirmed to be present on the machine:
Remediation: Properly sanitize all input before use in system commands. While many characters were properly redacted, the ‘`’ character was not. Do server-side validation of configuration settings to confirm all parameters contain expected content before accepting the changes. Fields containing IP addresses should be processed to ensure they contain only valid IP addresses.
A working Metasploit module for this attack path for both a fully unauthenticated Remote Code Execution exploit against servers using default credentials and an authenticated RCE exploitation has been created and will be released in upcoming updates. This attack can be performed by any malicious actor with network access to the device.
Impact
The vulnerabilities have a range of impacts depending on configuration. Disclosure of default credentials by the application poses a risk to system administrators who do not properly change administrative passwords during setup. Rapid7 determined the application did not appear to either enforce or request a changing of default credentials upon initial login.
Failure to obscure passwords to connect to external services could result in compromise of network service accounts and potential impacts to further resources in the environment.
The command injection vulnerabilities result in administrative access to the underlying system, impacting the confidentiality, availability, and integrity of the server and application both.
Vendor Statement
After multiple attempts to contact the vendor without response, Rapid7 elicited the assistance of TWCERT to facilitate communications with the vendor. After multiple correspondences, the vendor indicated the following, as per TWCERT:
“…they (MICI) have responded that they will not address the vulnerability in this product. They advised users not to expose the product to external networks. They stated that they will no longer respond to inquiries regarding this product.”
Remediation
Vendor has indicated that the vulnerabilities will not be patched and advised users that servers should not be exposed to the internet. However, as the vulnerabilities could also be exploited from an internal network perspective and result in administrative access to the underlying server, Rapid7 additionally recommends only exposing the server to strictly necessary internal networks after reviewing the risk of the device’s presence to the environment. Rapid7 recommends changing default device credentials and reviewing risks related to account credentials provided to the system for service integration purposes.
Rapid7 Customers
InsightVM and Nexpose customers should be able to assess their exposure to CVE-2025-48045, CVE-2025-48046 and CVE-2025-48047 with unauthenticated checks available in the May 28, 2025 content release.
Disclosure Timeline
Jan, 2025: Issue discovered by Anna Quinn
Thursday, Jan 30, 2025: Initial disclosure to vendor via contact form
Tuesday, Feb 25, 2025: Additional outreach to vendor via contact form
Tuesday, March 18, 2025: Rapid7 contacts TWCERT to determine proper channels for vendor engagement
Thursday, March 20, 2025: TWCERT puts Rapid7 in touch with vendor
Monday, March 24, 2025: Rapid7 follows up with vendor
Wednesday, March 26, 2025: Rapid7 follows up with vendor
Monday, March 31, 2025: Rapid7 requests additional assistance from TWCERT.
Tuesday, April 1, 2025: TWCERT requests further information
Wednesday, April 2, 2025: TWCERT confirmed receipt of vulnerability disclosure information by vendor and indicated vendor contact would occur after internal review.
Tuesday, April 8, 2025: Rapid7 follows up with vendor and TWCERT, requests an update by April 15, 2025.
Tuesday, April 22, 2025: Rapid7 requests an update
Friday, April 25, 2025: TWCERT relayed message from vendor requesting testing be done on newer versions of application. Rapid7 requests additional version(s) of the affected product from vendor.
Tuesday, April 29, 2025: TWCERT provides a version of NetFax Client for testing, however the vulnerabilities exist in NetFax Server, and as such the client could not be used for validation purposes. Rapid7 informs TWCERT, requests server application versions from vendor.
Friday, May 2, 2025: TWCERT provides a message from vendor indicating the vendor will not address vulnerabilities. Vendor indicates customers should ensure devices are not exposed externally. Vendor states they will not respond to further inquiries on the matter.
Rapid7 has been tracking a malware campaign that uses fake software installers disguised as popular apps like VPN and QQBrowser—to deliver Winos v4.0, a hard-to-detect malware that runs entirely in memory and gives attackers remote access.
The campaign was first spotted during a February 2025 MDR investigation. Since then, we’ve seen more samples using the same infection method—a multi-layered setup we call the Catena loader. Catena uses embedded shellcode and configuration switching logic to stage payloads like Winos v4.0 entirely in memory, evading traditional antivirus tools.
Once installed, it quietly connects to attacker-controlled servers—mostly hosted in Hong Kong—to receive follow-up instructions or additional malware. While we’ve seen no signs of widespread targeting, the operation appears focused on Chinese-speaking environments and shows signs of careful, long-term planning by a capable threat group.
Rapid7 has deployed detections for this activity and continues to monitor for new variants. Indicators and analysis related to this campaign are available in Rapid7 Intelligence Hub.
Introduction
This blog covers a malware campaign tracked by Rapid7 that uses trojanized NSIS installers to deploy Winos v4.0, a stealthy, memory-resident stager. The first sample was flagged during a February 2025 MDR investigation. Following that case, we identified additional related samples through threat hunting and malware analysis.
All observed samples relied on NSIS installers bundled with signed decoy apps, shellcode embedded in `.ini` files, and reflective DLL injection to quietly maintain persistence and avoid detection. We refer to this full infection chain as Catena, due to its modular, chain-like structure.
The campaign has so far been active throughout 2025, showing a consistent infection chain with some tactical adjustments—pointing to a capable and adaptive threat actor.
In this report, we start with a brief recap of the February 2025 MDR incident, which was also covered by other researchers. We then focus on newer samples found later in 2025 that follow the same core infection chain but introduce changes in delivery, tooling, and evasion—highlighting how the campaign continues to evolve.
How it started: QQBrowser Installer in MDR Case
In February 2025, Rapid7’s MDR team detected suspicious activity on a customer asset involving a trojanized NSIS installer masquerading as QQBrowser installer `QQBrowser_Setup_x64.exe`. While the file initially appeared legitimate, further analysis revealed it delivered malware via a multi-stage, memory-resident loader chain. Upon execution, the installer created an Axialis directory under %APPDATA% and dropped several files:
`Axialis.vbs` – a VBScript launcher
`Axialis.ps1` – a PowerShell-based loader `Axialis.dll` – a malicious DLL
`Config.ini` and `Config2.ini` – binary configuration files containing shellcode and embedded payloads
A desktop shortcut and the original QQBrowser setup binary used for deception
Upon execution, the malware follows this chain shown below.
Figure 1: QQBrowser-Based Infection Flow Observed in MDR Case
During runtime analysis, the `Axialis.dll` loader creates the mutex `VJANCAVESU` via the `CreateMutexA` API. If the mutex exists, it loads `Config2.ini`; if not, it loads `Config.ini`.
This behavior has been described by other researchers, who observed similar configuration switching logic in the DeepSeek campaigns — where the selected payload depended on the infection state. Both `.ini` files contain shellcode and embedded payload DLLs, all loaded and executed reflectively in memory.
Rapid7 analysis confirmed that the shellcode in `Config.ini` was built using the open-source sRDI loader.
Figure 2: Side-by-side comparison of shellcode from GitHub (left) and shellcode found in Config.ini (right)
The malware communicates with hardcoded command-and-control (C2) infrastructure over TCP port 18856 and HTTPS port 443.
Persistence is achieved through a combination of process monitoring and scheduled task registration. The embedded DLL in `Config.ini` created and executed `Monitor.bat`, which continuously checked for malware processes and relaunched them if terminated. To ensure persistence, the malware dropped `updated.ps1` and `PolicyManagement.xml`, which are used to register a scheduled task that re-executes the VBS loader `Decision.vbs` via `wscript.exe`.
The scheduled task executed weeks after initial compromise, suggesting long-term persistence. Interestingly, the malware includes a language check that looks for Chinese language settings on the host system. But even if the system isn’t using Chinese, the malware still executes. This suggests the check isn’t actually enforced—it could be a placeholder, an unfinished feature, or something the attackers plan to use in future versions. Either way, its presence hints at an intent to focus on Chinese-language environments, even if that logic isn’t fully implemented yet.
While infrastructure details (e.g., C2 IPs) varied, for example in our case involving 156.251.17.243[:]18852 and the reference blog citing 27.124.40.155[:]18852 — both campaigns used similar communication ports (18852 and 443), suggesting that the activity belongs to the same threat actor.
Campaign evolution
Following the initial discovery, Rapid7 continued tracking the campaign throughout early 2025. During this period, multiple incidents were observed reusing the same infection chain—abusing trojanized NSIS installers, reflective DLL loading, shellcode-embedded INI files, and staged persistence mechanisms. These variants were often disguised as legitimate software such as LetsVPN, Telegram, or Chrome installers.
However, in April 2025, we observed a tactical shift. Threat actors began modifying their approach: for instance, staging scripts like `Axialis.ps1` were dropped entirely, DLLs were invoked directly using `regsvr32.exe`, and new samples showed more efforts to evade antivirus detection. These changes suggest an evolving playbook—one that retains core infrastructure and execution logic but adapts to detection pressure and operational constraints.
Evolving tactics: LetsVPN Installer leading to Winos v4.0
The diagram below illustrates the Catena execution chain as observed in the LetsVPN variant.
Figure 4 Catena Loader: From LetsVPN Installer to Winos v4.0
The following sections break down this chain, stage by stage—from the initial installer and script logic to in-memory payload delivery and infrastructure interaction.
Our analysis started with `Lets.15.0.exe` SHA-256: 1E57AC6AD9A20CFAB1FE8EDD03107E7B63AB45CA555BA6CE68F143568884B003, a trojanized NSIS installer masquerading as a VPN setup. The installer included a decoy executable `Iatsvpn–Latest.exe` and a license file to appear legitimate. However, its true purpose was to deploy multi-stage, memory-resident malware across several directories.
Upon execution, the installer stages components in:
%LOCALAPPDATA%: first-stage loader `insttect.exe` and shellcode blob `Single.ini`
%APPDATA%\TrustAsia: second-stage payloads `Config.ini`, `Config2.ini` and loader DLL `intel.dll`
Figure 5: The extracted file structure by Lets.15.0.exe
The following sections walk through each step of this chain, starting with the NSIS installer and leading to in-memory payload execution.
Installer setup: NSIS script behavior
The `NSIS.nsi` script embedded in `Lets.15.0.exe` sets up both the fake VPN installation and the deployment of malware. It acts as the first step in the execution chain. The script starts by running a PowerShell command that adds Defender exclusions for all drives (C:\ to Z:), reducing system defenses.
First-stage payloads
The NSIS script begins by dropping initial payloads to %LOCALAPPDATA%:
`Single.ini`: a binary blob combining sRDI shellcode and an embedded DLL
`insttect.exe`: loader that reads and executes `Single.ini` in memory
Second-stage payloads
Next, the script drops second-stage files to %APPDATA%\TrustAsia:
`Config.ini`, `Config2.ini`: alternate sRDI payloads loaded later based on mutex logic
`intel.dll`: a secondary loader invoked via regsvr32.exe
To trigger this second stage, the NSIS script executes:
As seen in the February 2025 MDR incident, the NSIS script completes the decoy setup by dropping `IatsvpnLatest.exe`ba0fd15483437a036e7f9dc91a65caa6e9b9494ed3793710257c450a30b88b8a and creating a desktop shortcut pointing to it. Despite the filename containing a typo, the binary is a legitimate LetsVPN executable, signed with a valid digital certificate.
Figure 6: Malicious NSIS script
The following sections outline the role of each dropped binary in the execution chain.
Stage 1: Execution of insttect.exe and Single.ini file
We analyzed `insttect.exe`, a trojanized loader masquerading as a legitimate Tencent PC Manager installer. The binary, titled 腾讯电脑管家在线安装程序 (machine translation: “Tencent PC Manager Online Installation Program” (in both metadata and resource strings).
The binary is signed with an expired certificate issued by VeriSign Class 3 Code Signing CA (2010) and allegedly belongs to Tencent Technology (Shenzhen), valid from 2018-10-11 to 2020-02-02.
The binary includes deceptive artifacts such as localized UI strings in Chinese, internal references to Tencent development paths, and hardcoded XML updater config pointing to `QQPCDownload.dll`
Figure 7: Hardcoded PDB path from `insttect.exe`
These elements reinforce the loader’s appearance as legitimate software.
Upon execution, `insttect.exe` locates `%LOCALAPPDATA%\Single.ini`, allocates memory with PAGE_EXECUTE_READWRITE permissions, copies the file into that region, and transfers control to its start. As previously described, the payload uses the sRDI format—enabling the embedded shellcode to self-parse and reflectively load the DLL without separate extraction.
Windows API calls related to shellcode loading are resolved dynamically via hashed function names.
Figure 8: Hashed API Resolution Routine
The DLL embedded within `Single.ini` takes a snapshot of running processes and continuously checks for `360tray.exe` and `360safe.exe`. These are components of 360 Total Security, a popular antivirus product developed by Chinese vendor Qihoo 360.
However, when tested with a dummy `360tray.exe`, the malware showed no response—neither terminating the process nor altering its own behavior.
Stage 2: Execution of intel.dll and Config.ini files
The `.nsi script` drops `intel.dll`, `Config.ini`, and `Config2.ini` into %APPDATA%\TrustAsia, and uses nsExec::Exec to invoke intel.dll via a regsvr32 call.
Both `Config.ini` and `Config2.ini` initially appeared benign due to their generic names. However, as with earlier payloads, both `.ini` are binary blobs containing shellcode formatted using the Shellcode Reflective DLL Injection (sRDI) technique described earlier.
As noted in the QQBrowser case, earlier variants loaded the shellcode from disk using PowerShell scripts. In this version, execution is handled entirely in memory via `regsvr32.exe`, which invokes `intel.dll`. As is typical for DLLs executed this way, `intel.dll` exports the `DllRegisterServer` function, which is automatically called.
While this shift avoids PowerShell, it’s not necessarily more evasive, since `regsvr32.exe` is a well-known LOLBin and is commonly monitored by modern EDR solutions. Upon execution, `intel.dll` loader creates a hardcoded mutex `99907F23-25AB-22C5-057C-5C1D92466C65` using the `CreateMutexA` API, and checks for the presence of two indicators: the mutex itself, and a file named `Temp.aps` in %APPDATA%\TrustAsia. If both are found, `Config2.ini` is loaded; otherwise, the default `Config.ini` is used.
Figure 9: Handle to Config.ini being returned
Once the appropriate `.ini` file is chosen, the loader opens it using `CreateFileW` and loads its contents into memory. As seen in earlier stages, the `.ini` file contains a shellcode blob using the sRDI format, which self-parses and reflectively loads an embedded DLL.
The in-memory DLL, extracted and executed entirely from within the shellcode blob, exports a single function named `VFPower`, a naming convention consistent across all observed samples. Debug symbols embedded in the DLL reference a Chinese development path E:\冲锋\进行中\Code_Shellcode – 裸体上线用作注入\Release\Code_Shellcode.pdb (machine translation: E:\Charge\In Progress\Code_Shellcode – Naked online for injection \ Release \ Code _ Shellcode.pdb).
During runtime, this in-memory DLL creates a hardcoded mutex `zhuxianlu` (machine translation: main line) and verifies if it was launched from `UserAccountBroker.exe`. If true, it immediately initiates C2 communication, likely assuming it was started with elevated privileges. Otherwise, the malware continues execution by spawning five threads, each responsible for a specific task before ultimately reaching the same C2 routine.
Figure 10: Mutex Check and C2 Trigger Logic
The five threads carry out the following actions:
Thread 1 launches PowerShell via `ShellExecuteExA` to add a Microsoft Defender exclusion for the C:\ drive.
Thread 2 attempts to establish persistence via scheduled task registration as seen in the earlier QQBrowser incident described in the introduction. It generates two files:
`PolicyManagement.xml` — an XML file defining a scheduled task
`updated.ps1` — a PowerShell script that imports and registers the task
To ensure the script runs without restriction the malware first sets PowerShell policies to `Unrestricted` (for the current user) and `Bypass` (for the specific script). The scheduled task is configured to invoke `regsvr32.exe` at logon, which in turn re-executes either `intel.dll` or `insttect.exe` loader.
Although this operation failed during our analysis even with the Chinese language pack installed, it was attempted twice—we believe to ensure redundancy or persistence across both loaders. Both files `PolicyManagement.xml` and `updated.ps1` are deleted immediately after execution.
Thread 3 takes a snapshot of all running processes and scans for any instance of `Telegram.exe`, `telegram.exe`, or `WhatsApp.exe`. If any of these are detected, it creates an empty marker file named `Temp.aps` in %APPDATA%\TrustAsia, and then executes:
This triggers the second-stage loader. The presence of the `Temp.aps`alters the loader’s behavior, causing it to run `Config2.ini` instead of `Config.ini`.
Thread 4 checks for the existence of the file `TrustAsia\Exit.aps`. If found, the file is deleted and the malware terminates.
Thread 5 acts as a persistence watchdog for the second-stage loader. It creates two files: `target.pid`, which stores the process ID of the running regsvr32.exe instance executing `intel.dll` loader, and `monitor.bat`, a batch script that checks whether this process is still running. If not, the script attempts to relaunch it. This check runs every 15 seconds to ensure `intel.dll` remains continuously active.
Figure 11: Content of monitor.bat watchdog
Following thread execution, the final function is responsible for C2 communication. Since the earliest observed sample from February 2024, the malware has used Windows sockets and the `getaddrinfo` API to resolve a hardcoded IP and port 18852 which also seems to be consistent across all analyzed samples of `Config.ini`.
Once the connection is established, malware retrieves the next-stage payload from the C2 server, allocates a new memory region with PAGE_EXECUTE_READWRITE permissions, copies the downloaded content into memory, and transfers execution to it. This is the delivery of the final stage, observed as Winos v4.0 in recent samples.
Figure 12: Jump to final payload
Final payload Winos4.0
The `intel.dll` loader selects either `Config.ini` or `Config2.ini` based on runtime conditions, such as the presence of a mutex `VJANCAVESU` and a `Temp.aps`marker file. Each of these `.ini` files contains sRDI shellcode that connects to a different C2 server to download the next-stage payload which was Winos4.0 in our case.
In recent samples, the payloads were downloaded from:
`Config.ini` → 134.122.204[.]11:18852
`Config2.ini` → 103.46.185[.]44:443
Although being retrieved from different C2 servers, both payloads were nearly identical: 112 KB in size and structured as sRDI shellcode containing an embedded DLL. This DLL uses the same reflective loading technique seen in previous stages, exports a single-function `VFPower` and and includes debug metadata referencing a Chinese development path:
Based on available evidence supported by debug info, we can say this is Winos4.0 stager `上线模块.dll`( machine translation: `Online Module.dll`.)
Extracted configuration
The Winos v4.0 stager downloaded from 134.122.204[.]11:18852 contains an embedded configuration block. The data appears to control runtime behavior, C2 communication, and implant settings. A decoded sample is shown below:
Extracted Configuration from Payload (134.122.204[.]11:18852)
Configuration
Data
Description
p1
134.122.204[.]11
First CC IP address
o1
6074
First port
t1
1
Protocol (TCP)
p2
134.122.204[.]11
Second CC IP address
o2
6075
Second option port
t2
1
Protocol (TCP)
p3
134.122.204[.]11
Third CC IP address
o3
6076
Third option port
t3
1
Protocol (TCP)
dd
1
Implant execution delay in seconds
cl
1
Beaconing interval in seconds
fz
认默 (default)
Grouping
bb
1.0
Version
bz
2025.4.24
Generation date
jp
0
Keylogger
bh
0
End bluescreen
ll
0
Antitraffic monitoring
dl
0
Entry point
sh
0
Process daemon
kl
0
Process hollowing
bd
0
N/A
In previous incidents, Winos 4.0 has been linked to the Silver Fox APT group operation known for distributing malware like ValleyRAT via trojanized utilities and vulnerability exploitation. Notably, similar TTPs were observed in the CleverSoar campaign described by Rapid7 in November 2024 which also delivered Winos4.0 and checked system locale settings for Chinese or Vietnamese—suggesting targeting based on regional language.
Infrastructure
During our investigation, the hardcoded IP address 103.46.185[.]44 found in `Config.ini` was confirmed to host the final Winos 4.0 payload. Shodan scans showed it serving a binary blob that begins with recognizable sRDI shellcode and contains an embedded DLL identical to the Winos 4.0 stager (“Online Module”) analyzed in this report.
Pivoting on this sample using Shodan hash -646083836, we identified eight additional IPs distributing the exact same payload: 112.213.101[.]161, 112.213.101[.]139, 103.46.185[.]73, 47.83.184[.]193, 202.79.173[.]50, 202.79.173[.]54, 202.79.173[.]98, and 103.46.185[.]44.
Each host returned identical byte sequences, indicating a shared and coordinated infrastructure distributing the same stage-one loader across multiple nodes, mostly hosted in Hong Kong.
Figure 13: Shared Hosting of Identical Winos v4.0 Payloads
To expand this infrastructure mapping, we extracted additional C2 addresses from historic MDR case data and active threat hunting leads. These included:
Pivoting on these nodes using Shodan hash correlations revealed additional infrastructure often resolving to the same ASNs or hosting providers, such as
CTG Server Ltd. / MEGA-II IDC (AS152194) OK COMMUNICATION / LANDUPS LIMITED (AS150452) Alibaba Cloud (AS45102) Tcloudnet, Inc. (AS399077)
Conclusion
This campaign shows a well-organized, regionally focused malware operation using trojanized NSIS installers to quietly drop the Winos v4.0 stager. It leans heavily on memory-resident payloads, reflective DLL loading, and decoy software signed with legit certificates to avoid raising alarms.
The malware’s logic—using mutexes to choose payloads, hiding shellcode in INI files, and layering persistence tricks like scheduled tasks and watchdog scripts—points to an actor that’s refining, not reinventing, their playbook. Infrastructure overlaps and language-based targeting hint at ties to Silver Fox APT, with activity likely aimed at Chinese-speaking environments. Rapid7 continues to track this threat and has detections in place to help protect customers.
InsightIDR and Managed Detection and Response customers have existing detection coverage through Rapid7’s expansive library of detection rules. Below is a non-exhaustive list of detections that are deployed and will alert on behavior related to Catena. We will also continue to iterate detections as new variants emerge, giving customers continuous protection without manual tuning:
With the rise of traffic from AI agents, what’s considered a bot is no longer clear-cut. There are some clearly malicious bots, like ones that DoS your site or do credential stuffing, and ones that most site owners do want to interact with their site, like the bot that indexes your site for a search engine, or ones that fetch RSS feeds.
Historically, Cloudflare has relied on two main signals to verify legitimate web crawlers from other types of automated traffic: user agent headers and IP addresses. The User-Agent header allows bot developers to identify themselves, i.e. MyBotCrawler/1.1. However, user agent headers alone are easily spoofed and are therefore insufficient for reliable identification. To address this, user agent checks are often supplemented with IP address validation, the inspection of published IP address ranges to confirm a crawler’s authenticity. However, the logic around IP address ranges representing a product or group of users is brittle – connections from the crawling service might be shared by multiple users, such as in the case of privacy proxies and VPNs, and these ranges, often maintained by cloud providers, change over time.
Cloudflare will always try to block malicious bots, but we think our role here is to also provide an affirmative mechanism to authenticate desirable bot traffic. By using well-established cryptography techniques, we’re proposing a better mechanism for legitimate agents and bots to declare who they are, and provide a clearer signal for site owners to decide what traffic to permit.
Today, we’re introducing two proposals – HTTP message signatures and request mTLS – for friendly bots to authenticate themselves, and for customer origins to identify them. In this blog post, we’ll share how these authentication mechanisms work, how we implemented them, and how you can participate in our closed beta.
Existing bot verification mechanisms are broken
Historically, if you’ve worked on ChatGPT, Claude, Gemini, or any other agent, you’ve had several options to identify your HTTP traffic to other services:
You define a user agent, an HTTP header described in RFC 9110. The problem here is that this header is easily spoofable and there’s not a clear way for agents to identify themselves as semi-automated browsers — agents often use the Chrome user agent for this very reason, which is discouraged. The RFC states: “If a user agent masquerades as a different user agent, recipients can assume that the user intentionally desires to see responses tailored for that identified user agent, even if they might not work as well for the actual user agent being used.”
You publish your IP address range(s). This has limitations because the same IP address might be shared by multiple users or multiple services within the same company, or even by multiple companies when hosting infrastructure is shared (like Cloudflare Workers, for example). In addition, IP addresses are prone to change as underlying infrastructure changes, leading services to use ad-hoc sharing mechanisms like CIDR lists.
You go to every website and share a secret, like a Bearer token. This is impractical at scale because it requires developers to maintain separate tokens for each website their bot will visit.
We can do better! Instead of these arduous methods, we’re proposing that developers of bots and agents cryptographically sign requests originating from their service. When protecting origins, reverse proxies such as Cloudflare can then validate those signatures to confidently identify the request source on behalf of site owners, allowing them to take action as they see fit.
A typical system has three actors:
User: the entity that wants to perform some actions on the web. This may be a human, an automated program, or anything taking action to retrieve information from the web.
Agent: an orchestrated browser or software program. For example, Chrome on your computer, or OpenAI’s Operator with ChatGPT. Agents can interact with the web according to web standards (HTML rendering, JavaScript, subrequests, etc.).
Origin: the website hosting a resource. The user wants to access it through the browser. This is Cloudflare when your website is using our services, and it’s your own server(s) when exposed directly to the Internet.
In the next section, we’ll dive into HTTP Message Signatures and request mTLS, two mechanisms a browser agent may implement to sign outgoing requests, with different levels of ease for an origin to adopt.
Introducing HTTP Message Signatures
HTTP Message Signatures is a standard that defines the cryptographic authentication of a request sender. It’s essentially a cryptographically sound way to say, “hey, it’s me!”. It’s not the only way that developers can sign requests from their infrastructure — for example, AWS has used Signature v4, and Stripe has a framework for authenticating webhooks — but Message Signatures is a published standard, and the cleanest, most developer-friendly way to sign requests.
We’re working closely with the wider industry to support these standards-based approaches. For example, OpenAI has started to sign their requests. In their own words:
“Ensuring the authenticity of Operator traffic is paramount. With HTTP Message Signatures (RFC 9421), OpenAI signs all Operator requests so site owners can verify they genuinely originate from Operator and haven’t been tampered with” – Eugenio, Engineer, OpenAI
Without further delay, let’s dive in how HTTP Messages Signatures work to identify bot traffic.
Scoping standards to bot authentication
Generating a message signature works like this: before sending a request, the agent signs the target origin with a public key. When fetching https://example.com/path/to/resource, it signs example.com. This public key is known to the origin, either because the agent is well known, because it has previously registered, or any other method. Then, the agent writes a Signature-Input header with the following parameters:
A validity window (created and expires timestamps)
A Key ID that uniquely identifies the key used in the signature. This is a JSON Web Key Thumbprint.
A tag that shows websites the signature’s purpose and validation method, i.e. web-bot-auth for bot authentication.
In addition, the Signature-Agent header indicates where the origin can find the public keys the agent used when signing the request, such as in a directory hosted by signer.example.com. This header is part of the signed content as well.
For those building bots, we propose signing the authority of the target URI, i.e. crawler.search.google.com for Google Search, operator.openai.com for OpenAI Operator, workers.dev for Cloudflare Workers, and a way to retrieve the bot public key in the form of signature-agent, if present.
The User-Agent from the example above indicates that the software making the request is Chrome, because it is an agent that uses an orchestrated Chrome to browse the web. You should note that MyBotCrawler/1.1 is still present. The User-Agent header can actually contain multiple products, in decreasing order of importance. If our agent is making requests via Chrome, that’s the most important product and therefore comes first.
At Internet-level scale, these signatures may add a notable amount of overhead to request processing. However, with the right cryptographic suite, and compared to the cost of existing bot mitigation, both technical and social, this seems to be a straightforward tradeoff. This is a metric we will monitor closely, and report on as adoption grows.
Generating request signatures
We’re making several examples for generating Message Signatures for bots and agents available on Github (though we encourage other implementations!), all of which are standards-compliant, to maximize interoperability.
Imagine you’re building an agent using a managed Chromium browser, and want to sign all outgoing requests. To achieve this, the webextensions standard provides chrome.webRequest.onBeforeSendHeaders, where you can modify HTTP headers before they are sent by the browser. The event is triggered before sending any HTTP data, and when headers are available.
Here’s what that code would look like:
chrome.webRequest.onBeforeSendHeaders.addListener(
function (details) {
// Signature and header assignment logic goes here
// <CODE>
},
{ urls: ["<all_urls>"] },
["blocking", "requestHeaders"] // requires "installation_mode": "force_installed"
);
Cloudflare provides a web-bot-auth helper package on npm that helps you generate request signatures with the correct parameters. onBeforeSendHeaders is a Chrome extension hook that needs to be implemented synchronously. To do so, we import {signatureHeadersSync} from “web-bot-auth”. Once the signature completes, both Signature and Signature-Input headers are assigned. The request flow can then continue.
const request = new URL(details.url);
const created = new Date();
const expired = new Date(created.getTime() + 300_000)
// Perform request signature
const headers = signatureHeadersSync(
request,
new Ed25519Signer(jwk),
{ created, expires }
);
// `headers` object now contains `Signature` and `Signature-Input` headers that can be used
Using our debug server, we can now inspect and validate our request signatures from the perspective of the website we’d be visiting. We should now see the Signature and Signature-Input headers:
In this example, the homepage of the debugging server validates the signature from the RFC 9421 Ed25519 verifying key, which the extension uses for signing.
The above demo and code walkthrough has been fully written in TypeScript: the verification website is on Cloudflare Workers, and the client is a Chrome browser extension. We are cognisant that this does not suit all clients and servers on the web. To demonstrate the proposal works in more environments, we have also implemented bot signature validation in Go with a plugin for Caddy server.
Experimentation with request mTLS
HTTP is not the only way to convey signatures. For instance, one mechanism that has been used in the past to authenticate automated traffic against secured endpoints is mTLS, the “mutual” presentation of TLS certificates. As described in our knowledge base:
Mutual TLS, or mTLS for short, is a method formutual authentication. mTLS ensures that the parties at each end of a network connection are who they claim to be by verifying that they both have the correct privatekey. The information within their respectiveTLS certificates provides additional verification.
While mTLS seems like a good fit for bot authentication on the web, it has limitations. If a user is asked for authentication via the mTLS protocol but does not have a certificate to provide, they would get an inscrutable and unskippable error. Origin sites need a way to conditionally signal to clients that they accept or require mTLS authentication, so that only mTLS-enabled clients use it.
A TLS flag for bot authentication
TLS flags are an efficient way to describe whether a feature, like mTLS, is supported by origin sites. Within the IETF, we have proposed a new TLS flag called req mTLS to be sent by the client during the establishment of a connection that signals support for authentication via a client certificate.
This proposal leverages the tls-flags proposal under discussion in the IETF. The TLS Flags draft allows clients and servers to send an array of one bit flags to each other, rather than creating a new extension (with its associated overhead) for each piece of information they want to share. This is one of the first uses of this extension, and we hope that by using it here we can help drive adoption.
When a client sends the req mTLS flag to the server, they signal to the server that they are able to respond with a certificate if requested. The server can then safely request a certificate without risk of blocking ordinary user traffic, because ordinary users will never set this flag.
Let’s take a look at what an example of such a req mTLS would look like in Wireshark, a network protocol analyser. You can follow along in the packet capture here.
The extension number is 65025, or 0xfe01. This corresponds to an unassigned block of TLS extensions that can be used to experiment with TLS Flags. Once the standard is adopted and published by the IETF, the number would be fixed. To use the req mTLS flag the client needs to set the 80th bit to true, so with our block length of 12 bytes, it should contain the data 0b0000000000000000000001, which is the case here. The server then responds with a certificate request, and the request follows its course.
This example library allows you to configure Go to send req mTLS 0xfe01 bytes in the TLS Flags extension. If you’d like to test your implementation out, you can prompt your client for certificates against req-mtls.research.cloudflare.com using the Cloudflare Research client cloudflareresearch/req-mtls. For clients, once they set the TLS Flags associated with req mTLS, they are done. The code section taking care of normal mTLS will take over at that point, with no need to implement something new.
Two approaches, one goal
We believe that developers of agents and bots should have a public, standard way to authenticate themselves to CDNs and website hosting platforms, regardless of the technology they use or provider they choose. At a high level, both HTTP Message Signatures and request mTLS achieve a similar goal: they allow the owner of a service to authentically identify themselves to a website. That’s why we’re participating in the standardizing effort for both of these protocols at the IETF, where many other authentication mechanisms we’ve discussed here — from TLS to OAuth Bearer tokens –— been developed by diverse sets of stakeholders and standardized as RFCs.
Evaluating both proposals against each other, we’re prioritizing HTTP Message Signatures for Bots because it relies on the previously adopted RFC 9421 with several reference implementations, and works at the HTTP layer, making adoption simpler. request mTLS may be a better fit for site owners with concerns about the additional bandwidth, but TLS Flags has fewer implementations, is still waiting for IETF adoption, and upgrading the TLS stack has proven to be more challenging than with HTTP. Both approaches share similar discovery and key management concerns, as highlighted in a glossary draft at the IETF. We’re actively exploring both options, and would love to hear from both site owners and bot developers about how you’re evaluating their respective tradeoffs.
The bigger picture
In conclusion, we think request signatures and mTLS are promising mechanisms for bot owners and developers of AI agents to authenticate themselves in a tamper-proof manner, forging a path forward that doesn’t rely on ever-changing IP address ranges or spoofable headers such as User-Agent. This authentication can be consumed by Cloudflare when acting as a reverse proxy, or directly by site owners on their own infrastructure. This means that as a bot owner, you can now go to content creators and discuss crawling agreements, with as much granularity as the number of bots you have. You can start implementing these solutions today and test them against the research websites we’ve provided in this post.
Bot authentication also empowers site owners small and large to have more control over the traffic they allow, empowering them to continue to serve content on the public Internet while monitoring automated requests. Longer term, we will integrate these authentication mechanisms into our AI Audit and Bot Management products, to provide better visibility into the bots and agents that are willing to identify themselves.
Being able to solve problems for both origins and clients is key to helping build a better Internet, and we think identification of automated traffic is a step towards that. If you want us to start verifying your message signatures or client certificates, have a compelling use case you’d like us to consider, or any questions, please reach out.
In April of 2025, Rapid7 discovered and disclosed three new vulnerabilities affecting SonicWall Secure Mobile Access (“SMA”) 100 series appliances (SMA 200, 210, 400, 410, 500v). These vulnerabilities are tracked as CVE-2025-32819, CVE-2025-32820, and CVE-2025-32821. An attacker with access to an SMA SSLVPN user account can chain these vulnerabilities to make a sensitive system directory writable, elevate their privileges to SMA administrator, and write an executable file to a system directory. This chain results in root-level remote code execution. These vulnerabilities have been fixed in version 10.2.1.15-81sv.
Rapid7 would like to thank the SonicWall security team for quickly responding to our disclosure and going above and beyond over a holiday weekend to get a patch out.
Vulnerability table
CVE
Description
Affected Service
CVSS
CVE-2025-32819
An authenticated attacker with user privileges can delete any file on the SMA appliance as root to perform privilege escalation to the administrator account. Based on known (private) IOCs and Rapid7 incident response investigations, we believe this vulnerability may have been used in the wild.
An authenticated attacker with user privileges can inject a path traversal sequence to make any directory on the SMA appliance writable by all users, including the nobody user. Any existing file on the system can also be overwritten with junk contents as root.
An authenticated attacker with administrator privileges can inject shell command arguments to upload a fully controlled file anywhere that the nobody user can write to.
These vulnerabilities were discovered by Ryan Emmons, Staff Security Researcher at Rapid7, and are being disclosed in accordance with Rapid7’s coordinated vulnerability disclosure policy.
Remediation
To remediate CVE-2025-32819, CVE-2025-32820, and CVE-2025-32821, SonicWall SMA administrators should update to the latest version, 10.2.1.15-81sv. For additional information, please see SonicWall’s advisory.
Rapid7 customers
InsightVM and Nexpose customers will be able to assess their exposure to CVE-2025-32819, CVE-2025-32820, and CVE-2025-32821 with an unauthenticated vulnerability check expected to be available in today’s (May 7) content release.
Analysis
The appliance tested was ”SMA 500v for ESXi” running version 10.2.1.14-75sv, the latest available at the time of research.
CVE-2025-32819
An attacker with access to a low-privilege SMA user account can delete any file as root. This vulnerability appears to be a patch bypass for a previously reported arbitrary file delete vulnerability. That original vulnerability was disclosed by NCC Group in 2021, and a patch was previously released in the 10.2.0.9-41sv and 10.2.1.3-27sv patch cycle. Rapid7 is not aware of any specific CVE assigned to this original vulnerability; the NCC Group blog post states that a CVE was not shared with them, and we didn’t see a clear 1:1 match on the SonicWall PSIRT page.
Based on our testing, the unauthenticated arbitrary file delete vulnerability disclosed by NCC Group was patched by adding an authentication check. However, that authentication check is satisfied with a valid low-privilege session cookie, so exploitation is still viable. An attacker can exploit this vulnerability with low privileges to elevate to SMA administrator. This can be chained with CVE-2025-32820 and CVE-2025-32821 to establish root-level remote code execution on the SMA research target running 10.2.1.14-75sv. Note: Based on known (private) IOCs and Rapid7 incident response investigations, we believe this vulnerability may have been used in the wild.
In /usr/src/EasyAccess/www/conf/httpd.conf, we observe that the /fileshare/sonicfiles web path is mapped to the sonicfiles.py Flask application.
Within sonicfiles.py, we find the function main_handler, which is a main function that enforces authentication checks and dispatches various “RacNumber” SMB operations. At [A], we see an authorization check being performed before the primary API functionality is reachable.
@application.route('/sonicfiles', methods=['GET', 'POST'])
@application.route('/', methods=['GET', 'POST'])
def main_handler():
#Get the required config if its not set
#application.get_config()
prog = 'fileexplorer'
'''Alternate method for CSRF
referrer = request.referrer
parsed_referrer = urlparse(request.referrer)
if((referrer is None) or (parsed_referrer.hostname != request.host)):
print("Referrer something is wrong")
return HttpErrorCode["NOT_PERMITTED_AUTH"]
'''
#set the log level to Debug when don't get the setting from SMA settings.
application.set_log_level(logging.DEBUG)
authResult = application.authorizationCheck() # [A]
if authResult:
response = make_response(str(HttpErrorCode["NOT_PERMITTED_AUTH"][0]))
response.headers['content-type'] = 'text/plain'
response.headers['Cache-Control'] = 'no-cache'
logger.info("::SONICFILES:: Authorization check failed {}".format(authResult))
return response, HttpErrorCode["NOT_PERMITTED_AUTH"][1]
racNum = request.args.get('RacNumber', RacNumber.RAC_INVALID, int)
if racNum is RacNumber.RAC_INVALID:
return 'Invalid invocation', 500
smbshare = FileShare(application)
[..SNIP..]
Let’s investigate what application.authorizationCheck is. It’s defined in pythonApi.py:
The self.get_connection_id function is depicted below. It fetches the swap cookie ([B]), which is the primary session cookie, then decodes it as base64 ([C]) and returns it.
Since the primary authorizationCheck function is a SWIG function implemented in native code, the decompiled cleaned up C for that is depicted below. It calls sessionGetAndRefresh ([D]), which queries the web application’s SQLite primary database on disk, to determine whether the provided session is an authenticated one. If it’s valid (and if the CSRF token matches when the ‘POST’ method is used), it returns a success code ([E]).
That establishes that any low-privileged user can call RacNumber functions via the sonicfiles API. In 2021, NCC Group outlined how the RAC_DOWNLOAD_TAR function (RacNumber=44) could be exploited with a path traversal for privileged arbitrary file deletion. That download_tar code does not appear to have been modified from what the NCC Group blog post shows, since the “/tmp” directory string is still unsafely concatenated with tainted web parameters ([F]); only the authentication check outlined above in main_handler appears to have been implemented as a fix.
We’ll start by creating a user named lowpriv with low user-level SMA privileges. This user account should not have access to any administrative functionality, and it will act as our victim account for exploitation. We’ll login to the SMA web service listening on port 443 and establish that we have access to this standard user account.
We’ll create two attacker-owned files as root to demonstrate the privileged arbitrary file delete.
Next, we’ll grab our lowpriv user’s session cookies and use them to perform the malicious file delete web request. The server will return a generic 500 code error response.
With our console root shell, we can see that the root-owned /tmp/rootfile file has been deleted.
This can be leveraged to delete the /etc/EasyAccess/var/conf/persist.db file, which is the primary web server SQLite database. When that happens, the system will reboot and reset the SMA administrator password to “password”. Based on known (private) IOCs and Rapid7 incident response investigations, we believe that this specific technique may have been used in the wild.
CVE-2025-32820
An authenticated attacker with user-level low privileges can inject a path traversal sequence to an arbitrary directory on the SMA appliance to make it world-writable. This can be chained with CVE-2025-32819 and CVE-2025-32821 to establish root-level remote code execution on the SMA research target running 10.2.1.14-75sv. Additionally, if a file path is provided, any existing file on the system can be overwritten with junk contents as root, creating a persistent denial of service condition.
Let’s investigate this now. In authentication_api/client/__init__.py, we observe authentication checks implemented in before_request ([G]).
This authorization_check function is similar to the one we previously looked at. However, this function is implemented in Python, within smaauthorize.py, instead of in a C shared library. Below, we can see this logic. The third parameter is called requireAdmin, and it defaults to True ([H]). In this case, though, the call within before_request explicitly states that low-privilege users should be allowed via the False parameter input. The authorization code queries the primary web SQLite database to determine whether the user’s swap session cookie exists in the database ([I]). If so, the request will succeed.
The NxPostConnectionScriptFileResource endpoint sounds promising, since it deals with file operations. Within nxpostconnectionscript.py, we find the API endpoint logic for POST requests. A file input parameter called upfile is expected ([J]). A sanitized file name is extracted using secure_filename (to prevent path traversal) and assigned to the tmp_file variable ([K]). Then, the file contents are stored in tmp_file’s location. A file operation command is also executed using os.system, with the tmp_file argument sanitized using shlex.quote to prevent command injection ([L]).
This is all handled well. However, while the tmp_file path was created safely, the application later needs to reference just the file name without the prepended /tmp directory. In order to do so, it defines a new filePath variable by directly concatenating the unsanitized file.filename string with a different directory path ([M]). This is then wrapped in shlex.quote, appended to the string “chmod 777 ”, and executed using os.system ([N]). No command injection is possible, since the command string is appropriately escaped. Despite this, shlex.quote does not remove path traversal sequences, so a relative traversal file name can be supplied by the attacker to execute “chmod 777” as root on any path of the attacker’s choosing.
@swagger.doc(postDocument)
def post(self):
post_reqparser = reqparse.RequestParser()
post_reqparser.add_argument('upfile', required = True, type = FileStorage, location = 'files') # [J]
args = post_reqparser.parse_args()
[..SNIP..]
# store file in /tmp for examination
file = request.files['upfile']
tmp_file = '/tmp/' + secure_filename(file.filename) # [K]
file.save(tmp_file)
fileSize = os.stat(tmp_file).st_size
if (fileSize > smaApi.MAX_SCRIPT_FILE_LEN or fileSize == 0):
cmd = "rm -rf {}".format(shlex.quote(tmp_file)) # [L]
os.system(cmd)
raise BadRequest(getMessage(API_ERR_CODE_CLIENT_FILE_SIZE_INVALID).format(int(smaApi.MAX_SCRIPT_FILE_LEN / 1024)))
# check dir exists or not and if not create it
if (not os.path.exists(smaApi.POST_SCRIPTS_DIR)):
cmd = "mkdir {}; chmod 777 {}".format(shlex.quote(smaApi.POST_SCRIPTS_DIR), shlex.quote(smaApi.POST_SCRIPTS_DIR))
os.system(cmd)
if (not os.path.exists(smaApi.POST_SCRIPTS_DESC_DIR)):
cmd = "mkdir {}; chmod 777 {}".format(shlex.quote(smaApi.POST_SCRIPTS_DESC_DIR), shlex.quote(smaApi.POST_SCRIPTS_DESC_DIR))
os.system(cmd)
# move file to its destination
cmd = "mv {} {}".format(shlex.quote(tmp_file), shlex.quote(smaApi.POST_SCRIPTS_DIR))
os.system(cmd)
filePath = smaApi.POST_SCRIPTS_DIR + '/' + file.filename # [M]
cmd = "chmod 777 {}".format(shlex.quote(filePath)) # [N]
os.system(cmd)
[..SNIP..]
Exploitation
This is a niche primitive, since we do not control the command being executed. Fortunately, making any directory world-writable is exactly what we need to weaponize CVE-2025-32821, our arbitrary low-privilege file write as nobody. We’ll perform a web request to the vulnerable API endpoint as the lowpriv user. In that request, we’ll set upfile to a relative traversal sequence into /bin, which is on the root user’s PATH.
Our pspy monitor logs two commands being executed as root. The first command’s file path is sanitized using secure_filename, but the second is only sanitized using shlex.quote, resulting in a traversal to /bin.
CMD: UID=0 PID=15082 | sh -c mv /tmp/bin /usr/src/EasyAccess/var/conf/postscripts
CMD: UID=0 PID=15083 | sh -c chmod 777 /usr/src/EasyAccess/var/conf/postscripts/../../../../../../../../../bin/
Exploitation is confirmed with our console root shell, which shows that the /bin directory is now world-writable.
CVE-2025-32821
An authenticated attacker with administrator privileges can inject shell command arguments with an escape sequence to upload a fully controlled file anywhere that the nobody user can write to. This can be chained with CVE-2025-32820 to establish root-level remote code execution on the SMA research target running 10.2.1.14-75sv. It’s also possible to copy existing files that the nobody user can read, such as /etc/passwd or the application’s SQLite database, to the web root directory for data exfiltration.
We’ll start by taking a look at the main function in /cgi-bin/importlogo.
After confirming the user is an authenticated administrator and the HTTP method is “POST”, the application checks for the presence of an integer parameter called updateFavicon ([O]). If this is set to “1”, and if the defaultFavicon parameter is “0”, the application will call FUN_0804a0f0 with the first argument set to a FILE pointer from the multipart form file parameter called favicon1 ([P]). After confirming some basic validation checks, such as file size, the FUN_0804a0f0 function will write the uploaded file to disk at /usr/src/EasyAccess/www/htdocs/themes/favicon1.ico. Next, the portalName POST parameter is fetched and passed through safeSystemCmdArg2 ([Q]). This is a security function that searches for command injection characters, such as $, \n, ;, |, <, >, ^, and `. If any of those characters are detected, the function will return a truncated string of the characters up to that point. Then, a format string is created with the sanitized portalName value to craft the shell command string cp -f /usr/src/EasyAccess/www/htdocs/themes/favicon1.ico /usr/src/EasyAccess/uiaddon/{portalName_VALUE}/favicon.ico ([R]) and the command is executed via system_s_quiet ([S]), which is a wrapper for system that runs in the context of nobody.
Note that the provided portal name is not validated as a legitimate web portal name at any point in the code path thus far–it’s checked against valid portal names if updateFavicon is not set. So, we don’t need to provide a valid portal name. Additionally, although the portal name is sanitized for command injection characters, it is not sanitized for path traversals, it is not URL encoded, and hash symbols are not truncated. As a result, an attacker can provide a portalName value with a traversal sequence to a different file path, followed by a space and a hash symbol to escape “/favicon.ico”.
The result is that the attacker can upload their own fully controlled file and exploit the limited command injection to write it with any file name they’d like to any directory that nobody can write to.
Exploitation
We can perform the web request depicted below to exploit this arbitrary file write.
As expected, the test.txt file has been written to the web root.
We also note that the uploaded file has the executable bit set by default.
# ls -lha /usr/src/EasyAccess/www/htdocs/test.txt
-rwx------ 1 nobody nobody 7 May 1 12:10 /usr/src/EasyAccess/www/htdocs/test.txt
This detail is useful for exploitation, since it will facilitate easily writing an executable file to a directory on the root PATH for arbitrary remote code execution.
Chained Impact
The vulnerabilities disclosed in this document permit an attacker with SMA SSLVPN low-privilege user credentials to perform the following five steps:
Exploit CVE-2025-32819 to delete the primary SQLite database and reset the password of the default SMA admin user.
Login as admin to the SMA web interface.
Exploit CVE-2025-32820 to make the SMA appliance’s /bin directory world-writable.
Exploit CVE-2025-32821 to write the file /bin/lsb_release. This executable is not installed by default, but we observed that an automated job on the appliance routinely attempts to execute it as root every few minutes.
Wait for sh -c lsb_release to be executed automatically. When this happens, the attacker gains root-level remote code execution on the SMA device.
Demonstration
We’ll start by grabbing our low-privilege user’s cookies in our “assumed breach” scenario. This cookie string is swap="ZHNZZThVdlJzWHY1MkpWTDM0akFjbG9XWFgyd29Hdk1yVEtPZWdzSnJlbz0="; swcctn=LEj9kOzEjYibGOSEW9YE8ElgWwiOgigN.
Now, let’s reset the administrator’s password by exploiting CVE-2025-32819 and deleting the primary SQLite database. The SMA returns a 200 status with no body.
Refreshing the web page confirms it worked, though the application is not thrilled with our decision.
After a few seconds, the watchdog has had enough and the device is rebooted. When we refresh the page a couple of minutes later, things are looking as good as new.
After logging in using the credentials admin:password, we’re greeted with an end user product agreement, indicating that the device has been initialized.
We’ll input a free trial license key to get the device back in a functional state, though a real attacker would probably use a stolen one. Next, we’ll use our CVE-2025-32820 PoC to make /bin writable. The server should return a 500 error with the message “Failed to create description file.”
Lastly, we’ll set our sights on remote code execution as root by exploiting CVE-2025-32821. We throw the reverse shell PoC below at our victim and it responds with a 200 code and “success” in the body. Note that a hash symbol is also appended to our executable file contents; this is added because the file write occasionally seems to append a junk character to our command, though it doesn’t happen every time. In order to avoid any unexpected additions, we escape the rest of the line.
One minute later, our reverse shell arrives and root-level remote code execution is confirmed.
Disclosure timeline
May 2, 2025: Rapid7 shares vulnerability details with SonicWall security contacts. The SonicWall team acknowledges the disclosure 30 minutes later and confirms that patch development work will begin.
May 4, 2025: The SonicWall security team states that a fixed build will be shared on May 5 for patch validation.
May 5, 2025: The SonicWall security team shares the 10.2.1.15 build with Rapid7. The Rapid7 team validates that the patch is effective.
May 6, 2025: The SonicWall security team states that the patch will be targeting a May 7 release date.
May 7, 2025: SonicWall releases v10.2.1.15 and publishes a security advisory. After confirming the patch is generally available, Rapid7 publishes this disclosure.
An increasing number of frameworks describe the possible contents of a K–12 artificial intelligence (AI) curriculum and suggest possible learning activities (for example, see the UNESCO competency framework for students, 2024). In our March seminar, Lukas Höper and Carsten Schulte from the Department of Computing Education at Paderborn University in Germany shared with us a unit of work they’ve developed that could inform such a curriculum. At its core, the unit enhances young people’s awareness of how their personal data is used in the data-driven technologies that form part of their everyday lives.
Lukas HöperCarsten Schulte
Lukas Höper and Carsten Schulte are part of a larger team who are investigating how to teach school students about data science and Big Data.
Carsten explained that Germany’s informatics (computing) curriculum includes a competency area known as Informatics, People and Society (IPS), which explores the interrelationships between technology, individuals, and society, and how computation influences and is influenced by social, ethical, and cultural factors. However, research has suggested that teachers face several problems in delivering this topic, including:
Lack of subject knowledge
Lack of teaching material
Lack of integration with other topics in informatics lessons
A perception that IPS is the responsibility of other subjects
Some of the findings of that 2007 research were mirrored in a more recent local study in 2025, which found that although there have been some gains in subject knowledge in the interval period, the problems of a lack of teaching material and integration with other computer science (CS) topics persist, with IPS increasingly perceived as the responsibility of the informatics subject area alone. Despite this, within the informatics curriculum, IPS is often the first topic to be dropped when educators face time constraints — and concerns with what and how to assess the topic remain.
In this context, and as part of a larger, longitudinal project to promote data science teaching in schools called ProDaBi, Carsten and Lukas have been developing, implementing, and evaluating concepts and materials on the topics of data science and AI. Lukas explained the importance of students developing data awareness in the context of the digital systems they use in their everyday lives, such as search engines, streaming services, social media apps, digital assistants, and chatbots, and emphasised the difference between being a user of these systems and a data-aware user. Using the example of image recognition and ‘I am not a robot’ Captcha services, Lukas explained how young people need to develop a data-aware perspective of the secondary purposes of the data collected by these (and other) systems, as well as the more obvious, primary purposes.
Lukas went on to illustrate the human interaction system model, which presents a continuum of possible different roles, from the student as the user of digital artefacts to the student as the designer of digital artefacts.
Figure 1. Different roles in interactions with data-driven technologies
To become data-aware users of digital artefacts, students need to be able to understand and reflect on those digital artefacts. Only then can they proceed to become responsible designers of digital artefacts. However, when surveyed, some students were only moderately interested in engaging with the inner workings of the digital technologies they use in their everyday lives. Many students prefer to use the systems and are less interested in how they process data.
The explanatory model approach in computing education
Lukas explained how students often become more interested in data-driven technologies when learning about them with explanatory models. Such models can foster data awareness, giving students a different perspective of data-driven technologies and helping them become more empowered users of them.
To illustrate, Lukas gave the example of an explanatory model about the role of data in digital systems. Such a model can be used to introduce the idea that data is explicitly and implicitly collected in the interaction between the user and the technology, and used for primary and secondary purposes.
Figure 2. The four parts of the explanatory model
Lukas then introduced two teaching units that were developed for use with middle school children to evaluate the success of the explanatory model approach in computing education. The first unit explores location data collected by mobile phone networks and the second features recommendation systems used by movie streaming services such as Netflix and Amazon Prime.
Taking the second unit as their focus, Lukas and Carsten outlined the four parts of the explanatory model approach:
Part 1
The teaching unit begins by introducing recommendation systems and asking students to think about what a streaming service is, how a personalised start page is constructed, and how personal recommendations might be generated. Students then complete an unplugged activity to simulate the process of making movie recommendations for a peer:
Task 1: Students write down movie recommendations for another student.
Task 2: They then ask each other questions (they collect data).
Task 3: They write down revised movie recommendations.
Task 4: They share and evaluate their recommendations.
Task 5: Together they reflect on which collected data was helpful in this exercise and what kind of data a recommendation system might collect. This reflection introduces the concepts of explicit and implicit data collection.
Part 2
In part 2, students are given a prepared Jupyter Notebook, which allows them to explore a simulation of a recommendation system. Students rate movies and receive personal recommendations. They reconstruct a data model about users, using the idea of collaborative filtering with the k-nearest neighbours algorithm (see Figure 3).
Figure 3. Data model of movie ratings
Part 3
In part 3, the concepts of primary and secondary purposes for data collection are introduced. Students discuss examples of secondary purposes such as personalised paywalls for movies that can be purchased, and subscriptions based on the predictions of future behaviour. The discussion includes various topics about individual and societal issues (e.g. filter bubbles, behaviour engineering, information asymmetry, and responsible development of data-driven technologies).
Part 4
Finally, students use the explanatory model as an ‘analytical lens’. They choose other examples from their everyday lives of technologies that implement recommendation systems and analyse these examples, assessing the data practices involved. Students present their results in class and discuss their role in these situations and possible actions they can take to become more empowered, data-aware users.
Uses of explanatory models
Using the explanatory model is one approach to make the Informatics, People and Society strand of the German informatics curriculum more engaging for students, and addresses some of the problems teachers identify with delivering this competency area.
In presenting the idea of the explanatory model, Carsten and Lukas emphasised that the model in use delivers content as well as functioning as a tool to design teaching content. In the example above, we see how the explanatory model introduces the concepts of:
Explicit and implicit data collection
Primary and secondary purposes of that data
Data models
The explanatory model framework can also be used as a focus for academic research in computing education. For example, further research is needed to evaluate if explanatory models are appropriate or ‘correct’ models and to determine the extent to which they are useful in computing education.
In summary, an explanatory model provides a specific perspective on and explanation of particular computing concepts and digital artefacts. In the example given here, the model focuses on the role of data in a recommender system. Explanatory models are representations of concepts, artefacts, and socio-technical systems, but can also serve as tools to support teaching and learning processes and research in computing education.
Figure 4. Overview of the perspectives of explanatory models. Click to enlarge.
The teaching units referred to above are published on www.prodabi.de (in German and English).
See the background paper to the seminar, called ‘Learning an explanatory model of data-driven technologies can lead to empowered behaviour: A mixed-methods study in K-12 Computing education’.
In our current seminar series, we’re exploring teaching about AI and data science. Join us at our next seminar on Tuesday 13 May at 17:00–18:30 BST to hear Henriikka Vartiainen and Matti Tedre (University of Eastern Finland) discuss how to empower students by teaching them how to develop AI and machine learning (ML) apps without code in the classroom.
To sign up and take part in our research seminars, click below:
Any public certification authority (CA) can issue a certificate for any website on the Internet to allow a webserver to authenticate itself to connecting clients. Take a moment to scroll through the list of trusted CAs for your web browser (e.g., Chrome). You may recognize (and even trust) some of the names on that list, but it should make you uncomfortable that any CA on that list could issue a certificate for any website, and your browser would trust it. It’s a castle with 150 doors.
Certificate Transparency (CT) plays a vital role in the Web Public Key Infrastructure (WebPKI), the set of systems, policies, and procedures that help to establish trust on the Internet. CT ensures that all website certificates are publicly visible and auditable, helping to protect website operators from certificate mis-issuance by dishonest CAs, and helping honest CAs to detect key compromise and other failures.
In this post, we’ll discuss the history, evolution, and future of the CT ecosystem. We’ll cover some of the challenges we and others have faced in operating CT logs, and how the new static CT API log design lowers the bar for operators, helping to ensure that this critical infrastructure keeps up with the fast growth and changing landscape of the Internet and WebPKI. We’re excited to open source our Rust implementation of the new log design, built for deployment on Cloudflare’s Developer Platform, and to announce test logs deployed using this infrastructure.
What is Certificate Transparency?
In 2011, the Dutch CA DigiNotar was hacked, allowing attackers to forge a certificate for *.google.com and use it to impersonate Gmail to targeted Iranian users in an attempt to compromise personal information. Google caught this because they used certificate pinning, but that technique doesn’t scale well for the web. This, among other similar attacks, led a team at Google in 2013 to develop Certificate Transparency (CT) as a mechanism to catch mis-issued certificates. CT creates a public audit trail of all certificates issued by public CAs, helping to protect users and website owners by holding CAs accountable for the certificates they issue (even unwittingly, in the event of key compromise or software bugs). CT has been a great success: since 2013, over 17 billion certificates have been logged, and CT was awarded the prestigious Levchin Prize in 2024 for its role as a critical safety mechanism for the Internet.
Let’s take a brief look at the entities involved in the CT ecosystem. Cloudflare itself operates the Nimbus CT logs and the CT monitor powering the Merkle Towndashboard.
Certification Authorities (CAs) are organizations entrusted to issue certificates on behalf of website operators, which in turn can use those certificates to authenticate themselves to connecting clients.
CT-enforcing clients like the Chrome, Safari, and Firefox browsers are web clients that only accept certificates compliant with their CT policies. For example, a policy might require that a certificate includes proof that it has been submitted to at least two independently-operated public CT logs.
Log operators run CT logs, which are public, append-only lists of certificates. CAs and other clients can submit a certificate to a CT log to obtain a “promise” from the CT log that it will incorporate the entry into the append-only log within some grace period. CT logs periodically (every few seconds, typically) update their log state to incorporate batches of new entries, and publish a signed checkpoint that attests to the new state.
Monitors are third parties that continuously crawl CT logs and check that their behavior is correct. For instance, they verify that a log is self-consistent and append-only by ensuring that when new entries are added to the log, no previous entries are deleted or modified. Monitors may also examine logged certificates to help website operators detect mis-issuance.
Challenges in operating a CT log
Despite the success of CT, it is a less than perfect system. Eric Rescorla has an excellent writeup on the many compromises made to make CT deployable on the Internet of 2013. We’ll focus on the operational complexities of running a CT log.
Let’s look at the requirements for running a CT log from Chrome’s CT log policy (which are more or less mirrored by those of Safari and Firefox), and what can go wrong. The requirements center around integrity and availability.
To be considered a trusted auditing source, CT logs necessarily have stringent integrity requirements. Anything the log produces must be correct and self-consistent, meaning that a CT log cannot present two different views of the log to different clients, and must present a consistent history for its entire lifetime. Similarly, when a CT log accepts a certificate and promises to incorporate it by returning a Signed Certificate Timestamp (SCT) to the client, it must eventually incorporate that certificate into its append-only log.
The integrity requirements are unforgiving. A single bit-flip due to a hardware failure or cosmic ray can (andhas) caused logs to produce incorrect results and thus be disqualified by CT programs. Even software updates to running logs can be fatal, as a change that causes a correctness violation cannot simply be rolled back. Perhaps the greatest risk to individual log integrity is failing to incorporate certificates for which they issued SCTs, for example if they fail to commit those pending certificates to durable storage. See Andrew Ayer’s great synopsis for more examples of CT log failures (up to 2021).
A CT log must also meet certain availability requirements to effectively provide its core functionality as a publicly auditable log. Clients must be able to reliably retrieve log data — Chrome’s policy requires a minimum of 99% average uptime over a 90-day rolling period for each API endpoint — and any entries for which an SCT has been issued must be incorporated into the log within the grace period, called the Maximum Merge Delay (MMD), 24 hours in Chrome’s policy.
The design of the current CT log read APIs puts strain on the ability of log operators to meet uptime requirements. The API endpoints are dynamic and not easily cacheable without bespoke caching rules that are aware of the CT API. For instance, the get-entries endpoint allows a client to request arbitrary ranges of entries from a log, and the get-proof-by-hash requires the server to construct inclusion proofs for any certificate requested by the client. To serve these requests, CT log servers need to be backed by databases easily 5-10TB in size capable of serving tens of millions of requests per day. This increases operator complexity and expense, not to mention the high cost of bandwidth of serving these requests.
MMD violations are unfortunately not uncommon. Cloudflare’s own Nimbus logs have experienced prolonged outages in the past, most recently in November 2023 due to complete power loss in the datacenter running the logs. During normal log operation, if the log accepts entries more quickly than it incorporates them, the backlog can grow to exceed the MMD. Log operators can remedy this by rate-limiting or temporarily disabling the write APIs, but this can in turn contribute to violations of the uptime requirements.
The high bar for log operation has limited the organizations operating CT logs to only Cloudflare and five others! Losing one or two logs is enough to compromise the stability of the CT ecosystem. Clearly, a change is needed.
A next-generation CT log design
In May 2024, Let’s Encrypt announcedSunlight, an implementation of a next-generation CT log designed for the modern WebPKI, incorporating a decade of lessons learned from running CT and similar transparency systems. The new CT log design, called the static CT API, is partially based on the Go checksum database, and organizes log data as a series of tiles that are easy to cache and serve. The new design provides efficiency improvements that cut operation costs, help logs to meet availability requirements, and reduce the risk of integrity violations.
The static CT API is split into two parts, the monitoring APIs (so named because CT monitors are the primary clients), and the submission APIs for adding new certificates to the log.
The monitoring APIs replace the dynamic read APIs of RFC 6962, and organize log data into static, cacheable tiles. (See Russ Cox’s blog post for an in-depth explanation of tiled logs.) CT log operators can efficiently serve static tiles from S3-compatible object storage buckets and cache them using CDN infrastructure, without needing dedicated API servers. Clients can then download the necessary tiles to retrieve specific log entries or reconstruct arbitrary proofs.
The static CT API introduces another efficiency by deduplicating intermediate and root “issuer” certificates in a log entry’s certificate chain. The number of publicly-trusted issuer certificates is small (in the low thousands), so instead of storing them repeatedly for each log entry, only the issuer hash is stored. Clients can look up issuer certificates by hash from a separate endpoint.
The submission APIs remain backwards-compatible with RFC 6962, meaning that TLS clients and CAs can submit to them without any changes. However, there is one notable addition: the static CT specification requires logs to hold on to requests as it batches and sequences them, and responds with an SCT only after entries have been incorporated into the log. The specification defines a required SCT extension indicating the entry’s index in the log. At the cost of slightly delayed SCT issuance (on the order of seconds), this change eliminates one of the major pain points of operating a CT log (the Merge Delay).
Having the log index of a certificate available in an SCT enables further efficiencies. SCT auditing refers to the process by which TLS clients or monitors can check if a log has fulfilled its promise to incorporate a certificate for which it has issued an SCT. In the RFC 6962 API, checking if a certificate is present in a log when you don’t already know the index requires using the get-proof-by-hash endpoint to look up the entry by the certificate hash (and the server needs to maintain a mapping from hash to index to efficiently serve these requests). Instead, with the index immediately available in the SCT, clients can directly retrieve the specific log data tile covering that index, even with efficient privacy-preserving techniques.
Since it was announced, the static CT API has taken the CT ecosystem by storm. Aside from Sunlight and our brand new Azul (discussed below), there are at least two other independent implementations, Itko and Trillian Tessera. Several CT monitors (including crt.sh, certspotter, Censys, and our own Merkle Town) have added support for the new log format, and as of April 1, 2025, Chrome has begun accepting submissions for static CT API logs into their CT log program.
A static CT API implementation on Workers
This section discusses how we designed and built our static CT log implementation, Azul (short for azulejos, the colorful Portuguese and Spanish ceramic tiles). For curious readers and prospective CT log operators, we encourage you to follow the instructions in the repo to quickly set up your own static CT log. Questions and feedback in the form of GitHub issues are welcome!
The advent of the static CT API gave us the perfect opportunity to rethink how we run our CT logs. There were a few design decisions we made early on to shape the project.
First and foremost, we wanted to run our CT logs on our distributed global network. Especially after the painful November 2023 control plane outage, there’s been a push to deploy services on our highly available and resilient network instead of running in centralized datacenters.
Second, with Cloudflare’s deeply engrained culture of dogfooding (building Cloudflare on top of Cloudflare), we decided to implement the CT log on top of Cloudflare’s Developer Platform and Workers.
Dogfooding gives us an opportunity to find pain points in our product offerings, and to provide feedback to our development teams to improve the developer experience for everyone. We restricted ourselves to only features and default limits generally available to customers, so that we could have the same experience as an external Cloudflare developer, and would produce an implementation that anyone could deploy.
Another major design decision was to implement the CT log in Rust, a modern systems programming language with static typing and built-in memory safety that is heavily used across Cloudflare, and which already has mature (if sometimes lacking full feature parity) Workers bindings that we have used to build several production services. This also provided us with an opportunity to produce Rust crates porting Go implementations of various C2SP specifications that can be reused across other projects.
For the new logs to be deployable, they needed to be at least as performant as existing CT logs. As a point of reference, the Nimbus2025 log currently handles just over 33 million requests per day (~380/s) across the read APIs, and about 6 million per day (~70/s) across the write APIs.
Implementation
We based Azul heavily on Sunlight, a Go application built for deployment as a standalone server. As such, this section serves as a reference for translating a traditional server to Cloudflare’s serverless platform.
To start, let’s briefly review the Sunlight architecture (described in more detail in the README and original design doc). A Sunlight instance is a single Go process, serving one or multiple CT logs. It is backed by three different storage locations with different properties:
A “lock backend” which stores the current checkpoint for each log. This datastore needs to be strongly consistent, but only stores trivial amounts of data.
A per-log object storage bucket from which to serve tiles, checkpoints, and issuers to CT clients. This datastore needs to be strongly consistent, and to handle multiple terabytes of data.
A per-log deduplication cache, to return SCTs for previously-submitted (pre-)certificates. This datastore is best-effort (as duplicate entries are not fatal to log operation), and stores tens to hundreds of gigabytes of data.
Two major components handle the bulk of the CT log application logic:
A frontend HTTP server handles incoming requests to the submission APIs to add new certificates to the log, validates them, checks the deduplication cache, adds the certificate to a pool of entries to be sequenced, and waits for sequencing to complete before responding to the client.
The sequencer periodically (every 1s, by default) sequences the pool of pending entries, writes new tiles to the object backend, persists the latest checkpoint covering the new log state to the lock and object backends, and signals to waiting requests that the pool has been sequenced.
A static CT API log running on a traditional server using the Sunlight implementation.
Next, let’s look at how we can translate these components into ones suitable for deployment on Workers.
Making it work
Let’s start with the easy choices. The static CT monitoring APIs are designed to serve static, cacheable, compressible assets from object storage. The API should be highly available and have the capacity to serve any number of CT clients. The natural choice is Cloudflare R2, which provides globally consistent storage with capacity for large data volumes, customizability to configure caching and compression, and unbounded read operations.
A static CT API log running on Workers using a preliminary version of the Azul implementation which ran into performance limitations.
The static CT submission APIs are where the real challenge lies. In particular, they allow CT clients to submit certificate chains to be incorporated into the append-only log. We used Workers as the frontend for the CT log application. Workers run in data centers close to the client, scaling on demand to handle request load, making them the ideal place to run the majority of the heavyweight request handling logic, including validating requests, checking the deduplication cache (discussed below), and submitting the entry to be sequenced.
The next question was where and how we’d run the backend to handle the CT log sequencing logic, which needs to be stateful and tightly coordinated. We chose Durable Objects (DOs), a special type of stateful Cloudflare Worker where each instance has persistent storage and a unique name which can be used to route requests to it from anywhere in the world. DOs are designed to scale effortlessly for applications that can be easily broken up into self-contained units that do not need a lot of coordination across units. For example, a chat application can use one DO to control each chat room. In our model, then, each CT log is controlled by a single DO. This architecture allows us to easily run multiple CT logs within a single Workers application, but as we’ll see, the limitations of individual single-threaded DOs can easily become a bottleneck. More on this later.
With the CT log backend as a Durable Object, several other components fell into place: Durable Objects’ strongly-consistent transactional storage neatly fit the requirements for the “lock backend” to persist the log’s latest checkpoint, and we can use an alarm to trigger the log sequencing every second. We can also use location hints to place CT logs in locations geographically close to clients for reduced latency, similar to Google’s Argon and Xenon logs.
The choice of datastore for the deduplication cache proved to be non-obvious. The cache is best-effort, and intended to avoid re-sequencing entries that are already present in the log. The cache key is computed by hashing certain fields of the add-[pre-]chain request, and the cache value consists of the entry’s index in the log and the timestamp at which it was sequenced. At current log submission rates, the deduplication cache could grow in excess of 50 GB for 6 months of log data. In the Sunlight implementation, the deduplication cache is implemented as a local SQLite database, where checks against it are tightly coupled with sequencing, which ensures that duplicates from in-flight requests are correctly accounted for. However, this architecture did not translate well to Cloudflare’s architecture. The data size doesn’t comfortably fit within Durable Object Storage or single-database D1 limits, and it was too slow to directly read and write to remote storage from within the sequencing loop. Ultimately, we split the deduplication cache into two components: a local fixed-size in-memory cache for fast deduplication over short periods of time (on the order of minutes), and the other a long-term deduplication cache built on Cloudflare Workers KV a global, low-latency, eventually-consistent key-value store without storage limitations.
With this architecture, it was relatively straightforward to port the Go code to Rust, and to bring up a functional static CT log up on Workers. We’re done then, right? Not quite. Performance tests showed that the log was only capable of sequencing 20-30 new entries per second, well under the 70 per second target of existing logs. We could work around this by simply running more logs, but that puts strain on other parts of the CT ecosystem — namely on TLS clients and monitors, which need to keep state for each log. Additionally, the alarm used to trigger sequencing would often be delayed by multiple seconds, meaning that the log was failing to produce new tree heads at consistent intervals. Time to go back to the drawing board.
Making it fast
In the design thus far, we’re asking a single-threaded Durable Object instance to do a lot of multi-tasking. The DO processes incoming requests from the Frontend Worker to add entries to the sequencing pool, and must periodically sequence the pool and write state to the various storage backends. A log handling 100 requests per second needs to switch between 101 running tasks (the extra one for the sequencing), plus any async tasks like writing to remote storage — usually 10+ writes to object storage and one write to the long-term deduplication cache per sequenced entry. No wonder the sequencing task was getting delayed!
A static CT API log running on Workers using the Azul implementation with batching to improve performance.
We were able to work around these issues by adding an additional layer of DOs between the Frontend Worker and the Sequencer, which we call Batchers. The Frontend Worker uses consistent hashing on the cache key to determine which of several Batchers to submit the entry to, and the Batcher helps to reduce the number of requests to the Sequencer by buffering requests and sending them together in batches. When the batch is sequenced, the Batcher distributes the responses back to the Frontend Workers that submitted the request. The Batcher also handles writing updates to the deduplication cache, further freeing up resources for the Sequencer.
By limiting the scope of the critical block of code that needed to be run synchronously in a single DO, and leaning on the strengths of DOs by scaling horizontally where the workload allows it, we were able to drastically improve application performance. With this new architecture, the CT log application can handle upwards of 500 requests per second to the submission APIs to add new log entries, while maintaining a consistent sequencing tempo to keep per-request latency low (typically 1-2 seconds).
Developing a Workers application in Rust
One of the reasons I was excited to work on this project is that it gave me an opportunity to implement a Workers application in Rust, which I’d never done from scratch before. Not everything was smooth, but overall I would recommend the experience.
To be clear, these rough edges are expected! The Workers platform is continuously gaining new features, and it’s natural that the Rust bindings would fall behind. As more developers rely on (and contribute to, hint hint) the Rust bindings, the developer experience will continue to improve.
What is next for Certificate Transparency
The WebPKI is constantly evolving and growing, and upcoming changes, in particular shorter certificate lifetimes and larger post-quantum certificates, are going to place significantly more load on the CT ecosystem.
The CA/Browser Forum defines a set of Baseline Requirements for publicly-trusted TLS server certificates. As of 2020, the maximum certificate lifetime for publicly-trusted certificates is 398 days. However, there is a ballot measure to reduce that period to as low as 47 days by March 2029. Let’s Encrypt is going even further, and at the end of 2024 announced that they will be offering short-lived certificates with a lifetime of only six days by the end of 2025. Based on some back-of-the-envelope calculations using statistics from Merkle Town, these changes could increase the number of logged entries in the CT ecosystem by 16-20x.
If you’ve been keeping up with this blog, you’ll also know that post-quantum certificates are on the horizon, bringing with them larger signature and public key sizes. Today, a certificate with an P-256 ECDSA public key and issuer signature can be less than 1kB. Dropping in a ML-DSA44 public key and signature brings the same certificate size to 4.6 kB, assuming the SCTs use 96-byte UOVls-pkc signatures. With these choices, post-quantum certificates could require CT logs to store 4x the amount of data per log entry.
The static CT API design helps to ensure that CT logs are much better equipped to handle this increased load, especially if the load is distributed across multiple logs per operator. Our new implementation makes it easy for log operators to run CT logs on top of Cloudflare’s infrastructure, adding more operational diversity and robustness to the CT ecosystem. We welcome feedback on the design and implementation as GitHub issues, and encourage CAs and other interested parties to start submitting to and consuming from our test logs.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.