Post Syndicated from Brian Olsen original https://aws.amazon.com/blogs/big-data/how-atpco-enables-governed-self-service-data-access-to-accelerate-innovation-with-amazon-datazone/
This blog post is co-written with Raj Samineni from ATPCO.
In today’s data-driven world, companies across industries recognize the immense value of data in making decisions, driving innovation, and building new products to serve their customers. However, many organizations face challenges in enabling their employees to discover, get access to, and use data easily with the right governance controls. The significant barriers along the analytics journey constrain their ability to innovate faster and make quick decisions.
ATPCO is the backbone of modern airline retailing, enabling airlines and third-party channels to deliver the right offers to customers at the right time. ATPCO’s reach is impressive, with its fare data covering over 89% of global flight schedules. The company collaborates with more than 440 airlines and 132 channels, managing and processing over 350 million fares in its database at any given time. ATPCO’s vision is to be the platform driving innovation in airline retailing while remaining a trusted partner to the airline ecosystem. ATPCO aims to empower data-driven decision-making by making high quality data discoverable by every business unit, with the appropriate governance on who can access what.
In this post, using one of ATPCO’s use cases, we show you how ATPCO uses AWS services, including Amazon DataZone, to make data discoverable by data consumers across different business units so that they can innovate faster. We encourage you to read Amazon DataZone concepts and terminologies first to become familiar with the terms used in this post.
Use case
One of ATPCO’s use cases is to help airlines understand what products, including fares and ancillaries (like premium seat preference), are being offered and sold across channels and customer segments. To support this need, ATPCO wants to derive insights around product performance by using three different data sources:
- Airline Ticketing data – 1 billion airline ticket sales data processed through ATPCO
- ATPCO pricing data – 87% of worldwide airline offers are powered through ATPCO pricing data. ATPCO is the industry leader in providing pricing and merchandising content for airlines, global distribution systems (GDSs), online travel agencies (OTAs), and other sales channels for consumers to visually understand differences between various offers.
- De-identified customer master data – ATPCO customer master data that has been de-identified for sensitive internal analysis and compliance.
In order to generate insights that will then be shared with airlines as a data product, an ATPCO analyst needs to be able to find the right data related to this topic, get access to the data sets, and then use it in a SQL client (like Amazon Athena) to start forming hypotheses and relationships.
Before Amazon DataZone, ATPCO analysts needed to find potential data assets by talking with colleagues; there wasn’t an easy way to discover data assets across the company. This slowed down their pace of innovation because it added time to the analytics journey.
Solution
To address the challenge, ATPCO sought inspiration from a modern data mesh architecture. Instead of a central data platform team with a data warehouse or data lake serving as the clearinghouse of all data across the company, a data mesh architecture encourages distributed ownership of data by data producers who publish and curate their data as products, which can then be discovered, requested, and used by data consumers.
Amazon DataZone provides rich functionality to help a data platform team distribute ownership of tasks so that these teams can choose to operate less like gatekeepers. In Amazon DataZone, data owners can publish their data and its business catalog (metadata) to ATPCO’s DataZone domain. Data consumers can then search for relevant data assets using these human-friendly metadata terms. Instead of access requests from data consumer going to a ATPCO’s data platform team, they now go to the publisher or a delegated reviewer to evaluate and approve. When data consumers use the data, they do so in their own AWS accounts, which allocates their consumption costs to the right cost center instead of a central pool. Amazon DataZone also avoids duplicating data, which saves on cost and reduces compliance tracking. Amazon DataZone takes care of all of the plumbing, using familiar AWS services such as AWS Identity and Access Management (IAM), AWS Glue, AWS Lake Formation, and AWS Resource Access Manager (AWS RAM) in a way that is fully inspectable by a customer.
The following diagram provides an overview of the solution using Amazon DataZone and other AWS services, following a fully distributed AWS account model, where data sets like airline ticket sales, ticket pricing, and de-identified customer data in this use case are stored in different member accounts in AWS Organizations.

Implementation
Now, we’ll walk through how ATPCO implemented their solution to solve the challenges of analysts discovering, getting access to, and using data quickly to help their airline customers.
There are four parts to this implementation:
- Set up account governance and identity management.
- Create and configure an Amazon DataZone domain.
- Publish data assets.
- Consume data assets as part of analyzing data to generate insights.
Part 1: Set up account governance and identity management
Before you start, compare your current cloud environment, including data architecture, to ATPCO’s environment. We’ve simplified this environment to the following components for the purpose of this blog post:
- ATPCO uses an organization to create and govern AWS accounts.
- ATPCO has existing data lake resources set up in multiple accounts, each owned by different data-producing teams. Having separate accounts helps control access, limits the blast radius if things go wrong, and helps allocate and control cost and usage.
- In each of their data-producing accounts, ATPCO has a common data lake stack: An Amazon Simple Storage Service (Amazon S3) bucket for data storage, AWS Glue crawler and catalog for updating and storing technical metadata, and AWS LakeFormation (in hybrid access mode) for managing data access permissions.
- ATPCO created two new AWS accounts: one to own the Amazon DataZone domain and another for a consumer team to use for analytics with Amazon Athena.
- ATPCO enabled AWS IAM Identity Center and connected their identity provider (IdP) for authentication.
We’ll assume that you have a similar setup, though you might choose differently to suit your unique needs.
Part 2: Create and configure an Amazon DataZone domain
After your cloud environment is set up, the steps in Part 2 will help you create and configure an Amazon DataZone domain. A domain helps you organize your data, people, and their collaborative projects, and includes a unique business data catalog and web portal that publishers and consumers will use to share, collaborate, and use data. For ATPCO, their data platform team created and configured their domain.
Step 2.1: Create an Amazon DataZone domain
Persona: Domain administrator
Go to the Amazon DataZone console in your domain account. If you use AWS IAM Identity Center for corporate workforce identity authentication, then select the AWS Region in which your Identity Center instance is deployed. Choose Create domain.
- Enter a name and description.
- Leave Customize encryption settings (advanced) cleared.
- Leave the radio button selected for Create and use a new role. AWS creates an IAM role in your account on your behalf with the necessary IAM permissions for accessing Amazon DataZone APIs.
- Leave clear the quick setup option for Set-up this account for data consumption and publishing because we don’t plan to publish or consume data in our domain account.
- Skip Add new tag for now. You can always come back later to edit the domain and add tags.
- Choose Create Domain.
After a domain is created, you will see a domain detail page similar to the following. Notice that IAM Identity Center is disabled by default.

Step 2.2: Enable IAM Identity Center for your Amazon DataZone domain and add a group
Persona: Domain administrator
By default, your Amazon domain, its APIs, and its unique web portal are accessible by IAM principals in this AWS account with the necessary datazone IAM permissions. ATPCO wanted its corporate employees to be able to use Amazon DataZone with their corporate single sign-on SSO credentials without needing secondary federation to IAM roles. AWS Identity Center is the AWS cross-service solution for passing identity provider credentials. You can skip this step if you plan to use IAM principals directly for accessing Amazon DataZone.
Navigate to your Amazon DataZone domain’s detail page and choose Enable IAM Identity Center.
- Scroll down to the User management section and select Enable users in IAM Identity Center. When you do, User and group assignment method options appear below. Turn on Require assignments. This means that you need to explicitly allow (add) users and groups to access your domain. Choose Update domain.
Now let’s add a group to the domain to provide its members with access. Back on your domain’s detail page, scroll to the bottom and choose the User management tab. Choose Add, and select Add SSO Groups from the drop-down.
- Enter the first letters of the group name and select it from the options. After you’ve added the desired groups, choose Add group(s).
- You can confirm that the groups are added successfully on the domain’s detail page, under the User management tab by selecting SSO Users and then SSO Groups from the drop-down.
Step 2.3: Associate AWS accounts with the domain for segregated data publishing and consumption
Personas: Domain administrator and AWS account owners
Amazon DataZone supports a distributed AWS account structure, where data assets are segregated from data consumption (such as Amazon Athena usage), and data assets are in their own accounts (owned by their respective data owners). We call these associated accounts. Amazon DataZone and the other AWS services it orchestrates take care of the cross-account data sharing. To make this work, domain and account owners need to perform a one-time account association: the domain needs to be shared with the account, and the account owner needs to configure it for use with Amazon DataZone. For ATPCO, there are four desired associated accounts, three of which are the accounts with data assets stored in Amazon S3 and cataloged in AWS Glue (airline ticketing data, pricing data, and de-identified customer data), and a fourth account that is used for an analyst’s consumption.
The first part of associating an account is to share the Amazon DataZone domain with the desired accounts (Amazon DataZone uses AWS RAM to create the resource policy for you). In ATPCO’s case, their data platform team manages the domain, so a team member does these steps.
- Todo this in the Amazon DataZone console, sign in to the domain account and navigate to the domain detail page, and then scroll down and choose the Associated Accounts tab. Choose Request association.
- Enter the AWS account ID of the first account to be associated.
- Choose Add another account and repeat step one for the remaining accounts to be associated. For ATPCO, there were four to-be associated accounts.
- When complete, choose Request Association.

The second part of associating an account is for the account owner to then configure their account for use by Amazon DataZone. Essentially, this process means that the account owner is allowing Amazon DataZone to perform actions in the account, like granting access to Amazon DataZone projects after a subscription request is approved.
- Sign in to the associated account and go to the Amazon DataZone console in the same Region as the domain. On the Amazon DataZone home page, choose View requests.
- Select the name of the inviting Amazon DataZone domain and choose Review request.

- Choose the Amazon DataZone blueprint you want to enable. We select Data Lake in this example because ATPCO’s use case has data in Amazon S3 and consumption through Amazon Athena.

- Leave the defaults as-is in the Permissions and resources The Glue Manage Access role allows Amazon DataZone to use IAM and LakeFormation to manage IAM roles and permissions to data lake resources after you approve a subscription request in Amazon DataZone. The Provisioning role allows Amazon DataZone to create S3 buckets and AWS Glue databases and tables in your account when you allow users to create Amazon DataZone projects and environments. The Amazon S3 bucket for data lake is where you specify which S3bucket is used by Amazon DataZone when users store data with your account.

- Choose Accept & configure association. This will take you to the associated domains table for this associated account, showing which domains the account is associated with. Repeat this process for other to-be associated accounts.
After the associations are configured by accounts, you will see the status reflected in the Associated accounts tab of the domain detail page.

Step 2.4: Set up environment profiles in the domain
Persona: Domain administrator
The final step to prepare the domain is making the associated AWS accounts usable by Amazon DataZone domain users. You do this with an environment profile, which helps less technical users get started publishing or consuming data. It’s like a template, with pre-defined technical details like blueprint type, AWS account ID, and Region. ATPCO’s data platform team set up an environment profile for each associated account.
To do this in the Amazon DataZone console, the data platform team member sign in to the domain account and navigates to the domain detail page, and chooses Open data portal in the upper right to go to the web-based Amazon DataZone portal.
- Choose Select project in the upper-left next to the DataZone icon and select Create Project. Enter a name, like Domain Administration and choose Create. This will take you to your new project page.
- In the Domain Administration project page, choose the Environments tab, and then choose Environment profiles in the navigation pane. Select Create environment profile.
- Enter a name, such as Sales – Data lake blueprint.
- Select the Domain Administration project as owner, and the DefaultDataLake as the blueprint.
- Select the AWS account with sales data as well as the preferred Region for new resources, such as AWS Glue and Athena consumption.
- Leave All projects and Any database
- Finalize your selection by choosing Create Environment Profile.
Repeat this step for each of your associated accounts. As a result, Amazon DataZone users will be able to create environments in their projects to use AWS resources in specific AWS accounts forpublishing or consumption.

Part 3: Publish assets
With Part 2 complete, the domain is ready for publishers to sign in and start publishing the first data assets to the business data catalog so that potential data consumers find relevant assets to help them with their analyses. We’ll focus on how ATPCO published their first data asset for internal analysis—sales data from their airline customers. ATPCO already had the data extracted, transformed, and loaded in a staged S3 bucket and cataloged with AWS Glue.
Step 3.1: Create a project
Persona: Data publisher
Amazon DataZone projects enable a group of users to collaborate with data. In this part of the ATPCO use case, the project is used to publish sales data as an asset in the project. By tying the eventual data asset to a project (rather than a user), the asset will have long-lived ownership beyond the tenure of any single employee or group of employees.
- As a data publisher, obtain theURL of the domain’s data portal from your domain administrator, navigate to this sign-in page and authenticate with IAM or SSO. After you’re signed in to the data portal, choose Create Project, enter a name (such as Sales Data Assets) and choose Create.
- If you want to add teammates to the project, choose Add Members. On the Project members page, choose Add Members, search for the relevant IAM or SSO principals, and select a role for them in the project. Owners have full permissions in the project, while contributors are not able to edit or delete the project or control membership. Choose Add Members to complete the membership changes.
Step 3.2: Create an environment
Persona: Data publisher
Projects can be comprised of several environments. Amazon DataZone environments are collections of configured resources (for example, an S3 bucket, an AWS Glue database, or an Athena workgroup). They can be useful if you want to manage stages of data production for the same essential data products with separate AWS resources, such as raw, filtered, processed, and curated data stages.
- While signed in to the data portal and in the Sales Data Assets project, choose the Environments tab, and then select Create Environment. Enter a name, such as Processed, referencing the processed stage of the underlying data.
- Select the Sales – Data lake blueprint environment profile the domain administrator created in Part 2.
- Choose Create Environment. Notice that you don’t need any technical details about the AWS account or resources! The creation process might take several minutes while Amazon DataZone sets up Lake Formation, Glue, and Athena.
Step 3.3: Create a new data source and run an ingestion job
Persona: Data publisher
In this use case, ATPCO has cataloged their data using AWS Glue. Amazon DataZone can use AWS Glue as a data source. Amazon DataZone data source (for AWS Glue) is a representation of one or more AWS Glue databases, with the option to set table selection criteria based on their name. Similar to how AWS Glue crawlers scan for new data and metadata, you can run an Amazon DataZone ingestion job against an Amazon DataZone data source (again, AWS Glue) to pull all of the matching tables and technical metadata (such as column headers) as the foundation for one or more data assets. An ingestion job can be run manually or automatically on a schedule.
- While signed in to the data portal and in the Sales Data Assets project, choose the Data tab, and then select Data sources. Choose Create Data Source, and enter a name for your data source, such as Processed Sales data in Glue, select AWS Glue as the type, and choose Next.
- Select the Processed environment from Step 3.2. In the database name box, enter a value or select from the suggested AWS Glue databases that Amazon DataZone identified in the AWS account. You can add additional criteria and another AWS Glue database.
- For Publishing settings, select No. This allows you to review and enrich the suggested assets before publishing them to the business data catalog.
- For Metadata generation methods, keep this box selected. Amazon DataZone will provide you with recommended business names for the data assets and its technical schema to publish an asset that’s easier for consumers to find.
- Clear Data quality unless you have already set up AWS Glue data quality. Choose Next.
- For Run preference, select to run on demand. You can come back later to run this ingestion job automatically on a schedule. Choose Next.
- Review the selections and choose Create.
To run the ingestion job for the first time, choose Run in the upper right corner. This will start the job. The run time is dependent on the quantity of databases, tables, and columns in your data source. You can refresh the status by choosing Refresh.
Step 3.4: Review, curate, and publish assets
Persona: Data publisher
After the ingestion job is complete, the matching AWS Glue tables will be added to the project’s inventory. You can then review the asset, including automated metadata generated by Amazon DataZone, add additional metadata, and publish the asset.
- While signed in to the data portal and in the Sales Data Assets project, go to the Data tab, and select Inventory. You can review each of the data assets generated by the ingestion job. Let’s select the first result. In the asset detail page, you can edit the asset’s name and description to make it easier to find, especially in a list of search results.
- You can edit the Read Me section and add rich descriptions for the asset, with markdown support. This can help reduce the questions consumers message the publisher with for clarification.
- You can edit the technical schema (columns), including adding business names and descriptions. If you enabled automated metadata generation, then you’ll see recommendations here that you can accept or reject.
- After you are done enriching the asset, you can choose Publish to make it searchable in the business data catalog.
Have the data publisher for each asset follow Part 3. For ATPCO, this means two additional teams followed these steps to get pricing and de-identified customer data into the data catalog.
Part 4: Consume assets as part of analyzing data to generate insights
Now that the business data catalog has three published data assets, data consumers will find available data to start their analysis. In this final part, an ATPCO data analyst can find the assets they need, obtain approved access, and analyze the data in Athena, forming the precursor of a data product that ATPCO can then make available to their customer (such as an airline).
Step 4.1: Discover and find data assets in the catalog
Persona: Data consumer
As a data consumer, obtain the URL of the domain’s data portal from your domain administrator, navigate to in the sign-in page, and authenticate with IAM or SSO. In the data portal, enter text to find data assets that match what you need to complete your analysis. In the ATPCO example, the analyst started by entering ticketing data. This returned the sales asset published above because the description noted that the data was related to “sales, including tickets and ancillaries (like premium seat selection preferences).”
The data consumer reviews the detail page of the sales asset, including the description and human-friendly terms in the schema, and confirms that it’s of use to the analysis. They then choose Subscribe. The data consumer is prompted to select a project for the subscription request, in which case they follow the same instructions as creating a project in Step 3.1, naming it Product analysis project. Enter a short justification of the request. Choose Subscribe to send the request to the data publisher.
Repeat Steps 4.2 and 4.3 for each of the needed data assets for the analysis. In the ATPCO use case, this meant searching for and subscribing to pricing and customer data.
While waiting for the subscription requests to be approved, the data consumer creates an Amazon DataZone environment in the Product analysis project, similar to Step 3.2. The data consumer selects an environment profile for their consumption AWS account and the data lake blueprint.
Step 4.2: Review and approve subscription request
Persona: Data publisher
The next time that a member of the Sales Data Assets project signs in to the Amazon DataZone data portal, they will see a notification of the subscription request. Select that notification or navigate in the Amazon DataZone data portal to the project. Choose the Data tab and Incoming requests and then the Requested tab to find the request. Review the request and decide to either Approve or Reject, while providing a disposition reason for future reference.
Step 4.3: Analyze data
Persona: Data consumer
Now that the data consumer has subscribed to all three data assets needed (by repeating steps 4.1-4.2 for each asset), the data consumer navigates to the Product analysis project in the Amazon DataZone data portal. The data consumer can verify that the project has data asset subscriptions by choosing the Data tab and Subscribed data.

Because the project has an environment with the data lake blueprint enabled in their consumption AWS account, the data consumer will see an icon in the right-side tab called Query Data: Amazon Athena. By selecting this icon, they’re taken to the Amazon Athena console.

In the Amazon Athena console, the data consumer sees the data assets their DataZone project is subscribed to (from steps 4.1-4.2). They use the Amazon Athena query editor to query the subscribed data.

Conclusion
In this post, we walked you through an ATPCO use case to demonstrate how Amazon DataZone allows users across an organization to easily discover relevant data products using business terms. Users can then request access to data and build products and insights faster. By providing self-service access to data with the right governance guardrails, Amazon DataZone helps companies tap into the full potential of their data products to drive innovation and data-driven decision making. If you’re looking for a way to unlock the full potential of your data and democratize it across your organization, then Amazon DataZone can help you transform your business by making data-driven insights more accessible and productive.
To learn more about Amazon DataZone and how to get started, refer to the Getting started guide. See the YouTube playlist for some of the latest demos of Amazon DataZone and short descriptions of the capabilities available.
About the Author

Brian Olsen is a Senior Technical Product Manager with Amazon DataZone. His 15 year technology career in research science and product has revolved around helping customers use data to make better decisions. Outside of work, he enjoys learning new adventurous hobbies, with the most recent being paragliding in the sky.

Mitesh Patel is a Principal Solutions Architect at AWS. His passion is helping customers harness the power of Analytics, machine learning and AI to drive business growth. He engages with customers to create innovative solutions on AWS.
Raj Samineni is the Director of Data Engineering at ATPCO, leading the creation of advanced cloud-based data platforms. His work ensures robust, scalable solutions that support the airline industry’s strategic transformational objectives. By leveraging machine learning and AI, Raj drives innovation and data culture, positioning ATPCO at the forefront of technological advancement.
Sonal Panda is a Senior Solutions Architect at AWS with over 20 years of experience in architecting and developing intricate systems, primarily in the financial industry. Her expertise lies in Generative AI, application modernization leveraging microservices and serverless architectures to drive innovation and efficiency.


 Balaji Mohan is a senior modernization architect specializing in application and data modernization to the cloud. His business-first approach ensures seamless transitions, aligning technology with organizational goals. Using cloud-native architectures, he delivers scalable, agile, and cost-effective solutions, driving innovation and growth.
Balaji Mohan is a senior modernization architect specializing in application and data modernization to the cloud. His business-first approach ensures seamless transitions, aligning technology with organizational goals. Using cloud-native architectures, he delivers scalable, agile, and cost-effective solutions, driving innovation and growth. Souvik Bose is a Software Development Engineer working on Amazon OpenSearch Service.
Souvik Bose is a Software Development Engineer working on Amazon OpenSearch Service. Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.














































 Satya Chikkala is a Solutions Architect at Amazon Web Services. Based in Melbourne, Australia, he works closely with enterprise customers to accelerate their cloud journey. Beyond work, he is very passionate about nature and photography.
Satya Chikkala is a Solutions Architect at Amazon Web Services. Based in Melbourne, Australia, he works closely with enterprise customers to accelerate their cloud journey. Beyond work, he is very passionate about nature and photography. Vijay Velpula is a Data Lake Architect with AWS Professional Services. He assists customers in building modern data platforms by implementing big data and analytics solutions. Outside of his professional responsibilities, Velpula enjoys spending quality time with his family, as well as indulging in travel, hiking, and biking activities.
Vijay Velpula is a Data Lake Architect with AWS Professional Services. He assists customers in building modern data platforms by implementing big data and analytics solutions. Outside of his professional responsibilities, Velpula enjoys spending quality time with his family, as well as indulging in travel, hiking, and biking activities.





































 Carlos Gallegos is a Senior Analytics Specialist Solutions Architect at AWS. Based in Austin, TX, US. He’s an experienced and motivated professional with a proven track record of delivering results worldwide. He specializes in architecture, design, migrations, and modernization strategies for complex data and analytics solutions, both on-premises and on the AWS Cloud. Carlos helps customers accelerate their data journey by providing expertise in these areas. Connect with him on
Carlos Gallegos is a Senior Analytics Specialist Solutions Architect at AWS. Based in Austin, TX, US. He’s an experienced and motivated professional with a proven track record of delivering results worldwide. He specializes in architecture, design, migrations, and modernization strategies for complex data and analytics solutions, both on-premises and on the AWS Cloud. Carlos helps customers accelerate their data journey by providing expertise in these areas. Connect with him on  Jose Romero is a Senior Solutions Architect for Startups at AWS. Based in Austin, TX, US. He’s passionate about helping customers architect modern platforms at scale for data, AI, and ML. As a former senior architect in AWS Professional Services, he enjoys building and sharing solutions for common complex problems so that customers can accelerate their cloud journey and adopt best practices. Connect with him on
Jose Romero is a Senior Solutions Architect for Startups at AWS. Based in Austin, TX, US. He’s passionate about helping customers architect modern platforms at scale for data, AI, and ML. As a former senior architect in AWS Professional Services, he enjoys building and sharing solutions for common complex problems so that customers can accelerate their cloud journey and adopt best practices. Connect with him on  Arun Pradeep Selvaraj is a Senior Solutions Architect at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build, and reinvent. He is creative, fast-paced, deeply customer-obsessed and uses the working backwards process to build modern architectures to help customers solve their unique challenges. Connect with him on
Arun Pradeep Selvaraj is a Senior Solutions Architect at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build, and reinvent. He is creative, fast-paced, deeply customer-obsessed and uses the working backwards process to build modern architectures to help customers solve their unique challenges. Connect with him on 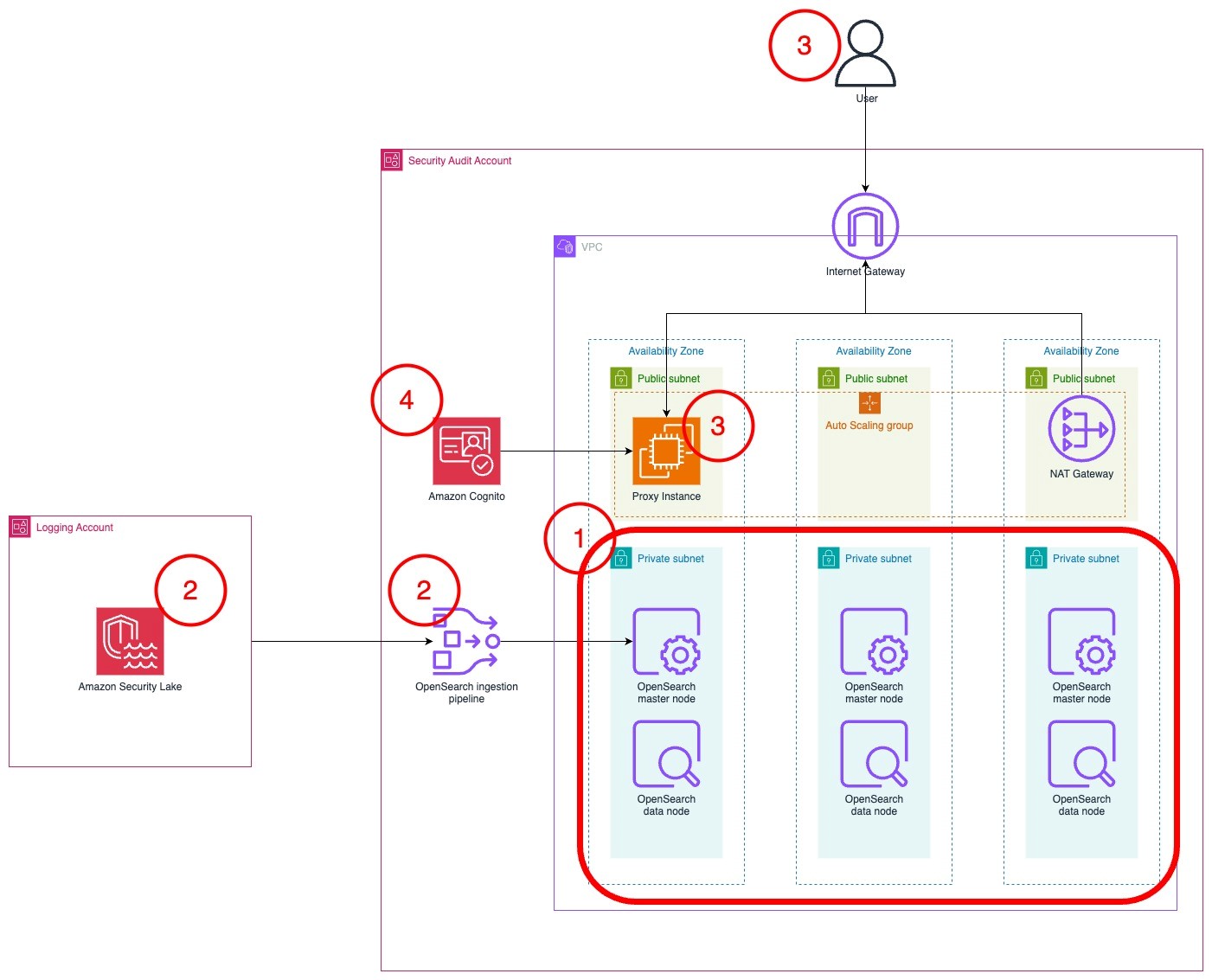



























 Under Authorized projects, you can pick the authorized projects allowed to use this environment profile to create an environment. By default, this is set to All projects.
Under Authorized projects, you can pick the authorized projects allowed to use this environment profile to create an environment. By default, this is set to All projects.










 As a consumer, you’re now able to explore data and create reports, or you can aggregate data and create new assets to publish in Amazon DataZone, becoming a producer of a new data product to share with other users and departments.
As a consumer, you’re now able to explore data and create reports, or you can aggregate data and create new assets to publish in Amazon DataZone, becoming a producer of a new data product to share with other users and departments. Carmen is a Solutions Architect at AWS, based in Milan (Italy). She is a Data Lover that enjoys helping companies in the adoption of Cloud technologies, especially with Data Analytics and Data Governance. Outside of work, she is a creative people who loves being in contact with nature and sometimes practicing adrenaline activities.
Carmen is a Solutions Architect at AWS, based in Milan (Italy). She is a Data Lover that enjoys helping companies in the adoption of Cloud technologies, especially with Data Analytics and Data Governance. Outside of work, she is a creative people who loves being in contact with nature and sometimes practicing adrenaline activities.



































 Raj Samineni is the Director of Data Engineering at ATPCO, leading the creation of advanced cloud-based data platforms. His work ensures robust, scalable solutions that support the airline industry’s strategic transformational objectives. By leveraging machine learning and AI, Raj drives innovation and data culture, positioning ATPCO at the forefront of technological advancement.
Raj Samineni is the Director of Data Engineering at ATPCO, leading the creation of advanced cloud-based data platforms. His work ensures robust, scalable solutions that support the airline industry’s strategic transformational objectives. By leveraging machine learning and AI, Raj drives innovation and data culture, positioning ATPCO at the forefront of technological advancement. Sonal Panda is a Senior Solutions Architect at AWS with over 20 years of experience in architecting and developing intricate systems, primarily in the financial industry. Her expertise lies in Generative AI, application modernization leveraging microservices and serverless architectures to drive innovation and efficiency.
Sonal Panda is a Senior Solutions Architect at AWS with over 20 years of experience in architecting and developing intricate systems, primarily in the financial industry. Her expertise lies in Generative AI, application modernization leveraging microservices and serverless architectures to drive innovation and efficiency.




















 Arpad Csoke is a Solutions Architect at Amazon Web Services. His responsibilities include helping large enterprise customers understand and utilize the AWS environment, acting as a technical consultant to contribute to solving their issues.
Arpad Csoke is a Solutions Architect at Amazon Web Services. His responsibilities include helping large enterprise customers understand and utilize the AWS environment, acting as a technical consultant to contribute to solving their issues.


 Mackenzie Johnson is a Senior Manager at ActionIQ. She is an innovative marketing strategist who’s passionate about the convergence of complementary technologies and amplifying joint value. With extensive experience across digital transformation storytelling, she thrives on educating enterprise businesses about the impact of CX based on a data-driven approach.
Mackenzie Johnson is a Senior Manager at ActionIQ. She is an innovative marketing strategist who’s passionate about the convergence of complementary technologies and amplifying joint value. With extensive experience across digital transformation storytelling, she thrives on educating enterprise businesses about the impact of CX based on a data-driven approach. Phil Catterall is a Senior Product Manager at ActionIQ and leads product development on ActionIQ’s foundational data management, processing, and query federation capabilities. He’s passionate about designing and building scalable data products to empower business users in new ways.
Phil Catterall is a Senior Product Manager at ActionIQ and leads product development on ActionIQ’s foundational data management, processing, and query federation capabilities. He’s passionate about designing and building scalable data products to empower business users in new ways. Sain Das is a Senior Product Manager on the Amazon Redshift team and leads Amazon Redshift GTM for partner programs including the Powered by Amazon Redshift and Redshift Ready programs.
Sain Das is a Senior Product Manager on the Amazon Redshift team and leads Amazon Redshift GTM for partner programs including the Powered by Amazon Redshift and Redshift Ready programs.













 Bandana Das is a Senior Data Architect at Amazon Web Services and specializes in data and analytics. She builds event-driven data architectures to support customers in data management and data-driven decision-making. She is also passionate about enabling customers on their data management journey to the cloud.
Bandana Das is a Senior Data Architect at Amazon Web Services and specializes in data and analytics. She builds event-driven data architectures to support customers in data management and data-driven decision-making. She is also passionate about enabling customers on their data management journey to the cloud. Gezim Musliaj is a Senior DevOps Consultant with AWS Professional Services. He is interested in various things CI/CD, data, and their application in the field of IoT, massive data ingestion, and recently MLOps and GenAI.
Gezim Musliaj is a Senior DevOps Consultant with AWS Professional Services. He is interested in various things CI/CD, data, and their application in the field of IoT, massive data ingestion, and recently MLOps and GenAI. Sameer Ranjha is a Software Development Engineer on the Amazon DataZone team. He works in the domain of modern data architectures and software engineering, developing scalable and efficient solutions.
Sameer Ranjha is a Software Development Engineer on the Amazon DataZone team. He works in the domain of modern data architectures and software engineering, developing scalable and efficient solutions. Sindi Cali is an Associate Consultant with AWS Professional Services. She supports customers in building data-driven applications in AWS.
Sindi Cali is an Associate Consultant with AWS Professional Services. She supports customers in building data-driven applications in AWS. Bhaskar Singh is a Software Development Engineer on the Amazon DataZone team. He has contributed to implementing AWS CloudFormation support for Amazon DataZone. He is passionate about distributed systems and dedicated to solving customers’ problems.
Bhaskar Singh is a Software Development Engineer on the Amazon DataZone team. He has contributed to implementing AWS CloudFormation support for Amazon DataZone. He is passionate about distributed systems and dedicated to solving customers’ problems.


 Aswath Srinivasan is a Senior Search Engine Architect at Amazon Web Services currently based in Munich, Germany. With over 17 years of experience in various search technologies, Aswath currently focuses on OpenSearch. He is a search and open-source enthusiast and helps customers and the search community with their search problems.
Aswath Srinivasan is a Senior Search Engine Architect at Amazon Web Services currently based in Munich, Germany. With over 17 years of experience in various search technologies, Aswath currently focuses on OpenSearch. He is a search and open-source enthusiast and helps customers and the search community with their search problems. Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.