Post Syndicated from Jeff Barr original https://aws.amazon.com/blogs/aws/aws-week-in-review-april-24-2023-amazon-codecatalyst-amazon-s3-on-snowball-edge-and-more/
As always, there’s plenty to share this week: Amazon CodeCatalyst is now generally available, Amazon S3 is now available on Snowball Edge devices, version 1.0.0 of AWS Amplify Flutter is here, and a lot more. Let’s dive in!
Last Week’s Launches
Here are some of the launches that caught my eye this past week:
Amazon CodeCatalyst – First announced at re:Invent in preview form (Announcing Amazon CodeCatalyst, a Unified Software Development Service), this unified software development and delivery service is now generally available. As Steve notes in the post that he wrote for the preview, “Amazon CodeCatalyst enables software development teams to quickly and easily plan, develop, collaborate on, build, and deliver applications on AWS, reducing friction throughout the development lifecycle.” During the preview we added the ability to use AWS Graviton2 for CI/CD workflows and deployment environments, along with other new features, as detailed in the What’s New.
Amazon S3 on Snowball Edge – You have had the power to create S3 buckets on AWS Snow Family devices for a couple of years, and to PUT and GET object. With this new launch you can, as Channy says, “…use an expanded set of Amazon S3 APIs to easily build applications on AWS and deploy them on Snowball Edge Compute Optimized devices.” This launch allows you to manage the storage using AWS OpsHub, and to address multiple Denied, Disrupted, Intermittent, and Limited Impact (DDIL) use cases. To learn more, read Amazon S3 Compatible Storage on AWS Snowball Edge Compute Optimized Devices Now Generally Available.
Amazon Redshift Updates – We announced multiple updates to Amazon Redshift including the MERGE SQL command so that you can combine a series of DML statements into a single statement, dynamic data masking to simplify the process of protecting sensitive data in your Amazon Redshift data warehouse, and centralized access control for data sharing with AWS Lake Formation.
AWS Amplify – You can now build cross-platform Flutter apps that target iOS, Android, Web, and desktop using a single codebase and with a consistent user experience. To learn more and to see how to get started, read Amplify Flutter announces general availability for web and desktop support. In addition to the GA, we also announced that AWS Amplify supports Push Notifications for Android, Swift, React Native, and Flutter apps.
X in Y – We made existing services available in additional regions and locations:
- Direct Connect location in Querétaro, Mexico.
- Migration Hub Refactor Spaces in 7 additional regions.
- AWS Backup for Amazon S3 in South America (São Paulo) and GovCloud (US) Regions.
- AWS Backup in Asia Pacific (Melbourne).
- Amazon ECS Service Connect in Europe (Zurich) and Middle East (UAE).
- Amazon GuardDuty in Asia Pacific (Melbourne).
- Amazon VPC Prefix Lists in Asia Pacific (Hyderabad, Melbourne) and Europe (Spain).
- AWS Control Tower in 7 additional regions.
- Amazon WorkSpaces Web Access with WSP in AWS GovCloud (US-West).
For a full list of AWS announcements, take a look at the What’s New at AWS page and consider subscribing to the page’s RSS feed. If you want even more detail, you can Subscribe to AWS Daily Feature Updates via Amazon SNS.
Interesting Blog Posts
Other AWS Blogs – Here are some fresh posts from a few of the other AWS Blogs:
- Increased visibility of your carbon emissions data with AWS Customer Carbon Footprint Tool.
- Identify objections in customer conversations using Amazon Comprehend to enhance customer experience without ML expertise.
- Create a CI/CD pipeline for .NET Lambda functions with AWS CDK Pipelines.
- Exploring new ETL and ELT capabilities for Amazon Redshift from the AWS Glue Studio visual editor.
- Analyze customer satisfaction scores with post-contact surveys using Amazon Connect Tasks.
- Understanding techniques to reduce AWS Lambda costs in serverless applications.
- Power microservices architectures with Amazon MemoryDB for Redis.
- Amazon SageMaker Data Wrangler for dimensionality reduction.
- Efficient truck routing with Amazon Location Service.
- Use IAM roles to connect GitHub Actions to actions in AWS
- Protect Your Web Applications with AWS WAF Ready Partners.
AWS Open Source – My colleague Ricardo writes a weekly newsletter to highlight new open source projects, tools, and demos from the AWS Community. Read edition 154 to learn more.
AWS Graviton Weekly – Marcos Ortiz writes a weekly newsletter to highlight the latest developments in AWS custom silicon. Read AWS Graviton weekly #33 to see what’s up.
Upcoming Events
Here are some upcoming live and online events that may be of interest to you:
AWS Community Day Turkey will take place in Istanbul on May 6, and I will be there to deliver the keynote. Get your tickets and I will see you there!
AWS Summits are coming to Berlin (May 4), Washington, DC (June 7 and 8), London (June 7), and Toronto (June 14). These events are free but I highly recommend that you register ahead of time.
.NET Enterprise Developer Day EMEA is a free one-day virtual conference on April 25; register now.
AWS Developer Innovation Day is also virtual, and takes place on April 26 (read Discover Building without Limits at AWS Developer Innovation Day for more info). I’ll be watching all day and sharing a live recap at the end; learn more and see you there.
And that’s all for today!
— Jeff;





 AWS Pi Day – Join us on March 14th for the third annual
AWS Pi Day – Join us on March 14th for the third annual 

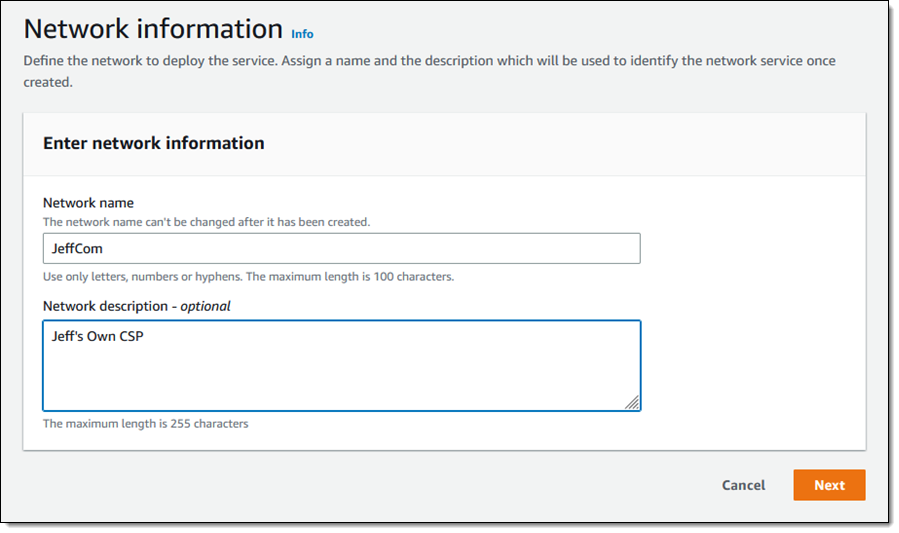
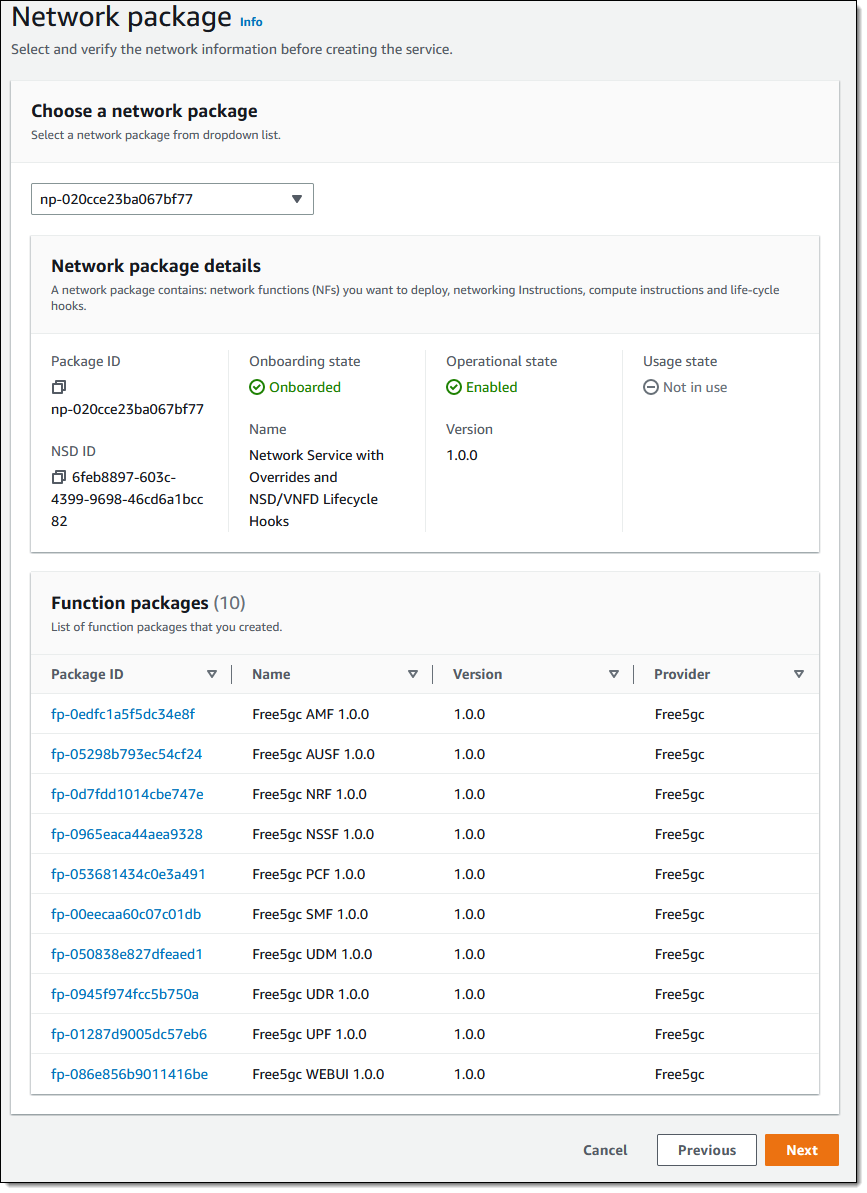
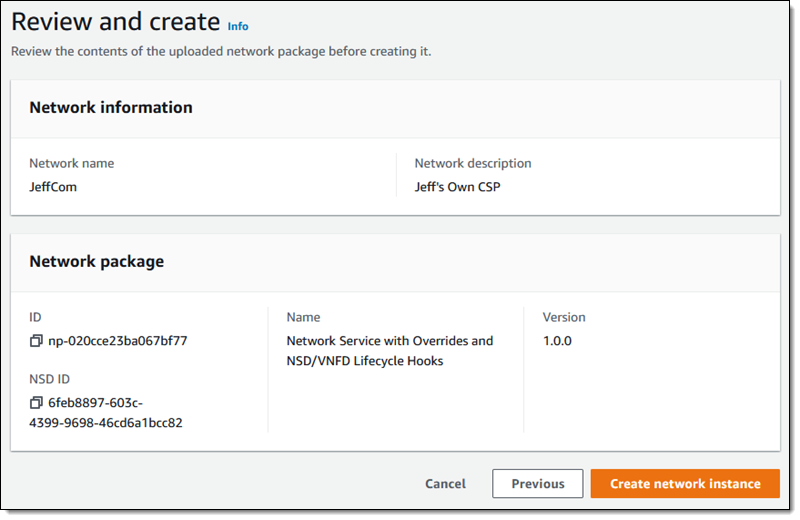
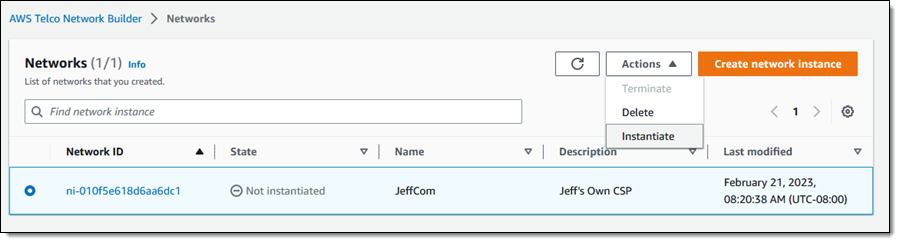
 In late 2021 we
In late 2021 we