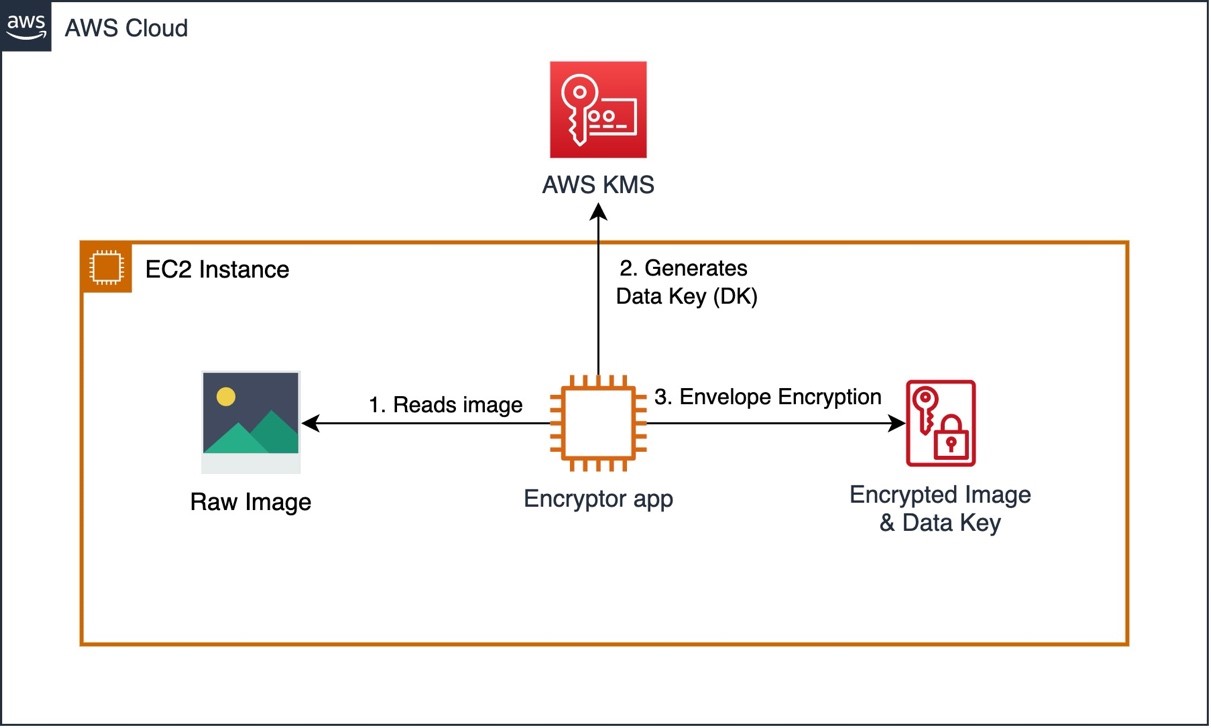
Post Syndicated from Garrett Galow original https://blog.cloudflare.com/open-api-transition/


Today, we are announcing the general availability of OpenAPI Schemas for the Cloudflare API. These are published via GitHub and will be updated regularly as Cloudflare adds and updates APIs. OpenAPI is the widely adopted standard for defining APIs in a machine-readable format. OpenAPI Schemas allow for the ability to plug our API into a wide breadth of tooling to accelerate development for ourselves and customers. Internally, it will make it easier for us to maintain and update our APIs. Before getting into those benefits, let’s start with the basics.
What is OpenAPI?
Much of the Internet is built upon APIs (Application Programming Interfaces) or provides them as services to clients all around the world. This allows computers to talk to each other in a standardized fashion. OpenAPI is a widely adopted standard for how to define APIs. This allows other machines to reliably parse those definitions and use them in interesting ways. Cloudflare’s own API Shield product uses OpenAPI schemas to provide schema validation to ensure only well-formed API requests are sent to your origin.
Cloudflare itself has an API that customers can use to interface with our security and performance products from other places on the Internet. How do we define our own APIs? In the past we used a standard called JSON Hyper-Schema. That had served us well, but as time went on we wanted to adopt more tooling that could both benefit ourselves internally and make our customer’s lives easier. The OpenAPI community has flourished over the past few years providing many capabilities as we will discuss that were unavailable while we used JSON Hyper-Schema. As of today we now use OpenAPI.
You can learn more about OpenAPI itself here. Having an open, well-understood standard for defining our APIs allows for shared tooling and infrastructure to be used that can read these standard definitions. Let’s take a look at a few examples.
Uses of Cloudflare’s OpenAPI schemas
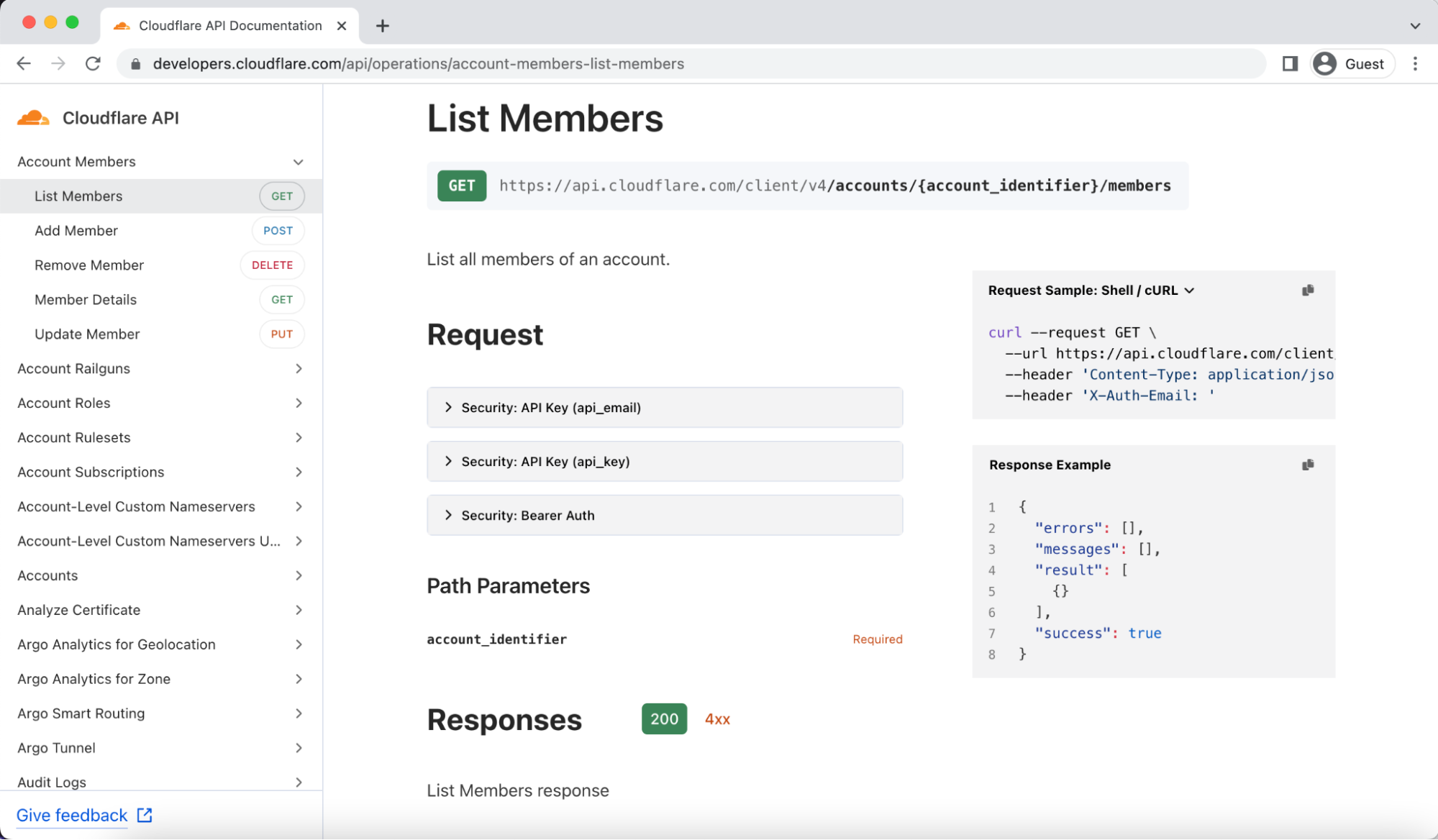
Most customers won’t need to use the schemas themselves to see value. The first system leveraging OpenAPI schemas is our new API Docs that were announced today. Because we now have OpenAPI schemas, we leverage the open source tool Stoplight Elements to aid in generating this new doc site. This allowed us to retire our previously custom-built site that was hard to maintain. Additionally, many engineers at Cloudflare are familiar with OpenAPI, so we gain teams can write new schemas more quickly and are less likely to make mistakes by using a standard that teams understand when defining new APIs.
There are ways to leverage the schemas directly, however. The OpenAPI community has a huge number of tools that only require a set of schemas to be able to use. Two such examples are mocking APIs and library generation.
Mocking Cloudflare’s API
Say you have code that calls Cloudflare’s API and you want to be able to easily run unit tests locally or integration tests in your CI/CD pipeline. While you could just call Cloudflare’s API in each run, you may not want to for a few reasons. First, you may want to run tests frequently enough that managing the creation and tear down of resources becomes a pain. Also, in many of these tests you aren’t trying to validate logic in Cloudflare necessarily, but your own system’s behavior. In this case, mocking Cloudflare’s API would be ideal since you can gain confidence that you aren’t violating Cloudflare’s API contract, but without needing to worry about specifics of managing real resources. Additionally, mocking allows you to simulate different scenarios, like being rate limited or receiving 500 errors. This allows you to test your code for typically rare circumstances that can end up having a serious impact.
As an example, Spotlight Prism could be used to mock Cloudflare’s API for testing purposes. With a local copy of Cloudflare’s API Schemas you can run the following command to spin up a local mock server:
$ docker run --init --rm \
-v /home/user/git/api-schemas/openapi.yaml:/tmp/openapi.yaml \
-p 4010:4010 stoplight/prism:4 \
mock -h 0.0.0.0 /tmp/openapi.yaml
Then you can send requests to the mock server in order to validate that your use of Cloudflare’s API doesn’t violate the API contract locally:
$ curl -sX PUT localhost:4010/zones/f00/activation_check \
-Hx-auth-email:[email protected] -Hx-auth-key:foobarbaz | jq
{
"success": true,
"errors": [],
"messages": [],
"result": {
"id": "023e105f4ecef8ad9ca31a8372d0c353"
}
}
This means faster development and shorter test runs while still catching API contract issues early before they get merged or deployed.
Library generation
Cloudflare has libraries in many programming languages like Terraform and Go, but we don’t support every possible programming language. Fortunately, using a tool like openapi generator, you can feed in Cloudflare’s API schemas and generate a library in a wide range of languages to then use in your code to talk to Cloudflare’s API. For example, you could generate a Java library using the following commands:
git clone https://github.com/openapitools/openapi-generator
cd openapi-generator
mvn clean package
java -jar modules/openapi-generator-cli/target/openapi-generator-cli.jar generate \
-i https://raw.githubusercontent.com/cloudflare/api-schemas/main/openapi.yaml \
-g java \
-o /var/tmp/java_api_client
And then start using that client in your Java code to talk to Cloudflare’s API.
How Cloudflare transitioned to OpenAPI
As mentioned earlier, we previously used JSON Hyper-Schema to define our APIs. We have roughly 600 endpoints that were already defined in the schemas. Here is a snippet of what one endpoint looks like in JSON Hyper-Schema:
{
"title": "List Zones",
"description": "List, search, sort, and filter your zones.",
"rel": "collection",
"href": "zones",
"method": "GET",
"schema": {
"$ref": "definitions/zone.json#/definitions/collection_query"
},
"targetSchema": {
"$ref": "#/definitions/response_collection"
},
"cfOwnership": "www",
"cfPlanAvailability": {
"free": true,
"pro": true,
"business": true,
"enterprise": true
},
"cfPermissionsRequired": {
"enum": [
"#zone:read"
]
}
}
Let’s look at the same endpoint in OpenAPI:
/zones:
get:
description: List, search, sort, and filter your zones.
operationId: zone-list-zones
responses:
4xx:
content:
application/json:
schema:
allOf:
- $ref: '#/components/schemas/components-schemas-response_collection'
- $ref: '#/components/schemas/api-response-common-failure'
description: List Zones response failure
"200":
content:
application/json:
schema:
$ref: '#/components/schemas/components-schemas-response_collection'
description: List Zones response
security:
- api_email: []
api_key: []
summary: List Zones
tags:
- Zone
x-cfPermissionsRequired:
enum:
- '#zone:read'
x-cfPlanAvailability:
business: true
enterprise: true
free: true
pro: true
You can see that the two look fairly similar and for the most part the same information is contained in each including method type, a description, and request and response definitions (although those are linked in $refs). The value of migrating from one to the other isn’t the change in how we define the schemas themselves, but in what we can do with these schemas. Numerous tools can parse the latter, the OpenAPI, while much fewer can parse the former, the JSON Hyper-Schema.
If this one API was all that made up the Cloudflare API, it would be easy to just convert the JSON Hyper-Schema into the OpenAPI Schema by hand and call it a day. Doing this 600 times, however, was going to be a huge undertaking. When considering that teams are constantly adding new endpoints, it would be impossible to keep up. It was also the case that our existing API docs used the existing JSON Hyper-Schema, so that meant that we would need to keep both schemas up to date during any transition period. There had to be a better way.
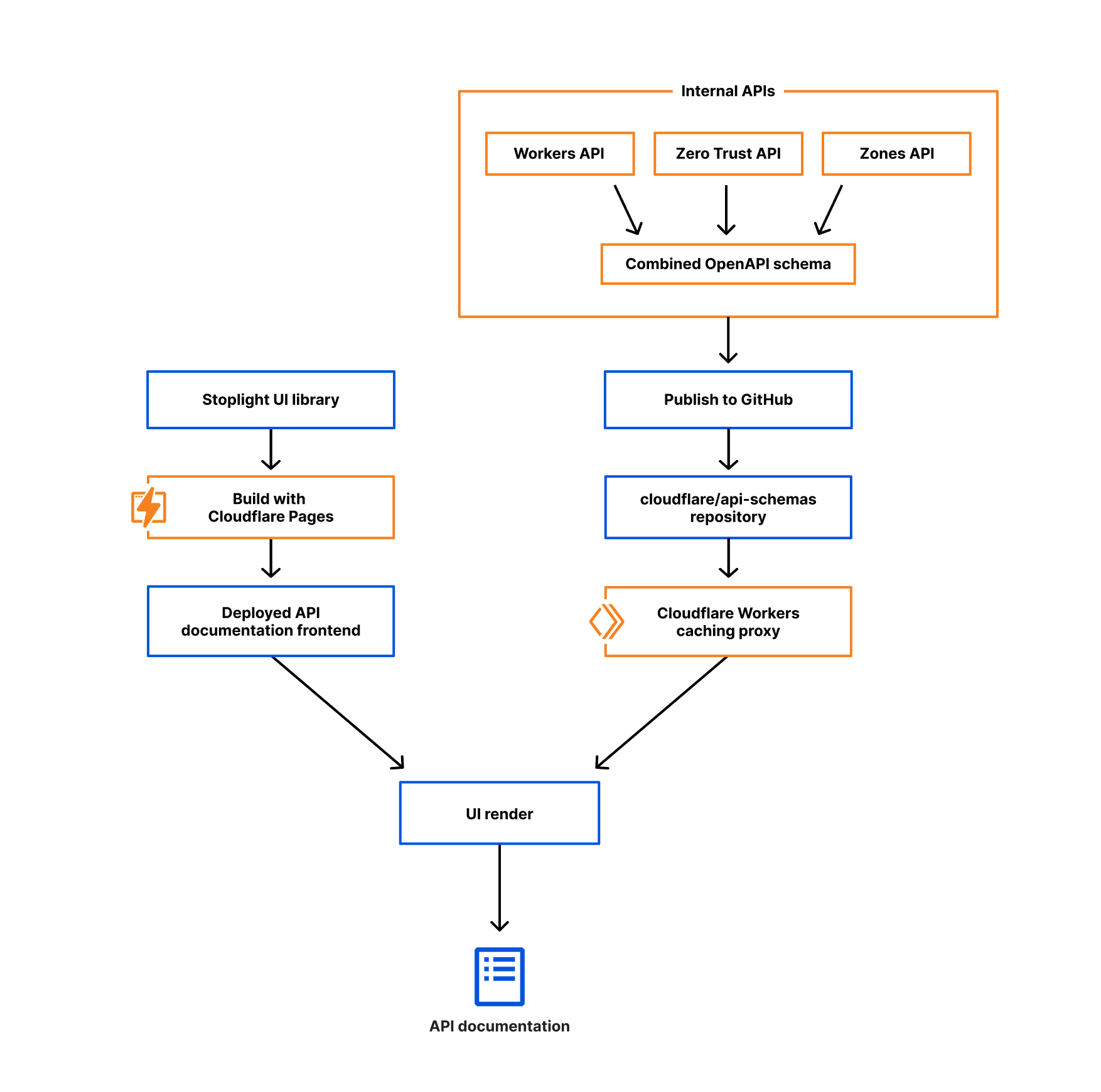
Auto conversion
Given both JSON Hyper-Schema and OpenAPI are standards, it reasons that it should be possible to take a file in one format and convert to the other, right? Luckily the answer is yes! We built a tool that took all existing JSON Hyper-Schema and output fully compliant OpenAPI schemas. This of course didn’t happen overnight, but because of existing OpenAPI tooling, we could iteratively improve the auto convertor and run OpenAPI validation tooling over the output schemas to see what issues the conversion tool still had.
After many iterations and improvements to the conversion tool, we finally had fully compliant OpenAPI Spec schemas being auto-generated from our existing JSON Hyper-Schema. While we were building this tool, teams kept adding and updating the existing schemas and our Product Content team was also updating text in the schemas to make our API docs easier to use. The benefit of this process is we didn’t have to slow any of that work down since anything that changed in the old schemas was automatically reflected in the new schemas!
Once the tool was ready, the remaining step was to decide when and how we would stop making updates to the JSON Hyper-Schemas and move all teams to the OpenAPI Schemas. The (now old) API docs were the biggest concern, given they only understood JSON Hyper-Schema. Thanks to the help of our Developer Experience and Product Content teams, we were able to launch the new API docs today and can officially cut over to OpenAPI today as well!
What’s next?
Now that we have fully moved over to OpenAPI, more opportunities become available. Internally, we will be investigating what tooling we can adopt in order to help reduce the effort of individual teams and speed up API development. One idea we are exploring is automatically creating openAPI schemas from code notations. Externally, we now have the foundational tools necessary to begin exploring how to auto generate and support more programming language libraries for customers to use. We are also excited to see what you may do with the schemas yourself, so if you do something cool or have ideas, don’t hesitate to share them with us!





















 Anna Montalat is a Senior Product Marketing Manager for AWS streaming data services which includes Amazon Managed Streaming for Apache Kafka (MSK), Kinesis Data Streams, Kinesis Video Streams, Kinesis Data Firehose, and Kinesis Data Analytics. She is passionate about bringing new and emerging technologies to market, working closely with service teams and enterprise customers. Outside of work, Anna skis through winter time and sails through summer.
Anna Montalat is a Senior Product Marketing Manager for AWS streaming data services which includes Amazon Managed Streaming for Apache Kafka (MSK), Kinesis Data Streams, Kinesis Video Streams, Kinesis Data Firehose, and Kinesis Data Analytics. She is passionate about bringing new and emerging technologies to market, working closely with service teams and enterprise customers. Outside of work, Anna skis through winter time and sails through summer.