Post Syndicated from Macey Neff original https://aws.amazon.com/blogs/compute/training-machine-learning-models-on-premises-for-data-residency-with-aws-outposts-rack/
This post is written by Sumit Menaria, Senior Hybrid Solutions Architect, and Boris Alexandrov, Senior Product Manager-Tech.
In this post, you will learn how to train machine learning (ML) models on premises using AWS Outposts rack and datasets stored locally in Amazon S3 on Outposts. With the rise in data sovereignty and privacy regulations, organizations are seeking flexible solutions that balance compliance with the agility of cloud services. Healthcare and financial sectors, for instance, harness machine learning for enhanced patient care and transaction safety, all while upholding strict confidentiality. Outposts rack provide a seamless hybrid solution by extending AWS capabilities to any on-premises or edge location, providing you the flexibility to store and process data wherever you choose. Data sovereignty regulations are highly nuanced and vary by country. This blog post addresses data sovereignty scenarios where training datasets need to be stored and processed in a geographic location without an AWS Region.
Amazon S3 on Outposts
As you prepare datasets for ML model training, a key component to consider is the storage and retrieval of your data, especially when adhering to data residency and regulatory requirements.
You can store training datasets as object data in local buckets with Amazon S3 on Outposts. In order to access S3 on Outposts buckets for data operations, you need to create access points and route the requests via an S3 on Outposts endpoint associated with your VPC. These endpoints are accessible both from within the VPC as well as on premises via the local gateway.

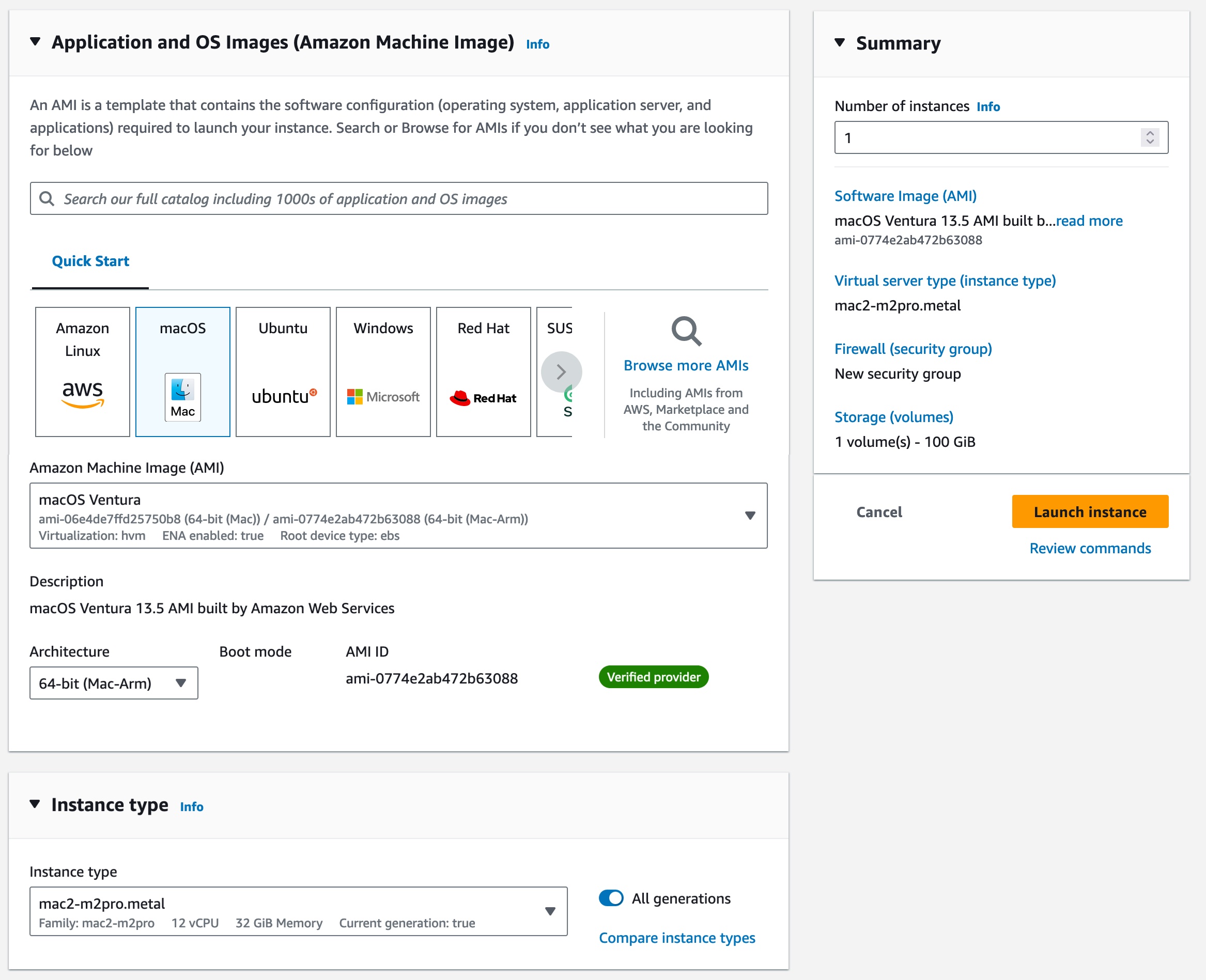
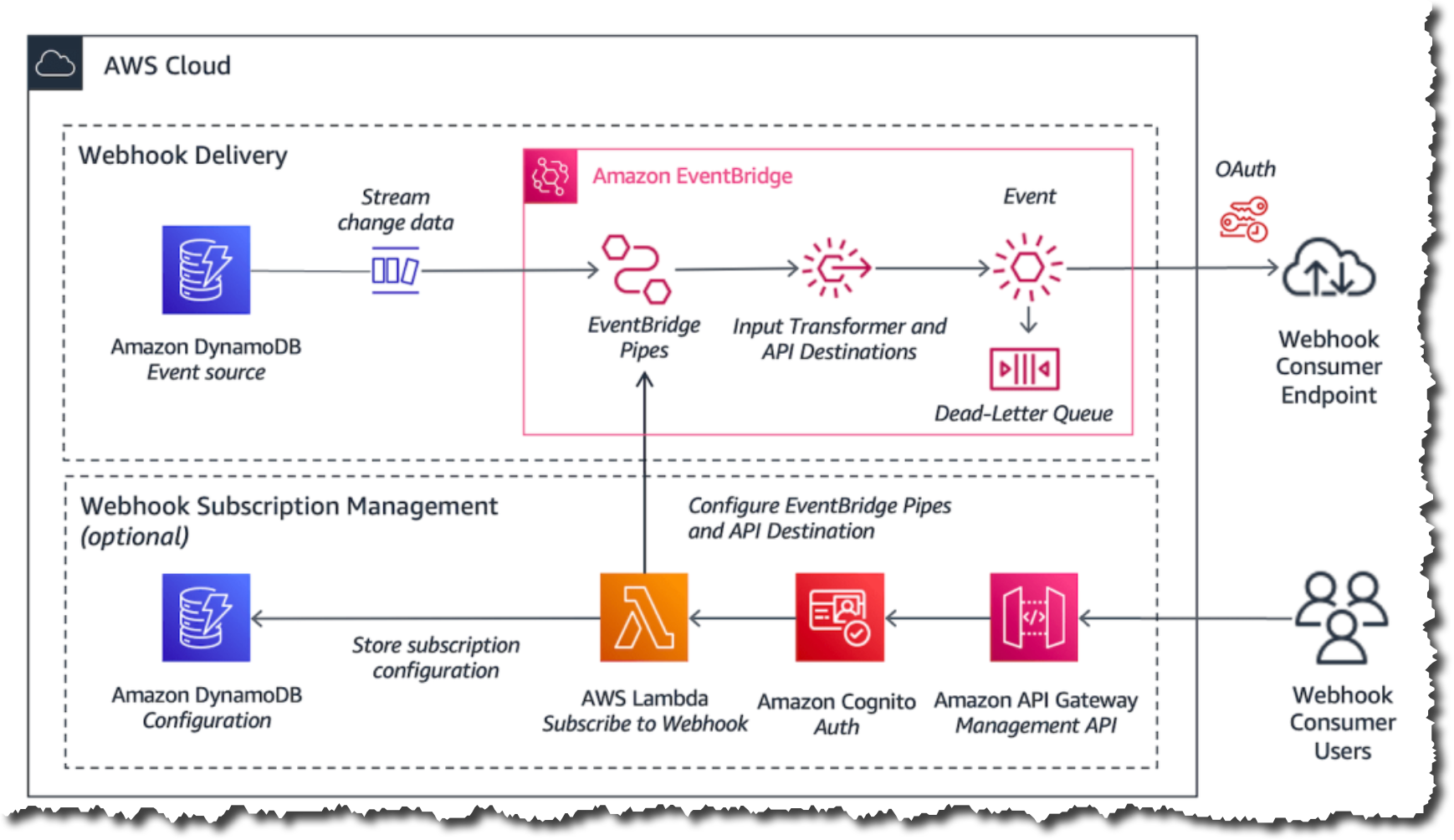
Solution overview
Using this sample architecture, you are going to train a YOLOv5 model on a subset of categories of the Common Objects in Context (COCO) dataset. The COCO dataset is a popular choice for object detection tasks offering a wide variety of image categories with rich annotations. It is also available under the AWS Open Data Sponsorship Program via fast.ai datasets.

This example is based on an architecture using an Amazon Elastic Compute Cloud (Amazon EC2) g4dn.8xlarge instance for model training on the Outposts rack. Depending on your Outposts rack compute configuration, you can use different instance sizes or types and make adjustments to training parameters, such as learning rate, augmentation, or model architecture accordingly. You will be using the AWS Deep Learning AMI to launch your EC2 instance, which comes with frameworks, dependencies, and tools to accelerate deep learning in the cloud.
For the training dataset storage, you are going to use an S3 on Outposts bucket and connect to it from your on-premises location via the Outposts local gateway. The local gateway routing mode can be direct VPC routing or Customer-owned IP (CoIP) depending on your workload’s requirements. Your local gateway routing mode will determine the S3 on Outposts endpoint configuration that you need to use.
1. Download and populate training dataset
You can download the training dataset to your local client machine using the following AWS CLI command:
aws s3 sync s3://fast-ai-coco/ .
After downloading, unzip annotations_trainval2017.zip, val2017.zip and train2017.zip files.
$ unzip annotations_trainval2017.zip
$ unzip val2017.zip
$ unzip train2017.zip
In the annotations folder, the files which you need to use are instances_train2017.json and instances_val2017.json, which contain the annotations corresponding to the images in the training and validation folders.
2. Filtering and preparing training dataset
You are going to use the training, validation, and annotation files from the COCO dataset. The dataset contains over 100K images across 80 categories, but to keep the training simple, you can focus on 10 specific categories of popular food items in supermarket shelves: banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, and cake. (Because who doesn’t like a bite after a model training.) Applications for training such models could be self-stock monitoring, automatic checkouts, or product placement optimization using computer vision in retail stores. Since YOLOv5 uses a specific annotations (labels) format, you need to convert the COCO dataset annotation to the target annotation.
3. Load training dataset to S3 on Outposts bucket
In order to load the training data on S3 on Outposts you need to first create a new bucket using the AWS Console or CLI, as well as an access point and endpoint for the VPC. You can use a bucket style access point alias to load the data, using the following CLI command:
$ cd /your/local/target/upload/path/
$ aws s3 sync . s3://trainingdata-o0a2b3c4d5e6d7f8g9h10f--op-s3
Replace the alias in the above CLI command with corresponding bucket alias name for your environment. The s3 sync command syncs the folders in the same structure containing the images and labels for the training and validation data, which you will be using later for loading it to the EC2 instance for model training.
4. Launch the EC2 instance
You can launch the EC2 instance with the Deep Learning AMI based on this getting started tutorial. For this exercise, the Deep Learning AMI GPU PyTorch 2.0.1 (Ubuntu 20.04) has been used.
5. Download YOLOv5 and install dependencies
Once you ssh into the EC2 instance, activate the pre-configured PyTorch environment and clone the YOLOv5 repository.
$ ssh -i /path/key-pair-name.pem ubuntu@instance-ip-address
$ conda activate pytorch
$ git clone https://github.com/ultralytics/yolov5.git
$ cd yolov5
Then, and install its necessary dependencies.
$ pip install -U -r requirements.txt
To ensure the compatibility between various packages, you may need to modify existing packages on your instance running the AWS Deep Learning AMI.
6. Load the training dataset from S3 on Outposts to the EC2 instance
For copying the training dataset to the EC2 instance, use the s3 sync CLI command and point it to your local workspace.
aws s3 sync s3://trainingdata-o0a2b3c4d5e6d7f8g9h10f--op-s3 .
7. Prepare the configuration files
Create the data configuration files to reflect your dataset’s structure, categories, and other parameters.
data.yml
train: /your/ec2/path/to/data/images/train
val: /your/ec2/path/to/data/images/val
nc: 10 # Number of classes in your dataset
names: ['banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake']
Create the model training parameter file using the sample configuration file from the YOLOv5 repository. You will need to update the number of classes to 10, but you can also change other parameters as you fine tune the model for performance.
parameters.yml:
# Parameters
nc: 10 # number of classes in your dataset
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# Backbone
backbone:
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# Head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
At this stage, the directory structure should look like below:
![Directory tree showing training dataset and model configuration structure]](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%20505%20570'%3E%3C/svg%3E)
8. Train the model
You can run the following command to train the model. The batch-size and epochs can vary depending on your vCPU and GPU configuration and you can further modify these values or add weights as you try with additional rounds of training.
$ python3 train.py —img-size 640 —batch-size 32 —epochs 50 —data /your/path/to/configuation_files/dataconfig.yaml —cfg /your/path/to/configuation_files/parameters.yaml
You can monitor the model performance as it iterates through each epoch
Starting training for 50 epochs...
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
0/49 6.7G 0.08403 0.05 0.04359 129 640: 100%|██████████| 455/455 [06:14<00:00,
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 9/9 [00:05<0
all 575 2114 0.216 0.155 0.0995 0.0338
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
1/49 8.95G 0.07131 0.05091 0.02365 179 640: 100%|██████████| 455/455 [06:00<00:00,
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 9/9 [00:04<00:00, 1.97it/s]
all 575 2114 0.242 0.144 0.11 0.04
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
2/49 8.96G 0.07068 0.05331 0.02712 154 640: 100%|██████████| 455/455 [06:01<00:00, 1.26it/s]
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 9/9 [00:04<00:00, 2.23it/s]
all 575 2114 0.185 0.124 0.0732 0.0273
Once the model training finishes, you can see the validation results against the batch of validation dataset and evaluate the model’s performance using standard metrics.
Validating runs/train/exp/weights/best.pt...
Fusing layers...
YOLOv5 summary: 157 layers, 7037095 parameters, 0 gradients, 15.8 GFLOPs
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 9/9 [00:06<00:00, 1.48it/s]
all 575 2114 0.282 0.222 0.16 0.0653
banana 575 280 0.189 0.143 0.0759 0.024
apple 575 186 0.206 0.085 0.0418 0.0151
sandwich 575 146 0.368 0.404 0.343 0.146
orange 575 188 0.265 0.149 0.0863 0.0362
broccoli 575 226 0.239 0.226 0.138 0.0417
carrot 575 310 0.182 0.203 0.0971 0.0267
hot dog 575 108 0.242 0.111 0.0929 0.0311
pizza 575 208 0.405 0.418 0.333 0.15
donut 575 228 0.352 0.241 0.19 0.0973
cake 575 234 0.369 0.235 0.203 0.0853
Results saved to runs/train/exp
Use the model for inference
In order to test the model performance, you can test it by passing a new image which is from a shelf in a supermarket with some of the objects that you trained the model on.

(pytorch) ubuntu@ip-172-31-48-165:~/workspace/source/yolov5$ python3 detect.py --weights /home/ubuntu/workspace/source/yolov5/runs/train/exp/weights/best.pt —source /home/ubuntu/workspace/inference/Inference-image.jpg
<<omitted output>>
Fusing layers...
YOLOv5 summary: 157 layers, 7037095 parameters, 0 gradients, 15.8 GFLOPs
image 1/1 /home/ubuntu/workspace/inference/Inference-image.jpg: 640x640 4 apples, 6 oranges, 1 cake, 5.3ms
Speed: 0.6ms pre-process, 5.3ms inference, 1.1ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs/detect/exp7
The response from the preceding model inference indicates that it predicted 4 apples, 6 oranges, and 1 cake in the image. The prediction may differ based on the image type used, and while a single sample image can give you a sense of the model’s performance, it will not provide a comprehensive understanding. For a more complete evaluation, it’s always recommended to test the model on a larger and more diverse set of validation images. Additional training and tuning of your parameters or datasets may be required to achieve better prediction.
Clean Up
You can terminate the following resources used in this tutorial after you have successfully trained and tested the model:
Conclusion
The seamless integration of compute on AWS Outposts with S3 on Outposts, coupled with on-premises ML model training capabilities, offers organizations a robust solution to tackle data residency requirements. By setting up this environment, you can ensure that your datasets remain within desired geographies while still utilizing advanced machine learning models and cloud infrastructure. In addition to this, it remains essential to diligently review and fine-tune your implementation strategies and guard rails in place to ensure your data remains within the boundaries of your regulatory requirements. You can read more about architecting for data residency in this blog post.
Reference































![Directory tree showing training dataset and model configuration structure]](https://d2908q01vomqb2.cloudfront.net/1b6453892473a467d07372d45eb05abc2031647a/2023/10/17/figure-3.jpg)