Post Syndicated from Shoukat Ghouse original https://aws.amazon.com/blogs/big-data/automated-data-governance-with-aws-glue-data-quality-sensitive-data-detection-and-aws-lake-formation/
Data governance is the process of ensuring the integrity, availability, usability, and security of an organization’s data. Due to the volume, velocity, and variety of data being ingested in data lakes, it can get challenging to develop and maintain policies and procedures to ensure data governance at scale for your data lake. Data confidentiality and data quality are the two essential themes for data governance. Data confidentiality refers to the protection and control of sensitive and private information to prevent unauthorized access, especially when dealing with personally identifiable information (PII). Data quality focuses on maintaining accurate, reliable, and consistent data across the organization. Poor data quality can lead to erroneous decisions, inefficient operations, and compromised business performance.
Companies need to ensure data confidentiality is maintained throughout the data pipeline and that high-quality data is available to consumers in a timely manner. A lot of this effort is manual, where data owners and data stewards define and apply the policies statically up front for each dataset in the lake. This gets tedious and delays the data adoption across the enterprise.
In this post, we showcase how to use AWS Glue with AWS Glue Data Quality, sensitive data detection transforms, and AWS Lake Formation tag-based access control to automate data governance.
Solution overview
Let’s consider a fictional company, OkTank. OkTank has multiple ingestion pipelines that populate multiple tables in the data lake. OkTank wants to ensure the data lake is governed with data quality rules and access policies in place at all times.
Multiple personas consume data from the data lake, such as business leaders, data scientists, data analysts, and data engineers. For each set of users, a different level of governance is needed. For example, business leaders need top-quality and highly accurate data, data scientists cannot see PII data and need data within an acceptable quality range for their model training, and data engineers can see all data except PII.
Currently, these requirements are hard-coded and managed manually for each set of users. OkTank wants to scale this and is looking for ways to control governance in an automated way. Primarily, they are looking for the following features:
- When new data and tables get added to the data lake, the governance policies (data quality checks and access controls) get automatically applied for them. Unless the data is certified to be consumed, it shouldn’t be accessible to the end-users. For example, they want to ensure basic data quality checks are applied on all new tables and provide access to the data based on the data quality score.
- Due to changes in source data, the existing data profile of data lake tables may drift. It’s required to ensure the governance is met as defined. For example, the system should automatically mark columns as sensitive if sensitive data is detected in a column that was earlier marked as public and was available publicly for users. The system should hide the column from unauthorized users accordingly.
For the purpose of this post, the following governance policies are defined:
- No PII data should exist in tables or columns tagged as
public. - If a column has any PII data, the column should be marked as
sensitive. The table should then also be markedsensitive. - The following data quality rules should be applied on all tables:
- All tables should have a minimum set of columns:
data_key,data_load_date, anddata_location. data_keyis a key column and should meet key requirements of being unique and complete.data_locationshould match with locations defined in a separate reference (base) table.- The
data_load_datecolumn should be complete.
- All tables should have a minimum set of columns:
- User access to tables is controlled as per the following table.
| User Description | Can Access Sensitive Tables | Can Access Sensitive Columns | Min Data Quality Threshold Needed to consume Data |
| Category 1 | Yes | Yes | 100% |
| Category 2 | Yes | No | 50% |
| Category 3 | No | No | 0% |
In this post, we use AWS Glue Data Quality and sensitive data detection features. We also use Lake Formation tag-based access control to manage access at scale.
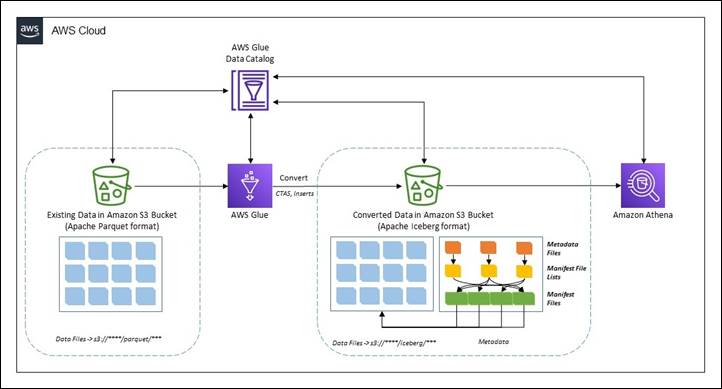
The following diagram illustrates the solution architecture.

The governance requirements highlighted in the previous table are translated to the following Lake Formation LF-Tags.
| IAM User | LF-Tag: tbl_class | LF-Tag: col_class | LF-Tag: dq_tag |
| Category 1 | sensitive, public | sensitive, public | DQ100 |
| Category 2 | sensitive, public | public | DQ100,DQ90,DQ50_80,DQ80_90 |
| Category 3 | public | public | DQ90, DQ100, DQ_LT_50, DQ50_80, DQ80_90 |
This post uses AWS Step Functions to orchestrate the governance jobs, but you can use any other orchestration tool of choice. To simulate data ingestion, we manually place the files in an Amazon Simple Storage Service (Amazon S3) bucket. In this post, we trigger the Step Functions state machine manually for ease of understanding. In practice, you can integrate or invoke the jobs as part of a data ingestion pipeline, via event triggers like AWS Glue crawler or Amazon S3 events, or schedule them as needed.
In this post, we use an AWS Glue database named oktank_autogov_temp and a target table named customer on which we apply the governance rules. We use AWS CloudFormation to provision the resources. AWS CloudFormation lets you model, provision, and manage AWS and third-party resources by treating infrastructure as code.
Prerequisites
Complete the following prerequisite steps:
- Identify an AWS Region in which you want to create the resources and ensure you use the same Region throughout the setup and verifications.
- Have a Lake Formation administrator role to run the CloudFormation template and grant permissions.
Sign in to the Lake Formation console and add yourself as a Lake Formation data lake administrator if you aren’t already an admin. If you are setting up Lake Formation for the first time in your Region, then you can do this in the following pop-up window that appears up when you connect to the Lake Formation console and select the desired Region.

Otherwise, you can add data lake administrators by choosing Administrative roles and tasks in the navigation pane on the Lake Formation console and choosing Add administrators. Then select Data lake administrator, identity your users and roles, and choose Confirm.

Deploy the CloudFormation stack
Run the provided CloudFormation stack to create the solution resources.
You need to provide a unique bucket name and specify passwords for the three users reflecting three different user personas (Category 1, Category 2, and Category 3) that we use for this post.
The stack provisions an S3 bucket to store the dummy data, AWS Glue scripts, results of sensitive data detection, and Amazon Athena query results in their respective folders.
The stack copies the AWS Glue scripts into the scripts folder and creates two AWS Glue jobs Data-Quality-PII-Checker_Job and LF-Tag-Handler_Job pointing to the corresponding scripts.

The AWS Glue job Data-Quality-PII-Checker_Job applies the data quality rules and publishes the results. It also checks for sensitive data in the columns. In this post, we check for the PERSON_NAME and EMAIL data types. If any columns with sensitive data are detected, it persists the sensitive data detection results to the S3 bucket.
AWS Glue Data Quality uses Data Quality Definition Language (DQDL) to author the data quality rules.
The data quality requirements as defined earlier in this post are written as the following DQDL in the script:
The following screenshot shows a sample result from the job after it runs. You can see this after you trigger the Step Functions workflow in subsequent steps. To check the results, on the AWS Glue console, choose ETL jobs and choose the job called Data-Quality-PII-Checker_Job. Then navigate to the Data quality tab to view the results.

The AWS Glue jobLF-Tag-Handler_Job fetches the data quality metrics published by Data-Quality-PII-Checker_Job. It checks the status of the DataQuality_PIIColumns result. It gets the list of sensitive column names from the sensitive data detection file created in the Data-Quality-PII-Checker_Job and tags the columns as sensitive. The rest of the columns are tagged as public. It also tags the table assensitive if sensitive columns are detected. The table is marked as public if no sensitive columns are detected.
The job also checks the data quality score for the DataQuality_BasicChecks result set. It maps the data quality score into tags as shown in the following table and applies the corresponding tag on the table.
| Data Quality Score | Data Quality Tag |
| 100% | DQ100 |
| 90-100% | DQ90 |
| 80-90% | DQ80_90 |
| 50-80% | DQ50_80 |
| Less than 50% | DQ_LT_50 |
The CloudFormation stack copies some mock data to the data folder and registers this location under AWS Lake Formation Data lake locations so Lake Formation can govern access on the location using service-linked role for Lake Formation.

The customer subfolder contains the initial customer dataset for the table customer. The base subfolder contains the base dataset, which we use to check referential integrity as part of the data quality checks. The column data_location in the customer table should match with locations defined in this base table.
The stack also copies some additional mock data to the bucket under the data-v1 folder. We use this data to simulate data quality issues.

It also creates the following resources:
- An AWS Glue database called
oktank_autogov_tempand two tables under the database:- customer – This is our target table on which we will be governing the access based on data quality rules and PII checks.
- base – This is the base table that has the reference data. One of the data quality rules checks that the customer data always adheres to locations present in the base table.
- AWS Identity and Access Management (IAM) users and roles:
- DataLakeUser_Category1 – The data lake user corresponding to the Category 1 user. This user should be able to access sensitive data but needs 100% accurate data.
- DataLakeUser_Category2 – The data lake user corresponding to the Category 2 user. This user should not be able to access sensitive columns in the table. It needs more than 50% accurate data.
- DataLakeUser_Category3 – The data lake user corresponding to the Category 3 user. This user should not be able to access tables containing sensitive data. Data quality can be 0%.
- GlueServiceDQRole – The role for the data quality and sensitive data detection job.
- GlueServiceLFTaggerRole – The role for the LF-Tags handler job for applying the tags to the table.
- StepFunctionRole – The Step Functions role for triggering the AWS Glue jobs.
- Lake Formation LF-Tags keys and values:
- tbl_class –
sensitive,public - dq_class –
DQ100,DQ90,DQ80_90,DQ50_80,DQ_LT_50 - col_class –
sensitive,public
- tbl_class –
- A Step Functions state machine named
AutoGovMachinethat you use to trigger the runs for the AWS Glue jobs to check data quality and update the LF-Tags. - Athena workgroups named
auto_gov_blog_workgroup_temporary_user1,auto_gov_blog_workgroup_temporary_user2, andauto_gov_blog_workgroup_temporary_user3. These workgroups point to different Athena query result locations for each user. Each user is granted access to the corresponding query result location only. This ensures a specific user doesn’t access the query results of other users. You should switch to a specific workgroup to run queries in Athena as part of the test for the specific user.
The CloudFormation stack generates the following outputs. Take note of the values of the IAM users to use in subsequent steps.

Grant permissions
After you launch the CloudFormation stack, complete the following steps:
- On the Lake Formation console, under Permissions choose Data lake permissions in the navigation pane.
- Search for the database
oktank_autogov_tempand tablecustomer. - If
IAMAllowedPrincipalsaccess if present, select it choose Revoke.

- Choose Revoke again to revoke the permissions.

Category 1 users can access all data except if the data quality score of the table is below 100%. Therefore, we grant the user the necessary permissions.
- Under Permissions in the navigation pane, choose Data lake permissions.
- Search for database
oktank_autogov_tempand tablecustomer. - Choose Grant
- Select IAM users and roles and choose the value for
UserCategory1from your CloudFormation stack output. - Under LF-Tags or catalog resources, choose Add LF-Tag key-value pair.
- Add the following key-value pairs:
- For the
col_classkey, add the valuespublicandsensitive. - For the
tbl_classkey, add the valuespublicandsensitive. - For the
dq_tagkey, add the valueDQ100.
- For the

- For Table permissions, select Select.
- Choose Grant.

Category 2 users can’t access sensitive columns. They can access tables with a data quality score above 50%.
- Repeat the preceding steps to grant the appropriate permissions in Lake Formation to
UserCategory2:- For the
col_classkey, add the valuepublic. - For the
tbl_classkey, add the valuespublicandsensitive. - For the
dq_tagkey, add the valuesDQ50_80,DQ80_90,DQ90, andDQ100.
- For the

- For Table permissions, select Select.
- Choose Grant.
Category 3 users can’t access tables that contain any sensitive columns. Such tables are marked as sensitive by the system. They can access tables with any data quality score.
- Repeat the preceding steps to grant the appropriate permissions in Lake Formation to UserCategory3:
- For the
col_classkey, add the valuepublic. - For the
tbl_classkey, add the valuepublic. - For the
dq_tagkey, add the valuesDQ_LT_50,DQ50_80,DQ80_90,DQ90, andDQ100.
- For the

- For Table permissions, select Select.
- Choose Grant.
You can verify the LF-Tag permissions assigned in Lake Formation by navigating to the Data lake permissions page and searching for the Resource type LF-Tag expression.

Test the solution
Now we can test the workflow. We test three different use cases in this post. You will notice how the permissions to the tables change based on the values of LF-Tags applied to the customer table and the columns of the table. We use Athena to query the tables.
Use case 1
In this first use case, a new table was created on the lake and new data was ingested to the table. The data file cust_feedback_v0.csv was copied to the data/customer location in the S3 bucket. This simulates new data ingestion on a new table called customer.
Lake Formation doesn’t allow any users to access this table currently. To test this scenario, complete the following steps:
- Sign in to the Athena console with the
UserCategory1user. - Switch the workgroup to
auto_gov_blog_workgroup_temporary_user1in the Athena query editor. - Choose Acknowledge to accept the workgroup settings.

- Run the following query in the query editor:

- On the Step Functions console, run the
AutoGovMachinestate machine. - In the Input – optional section, use the following JSON and replace the
BucketNamevalue with the bucket name you used for the CloudFormation stack earlier (for this post, we useauto-gov-blog):

The state machine triggers the AWS Glue jobs to check data quality on the table and apply the corresponding LF-Tags.

- You can check the LF-Tags applied on the table and the columns. To do so, when the state machine is complete, sign in to Lake Formation with the admin role used earlier to grant permissions.
- Navigate to the table
customerunder theoktank_autogov_tempdatabase and choose Edit LF-Tags to validate the tags applied on the table.

You can also validate that columns customer_email and customer_name are tagged as sensitive for the col_class LF-Tag.
- To check this, choose Edit Schema for the
customertable. - Select the two columns and choose Edit LF-Tags.

You can check the tags on these columns.

The rest of the columns are tagged as public.

- Sign in to the Athena console with
UserCategory1and run the same query again:
This time, the user is able to see the data. This is because the LF-Tag permissions we applied earlier are in effect.

- Sign in as
UserCategory2user to verify permissions. - Switch to workgroup
auto_gov_blog_workgroup_temporary_user2in Athena.
This user can access the table but can only see public columns. Therefore, the user shouldn’t be able to see the customer_email and customer_phone columns because these columns contain sensitive data as identified by the system.
- Run the same query again:

- Sign in to Athena and verify the permissions for
DataLakeUser_Category3. - Switch to workgroup
auto_gov_blog_workgroup_temporary_user3in Athena.
This user can’t access the table because the table is marked as sensitive due to the presence of sensitive data columns in the table.
- Run the same query again:

Use case 2
Let’s ingest some new data on the table.
- Sign in to the Amazon S3 console with the admin role used earlier to grant permissions.
- Copy the file
cust_feedback_v1.csvfrom thedata-v1folder in the S3 bucket to thedata/customerfolder in the S3 bucket using the default options.
This new data file has data quality issues because the column data_location breaks referential integrity with the base table. This data also introduces some sensitive data in column comment1. This column was earlier marked as public because it didn’t have any sensitive data.
The following screenshot shows what the customer folder should look like now.

- Run the AutoGovMachine state machine again and use the same JSON as the StartExecution input you used earlier:
The job classifies column comment1 as sensitive on the customer table. It also updates the dq_tag value on the table because the data quality has changed due to the breaking referential integrity check.
You can verify the new tag values via the Lake Formation console as described earlier. The dq_tag value was DQ100. The value is changed to DQ50_80, reflecting the data quality score for the table.

Also, earlier the value for the col_class tag for the comment1 column was public. The value is now changed to sensitive because sensitive data is detected in this column.

Category 2 users shouldn’t be able to access sensitive columns in the table.
- Sign in with
UserCategory2to Athena and rerun the earlier query:
The column comment1 is now not available for UserCategory2 as expected. The access permissions are handled automatically.

Also, because the data quality score goes down below 100%, this new dataset is now not available for the Category1 user. This user should have access to data only when the score is 100% as per our defined rules.
- Sign in with
UserCategory1to Athena and rerun the earlier query:
You will see the user is not able to access the table now. The access permissions are handled automatically.

Use case 3
Let’s fix the invalid data and remove the data quality issue.
- Delete the
cust_feedback_v1.csvfile from thedata/customerAmazon S3 location. - Copy the file
cust_feedback_v1_fixed.csvfrom thedata-v1folder in the S3 bucket to thedata/customerS3 location. This data file fixes the data quality issues. - Rerun the
AutoGovMachinestate machine.
When the state machine is complete, the data quality score goes up to 100% again and the tag on the table gets updated accordingly. You can verify the new tag as shown earlier via the Lake Formation console.

The Category1 user can access the table again.

Clean up
To avoid incurring further charges, delete the CloudFormation stack to delete the resources provisioned as part of this post.
Conclusion
This post covered AWS Glue Data Quality and sensitive detection features and Lake Formation LF-Tag based access control. We explored how you can combine these features and use them to build a scalable automated data governance capability on your data lake. We explored how user permissions changed when data was initially ingested to the table and when data drift was observed as part of subsequent ingestions.
For further reading, refer to the following resources:
- Getting started with AWS Glue Data Quality for ETL Pipelines
- Set up data quality rules across multiple datasets using AWS Glue Data Quality
- Set up alerts and orchestrate data quality rules with AWS Glue Data Quality
- Easily manage your data lake at scale using tag based access control in AWS Lake Formation
- Build a modern data architecture and data mesh pattern at scale using AWS Lake Formation tag-based access control
About the Author
 Shoukat Ghouse is a Senior Big Data Specialist Solutions Architect at AWS. He helps customers around the world build robust, efficient and scalable data platforms on AWS leveraging AWS analytics services like AWS Glue, AWS Lake Formation, Amazon Athena and Amazon EMR.
Shoukat Ghouse is a Senior Big Data Specialist Solutions Architect at AWS. He helps customers around the world build robust, efficient and scalable data platforms on AWS leveraging AWS analytics services like AWS Glue, AWS Lake Formation, Amazon Athena and Amazon EMR.











 Kartikay Khator is a Solutions Architect on the Global Life Science at Amazon Web Services. He is passionate about helping customers on their cloud journey with focus on AWS analytics services. He is an avid runner and enjoys hiking.
Kartikay Khator is a Solutions Architect on the Global Life Science at Amazon Web Services. He is passionate about helping customers on their cloud journey with focus on AWS analytics services. He is an avid runner and enjoys hiking. Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect and Amazon AppFlow expert. He’s on a mission to make life easier for customers who are facing complex data integration challenges. His secret weapon? Fully managed, low-code AWS services that can get the job done with minimal effort and no coding.
Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect and Amazon AppFlow expert. He’s on a mission to make life easier for customers who are facing complex data integration challenges. His secret weapon? Fully managed, low-code AWS services that can get the job done with minimal effort and no coding.






 Deepak Singh is a Senior Solutions Architect at Amazon Web Services with 20+ years of experience in Data & AIA. He enjoys working with AWS partners and customers on building scalable analytical solutions for their business outcomes. When not at work, he loves spending time with family or exploring new technologies in analytics and AI space.
Deepak Singh is a Senior Solutions Architect at Amazon Web Services with 20+ years of experience in Data & AIA. He enjoys working with AWS partners and customers on building scalable analytical solutions for their business outcomes. When not at work, he loves spending time with family or exploring new technologies in analytics and AI space. Piyush Patra is a Partner Solutions Architect at Amazon Web Services where he supports partners with their Analytics journeys and is the global lead for strategic Data Estate Modernization and Migration partner programs.
Piyush Patra is a Partner Solutions Architect at Amazon Web Services where he supports partners with their Analytics journeys and is the global lead for strategic Data Estate Modernization and Migration partner programs. Govind Mohan is an Associate Director with Cognizant with over 18 year of experience in data and analytics space, he has helped design and implement multiple large-scale data migration, application lift & shift and legacy modernization projects and works closely with customers in accelerating the cloud modernization journey leveraging Cognizant Data and Intelligence Toolkit (CDIT) platform.
Govind Mohan is an Associate Director with Cognizant with over 18 year of experience in data and analytics space, he has helped design and implement multiple large-scale data migration, application lift & shift and legacy modernization projects and works closely with customers in accelerating the cloud modernization journey leveraging Cognizant Data and Intelligence Toolkit (CDIT) platform. Kausik Dhar is a technology leader having more than 23 years of IT experience – primarily focused on Data & Analytics, Data Modernization, Application Development, Delivery Management, and Solution Architecture. He has played a pivotal role in guiding clients through the designing and executing large-scale data and process migrations, in addition to spearheading successful cloud implementations. Kausik possesses expertise in formulating migration strategies for complex programs and adeptly constructing data lake/Lakehouse architecture employing a wide array of tools and technologies.
Kausik Dhar is a technology leader having more than 23 years of IT experience – primarily focused on Data & Analytics, Data Modernization, Application Development, Delivery Management, and Solution Architecture. He has played a pivotal role in guiding clients through the designing and executing large-scale data and process migrations, in addition to spearheading successful cloud implementations. Kausik possesses expertise in formulating migration strategies for complex programs and adeptly constructing data lake/Lakehouse architecture employing a wide array of tools and technologies.















 Rajdip Chaudhuri is a Senior Solutions Architect with Amazon Web Services specializing in data and analytics. He enjoys working with AWS customers and partners on data and analytics requirements. In his spare time, he enjoys soccer and movies.
Rajdip Chaudhuri is a Senior Solutions Architect with Amazon Web Services specializing in data and analytics. He enjoys working with AWS customers and partners on data and analytics requirements. In his spare time, he enjoys soccer and movies.
 M Mehrtens has been working in distributed systems engineering throughout their career, working as a Software Engineer, Architect, and Data Engineer. In the past, M has supported and built systems to process terrabytes of streaming data at low latency, run enterprise Machine Learning pipelines, and created systems to share data across teams seamlessly with varying data toolsets and software stacks. At AWS, they are a Sr. Solutions Architect supporting US Federal Financial customers.
M Mehrtens has been working in distributed systems engineering throughout their career, working as a Software Engineer, Architect, and Data Engineer. In the past, M has supported and built systems to process terrabytes of streaming data at low latency, run enterprise Machine Learning pipelines, and created systems to share data across teams seamlessly with varying data toolsets and software stacks. At AWS, they are a Sr. Solutions Architect supporting US Federal Financial customers. Sindhu Achuthan is a Sr. Solutions Architect with Federal Financials at AWS. She works with customers to provide architectural guidance on analytics solutions using AWS Glue, Amazon EMR, Amazon Kinesis, and other services. Outside of work, she loves DIYs, to go on long trails, and yoga.
Sindhu Achuthan is a Sr. Solutions Architect with Federal Financials at AWS. She works with customers to provide architectural guidance on analytics solutions using AWS Glue, Amazon EMR, Amazon Kinesis, and other services. Outside of work, she loves DIYs, to go on long trails, and yoga.
















 Navnit Shuklaserves as an AWS Specialist Solution Architect with a focus on Analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled “Data Wrangling on AWS.
Navnit Shuklaserves as an AWS Specialist Solution Architect with a focus on Analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled “Data Wrangling on AWS. Patrick Muller works as a Senior Data Lab Architect at AWS. His main responsibility is to assist customers in turning their ideas into a production-ready data product. In his free time, Patrick enjoys playing soccer, watching movies, and traveling.
Patrick Muller works as a Senior Data Lab Architect at AWS. His main responsibility is to assist customers in turning their ideas into a production-ready data product. In his free time, Patrick enjoys playing soccer, watching movies, and traveling. Amogh Gaikwad is a Senior Solutions Developer at Amazon Web Services. He helps global customers build and deploy AI/ML solutions on AWS. His work is mainly focused on computer vision, and natural language processing and helping customers optimize their AI/ML workloads for sustainability. Amogh has received his master’s in Computer Science specializing in Machine Learning.
Amogh Gaikwad is a Senior Solutions Developer at Amazon Web Services. He helps global customers build and deploy AI/ML solutions on AWS. His work is mainly focused on computer vision, and natural language processing and helping customers optimize their AI/ML workloads for sustainability. Amogh has received his master’s in Computer Science specializing in Machine Learning. Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS customers make informed choices and tradeoffs about accelerating their data, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time with her family – usually on tennis courts.
Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS customers make informed choices and tradeoffs about accelerating their data, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time with her family – usually on tennis courts.







































 Aarthi Srinivasan is a Senior Big Data Architect with AWS Lake Formation. She likes building data lake solutions for AWS customers and partners. When not on the keyboard, she explores the latest science and technology trends and spends time with her family.
Aarthi Srinivasan is a Senior Big Data Architect with AWS Lake Formation. She likes building data lake solutions for AWS customers and partners. When not on the keyboard, she explores the latest science and technology trends and spends time with her family.




 Annie Nelson is a Senior Solutions Architect at AWS. She is a data enthusiast who enjoys problem solving and tackling complex architectural challenges with customers.
Annie Nelson is a Senior Solutions Architect at AWS. She is a data enthusiast who enjoys problem solving and tackling complex architectural challenges with customers. Keerthi Chadalavada is a Senior Software Development Engineer at AWS Glue. She is passionate about designing and building end-to-end solutions to address customer data integration and analytic needs.
Keerthi Chadalavada is a Senior Software Development Engineer at AWS Glue. She is passionate about designing and building end-to-end solutions to address customer data integration and analytic needs. Zach Mitchell is a Sr. Big Data Architect. He works within the product team to enhance understanding between product engineers and their customers while guiding customers through their journey to develop their enterprise data architecture on AWS.
Zach Mitchell is a Sr. Big Data Architect. He works within the product team to enhance understanding between product engineers and their customers while guiding customers through their journey to develop their enterprise data architecture on AWS. Gal Heyne is a Product Manager for AWS Glue with a strong focus on AI/ML, data engineering and BI. She is passionate about developing a deep understanding of customer’s business needs and collaborating with engineers to design easy to use data products.
Gal Heyne is a Product Manager for AWS Glue with a strong focus on AI/ML, data engineering and BI. She is passionate about developing a deep understanding of customer’s business needs and collaborating with engineers to design easy to use data products.









 Khandu Shinde is a Staff Engineer focused on Big Data Platforms and Solutions for Chime. He helps to make the platform scalable for Chime’s business needs with architectural direction and vision. He’s based in San Francisco where he plays cricket and watches movies.
Khandu Shinde is a Staff Engineer focused on Big Data Platforms and Solutions for Chime. He helps to make the platform scalable for Chime’s business needs with architectural direction and vision. He’s based in San Francisco where he plays cricket and watches movies. Edward Paget is a Software Engineer working on building Chime’s capabilities to mitigate risk to ensure our members’ financial peace of mind. He enjoys being at the intersection of big data and programming language theory. He’s based in Chicago where he spends his time running along the lake shore.
Edward Paget is a Software Engineer working on building Chime’s capabilities to mitigate risk to ensure our members’ financial peace of mind. He enjoys being at the intersection of big data and programming language theory. He’s based in Chicago where he spends his time running along the lake shore. Dylan Qu is a Specialist Solutions Architect focused on Big Data & Analytics with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.
Dylan Qu is a Specialist Solutions Architect focused on Big Data & Analytics with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.










 Ishan Gaur works as Sr. Big Data Cloud Engineer ( ETL ) specialized in AWS Glue. He’s passionate about helping customers building out scalable distributed ETL workloads and analytics pipelines on AWS.
Ishan Gaur works as Sr. Big Data Cloud Engineer ( ETL ) specialized in AWS Glue. He’s passionate about helping customers building out scalable distributed ETL workloads and analytics pipelines on AWS. Omar Elkharbotly is a Glue SME who works as Big Data Cloud Support Engineer 2 (DIST). He is dedicated to assisting customers in resolving issues related to their ETL workloads and creating scalable data processing and analytics pipelines on AWS.
Omar Elkharbotly is a Glue SME who works as Big Data Cloud Support Engineer 2 (DIST). He is dedicated to assisting customers in resolving issues related to their ETL workloads and creating scalable data processing and analytics pipelines on AWS.












 Ravi Itha is a Principal Consultant at AWS Professional Services with specialization in data and analytics and generalist background in application development. Ravi helps customers with enterprise data strategy initiatives across insurance, airlines, pharmaceutical, and financial services industries. In his 6-year tenure at Amazon, Ravi has helped the AWS builder community by publishing approximately 15 open-source solutions (accessible via
Ravi Itha is a Principal Consultant at AWS Professional Services with specialization in data and analytics and generalist background in application development. Ravi helps customers with enterprise data strategy initiatives across insurance, airlines, pharmaceutical, and financial services industries. In his 6-year tenure at Amazon, Ravi has helped the AWS builder community by publishing approximately 15 open-source solutions (accessible via  Srinivas Kandi is a Data Architect at AWS Professional Services. He leads customer engagements related to data lakes, analytics, and data warehouse modernizations. He enjoys reading history and civilizations.
Srinivas Kandi is a Data Architect at AWS Professional Services. He leads customer engagements related to data lakes, analytics, and data warehouse modernizations. He enjoys reading history and civilizations.










 Shubham Purwar is a Cloud Engineer (ETL) at AWS Bengaluru specialized in AWS Glue and Amazon Athena. He is passionate about helping customers solve issues related to their ETL workload and implement scalable data processing and analytics pipelines on AWS. In his free time, Shubham loves to spend time with his family and travel around the world.
Shubham Purwar is a Cloud Engineer (ETL) at AWS Bengaluru specialized in AWS Glue and Amazon Athena. He is passionate about helping customers solve issues related to their ETL workload and implement scalable data processing and analytics pipelines on AWS. In his free time, Shubham loves to spend time with his family and travel around the world. Nitin Kumar is a Cloud Engineer (ETL) at AWS with a specialization in AWS Glue. He is dedicated to assisting customers in resolving issues related to their ETL workloads and creating scalable data processing and analytics pipelines on AWS.
Nitin Kumar is a Cloud Engineer (ETL) at AWS with a specialization in AWS Glue. He is dedicated to assisting customers in resolving issues related to their ETL workloads and creating scalable data processing and analytics pipelines on AWS.











 Cristiane de Melo is a Solutions Architect Manager at AWS based in Bay Area, CA. She brings 25+ years of experience driving technical pre-sales engagements and is responsible for delivering results to customers. Cris is passionate about working with customers, solving technical and business challenges, thriving on building and establishing long-term, strategic relationships with customers and partners.
Cristiane de Melo is a Solutions Architect Manager at AWS based in Bay Area, CA. She brings 25+ years of experience driving technical pre-sales engagements and is responsible for delivering results to customers. Cris is passionate about working with customers, solving technical and business challenges, thriving on building and establishing long-term, strategic relationships with customers and partners. Archana Inapudi is a Senior Solutions Architect at AWS supporting Strategic Customers. She has over a decade of experience helping customers design and build data analytics, and database solutions. She is passionate about using technology to provide value to customers and achieve business outcomes.
Archana Inapudi is a Senior Solutions Architect at AWS supporting Strategic Customers. She has over a decade of experience helping customers design and build data analytics, and database solutions. She is passionate about using technology to provide value to customers and achieve business outcomes. Nikita Sur is a Solutions Architect at AWS supporting a Strategic Customer. She is curious to learn new technologies to solve customer problems. She has a Master’s degree in Information Systems – Big Data Analytics and her passion is databases and analytics.
Nikita Sur is a Solutions Architect at AWS supporting a Strategic Customer. She is curious to learn new technologies to solve customer problems. She has a Master’s degree in Information Systems – Big Data Analytics and her passion is databases and analytics. Zach Mitchell is a Sr. Big Data Architect. He works within the product team to enhance understanding between product engineers and their customers while guiding customers through their journey to develop their enterprise data architecture on AWS.
Zach Mitchell is a Sr. Big Data Architect. He works within the product team to enhance understanding between product engineers and their customers while guiding customers through their journey to develop their enterprise data architecture on AWS.










 Satish Sathiya is a Senior Product Engineer at Amazon Redshift. He is an avid big data enthusiast who collaborates with customers around the globe to achieve success and meet their data warehousing and data lake architecture needs.
Satish Sathiya is a Senior Product Engineer at Amazon Redshift. He is an avid big data enthusiast who collaborates with customers around the globe to achieve success and meet their data warehousing and data lake architecture needs.






 Anand Komandooru is a Senior Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “
Anand Komandooru is a Senior Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “ Li Liu is a Senior Database Specialty Architect with the Professional Services team at Amazon Web Services. She helps customers migrate traditional on-premise databases to the AWS Cloud. She specializes in database design, architecture, and performance tuning.
Li Liu is a Senior Database Specialty Architect with the Professional Services team at Amazon Web Services. She helps customers migrate traditional on-premise databases to the AWS Cloud. She specializes in database design, architecture, and performance tuning. Neil Potter is a Senior Cloud Application Architect at AWS. He works with AWS customers to help them migrate their workloads to the AWS Cloud. He specializes in application modernization and cloud-native design and is based in New Jersey.
Neil Potter is a Senior Cloud Application Architect at AWS. He works with AWS customers to help them migrate their workloads to the AWS Cloud. He specializes in application modernization and cloud-native design and is based in New Jersey. Vivek Shrivastava is a Principal Data Architect, Data Lake in AWS Professional Services. He is a big data enthusiast and holds 14 AWS Certifications. He is passionate about helping customers build scalable and high-performance data analytics solutions in the cloud. In his spare time, he loves reading and finds areas for home automation.
Vivek Shrivastava is a Principal Data Architect, Data Lake in AWS Professional Services. He is a big data enthusiast and holds 14 AWS Certifications. He is passionate about helping customers build scalable and high-performance data analytics solutions in the cloud. In his spare time, he loves reading and finds areas for home automation.












 Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data. Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community. Mahesh Mishra is a Principal Product Manager with AWS Lake Formation team. He works with many of AWS largest customers on emerging technology needs, and leads several data and analytics initiatives within AWS including strong support for Transactional Data Lakes.
Mahesh Mishra is a Principal Product Manager with AWS Lake Formation team. He works with many of AWS largest customers on emerging technology needs, and leads several data and analytics initiatives within AWS including strong support for Transactional Data Lakes.

 Elijah Ball has been a Sys Admin at Ontraport for 12 years. He is currently working to move Ontraport’s production workloads to AWS and develop data analysis strategies for Ontraport.
Elijah Ball has been a Sys Admin at Ontraport for 12 years. He is currently working to move Ontraport’s production workloads to AWS and develop data analysis strategies for Ontraport. Pablo Redondo is a Principal Solutions Architect at Amazon Web Services. He is a data enthusiast with over 16 years of FinTech and healthcare industry experience and is a member of the AWS Analytics Technical Field Community (TFC). Pablo has been leading the AWS Gain Insights Program to help AWS customers achieve better insights and tangible business value from their data analytics initiatives.
Pablo Redondo is a Principal Solutions Architect at Amazon Web Services. He is a data enthusiast with over 16 years of FinTech and healthcare industry experience and is a member of the AWS Analytics Technical Field Community (TFC). Pablo has been leading the AWS Gain Insights Program to help AWS customers achieve better insights and tangible business value from their data analytics initiatives. Vikram Honmurgi is a Customer Solutions Manager at Amazon Web Services. With over 15 years of software delivery experience, Vikram is passionate about assisting customers and accelerating their cloud journey, delivering frictionless migrations, and ensuring our customers capture the full potential and sustainable business advantages of migrating to the AWS Cloud.
Vikram Honmurgi is a Customer Solutions Manager at Amazon Web Services. With over 15 years of software delivery experience, Vikram is passionate about assisting customers and accelerating their cloud journey, delivering frictionless migrations, and ensuring our customers capture the full potential and sustainable business advantages of migrating to the AWS Cloud.








 Virendhar (Viru) Sivaraman is a strategic Senior Big Data & Analytics Architect with Amazon Web Services. He is passionate about building scalable big data and analytics solutions in the cloud. Besides work, he enjoys spending time with family, hiking & mountain biking.
Virendhar (Viru) Sivaraman is a strategic Senior Big Data & Analytics Architect with Amazon Web Services. He is passionate about building scalable big data and analytics solutions in the cloud. Besides work, he enjoys spending time with family, hiking & mountain biking. Vivek Shrivastava is a Principal Data Architect, Data Lake in AWS Professional Services. He is a Bigdata enthusiast and holds 14 AWS Certifications. He is passionate about helping customers build scalable and high-performance data analytics solutions in the cloud. In his spare time, he loves reading and finds areas for home automation.
Vivek Shrivastava is a Principal Data Architect, Data Lake in AWS Professional Services. He is a Bigdata enthusiast and holds 14 AWS Certifications. He is passionate about helping customers build scalable and high-performance data analytics solutions in the cloud. In his spare time, he loves reading and finds areas for home automation.