Post Syndicated from Stephanie Doyle original https://www.backblaze.com/blog/ai-ransomware-inside-the-exfiltration-playbook/

Ransomware used to mean locked files and paralyzed systems. But today, bad actors are just as focused on exfiltration—the silent theft of sensitive data—and using that data as leverage for extortion.
According to cybersecurity firm BlackFog, 94% of successful cyberattacks in 2024 involved data exfiltration, either alongside or instead of encryption. Whether it’s stolen patient records, credentials, or source code, the goal is simple: Extract something valuable and threaten to leak it if demands aren’t met.
In this article, we examine how exfiltration became a leading tactic, the trends driving its rise, and what organizations—and cloud storage providers—can do to defend against it.
What is exfiltration?
In cybersecurity, exfiltration refers to the unauthorized transfer of data from a system—often done stealthily, and almost always with malicious intent. Think of it as the digital equivalent of corporate espionage: Data is copied, compressed, and quietly smuggled out. Unlike ransomware encryption, which slams the door in your face, exfiltration leaves the front door looking untouched.
The data being exfiltrated is rarely random. Cybercriminals are increasingly strategic about what they take and why. Common targets include:
- User credentials
- Personally identifiable information (PII)
- Intellectual property and source code
- Encryption keys
- Shadow copies or backup snapshots
Tactics include exploiting cloud storage misconfigurations, hijacking legitimate credentials, or disguising traffic as everyday protocols like DNS or HTTPS. Increasingly, data exfiltration happens before the main event—laying the groundwork for extortion, credential stuffing, or resale on underground markets.
Recent cybersecurity trends related to exfiltration
Exfiltration has become the defining feature of modern cyberattacks, and the evidence is growing:
- Double extortion is now standard. Threat actors exfiltrate data first, then deploy ransomware—or skip the encryption altogether—to maximize leverage. According to the 2023 Unit 42 Report, 70% of ransomware incidents involved data theft.
- Infostealers, malicious programs designed to covertly harvest sensitive information, are on the rise. Over 2.1 billion credentials were stolen in 2024 alone, with malware like RedLine and Lumma making theft accessible to low-skilled attackers. While cybersecurity task forces (comprised of both government and enterprise actors) have made the news with high-profile disruptions of Lumma and other tools, the ability to use generative AI coding tools has meant that cyber attackers have a shortened time to deployment for malware tools.
- Time to exfiltration is shrinking. Fortinet’s 2025 Threat Landscape Report notes that attackers can extract data in under five hours, while defenders often take days to respond.
- Encrypted traffic masks malicious behavior. Emerging exfiltration techniques like QUIC-Exfil use modern, encrypted protocols to evade detection by traditional firewalls.
- State-sponsored actors prioritize stealth. Nation-state groups like Volt Typhoon have used long-term access to exfiltrate sensitive data undetected for months.
Together, these trends point to a world where stolen data is the main prize—and the threat doesn’t start when the ransom note arrives. It starts when your data quietly leaves the building.
Cloud misconfiguration and its role in exfiltration attacks
Exfiltration doesn’t always require malware—sometimes it only takes a misconfigured storage bucket or firewall rule. Cloud misconfigurations remain a leading cause of breaches, with public buckets, excessive identity and access management (IAM) privileges, and overly permissive network rules exposing data to the open internet.
Attackers exploit these gaps to quietly access or extract data without triggering alerts. A strong cloud posture management strategy—one that includes audit automation, implementing the principle of least privilege, and configuring features like Object Lock or Bucket Access Logs—is critical to reducing exposure.
Defending against exfiltration is a shared responsibility
As exfiltration becomes a primary threat, defense requires collaboration between cloud storage providers and their customers. Here’s how the most effective strategies work together.
Immutable backups and Object Lock
One of the strongest defenses is immutability. Backblaze B2’s Object Lock, for example, allows files to be written once and protected from modification, deletion, or encryption for a set period. Even if attackers compromise credentials, the data cannot be altered or removed.
Visibility and outlier detection
Cloud providers are investing in making advanced logging and behavioral analytics available to users to detect data theft in real time. Some examples of these types of features include:
- Granular access logging with IP and user-level metadata.
- Rate limiting and download caps to prevent mass theft.
- Outlier detection powered by machine learning to catch subtle deviations from baseline activity.
Best practices for customers
Storage-layer defenses work best when paired with customer-side security controls:
- Adopt zero trust architecture: Never assume implicit trust. Continuously validate users, devices, and behaviors.
- Use MFA and least-privilege access: Lock down credentials, rotate them regularly, and minimize exposure.
- Encrypt data at rest and in transit: Use strong encryption standards (AES-256, TLS 1.2+) and managed key systems.
- Monitor for exfiltration indicators: Watch for abnormal traffic volumes, geographic anomalies, and unexpected protocol usage.
- Run simulated breach drills: Test your team’s ability to detect and respond to stealthy data leaks.
Cloud storage companies can help provide critical security layers, but stopping exfiltration is ultimately a shared responsibility. Combining provider-level resilience with customer vigilance is the best path forward.
In a world of silent theft, vigilance is your best defense
Exfiltration isn’t just an add-on to ransomware. In this environment, locking the doors isn’t enough—You need to monitor the exits.
By combining immutable backups, smart logging, credential controls, and proactive monitoring, organizations can shift from passive victims to active defenders. The best defenses today aren’t just about blocking access; they’re about knowing what’s leaving and making sure it can’t be used against you.
The post AI & Ransomware: Inside the Exfiltration Playbook appeared first on Backblaze Blog | Cloud Storage & Cloud Backup

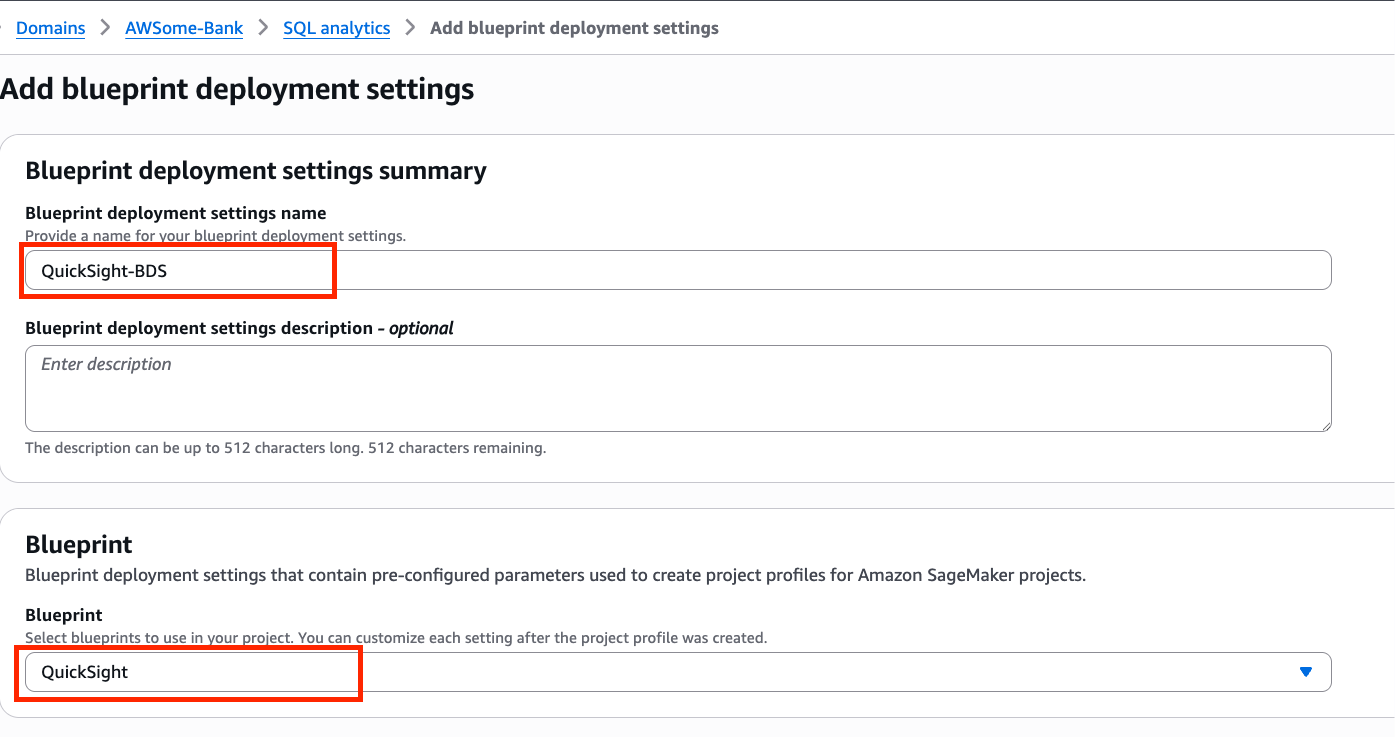
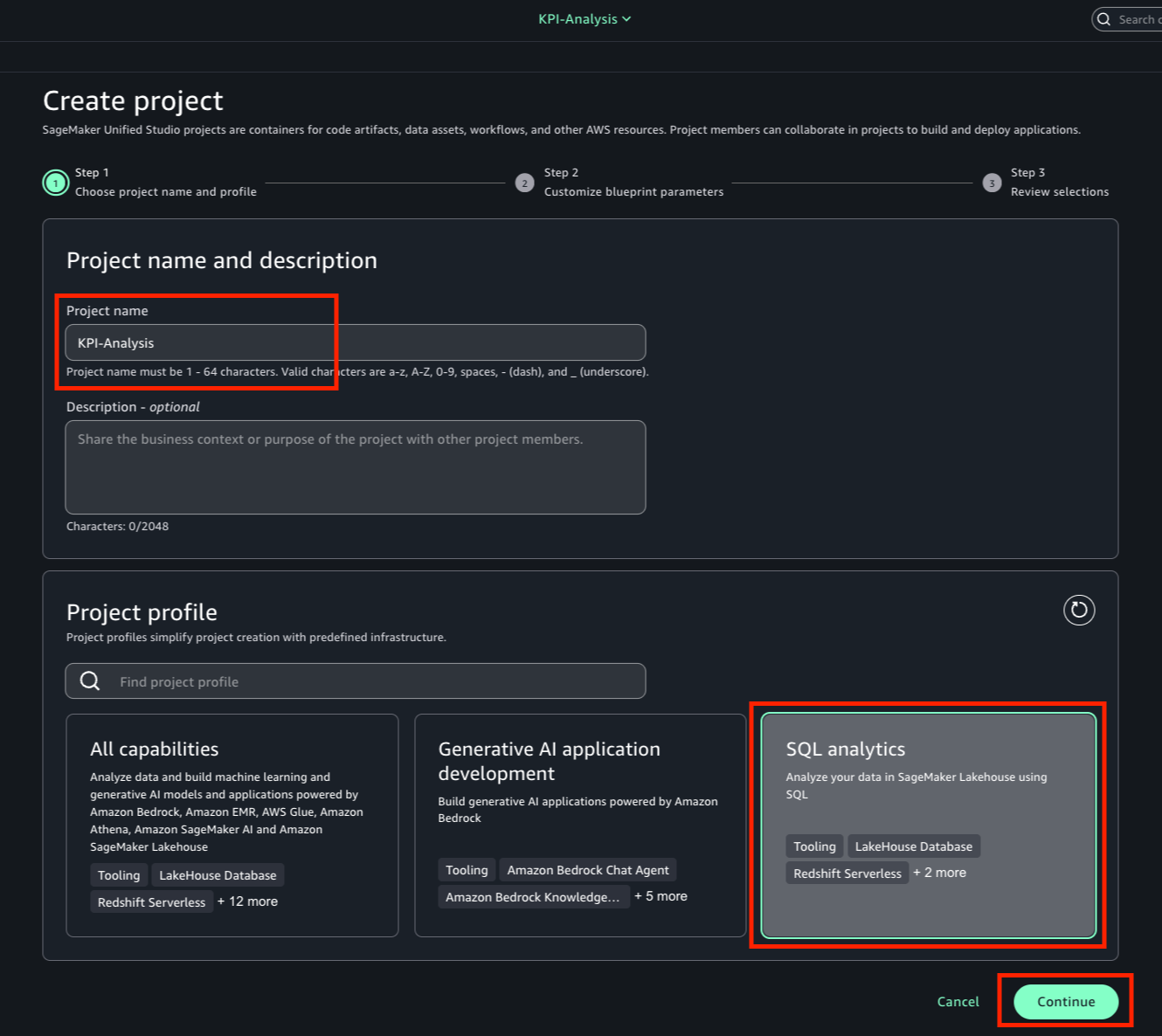
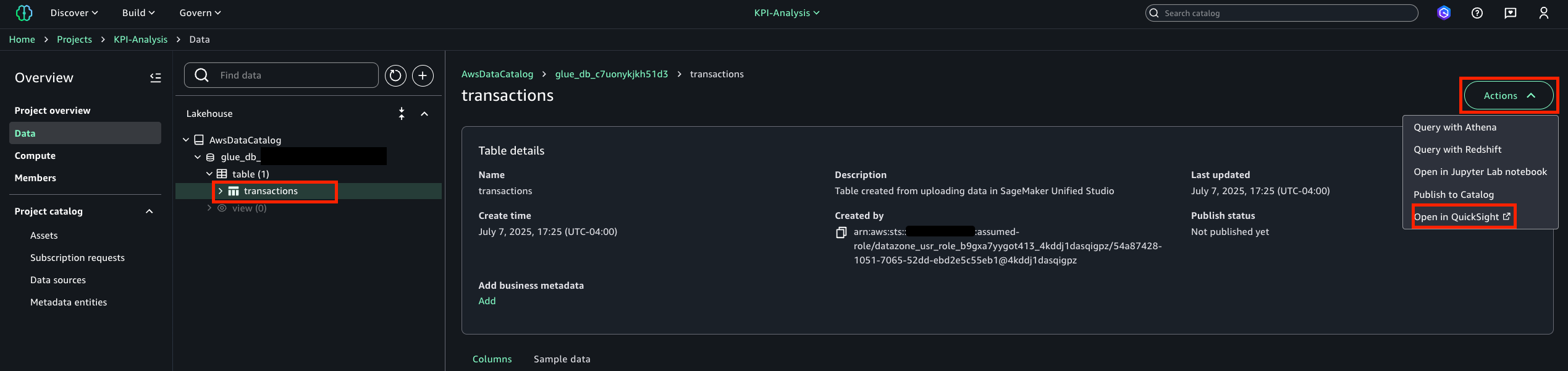
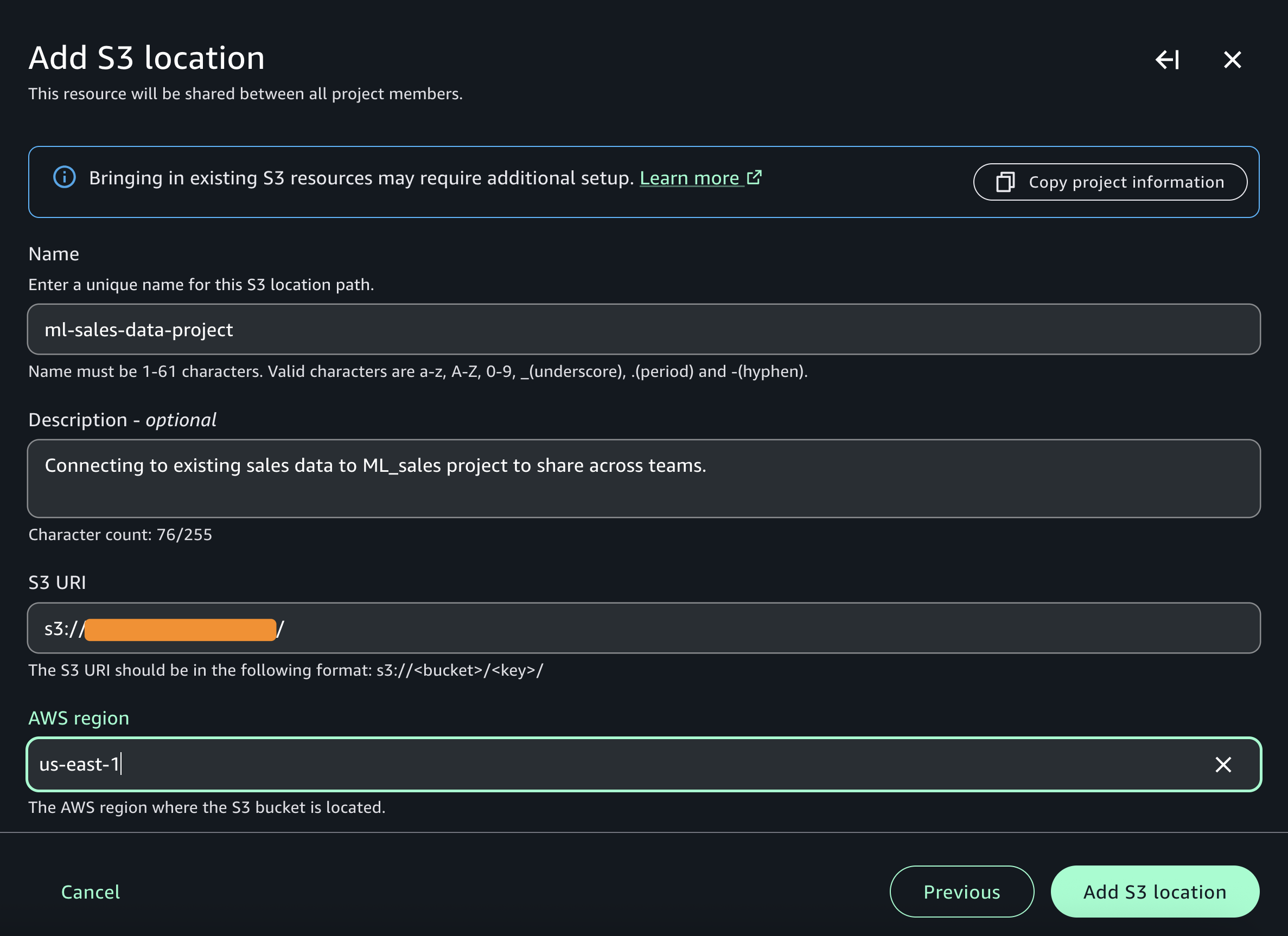
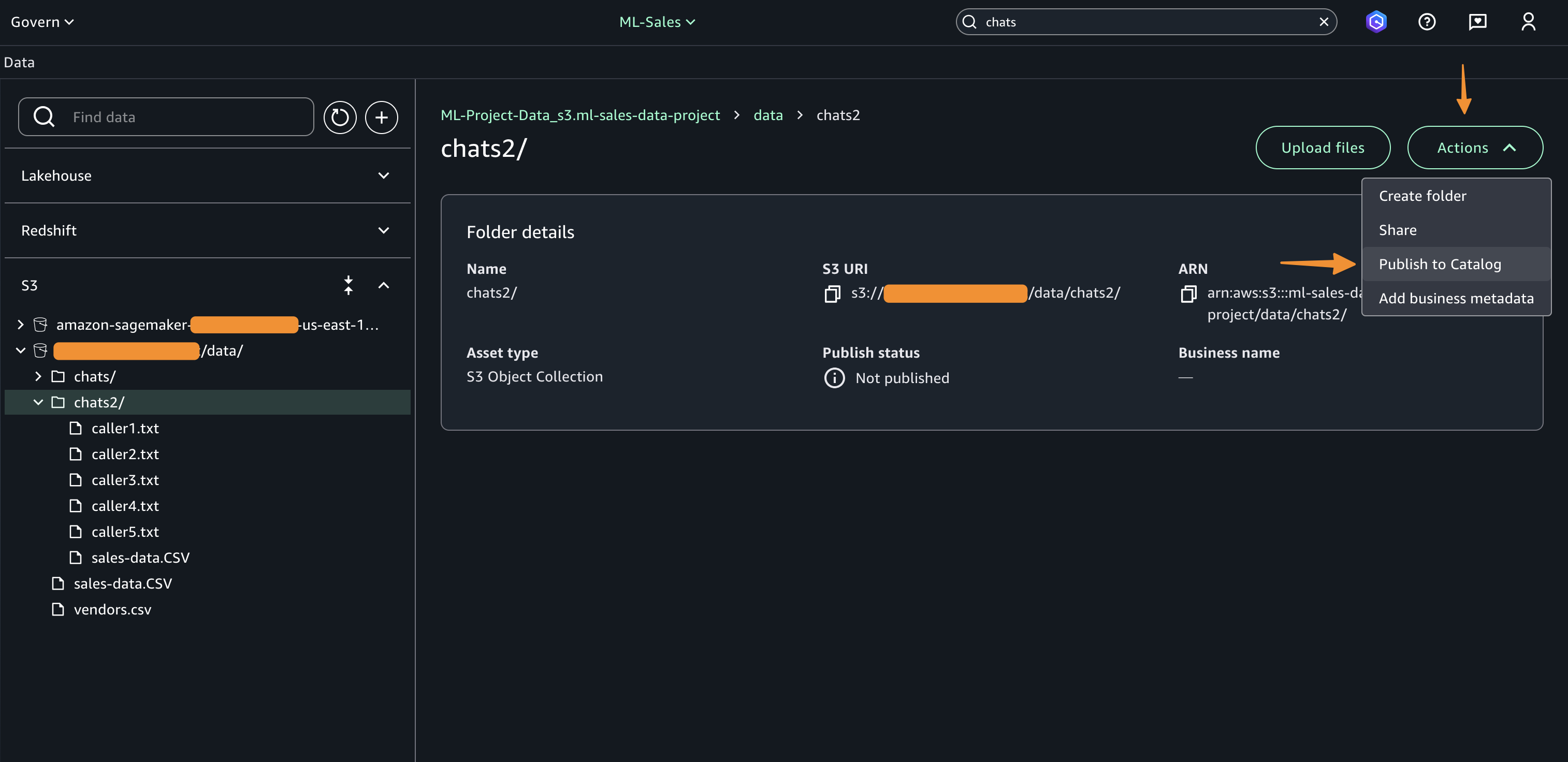
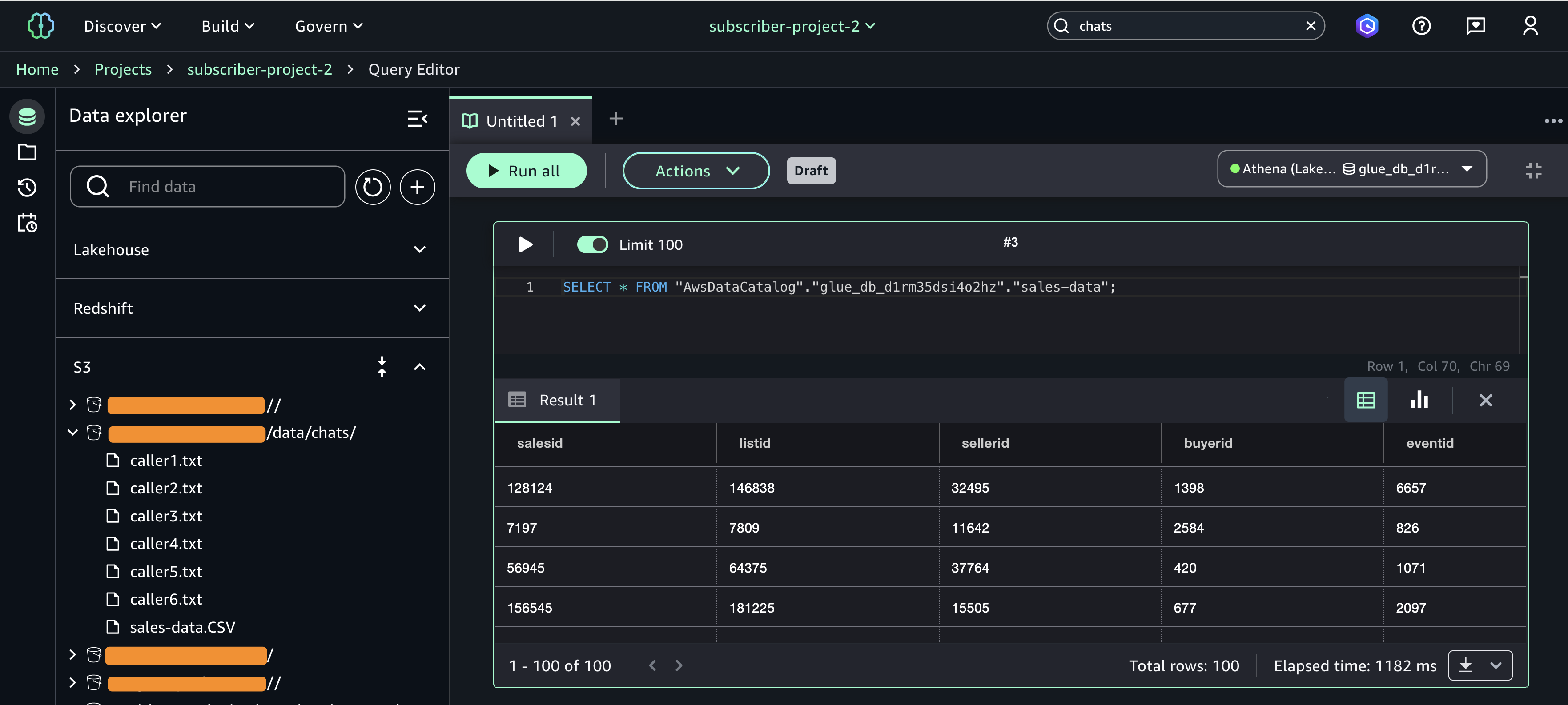
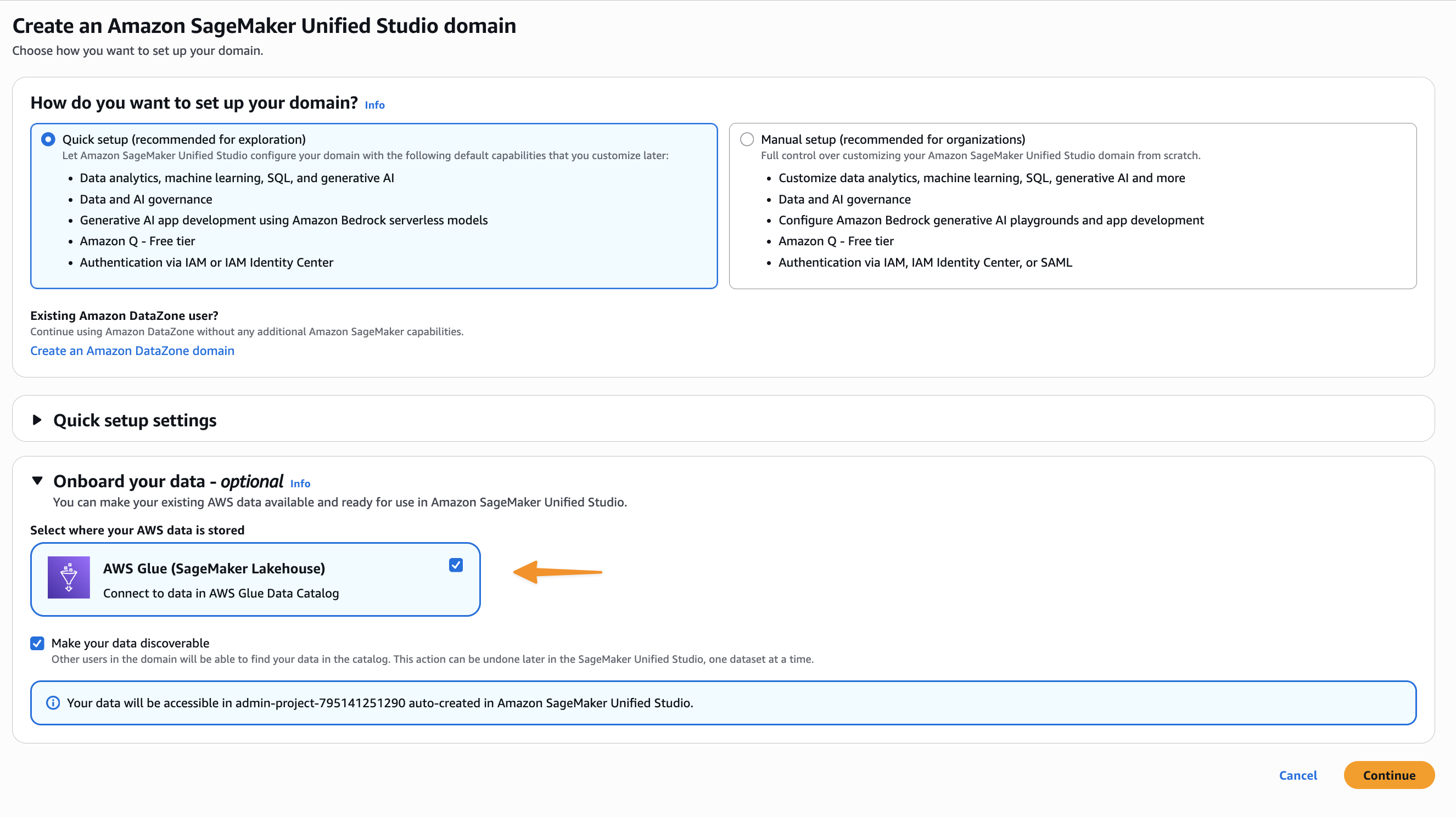




























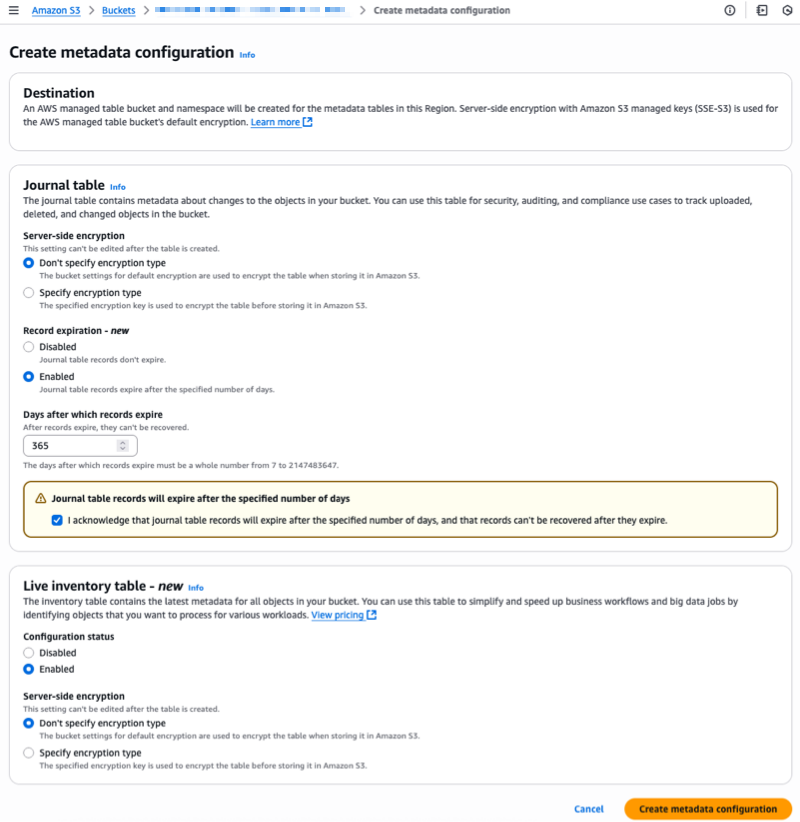
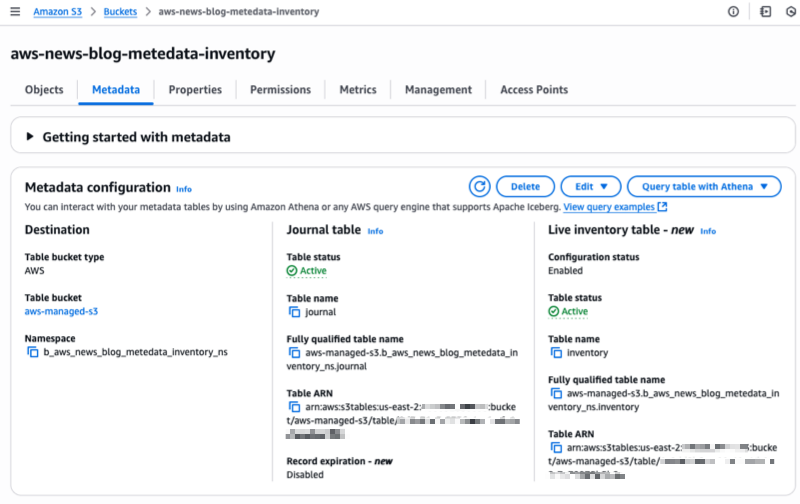
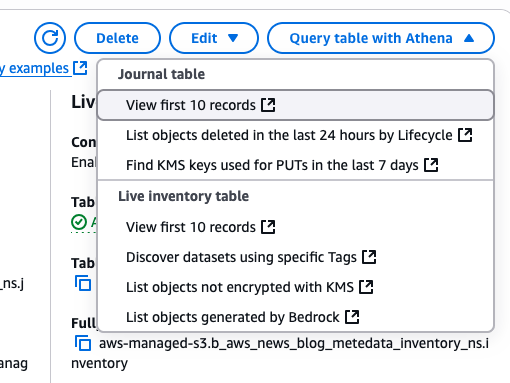
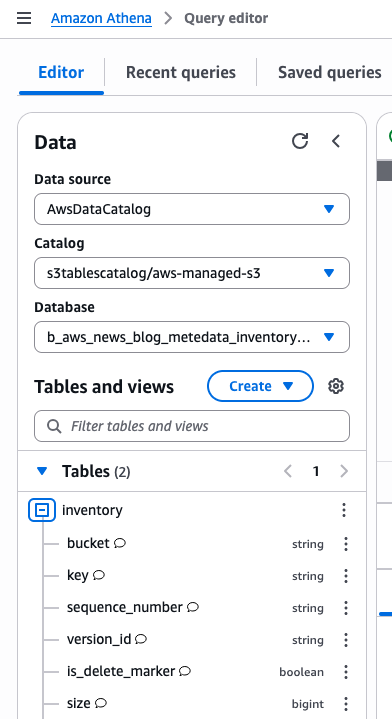
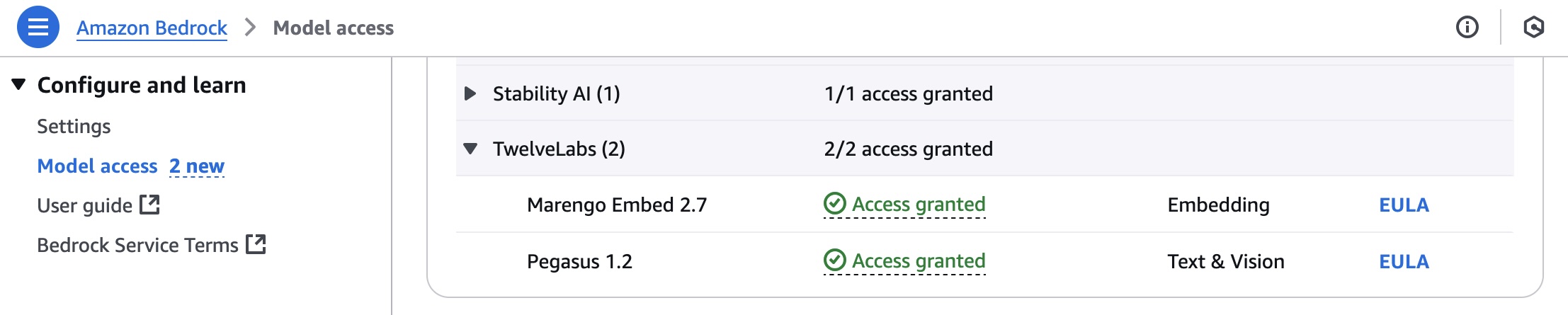
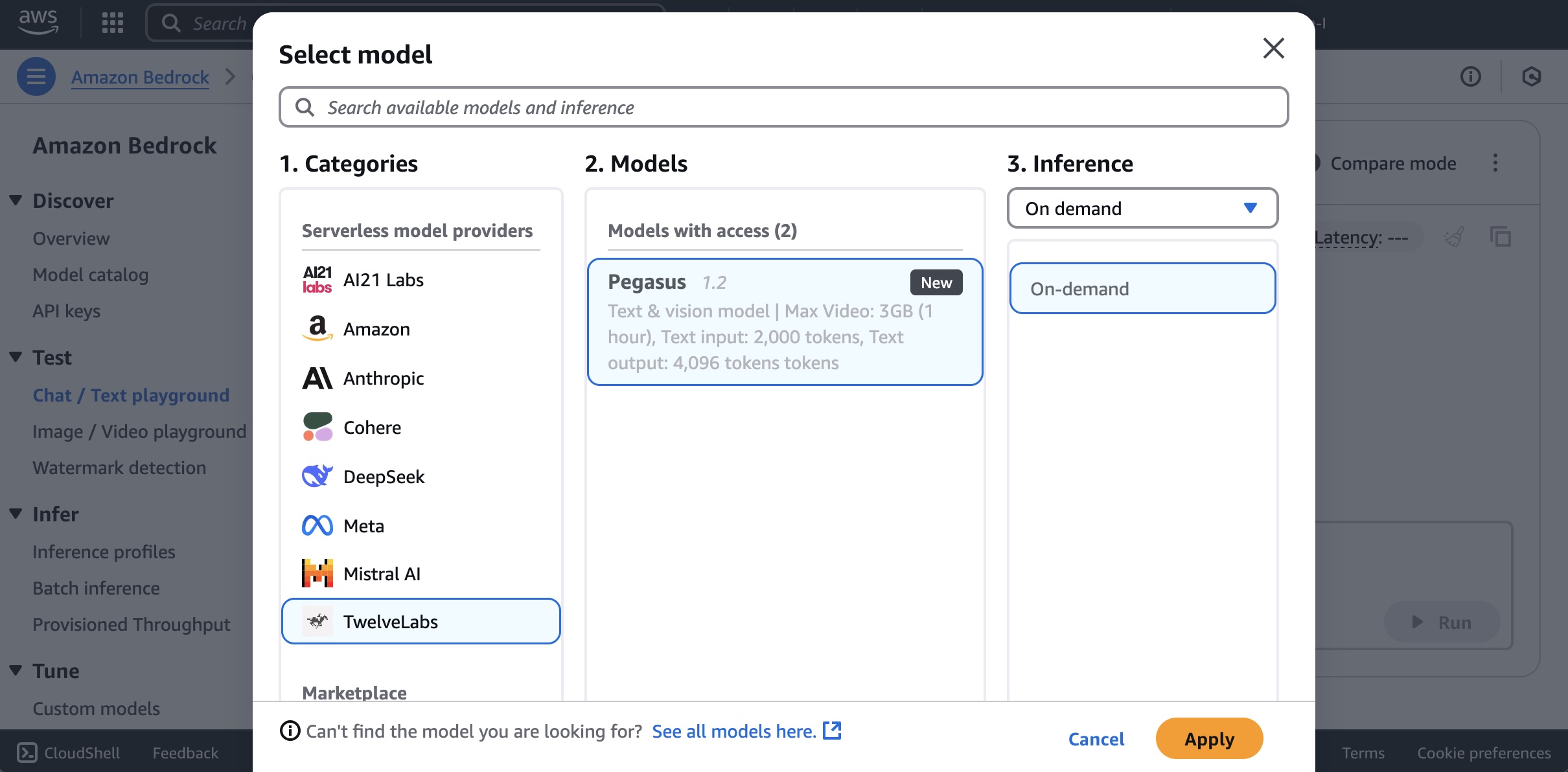








 Speaking of following people, AWS Builder Center makes it really straightforward to connect and engage with others, serving as the central hub for the AWS technical community. It brings together all the different ways that you can connect with fellow builders. For example, the Who to Follow section introduces you to AWS Heroes, Community Builders, and active community members who are sharing their knowledge and expertise in your areas of interest.
Speaking of following people, AWS Builder Center makes it really straightforward to connect and engage with others, serving as the central hub for the AWS technical community. It brings together all the different ways that you can connect with fellow builders. For example, the Who to Follow section introduces you to AWS Heroes, Community Builders, and active community members who are sharing their knowledge and expertise in your areas of interest.



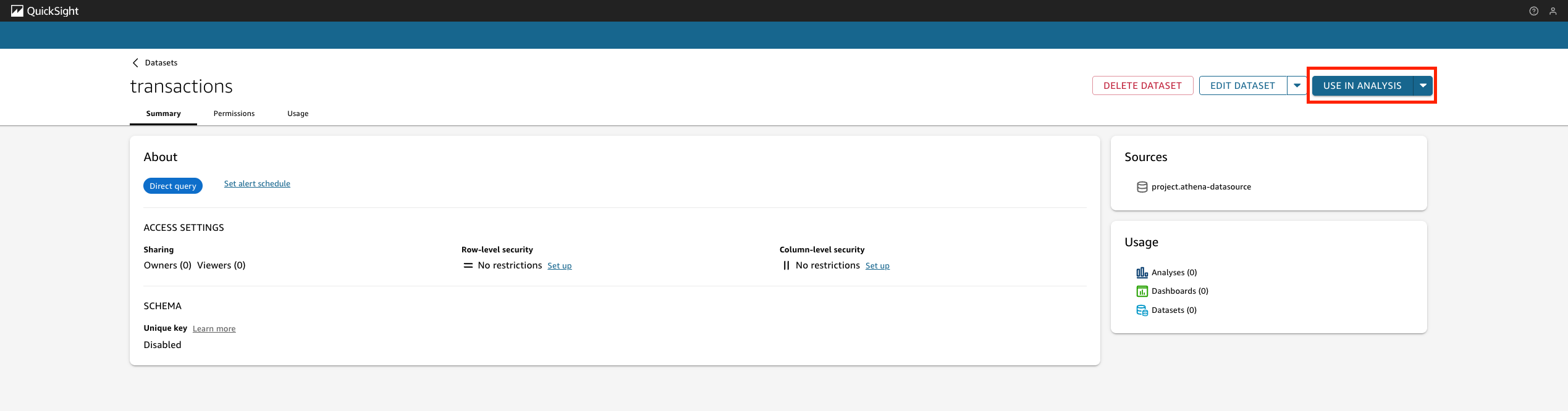
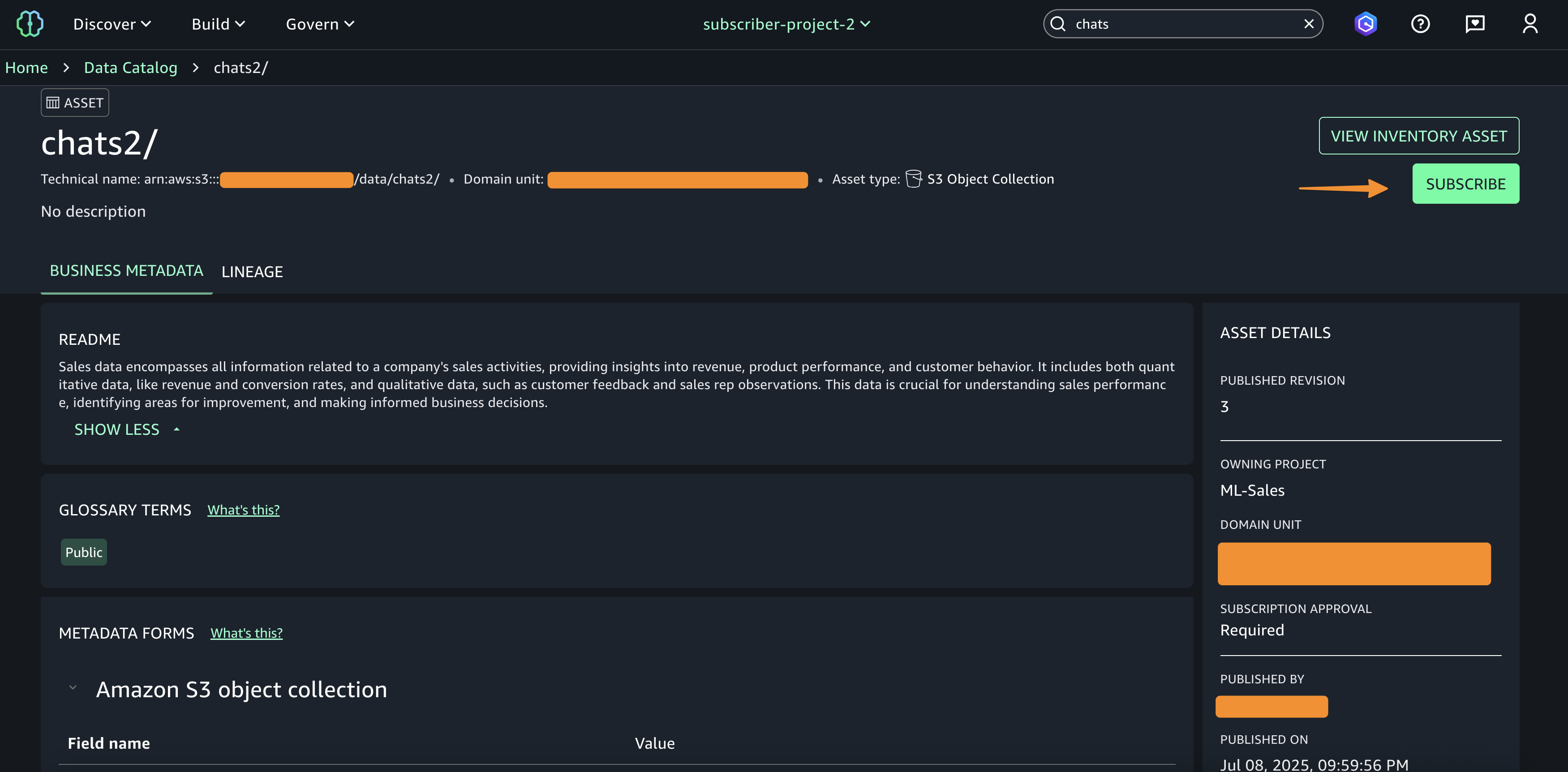
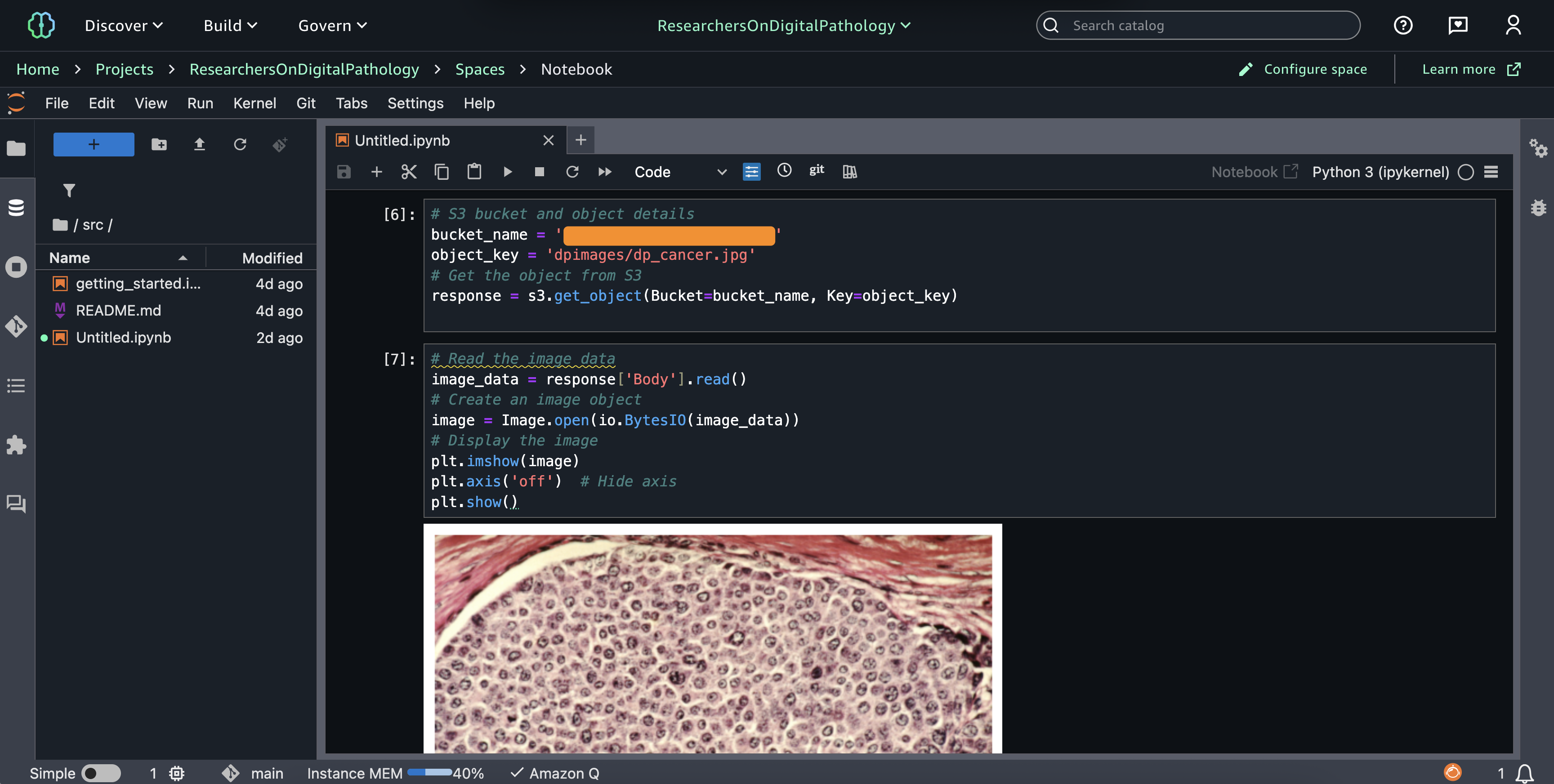
 AWS Builder Center gives you a more personalized and comprehensive way to showcase your AWS journey. Your unique profile comes with a custom URL and shareable QR code, making it straightforward to connect with others and share your presence in the AWS community.
AWS Builder Center gives you a more personalized and comprehensive way to showcase your AWS journey. Your unique profile comes with a custom URL and shareable QR code, making it straightforward to connect with others and share your presence in the AWS community.






























