Post Syndicated from Antje Barth original https://aws.amazon.com/blogs/aws/aws-week-in-review-aws-glue-crawlers-now-supports-apache-iceberg-amazon-rds-updates-and-more-july-10-2023/
The US celebrated Independence Day last week on July 4 with fireworks and barbecues across the country. But fireworks weren’t the only thing that launched last week. Let’s have a look!
Last Week’s Launches
Here are some launches that got my attention:
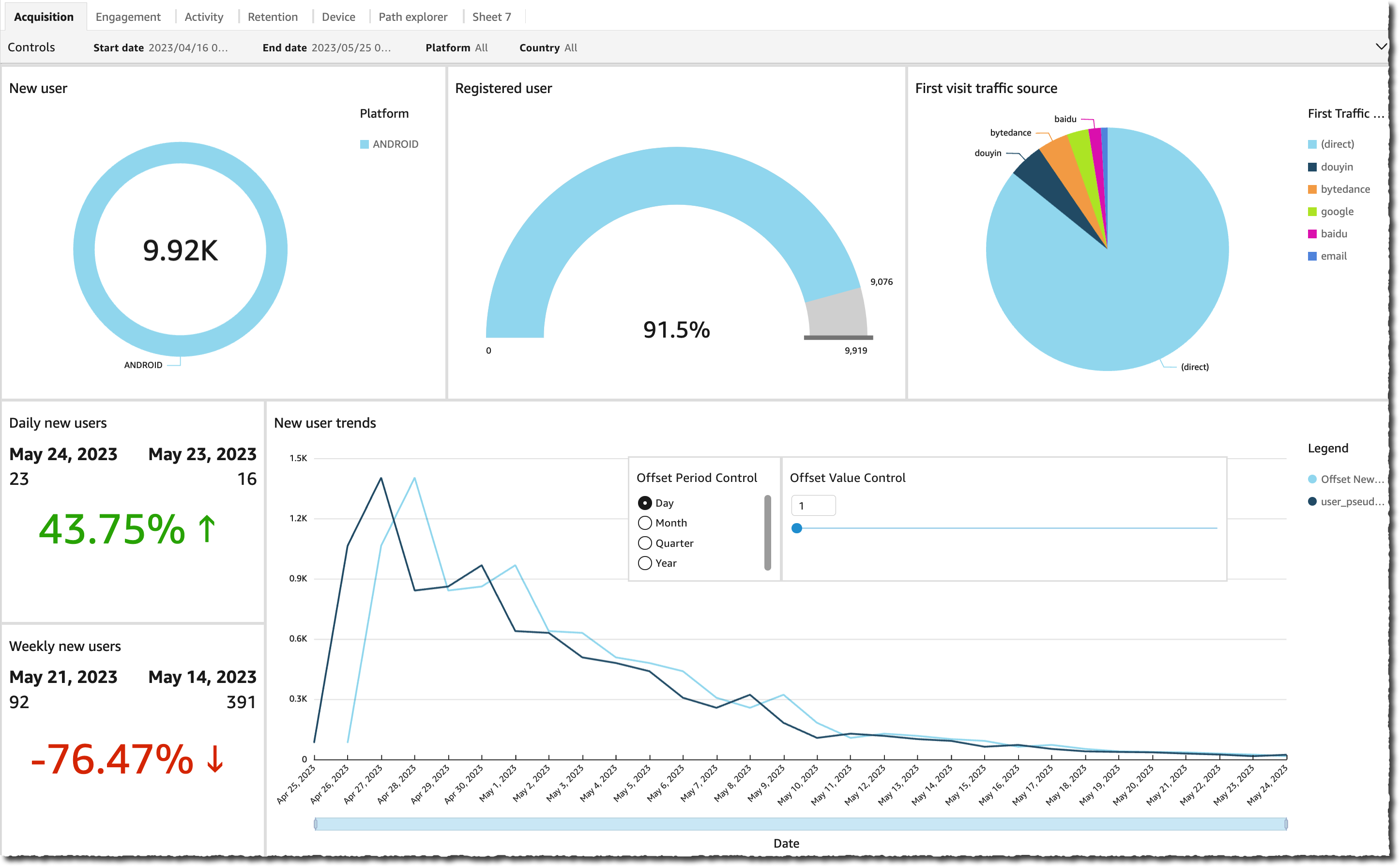
AWS Glue – AWS Glue Crawlers now supports Apache Iceberg tables. Apache Iceberg is an open-source table format for data stored in data lakes. You can now automatically register Apache Iceberg tables into AWS Glue Data Catalog by running the Glue Crawler. You can then query Glue Catalog Iceberg tables across various analytics engines and apply AWS Lake Formation fine-grained permissions when querying from Amazon Athena. Check out the AWS Glue Crawler documentation to learn more.
Amazon Relational Database Service (Amazon RDS) for PostgreSQL – PostgreSQL 16 Beta 2 is now available in the Amazon RDS Database Preview Environment. The PostgreSQL community released PostgreSQL 16 Beta 2 on June 29, 2023, which enables logical replication from standbys and includes numerous performance improvements. You can deploy PostgreSQL 16 Beta 2 in the preview environment and start evaluating the pre-release of PostgreSQL 16 on Amazon RDS for PostgreSQL.
In addition, Amazon RDS for PostgreSQL Multi-AZ Deployments with two readable standbys now supports logical replication. With logical replication, you can stream data changes from Amazon RDS for PostgreSQL to other databases for use cases such as data consolidation for analytical applications, change data capture (CDC), replicating select tables rather than the entire database, or for replicating data between different major versions of PostgreSQL. Check out the Amazon RDS User Guide for more details.
Amazon CloudWatch – Amazon CloudWatch now supports Service Quotas in cross-account observability. With this, you can track and visualize resource utilization and limits across various AWS services from multiple AWS accounts within a region using a central monitoring account. You no longer have to track the quotas by logging in to individual accounts, instead from a central monitoring account, you can create dashboards and alarms for the AWS service quota usage across all your source accounts from a central monitoring account. Setup CloudWatch cross-account observability to get started.
Amazon SageMaker – You can now associate a SageMaker Model Card with a specific model version in SageMaker Model Registry. This lets you establish a single source of truth for your registered model versions, with comprehensive, centralized, and standardized documentation across all stages of the model’s journey on SageMaker, facilitating discoverability and promoting governance, compliance, and accountability throughout the model lifecycle. Learn more about SageMaker Model Cards in the developer guide.
For a full list of AWS announcements, be sure to keep an eye on the What’s New at AWS page.
Other AWS News
Here are some additional blog posts and news items that you might find interesting:
Building generative AI applications for your startup – In this AWS Startups Blog post, Hrushikesh explains various approaches to build generative AI applications, and reviews their key component. Read the full post for the details.

Components of the generative AI landscape.
How Alexa learned to speak with an Irish accent – If you’re curious how Amazon researchers used voice conversation to generate Irish-accented training data in Alexa’s own voice, check out this Amazon Science Blog post.
AWS open-source news and updates – My colleague Ricardo writes this weekly open-source newsletter in which he highlights new open-source projects, tools, and demos from the AWS Community.
Upcoming AWS Events
Check your calendars and sign up for these AWS events:
 AWS Global Summits – Check your calendars and sign up for the AWS Summit close to where you live or work: Hong Kong (July 20), New York City (July 26), Taiwan (August 2-3), São Paulo (August 3), and Mexico City (August 30).
AWS Global Summits – Check your calendars and sign up for the AWS Summit close to where you live or work: Hong Kong (July 20), New York City (July 26), Taiwan (August 2-3), São Paulo (August 3), and Mexico City (August 30).
![]() AWS Community Days – Join a community-led conference run by AWS user group leaders in your region: Malaysia (July 22), Philippines (July 29-30), Colombia (August 12), and West Africa (August 19).
AWS Community Days – Join a community-led conference run by AWS user group leaders in your region: Malaysia (July 22), Philippines (July 29-30), Colombia (August 12), and West Africa (August 19).
![]() AWS re:Invent (November 27 – December 1) – Join us to hear the latest from AWS, learn from experts, and connect with the global cloud community. Registration is now open.
AWS re:Invent (November 27 – December 1) – Join us to hear the latest from AWS, learn from experts, and connect with the global cloud community. Registration is now open.
You can browse all upcoming in-person and virtual events.
That’s all for this week. Check back next Monday for another Week in Review!
— Antje
This post is part of our Week in Review series. Check back each week for a quick roundup of interesting news and announcements from AWS!