Post Syndicated from Prashanth Dudipala, Madhuri Andhale original https://aws.amazon.com/blogs/big-data/how-appzen-enhances-operational-efficiency-scalability-and-security-with-amazon-opensearch-serverless/
AppZen is a leading provider of AI-driven finance automation solutions. The company’s core offering centers around an innovative AI platform designed for modern finance teams, featuring expense management, fraud detection, and autonomous accounts payable solutions. AppZen’s technology stack uses computer vision, deep learning, and natural language processing (NLP) to automate financial processes and ensure compliance. With this comprehensive solution approach, AppZen has a well-established enterprise customer base that includes one-third of the Fortune 500 companies.
AppZen hosts all its workloads and application infrastructure on Amazon Web Services (AWS), continuously modernizing its technology stack to effectively operationalize and host its applications. Centralized logging, a critical component of this infrastructure, is essential for monitoring and managing operations across AppZen’s diverse workloads. As the company experienced rapid growth, the legacy logging solution struggled to keep pace with expanding needs. Consequently, modernizing this system became one of AppZen’s top priorities, prompting a comprehensive overhaul to enhance operational efficiency and scalability.
In this blog we show, how AppZen modernizes its central log analytics solution from Elasticsearch to Amazon OpenSearch Serverless providing an optimized architecture to meet above mentioned requirements.
Challenges with the legacy logging solution
With a growing number of business applications and workloads, AppZen had an increasing need for comprehensive operational analytics using log data across its multi-account organization in AWS Organizations. AppZen’s legacy logging solution created several key challenges. It lacked the flexibility and scalability to efficiently index and make the logs available for real-time analysis, which was crucial for tracking anomalies, optimizing workloads, and ensuring efficient operations.
The legacy logging solution consisted of a 70-node Elasticsearch cluster (with 30 hot nodes and 40 warm nodes), it struggled to keep up with the growing volume of log data as AppZen’s customer base expanded and new mission-critical workloads were added. This led to performance issues and increased operational complexity. Maintaining and managing the self-hosted Elasticsearch cluster required frequent software updates and infrastructure patching, resulting in system downtime, data loss, and added operational overhead for the AppZen CloudOps team.
Migrating the data to a patched node cluster took 7 days, far exceeding industry standard and AppZen’s operational requirements. This extended downtime introduced data integrity risk and directly impacted the operational availability of the centralized logging system crucial for teams to troubleshoot across critical workloads. The system also suffered frequent data loss that impacted real-time metrics monitoring, dashboarding, and alerting because its application log-collecting agent Fluent Bit lacked essential features such as backoff and retry.
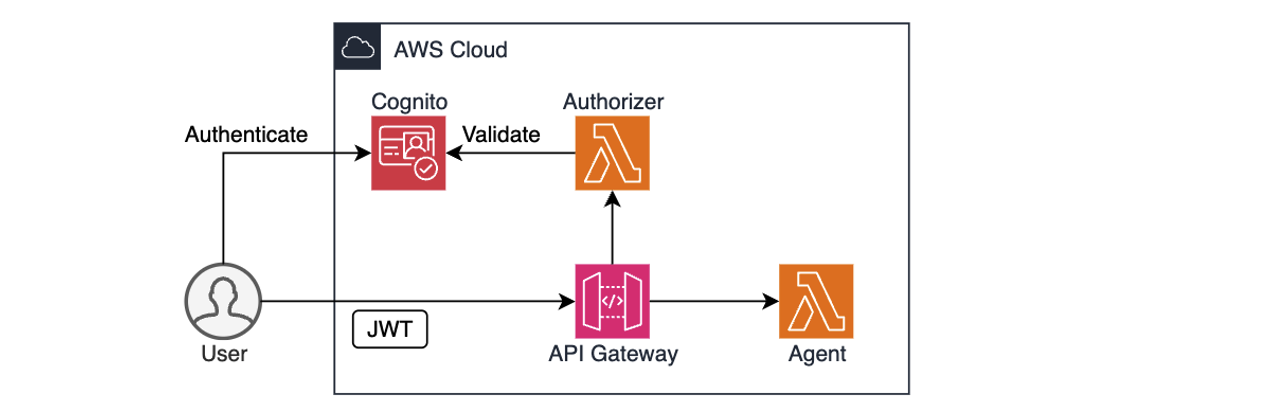
AppZen has an NGINX proxy instance controlling authorized user access to data hosted on Elasticsearch. Upgrades and patching of the instance introduced frequent system downtimes. All user requests are routed through this proxy layer, where the user’s permission boundary is evaluated. This had an added operations overhead for administrators to manage users and group mapping at the proxy layer.
Solution overview
AppZen re-platformed its central log analytics solution with Amazon OpenSearch Serverless and Amazon OpenSearch Ingestion. Amazon OpenSearch Serverless lets you run OpenSearch in the AWS Cloud, so you can run large workloads without configuring, managing, and scaling OpenSearch clusters. You can ingest, analyze, and visualize your time-series data without infrastructure provisioning. OpenSearch Ingestion is a fully managed data collector that simplifies data processing with built-in capabilities to filter, transform, and enrich your logs before analysis.
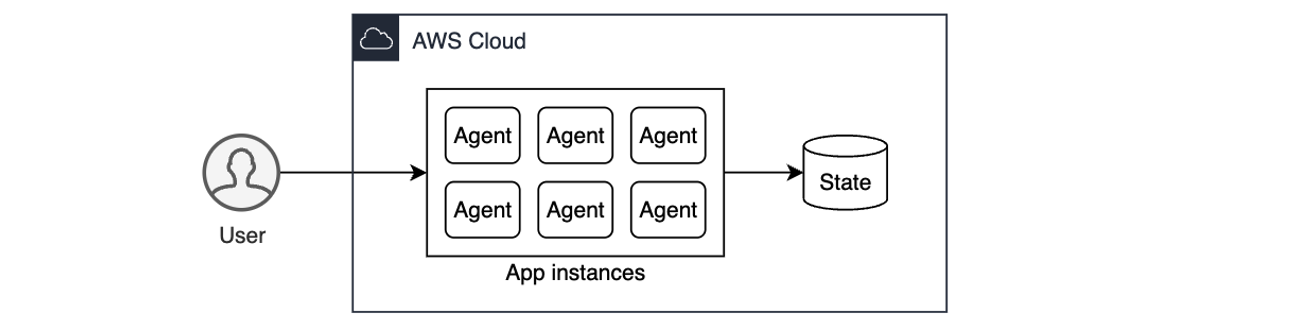
This new serverless architecture, shown in the following architecture diagram, is cost-optimized, secure, high-performing, and designed to scale efficiently for future business needs. It serves the following use cases:
- Centrally monitor business operations and data analysis for deep insights
- Application monitoring and infrastructure troubleshooting
Together, OpenSearch Ingestion and OpenSearch Serverless provide a serverless infrastructure capable of running large workloads without configuring, managing, and scaling the cluster. It provides data resilience with persistent buffers that can support the current 2 TB per day pipeline data ingestion requirement. IAM Identity Center support for OpenSearch Serverless helped manage users and their access centrally eliminating a need for NGINX proxy layer.
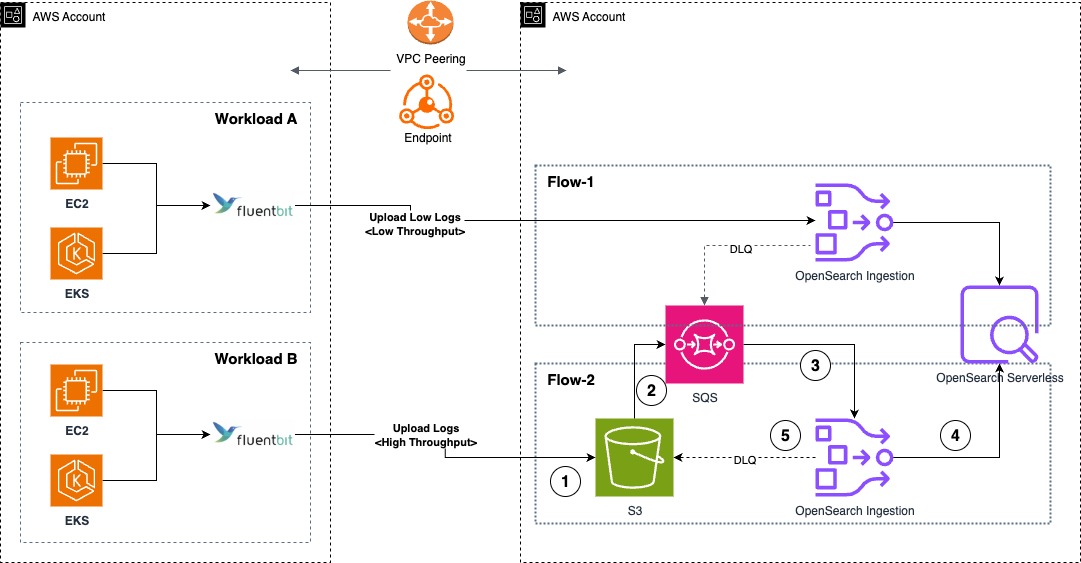
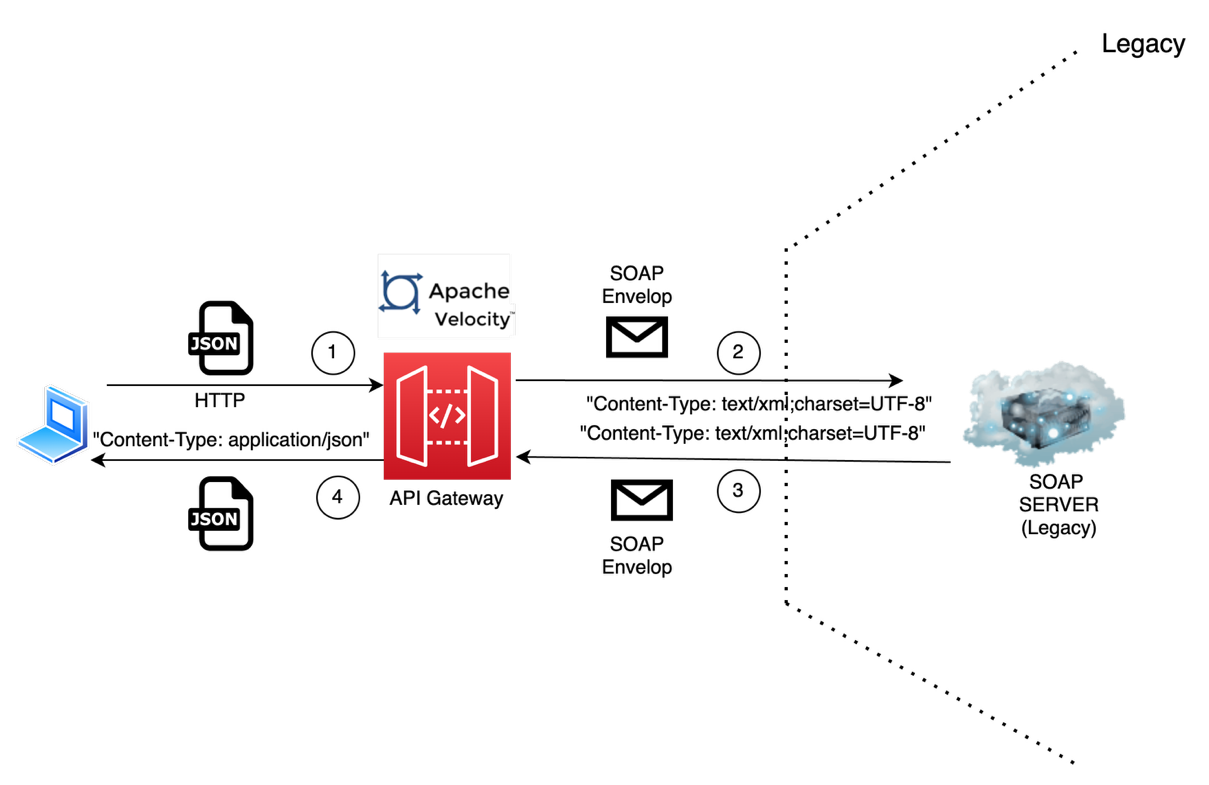
The architecture diagram also shows how separate ingestion pipelines were deployed. This configuration option improves deployment flexibility based on the workload’s throughput and latency requirements. In this architecture, Flow-1 is a push-based data source (such as HTTP and OTel logs) where the workload’s Fluent Bit DaemonSet is configured to ingest log messages into the OpenSearch Ingestion pipeline. These messages are retained in the pipeline’s persistent buffer to provide data durability. After processing the message, it’s inserted into OpenSearch Serverless.
And Flow-2 is a pull-based data source such as Amazon Simple Storage Service (Amazon S3) for OpenSearch Ingestion where the workload’s Fluent Bit DaemonSets are configured to sync data to an S3 bucket. Using S3 Event Notifications, the new log records creation notifications are sent to Amazon Simple Queue Service (Amazon SQS). OpenSearch Ingestion consumes this notification and processes the record to insert into OpenSearch Serverless, delegating the data durability to the data source. For both Flow-1 and Flow-2, the OpenSearch Ingestion pipelines are configured with a dead-letter queue to record failed ingestion messages to the S3 source, making them accessible for further analysis.
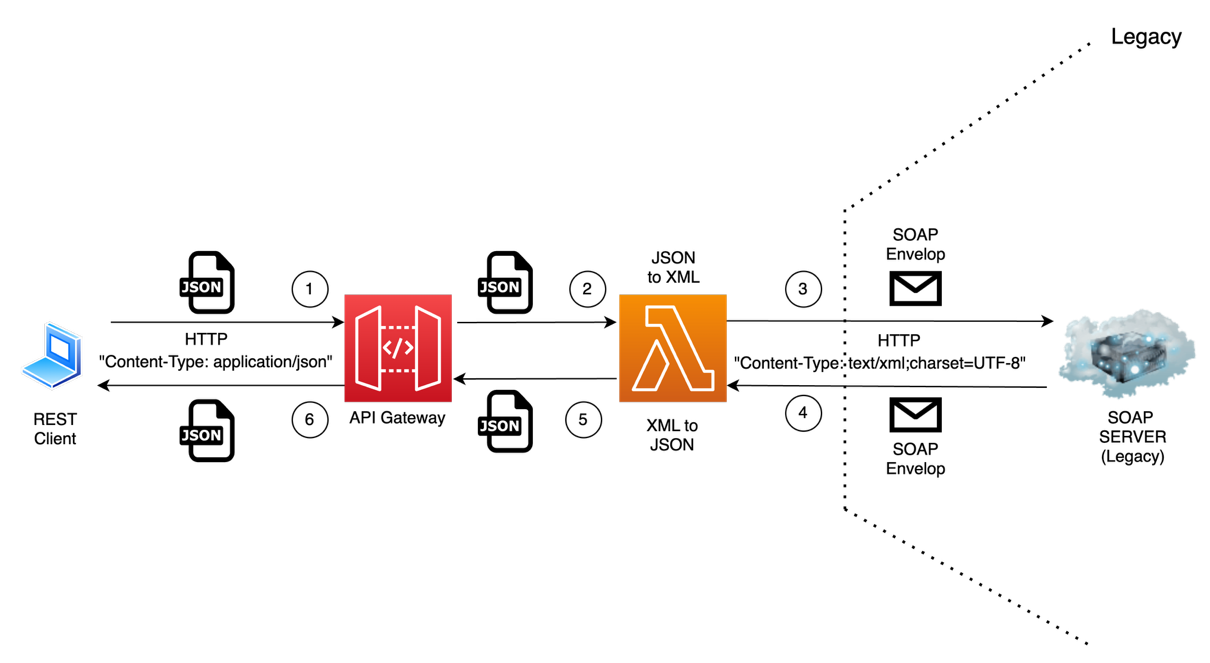
For service log analytics, AppZen adopted a pull-based approach as shown in the following figure, where all service logs published to Amazon CloudWatch are migrated an S3 bucket for further processing. An AWS Lambda processor is triggered when every new message is ingested to the S3 bucket, and the processed message is then uploaded to the S3 bucket for OpenSearch ingestion. The following diagram shows the OpenSearch Serverless architecture for the service log analytics pipeline.

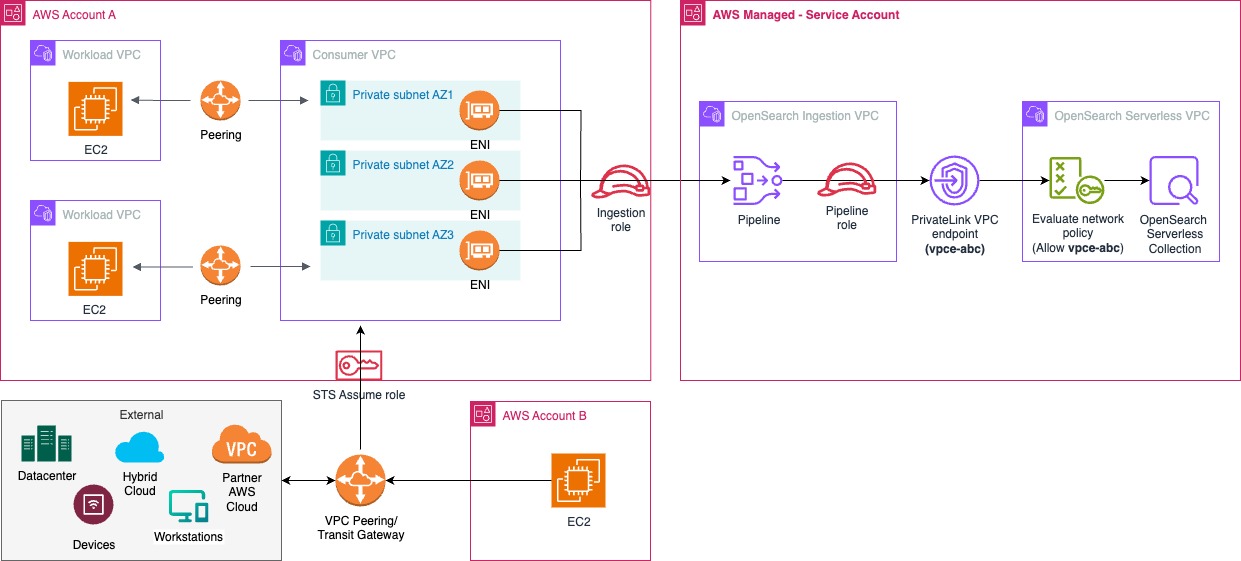
Workloads and infrastructure spread across multiple AWS accounts can securely send logs to the central log analytics platform over a private network using virtual private cloud (VPC) peering and AWS PrivateLink endpoints, as shown in the following figure. Both OpenSearch Ingestion and OpenSearch Serverless are provisioned in the same account and Region, with cross-account ingestion enabled for workloads in other member accounts of the AWS Organizations account.
Migration approach
The migration to OpenSearch Serverless and OpenSearch Ingestion involved performance evaluation and fine-tuning the configuration of the logging stack, followed by migration of production traffic to new platform. The first step was to configure and benchmark the infrastructure for cost-optimized performance.
Parallel ingestion to benchmark OCU capacity requirements
OpenSearch Ingestion scales elastically to meet throughput requirements during workload spikes. Enabling persistent buffering on ingestion pipelines with push-based data sources provided data durability and reliability. Data ingestion pipelines are ingesting at a rate of 2 TB per day. Due to AppZen’s 90-day data retention requirement around its ingested data, at any time, there is approximately 200 TB of indexed historical data stored in the OpenSearch Serverless cluster. To evaluate performance and costs before deploying to production, data sources were configured to ingest data in parallel into the new OpenSearch Serverless environment along with an existing setup already running in production with Elasticsearch.
To achieve parallel ingestion, AppZen installed another Fluent Bit DaemonSet configured to ingest into the new pipeline. This was for two reasons: 1) To avoid interruption due to changes to existing ingestion flow and 2) New workflows are much more straightforward when the data preprocessing step is offloaded to OpenSearch Ingestion, eliminating the need for custom lua script use in Fluent Bit.
Pipeline configuration
The production pipeline configuration was implemented with different strategies based on data source types. Push-based data sources were configured with persistent buffer enabled for data durability and a minimum of three OpenSearch Compute Units (OCUs) to provide high availability across three Availability Zones. In contrast, pull-based data sources, which used Amazon S3 as their source, didn’t require persistent buffering due to the inherent durability features of Amazon S3. Both pipeline types were initially configured with a minimum of three OCUs and a maximum of 50 OCUs to establish baseline performance metrics. This setup meant the team could monitor and analyze actual workload patterns, and therefore fine-tune worker configurations for optimal OCU usage. Through continuous monitoring and adjustment, the pipeline configurations were changed and optimized to efficiently handle both daily average loads and peak traffic periods, providing cost-effective and reliable data processing operations.
For AppZen’s throughput requirement, in the pull-based approach, they identified six Amazon S3 workers in the OpenSearch Ingestion pipelines optimally processing 1 OCU at 80% efficiency. Following the best practices recommendation, at this system.cpu.usage.value metrics threshold, the pipeline was configured to auto scale. With each worker capable of processing 10 messages, AppZen identified cost-optimized configuration of 50 OCUs as maximum OCU configuration for its pipelines that is capable of processing up to 3,000 messages in parallel. This pipeline configuration shown below supports its peak throughput requirements
Indexing strategy
When working with search engine, understanding index and shard management is crucial. Indexes and their corresponding shards consume memory and CPU resources to maintain metadata. A key challenge emerges when having numerous small shards in a system because it leads to higher resource consumption and operational overhead. In the traditional approach, you typically create indices at the microservice level for each environment (prod, qa, and dev). For example, indices would be named like prod-k1-service or prod-k2-service, where k1 and k2 represent different microservices. With hundreds of services and daily index rotation, this approach results in thousands of indices, making management complex and resource intensive. When implementing OpenSearch Serverless, you should adopt a consolidated indexing strategy that moves away from microservice-level index creation. Rather than creating individual indices like prod-k1-service and prod-k2-service for each microservice and environment, you should consolidate the data into broader environment-based indices such as prod-service, which contains all service data for the production environment. This consolidation is essential because OpenSearch Serverless scales based on resources and has specific limitations on the number of shards per OCU. This means that having a higher number of small shards will lead to higher OCU consumption.
However, although this consolidated approach can significantly reduce operational costs and simplify management through built-in data lifecycle policies, it presents a notable challenge for multi-tenant scenarios. Organizations with strict security requirements, where different teams need access to specific indices only, might find this consolidated approach challenging to implement. For such cases, a more granular indices approach might be necessary to maintain proper access control, even though it can result in higher resource consumption.
By carefully evaluating your security requirements and access control needs, you can choose between a consolidated approach for optimized resource utilization or a more granular approach that better supports fine-grained access control. Both approaches are supported in OpenSearch Serverless, so you can balance resource optimization with security requirements based on your specific use case.
Cost optimization
OpenSearch Ingestion allocates some OCUs from configured pipeline capacity for persistent buffering, which provides data durability. While monitoring, AppZen observed higher OCU usage for this persistent buffer when processing high-throughput workloads. To optimize this capacity configuration, AppZen decided to classify its workloads into push-based and pull-based categories depending on their throughput and latency requirements. Achieving this created new parallel pipelines to operate these flows in parallel, as shown in the architecture diagram earlier in the post. Fluent Bit agent collector configurations were accordingly modified based on the workload classification.
Depending on the cost and performance requirements for the workload, AppZen adopted the appropriate ingestion flow. For low latency and low-throughput workload requirements, AppZen chose the push-based approach. For high-throughput workload requirements, AppZen adopted the pull-based approach, which helped lower the persistent buffer OCU usage by relying on durability to the data source. In the pull-based approach, AppZen further optimized on the storage cost by configuring the pipeline to automatically delete the processed data from the S3 bucket after successful ingestion
Monitoring and dashboard
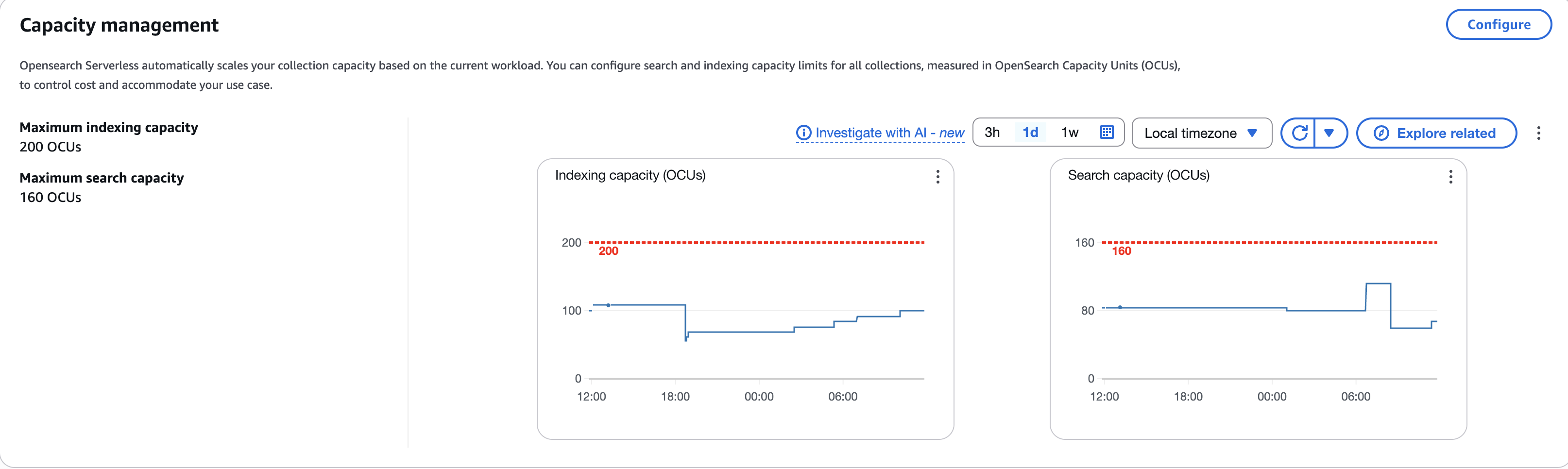
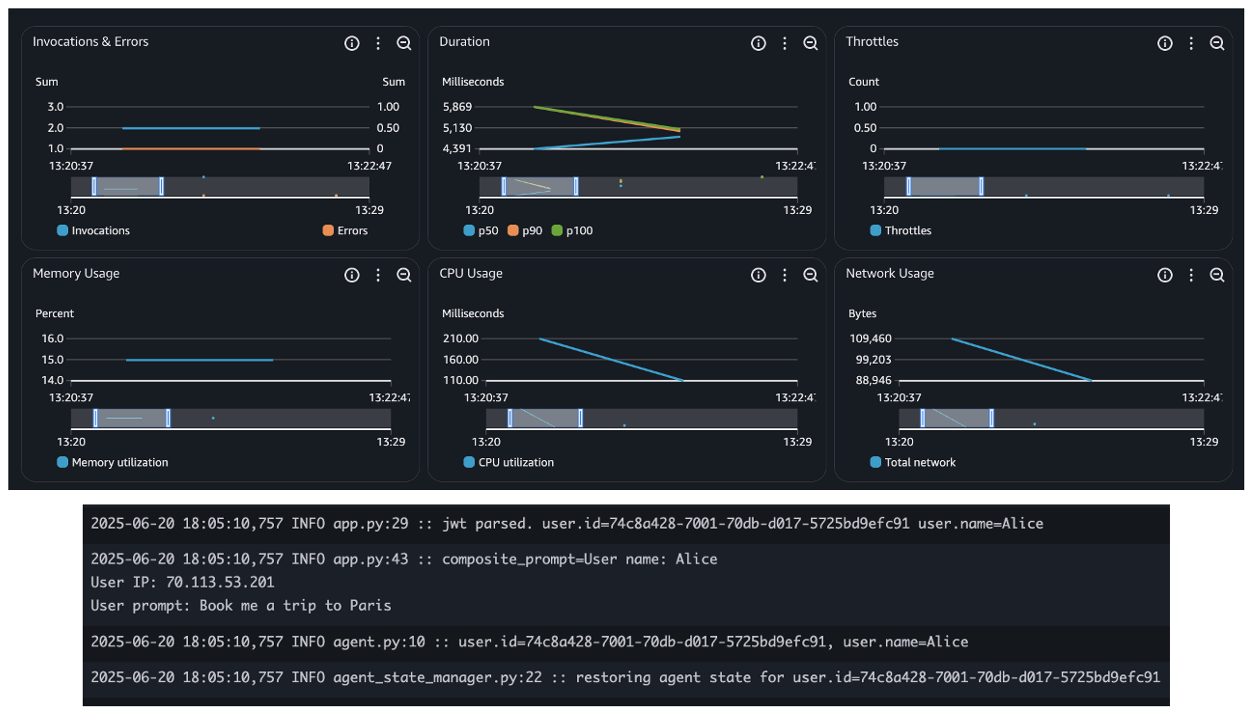
One of the key design principles for operational excellence in the cloud is to implement observability for actionable insights. This helps gain a comprehensive understanding of the workloads to help improve performance, reliability, and the cost involved. Both OpenSearch Serverless and OpenSearch Ingestion publish all metrics and logs data to Amazon CloudWatch. After identifying key operational OpenSearch Serverless metrics and OpenSearch Service pipeline metrics, AppZen set up CloudWatch alarms to send a notification when certain defined thresholds are met. The following screenshot shows the number of OCUs used to index and search collection data.
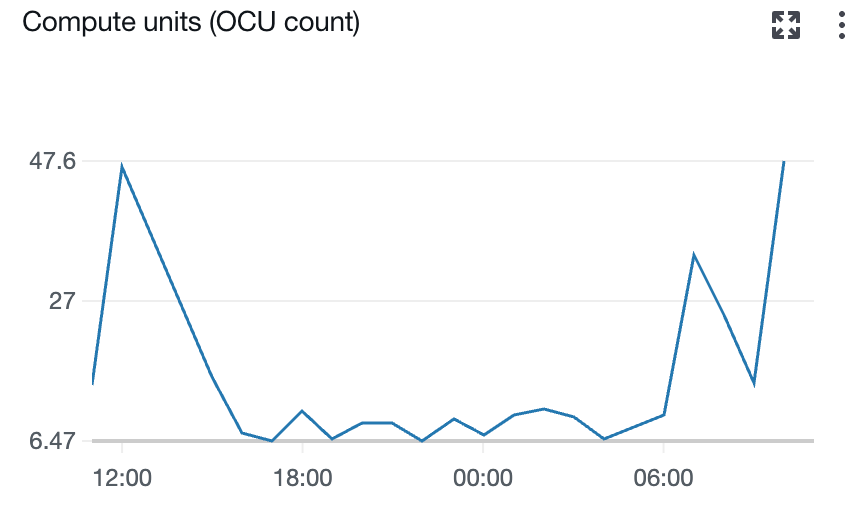
The following screenshot shows the number of Ingestion OCUs in use by the pipeline.
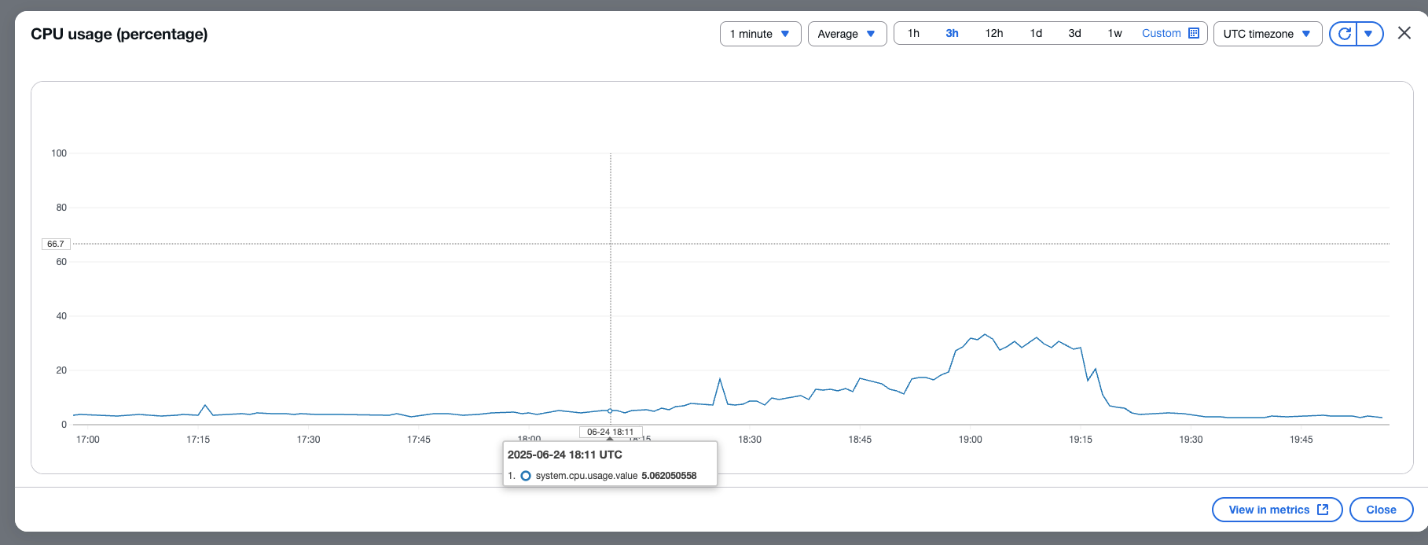
The following screenshot shows the percentage of available CPU usage for OCU.
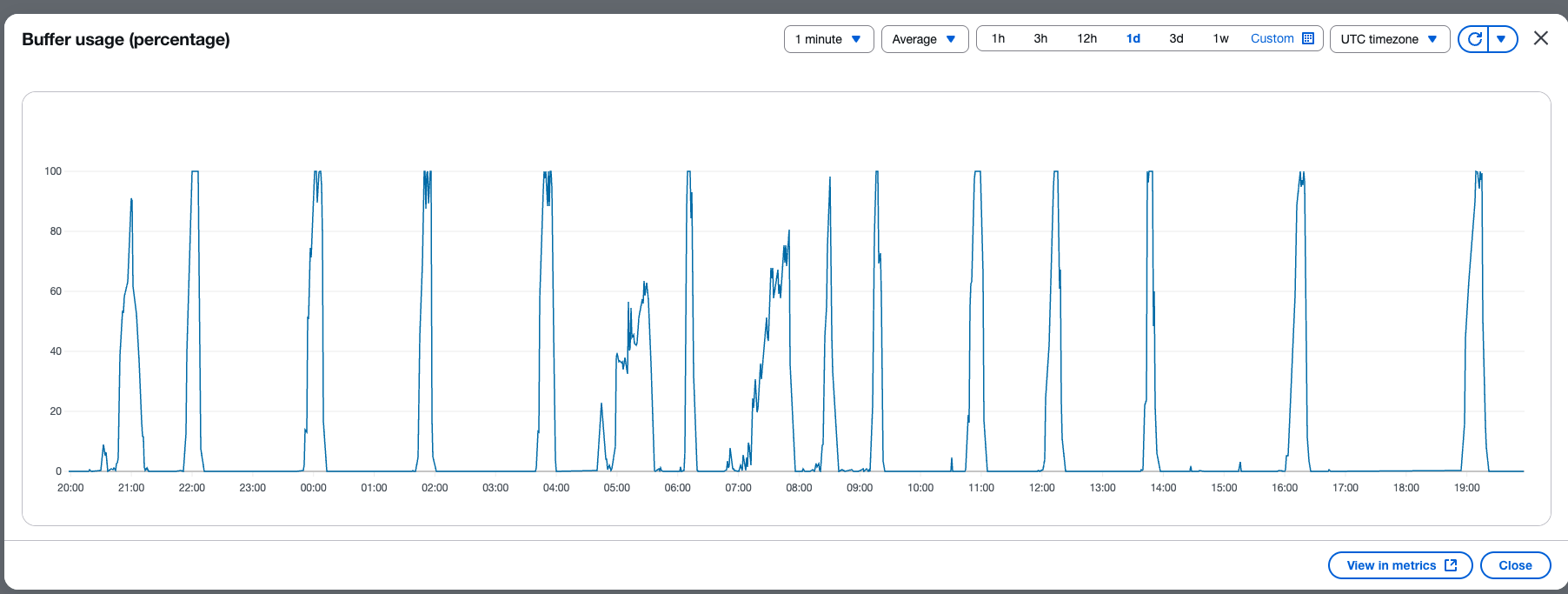
The following screenshot shows the percent usage of buffer based on the number of records in the buffer.
Conclusion
AppZen successfully modernized their logging infrastructure by migrating to a serverless architecture using Amazon OpenSearch Serverless and OpenSearch Ingestion. By adopting this new serverless solution, AppZen eliminated an operations overhead that involved 7 days of data migration effort during each quarterly upgrade and patching cycle of Kubernetes cluster hosting Elasticsearch nodes. Also, with the serverless approach, AppZen was able to avoid index mapping conflicts by using index templates and a new indexing strategy. This helped the team save an average 5.2 hours per week of operational effort and instead use the time to focus on other priority business challenges. AppZen achieved a better security posture through centralized access controls with OpenSearch Serverless, eliminating the overhead of managing a duplicate set of user permissions at the proxy layer. The new solution helped AppZen handle growing data volume and build real-time operational analytics while optimizing cost, improving scalability and resiliency. AppZen optimized costs and performance by classifying workloads into push-based and pull-based flows, so they could choose the appropriate ingestion approach based on latency and throughput requirements.
With this modernized logging solution, AppZen is well positioned to efficiently monitor their business operations, perform in-depth data analysis, and effectively monitor and troubleshooting the application as they continue to grow. Looking ahead, AppZen plans to use OpenSearch Serverless as a vector database, incorporating Amazon S3 Vectors, generative AI, and foundation models (FMs) to enhance operational tasks using natural language processing.
To implement a similar logging solution for your organization, begin by exploring AWS documentation on migrating to Amazon OpenSearch Serverless and setting up OpenSearch Serverless. For guidance on creating ingestion pipelines, refer to the AWS guide on OpenSearch Ingestion to begin modernizing your logging infrastructure.
About the authors
 Prashanth Dudipala is a DevOps Architect at AppZen, where he helps build scalable, secure, and automated cloud platforms on AWS. He’s passionate about simplifying complex systems, enabling teams to move faster, and sharing practical insights with the cloud community.
Prashanth Dudipala is a DevOps Architect at AppZen, where he helps build scalable, secure, and automated cloud platforms on AWS. He’s passionate about simplifying complex systems, enabling teams to move faster, and sharing practical insights with the cloud community.
 Madhuri Andhale is a DevOps Engineer at AppZen, focused on building and optimizing cloud-native infrastructure. She is passionate about managing efficient CI/CD pipelines, streamlining infrastructure and deployments, modernizing systems, and enabling development teams to deliver faster and more reliably. Outside of work, Madhuri enjoys exploring emerging technologies, traveling to new places, experimenting with new recipes, and finding creative ways to solve everyday challenges.
Madhuri Andhale is a DevOps Engineer at AppZen, focused on building and optimizing cloud-native infrastructure. She is passionate about managing efficient CI/CD pipelines, streamlining infrastructure and deployments, modernizing systems, and enabling development teams to deliver faster and more reliably. Outside of work, Madhuri enjoys exploring emerging technologies, traveling to new places, experimenting with new recipes, and finding creative ways to solve everyday challenges.
 Manoj Gupta is a Senior Solutions Architect at AWS, based in San Francisco. With over 4 years of experience at AWS, he works closely with customers like AppZen to build optimized cloud architectures. His primary focus areas are Data, AI/ML, and Security, helping organizations modernize their technology stacks. Outside of work, he enjoys outdoor activities and traveling with family.
Manoj Gupta is a Senior Solutions Architect at AWS, based in San Francisco. With over 4 years of experience at AWS, he works closely with customers like AppZen to build optimized cloud architectures. His primary focus areas are Data, AI/ML, and Security, helping organizations modernize their technology stacks. Outside of work, he enjoys outdoor activities and traveling with family.
 Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.










 Tarun Rai Madan is a Principal Product Manager at Amazon Web Services (AWS). He specializes in serverless technologies and leads product strategy to help customers achieve accelerated business outcomes with event-driven applications, using services like AWS Lambda, AWS Step Functions, Apache Kafka, and Amazon SQS/SNS. Prior to AWS, he was an engineering leader in the semiconductor industry, and led development of high-performance processors for wireless, automotive, and data center applications.
Tarun Rai Madan is a Principal Product Manager at Amazon Web Services (AWS). He specializes in serverless technologies and leads product strategy to help customers achieve accelerated business outcomes with event-driven applications, using services like AWS Lambda, AWS Step Functions, Apache Kafka, and Amazon SQS/SNS. Prior to AWS, he was an engineering leader in the semiconductor industry, and led development of high-performance processors for wireless, automotive, and data center applications. Masudur Rahaman Sayem is a Streaming Data Architect at AWS with over 25 years of experience in the IT industry. He collaborates with AWS customers worldwide to architect and implement sophisticated data streaming solutions that address complex business challenges. As an expert in distributed computing, Sayem specializes in designing large-scale distributed systems architecture for maximum performance and scalability. He has a keen interest and passion for distributed architecture, which he applies to designing enterprise-grade solutions at internet scale.
Masudur Rahaman Sayem is a Streaming Data Architect at AWS with over 25 years of experience in the IT industry. He collaborates with AWS customers worldwide to architect and implement sophisticated data streaming solutions that address complex business challenges. As an expert in distributed computing, Sayem specializes in designing large-scale distributed systems architecture for maximum performance and scalability. He has a keen interest and passion for distributed architecture, which he applies to designing enterprise-grade solutions at internet scale.




















{kind=link}