Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=dMWwsrAv0dU
Yearly Archives: 2024
Titans Sphere – The Failed 3D Game Controller for PC
Post Syndicated from LGR original https://www.youtube.com/watch?v=jJSCPIRdYVM
Истинската битка започна. „Росенец 2“ е сега
Post Syndicated from Емилия Милчева original https://www.toest.bg/istinskata-bitka-zapochna-rosenets-2-e-sega/

Политическата акция на „Да, България“, при която гумена лодка акостира на плажа до лятната резиденция на Ахмед Доган, беше символен опит да се отвоюва държавата от мафията. Същинският е сега, когато промените в Конституцията и в още няколко закона трябва да бъдат осъществени чрез кадровия подбор – в органите на съдебната власт, в новата антикорупционна комисия, в регулаторите и в службите. Преосноваването на държавата започва от нейните институции.
Това е истинската битка, която предстои, а не словесните атаки по телевизионни студиа и пред камерите за фактури за газ, „левче“ за бензин, за външен министър или кога да е ротацията. В сражението „Продължаваме промяната“ – „Демократична България“ залагат политическото си бъдеще и шанса да докажат, че са способни да се преборят за върховенството на правото, и да си върнат избиратели, обърнали им гръб заради „сглобяването“ с Бойко Борисов и особено с Делян Пеевски.
Възможно ли е?
Опраскване 2.0 на хоризонта или…?
Съдебната реформа може да бъде опраскана чрез ново прааас – когато ДПС и ГЕРБ заплашиха с предсрочни избори за Народно събрание заедно с европейските в началото на юни. Статуквото се ядоса на меморандума, предложен от ПП–ДБ на официалния партньор във фактическата коалиция ГЕРБ–СДС. Партиите на Бойко Борисов и на Ахмед Доган го приеха като ултиматум и извиване на ръце, а от ПП–ДБ обясниха, че е начало на преговори.
Ако има избори 2 в 1, „вероятността новият главен прокурор и новият председател на Върховния административен съд да бъдат избрани от сегашния състав на Висшия съдебен съвет се повишава неимоверно“, прогнозира във Facebook директорката на Българския институт за правни инициативи Биляна Гяурова-Вегертседер. Голяма е и вероятността работата си да продължат регулатори с изтекъл отдавна мандат, от чиито решения зависи всеки български гражданин и всеки бизнес. А това означава, че в тях ще бъдат запазени позициите на ГЕРБ и ДПС или по-скоро на Бойко Борисов, Делян Пеевски и уплътняващите ги обръчи. От това може да се предположи, че предстоят и други афери, подобни на „Червеи“, „Двете каки“, „Осемте джуджета“, „SS Club“ на Нотариуса, както и че ще има търговия с постове и влияние, ще има и натиск върху правосъдието.
Цялата мръсна пяна на аферите излиза при изслушванията във временната парламентарна комисия, създадена за изясняване на обстоятелствата около убийството на Мартин Божанов – Нотариуса. И макар че осмелилата се първа да съобщи за натиска върху нея съдийка Владислава Цариградска каза пред депутатите, че „мафия не се бори с публично изслушване на свидетелите на мафиотските действия“, все пак публичното осветяване на мафиотизацията на съдебната система е от огромно значение за обществената подкрепа за тази битка. Досега гражданите чуваха предимно от политици и неправителствени организации за поръчковите дела, за прокурорските бухалки и рекетираните бизнесмени, за подкупните съдии.
Сега обаче за първи път излизат и говорят магистрати, хора от съдебната система, и разказват „зловещи неща“, по определението на прокурор Невена Зартова. И нито един от последните двама главни прокурори, а също и настоящият изпълняващ функциите не са извадени пред скоба в този трилър, в който единственият труп е на върховенството на правото. Големите въпроси са ще назоват ли изслушваните магистрати имена на политици и ще бъде ли повикан за изслушване Делян Пеевски, след като председателят на комисията Никола Минчев от ПП заяви, че няма пречка това да стане.
За разлика от декември 2015 г., когато статуквото удари по законодателните промени още при гласуването им, този път заплашва да го направи, преди да бъде приложен механизъм за номинации и одобрение на кадрите. Вулгарният публичен език на Пеевски показа, че в ДПС са се разбеснели заради меморандума, който не им отрежда „квота“ в съдебната власт, нито в регулаторите, за каквато говореше преди време бившата председателка на ПГ на ГЕРБ Десислава Атанасова (настояща конституционна съдийка).
Христо Иванов и олигарсите зад него искат да вземат прокуратурата. Имаше добри разговори за Конституцията – как всичко ще е прозрачно, но Христо Иванов излъга. Христо Иванов пи мазно турско кафе и седеше в скута ми, докато се случи Конституцията, и всички идваха час през час, докато направихме промените, които са важни за България! Сега ще ми казва, че пак ще извади темата ДПС. ДПС крепи това правителство девет месеца. Маските паднаха, Христо, приятелю мой. Всичко свърши!
После Пеевски поиска очна ставка с Христо Иванов, за да стане ясно, че са водени разговори за различни назначения. Сред тях и на бившия прокурор и заместник-министър на правосъдието Андрей Янкулов от Антикорупционния фонд за главен прокурор или за шеф на Комисията за противодействие на корупцията и на настоящия прокурор Сава Петров за негов заместник. Иванов отрече да са водени такива разговори, коментирайки, че Пеевски е самовзривил опита на ДПС да се препозиционира като приемлива партия.
Това ще бъде решение на бъдещия Висш прокурорски съвет и аз много държа на това. Как ще изберем прокурорски съвет, е наистина много важна тема, политическа, която никой не би трябвало да изненада, че е във фокуса на моето внимание, нали така? Но ако бъдещият Висш прокурорски съвет избере някой с профила на г-н Янкулов, мисля, че ще бъде много добре за България, защото ако някой с профила на господин Янкулов беше избран, нямаше да има Нотариуса, нямаше да има „Осемте джуджета“, щеше да има реално разследване. Да, темата е следващият главен прокурор да не бъде както главния прокурор, който беше избран по времето на доминацията на ГЕРБ и ДПС – Гешев и Цацаров. Ако по мое време бяха избрани такива главни прокурори, аз бих си мълчал, бих бил по-кротък.
Ултиматум или (добро) начало
От известно време лидерът на ГЕРБ Бойко Борисов настояваше за коалиционно споразумение, но ето че ПП–ДБ изпревариха и предложиха проект на такова, но с условието, че ако не се приеме, следват избори 2 в 1 (за български и европейски парламент в началото на юни 2024 г.). Направиха го еднолично, без предварителни разговори с ГЕРБ (и с ДПС), и поставиха на масата предложението си за скрепяване на съвместното управление.
В продължение на 9 месеца лидерите на ПП–ДБ бяха подложени на критиките и недоволството на избирателите си заради това, че с приобщаването на ДПС и ГЕРБ към конституционното мнозинство са отстъпили от каузални цели, довело и до избор на подуправител на БНБ, номиниран от ДПС – Петър Чобанов. Експанзията на политическия терен на санкционирания заради корупция от САЩ и Великобритания председател на ПГ на ДПС Делян Пеевски е сред основните причини за гнева. Медийното му (само)утвърждаване като говорител по основните теми на управляващото мнозинство също отблъсква избиратели от ПП и ДБ.
И докато Христо Иванов се конфронтира с Пеевски, съпредседателят на ПП Кирил Петков предлага „всички малко да се успокоят“ и да укротят емоциите. Трудна работа – развали се рахатлъкът на Бойко Борисов, който формално е ядосан заради несъгласувани назначения, извършени във финансовия сектор, както и заради сливането на НАП и митниците. Последното беше обявено наскоро от Министерството на финансите и ръководството на митниците беше тутакси променено.
Кой съгласува смяната в Агенцията за държавен финансов контрол? В кой меморандум е записано това, ДНСК, БАБХ, митниците? От една и съща партия, еднолично, в разрез на всичко, което е разписано в този меморандум… Независимите регулатори са независими, не се парцелират между Борисов и Петков. Категорично не сме склонни да приемем предложението на ПП–ДБ.
И това – казано от политик, чиято партия обсеби регулаторите. Но Борисов е ядосан, тъй като с меморандума ПП–ДБ го карат да направи избор – с тях или с ДПС. Труден избор в ситуация, в която той отдавна не е лъвът в българската политика, а е по-скоро уморен от дългото управление и притискан и отвън, и отвътре. Европейският съюз е различен след войната на Русия с Украйна. Различна е и Европейската народна партия, където Борисов винаги се е хвалил с добрите си контакти. Но откритият съюз с ДПС – партия, чийто фронтмениджър е лице, санкционирано за корупция, е труден за преглъщане от евроатлантическите партньори. Още по-малко възможен е управленски съюз с проруски политически сили.
В настоящата ситуация Борисов няма как да прави онези толкова успешни прикляквания и на Изток, и на Запад, с които обичаше да се хвали, самоизтъквайки дипломатическия си усет. Завоите в днешната геополитическа ситуация не са приемливи, още повече в светлината на силно промотирания му в последните 9 месеца евроатлантизъм.
Предсрочните парламентарни избори няма да променят настоящото разпределение на силите в парламента. Така че по-вероятно е прагматикът Борисов да седне на масата на преговорите, осъзнавайки, че сегашната конфигурация е безалтернативна.
Механизъм за назначения и хоризонт от 4 години
Какво обаче е записано в меморандума, който толкова ядоса Пеевски и Борисов? Като всеки проектодоговор, и този съдържа повече, отколкото ще остане при подписването му от лидерите на коалициите. Лайтмотивът в него обаче е подробно разписаният механизъм за назначения в регулаторите, а също и споменатият за първи път публично хоризонт за пълен мандат.
Ключов е следният текст:
5.3.3. За целите на постигане на необходимото мнозинство от 2/3, страните ще оценят съвместно номинациите на други парламентарни групи и координирано ще подкрепят съответен брой кандидати, които в най-голяма степен съответстват на изискванията на конституцията и закона и принципите по параграфи 5.3.1 и 5.3.2, както и 2.1 и 2.2 по-горе.
Това означава, че и пресяването на кандидатите ще става като гласуването – заедно и координирано, а не като в случая с избора на конституционни съдии, при който всяка от двете коалиции предложи свой кандидат и после мнозинството гласува. Този механизъм означава, че процесът с номинациите може да се проточи, но също така е гаранция за обща политическа отговорност и недопускане на компрометирани фигури. Затова е и забраната за плаващи мнозинства – любим похват на ГЕРБ.
2.6. Забрана за плаващи мнозинства и зачитане на равнопоставеността на страните. Страните се ангажират да не разчитат на плаващи мнозинства и да не прибягват до договорки с други парламентарни сили за съответни техни действия и бездействия, насочени към осигуряването на избор на кандидат против обоснованите и навременно повдигнати възражения (вето) на другата страна. При спазване на принципите в параграф 2.2 за политическа неутралност, страните ще осигурят постигането на равно разпределение на броя кандидати, избирани за членове на съответния орган. Случаите, в които някоя от страните предложи да бъде избран кандидат на друга парламентарно представена партия, се отчитат за номинация на съответната страна, която прави предложението, и не водят до промяна на съотношението между страните.
Ако ГЕРБ иска и ДПС да има номинации, ще трябва да им отстъпи от своя дял. Има и някои неща, също толкова важни, колкото и механизмът за избор, и това са възможността сред номинираните да има представители на неправителствени организации, както и подробно разписаните проверки за интегритет. Тяхната тежест при избора е голяма.
2.8. Право на вето. Всяка една от страните има право да наложи вето на така предложените кандидати от другата страна, при условие че по време на изслушванията и проверката за интегритет са открити факти и данни за действия, които биха сериозно накърнили доверието в институцията, за която даденият кандидат се е кандидатирал. Страните действат добросъвестно и подхождат с уважение към всички кандидати и опазват тяхното достойнство.
Може ли да се мине без гласовете на ДПС при обновяване на регулаторите, след като с промените в Конституцията беше вкарано мнозинство от 160 гласа за избора? Преди това например председателят на Комисията за защита на конкуренцията се избираше с обикновено мнозинство.
Трудно, но не и невъзможно. Дебаркирането започна.
Ще падат ли цените на имотите през 2024?
Post Syndicated from VassilKendov original https://kendov.com/%D1%89%D0%B5-%D0%BF%D0%B0%D0%B4%D0%B0%D1%82-%D0%BB%D0%B8-%D1%86%D0%B5%D0%BD%D0%B8%D1%82%D0%B5-%D0%BD%D0%B0-%D0%B8%D0%BC%D0%BE%D1%82%D0%B8%D1%82%D0%B5-%D0%BF%D1%80%D0%B5%D0%B7-2024/
Анализ на пазара на недвижими имоти и факторите които влияят на цените
– Инфлация
– Нива на лихвите
– Политика на ЕЦБ и БНБ
– Достъпност до кредитиране
– Демография
– Инвестиране на сиви и корупционни капитали

Моля използвайте приложената форма за записване на час за среща
[contact-form-7]
The post Ще падат ли цените на имотите през 2024? appeared first on Kendov.com.
America’s Black Heroes
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=4oAThrel0Fg
Амнистия за деепричастието
Post Syndicated from original https://www.toest.bg/amnistiya-za-deeprichastieto/

Да употребяваме ли деепричастия? Този въпрос за мен винаги е имал положителен отговор и ми е звучал също толкова странно, колкото „Да употребяваме ли минало неопределено време?“ или „Да избягваме ли наречията?“. В българския език има деепричастия (мислейки), така както има сегашни деятелни причастия (мислещ), минали деятелни причастия – свършени (мислил) и несвършени (мислел) – и минали страдателни причастия (мислен). Защо да се лишаваме от изразните възможности, които ни предоставят причастията от един точно определен вид? И нарочени ли са всъщност те?
Личен опит vs. чужд опит
Опитвам се да си спомня за учител по български език или за преподавател в университета, който е бил настроен отрицателно към деепричастията, но нищо не се появява в съзнанието ми. Или съм имала голям късмет, или съм игнорирала съветите да се избягват тези граматични форми, защото:
- били тромави;
- правели речта по-изкуствена, по-книжна;
- били създадени по подражание на други езици;
- издавали езиковата немощ на автора/преводача на текста;
- трудно се употребявали, без да се допускат грешки.
Всички тези аргументи съм чувала от други хора, у повечето от които се е задействало самоцензурирането, и те съзнателно ограничават употребата на деепричастия в речта си. Не е лесно да се променят формирани с години езикови нагласи, но все отнякъде трябва да се започне. И така, нека да поразчистим камъните в градината на деепричастието.
Български по произход ли са тези форми?
Стопроцентово. Съвременните книжовни форми със завършек -йки всъщност са разклонение на – изненада! – сегашните деятелни причастия. Как така, ще попитате, е възможно ходейки например да има нещо общо с ходещ? В старобългарския език формата на сегашното деятелно причастие е била ходѧшть. Както преди, така и сега то се е изменяло по род и число (в миналото – и по падеж), съгласувайки се с името, което е определяло.
В някои случаи обаче е започнало да се употребява в застинала, неизменяема форма, най-често със завършек -ще или -щи, без да се съгласува с име. Примерите са от писмени паметници от ХIII и ХIV век. Така на преден план излиза глаголната, а не атрибутивната (тоест прилагателната) природа на причастието и по своята същност и функции то се доближава доста до съвременното деепричастие.
Но как от застиналата форма ходѧшти се стига до ходейки? Вследствие на смекчаване на съгласните настъпва следната метаморфоза: ходѧшти > ходеш’т’и > ходех’к’и > ходейки¹. Преходът се извършва в югозападните български говори, от които сме приели точно тези форми в съвременния книжовен език. Това не е станало нито гладко, нито изведнъж.
Установяване на деепричастията в новобългарския книжовен език
В пред- и следосвобожденската ни книжнина граматични форми с най-различни облици се борят да седнат на трона на деепричастието. Ето, вижте какъв е мащабът на конкуренцията: играюще, играющи, казав, казавше, казавши, играя, носяйки, бидейким, пеещем, ходещец, ходещиц… При това спестявам например форми като товарйъще, закусвайъще, употребявани от Г. С. Раковски, но пък ви компенсирам с едно изречение от Дядо Славейков, в което деепричастието има неповторим звуков ефект: Госпожа Хрисодактилица остави съпруга си и влѣзе в стайътъ си шушнещец.
Общо взето, през последните двайсет години на ХIХ век формите на -йки започват да надделяват над останалите и голяма роля за това има лансирането им от писатели като И. Вазов, П. П. Славейков, П. К. Яворов, П. Ю. Тодоров².
Ако приемем, че в началото на ХХ век деепричастието вече се е установило в книжовния ни език, достатъчни ли са ни били 120 години, за да го приемем безрезервно и да го използваме свободно в своята реч? Оказва се, че не. Доста затруднения среща то по пътя си и няма как да не признаем, че поне част от причините за ограничената му употреба са основателни.
Проблемът с книжната и изкуствената реч
Факт е, че деепричастието е в основата на обособена част в изречението, а обособените части „са характерни предимно за писмената реч и имат книжен характер, белег са на по-обработената реч“³. Илюстрирам го с пример от Смирненски: Очите се разтвориха в тревожно любопитство, по лицата легна бледината на страха и минувачите странно забързаха, шушнейки си плахо. Вероятността да срещнем деепричастия в публицистичната, художествената, официално-деловата или научната реч е многократно по-голяма, отколкото в живата реч.
Тук е важно да направим едно уточнение – „книжно“ значи не „изкуствено“, а най-вече „писмено“, макар че днес сме склонни да го асоциираме по-скоро с „официално“ и едва ли не „почти архаично“. Деепричастията просто са типични за писмената, обработена, тоест премислената, а не спонтанната реч и затова не виждам основания съзнателно да ограничаваме употребата им поне в писмени текстове. Имам предвид най-вече художествената литература и медийните публикации.
Езиково немощни ли са авторите и преводачите, употребяващи деепричастия?
Ако се увличат и текстовете им изобилстват от тези граматични форми – да, това ще натежи и наистина ще означава, че не умеят да си служат добре с различни синтактични конструкции. Но ако в една статия се срещат едно, две или три уместно употребени деепричастия, какъв е проблемът? В предишната публикация в тази рубрика например съм използвала допитвайки се и опитвайки се, без изобщо да регистрирам това – в процеса на писането тези форми са се появили естествено в съзнанието ми. Предполагам, че при много други хора е така, и това всъщност е нормално.
Кой от вас си казва: „Сега ще употребя прилагателно име, а тук е необходимо наречие, но я да се върна малко назад, за да поразредя съществителните“? Да, звучи абсурдно, но защо тогава проявяваме свръхчувствителност към деепричастията? Не е ли по-добре да се възползваме от по-богатата вариативност, която ни предоставят? Например освен
Приятно ми е, като си мисля за теб, да гледам звездното небе.
или
Приятно ми е, когато си мисля за теб, да гледам звездното небе.
може да кажем
Приятно ми е, мислейки си за теб, да гледам звездното небе.
В конкретния случай аз бих предпочела третия пример, защото ми звучи по-поетично. В други случаи може по-уместен да се окаже вариантът с подчинено изречение с като или когато – или пък някакъв четвърти, или пети вариант.
Предполагам, че преводачите често проиграват подобни възможности, когато търсят най-доброто съответствие на определена синтактична конструкция в оригинала. Да имаш един вариант повече винаги е за предпочитане.
Разбира се, подмолните камъни в превода не са малко и поне един от тях е свързан с нашата тема: ако за езика на оригинала са твърде характерни граматични форми, съответстващи на нашето деепричастие, опасността да се залитне при предаването им на български е съвсем реална. За английския език рисковете са ясни, но и в гръцкия, да речем, деепричастието се среща доста по-често и вещият преводач следва да отчита тази особеност.
Всъщност моето впечатление е, че ако има залитане при преводите, то по-скоро е в другата посока. От опасения да не се прекали с деепричастията те се свеждат до абсолютния минимум.
Граматиката е коварна и грешки дебнат отвсякъде
Уви, това важи с пълна сила за нашите граматични форми. За да е правилна употребата им, е необходимо да бъдат изпълнени две условия: 1) действието, означено с деепричастие, трябва да се извършва едновременно с основното действие в изречението, и 2) вършителят им да е един и същ.
Конникът профуча край мен, яздейки бял жребец.
Често обаче се нарушава второто условие и се стига дори до примери като
Вдигнах поглед към конника, яздейки бял жребец.
Двете условия чувствително ограничават употребата на деепричастието, но (сякаш това не е достатъчно) те не са единствените, които регулират появата му в речта. Ще дам само един пример за типологична грешка – когато вършителят на действието, означено с деепричастие, е неопределен:
Имайки предвид прогнозите, дефицитът в бюджета ще остане под 3%.
Изречението може да се редактира така:
Като се имат/имаме предвид прогнозите, дефицитът в бюджета ще остане под 3%.
От всички аргументи против употребата на деепричастия най-силен според мен е последният – възможността да се допуснат грешки, която изобщо не е за подценяване и може дори да откаже по-неуверените. Ако обаче знаем в кои случаи може да се подхлъзнем, и внимаваме повече, когато пишем, опасенията ще останат на заден план, а речта ни ще стане по-богата и по-разнообразна с деепричастия. Нека не се лишаваме от възможността, която езикът ни дава, и да ги използваме – с мярка, разбира се.
1 Харалампиев, И. История на българския език. Велико Търново: Фабер, 2001, с. 169 – 170.
2 История на новобългарския книжовен език. София: Издателство на БАН, 1989, с. 419 – 426.
3 Граматика на съвременния български книжовен език. Т. 3. Синтаксис. София: Издателство на БАН, с. 225.
Посвещавам публикацията на Боряна Телбис за любезното и аргументирано насърчение и на Стефан Русинов, който, нищейки проблемите на превода, не забравя и деепричастието.
Crazy Wide Angle – the 10mm F2.8 Full Frame
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=Uu5OnnxJ9xQ
the real reason not to use sigkill (revamp)
Post Syndicated from turnoff.us original http://turnoff.us/geek/the-real-reason-not-to-use-sigkill/
Асоциация „Родители“: „Като общество не сме напълно наясно какво искаме от това образование“
Post Syndicated from Надежда Цекулова original https://www.toest.bg/asotsiatsiya-roditeli-kato-obshtestvo-ne-sme-napulno-nayasno-kakvo-iskame-ot-tova-obrazovanie/

Родителите искат децата им да получат от образованието си както знания и умения, които да са им полезни в живота, така и ценности и собствен морал. Това сочи ново национално представително изследване на Асоциация „Родители“ за нагласите на родителите към българското образование „Българското училище – погледът на родителите“, проведено сред 807 пълнолетни родители през октомври–ноември 2023 г. със съдействието на агенция „Ноема“. Проучването бе представено преди дни на форум, в който участие взеха министърът на образованието Галин Цоков, председателят на Комисията по образование в парламента Красимир Вълчев и представители на образователни институции и родителски общности.
Надежда Цекулова разговаря с Яна Алексиева и Давид Кюранов от Асоциация „Родители“ за категоричното желание на всички за промяна, но и за устойчивостта на инерцията.


Яна Алексиева и Давид Кюранов © Асоциация „Родители“
Като журналист и родител си представям, че въпросът „Какво искаме от образованието на децата?“ би следвало да е обект на периодична дискусия между родителите и образователната система, а и самите деца. Уточнявам това, защото иначе първият ми въпрос може да прозвучи наивно – как ви хрумна да направите изследване за това какво очакват родителите от образованието?
Яна: Тук сме на едно мнение – това трябва да е непрекъснат процес, но в същото време такъв процес и такъв разговор под никаква форма не се води нито на национално ниво, нито дори на ниво възрастните в едно училище или в една детска градина. В обществото ни все още е валидна нагласата, че учителите знаят най-добре какво да направят за децата, и родителите биват питани само когато много се налага или настъпи някаква криза. Иначе казано, родителят е включен само когато учителят допусне да го включи, и то по начин, по който учителят прецени – процесът не е двустранен.
Виждаме през извадки и през анализа, който правим, че няма истинско включване, така че родителят да се чувства достатъчно равноправен в това да казва какво мисли за образованието на децата. Всичко е доста инструментално и формално дори когато родителите биват питани за нещо.
Давид: Но има и друга страна. Трябва да си кажем честно, че има и добри примери. И е трудно, защото да се работи активно с родителите и да бъдат те включени в образователния процес е реформа за българското образование. Дали тя е важна? Да, важна е заради нещо много просто и ясно, което и Андреас Шлайхер [ръководителят на Образователния център на Организацията за икономическо сътрудничество и развитие и създател на тестовете PISA – б.а.] каза, когато беше в България: най-успешните образователни системи са тези, в които родителите участват активно.
Много голямо впечатление ми направи големият процент на жените, на майките сред респондентите – 82%. Къде са бащите?
Давид: Във всяко семейство търсихме този родител, който основно се занимава с образованието на детето. В този смисъл присъствието на майката в такъв огромен процент е напълно в съответствие с тенденции, които сме проследявали в други изследвания през годините.
Това какво ни казва и всъщност доминацията на майките в грижата за образователното развитие има ли отношение към очакванията от образованието?
Яна: Влияе със сигурност, всяко нещо си има своето влияние. Интересното тук е, че този стереотип се затвърждава убедително и чрез професионалистите. Ние продължаваме да чуваме в училищата, че когато майката я няма, за нея се пита. Някак се приема, че бащата отива в училище само ако майката не може. Има и ситуации, в които бащата се търси като „следваща инстанция“, един вид: „Ще кажа на баща ти и ще видиш какво ще стане…“
Има тенденция за промяна, но тя все още е много нова. От друга страна, извън изследването мога смело да кажа, че всички събития, свързани с по-активно включване на бащите, се радват на огромен интерес.
Давид: Това е една сложна ситуация, но от учителите сме имали много пъти обратна връзка, че след като са започнали да търсят бащите по-често, с изненада са установили, че се разбират с тях дори по-лесно, отколкото с майките. Така че се надяваме бащите все по-активно да се саморазпознават и да бъдат разпознавани като фактор в образованието на децата.
Какво се оказа, че искат тези родители от образованието на децата си?
Давид: От социологическа гледна точка е интересно, че отговорът на въпроса излезе по най-чистия възможен начин – през отворен въпрос, в който родителите можеха сами да напишат това, което искат. И ако трябва да го синтезираме, родителите биха искали децата им да имат знания и умения, които им вършат реална работа в живота. Също така в рамките на образованието децата да се изграждат поетапно като личности, развивайки собствени ценности и собствен морал. И двете неща са важни.
Доколко това се случва в реалността?
Давид: Според данните ни отговорът е малко мъгляв и той е „Донякъде се случва“. Има един дял родители (между 25 и 33–34%), които са доста доволни от отделни аспекти на училищния живот. Става въпрос за общи процеси, свързани с комуникацията, да кажем честота на общуване с учителите, качество на информацията, която се получава, провеждане на различни инициативи…
Признавам, че бях доста изненадана от процента родители, които според изследването са доволни от родителските срещи – 36% напълно удовлетворени и още 46% по-скоро удовлетворени…
Яна: Ние също обсъждахме с екипа подробно тези резултати, защото чисто субективно аз не познавам родител, който е доволен от родителската среща в класическия ѝ вид.
И как обяснявате този парадокс? Защо не познаваме родители, които да са доволни от родителските срещи и от информацията, която получават, а от изследването излиза, че всъщност повечето родители са поне донякъде доволни?
Давид: Хубавото на такъв тип изследвания е, че те ни дават възможност да излезем от балона, в който сме ние самите. Защото родителските срещи в класическия им формат наистина не ни вършат много работа. Но когато изследвах данните и си задавах въпроса „Добре, какви са тия хора, които са толкова доволни?“, започнах да разбирам някои неща. И първото е, че основният контекст на отношенията родители–училище е огромната инерция. Инерция на статукво, на непроменяне на модела такъв, какъвто го помним от времето, когато ние сме били ученици – две родителски срещи на срок, излизаме след два часа без съществена информация за нашето дете, пък дори и за класа.
Най-интересният дял сред отговорите на въпроса дали са удовлетворени от този формат на родителските срещи, е и най-големият – на тези, които са отговорили с „По-скоро да“. Да кажеш, че нещо по-скоро става, не означава, че си доволен. В този смисъл подвеждащо е да гледаме графиката и да причисляваме тази голяма група родители към доволните. Те по-скоро приемат инерцията.
Яна: Големият въпрос е как излизаме от тази инерция и как мотивираме родителите осъзнато да помислят какво искат от училището и каква е тяхната роля.
Ние сме общество, което не е тренирано да изисква нещо повече, родителите не са изключение…
Яна: Да изискват, но и да дават. Важно е не само осъзнато да мислим за това какво очакваме от училището, но и какво можем да дадем.
Аз исках да направя преход към академичните очаквания. Защо според проучването родителите оценяват училището с оценка „много добър 4,57“, а в същото време след всеки значим изпит, национално външно оценяване или PISA ставаме свидетели (и автори) на апокалиптични прогнози за бъдещето на днешните ученици?
Давид: По отношение на удовлетворението от образователната подготовка, от една страна, се вижда, че пак има един дял между 10 и 25%, които подчертават, че са много доволни, но най-големият дял отново са хората, които казват, че тези неща „по-скоро вършат работа“. Това щеше да бъде странно, ако беше останало безкритично. Тоест ако след този въпрос, когато говорим с нашите респонденти за предложения, те бяха казали, че нещата са си съвсем добре. Но не е така. Когато стане дума за предложения за промени, един огромен дял от 85% казват, че промени задължително трябва да има. Така че общото послание по отношение на образователния процес и резултатите от него е, че той върши някаква работа, но недостатъчно, и промени трябва да има.
Искам да помоля да начертаем някаква конкретика. От какво са доволни родителите и от какво не са?
Давид: Като наблюдаваме данните, се вижда, че неща, свързани с обща грамотност или с това дали учениците учат и възпроизвеждат, се приемат за успешни. Тоест децата се научават да зазубрят и възпроизвеждат.
Яна: Но виждаме например, че голям дял от родителите искат едносменен режим, искат повече умения, да има повече отделено време за теми, свързани с живота на децата.
Давид: Реално нещата, от които родителите са по-малко доволни и искат да виждат повече възможности, са развиване на самостоятелно мислене, децата да учат с разбиране, да решават реални казуси. Мога да дам съвсем конкретен пример – според родителите липсва развиване на умения за правилно хранене и грижа за тялото. Те посочват, че това е конкретна нужда на децата, за която в училище въобще не става дума.
Яна: Ако трябва да сме още по-конкретни, говорим за липса на здравно образование и за невъзможност за интегриране на здравословен режим в самия учебен ден на децата.
Давид: Очевидно не само ние с Яна си задаваме въпроса как се отразява образованието на здравето – буквално, в чисто физически параметри, дори и да не споменаваме психическите. Родителите категорично подкрепят и заявяват нуждата да се работи повече в посока грижа за здравето.
Може ли да направим обобщението, че от една страна, има нужда и дори има предложения за промени, а от друга страна, като че ли няма осъзнатост, че реализацията на тези предложения всъщност изисква общо действие, някаква проактивност?
Давид: Да, съгласен съм с този извод. Той може да се види и през начина, по който ние самите презентираме това изследване. Институциите ни казват: „Да, родителят е много важен“. Но след това има риск да изпаднем в типичния институционален синдром „Чудесно изследване, приберете го в това чекмедже“. Тоест как правим крачката към това да започнем да включваме родителите в училище по смислен начин, а не да ги задължим с някаква формалистка програма. Защото основният въпрос, който се вижда кристално ясно в изследването, е „Каква всъщност е ролята на родителя в училище?“. За самите родители е трудно да си отговорят. И аз смятам, че не е и тяхна работа да си отговарят. Според мен е работа на училището да им предложи различни възможности.
Яна: Мисля, че е и въпрос на взаимно осъзнаване. Не бих искала да прозвучи, сякаш търсим някакъв конфликт между училището и родителите – точно обратното е. От една страна, училището трябва да е лидер, да води този процес. От друга, родителите трябва да се научим да си задаваме целенасочено въпроса „Като пращаме детето на училище, за какво го пращаме?“. От изследването виждаме нещо, което се наслагва през различи перспективи – че като общество не сме напълно наясно какво искаме от това образование. Липсва ясна визия на системата, която родителят да припознае – или дори ако щете, да се бунтува срещу нея.
Давид: Да подчертая и аз, че в никакъв случай не говорим за конфликт, а за това, че лидерът на училищната общност е училището. И ако искаме родителите да участват ефективно в образователния процес, те трябва да виждат в това ясен смисъл.
Можем ли на база на добри практики у нас или на чужд опит да формулираме какво значи „ясен смисъл“?
Яна: Ясният смисъл е благосъстоянието на детето. Или още по-просто – кои са тези първо, второ, трето, пето, с които родителят може да участва, за да стане средата по-добра за неговото дете и за всички деца в общността.
Миналата година в България беше една американска изследователка, която сподели, че само в бившия соцблок все още наблюдава това силно затруднение родителите да бъдат адекватно включени, а учителите да не са подготвени още от университета какви варианти за включване на родителите биха могли да използват.
Родителите водят своето дете в училище с надеждата то да е добре, да се учи и ако е възможно, да му се случват и други хубави неща там. Ясният смисъл би бил да им се дадат ясни възможности да допринасят за това.
Intel Clearwater Forest is Set to be a Tech Breakthrough Server Chip
Post Syndicated from John Lee original https://www.servethehome.com/intel-clearwater-forest-is-set-to-be-a-tech-breakthrough-server-chip/
This week we covered the Intel Foundry event and some of the new innovations in both fabrication and packaging technologies coming. Something we also wanted to cover is the innovation that Intel pre-announced for its Clearwater Forest line. This is set to be a high-core count game-changing server CPU with multiple technological breakthroughs. Let us get […]
The post Intel Clearwater Forest is Set to be a Tech Breakthrough Server Chip appeared first on ServeTheHome.
Enabling near real-time data analytics on the data lake
Post Syndicated from Grab Tech original https://engineering.grab.com/enabling-near-realtime-data-analytics
Introduction
In the domain of data processing, data analysts run their ad hoc queries on the data lake. The lake serves as an interface between our analytics and production environment, preventing downstream queries from impacting upstream data ingestion pipelines. To ensure efficient data processing in the data lake, choosing appropriate storage formats is crucial.
The vanilla data lake solution is built on top of cloud object storage with Hive metastore, where data files are written in Parquet format. Although this setup is optimised for scalable analytics query patterns, it struggles to handle frequent updates to the data due to two reasons:
- The Hive table format requires us to rewrite the Parquet files with the latest data. For instance, to update one record in a Hive unpartitioned table, we would need to read all the data, update the record, and write back the entire data set.
- Writing Parquet files is expensive due to the overhead of organising the data to a compressed columnar format, which is more complex than a row format.
The issue is further exacerbated by the scheduled downstream transformations. These necessary steps, which clean and process the data for use, increase the latency because the total delay now includes the combined scheduled intervals of these processing jobs.
Fortunately, the introduction of the Hudi format, which supports fast writes by allowing Avro and Parquet files to co-exist on a Merge On Read (MOR) table, opens up the possibility of having a data lake with minimal data latency. The concept of a commit timeline further allows data to be served with Atomicity, Consistency, Isolation, and Durability (ACID) guarantees.
We employ different sets of configurations for the different characteristics of our input sources:
- High or low throughput. A high-throughput source refers to one that has a high level of activity. One example of this can be our stream of booking events generated from each customer transaction. On the other hand, a low-throughput source would be one that has a relative low level of activity. An example of this can be transaction events generated from reconciliation happening on a nightly basis.
- Kafka (unbounded) or Relational Database Sources (bounded). Our sinks have sources that can be broadly categorised into unbounded and bounded sources. Unbounded sources are usually related to transaction events materialised as Kafka topics, representing user-generated events as they interact with the Grab superapp. Bounded sources usually refer to Relational Database (RDS) sources, whose size is bound to storage provisioned.
The following sections will delve into the differences between each source and our corresponding configurations optimised for them.
High throughput source
For our data sources with high throughput, we have chosen to write the files in MOR format since the writing of files in Avro format allows for fast writes to meet our latency requirements.
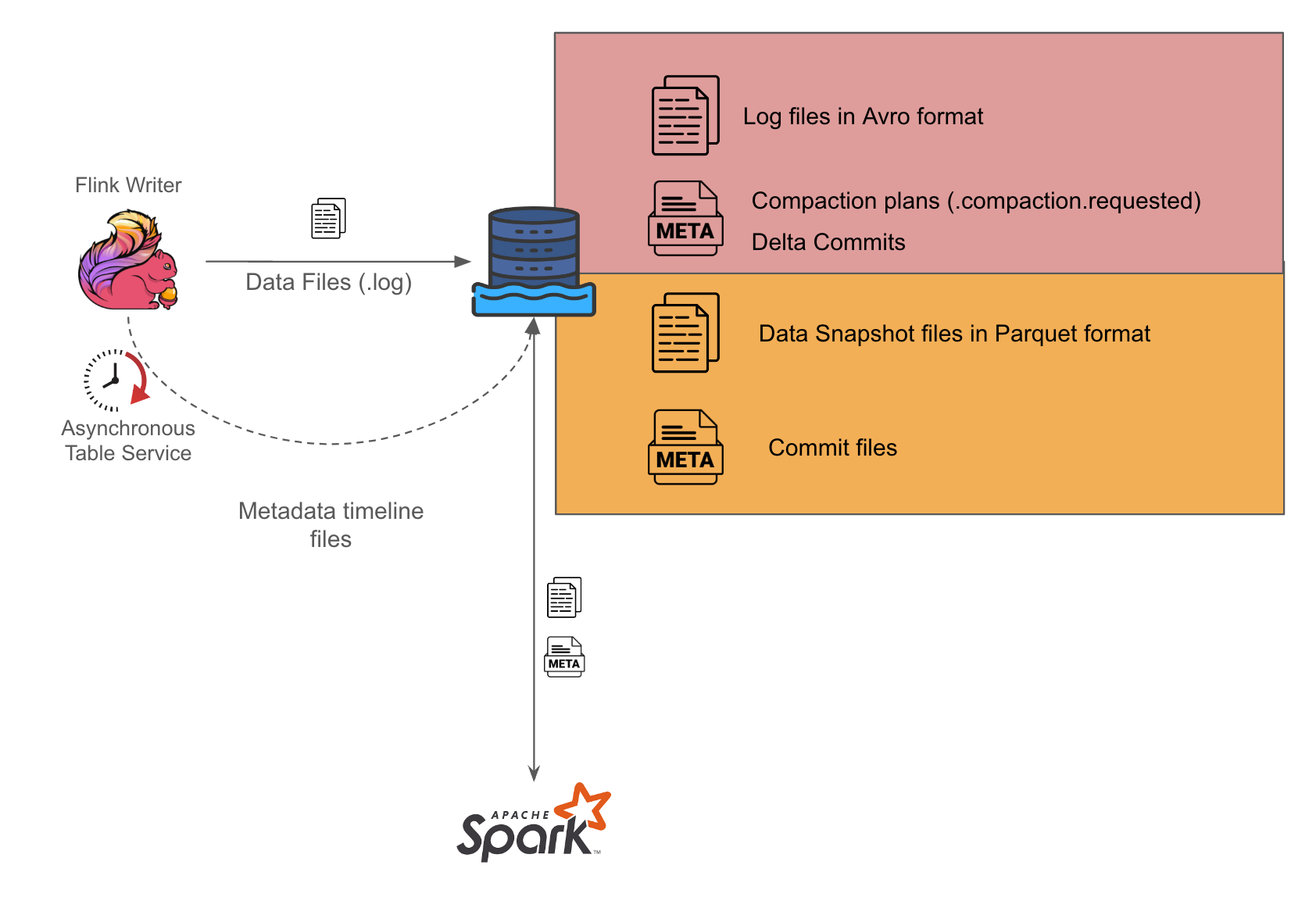
As seen in Figure 1, we use Flink to perform the stream processing and write out log files in Avro format in our setup. We then set up a separate Spark writer which periodically converts the Avro files into Parquet format in the Hudi compaction process.
We have further simplified the coordination between the Flink and Spark writers by enabling asynchronous services on the Flink writer so it can generate the compaction plans for Spark writers to act on. During the Spark job runs, it checks for available compaction plans and acts on them, placing the burden of orchestrating the writes solely on the Flink writer. This approach could help minimise potential concurrency problems that might otherwise arise, as there would be a single actor
orchestrating the associated Hudi table services.
Low throughput source
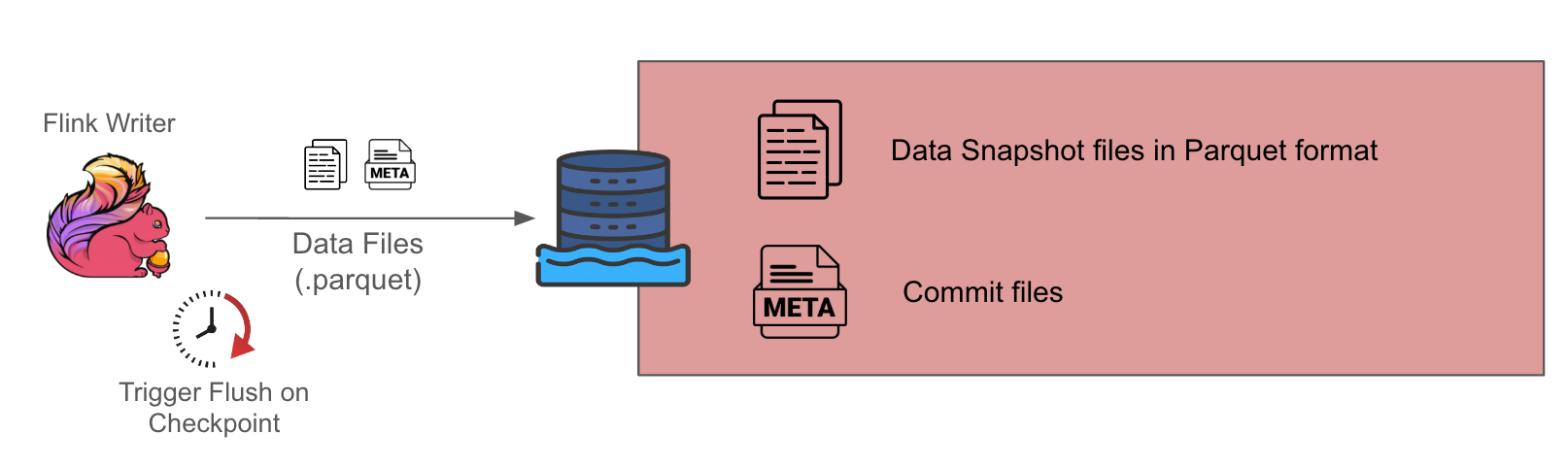
For low throughput sources, we gravitate towards the choice of Copy On Write (COW) tables given the simplicity of its design, since it only involves one component, which is the Flink writer. The downside is that it has higher data latency because this setup only generates Parquet format data snapshots at each checkpoint interval, which is typically about 10-15 minutes.
Connecting to our Kafka (unbounded) data source
Grab uses Protobuf as our central data format in Kafka, ensuring schema evolution compatibility. However, the derivation of the schema of these topics still requires some transformation to make it compatible with Hudi’s accepted schema. Some of these transformations include ensuring that Avro record fields do not contain just a single array field, and handling logical decimal schemas to transform them to fixed byte schema for Spark compatibility.
Given the unbounded nature of the source, we decided to partition it by Kafka event time up to the hour level. This ensured that our Hudi operations would be faster. Parquet file writes would be faster since they would only affect files within the same partition, and each Parquet file within the same event time partition would have a bounded size given the monotonically increasing nature of Kafka event time.
By partitioning tables by Kafka event time, we can further optimise compaction planning operations, since the amount of file lookups required is now reduced with the use of BoundedPartitionAwareCompactionStrategy. Only log files in recent partitions would be selected for compaction and the job manager need not list every partition to figure out which log files to select for compaction during the planning phase anymore.
Connecting to our RDS (bounded) data source
For our RDS, we decided to use the Flink Change Data Capture (CDC) connectors by Veverica to obtain the binlog streams. The RDS would then treat the Flink writer as a replication server and start streaming its binlog data to it for each MySQL change. The Flink CDC connector presents the data as a Kafka Connect (KC) Source record, since it uses the Debezium connector under the hood. It is then a straightforward task to deserialise these records and transform them into Hudi records, since
the Avro schema and associated data changes are already captured within the KC source record.
The obtained binlog timestamp is also emitted as a metric during consumption for us to monitor the observed data latency at the point of ingestion.
Optimising for these sources involves two phases:
- First, assigning more resources for the cold start incremental snapshot process where Flink takes a snapshot of the current data state in the RDS and loads the Hudi table with that snapshot. This phase is usually resource-heavy as there are a lot of file writes and data ingested during this process.
- Once the snapshotting is completed, Flink would then start to process the binlog stream and the observed throughput would drop to a level similar to the DB write throughput. The resources required by the Flink writer at this stage would be much lower than in the snapshot phase.
Indexing for Hudi tables
Indexing is important for upserting Hudi tables when the writing engine performs updates, allowing it to efficiently locate the file groups of the data to be updated.
As of version 0.14, the Flink engine only supports Bucket Index or Flink State Index. Bucket Index performs indexing of the file record by hashing the record key and matching it to a specific bucket of files indicated by the naming convention of the written data files. Flink State Index on the other hand stores the index map of record keys to files in memory.
Given that our tables include unbounded Kafka sources, there is a possibility for our state indexes to grow indefinitely. Furthermore, the requirement of state preservation for Flink State Index across version deployments and configuration updates adds complexity to the overall solution.
Thus, we opted for the simple Bucket Index for its simplicity and the fact that our Hudi table size per partition does not change drastically across the week. However, this comes with a limitation whereby the number of buckets cannot be updated easily and imposes a parallelism limit at which our Flink pipelines can scale. Thus, as traffic grows organically, we would find ourselves in a situation whereby our configuration grows obsolete and cannot handle the increased load.
To resolve this going forward, using consistent hashing for the Bucket Index would be something to explore to optimise our Parquet file sizes and allow the number of buckets to grow seamlessly as traffic grows.
Impact
Fresh business metrics
Post creation of our Hudi Data Ingestion solution, we have enabled various users such as our data analysts to perform ad hoc queries much more easily on data that has lower latency. Furthermore, Hudi tables can be seamlessly joined with Hive tables in Trino for additional context. This enabled the construction of operational dashboards reflecting fresh business metrics to our various operators, empowering them with the necessary information to quickly respond to any abnormalities (such as high-demand events like F1 or seasonal holidays).
Quicker fraud detection
Another significant user of our solution is our fraud detection analysts. This enabled them to rapidly access fresh transaction events and analyse them for fraudulent patterns, particularly during the emergence of a new attack pattern that hadn’t been detected by their rules engine. Our solution also allowed them to perform multiple ad hoc queries that involve lookbacks of various days’ worth of data without impacting our production RDS and Kafka clusters by using the data lake as the data interface, reducing the data latency to the minute level and, in turn, empowering them to respond more quickly to attacks.
What’s next?
As the landscape of data storage solutions evolves rapidly, we are eager to test and integrate new features like Record Level Indexing and the creation of Pre Join tables. This evolution extends beyond the Hudi community to other table formats such as IceBerg and DeltaLake. We remain ready to adapt ourselves to these changes and incorporate the advantages of each format into our data lake within Grab.
References
- Hudi: https://hudi.apache.org/docs/next/overview/
- Ververica Flink CDC: https://github.com/ververica/flink-cdc-connectors
- Debezium: https://debezium.io/documentation/reference/stable/connectors/mysql.html
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Orbital Argument
Post Syndicated from xkcd.com original https://xkcd.com/2898/

AWS HITRUST Shared Responsibility Matrix for HITRUST CSF v11.2 now available
Post Syndicated from Mark Weech original https://aws.amazon.com/blogs/security/aws-hitrust-shared-responsibility-matrix-for-hitrust-csf-v11-2-now-available/
The latest version of the AWS HITRUST Shared Responsibility Matrix (SRM)—SRM version 1.4.2—is now available. To request a copy, choose SRM version 1.4.2 from the HITRUST website.
SRM version 1.4.2 adds support for the HITRUST Common Security Framework (CSF) v11.2 assessments in addition to continued support for previous versions of HITRUST CSF assessments v9.1–v11.2. As with the previous SRM versions v1.4 and v1.4.1, SRM v1.4.2 enables users to trace the HITRUST CSF cross-version lineage and inheritability of requirement statements, especially when inheriting from or to v9.x and 11.x assessments.
The SRM is intended to serve as a resource to help customers use the AWS Shared Responsibility Model to navigate their security compliance needs. The SRM provides an overview of control inheritance, and customers also use it to perform the control scoring inheritance functions for organizations that use AWS services.
Using the HITRUST certification, you can tailor your security control baselines to a variety of factors—including, but not limited to, regulatory requirements and organization type. As part of their approach to security and privacy, leading organizations in a variety of industries have adopted the HITRUST CSF.
AWS doesn’t provide compliance advice, and customers are responsible for determining compliance requirements and validating control implementation in accordance with their organization’s policies, requirements, and objectives. You can deploy your environments on AWS and inherit our HITRUST CSF certification, provided that you use only in-scope services and apply the controls detailed on the HITRUST website.
What this means for our customers
The new AWS HITRUST SRM version 1.4.2 has been tailored to reflect both the Cross Version ID (CVID) and Baseline Unique ID (BUID) in the CSF object so that you can select the correct control for inheritance even if you’re still using an older version of the HITRUST CSF for your own assessment. As an additional benefit, the AWS HITRUST Inheritance Program also supports the control inheritance of AWS cloud-based workloads for new HITRUST e1 and i1 assessment types, in addition to the validated r2-type assessments offered through HITRUST.
For additional details on the AWS HITRUST program, see our HITRUST CSF compliance page.
At AWS, we’re committed to helping you achieve and maintain the highest standards of security and compliance. We value your feedback and questions. Contact the AWS HITRUST team at AWS Compliance Contact Us. If you have feedback about this post, submit comments in the Comments section below.
Introducing the .NET 8 runtime for AWS Lambda
Post Syndicated from Julian Wood original https://aws.amazon.com/blogs/compute/introducing-the-net-8-runtime-for-aws-lambda/
This post is written by Beau Gosse, Senior Software Engineer and Paras Jain, Senior Technical Account Manager.
AWS Lambda now supports .NET 8 as both a managed runtime and container base image. With this release, Lambda developers can benefit from .NET 8 features including API enhancements, improved Native Ahead of Time (Native AOT) support, and improved performance. .NET 8 supports C# 12, F# 8, and PowerShell 7.4. You can develop Lambda functions in .NET 8 using the AWS Toolkit for Visual Studio, the AWS Extensions for .NET CLI, AWS Serverless Application Model (AWS SAM), AWS CDK, and other infrastructure as code tools.

Creating .NET 8 function in the console
What’s new
Upgraded operating system
The .NET 8 runtime is built on the Amazon Linux 2023 (AL2023) minimal container image. This provides a smaller deployment footprint than earlier Amazon Linux 2 (AL2) based runtimes and updated versions of common libraries such as glibc 2.34 and OpenSSL 3.
The new image also uses microdnf as a package manager, symlinked as dnf. This replaces the yum package manager used in earlier AL2-based images. If you deploy your Lambda functions as container images, you must update your Dockerfiles to use dnf instead of yum when upgrading to the .NET 8 base image. For more information, see Introducing the Amazon Linux 2023 runtime for AWS Lambda.
Performance
There are a number of language performance improvements available as part of .NET 8. Initialization time can impact performance, as Lambda creates new execution environments to scale your function automatically. There are a number of ways to optimize performance for Lambda-based .NET workloads, including using source generators in System.Text.Json or using Native AOT.
Lambda has increased the default memory size from 256 MB to 512 MB in the blueprints and templates for improved performance with .NET 8. Perform your own functional and performance tests on your .NET 8 applications. You can use AWS Compute Optimizer or AWS Lambda Power Tuning for performance profiling.
At launch, new Lambda runtimes receive less usage than existing established runtimes. This can result in longer cold start times due to reduced cache residency within internal Lambda subsystems. Cold start times typically improve in the weeks following launch as usage increases. As a result, AWS recommends not drawing performance comparison conclusions with other Lambda runtimes until the performance has stabilized.
Native AOT
Lambda introduced .NET Native AOT support in November 2022. Benchmarks show up to 86% improvement in cold start times by eliminating the JIT compilation. Deploying .NET 8 Native AOT functions using the managed dotnet8 runtime rather than the OS-only provided.al2023 runtime gives your function access to .NET system libraries. For example, libicu, which is used for globalization, is not included by default in the provided.al2023 runtime but is in the dotnet8 runtime.
While Native AOT is not suitable for all .NET functions, .NET 8 has improved trimming support. This allows you to more easily run ASP.NET APIs. Improved trimming support helps eliminate build time trimming warnings, which highlight possible runtime errors. This can give you confidence that your Native AOT function behaves like a JIT-compiled function. Trimming support has been added to the Lambda runtime libraries, AWS .NET SDK, .NET Lambda Annotations, and .NET 8 itself.
Using.NET 8 with Lambda
To use .NET 8 with Lambda, you must update your tools.
- Install or update the .NET 8 SDK.
- If you are using AWS SAM, install or update to the latest version.
- If you are using Visual Studio, install or update the AWS Toolkit for Visual Studio.
- If you use the .NET Lambda Global Tools extension (
Amazon.Lambda.Tools), install the CLI extension and templates. You can upgrade existing tools withdotnet tool update -g Amazon.Lambda.Toolsand existing templates withdotnet new install Amazon.Lambda.Templates.
You can also use .NET 8 with Powertools for AWS Lambda (.NET), a developer toolkit to implement serverless best practices such as observability, batch processing, retrieving parameters, idempotency, and feature flags.
Building new .NET 8 functions
Using AWS SAM
- Run
sam init. - Choose 1- AWS Quick Start Templates.
- Choose one of the available templates such as Hello World Example.
- Select N for Use the most popular runtime and package type?
- Select
dotnet8as the runtime. Thedotnet8Hello World Example also includes a Native AOT template option. - Follow the rest of the prompts to create the .NET 8 function.

AWS SAM .NET 8 init options
You can amend the generated function code and use sam deploy --guided to deploy the function.
Using AWS Toolkit for Visual Studio
- From the Create a new project wizard, filter the templates to either the Lambda or Serverless project type and select a template. Use Lambda for deploying a single function. Use Serverless for deploying a collection of functions using AWS CloudFormation.
- Continue with the steps to finish creating your project.
- You can amend the generated function code.
- To deploy, right click on the project in the Solution Explorer and select Publish to AWS Lambda.
Using AWS extensions for the .NET CLI
- Run
dotnet new list --tag Lambdato get a list of available Lambda templates. - Choose a template and run
dotnet new <template name>. To build a function using Native AOT, usedotnet new lambda.NativeAOTordotnet new serverless.NativeAOTwhen using the .NET Lambda Annotations Framework. - Locate the generated Lambda function in the directory under
srcwhich contains the .csproj file. You can amend the generated function code. - To deploy, run
dotnet lambda deploy-functionand follow the prompts. - You can test the function in the cloud using
dotnet lambda invoke-functionor by using the test functionality in the Lambda console.
You can build and deploy .NET Lambda functions using container images. Follow the instructions in the documentation.
Migrating from .NET 6 to .NET 8 without Native AOT
Using AWS SAM
- Open the
template.yamlfile. - Update Runtime to
dotnet8. - Open a terminal window and rebuild the code using
sam build. - Run
sam deployto deploy the changes.
Using AWS Toolkit for Visual Studio
- Open the .csproj project file and update the
TargetFrameworktonet8.0. Update NuGet packages for your Lambda functions to the latest version to pull in .NET 8 updates. - Verify that the build command you are using is targeting the .NET 8 runtime.
- There may be additional steps depending on what build/deploy tool you’re using. Updating the function runtime may be sufficient.

Using AWS extensions for the .NET CLI or AWS Toolkit for Visual Studio
- Open the
aws-lambda-tools-defaults.jsonfile if it exists.- Set the framework field to
net8.0. If unspecified, the value is inferred from the project file. - Set the function-runtime field to
dotnet8.
- Set the framework field to
- Open the
serverless.templatefile if it exists. For anyAWS::Lambda::FunctionorAWS::Servereless::Functionresources, set the Runtime property todotnet8. - Open the .csproj project file if it exists and update the TargetFramework to net8.0. Update NuGet packages for your Lambda functions to the latest version to pull in .NET 8 updates.
Migrating from .NET 6 to .NET 8 Native AOT
The following example migrates a .NET 6 class library function to a .NET 8 Native AOT executable function. This uses the optional Lambda Annotations framework which provides idiomatic .NET coding patterns.
Update your project file
- Open the project file.
- Set
TargetFrameworktonet8.0. - Set
OutputTypetoexe. - Remove
PublishReadyToRunif it exists. - Add
PublishAotand set totrue. - Add or update NuGet package references to
Amazon.Lambda.AnnotationsandAmazon.Lambda.RuntimeSupport. You can update using the NuGet UI in your IDE, manually, or by running dotnet add package Amazon.Lambda.RuntimeSupport anddotnet add package Amazon.Lambda.Annotationsfrom your project directory.
Your project file should look similar to the following:
Updating your function code
-
- Reference the annotations library with
using Amazon.Lambda.Annotations; - Add
[assembly:LambdaGlobalProperties(GenerateMain = true)]to allow the annotations framework to create the main method. This is required as the project is now an executable instead of a library. - Add the below partial class and include a
JsonSerializableattribute for any types that you need to serialize, including for your function input and output This partial class is used at build time to generate reflection free code dedicated to serializing the listed types. The following is an example: - After the using statement, add the following to specify the serializer to use.
[assembly: LambdaSerializer(typeof(SourceGeneratorLambdaJsonSerializer<LambdaFunctionJsonSerializerContext>))]
Swap
LambdaFunctionJsonSerializerContextfor your context if you are not using the partial class from the previous step.Updating your function configuration
If you are using aws-lambda-tools-defaults.json.
- Set
function-runtimetodotnet8. - Set
function-architectureto match your build machine – eitherx86_64orarm64. - Set (or update)
environment-variablesto includeANNOTATIONS_HANDLER=<YourFunctionHandler>. Replace<YourFunctionHandler>with the method name of your function handler, so the annotations framework knows which method to call from the generated main method. - Set
function-handlerto the name of the executable assembly in your bin directory. By default, this is your project name, which tells the .NET Lambda bootstrap script to run your native binary instead of starting the .NET runtime. If your project file has AssemblyName then use that value for the function handler.
Deploy and test
- Deploy your function. If you are using
Amazon.Lambda.Tools, rundotnet lambda deploy-function. Check for trim warnings during build and refactor to eliminate them. - Test your function to ensure that the native calls into AL2023 are working correctly. By default, running local unit tests on your development machine won’t run natively and will still use the JIT compiler. Running with the JIT compiler does not allow you to catch native AOT specific runtime errors.
Conclusion
Lambda is introducing the new .NET 8 managed runtime. This post highlights new features in .NET 8. You can create new Lambda functions or migrate existing functions to .NET 8 or .NET 8 Native AOT.
For more information, see the AWS Lambda for .NET repository, documentation, and .NET on Serverless Land.
For more serverless learning resources, visit Serverless Land.
- Reference the annotations library with
AWS Customer Compliance Guides now publicly available
Post Syndicated from Kevin Donohue original https://aws.amazon.com/blogs/security/aws-customer-compliance-guides-now-publicly-available/
The AWS Global Security & Compliance Acceleration (GSCA) Program has released AWS Customer Compliance Guides (CCGs) on the AWS Compliance Resources page to help customers, AWS Partners, and assessors quickly understand how industry-leading compliance frameworks map to AWS service documentation and security best practices.
CCGs offer security guidance mapped to 16 different compliance frameworks for more than 130 AWS services and integrations. Customers can select from the frameworks and services available to see how security “in the cloud” applies to AWS services through the lens of compliance.
CCGs focus on security topics and technical controls that relate to AWS service configuration options. The guides don’t cover security topics or controls that are consistent across AWS services or those specific to customer organizations, such as policies or governance. As a result, the guides are shorter and are focused on the unique security and compliance considerations for each AWS service.
We value your feedback on the guides. Take our CCG survey to tell us about your experience, request new services or frameworks, or suggest improvements.
CCGs provide summaries of the user guides for AWS services and map configuration guidance to security control requirements from the following frameworks:
- National Institute of Standards and Technology (NIST) 800-53
- NIST Cybersecurity Framework (CSF)
- NIST 800-171
- System and Organization Controls (SOC) II
- Center for Internet Security (CIS) Critical Controls v8.0
- ISO 27001
- NERC Critical Infrastructure Protection (CIP)
- Payment Card Industry Data Security Standard (PCI-DSS) v4.0
- Department of Defense Cybersecurity Maturity Model Certification (CMMC)
- HIPAA
- Canadian Centre for Cyber Security (CCCS)
- New York’s Department of Financial Services (NYDFS)
- Federal Financial Institutions Examination Council (FFIEC)
- Cloud Controls Matrix (CCM) v4
- Information Security Manual (ISM-IRAP) (Australia)
- Information System Security Management and Assessment Program (ISMAP) (Japan)
CCGs can help customers in the following ways:
- Shorten the process of manually searching the AWS user guides to understand security “in the cloud” details and align configuration guidance to compliance requirements
- Determine the scope of controls applicable in risk assessments or audits based on which AWS services are running in customer workloads
- Assist customers who perform due diligence assessments on new AWS services under consideration for use in their organization
- Provide assessors or risk teams with resources to identify which security areas are handled by AWS services and which are the customer’s responsibility to implement, which might influence the scope of evidence required for assessments or internal security checks
- Provide a basis for developing security documentation such as control responses or procedures that might be required to meet various compliance documentation requirements or fulfill assessment evidence requests
The AWS Global Security & Compliance Acceleration (GSCA) Program connects customers with AWS partners that can help them navigate, automate, and accelerate building compliant workloads on AWS by helping to reduce time and cost. GSCA supports businesses globally that need to meet security, privacy, and compliance requirements for healthcare, privacy, national security, and financial sectors. To connect with a GSCA compliance specialist, complete the GSCA Program questionnaire.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
How AI code generation works
Post Syndicated from Jeimy Ruiz original https://github.blog/2024-02-22-how-ai-code-generation-works/
Generative AI coding tools are changing software production for enterprises. Not just for their code generation abilities—from vulnerability detection and facilitating comprehension of unfamiliar codebases, to streamlining documentation and pull request descriptions, they’re fundamentally reshaping how developers approach application infrastructure, deployment, and their own work experience.
We’re now witnessing a significant turning point. As AI models get better, refusing adoption would be like “asking an office worker to use a typewriter instead of a computer,” says Albert Ziegler, principal researcher and member of the GitHub Next research and development team.
In this post, we’ll dive into the inner workings of AI code generation, exploring how it functions, its capabilities and benefits, and how developers can use it to enhance their development experience while propelling your enterprise forward in today’s competitive landscape.
How to use AI to generate code
AI code generation refers to full or partial lines of code that are generated by machines instead of human developers. This emerging technology leverages advanced machine learning models, particularly large language models (LLMs), to understand and replicate the syntax, patterns, and paradigms found in human-generated code.
The AI models powering these tools, like ChatGPT and GitHub Copilot, are trained on natural language text and source code from publicly available sources that include a diverse range of code examples. This training enables them to understand the nuances of various programming languages, coding styles, and common practices. As a result, the AI can generate code suggestions that are syntactically correct and contextually relevant based on input from developers.
Favored by 55% of developers, our AI-powered pair programmer, GitHub Copilot, provides contextualized coding assistance based on your organization’s codebase across dozens of programming languages, and targets developers of all experience levels. With GitHub Copilot, developers can use AI to generate code in three ways:
1. Type code and AI can autocomplete the code
Autocompletions are the earliest version of AI code generation. John Berryman, a senior researcher of ML on the GitHub Copilot team, explains the user experience: “I’ll be writing code and taking a pause to think. While I’m doing that, the agent itself is also thinking, looking at surrounding code and content in neighboring tabs. Then it pops up on the screen as gray ‘ghost text’ that I can reject, partially accept, or fully accept and then, if necessary, modify.”
While every developer can reap the benefits of using AI coding tools, experienced programmers can often feel these gains even more so. “In many cases, especially for experienced programmers in a familiar environment, this suggestion speeds us up. I would have written the same thing. It’s just faster to hit ‘tab’ (thus accepting the suggestion) than it is to write out those 20 characters by myself,” says Johan Rosenkilde, principal researcher for GitHub Next.
Whether developers are new or highly skilled, they’ll often have to work in less familiar languages, and code completion suggestions using GitHub Copilot can lend a helping hand. “Using GitHub Copilot for code completion has really helped speed up my learning experience,” says Berryman. “I will often accept the suggestion because it’s something I wouldn’t have written on my own since I don’t know the syntax.”
Using an AI coding tool has become an invaluable skill in itself. Why? Because the more developers practice coding with these tools, the faster they’ll get at using them.
2. Explicit code comments codes using natural language to receive even better AI-generated code suggestions
For experienced developers in unfamiliar environments, tools like GitHub Copilot can even help jog their memories.
Let’s say a developer imports a new type of library they haven’t used before, or that they don’t remember. Maybe they’re looking to figure out the standard library function or the order of the argument. In these cases, it can be helpful to make GitHub Copilot more explicitly aware of where the developer wants to go by writing a comment.
“It’s quite likely that the developer might not remember the formula, but they can recognize the formula, and GitHub Copilot can remember it by being prompted,” says Rosenkilde. This is where natural language commentary comes into play: it can be a shortcut for explaining intent when the developer is struggling with the first few characters of code that they need.
If developers give specific names to their functions and variables, and write documentation, they can get better suggestions, too. That’s because GitHub Copilot can read the variable names and use them as an indicator for what that function should do.
Suddenly that changes how developers write code for the better, because code with good variable and function names are more maintainable. And oftentimes the main job of a programmer is to maintain code, not write it from scratch.
“When you push that code, someone is going to review it, and they will likely have a better time reviewing that code if it’s well named, if there’s even a hint of documentation in it, and so on,” says Rosenkilde. In this sense, the symbiotic relationship between the developer and the AI coding tool is not just beneficial for the developer, but for the entire team.
3. Chat directly with AI
With AI chatbots, code generation can be more interactive. GitHub Copilot Chat, for example, allows developers to interact with code by asking it to explain code, improve syntax, provide ideas, generate tests, and modify existing code—making it a versatile ally in managing coding tasks.
Rosenkilde uses the different functionalities of GitHub Copilot:
“When I want to do something and I can’t remember how to do it, I type the first few letters of it, and then I wait to see if Copilot can guess what I’m doing,” he says. “If that doesn’t work, maybe I delete those characters and I write a one liner in commentary and see whether Copilot can guess the next line. If that doesn’t work, then I go to Copilot Chat and explain in more detail what I want done.”
Typically, Copilot Chat returns with something much more verbose and complete than what you get from GitHub Copilot code completion. “Namely, it describes back to you what it is you want done and how it can be accomplished. It gives you code examples, and you can respond and say, oh, I see where you’re going. But actually I meant it like this instead,” says Rosenkilde.
But using AI chatbots doesn’t mean developers should be hands off. Mistakes in reasoning could lead the AI down a path of further mistakes if left unchecked. Berryman recommends that users should interact with the chat assistant in much the same way that you would when pair programming with a human. “Go back and forth with it. Tell the assistant about the task you are working on, ask it for ideas, have it help you write code, and critique and redirect the assistant’s work in order to keep it on the right track.”

The importance of code reviews
GitHub Copilot is designed to empower developers to execute their ideas. As long as there is some context for it to draw on, it will likely generate the type of code the developer wants. But this doesn’t replace code reviews between developers.
Code reviews play an important role in maintaining code quality and reliability in software projects, regardless of whether AI coding tools are involved. In fact, the earlier developers can spot bugs in the code development process, the cheaper it is by orders of magnitude.
Ordinary verification would be: does the code parse? Do the tests work? With AI code generation, Ziegler explains that developers should, “Scrutinize it in enough detail so that you can be sure the generated code is correct and bug-free. Because if you use tools like that in the wrong way and just accept everything, then the bugs that you introduce are going to cost you more time than you save.”
Rosenkilde adds, “A review with another human being is not the same as that, right? It’s a conversation between two developers about whether this change fits into the kind of software they’re building in this organization. GitHub Copilot doesn’t replace that.”
The advantages of using AI to generate code
When developer teams use AI coding tools across the software development cycle, they experience a host of benefits, including:
Faster development, more productivity
AI code generation can significantly speed up the development process by automating repetitive and time-consuming tasks. This means that developers can focus on high-level architecture and problem-solving. In fact, 88% of developers reported feeling more productive when using GitHub Copilot.
Rosenkilde reflects on his own experience with GitHub’s AI pair programmer: “95% of the time, Copilot brings me joy and makes my day a little bit easier. And this doesn’t change the code I would have written. It doesn’t change the way I would have written it. It doesn’t change the design of my code. All it does is it makes me faster at writing that same code.” And Rosenkilde isn’t alone: 60% of developers feel more fulfilled with their jobs when using GitHub Copilot.
Mental load alleviated
The benefits of faster development aren’t just about speed: they’re also about alleviating the mental effort that comes with completing tedious tasks. For example, when it comes to debugging, developers have to reverse engineer what went wrong. Detecting a bug can involve digging through an endless list of potential hiding places where it might be lurking, making it repetitive and tedious work.
Rosenkilde explains, “Sometimes when you’re debugging, you just have to resort to creating print statements that you can’t get around. Thankfully, Copilot is brilliant at print statements.”
A whopping 87% of developers reported spending less mental effort on repetitive tasks with the help of GitHub Copilot.
Less context switching
In software development, context switching is when developers move between different tasks, projects, or environments, which can disrupt their workflow and decrease productivity. They also often deal with the stress of juggling multiple tasks, remembering syntax details, and managing complex code structures.
With GitHub Copilot developers can bypass several levels of context switching, staying in their IDE instead of searching on Google or jumping into external documentation.
“When I’m writing natural language commentary,” says Rosenkilde, “GitHub Copilot code completion can help me. Or if I use Copilot Chat, it’s a conversation in the context that I’m in, and I don’t have to explain quite as much.”
Generating code with AI helps developers offload the responsibility of recalling every detail, allowing them to focus on higher-level thinking, problem-solving, and strategic planning.
Berryman adds, “With GitHub Copilot Chat, I don’t have to restate the problem because the code never leaves my trusted environment. And I get an answer immediately. If there is a misunderstanding or follow-up questions, they are easy to communicate with.”
What to look for in enterprise-ready AI code generation tools
Before you implement any AI into your workflow, you should always review and test tools thoroughly to make sure they’re a good fit for your organization. Here are a few considerations to keep in mind.
Compliance
- Regulatory compliance. Does the tool comply with relevant regulations in your industry?
- Compliance certifications. Are there attestations that demonstrate the tool’s compliance with regulations?
Security
- Encryption. Is the data transmission and storage encrypted to protect sensitive information?
- Access controls. Are you able to implement strong authentication measures and access controls to prevent unauthorized access?
- Compliance with security standards. Is the tool compliant with industry standards?
- Security audits. Does the tool undergo regular security audits and updates to address vulnerabilities?
Privacy
- Data handling. Are there clear policies for handling user data and does it adhere to privacy regulations like GDPR, CCPA, etc.?
- Data anonymization. Does the tool support anonymization techniques to protect user privacy?
Permissioning
- Role-based access control. Are you able to manage permissions based on user roles and responsibilities?
- Granular permissions. Can you control access to different features and functionalities within the tool?
- Opt-in/Opt-out mechanisms. Can users control the use of their data and opt out if needed?
Pricing
- Understand the pricing model. is it based on usage, number of users, features, or other metrics?
- Look for transparency. Is the pricing structure clear with no hidden costs?
- Scalability. Does the pricing scale with your usage and business growth?
Additionally, consider factors such as customer support, ease of integration with existing systems, performance, and user experience when evaluating AI coding tools. Lastly, it’s important to thoroughly assess how well the tool aligns with your organization’s specific requirements and priorities in each of these areas.
Visit the GitHub Copilot Trust Center to learn more around security, privacy, and other topics.
Can AI code generation be detected?
The short answer here is: maybe.
Let’s first give some context to the question. It’s never really the case that a whole code base is generated with AI, because large chunks of AI-generated code are very likely to be wrong. The standard code review process is a good way to avoid this, since large swaths of completely auto-generated code would stand out to a human developer as simply not working.
For smaller amounts of AI-generated code, there is no way at the moment to detect traces of AI in code with true confidence. There are offerings that purport to classify whether content has AI-generated text, but there are limited equivalents for code, since you’d need a dedicated model to do it. Ziegler explains, “Computer generated code is good enough that it doesn’t leave any particular traces and normally has no clear tells.”
At GitHub, the Copilot team makes use of a duplicate detection filter that detects exact duplicates in code. So, if you’re writing code and it’s an exact copy of something that exists elsewhere, then it’ll flag it.
Is AI code generation secure?
AI code generation is not any more insecure than human generated code. A combination of testing, manual code reviews, scanning, monitoring, and feedback loops can produce the same quality of code as your human-generated code.
When it comes to code generated by GitHub Copilot, developers can use tools like code scanning, which actively reviews your code for potential security issues in real-time and seamlessly integrates the findings into the developer workflow.
Ultimately, AI code generation will have vulnerabilities—but so does code written by human developers. As Ziegler explains, “It’s unclear whether computer generated code does particularly worse. So, the answer is not if you have GitHub Copilot, use a vulnerability checker. The answer is always use a vulnerability checker.”
Watch this video for more tips and words of advice around secure coding best practices with AI.
Empower your enterprise with AI code generation
While the benefits to using AI code generation tools can be significant, it’s important to note that human oversight remains crucial to ensure that the generated code aligns with project goals, coding standards, and business needs.
Tech leaders should embrace the use of AI code generation—not only to streamline development, but also to empower developer teams to collaborate, drive meaningful business outcomes, and deliver exceptional value to customers.
Learn more or get started with the world’s most widely adopted AI developer tool.
Want to learn how GitHub can help your organization do more with AI?
At GitHub Galaxy 2024, we’ll explore cutting-edge research and best practices in the rapidly evolving world of AI—empowering your business to maximize productivity and innovate at scale.
The post How AI code generation works appeared first on The GitHub Blog.
New Image/Video Prompt Injection Attacks
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/02/new-image-video-prompt-injection-attacks.html
Simon Willison has been playing with the video processing capabilities of the new Gemini Pro 1.5 model from Google, and it’s really impressive.
Which means a lot of scary new video prompt injection attacks. And remember, given the current state of technology, prompt injection attacks are impossible to prevent in general.
Chris Anderson | Infectious Generosity: The Ultimate Idea Worth Spreading | Talks at Google
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=byvPfzSoNsc
How to Rest
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=gxcKSi5rzRs
[$] When ELF notes reveal too much
Post Syndicated from corbet original https://lwn.net/Articles/962782/
The Linux kernel uses a number of hardening techniques to try to protect
itself against compromise; one of those is kernel address-space layout
randomization (KASLR). But randomization is of little benefit if the
kernel spills the beans on where its code has ended up. As it happens, the
kernel has been doing exactly that — since 2007, in a behavior that
predates the addition of KASLR. Some changes are in the
works to close that hole, but it is illustrative of just how hard some
secrets are to keep.