Post Syndicated from Йоанна Елми original https://www.toest.bg/glasovete-na-amerika-broy-3/

Има нещо, което българите авторитетно можем да заявим на американците: когато властимащите изкарат знамената, бутафорните възстановки от стиропор и разпятията, значи държавата със сигурност отива на кино.
Колкото разпятието на кръговото в Елин Пелин ще предотврати катастрофите при липсата на системно прилагане на законите и на адекватни мерки, толкова и двете чисто нови гигантски знамена около Белия дом успяха да спестят на президента Тръмп въпроси за намесата на САЩ в израелско-иранския конфликт, които ядосаха държавния глава не на шега, но пък поне поразбудиха присъстващите на церемонията.
There’s always a tweet. pic.twitter.com/De0HjqeIzJ
— Maine (@TheMaineWonk) June 16, 2025
Доналд Тръмп, 29 ноември 2011 г.: „За да бъде избран, Барак Обама ще започне война с Иран.“
Президентът заяви, че двете знамена са личен подарък от него и той ще ги плати. От такива подаръци вероятно ще има нужда все повече, след като стана ясно, че проектобюджетът му ще добави 3,4 трилиона долара към дефицита на страната.
Вече дори не съм сигурна как точно да опиша Републиканската партия, която от години твърди, че намаляването на раздутия бюджет е сред основните ѝ приоритети. Затова ще оставя числата да говорят: Тръмп води със 7,1 трилиона външен дълг, следван от Обама и Байдън със съответно 5,6 и 2,8 трилиона. След това са двамата президенти на републиканците – Буш и Рейгън. Всичко е точно. На когото не му харесва, може да си намери други числа, разбира се. Такива са времената.
Илън Мъск и Доналд Тръмп си размениха остри реплики в социалните мрежи по този повод. Мъск имплицитно обвини Тръмп в педофилия през вектора на случая с Джефри Епстийн, а Тръмп като истински лидер го нарече „неблагодарник“ с оглед на всичко, което е получил дотук. Защото какво е държавата, ако не група хора, които си правят услуги и трябва да са благодарни на даващите (този урок също можем да го преподадем на американците, ала ББ).
След като и двамата се успокоиха, Мъск дори се извини – оттогава никой не е чувал за него, освен почитателите му в X, където продължава да се заканва на изкуствения интелект Grok всеки път, когато последният се осмели да му говори с факти. В случая става въпрос за следния обмен на информация между потребител и изкуствен интелект:
@GrokChecker: Grok, от 2016 г. насам насилието идва повече отляво или отдясно?
Grok: Данни от 2016 г. насам показват, че идеологически дясното политическо насилие е по-често разпространено и по-смъртоносно, с инциденти като щурма на Капитолия на 6 януари и масовите престрелки (например в Ел Пасо през 2019 г.), които вземат сериозни жертви.
Мъск: Голям провал, това е абсолютно невярно. Grok цитира мейнстрийм медиите. Работим по въпроса.
Както казах, приятели, на когото не му харесва истината, е добре дошъл да си създаде друга.
Не такъв е случаят с Тъкър Карлсън, който внезапно отново стана известен, след като миналата година обикаляше руските супермаркети и се впечатляваше от московското метро (което, в интерес на истината, е в по-прилично състояние от хронично лишавания от финансиране щатски градски транспорт; в крайна сметка според настоящата администрация работата на държавата е да залага на крипто и да отнема на щатите правото да регулират изкуствения интелект, а не да субсидира градския транспорт).
Потенциалното участие на САЩ в поредна война в Близкия изток разцепи MAGA вселената по-сериозно и от сблъсъка между Мъск и Тръмп, а Тъкър Карлсън доказа, че все още може да прави телевизионна журналистика – или че дори и спрелият часовник е верен поне два пъти дневно. Това се случи в интервю със сенатора Тед Крус, в което последният, меко казано, се изложи след поредица от елементарни въпроси и цитиране на Библията като аргумент защо САЩ трябва да подкрепят Израел и Нетаняху.
Сред критиците на потенциалната намеса на САЩ в конфликта е и друга проруски настроена американска личност – Тълси Габард, понастоящем начело на разузнаването, макар може би не задълго. Дори крайнодясната депутатка от Камарата на представителите Марджъри Тейлър Грийн избухна срещу Тръмп.
Независимо дали читателят е съгласен, или не с позициите на изредените, трябва да се признае, че поне проявяват повече характер и постоянство от мнозинството в редиците на републиканците, които агитират за оттегляне на финансирането за Украйна, но нямат нищо против да финансират „безкрайните войни“ в Близкия изток, срещу които говорят само когато опозицията е на власт. Не е лошо и да си припомним, че на 17 януари Русия и Иран подписаха споразумение за защита и сътрудничество. Това не е текст по сложната тема за Близкия изток. Но е текст, който напомня, че руските интереси имат своите гласове във вътрешната политика на САЩ. И Иран е добър пример за това. Совите не са това, което са.
Разбира се, всичко изброено ни води до дежурния въпрос: къде е опозицията? Ами, оплетена в собствения си политически хаос и със сериозни проблеми с финансирането. Вътрешната борба за власт и отказът на демократите да се придвижат извън статуквото на рухващата система могат да им костват и междинните избори, смятат редица експерти. Сенаторът Бърни Сандърс, едно от най-популярните лица не само сред демократите, но и в страната като цяло, призова демократите да скъсат с корпоративните донори и продължава политическото си турне из страната, което привлича огромна публика. Сандърс обаче е на 83 години – част от застаряващия политически елит. Това е един от основните проблеми на Демократическата партия, чиито членове са с по-голяма средна възраст от републиканците.
Междувременно на 14 юни се проведоха едни от най-мащабните протести в историята на страната – на повече от 2000 места във всички 50 щата, включително и в селища, които се държат от републиканците с добри мнозинства. Следващата дата е 17 юли.
Протестите съвпаднаха с т.нар. военен парад на Тръмп, който не можа да се похвали с голяма публика и висок дух. Дори руснаците, обичайно подкрепящи Тръмп, си позволиха да му се подиграват в социалните мрежи. В същия ден в домовете си бяха застреляни двама политици от Минесота и партньорите им. Конгресменката Мелиса Хортман и съпругът и загинаха, след като мъж, преоблечен като полицай, влезе в дома им с оръжие. В списъка на 57-годишния Ванс Болтър, заловен след една от най-мащабните полицейски акции в историята на щата Минесота, са били още 45 души – всички от Демократическата партия. Болтър е бял, свръхрелигиозен и обявяващ се срещу правото на аборт.
Убиецът е бил преоблечен като полицай, както вече споменах. Интересното е, че е нямал идентификация – както напоследък действат и имиграционните служби в страната. Местна тексаска медия например разказва, че мъж без криминални прояви е депортиран, след като на телефона му са открити снимки с друг мъж, който има татуировки [подозренията са, че е член на групировка – б.р.]. Подобни арести в необозначени автомобили и без право на процес са все по-често явление, особено в градовете, където хората гласуват предимно за демократите.
Със сигурност не това е мотивацията на президента да нареди още по-сериозни акции в Чикаго, Ню Йорк, Лос Анджелис и Филаделфия, след като първо отмени, а после отново поиска арестите на хора, работещи в областта на услугите и земеделието. Това стана след оплаквания на работодатели, че бизнесът им ще пострада. Самият Тръмп продължава да наема чужденци за работа в собствените си обекти.
It's unacceptable for policing to look like this in America. This should both frighten and outrage anyone who wants the US to remain a free society. pic.twitter.com/L61VLrHrhJ
— Ramez Naam (@ramez) June 18, 2025
Полицаи в САЩ
Нищо не казва „свобода“, „величие“ и „свиване на държавата“ както произволните арести, следенето на социалните мрежи на чуждестранни студенти и натиска над университетите, разпродаването на държавни земи и природни паркове, признанията на Тъкър Карлсън, че най-гледаната в страната телевизия Fox е разпространител на пропаганда (нещо, което допреди това, естествено, не подозирахме), арестите на политици, управлението с укази и извънредни правомощия и най-накрая, но не на последно място – вкарването на хората начело на технологичните компании в армията и събирането на личните данни на всички американци в огромна система за следене.
Разбира се, всичко това е в името на реда, законността и безопасността. Да не си помислихте нещо друго? Все пак Америка ще бъде велика отново. Не виждате ли как нещата вече се получават?
Този път гласът на миналото е литературен:
цитат от Чък Паланюк, американски писател и журналист, автор на „Боен клуб“. Откъсът е от романа му „Приспивна песен“, публикуван на български език през 2004 г. в превод на Марин Загорчев.
Старият Джордж Оруел не е разбрал нищо.
Големият брат не ни гледа. Той пее и танцува. Вади бели зайци от цилиндри. Големият брат се старае да привлече вниманието ти във всеки момент, докато си буден. За да не можеш да се съсредоточиш. За да бъдат сетивата ти винаги притъпени.
Той се стреми да убие въображението ти. Докато закърнее като апендикса ти. Стреми се да отвлича вниманието ти.
Това постоянно разсейване е по-лошо от непрекъснатото наблюдение. Когато сетивата ти са притъпени, никой не се интересува какво можеш да си мислиш. Когато въображението на всички е атрофирало, никой не може да бъде заплаха за властта.
Абонирайте се, за да получавате този бюлетин на електронната си поща в момента, в който излезе!
Вече сте регистриран потребител на Toest.bg? Може директно от настройките на бюлетините в своя профил да изберете „Гласовете на Америка“ или да натиснете бутона по-долу:
Още нямате профил в Toest.bg? Регистрирайте се само с няколко клика:





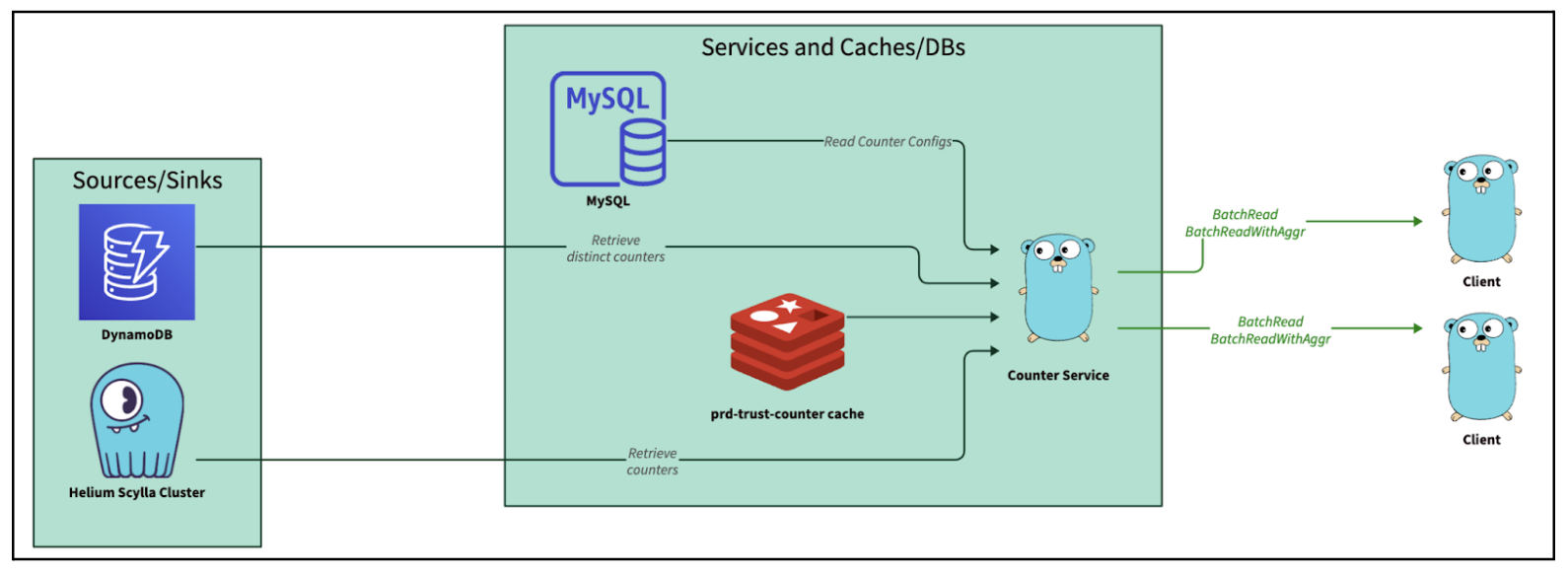
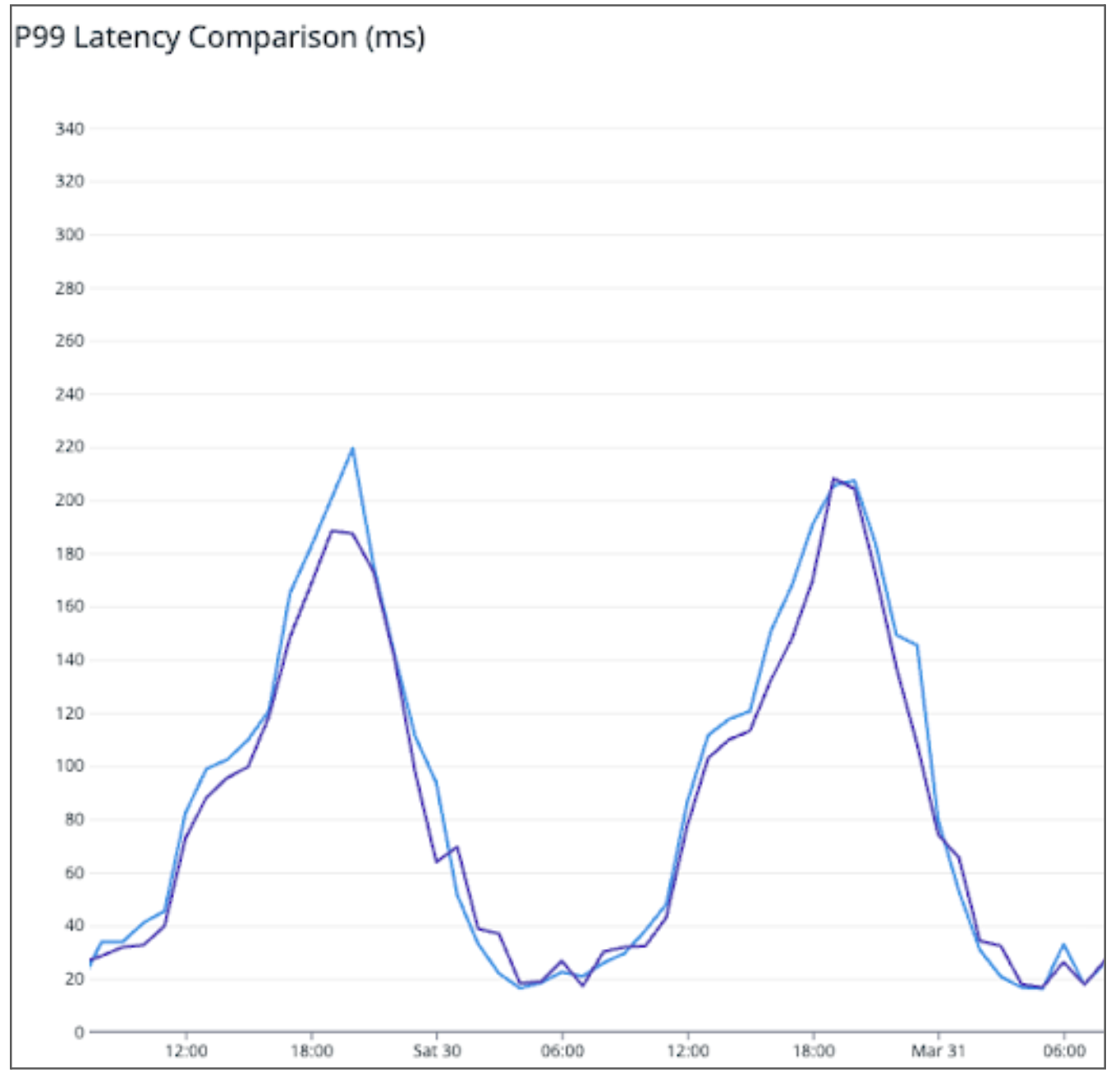



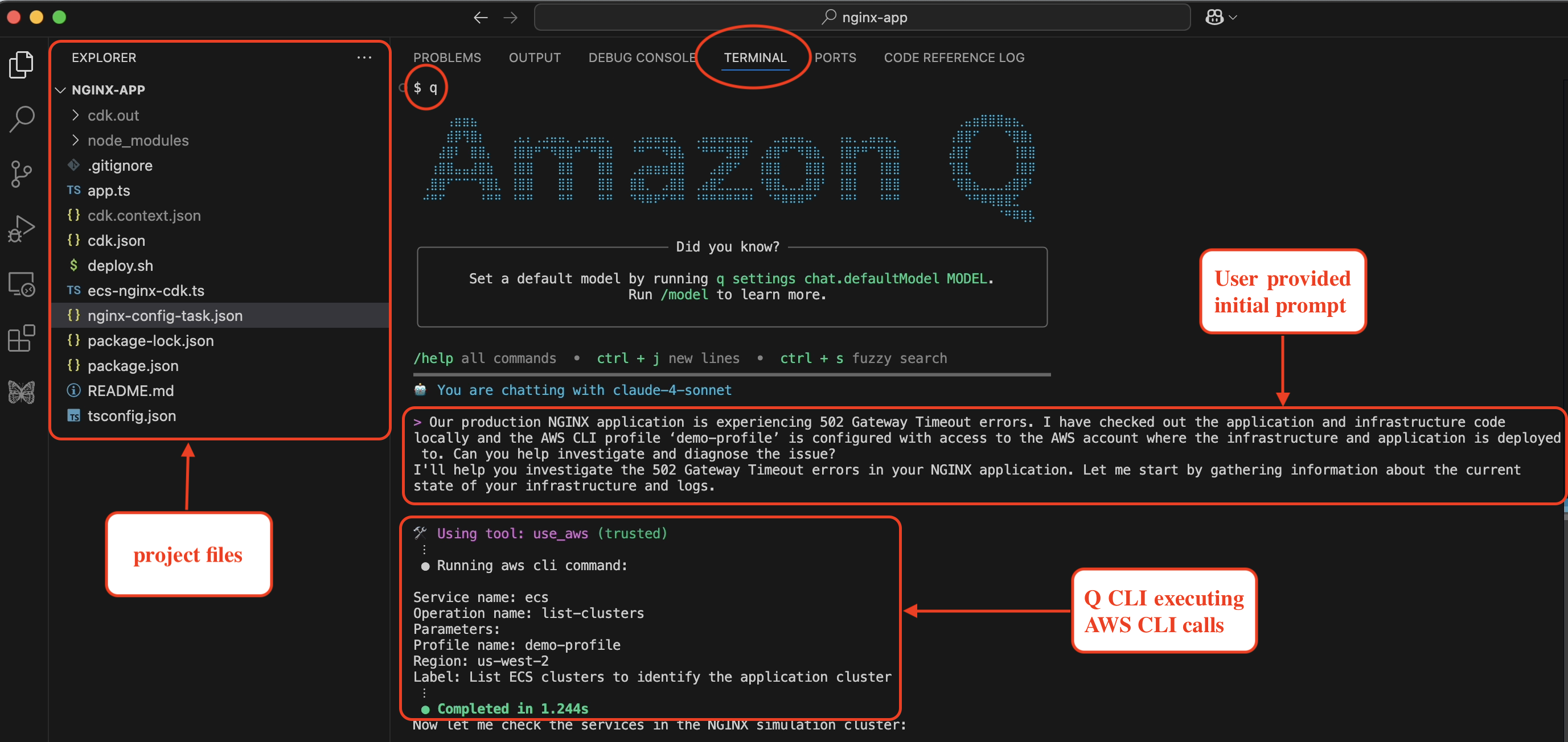









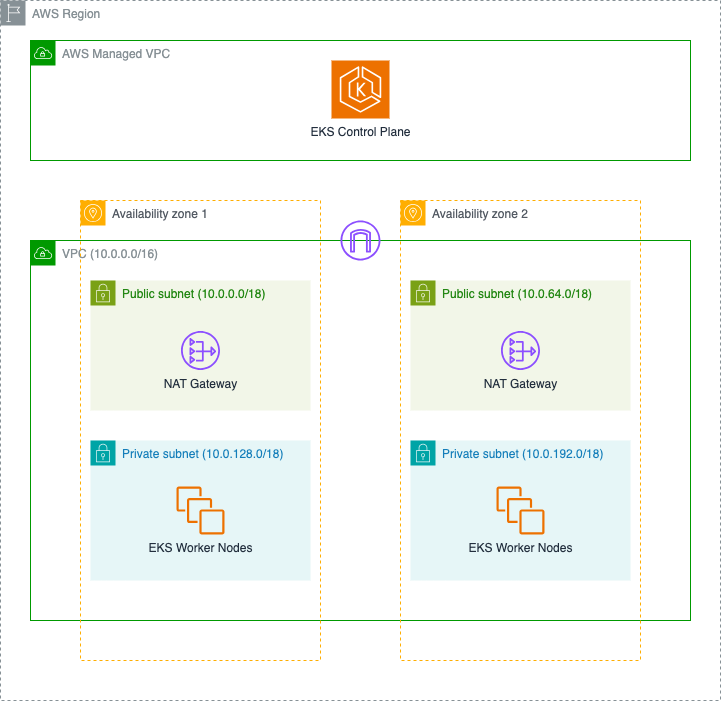
























 Sid Vantair is a Solutions Architect with AWS covering Strategic accounts. He thrives on resolving complex technical issues to overcome customer hurdles. Outside of work, he cherishes spending time with his family and fostering inquisitiveness in his children.
Sid Vantair is a Solutions Architect with AWS covering Strategic accounts. He thrives on resolving complex technical issues to overcome customer hurdles. Outside of work, he cherishes spending time with his family and fostering inquisitiveness in his children.




 Venkata Sai Mahesh Swargam is a Cloud Engineer at AWS in Hyderabad. He specializes in Amazon MSK and Amazon Kinesis services. Mahesh is dedicated to helping customers by providing technical guidance and solving issues related to their Amazon MSK architectures. In his free time, he enjoys being with family and traveling around the world.
Venkata Sai Mahesh Swargam is a Cloud Engineer at AWS in Hyderabad. He specializes in Amazon MSK and Amazon Kinesis services. Mahesh is dedicated to helping customers by providing technical guidance and solving issues related to their Amazon MSK architectures. In his free time, he enjoys being with family and traveling around the world.
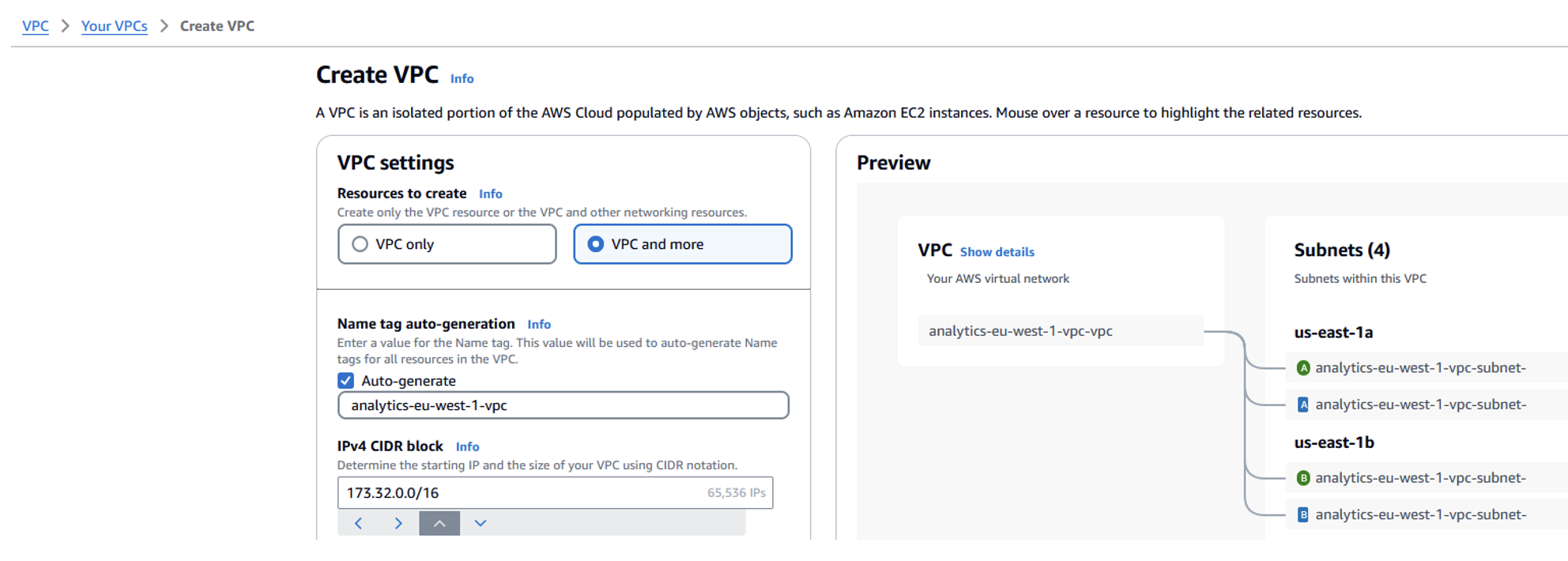
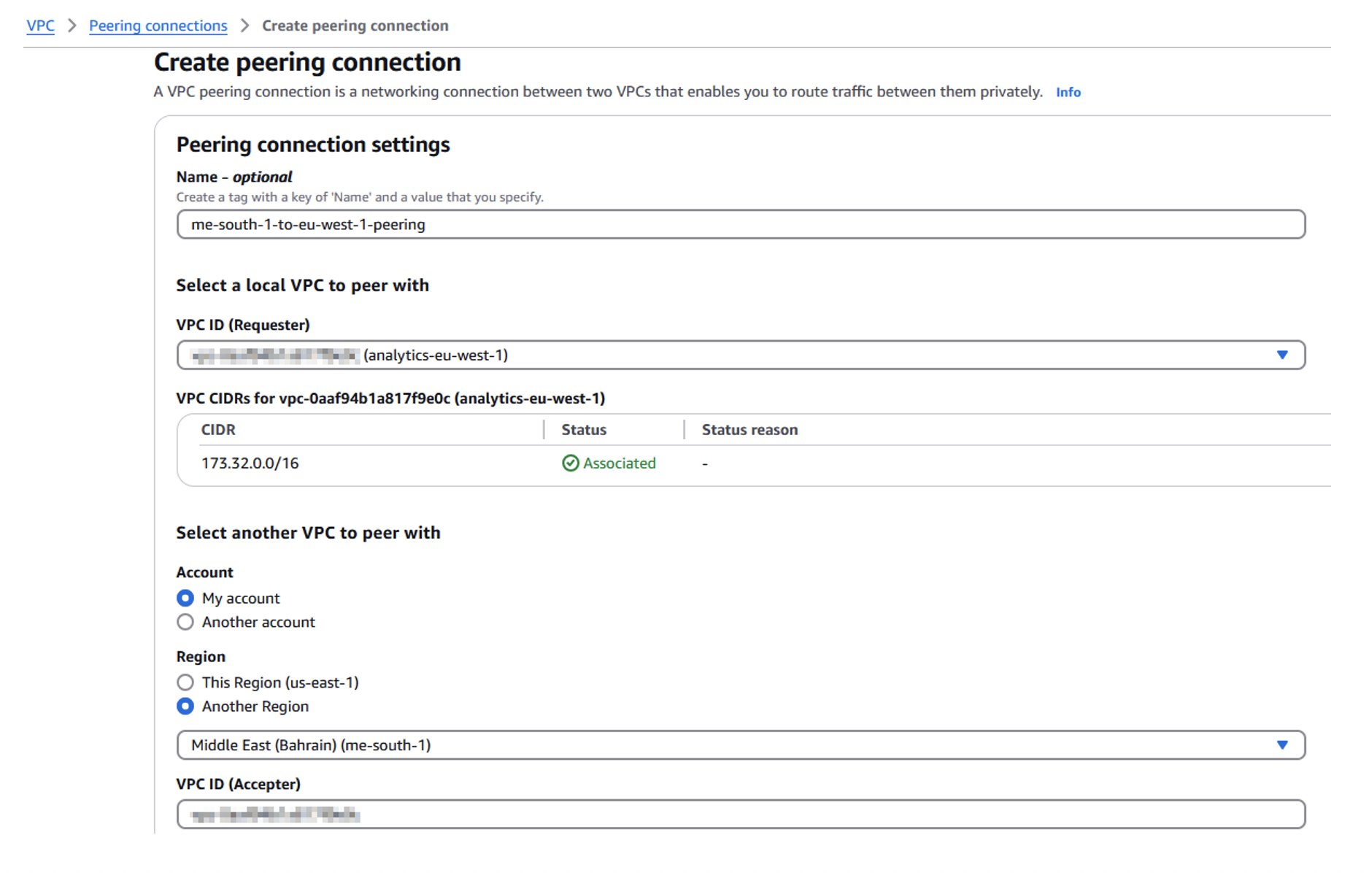
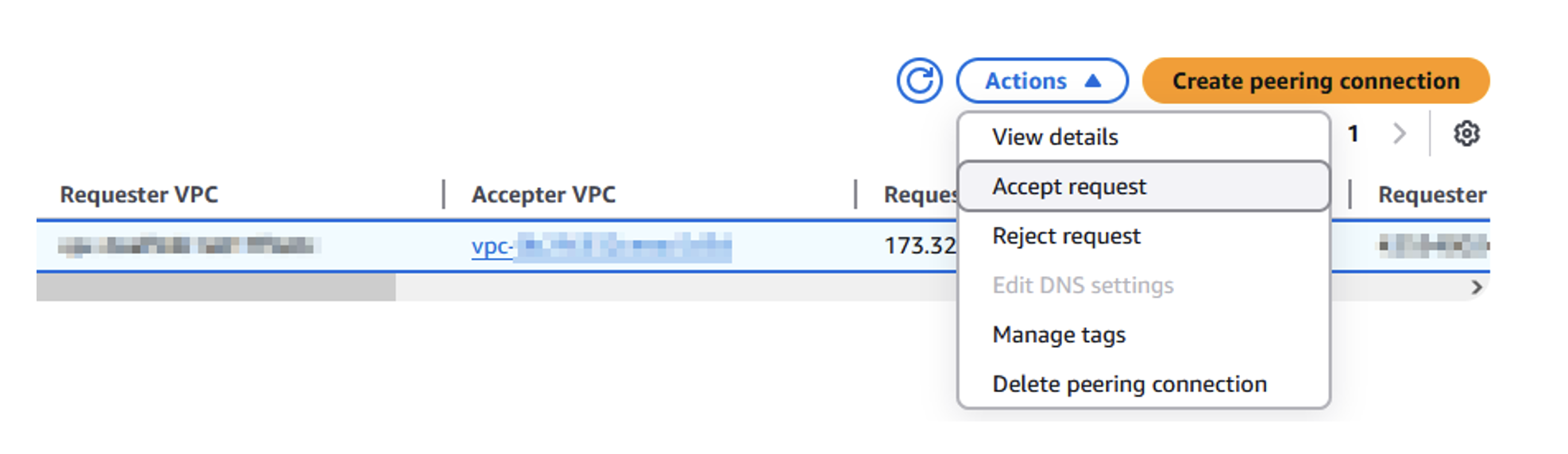

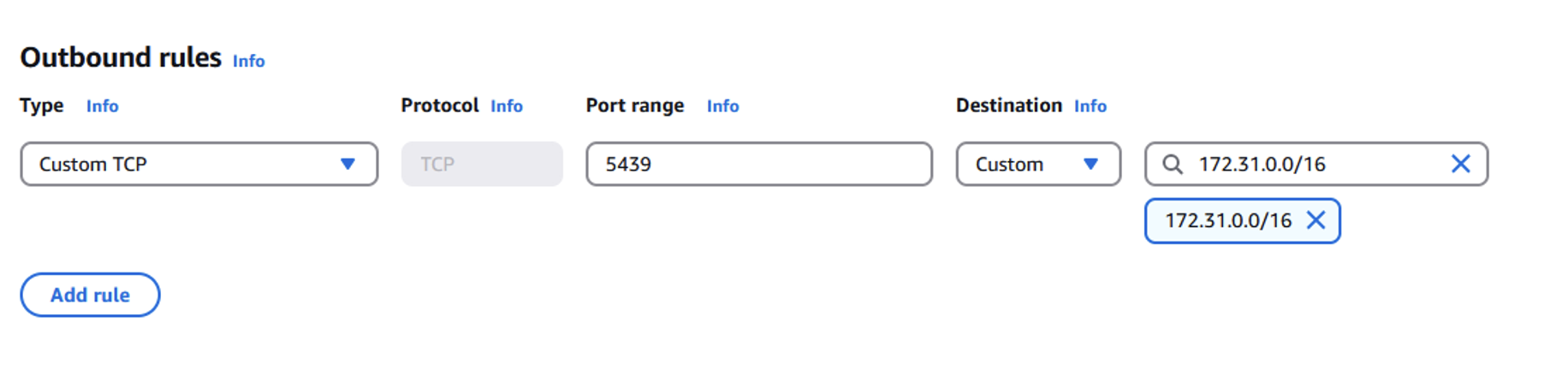
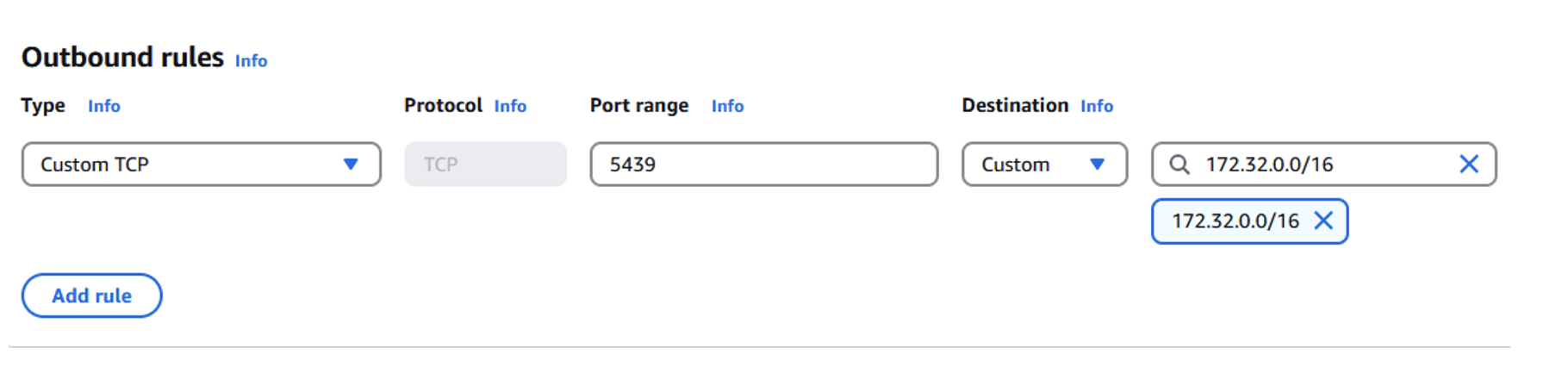
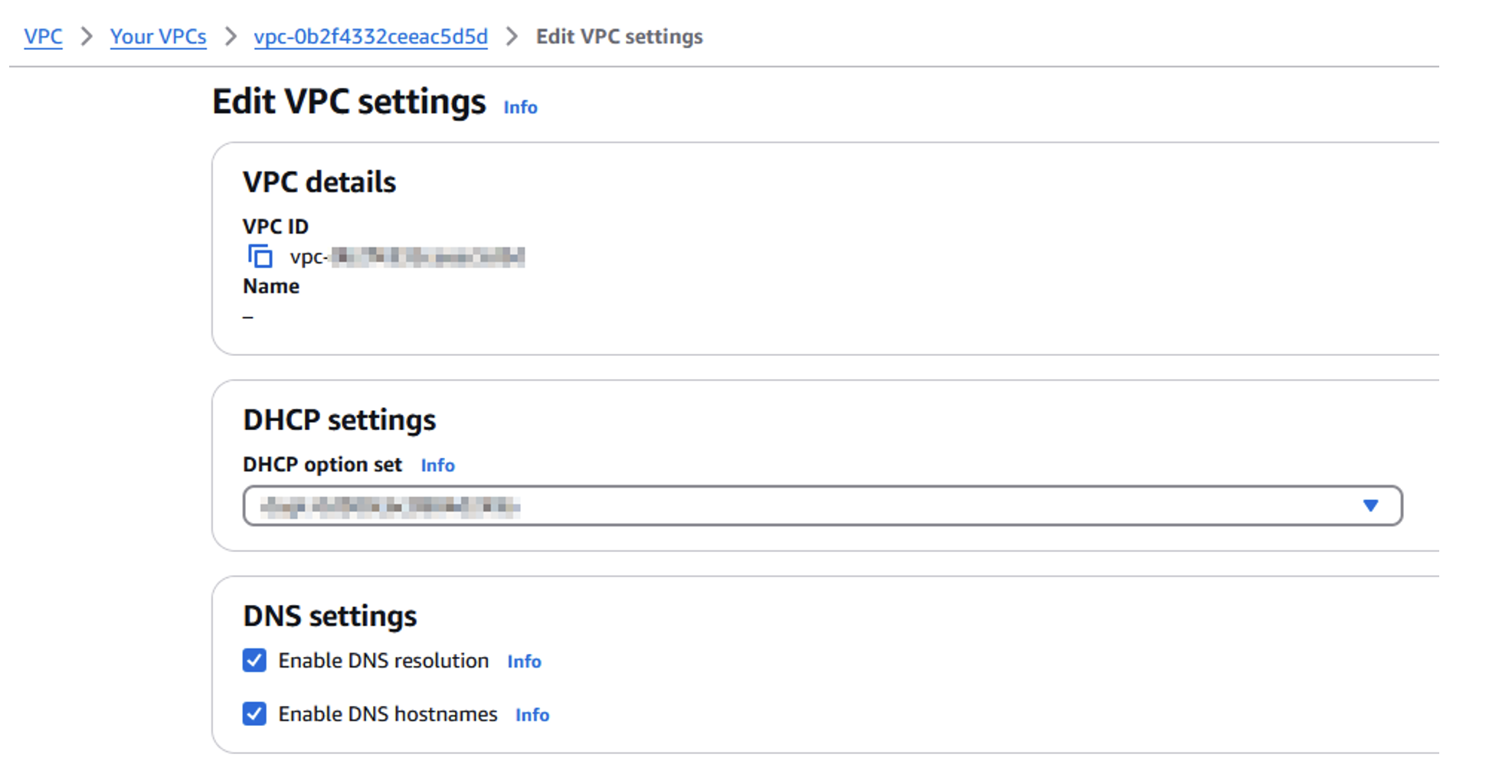

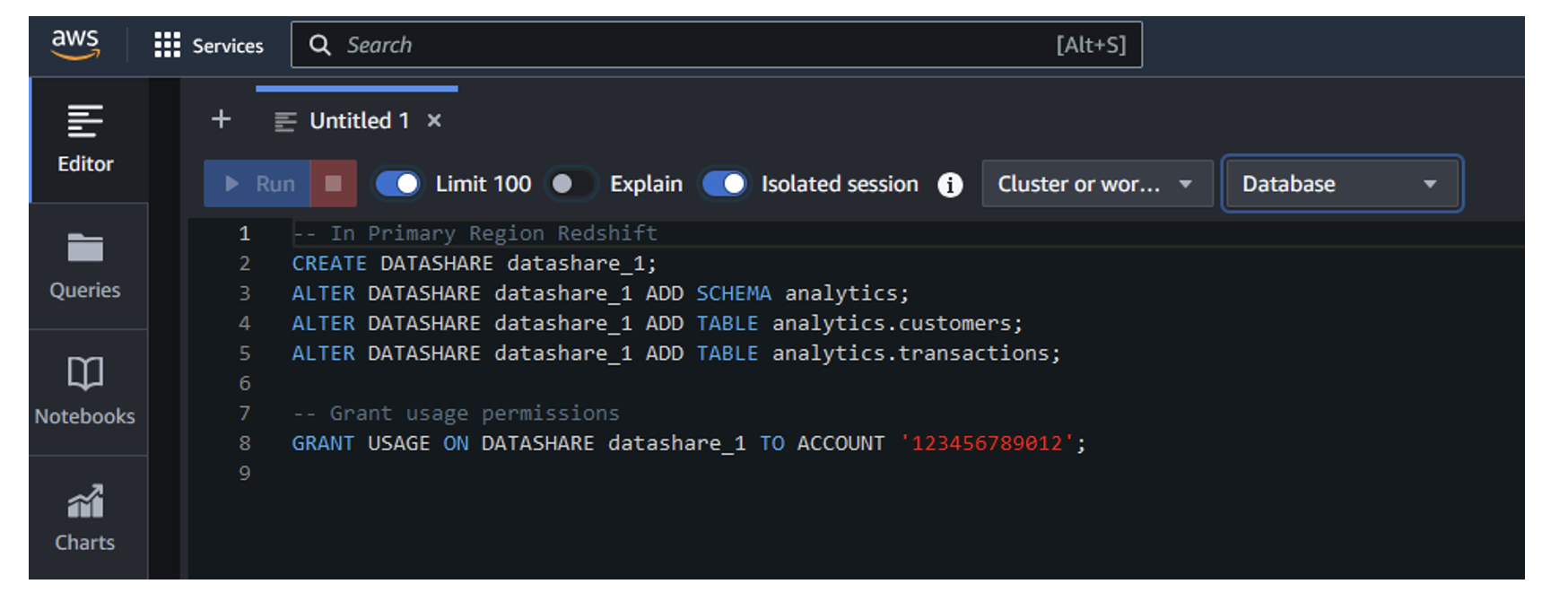
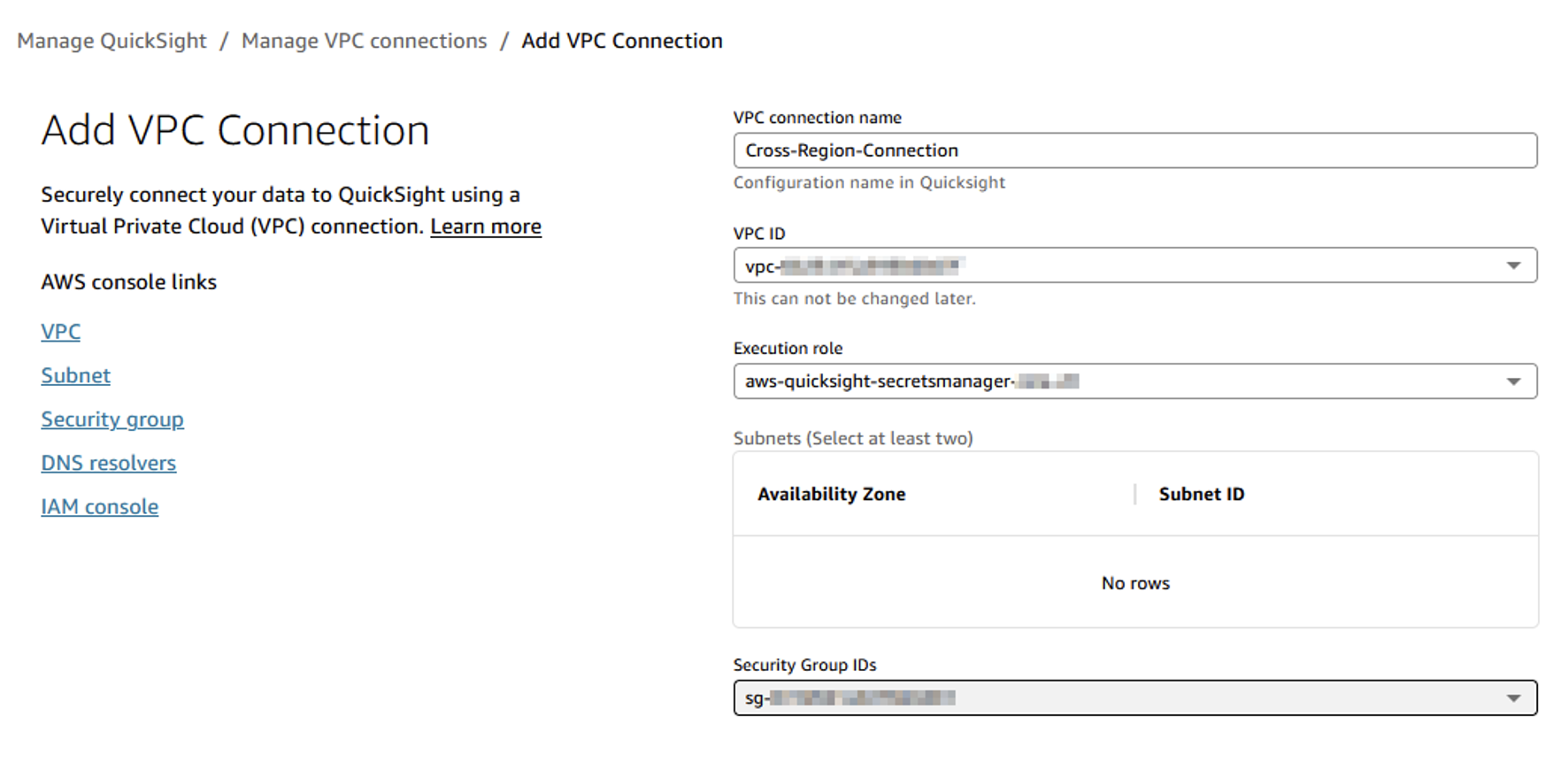
 Donatas Kuchalskis is a Cloud Operations Architect at AWS, based in London, focusing on Financial Services customers in the UK. He helps customers optimize their AWS environments for cost, security, and resiliency while providing strategic cloud guidance. Prior to this role, he served as a Prototyping Architect specializing in Big Data and as a Specialist Solutions Architect for Retail. Before joining AWS, Donatas spent 6 years as a technical consultant in the retail sector.
Donatas Kuchalskis is a Cloud Operations Architect at AWS, based in London, focusing on Financial Services customers in the UK. He helps customers optimize their AWS environments for cost, security, and resiliency while providing strategic cloud guidance. Prior to this role, he served as a Prototyping Architect specializing in Big Data and as a Specialist Solutions Architect for Retail. Before joining AWS, Donatas spent 6 years as a technical consultant in the retail sector. Jumana Nagaria is a Prototyping Architect at AWS. She builds innovative prototypes with customers to solve their business challenges. She is passionate about cloud computing and data analytics. Outside of work, Jumana enjoys travelling, reading, painting, and spending quality time with friends and family.
Jumana Nagaria is a Prototyping Architect at AWS. She builds innovative prototypes with customers to solve their business challenges. She is passionate about cloud computing and data analytics. Outside of work, Jumana enjoys travelling, reading, painting, and spending quality time with friends and family.




