AWS Key Management Service (AWS KMS) is pleased to launch key-level filtering for AWS KMS API usage in Amazon CloudWatch metrics, providing enhanced visibility to help customers improve their operational efficiency and aid in security and compliance risk management.
AWS KMS currently publishes account-level AWS KMS API usage metrics to Amazon CloudWatch, enabling you to monitor and manage your API usage. However, if you’re using numerous KMS keys, pinpointing the ones with the highest request rate quota usage or significant API costs becomes challenging. For example, if you have more than 10 active KMS keys in your account, prior to this launch you would have needed to build a custom CloudTrail and Amazon Athena based solution to locate which specific keys are driving the majority of API usage and costs. With the new CloudWatch metrics, which are available under the AWS/KMS namespace in CloudWatch, you can track, understand, and set alerts on detailed API usage at the individual KMS key level without building a costly customized solution.
This blog post explores several use cases to help you better take advantage of these newly introduced CloudWatch metrics to manage your AWS KMS API usage and costs. The use cases cover viewing and understanding your API usage at the key level, and creating CloudWatch alerts to detect unintentional runaway usage.
Overview of new CloudWatch metrics for KMS keys
With CloudWatch metrics for KMS keys, you can now do the following:
View the API usage for a specific KMS key, filtered by individual API operations (for example, Encrypt, Decrypt, or GenerateDataKey).
See the aggregated usage across cryptographic operations for a given KMS key.
Set up an alarm if a specific KMS key exceeds a specified threshold on a single API operation, or a set of API operations.
This streamlined approach allows you to quickly monitor, understand, and troubleshoot the API usage patterns of your KMS keys, without the overhead of the previous multi-step process. Let’s detail how these key-level API usage metrics can be used in two real-world examples.
Example 1: How to locate the KMS keys that consume the most API usage quota or contribute the most API charges
When you surpass your AWS KMS API request rate quotas, you can view your AWS KMS API utilization within the Service Quotas console. However, you might still find it cumbersome to identify the KMS keys that consume the largest amount of your request quota. When you receive the AWS KMS API charges that exceed your expectation, you can check the detailed billing usage in each AWS Region in Cost Explorer, but you cannot easily locate the KMS keys with the most API charges. This process becomes even more challenging when you manage a large number of KMS keys.
With the key-level API usage CloudWatch metrics, you can use the advanced metric query option to query CloudWatch Metrics Insights data with a user-friendly dialect of SQL to locate the KMS keys that consume the largest portion of the API usage quota or contribute the most API charges.
Walkthrough
To use Amazon CloudWatch Metrics Insights to identify the top 20 KMS keys that have the most cryptographic API usage up to the last 3 hours, complete the following steps:
In the navigation pane, choose Metrics, and then choose All metrics.
Choose the Multi source query tab.
For the data source, choose CloudWatch Metrics Insights.
You can enter the following example query in Editor view:
Note: In Builder view, the metric namespace, metric name, filter by, group by, order by, and limit options are shown. In Editor view, the same options as in Builder view are shown in query format.
SELECT SUM(SuccessfulRequest)
FROM SCHEMA("AWS/KMS", KeyArn, Operation)
GROUP BY KeyArn
ORDER BY MAX () DESC
LIMIT 20
Choose Run in the Editor view or Graph query in the Builder view.
Example 2: How to set a new detailed alarm on unintentional runaway AWS KMS API usage
Running big data processing workflows that read Amazon Simple Storage Service (Amazon S3) files encrypted by KMS keys is a common scenario for analytics, business reporting, or machine learning projects. Typically, these workflows read a limited number of files from S3 on each invocation. However, misconfigured workflows could unintentionally read a large number of S3 files, which could result in exceeding your AWS KMS API request rate quotas or incurring undesirable charges due to spiky AWS KMS API usage. Historically, to address this issue, you would have had to build a customized alarm system by following these steps: 1) send AWS CloudTrail events generated by AWS KMS to Amazon CloudWatch Logs; 2) write queries in Amazon CloudWatch Logs Insights to track your API request usage; and 3) enable anomaly detection on the corresponding CloudWatch Log Insights math expression.
Now, with key-level API usage CloudWatch metrics, you can directly enable anomaly detection on these metrics to set up alarms for anomalous AWS KMS API usage patterns. This provides a more streamlined and efficient way to monitor and detect potential runaway workflows. By using these CloudWatch metrics and anomaly detection capabilities, you can proactively identify and address unintended increases in AWS KMS API usage, helping to avoid unexpected charges or service disruptions in your analytics, reporting, or machine learning pipelines.
Walkthrough
Consider a scenario where you have an analytics workflow that runs frequently, which uses the Decrypt AWS KMS API operation on a KMS key to decrypt and read data from S3. You would like to enable anomaly detection on the KMS key to trigger an alarm when the Decrypt call volume to the specific KMS key sees a discernible trend or pattern. To do so, complete the following steps:
In the navigation pane, choose Metrics, and then choose All metrics.
Choose KMS, and then choose KeyArn, Operation.
In the search bar, enter the Amazon Resource Name (ARN) of the key, and then choose Search. Select the CloudWatch metric you would like to enable anomaly detection for.
Navigate to Graphed metrics, and using the Statistic and Period drop-down lists, choose the statistic and period that you would like to monitor. Then you can enable anomaly detection by selecting the Pulse icon.
Figure 1: How to enable anomaly detection on a SuccessfulRequest metric
Figure 2: Anomaly detection is enabled on the SuccessfulRequest metric. The gray band illustrates the expected range of values and the anomaly is in red
Conclusion
This blog post highlighted the newly introduced key-level filtering capability for the AWS KMS API usage in CloudWatch. We showed two real-world use cases to demonstrate how you can use the new CloudWatch metrics. These use cases include improving operational visibility, setting up proactive alarms on anomalies in KMS API usage patterns, and potentially tracking detailed key usage for compliance purposes.
If you have feedback about this blog post, submit comments in the Comments section below. If you have questions about this blog post, start a new thread in the AWS Key Management Service re:Post.
Thanks to everyone who joined us for the fifth annual AWS Pi Day on March 14. Since its inception in 2021, commemorating the Amazon Simple Storage Service (Amazon S3) 15th anniversary, AWS Pi Day has grown into a flagship event highlighting the transformative power of cloud technologies in data management, analytics, and AI.
This year’s virtual event featured in-depth discussions with Amazon Web Services (AWS) product teams showcasing our continued innovation in helping customers build robust data foundations for analytics and AI workloads.
Missed the live event? You can still access all content on-demand at the event page. Whether you’re developing data lakehouses, training AI models, creating generative AI applications, or optimizing analytics workloads, the shared insights will help you maximize the value of your data.
Last week’s launches Here are some launches that got my attention during the previous week.
Amazon Bedrock now supports multi-agent collaboration – With the availability of multi-agent collaboration in Amazon Bedrock, you can create networks of specialized agents that communicate and coordinate under the guidance of a supervisor agent. You can build, deploy, and manage networks of AI agents that work together to execute complex, multi-step workflows efficiently.
Availability of fully managed DeepSeek-R1 model in Amazon Bedrock – AWS is the first cloud service provider (CSP) to deliver DeepSeek-R1 as a fully managed, generally available model. Use the capabilities of DeepSeek-R1 for your generative AI applications with a single API through this fully managed service in Amazon Bedrock.
Amazon SageMaker Unified Studio is now generally available – You can now use Amazon SageMaker Unified Studio as your single data and AI development environment, where you can find and access all of your organization’s data and work using the best tools for your specific needs. With the new simplified permissions management, you can easily bring your existing AWS resources into the unified studio. You’ll be able to find, access, and query your organization’s data and AI assets while collaborating with your team to securely build and share your analytics and AI artifacts—from data and models to generative AI applications.
Amazon S3 reduces pricing for S3 object tagging by 35% – Amazon S3 reduces pricing for S3 object tagging by 35% in all AWS Regions to $0.0065 per 10,000 tags per month. Object tags are key-value pairs applied to S3 objects that can be created, updated, or deleted at any time during the lifetime of the object.
Serverless Land Patterns available in Visual Studio Code – Serverless Land‘s extensive application pattern library is now available directly into the Visual Studio Code (VS Code) IDE, making it easier for developers to build serverless applications. This integration eliminates the need to switch between your development environment and external resources when building serverless architectures by enabling you to browse, search, and implement pre-built serverless patterns directly in VS Code IDE.
Amplify Hosting Announces Skew Protection Support – AWS Amplify Hosting now offers Skew Protection, a feature that guarantees version consistency across your deployments. This feature ensures frontend requests are always routed to the correct server backend version—eliminating version skew and making deployments more reliable.
From community.aws Here are some of my favorite posts from community.aws. Create your AWS Builder ID to start sharing your tips and connect with fellow builders. Your Builder ID is a universal login credential that gives you access, beyond the AWS Management Console, to AWS tools and resources, including over 600 free training courses, community features, and developer tools such as Amazon Q Developer.
AWS Innovate: Generative AI + Data – Join a free online conference focusing on generative AI and data innovations in Latin America on April 8.
AWS Summits – The AWS Summit season is coming along! Join free online and in-person events that bring the cloud computing community together to connect, collaborate, and learn about AWS. Register in your nearest city: Paris (April 9), Amsterdam (April 16), London (April 30), and Poland (May 5).
AWS re:Inforce (June 16–18) – Our annual learning event devoted to all things AWS Cloud security in Philadelphia, PA. Registration opens in March, so be ready to join more than 5,000 security builders and leaders.
AWS DevDays are free, technical events where developers can learn about some of the hottest topics in cloud computing. DevDays offer hands-on workshops, technical sessions, live demos, and networking with AWS technical experts and your peers. Register to access AWS DevDays sessions on demand.
That’s all for this week. Check back next Monday for another Weekly Roundup!
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
This post is written by Anton Aleksandrov, Principal Solution Architect, AWS Serverless and Rajesh Kumar Pandey, Principal Engineer, AWS Lambda
AWS Lambda is a highly scalable and resilient serverless compute service. With over 1.5 million monthly active customers and tens of trillions of invocations processed, scalability and reliability are two of the most important service tenets. This post provides recommendations and insights for implementing highly distributed applications based on the Lambda service team’s experience building its robust asynchronous event processing system. It dives into challenges you might face, solution techniques, and best practices for handling noisy neighbors.
Overview
Developers building serverless applications create Lambda functions to run their code in the cloud. After uploading the code, the functions are invoked using synchronous or asynchronous mode.
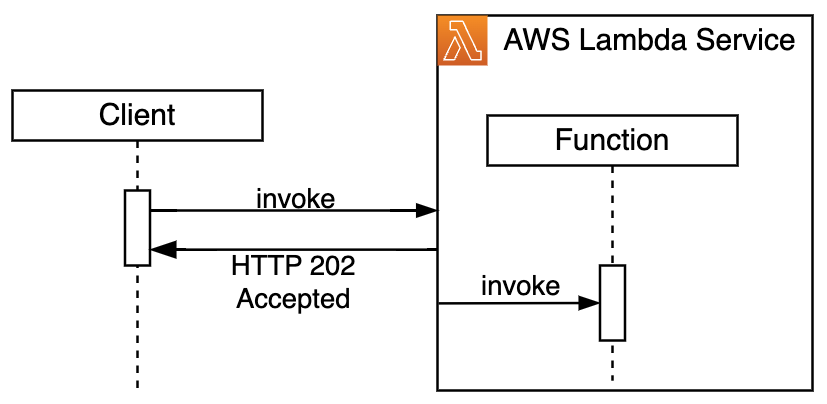
Synchronous invocations are commonly used for interactive applications that expect immediate responses, such as web APIs. The Lambda service receives the invocation request, invokes the function handler, waits for the handler response, and returns it in response to the original request. With synchronous invocations, the client waits for the function handler to return, and is responsible for managing timeouts and retries for failed invocations.
Figure 1. Synchronous invocation sequence diagram
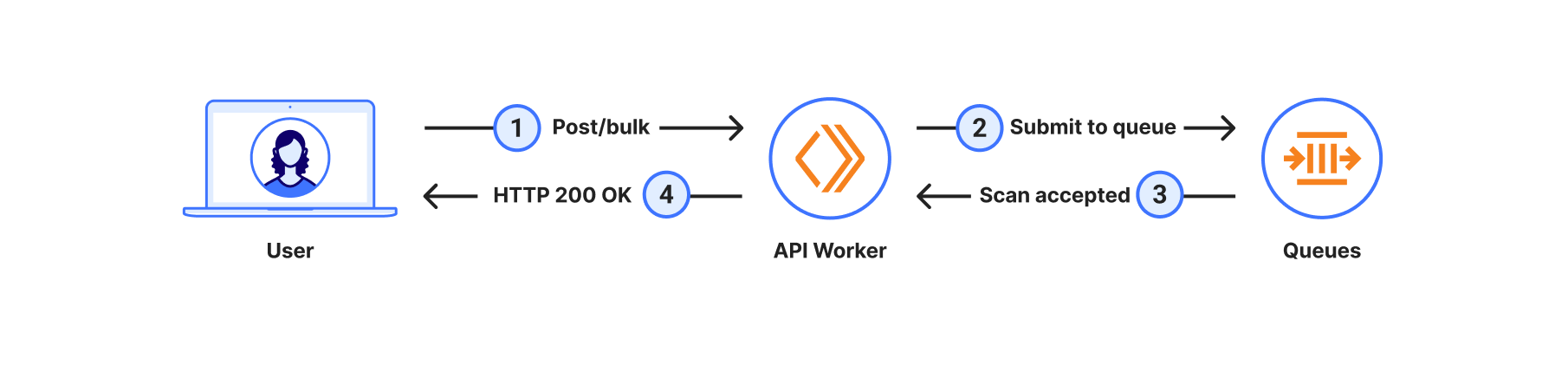
Asynchronous invocations enable decoupled function executions. Clients submit payloads for processing without expecting immediate responses. This is used for scenarios like asynchronous data processing or order/job submissions. The Lambda service immediately returns a confirmation for accepted invocation and proceeds to manage further handler invocation, timeouts, and retries asynchronously.
To accommodate asynchronous invocations, the Lambda service places requests into its internal queue and immediately returns HTTP 202 back to the client. After that, a separate internal poller component reads messages from the queue and synchronously invokes the function.
The same system also takes care of timeouts and retries in case of handler exceptions. When code execution completes, the system sends handler response to either onSuccess or onFailure destination, if configured.
Scaling highly distributed systems for billions of asynchronous requests presents unique challenges, such as managing noisy neighbors and potential traffic spikes to prevent system overload. Solutions vary by scale – what works for millions of requests may not suite billions. As workload size increases, solutions typically become more complex and costly, so right-sizing the approach is critical and should evolve with changing needs.
Simple queueing
A simple implementation of an asynchronous architecture can start with a single shared queue. This is a common approach for many asynchronous systems, particularly in early stages. It is effective when you’re not concerned about tenant isolation and when capacity planning indicates that a single queue can handle estimated incoming traffic efficiently.
Figure 5. Asynchronous workflow with a single queue
Even with this simple setup, it is critical to instrument your solution for observability to detect potential issues as soon as possible. You should monitor key metrics like queue backlog size, processing time, and errors, to indicate insufficient processing capacity early. Periods of unexpected traffic spikes and degraded performance may be a signal you have noisy neighbors impacting other tenants.Top of FormBottom of Form
To address this, you can scale your solution horizontally. You can implement random request placement across multiple queues to spread the load. Using a serverless service like Amazon SQS allows you to easily add and remove queues on-demand. One notable benefit of this approach is its simplicity – you do not need to introduce any complex routing mechanisms; requests are evenly spread across the queues. The downside is that you still do not have tenant boundaries. As your system grows, high-volume tenants and noisy neighbors can potentially affect all queues, thus impacting all tenants.
Figure 6. Asynchronous workflow with multiple queues and random request placement
Intelligent partitioning with consistent hashing
In order to further reduce potential impact, you can partition your tenants using sticky tenant-to-partition assignment with a hashing technique such as consistent hashing. This method uses a hash function to assign each tenant to a queue on a consistent hash ring.
Figure 7. Asynchronous workflow with multiple queues and consistent hashing placement
This technique ensures individual tenants stay in their queue partitions without the risk of disturbing the whole system. It helps to solve the problem where a few noisy neighbors have the potential to overflow all queues and as such impact all other tenants.
The consistent hashing approach proved to be efficient and enabled Lambda to offer robust asynchronous invocation performance to customers. As the volume of traffic and number of customers continued to grow, the Lambda service team came up with an innovative shuffle-sharding technique to further optimize the experience, and proactively eliminate any potential noisy-neighbor issues.
Shuffle-sharding
Drawing inspiration from the “The Power of Two Random Choices” paper, the Lambda team explored the shuffle-sharding technique for its asynchronous invocations processing. Using this technique, you shuffle-shard tenants into several randomly assigned queues. Upon receiving an asynchronous invocation, you place the message in the queue with the smallest backlog to optimize load distribution. This approach helps to minimize the likelihood of assigning tenants to a busy queue.
Figure 8. Asynchronous workflow with multiple queues and shuffle-sharding placement
To illustrate the benefit of this approach, consider a scenario where you’re using а 100 queues. The following formula helps to calculate the number of unique queue shards (combinations), where n is the total number of queues and r is the shard size (the number of queues you’re assigning per tenant).
With n=100, r=2 (each tenant is assigned randomly to 2 out of 100 queues), you get 4,950 unique combinations (shards). The probability of two tenants assigned to exactly the same shard is 0.02%. In case of r=3, the number of combinations spikes to 161,700. The probability of two tenants assigned to exactly the same shard drops to 0.0006%.
The shuffle-sharding technique proved remarkably effective. By distributing tenants across shards, the approach ensures that only a very small subset of tenants could be affected by a noisy neighbor. The potential impact is also minimized since each affected tenant maintains access to unaffected queues. As your workloads grow, increasing the number of queues enhances resilience and further reduces the probability of multiple tenants being assigned to the same shard. This significantly lowers the risk of a single point of failure, making shuffle sharding a robust strategy for workload isolation and fault tolerance.
Many distributed services will have a cohort of tenants with legitimate spiky asynchronous invocation traffic. This can be driven by seasonal factors, such as holiday shopping, or periodical batch processing. Recognizing these as real business needs, not malicious actions, you want to improve service quality for these tenants as well, while maintaining the overall system stability. For example, you can further improve solution performance by continuously monitoring queue depth to detect traffic spikes and route traffic to dynamically allocated dedicated queues. When you use Lambda asynchronous invocations, this internal complexity is managed for you by the service, ensuring seamless consumption experience.
Figure 9. Tenant D is automatically reallocated to a dedicated queue
Resilience and failure handling
“Everything fails, all the time” is a famous quote from Amazon’s Chief Technology Officer Werner Vogels. Lambda’s distributed and resilient architecture is built to withstand potential outages of its dependencies and internal components to limit the fallout for customers. Specifically for asynchronous invocation processing, the frontend service builds a processing backlog during an outage, allowing the backend to gradually recover without losing any in-flight messages.
Figure 10. Lambda service maintains resilience during component outage
Upon recovery, the service gradually ramps up the traffic to process the accumulated backlog. During this time, automated mechanisms are in place to coordinate between system components, preventing inadvertently DDoSing itself.
To further improve the recovery ramp-up process and provide a smooth restoration of normal operations, the Lambda service uses load-shedding technique to ensure fair resource allocation during recovery. While trying to drain the backlog as fast as possible, the service ensures that no single customer ends up consuming an outsized share of the available resources. Adopting such techniques can help you to improve your mean-time-to-recovery (MTTR).
Observability for asynchronous invocations processing
When using the Lambda service for asynchronous processing, you want to monitor your invocations for situational awareness and potential slowdowns. Use metrics such as AsyncEventReceived, AsyncEventAge, and AsyncEventDropped to get insights about internal processing.
AsyncEventReceived tracks the number of async invocations the Lambda service was able to successfully queue for processing. A drop in this metric indicates that invocations are not being delivered to the Lambda service and you should check your invocation source. Potential issues include misconfigurations, invalid access permissions, or throttling. Check your invocation source configuration, logs, and the function resource policy for further analysis.
AsyncEventAge tracks how long has a message spent in the internal queue before being processed by a function. This metric increases when async invocations processing is delayed due to insufficient concurrency, execution failures, or throttles. Increase your function concurrency to process more asynchronous invocations at a time and optimize function performance for better throughput, i.e. by increasing memory allocation to add more vCPU capacity. Experiment with adjusting batch size to enable functions to process more messages at a time. Use invocation logs to identify whether the problem is caused by function code throwing exceptions. Check Throttles and Errors metrics for further analysis.
AsyncEventDropped tracks the number of messages in the internal queue that were dropped because Lambda could not process them. This can be due to throttling, exceeding number of retries, exceeding maximum message age, or function code throwing an exception. Configure OnFailure destination or a dead-letter queue to avoid losing data and save dropped messages for re-processing. Use function logs and metrics described above to investigate whether you can address the issue by increasing function concurrency or allocating more memory.
By monitoring these metrics and addressing the underlying issues, you can ensure that your Lambda functions run smoothly, with minimal event processing delays and failures. You can also enable AWS X-Ray tracing to capture Lambda service traces. The AWS::Lambda trace segment captures the breakdown of the time that Lambda service spends routing requests to internal queues, the time a message spends in a queue, and the time before a function is invoked. This is a powerful tool to get insights into Lambda’s internal processing.
Conclusion
AWS Lambda processes tens of trillions of monthly invocations across more than 1.5 million active customers, demonstrating its exceptional scalability and resilience. Gaining an understanding of the underlying mechanisms of AWS services like Lambda enables you to proactively address potential challenges in your own applications. By learning how these services handle traffic, manage resources, and recover from failures, you can incorporate similar capabilities into your own solutions. For instance, leveraging Lambda’s asynchronous invocation metrics allows you to optimize workflow performance. This knowledge empowers you to implement strategies such as automated scaling, proactive monitoring, and graceful recovery during outages.
See below resources to learn about using queues and shuffle sharding at scale at Amazon
Abstract: Key lengths in symmetric cryptography are determined with respect to the brute force attacks with current technology. While nowadays at least 128-bit keys are recommended, there are many standards and real-world applications that use shorter keys. In order to estimate the actual threat imposed by using those short keys, precise estimates for attacks are crucial.
In this work we provide optimized implementations of several widely used algorithms on GPUs, leading to interesting insights on the cost of brute force attacks on several real-word applications.
In particular, we optimize KASUMI (used in GPRS/GSM),SPECK (used in RFID communication), andTEA3 (used in TETRA). Our best optimizations allow us to try 235.72, 236.72, and 234.71 keys per second on a single RTX 4090 GPU. Those results improve upon previous results significantly, e.g. our KASUMI implementation is more than 15 times faster than the optimizations given in the CRYPTO’24 paper [ACC+24] improving the main results of that paper by the same factor.
With these optimizations, in order to break GPRS/GSM, RFID, and TETRA communications in a year, one needs around 11.22 billion, and 1.36 million RTX 4090GPUs, respectively.
For KASUMI, the time-memory trade-off attacks of [ACC+24] can be performed with142 RTX 4090 GPUs instead of 2400 RTX 3090 GPUs or, when the same amount of GPUs are used, their table creation time can be reduced to 20.6 days from 348 days,crucial improvements for real world cryptanalytic tasks.
Attacks always get better; they never get worse. None of these is practical yet, and they might never be. But there are certainly more optimizations to come.
One of the many important tasks that the kernel’s memory-management
subsystem must handle is keeping track of how pages of memory are mapped
into the address spaces of the processes running on the system. As long as
mappings to a given page exist, that page must be kept in place. As it
turns out, tracking these mappings is harder than it seems it should be,
and the move to folios within the memory-management subsystem is adding
some complexities of its own. As a follow-up to the “mapcount madness” session that he ran at
the 2024 Linux Storage, Filesystem,
Memory-Management, and BPF summit, David Hildenbrand has posted a patch series
intended to improve the handling of mapping counts for folios — but exact
accounting remains elusive in some situations.
Accessing private content online, whether it’s checking email or streaming your favorite show, almost always starts with a “login” step. Beneath this everyday task lies a widespread human mistake we still have not resolved: password reuse. Many users recycle passwords across multiple services, creating a ripple effect of risk when their credentials are leaked.
Based on Cloudflare’s observed traffic between September – November 2024, 41% of successful logins across websites protected by Cloudflare involve compromised passwords. In this post, we’ll explore the widespread impact of password reuse, focusing on how it affects popular Content Management Systems (CMS), the behavior of bots versus humans in login attempts, and how attackers exploit stolen credentials to take over accounts at scale.
Scope of the analysis
Our data analysis focuses on traffic from Internet properties on Cloudflare’s free plan, which includes leaked credentials detection as a built-in feature. Leaked credentials refer to usernames and passwords exposed in known data breaches or credential dumps — for this analysis, our focus is specifically on leaked passwords. With 30 million Internet properties, comprising some 20% of the web, behind Cloudflare, this analysis provides significant insights. The data primarily reflects trends observed after the detection system was launched during Birthday Week in September 2024.
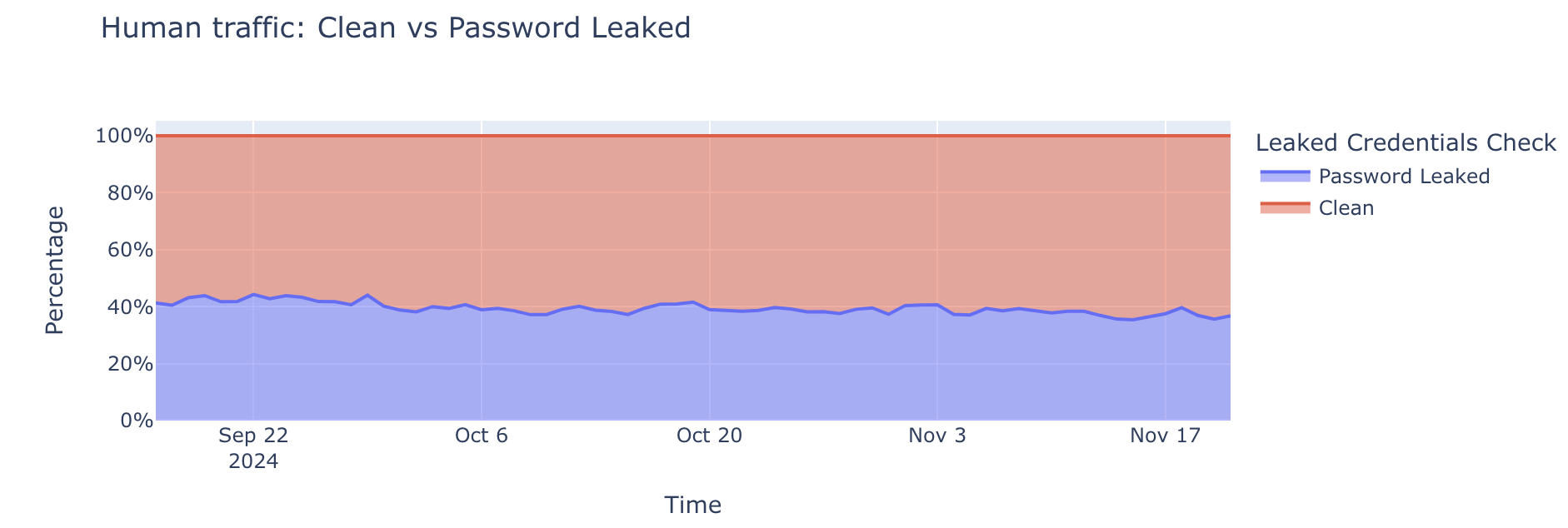
Nearly 41% of logins are at risk
One of the biggest challenges in authentication is distinguishing between legitimate human users and malicious actors. To understand human behavior, we focus on successful login attempts (those returning a 200 OK status code), as this provides the clearest indication of user activity and real account risk. Our data reveals that approximately 41% of successful human authentication attempts involve leaked credentials.
Despite growing awareness about online security, a significant portion of users continue to reuse passwords across multiple accounts. And according to a recent study by Forbes, users will, on average, reuse their password across four different accounts. Even after major breaches, many individuals don’t change their compromised passwords, or still use variations of them across different services. For these users, it’s not a matter of “if” attackers will use their compromised passwords, it’s a matter of “when”.
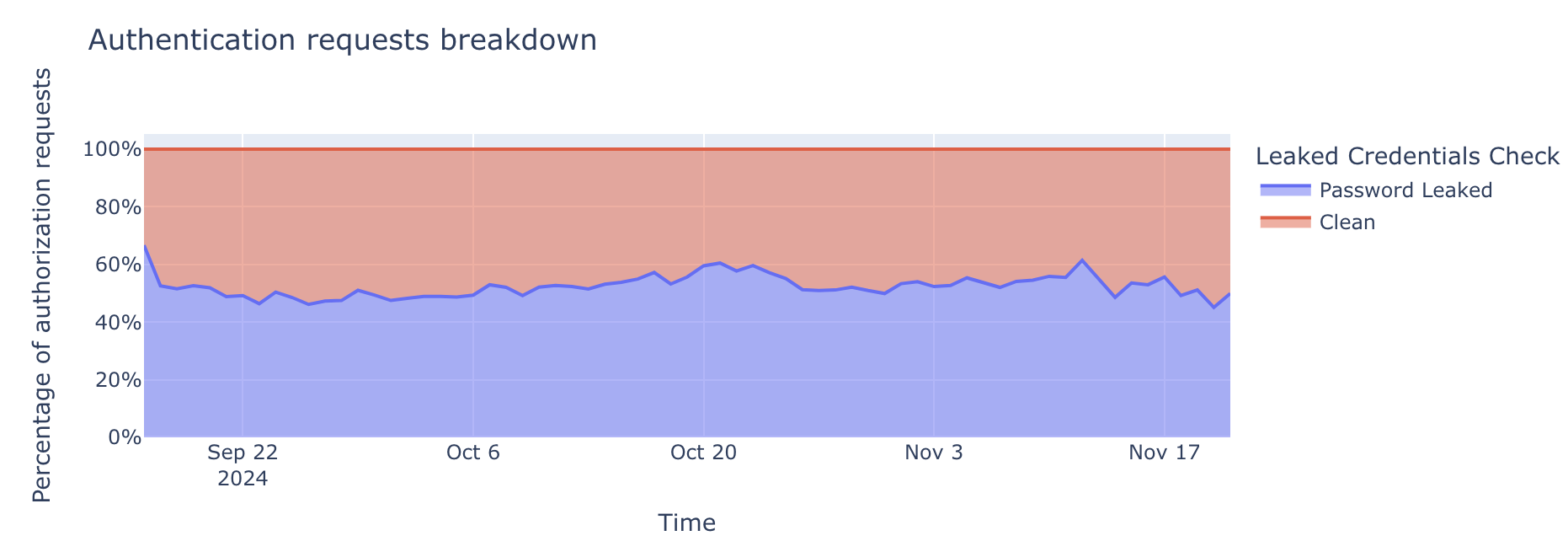
When we expand to include bot-driven traffic in this analysis, the problem of leaked credentials becomes even more noticeable. Our data reveals that 52% of all detected authentication requests contain leaked passwords found in our database of over 15 billion records, including the Have I Been Pwned (HIBP) leaked password dataset.
This percentage represents hundreds of millions of daily authentication requests, originating from both bots and humans. While not every attempt succeeds, the sheer volume of leaked credentials in real-world traffic illustrates how common password reuse is. Many of these leaked credentials still grant valid access, amplifying the risk of account takeovers.
Attackers heavily use leaked password datasets
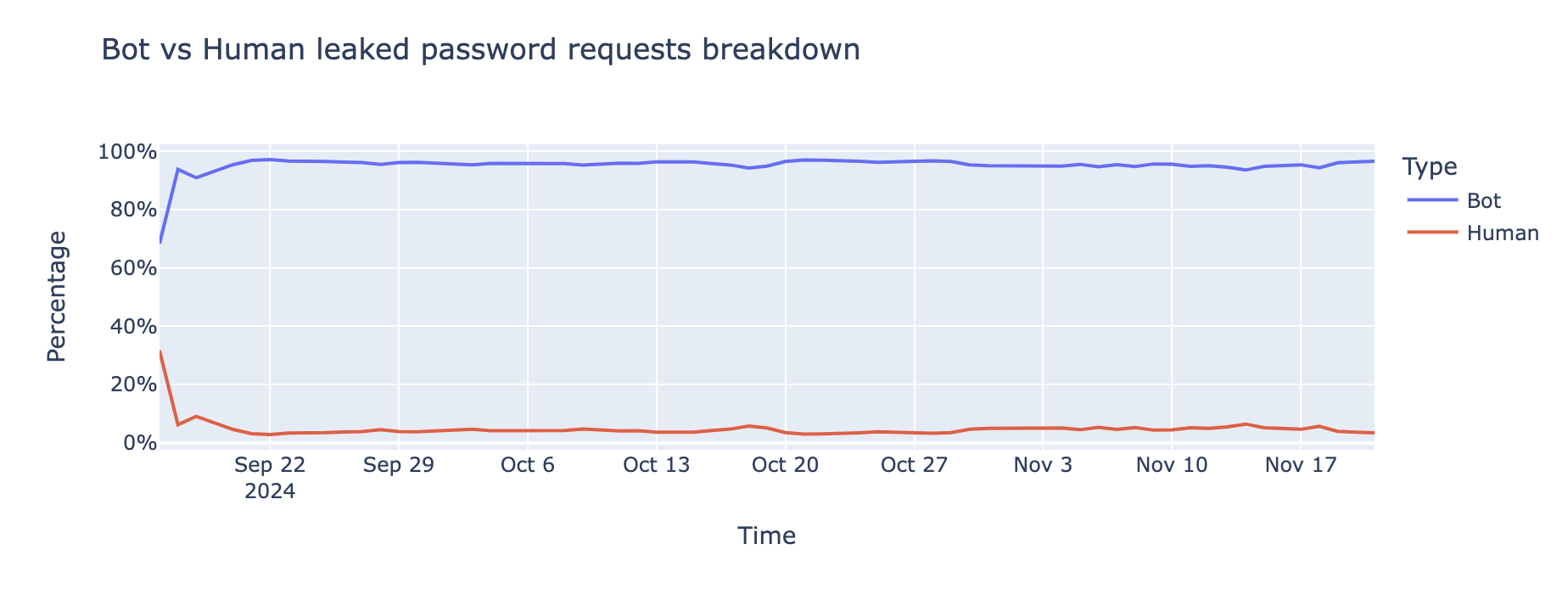
Bots are the driving force behind credential-stuffing attacks, the data indicates that95% of login attempts involving leaked passwords are coming from bots,indicating that they are part of credential stuffing attacks.
Equipped with credentials stolen from breaches, bots systematically target websites at scale, testing thousands of login combinations in seconds.
Data from the Cloudflare network exposes this trend, showing that bot-driven attacks remain alarmingly high over time. Popular platforms like WordPress, Joomla, and Drupal are frequent targets, due to their widespread use and exploitable vulnerabilities, as we will explore in the upcoming section.
Once bots successfully breach one account, attackers reuse the same credentials across other services to amplify their reach. They even sometimes try to evade detection by using sophisticated evasion tactics, such as spreading login attempts across different source IP addresses or mimicking human behavior, attempting to blend into legitimate traffic.
The result is a constant, automated threat vector that challenges traditional security measures and exploits the weakest link: password reuse.
Brute force attacks against WordPress
Content Management Systems (CMS) are used to build websites, and often rely on simple authentication and login plugins. This is convenient, but also makes them frequent targets of credential stuffing attacks due to their widespread adoption. WordPress is a very popular content management system with a well known user login page format. Because of this, websites built on WordPress often become common targets for attackers.
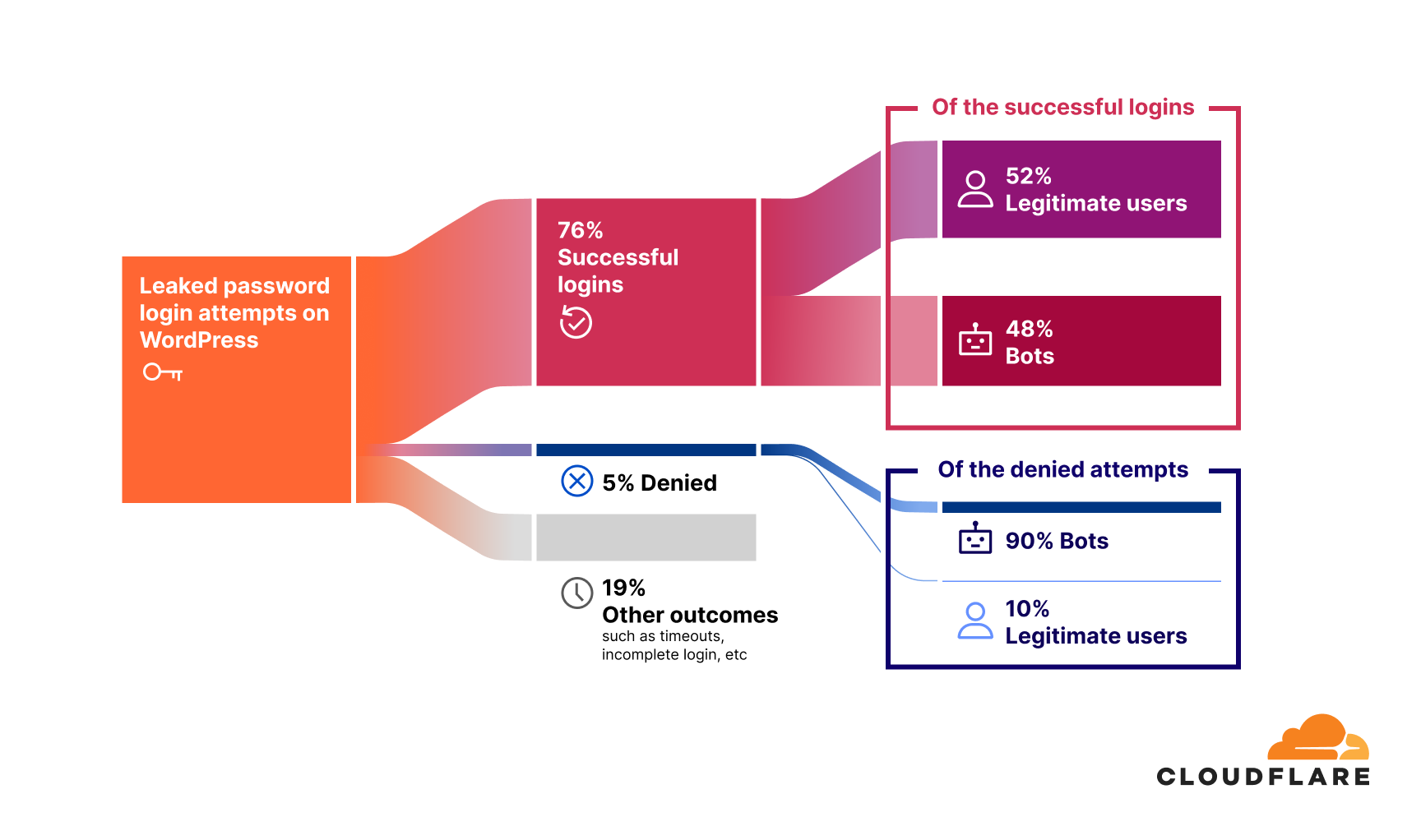
Across our network, WordPress accounts for a significant portion of authentication requests. This is unsurprising given its market share. However, what stands out is the alarming number of successful logins using leaked passwords, especially by bots.
76% of leaked password login attempts for websites built on WordPress are successful.
Of these, 48% of successful logins are bot-driven.This is a shocking figure that indicates nearly half of all successful logins are executed by unauthorized systems designed to exploit stolen credentials. Successful unauthorized access is often the first step in account takeover (ATO) attacks.
The remaining 52% of successful logins originate from legitimate, non-bot users. This figure, higher than the average of 41% across all platforms, highlights how pervasive password reuse is among real users, putting their accounts at significant risk.
Only 5% of leaked password login attempts result in access being denied.
This is a low number compared to the successful bot-driven login attempts, and could be tied to a lack of security measures like rate-limiting or multi-factor authentication (MFA). If such measures were in place, we would expect the share of denied attempts to be higher. Notably, 90% of these denied requests are bot-driven, reinforcing the idea that while some security measures are blocking automated logins, many still slip through.
The overwhelming presence of bot traffic in this category points to ongoing automated attempts to brute-force access.
The remaining 19% of login attempts fall under other outcomes, such as timeouts, incomplete logins, or users who changed their passwords, so they neither count as direct “successes” nor do they register as “denials”.
Keeping user accounts safe with Cloudflare
If you’re a user, start with changing reused or weak passwords and use unique, strong ones for each website or application. Enable multi-factor authentication (MFA) on all of your accounts that support it, and start exploring passkeys as a more secure, phishing-resistant alternative to traditional passwords.
For website owners, activate leaked credentials detection to monitor and address these threats in real time and issue password reset flows on leaked credential matches.
Additionally, enable features like Rate Limiting and Bot Management tools to minimize the impact of automated attacks. Audit password reuse patterns, identify leaked credentials within your systems, and enforce robust password hygiene policies to strengthen overall security.
By adopting these measures, both individuals and organizations can stay ahead of attackers and build stronger defenses.
At Cloudflare, we are constantly innovating and launching new features and capabilities across our product portfolio. Today, we’re releasing a number of new features aimed at improving the security tools available to our customers.
Automated security level: Cloudflare’s Security Level setting has been improved and no longer requires manual configuration. By integrating botnet data along with other request rate signals, all customers are protected from confirmed known malicious botnet traffic without any action required.
Cipher suite selection: You now have greater control over encryption settings via the Cloudflare dashboard, including specific cipher suite selection based on our client or compliance requirements.
Improved URL scanner: New features include bulk scanning, similarity search, location picker and more.
These updates are designed to give you more power and flexibility when managing online security, from proactive threat detection to granular control over encryption settings.
Automating Security Level to provide stronger protection for all
Cloudflare’s Security Level feature was designed to protect customer websites from malicious activity.
Available to all Cloudflare customers, including the free tier, it has always had very simple logic: if a connecting client IP address has shown malicious behavior across our network, issue a managed challenge. The system tracks malicious behavior by assigning a threat score to each IP address. The more bad behavior is observed, the higher the score. Cloudflare customers could configure the threshold that would trigger the challenge.
We are now announcing an update to how Security Level works, by combining the IP address threat signal with threshold and botnet data. The resulting detection improvements have allowed us to automate the configuration, no longer requiring customers to set a threshold.
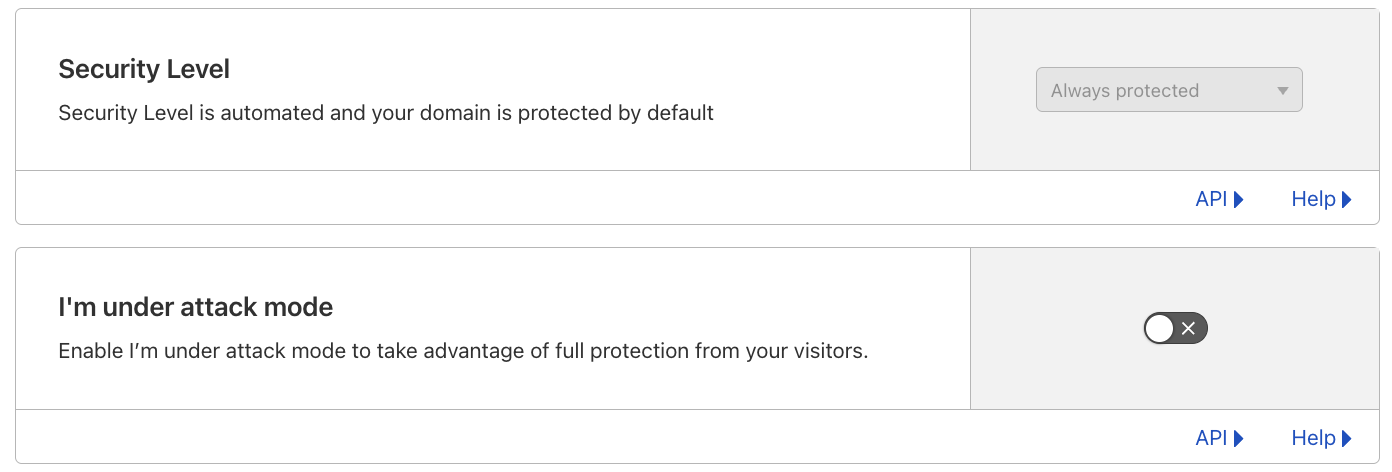
The Security Level setting is now Always protected in the dashboard, and ip_threat_score fields in WAF Custom Rules will no longer be populated. No change is required by Cloudflare customers. The “I am under attack” option remains unchanged.
Stronger protection, by default, for all customers
Although we always favor simplicity, privacy-related services, including our own WARP, have seen growing use. Meanwhile, carrier-grade network address translation (CGNATs) and outbound forward proxies have been widely used for many years.
These services often result in multiple users sharing the same IP address, which can lead to legitimate users being challenged unfairly since individual addresses don’t strictly correlate with unique client behavior. Moreover, threat actors have become increasingly adept at anonymizing and dynamically changing their IP addresses using tools like VPNs, proxies, and botnets, further diminishing the reliability of IP addresses as a standalone indicator of malicious activity. Recognising these limitations, it was time for us to revisit Security Level’s logic to reduce the number of false positives being observed.
In February 2024, we introduced a new security system that automatically combines the real-time DDoS score with a traffic threshold and a botnet tracking system. The real-time DDoS score is part of our autonomous DDoS detection system, which analyzes traffic patterns to identify potential threats. This system superseded and replaced the existing Security Level logic, and is deployed on all customer traffic, including free plans. After thorough monitoring and analysis over the past year, we have confirmed that these behavior-based mitigation systems provide more accurate results. Notably, we’ve observed a significant reduction in false positives, demonstrating the limitations of the previous IP address-only logic.
Better botnet tracking
Our new logic combines IP address signals with behavioral and threshold indicators to improve the accuracy of botnet detection. While IP addresses alone can be unreliable due to potential false positives, we enhance their utility by integrating them with additional signals. We monitor surges in traffic from known “bad” IP addresses and further refine this data by examining specific properties such as path, accept, and host headers.
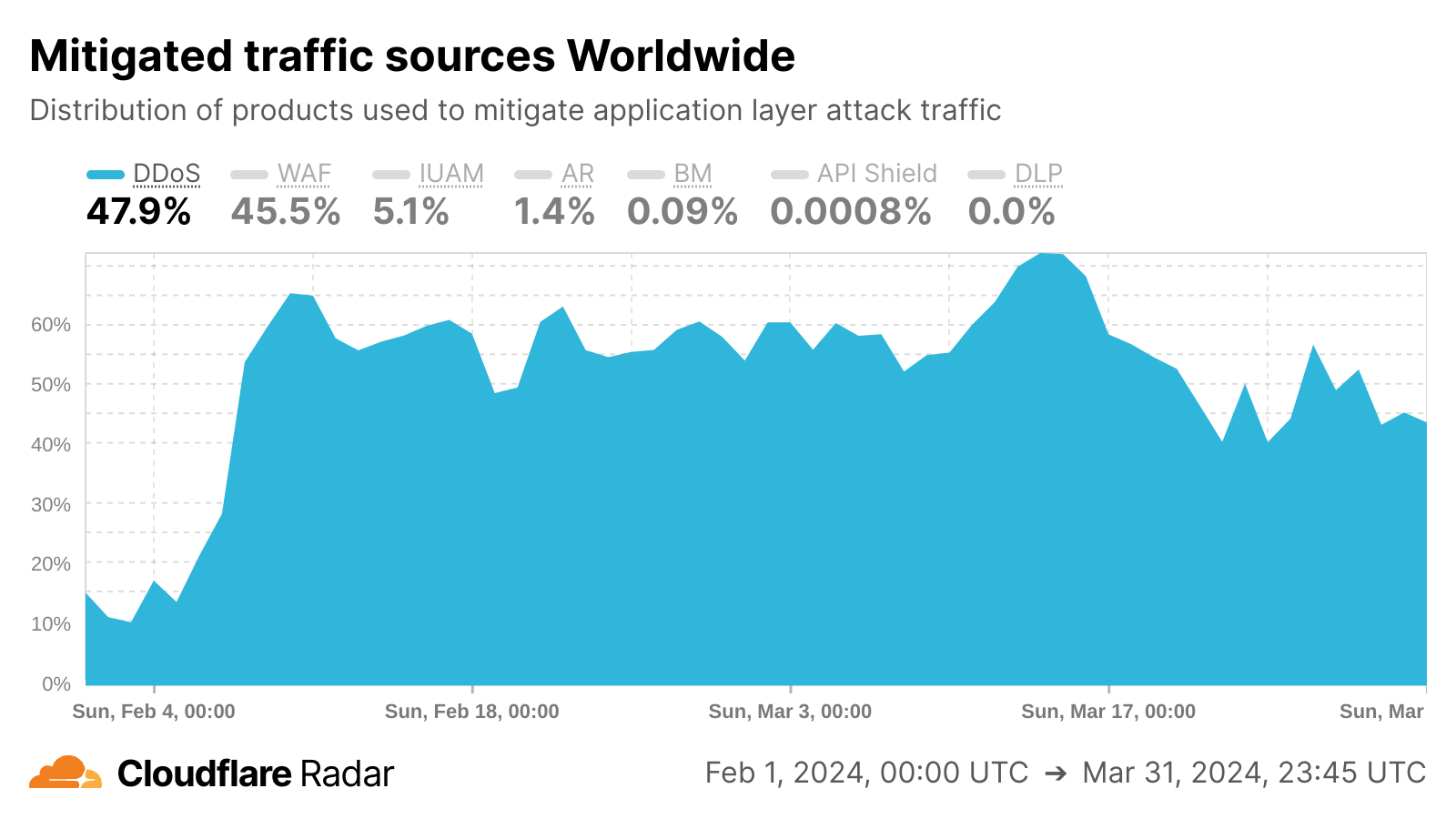
We also introduced a new botnet tracking system that continuously detects and tracks botnet activity across the Cloudflare network. From our unique vantage point as a reverse proxy for nearly 20% of all websites, we maintain a dynamic database of IP addresses associated with botnet activity. This database is continuously updated, enabling us to automatically respond to emerging threats without manual intervention. This effect is visible in the Cloudflare Radar chart below, as we saw sharp growth in DDoS mitigations in February 2024 as the botnet tracking system was implemented.
What it means for our customers and their users
Customers now get better protection while having to manage fewer configurations, and they can rest assured that their online presence remains fully protected. These security measures are integrated and enabled by default across all of our plans, ensuring protection without the need for manual configuration or rule management.
This improvement is particularly beneficial for users accessing sites through proxy services or CGNATs, as these setups can sometimes trigger unnecessary security checks, potentially disrupting access to websites.
What’s next
Our team is looking at defining the next generation of threat scoring mechanisms. This initiative aims to provide our customers with more relevant and effective controls and tools to combat today’s and tomorrow’s potential security threats.
Effective March 17, 2025, we are removing the option to configure manual rules using the threat score parameter in the Cloudflare dashboard. The “I’m Under Attack” mode remains available, allowing users to issue managed challenges to all traffic when needed.
By the end of Q1 2026, we anticipate disabling all rules that rely on IP threat score. This means that using the threat score parameter in the Rulesets API and via Terraform won’t be available after the end of the transition period. However, we encourage customers to be proactive and edit or remove the rules containing the threat score parameter starting today.
Cipher suite selection now available in the UI
Building upon our core security features, we’re also giving you more control over your encryption: cipher suite selection is now available in the Cloudflare dashboard!
When a client initiates a visit to a Cloudflare-protected website, a TLS handshake occurs, where clients present a list of supported cipher suites — cryptographic algorithms crucial for secure connections. While newer algorithms enhance security, balancing this with broad compatibility is key, as some customers prioritise reach by supporting older devices, even with less secure ciphers. To accommodate varied client needs, Cloudflare’s default settings emphasise wide compatibility, allowing customers to tailor cipher suite selection based on their priorities: strong security, compliance (PCI DSS, FIPS 140-2), or legacy device support.
Previously, customizing cipher suites required multiple API calls, proving cumbersome for many users. Now, Cloudflare introduces Cipher Suite Selection to the dashboard. This feature introduces user-friendly selection flows like security recommendations, compliance presets, and custom selections.
Understanding cipher suites
Cipher suites are collections of cryptographic algorithms used for key exchange, authentication, encryption, and message integrity, essential for a TLS handshake. During the handshake’s initiation, the client sends a “client hello” message containing a list of supported cipher suites. The server responds with a “server hello” message, choosing a cipher suite from the client’s list based on security and compatibility. This chosen cipher suite forms the basis of TLS termination and plays a crucial role in establishing a secure HTTPS connection. Here’s a quick overview of each component:
Key exchange algorithm: Secures the exchange of encryption keys between parties.
Authentication algorithm: Verifies the identities of the communicating parties.
Encryption algorithm: Ensures the confidentiality of the data.
Message integrity algorithm: Confirms that the data remains unaltered during transmission.
Perfect forward secrecyis an important feature of modern cipher suites. It ensures that each session’s encryption keys are generated independently, which means that even if a server’s private key is compromised in the future, past communications remain secure.
What we are offering
You can find cipher suite configuration under Edge Certificates in your zone’s SSL/TLS dashboard. There, you will be able to view your allow-listed set of cipher suites.
Additionally, you will be able to choose from three different user flows, depending on your specific use case, to seamlessly select your appropriate list. Those three user flows are: security recommendation selection, compliance selection, or custom selection. The goal of the user flows is to outfit customers with cipher suites that match their goals and priorities, whether those are maximum compatibility or best possible security.
1. Security recommendations
To streamline the process, we have turned our cipher suites recommendations into selectable options. This is in an effort to expose our customers to cipher suites in a tangible way and enable them to choose between different security configurations and compatibility. Here is what they mean:
Modern: Provides the highest level of security and performance with support for Perfect Forward Secrecy and Authenticated Encryption (AEAD). Ideal for customers who prioritize top-notch security and performance, such as financial institutions, healthcare providers, or government agencies. This selection requires TLS 1.3 to be enabled and the minimum TLS version set to 1.2.
Compatible: Balances security and compatibility by offering forward-secret cipher suites that are broadly compatible with older systems. Suitable for most customers who need a good balance between security and reach. This selection also requires TLS 1.3 to be enabled and the minimum TLS version set to 1.2.
Legacy: Optimizes for the widest reach, supporting a wide range of legacy devices and systems. Best for customers who do not handle sensitive data and need to accommodate a variety of visitors. This option is ideal for blogs or organizations that rely on older systems.
2. Compliance selection
Additionally, we have also turned our compliance recommendations into selectable options to make it easier for our customers to meet their PCI DSS or FIPS-140-2 requirements.
PCI DSS Compliance: Ensures that your cipher suite selection aligns with PCI DSS standards for protecting cardholder data. This option will enforce a requirement to set a minimum TLS version of 1.2, and TLS 1.3 to be enabled, to maintain compliance.
Since the list of supported cipher suites require TLS 1.3 to be enabled and a minimum TLS version of 1.2 in order to be compliant, we will disable compliance selection until the zone settings are updated to meet those requirements. This effort is to ensure that our customers are truly compliant and have the proper zone settings to be so.
FIPS 140-2 Compliance: Tailored for customers needing to meet federal security standards for cryptographic modules. Ensures that your encryption practices comply with FIPS 140-2 requirements.
3. Custom selection
For customers needing precise control, the custom selection flow allows individual cipher suite selection, excluding TLS 1.3 suites which are automatically enabled with TLS 1.3. To prevent disruptions, guardrails ensure compatibility by validating that the minimum TLS version aligns with the selected cipher suites and that the SSL/TLS certificate is compatible (e.g., RSA certificates require RSA cipher suites).
API
The API will still be available to our customers. This aims to support an existing framework, especially to customers who are already API reliant. Additionally, Cloudflare preserves the specified cipher suites in the order they are set via the API and that control of ordering will remain unique to our API offering.
With your Advanced Certificate Manager or Cloudflare for SaaS subscription, head to Edge Certificates in your zone’s SSL dashboard and give it a try today!
Smarter scanning, safer Internet with the new version of URL Scanner
Cloudflare’s URL Scanner is a tool designed to detect and analyze potential security threats like phishing and malware by scanning and evaluating websites, providing detailed insights into their safety and technology usage. We’ve leveraged our own URL Scanner to enhance our internal Trust & Safety efforts, automating the detection and mitigation of some forms of abuse on our platform. This has not only strengthened our own security posture, but has also directly influenced the development of the new features we’re announcing today.
Phishing attacks are on the rise across the Internet, and we saw a major opportunity to be “customer zero” for our URL Scanner to address abuse on our own network. By working closely with our Trust & Safety team to understand how the URL Scanner could better identify potential phishing attempts, we’ve improved the speed and accuracy of our response to abuse reports, making the Internet safer for everyone. Today, we’re excited to share the new API version and the latest updates to URL Scanner, which include the ability to scan from specific geographic locations, bulk scanning, search by Indicators of Compromise (IOCs), improved UI and information display, comprehensive IOC listings, advanced sorting options, and more. These features are the result of our own experiences in leveraging URL Scanner to safeguard our platform and our customers, and we’re confident that they will prove useful to our security analysts and threat intelligence users.
Scan up to 100 URLs at once by using bulk submissions
Cloudflare Enterprise customers can now conduct routine scans of their web assets to identify emerging vulnerabilities, ensuring that potential threats are addressed proactively, by using the Bulk Scanning API endpoint. Another use case for the bulk scanning functionality is developers leveraging bulk scanning to verify that all URLs your team is accessing are secure and free from potential exploits before launching new websites or updates.
Scanning of multiple URLs addresses the specific needs of our users engaged in threat hunting. Many of them maintain extensive lists of URLs that require swift investigation to identify potential threats. Currently, they face the task of submitting these URLs one by one, which not only slows down their workflow but also increases the manual effort involved in their security processes. With the introduction of bulk submission capabilities, users can now submit up to 100 URLs at a time for scanning.
How we built the bulk scanning feature
Let’s look at a regular workflow:
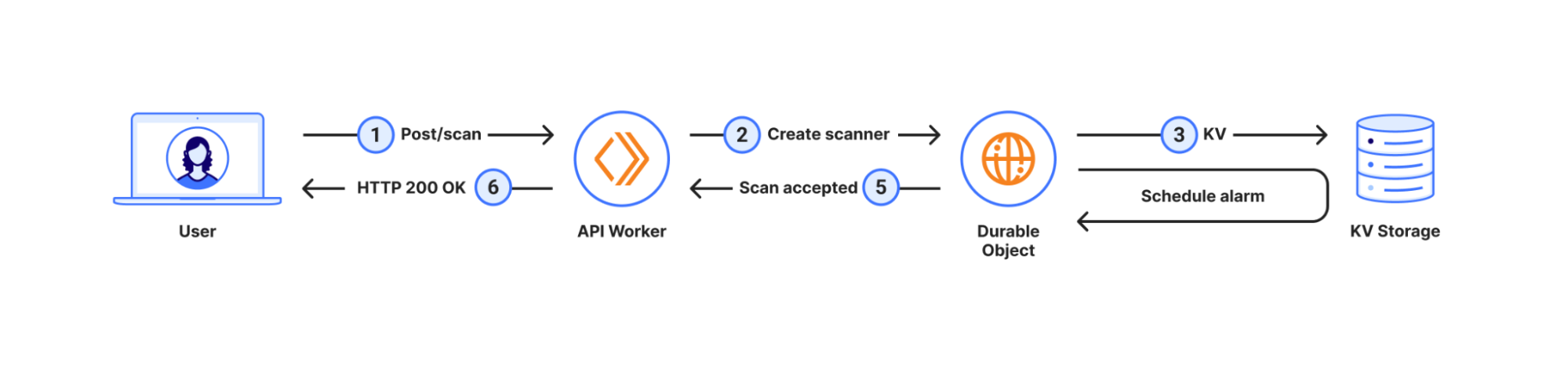
In this workflow, when the user submits a new scan, we create a Durable Object with the same ID as the scan, save the scan options, like the URL to scan, to the Durable Objects’s storage and schedule an alarm for a few seconds later. This allows us to respond immediately to the user, signalling a successful submission. A few seconds later the alarm triggers, and we start the scan itself.
However, with bulk scanning, the process is slightly different:
In this case, there are no Durable Objects involved just yet; the system simply sends each URL in the bulk scan submission as a new message to the queue.
Notice that in both of these cases the scan is triggered asynchronously. In the first case, it starts when the Durable Objects alarm fires and, in the second case, when messages in the queue are consumed. While the durable object alarm will always fire in a few seconds, messages in the queue have no predetermined processing time, they may be processed seconds to minutes later, depending on how many messages are already in the queue and how fast the system processes them.
When users bulk scan, having the scan done at some point in time is more important than having it done now. When using the regular scan workflow, users are limited in the number of scans per minute they can submit. However, when using bulk scan this is not a concern, and users can simply send all URLs they want to process in a single HTTP request. This comes with the tradeoff that scans may take longer to complete, which is a perfect fit for Cloudflare Queues. Having the ability to configure retries, max batch size, max batch timeouts, and max concurrency is something we’ve found very useful. As the scans are completed asynchronously, users can request the resulting scan reports via the API.
Discover related scans and better IOC search
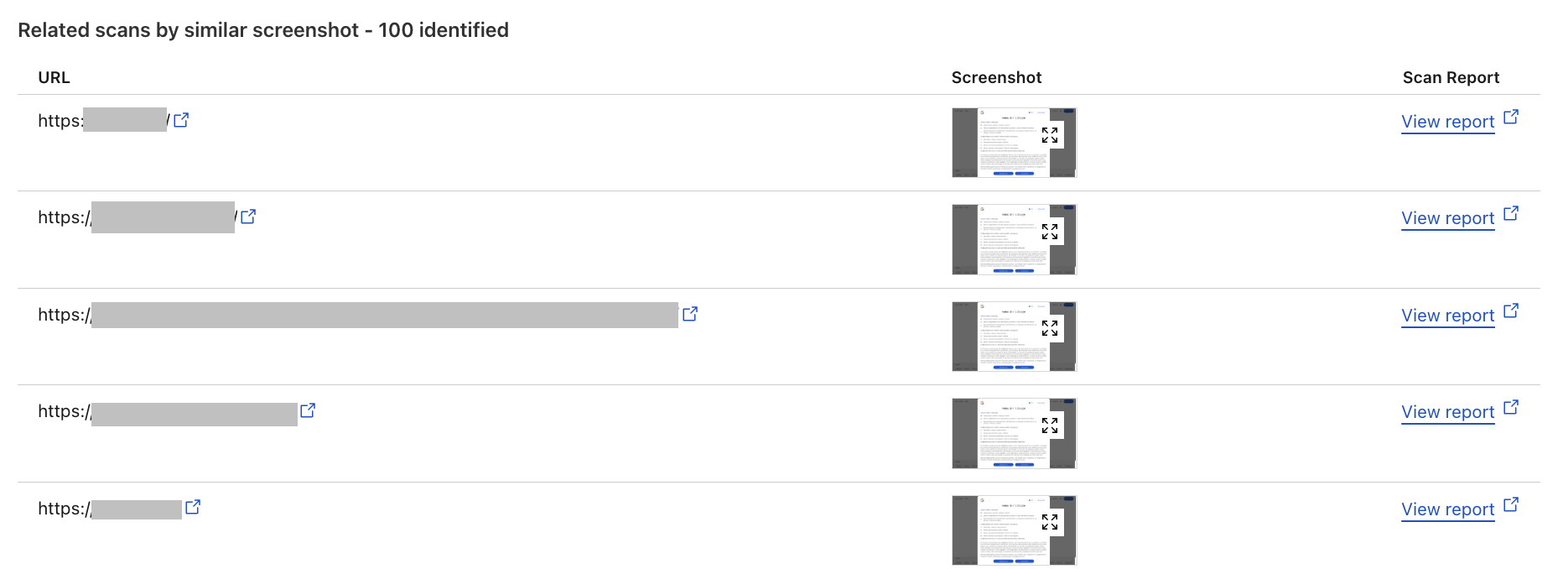
The Related Scans feature allows API, Cloudflare dashboard and Radar users alike to view related scans directly within the URL Scanner Report. This helps users analyze and understand the context of a scanned URL by providing insights into similar URLs based on various attributes. Filter and search through URL Scanner reports to retrieve information on related scans, including those with identical favicons, similar HTML structures, and matching IP addresses.
The Related Scans tab presents a table with key headers corresponding to four distinct filters. Each entry includes the scanned URL and a direct link to view the detailed scan report, allowing for quick access to further information.
We’ve introduced the ability to search by indicators of compromise (IOCs), such as IP addresses and hashes, directly within the user interface. Additionally, we’ve added advanced filtering options by various criteria, including screenshots, hashes, favicons, and HTML body content. This allows for more efficient organization and prioritization of URLs based on specific needs. While attackers often make minor modifications to the HTML structure of phishing pages to evade detection, our advanced filtering options enable users to search for URLs with similar HTML content. This means that even if the visual appearance of a phishing page changes slightly, we can still identify connections to known phishing campaigns by comparing the underlying HTML structure. This proactive approach helps users identify and block these threats effectively.
Another use case for the advanced filtering options is the search by hash; a user who has identified a malicious JavaScript file through a previous investigation can now search using the file’s hash. By clicking on an HTTP transaction, you’ll find a direct link to the relevant hash, immediately allowing you to pivot your investigation. The real benefit comes from identifying other potentially malicious sites that have that same hash. This means that if you know a given script is bad, you can quickly uncover other compromised websites delivering the same malware.
The user interface has also undergone significant improvements to enhance the overall experience. Other key updates include:
Page title and favicon surfaced, providing immediate visual context
Detailed summaries are now available
Redirect chains allow users to understand the navigation path of a URL
The ability to scan files from URLs that trigger an automatic file download
Download HAR files
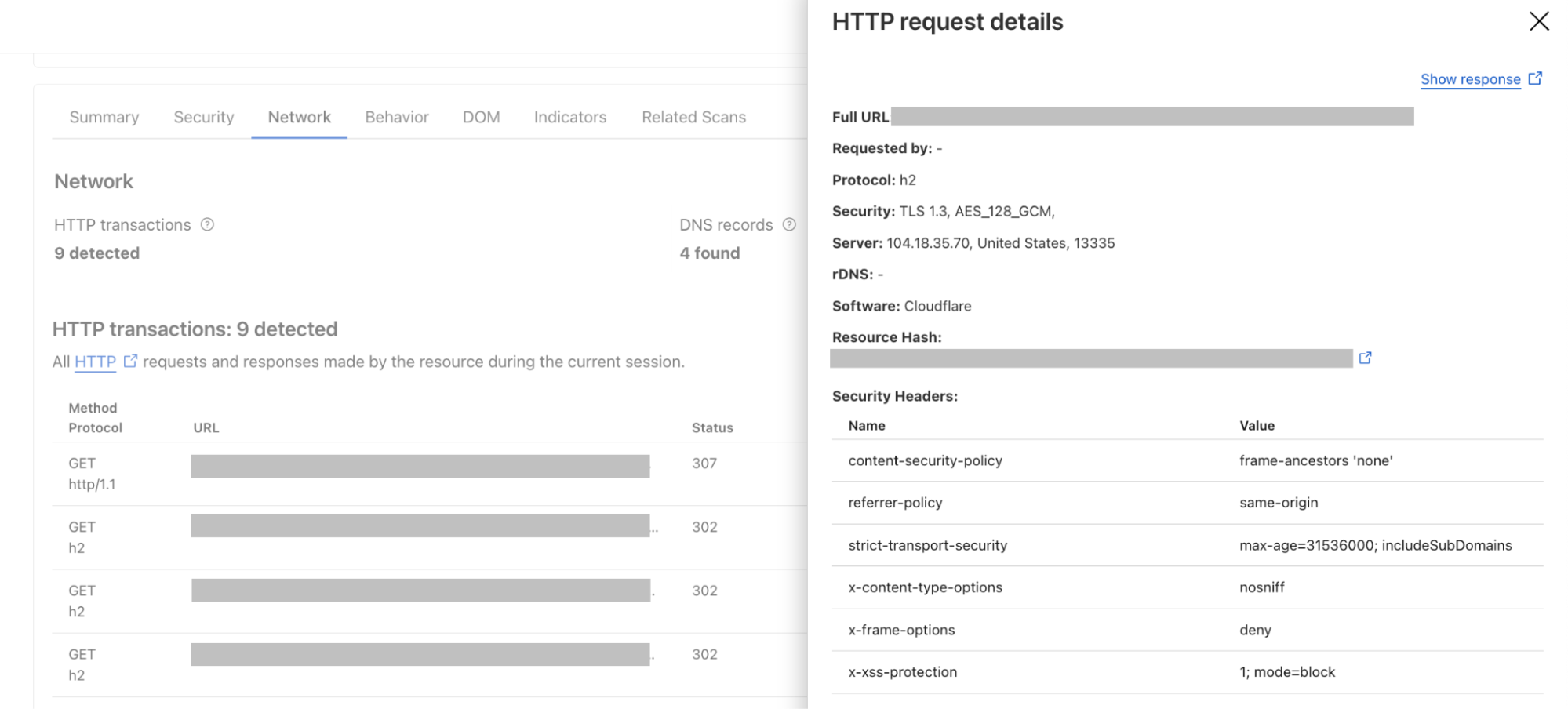
With the latest updates to our URL Scanner, users can now download both the HAR (HTTP Archive) file and the JSON report from their scans. The HAR file provides a detailed record of all interactions between the web browser and the scanned website, capturing crucial data such as request and response headers, timings, and status codes. This format is widely recognized in the industry and can be easily analyzed using various tools, making it invaluable for developers and security analysts alike.
For instance, a threat intelligence analyst investigating a suspicious URL can download the HAR file to examine the network requests made during the scan. By analyzing this data, they can identify potential malicious behavior, such as unexpected redirects and correlate these findings with other threat intelligence sources. Meanwhile, the JSON report offers a structured overview of the scan results, including security verdicts and associated IOCs, which can be integrated into broader security workflows or automated systems.
New API version
Finally, we’re announcing a new version of our API, allowing users to transition effortlessly to our service without needing to overhaul their existing workflows. Moving forward, any future features will be integrated into this updated API version, ensuring that users have access to the latest advancements in our URL scanning technology.
We understand that many organizations rely on automation and integrations with our previous API version. Therefore, we want to reassure our customers that there will be no immediate deprecation of the old API. Users can continue to use the existing API without disruption, giving them the flexibility to migrate at their own pace. We invite you to try the new API today and explore these new features to help with your web security efforts.
Never miss an update
In summary, these updates to Security Level, cipher suite selection, and URL Scanner help us provide comprehensive, accessible, and proactive security solutions. Whether you’re looking for automated protection, granular control over your encryption, or advanced threat detection capabilities, these new features are designed to empower you to build a safer and more secure online presence. We encourage you to explore these features in your Cloudflare dashboard and discover how they can benefit your specific needs.
We’ll continue to share roundup blog posts as we build and innovate. Follow along on the Cloudflare Blog for the latest news and updates.
At Cloudflare, we believe that every political candidate — regardless of their affiliation — should be able to run their campaign without the constant worry of cyber attacks. Unfortunately, malicious actors, such as nation-states, financially motivated attackers, and hackers, are often looking to disrupt campaign operations and messaging. These threats have the potential to interfere with the democratic process, weaken public confidence, and cause operational challenges for campaigns of all scales.
In 2020, in partnership with the non-profit, non-partisan Defending Digital Campaigns(DDC), we launched Cloudflare for Campaigns to offer a free package of cybersecurity tools to political campaigns, especially smaller ones with limited resources. Since then, we have helped over 250 political campaigns and parties across the US, regardless of affiliation.
This is why we are excited to announce that we have extended our Cloudflare for Campaigns product suite to include Email Security, to secure email systems that are essential to safeguarding the integrity and success of a political campaign. By preventing phishing, spoofing, and other email threats, it helps protect candidates, staff, and supporters from cyberattacks that could compromise sensitive data.
The front line of protection is email security
Phishing attacks on political campaigns have been a major cybersecurity threat in recent years, often leading to data breaches, leaks, and misinformation. In 2016,attackers targeted Democratic National Committee (DNC) staff with spear phishing emails disguised as Google security alerts, allowing hackers to access thousands of emails. In 2018, Russian intelligence agentsattempted to infiltrate Senator Claire McCaskill’s re-election campaign by sending emails to her staff, urging them to change their passwords.
This unsettling trend has affected political parties as well. In 2020, the Republican Party of Wisconsin fell victim to a phishing attack that resulted in hackers stealing $2.3 million.
During the2022 US midterm elections, Cloudflare safeguarded the email inboxes of more than 100 campaigns, election officials, and public organizations involved in the election process. These ranged from first-time candidates in local races to seasoned incumbents at the national level. In the three months leading up to the 2022 midterms, Cloudflare processed over 20 million emails and successfully blocked around 150,000 phishing attempts targeting campaign staff.
During the 2024 US election, we actively protected state and local election offices, political campaigns, state parties, independent media, and voting rights organizations. In addition, we safeguarded the inboxes of hundreds of political campaigns, ensuring secure and uninterrupted communications to help campaigns focus on their message and outreach without the fear of cyberattack derailing their efforts. Over the course of the year, Cloudflare:
Scanned 5.7 million emails for campaigns and political parties
Blocked 400,000 malicious messages before they reached campaign staff and teams
Detected and blocked 21,000 suspicious emails
Prevented 14,000 unique spoofing attempts
Providing tools to help political campaigns and parties stay secure online
We launched Cloudflare for Campaigns in 2020 to help political campaigns stay online amid cyber attacks. US campaign finance laws prohibit corporations from donating money or services to federal candidates or parties. However, we partner with Defending Digital Campaigns (DDC), approved by the Federal Election Commission, to offer free and discounted cybersecurity services. Through DDC, we provide tailored security solutions for resource-limited campaigns and parties facing heightened cyber threats.
“DDC is thrilled that Cloudflare is expanding their product offerings to campaigns with the addition of Email Security. This will expedite robust protections from the real and serious threats posed by phishing. Now campaigns, in concert with the DDoS protection Cloudflare provides via Cloudflare for Campaigns, will be able to easily enable a suite of core protections. This new offering further exemplifies Cloudflare’s extraordinary and generous commitment to protecting campaigns. Cloudflare has been one of DDC’s core partners since we were founded.”– Michael Kaiser, President & CEO of Defending Digital Campaigns
Over five years, our partnership has strengthened protections against DDoS attacks and web vulnerabilities. However, campaigns have frequently asked for help combating malicious emails that target campaign staff.
Cloudflare acquired Area 1 Security in 2022 to enhance its Zero Trust platform by integrating an email security solution that proactively identifies and blocks phishing threats before they reach users’ inboxes. Before the acquisition, Area 1 provided low-cost email security to political campaigns with direct FEC approval.
Fast-forward to 2025, and we are excited to officially integrate Email Security into our full Cloudflare for Campaigns portfolio to better protect US political parties and campaigns.
Access free Email Security for your political campaign or party with Cloudflare for Campaigns
Phishing protection: AI-powered threat detection that automatically identifies and blocks malicious emails before they reach their target
Email authentication: Built-in support for DMARC, DKIM, and SPF to prevent email spoofing
Real-time monitoring: Continuous scanning for suspicious activities and anomalies
Seamless integration: Easily integrates with existing email providers without disrupting workflows
Insightful reporting: Actionable analytics and reports to track security events and improve defenses
At Cloudflare, we are committed to helping build a better Internet — one where election campaigns can operate securely, free from the threat of cyber attacks.
Current campaigns and political parties that are protected under Cloudflare for Campaigns will receive an email with information on how to enable Email Security. If you are a campaign or a political party interested in applying for the project to get access to the full suite of products, please visit https://www.cloudflare.com/campaigns/usa.
In May 2024, Cloudflare signed the Cybersecurity and Infrastructure Security Agency (CISA) Secure By Design pledge. Since then, Cloudflare has been working to enhance the security of our products, ensuring that users are better protected from evolving threats.
Today we are excited to talk about the improvements we have made towards goal number one in the pledge, which calls for increased multi-factor authentication (MFA) adoption. MFA takes many forms across the industry, from app-based and hardware key authentication, to email or SMS. Since signing the CISA pledge we have continued to iterate on our MFA options for users, and most recently added support for social logins with Apple and Google, building on the strong foundation that both of these partners offer their users with required MFA for most accounts. Since introducing social logins last year, about 25% of our users use it weekly, and it makes up a considerable portion of our MFA secured users. There’s much more to do in this space, and we are continuing to invest in more options to help secure your accounts.
Mirror, mirror on the wall who is the most secure of them all?
According to the 2024 Verizon Data Breach Investigations Report, leaked credentials continue to be the top cause of application breaches. Even when users employ strong passwords, attackers often make use of techniques like credential stuffing, or password spraying, to gain unauthorized access to accounts. These approaches build on previous data breaches and are much quicker than brute force attacks of the past.
Ultimately, the most effective defense against these threats is multi-factor authentication (MFA). By requiring an additional verification step beyond just a password, MFA significantly strengthens account security. In fact, studies show that MFA can block 99.9% of automated attacks, reducing the risk of unauthorized access even if your credentials are compromised.
Every user on Cloudflare is protected by our built-in challenge system, which will prompt users for a multi-factor authentication code from their email whenever they log in from a new IP address. This provides an important layer of protection by default.
At Cloudflare, MFA is available to all Cloudflare customers, and we strongly encourage every user to enable at least one additional authentication factor to better protect their account.
What’s new?
We made a number of improvements over the course of 2024 to protect you, with more ways to secure your account and adopt MFA.
Social login with Google and Apple
Social login allows you to login to Cloudflare using the secure credentials you already use for your Google or Apple accounts. Most Apple and Google accounts have mandatory multi-factor authentication, so this approach provides a seamless and robust layer of security. By reducing the need to manage separate credentials, social login also makes it easier for customers to secure their accounts from the start.
Social login has quickly become one of our top login methods, comprising about 25% of all logins weekly on Cloudflare.
Leaked password notifications
Cloudflare automatically detects and notifies users who are using known, leaked passwords. These users are then asked to change their password when they log into Cloudflare. This ensures that users with leaked passwords can address this security lapse easily and keep themselves safe.
Improve your security posture
If you’re not already using MFA on your account, you have options. It’s never too late to reevaluate your security posture!
Replace default passwords with strong passwords
As much as we’re focused on MFA, creation of a strong password is the first line of defense for secure MFA! To safeguard our users, and in alignment with CISA Goal #2 (Default Passwords), Cloudflare does not provide users with preconfigured passwords, or “default passwords”, during initial password generation. This helps reduce the risk of automated attacks such as credential stuffing and brute force attempts which often target default logins.
Instead, Cloudflare advocates for strong user-generated passwords. Ideally, users choose unique passwords they have not used before and meet the CISA recommendations for password creation. Use of a password manager can help users adopt strong passwords and reduce friction. By enforcing unique strong passwords, our company ensures a higher level of security making unauthorized access significantly more difficult.
Enable MFA for your account
Cloudflare supports multiple MFA methods. The most secure option is to use a phishing-resistant security key like a YubiKey, or a hardware key that is built into your primary computer like Windows Hello or Apple’s TouchID. We also support Time-Based One-Time passwords (TOTP) using a mobile authenticator app like Google Authenticator or Microsoft Authenticator. Importantly, these apps support optional backup to the cloud, so if you ever lose your phone, you’ll still be able to get into your account. Don’t forget to download backup codes and store them somewhere safe like your password manager in case you lose your MFA device! Configure MFA for your account now in the Cloudflare dashboard.
Require MFA for all users in your Cloudflare account
If you’re an administrator for a Cloudflare account and want to ensure your users are all using MFA, you can set this as a policy on the account in the Manage Members experience. Note, this setting is not available if you have not used MFA, or if your users are using social login. For social login we encourage users to set up MFA on their associated accounts.
Enable SSO for your enterprise
For enterprise customers, single sign-on (SSO) is one of the most secure and convenient ways to manage authentication at scale. At Cloudflare, we offer SSO free of charge to all enterprise customers and actively encourage organizations to enable it for stronger security.
Quantum computers are actively being developed that will eventually have the ability to break the cryptography we rely on for securing modern communications. Recent breakthroughs in quantum computing have underscored the vulnerability of conventional cryptography to these attacks. Since 2017, Cloudflare has been at the forefront of developing, standardizing, and implementing post-quantum cryptography to withstand attacks by quantum computers.
Our mission is simple: we want every Cloudflare customer to have a clear path to quantum safety. Cloudflare recognizes the urgency, so we’re committed to managing the complex process of upgrading cryptographic algorithms, so that you don’t have to worry about it. We’re not just talking about doing it. Over 35% of the non-bot HTTPS traffic that touches Cloudflare today is post-quantum secure.
The National Institute of Standards and Technology (NIST) also recognizes the urgency of this transition. On November 15, 2024, NIST made a landmark announcement by setting a timeline to phase out RSA and Elliptic Curve Cryptography (ECC), the conventional cryptographic algorithms that underpin nearly every part of the Internet today. According to NIST’s announcement, these algorithms will be deprecated by 2030 and completely disallowed by 2035.
At Cloudflare, we aren’t waiting until 2035 or even 2030. We believe privacy is a fundamental human right, and advanced cryptography should be accessible to everyone without compromise. No one should be required to pay extra for post-quantum security. That’s why any visitor accessing a website protected by Cloudflare today benefits from post-quantum cryptography, when using a major browser like Chrome, Edge, or Firefox. (And, we are excited to see a small percentage of (mobile) Safari traffic in our Radar data.) Well over a third of the human traffic passing through Cloudflare today already enjoys this enhanced security, and we expect this share to increase as more browsers and clients are upgraded to support post-quantum cryptography.
While great strides have been made to protect human web traffic, not every application is a web application. And every organization has internal applications (both web and otherwise) that do not support post-quantum cryptography.
How should organizations go about upgrading their sensitive corporate network traffic to support post-quantum cryptography?
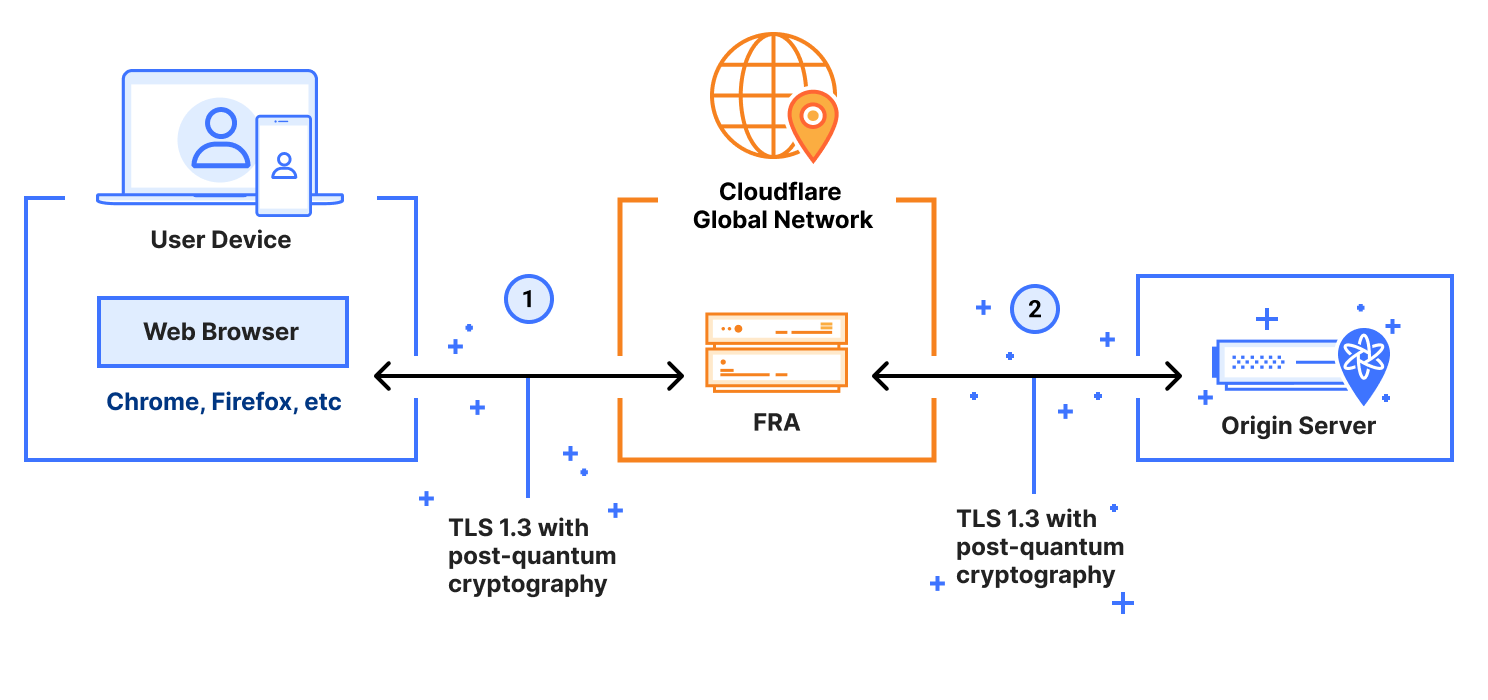
That’s where today’s announcement comes in. We’re thrilled to announce the first phase of end-to-end quantum readiness of our Zero Trust platform, allowing customers to protect their corporate network traffic with post-quantum cryptography. Organizations can tunnel their corporate network traffic though Cloudflare’s Zero Trust platform, protecting it against quantum adversaries without the hassle of individually upgrading each and every corporate application, system, or network connection.
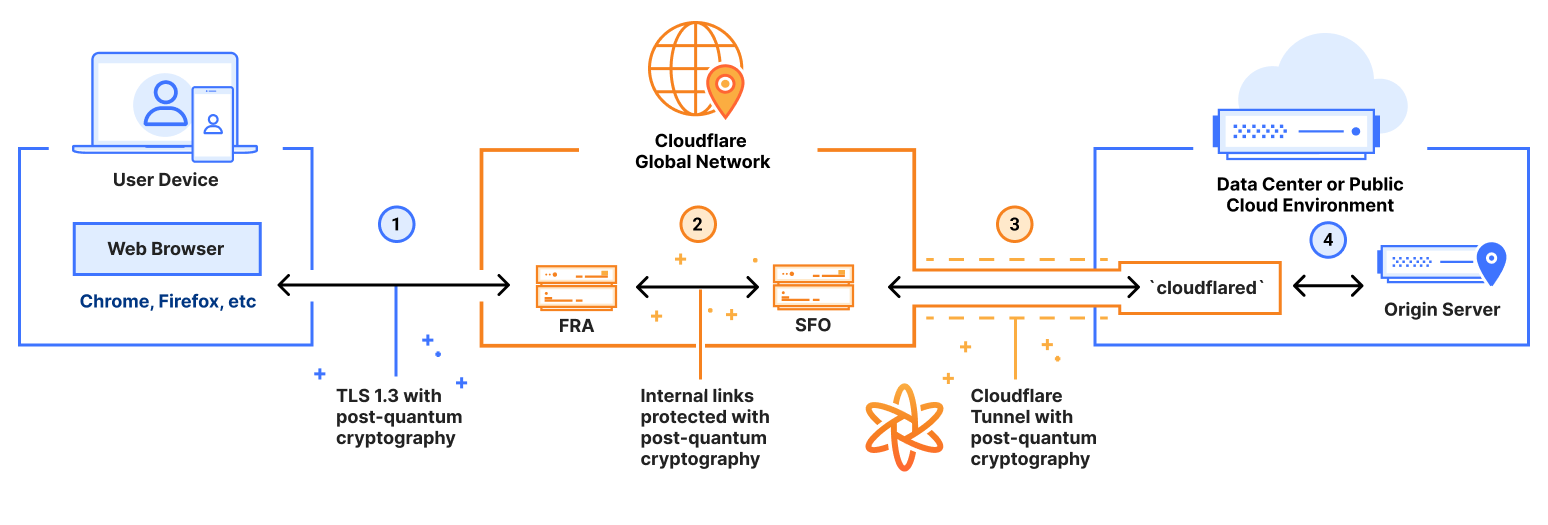
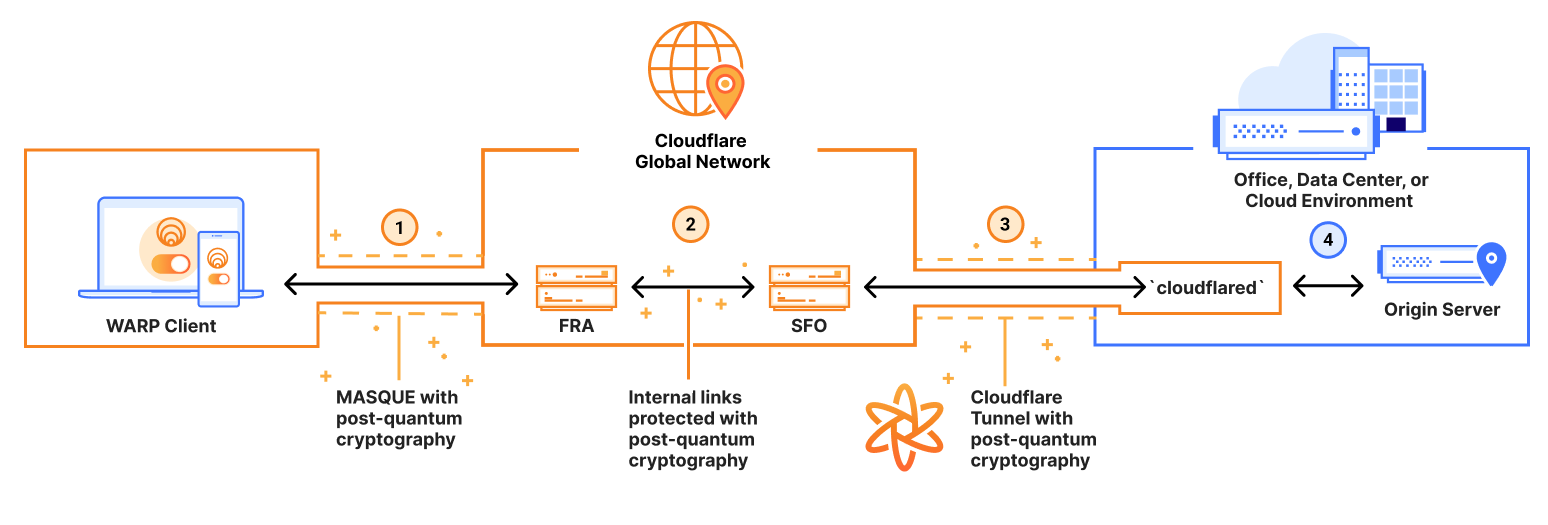
More specifically, organizations can use our Zero Trust platform to route communications from end-user devices (via web browser or Cloudflare’s WARP device client) to secure applications connected with Cloudflare Tunnel, to gain end-to-end quantum safety, in the following use cases:
Cloudflare’s clientless Access: Our clientless Zero Trust Network Access (ZTNA) solution verifies user identity and device context for every HTTPS request to corporate applications from a web browser. Clientless Access is now protected end-to-end with post-quantum cryptography.
Cloudflare’s WARP device client: By mid-2025, customers using the WARP device client will have all of their traffic (regardless of protocol) tunneled over a connection protected by post-quantum cryptography. The WARP client secures corporate devices by privately routing their traffic to Cloudflare’s global network, where Gateway applies advanced web filtering and Access enforces policies for secure access to applications.
Cloudflare Gateway: Our Secure Web Gateway (SWG) — designed to inspect and filter TLS traffic in order to block threats and unauthorized communications — now supports TLS with post-quantum cryptography.
In the remaining sections of this post, we’ll explore the threat that quantum computing poses and the challenges organizations face in transitioning to post-quantum cryptography. We’ll also dive into the technical details of how our Zero Trust platform supports post-quantum cryptography today and share some plans for the future.
Why transition to post-quantum cryptography and why now?
There are two key reasons to adopt post-quantum cryptography now:
1. The challenge of deprecating cryptography
History shows that updating or removing outdated cryptographic algorithms from live systems is extremely difficult. For example, although the MD5 hash function was deemed insecure in 2004 and long since deprecated, it was still in use with the RADIUS enterprise authentication protocol as recently as 2024. In July 2024, Cloudflare contributed to research revealing an attack on RADIUS that exploited its reliance on MD5. This example underscores the enormous challenge of updating legacy systems — this difficulty in achieving crypto-agility — which will be just as demanding when it’s time to transition to post-quantum cryptography. So it makes sense to start this process now.
2. The “harvest now, decrypt later” threat
Even though quantum computers lack enough qubits to break conventional cryptography today, adversaries can harvest and store encrypted communications or steal datasets with the intent of decrypting them once quantum technology matures. If your encrypted data today could become a liability in 10 to 15 years, planning for a post-quantum future is essential. For this reason, we have already started working with some of the most innovative banks, ISPs, and governments around the world as they begin their journeys to quantum safety.
The U.S. government is already addressing these risks. On January 16, 2025, the White House issued Executive Order 14144 on Strengthening and Promoting Innovation in the Nation’s Cybersecurity. This order requires government agencies to “regularly update a list of product categories in which products that support post-quantum cryptography (PQC) are widely available…. Within 90 days of a product category being placed on the list … agencies shall take steps to include in any solicitations for products in that category a requirement that products support PQC.”
Simply tunnel your traffic through Cloudflare’s quantum-safe connections to immediately protect against harvest-now-decrypt-later attacks, without the burden of upgrading every cryptographic library yourself.
Let’s take a closer look at how the migration to post-quantum cryptography is taking shape at Cloudflare.
A two-phase migration to post-quantum cryptography
At Cloudflare, we’ve largely focused on migrating the TLS (Transport Layer Security) 1.3 protocol to post-quantum cryptography. TLS primarily secures the communications for web applications, but it is also widely used to secure email, messaging, VPN connections, DNS, and many other protocols. This makes TLS an ideal protocol to focus on when migrating to post-quantum cryptography.
The migration involves updating two critical components of TLS 1.3: digital signatures used in certificates and key agreement mechanisms. We’ve made significant progress on key agreement, but the migration to post-quantum digital signatures is still in its early stages.
Phase 1: Migrating key agreement
Key agreement protocols enable two parties to securely establish a shared secret key that they can use to secure and encrypt their communications. Today, vendors have largely converged on transitioning TLS 1.3 to support a post-quantum key exchange protocol known as ML-KEM (Module-lattice based Key-Encapsulation Mechanism Standard). There are two main reasons for prioritizing migration of key agreement:
Performance: ML-KEM performs well with the TLS 1.3 protocol, even for short-lived network connections.
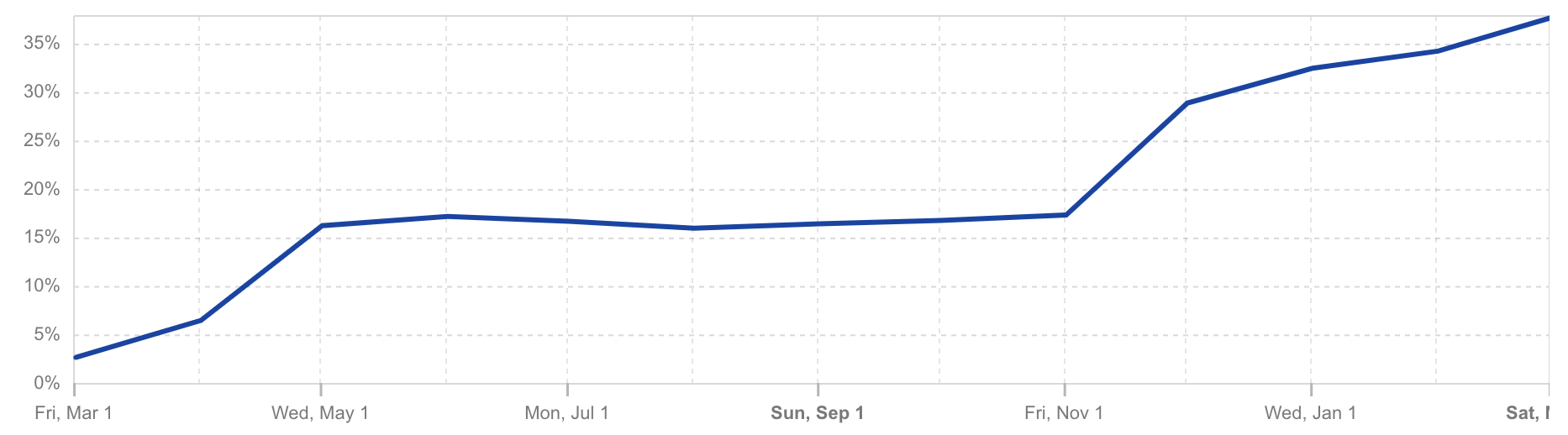
Security: Conventional cryptography is vulnerable to “harvest now, decrypt later” attacks. In this threat model, an adversary intercepts and stores encrypted communications today and later (in the future) uses a quantum computer to derive the secret key, compromising the communication. As of March 2025, well over a third of the human web traffic reaching the Cloudflare network is protected against these attacks by TLS 1.3 with hybrid ML-KEM key exchange.
Post-quantum encrypted share of human HTTPS request traffic seen by Cloudflare per Cloudflare Radar from March 1, 2024 to March 1, 2025. (Captured on March 13, 2025.)
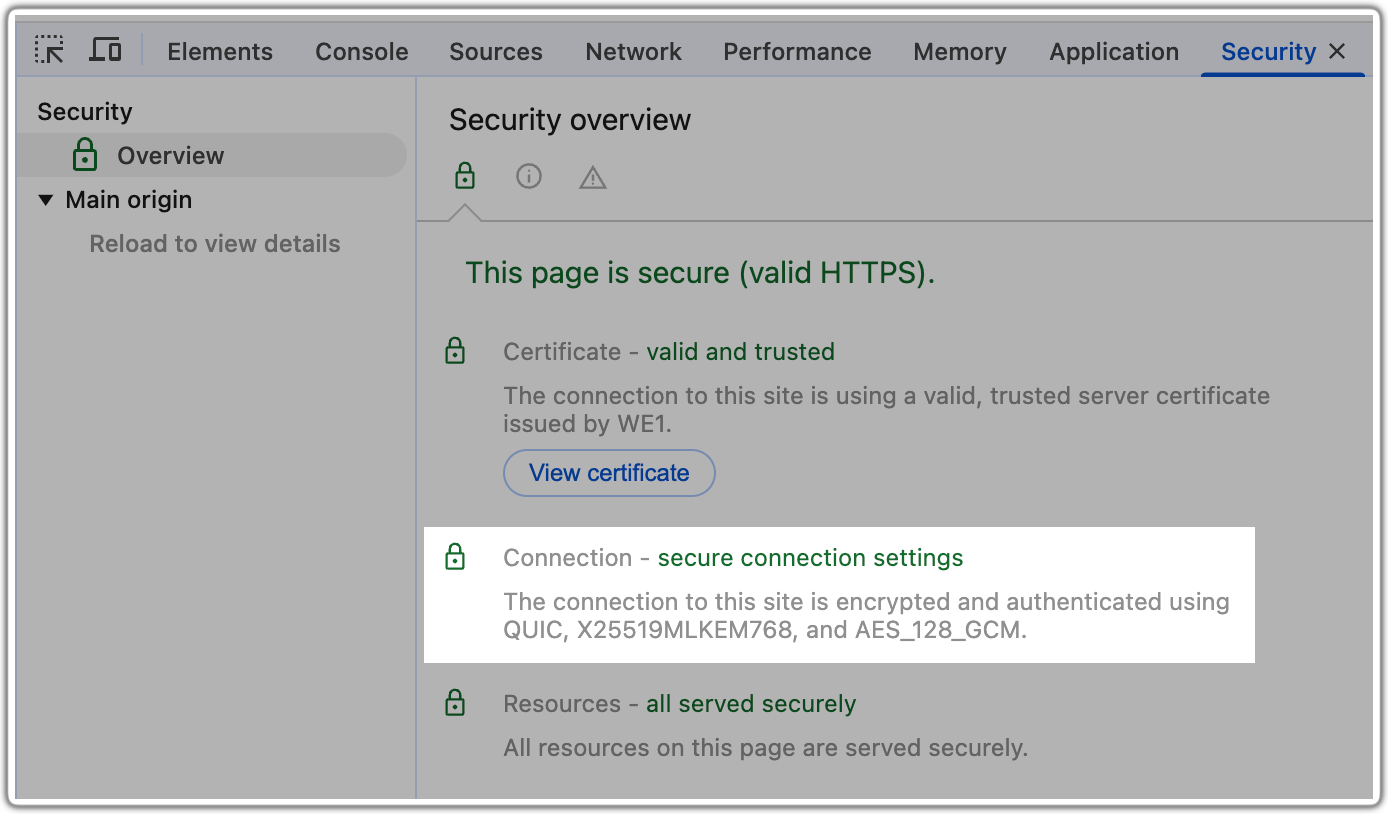
Here’s how to check if your Chrome browser is using ML-KEM for key agreement when visiting a website: First, Inspect the page, then open the Security tab, and finally look for X25519MLKEM768 as shown here:
This indicates that your browser is using key-agreement protocol ML-KEM in combination with conventional elliptic curve cryptography on curve X25519. This provides the protection of the tried-and-true conventional cryptography (X25519) alongside the new post-quantum key agreement (ML-KEM).
Phase 2: Migrating digital signatures
Digital signatures are used in TLS certificates to validate the authenticity of connections — allowing the client to be sure that it is really communicating with the server, and not with an adversary that is impersonating the server.
Post-quantum digital signatures, however, are significantly larger, and thus slower, than their current counterparts. This performance impact has slowed their adoption, particularly because they slow down short-lived TLS connections.
Fortunately, post-quantum signatures are not needed to prevent harvest-now-decrypt-later attacks. Instead, they primarily protect against attacks by an adversary that is actively using a quantum computer to tamper with a live TLS connection. We still have some time before quantum computers are able to do this, making the migration of digital signatures a lower priority.
Nevertheless, Cloudflare is actively involved in standardizing post-quantum signatures for TLS certificates. We are also experimenting with their deployment on long-lived TLS connections and exploring new approaches to achieve post-quantum authentication without sacrificing performance. Our goal is to ensure that post-quantum digital signatures are ready for widespread use when quantum computers are able to actively attack live TLS connections.
Cloudflare Zero Trust + PQC: future-proofing security
The Cloudflare Zero Trust platform replaces legacy corporate security perimeters with Cloudflare’s global network, making access to the Internet and to corporate resources faster and safer for teams around the world. Today, we’re thrilled to announce that Cloudflare’s Zero Trust platform protects your data from quantum threats as it travels over the public Internet. There are three key quantum-safe use cases supported by our Zero Trust platform in this first phase of quantum readiness.
Quantum-safe clientless Access
ClientlessCloudflare Access now protects an organization’s Internet traffic to internal web applications against quantum threats, even if the applications themselves have not yet migrated to post-quantum cryptography. (“Clientless access” is a method of accessing network resources without installing a dedicated client application on the user’s device. Instead, users connect and access information through a web browser.)
Here’s how it works today:
PQ connection via browser: (Labeled (1) in the figure.)
As long as the user’s web browser supports post-quantum key agreement, the connection from the device to Cloudflare’s network is secured via TLS 1.3 with post-quantum key agreement.
PQ within Cloudflare’s global network: (Labeled (2) in the figure)
If the user and origin server are geographically distant, then the user’s traffic will enter Cloudflare’s global network in one geographic location (e.g. Frankfurt), and exit at another (e.g. San Francisco). As this traffic moves from one datacenter to another inside Cloudflare’s global network, these hops through the network are secured via TLS 1.3 with post-quantum key agreement.
PQ Cloudflare Tunnel: (Labeled (3) in the figure)
Customers establish a Cloudflare Tunnel from their datacenter or public cloud — where their corporate web application is hosted — to Cloudflare’s network. This tunnel is secured using TLS 1.3 with post-quantum key agreement, safeguarding it from harvest-now-decrypt-later attacks.
Putting it together, clientless Access provides end-to-end quantum safety for accessing corporate HTTPS applications, without requiring customers to upgrade the security of corporate web applications.
Quantum-safe Zero Trust with Cloudflare’s WARP Client-to-Tunnel configuration (as a VPN replacement)
By mid-2025, organizations will be able to protect any protocol, not just HTTPS, by tunneling it through Cloudflare’s Zero Trust platform with post quantum cryptography, thus providing quantum safety as traffic travels across the Internet from the end-user’s device to the corporate office/data center/cloud environment.
Cloudflare’s Zero Trust platform is ideal for replacing traditional VPNs, and enabling Zero Trust architectures with modern authentication and authorization polices. Cloudflare’s WARP client-to-tunnel is a popular network configuration for our Zero Trust platform: organizations deploy Cloudflare’s WARP device client on their end users’ devices, and then use Cloudflare Tunnel to connect to their corporate office, cloud, or data center environments.
Here are the details:
PQ connection via WARP client (coming in mid-2025): (Labeled (1) in the figure)
The WARP client uses the MASQUE protocol to connect from the device to Cloudflare’s global network. We are working to add support for establishing this MASQUE connection with TLS 1.3 with post-quantum key agreement, with a target completion date of mid-2025.
PQ within Cloudflare’s global network: (Labeled (2) in the figure)
As traffic moves from one datacenter to another inside Cloudflare’s global network, each hop it takes through Cloudflare’s network is already secured with TLS 1.3 with post-quantum key agreement.
PQ Cloudflare Tunnel: (Labeled (3) in the figure)
As mentioned above, Cloudflare Tunnel already supports post-quantum key agreement.
Once the upcoming post-quantum enhancements to the WARP device client are complete, customers can encapsulate their traffic in quantum-safe tunnels, effectively mitigating the risk of harvest-now-decrypt-later attacks without any heavy lifting to individually upgrade their networks or applications. And this provides comprehensive protection for any protocol that can be sent through these tunnels, not just for HTTPS!
Quantum-safe SWG (end-to-end PQC for access to third-party web applications)
A Secure Web Gateway (SWG) is used to secure access to third-party websites on the public Internet by intercepting and inspecting TLS traffic.
Cloudflare Gateway is now a quantum-safe SWG for HTTPS traffic. As long as the third-party website that is being inspected supports post-quantum key agreement, then Cloudflare’s SWG also supports post-quantum key agreement. This holds regardless of the onramp that the customer uses to get to Cloudflare’s network (i.e. web browser, WARP device client, WARP Connector, Magic WAN), and only requires the use of a browser that supports post-quantum key agreement.
Cloudflare Gateway’s HTTPS SWG feature involves two post-quantum TLS connections, as follows:
PQ connection via browser: (Labeled (1) in the figure)
A TLS connection is initiated from the user’s browser to a data center in Cloudflare’s network that performs the TLS inspection. As long as the user’s web browser supports post-quantum key agreement, this connection is secured by TLS 1.3 with post-quantum key agreement.
PQ connection to the origin server: (Labeled (2) in the figure)
A TLS connection is initiated from a datacenter in Cloudflare’s network to the origin server, which is typically controlled by a third party. The connection from Cloudflare’s SWG currently supports post-quantum key agreement, as long as the third party’s origin server also already supports post-quantum key agreement. You can test this out today by using https://pq.cloudflareresearch.com/ as your third-party origin server.
Put together, Cloudflare’s SWG is quantum-ready to support secure access to any third-party website that is quantum ready today or in the future. And this is true regardless of the onramp used to get end users’ traffic into Cloudflare’s global network!
The post-quantum future: Cloudflare’s Zero Trust platform leads the way
Protecting our customers from emerging quantum threats isn’t just a priority — it’s our responsibility. Since 2017, Cloudflare has been pioneering post-quantum cryptography through research, standardization, and strategic implementation across our product ecosystem.
Today marks a milestone: We’re launching the first phase of quantum-safe protection for our Zero Trust platform. Quantum-safe clientless Access and Secure Web Gateway are available immediately, with WARP client-to-tunnel network configurations coming by mid-2025. As we continue to advance the state of the art in post-quantum cryptography, our commitment to continuous innovation ensures that your organization stays ahead of tomorrow’s threats. Let us worry about crypto-agility so that you don’t have to.
To learn more about how Cloudflare’s built-in crypto-agility can future-proof your business, visit our Post-Quantum Cryptography webpage.
Media workflows have always been complex, requiring seamless collaboration, robust storage, and advanced systems integration. Today, with the explosion of content demands and rapid technological advancements, media organizations need solutions that can scale, innovate, and empower teams to deliver faster and better.
Backblaze and CHESA, long-standing partners and leaders in media workflow solutions, are doubling down on their relationship with CHESA to elevate creative workflows with a joint go-to-market partnership. This enhanced partnership builds on years of success, combining Backblaze’s high-performance, secure cloud storage with CHESA’s expertise in media technology systems integration to provide even more impactful solutions tailored to the needs of modern media-driven organizations.
Together, we’re continuing to make it easier than ever for organizations to streamline content production, enhance accessibility, and achieve business objectives with greater efficiency. In this blog, I’ll explain the key benefits of this expanded collaboration and highlight how it’s already driving transformative results for clients like the Philadelphia Eagles.
The media workflow challenge
From production studios and broadcasters to professional sports teams and creative agencies, media organizations face a growing list of challenges:
Massive data volumes: Video, audio, and other rich media assets require scalable and secure storage solutions to handle terabytes or even petabytes of data.
Fragmented workflows: Teams often juggle multiple tools and platforms, leading to inefficiencies and bottlenecks.
Budget constraints: Organizations need cost-effective solutions that don’t compromise performance or security.
The expanded partnership between Backblaze and CHESA continues to address these pain points head-on by combining best-in-class cloud storage with tailored workflow solutions.
The Backblaze + CHESA solution
Real-world success: The Philadelphia Eagles
One of the most compelling examples of the Backblaze + CHESA partnership is the Philadelphia Eagles’ transition from traditional LTO tape storage to a cloud-based media workflow. With over 800TB under management, switching to cloud storage meant that the team instantly made their data more agile, scoring immediate access to faster content creation and remote workflows.
“Now I can easily share entire broadcasts by copying and sharing a link from our MAM. No need for FTP downloads or uploading to other platforms. It’s fast, seamless, and ensures everyone can view the content without issues.” —Stacy Kelleher, Director of Production, Philadelphia Eagles
Backblaze B2 integrated seamlessly with the Eagles’ preferred tech stack, which leverages a Quantum QXS storage area network (SAN) and Mimir, a cloud-based video production platform.
The challenge
The Eagles faced significant challenges with their legacy storage system:
Limited accessibility: LTO tape storage made it difficult to access archived footage, which hindered content production timelines quickly.
Time-consuming processes: Retrieving footage from physical tapes was manual and slow.
Scaling limitations: As the team’s content library grew, so did the complexity and cost of managing tape storage.
The solution
By leveraging the expanded capabilities of Backblaze and CHESA’s partnership, the Eagles:
Transitioned their extensive media library to Backblaze B2 Cloud Storage.
Integrated CHESA’s tailored media workflow solutions for seamless access and collaboration.
Gained immediate access to decades of archived footage, enabling faster content creation and improved fan engagement.
The results
The Eagles’ media team now enjoys:
Accelerated content production: Instant access to archived footage has streamlined workflows, allowing the team to create engaging content more efficiently.
Enhanced scalability: With Backblaze B2, the Eagles can easily scale their storage as their content library grows.
Improved fan engagement: Faster production timelines enable the team to deliver high-quality content that keeps fans connected and engaged.
Peripheral content drives revenue through monetized clicks like highlights and select moments. Quick sharing and streamlined proof-of-performance delivery keep sponsors satisfied.” —Ryan Lakey, Principal Lead, Solutions, CHESA
Accelerated media workflows
Integrating Backblaze B2 Cloud Storage with CHESA’s media workflow expertise has long been a cornerstone of success for media teams. By enhancing this integration, media teams can experience even faster workflows, immediate asset access, and seamless collaboration across tools and teams. By eliminating the delays associated with traditional storage methods, teams can:
Share assets effortlessly with collaborators anywhere in the world.
Spend less time managing infrastructure and more time creating impactful content.
Backblaze + CHESA benefits
Scalable and cost-effective storage
Backblaze B2 Cloud Storage offers always-hot, S3 compatible object storage at a fraction of the cost of traditional providers like Amazon S3. This cost-effectiveness, combined with CHESA’s expertise in designing and integrating scalable systems, ensures organizations can:
Scale their storage needs as projects grow or shrink.
Optimize budgets without compromising on performance.
Rely on predictable pricing that avoids surprise costs.
Enhanced data security and accessibility
In the media world, accessibility and security are paramount. Backblaze and CHESA provide solutions that keep media assets safe while ensuring real-time access for production teams. Key benefits include:
Secure, encrypted storage to protect sensitive media.
High availability for instant access to files when needed.
Resiliency and redundancy to ensure data integrity, even in the face of unexpected disruptions.
These capabilities have been critical for clients like professional sports teams, broadcasters, and creative agencies that manage vast libraries of high-value media content.
Comprehensive support and maintenance
CHESA’s dedicated support services and Backblaze’s reliable cloud infrastructure ensure organizations experience minimal downtime and sustained operational efficiency. This comprehensive support includes:
Proactive monitoring and maintenance.
Remote and onsite assistance for hardware, software, and workflows.
Consistent communication to address issues before they impact production.
Why this partnership matters
The expanded Backblaze and CHESA partnership is more than just a collaboration—it’s a commitment to empowering media organizations with innovative, efficient, and secure solutions. Here’s why it stands out:
Deeply customized solutions: Every organization’s needs are unique. Backblaze Solution Engineers and CHESA Workflow Engineers dive deep into clients’ specific workflows and objectives to design and implement solutions specifically tailored to their needs.
Unrivaled expertise, built over decades: Rely on the combined power of Backblaze and CHESA’s deep-rooted experience in cloud storage and media technology.
Your future-proof media strategy: Navigate the changing media landscape with confidence, leveraging our scalable and cutting-edge solutions.
Take the next step
Whether you’re a professional sports team looking to enhance fan engagement, a broadcaster aiming to streamline production, or a creative agency seeking cost-effective storage, Backblaze and CHESA are here to help.
Discover how our expanded solutions can revolutionize your media workflows. Visitour dedicated solution page to learn more and to schedule a consultation tailored to your organization’s needs.
Over the years, Cloudflare has gained fame for many things, including our technical blog, but also as a tech company securing the Internet using lava lamps, a story that began as a research/science project almost 10 years ago. In March 2025, we added another layer to its legacy: a “wall of entropy” made of 50 wave machines in constant motion at our Lisbon office, the company’s European HQ.
These wave machines are a new source of entropy, joining lava lamps in San Francisco, suspended rainbows in Austin, and double chaotic pendulums in London. The entropy they generate contributes to securing the Internet through LavaRand.
The new waves wall at Cloudflare’s Lisbon office sits beside the Radar Display of global Internet insights, with the 25th of April Bridge overlooking the Tagus River in the background.
It’s exciting to see waves in Portugal now playing a role in keeping the Internet secure, especially given Portugal’s deep maritime history.
The installation honors Portugal’s passion for the sea and exploration of the unknown, famously beginning over 600 years ago, in 1415, with pioneering vessels like caravels and naus/carracks, precursors to galleons and other ships. Portuguese sea exploration was driven by navigation schools and historic voyages “through seas never sailed before” (“Por mares nunca dantes navegados” in Portuguese), as described by Portugal’s famous poet, Luís Vaz de Camões, born 500 years ago (1524).
Anyone familiar with Portugal knows the sea is central to its identity. The small country has 980 km of coastline, where most of its main cities are located. Maritime areas make up 90% of its territory, including the mid-Atlantic Azores. In 1998, Lisbon’s Expo 98 celebrated the oceans and this maritime heritage. Since 2011, the small town of Nazaré also became globally famous among the surfing community for its giant waves.
Nazaré’s waves, famous since Garrett McNamara’s 23.8 m (78 ft) ride in 2011, hold Guinness World Records for the biggest waves ever surfed. Photos: Sam Khawasé & Beatriz Paula, from Cloudflare.
Portugal’s maritime culture also inspired literature and music, including poet Fernando Pessoa, who referenced it in his 1934 book Mensagem, and musician Rui Veloso, who dedicated his 1990s album Auto da Pimenta to Portugal’s historic connection to the sea.
How this chaos came to be
As Cloudflare’s CEO, Matthew Prince, said recently, this new wall of entropy began with an idea back in 2023: “What could we use for randomness that was like our lava lamp wall in San Francisco but represented our team in Portugal?”
The original inspiration came from wave motion machine desk toys, which were popular among some of our team members. Waves and the ocean not only provide a source of movement and randomness, but also align with Portugal’s maritime history and the office’s scenic view.
However, this was easier said than done. It turns out that making a wave machine wall is a real challenge, given that these toys are not as popular as they were in the past, and aren’t being manufactured in the size we needed any more. We scoured eBay and other sources but couldn’t find enough, consistent in style and in working order wave machines. We also discovered that off-the-shelf models weren’t designed to run 24/7, which was a critical requirement for our use.
Artistry to create wave machines
Undaunted, Cloudflare’s Places team, which ensures our offices reflect our values and culture, found a U.S.-based artisan that specializes in ocean wave displays to create the wave machines for us. Since 2009, his one-person business, Hughes Wave Motion Machines, has blended artistry, engineering, and research, following his transition from Lockheed Martin Space Systems, where he designed military and commercial satellites.
Timelapse of the mesmerizing office waves, set to the tune of an AI-generated song.
Collaborating closely, we developed a custom rectangular wave machine (18 inches/45 cm long) that runs nonstop — not an easy task — which required hundreds of hours of testing and many iterations. Featuring rotating wheels, continuous motors, and a unique fluid formula, these machines create realistic ocean-like waves in green, blue, and Cloudflare’s signature orange.
Here’s a quote from the artist himself about these wave machines:
“The machine’s design is a balancing act of matching components and their placement to how the fluid responds in a given configuration. There is a complex yet delicate relationship between viscosity, specific gravity, the size and design of the vessel, and the placement of each mechanical interface. Everything must be precisely aligned, centered around the fluid like a mathematical function. I like to say it’s akin to ’balancing a checkerboard on a beach ball in the wind.’”
The Cloudflare Places Team with Lisbon office architects and contractor testing wave machine placement, shelves, lighting, and mirrors to enhance movement and reflection, March 2024.
Despite delays, the Lisbon wave machines finally debuted on March 10, 2025 — an incredibly exciting moment for the Places team.
Some numbers about our wave-machine entropy wall:
50 wave machines, 50 motion wheels & motors, 50 acrylic containers filled with Hughes Wave Fluid Formula (two immiscible liquids)
3 liquid colors: blue, green, and orange
15 months from concept to completion
14 flips (side-to-side balancing movements) per minute — over 20,000 per day
Over 15 waves per minute
~0.5 liters of liquid per machine
LavaRand origins and walls of entropy
Cloudflare’s servers handle 71 million HTTP requests per second on average, with 100 million HTTP requests per second at peak. Most of these requests are secured via TLS, which relies on secure randomness for cryptographic integrity. A Cryptographically Secure Pseudorandom Number Generator (CSPRNG) ensures unpredictability, but only when seeded with high-quality entropy. Since chaotic movement in the real world is truly random, Cloudflare designed a system to harness it. Our 2024 blog post expands on this topic in a more technical way, but here’s a quick summary.
In 2017, Cloudflare launched LavaRand, inspired by Silicon Graphics’ 1997 concept However, the need for randomness in security was already a hot topic on our blog before that, such as in our discussions of securing systems and cryptography. Originally, LavaRand collected entropy from a wall of lava lamps in our San Francisco office, feeding an internal API that servers periodically query to include in their entropy pools. Over time, we expanded LavaRand beyond lava lamps, incorporating new sources of office chaos while maintaining the same core method.
A camera captures images of dynamic, unpredictable randomness displays. Shadows, lighting changes, and even sensor noise contribute entropy. Each image is then processed into a compact hash, converting it into a sequence of random bytes. These, combined with the previous seed and local system entropy, serve as input for a Key Derivation Function (KDF), which generates a new seed for a CSPRNG — capable of producing virtually unlimited random bytes upon request. The waves in our Lisbon office are now contributing to this pool of randomness.
Cloudflare’s LavaRand API makes this randomness accessible internally, strengthening cryptographic security across our global infrastructure. For example, when you use Math.random() in Cloudflare Workers, part of that randomness comes from LavaRand. Similarly, querying our drand API taps into LavaRand as well. Cloudflare offers this API to enable anyone to generate random numbers and even seed their own systems.
Our new Lisbon office space
Photo of the view from our Lisbon office, featuring ceiling lights arranged in a wave-like pattern.
Entropy also inspired the design ethos of our new Lisbon office, given that the wall of waves and the office are part of the same project. As soon as you enter, you’re greeted not only by the motion of the entropy wall but also by the constant movement of planet Earth on our Cloudflare Radar Display screen that stands next to it. But the waves don’t stop there — more elements throughout the space mimic the dynamic flow of the Internet itself. Unlike ocean tides, however, Internet traffic ebbs and flows with the motion of the Sun, not the Moon.
As you walk through the office, waves are everywhere — in the ceiling lights, the architectural contours, and even the floor plan, thoughtfully designed by our architect to reflect the fluid movement of water. The visual elements create a cohesive experience, reinforcing a sense of motion. Each meeting room embraces this maritime theme, named after famous Portuguese beaches — including, naturally, Nazaré.
We partnered with an incredible group of local Portuguese vendors for this construction project, where all the leads were women — something incredibly rare for the industry. The local teams worked with passion, proudly wore Cloudflare t-shirts, and fostered a warm, family-like atmosphere. They openly expressed pride in the project, sharing how it stood out from anything they had worked on before.
Our amazing third-party team and internal Places team, proudly rocking Cloudflare shirts after bringing this project to life.
Help us select a name for our new wall of entropy
Next, we have several name options for this new wall of entropy. Help us decide the best one, and register your vote using this form.
The Surf Board
Chaos Reef
Waves of Entropy
Wall of Waves
Whirling Wave Wall
Chaotic Wave Wall
Waves of Chaos
If you’re interested in working in Cloudflare’s Lisbon office, we’re hiring! Our career page lists our open roles in Lisbon, as well as our other locations in the U.S., Mexico, Europe and Asia.
Acknowledgements: This project was only possible with the effort, vision and help of John Graham-Cumming, Caroline Quick, Jen Preston, Laura Atwall, Carolina Beja, Hughes Wave Motion Machines, P4 Planning and Project Management, Gensler Europe, Openbook Architecture, and Vector Mais.
Ходихме да правим видеото на FOSSASIA Summit 2025.
С Марк и Гери сме правили някакви такива неща и преди, за State of the map (който обаче беше в Брюксел). Сега събитието беше в Банкок, който е на 10тина часа път, 5 часа напред в часовата зона, 20 градуса по-топъл и влажен като Бургас през лятото.
Та, подготвихме някакъв хардуер, и на вълни – първо Марк, после аз, накрая Гери – се добрахме до Банкок. Така Марк можеше да подготви локално каквото може, аз да донеса каквото липсва и Гери – каквото съвсем сме забравили (както се наложи).
Събитието се случваше в “True Digital Park Event Center”, което е място за събития и отдалечена работа (т.е. за “дигитални номади”, каквито се опитват да привлекат). Технически доста добре направено, с инфраструктура и с бая наляти пари в него. От нещата, които ми направиха впечатление:
– Залата има три големи LED екрана, които са на релси и могат да се местят по 3 от 4те стени, както и да правят един голям екран, 4.5м на 24м (в България има някакви такива екрани под наем, и цената винаги ми се е струвала безумна);
– Озвучаването беше на един голям цифров миксер някъде, и хората си ходеха с едни таблети и настройваха нивата в залите;
– Имаха портове за звук, Ethernet и контрол на всякакви неща (като осветление, пак RJ45) равномерно по стените;
– Практикаблите им (парчетата от сцена) бяха регулируеми, лесни за транспорт (на колела) и много стабилни. Жалко, че няма как да ползваме такива (но ако догодина пак е там и участваме, ще си искам предварително няколко такива);
– В една от малките зали вместо това имаше 3 проектора, та в общи линии от всякъде да виждаш какво се презентира (говорим за зала до около 50-60 човека);
Планът на самото събитие беше доста сложен – там имат зала от три части (донякъде като голямата зала на “Джон Атанасов), която за различни дни/части от деня щеше да е подредена различно, с местене на сцени и т.н.. Самите ние си го изяснявахме в движение, а някакви неща само по гол план не стават, та (разбира се) някакви неща се променяха в последния момент. Добре, че хората от мястото бяха разбрани (и супер учтиви).
(еххх, ако говорех езика, бях отишъл там един месец по-рано и бяхме правили заедно генералното планиране, какви неща можеше да направим …)
Имаше на практика два големи потока и три зали като за по-малки лекции/workshop-и (“training rooms”). Нашият план беше с приоритет да направим големите зали с нормалния FOSDEM-ски setup (камера, два video box-а, voctomix на един лаптоп), после да направим малките с един смален вариант, в който в един videobox слагаме USB камера и той го играе миксер (video-mixer-single ролята в github), и ако остане време, да подкараме Voc2Mix най-накрая.
По някаква причина аз бях сметнал, че с 6 box-а ще се справим – бяхме дали два на организаторите още на FOSDEM, аз носех 2 и Марк носеше два. Един ден преди събитието, когато аз бях кацнал, Марк пита дали съм сигурен в сметката си, щото 2+2+3 не е 5, а 7 (и да, канят се да ми направят тениска с 2+2+3=5), а техниката, която бяхме дали на организаторите беше останала в Германия. Та, в общи линии съвсем в последния момент един човек от FOSDEM staff-а закара 4 кутии до офиса на Гери, където той приключваше с някаква работа и откъдето щеше да ходи на летището, и това ни спаси. Имам да пращам много бири…
С двете големи зали се оправихме, малките обаче не работеха от първия ден и там си използваха в началото стария setup, който представлява странен софтуер, който се пуска на лаптоп, stream-ва екрана и звука, и го закарва до някакъв китайски provider. Никой май не го обича, но това имат засега, надявам се да можем да променим малко нещата.
А понеже не бяхме от съвсем началото и не бяхме наясно с начина на работа, имаше доста синхронизационни проблеми – кой stream къде отива (те имаха отделни за всяка зала за преди и след обяд, например), пускането на stream някъде го активираше и едни тестове преждевременно казаха на хората, че събитието е започнало, разнасяхме slide-ове по всякакви начини – за някои зали нямаше как да се ползват лекторските лаптопи (понеже мястото не можеше да занесе HDMI до сцената в някакви конфигурации), та имаше един лаптоп на контролните маси, до който трябваше да стигнат презентациите. Не може да си представите колко е трудно да се пренесе файл през 2025та година между два лаптопа, особено когато нямаш usb flash-ка, хората са с всякакви лаптопи (например без USB-A портове), и имат презентации във всякакви странни формати. И разбира се са ги променяли в последния момент.
Следващата година ще има кабел на сцената навсякъде и вероятно бан на всички Mac-ове.
И като стана въпрос за в последния момент, ние се зачудихме дали да не направим лекция за videobox-а, и разписах една – тия дни ще я допрегледам и кача. Основното послание беше, че тва не е rocket surgery, а аз отдавна исках да кажа нещо по темата…
Доброволците им бяха страхотни. Прилично количество студенти и т.н., но ако им дадеш задача, я правеха – в момента, в който някой застанеше на камерата, нямах притеснения, че ще свърши каквото трябва. Докато си водехме лекцията, трябваше да оставя един от тях да се разправя с лекторите, да могат да си пуснат презентациите от лаптопа (където нещата бяха комбинация от флашки, смяна на лаптопа и някакви неща в един google drive) и той се справи без някакъв проблем. Един от тях много помогна и с пазаруването на техника предварително – нямахме свестен вариант за наемане, но се оказа, че дори стативи можем да вземем евтино от някакви магазини там (личи си, че са по-близо от нас до aliexpress…).
За самият Банкок – изглеждаше ми като някаква смесица от щатите и България, умножено по много…
– Хората карат от грешната страна на пътя (така де, грешна за мен 🙂 )
– Кабелите им вървят по стълбове, както в някои древни времена при нас. Имам малко снимки, трябва да ги кача;
– Има супер лъскави неща до супер изпаднали. На street view много добре се вижда по пътя от хотела, в който бяхме (Marsi hotel) до мястото на събитието;
– Интернетът им е добре. Аз си взех една SIM карта на летището, и не ми направи проблем никъде, на някои места си я ползвах за hotspot. Като бонус, номерът ми започваше с +666…
(не си активирах roaming, а намерих начин за forward на моя номер натам, цените за roaming са безумни)
Някои неща обаче са съвсем различни:
– Почти всичката им храна е или люта, или сладка, или и двете. Аз съм поотвикнал от лютото, ама там дори не-лютото пак си беше прилична работа;
– Хората са много много учтиви. Толкова, че аз се чувствах като някакъв грубиян през повечето време;
– В главата ми още звучи “каа” (което е нещото, което добавено в края на изречението го прави в учтива форма). Направо очаквам хората да казват “Добър ден, каа”…
Прибирането ми беше супер уморително. Сутринта в неделя открих, че съм поръчал таксито за следващата седмица (но ми поръчаха от хотела нещо, та беше ок). Автоматичното гише нещо не мис е радваше на паспорта, та ми помагаха, после бях забравил вода в бутилката, не можах да се ориентирам по пътя в security check-а, и накрая си бях сложил boarding pass-а с грешната страна на скенера. Добре, че явно са свикнали с туристи-идиоти…
И 22 часа след ставането си, две мощни кафета и държане буден с жица си бях вкъщи. Прибрах се, наспах се, и скоро ще почна да наваксвам с работа 🙂
Phishing attacks have grown both in volume and in sophistication over recent years. Today’s threat isn’t just about sending out generic emails — bad actors are using advanced phishing techniques like 2 factor monster in the middle (MitM) attacks, QR codes to bypass detection rules, and using artificial intelligence (AI) to craft personalized and targeted phishing messages at scale. Industry organizations such as the Anti-Phishing Working Group (APWG) have shown that phishing incidents continue to climb year over year.
To combat both the increase in phishing attacks and the growing complexity, we have built advanced automation tooling to both detect and take action.
In the first half of 2024, Cloudflare resolved 37% of phishing reports using automated means, and the median time to take action on hosted phishing reports was 3.4 days. In the second half of 2024, after deployment of our new tooling, we were able to expand our automated systems to resolve 78% of phishing reports with a median time to take action on hosted phishing reports of under an hour.
In this post we dig into some of the details of how we implemented these improvements.
The phishing site problem
Cloudflare has observed a similar increase in the volume of phishing activity throughout 2023 and 2024. We receive abuse reports from anyone on the Internet that may have seen potentially abusive behaviors from websites using Cloudflare services. Our Trust & Safety investigators and engineers have been tasked with responding to these complaints, and more recently have been using the data from these reports to improve our threat intelligence, brand protection, and email security product offerings.
Cloudflare has always believed in using the vast amounts of traffic that flows through our network to improve threat detection and customer security. This has been at the core of how we protect our customers from DoS attacks and other cybersecurity threats. We’ve been applying the same concepts our internal teams use to mitigate phishing to improve detection of phishing on our network and our ability to detect and notify our customers about potential risks to their brand.
Prior to last year, phishing abuse reported to Cloudflare relied on manual, human review and intervention to remediate. Trust & Safety (T&S) investigators would have to look at each complaint, the allegations made by the reporter, and the content on the reported websites to make assessments as quickly as possible about whether the website was phishing or malware.
Given the growing scale of our customer base and phishing across the Internet, this became unsustainable. By collecting a group of internal experts on abuse, we were able to tackle this problem by using insights across our network, internal data from our Email Security product, external feeds from trusted sources, and years of abuse report processing data to automatically assess risk of likely phishing and recommend appropriate action.
Turning our intelligence inward
We built our automated phishing identification on the Cloudflare Developer Platform so that we could meet our scanning demand without concern for how we might scale. This allowed us to focus more on creating a great phishing detection engine and less on the infrastructure required to meet that demand.
Each URL submitted to our phishing detection Worker begins with an initial scan by the Cloudflare URL Scanner. The scan provides us with the rendered HTML, network requests, and attributes of the site. After scanning, we collect reputational information about the site by submitting the HTML and page resources to our in-house machine learning classifiers; meanwhile, the indicators of compromise (IOCs) are sent to our suite of threat feeds and domain categorization tools to highlight any known malicious sites or site categorizations.
Once we have all of this information collected, we expose it to a set of rules and heuristics that identify the URL as phishing or not based on how T&S investigators have traditionally responded to similar abuse reports and patterns of bad behaviors we’ve observed. Rules will suggest decisions to make against the reports, and remediations to make against harmful content. It is through this process that we were able to convert the manual reviews by T&S investigators into an automated flow of phishing identification. We also recognize that reporters make mistakes or even deliberately try to weaponize abuse processes. Our rules must therefore consider the possibility of false positives, in which reports are created against legitimate websites (intentionally or unintentionally). False positives can erode the trust of our customers and create incidents, so automation must include processes to disregard erroneous reports.
The magic of all of this was the powerful suite of tools on the Cloudflare Developer Platform. Whether it was using KV to store report summaries that could scale indefinitely or Durable Objects to keep running counters of an unlimited number of attributes that could be tracked or leveraged over time, we were able to integrate the solutions quickly allowing us easily add or remove new enrichments with little effort. We also made use of Hyperdrive to access the internal Postgres database that stores our abuse reports, Queues to manage the scanning jobs, Workers AI to run machine learning classifiers, and D1 to store detection logs for efficacy and evaluation review. To tie it all together, the team also deployed a Remix Pages UI to present all the phishing detection engine’s analysis to T&S investigators for follow-on investigations and evaluations of inconclusive results.
Architecture of Trust & Safety’s phishing automation detection pipeline
Moving forward
The same intelligence we’re gathering to expedite and refine abuse report processing isn’t just for abuse response; it’s also used to empower our customers. By analyzing patterns and trends of abusive behaviors — such as identifying common phrases used in phishing attempts, recognizing infrastructure used by malicious actors or spotting coordinated campaigns across multiple domains — we enhance the efficacy of our application security, email security, and threat intelligence products.
For our Brand Protection customers, this translates into a significant advantage: the ability to easily report suspected abuse directly from the Cloudflare dashboard. This feature ensures that potential phishing sites are addressed rapidly, minimizing the risk to your customers and brand reputation. Furthermore, the Trust and Safety team can use this information to take action on similar threats across the Cloudflare network, protecting all customers, even those who aren’t Brand Protection users.
Alongside our network-wide efforts, we’ve also been partnering with our customers, as well as experts outside of Cloudflare, to understand trends they are seeing in their own phishing mitigation efforts. By soliciting intelligence regarding the abuse issues that affect the attack’s targets, we can better identify and prevent abuse of Cloudflare products. We’ve been able to use these partnerships and discussions with external organizations to craft highly targeted rules that head off emerging patterns of phishing activity.
It takes a village: if you see something, say something
If you believe you’ve identified phishing activity that is passing through Cloudflare’s network, please report it via our abuse reporting form. For technical users who might be interested in a programmatic way to report to us, please review our abuse reporting API documentation.
We invite all of our customers to join us in helping make the Internet safer:
Enterprise customers should speak with their Customer Success Manager about enabling Brand Protection, included by default for all enterprise customers.
For existing users of the Brand Protection product, update your brand’s assets, so we can better identify the legitimate websites and logos of our customers vs. possible phishing activity.
As a Cloudflare customer, make sure your abuse contact is up-to-date in the Cloudflare dashboard.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.