Post Syndicated from Rohin Bhargava original https://aws.amazon.com/blogs/big-data/amazon-opensearch-service-under-the-hood-multi-az-with-standby/
Amazon OpenSearch Service recently announced Multi-AZ with standby, a new deployment option for managed clusters that enables 99.99% availability and consistent performance for business-critical workloads. With Multi-AZ with standby, clusters are resilient to infrastructure failures like hardware or networking failure. This option provides improved reliability and the added benefit of simplifying cluster configuration and management by enforcing best practices and reducing complexity.
In this post, we share how Multi-AZ with standby works under the hood to achieve high resiliency and consistent performance to meet the four 9s.
Background
One of the principles in designing highly available systems is that they need to be ready for impairments before they happen. OpenSearch is a distributed system, which runs on a cluster of instances that have different roles. In OpenSearch Service, you can deploy data nodes to store your data and respond to indexing and search requests, you can also deploy dedicated cluster manager nodes to manage and orchestrate the cluster. To provide high availability, one common approach for the cloud is to deploy infrastructure across multiple AWS Availability Zones. Even in the rare case that a full zone becomes unavailable, the available zones continue to serve traffic with replicas.
When you use OpenSearch Service, you create indexes to hold your data and specify partitioning and replication for those indexes. Each index is comprised of a set of primary shards and zero to many replicas of those shards. When you additionally use the Multi-AZ feature, OpenSearch Service ensures that primary shards and replica shards are distributed so that they’re in different Availability Zones.
When there is an impairment in an Availability Zone, the service would scale up in other Availability Zones and redistribute shards to spread out the load evenly. This approach was reactive at best. Additionally, shard redistribution during failure events causes increased resource utilization, leading to increased latencies and overloaded nodes, further impacting availability and effectively defeating the purpose of fault-tolerant, multi-AZ clusters. A more effective, statically stable cluster configuration requires provisioning infrastructure to the point where it can continue operating correctly without having to launch any new capacity or redistribute any shards even if an Availability Zone becomes impaired.
Designing for high availability
OpenSearch Service manages tens of thousands of OpenSearch clusters. We’ve gained insights into which cluster configurations like hardware (data or cluster-manager instance types) or storage (EBS volume types), shard sizes, and so on are more resilient to failures and can meet the demands of common customer workloads. Some of these configurations have been included in Multi-AZ with standby to simplify configuring the clusters. However, this alone is not enough. A key ingredient in achieving high availability is maintaining data redundancy.
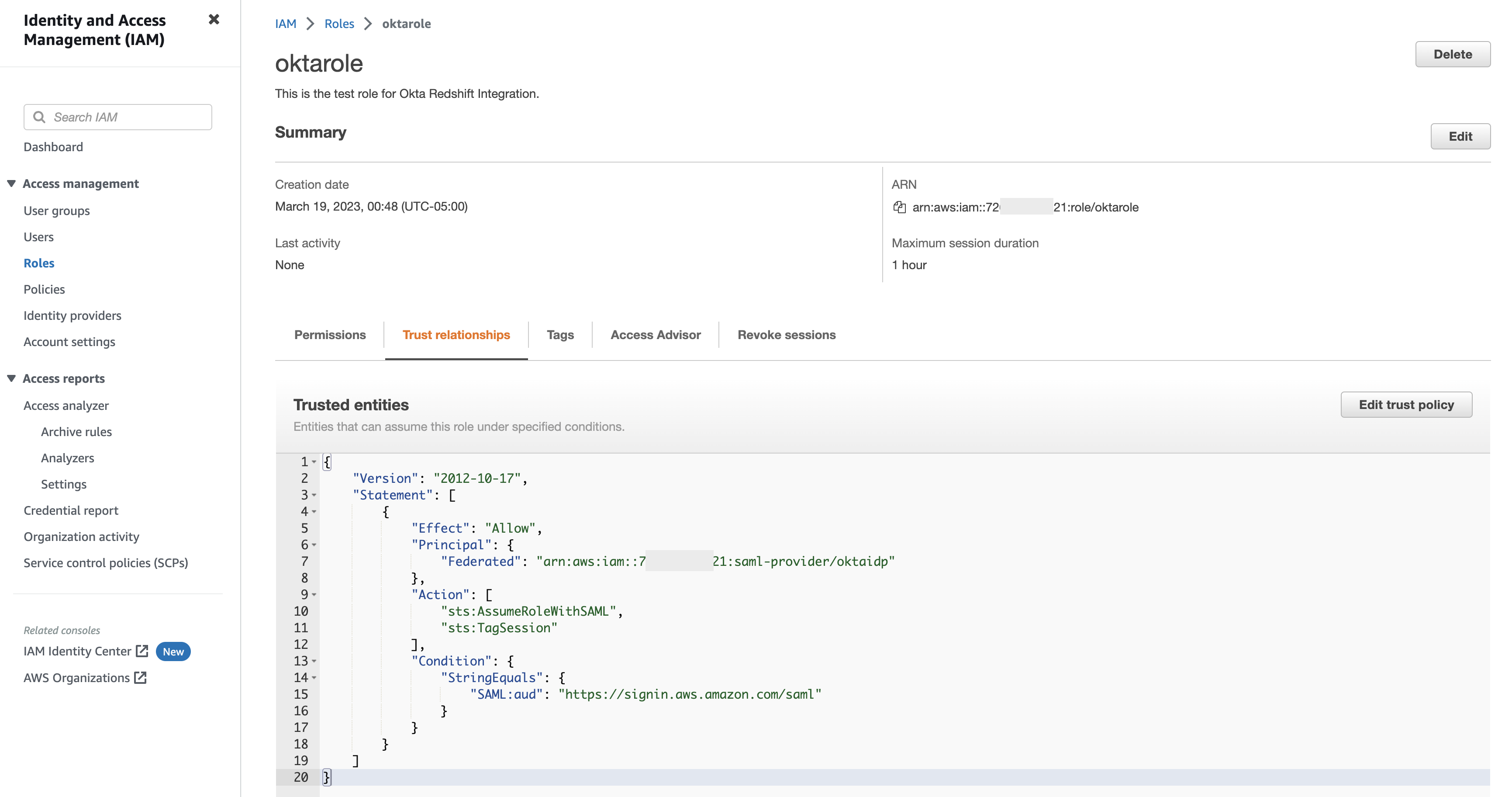
When you configure a single replica (two copies) for your indexes, the cluster can tolerate the loss of one shard (primary or replica) and still recover by copying the remaining shard. A two-replica (three copies) configuration can tolerate failure of two copies. In the case of a single replica with two copies, you can still sustain data loss. For example, you could lose data if there is a catastrophic failure in one Availability Zone for a prolonged duration, and at the same time, a node in a second zone fails. To ensure data redundancy at all times, the cluster enforces a minimum of two replicas (three copies) across all its indexes. The following diagram illustrates this architecture.

The Multi-AZ with standby feature deploys infrastructure in three Availability Zones, while keeping two zones as active and one zone as standby. The standby zone offers consistent performance even during zonal failures by ensuring same capacity at all times and by using a statically stable design without any capacity provisioning or data movements during failure. During normal operations, the active zone serves coordinator traffic for read and write requests and shard query traffic, and only replication traffic goes to the standby zone. OpenSearch uses synchronous replication protocol for write requests, which by design has zero replication lag, enabling the service to instantaneously promote a standby zone to active in the event of any failure in an active zone. This event is referred to as a zonal failover. The previously active zone is demoted to the standby mode and recovery operations to bring the state back to healthy begin.
Why zonal failover is critical but hard to do right
One or more nodes in an Availability Zone can fail due to a wide variety of reasons, like hardware failures, infrastructure failures like fiber cuts, power or thermal issues, or inter-zone or intra-zone networking problems. Read requests can be served by any of the active zones, whereas write requests need to be synchronously replicated to all copies across multiple Availability Zones. OpenSearch Service orchestrates two modes of failovers: read failovers and the write failovers.
The primarily goals of read failovers are high availability and consistent performance. This requires the system to constantly monitor for faults and shift traffic away from the unhealthy nodes in the impacted zone. The system takes care of handling the failovers gracefully, allowing all in-flight requests to finish while simultaneously shifting new incoming traffic to a healthy zone. However, it’s also possible for multiple shard copies across both active zones to be unavailable in cases of two node failures or one zone plus one node failure (often referred to as double faults), which poses a risk to availability. To solve this challenge, the system uses a fail-open mechanism to serve traffic off the third zone while it may still be in a standby mode to ensure the system remains highly available. The following diagram illustrates this architecture.

An impaired network device impacting inter-zone communication can cause write requests to significantly slow down, owing to the synchronous nature of replication. In such an event, the system orchestrates a write failover to isolate the impaired zone, cutting off all ingress and egress traffic. Although with write failovers the recovery is immediate, it results in all nodes along with its shards being taken offline. However, after the impacted zone is brought back after network recovery, shard recovery should still be able to use unchanged data from its local disk, avoiding full segment copy. Because the write failover results in the shard copy to be unavailable, we exercise write failovers with extreme caution, neither too frequently nor during transient failures.
The following graph depicts that during a zonal failure, automatic read failover prevents any impact to availability.
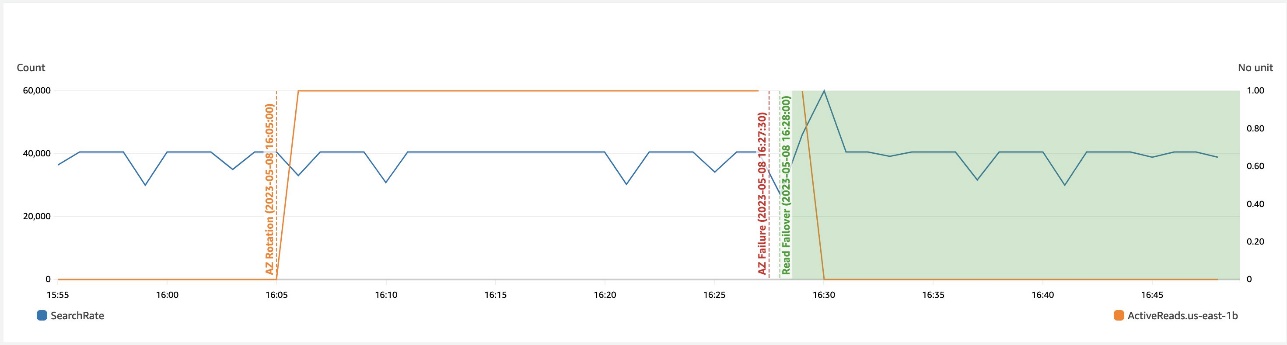
The following depicts that during a networking slowdown in a zone, write failover helps recover availability.

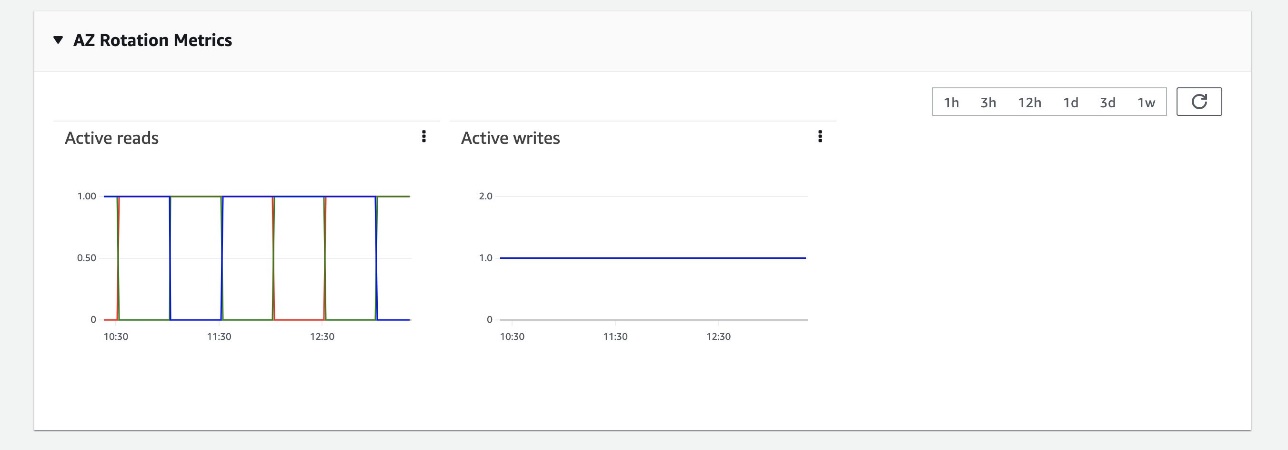
To ensure that the zonal failover mechanism is predictable (able to seamlessly shift traffic during an actual failure event), we regularly exercise failovers and keep rotating active and standby zones even during steady state. This not only verifies all network paths, ensuring we don’t hit surprises like clock skews, stale credentials, or networking issues during failover, but it also keeps gradually shifting caches to avoid cold starts on failovers, ensuring we deliver consistent performance at all times.
Improving the resiliency of the service
OpenSearch Service uses several principles and best practices to increase reliability, like automatic detection and faster recovery from failure, throttling excess requests, fail fast strategies, limiting queue sizes, quickly adapting to meet workload demands, implementing loosely coupled dependencies, continuously testing for failures, and more. We discuss a few of these methods in this section.
Automatic failure detection and recovery
All faults get monitored at a minutely granularity, across multiple sub-minutely metrics data points. Once detected, the system automatically triggers a recovery action on the impacted node. Although most classes of failures discussed so far in this post refer to binary failures where the failure is definitive, there is another kind of failure: non-binary failures, termed gray failures, whose manifestations are subtle and usually defy quick detection. Slow disk I/O is one example, which causes performance to be adversely impacted. The monitoring system detects anomalies in I/O wait times, latencies, and throughput, to detect and replace a node with slow I/O. Faster and effective detection and quick recovery is our best bet for a wide variety of infrastructure failures beyond our control.
Effective workload management in a dynamic environment
We’ve studied workload patterns that cause the system either to be overloaded with too many requests, maxing out CPU/memory, or a few rogue queries that can that either allocate huge chunks of memory or runaway queries that can exhaust multiple cores, either degrading the latencies of other critical requests or causing multiple nodes to fail due to the system’s resources running low. Some of the improvements in this direction are being done as a part of search backpressure initiatives, starting with tracking the request footprint at various checkpoints that prevents accommodating more requests and cancels the ones already running if they breach the resource limits for a sustained duration. To supplement backpressure in traffic shaping, we use admission control, which provides capabilities to reject a request at the entry point to avoid doing non-productive work (requests either time out or get cancelled) when the system is already run high on CPU and memory. Most of the workload management mechanisms have configurable knobs. No one size fits all workloads, therefore we use Auto-Tune to control them more granularly.
The cluster manager performs critical coordination tasks like metadata management and cluster formation, and orchestrates a few background operations like snapshot and shard placement. We added a task throttler to control the rate of dynamic mapping updates, snapshot tasks, and so on to prevent overwhelming it and to let critical operations run deterministically all the time. But what happens when there is no cluster manager in the cluster? The next section covers how we solved this.
Decoupling critical dependencies
In the event of cluster manager failure, searches continue as usual, but all write requests start to fail. We concluded that allowing writes in this state should still be safe as long as it doesn’t need to update the cluster metadata. This change further improves the write availability without compromising data consistency. Other service dependencies were evaluated to ensure downstream dependencies can scale as the cluster grows.
Failure mode testing
Although it’s hard to mimic all kinds of failures, we rely on AWS Fault Injection Simulator (AWS FIS) to inject common faults in the system like node failures, disk impairment, or network impairment. Testing with AWS FIS regularly in our pipelines helps us improve our detection, monitoring, and recovery times.
Contributing to open source
OpenSearch is an open-source, community-driven software. Most of the changes including the high availability design to support active and standby zones have been contributed to open source; in fact, we follow an open-source first development model. The fundamental primitive that enables zonal traffic shift and failover is based on a weighted traffic routing policy (active zones are assigned weights as 1 and standby zones are assigned weights as 0). Write failovers use the zonal decommission action, which evacuates all traffic from a given zone. Resiliency improvements for search backpressure and cluster manager task throttling are some of the ongoing efforts. If you’re excited to contribute to OpenSearch, open up a GitHub issue and let us know your thoughts.
Summary
Efforts to improve reliability is a never-ending cycle as we continue to learn and improve. With the Multi-AZ with standby feature, OpenSearch Service has integrated best practices for cluster configuration, improved workload management, and achieved four 9s of availability and consistent performance. OpenSearch Service also raised the bar by continuously verifying availability with zonal traffic rotations and automated tests via AWS FIS.
We are excited to continue our efforts into improving the reliability and fault tolerance even further and to see what new and existing solutions builders can create using OpenSearch Service. We hope this leads to a deeper understanding of the right level of availability based on the needs of your business and how this offering achieves the availability SLA. We would love to hear from you, especially about your success stories achieving high levels of availability on AWS. If you have other questions, please leave a comment.
About the authors
 Bukhtawar Khan is a Principal Engineer working on Amazon OpenSearch Service. He is interested in building distributed and autonomous systems. He is a maintainer and an active contributor to OpenSearch.
Bukhtawar Khan is a Principal Engineer working on Amazon OpenSearch Service. He is interested in building distributed and autonomous systems. He is a maintainer and an active contributor to OpenSearch.
 Gaurav Bafna is a Senior Software Engineer working on OpenSearch at Amazon Web Services. He is fascinated about solving problems in distributed systems. He is a maintainer and an active contributor to OpenSearch.
Gaurav Bafna is a Senior Software Engineer working on OpenSearch at Amazon Web Services. He is fascinated about solving problems in distributed systems. He is a maintainer and an active contributor to OpenSearch.
 Murali Krishna is a Senior Principal Engineer at AWS OpenSearch Service. He has built AWS OpenSearch Service and AWS CloudSearch. His areas of expertise include Information Retrieval, Large scale distributed computing, low latency real time serving systems etc. He has vast experience in designing and building web scale systems for crawling, processing, indexing and serving text and multimedia content. Prior to Amazon, he was part of Yahoo!, building crawling and indexing systems for their search products.
Murali Krishna is a Senior Principal Engineer at AWS OpenSearch Service. He has built AWS OpenSearch Service and AWS CloudSearch. His areas of expertise include Information Retrieval, Large scale distributed computing, low latency real time serving systems etc. He has vast experience in designing and building web scale systems for crawling, processing, indexing and serving text and multimedia content. Prior to Amazon, he was part of Yahoo!, building crawling and indexing systems for their search products.
 Ranjith Ramachandra is a Senior Engineering Manager working on Amazon OpenSearch Service. He is passionate about highly scalable distributed systems, high performance and resilient systems.
Ranjith Ramachandra is a Senior Engineering Manager working on Amazon OpenSearch Service. He is passionate about highly scalable distributed systems, high performance and resilient systems.
 Rohin Bhargava is a Sr. Product Manager with the Amazon OpenSearch Service team. His passion at AWS is to help customers find the correct mix of AWS services to achieve success for their business goals.
Rohin Bhargava is a Sr. Product Manager with the Amazon OpenSearch Service team. His passion at AWS is to help customers find the correct mix of AWS services to achieve success for their business goals.








 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike. Tomohiro Tanaka is a Senior Cloud Support Engineer on the AWS Support team. He’s passionate about helping customers build data lakes using ETL workloads. In his free time, he enjoys coffee breaks with his colleagues and making coffee at home.
Tomohiro Tanaka is a Senior Cloud Support Engineer on the AWS Support team. He’s passionate about helping customers build data lakes using ETL workloads. In his free time, he enjoys coffee breaks with his colleagues and making coffee at home. Chuhan Liu is a Software Development Engineer on the AWS Glue team. He is passionate about building scalable distributed systems for big data processing, analytics, and management. In his spare time, he enjoys playing tennis.
Chuhan Liu is a Software Development Engineer on the AWS Glue team. He is passionate about building scalable distributed systems for big data processing, analytics, and management. In his spare time, he enjoys playing tennis. Matt Su is a Senior Product Manager on the AWS Glue team. He enjoys helping customers uncover insights and make better decisions using their data with AWS Analytic services. In his spare time, he enjoys skiing and gardening.
Matt Su is a Senior Product Manager on the AWS Glue team. He enjoys helping customers uncover insights and make better decisions using their data with AWS Analytic services. In his spare time, he enjoys skiing and gardening.







 Bhupinder Chadha is a senior product manager for Amazon QuickSight focused on visualization and front end experiences. He is passionate about BI, data visualization and low-code/no-code experiences. Prior to QuickSight he was the lead product manager for Inforiver, responsible for building a enterprise BI product from ground up. Bhupinder started his career in presales, followed by a small gig in consulting and then PM for xViz, an add on visualization product.
Bhupinder Chadha is a senior product manager for Amazon QuickSight focused on visualization and front end experiences. He is passionate about BI, data visualization and low-code/no-code experiences. Prior to QuickSight he was the lead product manager for Inforiver, responsible for building a enterprise BI product from ground up. Bhupinder started his career in presales, followed by a small gig in consulting and then PM for xViz, an add on visualization product.









































 Hari Thatavarthy is a Senior Solutions Architect on the AWS Data Lab team. He helps customers design and build solutions in the data and analytics space. He believes in data democratization and loves to solve complex data processing-related problems. In his spare time, he loves to play table tennis.
Hari Thatavarthy is a Senior Solutions Architect on the AWS Data Lab team. He helps customers design and build solutions in the data and analytics space. He believes in data democratization and loves to solve complex data processing-related problems. In his spare time, he loves to play table tennis. Krishna Maddileti is a Senior Solutions Architect on the AWS Data Lab team. He partners with customers on their AWS journey and helps them with data engineering, data lakes, and analytics. In his spare time, he enjoys spending time with his family and playing video games with his 7-year-old.
Krishna Maddileti is a Senior Solutions Architect on the AWS Data Lab team. He partners with customers on their AWS journey and helps them with data engineering, data lakes, and analytics. In his spare time, he enjoys spending time with his family and playing video games with his 7-year-old. Yadukishore Tatavarthi is a Senior Partner Solutions Architect at AWS. He works closely with global system integrator partners to enable and support customers moving their workloads to AWS.
Yadukishore Tatavarthi is a Senior Partner Solutions Architect at AWS. He works closely with global system integrator partners to enable and support customers moving their workloads to AWS. Manish Kola is a Solutions Architect on the AWS Data Lab team. He partners with customers on their AWS journey.
Manish Kola is a Solutions Architect on the AWS Data Lab team. He partners with customers on their AWS journey. Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.





 Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat. Damon is a Principal Developer Advocate on the EMR team at AWS. He’s worked with data and analytics pipelines for over 10 years and splits his team between splitting service logs and stacking firewood.
Damon is a Principal Developer Advocate on the EMR team at AWS. He’s worked with data and analytics pipelines for over 10 years and splits his team between splitting service logs and stacking firewood.














 Daren Wong is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS.
Daren Wong is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS. Aleksandr Pilipenko is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS.
Aleksandr Pilipenko is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS. Hong Liang Teoh is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS.
Hong Liang Teoh is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS.













 Ali Alemi is a Streaming Specialist Solutions Architect at AWS. Ali advises AWS customers with architectural best practices and helps them design real-time analytics data systems that are reliable, secure, efficient, and cost-effective. He works backward from customers’ use cases and designs data solutions to solve their business problems. Prior to joining AWS, Ali supported several public sector customers and AWS consulting partners in their application modernization journey and migration to the cloud.
Ali Alemi is a Streaming Specialist Solutions Architect at AWS. Ali advises AWS customers with architectural best practices and helps them design real-time analytics data systems that are reliable, secure, efficient, and cost-effective. He works backward from customers’ use cases and designs data solutions to solve their business problems. Prior to joining AWS, Ali supported several public sector customers and AWS consulting partners in their application modernization journey and migration to the cloud. Rajeev Chakrabarti is a Kinesis specialist solutions architect.
Rajeev Chakrabarti is a Kinesis specialist solutions architect.


 Fei Peng is a Software Dev Engineer working in the Amazon Redshift team.
Fei Peng is a Software Dev Engineer working in the Amazon Redshift team.

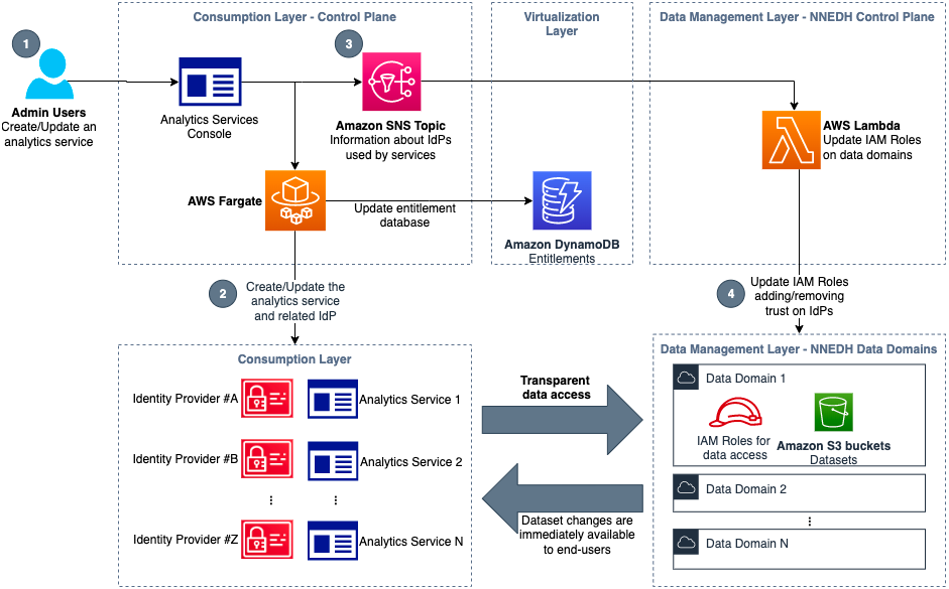
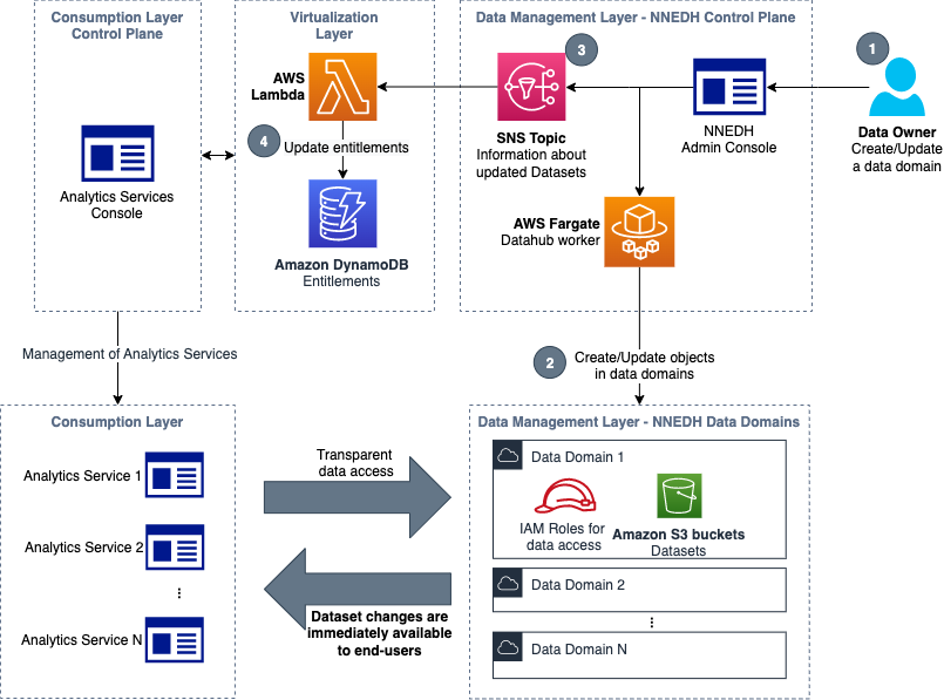
 Jonatan Selsing is former research scientist with a PhD in astrophysics that has turned to the cloud. He is currently the Lead Cloud Engineer at Novo Nordisk, where he enables data and analytics workloads at scale. With an emphasis on reducing the total cost of ownership of cloud-based workloads, while giving full benefit of the advantages of cloud, he designs, builds, and maintains solutions that enable research for future medicines.
Jonatan Selsing is former research scientist with a PhD in astrophysics that has turned to the cloud. He is currently the Lead Cloud Engineer at Novo Nordisk, where he enables data and analytics workloads at scale. With an emphasis on reducing the total cost of ownership of cloud-based workloads, while giving full benefit of the advantages of cloud, he designs, builds, and maintains solutions that enable research for future medicines. Hassen Riahi is a Sr. Data Architect at AWS Professional Services. He holds a PhD in Mathematics & Computer Science on large-scale data management. He works with AWS customers on building data-driven solutions.
Hassen Riahi is a Sr. Data Architect at AWS Professional Services. He holds a PhD in Mathematics & Computer Science on large-scale data management. He works with AWS customers on building data-driven solutions. Alessandro Fior is a Sr. Data Architect at AWS Professional Services. He is passionate about designing and building modern and scalable data platforms that accelerate companies to extract value from their data.
Alessandro Fior is a Sr. Data Architect at AWS Professional Services. He is passionate about designing and building modern and scalable data platforms that accelerate companies to extract value from their data.





 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.


 Ranjit Rajan is a Principal Data Lab Solutions Architect with AWS. Ranjit works with AWS customers to help them design and build data and analytics applications in the cloud.
Ranjit Rajan is a Principal Data Lab Solutions Architect with AWS. Ranjit works with AWS customers to help them design and build data and analytics applications in the cloud. Kannan Iyer is a Senior Data Lab Solutions Architect with AWS. Kannan works with AWS customers to help them design and build data and analytics applications in the cloud.
Kannan Iyer is a Senior Data Lab Solutions Architect with AWS. Kannan works with AWS customers to help them design and build data and analytics applications in the cloud. Alexandre Rezende is a Data Lab Solutions Architect with AWS. Alexandre works with customers on their Business Intelligence, Data Warehouse, and Data Lake use cases, design architectures to solve their business problems, and helps them build MVPs to accelerate their path to production.
Alexandre Rezende is a Data Lab Solutions Architect with AWS. Alexandre works with customers on their Business Intelligence, Data Warehouse, and Data Lake use cases, design architectures to solve their business problems, and helps them build MVPs to accelerate their path to production.