Post Syndicated from Danilo Poccia original https://aws.amazon.com/blogs/aws/simplify-how-you-manage-authorization-in-your-applications-with-amazon-verified-permissions-now-generally-available/
When developing a new application or integrating an existing one into a new environment, user authentication and authorization require significant effort to be correctly implemented. In the past, you would have built your own authentication system, but today you can use an external identity provider like Amazon Cognito. Yet, authorization logic is typically implemented in code.
This might begin simply enough, with all users assigned a role for their job function. However, over time, these permissions grow increasingly complex. The number of roles expands, as permissions become more fine-grained. New use cases drive the need for custom permissions. For instance, one user might share a document with another in a different role, or a support agent might require temporary access to a customer account to resolve an issue. Managing permissions in code is prone to errors, and presents significant challenges when auditing permissions and deciding who has access to what, particularly when these permissions are expressed in different applications and using multiple programming languages.
At re:Invent 2022, we introduced in preview Amazon Verified Permissions, a fine-grained permissions management and authorization service for your applications that can be used at any scale. Amazon Verified Permissions centralizes permissions in a policy store and helps developers use those permissions to authorize user actions within their applications. Similar to how an identity provider simplifies authentication, a policy store let you manage authorization in a consistent and scalable way.
To define fine-grained permissions, Amazon Verified Permissions uses Cedar, an open-source policy language and software development kit (SDK) for access control. You can define a schema for your authorization model in terms of principal types, resource types, and valid actions. In this way, when a policy is created, it is validated against your authorization model. You can simplify the creation of similar policies using templates. Changes to the policy store are audited so that you can see of who made the changes and when.
You can then connect your applications to Amazon Verified Permissions through AWS SDKs to authorize access requests. For each authorization request, the relevant policies are retrieved and evaluated to determine whether the action is permitted or not. You can reproduce those authorization requests to confirm that permissions work as intended.
Today, I am happy to share that Amazon Verified Permissions is generally available with new capabilities and a simplified user experience in the AWS Management Console.
Let’s see how you can use it in practice.
Creating a Policy Store with Amazon Verified Permissions
In the Amazon Verified Permissions console, I choose Create policy store. A policy store is a logical container that stores policies and schema. Authorization decisions are made based on all the policies present in a policy store.
To configure the new policy store, I can use different methods. I can start with a guided setup, a sample policy store (such as for a photo-sharing app, an online store, or a task manager), or an empty policy store (recommended for advanced users). I select Guided setup, enter a namespace for my schema (MyApp), and choose Next.

Resources are the objects that principals can act on. In my application, I have Users (principals) that can create, read, update, and delete Documents (resources). I start to define the Documents resource type.
I enter the name of the resource type and add two required attributes:
owner(String) to specify who is the owner of the document.isPublic(Boolean) to flag public documents that anyone can read.

I specify four actions for the Document resource type:
DocumentCreateDocumentReadDocumentUpdateDocumentDelete

I enter User as the name of the principal type that will be using these actions on Documents. Then, I choose Next.

Now, I configure the User principal type. I can use a custom configuration to integrate an external identity source, but in this case, I use an Amazon Cognito user pool that I created before. I choose Connect user pool.

In the dialog, I select the AWS Region where the user pool is located, enter the user pool ID, and choose Connect.

Now that the Amazon Cognito user pool is connected, I can add another level of protection by validating the client application IDs. For now, I choose not to use this option.
In the Principal attributes section, I select which attributes I am planning to use for attribute-based access control in my policies. I select sub (the subject), used to identify the end user according to the OpenID Connect specification. I can select more attributes. For example, I can use email_verified in a policy to give permissions only to Amazon Cognito users whose email has been verified.

As part of the policy store creation, I create a first policy to give read access to user danilop to the doc.txt document.

In the following code, the console gives me a preview of the resulting policy using the Cedar language.
Finally, I choose Create policy store.
Adding Permissions to the Policy Store
Now that the policy store has been created, I choose Policies in the navigation pane. In the Create policy dropdown, I choose Create static policy. A static policy contains all the information needed for its evaluation. In my second policy, I allow any user to read public documents. By default everything is forbidden, so in Policy Effect I choose Permit.
In the Policy scope, I leave All principals and All resources selected, and select the DocumentRead action. In the Policy section, I change the when condition clause to limit permissions to resources where isPublic is equal to true:
I enter a description for the policy and choose Create policy.
For my third policy, I create another static policy to allow full access to the owner of a document. Again, in Policy Effect, I choose Permit and, in the Policy scope, I leave All principals and All resources selected. This time, I also leave All actions selected.
In the Policy section, I change the when condition clause to limit permissions to resources where the owner is equal to the sub of the principal:
In my application, I need to allow read access to specific users that are not owners of a document. To simplify that, I create a policy template. Policy templates let me create policies from a template that uses placeholders for some of their values, such as the principal or the resource. The placeholders in a template are keywords that start with the ? character.
In the navigation pane, I choose Policy templates and then Create policy template. I enter a description and use the following policy template body. When using this template, I can specify the value for the ?principal and ?resource placeholders.
I complete the creation of the policy template. Now, I use the template to simplify the creation of policies. I choose Policies in the navigation pane, and then Create a template-linked policy in the Create policy dropdown. I select the policy template I just created and choose Next.
To give access to a user (danilop) for a specific document (new-doc.txt), I just pass the following values (note that MyApp is the namespace of the policy store):
- For the Principal:
MyApp::User::"danilop" - For the Resource:
MyApp::Document::"new-doc.txt"
I complete the creation of the policy. It’s now time to test if the policies work as expected.
Testing Policies in the Console
In my applications, I can use the AWS SDKs to run an authorization request. The console provides a way to to simulate what my applications would do. I choose Test bench in the navigation pane. To simplify testing, I use the Visual mode. As an alternative, I have the option to use the same JSON syntax as in the SDKs.
As Principal, I pass the janedoe user. As Resource, I use requirements.txt. It’s not a public document (isPublic is false) and the owner attribute is equal to janedoe‘s sub. For the Action, I select MyApp::Action::"DocumentUpdate".
When running an authorization request, I can pass Additional entities with more information about principals and resources associated with the request. For now, I leave this part empty.
I choose Run authorization request at the top to see the decision based on the current policies. As expected, the decision is allow. Here, I also see which policies hav been satisfied by the authorization request. In this case, it is the policy that allows full access to the owner of the document.
I can test other values. If I change the owner of the document and the action to DocumentRead, the decision is deny. If I then set the resource attribute isPublic to true, the decision is allow because there is a policy that permits all users to read public documents.
Handling Groups in Permissions
The administrative users in my application need to be able to delete any document. To do so, I create a role for admin users. First, I choose Schema in the navigation pane and then Edit schema. In the list of entity types, I choose to add a new one. I use Role as Type name and add it. Then, I select User in the entity types and edit it to add Role as a parent. I save changes and create the following policy:
In the Test bench, I run an authorization request to check if user jeffbarr can delete (DocumentDelete) resource doc.txt. Because he’s not the owner of the resource, the request is denied.
Now, in the Additional entities, I add the MyApp::User entity with jeffbarr as identifier. As parent, I add the MyApp::Role entity with admin as identifier and confirm. The console warns me that entity MyApp::Role::"admin" is referenced, but it isn’t included in additional entities data. I choose to add it and fix this issue.
I run an authorization request again, and it is now allowed because, according to the additional entities, the principal (jeffbarr) is an admin.
Using Amazon Verified Permissions in Your Application
In my applications, I can run an authorization requests using the isAuthorized API action (or isAuthrizedWithToken, if the principal comes from an external identity source).
For example, the following Python code uses the AWS SDK for Python (Boto3) to check if a user has read access to a document. The authorization request uses the policy store I just created.
import boto3
import time
verifiedpermissions_client = boto3.client("verifiedpermissions")
POLICY_STORE_ID = "XAFTHeCQVKkZhsQxmAYXo8"
def is_authorized_to_read(user, resource):
authorization_result = verifiedpermissions_client.is_authorized(
policyStoreId=POLICY_STORE_ID,
principal={"entityType": "MyApp::User", "entityId": user},
action={"actionType": "MyApp::Action", "actionId": "DocumentRead"},
resource={"entityType": "MyApp::Document", "entityId": resource}
)
print('Can {} read {} ?'.format(user, resource))
decision = authorization_result["decision"]
if decision == "ALLOW":
print("Request allowed")
return True
else:
print("Request denied")
return False
if is_authorized_to_read('janedoe', 'doc.txt'):
print("Here's the doc...")
if is_authorized_to_read('danilop', 'doc.txt'):
print("Here's the doc...")
I run this code and, as you can expect, the output is in line with the tests run before.
Availability and Pricing
Amazon Verified Permissions is available today in all commercial AWS Regions, excluding those that are based in China.
With Amazon Verified Permissions, you only pay for what you use based on the number of authorization requests and API calls made to the service.
Using Amazon Verified Permissions, you can configure fine-grained permissions using the Cedar policy language and simplify the code of your applications. In this way, permissions are maintained in a centralized store and are easier to audit. Here, you can read more about how we built Cedar with automated reasoning and differential testing.
Manage authorization for your applications with Amazon Verified Permissions.
— Danilo

















 Tome Tanasovski is a Technical Manager at AWS, for a team that manages capabilities into Amazon’s big data platforms via AWS Glue. Prior to working at AWS, Tome was an executive for a market-leading global financial services firm in New York City where he helped run the Firm’s Artificial Intelligence & Machine Learning Center of Excellence. Prior to this role he spent nine years in the Firm focusing on automation, cloud, and distributed computing. Tome has a quarter-of-a-century worth of experience in technology in the Tri-state area across a wide variety of industries including big tech, finance, insurance, and media.
Tome Tanasovski is a Technical Manager at AWS, for a team that manages capabilities into Amazon’s big data platforms via AWS Glue. Prior to working at AWS, Tome was an executive for a market-leading global financial services firm in New York City where he helped run the Firm’s Artificial Intelligence & Machine Learning Center of Excellence. Prior to this role he spent nine years in the Firm focusing on automation, cloud, and distributed computing. Tome has a quarter-of-a-century worth of experience in technology in the Tri-state area across a wide variety of industries including big tech, finance, insurance, and media. Brian Ross is a Senior Software Development Manager at AWS. He has spent 24 years building software at scale and currently focuses on serverless data integration with AWS Glue. In his spare time, he studies ancient texts, cooks modern dishes and tries to get his kids to do both.
Brian Ross is a Senior Software Development Manager at AWS. He has spent 24 years building software at scale and currently focuses on serverless data integration with AWS Glue. In his spare time, he studies ancient texts, cooks modern dishes and tries to get his kids to do both.

















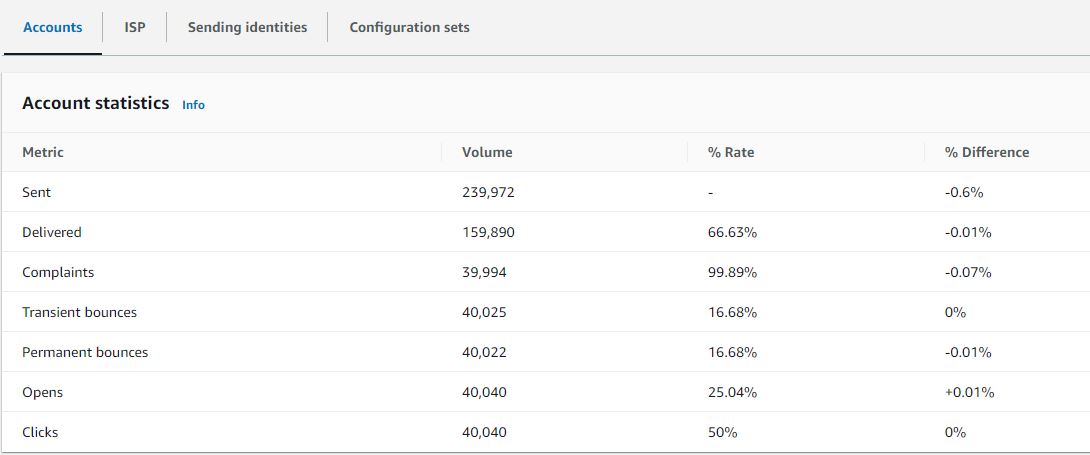
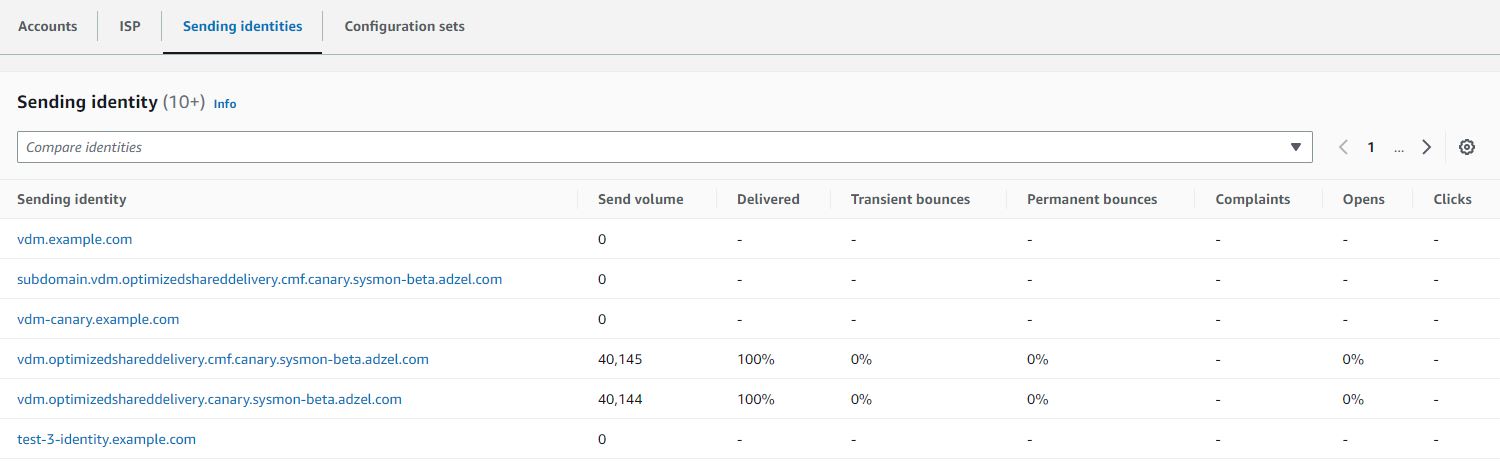

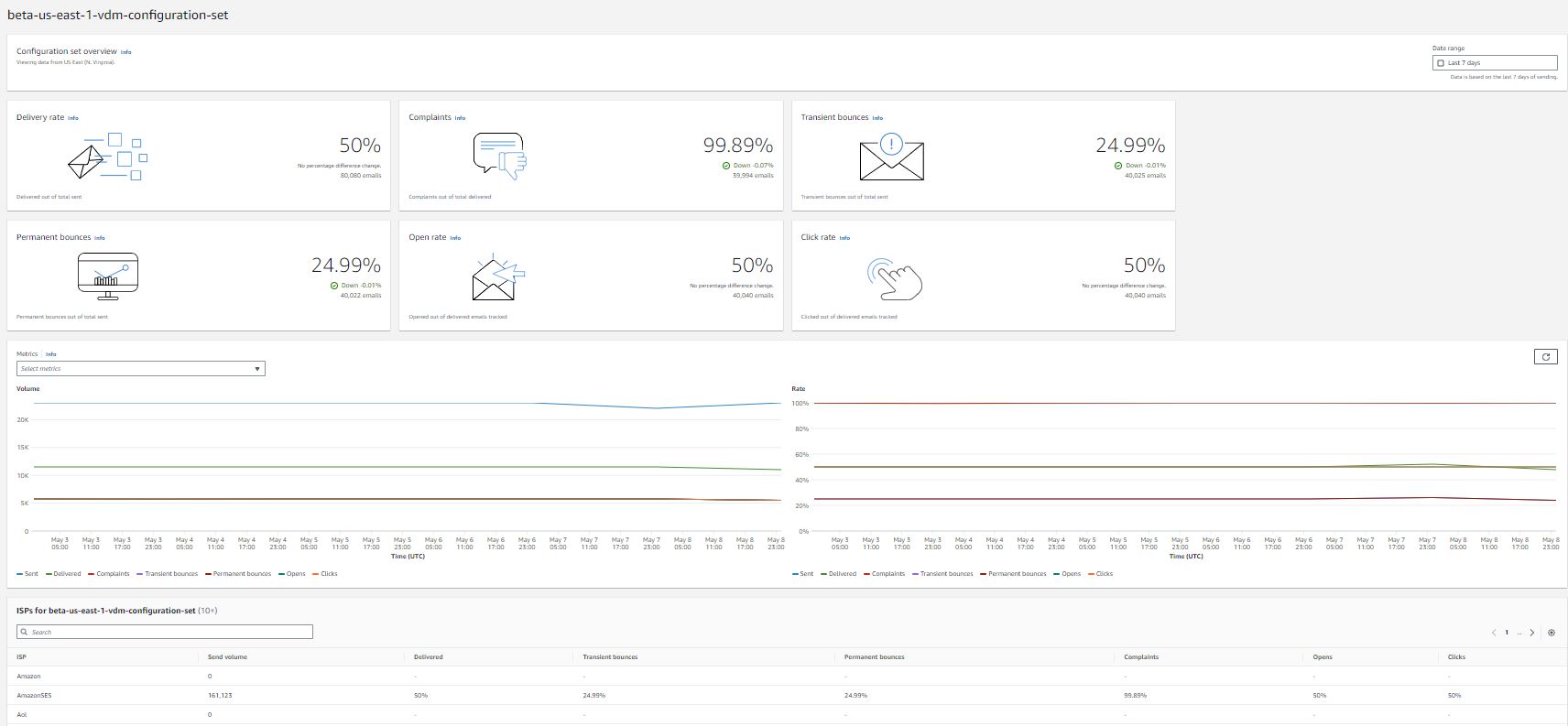

 If you have previously leased several standard dedicated IP addresses to use with Amazon SES, you would have created groups of those addresses, called dedicated IP pools. Grouping dedicated IPs together in a pool makes them easier to manage. A common scenario is to create one pool for sending marketing communications, and another for sending transactional emails. Your sender reputation for transactional emails is then isolated from that of your marketing emails. In this scenario, if a marketing campaign generates a large number of complaints, the delivery of your transactional emails is not impacted. If you already have dedicated IPs (standard) pools you can now convert these pools to managed IP pools in one click. Converting from a dedicated IP (standard) pool to a dedicated IP (managed) pool automatically transfers all of your standard IPs over to managed. So, you keep the same set of IPs, but you no longer have to worry about monitoring and managing them. You will no longer be charged per IP that you lease, but rather by the volume of emails that you send. For more information on pricing see the
If you have previously leased several standard dedicated IP addresses to use with Amazon SES, you would have created groups of those addresses, called dedicated IP pools. Grouping dedicated IPs together in a pool makes them easier to manage. A common scenario is to create one pool for sending marketing communications, and another for sending transactional emails. Your sender reputation for transactional emails is then isolated from that of your marketing emails. In this scenario, if a marketing campaign generates a large number of complaints, the delivery of your transactional emails is not impacted. If you already have dedicated IPs (standard) pools you can now convert these pools to managed IP pools in one click. Converting from a dedicated IP (standard) pool to a dedicated IP (managed) pool automatically transfers all of your standard IPs over to managed. So, you keep the same set of IPs, but you no longer have to worry about monitoring and managing them. You will no longer be charged per IP that you lease, but rather by the volume of emails that you send. For more information on pricing see the 

