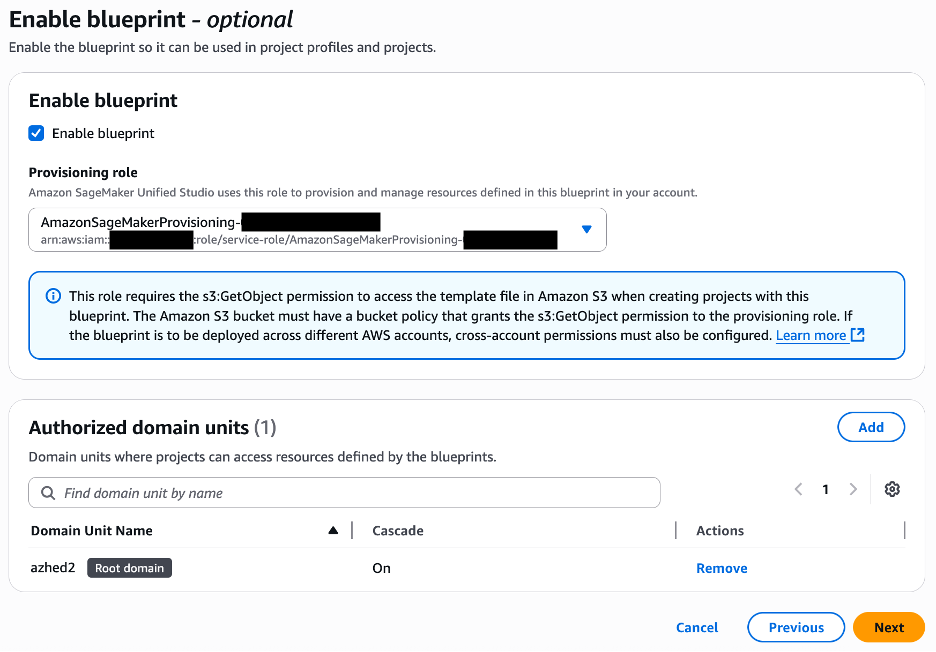
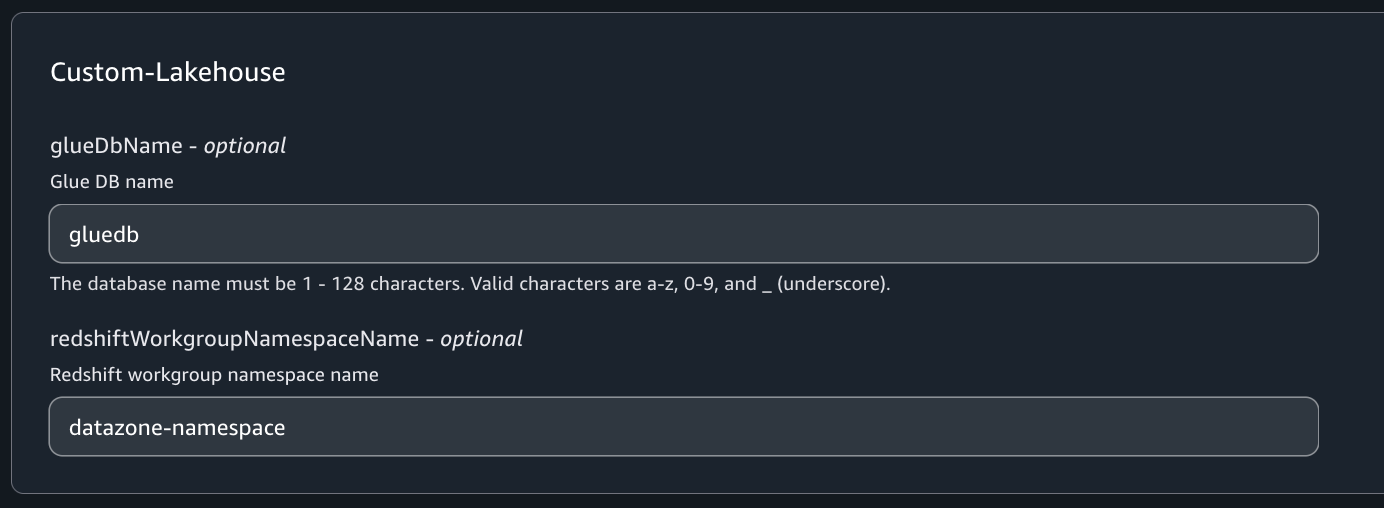
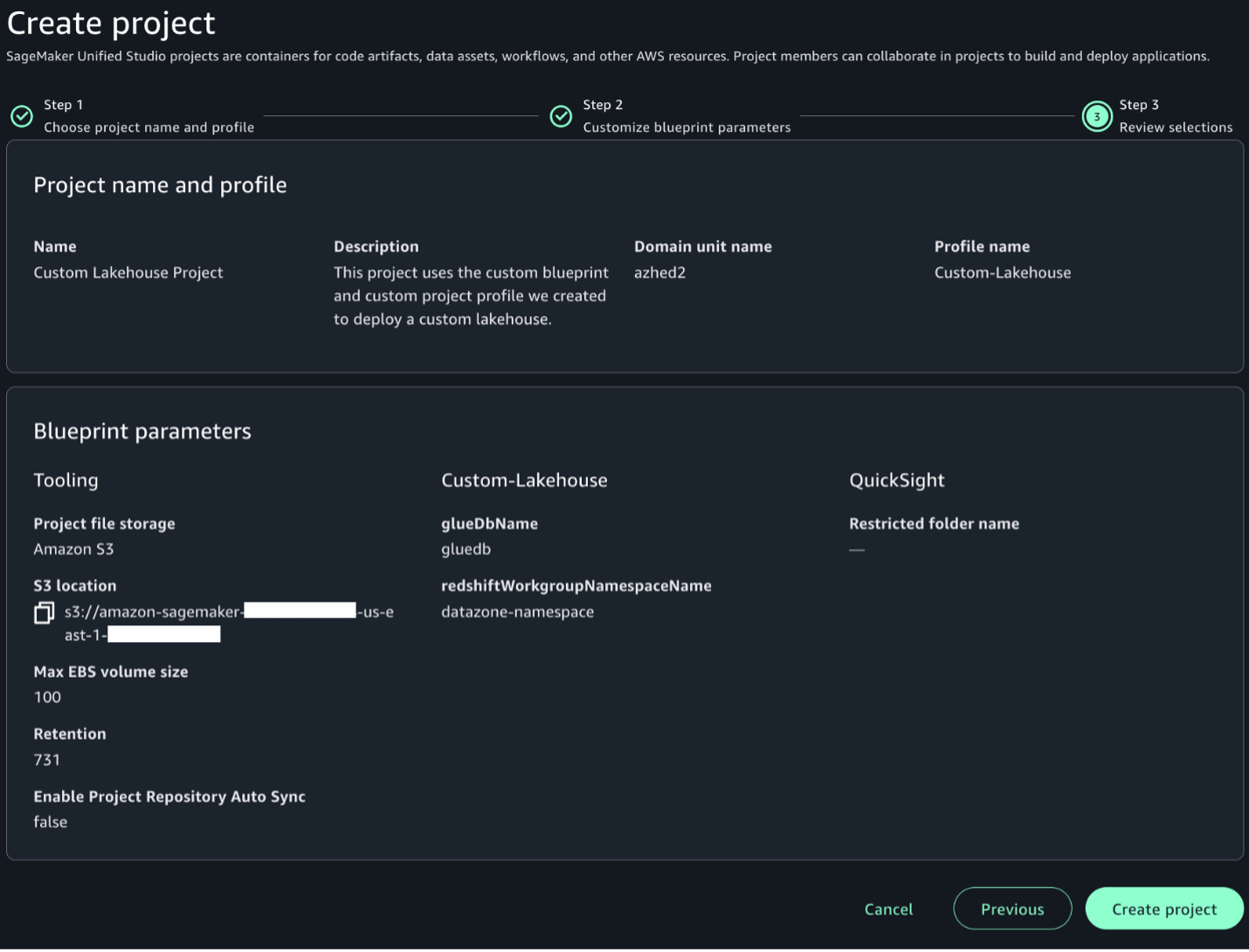
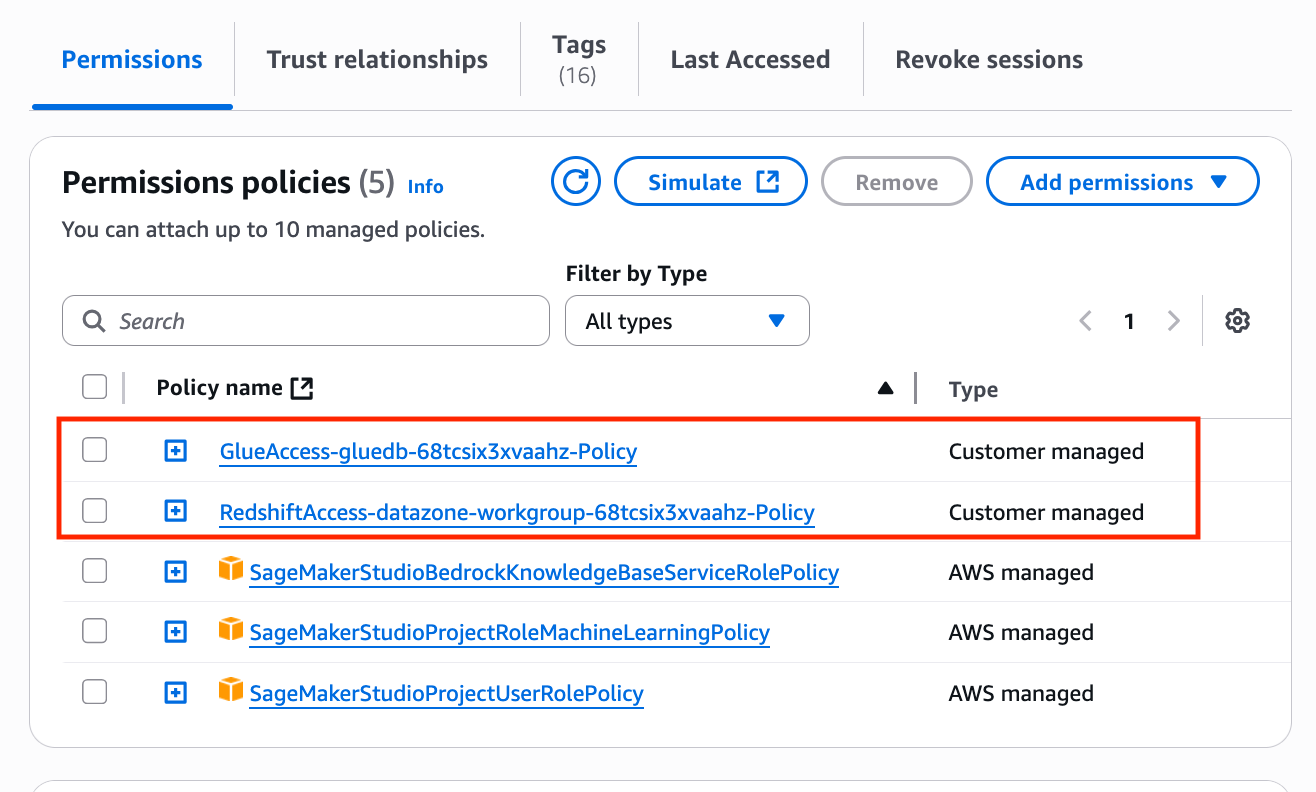
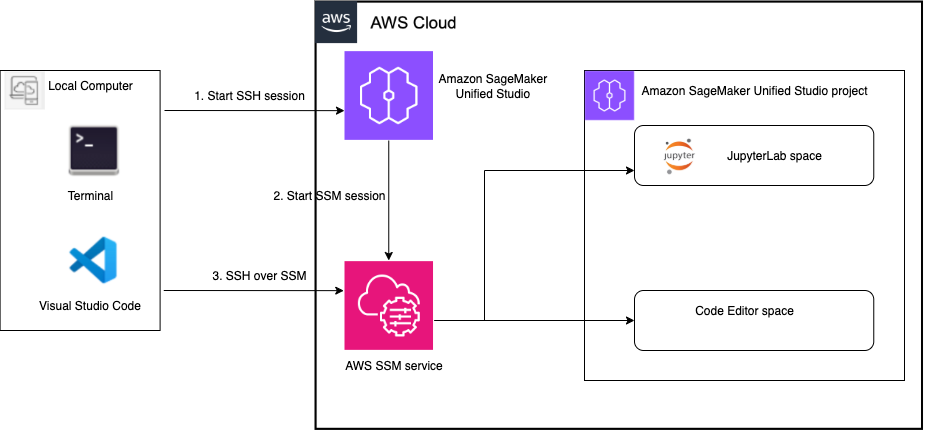
The whitepaper covers the core security principles of Amazon EKS Auto Mode, highlighting its unique approach to managing Kubernetes clusters. This includes how AWS has reimagined node management by building on top of Amazon Elastic Compute Cloud (Amazon EC2) managed instances, which introduces a new way for customers to delegate operational control of EC2 instances to an AWS service.
Designed for cloud architects, security professionals, and Kubernetes practitioners, the whitepaper serves as a comprehensive guide to understanding the security architecture of Amazon EKS Auto Mode. It represents the AWS commitment to providing secure, manageable, and innovative Kubernetes infrastructure solutions that minimize undifferentiated heavy lifting, so that customers can focus more on application development and less on infrastructure management.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Many organizations operating in regulated industries need complete control over encryption key management. While Identity Center already encrypts data at rest using AWS-owned keys, some customers require the ability to manage their own encryption keys for audit and compliance purposes.
With this launch, you can now use customer-managed KMS keys (CMKs) to encrypt Identity Center identity data at rest. CMKs provide you with full control over the key lifecycle, including creation, rotation, and deletion. You can configure granular access controls to keys with AWS Key Management Service (AWS KMS) key policies and IAM policies, helping to ensure that only authorized principals can access your encrypted data. At launch time, the CMK must reside in the same AWS account and Region as your IAM Identity Center instance. The integration between Identity Center and KMS provides detailed AWS CloudTrail logs for auditing key usage and helps meet regulatory compliance requirements.
Identity Center supports both single-Region and multi-Region keys to match your deployment needs. While Identity Center instances can currently only be deployed in a single Region, we recommend using multi-Region AWS KMS keys unless your company policies restrict you to single-Region keys. Multi-Region keys provide consistent key material across Regions while maintaining independent key infrastructure in each Region. This gives you more flexibility in your encryption strategy and helps future-proof your deployment.
Let’s get started Let’s imagine I want to use a CMK to encrypt the identity data of my Identity Center organization instance. My organization uses Identity Center to give employees access to AWS managed applications, such as Amazon Q Business or Amazon Athena.
As of today, some AWS managed applications cannot be used with Identity Center configured with a customer managed KMS key. See AWS managed applications that you can use with Identity Center to keep you updated with the ever evolving list of compatible applications.
The high-level process requires first to create a symmetric customer managed key (CMK) in AWS KMS. The key must be configured for encrypt and decrypt operations. Next, I configure the key policies to grant access to Identity Center, AWS managed applications, administrators, and other principals who need access the Identity Center and IAM Identity Center service APIs. Depending on your usage of Identity Center, you’ll have to define different policies for the key and IAM policies for IAM principals. The service documentation has more details to help you cover the most common use cases.
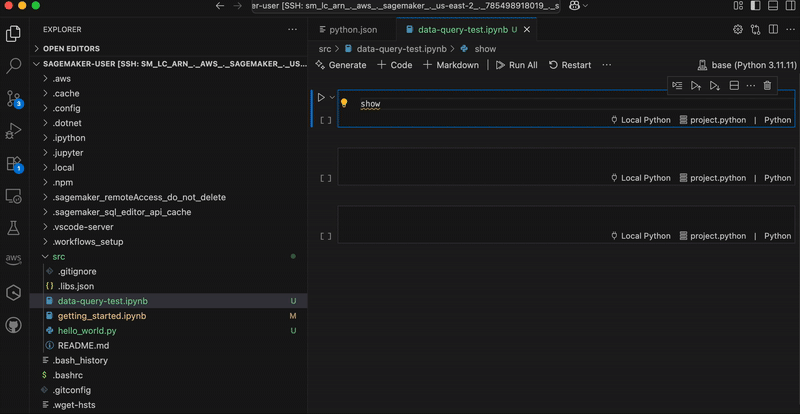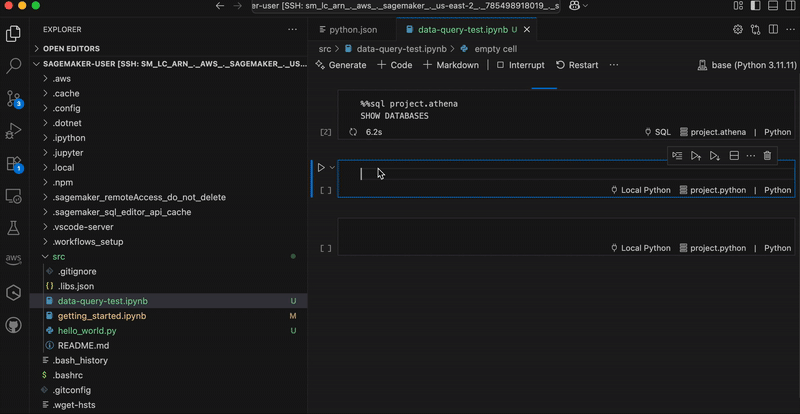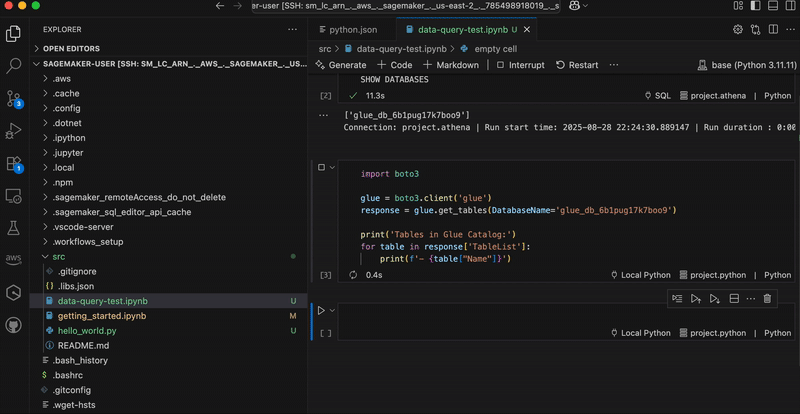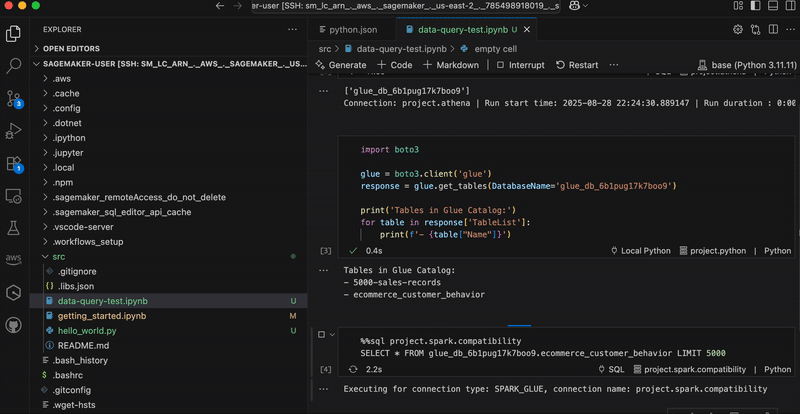
This demo is in three parts. I first create a customer managed key in AWS KMS and configure it with permissions that will authorize Identity Center and AWS managed applications to use it. Second, I update the IAM policies for the principals that will use the key from another AWS account, such as AWS applications administrators. Finally, I configure Identity Center to use the key.
Part 1: Create the key and define permissions
First, let’s create a new CMK in AWS KMS.
The key must be in the same AWS Region and AWS account as the Identity Center instance. You must create the Identity Center instance and the key in the management account of your organization within AWS Organization.
I navigate to the AWS Key Management Service (AWS KMS) console in the same Region as my Identity Center instance, then I choose Create a key. This launches me into the key creation wizard.
Under Step 1–Configure key, I select the key type–either Symmetric (a single key used for both encryption and decryption) or Asymmetric (a public-private key pair for encryption/decryption and signing/verification). Identity Center requires symmetric keys for encryption at rest. I select Symmetric.
For key usage, I select Encrypt and decrypt which allows the key to be used only for encrypting and decrypting data.
Under Advanced options, I select KMS – recommended for Key material origin, so AWS KMS creates and manages the key material.
For Regionality, I choose between Single-Region or Multi-Region key. I select Multi-Region key to allow key administrators to replicate the key to other Regions. As explained already, Identity Center doesn’t require this today but it helps to future-proof your configuration. Remember that you can not transform a single-Region key to a multi-Region one after its creation (but you can change the key used by Identity Center).
Then, I choose Next to proceed with additional configuration steps, such as adding labels, defining administrative permissions, setting usage permissions, and reviewing the final configuration before creating the key.
Under Step 2–Add Labels, I enter an Alias name for my key and select Next.
In this demo, I am editing the key policy by adding policy statements using templates provided in the documentation. I skip Step 3 and Step 4 and navigate to Step 5–Edit key policy.
Identity Center requires, at the minimum, permissions allowing Identity Center and its administrators to use the key. Therefore, I add three policy statements, the first and second authorize the administrators of the service, the third one to authorize the Identity Center service itself.
I also have to add additional policy statements to allow my use case: the use of AWS managed applications. I add these two policy statements to authorize AWS managed applications and their administrators to use the KMS key. The document lists additional use cases and their respective policies.
To help protect against IAM role name changes when permission sets are recreated, use the approach described in the Custom trust policy example.
Part 2: Update IAM policies to allow use of the KMS key from another AWS account
Any IAM principal that uses the Identity Center service APIs from another AWS account, such as Identity Center delegated administrators and AWS application administrators, need an IAM policy statement that allows use of the KMS key via these APIs.
I grant permissions to access the key by creating a new policy and attaching the policy to the IAM role relevant for my use case. You can also add these statements to the existing identity-based policies of the IAM role.
Part 3: Configure IAM Identity Center to use the key
I can configure a CMK either during the enablement of an Identity Center organization instance or on an existing instance, and I can change the encryption configuration at any time by switching between CMKs or reverting to AWS-owned keys.
Please note that an incorrect configuration of KMS key permissions can disrupt Identity Center operations and access to AWS managed applications and accounts through Identity Center. Proceed carefully to this final step and ensure you have read and understood the documentation.
After I have created and configured my CMK, I can select it under Advanced configuration when enabling Identity Center.
To configure a CMK on an existing Identity Center instance using the AWS Management Console, I start by navigating to the Identity Center section of the AWS Management Console. From there, I select Settings from the navigation pane, then I select the Management tab, and select Manage encryption in the Key for encrypting IAM Identity Center data at rest section.
At any time, I can select another CMK from the same AWS Account, or switch back to an AWS-managed key.
After choosing Save, the key change process takes a few seconds to complete. All service functionalities continue uninterrupted during the transition. If, for whatever reasons, Identity Center can not access the new key, an error message will be returned and Identity Center will continue to use the current key, keeping your identity data encrypted with the mechanism it is already encrypted with.
Things to keep in mind The encryption key you create becomes a crucial component of your Identity Center. When you choose to use your own managed key to encrypt identity attributes at rest, you have to verify the following points.
Have you configured the necessary permissions to use the KMS key? Without proper permissions, enabling the CMK may fail or disrupt IAM Identity Center administration and AWS managed applications.
Have you verified that your AWS managed applications are compatible with CMK keys? For a list of compatible applications, see AWS managed applications that you can use with IAM Identity Center. Enabling CMK for Identity Center that is used by AWS managed applications incompatible with CMK will result in operational disruption for those applications. If you have incompatible applications, do not proceed.
Is your organization using AWS managed applications that require additional IAM role configuration to use the Identity Center and Identity Store APIs? For each such AWS managed application that’s already deployed, check the managed application’s User Guide for updated KMS key permissions for IAM Identity Centre usage and update them as instructed to prevent application disruption.
Pricing and availability Standard AWS KMS charges apply for key storage and API usage. Identity Center remains available at no additional cost.
This capability is now available in all AWS commercial Regions, AWS GovCloud (US), and AWS China Regions. To learn more, visit the IAM Identity Center User Guide.
We look forward to learning how you use this new capability to meet your security and compliance requirements.
Today, Amazon Web Services (AWS) announced the general availability of Apache Airflow 3 on Amazon Managed Workflows for Apache Airflow (Amazon MWAA). This release transforms how organizations use Apache Airflow to orchestrate data pipelines and business processes in the cloud, bringing enhanced security, improved performance, and modern workflow orchestration capabilities to Amazon MWAA customers.
Amazon MWAA introduces Airflow 3 features that modernize workflow management for AWS customers. Following the April 2025 release of Airflow 3 by the Apache community, AWS has incorporated these capabilities into Amazon MWAA. Airflow now features a completely redesigned, intuitive UI that simplifies workflow orchestration for users across experience levels. With the Task Execution Interface (Task API), tasks can run both within Airflow and as standalone Python scripts, improving code portability and testing. Scheduler-managed Backfill moves operations from the CLI to the scheduler, providing centralized control and visibility through the Airflow UI. CLI security improvements replace direct database access with API calls, maintaining consistent security across interfaces. Airflow now supports event-driven workflows, enabling triggers from AWS services and external sources. Amazon MWAA also adds support for Python 3.12, bringing the latest language capabilities to workflow development.
This post explores the features of Airflow 3 on Amazon MWAA and outlines enhancements that improve your workflow orchestration capabilities. The service maintains the Amazon MWAA pay-as-you-go pricing model with no upfront commitments. You can begin immediately by visiting the Amazon MWAA console, launching new Apache Airflow environments through the AWS Management Console, AWS Command Line Interface (AWS CLI), AWS CloudFormation, or AWS SDK within minutes.
Architectural advancements in Airflow 3 on Amazon MWAA
Airflow 3 on Amazon MWAA introduces significant architectural improvements that enhance security, performance, and flexibility. These advancements create a more robust foundation for workflow orchestration while maintaining backward compatibility with existing workflows.
Enhanced security
Amazon MWAA with Airflow 3 changes the security model by making component isolation a standard practice rather than optional. In Airflow 2, the DAG processor (the component that parses and processes DAG files) runs within the scheduler process by default, but can optionally be separated into its own process for better scalability and security isolation. Airflow 3 makes this separation standard, maintaining consistent security practices across deployments.
API server and Task API
Building on this security foundation, a new API server component is introduced in Amazon MWAA with Airflow 3, which serves as an intermediary between task instances and the Airflow metadata database. This change improves your workflows’ security posture by minimizing direct access to the Airflow metadata database from tasks. Tasks now operate with least privilege database access, reducing the risk of one task affecting others and improving overall system stability through fewer direct database connections.
The standardized communication through well-defined API endpoints creates a foundation for more secure, scalable, and flexible workflow orchestration. The Task Execution Interface (Task API) helps tasks run both within Airflow and as standalone Python scripts, improving code portability and testing capabilities.
From data-aware to event-driven scheduling
Airflow’s evolution toward event-driven scheduling began with the introduction of data-aware scheduling in Airflow 2.4, so DAGs could be triggered based on data availability rather than time schedules alone. Amazon MWAA with Airflow 3 builds on this foundation through a transition that includes the renaming of datasets to assets and introduces advanced capabilities, including asset partitions, external event integration, and asset-centric workflow design.
The transition from datasets to assets represents more than a simple rename. A data asset is a collection of logically related data that can represent diverse data products, including database tables, persisted ML models, embedded dashboards, or directories containing files.
Amazon MWAA with Airflow 3 introduces a new asset-centric syntax that represents an important shift in how workflows can be designed. The @asset decorator helps developers put data assets at the center of their workflow design, creating more intuitive asset-driven pipelines.
The following code is an example of asset-aware DAG scheduling:
from airflow.sdk import DAG, Asset
from airflow.providers.standard.operators.python import PythonOperator
# Define the asset
customer_data_asset = Asset(name="customer_data", uri="s3://my-bucket/customer-data.csv")
def process_customer_data():
"""Process customer data..."""
# Implementation here
# Create the DAG and task
with DAG(dag_id="process_customer_data", schedule="@daily"):
PythonOperator(
task_id="process_data",
outlets=[customer_data_asset],
python_callable=process_customer_data
)
The following code shows an asset-centric approach with the @asset decorator:
from airflow.sdk import asset
@asset(uri="s3://my-bucket/customer-data.csv", schedule="@daily")
def customer_data():
"""Process customer data..."""
# Implementation here
The @asset decorator automatically creates an asset with the function name, a DAG with the same identifier, and a task that produces the asset. This reduces code complexity and facilitates automatic DAG creation, where each asset becomes a self-contained workflow unit.
External event-driven scheduling with Asset Watchers
A significant advancement in Amazon MWAA with Airflow 3 is the introduction of Asset Watchers, which help Airflow react to events happening outside of the Airflow system itself. Whereas previous versions supported internal cross-DAG dependencies, Asset Watchers extend this capability to external data systems and message queues through the AssetWatcher class.
Amazon MWAA with Airflow 3 includes support for Amazon Simple Queue Service (Amazon SQS) through Asset Watchers. This allows your workflows to be triggered by external messages and facilitates more event-driven scheduling. Airflow now supports event-driven workflows, enabling triggers from AWS services and external sources. Asset Watchers monitor external systems asynchronously and trigger workflow execution when specific events occur, enabling workflows to respond to business events, data updates, or system notifications without the overhead of traditional sensor-based polling mechanisms.
Modern React-based UI
Amazon MWAA with Airflow 3 features a completely redesigned, intuitive UI built with React and FastAPI that simplifies workflow orchestration for users across experience levels. The new interface provides more intuitive navigation and workflow visualization, with an enhanced grid view that offers better visibility into task status and history. Users will appreciate the addition of dark mode support, which reduces eye strain during extended use, and the overall faster performance that’s especially noticeable when working with large DAGs.
The new UI maintains familiar workflows while providing a more modern and efficient experience for DAG management and monitoring, making daily operations more productive for both developers and operators. The legacy UI has been completely removed, offering a cleaner, more consistent experience across the system. The foundation for the new UI is built on REST APIs and a set of internal APIs for UI operations, both of which are now based on FastAPI, creating a more cohesive and secure architecture for both programmatic access and UI operations.
Scheduler optimizations
Amazon MWAA with Airflow 3’s enhanced scheduler delivers performance improvements for task execution and workflow management. The redesigned scheduling engine processes tasks more efficiently, reducing the time between task submissions and executions. This optimization benefits data pipeline operations that require rapid task processing and timely workflow completion.
The scheduler now manages computing resources more effectively, enabling stable performance even as workloads scale. When running multiple DAGs simultaneously, the improved resource allocation system helps prevent bottlenecks and maintains consistent execution speeds. This advancement is particularly useful for organizations running complex workflows with varying resource requirements. The new scheduler also handles concurrent operations with increased precision, so teams can run multiple DAG instances simultaneously while maintaining system stability and predictable performance.
Enhanced scheduler backfill operations
Scheduler-managed backfill (the process of running DAGs for historical dates) moves operations from the CLI to the scheduler, providing centralized control and visibility through the Airflow UI. Amazon MWAA with Airflow 3 delivers important upgrades to the scheduler’s backfill capabilities, helping data teams process historical data more efficiently. The backfill process has been optimized for better performance, reducing the database load during these operations and making sure backfills can be completed more quickly, minimizing the impact on near real-time workflow execution.
Amazon MWAA with Airflow 3 also improves the management of backfill operations, with the scheduler providing better isolation between backfill jobs and supporting more efficient processing of historical datasets. Operators now have better monitoring tools to track the progress and status of their backfill jobs, resulting in more effective management of these critical data processing tasks.
Developer-focused improvements
Airflow 3 on Amazon MWAA delivers several enhancements designed to improve the developer experience, from simplified task definition to better workflow management capabilities.
Task SDK
The Task SDK provides a more intuitive way to define tasks and DAGs:
# Example using the Task SDK
from airflow.sdk import dag, task
from datetime import datetime
@dag(
start_date=datetime(2023, 1, 1),
schedule="@daily",
catchup=False
)
def modern_etl_workflow():
@task
def extract():
# Extract data from source
return {"data": [1, 2, 3, 4, 5]}
@task
def transform(input_data):
# Transform the data
return [x * 10 for x in input_data]
@task
def load(transformed_data):
# Load data to destination
print(f"Loading data: {transformed_data}")
# Define the workflow
extracted_data = extract()
transformed_data = transform(extracted_data["data"])
load(transformed_data)
# Instantiate the DAG
etl_dag = modern_etl_workflow()
This approach offers more intuitive data flow between tasks, better integrated development environment (IDE) support with improved type hinting, and more straightforward unit testing of task logic. The result is cleaner, more maintainable code that better represents the actual data flow of your pipelines. Teams adopting this pattern often find their DAGs become more readable and simpler to maintain over time, especially as workflows grow in complexity.
DAG versioning
Amazon MWAA with Airflow 3 includes basic DAG versioning capabilities that come by default with Airflow 3. Each time a DAG is modified and deployed, Airflow serializes and stores the DAG definition to preserve history. This automatic version tracking minimizes the need for manual record-keeping and ensures every modification is documented.
Through the Airflow UI, teams can access and review the history of their DAGs. This visual representation shows version numbers (v1, v2, v3, etc.) and helps teams understand how their workflows have evolved over time.
The DAG versioning supported in Amazon MWAA provides the capability to see different DAG versions that were run in the Airflow UI, offering improved workflow visibility and enhanced collaboration for data engineering teams managing complex, evolving data pipelines.
Python 3.12 support
Amazon MWAA adds support for Python 3.12, bringing the latest language capabilities to workflow development. This upgrade provides access to the latest Python language improvements, performance enhancements, and library updates, keeping your data pipelines modern and efficient.
Features not currently supported in Amazon MWAA
Although we are launching most of the Airflow 3 features on Amazon MWAA in this release, some features are not supported at this time:
DAG versioning (AIP-63) – Advanced versioning features beyond basic version tracking
Replace Flask AppBuilder (AIP-79) – Full replacement capabilities
Edge Executor and task isolations (AIP-69) – Remote execution capabilities
Multi-language support (AIP-72) – Support for languages other than Python
We plan to support these features in subsequent versions of Airflow on Amazon MWAA.
Conclusion
Airflow 3 on Amazon MWAA delivers enhanced workflow automation capabilities. The architectural improvements, enhanced security model, and developer-friendly features provide a solid foundation for building more reliable and maintainable data pipelines.The introduction of Asset Watchers changes how workflows can respond to external events, enabling truly event-driven scheduling. This capability, combined with the new asset-centric workflow design, makes Airflow 3 a more powerful and flexible orchestration service.
The scheduler optimizations deliver performance improvements for task execution and workflow management, and the enhanced backfill capabilities make historical data processing more efficient. The DAG versioning system improves workflow stability and collaboration, and Python 3.12 support keeps your data pipelines modern and efficient.
Organizations can now take advantage of these new features and improvements in Airflow 3 on Amazon MWAA to enhance their workflow orchestration capabilities. To get started, visit the Amazon MWAA product page.
About the authors
Anurag Srivastava works as a Senior Big Data Cloud Engineer at Amazon Web Services (AWS), specializing in Amazon MWAA. He’s passionate about helping customers build scalable data pipelines and workflow automation solutions on AWS.
Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect, Amazon MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on LinkedIn to keep up to date with the latest Amazon MWAA and AWS Glue features and news!
Ankit Sahu brings over 18 years of expertise in building innovative digital products and services. His diverse experience spans product strategy, go-to-market execution, and digital transformation initiatives. Currently, Ankit serves as Senior Product Manager at Amazon Web Services (AWS), where he leads the Amazon MWAA service.
Mohammad Sabeel works as a Senior Cloud Support Engineer at Amazon Web Services (AWS), specializing in AWS Analytics services including AWS Glue, Amazon MWAA, and Amazon Athena. With over 14 years of IT experience, he’s passionate about helping customers build scalable data processing pipelines and optimize their analytics solutions on AWS.
Satya Chikkala is a Solutions Architect at Amazon Web Services. Based in Melbourne, Australia, he works closely with enterprise customers to accelerate their cloud journey. Beyond work, he is very passionate about nature and photography.
Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backward from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data system transformations across industry verticals. His core area of expertise include technology strategy, data analytics, and data science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla.
Today, we’re announcing Amazon ECS Managed Instances, a new compute option for Amazon Elastic Container Service (Amazon ECS) that enables developers to use the full range of Amazon Elastic Compute Cloud (Amazon EC2) capabilities while offloading infrastructure management responsibilities to Amazon Web Service (AWS). This new offering combines the operational simplicity of offloading infrastructure with the flexibility and control of Amazon EC2, which means customers can focus on building applications that drive innovation, while reducing total cost of ownership (TCO) and maintaining AWS best practices.
Customers running containerized workloads told us they want to combine the simplicity of serverless with the flexibility of self-managed EC2 instances. Although serverless options provide an excellent general-purpose solution, some applications require specific compute capabilities, such as GPU acceleration, particular CPU architectures, or enhanced networking performance. Additionally, customers with existing Amazon EC2 capacity investments through EC2 pricing options couldn’t fully use these commitments with serverless offerings.
Amazon ECS Managed Instances provides a fully managed container compute environment that supports a broad range of EC2 instance types and deep integration with AWS services. By default, it automatically selects the most cost-optimized EC2 instances for your workloads, but you can specify particular instance attributes or types when needed. AWS handles all aspects of infrastructure management, including provisioning, scaling, security patching, and cost optimization, enabling you to concentrate on building and running your applications.
Let’s try it out
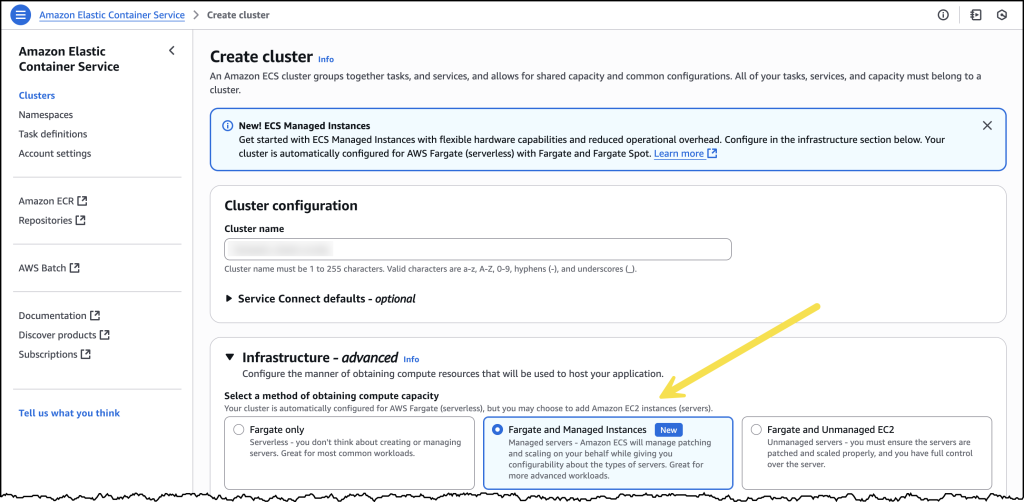
Looking at the AWS Management Console experience for creating a new Amazon ECS cluster, I can see the new option for using ECS Managed Instances. Let’s take a quick tour of all the new options.
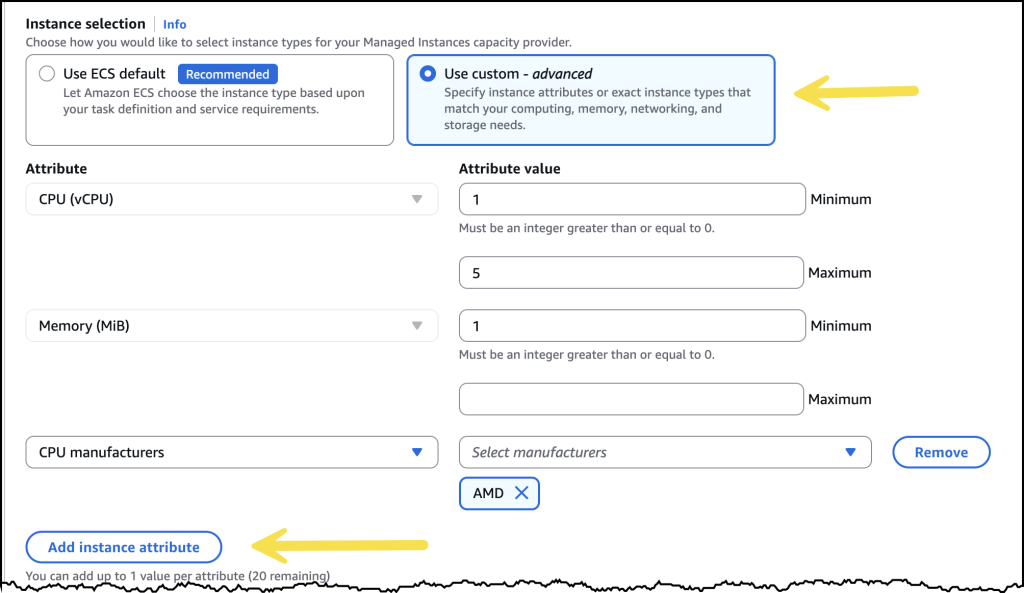
After I’ve selected Fargate and Managed Instances, I’m presented with two options. If I select Use ECS default, Amazon ECS will choose general purpose instance types based on grouping together pending Tasks, and picking the optimum instance type based on cost and resilience metrics. This is the most straightforward and recommended way to get started. Selecting Use custom – advanced opens up additional configuration parameters, where I can fine-tune the attributes of instances Amazon ECS will use.
By default, I see CPU and Memory as attributes, but I can select from 20 additional attributes to continue to filter the list of available instance types Amazon ECS can access.
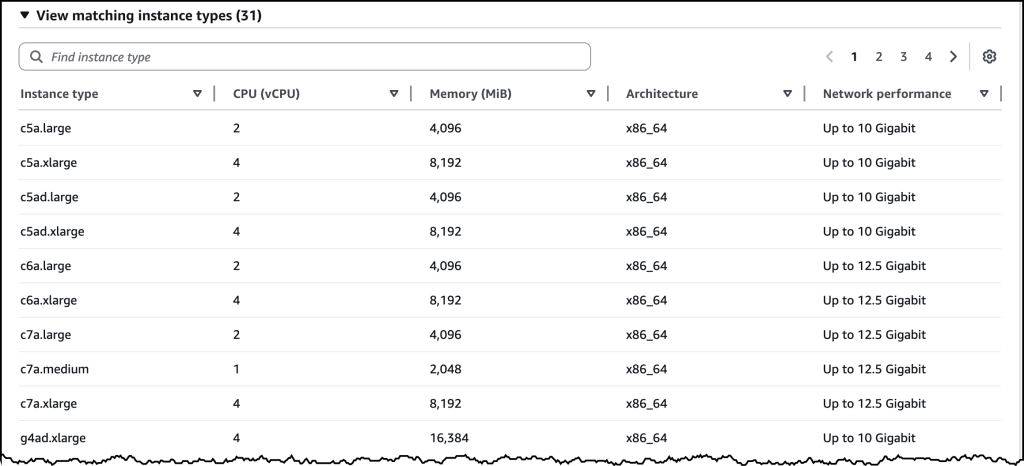
After I’ve made my attribute selections, I see a list of all the instance types that match my choices.
From here, I can create my ECS cluster as usual and Amazon ECS will provision instances for me on my behalf based on the attributes and criteria I’ve defined in the previous steps.
Key features of Amazon ECS Managed Instances
With Amazon ECS Managed Instances, AWS takes full responsibility for infrastructure management, handling all aspects of instance provisioning, scaling, and maintenance. This includes implementing regular security patches initiated every 14 days (due to instance connection draining, the actual lifetime of the instance may be longer), with the ability to schedule maintenance windows using Amazon EC2 event windows to minimize disruption to your applications.
The service provides exceptional flexibility in instance type selection. Although it automatically selects cost-optimized instance types by default, you maintain the power to specify desired instance attributes when your workloads require specific capabilities. This includes options for GPU acceleration, CPU architecture, and network performance requirements, giving you precise control over your compute environment.
To help optimize costs, Amazon ECS Managed Instances intelligently manages resource utilization by automatically placing multiple tasks on larger instances when appropriate. The service continually monitors and optimizes task placement, consolidating workloads onto fewer instances to dry up, utilize and terminate idle (empty) instances, providing both high availability and cost efficiency for your containerized applications.
Integration with existing AWS services is seamless, particularly with Amazon EC2 features such as EC2 pricing options. This deep integration means that you can maximize existing capacity investments while maintaining the operational simplicity of a fully managed service.
Security remains a top priority with Amazon ECS Managed Instances. The service runs on Bottlerocket, a purpose-built container operating system, and maintains your security posture through automated security patches and updates. You can see all the updates and patches applied to the Bottlerocket OS image on the Bottlerocket website. This comprehensive approach to security keeps your containerized applications running in a secure, maintained environment.
Available now
Amazon ECS Managed Instances is available today in US East (North Virginia), US West (Oregon), Europe (Dublin), Africa (Cape Town), Asia Pacific (Singapore), and Asia Pacific (Tokyo) AWS Regions. You can start using Managed Instances through the AWS Management Console, AWS Command Line Interface (AWS CLI), or infrastructure as code (IaC) tools such as AWS Cloud Development Kit (AWS CDK) and AWS CloudFormation. You pay for the EC2 instances you use plus a management fee for the service.
To learn more about Amazon ECS Managed Instances, visit the documentation and get started simplifying your container infrastructure today.
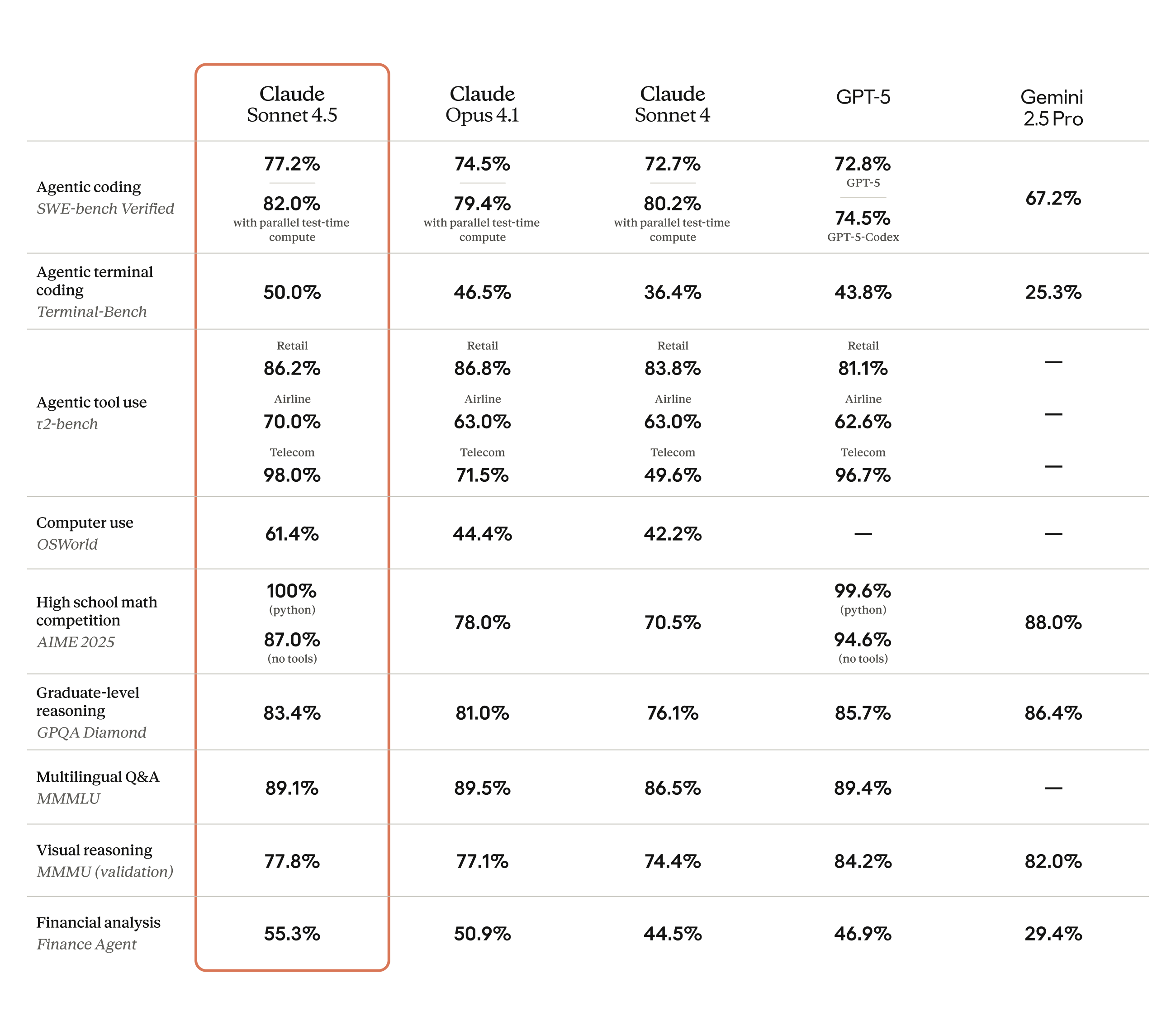
Today, we’re excited to announce that Claude Sonnet 4.5, powered by Anthropic, is now available in Amazon Bedrock, a fully managed service that offers a choice of high- performing foundation models from leading AI companies. This new model builds upon Claude 4’s foundation to achieve state-of-the-art performance in coding and complex agentic applications.
Claude Sonnet 4.5 demonstrates advancements in agent capabilities, with enhanced performance in tool handling, memory management, and context processing. The model shows marked improvements in code generation and analysis, from identifying optimal improvements to exercising stronger judgment in refactoring decisions. It particularly excels at autonomous long-horizon coding tasks, where it can effectively plan and execute complex software projects spanning hours or days while maintaining consistent performance and reliability throughout the development cycle.
By using Claude Sonnet 4.5 in Amazon Bedrock, developers gain access to a fully managed service that not only provides a unified API for foundation models but ensures their data stays under complete control with enterprise-grade tools for security, and optimization.
Claude Sonnet 4.5 also seamlessly integrates with Amazon Bedrock AgentCore, enabling developers to maximize the model’s capabilities for building complex agents. AgentCore’s purpose-built infrastructure complements the model’s enhanced abilities in tool handling, memory management, and context understanding. Developers can leverage complete session isolation, 8-hour long-running support, and comprehensive observability features to deploy and monitor production-ready agents from autonomous security operations to complex enterprise workflows.
Business applications and use cases Beyond its technical capabilities, Sonnet 4.5 delivers practical business value through consistent performance and advanced problem-solving abilities. The model excels at producing and editing business documents while maintaining reliable performance across complex workflows.
The model demonstrates strength in several key industries:
Cybersecurity – Claude Sonnet 4.5 can be used to deploy agents that autonomously patch vulnerabilities before exploitation, shifting from reactive detection to proactive defense.
Finance – Sonnet 4.5 handles everything from entry-level financial analysis to advanced predictive analysis, helping transform manual audit preparation into intelligent risk management.
Research – Sonnet 4.5 can better handle tools, context, and deliver ready-to-go office files to drive expert analysis into final deliverables and actionable insights.
Sonnet 4.5 features in the Amazon Bedrock API Here are some highlights of Sonnet 4.5 in the Amazon Bedrock API:
Smart Context Window Management – The new API introduces intelligent handling when AI models reach their maximum capacity. Instead of returning errors when conversations get too long, Claude Sonnet 4.5 will now generate responses up to the available limit and clearly indicate why it stopped. This eliminates frustrating interruptions and allows users to maximize their available context window.
Tool Use Clearing for Efficiency – Claude Sonnet 4.5 enables automatic cleanup of tool interaction history during long conversations. When conversations involve multiple tool calls, the system can automatically remove older tool results while preserving recent ones. This keeps conversations efficient and prevents unnecessary token consumption, reducing costs while maintaining conversation quality.
Cross-Conversation Memory – A new memory capability enables Sonnet 4.5 to remember information across different conversations through the use of a local memory file. Users can explicitly ask the model to remember preferences, context, or important information that persists beyond a single chat session. This creates more personalized and contextually aware interactions while keeping the information safe within the local file.
With these new capabilities for managing context, developers can build AI agents capable of handling long-running tasks at higher intelligence without hitting context limits or losing critical information as frequently.
Getting started To begin working with Claude Sonnet 4.5, you can access it through Amazon Bedrock using the correct model ID. A good practice is to use the Amazon Bedrock Converse API to write code once and seamlessly switch between different models, making it easier to experiment with Sonnet 4.5 or any of the other models available in Amazon Bedrock.
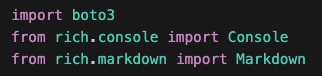
Let’s see this in action with a simple example. I’m going to use the Amazon Bedrock Converse API to send a prompt to Sonnet 4.5. I start by importing the modules I’m going to use. For this short example, I only need AWS SDK for Python (Boto3) so I can create a BedrockRuntimeClient. I’m also importing the rich package so I can format my output nicely later on.
Following best practices, I create a boto3 session and create an Amazon Bedrock client from it instead of creating one directly. This gives you explicit control over configuration, improves thread safety, and makes your code more predictable and testable compared to relying on the default session.
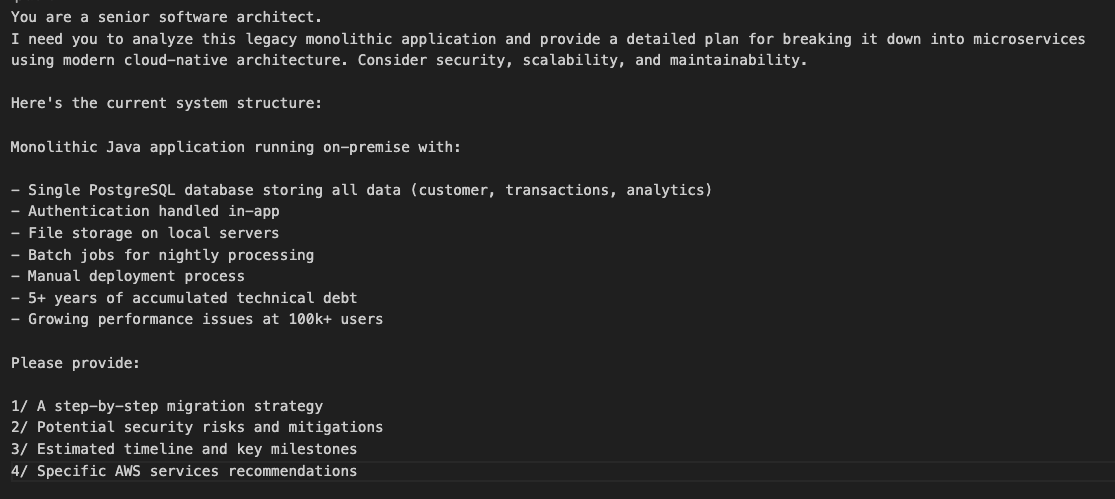
I want to give the model something with a bit of complexity instead of asking a simple question to demonstrate the power of Sonnet 4.5. So I’m going to give the model the current state of an imaginary legacy monolithic application written in Java with a single database and ask for a digital transformation plan which includes a migration strategy, risk assessment, estimated timeline and key milestones and specific AWS services recommendations.
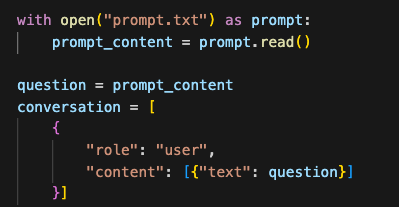
Because the prompt is quite long I put it in a text file locally and just load it up in code. I then set up the Amazon Bedrock converse payload setting the role to “user” to indicate that this is a message by the user of the application and add the prompt to the content.
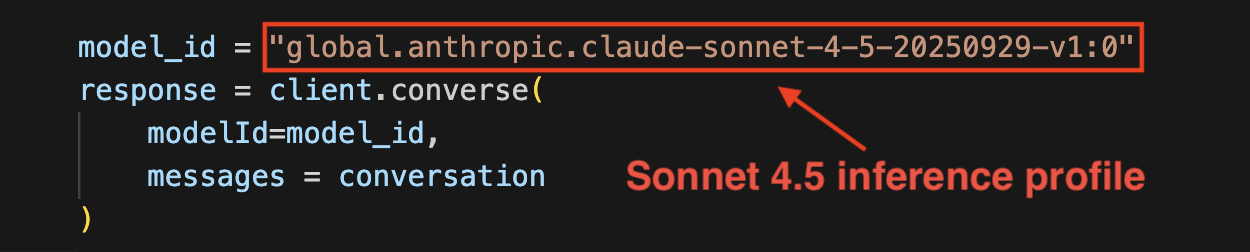
This is where the magic happens! We put it all together and call Claude Sonnet 4.5 using its model ID. Well, kind of. You can only access Sonnet 4.5 through an inference profile. This defines which AWS Regions will process your model requests and helps manage throughput and performance.
For this demo, I’ll be using one of Amazon Bedrock’s system-defined cross-Region inference profiles, which automatically routes requests across multiple Regions for optimal performance.
Now I just need to print to the screen to see the results. This is where I use the rich package I imported earlier just so we may have a nicely formatted output as I’m expecting a long response for this one. I also save the output to a file so I can have it handy as something to share with my teams.
Ok, let’s check the results! As expected, Sonnet 4.5 worked through my requirements and provided extensive and deep guidance for my digital transformation plan that I could start putting into practice. It included an executive summary, a step-by-step migration strategy split into phases with time estimates, and even some code samples to seed the development process and start breaking things down into microservices. It also provided the business cases for introducing technology and recommended the correct AWS services for each scenario. Here are some highlights from the report.
Claude Sonnet 4.5 is able to maintain consistency while delivering creative solutions making it an ideal choice for businesses seeking to use AI for complex problem-solving and development tasks. Its enhanced capabilities in following directions and using tools effectively translate into more reliable and innovative solutions across various business contexts.
Things to know Claude Sonnet 4.5 represents a significant step forward in agent capabilities, particularly excelling in areas where consistent performance and creative problem-solving are essential. Its enhanced abilities in tool handling, memory management, and context processing make it particularly valuable across key industries such as finance, research, and cybersecurity. Whether handling complex development lifecycles, executing long-running tasks, or tackling business-critical workflows, Claude Sonnet 4.5 combines technical excellence with practical business value.
To learn more about Amazon Bedrock explore our self-paced Amazon Bedrock Workshop and discover how to use available models and their capabilities in your applications.
Wow, can you all believe it? We’re nearing the end of the year already. Next thing you know, AWS re:Invent will be here! This is our biggest event that takes place every year in Las Vegas from December 1st to December 5th where we reveal and release many of the things that we’ve been working on. If you haven’t already, buy your tickets to AWS re:Invent 2025 to experience it in person. If you can’t make it to Vegas, don’t worry, make sure to stay tuned here on the AWS News Blog where will be covering many of the announcements as they happen.
However, there are plenty of new exciting new releases between now and then, so, as usual, let’s take a quick look at some of the highlights from last week so you can catch up on what’s been recently launched, starting with one of the most popular services: Amazon S3!
Last week was another S3 milestone with the addition of a preview in the AWS Console forAmazon S3 Tables. You can now take a quick peek at your S3 Tables right from the console, making it easier to understand their data structure and content without writing any SQL. This viewer-friendly feature is ready to use across all regions where S3 Tables are supported, with costs limited to just the S3 requests needed to display your table preview.
Other releases Here are some highlights from other services which also released some great stuff this week.
Amazon Bedrock AgentCore expands enterprise integration and automation options — Bedrock AgentCore services are leveling up their enterprise readiness with new support for Amazon VPC connectivity, AWS PrivateLink, AWS CloudFormation, and resource tagging, giving developers more control over security and infrastructure automation. These enhancements let you deploy AI agents that can securely access private resources, automate infrastructure deployment, and maintain organized resource management whether you’re using AgentCore Runtime for scalable agent deployment, Browser for web interactions, or Code Interpreter for secure code execution.
AWS X-Ray brings smart sampling for better error detection — AWS X-Ray now offers adaptive sampling that automatically adjusts trace capture rates within your defined limits, helping DevOps teams and SREs catch critical issues without oversampling during normal operations. The new capability includes Sampling Boost for increased sampling during anomalies and Anomaly Span Capture for targeted error tracing, giving teams better observability exactly when they need it while keeping costs in check.
AWS Clean Rooms enhances real-time collaboration wilth incremental ID mapping — AWS Clean Rooms now lets you update ID mapping tables with only new, modified, or deleted records through AWS Entity Resolution, making data synchronization across collaborators more efficient and timely. This improvement helps measurement providers maintain fresh datasets with advertisers and publishers while preserving privacy controls, enabling always-on campaign measurement without the need to reprocess entire datasets.
Short and sweet Here are some bite-sized updates that could prove really handy for your teams or workloads.
Keeping up with the latest EC2 instance types can be challenging. AWS Compute Optimizer now supports 99 additional instance types including the latest C8, M8, R8, and I8 families.
In competitive gaming, every millisecond counts! Amazon GameLift has launched a new Local Zone in Dallas bringing ultra-low latency game servers closer to players in Texas.
Don’t forget to check out all the upcoming AWS events happening across the globe. There are many exciting opportunities for you to attend free events where you can meet lots of people and learn a lot while enjoying a great day amongst other like-minded people in the tech industry.
And if you feel like competing for some cash, time is running out to be part of something extraordinary! The AWS AI Agent Global Hackathon continues until October 20, offering developers a unique opportunity to build innovative AI agents using AWS’s comprehensive gen AI stack. With over $45,000 in prizes and exclusive go-to-market opportunities up for grabs, don’t miss the chance to showcase your creativity and technical prowess in this global competition.
I hope you have found something useful or exciting within this last week’s launches. We post a weekly review every Monday to help you keep up with the latest from AWS so make sure to bookmark this and hopefully see you for the next one!
Today, I’m excited to announce the Nova Act extension — a tool that streamlines the path to build browser automation agents without leaving your IDE. The Nova Act extension integrates directly into IDEs like Visual Studio Code (VS Code), Kiro, and Cursor, helping you to create web-based automation agents using natural language with the Nova Act model.
Here’s a quick look at the Nova Act extension in Visual Studio Code:
The Nova Act extension is built on top of the Amazon Nova Act SDK (preview), our browser automation agents SDK (Software Development Kit). The Nova Act extension transforms traditional workflow development by eliminating context switching between coding and testing environments. You can now build, customize, and test production-grade agent scripts—all within your IDE—using features like natural language based generation, atomic cell-style editing, and integrated browser testing. This unified experience accelerates development velocity for tasks like form filling, QA automation, search, and complex multi-step workflows.
You can start with the Nova Act extension by describing your workflow in natural language to quickly generate an initial agent script. Customize it using the notebook-style builder mode to integrate APIs, data sources, and authentication, then validate it with local testing tools that simulate real-world conditions, including live step-by-step debugging of lengthy multi-step workflows.
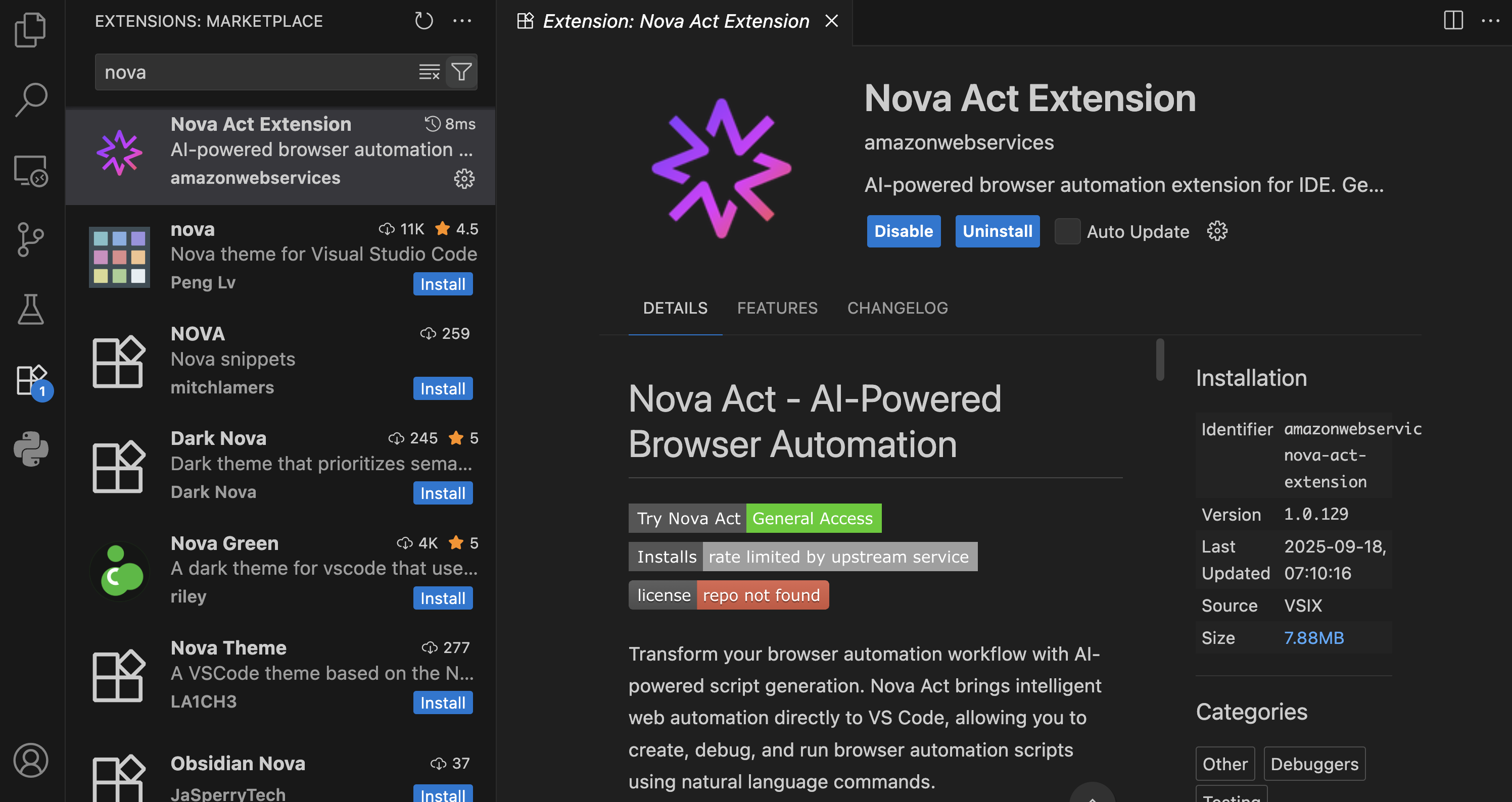
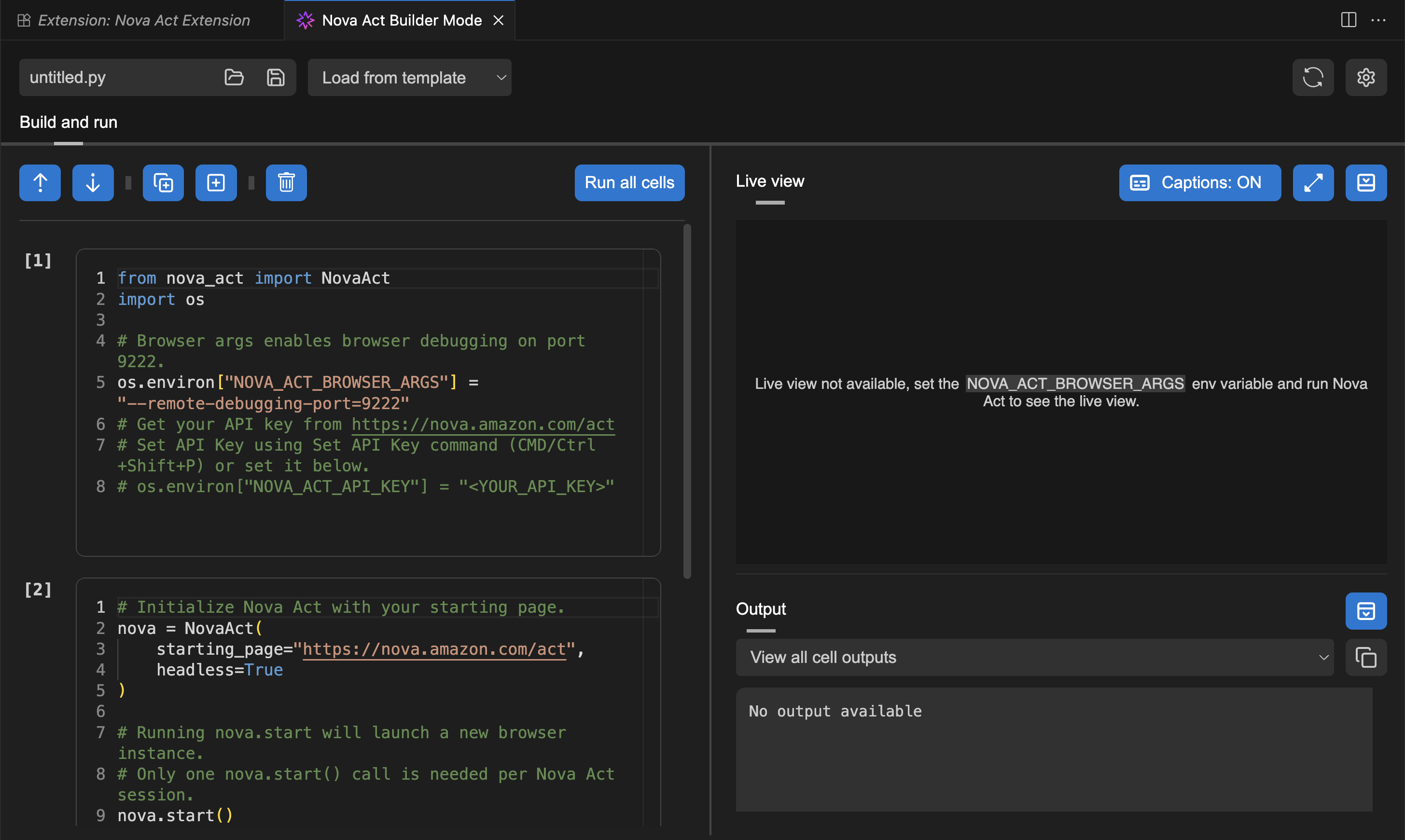
Getting started with the Nova Act extension First, I need to install the Nova Act extension from the extension manager in my IDE.
I’m using Visual Studio Code, and after choosing Extensions, I enter Nova Act. Then, I select the extension and choose Install.
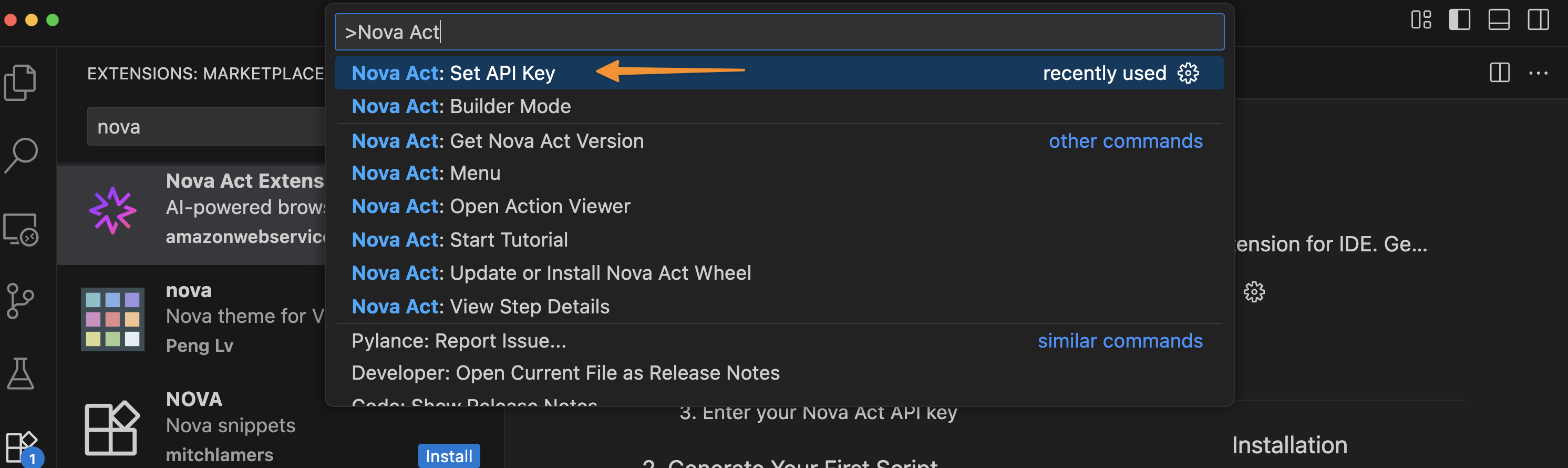
To get started, I need to obtain an API key. To do this, I navigate to the Nova Act page and follow the instructions to get the API key. I select Set API Key by opening the Command Palette with Cmd+Shift+P / Ctrl+Shift+P.
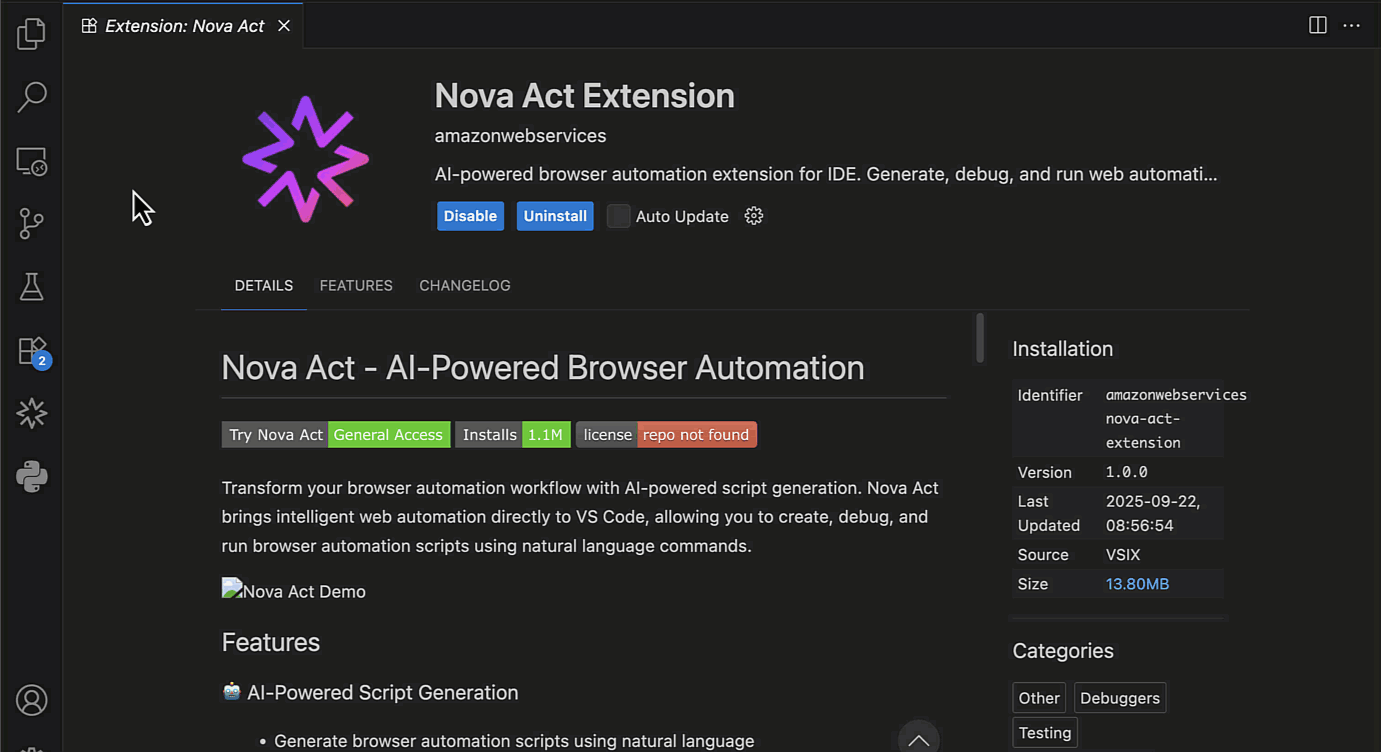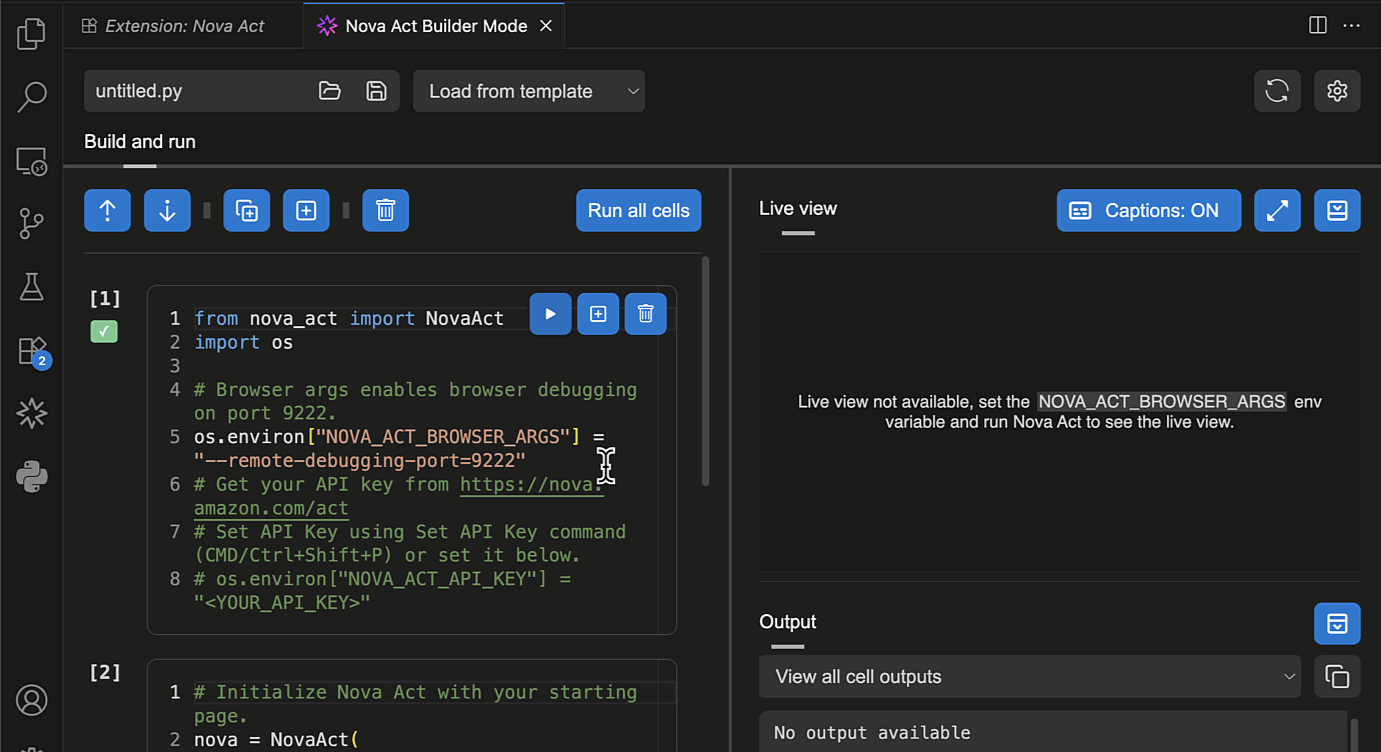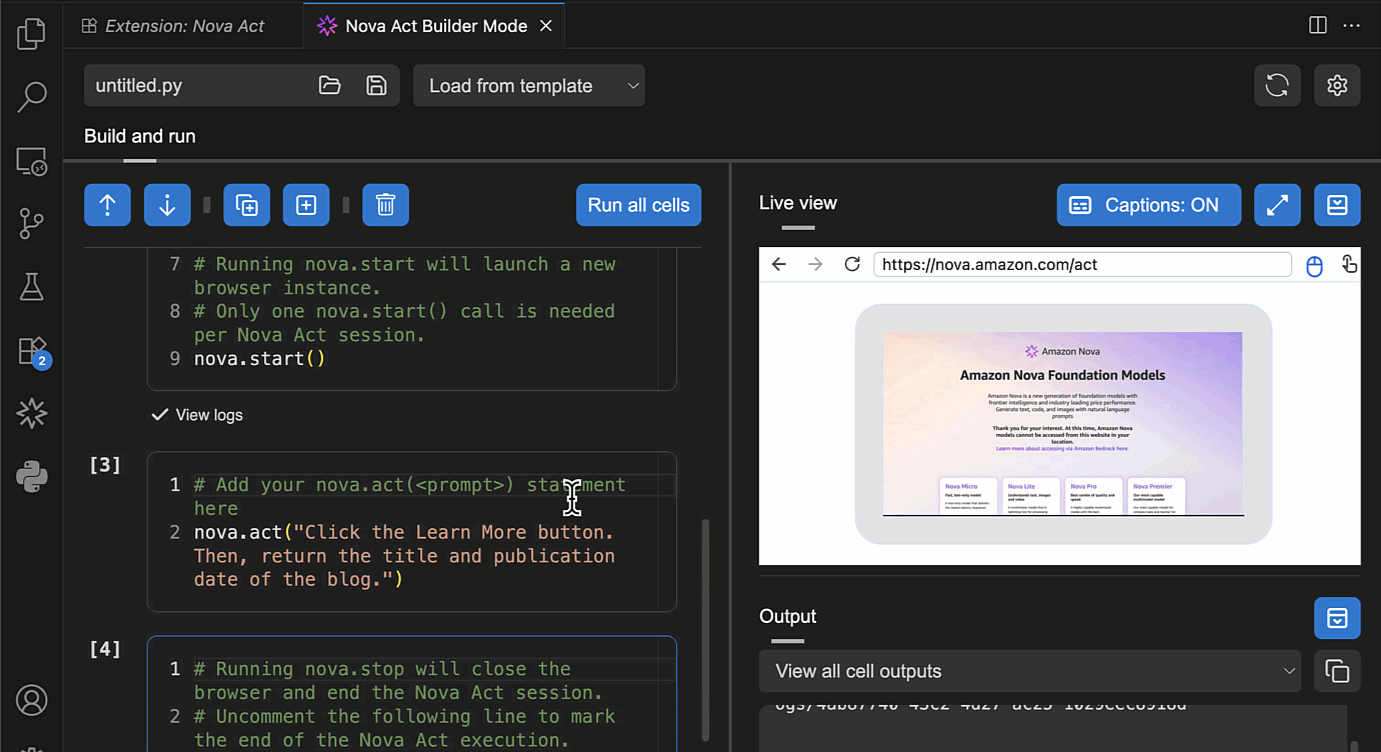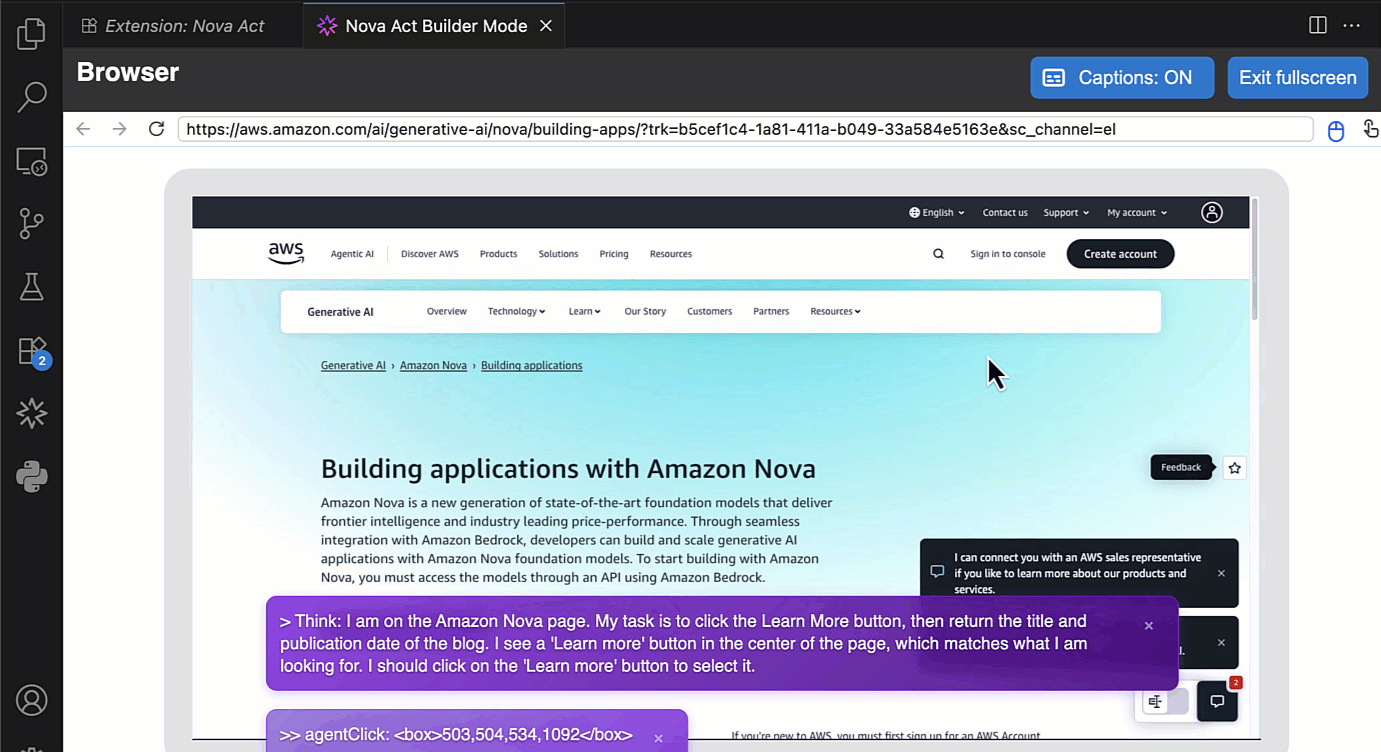
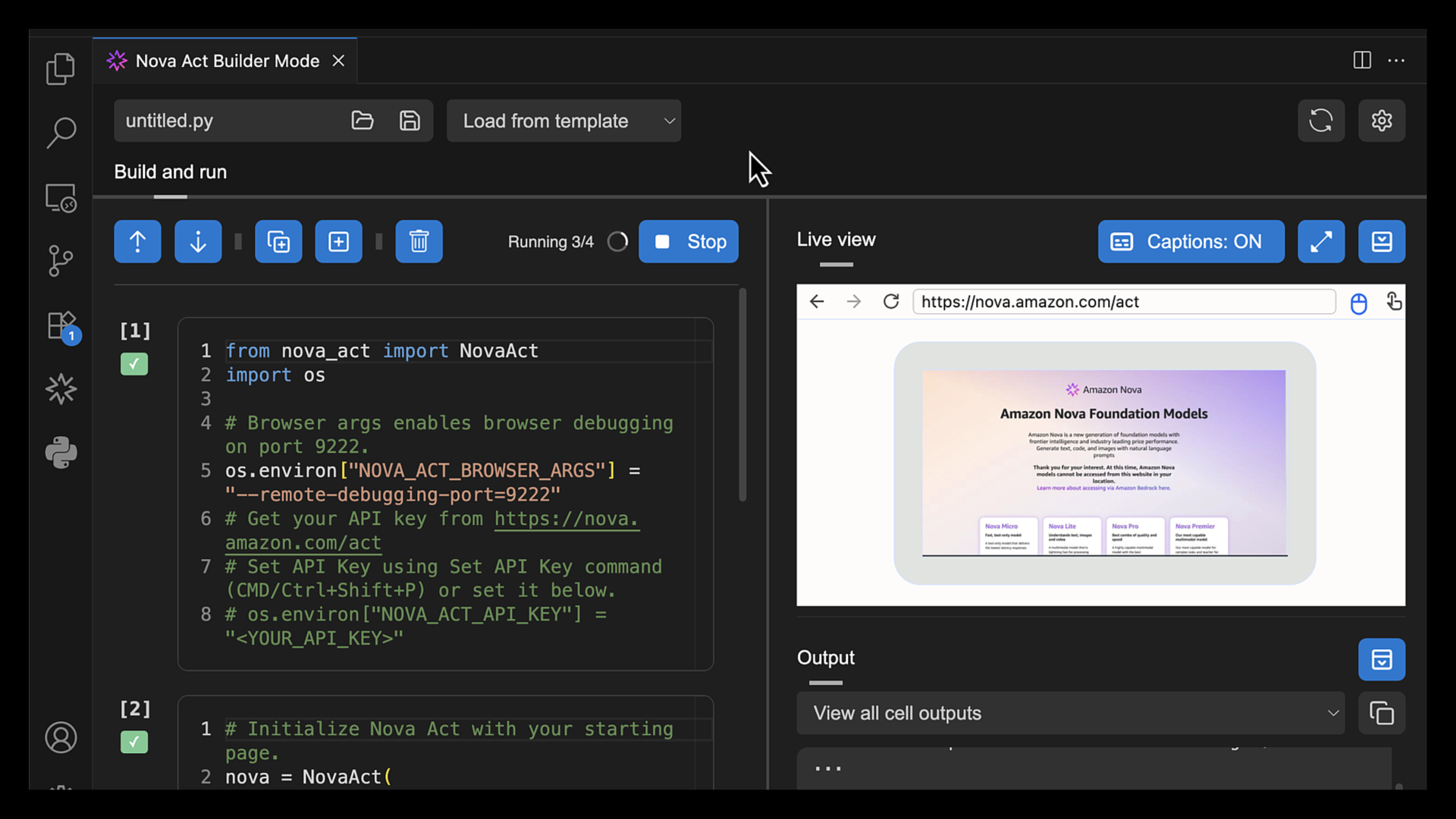
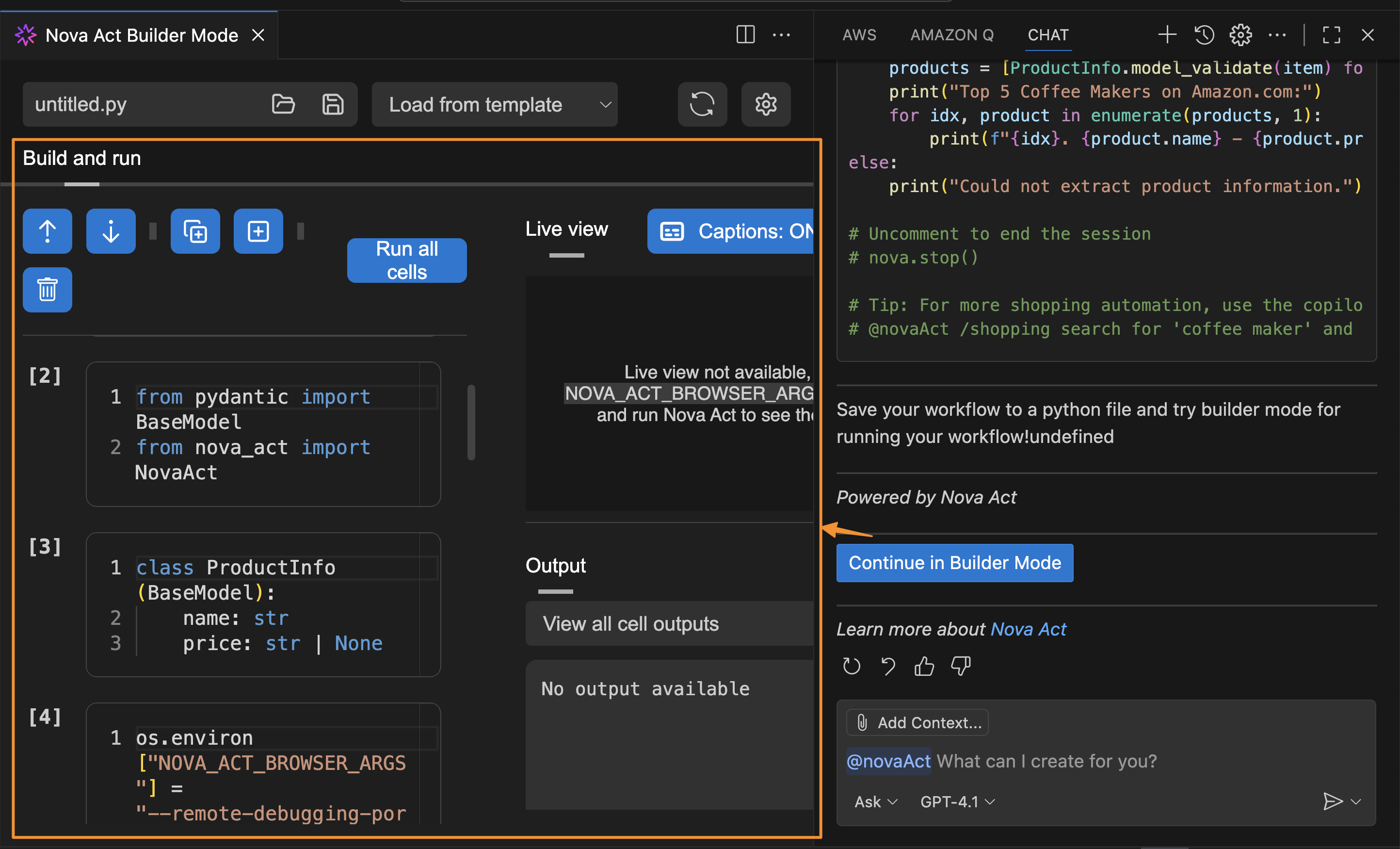
After I’ve entered my API key, I can try Builder Mode. This is a notebook-style builder mode that breaks complex automation scripts into modular cells, allowing me to test and debug each step individually before moving to the next.
Here, I can use the Nova Act SDK to build my agent. On the right side, I have a Live view panel to preview my agent’s actions in the browser and an Output panel to monitor execution logs, including the model’s thinking and actions.
To test the Nova Act extension, I choose Run all cells. This will start a new browser instance and act based on the given prompt.
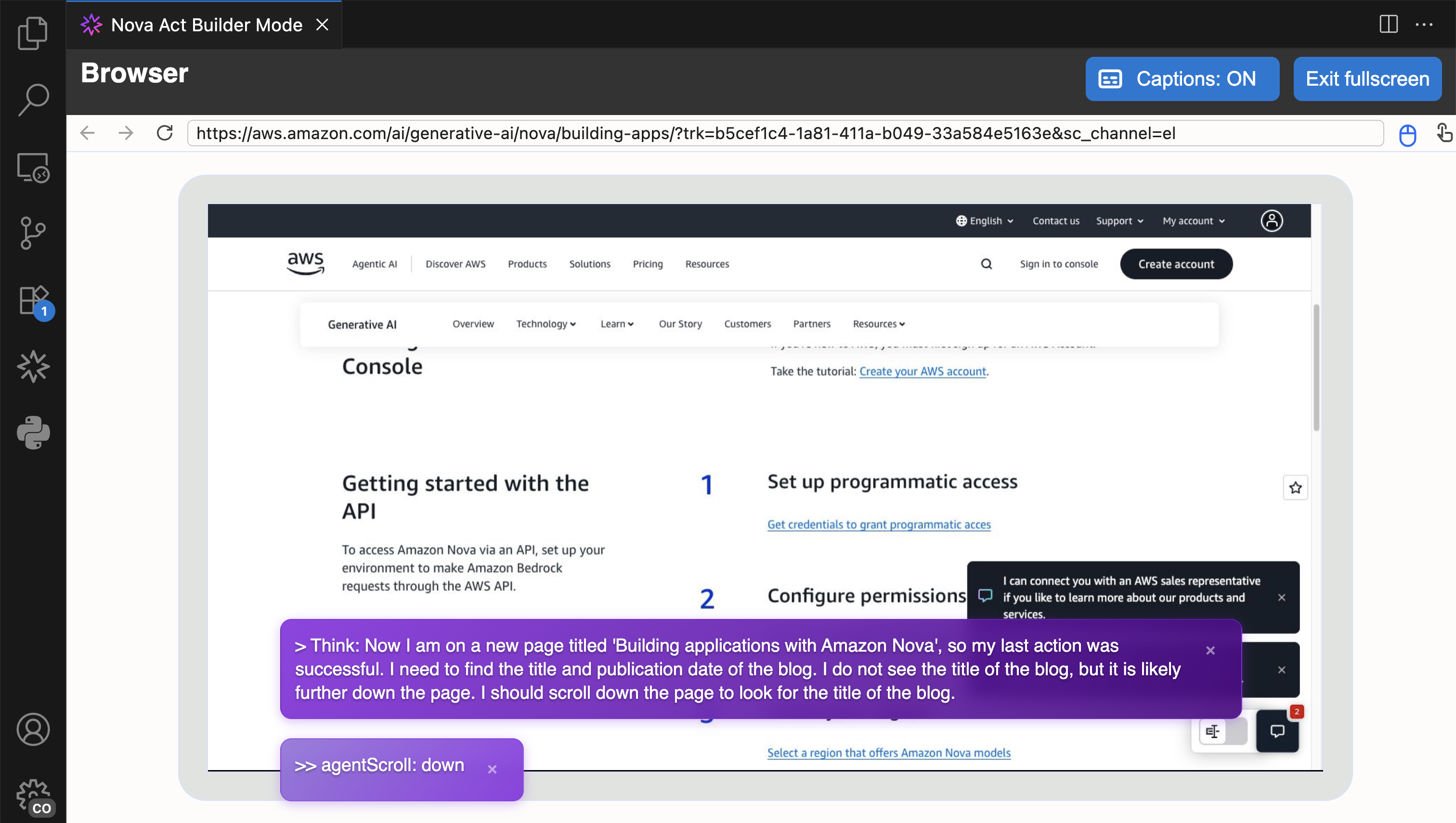
I choose Fullscreen to see how browser automation works.
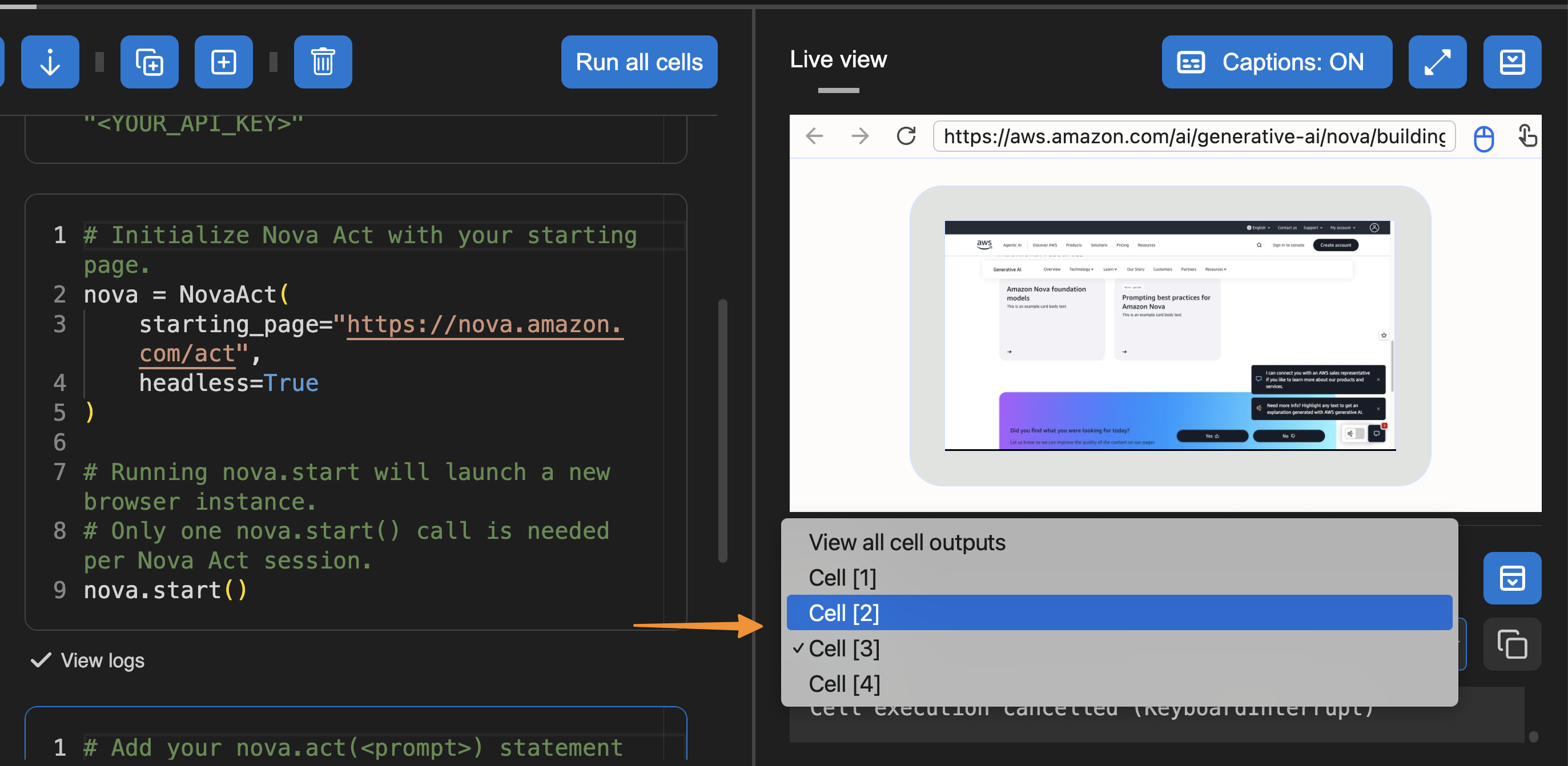
Another useful feature in Builder Mode is that I can navigate to the Output panel and select the cell to see its logs. This helps me debug or review logs specific to the cell I’m working on.
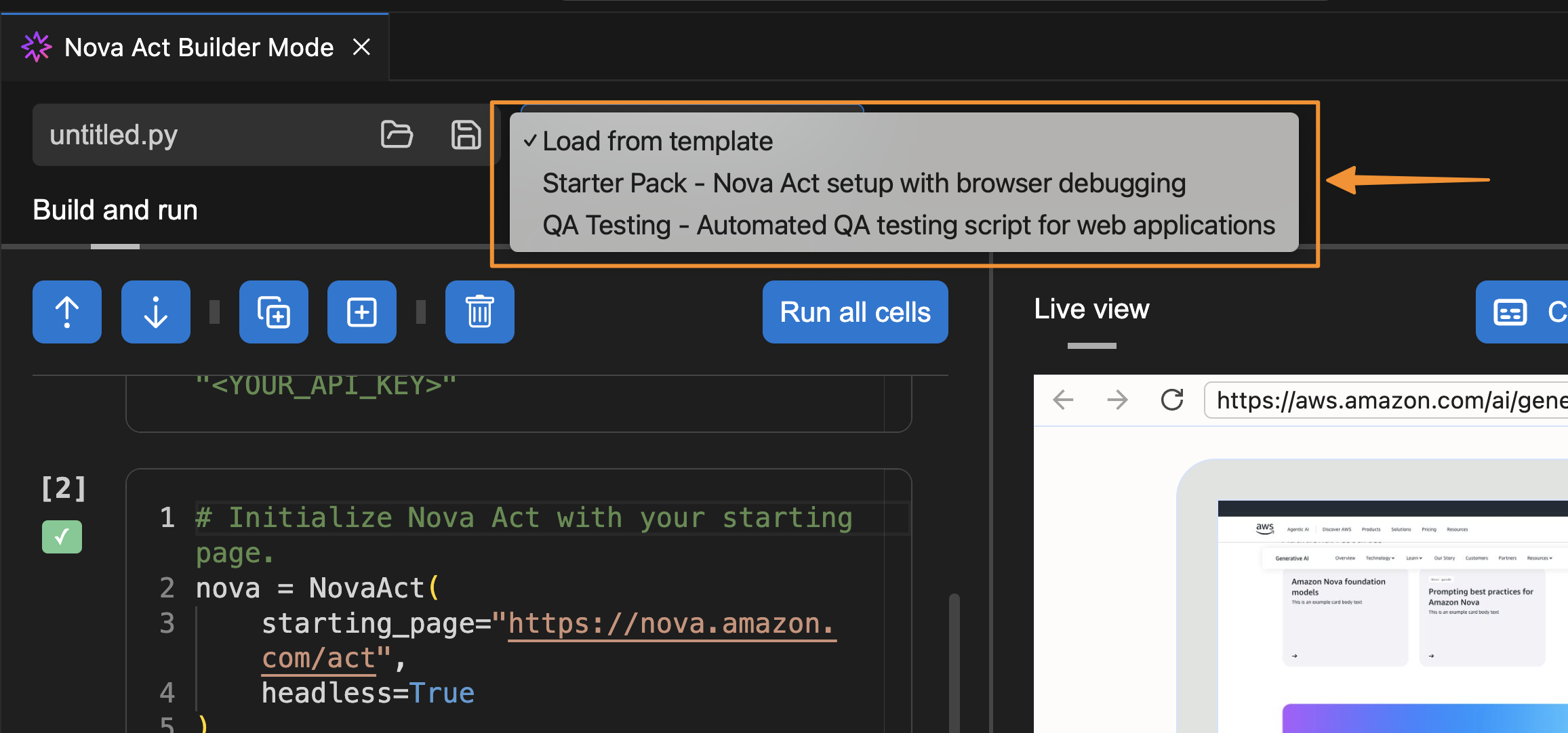
I can also select a template to get started.
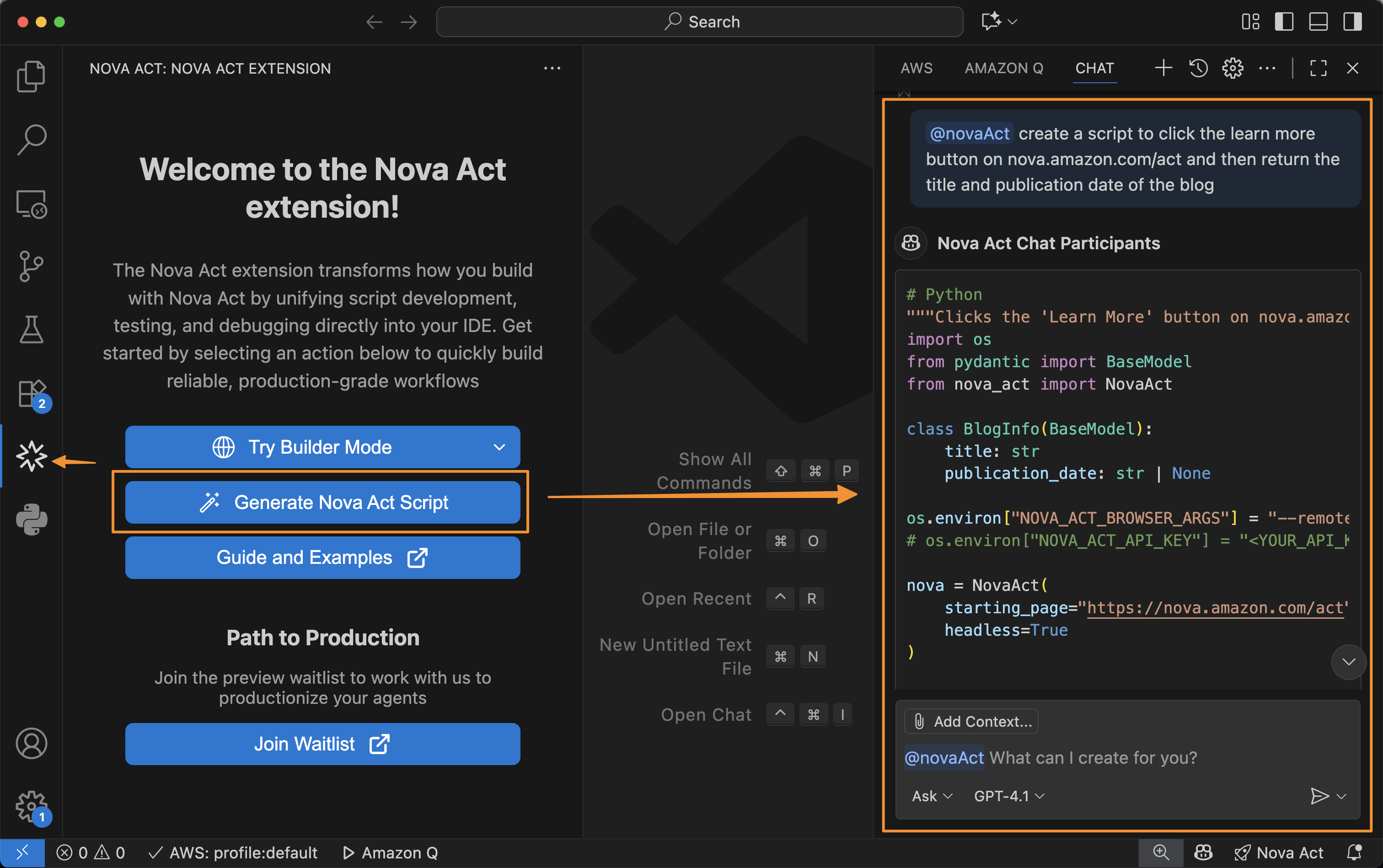
Besides using Builder Mode, I can also chat with Nova Act to create a script for me. To do that, I select the extension and choose Generate Nova Act Script. The Nova Act extension opens a chat dialog in the right panel and automatically creates a script for me.
After I finish creating the script, I can choose Start Builder Mode, and the Nova Act extension will help me create a Python file in Builder Mode. This creates a seamless integration because I can switch between chat capability and Builder Mode.
In the chat interface, I see three workflow modes available:
Ask: Describe tasks in natural language to generate automation scripts
Edit: Refine or customize generated scripts before execution
Agent: Run, monitor, and interact with the AI agent performing the workflow
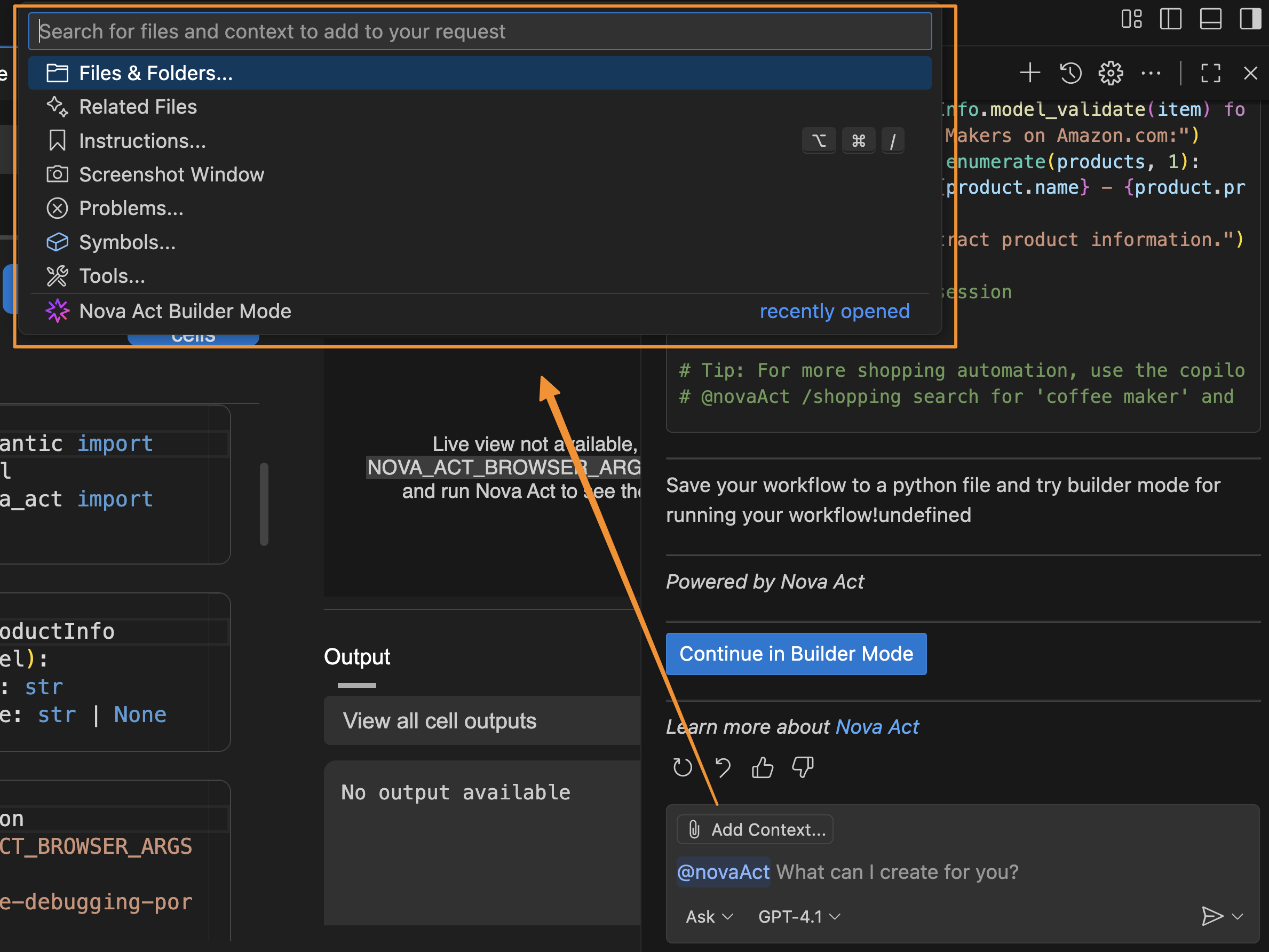
I can also add Context to provide relevant information about my active documents, instructions, problems, or additional Model Context Protocol (MCP) resources the agent can use, plus a screenshot of the current window. Providing this information helps the agent understand any specific requirements for the automation task.
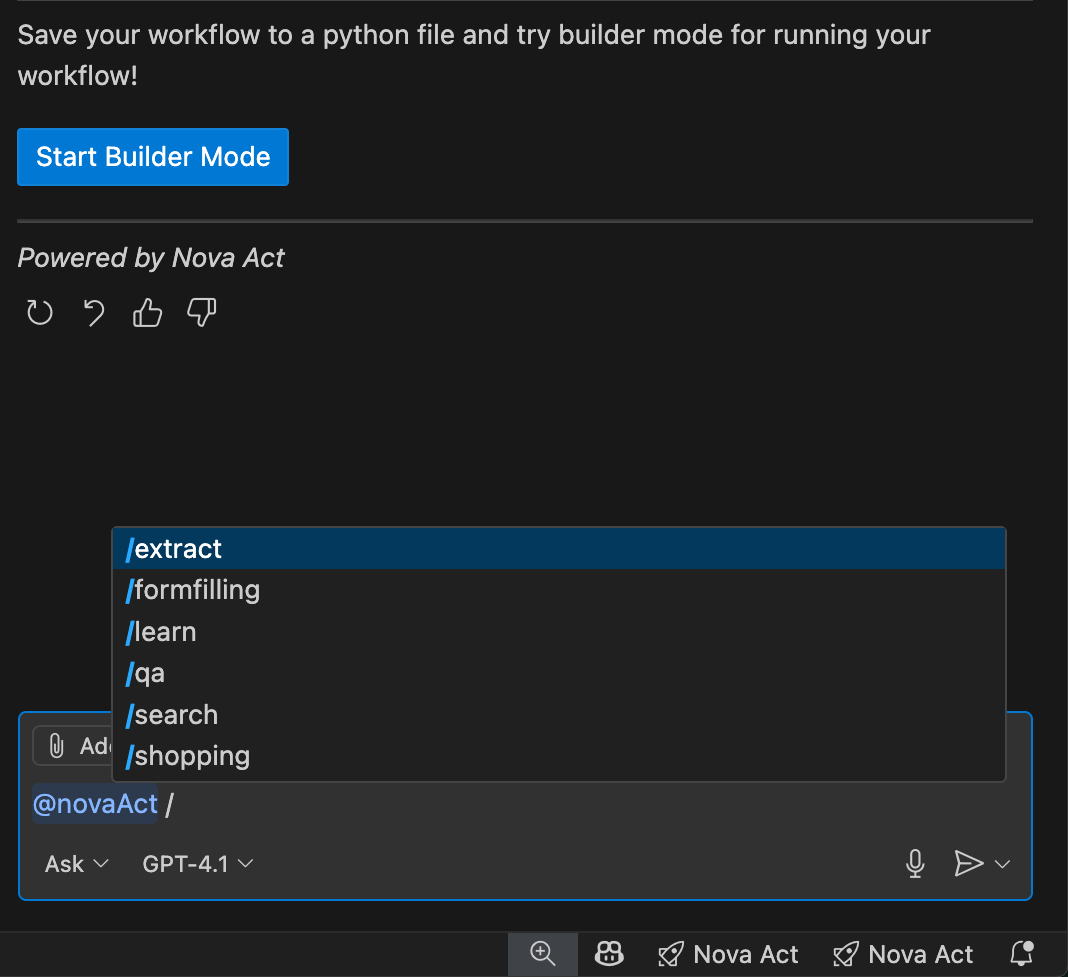
The Nova Act extension also provides a set of predefined templates that I can access by entering / in the chat. These templates are predefined automation scenarios designed to help quickly generate scripts for common web tasks.
I can use these templates (for example, @novaAct /shopping [my requirements]) to get tailored Python scripts for my workflow. At launch, Nova Act extension provides the following templates:
/search: Performs search and information gathering
/qa: Automates quality assurance and testing workflows
/formfilling: Completes forms and data entry tasks
This extension transforms my agent development workflow by positioning Nova Act extension as a full-stack agent builder tool—a complete agent IDE for the entire development lifecycle. I can prototype with natural language, customize with modular scripting, and validate with local testing—all without leaving my IDE—ensuring production-grade scripts.
Things to know Here are key points to note:
Supported IDEs: At launch, the Nova Act extension is available for Visual Studio Code, Cursor, and Kiro, with additional IDE support planned
Open source: The Nova Act extension is available under the Apache 2.0 license, allowing for community contributions and customization
Pricing: The Nova Act extension is available at no charge.
Get started with Nova Act extension by installing it from your IDE’s extension marketplace or visiting the GitHub repository for documentation and examples.
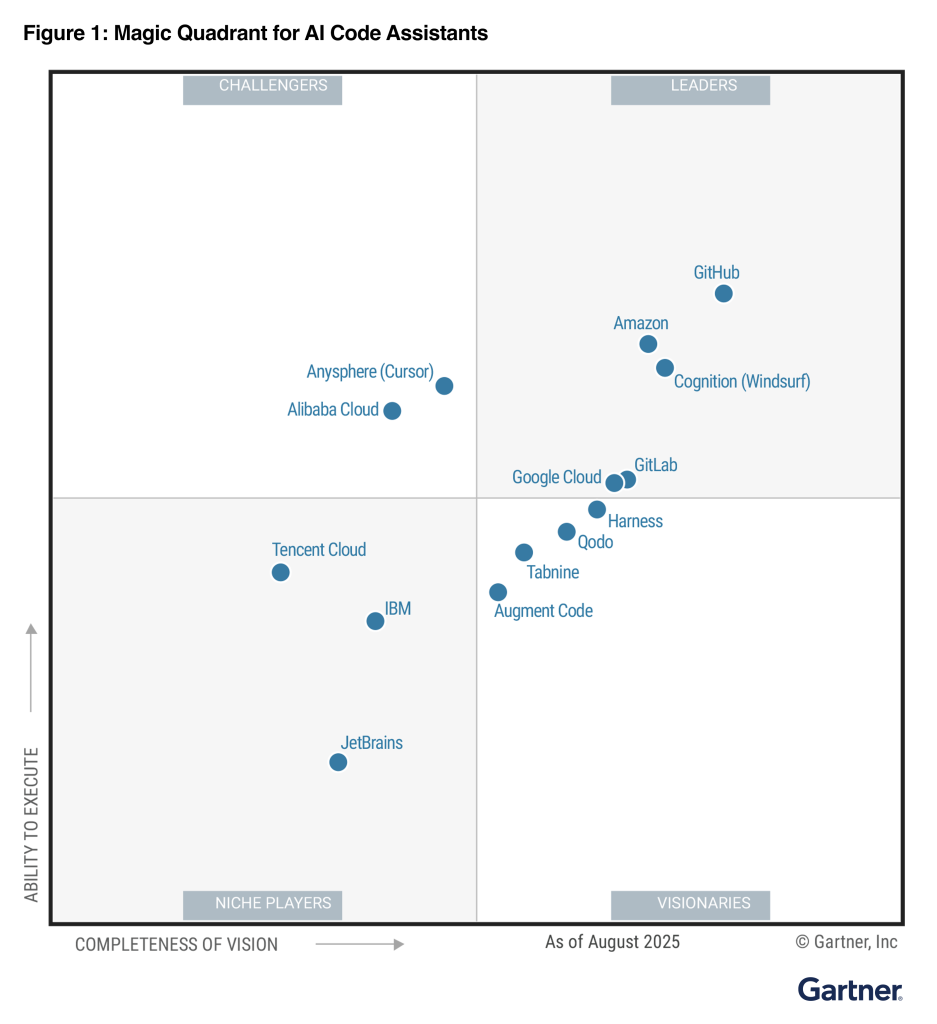
We are excited to share that AWS has been named a Leader in the 2025 Gartner Magic Quadrant for AI Code Assistants for the second year in row. This recognition highlights for us Amazon Q Developer’s commitment to innovation and delivering exceptional customer experiences. We believe this Leader placement showcases our rapid pace of innovation, which makes the whole software development lifecycle easier and increases developer productivity with enterprise-grade access controls and security. We are honored to be recognized by Gartner and are committed to continuing to innovate on behalf of our customers.
The Gartner Magic Quadrant evaluated AI code assistant providers based on their Ability to Execute and Completeness of Vision. Our innovations throughout the software life cycle (SDLC) include code generation, troubleshooting, transformation, cost optimization, and vulnerability scanning.
Leaders in this Magic Quadrant for AI Code Assistants continue to set the benchmark for end-to-end developer enablement through advanced AI capabilities. They consistently integrate cutting-edge models into robust, agentic workflows that enhance productivity, code quality, and security across the SDLC. These vendors exhibit a sharp understanding of enterprise needs, translating customer feedback into iterative improvements and differentiated innovation — such as long-context reasoning, hybrid deployment flexibility, and seamless integration across IDEs and DevSecOps platforms. Leaders also stand out through their operational maturity, supporting global enterprises with scalable infrastructure, regulatory compliance, and strong service-level reliability. Their growing ecosystems, deepening product integration, and strategic clarity ensure sustained influence across diverse developer and enterprise environments.
Amazon Web Service (AWS) recently announced that AWS Organizations now offers full AWS Identity and Access Management (IAM) policy language support for service control policies (SCPs). With this feature, you can use conditions, individual resource Amazon Resource Names (ARNs), and the NotAction element with Allow statements. Additionally, you can now use wildcards at the beginning or middle of the Action element strings and implement the NotResource element in both Allow and Deny statements in SCPs. This feature is now available across AWS commercial and AWS GovCloud (US) Regions.
In this blog post, we walk through a set of newly supported SCP language capabilities that simplify permission management cases. These enhancements enable more intuitive and concise policy designs. We explore how these capabilities address past limitations to reduce operational overhead and improve policy readability. We also show what the previous implementation looked like and provide an example of how the new capability makes the intent clearer and implementation simpler.
Overview of the newly supported elements
The following table lists the supported SCP language elements along with their purpose and applicable effects. Elements and effects shown in bold indicate newly supported capabilities.
Specifies the conditions for when the statement is in effect.
Allow, Deny
Additionally, you can now use the wildcard characters * and ? anywhere in the Action or NotAction element. Previously, these wildcards were only allowed by themselves or at the end of an element. For example, all of the following are now valid:
"servicename:action*"
"servicename:*action"
"servicename:some*action"
"servicename:*"
Navigating new SCP language capabilities
Let’s explore recommended policy strategies and best practices by walking through some examples.
Using Deny with NotResource
You can use the NotResource element to apply a policy across resources except those explicitly listed. This is especially useful for implementing broad deny-by-default policies with scoped exceptions, simplifying policy structure while enforcing strong boundaries.
Example 1:
The goal of this example is to enforce a resource perimeter that blocks access to resources outside the organization, except for a defined set of service-owned resources.
Previous implementation: The policy used a tag-based approach to manage exceptions. It required tagging IAM principals with dp:exclude:resource:s3=true to grant access to external resources. This created operational overhead in tag management and introduced potential security risks if tags were incorrectly applied.
Improved implementation: With support for NotResource in Deny statements, the updated SCP uses a single, consolidated Deny statement denying the action except for a defined set of AWS-owned resources.
This example denies access to Amazon Bedrock models except for one specific model.
Before this change: SCP relied on a broad permission baseline for AWS accounts within the organization by allowing access to Amazon Bedrock actions by default, while explicitly denying invocation of three specific models (examples: Deepseek, Anthropic, and meta). However, this approach requires continuous operational overhead to make sure policies are updated to deny access to newly added models to avoid exposure to potentially unwanted models.
Improved implementation: With support for NotResource in Deny statements, the updated SCP uses a single, consolidated Deny statement that denies actions except Amazon models.
By using the Condition element, you can specify the circumstances under which a policy statement is in effect. While optional, this element is now supported in Allow statements within SCPs, enabling more precise and scalable access control.
Note: We recommend using explicit Deny statements when authoring SCPs in most cases. Using Deny statements help make sure that each control works independently and remains enforceable. Relying solely on allow statements and the implicit deny-by-default model can lead to unintended access, because broader or overlapping Allow statements can override more restrictive ones.
The following example allows access to specific AWS services in certain AWS Regions.
Before this change: The policy uses a single Allow statement under the Sid: AllowSpecificServices. It lists broad service-level actions (for example, "ec2:", "s3:", and so on) in the Action element and applies them across resources ("Resource": "*"). Because AWS SCPs operate under a deny-by-default model, this setup effectively permits actions across the listed services while implicitly denying access to other services not included. For example, an explicit Deny restricts actions outside us-east-1, us-west-2, and eu-central-1 using a Region condition.
Improved implementation: In the updated example, the policy allows the same services, but only when they are requested in specific Regions (for example, "us-east-1", "us-west-2", and "eu-central-1"). This is achieved using the aws:RequestedRegion condition key in the Allow statement. This enhancement allows organizations to retain basic Allow logic while introducing contextual boundaries—such as limiting access by Region, account, or resource tag—previously only possible with Deny conditions.
Note: We recommend using one broad Allow statement and multiple targeted Deny statements in your policies. Avoid writing additional Allow statements that might overlap, because doing so could lead to unintended access. The recommended approach is to start with a broad Allow statement and then use Deny statements to refine and restrict access as needed.
Policy structure before support for Allow with conditions
Policy structure after support for Allow with conditions
To bring SCPs to full IAM policy language support, additional elements are now supported. While technically valid, some of these constructs require additional considerations and testing in practice because of their potential for unintended access if not carefully managed.
Newly supported feature
Important considerations
Action with wildcards (*, ?)
Can help shorten policies but use with caution—new actions added by AWS will match existing wildcard patterns as designed, potentially granting unintended permissions.
NotAction with wildcards (*, ?)
We recommend using NotAction with a Deny statement if you want to deny all actions except those listed, which helps future-proof your controls (for example, denying everything in Amazon EC2 except actions that don’t match “*vpn*”.
Allow with NotResource
Limited use cases. While supported, Allow with NotResource can default to including all resources—potentially allowing access to new resources added later. Use with caution and prefer explicit Deny statements when possible.
Allow with NotAction
Limited use cases. While supported, Allow with NotAction can unintentionally permit access to new actions added by AWS. Use with caution and prefer explicit Deny statements to maintain control as services evolve.
Allow with Resource other than wildcard “*”.
When using Allow with specific resources (not "*"), make sure your policy design avoids conflicting or overlapping Allow statements. Start with a broad Allow, then use targeted Deny statements to restrict access—this helps prevent unintended access from overlapping Allow statements.
Validate your policies with IAM Access Analyzer
You can use AWS IAM Access Analyzer to validate your SCPs before applying them, using both policy validation and custom policy checks.
IAM Access Analyzer validates your policy against IAM policy grammar and best practices. You can view policy validation check findings that include security warnings, errors, general warnings, and suggestions. These findings provide actionable recommendations to help you author policies that are both functional and aligned with security best practices.
Custom policy checks are an IAM Access Analyzer capability that security teams can use to help them accurately and proactively identify critical permissions in their policies. Custom policy checks can determine whether a new version of a policy is more permissive than the previous version. They use automated reasoning—a form of static analysis—to provide a higher level of security assurance in the cloud.
Custom policy checks can be embedded into continuous integration and continuous delivery (CI/CD) pipelines, so that policies can be checked without being deployed. Developers can also run custom policy checks from their local development environments and receive fast feedback on whether the policies they are authoring comply with your organization’s security standards. For more information refer to introducing IAM Access Analyzer custom policy checks.
Conclusion
The latest enhancements to AWS service control policies improve policy expressiveness and precision while reducing operational effort. By enabling constructs like Allow with conditions and specific resource ARNs, supporting NotResource in Deny statements, and expanding wildcard flexibility, you can simplify your policies and avoid layered or complex policies to achieve your goals. These updates bring SCPs in parity with IAM policy capabilities and empower organizations to implement cleaner, more intuitive access controls. As a best practice, it’s important to use these capabilities carefully—especially wildcard use—to avoid unintended permissions as AWS services evolve. We also encourage the implementation of explicit Deny statements as a best practice and using Allow statements when needed.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Amazon Web Services (AWS) is pleased to announce that the Summer 2025 System and Organization Controls (SOC) 1 report is now available. The report covers 183 services over the 12-month period from July 1, 2024 to June 30, 2025, giving customers a full year of assurance. The reports demonstrate our continuous commitment to adhering to the heightened expectations of cloud service providers.
AWS strives to continuously bring services into the scope of its compliance programs to help customers meet their architectural and regulatory needs. You can view the current list of services in scope on our Services in Scope page. As an AWS customer, you can reach out to your AWS account team if you have any questions or feedback about SOC compliance.
To learn more about AWS compliance and security programs, see AWS Compliance Programs. As always, we value feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
Amazon OpenSearch Ingestion is a powerful data ingestion pipeline that AWS customers use for many different purposes, such as observability, analytics, and zero-ETL search. Many customers today push logs, traces, and metrics from their applications to OpenSearch Ingestion to store and analyze this data.
Today, we are happy to announce that OpenSearch Ingestion pipelines now support cross-account ingestion for push-based sources such as HTTP and OpenTelemetry (OTel). Organizations can now use this feature to effortlessly share data across teams. For example, many organizations have central observability teams—now these teams can create OpenSearch Ingestion pipelines and share them with other teams in their organization. You can also use this feature to ingest data into Amazon OpenSearch Service domains or Amazon OpenSearch Serverless collections in other accounts.
Previously, sharing OpenSearch Ingestion pipelines across accounts required teams to use virtual private cloud (VPC) features to share access. For example, teams could use VPC peering, which is not always feasible, or AWS Transit Gateway. The new cross-account ingestion features in OpenSearch Ingestion can simplify your deployment and reduce cost for sharing pipelines.
Solution overview
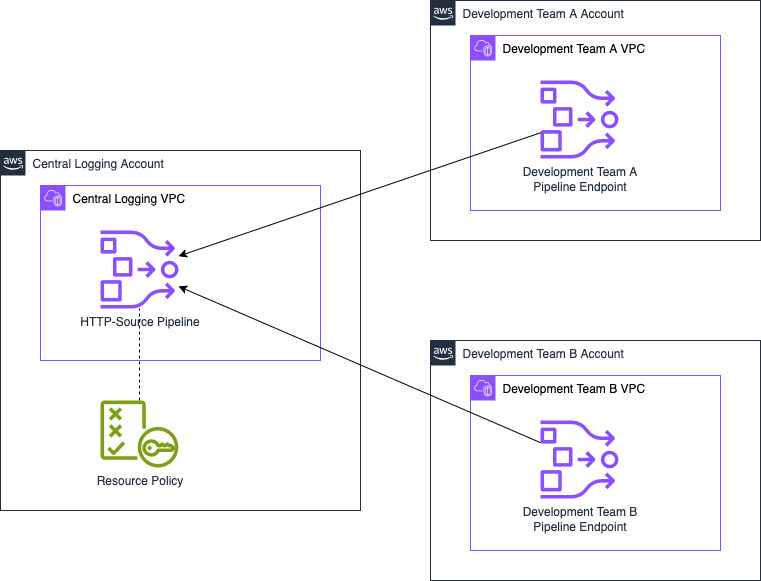
Let’s look at how to share a pipeline from a central logging account with two other development accounts (A and B). The central logging account can create an OpenSearch Ingestion pipeline using a push-based source, for example, HTTP. After creating the pipeline, a member of the central logging team can grant access to the other teams. They can use a resource policy that gives permissions to the two other team accounts to create pipeline endpoints. After making this change, the OpenSearch Ingestion pipeline is available for use by the other teams.
The following diagram illustrates this configuration.
In the following sections, we demonstrate how to implement this solution.
Prerequisites
First, the central logging account must have a VPC with two options enabled.
The development accounts that are going to connect to the pipeline also must have VPCs in the same region with the same DNS options enabled.
enableDnsSupport must be set to true
enableDnsHostnames must be set to true
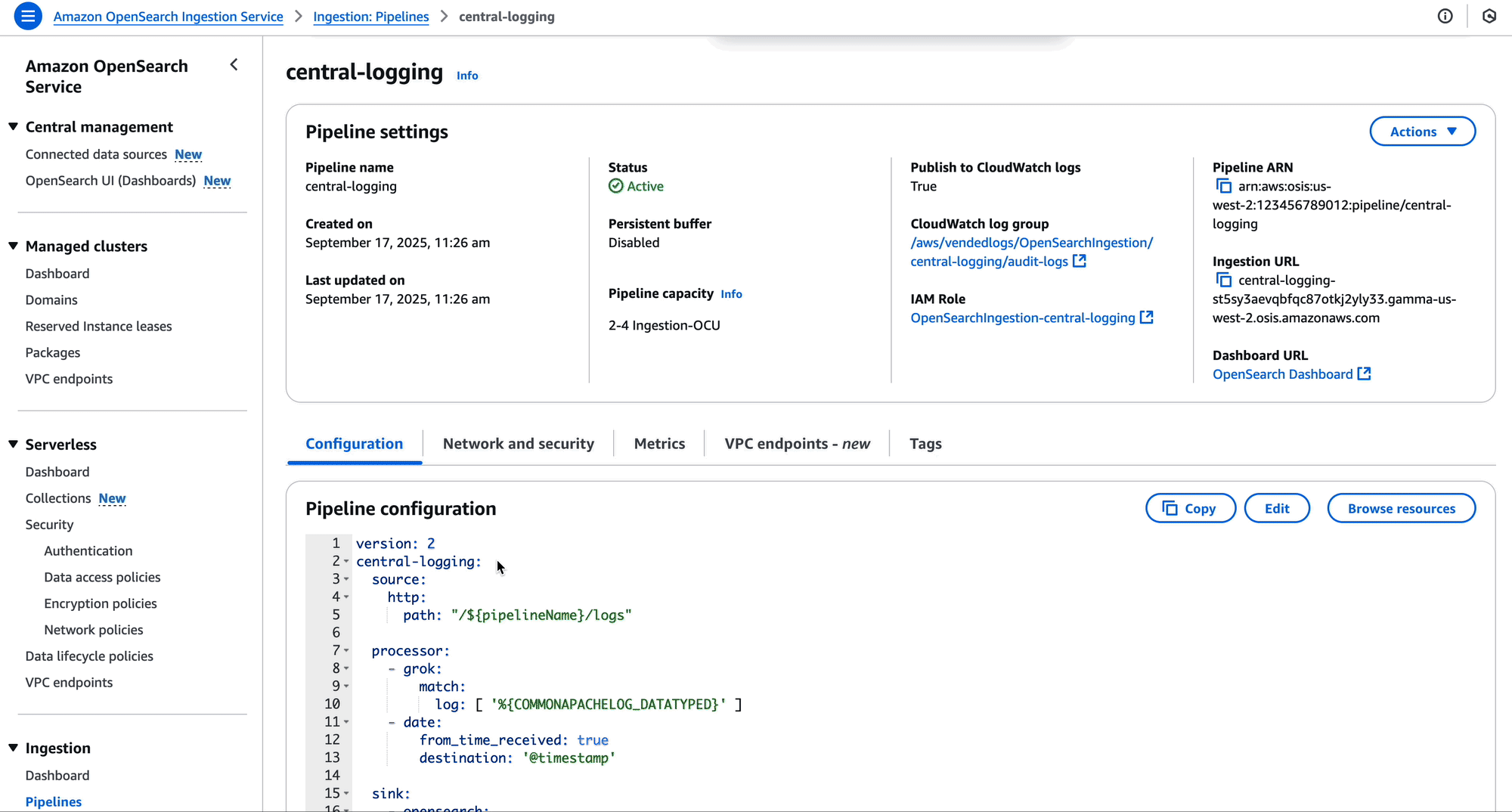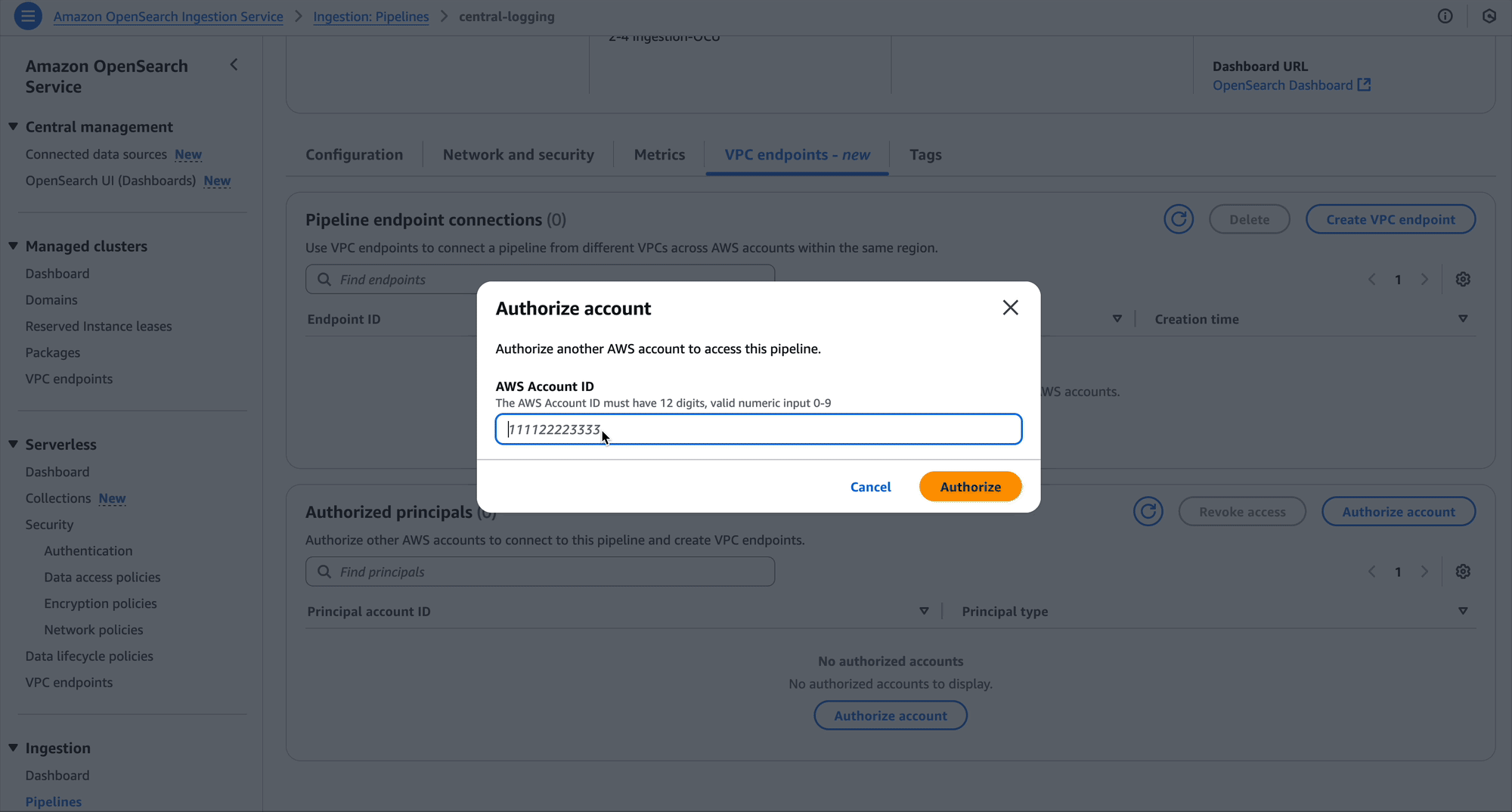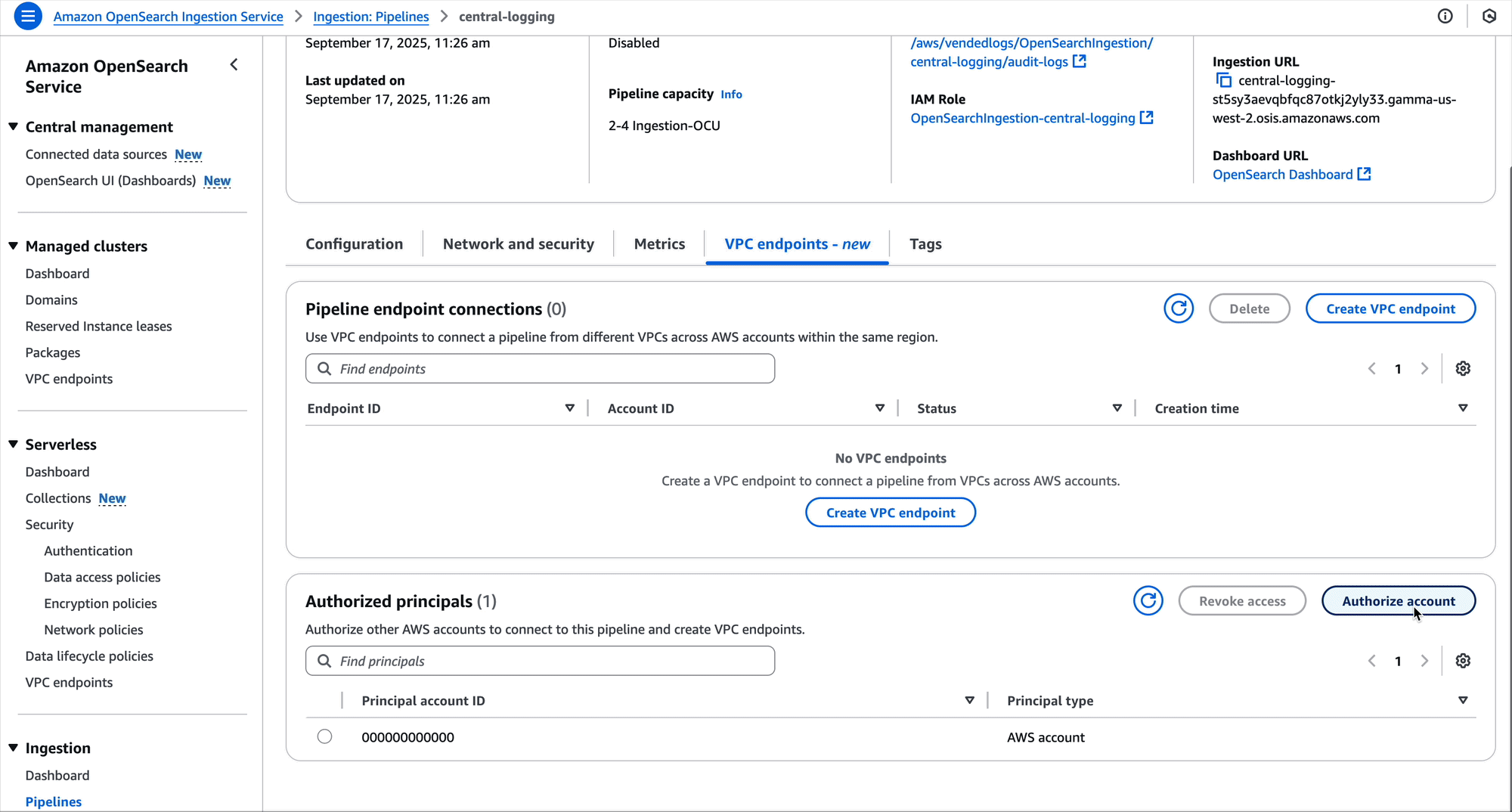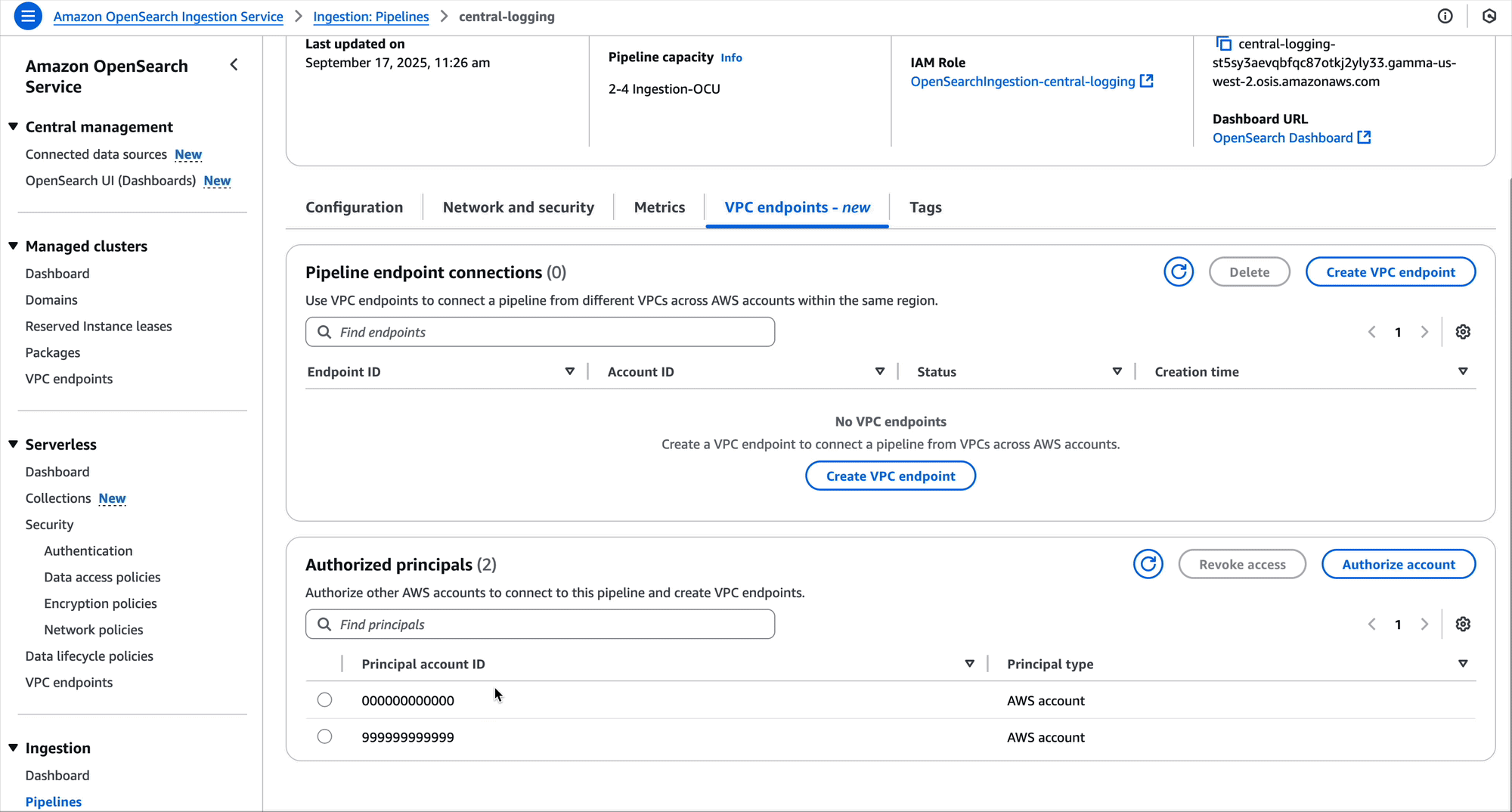
Create resource policy
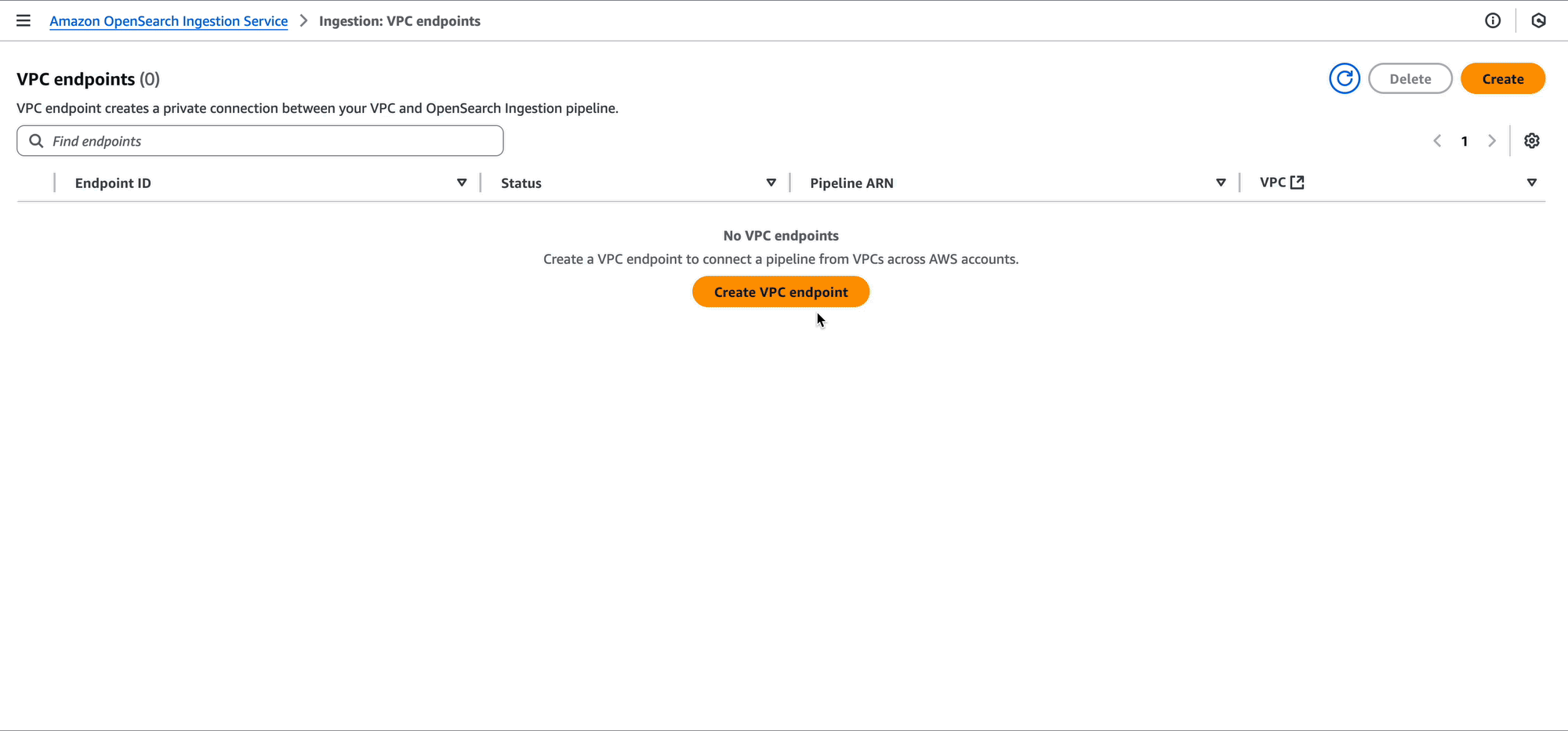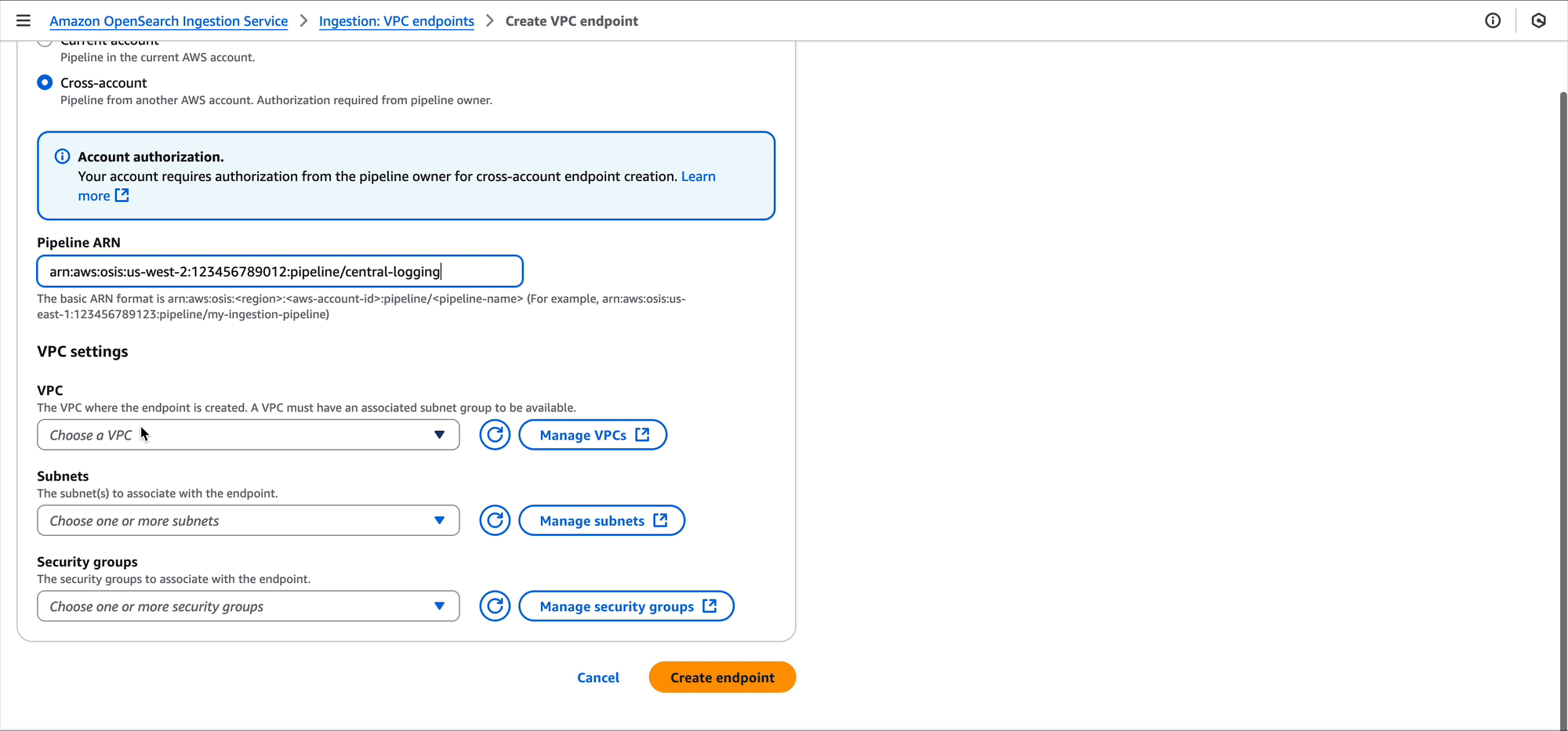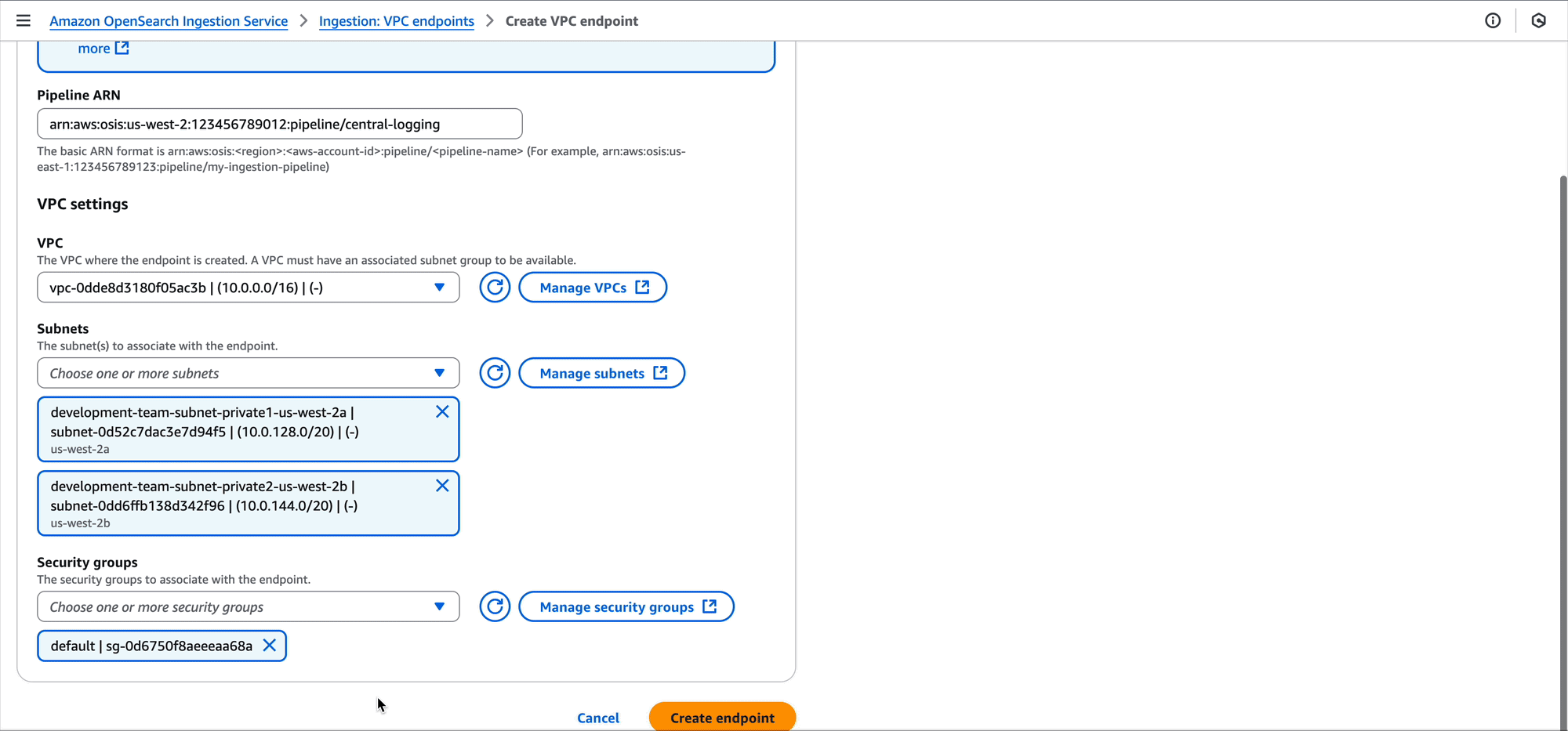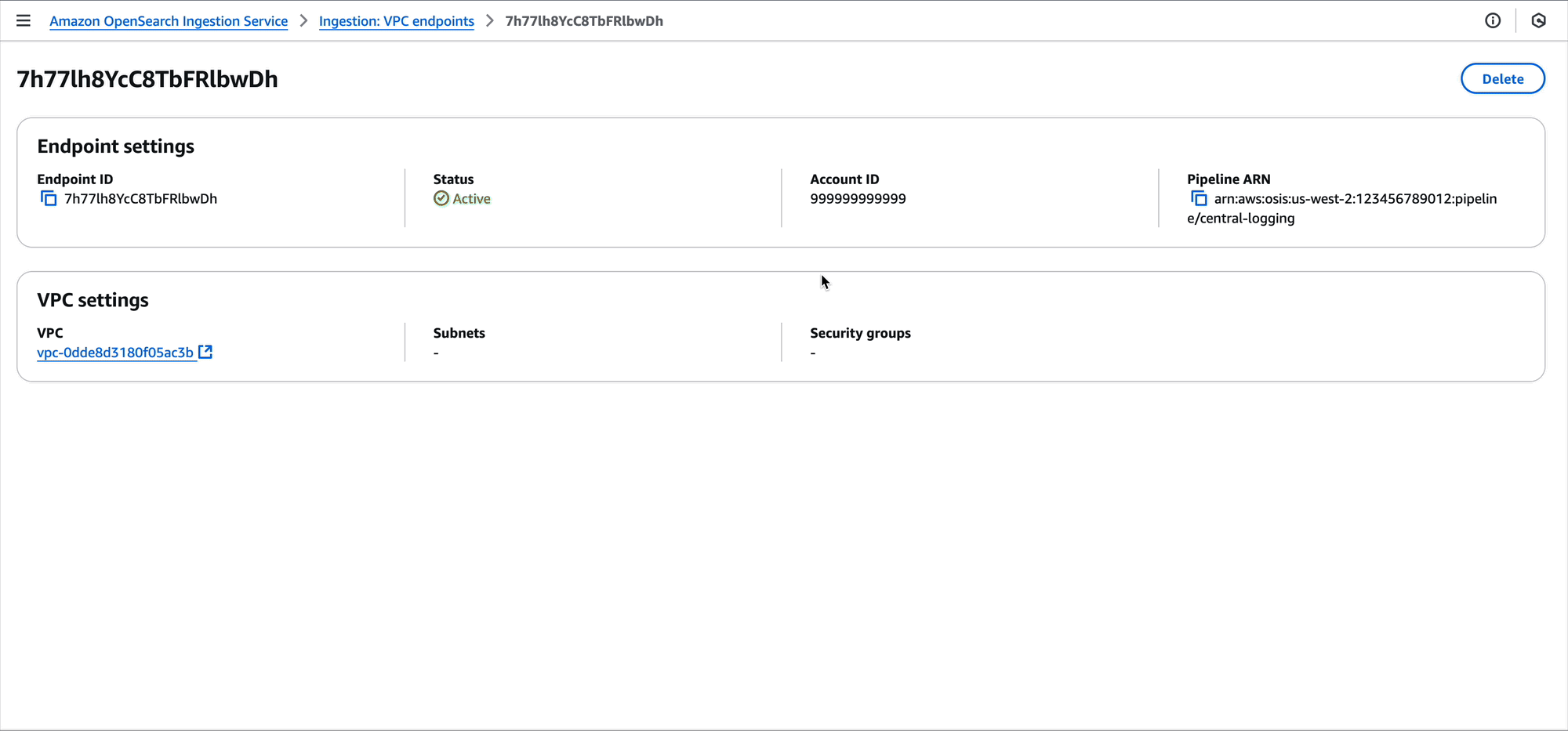
As the owner of the pipeline, you can create a resource policy that allows the two development accounts to create pipeline endpoints against your pipeline.
The following is an example resource policy for this scenario:
The OpenSearch Ingestion console makes it straightforward to create these policies, as shown in the following screenshot.
Create pipeline endpoint
Now that the central logging account has shared permissions on their pipeline, the development accounts can create pipeline endpoints. A pipeline endpoint is a connection from one VPC to an OpenSearch Ingestion pipeline.
The development accounts are responsible for creating the pipeline endpoints in the VPCs they want to connect from. They create this in the subnets they need and provide a security group. The security group should have an inbound rule allowing access port HTTPS over port 443 from any source that the development accounts need to ingest logs.
Development team A can create a pipeline endpoint using a command similar to the following:
Development team A can also use the OpenSearch Ingestion console to create the pipeline endpoint.
After performing this change, the VPC for development team A will have a pipeline endpoint. This pipeline endpoint now allows for ingesting data into the central logging pipeline. Now, Amazon Elastic Compute Cloud (Amazon EC2) instances, Amazon Elastic Container Service (Amazon ECS) tasks, Kubernetes pods, and other compute running in the VPC can ingest their log data into the pipeline using tools such as FluentBit.
At the same time or at a later time, development team B can create a pipeline endpoint as well. This team will create it for their own VPC.
After this, the pipeline will now have two pipeline endpoints, so both teams can ingest their log data into the central logging VPC.
Clean up
After a pipeline endpoint is created, either account can remove it. The development teams in our scenario can use the DeletePipelineEndpoint API to delete it from their accounts. Additionally, if the central logging account needs to remove a pipeline endpoint from a pipeline, it can use the RevokePipelineEndpointConnections API. Both options are available on the OpenSearch Ingestion console as well.
After the pipeline endpoints are removed, the central logging team can also remove the pipeline if they no longer need it.
Conclusion
The new pipeline endpoint feature for OpenSearch Ingestion simplifies how you can share pipelines for cross-account ingestion. This can help teams use the powerful features of OpenSearch Ingestion and open up new possibilities for teams or organizations using multiple accounts and VPCs. The new pipeline endpoint feature is available today in AWS Regions where OpenSearch Ingestion is available.
To get started with cross-account ingestion in OpenSearch Ingestion, refer to OpenSearch Ingestion documentation or try creating your first cross-account pipeline on the OpenSearch Ingestion console.
Today we are adding Qwen models from Alibaba in Amazon Bedrock. With this launch, Amazon Bedrock continues to expand model choice by adding access to Qwen3 open weight foundation models (FMs) in a full managed, serverless way. This release includes four models: Qwen3-Coder-480B-A35B-Instruct, Qwen3-Coder-30B-A3B-Instruct, Qwen3-235B-A22B-Instruct-2507, and Qwen3-32B (Dense). Together, these models feature both mixture-of-experts (MoE) and dense architectures, providing flexible options for different application requirements.
Amazon Bedrock provides access to industry-leading FMs through a unified API without requiring infrastructure management. You can access models from multiple model providers, integrate models into your applications, and scale usage based on workload requirements. With Amazon Bedrock, customer data is never used to train the underlying models. With the addition of Qwen3 models, Amazon Bedrock offers even more options for use cases like:
Code generation and repository analysis with extended context understanding
Building agentic workflows that orchestrate multiple tools and APIs for business automation
Balancing AI costs and performance using hybrid thinking modes for adaptive reasoning
Qwen3 models in Amazon Bedrock These four Qwen3 models are now available in Amazon Bedrock, each optimized for different performance and cost requirements:
Qwen3-Coder-480B-A35B-Instruct – This is a mixture-of-experts (MoE) model with 480B total parameters and 35B active parameters. It’s optimized for coding and agentic tasks and achieves strong results in benchmarks such as agentic coding, browser use, and tool use. These capabilities make it suitable for repository-scale code analysis and multistep workflow automation.
Qwen3-Coder-30B-A3B-Instruct – This is a MoE model with 30B total parameters and 3B active parameters. Specifically optimized for coding tasks and instruction-following scenarios, this model demonstrates strong performance in code generation, analysis, and debugging across multiple programming languages.
Qwen3-235B-A22B-Instruct-2507 – This is an instruction-tuned MoE model with 235B total parameters and 22B active parameters. It delivers competitive performance across coding, math, and general reasoning tasks, balancing capability with efficiency.
Qwen3-32B (Dense) – This is a dense model with 32B parameters. It is suitable for real-time or resource-constrained environments such as mobile devices and edge computing deployments where consistent performance is critical.
Architectural and functional features in Qwen3 The Qwen3 models introduce several architectural and functional features:
MoE compared with dense architectures – MoE models such as Qwen3-Coder-480B-A35B, Qwen3-Coder-30B-A3B-Instruct, and Qwen3-235B-A22B-Instruct-2507, activate only part of the parameters for each request, providing high performance with efficient inference. The dense Qwen3-32B activates all parameters, offering more consistent and predictable performance.
Agentic capabilities – Qwen3 models can handle multi-step reasoning and structured planning in one model invocation. They can generate outputs that call external tools or APIs when integrated into an agent framework. The models also maintain extended context across long sessions. In addition, they support tool calling to allow standardized communication with external environments.
Hybrid thinking modes – Qwen3 introduces a hybrid approach to problem-solving, which supports two modes: thinking and non-thinking. The thinking mode applies step-by-step reasoning before delivering the final answer. This is ideal for complex problems that require deeper thought. Whereas the non-thinking mode provides fast and near-instant responses for less complex tasks where speed is more important than depth. This helps developers manage performance and cost trade-offs more effectively.
Long-context handling – The Qwen3-Coder models support extended context windows, with up to 256K tokens natively and up to 1 million tokens with extrapolation methods. This allows the model to process entire repositories, large technical documents, or long conversational histories within a single task.
When to use each model The four Qwen3 models serve distinct use cases. Qwen3-Coder-480B-A35B-Instruct is designed for complex software engineering scenarios. It’s suited for advanced code generation, long-context processing such as repository-level analysis, and integration with external tools. Qwen3-Coder-30B-A3B-Instruct is particularly effective for tasks such as code completion, refactoring, and answering programming-related queries. If you need versatile performance across multiple domains, Qwen3-235B-A22B-Instruct-2507 offers a balance, delivering strong general-purpose reasoning and instruction-following capabilities while leveraging the efficiency advantages of its MoE architecture. Qwen3-32B (Dense) is appropriate for scenarios where consistent performance, low latency, and cost optimization are important.
Getting started with Qwen models in Amazon Bedrock To begin using Qwen models, in the Amazon Bedrock console, I choose Model Access from the Configure and learn section of the navigation pane. I then navigate to the Qwen models to request access. In the Chat/Text Playground section of the navigation pane, I can quickly test the new Qwen models with my prompts.
To integrate Qwen3 models into my applications, I can use any AWS SDKs. The AWS SDKs include access to the Amazon Bedrock InvokeModel and Converse API. I can also use these model with any agentic framework that supports Amazon Bedrock and deploy the agents using Amazon Bedrock AgentCore. For example, here’s the Python code of a simple agent with tool access built using Strands Agents:
from strands import Agent
from strands_tools import calculator
agent = Agent(
model="qwen.qwen3-coder-480b-instruct-v1:0",
tools=[calculator]
)
agent("Tell me the square root of 42 ^ 9")
with open("function.py", 'r') as f:
my_function_code = f.read()
agent(f"Help me optimize this Python function for better performance:\n\n{my_function_code}")
Now available Qwen models are available today in the following AWS Regions:
Qwen3-Coder-480B-A35B-Instruct is available in the US West (Oregon), Asia Pacific (Mumbai, Tokyo), and Europe (London, Stockholm) Regions.
Qwen3-Coder-30B-A3B-Instruct, Qwen3-235B-A22B-Instruct-2507, and Qwen3-32B are available in the US East (N. Virginia), US West (Oregon), Asia Pacific (Mumbai, Tokyo), Europe (Ireland, London, Milan, Stockholm), and South America (São Paulo) Regions.
In March, Amazon Web Services (AWS) became the first cloud service provider to deliver DeepSeek-R1 in a serverless way by launching it as a fully managed, generally available model in Amazon Bedrock. Since then, customers have used DeepSeek-R1’s capabilities through Amazon Bedrock to build generative AI applications, benefiting from the Bedrock’s robust guardrails and comprehensive tooling for safe AI deployment.
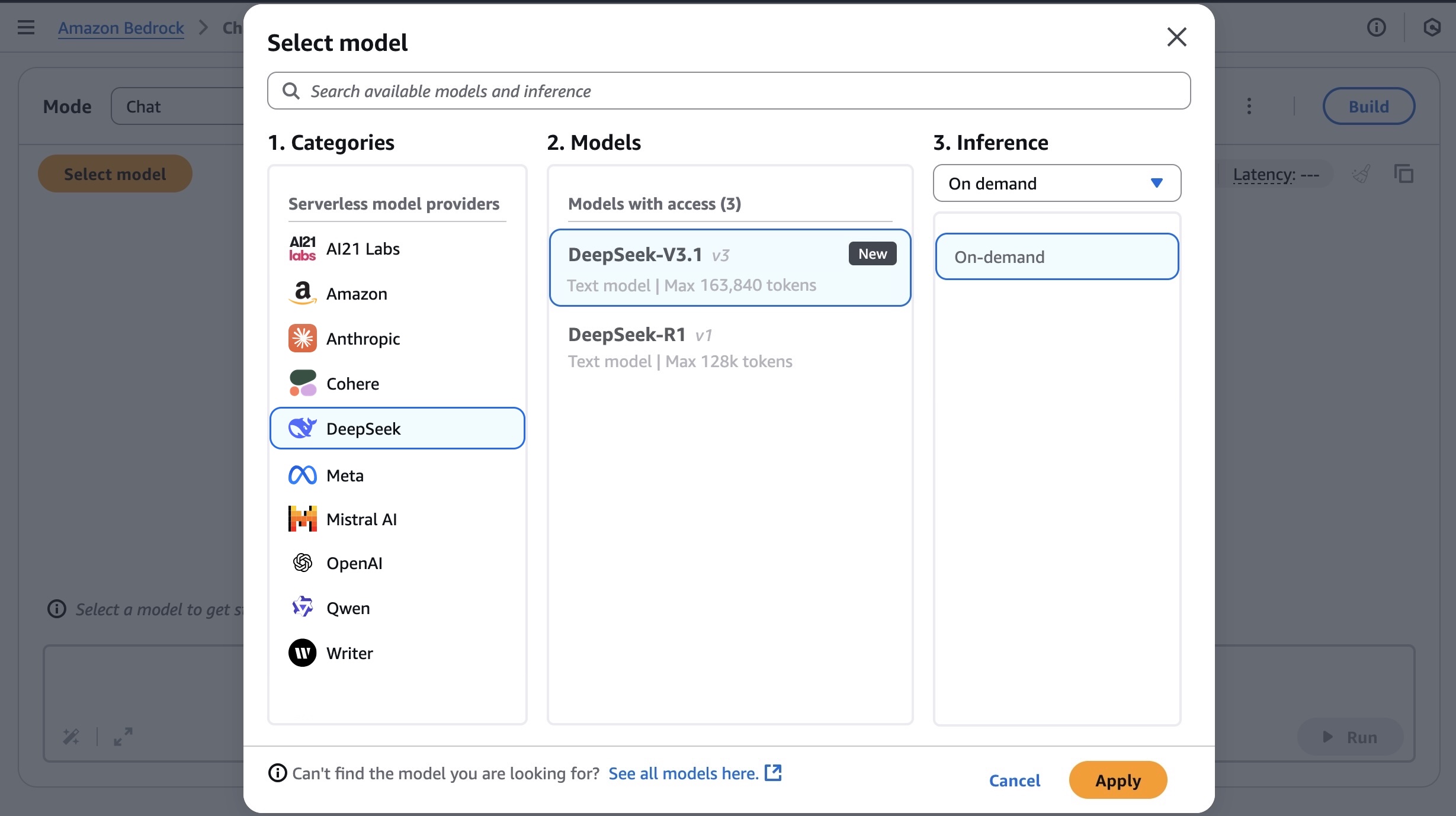
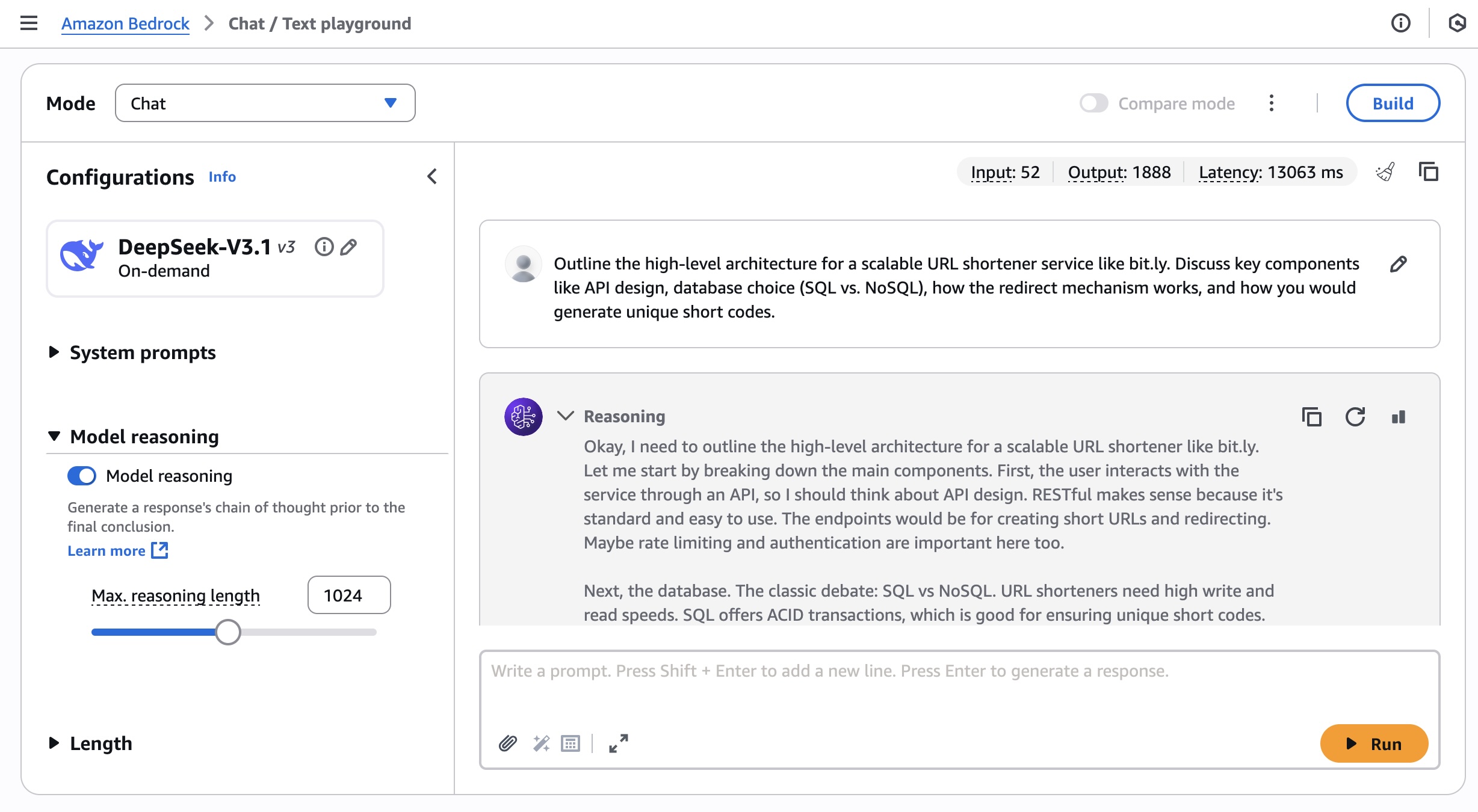
Today, I am excited to announce DeepSeek-V3.1 is now available as a fully managed foundation model in Amazon Bedrock. DeepSeek-V3.1 is a hybrid open weight model that switches between thinking mode (chain-of-thought reasoning) for detailed step-by-step analysis and non-thinking mode (direct answers) for faster responses.
According to DeepSeek, the thinking mode of DeepSeek-V3.1 achieves comparable answer quality with better results, stronger multi-step reasoning for complex search tasks, and big gains in thinking efficiency compared with DeepSeek-R1-0528.
DeepSeek-V3.1 model performance in tool usage and agent tasks has significantly improved through post-training optimization compared to previous DeepSeek models. DeepSeek-V3.1 also supports over 100 languages with near-native proficiency, including significantly improved capability in low-resource languages lacking large monolingual or parallel corpora. You can build global applications to deliver enhanced accuracy and reduced hallucinations compared to previous DeepSeek models, while maintaining visibility into its decision-making process.
Here are your key use cases using this model:
Code generation – DeepSeek-V3.1 excels in coding tasks with improvements in software engineering benchmarks and code agent capabilities, making it ideal for automated code generation, debugging, and software engineering workflows. It performs well on coding benchmarks while delivering high-quality results efficiently.
Agentic AI tools – The model features enhanced tool calling through post-training optimization, making it strong in tool usage and agentic workflows. It supports structured tool calling, code agents, and search agents, positioning it as a solid choice for building autonomous AI systems.
Enterprise applications – DeepSeek models are integrated into various chat platforms and productivity tools, enhancing user interactions and supporting customer service workflows. The model’s multilingual capabilities and cultural sensitivity make it suitable for global enterprise applications.
As I mentioned in my previous post, when implementing publicly available models, give careful consideration to data privacy requirements when implementing in your production environments, check for bias in output, and monitor your results in terms of data security, responsible AI, and model evaluation.
Get started with the DeepSeek-V3.1 model in Amazon Bedrock If you’re new to using the DeepSeek-V3.1 model, go to the Amazon Bedrock console, choose Model access under Bedrock configurations in the left navigation pane. To access the fully managed DeepSeek-V3.1 model, request access for DeepSeek-V3.1 in the DeepSeek section. You’ll then be granted access to the model in Amazon Bedrock.
Next, to test the DeepSeek-V3.1 model in Amazon Bedrock, choose Chat/Text under Playgrounds in the left menu pane. Then choose Select model in the upper left, and select DeepSeek as the category and DeepSeek-V3.1 as the model. Then choose Apply.
Using the selected DeepSeek-V3.1 model, I run the following prompt example about technical architecture decision.
Outline the high-level architecture for a scalable URL shortener service like bit.ly. Discuss key components like API design, database choice (SQL vs. NoSQL), how the redirect mechanism works, and how you would generate unique short codes.
You can turn the thinking on and off by toggling Model reasoning mode to generate a response’s chain of thought prior to the final conclusion.
Amazon SageMaker Unified Studio is a single data and AI development environment that brings together data preparation, analytics, machine learning (ML), and generative AI development in one place. By unifying these workflows, it saves teams from managing multiple tools and makes it straightforward for data scientists, analysts, and developers to build, train, and deploy ML models and AI applications while collaborating seamlessly.
In SageMaker Unified Studio, a project is a boundary where you can collaborate with other users to work on a business use case. A blueprint defines what AWS tools and services members of a project can use as they work with their data. Blueprints are defined by an administrator and are powered by AWS CloudFormation. Instead of manually piecing together project structures or workflow configurations, teams can rapidly spin up secure, compliant, and consistent analytics and AI environments. This streamlined approach significantly reduces setup time and provides standardized workspaces across the organization. Out of the box, SageMaker Unified Studio comes with several default blueprints.
We recently launched the custom blueprints feature in SageMaker Unified Studio. Organizations can now incorporate their specific dependencies, security controls using their own managed AWS Identity and Access Management (IAM) policies, and best practices, making it straightforward for them to align with internal standards. Because they’re defined through infrastructure as code (IaC), blueprints are straightforward to version control, share across teams, and evolve over time. This speeds up onboarding and keeps projects consistent and governed, no matter how big or distributed your data organization becomes.
For enterprises, this means more time focusing on insights, models, and innovation. The custom blueprints feature is designed to help teams move faster and stay consistent while maintaining their organization’s security controls and best practices. In this post, we show how to get started with custom blueprints in SageMaker Unified Studio.
Solution overview
We provide a CloudFormation template to implement a custom blueprint in SageMaker Unified Studio. The template deploys the following resources in the project environment:
The CloudFormation template uses parameters that are reserved to your SageMaker environment, such as datazoneEnvironmentEnvironmentId, datazoneEnvironmentProjectId, s3BucketArn, and privateSubnets. These parameters are automatically populated by SageMaker when creating the project. The parameters also help in retrieving other environment variables, such as SecurityGroupIds, as shown in the following snippets.
The following code illustrates defining reserved environment parameters:
"Parameters": {
"datazoneEnvironmentEnvironmentId": {
"Type": "String",
"Description": "EnvironmentId for which the resource will be created for."
},
"datazoneEnvironmentProjectId": {
"Type": "String",
"Description": "DZ projectId for which project the resource will be created for."
},
"s3BucketArn": {
"Type": "String",
"Description": "Project S3 Bucket ARN"
},
"privateSubnets": {
"Type": "String",
"Description": "Project Private Subnets"
}
}
The following code illustrates using reserved environment parameters to import other necessary values:
By default, SageMaker Unified Studio creates a project role and attaches several managed policies to the role. These managed policies are defined in the tooling blueprint. With custom blueprints, you can configure and attach your own IAM policies, in addition to the default policies, to the project role. To do this, include the IAM policies in your CloudFormation template and use the Export feature in the Outputs section, as shown in the following code. SageMaker Unified Studio gathers the policy information and adds it to the project role.
"GlueAccessManagedPolicy": {
"Description": "ARN of the created managed policy",
"Value": {
"Ref": "GlueAccessManagedPolicy"
},
"Export": {
"Name": {
"Fn::Sub": "datazone-managed-policy-glue-${glueDbName}-${datazoneEnvironmentEnvironmentId}"
}
}
},
"RedshiftAccessManagedPolicy": {
"Description": "ARN of the created Redshift managed policy",
"Value": {
"Ref": "RedshiftAccessManagedPolicy"
},
"Export": {
"Name": {
"Fn::Sub": "datazone-managed-policy-redshift-${redshiftWorkgroupName}-${datazoneEnvironmentEnvironmentId}"
}
}
}
Create custom blueprint
Complete the following steps to create a custom blueprint using the CloudFormation template:
On the Amazon SageMaker console, open the domain where you want to create a custom blueprint.
On the Blueprints tab, choose Create.
Under Name and description, enter a name and optional description.
Under Upload CloudFormation template, select Upload a template file and upload the provided template.
Choose Next. SageMaker will automatically detect the reserved parameters defined in the template, as shown in the following screenshot.
For Editable parameters, edit the Value column if necessary, and specify whether the values can be editable at the time of project creation.
Choose Next. As shown in the following screenshot, the reserved parameters described earlier are not shown on this page.
Select Enable blueprint.
Choose the provisioning role to be used by SageMaker to provision the environment resources.
Choose the domain units authorized to use the blueprint.
Choose Next.
Review the blueprint information and choose Create blueprint.
Create project profile
Complete the following steps to create a custom project profile that includes the custom blueprint created in the previous section:
On the SageMaker console, open your domain.
On the Project profiles tab, choose Create.
Enter the project profile name and optional description.
Select Custom create.
Choose the blueprints to be included in the project profile, including the custom blueprint you created in the previous section.
Choose the account and AWS Region to be used.
Choose the authorized users.
Select Enable project profile on creation.
Choose Create project profile.
Create project
Complete the following steps to create a new project that is based on the custom project profile and custom blueprint created in the previous sections:
In the SageMaker Unified Studio environment, choose Create project.
Enter a project name and optional description.
For Project profile, choose the profile created in the previous section.
Choose Continue.
On the Customize blueprint parameters page, review the parameters, modify as necessary, and choose Continue.
Review your selections and choose Create project.
SageMaker Unified Studio will create the project environments with the resources defined in your custom blueprint.
It will also attach the custom IAM policies defined and add them to the project role, as shown in the following screenshot.
Clean up
To avoid incurring additional costs, complete the following steps:
In this post, we discussed custom blueprints, a new option during administrator setup in SageMaker Unified Studio. We showed how to create new custom blueprints and create custom project profiles that include the newly created custom blueprints. We also demonstrated how to create projects that implement custom blueprints.
Custom blueprints in SageMaker Unified Studio are intended to streamline and standardize data, analytics and AI workflows. By helping organizations create templated environments with preconfigured resources, security controls, and best practices, custom blueprints can reduce setup time while providing consistency and compliance across projects.
Organizations can now enforce their specific security standards and access controls at the project level using the ability to incorporate custom IAM policies directly into these blueprints. This granular control over permissions helps organizations create projects that adhere to corporate security policies right from inception. Custom blueprints can help you scale analytics and AI/ML operations securely, by including tooling designed to version control these templates, share them across teams, and automatically apply custom IAM policies.
To learn more about custom blueprints in SageMaker Unified Studio, refer to Custom blueprints.
Serverless applications often comprise multiple AWS services, such as AWS Lambda, Amazon Simple Queue Service (Amazon SQS), Amazon EventBridge, and Amazon DynamoDB. Although serverless architectures make it easy to build applications that are generally simple to operate and scale, testing them requires extra steps for developers. Recently, AWS brought you the capability to help developers remotely debug Lambda functions to accelerate the development process. Today, we’re excited to announce new capabilities that further simplify the local testing experience for Lambda functions and serverless applications through integration with LocalStack, an AWS Partner, in the AWS Toolkit for Visual Studio Code.
In this post, we will show you how you can enhance your local testing experience for serverless applications with LocalStack using AWS Toolkit.
Challenges with local serverless development
When building serverless applications with infrastructure as code (IaC) tools like the AWS Serverless Application Model (AWS SAM), developers often face challenges during local integration testing of applications that depend on interactions across multiple AWS services. These friction points slow down the critical code-test-debug cycle. Developers might encounter the following common roadblocks:
Cloud-based validation slows iteration – Developers previously needed to deploy AWS SAM templates to the cloud to test changes, introducing delays in feedback loops. AWS research shows that developers spend considerable time on deployment and testing, rather than writing code.
Tool context switching adds friction – Developers routinely shift between integrated development environments (IDEs), command line interfaces (CLIs), and resource emulators like LocalStack, leading to fragmented workflows.
Manual setup increases configuration complexity – Port mapping and code edits for local service integration tests can introduce inconsistencies between local and cloud environments.
Service integration debugging is limited – Troubleshooting Lambda functions in the context of AWS service integrations, such as DynamoDB, Amazon Simple Storage Service (Amazon S3), or Amazon SQS, requires manual configuration, extending the duration of troubleshooting efforts.
These challenges directly impact developer productivity and make local testing of integrated serverless applications complex.
Solution overview
Starting today, AWS helps simplify local serverless development by integrating LocalStack directly into the AWS Toolkit for VS Code. This integration helps developers test and debug serverless applications—defined using IaC tools like AWS SAM—entirely within their IDE. The enhanced local testing experience delivers four major improvements:
Integrated LocalStack experience – Connect to LocalStack directly within VS Code and manage local resources alongside cloud resources through a unified interface.
Emulated service interactions – Test Lambda functions with their interactions with other AWS services like Amazon SQS, DynamoDB, and EventBridge locally.
Simplified debugging – Start debugging sessions with LocalStack emulated environment, with a single click – no manual port configurations or code changes required, streamlining the debugging workflow.
Streamlined workflow – Deploy, test, and debug serverless applications without leaving the IDE, avoiding context switching between tools.
To set up LocalStack in VS Code (either the free version supporting over 30 core services like Lambda, Amazon S3, DynamoDB, Amazon SQS, and Amazon API Gateway, or the Ultimate version with over 110 services and advanced debugging features) you need essential development tools, including Docker, the AWS Command Line Interface (AWS CLI), AWS SAM CLI, and your preferred IDE such as VS Code. This combination enables full local integration testing of AWS services, including Lambda functions, messaging queues, databases, event-driven architectures, and serverless workflows, so you can develop and test your entire AWS application stack locally before deploying to the cloud.
Automated setup process
LocalStack is a cloud service emulator that you can use to run AWS applications locally for testing and development. To enhance your local testing capabilities, you can install the LocalStack VSCode Extension directly from AWS Walkthrough in AWS Toolkit, which offers a streamlined setup process through an intelligent wizard. After installation, the extension automatically detects whether LocalStack is configured on your system and prompts you to run the setup wizard through a notification. The entire process is quick and requires no manual configuration.
LocalStack extension has an integrated authentication wizard, that simplifies the process of connecting your development environment to LocalStack. During setup, the wizard opens a browser-based authentication flow and maintains an active connection until authentication completes. After it’s verified, it securely stores the authentication token in the ~/.localstack/auth.json file, enabling communication between your local environment and LocalStack services.
The wizard also checks if LocalStack AWS CLI profiles exist, and if not found, automatically creates them by updating the ~/.aws/config and ~/.aws/credentials files with LocalStack-specific endpoints and credentials. This seamless integration of AWS profiles enhances the development workflow by allowing developers to easily switch between different AWS environments, including the local LocalStack setup. By leveraging these profiles, developers can effortlessly point their AWS CLI or SDK to the appropriate endpoint, whether it’s a real AWS account or the LocalStack instance running on their machine. This configuration not only ensures a clear separation between local and cloud environments but also minimizes the risk of cross-environment interference. The automatic creation of these profiles streamlines the setup process, reducing manual configuration errors and saving valuable development time. Visual Studio Code (VS Code) provides real-time feedback throughout the setup. The status bar initially displays an error or warning indicator when LocalStack is not configured and then transitions to a normal or connected state once a successful connection is established. After setup completes, you’re ready to deploy, test, and debug serverless applications locally—without additional configuration. These settings persist across VS Code sessions, so the setup process is a one-time task.The following figure illustrates the process to start and verify LocalStack from VS Code.
To learn more, including installation steps, configuration examples, and troubleshooting guidance, visit the LocalStack Docs.
Test a serverless application
To demonstrate the enhanced local testing capabilities, let’s explore a practical serverless pattern: building and testing an event-driven order processing system that integrates Lambda with Amazon SQS, API Gateway, and Amazon Simple Notification Service (Amazon SNS). The application processes orders through an event-driven workflow: orders are submitted through API Gateway to an SQS queue and processed by a Lambda function, and the status is published to Amazon SNS to trigger customer email notifications.
After you set up LocalStack in VS Code, you can test your entire serverless workflow without deploying to the cloud:
Deploy locally – Use the LocalStack AWS profile to deploy your AWS SAM application. The process mirrors cloud deployment but targets local endpoints. You can use the Application builder pane to initiate the deployment to LocalStack environment. The following figure illustrates the process of deploying a sample serverless application.
Debug Lambda function deployed in LocalStack – Set breakpoints in your Lambda function and step through execution using VS Code’s integrated debugger. With the AWS Toolkit extension, you can invoke your Lambda with one click and inspect live interactions across services, all while running against a LocalStack container on your machine. This setup makes it possible to debug your AWS applications in a controlled, local environment that mimics the cloud infrastructure, without the need for deploying actual AWS services.
Validate end-to-end Flows – Test complete workflows from message ingestion through processing and notification, confirming all service integrations work correctly before cloud deployment.
For an in-depth technical demonstration of this LocalStack integration, refer to this youtube video.
Best practices for local Lambda function testing
In this section, we discuss various strategies and best practices for local Lambda function testing.
Optimizing your development workflow
Consider the following strategies to optimize your development workflow:
Start with a strong testing foundation – Use the AWS SAM CLI to perform unit tests that validate the core programmatic and business logic of your Lambda functions. Isolating function behavior early helps identify logic errors before introducing external dependencies.
Establish environment parity early in the development process – Many production issues stem from discrepancies between local and cloud environments. Use consistent service versions, configurations, and data structures across environments to confirm that what works locally behaves the same in production.
Adopt IaC from day one – Whether you choose AWS SAM, AWS CloudFormation, or another IaC framework, defining your application infrastructure as code reduces configuration drift and makes your deployments reproducible across teams and environments.
Apply a progressive testing strategy – Follow a structured testing pyramid that starts with fast, isolated unit tests and builds up to broader integration and system-level validation. This layered approach helps you catch issues earlier—when they’re easier and less expensive to fix—while still providing full application coverage.
A strategic approach to testing
Testing should be an integrated part of your serverless development workflow—not an afterthought. Successful teams implement layered testing strategies that use both local and cloud environments to strike a balance between speed and accuracy:
Begin with unit tests that focus on isolated function logic. Use tools like the AWS SAM CLI, AWS Toolkit for VS Code and LocalStack extensions to run and debug functions locally.
After validation, proceed to local integration testing using LocalStack to confirm how your Lambda functions interact with services such as Amazon SQS, DynamoDB, and Amazon SNS. These tests typically complete within minutes and catch most service integration issues before they reach production.
After local testing, validate your application in the actual AWS environment. Cloud testing helps surface issues not present in local emulation, such as AWS Identity and Access Management (IAM) permission mismatches, Amazon Virtual Private Cloud (Amazon VPC) networking challenges, or service-specific nuances such as Lambda concurrency. For troubleshooting issues in the cloud environment, you can also remotely debug your Lambda functions using AWS Toolkit for VS Code.
Lastly, conduct performance testing in AWS to assess how your application handles real-world traffic. These longer-running tests help validate scaling behavior and system resilience under load.
The result is higher-quality applications delivered faster, with fewer production surprises and more confident deployments.
Security considerations
When using LocalStack for local development, follow these security best practices:
Isolate the local environment – Use Docker networking to restrict LocalStack access and bind services to localhost to prevent external connections.
Use placeholder credentials – Use test credentials (for example, test/test) instead of real AWS credentials.
Protect your data – Use synthetic or anonymized datasets instead of production data and regularly purge local data stores to reduce risk.
When to use local versus cloud testing
Although local testing offers significant advantages, it’s important to understand when to use it versus testing in the cloud. The following table lists the potential use cases for each strategy.
Testing Scenario
Local Testing
Cloud Testing
Reason
Function logic validation
✓
Fast feedback for core business logic
Service integration testing
✓
Quick validation of AWS service interactions
Rapid iteration during development
✓
Immediate feedback without deployment overhead
Cost-sensitive development environments
✓
Minimizes cloud resource costs during development
Offline development scenarios
✓
No internet connectivity required
Performance and scalability testing
✓
Requires actual AWS infrastructure for accurate results
IAM permission validation
✓
LocalStack doesn’t fully replicate IAM behavior
VPC networking scenarios
✓
Network configurations can’t be accurately emulated
Production-like load testing
✓
Real performance metrics only available in AWS
Final validation before deployment
✓
Supports compatibility with actual AWS environment
Conclusion
In this post, we discussed how to streamline local testing for AWS Serverless applications using LocalStack and the AWS Toolkit for VS Code. By running and debugging serverless applications directly in your IDE, you can reduce context switching, test complex integrations locally, and catch issues earlier—without deploying to the cloud.
We also showed how to apply progressive testing strategies that combine local emulation with cloud validation, optimize development costs, and build event-driven workflows with confidence.These enhancements lead to faster test cycles, lower development costs, and higher-quality deployments—all while staying fully in control of your development environment.
Have questions or feedback about this post? Connect with us on the AWS Compute Blog or join the AWS Developer community.
Amazon Web Services (AWS) successfully completed an onboarding audit with no findings for ISO 9001:2015, 27001:2022, 27017:2015, 27018:2019, 27701:2019, 20000-1:2018, and 22301:2019, and Cloud Security Alliance (CSA) STAR Cloud Controls Matrix (CCM) v4.0. EY CertifyPoint auditors conducted the audit and reissued the certificates on August 13, 2025. The objective of the audit was to enable AWS to expand their ISO and CSA STAR certifications to include AWS Resource Explorer and AWS Incident Response to their scope. The ISO standards cover areas including quality management, information security, cloud security, privacy protection, service management, and business continuity. The certifications demonstrate AWS’s commitment to maintaining robust security controls and protecting customer data across our services.
During this onboarding audit, we added two additional AWS services to the scope since the last certification issued on May 26, 2025. The following are the two additional services:
For a full list of AWS services that are certified under ISO and CSA Star, see the AWS ISO and CSA STAR Certified page. Customers can also access the certifications in the AWS Management Console through AWS Artifact.
If you have feedback about this post, submit comments in the Comments section below.
AWS recently announced that Amazon SageMaker now offers Amazon Simple Storage Service (Amazon S3) based shared storage as the default project file storage option for new Amazon SageMaker Unified Studio projects. This feature addresses the deprecation of AWS CodeCommit while providing teams with a straightforward and consistent way to collaborate on project files across the integrated development tools in SageMaker.
This new Amazon S3 storage option provides the following benefits:
Simplified collaboration – File sharing between project members directly without Git operations
Clear workspace separation – Built-in personal storage separation with Amazon Elastic Block Store (Amazon EBS) volumes
Global availability – Available in AWS Regions where SageMaker is supported
Although Amazon S3 is the default option for file storage, you can also use Git version control for more robust source control capabilities.
In this post, we discuss this new feature and how to get started using Amazon S3 shared storage in SageMaker Unified Studio.
Solution overview
When you create a new SageMaker Unified Studio domain, the service automatically configures Amazon S3 storage as your default project storage option. Each project receives a dedicated shared location in Amazon S3, accessible to project members, following the structure [bucket]/[domain-id]/[project-id]/shared/.
SageMaker tools JupyterLab and Code Editor provide the following to users:
A personal EBS volume for individual work in JupyterLab and Code Editor tools
A mounted shared folder containing the project’s Amazon S3 shared storage
Clear separation between personal and shared spaces
The shared storage is accessible across SageMaker integrated development tools:
JupyterLab and Code Editor show shared files along with personal files
Query Editor filters for relevant SQL notebooks
Visual ETL provides direct access to shared extract, transform, and load (ETL) workflows
Files saved to the shared location are immediately visible and available to project members. Users can continue working with personal files in their EBS volumes in tools like JupyterLab and Code Editor and explicitly move files to shared storage when ready to collaborate.If you want to use Git for collaboration, you can continue to do so by integrating projects with your GitHub version control, GitLab version control, or managed Bitbucket repositories.
Migration and version control options
For teams currently using Amazon CodeCommit, existing projects will remain fully functional. New projects will default to Amazon S3 storage. If you want to have version control for Amazon S3 based projects, you can enable versioning in Amazon S3 directly.
Prerequisites
You will need to complete the following prerequisites before you can follow the instructions in the next section:
To begin using Amazon S3 shared storage, complete the following steps:
Create a new SageMaker Unified Studio domain.
Create a new project (Amazon S3 storage is the default file storage option).
Open the new project and choose JupyterLab from the Build menu.
Save the new notebook you just created.
Rename the file.
After the project is saved, project users can view the saved notebook in the Project files section under the S3 path [bucket]/[domain-id]/[project-id]/shared/.
Enable version control using Git
To enable version control using Git, complete the following steps:
On the SageMaker console, create a new project profile.
Provide the necessary details for your project profile.
In the Project files storage section, the Amazon S3 option is selected by default. To enable version control for the project, you can use existing Git repository connections by selecting Git repository.
Use shared storage in Query Editor
To use the shared storage feature in Query Editor, complete the following steps:
Choose Query Editor from the Build menu.
Compose your query, and on the Actions menu, choose Save to save the query to shared storage.
Navigate back to the Project files section, where you can view the query notebook files under the S3 path [bucket]/[domain-id]/[project-id]/shared/.
Use shared storage in Visual ETL flows
To use the shared storage feature in Visual ETL flows, complete the following steps:
Choose Visual ETL flows from the Build menu.
Develop your ETL workflow and save the code to the project.
Navigate back to the Project files section, where you can view the files under the S3 path [bucket]/[domain-id]/[project-id]/shared/jobs/uploads/<ETL name>.
Clean up
Make sure you remove the SageMaker Unified Studio resources to mitigate any unexpected costs. This involves a few steps:
Delete the projects.
Delete the domain.
Delete the S3 bucket named amazon-datazone-AWSACCOUNTID-AWSREGION-DOMAINID
Conclusion
The launch of Amazon S3 shared storage in SageMaker represents another step in simplifying the analytics and machine learning (ML) development experience for our customers. By reducing the complexity of Git operations while maintaining robust collaboration capabilities, teams can now focus on building and deploying analytics and ML solutions faster. The feature is now available in Regions where SageMaker is available.
For detailed information about this feature, including setup instructions and best practices, refer to Unified storage in Amazon SageMaker Unified Studio. Share your feedback on this feature in the comments section.
In our previous blog post (Part 1 of our key replication series), Automatically replicate your card payment keys across AWS Regions, we explored an event-driven, serverless architecture using AWS PrivateLink to securely replicate card payment keys across AWS Regions. That solution demonstrated how to build a custom replication framework for payment cryptography keys.
Based on customer feedback requesting a more automated, no-code approach, we’re excited to announce an additional option to this capability with Multi-Region keys for AWS Payment Cryptography in Part 2 of our series.
By using this new feature, you can automatically synchronize payment cryptography keys from a primary Region to other Regions that you select, improving resilience and availability of payment applications. You can also choose between account-level replication or key-level replication, giving more flexibility in how to manage payment keys across Regions.
Multi-Region keys: Overview and benefits
The new Multi-Region key replication feature for AWS Payment Cryptography offers you flexible control over your key replication strategy through the following primary capabilities:
Control whether keys are replicated
Select specific Regions for key replication
Manage replication configuration changes
Configure either account-level or key-level replication to meet business needs
Multi-Region keys help deliver several benefits for global payment operations, including:
Improved availability: Access your payment keys even if a Region becomes unavailable
Disaster recovery: Maintain business continuity with replicated keys across Regions
Global operations: Support payment processing across multiple geographic regions
Simplified management: Centralized control with distributed availability
Consistent key IDs: The same key ID across Regions simplifies application development
Configuration options
Payment Cryptography provides two distinct methods for configuring Multi-Region key replication, giving flexibility to implement a strategy that best fits your organization’s needs. You can choose between a broad, account-level approach or a more granular, key-level method.
Account-level
With account-level configuration, AWS automatically replicates exportable symmetric keys created in your Payment Cryptography account from your designated primary Region to other Regions you specify. This simplifies key management in multi-Region deployments, provides consistent key availability in the Regions that you specify, and reduces the operational overhead of key management.
To configure account-level replication using the AWS Command Line Interface (AWS CLI), use the new enable-default-key-replication-regions API to set the Regions where AWS will replicate your keys. To remove Regions from your default replication list, use the disable-default-key-replication-regions API.
Note: Only symmetric keys created after the account-level replication is enabled will be replicated.
Key-level replication
By using key-level replication, you can achieve more granular control by:
Designating specific keys as multi-Region keys
Defining custom replication targets for each multi-Region key
Maintaining Region-specific keys when needed
Note: Within each Region, Payment Cryptography maintains redundancy of your keys across multiple Availability Zones for high availability. Multi-Region key replication extends across geographic boundaries, giving you additional resilience against Regional outages while maintaining control over where your keys are stored.
You can specify replication Regions during key creation using the --replication-regions parameter, using the AWS CLI, with the create-key or import-key APIs. For existing keys, you can use the new add-key-replication-regions and remove-key-replication-regions APIs to manage which regions receive your replicated keys.
Important: When you specify replication Regions during key creation, these settings take precedence over default replication Regions configured at the account level.
How it works
Figure 1 shows the process when you replicate a key in Payment Cryptography.
The key is created in your designated primary Region
Payment Cryptography automatically replicates the key material asynchronously to the specified replica Regions
The replicated keys maintain the same key ID across Regions; only the Region portion of the Amazon Resource Name (ARN) changes
The key in the primary Region is marked with MultiRegionKeyType: PRIMARY
Keys in replica Regions are marked with MultiRegionKeyType: REPLICA and include a reference to the primary Region
When deleting a key, its deletion cascades from the primary to replica Regions
Figure 1: Representation of key replication from us-east-1 to us-west-2
Example: Creating a multi-Region key at key level
The following is an example of creating a card verification key (CVK) in the primary Region (us-east-1) with replication to us-west-2:
When using multi-Region keys, several important aspects should be considered. Multi-Region key replication supports only symmetric keys with the exportable attribute enabled, and asymmetric keys are not supported. For billing purposes, AWS bills per key per Region, which means replicating to three Regions incurs costs for the primary key plus costs for each key in the replica Regions.
Key aliases and tags require separate management in each Region because they are not part of the replication process. While primary keys support modifications and updates, replica keys are read-only copies that support only cryptographic operations. Modifications must be made to the key in the primary Region, and Payment Cryptography automatically propagates these changes to the replica Regions. Monitor the replication status to confirm successful synchronization of these changes.
The deletion process for multi-Region keys follows specific behavior patterns that are important to understand. When a primary key is scheduled for deletion, associated replica keys are deleted immediately. The primary key enters a pending deletion state with a minimum 3-day waiting period, during which the deletion can be canceled. However, if you restore the primary key by canceling its deletion, you will need to re-enable replication to recreate the replica keys in your desired Regions. After the 3-day waiting period expires, the primary key is permanently deleted and becomes unrecoverable. Note that deleting a replica key affects only that specific Region and does not impact the primary key or other replica keys.
Multi-Region key replication operates with eventual consistency. When creating new keys or making changes to existing keys, these updates might not appear immediately across all Regions. Applications should be designed to handle this eventual consistency model and not assume immediate availability of keys or key changes in replica Regions. If your application requires strong consistency, implement polling mechanisms using the GetKey API to verify that changes have been synchronized before proceeding with key operations.
Logging and monitoring
Payment Cryptography logs API activity through AWS CloudTrail, which now includes new events and attributes specific to Multi-Region key replication.
New CloudTrail event
The service logs a new event type called SynchronizeMultiRegionKey, which appears in primary and replica Regions.
Primary Region events:
Two SynchronizeMultiRegionKey events are logged in the primary Region for each replication Region defined:
To start using Multi-Region key replication in Payment Cryptography:
Determine your primary Region.
Determine your replica Regions and if you will use account-level or key-level configuration.
Create new exportable symmetric keys or update existing keys to use the Multi-Region key replication feature.
Update your applications to use the consistent key IDs across Regions.
Conclusion
The new Multi-Region key replication feature in Payment Cryptography enhances our automatic key replication capabilities, providing improved resilience and simplified management for global payment applications. This feature helps make sure your payment cryptography keys are available when and where you need them, with the flexibility to choose between account-level or key-level replication strategies.
We’re pleased to announce the completion of our annual AWS Outsourced Service Provider’s Audit Report (OSPAR) audit cycle on August 7, 2025, based on the newly enhanced version 2.0 guidelines (OSPAR v2.0). AWS is the first global cloud service provider in Singapore to obtain the report using the new OSPAR v2.0 guidelines.
The Association of Banks in Singapore (ABS) established the Guidelines on Control Objectives and Procedures for Outsourced Service Providers (ABS Guidelines) to provide baseline controls criteria that outsourced service providers (OSPs) operating in Singapore should have in place. ABS enhanced the ABS Guidelines to version 2.0, which OSPs—such as AWS—need to comply with for the audit period commencing on or after January 1, 2025. The enhanced ABS Guidelines integrate key elements from the Monetary Authority of Singapore (MAS) regulatory updates on cyber hygiene, technology risk management, and business continuity management, and include new control domains such as data security, cryptography, software application development and management, and business continuity management.
The 2025 OSPAR certification cycle includes the addition of seven new services in scope, bringing the total number of services in scope to 170 in the AWS Asia Pacific (Singapore) Region. Newly added services in scope include the following:
Successfully completing the OSPAR assessment demonstrates that AWS continues to maintain a robust system of controls to meet these guidelines. This underscores our commitment to fulfill the security expectations for cloud service providers set by the financial services industry in Singapore.Customers can use OSPAR to streamline their due diligence processes, thereby reducing the effort and costs associated with compliance. OSPAR remains a core assurance program for our financial services customers because it is closely aligned with local regulatory requirements from MAS.
As always, we’re committed to bringing new services into the scope of our OSPAR program based on your architectural and regulatory needs. If you have questions about the OSPAR report, contact your AWS account team.
If you have feedback about this post, submit comments in the Comments section below.
Developers and machine learning (ML) engineers can now connect directly to Amazon SageMaker Unified Studio from their local Visual Studio Code (VS Code) editor. With this capability, you can maintain your existing development workflows and personalized integrated development environment (IDE) configurations while accessing Amazon Web Services (AWS) analytics and artificial intelligence and machine learning (AI/ML) services in a unified data and AI development environment. This integration provides seamless access from your local development environment to scalable infrastructure for running data processing, SQL analytics, and ML workflows. By connecting your local IDE to SageMaker Unified Studio, you can optimize your data and AI development workflows without disrupting your established development practices.
In this post, we demonstrate how to connect your local VS Code to SageMaker Unified Studio so you can build complete end-to-end data and AI workflows while working in your preferred development environment.
Solution overview
The solution architecture consists of three main components:
Local computer – Your development machine running VS Code with AWS Toolkit for Visual Studio Code and Microsoft Remote SSH installed. You can connect through the Toolkit for Visual Studio Code extension in VS Code by browsing available SageMaker Unified Studio spaces and selecting their target environment.
SageMaker Unified Studio – Part of the next generation of Amazon SageMaker, SageMaker Unified Studio is a single data and AI development where you can find and access your data and act on it using familiar AWS tools for SQL analytics, data processing, model development, and generative AI application development.
AWS Systems Manager – A secure, scalable remote access and management service that enables seamless connectivity between your local VS Code and SageMaker Unified Studio spaces to streamline data and AI development workflows.
The following diagram shows the interaction between your local IDE and SageMaker Unified Studio spaces.
Prerequisites
To try the remote IDE connection, you must have the following prerequisites:
Access to a SageMaker Unified Studio domain with connectivity to the internet. For domains set up in virtual private cloud (VPC)-only mode, your domain should have a route out to the internet through a proxy or a NAT gateway. If your domain is completely isolated from the internet, refer to the documentation for setting up the remote connection. If you don’t have a SageMaker Unified Studio domain, you can create one using the quick setup or manual setup option.
Access to or can create a SageMaker Unified Studio project.
A JupyterLab or Code Editor compute space with a minimum instance type requirement of 8 GB of memory. In this post, we use an ml.t3.large instance. SageMaker Distribution image version 2.8 or later is supported.
You have the latest stable VS Code with Microsoft Remote SSH (version 0.74.0 or later), and AWS Toolkit (version 3.74.0) extension installed on your local machine.
Solution implementation
To enable remote connectivity and connect to the space from VS Code, complete the following steps. To connect to a SageMaker Unified Studio space remotely, the space must have remote access enabled.
Navigate to your JupyterLab or Code Editor space. If it’s running, stop the space and choose Configure space to enable remote access, as shown in the following screenshot.
Turn on Remote access to enable the feature and choose Save and restart, as shown in the following screenshot.
Navigate to AWS Toolkit in your local VS Code installation.
On the SageMaker Unified Studio tab, choose Sign in to get started and provide your SageMaker Unified Studio domain URL, that is, https://<domain-id>.sagemaker.<region>.on.aws.
You will be prompted to be redirected to your web browser to allow access to AWS IDE extensions. Choose Open to open a new web browser tab.
Choose Allow access to connect to the project through VS Code.
You’ll receive a Request approved notification, indicating that you now have permissions to access the domain remotely.
You can now navigate back to your local VS Code to access your project to continue building ETL jobs and data pipelines, training and deploying ML models, or building generative AI applications. To connect to the project for data processing and ML development, follow these steps:
Choose Select a project to view your data and compute resources. All projects in the domain are listed, but you’re only allowed access to projects where you’re a project member.
You can only view one domain and one project at a time. To switch projects or sign out of a domain, choose the ellipsis icon.
You can also view compute and data resources that you created previously.
Connect your JupyterLab or Code Editor space by selecting the connectivity icon, as shown in the following image. Note: If this option does not show as available, then you may have remote access disabled in the space. If the space is in “Stopped” state, hover over the space and choose the connect button. This should enable remote access, start the space and connect to it. If the space is in “Running” state, the space must be restarted with remote access enabled. You can do this by stopping the space and connecting to it as shown below from the toolkit.
Another VS Code window will open that is connected to your SageMaker Unified Studio space using remote SSH.
Navigate to the Explorer to view your space’s notebooks, files, and scripts. From the AWS Toolkit, you can also view your data sources.
Use your custom VS Code setup with SageMaker Unified Studio resources
When you connect VS Code to SageMaker Unified Studio, you keep all your personal shortcuts and customizations. For example, if you use code snippets to quickly insert common analytics and ML code patterns, these continue to work with SageMaker Unified Studio managed infrastructure.
In the following graphic, we demonstrate using analytics workflow shortcuts. The “show-databases” code snippet queries Athena to show available databases, “show-glue-tables” lists tables in AWS Glue Data Catalog, and “query-ecommerce” retrieves data using Spark SQL for analysis.
You can also use shortcuts to automate building and training an ML model on SageMaker AI. In the below graphic, the code snippets show data processing, configuring, and launching a SageMaker AI training job. This approach demonstrates how data practitioners can maintain their familiar development setup while using managed data and AI resources in SageMaker Unified Studio.
Disabling remote access in SageMaker Unified Studio
As an administrator, if you want to disable this feature for your users, you can enforce it by adding the following policy to your project’s IAM role:
SageMaker Unified Studio by default shuts down idle resources such as JupyterLab and Code Editor spaces after 1 hour. If you’ve created a SageMaker Unified Studio domain for the purposes of this post, remember to delete the domain.
Conclusion
Connecting directly to Amazon SageMaker Unified Studio from your local IDE reduces the friction of moving between local development and scalable data and AI infrastructure. By maintaining your personalized IDE configurations, this reduces the need to adapt between different development environments. Whether you’re processing large datasets, training foundation models (FMs), or building generative AI applications, you can now work from your local setup while accessing the capabilities of SageMaker Unified Studio. Get started today by connecting your local IDE to SageMaker Unified Studio to streamline your data processing workflows and accelerate your ML model development.
About the authors
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.

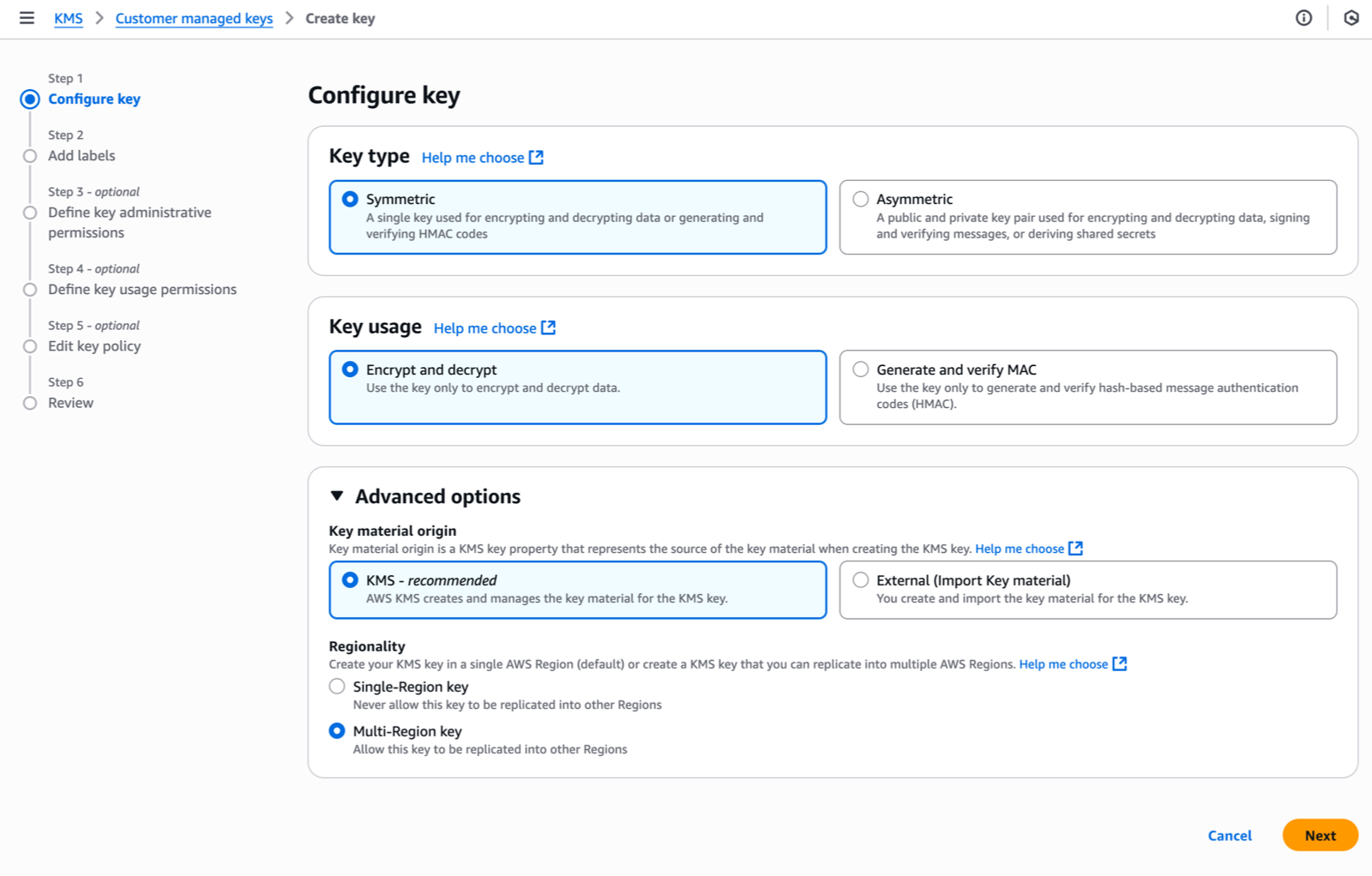
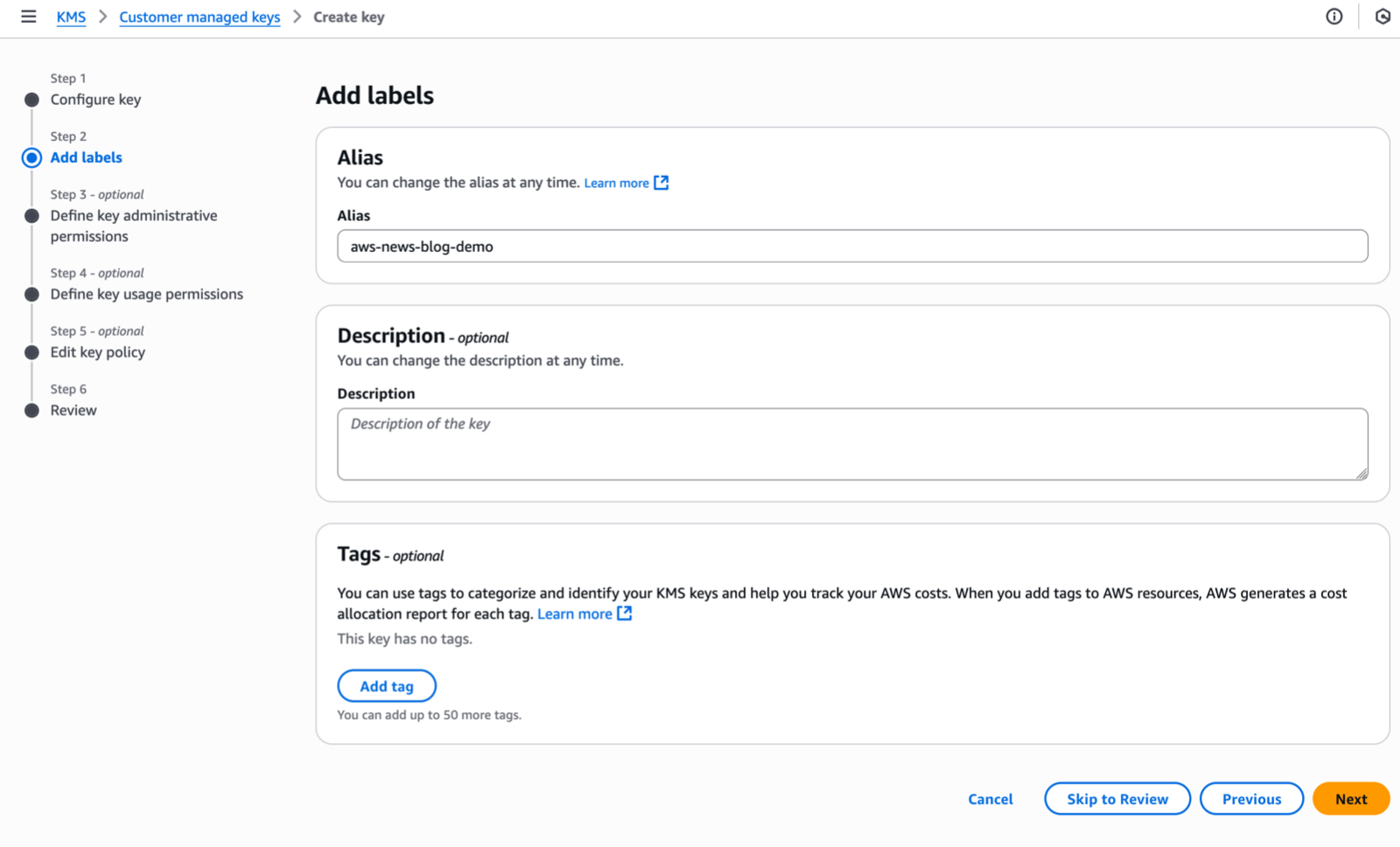
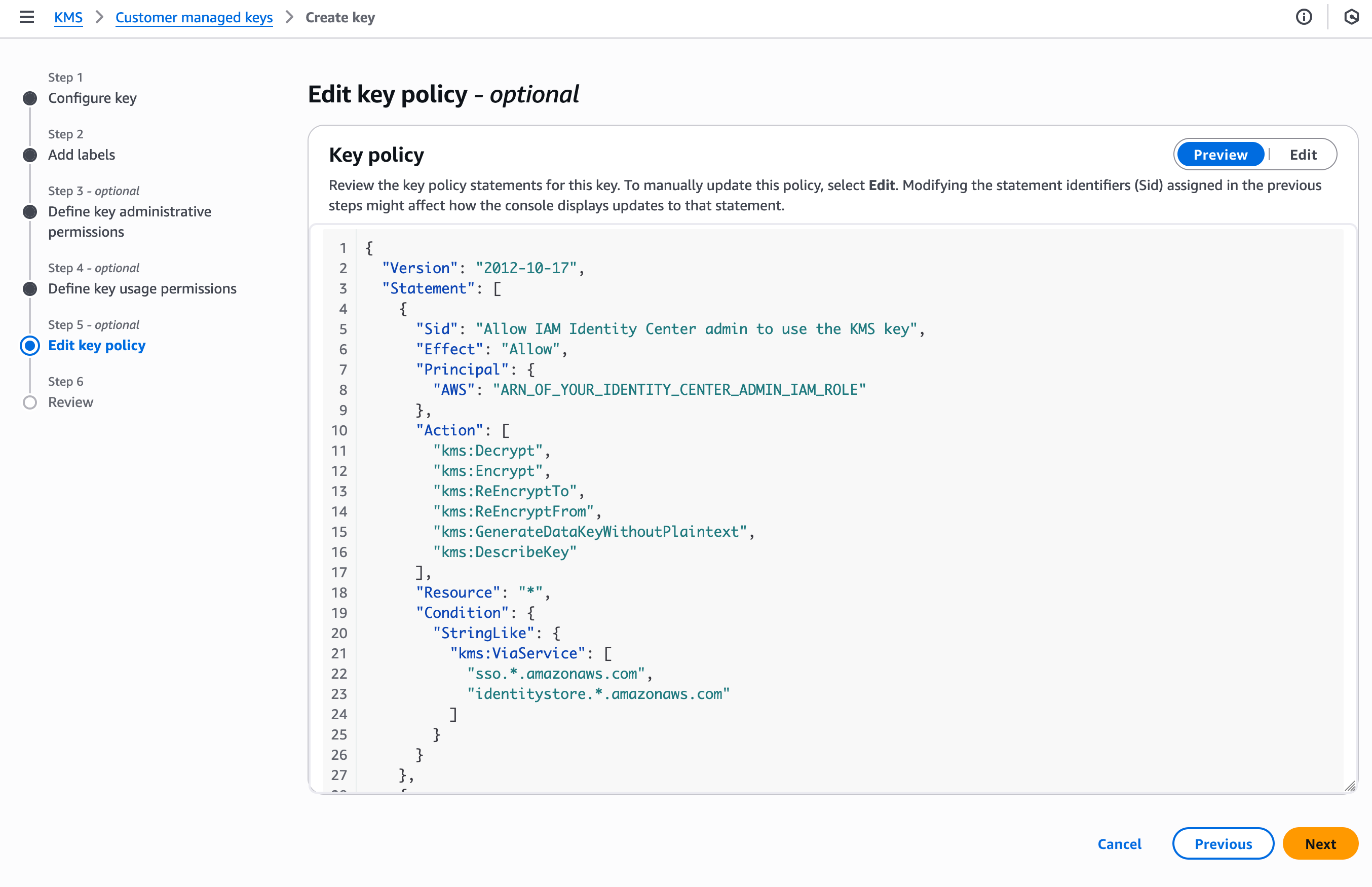
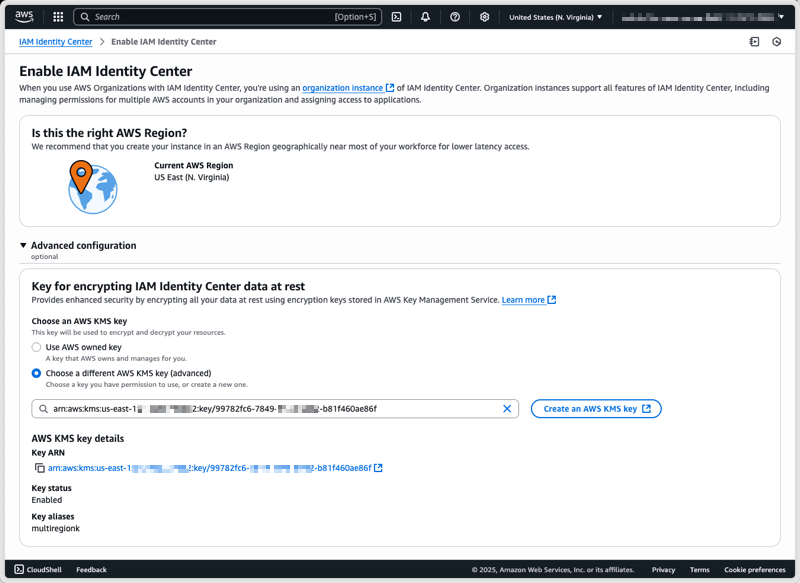
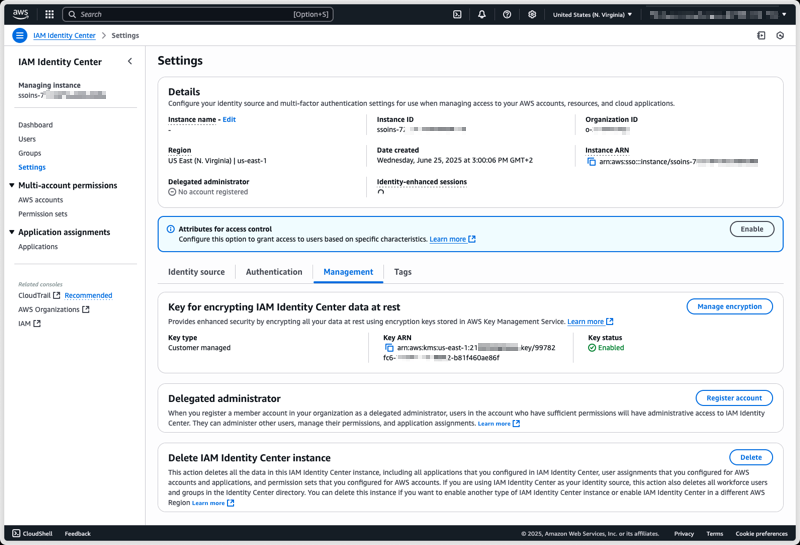
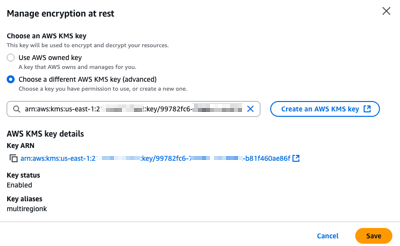
 Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect, Amazon MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on LinkedIn to keep up to date with the latest Amazon MWAA and AWS Glue features and news!
Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect, Amazon MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on LinkedIn to keep up to date with the latest Amazon MWAA and AWS Glue features and news! Ankit Sahu brings over 18 years of expertise in building innovative digital products and services. His diverse experience spans product strategy, go-to-market execution, and digital transformation initiatives. Currently, Ankit serves as Senior Product Manager at Amazon Web Services (AWS), where he leads the Amazon MWAA service.
Ankit Sahu brings over 18 years of expertise in building innovative digital products and services. His diverse experience spans product strategy, go-to-market execution, and digital transformation initiatives. Currently, Ankit serves as Senior Product Manager at Amazon Web Services (AWS), where he leads the Amazon MWAA service. Mohammad Sabeel works as a Senior Cloud Support Engineer at Amazon Web Services (AWS), specializing in AWS Analytics services including AWS Glue, Amazon MWAA, and Amazon Athena. With over 14 years of IT experience, he’s passionate about helping customers build scalable data processing pipelines and optimize their analytics solutions on AWS.
Mohammad Sabeel works as a Senior Cloud Support Engineer at Amazon Web Services (AWS), specializing in AWS Analytics services including AWS Glue, Amazon MWAA, and Amazon Athena. With over 14 years of IT experience, he’s passionate about helping customers build scalable data processing pipelines and optimize their analytics solutions on AWS. Satya Chikkala is a Solutions Architect at Amazon Web Services. Based in Melbourne, Australia, he works closely with enterprise customers to accelerate their cloud journey. Beyond work, he is very passionate about nature and photography.
Satya Chikkala is a Solutions Architect at Amazon Web Services. Based in Melbourne, Australia, he works closely with enterprise customers to accelerate their cloud journey. Beyond work, he is very passionate about nature and photography. Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backward from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data system transformations across industry verticals. His core area of expertise include technology strategy, data analytics, and data science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla.
Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backward from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data system transformations across industry verticals. His core area of expertise include technology strategy, data analytics, and data science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla.