Post Syndicated from Scott Rigney original https://aws.amazon.com/blogs/big-data/analyze-real-time-streaming-data-in-amazon-msk-with-amazon-athena/
Recent advances in ease of use and scalability have made streaming data easier to generate and use for real-time decision-making. Coupled with market forces that have forced businesses to react more quickly to industry changes, more and more organizations today are turning to streaming data to fuel innovation and agility.
Amazon Managed Streaming for Apache Kafka (MSK) is a fully managed service that makes it easy to build and run applications that use Apache Kafka, an open-source distributed event streaming platform designed for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. With Amazon MSK, you can capture real-time data from a wide range of sources such as database change events or web application user clickstreams. Since Kafka is highly optimized for writing and reading fresh data, it’s a great fit for operational reporting. However, gaining insight from this data often requires a specialized stream processing layer to write streaming records to a storage medium like Amazon S3, where it can be accessed by analysts, data scientists, and data engineers for historical analysis and visualization using tools like Amazon QuickSight.
When you want to analyze data where it lives and without developing separate pipelines and jobs, a popular choice is Amazon Athena. With Athena, you can use your existing SQL knowledge to extract insights from a wide range of data sources without learning a new language, developing scripts to extract (and duplicate) data, or managing infrastructure. Athena supports over 25 connectors to popular data sources including Amazon DynamoDB and Amazon Redshift which give data analysts, data engineers, and data scientists the flexibility to run SQL queries on data stored in databases running on-premises or in the cloud alongside data stored in Amazon S3. With Athena, there’s no data movement and you pay only for the queries you run.
What’s new
Starting today, you can now use Athena to query streaming data in MSK and self-managed Apache Kafka. This enables you to run analytical queries on real-time data held in Kafka topics and join that data with other Kafka topics as well as other data in your Amazon S3 data lake – all without the need for separate processes to first store the data on Amazon S3.
Solution overview
In this post, we show you how to get started with real-time SQL analytics using Athena and its connector for MSK. The process involves:
- Registering the schema of your streaming data with AWS Glue Schema Registry. Schema Registry is a feature of AWS Glue that allows you to validate and reliably evolve streaming data against JSON schemas. It can also serialize data into a compressed format, which helps you save on data transfer and storage costs.
- Creating a new instance of the Amazon Athena MSK Connector. Athena connectors are pre-built applications that run as serverless AWS Lambda applications, so there’s no need for standalone data export processes.
- Using the Athena console to run interactive SQL queries on your Kafka topics.
Get started with Athena’s connector for Amazon MSK
In this section, we’ll cover the steps necessary to set up your MSK cluster to work with Athena to run SQL queries on your Kafka topics.
Prerequisites
This post assumes you have a serverless or provisioned MSK cluster set up to receive streaming messages from a producing application. For information, see Setting up Amazon MSK and Getting started using Amazon MSK in the Amazon Managed Streaming for Apache Kafka Developer Guide.
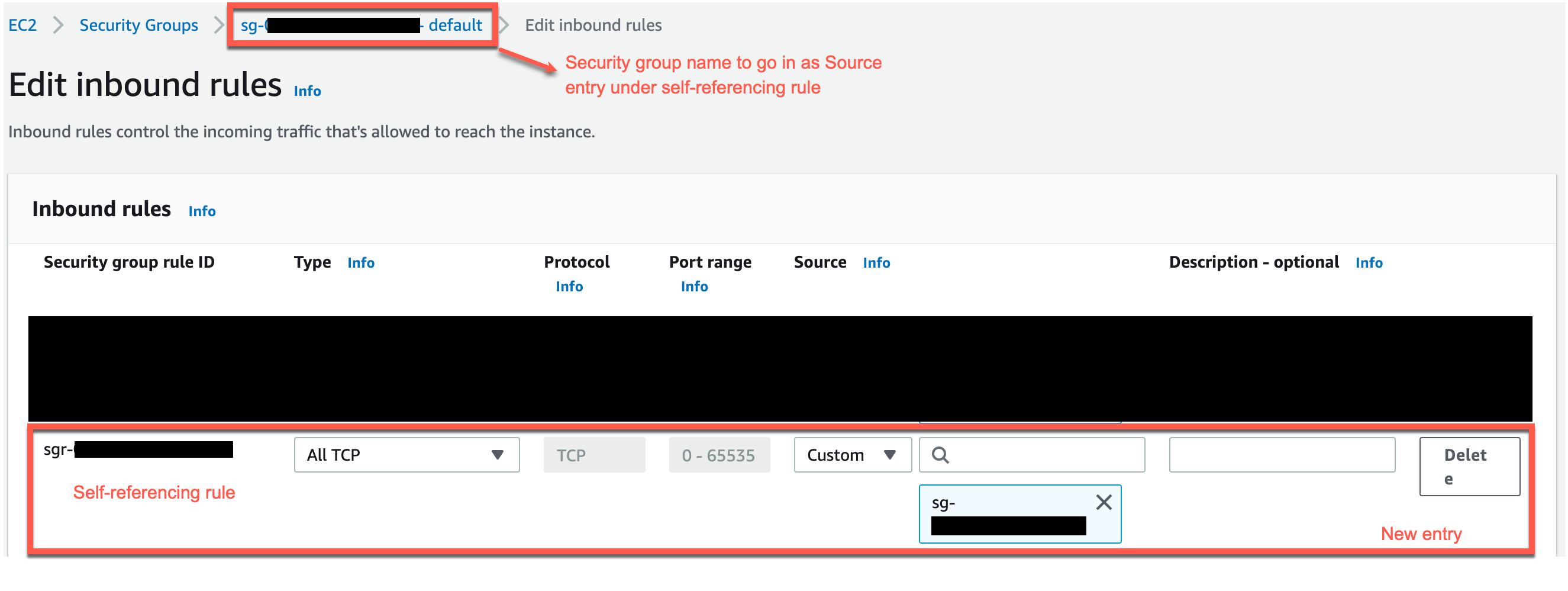
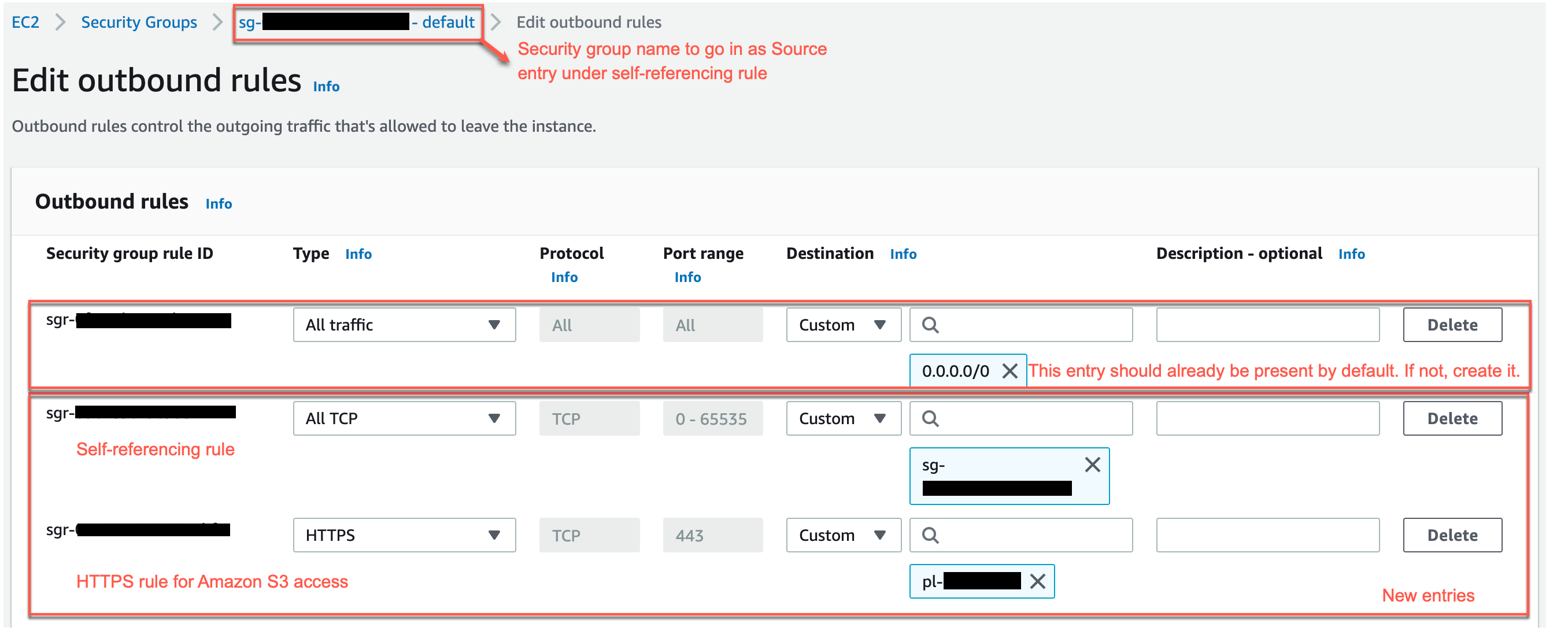
You’ll also need to set up a VPC and a security group before you use the Athena connector for MSK. For more information, see Creating a VPC for a data source connector. Note that with MSK Serverless, VPCs and security groups are created automatically, so you can get started quickly.
Define the schema of your Kafka topics with AWS Glue Schema Registry
To run SQL queries on your Kafka topics, you’ll first need to define the schema of your topics as Athena uses this metadata for query planning. AWS Glue makes it easy to do this with its Schema Registry feature for streaming data sources.
Schema Registry allows you to centrally discover, control, and evolve streaming data schemas for use in analytics applications such as Athena. With AWS Glue Schema Registry, you can manage and enforce schemas on your data streaming applications using convenient integrations with Apache Kafka. To learn more, see AWS Glue Schema Registry and Getting started with Schema Registry.
If configured to do so, the producer of data can auto-register its schema and changes to it with AWS Glue. This is especially useful in use cases where the contents of the data is likely to change over time. However, you can also specify the schema manually and will resemble the following JSON structure.
When setting up your Schema Registry, be sure to give it an easy-to-remember name, such as customer_schema, because you’ll reference it within SQL queries as you’ll see later on. For additional information on schema set up, see Schema examples for the AWS Glue Schema Registry.
Configure the Athena connector for MSK
With your schema registered with Glue, the next step is to set up the Athena connector for MSK. We recommend using the Athena console for this step. For more background on the steps involved, see Deploying a connector and connecting to a data source.
In Athena, federated data source connectors are applications that run on AWS Lambda and handle communication between your target data source and Athena. When a query runs on a federated source, Athena calls the Lambda function and tasks it with running the parts of your query that are specific to that source. To learn more about the query execution workflow, see Using Amazon Athena Federated Query in the Amazon Athena User Guide.
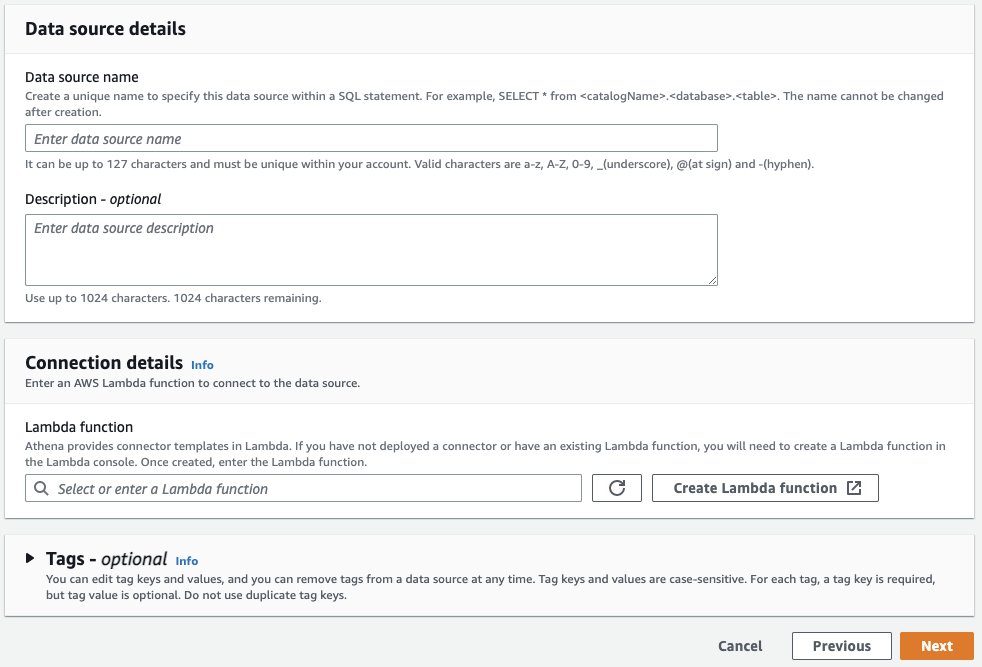
Start by accessing the Athena console and selecting Data sources on the left navigation, then choose Create data source:

Next, search for and select Amazon MSK from the available connectors and select Next.

In Data source details, give your connector a name, like msk, that’s easy to remember and reference in your future SQL queries. Under Connection details section, select Create Lambda function. This will bring you to the AWS Lambda console where you’ll provide additional configuration properties.
In the Lambda application configuration screen (not shown), you’ll provide the Application settings for your connector. To do this, you’ll need a few properties from your MSK cluster and schema registered in Glue.
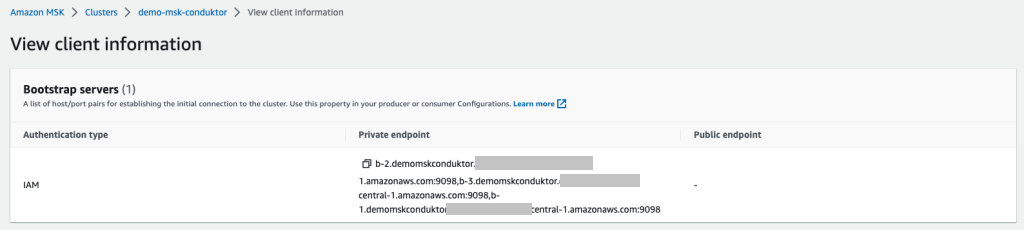
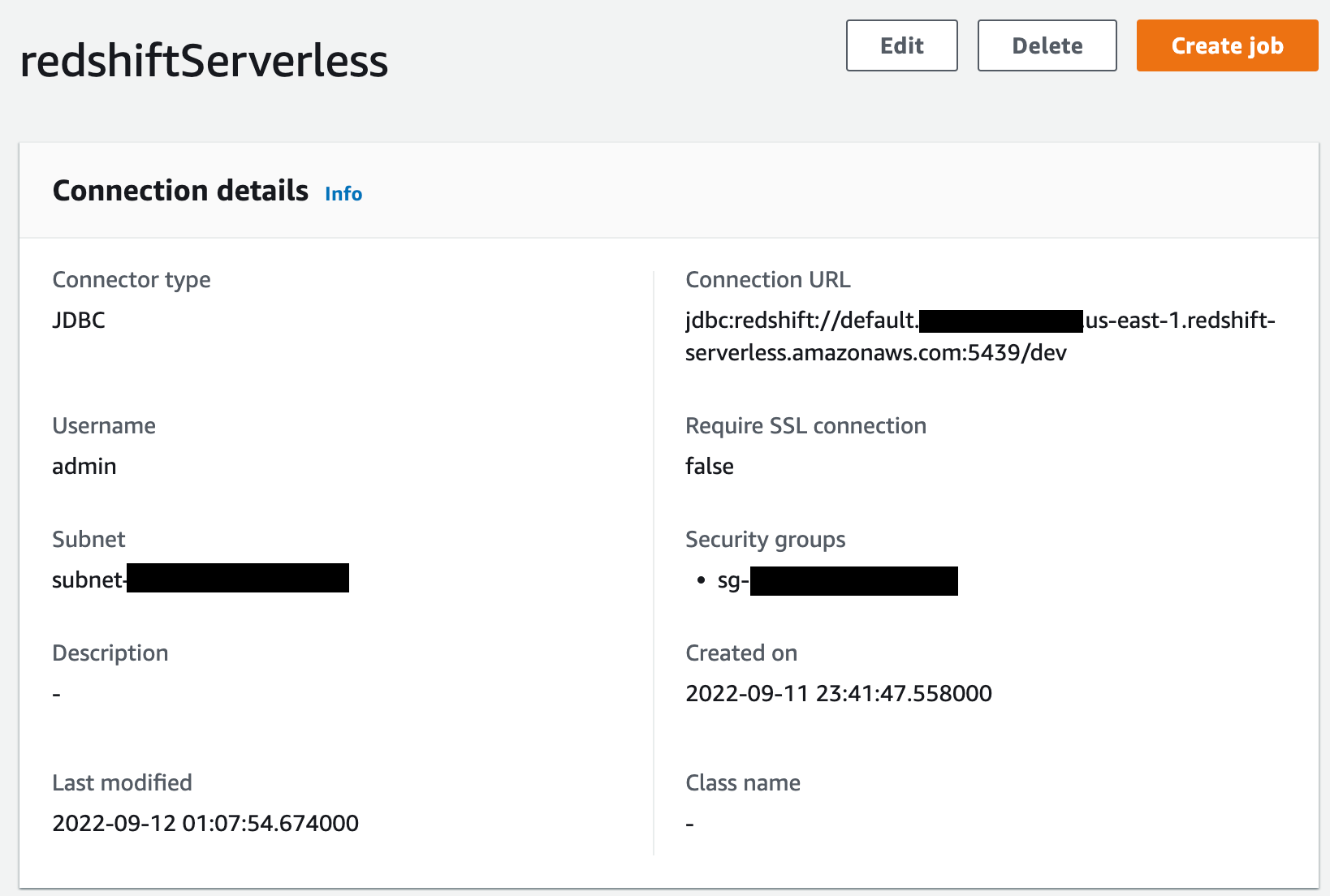
On another browser tab, use the MSK console to navigate to your MSK cluster and then select the Properties tab. Here you’ll see the VPC subnets and security group IDs from your MSK cluster which you’ll provide in the SubnetIds and SecurityGroupIds fields in the Athena connector’s Application settings form. You can find the value for KafkaEndpoint by clicking View client information.
In the AWS Glue console, navigate to your Schema Registry to find the GlueRegistryArn for the schema you wish to use with this connector.
After providing these and the other required values, click Deploy.
Return to the Athena console and enter the name of the Lambda function you just created in the Connection details box, then click Create data source.
Run queries on streaming data using Athena
With your MSK data connector set up, you can now run SQL queries on the data. Let’s explore a few use cases in more detail.
Use case: interactive analysis
If you want to run queries that aggregate, group, or filter your MSK data, you can run interactive queries using Athena. These queries will run against the current state of your Kafka topics at the time the query was submitted.
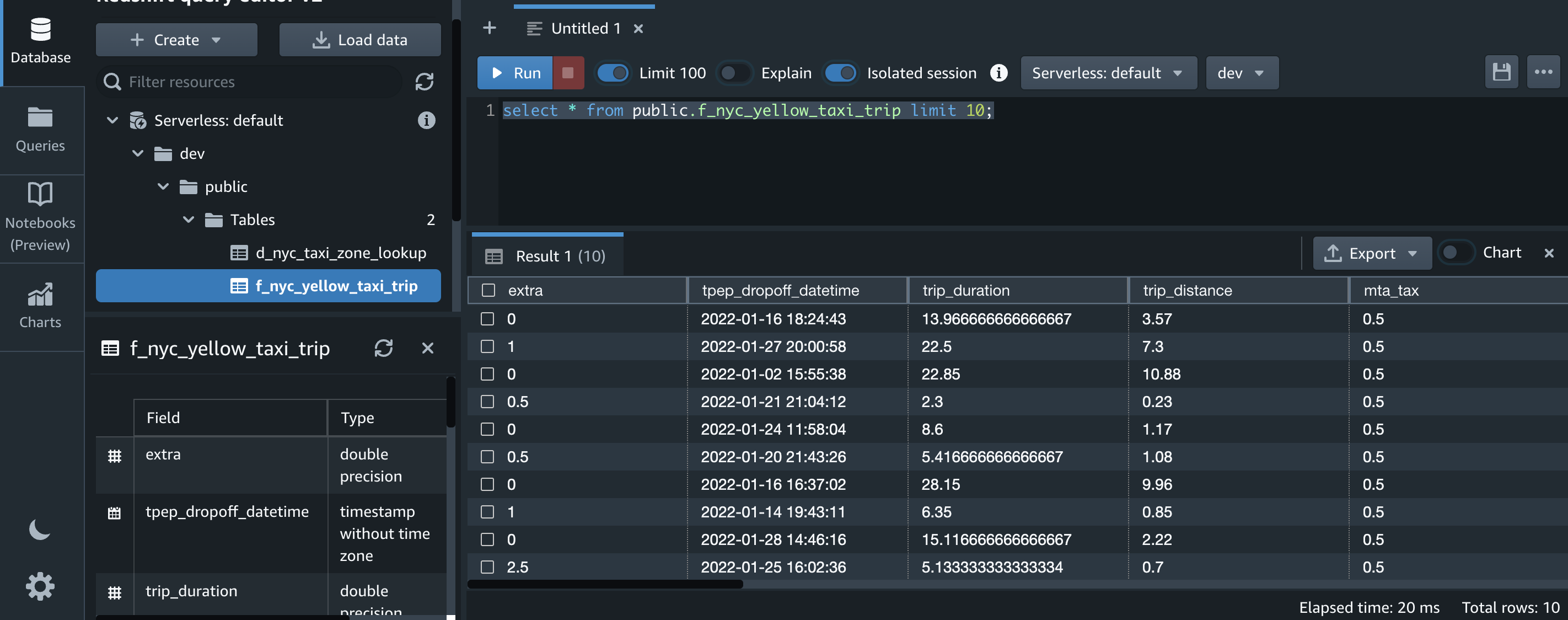
Before running any queries, it may be helpful to validate the schema and data types available within your Kafka topics. To do this, run the DESCRIBE command on your Kafka topic, which appears in Athena as a table, as shown below. In this query, the orders table corresponds to the topic you specified in the Schema Registry.
Now that you know the contents of your topic, you can begin to develop analytical queries. A sample query for a hypothetical Kafka topic containing e-commerce order data is shown below:
Because the orders table (and underlying Kafka topic) can contain an unbounded stream of data, the query above is likely to return a different value for SUM(order_total) with each execution of the query.
If you have data in one topic that you need to join with another topic, you can do that too:
Use case: ingesting streaming data to a table on Amazon S3
Federated queries run against the underlying data source which ensures interactive queries, like the ones above, are evaluated against the current state of your data. One consideration is that repeatedly running federated queries can put additional load on the underlying source. If you plan to perform multiple queries on the same source data, you can use Athena’s CREATE TABLE AS SELECT, also known as CTAS, to store the results of a SELECT query in a table on Amazon S3. You can then run queries on your newly created table without going back to the underlying source each time.
If you plan to do additional downstream analysis on this data, for example within dashboards on Amazon QuickSight, you can enhance the solution above by periodically adding new data to your table. To learn more, see Using CTAS and INSERT INTO for ETL and data analysis. Another benefit of this approach is that you can secure these tables with row-, column-, and table-level data governance policies powered by AWS Lake Formation to ensure only authorized users can access your table.
What else can you do?
With Athena, you can use your existing SQL knowledge to run federated queries that generate insights from a wide range of data sources without learning a new language, developing scripts to extract (and duplicate) data, or managing infrastructure. Athena provides additional integrations with other AWS services and popular analytics tools and SQL IDEs that allow you to do much more with your data. For example, you can:
- Visualize the data in business intelligence applications like Amazon QuickSight
- Design event-driven data processing workflows with Athena’s integration with AWS Step Functions
- Unify multiple data sources to produce rich input features for machine learning in Amazon SageMaker
Conclusion
In this post, we learned about the newly released Athena connector for Amazon MSK. With it, you can run interactive queries on data held in Kafka topics running in MSK or self-managed Apache Kafka. This helps you bring real-time insights to dashboards or enable point-in-time analysis of streaming data to answer time-sensitive business questions. We also covered how to periodically ingest new streaming data into Amazon S3 without the need for a separate sink process. This simplifies recurring analysis of your data without incurring round-trip queries to your underlying Kafka clusters and makes it possible to secure the data with access rules powered by Lake Formation.
We encourage you to evaluate Athena and federated queries on your next analytics project. For help getting started, we recommend the following resources:
- If you’re new to Athena and want to learn more about its features and capabilities, see Amazon Athena features.
- To learn more about Athena’s connector for MSK, see Amazon Athena MSK Connector.
- For a complete list of supported data sources, see Athena Data Source Connectors.
About the authors
 Scott Rigney is a Senior Technical Product Manager with Amazon Web Services (AWS) and works with the Amazon Athena team based out of Arlington, Virginia. He is passionate about building analytics products that enable enterprises to make data-driven decisions.
Scott Rigney is a Senior Technical Product Manager with Amazon Web Services (AWS) and works with the Amazon Athena team based out of Arlington, Virginia. He is passionate about building analytics products that enable enterprises to make data-driven decisions.
 Kiran Matty is a Principal Product Manager with Amazon Web Services (AWS) and works with the Amazon Managed Streaming for Apache Kafka (Amazon MSK) team based out of Palo Alto, California. He is passionate about building performant streaming and analytical services that help enterprises realize their critical use cases.
Kiran Matty is a Principal Product Manager with Amazon Web Services (AWS) and works with the Amazon Managed Streaming for Apache Kafka (Amazon MSK) team based out of Palo Alto, California. He is passionate about building performant streaming and analytical services that help enterprises realize their critical use cases.



































 Shannon Kalisky is a Senior Product Manager – Technical that covers natural language question patterns and model robustness for Amazon QuickSight Q.
Shannon Kalisky is a Senior Product Manager – Technical that covers natural language question patterns and model robustness for Amazon QuickSight Q.


































 Anusha Challa is a Senior Analytics Specialist Solutions Architect focused on Amazon Redshift. She has helped many customers build large scale data warehouses in the cloud and on premises.
Anusha Challa is a Senior Analytics Specialist Solutions Architect focused on Amazon Redshift. She has helped many customers build large scale data warehouses in the cloud and on premises. Bahadir Özavci is a Senior Software Engineer focused on Amazon Redshift. He primarily works on designing and building features for Amazon Redshift customers to provide a great IDE experience. Outside of work, you can find him cooking or playing roguelike video games.
Bahadir Özavci is a Senior Software Engineer focused on Amazon Redshift. He primarily works on designing and building features for Amazon Redshift customers to provide a great IDE experience. Outside of work, you can find him cooking or playing roguelike video games. Mohamed Shaaban is a Senior Software Engineer in Amazon Redshift and is based in Berlin, Germany. He has over 12 years of experience in the software engineering. He is passionate about cloud services and building solutions that delight customers. Outside of work, he is an amateur photographer who loves to explore and capture unique moments.
Mohamed Shaaban is a Senior Software Engineer in Amazon Redshift and is based in Berlin, Germany. He has over 12 years of experience in the software engineering. He is passionate about cloud services and building solutions that delight customers. Outside of work, he is an amateur photographer who loves to explore and capture unique moments. Erol Murtezaoglu, a Technical Product Manager at AWS, is an inquisitive and enthusiastic thinker with a drive for self-improvement and learning. He has a strong and proven technical background in software development and architecture, balanced with a drive to deliver commercially successful products. Erol highly values the process of understanding customer needs and problems in order to deliver solutions that exceed expectations.
Erol Murtezaoglu, a Technical Product Manager at AWS, is an inquisitive and enthusiastic thinker with a drive for self-improvement and learning. He has a strong and proven technical background in software development and architecture, balanced with a drive to deliver commercially successful products. Erol highly values the process of understanding customer needs and problems in order to deliver solutions that exceed expectations.


























































 Theo Tolv is a Senior Analytics Architect based in Stockholm, Sweden. He’s worked with small and big data for most of his career, and has built applications running on AWS since 2008. In his spare time he likes to tinker with electronics and read space opera.
Theo Tolv is a Senior Analytics Architect based in Stockholm, Sweden. He’s worked with small and big data for most of his career, and has built applications running on AWS since 2008. In his spare time he likes to tinker with electronics and read space opera. Bruce Ross is a Senior Solutions Architect at AWS in the New York Area. Bruce is the Lens Leader for the Well-Architected Framework. He has been involved in IT and Content Development for over 20 years. He is an avid sailor and angler, and enjoys R&B, jazz, and classical music.
Bruce Ross is a Senior Solutions Architect at AWS in the New York Area. Bruce is the Lens Leader for the Well-Architected Framework. He has been involved in IT and Content Development for over 20 years. He is an avid sailor and angler, and enjoys R&B, jazz, and classical music.











 DoYeun Kim is the Head of Data Engineering at SOCAR. He is a passionate software engineering professional with 19+ years experience. He leads a team of 10+ engineers who are responsible for the data platform, data warehouse and MLOps engineering, as well as building in-house data products.
DoYeun Kim is the Head of Data Engineering at SOCAR. He is a passionate software engineering professional with 19+ years experience. He leads a team of 10+ engineers who are responsible for the data platform, data warehouse and MLOps engineering, as well as building in-house data products. SangSu Park is a Lead Data Architect in SOCAR’s cloud DB team. His passion is to keep learning, embrace challenges, and strive for mutual growth through communication. He loves to travel in search of new cities and places.
SangSu Park is a Lead Data Architect in SOCAR’s cloud DB team. His passion is to keep learning, embrace challenges, and strive for mutual growth through communication. He loves to travel in search of new cities and places. YoungMin Park is a Lead Architect in SOCAR’s cloud infrastructure team. His philosophy in life is-whatever it may be-to challenge, fail, learn, and share such experiences to build a better tomorrow for the world. He enjoys building expertise in various fields and basketball.
YoungMin Park is a Lead Architect in SOCAR’s cloud infrastructure team. His philosophy in life is-whatever it may be-to challenge, fail, learn, and share such experiences to build a better tomorrow for the world. He enjoys building expertise in various fields and basketball. Younggu Yun is a Senior Data Lab Architect at AWS. He works with customers around the APAC region to help them achieve business goals and solve technical problems by providing prescriptive architectural guidance, sharing best practices, and building innovative solutions together. In his free time, his son and he are obsessed with Lego blocks to build creative models.
Younggu Yun is a Senior Data Lab Architect at AWS. He works with customers around the APAC region to help them achieve business goals and solve technical problems by providing prescriptive architectural guidance, sharing best practices, and building innovative solutions together. In his free time, his son and he are obsessed with Lego blocks to build creative models. Vicky Falconer leads the AWS Data Lab program across APAC, offering accelerated joint engineering engagements between teams of customer builders and AWS technical resources to create tangible deliverables that accelerate data analytics modernization and machine learning initiatives.
Vicky Falconer leads the AWS Data Lab program across APAC, offering accelerated joint engineering engagements between teams of customer builders and AWS technical resources to create tangible deliverables that accelerate data analytics modernization and machine learning initiatives.