Post Syndicated from Sohaib Katariwala original https://aws.amazon.com/blogs/big-data/optimizing-vector-search-using-amazon-s3-vectors-and-amazon-opensearch-service/
NOTE: As of July 15, the Amazon S3 Vectors Integration with Amazon OpenSearch Service is in preview release and is subject to change.
The way we store and search through data is evolving rapidly with the advancement of vector embeddings and similarity search capabilities. Vector search has become essential for modern applications such as generative AI and agentic AI, but managing vector data at scale presents significant challenges. Organizations often struggle with the trade-offs between latency, cost, and accuracy when storing and searching through millions or billions of vector embeddings. Traditional solutions either require substantial infrastructure management or come with prohibitive costs as data volumes grow.
We now have a public preview of two integrations between Amazon Simple Storage Service (Amazon S3) Vectors and Amazon OpenSearch Service that give you more flexibility in how you store and search vector embeddings:
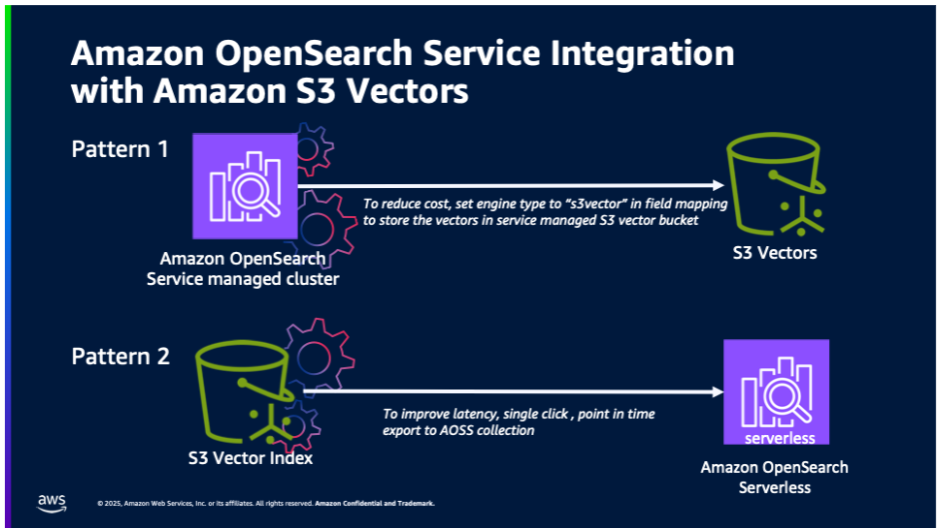
- Cost-optimized vector storage: OpenSearch Service managed clusters using service-managed S3 Vectors for cost-optimized vector storage. This integration will support OpenSearch workloads that are willing to trade off higher latency for ultra-low cost and still want to use advanced OpenSearch capabilities (such as hybrid search, advanced filtering, geo filtering, and so on).
- One-click export from S3 Vectors: One-click export from an S3 vector index to OpenSearch Serverless collections for high-performance vector search. Customers who build natively on S3 Vectors will benefit from being able to use OpenSearch for faster query performance.
By using these integrations, you can optimize cost, latency, and accuracy by intelligently distributing your vector workloads by keeping infrequent queried vectors in S3 Vectors and using OpenSearch for your most time-sensitive operations that require advanced search capabilities such as hybrid search and aggregations. Further, OpenSearch performance tuning capabilities (that is, quantization, k-nearest neighbor (knn) algorithms, and method-specific parameters) help to improve the performance with little compromise of cost or accuracy.
In this post, we walk through this seamless integration, providing you with flexible options for vector search implementation. You’ll learn how to use the new S3 Vectors engine type in OpenSearch Service managed clusters for cost-optimized vector storage and how to use one-click export from S3 Vectors to OpenSearch Serverless collections for high-performance scenarios requiring sustained queries with latency as low as 10ms. By the end of this post, you’ll understand how to choose and implement the right integration pattern based on your specific requirements for performance, cost, and scale.
Service overview
Amazon S3 Vectors is the first cloud object store with native support to store and query vectors with sub-second search capabilities, requiring no infrastructure management. It combines the simplicity, durability, availability, and cost-effectiveness of Amazon S3 with native vector search functionality, so you can store and query vector embeddings directly in S3. Amazon OpenSearch Service provides two complementary deployment options for vector workloads: Managed Clusters and Serverless Collections. Both harness Amazon OpenSearch’s powerful vector search and retrieval capabilities, though each excels in different scenarios. For OpenSearch users, the integration between S3 Vectors and Amazon OpenSearch Service offers unprecedented flexibility in optimizing your vector search architecture. Whether you need ultra-fast query performance for real-time applications or cost-effective storage for large-scale vector datasets, this integration lets you choose the approach that best fits your specific use case.
Understanding Vector Storage Options
OpenSearch Service provides multiple options for storing and searching vector embeddings, each optimized for different use cases. The Lucene engine, which is OpenSearch’s native search library, implements the Hierarchical Navigable Small World (HNSW) method, offering efficient filtering capabilities and strong integration with OpenSearch’s core functionality. For workloads requiring additional optimization options, the Faiss engine (Facebook AI Similarity Search) provides implementations of both HNSW and IVF (Inverted File Index) methods, along with vector compression capabilities. HNSW creates a hierarchical graph structure of connections between vectors, enabling efficient navigation during search, while IVF organizes vectors into clusters and searches only relevant subsets during query time. With the introduction of the S3 engine type, you now have a cost-effective option that uses Amazon S3’s durability and scalability while maintaining sub-second query performance. With this variety of options, you can choose the most suitable approach based on your specific requirements for performance, cost, and accuracy. For instance, if your application requires sub-50 ms query responses with efficient filtering, Faiss’s HNSW implementation is the best choice. Alternatively, if you need to optimize storage costs while maintaining reasonable performance, the new S3 engine type would be more appropriate.
Solution overview
In this post, we explore two primary integration patterns:
OpenSearch Service managed clusters using service-managed S3 Vectors for cost-optimized vector storage.
For customers already using OpenSearch Service domains who want to optimize costs while maintaining sub-second query performance, the new Amazon S3 engine type offers a compelling solution. OpenSearch Service automatically manages vector storage in Amazon S3, data retrieval, and cache optimization, eliminating operational overhead.
One-click export from an S3 vector index to OpenSearch Serverless collections for high-performance vector search.
For use cases requiring faster query performance, you can migrate your vector data from an S3 vector index to an OpenSearch Serverless collection. This approach is ideal for applications that require real-time response times and gives you the benefits that come with Amazon OpenSearch Serverless, including advanced query capabilities and filters, automatic scaling and high availability, and no administration. The export process automatically handles schema mapping, vector data transfer, index optimization, and connection configuration.
The following illustration shows the two integration patterns between Amazon OpenSearch Service and S3 Vectors.
Prerequisites
Before you begin, make sure you have:
- An AWS account
- Access to Amazon S3 and Amazon OpenSearch Service
- An OpenSearch Service domain (for the first integration pattern)
- Vector data stored in S3 Vectors (for the second integration pattern)
Integration pattern 1: OpenSearch Service managed cluster using S3 Vectors
To implement this pattern:
- Create an OpenSearch Service Domain using OR1 instances on OpenSearch version 2.19.
- While creating the OpenSearch Service domain, choose the Enable S3 Vectors as an engine option in the Advanced features section.
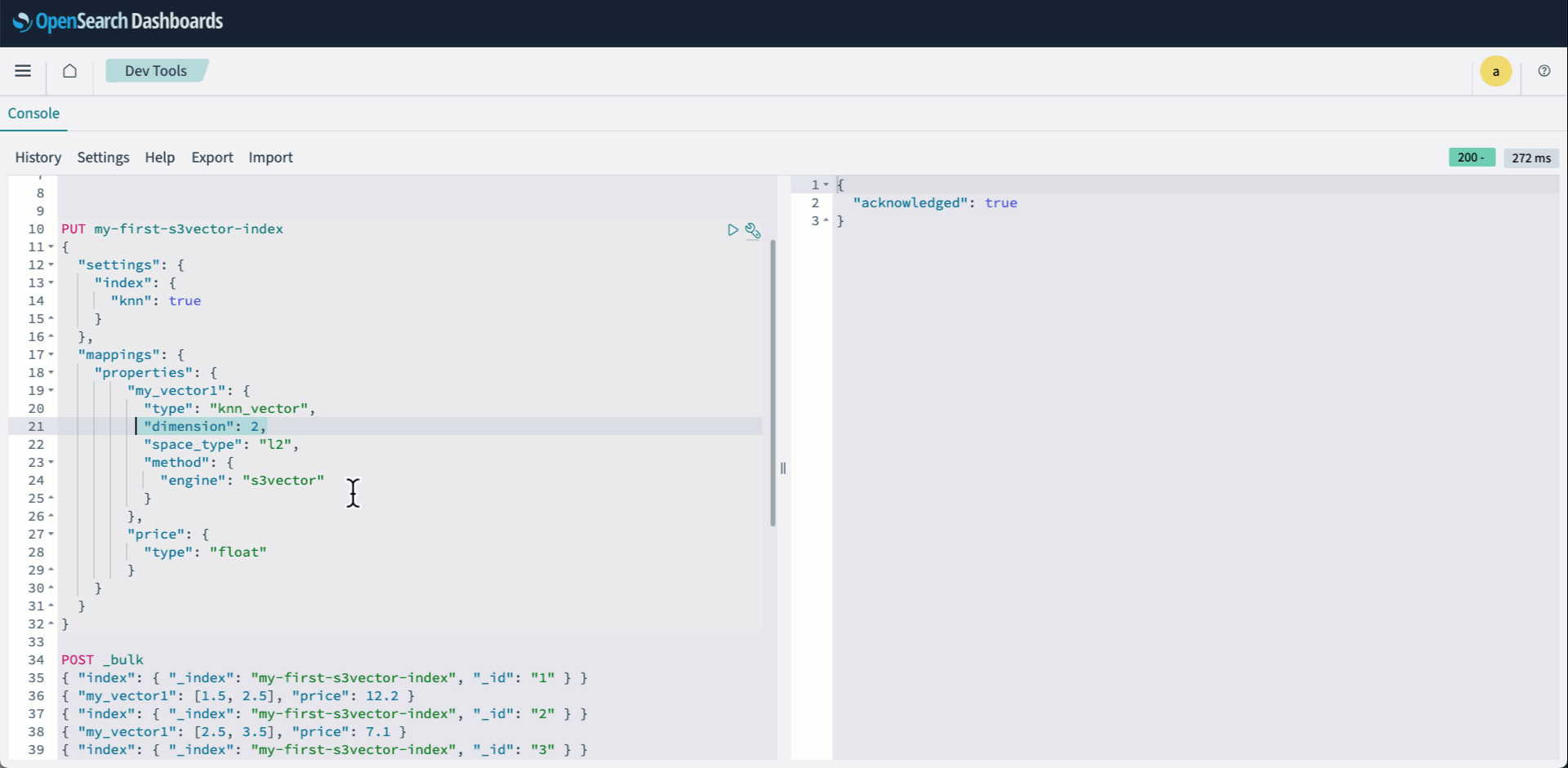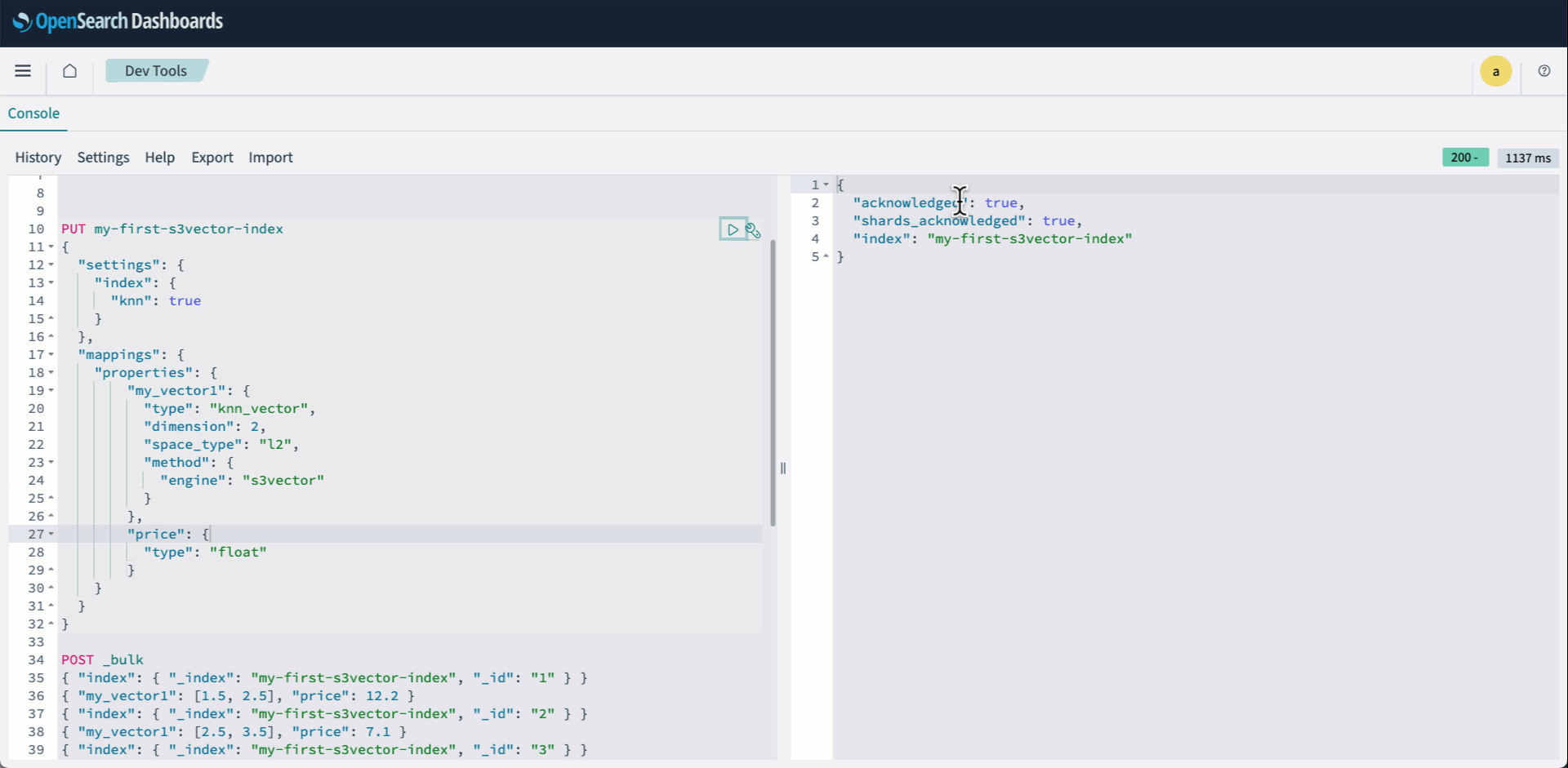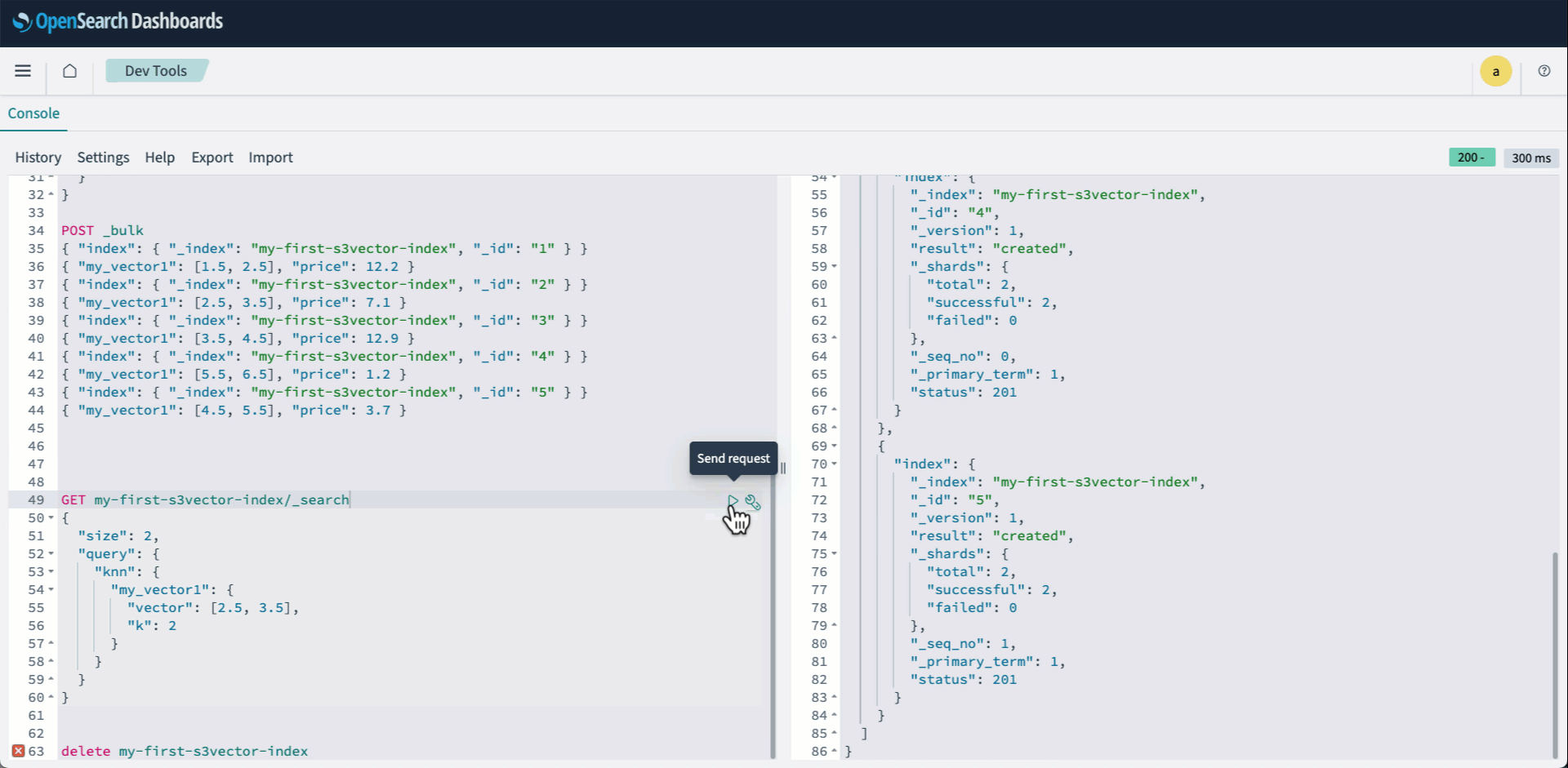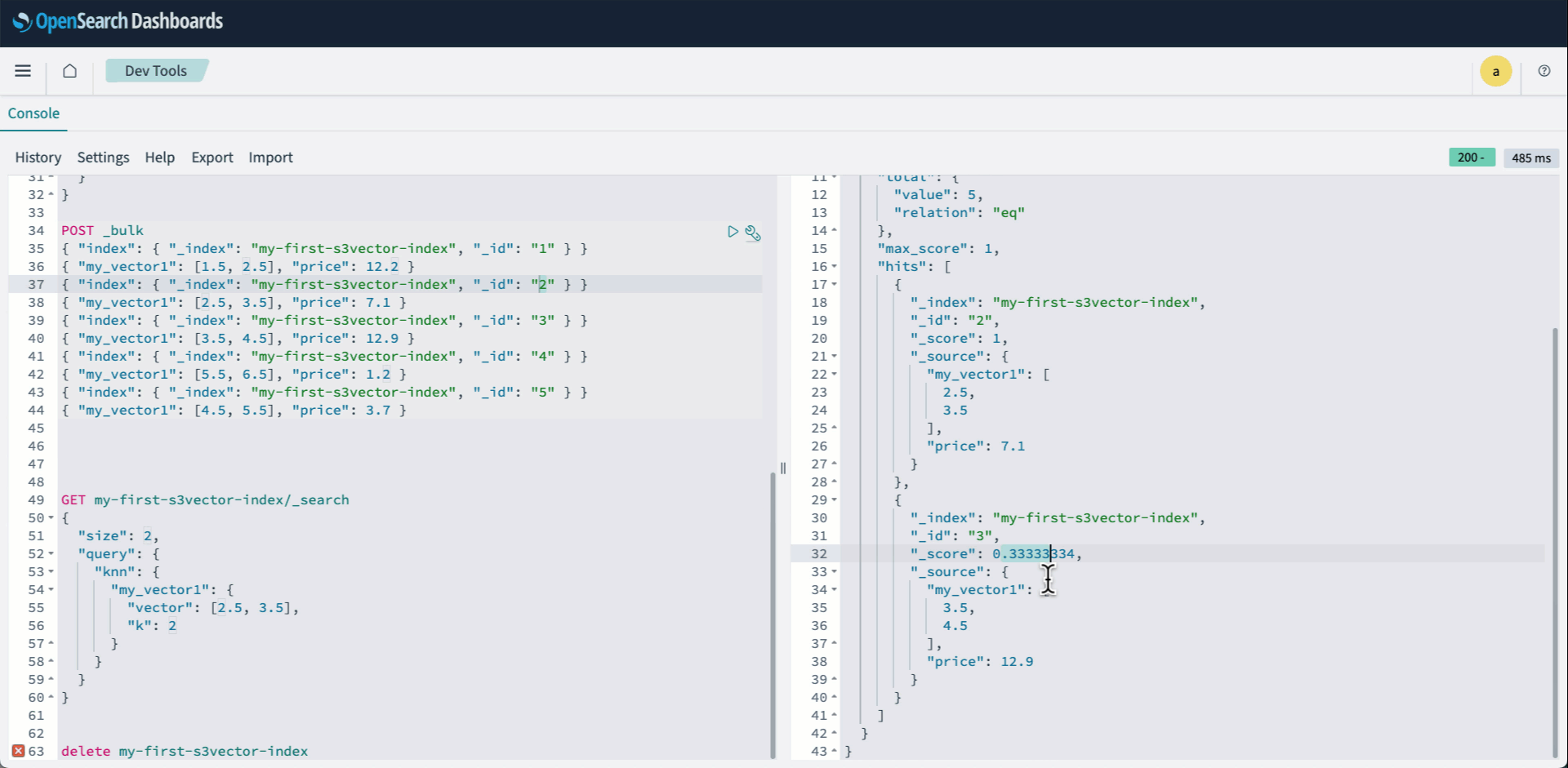
- Sign in to OpenSearch Dashboards and open Dev tools. Then create your knn index and specify s3vector as the engine.
- Index your vectors using the Bulk API:
- Run a knn query as usual:
The following animation demonstrates steps 2-4 above.
Integration pattern 2: Export S3 vector indexes to OpenSearch Serverless
To implement this pattern:
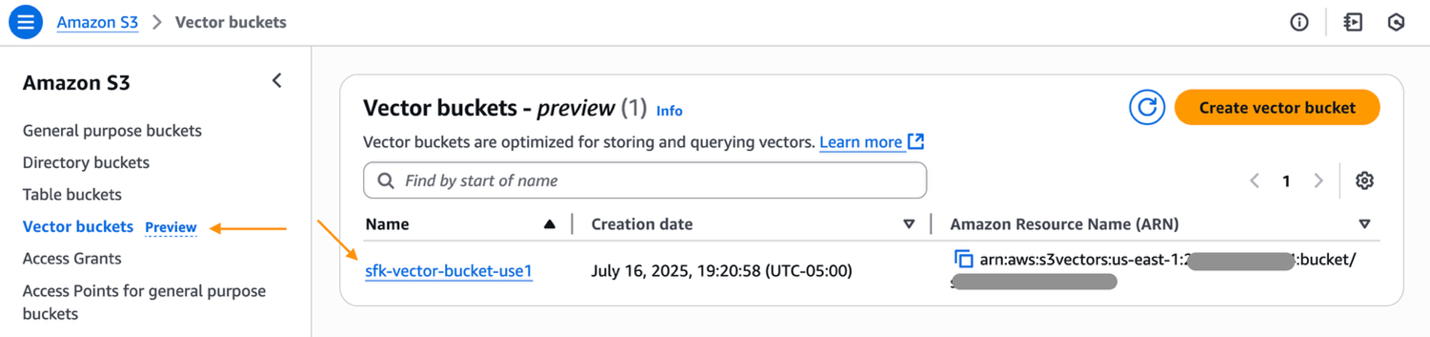
- Navigate to the AWS Management Console for Amazon S3 and select your S3 vector bucket.
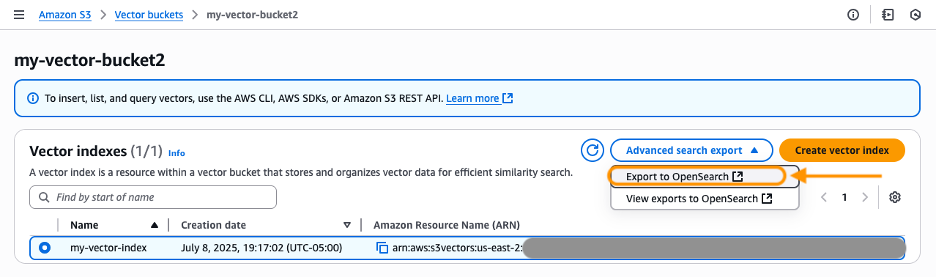
- Select a vector index that you want to export. Under Advanced search export, select Export to OpenSearch.
Alternatively, you can:
- Navigate to the OpenSearch Service console.
- Select Integrations from the navigation pane.
- Here you will see a new Integration Template to Import S3 vectors to OpenSearch vector engine – preview. Select Import S3 vector index.
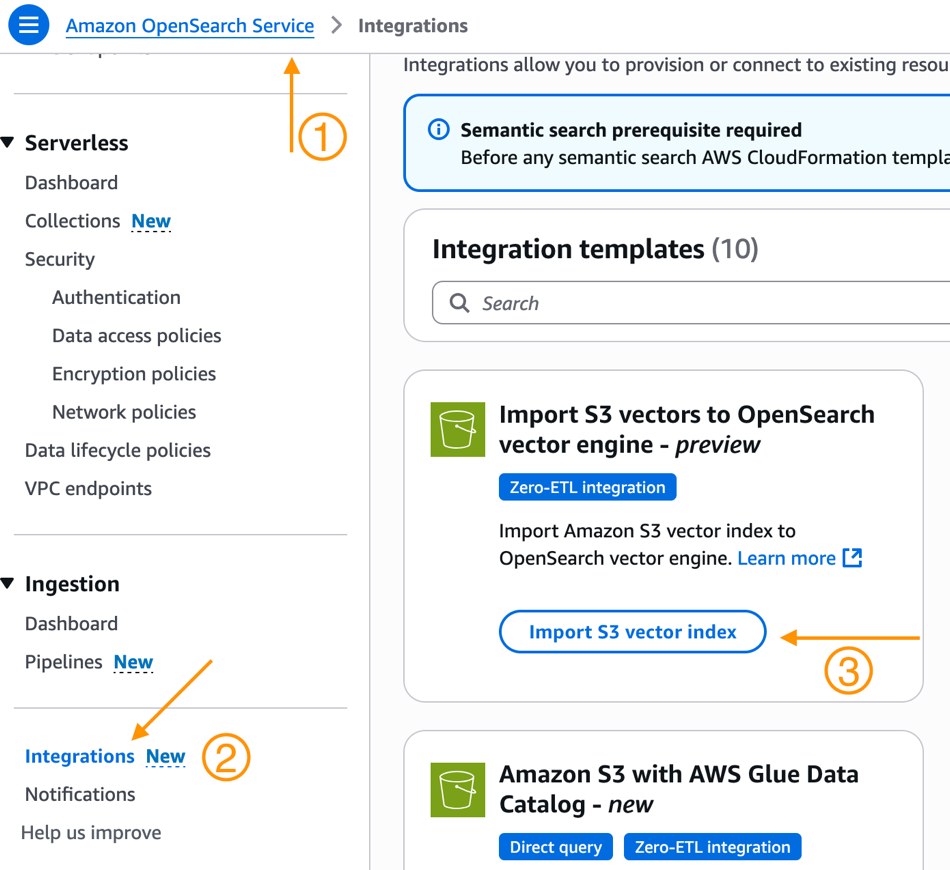
- You will now be brought to the Amazon OpenSearch Service integration console with the Export S3 vector index to OpenSearch vector engine template pre-selected and pre-populated with your S3 vector index Amazon Resource Name (ARN). Select an existing role that has the necessary permissions or create a new service role.
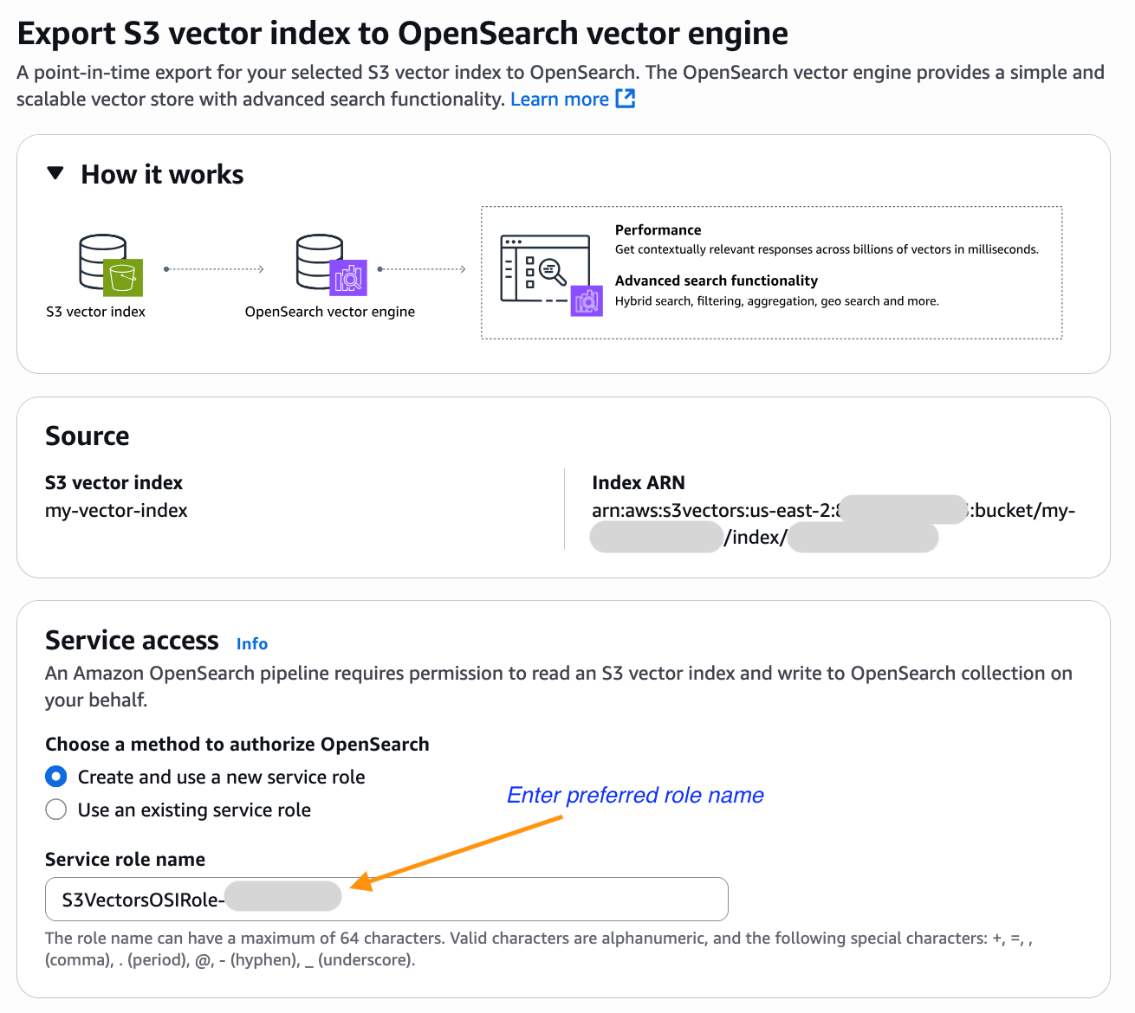
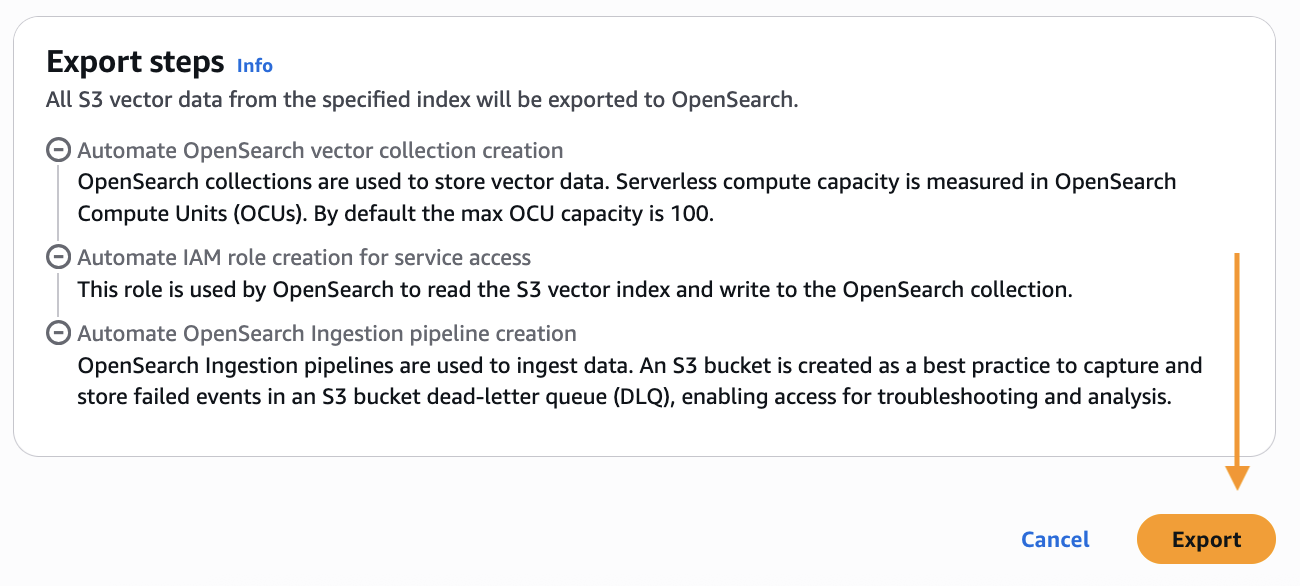
- Scroll down and choose Export to start the steps to create a new OpenSearch Serverless collection and copy data from your S3 vector index into an OpenSearch knn index.
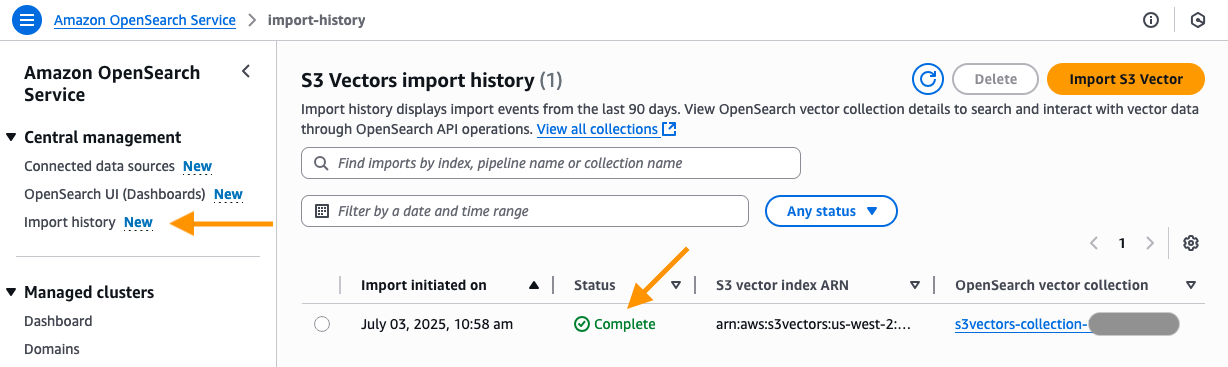
- You will now be taken to the Import history page in the OpenSearch Service console. Here you will see the new job that was created to migrate your S3 vector index into the OpenSearch serverless knn index. After the status changes from In Progress to Complete, you can connect to the new OpenSearch serverless collection and query your new OpenSearch knn index.
The following animation demonstrates how to connect to the new OpenSearch serverless collection and query your new OpenSearch knn index using Dev tools.
Cleanup
To avoid ongoing charges:
- For Pattern 1:
- Delete the OpenSearch index using S3 vectors.
- Delete the OpenSearch Service managed cluster if no longer needed.
- For Pattern 2:
- Delete the import task from the Import history section of the OpenSearch Service console. Deleting this task will remove both the OpenSearch vector collection and the OpenSearch Ingestion pipeline that was automatically created by the import task.
Conclusion
The innovative integration between Amazon S3 Vectors and Amazon OpenSearch Service marks a transformative milestone in vector search technology, offering unprecedented flexibility and cost-effectiveness for enterprises. This powerful combination delivers the best of both worlds: The renowned durability and cost efficiency of Amazon S3 merged seamlessly with the advanced AI search capabilities of OpenSearch. Organizations can now confidently scale their vector search solutions to billions of vectors while maintaining control over their latency, cost, and accuracy. Whether your priority is ultra-fast query performance with latency as low as 10ms through OpenSearch Service, or cost-optimized storage with impressive sub-second performance using S3 Vectors or implementing advanced search capabilities in OpenSearch, this integration provides the perfect solution for your specific needs. We encourage you to get started today by trying S3 Vectors engine in your OpenSearch managed clusters and testing the one-click export from S3 vector indexes to OpenSearch Serverless.
For more information, visit:
- Amazon S3 Vectors documentation
- Amazon OpenSearch Service documentation
- OpenSearch Service integration with Amazon S3 Vectors
- Amazon OpenSearch Service Vector database blog
About the Authors
 Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service based out of Chicago, IL. His interests are in all things data and analytics. More specifically he loves to help customers use AI in their data strategy to solve modern day challenges.
Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service based out of Chicago, IL. His interests are in all things data and analytics. More specifically he loves to help customers use AI in their data strategy to solve modern day challenges.
 Mark Twomey is a Senior Solutions Architect at AWS focused on storage and data management. He enjoys working with customers to put their data in the right place, at the right time, for the right cost. Living in Ireland, Mark enjoys walking in the countryside, watching movies, and reading books.
Mark Twomey is a Senior Solutions Architect at AWS focused on storage and data management. He enjoys working with customers to put their data in the right place, at the right time, for the right cost. Living in Ireland, Mark enjoys walking in the countryside, watching movies, and reading books.
 Sorabh Hamirwasia is a senior software engineer at AWS working on the OpenSearch Project. His primary interest include building cost optimized and performant distributed systems.
Sorabh Hamirwasia is a senior software engineer at AWS working on the OpenSearch Project. His primary interest include building cost optimized and performant distributed systems.
 Pallavi Priyadarshini is a Senior Engineering Manager at Amazon OpenSearch Service leading the development of high-performing and scalable technologies for search, security, releases, and dashboards.
Pallavi Priyadarshini is a Senior Engineering Manager at Amazon OpenSearch Service leading the development of high-performing and scalable technologies for search, security, releases, and dashboards.
 Bobby Mohammed is a Principal Product Manager at AWS leading the Search, GenAI, and Agentic AI product initiatives. Previously, he worked on products across the full lifecycle of machine learning, including data, analytics, and ML features on SageMaker platform, deep learning training and inference products at Intel.
Bobby Mohammed is a Principal Product Manager at AWS leading the Search, GenAI, and Agentic AI product initiatives. Previously, he worked on products across the full lifecycle of machine learning, including data, analytics, and ML features on SageMaker platform, deep learning training and inference products at Intel.





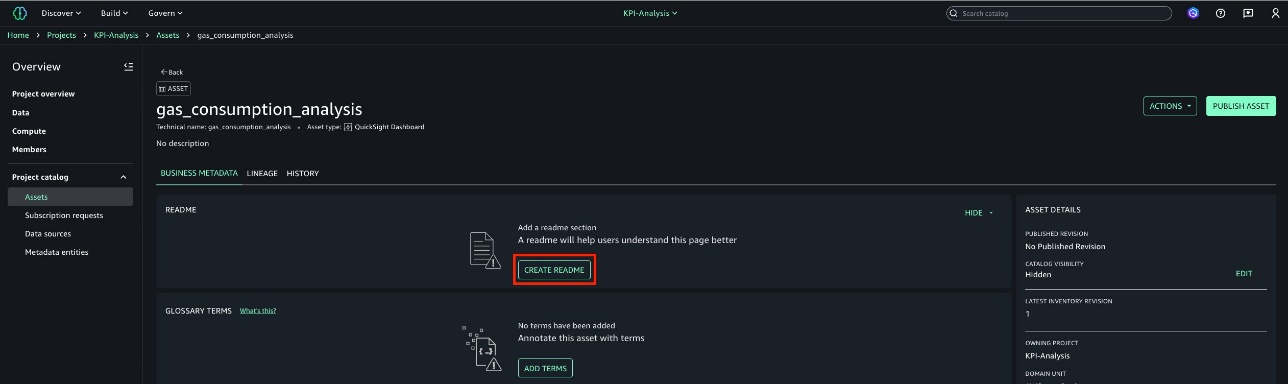
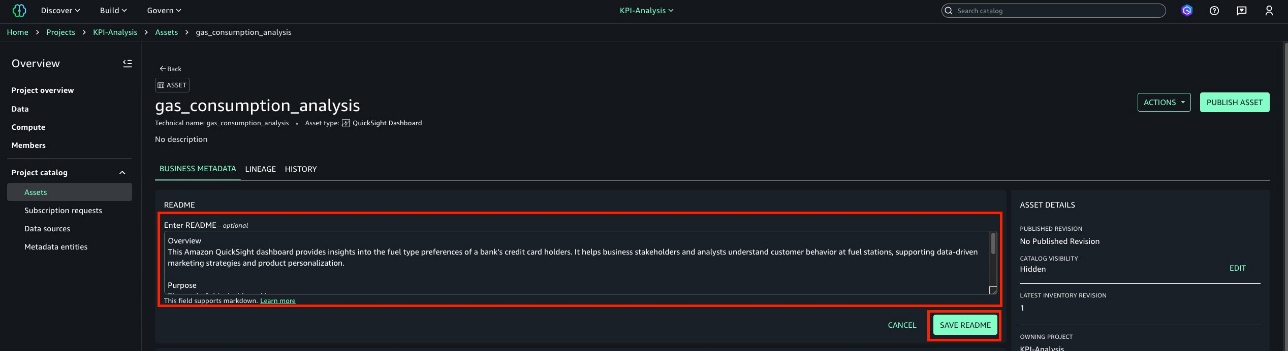
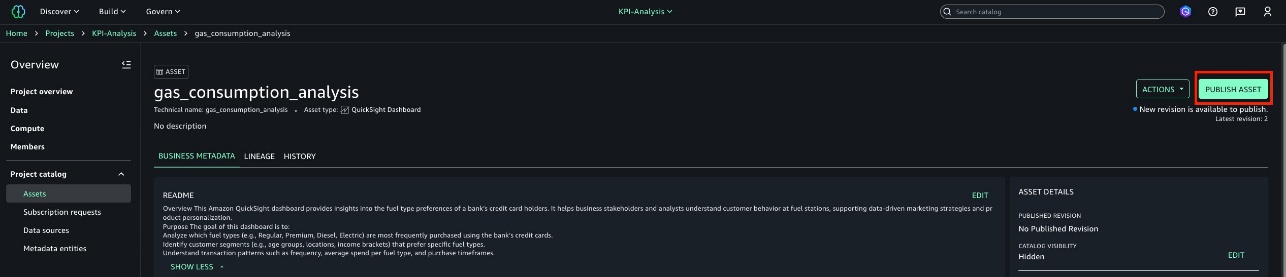


 Ramon Lopez is a Principal Solutions Architect for Amazon QuickSight. With many years of experience building BI solutions and a background in accounting, he loves working with customers, creating solutions, and making world-class services. When not working, he prefers to be outdoors in the ocean or up on a mountain.
Ramon Lopez is a Principal Solutions Architect for Amazon QuickSight. With many years of experience building BI solutions and a background in accounting, he loves working with customers, creating solutions, and making world-class services. When not working, he prefers to be outdoors in the ocean or up on a mountain. Leonardo Gomez is a Principal Analytics Specialist Solutions Architect at AWS. He has over a decade of experience in data management, helping customers around the globe address their business and technical needs. Connect with him on
Leonardo Gomez is a Principal Analytics Specialist Solutions Architect at AWS. He has over a decade of experience in data management, helping customers around the globe address their business and technical needs. Connect with him on 

































 Speaking of following people, AWS Builder Center makes it really straightforward to connect and engage with others, serving as the central hub for the AWS technical community. It brings together all the different ways that you can connect with fellow builders. For example, the Who to Follow section introduces you to AWS Heroes, Community Builders, and active community members who are sharing their knowledge and expertise in your areas of interest.
Speaking of following people, AWS Builder Center makes it really straightforward to connect and engage with others, serving as the central hub for the AWS technical community. It brings together all the different ways that you can connect with fellow builders. For example, the Who to Follow section introduces you to AWS Heroes, Community Builders, and active community members who are sharing their knowledge and expertise in your areas of interest.



 AWS Builder Center gives you a more personalized and comprehensive way to showcase your AWS journey. Your unique profile comes with a custom URL and shareable QR code, making it straightforward to connect with others and share your presence in the AWS community.
AWS Builder Center gives you a more personalized and comprehensive way to showcase your AWS journey. Your unique profile comes with a custom URL and shareable QR code, making it straightforward to connect with others and share your presence in the AWS community.








 Before continuing with this AWS Weekly Roundup, I’d like to share that last month I moved with my family to San Francisco, California, to start a new role as Developer Advocate/SDE, GenAI.
Before continuing with this AWS Weekly Roundup, I’d like to share that last month I moved with my family to San Francisco, California, to start a new role as Developer Advocate/SDE, GenAI.