Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/aws-weekly-roundup-farewell-ec2-classic-ebs-at-15-years-and-more-sept-4-2023/
Last week, there was some great reading about Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Elastic Block Store (Amazon EBS) written by AWS tech leaders.
Dr. Werner Vogels wrote Farewell EC2-Classic, it’s been swell, celebrating the 17 years of loyal duty of the original version that started what we now know as cloud computing. You can read how it made the process of acquiring compute resources simple, even though the stack running behind the scenes was incredibly complex.

We have come a long way since 2006, and we’re not done innovating for our customers. As celebrated in this year’s AWS Storage Day, Amazon EBS was launched 15 years ago this month. James Hamilton, SVP and distinguished engineer at Amazon, wrote Amazon EBS at 15 Years, about how the service has evolved to handle over 100 trillion I/O operations a day, and transfers over 13 exabytes of data daily.

As Dr. Werner said in his piece, “it’s a reminder that building evolvable systems is a strategy, and revisiting your architectures with an open mind is a must.” Our innovation efforts driven by customer feedback continue today, and this week is no different.
Last Week’s Launches
Here are some launches that got my attention:
Renaming Amazon Kinesis Data Analytics to Amazon Managed Service for Apache Flink – You can now use Amazon Managed Service for Apache Flink, a fully managed and serverless service for you to build and run real-time streaming applications using Apache Flink. All your existing running applications in Kinesis Data Analytics will work as-is, without any changes. To learn more, see my blog post.
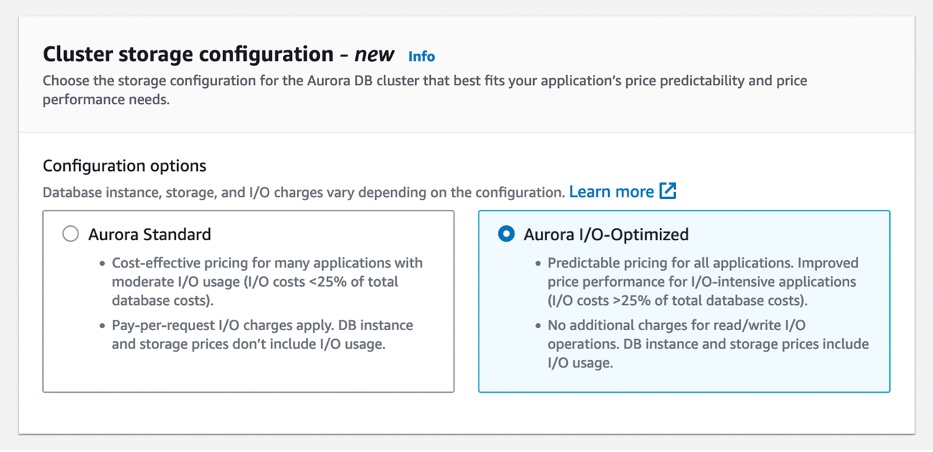
Extended Support for Amazon Aurora and Amazon RDS – You can now get more time for support, up to three years, for Amazon Aurora and Amazon RDS database instances running MySQL 5.7, PostgreSQL 11, and higher major versions. This e will allow you time to upgrade to a new major version to help you meet your business requirements even after the community ends support for these versions.
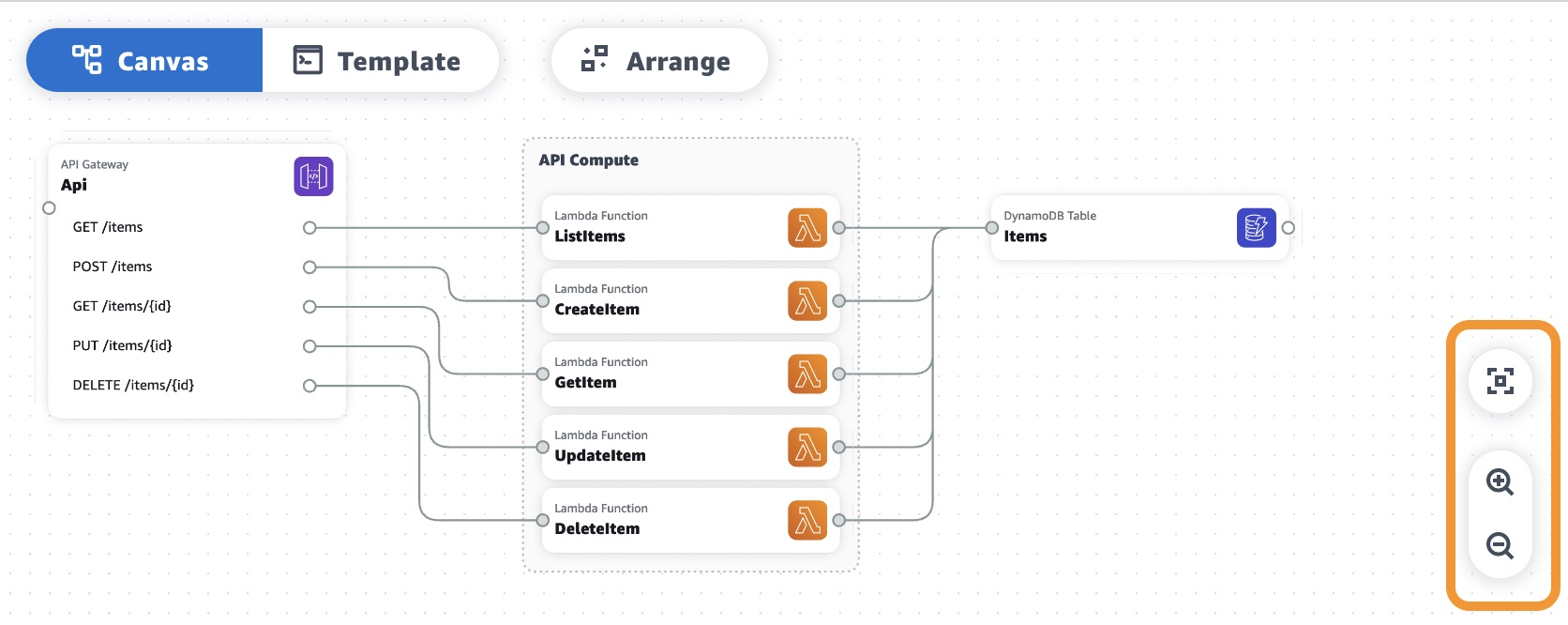
Enhanced Starter Template for AWS Step Functions Workflow Studio – You can now use starter templates to streamline the process of creating and prototyping workflows swiftly, plus a new code mode, which enables builders to move easily between design and code authoring views. With the improved authoring experience in Workflow Studio, you can seamlessly alternate between a drag-and-drop visual builder experience or the new code editor so that you can pick your preferred tool to accelerate development.
To learn more, see Enhancing Workflow Studio with new features for streamlined authoring in the AWS Compute Blog.
Email Delivery History for Every Email in Amazon SES – You can now troubleshoot individual email delivery problems, confirm delivery of critical messages, and identify engaged recipients on a granular, single email basis. Email senders can investigate trends in delivery performance and see delivery and engagement status for each email sent using Amazon SES Virtual Deliverability Manager.

Response Streaming through Amazon SageMaker Real-time Inference – You can now continuously stream inference responses back to the client to help you build interactive experiences for various generative AI applications such as chatbots, virtual assistants, and music generators.

For more details on how to use response streaming along with examples, see Invoke to Stream an Inference Response and How containers should respond in the AWS documentation, and Elevating the generative AI experience: Introducing streaming support in Amazon SageMaker hosting in the AWS Machine Learning Blog.
For a full list of AWS announcements, be sure to keep an eye on the What’s New at AWS page.
Other AWS News
Some other updates and news that you might have missed:
AI & Sports: How AWS & the NFL are Changing the Game – Over the last 5 years, AWS has partnered with the National Football League (NFL), helping fans better understand the game, helping broadcasters tell better stories, and helping teams use data to improve operations and player safety. Watch AWS CEO, Adam Selipsky, former NFL All-Pro Larry Fitzgerald, and the NFL Network’s Cynthia Frelund during their earlier livestream discussing the intersection of artificial intelligence and machine learning in sports.
Amazon Bedrock Story from Amazon Science – This is a good article explaining the benefits of using Amazon Bedrock to build and scale generative AI applications with leading foundation models, including Amazon’s Titan FMs, which focus on responsible AI to avoid toxic content.
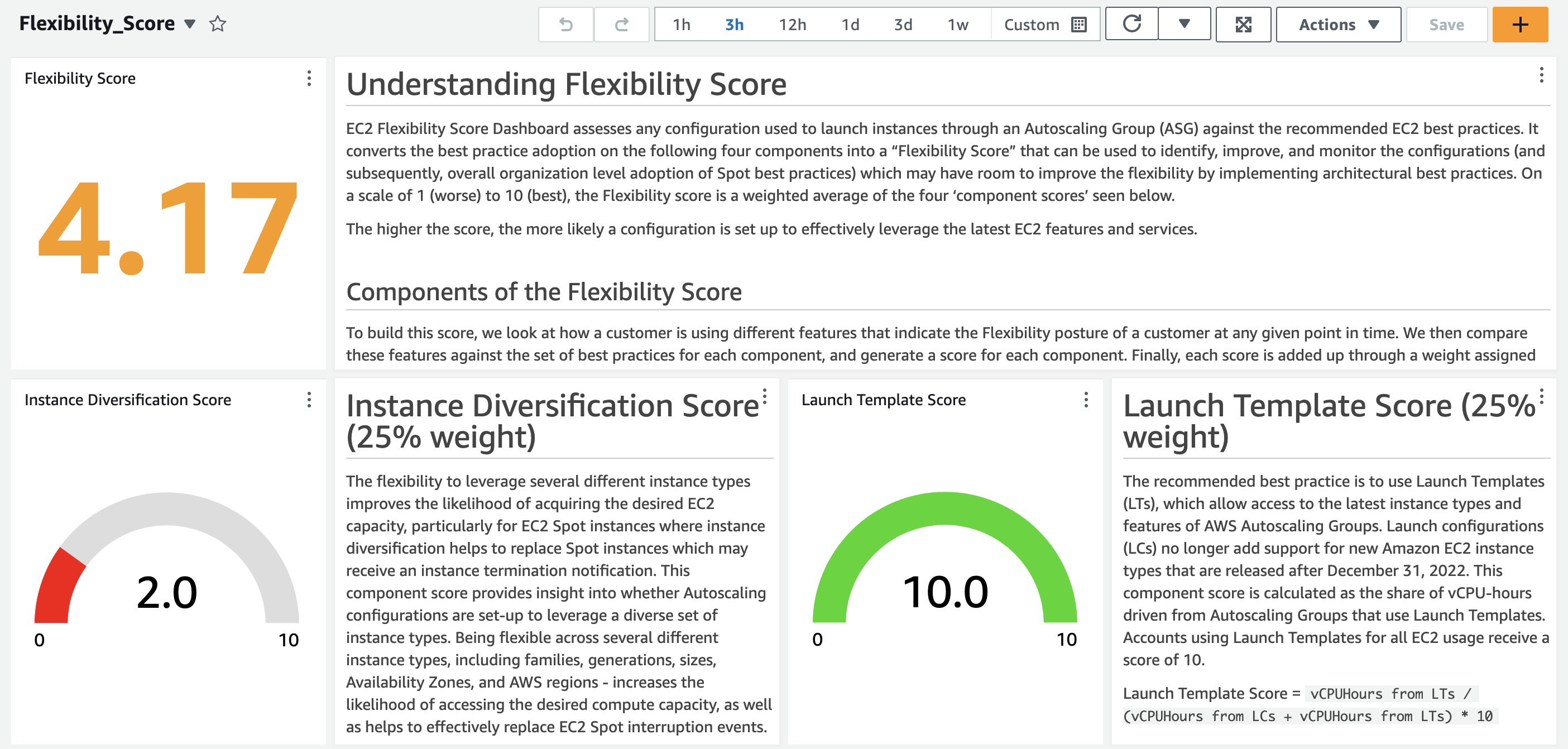
Amazon EC2 Flexibility Score – This is an open source tool developed by AWS to assess any configuration used to launch instances through an Auto Scaling Group (ASG) against the recommended EC2 best practices. It converts the best practice adoption into a “flexibility score” that can be used to identify, improve, and monitor the configurations.
To learn more open-source news and updates, see this newsletter curated by my colleague Ricardo to bring you the latest open source projects, posts, events, and more.
Upcoming AWS Events
Check your calendars and sign up for these AWS events:
AWS re:Invent – ![]() Ready to start planning your re:Invent? Browse the session catalog now. Join us to hear the latest from AWS, learn from experts, and connect with the global cloud community.
Ready to start planning your re:Invent? Browse the session catalog now. Join us to hear the latest from AWS, learn from experts, and connect with the global cloud community.
AWS Global Summits![]() – The last in-person AWS Summit will be held in Johannesburg on Sept. 26.
– The last in-person AWS Summit will be held in Johannesburg on Sept. 26.
AWS Community Days ![]() – Join a community-led conference run by AWS user group leaders in your region: Aotearoa (Sept. 6), Lebanon (Sept. 9), Munich (Sept. 14), Argentina (Sept. 16), Spain (Sept. 23), and Chile (Sept. 30). Visit the landing page to check out all the upcoming AWS Community Days.
– Join a community-led conference run by AWS user group leaders in your region: Aotearoa (Sept. 6), Lebanon (Sept. 9), Munich (Sept. 14), Argentina (Sept. 16), Spain (Sept. 23), and Chile (Sept. 30). Visit the landing page to check out all the upcoming AWS Community Days.
CDK Day – A community-led fully virtual event on Sept. 29 with tracks in English and Spanish about CDK and related projects. Learn more at the website.
You can browse all upcoming AWS-led in-person and virtual events, and developer-focused events such as AWS DevDay.
— Channy
This post is part of our Weekly Roundup series. Check back each week for a quick roundup of interesting news and announcements from AWS!
 Since we
Since we 







 Leadership session – To kick off the day, we have a leadership session featuring
Leadership session – To kick off the day, we have a leadership session featuring 

 Lastly, we published a new ebook titled “
Lastly, we published a new ebook titled “
 The new Tel Aviv Region is ready to support your business. You can find a detailed list of the services available in this Region on the
The new Tel Aviv Region is ready to support your business. You can find a detailed list of the services available in this Region on the 



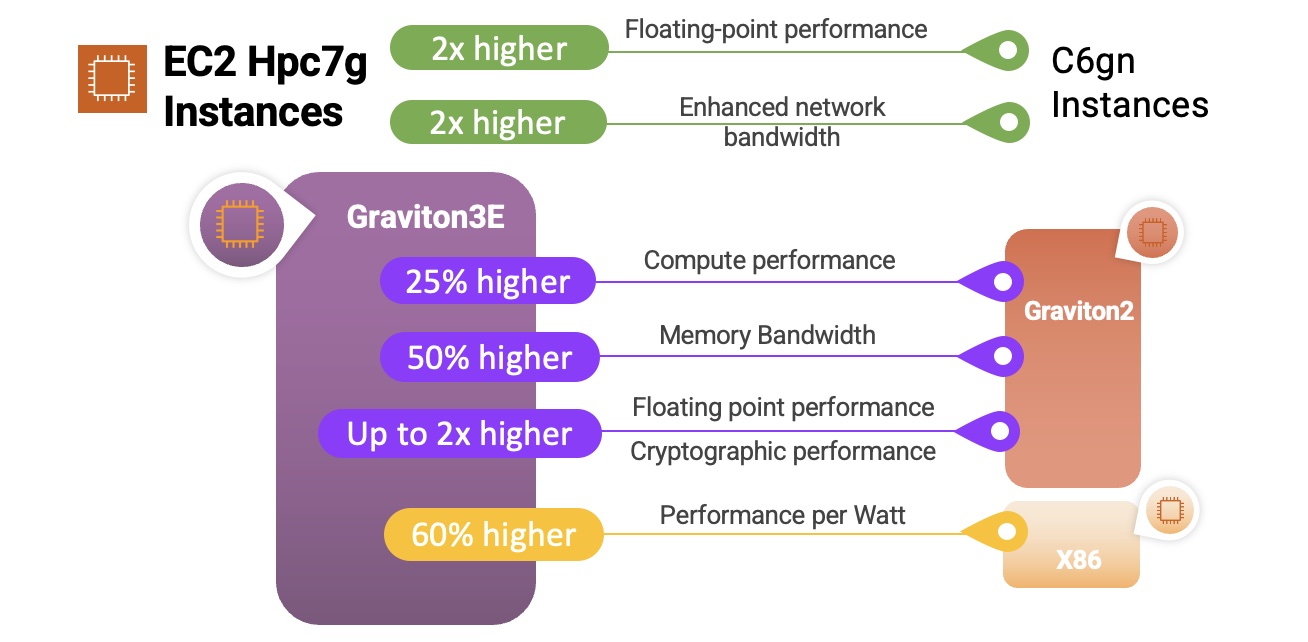


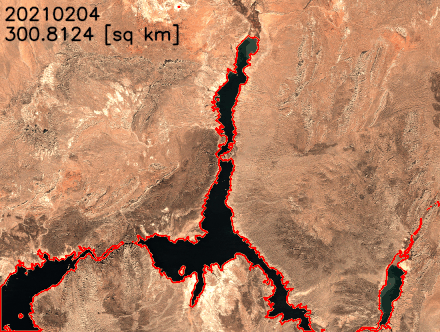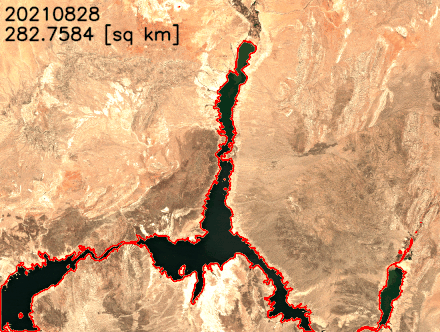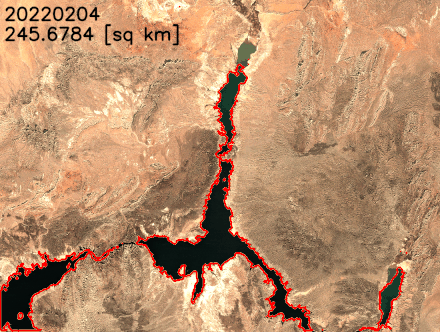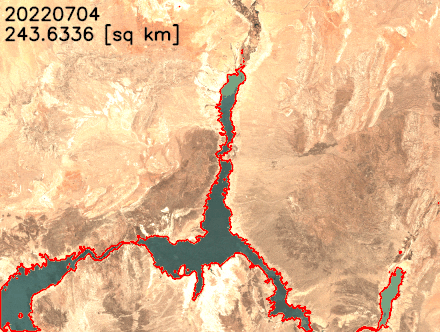
 During the preview, we had lots of interest and great feedback from customers. Today, Amazon SageMaker geospatial capabilities are generally available with new security updates and additional sample use cases.
During the preview, we had lots of interest and great feedback from customers. Today, Amazon SageMaker geospatial capabilities are generally available with new security updates and additional sample use cases.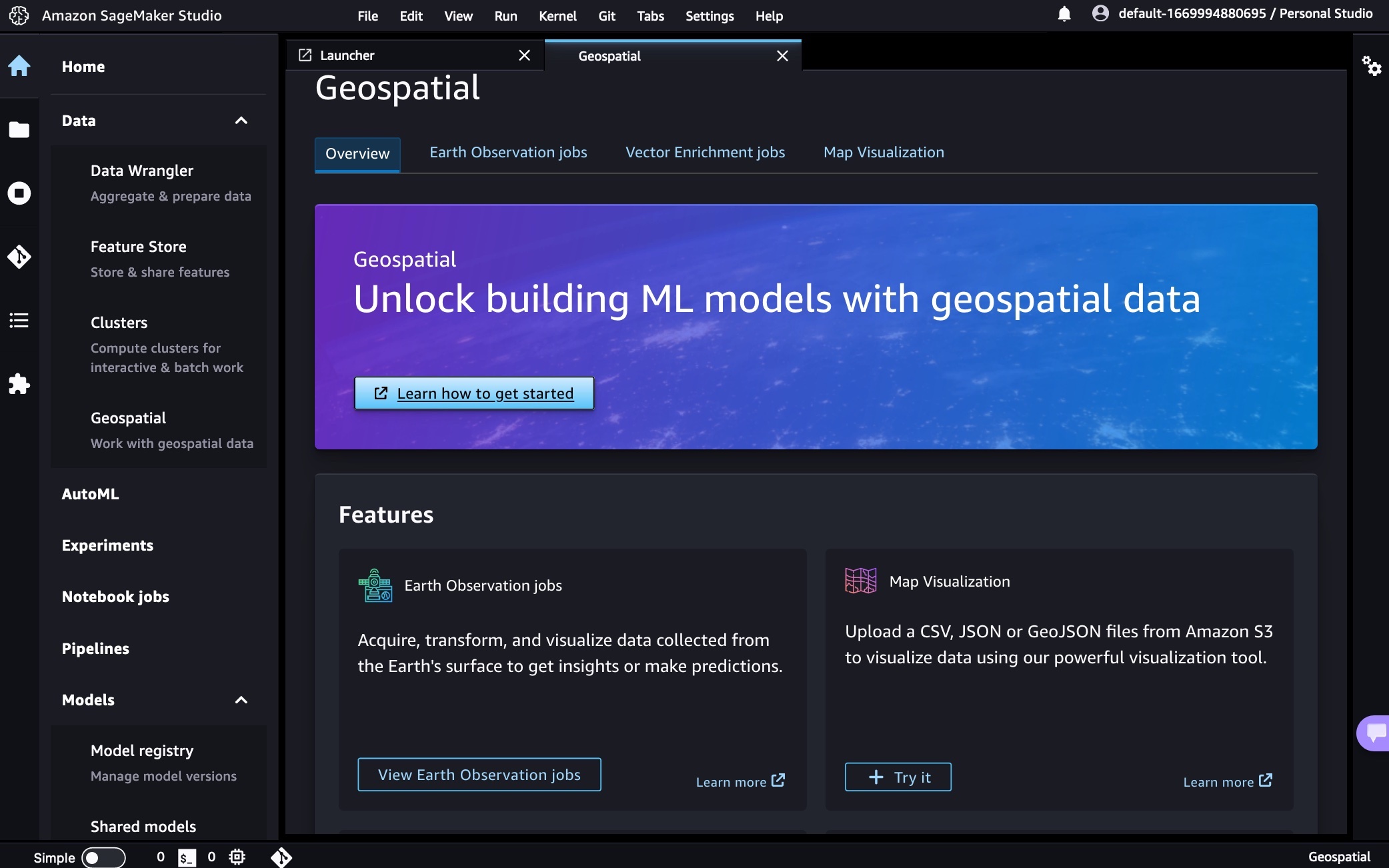



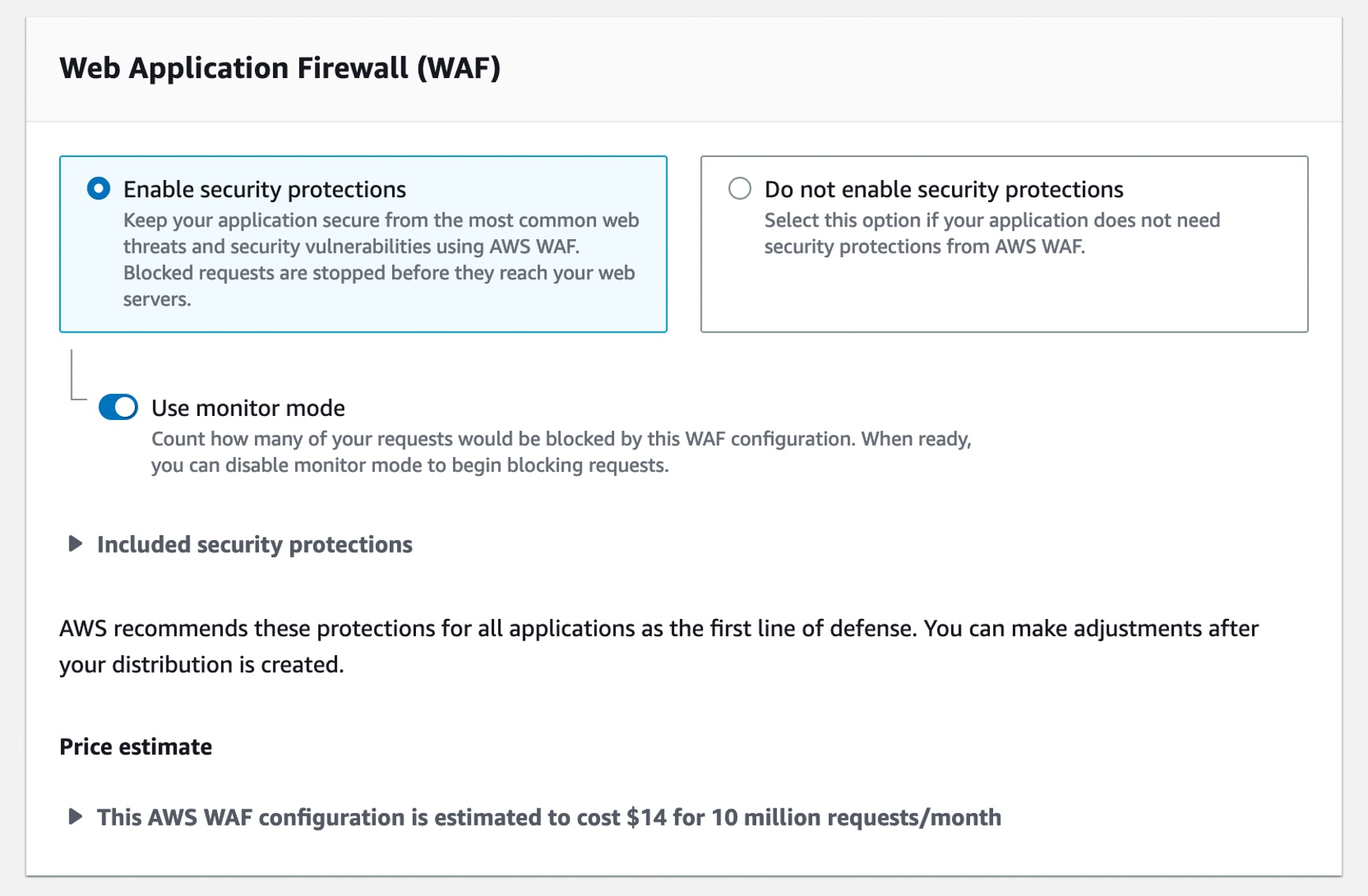













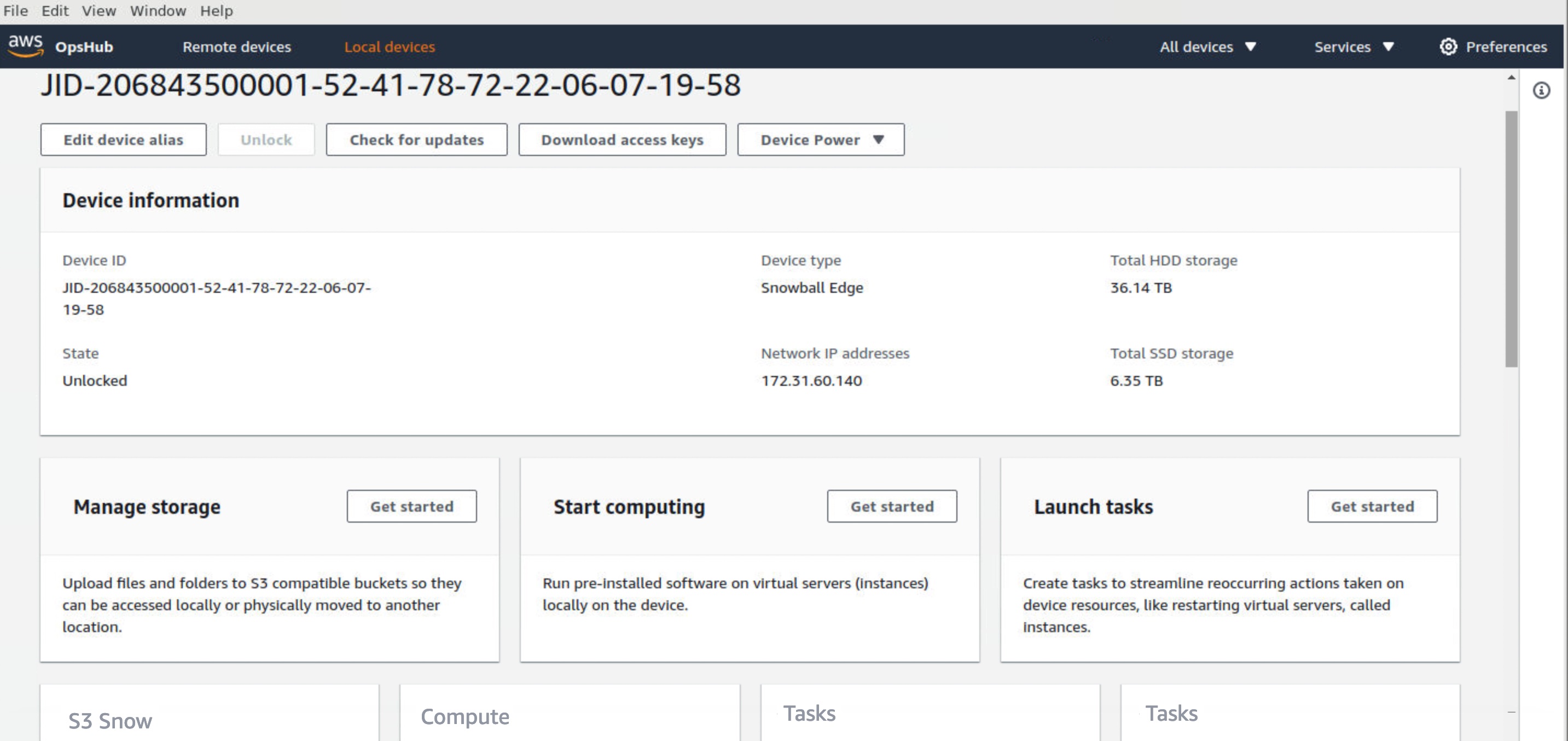
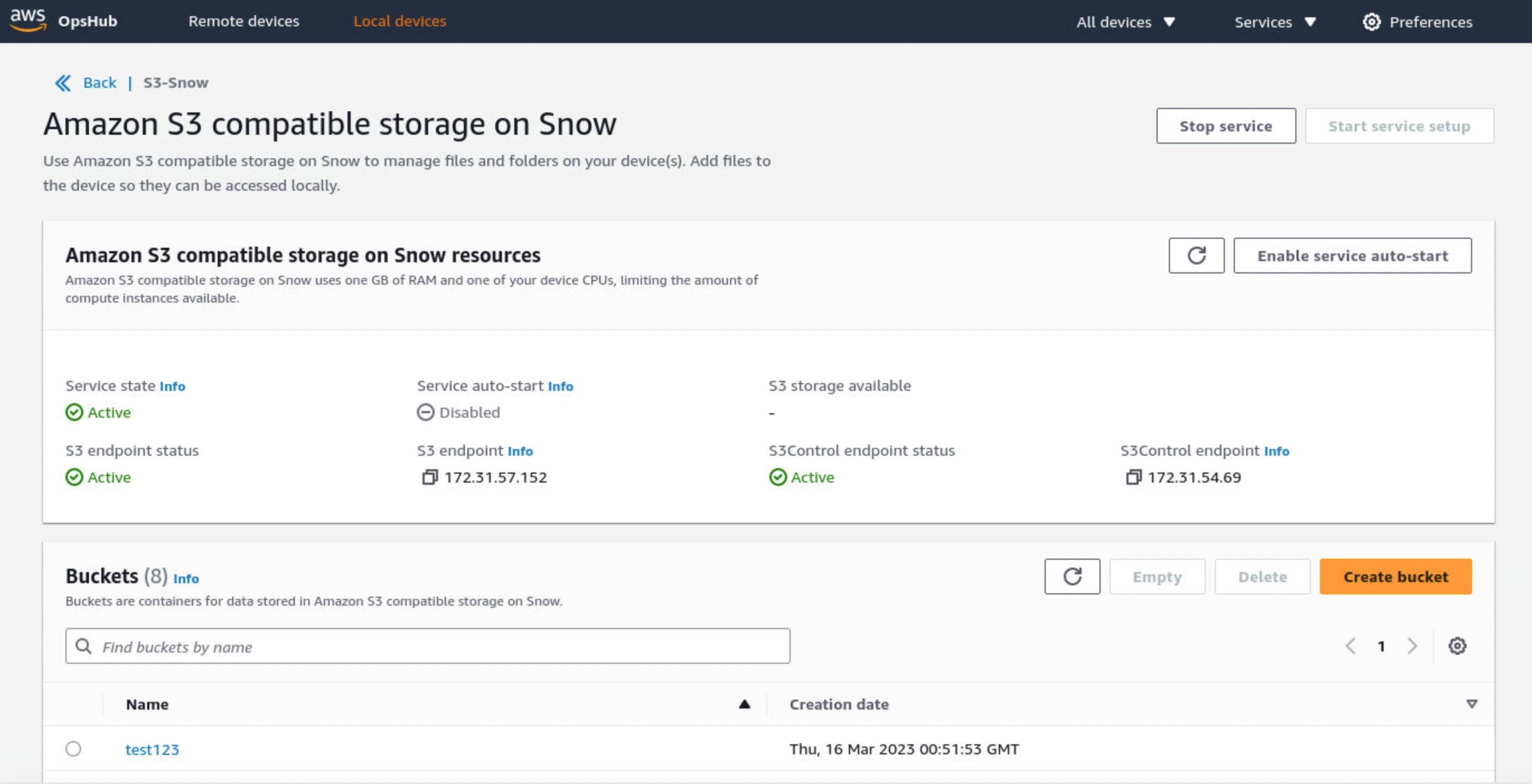
 Each new service is optimized for space- or weight-constrained environments, portability, and flexible networking options. For example, Snowball Edge devices have
Each new service is optimized for space- or weight-constrained environments, portability, and flexible networking options. For example, Snowball Edge devices have 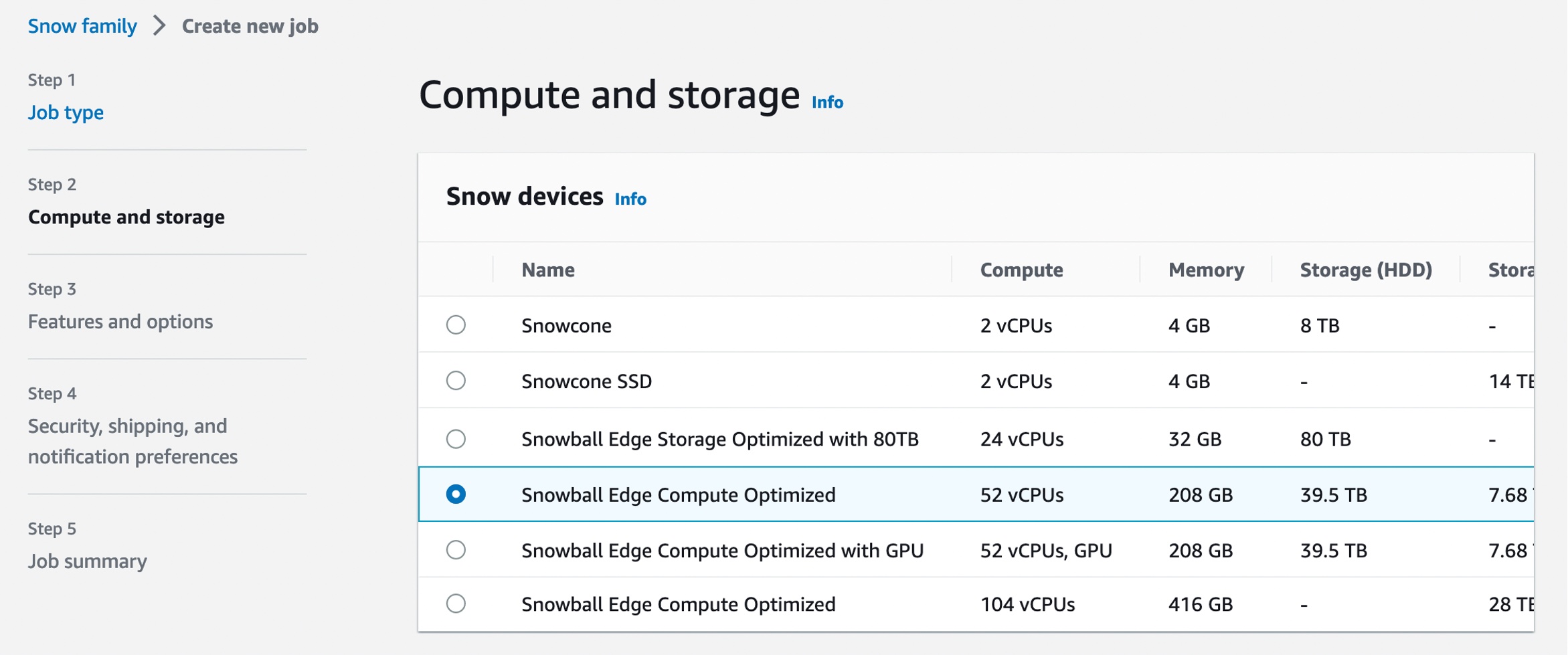



 Last weekend, I enjoyed the spring vibes at
Last weekend, I enjoyed the spring vibes at 

 AWS Global Summits – Check your calendars and sign up for the AWS Summit closest to your city:
AWS Global Summits – Check your calendars and sign up for the AWS Summit closest to your city: