Post Syndicated from Marcia Villalba original https://aws.amazon.com/blogs/aws/now-open-aws-region-in-the-united-arab-emirates-uae/
 The AWS Region in the United Arab Emirates is now open. The official name is Middle East (UAE), and the API name is me-central-1. You can start using it today to deploy workloads and store your data in the United Arab Emirates. The AWS Middle East (UAE) Region is the second Region in the Middle East, joining the AWS Middle East (Bahrain) Region.
The AWS Region in the United Arab Emirates is now open. The official name is Middle East (UAE), and the API name is me-central-1. You can start using it today to deploy workloads and store your data in the United Arab Emirates. The AWS Middle East (UAE) Region is the second Region in the Middle East, joining the AWS Middle East (Bahrain) Region.
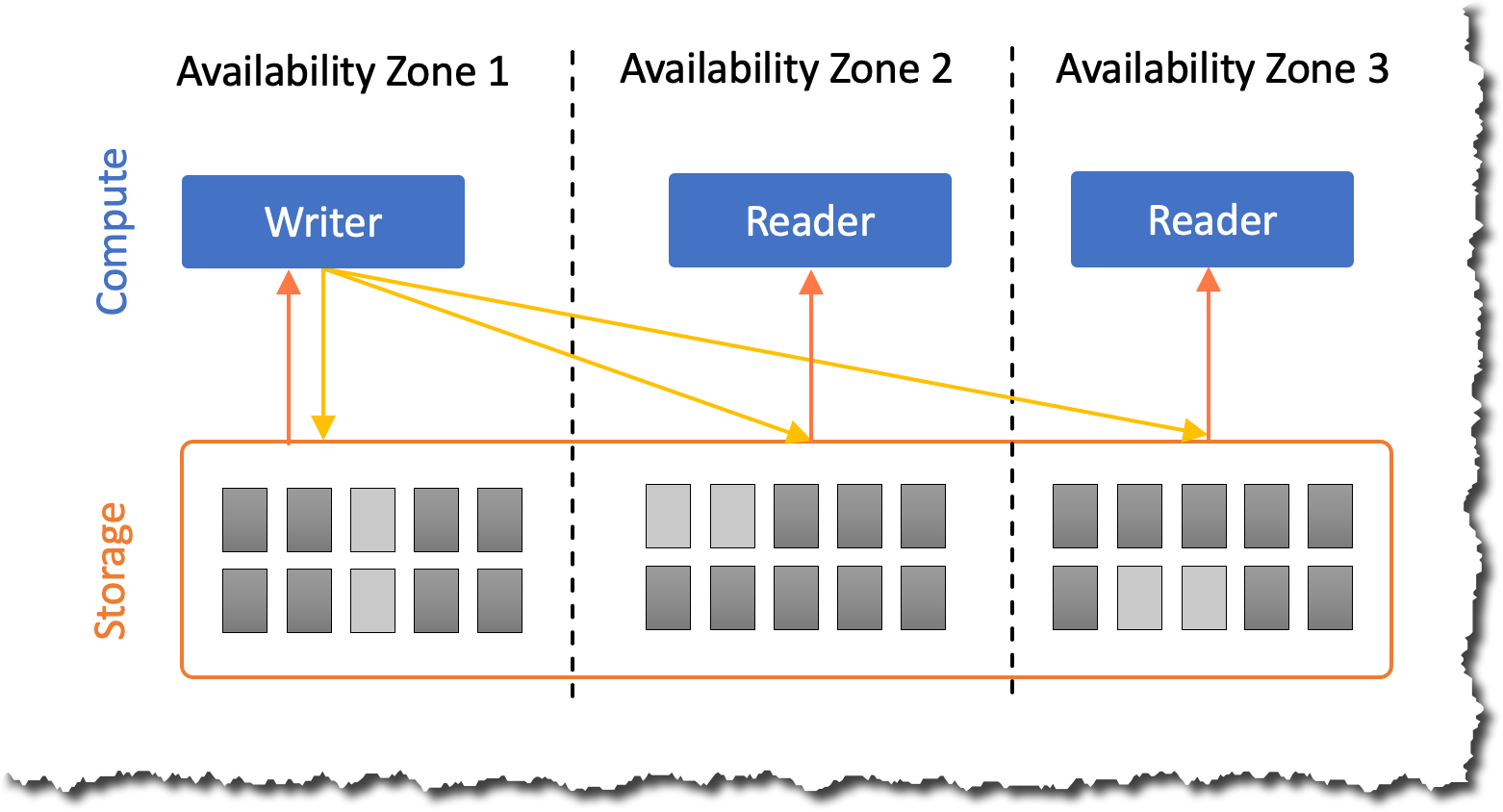
The Middle East (UAE) Region has three Availability Zones that you can use to reliably spread your applications across multiple data centers. Each Availability Zone is a fully isolated partition of AWS infrastructure that contains one or more data centers.
Availability Zones are in separate and distinct geographic locations with enough distance to reduce the risk of a single event affecting the availability of the Region but near enough for business continuity for applications that require rapid failover and synchronous replication. This gives you the ability to operate production applications that are more highly available, more fault-tolerant, and more scalable than would be possible from a single data center.
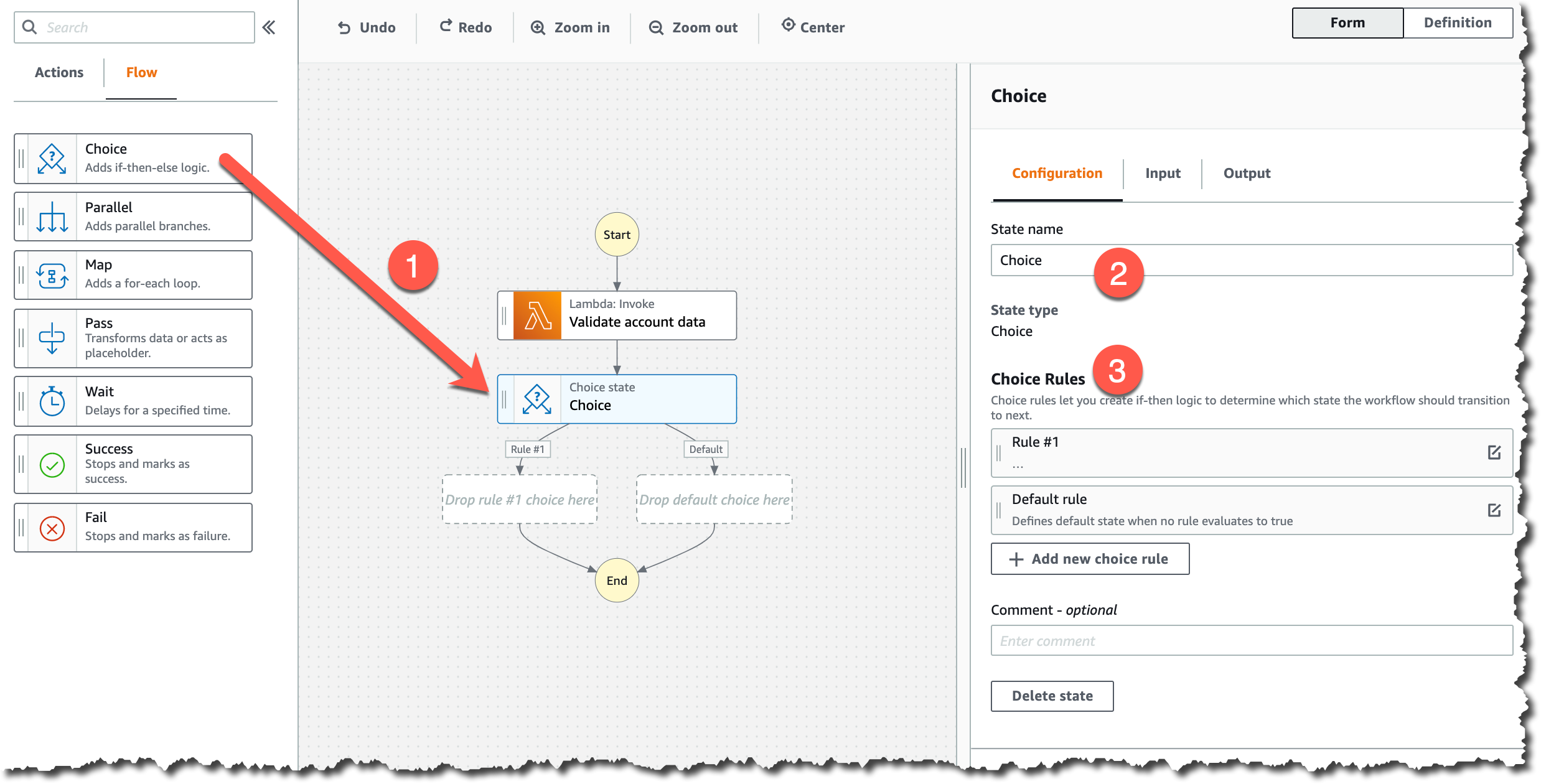
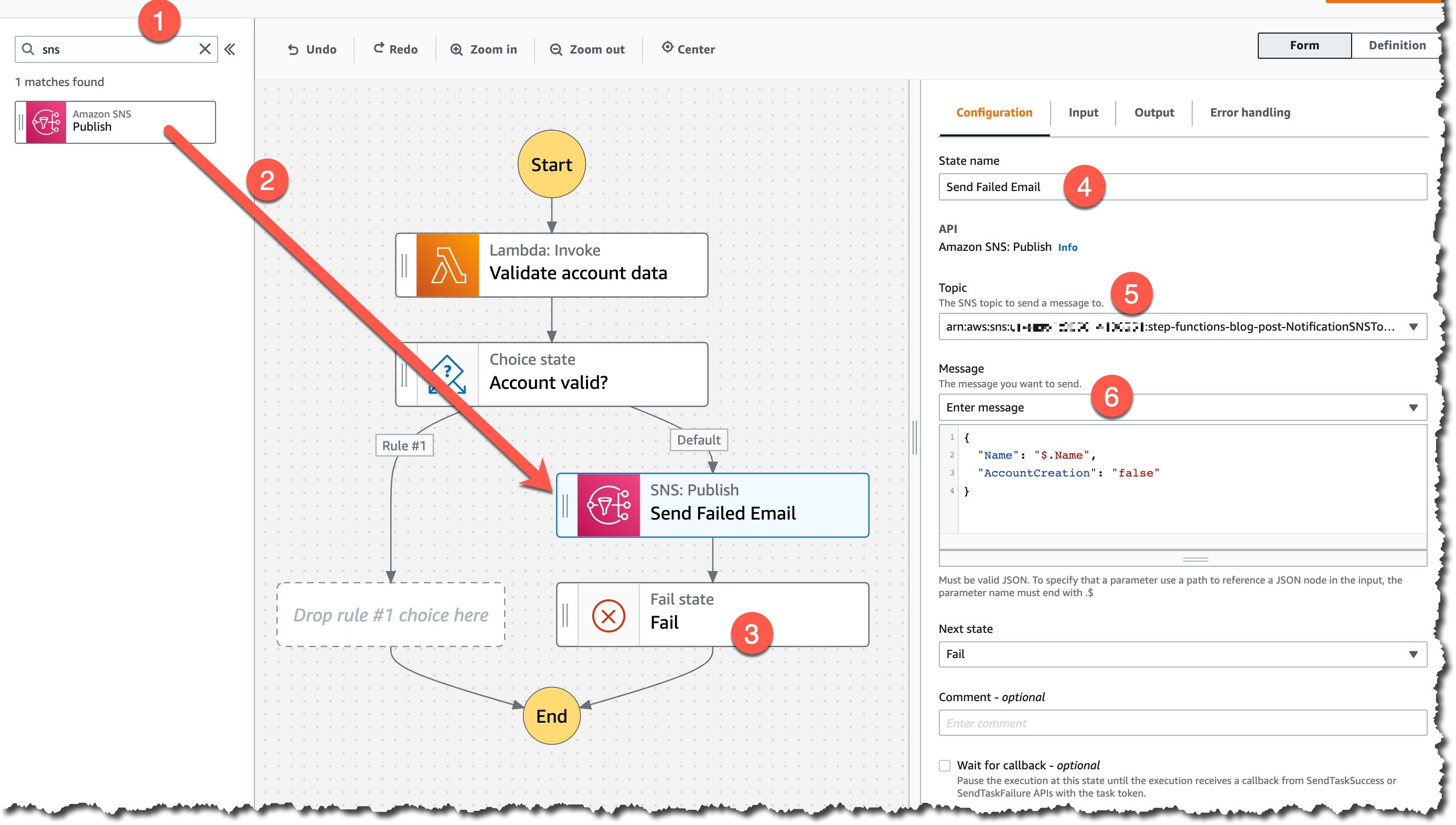
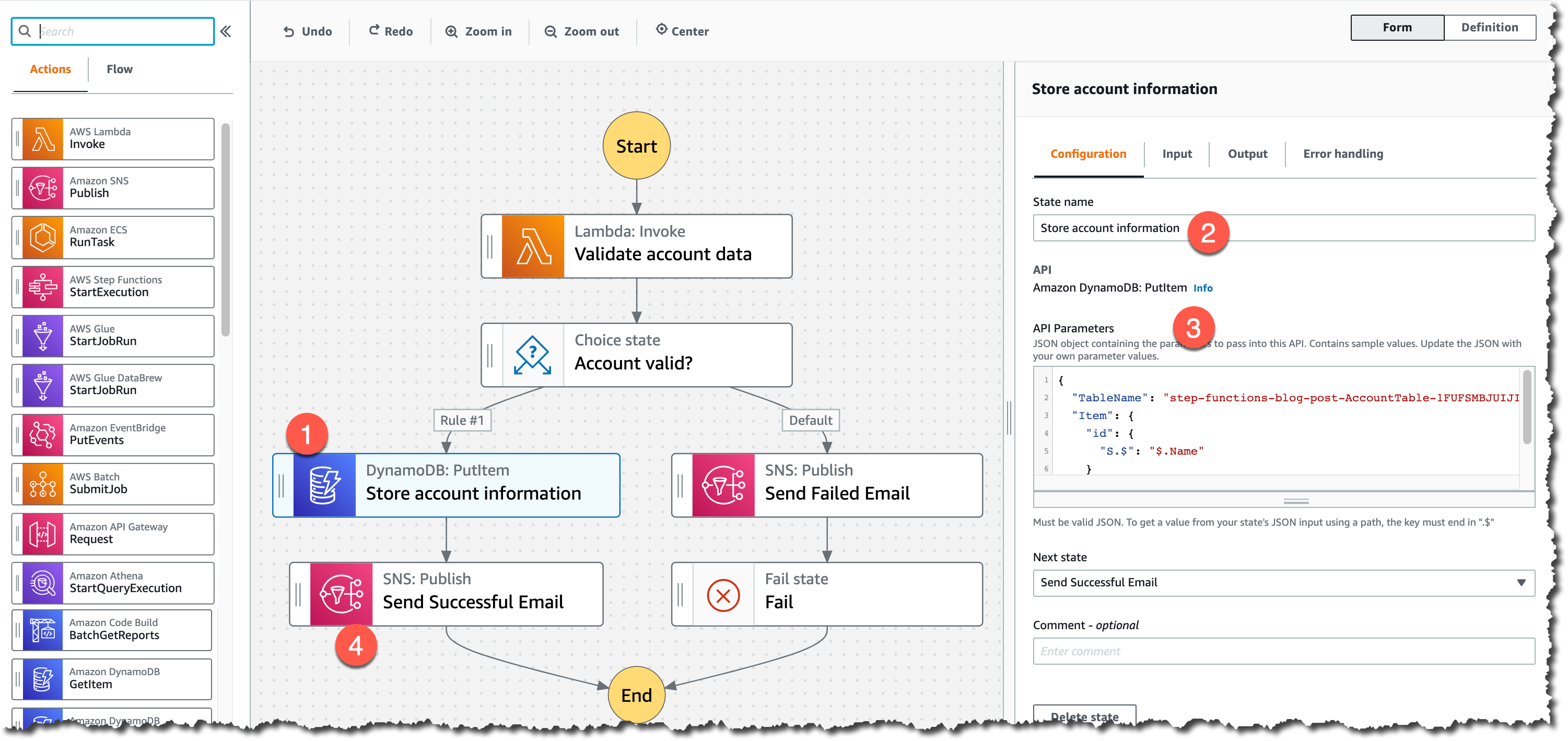
Instances and Services
Applications running in this three-AZ Region can use C5, C5d, C6g, M5, M5d, M6g, M6gd, R5, R5d, R6g, I3, I3en, T3, and T4g instances, and can use a long list of AWS services including: Amazon API Gateway, Amazon Aurora, AWS AppConfig, Amazon CloudWatch, Amazon CloudWatch Logs, Amazon DynamoDB, Amazon EC2 Auto Scaling, Amazon ElastiCache, Amazon Elastic Block Store (Amazon EBS), Elastic Load Balancing, Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Container Registry (Amazon ECR), Amazon Elastic Container Service (Amazon ECS), Amazon EMR, Amazon OpenSearch Service, Amazon EventBridge, Amazon Kinesis Data Streams, Amazon Redshift, Amazon Relational Database Service (Amazon RDS), Amazon Route 53, Amazon Simple Notification Service (Amazon SNS), Amazon Simple Queue Service (Amazon SQS), Amazon Simple Storage Service (Amazon S3), Amazon Simple Workflow Service (Amazon SWF), Amazon Virtual Private Cloud (Amazon VPC), AWS Application Auto Scaling, AWS Certificate Manager, AWS CloudFormation, AWS CloudTrail, AWS CodeDeploy, AWS Config, AWS Database Migration Service, AWS Direct Connect, AWS Identity and Access Management (IAM), AWS Key Management Service (AWS KMS), AWS Lambda, AWS Marketplace, AWS Health Dashboard, AWS Secrets Manager, AWS Step Functions, AWS Support API, AWS Systems Manager, AWS Trusted Advisor, VM Import/Export, AWS VPN, and AWS X-Ray.
AWS in the Middle East
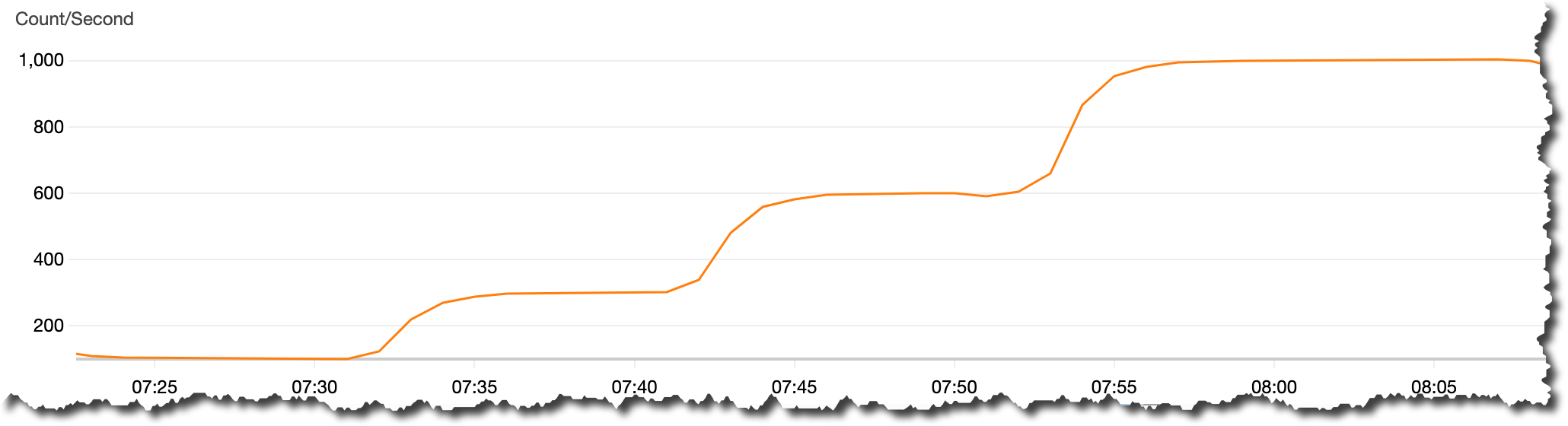
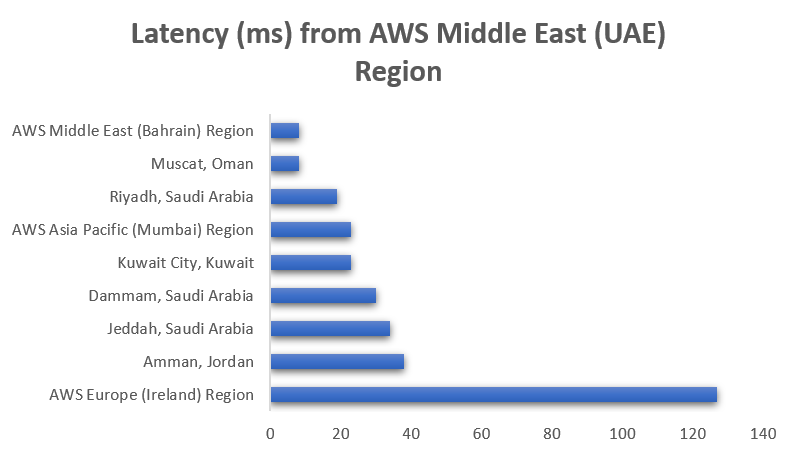
In addition to the two Regions—Bahrain and UAE—the Middle East has two AWS Direct Connect locations, allowing customers to establish private connectivity between AWS and their data centers and offices, as well as two Amazon CloudFront edge locations, one in Dubai and another in Fujairah. The UAE Region also offers low-latency connections to other AWS Regions in the area, as shown in the following chart:
Since 2017, AWS has established offices in Dubai and Bahrain along with a broad network of partners. We continue to build our teams in the Middle East by adding account managers, solutions architects, business developers, and professional services consultants to help customers of all sizes build or move their workloads to the cloud. Visit the Amazon career page to check out the roles we are hiring for.
In addition to Infrastructure, AWS continues to make investments in education initiatives, training, and start-up enablement to support UAE’s digital transformation and economic development plans.
- AWS Activate – This global program provides start-ups with credits, training, and support so they can build their business on AWS.
- AWS Training and Certification – This program helps developers build cloud skills using digital or classroom training and to validate those skills by earning an industry-recognized credential.
- AWS Educate and AWS Academy – These programs provide higher education institutions, educators, and students with cloud computing courses and certifications.
AWS Customers in the Middle East
We have many amazing customers in the Middle East that are doing incredible things with AWS, for example:
The Ministry of Health and Prevention (MoHAP) implements the health care policy in the UAE. MoHAP is working with AWS to modernize their patient experience. With AWS, MoHAP can connect 100 percent of care providers—public and private—to further enhance their data strategy to support predictive and population health programs.
GEMS Education is one of the largest private K–12 operators in the world. Using AWS services like artificial intelligence and machine learning, GEMS developed an all-in-one integrated ED Tech platform called LearnOS. This platform supports teachers and creates personalized learning experiences. For example, with the use of Amazon Rekognition, they reduced 93 percent of the time spent in marking attendance. They also developed an automated quiz generation and assessment platform using Amazon EC2 and Amazon SageMaker. In addition, the algorithms can predict student year-end performance with up to 95 percent accuracy and recommend personalized reading materials.
YAP is a fast-growing regional financial super app that focuses on improving the digital banking experience. It functions as an independent app with no physical branches, making it the first of its kind in the UAE. AWS has helped fuel YAP’s growth and enabled them to scale to become a leading regional FinTech, giving them the elasticity to control costs as their user base has grown to over 130,000 users. With AWS, YAP can scale fast as they launch new markets, reducing the time to build and deploy complete infrastructure from months to weeks.
Available Now
The new Middle East (UAE) Region is ready to support your business. You can find a detailed list of the services available in this Region on the AWS Regional Service List.
With this launch, AWS now spans 87 Availability Zones within 27 geographic Regions around the world. We also have announced plans for 21 more Availability Zones and seven more AWS Regions in Australia, Canada, India, Israel, New Zealand, Spain, and Switzerland.
For more information on our global infrastructure, upcoming Regions, and the custom hardware we use, visit the Global Infrastructure page.
— Marcia




 ” to my colleagues, and have a coffee while asking all your serverless questions. You can find all the upcoming AWS Summits in the events section at the end of this post.
” to my colleagues, and have a coffee while asking all your serverless questions. You can find all the upcoming AWS Summits in the events section at the end of this post.