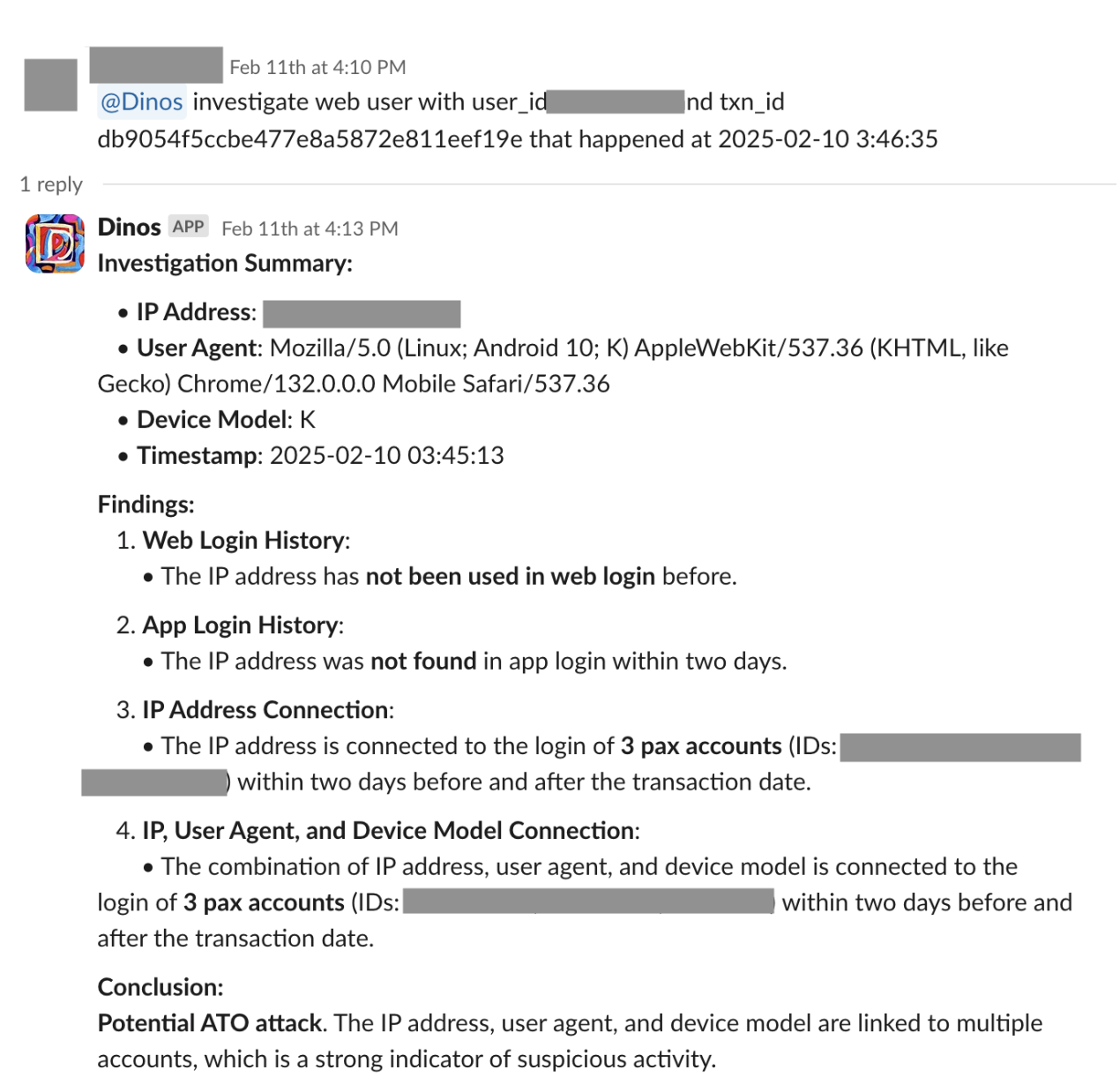
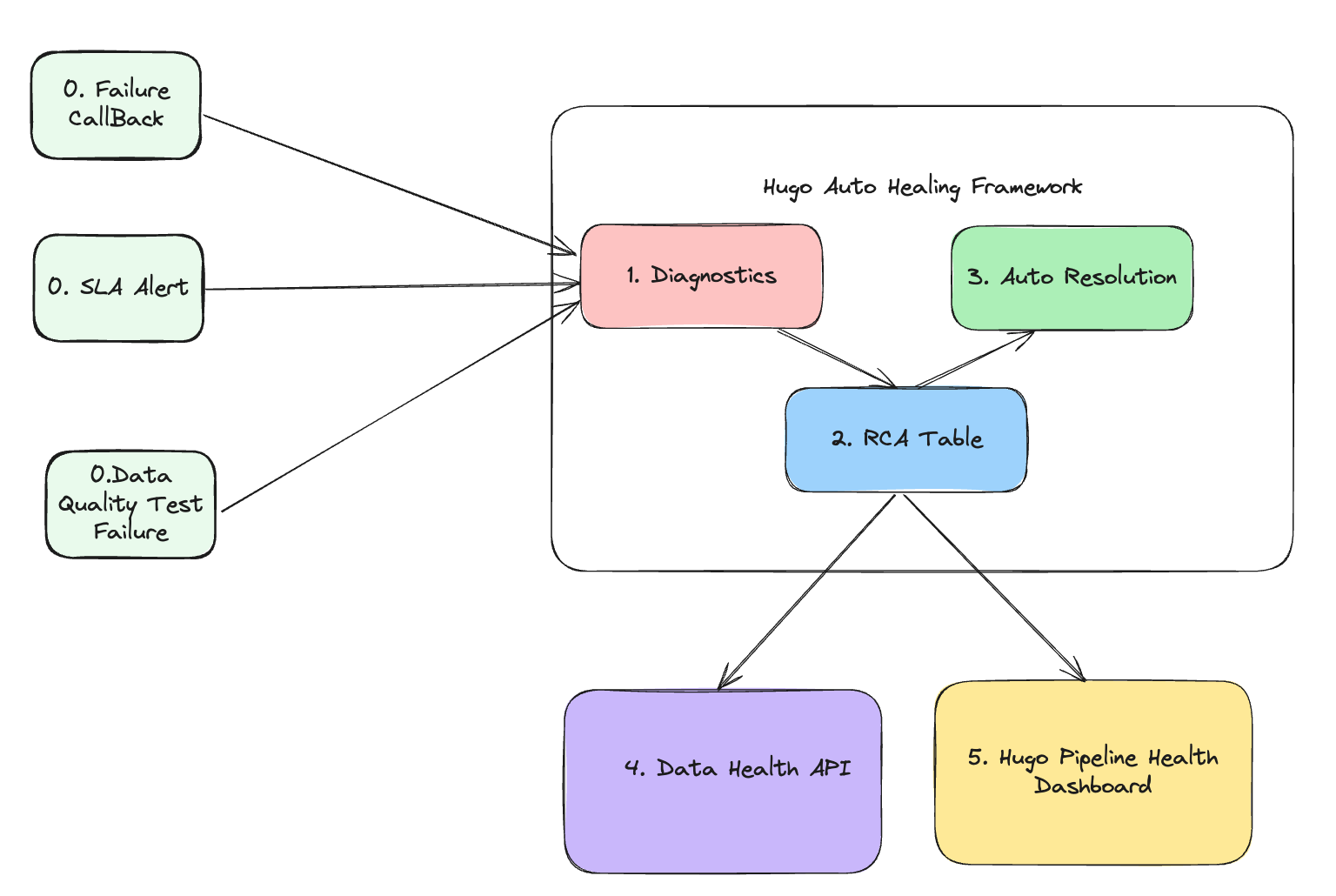
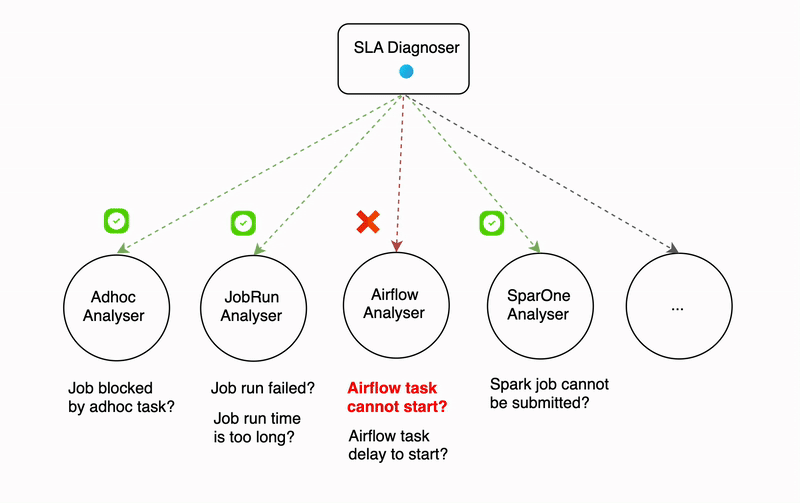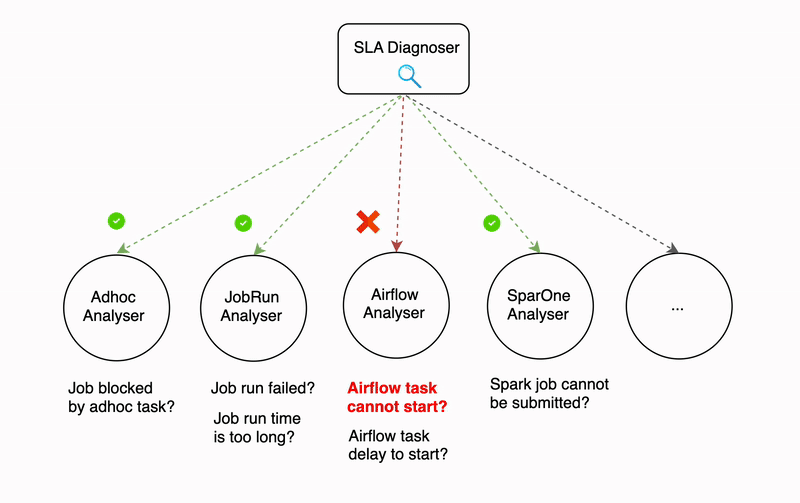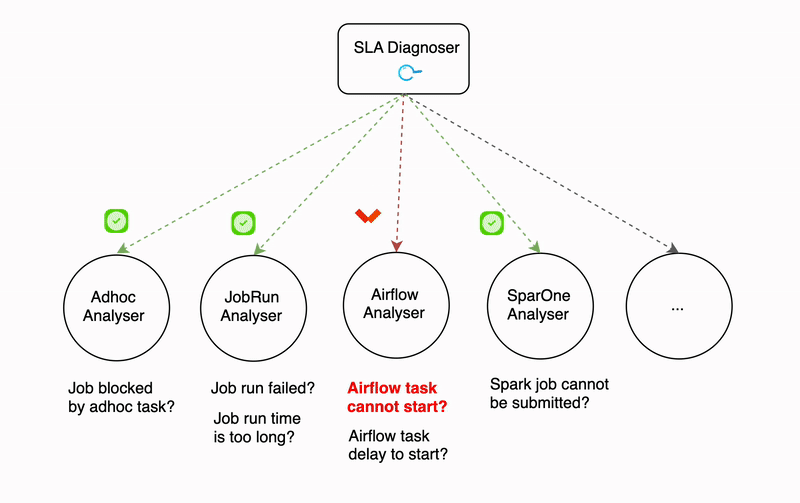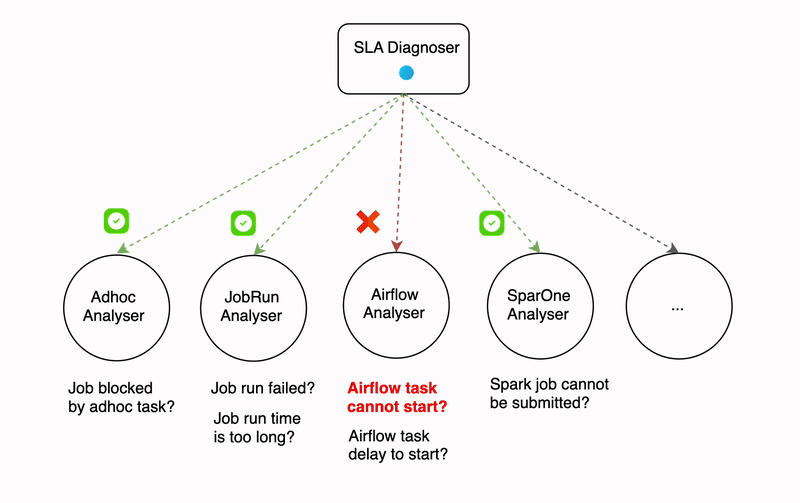
DispatchGym is a research framework designed to facilitate Reinforcement Learning (RL) studies and applications for the dispatch system, which matches bookings with drivers. The primary goal is to empower data scientists with a tool that allows them to independently develop and test RL-related concepts for dispatching systems. It accelerates research by providing a suite of modules that include a reinforcement learning algorithm, a dispatching process simulation, and an interface connecting the two through the Gymnasium API.
To ensure efficient and cost-effective RL research without compromising on quality, DispatchGym aims to be both comprehensive and accessible. Anyone with basic RL knowledge and Python programming skills can use it to explore new ideas in RL and dispatch system logic.
This article walks you through the principles behind DispatchGym, how these principles effectively and efficiently empower impactful research, and how it can be applied to solve real world problems.
The challenge with RL
Although RL methods can be applied to a wide variety of problems that can be formulated as a Markov Decision Process (MDP), designing an effective RL-based solution is not a trivial task. The primary challenges stem from two key components: the reward function and the lever.
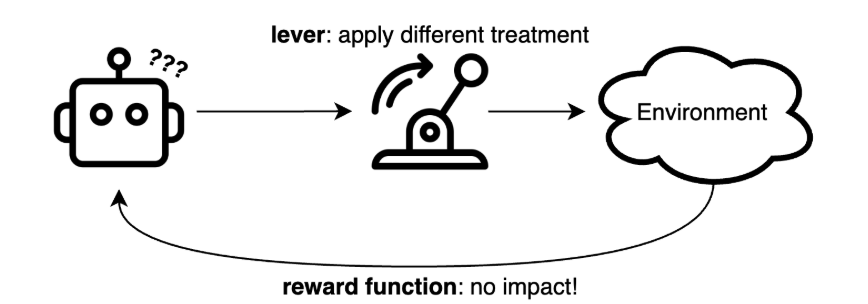
In RL, the reward function represents the objective we aim to maximize. At first glance, it might seem straightforward to plug in any metric, such as the company’s profit or the number of completed bookings per day. However, these metrics are not always sensitive to the lever that RL can manipulate, or the lever itself may not significantly influence the objective. For example, consider a setup where we aim to maximize the daily number of completed bookings by adjusting the maximum number of candidate drivers considered to each booking. Beyond a minimal threshold (e.g., one driver), further increasing this limit provides negligible benefits. As a result, RL struggles to determine whether setting this limit to 11 or 15 would result in higher rewards.
In summary, when a lever exerts weak influence on a reward function, the RL setup becomes ineffective. Therefore, we should strive to select a lever that strongly influences the reward function and define a reward function that is both sensitive to manipulations of that lever and aligned with our overall goal. Note that the reward function does not have to be identical to our ultimate objective; it merely needs to be highly correlated with it.
Figure 1. Illustration of weak lever influence on a reward function.
Empowering research with DispatchGym
The primary application of DispatchGym is to accelerate and broaden cost-effective research and impactful RL applications for Grab’s dispatching system. A system which is responsible for assigning a driver to each booking. To achieve this, DispatchGym must have the following characteristics:
Reliable
The simulation component should be accurate enough to capture essential behaviors strongly linked to the metrics of interest, without necessarily modeling everything else. While it’s beneficial if the simulation can do more than the specific use case (e.g., simulating both batching and allocation when only allocation is needed), it is not strictly required.
Cost-effective
Updating all of DispatchGym’s components should require minimal monetary and labor costs to enable rapid iteration. This includes keeping the simulation component aligned with real system behaviors, incorporating the latest technologies in the optimization component, and maintaining seamless integration between the simulation and optimization components.
Empowering
It should be as easy as possible for data scientists and engineers to modify any DispatchGym component and then run experiments. This flexibility is crucial because new research typically requires adjustments to both the simulation and optimization components. By granting users the freedom to adapt DispatchGym, the framework fosters continuous innovation.
Research-friendly simulated environment
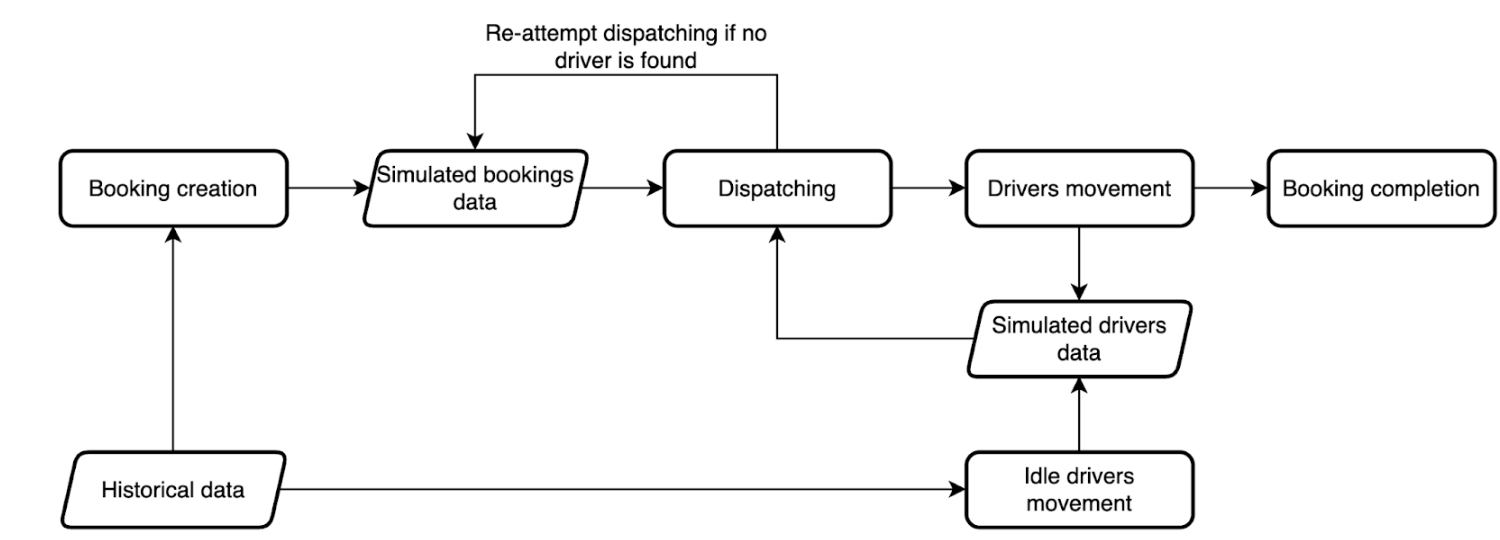
The simulation component of DispatchGym, or the “simulated environment,” is designed with reliability, cost-effectiveness, and user empowerment in mind. It models the full dispatching process, from booking creation and driver dispatch to driver movement and booking completion. While this environment may not be perfectly accurate in absolute terms (there can be differences between real and simulated metric values), it emphasizes directional accuracy. This means that the metric trends (up or down) in the simulation closely match real-world behavior. This focus on directional accuracy is crucial because most research involves sim-to-sim comparisons, where shifts in metrics are the most important. Verifying directional accuracy is also simpler and more practical for evaluating simulation performance. For instance, we can test various supply-demand imbalance scenarios and check whether a supply-rich situation indeed fulfills more bookings, and vice versa.
Figure 2. Simulated processes.
The simulated environment’s cost-effectiveness and empowerment features come from a modular architecture and Python, a research-friendly programming language. The modular design offers a gentle learning curve, allowing users to easily navigate and make necessary changes in the codebase. Meanwhile, Python is selected to lower the entry barrier for adopting DispatchGym. To mitigate Python’s runtime overhead, DispatchGym leverages Numba to significantly speed up simulation execution.
DispatchGym in action
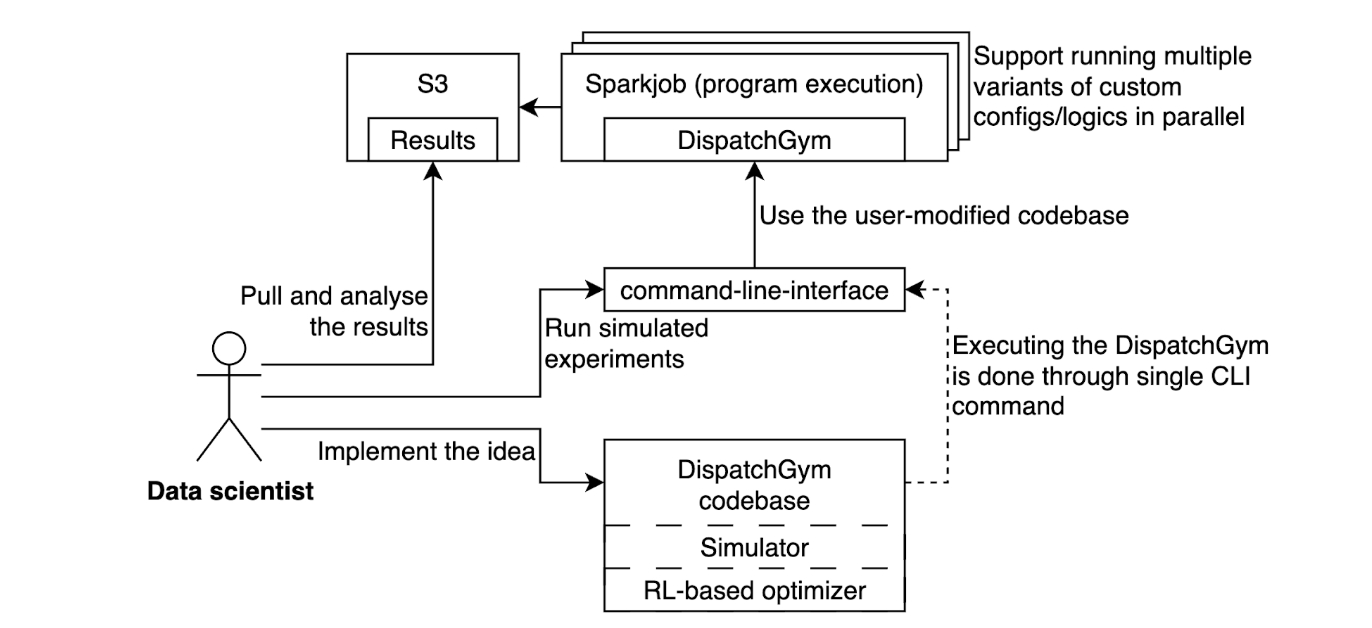
Data scientists use DispatchGym by modifying a local copy of the codebase to implement their ideas. They then upload the updated codebase to an internal infrastructure using a single CLI command, which spawns a Spark job to run the DispatchGym program. This setup grants complete flexibility over the simulation and optimization components without requiring users to manage the underlying infrastructure.
Figure 3. Data scientist interactions with DispatchGym.
Applying RL approach for dispatch
Amongst its many uses, DispatchGym was applied in building an effective contextual bandit strategy for the auto-adaptive tuning of dispatch-related hyperparameters. Its flexibility allowed us to experiment with various contextual bandit model variants, including linear bandits, neural-linear bandits, and Gaussian-process bandits, as well as multiple action sampling strategies, such as epsilon-greedy, Thompson sampling, SquareCB, and FastCB. These capabilities accelerated our progress in determining the best combination of levers, reward functions, and contextual bandits for improved fulfilment efficiency and reliability.
Conclusion
DispatchGym provides us a framework that equips data scientists with everything they need to develop and test RL solutions for dispatch systems. By integrating an RL optimization approach and a realistic dispatch simulation using a Gymnasium API, it enables rapid exploration and iteration of RL applications with just basic RL knowledge and Python programming language.
A major hurdle in applying RL to dispatch problems modeled as MDP is ensuring that the reward function aligns with ultimate business goals and is sensitive to the lever under control. If the lever (e.g., tweaking driver count) does not meaningfully influence the reward, the RL approach falters. DispatchGym addresses this by making it easy for data scientists to determine the most effective combinations of levers, reward functions, and RL approaches, ultimately driving positive business impact.
DispatchGym’s architecture focuses on reliability, cost-effectiveness, and user empowerment. Its simulation is designed to capture critical metrics and reflect real-world trends (directional accuracy), while its Python-based modular design enhanced by Numba enables easy prototyping. Researchers can adjust the environment locally before deploying changes seamlessly via a command-line interface, avoiding infrastructure overhead. These design decisions and capabilities empower data scientists to refine contextual bandit approaches for optimizing dispatch hyperparameters and explore innovative RL applications in the dispatch process.
We would like to thank Chongyu Zhou, Guowei Wong, and Roman Kotelnikov for their collaboration in developing the RL-based optimizer.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
The Integrity Data Platform (IDP) team decided to rewrite one of our heavy Queries Per Second (QPS) Golang microservices in Rust. It resulted in 70% infrastructure savings at a similar performance, but was not without its pitfalls. This article will elaborate on:
How we picked what to rewrite in Rust.
Approach taken to tackle the rewrite.
The pitfalls and speed bumps along the way.
Was it worthwhile?
Introduction
Grab is predominantly based on a microservice architecture, with the vast majority of microservices being hosted in a monorepo and written in Golang. It has served the company well so far, as the “simplicity” of Golang allows developers to ramp up and iterate quickly.
However, Rust has seen some gradual adoption across the company. Starting with a few minor CLIs, which then progressed to notable success with a Rust-based reverse proxy in Catwalk for model serving. Additionally, a growing community of Rust enthusiasts within the organisation has expressed interest in advocating for and expanding the adoption of Rust more proactively.
After achieving success with several projects on the ML platform and addressing concerns about Rust’s ability to handle traffic at scale, the next logical step was to assess the Return on Investment (ROI) of rewriting a Golang microservice in Rust.
Background
Rust has the reputation of being highly efficient yet poses a steep learning curve. Rust is often touted to perform close to C, doing away with garbage collection while remaining memory safe through strict compile checks and the borrow checker. It is loved by developers for having rich features like being multi-paradigm (supporting both functional and OOP style), having a rich type system, and doing away with nil pointers and errors.
However, regardless of how well regarded a certain language is in the industry, rewrites of any system should always be considered very carefully. When it comes to “legacy software”, there is a prevalent assumption that rewriting legacy software is a solution to eliminate technical debt and phase out legacy systems. The reality is often more nuanced.
Legacy code occurs when the developers who originally wrote the code are no longer working on the project. There are often business logic and edge-cases baked into complex legacy codebases of which the context has been lost over time. In practice, rewrites frequently take longer than anticipated and tend to reintroduce bugs and edge cases that must be identified and resolved all over again.
Rewriting vs refactoring has been written at length across the internet, you can read more about it here.
The trade-offs of rewriting need to be properly weighed and balanced. It must take into consideration:
How much engineering bandwidth goes into the rewrite?
What is the complexity of the rewrite?
What tangible benefits are brought about by the rewrite?
Rewriting a system solely for the purpose of “rewriting it in Rust” is not a strong enough business justification.
A legitimate concern was the steep learning curve of Rust, coupled with the risk of having only one team member proficient in the language, which would make its adoption unsustainable.
Therefore, we established a set of guidelines to follow when identifying a suitable system for a potential rewrite:
The system must be “simple” enough in functionality. For example, it has one or two main functionalities that can be rewritten in a reasonable amount of time and have its complexity constrained.
The system targeted should have large enough traffic such that cost savings brought about by adopting Rust is something tangible when balanced against the effort.
The members of the team must be comfortable and willing to pick up the language and achieve a certain level of familiarity to make maintaining the service sustainable.
Finding the right service
The ideal service should have a sufficiently large infrastructure footprint to justify the potential cost savings, while also being straightforward in functionality to minimise time spent on handling edge cases and complex business logic.
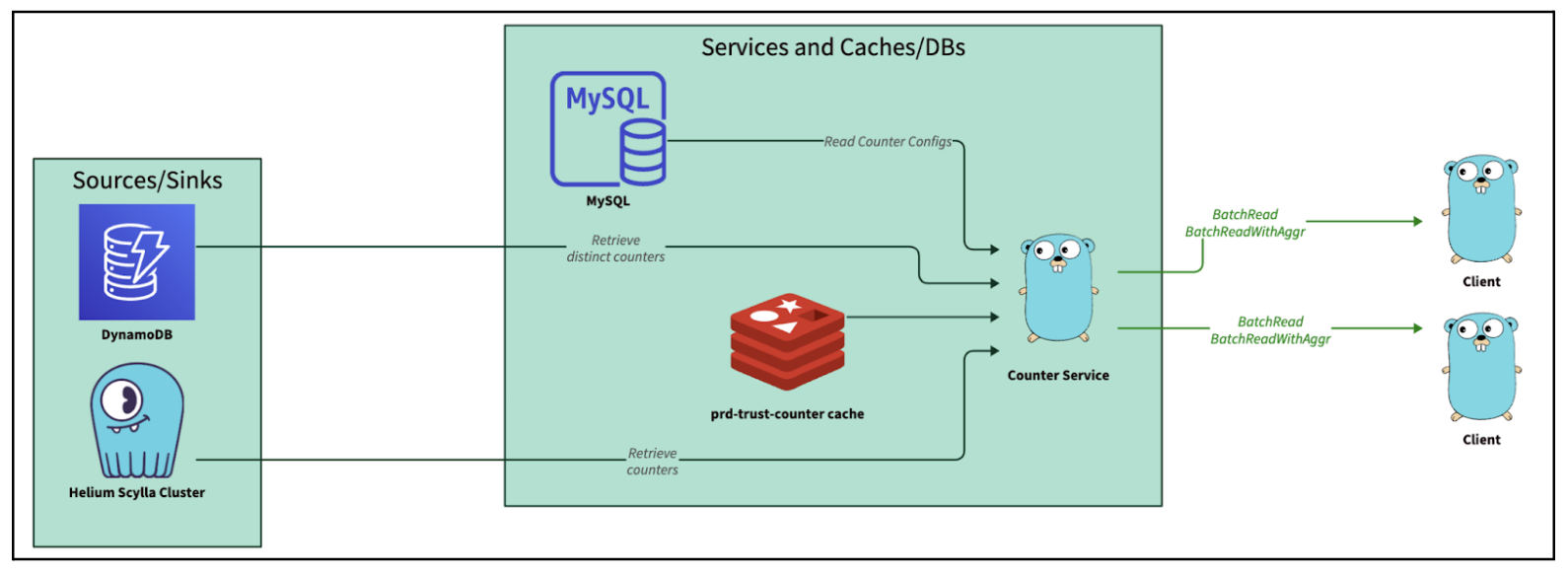
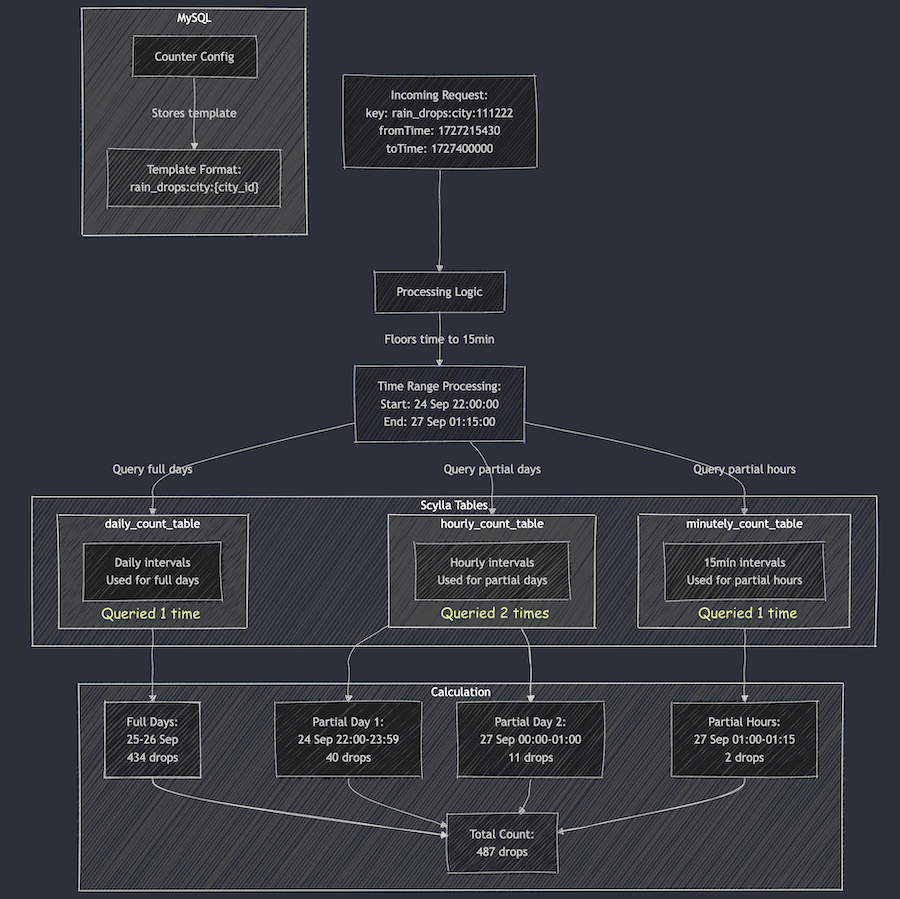
Looking across the stack of microservices in Integrity, Counter Service stands out. As its name implies, Counter Service is a service that “counts” and serves the counters for ML models and fraud rules. The original service has two primary functionalities:
Consuming from streams, counting events and writing to Scylla.
Exposing Google Remote Procedure Call (GRPC) endpoints to query from Scylla (and Redis) and return counts of events based on query keys. For example, BatchRead. BatchRead’s functionality of Counter Service serves up to tens of thousands of QPS at peak and is fairly constrained in functionality. Hence, it fulfilled our target criteria of being “simple” in functionality yet serving a large enough amount of traffic that justifies the ROI of a rewrite.
Figure 1: BatchRead flow of Counter Service, reading data from Scylla, DynamoDB, Redis, MySQL and serving the counters through GRPC.
Rewrite approach
There are a few ways to approach a rewrite in another language. One popular way is to convert your code line by line. If the languages are close enough, it might even be possible to programmatically convert your code like C2Rust.
We decided not to use such an approach for our rewrite. The major reason is that idiomatic Golang was not necessarily idiomatic Rust. We wanted to approach this rewrite with a fresh perspective and treat this as a true rewrite.
We treated the application like a black box, with the interfaces well defined, like GRPC endpoints and contracts. Similar to a function, you could call the API and get a deterministic result, and we had the data that was stored in Scylla.
Based on how we understood the application to work based on its specs and contract, we chose to rewrite the application logic from scratch to meet the API contract and to get as close as identical outputs from the new black box.
OSS library support
We started out by mapping out the key external dependencies and checking how well they were supported in the Rust ecosystem and in open source.
All the functionality we need is available through libraries in the Rust ecosystem. However, we found that some libraries are not particularly “popular,” as indicated by their relatively low number of GitHub stars.
The practical concern with using less “popular” libraries is the risk of limited community support or potential abandonment over time. That said, if an “unpopular” library is officially maintained by the associated open-source project—for instance, the Scylla driver has only about 500 stars but is officially provided by the Scylla project—we would need to ensure confidence that it will continue to receive active support.
Out of the list of libraries above, the “unpopular” and unofficial libraries can be narrowed down to two libraries:
Datadog – Cadence
Redis – Fred
For Datadog, there is no “official” Datadog Rust client. Yet, we picked Cadence as the API looked intuitive and the features we needed were already supported.
In regards to Redis, after testing it, we discovered that the support was not up to par with our requirements. We then opted for a newer and less popular library, fred.rs that seemed to be actively being developed by the community.
Company specific internal libraries
With the vast majority of microservices being written in Golang, most internal libraries are also written in Golang. Opting to rewrite a service in Rust means we are not able to use these internal libraries.
Examples include:
An internal configuration library that utilises Go Templates to template configurations for different environments (staging and production).
The internal configuration library has its own wrappers and injectors to pull and render secrets.
To overcome this gap and re-use Go Templates and configuration language, we decided to write a simple wrapper and parser using the nom parser combinator to parse the templates and render the config.
Nom poses a steep learning curve. But once familiarised, it is flexible and performant enough to build an equivalent to the internal library. Parser combinators are an interesting subset of tooling that allows you to create some fairly elegant parsers.
Road bumps
The borrow checker
One of the most striking paradigm shifts for developers transitioning to Rust is adapting to the strict rules of the borrow checker, which enforces that variables cannot be reused multiple times unless explicitly cloned or borrowed.
Interestingly, the borrow checker was not the biggest hurdle for new developers. The key is to avoid introducing lifetimes too early in the development process, as this can lead to premature code optimisation.
In many cases, adding a few clones (and occasionally Arcs) can help new developers get up to speed and iterate more quickly during development. The resulting code is usually “fast” enough for initial purposes. After that, the code can be revisited to eliminate unnecessary clones for improved performance. An efficient approach to this can be taken by using Flamegraph to profile your code and identify memory allocation bottlenecks.
Async gotchas
When rewriting Golang logic in Rust, there are fundamental differences in how they treat concurrency and parallelism.
One of Golang’s most remarkable strengths is its ability to deliver high-performance concurrency while preserving simplicity.
There are two fundamental approaches to concurrency in programming languages, namely:
Preemptive scheduling (stackful coroutines).
Cooperative scheduling (stackless coroutines).
Preemptive vs cooperative scheduling is an in-depth topic with the gist of it being, Golang uses preemptive scheduling and each “Goroutine” has a stack that needs a runtime. The Golang scheduler has the power to “preempt” and “freeze” functions and switch to another stack like stackful coroutine. This is a gross oversimplification of the nuances. For more details, this is a good introduction to the topic.
Rust opts for cooperative scheduling whereby it has no runtime and each coroutine does not maintain a stack. Hence, it has no ability to “freeze” a function and swap context. This allows Rust to be more efficient in terms of memory and resources, as it maintains a state machine. However, the consequence is that this moves the complexity up the stack to the programming language itself. Similar to Javascript, functions are “coloured”, and the developer has to explicitly annotate their functions to be async or sync. Await points need to be explicitly called and control needs to be “yielded” (i.e. cooperative and stackless) so the Rust program knows when it is allowed to stop and swap between coroutines. To read more on this, refer to this and this article for the history of async Rust.
Needing to annotate a function is a classic complaint that is addressed in the article “What Colour is Your Function” that highlights developers’ responsibility to explicitly colour their function and consciously think about blocking vs non-blocking code.
Contrast this with Golang, where you simply need to add the go keyword without thinking about which code might block the execution and use channels to communicate across Goroutines. Golang allows the developer to achieve high performance without much cognitive overhead.
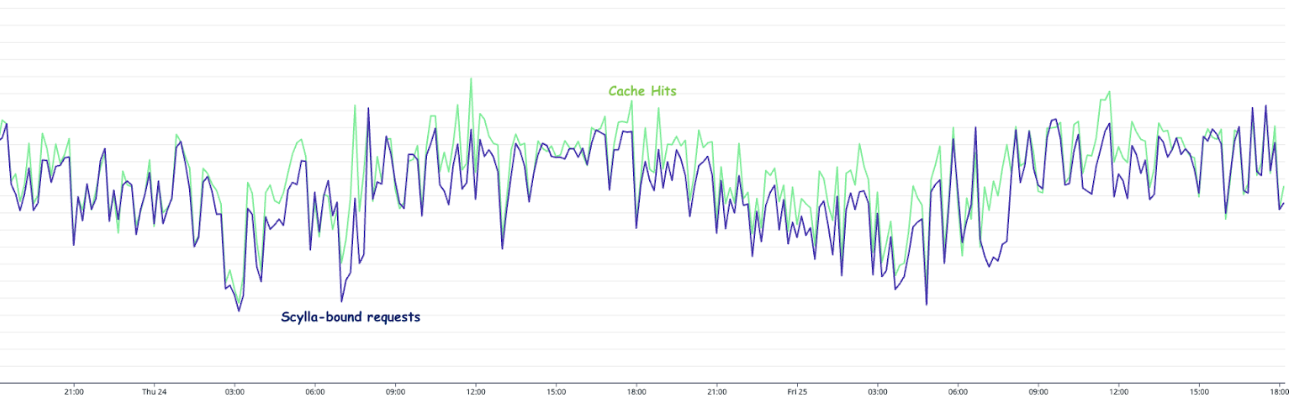
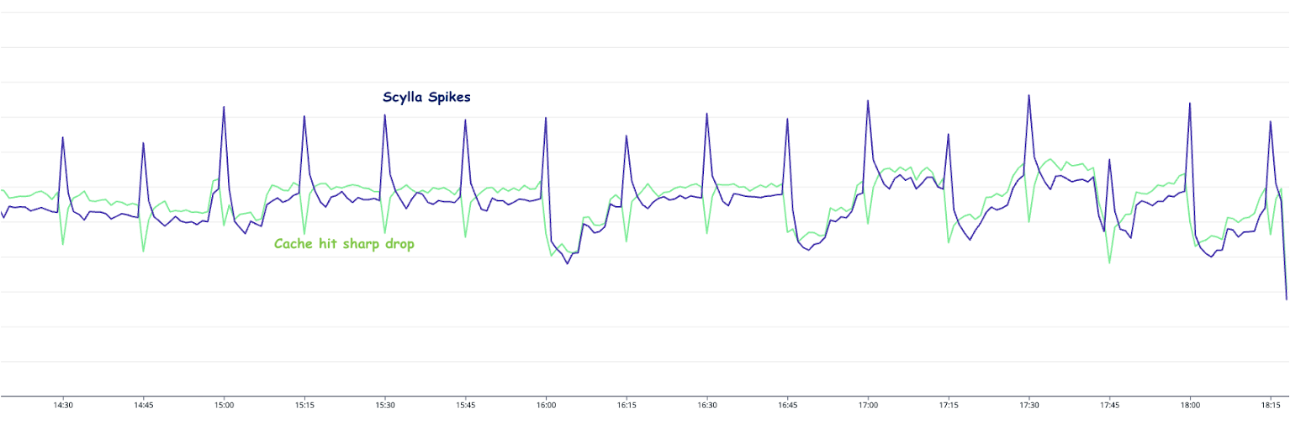
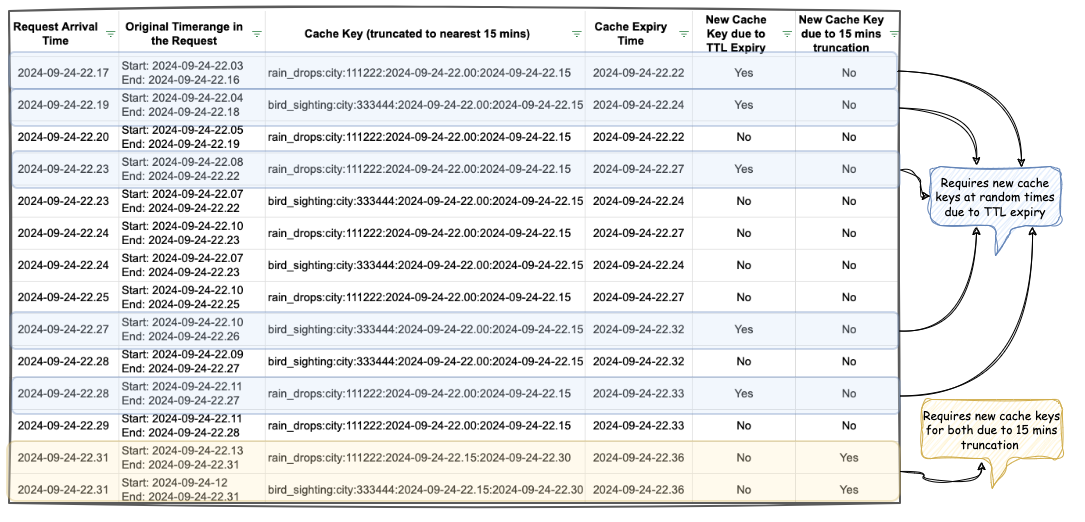
This is especially important for developers new to Rust. As the lack of experience in async and blocking code can be somewhat of a footgun. In the initial rewrite of Rust, we made an amateur mistake of using a synchronous Redis function to call the Redis cache. It resulted in the application performing poorly until we corrected it with the non-blocking asynchronous version using the Fred redis library.
Impact
Following the eventful process of rewriting the service from the ground up in Rust, the outcomes proved to be quite intriguing.
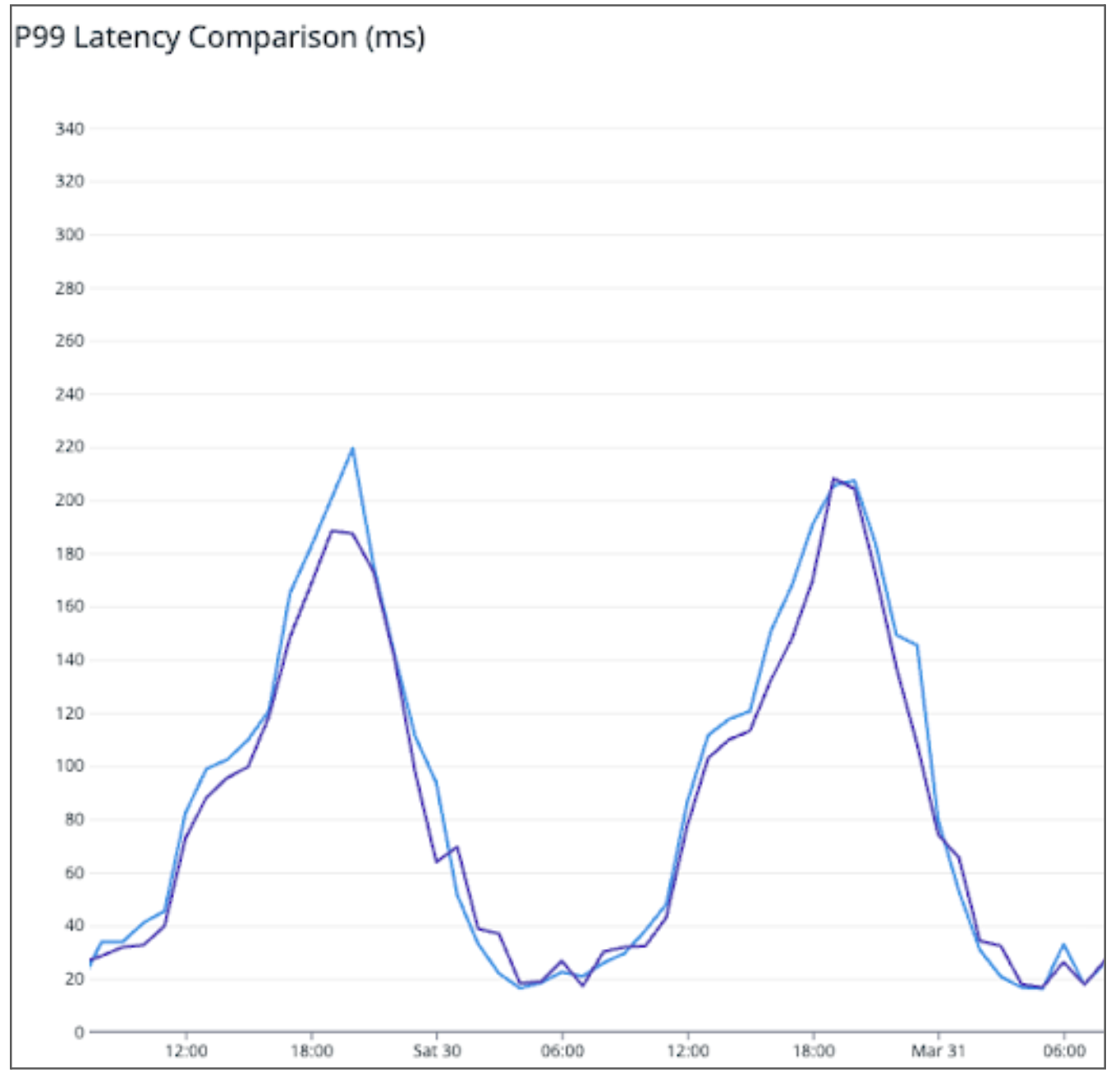
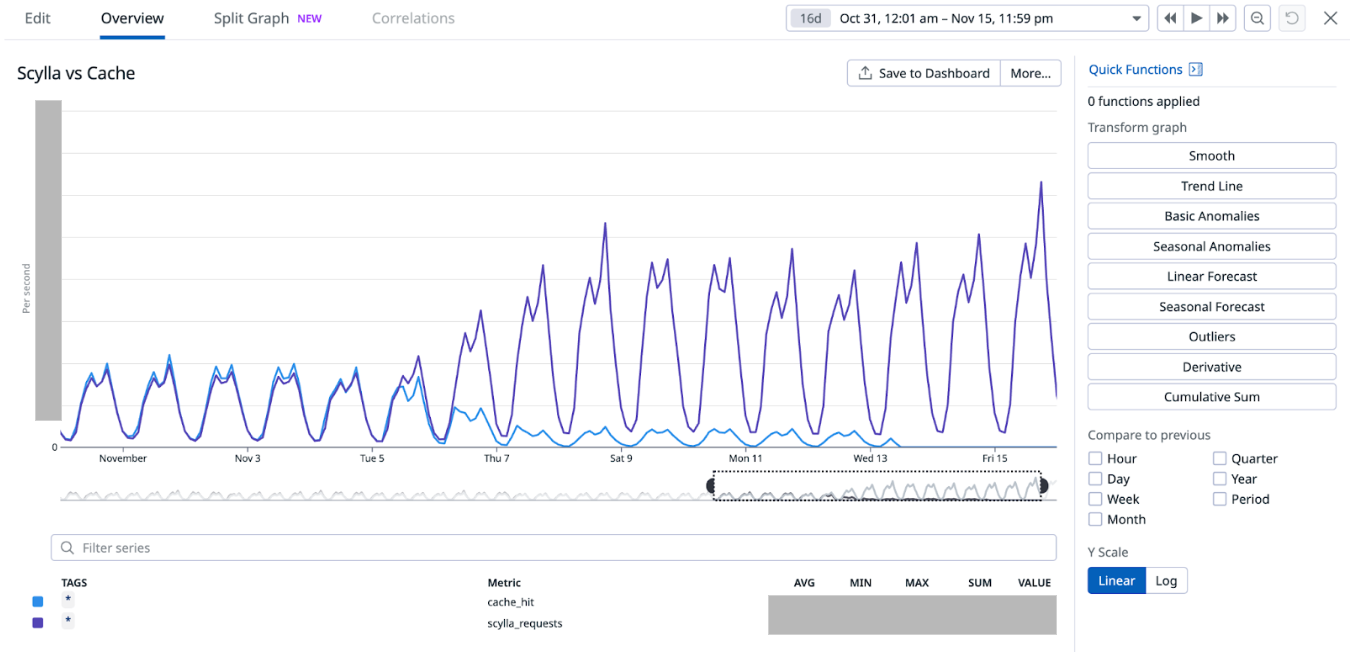
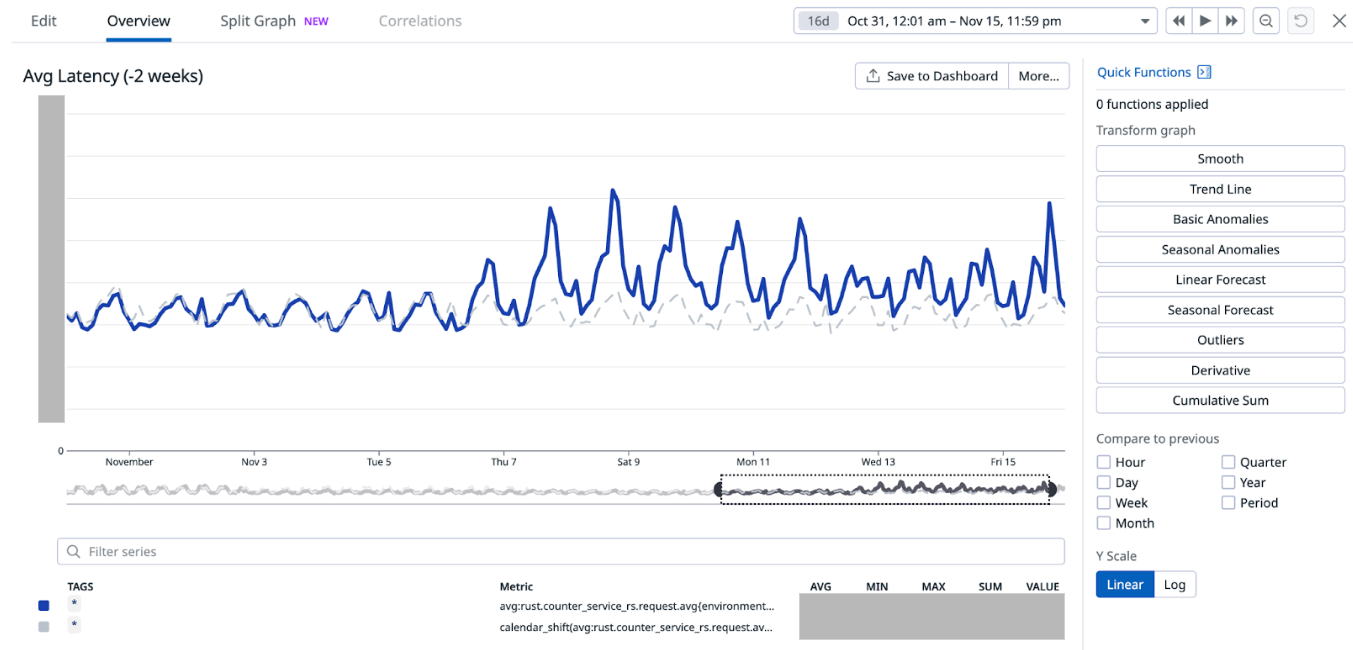
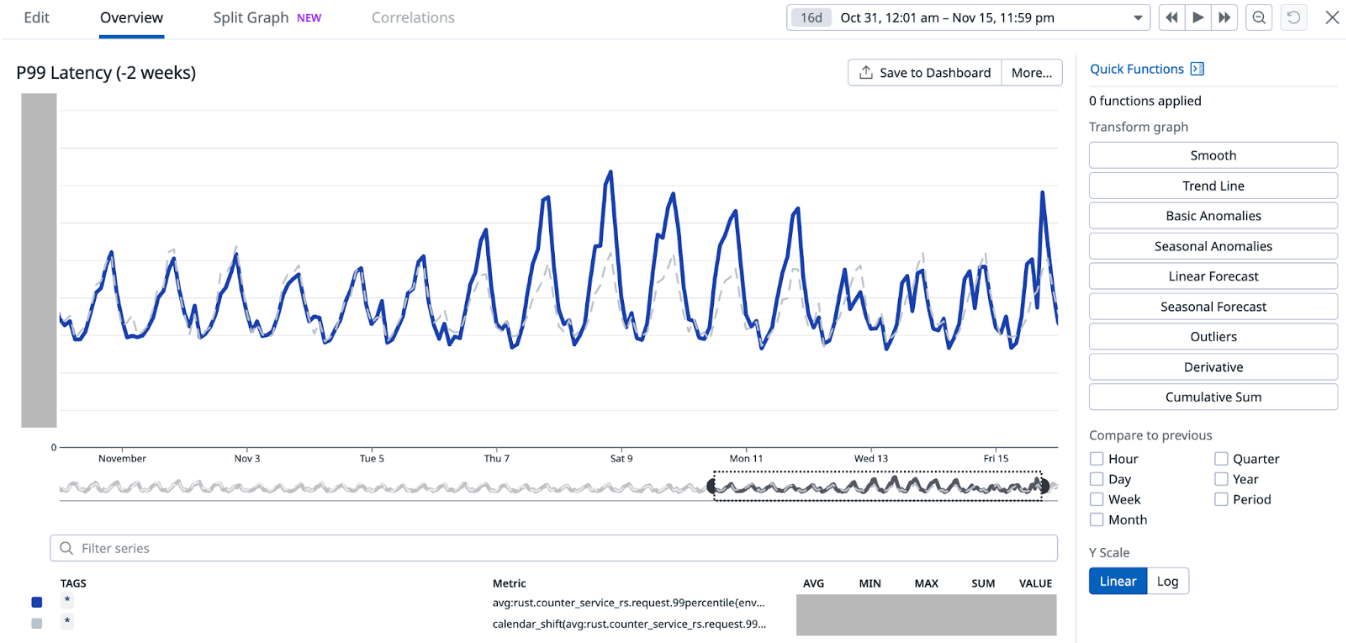
Shadowing traffic to both services as seen in Figure 2, the P99 latency is similar (or perhaps even slightly worse) in the Rust service compared to the original Golang one.
Figure 2: P99 latency comparison between the Golang service (purple) and Rust service (blue).
Normalising the QPS and resource consumption, we see from Table 2 that Rust consumes ~20% of the resources of the original Golang application, resulting in 5x savings in terms of resource consumption.
Table 2: Comparison of resource consumption between Rust and Golang service.
Service
Indicative QPS
Resources
Original Golang Service
1,000
20 Cores
New Rust Service
1,000
4.5 Cores
Learnings and conclusion
The outcomes and insights from this rewrite have been eye-opening, debunking certain myths while also validating others.
Myth 1: Rust is blazingly fast! Faster than Golang!
Verdict: Disproved.
Golang is “fast enough” for most use cases. It’s a mature language built with concurrency at its core, and it performs exceptionally well in its intended domain. While Rust can outperform Golang due to its higher performance ceiling and finer-grained control, rewriting a Golang service in Rust solely for performance improvements is unlikely to yield significant benefits.
Myth 2: Rust is more efficient than Golang
Verdict: True.
Rewriting a Golang service in Rust will probably give you 50% savings in compute. Rust does fulfill its promise of being memory safe without garbage collection, allowing it to be one of the more efficient languages out there. This is in line with other discoveries in the market.
Myth 3: The learning curve of Rust is too high
Verdict: It depends.
Pure synchronous Rust is fine. As long as you don’t overcomplicate the code and only clone what is needed, it is mostly true. The language is easy enough to pick up for most experienced developers. Even with cloning sprinkled in, the code is usually “fast enough”. The compiler is a good teacher, the compiler error messages are amazing, and if your code compiles, it probably works. Also, the Clippy linter is amazing.
However, introducing async can be challenging. Async is something quite different from what you would encounter in other languages like Go. Improper use of blocking code in async code can result in nuanced bugs that can catch inexperienced Rust developers off-guard.
Evaluating the worth of the rewrite
Yes, the effort was worth it for this service. The trade-off between development effort spent and the cost savings were justified.
As a side effect, the service is 80% cheaper and probably more bug free, as Rust eliminates a class of common Golang errors like Null pointers and concurrent map writes by virtue of the design of the language. If your code compiles, you usually have the confidence that it will work as you expect due to the language being more explicit.
Would we encourage choosing Rust over Golang for new microservices? Absolutely, as the resulting service is likely to be at least 50% more efficient than its Go counterpart. However, this decision presents an important and exciting opportunity for management and leaders to invest in empowering their engineers by equipping them with the skills to master Rust’s unique concepts, such as Async and Lifetimes. While the initial development pace might be slower as the team builds proficiency, this investment can unlock long-term benefits. Once the workforce is skilled in Rust, development speed should align with expectations, and the resulting systems are likely to be more stable and secure, thanks to Rust’s inherent safety features.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
In the fast-paced world of data analytics, real-time processing has become a necessity. Modern businesses require insights not just quickly, but in real-time to make informed decisions and stay ahead of the competition. Apache Flink has emerged as a powerful tool in this domain, offering state-of-the-art stream processing capabilities. In this blog, we introduce our FlinkSQL interactive solution in accompanying productionising automation, and enhancing our users’ stream processing development journey.
Preface
Last year, we introduced Zeppelin notebooks for Flink, as detailed in our previous post Rethinking Stream Processing: Data Exploration in an effort to enhance data exploration for downstream data users. However, as our use cases evolved over time, we quickly hit a few technical roadblocks.
Flink version maintenance
Zeppelin notebook source code is maintained by a community separate from Flink’s community. As of writing, the latest Flink version supported is 1.17, whilst the latest Flink is already on version 1.20. This discrepancy in version support hinders our Flink upgrading efforts.
Cluster start up time
Our design to spin up a Zeppelin cluster per user on demand invokes a cold start delay, taking roughly around 5 minutes for the notebook to be ready. This delay is not suitable for use cases that require quick insights from production data. We quickly noticed that the user uptake of this solution was not as high as we expected.
Integration challenges
Whilst Zeppelin notebooks were useful for serving individual developers, we experienced difficulty integrating it with other internal platforms. We designed Zeppelin to empower solo data explorers, but other internal platforms like dashboards or automated pipelines needed a way to aggregate data from Kafka and Zeppelin just couldn’t keep up. The notebook setup was too isolated, requiring a workaround to share insights or plug into existing tools. For instance, if a team wanted to pull aggregated real-time metrics into a monitoring system, they had to export data manually, which is far from seamless access that we aimed for.
Introducing FlinkSQL interactive
With those considerations in mind, we decided to swap out our Zeppelin cluster with a shared FlinkSQL gateway cluster. We simplified our solution by removing some features our notebooks offered, focusing only on features that promote data democratisation.
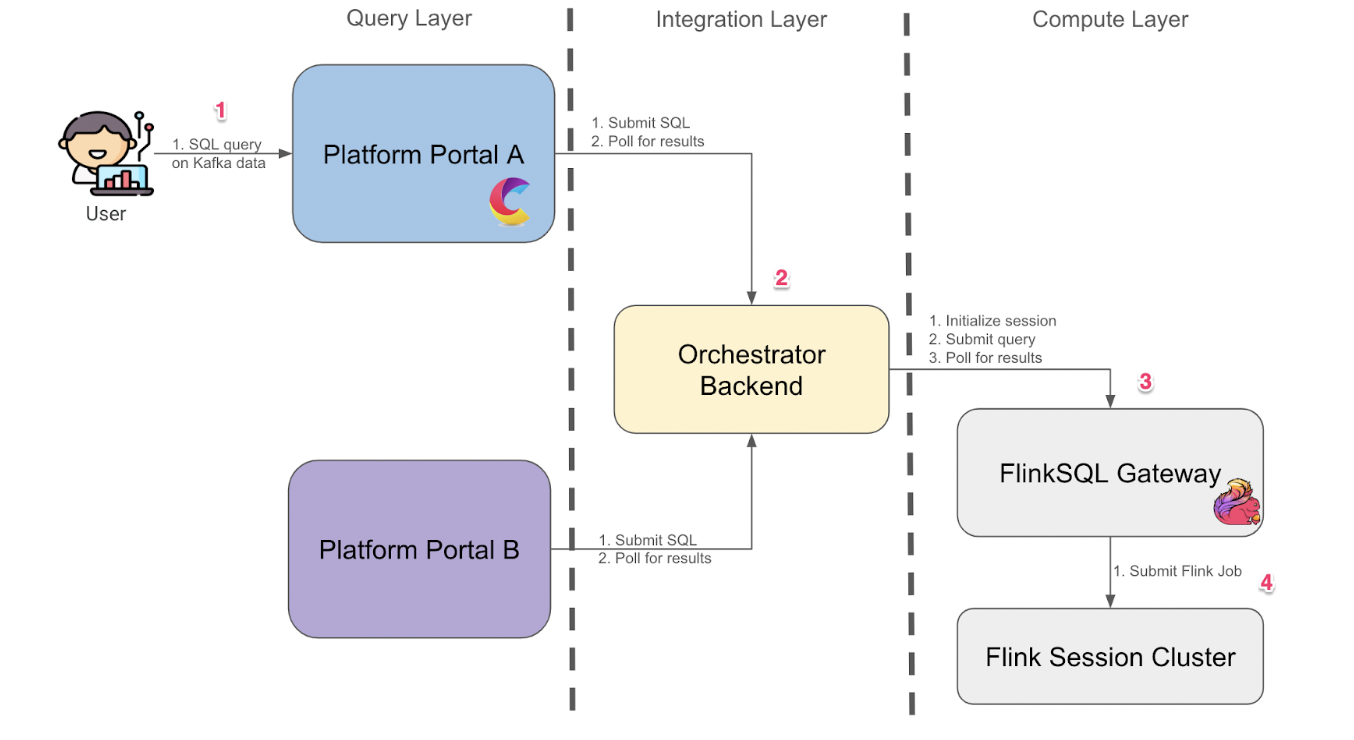
Figure 1: Shared FlinkSQL gateway architecture
We split our solution into 3 layers:
Compute layer
Integration layer
Query layer
Users first interact with our platform portal to submit queries for data from Kafka online store using SQL (1). Upon submission, our backend orchestrator then creates a session for the user (2) and submits the SQL query to our FlinkSQL gateway using their inbuilt REST API (3). The FlinkSQL gateway then packages the SQL query into a Flink job to be submitted to our Flink session cluster (4) before collating its results. The subsequent results would be polled from the query layer to be displayed back to the user.
Compute layer
With FlinkSQL gateway acting as the main compute engine for ad-hoc queries, it is now more straightforward to perform Flink version upgrades along with our solution, since the FlinkSQL gateway is packaged along with the main Flink distribution. We do not need to maintain Flink shims for each version as adapters between the Flink compute cluster and Zeppelin notebook cluster.
Another advantage of using the shared FlinkSQL gateway was the reduced cold start time for each ad-hoc queries. Since all users share the same FlinkSQL cluster instead of having their own Zeppelin cluster, there was no need to wait for cluster startup during initialisation of their sessions. This brought the lead time to the first results displayed down from 5 minutes to 1 minute. There was still lead time involved as the tool provisions task managers on an ad-hoc basis to balance availability of such developer tools and the associated cost.
Integration layer
The Integration layer serves as the glue between the user-facing query layer and the underlying compute layer, ensuring seamless communication and security across our ecosystem. With the shift to a shared FlinkSQL gateway, we recognised the need for an intermediary that could handle authentication, authorisation, orchestration, and integration with internal platforms – all while abstracting the complexities of Flink’s native REST API.
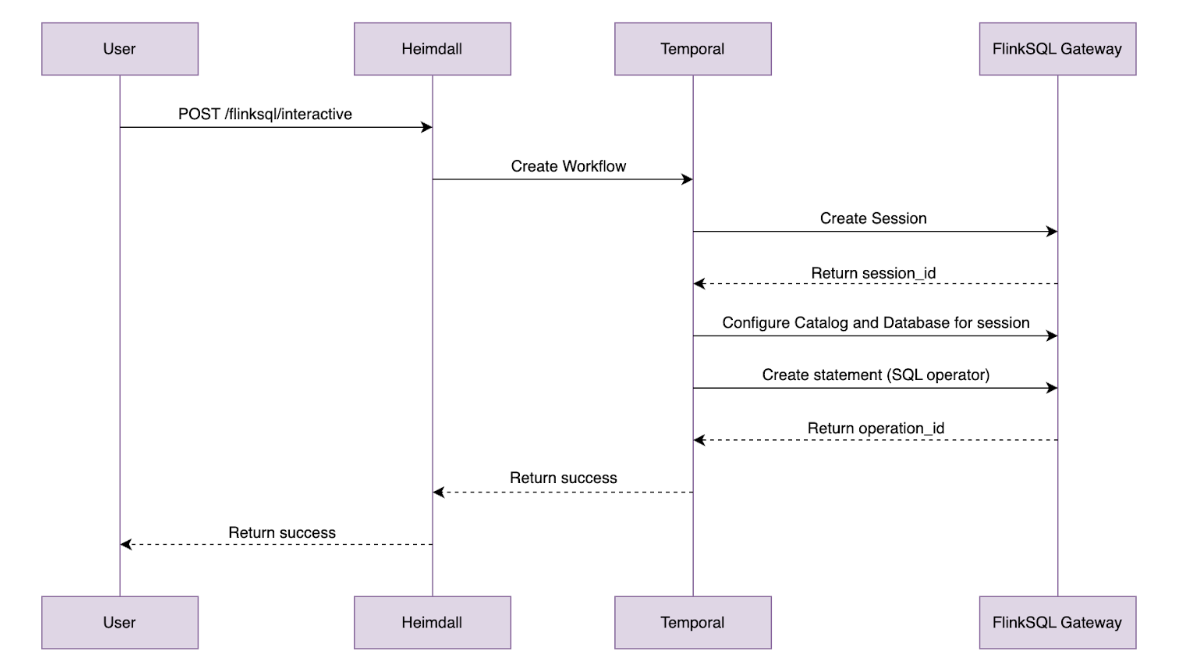
Figure 2: FlinkSQL gateway
The FlinkSQL gateway’s built-in REST API gets the job done for basic query submission, but it falls short in areas like session management, requiring multiple POST requests just to fetch results. To address this, we extended a custom control plane with its own set of REST APIs, layered on top of the gateway.
We then extend these sessions and integrate them to our inhouse authentication and authorisation platform. For each query made, the control plane authenticates the user, spins up lightweight sessions and manages the communication between the caller and the Flink Session Cluster. If you are interested, check out our previous blog post, An elegant platform, for more details on the above mentioned streaming platform and its control plane.
The integration layer also caters to B2B needs via our Headless APIs. By exposing the endpoints, developers are able to integrate real-time processing into their own tools. To run a query, programs can simply make a POST request with the SQL query and an operation ID would be returned. This operation ID could then be used in subsequent GET requests to fetch the paginated results of the unbounded query. This setup is ideal for internal platforms that need to query Kafka data programmatically. By abstracting these complexities, it ensures that users, whether individual analysts or internal platforms—can tap into Kafka data without wrestling with Flink’s raw interfaces.
Query layer
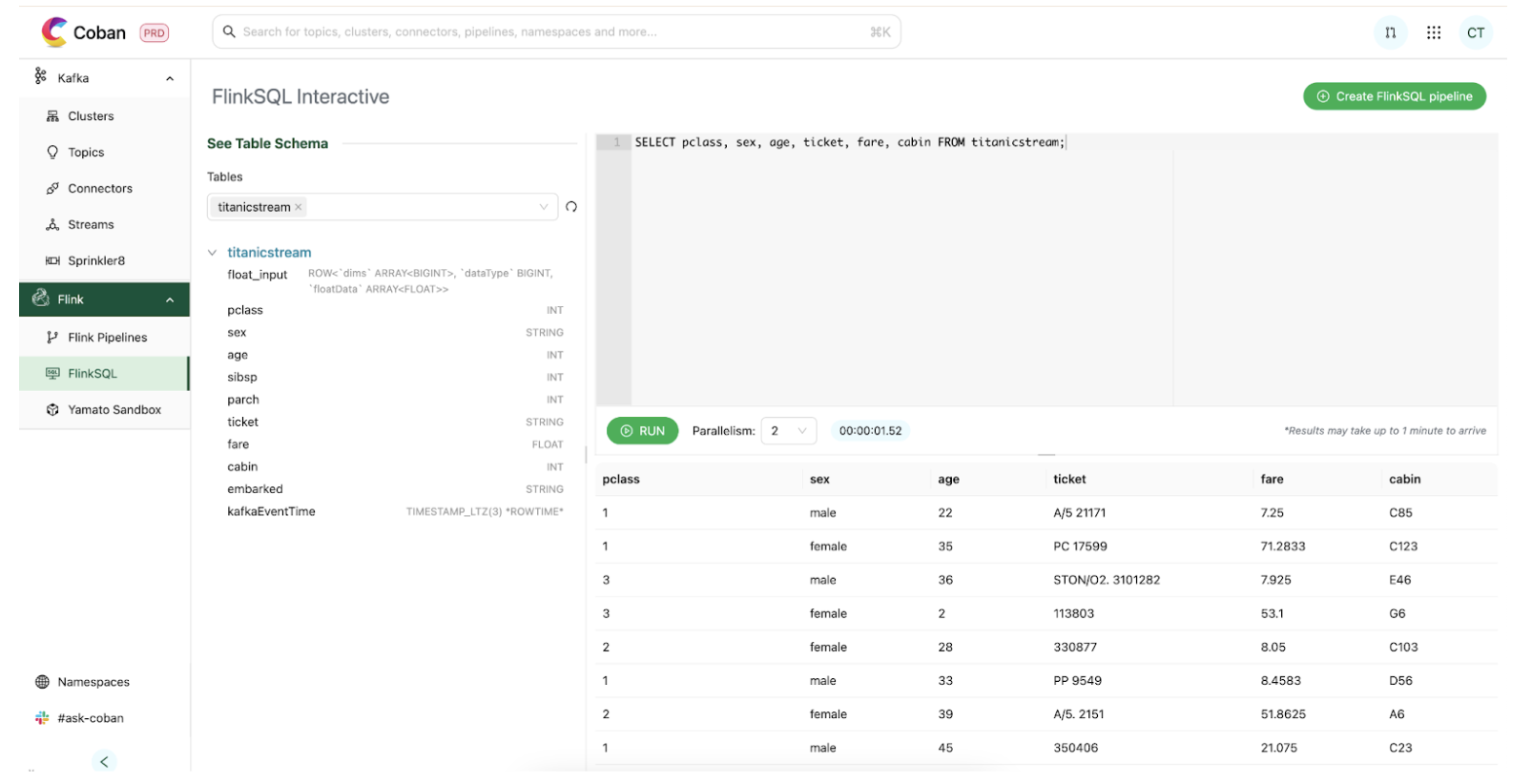
We then proceed to pair our APIs developed with an Interactive UI to build a Query layer that serves both human workflows. This is where users meet our platform.
Figure 3: Flink query layer’s user flow
Through our platform portal, users land in a clean SQL editor. We used a Hive Metastore (HMS) catalog that translates Kafka topics into tables. Users don’t need to decode stream internals; they can jump straight into it by simply selecting a table to query on. Once a query is submitted, it is then handled by the integration layer which routes it through the control plane to the gateway. Results are then streamed back, appearing in the UI within one minute, a significant improvement from the five minute Zeppelin cold starts.
This all crystalises into the user flow demonstrated in Figure 3, where we can easily retrieve Titanic data from a Kafka stream with a short command:
SELECT COUNT(*) FROM titanicstream WHERE kafkaEventTime > NOW() - INTERVAL '1' HOUR.
This setup enables a few use cases for our teams, such as:
Fraud analysts using the real-time data to debug and spot patterns in fraudulent transactions.
Data scientists querying live signals to validate their prediction models.
Engineers validating the messages sent from their system to confirm they are properly structured and accurately delivered.
Productionising FlinkSQL
With data being democratised, we see more users building use cases around our online data store and utilising the above tools to build new stream processing pipelines expressed as SQL queries. To simplify the last step of the software development lifecycle of deployment, we have also developed a tool to create a configuration based stream processing pipeline, with the business logic expressed as a SQL statement.
Figure 4: Portal for FlinkSQL pipeline creation
We host connectors for users to connect to other platforms within Grab, such as Kafka and our internal feature stores. Users could simply use them off-the-shelf and configure according to their needs before deploying their stream processing pipeline.
Users would then proceed to submit their streaming logic as a SQL statement. In the example illustrated in the diagram, the logic expressed is a simple filter on a Kafka stream for sinking the filtered events into a separate Kafka stream.
Users have the ability to then define the parallelism and associated resources they want to run their Flink jobs with. Upon submission, the associated resources would be provisioned and the Flink pipeline would be automatically deployed. Behind the scenes, we manage the application JAR file that is being used to run the job that dynamically parses these configurations and translates them into a proper Flink job graph to be submitted to the Flink cluster.
Within 10 minutes, users would have completed deploying their stream processing pipeline to production.
Conclusion
With our full suite of solutions for low code development via FlinkSQL, from exploration and design, to development and then deployment, we have simplified the journey for developing business use cases off online streaming stores. By offering both a user-friendly interface for low-code users and a robust API for developers, these tools empower businesses to harness the full potential of real-time data processing. Whether you are a data analyst looking for quick insights or a developer integrating real-time analytics into your applications, our tools are able to lower the barrier of entry to utilising real-time data.
After we released these solutions, we quickly saw an uptick in pipelines created as well as the number of interactive queries fired. This result was encouraging and we hope that this would gradually bring upon a paradigm shift, enabling Grab to make data-driven operational decisions on real-time signals, empowering us with the ability to react to ever-changing market conditions in the most efficient manner.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
In my spare time I enjoy building Gundam models, which are model kits to build iconic mechas from the Gundam universe. You might be wondering what this has to do with software engineering. Product engineers can be seen as the engineers who take these kits and build the Gundam itself. They are able to utilize all pieces and build a working product that is fun to collect or even play with!
Platform engineers, on the other hand, supply the tools needed to build these kits (like clippers and files) and maybe even build a cool display so everyone can see the final product. They ensure that whoever is constructing it has all the necessary tools, even if they don’t physically build the Gundam themselves.
About a year ago, my team at GitHub moved to the infrastructure organization, inheriting new roles and Areas of Responsibility (AoRs). Previously, the team had tackled external customer problems, such as building the new deployment views across environments. This involved interacting with users who depend on GitHub to address challenges within their respective industries. Our new customers as a platform engineering team are internal, which makes our responsibilities different from the product-focused engineering work we were doing before.
Going back to my Gundam example, rather than constructing kits, we’re now responsible for building the components of the kits. Adapting to this change meant I had to rethink my approach to code testing and problem solving.
Whether you’re working on product engineering or on the platform side, here are a few best practices to tackle platform problems.
Understanding your domain
One of the most critical steps before tackling problems is understanding the domain. A “domain” is the business and technical subject area in which a team and platform organization operate. This requires gaining an understanding of technical terms and how these systems interact to provide fast and reliable solutions. Here’s how to get up to speed:
Talk to your neighbors: Arrange a handover meeting with a team that has more knowledge and experience with the subject matter. This meeting provides an opportunity to ask questions about terminology and gain a deeper understanding of the problems the team will be addressing.
Investigate old issues: If there is a backlog of issues that are either stale or still persistent, they may give you a better understanding of the system’s current limitations and potential areas for improvement.
Read the docs: Documentation is a goldmine of knowledge that can help you understand how the system works.
Bridging concepts to platform-specific skills
While the preceding advice offers general guidance applicable to both product and platform teams, platform teams — serving as the foundational layer — necessitate a more in-depth understanding.
Networks: Understanding network fundamentals is crucial for all engineers, even those not directly involved in network operations. This includes concepts like TCP, UDP, and L4 load balancing, as well as debugging tools such as dig. A solid grasp of these areas is essential to comprehend how network traffic impacts your platform.
Operating systems and hardware: Selecting appropriate virtual machines (VMs) or physical hardware is vital for both scalability and cost management. Making well-informed choices for particular applications requires a strong grasp of both. This is closely linked to choosing the right operating system for your machines, which is important to avoid systems with vulnerabilities or those nearing end of life.
Infrastructure as Code (IaC): Automation tools like Terraform, Ansible, and Consul are becoming increasingly essential. Proficiency in these tools is becoming a necessity as they significantly decrease human error during infrastructure provisioning and modifications.
Distributed systems: Dealing with platform issues, particularly in distributed systems, necessitates a deep understanding that failures are inevitable. Consequently, employing proactive solutions like failover and recovery mechanisms is crucial for preserving system reliability and preventing adverse user experiences. The optimal approach for this depends entirely on the specific problem and the desired system behavior.
Knowledge sharing
By sharing lessons and ideas, engineers can introduce new perspectives that lead to breakthroughs and innovations. Taking the time to understand why a project or solution did or didn’t work and sharing those findings provides new perspectives that we can use going forward.
Here are three reasons why knowledge sharing is so important:
Teamwork makes the dream work: Collaboration often results in quicker problem resolution and fosters new solution innovation, as engineers have the opportunity to learn from each other and expand upon existing ideas.
Prevent lost knowledge: If we don’t share our lessons learned, we prevent the information from being disseminated across the team or organization. This becomes a problem if an engineer leaves the company or is simply unavailable.
Improve our customer success: As engineers, our solutions should effectively serve our customers. By sharing our knowledge and lessons learned, we can help the team build reliable, scalable, and secure platforms, which will enable us to create better products that meet customer needs and expectations!
But big differences start to appear between product engineering and infrastructure engineering when it comes to the impact radius and the testing process.
Impact radius
With platforms being the fundamental building blocks of a system, any change (small or large) can affect a wide range of products. Our team is responsible for DNS, a foundational service that impacts numerous products. Even a minor alteration to this service can have extensive repercussions, potentially disrupting access to content across our site and affecting products ranging from GitHub Pages to GitHub Copilot.
Understand the radius: Or understand the downstream dependencies. Direct communication with teams that depend on our service provides valuable insights into how proposed changes may affect other services.
Postmortems: By looking at past incidents related to our platform and asking “What is the impact of this incident?”, we can form more context around what change or failure was introduced, how our platform played a role in it, and how it was fixed.
Monitoring and telemetry: Condense important monitoring and logging into a small and quickly digestible medium to give you the general health of the system. This could be a Single Availability Metric (SAM), for example. The ability to quickly glance at a single dashboard allows engineers to rapidly pinpoint the source of an issue and streamlines the debugging and incident mitigation process, as compared to searching through and interpreting detailed monitors or log messages.
Testing changes
Testing changes in a distributed environment can be challenging, especially for services like DNS. A crucial step in solving this issue is utilizing a test site as a “real” machine where you can implement and assess all your changes.
Infrastructure as Code (IaC): When using tools like Terraform or Ansible, it’s crucial to test fundamental operations like provisioning and deprovisioning machines. There are circumstances where a machine will need to be re-provisioned. In these cases, we want to ensure the machine is not accidentally deleted and that we retain the ability to create a new one if needed.
End-to-End (E2E): Begin directing some network traffic to these servers. Then the team can observe host behavior by directly interacting with it, or we can evaluate functionality by diverting a small portion of traffic.
Self-healing: We want to test the platform’s ability to recover from unexpected loads and identify bottlenecks before they impact our users. Early identification of bottlenecks or bugs is crucial for maintaining the health of our platform.
Ideally changes will be implemented on a host-by-host basis once testing is complete. This approach allows for individual machine rollback and prevents changes from being applied to unaffected hosts.
What to remember
Platform engineering can be difficult. The systems GitHub operates with are complex and there are a lot of services and moving parts. However, there’s nothing like seeing everything come together. All the hard work our engineering teams do behind the scenes really pays off when the platform is running smoothly and teams are able to ship faster and more reliably — which allows GitHub to be the home to all developers.
Grab, Southeast Asia’s leading superapp, has created many internal applications to support its diverse range of internal and external business needs. Authentication1 and authorisation2 serve as fundamental components of application development, as robust identity and access management are essential for all systems.
We recognised the need for a centralised internal system to manage access, authentication, and authorisation. This system would streamline access management, ensure compliance with audit requirements, enhance developer velocity, and simplify authentication and authorisation processes for both developers and business operations.
Grab created Concedo to fulfill this requirement by providing a mechanism for services to configure their access control based on their specific role to permission matrix (R2PM)3. This allows for quick and easy integration with Concedo, enabling developers to expedite the shipping of their systems without investing excessive time in building the authentication and authorisation module.
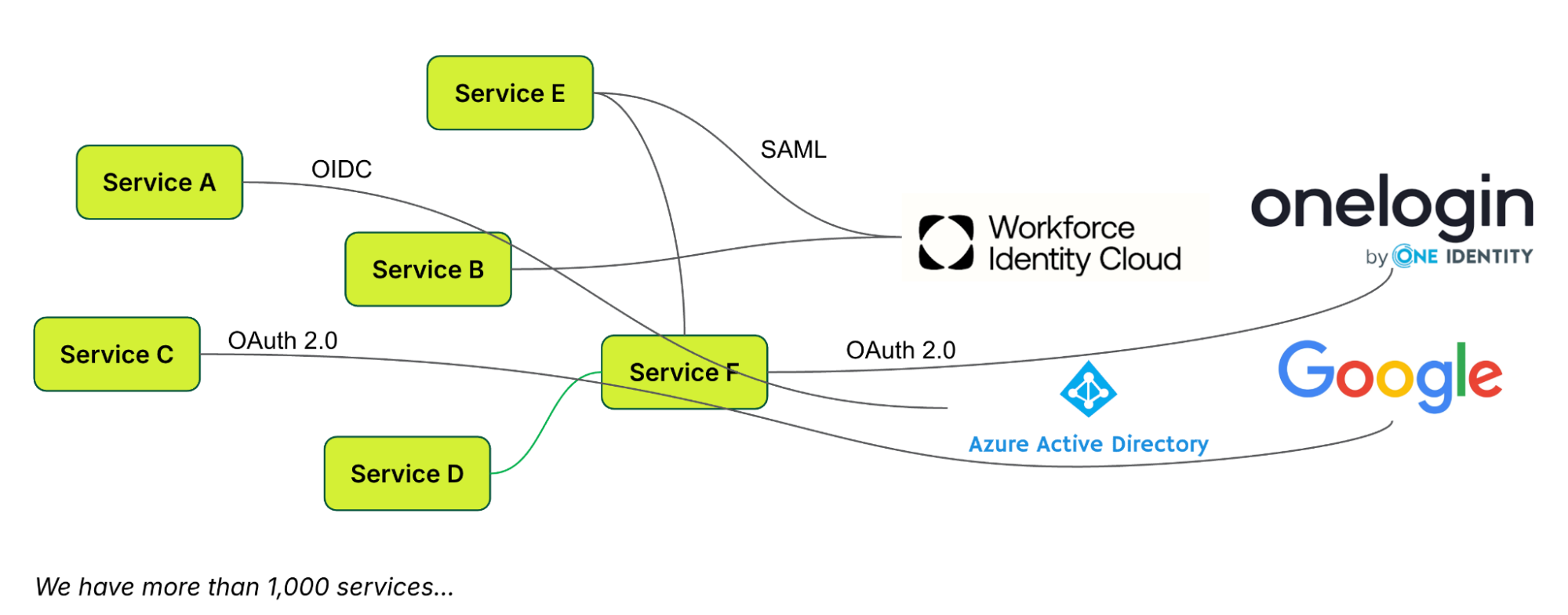
The authentication mechanism, based on Google’s OAuth2.04, includes custom features that enhance identity for service integration. However, this customisation isn’t standard, creating integration challenges with external platforms like Databricks and Datadog. These platforms then use their own authentication and authorisation, resulting in a fragmented and undesirable sign-on experience for users.
Figure 1. Undesired user sign-on experience due to fragmented authentication approaches.
The inconsistency in user experience also resulted in complications. The lack of standardisation led to difficulties in establishing authentication and authorisation for individual applications. Additionally, it created substantial administrative overhead due to the necessity of managing multiple identities. The absence of standardisation also hindered transparency in access control across all applications.
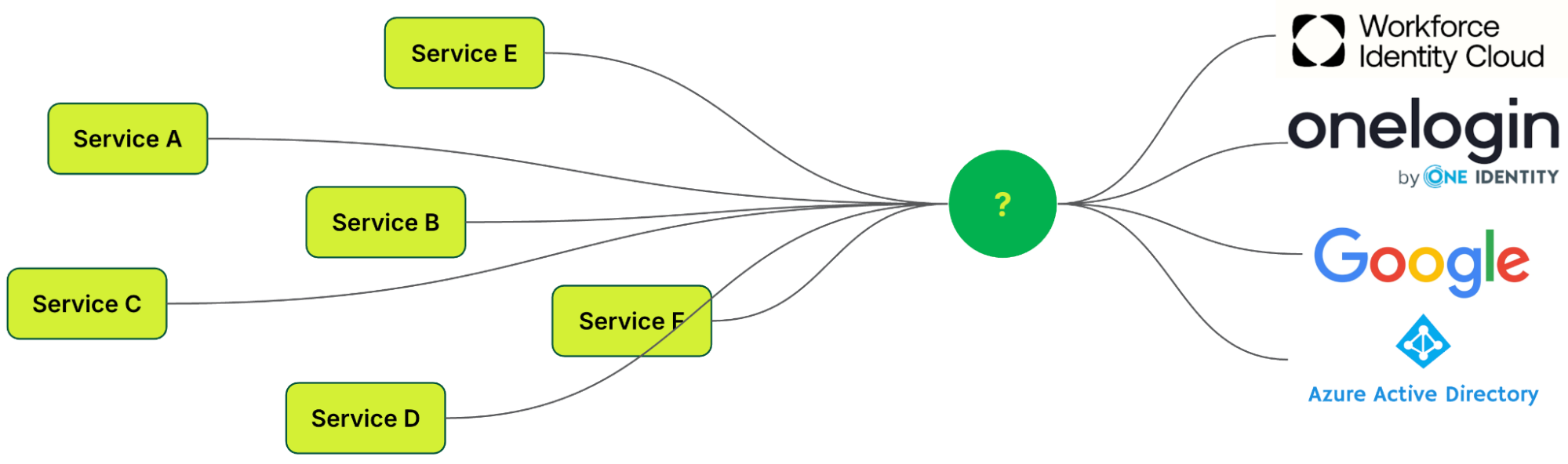
This led us to inquire how a standardised protocol could be established to function seamlessly across all applications, regardless of whether they were developed internally or sourced from external platforms.
Figure 2. Desired state, having something in between the different identity providers (IdP).
Choosing among industry standards
We wanted to build a platform to serve both authentication and authorisation, providing a seamless integration and user sign-on experience. We then asked ourselves, “What are the current industry standards we can leverage on?”.
Security Assertion Markup Language (SAML): An authentication protocol which leverages heavily on session cookies to manage each authentication session.
Open Authorisation (OAuth): An authorisation protocol which focuses on granting access for particular details rather than providing user identity information.
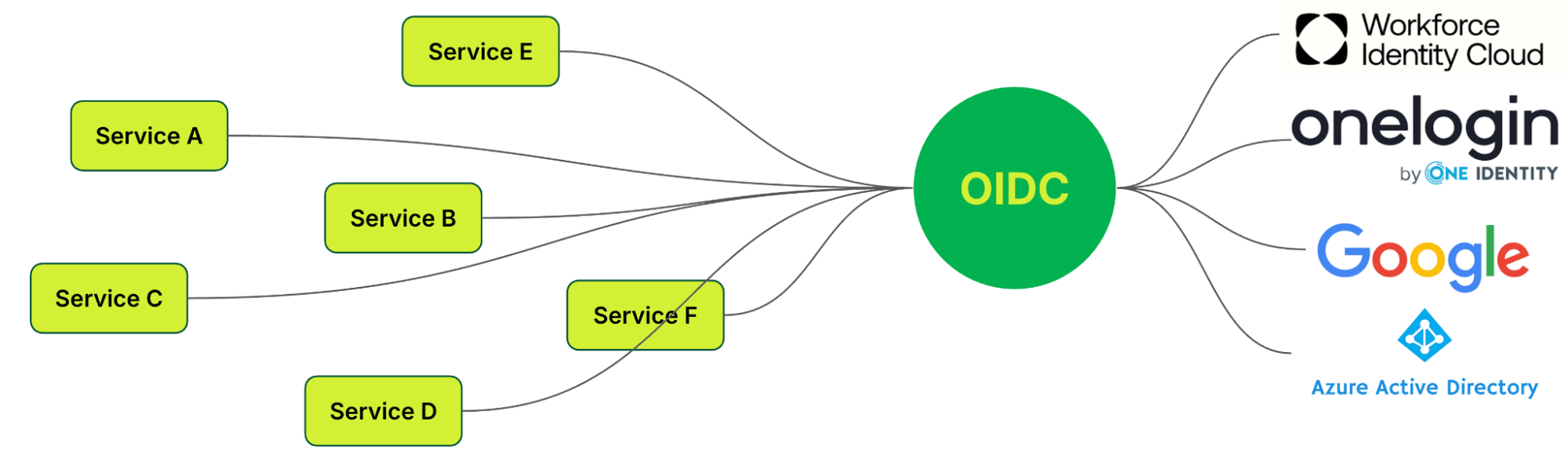
OpenID Connect (OIDC)5: An authentication protocol built on OAuth 2.0, enabling single sign-on (SSO). OIDC unifies and standardises user authentication, making it a solution for organisations with numerous applications.
OIDC enhances user experience by redirecting them to an identity provider (IdP) like Google or Microsoft for authentication when accessing an application. Upon successful verification, the IdP sends a secure token with the user’s identity information back to the application, granting access without the need for additional credentials.
With OIDC, authentication and authorisation are fully implemented, enabling seamless integration across platforms, including mobile, API, and browser-based applications, while also providing SSO functionality.
Figure 3. Desired state with the protocol decided.
OIDC seemed like an ideal solution, but it came with potential drawbacks:
OIDC relies on trusting a third-party authentication service. Any disruption to this service could result in downtime.
Compromised credentials could affect access to multiple services.
In the following section, we will explore our strategies in mitigating these challenges effectively.
Implementing the chosen standard
With OIDC chosen as the standard, the focus shifted to implementation.
We have always been a supporter of open source projects. Rather than building a platform from the ground up, we leveraged existing solutions while seeking opportunities to contribute back to the open source community.
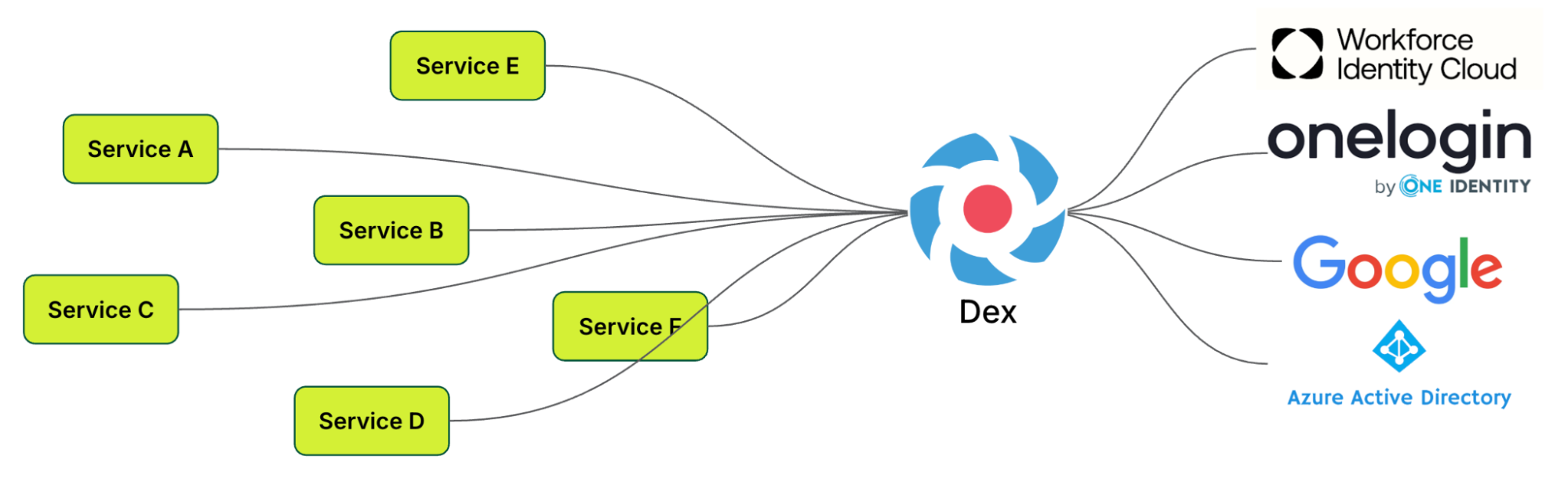
The team explored Cloud Native Computing Foundation (CNCF) projects and discovered Dex – A federated OpenID connect provider that aims to allow integration of any IdP into an application using OIDC. Dex was selected as our open-source platform of choice due to its alignment with our high-level objectives.
Figure 4. Desired state with Dex as the platform foundation.
How Dex works
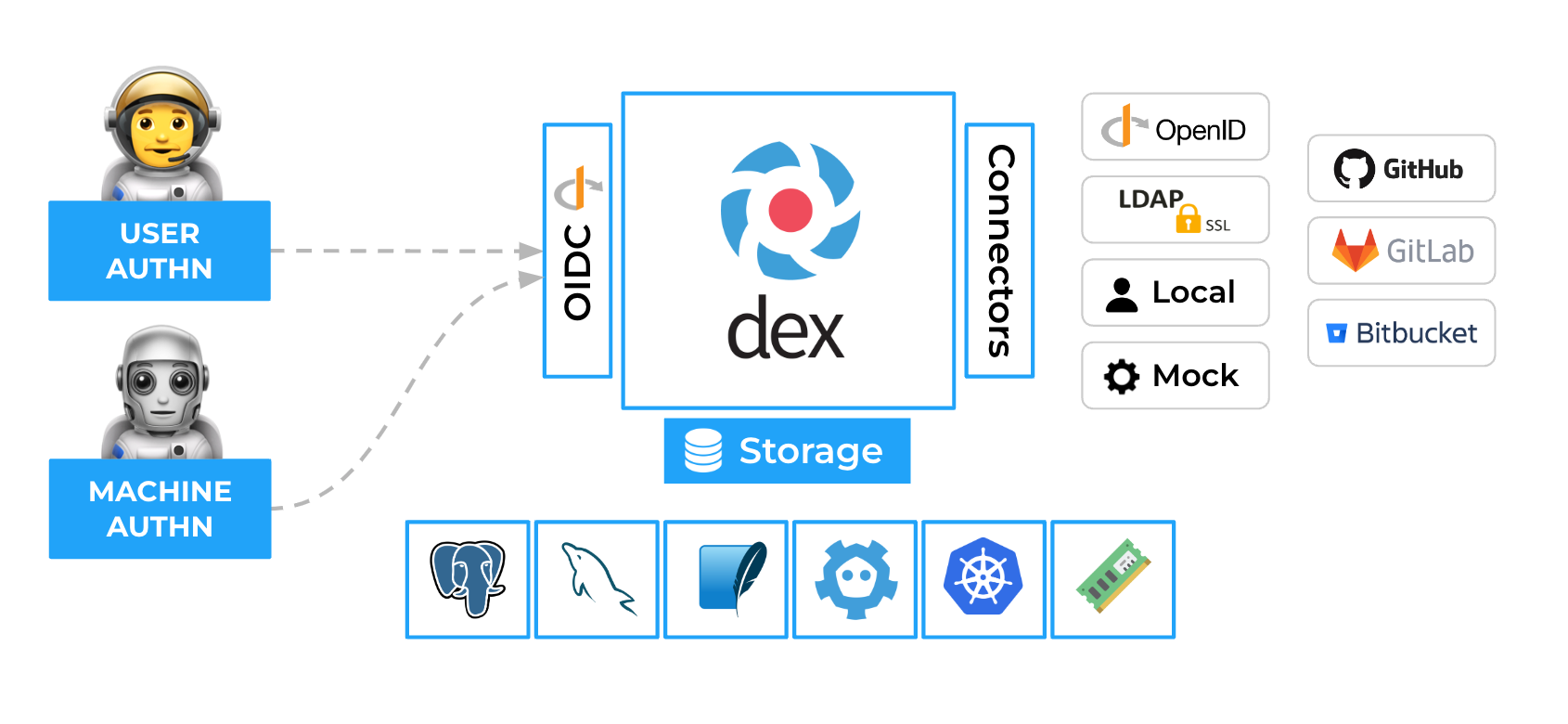
Figure 5. High level architecture of Dex. [Source](https://dexidp.io/docs/)
When a user or machine tries to access a protected application or service, they are redirected to Dex for authentication. Dex acts as a middleman (identity aggregator) between the user and various IdPs to establish an authenticated session.
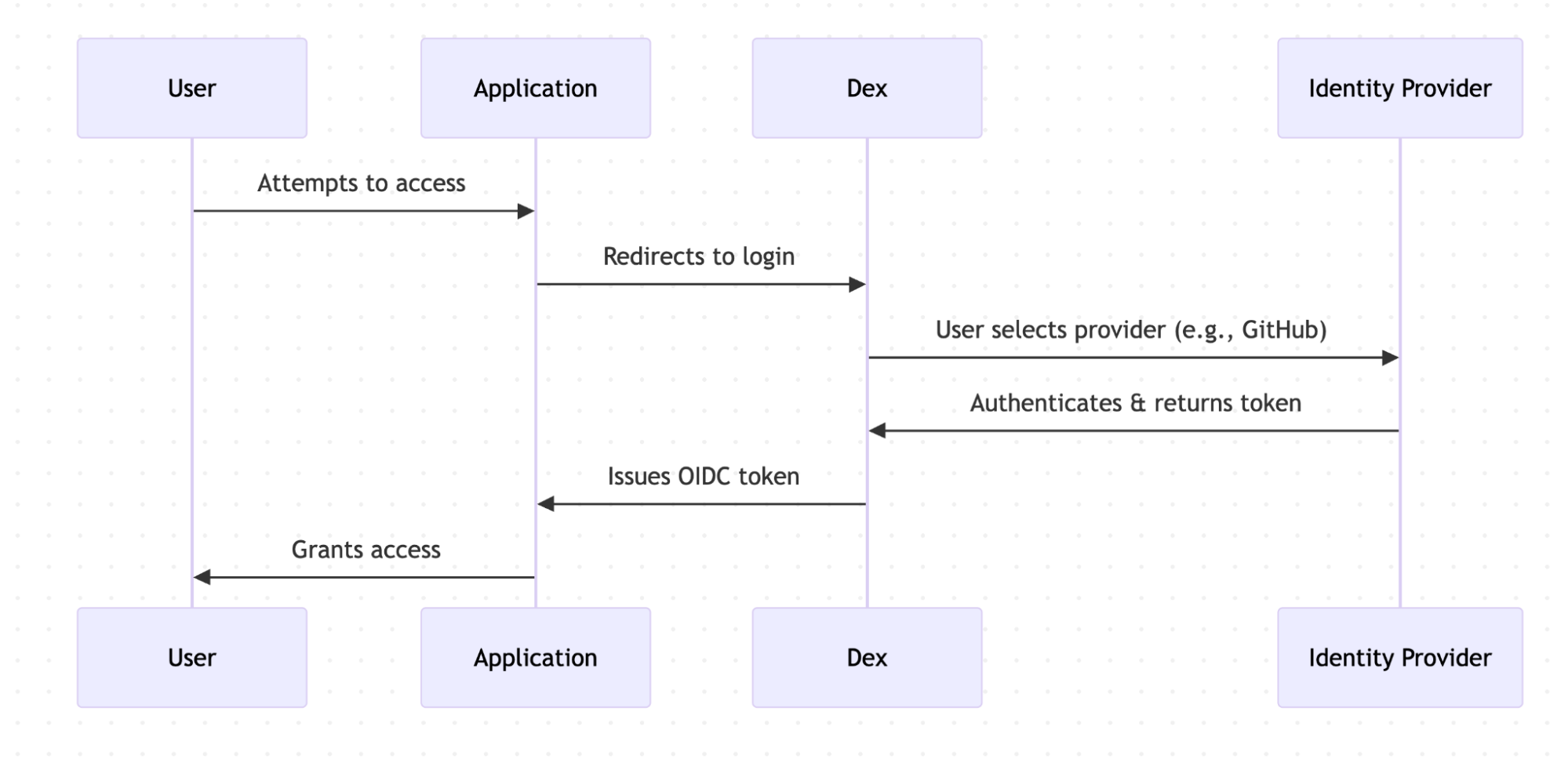
Figure 6. Simplified sequence diagram of how authentication works for Dex.
Dex’s key features include enabling SSO experiences, allowing users to access multiple applications after authenticating through a single provider. Dex also supports multiple IdP use cases and provides standardised OIDC authentication tokens.
Dex implementation separated application authentication concerns, established a single source of truth for identity, enabled new IdP additions, ensured adherence to security best practices, and provided scalability for deployments of all sizes.
How Dex is streamlining authentication and authorisation
Token delegation
When services communicate with each other, one service often assigns an identity to ensure that authorisation can be carried out on a specific service. For example, in figure 7, a service account or robot account is typically used as an identity so that service B can identify the caller.
Figure 7. Service identification through service account.
Although service accounts are the recommended approach for enabling Service B to identify the caller, they come with challenges that must be addressed:
Service account compromise: Service accounts often have high-level privileges and typically broad access to Service B. If compromised, they pose a significant security risk, making careful management essential.
Access control issue: The other approach creates unnecessary complexity by requiring Service A to handle user-level permissions for Service B. This violates the principle of separation of concerns.
To address this issue, Dex introduced a token exchange feature.
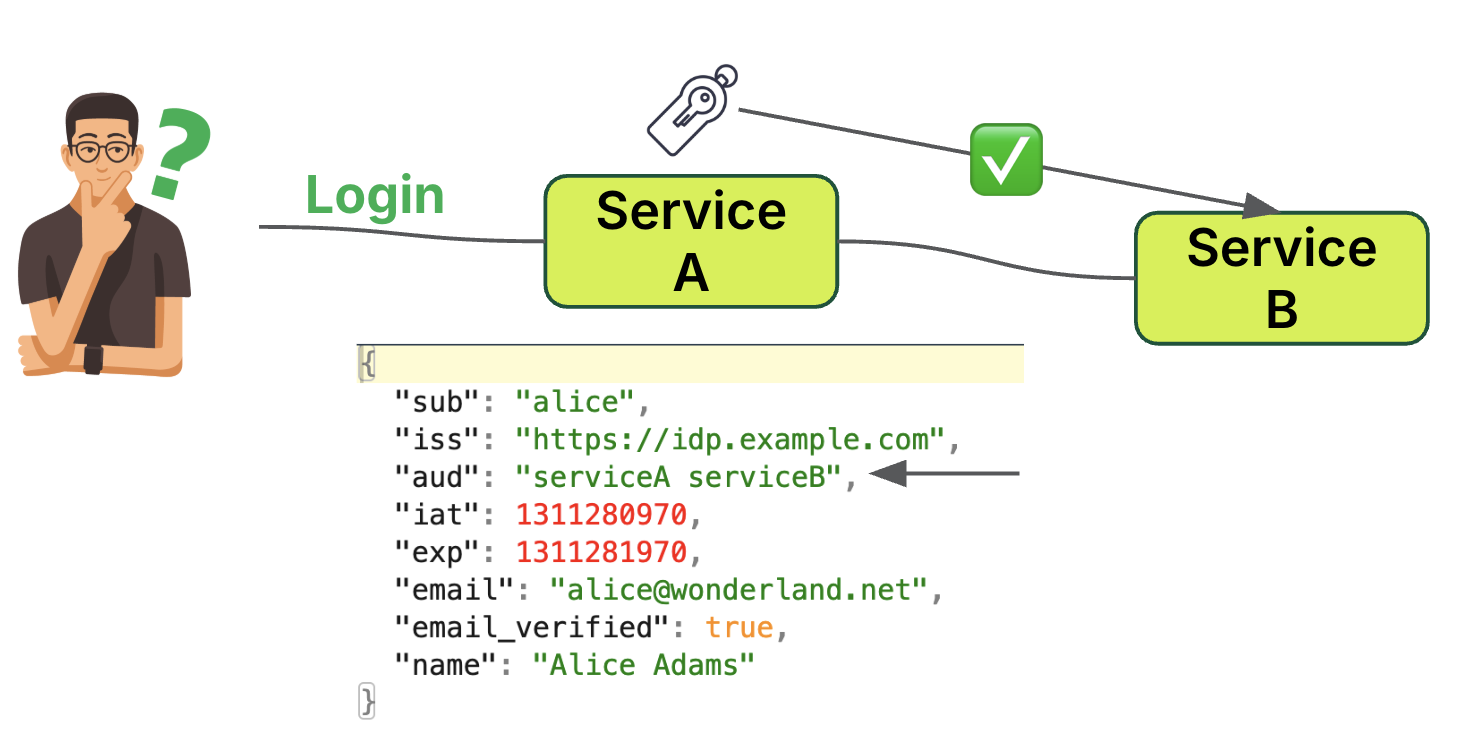
Figure 8. Token exchange example with trusted peers established.
The token exchange process involves two main components; token minting and trust relationship.
Token minting
The user (Alice) logs into Service A.
Service A, acting as a trusted peer, is authorised to mint tokens.
Service A generates a token valid for both Service A and Service B. This is reflected in the token’s “aud” (audience) field: “aud”: “serviceA serviceB”
Trust relationship
Service B must be configured to trust Service A as a peer.
Service B accepts tokens minted by Service A.
This approach differs from the service account-based scenario by using a trust-based peer relationship. Service A is authorised to mint tokens for Service B providing a more sophisticated but preferred method. The token is properly scoped for both services, ensuring a clear audit trail of token issuance, while reducing token manipulation risks.
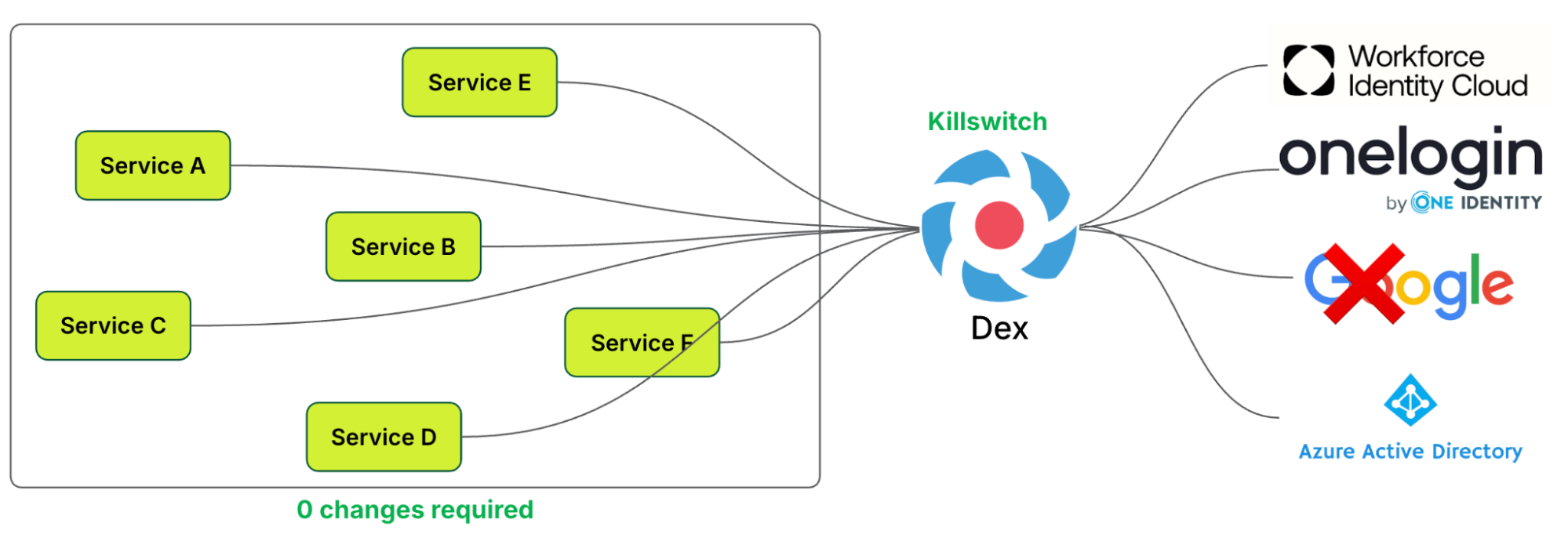
Kill switch
As highlighted earlier,
OIDC relies on trusting a third-party authentication service. Any disruption to this service could result in downtime.
Dex’s ability to support multiple IdPs enables traffic to be shifted to a different IdP if one, such as Google, experiences an outage. This “kill switch” mechanism ensures that integrated services are not disrupted and do not require any changes to mitigate the issue. It is only triggered during specific IdP outages.
Figure 9. Trigger kill switch without having other services changing from their end.
Looking forward
Following the successful implementation of Dex as the unified authentication provider, the next phase in enhancing our identity and access management infrastructure is to leverage this robust identity foundation to establish a unified and simplified authorisation model. This initiative is driven by the recognition that the current authorisation landscape remains fragmented and complex, leading to potential inefficiencies and security vulnerabilities.
By centralising authorisation and aligning it with the unified identity provided by Dex, we can streamline access control, improve user experience, and strengthen security across our applications and services. This will involve consolidating authorisation policies, standardising access control mechanisms, and simplifying the management of user permissions.
Shoutout to the awesome Concedo team for driving Dex integration and to our leadership for steering the way toward a simpler, unified authentication and authorisation journey!
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Definition of terms
Authentication: Who you are. Making sure you are who you say you are by verifying your identity. ↩
Authorisation: What you can do. Defining the resources or actions you are allowed to access or perform after your identity has been verified. ↩
Role-to-Permission Matrix (R2PM): A structured framework used to map roles within an organisation to the permissions or access rights each role has in a system, application, or process. This matrix serves as a critical component in access control and identity management, ensuring that users have appropriate access based on their roles while minimising the risk of unauthorised access. ↩
Open Authorisation (OAuth 2.0): Protocol for authorisation. For example, Google Login on third-party portals allows your identity to remain with Google, but third-party portals can obtain limited access to specific data such as your profile photo. ↩
OpenID Connect (OIDC): Identity protocol built on top of OAuth 2.0. On top of authorisation provided by OAuth 2.0, it verifies and provides a trusted identity. ↩
In March 2023, I embarked on a mission to explore the potential of Large Language Models (LLMs) within Grab. What started off as an attempt to solve a specific problem—reducing the burden on our ML Platform team’s support channels, ended up becoming something much bigger. The creation of GrabGPT, an internal ChatGPT-like tool that has transformed how folks in Grab interact with AI. This is the story of how a failed experiment led to one of Grab’s most impactful internal tools.
The problem: Overwhelmed support channels
As part of Grab’s machine learning platform team, we were drowning in user inquiries. Slack channels were flooded with questions and our on-call engineers were spending more time answering repetitive queries than building innovative solutions. This led me to ponder on this question, “could we use LLMs to build a chatbot that understands our platform’s documentation and answers these questions automatically?”
The first attempt: A chatbot for platform support
I started by exploring open-source frameworks to build a chatbot. I stumbled upon chatbot-ui, a simple yet powerful tool that could be wired up with LLMs. My idea was to feed the chatbot our platform’s Q\&A documentation (over 20,000 words) and let it handle user queries.
But there was a catch: GPT-3.5-turbo could only handle 8,000 tokens (~2,000 words). I spent days summarising the documentation, reducing it to less than 800 words. While the chatbot worked for a handful of frequently asked questions, it was clear that this approach wasn’t scalable. I tried with embedding search and it didn’t work that well too, so I decided to give up on this idea.
The pivot: Why not build Grab’s own ChatGPT?
As I stepped back, a new thought struck me: Grab doesn’t have its own ChatGPT-like tool yet. I had the frameworks, the LLM knowledge, and most importantly—access to Grab’s model-serving platform, catwalk. Why not build an internal tool that any Grabber could use?
Over a weekend, I extended the existing frameworks, added Google login for authentication, and deployed the tool internally. I called it Grab’s ChatGPT. Little did I know, this would become one of the most widely used tools in the company.
The tool quickly became a staple for Grabbers, especially in regions where ChatGPT was inaccessible (e.g., China). The name evolved too—our PM suggested GrabGPT, and it stuck.
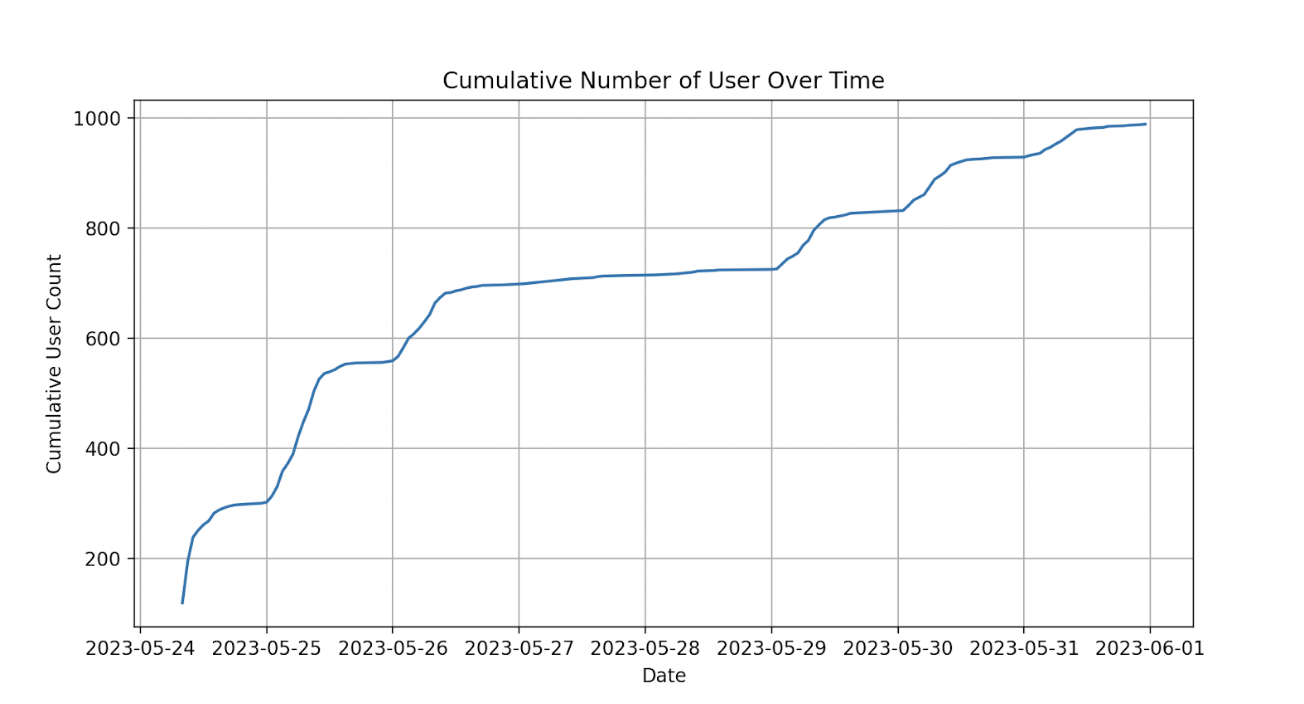
The Success: GrabGPT takes off
The response was overwhelming:
Day 1: 300 users registered.
Day 2: 600 new users.
Week 1: 900 new users
Month 3: Over 3000 users, with 600 daily active users
Today: Almost all Grabbers are using GrabGPT.
Figure 1: Number of GrabGPT users in one month
Why GrabGPT works: More than just technology
The success of GrabGPT isn’t just about the tech,it’s about timing, security, and accessibility. Here’s why it resonated so deeply within Grab:
Data security: GrabGPT operates on a private route, ensuring that sensitive company data never leaves our infrastructure.
Global accessibility: Unlike ChatGPT, which is banned in some regions, GrabGPT is accessible to all Grabbers, regardless of location.
Model agnosticism: GrabGPT isn’t tied to a single LLM provider. It supports models from OpenAI, Claude, Gemini, and more.
Auditability: Every interaction on GrabGPT is auditable, making it a favorite of our data security and governance teams.
The broader impact: A catalyst for LLM strategy
GrabGPT didn’t just solve an immediate problem, it sparked a broader conversation about how LLMs can be leveraged across Grab. It showed that a single engineer, provided with the right tools and timing, can create something transformative. Today, GrabGPT is more than a tool; it’s a testament to the power of experimentation and adaptability.
Lessons learned
Failure is a stepping stone: My initial failure with the support chatbot which then led me to a much bigger opportunity.
Timing matters: GrabGPT succeeded because it addressed a critical need at the right time.
Think big, start small: What began as a weekend project became a company-wide tool.
Collaboration is key: The enthusiasm and contributions from other Grabbers were instrumental in scaling GrabGPT.
Conclusion
GrabGPT is a story of resilience, innovation, and the unexpected rewards from thinking outside the box. It’s a reminder that sometimes, the best solution comes from pivoting away from what doesn’t work and embracing new possibilities. As LLMs continue to evolve, I’m excited to see how GrabGPT will grow and inspire even more innovation within Grab.
I would like to end this article by letting readers know that if you’re working on a project and feel stuck, don’t be afraid to pivot. You never know, your next failure might just be the beginning of your greatest success. And if you’re at Grab, give GrabGPT a try. It might just change the way you work!
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Originally, Issues search was limited by a simple, flat structure of queries. But with advanced search syntax, you can now construct searches using logical AND/OR operators and nested parentheses, pinpointing the exact set of issues you care about.
Building this feature presented significant challenges: ensuring backward compatibility with existing searches, maintaining performance under high query volume, and crafting a user-friendly experience for nested searches. We’re excited to take you behind the scenes to share how we took this long-requested feature from idea to production.
Here’s what you can do with the new syntax and how it works behind the scenes
Issues search now supports building queries with logical AND/OR operators across all fields, with the ability to nest query terms. For example is:issue state:open author:rileybroughten (type:Bug OR type:Epic) finds all issues that are open AND were authored by rileybroughten AND are either of type bug or epic.
How did we get here?
Previously, as mentioned, Issues search only supported a flat list of query fields and terms, which were implicitly joined by a logical AND. For example, the query assignee:@me label:support new-project translated to “give me all issues that are assigned to me AND have the label support ANDcontain the text new-project.”
But the developer community has been asking for more flexibility in issue search, repeatedly, for nearly a decade now. They wanted to be able to find all issues that had either the label support or the label question, using the query label:support OR label:question. So, we shipped an enhancement towards this request in 2021, when we enabled an OR style search using a comma-separated list of values.
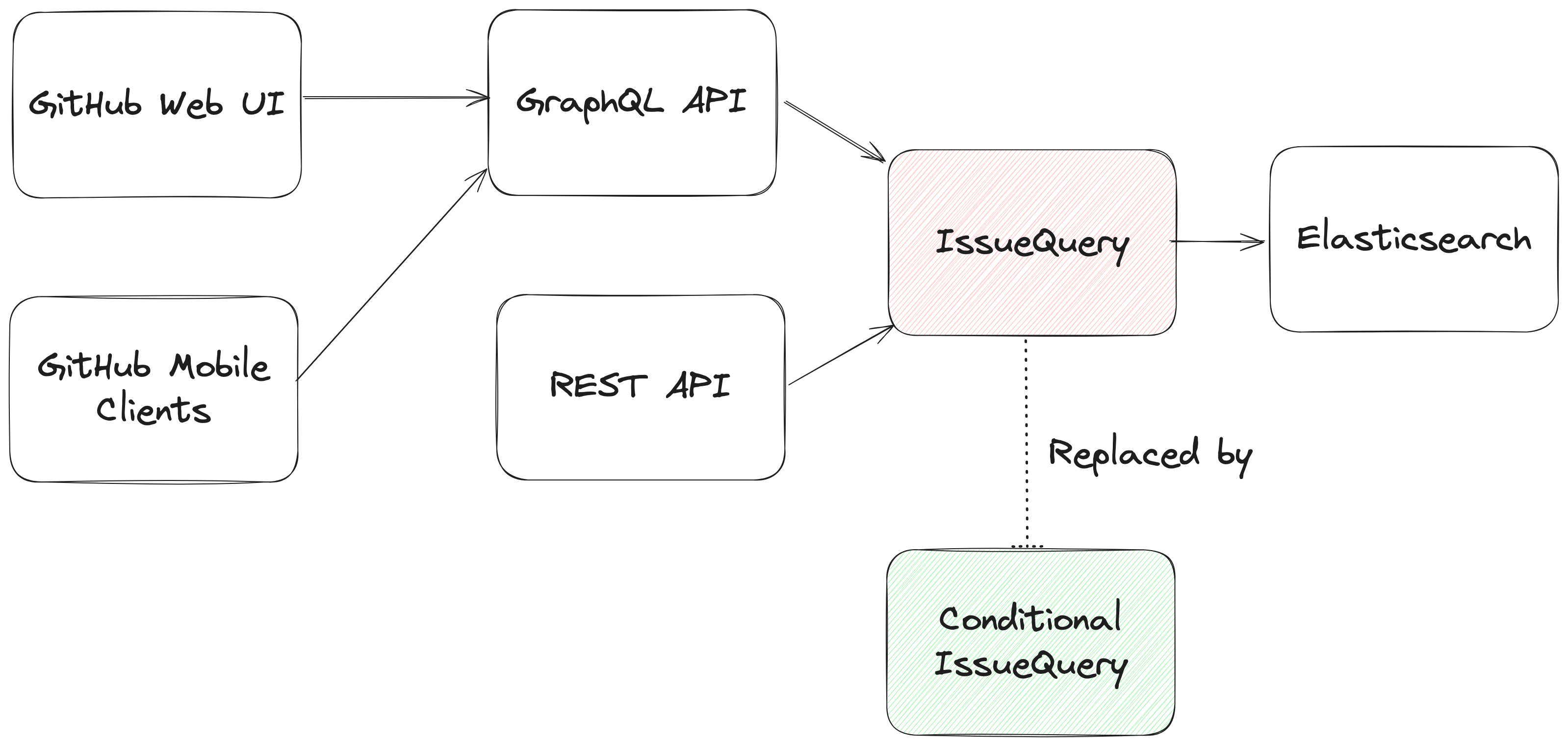
From an architectural perspective, we swapped out the existing search module for Issues (IssuesQuery), with a new search module (ConditionalIssuesQuery), that was capable of handling nested queries while continuing to support existing query formats.
This involved rewriting IssueQuery, the search module that parsed query strings and mapped them into Elasticsearch queries.
To build a new search module, we first needed to understand the existing search module, and how a single search query flowed through the system. At a high level, when a user performs a search, there are three stages in its execution:
Parse: Breaking the user input string into a structure that is easier to process (like a list or a tree)
Query: Transforming the parsed structure into an Elasticsearch query document, and making a query against Elasticsearch.
Normalize: Mapping the results obtained from Elasticsearch (JSON) into Ruby objects for easy access and pruning the results to remove records that had since been removed from the database.
Each stage presented its own challenges, which we’ll explore in more detail below. The Normalize step remained unchanged during the re-write, so we won’t dive into that one.
Parse stage
The user input string (the search phrase) is first parsed into an intermediate structure. The search phrase could include:
Query terms: The relevant words the user is trying to find more information about (ex: “models”)
Search filters: These restrict the set of returned search documents based on some criteria (ex: “assignee:Deborah-Digges”)
Example search phrase:
Find all issues assigned to me that contain the word “codespaces”:
is:issue assignee:@me codespaces
Find all issues with the label documentation that are assigned to me:
assignee:@me label:documentation
The old parsing method: flat list
When only flat, simple queries were supported, it was sufficient to parse the user’s search string into a list of search terms and filters, which would then be passed along to the next stage of the search process.
The new parsing method: abstract syntax tree
As nested queries may be recursive, parsing the search string into a list was no longer sufficient. We changed this component to parse the user’s search string into an Abstract Syntax Tree (AST) using the parsing library parslet.
We defined a grammar (a PEG or Parsing Expression Grammar) to represent the structure of a search string. The grammar supports both the existing query syntax and the new nested query syntax, to allow for backward compatibility.
A simplified grammar for a boolean expression described by a PEG grammar for the parslet parser is shown below:
class Parser < Parslet::Parser
rule(:space) { match[" "].repeat(1) }
rule(:space?) { space.maybe }
rule(:lparen) { str("(") >> space? }
rule(:rparen) { str(")") >> space? }
rule(:and_operator) { str("and") >> space? }
rule(:or_operator) { str("or") >> space? }
rule(:var) { str("var") >> match["0-9"].repeat(1).as(:var) >> space? }
# The primary rule deals with parentheses.
rule(:primary) { lparen >> or_operation >> rparen | var }
# Note that following rules are both right-recursive.
rule(:and_operation) {
(primary.as(:left) >> and_operator >>
and_operation.as(:right)).as(:and) |
primary }
rule(:or_operation) {
(and_operation.as(:left) >> or_operator >>
or_operation.as(:right)).as(:or) |
and_operation }
# We start at the lowest precedence rule.
root(:or_operation)
end
For example, this user search string: is:issue AND (author:deborah-digges OR author:monalisa ) would be parsed into the following AST:
Once the query is parsed into an intermediate structure, the next steps are to:
Transform this intermediate structure into a query document that Elasticsearch understands
Execute the query against Elasticsearch to obtain results
Executing the query in step 2 remained the same between the old and new systems, so let’s only go over the differences in building the query document below.
The old query generation: linear mapping of filter terms using filter classes
Each filter term (Ex: label:documentation) has a class that knows how to convert it into a snippet of an Elasticsearch query document. During query document generation, the correct class for each filter term is invoked to construct the overall query document.
The new query generation: recursive AST traversal to generate Elasticsearch bool query
We recursively traversed the AST generated during parsing to build an equivalent Elasticsearch query document. The nested structure and boolean operators map nicely to Elasticsearch’s boolean query with the AND, OR, and NOT operators mapping to the must, should, and should_not clauses.
We re-used the building blocks for the smaller pieces of query generation to recursively construct a nested query document during the tree traversal.
Continuing from the example in the parsing stage, the AST would be transformed into a query document that looked like this:
With this new query document, we execute a search against Elasticsearch. This search now supports logical AND/OR operators and parentheses to search for issues in a more fine-grained manner.
Considerations
Issues is one of the oldest and most heavily -used features on GitHub. Changing core functionality like Issues search, a feature with an average of nearly 2000 queries per second (QPS)—that’s almost 160M queries a day!—presented a number of challenges to overcome.
Ensuring backward compatibility
Issue searches are often bookmarked, shared among users, and linked in documents, making them important artifacts for developers and teams. Therefore, we wanted to introduce this new capability for nested search queries without breaking existing queries for users.
We validated the new search system before it even reached users by:
Testing extensively: We ran our new search module against all unit and integration tests for the existing search module. To ensure that the GraphQL and REST API contracts remained unchanged, we ran the tests for the search endpoint both with the feature flag for the new search system enabled and disabled.
Validating correctness in production with dark-shipping: For 1% of issue searches, we ran the user’s search against both the existing and new search systems in a background job, and logged differences in responses. By analyzing these differences we were able to fix bugs and missed edge cases before they reached our users.
We weren’t sure at the outset how to define “differences,” but we settled on “number of results” for the first iteration. In general, it seemed that we could determine whether a user would be surprised by the results of their search against the new search capability if a search returned a different number of results when they were run within a second or less of each other.
Preventing performance degradation
We expected more complex nested queries to use more resources on the backend than simpler queries, so we needed to establish a realistic baseline for nested queries, while ensuring no regression in the performance of existing, simpler ones.
For 1% of Issue searches, we ran equivalent queries against both the existing and the new search systems. We used scientist, GitHub’s open source Ruby library, for carefully refactoring critical paths, to compare the performance of equivalent queries to ensure that there was no regression.
Preserving user experience
We didn’t want users to have a worse experience than before just because more complex searches were possible.
We collaborated closely with product and design teams to ensure usability didn’t decrease as we added this feature by:
Limiting the number of nested levels in a query to five. From customer interviews, we found this to be a sweet spot for both utility and usability.
Providing helpful UI/UX cues: We highlight the AND/OR keywords in search queries, and provide users with the same auto-complete feature for filter terms in the UI that they were accustomed to for simple flat queries.
Minimizing risk to existing users
For a feature that is used by millions of users a day, we needed to be intentional about rolling it out in a way that minimized risk to users.
We built confidence in our system by:
Limiting blast radius: To gradually build confidence, we only integrated the new system in the GraphQL API and the Issues tab for a repository in the UI to start. This gave us time to collect, respond to, and incorporate feedback without risking a degraded experience for all consumers. Once we were happy with its performance, we rolled it out to the Issues dashboard and the REST API.
Testing internally and with trusted partners: As with every feature we build at GitHub, we tested this feature internally for the entire period of its development by shipping it to our own team during the early days, and then gradually rolling it out to all GitHub employees. We then shipped it to trusted partners to gather initial user feedback.
And there you have it, that’s how we built, validated, and shipped the new and improved Issues search!
Feedback
Want to try out this exciting new functionality? Head to our docs to learn about how to use boolean operators and parentheses to search for the issues you care about!
If you have any feedback for this feature, please drop us a note on our community discussions.
Acknowledgements
Special thanks to AJ Schuster, Riley Broughten, Stephanie Goldstein, Eric Jorgensen Mike Melanson and Laura Lindeman for the feedback on several iterations of this blog post!
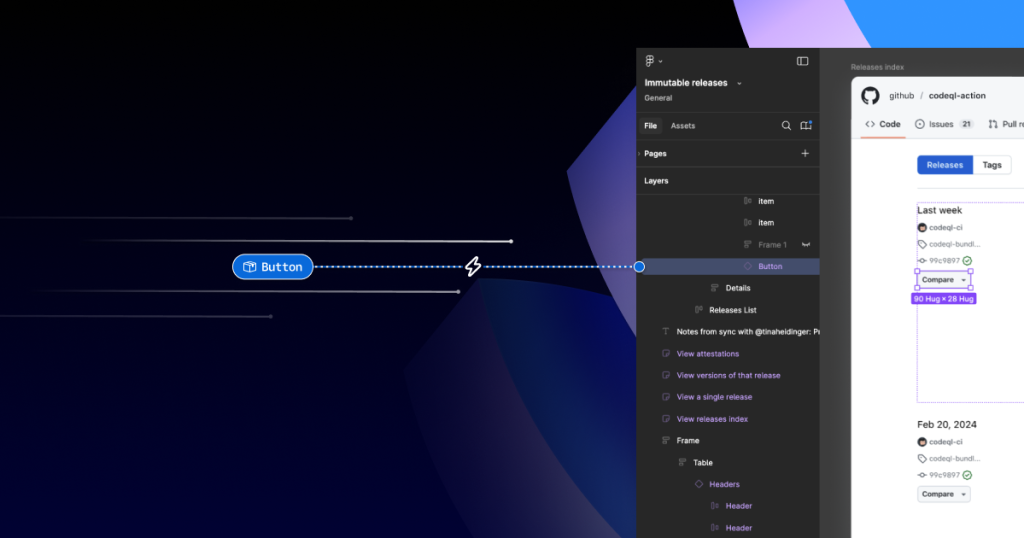
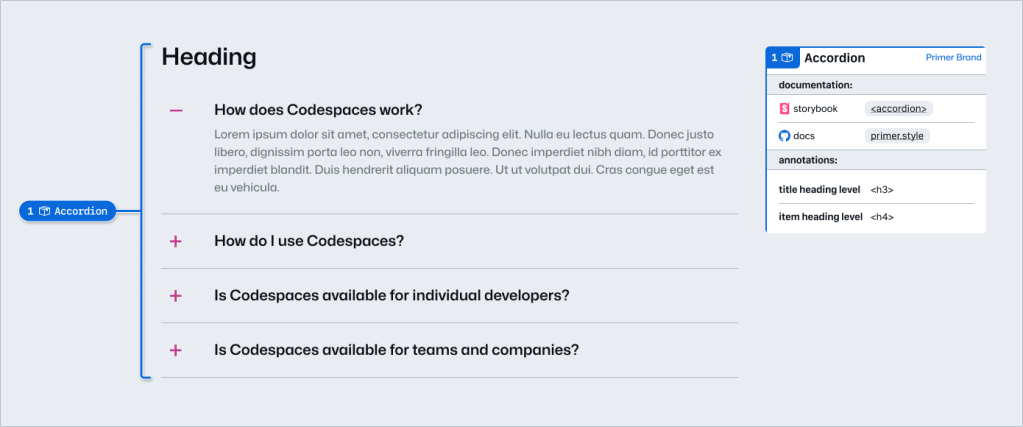
In part one of our design system annotation series, we discussed the ways in which accessibility can get left out of design system components from one instance to another. Our solution? Using a set of “Preset annotations” for each component with Primer. This allows designers to include specific pre-set details that aren’t already built into the component and visually communicated in the design itself.
That being said, Preset annotations are unique to each design system — and while ours may be a helpful reference for how to build them — they’re not something other organizations can utilize if you’re not also using the Primer design system.
Luckily, you can build your own. Here’s how.
How to make Preset annotations for your design system
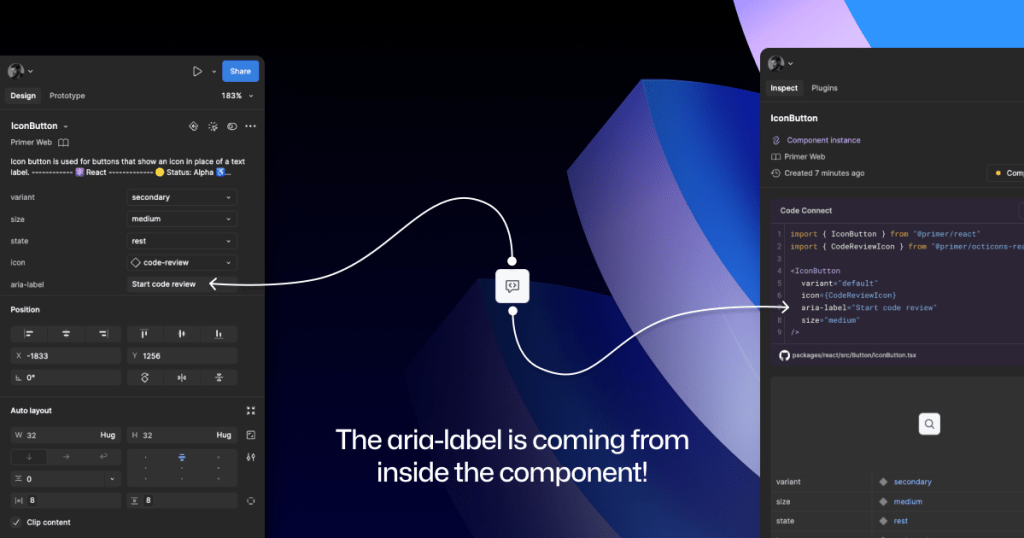
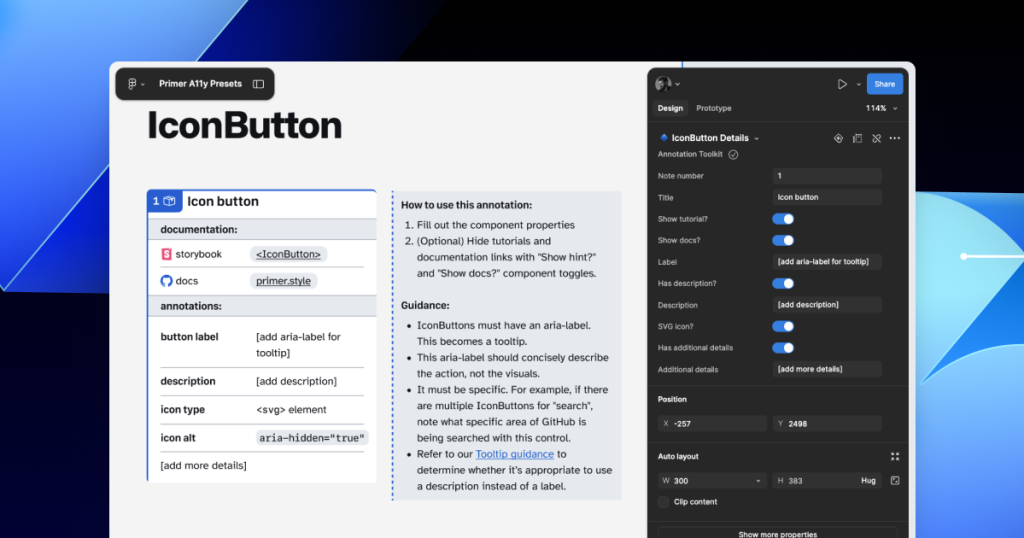
Start by assessing components to understand which ones would need Preset annotations—not all of them will. Prioritize components that would benefit most from having a Preset annotation, and build that key information into each one. Next, determine what properties should be included. Only include key information that isn’t conveyed visually, isn’t in the component properties, and isn’t already baked into a coded component.
Prioritizing components
When a design system has 60+ components, knowing where to start can be a challenge. Which components need these annotations the most? Which ones would have the highest impact for both design teams and our users?
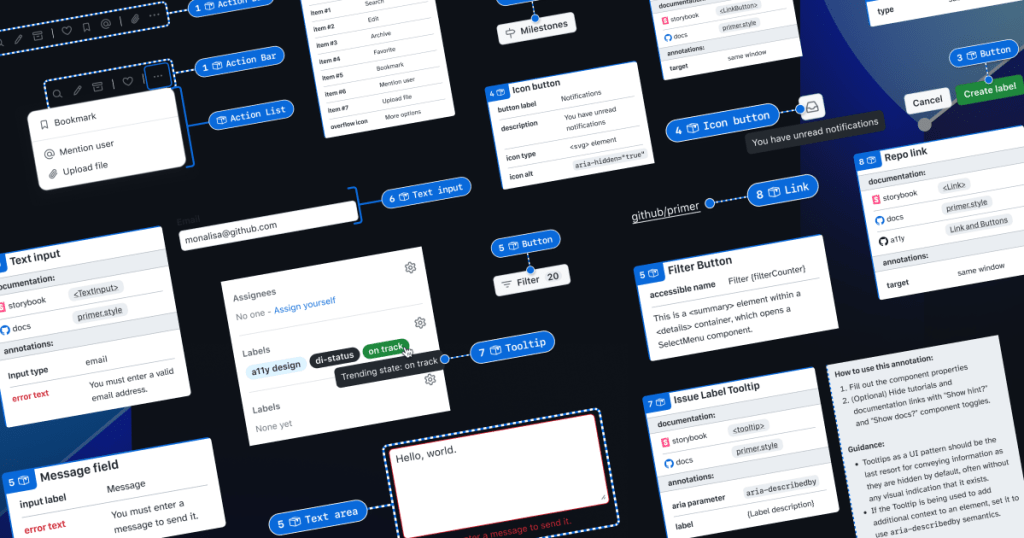
When we set out to create a new set of Preset annotations based on our proof of concept, we decided to use ten Primer components that would benefit the most. To help pick them, we used an internal tool called Primer Query that tracks all component implementations across the GitHub codebase as well as any audit issues connected to them. Here is a video breakdown of how it works, if you’re curious.
We then prioritized new Preset annotations based on the following criteria:
Components that align to organization priorities (i.e. high value products and/or those that receive a lot of traffic).
Components that appear frequently in accessibility audit issues.
Components with React implementations (as our preferred development framework).
Most frequently implemented components.
Mapping out the properties
For each component, we cross-referenced multiple sources to figure out what component properties and attributes would need to be added in each Preset annotation. The things we were looking for may only exist in one or two of those places, and thus are less likely to be accounted for all the way through the design and development lifecycle. The sources include:
Component documentation on Primer.style
Design system docs should contain usage guidance for designers and developers, and accessibility requirements should be a part of this guidance as well. Some of the guidance and requirements get built into the component’s Figma asset, while some only end up in the coded component.
Look for any accessibility requirements that are not built into either Figma or code. If it’s built in, putting the same info in the Preset annotation may be redundant or irrelevant.
Coded demos in Storybook
Our component sandbox helped us see how each component is built in React or Rails, as well as what the HTML output is. We looked for any code structure or accessibility attributes that are not included in the component documentation or the Figma asset itself—especially when they may vary from one implementation to another.
Component properties in the Figma asset library
Library assets provide a lot of flexibility through text layers, image fills, variants, and elaborate sets of component properties. We paid close attention to these options to understand what designers can and can’t change. Worthwhile additions to a Preset Annotation are accessibility attributes, requirements, and usage guidance in other sources that aren’t built into the Figma component.
Other potential sources
Experiences from team members: The designers, developers, and accessibility specialists you work with may have insight into things that the docs and design tools may have missed. If your team and design system have been around for a while, their insights may be more valuable than those you’ll find in the docs, component demos, or asset libraries. Take some time to ask which components have had challenging bugs and which get intentionally broken when implemented.
Findings from recent audits: Design system components themselves may have unresolved audit issues and remediation recommendations. If that’s the case, those issues are likely present in Storybook demos and may be unaccounted for in the component documentation. Design system audit issues may have details that both help create a Preset annotation and offer insights about what should not be carried over from existing resources.
What we learned from creating Preset annotations
Preset annotations may not be for every team or organization. However, they are especially well suited for younger design systems and those that aren’t well adopted.
Mature design systems like Primer have frequent updates. This means that without close monitoring, the design system components themselves may fall out of sync with how a Preset annotation is built. This can end up causing confusion and rework after development starts, so it may be wise to make sure there’s some capacity to maintain these annotations after they’ve been created.
For newer teams at GitHub, new members of existing teams, and team members who were less familiar with the design system, the built-in guidance and links to documentation and component demos proved very useful. Those who are more experienced are also able to fine-tune the Presets and how they’re used.
If you don’t already have extensive experience with the design system components (or peers to help build them), it can take a lot of time to assess and map out the properties needed to build a Preset. It can also be challenging to name a component property succinctly enough that it doesn’t get truncated in Figma’s properties panel. If the context is not self-evident, some training or additional documentation may help.
It’s not always clear that you need a Preset annotation
There may be enough overlap between the Preset annotation for a component and types of annotations that aren’t specific to the design system. For example, the GitHub Annotation Toolkit has components to annotate basic <textarea> form elements in addition to a Preset annotation for our <TextArea> Primer component:
In many instances, this flexibility may be confusing because you could use either annotation. For example, the Primer <TextArea> Preset has built-in links to specific Primer docs, and while the non-Preset version doesn’t, you could always add the links manually. While there’s some overlap between the two, using either one is better than none.
One way around this confusion is to add Primer-specific properties to the default set of annotations. This would allow you to do things like toggle a boolean property on a normal Button annotation and have it show links and properties specific to your design system’s button component.
Our Preset creation process may unlock automation
There are currently a number of existing Figma plugins that advertise the ability to scan a design file to help with annotations. That being said, the results are often mixed and contain an unmanageable amount of noise and false positives. One of the reasons these issues happen is that these public plugins are design system agnostic.
Current automated annotation tools aren’t able to understand that any design system components are being used without bespoke programming or thorough training of AI models. For plugins like this to be able to label design elements accurately, they first need to understand how to identify the components on the canvas, the variants used, and the set properties.
With that in mind, perhaps the most exciting insight is that the process of mapping out component properties for a Preset annotation—the things that don’t get conveyed in the visual design or in the code—is also something that would need to be done in any attempt to automate more usable annotations.
In other words, if a team uses a design system and wants to automate adding annotations, the tool they use would need to understand their components. In order for it to understand their components well enough to automate accurately, these hidden component properties would need to be mapped out. The task of creating a set of Preset annotations may be a vital stepping stone to something even more streamlined.
A promising new method: Figma’s Code Connect
While building our new set of Preset annotations, we experimented with other ways to enhance Primer with annotations. Though not all of those experiments worked out, one of them did: adding accessibility attributes through Code Connect.
Primer was one of the early adopters of Figma’s new Code Connect feature in Dev Mode. Says Lukas Oppermann, our staff systems designer, “With Code Connect, we can actually move the design and the code a little bit further apart again. We can concentrate on creating the best UX for the designers working in Figma with design libraries and, on the code side, we can have the best developer experience.”
To that end, Code Connect allows us to bypass much of our Preset annotations, as well as the downsides of some of our other experiments. It does this by adding key accessibility details directly into the code that developers can export from Figma.
GitHub’s Octicons are used in many of our Primer components. They are decorative by default, but they sometimes need alt text or aria-label attributes depending on how they’re used. In the IconButton component, that button uses an Octicon and needs an accessible name to describe its function.
When using a basic annotation kit, this may mean adding stamps for a Button and Decorative Image as well as a note in the margins that specifies what the aria-label should be. When using Preset annotations, there are fewer things to add to the canvas and the annotation process takes less time.
With Code Connect set up, Lukas added a hidden layer in the IconButton Figma component. It has a text property for aria-label which lets designers add the value directly from the component properties panel. No annotations needed. The hidden layer doesn’t disrupt any of the visuals, and the aria-label property gets exported directly with the rest of the component’s code.
It takes time to set up Code Connect with each of your design system components. Here are a few tips to help:
Consistency is key. Make sure that the properties you create and how you place hidden layers is consistent across components. This helps set clear expectations so your teams can understand how these hidden layers and properties function.
Use a branch of your design system library to experiment. Hiding attributes like aria-label is quite simple compared to other complex information that Preset annotations are capable of handling.
Use visual regression testing (VRT). Adding complexity directly to a component comes with increased risk of things breaking in the future, especially for those with many variants. Figma’s merge conflict UI is helpful, but may not catch everything.
We’ve made the GitHub Annotation Toolkit open source, so you can see first-hand how we’ve implemented our Primer A11y Preset annotations and visual regression tests. Check it out and start annotating today!
When it comes to design systems, every organization tends to be at a different place in their accessibility journey. Some have put a great deal of work into making their design system accessible while others have a long way to go before getting there. To help on this journey, many organizations rely on accessibility annotations to make sure there are no access barriers when a design is ready to be built.
However, it’s a common misconception (especially for organizations with mature design systems) that accessible components will result in accessible designs. While design systems are fantastic for scaling standards and consistency, they can’t prevent every issue with our designs or how we build them. Access barriers can still slip through the cracks and make it into production.
This is the root of the problem our Accessibility Design team set out to solve.
In this two-part series, we’ll show you exactly how accessible design system components can produce inaccessible designs. Then we’ll demonstrate our solution: integrating annotations with our Primer components. This allows us to spend less time annotating, increases design system adoption, and reaches teams who may not have accessibility support. And in our next post, we’ll walk you through how you can do the same for your own components.
Let’s dig in.
What are annotations and their benefits?
Annotations are notes included in design projects that help make the unseen explicit by conveying design intent that isn’t shown visually. They improve the usability of digital experiences by providing a holistic picture for developers of how an experience should function. Integrating annotations into our design process helps our teams work better together by closing communication gaps and preventing quality issues, accessibility audit issues, and expensive re-work.
Some of the questions annotations help us answer include:
How is assistive technology meant to navigate a page from one element to another?
What’s the alternative text for informative images and buttons without labels?
How does content shift depending on viewport size, screen orientation, or zoom level?
Which virtual keyboard should be used for a form input on mobile?
How should focus be managed for complex interactions?
Our answers to questions like this—or the lack thereof—can make or break the experience of the web for a lot of people, especially users with disabilities. Some annotation tools are built specifically to help with this by guiding designers to include key details about web standards, platform functionality, and accessibility (a11y).
Most public annotation kits are well suited for teams who are creating new design system components, teams who aren’t already using a design system, or teams who don’t have specialized accessibility knowledge. They usually help annotate things like:
Controls such as buttons and links
Structural elements such as headings and landmarks
Forms and other elements that require labels and semantic roles
Focus order for assistive technology and keyboard navigation
GitHub’s annotation’s toolkit
One of our top priorities is to meet our colleagues where they’re at. We wanted all our designers to be able to use annotations out of the box because we believe they shouldn’t need to be a certified accessibility specialist in order to get things built in an accessible way.
To this end, last year we began creating an internal Figma library—the GitHub Annotation Toolkit—which is now open source! Our toolkit builds on the legacy of the former Inclusive Design team at CVS Health. Their two open source annotation kits help make documentation that’s easy to create and consume, and are among the most widely used annotation libraries in the Figma Community.
While they add clarity, annotations can also add overhead. If teams are only relying on specialists to interpret designs and technical specifications for developers, the hand-off process can take longer than it needs to. To create our annotation toolkit, we rebuilt its predecessor from the ground up to avoid that overhead, making extensive improvements and adding inline documentation to make it more intuitive and helpful for all of our designers—not just accessibility specialists.
Design systems can also help reduce that overhead. When you audit your design systems for accessibility, there’s less need for specialist attention on every product feature, since you’re using annotations to add technical semantics and specialist knowledge into every component. This means that designers and developers only need to adhere to the usage guidelines consistently, right?
The problems with annotations and design system components
Unfortunately, it’s not that simple.
Accessibility is not binary
While design systems can help drive more accessible design at scale, they are constantly evolving and the work on them is never done. The accessibility of any component isn’t binary. Some may have a few severe issues that create access barriers, such as being inoperable with a keyboard or missing alt text. Others may have a few trivial issues, such as generic control labels.
Most of the time, it will be a misnomer to claim that your design system is “fully accessible.” There’s always more work to do—it’s just a question of how much. The Web Content Accessibility Guidelines (WCAG) are a great starting point, but their “Success Criteria” isn’t tailored for the unique context that is your website or product or audience.
While the WCAG should be used as a foundation to build from, it’s important to understand that it can’t capture every nuance of disabled users’ needs because your users’ needs are not every user’s needs. It would be very easy to believe that your design system is “fully accessible” if you never look past WCAG to talk to your users. If Primer has accessible components, it’s because we feel that direct participation and input from daily assistive technology users is the most important aspect of our work. Testing plans with real users—with and without disabilities—is where you really find what matters most.
Accessible components do not guarantee accessible designs
Arranging a series of accessible components on a page does not automatically create an accurate and informative heading hierarchy. There’s a good chance that without additional documentation, the heading structure won’t make sense visually—nor as a medium for navigating with assistive technology.
It’s great when accessible components are flexible and responsive, but what about when they’re placed in a layout that the component guidance doesn’t account for? Do they adapt to different zoom levels, viewport sizes, and screen orientations? Do they lose any functionality or context when any of those things change?
Component usage is contextual. You can add an image or icon to your design, but the design system docs can’t write descriptive text for you. You can use the same image in multiple places, but the image description may need to change depending on context.
Design system components in Figma don’t include all the details
Annotation kits don’t include components for specific design systems because almost every organization is using their own. When annotation kits are adopted, teams often add ways to label their design system components.
This labeling lets developers know they can use something that’s already been built, and that they don’t need to build something from scratch. It also helps identify any design system components that get ‘detached’ in Figma. And it reduces the number of things that need to be annotated.
Let’s look at an example:
If we’re using this Primer Button component from the Primer Web Figma library, there are a few important things that we won’t know just by looking at the design or the component properties:
Functional differences when components are implemented. Is this a link that just looks visually like a button? If so, a developer would use the <LinkButton> React component instead of <Button>.
Accessible labels for folks using assistive technology. The icon may need alt text. In some cases, the button text might need some visually-hidden text to differentiate it from similar buttons. How would we know what that text is? Without annotations, the Figma component doesn’t have a place to display this.
Whether user data is submitted. When a design doesn’t include an obvious form with input fields, how do we convey that the button needs specific attributes to submit data?
It’s risky to leave questions like this unanswered, hoping someone notices and guesses the correct answer.
A solution that streamlines the annotation process while minimizing risk
When creating new components, a set of detailed annotations can be a huge factor in how robust and accessible they are. Once the component is built, design teams can start to add instances of that component in their designs. When those designs are ready to be annotated, those new components shouldn’t need to be annotated again. In most cases, it would be redundant and unnecessary—but not in every case.
There are some important details in many Primer components that may change from one instance to another. If we use the CVS Health annotation kit out of the box, we should be able to capture those variations, but we wouldn’t be able to avoid those redundant and unnecessary annotations. As we built our own annotation toolkit, we built a set of annotations for each Primer component to do both of those things at once.
This accordion component has been thoroughly annotated so that an engineer has everything they need to build it the first time. These include heading levels, semantics for <detail> and <summary> elements, landmarks, and decorative icons. All of this is built into the component so we don’t need to annotate most of this when adding the accordion to our new designs.
However, there are two important things we need to annotate, as they can change from one instance to another:
The optional title at the top.
The heading level of each item within the accordion.
If we don’t specify these things, we’re leaving it to chance that the page’s heading structure will break or that the experience will be confusing for people to understand and navigate the page. The risks may be low for a single button or basic accordion, but they grow with pattern complexity, component nesting, interaction states, duplicated instances, and so on.
Instead of annotating what’s already built into the component or leaving these details to chance, we can add two quick annotations. One Stamp to point to the component, and one Details annotation where we fill in some blanks to make the heading levels clear.
Because the prompts for specific component details are pre-set in the annotation, we call them Preset annotations.
Introducing our Primer A11y Preset annotations
With this proof of concept, we selected ten frequently used Primer components for the same treatment and built a new set of Preset annotations to document these easily missed accessibility details—our Primer A11y Presets.
Those Primer components tend to contribute to more accessibility audit issues when key details are missing on implementation. Issues for these components relate to things like lack of proper labels, error validation messages, or missing HTML or ARIA attributes.
Each of our Preset annotations is linked to component docs and Storybook demos. This will hopefully help developers get straight to the technical info they need without designers having to find and add links manually. We also included guidance for how to fill out each Preset, as well as how to use the component in an accessible way. This helps designers get support inline without leaving their Figma canvas.
Want to create your own? Check out Design system annotations, part 2
Button components in Google’s Material Design and Shopify’s Polaris, IBM’s Carbon, or our Primer design system are all very different from one another. Because Preset annotations are based on specific components, they only work if you’re also using the design system they’re made for.
In part 2 of this series, we’ll walk you through how you can build your own set of Preset annotations for your design system, as well as some different ways to document important accessibility details before development starts.
You may also like:
If you’re more of a visual learner, you can watch Alexis Lucio explore Preset annotations during GitHub’s Dev Community Event to kick off Figma’s Config 2024.
In the blog our previous introduction to the SOP-driven LLM Agent Framework, we the potential of LLM agent framework to revolutionise business operations was discussed. Now, we’re excited to explore a compelling use case: automating Account Takeover (ATO) investigations in Risk Operations (RiskOps). This framework has significantly reduced manual effort, improved efficiency, and minimised errors in the investigation process, setting a new standard for secure and streamlined operations.
The challenge in RiskOps
Traditionally, ATO investigations have been fraught with challenges due to their complexity and the manual effort required. Analysts must sift through vast amounts of data, cross-referencing multiple systems and executing numerous SQL queries to make informed decisions. This process is not only labor-intensive but also susceptible to human error, which can lead to inconsistencies and potential security breaches.
The manual approach often involves:
Time-consuming data analysis: Analysts spend significant time gathering and interpreting data from disparate sources, leading to delays and inefficiencies.
Decision fatigue: Continuous decision-making in a high-pressure environment can result in oversight or errors, especially when relying on predefined thresholds without adaptive insights.
Resource constraints: The need for specialised skills to handle SQL queries and interpret complex patterns limits the scalability of the process.
These challenges highlight the need for a more efficient, reliable, and scalable solution.
Leveraging the SOP agent framework
Our framework transforms the ATO investigation process by mirroring manual workflows while leveraging advanced automation.
At its core, a Standard Operating Procedure (SOP) guides the investigation process. This comprehensive SOP, is designed with an intuitive tree structure. It outlines the sequence of investigative actions, required data for each step, necessary SQL queries and external function calls, as well as decision criteria guiding the investigation. Figure 1 shows the example of ATO investigation SOP.
Figure 1: Example of fictional ATO investigation SOP
The SOP is written in natural language in an indentation format. Users can easily define SOPs using an intuitive editor. This format also clearly denotes the specific functions or queries associated with each step in the SOP. The @function_name notation (eg. @IP_web_login_history) makes it easy to identify where external calls are made within the process, highlighting the integration points between the SOP-driven LLM agent framework and the existing systems or databases.
Dynamic execution
The dynamic execution engine consists of the SOP planner and the Worker Agent, working in tandem to drive efficient operations. The SOP planner serves as the navigator, guiding the investigation’s path by generating the necessary SOP steps and determining the appropriate APIs to call. It uses a structured execution approach inspired by Depth-First Search (DFS) to ensure thorough and systematic processing. Meanwhile, the Worker Agent acts as the executor, interpreting the JSON-formatted SOPs, invoking required APIs or SQL queries, and storing results. This continuous interplay between the SOP planner and the Worker Agent establishes an efficient feedback loop, propelling the investigation forward with precision and reliability.
The automated investigation process begins at the root of the SOP tree and methodically progresses through each defined step. At each juncture, the system executes specified SQL queries as needed, retrieving and analysing relevant data. Based on this analysis, the framework evaluates step specific criteria and makes informed decisions that guide subsequent steps. This iterative process allows the investigation to delve as deeply into the data as the SOP dictates, ensuring both thoroughness and efficiency.
As the investigation concludes, having completed all of the steps, the framework enters its final phase. It compiles a comprehensive summary of the entire process, synthesising all gathered information to generate a final decision. The culmination of this process is a detailed report that encapsulates the investigation’s findings and provides clear, actionable conclusions.
This automated approach combines the best of human expertise with computational efficiency. It maintains the depth and detail of a human-conducted investigation while leveraging the speed and consistency of automation. The result is a powerful tool that can handle complex investigations with precision and reliability, making it an invaluable asset in various fields requiring thorough and systematic analysis.
Figure 2: Example of dynamic execution
Efficiency, impact and future potential
The SOP-driven LLM agent framework has demonstrated remarkable efficiency and impact in automating RiskOps processes. By automating data handling and leveraging AI to adapt to emerging patterns, the framework has significantly reduced manual tasks and streamlined operations. Figure 3 shows an example of an automated RiskOps process integrated with Slack.
Figure 3: Slack integration
Key achievements of automating RiskOps process:
Reduction in handling time from 22 to 3 minutes per ticket.
Automation of 87% of ATO cases since launch.
Achievement of a zero-error rate, enhancing both efficiency and security.
These results not only demonstrate the framework’s effectiveness in streamlining RiskOps but also provide stakeholders with increased confidence in the security and reliability of their operations.
The success of the framework in automating ATO investigations opens the door to a wider range of applications across various sectors. By adapting the framework to different processes, organisations can achieve similar improvements in efficiency and reliability, leading to a more responsive and agile business environment.
Conclusion
The SOP-driven LLM agent framework is more than an automation tool. It’s a catalyst for transforming enterprise operations. By applying it to ATO investigations, we’ve demonstrated its potential to enhance efficiency, reliability, and security. As we continue to explore its capabilities, we anticipate unlocking new levels of productivity and innovation across industries.
We look forward to sharing more as we explore how this groundbreaking framework can be applied to various challenges, helping organisations navigate the complexities of modern operations with confidence and precision.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
At GitHub, we’re committed to making our tools truly accessible for every developer, regardless of ability or toolset. The command line interface (CLI) is a vital part of the developer experience, and the GitHub CLI is our product that brings the power of GitHub to your terminal.
When it comes to accessibility, the terminal is fundamentally different from a web browser or a graphical user interface, with a lineage that predates the web itself. While standards like the Web Content Accessibility Guidelines (WCAG) provide a clear path for making web and graphical applications accessible, there is no equivalent, comprehensive standard for the terminal and CLIs. The W3C offers some high-level guidance for non-web software, but it stops short of prescribing concrete techniques, leaving much open to interpretation and innovation.
This gap has challenged us to think creatively and purposefully about what accessibility should look like in the terminal. Our recent Public Preview is focused on addressing the needs of three key groups: users who rely on screen readers, users who need high contrast between background and text, and users who require customizable color options. Our work aims to make the GitHub CLI more inclusive for all, regardless of how you interact with your terminal. Run gh a11y in the latest version of the GitHub CLI to enable these features, or read on to learn about our path to designing and implementing them.
Understanding the terminal landscape
Text-based and command-line applications differ fundamentally from graphical or web applications. On a web page, assistive technologies like screen readers make use of the document object model (DOM) to infer structure and context of the page. Web pages can be designed such that the DOM’s structure is friendly to these technologies without impacting the visual design of the page. By contrast, CLI’s primary output is plain text, without hidden markup. A terminal emulator acts as the “user agent” for text apps, rendering characters as directed by the server application. Assistive technologies access this matrix of characters, analyze its layout, and try to infer structure. As the WCAG2ICT guidance notes, accessibility in this space means ensuring that all text output is available to assistive technologies, and that structural information is conveyed in a way that’s programmatically determinable—even if no explicit markup is present.
In our quest to improve the GitHub CLI’s usability for blind, low-vision, and colorblind users, we found ourselves navigating a landscape with lots of guidance, but few concrete techniques for implementing accessible experiences. We studied how assistive technology interacts with terminals: how screen readers review output, how color and contrast can be customized, and how structural cues can be inferred from plain text. Our recent Public Preview contains explorations into various use cases in these spaces.
Rethinking prompts and progress for screen readers
One of the GitHub CLI’s strengths as a command-line application is its rich prompting experience, which gives our users an interactive interface to enter command options. However, this rich interactive experience poses a hurdle for speech synthesis screen readers: Non-alphanumeric visual cues and uses of constant screen redraws for visual or other effects can be tricky to correctly interpret as speech.
A demo video with sound of screen reader reading legacy prompter.
To reduce confusion and make it easier for blind and low vision users to confidently answer questions and navigate choices, we’re introducing a prompting experience that allows speech synthesis screen readers to accurately convey prompts to users. Our new prompter is built using Charm’s open source charmbracelet/huhprompting library.
A demo of a screenreader correctly reading a prompt.
Another use case where the terminal is redrawn for visual effect is when showing progress bars. Our existing implementation uses a “spinner” made by redrawing the screen to display different braille characters (yes, we appreciate the irony) to give the user the indication that their command is executing. Speech synthesis screen readers do not handle this well:
A demo of a screenreader and an old spinner.
This has been replaced with a static text progress indicator (with a relevant message to the action being taken where possible, falling back to a general “Working…” message). We’re working on identifying other areas we can further improve the contextual text.
A demo video of the new progress indicator experience.
Color, contrast, and customization
Color is more than decoration in the terminal: It’s a vital tool for highlighting information, signaling errors, and guiding workflows. But color can also be a barrier—if contrast between the color of the terminal background and the text displayed on it is too low, some users will have difficulty discerning the displayed information. Unlike in a web browser, a terminal’s background color is not set by the application. That task is handled by the user’s terminal emulator. In order to maintain contrast, it is important that a command line application takes into account this variable.
Our legacy color palette used for rendering Markdown did not take the terminal’s background color into account, leading to low contrast in some cases.
The colors themselves also matter. Different terminal environments have varied color capabilities (some support 4-bit, some 8-bit, some 24-bit, etc). No matter the capability, terminals enable users to customize their color preferences, choosing how different hues are displayed. However, most terminals only support changing a limited subset of colors: namely, the sixteen colors in the ANSI 4-bit color table. The GitHub CLI has made extensive efforts to align our color palettes to 4-bit colors so our users can completely customize their experience using their terminal preferences. We built on top of the accessibility foundations pioneered by Primer when deciding which 4-bit colors to use.
Building for the CLI community
Our improvements aim to support a wide range of developer needs, from blind users who need screen readers, to low vision users who need high contrast, to colorblind users who require customizable color options. But this Public Preview does not mark the end of our team’s commitment to enabling all developers to use the GitHub CLI. We intend to make it easier for our extension authors to implement the same accessibility improvements that we’ve made to the core CLI. This will allow users to have a cohesive experience across all GitHub CLI commands, official or community-maintained, and so that more workflows can be made accessible by default. We’re also looking into experiences to customize the formatting of tables output by commands to be more easily read/interpreted by screen readers. We’re excited to continue our accessibility journey.
We couldn’t have come this far without collaboration with our friends at Charm and our colleagues on the GitHub Accessibility team.
A call for feedback
We invite you to help us in our goal to make the GitHub CLI an experience for all developers:
Try it out: Update the GitHub CLI to v2.72.0 and run gh a11y in your terminal to learn more about enabling these new accessible features.
Connect with us: If you have a lived experience relevant to our accessibility personas, reach out to the accessibility team or get involved in our discussion panel.
Looking forward
Adapting accessibility standards for the command line is a challenge—and an opportunity. We’re committed to sharing our approach, learning from the community, and helping set a new standard for accessible CLI tools.
Thank you for building a more accessible GitHub with us.
Want to help us make GitHub the home for all developers?Learn more about GitHub’s accessibility efforts.
Most developers are familiar with the standard Git workflow. You create a branch, make changes, and push those changes back to the same branch on the main repository. Git calls this a centralized workflow. It’s straightforward and works well for many projects.
However, sometimes you might want to pull changes from a different branch directly into your feature branch to help you keep your branch updated without constantly needing to merge or rebase. However, you’ll still want to push local changes to your own branch. This is where triangular workflows come in.
It’s possible that some of you have already used triangular workflows, even without knowing it. When you fork a repo, contribute to your fork, then open a pull request back to the original repo, you’re working in a triangular workflow. While this can work seamlessly on github.com, the process hasn’t always been seamless with the GitHub CLI.
The GitHub CLI team has recently made improvements (released in v2.71.2) to better support these triangular workflows, ensuring that the gh pr commands work smoothly with your Git configurations. So, whether you’re working on a centralized workflow or a more complex triangular one, the GitHub CLI will be better equipped to handle your needs.
If you’re already familiar with how Git handles triangular workflows, feel free to skip ahead to learn about how to use gh pr commands with triangular workflows. Otherwise, let’s get into the details of how Git and the GitHub CLI have historically differed, and how four-and-a-half years after it was first requested, we have finally unlocked managing pull requests using triangular workflows in the GitHub CLI.
First, a lesson in Git fundamentals
To provide a framework for what we set out to do, it’s important to first understand some Git basics. Git, at its core, is a way to store and catalog changes on a repository and communicate those changes between copies of that repository. This workflow typically looks like the diagram below:
Figure 1: A typical git branch setup
The building blocks of this diagram illustrate two important Git concepts you likely use every day, a ref and push/pull.
Refs
A ref is a reference to a repository and branch. It has two parts: the remote, usually a name like origin or upstream, and the branch. If the remote is the local repository, it is blank. So, in the example above, origin/branch in the purple box is a remote ref, referring to a branch named branch on the repository name origin, while branch in the green box is a local ref, referring to a branch named branch on the local machine.
While working with GitHub, the remote ref is usually the repository you are hosting on GitHub. In the diagram above, you can consider the purple box GitHub and the green box your local machine.
Pushing and pulling
A push and a pull refer to the same action, but from two different perspectives. Whether you are pushing or pulling is determined by whether you are sending or receiving the changes. I can push a commit to your repo, or you can pull that commit from my repo, and the references to that action would be the same.
To disambiguate this, we will refer to different refs as the headRef or baseRef, where the headRef is sending the changes (pushing them) and the baseRef is receiving the changes (pulling them).
Figure 2: Disambiguating headRef and baseRef for push/pull operations
When dealing with a branch, we’ll often refer to the headRef of its pull operations as its pullRef and the baseRef of its push operations as its pushRef. That’s because, in these instances, the working branch is the pull’s baseRef and the push’s headRef, so they’re already disambiguated.
The @{push} revision syntax
Turns out, Git has a handy built-in tool for referring to the pushRef for a branch: the @{push} revision syntax. You can usually determine a branch’s pushRef by running the following command:
git rev-parse --abbrev-ref @{push}
This will result in a human-readable ref, like origin/branch, if one can be determined.
Pull Requests
On GitHub, a pull request is a proposal to integrate changes from one ref to another. In particular, they act as a simple “pause” before performing the actual integration operation, often called a merge, when changes are being pushed from ref to another. This pause allows for humans (code reviews) and robots (GitHub Copilot reviews and GitHub Actions workflows) to check the code before the changes are integrated. The name pull request came from this language specifically: You are requesting that a ref pulls your changes into itself.
Figure 3: Demonstrating how GitHub Pull Requests correspond to pushing and pulling
Common Git workflows
Now that you understand the basics, let’s talk about the workflows we typically use with Git every day.
A centralized workflow is how most folks interact with Git and GitHub. In this configuration, any given branch is pushing and pulling from a remote ref with the same branch name. For most of us, this type of configuration is set up by default when we clone a repo and push a branch. It is the situation shown in Figure 1.
In contrast, a triangular workflow pushes to and pulls from different refs. A common use case for this configuration is to pull directly from a remote repository’s default branch into your local feature branch, eliminating the need to run commands like git rebase <default> or git merge <default> on your feature branch to ensure the branch you’re working on is always up to date with the default branch. However, when pushing changes, this configuration will typically push to a remote ref with the same branch name as the feature branch.
Figure 4: juxtaposing centralized workflows from triangular workflows.
We complete the triangle when considering pull requests: the headRef is the pushRef for the local ref and the baseRef is the pullRef for the local branch:
Figure 5: a triangular workflow
We can go one step further and set up triangular workflows using different remotes as well. This most commonly occurs when you’re developing on a fork. In this situation, you usually give the fork and source remotes different names. I’ll use origin for the fork and upstream for the source, as these are common names used in these setups. This functions exactly the same as the triangular workflows above, but the remotes and branches on the pushRef and pullRef are different:
Figure 6: juxtaposing triangular workflows and centralized workflows with different remotes such as with forks
Using a Git configuration file for triangular workflows
There are two primary ways that you can set up a triangular workflow using the Git configuration – typically defined in a `.git/config` or `.gitconfig` file. Before explaining these, let’s take a look at what the relevant bits of a typical configuration look like in a repo’s `.git/config` file for a centralized workflow:
Figure 7: A typical Git configuration setup found in .git/config
The [remote “origin”] part is naming the Git repository located at github.com/OWNER/REPO.git to origin, so we can reference it elsewhere by that name. We can see that reference being used in the specific [branch] configurations for both the default and branch branches in their remote keys. This key, in conjunction with the branch name, typically makes up the branch’s pushRef: in this example, it is origin/branch.
The remote and merge keys are combined to make up the branch’s pullRef: in this example, it is origin/branch.
Setting up a triangular branch workflow
The simplest way to assemble a triangular workflow is to set the branch’s merge key to a different branch name, like so:
Figure 8: a triangular branch’s Git configuration found in .git/config
This will result in the branch pullRef as origin/default, but pushRef as origin/branch, as shown in Figure 9.
Figure 9: A triangular branch workflow
Setting up a triangular fork workflow
Working with triangular forks requires a bit more customization than triangular branches because we are dealing with multiple remotes. Thus, our remotes in the Git config will look different than the one shown previously in Figure 7:
Figure 10: a Git configuration for a multi-remote Git setup found in .git/config
Upstream and origin are the most common names used in this construction, so I’ve used them here, but they can be named anything you want1.
However, toggling a branch’s remote key between upstream and origin won’t actually set up a triangular fork workflow—it will just set up a centralized workflow with either of those remotes, like the centralized workflow shown in Figure 6. Luckily, there are two common Git configuration options to change this behavior.
Setting a branch’s pushremote
A branch’s configuration has a key called pushremote that does exactly what the name suggests: configures the remote that the branch will push to. A triangular fork workflow config using pushremote may look like this:
Figure 11: a triangular fork’s Git config using pushremote found in .git/config
This assembles the triangular fork repo we see in Figure 12. The pullRef is upstream/default, as determined by combining the remote and merge keys, while the pushRef is origin/branch, as determined by combining the pushremote key and the branch name.
Figure 12: A triangular fork workflow
Setting a repo’s remote.pushDefault
To configure all branches in a repository to have the same behavior as what you’re seeing in Figure 12, you can instead set the repository’s pushDefault. The config for this is below:
Figure 13: a triangular fork’s Git config using remote.pushDefault found in .git/config
This assembles the same triangular fork repo as shown in Figure 12 above, however this time the pushRef is determined by combining the remote.pushDefault key and the branch name, resulting in origin/branch.
When using the branch’s pushremote and the repo’s remote.pushDefault keys together, Git will preferentially resolve the branch’s configuration over the repo’s, so the remote set on pushremote supersedes the remote set on remote.pushDefault.
Updating the gh pr command set to reflect Git
Previously, the gh pr command set did not resolve pushRefs and pullRefs in the same way that Git does. This was due to technical design decisions that made this change both difficult and complex. Instead of discussing that complexity—a big enough topic for a whole article in itself—I’m going to focus here on what you can now do with the updated gh pr command set.
If you set up triangular Git workflows in the manner described above, we will automatically resolve gh pr commands in accordance with your Git configuration.
To be slightly more specific, when trying to resolve a pull request for a branch, the GitHub CLI will respect whatever @{push} resolves to first, if it resolves at all. Then it will fall back to respect a branch’s pushremote, and if that isn’t set, finally look for a repo’s remote.pushDefault config settings.
What this means is that the CLI is assuming your branch’s pullRef is the pull request’s baseRef and the branch’s pushRef is the pull requests headRef. In other words, if you’ve configured git pull and git push to work, then gh pr commands should just work.2 The diagram below, a general version of Figure 5, demonstrates this nicely:
Figure 14: the triangular workflow supported by the GitHub CLI with respect to a branch’s pullRef and pushRef. This is the generalized version of Figure 5
Conclusion
We’re constantly working to improve the GitHub CLI, and we’d like the behavior of the GitHub CLI to reasonably reflect the behavior of Git. This was a team effort—everyone contributed to understanding, reviewing, and testing the code to enable this enhanced gh pr command set functionality.
It also couldn’t have happened without the support of our contributors, so we extend our thanks to them:
CLI native support for triangular workflows was 4.5 years in the making, and we’re proud to have been able to provide this update for the community.
The GitHub CLI Team @andyfeller, @babakks, @bagtoad, @jtmcg, @mxie, @RyanHecht, and @williammartin
Some commands in gh are opinionated about remote names and will resolve remotes in this order: upstream, github, origin, <other remotes unstably sorted>. There is a convenience command you can run to supersede this:* gh repo set-default [<repository>]to override the default behavior above and preferentially resolve<repository>as the default remote repo.↩
If you find a git configuration that doesn’t work, please open an issue in the OSS repo so we can fix it. ↩
We’re excited to introduce an innovative Large Language Model (LLM) agent framework that reimagines how enterprises can harness the power of AI to streamline operations and boost productivity. At its core, this framework leverages Standard Operating Procedures (SOPs) to guide AI-driven execution, ensuring reliability and consistency in complex processes. Initial evaluations have shown remarkable results, with over 99.8% accuracy in real-world use cases. For example, the framework has powered solutions like the Account Takeover Investigations (ATI) bot, which achieved a 0 false rate while reducing investigation time from 23 minutes to just 3, automating 87% of cases. The fraud investigation use case also reduced the average handling time (AHT) by 45%, saving over 300 man-hours monthly with a 0 false rate, demonstrating its potential to transform even the most intricate enterprise operations with a high degree of accuracy.
The framework’s capabilities extend far beyond just accuracy, it offers a versatile suite of tools that revolutionise automation and app development, enabling AI-powered solutions up to 10 times faster than traditional methods.
The power of SOPs in AI automation
Traditional agent-based applications often use LLMs as the core controller to navigate through standard operating procedure (SOPs). However, this approach faces several challenges. LLMs may make incorrect decisions or invent non-existent steps due to hallucination. As generative models, they struggle to consistently produce results in a fixed format. Moreover, navigating complex SOPs with multiple branching pathways is particularly challenging for LLMs. These issues can lead to inefficiencies and inaccuracies in implementing business operations, especially when dealing with intricate, multi-step procedures.
Our framework addresses these challenges head-on by leveraging the structure and reliability of SOPs. We represent SOPs as a tree, with nodes encapsulating individual actions or decision points. This structure supports both sequential and conditional branching operations, mirroring the hierarchical nature of real-world business processes.
To make this powerful tool accessible to all, we’ve developed an intuitive SOP editor that allows non-technical users to easily define and visualise complex workflows. These visual representations are then converted into a structured, indented format that our system can interpret and execute efficiently.
Figure 1: SOP editor in our framework
The example above demonstrates how our framework transforms the customer support process by mirroring manual workflows while leveraging advanced automation. The SOP is written in natural language using an indentation format, making it easy for users to define and understand. The @function_name (@get_order_detail) notation clearly identifies where external calls are made within the process, highlighting the integration points between the SOP-driven LLM agent framework and existing systems or databases.
The magic behind the scenes
The framework’s strength lies in the synergy between three key components: the planner module, LLM-powered worker agent, and user agent. This intelligent trio works in harmony to deliver a seamless, efficient, and adaptable automation experience.
The planner module employs a Depth-First Search (DFS) algorithm to navigate the SOP tree, ensuring thorough execution with step-by-step prompt generation and sophisticated backtracking mechanisms. The LLM-powered worker agent dynamically updates its understanding and makes decisions based on the most current information. Our approach tackles hallucination and improves efficiency through context compression and strategic limitation of available Application Programming Interface tools (APIs). The framework’s dynamic branching capability allows for adaptive navigation based on real-time data and analysis.
Serving as the primary user interface, the user agent offers multilingual interaction, accurate intent identification, and seamless handling of out-of-order scenarios.
By combining structured SOPs with flexible LLM-powered agents and advanced algorithmic approaches, our framework adeptly handles complex, real-world scenarios while maintaining reliability and consistency. This innovative architecture effectively mitigates common LLM challenges, resulting in a robust system capable of navigating intricate business processes with high accuracy and adaptability.
Beyond SOPs: A suite of powerful features
While SOPs form the backbone of our framework, we’ve incorporated several other cutting-edge features to create a truly comprehensive solution. Our Graph Retrieval-Augmented Generation (GRAG) pipeline enhances information retrieval and content generation tasks, allowing for more accurate and context-aware responses. The workflow feature enables chaining multiple plugins together to handle complex processes effortlessly, improving efficiency across various departments.
Our plugin system seamlessly integrates with various technologies such as API, Python, and SQL, providing the flexibility to meet diverse needs. Whether you’re an engineer coding in Python, a data analyst working with SQL, or a risk operations specialist, our plugin system adapts to your preferred tools. Additionally, our playground feature allows users to develop, test, and refine LLM applications easily in an interactive environment, supporting the latest multi-modal APIs for accelerated innovation.
Figure 2: Workflow builder feature in our framework
Empowering teams through versatility and accessibility
Our framework is designed to empower teams across the organisation. The multilingual capabilities of our user agent ensure that language barriers don’t hinder adoption or efficiency. For scenarios requiring human intervention, we’ve implemented a state stack that allows for pausing and resuming execution seamlessly. This feature ensures that complex processes can be handled with the right balance of automation and human oversight.
Security and transparency at the forefront
In an era where data security and process transparency are paramount, our framework doesn’t fall short. It’s designed with a security-first approach, ensuring granular access control so that users only access information they’re authorised to see. Additionally, we provide detailed logging and visualisation of each execution, offering complete explainability of the automation process. This level of transparency not only aids in troubleshooting but also helps in building trust in the AI-driven processes across the organisation.
Looking ahead
As we continue to refine and expand this LLM agent framework, we’re excited to explore its potential across different industries. We’ll be sharing more about each of these features in the future and showcase how they can be leveraged to solve specific business challenges and explore real-world applications.
Look forward to more in-depth explorations of the framework’s capabilities, use cases, and technical innovations. With this revolutionary approach, you’re not just automating tasks – you’re transforming the way your enterprise operates, unleashing the true power of LLM in your organisation.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Recently we launched sub-issues, a feature designed to tackle complex issue management scenarios. This blog post delves into the journey of building sub-issues, what we learned along the way, how we implemented sub-issues, and the benefits of being able to use sub-issues to build itself.
What are sub-issues?
Sub-issues are a way to break a larger issue into smaller, more manageable tasks. With this feature, you can now create hierarchical lists within a single issue, making it easier to track progress and dependencies. By providing a clear structure, sub-issues help teams stay organized and focused on their goals.
For example, I often realize that a batch of work requires multiple steps, like implementing code in different repositories. Breaking this task into discrete sub-issues makes it easier to track progress and more clearly define the work I need to do. In practice we’ve noticed this helps keep linked PRs more concise and easier to review.
A brief history
Issues have long been at the heart of project management on GitHub. From tracking bugs to planning feature development, issues provide a flexible and collaborative way for teams to organize their work. Over time, we’ve enriched this foundation with tools like labels, milestones, and task lists, all to make project management even more intuitive and powerful.
One of the key challenges we set out to solve was how to better represent and manage hierarchical tasks within issues. As projects grow in complexity, breaking down work into smaller, actionable steps becomes essential. We want to empower users to seamlessly manage these nested relationships while maintaining the simplicity and clarity GitHub is known for.
Our journey toward sub-issues began with a fundamental goal: to create a system that integrates deeply into the GitHub Issues experience, enabling users to visually and functionally organize their work without adding unnecessary complexity. Achieving this required careful design and technical innovation.
Building sub-issues
To build sub-issues, we began by designing a new hierarchical structure for tasks rather than modifying the existing task list functionality. We introduced the ability to nest tasks within tasks, creating a hierarchical structure. This required updates to our data models and rendering logic to support nested sub-issues.
From a data modeling perspective, the sub-issues table stores the relationships between parent and child issues. For example, if Issue X is a parent of Issue Y, the sub-issues table would store this link, ensuring the hierarchical relationship is maintained.
In addition, we roll up sub-issue completion information into a sub-issue list table. This allows us to performantly get progress without having to traverse through a list of sub-issues. For instance, when Issue Y is completed, the system automatically updates the progress of Issue X, eliminating the need to manually check the status of all sub-issues.
We wanted a straightforward representation of sub-issues as relationships in MySQL. This approach provided several benefits, including easier support for sub-issues in environments like GitHub Enterprise Server and GitHub Enterprise Cloud with data residency.
We exposed sub-issues through GraphQL endpoints, which let us build upon the new Issues experience and leverage newly crafted list-view components. This approach provided some benefits, including more efficient data fetching and enhanced flexibility in how issue data is queried and displayed. Overall, we could move faster because we reused existing components and leveraged new components that would be used in multiple features. This was all made possible by building sub-issues in the React ecosystem.
We also focused on providing intuitive controls for creating, editing, and managing sub-issues. To this end, we worked closely with accessibility designers and GitHub’s shared components team that built the list view that powers sub-issues.
Our goal was to make it as easy as possible for users to break down their tasks without disrupting their workflow.
Using sub-issues in practice
Dogfooding is a best practice at GitHub and it’s how we build GitHub! We used sub-issues extensively within our own teams throughout the company to manage complex projects and track progress. Having a discrete area to manage our issue hierarchy resulted in a simpler, more performant experience. Through this hands-on experience, we identified areas for improvement and ensured that the feature met our high standards.
Our teams found that sub-Issues significantly improved their ability to manage large projects. By breaking down tasks into smaller, actionable items, they maintained better visibility and control over their work. The hierarchical structure also made it easier to identify dependencies and ensure nothing fell through the cracks.
Gathering early feedback
Building sub-issues was a team effort. Feedback from our beta testers was instrumental in shaping the final product and ensuring it met the needs of our community. For example, understanding how much metadata to display in the sub-issue list was crucial. We initially started with only issue titles, but eventually added the issue number and repository name, if the issue was from another repository.
Building features at GitHub makes it really easy to improve our own features as we go. It was really cool to start breaking down the sub-issues work using sub-issues. This allowed us to experience the feature firsthand and identify any pain points or areas for improvement. For example, the has:sub-issues-progress and has:parent-issue filters evolved from early discussions around filtering syntax. This hands-on approach ensured that we delivered a polished and user-friendly product.
These lessons have been invaluable in not only improving sub-issues, but also in shaping our approach to future feature development. By involving users early and actively using our own features, we can continue to build products that truly meet the needs of our community. These practices will be important to our development process going forward, ensuring that we deliver high-quality, user-centric solutions.
Call to action
Sub-issues are designed to help you break down complex tasks into manageable pieces, providing clarity and structure to your workflows. Whether you’re tracking dependencies, managing progress, or organizing cross-repository work, sub-issues offer a powerful way to stay on top of your projects.
We’d love for you to try sub-issues and see how they can improve your workflow. Your feedback is invaluable in helping us refine and enhance this feature. Join the conversation in our community discussion to share your thoughts, experiences, and suggestions.
Thank you for being an integral part of the GitHub community. Together, we’re shaping the future of collaborative development!
At Grab, we operate a set of services that manage and provide counts of various items. While this may seem straightforward, the scale at which this feature operates—benefiting millions of Grab users daily—introduces complexity. This feature is divided into three microservices: one for “writing” counts, another for handling “read” requests, and a third serving as the backend for a portal used by data scientists and analysts to configure these counters.
This article focuses on the service responsible for handling “read” requests. This service is backed by Scylla storage and a Redis cache. It also connects to a MySQL RDS to retrieve “counter configurations” that are necessary for processing incoming requests. Written in Rust, the service serves tens of thousands of queries per second (QPS) during peak times, with each request typically being a “batch request” requiring multiple lookups (~10) on Scylla.
Recently, the service has encountered performance challenges, causing periodic spikes in Scylla QPS. These spikes occur throughout the day but are particularly evident during peak hours. To understand this better, we’ll first walk you through how this service operates, particularly how it serves incoming requests. We will then explain our proposed solution and the outcomes of our experiment.
Anatomy of a request
Each counter configuration stored in MySQL has a template that dictates the format of incoming queries. For example, this sample counter configuration is used to count the raindrops for a specific city:
An incoming request using this counter might look like this:
{
"key": "rain_drops:city:111222",
"fromTime": 1727215430, // 24 September 2024 22:03:50
"toTime": 1727400000, // 27 September 2024 01:20:00
}
This request seeks the number of raindrops in our imaginary city with city ID: 111222, between 1727215430 (24 September 2024 22:03:50) and 1727400000 (27 September 2024 01:20:00).
Another service keeps track of raindrops by city and writes the minutely (truncated at 15 minutes), hourly, and daily counts to three different Scylla tables:
minutely_count_table
hourly_count_table
daily_count_table
The service processing the request rounds down the time to the nearest 15 minutes. As a result, the request is processed with the following time range:
Start time: 24 September 2024 22:00:00
End time: 27 September 2024 01:15:00
Let’s assume we have the following data in these three tables for “rain_drops:city:111222”. The datapoints used in the above example request are highlighted in bold.
minutely_count_table:
key
minutely_timestamp
count
rain_drops:city:111222
2024-09-24T22:00:00Z
3
rain_drops:city:111222
2024-09-24T22:15:00Z
2
rain_drops:city:111222
2024-09-24T22:30:00Z
4
rain_drops:city:111222
2024-09-24T22:45:00Z
1
…
…
…
rain_drops:city:111222
2024-09-27T01:00:00Z
2
rain_drops:city:111222
2024-09-27T01:15:00Z
3
hourly_count_table:
key
hourly_timestamp
count
rain_drops:city:111222
2024-09-24T22:00:00Z
18
rain_drops:city:111222
2024-09-24T23:00:00Z
22
rain_drops:city:111222
2024-09-25T00:00:00Z
15
…
…
…
rain_drops:city:111222
2024-09-27T00:00:00Z
11
rain_drops:city:111222
2024-09-27T01:00:00Z
9
daily_count_table:
key
daily_timestamp
count
rain_drops:city:111222
2024-09-24T00:00:00Z
214
rain_drops:city:111222
2024-09-25T00:00:00Z
189
rain_drops:city:111222
2024-09-26T00:00:00Z
245
rain_drops:city:111222
2024-09-27T00:00:00Z
78
Now, let’s see how the service calculates the total count for the incoming request with “rain_drops:city:111222” based on the provided data:
Time range:
From: 24 September 2024 22:03:50
To: 27 September 2024 01:20:00
For the full days within the range, specifically 25th and 26th September, we can use data from the daily_count_table. However, for the start (24th September) and end (27th September) date of the range, we cannot use data from the daily_count_table as the range only includes portions of these dates. Instead, we will use a combination of data from the hourly_count_table and minutely_count_table to accurately capture the counts for these days.
Query the daily_count_table:
Sum (full day: 25 and 26th Sep): 189 + 245 = 434
Query the hourly_count_table:
For 24th September (from 22:00:00 to 23:59:59):
Hourly count: 18 + 22 = 40
For 27th September (from 00:00:00 to 01:00:00):
Hourly count: 11
Query the minutely_count_table:
For 27th September (from 01:00:00 to 01:15:00):
Minutely count: 2
Total count:
Total = Daily count (25th and 26th) + Hourly count (24th) + Hourly count (27th) + Minutely count (27th)
= 434 + 40 + 11 + 2
= 487
Figure 1: The example request for “rain_drops:city:111222” is handled using data from three different Scylla tables.
As shown in the calculation, when the service receives the request, it comes up with the total count of raindrops by querying three Scylla tables and summing them up using some specific rules within the service itself.
Querying the cache
In the previous section, we explained how Scylla handles a query. If we cached the response for the same request earlier, retrieval from the cache follows a simpler logic. For instance, for the example request, the total count is stored using the floored start and end times (rounded to the nearest 15-minute window within an hour), which was used for the Scylla query instead of the original time in the request. The cache key-value pair would look like this:
Timestamps 1727215200 and 1727399700 represent the adjusted start and end times of 24 September 2024 22:00:00 and 27 September 2024 01:15:00, respectively. It has a Time-To-Live (TTL) of 5 minutes. During this TTL window, any request for the key “rain_drops:city:111222” having the same start and end times (after rounding to the nearest 15 minutes) will be read from the cache instead of querying Scylla.
For example, for the following three start times, although they are different, after flooring the request to the nearest 15 minutes, the start time becomes 24 September 2024 22:00:00 for all of them, which is the same start time as the one in the cache.
24 September 2024 22:01:00
24 September 2024 22:02:00
24 September 2024 22:06:00
In day-to-day operations, this caching setup allows roughly half of our total production requests to be served by the Redis cache.
Figure 2. The graph visualises the relative quantity of cache hits vs Scylla-bound requests.
Problem statement
The setup consisting of Scylla and Redis cache works well. Particularly because Scylla-bound queries need to look up 1-3 tables (minutely, hourly, daily, depending on the time range) and perform the summation as explained earlier, whereas a single cache lookup gets the final value for the same query. However, as our cache key pattern follows the 15-minute truncation strategy, along with a 5-minute cache TTL, it leads to an interesting phenomenon – our cache hits plummet and Scylla QPS spikes at the end of every 15 minutes.
Figure 3. Graph showing 15-minute spikes in Scylla-bound requests accompanied by a decline in cache hit rates.
This occurs primarily due to the fact that almost all requests to our service are for recent data. Due to this, at the end of every 15-minute block within an hour (i.e., 00, 15, 30, 45), most of the requests require creating new cache keys for the latest 15-minute block. At this point in time, there may be many unexpired (i.e., have not reached 5 min TTL) cache keys from the previous 15-minutes block, but they become less relevant as most requests are asking for recent data.
The table in Figure 4 shows example data for configurations “rain_drops:city:111222” and “bird_sighting:city:333444”. For these two configurations, new cache keys are created due to TTL expiry at random times. However, at the end of the 15-minute block, which, in this case is at the end of 22:00-22:15 block, both configurations need new cache keys for the new 15-minute time block that has just started (i.e., start of 22:15-22:30), even though some of their cache keys from the previous 15-minute block are still valid. This requirement of creating new cache keys for most of the requests at the end of a 15-minute block causes spikes in Scylla QPS and a sharp decline in cache hits.
One question that arises is – “Why don’t we see a spike every 5 minutes for cache key TTL expiry?” This is because, within the 15 minutes block, new cache keys are continuously created when a key reaches TTL and a new request for that is received. Since this happens all the time as shown in Figure 4, we do not see a sharp spike. In other words, although Scylla does receive more queries due to cache TTL expiry, it does not lead to a spike in Scylla queries or a sharp drop in cache hits. This is because the cache keys are always being created and invalidated due to TTL expiry instead of following a fixed 5-minute block similar to the 15-minute block we use for our truncation strategy.
Figure 4. This table visualises scenarios when new cache keys are required due to TTL expiry vs due to 15-minute truncation strategy.
These Scylla QPS spikes at the end of every 15-minute block lead to a highly imbalanced Scylla QPS. This often causes high latency in our service during the 15-minute blocks that fall within the peak traffic hours. This further causes more requests to time out, eventually increasing the number of failed requests.
Proposed solution
We propose mitigating this issue by completely removing the Redis-backed caching mechanism from the service. Our observations indicate that the Scylla spikes at the end of 15-minute blocks occur due to cache hit misses. Therefore, removing the caching should eliminate the spikes and provide for a more balanced load.
We acknowledge that this may seem counterintuitive from an overall performance standpoint as removing caching means all queries will be Scylla-bound, potentially impacting the overall performance since caching usually speeds up processes. In addition, caching also comes with an advantage where for cache hits, the service does not need to do the summation on Scylla results from minutely, hourly, and the daily table. Despite these shortcomings, we hypothesise that removing caching should not have an adverse impact on the overall performance. This is based on the fact the Scylla has its own sophisticated caching mechanism. However, our existing setup uses Redis for caching, underutilising Scylla’s cache as the most subsequent queries hit the Redis cache instead.
In summary, we propose eliminating the Redis caching component from our current architecture. This change is expected to resolve the Scylla query spikes observed at the end of every 15-minute block. By relying on Scylla’s native caching mechanism, we anticipate maintaining the service’s overall performance more effectively. The removal of Redis is counterbalanced by the optimised utilisation of Scylla’s built-in caching capabilities.
Experiment
Procedure
The experiment was done on an important live service serving thousands of QPS. To avoid disruptions, we followed a gradual approach. We first turned off caching for a few configurations. If there were no adverse impacts observed, we incrementally disabled cache for more configurations. We controlled the rollout increment by using a mathematical operator on the configuration IDs. This approach is simple and allows us to deterministically disable the cache for specific configurations across all requests, as opposed to using a percentage rollout which randomly disables the cache for different configurations across different requests. This is also due to the fact that the number of configurations is relatively steady and small (less than a thousand). Since these configurations are already fully cached in the service memory from RDS, there will be no performance impact of having a condition that operates on these configurations.
To make sense of the graphs and metrics reported in this section, it is important to understand the traffic pattern of this service. The service usually sees two peaks every day: noon and another around 6-7 PM. On a weekly basis, we usually see the highest traffic on Friday, with the busiest period being from 6-8 PM.
In addition, the timeline of when and how we made various changes to our setup is important to accurately interpret our results.
Experiment timeline: Nov 5 – Nov 13, 2024:
Redis cache disabled for ~5% of the counter configurations – Nov 5, 2024, 10.26 AM (Canary started: 10.00 AM)
Redis cache disabled for ~25% of the counter configurations – Nov 5, 2024, 12.44 PM (Canary started: 12.20 PM)
Redis cache disabled for ~35% of the counter configurations – Nov 6, 2024, 10.50 AM (Canary started: 10.21 AM)
Redis cache disabled for ~75% of the counter configurations – Nov 7, 2024, 10.53 AM (Canary started: 10.26 AM)
Experimenting with running a major compaction job during the day time: Tue, Nov 12, 2024, between 2-5 PM (on all nodes)
Day time scheduled major compaction job starts from: Tue, Nov 13, 2024, between 2-5 PM (on all nodes)
Redis cache disabled for 100% of the counter configs – Wed, 13 Nov 2024, 10:56 AM (Canary started: 10:32 AM)
Unless otherwise specified, the graphs and metrics we report in this article uses this fixed time window: Oct 31 (Thu) 12.00 AM – Nov 15 (Friday) 11.59 PM SGT. This time window covers the entire experiment period with some buffer to observe the experiment’s impact.
Observations
As we progressively disabled read from external Redis cache over the span of 8 days (Nov 5 – Nov 13), we made interesting observations and experimented with some Scylla configuration changes on our end. We describe them in the following sections.
Scylla hit vs. cache hit
As we progressively disabled Redis cache for most of the counters, one obvious impact was the gradual increase in Scylla-bound QPS and similar decrease in Redis-cache hit. When Redis-cache was enabled for 100% of the configurations, 50% of the requests were bound for Scylla and the other 50% were for Redis. At the end of the experiment, after fully disabling Redis cache, 100% of the requests were Scylla-bound.
Figure 5. Gradual increase in Scylla QPS and simultaneous decrease in Redis cache hit.
15-minutes and hourly spikes
We noticed that the 15-minute spikes in Scylla QPS as well as the associated latency slowly became less prominent and eventually disappeared from the graph after we completely disabled the Redis cache. However, we noticed that the hourly spike still remained. This is attributed to the higher QPS from the clients calling this service at the turn of every hour. As a result, limited optimisation can be done to reduce the hourly spike on this service’s end.
Figure 6. The 15-minute spikes in Scylla QPS disappeared after the external Redis cache was fully disabled. This graph uses a smaller time window to show the earlier spikes. It also shows the persistence of hourly spikes after the experiment which is attributed to the clients of this service sending more requests at the start of every hour.
Figure 7. The graph shows that the 15-minute spikes in Scylla’s latency disappeared after the external Redis cache was fully disabled. This graph uses a smaller time window to show the earlier spikes. It also shows the persistence of hourly spikes in latency after the experiment which is attributed to the clients of this service sending more requests at the start of every hour.
Service latency and additional Scylla compaction job
When we disabled Redis cache for about 75% of the counters configurations on Nov 7 (which accounts for about 85% of the overall QPS), we noticed an increase in the overall average service latency, from between 6-8 ms to 7-12 ms (P99 went from ~30-50ms to ~30-70ms). This caused a spike in open circuit breaker (CB) events on Hystrix. At this point, before disabling cache for more counters, on Nov 12, we experimented with running an additional major compaction job on Scylla between 2-5 PM on all our Scylla nodes, progressively on each availability zone (AZ). It is noteworthy that we already have a scheduled major compaction job that runs around 3 AM every day. The outcome of this experiment was quite positive. It brought back the average and P99 latency almost to the prior level when we had Redis cache enabled for 100% of the counters. This also had a similar effect on the Hystrix CB open events. Based on this observation, we made this additional day time major compaction job as a daily scheduled job. We disabled Redis cache for 100% of the counters the next day (Nov 13). This expectedly increased the Scylla QPS, with no noticeable adverse effect on the service latency or Hystrix CB open events.
Figure 8. This graph shows how the average latency changed as a result of the experiment. The higher spikes correspond to the time when Redis cache was being progressively disabled before introducing the day time Scylla compaction job. The spikes lessened after the compaction job was introduced on Nov 12 (Note: Friday spike was due to higher traffic in general).
Figure 9. This graph shows how the P99 latency changed as a result of the experiment. The higher spikes correspond to the time when Redis cache was being progressively disabled before introducing the day time Scylla compaction job. The spikes lessened after the compaction job was introduced on Nov 12 (Note: Friday spike was due to higher traffic in general).
Scylla’s own cache
One of our hypotheses was that we were not using Scylla cache due to our system’s design, along with all the service specific characteristics discussed earlier. Our experimental results show that this is indeed the case. We observed a significant increase in Scylla reads with Scylla’s own cache hits, while Scylla reads with Scylla’s own cache misses remained about the same despite our Scylla cluster receiving double the traffic. Percentage-wise, before disabling the external Redis cache, Scylla hit its own cache for ~30% of the total reads, and after we have completely disabled the external Redis cache, Scylla hit its cache for about 70% of the reads. We believe that this largely contributes to the overall performance of the service despite fully decommissioning the expensive Redis cache component from our system architecture.
Figure 10. Significant increase in Scylla reads after disable Redis cache.
Figure 11. No change in Scylla cache miss despite the doubling of Scylla traffic.
Scylla CPU and memory usage
Contrary to our assumption, although the Scylla QPS doubled due to the change done as part of this experiment, there was marginal increase in Scylla CPU usage (from ~50% to ~52% at peak). In terms of memory, Scylla log-structured allocator (LSA) memory usage remains consistent. For Non-LSA memory, the maximum utilisation did not increase. However, we noticed two daily spikes instead of one existed before the experiment. The second spike results from the newly added daily major compaction job. Notably,the overall non-LSA peak has slightly decreased after the introduction of the new compaction job.
Figure 12. Relatively steady Scylla CPU utilisation.
Figure 13. Non-LSA memory usage spikes twice a day after the experiment. The new spike corresponds to the newly added day time compaction job.
Conclusion
In summary, we were able to maintain the same service performance while removing an expensive Redis cache component from our system architecture, which accounted for about 25% of the overall service cost. This has been made possible primarily by significant increase in the utilisation of Scylla’s own cache and adding a daily major compaction job on all our Scylla nodes.
In the future, we plan to further experiment with different Scylla configurations for potential performance gain, specifically to improve the latency.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
At Grab, we operate a set of services that manage and provide counts of various items. While this may seem straightforward, the scale at which this feature operates—benefiting millions of Grab users daily—introduces complexity. This feature is divided into three microservices: one for “writing” counts, another for handling “read” requests, and a third serving as the backend for a portal used by data scientists and analysts to configure these counters.
This article focuses on the service responsible for handling “read” requests. This service is backed by Scylla storage and a Redis cache. It also connects to a MySQL RDS to retrieve “counter configurations” that are necessary for processing incoming requests. Written in Rust, the service serves tens of thousands of queries per second (QPS) during peak times, with each request typically being a “batch request” requiring multiple lookups (~10) on Scylla.
Recently, the service has encountered performance challenges, causing periodic spikes in Scylla QPS. These spikes occur throughout the day but are particularly evident during peak hours. To understand this better, we’ll first walk you through how this service operates, particularly how it serves incoming requests. We will then explain our proposed solution and the outcomes of our experiment.
Anatomy of a request
Each counter configuration stored in MySQL has a template that dictates the format of incoming queries. For example, this sample counter configuration is used to count the raindrops for a specific city:
An incoming request using this counter might look like this:
{
"key": "rain_drops:city:111222",
"fromTime": 1727215430, // 24 September 2024 22:03:50
"toTime": 1727400000, // 27 September 2024 01:20:00
}
This request seeks the number of raindrops in our imaginary city with city ID: 111222, between 1727215430 (24 September 2024 22:03:50) and 1727400000 (27 September 2024 01:20:00).
Another service keeps track of raindrops by city and writes the minutely (truncated at 15 minutes), hourly, and daily counts to three different Scylla tables:
minutely_count_table
hourly_count_table
daily_count_table
The service processing the request rounds down the time to the nearest 15 minutes. As a result, the request is processed with the following time range:
Start time: 24 September 2024 22:00:00
End time: 27 September 2024 01:15:00
Let’s assume we have the following data in these three tables for “rain_drops:city:111222”. The datapoints used in the above example request are highlighted in bold.
minutely_count_table:
key
minutely_timestamp
count
rain_drops:city:111222
2024-09-24T22:00:00Z
3
rain_drops:city:111222
2024-09-24T22:15:00Z
2
rain_drops:city:111222
2024-09-24T22:30:00Z
4
rain_drops:city:111222
2024-09-24T22:45:00Z
1
…
…
…
rain_drops:city:111222
2024-09-27T01:00:00Z
2
rain_drops:city:111222
2024-09-27T01:15:00Z
3
hourly_count_table:
key
hourly_timestamp
count
rain_drops:city:111222
2024-09-24T22:00:00Z
18
rain_drops:city:111222
2024-09-24T23:00:00Z
22
rain_drops:city:111222
2024-09-25T00:00:00Z
15
…
…
…
rain_drops:city:111222
2024-09-27T00:00:00Z
11
rain_drops:city:111222
2024-09-27T01:00:00Z
9
daily_count_table:
key
daily_timestamp
count
rain_drops:city:111222
2024-09-24T00:00:00Z
214
rain_drops:city:111222
2024-09-25T00:00:00Z
189
rain_drops:city:111222
2024-09-26T00:00:00Z
245
rain_drops:city:111222
2024-09-27T00:00:00Z
78
Now, let’s see how the service calculates the total count for the incoming request with “rain_drops:city:111222” based on the provided data:
Time range:
From: 24 September 2024 22:03:50
To: 27 September 2024 01:20:00
For the full days within the range, specifically 25th and 26th September, we can use data from the daily_count_table. However, for the start (24th September) and end (27th September) date of the range, we cannot use data from the daily_count_table as the range only includes portions of these dates. Instead, we will use a combination of data from the hourly_count_table and minutely_count_table to accurately capture the counts for these days.
Query the daily_count_table:
Sum (full day: 25 and 26th Sep): 189 + 245 = 434
Query the hourly_count_table:
For 24th September (from 22:00:00 to 23:59:59):
Hourly count: 18 + 22 = 40
For 27th September (from 00:00:00 to 01:00:00):
Hourly count: 11
Query the minutely_count_table:
For 27th September (from 01:00:00 to 01:15:00):
Minutely count: 2
Total count:
Total = Daily count (25th and 26th) + Hourly count (24th) + Hourly count (27th) + Minutely count (27th)
= 434 + 40 + 11 + 2
= 487
Figure 1: The example request for “rain_drops:city:111222” is handled using data from three different Scylla tables.
As shown in the calculation, when the service receives the request, it comes up with the total count of raindrops by querying three Scylla tables and summing them up using some specific rules within the service itself.
Querying the cache
In the previous section, we explained how Scylla handles a query. If we cached the response for the same request earlier, retrieval from the cache follows a simpler logic. For instance, for the example request, the total count is stored using the floored start and end times (rounded to the nearest 15-minute window within an hour), which was used for the Scylla query instead of the original time in the request. The cache key-value pair would look like this:
Timestamps 1727215200 and 1727399700 represent the adjusted start and end times of 24 September 2024 22:00:00 and 27 September 2024 01:15:00, respectively. It has a Time-To-Live (TTL) of 5 minutes. During this TTL window, any request for the key “rain_drops:city:111222” having the same start and end times (after rounding to the nearest 15 minutes) will be read from the cache instead of querying Scylla.
For example, for the following three start times, although they are different, after flooring the request to the nearest 15 minutes, the start time becomes 24 September 2024 22:00:00 for all of them, which is the same start time as the one in the cache.
24 September 2024 22:01:00
24 September 2024 22:02:00
24 September 2024 22:06:00
In day-to-day operations, this caching setup allows roughly half of our total production requests to be served by the Redis cache.
Figure 2. The graph visualises the relative quantity of cache hits vs Scylla-bound requests.
Problem statement
The setup consisting of Scylla and Redis cache works well. Particularly because Scylla-bound queries need to look up 1-3 tables (minutely, hourly, daily, depending on the time range) and perform the summation as explained earlier, whereas a single cache lookup gets the final value for the same query. However, as our cache key pattern follows the 15-minute truncation strategy, along with a 5-minute cache TTL, it leads to an interesting phenomenon – our cache hits plummet and Scylla QPS spikes at the end of every 15 minutes.
Figure 3. Graph showing 15-minute spikes in Scylla-bound requests accompanied by a decline in cache hit rates.
This occurs primarily due to the fact that almost all requests to our service are for recent data. Due to this, at the end of every 15-minute block within an hour (i.e., 00, 15, 30, 45), most of the requests require creating new cache keys for the latest 15-minute block. At this point in time, there may be many unexpired (i.e., have not reached 5 min TTL) cache keys from the previous 15-minutes block, but they become less relevant as most requests are asking for recent data.
The table in Figure 4 shows example data for configurations “rain_drops:city:111222” and “bird_sighting:city:333444”. For these two configurations, new cache keys are created due to TTL expiry at random times. However, at the end of the 15-minute block, which, in this case is at the end of 22:00-22:15 block, both configurations need new cache keys for the new 15-minute time block that has just started (i.e., start of 22:15-22:30), even though some of their cache keys from the previous 15-minute block are still valid. This requirement of creating new cache keys for most of the requests at the end of a 15-minute block causes spikes in Scylla QPS and a sharp decline in cache hits.
One question that arises is – “Why don’t we see a spike every 5 minutes for cache key TTL expiry?” This is because, within the 15 minutes block, new cache keys are continuously created when a key reaches TTL and a new request for that is received. Since this happens all the time as shown in Figure 4, we do not see a sharp spike. In other words, although Scylla does receive more queries due to cache TTL expiry, it does not lead to a spike in Scylla queries or a sharp drop in cache hits. This is because the cache keys are always being created and invalidated due to TTL expiry instead of following a fixed 5-minute block similar to the 15-minute block we use for our truncation strategy.
Figure 4. This table visualises scenarios when new cache keys are required due to TTL expiry vs due to 15-minute truncation strategy.
These Scylla QPS spikes at the end of every 15-minute block lead to a highly imbalanced Scylla QPS. This often causes high latency in our service during the 15-minute blocks that fall within the peak traffic hours. This further causes more requests to time out, eventually increasing the number of failed requests.
Proposed solution
We propose mitigating this issue by completely removing the Redis-backed caching mechanism from the service. Our observations indicate that the Scylla spikes at the end of 15-minute blocks occur due to cache hit misses. Therefore, removing the caching should eliminate the spikes and provide for a more balanced load.
We acknowledge that this may seem counterintuitive from an overall performance standpoint as removing caching means all queries will be Scylla-bound, potentially impacting the overall performance since caching usually speeds up processes. In addition, caching also comes with an advantage where for cache hits, the service does not need to do the summation on Scylla results from minutely, hourly, and the daily table. Despite these shortcomings, we hypothesise that removing caching should not have an adverse impact on the overall performance. This is based on the fact the Scylla has its own sophisticated caching mechanism. However, our existing setup uses Redis for caching, underutilising Scylla’s cache as the most subsequent queries hit the Redis cache instead.
In summary, we propose eliminating the Redis caching component from our current architecture. This change is expected to resolve the Scylla query spikes observed at the end of every 15-minute block. By relying on Scylla’s native caching mechanism, we anticipate maintaining the service’s overall performance more effectively. The removal of Redis is counterbalanced by the optimised utilisation of Scylla’s built-in caching capabilities.
Experiment
Procedure
The experiment was done on an important live service serving thousands of QPS. To avoid disruptions, we followed a gradual approach. We first turned off caching for a few configurations. If there were no adverse impacts observed, we incrementally disabled cache for more configurations. We controlled the rollout increment by using a mathematical operator on the configuration IDs. This approach is simple and allows us to deterministically disable the cache for specific configurations across all requests, as opposed to using a percentage rollout which randomly disables the cache for different configurations across different requests. This is also due to the fact that the number of configurations is relatively steady and small (less than a thousand). Since these configurations are already fully cached in the service memory from RDS, there will be no performance impact of having a condition that operates on these configurations.
To make sense of the graphs and metrics reported in this section, it is important to understand the traffic pattern of this service. The service usually sees two peaks every day: noon and another around 6-7 PM. On a weekly basis, we usually see the highest traffic on Friday, with the busiest period being from 6-8 PM.
In addition, the timeline of when and how we made various changes to our setup is important to accurately interpret our results.
Experiment timeline: Nov 5 – Nov 13, 2024:
Redis cache disabled for ~5% of the counter configurations – Nov 5, 2024, 10.26 AM (Canary started: 10.00 AM)
Redis cache disabled for ~25% of the counter configurations – Nov 5, 2024, 12.44 PM (Canary started: 12.20 PM)
Redis cache disabled for ~35% of the counter configurations – Nov 6, 2024, 10.50 AM (Canary started: 10.21 AM)
Redis cache disabled for ~75% of the counter configurations – Nov 7, 2024, 10.53 AM (Canary started: 10.26 AM)
Experimenting with running a major compaction job during the day time: Tue, Nov 12, 2024, between 2-5 PM (on all nodes)
Day time scheduled major compaction job starts from: Tue, Nov 13, 2024, between 2-5 PM (on all nodes)
Redis cache disabled for 100% of the counter configs – Wed, 13 Nov 2024, 10:56 AM (Canary started: 10:32 AM)
Unless otherwise specified, the graphs and metrics we report in this article uses this fixed time window: Oct 31 (Thu) 12.00 AM – Nov 15 (Friday) 11.59 PM SGT. This time window covers the entire experiment period with some buffer to observe the experiment’s impact.
Observations
As we progressively disabled read from external Redis cache over the span of 8 days (Nov 5 – Nov 13), we made interesting observations and experimented with some Scylla configuration changes on our end. We describe them in the following sections.
Scylla hit vs. cache hit
As we progressively disabled Redis cache for most of the counters, one obvious impact was the gradual increase in Scylla-bound QPS and similar decrease in Redis-cache hit. When Redis-cache was enabled for 100% of the configurations, 50% of the requests were bound for Scylla and the other 50% were for Redis. At the end of the experiment, after fully disabling Redis cache, 100% of the requests were Scylla-bound.
Figure 5. Gradual increase in Scylla QPS and simultaneous decrease in Redis cache hit.
15-minutes and hourly spikes
We noticed that the 15-minute spikes in Scylla QPS as well as the associated latency slowly became less prominent and eventually disappeared from the graph after we completely disabled the Redis cache. However, we noticed that the hourly spike still remained. This is attributed to the higher QPS from the clients calling this service at the turn of every hour. As a result, limited optimisation can be done to reduce the hourly spike on this service’s end.
Figure 6. The 15-minute spikes in Scylla QPS disappeared after the external Redis cache was fully disabled. This graph uses a smaller time window to show the earlier spikes. It also shows the persistence of hourly spikes after the experiment which is attributed to the clients of this service sending more requests at the start of every hour.
Figure 7. The graph shows that the 15-minute spikes in Scylla’s latency disappeared after the external Redis cache was fully disabled. This graph uses a smaller time window to show the earlier spikes. It also shows the persistence of hourly spikes in latency after the experiment which is attributed to the clients of this service sending more requests at the start of every hour.
Service latency and additional Scylla compaction job
When we disabled Redis cache for about 75% of the counters configurations on Nov 7 (which accounts for about 85% of the overall QPS), we noticed an increase in the overall average service latency, from between 6-8 ms to 7-12 ms (P99 went from ~30-50ms to ~30-70ms). This caused a spike in open circuit breaker (CB) events on Hystrix. At this point, before disabling cache for more counters, on Nov 12, we experimented with running an additional major compaction job on Scylla between 2-5 PM on all our Scylla nodes, progressively on each availability zone (AZ). It is noteworthy that we already have a scheduled major compaction job that runs around 3 AM every day. The outcome of this experiment was quite positive. It brought back the average and P99 latency almost to the prior level when we had Redis cache enabled for 100% of the counters. This also had a similar effect on the Hystrix CB open events. Based on this observation, we made this additional day time major compaction job as a daily scheduled job. We disabled Redis cache for 100% of the counters the next day (Nov 13). This expectedly increased the Scylla QPS, with no noticeable adverse effect on the service latency or Hystrix CB open events.
Figure 8. This graph shows how the average latency changed as a result of the experiment. The higher spikes correspond to the time when Redis cache was being progressively disabled before introducing the day time Scylla compaction job. The spikes lessened after the compaction job was introduced on Nov 12 (Note: Friday spike was due to higher traffic in general).
Figure 9. This graph shows how the P99 latency changed as a result of the experiment. The higher spikes correspond to the time when Redis cache was being progressively disabled before introducing the day time Scylla compaction job. The spikes lessened after the compaction job was introduced on Nov 12 (Note: Friday spike was due to higher traffic in general).
Scylla’s own cache
One of our hypotheses was that we were not using Scylla cache due to our system’s design, along with all the service specific characteristics discussed earlier. Our experimental results show that this is indeed the case. We observed a significant increase in Scylla reads with Scylla’s own cache hits, while Scylla reads with Scylla’s own cache misses remained about the same despite our Scylla cluster receiving double the traffic. Percentage-wise, before disabling the external Redis cache, Scylla hit its own cache for ~30% of the total reads, and after we have completely disabled the external Redis cache, Scylla hit its cache for about 70% of the reads. We believe that this largely contributes to the overall performance of the service despite fully decommissioning the expensive Redis cache component from our system architecture.
Figure 10. Significant increase in Scylla reads after disable Redis cache.
Figure 11. No change in Scylla cache miss despite the doubling of Scylla traffic.
Scylla CPU and memory usage
Contrary to our assumption, although the Scylla QPS doubled due to the change done as part of this experiment, there was marginal increase in Scylla CPU usage (from ~50% to ~52% at peak). In terms of memory, Scylla log-structured allocator (LSA) memory usage remains consistent. For Non-LSA memory, the maximum utilisation did not increase. However, we noticed two daily spikes instead of one existed before the experiment. The second spike results from the newly added daily major compaction job. Notably,the overall non-LSA peak has slightly decreased after the introduction of the new compaction job.
Figure 12. Relatively steady Scylla CPU utilisation.
Figure 13. Non-LSA memory usage spikes twice a day after the experiment. The new spike corresponds to the newly added day time compaction job.
Conclusion
In summary, we were able to maintain the same service performance while removing an expensive Redis cache component from our system architecture, which accounted for about 25% of the overall service cost. This has been made possible primarily by significant increase in the utilisation of Scylla’s own cache and adding a daily major compaction job on all our Scylla nodes.
In the future, we plan to further experiment with different Scylla configurations for potential performance gain, specifically to improve the latency.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Although Grab is a tech company, not everyone is an engineer. Many team members don’t use GitLab daily, and Markdown’s quirks can be challenging for them. This made adopting the Docs-as-Code culture a hurdle, particularly for non-engineering teams responsible for key engineering-facing documents. In this article, we’ll discuss how we’ve streamlined the Docs-as-Code process for technical contributors, specifically non-engineers, who are not very familiar with GitLab and might face challenges with Markdown. For more on the benefits of the Docs-as-Code approach, check out this blog on the subject.
As part of our ongoing efforts to enhance the TechDocs experience, we’ve introduced a rich text editor for those who prefer a WYSIWYG (What You See Is What You Get) interface on top of a Git workflow, helping to simplify authoring. We’ll also cover how we plan to improve the workflow for non-engineering teams contributing to service and standalone documentation.
The need for a rich text editor
Ask any developer today, and they’ll likely tell you that Markdown is the go-to format for documentation. Due to its simplicity, whether it’s GitHub, GitLab, Bitbucket, or other platforms, Markdown has become the default choice, even for issue tracking. It’s also integrated into most text editors, like IntelliJ, VS Code, Vim, and Emacs, with handy plugins for syntax highlighting and previewing.
Engineers are gradually embracing the Docs-as-Code approach and enjoying the benefits of writing the documentation in Markdown format directly in their IDEs and pushing them out as merge requests (MR). However, non-engineers face the nuance of writing in Markdown and going through the Git workflow. This is when the call for a WYSIWYG (What You See Is What You Get) editor aka TechDocs editor came about. This solution brought about several benefits to non-engineers. It provides a familiar, UI-based experience for editing, but it still aligns with the Docs-as-Code model. This tool allows users to edit documentation via a simple UI in the Backstage portal without having to deal with the complexities of MkDocs, entity catalogs, or Markdown syntax. In the context Backstage, “entities” refer to services, platforms, tools, or libraries, and documentation is often tied to these entities to provide context sensitivity. The goal was to make it easy for people to focus on content, not the tools, and enable quick updates without the technical overhead.
We’ve kept GitLab as the central storage system, but now, with the TechDocs editor, non-engineers can contribute with ease. Figure 1 highlights our editor’s features:
Reordering
Renaming
Deleting pages
Switching between normal and Markdown views
Formatting text with titles, bullets, numbering
Figure 1: TechDocs editor in Helix TechDocs portal
Our goal for our editor is to make it more flexible, performant, and user-friendly. Based on user feedback, key priorities include customisation, extensibility for non-standard Markdown elements, and long-term maintainability.
To achieve this, we selected the Lexical framework. Compared to other Markdown-based tools like Toast UI, Lexical offers greater extensibility, allowing us to implement advanced features such as autocomplete and support for non-standard Markdown elements like Kroki diagrams.
The following flowchart illustrates how Markdown content is imported and exported within the Lexical editor, ensuring seamless integration with TechDocs.
Figure 2: Lexical Markdown transformer flow chart
By continuously iterating based on user needs, we aim to make Docs-as-Code accessible not just for engineers but for anyone contributing to documentation at Grab.
User journeys
We explored various workflows to streamline the documentation lifecycle, focusing on both creation and editing processes. By integrating these workflows into the developer portal, we ensured that users can easily create and edit documentation, enhancing overall efficiency and collaboration.
Here are the three key user journeys we focused on addressing:
Journey 1: Edit existing TechDocs
High level workflow definition:
Toggle to ‘edit’ mode: The user switches to the edit mode to start making changes to the TechDocs.
User starts editing TechDocs: The user begins the process of editing the documentation and clicks save.
User gets redirected to GitLab: If not authenticated, they are redirected to GitLab for authentication. Once authenticated, a merge request is created to update the entity YAML file and add the new TechDocs.
Access check: The system checks if the user has access to the TechDocs file repository. If not, they are prompted to request access.
Figure 3: User journey 1
Journey 2: Create stand-alone TechDocs from “Documentation” page
High level workflow definition:
User authentication:
If the user is not authenticated, they are redirected to GitLab for authentication.
If the user is already authenticated, the process skips to the next step.
Registering merge requests:
The MR is registered to a scheduler job to automatically register a new entity catalog when it detects that the MR has been merged.
This workflow ensures that users are authenticated via GitLab before proceeding and that new entity catalogs are automatically registered upon the merging of MRs.
Figure 4: User journey 2
Journey 3: Create TechDocs from “Docs” tab on entity page
High level workflow definition:
Start creating TechDocs:
User selects ‘create TechDocs’ on the ‘Docs’ tab in the Helix TechDocs portal UI.
Save and redirect:
User clicks ‘save’ and is redirected to GitLab with a merge request (MR) created to update the entity YAML file and add new TechDocs.
Access check and MR registration:
If the user has access to the entity YAML file repository, proceed with the MR. If not, prompt the user to get access.
Register the MR to a scheduler job to automatically refresh the entity catalog when it detects the MR as merged.
Figure 5: User journey 3
Phased rollout
We phased the rollout of our Markdown editor to ensure a smooth transition, allowing users to gradually adapt while we gathered feedback and iterated on features. This approach helped us address challenges early, refine usability, and deliver meaningful improvements with each phase.
Phase 1: Initial Markdown editor for developer portal
In Phase 1, we built a basic editor aligned with our documentation standards. Users can create and edit TechDocs for different entity catalogs, with support for basic Markdown and image previews for both absolute and relative paths. The editor tracks concurrent editing sessions and shows pending merge requests. It also includes Markdown configuration options to add, rename, reorganise, or delete pages. Additionally, our GitLab integration consolidates changes into a single commit and opens a merge request.
Phase 2: Independent documentation creation
Phase 2 includes expanded functionality to support independent documentation creation and related features, such as:
HTML preview and image uploads (relative paths).
Save drafts locally in the browser.
Pending MRs listed in the editor.
Draw.io and Excalidraw integration for diagrams.
MkDocs updates: change site name.
Auto-registeration of new entity catalogs when MRs are merged.
Phase 3: Advanced editor capabilities
Phase 3 introduced additional features, such as:
Support for Kroki / Mermaid diagrams.
Display concurrent edit sessions for better collaboration.
Each phase improved the editor, enhancing TechDocs at Grab with seamless GitLab integration and user-friendly features.
Integrating the ability to do a live preview
While syntax highlighting in the TechDocs editor is helpful, it can’t fully predict how the final Markdown document will appear once rendered due to Markdown flavour inconsistencies. This is especially true for elements like images, tables, and diagrams, where visual verification is crucial. To minimise these risks, the TechDocs editor includes a live preview feature, allowing users to see the fully rendered document alongside the editor in a split-screen view. This lets users verify their work as they go, preventing the need to switch back and forth between the editor and the final document, saving time and reducing potential formatting errors.
However, like most live preview features, performance challenges can arise. For larger documents, the process of continuously converting Markdown to HTML can slow down editing. External resources such as images that need to be re-rendered, can cause visual glitches or delays in the preview. Running scripts or using plugins with extended grammar also adds to the performance load, requiring frequent re-execution and potentially slowing down the experience.
To mitigate these issues, the TechDocs editor uses an inbuilt preview feature that shows users exactly how their changes are going to appear on the portal once their changes are merged. This ensures that users can confidently make adjustments and understand the final presentation before committing their updates. Additionally, the live preview feature enables more efficient collaboration by providing real-time feedback on content and formatting, further enhancing the overall documentation workflow.
GitLab integration strategy
The TechDocs editor integrates seamlessly with GitLab, allowing users to make changes effortlessly through OAuth2 authentication. When users log into the editor, they simply click the “Connect with GitLab” button, which provides access via the OAuth 2.0 protocol. Once connected, all modifications made within the editor are executed using the user’s GitLab credentials, streamlining the documentation process and ensuring a smooth experience for users as they update their documentation directly within the TechDocs framework.
To minimise Git conflicts, we considered and implemented some of these approaches:
Display pending merge requests at the top of the editor to alert users of existing changes.
Show who else is editing the same TechDocs to help users coordinate and avoid conflicts.
Include tools to automatically or semi-automatically resolve Git conflicts.
Conclusion
Bringing Docs-as-Code to a broader audience at Grab meant addressing the challenges faced by non-engineering contributors. With the introduction of a WYSIWYG editor, seamless GitLab integration, and a live preview feature, we’ve made it easier for everyone to contribute without needing deep Markdown expertise.
As we continue to improve the TechDocs editor, our focus remains on removing barriers to documentation, enhancing collaboration, and ensuring that our docs evolve alongside our fast-moving engineering teams.
Docs-as-Code isn’t just about engineers writing documentation—it’s about making documentation a natural and frictionless part of the development process for everyone.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
One-on-one meetings with your manager are one of the most valuable tools you have for career growth, problem-solving, and unlocking new opportunities. So if you’re only using them to provide status updates, you’re leaving a lot on the table.
I didn’t fully realize this potential until I mentioned in a one-on-one that I was interested in mentorship and growing my leadership skills. Not long after, I was asked to co-lead a project with an intern to build an internal tool that helped surface enterprise configuration details. This gave me the opportunity to take technical ownership on a project while mentoring someone in a real-world context—both of which pushed me outside my comfort zone in the best way. That experience made it clear: When used intentionally, one-on-ones can open doors you didn’t even know were there.
Many engineers treat one-on-ones as a low-stakes standup: reporting work, mentioning blockers, and getting general feedback. While that can be useful, it barely scratches the surface of what these meetings can accomplish. Instead, think of them as a system design review for your role—a time to debug challenges, optimize your workflow, and align on long-term career goals.
Reframing your perception of what a one-on-one can accomplish
A well-structured one-on-one meeting with your manager isn’t just a check-in, it’s an opportunity to shape your work environment and career trajectory. You wouldn’t build a system without evaluating its constraints, dependencies, and long-term maintainability. Why approach your career any differently?
Start by shifting your mindset: These meetings are not status updates. Your manager already sees your pull requests, sprint velocity, and planning docs. Instead, use this time to highlight what matters—what you’ve shipped, the value it’s delivered, and where the friction is.
You can also use this space to validate decisions and gather context. If you’re weighing different paths forward, don’t just ask for approval—frame the conversation in terms of trade-offs:
“Here are the pros and cons of refactoring this service now versus later. How does this align with our broader business goals?”
Treat your manager like a decision-making API: Feed in the relevant signals, surface what’s unclear, and work together on an informed response.
Use one-on-ones for career versioning (even before you’re “ready”)
One-on-one meetings are a great time to discuss your long-term career growth—even if you’re not actively seeking a promotion. Instead of waiting until promotion season, start having these conversations early to build clarity, direction, and momentum over time.
If you’re more than a year away from seeking a promotion, start talking to your manager about:
Where am I already meeting expectations?
Where should I focus on strengthening my skills?
If you’re approaching the next level or considering going up for promotion soon, try focusing the conversation on:
What kind of work would demonstrate readiness for the next level?
Are there specific opportunities I can take on to grow my scope or visibility?
By treating growth as an iterative process rather than an all-or-nothing milestone, you can continuously improve and course-correct based on early feedback.
A useful framework for structuring these discussions is the Three Circles of Impact:
Individual Contributions – The direct value of your work.
Collaboration – How you work with and support others across the team.
Enabling Others – Mentorship, knowledge sharing, or improving systems and tooling for your peers.
If you’re not sure how to show impact across all three, your one-on-one is a great place to explore it. The key is surfacing your goals early so your manager can help guide you toward the kinds of work that will stretch your skills and broaden your influence.
The more you shape your contributions around these areas, the clearer your readiness for growth becomes—and the easier it is for your manager to advocate on your behalf.
Your manager can’t debug what they don’t see
Managers don’t have full visibility into your day-to-day experience, so one-on-ones are the right time to highlight persistent blockers and unclear expectations.
For instance, I once brought up a latency issue I was chasing down. The endpoint’s performance was slightly above our service level objective (SLO) target, and I had already spent a good chunk of time optimizing it. But in that conversation, my manager offered a different lens:
“Are we optimizing for the right thing? We control the SLO. If the extra latency is due to how the system is designed (and if users aren’t impacted) maybe the right move is to revisit the threshold instead of squeezing more performance out of it.”
That single conversation saved me hours and helped me reframe the problem entirely. Sometimes, the fix isn’t in your code—it’s in how you’re measuring success.
Make your one-on-ones work for you
Your one-on-ones will become far more effective—and lead to real growth—when you treat them as time to think strategically, not just check in. Reframing these meetings around your goals, your environment, and your long-term development puts you in a much stronger position to advocate for yourself and your work.
Start thinking about your career progression earlier than feels natural. Come prepared. Bring in what’s going well, what’s stuck, and where you want to grow. And remember: your manager can’t fix what they don’t know about, and they can’t support your goals if you never share them.
If this shift feels unfamiliar, you’re not alone. The Engineer’s Survival Guide helped me reframe my thinking around one-on-ones.
Here are a few ideas that stuck with me:
Your manager isn’t a mind reader.
You can’t expect guidance if you don’t come with a direction.
Your growth is a shared effort, but it starts with you.
The earlier you see one-on-ones as a tool for impact and growth, the more value you’ll get from them.
Hugo plays a pivotal role in enabling data ingestion for Grab’s data lake, managing over 4,000 pipelines onboarded by users. The stability of Hugo pipelines is contingent upon the health of both the data sources and various Hugo components. Given the complexity of this system, pipeline failures occasionally occur, necessitating user intervention when retry mechanisms prove insufficient. These incidents present challenges such as:
Limited user visibility into pipeline issues.
Uncertainty about resolution steps due to extensive documentation.
An overwhelmed Hugo on-call team dealing with ad-hoc requests and growing infrastructure dependencies.
Raised Data Production Issues (DPIs) lacking clear Root Cause Analysis (RCA), hindering effective management.
Such challenges ultimately increase data downtime due to prolonged issue triage and resolution times.
To address these problems, we conducted a thorough analysis of failure modes and the efforts required to resolve them. Based on our findings, we propose a comprehensive automation solution.
This blog outlines the architecture and implementation of our proposed solution, consisting of modules like Signal, Diagnosis, RCA Table, Auto-resolution, Data Health API, and Data Health WorkBench, each with a specific function to enhance Hugo’s monitoring, diagnosis, and resolution capabilities.
The blog further details the impact of these automated features, such as enhanced data visibility, reduced on-call workload, and concludes with our next steps, which focus on advancing auto-resolution strategies, enriching the Data Health Workbench, and broadening diagnostics to include more infrastructure components, like Flink, for comprehensive coverage.
Architecture details
We designed the solution based on these principles:
Identify different failure modes based on past issues and analysis from first principles.
Analyse temporal relationships of pipeline execution steps to diagnose issues to failure modes.
Focus on auto-resolution, and add additional features to cover gaps which can’t be immediately addressed by auto-resolution or diagnosis.
The following diagram shows the solution we proposed.
Figure 1. Architecture
The architecture consists of five core modules, each with a specific function:
Signal module: This module is responsible for collecting signals. It gathers three different types of signals that collectively define the health status of the data lake table. The signals include:
Failure callback signal: This indicates whether the pipeline runs involving this data lake table are successful or not.
SLA alert signal: This indicates whether the pipeline execution involving this data lake table meets the Service Level Agreement (SLA). For an hourly batch job, the expectation is to complete within one hour.
Data quality test failure signal: This represents various types of completeness checks to ensure that data lake tables are consistent with the source tables based on their pipeline strategies.
Diagnosis module: This is the core module responsible for diagnosing the root cause of 3 types of failures collected in the Signal module. It determines:
The root cause of the failure.
The assignee responsible for fixing the error.
The auto-resolution method to fix the issue.
Manual resolution steps if the auto-resolution fails.
RCA table: This module stores the following information:
Signals
Assignee information
Diagnosis results
Auto-resolution methods
Manual resolution steps
Auto-resolution module: This module executes the auto-resolution methods to resolve issues automatically.
Data health API: This module provides API access to other platforms. External platforms or pipelines that rely on Hugo onboarded tables can subscribe to the health status and investigate the root cause when a table is deemed unhealthy.
Hugo pipeline health dashboard: A centralised dashboard for Hugo users to visualise the health status of tables, auto resolution status, and manual fix button.
By leveraging these modules, the architecture ensures robust monitoring, diagnosis, and resolution of issues, leading to improved data health and operational efficiency.
Implementation
Signal module
There are two methods for generating these three signals. The failure signal is generated through an airflow callback, while the SLA miss and data completeness test signals are produced by Genchi. Genchi is a data quality observability platform at Grab that performs data quality checks and acts as a crucial enabler for the enforcement of data contracts.
Diagnosis module
As soon as an alert is created, the diagnosis begins. To avoid lengthy diagnosis times, Hugo has developed an innovative approach that eliminates the requirement for parsing extensive logs, such as Spark executor logs or Airflow logs. Instead, it gathers signals transmitted by the computation engine or Grab’s internal platforms.
The diagnosis process can be time-consuming, even with efforts to reduce the time it takes. For example, the SLA diagnoser uses multiple analysers that run sequentially, and some of these analysers (like the Airflow analyser) make API calls that can take a significant amount of time. The more analysers that are involved in the diagnosis process, the longer it can take.
Figure 2. Diagnosis process
Parallelism in diagnosis serves as a solution to lower the overall latency when there is a surge in error traffic. The degree of parallelism differs based on the type of signal. For example, the failure signal diagnosis can be executed in thousands of processes at once, while for SLA miss and data quality test failures signals, the parallelism is determined by the number of partitions in the Kafka topic since these signals are received from Kafka.
Auto-resolution module
Auto-resolution is a flexible framework that enables the implementation of custom handlers for various types of failures. One of the common handlers employs a retry mechanism with backoff for transient errors. For instance, if Hugo receives a failure callback indicating that the root cause is a database replica lag, it would wait for an hour before re-triggering the job. This auto-resolution process runs asynchronously with the diagnosis process.
Data health API
The data health information includes a unique identifier, current status, error details, and the time of the last health check, providing a comprehensive snapshot of the dataset’s health.
Hugo converts the detailed information available in its internal data health API to the data health API specification format to be consumed by Kinabalu, our internal system designed to automate and streamline incident management processes by integrating with multiple systems such as Slack, Jira, Splunk on-call, and Datadog.
Hugo pipeline health dashboard
The Data Health Workbench is a centralised dashboard for Hugo users to visualise the health status of tables, auto-resolution status, and manual fix buttons. It provides a comprehensive view of data health and facilitates efficient issue resolution.
The key features are as follows:
Health status visualisation: Displays the current health status of tables, making it easy to identify unhealthy tables.
Assignee information: Indicates the assignee responsible for fixing the issue, ensuring clear accountability.
How-to-fix guide: Provides step-by-step instructions on how to resolve the issue, empowering users to take immediate action.
Action: Offers an action button to initiate the resolution process with a single click, streamlining issue resolution.
Admin feature with detailed diagnosis information: Provides admins supplementary information, including the reasoning behind the root cause identification and assignee determination, which allows for a deeper understanding of the root cause of issues.
By leveraging the Data Health Workbench, Hugo users can efficiently monitor and manage data health, ensuring data integrity and operational efficiency.
Figure 3. Data Health Workbench
Impact
The implementation of Hugo’s auto-healing and diagnosis features has resulted in significant improvements in stability and operational efficiency for our data pipelines. Here are some key outcomes:
Enhanced data visibility: We’ve improved the visibility into the health of datasets, allowing for quick identification of issues and more informed decision-making.
Timely resolution of data issues: With automated diagnostic and resolution processes, we ensure that data issues are addressed promptly, minimising data downtime and enhancing overall data availability.
Reduced on-call workload: By automating many of the common failure resolutions, the workload on Hugo on-call teams has been significantly reduced. This allows teams to focus on more complex and impactful tasks.
Scalable solution for managing complexity: The auto-resolution framework is well-equipped to handle the increasing complexity of data infrastructure, offering scalable solutions for transient errors through custom handlers and retry mechanisms.
Improved data contract management: By providing detailed pipeline health information via the Data Health API, we enable precise and accurate DPIs, complete with root cause analysis and assignee information, enhancing the management and resolution of data contract breaches.
Valuable reference for other platforms: The insights and methodologies developed through this initiative provide a valuable reference for other platform teams at Grab looking to implement similar automation and diagnostic capabilities.
Support for Grab’s success: These enhancements support Grabbers by ensuring easy access to the datasets they need and contribute to the overall success of Grab through reliable data availability.
Next steps
Our next steps involve advancing auto-resolution strategies by focusing on complex solutions like pipeline runtime optimisation to boost efficiency and minimise processing delays. We will enrich the Data Health Workbench with detailed information, enabling users to visualise and understand pipeline health more effectively and make informed corrective actions. Additionally, we plan to broaden our diagnosis capabilities by integrating more infrastructure components, such as Flink health information, to ensure a comprehensive and holistic monitoring approach for all engines within Hugo.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Software development is filled with repetitive tasks—managing issues, handling approvals, triggering CI/CD workflows, and more. But what if you could automate these types of tasks directly within GitHub Issues? That’s the promise of IssueOps, a methodology that turns GitHub Issues into a command center for automation.
Whether you’re a solo developer or part of an engineering team, IssueOps helps you streamline operations without ever leaving your repository.
In this article, I’ll explore the concept of IssueOps using state-machine terminology and strategies to help you work more efficiently on GitHub. After all, who doesn’t love automation?
What is IssueOps?
IssueOps is the practice of using GitHub Issues, GitHub Actions, and pull requests (PR) as an interface for automating workflows. Instead of switching between tools or manually triggering actions, you can use issue comments, labels, and state changes to kick off CI/CD pipelines, assign tasks, and even deploy applications.
Much like the various other *Ops paradigms (ChatOps, ClickOps, and so on), IssueOps is a collection of tools, workflows, and concepts that, when applied to GitHub Issues, can automate mundane, repetitive tasks. The flexibility and power of issues, along with their relationship to pull requests, create a near limitless number of possibilities, such as managing approvals and deployments. All of this can really help to simplify your workflows on GitHub. I’m speaking from personal experience here.
It’s important to note that IssueOps isn’t just a DevOps thing! Where DevOps offers a methodology to bring developers and operations into closer alignment, IssueOps is a workflow automation practice centered around GitHub Issues. IssueOps lets you run anything from complex CI/CD pipelines to a bed and breakfast reservation system. If you can interact with it via an API, there’s a good chance you can build it with IssueOps!
So, why use IssueOps?
There are lots of benefits to utilizing IssueOps. Here’s how it’s useful in practice:
It’s event driven, so you can automate the boring stuff: IssueOps lets you automate workflows directly from GitHub Issues and pull requests, turning everyday interactions—from kicking off a CI/CD pipeline and managing approvals to updating project boards—into powerful triggers for GitHub Actions.
It’s customizable, so you can tailor workflows to your needs: No two teams work the same way, and IssueOps is flexible enough to adapt. Whether you’re automating bug triage or triggering deployments, you can customize workflows based on event type and data provided.
It’s transparent, so you can keep a record: All actions taken on an issue are logged in its timeline, creating an easy-to-follow record of what happened and when.
It’s immutable, so you can audit whenever you need: Because IssueOps uses GitHub Issues and pull requests as a source of truth, every action leaves a record. No more chasing approvals in Slack or manually triggering workflows: IssueOps keeps everything structured, automated, and auditable right inside GitHub.
Defining IssueOps workflows and how they’re like finite-state machines
Most IssueOps workflows follow the same basic pattern:
A user opens an issue and provides information about a request
The issue is validated to ensure it contains the required information
The issue is submitted for processing
Approval is requested from an authorized user or team
The request is processed and the issue is closed
Suppose you’re an administrator of an organization and want to reduce the overhead of managing team members. In this instance, you could use IssueOps to build an automated membership request and approval process. Within a workflow like this, you’d have several core steps:
A user creates a request to be added to a team
The request is validated
The request is submitted for approval
An administrator approves or denies this request
The request is processed
If approved, the user is added to the team
If denied, the user is not added to the team
The user is notified of the outcome
When designing your own IssueOps workflows, it can be very helpful to think of them as a finite-state machine: a model for how objects move through a series of states in response to external events. Depending on certain rules defined within the state machine, a number of different actions can take place in response to state changes. If this is a little too complex, you can also think of it like a flow chart.
To apply this comparison to IssueOps, an issue is the object that is processed by a state machine. It changes state in response to events. As the object changes state, certain actions may be performed as part of a transition, provided any required conditions (guards) are met. Once an end state is reached, the issue can be closed.
This breaks down into a few key concepts:
State: A point in an object’s lifecycle that satisfies certain condition(s).
Event: An external occurrence that triggers a state change.
Transition: A link between two states that, when traversed by an object, will cause certain action(s) to be performed.
Action: An atomic task that is performed when a transition is taken.
Guard: A condition that is evaluated when a trigger event occurs. A transition is taken only if all associated guard condition(s) are met.
Here’s a simple state diagram for the example I discussed above.
Now, let’s dive into the state machine in more detail!
Key concepts behind state machines
The benefit of breaking your workflow down into these components is that you can look for edge cases, enforce conditions, and create a robust, reliable result.
States
Within a state machine, a state defines the current status of an object. As the object transitions through the state machine, it will change states in response to external events. When building IssueOps workflows, common states for issues include opened, submitted, approved, denied, and closed.
These should suffice as the core states to consider when building our workflows in our team membership example above.
Events
In a state machine, an event can be any form of interaction with the object and its current state. When building your own IssueOps, you should consider events from both the user and GitHub points of view.
In our team membership request example, there are several events that can trigger a change in state. The request can be created, submitted, approved, denied, or processed.
In this example, a user interacting with an issue—such as adding labels, commenting, or updating milestones—can also change its state. In GitHub Actions, there are many events that can trigger your workflows (see events that trigger workflows).
Here are a few interactions, or events, that would affect our example IssueOps workflow when it comes to managing team members:
Request
Event
State
Request is created
issues
opened
Request is approved
issue_comment
created
Request is denied
issue_comment
created
As you can see, the same GitHub workflow trigger can apply to multiple events in our state machine. Because of this, validation is key. Within your workflows, you should check both the type of event and the information provided by the user. In this case, we can conditionally trigger different workflow steps based on the content of the issue_comment event.
A transition is simply the change from one state to another. In our example, for instance, a transition occurs when someone opens an issue. When a request meets certain conditions, or guards, the change in state can take place. When the transition occurs, some actions or processing may take place, as well.
With our example workflow, you can think of the transitions themselves as the lines connecting different nodes in the state diagram. Or the lines connecting boxes in a flow chart.
Guards
Guards are conditions that must be verified before an event can trigger a transition to a different state. In our case, we know the following guards must be in place:
A request should not transition to an Approved state unless an administrator comments .approve on the issue.
A request should not transition to a Denied state unless an administrator comments .deny on the issue.
What about after the request is approved and the user is added to the team? This is referred to as an unguarded transition. There are no conditions that must be met, so the transition happens immediately!
Actions
Lastly, actions are specific tasks that are performed during a transition. They may affect the object itself, but this is not a requirement in our state machine. In our example, the following actions may take place at different times:
Administrators are notified that a request has been submitted
The user is added to the requested team
The user is notified of the outcome
A real-world example: Building a team membership workflow with IssueOps
Now that all of the explanation is out of the way, let’s dive into building our example! For reference, we’ll focus on the GitHub Actions workflows involved in building this automation. There are some additional repository and permissions settings involved that are discussed in more detail in these IssueOps docs.
Step 1: Issue form template
GitHub issue forms let you create standardized, formatted issues based on a set of form fields. Combined with the issue-ops/parser action, you can get reliable, machine-readable JSON from issue body Markdown. For our example, we are going to create a simple form that accepts a single input: the team where we want to add the user.
name: Team Membership Request
description: Submit a new membership request
title: New Team Membership Request
labels:
- team-membership
body:
- type: input
id: team
attributes:
label: Team Name
description: The team name you would like to join
placeholder: my-team
validations:
required: true
When issues are created using this form, they will be parsed into JSON, which can then be passed to the rest of the IssueOps workflow.
{
"team": "my-team"
}
Step 2: Issue validation
With a machine-readable issue body, we can run additional validation checks to ensure the information provided follows any rules we might have in place. For example, we can’t automatically add a user to a team if the team doesn’t exist yet! That is where the issue-ops/validator action comes into play. Using an issue form template and a custom validation script, we can confirm the existence of the team ahead of time.
module.exports = async (field) => {
const { Octokit } = require('@octokit/rest')
const core = require('@actions/core')
const github = new Octokit({
auth: core.getInput('github-token', { required: true })
})
try {
// Check if the team exists
core.info(`Checking if team '${field}' exists`)
await github.rest.teams.getByName({
org: process.env.GITHUB_REPOSITORY_OWNER ?? '',
team_slug: field
})
core.info(`Team '${field}' exists`)
return 'success'
} catch (error) {
if (error.status === 404) {
// If the team does not exist, return an error message
core.error(`Team '${field}' does not exist`)
return `Team '${field}' does not exist`
} else {
// Otherwise, something else went wrong...
throw error
}
}
}
When included in our IssueOps workflow, this adds any validation error(s) to the comment on the issue.
Step 3: Issue workflows
The main “entrypoint” of this workflow occurs when a user creates or edits their team membership request issue. This workflow should focus heavily on validating any user inputs! For example, what should happen if the user inputs a team that does not exist?
In our state machine, this workflow is responsible for handling everything up to the opened state. Any time an issue is created, edited, or updated, it will re-run validation to ensure the request is ready to be processed. In this case, an additional guard condition is introduced. Before the request can be submitted, the user must comment with .submit after validation has passed.
name: Process Issue Open/Edit
on:
issues:
types:
- opened
- edited
- reopened
permissions:
contents: read
id-token: write
issues: write
jobs:
validate:
name: Validate Request
runs-on: ubuntu-latest
# This job should only be run on issues with the `team-membership` label.
if: ${{ contains(github.event.issue.labels.*.name, 'team-membership') }}
steps:
# This is required to ensure the issue form template and any validation
# scripts are included in the workspace.
- name: Checkout
id: checkout
uses: actions/checkout@v4
# Since this workflow includes custom validation scripts, we need to
# install Node.js and any dependencies.
- name: Setup Node.js
id: setup-node
uses: actions/setup-node@v4
# Install dependencies from `package.json`.
- name: Install Dependencies
id: install
run: npm install
# GitHub App authentication is required if you want to interact with any
# resources outside the scope of the repository this workflow runs in.
- name: Get GitHub App Token
id: token
uses: actions/create-github-app-token@v1
with:
app-id: ${{ vars.ISSUEOPS_APP_ID }}
private-key: ${{ secrets.ISSUEOPS_APP_PRIVATE_KEY }}
owner: ${{ github.repository_owner }}
# Remove any labels and start fresh. This is important because the
# issue may have been closed and reopened.
- name: Remove Labels
id: remove-label
uses: issue-ops/labeler@v2
with:
action: remove
github_token: ${{ steps.token.outputs.token }}
labels: |
validated
approved
denied
issue_number: ${{ github.event.issue.number }}
repository: ${{ github.repository }}
# Parse the issue body into machine-readable JSON, so that it can be
# processed by the rest of the workflow.
- name: Parse Issue Body
id: parse
uses: issue-ops/parser@v4
with:
body: ${{ github.event.issue.body }}
issue-form-template: team-membership.yml
workspace: ${{ github.workspace }}
# Validate early and often! Validation should be run any time an issue is
# interacted with, to ensure that any changes to the issue body are valid.
- name: Validate Request
id: validate
uses: issue-ops/validator@v3
with:
add-comment: true
github-token: ${{ steps.token.outputs.token }}
issue-form-template: team-membership.yml
issue-number: ${{ github.event.issue.number }}
parsed-issue-body: ${{ steps.parse.outputs.json }}
workspace: ${{ github.workspace }}
# If validation passes, add the validated label to the issue.
- if: ${{ steps.validate.outputs.result == 'success' }}
name: Add Validated Label
id: add-label
uses: issue-ops/labeler@v2
with:
action: add
github_token: ${{ steps.token.outputs.token }}
labels: |
validated
issue_number: ${{ github.event.issue.number }}
repository: ${{ github.repository }}
# The `issue-ops/validator` action will automatically notify the user that
# the request was validated. However, you can optionally add instruction
# on what to do next.
- if: ${{ steps.validate.outputs.result == 'success' }}
name: Notify User (Success)
id: notify-success
uses: peter-evans/create-or-update-comment@v4
with:
issue-number: ${{ github.event.issue.number }}
body: |
Hello! Your request has been validated successfully!
Please comment with `.submit` to submit this request.
Step 4: Issue comment workflows
Once the issue is created, any further processing is triggered using issue comments—and this can be done with one workflow. However, to make things a bit easier to follow, we’ll break this into a few separate workflows.
Submit workflow
The first workflow handles the user submitting the request. The main task it performs is validating the issue body against the form template to ensure it hasn’t been modified.
name: Process Submit Comment
on:
issue_comment:
types:
- created
permissions:
contents: read
id-token: write
issues: write
jobs:
submit:
name: Submit Request
runs-on: ubuntu-latest
# This job should only be run when the following conditions are true:
#
# - A user comments `.submit` on the issue.
# - The issue has the `team-membership` label.
# - The issue has the `validated` label.
# - The issue does not have the `approved` or `denied` labels.
# - The issue is open.
if: |
startsWith(github.event.comment.body, '.submit') &&
contains(github.event.issue.labels.*.name, 'team-membership') == true &&
contains(github.event.issue.labels.*.name, 'approved') == false &&
contains(github.event.issue.labels.*.name, 'denied') == false &&
github.event.issue.state == 'open'
steps:
# First, we are going to re-run validation. This is important because
# the issue body may have changed since the last time it was validated.
# This is required to ensure the issue form template and any validation
# scripts are included in the workspace.
- name: Checkout
id: checkout
uses: actions/checkout@v4
# Since this workflow includes custom validation scripts, we need to
# install Node.js and any dependencies.
- name: Setup Node.js
id: setup-node
uses: actions/setup-node@v4
# Install dependencies from `package.json`.
- name: Install Dependencies
id: install
run: npm install
# GitHub App authentication is required if you want to interact with any
# resources outside the scope of the repository this workflow runs in.
- name: Get GitHub App Token
id: token
uses: actions/create-github-app-token@v1
with:
app-id: ${{ vars.ISSUEOPS_APP_ID }}
private-key: ${{ secrets.ISSUEOPS_APP_PRIVATE_KEY }}
owner: ${{ github.repository_owner }}
# Remove the validated label. This will be re-added if validation passes.
- name: Remove Validated Label
id: remove-label
uses: issue-ops/labeler@v2
with:
action: remove
github_token: ${{ steps.token.outputs.token }}
labels: |
validated
issue_number: ${{ github.event.issue.number }}
repository: ${{ github.repository }}
# Parse the issue body into machine-readable JSON, so that it can be
# processed by the rest of the workflow.
- name: Parse Issue Body
id: parse
uses: issue-ops/parser@v4
with:
body: ${{ github.event.issue.body }}
issue-form-template: team-membership.yml
workspace: ${{ github.workspace }}
# Validate early and often! Validation should be run any time an issue is
# interacted with, to ensure that any changes to the issue body are valid.
- name: Validate Request
id: validate
uses: issue-ops/validator@v3
with:
add-comment: false # Don't add another validation comment.
github-token: ${{ steps.token.outputs.token }}
issue-form-template: team-membership.yml
issue-number: ${{ github.event.issue.number }}
parsed-issue-body: ${{ steps.parse.outputs.json }}
workspace: ${{ github.workspace }}
# If validation passed, add the validated and submitted labels to the issue.
- if: ${{ steps.validate.outputs.result == 'success' }}
name: Add Validated Label
id: add-label
uses: issue-ops/labeler@v2
with:
action: add
github_token: ${{ steps.token.outputs.token }}
labels: |
validated
submitted
issue_number: ${{ github.event.issue.number }}
repository: ${{ github.repository }}
# If validation succeeded, alert the administrator team so they can
# approve or deny the request.
- if: ${{ steps.validate.outputs.result == 'success' }}
name: Notify Admin (Success)
id: notify-success
uses: peter-evans/create-or-update-comment@v4
with:
issue-number: ${{ github.event.issue.number }}
body: |
👋 @issue-ops/admins! The request has been validated and is
ready for your review. Please comment with `.approve` or `.deny`
to approve or deny this request.
Deny workflow
If the request is denied, the user should be notified and the issue should close.
name: Process Denial Comment
on:
issue_comment:
types:
- created
permissions:
contents: read
id-token: write
issues: write
jobs:
submit:
name: Deny Request
runs-on: ubuntu-latest
# This job should only be run when the following conditions are true:
#
# - A user comments `.deny` on the issue.
# - The issue has the `team-membership` label.
# - The issue has the `validated` label.
# - The issue has the `submitted` label.
# - The issue does not have the `approved` or `denied` labels.
# - The issue is open.
if: |
startsWith(github.event.comment.body, '.deny') &&
contains(github.event.issue.labels.*.name, 'team-membership') == true &&
contains(github.event.issue.labels.*.name, 'submitted') == true &&
contains(github.event.issue.labels.*.name, 'validated') == true &&
contains(github.event.issue.labels.*.name, 'approved') == false &&
contains(github.event.issue.labels.*.name, 'denied') == false &&
github.event.issue.state == 'open'
steps:
# This time, we do not need to re-run validation because the request is
# being denied. It can just be closed.
# However, we do need to confirm that the user who commented `.deny` is
# a member of the administrator team.
# GitHub App authentication is required if you want to interact with any
# resources outside the scope of the repository this workflow runs in.
- name: Get GitHub App Token
id: token
uses: actions/create-github-app-token@v1
with:
app-id: ${{ vars.ISSUEOPS_APP_ID }}
private-key: ${{ secrets.ISSUEOPS_APP_PRIVATE_KEY }}
owner: ${{ github.repository_owner }}
# Check if the user who commented `.deny` is a member of the
# administrator team.
- name: Check Admin Membership
id: check-admin
uses: actions/github-script@v7
with:
github-token: ${{ steps.token.outputs.token }}
script: |
try {
await github.rest.teams.getMembershipForUserInOrg({
org: context.repo.owner,
team_slug: 'admins',
username: context.actor,
})
core.setOutput('member', 'true')
} catch (error) {
if (error.status === 404) {
core.setOutput('member', 'false')
}
throw error
}
# If the user is not a member of the administrator team, exit the
# workflow.
- if: ${{ steps.check-admin.outputs.member == 'false' }}
name: Exit
run: exit 0
# If the user is a member of the administrator team, add the denied label.
- name: Add Denied Label
id: add-label
uses: issue-ops/labeler@v2
with:
action: add
github_token: ${{ steps.token.outputs.token }}
labels: |
denied
issue_number: ${{ github.event.issue.number }}
repository: ${{ github.repository }}
# Notify the user that the request was denied.
- name: Notify User
id: notify
uses: peter-evans/create-or-update-comment@v4
with:
issue-number: ${{ github.event.issue.number }}
body: |
This request has been denied and will be closed.
# Close the issue as not planned.
- name: Close Issue
id: close
uses: actions/github-script@v7
with:
script: |
await github.rest.issues.update({
issue_number: ${{ github.event.issue.number }},
owner: context.repo.owner,
repo: context.repo.repo,
state: 'closed',
state_reason: 'not_planned'
})
Approve workflow
Finally, we need to handle request approval. In this case, we need to add the user to the team, notify them, and close the issue.
name: Process Approval Comment
on:
issue_comment:
types:
- created
permissions:
contents: read
id-token: write
issues: write
jobs:
submit:
name: Approve Request
runs-on: ubuntu-latest
# This job should only be run when the following conditions are true:
#
# - A user comments `.approve` on the issue.
# - The issue has the `team-membership` label.
# - The issue has the `validated` label.
# - The issue has the `submitted` label.
# - The issue does not have the `approved` or `denied` labels.
# - The issue is open.
if: |
startsWith(github.event.comment.body, '.approve') &&
contains(github.event.issue.labels.*.name, 'team-membership') == true &&
contains(github.event.issue.labels.*.name, 'submitted') == true &&
contains(github.event.issue.labels.*.name, 'validated') == true &&
contains(github.event.issue.labels.*.name, 'approved') == false &&
contains(github.event.issue.labels.*.name, 'denied') == false &&
github.event.issue.state == 'open'
steps:
# This time, we do not need to re-run validation because the request is
# being approved. It can just be processed.
# This is required to ensure the issue form template is included in the
# workspace.
- name: Checkout
id: checkout
uses: actions/checkout@v4
# We do need to confirm that the user who commented `.approve` is a member
# of the administrator team. GitHub App authentication is required if you
# want to interact with any resources outside the scope of the repository
# this workflow runs in.
- name: Get GitHub App Token
id: token
uses: actions/create-github-app-token@v1
with:
app-id: ${{ vars.ISSUEOPS_APP_ID }}
private-key: ${{ secrets.ISSUEOPS_APP_PRIVATE_KEY }}
owner: ${{ github.repository_owner }}
# Check if the user who commented `.approve` is a member of the
# administrator team.
- name: Check Admin Membership
id: check-admin
uses: actions/github-script@v7
with:
github-token: ${{ steps.token.outputs.token }}
script: |
try {
await github.rest.teams.getMembershipForUserInOrg({
org: context.repo.owner,
team_slug: 'admins',
username: context.actor,
})
core.setOutput('member', 'true')
} catch (error) {
if (error.status === 404) {
core.setOutput('member', 'false')
}
throw error
}
# If the user is not a member of the administrator team, exit the
# workflow.
- if: ${{ steps.check-admin.outputs.member == 'false' }}
name: Exit
run: exit 0
# Parse the issue body into machine-readable JSON, so that it can be
# processed by the rest of the workflow.
- name: Parse Issue body
id: parse
uses: issue-ops/parser@v4
with:
body: ${{ github.event.issue.body }}
issue-form-template: team-membership.yml
workspace: ${{ github.workspace }}
- name: Add to Team
id: add
uses: actions/github-script@v7
with:
github-token: ${{ steps.token.outputs.token }}
script: |
const parsedIssue = JSON.parse('${{ steps.parse.outputs.json }}')
await github.rest.teams.addOrUpdateMembershipForUserInOrg({
org: context.repo.owner,
team_slug: parsedIssue.team,
username: '${{ github.event.issue.user.login }}',
role: 'member'
})
- name: Notify User
id: notify
uses: peter-evans/create-or-update-comment@v4
with:
issue-number: ${{ github.event.issue.number }}
body: |
This request has been processed successfully!
- name: Close Issue
id: close
uses: actions/github-script@v7
with:
script: |
await github.rest.issues.update({
issue_number: ${{ github.event.issue.number }},
owner: context.repo.owner,
repo: context.repo.repo,
state: 'closed',
state_reason: 'completed'
})
Take this with you
And there you have it! With a handful of standardized workflows, you have an end-to-end, issue-driven process in place to manage team membership. This can be extended as far as you want, including support for removing users, auditing access, and more. With IssueOps, the sky is the limit!
Here’s the best thing about IssueOps: It brings another level of automation to a surface I’m constantly using—and that’s GitHub. By using issues and pull requests as control centers for workflows, teams can reduce friction, improve efficiency, and keep everything transparent. Whether you want to automate deployments, approvals, or bug triage, IssueOps makes it all possible, without ever leaving your repo.
In my experience, it’s always best to start small and experiment with what works best for you. With just a bit of time, you’ll see your workflows get smoother with every commit (I know I have). Happy coding! ✨
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.