Post Syndicated from Lewis Tang original https://aws.amazon.com/blogs/architecture/augmentation-patterns-to-modernize-a-mainframe-on-aws/
Customers with mainframes want to use Amazon Web Services (AWS) to increase agility, maximize the value of their investments, and innovate faster. On June 8, 2022, AWS announced the general availability of AWS Mainframe Modernization, a new service that makes it faster and simpler for customers to modernize mainframe-based workloads.
In this post, we discuss the common use cases and the augmentation architecture patterns that help liberate data from mainframe for modern data analytics, get rid of expensive and unsupported tape storage solutions for mainframe, build new capabilities that integrate with core mainframe workloads, and enable agile development and testing by adopting CI/CD for mainframe.
Pattern 1: Augment mainframe data retention with backup and archival on AWS
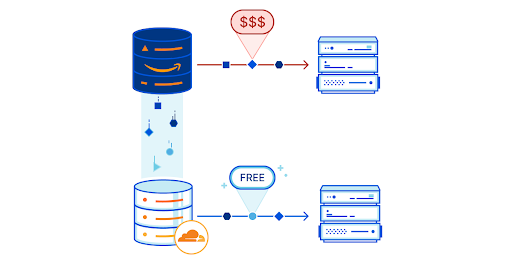
Mainframes process and generate the most business-critical data. It’s imperative to provide data protection via solutions, such as data backup, archiving, and disaster recovery. Mainframes usually use automated tape libraries—virtual tape libraries for backup and archive. These tapes need to be stored, organized, and transported to vaults and disaster recovery sites. All this can be very expensive and rigid.
There is a more cost-effective approach that helps simplify the operations of tape libraries: leverage AWS partner tools, such as Model9, to transparently migrate the data on tape storage to AWS.
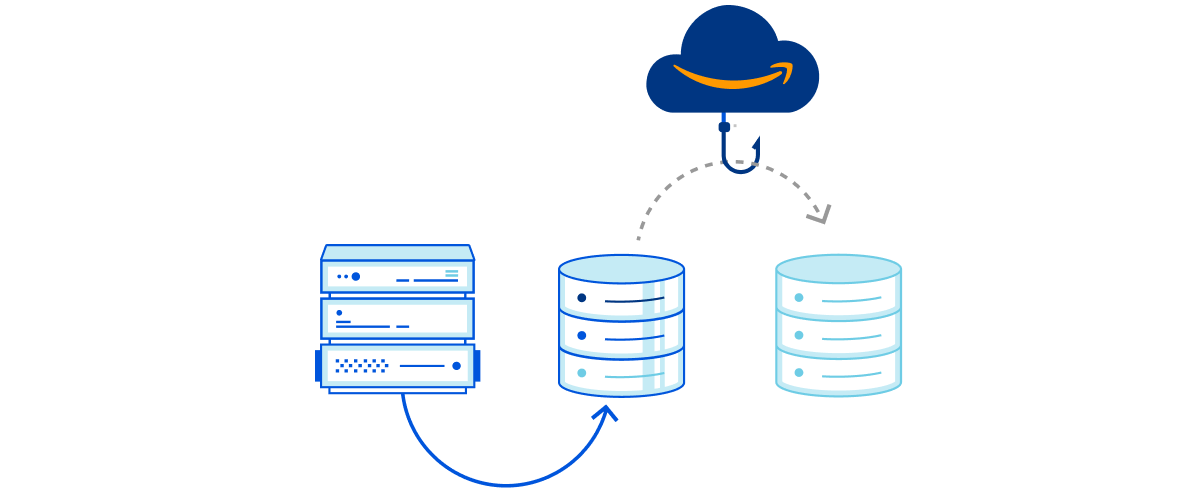
As depicted in Figure 1, mainframe data can be transferred via the secured network connection using AWS Transfer Family services or AWS DataSync to AWS cloud storage services, such as Amazon Elastic File System, Amazon Elastic Block Store, and Amazon Simple Storage Service (S3). After data is stored in AWS cloud, you can configure and move data among these services to meet with the business data processing need. Depending on data storage requirements, data storage costs can be further optimized by configuring S3 Lifecyle policies to move data among Amazon S3 storage classes. For long-term data archiving purpose, you can choose S3 Glacier storage class to achieve durability, resilience, and the optimal cost effectiveness.

Figure 1. Mainframe data backup and archival augmentation
Pattern 2: Augment mainframe with agile development and test environments including CI/CD pipeline on AWS
For any business-critical business application, a typical mainframe workload requires development and test environments to support production workloads. It’s common to see the lengthy application development lifecycle, a lack of automated testing, and an absent CI/CD pipeline with most of mainframes. Furthermore, the existing mainframe development processes and tools are outdated, as they are unable to keep up with the business pace, resulting in a growing backlog. Organizations with mainframes look for application development solutions to solve these challenges.
As demonstrated in Figure 2, AWS developer tools orchestrate code compilation, testing, and deployment among mainframe test environments. Mainframe test environments are either provided by the mainframe vendors as emulators or by AWS partners, such as Micro Focus. You can load the preferred developer tools and run an integrated development environment (IDE) from Amazon WorkSpaces or Amazon AppStream 2.0. Developers create or modify code in the IDE, and then commit and push their code to AWS CodeCommit. As soon as the code is pushed, an event is generated and triggers the pipeline in AWS CodePipeline to build the new code in a compilation environment via AWS CodeBuild. The pipeline pushes the new code to the test environment.
To optimize cost, you can scale the test environment capacity to meet needs. The tests are executed, and the test environment can be shut down when not in use. When the tests are successful, the pipeline pushes the code back to the mainframe via AWS CodeDeploy and an intermediary server. On the mainframe side, the code can go through a recompilation and final testing before being pushed to production.
You can further optimize operations and licensing cost of mainframe emulator by leveraging the managed integrated development and test environment provided by AWS Mainframe Modernization service.

Figure 2. Mainframe CI/CD augmentation
Pattern 3: Augment mainframe with agile data analytics on AWS
Core business applications running on mainframes generate a lot of data throughout the years. Decades of historical business transactions and massive amounts of user data present an opportunity to develop deep business insight. By creating a data lake using the AWS big data services, you can gain faster analytics capabilities and better insight into core business data originated from mainframe applications.
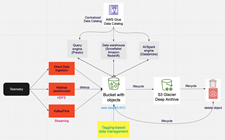
Figure 3 depicts data being pulled from relational, hierarchical, or mainframe file-based data stores on mainframes. These data are presented in various formats and stored as DB2 for z/OS, VSAM, IMS DB, IDMS, DMS, or other formats. You can use AWS partners data replication and change data capture tools from AWS Marketplace or AWS cloud services, such as Amazon Managed Streaming for Apache Kafka for near real-time data streaming, Transfer Family services, and DataSync for moving data in batch from mainframes to AWS.
Once data are replicated to AWS, you can further process data using the services like AWS Lambda, or Amazon Elastic Container Service and store the processed data on various AWS storage services, such as Amazon DynamoDB, Amazon Relational Database Service, and Amazon S3.
By using AWS big data and data analytics services, such as Amazon EMR, Amazon Redshift, Amazon Athena, AWS Glue, and Amazon QuickSight, you can develop deep business insight and present flexible visuals to your customers. Read more about mainframe data integration.

Figure 3. Mainframe data analytics augmentation
Pattern 4: Augment mainframe with new functions and channels on AWS
Organizations with a mainframe use AWS to innovate and iterate quickly, as they often lack agility. For example, a common scenario for a bank could be providing a mobile application for customer engagements, such as supporting a marketing campaign for a new credit card.
As depicted in Figure 4, with the data replicated from mainframes to AWS cloud and analyzed by AWS big data and analytics services, new business functions can be developed on cloud-native applications by using Amazon API Gateway, AWS Lambda, and AWS Fargate. These new business applications can interact with mainframe data, and the combination can give deep business insight.
To add new innovation capabilities, with time-series data generated by the new business function applications, using Amazon Forecast can predict domain-specific metrics, such as inventory, workforce, web traffic, and finances. Amazon Lex can build virtual agents, automate informational response to customer enquiries, and improve business productivity. Adding Amazon SageMaker, you can prepare data gathered from mainframe and new business applications at scale to build, train, and deploy machine learning models for any business cases.
You can further improve customer engagement by incorporating Amazon Connect and Amazon Pinpoint to build multichannel communications.

Figure 4. Mainframe new functions and channels augmentation
Conclusion
To increase agility, maximize the value of investments, and innovate faster, organizations can adopt the patterns discussed in this post to augment mainframes by using AWS services to build resilient data protection solution, provision agile CI/CD integrated development and test environment, liberate mainframe data and developing innovation solutions for new digital customer experience. With AWS Mainframe Modernization service, you can accelerate this journey and innovate faster.












 We launched
We launched 
 This team came together to build a best-in-class gene-editing prediction platform. CRISPR (
This team came together to build a best-in-class gene-editing prediction platform. CRISPR (











 Completed.
Completed.