Post Syndicated from Fei Lang original https://aws.amazon.com/blogs/big-data/amazon-emr-studio-preview-a-new-notebook-first-ide-experience-with-amazon-emr/
We’re happy to announce Amazon EMR Studio (Preview), an integrated development environment (IDE) that makes it easy for data scientists and data engineers to develop, visualize, and debug applications written in R, Python, Scala, and PySpark. EMR Studio provides fully managed Jupyter notebooks and tools like Spark UI and YARN Timeline Service to simplify debugging. EMR Studio uses AWS Single Sign-On (AWS SSO), and allows you to log in directly with your corporate credentials without signing in to the AWS Management Console.
With EMR Studio, you can run notebook code on Amazon EMR running on Amazon Elastic Compute Cloud (Amazon EC2) or Amazon EMR on Amazon Elastic Kubernetes Service (Amazon EKS), and debug your applications. For more information about Amazon EMR on Amazon EKS, see What is Amazon EMR on EKS.
EMR Studio kernels and applications run on EMR clusters, so you get the benefit of distributed data processing with the performance-optimized Apache Spark runtime that Amazon EMR provides. You can also install custom kernels and libraries, collaborate with peers using code repositories such as GitHub and Bitbucket, or run parameterized notebooks as part of scheduled workflows using orchestration services like Apache Airflow or Amazon Managed Workflows for Apache Airflow (Amazon MWAA). Administrators can set up EMR clusters that can be used by EMR Studio users, or create predefined AWS CloudFormation templates for Amazon EMR and allow you to simply choose a template for creating your own cluster.
In this post, we discuss the benefits that EMR Studio offers and we introduce to you some of its capabilities. To learn more about creating and using EMR Studios, see Use Amazon EMR Studio.
Benefits of using EMR Studio
EMR Studio offers the following benefits:
- Set up a unified experience to develop and diagnose EMR Spark applications – Administrators can set up EMR Studio to allow you to log in using your corporate credentials without having to sign in to the AWS console. You get a single unified environment to interactively explore, process, and visualize data using notebooks, build and schedule pipelines, and debug applications without having to log in to EMR clusters.
- Use fully managed Jupyter notebooks – With EMR Studio, you can develop analytics and data science applications in R, Python, Scala, and PySpark with fully managed Jupyter notebooks. You can take advantage of distributed processing using the performance-optimized Amazon EMR runtime for Apache Spark with Jupyter kernels and applications running on EMR clusters. you can attach notebooks to an existing cluster that uses Amazon EC2 instances, or to an EMR on EKS virtual cluster. You can also start your own clusters using templates pre-configured by administrators.
- Collaborate with others using code repositories – From the EMR Studio notebooks environment, you can connect to code repositories such as AWS CodeCommit, GitHub, and Bitbucket to collaborate with peers.
- Run custom Python libraries and kernels – From EMR Studio, you can install custom Python libraries or Jupyter kernels required for your applications directly to the EMR clusters.
- Automate workflows using pipelines – EMR Studio makes it easy to move from prototyping to production. You can create EMR Studio notebooks that can be programmatically invoked with parameters, and use APIs to run the parameterized notebooks. You can also use orchestration tools such as Apache Airflow or Amazon MWAA to run notebooks in automated workflows.
- Simplified debugging – With EMR Studio, you can debug jobs and access logs without logging in to the cluster. EMR Studio provides native application interfaces such as Spark UI and YARN Timeline. When a notebook is run in EMR Studio, the application logs are uploaded to Amazon Simple Storage Service (Amazon S3). As a result, you can access logs and diagnose applications even after your EMR cluster is terminated. You can quickly locate the job to debug by filtering based on the cluster or time when the application was run.
In the following section, we demonstrate some of the capabilities of Amazon EMR Studio using a sample notebook. For our sample notebook, we use the open-source, real-time COVID-19 US daily case reports provided by Johns Hopkins University CSSE from the following GitHub repo.
Notebook-first IDE experience with AWS SSO integration
EMR Studio makes it simple to interact with applications on an EMR cluster. After an administrator sets up EMR Studio and provides the access URL (which looks like https://es-*************************.emrstudio.us-east-1.amazonaws.com), you can log in to EMR Studio with your corporate credentials.
After you log in to EMR Studio, you get started by creating a Workspace. A Workspace is a collection of one or more notebooks for a project. The Workspaces and the notebooks that you create in EMR Studio are automatically saved in an Amazon S3 location.
Now, we create a Workspace by completing the following steps:
- On the EMR Studio Dashboard page, choose Create Workspace.

- On the Create a Workspace page, enter a Workspace name and a Description.

Naming the Workspace helps identify your project. Your workspace is automatically saved, and you can find it later on the Workspaces page. For this post, we name our Workspace EMR-Studio-WS-Demo1.

- On the Subnet drop-down menu, choose a subnet for your Workspace.
Each subnet belongs to the same Amazon Virtual Private Cloud (Amazon VPC) as your EMR Studio. Your administrator may have set up one or more subnets to use for your EMR clusters. You should choose a subnet that matches the subnet where you use EMR clusters. If you’re not sure about which subnet to use, contact your administrator.
- For S3 location, choose the Amazon S3 location where EMR Studio backs up all notebook files in the Workspace.
This location is where your Workspace and all the notebooks in the Workspace are automatically saved.
- In the Advanced configuration section, you can attach an EMR cluster to your Workspace.
For this post, we skip this step. EMR Studio allows you to create Workspaces and notebooks without attaching to an EMR cluster. You can attach an EMR cluster later when you’re ready to run your notebooks.
- Choose Create Workspace.
Fully managed environment for managing and running Jupyter-based notebooks
EMR Studio provides a fully managed environment to help organize and manage Workspaces. Workspaces are the primary building blocks of EMR Studio, and they preserve the state of your notebooks. You can create different Workspaces for each project. From within a Workspace, you can create notebooks, link your Workspace to a code repository, and attach your Workspace to an EMR cluster to run notebooks. Your Workspaces and the notebooks and settings it contains are automatically saved in the Amazon S3 location that you specify.
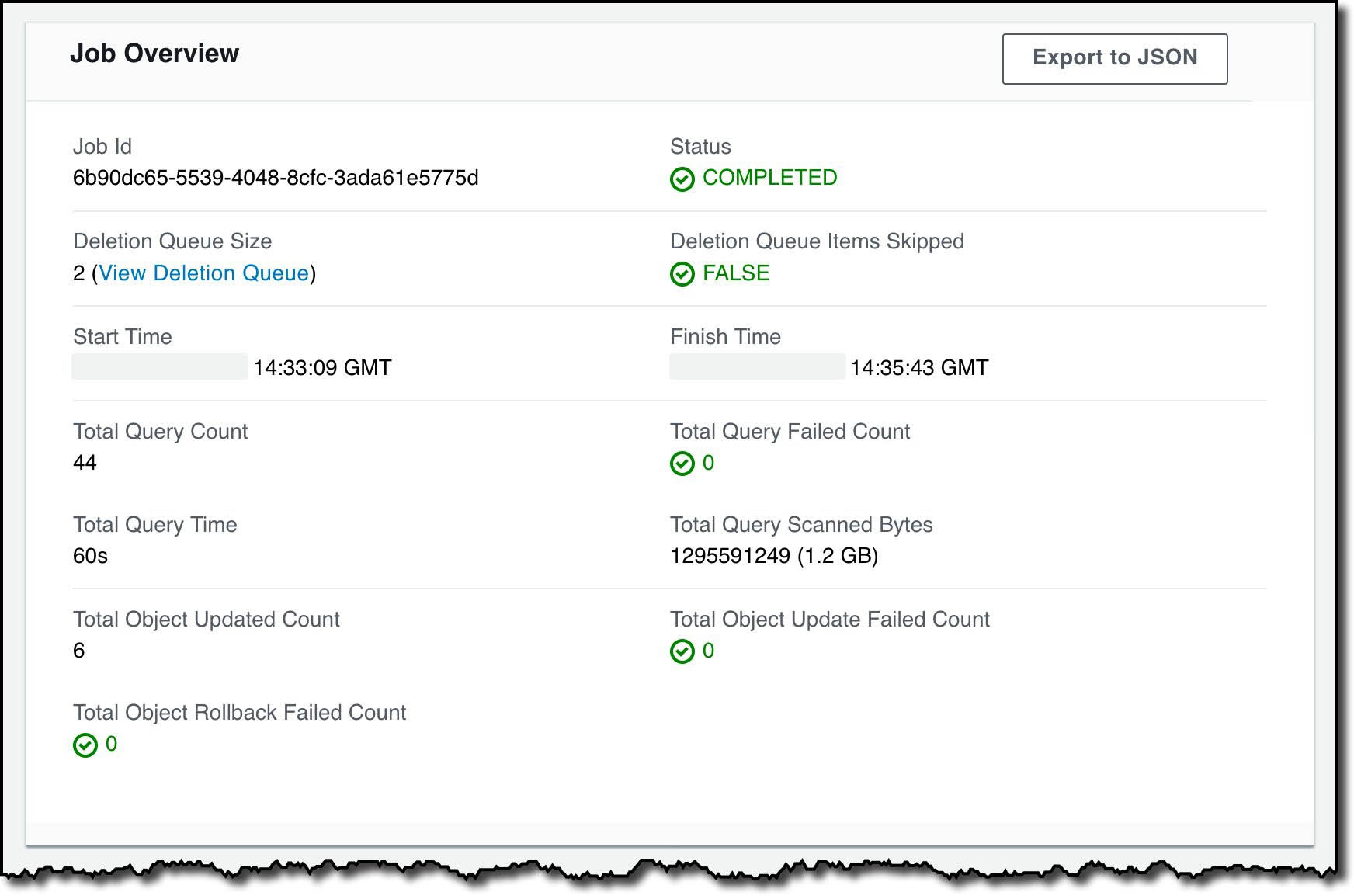
If you created the workspace EMR-Studio-WS-Demo1 by following the preceding steps, it appears on the Workspaces page with the name EMR-Studio-WS-Demo1 along with status Ready, creation time, and last modified timestamp.

The following table describes each possible Workspace status.
| Status | Meaning |
Starting |
The Workspace is being prepared, but is not yet ready to use. |
Ready |
You can open the Workspace to use the notebook editor. When a Workspace has a Ready status, you can open or delete it. |
Attaching |
The Workspace is being attached to a cluster. |
Attached |
The Workspace is attached to an EMR cluster. If a Workspace is not attached to an EMR cluster, you need to attach it to an EMR cluster before you can run any notebook code in the Workspace. |
Idle |
The Workspace is stopped and currently idle. When you launch an idle Workspace, the Workspace status changes from
|
Stopping |
The Workspace is being stopped. |
Deleting |
When you delete a Workspace, it’s marked for deletion. EMR Studio automatically deletes Workspaces marked for deletion. After a Workspace is deleted, it no longer shows in the list of Workspaces. |
You can choose the Workspace that you created (EMR-Studio-WS-Demo1) to open it. This opens a new web browser tab with the JupyterLab interface. The icon-denoted tabs on the left sidebar allow you to access tool panels such as the file browser or JupyterLab command palette. To learn more about the EMR Studio Workspace interface, see Understand the Workspace User Interface.
EMR Studio automatically creates an empty notebook with the same name as the Workspace. For this post, we the Workspace that we created, it automatically creates EMR-Studio-WS-Demo1.ipynb. In the following screenshot, no cluster or kernel is specified in the top right corner, because we didn’t choose to attach any cluster while creating the Workspace. You can write code in your new notebook, but before you run your code, you need to attach it to an EMR cluster and specify a kernel. To attach your workspace to a cluster, choose the EMR clusters icon on the left panel.

Linking Git-based code repositories with your Workspace
You can collaborate with your peers by sharing notebooks as code via code repositories. EMR Studio supports the following Git-based services:
- AWS CodeCommit
- GitHub
- Bitbucket
This capability provides the following benefits:
- Version control – Record code changes in a version control system so you can review the history of your changes and selectively revert them.
- Collaboration – Share code with team members working in different Workspaces through remote Git-based repositories. Workspaces can clone or merge code from remote repositories and push changes back to those repositories.
- Code reuse – Many Jupyter notebooks that demonstrate data analysis or machine learning techniques are available in publicly hosted repositories, such as GitHub. You can associate your Workspace with a GitHub repository to reuse the Jupyter notebooks contained in a repository.
To link Git repositories to your Workspace, you can link an existing repository or create a new one. When you link an existing repository, you choose from a list of Git repositories associated with the AWS account in which your EMR Studio was created.
We add a new repository by completing the following steps:
- Choose the Git icon.
- For Repository name¸ enter a name (for example,
emr-notebook). - For Git repository URL, enter the URL for the Git repo (for this post, we use the sample notebook at
https://github.com/emrnotebooks/notebook_execution). - For Git credentials, select your credentials. Because we’re using a public repo, we select Use a public repository without credentials.
- Choose Add repository.


After it’s added, we can see the repo on the Git repositories drop-down menu.
- Choose the repo to link to the Workspace.
You can link up to three Git repositories with an EMR Studio Workspace. For more information, see Link Git-Based Repositories to an EMR Studio Workspace.
- Choose the File browser icon to locate the Git repo we just linked.


Attaching and detaching Workspaces to and from EMR clusters
EMR Studio kernels and applications run on EMR clusters, so you get the benefit of distributed data processing using the performance-optimized EMR runtime for Apache Spark. You can attach your Workspace to an EMR cluster and get distributed data processing using Spark or custom kernels. You can use primary node capacity to run non-distributed applications.
In addition to using Amazon EMR clusters running on Amazon EC2, you can attach a Workspace to an Amazon EMR on EKS virtual cluster to run notebook code. For more information about how to use an Amazon EMR on EKS cluster in EMR Studio, see Use an Amazon EMR on EKS Cluster to Run Notebook Code.
Before you can run your notebooks, you must attach your Workspace to an EMR cluster. For more information about clusters, see Create and Use Clusters with EMR Studio.
To run the Git repo notebooks that we linked in the previous step, complete the following steps:
- Choose the EMR cluster
- Attach the Workspace to an existing EMR cluster running on Amazon EC2 instances.

- Open the notebook
demo_pyspark.ipynbfrom the Git repoemr-notebookthat we linked to the Workspace.

In the upper right corner of the Workspace UI, we can see the ID of the EMR cluster being attached to our Workspace, as well as the kernel selected to run the notebook.
- Record the value of the cluster ID (for example,
<j-*************>).
We use this value later to locate the EMR cluster for application debugging purposes.

You can also detach the Workspace from the cluster in the Workspace UI and re-attach it to another cluster. For more information, see Detach a Cluster from Your Workspace.
Being able to easily attach and detach to and from any EMR cluster allows you to move any workload from prototyping into production. For example, you can start your prototype development by attaching your workspace to a development EMR cluster and working with test datasets. When you’re ready to run your notebook with larger production datasets, you can detach your workspace from the development EMR cluster and attach it to a larger production EMR cluster.
Installing and loading custom libraries and kernels
You can install notebook-scoped libraries with a PySpark kernel in EMR Studio. The libraries installed are isolated to your notebook session and don’t interfere with libraries installed via EMR bootstrap actions, or libraries installed by other EMR Studio notebook sessions that may be running on the same EMR cluster. After you install libraries for your Workspace, they’re available for other notebooks in the Workspace in the same session.
Our sample notebook demo_pyspark.ipynb is a Python script. It uses real-time COVID-19 US daily case reports as input data. The following parameters are defined in the first cell:
- DATE – The given date used when the notebook job is started.
- TOP_K – The top k US states with confirmed COVID-19 cases. We use this to plot Graph a.
- US_STATES – The names of the specific US states being checked for the fatality rates of COVID-19 patients. We use this plot Graph b.
The parameters can be any of the Python data types.
Running this notebook plots two graphs:
- Graph a – Visualizes the top k US states with most the COVID-19 cases on a given date
- Graph b – Visualizes the fatality rates among specific US states on a given date
In our notebook, we install notebook-scoped libraries by running the following code from within a notebook cell:
We use these libraries in the subsequent cells for the further data analysis and visualization steps in the notebook.
The following set of parameters is used to run the notebook:
Running all the notebook cells generates two graphs. Graph a shows the top six US states with confirmed COVID-19 cases on October 15, 2020.

Graph b shows the fatality rates of COVID-19 patients in Texas, Wisconsin, and Nevada on October 15, 2020.

EMR Studio also allows you to install Jupyter notebook kernels and Python libraries on a cluster primary node, which makes your custom environment available to any EMR Studio Workspace attached the cluster. To install the sas_kernel kernel on a cluster primary node, run the following code within a notebook cell:
The following screenshot shows your output.

For more information about how to install kernels and use libraries, see Installing and Using Kernels and Libraries.
Diagnosing applications and jobs with EMR Studio
In EMR Studio, you can quickly debug jobs and access logs without logging in to the cluster, such as setting up a web proxy through an SSH connection, for both active and stopped clusters. You can use native application interfaces such as Spark UI and YARN Timeline Service directly from EMR Studio. EMR Studio also allows you to quickly locate the cluster or job to debug by using filters such as cluster state, creation time, and cluster ID. For more information, see Diagnose Applications and Jobs with EMR Studio.
Now, we show you how to open a native application interface to debug the notebook job that already finished.
- On the EMR Studio page, choose Clusters.
A list appears with all the EMR clusters launched under the same AWS account. You can filter the list by cluster state, cluster ID, or creation time range by entering values in the provided fields.
- Choose the cluster ID of the EMR cluster that we attached to the Workspace
EMR-Studio-WS-Demo1for running notebookdemo_pyspark.ipynb. - For Spark job debugging, on the Launch application UIs menu, choose Spark History Server.


The following screenshot shows you the Spark job debugging UI.

We can traverse the details for our notebook application by checking actual logs from the Spark History Server, as in the following screenshot.

- For Yarn application debugging, on the Launch application UIs menu, choose Yarn Timeline Server.
The following screenshot shows the Yarn debugging UI.

Orchestrating analytics notebook jobs to build ETL production pipelines
EMR Studio makes it easy for you to move any analytics workload from prototyping to production. With EMR Studio, you can run parameterized notebooks as part of scheduled workflows using orchestration services like AWS Step Functions and Apache Airflow or Amazon MWAA.
In this section, we show a simple example of how to orchestrate running notebook workflows using Apache Airflow.
We have a fully tested notebook under an EMR Studio Workspace, and want to schedule a workflow that runs the notebook on an on-demand EMR cluster every 10 minutes.
Record the value of the Workspace ID (for example, e-*****************************) and the notebook file path relative to the home directory within the Workspace (for example, demo.ipynb or my_folder/demo.ipynb)
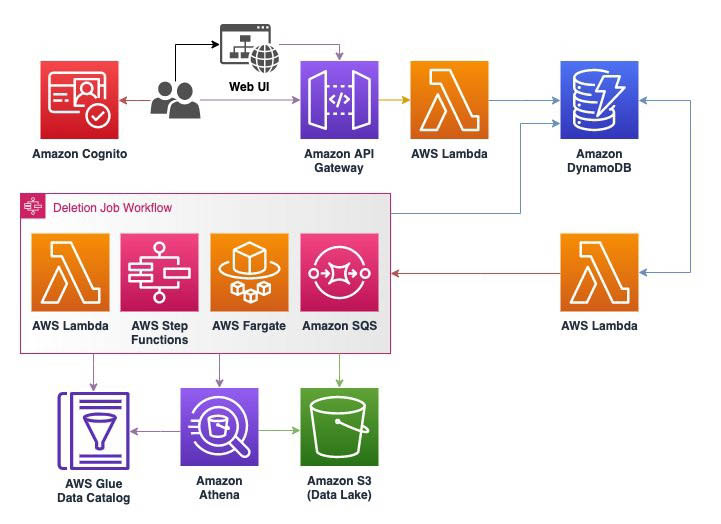
The workflow that we create takes care of the following tasks:
- Create an EMR cluster.
- Wait until the cluster is ready.
- Start running a notebook defined by the Workspace ID, notebook file path, and the cluster created.
- Wait until the notebook is complete.

The following screenshot is the tree view of this example DAG. The DAG definition is available on the GitHub repo. Make sure you replace any placeholder values with the actual ones before using.

When you open the Gantt chart of one of the successful notebooks, we can see the timeline of our workflow. The time spent creating the cluster and creating a notebook execution is negligible compared to the time spent waiting for the cluster to be ready and waiting for the notebook to finish, which meets the expectation of our SLA.

This example is a just starting point. Try it out and extend it with more sophisticated workflows that suit your needs.
Summary
In this post, we highlighted some of the capabilities of EMR Studio, such as the ability to log in via AWS SSO, access fully managed Jupyter notebooks, link Git-based code repositories, change clusters, load custom Python libraries and kernels, diagnose clusters and jobs using native application UIs, and orchestrate notebook jobs using Apache Airflow or Amazon MWAA.
There is no additional charge for using EMR Studio in public preview, and you only pay for the use of the EMR cluster or other AWS services such as AWS Service Catalog. For more information, see the EMR Studio FAQs.
EMR Studio is available on Amazon EMR release version 6.2 and later, in the US East (N. Virginia), US West (Oregon), and EU (Ireland) Regions for public preview. For the latest Region availability for the public preview, see Considerations.
If you have questions or suggestions, feel free to leave a comment.
About the Authors
 Fei Lang is a Senior Big Data Architect at Amazon Web Services. She is passionate about building the right big data solution for customers. In her spare time, she enjoys the scenery of the Pacific Northwest, going for a swim, and spending time with her family.
Fei Lang is a Senior Big Data Architect at Amazon Web Services. She is passionate about building the right big data solution for customers. In her spare time, she enjoys the scenery of the Pacific Northwest, going for a swim, and spending time with her family.
 Shuang Li is a Senior Product Manager for Amazon EMR at AWS. She holds a doctoral degree in Computer Science and Engineering from Ohio State University.
Shuang Li is a Senior Product Manager for Amazon EMR at AWS. She holds a doctoral degree in Computer Science and Engineering from Ohio State University.
 Ray Liu is a Software Development Engineer at AWS. Besides work, he enjoys traveling and spending time with family.
Ray Liu is a Software Development Engineer at AWS. Besides work, he enjoys traveling and spending time with family.
 Kendra Ellis is a Programmer Writer at AWS.
Kendra Ellis is a Programmer Writer at AWS.






 Herain Oberoi leads Product Marketing for AWS’s Databases, Analytics, BI, and Blockchain services. His team is responsible for helping customers learn about, adopt, and successfully use AWS services. Prior to AWS, he held various product management and marketing leadership roles at Microsoft and a successful startup that was later acquired by BEA Systems. When he’s not working, he enjoys spending time with his family, gardening, and exercising.
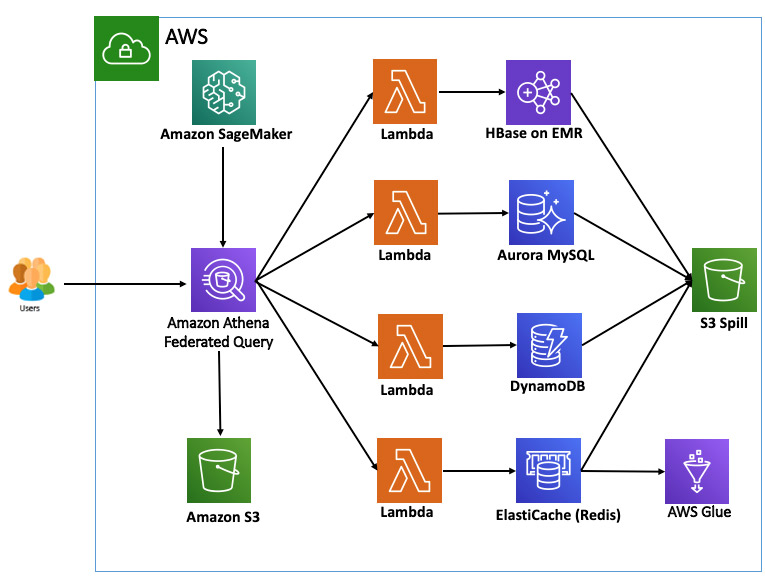
Herain Oberoi leads Product Marketing for AWS’s Databases, Analytics, BI, and Blockchain services. His team is responsible for helping customers learn about, adopt, and successfully use AWS services. Prior to AWS, he held various product management and marketing leadership roles at Microsoft and a successful startup that was later acquired by BEA Systems. When he’s not working, he enjoys spending time with his family, gardening, and exercising. Traditionally, organizations rely on manual audits of large amounts of data, which is not scalable and is prone to human error. Others use rule-based methods based on arbitrary ranges, which are often static, do not easily adapt to seasonality changes, and lead to too many false detections.
Traditionally, organizations rely on manual audits of large amounts of data, which is not scalable and is prone to human error. Others use rule-based methods based on arbitrary ranges, which are often static, do not easily adapt to seasonality changes, and lead to too many false detections.






 Vishwa Gupta is a Data and ML Engineer with AWS Professional Services Intelligence Practice. He helps customers implement big data and analytics platform and solutions. Outside of work, he enjoys spending time with family, traveling, and playing badminton.
Vishwa Gupta is a Data and ML Engineer with AWS Professional Services Intelligence Practice. He helps customers implement big data and analytics platform and solutions. Outside of work, he enjoys spending time with family, traveling, and playing badminton. Sreeram Thoom is a Data Architect at Amazon Web Services.
Sreeram Thoom is a Data Architect at Amazon Web Services.
 Florian Mair is a Solutions Architect at AWS.He is a t echnologist that helps customers in Germany succeed and innovate by solving business challenges using AWS Cloud services. Besides working as a Solutions Architect, Florian is a passionate mountaineer, and has climbed some of the highest mountains across Europe.
Florian Mair is a Solutions Architect at AWS.He is a t echnologist that helps customers in Germany succeed and innovate by solving business challenges using AWS Cloud services. Besides working as a Solutions Architect, Florian is a passionate mountaineer, and has climbed some of the highest mountains across Europe.







 Jose Kunnackal John is a principal product manager for Amazon QuickSight.
Jose Kunnackal John is a principal product manager for Amazon QuickSight. Sahitya Pandiri is a technical program manager with Amazon Web Services.
Sahitya Pandiri is a technical program manager with Amazon Web Services.


















 Rumeshkrishnan Mohan is a Big Data Consultant with Amazon Web Services. He works with Global Customers in building their data lakes.
Rumeshkrishnan Mohan is a Big Data Consultant with Amazon Web Services. He works with Global Customers in building their data lakes. Krithivasan Balasubramaniyan is Senior Consultant at Amazon Web Services. He enables global enterprise customers in their digital transformation journey and helps architect cloud native solutions.
Krithivasan Balasubramaniyan is Senior Consultant at Amazon Web Services. He enables global enterprise customers in their digital transformation journey and helps architect cloud native solutions.





 Manash Deb is a Senior Analytics Specialist Solutions Architect. He has worked in different database and data warehousing technologies for more than 15 years.
Manash Deb is a Senior Analytics Specialist Solutions Architect. He has worked in different database and data warehousing technologies for more than 15 years. Debu Panda, a senior product manager at AWS, is an industry leader in analytics, application platform, and database technologies. He has more than 20 years of experience in the IT industry and has published numerous articles on analytics, enterprise Java, and databases and has presented at multiple conferences. He is lead author of the EJB 3 in Action (Manning Publications 2007, 2014) and Middleware Management (Packt).
Debu Panda, a senior product manager at AWS, is an industry leader in analytics, application platform, and database technologies. He has more than 20 years of experience in the IT industry and has published numerous articles on analytics, enterprise Java, and databases and has presented at multiple conferences. He is lead author of the EJB 3 in Action (Manning Publications 2007, 2014) and Middleware Management (Packt). Fei Peng is a Software Dev Engineer working in the Amazon Redshift team.
Fei Peng is a Software Dev Engineer working in the Amazon Redshift team.








 Chris Deigan is an AWS Solution Engineer in London, UK. Chris works with AWS Solution Architects to create standardized tools, code samples, demonstrations, and quick starts.
Chris Deigan is an AWS Solution Engineer in London, UK. Chris works with AWS Solution Architects to create standardized tools, code samples, demonstrations, and quick starts. Matteo Figus is an AWS Solution Engineer based in the UK. Matteo works with the AWS Solution Architects to create standardized tools, code samples, demonstrations and quickstarts. He is passionate about open-source software and in his spare time he likes to cook and play the piano.
Matteo Figus is an AWS Solution Engineer based in the UK. Matteo works with the AWS Solution Architects to create standardized tools, code samples, demonstrations and quickstarts. He is passionate about open-source software and in his spare time he likes to cook and play the piano. Nick Lee is an AWS Solution Engineer based in the UK. Nick works with the AWS Solution Architects to create standardized tools, code samples, demonstrations and quickstarts. In his spare time he enjoys playing football and squash, and binge-watching TV shows.
Nick Lee is an AWS Solution Engineer based in the UK. Nick works with the AWS Solution Architects to create standardized tools, code samples, demonstrations and quickstarts. In his spare time he enjoys playing football and squash, and binge-watching TV shows. Adir Sharabi is a Solutions Architect with Amazon Web Services. He works with AWS customers to help them architect secure, resilient, scalable and high performance applications in the cloud. He is also passionate about Data and helping customers to get the most out of it.
Adir Sharabi is a Solutions Architect with Amazon Web Services. He works with AWS customers to help them architect secure, resilient, scalable and high performance applications in the cloud. He is also passionate about Data and helping customers to get the most out of it. Cristina Fuia is a Specialist Solutions Architect for Analytics at AWS. She works with customers across EMEA helping them to solve complex problems, design and build data architectures so that they can get business value from analyzing their data.
Cristina Fuia is a Specialist Solutions Architect for Analytics at AWS. She works with customers across EMEA helping them to solve complex problems, design and build data architectures so that they can get business value from analyzing their data.









 Saurabh Bhutyani is a Senior Big Data Specialist Solutions Architect at Amazon Web Services. He is an early adopter of open-source big data technologies. At AWS, he works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.
Saurabh Bhutyani is a Senior Big Data Specialist Solutions Architect at Amazon Web Services. He is an early adopter of open-source big data technologies. At AWS, he works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation. Amir Basirat is a Big Data Specialist Solutions Architect at Amazon Web Services, focused on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation, where he helps customers craft distributed analytics applications on the AWS platform. Prior to his AWS Cloud journey, he worked as a big data specialist for different technology companies. He also has a PhD in computer science, where his research primarily focused on large-scale distributed computing and neural networks.
Amir Basirat is a Big Data Specialist Solutions Architect at Amazon Web Services, focused on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation, where he helps customers craft distributed analytics applications on the AWS platform. Prior to his AWS Cloud journey, he worked as a big data specialist for different technology companies. He also has a PhD in computer science, where his research primarily focused on large-scale distributed computing and neural networks.




 data management product, which uses
data management product, which uses