Post Syndicated from Utkarsh Mittal original https://aws.amazon.com/blogs/big-data/amazon-datazone-announces-integration-with-aws-lake-formation-hybrid-access-mode-for-the-aws-glue-data-catalog/
Last week, we announced the general availability of the integration between Amazon DataZone and AWS Lake Formation hybrid access mode. In this post, we share how this new feature helps you simplify the way you use Amazon DataZone to enable secure and governed sharing of your data in the AWS Glue Data Catalog. We also delve into how data producers can share their AWS Glue tables through Amazon DataZone without needing to register them in Lake Formation first.
Overview of the Amazon DataZone integration with Lake Formation hybrid access mode
Amazon DataZone is a fully managed data management service to catalog, discover, analyze, share, and govern data between data producers and consumers in your organization. With Amazon DataZone, data producers populate the business data catalog with data assets from data sources such as the AWS Glue Data Catalog and Amazon Redshift. They also enrich their assets with business context to make it straightforward for data consumers to understand. After the data is available in the catalog, data consumers such as analysts and data scientists can search and access this data by requesting subscriptions. When the request is approved, Amazon DataZone can automatically provision access to the data by managing permissions in Lake Formation or Amazon Redshift so that the data consumer can start querying the data using tools such as Amazon Athena or Amazon Redshift.
To manage the access to data in the AWS Glue Data Catalog, Amazon DataZone uses Lake Formation. Previously, if you wanted to use Amazon DataZone for managing access to your data in the AWS Glue Data Catalog, you had to onboard your data to Lake Formation first. Now, the integration of Amazon DataZone and Lake Formation hybrid access mode simplifies how you can get started with your Amazon DataZone journey by removing the need to onboard your data to Lake Formation first.
Lake Formation hybrid access mode allows you to start managing permissions on your AWS Glue databases and tables through Lake Formation, while continuing to maintain any existing AWS Identity and Access Management (IAM) permissions on these tables and databases. Lake Formation hybrid access mode supports two permission pathways to the same Data Catalog databases and tables:
- In the first pathway, Lake Formation allows you to select specific principals (opt-in principals) and grant them Lake Formation permissions to access databases and tables by opting in
- The second pathway allows all other principals (that are not added as opt-in principals) to access these resources through the IAM principal policies for Amazon Simple Storage Service (Amazon S3) and AWS Glue actions
With the integration between Amazon DataZone and Lake Formation hybrid access mode, if you have tables in the AWS Glue Data Catalog that are managed through IAM-based policies, you can publish these tables directly to Amazon DataZone, without registering them in Lake Formation. Amazon DataZone registers the location of these tables in Lake Formation using hybrid access mode, which allows managing permissions on AWS Glue tables through Lake Formation, while continuing to maintain any existing IAM permissions.
Amazon DataZone enables you to publish any type of asset in the business data catalog. For some of these assets, Amazon DataZone can automatically manage access grants. These assets are called managed assets, and include Lake Formation-managed Data Catalog tables and Amazon Redshift tables and views. Prior to this integration, you had to complete the following steps before Amazon DataZone could treat the published Data Catalog table as a managed asset:
- Identity the Amazon S3 location associated with Data Catalog table.
- Register the Amazon S3 location with Lake Formation in hybrid access mode using a role with appropriate permissions.
- Publish the table metadata to the Amazon DataZone business data catalog.
The following diagram illustrates this workflow.

With the Amazon DataZone’s integration with Lake Formation hybrid access mode, you can simply publish your AWS Glue tables to Amazon DataZone without having to worry about registering the Amazon S3 location or adding an opt-in principal in Lake Formation by delegating these steps to Amazon DataZone. The administrator of an AWS account can enable the data location registration setting under the DefaultDataLake blueprint on the Amazon DataZone console. Now, a data owner or publisher can publish their AWS Glue table (managed through IAM permissions) to Amazon DataZone without the extra setup steps. When a data consumer subscribes to this table, Amazon DataZone registers the Amazon S3 locations of the table in hybrid access mode, adds the data consumer’s IAM role as an opt-in principal, and grants access to the same IAM role by managing permissions on the table through Lake Formation. This makes sure that IAM permissions on the table can coexist with newly granted Lake Formation permissions, without disrupting any existing workflows. The following diagram illustrates this workflow.

Solution overview
To demonstrate this new capability, we use a sample customer scenario where the finance team wants to access data owned by the sales team for financial analysis and reporting. The sales team has a pipeline that creates a dataset containing valuable information about ticket sales, popular events, venues, and seasons. We call it the tickit dataset. The sales team stores this dataset in Amazon S3 and registers it in a database in the Data Catalog. The access to this table is currently managed through IAM-based permissions. However, the sales team wants to publish this table to Amazon DataZone to facilitate secure and governed data sharing with the finance team.
The steps to configure this solution are as follows:
- The Amazon DataZone administrator enables the data lake location registration setting in Amazon DataZone to automatically register the Amazon S3 location of the AWS Glue tables in Lake Formation hybrid access mode.
- After the hybrid access mode integration is enabled in Amazon DataZone, the finance team requests a subscription to the sales data asset. The asset shows up as a managed asset, which means Amazon DataZone can manage access to this asset even if the Amazon S3 location of this asset isn’t registered in Lake Formation.
- The sales team is notified of a subscription request raised by the finance team. They review and approve the access request. After the request is approved, Amazon DataZone fulfills the subscription request by managing permissions in the Lake Formation. It registers the Amazon S3 location of the subscribed table in Lake Formation hybrid mode.
- The finance team gains access to the sales dataset required for their financial reports. They can go to their DataZone environment and start running queries using Athena against their subscribed dataset.
Prerequisites
To follow the steps in this post, you need an AWS account. If you don’t have an account, you can create one. In addition, you must have the following resources configured in your account:
- An S3 bucket
- An AWS Glue database and crawler
- IAM roles for different personas and services
- An Amazon DataZone domain and project
- An Amazon DataZone environment profile and environment
- An Amazon DataZone data source
If you don’t have these resources already configured, you can create them by deploying the following AWS CloudFormation stack:
- Choose Launch Stack to deploy a CloudFormation template.

- Complete the steps to deploy the template and leave all settings as default.
- Select I acknowledge that AWS CloudFormation might create IAM resources, then choose Submit.
After the CloudFormation deployment is complete, you can log in to the Amazon DataZone portal and manually trigger a data source run. This pulls any new or modified metadata from the source and updates the associated assets in the inventory. This data source has been configured to automatically publish the data assets to the catalog.
- On the Amazon DataZone console, choose View domains.
You should be logged in using the same role that is used to deploy CloudFormation and verify that you are in the same AWS Region.

- Find the domain
blog_dz_domain, then choose Open data portal. - Choose Browse all projects and choose Sales producer project.

- On the Data tab, choose Data sources in the navigation pane.
- Locate and choose the data source that you want to run.

This opens the data source details page.
- Choose the options menu (three vertical dots) next to
tickit_datasourceand choose Run.


The data source status changes to Running as Amazon DataZone updates the asset metadata.
Enable hybrid mode integration in Amazon DataZone
In this step, the Amazon DataZone administrator goes through the process of enabling the Amazon DataZone integration with Lake Formation hybrid access mode. Complete the following steps:
- On a separate browser tab, open the Amazon DataZone console.
Verify that you are in the same Region where you deployed the CloudFormation template.
- Choose View domains.
- Choose the domain created by AWS CloudFormation,
blog_dz_domain. - Scroll down on the domain details page and choose the Blueprints tab.
A blueprint defines what AWS tools and services can be used with the data assets published in Amazon DataZone. The DefaultDataLake blueprint is enabled as part of the CloudFormation stack deployment. This blueprint enables you to create and query AWS Glue tables using Athena. For the steps to enable this in your own deployments, refer to Enable built-in blueprints in the AWS account that owns the Amazon DataZone domain.
- Choose the
DefaultDataLakeblueprint.

- On the Provisioning tab, choose Edit.

- Select Enable Amazon DataZone to register S3 locations using AWS Lake Formation hybrid access mode.


You have the option of excluding specific Amazon S3 locations if you don’t want Amazon DataZone to automatically register them to Lake Formation hybrid access mode.
- Choose Save changes.


Request access
In this step, you log in to Amazon DataZone as the finance team, search for the sales data asset, and subscribe to it. Complete the following steps:
- Return to your Amazon DataZone data portal browser tab.
- Switch to the finance consumer project by choosing the dropdown menu next to the project name and choosing Finance consumer project.
From this step onwards, you take on the persona of a finance user looking to subscribe to a data asset published in the previous step.

- In the search bar, search for and choose the
salesdata asset.

- Choose Subscribe.



The asset shows up as managed asset. This means that Amazon DataZone can grant access to this data asset to the finance team’s project by managing the permissions in Lake Formation.
- Enter a reason for the access request and choose Subscribe.


Approve access request
The sales team gets a notification that an access request from the finance team is submitted. To approve the request, complete the following steps:
- Choose the dropdown menu next to the project name and choose Sales producer project.
You now assume the persona of the sales team, who are the owners and stewards of the sales data assets.
- Choose the notification icon at the top-right corner of the DataZone portal.
- Choose the Subscription Request Created task.

- Grant access to the sales data asset to the finance team and choose Approve.



Analyze the data
The finance team has now been granted access to the sales data, and this dataset has been to their Amazon DataZone environment. They can access the environment and query the sales dataset with Athena, along with any other datasets they currently own. Complete the following steps:
- On the dropdown menu, choose Finance consumer project.
On the right pane of the project overview screen, you can find a list of active environments available for use.
- Choose the Amazon DataZone environment
finance_dz_environment.

- In the navigation pane, under Data assets, choose Subscribed.
- Verify that your environment now has access to the sales data.

It may take a few minutes for the data asset to be automatically added to your environment.
- Choose the new tab icon for Query data.


A new tab opens with the Athena query editor.
- For Database, choose
finance_consumer_db_tickitdb-<suffix>.
This database will contain your subscribed data assets.

- Generate a preview of the sales table by choosing the options menu (three vertical dots) and choosing Preview table.


Clean up
To clean up your resources, complete the following steps:
- Switch back to the administrator role you used to deploy the CloudFormation stack.
- On the Amazon DataZone console, delete the projects used in this post. This will delete most project-related objects like data assets and environments.
- On the AWS CloudFormation console, delete the stack you deployed in the beginning of this post.
- On the Amazon S3 console, delete the S3 buckets containing the tickit dataset.
- On the Lake Formation console, delete the Lake Formation admins registered by Amazon DataZone.
- On the Lake Formation console, delete tables and databases created by Amazon DataZone.
Conclusion
In this post, we discussed how the integration between Amazon DataZone and Lake Formation hybrid access mode simplifies the process to start using Amazon DataZone for end-to-end governance of your data in the AWS Glue Data Catalog. This integration helps you bypass the manual steps of onboarding to Lake Formation before you can start using Amazon DataZone.
For more information on how to get started with Amazon DataZone, refer to the Getting started guide. Check out the YouTube playlist for some of the latest demos of Amazon DataZone and short descriptions of the capabilities available. For more information about Amazon DataZone, see How Amazon DataZone helps customers find value in oceans of data.
About the Authors
 Utkarsh Mittal is a Senior Technical Product Manager for Amazon DataZone at AWS. He is passionate about building innovative products that simplify customers’ end-to-end analytics journeys. Outside of the tech world, Utkarsh loves to play music, with drums being his latest endeavor.
Utkarsh Mittal is a Senior Technical Product Manager for Amazon DataZone at AWS. He is passionate about building innovative products that simplify customers’ end-to-end analytics journeys. Outside of the tech world, Utkarsh loves to play music, with drums being his latest endeavor.
 Praveen Kumar is a Principal Analytics Solution Architect at AWS with expertise in designing, building, and implementing modern data and analytics platforms using cloud-centered services. His areas of interests are serverless technology, modern cloud data warehouses, streaming, and generative AI applications.
Praveen Kumar is a Principal Analytics Solution Architect at AWS with expertise in designing, building, and implementing modern data and analytics platforms using cloud-centered services. His areas of interests are serverless technology, modern cloud data warehouses, streaming, and generative AI applications.
 Paul Villena is a Senior Analytics Solutions Architect in AWS with expertise in building modern data and analytics solutions to drive business value. He works with customers to help them harness the power of the cloud. His areas of interests are infrastructure as code, serverless technologies, and coding in Python
Paul Villena is a Senior Analytics Solutions Architect in AWS with expertise in building modern data and analytics solutions to drive business value. He works with customers to help them harness the power of the cloud. His areas of interests are infrastructure as code, serverless technologies, and coding in Python

























 Andrea Filippo is a Partner Solutions Architect at AWS supporting Public Sector partners and customers in Italy. He focuses on modern data architectures and helping customers accelerate their cloud journey with serverless technologies.
Andrea Filippo is a Partner Solutions Architect at AWS supporting Public Sector partners and customers in Italy. He focuses on modern data architectures and helping customers accelerate their cloud journey with serverless technologies. Emanuele is a Solutions Architect at AWS, based in Italy, after living and working for more than 5 years in Spain. He enjoys helping large companies with the adoption of cloud technologies, and his area of expertise is mainly focused on Data Analytics and Data Management. Outside of work, he enjoys traveling and collecting action figures.
Emanuele is a Solutions Architect at AWS, based in Italy, after living and working for more than 5 years in Spain. He enjoys helping large companies with the adoption of cloud technologies, and his area of expertise is mainly focused on Data Analytics and Data Management. Outside of work, he enjoys traveling and collecting action figures. Varsha Velagapudi is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about simplifying customers’ AI/ML and analytics journey to help them succeed in their day-to-day tasks. Outside of work, she enjoys nature and outdoor activities, reading, and traveling.
Varsha Velagapudi is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about simplifying customers’ AI/ML and analytics journey to help them succeed in their day-to-day tasks. Outside of work, she enjoys nature and outdoor activities, reading, and traveling.

 Andries Engelbrecht is a Principal Partner Solutions Architect at Snowflake and works with strategic partners. He is actively engaged with strategic partners like AWS supporting product and service integrations as well as the development of joint solutions with partners. Andries has over 20 years of experience in the field of data and analytics.
Andries Engelbrecht is a Principal Partner Solutions Architect at Snowflake and works with strategic partners. He is actively engaged with strategic partners like AWS supporting product and service integrations as well as the development of joint solutions with partners. Andries has over 20 years of experience in the field of data and analytics. Deenbandhu Prasad is a Senior Analytics Specialist at AWS, specializing in big data services. He is passionate about helping customers build modern data architectures on the AWS Cloud. He has helped customers of all sizes implement data management, data warehouse, and data lake solutions.
Deenbandhu Prasad is a Senior Analytics Specialist at AWS, specializing in big data services. He is passionate about helping customers build modern data architectures on the AWS Cloud. He has helped customers of all sizes implement data management, data warehouse, and data lake solutions. Brian Dolan joined Amazon as a Military Relations Manager in 2012 after his first career as a Naval Aviator. In 2014, Brian joined Amazon Web Services, where he helped Canadian customers from startups to enterprises explore the AWS Cloud. Most recently, Brian was a member of the Non-Relational Business Development team as a Go-To-Market Specialist for Amazon DynamoDB and Amazon Keyspaces before joining the Analytics Worldwide Specialist Organization in 2022 as a Go-To-Market Specialist for AWS Glue.
Brian Dolan joined Amazon as a Military Relations Manager in 2012 after his first career as a Naval Aviator. In 2014, Brian joined Amazon Web Services, where he helped Canadian customers from startups to enterprises explore the AWS Cloud. Most recently, Brian was a member of the Non-Relational Business Development team as a Go-To-Market Specialist for Amazon DynamoDB and Amazon Keyspaces before joining the Analytics Worldwide Specialist Organization in 2022 as a Go-To-Market Specialist for AWS Glue. Nidhi Gupta is a Sr. Partner Solution Architect at AWS. She spends her days working with customers and partners, solving architectural challenges. She is passionate about data integration and orchestration, serverless and big data processing, and machine learning. Nidhi has extensive experience leading the architecture design and production release and deployments for data workloads.
Nidhi Gupta is a Sr. Partner Solution Architect at AWS. She spends her days working with customers and partners, solving architectural challenges. She is passionate about data integration and orchestration, serverless and big data processing, and machine learning. Nidhi has extensive experience leading the architecture design and production release and deployments for data workloads. Scott Teal is a Product Marketing Lead at Snowflake and focuses on data lakes, storage, and governance.
Scott Teal is a Product Marketing Lead at Snowflake and focuses on data lakes, storage, and governance.












 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike. Chuhan Liu is a Software Development Engineer on the AWS Glue team. He is passionate about building scalable distributed systems for big data processing, analytics, and management. In his spare time, he enjoys playing tennis.
Chuhan Liu is a Software Development Engineer on the AWS Glue team. He is passionate about building scalable distributed systems for big data processing, analytics, and management. In his spare time, he enjoys playing tennis. XiaoRun Yu is a Software Development Engineer on the AWS Glue team. He is working on building new features for AWS Glue to help customers. Outside of work, Xiaorun enjoys exploring new places in the Bay Area.
XiaoRun Yu is a Software Development Engineer on the AWS Glue team. He is working on building new features for AWS Glue to help customers. Outside of work, Xiaorun enjoys exploring new places in the Bay Area. Sean Ma is a Principal Product Manager on the AWS Glue team. He has a track record of more than 18 years innovating and delivering enterprise products that unlock the power of data for users. Outside of work, Sean enjoys scuba diving and college football.
Sean Ma is a Principal Product Manager on the AWS Glue team. He has a track record of more than 18 years innovating and delivering enterprise products that unlock the power of data for users. Outside of work, Sean enjoys scuba diving and college football. Mohit Saxena is a Senior Software Development Manager on the AWS Glue team. His team focuses on building distributed systems to enable customers with interactive and simple to use interfaces to efficiently manage and transform petabytes of data seamlessly across data lakes on Amazon S3, databases and data-warehouses on cloud.
Mohit Saxena is a Senior Software Development Manager on the AWS Glue team. His team focuses on building distributed systems to enable customers with interactive and simple to use interfaces to efficiently manage and transform petabytes of data seamlessly across data lakes on Amazon S3, databases and data-warehouses on cloud.







 Sushanth Kothapally is a Solutions Architect at Amazon Web Services supporting Automotive and Manufacturing customers. He is passionate about designing technology solutions to meet business goals and has keen interest in serverless and event-driven architectures.
Sushanth Kothapally is a Solutions Architect at Amazon Web Services supporting Automotive and Manufacturing customers. He is passionate about designing technology solutions to meet business goals and has keen interest in serverless and event-driven architectures. Senthil Kamala Rathinam is a Solutions Architect at Amazon Web Services specializing in Data and Analytics. He is passionate about helping customers to design and build modern data platforms. In his free time, Senthil loves to spend time with his family and play badminton.
Senthil Kamala Rathinam is a Solutions Architect at Amazon Web Services specializing in Data and Analytics. He is passionate about helping customers to design and build modern data platforms. In his free time, Senthil loves to spend time with his family and play badminton.



















 Alan Peaty is a Senior Partner Solutions Architect at AWS. Alan helps Global Systems Integrators (GSIs) and Global Independent Software Vendors (GISVs) solve complex customer challenges using AWS services. Prior to joining AWS, Alan worked as an architect at systems integrators to translate business requirements into technical solutions. Outside of work, Alan is an IoT enthusiast and a keen runner who loves to hit the muddy trails of the English countryside.
Alan Peaty is a Senior Partner Solutions Architect at AWS. Alan helps Global Systems Integrators (GSIs) and Global Independent Software Vendors (GISVs) solve complex customer challenges using AWS services. Prior to joining AWS, Alan worked as an architect at systems integrators to translate business requirements into technical solutions. Outside of work, Alan is an IoT enthusiast and a keen runner who loves to hit the muddy trails of the English countryside. Parag Srivastava is a Solutions Architect at AWS, helping enterprise customers with successful cloud adoption and migration. During his professional career, he has been extensively involved in complex digital transformation projects. He is also passionate about building innovative solutions around geospatial aspects of addresses.
Parag Srivastava is a Solutions Architect at AWS, helping enterprise customers with successful cloud adoption and migration. During his professional career, he has been extensively involved in complex digital transformation projects. He is also passionate about building innovative solutions around geospatial aspects of addresses.















































 Satya Adimula is a Senior Data Architect at AWS based in Boston. With over two decades of experience in data and analytics, Satya helps organizations derive business insights from their data at scale.
Satya Adimula is a Senior Data Architect at AWS based in Boston. With over two decades of experience in data and analytics, Satya helps organizations derive business insights from their data at scale.







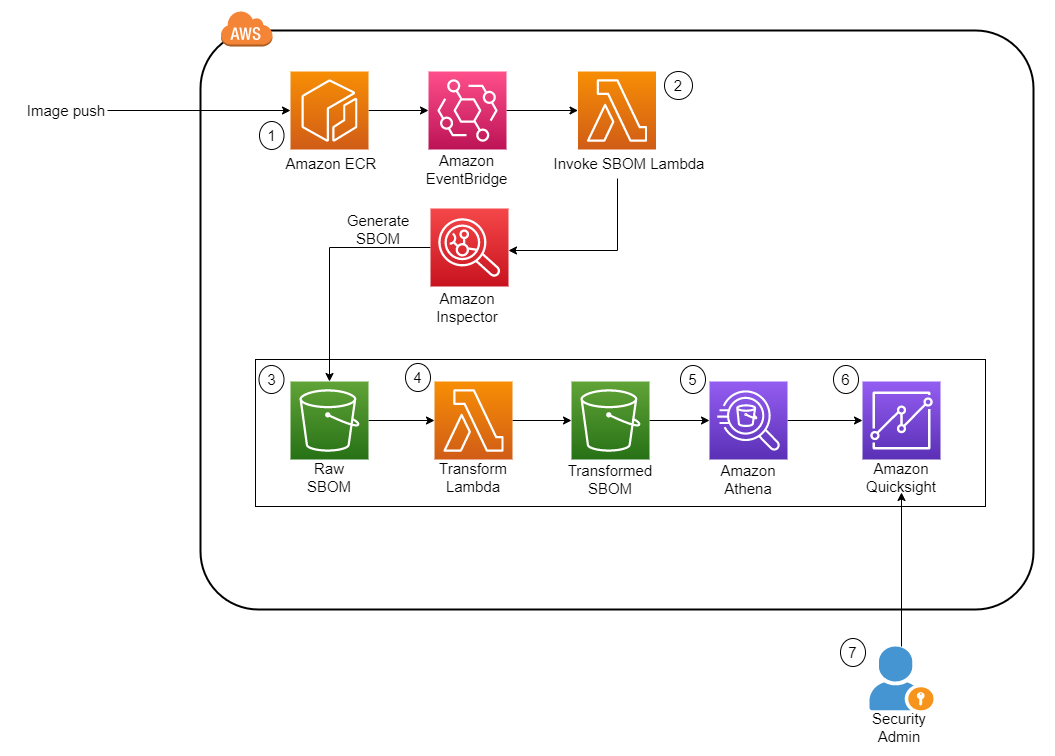



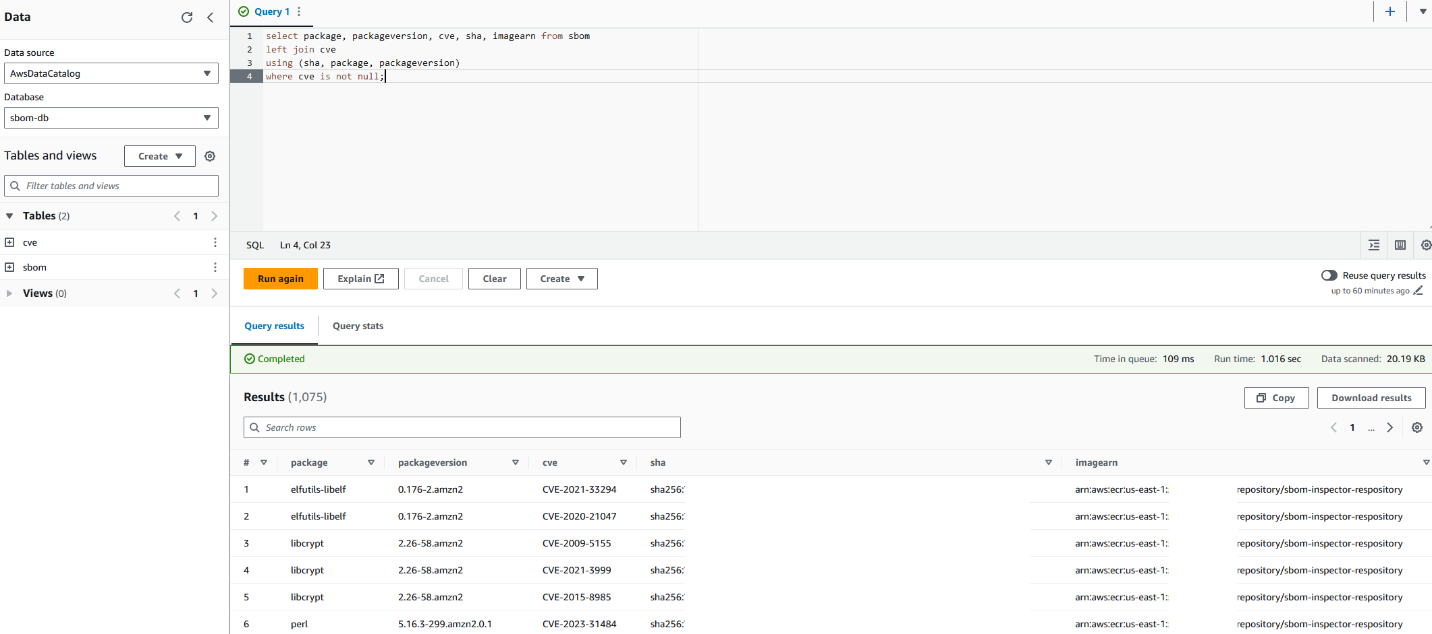

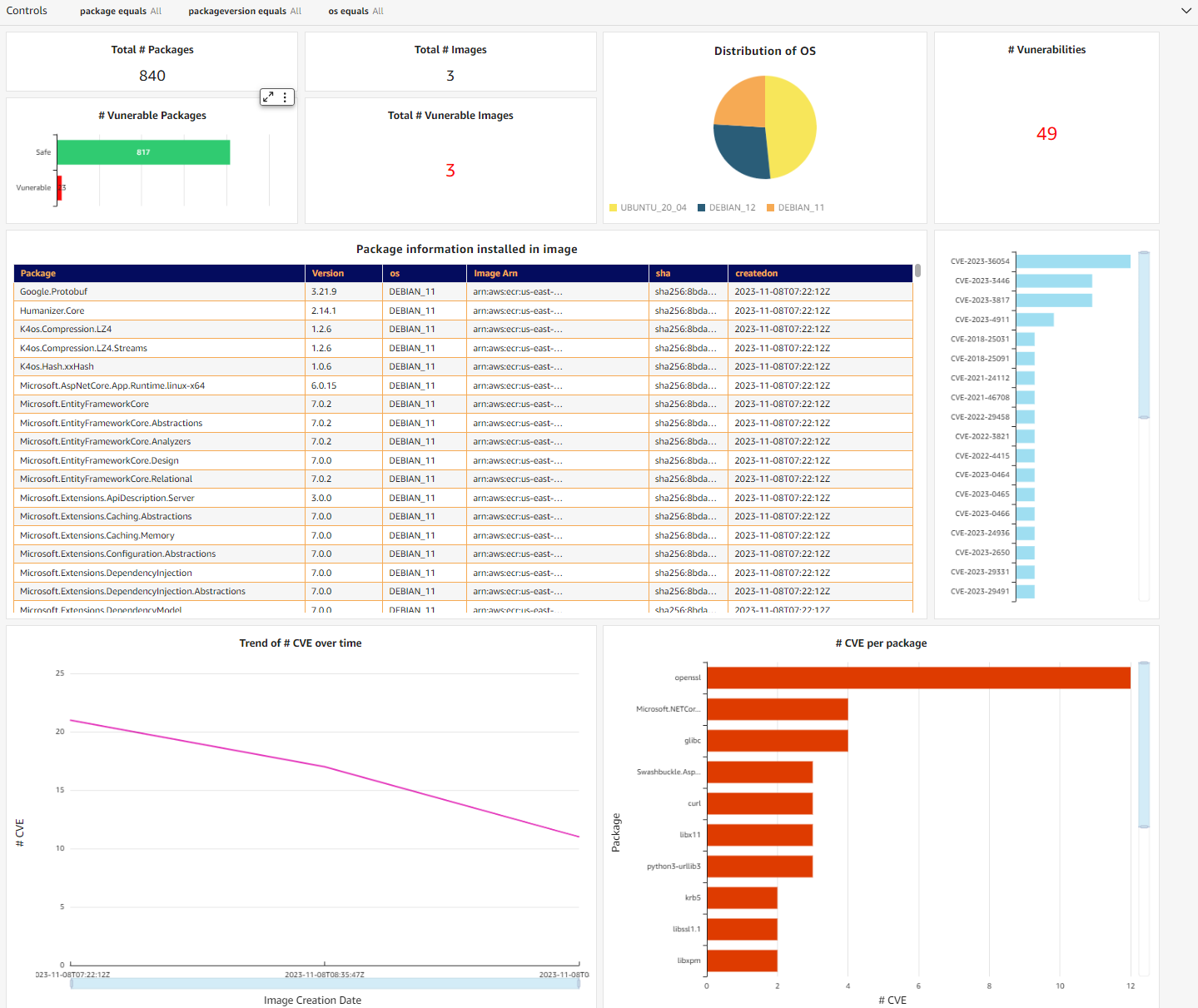




 Toney Thomas is a Data Architect and Data Engineering Lead at Bluestone, renowned for his role in envisioning and coining the company’s pioneering data strategy. With a strategic focus on harnessing the power of advanced technology to tackle intricate business challenges, Toney leads a dynamic team of Data Engineers, Reporting Engineers, Quality Assurance specialists, and Business Analysts at Bluestone. His leadership extends to driving the implementation of robust data governance frameworks across diverse organizational units. Under his guidance, Bluestone has achieved remarkable success, including the deployment of innovative platforms such as a fully governed data mesh business data system with embedded data quality mechanisms, aligning seamlessly with the organization’s commitment to data democratization and excellence.
Toney Thomas is a Data Architect and Data Engineering Lead at Bluestone, renowned for his role in envisioning and coining the company’s pioneering data strategy. With a strategic focus on harnessing the power of advanced technology to tackle intricate business challenges, Toney leads a dynamic team of Data Engineers, Reporting Engineers, Quality Assurance specialists, and Business Analysts at Bluestone. His leadership extends to driving the implementation of robust data governance frameworks across diverse organizational units. Under his guidance, Bluestone has achieved remarkable success, including the deployment of innovative platforms such as a fully governed data mesh business data system with embedded data quality mechanisms, aligning seamlessly with the organization’s commitment to data democratization and excellence. Ben Vengerovsky is a Data Platform Product Manager at Bluestone. He is passionate about using cloud technology to revolutionize the company’s data infrastructure. With a background in mortgage lending and a deep understanding of AWS services, Ben specializes in designing scalable and efficient data solutions that drive business growth and enhance customer experiences. He thrives on collaborating with cross-functional teams to translate business requirements into innovative technical solutions that empower data-driven decision-making.
Ben Vengerovsky is a Data Platform Product Manager at Bluestone. He is passionate about using cloud technology to revolutionize the company’s data infrastructure. With a background in mortgage lending and a deep understanding of AWS services, Ben specializes in designing scalable and efficient data solutions that drive business growth and enhance customer experiences. He thrives on collaborating with cross-functional teams to translate business requirements into innovative technical solutions that empower data-driven decision-making. Rada Stanic is a Chief Technologist at Amazon Web Services, where she helps ANZ customers across different segments solve their business problems using AWS Cloud technologies. Her special areas of interest are data analytics, machine learning/AI, and application modernization.
Rada Stanic is a Chief Technologist at Amazon Web Services, where she helps ANZ customers across different segments solve their business problems using AWS Cloud technologies. Her special areas of interest are data analytics, machine learning/AI, and application modernization.






 Michael Greenshtein is an Analytics Specialist Solutions Architect for the Public Sector.
Michael Greenshtein is an Analytics Specialist Solutions Architect for the Public Sector. Gonzalo Herreros is a Senior Big Data Architect on the AWS Glue team.
Gonzalo Herreros is a Senior Big Data Architect on the AWS Glue team.








 Xiaoxi Liu is a Software Development Engineer on the AWS Glue team. Her passion is building scalable distributed systems for efficiently managing big data on the cloud, and her concentrations are distributed system, big data, and cloud computing.
Xiaoxi Liu is a Software Development Engineer on the AWS Glue team. Her passion is building scalable distributed systems for efficiently managing big data on the cloud, and her concentrations are distributed system, big data, and cloud computing. Akira Ajisaka is a Senior Software Development Engineer on the AWS Glue team. He likes open source software and distributed systems. In his spare time, he enjoys playing arcade games.
Akira Ajisaka is a Senior Software Development Engineer on the AWS Glue team. He likes open source software and distributed systems. In his spare time, he enjoys playing arcade games. Shenoda Guirguis is a Senior Software Development Engineer on the AWS Glue team. His passion is in building scalable and distributed data infrastructure and processing systems. When he gets a chance, Shenoda enjoys reading and playing soccer.
Shenoda Guirguis is a Senior Software Development Engineer on the AWS Glue team. His passion is in building scalable and distributed data infrastructure and processing systems. When he gets a chance, Shenoda enjoys reading and playing soccer.













 Durga Prasad is a Sr Lead Consultant enabling customers build their Data Analytics solutions on AWS. He is a coffee lover and enjoys playing badminton.
Durga Prasad is a Sr Lead Consultant enabling customers build their Data Analytics solutions on AWS. He is a coffee lover and enjoys playing badminton. Murali Reddy is a Lead Consultant at Amazon Web Services (AWS), helping customers build and implement data analytics solution. When he’s not working, Murali is an avid bike rider and loves exploring new places.
Murali Reddy is a Lead Consultant at Amazon Web Services (AWS), helping customers build and implement data analytics solution. When he’s not working, Murali is an avid bike rider and loves exploring new places.




















 Michael Hamilton is a Sr Analytics Solutions Architect focusing on helping enterprise customers modernize and simplify their analytics workloads on AWS. He enjoys mountain biking and spending time with his wife and three children when not working.
Michael Hamilton is a Sr Analytics Solutions Architect focusing on helping enterprise customers modernize and simplify their analytics workloads on AWS. He enjoys mountain biking and spending time with his wife and three children when not working. Daniel Rozo is a Senior Solutions Architect with AWS supporting customers in the Netherlands. His passion is engineering simple data and analytics solutions and helping customers move to modern data architectures. Outside of work, he enjoys playing tennis and biking.
Daniel Rozo is a Senior Solutions Architect with AWS supporting customers in the Netherlands. His passion is engineering simple data and analytics solutions and helping customers move to modern data architectures. Outside of work, he enjoys playing tennis and biking.













 Basheer Sheriff is a Senior Solutions Architect at AWS. He loves to help customers solve interesting problems leveraging new technology. He is based in Melbourne, Australia, and likes to play sports such as football and cricket.
Basheer Sheriff is a Senior Solutions Architect at AWS. He loves to help customers solve interesting problems leveraging new technology. He is based in Melbourne, Australia, and likes to play sports such as football and cricket. Shunsuke Goto is a Prototyping Engineer working at AWS. He works closely with customers to build their prototypes and also helps customers build analytics systems.
Shunsuke Goto is a Prototyping Engineer working at AWS. He works closely with customers to build their prototypes and also helps customers build analytics systems.



 Kinshuk Pahare is a leader in AWS Glue’s product management team. He drives efforts on the platform, developer experience, and big data processing frameworks like Apache Spark, Ray, and Python Shell.
Kinshuk Pahare is a leader in AWS Glue’s product management team. He drives efforts on the platform, developer experience, and big data processing frameworks like Apache Spark, Ray, and Python Shell.





 Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing Tennis.
Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing Tennis. Joe Morotti is a Senior Solutions Architect at Amazon Web Services (AWS), working with Enterprise customers across the Midwest US to develop innovative solutions on AWS. He has held a wide range of technical roles and enjoys showing customers the art of the possible. He has attained seven AWS certification and has a passion for AI/ML and the contact center space. In his free time, he enjoys spending quality time with his family exploring new places and overanalyzing his sports team’s performance.
Joe Morotti is a Senior Solutions Architect at Amazon Web Services (AWS), working with Enterprise customers across the Midwest US to develop innovative solutions on AWS. He has held a wide range of technical roles and enjoys showing customers the art of the possible. He has attained seven AWS certification and has a passion for AI/ML and the contact center space. In his free time, he enjoys spending quality time with his family exploring new places and overanalyzing his sports team’s performance. Uma Ramadoss is a specialist Solutions Architect at Amazon Web Services, focused on the Serverless platform. She is responsible for helping customers design and operate event-driven cloud-native applications and modern business workflows using services like Lambda, EventBridge, Step Functions, and Amazon MWAA.
Uma Ramadoss is a specialist Solutions Architect at Amazon Web Services, focused on the Serverless platform. She is responsible for helping customers design and operate event-driven cloud-native applications and modern business workflows using services like Lambda, EventBridge, Step Functions, and Amazon MWAA.