Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/preview-amazon-opensearch-serverless-run-search-and-analytics-workloads-without-managing-clusters/
Most AWS analytics services have compelling serverless offerings that make it even easier for customers to analyze vast amounts of data without having to configure, scale, or manage the underlying infrastructure.
Along with other serverless analytics, such as Amazon QuickSight for business intelligence and AWS Glue for data integration, we have introduced Amazon EMR Serverless, Amazon MSK Serverless, and Amazon Redshift Serverless this year.
Today, we announce the preview release of a new serverless option for Amazon OpenSearch Service that makes it easy for customers to run large-scale search and analytics workloads without managing clusters. It automatically provisions and scales the underlying resources to deliver fast data ingestion and query responses for even the most demanding and unpredictable workloads, eliminating the need to configure and optimize clusters.
With Amazon OpenSearch Serverless, you do not need to account for factors that are hard to know in advance, such as the frequency and complexity of queries or the volume of data expected to be analyzed. Instead of managing infrastructure, you can focus on using OpenSearch for exploring and deriving insights from your data. You can also get started using familiar APIs to load and query data and use OpenSearch Dashboards for interactive data analysis and visualization.
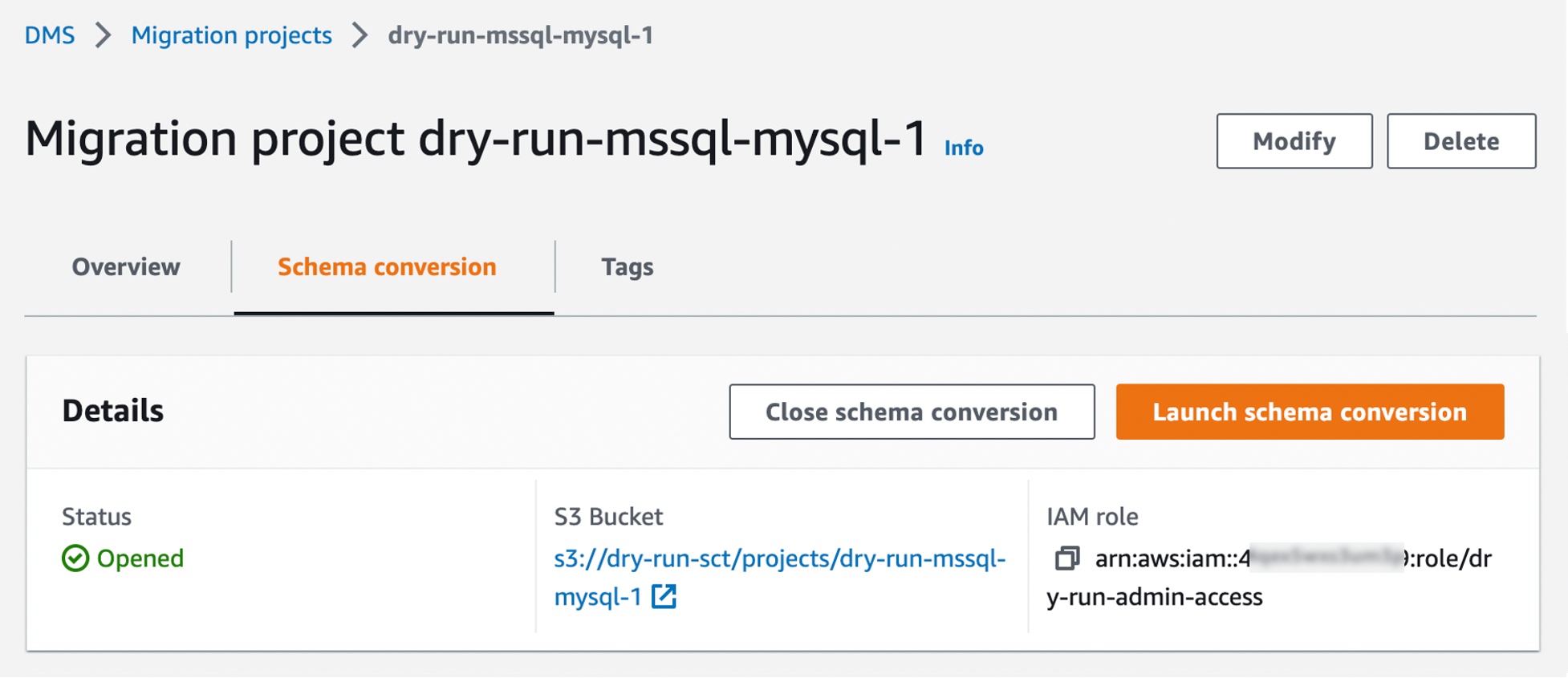
Configure Your OpenSearch Serverless Collection
To get started with Amazon OpenSearch Serverless, you create a Collection via the AWS Management Console, AWS Command-Line Interface (AWS CLI), or AWS API.

Before the launch of OpenSearch Serverless, you created a managed cluster, specifying instance types, counts, and storage options, and then managed the lifecycle and shard strategy for indices within that cluster. With OpenSearch Serverless, you create a Collection, which manages a group of indices that work together to support a specific workload. You no longer need to specify the hardware or manage the indices directly.

To create an OpenSearch Serverless collection and secure data, set up Encryption policies to assign AWS KMS keys to one or more collections and attach Network policies to collections to control the access from specified VPCs and public IP addresses.

To create an encryption policy, choose Encryption policies in the left navigation pane and Create encryption policy. Encryption at rest secures the indices within your collection. For each collection, AWS KMS generates a unique, symmetric encryption key. Encryption policies are the optimal way to manage AWS KMS keys across multiple collections. You can define the target collection name or a prefix that automatically applies the encryption settings from this policy to the collection.

In order for users to access a collection, choose Network policies in the left navigation pane and Create network policy. Network policies determine whether your collection is accessible over the internet from public networks or whether it must be accessed through OpenSearch Serverless–managed VPC endpoints.

You can define multiple rules for each collection, either the Public or VPC, as a recommended option for the Access Type. If you select a public option, you can access the collection from OpenSearch Dashboards.
Also, you can configure access for OpenSearch Dashboards and the OpenSearch endpoint. For the Resource type, enable both Access to OpenSearch endpoints and Access to OpenSearch Dashboards. In both input boxes, select the Collection Name property and your collection name or prefix.
Finally, to create an OpenSearch Serverless collection, choose Create collection in the home page or choose Collections in the left navigation pane and choose Create collection.

Input your collection name, description, and collection type, either Time series or Search by your data type.
- Time series – The log analytics segment that focuses on analyzing large volumes of semistructured, machine-generated data in real time for operational, security, user behavior, and business insights.
- Search – Full-text search that powers applications in your internal networks (content management systems, legal documents) and internet-facing applications such as e-commerce website search and content search.
When you choose Create, a collection typically takes less than a minute to initialize.
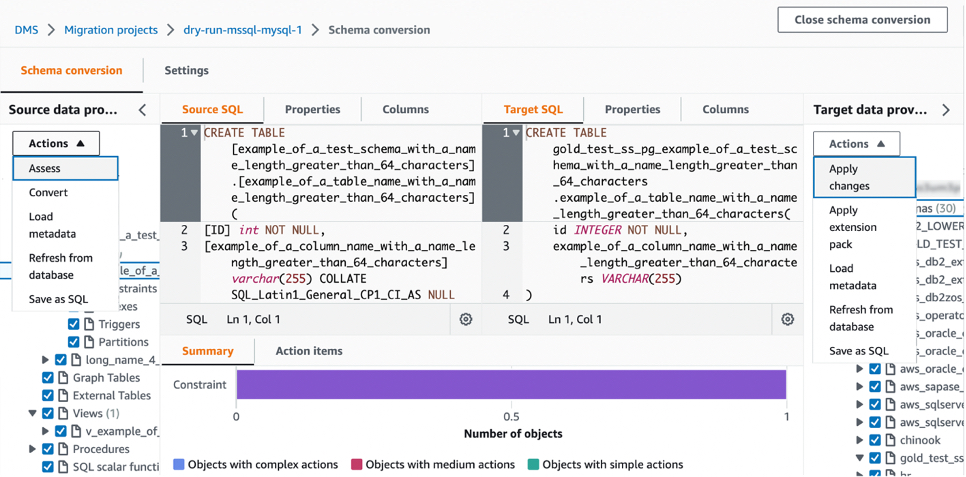
Upload and Search Data in Your Collection
Before uploading and searching data in your collection, configure the IAM policy to access the actual data within a collection. Choose Data access policies in the left navigation pane and Create data access policy.
You can apply multiple policies simultaneously to the same resource. Each policy contains a set of rules. Each rule has a resource (collection or index), permissions for the resource, and a list of principals (IAM users, role ARNs, or SAML identities).
Here is a sample policy that provides a single user the minimum permissions required to create an index in your collection, index some data, and search for it. Replace the principal ARN with the ARN of the account that you’ll use to sign in to OpenSearch Dashboards.
[
{
"Rules": [
{
"ResourceType": "index",
"Resource": [
"index/books/*"
],
"Permission": [
"aoss:CreateIndex",
"aoss:ReadDocument",
"aoss:UpdateIndex",
"aoss:DeleteIndex",
"aoss:WriteDocument"
]
}
],
"Principal": [
"arn:aws:iam::123456789012:user/admin"
]
}
]Now, you can upload data to an OpenSearch Serverless collection using Postman or curl. You can also use Dev Tools within the OpenSearch Dashboards console. Choose OpenSearch Dashboards on the detail page of your collection.

Sign in to OpenSearch Dashboards using the AWS access and secret keys for the principal that you specified in your data access policy. Within OpenSearch Dashboards, open the left navigation menu and choose Dev Tools.
To create a single index called books-index, run PUT books-index, and index your first single document into books-index.

You can also query search data in Dev Tools.
GET books_index/_search
{
"query": {
"simple_query_string": {
"query": "Jeff",
"fields": ["author"]
}
}
}In the case of time-series data, you can ingest data with all of the streaming ingestion options, such as native OpenSearch streaming APIs, Amazon Kinesis Data Firehose, AWS Glue, and a wide range of open-source streaming ingestion pipelines like Logstash, FluentBit, Fluentd, and Data Prepper.
In addition, you can snapshot your data from a managed cluster on OpenSearch Service and restore it to your collection, making it easy to migrate your workloads. Once your data is in your collection, you can then query it using your favorite OpenSearch client and interactively analyze and visualize your data using OpenSearch Dashboards.
Things to Know
Here are a couple of things to keep in mind about additional features and considerations when you choose Amazon OpenSearch Serverless:
- SAML Authentications – You can use your existing identity provider to offer single sign-on (SSO) for the OpenSearch Dashboards endpoints of OpenSearch Serverless SAML authentication lets you use third-party identity providers to sign in to OpenSearch Dashboards to index and search data. OpenSearch Serverless supports providers that use the SAML 2.0 standard, such as Okta, Keycloak, Active Directory Federation Services, and Auth0.
- Private VPC Endpoints – You can use AWS PrivateLink to create a private connection between your VPC and OpenSearch Serverless. You can access your collections as if they were in your VPC without the use of an internet gateway, NAT device, VPN connection, or AWS Direct Connect connection. To create an interface endpoint, choose VPC endpoints in the left navigation pane of OpenSearch Service.
- Managed Clusters – You may prefer to use an option of Amazon OpenSearch Service’s managed clusters in scenarios where you need tight control over cluster configuration or specific customizations. For example, your workloads may need custom plugins that run best on accelerated computing instances and need more control on configuration such as data sharding strategy. You can choose either provisioned instances or serverless according to the requirements of your workload.
Join the Preview
The preview release of Amazon OpenSearch Serverless is now available in the US East (N. Virginia, Ohio), US West (Oregon), EU (Ireland), Asia Pacific (Tokyo). With OpenSearch Serverless, there are no upfront costs, and you pay only for the data that is ingest and the queries you run. For pricing details, see the OpenSearch Service pricing page. To learn more, visit the Amazon OpenSearch Service User Guide.
We want to hear more feedback during the preview. Please send feedback to AWS re:Post for Amazon OpenSearch Service or through your usual AWS support contacts.
– Channy

















































 Choose Create instance profile and specify your default VPC or a new VPC,
Choose Create instance profile and specify your default VPC or a new VPC,