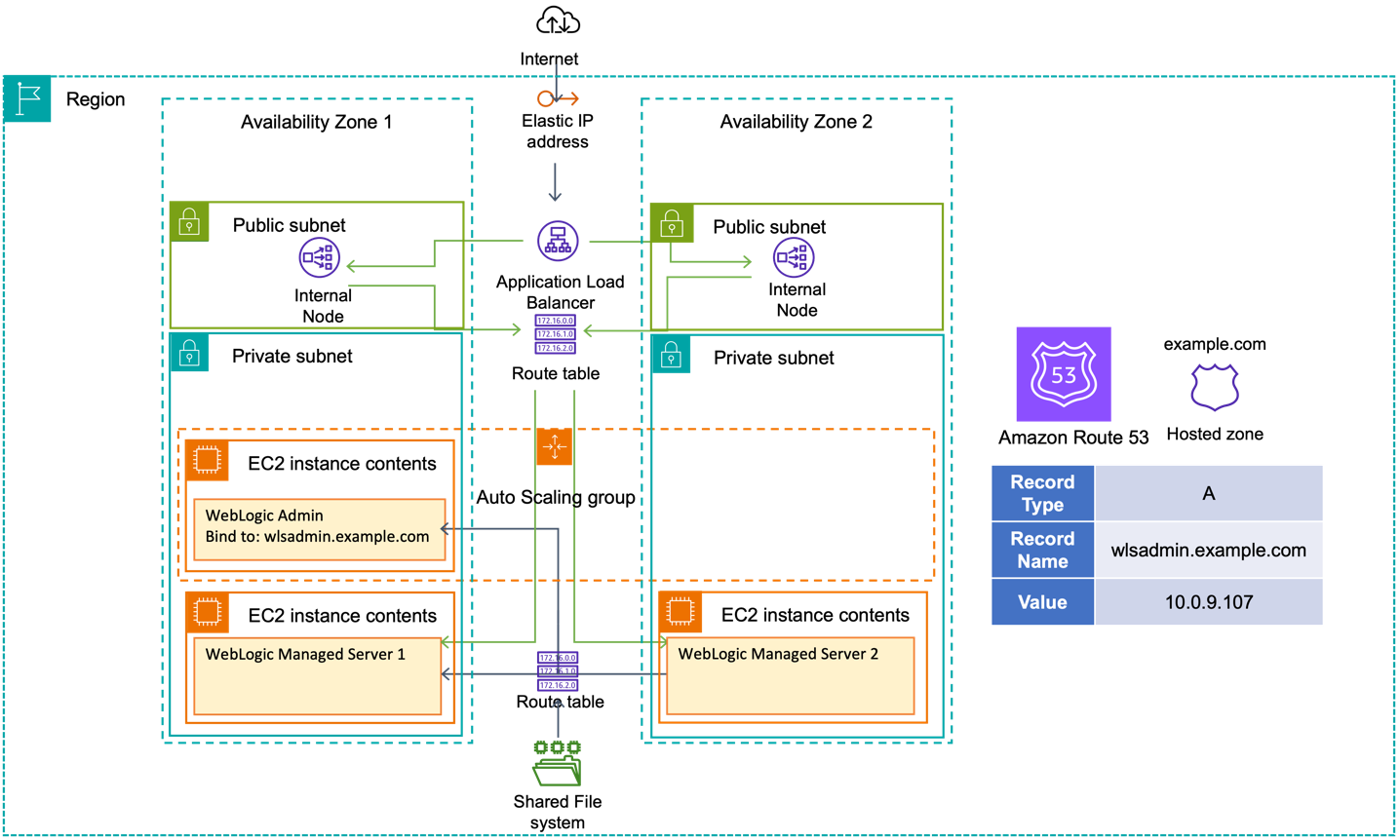
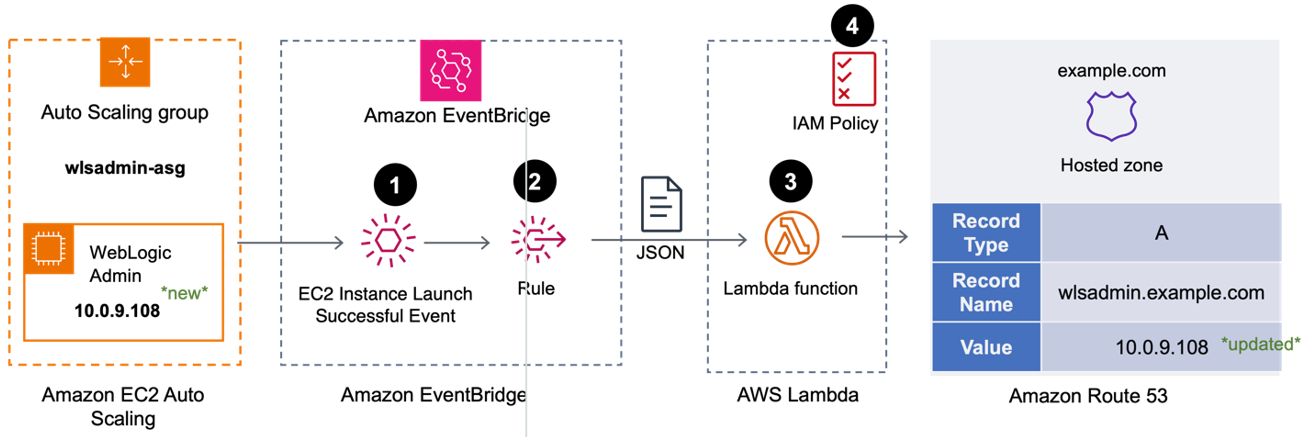
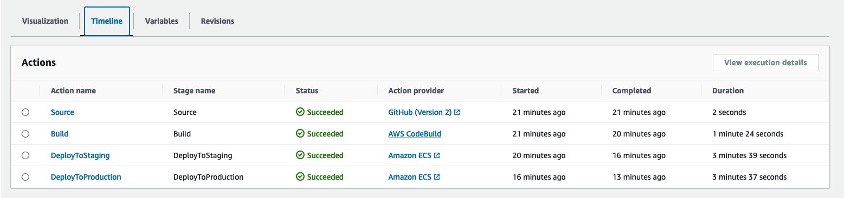
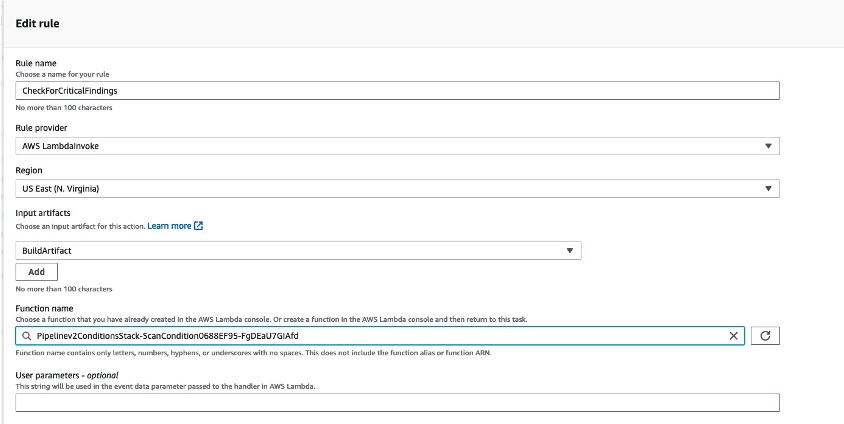
Post Syndicated from B. Schneier original https://www.schneier.com/blog/archives/2024/10/ai-and-the-sec-whistleblower-program.html
Tax farming is the practice of licensing tax collection to private contractors. Used heavily in ancient Rome, it’s largely fallen out of practice because of the obvious conflict of interest between the state and the contractor. Because tax farmers are primarily interested in short-term revenue, they have no problem abusing taxpayers and making things worse for them in the long term. Today, the U.S. Securities and Exchange Commission (SEC) is engaged in a modern-day version of tax farming. And the potential for abuse will grow when the farmers start using artificial intelligence.
In 2009, after Bernie Madoff’s $65 billion Ponzi scheme was exposed, Congress authorized the SEC to award bounties from civil penalties recovered from securities law violators. It worked in a big way. In 2012, when the program started, the agency received more than 3,000 tips. By 2020, it had more than doubled, and it more than doubled again by 2023. The SEC now receives more than 50 tips per day, and the program has paid out a staggering $2 billion in bounty awards. According to the agency’s 2023 financial report, the SEC paid out nearly $600 million to whistleblowers last year.
The appeal of the whistleblower program is that it alerts the SEC to violations it may not otherwise uncover, without any additional staff. And since payouts are a percentage of fines collected, it costs the government little to implement.
Unfortunately, the program has resulted in a new industry of private de facto regulatory enforcers. Legal scholar Alexander Platt has shown how the SEC’s whistleblower program has effectively privatized a huge portion of financial regulatory enforcement. There is a role for publicly sourced information in securities regulatory enforcement, just as there has been in litigation for antitrust and other areas of the law. But the SEC program, and a similar one at the U.S. Commodity Futures Trading Commission, has created a market distortion replete with perverse incentives. Like the tax farmers of history, the interests of the whistleblowers don’t match those of the government.
First, while the blockbuster awards paid out to whistleblowers draw attention to the SEC’s successes, they obscure the fact that its staffing level has slightly declined during a period of tremendous market growth. In one case, the SEC’s largest ever, it paid $279 million to an individual whistleblower. That single award was nearly one-third of the funding of the SEC’s entire enforcement division last year. Congress gets to pat itself on the back for spinning up a program that pays for itself (by law, the SEC awards 10 to 30 percent of their penalty collections over $1 million to qualifying whistleblowers), when it should be talking about whether or not it’s given the agency enough resources to fulfill its mission to “maintain fair, orderly, and efficient markets.”
Second, while the stated purpose of the whistleblower program is to incentivize individuals to come forward with information about potential violations of securities law, this hasn’t actually led to increases in enforcement actions. Instead of legitimate whistleblowers bringing the most credible information to the SEC, the agency now seems to be deluged by tips that are not highly actionable.
But the biggest problem is that uncovering corporate malfeasance is now a legitimate business model, resulting in powerful firms and misaligned incentives. A single law practice led by former SEC assistant director Jordan Thomas captured about 20 percent of all the SEC’s whistleblower awards through 2022, at which point Thomas left to open up a new firm focused exclusively on whistleblowers. We can admire Thomas and his team’s impact on making those guilty of white-collar crimes pay, and also question whether hundreds of millions of dollars of penalties should be funneled through the hands of an SEC insider turned for-profit business mogul.
Whistleblower tips can be used as weapons of corporate warfare. SEC whistleblower complaints are not required to come from inside a company, or even to rely on insider information. They can be filed on the basis of public data, as long as the whistleblower brings original analysis. Companies might dig up dirt on their competitors and submit tips to the SEC. Ransomware groups have used the threat of SEC whistleblower tips as a tactic to pressure the companies they’ve infiltrated into paying ransoms.
The rise of whistleblower firms could lead to them taking particular “assignments” for a fee. Can a company hire one of these firms to investigate its competitors? Can an industry lobbying group under scrutiny (perhaps in cryptocurrencies) pay firms to look at other industries instead and tie up SEC resources? When a firm finds a potential regulatory violation, do they approach the company at fault and offer to cease their research for a “kill fee”? The lack of transparency and accountability of the program means that the whistleblowing firms can get away with practices like these, which would be wholly unacceptable if perpetrated by the SEC itself.
Whistleblowing firms can also use the information they uncover to guide market investments by activist short sellers. Since 2006, the investigative reporting site Sharesleuth claims to have tanked dozens of stocks and instigated at least eight SEC cases against companies in pharma, energy, logistics, and other industries, all after its investors shorted the stocks in question. More recently, a new investigative reporting site called Hunterbrook Media and partner hedge fund Hunterbrook Capital, have churned out 18 investigative reports in their first five months of operation and disclosed short sales and other actions alongside each. In at least one report, Hunterbrook says they filed an SEC whistleblower tip.
Short sellers carry an important disciplining function in markets. But combined with whistleblower awards, the same profit-hungry incentives can emerge. Properly staffed regulatory agencies don’t have the same potential pitfalls.
AI will affect every aspect of this dynamic. AI’s ability to extract information from large document troves will help whistleblowers provide more information to the SEC faster, lowering the bar for reporting potential violations and opening a floodgate of new tips. Right now, there is no cost to the whistleblower to report minor or frivolous claims; there is only cost to the SEC. While AI automation will also help SEC staff process tips more efficiently, it could exponentially increase the number of tips the agency has to deal with, further decreasing the efficiency of the program.
AI could be a triple windfall for those law firms engaged in this business: lowering their costs, increasing their scale, and increasing the SEC’s reliance on a few seasoned, trusted firms. The SEC already, as Platt documented, relies on a few firms to prioritize their investigative agenda. Experienced firms like Thomas’s might wield AI automation to the greatest advantage. SEC staff struggling to keep pace with tips might have less capacity to look beyond the ones seemingly pre-vetted by familiar sources.
But the real effects will be on the conflicts of interest between whistleblowing firms and the SEC. The ability to automate whistleblower reporting will open new competitive strategies that could disrupt business practices and market dynamics.
An AI-assisted data analyst could dig up potential violations faster, for a greater scale of competitor firms, and consider a greater scope of potential violations than any unassisted human could. The AI doesn’t have to be that smart to be effective here. Complaints are not required to be accurate; claims based on insufficient evidence could be filed against competitors, at scale.
Even more cynically, firms might use AI to help cover up their own violations. If a company can deluge the SEC with legitimate, if minor, tips about potential wrongdoing throughout the industry, it might lower the chances that the agency will get around to investigating the company’s own liabilities. Some companies might even use the strategy of submitting minor claims about their own conduct to obscure more significant claims the SEC might otherwise focus on.
Many of these ideas are not so new. There are decades of precedent for using algorithms to detect fraudulent financial activity, with lots of current-day application of the latest large language models and other AI tools. In 2019, legal scholar Dimitrios Kafteranis, research coordinator for the European Whistleblowing Institute, proposed using AI to automate corporate whistleblowing.
And not all the impacts specific to AI are bad. The most optimistic possible outcome is that AI will allow a broader base of potential tipsters to file, providing assistive support that levels the playing field for the little guy.
But more realistically, AI will supercharge the for-profit whistleblowing industry. The risks remain as long as submitting whistleblower complaints to the SEC is a viable business model. Like tax farming, the interests of the institutional whistleblower diverge from the interests of the state, and no amount of tweaking around the edges will make it otherwise.
Ultimately, AI is not the cause of or solution to the problems created by the runaway growth of the SEC whistleblower program. But it should give policymakers pause to consider the incentive structure that such programs create, and to reconsider the balance of public and private ownership of regulatory enforcement.
This essay was written with Nathan Sanders, and originally appeared in The American Prospect.