Post Syndicated from Sandeep Adwankar original https://aws.amazon.com/blogs/big-data/aws-glue-crawlers-support-cross-account-crawling-to-support-data-mesh-architecture/
Data lakes have come a long way, and there’s been tremendous innovation in this space. Today’s modern data lakes are cloud native, work with multiple data types, and make this data easily available to diverse stakeholders across the business. As time has gone by, data lakes have grown significantly and have evolved to data meshes as a way to scale. Thoughtworks defines a data mesh as “a shift in a modern distributed architecture that applies platform thinking to create self-serve data infrastructure, treating data as the product.”
Data mesh advocates for decentralized ownership and delivery of enterprise data management systems that benefit several personas. Data producers can use the data mesh platform to create datasets and share them across business teams to ensure data availability, reliability, and interoperability across functions and data subject areas. Data consumers now have better data sharing with data mesh and federation across business units without compromising data security. The data governance team can support distributed data, where all data is accessible to those with the proper authority to access it. With data mesh, data doesn’t have to be consolidated into a single data lake or account and can remain within different databases and data lakes. An essential capability needed in such a data lake architecture is the ability to continuously understand changes in the data lakes in various other domains and make those available to data consumers. Without such a capability, manual work is needed to understand producers’ updates and make them available to consumers and governance.
AWS customers use a modern data architecture to facilitate governance and data sharing across logical or physical governance boundaries to create data domains aligned to lines of business. Each line of business creates and manages their dataset on Amazon Simple Storage Service (Amazon S3) and uses AWS Glue crawlers to discover new datasets and register them to the AWS Glue Data Catalog, add new tables and partitions, and detect schema changes. These datasets are shared with data consumers that access the data using services like Amazon Athena, Amazon Redshift, Amazon EMR, and more.
In the post Introducing AWS Glue crawlers using AWS Lake Formation permission management, we introduced a new set of capabilities in AWS Glue crawlers and AWS Lake Formation that simplifies crawler setup and supports centralized permissions for in-account and cross-account crawling of S3 data lakes. In this post, we demonstrate the same capability for a data mesh architecture in which we establish a central governance layer to catalog the data owned by the data producer and share it with the data consumer for ease of discovery. The AWS Glue crawler cross-account capability allows you to crawl data sources in different producer accounts while still having those changes cataloged in a centralized governance account. Customers prefer the central governance experience over writing bucket policies separately in each bucket owning the account of a data mesh producer. To build a data mesh architecture, now you can author permissions in a single Lake Formation governance to manage access to data locations and crawlers spanning multiple accounts in the data mesh.
According to the Allstate Corporation:
“By leveraging the power of AWS Lake Formation in our modern data architecture, we will be able to further unlock the potential of our data and empower our analytics community to drive innovation and build data-driven applications. The granular data access and collaboration provided by this architecture will enable us to build a truly unified data and analytics experience, bringing us one step closer to realizing our vision of becoming a fully data-driven enterprise.”
– Prashant Mehrotra, Director – Machine Learning and R&D, Allstate
In this post, we walk through the creation of a simplified data mesh architecture that shows how to use an AWS Glue crawler with Lake Formation to automate bringing changes from data producer domains to data consumers while maintaining centralized governance.
Solution overview
In a data mesh architecture, you have several producer accounts that own S3 buckets, several consumer accounts who wants to access shared datasets, and a central governance account to manage data shares between producers and consumers. This central governance account doesn’t own any S3 bucket or actual tables.
The following figure shows a simplified data mesh architecture with a single producer account, a centralized governance account, and a single consumer account. The data mesh producer account hosts the encrypted S3 bucket, which is shared with the central governance account. The central governance account registers the S3 bucket with Lake Formation using an AWS Identity and Access Management (IAM) role, which has permissions to the S3 bucket and AWS Key Management Service (AWS KMS). The central account creates the database for storing the dataset schema and shares it with the producer account. The producer account, as the S3 bucket owner, runs a crawler to crawl the buckets registered with the central account using Lake Formation permissions and populates the database. Now the shared database with new datasets are available to share with consumers in the data mesh. The central governance account can now share the database with a consumer admin, who can delegate access to other personas (such as data analysts) in the consumer account for data access.

In the following sections, we provide AWS CloudFormation templates to set up the resources in each account. Then we provide the steps to configure the crawler, manage permissions and sharing, and validate the solution by running queries with Athena.
Prerequisites
Complete the following steps in each account (producer, central governance, and consumer) to update the Data Catalog settings to use Lake Formation permissions to control catalog resources instead of IAM-based access control:
- Sign in to the Lake Formation console as admin.
- If this is the first time accessing the Lake Formation console, add yourself as the data lake administrator.

- In the navigation pane, under Data catalog, choose Settings.
- Uncheck Use only IAM access control for new databases.
- Uncheck Use only IAM access control for new tables in new databases.
- Keep Version 3 as the current cross-account version.
- Choose Save.

Set up resources in the central governance account
The CloudFormation template for the central account creates a CentralDataMeshOwner user assigned as Lake Formation admin. The CentralDataMeshOwner user in the central governance account performs the necessary steps to share the central catalogs with the producer and consumer accounts. The CentralDataMeshOwner user also sets up a custom Lake Formation service role to register the S3 data lake location. Complete the following steps:
- Log in to the central governance account console as IAM administrator.
- Choose Launch Stack to deploy the CloudFormation template:

- For DataMeshOwnerUserName, keep the default (
CentralDataMeshOwner). - For ProducerAWSAccount, enter the producer account ID.
- Create the stack.
- After the stack launches, on the AWS CloudFormation console, navigate to the Resources tab of the stack.
- Note down the value of
RegisterLocationServiceRole. - Choose the
LFUsersPasswordvalue to navigate to the AWS Secrets Manager console. - In the Secret value section, choose Retrieve secret value.
- Note down the secret value for the password for IAM user
CentralDataMeshOwner.
Set up resources in the producer account
The CloudFormation template for the producer account creates the following resources:
- IAM user
LOBProducerSteward - S3 bucket
retail-datalake-<producer account id >-<producer region> - KMS key used for bucket encryption
- Required S3 bucket policies to provide access to the central governance account
- AWS Glue crawler and crawler IAM role with necessary permissions
Complete the following steps:
- Log in to the producer account console as IAM administrator.
- Choose Launch Stack to deploy the CloudFormation template:
- For CentralAccountID, enter the central account ID.
- For CentralAccountLFServiceRole, enter the value of
RegisterLocationServiceRolefrom CloudFormation noted earlier. - Create the stack.
- When the stack is complete, on the AWS CloudFormation console, navigate to the Resources tab of the stack.
- Note down the
AWSGlueServiceRolevalue. - Choose the
ProducerStewardUserCredentialsvalue to navigate to the Secrets Manager console. - In the Secret value section, choose Retrieve secret value.
- Note down the secret value for the password for IAM user
LOBProducerSteward. - On the Amazon S3 console, check the bucket policies for
retail-datalake-<producer account id >-<producer region>and make sure it is shared with the central governance account IAM role.
This is required for registering the bucket with Lake Formation in the central account so that the account can manage the data sharing.
- On the AWS KMS console, check that the bucket is encrypted with the customer managed key and the key is shared with the central governance account.
Set up resources in the consumer account
The CloudFormation template for the consumer account creates the following resources:
- IAM user
ConsumerAdminUserassigned to the data lake admin - IAM user
LFBusinessAnalyst1 - S3 bucket for Athena output
- Athena workgroup
Complete the following steps:
- Log in to the consumer account console as IAM administrator.
- Choose Launch Stack to deploy the CloudFormation template:
- Create the stack.
- When the stack is complete, on the AWS CloudFormation console, navigate to the Resources tab of the stack.
- Choose the
AllConsumerUsersCredentialsvalue to navigate to the Secrets Manager console. - In the Secret value section, choose Retrieve secret value.
- Note down the secret value for the password for the IAM user
ConsumerAdminUser.
Now that all the accounts have been set up, we set up cross-account sharing on AWS with a central governance account to manage sharing of permissions across producers and consumers.
Configure the central governance account to manage sharing with the producer account
Sign in to the central governance account as CentralDataMeshOwner using the password noted earlier through the central governance account CloudFormation stack. Then complete the following steps:
- On Lake Formation console, choose Data lake locations under Register and ingest in the navigation pane.
- For Amazon S3 path, provide the path
retail-datalake-<producer account id >-<region>. - For IAM role, choose the IAM role created using the CloudFormation stack.
This role has permissions for the accessing the encrypted S3 bucket and its key. Do not choose the role AWSServiceRoleForLakeFormationDataAccess.
- Choose Register location.

- In the navigation pane, choose Databases.
- Choose Create database.
- For Database name¸ enter
datameshtestdatabase. - Choose Create database.
- In the navigation pane, choose Data locations and choose Grant.

- Select External account and provide the producer account for AWS account ID, AWS organization ID, or IAM principal ARN.
- For Storage location, provide the data lake bucket path.
- Select Grantable, then choose Grant.
- Choose Data lake permissions, then choose Grant.
- Select External accounts and provide the producer account number.
- For Databases, choose
datameshtestdatabase. - For Database permissions and Grantable permissions, select Create table, Alter, and Describe.
- Choose Grant.






Configure the crawler in the producer account to populate the schema
Sign in to producer account as LOBProducerSteward with the password noted earlier through the producer account CloudFormation stack, then complete the following steps:
- On the AWS RAM console, accept the pending resource share from the central account.
- On the Lake Formation console, choose Databases under Data catalog in the navigation pane.
- Choose
datameshtestdatabase, and on the Action menu, choose Create resource link. - For Resource link name, enter
datameshtestdatabaselink. - Choose Create.

- On the AWS Glue console, choose Crawlers in the navigation pane.
- Choose the crawler
CrossAccountCrawler-<accountid>. - Choose Edit, then choose Configure security settings.
- Select Use Lake Formation credentials for crawling S3 data source.
- Select In a different account and provide the account ID of the central governance account.
- Choose Next.

- Choose
datameshtestdatabaselinkas the database and choose Update.

- In the navigation pane, choose Data locations and choose Grant.
- Select My account, and choose the crawler IAM role for IAM users and roles.
- For Storage locations, choose the bucket
retail-datalake-<accountid>-<region>. - For Registered account location, enter the central account ID.
- Choose Grant.
 Alternatively, you can also use the AWS CLI to grant data location permission on bucket registered in central account to the crawler role using below command:
Alternatively, you can also use the AWS CLI to grant data location permission on bucket registered in central account to the crawler role using below command:
For using CLI, refer to Installing or updating the latest version of the AWS CLI.
- In the navigation pane, choose Data lake permissions.
- Choose the crawler IAM role for the principal account.
- Choose
datameshtestdatabasefor the database. - For Database permissions, select Create, Describe, and Alter.
- Choose Grant.

- Choose the crawler IAM role for the principal account.
- Choose
datameshtestdatabaselinkfor the database. - For Resource link permissions, select Describe.
- Choose Grant.
- Run the crawler.



 Alternatively, you can also use the AWS CLI to grant data location permission on bucket registered in central account to the crawler role using below command:
Alternatively, you can also use the AWS CLI to grant data location permission on bucket registered in central account to the crawler role using below command:

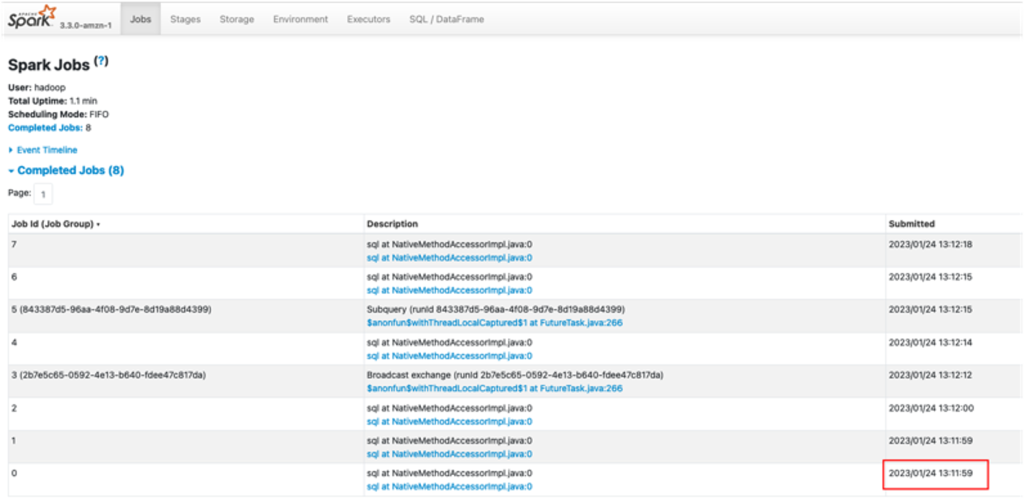
The following screenshot shows the details after a successful run.

When the crawler is complete, you can validate the table created under the database datameshtestdatabaselink.


This table is owned by the producer account and available in the central governance account under the shared database datameshtestdatabase. Now the data lake admin in the central governance account can share the database and populated table with the consumer account.
Configure the central governance account to manage sharing of read-only access with the consumer account
Sign in to the central governance account as CentralDataMeshOwner with the password noted earlier through the central governance account CloudFormation stack, then complete the following steps:
- Grant database permissions to the consumer account.
- For Principals, choose external account and provide <consumer accountID>
- For Databases, select
datameshtestdatabase. - For Database permissions, select Describe.
- For Grantable permissions¸ select Describe.
- Choose Grant.


- Grant table permissions to the consumer account.
- For Principals, choose external account and provide
<consumer accountID>. - For Databases, select
datameshtestdatabase. - For Tables, select
retail_datalake_<accountID>_<region>. - For Table permissions, select Select and Describe.
- For Grantable permissions¸ select Select and Describe.
- Choose Grant.






Configure the consumer account as the consumer account data lake admin
Sign to the consumer account as ConsumerAdminUser with the password noted earlier through the consumer account CloudFormation stack. (Note that in the consumer account Lake Formation configuration, both ConsumerAdminUser and LFBusinessAnalyst1 have the same password.)
- On the AWS RAM console, accept the resource share from the central account.
- On the Lake Formation console, validate that the shared database datameshtestdatabase is available and create the resource link datameshtestdatabaselink using the shared database.
The following screenshot shows the details after the resource link is created.

- On the Lake Formation console, choose Grant.
- Choose LFBusinessAnalyst1 for IAM users and roles.
- Choose
datameshtestdatabasefor the database under Named data catalog resources. - Select Describe for Database permissions.
- On the Lake Formation console, choose Grant.
- Choose
LFBusinessAnalyst1for IAM users and roles. - Choose
datameshtestdatabaselinkfor the database under Named data catalog resources. - Select Describe for Resource link permissions.
- On the Lake Formation console, choose Grant.
- Choose
LFBusinessAnalyst1for IAM users and roles. - Choose
retail_datalake_<accountid>_<region>for the table under Named data catalog resources. - Select Select and Describe for Table permissions.
Run queries in the consumer account
Sign to the consumer account console as LFBusinessAnalyst1 with the password noted earlier through the consumer account CloudFormation stack, then complete the following steps:
- On the Athena console, and choose
lfconsumer-workgroupas the Athena workgroup. - Run the following query to validate access:

We have successfully registered the dataset and created a Data Catalog in the central governance account. We crawled the data lake that was registered with the central governance account using Lake Formation permissions from the producer account and populated the schema. We granted Lake Formation permission on the database and table from the central account to the consumer user and validated consumer user access to the data using Athena.
Clean up
To avoid unwanted charges to your AWS account, delete the AWS resources:
- Sign in to the CloudFormation console as the IAM admin used for creating the CloudFormation stack in all three accounts.
- Delete the stacks you created.
Conclusion
In this post, we showed how to set up cross-account crawling using a central governance account with the new AWS Glue crawler capability of Lake Formation integration. This capability allows data producers to set up crawling capabilities in their own domain so that changes are seamlessly available to data governance and data consumers. Implementing a data mesh with AWS Glue crawlers, Lake Formation, Athena, and other analytical services provide a well-understood, performant, scalable, and cost-effective solution to integrate, prepare, and serve data.
If you have questions or suggestions, submit them in the comments section.
For more resources, refer to the following:
- Design a data mesh architecture using AWS Lake Formation and AWS Glue
- Introducing AWS Glue crawlers using AWS Lake Formation permission management
About the authors
 Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
 Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
 Piyali Kamra is a seasoned enterprise architect and a hands-on technologist who believes that building large scale enterprise systems is not an exact science but more like an art, in which tools and technologies must be carefully selected based on the team’s culture , strengths , weaknesses and risks , in tandem with having a futuristic vision as to how you want to shape your product a few years down the road.
Piyali Kamra is a seasoned enterprise architect and a hands-on technologist who believes that building large scale enterprise systems is not an exact science but more like an art, in which tools and technologies must be carefully selected based on the team’s culture , strengths , weaknesses and risks , in tandem with having a futuristic vision as to how you want to shape your product a few years down the road.





























 Takeshi Nakatani is a Principal Bigdata Consultant on Professional Services team in Tokyo. He has 25 years of experience in IT industry, expertised in architecting data infrastructure. On his days off, he can be a rock drummer or a motorcyclyst.
Takeshi Nakatani is a Principal Bigdata Consultant on Professional Services team in Tokyo. He has 25 years of experience in IT industry, expertised in architecting data infrastructure. On his days off, he can be a rock drummer or a motorcyclyst.






 Anish Moorjani is a Data Engineer in the Data and Analytics team at SafetyCulture. He helps SafetyCulture’s analytics infrastructure scale with the exponential increase in the volume and variety of data.
Anish Moorjani is a Data Engineer in the Data and Analytics team at SafetyCulture. He helps SafetyCulture’s analytics infrastructure scale with the exponential increase in the volume and variety of data. Randy Chng is an Analytics Solutions Architect at Amazon Web Services. He works with customers to accelerate the solution of their key business problems.
Randy Chng is an Analytics Solutions Architect at Amazon Web Services. He works with customers to accelerate the solution of their key business problems.






















 Scott Chang is a Solution Architecture at AWS based in San Francisco. He has over 14 years of hands-on experience in Networking also familiar with Security and Site Reliability Engineering. He works with one of major strategic customers in west region to design highly scalable, innovative and secure cloud solutions.
Scott Chang is a Solution Architecture at AWS based in San Francisco. He has over 14 years of hands-on experience in Networking also familiar with Security and Site Reliability Engineering. He works with one of major strategic customers in west region to design highly scalable, innovative and secure cloud solutions. Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch service. He builds large scale search applications and solutions. Muthu is interested in the topics of networking and security and is based out of Austin, Texas
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch service. He builds large scale search applications and solutions. Muthu is interested in the topics of networking and security and is based out of Austin, Texas
 Ali Alemi is a Streaming Specialist Solutions Architect at AWS. Ali advises AWS customers with architectural best practices and helps them design real-time analytics data systems that are reliable, secure, efficient, and cost-effective. He works backward from customers’ use cases and designs data solutions to solve their business problems. Prior to joining AWS, Ali supported several public sector customers and AWS consulting partners in their application modernization journey and migration to the cloud.
Ali Alemi is a Streaming Specialist Solutions Architect at AWS. Ali advises AWS customers with architectural best practices and helps them design real-time analytics data systems that are reliable, secure, efficient, and cost-effective. He works backward from customers’ use cases and designs data solutions to solve their business problems. Prior to joining AWS, Ali supported several public sector customers and AWS consulting partners in their application modernization journey and migration to the cloud.


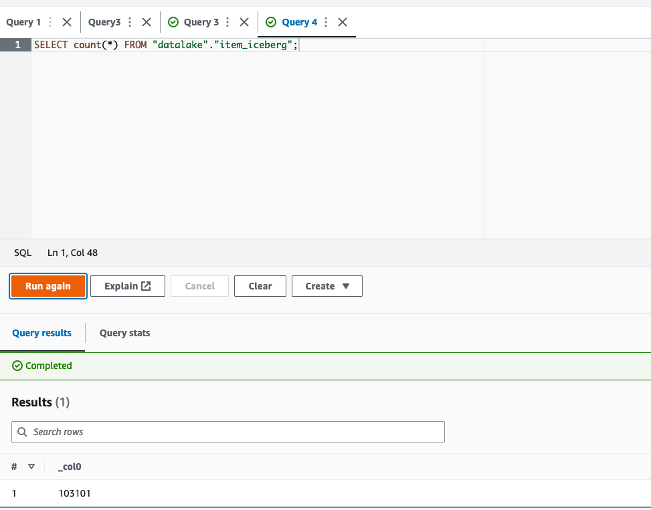
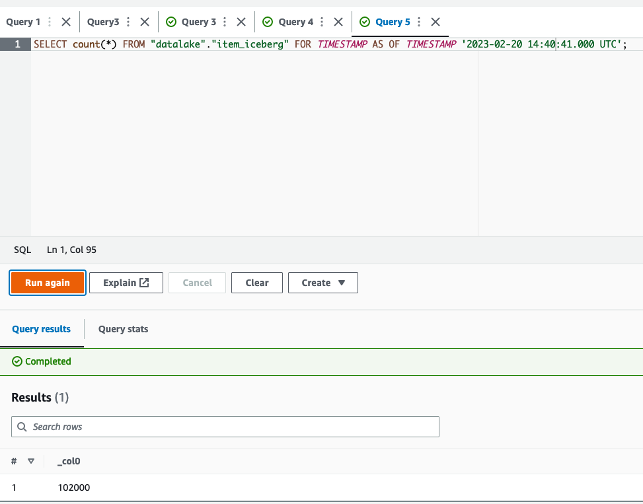
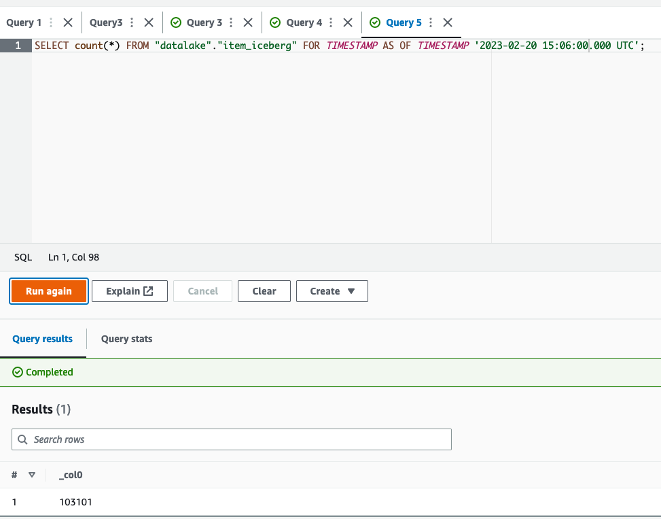
 The queries in
The queries in 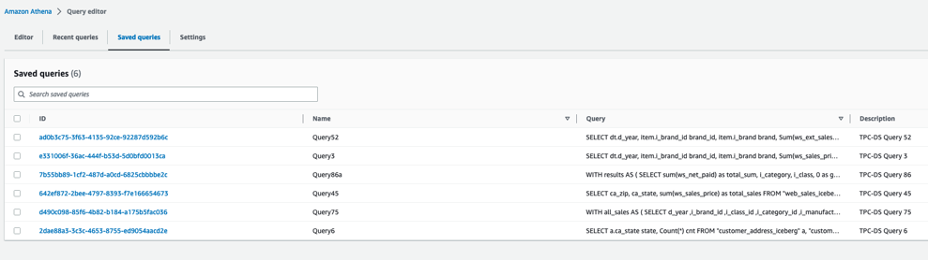 The following queries are listed:
The following queries are listed:

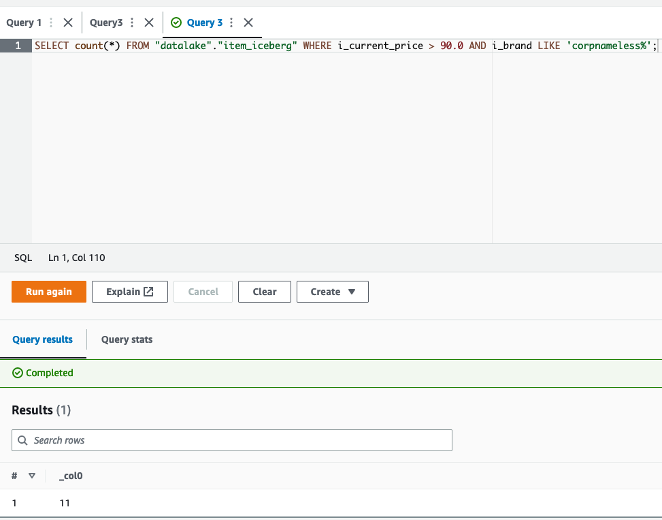




 Rohit Pujari is the Head of Product for Embedded Analytics at QuickSight. He is passionate about shaping the future of infusing data-rich experiences into products and applications we use every day. Rohit brings a wealth of experience in analytics and machine learning from having worked with leading data companies, and their customers. During his free time, you can find him lining up at the local ice cream shop for his second scoop.
Rohit Pujari is the Head of Product for Embedded Analytics at QuickSight. He is passionate about shaping the future of infusing data-rich experiences into products and applications we use every day. Rohit brings a wealth of experience in analytics and machine learning from having worked with leading data companies, and their customers. During his free time, you can find him lining up at the local ice cream shop for his second scoop.








 Vaidy Kalpathy is a Senior Data Lab Solution Architect at AWS, where he helps customers modernize their data platform and defines end to end data strategy including data ingestion, transformation, security, visualization. He is passionate about working backwards from business use cases, creating scalable and custom fit architectures to help customers innovate using data analytics services on AWS.
Vaidy Kalpathy is a Senior Data Lab Solution Architect at AWS, where he helps customers modernize their data platform and defines end to end data strategy including data ingestion, transformation, security, visualization. He is passionate about working backwards from business use cases, creating scalable and custom fit architectures to help customers innovate using data analytics services on AWS.

 Kalyan Janaki is Senior Big Data & Analytics Specialist with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.
Kalyan Janaki is Senior Big Data & Analytics Specialist with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.








 Naresh Gautam is a Data Analytics and AI/ML leader at AWS with 20 years of experience, who enjoys helping customers architect highly available, high-performance, and cost-effective data analytics and AI/ML solutions to empower customers with data-driven decision-making. In his free time, he enjoys meditation and cooking.
Naresh Gautam is a Data Analytics and AI/ML leader at AWS with 20 years of experience, who enjoys helping customers architect highly available, high-performance, and cost-effective data analytics and AI/ML solutions to empower customers with data-driven decision-making. In his free time, he enjoys meditation and cooking. Srikanth Sopirala is a Principal Analytics Specialist Solutions Architect at AWS. He is a seasoned leader with over 20 years of experience, who is passionate about helping customers build scalable data and analytics solutions to gain timely insights and make critical business decisions. In his spare time, he enjoys reading, spending time with his family, and road biking.
Srikanth Sopirala is a Principal Analytics Specialist Solutions Architect at AWS. He is a seasoned leader with over 20 years of experience, who is passionate about helping customers build scalable data and analytics solutions to gain timely insights and make critical business decisions. In his spare time, he enjoys reading, spending time with his family, and road biking. Harsh Vardhan is an AWS Solutions Architect, specializing in analytics. He has over 5 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.
Harsh Vardhan is an AWS Solutions Architect, specializing in analytics. He has over 5 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.



 Flora Wu is a Sr. Resident Architect at AWS Data Lab. She helps enterprise customers create data analytics strategies and build solutions to accelerate their businesses outcomes. In her spare time, she enjoys playing tennis, dancing salsa, and traveling.
Flora Wu is a Sr. Resident Architect at AWS Data Lab. She helps enterprise customers create data analytics strategies and build solutions to accelerate their businesses outcomes. In her spare time, she enjoys playing tennis, dancing salsa, and traveling. Daniel Li is a Sr. Solutions Architect at Amazon Web Services. He focuses on helping customers develop, adopt, and implement cloud services and strategy. When not working, he likes spending time outdoors with his family.
Daniel Li is a Sr. Solutions Architect at Amazon Web Services. He focuses on helping customers develop, adopt, and implement cloud services and strategy. When not working, he likes spending time outdoors with his family.









 Sushant Majithia is a Principal Product Manager for EMR at Amazon Web Services.
Sushant Majithia is a Principal Product Manager for EMR at Amazon Web Services. Vishal Vyas is a Senior Software Engineer for EMR at Amazon Web Services.
Vishal Vyas is a Senior Software Engineer for EMR at Amazon Web Services. Matthew Liem is a Senior Solution Architecture Manager at AWS.
Matthew Liem is a Senior Solution Architecture Manager at AWS.






 Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specialized in building enterprise data platforms, data warehousing, and analytics solutions. He has over 16 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe.
Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specialized in building enterprise data platforms, data warehousing, and analytics solutions. He has over 16 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe. Yanzhu Ji is a Product Manager on the Amazon Redshift team. She worked on the Amazon Redshift team as a Software Engineer before becoming a Product Manager. She has a rich experience of how the customer-facing Amazon Redshift features are built from planning to launching, and always treats customers’ requirements as first priority. In her personal life, Yanzhu likes painting, photography, and playing tennis.
Yanzhu Ji is a Product Manager on the Amazon Redshift team. She worked on the Amazon Redshift team as a Software Engineer before becoming a Product Manager. She has a rich experience of how the customer-facing Amazon Redshift features are built from planning to launching, and always treats customers’ requirements as first priority. In her personal life, Yanzhu likes painting, photography, and playing tennis. Dinesh Kumar is a Database Engineer with more than a decade of experience working in the databases, data warehousing, and analytics space. Outside of work, he enjoys trying different cuisines and spending time with his family and friends.
Dinesh Kumar is a Database Engineer with more than a decade of experience working in the databases, data warehousing, and analytics space. Outside of work, he enjoys trying different cuisines and spending time with his family and friends.




































 Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration, and strategy. He is passionate about technology and enjoys building and experimenting in the analytics and AI/ML space.
Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration, and strategy. He is passionate about technology and enjoys building and experimenting in the analytics and AI/ML space. Rajdip Chaudhuri is Solutions Architect with Amazon Web Services specializing in data and analytics. He enjoys working with AWS customers and partners on data and analytics requirements. In his spare time, he enjoys soccer.
Rajdip Chaudhuri is Solutions Architect with Amazon Web Services specializing in data and analytics. He enjoys working with AWS customers and partners on data and analytics requirements. In his spare time, he enjoys soccer.