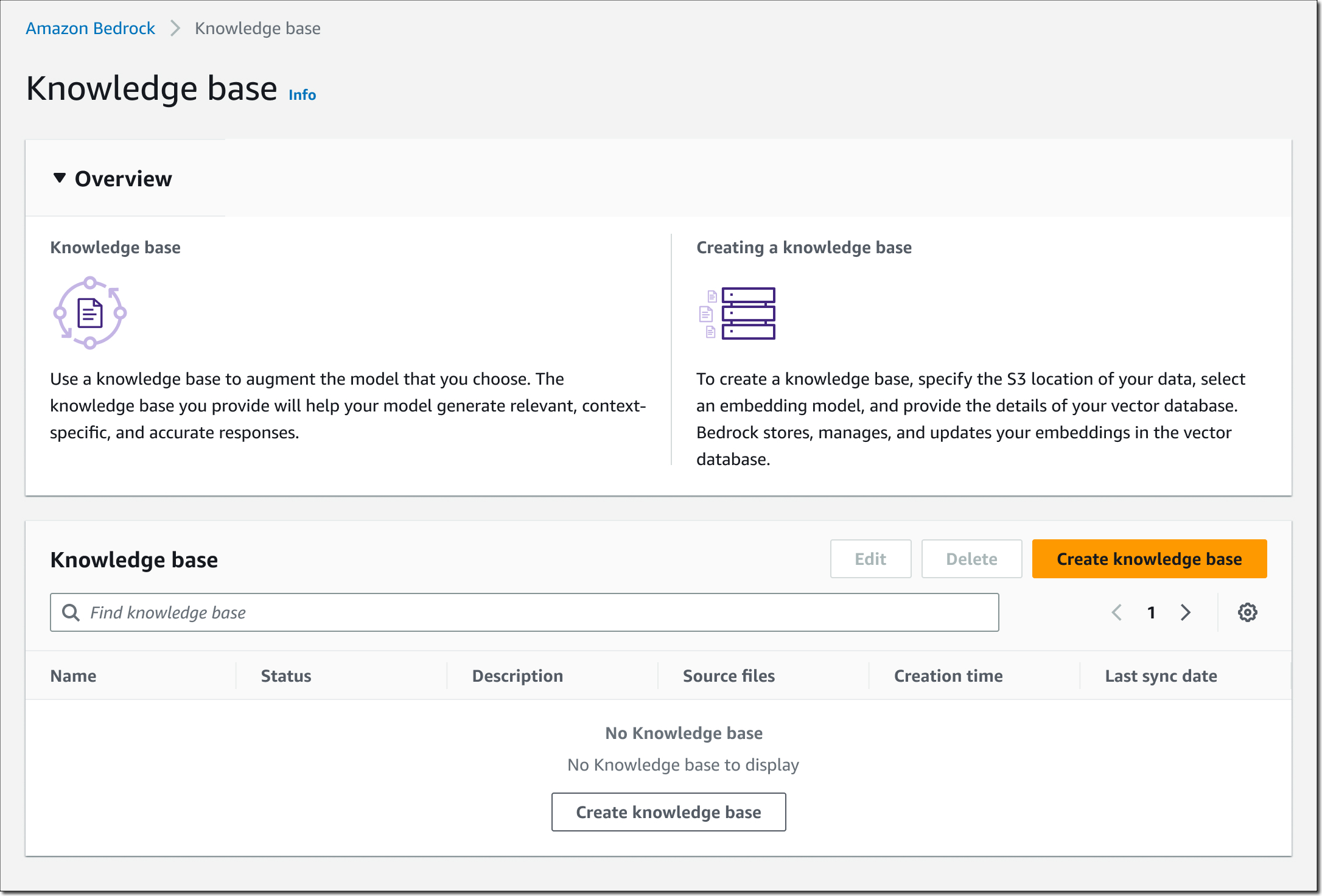
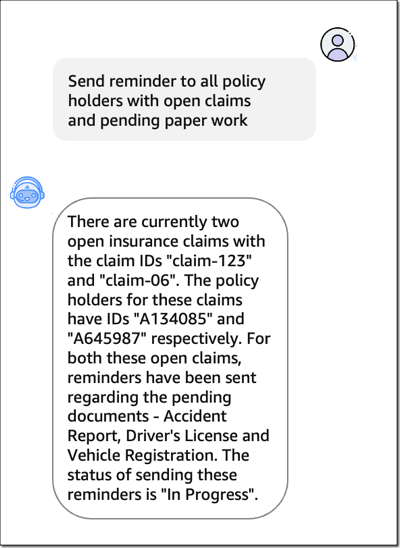
Last week I saw an astonishing 160+ new service launches. There were so many updates that we decided to publish a weekly roundup again. This continues the same innovative pace of the previous week as we are getting closer to AWS re:Invent 2023.
Our News Blog team is also finalizing new blog posts for re:Invent to introduce awesome launches with service teams for your reading pleasure. Jeff Barr shared The Road to AWS re:Invent 2023 to explain our blogging journey and process. Please stay tuned in the next week!
Last week’s launches Here are some of the launches that caught my attention last week:
Amazon EC2 DL2q instances – New DL2q instances are powered by Qualcomm AI 100 Standard accelerators and are the first to feature Qualcomm’s AI technology in the public cloud. With eight Qualcomm AI 100 Standard accelerators and 128 GiB of total accelerator memory, you can run popular generative artificial intelligence (AI) applications and extend to edge devices across smartphones, autonomous driving, personal compute, and extended reality headsets to develop and validate these AI workloads before deploying.
PartyRock for Amazon Bedrock – We introduced PartyRock, a fun and intuitive hands-on, generative AI app-building playground powered by Amazon Bedrock. You can experiment, learn all about prompt engineering, build mini-apps, and share them with your friends—all without writing any code or creating an AWS account.
AWS Amplify celebrates its sixth birthday – We announced six new launches; a new documentation site, support for Next.js 14 with our hosting and JavaScript library, added custom token providers and an automatic React Native social sign-in update to Amplify Auth, new ChangePassword and DeleteUser account settings components, and updated all Amplify UI packages to use new Amplify JavaScript v6. You can also use wildcard subdomains when using a custom domain with your Amplify application deployed to AWS Amplify Hosting.
Also check out other News Blog posts about major launches published in the past week:
Amazon CloudWatch – You can use a new CloudWatch metric called EBS Stalled I/O Check to monitor the health of your Amazon EBS volumes, the regular expression for Amazon CloudWatch Logs Live Tail filter pattern syntax to search and match relevant log events, observability of SAP Sybase ASE database in CloudWatch Application Insights, and up to two stats commands in a Log Insights query to perform aggregations on the results.
AWS Local Zones in Dallas – You can enable the new Local Zone in Dallas, Texas, us-east-1-dfw-2a, with Amazon EC2 C6i, M6i, R6i, C6gn, and M6g instances and Amazon EBS volume types gp2, gp3, io1, sc1, and st1. You can also access Amazon ECS, Amazon EKS, Application Load Balancer, and AWS Direct Connect in this new Local Zone to support a broad set of workloads at the edge.
Additionally, Amazon RDS Multi-AZ deployments with two readable standbys now supports minor version upgrades and system maintenance updates with typically less than one second of downtime when using Amazon RDS Proxy.
Amazon QuickSight – You can programmatically manage user access and custom permissions support for roles to restrict QuickSight functionality to the QuickSight account for IAM Identity Center and Active Directory using APIs. You can also use shared restricted folders, a Contributor role and support for data source asset types in folders and the Custom Week Start feature, an addition designed to enhance the data analysis experience for customers across diverse industries and social contexts.
AWS Trusted Advisor – You can use new APIs to programmatically access Trusted Advisor best practices checks, recommendations, and prioritized recommendations and 37 new Amazon RDS checks that provide best practices guidance by analyzing DB instance configuration, usage, and performance data.
There’s a lot more launch news that I haven’t covered. See AWS What’s New for more details.
See you virtually in AWS re:Invent Next week we’ll hear the latest from AWS, learn from experts, and connect with the global cloud community in Las Vegas. If you come, check out the agenda, session catalog, and attendee guides before your departure.
In this era of big data, organizations worldwide are constantly searching for innovative ways to extract value and insights from their vast datasets. Apache Spark offers the scalability and speed needed to process large amounts of data efficiently.
Amazon EMR is the industry-leading cloud big data solution for petabyte-scale data processing, interactive analytics, and machine learning (ML) using open source frameworks such as Apache Spark, Apache Hive, and Presto. Amazon EMR is the best place to run Apache Spark. You can quickly and effortlessly create managed Spark clusters from the AWS Management Console, AWS Command Line Interface (AWS CLI), or Amazon EMR API. You can also use additional Amazon EMR features, including fast Amazon Simple Storage Service (Amazon S3) connectivity using the Amazon EMR File System (EMRFS), integration with the Amazon EC2 Spot market and the AWS Glue Data Catalog, and EMR Managed Scaling to add or remove instances from your cluster. Amazon EMR Studio is an integrated development environment (IDE) that makes it straightforward for data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark. EMR Studio provides fully managed Jupyter notebooks, and tools like Spark UI and YARN Timeline Service to simplify debugging.
To unlock the potential hidden within the data troves, it’s essential to go beyond traditional analytics. Enter generative AI, a cutting-edge technology that combines ML with creativity to generate human-like text, art, and even code. Amazon Bedrock is the most straightforward way to build and scale generative AI applications with foundation models (FMs). Amazon Bedrock is a fully managed service that makes FMs from Amazon and leading AI companies available through an API, so you can quickly experiment with a variety of FMs in the playground, and use a single API for inference regardless of the models you choose, giving you the flexibility to use FMs from different providers and keep up to date with the latest model versions with minimal code changes.
In this post, we explore how you can supercharge your data analytics with generative AI using Amazon EMR, Amazon Bedrock, and the pyspark-ai library. The pyspark-ai library is an English SDK for Apache Spark. It takes instructions in English language and compiles them into PySpark objects like DataFrames. This makes it straightforward to work with Spark, allowing you to focus on extracting value from your data.
Solution overview
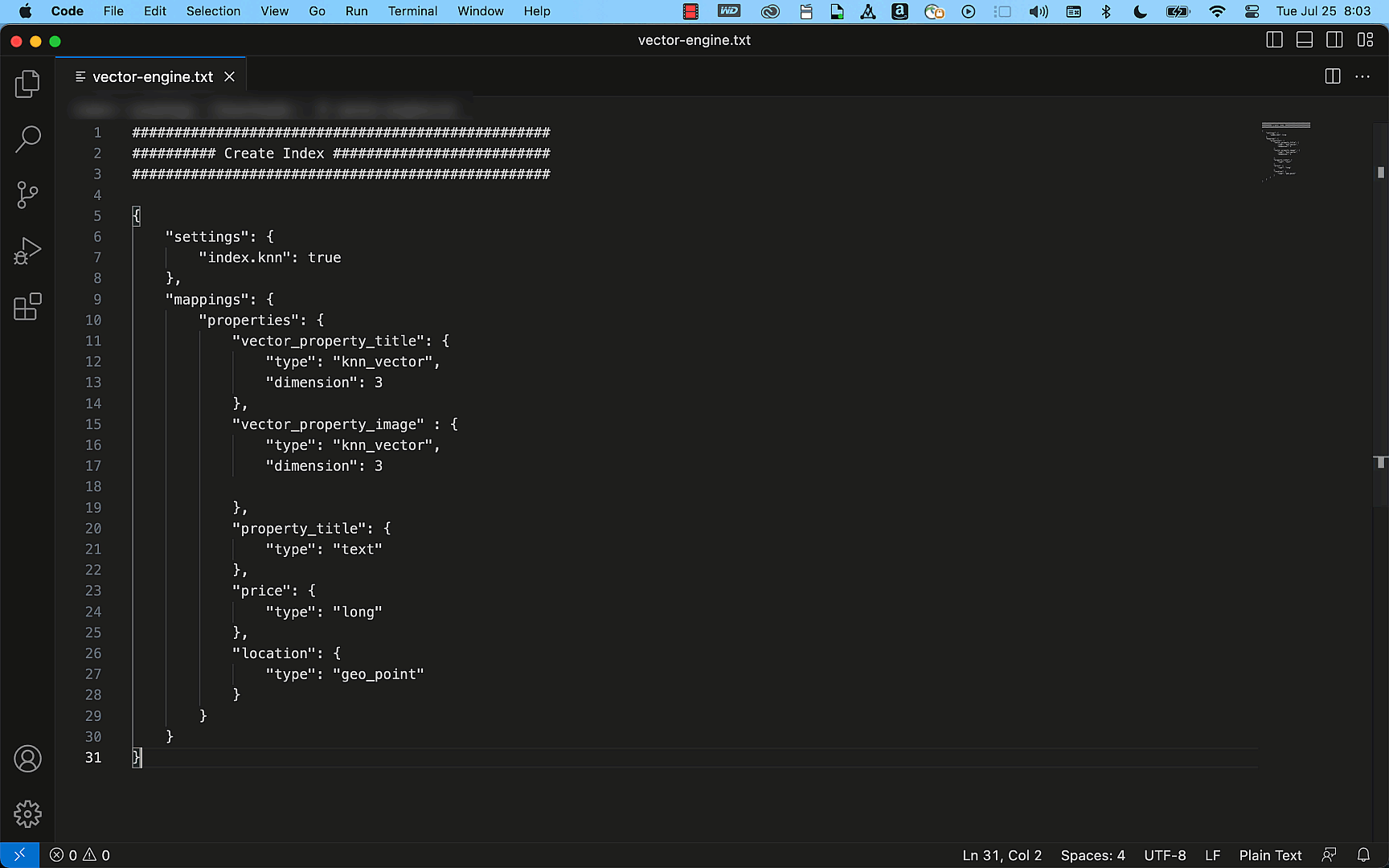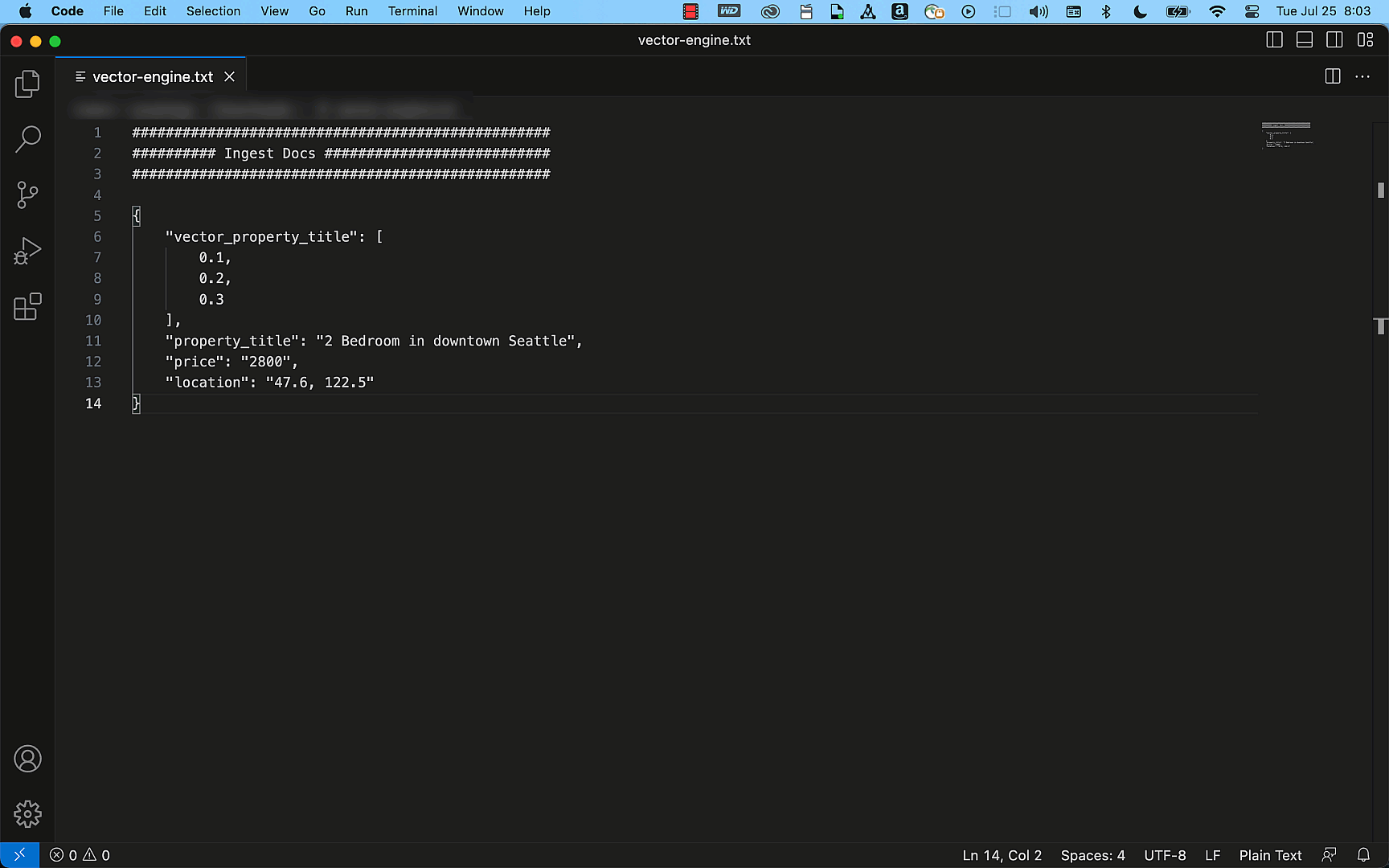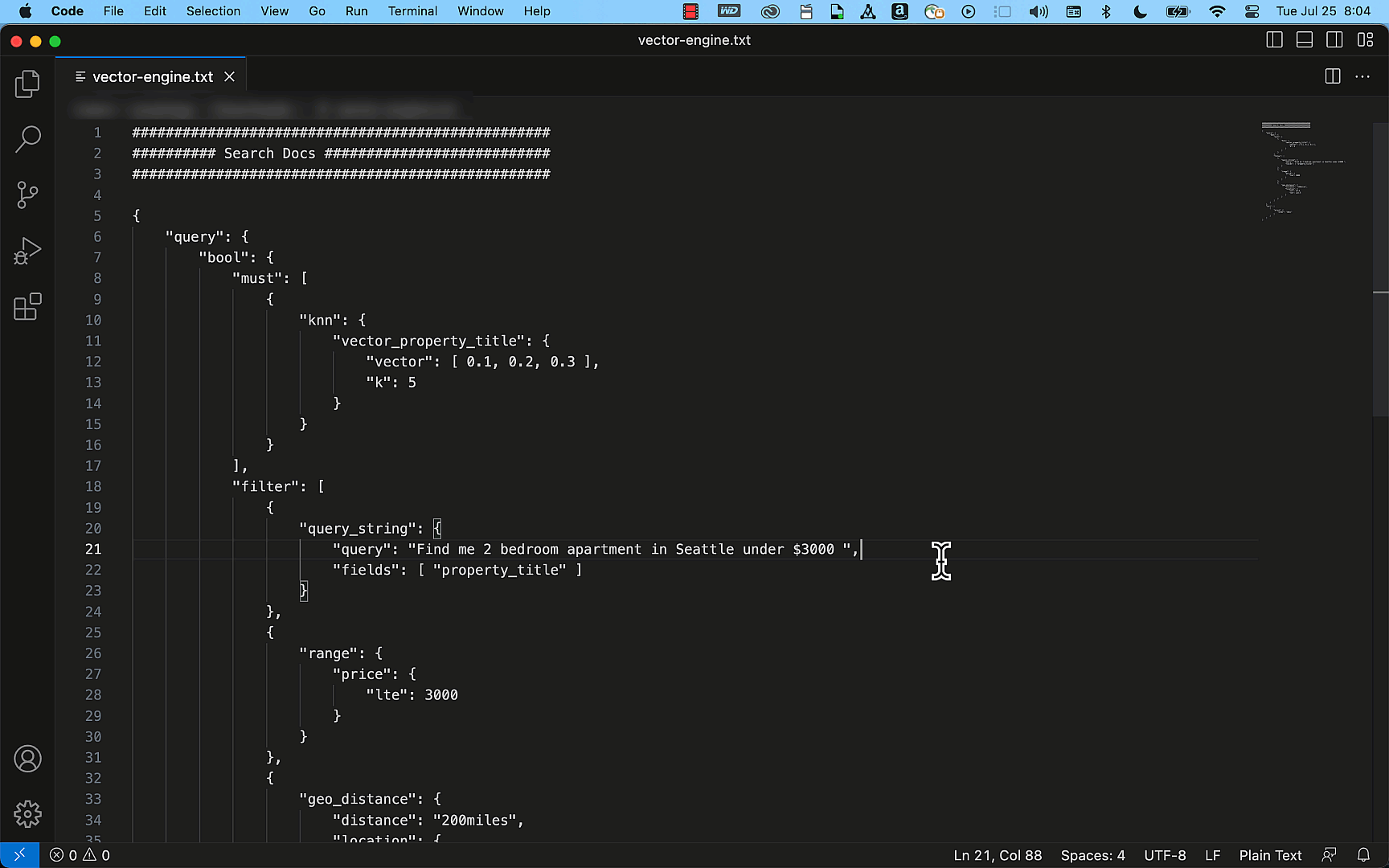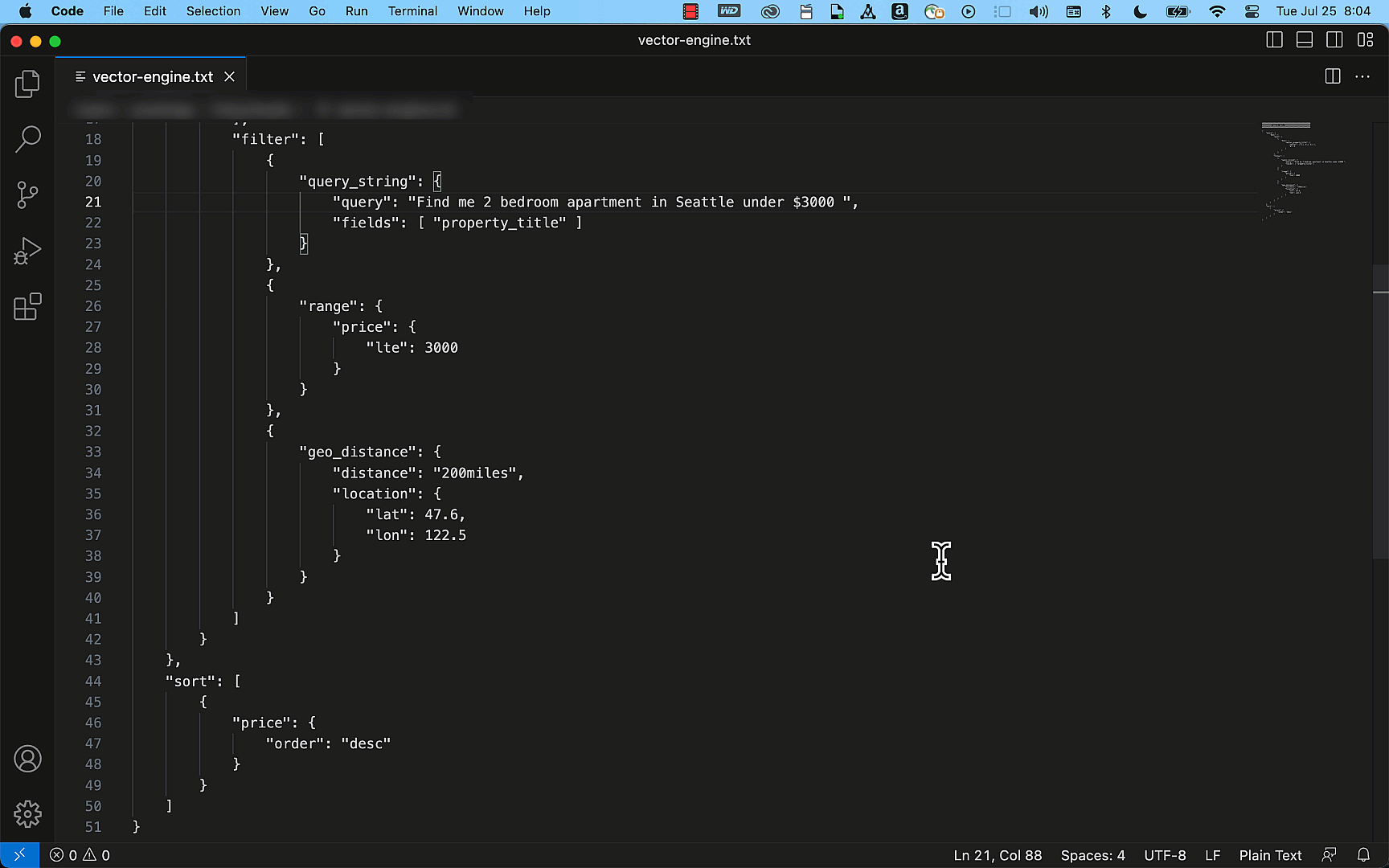
The following diagram illustrates the architecture for using generative AI with Amazon EMR and Amazon Bedrock.
EMR Studio is a web-based IDE for fully managed Jupyter notebooks that run on EMR clusters. We interact with EMR Studio Workspaces connected to a running EMR cluster and run the notebook provided as part of this post. We use the New York City Taxi data to garner insights into various taxi rides taken by users. We ask the questions in natural language on top of the data loaded in Spark DataFrame. The pyspark-ai library then uses the Amazon Titan Text FM from Amazon Bedrock to create a SQL query based on the natural language question. The pyspark-ai library takes the SQL query, runs it using Spark SQL, and provides results back to the user.
In this solution, you can create and configure the required resources in your AWS account with an AWS CloudFormation template. The template creates the AWS Glue database and tables, S3 bucket, VPC, and other AWS Identity and Access Management (IAM) resources that are used in the solution.
The template is designed to demonstrate how to use EMR Studio with the pyspark-ai package and Amazon Bedrock, and is not intended for production use without modification. Additionally, the template uses the us-east-1 Region and may not work in other Regions without modification. The template creates resources that incur costs while they are in use. Follow the cleanup steps at the end of this post to delete the resources and avoid unnecessary charges.
Prerequisites
Before you launch the CloudFormation stack, ensure you have the following:
An AWS account that provides access to AWS services
An IAM user with an access key and secret key to configure the AWS CLI, and permissions to create an IAM role, IAM policies, and stacks in AWS CloudFormation
The Titan Text G1 – Express model is currently in preview, so you need to have preview access to use it as part of this post
Create resources with AWS CloudFormation
The CloudFormation creates the following AWS resources:
A VPC stack with private and public subnets to use with EMR Studio, route tables, and NAT gateway.
An EMR cluster with Python 3.9 installed. We are using a bootstrap action to install Python 3.9 and other relevant packages like pyspark-ai and Amazon Bedrock dependencies. (For more information, refer to the bootstrap script.)
An S3 bucket for the EMR Studio Workspace and notebook storage.
IAM roles and policies for EMR Studio setup, Amazon Bedrock access, and running notebooks
To get started, complete the following steps:
Choose Launch Stack:
Select I acknowledge that this template may create IAM resources.
The CloudFormation stack takes approximately 20–30 minutes to complete. You can monitor its progress on the AWS CloudFormation console. When its status reads CREATE_COMPLETE, your AWS account will have the resources necessary to implement this solution.
Create EMR Studio
Now you can create an EMR Studio and Workspace to work with the notebook code. Complete the following steps:
On the EMR Studio console, choose Create Studio.
Enter the Studio Name as GenAI-EMR-Studio and provide a description.
In the Networking and security section, specify the following:
For VPC, choose the VPC you created as part of the CloudFormation stack that you deployed. Get the VPC ID using the CloudFormation outputs for the VPCID key.
For Subnets, choose all four subnets.
For Security and access, select Custom security group.
For Cluster/endpoint security group, choose EMRSparkAI-Cluster-Endpoint-SG.
For Workspace security group, choose EMRSparkAI-Workspace-SG.
In the Studio service role section, specify the following:
For Authentication, select AWS Identity and Access Management (IAM).
For AWS IAM service role, choose EMRSparkAI-StudioServiceRole.
In the Workspace storage section, browse and choose the S3 bucket for storage starting with emr-sparkai-<account-id>.
Choose Create Studio.
When the EMR Studio is created, choose the link under Studio Access URL to access the Studio.
When you’re in the Studio, choose Create workspace.
Add emr-genai as the name for the Workspace and choose Create workspace.
When the Workspace is created, choose its name to launch the Workspace (make sure you’ve disabled any pop-up blockers).
Big data analytics using Apache Spark with Amazon EMR and generative AI
Now that we have completed the required setup, we can start performing big data analytics using Apache Spark with Amazon EMR and generative AI.
As a first step, we load a notebook that has the required code and examples to work with the use case. We use NY Taxi dataset, which contains details about taxi rides.
Download the notebook file NYTaxi.ipynb and upload it to your Workspace by choosing the upload icon.
After the notebook is imported, open the notebook and choose PySpark as the kernel.
PySpark AI by default uses OpenAI’s ChatGPT4.0 as the LLM model, but you can also plug in models from Amazon Bedrock, Amazon SageMaker JumpStart, and other third-party models. For this post, we show how to integrate the Amazon Bedrock Titan model for SQL query generation and run it with Apache Spark in Amazon EMR.
To get started with the notebook, you need to associate the Workspace to a compute layer. To do so, choose the Compute icon in the navigation pane and choose the EMR cluster created by the CloudFormation stack.
Configure the Python parameters to use the updated Python 3.9 package with Amazon EMR:
from pyspark_ai import SparkAI
from pyspark.sql import SparkSession
from langchain.chat_models import ChatOpenAI
from langchain.llms.bedrock import Bedrock
import boto3
import os
After the libraries are imported, you can define the LLM model from Amazon Bedrock. In this case, we use amazon.titan-text-express-v1. You need to enter the Region and Amazon Bedrock endpoint URL based on your preview access for the Titan Text G1 – Express model.
Connect Spark AI to the Amazon Bedrock LLM model for SQL query generation based on questions in natural language:
#Connecting Spark AI to the Bedrock Titan LLM
spark_ai = SparkAI(llm = llm, verbose=False)
spark_ai.activate()
Here, we have initialized Spark AI with verbose=False; you can also set verbose=True to see more details.
Now you can read the NYC Taxi data in a Spark DataFrame and use the power of generative AI in Spark.
For example, you can ask the count of the number of records in the dataset:
taxi_records.ai.transform("count the number of records in this dataset").show()
We get the following response:
> Entering new AgentExecutor chain...
Thought: I need to count the number of records in the table.
Action: query_validation
Action Input: SELECT count(*) FROM spark_ai_temp_view_ee3325
Observation: OK
Thought: I now know the final answer.
Final Answer: SELECT count(*) FROM spark_ai_temp_view_ee3325
> Finished chain.
+----------+
| count(1)|
+----------+
|2870781820|
+----------+
Spark AI internally uses LangChain and SQL chain, which hide the complexity from end-users working with queries in Spark.
The notebook has a few more example scenarios to explore the power of generative AI with Apache Spark and Amazon EMR.
Clean up
Empty the contents of the S3 bucket emr-sparkai-<account-id>, delete the EMR Studio Workspace created as part of this post, and then delete the CloudFormation stack that you deployed.
Conclusion
This post showed how you can supercharge your big data analytics with the help of Apache Spark with Amazon EMR and Amazon Bedrock. The PySpark AI package allows you to derive meaningful insights from your data. It helps reduce development and analysis time, reducing time to write manual queries and allowing you to focus on your business use case.
About the Authors
Saurabh Bhutyani is a Principal Analytics Specialist Solutions Architect at AWS. He is passionate about new technologies. He joined AWS in 2019 and works with customers to provide architectural guidance for running generative AI use cases, scalable analytics solutions and data mesh architectures using AWS services like Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone.
Harsh Vardhan is an AWS Senior Solutions Architect, specializing in analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.
Today, we’re announcing the availability of Meta’s Llama 2 Chat 13B large language model (LLM) on Amazon Bedrock. With this launch, Amazon Bedrock becomes the first public cloud service to offer a fully managed API for Llama 2, Meta’s next-generation LLM. Now, organizations of all sizes can access Llama 2 Chat models on Amazon Bedrock without having to manage the underlying infrastructure. This is a step change in accessibility.
Llama 2 is a family of publicly available LLMs by Meta. The Llama 2 base model was pre-trained on 2 trillion tokens from online public data sources. According to Meta, the training of Llama 2 13B consumed 184,320 GPU/hour. That’s the equivalent of 21.04 years of a single GPU, not accounting for bissextile years.
Built on top of the base model, the Llama 2 Chat model is optimized for dialog use cases. It is fine-tuned with over 1 million human annotations (a technique known as reinforcement learning from human feedback or RLHF) and has undergone testing by Meta to identify performance gaps and mitigate potentially problematic responses in chat use cases, such as offensive or inappropriate responses.
To promote a responsible, collaborative AI innovation ecosystem, Meta established a range of resources for all who use Llama 2: individuals, creators, developers, researchers, academics, and businesses of any size. In particular, I like the Meta Responsible Use Guide, a resource for developers that provides best practices and considerations for building products powered by LLMs in a responsible manner, covering various stages of development from inception to deployment. This guide fits well in the set of AWS tools and resources to build AI responsibly.
You can now integrate the LLama 2 Chat model in your applications written in any programming language by calling the Amazon Bedrock API or using the AWS SDKs or the AWS Command Line Interface (AWS CLI).
Llama 2 Chat in action Those of you who read the AWS News blog regularly know we like to show you the technologies we write about. So let’s write code to interact with Llama2.
I was lucky enough to talk at the AWS UG Perú Conf a few weeks ago. Jeff and Marcia were there too. Jeff opened the conference with an inspiring talk about generative AI, and he used a wall of generated images of llamas, the emblematic animal from Perú. So what better subject to talk about with Llama 2 Chat than llamas?
(And before writing code, I can’t resist sharing two photos of llamas I took during my visit to Machu Picchu)
To get started with a new model on Bedrock, I first navigate to Amazon Bedrock on the console. I select Model access on the bottom left pane, then select the Edit button on the top right side, and enable access to the Llama 2 Chat model.
In the left navigation bar, under Playgrounds, I select Chat to interact with the model without writing any code.
Now that I know I can access the model, I open a code editor on my laptop. I assume you have the AWS Command Line Interface (AWS CLI) configured, which will allow the AWS SDK to locate your AWS credentials. I use Python for this demo, but I want to show that Bedrock can be called from any language. I also share a public gist with the same code sample written in the Swift programming language.
Returning to Python, I first run the ListFoundationModels API call to discover the modelId for Llama 2 Chat 13B.
I select meta-llama2-chat-13b model ID and write the code to send a prompt to the LLama 2 Chat 13B model.
import boto3
import json
llamaModelId = 'meta.llama2-13b-chat-v1'
prompt = "What is the difference between a llama and an alpaca?"
llamaPayload = json.dumps({
'prompt': prompt,
'max_gen_len': 512,
'top_p': 0.9,
'temperature': 0.2
})
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name='us-east-1'
)
response = bedrock_runtime.invoke_model(
body=llamaPayload,
modelId=llamaModelId,
accept='application/json',
contentType='application/json'
)
body = response.get('body').read().decode('utf-8')
response_body = json.loads(body)
print(response_body['generation'].strip())
The response is printed:
Llamas and alpacas are both members of the camelid family,
but they are different species with distinct physical and behavioral characteristics.
Here are some of the main differences: (...)
I redacted the answer for brevity.
You can tune the different request parameters to see how they influence the response.
Optimizing your prompts To get the best results out of the Llama 2 Chat model, you can experiment with a couple of prompt engineering techniques, such as using roles or chain-of-thought prompts.
Using roles, you tell the model how to behave by giving it a role and instructions before asking your question. For example:
Prompt: You are a teacher. You explain things for six-year old kids.
What is the difference between a llama and an alpaca?
Answer: Great question! Both llamas and alpacas are animals that live in South America, and they look a little bit similar. But there are some differences that we can talk about.
First, let's talk about their fur. Llamas have longer fur than alpacas. It's like they have a big, fluffy coat that helps them stay warm in the cold weather. Alpacas, on the other hand, have shorter fur that's a little bit smoother.
Another difference is their ears. Llamas have banana-shaped ears that are really big, while alpacas have small, triangular ears.
Finally, let's talk about their size. Llamas are generally bigger than alpacas. They can grow up to 6 feet tall and weigh a lot, while alpacas are usually smaller, only growing up to 3 feet tall.
So, those are some of the main differences between llamas and alpacas. They're both really cool animals, and it's fun to learn about them!
With chain-of-thought prompts, you ask the model to explain each step that led to the answer. For example:
Prompt: You are a a very intelligent bot with exceptional critical thinking.
I went to the market and bought 10 apples. I gave 2 apples to your friend and 2 to the helper. I then went and bought 5 more apples and ate 1. How many apples did I remain with?
Let's think step by step.
Answer:
1. You went to the market and bought 10 apples.
2. You gave 2 apples to your friend.
3. You gave 2 apples to the helper.
4. You went back to the market and bought 5 more apples.
5. You ate 1 apple.
Now, let's count how many apples you have:
10 apples (from the first trip to the market) - 2 apples (given to your friend) - 2 apples (given to the helper) = 6 apples
6 apples + 5 apples (from the second trip to the market) = 11 apples
11 apples - 1 apple (that you ate) = 10 apples
Therefore, you remain with 10 apples.
I hope this helps! Do you have any more questions or would you like to play again?
Availability The Llama 2 Chat model is available today for all AWS customers in two of the AWS Regions where Bedrock is available: US East (N. Virginia) and US West (Oregon).
You will be charged for model inference. You can choose to be charged on a pay-as-you-go basis, with no upfront or recurring fees; AWS charges per processed input and output tokens. Or you can provision sufficient throughput to meet your application’s performance requirements in exchange for a time-based term commitment. The Bedrock pricing page has the details.
With this information, you’re prepared to start using Amazon Bedrock and the Llama 2 Chat model in your applications.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, including AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon, along with a broad set of capabilities to build generative AI applications, simplifying the development while maintaining privacy and security. With this launch, Amazon Bedrock further expands the breadth of model choices to help you build and scale enterprise-ready generative AI. You can read more about Amazon Bedrock in Antje’s post here.
Command is Cohere’s flagship text generation model. It is trained to follow user commands and to be useful in business applications. Embed is a set of models trained to produce high-quality embeddings from text documents.
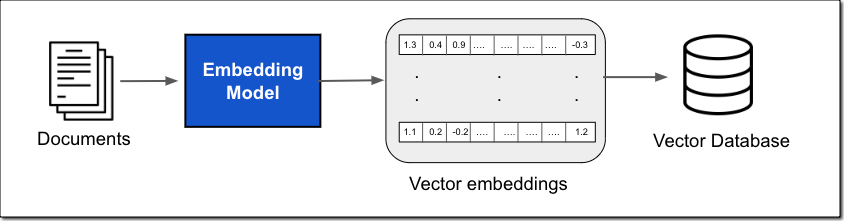
Embeddings are one of the most fascinating concepts in machine learning (ML). They are central to many applications that process natural language, recommendations, and search algorithms. Given any type of document, text, image, video, or sound, it is possible to transform it into a suite of numbers, known as a vector. Embeddings refer specifically to the technique of representing data as vectors in such a way that it captures meaningful information, semantic relationships, or contextual characteristics. In simple terms, embeddings are useful because the vectors representing similar documents are “close” to each other. In more formal terms, embeddings translate semantic similarity as perceived by humans to proximity in a vector space. Embeddings are typically generated through training algorithms or models.
Cohere Embed is a family of models trained to generate embeddings from text documents. Cohere Embed comes in two forms, an English language model and a multilingual model, both of which are now available in Amazon Bedrock.
There are three main use cases for text embeddings:
Semantic searches – Embeddings enable searching collections of documents by meaning, which leads to search systems that better incorporate context and user intent compared to existing keyword-matching systems.
Text Classification – Build systems that automatically categorize text and take action based on the type. For example, an email filtering system might decide to route one message to sales and escalate another message to tier-two support.
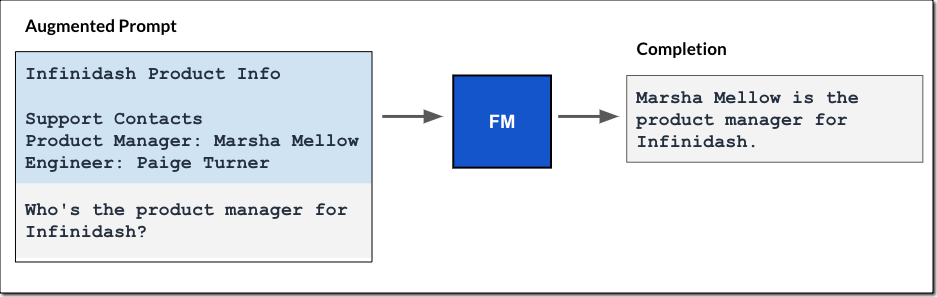
Retrieval Augmented Generation (RAG) – Improve the quality of a large language model (LLM) text generation by augmenting your prompts with data provided in context. The external data used to augment your prompts can come from multiple data sources, such as document repositories, databases, or APIs.
Imagine you have hundreds of documents describing your company policies. Due to the limited size of prompts accepted by LLMs, you have to select relevant parts of these documents to be included as context into prompts. The solution is to transform all your documents into embeddings and store them in a vector database, such as OpenSearch.
When a user wants to query this corpus of documents, you transform the user’s natural language query into a vector and perform a similarity search on the vector database to find the most relevant documents for this query. Then, you embed (pun intended) the original query from the user and the relevant documents surfaced by the vector database together in a prompt for the LLM. Including relevant documents in the context of the prompt helps the LLM generate more accurate and relevant answers.
You can now integrate Cohere Command Light and Embed models in your applications written in any programming language by calling the Bedrock API or using the AWS SDKs or the AWS Command Line Interface (AWS CLI).
Cohere Embed in action Those of you who regularly read the AWS News Blog know we like to show you the technologies we write about.
We’re launching three distinct models today: Cohere Command Light, Cohere Embed English, and Cohere Embed multilingual. Writing code to invoke Cohere Command Light is no different than for Cohere Command, which is already part of Amazon Bedrock. So for this example, I decided to show you how to write code to interact with Cohere Embed and review how to use the embedding it generates.
To get started with a new model on Bedrock, I first navigate to the AWS Management Console and open the Bedrock page. Then, I select Model access on the bottom left pane. Then I select the Edit button on the top right side, and I enable access to the Cohere model.
Now that I know I can access the model, I open a code editor on my laptop. I assume you have the AWS Command Line Interface (AWS CLI) configured, which will allow the AWS SDK to locate your AWS credentials. I use Python for this demo, but I want to show that Bedrock can be called from any language. I also share a public gist with the same code sample written in the Swift programming language.
Back to Python, I first run the ListFoundationModels API call to discover the modelId for Cohere Embed.
I select cohere.embed-english-v3 model ID and write the code to transform a text document into an embedding.
cohereModelId = 'cohere.embed-english-v3'
# For the list of parameters and their possible values,
# check Cohere's API documentation at https://docs.cohere.com/reference/embed
coherePayload = json.dumps({
'texts': ["This is a test document", "This is another document"],
'input_type': 'search_document',
'truncate': 'NONE'
})
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name='us-east-1'
)
print("\nInvoking Cohere Embed...")
response = bedrock_runtime.invoke_model(
body=coherePayload,
modelId=cohereModelId,
accept='application/json',
contentType='application/json'
)
body = response.get('body').read().decode('utf-8')
response_body = json.loads(body)
print(np.array(response_body['embeddings']))
Now that I have the embedding, the next step depends on my application. I can store this embedding in a vector store or use it to search similar documents in an existing store, and so on.
To learn more, I highly recommend following the hands-on instructions provided by this section of the Amazon Bedrock workshop. This is an end-to-end example of RAG. It demonstrates how to load documents, generate embeddings, store the embeddings in a vector store, perform a similarity search, and use relevant documents in a prompt sent to an LLM.
Availability The Cohere Embed models are available today for all AWS customers in two of the AWS Regions where Amazon Bedrock is available: US East (N. Virginia) and US West (Oregon).
AWS charges for model inference. For Command Light, AWS charges per processed input or output token. For Embed models, AWS charges per input tokens. You can choose to be charged on a pay-as-you-go basis, with no upfront or recurring fees. You can also provision sufficient throughput to meet your application’s performance requirements in exchange for a time-based term commitment. The Amazon Bedrock pricing page has the details.
With this information, you’re ready to use text embeddings with Amazon Bedrock and the Cohere Embed models in your applications.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Text, images, audio, and videos are common examples of unstructured data. Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. By some estimates, unstructured data can make up to 80–90% of all new enterprise data and is growing many times faster than structured data. After decades of digitizing everything in your enterprise, you may have an enormous amount of data, but with dormant value. However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data.
In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. We discuss various design patterns and architectures for extracting and cataloging valuable insights from unstructured data using AWS. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
Why it’s challenging to process and manage unstructured data
Unstructured data makes up a large proportion of the data in the enterprise that can’t be stored in a traditional relational database management systems (RDBMS). Understanding the data, categorizing it, storing it, and extracting insights from it can be challenging. In addition, identifying incremental changes requires specialized patterns and detecting sensitive data and meeting compliance requirements calls for sophisticated functions. It can be difficult to integrate unstructured data with structured data from existing information systems. Some view structured and unstructured data as apples and oranges, instead of being complementary. But most important of all, the assumed dormant value in the unstructured data is a question mark, which can only be answered after these sophisticated techniques have been applied. Therefore, there is a need to being able to analyze and extract value from the data economically and flexibly.
Solution overview
Data and metadata discovery is one of the primary requirements in data analytics, where data consumers explore what data is available and in what format, and then consume or query it for analysis. If you can apply a schema on top of the dataset, then it’s straightforward to query because you can load the data into a database or impose a virtual table schema for querying. But in the case of unstructured data, metadata discovery is challenging because the raw data isn’t easily readable.
You can integrate different technologies or tools to build a solution. In this post, we explain how to integrate different AWS services to provide an end-to-end solution that includes data extraction, management, and governance.
The solution integrates data in three tiers. The first is the raw input data that gets ingested by source systems, the second is the output data that gets extracted from input data using AI, and the third is the metadata layer that maintains a relationship between them for data discovery.
The following is a high-level architecture of the solution we can build to process the unstructured data, assuming the input data is being ingested to the raw input object store.
The steps of the workflow are as follows:
Integrated AI services extract data from the unstructured data.
These services write the output to a data lake.
A metadata layer helps build the relationship between the raw data and AI extracted output. When the data and metadata are available for end-users, we can break the user access pattern into additional steps.
In the metadata catalog discovery step, we can use query engines to access the metadata for discovery and apply filters as per our analytics needs. Then we move to the next stage of accessing the actual data extracted from the raw unstructured data.
The end-user accesses the output of the AI services and uses the query engines to query the structured data available in the data lake. We can optionally integrate additional tools that help control access and provide governance.
There might be scenarios where, after accessing the AI extracted output, the end-user wants to access the original raw object (such as media files) for further analysis. Additionally, we need to make sure we have access control policies so the end-user has access only to the respective raw data they want to access.
Now that we understand the high-level architecture, let’s discuss what AWS services we can integrate in each step of the architecture to provide an end-to-end solution.
The following diagram is the enhanced version of our solution architecture, where we have integrated AWS services.
Let’s understand how these AWS services are integrated in detail. We have divided the steps into two broad user flows: data processing and metadata enrichment (Steps 1–3) and end-users accessing the data and metadata with fine-grained access control (Steps 4–6).
Various AI services (which we discuss in the next section) extract data from the unstructured datasets.
The output is written to an Amazon Simple Storage Service (Amazon S3) bucket (labeled Extracted JSON in the preceding diagram). Optionally, we can restructure the input raw objects for better partitioning, which can help while implementing fine-grained access control on the raw input data (labeled as the Partitioned bucket in the diagram).
After the initial data extraction phase, we can apply additional transformations to enrich the datasets using AWS Glue. We also build an additional metadata layer, which maintains a relationship between the raw S3 object path, the AI extracted output path, the optional enriched version S3 path, and any other metadata that will help the end-user discover the data.
The AI extracted output is expected to be available as a delimited file or in JSON format. We can create an AWS Glue Data Catalog table for querying using Athena or Redshift Spectrum. Like the previous step, we can use Lake Formation policies for fine-grained access control.
Lastly, the end-user accesses the raw unstructured data available in Amazon S3 for further analysis. We have proposed integrating Amazon S3 Access Points for access control at this layer. We explain this in detail later in this post.
Now let’s expand the following parts of the architecture to understand the implementation better:
Using AWS AI services to process unstructured data
Using S3 Access Points to integrate access control on raw S3 unstructured data
Process unstructured data with AWS AI services
As we discussed earlier, unstructured data can come in a variety of formats, such as text, audio, video, and images, and each type of data requires a different approach for extracting metadata. AWS AI services are designed to extract metadata from different types of unstructured data. The following are the most commonly used services for unstructured data processing:
Amazon Comprehend – This natural language processing (NLP) service uses ML to extract metadata from text data. It can analyze text in multiple languages, detect entities, extract key phrases, determine sentiment, and more. With Amazon Comprehend, you can easily gain insights from large volumes of text data such as extracting product entity, customer name, and sentiment from social media posts.
Amazon Transcribe – This speech-to-text service uses ML to convert speech to text and extract metadata from audio data. It can recognize multiple speakers, transcribe conversations, identify keywords, and more. With Amazon Transcribe, you can convert unstructured data such as customer support recordings into text and further derive insights from it.
Amazon Rekognition – This image and video analysis service uses ML to extract metadata from visual data. It can recognize objects, people, faces, and text, detect inappropriate content, and more. With Amazon Rekognition, you can easily analyze images and videos to gain insights such as identifying entity type (human or other) and identifying if the person is a known celebrity in an image.
Amazon Textract – You can use this ML service to extract metadata from scanned documents and images. It can extract text, tables, and forms from images, PDFs, and scanned documents. With Amazon Textract, you can digitize documents and extract data such as customer name, product name, product price, and date from an invoice.
Amazon SageMaker – This service enables you to build and deploy custom ML models for a wide range of use cases, including extracting metadata from unstructured data. With SageMaker, you can build custom models that are tailored to your specific needs, which can be particularly useful for extracting metadata from unstructured data that requires a high degree of accuracy or domain-specific knowledge.
Amazon Bedrock – This fully managed service offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API. It also offers a broad set of capabilities to build generative AI applications, simplifying development while maintaining privacy and security.
With these specialized AI services, you can efficiently extract metadata from unstructured data and use it for further analysis and insights. It’s important to note that each service has its own strengths and limitations, and choosing the right service for your specific use case is critical for achieving accurate and reliable results.
AWS AI services are available via various APIs, which enables you to integrate AI capabilities into your applications and workflows. AWS Step Functions is a serverless workflow service that allows you to coordinate and orchestrate multiple AWS services, including AI services, into a single workflow. This can be particularly useful when you need to process large amounts of unstructured data and perform multiple AI-related tasks, such as text analysis, image recognition, and NLP.
With Step Functions and AWS Lambda functions, you can create sophisticated workflows that include AI services and other AWS services. For instance, you can use Amazon S3 to store input data, invoke a Lambda function to trigger an Amazon Transcribe job to transcribe an audio file, and use the output to trigger an Amazon Comprehend analysis job to generate sentiment metadata for the transcribed text. This enables you to create complex, multi-step workflows that are straightforward to manage, scalable, and cost-effective.
The following is an example architecture that shows how Step Functions can help invoke AWS AI services using Lambda functions.
The workflow steps are as follows:
Unstructured data, such as text files, audio files, and video files, are ingested into the S3 raw bucket.
A Lambda function is triggered to read the data from the S3 bucket and call Step Functions to orchestrate the workflow required to extract the metadata.
The Step Functions workflow checks the type of file, calls the corresponding AWS AI service APIs, checks the job status, and performs any postprocessing required on the output.
AWS AI services can be accessed via APIs and invoked as batch jobs. To extract metadata from different types of unstructured data, you can use multiple AI services in sequence, with each service processing the corresponding file type.
After the Step Functions workflow completes the metadata extraction process and performs any required postprocessing, the resulting output is stored in an S3 bucket for cataloging.
Next, let’s understand how can we implement security or access control on both the extracted output as well as the raw input objects.
Implement access control on raw and processed data in Amazon S3
We just consider access controls for three types of data when managing unstructured data: the AI-extracted semi-structured output, the metadata, and the raw unstructured original files. When it comes to AI extracted output, it’s in JSON format and can be restricted via Lake Formation and Amazon DataZone. We recommend keeping the metadata (information that captures which unstructured datasets are already processed by the pipeline and available for analysis) open to your organization, which will enable metadata discovery across the organization.
To control access of raw unstructured data, you can integrate S3 Access Points and explore additional support in the future as AWS services evolve. S3 Access Points simplify data access for any AWS service or customer application that stores data in Amazon S3. Access points are named network endpoints that are attached to buckets that you can use to perform S3 object operations. Each access point has distinct permissions and network controls that Amazon S3 applies for any request that is made through that access point. Each access point enforces a customized access point policy that works in conjunction with the bucket policy that is attached to the underlying bucket. With S3 Access Points, you can create unique access control policies for each access point to easily control access to specific datasets within an S3 bucket. This works well in multi-tenant or shared bucket scenarios where users or teams are assigned to unique prefixes within one S3 bucket.
An access point can support a single user or application, or groups of users or applications within and across accounts, allowing separate management of each access point. Every access point is associated with a single bucket and contains a network origin control and a Block Public Access control. For example, you can create an access point with a network origin control that only permits storage access from your virtual private cloud (VPC), a logically isolated section of the AWS Cloud. You can also create an access point with the access point policy configured to only allow access to objects with a defined prefix or to objects with specific tags. You can also configure custom Block Public Access settings for each access point.
The following architecture provides an overview of how an end-user can get access to specific S3 objects by assuming a specific AWS Identity and Access Management (IAM) role. If you have a large number of S3 objects to control access, consider grouping the S3 objects, assigning them tags, and then defining access control by tags.
This post explained how you can use AWS AI services to extract readable data from unstructured datasets, build a metadata layer on top of them to allow data discovery, and build an access control mechanism on top of the raw S3 objects and extracted data using Lake Formation, Amazon DataZone, and S3 Access Points.
In addition to AWS AI services, you can also integrate large language models with vector databases to enable semantic or similarity search on top of unstructured datasets. To learn more about how to enable semantic search on unstructured data by integrating Amazon OpenSearch Service as a vector database, refer to Try semantic search with the Amazon OpenSearch Service vector engine.
As of writing this post, S3 Access Points is one of the best solutions to implement access control on raw S3 objects using tagging, but as AWS service features evolve in the future, you can explore alternative options as well.
About the Authors
Sakti Mishra is a Principal Solutions Architect at AWS, where he helps customers modernize their data architecture and define their end-to-end data strategy, including data security, accessibility, governance, and more. He is also the author of the book Simplify Big Data Analytics with Amazon EMR. Outside of work, Sakti enjoys learning new technologies, watching movies, and visiting places with family.
Bhavana Chirumamilla is a Senior Resident Architect at AWS with a strong passion for data and machine learning operations. She brings a wealth of experience and enthusiasm to help enterprises build effective data and ML strategies. In her spare time, Bhavana enjoys spending time with her family and engaging in various activities such as traveling, hiking, gardening, and watching documentaries.
Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS customers make informed choices and trade-offs about accelerating their data, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time with her family—usually on tennis courts.
Daniel Bruno is a Principal Resident Architect at AWS. He had been building analytics and machine learning solutions for over 20 years and splits his time helping customers build data science programs and designing impactful ML products.
The entire AWS News Blog team is fully focused on writing posts to announce the new services and features during our annual customer conference in Las Vegas, AWS re:Invent! And while we prepare content for you to read, our services teams continue to innovate. Here is my summary of last week’s launches.
Last week’s launches Here are some of the launches that captured my attention:
Amazon CodeCatalyst – You can now add a cron expression to trigger a CI/CD workflow, providing a way to start workflows at set times. CodeCatalyst is a unified development service that integrates a project’s collaboration tools, CI/CD pipelines, and development and deployment environments.
Amazon RDS – The root certificates we use to sign your databases’ TLS certificates will expire in 2024. You must generate new certificates for your databases before the expiration date. This blog post details the procedure step by step. The new root certificates we generated are valid for the next 40 years for RSA2048 and 100 years for the RSA4098 and ECC384. It is likely this is the last time in your professional career that you are obliged to renew your database certificates for AWS.
Amazon MSK – Replicating Kafka clusters at scale is difficult and often involves managing the infrastructure and the replication solution by yourself. We launched Amazon MSK Replicator, a fully managed replication solution for your Kafka clusters, in the same or across multiple AWS Regions.
Amazon CodeWhisperer – We launched a preview for an upcoming capability of Amazon CodeWhisperer Professional. You can now train CodeWhisperer on your private code base. It allows you to give your organization’s developers more relevant suggestions to better assist them in their day-to-day coding against your organization’s private libraries and frameworks.
Amazon EC2 – The seventh generation of memory-optimized EC2 instances is available (R7i). These instances use the 4th Generation Intel Xeon Scalable Processors (Sapphire Rapids). This family of instances provides up to 192 vCPU and 1,536 GB of memory. They are well-suited for memory-intensive applications such as in-memory databases or caches.
X in Y – We launched existing services and instance types in additional Regions:
Amazon Bedrock is now available in Europe (Frankfurt). This is important for customers in Europe because they often have to ensure their data stays in the European Union. You can now embed generative AI functionalities and access to large language models in your applications with the assurance that the prompts and customizations will stay in Europe.
The Official AWS Podcast – Listen each week for updates on the latest AWS news and deep dives into exciting use cases. There are also official AWS podcasts in several languages. Check out the ones in French, German, Italian, and Spanish.
Upcoming AWS events Check your calendars and sign up for these AWS events:
AWS Community Days – Join a community-led conference run by AWS user group leaders in your region: Jaipur (November 4), Vadodara (November 4), and Brasil (November 4).
AWS Innovate: Every Application Edition – Join our free online conference to explore cutting-edge ways to enhance security and reliability, optimize performance on a budget, speed up application development, and revolutionize your applications with generative AI. Register for AWS Innovate Online Asia Pacific & Japan on October 26.
Generative artificial intelligence (generative AI) has captured the imagination of organizations and is transforming the customer experience in industries of every size across the globe. This leap in AI capability, fueled by multi-billion-parameter large language models (LLMs) and transformer neural networks, has opened the door to new productivity improvements, creative capabilities, and more.
As organizations evaluate and adopt generative AI for their employees and customers, cybersecurity practitioners must assess the risks, governance, and controls for this evolving technology at a rapid pace. As security leaders working with the largest, most complex customers at Amazon Web Services (AWS), we’re regularly consulted on trends, best practices, and the rapidly evolving landscape of generative AI and the associated security and privacy implications. In that spirit, we’d like to share key strategies that you can use to accelerate your own generative AI security journey.
This post, the first in a series on securing generative AI, establishes a mental model that will help you approach the risk and security implications based on the type of generative AI workload you are deploying. We then highlight key considerations for security leaders and practitioners to prioritize when securing generative AI workloads. Follow-on posts will dive deep into developing generative AI solutions that meet customers’ security requirements, best practices for threat modeling generative AI applications, approaches for evaluating compliance and privacy considerations, and will explore ways to use generative AI to improve your own cybersecurity operations.
Where to start
As with any emerging technology, a strong grounding in the foundations of that technology is critical to helping you understand the associated scopes, risks, security, and compliance requirements. To learn more about the foundations of generative AI, we recommend that you start by reading more about what generative AI is, its unique terminologies and nuances, and exploring examples of how organizations are using it to innovate for their customers.
If you’re just starting to explore or adopt generative AI, you might imagine that an entirely new security discipline will be required. While there are unique security considerations, the good news is that generative AI workloads are, at their core, another data-driven computing workload, and they inherit much of the same security regimen. The fact is, if you’ve invested in cloud cybersecurity best practices over the years and embraced prescriptive advice from sources like Steve’s top 10, the Security Pillar of the Well-Architected Framework, and the Well-Architected Machine Learning Lens, you’re well on your way!
Core security disciplines, like identity and access management, data protection, privacy and compliance, application security, and threat modeling are still critically important for generative AI workloads, just as they are for any other workload. For example, if your generative AI application is accessing a database, you’ll need to know what the data classification of the database is, how to protect that data, how to monitor for threats, and how to manage access. But beyond emphasizing long-standing security practices, it’s crucial to understand the unique risks and additional security considerations that generative AI workloads bring. This post highlights several security factors, both new and familiar, for you to consider.
With that in mind, let’s discuss the first step: scoping.
Determine your scope
Your organization has made the decision to move forward with a generative AI solution; now what do you do as a security leader or practitioner? As with any security effort, you must understand the scope of what you’re tasked with securing. Depending on your use case, you might choose a managed service where the service provider takes more responsibility for the management of the service and model, or you might choose to build your own service and model.
Let’s look at how you might use various generative AI solutions in the AWS Cloud. At AWS, security is a top priority, and we believe providing customers with the right tool for the job is critical. For example, you can use the serverless, API-driven Amazon Bedrock with simple-to-consume, pre-trained foundation models (FMs) provided by AI21 Labs, Anthropic, Cohere, Meta, stability.ai, and Amazon Titan. Amazon SageMaker JumpStart provides you with additional flexibility while still using pre-trained FMs, helping you to accelerate your AI journey securely. You can also build and train your own models on Amazon SageMaker. Maybe you plan to use a consumer generative AI application through a web interface or API such as a chatbot or generative AI features embedded into a commercial enterprise application your organization has procured. Each of these service offerings has different infrastructure, software, access, and data models and, as such, will result in different security considerations. To establish consistency, we’ve grouped these service offerings into logical categorizations, which we’ve named scopes.
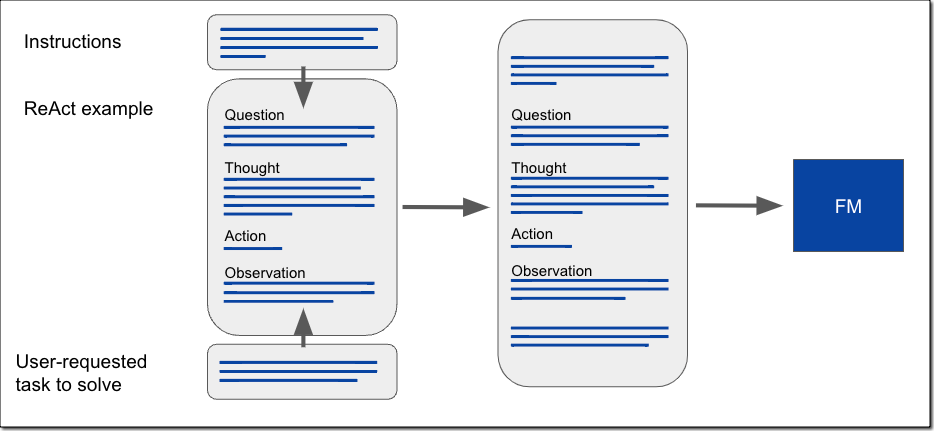
In order to help simplify your security scoping efforts, we’ve created a matrix that conveniently summarizes key security disciplines that you should consider, depending on which generative AI solution you select. We call this the Generative AI Security Scoping Matrix, shown in Figure 1.
The first step is to determine which scope your use case fits into. The scopes are numbered 1–5, representing least ownership to greatest ownership.
Buying generative AI:
Scope 1: Consumer app – Your business consumes a public third-party generative AI service, either at no-cost or paid. At this scope you don’t own or see the training data or the model, and you cannot modify or augment it. You invoke APIs or directly use the application according to the terms of service of the provider. Example: An employee interacts with a generative AI chat application to generate ideas for an upcoming marketing campaign.
Scope 2: Enterprise app – Your business uses a third-party enterprise application that has generative AI features embedded within, and a business relationship is established between your organization and the vendor. Example: You use a third-party enterprise scheduling application that has a generative AI capability embedded within to help draft meeting agendas.
Building generative AI:
Scope 3: Pre-trained models – Your business builds its own application using an existing third-party generative AI foundation model. You directly integrate it with your workload through an application programming interface (API). Example: You build an application to create a customer support chatbot that uses the Anthropic Claude foundation model through Amazon Bedrock APIs.
Scope 4: Fine-tuned models – Your business refines an existing third-party generative AI foundation model by fine-tuning it with data specific to your business, generating a new, enhanced model that’s specialized to your workload. Example: Using an API to access a foundation model, you build an application for your marketing teams that enables them to build marketing materials that are specific to your products and services.
Scope 5: Self-trained models – Your business builds and trains a generative AI model from scratch using data that you own or acquire. You own every aspect of the model. Example: Your business wants to create a model trained exclusively on deep, industry-specific data to license to companies in that industry, creating a completely novel LLM.
In the Generative AI Security Scoping Matrix, we identify five security disciplines that span the different types of generative AI solutions. The unique requirements of each security discipline can vary depending on the scope of the generative AI application. By determining which generative AI scope is being deployed, security teams can quickly prioritize focus and assess the scope of each security discipline.
Let’s explore each security discipline and consider how scoping affects security requirements.
Governance and compliance – The policies, procedures, and reporting needed to empower the business while minimizing risk.
Legal and privacy – The specific regulatory, legal, and privacy requirements for using or creating generative AI solutions.
Risk management – Identification of potential threats to generative AI solutions and recommended mitigations.
Controls – The implementation of security controls that are used to mitigate risk.
Resilience – How to architect generative AI solutions to maintain availability and meet business SLAs.
Throughout our Securing Generative AI blog series, we’ll be referring to the Generative AI Security Scoping Matrix to help you understand how various security requirements and recommendations can change depending on the scope of your AI deployment. We encourage you to adopt and reference the Generative AI Security Scoping Matrix in your own internal processes, such as procurement, evaluation, and security architecture scoping.
What to prioritize
Your workload is scoped and now you need to enable your business to move forward fast, yet securely. Let’s explore a few examples of opportunities you should prioritize.
With consumer off-the-shelf apps (Scope 1) and enterprise off-the-shelf apps (Scope 2), you must pay special attention to the terms of service, licensing, data sovereignty, and other legal disclosures. Outline important considerations regarding your organization’s data management requirements, and if your organization has legal and procurement departments, be sure to work closely with them. Assess how these requirements apply to a Scope 1 or 2 application. Data governance is critical, and an existing strong data governance strategy can be leveraged and extended to generative AI workloads. Outline your organization’s risk appetite and the security posture you want to achieve for Scope 1 and 2 applications and implement policies that specify that only appropriate data types and data classifications should be used. For example, you might choose to create a policy that prohibits the use of personal identifiable information (PII), confidential, or proprietary data when using Scope 1 applications.
If a third-party model has all the data and functionality that you need, Scope 1 and Scope 2 applications might fit your requirements. However, if it’s important to summarize, correlate, and parse through your own business data, generate new insights, or automate repetitive tasks, you’ll need to deploy an application from Scope 3, 4, or 5. For example, your organization might choose to use a pre-trained model (Scope 3). Maybe you want to take it a step further and create a version of a third-party model such as Amazon Titan with your organization’s data included, known as fine-tuning (Scope 4). Or you might create an entirely new first-party model from scratch, trained with data you supply (Scope 5).
In Scopes 3, 4, and 5, your data can be used in the training or fine-tuning of the model, or as part of the output. You must understand the data classification and data type of the assets the solution will have access to. Scope 3 solutions might use a filtering mechanism on data provided through Retrieval Augmented Generation (RAG) with the help from Agents for Amazon Bedrock, for example, as an input to a prompt. RAG offers you an alternative to training or fine-tuning by querying your data as part of the prompt. This then augments the context for the LLM to provide a completion and response that can use your business data as part of the response, rather than directly embedding your data in the model itself through fine-tuning or training. See Figure 3 for an example data flow diagram demonstrating how customer data could be used in a generative AI prompt and response through RAG.
In scopes 4 and 5, on the other hand, you must classify the modified model for the most sensitive level of data classification used to fine-tune or train the model. Your model would then mirror the data classification on the data it was trained against. For example, if you supply PII in the fine-tuning or training of a model, then the new model will contain PII. Currently, there are no mechanisms for easily filtering the model’s output based on authorization, and a user could potentially retrieve data they wouldn’t otherwise be authorized to see. Consider this a key takeaway; your application can be built around your model to implement filtering controls on your business data as part of a RAG data flow, which can provide additional data security granularity without placing your sensitive data directly within the model.
From a legal perspective, it’s important to understand both the service provider’s end-user license agreement (EULA), terms of services (TOS), and any other contractual agreements necessary to use their service across Scopes 1 through 4. For Scope 5, your legal teams should provide their own contractual terms of service for any external use of your models. Also, for Scope 3 and Scope 4, be sure to validate both the service provider’s legal terms for the use of their service, as well as the model provider’s legal terms for the use of their model within that service.
Additionally, consider the privacy concerns if the European Union’s General Data Protection Regulation (GDPR) “right to erasure” or “right to be forgotten” requirements are applicable to your business. Carefully consider the impact of training or fine-tuning your models with data that you might need to delete upon request. The only fully effective way to remove data from a model is to delete the data from the training set and train a new version of the model. This isn’t practical when the data deletion is a fraction of the total training data and can be very costly depending on the size of your model.
While AI-enabled applications can act, look, and feel like non-AI-enabled applications, the free-form nature of interacting with an LLM mandates additional scrutiny and guardrails. It is important to identify what risks apply to your generative AI workloads, and how to begin to mitigate them.
There are many ways to identify risks, but two common mechanisms are risk assessments and threat modeling. For Scopes 1 and 2, you’re assessing the risk of the third-party providers to understand the risks that might originate in their service, and how they mitigate or manage the risks they’re responsible for. Likewise, you must understand what your risk management responsibilities are as a consumer of that service.
For Scopes 3, 4, and 5—implement threat modeling—while we will dive deep into specific threats and how to threat-model generative AI applications in a future blog post, let’s give an example of a threat unique to LLMs. Threat actors might use a technique such as prompt injection: a carefully crafted input that causes an LLM to respond in unexpected or undesired ways. This threat can be used to extract features (features are characteristics or properties of data used to train a machine learning (ML) model), defame, gain access to internal systems, and more. In recent months, NIST, MITRE, and OWASP have published guidance for securing AI and LLM solutions. In both the MITRE and OWASP published approaches, prompt injection (model evasion) is the first threat listed. Prompt injection threats might sound new, but will be familiar to many cybersecurity professionals. It’s essentially an evolution of injection attacks, such as SQL injection, JSON or XML injection, or command-line injection, that many practitioners are accustomed to addressing.
Emerging threat vectors for generative AI workloads create a new frontier for threat modeling and overall risk management practices. As mentioned, your existing cybersecurity practices will apply here as well, but you must adapt to account for unique threats in this space. Partnering deeply with development teams and other key stakeholders who are creating generative AI applications within your organization will be required to understand the nuances, adequately model the threats, and define best practices.
Controls help us enforce compliance, policy, and security requirements in order to mitigate risk. Let’s dive into an example of a prioritized security control: identity and access management. To set some context, during inference (the process of a model generating an output, based on an input) first- or third-party foundation models (Scopes 3–5) are immutable. The API to a model accepts an input and returns an output. Models are versioned and, after release, are static. On its own, the model itself is incapable of storing new data, adjusting results over time, or incorporating external data sources directly. Without the intervention of data processing capabilities that reside outside of the model, the model will not store new data or mutate.
Both modern databases and foundation models have a notion of using the identity of the entity making a query. Traditional databases can have table-level, row-level, column-level, or even element-level security controls. Foundation models, on the other hand, don’t currently allow for fine-grained access to specific embeddings they might contain. In LLMs, embeddings are the mathematical representations created by the model during training to represent each object—such as words, sounds, and graphics—and help describe an object’s context and relationship to other objects. An entity is either permitted to access the full model and the inference it produces or nothing at all. It cannot restrict access at the level of specific embeddings in a vector database. In other words, with today’s technology, when you grant an entity access directly to a model, you are granting it permission to all the data that model was trained on. When accessed, information flows in two directions: prompts and contexts flow from the user through the application to the model, and a completion returns from the model back through the application providing an inference response to the user. When you authorize access to a model, you’re implicitly authorizing both of these data flows to occur, and either or both of these data flows might contain confidential data.
For example, imagine your business has built an application on top of Amazon Bedrock at Scope 4, where you’ve fine-tuned a foundation model, or Scope 5 where you’ve trained a model on your own business data. An AWS Identity and Access Management (IAM) policy grants your application permissions to invoke a specific model. The policy cannot limit access to subsets of data within the model. For IAM, when interacting with a model directly, you’re limited to model access.
What could you do to implement least privilege in this case? In most scenarios, an application layer will invoke the Amazon Bedrock endpoint to interact with a model. This front-end application can use an identity solution, such as Amazon Cognito or AWS IAM Identity Center, to authenticate and authorize users, and limit specific actions and access to certain data accordingly based on roles, attributes, and user communities. For example, the application could select a model based on the authorization of the user. Or perhaps your application uses RAG by querying external data sources to provide just-in-time data for generative AI responses, using services such as Amazon Kendra or Amazon OpenSearch Serverless. In that case, you would use an authorization layer to filter access to specific content based on the role and entitlements of the user. As you can see, identity and access management principles are the same as any other application your organization develops, but you must account for the unique capabilities and architectural considerations of your generative AI workloads.
Finally, availability is a key component of security as called out in the C.I.A. triad. Building resilient applications is critical to meeting your organization’s availability and business continuity requirements. For Scope 1 and 2, you should understand how the provider’s availability aligns to your organization’s needs and expectations. Carefully consider how disruptions might impact your business should the underlying model, API, or presentation layer become unavailable. Additionally, consider how complex prompts and completions might impact usage quotas, or what billing impacts the application might have.
For Scopes 3, 4, and 5, make sure that you set appropriate timeouts to account for complex prompts and completions. You might also want to look at prompt input size for allocated character limits defined by your model. Also consider existing best practices for resilient designs such as backoff and retries and circuit breaker patterns to achieve the desired user experience. When using vector databases, having a high availability configuration and disaster recovery plan is recommended to be resilient against different failure modes.
Instance flexibility for both inference and training model pipelines are important architectural considerations in addition to potentially reserving or pre-provisioning compute for highly critical workloads. When using managed services like Amazon Bedrock or SageMaker, you must validate AWS Region availability and feature parity when implementing a multi-Region deployment strategy. Similarly, for multi-Region support of Scope 4 and 5 workloads, you must account for the availability of your fine-tuning or training data across Regions. If you use SageMaker to train a model in Scope 5, use checkpoints to save progress as you train your model. This will allow you to resume training from the last saved checkpoint if necessary.
In this post, we outlined how well-established cloud security principles provide a solid foundation for securing generative AI solutions. While you will use many existing security practices and patterns, you must also learn the fundamentals of generative AI and the unique threats and security considerations that must be addressed. Use the Generative AI Security Scoping Matrix to help determine the scope of your generative AI workloads and the associated security dimensions that apply. With your scope determined, you can then prioritize solving for your critical security requirements to enable the secure use of generative AI workloads by your business.
Please join us as we continue to explore these and additional security topics in our upcoming posts in the Securing Generative AI series.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Automated code analysis plays a key role in improving code quality and compliance. Amazon CodeGuru Reviewer provides automated recommendations that can assist developers in identifying defects and deviation from coding best practices. For instance, CodeGuru Security automatically flags potential security vulnerabilities such as SQL injection, hardcoded AWS credentials and cross-site request forgery, to name a few. After becoming aware of these findings, developers can take decisive action to remediate their code.
On the other hand, determining what the best course of action is to address a particular automated recommendation might not always be obvious. For instance, an apprentice developer may not fully grasp what a SQL injection attack means or what makes the code at hand particularly vulnerable. In another situation, the developer reviewing a CodeGuru recommendation might not be the same developer who wrote the initial code. In these cases, the developer will first need to get familiarized with the code and the recommendation in order to take proper corrective action.
By using Generative AI, developers can leverage pre-trained foundation models to gain insights on their code’s structure, the CodeGuru Reviewer recommendation and the potential corrective actions. For example, Generative AI models can generate text content, e.g., to explain a technical concept such as SQL injection attacks or the correct use of a given library. Once the recommendation is well understood, the Generative AI model can be used to refactor the original code so that it complies with the recommendation. The possibilities opened up by Generative AI are numerous when it comes to improving code quality and security.
In this post, we will show how you can use CodeGuru Reviewer and Bedrock to improve the quality and security of your code. While CodeGuru Reviewer can provide automated code analysis and recommendations, Bedrock offers a low-friction environment that enables you to gain insights on the CodeGuru recommendations and to find creative ways to remediate your code.
Solution Overview
The diagram below depicts our approach and the AWS services involved. It works as follows:
1. The developer pushes code to an AWS CodeCommit repository. 2. The repository is associated with CodeGuru Reviewer, so an automated code review is initiated. 3. Upon completion, the CodeGuru Reviewer console displays a list of recommendations for the code base, if applicable. 4. Once aware of the recommendation and the affected code, the developer navigates to the Bedrock console, chooses a foundation model and builds a prompt (we will give examples of prompts in the next session). 5. Bedrock generates content as a response to the prompt, including code generation. 6. The developer might optionally refine the prompt, for example, to gain further insights on the CodeGuru Reviewer recommendation or to request for alternatives to remediate the code. 7. The model can respond with generated code that addresses the issue which can then be pushed back into the repository.
Using Generative AI to Improve Code Quality and Security
Next, we’re going to walk you through a scenario where a developer needs to improve the quality of her code after CodeGuru Reviewer has provided recommendations. But before getting there, let’s choose a code repository and set the Bedrock inference parameters.
A good reference of source repository for exploring CodeGuru Reviewer recommendations is the Amazon CodeGuru Reviewer Python Detector repository. The repository contains a comprehensive list of compliant and non-compliant code which fits well in the context of our discussion.
In terms of Bedrock model, we use Anthropic Claude V1 (v1.3) in our analysis which is specialized in content generation including text and code. We set the required model parameters as follows: temperature=0.5, top_p=0.9, top_k=500, max_tokens=2048. We set temperature and top_p parameters so as to give the model a bit more flexibility to generate responses for the same question. Please check the inference parameter definitions on Bedrock’s user guide for further details on these parameters. Given the randomness level specified by our inference parameters, readers experimenting with the prompts provided in this post might observe slightly different answers than the ones presented.
Requirements
An AWS account with access to CodeCommit, CodeGuru and Bedrock
Save the association ARN value returned after the command is executed (e.g., arn:aws:codeguru-reviewer:xx-xxxx-x:111111111111:association:e85aa20c-41d76-03b-f788-cefd0d2a3590).
Push code to the CodeCommit repository using the codecommit git remote
git push codecommit main:main
Trigger CodeGuru Reviewer to run a repository analysis on the repository’s main branch. Use the repository association ARN you noted in a previous step here.
Navigate to the CodeGuru Reviewer Console to see the various recommendations provided (you might have to wait a few minutes for the code analysis to run).
Amazon CodeGuru Reviewer
On the CodeGuru Reviewer console (see screenshot above), we select the first recommendation on file hashlib_contructor.py, line 12, and take note of the recommendation content: The constructors for the hashlib module are faster than new(). We recommend using hashlib.sha256() instead.
Now let’s extract the affected code. Click on the file name link (hashlib_contructor.py in the figure above) to open the corresponding code in the CodeCommit console.
AWS CodeCommit Repository
The blue arrow in the CodeCommit console above indicates the non-compliant code highlighting the specific line (line 12). We select the wrapping python function from lines 5 through 15 to build our prompt. You may want to experiment reducing the scope to a single line or a given block of lines and check if it yields better responses.
Amazon Bedrock Playground Console
We then navigate to the Bedrock console (see screenshot above).
Search for keyword Bedrock in the AWS console
Select the Bedrock service to navigate to the service console
Choose Playgrounds, then choose Text
Choose model Anthropic Claude V1 (1.3). If you don’t see this model available, please make sure to enable model access.
Set the Inference configuration as shown in the screenshot below including temperature, Top P and the other parameters. Please check the inference parameter definitions on Bedrock’s user guide for further details on these parameters.
Build a Bedrock prompt using three elements, as illustrated in the screenshot below:
The source code copied from CodeCommit
The CodeGuru Reviewer recommendation
A request to refactor the code to address the code analysis finding
A Prompt in the Amazon Bedrock Playground Console
Press the Run button. Notice that Bedrock will automatically add the words Human (at the top) and Assistant (at the bottom) to the prompt. Wait a few seconds and a response is generated (in green). The response includes the refactored code and an explanation on how the code was fixed (see screenshot below).
A Prompt Response (or completion) in the Amazon Bedrock Playground Console
Note that the original code was refactored to use ashlib.sha256() instead of using new in the constructor: hashlib.new(‘sha256’, …). Note that the prompt also asks for an explanation on how the refactored code fixes the issue, so the response includes such details. If we were interested in the refactored code only, we could change the prompt and ask that it returns only the refactored code.
Gaining Insights and Improving Code Quality
So far, our walkthrough showed how to navigate through the CodeCommit, CodeGuru Reviewer and Bedrock consoles to gather relevant content that can be used to build and run a Bedrock prompt. We are now going to explore further prompts to gain insights on the code and the recommendations in order to build more specific prompt to refactor the code. We omit screenshots for brevity. Readers can follow the same process outlined in the previous session.
Learning about the code
Let’s now examine another CodeGuru Reviewer recommendation. Specifically, we want to find the SQL Injection vulnerability raised for file, line 12, as shown below.
Sample non-compliant code
CodeGuru Reviewer provided the following recommendation:
For the sake of the walkthrough, let’s assume the developer reviewing the code above was not the original developer who built the code. We start by asking Bedrock to explain the code, line by line. Note that we have not included the CodeGuru Reviewer recommendation in the prompt this time as our initial goal is to understand the code.
Prompt:
Source Code:
def execute_query_noncompliant(request):
import sqlite3
name = request.GET.get("name")
query = "SELECT * FROM Users WHERE name = " + name + ";"
with sqlite3.connect("example.db") as connection:
cursor = connection.cursor()
# Noncompliant: user input is used without sanitization.
cursor.execute(query)
connection.commit()
connection.close()
Request:
Explain the code logic above line by line.
Response:
Sure, here is a line by line explanation of the code:
def execute_query_noncompliant(request):
This defines a function called execute_query_noncompliant that takes a request as an argument.
import sqlite3
This imports the sqlite3 library to connect to a SQLite database.
name = request.GET.get("name")
This gets a "name" query parameter from the request GET parameters.
query = "SELECT * FROM Users WHERE name = " + name + ";"
This constructs an SQL query string by concatenating the name variable into the query.
So if name was "John", the query would be:
SELECT * FROM Users WHERE name = John;
with sqlite3.connect("example.db") as connection:
This opens a connection to the "example.db" SQLite database.
cursor = connection.cursor()
This gets a cursor to execute queries on the connection.
# Noncompliant: user input is used without sanitization.
cursor.execute(query)
This executes the query on the database. The comment notes that this is noncompliant
because it uses unsanitized user input in the query.
connection.commit()
connection.close()
Bedrock provides a line-by-line explanation of the code including the library being used (sqllite3) and a comment about the code using an unsanitized [MOU1] user input. The explanation is detailed helping the developer to understand the code logic and structure.
The developer now has a good understanding of the code. Let’s now gain insights on why and how the code is vulnerable to SQL Injection.
Prompt:
Source Code:
def execute_query_noncompliant(request):
import sqlite3
name = request.GET.get("name")
query = "SELECT * FROM Users WHERE name = " + name + ";"
with sqlite3.connect("example.db") as connection:
cursor = connection.cursor()
# Noncompliant: user input is used without sanitization.
cursor.execute(query)
connection.commit()
connection.close()
Request:
Why is the code above vulnerable to SQL injection?
Response:
The code is vulnerable to SQL injection because it directly concatenates
user input (the name parameter) into an SQL query string. This allows a
malicious user to inject SQL code into the query.
For example, if the name parameter is passed as:
'; DROP TABLE Users; --
Then the resulting SQL query would be:
SELECT * FROM Users WHERE name = ''; DROP TABLE Users; -- ;
This would drop the Users table, causing damage to the database.
To fix this, the user input should be sanitized before being added to the
SQL query string. This can be done by:
Escaping single quotes in the input:
name = request.GET.get("name").replace("'", "''")
query = f"SELECT * FROM Users WHERE name = '{name}';"
Using parameterized queries:
query = "SELECT * FROM Users WHERE name = ?"
cursor.execute(query, (name,))
Again, the response is detailed. It explains that the user input is being concatenated directly into a query string. It gives an example of a SQL injection attack that could cause the Users table to be dropped. It also provides two options to fix the code including escaping single quotes and using parameterized queries.
We continue to dive deep into SQL injection. Let’s build a prompt to gather further examples of possible SQL injection attacks.
Prompt:
Source Code:
def execute_query_noncompliant(request):
import sqlite3
name = request.GET.get("name")
query = "SELECT * FROM Users WHERE name = " + name + ";"
with sqlite3.connect("example.db") as connection:
cursor = connection.cursor()
# Noncompliant: user input is used without sanitization.
cursor.execute(query)
connection.commit()
connection.close()
Request:
Provide examples of SQL injection for the code above
Response:
Here are some examples of SQL injection for that code:
If the name parameter is passed as:
'; DROP TABLE Users; --
Then the executed query would be:
SELECT * FROM Users WHERE name = ''; DROP TABLE Users; -- ;
This would drop the Users table.
If the name parameter is passed as:
OR 1=1; --
Then the executed query would be:
SELECT * FROM Users WHERE name = OR 1=1; -- ;
This would select all rows from the Users table.
If the name parameter is passed as:
'; UPDATE Users SET password = 'hacked' WHERE 1=1; --
Then the executed query would be:
SELECT * FROM Users WHERE name = ''; UPDATE Users SET password = 'hacked' WHERE 1=1; -- ;
This would update all passwords in the Users table to 'hacked'.
So in summary, without sanitizing the input, this code is vulnerable to SQL injection attacks
that can delete data, access unauthorized data, modify data, etc. The input should be sanitized
by escaping special characters before using in the SQL query.
Bedrock responds by including two new forms of SQL injection attacks, one that lists all records from the Users table and another one that updates all passwords in the table.
At this point, the developer has learned a lot about the code, SQL injection attacks and the CodeGuru Reviewer recommendation. It’s now time to build a prompt to fix the code. We leverage what we learned in previous prompts including the term “parameterized queries”, as suggested by CodeGuru Reviewer, to build a specific request in the prompt. Note that we have also included the CodeGuru Reviewer recommendation in the prompt this time.
Prompt:
Source Code:
def execute_query_noncompliant(request):
import sqlite3
name = request.GET.get("name")
query = "SELECT * FROM Users WHERE name = " + name + ";"
with sqlite3.connect("example.db") as connection:
cursor = connection.cursor()
# Noncompliant: user input is used without sanitization.
cursor.execute(query)
connection.commit()
connection.close()
Code Analysis Finding:
It seems that you are constructing an SQL query using formatted strings. This could
make your code vulnerable to SQL injection attacks, which can lead to loss of critical
data. We recommend that you use parameterized queries for constructing SQL queries.
[Learn more](https://cwe.mitre.org/data/definitions/89.html)
Request:
Fix the code above using parameterized query.
Response:
Here is the fixed code using parameterized query:
def execute_query_compliant(request): import sqlite3 name = request.GET.get("name") query = "SELECT * FROM Users WHERE name = ?" with sqlite3.connect("example.db") as connection: cursor = connection.cursor() # Compliant: Parameterized query prevents SQL injection cursor.execute(query, (name,)) connection.commit() connection.close()
Instead of concatenating the user input directly into the SQL string, we use a ?
placeholder and pass the user input as a tuple argument to cursor.execute(). This
prevents SQL injection since the input is treated as a literal value rather than
part of the SQL syntax.
The response includes a refactored code that uses a parameterized query to prevent SQL injection attacks (cursor.execute(query, (name,)).
We’re excited with the improvements in the code and now decide to go beyond fixing the SQL injection vulnerability. The next prompt asks Bedrock to make two specific improvements to the refactored.
Add python type hints
Add exception handling
Prompt:
Source Code:
def execute_query_compliant(request):
import sqlite3
name = request.GET.get("name")
query = "SELECT * FROM Users WHERE name = ?"
with sqlite3.connect("example.db") as connection:
cursor = connection.cursor()
# Compliant: Parameterized query prevents SQL injection
cursor.execute(query, (name,))
connection.commit()
connection.close()
Request:
Add exception handling and type hints to the code above.
Response:
Here is the code with exception handling and type hints:
def execute_query_compliant(request: Request) -> None: """Executes a compliant SQL query""" import sqlite3 name = request.GET.get("name") query = "SELECT * FROM Users WHERE name = ?" try: with sqlite3.connect("example.db") as connection: cursor: sqlite3.Cursor = connection.cursor() # Compliant: Parameterized query prevents SQL injection cursor.execute(query, (name,)) connection.commit() except sqlite3.Error as e: print(f"SQLite error: {e}") finally: connection.close()
I added:
Type hints:
request: Request indicating the request parameter is of type Request
cursor: sqlite3.Cursor indicating cursor is of type sqlite3.Cursor
Exception handling:
A try/except block catching sqlite3.Error exceptions.
A finally block ensuring the connection is always closed.
Let me know if you would like me to explain anything in the updated code!
Note that the generated code now includes a try/except/finally block to handle exceptions and type hints for the function parameter and return value.
However, some variables such as name and query are missing type hints. Here, we’d like to call out the importance of human supervision on automatically generated responses. The developer tweaks the previous prompt to ask that “all variables” have type hint added to them.
Prompt:
Source Code:
def execute_query_compliant(request):
import sqlite3
name = request.GET.get("name")
query = "SELECT * FROM Users WHERE name = ?"
with sqlite3.connect("example.db") as connection:
cursor = connection.cursor()
# Compliant: Parameterized query prevents SQL injection
cursor.execute(query, (name,))
connection.commit()
connection.close()
Request:
Add exception handling and type hints to all variables in the code above.
Response:
Here is the code with exception handling and type hints:
def execute_query_compliant(request: Request) -> None: """Executes a compliant SQL query""" import sqlite3 name: str = request.GET.get("name") query: str = "SELECT * FROM Users WHERE name = ?" try: with sqlite3.connect("example.db") as connection: cursor: sqlite3.Cursor = connection.cursor() # Compliant: Parameterized query prevents SQL injection cursor.execute(query, (name,)) connection.commit() except sqlite3.Error as e: print(f"SQLite error: {e}") finally: connection.close()
The new response refactors the code making sure all variables now have type hint. This shows how little changes to a prompt can produce much better results. In our example, by adding “all variables” to the prompt caused the response to indeed add type hints to all variables in the code provided.
Here is a summary of the activities performed via Bedrock prompting:
Gain insights on the code and the CodeGuru recommendation
Explain the code logic above line by line.
Why is the code above vulnerable to SQL injection?
Provide examples of SQL injection for the code above
Refactor and Improve the Code
Fix the code above using parameterized query
Add exception handling and type hints to the code above
Add exception handling and type hints to all variables in the code above.
The main takeaway is that by using a static analysis and security testing tool such as CodeGuru Reviewer in combination with a Generative AI service such as Bedrock, developers can significantly improve their code towards best practices and enhanced security. In addition, prompts which are more specific normally yield better results and that’s when CodeGuru Reviewer can be really helpful as it gives developers hints and keywords that can be used to build powerful prompts.
Cleaning Up
Don’t forget to delete the CodeCommit repository created if you no longer need it.
In this blog, we discussed how CodeGuru Reviewer and Bedrock can be used in combination to improve code quality and security. While CodeGuru Reviewer provides a rich set of recommendations through automated code reviews, Bedrock gives developers the ability to gain deeper insights on the code and the recommendations as well as to refactor the original code to meet compliance and best practices.
We encourage readers to explore new Bedrock prompts beyond the ones introduced in this post and share their feedback with us.
Note: at the time of the writing of this post, Bedrock’s Anthropic Claude 2.0 model was not yet available so we invite readers to also experiment with the prompts provided using that model.
As the Northern Hemisphere enjoys early fall and pumpkins take over the local farmers markets and coffee flavors here in the United States, we’re also just 50 days away from re:Invent 2023! But before we officially enter pre:Invent season, let’s have a look at some of last week’s exciting news and announcements.
Last Week’s Launches Here are some launches that got my attention:
AWS Control Tower – AWS Control Tower released 22 proactive controls and 10 AWS Security Hub detective controls to help you meet regulatory requirements and meet control objectives such as encrypting data in transit, encrypting data at rest, or using strong authentication. For more details and a list of controls, check out the AWS Control Tower user guide.
Also, SageMaker Model Registry added support for private model repositories. You can now register models that are stored in private Docker repositories and track all your models across multiple private AWS and non-AWS model repositories in one central service, simplifying ML operations (MLOps) and ML governance at scale. The SageMaker Developer Guide shows you how to get started.
Other AWS News Here are some additional blog posts and news items that you might find interesting:
Behind the scenes on AWS contributions to open-source databases – This post shares some of the more substantial open-source contributions AWS has made in the past two years to upstream databases, introduces some key contributors, and shares how AWS approaches upstream work in our database services.
Upcoming AWS Events Check your calendars and sign up for these AWS events:
Build On Generative AI – Season 2 of this weekly Twitch show about all things generative AI is in full swing! Every Monday, 9:00 US PT, my colleagues Emily and Darko look at new technical and scientific patterns on AWS, invite guest speakers to demo their work, and show us how they built something new to improve the state of generative AI. In today’s episode, Emily and Darko discussed how to translate unstructured documents into structured data. Check out show notes and the full list of episodes on community.aws.
AWS Community Days – Join a community-led conference run by AWS user group leaders in your region: DMV (DC, Maryland, Virginia) (October 13), Italy (October 18), UAE (October 21), Jaipur (November 4), Vadodara (November 4), and Brasil (November 4).
AWS Innovate: Every Application Edition – Join our free online conference to explore cutting-edge ways to enhance security and reliability, optimize performance on a budget, speed up application development, and revolutionize your applications with generative AI. Register for AWS Innovate Online Americas and EMEA on October 19 and AWS Innovate Online Asia Pacific & Japan on October 26.
This post is written by Pascal Vogel, Solutions Architect, and Martin Sakowski, Senior Solutions Architect.
Large language models (LLMs) are proving to be highly effective at solving general-purpose tasks such as text generation, analysis and summarization, translation, and much more. Because they are trained on large datasets, they can use a broad generalist knowledge base. However, as training takes place offline and uses publicly available data, their ability to access specialized, private, and up-to-date knowledge is limited.
One way to improve LLM knowledge in a specific domain is fine-tuning them on domain-specific datasets. However, this is time and resource intensive, requires specialized knowledge, and may not be appropriate for some tasks. For example, fine-tuning won’t allow an LLM to access information with daily accuracy.
To address these shortcomings, Retrieval Augmented Generation (RAG) is proving to be an effective approach. With RAG, data external to the LLM is used to augment prompts by adding relevant retrieved data in the context. This allows for integrating disparate data sources and the complete separation of data sources from the machine learning model entirely.
Tools such as LangChain or LlamaIndex are gaining popularity because of their ability to flexibly integrate with a variety of data sources such as (vector) databases, search engines, and current public data sources.
In the context of LLMs, semantic search is an effective search approach, as it considers the context and intent of user-provided prompts as opposed to a traditional literal search. Semantic search relies on word embeddings, which represent words, sentences, or documents as vectors. Consequently, documents must be transformed into embeddings using an embedding model as the basis for semantic search. Because this embedding process only needs to happen when a document is first ingested or updated, it’s a great fit for event-driven compute with AWS Lambda.
This blog post presents a solution that allows you to ask natural language questions of any PDF document you upload. It combines the text generation and analysis capabilities of an LLM with a vector search on the document content. The solution uses serverless services such as AWS Lambda to run LangChain and Amazon DynamoDB for conversational memory.
Amazon Bedrock is used to provide serverless access to foundational models such as Amazon Titan and models developed by leading AI startups, such as AI21 Labs, Anthropic, and Cohere. See the GitHub repository for a full list of available LLMs and deployment instructions.
You learn how the solution works, what design choices were made, and how you can use it as a blueprint to build your own custom serverless solutions based on LangChain that go beyond prompting individual documents. The solution code and deployment instructions are available on GitHub.
Solution overview
Let’s look at how the solution works at a high level before diving deeper into specific elements and the AWS services used in the following sections. The following diagram provides a simplified view of the solution architecture and highlights key elements:
The process of interacting with the web application looks like this:
This upload triggers a metadata extraction and document embedding process. The process converts the text in the document into vectors. The vectors are loaded into a vector index and stored in S3 for later use.
When a user chats with a PDF document and sends a prompt to the backend, a Lambda function retrieves the index from S3 and searches for information related to the prompt.
An LLM then uses the results of this vector search, previous messages in the conversation, and its general-purpose capabilities to formulate a response to the user.
As can be seen on the following screenshot, the web application deployed as part of the solution allows you to upload documents and list uploaded documents and their associated metadata, such as number of pages, file size, and upload date. The document status indicates if a document is successfully uploaded, is being processed, or is ready for a conversation.
By clicking on one of the processed documents, you can access a chat interface, which allows you to send prompts to the backend. It is possible to have multiple independent conversations with each document with separate message history.
Embedding documents
When a new document is uploaded to the S3 bucket, an S3 event notification triggers a Lambda function that extracts metadata, such as file size and number of pages, from the PDF file and stores it in a DynamoDB table. Once the extraction is complete, a message containing the document location is placed on an Amazon Simple Queue Service (Amazon SQS) queue. Another Lambda function polls this queue using Lambda event source mapping. Applying the decouple messaging pattern to the metadata extraction and document embedding functions ensures loose coupling and protects the more compute-intensive downstream embedding function.
The embedding function loads the PDF file from S3 and uses a text embedding model to generate a vector representation of the contained text. LangChain integrates with text embedding models for a variety of LLM providers. The resulting vector representation of the text is loaded into a FAISS index. FAISS is an open source vector store that can run inside the Lambda function memory using the faiss-cpu Python package. Finally, a dump of this FAISS index is stored in the S3 bucket besides the original PDF document.
Generating responses
When a prompt for a specific document is submitted via the Amazon API Gateway REST API endpoint, it is proxied to a Lambda function that:
Loads the FAISS index dump of the corresponding PDF file from S3 and into function memory.
Performs a similarity search of the FAISS vector store based on the prompt.
If available, retrieves a record of previous messages in the same conversation via the DynamoDBChatMessageHistory integration. This integration can store message history in DynamoDB. Each conversation is identified by a unique ID.
Finally, a LangChain ConversationalRetrievalChain passes the combination of the prompt submitted by the user, the result of the vector search, and the message history to an LLM to generate a response.
Web application and file uploads
A static web application serves as the frontend for this solution. It’s built with React, TypeScript, Vite, and TailwindCSS and deployed via AWS Amplify Hosting, a fully managed CI/CD and hosting service for fast, secure, and reliable static and server-side rendered applications. To protect the application from unauthorized access, it integrates with an Amazon Cognito user pool. The API Gateway uses an Amazon Cognito authorizer to authenticate requests.
Users upload PDF files directly to the S3 bucket using S3 presigned URLs obtained via the REST API. Several Lambda functions implement API endpoints used to create, read, and update document metadata in a DynamoDB table.
Extending and adapting the solution
The solution provided serves as a blueprint that can be enhanced and extended to develop your own use cases based on LLMs. For example, you can extend the solution so that users can ask questions across multiple PDF documents or other types of data sources. LangChain makes it easy to load different types of data into vector stores, which you can then use for semantic search.
The solution presented in this blog post uses similarity search to find information in the vector database that closely matches the user-supplied prompt. While this works well in the presented use case, you can also use other approaches, such as maximal marginal relevance, to find the most relevant information to provide to the LLM. When searching across many documents and receiving many results, techniques such as MapReduce can improve the quality of the LLM responses.
Depending on your use case, you may also want to select a different LLM to achieve an ideal balance between quality of results and cost. Amazon Bedrock is a fully managed service that makes foundational models (FMs) from leading AI startups and Amazon available via an API, so you can choose from a wide range of FMs to find the model that’s best suited for your use case. You can use models such as Amazon Titan, Jurassic-2 from AI21 Labs, or Anthropic Claude.
AWS serverless services make it easier to focus on building generative AI applications by providing automatic scaling, built-in high availability, and a pay-for-use billing model. Event-driven compute with AWS Lambda is a good fit for compute-intensive, on-demand tasks such as document embedding and flexible LLM orchestration.
The solution in this blog post combines the capabilities of LLMs and semantic search to answer natural language questions directed at PDF documents. It serves as a blueprint that can be extended and adapted to fit further generative AI use cases.
Last week I attended the AWS Summit Johannesburg. This was the first summit to be hosted in my own country and my own city since 2019 so it was very special to have the opportunity to attend. It was great to get to meet with so many of our customers and hear how they are building on AWS.
Now on to the AWS updates. I’ve compiled a few announcements and upcoming events you need to know about. Let’s get started!
Last Week’s Launches Amazon Bedrock Is Now Generally Available – Amazon Bedrock was announced in preview in April of this year as part of a set of new tools for building with generative AI on AWS. Last week’s announcement of this service being generally available was received with a lot of excitement and customers have already been sharing what they are building with Amazon Bedrock. I quite enjoyed this lighthearted post from AWS Serverless Hero Jones Zachariah Noel about the “Bengaluru with traffic-filled roads” image he produced using Stability AI’s Stable Diffusion XL image generation model on Amazon Bedrock.
Amazon MSK Introduces Managed Data Delivery from Apache Kafka to Your Data Lake – Amazon MSK was released in 2019 to help our customers reduce the work needed to set up, scale, and manage Apache Kafka in production. Now you can continuously load data from an Apache Kafka cluster to Amazon Simple Storage Service (Amazon S3).
Other AWS News A few more news items and blog posts you might have missed:
For a full list of AWS announcements, be sure to keep an eye on the What’s New at AWS page.
Upcoming AWS Events We have the following upcoming events:
AWS Cloud Days (October 10, 24) – Connect and collaborate with other like-minded folks while learning about AWS at the AWS Cloud Day in Athens and Prague.
AWS Innovate Online (October 19) – Register for AWS Innovate Online to learn how you can build, run, and scale next-generation applications on the most extensive cloud platform. There will be 80+ sessions delivered in five languages and you’ll receive a certificate of attendance to showcase all you’ve learned.
We’re focused on improving our content to provide a better customer experience, and we need your feedback to do so. Take this quick survey to share insights on your experience with the AWS Blog. Note that this survey is hosted by an external company, so the link doesn’t lead to our website. AWS handles your information as described in the AWS Privacy Notice.
This April, we announced Amazon Bedrock as part of a set of new tools for building with generative AI on AWS. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, including AI21 Labs, Anthropic, Cohere, Stability AI, and Amazon, along with a broad set of capabilities to build generative AI applications, simplifying the development while maintaining privacy and security.
Today, I’m happy to announce that Amazon Bedrock is now generally available! I’m also excited to share that Meta’s Llama 2 13B and 70B parameter models will soon be available on Amazon Bedrock.
Amazon Bedrock’s comprehensive capabilities help you experiment with a variety of top FMs, customize them privately with your data using techniques such as fine-tuning and retrieval-augmented generation (RAG), and create managed agents that perform complex business tasks—all without writing any code. Check out my previous posts to learn more about agents for Amazon Bedrock and how to connect FMs to your company’s data sources.
Note that some capabilities, such as agents for Amazon Bedrock, including knowledge bases, continue to be available in preview. I’ll share more details on what capabilities continue to be available in preview towards the end of this blog post.
Since Amazon Bedrock is serverless, you don’t have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with.
Amazon Bedrock is integrated with Amazon CloudWatch and AWS CloudTrail to support your monitoring and governance needs. You can use CloudWatch to track usage metrics and build customized dashboards for audit purposes. With CloudTrail, you can monitor API activity and troubleshoot issues as you integrate other systems into your generative AI applications. Amazon Bedrock also allows you to build applications that are in compliance with the GDPR and you can use Amazon Bedrock to run sensitive workloads regulated under the U.S. Health Insurance Portability and Accountability Act (HIPAA).
Get Started with Amazon Bedrock You can access available FMs in Amazon Bedrock through the AWS Management Console,AWS SDKs, and open-source frameworks such as LangChain.
In the Amazon Bedrock console, you can browse FMs and explore and load example use cases and prompts for each model. First, you need to enable access to the models. In the console, select Model access in the left navigation pane and enable the models you would like to access. Once model access is enabled, you can try out different models and inference configuration settings to find a model that fits your use case.
For example, here’s a contract entity extraction use case example using Cohere’s Command model:
The example shows a prompt with a sample response, the inference configuration parameter settings for the example, and the API request that runs the example. If you select Open in Playground, you can explore the model and use case further in an interactive console experience.
Amazon Bedrock offers chat, text, and image model playgrounds. In the chat playground, you can experiment with various FMs using a conversational chat interface. The following example uses Anthropic’s Claude model:
As you evaluate different models, you should try various prompt engineering techniques and inference configuration parameters. Prompt engineering is a new and exciting skill focused on how to better understand and apply FMs to your tasks and use cases. Effective prompt engineering is about crafting the perfect query to get the most out of FMs and obtain proper and precise responses. In general, prompts should be simple, straightforward, and avoid ambiguity. You can also provide examples in the prompt or encourage the model to reason through more complex tasks.
Inference configuration parameters influence the response generated by the model. Parameters such as Temperature, Top P, and Top K give you control over the randomness and diversity, and Maximum Length or Max Tokens control the length of model responses. Note that each model exposes a different but often overlapping set of inference parameters. These parameters are either named the same between models or similar enough to reason through when you try out different models.
We discuss effective prompt engineering techniques and inference configuration parameters in more detail in week 1 of the Generative AI with Large Language Models on-demand course, developed by AWS in collaboration with DeepLearning.AI. You can also check the Amazon Bedrock documentation and the model provider’s respective documentation for additional tips.
Next, let’s see how you can interact with Amazon Bedrock via APIs.
Using the Amazon Bedrock API Working with Amazon Bedrock is as simple as selecting an FM for your use case and then making a few API calls. In the following code examples, I’ll use the AWS SDK for Python (Boto3) to interact with Amazon Bedrock.
List Available Foundation Models First, let’s set up the boto3 client and then use list_foundation_models() to see the most up-to-date list of available FMs:
Run Inference Using Amazon Bedrock’s InvokeModel API Next, let’s perform an inference request using Amazon Bedrock’s InvokeModel API and boto3 runtime client. The runtime client manages the data plane APIs, including the InvokeModel API.
The InvokeModel API expects the following parameters:
The modelId parameter identifies the FM you want to use. The request body is a JSON string containing the prompt for your task, together with any inference configuration parameters. Note that the prompt format will vary based on the selected model provider and FM. The contentType and accept parameters define the MIME type of the data in the request body and response and default to application/json. For more information on the latest models, InvokeModel API parameters, and prompt formats, see the Amazon Bedrock documentation.
Example: Text Generation Using AI21 Lab’s Jurassic-2 Model Here is a text generation example using AI21 Lab’s Jurassic-2 Ultra model. I’ll ask the model to tell me a knock-knock joke—my version of a Hello World.
Who's there?
Boo!
Boo who?
Don't cry, it's just a joke!
You can also use the InvokeModel API to interact with embedding models.
Example: Create Text Embeddings Using Amazon’s Titan Embeddings Model Text embedding models translate text inputs, such as words, phrases, or possibly large units of text, into numerical representations, known as embedding vectors. Embedding vectors capture the semantic meaning of the text in a high-dimension vector space and are useful for applications such as personalization or search. In the following example, I’m using the Amazon Titan Embeddings model to create an embedding vector.
Note that Amazon Titan Embeddings is available today. The Amazon Titan Text family of models for text generation continues to be available in limited preview.
Run Inference Using Amazon Bedrock’s InvokeModelWithResponseStream API The InvokeModel API request is synchronous and waits for the entire output to be generated by the model. For models that support streaming responses, Bedrock also offers an InvokeModelWithResponseStream API that lets you invoke the specified model to run inference using the provided input but streams the response as the model generates the output.
Streaming responses are particularly useful for responsive chat interfaces to keep the user engaged in an interactive application. Here is a Python code example using Amazon Bedrock’s InvokeModelWithResponseStream API:
response = bedrock_runtime.invoke_model_with_response_stream(
modelId=modelId,
body=body)
stream = response.get('body')
if stream:
for event in stream:
chunk=event.get('chunk')
if chunk:
print(json.loads(chunk.get('bytes').decode))
Data Privacy and Network Security With Amazon Bedrock, you are in control of your data, and all your inputs and customizations remain private to your AWS account. Your data, such as prompts, completions, and fine-tuned models, is not used for service improvement. Also, the data is never shared with third-party model providers.
Your data remains in the Region where the API call is processed. All data is encrypted in transit with a minimum of TLS 1.2 encryption. Data at rest is encrypted with AES-256 using AWS KMS managed data encryption keys. You can also use your own keys (customer managed keys) to encrypt the data.
You can configure your AWS account and virtual private cloud (VPC) to use Amazon VPC endpoints (built on AWS PrivateLink) to securely connect to Amazon Bedrock over the AWS network. This allows for secure and private connectivity between your applications running in a VPC and Amazon Bedrock.
Governance and Monitoring Amazon Bedrock integrates with IAM to help you manage permissions for Amazon Bedrock. Such permissions include access to specific models, playground, or features within Amazon Bedrock. All AWS-managed service API activity, including Amazon Bedrock activity, is logged to CloudTrail within your account.
Amazon Bedrock emits data points to CloudWatch using the AWS/Bedrock namespace to track common metrics such as InputTokenCount, OutputTokenCount, InvocationLatency, and (number of) Invocations. You can filter results and get statistics for a specific model by specifying the model ID dimension when you search for metrics. This near real-time insight helps you track usage and cost (input and output token count) and troubleshoot performance issues (invocation latency and number of invocations) as you start building generative AI applications with Amazon Bedrock.
Billing and Pricing Models Here are a couple of things around billing and pricing models to keep in mind when using Amazon Bedrock:
Billing – Text generation models are billed per processed input tokens and per generated output tokens. Text embedding models are billed per processed input tokens. Image generation models are billed per generated image.
Pricing Models – Amazon Bedrock offers two pricing models, on-demand and provisioned throughput. On-demand pricing allows you to use FMs on a pay-as-you-go basis without having to make any time-based term commitments. Provisioned throughput is primarily designed for large, consistent inference workloads that need guaranteed throughput in exchange for a term commitment. Here, you specify the number of model units of a particular FM to meet your application’s performance requirements as defined by the maximum number of input and output tokens processed per minute. For detailed pricing information, see Amazon Bedrock Pricing.
(Available in Preview) The Amazon Titan Text family of text generation models, Stability AI’s Stable Diffusion XL image generation model, and agents for Amazon Bedrock, including knowledge bases, continue to be available in preview. Reach out through your usual AWS contacts if you’d like access.
(Coming Soon) The Llama 2 13B and 70B parameter models by Meta will soon be available via Amazon Bedrock’s fully managed API for inference and fine-tuning.
In July, we announced the preview of agents for Amazon Bedrock, a new capability for developers to create generative AI applications that complete tasks. Today, I’m happy to introduce a new capability to securely connect foundation models (FMs) to your company data sources using agents.
With a knowledge base, you can use agents to give FMs in Bedrock access to additional data that helps the model generate more relevant, context-specific, and accurate responses without continuously retraining the FM. Based on user input, agents identify the appropriate knowledge base, retrieve the relevant information, and add the information to the input prompt, giving the model more context information to generate a completion.
Agents for Amazon Bedrock use a concept known as retrieval augmented generation (RAG) to achieve this. To create a knowledge base, specify the Amazon Simple Storage Service (Amazon S3) location of your data, select an embedding model, and provide the details of your vector database. Bedrock converts your data into embeddings and stores your embeddings in the vector database. Then, you can add the knowledge base to agents to enable RAG workflows.
Primer on Retrieval Augmented Generation, Embeddings, and Vector Databases RAG isn’t a specific set of technologies but a concept for providing FMs access to data they didn’t see during training. Using RAG, you can augment FMs with additional information, including company-specific data, without continuously retraining your model.
Continuously retraining your model is not only compute-intensive and expensive, but as soon as you’ve retrained the model, your company might have already generated new data, and your model has stale information. RAG addresses this issue by providing your model access to additional external data at runtime. Relevant data is then added to the prompt to help improve both the relevance and the accuracy of completions.
This data can come from a number of data sources, such as document stores or databases. A common implementation for document search is converting your documents, or chunks of the documents, into vector embeddings using an embedding model and then storing the vector embeddings in a vector database, as shown in the following figure.
The vector embedding includes the numeric representations of text data within your documents. Each embedding aims to capture the semantic or contextual meaning of the data. Each vector embedding is put into a vector database, often with additional metadata such as a reference to the original content the embedding was created from. The vector database then indexes the vectors, which can be done using a variety of approaches. This indexing enables quick retrieval of relevant data.
Compared to traditional keyword search, vector search can find relevant results without requiring an exact keyword match. For example, if you search for “What is the cost of product X?” and your documents say “The price of product X is […]”, then keyword search might not work because “price” and “cost” are two different words. With vector search, it will return the accurate result because “price” and “cost” are semantically similar; they have the same meaning. Vector similarity is calculated using distance metrics such as Euclidean distance, cosine similarity, or dot product similarity.
The vector database is then used within the prompt workflow to efficiently retrieve external information based on an input query, as shown in the figure below.
The workflow starts with a user input prompt. Using the same embedding model, you create a vector embedding representation of the input prompt. This embedding is then used to query the database for similar vector embeddings to return the most relevant text as the query result.
The query result is then added to the prompt, and the augmented prompt is passed to the FM. The model uses the additional context in the prompt to generate the completion, as shown in the following figure.
Similar to the fully managed agents experience I described in the blog post on agents for Amazon Bedrock, the knowledge base for Amazon Bedrock manages the data ingestion workflow, and agents manage the RAG workflow for you.
Get Started with Knowledge Bases for Amazon Bedrock You can add a knowledge base by specifying a data source, such as Amazon S3, select an embedding model, such as Amazon Titan Embeddings to convert the data into vector embeddings, and a destination vector database to store the vector data. Bedrock takes care of creating, storing, managing, and updating your embeddings in the vector database.
If you add knowledge bases to an agent, the agent will identify the appropriate knowledge base based on user input, retrieve the relevant information, and add the information to the input prompt, providing the model with more context information to generate a response, as shown in the figure below. All information retrieved from knowledge bases comes with source attribution to improve transparency and minimize hallucinations.
Let me walk you through those steps in more detail.
Create a Knowledge Base for Amazon Bedrock Let’s assume you’re a developer at a tax consulting company and want to provide users with a generative AI application—a TaxBot—that can answer US tax filing questions. You first create a knowledge base that holds the relevant tax documents. Then, you configure an agent in Bedrock with access to this knowledge base and integrate the agent into your TaxBot application.
To get started, open the Bedrock console, select Knowledge base in the left navigation pane, then choose Create knowledge base.
Step 1 – Provide knowledge base details. Enter a name for the knowledge base and a description (optional). You also must select an AWS Identity and Access Management (IAM) runtime role with a trust policy for Amazon Bedrock, permissions to access the S3 bucket you want the knowledge base to use, and read/write permissions to your vector database. You can also assign tags as needed.
Step 2 – Set up data source. Enter a data source name and specify the Amazon S3 location for your data. Supported data formats include .txt, .md, .html, .doc and .docx, .csv, .xls and .xlsx, and .pdf files. You can also provide an AWS Key Management Service (AWS KMS) key to allow Bedrock to decrypt and encrypt your data and another AWS KMS key for transient data storage while Bedrock is converting your data into embeddings.
Choose the embedding model, such as Amazon Titan Embeddings – Text, and your vector database. For the vector database, as mentioned earlier, you can choose between vector engine for Amazon OpenSearch Serverless, Pinecone, or Redis Enterprise Cloud.
Important note on the vector database: Amazon Bedrock is not creating a vector database on your behalf. You must create a new, empty vector database from the list of supported options and provide the vector database index name as well as index field and metadata field mappings. This vector database will need to be for exclusive use with Amazon Bedrock.
The configuration for Pinecone and Redis Enterprise Cloud is similar. Check out this Pinecone blog post and this Redis Inc. blog post for more details on how to set up and prepare their vector database for Bedrock.
Step 3 – Review and create. Review your knowledge base configuration and choose Create knowledge base.
Back in the knowledge base details page, choose Sync for the newly created data source, and whenever you add new data to the data source, to start the ingestion workflow of converting your Amazon S3 data into vector embeddings and upserting the embeddings into the vector database. Depending on the amount of data, this whole workflow can take some time.
Next, I’ll show you how to add the knowledge base to an agent configuration.
Add a Knowledge Base to Agents for Amazon Bedrock You can add a knowledge base when creating or updating an agent for Amazon Bedrock. Create an agent as described in this AWS News Blog post on agents for Amazon Bedrock.
For my tax bot example, I’ve created an agent called “TaxBot,” selected a foundation model, and provided these instructions for the agent in step 2: “You are a helpful and friendly agent that answers US tax filing questions for users.” In step 4, you can now select a previously created knowledge base and provide instructions for the agent describing when to use this knowledge base.
These instructions are very important as they help the agent decide whether or not a particular knowledge base should be used for retrieval. The agent will identify the appropriate knowledge base based on user input and available knowledge base instructions.
For my tax bot example, I added the knowledge base “TaxBot-Knowledge-Base” together with these instructions: “Use this knowledge base to answer tax filing questions.”
Once you’ve finished the agent configuration, you can test your agent and how it’s using the added knowledge base. Note how the agent provides a source attribution for information pulled from knowledge bases.
Sign up to Learn More about Amazon Bedrock (Preview) Amazon Bedrock is currently available in preview. Reach out through your usual AWS support contacts if you’d like access to knowledge bases for Amazon Bedrock as part of the preview. We’re regularly providing access to new customers. To learn more, visit the Amazon Bedrock Features page and sign up to learn more about Amazon Bedrock.
Another significant milestone has been achieved by the AWS User Group Philippines. They just celebrated their tenth anniversary by running 2 days of AWS Community Day Philippines. Here are a few photos from the event, including Jeff Barr sharing his experiences attending AWS User Group meetup, in Manila, Philippines 10 years ago.
Big congratulations to AWS Community Heroes, AWS Community Builders, AWS User Group leaders and all volunteers who organized and delivered AWS Community Days! Also, thank you to everyone who attended and help support our AWS communities.
Last Week’s Launches We had interesting launches last week, including from AWS Summit, New York. Here are some of my personal highlights:
(Preview) Agents for Amazon Bedrock – You can now create managed agents for Amazon Bedrock to handle tasks using API calls to company systems, understand user requests, break down complex tasks into steps, hold conversations to gather more information, and take actions to fulfill requests.
(Coming Soon) New LLM Capabilities in Amazon QuickSight Q – We are expanding the innovation in QuickSight Q by introducing new LLM capabilities through Amazon Bedrock. These Generative BI capabilities will allow organizations to easily explore data, uncover insights, and facilitate sharing of insights.
AWS Glue Studio support for Amazon CodeWhisperer – You can now write specific tasks in natural language (English) as comments in the Glue Studio notebook, and Amazon CodeWhisperer provides code recommendations for you.
(Preview) Vector Engine for Amazon OpenSearch Serverless – This capability empowers you to create modern ML-augmented search experiences and generative AI applications without the need to handle the complexities of managing the underlying vector database infrastructure.
Last week, Amazon SageMaker Canvas also released a set of new capabilities:
AWS Open-Source Updates As always, my colleague Ricardo has curated the latest updates for open-source news at AWS. Here are some of the highlights.
cdk-aws-observability-accelerator is a set of opinionated modules to help you set up observability for your AWS environments with AWS native services and AWS-managed observability services such as Amazon Managed Service for Prometheus, Amazon Managed Grafana, AWS Distro for OpenTelemetry (ADOT) and Amazon CloudWatch.
iac-devtools-cli-for-cdk is a command line interface tool that automates many of the tedious tasks of building, adding to, documenting, and extending AWS CDK applications.
Upcoming AWS Events There are upcoming events that you can join to learn. Let’s start with AWS events:
Open for Registration for AWS re:Invent We want to be sure you know that AWS re:Invent registration is now open!
This learning conference hosted by AWS for the global cloud computing community will be held from November 27 to December 1, 2023, in Las Vegas.
Pro-tip: You can use information on the Justify Your Trip page to prove the value of your trip to AWS re:Invent trip.
Give Us Your Feedback We’re focused on improving our content to provide a better customer experience, and we need your feedback to do so. Please take this quick survey to share insights on your experience with the AWS Blog. Note that this survey is hosted by an external company, so the link does not lead to our website. AWS handles your information as described in the AWS Privacy Notice.
That’s all for this week. Check back next Monday for another Week in Review.
P.S. We’re focused on improving our content to provide a better customer experience, and we need your feedback to do so. Please take this quick survey to share insights on your experience with the AWS Blog. Note that this survey is hosted by an external company, so the link does not lead to our website. AWS handles your information as described in the AWS Privacy Notice.
This April, Swami Sivasubramanian, Vice President of Data and Machine Learning at AWS, announced Amazon Bedrock and Amazon Titan models as part of new tools for building with generative AI on AWS. Amazon Bedrock, currently available in preview, is a fully managed service that makes foundation models (FMs) from Amazon and leading AI startups—such as AI21 Labs, Anthropic, Cohere, and Stability AI—available through an API.
Today, I’m excited to announce the preview of agents for Amazon Bedrock, a new capability for developers to create fully managed agents in a few clicks. Agents for Amazon Bedrock accelerate the delivery of generative AI applications that can manage and perform tasks by making API calls to your company systems. Agents extend FMs to understand user requests, break down complex tasks into multiple steps, carry on a conversation to collect additional information, and take actions to fulfill the request.
Using agents for Amazon Bedrock, you can automate tasks for your internal or external customers, such as managing retail orders or processing insurance claims. For example, an agent-powered generative AI e-commerce application can not only respond to the question, “Do you have this jacket in blue?” with a simple answer but can also help you with the task of updating your order or managing an exchange.
For this to work, you first need to give the agent access to external data sources and connect it to existing APIs of other applications. This allows the FM that powers the agent to interact with the broader world and extend its utility beyond just language processing tasks. Second, the FM needs to figure out what actions to take, what information to use, and in which sequence to perform these actions. This is possible thanks to an exciting emerging behavior of FMs—their ability to reason. You can show FMs how to handle such interactions and how to reason through tasks by building prompts that include definitions and instructions. The process of designing prompts to guide the model towards desired outputs is known as prompt engineering.
Introducing Agents for Amazon Bedrock Agents for Amazon Bedrock automate the prompt engineering and orchestration of user-requested tasks. Once configured, an agent automatically builds the prompt and securely augments it with your company-specific information to provide responses back to the user in natural language. The agent is able to figure out the actions required to automatically process user-requested tasks. It breaks the task into multiple steps, orchestrates a sequence of API calls and data lookups, and maintains memory to complete the action for the user.
With fully managed agents, you don’t have to worry about provisioning or managing infrastructure. You’ll have seamless support for monitoring, encryption, user permissions, and API invocation management without writing custom code. As a developer, you can use the Bedrock console or SDK to upload the API schema. The agent then orchestrates the tasks with the help of FMs and performs API calls using AWS Lambda functions.
Primer on Advanced Reasoning and ReAct You can help FMs to reason and figure out how to solve user-requested tasks with a reasoning technique called ReAct (synergizing reasoning and acting). Using ReAct, you can structure prompts to show an FM how to reason through a task and decide on actions that help find a solution. The structured prompts include a sequence of question-thought-action-observation examples.
The question is the user-requested task or problem to solve. The thought is a reasoning step that helps demonstrate to the FM how to tackle the problem and identify an action to take. The action is an API that the model can invoke from an allowed set of APIs. The observation is the result of carrying out the action. The actions that the FM is able to choose from are defined by a set of instructions that are prepended to the example prompt text. Here is an illustration of how you would build up a ReAct prompt:
The good news is that Bedrock performs the heavy lifting for you! Behind the scenes, agents for Amazon Bedrock build the prompts based on the information and actions you provide.
Now, let me show you how to get started with agents for Amazon Bedrock.
Create an Agent for Amazon Bedrock Let’s assume you’re a developer at an insurance company and want to provide a generative AI application that helps the insurance agency owners automate repetitive tasks. You create an agent in Bedrock and integrate it into your application.
To get started with the agent, open the Bedrock console, select Agents in the left navigation panel, then choose Create Agent.
Select a foundation model from Bedrock that fits your use case. Here, you provide an instruction to your agent in natural language. The instruction tells the agent what task it’s supposed to perform and the persona it’s supposed to assume. For example, “You are an agent designed to help with processing insurance claims and managing pending paperwork.”
Add action groups. An action is a task that the agent can perform automatically by making API calls to your company systems. A set of actions is defined in an action group. Here, you provide an API schema that defines the APIs for all the actions in the group. You also must provide a Lambda function that represents the business logic for each API. For example, let’s define an action group called ClaimManagementActionGroup that manages insurance claims by pulling a list of open claims, identifying outstanding paperwork for each claim, and sending reminders to policy holders. Make sure to capture this information in the action group description. The business logic for my action group is captured in the Lambda function InsuranceClaimsLambda. This AWS Lambda function implements methods for the following API calls: open-claims, identify-missing-documents, and send-reminders.Here’s a short extract from my OrderManagementLambda:
import json
import time
def open_claims():
...
def identify_missing_documents(parameters):
...
def send_reminders():
...
def lambda_handler(event, context):
responses = []
for prediction in event['actionGroups']:
response_code = ...
action = prediction['actionGroup']
api_path = prediction['apiPath']
if api_path == '/claims':
body = open_claims()
elif api_path == '/claims/{claimId}/identify-missing-documents':
parameters = prediction['parameters']
body = identify_missing_documents(parameters)
elif api_path == '/send-reminders':
body = send_reminders()
else:
body = {"{}::{} is not a valid api, try another one.".format(action, api_path)}
response_body = {
'application/json': {
'body': str(body)
}
}
action_response = {
'actionGroup': prediction['actionGroup'],
'apiPath': prediction['apiPath'],
'httpMethod': prediction['httpMethod'],
'httpStatusCode': response_code,
'responseBody': response_body
}
responses.append(action_response)
api_response = {'response': responses}
return api_response
Note that you also must provide an API schema in the OpenAPI schema JSON format. Here’s what my API schema file insurance_claim_schema.json looks like:
{"openapi": "3.0.0",
"info": {
"title": "Insurance Claims Automation API",
"version": "1.0.0",
"description": "APIs for managing insurance claims by pulling a list of open claims, identifying outstanding paperwork for each claim, and sending reminders to policy holders."
},
"paths": {
"/claims": {
"get": {
"summary": "Get a list of all open claims",
"description": "Get the list of all open insurance claims. Return all the open claimIds.",
"operationId": "getAllOpenClaims",
"responses": {
"200": {
"description": "Gets the list of all open insurance claims for policy holders",
"content": {
"application/json": {
"schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"claimId": {
"type": "string",
"description": "Unique ID of the claim."
},
"policyHolderId": {
"type": "string",
"description": "Unique ID of the policy holder who has filed the claim."
},
"claimStatus": {
"type": "string",
"description": "The status of the claim. Claim can be in Open or Closed state"
}
}
}
}
}
}
}
}
}
},
"/claims/{claimId}/identify-missing-documents": {
"get": {
"summary": "Identify missing documents for a specific claim",
"description": "Get the list of pending documents that need to be uploaded by policy holder before the claim can be processed. The API takes in only one claim id and returns the list of documents that are pending to be uploaded by policy holder for that claim. This API should be called for each claim id",
"operationId": "identifyMissingDocuments",
"parameters": [{
"name": "claimId",
"in": "path",
"description": "Unique ID of the open insurance claim",
"required": true,
"schema": {
"type": "string"
}
}],
"responses": {
"200": {
"description": "List of documents that are pending to be uploaded by policy holder for insurance claim",
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"pendingDocuments": {
"type": "string",
"description": "The list of pending documents for the claim."
}
}
}
}
}
}
}
}
},
"/send-reminders": {
"post": {
"summary": "API to send reminder to the customer about pending documents for open claim",
"description": "Send reminder to the customer about pending documents for open claim. The API takes in only one claim id and its pending documents at a time, sends the reminder and returns the tracking details for the reminder. This API should be called for each claim id you want to send reminders for.",
"operationId": "sendReminders",
"requestBody": {
"required": true,
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"claimId": {
"type": "string",
"description": "Unique ID of open claims to send reminders for."
},
"pendingDocuments": {
"type": "string",
"description": "The list of pending documents for the claim."
}
},
"required": [
"claimId",
"pendingDocuments"
]
}
}
}
},
"responses": {
"200": {
"description": "Reminders sent successfully",
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"sendReminderTrackingId": {
"type": "string",
"description": "Unique Id to track the status of the send reminder Call"
},
"sendReminderStatus": {
"type": "string",
"description": "Status of send reminder notifications"
}
}
}
}
}
},
"400": {
"description": "Bad request. One or more required fields are missing or invalid."
}
}
}
}
}
}
When a user asks your agent to complete a task, Bedrock will use the FM you configured for the agent to identify the sequence of actions and invoke the corresponding Lambda functions in the right order to solve the user-requested task.
In the final step, review your agent configuration and choose Create Agent.
Congratulations, you’ve just created your first agent in Amazon Bedrock!
Deploy an Agent for Amazon Bedrock To deploy an agent in your application, you must create an alias. Bedrock then automatically creates a version for that alias.
In the Bedrock console, select your agent, then select Deploy, and choose Create to create an alias.
Provide an alias name and description and choose whether to create a new version or use an existing version of your agent to associate with this alias.
This saves a snapshot of the agent code and configuration and associates an alias with this snapshot or version. You can use the alias to integrate the agent into your applications.
Now, let’s test the insurance agent! You can do this right in the Bedrock console.
Let’s ask the agent to “Send reminder to all policy holders with open claims and pending paper work.” You can see how the FM-powered agent is able to understand the user request, break down the task into steps (collect the open insurance claims, lookup the claim IDs, send reminders), and perform the corresponding actions.
Agents for Amazon Bedrock can help you increase productivity, improve your customer service experience, or automate DevOps tasks. I’m excited to see what use cases you will implement!
Learn the Fundamentals of Generative AI If you’re interested in the fundamentals of generative AI and how to work with FMs, including advanced prompting techniques and agents, check out this this new hands-on course that I developed with AWS colleagues and industry experts in collaboration with DeepLearning.AI:
P.S. We’re focused on improving our content to provide a better customer experience, and we need your feedback to do so. Please take this quick survey to share insights on your experience with the AWS Blog. Note that this survey is hosted by an external company, so the link does not lead to our website. AWS handles your information as described in the AWS Privacy Notice.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
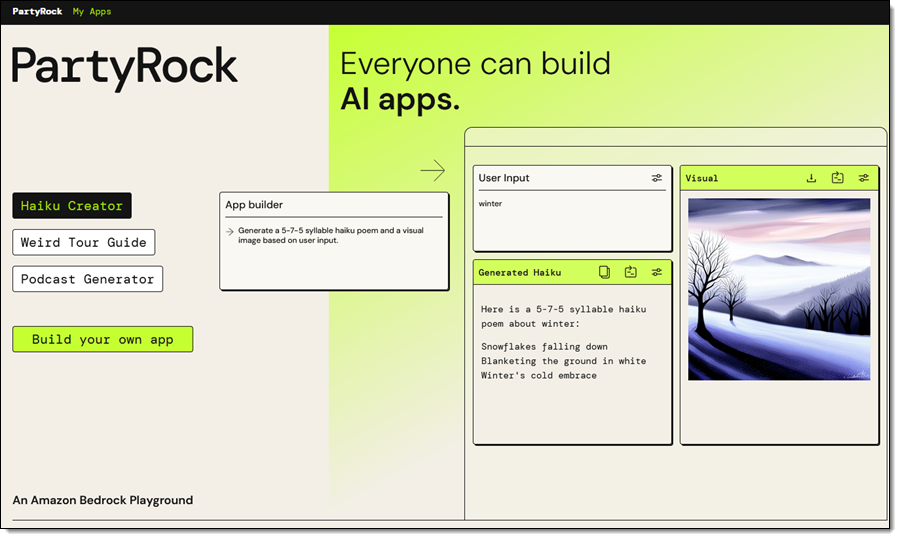
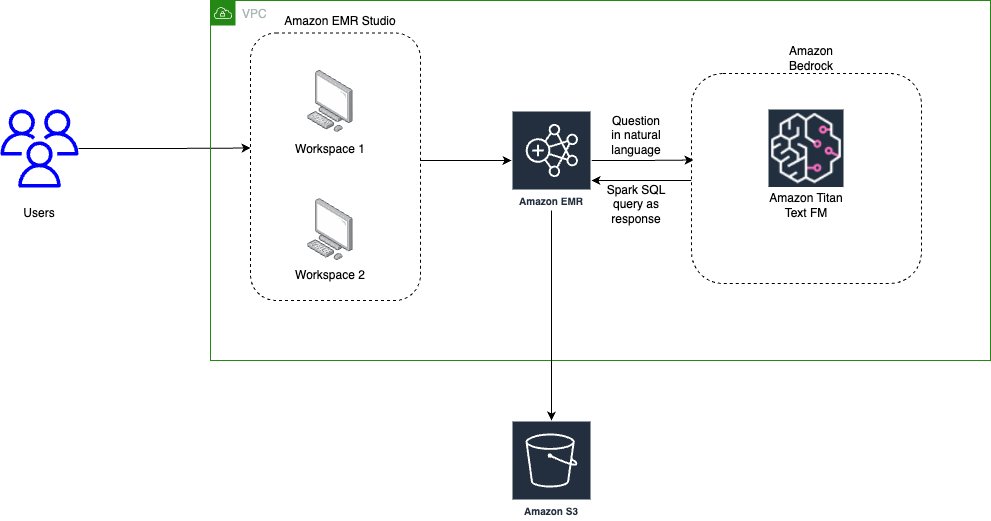






 Saurabh Bhutyani is a Principal Analytics Specialist Solutions Architect at AWS. He is passionate about new technologies. He joined AWS in 2019 and works with customers to provide architectural guidance for running generative AI use cases, scalable analytics solutions and data mesh architectures using AWS services like Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone.
Saurabh Bhutyani is a Principal Analytics Specialist Solutions Architect at AWS. He is passionate about new technologies. He joined AWS in 2019 and works with customers to provide architectural guidance for running generative AI use cases, scalable analytics solutions and data mesh architectures using AWS services like Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone. Harsh Vardhan is an AWS Senior Solutions Architect, specializing in analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.
Harsh Vardhan is an AWS Senior Solutions Architect, specializing in analytics. He has over 8 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.




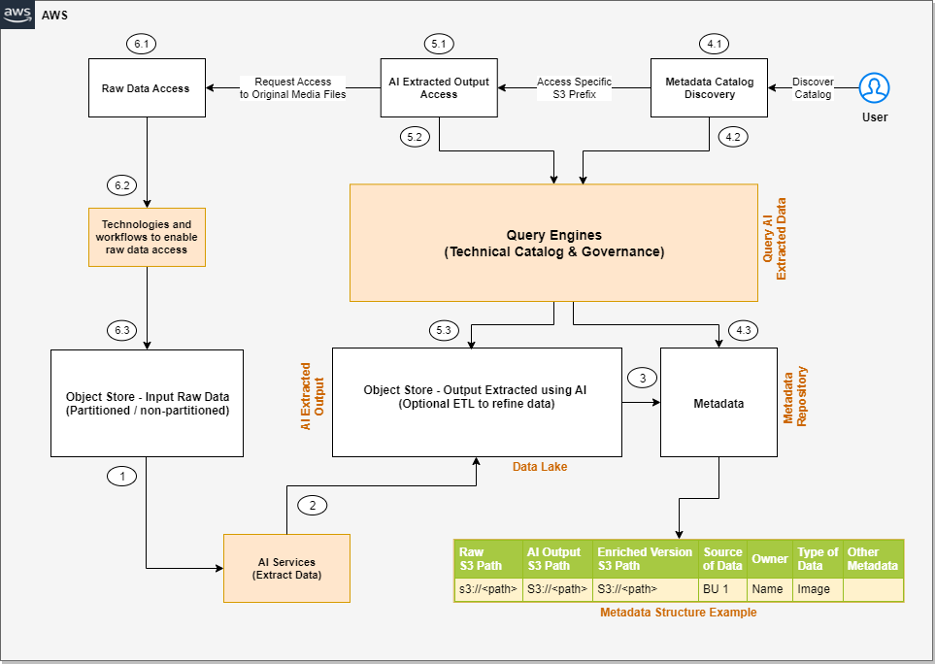

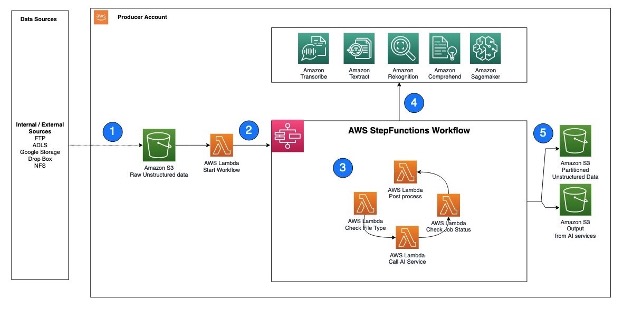
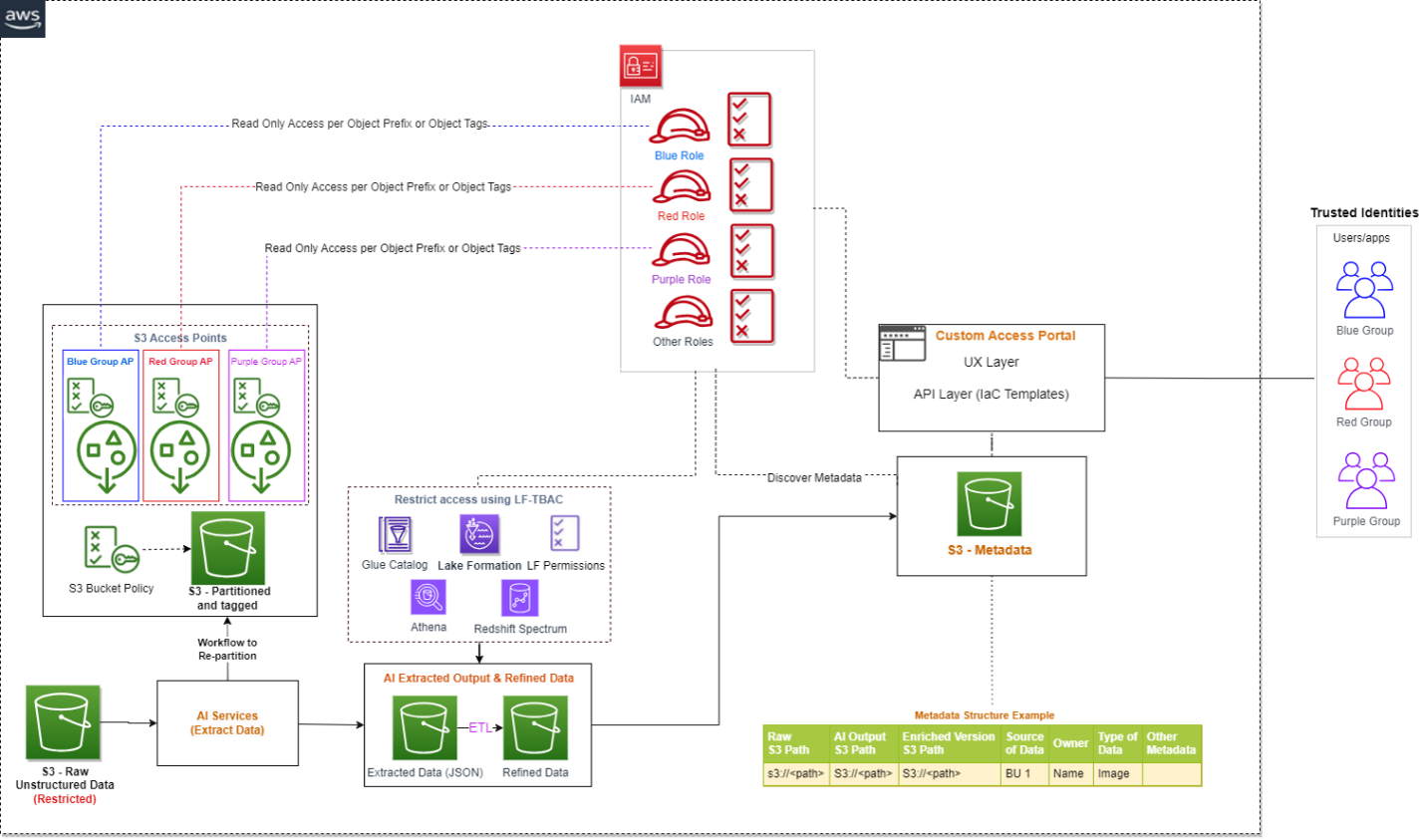
 Sakti Mishra is a Principal Solutions Architect at AWS, where he helps customers modernize their data architecture and define their end-to-end data strategy, including data security, accessibility, governance, and more. He is also the author of the book
Sakti Mishra is a Principal Solutions Architect at AWS, where he helps customers modernize their data architecture and define their end-to-end data strategy, including data security, accessibility, governance, and more. He is also the author of the book  Bhavana Chirumamilla is a Senior Resident Architect at AWS with a strong passion for data and machine learning operations. She brings a wealth of experience and enthusiasm to help enterprises build effective data and ML strategies. In her spare time, Bhavana enjoys spending time with her family and engaging in various activities such as traveling, hiking, gardening, and watching documentaries.
Bhavana Chirumamilla is a Senior Resident Architect at AWS with a strong passion for data and machine learning operations. She brings a wealth of experience and enthusiasm to help enterprises build effective data and ML strategies. In her spare time, Bhavana enjoys spending time with her family and engaging in various activities such as traveling, hiking, gardening, and watching documentaries. Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS customers make informed choices and trade-offs about accelerating their data, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time with her family—usually on tennis courts.
Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS customers make informed choices and trade-offs about accelerating their data, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time with her family—usually on tennis courts. Daniel Bruno is a Principal Resident Architect at AWS. He had been building analytics and machine learning solutions for over 20 years and splits his time helping customers build data science programs and designing impactful ML products.
Daniel Bruno is a Principal Resident Architect at AWS. He had been building analytics and machine learning solutions for over 20 years and splits his time helping customers build data science programs and designing impactful ML products.