Post Syndicated from Danilo Poccia original https://aws.amazon.com/blogs/aws/introducing-vpc-lattice-simplify-networking-for-service-to-service-communication-preview/
Modern applications are built using modular and distributed components. Each component is a service that implements its own subset of functionalities. To make these services communicate with each other, you need a way to let them discover where they are, authorize access, and route traffic. When troubleshooting issues, you need to keep communication configurations under control so that you can quickly understand what is happening at the application, service, and network levels. This can take a lot of your time.
Today, we are making available in preview Amazon VPC Lattice, a new capability of Amazon Virtual Private Cloud (Amazon VPC) that gives you a consistent way to connect, secure, and monitor communication between your services. With VPC Lattice, you can define policies for traffic management, network access, and monitoring so you can connect applications in a simple and consistent way across AWS compute services (instances, containers, and serverless functions). VPC Lattice automatically handles network connectivity between VPCs and accounts and network address translation between IPv4, IPv6, and overlapping IP addresses. VPC Lattice integrates with AWS Identity and Access Management (IAM) to give you the same authentication and authorization capabilities you are familiar with when interacting with AWS services today, but for your own service-to-service communication. With VPC Lattice, you have common controls to route traffic based on request characteristics and weighted routing for blue/green and canary-style deployments. For example, VPC Lattice allows you to mix and match compute types for a given service, which helps you modernize a monolith application architecture to microservices.
VPC Lattice is designed to be noninvasive, allowing teams across your organization to incrementally opt in over time. In this way, you are able to deliver applications faster by focusing on your application logic, while VPC Lattice handles service-to-service networking, security, and monitoring requirements.
How Amazon VPC Lattice Works
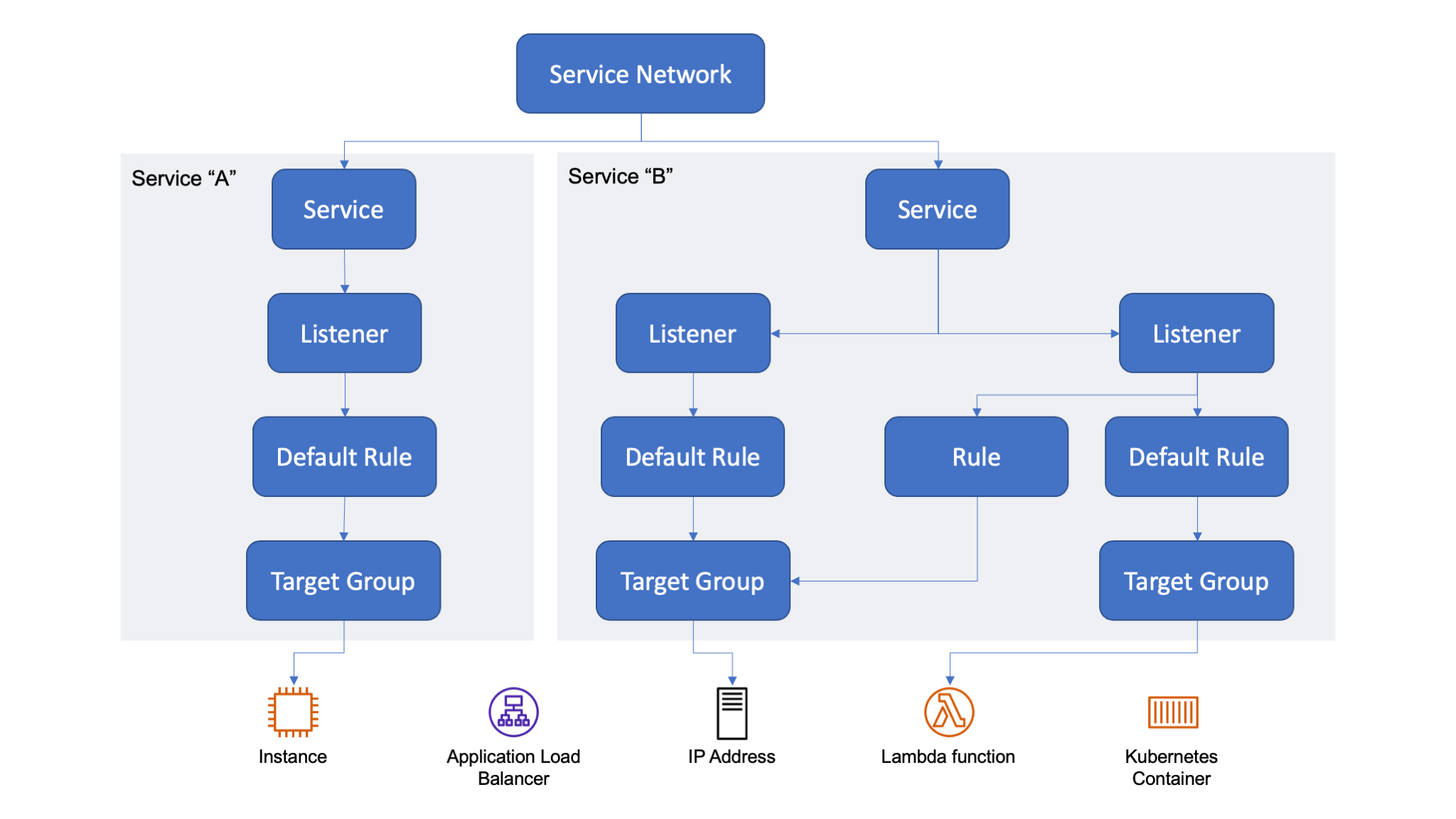
With VPC Lattice, you create a logical application layer network, called a service network, that connects clients and services across different VPCs and accounts, abstracting network complexity. A service network is a logical boundary that is used to automatically implement service discovery and connectivity as well as apply access and observability policies to a collection of services. It offers inter-application connectivity over HTTP/HTTPS and gRPC protocols within a VPC.
Once a VPC has been enabled for a service network, clients in the VPC will automatically be able to discover the services in the service network through DNS and will direct all inter-application traffic through VPC Lattice. You can use AWS Resource Access Manager (RAM) to control which accounts, VPCs, and applications can establish communication via VPC Lattice.
A service is an independently deployable unit of software that delivers a specific task or function. In VPC Lattice, a service is a logical component that can live in any VPC or account and can run on a mixture of compute types (virtual machines, containers, and serverless functions). A service configuration consists of:
- One or two listeners that define the port and protocol that the service is expecting traffic on. Supported protocols are HTTP/1.1, HTTP/2, and gRPC, including HTTPS for TLS-enabled services.
- Listeners have rules that consist of a priority, which specifies the order in which rules should be processed, one or more conditions that define when to apply the rule, and actions that forward traffic to target groups. Each listener has a default rule that takes effect when no additional rules are configured, or no conditions are met.
- A target group is a collection of targets, or compute resources, that are running a specific workload you are trying to route toward. Targets can be Amazon Elastic Compute Cloud (Amazon EC2) instances, IP addresses, and Lambda functions. For Kubernetes workloads, VPC Lattice can target services and pods via the AWS Gateway Controller for Kubernetes. To have access to the AWS Gateway Controller for Kubernetes, you can join the preview.

To configure service access controls, you can use access policies. An access policy is an IAM resource policy that can be associated with a service network and individual services. With access policies, you can use the “PARC” (principal, action, resource, and condition) model to enforce context-specific access controls for services. For example, you can use an access policy to define which services can access a service you own. If you use AWS Organizations, you can limit access to a service network to a specific organization.
VPC Lattice also provides a service directory, a centralized view of the services that you own or have been shared with you via AWS RAM.
Using Amazon VPC Lattice
We expect people with different roles can use VPC Lattice. For example:
- The service network administrator can:
- Create and manage a service network.
- Define access and monitoring for the service network.
- Associate client and services.
- Share the service network with other AWS accounts.
- The service owner can:
- Create and manage a service, including access and monitoring.
- Define routing, for example, configuring listeners and rules that point to the target groups where the service is running.
- Associate a service to service networks.
Let’s see how this works in practice. In this quick walkthrough, I am covering both roles.
Creating Two Backend Services
There is nothing specific to VPC Lattice in this section. I am just creating a couple of services, one running on Amazon EC2 and one on AWS Lambda, that I’ll use later when I configure networking with VPC Lattice.
In an Amazon Linux EC2 instance, I create a web app that replies “Hello from the instance” to HTTP requests. To allow access to the instance from clients coming via VPC Lattice, I add an inbound rule to the security group to allow TCP traffic on port 8080 from the VPC Lattice AWS-managed prefix list.
Here’s the app.py file. I am using Python and Flask for this app, but you don’t need to know them to follow along with the post.
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return 'Hello from the instance'
@app.route('/<path>')
def somePath(path):
return 'Hello from the instance at path "{}"'.format(path)
app.run(host='0.0.0.0', port=8080)
Here’s the requirements.txt file with the Python dependencies. There’s only one line because the only module I need is flask:
I install the dependencies:
pip3 install -r requirements.txt
Then, I start the web app using the nohup command to keep it running in case I log out of the instance:
nohup flask run --host=0.0.0.0 --port 8080 &
On the EC2 instance, the web service is now listening to HTTP traffic on port 8080.
In the Lambda console, I create a simple function using the Node.js 18.x runtime that replies “Hello from the function” to all invocations.
exports.handler = async (event) => {
const response = {
statusCode: 200,
body: JSON.stringify('Hello from the function'),
};
return response;
};
The two services are now both ready. Let’s use VPC Lattice to configure networking.
Creating VPC Lattice Target Groups
I start by creating two target groups, one for the EC2 instance and one for the Lambda function. In the VPC console, there is a new VPC Lattice section in the navigation pane. There, I choose Target groups and then Create target group.
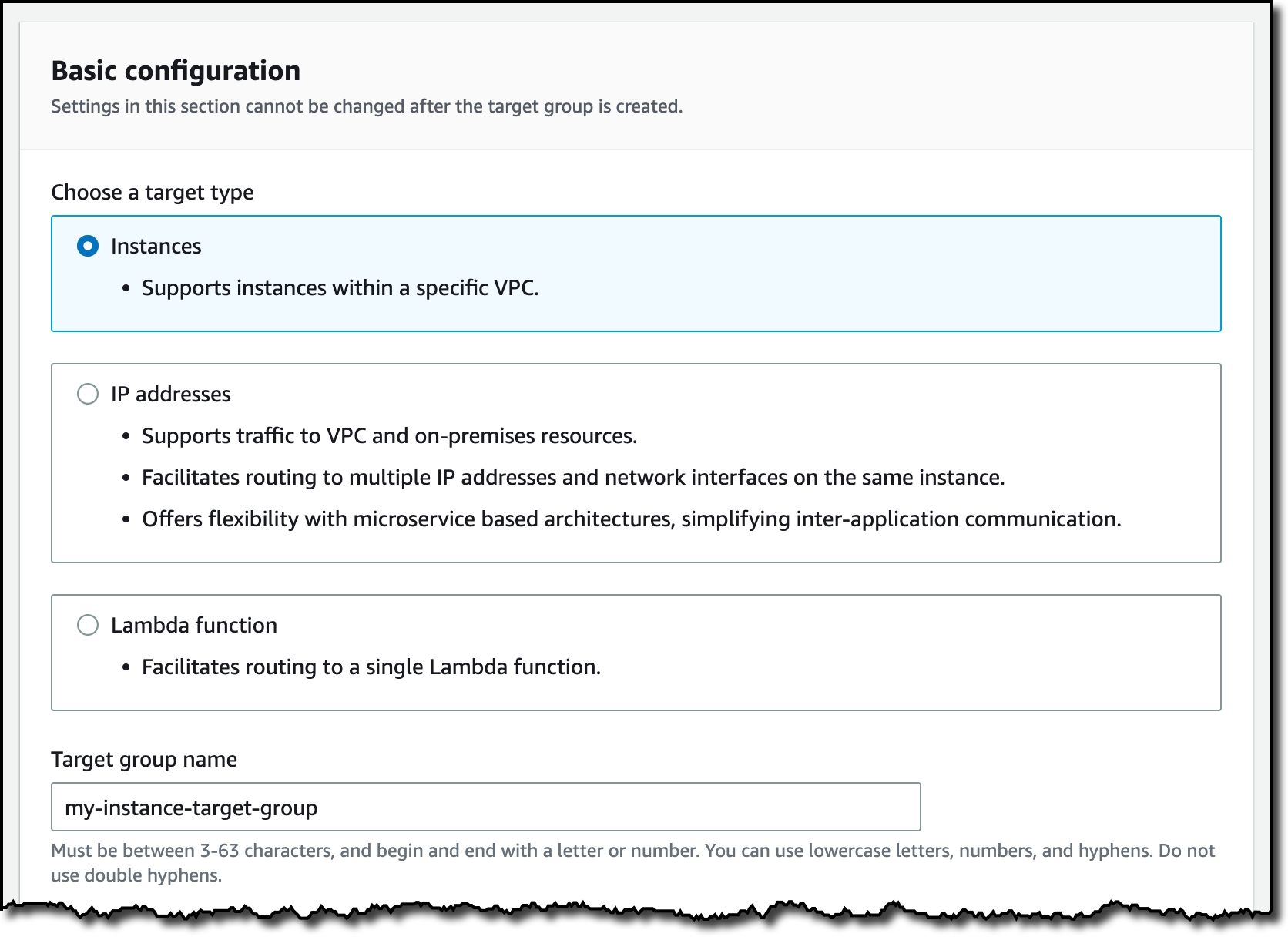
For the first target group, I choose the Instances target type and enter a name.

I choose the protocol (HTTP) and port (8080) used by the web app running on the instance. I select the VPC where the instance is running and the protocol version (HTTP1).

Now I can configure the health check that will be used to test the target status. In this case, I use the default values proposed by the console.

In the next step, I can register the targets. I select the instance on which the web app is running from the list and choose to include it.

I review the selected targets (one instance in this case) and choose Submit.
In a similar way, I create a target group for the Lambda function. This time, I select the function from the list. I can choose which function version or function alias to use. For simplicity, I use the $LATEST version.

Creating VPC Lattice Services
Now that the target groups are ready, I choose Services in the navigation pane and then Create service. I enter a name and a description.

Now, I can choose the authentication type. If I choose None, the service network does not authenticate or authorize client access, and the auth policy, if present, is not used. I select AWS IAM and then, from the Apply policy template dropdown, the template that allows both authenticated and unauthenticated access.

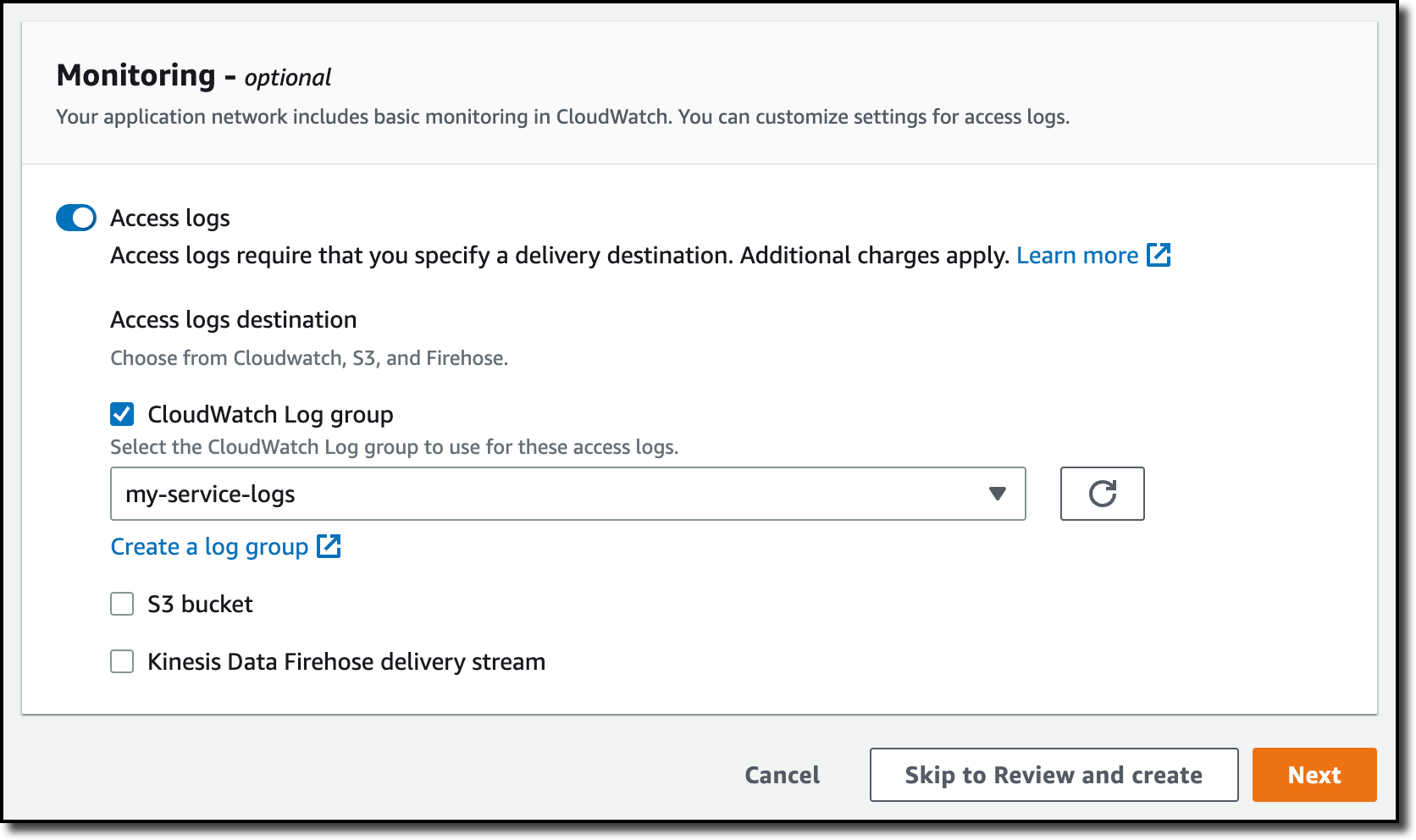
In the Monitoring section, I turn on Access logs. As the destination for the access logs, I use an Amazon CloudWatch Log group that I created before. I also have the option to use an Amazon Simple Storage Service (Amazon S3) bucket or a Amazon Kinesis Data Firehose delivery stream.
In the next step, I define routing for the service. I choose Add listener. For the protocol, I configure the service to listen using HTTPS. In the default action, I choose to send two-thirds (Weight 20) of the requests to the instance target group and one-third (Weight 10) to the function target group.

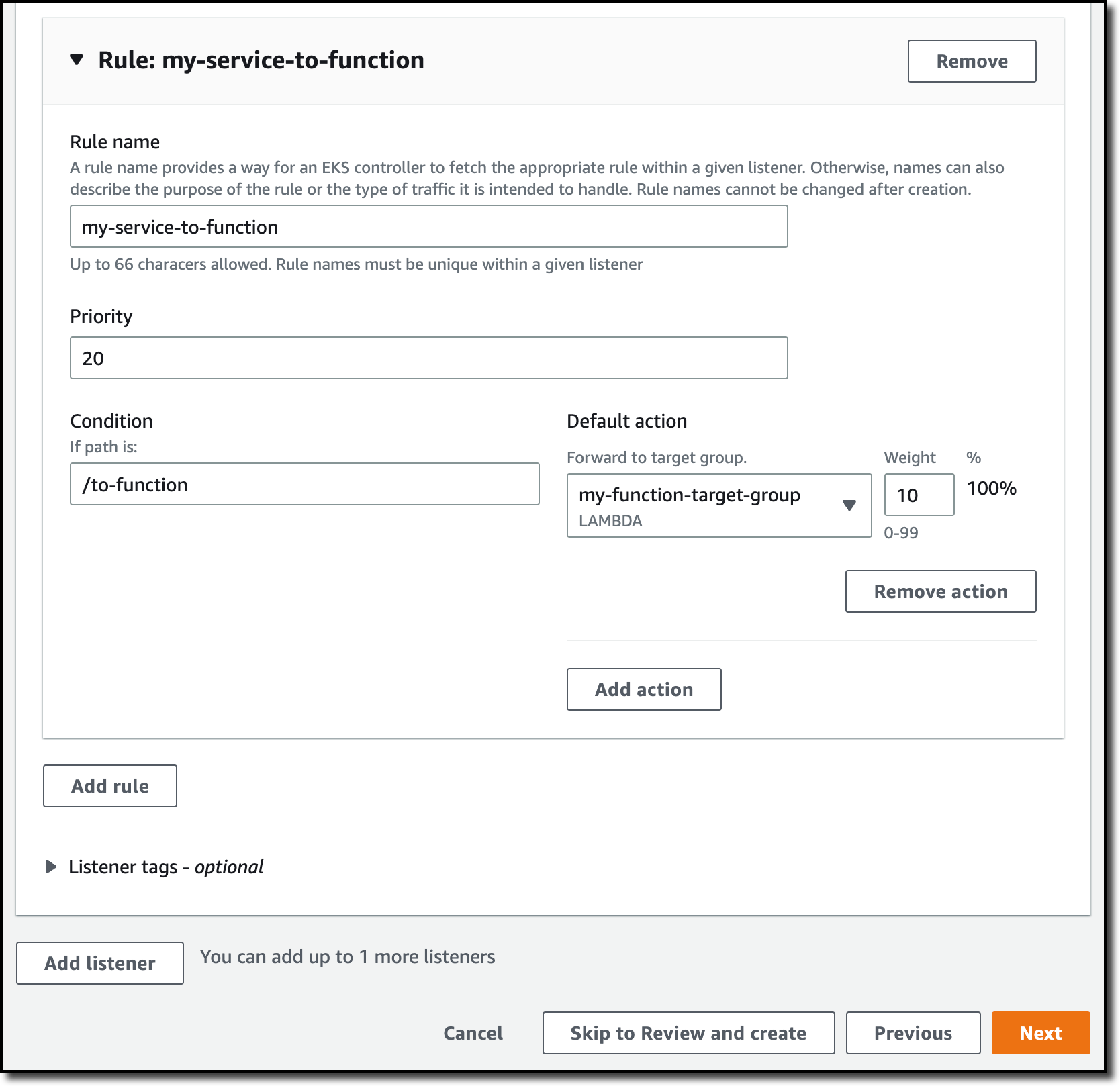
Then, I add two additional rules. The first rule (Priority 10) sends all requests where the path is /to-instance to the instance target group.

The second rule (Priority 20) sends all traffic where the path is /to-function to the function target group.

In the next step, I am asked to associate the service with one or more service networks. I didn’t create a service network yet, so I skip this step for now and choose Next. I review the configuration and create the service.
Creating VPC Lattice Service Networks
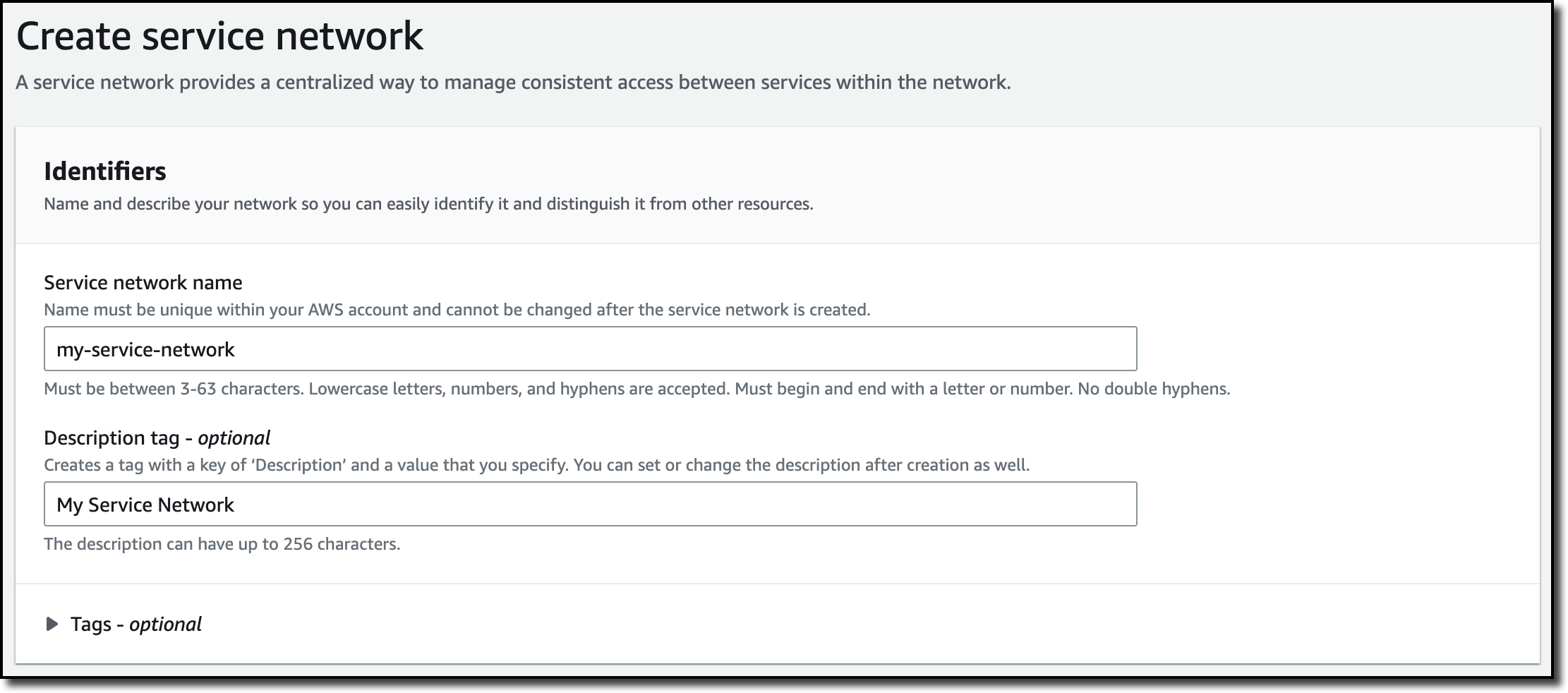
Now, I create the service network so that I can associate the service and the VPCs I want to use. I choose Service network from the navigation pane and then Create service network. I enter a name and a description for the service network.

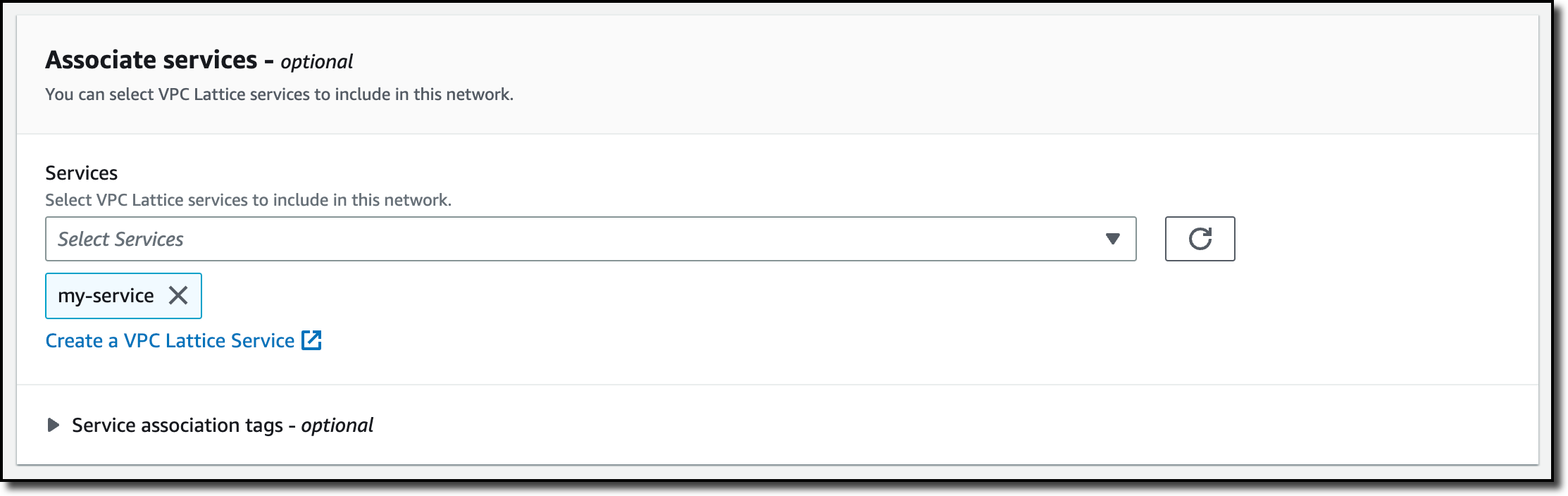
In the Associate services, I select the service I just created.

In the VPC associations, I select the VPC used by the instance where the web app runs. This can help in the future because it allows the web app to call other services associated with the service network.

Then, I select a second VPC where I have another EC2 instance that I want to use to run some tests.

For simplicity, in the Access section, I select the None auth type.

In the Monitoring section, I choose to send the access logs for the whole service network to an S3 bucket.

I review the summary of the configuration and create the service network. After a few seconds all service and VPC associations are active, and I can start using the service.
I write down the domain name of the service from the list of service associations.

Testing Access to the Service Using VPC Lattice
I look at the Routing tab of the service to find a nice recap of how the listener is handling routing towards the different target groups.

Then, I log into the EC2 instance in my second VPC and use curl to call the service domain name. As expected, I get about two-thirds of the responses from the instance and one-third from the function.
curl https://my-service-03e92ee54968d87ca.7d67968.vpc-lattice-svcs.us-west-2.on.aws
Hello from the instance
curl https://my-service-03e92ee54968d87ca.7d67968.vpc-lattice-svcs.us-west-2.on.aws
Hello from the instance
curl https://my-service-03e92ee54968d87ca.7d67968.vpc-lattice-svcs.us-west-2.on.aws
"Hello from the function"
When I call the /to-instance and /to-function paths, the additional rules forward the requests to the instance and the function, respectively.
curl https://my-service-03e92ee54968d87ca.7d67968.vpc-lattice-svcs.us-west-2.on.aws/to-instance
Hello from the instance "to-instance" path
curl https://my-service-03e92ee54968d87ca.7d67968.vpc-lattice-svcs.us-west-2.on.aws/to-function
"Hello from the function"
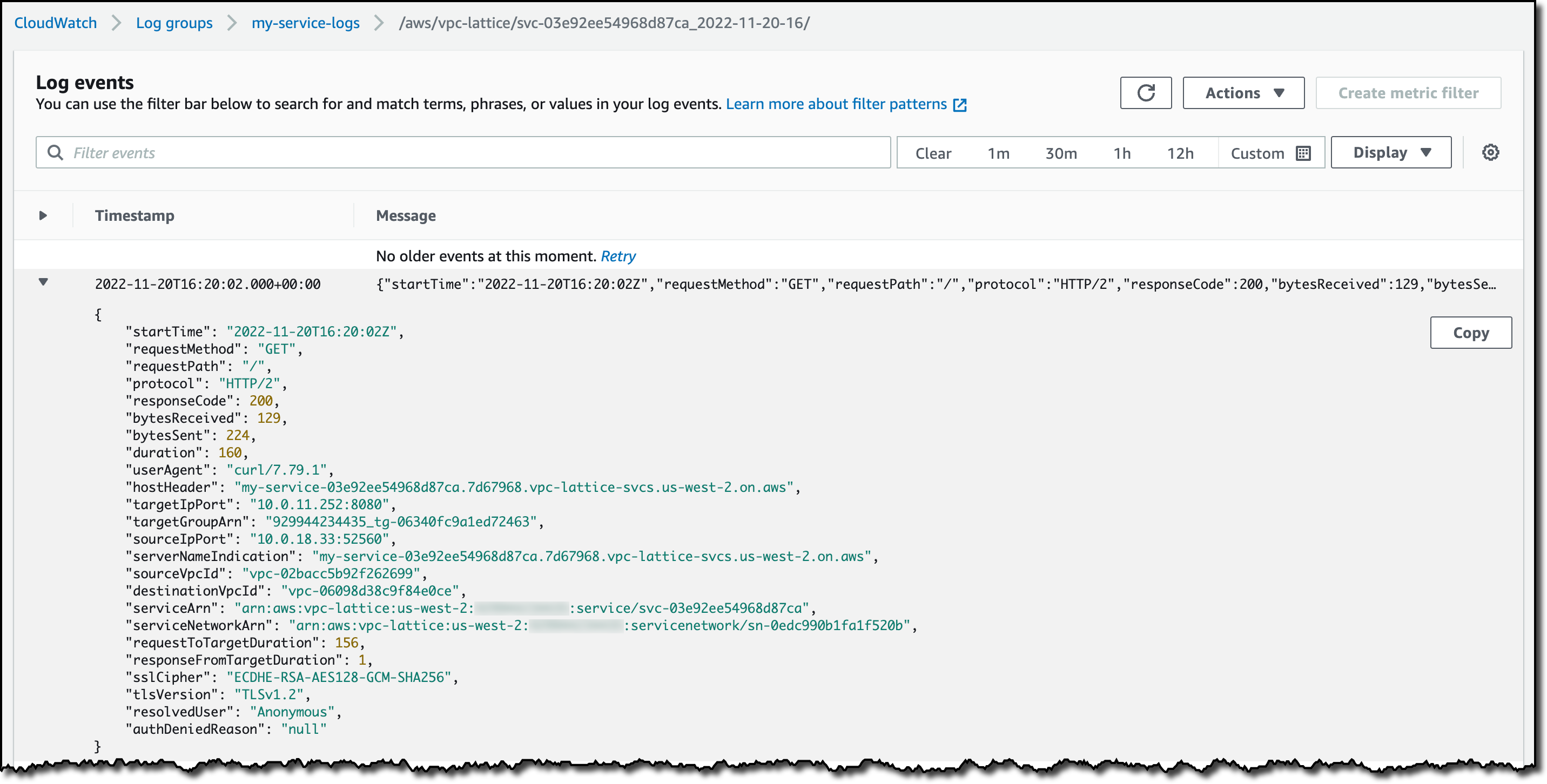
I can now review access to my service using the access log subscriptions I configured before.
For the service, I look in the CloudWatch Log group. There, I find a log stream containing detailed access information about the service.

The access log for all services associated with the service network is on the S3 bucket. I have only one service for now, but more are coming.

Available in Preview
Amazon VPC Lattice is available in preview in the US West (Oregon) Region.
VPC Lattice provides deployment consistency across AWS compute types so that you can connect your services across instances, containers, and serverless functions. You can use VPC Lattice to apply granular and rich traffic controls, such as policy-based routing and weighted targets to support blue/green and canary-style deployments.
VPC Lattice allows monitoring and troubleshooting service-to-service communication with detailed access logs and metrics that capture request type, volume of traffic, error rates, response time, and more. In this blog post, I only scratched the surface of what you can do with VPC Lattice.
Simplify the way you connect, secure, and monitor service-to-service communication with Amazon VPC Lattice.





 Kinnar Kumar Sen is a Sr. Solutions Architect at Amazon Web Services (AWS) focusing on Flexible Compute. As a part of the EC2 Flexible Compute team, he works with customers to guide them to the most elastic and efficient compute options that are suitable for their workload running on AWS. Kinnar has more than 15 years of industry experience working in research, consultancy, engineering, and architecture.
Kinnar Kumar Sen is a Sr. Solutions Architect at Amazon Web Services (AWS) focusing on Flexible Compute. As a part of the EC2 Flexible Compute team, he works with customers to guide them to the most elastic and efficient compute options that are suitable for their workload running on AWS. Kinnar has more than 15 years of industry experience working in research, consultancy, engineering, and architecture.

 .
. 

 Al MS is a product manager for Amazon EMR at Amazon Web Services.
Al MS is a product manager for Amazon EMR at Amazon Web Services.