Post Syndicated from Jonathan Nguyen original https://aws.amazon.com/blogs/architecture/how-usaa-built-an-amazon-s3-malware-scanning-solution/
United Services Automobile Association (USAA) is a San Antonio-based insurance, financial services, banking, and FinTech company supporting millions of military members and their families. USAA has partnered with Amazon Web Services (AWS) to digitally transform and build multiple USAA solutions that help keep members safe and save members money and time.
Why build a S3 malware scanning solution?
As complex companies’ businesses continue to grow, there may be an increased need for collaboration and interactions with outside vendors. Prior to developing an Amazon Simple Storage Solution (Amazon S3) scanning solution, a security review and approval process for application teams to ingest data into an AWS Organization from external vendors’ AWS accounts may be warranted, to ensure additional threats are not being introduced. This could result in a lengthy review and exception process, and subsequently, could hinder the velocity of application teams’ collaboration with external vendors.
USAA security standards, like those of most companies, require all data from external vendors to be treated as untrusted, and therefore must be scanned by an antivirus or antimalware solution prior to being ingested by downstream processes within the AWS environment. Companies looking to automate the scanning process may want to consider a solution where all incoming external data flow through a demilitarized drop zone to be scanned, and subsequently released to downstream processes if malware and viruses are not detected.
S3 malware scanning solution overview
Dedicated AWS accounts should be provisioned for specific data classifications and used as a demilitarized zone (DMZ) for an untrusted staging area. The solution discussed in this blog uses a dedicated staging AWS account that controls the release of Amazon S3 objects to other AWS accounts within an AWS Organization. AWS accounts within an AWS Organization should follow security best practices in terms of infrastructure, networking, logging, and security. External vendors should explicitly be given limited permissions to appropriate resources in their respective staging S3 bucket.
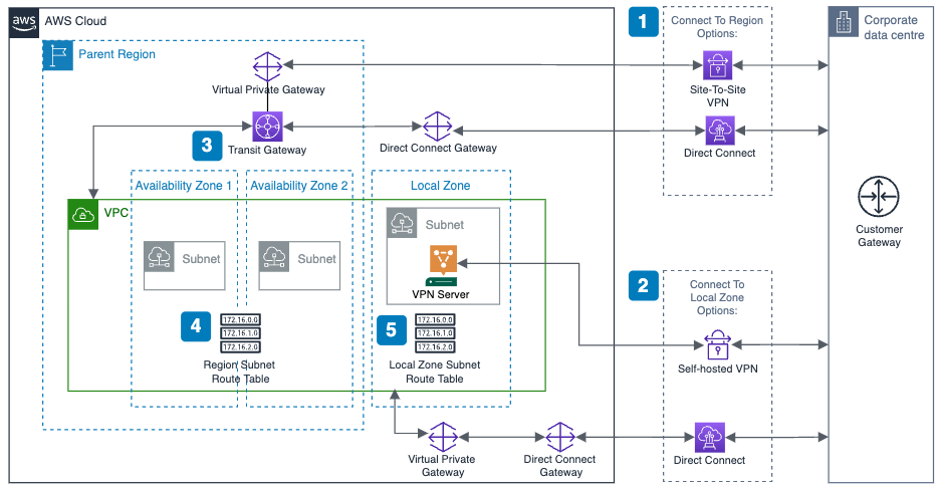
A staging S3 bucket should have specific resource policies restricting which applications and identity and access management (IAM) principals can interact with S3 objects using object attributes, such as object tags, to determine whether an object has been scanned, and what the results of that scan are. Additional guardrails are implemented using Service Control Policies (SCP) to restrict authorized IAM principals to create or modify S3 object attributes (Figure 1).

Figure 1. Amazon S3 antivirus and antimalware scanning architecture workflow
- The external vendor copies an object to the staging S3 bucket.
- The staging S3 bucket has event notifications configured and generates an event.
- The S3 PutObject event is sent to an Object Created Amazon Simple Queue Service (Amazon SQS) queue topic.
- An Amazon Elastic Compute Cloud (Amazon EC2) Auto Scaling group is configured to scale based on messages in the Object Created SQS queue.
- An antivirus and antimalware scanning service application on the Amazon EC2 instances takes the following actions on objects within the Object Created Amazon SQS queue:
a. Tag the S3 object with an “In Progress” status.
b. Get the object from the Staging S3 bucket and stores it in a local ephemeral file system.
c. Scan the copied object using antivirus or antimalware tool.
d. Based on the antivirus or antimalware scan results, tag the S3 object with the scan results (for example, No_Malware_Detected vs. Malware_Detected).
e. Create and publish a payload to the Object Scanned Amazon Simple Notification Service (Amazon SNS) topic, allowing application team filtering.
f. Delete the message from the Object Created SQS queue. - Application teams are subscribed to the Object Scanned SNS topic with a filter for their application.
- For any objects where a virus or malware is detected, a company can use its cyber threat response team to conduct a thorough analysis and take appropriate actions.
USAA built a custom anti-virus and anti-malware scanning application using EC2 instances, using a private, hardened Amazon Machine Image (AMI). For cost-efficacy purposes, the EC2 automatic scaling event can be configured based on Object Created SQS queue depth and Service Level Objective (SLO). A serverless version of an anti-virus and anti-malware solution can be used instead of an EC2 application, depending on your specific use-case and other factors. Some important factors include antivirus and antimalware tool serverless support, resource tuning and configuration requirements, and additional AWS services to manage that could possibly result in a bottleneck. If your enterprise is going with a serverless approach, you can use open-source tools such as ClamAV using Lambda functions.
In the event of an infected object, proper guardrails and response mechanisms need to be in place. USAA teams have developed playbooks to monitor the health and performance of S3 scanning solution, as well as responding to detected virus or malware.
This cloud native, event-driven solution has benefited multiple USAA application teams who have previously requested the ability to ingest data into AWS workloads from teams outside of USAA’s AWS Organization, and allowed additional capabilities and functionality to better serve their members. To enhance this solution even further, USAA’s security team plans to incorporate additional mechanisms to find specific objects that either failed or required additional processing, without having to scan all objects in the buckets. This can be accomplished by including an additional AWS Lambda function and Amazon DynamoDB table to track object metadata as objects get added to the Object Created SQS queue for processing. The metadata could possibly include information such as S3 bucket origin, S3 object key, version ID, scan status, and the original S3 event payload to replay the event into the Object Created SQS queue. The Lambda function primarily ensures the DynamoDB table is kept up to date as objects are processed, as well as handling issues for objects that may need to be reprocessed. The DynamoDB table also has time-to-live (TTL) configured to clear records as they expire from the Staging S3 bucket.
Conclusion
In this post, we reviewed how USAA’s Public Cloud Security team facilitated collaboration and interactions with external vendors and AWS workloads securely by creating a scalable solution to scan S3 objects for virus and malware prior to releasing objects downstream. The solution uses native AWS services and can be utilized for any use-cases requiring antivirus or antimalware capabilities. Because the S3 object scanning solution uses EC2 instances, you can use your existing antivirus or antimalware enterprise tool.