Post Syndicated from Arun Chellappa Ganesan original https://aws.amazon.com/blogs/architecture/hybrid-cloud-journey-using-amazon-outposts-and-aws-local-zones/
This post was co-written with Amy Flanagan, Vice President of Architecture and leader of the Virtual Architecture Team (VAT) at athenahealth, and Anusha Dharmalingam, Executive Director and Senior Architect at athenahealth.
athenahealth has embarked on an ambitious journey to modernize its technology stack by leveraging AWS’s hybrid cloud solutions. This transformation aims to enhance scalability, performance, and developer productivity, ultimately improving the quality of care provided to its patients.
athenahealth’s core products, including revenue cycle management, electronic health records, and patient engagement portals, have been built and refined over 25 years. The company initially deployed its Perl-based web application stack centrally in data centers, allowing it to scale horizontally to meet the growing demands of healthcare providers. However, as the company expanded, it encountered significant scaling and operational challenges in maintaining legal applications due to its monolithic architecture and tightly coupled codebase.
The need for modernization
With a legacy system acting as a multi-purpose database, athenahealth faced issues with developer productivity and operational efficiency. The monolithic architecture led to complex dependencies and made it difficult to implement new features. Realizing the need to modernize, athenahealth decided to refactor its applications and move to the cloud, taking advantage of AWS’s robust infrastructure and services.
Decomposing monoliths to microservices
athenahealth adopted the strangler fig pattern to decompose its monolithic applications into microservices. Starting with peripheral services, they gradually moved to core services, using containers and modern development practices. 80% of athenahealth’s AWS footprint are containerized workloads deployed on Amazon Elastic Container Service (Amazon ECS). Java became the primary language for these microservices, with purpose-built databases like Amazon DynamoDB, Amazon RDS for PostgreSQL, and Amazon OpenSearch.
Event-driven communication between services was facilitated through Amazon EventBridge, Amazon Managed Streaming for Apache Kafka (Amazon MSK), and Amazon Simple Queue Service (Amazon SQS). A data lake was established on Amazon Simple Storage Service (Amazon S3), fed by change data capture from relational databases. Despite progress, refactoring core services proved time-consuming and challenging.
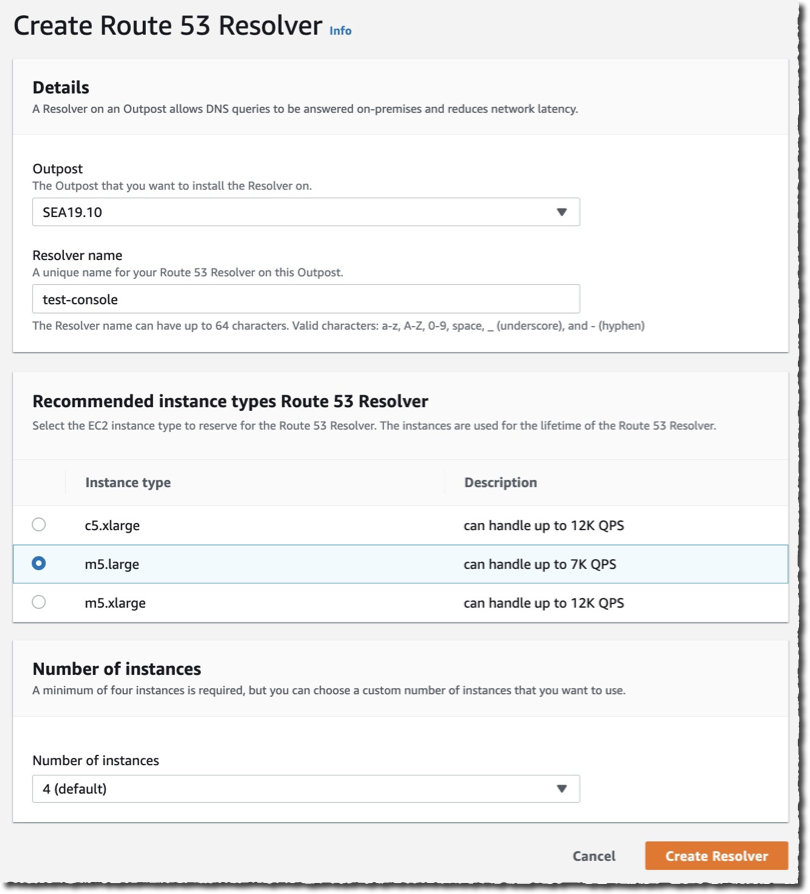
Introducing AWS Outposts and AWS Local Zones
To address these challenges, athenahealth leveraged AWS Local Zones and AWS Outposts, extending AWS infrastructure and services to their on-premises data centers. This hybrid cloud approach allowed athenahealth to deploy modernized code while maintaining low-latency access to existing databases. Deployment across both AWS Local Zones close to the datacenter and AWS Outposts in the datacenter enabled athenahealth to get a highly available hybrid architecture. Local Zones offers additional elasticity, making it suitable for specific use cases. Additionally, the combination of deployment solutions enables optimal access to athenahealth on-premises services and AWS Regional services.
Benefits of AWS Outposts and AWS Local Zones
- Scalability and performance: Outposts and Local Zones enabled athenahealth to curb the growth of their monolithic codebase, allowing for seamless integration of modern microservices with existing systems.
- Developer productivity: Developers were able to focus on container-based workloads, using familiar tools and environments, thereby reducing context switching and improving efficiency.
- Operational efficiency: By running containerized applications on Outposts and Local Zones, athenahealth achieved consistent performance and reliability, crucial for healthcare applications.
Hybrid cloud architecture
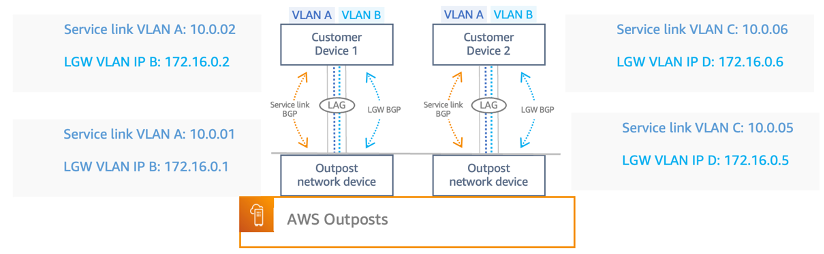
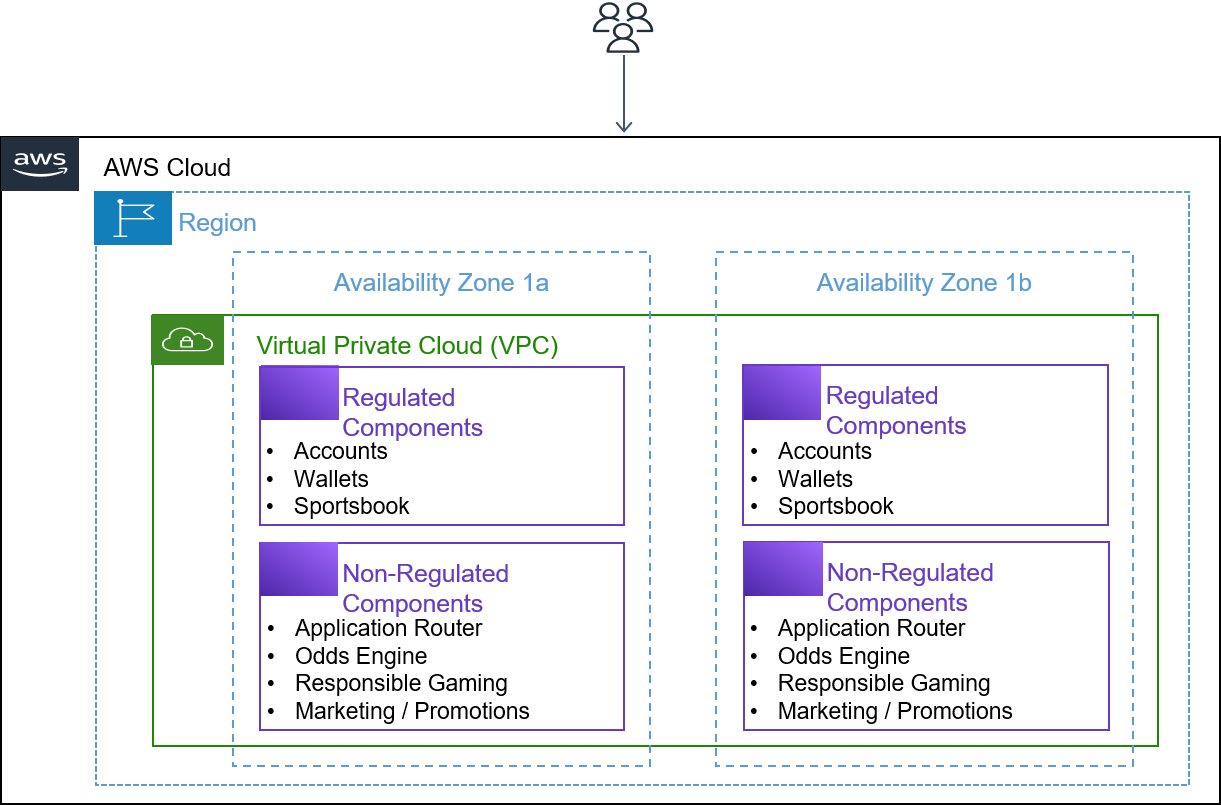
athenahealth’s hybrid cloud architecture includes two data centers geographically distributed for high availability and disaster recovery. As shown in Figure 1, the company operates two data centers that are geographically distributed, each housing two Outposts and connecting to two Local Zones. This configuration not only supports geo-proximity-based traffic distribution for optimal performance but also establishes a primary and standby setup for disaster recovery purposes. By connecting these Outposts to separate AWS Regions, athenahealth achieves additional redundancy, enhancing their system’s resilience and ensuring continuous operation. In addition, within a single Region the deployment across Outpost and Local Zone provides high availability for the applications. This hybrid setup enables athenahealth to seamlessly integrate their legacy monolithic application with modernized microservices. By using AWS Outposts and AWS Local Zones as an extension of their data centers, athenahealth can run containerized applications with low-latency access to on-premises databases. This architecture supports the company’s goals of curbing the growth of their monolithic codebase and improving developer productivity by allowing for consistent performance and reliability across their infrastructure. With two Outposts and two Local Zones deployed, athenahealth ensures that their critical healthcare services remain available and reliable, meeting the stringent demands of the industry.

Figure 1. AWS Outposts and AWS Local Zones at athenahealth
Application deployment
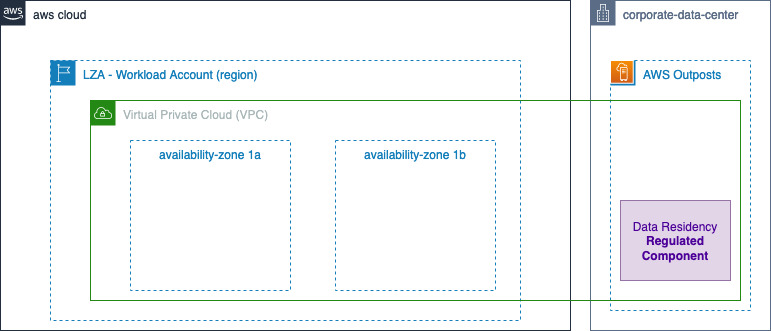
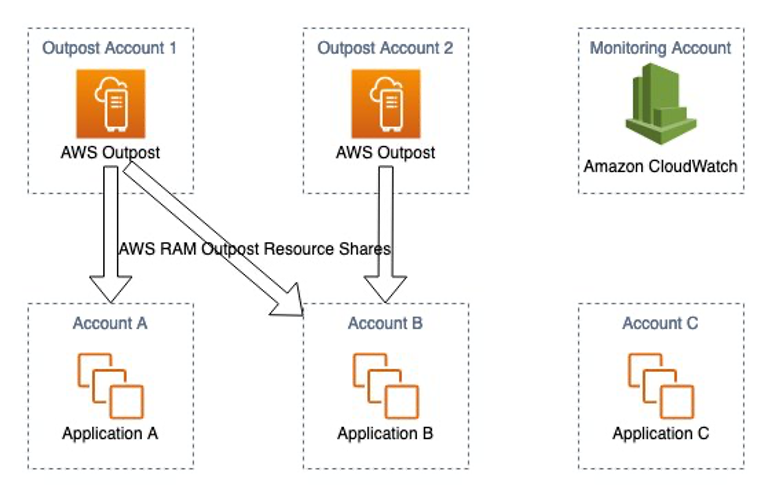
athenahealth’s hybrid cloud architecture is designed to optimize the deployment of containerized workloads while ensuring efficient use of AWS Outposts’ capacity and elastic AWS Local Zone capacity. By leveraging Amazon Elastic Kubernetes Service (EKS), athenahealth deploys application containers on Outposts and AWS Local Zones, enabling low-latency access to on-premises databases. The control plane for these applications is managed in the AWS Region, while the worker nodes run locally on the Outposts and Local Zones. This setup ensures that critical applications requiring immediate data access can operate with minimal latency, thereby maintaining high performance and reliability.
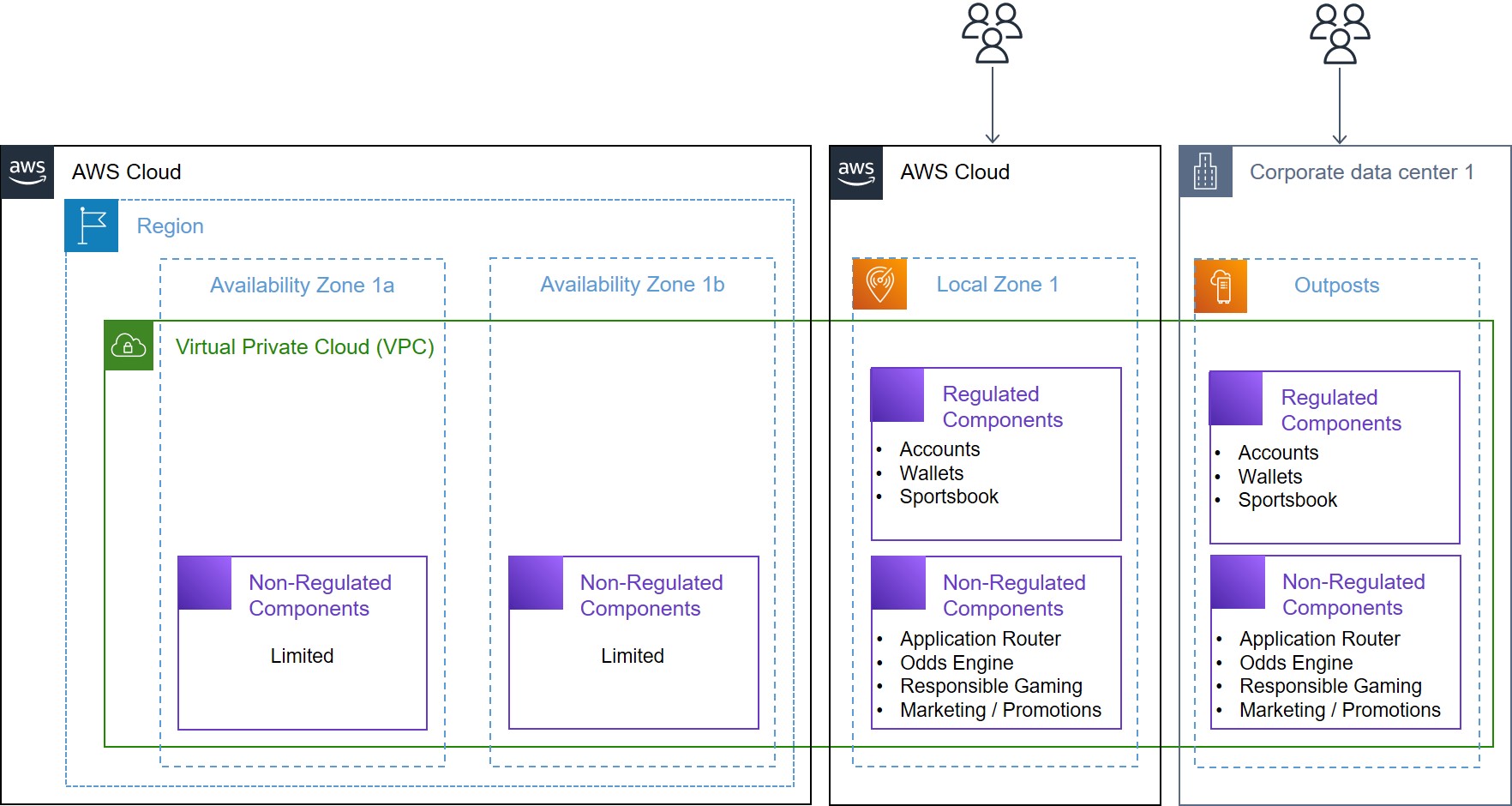
To further optimize the use of AWS resources, athenahealth deploys non-latency-sensitive services, such as logging, monitoring, and CI/CD, directly in AWS Regions, as shown in Figure 2. These services do not require direct access to on-premises databases, allowing athenahealth to preserve the limited capacity of Outposts for applications that truly benefit from low-latency access. By strategically dividing the deployment of applications between Outposts and Local Zones and AWS Regions, athenahealth achieves a balanced, efficient, and scalable hybrid cloud environment that supports the company’s ongoing modernization efforts.

Figure 2. Amazon EKS on Amazon Outposts
Primary use cases
athenahealth’s primary use cases for their hybrid cloud architecture focus on curbing the growth of their monolithic codebase while facilitating modernization and cloud migration. By leveraging AWS Outposts and AWS Local Zones, they supported two key use cases:
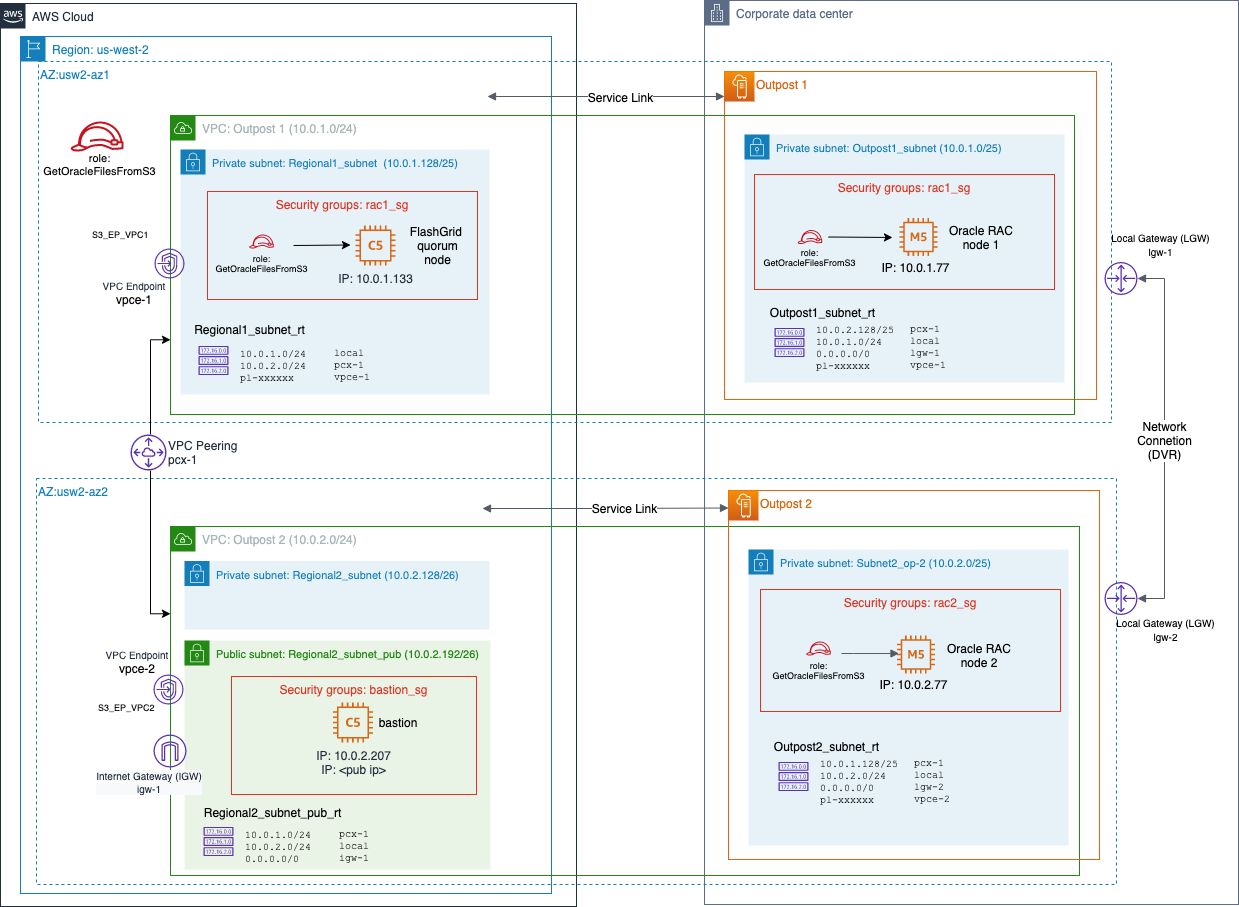
- Enabling microservices running in AWS Regions to access on-premises databases with low latency
- Offloading certain features of their monolithic application to Outposts and Local Zones, as shown in Figure 3
This approach reduces the load on legacy systems and enhances service delivery. These strategies allow athenahealth to maintain efficient operations and accelerate their transition to a hybrid cloud-based infrastructure.

Figure 3. Microservices running in AWS Regions interact with on-premises databases through Outposts and Local Zones, ensuring low-latency data access
Conclusion
This technology transformation is a significant step forward, enabling athenahealth to be more agile, efficient, and responsive to the evolving needs of its vast network of healthcare providers and patients. athenahealth’s journey to AWS hybrid cloud showcases the transformative power of modernizing legacy systems. With increased scalability, improved application performance, and streamlined developer workflows, the company can now focus even more on its core mission of delivering innovative, patient-centric solutions that improve health outcomes. As athenahealth progresses, it will continue to refine its hybrid cloud strategy, ensuring the delivery of high-quality healthcare services to clinicians and patients alike.






























![Directory tree showing training dataset and model configuration structure]](https://d2908q01vomqb2.cloudfront.net/1b6453892473a467d07372d45eb05abc2031647a/2023/10/17/figure-3.jpg)



















 Leadership session – To kick off the day, we have a leadership session featuring
Leadership session – To kick off the day, we have a leadership session featuring