Post Syndicated from Matthew John Cheetham original https://github.blog/2022-04-07-git-credential-manager-authentication-for-everyone/
Universal Git Authentication
“Authentication is hard. Hard to debug, hard to test, hard to get right.” – Me
These words were true when I wrote them back in July 2020, and they’re still true today. The goal of Git Credential Manager (GCM) is to make the task of authenticating to your remote Git repositories easy and secure, no matter where your code is stored or how you choose to work. In short, GCM wants to be Git’s universal authentication experience.
In my last blog post, I talked about the risk of proliferating “universal standards” and how introducing Git Credential Manager Core (GCM Core) would mean yet another credential helper in the wild. I’m therefore pleased to say that we’ve managed to successfully replace both GCM for Windows and GCM for Mac and Linux with the new GCM! The source code of the older projects has been archived, and they are no longer shipped with distributions like Git for Windows!
In order to celebrate and reflect this successful unification, we decided to drop the “Core” moniker from the project’s name to become simply Git Credential Manager or GCM for short.

If you have followed the development of GCM closely, you might have also noticed we have a new home on GitHub in our own organization, github.com/GitCredentialManager!
We felt being homed under github.com/microsoft or github.com/github didn’t quite represent the ethos of GCM as an open, universal and agnostic project. All existing issues and pull requests were migrated, and we continue to welcome everyone to contribute to the project.
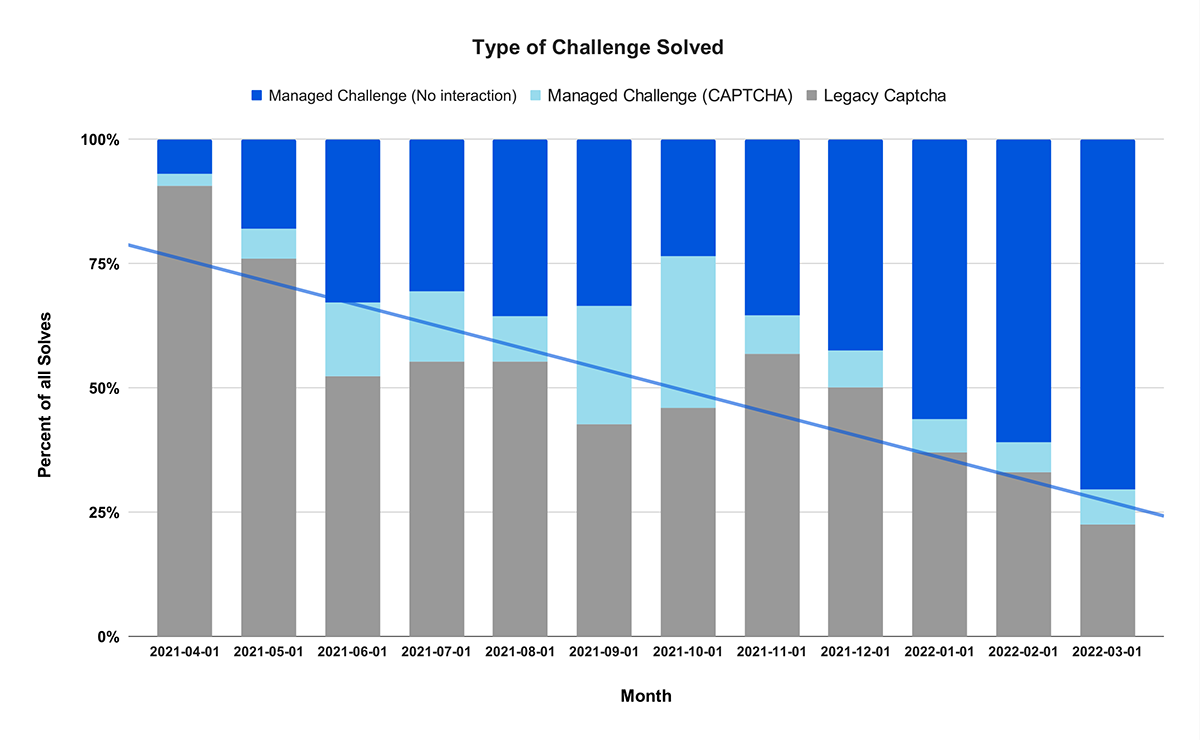
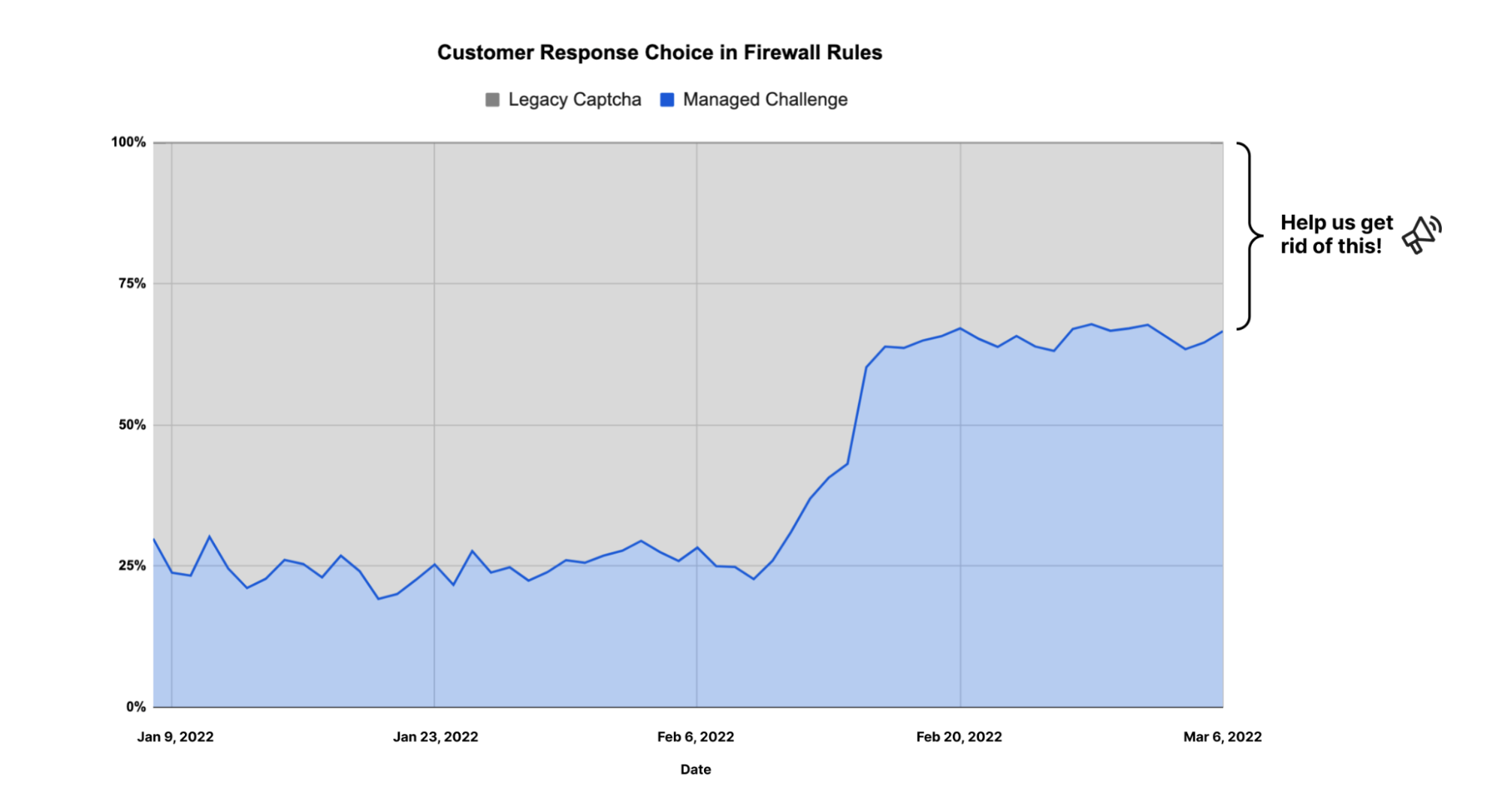
Interacting with HTTP remotes without the help of a credential helper like GCM is becoming more difficult with the removal of username/password authentication at GitHub and Bitbucket. Using GCM makes it easy, and with exciting developments such as using GitHub Mobile for two-factor authentication and OAuth device code flow support, we are making authentication more seamless.
Hello, Linux!

In the quest to become a universal solution for Git authentication, we’ve worked hard on getting GCM to work well on various Linux distributions, with a primary focus on Debian-based distributions.
Today we have Debian packages available to download from our GitHub releases page, as well as tarballs for other distributions (64-bit Intel only). Being built on the .NET platform means there should be a reduced effort to build and run anywhere the .NET runtime runs. Over time, we hope to expand our support matrix of distributions and CPU architectures (by adding ARM64 support, for example).
Due to the broad and varied nature of Linux distributions, it’s important that GCM offers many different credential storage options. In addition to GPG encrypted files, we added support for the Secret Service API via libsecret (also see the GNOME Keyring), which provides a similar experience to what we provide today in GCM on Windows and macOS.
Windows Subsystem for Linux
In addition to Linux distributions, we also have special support for using GCM with Windows Subsystem for Linux (WSL). Using GCM with WSL means that all your WSL installations can share Git credentials with each other and the Windows host, enabling you to easily mix and match your development environments.
You can read more about using GCM inside of your WSL installations here.
Hello, GitLab
Being universal doesn’t just mean we want to run in more places, but also that we can help more users with whatever Git hosting service they choose to use. We are very lucky to have such an engaged community that is constantly working to make GCM better for everyone.
On that note, I am thrilled to share that through a community contribution, GCM now has support for GitLab. Welcome to the family!

Look Ma, no terminals!
We love the terminal and so does GCM. However, we know that not everyone feels comfortable typing in commands and responding to prompts via the keyboard. Also, many popular tools and IDEs that offer Git integration do so by shelling out to the git executable, which means GCM may be called upon to perform authentication from a GUI app where there is no terminal(!)
GCM has always offered full graphical authentication prompts on Windows, but thanks to our adoption of the Avalonia project that provides a cross-platform .NET XAML framework, we can now present graphical prompts on macOS and Linux.

GCM continues to support terminal prompts as a first-class option for all prompts. We detect environments where there is no GUI (such as when connected over SSH without display forwarding) and instead present the equivalent text-based prompts. You can also manually disable the GUI prompts if you wish.
Securing the software supply chain
Keeping your source code secure is a critical step in maintaining trust in software, whether that be keeping commercially sensitive source code away from prying eyes or protecting against malicious actors making changes in both closed and open source projects that underpin much of the modern world.
In 2020, an extensive cyberattack was exposed that impacted parts of the US federal government as well as several major software companies. The US president’s recent executive order in response to this cyberattack brings into focus the importance of mechanisms such as multi-factor authentication, conditional access policies, and generally securing the software supply chain.
Store ALL the credentials
Git Credential Manager creates and stores credentials to access Git repositories on a host of platforms. We hold in the highest regard the need to keep your credentials and access secure. That’s why we always keep your credentials stored using industry standard encryption and storage APIs.
GCM makes use of the Windows Credential Manager on Windows and the login keychain on macOS.
In addition to these existing mechanisms, we also support several alternatives across supported platforms, giving you the choice of how and where you wish to store your generated credentials (such as GPG-encrypted credential files).

GCM can now also use Git’s git-credential-cache helper that is commonly built and available in many Git distributions. This is a great option for cloud shells or ephemeral environments when you don’t want to persist credentials permanently to disk but still want to avoid a prompt for every git fetch or git push.
Modern windows authentication (experimental)
Another way to keep your credentials safe at rest is with hardware-level support through technologies like the Trusted Platform Module (TPM) or Secure Enclave. Additionally, enterprises wishing to make sure your device or credentials have not been compromised may want to enforce conditional access policies.
Integrating with these kinds of security modules or enforcing policies can be tricky and is platform-dependent. It’s often easier for applications to hand over responsibility for the credential acquisition, storage, and policy
enforcement to an authentication broker.
An authentication broker performs credential negotiation on behalf of an app, simplifying many of these problems, and often comes with the added benefit of deeper integration with operating system features such as biometrics.
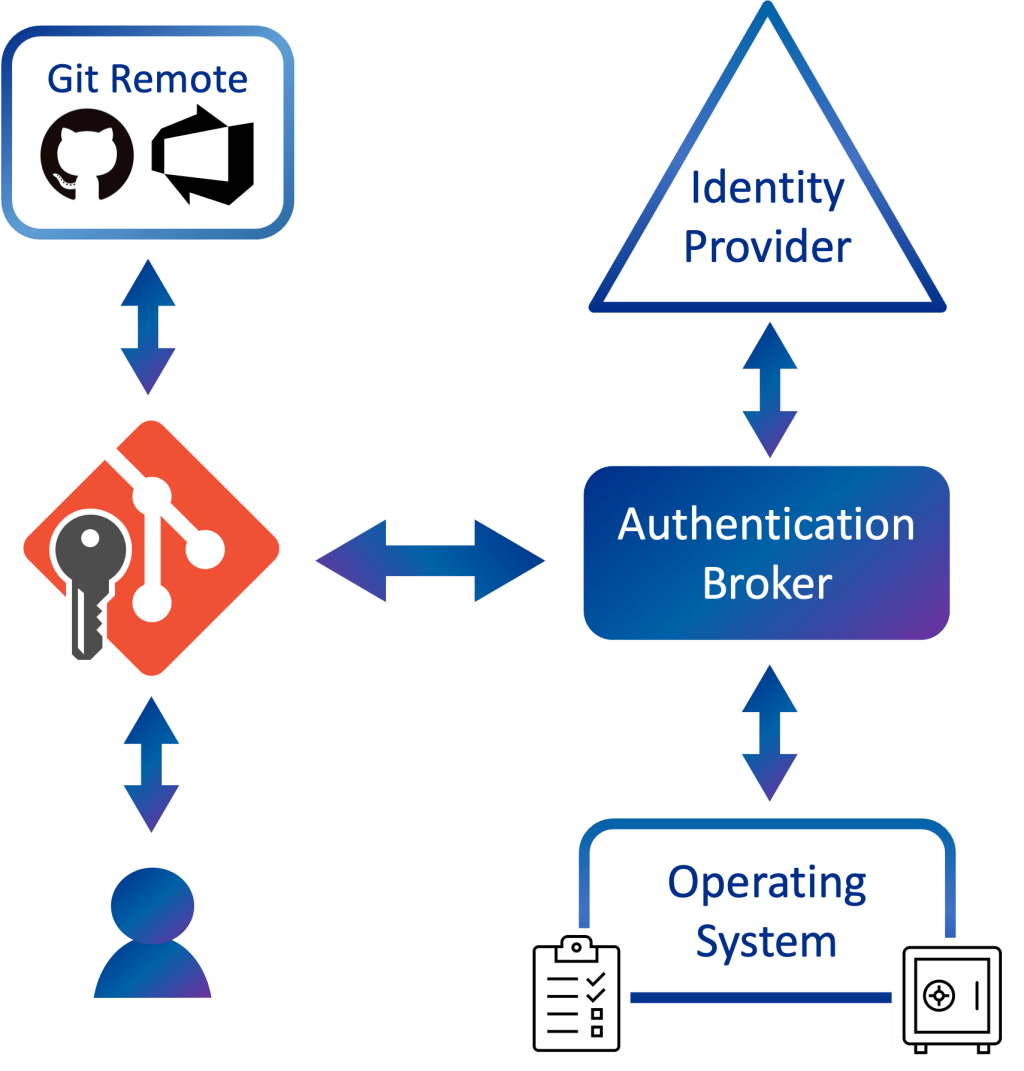
I’m happy to announce that GCM has gained experimental support for brokered authentication (Windows-only at the moment)!
On Windows, the authentication broker is a component that was first introduced in Windows 10 and is known as the Web Account Manager (WAM). WAM enables apps like GCM to support modern authentication experiences such as Windows Hello and will apply conditional access policies set by your work or school.
Please note that support for the Windows broker is currently experimental and limited to authentication of Microsoft work and school accounts against Azure DevOps.
Click here to read more about GCM and WAM, including how to opt-in and current known issues.
Even more improvements
GCM has been a hive of activity in the past 18 months, with too many new features and improvements to talk about in detail! Here’s a quick rundown of additional updates since our July 2020 post:
- Automatic on-premises/self-hosted instance detection
- GitHub Enterprise Server and GitHub AE support
- Shared Microsoft Identity token caches with other developer tools
- Improved network proxy support
- Custom TLS/SSL root certificate support
- Admin-less Windows installer
- Improved command line handling and output
- Enterprise default setting support on Windows
- Multi-user support
- Better diagnostics
Thank you!
The GCM team would also like to personally thank all the people who have made contributions, both large and small, to the project:
@vtbassmatt, @kyle-rader, @mminns, @ldennington, @hickford, @vdye, @AlexanderLanin, @derrickstolee, @NN, @johnemau, @karlhorky, @garvit-joshi, @jeschu1, @WormJim, @nimatt, @parasychic, @cjsimon, @czipperz, @jamill, @jessehouwing, @shegox, @dscho, @dmodena, @geirivarjerstad, @jrbriggs, @Molkree, @4brunu, @julescubtree, @kzu, @sivaraam, @mastercoms, @nightowlengineer
Future work
While we’ve made a great deal of progress toward our universal experience goal, we’re not slowing down anytime soon; we’re still full steam ahead with GCM!
Our focus for the next period will be on iterating and improving our authentication broker support, providing stronger protection of credentials, and looking to increase performance and compatibility with more environments and uses.