Smart Device Manufacturer Liability and Redress for Third-Party Cyberattack Victims
Abstract: Smart devices are used to facilitate cyberattacks against both their users and third parties. While users are generally able to seek redress following a cyberattack via data protection legislation, there is no equivalent pathway available to third-party victims who suffer harm at the hands of a cyberattacker. Given how these cyberattacks are usually conducted by exploiting a publicly known and yet un-remediated bug in the smart device’s code, this lacuna is unreasonable. This paper scrutinises recent judgments from both the Supreme Court of the United Kingdom and the Supreme Court of the Republic of Ireland to ascertain whether these rulings pave the way for third-party victims to pursue negligence claims against the manufacturers of smart devices. From this analysis, a narrow pathway, which outlines how given a limited set of circumstances, a duty of care can be established between the third-party victim and the manufacturer of the smart device is proposed.
In 2000, I wrote: “If McDonald’s offered three free Big Macs for a DNA sample, there would be lines around the block.”
Burger King in Brazil is almost there, offering discounts in exchange for a facial scan. From a marketing video:
“At the end of the year, it’s Friday every day, and the hangover kicks in,” a vaguely robotic voice says as images of cheeseburgers glitch in and out over fake computer code. “BK presents Hangover Whopper, a technology that scans your hangover level and offers a discount on the ideal combo to help combat it.” The stunt runs until January 2nd.
Welcome to the 24th edition of the AWS Serverless ICYMI (in case you missed it) quarterly recap. Every quarter, we share all the most recent product launches, feature enhancements, blog posts, webinars, live streams, and other interesting things that you might have missed!
In case you missed our last ICYMI, check out what happened last quarter here.
2023 Q4 Calendar
ServerlessVideo
ServerlessVideo at re:Invent 2024
ServerlessVideo is a demo application built by the AWS Serverless Developer Advocacy team to stream live videos and also perform advanced post-video processing. It uses several AWS services including AWS Step Functions, Amazon EventBridge, AWS Lambda, Amazon ECS, and Amazon Bedrock in a serverless architecture that makes it fast, flexible, and cost-effective. Key features include an event-driven core with loosely coupled microservices that respond to events routed by EventBridge. Step Functions orchestrates using both Lambda and ECS for video processing to balance speed, scale, and cost. There is a flexible plugin-based architecture using Step Functions and EventBridge to integrate and manage multiple video processing workflows, which include GenAI.
ServerlessVideo allows broadcasters to stream video to thousands of viewers using Amazon IVS. When a broadcast ends, a Step Functions workflow triggers a set of configured plugins to process the video, generating transcriptions, validating content, and more. The application incorporates various microservices to support live streaming, on-demand playback, transcoding, transcription, and events. Learn more about the project and watch videos from reinvent 2023 at video.serverlessland.com.
AWS Lambda introduced integration with AWS Application Composer, allowing users to view and export Lambda function configuration details for infrastructure as code (IaC) workflows.
For Kafka event sources, AWS enabled failed event destinations to prevent functions stalling on failing batches by rerouting events to SQS, SNS, or S3. AWS also enhanced Lambda auto scaling for Kafka event sources in November to reach maximum throughput faster, reducing latency for workloads prone to large bursts of messages.
AWS launched support for Python 3.12 and Java 21 Lambda runtimes, providing updated libraries, smaller deployment sizes, and better AWS service integration. AWS also introduced a simplified console workflow to automate complex network configuration when connecting functions to Amazon RDS and RDS Proxy.
Additionally in December, AWS enabled faster individual Lambda function scaling allowing each function to rapidly absorb traffic spikes by scaling up to 1000 concurrent executions every 10 seconds.
Amazon ECS and AWS Fargate
In Q4 of 2023, AWS introduced several new capabilities across its serverless container services including Amazon ECS, AWS Fargate, AWS App Runner, and more. These features help improve application resilience, security, developer experience, and migration to modern containerized architectures.
In October, Amazon ECS enhanced its task scheduling to start healthy replacement tasks before terminating unhealthy ones during traffic spikes. This prevents going under capacity due to premature shutdowns. Additionally, App Runner launched support for IPv6 traffic via dual-stack endpoints to remove the need for address translation.
Also in November, the open source Finch container tool for macOS became generally available. Finch allows developers to build, run, and publish Linux containers locally. A new website provides tutorials and resources to help developers get started.
In Q4 2023, AWS Step Functions announced the redrive capability for Standard Workflows. This feature allows failed workflow executions to be redriven from the point of failure, skipping unnecessary steps and reducing costs. The redrive functionality provides an efficient way to handle errors that require longer investigation or external actions before resuming the workflow.
Step Functions also launched support for HTTPS endpoints in AWS Step Functions, enabling easier integration with external APIs and SaaS applications without needing custom code. Developers can now connect to third-party HTTP services directly within workflows. Additionally, AWS released a new test state capability that allows testing individual workflow states before full deployment. This feature helps accelerate development by making it faster and simpler to validate data mappings and permissions configurations.
AWS announced optimized integrations between AWS Step Functions and Amazon Bedrock for orchestrating generative AI workloads. Two new API actions were added specifically for invoking Bedrock models and training jobs from workflows. These integrations simplify building prompt chaining and other techniques to create complex AI applications with foundation models.
Finally, the Step Functions Workflow Studio is now integrated in the AWS Application Composer. This unified builder allows developers to design workflows and define application resources across the full project lifecycle within a single interface.
Amazon EventBridge
Amazon EventBridge announced support for new partner integrations with Adobe and Stripe. These integrations enable routing events from the Adobe and Stripe platforms to over 20 AWS services. This makes it easier to build event-driven architectures to handle common use cases.
Amazon SQS has introduced several major new capabilities and updates. These improve visibility, throughput, and message handling for users. Specifically, Amazon SQS enabled AWS CloudTraillogging of key SQS APIs. This gives customers greater visibility into SQS activity. Additionally, SQS increased the throughput quota for the high throughput mode of FIFO queues. This was significantly increased in certain Regions. It also boosted throughput in Asia Pacific Regions. Furthermore, Amazon SQS added dead letter queue redrive support. This allows you to redrive messages that failed and were sent to a dead letter queue (DLQ).
Serverless at AWS re:Invent
Serverless videos from re:Invent
Visit the Serverless Land YouTube channel to find a list of serverless and serverless container sessions from reinvent 2023. Hear from experts like Chris Munns and Julian Wood in their popular session, Best practices for serverless developers, or Nathan Peck and Jessica Deen in Deploying multi-tenant SaaS applications on Amazon ECS and AWS Fargate.
EDA Day Nashville
EDA Day Nashville
The AWS Serverless Developer Advocacy team hosted an event-driven architecture (EDA) day conference on October 26, 2022 in Nashville, Tennessee. This inaugural GOTO EDA day convened over 200 attendees ranging from prominent EDA community members to AWS speakers and product managers. Attendees engaged in 13 sessions, two workshops, and panels covering EDA adoption best practices. The event built upon 2022 content by incorporating additional topics like messaging, containers, and machine learning. It also created opportunities for students and underrepresented groups in tech to participate. The full-day conference facilitated education, inspiration, and thoughtful discussion around event-driven architectural patterns and services on AWS.
The Serverless landing page has more information. The Lambda resources page contains case studies, webinars, whitepapers, customer stories, reference architectures, and even more Getting Started tutorials.
You can also follow the Serverless Developer Advocacy team on Twitter to see the latest news, follow conversations, and interact with the team.
This is an old piece of malware—the Chameleon Android banking Trojan—that now disables biometric authentication in order to steal the PIN:
The second notable new feature is the ability to interrupt biometric operations on the device, like fingerprint and face unlock, by using the Accessibility service to force a fallback to PIN or password authentication.
The malware captures any PINs and passwords the victim enters to unlock their device and can later use them to unlock the device at will to perform malicious activities hidden from view.
Last month, I convened the Second Interdisciplinary Workshop on Reimagining Democracy (IWORD 2023) at the Harvard Kennedy School Ash Center. As with IWORD 2022, the goal was to bring together a diverse set of thinkers and practitioners to talk about how democracy might be reimagined for the twenty-first century.
My thinking is very broad here. Modern democracy was invented in the mid-eighteenth century, using mid-eighteenth-century technology. Were democracy to be invented from scratch today, with today’s technologies, it would look very different. Representation would look different. Adjudication would look different. Resource allocation and reallocation would look different. Everything would look different, because we would have much more powerful technology to build on and no legacy systems to worry about.
Such speculation is not realistic, of course, but it’s still valuable. Everyone seems to be talking about ways to reform our existing systems. That’s critically important, but it’s also myopic. It represents a hill-climbing strategy of continuous improvements. We also need to think about discontinuous changes that you can’t easily get to from here; otherwise, we’ll be forever stuck at local maxima.
I wrote about the philosophy more in this essay about IWORD 2022. IWORD 2023 was equally fantastic, easily the most intellectually stimulating two days of my year. The event is like that; the format results in a firehose of interesting.
Summaries of all the talks are in the first set of comments below. (You can read a similar summary of IWORD 2022 here.) Thank you to the Ash Center and the Belfer Center at Harvard Kennedy School, and the Knight Foundation, for the funding to make this possible.
Next year, I hope to take the workshop out of Harvard and somewhere else. I would like it to live on for as long as it is valuable.
Now, I really want to explain the format in detail, because it works so well.
I used a workshop format I and others invented for another interdisciplinary workshop: Security and Human Behavior, or SHB. It’s a two-day event. Each day has four ninety-minute panels. Each panel has six speakers, each of whom presents for ten minutes. Then there are thirty minutes of questions and comments from the audience. Breaks and meals round out the day.
The workshop is limited to forty-eight attendees, which means that everyone is on a panel. This is important: every attendee is a speaker. And attendees commit to being there for the whole workshop; no giving your talk and then leaving. This makes for a very collaborative environment. The short presentations means that no one can get too deep into details or jargon. This is important for an interdisciplinary event. Everyone is interesting for ten minutes.
The final piece of the workshop is the social events. We have a night-before opening reception, a conference dinner after the first day, and a final closing reception after the second day. Good food is essential.
Honestly, it’s great but it’s also it’s exhausting. Everybody is interesting for ten minutes. There’s no down time to zone out or check email. And even though a shorter event would be easier to deal with, the numbers all fit together in a way that’s hard to change. A one-day event means only twenty-four attendees/speakers, and that’s not a critical mass. More people per panel doesn’t work. Not everyone speaking creates a speaker/audience hierarchy, which I want to avoid. And a three-day, slower-paced event is too long. I’ve thought about it long and hard; the format I’m using is optimal.
They’re Ryukyuan pygmy squid (Idiosepius kijimuna) and Hannan’s pygmy squid (Kodama jujutsu). The second one represents an entire new genus.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
And, yes, this is the eighteenth anniversary of Friday Squid Blogging. The first squid post is from January 6, 2006, and I have been posting them weekly since then. Never did I believe there would be so much to write about squid—but the links never seem to end.
We don’t have a useful quantum computer yet, but we do have quantum algorithms. Shor’s algorithm has the potential to factor large numbers faster than otherwise possible, which—if the run times are actually feasible—could break both the RSA and Diffie-Hellman public-key algorithms.
Now, computer scientist Oded Regev has a significant speed-up to Shor’s algorithm, at the cost of more storage.
The improvement was profound. The number of elementary logical steps in the quantum part of Regev’s algorithm is proportional to n1.5 when factoring an n-bit number, rather than n2 as in Shor’s algorithm. The algorithm repeats that quantum part a few dozen times and combines the results to map out a high-dimensional lattice, from which it can deduce the period and factor the number. So the algorithm as a whole may not run faster, but speeding up the quantum part by reducing the number of required steps could make it easier to put it into practice.
Of course, the time it takes to run a quantum algorithm is just one of several considerations. Equally important is the number of qubits required, which is analogous to the memory required to store intermediate values during an ordinary classical computation. The number of qubits that Shor’s algorithm requires to factor an n-bit number is proportional to n, while Regev’s algorithm in its original form requires a number of qubits proportional to n1.5—a big difference for 2,048-bit numbers.
Again, this is all still theoretical. But now it’s theoretically faster.
The dust has settled after another re:Invent. I once again had the privilege of organizing the DevOps and Developer Productivity (DOP) track along with Jessie VanderVeen, Anubhav Rao and countless others. For 2022, the DOP track included 59 sessions. If you weren’t able to attend, I have compiled a list of the on-demand sessions for you below.
DOP225 – Build without limits: The next-generation developer experience at AWS – Join this talk to explore the next-generation AWS developer experience. Adam Seligman, Vice President of AWS Generative Builders, provides updates on the latest AWS developer tools and services, including capabilities powered by generative AI, low-code abstractions, cloud development, and operations. See demos of key developer services and how they integrate to help enhance productivity and innovation. Discover how AWS is empowering builders of virtually all skill levels to build, deploy, and scale resilient cloud applications quickly. Learn how the continuous evolution of AWS developer tools and integration and cloud capabilities creates new opportunities to innovate and accomplish more.
DOP201 – Best practices for Amazon CodeWhisperer – Generative AI can create new content and ideas, including conversations, stories, images, videos, and music. Learning how to interact with generative AI effectively and proficiently is a skill worth developing. Join this session to learn about best practices for engaging with Amazon CodeWhisperer, which uses an underlying foundation model to radically improve developer productivity by generating code suggestions in real time.
DOP202 – Realizing the developer productivity benefits of Amazon CodeWhisperer – Developers spend a significant amount of their time writing undifferentiated code. Amazon CodeWhisperer radically improves productivity by generating code suggestions in real time to alleviate this burden. In this session, learn how CodeWhisperer can “write” much of this undifferentiated code, allowing developers to focus on business logic and accelerate the pace of their innovation.
DOP205 – Accelerate DevOps with generative AI and Amazon CodeCatalyst – In this session, see a demo of the newest generative AI features in Amazon CodeCatalyst. Learn how you can input simple instructions to produce ready-to-use code, automatically adjust infrastructure, and update CI/CD workflows. Explore how you can generate concise summaries of intricate pull requests. Join this session to see firsthand how these practical additions to CodeCatalyst simplify application delivery, improve team collaboration, and speed up the software development lifecycle from concept to deployment. Discover the groundbreaking impact that AI can have on DevOps through the lens of CodeCatalyst.
DOP206 – AWS infrastructure as code: A year in review – AWS provides services that help with the creation, deployment, and maintenance of application infrastructure in a programmatic, descriptive, and declarative way. These services help provide rigor, clarity, and reliability to application development. Join this session to learn about the new features and improvements for AWS infrastructure as code with AWS CloudFormation and AWS Cloud Development Kit (AWS CDK) and how they can benefit your team.
DOP207 – Build and run it: Streamline DevOps with machine learning on AWS – While organizations have improved how they deliver and operate software, development teams still run into issues when performing manual code reviews, looking for hard-to-find defects, and uncovering security-related problems. Developers have to keep up with multiple programming languages and frameworks, and their productivity can be impaired when they have to search online for code snippets. Additionally, they require expertise in observability to successfully operate the applications they build. In this session, learn how companies like Fidelity Investments use machine learning–powered tools like Amazon CodeWhisperer and Amazon DevOps Guru to boost application availability and write software faster and more reliably.
DOP208 – Continuous integration and delivery for AWS – AWS provides one place where you can plan work, collaborate on code, build, test, and deploy applications with continuous integration/continuous delivery (CI/CD) tools. In this session, learn about how to create end-to-end CI/CD pipelines using infrastructure as code on AWS.
DOP209 – Governance and security with infrastructure as code – In this session, learn how to use AWS CloudFormation and the AWS CDK to deploy cloud applications in regulated environments while enforcing security controls. Find out how to catch issues early with cdk-nag, validate your pipelines with cfn-guard, and protect your accounts from unintended changes with CloudFormation hooks.
DOP210 – Introducing Amazon CodeCatalyst Enterprise – Amazon CodeCatalyst brings together the things you need to build, deploy, and collaborate on software on AWS into one integrated software development service. With CodeCatalyst Enterprise, organizations can now deliver a pre-paved path to production that complies with IT and security policies and integrates with existing infrastructure investments such as identity and access management (IAM), virtual private cloud (VPC), and custom blueprints. This helps platform engineers and IT to deliver a flexible yet compliant way for developers to start building and collaborating on new software projects in minutes. Join this session to discover the new ways that CodeCatalyst helps enterprise developers build and ship code faster while spending more time doing the work they love.
DOP211 – Boost developer productivity with Amazon CodeWhisperer – Generative AI is transforming the way that developers work. Writing code is already getting disrupted by tools like Amazon CodeWhisperer, which enhances developer productivity by providing real-time code completions based on natural language prompts. In this session, get insights into how to evaluate and measure productivity with the adoption of generative AI–powered tools. Learn from the AWS Disaster Recovery team who uses CodeWhisperer to solve complex engineering problems by gaining efficiency through longer productivity cycles and increasing velocity to market for ongoing fixes. Hear how integrating tools like CodeWhisperer into your workflows can boost productivity.
DOP212 – New AWS generative AI features and tools for developers – Explore how generative AI coding tools are changing the way developers and companies build software. Generative AI–powered tools are boosting developer and business productivity by automating tasks, improving communication and collaboration, and providing insights that can inform better decision-making. In this session, see the newest AWS tools and features that make it easier for builders to solve problems with minimal technical expertise and that help technical teams boost productivity. Walk through how organizations like FINRA are exploring generative AI and beginning their journey using these tools to accelerate their pace of innovation.
DOP220 – Simplify building applications with AWS SDKs – AWS SDKs play a vital role in using AWS services in your organization’s applications and services. In this session, learn about the current state and the future of AWS SDKs. Explore how they can simplify your developer experience and unlock new capabilities. Discover how SDKs are evolving, providing a consistent experience in multiple languages and empowering you to do more with high-level abstractions to make it easier to build on AWS. Learn how AWS SDKs are built using open source tools like Smithy, and how you can use these tools to build your own SDKs to serve your customers’ needs.
DOP228 – Amazon Q: Your new assistant and expert guide for building with AWS – In this session, learn how Amazon Q is transforming the developer experience by speeding up a range of tasks as you research how to get started, evaluate system design, build secure and scalable applications, upgrade existing applications, and optimize application performance. Learn firsthand how Amazon Q capabilities for building, troubleshooting, and transforming applications faster and more easily frees you up to focus on experimentation and innovation.
DOP229 – Automate app upgrades & maintenance using Amazon Q Code Transformation – Developers spend significant time completing the undifferentiated work of maintaining and upgrading legacy applications. Teams need to balance investments in building new features with mandatory patching and update work. Now, using the power of generative AI, Amazon Q can expedite these critical upgrade tasks, transforming applications to use the latest language features and versions. Join the session to learn how your team can automate Java application upgrades and soon port .NET framework applications to cross-platform .NET.
As we kick off 2024, I wanted to take a moment to highlight the top posts from 2023. Without further ado, here are the top 10 AWS DevOps blog posts of 2023.
Unit Testing AWS Lambda with Python and Mock AWS Services – When building serverless event-driven applications using AWS Lambda, it is best practice to validate individual components. Unit testing can quickly identify and isolate issues in AWS Lambda function code. The techniques outlined in this blog demonstrates unit test techniques for Python-based AWS Lambda functions and interactions with AWS Services.
How to use Amazon CodeWhisperer using Okta as an external IdP – Customers using Amazon CodeWhisperer often want to enable their developers to sign in using existing identity providers (IdP), such as Okta. CodeWhisperer provides support for authentication either through AWS Builder Id or AWS IAM Identity Center. AWS Builder ID is a personal profile for builders. It is designed for individual developers, particularly when working on personal projects or in cases when organization does not authenticate to AWS using the IAM Identity Center. IAM Identity Center is better suited for enterprise developers who use CodeWhisperer as employees of organizations that have an AWS account. The IAM Identity Center authentication method expands the capabilities of IAM by centralizing user administration and access control. Many customers prefer using Okta as their external IdP for Single Sign-On (SSO). They aim to leverage their existing Okta credentials to seamlessly access CodeWhisperer. To achieve this, customers utilize the IAM Identity Center authentication method.
Introducing Amazon CodeWhisperer for command line – The command line is used by over thirty million engineers to write, build, run, debug, and deploy software. However, despite how critical it is to the software development process, the command line is notoriously hard to use. Its output is terse, its interface is from the 1970s, and it offers no hints about the ‘right way’ to use it. With tens of thousands of command line applications (called command-line interfaces or CLIs), it’s almost impossible to remember the correct input syntax. The command line’s lack of input validation also means typos can cause unnecessary errors, security risks, and even production outages. It’s no wonder that most software engineers find the command line an error-prone and often frustrating experience.
10 ways to build applications faster with Amazon CodeWhisperer – Amazon CodeWhisperer is a powerful generative AI tool that gives me coding superpowers. Ever since I have incorporated CodeWhisperer into my workflow, I have become faster, smarter, and even more delighted when building applications. However, learning to use any generative AI tool effectively requires a beginner’s mindset and a willingness to embrace new ways of working.
Secure CDK deployments with IAM permission boundaries – The AWS Cloud Development Kit (CDK) accelerates cloud development by allowing developers to use common programming languages when modelling their applications. To take advantage of this speed, developers need to operate in an environment where permissions and security controls don’t slow things down, and in a tightly controlled environment this is not always the case. Of particular concern is the scenario where a developer has permission to create AWS Identity and Access Management (IAM) entities (such as users or roles), as these could have permissions beyond that of the developer who created them, allowing for an escalation of privileges. This approach is typically controlled through the use of permission boundaries for IAM entities, and in this post you will learn how these boundaries can now be applied more effectively to CDK development – allowing developers to stay secure and move fast.
How to import existing resources into AWS CDK Stacks – Many customers have provisioned resources through the AWS Management Console or different Infrastructure as Code (IaC) tools, and then started using AWS Cloud Development Kit (AWS CDK) in a later stage. After introducing AWS CDK into the architecture, you might want to import some of the existing resources to avoid losing data or impacting availability.
Develop a serverless application in Python using Amazon CodeWhisperer – While writing code to develop applications, developers must keep up with multiple programming languages, frameworks, software libraries, and popular cloud services from providers such as AWS. Even though developers can find code snippets on developer communities, to either learn from them or repurpose the code, manually searching for the snippets with an exact or even similar use case is a distracting and time-consuming process. They have to do all of this while making sure that they’re following the correct programming syntax and best coding practices.
Optimize software development with Amazon CodeWhisperer – Businesses differentiate themselves by delivering new capabilities to their customers faster. They must leverage automation to accelerate their software development by optimizing code quality, improving performance, and ensuring their software meets security/compliance requirements. Trained on billions of lines of Amazon and open-source code, Amazon CodeWhisperer is an AI coding companion that helps developers write code by generating real-time whole-line and full-function code suggestions in their IDEs. Amazon CodeWhisperer has two tiers: the individual tier is free for individual use, and the professional tier provides administrative capabilities for organizations seeking to grant their developers access to CW. This blog provides a high-level overview of how developers can use CodeWhisperer.
How to write and execute integration tests for AWS CDK applications – Automated integration testing validates system components and boosts confidence for new software releases. Performing integration tests on resources deployed to the AWS cloud enables the validation of AWS Identity and Access Management (IAM) policies, service limits, application configuration, and runtime code. For developers that are currently leveraging AWS Cloud Development Kit (AWS CDK) as their Infrastructure as Code tool, there is a testing framework available that makes integration testing easier to implement in the software release.
Building NET 7 Applications with AWS CodeBuild – AWS CodeBuild is a fully managed DevOps service for building and testing your applications. As a fully managed service, there is no infrastructure to manage and you pay only for the resources that you use when you are building your applications. CodeBuild provides a default build image that contains the current Long Term Support (LTS) version of the .NET SDK.
A big thank you to all our readers! Your feedback and collaboration are appreciated and help us produce better content.
Kaspersky researchers are detailing “an attack that over four years backdoored dozens if not thousands of iPhones, many of which belonged to employees of Moscow-based security firm Kaspersky.” It’s a zero-click exploit that makes use of four iPhone zero-days.
The most intriguing new detail is the targeting of the heretofore-unknown hardware feature, which proved to be pivotal to the Operation Triangulation campaign. A zero-day in the feature allowed the attackers to bypass advanced hardware-based memory protections designed to safeguard device system integrity even after an attacker gained the ability to tamper with memory of the underlying kernel. On most other platforms, once attackers successfully exploit a kernel vulnerability they have full control of the compromised system.
On Apple devices equipped with these protections, such attackers are still unable to perform key post-exploitation techniques such as injecting malicious code into other processes, or modifying kernel code or sensitive kernel data. This powerful protection was bypassed by exploiting a vulnerability in the secret function. The protection, which has rarely been defeated in exploits found to date, is also present in Apple’s M1 and M2 CPUs.
Here is a quick rundown of this 0-click iMessage attack, which used four zero-days and was designed to work on iOS versions up to iOS 16.2.
Attackers send a malicious iMessage attachment, which the application processes without showing any signs to the user.
This attachment exploits the remote code execution vulnerability CVE-2023-41990 in the undocumented, Apple-only ADJUST TrueType font instruction. This instruction had existed since the early nineties before a patch removed it.
It uses return/jump oriented programming and multiple stages written in the NSExpression/NSPredicate query language, patching the JavaScriptCore library environment to execute a privilege escalation exploit written in JavaScript.
This JavaScript exploit is obfuscated to make it completely unreadable and to minimize its size. Still, it has around 11,000 lines of code, which are mainly dedicated to JavaScriptCore and kernel memory parsing and manipulation.
It exploits the JavaScriptCore debugging feature DollarVM ($vm) to gain the ability to manipulate JavaScriptCore’s memory from the script and execute native API functions.
It was designed to support both old and new iPhones and included a Pointer Authentication Code (PAC) bypass for exploitation of recent models.
It uses the integer overflow vulnerability CVE-2023-32434 in XNU’s memory mapping syscalls (mach_make_memory_entry and vm_map) to obtain read/write access to the entire physical memory of the device at user level.
It uses hardware memory-mapped I/O (MMIO) registers to bypass the Page Protection Layer (PPL). This was mitigated as CVE-2023-38606.
After exploiting all the vulnerabilities, the JavaScript exploit can do whatever it wants to the device including running spyware, but the attackers chose to: (a) launch the IMAgent process and inject a payload that clears the exploitation artefacts from the device; (b) run a Safari process in invisible mode and forward it to a web page with the next stage.
The web page has a script that verifies the victim and, if the checks pass, receives the next stage: the Safari exploit.
The Safari exploit uses CVE-2023-32435 to execute a shellcode.
The shellcode executes another kernel exploit in the form of a Mach object file. It uses the same vulnerabilities: CVE-2023-32434 and CVE-2023-38606. It is also massive in terms of size and functionality, but completely different from the kernel exploit written in JavaScript. Certain parts related to exploitation of the above-mentioned vulnerabilities are all that the two share. Still, most of its code is also dedicated to parsing and manipulation of the kernel memory. It contains various post-exploitation utilities, which are mostly unused.
The exploit obtains root privileges and proceeds to execute other stages, which load spyware. We covered these stages in our previous posts.
This is nation-state stuff, absolutely crazy in its sophistication. Kaspersky discovered it, so there’s no speculation as to the attacker.
A helpful summary of which US retail stores are using facial recognition, thinking about using it, or currently not planning on using it. (This, of course, can all change without notice.)
Three years ago, I wrote that campaigns to ban facial recognition are too narrow. The problem here is identification, correlation, and then discrimination. There’s no difference whether the identification technology is facial recognition, the MAC address of our phones, gait recognition, license plate recognition, or anything else. Facial recognition is just the easiest technology right now.
Kinesis Agent is a standalone Java software application that offers a straightforward way to collect and send data to Amazon Kinesis Data Streams and Amazon Kinesis Data Firehose. The agent continuously monitors a set of files and sends new data to the desired destination. The agent handles file rotation, checkpointing, and retry upon failures. It delivers all of your data in a reliable, timely, and simple manner. It also emits Amazon CloudWatch metrics to help you better monitor and troubleshoot the streaming process.
This post describes the steps to send data from a containerized application to Kinesis Data Firehose using Kinesis Agent. More specifically, we show how to run Kinesis Agent as a sidecar container for an application running in Amazon Elastic Container Service (Amazon ECS). After the data is in Kinesis Data Firehose, it can be sent to any supported destination, such as Amazon Simple Storage Service (Amazon S3).
In order to present the key points required for this setup, we assume that you are familiar with Amazon ECS and working with containers. We also avoid the implementation details and packaging process of our test data generation application, referred to as the producer.
Solution overview
As depicted in the following figure, we configure a Kinesis Agent container as a sidecar that can read files created by the producer container. In this instance, the producer and Kinesis Agent containers share data via a bind mount in Amazon ECS.
Prerequisites
You should satisfy the following prerequisites for the successful completion of this task:
Familiarity working with containers and Amazon ECS
With these prerequisites in place, you can begin next step to package a Kinesis Agent and your desired agent configuration as a container in your local development machine.
Create a Kinesis Agent configuration file
We use the Kinesis Agent configuration file to configure the source and destination, among other data transfer settings. The following code uses the minimal configuration required to read the contents of files matching /var/log/producer/*.log and publish them to a Kinesis Data Firehose delivery stream called kinesis-agent-demo:
To deploy Kinesis Agent as a sidecar in Amazon ECS, you first have to package it as a container image. The container must have Kinesis Agent, which and find binaries, and the Kinesis Agent configuration file that you prepared earlier. Its entry point must be configured using the start-aws-kinesis-agent script. This command is installed when you run the yum install aws-kinesis-agent step. The resulting Dockerfile should look as follows:
FROM amazonlinux
RUN yum install -y aws-kinesis-agent which findutils
COPY agent.json /etc/aws-kinesis/agent.json
CMD ["start-aws-kinesis-agent"]
Run the docker build command to build this container:
docker build -t kinesis-agent .
After the image is built, it should be pushed to a container registry like Amazon ECR so that you can reference it in the next section.
Create an ECS task definition with Kinesis Agent and the application container
Now that you have Kinesis Agent packaged as a container image, you can use it in your ECS task definitions to run as sidecar. To do that, you create an ECS task definition with your application container (called producer) and Kinesis Agent container. All containers in a task definition are scheduled on the same container host and therefore can share resources such as bind mounts.
In the following sample container definition, we use a bind mount called logs_dir to share a directory between the producer container and kinesis-agent container.
You can use the following template as a starting point, but be sure to change taskRoleArn and executionRoleArn to valid IAM roles in your AWS account. In this instance, the IAM role used for taskRoleArn must have write permissions to Kinesis Data Firehose that you specified earlier in the agent.json file. Additionally, make sure that the ECR image paths and awslogs-region are modified as per your AWS account.
Finally, you can run a new ECS task using the task definition you just created using the aws ecs run-task command. When the task is started, you should be able to see two containers running under that task on the Amazon ECS console.
Conclusion
This post showed how straightforward it is to run Kinesis Agent in a containerized environment. Although we used Amazon ECS as our container orchestration service in this post, you can use a Kinesis Agent container in other environments such as Amazon Elastic Kubernetes Service (Amazon EKS).
Buddhike de Silva is a Senior Specialist Solutions Architect at Amazon Web Services. Buddhike helps customers run large scale streaming analytics workloads on AWS and make the best out of their cloud journey.
TikTok seems to be skewing things in the interests of the Chinese Communist Party. (This is a serious analysis, and the methodology looks sound.)
Conclusion: Substantial Differences in Hashtag Ratios Raise
Concerns about TikTok’s Impartiality
Given the research above, we assess a strong possibility that content on TikTok is either amplified or suppressed based on its alignment with the interests of the Chinese Government. Future research should aim towards a more comprehensive analysis to determine the potential influence of TikTok on popular public narratives. This research should determine if and how TikTok might be utilized for furthering national/regional or international objectives of the Chinese Government.
To test PIGEON’s performance, I gave it five personal photos from a trip I took across America years ago, none of which have been published online. Some photos were snapped in cities, but a few were taken in places nowhere near roads or other easily recognizable landmarks.
That didn’t seem to matter much.
It guessed a campsite in Yellowstone to within around 35 miles of the actual location. The program placed another photo, taken on a street in San Francisco, to within a few city blocks.
Not every photo was an easy match: The program mistakenly linked one photo taken on the front range of Wyoming to a spot along the front range of Colorado, more than a hundred miles away. And it guessed that a picture of the Snake River Canyon in Idaho was of the Kawarau Gorge in New Zealand (in fairness, the two landscapes look remarkably similar).
This kind of thing will likely get better. And even if it is not perfect, it has some pretty profound privacy implications (but so did geolocation in the EXIF data that accompanies digital photos).
Sqids (pronounced “squids”) is an open-source library that lets you generate YouTube-looking IDs from numbers. These IDs are short, can be generated from a custom alphabet and are guaranteed to be collision-free.
I haven’t dug into the details enough to know how they can be guaranteed to be collision-free.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Artificial intelligence is poised to upend much of society, removing human limitations inherent in many systems. One such limitation is information and logistical bottlenecks in decision-making.
Traditionally, people have been forced to reduce complex choices to a small handful of options that don’t do justice to their true desires. Artificial intelligence has the potential to remove that limitation. And it has the potential to drastically change how democracy functions.
Imagine your next sit-down dinner and being able to have a long conversation with a chef about your meal. You could end up with a bespoke dinner based on your desires, the chef’s abilities and the available ingredients. This is possible if you are cooking at home or hosted by accommodating friends.
But it is infeasible at your average restaurant: The limitations of the kitchen, the way supplies have to be ordered and the realities of restaurant cooking make this kind of rich interaction between diner and chef impossible. You get a menu of a few dozen standardized options, with the possibility of some modifications around the edges.
That’s a lossy bottleneck. Your wants and desires are rich and multifaceted. The array of culinary outcomes are equally rich and multifaceted. But there’s no scalable way to connect the two. People are forced to use multiple-choice systems like menus to simplify decision-making, and they lose so much information in the process.
People are so used to these bottlenecks that we don’t even notice them. And when we do, we tend to assume they are the inevitable cost of scale and efficiency. And they are. Or, at least, they were.
The possibilities
Artificial intelligence has the potential to overcome this limitation. By storing rich representations of people’s preferences and histories on the demand side, along with equally rich representations of capabilities, costs and creative possibilities on the supply side, AI systems enable complex customization at scale and low cost. Imagine walking into a restaurant and knowing that the kitchen has already started work on a meal optimized for your tastes, or being presented with a personalized list of choices.
There have been some early attempts at this. People have used ChatGPT to design meals based on dietary restrictions and what they have in the fridge. It’s still early days for these technologies, but once they get working, the possibilities are nearly endless. Lossy bottlenecks are everywhere.
Take labor markets. Employers look to grades, diplomas and certifications to gauge candidates’ suitability for roles. These are a very coarse representation of a job candidate’s abilities. An AI system with access to, for example, a student’s coursework, exams and teacher feedback as well as detailed information about possible jobs could provide much richer assessments of which employment matches do and don’t make sense.
Or apparel. People with money for tailors and time for fittings can get clothes made from scratch, but most of us are limited to mass-produced options. AI could hugely reduce the costs of customization by learning your style, taking measurements based on photos, generating designs that match your taste and using available materials. It would then convert your selections into a series of production instructions and place an order to an AI-enabled robotic production line.
Or software. Today’s computer programs typically use one-size-fits-all interfaces, with only minor room for modification, but individuals have widely varying needs and working styles. AI systems that observe each user’s interaction styles and know what that person wants out of a given piece of software could take this personalization far deeper, completely redesigning interfaces to suit individual needs.
Removing democracy’s bottleneck
These examples are all transformative, but the lossy bottleneck that has the largest effect on society is in politics. It’s the same problem as the restaurant. As a complicated citizen, your policy positions are probably nuanced, trading off between different options and their effects. You care about some issues more than others and some implementations more than others.
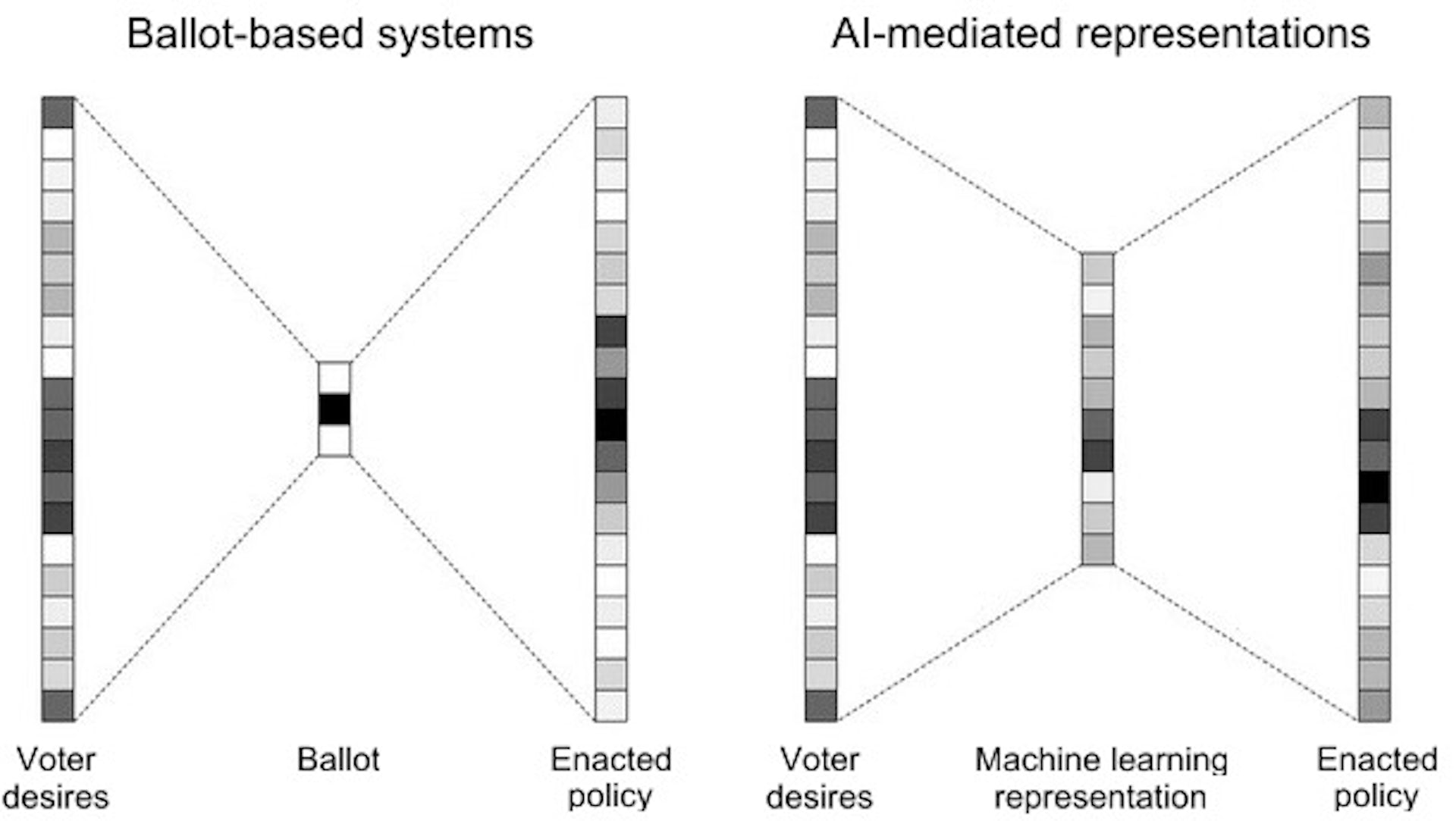
If you had the knowledge and time, you could engage in the deliberative process and help create better laws than exist today. But you don’t. And, anyway, society can’t hold policy debates involving hundreds of millions of people. So you go to the ballot box and choose between two—or if you are lucky, four or five—individual representatives or political parties.
Imagine a system where AI removes this lossy bottleneck. Instead of trying to cram your preferences to fit into the available options, imagine conveying your political preferences in detail to an AI system that would directly advocate for specific policies on your behalf. This could revolutionize democracy.
Ballots are bottlenecks that funnel a voter’s diverse views into a few options. AI representations of individual voters’ desires overcome this bottleneck, promising enacted policies that better align with voters’ wishes. Tantum Collins, CC BY-ND
One way is by enhancing voter representation. By capturing the nuances of each individual’s political preferences in a way that traditional voting systems can’t, this system could lead to policies that better reflect the desires of the electorate. For example, you could have an AI device in your pocket—your future phone, for instance—that knows your views and wishes and continually votes in your name on an otherwise overwhelming number of issues large and small.
Combined with AI systems that personalize political education, it could encourage more people to participate in the democratic process and increase political engagement. And it could eliminate the problems stemming from elected representatives who reflect only the views of the majority that elected them—and sometimes not even them.
On the other hand, the privacy concerns resulting from allowing an AI such intimate access to personal data are considerable. And it’s important to avoid the pitfall of just allowing the AIs to figure out what to do: Human deliberation is crucial to a functioning democracy.
Also, there is no clear transition path from the representative democracies of today to these AI-enhanced direct democracies of tomorrow. And, of course, this is still science fiction.
First steps
These technologies are likely to be used first in other, less politically charged, domains. Recommendation systems for digital media have steadily reduced their reliance on traditional intermediaries. Radio stations are like menu items: Regardless of how nuanced your taste in music is, you have to pick from a handful of options. Early digital platforms were only a little better: “This person likes jazz, so we’ll suggest more jazz.”
Today’s streaming platforms use listener histories and a broad set of features describing each track to provide each user with personalized music recommendations. Similar systems suggest academic papers with far greater granularity than a subscription to a given journal, and movies based on more nuanced analysis than simply deferring to genres.
A world without artificial bottlenecks comes with risks—loss of jobs in the bottlenecks, for example—but it also has the potential to free people from the straitjackets that have long constrained large-scale human decision-making. In some cases—restaurants, for example—the impact on most people might be minor. But in others, like politics and hiring, the effects could be profound.
Apple is rolling out a new “Stolen Device Protection” feature that seems well thought out:
When Stolen Device Protection is turned on, Face ID or Touch ID authentication is required for additional actions, including viewing passwords or passkeys stored in iCloud Keychain, applying for a new Apple Card, turning off Lost Mode, erasing all content and settings, using payment methods saved in Safari, and more. No passcode fallback is available in the event that the user is unable to complete Face ID or Touch ID authentication.
For especially sensitive actions, including changing the password of the Apple ID account associated with the iPhone, the feature adds a security delay on top of biometric authentication. In these cases, the user must authenticate with Face ID or Touch ID, wait one hour, and authenticate with Face ID or Touch ID again. However, Apple said there will be no delay when the iPhone is in familiar locations, such as at home or work.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.









 Buddhike de Silva is a Senior Specialist Solutions Architect at Amazon Web Services. Buddhike helps customers run large scale streaming analytics workloads on AWS and make the best out of their cloud journey.
Buddhike de Silva is a Senior Specialist Solutions Architect at Amazon Web Services. Buddhike helps customers run large scale streaming analytics workloads on AWS and make the best out of their cloud journey.