Post Syndicated from Macey Neff original https://aws.amazon.com/blogs/compute/integrating-aws-waf-with-your-amazon-lightsail-instance/
This blog post is written by Riaz Panjwani, Solutions Architect, Canada CSC and Dylan Souvage, Solutions Architect, Canada CSC.
Security is the top priority at AWS. This post shows how you can level up your application security posture on your Amazon Lightsail instances with an AWS Web Application Firewall (AWS WAF) integration. Amazon Lightsail offers easy-to-use virtual private server (VPS) instances and more at a cost-effective monthly price.
Lightsail provides security functionality built-in with every instance through the Lightsail Firewall. Lightsail Firewall is a network-level firewall that enables you to define rules for incoming traffic based on IP addresses, ports, and protocols. Developers looking to help protect against attacks such as SQL injection, cross-site scripting (XSS), and distributed denial of service (DDoS) can leverage AWS WAF on top of the Lightsail Firewall.
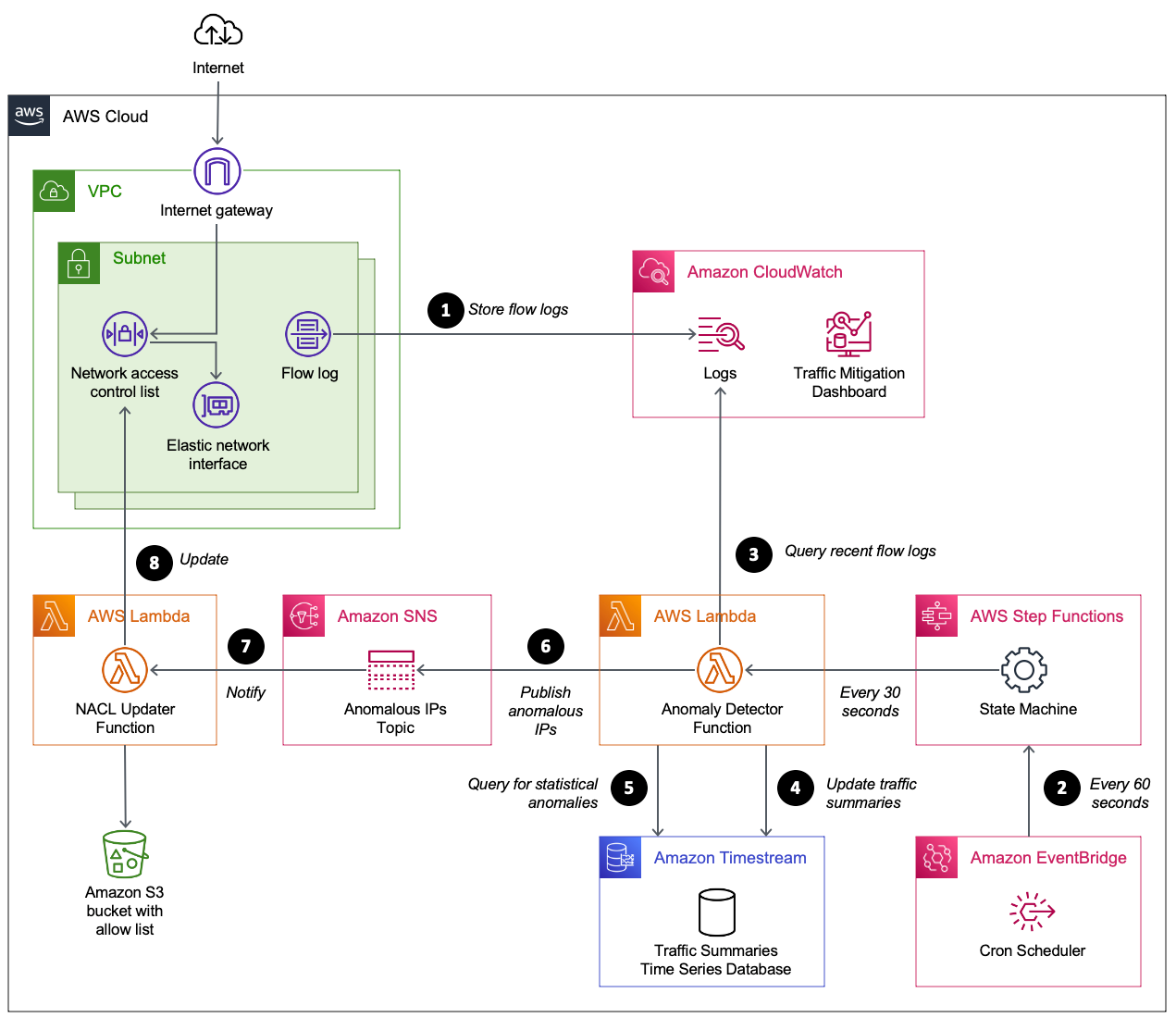
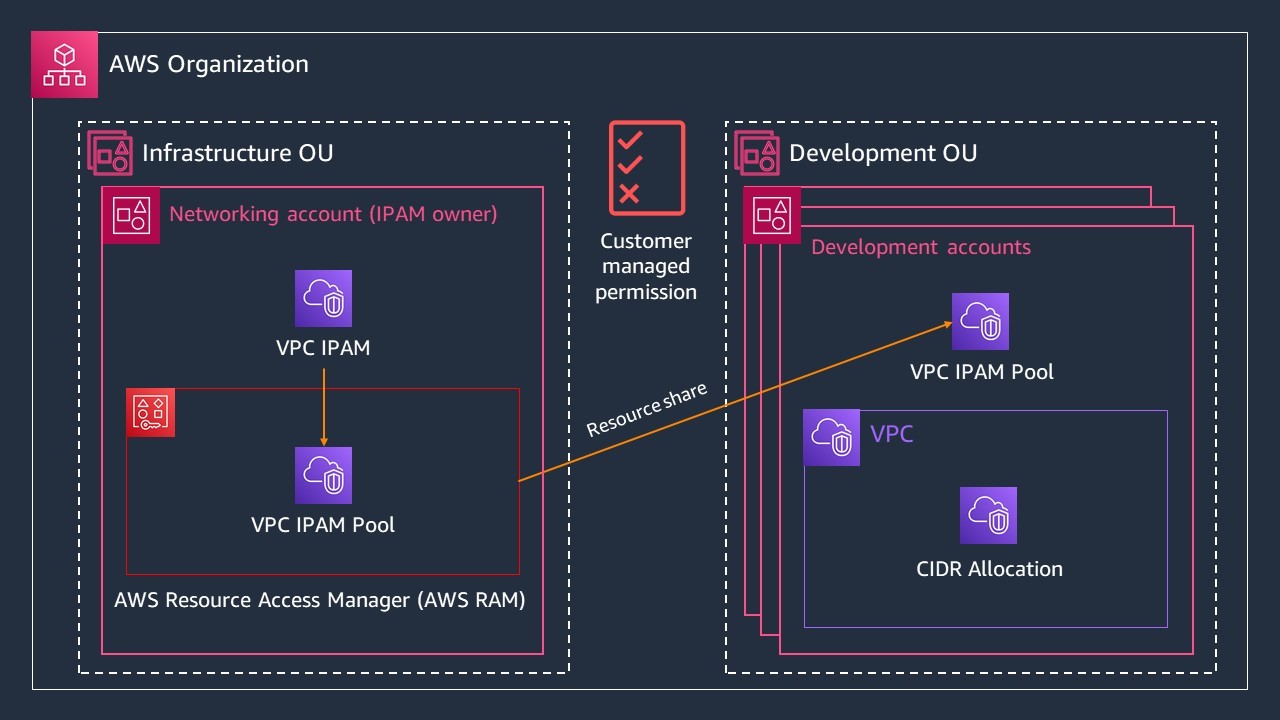
As of this post’s publishing, AWS WAF can only be deployed on Amazon CloudFront, Application Load Balancer (ALB), Amazon API Gateway, and AWS AppSync. However, Lightsail can’t directly act as a target for these services because Lightsail instances run within an AWS managed Amazon Virtual Private Cloud (Amazon VPC). By leveraging VPC peering, you can deploy the aforementioned services in front of your Lightsail instance, allowing you to integrate AWS WAF with your Lightsail instance.
Solution Overview
This post shows you two solutions to integrate AWS WAF with your Lightsail instance(s). The first uses AWS WAF attached to an Internet-facing ALB. The second uses AWS WAF attached to CloudFront. By following one of these two solutions, you can utilize rule sets provided in AWS WAF to secure your application running on Lightsail.
Solution 1: ALB and AWS WAF
This first solution uses VPC peering and ALB to allow you to use AWS WAF to secure your Lightsail instances. This section guides you through the steps of creating a Lightsail instance, configuring VPC peering, creating a security group, setting up a target group for your load balancer, and integrating AWS WAF with your load balancer.

Creating the Lightsail Instance
For this walkthrough, you can utilize an AWS Free Tier Linux-based WordPress blueprint.
1. Navigate to the Lightsail console and create the instance.
2. Verify that your Lightsail instance is online and obtain its private IP, which you will need when configuring the Target Group later.

Attaching an ALB to your Lightsail instance
You must enable VPC peering as you will be utilizing an ALB in a separate VPC.
1. To enable VPC peering, navigate to your account in the top-right corner, select the Account dropdown, select Account, then select Advanced, and select Enable VPC Peering. Note the AWS Region being selected, as it is necessary later. For this example, select “us-east-2”.  2. In the AWS Management Console, navigate to the VPC service in the search bar, select VPC Peering Connections and verify the created peering connection.
2. In the AWS Management Console, navigate to the VPC service in the search bar, select VPC Peering Connections and verify the created peering connection.

3. In the left navigation pane, select Security groups, and create a Security group that allows HTTP traffic (port 80). This is used later to allow public HTTP traffic to the ALB.
4. Navigate to the Amazon Elastic Compute Cloud (Amazon EC2) service, and in the left pane under Load Balancing select Target Groups. Proceed to create a Target Group, choosing IP addresses as the target type.
5. Proceed to the Register targets section, and select Other private IP address. Add the private IP address of the Lightsail instance that you created before. Select Include as Pending below and then Create target group (note that if your Lightsail instance is re-launched the target group must be updated as the private IP address may change).
6. In the left pane, select Load Balancers, select Create load balancers and choose Application Load Balancer. Ensure that you select the “Internet-facing” scheme, otherwise, you will not be able to connect to your instance over the internet.
7. Select the VPC in which you want your ALB to reside. In this example, select the default VPC and all the Availability Zones (AZs) to make sure of the high availability of the load balancer.
8. Select the Security Group created in Step 3 to make sure that public Internet traffic can pass through the load balancer.
9. Select the target group under Listeners and routing to the target group you created earlier (in Step 5). Proceed to Create load balancer.
10. Retrieve the DNS name from your load balancer again by navigating to the Load Balancers menu under the EC2 service.
11. Verify that you can access your Lightsail instance using the Load Balancer’s DNS by copying the DNS name into your browser.

Integrating AWS WAF with your ALB
Now that you have ALB successfully routing to the Lightsail instance, you can restrict the instance to only accept traffic from the load balancer, and then create an AWS WAF web Access Control List (ACL).
1. Navigate back to the Lightsail service, select the Lightsail instance previously created, and select Networking. Delete all firewall rules that allow public access, and under IPv4 Firewall add a rule that restricts traffic to the IP CIDR range of the VPC of the previously created ALB.

2. Now you can integrate the AWS WAF to the ALB. In the Console, navigate to the AWS WAF console, or simply navigate to your load balancer’s integrations section, and select Create web ACL.

3. Choose Create a web ACL, and then select Add AWS resources to add the previously created ALB.
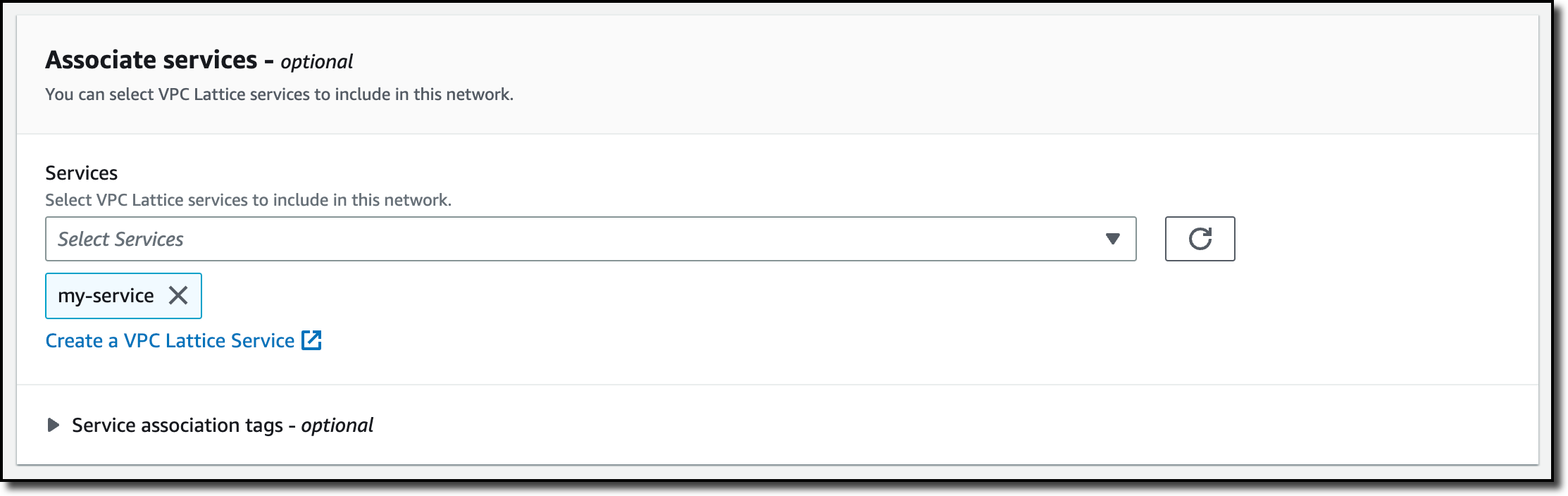
4. Add any rules you want to your ACL, these rules will govern the traffic allowed or denied to your resources. In this example, you can add the WordPress application managed rules.
5. Leave all other configurations as default and create the AWS WAF.
6. You can verify your firewall is attached to the ALB in the load balancer Integrations section.
Solution 2: CloudFront and AWS WAF
Now that you have set up ALB and VPC peering to your Lightsail instance, you can optionally choose to add CloudFront to the solution. This can be done by setting up a custom HTTP header rule in the Listener of your ALB, setting up the CloudFront distribution to use the ALB as an origin, and setting up an AWS WAF web ACL for your new CloudFront distribution. This configuration makes traffic limited to only accessing your application through CloudFront, and is still protected by WAF.
1. Navigate to the CloudFront service, and click Create distribution.
2. Under Origin domain, select the load balancer that you had created previously.
3. Scroll down to the Add custom header field, and click Add header.
4. Create your header name and value. Note the header name and value as you will need it later in the walkthrough.
5. Scroll down to the Cache key and origin requests section. Under Cache policy, choose CachingDisabled.
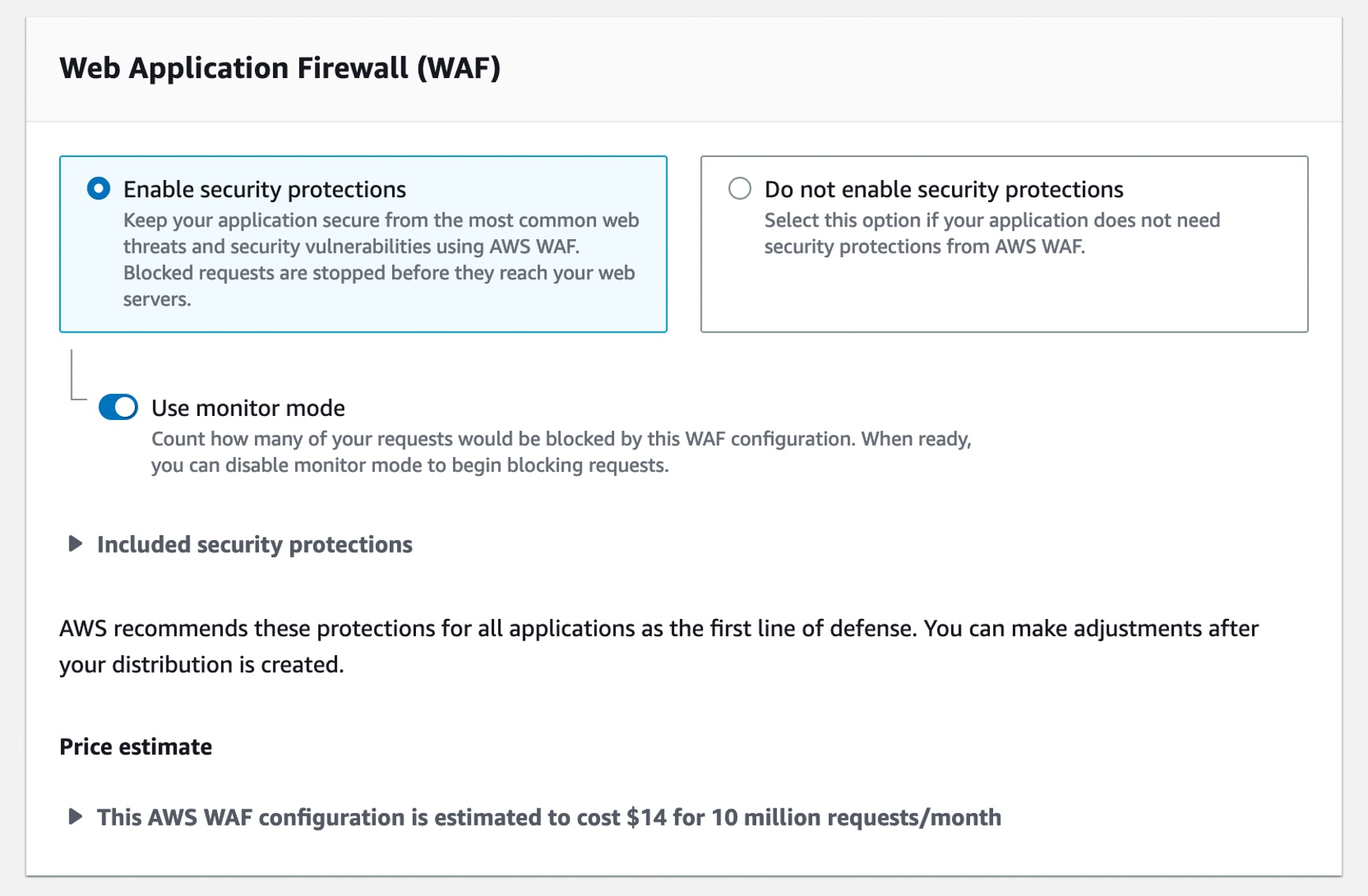
6. Scroll to the Web Application Firewall (WAF) section, and select Enable security protections.
7. Leave all other configurations as default, and click Create distribution.
8. Wait until your CloudFront distribution has been deployed, and verify that you can access your Lightsail application using the DNS under Domain name.

9. Navigate to the EC2 service, and in the left pane under Load Balancing, select Load Balancers.
10. Select the load balancer you created previously, and under the Listeners tab, select the Listener you had created previously. Select Actions in the top right and then select Manage rules.
11. Select the edit icon at the top, and then select the edit icon beside the Default rule.

12. Select the delete icon to delete the Default Action.

13. Choose Add action and then select Return fixed response.

14. For Response code, enter 403, this will restrict access to CloudFront.
15. For Response body, enter “Access Denied”.
16. Select Update in the top right corner to update the Default rule.

17. Select the insert icon at the top, then select Insert Rule.

18. Choose Add Condition, then select Http header. For Header type, enter the Header name, and then for Value enter the Header Value chosen previously.
19. Choose Add Action, then select Forward to and select the target group you had created in the previous section.
20. Choose Save at the top right corner to create the rule.

21. Retrieve the DNS name from your load balancer again by navigating to the Load Balancers menu under the EC2 service.
22. Verify that you can no longer access your Lightsail application using the Load Balancer’s DNS.

23. Navigate back to the CloudFront service and select the Distribution you had created. Under the General tab, select the Web ACL link under the AWS WAF section. Modify the Web ACL to leverage any managed or custom rule sets.

You have successfully integrated AWS WAF to your Lightsail instance! You can access your Lightsail instance via your CloudFront distribution domain name!
Clean Up Lightsail console resources
To start, you will delete your Lightsail instance.
- Sign in to the Lightsail console.
- For the instance you want to delete, choose the actions menu icon (⋮), then choose Delete.
- Choose Yes to confirm the deletion.
Next you will delete your provisioned static IP.
- Sign in to the Lightsail console.
- On the Lightsail home page, choose the Networking tab.
- On the Networking page choose the vertical ellipsis icon next to the static IP address that you want to delete, and then choose Delete.
Finally you will disable VPC peering.
- In the Lightsail console, choose Account on the navigation bar.
- Choose Advanced.
- In the VPC peering section, clear Enable VPC peering for all AWS Regions.
Clean Up AWS console resources
To start, you will delete your Load balancer.
- Navigate to the EC2 console, choose Load balancers on the navigation bar.
- Select the load balancer you created previously.
- Under Actions, select Delete load balancer.
Next, you will delete your target group.
- Navigate to the EC2 console, choose Target Groups on the navigation bar.
- Select the target group you created previously.
- Under Actions, select Delete.
Now you will delete your CloudFront distribution.
- Navigate to the CloudFront console, choose Distributions on the navigation bar.
- Select the distribution you created earlier and select Disable.
- Wait for the distribution to finish deploying.
- Select the same distribution after it is finished deploying and select Delete.
Finally, you will delete your WAF ACL.
- Navigate to the WAF console, and select Web ACLS on the navigation bar.
- Select the web ACL you created previously, and select Delete.
Conclusion
Adding AWS WAF to your Lightsail instance enhances the security of your application by providing a robust layer of protection against common web exploits and vulnerabilities. In this post, you learned how to add AWS WAF to your Lightsail instance through two methods: Using AWS WAF attached to an Internet-facing ALB and using AWS WAF attached to CloudFront.
Security is top priority at AWS and security is an ongoing effort. AWS strives to help you build and operate architectures that protect information, systems, and assets while delivering business value. To learn more about Lightsail security, check out the AWS documentation for Security in Amazon Lightsail.
















 Chaitanya Shah is a Sr. Technical Account Manager(TAM) with AWS, based out of New York. He has over 22 years of experience working with enterprise customers. He loves to code and actively contributes to the AWS solutions labs to help customers solve complex problems. He provides guidance to AWS customers on best practices for their AWS Cloud migrations. He is also specialized in AWS data transfer and the data and analytics domain.
Chaitanya Shah is a Sr. Technical Account Manager(TAM) with AWS, based out of New York. He has over 22 years of experience working with enterprise customers. He loves to code and actively contributes to the AWS solutions labs to help customers solve complex problems. He provides guidance to AWS customers on best practices for their AWS Cloud migrations. He is also specialized in AWS data transfer and the data and analytics domain.