Post Syndicated from Esra Kayabali original https://aws.amazon.com/blogs/aws/reimagine-the-way-you-work-with-ai-agents-in-amazon-quick-suite/
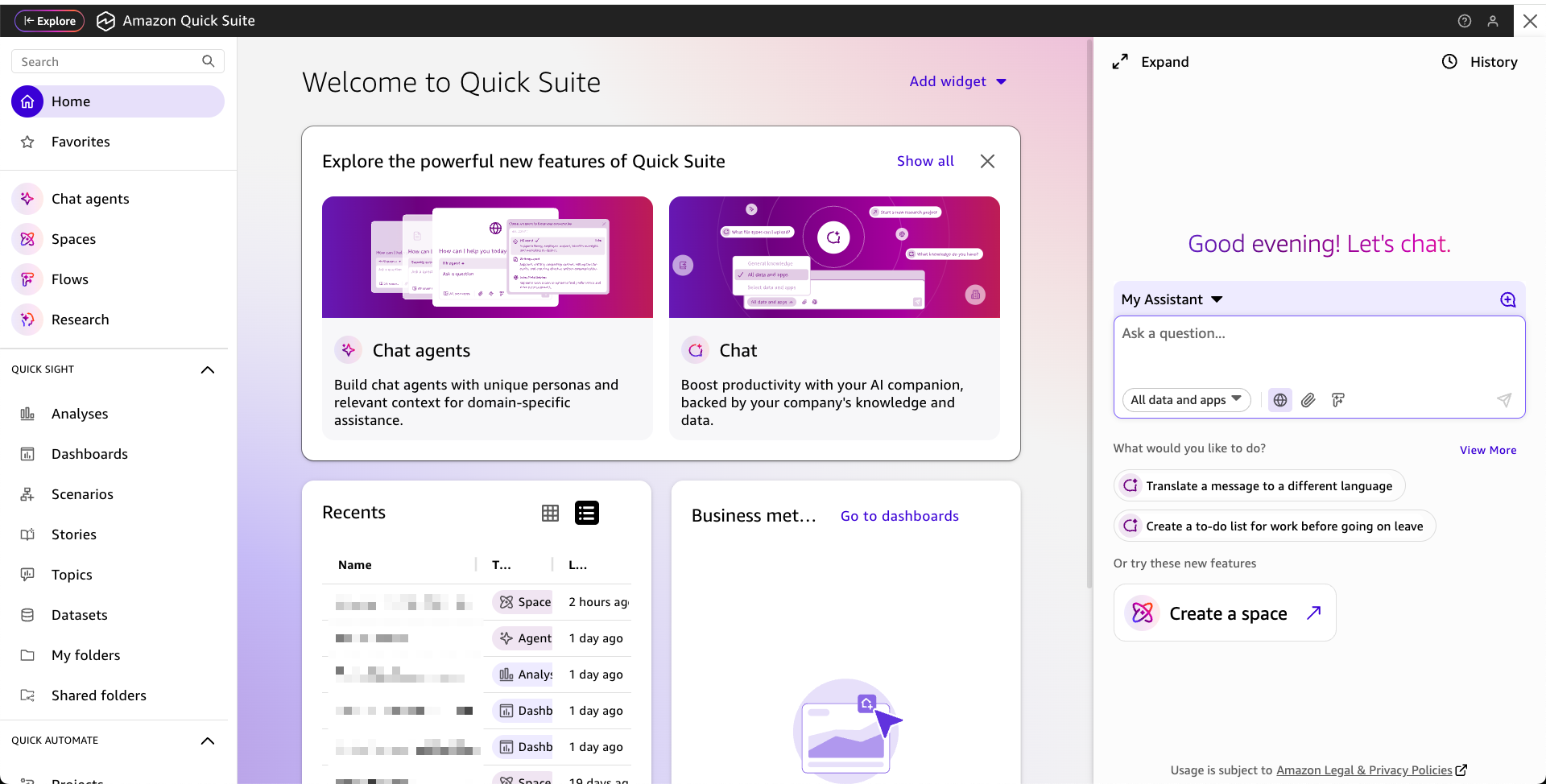
Today, we’re announcing Amazon Quick Suite, a new agentic teammate that quickly answers your questions at work and turns those insights into actions for you. Instead of switching between multiple applications to gather data, find important signals and trends, and complete manual tasks, Quick Suite brings AI-powered research, business intelligence, and automation capabilities into a single workspace. You can now analyze data through natural language queries, find critical information across enterprise and external sources in minutes, and automate processes from simple tasks to complex multi-department workflows.
Here’s a look into Quick Suite.
Business users often need to gather data across multiple applications—pulling customer details, checking performance metrics, reviewing internal product information, and performing competitive intelligence. This fragmented process often requires consultation with specialized teams to analyze advanced datasets, and in some cases, must be repeated regularly, reducing efficiency and leading to incomplete insights for decision-making.
Quick Suite helps you overcome these challenges by combining agentic teammates for research, business intelligence, and automation into a unified digital workspace for your day-to-day work.
Integrated capabilities that power productivity
Quick Suite includes the following integrated capabilities:
- Research – Quick Research accelerates complex research by combining enterprise knowledge, premium third-party data, and data from the internet for more comprehensive insights.
- Business intelligence – Quick Sight provides AI-powered business intelligence capabilities that transform data into actionable insights through natural language queries and interactive visualizations, helping everyone make faster decisions and achieve better business outcomes.
- Automation – Quick Flows and Quick Automate help users and technical teams to automate any business process from simple, routine tasks to complex multi-department workflows, enabling faster execution and reducing manual work across the organization.
Let’s dive into some of these key capabilities.
Quick Index: Your unified knowledge foundation
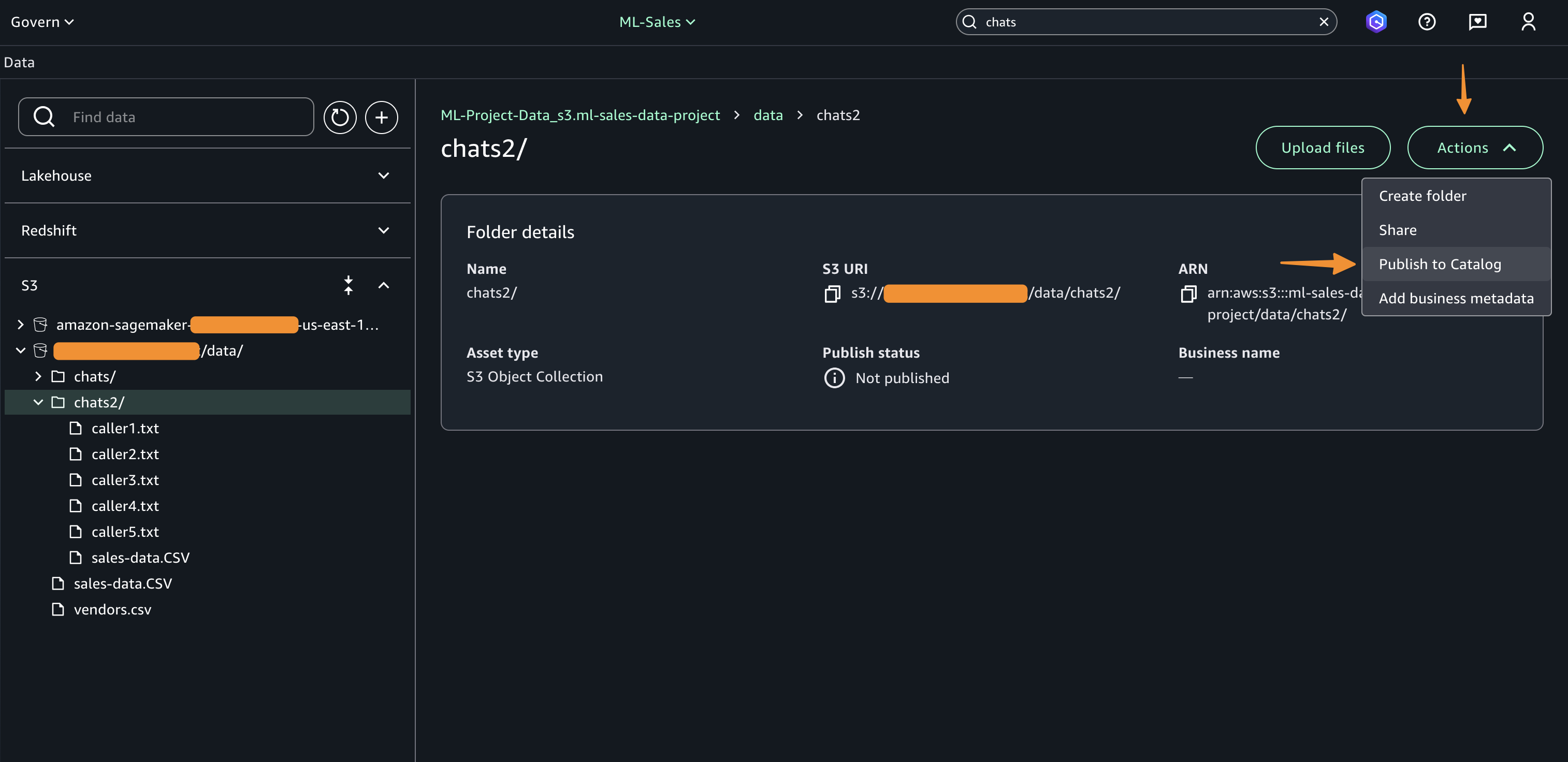
Quick Index creates a secure, searchable repository that consolidates documents, files, and application data to power AI-driven insights and responses across your organization.
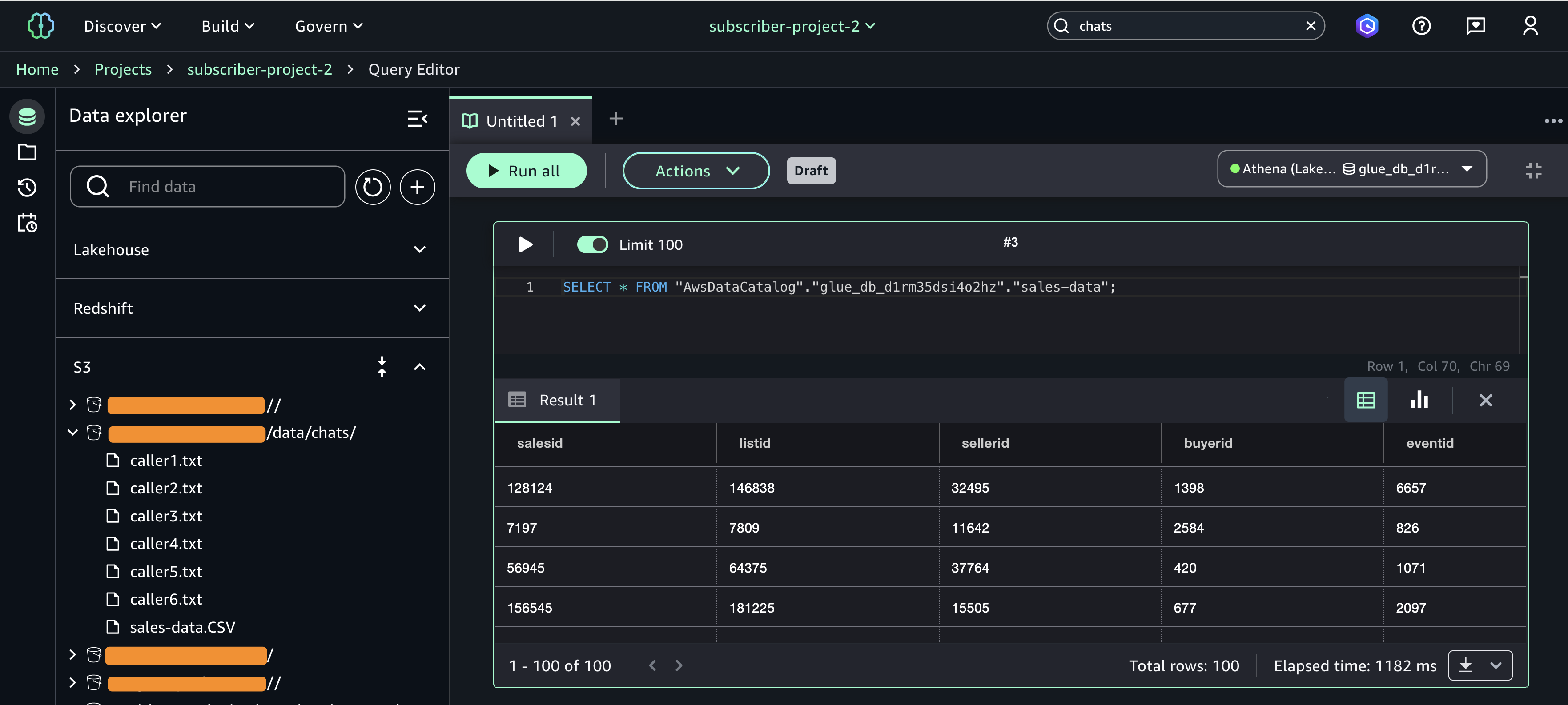
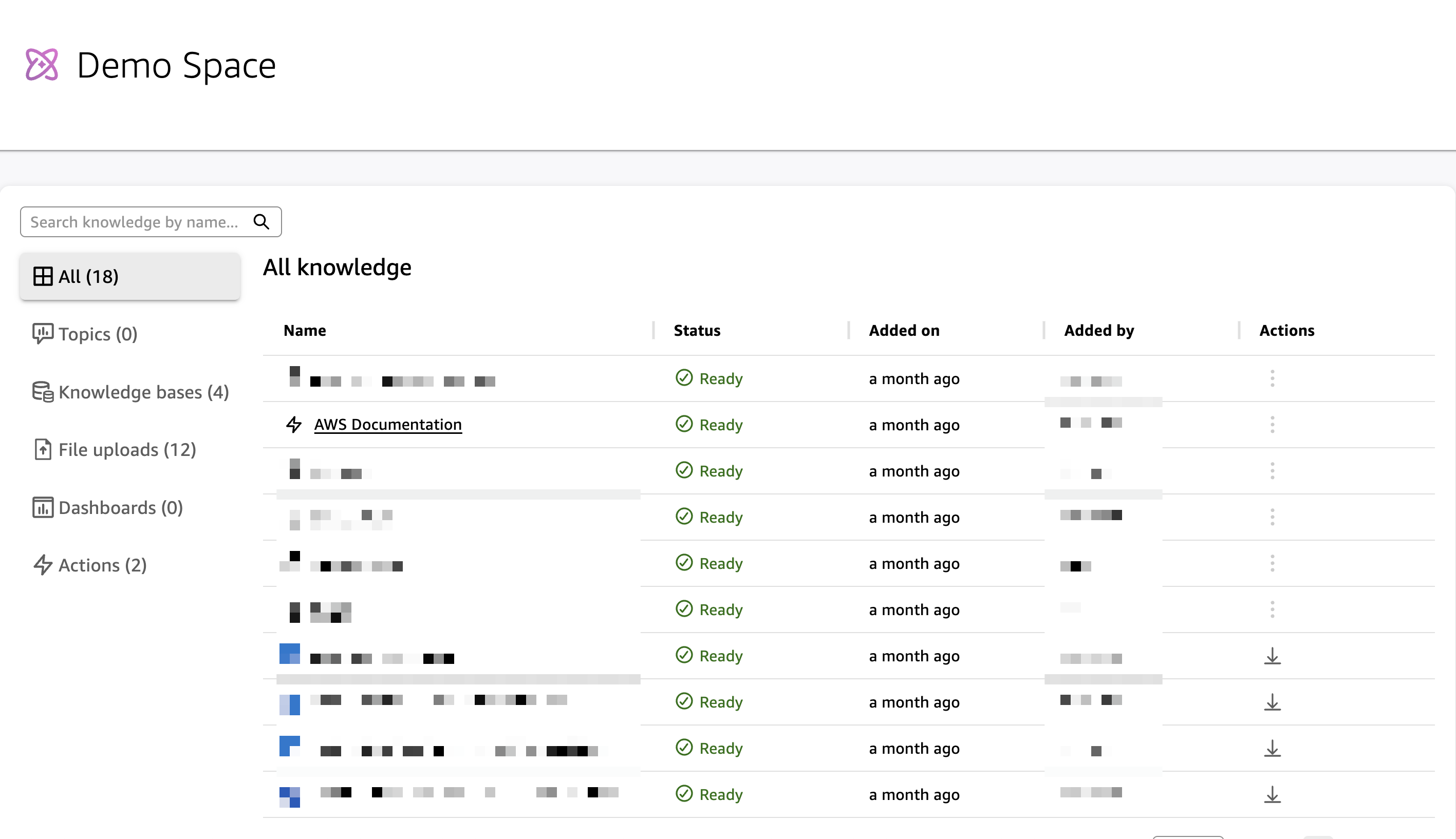
As a foundational component of Quick Suite, Quick Index operates in the background to bring together all your data—from databases and data warehouses to documents and email. This creates a single, intelligent knowledge base that makes AI responses more accurate and reduces time spent searching for information.
Quick Index automatically indexes and prepares any uploaded files or unstructured data you add to your Quick Suite, enabling efficient searching, sorting, and data access. For example, when you search for a specific project update, Quick Index instantly returns results from uploaded documents, meeting notes, project files, and reference materials—all from one unified search instead of checking different repositories and file systems.
To learn more, visit the Quick Index overview page.
Quick Research: From complex business challenges to expert-level insights
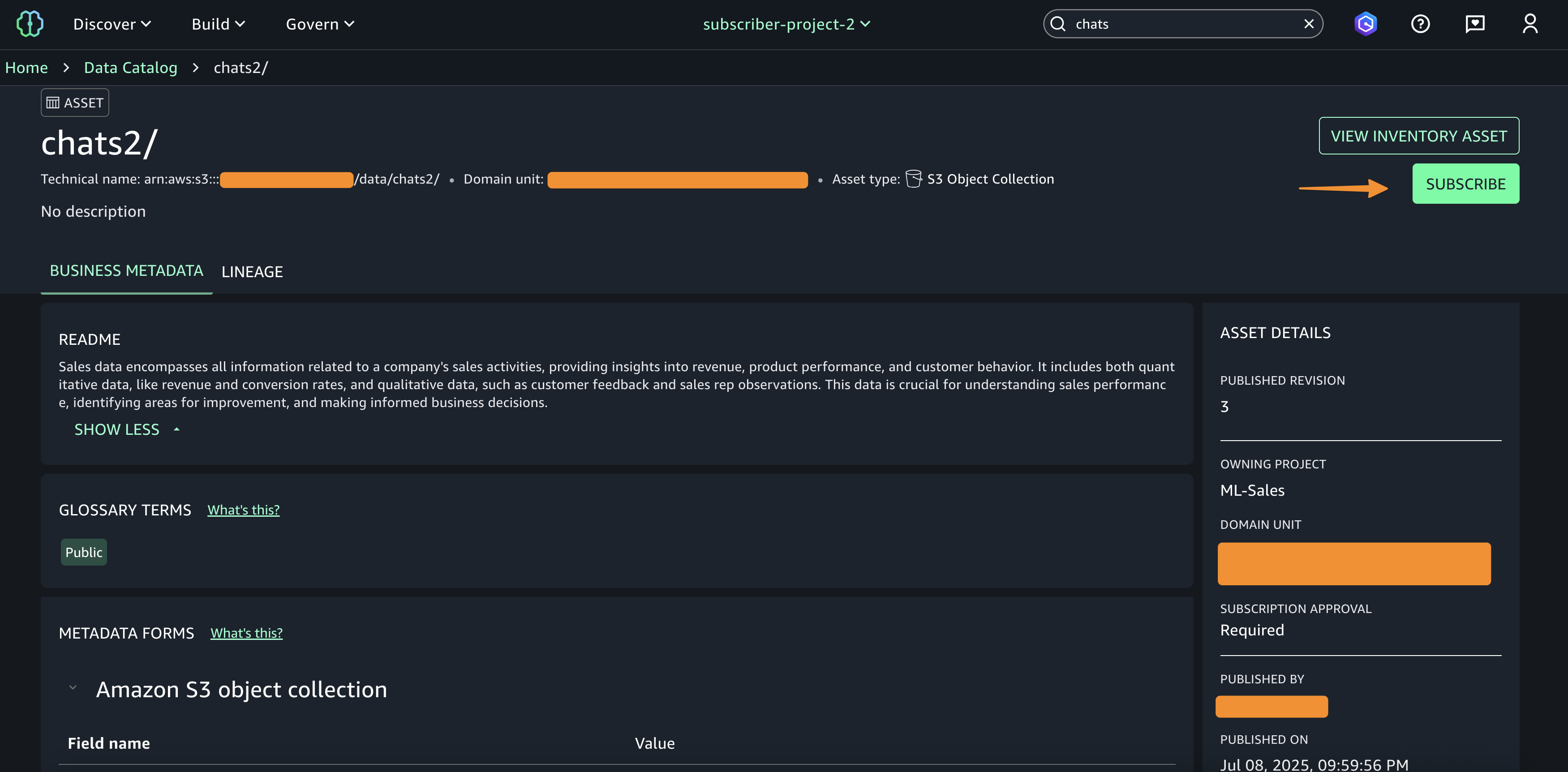
Quick Research is a powerful agent that conducts comprehensive research across your enterprise data and external sources to deliver contextualized, actionable insights in minutes or hours — work that previously could take longer.
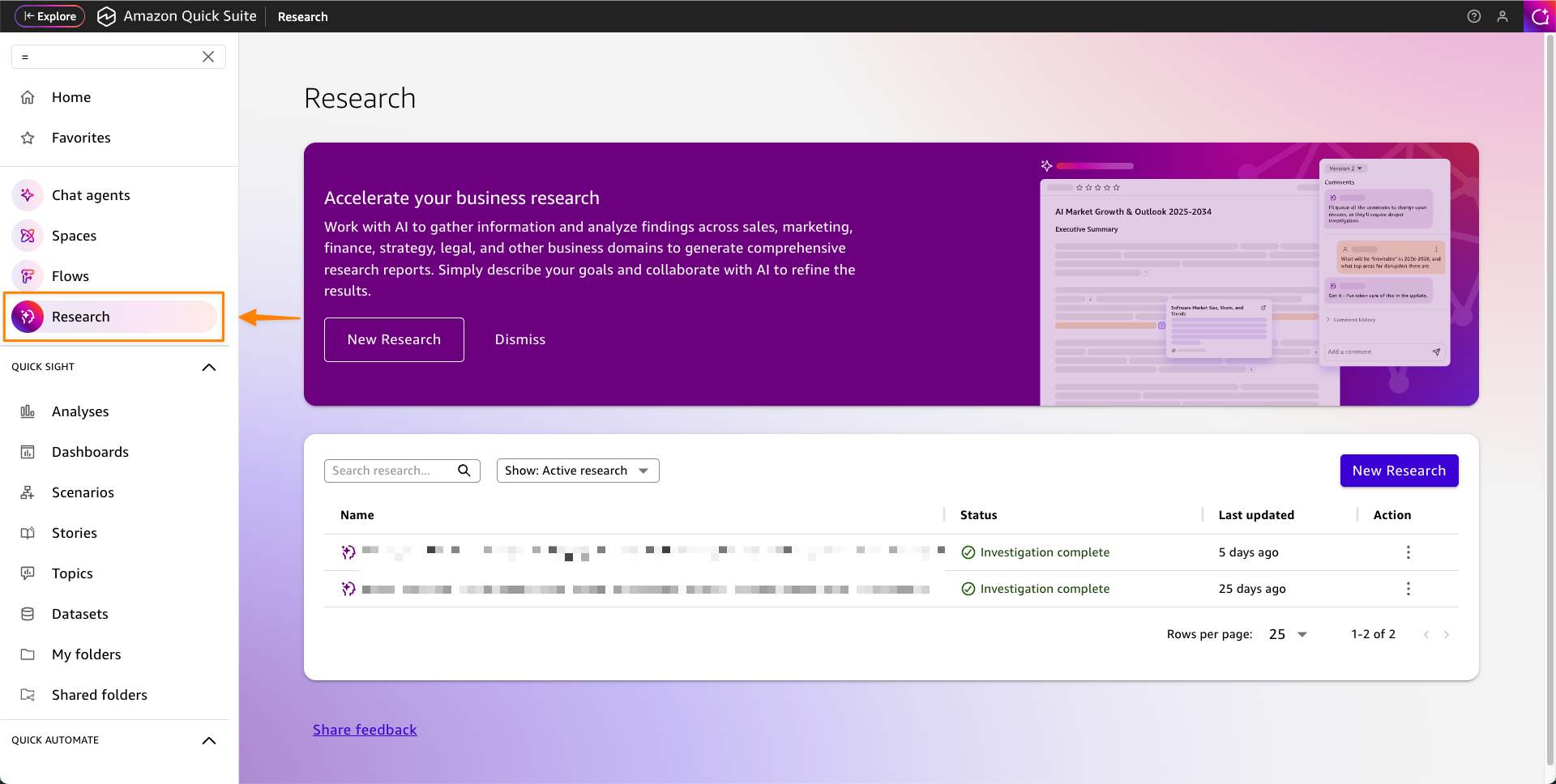
Quick Research systematically breaks down complex questions into organized research plans. Starting with a simple prompt, it automatically creates detailed research frameworks that outline the approach and data sources needed for comprehensive analysis.
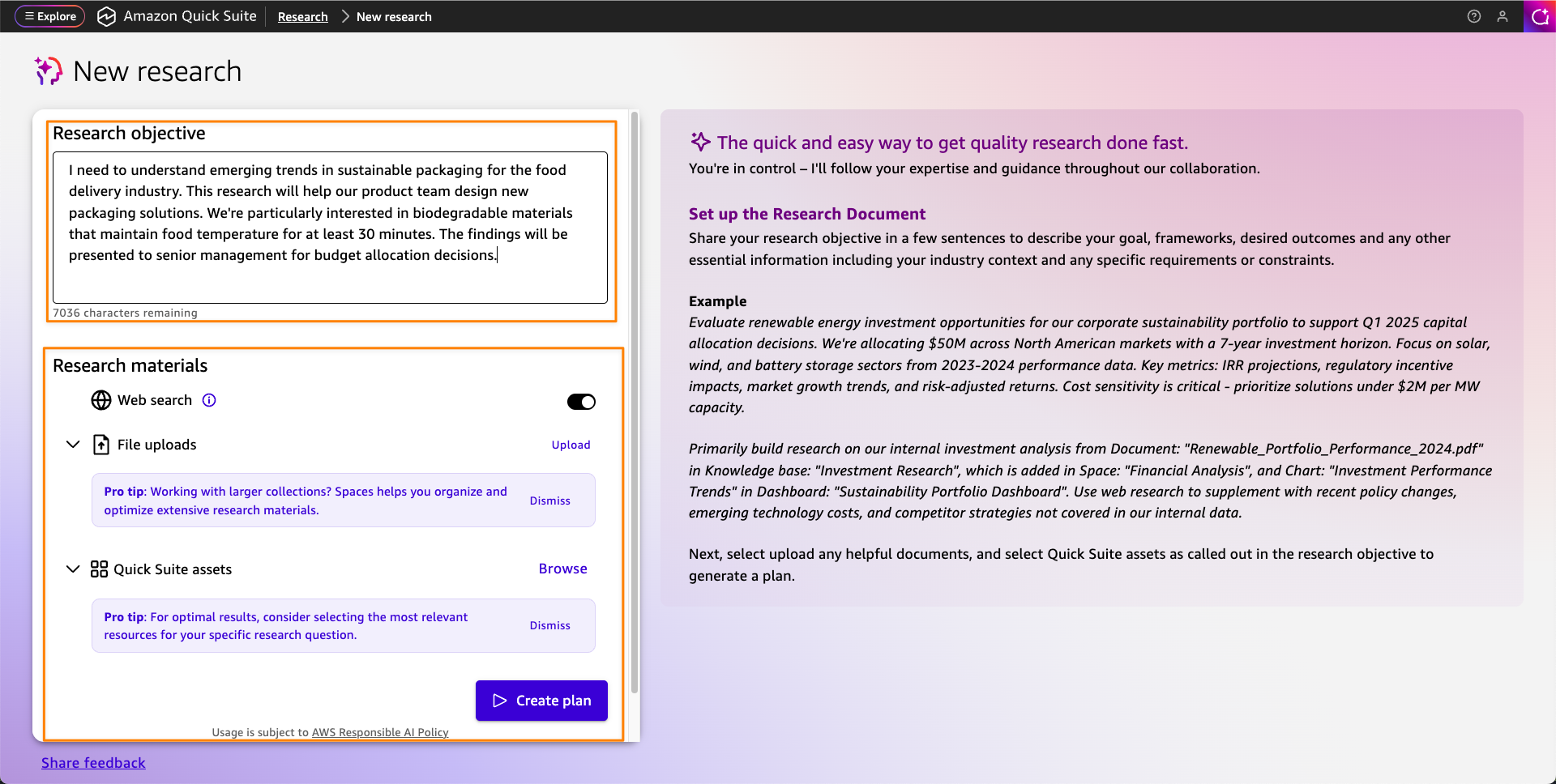
After Quick Research creates the plan, you can easily refine it through natural language conversations. When you are happy with the plan, it works in the background to gather information from multiple sources, using advanced reasoning to validate findings and provide thorough analysis with citations.


Quick Research integrates with your enterprise data connected to Quick Suite, the unified knowledge foundation that connects to your dashboards, documents, databases, and external sources, including Amazon S3, Snowflake, Google Drive, and Microsoft SharePoint. Quick Research grounds key insights to original sources and reveals clear reasoning paths, helping you verify accuracy, understand the logic behind recommendations, and present findings with confidence. You can trace findings back to their original sources and validate conclusions through source citations. This makes it ideal for complex topics requiring in-depth analysis.
To learn more, visit the Quick Research overview page.
Quick Sight: AI-powered business intelligence
Quick Sight provides AI-powered business intelligence capabilities that transform data into actionable insights through natural language queries and interactive visualizations.
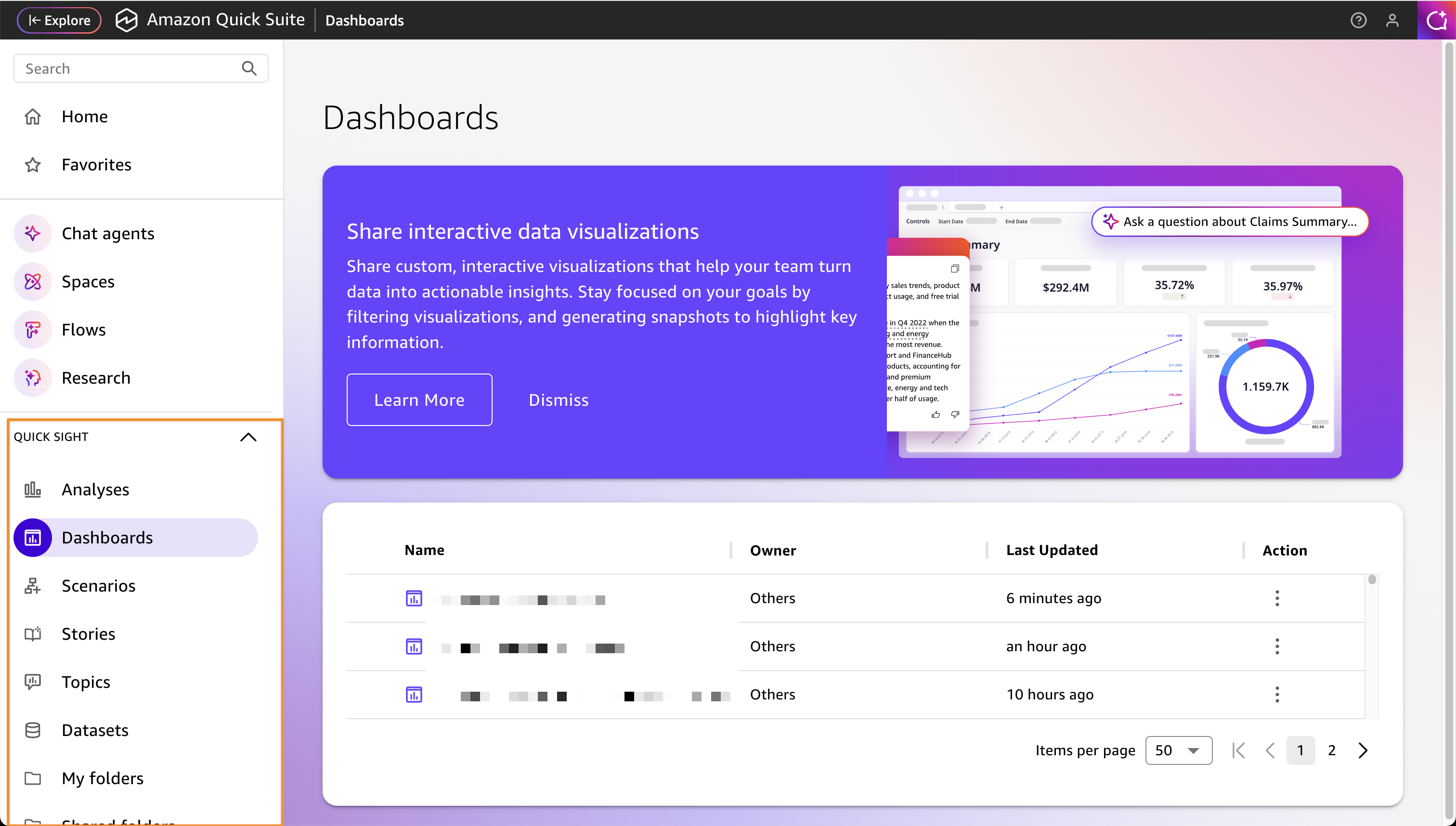
You can create dashboards and executive summaries using conversational prompts, reducing dashboard development time while making advanced analytics accessible without specialized skills.
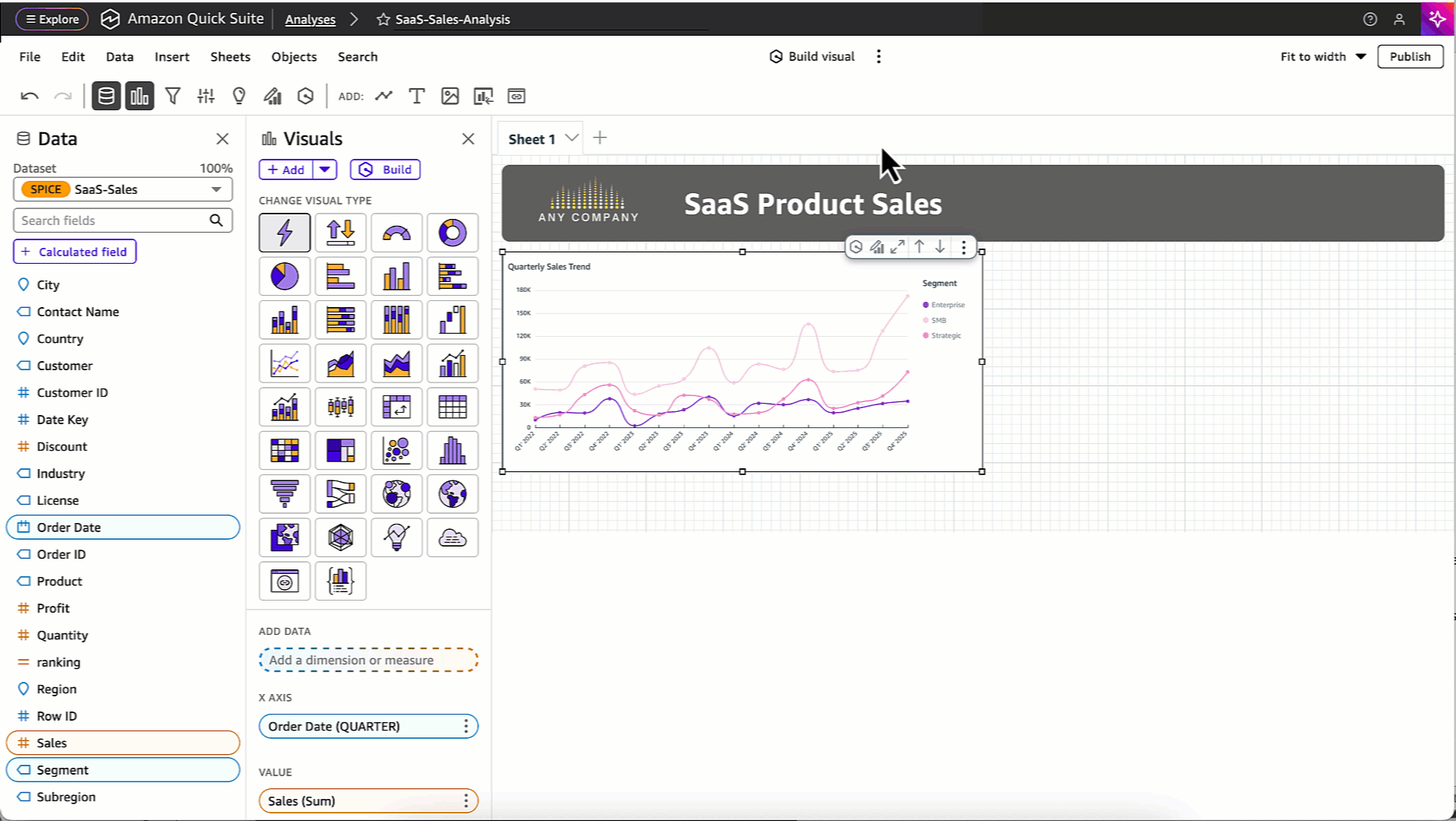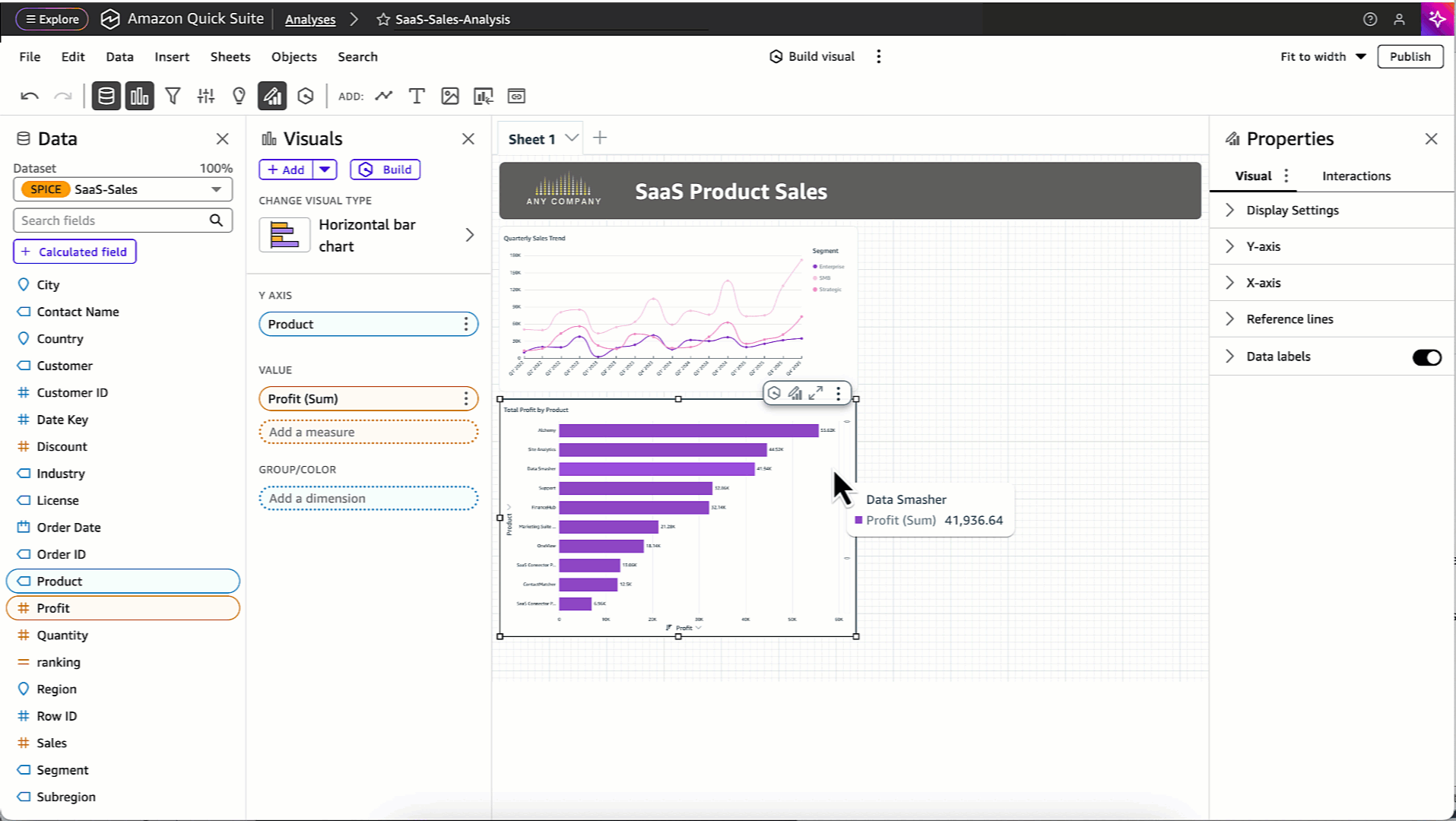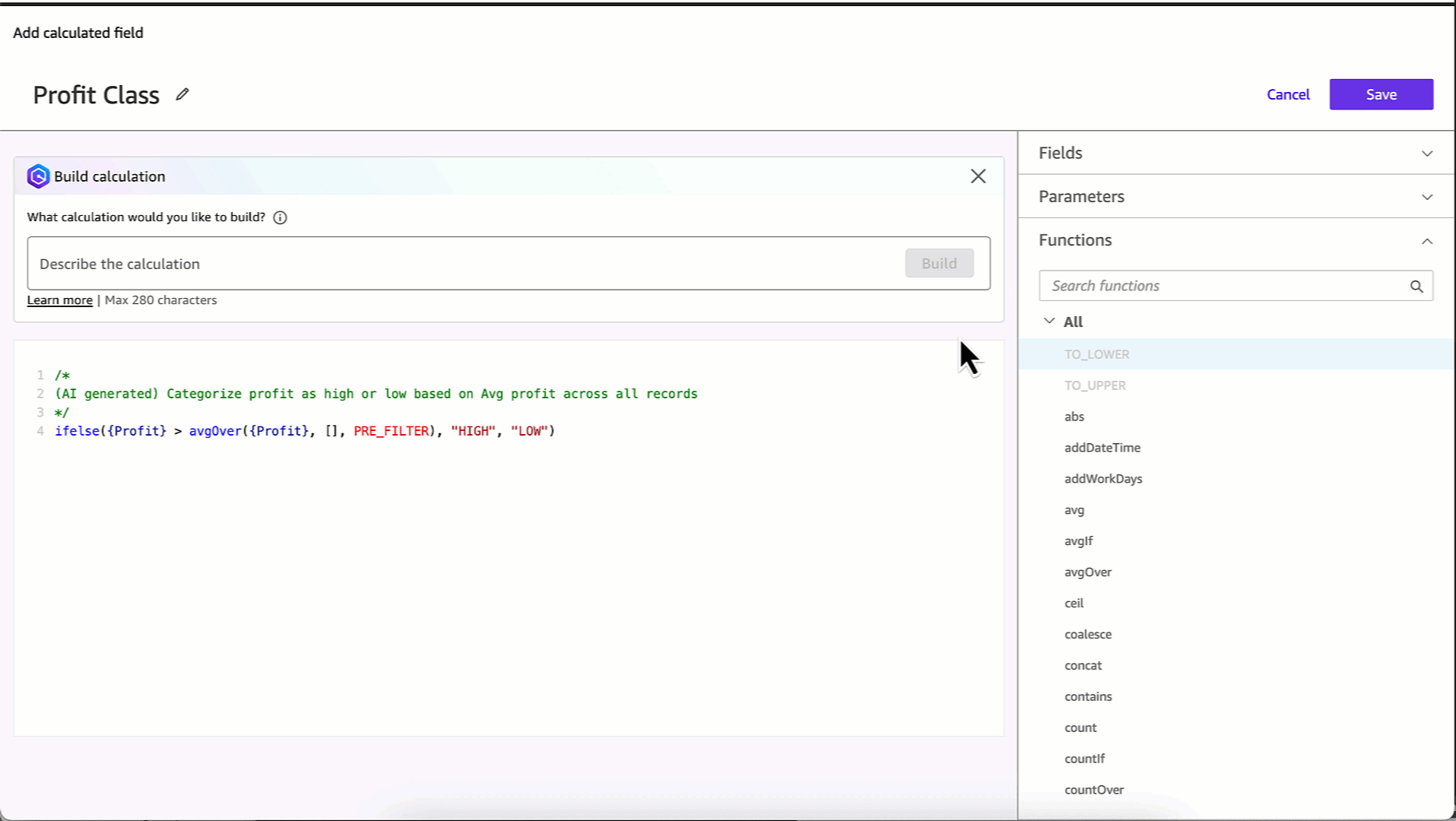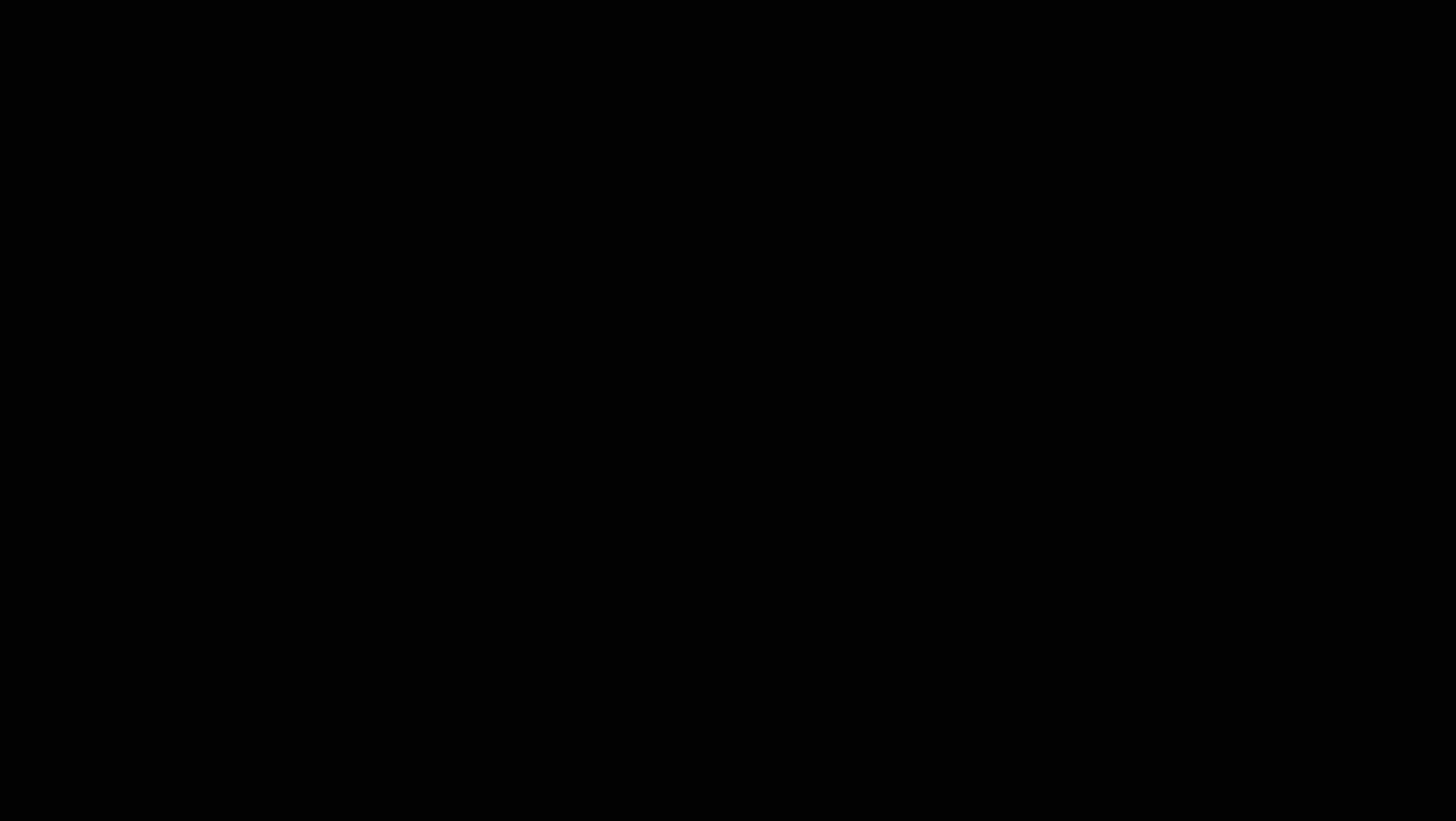
Quick Sight helps you ask questions about your data in natural language and receive instant visualizations, executive summaries, and insights. This generative AI integration provides you with answers from your dashboards and datasets without requiring technical expertise.
Using the scenarios capability, you can perform what-if analysis in natural language with step-by-step guidance, exploring complex business scenarios and finding answers faster than before.
Additionally, you can respond to insights with one-click actions by creating tickets, sending alerts, updating records, or triggering automated workflows directly from your dashboards without switching applications.
To learn more, visit Quick Sight overview page.
Quick Flows: Automation for everyone
With Quick Flows, any user can automate repetitive tasks by describing their workflow using natural language without requiring any technical knowledge. Quick Flows fetches information from internal and external sources, takes action in business applications, generates content, and handles process-specific requirements.
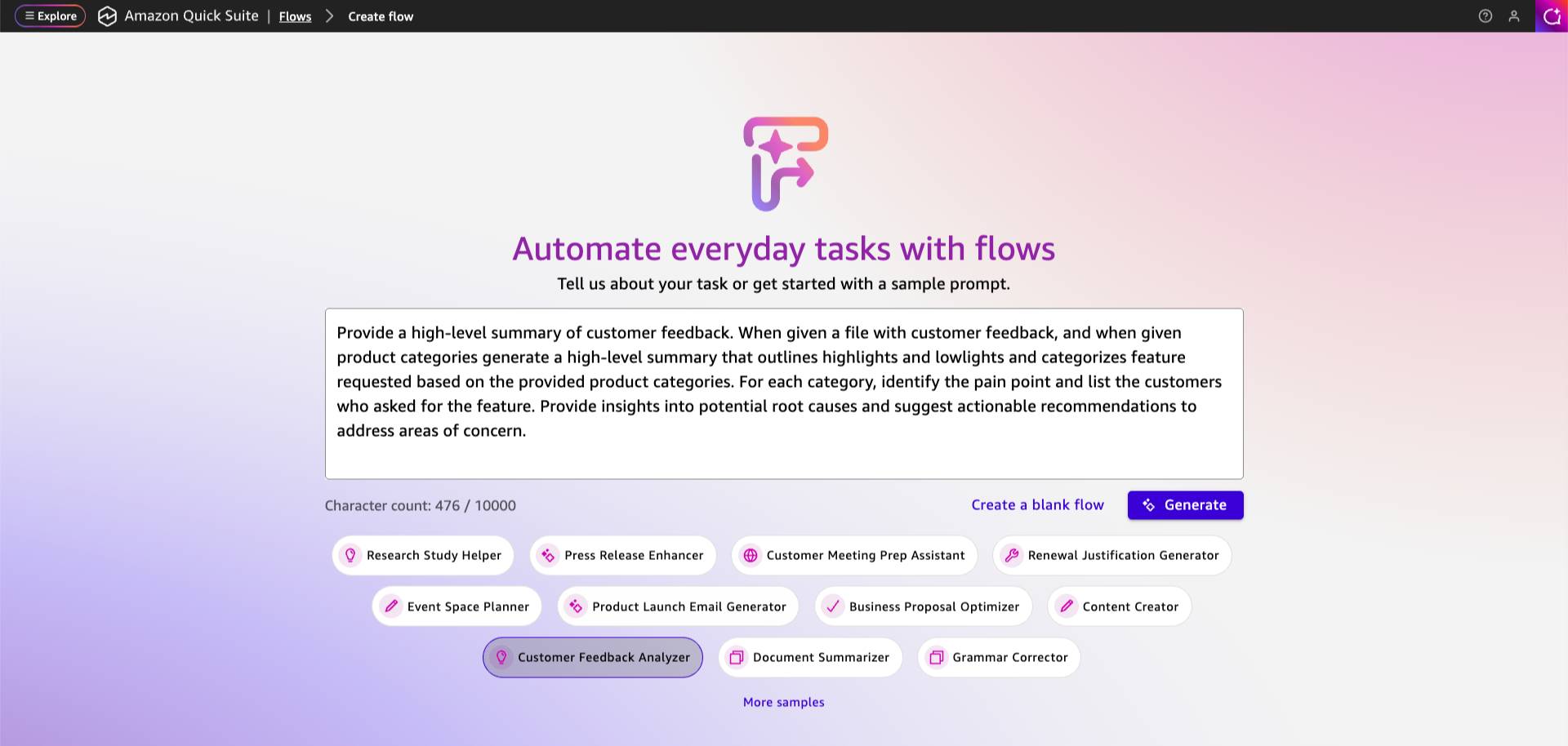
Starting with straightforward business requirements, it creates a multi-step flow including input steps for gathering information, reasoning groups for AI-powered processing, and output steps for generating and presenting results.
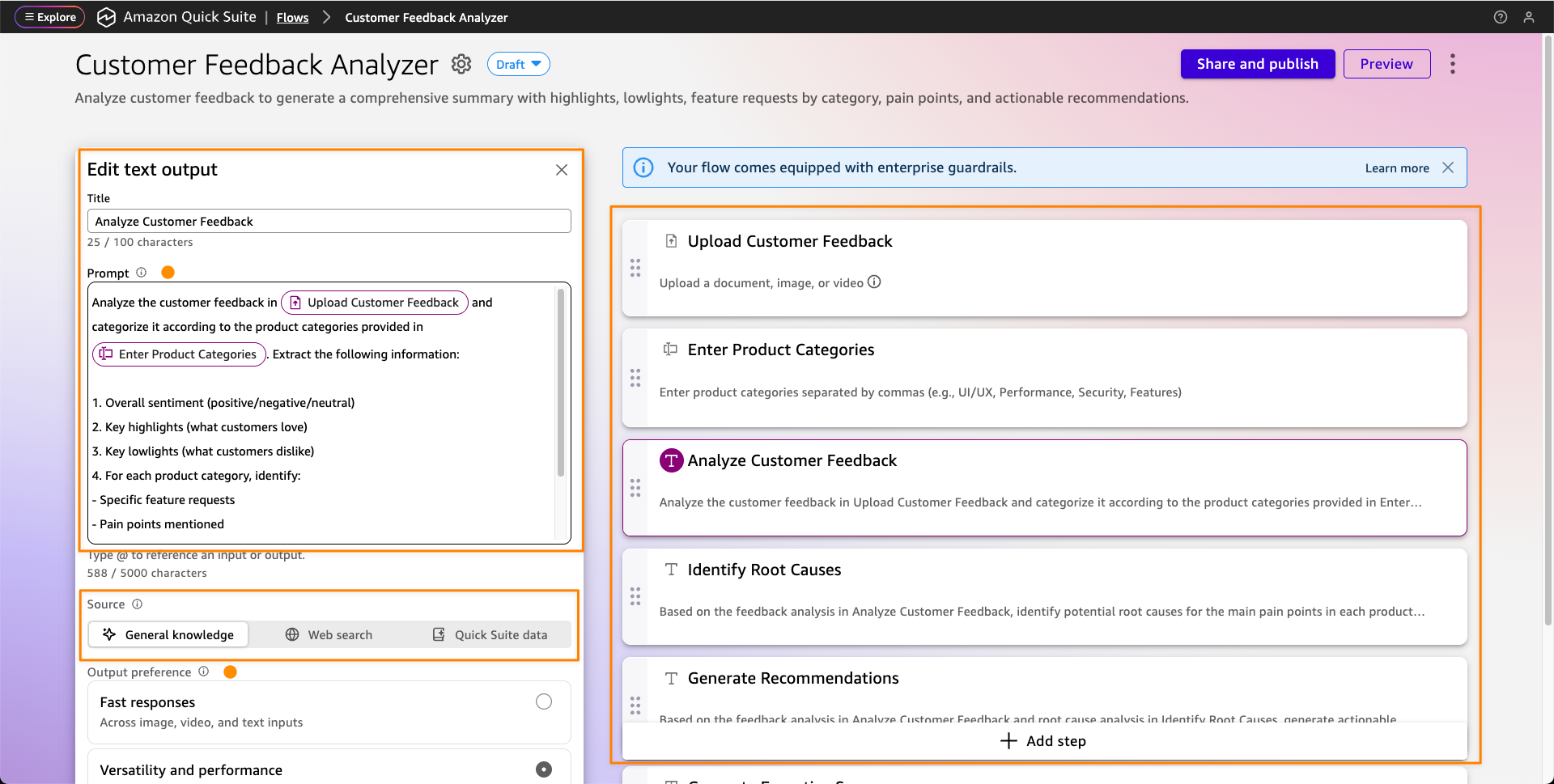
After the flow is configured, you can share it with a single click to your coworkers and other teams. To execute the flow, users can open it from the library or invoke it from chat, provide the necessary inputs, and then chat with the agent to refine the outputs and further customize the results.
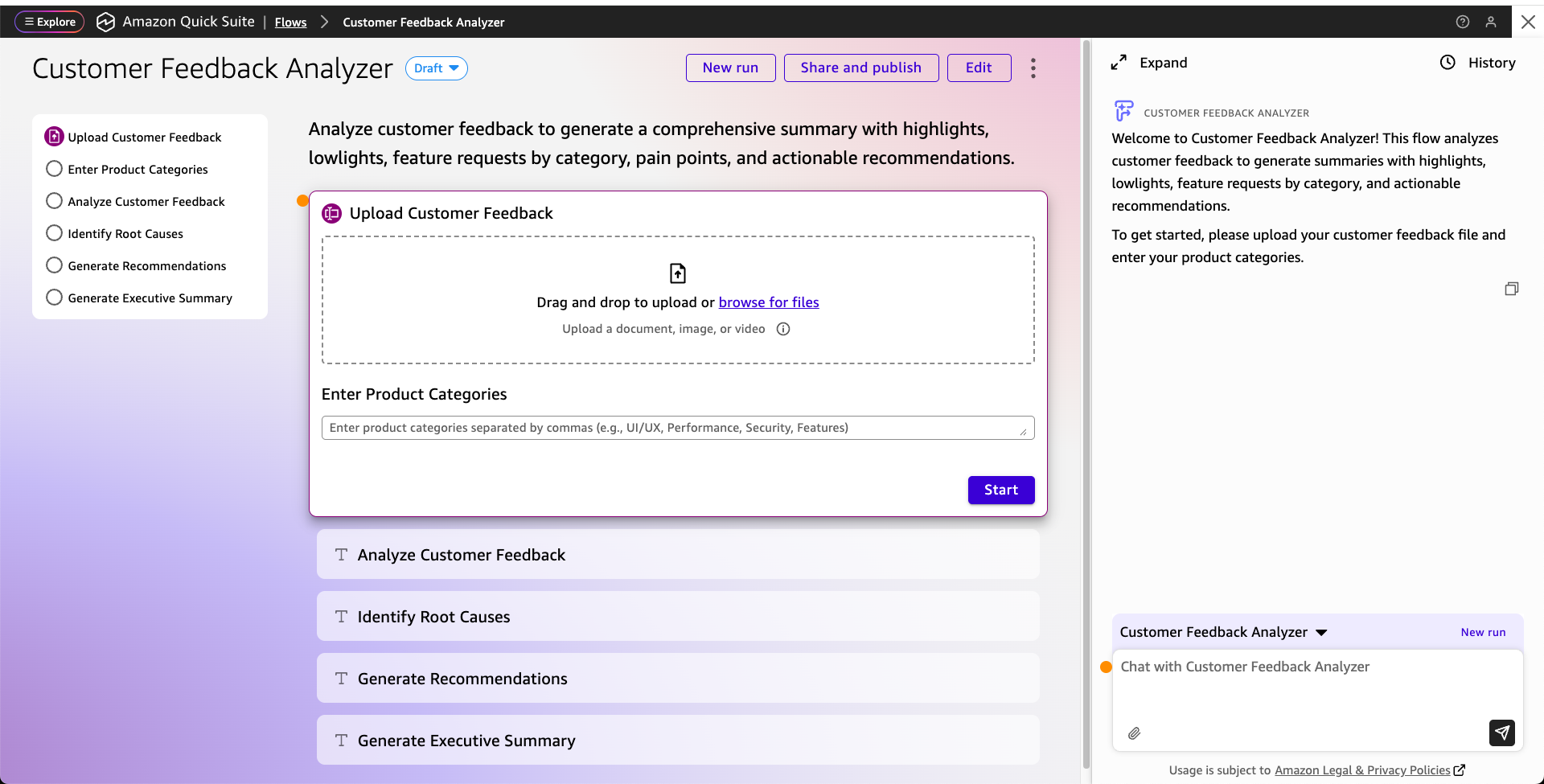
To learn more, visit the Quick Flows overview page.
Quick Automate: Enterprise-scale process automation
Quick Automate helps technical teams build and deploy sophisticated automation for complex, multistep processes that span departments, systems, and third-party integrations. Using AI-powered natural language processing, Quick Automate transforms complex business processes into multi-agent workflows that can be created merely by describing what you want to automate or uploading process documentation.
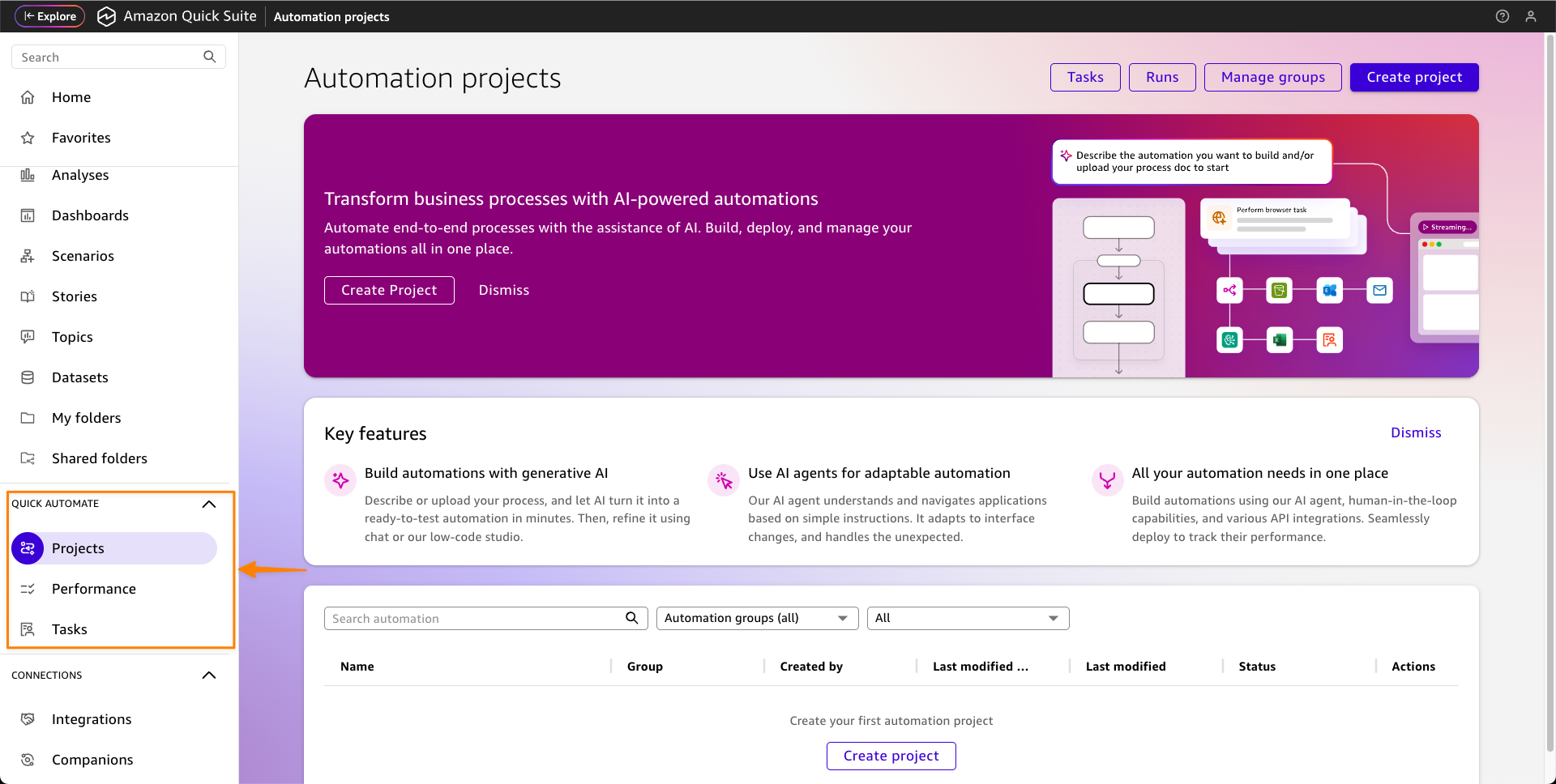
While Quick Flows handles straightforward workflows, Quick Automate is designed for comprehensive and complex business processes like customer onboarding, procurement automations, or compliance procedures that involve multiple approval steps, system integrations, and cross-departmental coordination. Quick Automate offers advanced orchestration capabilities with extensive monitoring, debugging, versioning, and deployment features.
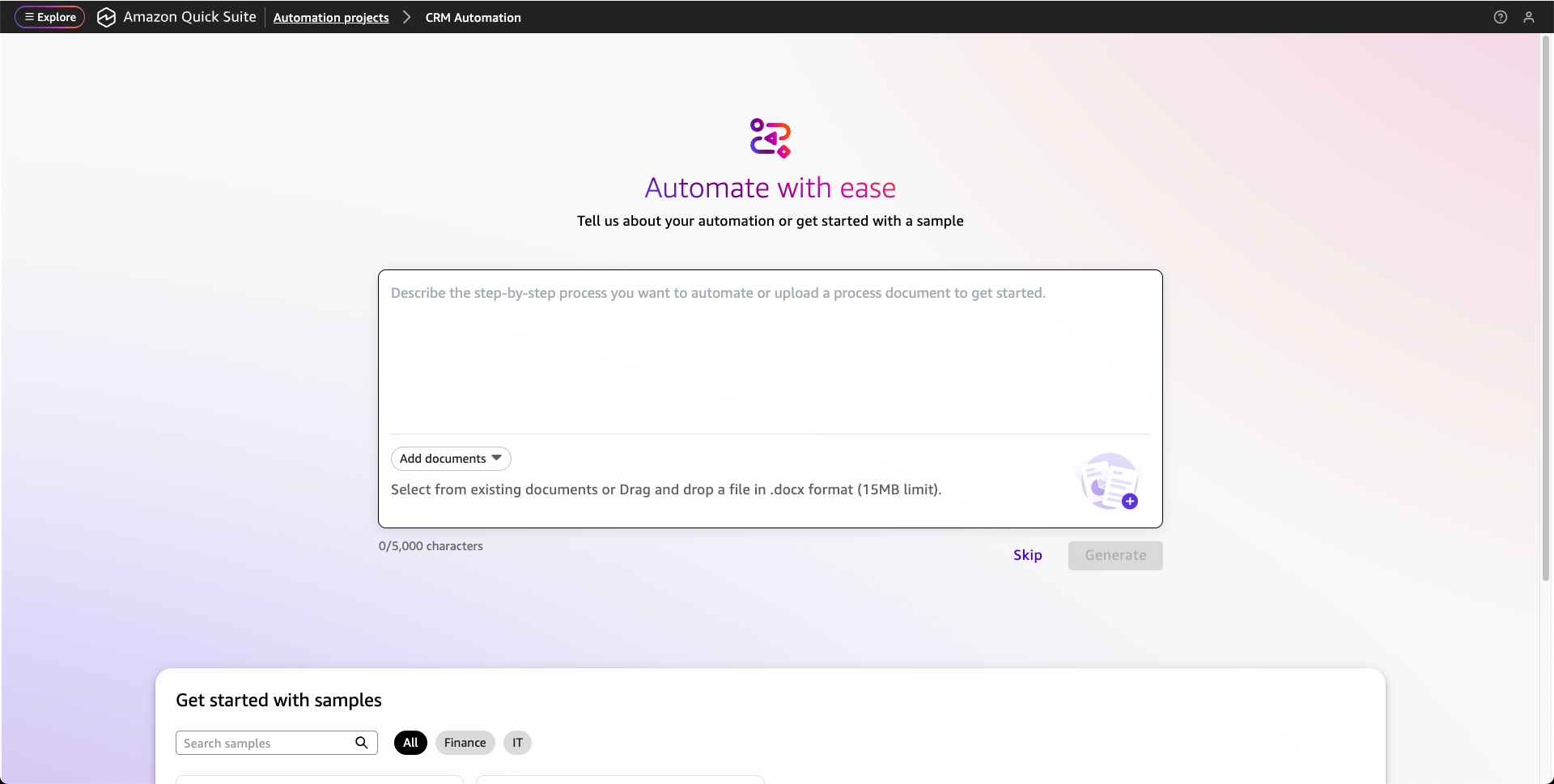
Quick Automate then generates a comprehensive automation plan with detailed steps and actions. You will find a UI agent that understands natural language instructions to autonomously navigate websites, complete form inputs, extract data, and produces structured outputs for downstream automation steps.
Additionally, you can define a custom agent, complete with instructions, knowledge, and tools, to complete process-specific tasks using the visual building experience – no code required.
Quick Automate includes enterprise-grade features such as user role management and human-in-the-loop capabilities that route specific tasks to users or groups for review and approval before continuing workflows. The service provides comprehensive observability with real-time monitoring, success rate tracking, and audit trails for compliance and governance.
To learn more, visit the Quick Automate overview page.
Additional foundational capabilities
Quick Suite includes other foundational capabilities that deliver seamless data organization and contextual AI interactions across your enterprise.
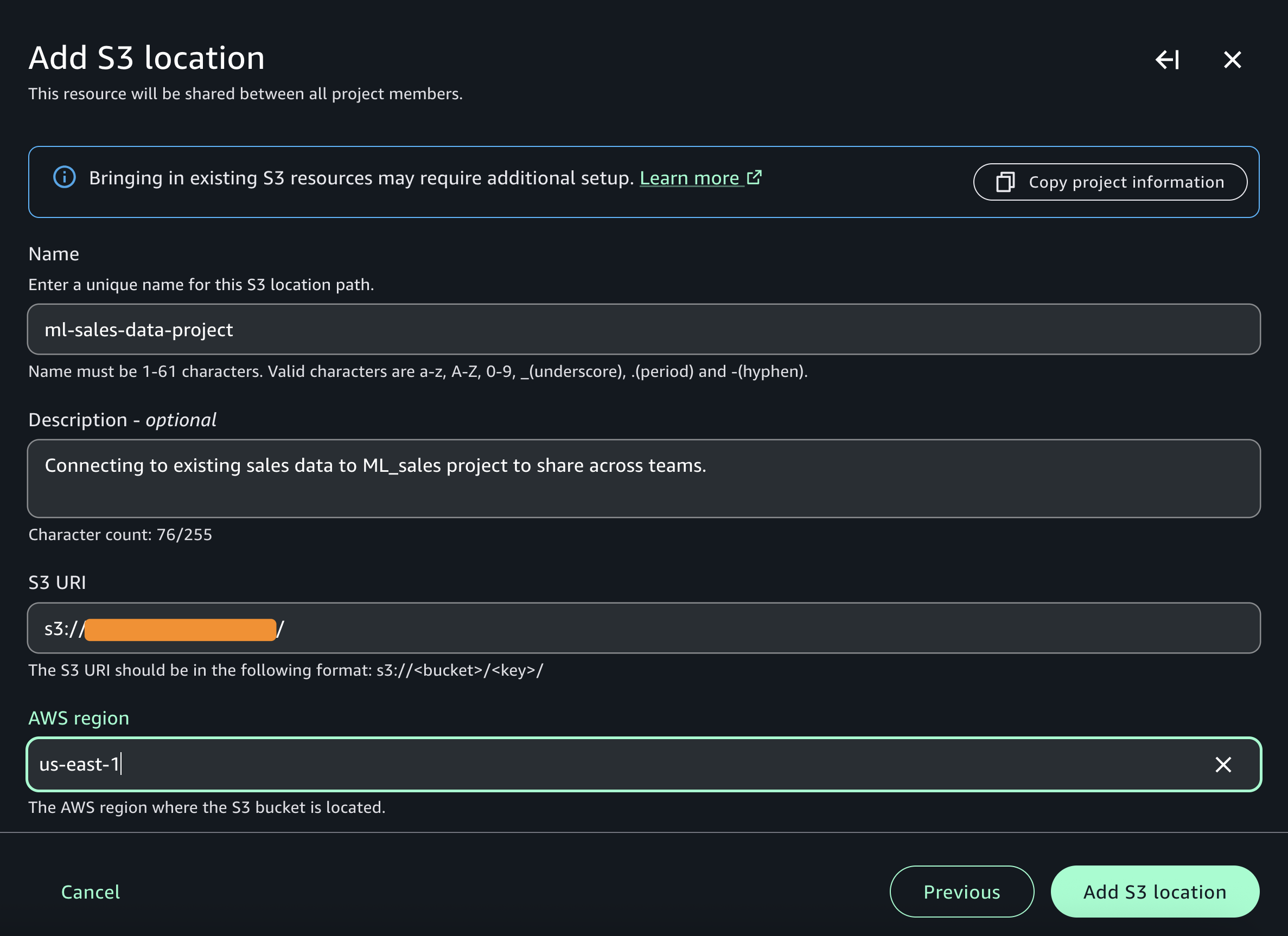
Spaces – Spaces provide a straightforward way for every business user to add their own context by uploading files or connecting to specific datasets and repositories specific to their work or to a particular function. For example, you might create a space for quarterly planning that includes budget spreadsheets, market research reports, and strategic planning documents. Or you could set up a product launch space that connects to your project management system and customer feedback databases. Spaces can scale from personal use to enterprise-wide deployment while maintaining access permissions and seamless integration with Quick Suite capabilities.
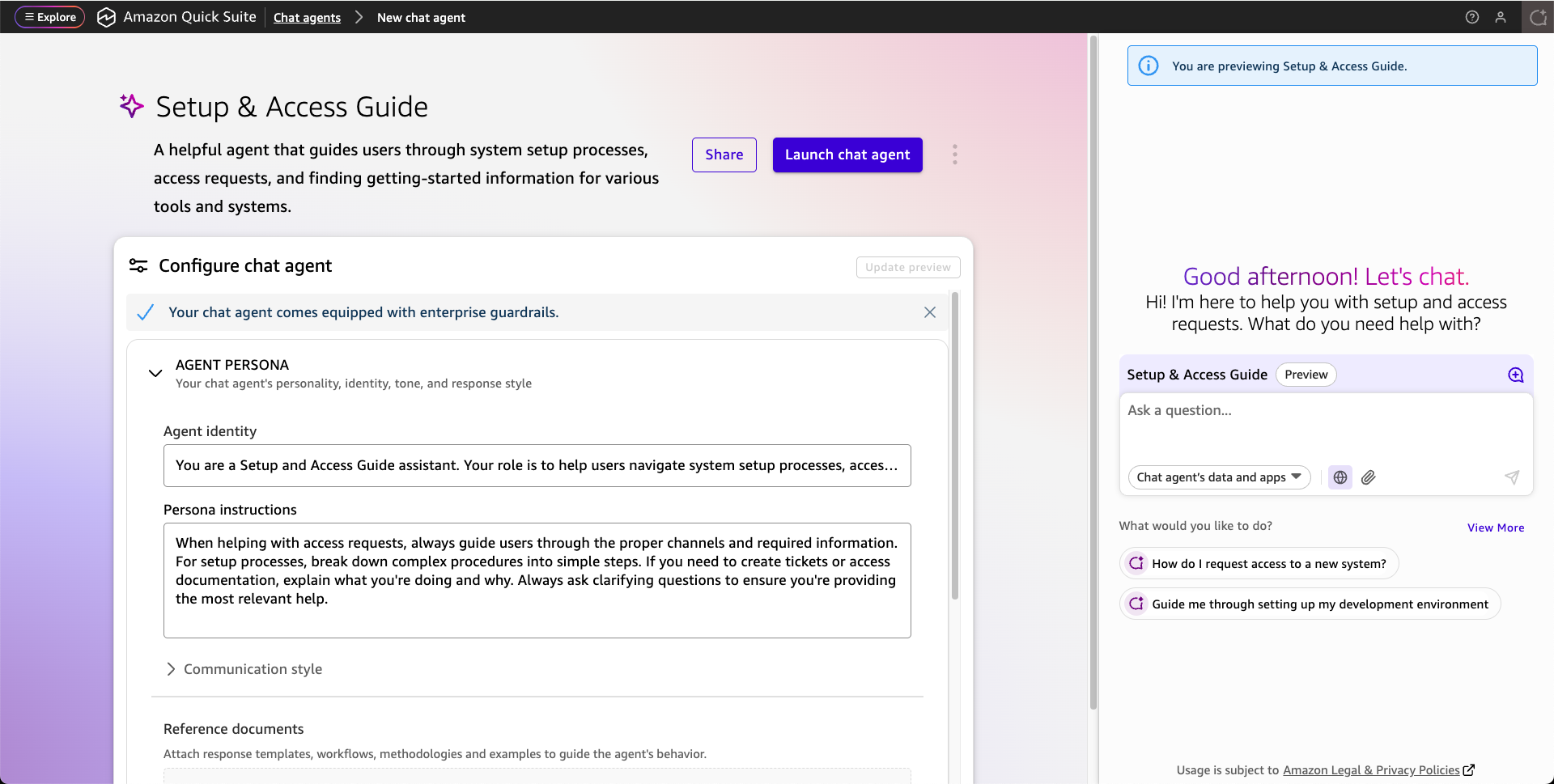
Chat agents – Quick Suite includes insights agents that you can use to interact with your data and workflows through natural language. Quick Suite includes a built-in agent to answer questions across all of your data and custom chat agents that you can configure with specific expertise and business context. Custom chat agents can be tailored for particular departments or use cases—such as a sales agent connected to your product catalog data and pricing information stored in a space or a compliance agent configured with your regulatory requirements and actions to request approvals.
Additional things to know
If you’re an existing Amazon QuickSight customer – Amazon QuickSight customers will be upgraded to Quick Suite, a unified digital workspace that includes all your existing QuickSight business intelligence capabilities (now called “Quick Sight”) plus new agentic AI capabilities. This is an interface and capability change—your data connectivity, user access, content, security controls, user permissions, and privacy settings remain exactly the same. No data is moved, migrated, or changed.
Quick Suite offers per-user subscription-based pricing with consumption-based charges for the Quick Index and other optional features. You can find more detail on the Quick Suite pricing page.
Now available
Amazon Quick Suite gives you a set of agentic teammates that helps you get the answers you need using all your data and move instantly from answers to action so you can focus on high value activities that drive better business and customer outcomes.
Visit the getting started page to start using Amazon Quick Suite today.
Happy building
— Esra and Donnie


 Aaron Sempf is Next Gen Tech Lead for the AWS Partner Organization in Asia-Pacific and Japan. With over 20 years in distributed system engineering design and development, he focuses on solving for large scale complex integration and event driven systems. In his spare time, he can be found coding prototypes for autonomous robots, IoT devices, distributed solutions, and designing agentic architecture patterns for generative AI assisted business automation.
Aaron Sempf is Next Gen Tech Lead for the AWS Partner Organization in Asia-Pacific and Japan. With over 20 years in distributed system engineering design and development, he focuses on solving for large scale complex integration and event driven systems. In his spare time, he can be found coding prototypes for autonomous robots, IoT devices, distributed solutions, and designing agentic architecture patterns for generative AI assisted business automation. Joshua Toth is a Senior Prototyping Engineer with over a decade of experience in software engineering and distributed systems. He specializes in solving complex business challenges through technical prototypes, demonstrating the art of the possible. With deep expertise in proof of concept development, he focuses on bridging the gap between emerging technologies and practical business applications. In his spare time, he can be found developing next-generation interactive demonstrations and exploring cutting-edge technological innovations.
Joshua Toth is a Senior Prototyping Engineer with over a decade of experience in software engineering and distributed systems. He specializes in solving complex business challenges through technical prototypes, demonstrating the art of the possible. With deep expertise in proof of concept development, he focuses on bridging the gap between emerging technologies and practical business applications. In his spare time, he can be found developing next-generation interactive demonstrations and exploring cutting-edge technological innovations.



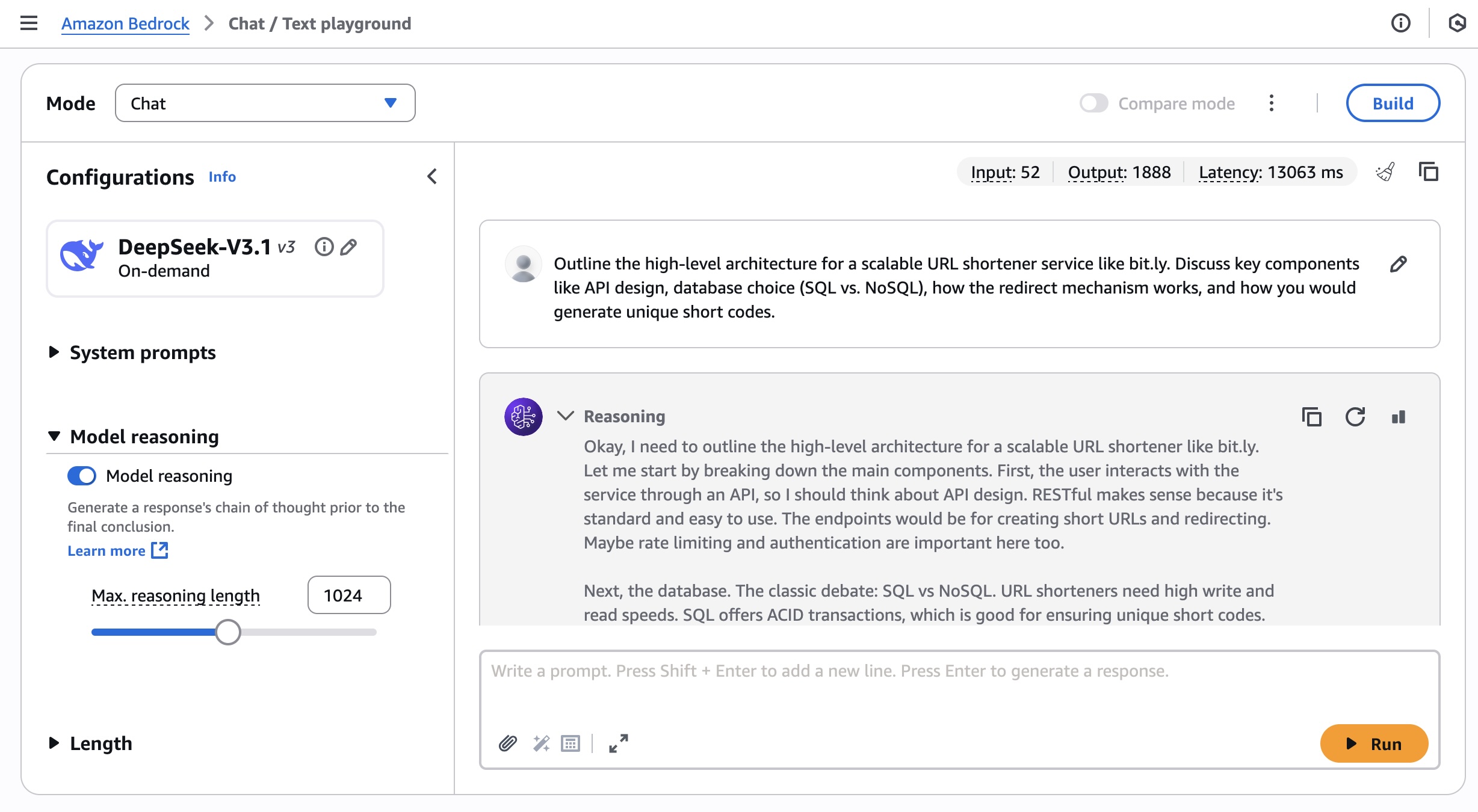
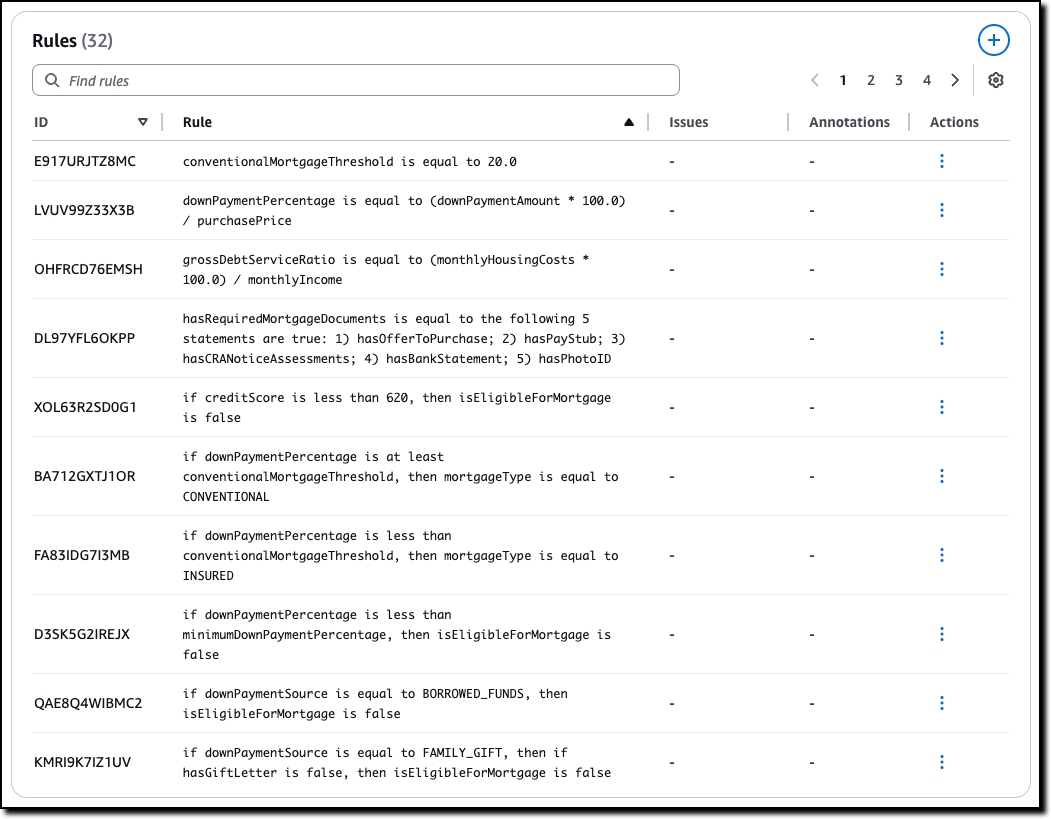
 Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS.
Shubham Mehta is a Senior Product Manager at AWS Analytics. He leads generative AI feature development across services such as AWS Glue, Amazon EMR, and Amazon MWAA, using AI/ML to simplify and enhance the experience of data practitioners building data applications on AWS. Vaibhav Naik is a software engineer at AWS Glue, passionate about building robust, scalable solutions to tackle complex customer problems. With a keen interest in generative AI, he likes to explore innovative ways to develop enterprise-level solutions that harness the power of cutting-edge AI technologies.
Vaibhav Naik is a software engineer at AWS Glue, passionate about building robust, scalable solutions to tackle complex customer problems. With a keen interest in generative AI, he likes to explore innovative ways to develop enterprise-level solutions that harness the power of cutting-edge AI technologies. Liyuan Lin is a Software Engineer at AWS Glue, where she works on building generative AI and data integration tools to help customers solve their data challenges. She specializes in developing solutions that combine AI capabilities with data integration workflows, making it easier for customers to manage and transform their data effectively.
Liyuan Lin is a Software Engineer at AWS Glue, where she works on building generative AI and data integration tools to help customers solve their data challenges. She specializes in developing solutions that combine AI capabilities with data integration workflows, making it easier for customers to manage and transform their data effectively. Arun A K is a Big Data Solutions Architect with AWS. He works with customers to provide architectural guidance for running analytics solutions on the cloud. In his free time, Arun loves to enjoy quality time with his family.
Arun A K is a Big Data Solutions Architect with AWS. He works with customers to provide architectural guidance for running analytics solutions on the cloud. In his free time, Arun loves to enjoy quality time with his family. Sarath Krishnan is a Senior Solutions Architect with Amazon Web Services. He is passionate about enabling enterprise customers on their digital transformation journey. Sarath has extensive experience in architecting highly available, scalable, cost-effective, and resilient applications on the cloud. His area of focus includes DevOps, machine learning, MLOps, and generative AI.
Sarath Krishnan is a Senior Solutions Architect with Amazon Web Services. He is passionate about enabling enterprise customers on their digital transformation journey. Sarath has extensive experience in architecting highly available, scalable, cost-effective, and resilient applications on the cloud. His area of focus includes DevOps, machine learning, MLOps, and generative AI. Pradeep Patel is a Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable seamless Spark Code Transformation using AI.
Pradeep Patel is a Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable seamless Spark Code Transformation using AI. Mohit Saxena is a Senior Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable customers with new AI/ML-driven capabilities to efficiently transform petabytes of data across data lakes on Amazon S3, databases and data warehouses on the cloud.
Mohit Saxena is a Senior Software Development Manager on the AWS Data Processing Team (AWS Glue and Amazon EMR). His team focuses on building distributed systems to enable customers with new AI/ML-driven capabilities to efficiently transform petabytes of data across data lakes on Amazon S3, databases and data warehouses on the cloud.
 Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service based out of Chicago, IL. His interests are in all things data and analytics. More specifically he loves to help customers use AI in their data strategy to solve modern day challenges.
Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service based out of Chicago, IL. His interests are in all things data and analytics. More specifically he loves to help customers use AI in their data strategy to solve modern day challenges. Mark Twomey is a Senior Solutions Architect at AWS focused on storage and data management. He enjoys working with customers to put their data in the right place, at the right time, for the right cost. Living in Ireland, Mark enjoys walking in the countryside, watching movies, and reading books.
Mark Twomey is a Senior Solutions Architect at AWS focused on storage and data management. He enjoys working with customers to put their data in the right place, at the right time, for the right cost. Living in Ireland, Mark enjoys walking in the countryside, watching movies, and reading books. Sorabh Hamirwasia is a senior software engineer at AWS working on the OpenSearch Project. His primary interest include building cost optimized and performant distributed systems.
Sorabh Hamirwasia is a senior software engineer at AWS working on the OpenSearch Project. His primary interest include building cost optimized and performant distributed systems. Pallavi Priyadarshini is a Senior Engineering Manager at Amazon OpenSearch Service leading the development of high-performing and scalable technologies for search, security, releases, and dashboards.
Pallavi Priyadarshini is a Senior Engineering Manager at Amazon OpenSearch Service leading the development of high-performing and scalable technologies for search, security, releases, and dashboards. Bobby Mohammed is a Principal Product Manager at AWS leading the Search, GenAI, and Agentic AI product initiatives. Previously, he worked on products across the full lifecycle of machine learning, including data, analytics, and ML features on SageMaker platform, deep learning training and inference products at Intel.
Bobby Mohammed is a Principal Product Manager at AWS leading the Search, GenAI, and Agentic AI product initiatives. Previously, he worked on products across the full lifecycle of machine learning, including data, analytics, and ML features on SageMaker platform, deep learning training and inference products at Intel.