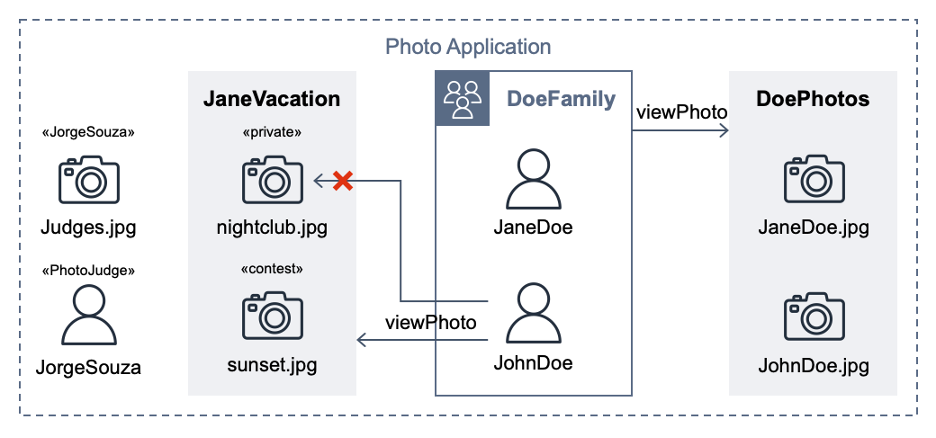
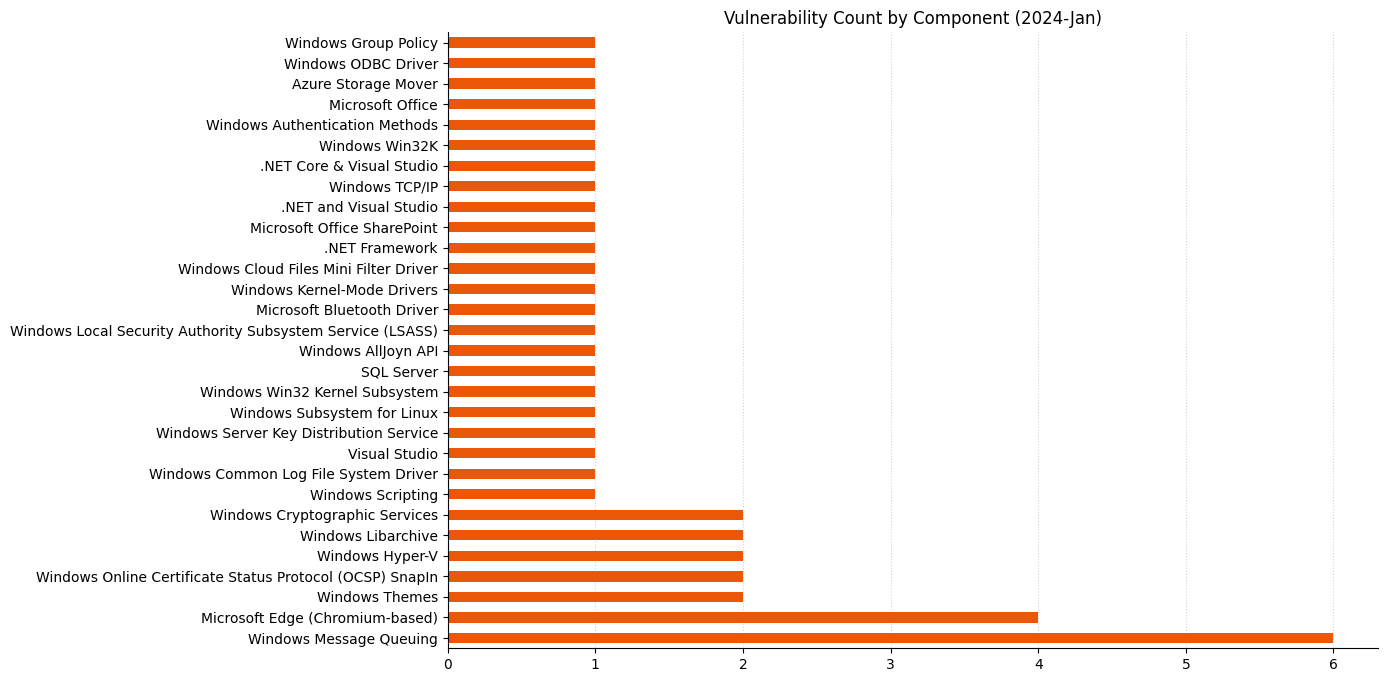
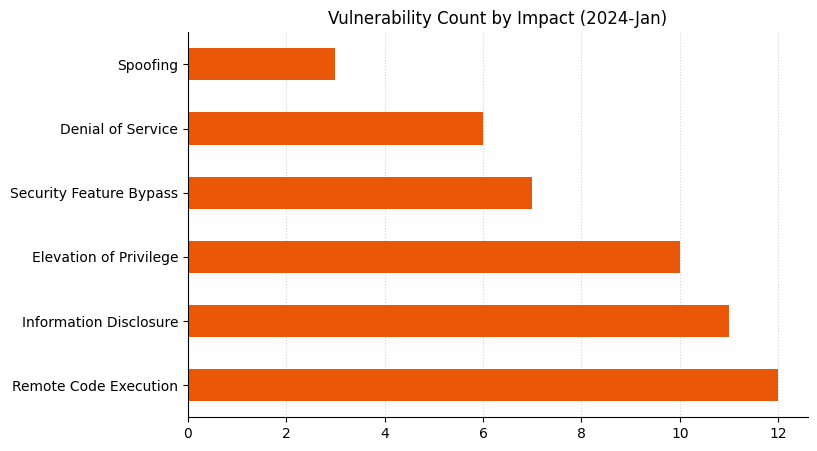
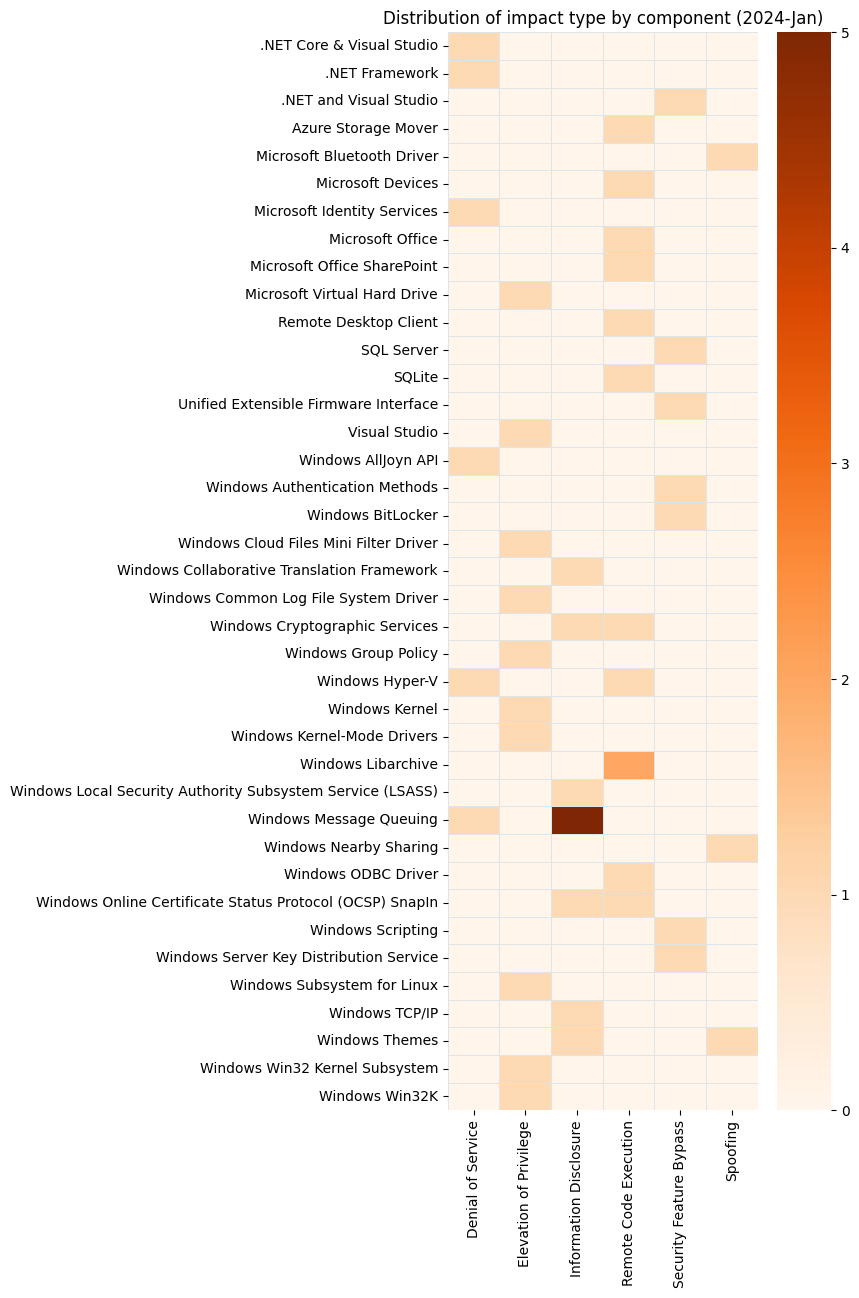
Post Syndicated from Anshu Agarwal original https://aws.amazon.com/blogs/big-data/achieve-high-availability-in-amazon-opensearch-multi-az-with-standby-enabled-domains-a-deep-dive-into-failovers/
Amazon OpenSearch Service recently introduced Multi-AZ with Standby, a deployment option designed to provide businesses with enhanced availability and consistent performance for critical workloads. With this feature, managed clusters can achieve 99.99% availability while remaining resilient to zonal infrastructure failures.
In this post, we explore how search and indexing works with Multi-AZ with Standby and delve into the underlying mechanisms that contribute to its reliability, simplicity, and fault tolerance.
Background
Multi-AZ with Standby deploys OpenSearch Service domain instances across three Availability Zones, with two zones designated as active and one as standby. This configuration ensures consistent performance, even in the event of zonal failures, by maintaining the same capacity across all zones. Importantly, this standby zone follows a statically stable design, eliminating the need for capacity provisioning or data movement during failures.
During regular operations, the active zone handles coordinator traffic for both read and write requests, as well as shard query traffic. The standby zone, on the other hand, only receives replication traffic. OpenSearch Service utilizes a synchronous replication protocol for write requests. This enables the service to promptly promote a standby zone to active status in the event of a failure (mean time to failover <= 1 minute), known as a zonal failover. The previously active zone is then demoted to standby mode, and recovery operations commence to restore its healthy state.
Search traffic routing and failover to guarantee high availability
In an OpenSearch Service domain, a coordinator is any node that handles HTTP(S) requests, especially indexing and search requests. In a Multi-AZ with Standby domain, the data nodes in the active zone act as coordinators for search requests.
During the query phase of a search request, the coordinator determines the shards to be queried and sends a request to the data node hosting the shard copy. The query is run locally on each shard and matched documents are returned to the coordinator node. The coordinator node, which is responsible for sending the request to nodes containing shard copies, runs the process in two steps. First, it creates an iterator that defines the order in which nodes need to be queried for a shard copy so that traffic is uniformly distributed across shard copies. Subsequently, the request is sent to the relevant nodes.
In order to create an ordered list of nodes to be queried for a shard copy, the coordinator node uses various algorithms. These algorithms include round-robin selection, adaptive replica selection, preference-based shard routing, and weighted round-robin.
For Multi-AZ with Standby, the weighted round-robin algorithm is used for shard copy selection. In this approach, active zones are assigned a weight of 1, and the standby zone is assigned a weight of 0. This ensures that no read traffic is sent to data nodes in the standby Availability Zone.
The weights are stored in cluster state metadata as a JSON object:
As shown in the following screenshot, the us-east-1b Region has its zone status as StandBy, indicating that the data nodes in this Availability Zone are in standby state and don’t receive search or indexing requests from the load balancer.

To maintain steady-state operations, the standby Availability Zone is rotated every 30 minutes, ensuring all network parts are covered across Availability Zones. This proactive approach verifies the availability of read paths, further enhancing the system’s resilience during potential failures. The following diagram illustrates this architecture.

In the preceding diagram, Zone-C has a weighted round-robin weight set to zero. This ensures that the data nodes in the standby zone don’t receive any indexing or search traffic. When the coordinator queries data nodes for shard copies, it uses a weighted round-robin weight to decide on the order in which nodes to be queried. Because the weight is zero for the standby Availability Zone, coordinator requests are not sent.
In an OpenSearch Service cluster, the active and standby zones can be checked at any time using Availability Zone rotation metrics, as shown in the following screenshot.

During zonal outages, the standby Availability Zone seamlessly switches to fail-open mode for search requests. This means that the shard query traffic is routed to all Availability Zones, even those in standby, when a healthy shard copy is unavailable in the active Availability Zone. This fail-open approach safeguards search requests from disruption during failures, ensuring continuous service. The following diagram illustrates this architecture.

In the preceding diagram, during the steady state, the shard query traffic is sent to the data node in the active Availability Zones (Zone-A and Zone-B). Due to node failures in Zone-A, the standby Availability Zone (Zone-C) fails open to take shard query traffic so that there isn’t any impact to the search requests. Eventually, Zone-A is detected as unhealthy and the read failover switches the standby to Zone-A.
How failover ensures high availability during write impairment
The OpenSearch Service replication model follows a primary backup model, characterized by its synchronous nature, where acknowledgement from all shard copies is necessary before a write request can be acknowledged to the user. One notable drawback of this replication model is its susceptibility to slowdowns in the event of any impairment in the write path. These systems rely on an active leader node to identify failures or delays and then broadcast this information to all nodes. The duration it takes to detect these issues (mean time to detect) and subsequently resolve them (mean time to repair) largely determines how long the system will operate in an impaired state. Additionally, any networking event that affects inter-zone communications can significantly impede write requests due to the synchronous nature of replication.
OpenSearch Service utilizes an internal node-to-node communication protocol for replicating write traffic and coordinating metadata updates through an elected leader. Consequently, putting the zone experiencing stress in standby wouldn’t effectively address the issue of write impairment.
Zonal write failover: Cutting off inter-zone replication traffic
For Multi-AZ with Standby, to mitigate potential performance issues caused during unforeseen events like zonal failures and networking events, zonal write failover is an effective approach. This approach involves graceful removal of nodes in the impacted zone from the cluster, effectively cutting off ingress and egress traffic between zones. By severing the inter-zone replication traffic, the impact of zonal failures can be contained within the affected zone. This provides a more predictable experience for customers and ensures that the system continues to operate reliably.
Graceful write failover
The orchestration of a write failover within OpenSearch Service is carried out by the elected leader node through a well-defined mechanism. This mechanism involves a consensus protocol for cluster state publication, ensuring unanimous agreement among all nodes to designate a single zone (at all times) for decommissioning. Importantly, metadata related to the affected zone is replicated across all nodes to ensure its persistence, even during a full restart in the event of an outage.
Furthermore, the leader node ensures a smooth and graceful transition by initially placing the nodes in the impacted zones on standby for a duration of 5 minutes before initiating I/O fencing. This deliberate approach prevents any new coordinator traffic or shard query traffic from being directed to the nodes within the impacted zone. This, in turn, allow these nodes to complete their ongoing tasks gracefully and gradually handle any inflight requests before being taken out of service. The following diagram illustrates this architecture.

In the process of implementing a write failover for a leader node, OpenSearch Service follows these key steps:
- Leader abdication – If the leader node happens to be located in a zone scheduled for write failover, the system ensures that the leader node voluntarily steps down from its leadership role. This abdication is carried out in a controlled manner, and the entire process is handed over to another eligible node, which then takes charge of the actions required.
- Prevent reelection of to-be-decommissioned leader – To prevent the reelection of a leader from a zone marked for write failover, when the eligible leader node initiates the write failover action, it takes measures to ensure that any to-be-decommissioned leader nodes do not participate in any further elections. This is achieved by excluding the to-be-decommissioned leader node from the voting configuration, effectively preventing it from voting during any critical phase of the cluster’s operation.
Metadata related to the write failover zone is stored within the cluster state, and this information is published to all nodes in the distributed OpenSearch Service cluster as follows:
The following screenshot depicts that during a networking slowdown in a zone, write failover helps recover availability.

Zonal recovery after write failover
The process of zonal recommissioning plays a crucial role in the recovery phase following a zonal write failover. After the impacted zone has been restored and is considered stable, the nodes that were previously decommissioned will rejoin the cluster. This recommissioning typically occurs within a time frame of 2 minutes after the zone has been recommissioned.
This enables them to synchronize with their peer nodes and initiates the recovery process for replica shards, effectively restoring the cluster to its desired state.
Conclusion
The introduction of OpenSearch Service Multi-AZ with Standby provides businesses with a powerful solution to achieve high availability and consistent performance for critical workloads. With this deployment option, businesses can enhance their infrastructure’s resilience, simplify cluster configuration and management, and enforce best practices. With features like weighted round-robin shard copy selection, proactive failover mechanisms, and fail-open standby Availability Zones, OpenSearch Service Multi-AZ with Standby ensures a reliable and efficient search experience for demanding enterprise environments.
For more information about Multi-AZ with Standby, refer to Amazon OpenSearch Service Under the Hood: Multi-AZ with Standby.
About the Author
 Anshu Agarwal is a Senior Software Engineer working on AWS OpenSearch at Amazon Web Services. She is passionate about solving problems related to building scalable and highly reliable systems.
Anshu Agarwal is a Senior Software Engineer working on AWS OpenSearch at Amazon Web Services. She is passionate about solving problems related to building scalable and highly reliable systems.
 Rishab Nahata is a Software Engineer working on OpenSearch at Amazon Web Services. He is fascinated about solving problems in distributed systems. He is active contributor to OpenSearch.
Rishab Nahata is a Software Engineer working on OpenSearch at Amazon Web Services. He is fascinated about solving problems in distributed systems. He is active contributor to OpenSearch.
 Bukhtawar Khan is a Principal Engineer working on Amazon OpenSearch Service. He is interested in distributed and autonomous systems. He is an active contributor to OpenSearch.
Bukhtawar Khan is a Principal Engineer working on Amazon OpenSearch Service. He is interested in distributed and autonomous systems. He is an active contributor to OpenSearch.
 Ranjith Ramachandra is an Engineering Manager working on Amazon OpenSearch Service at Amazon Web Services.
Ranjith Ramachandra is an Engineering Manager working on Amazon OpenSearch Service at Amazon Web Services.